
arxiv_id
stringlengths 11
13
| markdown
stringlengths 2.09k
423k
| paper_doi
stringlengths 13
47
⌀ | paper_authors
sequencelengths 1
1.37k
| paper_published_date
stringdate 2014-06-03 19:36:41
2024-08-02 10:23:00
| paper_updated_date
stringdate 2014-06-27 01:00:59
2025-04-23 08:12:32
| categories
sequencelengths 1
7
| title
stringlengths 16
236
| summary
stringlengths 57
2.54k
|
|---|---|---|---|---|---|---|---|---|
2408.01050v1 | ## The Impact of Hyperparameters on Large Language Model Inference Performance: An Evaluation of vLLM and HuggingFace Pipelines
## Matias Martinez
Universitat Polit` ecnica de Catalunya (UPC) - BarcelonaTech Barcelona, Spain [email protected]
Abstract -The recent surge of open-source large language models (LLMs) enables developers to create AI-based solutions while maintaining control over aspects such as privacy and compliance, thereby providing governance and ownership of the model deployment process. To utilize these LLMs, inference engines are needed. These engines load the model's weights onto available resources, such as GPUs, and process queries to generate responses. The speed of inference, or performance, of the LLM, is critical for real-time applications, as it computes millions or billions of floating point operations per inference. Recently, advanced inference engines such as vLLM have emerged, incorporating novel mechanisms such as efficient memory management to achieve state-of-the-art performance. In this paper, we analyze the performance, particularly the throughput (tokens generated per unit of time), of 20 LLMs using two inference libraries: vLLM and HuggingFace's pipelines . We investigate how various hyperparameters, which developers must configure, influence inference performance. Our results reveal that throughput landscapes are irregular, with distinct peaks, highlighting the importance of hyperparameter optimization to achieve maximum performance. We also show that applying hyperparameter optimization when upgrading or downgrading the GPU model used for inference can improve throughput from HuggingFace pipelines by an average of 9.16% and 13.7%, respectively.
## I. INTRODUCTION
Large language models (LLM) have revolutionized the manner in which developers build intelligent software solutions, affecting several areas, including software engineering ([52], [54], [25], [18]). One of the primary drivers of this revolution is the emergence of open-source LLMs, which offer publicly accessible architecture, code, checkpoints (model weights) and, eventually, training data. Open-source LLMs enables developers to create AI-based solutions while maintaining control over aspects such as privacy and compliance, and, at the same type, providing governance and ownership of the model deployment process. Platforms such as HuggingFace (HF) have contributed to the success of open-source AI by providing, for instance, more than 700.000 models for download, including LLMs such as CodeLlama [39].
Inference engines (or frameworks) are software components that make LLMs operable. They have as main responsibility to load the model's weighs into the available devices (GPU and/or CPU), and to make the inference i.e., to generate a prediction/output/response based on input data. HuggingFace, for instance, provides inference mechanisms in its
## Listing 1: HuggingFace pipeline
model = AutoModelForCausalLM . from pretrained ( model name , device map=' auto ' , [ . . . ] ) return p i p e l i n e ( ' t e x t -generation ' ,
model=model , max new t okens =100 , model kwargs= { ' t o r c h dtype ' : t o r c h . bfl o a t 1 6 } [ . . . ] )
Transformer library [48], such as the pipelines , which are objects that abstract complex code used for inference (by wrapping other libraries such as PyTorch) and offer a simple API dedicated to several tasks, including text generation.
A key factor for the success of an inference engine is performance , i.e., the speed of serving, because it directly impacts the user experience of AI-powered systems and on the cost (since LLMs require specialized hardware such as GPUs). A measure of LLM performance is throughput , expressed in tokens generated by an LLM per unit of time. Increasing the throughput of LLM inference, and therefore reducing the cost per request, is becoming primordial [27].
Recently, state-of-the-art inference engines have emerged with the goal of improving inference performance. One of them is vLLM [27], launched in June 2023, which implements a memory-efficient inference engine for LLM. Inference engines such as vLLM or these from HuggingFace can be integrated into applications with a few lines of code, as Listing 1 shows.
However, the inference engine has hyperparameters that developers need to set by the developers. For example, Listing 1 shows a real utilization of HuggingFace pipelines , 1 which first loads the model (it has one hyperparameter device\_map ) and then creates a pipeline with the model as a parameter and some hyperparameters (e.g, max\_new\_tokens ). Listing 2 shows real code (but simplified) that uses vLLM 2 . The first line loads the model (with hyperparameter tensor\_parallel\_size ), the second performs inferences from a list of prompts (receives two hyperparameter temperature and top\_p ).
There are hyperparameters that have a direct incidence
1
https://github.com/adit-copilot/EnchantedQuest/blob/
48d6256c482abc40a8c916c6c8d1a7c5edb2c6fa/retrival/qa pipeline.py#L46
2 https://github.com/tencent-ailab/persona-hub/blob/
5e9b7d0a29eff2e2eaf01cc8c74d4abb731fb4a0/code/vllm synthesize.py#L37
## Listing 2: vLLM
l l m = LLM( model=model path , t e n s o r p a r a l l e l s i z e =4) # t e n s o r p a r a l l e l s i z e based on t h e GPUs you are using outputs = l l m . generate ( prompts , SamplingParams ( temperature =0.6 , t o p p =0.95 , [ . . . ] ) )
in throughput while others such as temperature direct affects the output from an LLM. In this paper, we focus on the former. One of them is tensor\_parallel\_size from vLLM , which indicates the number of GPUs to use for distributed execution with tensor parallelism. The value of this hyperparameter needs to be set by the developer according to the resources available in the deployment infrastructure. In the code from Listing 2, tensor\_parallel\_size is hardcoded to 4 and includes the comment: '#tensor parallel size based on the GPUs you are using' .
Another hyperparameter that affects throughput is batch size , which refers to the number of input instances processed simultaneously by the model in a single inference call. According to [50], the batch size is one of the most important hyperparameters to tune during the training phase, affecting, for example, accuracy and training time. In inference, increasing batch size typically increases throughput [27]. However, determining the batch size is challenging as is subject to limitations of the memory capacity of the hardware (e.g., it is not able to allocate the memory for numerous inputs on a large batch). On the other hand, a low value can lead to hardware being underutilized.
In this paper, we study how hyperparameters of inference engines affect the throughput of LLM. In particular, we examine the throughput landscape defined by the spaces of two hyperparameters, the number of GPUs to be used, and the batch size. We study LLM inference in the context of the code completion task, which is implemented by products such as Microsoft GitHub Copilot [56], [57]. As noted by [47], copilot efficiency is essential because LLM inference is costly and unsustainable on a massive scale. In our experiment, we study 20 open-source LLM, all from key players in the AI industry such as Meta, Google, Microsoft, Mistral, and HuggingFace, and two popular libraries that enable inference: HuggingFace Transformers [48] and vLLM [27].
Our results reveal that the throughput landscapes are irregular, with distinct peaks, underscoring the importance of hyperparameter optimization for maximizing inference performance. Motivated by these findings, we conduct an experiment on hyperparameter optimization. We examined two use cases focusing on changes in the inference infrastructure, such as upgrading or downgrading the GPU model. Our experiment shows that adjusting the number of GPU hyperparameters and/or batch size using our tool InfPop (based on Hyperopt [5]) in Hugging Face inference improves throughput by an average of 9.16% when upgrading the GPU model (from Nvidia V100 to A100) and by 13.7% when downgrading (from Nvidia A100 to V100).
All data, plots, and scripts are available in our Appendix [1]. The paper continues as follows. Section II presents the research question we investigate. Section III describes the research protocol. Section IV presents the results. Section V presents the discussion. Section VI discusses related work. Section VII presents the conclusions and future work.
## II. RESEARCH QUESTIONS
The research questions that guide this experiment are the following:
RQ1: What is the shape of the throughput landscape across the hyperparameter space defined by the batch size and the number of GPUs on vLLM inference?
For each LLM under study, we visually inspect the throughput distribution within the hyperparameter space defined by the number of GPUs and the batch size to analyze its shape. In particular, we search for: peaks, flat regions, or valleys.
This analysis gives us the first sing to know whether hyperparameter optimization should be applied to maximize or minimize a metric, such as throughput. For example, a peak in the landscape is a sign that there is a set of hyperparameters that maximize throughput.
## RQ2: For online inference, how does throughput vary with different numbers of GPUs (hardware scaling)?
The purpose of this question is to study the impact of the number of GPUs on throughput. This question could help us to know, for example, whether having more GPUs in the inference infrastructure (called GPU scaling ) allows an inference engine to improve throughput.
In this research question, we focus on online inference , each query done to the model (i.e., a request) through the inference library includes just one input. As a result, the model generates one output (or eventually more than one if applying, for example, beam search) for that single input.
## RQ3: For batched inference, how does throughput vary with the batch size?
This research question focuses on the batch inference. In contrast to the previous one, where the query to the LLM consists of one single input, the batching considers n inputs in a single query. This n is the batch size , which is an hyperparameter of the inference processes. Choosing an appropriate batch size n is challenging. On the one hand, a high batch size value would lead to throughput improvements but also may lead to out-of-memory. On the other hand, a low value may lead to resources (e.g., GPUs) being underutilized. Here, we study the relation between the space of the hyperparameter batch size and the throughput from inference engines.
## RQ4: How does throughput vary between different GPU models during inference?
Each new generation of GPUs boasts improved performance including throughput [8]. In this research question, we measure the variation in throughput across two GPU models, one representing a recent and widely used model, and another model from a previous generation.
RQ5: To what extent does applying Hyperparameter Optimization improve throughput in LLM?
The goal is to present an use case in which hyperparameter optimization of LLM inference produces improvements in throughput. In particular, we apply hyperparameter optimization (using our approach InfPop ) in cases where there are changes on the hardware infrastructure used for inference. Thus, hyperparameter optimization finds a new hyperparameter values that maximize throughput on the new hardware.
## III. EXPERIMENTAL PROTOCOL
In order to answer the research questions, we conduct an experiment that consists of executing the code-completion task for a set of incomplete programs. That completion is done by doing inference calls to a LLM using an inference engine. The experiment is designed as follows.
## A. Selection of the inference engines to evaluate
We evaluate inference using two inference engines.
1) Inference from HuggingFace Transformers library: We select it for the following reasons. First, it offers simple, easy to use, and concise APIs to perform inference on LLM. For example, pipelines abstracts most of the complex code from the library, and provides a simple API dedicated to several tasks, including Text Generation. An example for this pipeline is shown in Listing 1. Internally, that code uses a pipeline TextGenerationPipeline . In the remainder of the paper, we will refer to the HuggingFace pipeline for text generation it as HF pl . Secondly, HuggingFace provides thousads of models which can be used with HF pl for inference. Lastly, HF Transformers has is a relevant library in the the scene of open-source on AI: it has ≈ 130.000 stars on GitHub.
2) vLLM : originaly materialized to implement PagedAttention [27] a technique for efficient management of attention key and value memory of transformer architecture. We choose to study vLLM for different reasons, including: a) It provides state-of-the-art inference performance on LLM [27]. b) introduces a novel memory management (PagedAttention [27]), then integrated to other inference engines [28] such as TensorRT-LLM [38]. c) It integrates with HuggingFace models, enabling it to work with state-of-the-art LLMs. d) Popularity: more than 23.000 Github stars since its launch (June 2023). e) Integrated with other LLM libraries and frameworks such as LangChain 3 .
## B. Selection criteria of the LLM to evaluate
We select a model if all the following criteria are met.
- · Model based on the Transformer architecture [45], which is effective for code completion tasks [41].
- · As our study focuses on large language models (LLM), the model must have ≈ > 1 billion parameters.
- · Evaluated on HumanEval [7] to demonstrate their competence in the code generation task.
3 https://python.langchain.com/v0.2/docs/integrations/llms/vllm/
TABLE I: LLMs considered in this study.
| HuggingFace model id | #Params (Billion) | HumanEval (pass@1) |
|-----------------------------------|---------------------|----------------------|
| bigscience/bloom-1b7 [49] | 1.7 | 4.4 |
| bigscience/bloom-3 [49] | 3 | 6.3 |
| bigscience/bloom-7b1 [49] | 7.1 | 8.1 |
| facebook/CodeLlama-7b [39] | 7 | 38.4 |
| facebook/CodeLlama-13b [39] | 13 | 43.3 |
| facebook/CodeLlama-34b [39] | 34 | 53.7 |
| facebook/CodeLlama-70b | 70 | 57.3 |
| mistralai/Codestral-22B | 22 | 81.1 |
| mistralai/Mistral-7B-v0.1 [23] | 7 | 30.5 |
| mistralai/Mixtral-8x7B-v0.1 [24] | 46.7 | 40.2 |
| gemma-ai/gemma-2b [43] | 2 | 22 |
| gemma-ai/gemma-7b [43] | 7 | 32.3 |
| microsoft/phi-1 [20] | 1.3 | 50.6 |
| microsoft/phi-1.5 [30] | 1.3 | 41.4 |
| microsoft/phi-2 [22] | 2.7 | 49.4 |
| bigcode/starcoder-15b [29] | 15.5 | 28.7 |
| bigcode/starcoder2-3b [31] | 3 | 31.7 |
| bigcode/starcoder2-7b [31] | 7 | 46.3 |
| WizardLMTeam/WizardCoder-15B [32] | 15 | 59.8 |
| WizardLMTeam/WizardCoder-33B [32] | 33 | 79.9 |
- · Model's weights (checkpoints) are available on the HuggingFace hub 4 .
- · Model's architecture implemented in the HuggingFace Transformers library 5 [48].
- · Model tagged with 'Text-Generation' tag 6 in the HuggingFace site for ensuring usage with HF pipeline.
- · Model supported by the vLLM library.
To select the models to study, we first inspect the vLLM documentation and its Github repository to detect the supported models. As vLLM uses HuggingFace Transformers library, this strategy allows us to select models supported by both the HF pl and vLLM . For each supported model, we read its documentation, related paper, HuggingFace model card, and the dashboard Paper-on-Code 7 to check all mentioned criteria.
Table I shows the 20 LLM that meet the criteria mentioned above and work in our infrastructure. It shows the numbers of parameters, which range from 1.3 to 70 billions, and the HumanEval (pass@1) reported by the models's authors. We include LLM from key players in the AI industry, such as Meta, Google, Microsoft, Mistral, and HuggingFace 8 ([29], [31]). Other models are discarded because they do not meet some of the criteria. For example, Moisaic [44] has not been evaluated in HumanEval; CodeGen [37] and Incoder [13] are not supported by vLLM (last check June 2024). Microsoft-Phi3 was later discarded because it failed in our infrastructure.
## C. Evaluation benchmark
HumanEval [7] is a dataset of 164 handwritten programming problems proposed by OpenAI to evaluate functional
4 HuggingFace model hub: https://huggingface.co/models
5 Model architectures implemented in HuggingFace transformer library: https://github.com/huggingface/transformers/tree/ 14ff5dd962c1bd0a4e3adaac347ba396d8df5add/src/transformers/models and https://huggingface.co/docs/transformers/
6 https://huggingface.co/models?pipeline tag=text-generation
7 https://paperswithcode.com/sota/code-generation-on-humaneval
8 HuggingFace participates via BigCode: https://www.bigcode-project.org/
correctness and measure the problem-solving capabilities of their code-based models. We consider HumanEval as it has been used by big AI players (e.g., OpenAI, Meta, Google, Microsoft) to evaluate the capaibilities of their LLMs.
Researchers created new benchmarks from HumanEval, to evaluate other tasks beyond function generation. For example, Fried et al. [13] and Bavarian et al. [4] evaluated code infiling task, which consists of predicting missing text spans that are consistent with the preceding and subsequent code.
To evaluate the code completion task, we select Singleline infilling 9 [13]. They created it by marking out each nonblank line of code in the canonical function implementation from each HumanEval problem. In total, Single-line infilling contains 1033 examples. We use this bechmark in a slightly different manner: we query a model to generate code just based on the preceding code, and we ignore the subsequent code as code completion is not infilling.
## D. Hardware used
We use two high-performance computation nodes available in our host infrastructure: two CPU Intel Xeon E5-2698 and 512 GB of RAM. The first one is equipped with eight Nvidia A100 GPUs with 40 GB [8] . We choose this node because that GPU has been extensively used to train and evaluate stateof-the-art LLMs considered in our study. The second node is equipped with a GPU model from a previous generation: Nvidia V100 10 , which is the first Tensor Core GPU introduced by Nvidia designed specifically for deep learning. The node is equipped with eight V100 with 32 GB. We choose to consider V100 as a 'previous generation' GPU because it has been used to train and evaluate some considered LLMs (e.g. Bloom [49]).
## E. Executing Inference trials on the Single-line infilling
We call a trial to the execution of the code completion tasks for all items from the Single-line infilling benchmark by querying one LLM m , using an inference engine e ( e ∈ [ HF pl , vLLM ]) , executed on n GPUs ( n ∈ [1 , 2 4 8] , , ) of model g ( g ∈ [ A 100 , V 100] ), with a batch size b ( b ∈ [1 , 2 4 8 16 32 64 128 256 1028] , , , , , , , , ). We run trials resulting from all the combinations between m e , , n , g and b . Note that, for each trial with batch size b , we create x inference invocations, each with b elements from the benchmark ( x results from the division between the size of the benchmark and b ). In vLLM , we modify the parameter of the constructor of class LLM . tensor\_parallel\_size for pasing the number of GPUs to be used, and pass b queries to the method generate from that class, where b is the batch size of the trial. In HF pl , we keep device\_map="auto" from the pipeline and, at the same time, we restringe the visible GPUs by changing the evironmental variable CUDA\_VISIBLE\_DEVICES . For example, for a trial that uses 2 GPUs, we set the value 0,1 .
9 https://github.com/openai/human-eval-infilling/blob/ 88062ff9859c875d04db115b698ed4b0f0395170/data/ HumanEval-SingleLineInfilling.jsonl.gz 10
Nvidia V100 whitepaper: https://images.nvidia.com/content/ volta-architecture/pdf/volta-architecture-whitepaper.pdf
Then, the other GPUs ( 2 . . . 8 ) are not visible. This strategy allows the pipeline, thanks to the auto configuration provides by the HF Accelerate library, to determine automatically the model deployment on the available (and visible) devices. For the batch size, we pass the value b via hyperparameter batch\_size from the pipeline.
We keep the default values for the other hyperparameters from the inference engine, except for two. First, we indicate the inference engine to generate up to 5 tokens. Second, we unify the floating-point precision used. All models from Table I use by default half-precision floating point (FP16/float16) with the exception of one (bigcode/starcoder2-3b) that uses full-precision floating point (FP32/float32). To ensure a fair comparison between models and engines, we explicitly set the hyperparameter precision to FP16 in both inference engines as is the value from the large majority. For each trial, we calculate throughput as the number of tokens generated during the trial (composed by x inference invocations) divided by the execution time of the trial in seconds (t/s).
## F. Data analysis to answer the research questions
Once executed all trials, we apply the following analysis to answer each research question.
- 1) RQ1: We plot the throughput landscapes using the Python library matplotlib. There is a plot for each combination of: a) hardware, b) inference engine, and c) LLM. We then inspect the shape of all the landscapes to select the representative cases for discussion.
- 2) RQ2: We select the trials with batch size equal to one. Then, for each LLM, we plot the throughput evolution with different numbers of GPUs, and report the number of GPUs that maximize throughput. We test the hypothesis H 0 : there is no statistically significant difference in throughput across different numbers of GPUs by appling an analysis of variance (ANOVA). In this test, each group corresponds to the trial with the same number of GPUs used on inference (1, 2, 4 and 8). Finally, we compare throughput between the two inference engines, vLLM and HF pl .
- 3) RQ3: For each combination of a) inference engine, b) GPU model, c) number of GPUs, and d) LLM, we plot the evolution throughput with the batch size. Then, for each combination, we test the null hypothesis H 0 : There is no a significant difference in the throughput values based on the batch size using Analysis of Variance test (ANOVA)
- 4) RQ4: To compare the throughput obtained with a Nvidia A100 with that one obtained with a Nvidia V100, we first compare the throughput from pairs of trials, one from A100, the other from V100, but sharing the other hyperparameters (LLM, batch size, number of GPUs). Moreover, we compute, for each inference engine, the Wilcoxon Signed-Rank Test to test the null hypothesis H 0 : The difference in throughput between Nvidia A100 and v100 is not significant .
- 5) RQ5: We evaluate the impact of hyperparameter optimization in two experiments: 1) Upgrading and 2) Downgrading GPU. Both consider two GPUs models, previous (P) and new (N). For studying the Upgrading , P becomes the
Nvidia V100 model, and N is Nvidia A100. For Downgrading , P is A100 and N is V100. Each experiment is as follows. For each pair LLM and inference engine, we search the set of hyperparameters HP orig that maximize throughput on P. Then, we measure throughput of using HP orig on N. After that, we apply hyperparameter optimization on N to find new hyperparameters HP best that maximize throughput on N. Finally, we compare throughput from HP best and HP orig to measure the impact of HF pl .
To apply hyperparameter optimization on inference engines, we implement InfPop (Inference hyperParameter Optimization). Internally, InfPop uses Hyperopt [5], a stateof-the-art hyperparameter optimization, used hyperoptimizing other software engineering tasks [33], [34]. InfPop receives as input: 1) a list of queries to pass to a LLM (in our experiment, queries for code-completion from the Single-line infilling benchmark), 2) a specification of the hyperparameter space. In this experiment, we consider two hyperparameters: number of GPUs and batch size. 3) An objective/fitness function : In this study, the function used by InfPop aims at maximizing inference throughput on the mentioned queries. InfPop produces as output a set of values for the hyperparameters that maximize the objective. We hyperoptimize vLLM and HF pl on each LLM. Given the stochastic nature of Hyperopt, we conduct each experiment 10 times and report the average results.
## IV. RESULTS
A. RQ1: What is the shape of the throughput landscape across the hyperparameter space defined by the batch size and the number of GPUs on vLLM inference?
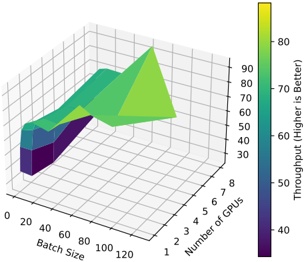
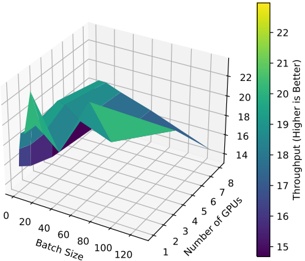
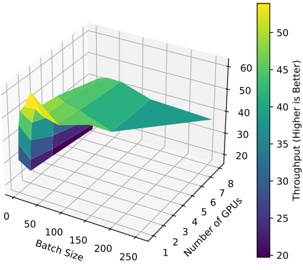
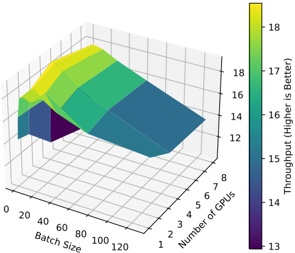
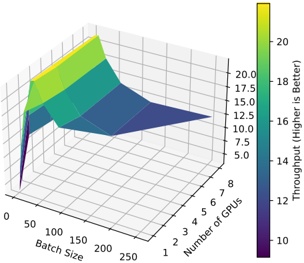
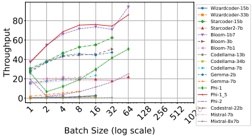
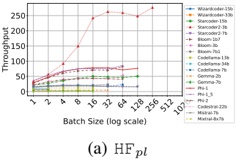
Figure 1 shows six plots, each corresponding to an LLM and an inference engine. In Appendix [1] we include all of them, including interactive versions that facilitate the visualization and analysis. Two axes represent the hyperparameter space: batch size and number of GPUs, while the third one -the vertical one- corresponds to the throughput. This analysis does not aim to perform a rigorous classification of these shapes, but to provide evidence though these examples, that the throughput landscapes are not uniform, thus hyperparameter optimization would be useful.
Figure 1a shows the Bloom-1b7 landscape using HF pl . It has two peaks where the throughput is much higher ( ≈ 94 5 . ) than in other parts of the landscape (between 60 and 70 t/s): one uses one GPU and another uses eight GPUs, both with batch size 64. Increasing that increasing the batch size above 64 produces memory errors.
The second case, Fig. 1b, shows the landscape for CodeLlama and HF pl . It presents different peaks, most notably: 1) one single GPU and and batch size 16, 2) two GPUs and batch size 64, and 3) four GPUs and batch size 128. This shows that for CodeLlama when one increases the GPUs, the batch size should be also adjusted. This case also shows the challenging of determining optimal hyperparameter values: Codellama-7B using one single GPU can infer batches up to size 16. Putting values of 32 or greater produces memory errors.
The third case, Fig. 1c corresponds to Mistral-7b and HF pl . It has a peak at one GPU and batch size 32. Greater batches with one GPU cause memory errors. Beyond this peak, the landscape presents a descending inclined plane as the batch enlarges. The landscape also exhibits high values of throughput (similar to the mentioned peak) with four GPU and small batches (4 and 8). With 4 GPUs, increasing the batch size decreases the throughput.
The fourth case, Fig. 1d corresponds to Gemma-2 and vLLM . We observe that: 1) There is a significant improvement of throughput when using 4 or 8 GPUS compared to using 1 or 2 GPUs. 2) The landscape has a plateau : a vast zone where the values are relatively constant, do not change significantly throughout the plateau, and represent a high-throughput region. We can observe it in yellow. This plateau is located in the region bounded by 4 to 8 GPUs and batch sizes ranging from 128 to 1024. 3) The throughput given with eight GPUs is slightly higher than that with four. 4) The highest throughput is with a batch size equal to 258: increasing the size slightly impacts throughput. However, the reduction is more evident when the batch size is smaller than 258.
The fifth case, Fig. 1e corresponds to Starcoder-15b and HF pl . It has a peak with one GPU and batch size 32 and increasing the batch size to a value just greater than the peak produces a memory error. However, this landscape has two main differences with respect to the two previous examples. First, it has a second peak when using two GPUs and a larger batch size (128). Secondly, the throughput landscape shows a downward slope, indicating that throughput decreases as the number of GPUs increases.
Hardware specifics. The previous landscapes resulted from the execution of inference on a computing node equipped with Nvidia A100. We also inspect the landscape resulted from the V100. Even in the majority of cases the landscapes from both models produces similar shapes (A100 shapes have higher peaks, i.e. higher throughput, because it is a more recent and advanced model), others exhibit more noticeable differences. For example, Fig. 1f shows the execution of StarCoder-15b in a V100 (the Fig at its left shows the landscape of this model from A100). We observe that the shape is different: there is not a peak but a thin and long plateau region bounded by 2 and 8 GPUs batch sizes 8 and 16. This means that, a LLM is deployed in a another GPU model, it might be necessary to adjust the hyperparameters in order to maximize the throughput. In RQ5 we study this.
Visual inspection of the throughput landscape from inference using HF pl and vLLM shows irregular landscapes, some with marked peaks. Consequently, to ensure throughput maximization for a particular inference engine and hardware would require an inspection of the landscape.
B. RQ2: For online inference, how does throughput vary with different numbers of GPUs (hardware scaling)?
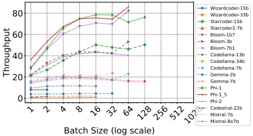
Table II and Figure 2 show the throughput of online inference performed by HF pl and vLLM when scaling Nvidia
(a) Bloom-1b7 HF pl Nvidia A100
(d) Gemma-2b
(b) Codellama-7b HF pl Nvidia A100
(c) Mistral-7b HF pl Nvidia A100
vLLM
Nvidia A100
(e) Starcoder-15b
HF
pl
Nvidia A100
(f) Starcoder-15b HF pl Nvidia V100
Fig. 1: Throughput landscape across the hyperparameter space (batch size and GPUs).
| | HF | pl | vLLM | vLLM | vLLM | vLLM | vLLM |
|-----------------|------|--------|--------|--------------|--------------|--------|--------|
| | | (Best) | | (Same #GPUs) | (Same #GPUs) | (Best) | (Best) |
| LLM | | GPUs | Thp | Thp | Impr. GPUs | Thp | Impr. |
| Bloom-1b7 | | 1 37.6 | | 133.1 | 3.5X 1 | 133.1 | 3.5X |
| Bloom-3b | 1 | 27.3 | 98.6 | 3.6X | 1 | 98.6 | 3.6X |
| Bloom-7b1 | 1 | 16.8 | 64 | 3.8X | 2 | 67.2 | 4.0X |
| Codellama-7b | | 15.7 | 63 | 4.0X | 1 | 63 | 4.0X |
| Codellama-13b | 1 2 | 9.7 | 40.6 | 4.2X | 4 | 48.2 | 5.0X |
| Codellama-34b | | 4.1 | 32.4 | 7.9X | 8 | 34.7 | 8.5X |
| Codellama-70b | 4 8 | 1.8 | 21.7 | 12.1X | 8 | 21.7 | 12.1X |
| Codestral-22b | 4 | 5.4 | 53.2 | 9.9X | 8 | 64.7 | 12.0X |
| Gemma-2b | 1 | 28.8 | 132.3 | 4.6X | 1 | 132.3 | 4.6X |
| Gemma-7b | 4 | 6.4 | 70.8 | 11.1X | 4 | 70.8 | 11.1X |
| Mistral-7b | 1 | 14.3 | 62.3 | 4.4X | 4 | 66.5 | 4.7X |
| Mixtral-8x7b | 8 | 4.1 | 58 | 14.1X | 4 | 59.2 | 14.4X |
| Phi-1 | 2 | 29 | 73.7 | 2.5X | 1 | 158.5 | 5.5X |
| Phi-1 5 | 1 | 37 | 171.5 | 4.6X | 1 | 171.5 | 4.6X |
| Phi-2 | 2 | 22 | 68.9 | 3.1X | 1 | 110.3 | 5.0X |
| Starcoder-15b | 1 | 30.7 | 32.5 | 1.1X | 8 | 58.4 | 1.9X |
| Starcoder2-3b | 1 | 44.8 | 104.1 | 2.3X | 1 | 104.1 | 2.3X |
| Starcoder2-7b | 1 | 15.7 | 61.1 | 3.9X | 4 | 62.3 | 4.0X |
| Wizardcoder-15b | 2 | 8 | 45.7 | 5.7X | 8 | 57.3 | 7.2X |
| Wizardcoder-33b | 4 | 1.6 | 36.8 | 23.0X | 8 | 43.8 | 27.4X |
TABLE II: Throughput (Thp) from HF pl and vLLM on A100.
A100 GPUs. The table shows: 1) for HF pl , the number of GPUs that maximizes the throughput for each model (column Best), 2) for vLLM , in column Same, the throughput using that number of GPUs (for a fair comparison), 3) for vLLM , the number of GPUs that maximizes the throughput for each
Fig. 2: Throughput Variation with Different Numbers of GPUs (Nvidia A100) during Online Inference (batch size = 1).
model (column Best). Tables showing the throughput per GPU, and the results from V100 can be found in our appendix [1].
We observe that the scaling hardware when using HuggingFace has a different effect than when using vLLM . All findings also apply for Nvidia V100.
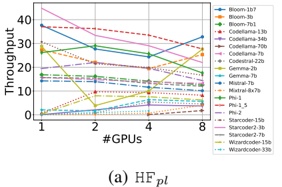
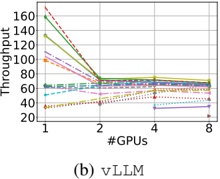
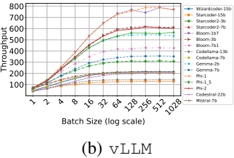
1) vLLM : From Figure 2b we identify two primary observations. First, scaling from 1 to 2 GPUs using vLLM has a strong (negative) impact on throughput of some models (e.g., Microsoft Phi-1), even for others (such as CodeLlama-13b) has a moderate (positive) impact. Second, scaling from 2 to 4, and then from 4 to 8 GPUs has less impact on throughput: the plot shows that the throughput of most of the model is bounded between 60 and 80 t/s.
We also observe: a) with one GPU, throughput presents a large variability in the models: it goes from 32.5 to 171.5
- t/s. This variability is reduced after scaling. b) 8 models with ≤ 3 billion parameters maximize throughput using a single GPU, c) when scaling to two GPUs, there are two effects: the first one is that throughput dramatically drops (which is the case for the 'smaller' models previously mentioned); the second one is the throughput slinging vary positively in most of models with 13-15 billion parameters. d) Models with 713 billion parameters maximize throughput using 4 GPUs. e) Models with more than 15 billions parameters typicaly maximize throughput with 8 GPUS.
- a) Statistical test for vLLM : Taking into account all GPUs, the ANOVA test rejects the null hypothesis H 0 at the significant level α = 0 05 . (F-statistic: 5.44, p-value: 0.002) which indicates that there is a statistically significant difference in throughput across different numbers of GPUs for both A100 and V100 GPUs. We suspect that this significant difference is dragged by one of the analyzed groups, GPU 1, which maximizes throughput for some LLM. For that, we performed two additional tests. First, the re-execution of the ANOV A test by just considering trials with 2, 4 and 8 GPUs failed to reject H 0 . Secondly, Tukey HSD test (Honestly Significant Difference) reveals significant differences in performance metrics between using GPU 1 and each of the other groups (2, 4, and 8). However, no significant differences were found between GPUs 2, 4, and 8.
- 2) HF pl : From Figure 2a, we observe two major differences with respect to vLLM : 1) the throughput are lower than using vLLM , independently of the number of GPUs used; 2) when scaling, there is no dominant pattern evolution of throughput as for vLLM . Moreover: a) Scaling GPU results in a very slight decrease of throughput from models with 7b parameters (Bloom-7B1, CodeLlama-7b, Mistral-7b). b) The decline is more pronounced in StarCoder2-3b. c) Scaling cause down and up (e.g., Bloom-1b7, Bloom3-b). d) Scaling cause up and down (e.g., Phi-1, Phi-2). In conclusion, using the HF pl , scaling generally does not improve throughput for most LLMs (with few exceptions such as Phi-1 and Gemma-7).
- a) Statistical test for HF pl : Based on the results of the ANOVA test, we cannot reject the null hypothesis ( H 0 ) at the 0.05 significance level (F-statistic: 0.37, p-value: 0.77). This means that there is not enough statistical evidence to suggest that the means of the groups -number of GPUs- are significantly different, which can be translated as scaling up GPUs does not produce significant changes in throughput.
- 3) Comparison between Inference Engines: Table II shows the throughput for each model (columns Thp ) and the improvement in throughput. Taking into account the number of GPUs that led HF pl to maximize throughput (column vLLM Same ), vLLM achieves a mean (median) improvement of 4.3 X (6.47 X ). However, for 12 LLMs, vLLM maximizes throughput by using a different number of GPUs (column vLLM Best ), achieving a mean (median) improvement of 7.26 X (4.80 X ) with respect to HF pl . In nine of these 12 cases, vLLM achieves the gain by using more GPUs and, in the remaining three cases, fewer GPUs. This shows that both vLLM and HF pl need to be optimized separately, at least on the number of GPUs, to
increase throughput.
The reason behind the difference in throughput is that vLLM was designed to achieve fast inference. For that, vLLM introduces key improvements. We briefly discuss two of them. First, vLLM uses PagedAttention [27], a new attention algorithm that manages the attention keys and values from the Transformer architecture [45]. In autoregressive decoding, all the input tokens to the LLM produce their attention key and value tensors, and these tensors are kept in GPU memory to generate the next tokens. This has several problems for LLMs, such as the large amount of memory required and memory waste [26]. PagedAttention proposes a solution inspired by the idea of virtual memory and paging in operating systems: it allows storing continuous keys and values in noncontiguous memory space. The second improvement is Continuous batching , initially proposed by [51]. During inference, instead of waiting until every sequence in a batch has completed generation (as traditional static batching does) this approach, once a sequence in a batch has completed generation, a new sequence is inserted in its place. This yields a higher resource utilization than static batching [42] and thus increases throughput.
Answer to RQ2: For vLLM , GPU scalability benefits larger LLMs ( ≈ 13 billion parameters or more), maximizing throughput with the use of eight GPUs. However, scaling up GPUs penalizes smaller models ( ≈ 3 billion parameters or fewer), decreasing their throughput. For these smaller models, the optimal configuration is using 1 or 2 GPUs. In contrast, using HF pl , scaling hardware does not significantly increase throughput for most of the LLMs studied. Additionally, on the same hardware, vLLM achieves an average throughput that is 6.47 times higher than that of HF pl .
Implications: HF pl may conduct to under-optimal results when the node has more than one GPU (since it uses all GPUs). Furthermore, we recommend hyperoptimizing the number of GPUs to be used during inference.
C. RQ3: For batched inference, how does throughput vary with the batch size?
We study how the throughput varies according to the batch size by using a particular number of GPUs.
- 1) HF pl : Figure 3 shows the throughput using 1, 2, 4 and 8 Nvidia A100 GPUs and HF pl .We observe: a) The four plots show similar trend. b) Scaling on hardware (more GPUs) allow to have larger batches. The reason is that there is more memory on the GPU to allocate bigger batches and thus compute more inputs in parallel. c) the maximum throughput is usually reached with the largest batch size that correctly works. For example, Phi-1 achieves the maximum throughput with a batch size 64, larger batches produce memory errors.
- a) Statistical test for HF pl : We compute the ANOVA test for each group of GPU configurations (1, 2, 4, and 8). For both Nvidia A100 and V100, we reject the null hypothesis H 0 for 1, 2 and 4 GPUs, at the significant level α = 0 05 . . All
(a) 1 GPU
(b) 2 GPUs
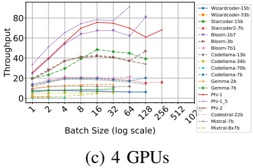
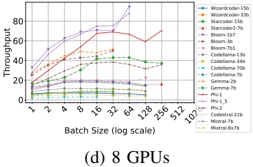
Fig. 3: Throughput at difference batch sizes for HF pl using Nvidia A1000 GPUs (outlier Starcoder2-3b removed and shown in Figure 4a)
with the exception of the Starcoder-2-3b mentioned above, throughput never passes 100 t/s. These findings also apply for the inference using 1, 4 and 8 GPUS and GPU Nvidia V100.
Fig. 4: Comparison of throughput using two Nvidia A1000 GPUs between HF pl (left) and vLLM (right)
p-values are shown in our appendix. In contrast, we cannot reject H 0 when the trial has eight GPUs.
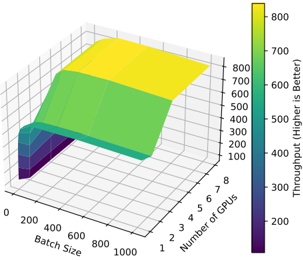
2) vLLM : Figure 4b shows the throughput obtaining with different batch sizes and using two GPUs. The plots for one, four, and eight GPUs exhibit a similar trend and are available in our appendix [1]. From these plots, we observe that: 1) Throughput generally increases with batch size across most models. 2) The improvement is more noticeable for smaller to medium batches (up to 128). 3) Most models achieve their highest throughput around batch sizes of 64 to 256. Beyond this point, throughput tends to plateau, indicating that increasing batch size further does not significantly improve throughput. 4) For some models, such as Starcoder-15b and Gemma-2b, after the plateau, the throughput shows a slight, but not significant, decrease. 5) Moreover, for Bloom-1b7 (as well as for other models using 4 or 8 GPUS) the throughput shows a slight decrease followed by a subsequent increase. All these points mean that optimizing the batch size is crucial to maximize throughput in LLM. when using vLLM inference.
- a) Statistical test: For both types of hardware, Nvidia A100 and V100, and for each number of GPUs, we reject the null hypothesis H 0 at the significant level α = 0 05 . (p-values listed in the appendix).
3) Comparison HF pl and vLLM : Figure 4 shows the throughput from HF pl and vLLM both using two Nvidia A100 GPUs) We observe that: a) with batch size 1, in both engines the throughput is below to 100 t/s. b) However, throughput from vLLM increases rapidly with batch size. For HF pl the increase is moderate for some models (e.g., Phi-1, Bloom1b7) or null for others (CodeLlama-7b). c) Starcoder-2-3b with HF pl outperforms the other models and has a huge increase from batch size 4. d) Since batch size 4, the throughput from vLLM is between 100 and almost 800 t/s. In contrast, for HF pl , a) Statistical test: We apply Wilcoxon Signed-Rank Test to test the null hytothesis H 0 : The difference in throughput between vLLM and HF pl is not significant. For all number and model of GPUs, the test rejects H 0 at the 0.05 significance level (all p-values are in our appendix). Moreover, we measure the effect size employing Cliff's delta ( δ ) in order to quantify the magnitude of differences between the throughput from vLLM and HF pl . Across all the number and models of GPUs evaluated, the mean δ is 0.8762. This indicates a very large effect size, suggesting a significant difference between the two groups, with vLLM scoring higher than HF pl .
Answer to RQ3: In HF pl , increasing the batch size leads to slight or moderate increases in throughput for some models (e.g., CodeLlama-7b) and steep increases for others (e.g., Bloom-1b7). Increasing the size of the batch that maximize the throughput often results in out-of-memory errors. Scaling up GPUs allows HF pl to process larger batches. Conversely, increasing vLLM significantly impacts small to medium batches (fewer than 64). For larger batches, changes in throughput are not substantial and do not cause out-of-memory. Overall, vLLM achieves significantly higher throughput than HF pl on the two hardware devices tested.
Implications: Optimizing batch size is crucial to maximize throughput in LLM. In HF pl , determining the optimal batch size and number of GPUs to achieve maximum throughput is challenging because is bonded by the GPU memory. This insight is valuable for hyperparameter optimization, especially in scenarios where throughput is a critical performance metric.
## D. RQ4: How does throughput vary between different GPU models during inference?
For vLLM , the increase of throughput using A100 compared to V100 is on average 83.5% (median 77.6). The models that exhibit the largest difference are Gemma-7b, Codellama13b, 34b and 70b, Wizardcoder-15b, all with 100% or greater improvement by using A100. Appendix [1] includes a detailed table with the improvement for each model and hardware.
We compute Wilcoxon Signed-Rank Test to test the null hypothesis H 0 : The difference in throughput between Nvidia
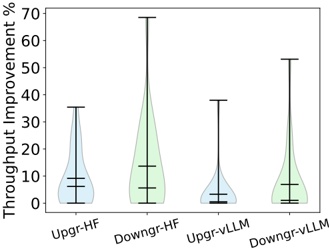
Fig. 5: Distribution of throughput improvement for HF pl given by hyperparameter optimization in hardware upgrading (from Nvidia V100 to A100) and downgrading (from A100 to V100).
A100 and V100 is not significant for vLLM . We reject H 0 at the significant level α = 0 05 . (p-value = 2.01). We measure the effect size to quantify the differences of throughput between A100 and V100 using Cliff's delta [9]. A delta value of 0.406 suggests a moderate effect size, indicating a moderate difference between A100 and V100 using vLLM .
For HF pl , the increase of throughput using A100 is lower on average, 47% (median 23.3%). Notally, the increase is greater for the largest models such as WizardCoder-33b (535.6%) and Codellama-70b-hf (276%), but smaller for the small models such as Gemma-2b (1.9%), Phi-2 (21.8%). We reject H 0 for HF pl at the significant level α = 0 05 . (p-value = 3.88). The measurement of effect size using Cliff's delta is 0.1333, which indicates a small but noticeable effect accross throughput from A100 and V100.
Answer to RQ4: Upgrading (or downgrading) the GPU model has a significant impact on the throughput of vLLM , with an improvement of 83.5% on average) and on HF pl with an improvement of 47% on average.
Implications: Developers of AI-based systems need to analyze the following trade-off, either: a) Maximizing Throughput: Opt for the Nvidia A100 to achieve maximum throughput. This choice involves higher costs due to the premium price of state-of-the-art hardware; or b) Reducing Operational Costs: Choose older hardware like Nvidia V100, which might result in lower throughput but eventually reduce operational expenses. This option is particularly advantageous for LLMs where the difference in throughput between A100 and V100 is modest (e.g., HF pl and small LLMs such as Microsoft-Phi).
## E. RQ5: To what extent does applying Hyperparameter Optimization improve throughput in LLM?
Fig 5 shows the distribution of improvement in throughput given by the new hyperparameter values found by our tool InfPop , in the context of GPU upgrade (from Nvidia V100 to A100) and downgrade (from A100 to V100). For upgrade, optimization produces HF pl a median increase (avg) in throughput of 6.4% (9.16%). For some models, e.g., Starcoder15b the improvement is higher (24%), while for others three there is no improvement (i.e., the best configuration, in terms of throughput, of HF pl on V100 is also the best on A100). For downgrade, the median improvements are 5.61% (average 13.7%). For vLLM the improvements are lower, in both upgrading (median 3.3%) and downgrading (median 6.9%). The reason is that, as shown in Figure 4, optimizing the evaluated hyperparameters in vLLM has a lesser impact on throughput than in HF pl .
Answer to RQ5: Our results suggest that applying hyperparameter optimization during changes in the inference infrastructure -such as upgrades or downgrades of GPU devices- can yield improvements in throughput. On average, hyperparameter optimization enhances throughput from HF pl by 9.16% during GPU upgrades and 13.7% during GPU downgrades.
Implications: Applying hyperparameter optimization during hardware upgrades (e.g., GPU) is crucial to maximize the benefits provided by the new hardware. Applying hyperparameter optimization during hardware downgrades is essential because the transition from a newer model (A100) to an older one (V100) typically results in a decrease in throughput. This study demonstrates that hyperparameter optimization can help to mitigate these performance losses.
## V. DISCUSSION
## A. Deployment of LLMs on available hardware
Both vLLM and HF pl inference engines are able to deploy the largest LLM using the CPU and just one GPU. The reason is that these engines provide specially mechanisms, such as HF Accelerate [19] activated via the hyperparameter device\_map="auto" , to determine automatically where to put each layer of the model depending on the available resources. In the case of Accelerate, it first uses the maximum space available on the GPU(s), and when it still needs space, it stores the remaining weights on the CPU, RAM, and finally on the hard drive as memory-mapped tensors. For example, Starcoder2-3b and CodeLlama-7b fully fit in one GPU (either A100 or V100). From Table II we observe using just 1 GPU maximizes their throughput. For them, if one uses HF pl with device\_map="auto" on a infrastructure with more than one A100 GPU, the throughput would be negatively affected. The other models can perform the inference with 1 GPU, but also needs to store weights on CPUs and eventually on disk (e.g., Mixtral), damaging the throughput.
The amount of GPU memory has an impact. For example, HF pl achieves to store all CodeLlama-70b weights in eight A100s, each with 40Gb. However, it cannot do that on the eight V100 with 32GB, which requires the storage of some parameters in the CPU. This has an impact on throughput (1.79 vs 0.21), beyond the technological improvements introduced by the Nvidia A100.
B. Correlation between throughput, HumanEval score and number of parameters
Table II shows that, for both HF pl and vLLM , those that maximize throughput are the models with smaller number of parameters, such as Bloom-1b7, Gemma-2, and Starcoder23b. The Pearson correlation between parameters and throughput (columns HF pl Best , vLLM Same and vLLM Best ) returns coefficients between -0.623 and -0.67, suggesting a noticeable inverse relationship between throughput and the number of parameters (p-values between 0.001 and 0.003).
The largest models generally achieve the highest performance scores in HumanEval, as shown in Table I. The correlation coefficient between HumanEval and the parameters is 0.527 (p-value 0.017), indicating a moderate positive relationship. This suggests that models with more parameters tend to have higher HumanEval scores.
We also compare the correlation between throughput and HumanEval. For HF pl the coefficient is -0 58 . (p-value 0.0072). As throughput increases, HumanEval tends to decrease. For vLLM , considering the 'best' throughput (Table II) the coefficient is -0.35 (p-value 0.122): As throughput increases, HumanEval tends to decrease slightly. At the significant level α = 0 05 . , the correlation is not significant. These results suggest that vLLM achieves a more favorable trade-off between performance and throughput compared to HF pl .
## C. Threats to Validity
It could be the risk that HumanEval is not representative of the code completion task. Neverteless, we consider it because it has been used on similar tasks such as infilling [13], [4].
There are other inference engines that could eventually achieve state-of-the-art throughput, such as TensorRTLLM [38]. We choose vLLM over other efficient engines because it first introduced a novel mechanism (PagedAttention [27]), later adopted by other engines such as TensorRTLLM.
## VI. RELATED WORK
Wang et al. [46] presented EcoOptiGen, a hyperparameter optimization for LLM inference. Their and our work have substantial differences. They hyperoptimize the inference of closed LLM from OpenAI, accessible through an API for optimizing accuracy. In contrast, our work optimizes on throughput by exploring parameters such as number of GPUs, batch sizes, which are not accessible via the OpenAI API.
Previous work has study inference issues. Gao et al. [14] studied low GPU utilization issues from jobs submitted to Platform-X, a Microsoft internal deep learning platform. They classified 706 issues discovered across 400 deep learning jobs, and found that the 25.64% of the issues were related to 'Improper Batch Size' and the 3.12% are related to 'Insufficient GPU Memory'. Zhang et al. [53] conducted a similar study another deep learning platform in Microsoft (Philly) and found that 8.8% of the issues were related to GPU out-ofmemory. These results show that InfPop (after changing the fitness function) could be useful to avoid these types of issues. Motivated by the out of memory failures, tools such as DNNMem [16] and DNNPerf [15] were proposed for predicting GPU memory consumption and performance of deep learning models. Similarly, Cao et al. [6] studied performance problems of TensorFLow and Keras frameworks from StackOverflow posts. They found 12 performance problems related to 'Improper Hyper Parameter'. In future work, InfPop could be adapted to try to fix them.
Previous work has also focused on studying training and/or inference configuration via hyperparameters. McCandlish et al. [35] predicted the largest useful batch size for neural network training, addressing the trade-off between training speed and computational efficiency. In our paper, we focus on inference. Gao et al. [17] proposed DnnSAT, a resource-guided approach for deep learning models to help existing AutoML tools [21] (such as Hyperparameter Optimization) efficiently reduce the configuration space. DnnSAT could be integrated into our tool InfPop to reduce the number of configurations.
Previous work has conducted related empirical work on LLM inferences. Samsi et al. [40] benchmarked the energy consumed by Llama models: 7b, 13b and 65B. Beyond the research goals, there are some differences with our work, notably the model evaluated (3 vs. 20) and the inference libraries (Llama scripts [11], based on Pytorch and FairScale [12], vs HF pl and vLLM ). Xhou et al. [55] evaluated the speedups achieved by employing quantization techniques on two models LLaMA-2-7B and 13B. Argerich et al. [3] presented EnergyMeter, a software-based tool to measure the energy consumption of different hardware components. For evaluation, they considered LLMs with at most 7b parameters (we consider LLMs up to 70b) and use HuggingFace Transformers for inference. Coignion et al. [10] evaluated the code generated by 18 LLMs on the Leetcode benchmark. The main differences from our work, beyond the goal, are the LLMs evaluated (they consider smaller LLMs, up to 15b parameters) and the inference engine used (DeepSpeed vs HF pl and vLLM ). Yarally et al. [50] studied how batch inference affects the energy consumption of computer vision tasks using Pytorch. Alizadeh et al. [2] evaluated the energy consumption of deep learning runtime infrastructures such as ONNX, PyTorch and TensorFlow. Beyond differences in research goals, these two works do not focus on LLMs.
## VII. CONCLUSIONS AND FUTURE WORK
In this paper, we conduct a large-scale evaluation of the throughput of 20 LLMs using two inference engines. We inspect the throughput landscape from the hyperparameter space and demonstrate that hyperparameter optimization can be applied to improve throughput.
In future work, we plan to: 1) Evaluate the performance of other inference engines such as those listed in the surveys [36], [55]. 2) Analyze the landscapes from other measures such as resource utilization (CPU, GPU) or latency. 3) Incorporate these measures into InfPop 's optimization objective. 4) Evaluate other hyperparameter optimization approaches and space reduction techniques such as [6] 5) Study and optimize
others hyperparameters that may affect throughput and the eventual new measures. 6) Incorporate the specification of these hyperparameter spaces into InfPop . 7) Release a usable version of InfPop and present its architecture, design, implementation decisions, and usage in a demo/tool track paper.
## REFERENCES
- [1] Appendix.https://anonymous.4open.science/r/infpop-0223/, 2024.
- [2] Negar Alizadeh and Fernando Castor. Green ai: A preliminary empirical study on energy consumption in dl models across different runtime infrastructures. arXiv preprint arXiv:2402.13640 , 2024.
- [3] Mauricio Fadel Argerich and Marta Pati˜ no-Mart´ ınez. Measuring and improving the energy efficiency of large language models inference. IEEE Access , 12:80194-80207, 2024.
- [4] Mohammad Bavarian, Heewoo Jun, Nikolas Tezak, John Schulman, Christine McLeavey, Jerry Tworek, and Mark Chen. Efficient training of language models to fill in the middle, 2022.
- [5] James Bergstra, Daniel Yamins, and David Cox. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In Sanjoy Dasgupta and David McAllester, editors, Proceedings of the 30th International Conference on Machine Learning , volume 28 of Proceedings of Machine Learning Research , pages 115-123, Atlanta, Georgia, USA, 17-19 Jun 2013. PMLR.
- [6] Junming Cao, Bihuan Chen, Chao Sun, Longjie Hu, Shuaihong Wu, and Xin Peng. Understanding performance problems in deep learning systems. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering , pages 357-369, 2022.
- [7] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code, 2021.
- [8] Jack Choquette, Wishwesh Gandhi, Olivier Giroux, Nick Stam, and Ronny Krashinsky. Nvidia a100 tensor core gpu: Performance and innovation. IEEE Micro , 41(2):29-35, 2021.
- [9] Norman Cliff. Dominance statistics: Ordinal analyses to answer ordinal questions. Psychological bulletin , 114(3):494, 1993.
- [10] Tristan Coignion, Cl´ ement Quinton, and Romain Rouvoy. A Performance Study of LLM-Generated Code on Leetcode. In 28th International Conference on Evaluation and Assessment in Software Engineering (EASE'24) , Proceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering (EASE'24), Salerno, Italy, June 2024.
- [11] Facebook Research,. Llama. https://github.com/facebookresearch/llama, 2023.
- [12] FairScale authors. Fairscale: A general purpose modular pytorch library for high performance and large scale training. https://github.com/ facebookresearch/fairscale, 2021.
- [13] Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen-tau Yih, Luke Zettlemoyer, and Mike Lewis. Incoder: A generative model for code infilling and synthesis. arXiv preprint arXiv:2204.05999 , 2022.
- [14] Y. Gao, Y. He, X. Li, B. Zhao, H. Lin, Y. Liang, J. Zhong, H. Zhang, J. Wang, Y. Zeng, K. Gui, J. Tong, and M. Yang. An empirical study on low gpu utilization of deep learning jobs. In 2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE) , pages 880880, Los Alamitos, CA, USA, apr 2024. IEEE Computer Society.
- [15] Yanjie Gao, Xianyu Gu, Hongyu Zhang, Haoxiang Lin, and Mao Yang. Runtime performance prediction for deep learning models with graph neural network. In 2023 IEEE/ACM 45th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP) , pages 368-380, 2023.
- [16] Yanjie Gao, Yu Liu, Hongyu Zhang, Zhengxian Li, Yonghao Zhu, Haoxiang Lin, and Mao Yang. Estimating gpu memory consumption of deep learning models. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering , ESEC/FSE 2020, page 1342-1352, New York, NY, USA, 2020. Association for Computing Machinery.
- [17] Yanjie Gao, Yonghao Zhu, Hongyu Zhang, Haoxiang Lin, and Mao Yang. Resource-guided configuration space reduction for deep learning models. In 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE) , pages 175-187. IEEE, 2021.
- [18] Hadi Ghaemi, Zakieh Alizadehsani, Amin Shahraki, and Juan M Corchado. Transformers in source code generation: A comprehensive survey. Journal of Systems Architecture , page 103193, 2024.
- [19] Sylvain Gugger, Lysandre Debut, Thomas Wolf, Philipp Schmid, Zachary Mueller, Sourab Mangrulkar, Marc Sun, and Benjamin Bossan. Accelerate: Training and inference at scale made simple, efficient and adaptable. https://github.com/huggingface/accelerate, 2022.
- [20] Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio C´ esar Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. Textbooks are all you need. arXiv preprint arXiv:2306.11644 , 2023.
- [21] Frank Hutter, Lars Kotthoff, and Joaquin Vanschoren. Automated machine learning: methods, systems, challenges . Springer Nature, 2019.
- [22] Mojan Javaheripi, S´ ebastien Bubeck, Marah Abdin, Jyoti Aneja, Sebastien Bubeck, Caio C´ esar Teodoro Mendes, Weizhu Chen, Allie Del Giorno, Ronen Eldan, Sivakanth Gopi, et al. Phi-2: The surprising power of small language models. Microsoft Research Blog , 2023.
- [23] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825 , 2023.
- [24] Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088 , 2024.
- [25] Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. A survey on large language models for code generation. arXiv preprint arXiv:2406.00515 , 2024.
- [26] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Yu, Joey Gonzalez, Hao Zhang, and Ion Stoica. vllm: Easy, fast, and cheap llm serving with pagedattention. https://blog.vllm. ai/2023/06/20/vllm.html, 2023.
- [27] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , 2023.
- [28] Baolin Li, Yankai Jiang, Vijay Gadepally, and Devesh Tiwari. Llm inference serving: Survey of recent advances and opportunities. arXiv preprint arXiv:2407.12391 , 2024.
- [29] Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161 , 2023.
- [30] Yuanzhi Li, S´ ebastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. Textbooks are all you need ii: phi-1.5 technical report. arXiv preprint arXiv:2309.05463 , 2023.
- [31] Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. Starcoder 2 and the stack v2: The next generation. arXiv preprint arXiv:2402.19173 , 2024.
- [32] Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568 , 2023.
- [33] Andre Lustosa and Tim Menzies. Optimizing predictions for very small data sets: a case study on open-source project health prediction. arXiv:2301.06577, 2023.
- [34] Matias Martinez, Jean-R´ emy Falleri, and Martin Monperrus. Hyperparameter optimization for ast differencing. IEEE Transactions on Software Engineering , 49(10):4814-4828, 2023.
- [35] Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota Team. An empirical model of large-batch training. arXiv preprint arXiv:1812.06162 , 2018.
- [36] Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Hongyi Jin, Tianqi Chen, and Zhihao Jia. Towards efficient generative large language model serving: A survey from algorithms to systems. arXiv preprint arXiv:2312.15234 , 2023.
- [37] Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthesis. ICLR , 2023.
- [38] Nvidia. Tensorrt-llm. https://github.com/NVIDIA/TensorRT-LLM, 2023.
- [39] Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, J´ er´ emy Rapin, et al. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950 , 2023.
- [40] Siddharth Samsi, Dan Zhao, Joseph McDonald, Baolin Li, Adam Michaleas, Michael Jones, William Bergeron, Jeremy Kepner, Devesh Tiwari, and Vijay Gadepally. From words to watts: Benchmarking the energy costs of large language model inference. In 2023 IEEE High Performance Extreme Computing Conference (HPEC) , pages 1-9, 2023.
- [41] Alexey Svyatkovskiy, Shao Kun Deng, Shengyu Fu, and Neel Sundaresan. Intellicode compose: code generation using transformer. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering , ESEC/FSE 2020, page 1433-1443, New York, NY, USA, 2020. Association for Computing Machinery.
- [42] Eric Liang Sy Cade Daniel, Chen Shen and Richard Liaw. How continuous batching enables 23x throughput in llm inference while reducing p50 latency. https://www.anyscale.com/blog/ continuous-batching-llm-inference, 2023.
- [43] Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi` ere, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295 , 2024.
- [44] MosaicML NLP Team. Introducing mpt-7b: A new standard for opensource, commercially usable llms, 2023. Accessed: 2023-05-05.
- [45] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems , 30, 2017.
- [46] Chi Wang, Xueqing Liu, and Ahmed Hassan Awadallah. Cost-effective hyperparameter optimization for large language model generation inference. In Aleksandra Faust, Roman Garnett, Colin White, Frank Hutter, and Jacob R. Gardner, editors, Proceedings of the Second International Conference on Automated Machine Learning , volume 228 of Proceedings of Machine Learning Research , pages 21/1-17. PMLR, 12-15 Nov 2023.
- [47] Ryen W. White. Navigating complex search tasks with ai copilots, 2023. [48] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. Transformers: State-of-the-art natural language processing. In Qun Liu and David Schlangen, editors, Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages 38-45, Online, October 2020. Association for Computational Linguistics.
- [49] BigScience Workshop, Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ili´, c Daniel Hesslow, Roman Castagn´ e, Alexandra Sasha Luccioni, Franc ¸ois Yvon, et al. Bloom: A 176bparameter open-access multilingual language model. arXiv preprint arXiv:2211.05100 , 2022.
- [50] Tim Yarally, Lu´ ıs Cruz, Daniel Feitosa, June Sallou, and Arie van Deursen. Batching for green ai -an exploratory study on inference. In 2023 49th Euromicro Conference on Software Engineering and Advanced Applications (SEAA) , pages 112-119, 2023.
- [51] Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for TransformerBased generative models. In 16th USENIX Symposium on Operating
- Systems Design and Implementation (OSDI 22) , pages 521-538, Carlsbad, CA, July 2022. USENIX Association.
- [52] Quanjun Zhang, Chunrong Fang, Yang Xie, Yaxin Zhang, Yun Yang, Weisong Sun, Shengcheng Yu, and Zhenyu Chen. A survey on large language models for software engineering. arXiv preprint arXiv:2312.15223 , 2023.
- [53] Ru Zhang, Wencong Xiao, Hongyu Zhang, Yu Liu, Haoxiang Lin, and Mao Yang. An empirical study on program failures of deep learning jobs. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering , ICSE '20, page 1159-1170, New York, NY, USA, 2020. Association for Computing Machinery.
- [54] Ziyin Zhang, Chaoyu Chen, Bingchang Liu, Cong Liao, Zi Gong, Hang Yu, Jianguo Li, and Rui Wang. Unifying the perspectives of nlp and software engineering: A survey on language models for code. arXiv preprint arXiv:2311.07989 , 2023.
- [55] Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, et al. A survey on efficient inference for large language models. arXiv preprint arXiv:2404.14294 , 2024.
- [56] Albert Ziegler, Eirini Kalliamvakou, X. Alice Li, Andrew Rice, Devon Rifkin, Shawn Simister, Ganesh Sittampalam, and Edward Aftandilian. Productivity assessment of neural code completion. In Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming , MAPS 2022, page 21-29, New York, NY, USA, 2022. Association for Computing Machinery.
- [57] Albert Ziegler, Eirini Kalliamvakou, X. Alice Li, Andrew Rice, Devon Rifkin, Shawn Simister, Ganesh Sittampalam, and Edward Aftandilian. Measuring github copilot's impact on productivity. Commun. ACM , 67(3):54-63, feb 2024. | null | [
"Matias Martinez"
] | 2024-08-02T06:56:59+00:00 | 2024-08-02T06:56:59+00:00 | [
"cs.SE",
"cs.CL",
"cs.LG"
] | The Impact of Hyperparameters on Large Language Model Inference Performance: An Evaluation of vLLM and HuggingFace Pipelines | The recent surge of open-source large language models (LLMs) enables
developers to create AI-based solutions while maintaining control over aspects
such as privacy and compliance, thereby providing governance and ownership of
the model deployment process. To utilize these LLMs, inference engines are
needed. These engines load the model's weights onto available resources, such
as GPUs, and process queries to generate responses. The speed of inference, or
performance, of the LLM, is critical for real-time applications, as it computes
millions or billions of floating point operations per inference. Recently,
advanced inference engines such as vLLM have emerged, incorporating novel
mechanisms such as efficient memory management to achieve state-of-the-art
performance. In this paper, we analyze the performance, particularly the
throughput (tokens generated per unit of time), of 20 LLMs using two inference
libraries: vLLM and HuggingFace's pipelines. We investigate how various
hyperparameters, which developers must configure, influence inference
performance. Our results reveal that throughput landscapes are irregular, with
distinct peaks, highlighting the importance of hyperparameter optimization to
achieve maximum performance. We also show that applying hyperparameter
optimization when upgrading or downgrading the GPU model used for inference can
improve throughput from HuggingFace pipelines by an average of 9.16% and 13.7%,
respectively. |
2408.01051v1 | ## From Stem to Stern: Contestability Along AI Value Chains
## Agathe Balayn ∗
## Yulu Pi ∗
[email protected] Delft University of Technology Delft, The Netherlands
David Gray Widder [email protected] Cornell University United States of America
## Kars Alfrink
[email protected] Delft University of Technology Delft, The Netherlands
Naveena Karusala [email protected] Harvard University United States of America
## Christelle Tessono
[email protected] University of Toronto Canada [email protected] University of Warwick Coventry, United Kingdom
## Mireia Yurrita
[email protected] Delft University of Technology Delft, The Netherlands
## Henrietta Lyons
[email protected] University of Melbourne Melbourne, Australia
## Blair Attard-Frost
[email protected] University of Toronto Canada
## ABSTRACT
Sohini Upadhyay [email protected] Harvard University United States of America
## Cagatay Turkay
[email protected] University of Warwick United Kingdom
Ujwal Gadiraju [email protected] Delft University of Technology Delft, The Netherlands
## ACMReference Format:
This workshop will grow and consolidate a community of interdisciplinary CSCW researchers focusing on the topic of contestable AI. As an outcome of the workshop, we will synthesize the most pressing opportunities and challenges for contestability along AI value chains in the form of a research roadmap. This roadmap will help shape and inspire imminent work in this field. Considering the length and depth of AI value chains, it will especially spur discussions around the contestability of AI systems along various sites of such chains. The workshop will serve as a platform for dialogue and demonstrations of concrete, successful, and unsuccessful examples of AI systems that (could or should) have been contested, to identify requirements, obstacles, and opportunities for designing and deploying contestable AI in various contexts. This will be held primarily as an in-person workshop, with some hybrid accommodation. The day will consist of individual presentations and group activities to stimulate ideation and inspire broad reflections on the field of contestable AI. Our aim is to facilitate interdisciplinary dialogue by bringing together researchers, practitioners, and stakeholders to foster the design and deployment of contestable AI.
## KEYWORDS
AI, Contestability, Contestable AI, Supply Chain, Value Chain
∗ Both authors contributed equally to the paper
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for third-party components of this work must be honored. For all other uses, contact the owner/author(s).
CSCW Companion '24, November 9-13, 2024, San Jose, Costa Rica
© 2024 Copyright held by the owner/author(s).
ACM ISBN 979-8-4007-1114-5/24/11
https://doi.org/10.1145/3678884.3681831
Agathe Balayn, Yulu Pi, David Gray Widder, Kars Alfrink, Mireia Yurrita, Sohini Upadhyay, Naveena Karusala, Henrietta Lyons, Cagatay Turkay, Christelle Tessono, Blair Attard-Frost, and Ujwal Gadiraju. 2024. From Stem to Stern: Contestability Along AI Value Chains. In Companion of the 2024 Computer-Supported Cooperative Work and Social Computing (CSCW Companion '24), November 9-13, 2024, San Jose, Costa Rica. ACM, New York, NY, USA, 5 pages. https://doi.org/10.1145/3678884.3681831
## 1 BACKGROUND
In recent years, the Computer-SupportedCooperative Work (CSCW), Human-ComputerInteraction (HCI), and Artificial Intelligence (AI) communities have become interested in contestable AI as a means to confront, acknowledge, and rectify the negative impacts caused by AI systems. Contestable AI refers to AI systems that are open and responsive to human dispute and intervention throughout their lifecycle [2]. This interest is evident in theoretical and empirical research and practice [3, 11, 14, 17], as well as AI governance initiatives that aim to explore contestability as a means to enhance human agency [8] and address ethical and societal implications of AI. For example, consider the 2020 United Kingdom school exam grading controversy [12]: students protested the use of an AI algorithm to determine their grades, holding signs that read 'Your algorithm does not know me.' This highlighted the urgent need for AI systems and processes that are open to human intervention and responsive to disputes.
Contestable AI is a growing interdisciplinary field. Legal scholars have proposed the right to contest [5], which ensures a level of protection for individuals affected by algorithmic decisions [9]. Meanwhile, HCI and CSCW researchers view contestability from a design perspective, focusing on making AI systems contestable to developers and end users by design [1, 2, 10, 21]. While these efforts have made significant progress in directing the conversation towards making AI more responsive and accountable through
ongoing learning based on feedback and contestation [16], their main focus remains on contesting AI design or outputs [4] within specific domains such as content moderation [19].
A broader perspective on contestability can be gained by considering AI systems as dynamic sociotechnical systems with temporal and spatial dimensions. This approach expands our horizons to consider contestable AI as a value chain problem 1 [6, 7, 20]). This encompasses the entirety of the AI lifecycle, including various actions taken by different actors: the extraction of materials, the construction of physical infrastructures, the decision-making process in data collection, model development, modes of human oversight and the impact on individuals, society and the environment. CSCW methodologies and prior insights around collaborative work are of particular relevance to investigating the AI value chain through the lens of contestability.
Exploring contestable AI along the AI value chain broadens the scope of potential sites and angles for contestation. For instance, harms arising further up the AI value chain, such as poor labor conditions, negative environmental impacts, and the inappropriate collection and use of personal data, remain relatively absent from the academic discourse around contestable AI. In recent years, activist efforts have emerged in response to the growing concerns surrounding AI systems and their impact on society. Should those activities fall into our discussion of contestable AI, and if so, how? One notable example is the Data Centre Activism in Chile, Ireland, and the Netherlands [13]. Activists in these countries have protested against the construction and expansion of data centers, citing concerns about their environmental impact, energy consumption, and the potential for AI systems to exacerbate social inequalities. These real-life examples show that contestability could entail public discourse and policy debates, involving individuals utilizing social media platforms to raise their concerns or actively engaging in decisions around AI. However, there is a lack of discussion regarding how these practices fit within the scope of contestable AI and the unique challenges and opportunities faced.
Moreover, adopting the value-chain perspective in contestable AI exposes and prompts discussion of the inherent challenges of attributing responsibility. Contesting AI may face the 'many hands problem,' as the design or output being contested may result from a chain of different actors contributing in different ways and capacities to the production, deployment, and use [7]. This raises crucial questions: what and who exactly are we contesting, and who precisely bears the responsibility to address the contestation? It also opens the door to moving beyond individualistic approaches, and exploring how communities or society can contest AI collectively.
To address these issues and support this emerging research area, the goal of this workshop is to explore the impacts, challenges, opportunities, and limitations of contestable AI along the AI value chain around the world. We are particularly interested in empirical studies, including real-world case studies and user studies with both positive and negative outcomes, along with reflections on lessons learned. Additionally, we seek descriptions of unique contexts for contestable AI and their varied and specific challenges, and visionary discussions, and proposals about the implications of
1 The literature uses the terms 'AI value chain', e.g., [15], and 'AI supply chain', e.g., [7, 20]. We use them interchangeably in this workshop.
contestable AI on the design and governance of AI systems. Focusing on real-world scenarios and the entire AI value chain provides a unique, concrete, and more comprehensive perspective on contestable AI, different from previous workshops on contestability [18].
## 2 WORKSHOP GOAL
Through a series of talks, keynotes, and group work, we expect the workshop to achieve the following outcomes:
- · Developing a holistic understanding of the requirements, challenges, existing support, and forthcoming opportunities to inform future research and practice on contestable AI.
- · Identifying and synthesizing unique contributions of the CSCW community in contestable AI.
- · Fostering an interdisciplinary community of researchers and practitioners spanning relevant disciplines (e.g., HCI, AI, law, economics, political science, among others).
- · Developing shared vocabulary and priorities across disciplines and communities to design for contestability along AI chains.
- · Publishing an article in the Communications of the ACM (CACM) sketching out a roadmap for contestable AI research that can inspire and shape research in this nexus over the next 10 years.
## 3 WORKSHOP STRUCTURE
## 3.1 Workshop schedule
We schedule the workshop for one day, as outlined in Table 1. After the workshop, the organizers and interested participants will gather (virtually), generate a summary of the key insights gleaned from the workshop discussions, and craft a roadmap for future research.
Table 1: Tentative Workshop Schedule
| 09:00-09:20 | Introduction of the workshop organizers &goals |
|---------------|--------------------------------------------------|
| 09:20-09:50 | Keynote 1 |
| 09:50-10:35 | Participant presentations 1 |
| 10:35-10:50 | Coffee break |
| 10:50-11:40 | Participant presentations 2 |
| 11:40-12:00 | Introduction of the group activities |
| 12:00-12:45 | [GA1] Mapping and brainstorming |
| 12:45-14:00 | Lunch |
| 14:00-14:30 | Keynote 2 |
| 14:30-15:30 | [GA2] Deep-dive on sites of the AI supply chain |
| 15:30-15:45 | Coffee break |
| 15:45-17:00 | [GA3] Deep dive on transversal themes |
| 17:00-17:30 | Synthesis of the workshop's insights |
| 17:30-17:45 | Open discussion and closing |
## 3.2 Activity Description
The workshop will consist of the following activities.
Participant presentation: Wewillask each participant to present an overview of their submission. Depending on the number of submissions, we will accommodate the length of the presentations to create room for every submission to be presented.
Keynote: Wewill invite keynote speakers whose insightful perspectives may not be fully represented in the submissions received. These speakers may include individuals from civil society or legal scholars, with whom we are already in contact.
GA1: Mapping of the presentations onto sites of the value chain and brainstorming: Following participants' presentations, we will ask them to use a physical and / or virtual board to place their work on a map for contestable AI. This map will be preliminarily prepared by the workshop organizers (-who, what, why, when, how-, and -challenges, needs, opportunities- across the sites of the AI value chain), and will serve to kick off discussions. We will encourage participants to conduct the activity collaboratively, discuss potential challenges and disagreements they face, observe similarities between their use cases, and identify additional relevant dimensions and extensions to the map. This exercise will also be useful to identify blind spots in the contestable AI space.
GA2: Deep-dive on contestability sites: We will ask participants to group themselves based on the sites in the map for which they have the most experience, and to start discussing commonalities, differences, and challenges and opportunities they face. We will then ask them to report on their discussions, and to make the collective exercise of identifying recurring topics across the sites.
GA3: Deep-dive on transversal themes: The third group exercise will consist of delving deeper into certain recurring (transversal) topics that come out from the presentations and group activities. We will again encourage participants to reflect on the needs and opportunities for each of these themes and ideate on how to research these topics. Examples of such themes are: individual versus collaborative contestability, contestability within versus contestability from the outside of the supply chain, ultimate goals of contestability and relevant means for contesting, the specificities of contestability across geographic and cultural locations.
Synthesizing a roadmap for future research: In plenary sessions and smaller groups, we will accumulate the findings of the workshop, and devise the best way to synthesize them into a research roadmap for contestable AI. This will particularly focus on specific challenges, needs, and future opportunities in contestable AI along AI value chains.
## 4 PRACTICALITIES
We envision the workshop to be held primarily in-person, with a limited capacity for virtual participation, using an online goup chat. Plenary sessions will be streamed via videoconferencing. To accommodateparticipants who may not be able to attend in person, we will allow them to present their work remotely via asynchronous video recordings or through live remote presentation. If more than six participants are online, we will group them and accommodate their participation in the group activities. Five workshop organizers will potentially be online and involved via Zoom.
To support the various activities, we will need access to a standard conference room that can accommodate up to 40 people (we envision a maximum of 30 participants in the workshop, and 10 in-person workshop organizers). Standard audiovisual equipment for the presentations and group sessions will also be required.
Ideally, the seating will be flexible, to cater for the presentation and group activities. Several tables to conduct the group activities will be needed. Other resources such as whiteboards, large blank papers, pens, and sticky notes can facilitate group sessions.
## 5 WORKSHOP ATTENDANCE
## 5.1 Workshop participants
We will recruit workshop participants via a call for submissions. Each author of accepted submissions will be granted a seat at the workshop. The call for submissions will be circulated on various HCI mailing lists and social media. Submission authors will be asked to send their submissions to the email address for the workshop before September 15th, 2024. At least two workshop organizers will review each submission.
If we do not reach the maximum number of participants via this process, we will open participation to people who do not have any submissions. For that, we will invite interested people to send a brief statement describing one's motivation to the workshop organizers who will then confirm the participant's spot. We will also directly reach out to our contacts, e.g., from civil society, and invite them to ensure participants' diversity.
We will invite submissions that can contribute to raising discussions for setting an agenda around contestable AI along the AI value chain. These submissions can focus on various sites of the AI value chain, and discuss who might want to contest what and towards which end-goal, when and how to contest, the challenges, needs, supports, and opportunities for contestation, and the limitations of current contestability works. The submissions should not exceed 4000 words with unlimited references and supplementary material.
We encourage submissions from various disciplines. Not only can these submissions deal with HCI/CSCW or algorithmic work, but also policy perspectives and the views of advocacy organizations.
## 5.2 Workshop organizers
The diverse backgrounds of the workshop organizers allow us to cover computer science and human-computer interaction, across various continents, with expertise primarily stemming from academia but also industry and policy making.
- · Agathe Balayn is a postdoctoral researcher at Deft University of Technology. Her work lies at the intersection between the technical underpinnings of AI, their operationalization in practice, and AI policy. She has conducted extensive qualitative work in organizations producing and consuming AI systems, to understand the concerns of stakeholders along the AI supply chain, the factors impacting their practices, and the harms that might arise.
- · Yulu Pi is a PhD student at the Centre for Interdisciplinary Methodologies, University of Warwick. She also works on the IN-DEPTH EU AI TOOLKIT project for the Leverhulme Centre for the Future of Intelligence. Her research focuses on empowering those affected by AI through explainability and contestability. Her work extends beyond technical and design issues to consider how these concepts can be incorporated into AI governance.
- · David Gray Widder studies how people creating AI systems think about the downstream harms their systems make possible, and the wider cultural, political, and economic logics which shape
- these thoughts. He is a Postdoctoral Fellow at the Digital Life Initiative at Cornell Tech. He has previously conducted research at Intel Labs, Microsoft Research, and NASA's JPL.
- · Kars Alfrink is a designer, researcher, and educator working at the intersection of emerging technologies, social progress, and the built environment. He is currently a postdoctoral researcher at Delft University of Technology, focusing on contestable AI. With over 15 years of experience in design, he has previously worked as a consultant, entrepreneur, and educator and has held various roles in web agencies.
- · Mireia Yurrita is a PhD student at Delft University of Technology, as well as a Marie Curie fellow at the DCODE Network. Mireia's research interests lie at the intersection of Human-AI Interaction and Algorithmic Fairness, Accountability and Transparency. Mireia has previously researched into the effect of contestability on decision subjects' fairness perceptions, as well as, algorithmic decision subjects needs for meaningful contestability.
- · Sohini Upadhyay is a Computer Science PhD candidate at Harvard University. She has worked on algorithmic recourse and XAI, and her current interests in AI contestation span microscale approaches to information needs to macroscale perspectives on socio-technical interventions and collective action. She has interned at the Surveillance Technology Oversight Project and the Technology for Liberty Project at the ACLU of Massachusetts.
- · Naveena Karusala is a postdoctoral fellow at the Center for Research on Computation and Society at Harvard University. Her research is at the intersection of human-centered AI and the future of care work. She examines how emerging AI technologies might be designed to support more just care infrastructures that better recognize the labor, autonomy, and rights of care workers and care recipients.
- · Henrietta Lyons is a PhD candidate in the School of Computing and Information Systems at the University of Melbourne. Her research focuses on how contestability in algorithmic decisionmaking can be operationalised, and on people's perceptions of different appeal processes for algorithmic decisions. She is interested in the societal impacts of the use of AI and the design of responsible AI systems.
- · Cagatay Turkay is a Professor at the Centre for Interdisciplinary Methodologies at the University of Warwick. His research investigates the interactions between data, algorithms and people, and explores the role of interactive data visualisations and other interaction mediums such as natural language. He has been chairing events such as IEEE VIS, BioVis and EuroVA.
- · Christelle Tessono is a technology policy researcher and advocate pursuing her graduate studies at the University of Toronto. She helps lead a national coalition to ban facial recognition in Canada. Her research seeks to address the relationship between digital technology and racial inequality from a policy lens. This has led her to work on projects related to political advertising on social media platforms, gig work, facial recognition technology, AI governance.
- · Blair Attard-Frost is a PhD Candidate and SSHRC Joseph-Armand Bombardier Canada Graduate Scholar at the University of Toronto.
- Blair applies a transfeminist lens to investigate Canada's AI governance system and the contestability of AI governance practices. Drawing on 10+ years of experience working across the public sector and industry, they teach courses on AI policy and advocate for community-led AI governance.
- · Ujwal Gadiraju is an Assistant Professor at Delft University of Technology and a Director of the Delft 'Design@Scale' AI Lab. He co-leads a research line on Crowd Computing and HumanCentered AI. His work lies at the intersection of HCI, AI, and information retrieval. His goal is to help people far and wide by fostering meaningful reliance on AI.
## REFERENCES
- [1] Kars Alfrink, Ianus Keller, Neelke Doorn, and Gerd Kortuem. 2023. Contestable Camera Cars: A Speculative Design Exploration of Public AI That Is Open and Responsive to Dispute. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . ACM, 1-16. https://doi.org/10/gr5wcx
- [2] Kars Alfrink, Ianus Keller, Gerd Kortuem, and Neelke Doorn. 2022. Contestable AI by Design: Towards a Framework. Minds and Machines 33, 4 (Aug. 2022), 613-639. https://doi.org/10/gqnjcs
- [3] Marco Almada. 2019. Human intervention in automated decision-making: Toward the construction of contestable systems. In Proceedings of the Seventeenth International Conference on Artificial Intelligence and Law . ACM, Montreal QC Canada, 2-11. https://doi.org/10.1145/3322640.3326699
- [4] Blair Attard-Frost. 2023. Ai countergovernance. https://www.midnightsunmag.ca/ai-countergovernance/
- [5] Emre Bayamlıoğlu. 2022. The right to contest automated decisions under the General Data Protection Regulation: Beyond the so-called 'right to explanation'. Regulation & Governance 16, 4 (2022), 1058-1078. https://doi.org/10.1111/rego.12391
- [6] Jennifer Cobbe. 2024. Governance and interdependence in data-driven supply chains. Global Governance by Data: Infrastructures of Algorithmic Rule (2024).
- [7] Jennifer Cobbe, Michael Veale, and Jatinder Singh. 2023. Understanding accountability in algorithmic supply chains. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency . 1186-1197.
- [8] Rosanna Fanni, Valerie Eveline Steinkogler, Giulia Zampedri, and Jo Pierson. [n. d.]. Enhancing human agency through redress in Artificial Intelligence Systems. 38, 2 ([n. d.]), 537-547. https://doi.org/10.1007/s00146-022-01454-7
- [9] Margot E. Kaminski and Jennifer M. Urban. 2021. The Right to Contest AI. Columbia Law Review 121, 7 (2021). https://ssrn.com/abstract=3965041 U of Colorado Law Legal Studies Research Paper No. 21-30.
- [10] Naveena Karusala, Sohini Upadhyay, Rajesh Veeraraghavan, and Krzysztof Z Gajos. 2024. Understanding Contestability on the Margins: Implications for the Design of Algorithmic Decision-making in Public Services. In Proceedings of the CHI Conference on Human Factors in Computing Systems . 1-16.
- [11] Daniel N. Kluttz, Nitin Kohli, and Deirdre K. Mulligan. 2020. Shaping Our Tools: Contestability as a Means to Promote Responsible Algorithmic Decision Making in the Professions . Cambridge University Press, 137-152.
- [12] Daan Kolkman. 2020. 'F **k the algorithm'?: What the world can learn from the UK's A-level grading fiasco. https://blogs.lse.ac.uk/impactofsocialsciences/2020/08/26/fk-the-algorithm-what-the-world-can-l Accessed: May 19, 2024.
- [13] Stéphanie Lehuedé. 2024. An elemental ethics for artificial intelligence: water as resistance within AI's value chain. AI & Society (2024). https://doi.org/10.1007/s00146-024-01922-2
- [14] Henrietta Lyons, Eduardo Velloso, and Tim Miller. 2021. Conceptualising Contestability: Perspectives on Contesting Algorithmic Decisions. Proceedings of the ACM on Human-Computer Interaction 5, CSCW1 (April 2021), 1-25. https://doi.org/10.1145/3449180
- [15] Tambiama Madiega. 2021. Artificial intelligence act. European Parliament: European Parliamentary Research Service (2021).
- [16] Deirdre K. Mulligan and Kenneth A. Bamberger. 2019. Procurement As Policy: Administrative Process for Machine Learning. Berkeley Technology Law Journal 34 (2019). https://doi.org/10.2139/ssrn.3464203
- [17] Thomas Ploug and Søren Holm. 2020. The four dimensions of contestable AI diagnostics -A patient-centric approach to explainable AI. Artificial intelligence in medicine 107 (2020), 101901. https://www.sciencedirect.com/science/article/pii/S0933365720301330
- [18] Kristen Vaccaro, Karrie Karahalios, Deirdre K. Mulligan, Daniel Kluttz, and Tad Hirsch. 2019. Contestability in Algorithmic Systems. In Companion Publication of the 2019 Conference on Computer Supported Cooperative Work and Social Computing (Austin, TX, USA) (CSCW '19 Companion) . Association for Computing Machinery, New York, NY, USA, 523-527.
From Stem to Stern: Contestability Along AI Value Chains https://doi.org/10.1145/3311957.3359435
- [19] Kristen Vaccaro, Ziang Xiao, Kevin Hamilton, and Karrie Karahalios. 2021. Contestability For Content Moderation. Proc. ACM Hum.-Comput. Interact. 5, CSCW2, Article 318 (oct 2021), 28 pages. https://doi.org/10.1145/3476059
- [20] David Gray Widder and Dawn Nafus. 2023. Dislocated accountabilities in the 'AI supply chain': Modularity and developers' notions of responsibility. Big Data
CSCW Companion '24, November 9-13, 2024, San Jose, Costa Rica
- & Society 10, 1 (2023), 20539517231177620.
- [21] Mireia Yurrita, Agathe Balayn, and Ujwal Gadiraju. 2023. Generating ProcessCentric Explanations to Enable Contestability in Algorithmic Decision-Making: Challenges and Opportunities. arXiv preprint arXiv:2305.00739 (2023).
This figure "acm-jdslogo.png" is available in "png"GLYPH<10> format from:
http://arxiv.org/ps/2408.01051v1 | null | [
"Agathe Balayn",
"Yulu Pi",
"David Gray Widder",
"Kars Alfrink",
"Mireia Yurrita",
"Sohini Upadhyay",
"Naveena Karusala",
"Henrietta Lyons",
"Cagatay Turkay",
"Christelle Tessono",
"Blair Attard-Frost",
"Ujwal Gadiraju"
] | 2024-08-02T06:57:52+00:00 | 2024-08-02T06:57:52+00:00 | [
"cs.AI",
"cs.CY",
"cs.HC"
] | From Stem to Stern: Contestability Along AI Value Chains | This workshop will grow and consolidate a community of interdisciplinary CSCW
researchers focusing on the topic of contestable AI. As an outcome of the
workshop, we will synthesize the most pressing opportunities and challenges for
contestability along AI value chains in the form of a research roadmap. This
roadmap will help shape and inspire imminent work in this field. Considering
the length and depth of AI value chains, it will especially spur discussions
around the contestability of AI systems along various sites of such chains. The
workshop will serve as a platform for dialogue and demonstrations of concrete,
successful, and unsuccessful examples of AI systems that (could or should) have
been contested, to identify requirements, obstacles, and opportunities for
designing and deploying contestable AI in various contexts. This will be held
primarily as an in-person workshop, with some hybrid accommodation. The day
will consist of individual presentations and group activities to stimulate
ideation and inspire broad reflections on the field of contestable AI. Our aim
is to facilitate interdisciplinary dialogue by bringing together researchers,
practitioners, and stakeholders to foster the design and deployment of
contestable AI. |
2408.01053v1 | ## Orientational order in liquid crystal surface induced by evaporation of water droplet
AUTHOR NAMES
Yusaku Abe and Yu Matsuda
## AUTHOR ADDRESS
Department of Modern Mechanical Engineering, Waseda University, 3-4-1 Ookubo, Shinjuku- ku, Tokyo, 169-8555, Japan.
## KEYWORDS
Pattern formation, Evaporation, self-assembly, Droplet
## ABSTRACT
The evaporation of a droplet induces variety of ordered patterns near the contact line between the droplet and a substrate. This pattern formation involves both the behavior of colloidal suspensions and interactions between a droplet and a substrate. Although studies on the effect of the behavior of colloidal suspensions on the deposition process have been actively conducted, studies on the effect of the interaction between a droplet and a substrate have not been actively conducted because the observation of the interaction is difficult owing to the lack of structural changes in the substrate by the interaction. In this study, we investigated the solvent-substrate interactions by using a water droplet and liquid crystals as a substrate, where the liquid crystals were placed on a glass slide. The orientation patterns of the liquid crystals were induced at the contact line between the water droplet and the liquid crystal and were observed using a polarized optical microscope. Pinning and depinning events were observed at a certain anchoring strength of the liquid crystal on the glass slide and formed linear patterns on the surface of the liquid crystal. Additionally, the interfacial tension between the water and liquid crystal slowly varied at this anchoring strength owing to the variation in the orientation of the liquid crystals. These results indicated that the evaporationinduced patterns appeared when the strength of the solvent-substrate interactions was neutral. The interaction between a droplet and a substrate is important for the fabrication of desired ordered patterns.
## INTRODUCTION
Pattern formation induced by the evaporation of droplets has been used to assemble the microstructures. When droplets containing colloidal suspensions evaporate, these suspensions 1 collect near the contact line owing to convection and capillary flow. 2-6 This local increase of the density of the suspensions will induce the pinning of the contact line and deposition of suspensions. Coffee ring effect is a well-known example of this phenomenon, in which colloidal 4 particles accumulate near the contact line due to capillary flow and deposit in circular pattern along the contact line. 1,7,8
Understanding and controlling pattern formation by the evaporation of droplets is of interest because patterning by the evaporation can easily form ordered structures. 9-11 In particular, patterns formed during the evaporation are diverse for anisotropic colloidal suspensions. 12-15 For highly anisotropic colloidal suspensions, a local increase in the concentration of the suspensions near the contact line will induce phase transition from isotropic to nematic phase. For example, in the evaporation of droplets containing amyloid fibril rigid filamentous colloids, these colloids may deposit in the nematic phase near the contact line. 12 The evaporation of droplets containing highly anisotropic materials, such as carbon nanotubes, 16,17 DNA, 18,19 and porphyrin trimers, 20 forms various ordered patterns. It is considered that these patterns mainly depend on the behavior of colloidal suspensions and solvent-substrate interactions. The behavior of colloidal suspensions has been studied extensively. The concentration, particle aspect ratio, and evaporation rate have been known to affect the pattern formed. 8,21 However, it is difficult to evaluate the effect of the solventsubstrate interactions on the pattern formation because the observations of the effects are difficult.
This difficulty depends on the lack of structural changes in the general solid substrate, such as glass slides and mica, during evaporation.
In this study, we investigated the solvent-substrate interactions during the evaporation of diluted water droplet on a substrate of liquid crystals, which was placed on a glass slide. Observing the evaporation of the water droplet on liquid crystal, we studied the structural changes in the substrates (liquid crystals) using polarized optical microscopy (POM). Additionally, strength of interfacial interactions between solvents and substrates at the contact line can be varied by changing the anchoring strength of the liquid crystal molecules on the glass slide. We successfully observed the changes in the solvent-substrate interactions as the pinning strength of the contact line between the droplet and the liquid crystal substrate. We investigated the pinning and depinning events at the contact line in various anchoring strength of the liquid crystal. We found that the solvent-substrate interactions changed the behavior of the contact line during the evaporation. Under certain conditions, patterns were formed on the surface of liquid crystals by changing the orientation of the liquid crystal molecules on the surface. These results suggest that evaporation forms patterns solely by solvent-substrate interactions, even in the absence of colloidal suspensions inside the droplets.
## EXPERIMENTAL SECTION
## Materials
The liquid crystal 4-Cyano-4'-pentylbiphenyl (5CB, 98% pure) and trichlorooctadecylsilane (85% pure) was purchased from Tokyo Chemical Industry Co., Ltd, Japan.
Isopropyl alcohol, (IPA, 99.7% pure), methanol (99.8% pure), chloroform (99.0% pure), and Contaminon® were purchased from Fujifilm Wako Pure Chemical Corporation, Japan. Purchased chemicals were used as received without further modification or purification. Water used in all experiments was purified using a Milli-Q water purification system (Direct-Q UV3; Merck, Germany). Mirco slide glasses (26 mm by 76 mm by 0.8-1.0 mm) were purchased from Matsunami Glass Ind., Ltd.
## Preparation of hydrophilic and hydrophobic glass slides
We prepared hydrohalic and hydrophobic glass slides to control the anchoring strength of the liquid crystals on the glass slide by varying the contact angle between the glass slide and the liquid crystals. The surface modification of glass slide was conducted by following procedures. First, glass slides were rinsed with IPA and water. Then, the cleaned glass slides were washed with Contaminon® using a bath-type sonicator (Bransonic® M1800Yamato Scientific Co., Ltd., Japan) to remove organic matter. Subsequently, the obtained hydrophilic glass slides were dried and stored in methanol. Hydrophobic glass slides were prepared from these hydrophilic glass slides. Hydrophilic glass slides were rinsed with chloroform to remove methanol. Then, these glass slides were surface modified with silane-coupling in chloroform; trichlorooctadecylsilane was used as a silane coupling agent.
## Observation of evaporation behavior of water droplets
The 5CB droplet placed on a hydrophilic/hydrophobic glass slide was used as a substrate. We kept our experimental system at 20°C; the 5CB droplets exhibit a nematic phase in this condition. The contact angle of a static 5CB droplet of 1.5 µL was measured by the sessile drop method using a commercial contact angle meter (Dropmaster DMs-401; Kyowa Interface Science
Co., Ltd., Japan) to confirm the anchoring strength. Then, a water droplet of 0.5 µL was placed on the 5CB droplet using the syringe of the contact angle meter.
We imaged the evaporation behavior of water droplet on 5CB droplet surface using a polarized light microscope (BX53M; Olympus Co. Ltd., Japan) with an objective lens of 10×, N.A. of 0.25, and W.D. of 21 mm (LMPLFLN10X, Olympus Co. Ltd., Japan). We can visualize whether liquid crystal has orientational order or not by using both a polarizer and an analyzer. We can also investigate the orientation of liquid crystal molecules because more polarized light is absorbed when molecular stacking is perpendicular to the light polarization direction. Cross-polarized and λ plate images and movies were taken with a CMOS camera (Floyd multi interface digital camera; WRAYMER inc., Japan). The movies with frame rate 28.6 Hz were recorded with 35 ms exposure time for 30 min.
## RESULTS AND DISUCSSION
## Relationship between contact angle and anchoring strength of 5CB
In our experiments, we used 5CB exhibiting a nematic phase at 20°C. Figure 1a-c shows the shape dependence of 5CB droplets on glass slides with different wettability. The contact angles of a 5CB droplet were 44° (hydrophobic glass slides), 20° (untreated glass slides), and 10° (hydrophilic glass slides), respectively. By considering the balance of forces at the contact line, the interfacial tension at interface between glass slides and liquid crystal 𝛾𝛾 GL is given by
$$\gamma _ { G L } = \gamma _ { G } - \gamma _ { L } \cdot \cos \theta$$
where 𝜃𝜃 is the contact angle between the 5CB droplet and the glass slide, and 𝛾𝛾 G and 𝛾𝛾 L are surface tension of glass slides and liquid crystal, respectively. In this study, 𝛾𝛾 G and 𝛾𝛾 L are constant at each wettability condition because these properties are substance-specific values. As the wettability increases, surface tension 𝛾𝛾 GL decreases. The anchoring strength of 5CB on the glass slide decreases as a decrease in the surface tension at interface between glass slides and liquid crystal 𝛾𝛾 GL . Then, the anchoring strength of 5CB decreases as an increase in the wettability. Figure 1d is a typical POM image around the edge of 5CB droplet on a glass slide when the contact angle of 5CB droplets was 44°. The birefringence on a glass slide was observed, indicating that the 5CB molecules at the surface aligned. Figure 1e and f are a bright-field microscopy image and a POM image of a contact line between diluted water and 5CB, respectively. In the bright-field microscopy image, color difference between water and 5CB is negligible. On the other hand, in the POM image, color is different between water and 5CB because water molecules were not aligned but 5CB molecules at the surface were aligned.
## Characterization of evaporation of the water droplets
We performed POM visualization during the evaporation of a diluted water droplet on a 5CB substrate with increasing the contact angle of 5CB to glass slides, specifically 44°, 20°, and 10°. As the contact angle decreases, the anchoring strength of 5CB decreases. Then, as the anchoring strength decreases, interactions between a water droplet and a liquid crystal substrate becomes stronger. As illustrated in Figure 2, water droplets evaporated over time, while 5CB droplets didn't evaporate because of their non-volatility.
For the lowest wettability of 44° (Figure 2a-d), the radius of the water droplet decreased with time. The evaporation of the water droplet did not induce the orientation change of 5CB
molecular as the color of a 5CB droplet in the POM image did not change. This result suggests that solvent-substrate interactions are weak. For the contact angle of 5CB to a glass slide of 20°, we observed changes in both the water droplet radius and orientation structure of the 5CB molecules (Figure2e-h). As seen in Figure 2e and f, while the water droplet radius hardly changed in the first 10 min, the radius rapidly decreased at 20 min. We also observed the change of the orientation structure of the 5CB molecules, which recognized as patterns in a POM image. The color of the POM image was different from the surrounding area at the position where the initial contact line existed after 20 min (Figure 2g). Moreover, three radial lines appeared as the contact line receded. These results indicate that the orientation of the 5CB molecule is affected by the evaporation of the water droplets when anchoring strength of 5CB decreased due to the higher wettability with the contact angle of 20°. It is considered that the pattern at the initial contact line position was formed by the strong solvent-substrate interactions caused by the pinning of the contact line. The radial lines appear to be line defects generated by the 5CB defects near the initial contact line and pulled during shearing these defects in the evaporation after the depinning of the contact line. For the highest wettability with the contact angle of 10° (Figure 2i-l), the contact line was not moved during the experiment (30 min). This is because the pinning strength was increased due to the stronger solvent-substrate interactions.
## Movement of the contact line
Upon conducting experiments under various wettability conditions, we were able to demonstrate that the movement speed of the contact line changed depending on the wettability of the glass slides. Figure 3 shows the time-series variation in the normalized radius of the water droplets at different wettability conditions. When the contact angle of 5CB to glass slides was 44°, the lowest wettability, the radius of the water droplet monotonically decreased. On the other hand,
when the contact angle of 5CB to glass slides was 10°, the highest wettability, the radius of the water droplet was almost constant. When the contact angle of 5CB to glass slides was 20°, medium wettability, radius of the water droplet was almost constant for the first 15 min, and then decreased monotonically.
These results show that the pinning strength between the water droplet and the 5CB droplet depends on the wettability of the 5CB to the glass slide. That is, the pinning strength increases as the wettability of glass slides increases and the anchoring strength of 5CB decreases. In conjunction with the POM images (Figure 2), pinning and depinning occurred continuously alternatively when the solvent-substrate interaction was neither too strong nor too weak; the contact angle of 20° in this study. We also found that repeat of pinning and depinning may induced two types of patterns on the surface of liquid crystal: one is the pattern along the contact line, and the other is the radial pattern perpendicular to the contact line (Figure 2, Figure 3).
## Orientation of the liquid crystal molecules
When solvent-substrate interaction satisfies certain strength conditions, patterns are induced on the substrate surface owing to the solvent evaporation. In this study, this condition was satisfied when the contact angle of 5CB to glass slides was 20°. Figure 4 shows the polarized light transmission images of induced patterns with the λ -plate. Figure 4a and b are the images of the same location with polarization planes perpendicular to each other. In Figure 4, two types of patterns were recognized: one is the pattern along the initial contact line position, and the other is the radial pattern perpendicular to the initial contact line. The high transmittance on the pattern along the initial contact line is observed in Figure 4a, indicating that 5CB molecules were oriented parallel to the initial contact line. On the other hand, the high transmittance on the radial pattern
along the evaporation direction is observed in Figure 4b, indicating that 5CB molecules were oriented parallel to the evaporation direction. These results indicate that liquid crystal molecules are oriented in a particular direction in the pattern formation.
## Configuration of the contact line during evaporation
Pattern formation induced by evaporation is affected by solvent-substrate interactions. In this study, considering the force between water and liquid crystal phases at the contact line, we investigated the solvent-substrate interactions. The contact angles 𝛼𝛼 and 𝛽𝛽 are defined as illustrated in Figure 5a and b, where γw , γLC , and γw-LC are the surface tension between water and surrounding air, that between liquid crystal and air, and the interfacial tension between water and liquid crystal, respectively. It is noted that the shape of the water droplet is a stacked form of a spherical cap. The following equation is obtained from the horizonal force balance
$$\gamma _ { L C } \cos \alpha = ( \gamma _ { w } + \gamma _ { w - L C } ) \cos \beta \,.$$
Assuming that the variations of 𝛾𝛾 LC and 𝛾𝛾 w were small compared with those of cos 𝛼𝛼 and cos 𝛽𝛽 in our experiments, we obtain the following relation:
$$\gamma _ { w - L C } \, \stackrel { \infty } { \alpha } \, \frac { \cos \beta } { \cos \alpha }.$$
Hence, considering the ratio of cos 𝛽𝛽 to cos 𝛼𝛼 , we can evaluate the strength of surface tension between the water droplet and the 5CB substrate. Figure 5c shows the time-series variation of the ratio cos 𝛽𝛽 / cos 𝛼𝛼 at different wettability of the 5CB to the glass slide (44°, 20°, and 10°). Comparing the time histories of the ratios with those of the droplet radius shown in Figure 3, we discuss the dependence of γw-LC on the motion of the contact line and the wettability of the 5CB
to the glass slide. The variation in the ratio for the contact angle of the 5CB to glass slides of 44° was greater than that of 10°. For the contact angle of 5CB to glass slides of 20°, the variation in the ratio slowly decreased before the contact line moved (first 15 min). Subsequently, the ratio sharply decreased after the contact line moved (after 15 min). These results indicated that the surface tension was unstable for high anchoring strength (the contact angle of the 5CB to the glass slide was large), and vice versa. We also found that the interfacial tension γw-LC was stable when the contact line was strongly pinned for the contact angle of the 5CB to the glass slide of 10° and 20° (only for first 15 min). In cases where movement of the contact line and pinning occurred alternately, the interfacial tension γw-LC gradually decreased and the pinning was released when γw-LC fell below a certain threshold. We revealed that the movement of the contact line could be evaluated by the surface tension between the water droplet and the 5CB substrate.
Figure 5c shows the time-series of the normalized volume of the water droplets at different wettability of the 5CB to the glass slide (44°, 20°, and 10°). The rate of decrease of the normalized volume was greater when the contact line moved continuously. This rate for the contact angle of 20° drastically decreased during the movement of the contact line. These results suggest that the evaporation rate is faster when the contact line is not pinned than when the line is pinned.
## CONCLUSIONS
In summary, we investigated pattern formation during solvent evaporation by focusing on solventsubstrate interactions. The water droplet was placed on the liquid crystals of 5CB, which was placed on a glass slide. The patterns of the 5CB orientation induced by the evaporation of the water droplet were visualized by a POM. Experiments were performed at various interfacial tensions
between water and 5CB by changing the anchoring strength of the liquid crystals on the glass slide. At a certain surface condition, pinning and depinning of the contact line between the water droplet and the 5CB substrate alternately occurred, and the water droplet induced highly ordered linear patterns on the surface of the 5CB. In these linear patterns, the 5CB molecules oriented in a specific direction; Patterns also had highly order at the molecular scale. We found that not only the properties of colloid suspensions but also pinning and depinning events determined by solventsubstrate interactions have a strong influence on the pattern formation induced by the evaporation of solvent. The findings of this study may contribute to the further control of self-assembly by solvent evaporation and the development of highly ordered and functional materials.
## AUTHOR INFORMATION
## Author Contributions
The manuscript was written through contributions of all authors. All authors have given approval to the final version of the manuscript.
Yusaku Abe: conceptualization, data curation, formal analysis, funding acquisition, investigation, methodology, visualization, writing-original draft, and writing-review & editing. Yu Matsuda: investigation, methodology, supervision, writing-original draft, and writing-review & editing.
## Funding Sources
This work was partially supported by JST, ACT-X Grant Number JPMJAX21A, Japan.
## ACKNOWLEDGMENT
The authors than Yuki Toyama for assistance with the measurements of contact angle and POM.
## REFERENCES
- (1) Deegan, R. D.; Bakajin, O.; Dupont, T. F.; Huber, G.; Nagel, S. R.; Witten, T. A. Capillary Flow as the Cause of Ring Stains from Dried Liquid Drops. Nature 1997 , 389 (6653), 827-829.
- (2) Gelderblom, H.; Diddens, C.; Marin, A. Evaporation-Driven Liquid Flow in Sessile Droplets. Soft Matter 2022 , 18 (45), 8535-8553.
- (3) Mondal, R.; Basavaraj, M. G. Influence of the Drying Configuration on the Patterning of Ellipsoids - Concentric Rings and Concentric Cracks. Phys. Chem. Chem. Phys. 2019 , 21 (36), 20045 -20054.
- (4) Zhang, C.; Akcora, P. Evaporation Controlled Particle Patterns in a Polymer Droplet. RSC Adv. 2017 , 7 (30), 18321-18326.
- (5) Xu, J.; Xia, J.; Hong, S. W.; Lin, Z.; Qiu, F.; Yang, Y. Self-Assembly of Gradient Concentric Rings via Solvent Evaporation from a Capillary Bridge. Phys. Rev. Lett. 2006 , 96 (6), 066104.
- (6) Sun, J.; Bao, B.; He, M.; Zhou, H.; Song, Y. Recent Advances in Controlling the Depositing Morphologies of Inkjet Droplets. ACS Appl. Mater. Interfaces 2015 , 7 (51), 2808628099.
- (7) Ooi, Y.; Hanasaki, I.; Mizumura, D.; Matsuda, Y. Suppressing the Coffee-Ring Effect of Colloidal Droplets by Dispersed Cellulose Nanofibers. Sci. Technol. Adv. Mater. 2017 , 18 (1), 316-324.
- (8) Weon, B. M.; Je, J. H. Capillary Force Repels Coffee-Ring Effect. Phys. Rev. E Stat. Nonlin. Soft Matter Phys. 2010 , 82 (1 Pt 2), 015305.
- (9) Lee, L.-T.; Leite, C. A. P.; Galembeck, F. Controlled Nanoparticle Assembly by Dewetting of Charged Polymer Solutions. Langmuir 2004 , 20 (11), 4430-4435.
- (10) Gao, A.; Liu, J.; Ye, L.; Schönecker, C.; Kappl, M.; Butt, H.-J.; Steffen, W. Control of Droplet Evaporation on Oil-Coated Surfaces for the Synthesis of Asymmetric Supraparticles. Langmuir 2019 , 35 (43), 14042-14048.
- (11) Srivastava, S.; Wahith, Z. A.; Gang, O.; Colosqui, C. E.; Bhatia, S. R. Dual -scale Nanostructures via Evaporative Assembly. Adv. Mater. Interfaces 2020 , 7 (7), 1901954.
- (12) Almohammadi, H.; Fu, Y.; Mezzenga, R. Evaporation-Driven Liquid-Liquid Crystalline Phase Separation in Droplets of Anisotropic Colloids. ACS Nano 2023 , 17 (3), 3098-3106.
- (13) Park, S. M.; Yoon, D. K. Evaporation-Induced Self-Assembly of Liquid Crystal Biopolymers. Mater Horiz 2024 . https://doi.org/10.1039/d3mh01585h.
- (14) Xie, Y.; Li, Y.; Wei, G.; Liu, Q.; Mundoor, H.; Chen, Z.; Smalyukh, I. I. Liquid Crystal Self-Assembly of Upconversion Nanorods Enriched by Depletion Forces for Mesostructured Material Preparation. Nanoscale 2018 , 10 (9), 4218-4227.
- (15) Onsager, L. The Effects of Shape on the Interaction of Colloidal Particles. Ann. N. Y. Acad. Sci. 1949 , 51 (4), 627-659.
- (16) Zhang, S.; Li, Q.; Kinloch, I. A.; Windle, A. H. Ordering in a Droplet of an Aqueous Suspension of Single-Wall Carbon Nanotubes on a Solid Substrate. Langmuir 2010 , 26 (3), 21072112.
- (17) Xiao, L.; Wei, J.; Gao, Y.; Yang, D.; Li, H. Formation of Gradient Multiwalled Carbon Nanotube Stripe Patterns by Using Evaporation-Induced Self-Assembly. ACS Appl. Mater. Interfaces 2012 , 4 (8), 3811-3817.
- (18) Smalyukh, I. I.; Zribi, O. V.; Butler, J. C.; Lavrentovich, O. D.; Wong, G. C. L. Structure and Dynamics of Liquid Crystalline Pattern Formation in Drying Droplets of DNA. Phys. Rev. Lett. 2006 , 96 (17), 177801.
- (19) Li, B.; Han, W.; Byun, M.; Zhu, L.; Zou, Q.; Lin, Z. Macroscopic Highly Aligned DNA Nanowires Created by Controlled Evaporative Self-Assembly. ACS Nano 2013 , 7 (5), 4326-4333.
- (20) van Hameren, R.; Schön, P.; van Buul, A. M.; Hoogboom, J.; Lazarenko, S. V.; Gerritsen, J. W.; Engelkamp, H.; Christianen, P. C. M.; Heus, H. A.; Maan, J. C.; Rasing, T.; Speller, S.; Rowan, A. E.; Elemans, J. A. A. W.; Nolte, R. J. M. Macroscopic Hierarchical Surface Patterning of Porphyrin Trimers via Self-Assembly and Dewetting. Science 2006 , 314 (5804), 1433-1436.
- (21) Davidson, Z. S.; Huang, Y.; Gross, A.; Martinez, A.; Still, T.; Zhou, C.; Collings, P. J.; Kamien, R. D.; Yodh, A. G. Deposition and Drying Dynamics of Liquid Crystal Droplets. Nat. Commun. 2017 , 8 , 15642.
- (22) Marín, Á. G.; Gelderblom, H.; Lohse, D.; Snoeijer, J. H. Order-to-Disorder Transition in Ring-Shaped Colloidal Stains. Phys. Rev. Lett. 2011 , 107 (8), 085502.
- (23) Dugyala, V. R.; Lama, H.; Satapathy, D. K.; Basavaraj, M. G. Role of Particle Shape Anisotropy on Crack Formation in Drying of Colloidal Suspension. Sci. Rep. 2016 , 6 (1), 30708.
Figure 1. (a-c) measurements of contact angle of 5CB droplets on different wettability glass slides, 44° (a), 20° (b), and 10° (c), respectively. (d) a POM image around the edge of 5CB droplet on a glass slide. (e, f) a bright-field microscopy image and a POM image of a contact line between water and 5CB.

Figure 2. POM images every 10 min after dropping water at different wettability, 44° (a-d), 20° (e-h), and 10° (i-l), respectively. Scale bars are 200 µm.
Figure 3. Normalized radius of a water droplet as a function of time for each wettability of glass slides. 𝑅𝑅 and 𝑅𝑅 ini are radius of a water droplet and radius of a water droplet at 1 min, respectively.
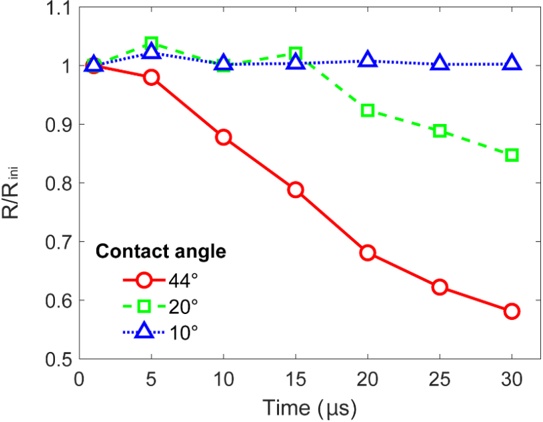
Figure 4. Polarized light transmission images around the contact line with λ -plate. (a) Direction of polarized light is vertical. An initial contact line is identified by black arrows. (b) Direction of polarized light is horizontal. Direction of movement of the contact line is identified by a white arrow.


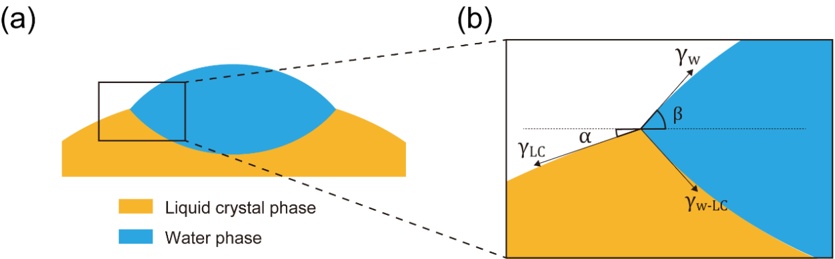
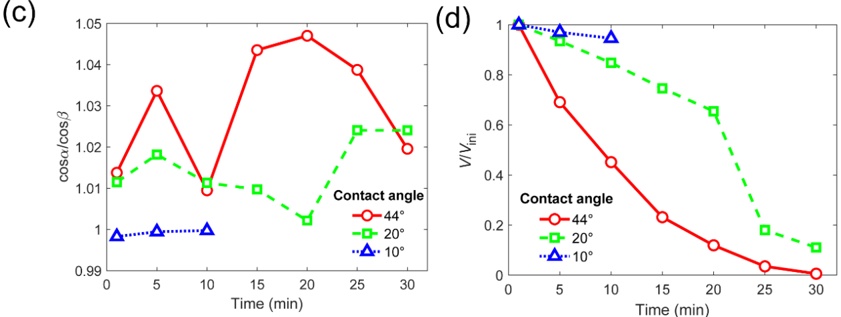
Time (min)
Figure 5. (a) Schematic representation of a cross-section of a water droplet on a 5CB droplet (b) Close-up of the contact line in (a). (c) Relative strength of surface tension between water and 5CB as a function of time for each wettability of glass slides. (d) Normalized volume of a water droplet as a function of time for each wettability of glass slides. 𝑉𝑉 and 𝑉𝑉 ini are volume of a water droplet and volume of a water droplet at 1 min, respectively. In (c) and (d), data is missing when the contact angle is 10° because it was difficult to measure after 15 min. | null | [
"Yusaku Abe",
"Yu Matsuda"
] | 2024-08-02T07:01:01+00:00 | 2024-08-02T07:01:01+00:00 | [
"cond-mat.soft",
"physics.chem-ph"
] | Orientational order in liquid crystal surface induced by evaporation of water droplet | The evaporation of a droplet induces variety of ordered patterns near the
contact line between the droplet and a substrate. This pattern formation
involves both the behavior of colloidal suspensions and interactions between a
droplet and a substrate. Although studies on the effect of the behavior of
colloidal suspensions on the deposition process have been actively conducted,
studies on the effect of the interaction between a droplet and a substrate have
not been actively conducted because the observation of the interaction is
difficult owing to the lack of structural changes in the substrate by the
interaction. In this study, we investigated the solvent-substrate interactions
by using a water droplet and liquid crystals as a substrate, where the liquid
crystals were placed on a glass slide. The orientation patterns of the liquid
crystals were induced at the contact line between the water droplet and the
liquid crystal and were observed using a polarized optical microscope. Pinning
and depinning events were observed at a certain anchoring strength of the
liquid crystal on the glass slide and formed linear patterns on the surface of
the liquid crystal. Additionally, the interfacial tension between the water and
liquid crystal slowly varied at this anchoring strength owing to the variation
in the orientation of the liquid crystals. These results indicated that the
evaporation-induced patterns appeared when the strength of the
solvent-substrate interactions was neutral. The interaction between a droplet
and a substrate is important for the fabrication of desired ordered patterns. |
2408.01054v1 | ## Distribution Aggregation via Continuous Thiele's Rules
Jonathan Wagner , * and Reshef Meir
Technion-Israel Institute of Technology
Abstract. We introduce the class of Continuous Thiele's Rules that generalize the familiar Thiele's rules [15] of multi-winner voting to distribution aggregation problems. Each rule in that class maximizes ∑ i f ( π i ) where π i is an agent i 's satisfaction and f could be any twice differentiable, increasing and concave real function. Based on a single quantity we call the 'Inequality Aversion' of f (elsewhere known as "Relative Risk Aversion"), we derive bounds on the Egalitarian loss, welfare loss and the approximation of Average Fair Share , leading to a quantifiable, continuous presentation of their inevitable trade-offs. In particular, we show that the Nash Product Rule satisfies Average Fair Share in our setting.
## 1 Introduction
In distribution aggregation problems [9] we study the problem of reaching a collective decision that concerns the division of some continuous public resource into different channels, e.g. the public budget allocated between various objectives (or 'projects') [13], time or land allocated between different activities, etc. The important defining feature is that we allocate any public resource, meaning that all alternatives serve, in principle, everyone, albeit to variable extents according to personal taste. That is in contrast to different branches of Social Choice, e.g. Cake cutting [20] or Fair Division [18] where we allocate resources among agents which enjoy them individually as private goods. The collective decision is reached via some voting rule or 'mechanism' that inputs everyone's preference regarding the different possible outcomes and outputs an outcome that would be implemented.
## 1.1 Preference Modeling
Accordingly, the preference of generic agents in distribution aggregation concerns the distribution as a whole rather than some personal endowment. In general, the full structure of such preference might be complex. Realistically, however, an aggregation rule that requires deep inquiry into each voter's personal preference seems too bothering and not very likely. Thus, as in other areas of Social Choice, "single-peaked" preferences where an agent's optimal outcome entails the complete description of her preferences over the decision space, are many times favored as a reasonable compromise between the accuracy and applicability [17, 6]. Moreover, such models typically perform better in terms of strategy-proofness. Specifically, /lscript p -norm preference where an agent (dis)satisfaction is expressed as the distance ∥ ∥ x i -x ∥ ∥ p between her preferred distribution x i to the one implemented x , and especially /lscript 1 is probably the most prevailing choice [9, 14, 13]. In our work we adopt the /lscript 1
∗ Corresponding Author. Email: [email protected]
model, albeit adhering to its equivalent, less common representation that was introduced in [14] of overlap utilities. That is, an agent i enjoys | x i ∩ x | = ∑ j min( x , x i j j ) in allocation x , where j covers the set of alternatives. This formulation not only lets us more conveniently relate to satisfaction rather than dissatisfaction, but also mirrors the canonical notion in the discrete multi-winner voting setting of | A i ∩ W A | , i being the set of alternatives approved by agent i and W the winning set.
## 1.2 Axiomatic Demands And Their Incompatibilities
A well known fact that dates back as far as to Arrow's Theorem [1] is that good axiomatic properties of social choice rules are often contradictory. For instance, the utilitarian welfare maximizing allocation x ∈ arg max ∑ i | x i ∩ x | is known to also promise strategyproofness [14, 13], while the egalitarian maxmin allocation x = max y min i | x i ∩ y | can be advocated as the more fair solution and in particular guarantees a 1 n satisfaction the least for every agent. The Nash Product Rule x = max y ∑ i ln ( | x i ∩ x | ) is somewhat a middle ground between the two, that, as we later show, satisfies Average Justified Representation ( AFS ) that cares for the well being of subgroups rather than just individuals. Each of these three admits a certain demand that captures a different angle on social justice. Not surprisingly, they are generically incompatible with each other. In particular, [6] shows that even the weakest Justified Representation demand of 'proportionality' is incompatible with welfare maximization and strategyproofness.
## 1.2.1 Contribution
In this work, we offer non-axiomatic approach to deal with these impossibilities, via studying the class of Continuous Theile's Rules that maximize ∑ i f ( | x i ∩ x | ) where f could be any concave real function.
1 + 1 2 + 1 3 + · · · + 1 | A i ∩ W | that satisfies Extended Justified Representation [3]. When applied to our continuous setting, much resemblance is found between corresponding rules and the properties they guarantee. The advantage in moving to a continuous space is that we can consider a continuum of rules that lie 'in between' those that properly satisfy different axioms, and characterize the trade-off
The original Thiele's Voting Rules [15] are a well known class of multi-winner voting rules, each characterized by a function f , that choose the winning set W to maximize ∑ i f ( | A i ∩ W | ) . In affinity to the discussion above, this class includes some of the most practiced and well studied multi-winner voting rules, e.g. the welfare maximizing k -approval with f = id , the egalitarian ChamberlinCourant with f = 1 | A i ∩ W |≥ 1 , and PAV where f ( | A i ∩ W | ) =
each of them offers in terms of approximating either axiom. We will show how a rule's approximation guarantees depend on the Inequality Aversion of f , IAV f = -tf ′ ( t ) f ′′ ( t ) (elsewhere known as 'Relative Risk Aversion' [8]). In particular, we show that in our setup the Nash product rule satisfies AFS by its full meaning.
## 1.3 Related Work
Compared to its neighbouring branches of Social Choice, the literature on distribution aggregation is not abundant. The most natural application is Participatory Budgeting (PB) that has drawn increased attention in late years, however that literature mainly focuses on the discrete form where each project has a fixed cost [19, 2, 21], which is in compliance with the vast majority of PB instances in reality. In some works, the aggregation rule outputs a distribution while preferences are yet binary or ordinal [4, 5, 16]. As customary in Social Choice, the divisible PB literature treats the trade-off between fairness and welfare-optimality mainly by means of offering different mechanisms that can or cannot satisfy specific axiomatic properties [9, 4, 13]. [13] introduces the class of strategy-proof Moving-Phantom mechanisms within which the ( /lscript 1 ) welfare maximizing mechanism is the only pareto-efficient one, while the novel "Independent-Market" mechanism is the only one to satisfy a fairly weak notion of proportional fairness. This incompatibility of efficiency, strategy-proofness and proportionality has lately been proven to be generally inevitable [6] under /lscript 1 and /lscript ∞ preferences. Remarkably, however, [6] also shows that under Minimal Quotient preferences - where the satisfaction of agent i in x equals min { j x i > : j 0 } x j x i
j
- these typically contradicting objectives can be achieved all at once. The most closely related predecessor of our work is found in [16], where group-fairness and welfare guarantees of different CTR rules (however named differently) are compared, under preference model slightly different than ours. Our work expands on it by considering egalitarian fairness two, and characterizing the trade-off by a single parameter. Other "flexible" approaches for handling the inherent trade-off include the relaxation of some of the axioms [4, 14], or searching for approximation guarantees different rules hold for different axioms [10, 11]. Under /lscript 1 preferences in particular, in [7] and [12] fairness is measured as the /lscript 1 distance of an allocation to the preferences mean. They introduce optimal rules for minimizing that gap within the Moving-Phantom class [13], with quantifiable bounds. However, to the best of our knowledge, the introduction of a continuum of parameterized rules to our choice, where each offers a concrete approximation guarantees, have not yet been attempted.
## 2 Preliminaries
Let [ n ] be a set of agents and [ m ] be a set of alternatives, where [ k ] := { 1 , ..., k } for each positive integer k . Subsets of [ n ] are denoted by lowercase letters e.g. s ⊂ [ n ] , and in many places we abuse the notation to represent also the subset size. For vectors in R m + := { y ∈ R m | y j ≥ 0 ∀ j ∈ [ m ] } , we denote | y | = ∑ j y j and y ≤ z means y j ≤ z j ∀ j . For any tuple y , . . . , y 1 t , we define the overlap ( y 1 ∩ · · · ∩ y t ) by ( y 1 ∩ · · · ∩ y t ) j := min 1 ≤ ≤ q t y q j . An allocation x ∈ ∆ m := { y ∈ R m + | ∑ m j =1 y j = 1 } is a distribution of some continuously divisible resource (e.g. time, money) among the m alternatives, where we normalize the overall budget to 1 . The preferences of every agent i are expressed by a single allocation x i ∈ ∆ m that she would like to be implemented ideally, and /vector x := ( x , . . . , x 1 n ) ∈ (∆ m n ) is the preferences profile . We denote by /vector x -i the partial profile consisting of all agents excluding i , and /vector x -s accordingly for a subset s ⊂ [ n ] . The satisfaction of agent i in allocation x is π i x := | x i ∩ x | = ∑ j min( x , x i j j ) . Or, just π i when specifying the allocation is unnecessary.
## 2.1 Aggregation Rules and their Properties
Definition 1. An aggregation rule is a function F : (∆ m n ) → ∆ m that inputs the preferences profile /vector x and outputs an allocation x ∈ ∆ m .
We survey here several properties that may or may not be satisfied by an allocation x given a profile /vector x . We say that an aggregation rule F satisfies any of these properties if for all /vector x ∈ (∆ m n ) , F /vector ( x ) satisfies the corresponding property with respect to /vector x .
- · Efficiency ( EFF ): An allocation x is efficient if no other allocation y ∈ ∆ m exists such that π i x ≥ π i y ∀ i ∈ [ n ] with at least one agent for which that inequality is strict.
- · Range Respecting ( RR ): An allocation x is Range Respecting if min i x i j ≤ x j ≤ max x i i j ∀ j ∈ [ m ] . Note that EFF = ⇒ RR .
- · Individual Fair Share ( IFS ): An allocation x satisfies Individual Fair Share if π i x ≥ 1 n ∀ i ∈ [ n ] . From an agents' individual perspective, that means that x allocates at least 1 /n of the budget according to her desire.
- · Average Fair Share ( AFS ): A subset of agents s ⊂ [ n ] is called α -cohesive for some 0 < α ≤ | s | n if ∣⋂ ∣ i ∈ s x i ∣ ∣ ≥ α . An allocation x satisfies Average Fair Share if for every α ∈ (0 , 1] , if s ⊂ [ n ] is α -cohesive then 1 | s | i ∈ s π i x ≥ α .
- ∑ · Core Stability ( CS ): An allocation x satisfies Core Stability if for every s ⊂ [ n ] , no y ∈ R m + exists such that | y | = | s | n and π i y ≥ π i x ∀ i ∈ s with strict inequality for at least one member of s .
- · Proportionality ( PROP ) [13]: This much weaker demand requires the fulfilment of all Fair Share axioms above, but only for a simple structure of the preference profile (in which they all coincide). Single-minded profiles are profiles where x i is a unit vector for all i , in other words that every agent wishes to allocate the full budget to a single alternative. If /vector x is single-minded, then x satisfies proportionality if x = 1 n ∑ i x i . The next two properties refer directly to rules rather than allocations.
- · Participation ( PAR ): Aggregation rule F satisfies (strict) participation if
$$| F ( \vec { x } ) \cap x ^ { i } | \stackrel { ( > ) } { \geq } | F ( \vec { x } _ { - i } ) \cap x ^ { i } | \ \forall \vec { x }, x ^ { i }$$
meaning that agents should always prefer voting over abstaining.
- · Strategyproofness ( SP ): Aggregation rule F is strategyproof is for all x i and /vector x -i ,
$$| F ( x ^ { i }, \vec { x } _ { - i } ) \cap x ^ { i } | \geq | F ( y, \vec { x } _ { - i } ) \cap x ^ { i } | \ \forall y \in \Delta ^ { m }$$
meaning, no agnet i can increase her satisfaction by misreporting some y ∈ ∆ m instead of her true preference x i .
## 3 Continuous Theile's Rules
In this paper we study the following class of mechanisms.
Definition 2 (Continuous Thiele's Aggregation Rules) . For any increasing, twice differentiable and strictly concave function f : [0 , 1] → R , we define the corresponding Continuous Thiele's Rule (CTR) T f by
$$T _ { f } ( \vec { x } ) \in \arg \max _ { x \in \Delta ^ { m } } \sum _ { i = 1 } ^ { n } f ( \pi _ { x } ^ { i } )$$
## 3.1 Optimal allocations
CTRs can be computed efficiently via convex optimization as ∑ n i =1 f ( π i x ) is a concave function of x (note that π i x = ∑ j min( x , x i j j ) is in itself a sum of concave functions). . Thanks to that, optimal allocations can be characterized conveniently by first order conditions. We formalize here these constraints that will help us derive much of our later results.
Definition 3. Let x ∈ ∆ m . For each j ∈ [ m ] ,
$$s _ { j } ^ { \uparrow ( \downarrow ) } ( x ) \coloneqq \{ i \in [ n ] | x _ { j } ^ { i } > ( \geq ) x _ { j } \}$$
/negationslash
That is, s ↑ j ( x ) consists of all agents i ∈ [ n ] for which increasing (or reducing, for s ↓ ) x j while keeping all other { x k } k = j fixed will increase (reduce) their satisfaction π i x . The reason we distinguish between the two is that if x i j = x j for some agent i , she suffers from a reduction in x j while not gaining if we increase it. If no such agent exist, the sets coincide and we can just write s j . We also do that for the sake of abbreviation in many places, where the intention should be clear or the distinction is not crucial.
Notation 4. For every agent i and allocation x ,
$$\sigma _ { x } ^ { \uparrow ( \downarrow ) } ( i ) \coloneqq \{ j \in [ m ] | i \in s _ { j } ^ { \uparrow ( \downarrow ) } ( x ) \}$$
Next, we want to define the partial derivative of ∑ n i =1 f ( π i x ) w.r.t. alternative j ∈ [ m ] .
Definition 5 (marginal contributions) . Let x ∈ ∆ m . For every j ∈ [ m ] ,
$$m c _ { j } ^ { \uparrow ( \downarrow ) } ( x ) \coloneqq \sum _ { i \in s _ { j } ^ { \uparrow ( \downarrow ) } ( x ) } f ^ { \prime } ( \pi _ { x } ^ { i } )$$
Note that mc j ( x ) depends on x j only through s j , however the contribution of each member to the sum is a function of their overall satisfaction π i x := ∑ j min( x , x i j j ) . In case x i k = x k for some k ∈ [ m ] (whether k = j or other), f ′ ( π i x ) does not exist, and we take the right or left derivative accordingly.
Proposition 1 (MRS condition) . x ∈ arg max y ∈ ∆ m ∑ i f ( π i y ) if and only if
$$m c _ { j } ^ { \uparrow } ( x ) \leq m c _ { k } ^ { \downarrow } ( x ) \ \forall j, k \in [ m ]$$
Note that when s ↑ j = s ↓ j and s ↑ k = s ↓ k , marginal contributions also coincide and the two inequalities for j and k are reduced to the equation mc j = mc k . Intuitively, optimal allocations must admit the MRS demand because if mc ↑ j ( x ) > mc ↓ k ( x ) for some j and k , increasing x j at the expense of x k would increase ∑ i f ( π i ) , up to the point where the MRS condition is satisfied. (And, every local maximum of a concave function is also a global one).
## 3.2 Axiomatic Properties of CTRs
We start with examining the satisfaction of the axiomatic demands mention above for CTRs. It is easy to observe that EFF and PAR are satisfied by all members in the class. As for other demands, their performance is not as satisfying.
Proposition 2. No CTR satisfies SP .
Proof. Consider the following counter example. Let n = m = 2 , x 1 = ( 5 . , . 5) and x 2 = (0 1) , . Let x = T f ( /vector x ) . Since T f satisfies RR , we know that x = ( y, 1 -y ) for some y ∈ [0 , 0 5] . , so that s 1 = 1 , s 2 = 2 , π 1 x = y +0 5 . and π 2 x = 1 -y . Thus,
$$f ^ { \prime } ( y + 0. 5 ) = m c _ { 1 } = m c _ { 2 } = f ^ { \prime } ( 1 - y ) \implies y =. 2 5$$
( f ′ is strictly decreasing, thus injective). Now assume agent 1 misreports ˆ x 1 = (1 0) , instead, and call the new outcome ( z, 1 -z ) . Then
$$f ^ { \prime } ( z ) = m c _ { 1 } = m c _ { 2 } = f ^ { \prime } ( 1 - z ) \implies z =. 5$$
and agent 1 's satisfaction has increased from 0 75 . to 1 .
Whenit comes to proportional fairness, the only CTR that achieves any such demand (for m > 2 ) is the logarithmic rule where f = ln , aka the Nash Product Rule, that satisfies the relatively strong AFS . That stands in alignment with the discrete model where the PAV rule that maximizes ∑ i H | ( A i ∩ W | ) (where H is the harmonic function) is the only Thiele rule that admits a somewhat weaker demand called EJR [3]. The proof of Nash Rule's AFS property is dismissed here as a particular case of Theorem 9. On the contrary, we show that it is the only CTR that satisfies the much weaker PROP .
Proposition 3. For m > 2 , the Nash rule T ln is the only CTR that satisfies PROP .
Proof. Let /vector x be a single-minded preferences vector, and T f ( /vector x ) = x . By MRS, s f j ′ ( x j ) = s k f ′ ( x k ) ∀ j, k (note that under single-minded profiles mc ↑ j = mc ↓ j for all j such that 0 < x j < 1 ). If x satisfies PROP then x j = s j n , yielding
$$s _ { j } f ^ { \prime } ( \frac { s _ { j } } { n } ) = s _ { k } f ^ { \prime } ( \frac { s _ { k } } { n } ) \, \Longrightarrow \, \frac { s _ { j } } { n } f ^ { \prime } ( \frac { s _ { j } } { n } ) = \frac { s _ { k } } { n } f ^ { \prime } ( \frac { s _ { k } } { n } )$$
Satisfying this for general n, 1 ≤ s , s j k ≤ n means that xf ′ ( x ) is a constant function, thus f = ln .
Moreover, the logarithmic CTR does not satisfy CS .
Example 4. Let m = 3 and [ n ] consisting of 3 disjoint sets n , n 1 2 , n 3 such that n 1 = n 2 = 0 3 . n, n 3 = 0 4 . n . Each of the subsets is homogeneous with preferences x 1 = (1 0 0) , , , x 2 = ( 5 . , . 5 0) , , x 3 = (0 0 1) , , respectively. Then T ln ( /vector x ) = x = ( 5 . , 0 , . 5) . However, with y = (0 55 0 05) . , . , | y | = n 1 + n 2 n , every agent i ∈ n 1 ∪ n 2 has π i y = 0 55 . > π i x = 0 5 . .
Interestingly, the Nash product does output a core solution under preference model not too far from /lscript 1 [4]. Whether the core is always non-empty, and what rule can find core solutions when they exist, remains an open question.
## 4 Utilitarian vs. Egalitarian Welfare
After reviewing the not-very-impressive axiomatic performance of CTR rules, we develop in this section a more explicit presentation of the compromise one has to make between utilitarianism and distributive fairness. We start with the notion of Inequality Aversion captured in a concave function f .
Definition 6 ( Inequality Aversion) . For any twice differentiable f : [0 , 1] → R , the Inequality Aversion of f , IAV f : (0 , 1] → R is
$$I A V _ { f } ( t ) = - \frac { t f ^ { \prime } ( t ) } { f ^ { \prime \prime } ( t ) }$$
More commonly, -tf ′ ( t ) f ′′ ( t ) is known as the "Relative Risk Aversion" of f , a major concept in decision making under uncertainty [8]. While the two contexts are unrelated, the technical similarity is comprehensible. In principle, the concavity of f implies 1 n ∑ i f ( π i x ) ≤ f ( 1 n ∑ i π i x ) , and -tf ′ ( t ) f ′′ ( t ) is a proxy for how big the gap is. The higher -tf ′ ( t ) f ′′ ( t ) is, the less dispersed will be the optimal distribution for { π i x } i ∈ [ n ] . In decision making under uncertainty, f represents utility and 1 n ∑ i f ( π i x ) is the expectancy E f L [ ( ) ] for some random variable L distributed over { π i x } i ∈ [ n ] , whereas in our case f is a function chosen by a social planner to promote her normative balance between fairness (low disparity) and overall welfare ∑ i f ( π i x ) . Here are some examples for the IAV of different functions.
| f | IAV f |
|-----------------------------------|-----------------------|
| - t - p , p> 0 - e t - p , p> 0 p | = 1 + p ∀ t ∈ (0 , 1] |
| | ≥ 1 + p ∀ t ∈ (0 , 1] |
| t , 1 >p> 0 | = 1 - p ∀ t ∈ (0 , 1] |
| ln( t ) | = 1 ∀ t ∈ (0 , 1] |
| t (2 - t ) | ≤ 1 ∀ t ∈ (0 , 1] |
The lemma below shows an equivalent representation for IAV that will later come handy. Then, Example 6 that follows will provides a clear intuition to its major role here. When writing IAV = ( ≤ )( ≥ ) λ , we mean that the corresponding relation holds in all [0 , 1] .
Lemma 5. The following are equivalent for any twice differentiable concave function f : [0 , 1] → R :
- · IAV f ( ≤ ) ≥ λ for some λ > 0 .
- · ∀ α > 1 , f ′ ( t ) f ′ ( αt ) ( ≤ ) ≥ α λ
Proof. Essentially, -tf ′′ ( t ) f ′ ( t ) ( ≤ ) ≥ λ means that f ′ ( ) t decreases faster (slower) than t -λ :
$$& \frac { \text{d} } { \text{d} t } \left [ t ^ { \lambda } f ^ { \prime } ( t ) \right ] = t ^ { \lambda - 1 } ( \lambda f ^ { \prime } ( t ) + t f ^ { \prime \prime } ( t ) ) \leq 0 \iff - \frac { t f ^ { \prime \prime } ( t ) } { f ^ { \prime } ( t ) } \geq \lambda \\ & \text{And if } t ^ { \lambda } f ^ { \prime } ( t ) \text{ is non-increasing (non-decreasing), then } \quad \text{$\quad.$}.$$
And if t λ f ′ ( ) t is non-increasing (non-decreasing), then
$$\forall \alpha > 1, \ t ^ { \lambda } f ^ { \prime } ( t ) \stackrel { ( \leq ) } { \geq } ( \alpha t ) ^ { \lambda } f ^ { \prime } ( \alpha t ) \iff \frac { f ^ { \prime } ( t ) } { f ^ { \prime } ( \alpha t ) } \stackrel { ( \leq ) } { \geq } \alpha ^ { \lambda }$$
Example 6. Consider a single-minded profile for m = 2 where s 2 > s 1 . MRS at the outcome x = T f ( /vector x ) gives
$$\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \delta$$
If λ bounds IAV f , it also bounds the extent to which T f favors the majority s 2 . If IAV f ≥ λ ,
$$( \frac { x _ { 2 } } { x _ { 1 } } ) ^ { \lambda } & \leq \frac { f ^ { \prime } ( x _ { 1 } ) } { f ^ { \prime } ( x _ { 2 } ) } \implies \frac { \pi _ { x } ^ { 2 } } { \pi _ { x } ^ { 1 } } = \frac { x _ { 2 } } { x _ { 1 } } \leq ( \frac { s _ { 2 } } { s _ { 1 } } ) ^ { 1 / \lambda } \\ p \text{articular, for } \lambda \to \infty \, w e \, \text{ get the egalitarian maxmin allocati.}$$
In particular, for λ → ∞ we get the egalitarian maxmin allocation x 1 = x 2 . For IAV f ≤ λ we will have the inequalities reversed :
$$( \frac { x _ { 2 } } { x _ { 1 } } ) ^ { \lambda } \geq \frac { f ^ { \prime } ( x _ { 1 } ) } { f ^ { \prime } ( x _ { 2 } ) } \implies \frac { \pi _ { x } ^ { 2 } } { \pi _ { x } ^ { 1 } } = \frac { x _ { 2 } } { x _ { 1 } } \geq ( \frac { s _ { 2 } } { s _ { 1 } } ) ^ { 1 / \lambda }$$
so that at the limit λ → 0 the welfare maximizing allocation x = (1 0) , is achieved. Finally, if IAV = 1 (meaning f = ln ) the budget is allocated proportionally, x j = s j s j + s k .
Our main results, presented in this section, build on the idea demonstrated in Example 6 to provide fairness / welfare guarantees within the CTR class.
We can figuratively map this class to (0 , ∞ ) based on the IAV parameter, as demonstrated in Figure 4. At the left limit λ = 0 we have the welfare maximizing rule F /vector ( x ) = arg max ∑ i π i . Theorem 7 bounds the welfare loss as a function of the upper bound on the IAV . On the other hand, for 1 ≥ IAV ≥ λ we get increasingly close approximations of AFS as coming closer to the Nash Product Rule where IAV = 1 (Theorem 9), and at the right limit IAV ≥ λ →∞ we have the egalitarian rule (Theorem 12). In other words 0 < IAV < 1 correspond to rules that favor utilitarian over egalitarian welfare (to various degrees), IAV > 1 means favoring egalitarianism, and the Nash rule with IAV = 1 is point of "exact balance" between the two.
$$\begin{smallmatrix} \lambda = 0 & \xrightarrow { \lambda = 1 \left ( f = ln \right ) } \\ \text{utilitarian welfare} & \text{Justified Representation} & \text{egalitarian welfare} \end{smallmatrix}$$
## 4.1 Welfare Loss
Theorem 7 below shows the welfare preserved when the IAV is small enough, and is preceded by some necessary definitions.
Definition 7. The Welfare in allocation x is W x ( ) := ∑ i π i x . Definition 8. The Welfare loss of allocation x is defined
$$\text{WI} ( x ) = 1 - \frac { W ( x ) } { \max _ { y \Delta ^ { m } } W ( y ) }$$
Notation 9. Given two allocations x and y , we write:
$$J _ { x } & \coloneqq \{ j \in [ m ] | x _ { j } \geq y _ { j } \} \, ; \, J _ { y } \coloneqq \{ j \in [ m ] | x _ { j } < y _ { j } \} \\ \delta _ { j } & \coloneqq | x _ { j } - y _ { j } | \, \forall j \in [ m ] \, ; \, a n d \, \delta \coloneqq \sum _ { j \in J _ { x } } \delta _ { j } = \sum _ { j \in J _ { y } } \delta _ { j } \\ \text{The difference in satisfaction between $x$ to $u$ for every $\,$event$ is}$$
The difference in satisfaction between x to y for every agent is thus bounded by
$$\pi _ { y } ^ { i } - \pi _ { x } ^ { i } \leq \sum _ { k \in J _ { y } \cap \sigma _ { x } ^ { \uparrow } ( i ) } \delta _ { k } - \sum _ { j \in J _ { x } \cap \sigma _ { x } ^ { \downarrow } ( i ) } \delta _ { j }$$
Indeed, an agent might gain less then all of δ k for k ∈ J y ∩ σ ↑ x ( ) i if x k < x i k < y k , and may lose some of δ j even if j / J ∈ x ∩ σ ↓ x ( ) i in case y j < x i j < x j .
Theorem 7. Let x = T f ( /vector x ) such that IAV f ≤ λ . Then
$$\text{WI} ( x ) \leq \frac { \lambda m ^ { \lambda } } { \lambda m ^ { \lambda } + \lambda + 1 }$$
Proof. Let x = T f ( /vector x ) and y = arg max i π i . Then
$$\text{WL} ( x ) \leq \frac { \sum _ { i } } { \lambda m ^ { \lambda } + \lambda + 1 } \\ \text{roof} \text{ } Let x = T _ { f } ( \vec { x } ) \text{ and } y = \arg \max \sum _ { i } \pi ^ { i }. \text{Then} \\ W ( y ) - W ( x ) & \leq \sum _ { k \in J _ { y } } s _ { k } ^ { \uparrow } ( x ) \delta _ { k } - \sum _ { j \in J _ { x } } s _ { j } ^ { \downarrow } ( x ) \delta _ { j } \\ & \leq s _ { \max } ^ { \uparrow } \sum _ { k \in J _ { y } } \delta _ { k } - \sum _ { j \in J _ { x } } s _ { j } ^ { \downarrow } \delta _ { j } \\ & = \sum _ { j \in J _ { x } } ( s _ { \max } ^ { \uparrow } - s _ { j } ^ { \downarrow } ( x ) ) \delta _ { j } \\ & \leq \sum _ { j \in J _ { x } } ( s _ { \max } ^ { \uparrow } - s _ { j } ^ { \downarrow } ( x ) ) x _ { j }$$
where s ↑ max := max k ∈ J y s ↑ k and we used ∑ k ∈ J y δ k = ∑ j ∈ J x δ j and δ j ≤ x j . Now, by MRS and IAV f ≤ λ we have for all j, k ∈ [ m ] :
$$& s _ { k } ^ { \uparrow } f ^ { \prime } ( 1 ) \leq m c _ { k } ^ { \uparrow } \leq m c _ { j } ^ { \downarrow } \leq s _ { j } ^ { \downarrow } f ^ { \prime } ( x _ { j } ) \\ & \implies s _ { k } ^ { \uparrow } \leq s _ { j } ^ { \downarrow } \frac { f ^ { \prime } ( x _ { j } ) } { f ^ { \prime } ( 1 ) } \leq s _ { j } ^ { \downarrow } ( \frac { 1 } { x _ { j } } ) ^ { \lambda } \\ \text{fore $\sum_{iota=\dots,\ (s _ { \max } ^ { \uparrow } - s _ { i } ^ { \downarrow } ( x ) ) x_{i} < s _ { \max } ^ { \uparrow } \sum_{iota=\dots,\ (1}$}$$
and therefore ∑ j ∈ J x ( s ↑ max -s ↓ j ( x )) x j ≤ s ↑ max ∑ j ∈ J x (1 -x λ j ) x j . The function g t ( ) = (1 -t λ ) t is concave and has a maximum λ ( λ +1) λ +1 λ at t ∗ = ( λ +1) -1 λ . Thus,
$$\sum _ { j \in J _ { x } } ( 1 - x _ { j } ^ { \lambda } ) x _ { j } & \leq \frac { \sum _ { j \in J _ { x } } x _ { j } } { t ^ { * } } g ( t ^ { * } ) = \sum _ { j \in J _ { x } } x _ { j } \frac { \lambda } { \lambda + 1 } \leq \frac { \lambda } { \lambda + 1 } \\..$$
Now,
$$w, \\ W ( x ) & = \sum _ { i } \pi _ { x } ^ { i } \geq \sum _ { i } \sum _ { j \in \sigma ( i ) } x _ { j } = \sum _ { j } s _ { j } ^ { \downarrow } x _ { j } \\ & \geq s _ { \max } ^ { \uparrow } \sum _ { j } x _ { j } ^ { \lambda } \cdot x _ { j } \geq s _ { \max } ^ { \uparrow } m \left ( \frac { 1 } { m } \right ) ^ { 1 + \lambda } \\ & = s _ { \max } ^ { \uparrow } \left ( \frac { 1 } { m } \right ) ^ { \lambda } \\ \intertext { \ierefore, }$$
Therefore,
$$\frac { W ( y ) - W ( x ) } { W ( x ) } & \leq m ^ { \lambda } \frac { \lambda } { \lambda + 1 } \\ \Longrightarrow \frac { W ( y ) - W ( x ) } { W ( y ) } & \leq \frac { m ^ { \lambda } \frac { \lambda } { \lambda + 1 } } { 1 + m ^ { \lambda } \frac { \lambda } { \lambda + 1 } } = \frac { \lambda m ^ { \lambda } } { \lambda m ^ { \lambda } + \lambda + 1 }$$
Corollary 8 (Welfare loss in single minded profiles) . In the special case of single-minded preferences (where every voter allocates the full budget to some unique alternative j ∈ [ m ] ), the utilitarian allocation puts all budget on the alternative with highest support, meaning W y ( ) = s ↑ max , yielding
$$\text{WI} ( x ) = \leq \frac { s _ { \max } ^ { \uparrow } \sum _ { j \in J _ { x } } x _ { j } \frac { \lambda } { \lambda + 1 } } { s _ { \max } ^ { \uparrow } }$$
/negationslash
$$\text{WI} ( x ) \leq \frac { m - 1 } { m } \frac { \lambda } { \lambda + 1 }$$
Moreover, since s f j ′ ( x j ) = s k f ′ ( x k ) means x k ≥ x j ⇐⇒ s k ≥ s j , if s k = s ↑ max then x k = max j x j ≥ 1 m and thus ∑ j ∈ J x x j = ∑ j = k x j ≤ m -1 m . Hence,
## 4.2 Approximate AFS
The next Theorem shows how good an approximation of AFS we can guarantee when increasing the (lower bound on) IAF towards 1 .
Theorem 9 ( λ -AFS) . Let x = T f ( /vector x ) such that 1 ≥ IAV f ≥ λ . Then, For every α -cohesive set s ∈ [ n ]
$$\frac { 1 } { | s | } \sum _ { i \in s } \pi _ { x } ^ { i } \geq \alpha ^ { \frac { 1 } { \lambda } }$$
Proof. Let an α -cohesive group s ⊂ [ n ] . Since | ⋂ i ∈ s x i | ≥ α ≥ α 1 λ , if ⋂ i ∈ s x i if covered by x we are done. Otherwise, there exists j ∈ [ m ] such that min i ∈ s x i j > x j and, since f ′ is convex,
$$\ m c _ { j } ^ { \uparrow } = \sum _ { i \in s _ { j } ^ { \uparrow } } f ^ { \prime } ( \pi _ { x } ^ { i } ) \geq \sum _ { i \in s } f ^ { \prime } ( \pi _ { x } ^ { i } ) \geq s f ^ { \prime } ( \pi ^ { s } )$$
where π s := ∑ i ∈ s π i x By MRS, sf ′ ( π s ) ≤ mc ↓ k ∀ k ∈ [ m ] . Thus, would now like to bound min k mc ↓ k . To do that, Let σ i ( ) = { k ∈ [ m i ] | ∈ s ↓ k } for every agent i and note that π i x ≥ ∑ k ∈ σ i ( ) x k . Now,
$$\mu _ { \mu } = \mu _ { \mu } \dots \dots \dots \dots \dots \dots \nu _ { \mu } \leq \kappa \in \sigma _ { ( i ) } \mu _ { \mu } \dots \dots, \\ \sum _ { k } m c _ { k } \cdot x _ { k } & = \sum _ { k } x _ { k } \sum _ { i \in s _ { k } } f ^ { \prime } ( \pi _ { x } ^ { i } ) = \sum _ { i } \sum _ { k \in \sigma ( i ) } x _ { k } f ^ { \prime } ( \pi ^ { i } ) \\ & \leq \sum _ { i } \sum _ { k \in \sigma ( i ) } x _ { k } f ^ { \prime } \left ( \sum _ { k \in \sigma ( i ) } x _ { k } \right ) \leq n f ^ { \prime } ( 1 ) \\ \dots$$
where the last inequality is due to the fact that tf ′ ( ) t is an increasing function by IAV f ≤ 1 . As ∑ k x k = 1 , there must exist k ∈ [ m ] such that mc k ≤ nf ′ (1) . Hence,
$$s f ^ { \prime } ( \pi ^ { s } ) \leq n f ^ { \prime } ( 1 ) \, \Longrightarrow \, \frac { s } { n } \leq \frac { f ^ { \prime } ( 1 ) } { f ^ { \prime } ( \pi ^ { s } ) } \leq ( \pi ^ { s } ) ^ { \lambda }$$
$$\text{Overall, we showed $\pi^{s} \geq \min \left ( \alpha, \left ( \frac { s } { n } \right ) ^ { \frac { 1 } { \lambda } } \right ) \geq \alpha ^ { \frac { 1 } { \lambda } }. \\ \text{A} \quad r _ { - - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rho _ { - 1 } \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \rq \langle$$
## 4.3 Egalitarian Loss and Individual Shares
Wemove on now to discuss the egalitarian guarantees we can provide for high enough IAV . We aim on arguing that T f approaches the egalitarian rule at the limit IAV f → ∞ . First, we have the next result on individual share.
Proposition 10. Let x = T f ( /vector x ) such that IAV f ≥ λ and π min x := min i π i x . Then
$$\pi _ { x } ^ { \min } \geq \frac { 1 } { 1 + ( m - 1 ) ( n - 1 ) ^ { \frac { 1 } { x } } }$$
Proof. Since every agent must be in s ↑ j for at least one j ∈ [ m ] (unless her satisfaction is 1 ), there exist j ∈ [ m ] such that s ↑ j ≥ f ′ ( π min x ) . Thus, due to the MRS conditions,
$$\forall k \in [ m ], \ \ f ^ { \prime } ( \pi _ { x } ^ { \min } ) \leq m c _ { k } ^ { \downarrow } \leq ( n - 1 ) f ^ { \prime } ( \min _ { i \in s _ { k } } \pi _ { x } ^ { i } ) \\ \implies ( n - 1 ) ^ { \frac { 1 } { x } } \pi _ { x } ^ { \min } \geq \min _ { i \in s _ { k } } \pi _ { x } ^ { i } \geq x _ { k }$$
and in particular, π min x ≥ x j . Thus,
/negationslash
$$1 = x _ { j } + \sum _ { k \neq j } x _ { k } \leq \pi _ { x } ^ { \min } \left ( 1 + ( m - 1 ) ( n - 1 ) ^ { \frac { 1 } { x } } \right )$$
For λ → ∞ that bound is 1 /m which is max y ∈ ∆ m min i π i y in the worst case. The following definition formalizes "being close to egalitarian rule" by its full meaning.
Definition 10. The egalitarian loss of allocation x is defined
$$\mathrm E L ( x ) \coloneqq 1 - \frac { \min _ { i } \pi _ { x } ^ { i } } { \max _ { y \in \Delta ^ { m } } \min _ { i } \pi _ { y } ^ { i } }$$
.
Nevertheless, Proposition 10 alone does give an upper bound on the egalitarian loss for single-minded profiles.
Corollary 11 (egalitarian loss in single-minded profiles) . The egalitarian allocation for single minded profiles is uniform (assuming all projects j have non-empty support s j ), making π i = 1 /m ∀ i . Thus, by Proposition 10
$$\mathrm E L ( x ) = 1 - \frac { \pi _ { x } ^ { \min } } { 1 / m } \leq 1 - \frac { m } { 1 + ( m - 1 ) ( n - 1 ) ^ { \frac { 1 } { x } } }$$
Bounding EL ( x ) for general profiles, is, however, much more challenging. Our way of doing that can be roughly presented as follows. The egalitarian rule allocation is characterized by the fact the no improvement on all argmin agents is possible, in other words a shift in any direction will harm (or will not benefit) some of them. The proof of Theorem 12 below will show that for large enough IAV , a unanimous improvement is not feasible on all agents with satisfaction close to minimal , thereby limiting the increase in minimum satisfaction. Formalizing that requires the following notion.
Definition 11 (Directional Derivative) . For every agent i an two allocations x, y ∈ ∆ m , define the derivative of π i towards y at x as
Note that
$$\frac { \partial \pi _ { x } ^ { i } } { \partial ( y - x ) } \coloneqq \frac { \mathrm d } { \mathrm d \alpha } \pi ^ { i } ( \alpha y + ( 1 - \alpha ) x ) \Big | _ { \alpha = 0 } \\ \tt t e t \, \text{that}$$
$$\intertext { v o u a } \frac { \partial \pi _ { x } ^ { i } } { \partial ( y - x ) } & = \frac { d } { d \alpha } \left [ \sum _ { j } \min ( \alpha y _ { j } + ( 1 - \alpha ) x _ { j }, x _ { j } ^ { i } ) \right ] \\ & = \sum _ { k \in J _ { y } \cap \sigma _ { x } ^ { \dagger } ( i ) } \delta _ { k } - \sum _ { j \in J _ { x } \cap \sigma _ { x } ^ { \dagger } ( i ) } \delta _ { j } \\ & \geq \pi _ { y } ^ { i } - \pi _ { x } ^ { i } \\ \intertext { v o u a a } \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
We are now ready to this part's main result.
Definition 12. For all m,n,λ, let
$$\gamma ( m, n, \lambda ) \coloneqq \max _ { \omega \in [ 0, 1 ] } \min \left ( m \omega \,, 1 - \left ( \frac { \omega } { n - 1 } \right ) ^ { \frac { 1 } { 4 } } \right )$$
Theorem 12. Let x = T f ( /vector x ) where IAV f ≥ λ . Then
$$\mathbf E L ( x ) \leq \gamma ( m, n, \lambda )$$
Note that γ m,n,λ ( ) ≤ 1 and that lim λ →∞ γ m,n, λ ( ) = 0 for all m,n . Table 1 shows some values of γ m,n,λ ( ) .
| m | λ = 0 . 1 | λ = 1 | λ = 10 | λ = 100 |
|-----|-------------|---------|----------|-----------|
| 3 | 1 | 0.997 | 0.474 | 0.079 |
| 8 | 1 | 0.999 | 0.519 | 0.087 |
| 12 | 1 | 0.999 | 0.537 | 0.09 |
| 20 | 1 | 0.999 | 0.558 | 0.094 |
Table 1. Different values of γ m, n, λ ( ) for n = 100 .
Proof. and y the maxmin allocation. Since x is an optimum of ∑ i f ( π i ) ,
$$0 \geq \frac { \partial } { \partial ( y - x ) } \left [ \sum _ { i } f ( \pi ^ { i } ) \right ] = \sum _ { i } f ^ { \prime } ( \pi ^ { i } ) \frac { \partial \pi _ { x } ^ { i } } { \partial ( y - x ) }$$
Now let us add some notations. Let s 1 be all agents i for which π i y > π i x , and s 2 := [ n ] \ s 1 . Denote ρ := min i ∈ s 2 π i x and µ := min i ∈ arg min i π i x ∂π i x ∂ y ( -x ) . Surely arg min i π i x ⊆ s 1 , therefore
$$\stackrel { \bullet } { \text{all} } \\ \text{s}, \quad 0 \geq \frac { \partial } { \partial ( y - x ) } \left [ \sum _ { i } f ( \pi ^ { i } ) \right ] \geq f ^ { \prime } ( \pi _ { x } ^ { \min } ) \cdot \mu - ( n - 1 ) f ^ { \prime } ( \rho ) \\ \implies \frac { n - 1 } { \mu } \geq \frac { f ^ { \prime } ( \pi _ { x } ^ { \min } ) } { f ^ { \prime } ( \rho ) } \geq \left ( \frac { \rho } { \pi _ { x } ^ { \min } } \right ) ^ { \lambda } \\ \text{Since } \alpha = \pi ^ { i } \text{ for some agent in } \varepsilon _ { \lambda } \ \pi ^ { \min } < \alpha \text{ And } \pi ^ { \min } - \pi ^ { \min } <$$
Since ρ = π i x for some agent in s 2 , π min y ≤ ρ . And, π min y -π min x ≤ µ because the directional derivative is greater then the actual gain in satisfaction for every agent. Thus,
$$( n - 1 ) \left ( \frac { \pi _ { x } ^ { \min } } { \pi _ { y } ^ { \min } } \right ) ^ { \lambda } \geq \pi _ { y } ^ { \min } - \pi _ { x } ^ { \min } \\. \quad.$$
Thus, if π min y -π min x = ω ∈ [0 , 1] , then EL ( x ) = ω π min y ≤ mω because π min y ≥ 1 m , and on the other hand, EL ( x ) = 1 -π min x π min y ≤
$$1 - \left ( \frac { \omega } { n - 1 } \right ) ^ { \frac { 1 } { \lambda } }. \, \text{Thus}, \\ /$$
$$\mathbf E L ( x ) \leq \min \left ( m \omega \,, 1 - \left ( \frac { \omega } { n - 1 } \right ) ^ { \frac { 1 } { \lambda } } \right ) \leq \gamma ( m, n, \lambda )$$
## 5 Discussion
This article presents a less common approach to the well known welfare-fairness trade-offs introduced in almost every Social Choice problem. Instead of separately testing the performance of different rules [9, 4], we offered a class of rules that almost none of them properly satisfy common axioms, but rather introduce a continuum of quantifiable trade-off points between the contradicting desires. From a practical point of view, such presentation of the range of possibilities might be more appealing and convenient to work with for social planners. Graph (a) in Figure 5 compares our results for welfare and egalitarian loss as functions of λ .
As this is a work in progress, we surely hope for possible improvements in some of our results. For example, we presented significantly lower bounds for welfare and egalitarian losses under single-minded profiles (Figure 5 graph (b)). Intuitively, however, in single-minded profiles the interests of different agents are as contradictory as they could be, leading to the conjecture that they might actually be the worst possible cases. We thus hope for some room for improvement in the results for general profiles as well. Moreover, some potentially interesting directions still await for further investigation. E.g., we did not look for approximate strategy-proofness in this article. Intuitively, what makes the strategy-proofness of the utilitarian rule is that mc j = s j for all j , making it impossible for an agent i ∈ s j to force an increase in x j towards x i j via manipulating her vote. On the other hand, the IAV of a function determines the impact that low satisfaction has compared to size in mc j = ∑ j f ′ ( π i ) . Thus, we might expect a bound on the agent's ability to increase mc j that depends on the IAV .
## References
- [1] K. J. Arrow. A difficulty in the concept of social welfare. Journal of political economy , 58(4):328-346, 1950.
## (a) Loss bounds on general profiles
(b) Loss bounds on single-minded profiles
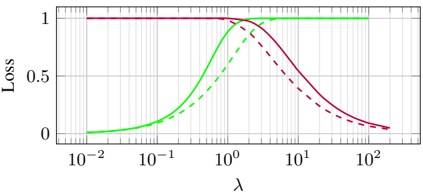
Figure 1. Green lines show welfare loss upper bounds, scarlet lines show Egalitarian loss. Thick lines are for m = 15 and n = 100 , dashed lines for
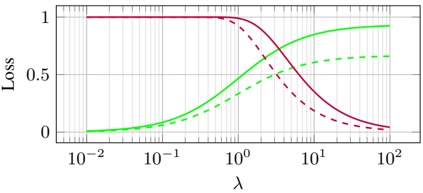
- m = 3 and ziz and N. Shah. Participatory budgeting: Models and approaches. n = 20 . [2] H. A Pathways Between Social Science and Computational Social Science: Theories, Methods, and Interpretations , pages 215-236, 2021.
- [3] H. Aziz, M. Brill, V . Conitzer, E. Elkind, R. Freeman, and T. Walsh. Justified representation in approval-based committee voting. Social Choice and Welfare , 48(2):461-485, 2017.
- [4] H. Aziz, A. Bogomolnaia, and H. Moulin. Fair mixing: the case of dichotomous preferences. In Proceedings of the 2019 ACM Conference on Economics and Computation , pages 753-781, 2019.
- [5] A. Bogomolnaia, H. Moulin, and R. Stong. Collective choice under dichotomous preferences. Journal of Economic Theory , 122(2):165184, 2005.
- [6] F. Brandt, M. Greger, E. Segal-Halevi, and W. Suksompong. Optimal budget aggregation with single-peaked preferences. arXiv preprint arXiv:2402.15904 , 2024.
- [7] I. Caragiannis, G. Christodoulou, and N. Protopapas. Truthful aggregation of budget proposals with proportionality guarantees. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 36, pages 4917-4924, 2022.
- [8] J. S. Dyer and R. K. Sarin. Relative risk aversion. Management science , 28(8):875-886, 1982.
- [9] E. Elkind, W. Suksompong, and N. Teh. Settling the score: Portioning with cardinal preferences. arXiv preprint arXiv:2307.15586 , 2023.
- [10] B. Fain, A. Goel, and K. Munagala. The core of the participatory budgeting problem. In Web and Internet Economics: 12th International Conference, WINE 2016, Montreal, Canada, December 11-14, 2016, Proceedings 12 , pages 384-399. Springer, 2016.
- [11] R. Fairstein, R. Meir, D. Vilenchik, and K. Gal. Welfare vs. representation in participatory budgeting. arXiv preprint arXiv:2201.07546 , 2022.
- [12] R. Freeman and U. Schmidt-Kraepelin. Project-fair and truthful mechanisms for budget aggregation. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 38, pages 9704-9712, 2024.
- [13] R. Freeman, D. M. Pennock, D. Peters, and J. Wortman Vaughan. Truthful aggregation of budget proposals. In Proceedings of the 2019 ACM Conference on Economics and Computation , pages 751-752, 2019.
- [14] A. Goel, A. K. Krishnaswamy, S. Sakshuwong, and T. Aitamurto. Knapsack voting for participatory budgeting. ACM Transactions on Economics and Computation (TEAC) , 7(2):1-27, 2019.
- [15] S. Janson. Phragmén's and thiele's election methods, 2018.
- [16] M. Michorzewski, D. Peters, and P. Skowron. Price of fairness in budget division and probabilistic social choice. In Proceedings of the AAAI conference on artificial intelligence , volume 34, pages 21842191, 2020.
- [17] H. Moulin. On strategy-proofness and single peakedness. Public Choice , 35(4):437-455, 1980.
- [18] H. Moulin. Fair division in the internet age. Annual Review of Economics , 11:407-441, 2019.
- [19] D. Peters, G. Pierczy´ski, and P. Skowron. n Proportional participatory
budgeting with additive utilities. Advances in Neural Information Processing Systems , 34:12726-12737, 2021.
- [20] A. D. Procaccia. Cake cutting algorithms. 2016.
- [21] N. Talmon and P. Faliszewski. A framework for approval-based budgeting methods. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 33, pages 2181-2188, 2019. | null | [
"Jonathan Wagner",
"Reshef Meir"
] | 2024-08-02T07:01:09+00:00 | 2024-08-02T07:01:09+00:00 | [
"cs.GT"
] | Distribution Aggregation via Continuous Thiele's Rules | We introduce the class of \textit{Continuous Thiele's Rules} that generalize
the familiar \textbf{Thiele's rules} \cite{janson2018phragmens} of multi-winner
voting to distribution aggregation problems. Each rule in that class maximizes
$\sum_if(\pi^i)$ where $\pi^i$ is an agent $i$'s satisfaction and $f$ could be
any twice differentiable, increasing and concave real function. Based on a
single quantity we call the \textit{'Inequality Aversion'} of $f$ (elsewhere
known as "Relative Risk Aversion"), we derive bounds on the Egalitarian loss,
welfare loss and the approximation of \textit{Average Fair Share}, leading to a
quantifiable, continuous presentation of their inevitable trade-offs. In
particular, we show that the Nash Product Rule satisfies\textit{ Average Fair
Share} in our setting. |
2408.01055v1 | ## LLM as Runtime Error Handler: A Promising Pathway to Adaptive Self-Healing of Software Systems
Zhensu Sun Singapore Management University Singapore [email protected]
## Xiaoning Du
Monash University
Australia [email protected]
## Haotian Zhu
Singapore Management University Singapore [email protected]
## Li Li
Bowen Xu North Carolina State University USA
[email protected]
## David Lo
Beihang University China [email protected]
## ABSTRACT
Unanticipated runtime errors, lacking predefined handlers, can abruptly terminate execution and lead to severe consequences, such as data loss or system crashes. Despite extensive efforts to identify potential errors during the development phase, such unanticipated errors remain a challenge to to be entirely eliminated, making the runtime mitigation measurements still indispensable to minimize their impact. Automated self-healing techniques, such as reusing existing handlers, have been investigated to reduce the loss coming through with the execution termination. However, the usability of existing methods is retained by their predefined heuristic rules and they fail to handle diverse runtime errors adaptively. Recently, the advent of Large Language Models (LLMs) has opened new avenues for addressing this problem. Inspired by their remarkable capabilities in understanding and generating code, we propose to deal with the runtime errors in a real-time manner. The runtime context, such as error messages and program states, can be exploited to produce corresponding exception handling strategies with extended diversity and quality.
Singapore Management University Singapore [email protected] handlers and naturally uncaught, can lead to program crashes, exposure of sensitive information, or other severe consequences [1]. For example, the infamous Heartbleed bug in OpenSSL [14] was caused by an unanticipated out-of-bound error, which allows attackers to request a server to return a chunk of its own memory. To prevent such errors, substantial efforts have been dedicated to identifying possible errors in the source code through techniques such as software testing and verification [28, 61]. However, identifying all possible runtime errors and offering them corresponding exception handlers remains a challenging and often impractical goal.
Motivated by our idea, we propose Healer, the first LLM-assisted self-healing framework for handling runtime errors. When an unexpected, thus unhandled, runtime error occurs, Healer will be activated to generate a piece of error-handling code with the help of its internal LLM and the code will be executed inside the runtime environment owned by the framework to obtain a rectified program state from which the program should continue its execution. Our exploratory study evaluates the performance of Healer using four different code benchmarks and three state-of-the-art LLMs, GPT-3.5, GPT-4, and CodeQwen-7B. Results show that, without the need for any fine-tuning, GPT-4 can successfully help programs recover from 72.8% of runtime errors, highlighting the potential of LLMs in handling runtime errors. Moreover, in our experiments, Healer introduces negligible latency in normal code execution (less than 1 ms per program) and an acceptable overload for error handling (less than 4 seconds for the LLM to generate the handling code), making it a suitable real-time reactor.
## 1 INTRODUCTION
Runtime error handling [55] is an essential component of software reliability engineering, requiring developers to be able to anticipate possible errors and prepare corresponding error handlers beforehand. Unanticipated runtime errors, being lack of corresponding
Given the near inevitability of unanticipated runtime errors, dynamic countermeasures are demanded to minimize their impact when they really happen. This requirement has led to the development of self-healing systems [19, 41], where the one at the program level aims to automatically recover from abnormal program states and restore program functionality as much as possible. Notably, to heal a program execution is not to patch the code against an error but to revise the runtime state, such as variable values and environment configurations, to recover the program execution. A successful healing should not only proceed the execution without termination, but also correct the runtime state so that the rest of the execution can continue meaningfully. The core challenge for a self-healing system is that the specific errors and their locations are unknown in advance, requiring the system to react in real time. Consequently, it relies on predefined heuristic strategies, such as rolling back to a checkpoint [10] and matching existing error handlers [20]. Although self-healing systems have been widely studied for decades, limited by their rule-based nature, these strategies are not adaptive enough to deal with diverse errors that impede their adoption. A large-scale industry practitioner study highlights that one of the main challenges encountered with engineering such systems is the complexity of defining the adaptation rules [56].
Ideally, a self-healing system might employ human developers to be always on call and manually correct the state according to the error that occurred, which is impractical for real-world applications. Recently, the emergence of Large Language Models (LLMs) has introduced new opportunities to revolutionize this field. LLMs have shown remarkable performance in code-related tasks [21]. For instance, AlphaCode2 [3] has outperformed 85% of human participants in a programming competition, showcasing impressive capabilities in understanding both source code and natural language.
SMU Classification: Restricted
An execution successfully recovers from the error using Healer
Figure 1: A motivating example of how Healer handles the runtime errors to recover the execution of the program.
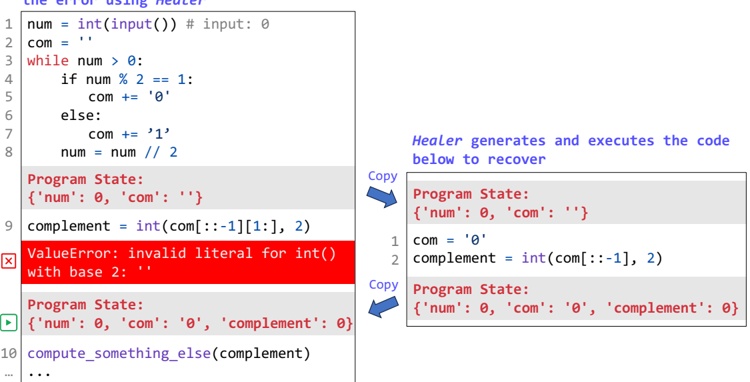
This skill set enables LLMs to understand the context of runtime errors, such as error messages and program states, and provide case-by-case solutions for each unanticipated runtime error in real time. Since human developers cannot monitor programs around the clock, we propose leveraging LLMs as virtual 'developers' who are always available to handle the error. To be specific, when an unanticipated runtime error occurs, an LLM can be invoked with the error context in the prompt and generate an appropriate code script that is not to be merged into the original program but is executed dynamically to recover the program from the faulty state. Moreover, LLMs can generate solutions within seconds, enabling real-time error resolution.
To explore the feasibility of our idea, we design an LLM-assisted runtime error handling framework, Healer. Healer acts as the default error handler for runtime exceptions that lack corresponding handlers and is also a last resort to prevent program crashes. Upon an error's occurrence, Healer gathers its context, including program state, error messages, and the erroneous source code. Using the collected information as a prompt, Healer instructs its LLM to generate a handling code snippet. The goal of the handling code is to survive the error and correct the program state, i.e., avoid the termination caused by the error and enable the program to continue its execution with the corrected state. The code is executed in an isolated environment to produce an error-free new program state. Based on this new state, the program can continue its execution from the point of error without termination.
run and produce the correct result for the input number. Handling in this way appears simple but is difficult to achieve with rulebased error-handling techniques. For example, Martin [42] proposes transforming the input value to fit the 'comfort zone,' an input space within which the program behaves acceptably. In this case, since the input num is 0, which the program cannot handle correctly, it would be transformed to a safe value (any value higher than 0), which avoids the error but leads to an incorrect final result. Similarly, Carzaniga et al. [11] proposed an automated method that replaces the failed operations with equivalent ones. This method generates equivalent alternatives by rewriting the code according to predefined human-written rules, which is labor-intensive and requires developers to anticipate potential errors.
To illustrate how Healer facilitates runtime error handling, we present a motivating example in Figure 1. The program aims to find the complement of a given number. However, the original code does not consider the case when the input number is less than 1. Thus, when the input number is 0, the code raises a ValueError because the variable com is an empty string, an invalid value for the int() function. Healer understands the root cause of the error and corrects the invalid value of com by assigning a '0' to it. With the corrected variable value, the program can continue to
To assess the feasibility of using LLMs for runtime error handling, we implement Healer as an executor for Python and conduct an exploratory study. We evaluate Healer on four different code benchmarks, containing a total of 1,185 (code, test case) pairs, where the code raises runtime errors with the test case, and test Healer empowered by three state-of-the-art LLMs, including two closed-source LLMs, GPT-3.5 and GPT-4, and one open-source LLM, CodeQwen. GPT-4 and CodeQwen are the best-performing closed-source and open-source LLMs, respectively, according to the EvalPlus leaderboard [31]. Initially, we investigate whether Healer, under a zero-shot setting, could effectively avoid the interruption and correct the faulty program state for the runtime errors during execution. The results show that without any fine-tuning, GPT-4 could continue execution in 72.8% of the instances and produce correct results in 39.6% of the instances, demonstrating the significant potential of LLMs for runtime error handling. We further examine the performance of Healer across various types of runtime errors. Among the 12 types of runtime errors in the benchmarks, LLMs display varying performance levels. For example, GPT-4 successfully handles 88.1% of AttributeErrors but only 50.0% of FileNotFoundErrors. Additionally, we create an instruction-tuning dataset using the (prompt, handling code) pairs generated in our experiments,
and fine-tune the GPT-3.5 and CodeQwen to assess its effectiveness. Wedo not fine-tune GPT-4 because we cannot access its fine-tuning API. After fine-tuning, the performance of GPT-3.5 and CodeQwen improves significantly. Specifically, there are 31.7% and 23.1% increases in instances that are free of interruption and 26.8% and 65.8% improvements in instances yielding correct results. Notably, the fine-tuned GPT-3.5 achieves performance even comparable to GPT4. Finally, we conduct a qualitative analysis to assess the overhead introduced by Healer. The results show that Healer introduces negligible latency in normal code execution (less than 1 ms per program) and an acceptable overload for error handling (less than 4 seconds for the LLM to generate the handling code), enabling real-time responses to runtime errors.
The main contribution of this paper is summarized as follows:
- · We, for the first time, propose to use LLMs to handle runtime errors, rejuvenating the research on self-healing software systems with a new direction.
- · We design an LLM-assisted runtime error handling framework, Healer, which mitigates runtime errors using the handling code generated by LLMs.
- · We conduct an exploratory study to assess the feasibility of LLMassisted runtime error handling , evaluating Healer on four different code benchmarks and three state-of-the-art LLMs.
All the data and source code used in this study are available at https://anonymous.4open.science/r/ErrorHandler-3861.
## 2 BACKGROUND AND RELATED WORK
In this section, we first recap the error-handling mechanisms in modern programming languages and then introduce the research on self-healing systems and the use of LLMs for code, respectively.
## 2.1 Error Handling in Modern Programming Languages
Modernprogramminglanguages typically incorporate built-in errorhandling mechanisms, with the try-catch block being a core component. This construct consists of a try block, which encloses code that might throw exceptions, and a catch block, which defines the error handler for exceptions thrown within the try block 1 . When developers anticipate an exception in a specific code segment, they can encapsulate that segment within a try block and implement an error handler within the catch block. If an exception occurs inside the try block, execution jumps to the catch block where the error handler is executed. Once the error handler completes without terminating the program, the program continues running the code following the try-catch block.
For errors occurring in code segments not enclosed by a try-catch block, the runtime environment halts execution and searches for an error handler by traversing up the call stack. This search continues until a suitable exception handler is found or the top of the call stack is reached. If no matching handler is found, the program typically terminates, often generating an error message and stack trace to assist with debugging, which can be seen as the default error handler. When this default error handler is triggered, the program's normal
1 Notably, we use the terms 'exceptions' and 'errors' interchangeably throughout the rest of this paper.
flow is disrupted, leading to potential unintended consequences or crashes. For example, in a financial application, the disruption might result in inconsistent transaction states, causing significant data integrity issues.
## 2.2 Self-healing Systems
Self-healing systems, as defined by Ghosh et al. [19], are designed to ' recover from the abnormal (or 'unhealthy') state and return to the normative ('healthy') state, and function as it was prior to disruption '. It is a long-standing research area aimed at enhancing system reliability and availability, often classified as a subclass of fault-tolerant [40] or self-adaptive [34] systems. The self-healing process involves three primary steps: (1) Maintenance of health: ensuring the normal functionality of the system, such as preparing redundant components [23]; (2) Detection of system failure: identifying abnormal states within the system, such as monitoring [17]; and (3) Recovery from failure: transforming a system state containing one or more errors (and possibly faults) into a state without detected errors [6].
In this paper, the proposed method is a recovery step at program level. For this step, various methods have been proposed, including restarting [9], rolling back to a checkpoint [10], trying alternative methods [11], modifying input [33], reusing existing error handlers [20], preparing default error handlers [43], or combining multiple strategies [12]. The core idea behind these studies is to heuristically construct a set of fixed recovery strategies and apply them when some specific errors occur, which is typically rule-based. For example, Failure-Oblivious Computing [43] ignores invalid memory writes (such as out-of-bounds writes and null dereferences) and generates default values for invalid memory reads. Gu et al. [20] handle errors by synthesizing handlers in two ways: (1) transforming the type of the error to fit existing error handlers and (2) returning early with a default value. Carzaniga et al. [10] propose restoring the application state to a previously set checkpoint and then selecting and executing an equivalent sequence of operations that might avoid the error. While effective in certain scenarios, their rule-based nature limits their generalization and adaptability. To the best of our knowledge, this is the first work to demonstrate that LLMs can effectively achieve the recovery, creating a new technical pathway for this long-standing research field (widely studied for decades). Compared with these rule-based methods, LLMs can dynamically adapt to a wide range of scenarios by understanding the source code context and natural language error messages, making them more flexible and generalizable.
## 2.3 Large Language Models for Code
Typically, LLMs are Transformer [51] models pre-trained on large corpora of textual data, including books, research papers, web contents, etc. These models have gained great popularity because of their versatility and effectiveness, and software engineering is no exception. Recent studies [21, 60] have highlighted the capability of LLMs in code recognition, understanding, and generation, etc. Numerous LLMs designed for code have been proposed, such as CodeGen [35], StarCoder [29], and CodeLlama [44]. These models are pre-trained on code corpora to predict the next token, making
them proficient at continuing a given source code but less effective at understanding human instructions.
More recently, the instruction tuning technique has been proposed and enables LLMs to understand and follow complex instructions [8, 38], such as ' You are working on a 3D block-based game, where each block can have a specific state that determines its behavior and appearance. Your task is to implement the following features: ... '. The instruction-tuned LLMs, such as GPT-4 [2], CodeQwen [7], and MagiCoder [54], apply to more complex code-related tasks and better aligns with human developers' intention. In this paper, we focus on such instruction-tuned LLMs, as handling runtime errors requires understanding multiple aspects of the error context, such as error messages and program state, which involves multiple modalities.
Instruction-tuned LLMs can be applied to specific tasks through either prompting or further fine-tuning. Fine-tuning involves updating the model's weights through additional training on a dataset tailored to a particular task. In contrast, prompting does not require additional training. It involves providing the LLM with a task description and, optionally, a few examples that break down how the task can be accomplished. Studies have shown that even without fine-tuning, LLMs can still perform impressively in many coding tasks, including bug fixing [49], code execution [48], and fault localization [27, 57]. In this paper, we apply LLMs to recover the program from a faulty state, a unique and unexplored task that is extremely rare in the practice of LLMs but important for selfhealing systems. We address several technical challenges, including how to construct prompts that help the LLM understand a specific task, how to interact with the runtime environment for the LLM to handle errors, and how to improve the LLM's performance in the task.
## 2.4 Why not LLM-based APR?
Recently, LLM has been widely applied in Automate Program Repair (APR) and shows promising performance. For example, Xia and Zhang [58] reveal that the LLM-based APR method is able to achieve the new state-of-the-art in program repair performance. This naturally raises the question: if we can statically fix the root causes of runtime errors using LLMs, why do we still need LLMs to recover from failures?
Firstly, it's important to clarify that LLM-assisted runtime error handling is not a replacement for LLM-based APR but rather a supplement. APR requires locating the bug first, which has long been a challenge in both the research community and industrial practices. Undetected bugs, even those that are easy to fix if identified, can escape APR tools and lead to dangerous errors during runtime. In contrast, when a runtime error occurs, its location is immediately available, allowing the handler to create a specific context-aware solution. We thus argue that LLM-assisted runtime error handling creates an additional layer of defense in software robustness, serving as a last-resort mechanism to prevent the consequences of unhandled errors.
To support this argument, we experimentally investigate this supplementary relationship between LLM-based APR and LLM-based runtime error handling on an APR benchmark, DebugBench [49],
Figure 2: The workflow of Healer. When a runtime error occurs, Healer collects the error context, prompts the LLM with the context, and generates the handling code. The handling code is then executed in an isolated environment to recover the program from the faulty state.
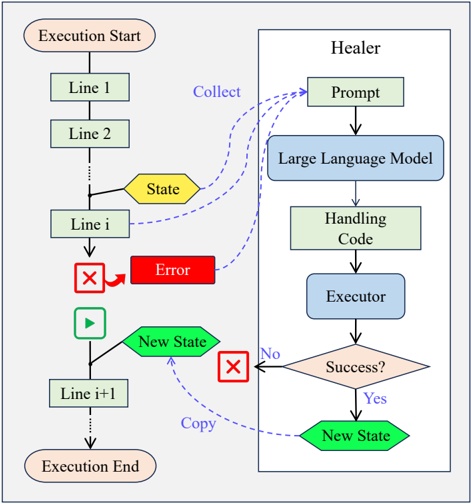
containing over 1,000 buggy Python code. The authors of DebugBench employed LLMs to statically fix these buggy code snippets and released the revised versions. We execute these fixed snippets, finding that those fixed by GPT-3.5 and GPT-4 raised 251 and 109 runtime errors, respectively. These runtime errors are subsequently handled using our proposed method, leveraging the same LLM that performed the initial fixing. After the handling, 153 (60.0%) sessions for GPT-3.5 and 93 (85.33%) sessions for GPT-4 no longer raised errors, with 51 (20.3%) and 43 (39.4%) of these sessions ultimately producing the correct results as expected by the test cases. Therefore, our findings highlight the effectiveness of integrating LLM-assisted runtime error handling with LLM-based APR to further enhance software reliability and robustness.
## 3 PROPOSED FRAMEWORK
In this section, we introduce Healer, the first error-handling framework that leverages LLMs to handle unanticipated runtime errors. We begin with an overview of the framework, followed by detailed descriptions of its main components, prompt strategy, and a proofof-conception implementation for Python.
## 3.1 Overview
Healer is an error-handling framework designed to handle unanticipated runtime errors during program execution. We first define the problem and then introduce the workflow of Healer.
Requirements : As described in Section 1, unanticipated runtime errors are almost inevitable in practice, necessitating a mechanism to recover the program from such errors when they really occur. A key assumption according to the nature of unanticipated runtime errors is the lack of prior knowledge about their occurrence, such as their location, preventing the pre-implementation of specific error handlers. Under this assumption, an effective error-handling mechanism must recover the program from the faulty state in real time, allowing it to continue executing its intended functionality. Specifically, a successful handling should satisfy the following requirements:
- · Proceed the execution : The execution session should not terminate due to the error and should continue executing its remaining code. This requirement alone is easy to achieve by simply ignoring the error. However, it leaves the faulty state unchanged, potentially causing unexpected behaviors in the remaining code.
- · Correct the program state : The handling should correct the faulty state that caused the error, enabling the remaining code to execute with a correct initial state. For example, if the type of a variable is invalid and causes a type error, the handling should correct the type of the variable to the expected type. Notably, an incorrect program state could still proceed the execution, but it may lead to unexpected behaviors, such as wrong computing results, or even more severe errors.
- · Real-time response : The handling should be completed within a reasonable time frame to avoid excessively blocking the execution, thus minimizing side effects.
Workflow : Healer acts as a default error handler for the program, which can be seen as a last resort for handling unanticipated runtime errors. It will be activated when a runtime error occurs without an available error handler. The framework handles the errors relying on an internal LLM, which generates a piece of code, named handling code by understanding the error context. The workflow of Healer is illustrated in Figure 2. To ease the understanding, we assume the framework is applied for an interpreted programming language, such as Python and JavaScript, where the code is executed line by line, and the program state is inherently maintained. We discuss the application of Healer for compiled languages in Section 6. Formally, consider a program 𝑃 with 𝑛 lines as 𝑃 = { 𝐿 , 𝐿 1 2 , ..., 𝐿 𝑛 } . If an error 𝐸 occurs at line 𝐿 𝑖 without an available error handler, Healer is activated. It first collects the error context, including the error message, the program state 𝑆 , the entire code snippet, and the erroneous line, to construct a prompt. The internal LLM is then instructed with this prompt to generate a piece of handling code 𝐿 ′ 𝑖 . This code 𝐿 ′ 𝑖 is executed under the state 𝑆 of the original program using an executor isolated from the original program environment. If the execution of 𝐿 ′ 𝑖 is successful, the resulting program state 𝑆 ′ is integrated back to the original program state, allowing the program to continue from line 𝐿 𝑖 + 1. Notably, although the state is corrected for the current session, the original program is not fixed and thus still needs to be reproduced and fixed in future development, which is beyond the scope of this paper. If unsuccessful, the program is terminated, and the error is reported, following traditional error handling mechanisms.
## 3.2 Main Components
Healer consists of two main components: an LLM and an isolated executor. The former is used for generating the handling code given the error context, while the latter executes the handling code in an isolated environment and updates the program state of the original program.
Large Language Model : The LLM inside Healer needs to be capable of the error-handling task. As introduced in Section 2.3, LLMs trained with instruction tuning can understand and follow complex instructions. Using instruction-based LLMs, such as GPT-4 [2], we can prompt the LLM to generate handling code by providing proper prompts. We present our prompt strategy in Section 3.3. Moreover, the LLM can be further fine-tuned on a task-specific dataset to better align with the intention of the task. However, to the best of our knowledge, a decent dataset specifically for the error-handling task is currently unavailable. Although there are many human-crafted error handlers in open-source codebases, they do not consider the dynamic context of errors, especially the program state, and thus lack the knowledge of properly modifying the program state to recover from the error. To fill this gap, we create an instruction-tuning dataset to fine-tune the LLMs for the runtime error-handling task. Weintroduce and evaluate our dataset in Section 4.4 and Section 5.3, respectively.
Executor : The handling code generated by the LLM needs to be executed to produce a new program state. However, directly executing the code in the original session can be risky, as the code generated by LLMs may contain malicious code or vulnerabilities [39, 59]. To mitigate potential security risks, Healer adopts an executor that is isolated from the original program. It could be a new session, a sandbox, or a virtual machine, depending on the security level required by the system. The execution is not to re-run the original program from the beginning but to execute the handling code with the program state before the error occurs. Given an error at line 𝐿 𝑖 and handling code 𝐿 ′ 𝑖 , the executor initializes its state with 𝑠 𝑖 -1 (the program state before the error) and then executes 𝐿 ′ 𝑖 . If the handling code executes successfully, a new state 𝑠 ′ 𝑖 is produced. Healer then updates the original program state to 𝑠 ′ 𝑖 and continues the execution of the original program from line 𝐿 𝑖 + 1.
## 3.3 Prompt Construction
Theperformance of LLMs heavily relies on the provided prompt [32]. In Healer, the interaction between the LLM and Healer is conversational, where Healer first prompts its LLM with a system prompt and then a user prompt. The system prompt is a predefined instruction guiding the LLM's behavior, tone, or response style, while the user prompt is the input provided by the user during the conversation. The LLM does not respond to the system prompt but follows its instructions when it responds to the user prompt. In Healer, the system prompt introduces the requirements and constraints of the error handling task, and the user prompt provides the context of the occurred error.
- 3.3.1 System Prompt. The system prompt is structured into four parts: task description, goals, constraints, and examples. These four parts are concatenated to form the system prompt, which will be sent to the LLM as the first prompt in the conversation. In the
following, we introduce each part and present the prompt of that part. Notably, the presented prompt is a template, and the actual prompt will fill in its placeholders, i.e., the terms surrounded with curly braces, with specific information. There are two placeholders, {Language} and {Keywords}, which will be filled with the specific programming language name and unsupported keywords, respectively.
At the beginning, we describe the error-handling task as a code completion task, where the LLM is asked to replace a specified code block (the block that raises the error) with the correct code based on the provided information. Compared with directly instructing the LLM to recover runtime errors, this proxy task achieves the same effects but is more unambiguous and understandable for the LLM.
## Task Descriptions
You are an intelligent {Language} expert. The user will provide you with a piece of buggy {Language} code, along with an error message and program state. Your task is to generate correct lines to replace the lines where the errors occur. However, you can NOT change the rest of the code except the erroneous lines. The erroneous lines will be wrapped with <error> and </error>. You can use any built-in functions or libraries in the generated lines. You can also use the variables in the program state.
In addition to the task description, we specify the goals of the generated code. The goals are designed according to the requirements defined in Section 3.1.
## Goals
Your code should achieve two goals: 1) Survive the error to ensure no more execptions will be raised, such as correcting wrong values in the program state, initializing undefined variables, or importing missing libraries; 2) Maintain the same functionality as the original code.
We also establish constraints to ensure that the generated code adheres to a specific format suitable for execution.
## Constraints
The code MUST be written in {Language} and should not omit any details. The code MUST be complete and correct in syntax. The code will be executed so its indentation should start from the first column. You are NOT allowed to use these keywords: {Keywords}. You MUST put <code></code> on the boundary of the generated code. Do not write anything else in your response.
At the end of the system prompt, we include a user prompt and its corresponding handling code, as the example to help the LLM understand the task better.
## Example
Here is one example: ... (omitted due to space limitation)
3.3.2 User Prompt. In addition to the source code, many runtime details can be collected, such as the error message, error location, and program state. As exemplified in Figure 3, Healer constructs prompt by combining this information from the runtime environment and then feeding it to the LLM.
- · Source Code : The source code of the program provides the basic context for the LLM to understand and survive the error.
- · Error Message : The error message is a string describing the error, either the default exception message or a customized message. It provides hints about the error type and potential cause.
- · Error Location : The error location is the position in the source code where the exception is raised. It saves the LLM from locating the error by itself and thus avoids potential misunderstanding. In the prompt, the position is not directly indicated using line numbers. Instead, we enclose the code block where the error occurs with the tags <error> and </error>, as a more explicit representation.
- · Program State : The program state is a collection of variables and their values at the moment when the error occurs. By checking the program state, the LLM can understand the context of the error and generate the handling code accordingly.
## 3.4 Implementation
We implement Healer for Python as a proof of concept, which is available in our artifacts. The implementation is to demonstrate the feasibility and effectiveness of Healer, and it is not optimized for performance, security, or scalability, which would require further enhancement for practical use.
Healer is implemented as a code executor, accepting source code strings as input and executing them using the Healer process. Upon receiving the source code, the implementation first instruments the code using Python's ast module, wrapping each statement in a tryexcept block. Notably, the statements inside loops are not wrapped to avoid the overhead of exception handling in each iteration. In the except block, the implementation uses a customized exception handler to handle the runtime errors. The customized handler follows the steps illustrated in Figure 2. Given a caught exception, the handler collects the error type and message from the exception object and the program state using Python's built-in functions, locals() and globals() , which respectively return a dictionary of all the local and global variables. The collected information is formatted into the user and system prompts based on the templates introduced in Section 3.3. It then interacts with the LLM through RESTful APIs, sending the prompts to the LLM server as HTTP requests and receiving the handling code as the response. Upon receiving the handling code, the handler starts a new Python session and executes the handling code using the exec() function, a built-in Python function for dynamically executing source code. The program state for exec() is initialized with the collected program state. If the handling code executes successfully, the implementation compares the new program state with the original to identify differences and integrates these differences into the original program's state. To prevent infinite loops or other malicious behaviors, the implementation enforces a 60-second timeout limit for the execution of the handling code.
SMU Classification: Restricted
## Error Message
## System Prompt
Figure 3: An example of the prompt construction workflow in Healer. Both the system prompt and user prompt are constructed based on pre-defined templates.
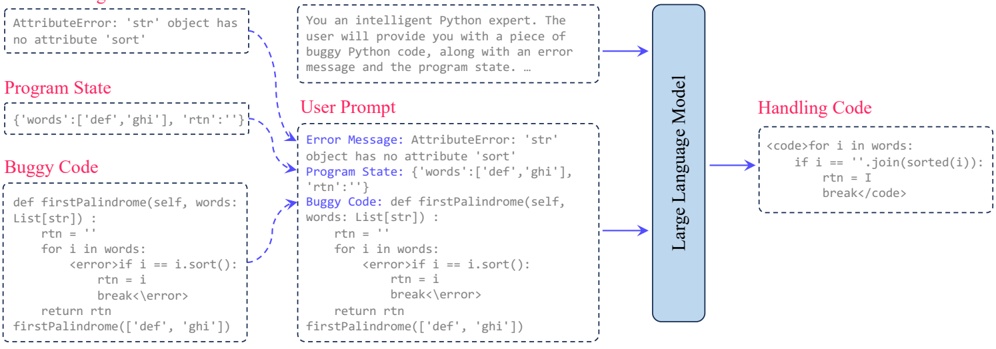
## 4 EXPERIMENTAL SETUP
This section details the setup of our experiments, including benchmarks, large language models, the instruction tuning dataset, evaluation metrics, and implementation details. The rationale behind our set up is driven by answering the following four research questions:
- · RQ1: How effective is Healer in handling runtime errors?
- · RQ2: How does the performance of Healer vary in handling different types of runtime errors?
six different LLMs, including GPT-3.5 (ChatGPT) [37], GPT-4 (gpt4-1106-preview) [2], CodeLlama (34B) [44], CodeT5+ (16B) [52], Mistral (7B) [25], and StarCoder (15B) [29]. These snippets are executed with the provided test cases in our local environment, and those (code, test case) pairs that raise runtime errors are kept. Totally, we obtain 295 instances from HumanEval+ and 226 instances from MBPP+. The detailed statistics of the runtime errors from each LLM are shown on the left of Table 1.
- · RQ3: How much performance of Healer gained by instruction tuning?
- · RQ4: What is the overhead introduced by Healer?
## 4.1 Benchmarks
In these experiments, we focus on Python due to its popularity and robust support for dynamic code execution. We evaluate the performance of Healer against runtime errors in three types of programs: (1) human-written code, (2) LLM-generated code, and (3) code with implanted bugs. To this end, we use four popular benchmarks: CodeNet for human-written code, HumanEval+ and MBPP+ for LLM-generated code, and DebugBench for code with implanted bugs.
CodeNet [24] includes 4,053 programming challenges for various programming languages from the AIZU Online Judge [26] and AtCoder [4] platforms, each with multiple implementations submitted by distinct programmers. For each challenge, at least one test case is provided. We run the code snippets on our local machine with the provided test cases and keep the (code, test case) pairs that raise runtime errors. This process yields 228 instances.
HumanEval+ and MBPP+ [31] are enhanced versions of HumanEval [13] and MBPP [5], benchmarks used to evaluate the performance of LLMs in code generation. They contain 164 and 400 Python coding tasks, respectively, each associated with several test cases In the paper of these two benchmarks, multiple LLMs are evaluated, and the code snippets generated during the evaluation are publicly available [15]. We reuse the code snippets generated by
DebugBench [49] is a benchmark designed to evaluate the debugging ability of LLMs, which is also applicable for runtime error handling. We use its Python subset, containing 1,414 code snippets from the LeetCode platform, each implanted with one or more bugs. This benchmark does not provide test cases, as they test the correctness of the code snippets by submitting them to the LeetCode platform. We thus extract example test cases from the problem descriptions, associating each code snippet with 2 to 4 test cases. Similarly, we run all implementations with the extracted test cases and keep the (code, test case) pairs that raise runtime errors, resulting in 436 instances.
## 4.2 Large Language Models
In our experiments, we respectively evaluate the best-performing closed-source and open-source LLMs, GPT-4 [2] and CodeQwen [7], in the code generation task according to the EvalPlus leaderboard [31] (accessed on May 2024). Additionally, we include GPT-3.5 [37], which is the previous version of GPT-4, to compare the performance of the two versions. All models are pre-trained by their creators, and by default, we do not perform further training unless otherwise stated. Notably, as the ground truth, i.e., the handling code for each sample, does not exist in the benchmarks, potential data leakage issues are avoided.
## 4.3 Evaluation Metrics
In each benchmark, all code snippets raise runtime errors when executed with their associated test cases. The effectiveness of Healer
is measured by its ability to recover from these runtime errors. As defined in Section 3.1, except for the time constraint, two requirements are considered for a successful recovery: (1) survive the error and (2) heal the program state. Accordingly, we define two statuses for each instance: PROCEED and CORRECT .
PROCEED means the program, used to be faulty, now completes its execution without being interrupted by any runtime errors. CORRECT indicates that the program not only executes without interruption but also produces correct results, i.e., the output matches the ground truth of the test case. Achieving a correct result requires the remaining code after the error point to execute correctly, relying on Healer to heal the program state. However, the program in the benchmarks may not be correctly implemented, where a healed program state could still lead to an incorrect result. We count the number of CORRECT and PROCEED instances and calculate their percentages.
## 4.4 Instruction-tuning Dataset
We created an instruction-tuning dataset to fine-tune the LLMs for runtime error handling. It consists of 586 (prompt, handling code) pairs, where the prompt is constructed using the strategy described in Section 3.3 and the handling code leads to the CORRECT status. These instances are produced using samples from all benchmarks except the human-written benchmark, CodeNet, which is reserved as the test set for the fine-tuned LLMs. Specifically, we run GPT3.5 and GPT-4 to handle the runtime errors in each instance from the selected benchmarks and record the handling code. For each CORRECT instance, we pair the prompt and its corresponding handling code as a sample in the dataset. This dataset will be used to answer RQ3 (Section 5.3) and is available in our artifacts to facilitate future research or applications.
## 4.5 Implementation Details
In our experiments, we use the OpenAI APIs to invoke GPT-3.5 (gpt-3.5-turbo-0125) and GPT-4 (gpt-4-turbo-2024-04-09) and the Huggingface Transformers library with PyTorch to implement CodeQwen (CodeQwen1.5-7B-Chat). The experiments for CodeQwen are conducted on a machine with 20 vCPU, 100GB RAM, and an NVIDIA GeForce RTX L20 GPU (48GB RAM). During inference, we use the default hyper-parameters for all models but set the maximum input length to 4,096 tokens for CodeQwen due to GPU memory limitations. This may result in input text truncation for CodeQwen, and we will discuss the potential impact of this truncation in Section 6.1.
## 5 RESULTS
In this section, we report our experimental results and answer the four research questions.
## 5.1 RQ1: Effectiveness of Healer
This experiment assesses the effectiveness of Healer by analyzing the execution outcomes of the instances in the benchmarks. For each benchmark, we execute each code snippet with its paired test case and respectively handle the runtime errors using the three LLMs, GPT-3.5, GPT-4, and CodeQwen, following the framework described in Section 3. We record the final execution status of each instance and compute the two metrics: CORRECT and PROCEED .
The results, as shown in Table 1, indicate that Healer can effectively heal the runtime errors, thereby improving program availability. On average of all benchmarks, GPT-4, GPT-3.5, and CodeQwen can respectively proceed 72.8%, 48.2%, and 35.4% of the execution, and help 39.6%, 24.0%, and 13.3% of the program produce correct results. It provides compelling evidence that handling runtime errors using LLMs is a feasible and promising direction. Among the LLMs, GPT-4 consistently achieves the best performance across all benchmarks, with the highest CORRECT and PROCEED metrics. For example, on the DebugBench benchmark, GPT-4 successfully completes the execution of 338 instances and corrects the faulty states for at least 177 instances, accounting for 77.5% and 40.6% of the total errors. Even for code snippets written by LLMs, such as those in HumanEval and MBPP, Healer facilitated more correct results during execution. For example, GPT-4 enhances the execution outcomes of the code it generates by successfully correcting 11 additional instances in HumanEval and 1 additional instance in MBPP. This illustrates that LLMs can be used to mitigate the runtime errors they cause during code generation.
Answer to RQ1: Healer can effectively handle runtime errors and improve the availability and reliability of programs, particularly GPT-4-based Healer is able to continue execution in 72.8% of the instances and produce correct results in 39.6% of the instances.
## 5.2 RQ2: Effects of Error Types
In RQ2, we investigate the performance of Healer on different types of runtime errors. To be specific, we merge the instances of all the benchmarks and categorize them based on their error types. There are 12 types of runtime errors in total, but we analyze only those with more than 10 occurrences, combining the rest into the 'Others' category. This resulted in 7 categories: TypeError, AttributeError, IndexError, ValueError, NameError, FileNotFoundError, and Others. Each category is accompanied by an example error message to facilitate understanding. All of them are common errors in Python programs and are frequently encountered in practice. We calculate the number and proportion of instances with CORRECT and PROCEED for each category across the three LLMs.
As revealed in Table 2, LLMs exhibit varying performance across different error types. For example, GPT-4 continues the execution for 88.1% of AttributeError instances and 80.9% of IndexError instances but only 50.0% of FileNotFoundError instances and 62.8% of ValueError instances. This suggests that the effectiveness of LLMs varies by error type, indicating that error type could be an important factor when applying Healer. This observation implies that the reliability of error handling could be enhanced by applying Healer selectively based on the error type.
Interestingly, we find that different LLMs excel at handling different error types. For GPT-3.5, IndexError instances are the easiest to handle, with 55.2% of them free of interruption, while CodeQwen handles AttributeError best, with a 45.2% PROCEED. It suggests that the LLMs may have different capabilities in handling different
Table 1: The performance of GPT-4, GPT-3.5, and CodeQwen on all the benchmarks in a zero-shot setting.
| | | #Errors | GPT-4 | GPT-4 | GPT-3.5 | GPT-3.5 | CodeQwen |
|------------|------------|-----------|-------------|-------------|------------|-------------|------------|
| Benchmark | Benchmark | | CORRECT | PROCEED | CORRECT | PROCEED | CORRECT |
| CodeNet | CodeNet | 228 | 96 (42.1%) | 167 (73.2%) | 71 (31.1%) | 120 (52.6%) | 38 (16.7%) |
| | CodeLlama | 70 | 33 (47.1%) | 44 (62.9%) | 25 (35.7%) | 40 (57.1%) | 9 (12.9%) |
| | CodeT5+ | 57 | 21 (36.8%) | 37 (64.9%) | 12 (21.1%) | 29 (50.9%) | 8 (14.0%) |
| | GPT-3.5 | 43 | 10 (23.3%) | 31 (72.1%) | 3 (7.0%) | 16 (37.2%) | 6 (14.0%) |
| | GPT-4 | 19 | 11 (57.9%) | 19 (100.0%) | 4 (21.1%) | 12 (63.2%) | 2 (10.5%) |
| | Mistral | 37 | 13 (35.1%) | 24 (64.9%) | 7 (18.9%) | 17 (45.9%) | 4 (10.8%) |
| | StarCoder | 69 | 26 (37.7%) | 40 (58.0%) | 21 (30.4%) | 27 (39.1%) | 13 (18.8%) |
| | CodeLlama | 30 | 12 (40.0%) | 24 (80.0%) | 8 (26.7%) | 15 (50.0%) | 4 (13.3%) |
| | CodeT5+ | 49 | 22 (44.9%) | 37 (75.5%) | 8 (16.3%) | 19 (38.8%) | 5 (10.2%) |
| | GPT-3.5 | 14 | 1 (7.1%) | 13 (92.9%) | 0 (0.0%) | 7 (50.0%) | 0 (0.0%) |
| | GPT-4 | 3 | 1 (33.3%) | 3 (100.0%) | 1 (33.3%) | 1 (33.3%) | 0 (0.0%) |
| | Mistral | 73 | 25 (34.2%) | 50 (68.5%) | 10 (13.7%) | 25 (34.2%) | 8 (11.0%) |
| | StarCoder | 57 | 21 (36.8%) | 36 (63.2%) | 17 (29.8%) | 28 (49.1%) | 7 (12.3%) |
| DebugBench | DebugBench | 436 | 177 (40.6%) | 338 (77.5%) | 97 (22.2%) | 215 (49.3%) | 53 (12.2%) |
Table 2: The performance of GPT-4, GPT-3.5, and CodeQwen in handling different types of runtime errors.
| Error Type | Example Error Message | Total | GPT-4 | GPT-4 | GPT-3.5 | GPT-3.5 | CodeQwen | CodeQwen |
|-------------------|--------------------------------------------------|---------|-------------|-------------|-------------|-------------|------------|-------------|
| Error Type | Example Error Message | Total | CORRECT | PROCEED | CORRECT | PROCEED | CORRECT | PROCEED |
| TypeError | can't multiply sequence by non-int of type 'str' | 312 | 145 (46.5%) | 214 (68.6%) | 85 (27.2%) | 152 (48.7%) | 56 (17.9%) | 114 (36.5%) |
| AttributeError | 'map' object has no attribute 'sort' | 42 | 14 (33.3%) | 37 (88.1%) | 9 (21.4%) | 19 (45.2%) | 6 (14.3%) | 19 (45.2%) |
| IndexError | list index out of range | 183 | 57 (31.1%) | 148 (80.9%) | 41 (22.4%) | 101 (55.2%) | 21 (11.5%) | 61 (33.3%) |
| ValueError | not enough values to unpack (expected 2, got 0) | 78 | 22 (28.2%) | 49 (62.8%) | 15 (19.2%) | 38 (48.7%) | 4 (5.1%) | 28 (35.9%) |
| NameError | name 'lst' is not defined | 520 | 211 (40.6%) | 379 (72.9%) | 122 (23.5%) | 241 (46.3%) | 68 (13.1%) | 187 (36.0%) |
| FileNotFoundError | No such file or directory: 'pypy3' | 16 | 5 (31.3%) | 8 (50.0%) | 4 (25.0%) | 6 (37.5%) | 0 (0.0%) | 1 (6.3%) |
| Others | integer division or modulo by zero | 34 | 15 (44.1%) | 28 (82.4%) | 8 (23.5%) | 14 (41.2%) | 2 (5.9%) | 9 (26.5%) |
types of errors, highlighting the importance of understanding the strengths and weaknesses of each LLM for effective error handling.
Table 3: The comparison between fine-tuned and original versions for GPT-3.5 and CodeQwen. GPT-4 is used as a reference as we don't have access to its fine-tuning API.
Answer to RQ2: LLMs exhibit different performance levels across various runtime error types. GPT-4 handles AttributeError and IndexError most effectively, with PROCEED of 88.1% and 80.9%, respectively.
## 5.3 RQ3: Impact of Fine-tuning
To answer RQ3, we fine-tune the LLMs to find out how much their performance could be improved. Two LLMs, GPT-3.5 and CodeQwen, are fine-tuned in this experiment, while GPT-4 is used as a reference as we do not have access to fine-tune it. The fine-tuning dataset is the instruction-tuning dataset introduced in Section 4.4, which contains 586 training samples. With this dataset, GPT-3.5 is fine-tuned via the commercial API provided by OpenAI, where the hyperparameters are automatically determined [36]. CodeQwen is fine-tuned on our machine using LoRA [22], a parameter-efficient
| LLM | Version | CodeNet (228) | CodeNet (228) | CodeNet (228) | CodeNet (228) |
|----------|-----------|-----------------|-----------------|-----------------|-----------------|
| LLM | Version | CORRECT | CORRECT | PROCEED | PROCEED |
| GPT-4 | Original | 96 | | 167 | |
| GPT-3.5 | Original | 71 | | 120 | |
| GPT-3.5 | Finetuned | 90 | 26.8% ↑ | 158 | 31.7% ↑ |
| CodeQwen | Original | 38 | | 91 | |
| CodeQwen | Finetuned | 63 | 65.8% ↑ | 112 | 23.1% ↑ |
fine-tuning method. After the fine-tuning, we evaluate the performance of the fine-tuned LLMs on CodeNet.
The results, presented in Table 3, show that fine-tuning significantly enhances LLM's performance in handling runtime errors. Both GPT-3.5 and CodeQwen exhibit substantial improvements, with GPT-3.5 achieving 26.8% more CORRECT and 31.7% more PROCEED instances, and CodeQwen achieving 65.8% more CORRECT and 23.1% more PROCEED instances. Remarkably, the fine-tuned GPT-3.5 successfully produces 90 CORRECT instances, closely approaching GPT-4's performance, which yields 96 CORRECT instances. Similarly, the fine-tuned CodeQwen also achieved competitive results comparable to GPT-3.5. This indicates that finetuning can be a powerful approach to developing task-specific LLMs for runtime error handling, potentially surpassing general-purpose LLMs in effectiveness.
Answer to RQ3: Fine-tuning significantly improves LLM performance in handling runtime errors. GPT-3.5 demonstrates a 26.8% increase in CORRECT instances and a 31.7% increase in PROCEED instances on CodeNet, achieving a performance level comparable to GPT-4.
## 5.4 RQ4: Overhead of Healer
In RQ4, we evaluate the overhead introduced by Healer when handling runtime errors. The overhead is divided into two parts: the overhead to normal program execution and the overhead during the error-handling process.
To determine the impact of Healer on normal program execution, we test the overhead introduced by the try-catch blocks, the error-handling mechanism to trigger Healer in our implementation. Specifically, we prepare two pieces of Python code: one containing an assignment statement and the other containing the same statement but wrapped in a try-catch block. The assignment statement will not raise any exceptions, and thus the time difference between the two code snippets can be attributed to the cost for the try-catch to detect exceptions. We execute both code snippets one million times and compute the difference in the consumed time. The results show that the code with a try-catch block costs only 4.5 ms more for one million runs, indicating that the overhead to normal program execution is negligible. It aligns with the claim in the official Python document, i.e., 'A try/except block is extremely efficient if no exceptions are raised' [16].
The primary overhead during the error-handling process arises from the LLMs' inference times. We measured the average time required by CodeQwen (deployed on our local machine using Huggingface Transformers) and GPT-3.5 and GPT-4 (deployed on OpenAI's remote server) to generate the handling code for the benchmarks. On average, CodeQwen, GPT-3.5, and GPT-4 take 1.7 seconds, 1.6 seconds, and 3.1 seconds, respectively, to generate the handling code for the occurred error. These durations are deemed acceptable, compared with the consequences of the execution interruption. Given the rapid advancements in LLMs, we anticipate continued improvements in their efficiency.
Answer to RQ4: The try-catch mechanism adds only 4.5 ms latency for one million runs, and the LLMs' inference times (1.7s for CodeQwen, 1.6s for GPT-3.5, and 3.1s for GPT-4) allow for real-time error handling, demonstrating the feasibility of using Healer in practice.
## 6 DISCUSSION
In this section, we discuss the threats to validity and the issues with Healer, including its trustworthiness, operational cost, and extension to other programming languages.
## 6.1 Threats to Validity
Internal validity: The main threat to internal validity is the difference in hyper-parameters among the LLMs used in this study. We evaluate the performance of Healer using the commercial LLMs, GPT-3.5 and GPT-4, and the open-source LLM, CodeQwen. In our experiments, we use the default hyper-parameters for these models during inference, except for the CodeQwen's context window. The context window for CodeQwen is set to 4096 tokens, which is significantly smaller than the context windows of GPT-3.5 and GPT-4. This limitation is due to the deployment of CodeQwen on our local machine, where 4096 tokens is the maximum context window supported by the server. This constraint may affect CodeQwen's performance in handling runtime errors, as some prompts exceed this window size and are truncated. This could result in an unfair comparison between CodeQwen and GPT-4. However, we qualitatively analyzed the prompt length distribution, where less than 1% of the prompts are truncated. Therefore, we believe the impact of this truncation is trivial.
External validity: The threats to external validity mainly lie in the selection of benchmarks. The benchmarks used in this paper are limited to four Python benchmarks, which may not encompass all practical scenarios. Although these benchmarks include the most common error types in Python programs, certain error types may still be unrepresented, potentially limiting the generalizability of the conclusions to real-world scenarios.
Construct validity: Bias in performance evaluation is a common threat to construct validity. In our experiment, we introduce two metrics, CORRECT and SURVIVED, to measure the effectiveness of Healer in handling runtime errors. While these metrics are intuitive, they may not be optimal. For instance, even if an error is successfully handled, the resulting program output may still be incorrect due to flaws in the original source code.
## 6.2 Trustworthiness of the Handling Code
As revealed by various studies [39, 46, 60], the code generated by LLMs is not guaranteed to be secure. It may contain malicious code injected by attackers or vulnerable code, leading to security issues. Moreover, due to the randomness in the generation process, the generated code may exhibit unpredictable behaviors. Healer, operating without human intervention, directly executes the generated code to handle runtime errors, which could be risky. Currently, popular AI systems, such as ChatGPT, mitigate such security risks by running model-generated code in a sandboxed environment with limited permissions. Similarly, Healer adopts this strategy.
However, since Healer needs to update the program state of the target program rather than merely displaying execution results, more sophisticated security mechanisms are required to safeguard the target program. Continued research is essential to ensure the security and reliability of handling code in Healer.
## 6.3 Operational Cost for Using Healer
Healer involves an LLM for generating handling code, which introduces additional costs associated with the LLM inference. Typically, Healer can interact with LLMs either deployed on remote servers or on user devices. Remote servers may incur additional costs due to operational expenses or commercial fees. In our experiments, we used the commercial APIs of GPT-3.5 and GPT-4 to generate handling code, with costs around $0.002 and $0.02 per handling code, respectively. On-device inference can significantly reduce costs and enhance the reliability of Healer by eliminating the dependence on remote servers. Various techniques, such as model compression [47] and quantization [30], have been developed to enable model inference on user devices. For example, LLAMA.cpp [18] can run Llama2-13B [50] on a single M2 Ultra MacBook with fast inference speeds (61.44 ms per token). As the field of LLMs progresses, we anticipate further advancements in reducing the resource requirements for LLMs.
## 6.4 Extension to Other Programming Languages
As introduced in Section 3.4, we implement Healer in Python. However, as a general framework for handling runtime errors, Healer is not limited to Python and can be extended to other programming languages. The applicability of Healer to a programming language depends on two factors: (1) the availability of LLMs for the language, and (2) the feasibility of executing dynamically generated code during runtime. Currently, most of SOTA LLMs [2, 7, 29] are pre-trained on multiple programming languages. For example, CodeQwen [7] supports 92 programming languages, covering all the mainstream languages. Therefore, the first factor is a minor concern. The second factor depends on the programming language itself. Typically, interpreted languages, such as Python, JavaScript, and Ruby, are more suitable for Healer, as they natively support the execution of dynamically generated code. Compiled languages, such as Java, C++, and Rust, precompile the source code before execution, introducing extra complexity to dynamic code execution. However, there are usually some workarounds in such languages. For example, Java provides the Java Compiler API to compile the code at runtime. Therefore, technically, Healer can be applied to a wide range of programming languages.
## 7 CONCLUSION AND FUTURE WORK
In this paper, we introduced Healer, an innovative framework that uses Large Language Models (LLMs) to handle unanticipated runtime errors dynamically. Our study demonstrated that LLMs, particularly GPT-4, can effectively generate handling code snippets, successfully surviving a significant portion of runtime errors, 72.8% of errors in our experiments. Moreover, fine-tuning further enhanced performance, showing promise for LLM-assisted error recovery. Healer opens up a new technical pathway towards selfhealing systems, where LLMs are employed as error handlers to recover from runtime errors automatically.
Throughout the study, we identified several avenues for future research. Firstly, the performance of Healer can be further enhanced through methods like prompt engineering [53] and instruction tuning [45]. Secondly, addressing the trustworthiness of code generated by LLMs is crucial, necessitating mechanisms specifically designed for Healer. Lastly, integrating Healer into the runtime environment is an interesting topic, offering more accessible and efficient error-handling mechanisms that benefit the development of self-healing systems.
## REFERENCES
- [1] 2024. CWE - CWE-248: Uncaught Exception (4.14). https://cwe.mitre.org/data/ definitions/248.html Accessed: 2024-06-03.
- [2] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
- [3] AlphaCode Team, Google DeepMind. 2023. AlphaCode 2 Technical Report. https://storage.googleapis.com/deepmind-media/AlphaCode2/ AlphaCode2\_Tech\_Report.pdf Accessed: 2024-05-23.
- [4] AtCoder. 2024. AtCoder. https://atcoder.jp/ Accessed: 2024-05-26.
- [5] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732 (2021).
- [6] Algirdas Avizienis, J-C Laprie, Brian Randell, and Carl Landwehr. 2004. Basic concepts and taxonomy of dependable and secure computing. IEEE transactions on dependable and secure computing 1, 1 (2004), 11-33.
- [7] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. 2023. Qwen Technical Report. arXiv preprint arXiv:2309.16609 (2023).
- [8] Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, et al. 2023. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023 (2023).
- [9] George Candea, Emre Kiciman, Steve Zhang, Pedram Keyani, and Armando Fox. 2003. JAGR: An autonomous self-recovering application server. In 2003 Autonomic Computing Workshop . IEEE, 168-177.
- [10] Antonio Carzaniga, Alessandra Gorla, Andrea Mattavelli, Nicolo Perino, and Mauro Pezze. 2013. Automatic recovery from runtime failures. In 2013 35th International Conference on Software Engineering (ICSE) . IEEE, 782-791.
- [11] Antonio Carzaniga, Alessandra Gorla, Nicolò Perino, and Mauro Pezzè. 2010. Automatic workarounds for web applications. In Proceedings of the eighteenth ACM SIGSOFT international symposium on Foundations of software engineering . 237-246.
- [12] Hervé Chang, Leonardo Mariani, and Mauro Pezze. 2013. Exception handlers for healing component-based systems. ACM Transactions on Software Engineering and Methodology (TOSEM) 22, 4 (2013), 1-40.
- [13] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021).
- [14] Zakir Durumeric, Frank Li, James Kasten, Johanna Amann, Jethro Beekman, Mathias Payer, Nicolas Weaver, David Adrian, Vern Paxson, Michael Bailey, et al. 2014. The matter of heartbleed. In Proceedings of the 2014 conference on internet measurement conference . 475-488.
- [15] EvalPlus. 2024. EvalPlus Releases. https://github.com/evalplus/evalplus/releases Accessed: 2024-05-26.
- [16] Python Software Foundation. 2024. Python FAQ: How fast are exceptions? https://docs.python.org/3/faq/design.html#how-fast-are-exceptions Accessed: 2024-08-01.
- [17] David Garlan and Bradley Schmerl. 2002. Model-based adaptation for self-healing systems. In Proceedings of the first workshop on Self-healing systems . 27-32.
- [18] Georgi Gerganov. 2023. llama.cpp: Port of Facebook's LLaMA model in C/C++. https://github.com/ggerganov/llama.cpp Accessed: 2024-05-30.
- [19] Debanjan Ghosh, Raj Sharman, H Raghav Rao, and Shambhu Upadhyaya. 2007. Self-healing systems-survey and synthesis. Decision support systems 42, 4 (2007), 2164-2185.
- [20] Tianxiao Gu, Chengnian Sun, Xiaoxing Ma, Jian Lü, and Zhendong Su. 2016. Automatic runtime recovery via error handler synthesis. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering . 684-695.
- [21] Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2023. Large Language Models for Software Engineering: A Systematic Literature Review. arXiv:2308.10620 [cs.SE]
- [22] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021).
- [23] Michael N Huhns, Vance T Holderfield, and Rosa Laura Zavala Gutierrez. 2003. Robust software via agent-based redundancy. In Proceedings of the second international joint conference on Autonomous agents and multiagent systems . 1018-1019.
- [24] IBM. 2024. Project CodeNet. https://github.com/IBM/Project\_CodeNet Accessed: 2024-05-26.
- [25] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. 2023. Mistral 7B. arXiv preprint arXiv:2310.06825 (2023).
- [26] Aizu Online Judge. 2024. Aizu Online Judge Home. https://onlinejudge.uaizu.ac.jp/home Accessed: 2024-05-26.
- [27] Sungmin Kang, Gabin An, and Shin Yoo. 2023. A preliminary evaluation of llm-based fault localization. arXiv preprint arXiv:2308.05487 (2023).
- [28] Pavneet Singh Kochhar, Ferdian Thung, Nachiappan Nagappan, Thomas Zimmermann, and David Lo. 2015. Understanding the test automation culture of app developers. In 2015 IEEE 8th International Conference on Software Testing, Verification and Validation (ICST) . IEEE, 1-10.
- [29] Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161 (2023).
- [30] Tailin Liang, John Glossner, Lei Wang, Shaobo Shi, and Xiaotong Zhang. 2021. Pruning and quantization for deep neural network acceleration: A survey. Neurocomputing 461 (2021), 370-403.
- [31] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2024. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in Neural Information Processing Systems 36 (2024).
- [32] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. Comput. Surveys 55, 9 (2023), 1-35.
- [33] Fan Long, Vijay Ganesh, Michael Carbin, Stelios Sidiroglou, and Martin Rinard. 2012. Automatic input rectification. In 2012 34th International Conference on Software Engineering (ICSE) . IEEE, 80-90.
- [34] Frank D Macías-Escrivá, Rodolfo Haber, Raul Del Toro, and Vicente Hernandez. 2013. Self-adaptive systems: A survey of current approaches, research challenges and applications. Expert Systems with Applications 40, 18 (2013), 7267-7279.
- [35] Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2022. Codegen: An open large language model for code with multi-turn program synthesis. arXiv preprint arXiv:2203.13474 (2022).
- [36] OpenAI. 2024. Fine-Tuning Integrations. https://platform.openai.com/docs/ guides/fine-tuning/fine-tuning-integrations Accessed: 2024-05-26.
- [37] OpenAI. 2024. GPT-3.5 Turbo Model Documentation. https://platform.openai. com/docs/models/gpt-3-5-turbo Accessed: 2024-05-21.
- [38] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems 35 (2022), 27730-27744.
- [39] Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2022. Asleep at the keyboard? assessing the security of github copilot's code contributions. In 2022 IEEE Symposium on Security and Privacy (SP) . IEEE, 754-768.
- [40] William H Pierce. 2014. Failure-tolerant computer design . Academic Press.
- [41] Harald Psaier and Schahram Dustdar. 2011. A survey on self-healing systems: approaches and systems. Computing 91 (2011), 43-73.
- [42] Martin C Rinard. 2007. Living in the comfort zone. ACM SIGPLAN Notices 42, 10 (2007), 611-622.
- [43] Martin C Rinard, Cristian Cadar, Daniel Dumitran, Daniel M Roy, Tudor Leu, and William S Beebee. 2004. Enhancing Server Availability and Security Through Failure-Oblivious Computing.. In Osdi , Vol. 4. 21-21.
- [44] Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950 (2023).
- [45] Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al. 2021. Multitask prompted training enables zero-shot task generalization. arXiv preprint arXiv:2110.08207 (2021).
- [46] Xinyue Shen, Zeyuan Chen, Michael Backes, and Yang Zhang. 2023. In chatgpt we trust? measuring and characterizing the reliability of chatgpt. arXiv preprint arXiv:2304.08979 (2023).
- [47] Jieke Shi, Zhou Yang, Bowen Xu, Hong Jin Kang, and David Lo. 2022. Compressing pre-trained models of code into 3 mb. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering . 1-12.
- [48] Beatriz Souza and Michael Pradel. 2023. Lexecutor: Learning-guided execution. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering . 1522-1534.
- [49] Runchu Tian, Yining Ye, Yujia Qin, Xin Cong, Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2024. Debugbench: Evaluating debugging capability of large language models. arXiv preprint arXiv:2401.04621 (2024).
- [50] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
- [51] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- [52] Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi DQ Bui, Junnan Li, and Steven CH Hoi. 2023. Codet5+: Open code large language models for code understanding and generation. arXiv preprint arXiv:2305.07922 (2023).
- [53] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35 (2022), 24824-24837.
- [54] Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. 2023. Magicoder: Source code is all you need. arXiv preprint arXiv:2312.02120 (2023).
- [55] Westley Weimer and George C Necula. 2004. Finding and preventing run-time error handling mistakes. In Proceedings of the 19th annual ACM SIGPLAN Conference on Object-oriented programming, systems, languages, and applications . 419-431.
- [56] Danny Weyns, Ilias Gerostathopoulos, Nadeem Abbas, Jesper Andersson, Stefan Biffl, Premek Brada, Tomas Bures, Amleto Di Salle, Patricia Lago, Angelika Musil, et al. 2022. Preliminary results of a survey on the use of self-adaptation in industry. In Proceedings of the 17th Symposium on Software Engineering for Adaptive and Self-Managing Systems . 70-76.
- [57] Ratnadira Widyasari, Jia Wei Ang, Truong Giang Nguyen, Neil Sharma, and David Lo. 2024. Demystifying Faulty Code with LLM: Step-by-Step Reasoning for Explainable Fault Localization. arXiv preprint arXiv:2403.10507 (2024).
- [58] Chunqiu Steven Xia and Lingming Zhang. 2023. Keep the Conversation Going: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT. arXiv preprint arXiv:2304.00385 (2023).
- [59] Zhou Yang, Jieke Shi, Junda He, and David Lo. 2022. Natural attack for pre-trained models of code. In Proceedings of the 44th International Conference on Software Engineering . 1482-1493.
- [60] Zhou Yang, Zhensu Sun, Terry Zhuo Yue, Premkumar Devanbu, and David Lo. 2024. Robustness, security, privacy, explainability, efficiency, and usability of large language models for code. arXiv preprint arXiv:2403.07506 (2024).
- [61] Jian Zhou, Hongyu Zhang, and David Lo. 2012. Where should the bugs be fixed? more accurate information retrieval-based bug localization based on bug reports. In 2012 34th International conference on software engineering (ICSE) . IEEE, 14-24. | null | [
"Zhensu Sun",
"Haotian Zhu",
"Bowen Xu",
"Xiaoning Du",
"Li Li",
"David Lo"
] | 2024-08-02T07:03:00+00:00 | 2024-08-02T07:03:00+00:00 | [
"cs.SE",
"cs.AI",
"cs.CR"
] | LLM as Runtime Error Handler: A Promising Pathway to Adaptive Self-Healing of Software Systems | Unanticipated runtime errors, lacking predefined handlers, can abruptly
terminate execution and lead to severe consequences, such as data loss or
system crashes. Despite extensive efforts to identify potential errors during
the development phase, such unanticipated errors remain a challenge to to be
entirely eliminated, making the runtime mitigation measurements still
indispensable to minimize their impact. Automated self-healing techniques, such
as reusing existing handlers, have been investigated to reduce the loss coming
through with the execution termination. However, the usability of existing
methods is retained by their predefined heuristic rules and they fail to handle
diverse runtime errors adaptively. Recently, the advent of Large Language
Models (LLMs) has opened new avenues for addressing this problem. Inspired by
their remarkable capabilities in understanding and generating code, we propose
to deal with the runtime errors in a real-time manner using LLMs.
Specifically, we propose Healer, the first LLM-assisted self-healing
framework for handling runtime errors. When an unhandled runtime error occurs,
Healer will be activated to generate a piece of error-handling code with the
help of its internal LLM and the code will be executed inside the runtime
environment owned by the framework to obtain a rectified program state from
which the program should continue its execution. Our exploratory study
evaluates the performance of Healer using four different code benchmarks and
three state-of-the-art LLMs, GPT-3.5, GPT-4, and CodeQwen-7B. Results show
that, without the need for any fine-tuning, GPT-4 can successfully help
programs recover from 72.8% of runtime errors, highlighting the potential of
LLMs in handling runtime errors. |
2408.01056v1 | ## The NING Humanoid: The Concurrent Design and Development of a Dynamic and Agile Platform
Yan Ning, Song Liu, Taiwen Yang, Liang Zheng, and Ling Shi
Abstract -The recent surge of interest in agile humanoid robots achieving dynamic tasks like jumping and flipping necessitates the concurrent design of a robot platform that combines exceptional hardware performance with effective control algorithms. This paper introduces the NING Humanoid, an agile and robust platform aimed at achieving human-like athletic capabilities. The NING humanoid features high-torque actuators, a resilient mechanical co-design based on the Centroidal dynamics, and a whole-body model predictive control (WB-MPC) framework. It stands at 1.1 meters tall and weighs 20 kg with 18 degrees of freedom (DOFs). It demonstrates impressive abilities such as walking, push recovery, and stair climbing at a high control bandwidth. Our presentation will encompass a hardware co-design, the control framework, as well as simulation and real-time experiments.
## I. INTRODUCTION
Recent years have witnessed a remarkable impact on research and industry fields due to the impressive capabilities demonstrated by humanoid robots like Atlas [1], Digit [2], and Optimus [3]. These advancements have promptly increased focus on the development of humanoid robots capable of executing operational tasks and dynamic motions such as running, jumping and flipping. However, the existing robot platforms still face limitations of flexibility and robustness for control. Thus, significant challenges remains in optimizing the concurrent design of hardware and control models to enhance robot dynamic performance.
This work presents the design and development of the NING humanoid, an agile and robust robot platform that achieves advanced dynamic performance. The NING humanoid combines a tightly integrated co-design based on the centroidal dynamic model [4], [5], high-power-density actuators, and a WB-MPC-based controller. Notably, the NING humanoid demonstrates stable rough-terrain walking, push recovery, stair-climbing capabilities in experiments, and back-flipping in simulation. The subsequent sections present the hardware design, the control framework, and simulation and experiment results.
## II. RELATED WORKS
Humanoids which perform extremely dynamic motions highly rely on the actuators. The Atlas performs advanced movements like backflips with hybrid-hydraulic actuators,
This work was supported by the Noetix Robotics company.
Y. Ning and L. Shi are with the Department of Electronic and Computer Engineering, the Hong Kong University of Science and Technology, Clear Water Bay, Hong Kong SAR (email: { yningaa, eesling @connect.ust.hk). }
S. Liu, T. Yang, and L. Zheng are with the Noetix Robotics company, Beijing, China (email: { song.liu, taiwen.yang, zhengliang @noetixrobotics.com). }
Fig. 1. The NING humanoid platform at experimental scenarios.

while the Digit robot utilizes series-elastic actuators (SEAs) for precise torque control. Although these kinds of actuators demonstrate excellent performance, the research and maintenance cost is significant. Therefore, quasi-direct-drive (QDD) actuators are commonly applied in humanoids with low cost, high power density and smooth backdrivability at limb ends. Current QDD-based humanoids like the Unitree H1 [6] and the Artemis [7] from UCLA have already achieved large impact robustness and athletic capabilities. However, they may lose agility due to a large size, which may be dangerous for operators and large cost in maintenance.
Furthermore, the reduced system models, like the Springloaded-inverted-pendulum (SLIP) model [8] or the centroidal dynamic model [4], [9], are commonly used to simplify the complex control calculation. Criteria shows that the inertia and mass of limbs and other parts significantly affect the approximation error in robot dynamics [10]. Thus, the design principle should concurrently consider the dynamic model and hardware layout to make the system more agile for control and improve the overall performance. In terms of transmission mechanism, the Digit robot uses multi-bar linkage [2] which is nonlinear and complicated for control, while the MIT humanoid employs synchronous belt between joints [11] which may lose some rigidity and affect the accuracy. Motivated by such limitations, we design and develop the NING humanoid achieving high-dynamic tasks with more agility, more robustness and low cost.
## III. HARDWARE DESIGN
The NING humanoid is designed to be robust for continuous impact and perform dynamic locomotion, which weighs near 20 kg and has 18 degree of freedom (DoFs) in total, 5 per leg and 4 per arm. An overview of size and joint arrangement is shown in Fig. 2. The actuators operate at a high bandwidth as 1kHz through the Ethercat policy. An Intel
Fig. 2. The design details of the NING humanoid, including robot size, transmission mechanism, axes and joints.
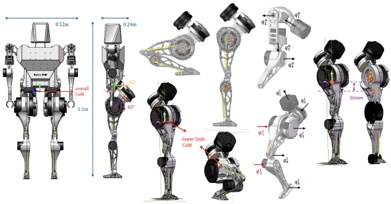
NUC and an IMU are used for whole-body state estimation and real-time locomotion computation.
## A. Actuation and Mechanism
There are three types of modular QDD actuators in the NING humanoid, corresponding to joint demands simulated based on tasks. Such actuators have low gear reduction ratios, high torque density and low cost. They largely improve the locomotion performance due to smooth back-drivability and accurate torque feedback at the joints.
As the impact of contact between the foot and the ground is huge on every locomotion steps, high-strength mechanical parts and rigid transmission mechanism are required for hardware robustness. Therefore, most parts are manufactured as aluminum 7075 and the key stress components are machined with high stiffness steel. In order not to lose transmission linearity and mechanism rigidity, four bar linkage mechanism is utilized to pass the rotation and torque of actuators simultaneously to the knee and ankle joints shown in Fig. 2.
## B. Model-based Concurrent Design
The approximation gap between the dynamic model and the real robot should be minimized to improve the locomotion agility and whole-body control accuracy. Based on the Centroidal Inertia Isotropy (CII) [10] and the centroidal momentum matrix [4], the NING humanoid is co-designed to concentrate the heavy actuators close to the Center of Mass (CoM) of the whole body and reduce the weight of the limbs. The roll and yaw actuators at the hip are tilted to 45 degrees to give a more compact design of the crotch. It can be seen in Fig. 2 that the CoM of a single leg is quite near the CoM of the overall body, and it varies little at different postures. Moreover, the movement range of the upper and lower limbs are still wide to achieve diverse motions.
## IV. CONTROL FRAMEWORK
The WB-MPC control framework follows the work of the MIT Cheetah [12], [13] and Humanoid [14]. The MPC-based locomotion control uses the enhanced centroidal dynamics to predict the future states of the humanoid, while the WBC controller optimizes the current states and output joint torques and accelerations. A simple PD controller is applied for the motors to follow target indices of different actuators.
The locomotion MPC problem is formulated as a convex quadratic programming (QP) problem using the reduced
Fig. 3. Illustrations of back-flipping in simulation and the results of different joint torques in each leg.
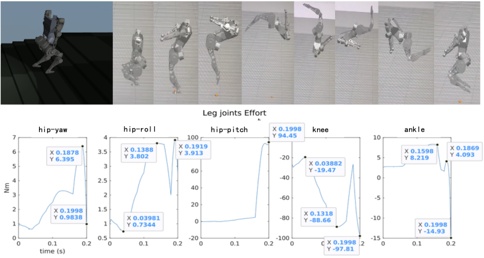
centroidal dynamics to predict step placement of the robot, while the WBC problem is formulated as a convex QP using the full humanoid model. The WBC objective function is,
$$\min _ { \ddot { q }, \tau, \mu } \| A _ { t } \ddot { q } + \dot { A } _ { t } \dot { q } - \dot { r } _ { t } \| ^ { 2 } + \| \dot { u } ^ { d } - \dot { u } \| ^ { 2 } + \| \tau \| ^ { 2 }, \quad ( 1 )$$
subject to constraints including discrete linear dynamics, locomotion tasks regrading to the torse pose and joint angles, ground contact wrench cone, and actuator and power limits, where A t is the task Jacobian matrix; ˙ r t is the commanded task dynamics; u d and u are the desired and actual reaction wrench between the foot and the ground, and τ is the joint torques. By applying an efficient QP solver, qpOASES [15], the WBC problem (1) could be solved in real-time.
## V. SIMULATION & EXPERIMENTS
The simulation is setup on the MuJoCo [16] platform, using a 3D urdf model with mass and inertia attached on the torso and limb axes. Different dynamic tasks like walking, stair-climbing and back-flipping are successfully simulated shown in Fig. 3. The online controller is further fine-tuned for real-time implementation.
In these experiments, the NING humanoid could switch states between stable standing and walking. It passes three dynamic locomotion scenarios shown as Fig. 1: traversing rough grass and snow terrains, performing a push and slippery recovery, and climbing slopes at 10 degrees and low stairs. The gait pace could be self-adjusted based on the terrain reaction force feedback for the robot to resist unknown disturbances.
## VI. CONCLUSION
In conclusion, to perform dynamic tasks, we design the NING humanoid as an agile and robust platform. Based on co-design principles, we integrate exceptional QDD actuators, concentrate inertia at joints based on robot dynamics, utilize linear four bar linkage as transmission to improve the control flexibility, and implement a WB-MPC controller. The simulation and experiments are conducted to show the performance of the NING humanoid. We will further augment perception-based state estimation and trajectory planning on the platform to achieve more advanced movements.
## APPENDIX
## A. Specification of the Actuators
Fig. 4. The specification each QDD actuator utilized in the NING humanoid
## B. Comparison between Inertia of Different Designs
Fig. 5. The comparison of CoM and momentum of inertia change based on different design principles.

## C. Illustrations of the Design and Experiments
Fig. 6. Illustrations of movements designed for the NING humanoid.

Fig. 7. Illustrations of experiments conducted on the NING humanoid.

## D. The demonstration
The demonstration video link is attached below, where the simulation and experiment are presented. All the rights are reserved by the Noetix company and the authors.
The video address: https://youtu.be/uWkuRK9mgyY.
## REFERENCES
- [1] The Atlas robot, https://www.bostondynamics.com/atlas, Boston Dynamics, 2024.
- [2] The Digit robot, https://agilityrobotics.com/products/digit, Agility Robotics, 2024.
- [3] The Tesla Optimus, https://www.tesla.com/AI, Tesla, 2024.
- [4] D. E. Orin and A. Goswami, 'Centroidal momentum matrix of a humanoid robot: Structure and properties,' in Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2008.
- [5] David E. Orin, Ambarish Goswami, and Sung-Hee Lee. 'Centroidal dynamics of a humanoid robot,' Autonomous Robots, 2013.
- [6] Unitree H1, https://m.unitree.com/h1/, Unitree Robotics.
- [7] Taoyuanmin Zhu, 'Design of a highly dynamic humanoid robot,' [Phd thesis, the University of California, Los Angeles]. Retrieved from https://escholarship.org/content.
- [8] Y. Liu, P. M. Wensing, D. E. Orin, and Y. F. Zheng, 'Dynamic walking in a humanoid robot based on a 3d actuated dual-slip model,' in Proceedings of IEEE International Conference on Robotics and Automation (ICRA), 2015.
- [9] G. Garc ´ ıa, R. Griffin, and J. Pratt, 'Mpc-based locomotion control of bipedal robots with line-feet contact using centroidal dynamics,' in Proceedings of IEEE-RAS 20th International Conference on Humanoid Robots (Humanoids), 2020.
- [10] Y. Sim and J. Ramos, 'Tello leg: The study of design principles and metrics for dynamic humanoid robots,' IEEE Robotics and Automation Letters, 2022.
- [11] A. SaLoutos, E. Stanger-Joncs, Y. Ding, M. Chignoli and S. Kim, 'Design and Development of the MIT Humanoid: A Dynamic and Robust Research Platform,' in Proceedings of IEEE/RAS 22nd International Conference on Humanoid Robots (Humanoids), Austin, TX, USA, 2023.
- [12] J. Di Carlo, P. M. Wensing, B. Katz, G. Bledt, and S. Kim, 'Dynamic locomotion in the mit cheetah 3 through convex model-predictive control,' in Proceedings of IEEE-RSJ International Conference on Intelligent Robots and Systems (IROS), 2018.
- [13] G. Bledt, P. M. Wensing, and S. Kim, 'Policy-regularized model predictive control to stabilize diverse quadrupedal gaits for the mit cheetah,' in Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017.
- [14] Y. Ding, C. Khazoom, M. Chignoli, and S. Kim, 'Orientationaware model predictive control with footstep adaptation for dynamic humanoid walking,' in Proceedings of IEEE/RAS 21st International Conference on Humanoid Robots (Humanoids), 2022.
- [15] H. Ferreau, C. Kirches, A. Potschka, H. Bock, and M. Diehl, 'qpOASES: A parametric active-set algorithm for quadratic programming,' Mathematical Programming Computation, vol. 6, no. 4, pp. 327-363, 2014.
- [16] E. Todorov, T. Erez and Y. Tassa, 'MuJoCo: A physics engine for model-based control,' in Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, 2012. | null | [
"Yan Ning",
"Song Liu",
"Taiwen Yang",
"Liang Zheng",
"Ling Shi"
] | 2024-08-02T07:03:45+00:00 | 2024-08-02T07:03:45+00:00 | [
"cs.RO"
] | The NING Humanoid: The Concurrent Design and Development of a Dynamic and Agile Platform | The recent surge of interest in agile humanoid robots achieving dynamic tasks
like jumping and flipping necessitates the concurrent design of a robot
platform that combines exceptional hardware performance with effective control
algorithms. This paper introduces the NING Humanoid, an agile and robust
platform aimed at achieving human-like athletic capabilities. The NING humanoid
features high-torque actuators, a resilient mechanical co-design based on the
Centroidal dynamics, and a whole-body model predictive control (WB-MPC)
framework. It stands at 1.1 meters tall and weighs 20 kg with 18 degrees of
freedom (DOFs). It demonstrates impressive abilities such as walking, push
recovery, and stair climbing at a high control bandwidth. Our presentation will
encompass a hardware co-design, the control framework, as well as simulation
and real-time experiments. |
2408.01057v3 | ## Supporting Industry Computing Researchers in Assessing, Articulating, and Addressing the Potential Negative Societal Impact of Their Work
WESLEY HANWEN DENG ∗ , Carnegie Mellon University, USA SOLON BAROCAS † , Microsoft Research, USA JENNIFER WORTMAN VAUGHAN † , Microsoft Research, USA
Recent years have witnessed increasing calls for computing researchers to grapple with the societal impacts of their work. Tools such as impact assessments have gained prominence as a method to uncover potential impacts, and a number of publication venues now encourage authors to include an impact statement in their submissions. Despite this recent push, little is known about the way researchers go about assessing, articulating, and addressing the potential negative societal impact of their work - especially in industry settings, where research outcomes are often quickly integrated into products and services. In addition, while there are nascent efforts to support researchers in this task, there remains a dearth of empirically-informed tools and processes. Through interviews with 25 industry computing researchers across different companies and research areas, we identify four key factors that influence how they grapple with (or choose not to grapple with) the societal impact of their research: the relationship between industry researchers and product teams; organizational dynamics and cultures that prioritize innovation and speed; misconceptions about societal impact; and a lack of sufficient infrastructure to support researchers. To develop an effective impact assessment template tailored to industry computing researchers' needs, we conduct an iterative co-design process with these 25 industry researchers, along with an additional 16 researchers and practitioners with prior experience and expertise in reviewing and developing impact assessments or responsible computing practices more broadly. Through the co-design process, we develop 10 design considerations to facilitate the effective design, implementation, and adaptation of an impact assessment template for use in industry research settings and beyond, as well as our own 'Societal Impact Assessment' template with concrete scaffolds. We explore the effectiveness of this template through a user study with 15 industry research interns, revealing both its strengths and limitations. Finally, we discuss the implications for future researchers, organizations, and policymakers seeking to foster more responsible research practices.
Additional Key Words and Phrases: Responsible Computing, Ethics, Impact Assessment
## ACMReference Format:
Wesley Hanwen Deng, Solon Barocas, and Jennifer Wortman Vaughan. 2025. Supporting Industry Computing Researchers in Assessing, Articulating, and Addressing the Potential Negative Societal Impact of Their Work. Proc. ACM Hum.-Comput. Interact. 9, 2, Article CSCW178 (April 2025), 37 pages. https://doi.org/10.1145/3711076
∗ This work was conducted while the author was an intern at Microsoft Research. † Both authors contributed equally to this research.
Authors' addresses: Wesley Hanwen Deng, [email protected], Carnegie Mellon University, 5000 Forbes Ave, Pittsburgh, PA, 15213, USA; Solon Barocas, [email protected], Microsoft Research, 300 Lafayette St., New York, NY, 10012, USA; Jennifer Wortman Vaughan, [email protected], Microsoft Research, 300 Lafayette St., New York, NY, 10012, USA.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected].
2573-0142/2025/4-ARTCSCW178 $15.00
© 2025 Copyright held by the owner/author(s). Publication rights licensed to ACM.
## 1 INTRODUCTION
In recent years, many organizations across the academy [2, 9, 18, 32, 35, 61, 68, 73, 80, 98], government [96, 97, 138, 140], civil society [3, 88, 99, 113, 128, 138], and industry [61, 89, 90, 100, 143] have published reports and explored tools and processes to better support computing researchers in grappling with the potential negative societal impact of their research. Among other tools, impact assessments have become popular as a way to support both researchers and practitioners in assessing, articulating, and addressing the impact of their work [33, 56, 88, 93, 138]. At a high level, an impact assessment is a systematic process used to identify, assess, and address the potential impact of a proposed project, program, or policy on people, organizations, and society as a whole [37, 88, 90].
To date, very little of this work has focused on the way industry computing researchers in particular go about assessing and addressing the potential negative societal impacts of their work. Despite a growing line of research on building tools to support practitioners (e.g., product teams) in reflecting and anticipating the societal impact of their work [13, 46, 95, 146, 154], prior work from CSCW and the broader field of HCI suggests that resources for responsible computing in industry are not as readily available as one might hope [40, 62, 64, 82, 111, 145, 152], raising the prospect that industry researchers are similarly lacking in support. Given the proximity that industry research has to practice - and thus its increased likelihood of being integrated into products and services there is an acute need to better understand how industry researchers are currently approaching this challenge. This need is especially urgent in light of the recent rise of generative AI and the risks it poses [16, 76, 147], since much of the research on generative AI takes place in industry contexts.
Despite these efforts, the path forward remains unclear [3, 10, 17, 23, 44, 71, 81, 94, 118]. A small but growing line of work has begun to empirically investigate computing researchers' practices around attempting to confront the negative societal impact of their work. This research has revealed that current efforts are not fully effective [10, 23, 81, 94], due in part to a general lack of incentives and support for self-reflection, including from academic institutions [3, 18, 44].
In addition, while several tools and processes have been proposed to help computing researchers better grapple with the potential negative societal impacts of their work [18, 33, 56, 99, 113, 138, 140], few of these are informed by empirical research. As HCI research has repeatedly demonstrated, such support is unlikely to be effective unless it is informed by an understanding of the on-theground challenges faced by its intended users [12, 40, 72, 77, 84, 115, 153, 156].
To this end, our paper explores the following research questions:
Prior work has pointed out that fostering more responsible research practices in computing will require significant changes across a range of institutions and sectors [18, 44, 68, 80, 88, 113, 116, 138]. While we endorse many of these more ambitious proposals, change can be costly and slow, progressing in fits and starts. Our goal is thus to develop an effective impact assessment tool that researchers can adopt immediately and that can be adapted to different organizational settings and arrangements as these broader changes in practices, policies, and norms ideally unfold.
- · RQ1 : What are industry computing researchers' current perceptions, practices, and challenges around assessing, articulating, and addressing the potential negative societal impact of their research?
- · RQ3 : How might we fulfill these design considerations to develop an effective societal impact assessment template for industry computing researchers?
- · RQ2 : What are some design considerations for designing and implementing an impact assessment template to support industry computing researchers in effectively assessing, articulating, and addressing potential negative societal impacts?
Fig. 1. An overview of the first two contributions or our work. On the left side, we present the empirical findings on current perceptions, practices, and practical challenges (Section 5). On the right side, we present the design considerations for the impact assessment template content and structure (in blue; see Section 6.1) and using the template within an organization (in green; see Section 6.2).
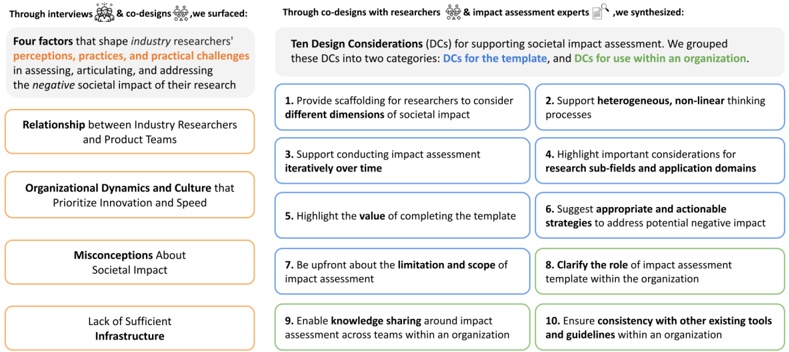
To investigate our research questions, we first conducted study sessions with 25 industry computing 1 researchers across different organizations and research areas. These researchers are formally employed by private companies, but also publish and present their research findings and innovations at peer-reviewed conferences or journals in the field of computing. Each study session was broken into two components: a semi-structured interview and a co-design activity. The semi-structured interview was aimed at understanding industry researchers' perceptions of the need to grapple with the potential negative societal impact of their research as well as their current practices for doing so, including the challenges they commonly encounter. The co-design activity with researchers was focused on soliciting their needs for effectively conducting impact assessment through the iterative co-design of a research-specific impact assessment, which we call the Societal Impact Assessment (SIA) template. To complement the feedback from industry computing researchers, who represent the intended users of the template, we also involved 16 researchers and practitioners with prior experience in developing and reviewing impact assessments or responsible computing practices more broadly (whom we refer to as 'impact assessment experts' throughout this paper) in the co-design process. These participants represent potential administrators or reviewers of the template and are included to ensure that the template fulfills its purpose of effective self reflection. Finally, to further understand the usability and usefulness of the SIA template, we recruited 15 interns from a range of industry research teams at a large U.S.-based technology company.
Our paper ultimately makes three main contributions:
- · An empirical understanding of industry computing researchers' perceptions, practices, and challenges around assessing, articulating, and addressing the potential negative societal impact of their research. Our findings reveal four factors that influence how industry computing researchers grapple with (or choose not to grapple with) the societal impact of
1 We adopt a broad definition of 'computing.' We cover all areas traditionally viewed as part of computer science, as well as social science and design research that examines the socio-technical aspects of technology along with research at the intersection of computer science and other fields, like biology. In adopting this broad definition, our aim is to be inclusive of the types of research that typically occur in industry research labs.
their research: the relationship between industry researchers and product teams (Section 5.1), organizational cultures that prioritize innovation and speed (Section 5.2), disagreements and misconceptions about societal impact (Section 5.3), and the lack or inadequacy of infrastructure to support impact assessment in industry settings (Section 5.4).
- · A version of the Societal Impact Assessment (SIA) template iteratively co-designed with industry computing researchers and impact assessment experts across different organizations and research areas (Section 7), along with results from a one-week user study that reveal the strengths and limitations of the SIA template (Section 8).
- · A set of 10 empirically-informed design considerations to facilitate the proper design, implementation, and adaptation of impact assessment templates in industry research settings and beyond (Section 6). These design considerations are formulated though the co-design with both industry computing researchers and the impact assessment experts. Figure 1 contains an overview of these design considerations, color-coded to indicate which pertain to template content and structure and which to the use of the template within an organization.
## 2 BACKGROUND
Recent calls for computing researchers to grapple with the societal impacts of their work have ushered in a sea-change in thinking about what it means to engage in responsible research in computing. Traditionally, the scope of responsible research practices was thought to include threats to research integrity (such as fraud or a failure to disclose limitations) [8, 127] and the dangers posed by the process of conducting research (such as the risks to the human subjects enlisted in a study or the mishandling of their data) [8, 18]. Recent calls expand the scope to include the risks of downstream harm to society more broadly due to the dissemination of research findings and their associated artifacts. Notably, while Institutional Review Boards address ethical issues that arise in the process of conducting research, they purposefully (and are often legally obligated to) avoid considering the dangers that research findings might pose to society overall [18, 49, 151]. As a result, while there is growing concern around downstream harms, there are no well-established processes for dealing with them. In what follows, we offer an overview of how concerns with societal impact have worked their way through the research community over the past few years and the mechanisms that have been proposed or adopted to address them.
A number of computer science conferences, especially in AI and machine learning, have responded to these calls with changes to their paper submission requirements or instructions and their peer review processes. In 2020, the Neural Information Processing Systems (NeurIPS) conference
In March 2018, Hecht et al. suggested that computer science reviewers should critically examine both the potential positive and negative impacts of research and called for the development of formal guidelines to aid this process [61]. In May 2021, the Partnership on AI issued recommendations for the responsible publication of AI research, encouraging researchers to consider the downstream consequences of research early in the research process and disclose relevant information about the risks of downstream harms [99]. The National Academies of Sciences, Engineering, and Medicine followed in May 2022 with a report that likewise called on computer science as a field to integrate concerns with the societal implications of research into the research and publication process [96]. In July 2022, the Ada Lovelace Institute, the Canadian Institute For Advanced Research (CIFAR), and the Partnership on AI released a joint report on "A Culture of Ethical AI" offering many similar recommendations targeted at the organizers of AI conferences, with the goal of encouraging greater reflection by researchers on the societal impacts of their work [30]. Later that year, in December 2022, the Ada Lovelace Institute also issued its own, much longer report, offering more detailed recommendations for Ethics Review Committees that could help anticipate and address the societal impacts of AI research [3].
introduced a requirement that authors 'include a section in their submissions discussing the broader impact of their work, including possible societal consequences - both positive and negative' [80]. A workshop took place at NeurIPS that same year on 'Navigating the Broader Impacts of AI Research' [9]. The subsequent year, in an effort to provide more guidance and flexibility to authors, this requirement was relaxed and a prompt about negative societal impact was incorporated into a broader 'paper checklist' designed to encourage responsible research practices [19]. Other major AI conferences, such as the International Conference on Machine Learning (ICML), the Conference on Computer Vision and Pattern Recognition (CVPR), and the Annual Meetings of the Association for Computational Linguistics (ACL) have introduced similar requirements [2, 35, 68], as has the International AAAI Conference on Web and Social Media (ICWSM) [1]. In 2024, organizers of the ACM Conference on Fairness, Transparency, and Accountability (FAccT) encouraged researchers to include an 'adverse impact statement' in their submissions, arguing that researchers working on ethical issues in computing need to consider the potential negative societal impact of their own work, too [98]. To aid researchers in fulfilling these new requirements or recommendations, conference organizers and researchers in related fields have written informal guides to support computing researchers in writing impact statements [2, 7, 60, 98].
Finally, funding bodies have also begun to incorporate these considerations into their review processes. In 2020, a cross-disciplinary group of researchers at Stanford developed an Ethics and Society Review Process to 'facilitate ethical and societal reflection as a requirement to access funding,' focusing on early assessment and mitigation of negative societal impacts in computing research [18, 32]. In January 2023, the National AI Research Resource Task Force - a group convened by the National Science Foundation and White House Office of Science and Technology Policy at the behest of the United States Congress - issued a report offering recommendations for how the United States government should go about setting up a public resource to support AI research [97, 140]. The report suggested that consideration of societal impacts should be a part of the process of reviewing proposals to use public resources.
## 3 RELATED WORK
## 3.1 Challenges in Considering Potential Negative Societal Impact
Despite the aforementioned growing calls for computing researchers to attend to the potential negative societal impacts of their work, it is still far from clear how this can be done effectively [3, 10, 23, 44, 81, 94]. For example, examining the broader impact statements written in NeurIPS 2020 papers, Ashurst et al. found that researchers have struggled to fulfill these requirements and to follow these suggestions, and that the quality of the resulting reflections and mitigations is spotty at best [10]. It appears that the guidelines provided by conference organizers and researchers are not sufficiently effective. Other work also suggested that it is unclear if researchers devoted sufficient effort to reflect on the societal impact of their research beyond simply completing these requirements [81, 94].
A small but growing line of empirical work has started to surface practical challenges faced by computing researchers when grappling with the potential negative societal impact of their work [3, 18, 44, 116]. To start with, there are limited tools and systemic guidelines to support assessing, articulating, and addressing potential negative societal impact, leaving researchers to do much of the reflection and possible mitigation on their own [18, 44]. A report from the Ada Lovelace Institute suggested that traditional research ethics processes, such as IRBs, are often not well-suited for computing research such as AI and ML [3]. Moreover, through a series of interviews, Do & Pang et al. found that academic computing researchers often lack sufficient training, experience, as well as opportunities to collaborate with experts from diverse backgrounds in grappling with
unintended consequences of their research [44]. This work suggests that there is a lack of incentives for researchers to consider the negative societal impact of their work, as the process might be at odds with some researchers' goals to publish quickly [3, 44]. In contrast, Rubambiza et al. find that computing researchers may care quite a lot about the societal impact of their work, but are forced to compromise on their vision of societal impact or place less emphasis on societal impact in order to satisfy different audiences (e.g., collaborators, funders, peer reviewers, etc.) whose buy-in is required to execute the research project and publish the findings [116].
Although a small body of prior work has engaged industry computing researchers as part of their study participants in relevant tasks [40, 46, 83], it does not empirically examine the current practices and practical challenges around assessing negative societal impact faced by industry researchers . Understanding these aspects is critical and timely, considering the close relationship between industry research and product and the emerging discussions around the difficulties of assessing impact at later stages of the research-to-practice pipeline [144]. Although there is a growing body of CSCW and broader HCI research literature aimed at understanding the current practices, challenges, and needs of industry developer teams in building responsible technology [40, 41, 46, 62, 64, 82, 84, 106, 111, 145, 150, 156], there has been little focus on industry researchers . Therefore, our work extends the empirical findings from prior studies to uncover factors influencing how industry computing researchers grapple with (or choose not to grapple with) societal impact. These insights also lay the empirical groundwork for developing tools and processes that support computing researchers in industry and beyond.
## 3.2 Tools and Processes to Support Anticipating Potential Harms
CSCW, design, and HCI research more broadly have a rich history of creating tools and processes aimed at helping designers and developers anticipate potential failures, risks, and harms of the technology they are creating. This work often seeks to foster a greater appreciation of the issues that might arise across various technology deployments and real-world usage scenarios and thus to help developers better anticipate and address them [11, 13, 26, 34, 36, 50, 51, 53, 65, 69, 75, 95, 131, 158]. For example, value sensitive design is a theoretically-grounded design paradigm that can be applied to develop technologies that uphold the values of all potentially impacted stakeholders by identifying and addressing those values early in the technology development process [51-53]. Envisioning Cards , a practical tool derived from value sensitive design, can stimulate reflection and dialogue about the long-term impacts of new technology on different stakeholders [95]. Through a series of workshops with industry technology developers, Elsayed-Ali et al. iteratively designed and evaluated Responsible & Inclusive Cards aimed at promoting critical reflection on the potential impacts of industry technology work [46]. Other common methods such as design fiction [21, 50, 85] and speculative design [11, 47, 75] are often used by CSCW and design researchers to imagine and create future scenarios and objects, in order to help researchers and practitioners explore, reflect, and anticipate the potential societal impact of technology. For example, Timelines is a design activity that assists technology developers in reflecting on the ethical concerns related to technical developments by creating fictional stories from news headlines [154]. More recently, HCI researchers have explored leveraging generative AI in scaffolding computing researchers and technology developers in anticipating the potential harms caused by their work [28, 102, 146]. With few exceptions (such as the work of Pang et al. [102], which targets researchers within the academy), these tools are primarily targeted at practitioners, rather than researchers. Our work draws inspiration from these works to better understand the unique challenges faces by industry computing researchers specifically and to develop empirically-informed recommendations and tools for this distinct community.
Recently, impact assessments have emerged as a particularly common approach to encouraging proactive anticipation and potential mitigation of harms in computing innovations [93]. These
emerging impact assessments for computing innovations often draw inspiration from impact assessments that have already been deployed to attempt to capture various aspects of responsible technology creation, such as fiscal impact [74], environmental impact [31, 92], data protection [37], and privacy [57]. For example, the Chief Information Officers Council of the U.S. and the Government of Canada have each developed a questionnaire-based algorithmic impact assessment as a resource to guide organizations and institutions in 'assess[ing] and mitigat[ing] the impacts associated with deploying an automated decision system' [33, 56]. In collaboration with the Ada Lovelace Institute, the UK National Health Service AI lab piloted an algorithmic impact assessment to help developers 'maximise the benefits and mitigate the harms of AI technologies in healthcare' [139]. Similarly, in the private sector, Microsoft recently began requiring product teams to complete a responsible AI impact assessment prior to the launch of any AI-based features [89, 90].
Existing impact assessments for computing innovations are designed for technology developers, often for deployed technologies that have clear use cases in mind [22, 93]. These tools are not immediately appropriate for assessing the impact of research publications or other research artifacts, which may be harder to predict since the potential use cases are more open-ended. Furthermore, there is limited empirical knowledge on designing usable and effective tools for computing researchers to assess societal impacts. [44]. In this study, we aim to bridge this gap by iteratively designing and developing an empirically-informed impact assessment template for industry computing researchers, drawing from existing tools and grounded in empirical evidences from our co-design sessions.
## 3.3 Understanding and Supporting Responsible Computing in Industry Settings
Within the CSCW and broader HCI communities, there has been a significant push to enhance our understanding of industry practitioners' current practices, challenges, and needs around responsible technology design, and to develop tools and guidelines to support them [40, 41, 62, 64, 84, 105, 106, 108, 111, 117, 123, 124, 145, 150, 152, 156, 157]. This research has underscored how organizational dynamics and culture influence responsible and ethical computing practices. For example, a culture that predominantly values moving fast and scaling up can obstruct the use of tools designed to encourage thoughtful reflection [41, 82, 84, 148]. Moreover, power dynamics in the workplace can significantly affect responsible innovations and technology developments. For example, recent works by Rakova et al. [111] and Wong et al. [152] each revealed how 'ethics workers' within companies frequently encountered pushback from leadership when advocating for more responsible technologies. Researchers have also developed tools and processes to support workers' reflexive and anticipation work in industry practice, including the Responsible & Inclusive Cards mentioned above [13, 46, 146]. On the practical side, works have further emphasized the importance of integrating support for responsible development into teams' existing tools and workflows [40, 62, 78, 84, 145, 146, 157].
However, the vast majority of this prior research has focused on teams creating and deploying products as opposed to industry researchers producing academic publications or other research artifacts like data or code. In our study, we specifically investigate how organizational dynamics and company culture might influence industry researchers' capacity and willingness to assess, articulate, and address the potential negative societal impacts of their work. Through interviews and co-design with industry researchers, we develop an impact assessment template tailored specifically for industry research rather than product design and development.
## 4 METHODS
To investigate our research questions, we conducted a series of interviews with 25 industry computing researchers, an iterative co-design process with the same 25 industry computing researchers and 16 impact assessment experts, and a user study with 15 interns working in industry research. We
Iterative co-design with both researchers and experts
RQ3: Develop of a usable and useful impact assessment template (Section 7, 8)
Fig. 2. Overview of our methods and how each study component maps to our research questions and results.
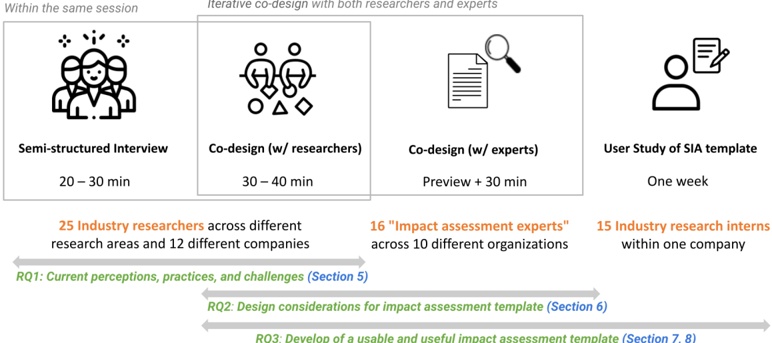
illustrate our method in Figure 2. Each activity is described below, and full protocols are provided in the supplementary material. 2
All studies were conducted over a video conferencing platform between June and August 2023. Sessions were recorded except in cases in which participants opted out and were transcribed using transcription software. Participant quotes were anonymized at the individual, team, and organization levels. Participation in the studies was voluntary and participants were told that they were free to skip any questions they were uncomfortable answering and to leave the study at any time for any reason. Participants in each study were compensated with a $50 gift card. All studies were approved by our institution's IRB.
## 4.1 Creating the Initial Prototype of the Impact Assessment Template
To create the initial prototype of the societal impact assessment template that we used as a basis for iteration in the co-design sessions, we began by synthesizing insights from prior academic literature and other reports on assessing the impact of research in areas such as AI, HCI, and medical research [3, 5, 88, 98, 138]. From these, we formulated a list of initial design considerations. We also drew inspiration from publicly available impact assessment templates such as the responsible AI impact assessment template from Microsoft [89, 90], the algorithmic impact assessments from the UK NHS AI lab [138], the CIO Council of the U.S. [33], and the Government of Canada [56], and the privacy impact assessments from the Government of Canada [57] and introduced by the EU with the General Data Protection Regulation (GDPR) [37]. When designing the template scaffolding content, we also drew inspiration from artifacts in value sensitive design [6, 51, 95, 120, 154, 158], tools and guidelines for conducting responsible computing research [2, 19, 65, 68, 127], as well as survey papers discussing the taxonomy of socio-technical harms [119, 147]. The resulting template, included in the supplemental material, was intended to guide industry researchers through a step-by-step process to consider the intended uses and applications of their work, identify potential stakeholders, anticipate positive societal impact, anticipate potential negative societal impact, and formulate possible mitigations.
2 The supplementary material will be available with the full published version of this paper.
| ID | Years | Research Area | ID | Years | Research Area |
|------|---------|-------------------------------------|------|---------|------------------------------|
| P01 | 0-3 | Augmented Reality (AR) | P14 | 3-10 | VR, AR |
| P02 | 3-10 | HCI, Responsible AI (RAI) | P15 | 0-3 | Computer Vision |
| P03 | 0-3 | Reinforcement Learning | P16 | 3-10 | VR, AR |
| P04 | 3-10 | Accessibility | P17 | 10+ | Reinforcement Learning |
| P05 | 10+ | Hardware security | P18 | 3-10 | HCI, Responsible AI |
| P06 | 0-3 | AI, Philosophy | P19 | 3-10 | Sociology, CSCW |
| P07 | 0-3 | Virtual Reality (VR), Accessibility | P20 | 0-3 | NLP, RAI |
| P08 | 10+ | AI, Accessibility | P21 | 3-10 | AI, HCI, Healthcare |
| P09 | 3-10 | Computational Biology | P22 | 3-10 | NLP, Computer Vision |
| P10 | 3-10 | Psychology, CSCW | P23 | 0-3 | HCI, NLP |
| P11 | 0-3 | Computer Vision, Accessibility | P24 | 0-3 | Computer Graphics |
| P12 | 3-10 | Natural Language Processing (NLP) | P25 | 10+ | Computational Social Science |
| P13 | 3-10 | NLP, Education | | | |
Table 1. Details about the industry researchers who participated in our interview and co-design study. Overall, the researchers work at 12 companies: 10 large technology companies with 25,000 or more employees and two smaller technology companies with 5,000-24,000 employees.
19 researchers are from the U.S., 4 from Europe, and 1 from Australia.
## 4.2 Interview and Co-Design Sessions with Industry Researchers
After creating the initial prototype of the template, we began conducting sessions with 25 industry researchers across organizations and research areas. Each 60-minute session was broken into two components: a semi-structured interview and a co-design activity. Ideally, we would have conducted all interviews first and then invited back the same group of participants for co-design sessions. However, we decided to conduct interviews and co-design sessions together due to the challenges of participants declining to return for a separate co-design session (as documented by prior work [41, 77, 111]) and limited time for conducting the study. During the early stages of the project, we placed more emphasis on the semi-structured interviews. Later, we shifted more of the session time to the critique and co-design of the template itself. Between sessions, we updated the impact assessment template based on feedback from participants, as shown in Figure 3 and detailed in the appendix. This iterative co-design process drew parallels with methodologies deployed in prior work [e.g. 39, 46, 64, 84, 127].
The co-design sessions with researchers were intended to better understand the opportunities for supporting researchers in conducting impact assessment. Within the session, participants were asked to bring a publicly available (e.g., previously published or available on a public platform like arXiv) research paper they had authored as a case study to keep in mind when walking through the template. We first gave participants a high-level overview of the impact assessment template. We then went through the template, asking participants to consider how they would answer the questions with respect to their projects and provide item-level feedback, for instance, identifying
The semi-structured interview was designed to explore industry researchers' perceptions, current practices, and challenges around assessing potential negative societal impact of their work. Weasked participants about their research, their research team, and their relationships with product teams. We then asked them to define the societal impact of industry computing research. Adopting a directed storytelling interview approach similar to prior work [38, 48], we guided participants to reflect on their current practices around whether, when, and how they (try to) assess and mitigate the potential negative societal impact of their work. Finally, we probed deeper into the practical challenges they had encountered.
## Iteratively co-design with both industry computing researchers and impact assessment experts for the Societal Impact Assessment (SIA) Template
Fig. 3. Overview of the iterative co-design process. Version 7 is the SIA Template described in Section 7 and used in our user study. Version 1 and Version 7 are included in the supplementary materials.
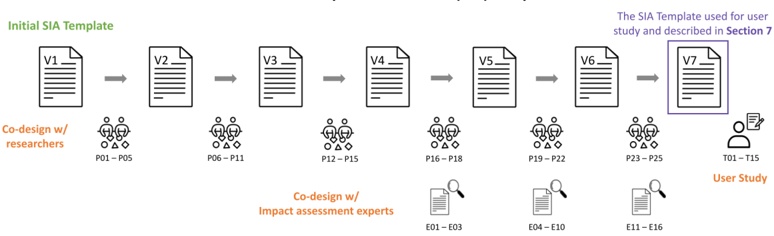
sections of the template that might be hard for their team to use. For each component of the template, we also encouraged participants to share what they thought might be helpful for them to better complete the task. We asked participants to share at which research stages would they want to use the template in their own research, as well as how they envision the outcomes of the impact assessment being presented to other researchers, the product teams in their organizations, and the public. Note that we made a conscious decision to focus on designing the content of the impact assessment, deliberately choosing not to concern ourselves with how this would be implemented in an interactive tool. This decision was primarily based on the understanding that the format of interaction would likely need to be tailored specifically to the organization and its context of use. We address this topic as future work in Section 9.2.
To recruit industry researcher participants, we adopted a purposive sampling approach [29]. Our aim was to recruit computing researchers who (1) are currently employed in industry and (2) publish and present their research findings and innovations in peer-reviewed venues such as academic conferences or journals. We allowed two exceptions to the first criterion, allowing two participants (P21 and P25) who currently work in academia but spent extensive periods of time in industry research labs before becoming professors. We believe their experiences could contribute insight into the challenges specific to industry settings. Participants were recruited through direct contacts at large technology companies, email lists within industry research labs, and snowball sampling. The 25 researchers who participated spanned 12 technology companies, work in diverse areas of computing research, and possess various levels of experience. Table 1 provides an overview of the participants' research area and relevant experience.
## 4.3 Co-Design Sessions with Impact Assessment Experts
To complement the insights from industry computing researchers - the target users of impact assessment templates - we also conducted a series of 30-minute co-design sessions with impact assessment experts : researchers and practitioners with prior experience in developing and reviewing impact assessments or research or policy-making experience around responsible computing and technology more broadly (See Table 2). The goal of these sessions was to ensure that the impact assessment template fulfilled its purpose in uncovering potential negative societal impacts. We began conducting these sessions after making several iterations on the template and interleaved them with the co-design sessions with industry researchers, as illustrated in Figure 3. In preparation for each expert co-design session, we shared a current version of the template with the participant and gave
Table 2. Details about the impact assessment experts who participated in our co-design study. All have experience developing and reviewing impact assessments in their own organization (denoted 'Internal impact assessments'), working with impact assessments in other contexts ('Other impact assessments'), or in research or policy-making on responsible computing more broadly ('Other responsible computing').
| ID | Organization | Research/Practice Domain | Relevant Experience |
|------|----------------|-------------------------------------|-----------------------------|
| E01 | Industry | Responsible AI (RAI); Healthcare | Internal impact assessments |
| E02 | Civil society | Public policy; RAI | Internal impact assessments |
| E03 | Academy | Science and Technology Studies; RAI | Other impact assessments |
| E04 | Civil society | AI safety and governance | Internal impact assessments |
| E05 | Academy | Philosophy of science | Other responsible computing |
| E06 | Industry | Public policy; RAI | Internal impact assessments |
| E07 | Industry | RAI; Healthcare | Internal impact assessments |
| E08 | Civil society | Privacy; RAI | Other responsible computing |
| E09 | Civil society | Public Policy; RAI | Other impact assessments |
| E10 | Academy | Philosophy | Other responsible computing |
| E11 | Industry | Public policy; RAI | Internal impact assessments |
| E12 | Industry | Public policy; Philosophy | Internal impact assessments |
| E13 | Academy | Bioethics; Political science | Internal impact assessments |
| E14 | Academy | Philosophy; RAI | Other responsible computing |
| E15 | Industry | AI safety and governance | Internal impact assessments |
| E16 | Civil society | AI safety and governance | Other impact assessments |
them the opportunity to optionally review and annotate it with any preliminary feedback. During the session, we first solicited feedback on the template's structure and goals. We then prompted the participant to critique each section and provide fine-grained feedback. Finally, we asked the participant to envision how the template might be operationalized in their current organization. We incorporated participants' feedback when producing the next iteration of the template.
To recruit participants, we again adopted a purposive sampling approach [29]. In particular, the authors leveraged their connections with impact assessment experts across academia, industry, and civil society. Among the 21 impact assessment experts we emailed, 16 expressed interest. Of these, 14 participated in a full 30-minute session, while two opted to review the template and annotate it with their feedback without joining a live session. Overall, five of the experts were from civil society organizations, five from academia, and six were employed in industry. Table 2 offers more background information on these experts.
## 4.4 User Study of the SIA template
By the time we produced V7 of the template, we had reached data saturation with the co-design activities with researchers and impact assessment experts. Similar to previous co-design studies [39, 64, 84], we stopped iterating on the template at this point and turned to a user study . While we do not view V7 as a 'perfect' or 'final' version of the template, the user study was intended to give us more insight into the template's usability and usefulness in practice.
Participants in the user study were given one week to complete V7 of the template with respect to an ongoing research project. After completing the template, they were given an exit survey and asked to sign up for an exit interview. The exit survey first asked questions about their usage of the template, such as the amount of time they spent filling it out and how many times they revisited it during the one-week study period. It then asked about the template's overall usability, for example,
asking participants to provide Likert scale ratings for statements like 'the template's organization is logical and intuitive to navigate.' Next, participants were asked whether the template helped them identify potential stakeholders, positive societal impacts, and negative societal impacts. Finally, they were asked for Likert scale ratings of the template's overall usefulness. In the exit interview, which lasted 15-40 min, participants were asked to share any additional thoughts on their experience filling out the template and probed more deeply about their survey responses.
To recruit the participants, we shared a recruitment message in email lists and message boards within the technology company. Initially, 17 research interns signed up for the study, of which 15 filled out the template, completed the exit survey, and participated in an exit interview. Table 3 provides more information about the participants in the user study.
For the user study, we recruited current research interns (primarily PhD students) from a large U.S.-based technology company. Ideally we would have recruited full-time industry researchers across organizations satisfying the same criteria as the participants in the interview and co-design sessions. However, some researchers were reluctant to join because of the potential risk of getting scooped by sharing their ongoing, unpublished research projects. Additionally, full-time researchers were hesitant to make the required time commitment over the course of a week. We believe that recruiting research interns still allowed us to gain valuable insights on the usability and usefulness of the template. We discuss these limitations further in Section 9.3.
## 4.5 Data Analysis
In total, the interviews, co-design sessions, and user study exit interviews yielded approximately 29 hours of recorded audio, which was automatically transcribed, as well as detailed notes taken by the interviewer for the 11 sessions in which the participants opted out of recording. We additionally had the two annotated templates from the impact assessment experts who chose to provide asynchronous feedback and responses to the 15 exit surveys from the user study. To analyze the transcripts from our interviews and co-design sessions, we adopted the reflexive thematic analysis approach described by Braun [25], similar to prior work examining data from interview and co-design activities [46, 64, 84]. All of the authors convened frequently throughout the interviews and co-design sessions to conduct interpretation sessions and discuss the insights. The first author conducted open coding of the transcripts after each interpretation session. Some open codes that emerged from the interviews and co-design sessions with industry computing researchers include: "Participants deflect the responsibility of assessing and addressing the impact of their research to product teams" and "Participants tend to oscillate between identifying stakeholders and assessing the potential impact when co-designing the template." Following the guidelines provided by Braun and Clarke [24], during this coding process, authors continuously discussed discrepancies in interpretation, and the first author iteratively refined the codes based on these discussions [25, 86]. For the user study, we analyzed the exit survey data and computed descriptive statistics. We also performed open coding of the open-text responses to the exit survey and the transcripts of the exit interviews, aiming to synthesize qualitative insights that complement the quantitative evaluation provided by participants. Notice that we chose not to perform and report a content-wise analysis of the template like prior work [cf. 81, 94] because doing so would reveal details about participants' ongoing, unpublished research projects.
## 5 CURRENT PERCEPTIONS, PRACTICES, AND PRACTICAL CHALLENGES
In this section, we identify and explore four factors that influence how industry researchers grapple with (or choose not to grapple with) the potential negative societal impact of their research, summarized in the left part of Figure 1. Some of our results validate findings from prior empirical work [3, 18, 44, 81, 94]; we call out these connections to prior work when they arise. contributes the necessary empirical evidence to be confident of the generality of these observations. Our findings
also extend the existing literature by highlighting structures and dynamics that are unique to computing research in industry.
## 5.1 Relationships between Industry Researchers and Product Teams
Overall, we found that the complex relationships between industry researchers and product teams heavily shape participants' perceptions and current practices around assessing, articulating, and addressing the negative societal impact of their work. In particular, many participants believe that their research has impact through (and only through) its incorporation into products and services. This belief motivates them to attempt to grapple with its potential negative societal impact. However, participants often encountered practical challenges in doing so due to a lack of both transparency and agency around the specifics of when and how their research might be used by product teams. These practical challenges eventually led to participants deflecting the responsibility of grappling with the potential negative societal impact of their own research to product teams and other decision makers within their organizations. Below, we describe these results in more detail.
To this end, we found that participants are particularly motivated to reflect on and assess the potential negative societal impact of their research when they know it will be incorporated into products and services . For example, P17 shared with us that their team was 'just doing [their] own thing' when their work 'was largely theoretical,' but 'started to look into what could go wrong if our research is being widely adopted' when the ML systems they built were incorporated into products. Similarly, P11 suggested that in their organization, conversations about the negative impact of their research often 'happened when a research project was being integrated into a product feature...otherwise we somehow feel like this conversation can wait.' They further acknowledged that prioritizing only research that is being incorporated into products is not a best practice, but their team needed to 'sort out priorities' given limited time and resources.
Many participants expressed a belief that societal impact arises when (and only when) industry research is incorporated into products and services . P04, P07, P11, P15, P18, and P23 all explicitly mentioned that their own research would have only limited impact if it were not integrated into their companies' products and services. P11 told us that their 'research impact is defined by the product impact,' and that industry research can be more impactful than work done in academia due to the 'potential to improve the quality of life for many people through [the] company's products.' Similarly, P13, P21, and P25 - who all had spent multiple years as tenure-track professors in academia in addition to researchers in industry labs - emphasized impact through products and services as a differentiating factor between academic and industry research. As P21 put it: 'In school, you mostly hear people talk about impact as coming up with creative new ideas, getting accepted to conferences, getting grants, [and] having lots of citations. But in a company, my colleagues and I mostly get really excited when your ideas can actually be in the hands of users through products...that's how the impact is being defined there.'
In contrast, several participants with limited contact with product teams rarely assessed the societal impact of their work and believed it was unnecessary . For example, P24, who works on improving the computational efficiency of graphics rendering algorithms and 3D modeling, did not see a need to think about the impact of their work on society 'because the research outcomes are tools for other researchers...not used directly by our customers. ' In addition, when the incorporation of research into products and services effectively motivated participants to consider potential negative societal impact, we found that participants frequently limited their focus to existing customers and intended stakeholders , neglecting indirect stakeholders or other segments of society who might be impacted by their research.
Interestingly, many participants shared that industry researchers do not necessarily know specifically when, where, and how their research will be incorporated into the products,
leading to practical challenges for assessing and addressing negative societal impact . For example, P04, who works closely with product teams on improving the accessibility of mobile apps, told us there were often 'non-disclosure agreements among teams' that essentially left them out on knowing 'whether or not [their] research will eventually be adopted by product teams.' Because of this, P04 suggested that it wouldn't be feasible for them to assess the potential societal impact of their research. Even those researchers who were certain their research would be used by a product team often reported a lack of agency regarding the way in which it would be incorporated. For example, P21 said: 'Once [the product teams] take [the research results], they can really do whatever...and in marketing, they can spin it however they want...I mean you would hope that they would use it responsibly, but really you basically lose control.' Similarly, P23, who works closely with a product team implementing a recommendation system, told us that they were 'pretty much out of touch with [their] own work' once the product team started to incorporate it. This participant suggested that they wish they could 'sit in on some early meetings discussing how our research is being used' so that it would be feasible for them to 'flag anything that might cause downstream harms.'
To this end, we found that many participants tend to deflect the responsibility of assessing and addressing the potential negative societal impact of their own research to product teams and other decision makers within their organizations . For example, P23 suggested that 'it would be unfair to expect us to mitigate harms when the product people are the ones who misuse our research.' Similarly, P11, who works on machine learning models, believed that product teams should be accountable for assessing any negative impact of their research when it is incorporated into products since they are the ones 'deciding what to do with the models we provide.' P04, P05, P16, P18, and P21 all explicitly stated their belief that the primary responsibility for assessing and addressing the potential negative impacts of industry research should rest with product teams, again citing researchers' lack of transparency and agency.
## 5.2 Organizational Dynamics and Cultures that Prioritize Innovation and Speed
A rich line of prior work in the CSCW and broader HCI community has underscored how organizational dynamics and culture influence industry product teams' responsible computing practices [3941, 64, 82, 84, 106, 111, 150]. In line with this, our study reveals how industry researchers are shaped by organizational dynamics and culture - particularly the prioritization of innovation and speed when assessing, articulating, and addressing the potential negative societal impacts of their work.
Among all participants, those in junior roles (P01, P15, P23) expressed particularly strong reluctance to assess and discuss the potential negative societal impact of their work . For instance, P15 told us that they felt pressure to 'establish myself and show that my research is valuable for the company by improving the product.' Although they considered the potential misuse of a face-swapping computer vision algorithm they were working on, especially by users under 18, this participant ultimately did not voice these concerns, stating 'I don't want to be a buzz killer when my manager is very excited about something.' Similarly, P23 shared with us that 'I'm still trying
To start with, many participants shared that they were reluctant or even unwilling to assess and discuss the potential negative societal impact of their work because of an organizational culture of emphasizing the positive side of innovation . For example, P02 reflected that the 'predominant narrative focuses on how many great things the company will contribute to the world.' Because of this, they believed that industry researchers often inadvertently viewed their work through 'rose-tinted glasses' and felt 'peer pressure to always signal how [their] own research agenda is somewhat aligned with [the] company's mission.' In some cases, researchers feared retribution for speaking out about negative impact. For instance, P16 commented on how previous layoffs of industry researchers working on AI ethics had a chilling affect on them and their colleagues, dissuading them from sharing potential negative societal impacts with their managers.
to figure out my role in the team. At least at this stage, what I talk most about to people is how my research can help them instead of the harms my work can do.' Although this participant recognized the importance of assessing potential negative societal impacts, they felt it might conflict with their 'career development as the most recent employee of the team.'
As a result of this culture, participants reported that their efforts to assess and address negative societal impact were often ignored or pushed back on due to mismatched incentives . Specifically, many participants, including P04, P07, P08, P10-P13, P19 and P21, shared stories about how their colleagues from other teams (both in research and product development) often overlooked advice from researchers on assessing and mitigating negative societal impacts. P10, for instance, recounted a time when a team integrated facial recognition algorithms into tools developed for internal workers, disregarding the internal guidelines suggested by their research group. The participant described that the development team is 'encouraged to move forward without any ethical guidance...they're not incentivized in any way, shape, or form to be ethical. They are just trying to create a prototype as fast as possible, and because they report to a general manager who is not in research, they can basically ignore us.' Similarly, P08 shared that by the time they published a paper and highlighted the limitations of their AI models, which were designed for an alt-text generation pipeline, the product team working with them had already incorporated their research into new features to achieve the team's quarterly goal. Reflecting on this, P8 stated ' we spend time writing a paper and wait for peer review, but [product teams] won't wait for our publications...they generally don't read our paper or guidelines. We need ways to affect their day-to-day practice, and the way that you affect their day-to-day practice is through these various compliance programs, or even their KPIs.'
Furthermore, the 'move fast and ship products' culture [82] in technology companies also introduces practical challenges for researchers to appropriately assess and address potential negative impact . For instance, many participants noted that some computing researchers in their companies tend to 'move fast and do groundbreaking innovation' (P16), while some product teams aim to 'launch new product features as fast as possible' (P20). P13 recounted an instance where their research team developed a computer vision algorithm that 'took a very binary gender view of the world' and they 'didn't feel comfortable releasing it until [they] could do something about that.' However, they and their colleagues felt 'internal pressure from the product manager to get things out quickly.' This participant concluded that 'the pressure to get things out quickly is often at odds with carefully assessing the unintended consequences of it.'
## 5.3 Disagreements and Misconceptions around Societal Impact
A number of our study participants believed that assessing the negative societal impact of their work was unnecessary due to their specific areas of research . Echoing prior work [3, 44, 81], we heard this from participants whose research contributions were in theoretical areas of computer science (e.g., machine learning theory), as well as those whose primary research goals were aimed at doing good, for example, mitigating the potential harms of other computing research. Other participants felt that assessing the potential negative societal impacts of their research was unnecessary due to the highly regulated nature of their research application areas , such as medicine, finance, and healthcare. P09, for instance, noted 'the only [potential negative societal impact] I could think about is people making bio-weapons...the problem is that building bio-weapons is hard and requires a lot of resources. It's a bit unnecessary for me and people to worry about the malicious usage because the government will definitely notice if someone is making my research into bio-weapons.' P14, who works on VR/AR research in a Fintech company, expressed that there is no need for researchers to complete impact assessments since the stringent regulations in finance would enforce that care would be taken downstream in deployment. In particular, this participant mentioned that since their company has 'security engineering teams to prevent the malicious actors
and law professionals to handle any legal disputes or litigation,' their responsibility as a research scientist is simply to innovate. We note that both P09 and P14 called out only examples of malicious misuse when contemplating potential negative societal impacts. However, during the co-design process, both P09 and P14 identified potential accidental misuses of their research and agreed that there was still value in assessing and articulating these potential misuses of their work.
All but two participants in our study conflated ensuring research integrity and attending to the welfare of human subjects with addressing the downstream societal impact of research . While prior work has surfaced similar misconceptions [8, 44], we were particularly surprised by how prevalent such misconceptions were among our participants, with participants of varying seniority levels, working in areas including sociology, human-computer interaction, and responsible AI, all hitting this pitfall. For example, when asked to describe an instance when their team attempted to assess the potential negative societal impact of their research, P10 recounted how their team had protected the privacy of participants outside the U.S. while conducting research. After we clarified the question and the participant realized their misunderstanding, they began to reflect on how their team had also been conflating these concepts during their research meetings: 'I guess we have been kind of mixing these two concepts together in our project meetings...but now that I think about it carefully, protecting participants' privacy is actually different from preventing downstream harms.' Consequently, P10 believed that it would be beneficial to provide researchers with learning material and training opportunities around disentangling these concepts and appropriately addressing ethical issues throughout the research lifecycle.
## 5.4 Lack of Sufficient Infrastructure
Prior research has already highlighted the severe absence of efficient and effective infrastructure to support computing researchers in assessing and addressing potential negative impacts [3, 10, 18, 23, 44, 81, 94]. Many industry researchers in our study noted that, while there are processes within their organizations for brainstorming the positive impact of their research, there are often no such processes for assessing and addressing the potential negative societal impact . For example, P01 told us that their team usually schedules multiple 'research brainstorming sessions, ' often resulting in formal documentation around their projects' potential positive impacts, managed by the team lead. In stark contrast, when assessing their research's potential negative impact, this participant's team relies on 'spontaneous conversations about what might go wrong in one meeting...maybe some follow-up if someone happens to bring this up again in a later meeting.' P21 said that while discussions about negative impact occur, there is no formal process, so discussions are often being relegated to 'side chatter. '
In contrast, some participants mentioned that in their companies, formal processes are beginning to emerge to involve industry researchers in assessing and addressing the potential negative societal impact of their research. These processes often come up in the context of discussions around legal and compliance considerations that occur when the company is releasing research artifacts through open source or incorporating research into products. Many participants pointed out a lack of support around cross-functional communication and collaboration between researchers and legal or compliance teams . For example, P22 shared the communication gaps they experienced when discussing the release of an image captioning model with their in-house legal teams: 'I found it useful when legal folks came to talk to us, but the discussion between us was not efficient...I was very confused about all the terminologies they threw at us...[it] felt like we needed a translator despite both speaking English.' Similarly, P14 described feeling 'unprepared and confused' in discussions about the potential misuse of augmented reality services with the company's compliance team, adding 'we all agreed that understanding the platform policies was important to consider the different downstream use cases of our work...but none of us on the research team was aware of those policies
before that chat...I wish we talked to them earlier on.' In light of this, this participant emphasized the need for processes that foster better integrated communication and collaboration between research and compliance teams, particularly for assessing and addressing potential negative impacts.
Participants also mentioned the lack of support and effective infrastructure from publication venues like conferences that require a discussion of societal impact or an explicit broader impact statement. In line with the hypothesis from prior work that authors often write impact statements without sufficient reflexivity [81, 94], we repeatedly heard from many participants (P01, P02, P05P09, P12-P16, P20, P21, P23, P25) that they only start considering the broader impact statement close to the paper deadline . Participants like P13 and P21 expressed a desire for conferences or their own organizations to provide more concrete guidance on assessing and reporting the societal impact of their work. Corroborating findings from prior work [44], many participants in our study mentioned that, without sufficient scaffolding, the conference requirements do not motivate them to conduct a careful impact assessment and can feel burdensome . For example, P03 told us that a rigid broader impact statement requirement did not fundamentally motivate them to assess the impact of their research, as 'anything that dictates how to structure your paper or mandates content...feels like it's taking away some of your agency.' P17 suggested that these conference requirements are treated as mere checklists by industry researchers without 'a norm and culture among the community to treat evaluating the downstream impact of our work as the first class problem. ' In addition, P19 noted that adding a conference requirement without providing sufficient training and support inadvertently adds burden to researchers.
## 6 DESIGN CONSIDERATIONS FOR SOCIETAL IMPACT ASSESSMENT
In this section, we synthesize a list of design considerations (DCs) for the design and implementation of societal impact assessments for computing researchers, as overviewed in Figure 1. We support each DC with empirical evidence from the co-design process with 25 industry computing researchers (whom we refer to as 'researchers' for brevity throughout this section) and 16 impact assessment experts (whom we refer to simply as 'experts'). Additionally, we briefly discuss how each DC might be realized in practice, as suggested by both researchers and experts. We present these DCs in two subsections: those that pertain to template content and structure (Section 6.1), and those that pertain to use within an organization (Section 6.2). In Section 7, we demonstrate how to operationalize these DCs within an actual impact assessment template.
## 6.1 Design Considerations for Template Content and Structure
DC-1. Provide scaffolding for researchers to consider different dimensions of societal impact. This scaffolding could take the form of brainstorming examples, checklists, and guided questions for each dimension.
This sentiment was echoed by all experts. For instance, E07 shared that they observed that researchers often 'stay in their comfort zone' and 'keep bringing up commonplaces' whenconsidering potential downstream harms, rather than 'critically examin[ing] how research could unfold in different ways in the real world.' E03 believed that in addition to considering stakeholders and types of societal impact, the template should also encourage researchers to 'specifically reflect on the longterm and indirect effects of their research on society.' Multiple experts also emphasized the need to
In response to the lack of infrastructure for assessing negative societal impact (Section 5.4), researchers unanimously expressed a desire for processes to help them grapple with the diversity and complexity of potential impacts. These include the various types of stakeholders possibly impacted, the ways in which the research is used, and the different types of societal impact. P13 mentioned constantly being 'afraid of missing some important elements that need consideration.' P19 suggested including scaffolds such as checklists to ensure that researchers address all important considerations.
include a list of concrete examples under each dimension, as they are 'really the best way to get someone to think about a risk or aspect that they hadn't previously considered' (E16).
DC-2. Support heterogeneous, non-linear thinking processes. Specifically, allow researchers to complete the sections of the impact assessment template non-sequentially, in the order they prefer.
While most researchers found the identification of potential stakeholders to be a natural starting point for considering potential impacts, others expressed different preferences. P09 suggested they would prefer to 'start with thinking about the type of impact,' while P23 found it 'more natural to first figure out how people in general might misuse my work, then dive into more details on specific groups of stakeholders.' E07 suggested including 'a questionnaire at the beginning of the template to solicit [a] preference, then adapt the [template] structure based on the response.'
While many existing impact assessments in other domains instruct practitioners to proceed in a linear manner [33, 37, 56], we observed that researchers frequently jumped between different sections of the template. For instance, P17 oscillated between identifying stakeholders and thinking through how these stakeholders might misuse or be impacted by their research, commenting: 'I wonder if there is a way to design the template so that it's easier to simultaneously consider the stakeholders and the negative impact.' P20 went back and forth between considering the limitations of the research and brainstorming the potential negative impact. E06 emphasized that researchers need to consider the 'interactions and trade-offs between the categories of impact,' suggesting that researchers should 'be reminded to reconsider stakeholders while responding to questions in subsequent sections, to prevent overlooking marginalized communities that were not recognized earlier.'
## DC-3. Support conducting the impact assessment iteratively over time. Design the template to be revisited and updated throughout the research process, accommodating changes and new insights as the project evolves.
Many researchers brought up that impact assessment 'shouldn't be a one-shot process' (P16), and that researchers should instead 'fill out this template when starting the project and revisit it from time to time' (P21). Similarly, experts advocated for treating the template as a 'dynamic document, revisited as research progresses' (E09). E05 highlighted the necessity of continuous impact assessment, noting the pitfalls they observed: 'researchers sometimes try to get all questions down in one pass...which shouldn't be the case since they are supposed to iterate on their answers throughout the process...new problems will always emerge as the research evolves.' Both researchers and experts suggested that the template could include version control or progress-tracking features so that researchers could 'have iterated documentation available to reflect on how their thinking [about the societal impact] evolve[d] throughout the research process' (E01).
DC-4. Highlight important considerations for specific research sub-fields and application domains. Specifically, augment the template with domain-specific examples, terminology, and considerations so that the template is more relevant and effective for researchers within particular fields.
Throughout the co-design study, all researchers repeatedly told us that they wished the template would highlight important considerations for their specific research sub-fields and application domains. For example, many researchers working in AI suggested that the template should support AI researchers to 'consider different stages of [the] AI lifecycle, such as problem formulation' (P06). P16 believed it was important to include 'physical health risks and psychological effects unique to our VR research.' Several experts echoed these concerns. For instance, both E01 and E05 used computing research in healthcare as an example, suggesting the template should remind researchers working in a healthcare context to consider 'what type of hospitals are you working with to get your data? Is it public or private?' (E01) and 'differences between private health insurance companies and public health
systems' (E05). Other experts suggested that the environmental impact of model training should be highlighted in the societal impact template for researchers working on large language models.
In practice, experts suggested that template designers could start with a general version of the template, then adapt it to different research domains. One way to achieve this is by including additional modules pertinent to specific research areas. Echoing the recommendations made in prior work examining other forms of impact assessments [18, 93], experts in our study highlighted the need to 'incorporate diverse perspectives from different domains' (E03) and 'assemble a group of researchers in a specific area to tailor the impact assessment template' (E06) to be suitable for a specific domain.
## DC-5. Highlight the value of completing the template. This could include surfacing more positive impacts of the research, improving the rigor of the research, and surfacing future work.
Experts concurred that the template should emphasize its role in enhancing research quality to mitigate the perception that completing an impact assessment is a punitive and burdensome process. E09 recounted that senior leadership in their organization clarified that 'the purpose of impact assessment tools is not punitive but to help improve research quality...and maximize positive impact while minimizing negative ones.' Both E02 and E13 emphasized that aligning the template with researchers' interests is crucial for gaining researcher buy-in.
The challenge of incentivizing researchers to complete impact assessments is well-documented [3, 10, 18, 109]; see Sections 3.1 and 5.4. During the co-design process, almost all researchers indicated they would be more likely to complete an impact assessment if it had a clear benefit for their research. As a comparison, P25 shared that they are 'a big fan of pre-registration in fields like experimental psychology and medicine...since I know [completing pre-registration] would make my work better.' Many researchers found that they appreciated the activities that helped them identify the positive societal impact and limitations of their work, as they are 'something that can directly benefit paper writing' (P22). Some, including P02, P04, P09, P13, and P19, also recognized the benefit of identifying negative impacts early to improve their problem formulation and research design; P19 suggested the template designers should emphasize this benefit.
## DC-6. Suggest appropriate and actionable strategies to address potential negative impact. The template should also assist researchers with the prioritization of impacts.
Resonating with findings from prior work [44], both researchers and experts emphasized that the template should extend beyond simply identifying negative impacts to provide actionable steps for developing a harms mitigation plan. For example, P02 told us that they would 'not feel comfortable to finish an impact assessment without knowing concrete next steps for mitigating harms.' E04 told us that when reviewing impact assessments in their organization, they observed that researchers often acknowledge harms without proposing solutions. To this end, E04 believed that it is crucial for the template to 'prompt people in that general direction to think about appropriate mitigation, instead of just pointing out harms.' Meanwhile, many experts acknowledged the practical difficulty of fully anticipating the likelihood and magnitude of harm. Nonetheless, they believe the template should at least help researchers begin assessing these factors to 'identify high priority risks and prioritize mitigation' (E08). In addition, the template should aid in allocating responsibility for addressing potential negative impact. For example, when critiquing the template (V5), E05 noted that the template should 'acknowledge that some mitigation might come from the researchers, but some might be from the company or society as a whole.' Hence, E05 recommended that the template should 'provide space for researchers to write down: who is responsible for the mitigation? If [researchers] are not responsible, do [they] know whose job it is? [Researchers] can offload responsibilities to someone else, but it is [their] job to clearly indicate who is responsible in the assessment. '
DC-7. Be up front about the limitations and scope of impact assessment. Limitations include the impossibility of anticipating every potential negative impact, the impossibility of foreseeing long-term impacts prior to applying the research in practice, difficulties in quantifying societal effects, and the subjective nature of interpreting societal impact.
Experts noted that a single research team 'can't exhaust all the potential use cases [of the research] or predict how people from a different culture or region might be impacted by their work' (E04), and as such, recommended that template designers frame impact assessment as one component of a broader, continuous dialogue. Many experts stressed that to be effective, self-reflection through the template should lead to further action. E06 suggested that the 'template should be a starting point for researchers to consider who else they should consult.' Similarly, E15 highlighted that, even after completing the template, 'researchers should collaborate with product and compliance teams to monitor the usage of the research, as some harms may only become evident later.' Echoing prior research [3, 88], experts advised that template designers should include disclaimers outlining these and other limitations of impact assessment.
## 6.2 Design Considerations for Use Within an Organization
The following design considerations apply when the impact assessment template will be used within an organization, for example, as part of internal compliance processes.
DC-8. Clarify the role of the impact assessment template within the organization. Specifically, clearly articulate how the completed template will be used and shared within the organization, including any influence it may have on the release or use of research findings. Specify procedures for reviewing completed templates and how the results impact project trajectories.
Experts suggested several key questions to answer when using the template within an organization: At what stage will researchers fill out the template? Who is responsible for completing and reviewing it? Is the process voluntary or mandatory? What incentives or mechanisms are in place to encourage template completion? How does the template integrate with existing organizational procedures? Responses to these questions would vary across organizations. Organizations could potentially develop companion guidelines that cover these questions, similar to Microsoft's Responsible AI Impact Assessment Guide for product teams [89].
Experts emphasized the importance of clarity on how 'socially the template will be situated within an organization' (E09). For example, the template should 'clearly indicate the audience for the questions and ensure appropriate language is used' (E05), since researchers may be accustomed to academic styles of writing which would not be suitable for communicating with stakeholders like product teams. Understanding the intended audience can also incentivize higher quality responses. E12 shared that in their organization, 'once we told the researchers that their manager will read [the assessment], some C-suite executives will also see it...now we see a drastic improvement in the quality of the assessments.'
DC-9. Enable knowledge sharing around impact assessments across teams within an organization. This includes sharing outcomes, examples, experiences, and insights.
Similar to what Do & Pang et al. found in their study with academic computer science researchers [44], many industry researchers in our study also expressed an interest in learning from the experiences of others, especially those in related research areas or within the same organization. For instance, P07 was curious about 'how other VR researchers plan to monitor abusive behaviors' and P15 wanted to know 'what other researchers in my company typically include for this question about the possible stakeholders.' Experts also underscored the importance of enabling knowledge sharing among teams in research, product, and compliance. E02, for example, suggested having
researchers document 'challenges faced while filling out the template for some nice self-reflection...and also [to] provide some valuable insights for other researchers.'
Some researchers mentioned seeing value in their companies hosting a 'workshop to reflect on effective ways to complete the template' (P16). Resonating with recommendations from prior work [18, 44], many experts proposed collecting case studies and news articles on unintended consequences of computing research, alongside 'exemplar assessments to guide those unfamiliar with the impact assessment process' (E12). Some experts, however, cautioned against relying on repositories of completed templates. E02 and E07 both expressed concerns that this might inadvertently encourage researchers to copy answers without deeply reflecting on their own research.
## DC-10. Ensure consistency with other existing tools and guidelines within an organization. For example, reference and integrate other existing documents and resources within the template.
Experts emphasized that template designers need to be cognizant of existing resources and processes within the organization, ensuring the template complements rather than conflicts with or duplicates them. For example, some experts suggested that the template should 'leverage resources from existing departments or programs in the company' (E14) or even 'directly plug into an existing process' (E12). Related to DC-5, experts recommended the template should highlight the additional value it could provide to researchers while ensuring it is coherent with other organizational infrastructure.
In line with the findings of past work on responsible computing in industry [40, 62, 77, 84, 156], many experts highlighted the need to tailor the template to align with institutional infrastructure. E07 noted while reviewing the template, 'We have known limitations and [...] misuse in the <internal reviewing tool>. I am wondering if there is a way to connect both [the internal tool and this impact assessment].' When envisioning using the template within their organization, E11 suggested that 'for misuse, I would also suggest adding <common internal term>, because that is the language we use.'
## 7 THE SOCIETAL IMPACT ASSESSMENT TEMPLATE
In addition to the previous 10 design considerations, the iterative co-design activity also yielded seven versions of the Societal Impact Assessment template (Figure 3). In this section, we provide a high-level description of Version 7 (referred to simply as the SIA template for the rest of this paper). The SIA template includes a list of scaffolding elements and 16 questions divided into 4 main sections (Figure 4). We include the full SIA template in the supplementary materials and at https://perma.cc/B396-DMTV.
As described in Section 4.1, the scaffolding elements and questions in Version 1 of the SIA template drew on a rich line of prior tools and research. They were then iteratively refined by incorporating feedback from both industry computing researchers and impact assessment experts throughout the co-design process. The resulting SIA template, along with the previous 10 high-level design considerations, serve as two complementary resources for future researchers and practitioners to build on, perhaps when developing impact assessment tools and processes for their own organizations. In this section, we demonstrate how (most of) the design considerations in Section 6 were fulfilled in the SIA template. Note that DC-4 is not sufficiently addressed by the current SIA template, nor are DC-8 through DC-10, since these pertain to the template's use within a specific organizational context. We discuss these limitations and future improvements in Sections 8 and 9.2.
Onboarding Section. Because researchers are not necessarily familiar with the process of conducting impact assessments, may not be well-motivated to do so, or might even misunderstand what constitutes societal impact, we provide an onboarding video for researchers who plan to use the SIA template. In the onboarding video, we first highlight the reasons for using the SIA template to motivate researchers to complete it throughout the research life cycle ( DC-5 ). We clarify that
the template is not for addressing risks to human subjects in research, a common misconception (Section 5.3), nor is it a substitute for existing institutional review processes ( DC-10 ). While previewing the template's structure (Figure 4), we highlight that researchers may skip back and forth between the three subsections on potential impact to support non-linear thinking ( DC-2 ). Finally, researchers are instructed to document any challenges faced in answering questions and potentially revisit them, instead of skipping them or providing inadequate responses ( DC-3 and DC-7 ).
Fig. 4. Overview of the SIA template's structure. Please refer to the SIA template included in the supplementary materials for more details on the questions we included in each section and how we guide researchers in thinking through these questions.
Section 1: Research Project Background. To ensure an effective impact assessment, researchers should describe their project in accessible language for the template's intended readers ( DC-8 ). Therefore, this section first requires a research project description with sufficient details using sufficiently accessible language for readers such as product and compliance teams to understand. We then provide a list of potential assets that researchers might release (e.g., paper, data, code, demos) and prompt researchers to reflect on whether these assets will be shared publicly or only internally within their own institution, as the release of different assets and different release plans can raise different risks ( DC-6 ).
Section 2: Intended Uses and Applications. Because the likelihood of industry research being integrated into products and services might affect the risks raised by the research or the urgency to address them ( DC-6 ), this section guides researchers to share the envisioned applications of the research, with a focus on its relevance to products or services within the organization. This information also serves as a basis for researchers to refer to when considering dimensions of potential impact in the remaining sections.
Section 3: Potential Impact. Here we provide a substantial amount of support for researchers to consider various dimensions of societal impact ( DC-1 ). In the template, we highlight that this section should only serve as a starting point for impact assessment, and researchers should revisit their responses as many times as needed throughout their research ( DC-3 & DC-7 ). Finally, we repeatedly remind researchers that they may skip back and forth between the three subsections, as thinking through impacts may require non-linear thinking (e.g., first thinking about possible harms before considering specific stakeholders) ( DC-2 ). As shown in Figure 4, we decided not to number the three subsections to encourage researchers to complete them in any order ( DC-2 ).
- - Intended Positive Societal Impact. Before diving into negative societal impact, this subsection prompts researchers to think through the intended positive societal impact of their research, by asking them to describe the best-case scenario for all the impacted stakeholders they envisioned in the Stakeholders subsection. To scaffold brainstorming, the SIA template includes a brief description
- - Stakeholders. This subsection scaffolds researchers to identify the possible stakeholders who might use or be impacted by their research, including its future applications. We list individuals (directly and indirectly impacted), marginalized groups, companies, industries, governments, and civil society as potential stakeholders to encourage researchers to think broadly about those who might take up or be impacted by their work. Brief descriptions are provided for each stakeholder category to assist those less experienced in considering these groups.
of each of the following potential types of impact for researchers to consider: economic impact, policy impact, environmental impact, cultural impact, and knowledge impact.
- - Potential Negative Societal Impact. This subsection starts by guiding researchers in considering and documenting the limitations of their research, on the belief that it is helpful to consider how undisclosed or unrecognized limitations can lead to unintentional misuse of research findings and corresponding negative societal impacts. Researchers are then prompted to contemplate potential harms stemming from misuse (accidental unintended use), abuse (intentional malicious use), and intended use (Figure 5). We provide concrete examples for each of these three scenarios to support brainstorming.
Section 4: Planning for Mitigation. This final section guides researchers step-by-step through developing actionable strate-
Fig. 5. Illustration included in the SIA template to guide researchers thinking through scenarios leading to potential negative societal impact.
gies to address potential negative societal impacts surfaced in the previous section ( DC-6 ). The section first helps researchers assess the seriousness of the identified risks by considering the likelihood, magnitude, concentration, and time horizon of the potential negative impacts, and asks researchers to document which risks they view as high and low priority in light of these differences. We then provide a list of methods to help researchers plan possible mitigations throughout different stages of the research life cycle. Finally, we ask researchers how the risks identified as high-priority can be mitigated and what actions they can take to ensure that these mitigations are put in place. To more realistically reflect the scope of what researchers themselves might be able to do to address identified risks ( DC-7 ), we also inquire about steps they can take to encourage others to implement these mitigations if they cannot do so themselves.
## 8 USER STUDY OF THE SOCIETAL IMPACT ASSESSMENT (SIA) TEMPLATE
In this section, we present the findings from the one-week user study, described in Section 4.4 . We report the participants' ratings from the exit survey and their comments from their exit interviews, conducted after they had a week to complete the template. For each rating, we report the mean value ( 𝜇 ) and standard deviation ( 𝜎 ) on a scale of 1 to 5, where 1 represents 'strongly disagree' and 5 represents 'strongly agree.'
As shown in Table 3, participants were in different stages of their research projects: four in early stages, eight in the middle, and three late stages, writing up results. On average, they spent 81.26 minutes (SD=37.58) filling out the template, with reported times ranging from 25 to 150 minutes. Out of the 15 participants, 11 reported revisiting the template during the one-week user study period: four revisited it once, four revisited it twice, one revisited it three times, one revisited it four times, and one revisited it six times.
## 8.1 Perceived Strengths of the SIA Template
In general, participants perceived the template's structure and content as clear and easy to navigate . 87% of participants (13/15) agreed (i.e., selected either 'agree' or 'strongly agree' in the exit survey) that the template is 'easy to understand' ( 𝜇 =4.27, 𝜎 =0.71) and the 'instructions provided with the template are clear' ( 𝜇 =4.33, 𝜎 =0.72). A significant 93% of participants (14/15) agreed that the 'template's organization makes sense and is intuitive to navigate' ( 𝜇 =4.40, 𝜎 =0.83). T08 noted in their exit survey that the SIA template presented ' a thoughtfully laid out and thought-provoking assessment. Very relevant to the current state of technological advances in [their] research field.'
The template also effectively facilitated the identification of unconsidered aspects of societal impact, promoting researchers' critical reflection . Participants rated it highly for the template's utility in identifying potential stakeholders who could benefit from or be impacted by the research ( 𝜇 =4.27, 𝜎 =0.59 and 𝜇 =4.40, 𝜎 =0.74, respectively), as well as potential positive ( 𝜇 =4.00, 𝜎 =0.93) and negative ( 𝜇 =4.07, 𝜎 =1.03) societal impacts. T04 reported that the template prompted them to consider 'minority job candidates who might be affected' and to rethink how their work should be framed and presented. T13 highlighted in the exit survey that 'it was very helpful to think about stakeholders in an increasingly broader context, starting with individuals and ending at governmental level. ' T07 mentioned in their exit survey that 'I originally thought my research had no negative impact because it was merely assistive tech for blind people...but when I really thought about it when filling it out, I found that there were unintended consequences I never thought of.' They added during the exit interview that they would update the system design to potentially mitigate these unintended harms.
Finally, completing the template improved participants' personal motivation to grapple with the potential negative societal impact of their work. Anotable 80% of participants (12/15) agreed that 'the template convinced (or further convinced) me that I should consider and grapple with the potential negative societal impact of my research' ( 𝜇 =4.20, 𝜎 =0.86). All participants agreed that they would 'recommend this template to others conducting computing research' ( 𝜇 =4.27, 𝜎 =0.45). Participants such as T02, T06, T13, and T14 specifically mentioned in both their exit surveys and exit interviews that they would continue using the template themselves for future research projects to assess, articulate, and address potential negative societal impacts.
Additionally, participants found that completing the template was valuable for their research . In particular, a majority of participants (14/15) felt the template could help them 'draft a societal impact statement to include in my research paper' ( 𝜇 =4.40, 𝜎 =0.73). T12 felt 'more prepared to write a blog post about the work after using this template.' In addition, 73% of participants (11/15) found 'the template adds value to the research process' ( 𝜇 =4.07, SD = 0.79). During the exit interview, many participants, including T01, T03-07, T11, and T13, indicated that completing the template helped them enhance the rigor of their research and identify new research directions.
## 8.2 Perceived Limitations and Potential Future Iterations of the SIA Template
Despite overall positive feedback, a number of participants (8 out of 15) felt neutral or disagreed (i.e., selected either 'neutral,' 'disagree,' or 'strongly disagree' in the exit survey) with the statement that 'I would use this template again in the future' ( 𝜇 =3.53, 𝜎 =4.27). Through the exit interview, we identified two main reasons why participants were hesitant about using the template. First, the current SIA template is viewed as too long . Around half of the participants (7/15) disagreed that 'the template length is suitable to help with self-reflection,' with three selecting 'neutral' and four selecting 'disagree' ( 𝜇 =3.40, 𝜎 =1.06). T04's comment in the exist survey captured many participants' concerns: 'It was long - I would do this if properly incentivized (if we were going to talk about it in a meeting for a project, for example), but it's maybe too long for me to fill out voluntarily on my other projects when I already have other tasks to do. On the flip side, it was really useful for thinking about new research directions (that help with the societal impact goal), so I might voluntarily use it.'
Second, the current SIA template is not fully suitable for some research areas. Around half of the participants (7/15) felt neutral or disagreed with the statement that 'I believe the current template is appropriate for my particular area of research' ( 𝜇 =3.73, 𝜎 =1.10). T02, who works on reinforcement learning theory, shared during the interview that 'most questions in section 3 are not applicable for this project' because their project set-up is very specific and only a small group of reinforcement learning theorists can make use of their current results. Similarly, T10 shared in their exit survey that: 'I think this template is really well suited to people doing systems design and development work. For those working in more critical/communications/sociology field the template
| ID | Research Area | Project Stage | Time Spent | Revisit # | Length |
|------|------------------------|------------------------|--------------|-------------|----------|
| T01 | NLP | Executing the research | 90 (Minutes) | 1 | 1,062 |
| T02 | Reinforcement Learning | Executing the research | 25 | 0 | 147 |
| T03 | Mathematics | Early brainstorming | 60 | 1 | 702 |
| T04 | Machine Learning | Executing the research | 75 | 2 | 1,079 |
| T05 | AI, Healthcare | Early brainstorming | 75 | 0 | 1,312 |
| T06 | Robotics, AI | Executing the research | 30 | 0 | 246 |
| T07 | Accessibility | Executing the research | 90 | 3 | 1,189 |
| T08 | HCI, Design | Early brainstorming | 150 | 2 | 702 |
| T09 | NLP, HCI | Executing the research | 60 | 2 | 979 |
| T10 | Sociology | Executing the research | 75 | 1 | 672 |
| T11 | VR, AR | Preparing publication | 60 | 0 | 1,143 |
| T12 | NLP, HCI | Executing the research | 90 | 1 | 418 |
| T13 | NLP | Preparing publication | 150 | 6 | 1,136 |
| T14 | NLP | Early brainstorming | 90 | 1 | 461 |
| T15 | NLP, Accessibility | Preparing publication | 120 | 4 | 838 |
Table 3. Research interns who participated in our one-week user study. Research areas, project stage, the time spent completing the SIA template, and the number of revisions were all self reported. Length is the word count of their template responses.
isn't as applicable. ' However, during the exit interview, T10 mentioned that they could see that with a modification, ideally by researchers and domain experts in their own areas, they could 'make the template more useful to qualitative research based on the current structure and content.'
In line with our observations from the co-design study (DC-2 in Section 6.1), around half of the participants (8/15) indicated they navigated back and forth between sections when completing the 'Potential Impact' portion of the template. However, participants desired more support for non-linear thinking when contemplating the many possible dimensions of societal impact . For example, T05 shared in the survey that they 'had difficulty going back and forth between sections (stakeholders, harms, etc)' and suggested alternative presentation, such as a table that 'detail[s] each consideration (columns) for each stakeholder (rows).' During the exit interview, many participants discussed the idea of making the template more interactive and dynamic to allow researchers to move between sections more easily.
Validating experts' suggestions that the template should help researchers prioritize risks and develop appropriate responses (DC-6 in Section 6.1), many participants, such as T01, T03, T07-T11, and T13-T15, shared in their exit interviews that they found the scaffold for determining the seriousness of possible harms and for planing mitigation useful. However, some participants shared that they desired even greater support to effectively evaluate the likelihood and magnitude of harms and to formulate appropriate mitigations . For example, T08 believed that they needed to engage with users and discuss design alternatives to identify suitable mitigations. This need for additional support explains why participants rated 'Helping me prepare mitigations for the potential negative societal impact of my research' relatively low ( 𝜇 =3.67, 𝜎 =1.13). In the exit interviews, some participants, such as T01, T04, and T13, suggested that we make the template more interactive, perhaps using generative AI to aid in brainstorming.
Interestingly, 7 out of 15 participants disagreed that 'the template helped me overcome some of the practical challenges that have kept me from considering and grappling with the potential negative societal impact of my research' ( 𝜇 =3.47, 𝜎 =1.19). Through the exit interview, we learned that this
was because they 'didn't perceive any practical challenges preventing [them] from assessing the negative societal impact in the first place' (T09). This feedback may be attributed to the recruitment of industry research interns rather than full-time industry researchers for the one-week user study, a limitation we discuss in the following section.
## 9 DISCUSSION
## 9.1 Unique Challenges for Industry Computing Researchers
Our work extends prior empirical research by highlighting the unique challenges faced by industry computing researchers when grappling with the potential negative societal impact of their work (Section 5). In particular, they encounter challenges shaped by team structures and organizational hierarchies (Section 5.1), organizational dynamics and culture (Section 5.2), and infrastructure provided - or not provided - by their companies (Section 5.4).
Our findings also indicate that even when industry computing researchers are encouraged to consider the potential negative impacts of their work, they often face communication and collaboration barriers with product or compliance teams. These barriers arise from differences in knowledge and vocabulary (Section 5.4), differing timelines and priorities stemming from different job responsibilities (Section 5.2), as well as a lack of transparency into and control over how researchers' work will be incorporated into products and services (Section 5.1). One promising direction is to create 'boundary objects' that can sit among researchers, product teams, and legal and compliance teams to facilitate collaboration [79, 104, 129, 135]. The SIA template itself could potentially serve as a prototype for developing future boundary objects to help researchers communicate their findings in a format and language accessible to other team members within their organizations. Future research should also explore how the SIA template can be integrated with other existing responsible computing tools that have been adopted in industry [20, 55, 66, 67, 91, 114].
Like their peers in the academy, industry computing researchers aim to publish and present at peer-reviewed conferences. As a result, they share similar concerns as researchers in the academy who worry that highlighting the potential negative societal impacts of their work might decrease the likelihood of their work being accepted at these conferences - and thus affect their careers [3, 18, 44]. But industry computing researchers differ from their peers in the academy because their attempts to grapple with these impacts may also be at odds with their companies' interests, placing their jobs at more immediate risk [c.f. 149].
In line with the extensive empirical research on responsible computing and AI development under the organizational cultures and dynamics within industry settings [39-41, 64, 82, 84, 105, 106, 111, 145, 150, 152, 156], we recognize that the challenges faced by industry researchers in addressing negative societal impacts often stem from business-oriented incentives that prioritize existing customers, larger consumer groups, or wealthier markets segments. Addressing these challenges requires political changes that fundamentally alter the prevailing culture of innovation [82, 111, 152] and power dynamics between technology workers and leadership [41, 106, 148, 150]. While we offer practical approaches that could benefit industry computing researchers and technology companies in the short term, broader changes to the technology industry might be required.
## 9.2 Beyond a Societal Impact Assessment Template
Guiding industry computing researchers to engage in self reflection and complete the impact assessment template is merely an initial step towards addressing the potential negative impacts from industry research. To be effective, impact assessments conducted within companies must be complemented by external mechanisms and policies to drive meaningful changes in technology design and deployment [3, 88, 99].
Social science and legal scholars have cautioned against 'performative accountability,' where companies may appear committed to accountability (e.g., by conducting an impact assessment) but engage in practices that undermine public values in reality [45, 54, 141, 142]. Therefore, future researchers, practitioners, and policymakers should draw lessons from the experiences of other fields with impact assessment processes such as environmental impact assessments [31, 107], human right impact assessments [137], and data protection impact assessments [37, 57], among others, in seeking to develop an effective impact assessment for research [5, 88, 93, 113]. Future work should also draw from works in these domains to explore possible ways to try to get people to actually use the impact assessment, ranging from large-scale changes to the norms of the research community to formal policy requirements within particular institutions [116].
Future work should also consider changes to the format of the SIA template to try to overcome some of limitations we identified in Section 8.2. Our co-design mainly focused on the content of a static template; future research could explore new forms of impact assessment beyond a template, such as interactive tools or guidelines [c.f. 6, 65, 95, 101, 102, 120, 126, 154, 155]. An increasing line of recent work has also explored the use of emerging generative AI technologies to assist in brainstorming and creating incident cases [28, 73, 101-103, 112]. However, these studies have also highlighted the caveats and limitations of using generative AI in tasks like impact assessment [28, 112]. More work needs to be done to provide more engaging and effective scaffolding.
In their recent work, Metcalf et al. have also highlighted the risk of conducting impact assessments without the meaningful engagement from diverse stakeholders, as the assessment outcomes might be 'inappropriately distant from the harms experienced by people' [88]. Impact assessments of industry research additionally need to be (1) evaluated by researchers and experts with diverse backgrounds and (2) contested by the communities impacted by the research. Recent work done by Kieslich et al. also demonstrated the importance of engaging end users in anticipating AI impacts [73]. Drawing from prior HCI research [c.f. 104, 120-122, 126, 135, 154], future research could explore tools and processes to facilitate meaningful conversations and deliberations between researchers and diverse community members in discussing how certain research might impact their lives. Researchers should also work closely with policymakers to explore the possibility of incorporating these tools into formal regulatory processes (e.g., in the decision-making of government funding bodies) [87, 110, 113].
## 9.3 Limitations
As mentioned in Section 8.2, one key limitation of our work is the validity of using industry research interns from a single company for the one-week user study . Although testing with research interns still provided valuable insights into the usability and usefulness of our template, their experience and challenges might differ from those of full-time researchers due to variations in their roles, responsibilities, and experiences. In addition, although a one-week study period allowed us to start to understand how researchers would use the template, ideally, we would observe its usage throughout the entire lifecycle of a research project - from formulating research questions to executing the research, publishing papers, and integrating findings into actual products. To this end, future work should explore ecologically valid methods for evaluating the template within an organizational context. For instance, researchers could conduct a longitudinal study to examine how full-time industry researchers use a version of the SIA template, tailored to their specific research domain and organizational dynamics, at different stages of a research project [c.f. 106]. Future work could also explore how different research roles in industry (e.g., research interns, fulltime researchers, and research managers) might have different incentives when using the impact assessment for their research. Researchers could also collaborate with conference organizers to study how researchers fulfill conference requirements using the SIA template [c.f. 133], or perform
a between-subjects study comparing the quality of impact statements between researchers who use the template and those who do not [c.f. 132].
Finally, ideally, we would have left more time between the interviews and co-design sessions to allow more reflections on the interview data to update the impact assessment template.
Another limitation is that our purposive and snowball sampling approach limited the diversity of practitioners involved . Despite efforts to recruit participants from diverse regions, the majority of industry researchers and experts in our study were from the U.S. and U.K. Therefore, future research is necessary to determine whether our empirical findings and design considerations are applicable in non-Western organizational contexts [70, 134]. Moreover, our positionality as U.S.-based researchers with backgrounds in AI and HCI influenced our data interpretation and the integration of participant feedback into the template's design and development [63]. Therefore, we call for future work on this topic conducted by individuals with different backgrounds, including those outside academia and industry.
## 9.4 Potential Negative Societal Impact and a Plan for Mitigation
Olteanu et al. [98] recently argued that research on ethical issues in computing can also create their own risks of harm. Our work is no exception. To assess these risks, we conducted an impact assessment of our own work using the SIA template. We identified a number of dangers. First, researchers and companies who use our template might be left with a false sense of confidence after completing their impact assessments, mistakenly believing that they have exhausted all potential harms that might arise due to the research in question. Second, they might also conclude that it is enough to just conduct the assessment without taken meaningful action towards addressing any of the identified harms. To address these risks, we explicitly highlight them within the template itself, in line with 6.1, and we offer concrete future steps for other researchers and organizations to avoid this in Section 9.2. When open-sourcing the SIA template through a project web page, we plan to further underscore the appropriate use of impact assessments and the importance of continuous monitoring.
Finally, conducting an impact assessment might create an unreasonable burden on researchers , in line with feedback from the user study. Like IRBs, impact assessments also run the risk of stifling research freedom if the procedures are designed poorly [58, 125]. To guard against these risks, organizations should formally recognize the 'invisible labor' that goes into responsible computing practices [cf. 4, 41, 130, 152], appropriately accounting for these efforts in employees' job descriptions and performance reviews. Organizations should also establish and support teams that can train researchers, provide advice, and help reason through difficult questions [cf. 18, 99].
For-profit companies might exploit the SIA template as a tool for ethics washing [4, 39, 111, 148], as others have observed in prior research studying responsible AI [39, 84, 111], privacy and data protection [14, 59, 136, 142], and environmental justice [27, 42, 107, 141]. Prior work on algorithmic auditing [15, 18, 43, 44, 87, 109] offers helpful suggestions for how to ensure the integrity of the impact assessment process and bring about meaningful change, often via external review.
## 10 CONCLUSION
Through interviews with 25 industry computing researchers, co-design sessions with both these researchers and 16 impact assessment experts, and a user study with 15 industry research interns, this paper (1) sheds light on current perceptions, practices, and challenges among computing researchers seeking to confront the potential negative societal impacts of their work (Section 5), (2) provides guidance for researchers, organizations, and policymakers to improve these practices and overcome identified challenges (Section 6), and (3) offers a version of the SIA template with tangible scaffolding materials (Section 7) along with its user study (Section 8) to help computing as a field of research do more to grapple with the consequences of its work. By connecting and contrasting
these contributions with literature from CSCW, design, and the broader fields of HCI and social science, we illuminate paths for future researchers, industry practitioners and organizations, and policy makers to better support responsible research practices in industry settings and beyond.
## ACKNOWLEDGMENTS
We thank all participating industry researchers, impact assessment experts, and industry research interns for making this work possible. We are grateful to Snehal Prabhudesai, Yuda Song, and Samantha Dalal for joining the pilot interview study. We thank Ken Holstein, Motahhare Eslami, Kevin Feng, and Ezra Awumey for their feedback on the draft. Finally, we thank Alicia Edelman Pelton, Forough Poursabzi-Sangdeh, Sunnie Kim, Rock Pang, Michael Madaio, Nari Johnson, Hoda Heidari, Alex London, Jason Hong, Jeff Bigham, Lauren Wilcox, Eric Horvitz, the CMU FEAT reading group, the Microsoft Research FATE group, and Microsoft's Aether RADD focus group for many useful discussions.
## REFERENCES
- [1] AAAI ICWSM 2024 Organizing Committee. 2024. AAAI ICWSM Paper Checklist. (2024). https://drive.google.com/ file/d/1RMsfCq\_dVFwVIpzBUT8wUTdym-Qwi-sV/view?usp=sharing
- [3] Ada Lovelace Institute. 2022. Looking before we leap: Expanding ethical review processes for AI and data science research. (December 2022). https://www.adalovelaceinstitute.org/wp-content/uploads/2022/12/Ada-LovelaceInstitute-Looking-before-we-leap-Dec-2022.pdf
- [2] ACL, Ethic Policy. 2023. ACL 2023 Responsible NLP Research and Ethics Policy. (March 2023). https://2023.aclweb. org/calls/main\_conference/#ethics-policy
- [4] Sanna J Ali, Angèle Christin, Andrew Smart, and Riitta Katila. 2023. Walking the Walk of AI Ethics: Organizational Challenges and the Individualization of Risk among Ethics Entrepreneurs. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency . 217-226.
- [6] Artefact. 2022. The Tarot Cards of Tech: Discover the power of predicting impact. (Nov 2022). https://tarotcardsoftech. artefactgroup.com/.
- [5] Norberto Nuno Gomes de Andrade and Verena Kontschieder. 2021. AI impact assessment: a policy prototyping experiment. Available at SSRN 3772500 (2021).
- [7] Carolyn Ashurst, Markus Anderljung, Carina Prunkl, Jan Leike, Yarin Gal, Toby Shevlane, and Allan Dafoe. 2020. A Guide to Writing the NeurIPS Impact Statement. (May 2020). https://medium.com/@GovAI/a-guide-to-writing-theneurips-impact-statement-4293b723f832
- [9] Carolyn Ashurst, Solon Barocas, Rosie Campbell, Deborah Raji, and Stuart Russell. 2020. Navigating the Broader Impacts of AI Research. NeurIPS workshop. https://ai-broader-impacts-workshop.github.io/
- [8] Carolyn Ashurst, Solon Barocas, Rosie Campbell, and Deborah Raji. 2022. Disentangling the components of ethical research in machine learning. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency . 2057-2068.
- [10] Carolyn Ashurst, Emmie Hine, Paul Sedille, and Alexis Carlier. 2022. AI ethics statements: analysis and lessons learnt from NeurIPS broader impact statements. In 2022 ACM Conference on Fairness, Accountability, and Transparency . 2047-2056.
- [12] Agathe Balayn, Mireia Yurrita, Jie Yang, and Ujwal Gadiraju. 2023. 'Fairness Toolkits, A Checkbox Culture?' On the Factors that Fragment Developer Practices in Handling Algorithmic Harms. In Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society . 482-495.
- [11] James Auger. 2013. Speculative design: crafting the speculation. Digital Creativity 24, 1 (2013), 11-35.
- [13] Stephanie Ballard, Karen M Chappell, and Kristen Kennedy. 2019. Judgment call the game: Using value sensitive design and design fiction to surface ethical concerns related to technology. In Proceedings of the 2019 on Designing Interactive Systems Conference . 421-433.
- [15] Jack Bandy and Nicholas Diakopoulos. 2020. Auditing news curation systems: A case study examining algorithmic and editorial logic in Apple News. In Proceedings of the International AAAI Conference on Web and Social Media , Vol. 14. 36-47.
- [14] Kenneth A Bamberger and Deirdre K Mulligan. 2011. Privacy on the Books and on the Ground. Stanford Law Review (2011), 247-315.
- [16] Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?. In Proceedings of the 2021 ACM Conference on Fairness,
| | Accountability, and Transparency (FAccT) . 610-623. https://doi.org/10.1145/3442188.3445922 |
|------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [17] | Luciana Benotti and Patrick Blackburn. 2022. Ethics consideration sections in natural language processing papers. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing . 4509-4516. |
| [18] | Michael S Bernstein, Margaret Levi, David Magnus, Betsy A Rajala, Debra Satz, and Quinn Waeiss. 2021. Ethics and society review: Ethics reflection as a precondition to research funding. Proceedings of the National Academy of Sciences 118, 52 (2021), e2117261118. |
| [19] | Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan. 2021. Introducing the NeurIPS 2021 paper checklist. NeurIPS blog. https://blog.neurips.cc/2021/03/26/introducing-the-neurips-2021-paper-checklist/ |
| [20] | Sarah Bird, Miro Dudík, Richard Edgar, Brandon Horn, Roman Lutz, Vanessa Milan, Mehrnoosh Sameki, Hanna Wallach, and Kathleen Walker. 2020. Fairlearn: A toolkit for assessing and improving fairness in AI . Technical Report MSR-TR-2020-32. Microsoft. https://www.microsoft.com/en-us/research/publication/fairlearn-a-toolkit-for- assessing-and-improving-fairness-in-ai/ |
| [21] | Mark Blythe. 2014. Research through design fiction: narrative in real and imaginary abstracts. In Proceedings of the SIGCHI conference on human factors in computing systems . 703-712. |
| [22] | Edyta Bogucka, Marios Constantinides, Sanja Šćepanović, and Daniele Quercia. 2024. Co-designing an AI impact assessment report template with AI practitioners and AI compliance experts. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , Vol. 7. 168-180. |
| [23] | Margarita Boyarskaya, Alexandra Olteanu, and Kate Crawford. 2020. Overcoming Failures of Imagination in AI Infused System Development and Deployment. arXiv preprint arXiv:2011.13416 (2020). |
| [24] | Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology. Qualitative research in psychology 3, 2 (2006), 77-101. |
| [25] | Virginia Braun and Victoria Clarke. 2019. Reflecting on reflexive thematic analysis. Qualitative research in sport, exercise and health 11, 4 (2019), 589-597. |
| [26] | Philip AE Brey. 2012. Anticipatory ethics for emerging technologies. NanoEthics 6, 1 (2012), 1-13. |
| [27] | Howard Brown and Timothy Larson. 1998. Making business integration work: A survival strategy for EHS managers. Environmental Quality Management 7, 3 (1998), 1-8. |
| [28] | Zana Buçinca, Chau Minh Pham, Maurice Jakesch, Marco Tulio Ribeiro, Alexandra Olteanu, and Saleema Amershi. 2023. AHA!: Facilitating AI Impact Assessment by Generating Examples of Harms. arXiv preprint arXiv:2306.03280 (2023). |
| [29] | Steve Campbell, Melanie Greenwood, Sarah Prior, Toniele Shearer, Kerrie Walkem, Sarah Young, Danielle Bywaters, and Kim Walker. 2020. Purposive sampling: complex or simple? Research case examples. Journal of research in Nursing 25, 8 (2020), 652-661. |
| [30] | Canadian Institute For Advanced Research. 2022. A Culture of Ethical AI. (July 2022). https://cifar.ca/wp-content/ uploads/2022/08/CIFAR-AI-Insights-EN-FINAL-AODA.pdf |
| [31] | Matthew Cashmore, Richard Gwilliam, Richard Morgan, Dick Cobb, and Alan Bond. 2004. The interminable issue of effectiveness: substantive purposes, outcomes and research challenges in the advancement of environmental impact assessment theory. Impact Assessment and Project Appraisal 22, 4 (2004), 295-310. |
| [32] | Center for Advanced Study in the Behavioral Sciences. 2020. Ethics & Society Review · Stanford University. (2020). https://casbs.stanford.edu/ethics-society-review-stanford-university |
| [33] | Chief Information Officers Council, U.S. 2021. Algorithmic Impact Assessment. (May 2021). https://www.cio.gov/aia- eia-js/#/ |
| [34] | Adele E Clarke et al. 2016. Anticipation work: Abduction, simplification, hope. Boundary objects and beyond: Working with Leigh Star 85 (2016). |
| [35] | CVPR, Ethics Guidelines. 2023. CVPR 2024 Ethics Guidelines for Authors. (November 2023). https://cvpr2023.thecvf. com/Conferences/2023/EthicsGuidelines |
| [36] | Lachlan D. Urquhart and Peter J. Craigon. 2021. The Moral-IT Deck: a tool for ethics by design. Journal of Responsible Innovation 8, 1 (2021), 94-126. |
| [37] | Data Protection Impact Assessment, General Data Protection Regulation. 2023. GDPR, Privacy Impact Assess- ment. (Nov 2023). https://gdpr-info.eu/issues/privacy-impact-assessment/#:~:text=Basically%2C%20a%20data% 20protection%20impact,of%20the%20GDPR%20is%20relevant. |
| [38] | Scott Davidoff, Min Kyung Lee, Charles Yiu, John Zimmerman, and Anind K Dey. 2006. Principles of smart home control. In UbiComp 2006: Ubiquitous Computing: 8th International Conference, UbiComp 2006 Orange County, CA, USA, September 17-21, 2006 Proceedings 8 . Springer, 19-34. |
| [39] | Wesley Hanwen Deng, Boyuan Guo, Alicia Devrio, Hong Shen, Motahhare Eslami, and Kenneth Holstein. 2023. |
- [39] Wesley Hanwen Deng, Boyuan Guo, Alicia Devrio, Hong Shen, Motahhare Eslami, and Kenneth Holstein. 2023. Understanding Practices, Challenges, and Opportunities for User-Engaged Algorithm Auditing in Industry Practice. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . 1-18.
- [40] Wesley Hanwen Deng, Manish Nagireddy, Michelle Seng Ah Lee, Jatinder Singh, Zhiwei Steven Wu, Kenneth Holstein, and Haiyi Zhu. 2022. Exploring How Machine Learning Practitioners (Try To) Use Fairness Toolkits. In 2022 ACM Conference on Fairness, Accountability, and Transparency . ACM, Seoul Republic of Korea, 473-484. https://doi.org/10.1145/3531146.3533113
- [42] Andrea di Miceli, Birgit Hagen, Maria Pia Riccardi, Francesco Sotti, and Davide Settembre-Blundo. 2021. Thriving, Not Just Surviving in Changing Times: How Sustainability, Agility and Digitalization Intertwine with Organizational Resilience. Sustainability (2021).
- [41] Wesley Hanwen Deng, Nur Yildirim, Monica Chang, Motahhare Eslami, Kenneth Holstein, and Michael Madaio. 2023. Investigating Practices and Opportunities for Cross-functional Collaboration around AI Fairness in Industry Practice. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency . 705-716.
- [43] Nicholas Diakopoulos. 2015. Algorithmic accountability: Journalistic investigation of computational power structures. Digital journalism 3, 3 (2015), 398-415.
- [45] Lauren B Edelman and Shauhin A Talesh. 2011. To comply or not to comply-That isn't the question: How organizations construct the meaning of compliance. Explaining compliance: Business responses to regulation (2011), 103-122.
- [44] Kimberly Do, Rock Yuren Pang, Jiachen Jiang, and Katharina Reinecke. 2023. 'That's important, but...': How Computer Science Researchers Anticipate Unintended Consequences of Their Research Innovations. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . 1-16.
- [46] Salma Elsayed-Ali, Sara E Berger, Vagner Figueredo De Santana, and Juana Catalina Becerra Sandoval. 2023. Responsible & Inclusive Cards: An online card tool to promote critical reflection in technology industry work practices. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . 1-14.
- [48] Shelley Evenson. 2006. Directed storytelling: Interpreting experience for design. Design Studies: Theory and research in graphic design (2006), 231-240.
- [47] Chris Elsden, David Chatting, Abigail C Durrant, Andrew Garbett, Bettina Nissen, John Vines, and David S Kirk. 2017. On speculative enactments. In Proceedings of the 2017 CHI conference on human factors in computing systems . 5386-5399.
- [49] United States. National Commission for the Protection of Human Subjects of Biomedical and Behavioral Research. 1978. The Belmont report: ethical principles and guidelines for the protection of human subjects of research . Vol. 1. Department of Health, Education, and Welfare, National Commission for the ....
- [51] Batya Friedman and David G Hendry. 2019. Value sensitive design: Shaping technology with moral imagination . Mit Press.
- [50] Sarah Fox, Amanda Menking, Stephanie Steinhardt, Anna Lauren Hoffmann, and Shaowen Bardzell. 2017. Imagining intersectional futures: Feminist approaches in CSCW. In Companion of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing . 387-393.
- [52] Batya Friedman, Peter H Kahn, Alan Borning, and Alina Huldtgren. 2013. Value sensitive design and information systems. Early engagement and new technologies: Opening up the laboratory (2013), 55-95.
- [54] Ben Gansky and Sean McDonald. 2022. CounterFAccTual: How FAccT undermines its organizing principles. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency . 1982-1992.
- [53] Batya Friedman and Lisa P Nathan. 2010. Multi-lifespan information system design: A research initiative for the HCI community. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems . 2243-2246.
- [55] Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford. 2021. Datasheets for datasets. Commun. ACM 64, 12 (2021), 86-92.
- [57] Government of Canada. 2023. Privacy Impact Assessment, Office of teh Privacy Commissioner of Canada. (Nov 2023). https://www.priv.gc.ca/en/privacy-topics/privacy-impact-assessments/
- [56] Government of Canada. 2020. Algorithmic Impact Assessment, Government of Canada. (May 2020). https: //open.canada.ca/data/en/dataset/5423054a-093c-4239-85be-fa0b36ae0b2e
- [58] Christine Grady. 2015. Institutional review boards: Purpose and challenges. Chest 148, 5 (2015), 1148-1155.
- [60] Brent Hecht. 2020. Suggestions for Writing NeurIPS 2020 Broader Impacts Statements. (2020). https://brenthecht. medium.com/suggestions-for-writing-neurips-2020-broader-impacts-statements-121da1b765bf
- [59] Marco Gutfleisch, Jan H Klemmer, Niklas Busch, Yasemin Acar, M Angela Sasse, and Sascha Fahl. 2022. How does usable security (not) end up in software products? results from a qualitative interview study. In 43rd IEEE Symposium on Security and Privacy, IEEE S&P . 22-26.
- [61] Brent Hecht, Lauren Wilcox, Jeffrey P Bigham, Johannes Schöning, Ehsan Hoque, Jason Ernst, Yonatan Bisk, Luigi De Russis, Lana Yarosh, Bushra Anjum, et al. 2021. It's time to do something: Mitigating the negative impacts of computing through a change to the peer review process. arXiv preprint arXiv:2112.09544 (2021).
- [62] AmyK.Heger, Liz B. Marquis, Mihaela Vorvoreanu, Hanna Wallach, and Jennifer Wortman Vaughan. 2022. Understanding Machine Learning Practitioners' Data Documentation Perceptions, Needs, Challenges, and Desiderata. Proceedings of the ACM on Human-Compututer Interaction 6, CSCW2, Article 340 (2022), 29 pages. https://doi.org/10.1145/3555760
- [63] Andrew Gary Darwin Holmes. 2020. Researcher Positionality-A Consideration of Its Influence and Place in Qualitative Research-A New Researcher Guide. Shanlax International Journal of Education 8, 4 (2020), 1-10.
- [65] Matthew K Hong, Adam Fourney, Derek DeBellis, and Saleema Amershi. 2021. Planning for natural language failures with the ai playbook. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems . 1-11.
- [64] Kenneth Holstein, Bruce M McLaren, and Vincent Aleven. 2019. Designing for complementarity: Teacher and student needs for orchestration support in AI-enhanced classrooms. (2019), 157-171.
- [66] IBM Resaerch Trusted AI. 2021. AIF360 API. (2021). https://aif360.res.ibm.com/
- [68] ICML, Publication Ethics. 2023. International Conference on Machine Learning, Publication Ethics. (November 2023). https://icml.cc/Conferences/2023/PublicationEthics
- [67] IBM Resaerch Trusted AI. 2021. AIX360 API. (2021). https://aix360.mybluemix.net/
- [69] Marina Jirotka, Barbara Grimpe, Bernd Stahl, Grace Eden, and Mark Hartswood. 2017. Responsible research and innovation in the digital age. Commun. ACM 60, 5 (2017), 62-68.
- [71] Nari Johnson and Hoda Heidari. 2023. Assessing AI Impact Assessments: A Classroom Study. arXiv preprint arXiv:2311.11193 (2023).
- [70] Anna Jobin, Marcello Ienca, and Effy Vayena. 2019. The global landscape of AI ethics guidelines. Nature Machine Intelligence 1, 9 (2019), 389-399.
- [72] Harmanpreet Kaur, Harsha Nori, Samuel Jenkins, Rich Caruana, Hanna Wallach, and Jennifer Wortman Vaughan. 2020. Interpreting interpretability: understanding data scientists' use of interpretability tools for machine learning. In Proceedings of the 2020 CHI conference on human factors in computing systems . 1-14.
- [74] Zenia Kotval. 2006. Fiscal Impact Analysis: Methods, Cases, and Intellectual Debate Zenia Kotval and John Mullin With research assistance from Maureen Lempke. (2006).
- [73] Kimon Kieslich, Nicholas Diakopoulos, and Natali Helberger. 2023. Anticipating Impacts: Using Large-Scale Scenario Writing to Explore Diverse Implications of Generative AI in the News Environment. arXiv preprint arXiv:2310.06361 (2023).
- [75] Sandjar Kozubaev, Chris Elsden, Noura Howell, Marie Louise Juul Søndergaard, Nick Merrill, Britta Schulte, and Richmond Y Wong. 2020. Expanding modes of reflection in design futuring. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems . 1-15.
- [77] Michelle Seng Ah Lee and Jat Singh. 2021. The landscape and gaps in open source fairness toolkits. In Proceedings of the 2021 CHI conference on human factors in computing systems . 1-13.
- [76] Sachin Kumar, Vidhisha Balachandran, Lucille Njoo, Antonios Anastasopoulos, and Yulia Tsvetkov. 2023. Language Generation Models Can Cause Harm: So What Can We Do About It? An Actionable Survey. In Proceedings of the The 17th Conference of the European Chapter of the Association for Computational Linguistics .
- [78] Weixin Liang, Nazneen Rajani, Xinyu Yang, Ezinwanne Ozoani, Eric Wu, Yiqun Chen, Daniel Scott Smith, and James Zou. 2024. What's documented in AI? Systematic Analysis of 32K AI Model Cards. arXiv preprint arXiv:2402.05160 (2024).
- [80] Hsuan-Tien Lin, Maria-Florina Balcan, Raia Hadsell, and Marc'Aurelio Ranzato. 2020. Getting Started with NeurIPS 2020. NeurIPS blog. https://neuripsconf.medium.com/getting-started-with-neurips-2020-e350f9b39c28
- [79] Q Vera Liao, Hariharan Subramonyam, Jennifer Wang, and Jennifer Wortman Vaughan. 2023. Designerly understanding: Information needs for model transparency to support design ideation for AI-powered user experience. In Proceedings of the 2023 CHI conference on human factors in computing systems . 1-21.
- [81] David Liu, Priyanka Nanayakkara, Sarah Ariyan Sakha, Grace Abuhamad, Su Lin Blodgett, Nicholas Diakopoulos, Jessica R Hullman, and Tina Eliassi-Rad. 2022. Examining Responsibility and Deliberation in AI Impact Statements and Ethics Reviews. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society . 424-435.
- [83] Michael Madaio, Shivani Kapania, Rida Qadri, Ding Wang, Andrew Zaldivar, Remi Denton, and Lauren Wilcox. 2024. Learning about Responsible AI On-The-Job: Learning Pathways, Orientations, and Aspirations. In The 2024 ACM Conference on Fairness, Accountability, and Transparency . 1544-1558.
- [82] Michael Madaio, Lisa Egede, Hariharan Subramonyam, Jennifer Wortman Vaughan, and Hanna Wallach. 2022. Assessing the Fairness of AI Systems: AI Practitioners' Processes, Challenges, and Needs for Support. Proceedings of the ACM on Human-Computer Interaction 6, CSCW1 (2022), 26 pages.
- [84] Michael A Madaio, Luke Stark, Jennifer Wortman Vaughan, and Hanna Wallach. 2020. Co-designing checklists to understand organizational challenges and opportunities around fairness in ai. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems . 1-14.
- [86] Nora McDonald, Sarita Schoenebeck, and Andrea Forte. 2019. Reliability and inter-rater reliability in qualitative research: Norms and guidelines for CSCW and HCI practice. Proceedings of the ACM on human-computer interaction 3, CSCW (2019), 1-23.
- [85] Thomas Markussen and Eva Knutz. 2013. The poetics of design fiction. In Proceedings of the 6th International Conference on Designing Pleasurable Products and Interfaces . 231-240.
| [87] | Danaë Metaxa, Joon Sung Park, Ronald E Robertson, Karrie Karahalios, Christo Wilson, Jeff Hancock, Christian Sandvig, et al. 2021. Auditing algorithms: Understanding algorithmic systems from the outside in. Foundations and Trends® in Human-Computer Interaction 14, 4 (2021), 272-344. |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [88] | Jacob Metcalf, Emanuel Moss, Elizabeth Anne Watkins, Ranjit Singh, and Madeleine Clare Elish. 2021. Algorithmic impact assessments and accountability: The co-construction of impacts. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency . 735-746. |
| [89] | Microsoft. 2022. Microsoft Responsible AI Impact Assessment Guide. (June 2022). https://blogs.microsoft.com/wp- content/uploads/prod/sites/5/2022/06/Microsoft-RAI-Impact-Assessment-Guide.pdf |
| [90] | Microsoft. 2022. Microsoft Responsible AI Impact Assessment Template. (June 2022). https://blogs.microsoft.com/wp- content/uploads/prod/sites/5/2022/06/Microsoft-RAI-Impact-Assessment-Template.pdf |
| [91] | Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. Model cards for model reporting. In Proceedings of the conference on fairness, accountability, and transparency . 220-229. |
| [92] | Richard K Morgan. 2012. Environmental impact assessment: the state of the art. Impact assessment and project appraisal 30, 1 (2012), 5-14. |
| [93] | Emanuel Moss, Elizabeth Anne Watkins, Ranjit Singh, Madeleine Clare Elish, and Jacob Metcalf. 2021. Assembling accountability: algorithmic impact assessment for the public interest. Available at SSRN 3877437 (2021). |
| [94] | Priyanka Nanayakkara, Jessica Hullman, and Nicholas Diakopoulos. 2021. Unpacking the expressed consequences of AI research in broader impact statements. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society 795-806. |
| [95] | Lisa P Nathan, Batya Friedman, Predrag Klasnja, Shaun K Kane, and Jessica K Miller. 2008. Envisioning systemic effects on persons and society throughout interactive system design. In Proceedings of the 7th ACM conference on Designing interactive systems . 1-10. |
| [96] | National Academies of Sciences, Engineering, and Medicine et al. 2022. Fostering Responsible Computing Research: Foundations and Practices. (2022). |
| [97] | National Artificial Intelligence Research Resource Task Force. 2023. Strengthening and Democratizing the U.S. Artificial Intelligence Innovation Ecosystem. (Janurary 2023). https://www.ai.gov/wp-content/uploads/2023/01/NAIRR-TF- Final-Report-2023.pdf |
| [98] | Alexandra Olteanu, Michael Ekstrand, Carlos Castillo, and Jina Suh. 2023. Responsible AI Research Needs Impact Statements Too. arXiv preprint arXiv:2311.11776 (2023). |
| [99] | Partnership on AI. 2021. Managing the Risks of AI Research: Six Recommendations for Responsible Publication. (2021). https://partnershiponai.org/paper/responsible-publication-recommendations/ |
| [100] | OpenAI. 2022. OpenAI: Our approach to alignment research. https://openai.com/blog/our-approach-to-alignment- research/ |
| [101] | Rock Yuren Pang and Katharina Reinecke. 2023. Anticipating Unintended Consequences of Technology Using Insights from Creativity Support Tools. arXiv preprint arXiv:2304.05687 (2023). |
| [102] | Rock Yuren Pang, Sebastin Santy, René Just, and Katharina Reinecke. 2024. BLIP: Facilitating the Exploration of Undesirable Consequences of Digital Technologies. In Proceedings of the CHI Conference on Human Factors in Computing Systems . 1-18. |
| [103] | Joon Sung Park, Lindsay Popowski, Carrie Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2022. Social simulacra: Creating populated prototypes for social computing systems. In Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology . 1-18. |
| [104] | Soya Park, April Yi Wang, Ban Kawas, Q Vera Liao, David Piorkowski, and Marina Danilevsky. 2021. Facilitating knowledge sharing from domain experts to data scientists for building nlp models. In 26th International Conference on Intelligent User Interfaces . 585-596. |
| [105] | Samir Passi and Solon Barocas. 2019. Problem formulation and fairness. In Proceedings of the Conference on Fairness, Accountability, and Transparency . 39-48. |
| [106] | Samir Passi and Steven J Jackson. 2018. Trust in data science: Collaboration, translation, and accountability in corporate data science projects. Proceedings of the ACM on Human-Computer Interaction 2, CSCW (2018), 1-28. |
| [107] | Judith Petts. 2009. Handbook of Environmental Impact Assessment, Volume 2: Impact and Limitations . Vol. 2. John Wiley & Sons. |
| [108] | David Piorkowski, Soya Park, April Yi Wang, Dakuo Wang, Michael Muller, and Felix Portnoy. 2021. How ai developers overcome communication challenges in a multidisciplinary team: A case study. Proceedings of the ACM on Human-Computer Interaction 5, CSCW1 (2021), 1-25. |
| [109] | Carina EA Prunkl, Carolyn Ashurst, Markus Anderljung, Helena Webb, Jan Leike, and Allan Dafoe. 2021. Institution- |
- [109] Carina EA Prunkl, Carolyn Ashurst, Markus Anderljung, Helena Webb, Jan Leike, and Allan Dafoe. 2021. Institutionalizing ethics in AI through broader impact requirements. Nature Machine Intelligence 3, 2 (2021), 104-110.
## CSCW178:34
| [110] | Inioluwa Deborah Raji, Andrew Smart, Rebecca N White, Margaret Mitchell, Timnit Gebru, Ben Hutchinson, Jamila Smith-Loud, Daniel Theron, and Parker Barnes. 2020. Closing the AI accountability gap: Defining an end-to-end framework for internal algorithmic auditing. In Proceedings of the 2020 conference on fairness, accountability, and transparency . 33-44. |
|---------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [111] | Bogdana Rakova, Jingying Yang, Henriette Cramer, and Rumman Chowdhury. 2021. Where responsible AI meets reality: Practitioner perspectives on enablers for shifting organizational practices. Proceedings of the ACM on Human-Computer Interaction 5, CSCW1 (2021), 1-23. |
| [112] | Charvi Rastogi, Marco Tulio Ribeiro, Nicholas King, Harsha Nori, and Saleema Amershi. 2023. Supporting human-ai collaboration in auditing llms with llms. In Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society 913-926. |
| [113] | Dillon Reisman, Jason Schultz, Kate Crawford, and Meredith Whittaker. 2018. Algorithmic Impact Assessments: A Practical Framework for Public Agency. AI Now (2018). |
| [114] | People + AI Research. 2021. People AI Guidebook. (2021). https://pair.withgoogle.com/guidebook/ |
| [115] | Brianna Richardson, Jean Garcia-Gathright, Samuel F Way, Jennifer Thom, and Henriette Cramer. 2021. Towards Fairness in Practice: A Practitioner-Oriented Rubric for Evaluating Fair ML Toolkits. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems . 1-13. |
| [116] | Gloire Rubambiza, Phoebe Sengers, Hakim Weatherspoon, and Jen Liu. 2024. Seam Work and Simulacra of Societal Impact in Networking Research: A Critical Technical Practice Approach. In Proceedings of the CHI Conference on Human Factors in Computing Systems . 1-19. |
| [117] | Malak Sadek, Marios Constantinides, Daniele Quercia, and Céline Mougenot. 2024. Guidelines for Integrating Value Sensitive Design in Responsible AI Toolkits. In Proceedings of the CHI Conference on Human Factors in Computing Systems . 1-20. |
| [118] | Andrew D Selbst. 2021. AN INSTITUTIONAL VIEW OF ALGORITHMIC IMPACT. Harvard Journal of Law & Technology 35, 1 (2021). |
| [119] | Renee Shelby, Shalaleh Rismani, Kathryn Henne, AJung Moon, Negar Rostamzadeh, Paul Nicholas, N'Mah Yilla- Akbari, Jess Gallegos, Andrew Smart, Emilio Garcia, et al. 2023. Sociotechnical harms of algorithmic systems: Scoping a taxonomy for harm reduction. In Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society . 723-741. |
| [120] | Hong Shen, Wesley H Deng, Aditi Chattopadhyay, Zhiwei Steven Wu, Xu Wang, and Haiyi Zhu. 2021. Value cards: An educational toolkit for teaching social impacts of machine learning through deliberation. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency . 850-861. |
| [121] | Hong Shen, Haojian Jin, Ángel Alexander Cabrera, Adam Perer, Haiyi Zhu, and Jason I Hong. 2020. Designing alter- native representations of confusion matrices to support non-expert public understanding of algorithm performance. Proceedings of the ACM on Human-Computer Interaction 4, CSCW2 (2020), 1-22. |
| [122] | Hong Shen, Leijie Wang, Wesley H Deng, Ciell Brusse, Ronald Velgersdijk, and Haiyi Zhu. 2022. The Model Card Authoring Toolkit: Toward Community-centered, Deliberation-driven AI Design. In 2022 ACM Conference on Fairness, Accountability, and Transparency . 440-451. |
| [123] | Eli Sherman and Ian Eisenberg. 2024. AI Risk Profiles: A Standards Proposal for Pre-deployment AI Risk Disclosures. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 38. 23047-23052. |
| [124] | Ben Shneiderman. 2020. Bridging the gap between ethics and practice: guidelines for reliable, safe, and trustworthy human-centered AI systems. ACM Transactions on Interactive Intelligent Systems (TiiS) 10, 4 (2020), 1-31. |
| [125] | George Silberman and Katherine L Kahn. 2011. Burdens on research imposed by institutional review boards: the state of the evidence and its implications for regulatory reform. The Milbank Quarterly 89, 4 (2011), 599-627. |
| [126] | CEstelle Smith, BowenYu, Anjali Srivastava, Aaron Halfaker, Loren Terveen, and Haiyi Zhu. 2020. Keeping community in the loop: Understanding wikipedia stakeholder values for machine learning-based systems. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems . 1-14. |
| [127] | Jessie J Smith, Saleema Amershi, Solon Barocas, Hanna Wallach, and Jennifer Wortman Vaughan. 2022. REAL ML: Recognizing, Exploring, and Articulating Limitations of Machine Learning Research. In 2022 ACM Conference on Fairness, Accountability, and Transparency . 587-597. |
| [128] | Data & Society. 2023. Data & Society Announces the Launch of its Algorithmic Impact Methods Lab. https: //datasociety.net/algorithmic-impact-methods-lab/ |
| [129] | Susan Leigh Star and James R Griesemer. 1989. Institutional ecology,translations' and boundary objects: Amateurs and professionals in Berkeley's Museum of Vertebrate Zoology, 1907-39. Social studies of science 19, 3 (1989), 387-420. |
| [130] | Susan Leigh Star and Anselm Strauss. 1999. Layers of silence, arenas of voice: The ecology of visible and invisible work. Computer supported cooperative work 8, 1-2 (1999), 9-30. |
| [131] | Stephanie B Steinhardt and Steven J Jackson. 2015. Anticipation work: Cultivating vision in collective practice. In |
- [131] Stephanie B Steinhardt and Steven J Jackson. 2015. Anticipation work: Cultivating vision in collective practice. In Proceedings of the 18th ACM conference on computer supported cooperative work & social computing . 443-453.
| [132] | Ivan Stelmakh, Charvi Rastogi, Nihar B Shah, Aarti Singh, and Hal Daumé III. 2023. A large scale randomized controlled trial on herding in peer-review discussions. Plos one 18, 7 (2023), e0287443. |
|---------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [133] | Ivan Stelmakh, Nihar B Shah, Aarti Singh, and Hal Daumé III. 2021. Prior and prejudice: The novice reviewers' bias against resubmissions in conference peer review. Proceedings of the ACM on Human-Computer Interaction 5, CSCW1 (2021), 1-17. |
| [134] | Christian Sturm, Alice Oh, Sebastian Linxen, Jose Abdelnour Nocera, Susan Dray, and Katharina Reinecke. 2015. How WEIRD is HCI? Extending HCI principles to other countries and cultures. In Proceedings of the 33rd Annual ACM Conference Extended Abstracts on Human Factors in Computing Systems . 2425-2428. |
| [135] | Hariharan Subramonyam, Jane Im, Colleen Seifert, and Eytan Adar. 2022. Solving separation-of-concerns problems in collaborative design of human-AI systems through leaky abstractions. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems . 1-21. |
| [136] | Mohammad Tahaei, Alisa Frik, and Kami Vaniea. 2021. Privacy champions in software teams: understanding their motivations, strategies, and challenges. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems . 1-15. |
| [137] | Jacqueline Rita Tedaldi, Nora Götzmann, Elin Wrzoncki, Roya Høvsgaard, Tulika Bansal, and Cathrine Bloch Veiberg. 2016. Human Rights Impact Assessment Guidance and Toolbox. (2016). |
| [138] | The Ada Lovelace Insitute. 2022. Algorithmic impact assessment: a case study in healthcare. (Feb 2022). https: //www.adalovelaceinstitute.org/report/algorithmic-impact-assessment-case-study-healthcare/ |
| [139] | The Ada Lovelace Insitute. 2022. Pioneering framework for assessing the impact of medical AI set to be trialled by NHS in world-first pilot. (Feb 2022). https://www.adalovelaceinstitute.org/press-release/algorithmic-impact- assessment-nhs/ |
| [140] | The White House. 2023. National Artificial Intelligence Research Resource Task Force Releases Final Report. (Janu- rary 2023). https://www.whitehouse.gov/ostp/news-updates/2023/01/24/national-artificial-intelligence-research- resource-task-force-releases-final-report/ |
| [141] | Laurence Vigneau, Michael Humphreys, and Jeremy Moon. 2015. How do firms comply with international sustain- ability standards? Processes and consequences of adopting the global reporting initiative. Journal of business ethics 131 (2015), 469-486. |
| [142] | Ari Ezra Waldman. 2021. Industry unbound: The inside story of privacy, data, and corporate power . Cambridge University Press. |
| [143] | Kent Walker and Marian Croak. 2021. An update on our progress in responsible AI innovation. (2021). https: //blog.google/technology/ai/update-our-progress-responsible-ai-innovation/ |
| [144] | Hanna Wallach. 2021. Navigating the Broader Impacts of Machine Learning Research. https: //hannawallach.medium.com/navigating-the-broader-impacts-of-machine-learning-research-f2d72a37a5b? source=friends_link&sk=3b9e2ab57cb142e00cf0b55fe5bc1df3 |
| [145] | Qiaosi Wang, Michael Adam Madaio, Shivani Kapania, Shaun Kane, Michael Terry, Lauren Wilcox, et al. 2023. Designing Responsible AI: Adaptations of UX Practice to Meet Responsible AI Challenges. (2023). |
| [146] | Zijie J. Wang, Chinmay Kulkarni, Lauren Wilcox, Michael Terry, and Michael Madaio. 2024. Farsight: Fostering Responsible AI Awareness During AI Application Prototyping. In Proceedings of the CHI Conference on Human Factors in Computing Systems . 1-40. |
| [147] | Laura Weidinger, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po-Sen Huang, John F. J. Mellor, Amelia Glaese, Myra Cheng, Borja Balle, Atoosa Kasirzadeh, Courtney Biles, Sande Minnich Brown, Zachary Kenton, William T. Hawkins, Tom Stepleton, Abeba Birhane, Lisa Anne Hendricks, Laura Rimell, William S. Isaac, Julia Haas, Sean Legassick, Geoffrey Irving, and Iason Gabriel. 2022. Taxonomy of Risks posed by Language Models. Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (2022). https://api.semanticscholar.org/CorpusID:249872629 |
| [148] | David Gray Widder and Dawn Nafus. 2023. Dislocated accountabilities in the 'AI supply chain': Modularity and developers' notions of responsibility. Big Data & Society 10, 1 (2023), 20539517231177620. |
| [149] | David Gray Widder, Sarah West, and Meredith Whittaker. 2023. Open (for Business): big tech, concentrated power, and the political economy of open AI. Concentrated Power, and the Political Economy of Open AI (August 17, 2023) (2023). |
| [150] | David Gray Widder, Derrick Zhen, Laura Dabbish, and James Herbsleb. 2023. It's about power: What ethical concerns do software engineers have, and what do they (feel they can) do about them?. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency . 467-479. |
| [151] | Erin D Williams and Michele Schoonmaker. 2005. Federal protection for human research subjects: an analysis of the common rule and its interactions with FDA regulations and the HIPAA Privacy Rule. Congressional Information Service, Library of Congress. |
| [152] | Richmond Y Wong. 2021. Tactics of Soft Resistance in User Experience Professionals' Values Work. Proceedings of the |
- [152] Richmond Y Wong. 2021. Tactics of Soft Resistance in User Experience Professionals' Values Work. Proceedings of the ACM on Human-Computer Interaction 5, CSCW2 (2021), 1-28.
[153] Richmond Y. Wong, Michael A. Madaio, and Nick Merrill. 2022. Seeing Like a Toolkit: How Toolkits Envision the Work of AI Ethics. Proceedings of the ACM on Human-Computer Interaction 7 (2022), 1 - 27. https://api.semanticscholar. org/CorpusID:246904325
- [155] Qian Yang, Justin Cranshaw, Saleema Amershi, Shamsi T Iqbal, and Jaime Teevan. 2019. Sketching nlp: A case study of exploring the right things to design with language intelligence. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems . 1-12.
[154] Richmond Y Wong and Tonya Nguyen. 2021. Timelines: A world-building activity for values advocacy. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems . 1-15.
- [156] Nur Yildirim, Mahima Pushkarna, Nitesh Goyal, Martin Wattenberg, and Fernanda Viégas. 2023. Investigating How Practitioners Use Human-AI Guidelines: A Case Study on the People+ AI Guidebook. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . 1-13.
- [158] Haiyi Zhu, Bowen Yu, Aaron Halfaker, and Loren Terveen. 2018. Value-sensitive algorithm design: Method, case study, and lessons. Proceedings of the ACM on Human-Computer Interaction 2, CSCW (2018), 1-23.
- [157] Amy X Zhang, Michael Muller, and Dakuo Wang. 2020. How do data science workers collaborate? roles, workflows, and tools. Proceedings of the ACM on Human-Computer Interaction 4, CSCW1 (2020), 1-23.
## A APPENDIX
## A.1 Evolution of the SIA Template
In the supplementary material, we include the initial prototype of the SIA template ( V1, used with participants P01-P05 ) and the version used in the user study (V7). Here we briefly describe the major changes that were made in each version of the template between V1 and V7. In every iteration, we additionally made wording and formatting changes throughout the template based on participants' feedback.
## V2 (used with participants P06-P11) :
- · Added more examples in the scaffolding provided in the 'Potential Negative Societal Impact' section to cover a more diverse range of computing research topics.
- · Rephrased the questions in the first two sections ('Research Project Background' and 'Intended Users and Applications') to make them more directly applicable to research projects instead of product and service development.
- · Moved the 'Misuse (unintentional, accidental misuse)' section right after the 'Known Limitation' section within the 'Potential Negative Societal Impact' section since participants P01-P05 often naturally thought about misuse after considering limitations.
## V3 (used with participants P12-P15) :
- · Emphasized the non-linear nature of brainstorming stakeholders by reminding researchers to revisit the stakeholders section if they think of more stakeholders later.
- · Added a sentence to highlight the differences between assessing societal impact and preventing risks to human subjects, as participants often confused these concepts.
- · Added examples to the scaffolding in the 'Intended Positive Societal Impact' section, as participants often needed help in this area.
## V4 (used with participants P16-P18 and E01-E03) :
- · Further emphasized the heterogeneous, non-linear thinking processes of impact assessment by adding notes suggesting researchers complete the sections of the template non-sequentially, in their preferred order.
- · Added a 3-minute introduction video as onboarding material, as described in Section 7.
- · Added a section titled "Why would you want to use this template" at the top as motivation.
## V5 (used with participants P19-P22 and E04-E10) :
- · Reorganized the categories within the stakeholders section to distinguish industry, civil society, and governments, with a concise description of each to scaffold brainstorming, as suggested by impact assessment experts.
- · Added more categories of limitations in the 'Known Limitations' section to cover potential limitations of design and qualitative industry computing research.
- · Added illustrations (e.g., Figures 4 and 5) throughout the template to help researchers better understand the organization of the template and key concepts.
- · Provided a keyword summary for all scaffolding examples throughout the template for more efficient access.
## V6 (used with participants P23-P25 and E11-E16) :
- · Added instructions to remind researchers to document different versions of their project, their thinking process, and the challenges they encountered. Encouraged transparency about struggles throughout the template.
- · Highlighted the limitations of the impact assessment template, noting that it is not meant to replace other existing mechanisms or compliance processes in the company, within the onboarding video and instructions.
- · Incorporated the sentence 'While thinking about the scenarios, consider which group(s) of stakeholders you identified in Section 3 might be harmed. In what ways?' into all questions in the 'Potential Impact' section to better facilitate thinking about negative impact and stakeholders together.
- · Reorganized the strategies for addressing potential negative societal impact based on feedback from impact assessment experts.
## V7 (used with participants T01-T15) :
- · Based on feedback from impact assessment experts, expanded the 'Planning for Mitigations' section to guide researchers in determining the seriousness of the risks posed by potential negative societal impacts and how to prioritize them. Added scaffolding questions to prompt researchers to consider the likelihood, magnitude, concentration, and time horizon of the potential negative societal impact.
- · Streamlined the template to ensure the format and structure were ready for the user study.
- · Further improved the clarity of the questions and the transitions between all sections. | 10.1145/3711076 | [
"Wesley Hanwen Deng",
"Solon Barocas",
"Jennifer Wortman Vaughan"
] | 2024-08-02T07:10:11+00:00 | 2025-01-18T17:35:00+00:00 | [
"cs.HC"
] | Supporting Industry Computing Researchers in Assessing, Articulating, and Addressing the Potential Negative Societal Impact of Their Work | Recent years have witnessed increasing calls for computing researchers to
grapple with the societal impacts of their work. Tools such as impact
assessments have gained prominence as a method to uncover potential impacts,
and a number of publication venues now encourage authors to include an impact
statement in their submissions. Despite this push, little is known about the
way researchers assess, articulate, and address the potential negative societal
impact of their work -- especially in industry settings, where research
outcomes are often quickly integrated into products. In addition, while there
are nascent efforts to support researchers in this task, there remains a dearth
of empirically-informed tools and processes. Through interviews with 25
industry computing researchers across different companies and research areas,
we first identify four key factors that influence how they grapple with (or
choose not to grapple with) the societal impact of their research. To develop
an effective impact assessment template tailored to industry computing
researchers' needs, we conduct an iterative co-design process with these 25
industry researchers and an additional 16 researchers and practitioners with
prior experience and expertise in reviewing and developing impact assessments
or broad responsible computing practices. Through the co-design process, we
develop 10 design considerations to facilitate the effective design,
development, and adaptation of an impact assessment template for use in
industry research settings and beyond, as well as our own ``Societal Impact
Assessment'' template with concrete scaffolds. We explore the effectiveness of
this template through a user study with 15 industry research interns, revealing
both its strengths and limitations. Finally, we discuss the implications for
future researchers and organizations seeking to foster more responsible
research practices. |
2408.01059v1 | ## Bosonic Holes in Quadratic Bosonic Systems
Jia-Ming Hu, 1 Bo Wang, 1 and Ze-Liang Xiang 1, ∗
1 School of Physics, Sun Yat-sen University, Guangzhou 510275, China.
The concept of electron holes plays a significant role in condensed matter physics. Here we develop the concept of bosonic holes, which exhibit negative particle excitations, in quadratic bosonic systems. Unlike electron holes, the Fock states of bosonic holes are biorthogonal, and their excitation can be interpreted as removing particles from a mean-particle number with a mean-field background. Furthermore, we find that quadratic bosonic Hamiltonians related by non-unitary and local particlehole (PH) transformation possess the same locality structure and spectral properties in different spaces, reflecting the PH duality. Based on this, we study the generation of PH entanglement in two-mode cases and the PH Aharonov-Bohm effect in the three-mode case, which results in a PH chiral flow with time-reversal symmetry breaking. Our findings provide a new way to understand and explore unusual physical phenomena in particle-non-conserving and non-Hermitian systems.
In quadratic systems, Hamiltonians with pairing interactions feature particle non-conservation and play an essential role in various interesting quantum phenomena. In condensed matter physics, they are the basic form of weakly interacting Bose gases and fermionic superconductors in the mean-field approximation, giving rise to superfluidity [1] and superconductivity [2]. In quantum optics, the bosonic pairing is known as the parametric amplifier interaction [3, 4] and is regarded as a key resource for generating squeezing and entanglement [5-8].
The excitation spectrum of quadratic systems can be well described by a Bogoliubov-de-Gennes (BdG) Hamiltonian [9-11], in which the hole degrees of freedom appear. In the fermionic systems, the quasi-particles in a fermionic superconductor are superpositions of electrons and holes [12, 13]. The absence of the Pauli exclusion principle implies that bosonic holes can significantly differ from electron holes. For instance, bosonic pairing interactions in the BdG Hamiltonian can be regarded as dissipative particle-hole conversions [14]. Therefore, pairing interactions can be used as an alternative way to introduce non-Hermiticity in bosonic systems besides coupling with the dissipative baths [15, 16]. This has garnered growing attention in studying the quadratic bosonic topological models [5-8, 10, 17], in which a set of remarkable properties are predicted, such as quadraturedependent chiral transport and amplification [18-20], and unstable edge modes [21-25]. In particular, the nonHermitian Aharonov-Bohm (AB) interference effect in bosonic PH loops has been confirmed in experiments [14]. However, the bosonic hole, which is so important as a new degree of freedom, still lacks a clear physical picture and a rigorous theory to depict it.
In this letter, we characterize bosonic holes and reveal the PH duality in quadratic bosonic systems (QBSs). We find that bosonic holes , forming one-half of the basis of the bosonic BdG Hamiltonian, are pseudo-bosonic modes. A non-unitary PH transformation can be used to obtain the biorthogonal Fock states of bosonic holes, which are occupied by negative particle numbers due to the constraint of the bosonic commutation relation. Nev- ertheless, they may be observable when the excitation of holes is relative to a mean-particle number or macroscopic occupation of particles. This mean-particle number plays a role as the 'Fermi surface' and can be formed by displacing the particle or hole mode with a driving field, whose frequency can be analogous to the 'Fermi level' (see Fig. 1). In this picture, effective Hermitian and non-Hermitian QBHs can be related by the local PH transformation, while the locality structure and spectral properties are preserved, such called the PH duality. The dual QBSs show the same physics in the spaces with a single PH inversion, where their biorthogonal eigenstates can be well interpreted as the superposition states involving holes, allowing the study of novel physical phenomena in the PH space. In this setting, we explore the generation of PH entanglement in the two-mode cases, including the PH entangled ground states and the sensitivity of PH entanglement to initial states. Moreover, the Hermitian AB effect in PH loops is investigated, and we find the chiral flow in the 'single-hole trimer' with time-reversal symmetry breaking.
Hole degrees of freedom in QBHs. -We start with a general Hermitian quadratic Hamiltonian ˆ H = ∑ i,j ˆ a † i A ij ˆ a j +1 2(ˆ / a † i B ij ˆ a † j +ˆ a i B ∗ ij ˆ ). a j The Hermiticity of ˆ H imposes the condition A ij = A ∗ ji in the particleconserving terms, and the bosonic commutation relation allows us to take B ij = B ji in the particle-nonconserving pairing interactions. Defining the Nambu array ˆ = (ˆ α a 1 · · · ˆ a N , a ˆ † 1 · · · ˆ a † N ) T , the Hamiltonian can be rewritten as ˆ H = 1 2ˆ / α Hα † ˆ, while the Heisenberg equation is given by i∂ α t ˆ = H ˆ, where α
$$\underset { \underset { \varepsilon _ { - } } { \mathcal { H } } } { \mathfrak { r } _ { - } } \quad H = \left ( \begin{array} { c c } \mathcal { A } & \mathcal { B } \\ \mathcal { B } ^ { * } & \mathcal { A } ^ { * } \end{array} \right ), \quad \mathcal { H } = \tau _ { 3 } H = \left ( \begin{array} { c c } \mathcal { A } & \mathcal { B } \\ - \mathcal { B } ^ { * } & - \mathcal { A } ^ { * } \end{array} \right ), \ \ ( 1 )$$
and τ i = σ i ⊗ I N from the Pauli matrices σ i ( i = 1 2 3). , , Instead of the Hermitian H , the Heisenberg dynamical matrix H with pseudo Hermiticity, τ 3 H τ 3 = H † , inherently respects PH symmetry, τ 1 H τ 1 = -H ∗ . Furthermore, the eigenvalues of H are consistent with the system spectrum, so that it can be treated as the bosonic BdG
̸
Hamiltonian [10, 11]. Substituting the BdG Hamiltonian into the second-quantized Hamiltonian ˆ H = 1 2ˆ ¯ / α † H ˆ α with ˆ ¯ α † = ˆ α τ † 3 = (ˆ a † 1 · · · ˆ a N † , -ˆ a 1 · · · -ˆ a N ), the annihilation operators of bosonic holes can be regarded as ˆ a † i in ˆ [14, 20], while their creation operators are given α by -ˆ a i in ˆ , ¯ α † instead of ˆ a i in ˆ , α † to fulfill the bosonic commutation relation, [ˆ a , † i -ˆ ] a j = [ ˆ h , h i ˆ ¯ † j ] = δ ij . Similar to the situation in electron systems, bosonic particle and hole operators are redundant, i.e., the bosonic holes are equivalent to the bosonic particles with opposite frequencies. However, bosonic holes feature negative particle excitations due to the bosonic commutation relation, ˆ ˆ a a † i i + ˆ ¯ h h † i ˆ i = -1, and they are pseudo-bosonic modes because ¯ ˆ h † i = ˆ h † i [26-28]. These introduce a redundancy in the Nambu notation with ˆ ¯ α † = ˆ α τ τ T 1 3 , leading to the combination of PH symmetry and pseudo-Hermiticity of H , i.e., τ 3 τ 1 H τ 1 τ 3 = -H T .
Hence, the eigenvalues of H can be divided into two groups { ϵ n , -ϵ n } . Like particles and holes, the eigenmodes with the frequencies ϵ n are equivalent to those with the frequencies -ϵ n . However, they cannot simultaneously hold a positive excitation on the eigenstates of ˆ . H For this reason, ˆ H can be rewritten in terms of two sets of eigenmodes with two sets of eigenstates. In the real spectrum regime ( ϵ n ∈ R ),
$$\hat { H } = \sum _ { n = 1 } ^ { N } \epsilon _ { n } ( \hat { \psi } _ { n } ^ { \dagger } \hat { \psi } _ { n } + \frac { 1 } { 2 } ) = \sum _ { n = 1 } ^ { N } - \epsilon _ { n } ( \hat { \phi } _ { n } ^ { \dagger } \hat { \phi } _ { n } + \frac { 1 } { 2 } ), \quad ( 2 ) \quad \text{PH tta} \\ \text{frequ} \\ \text{Fi} \sigma$$
where ˆ ψ † n = ˆ α τ † 3 | ψ n ⟩ = ˆ ϕ n , ˆ ¯ ϕ † n = -ˆ ψ n , and | ψ n ⟩ are the eigenvectors of H with the eigenvalues ϵ n . It is clear that ˆ ψ n are normal bosonic modes only composed of particles, while ˆ ϕ n are pseudo-bosonic modes only composed of bosonic holes due to PH symmetry, thus called quasi-particles and quasi-holes. In the complex spectrum regime ( ϵ n / ∈ R ),
$$\hat { H } = \sum _ { n = 1 } ^ { N } \epsilon _ { n } ( \hat { \psi } _ { n } ^ { \dagger } \hat { \psi } _ { n ^ { * } } + \frac { 1 } { 2 } ) = \sum _ { n = 1 } ^ { N } - \epsilon _ { n } ( \hat { \bar { \phi } } _ { n ^ { * } } ^ { \dagger } \hat { \phi } _ { n } + \frac { 1 } { 2 } ), \ \ ( 3 ) \quad \begin{array} { c } \text{states} \\ \hat { \Omega } ^ { - 1 } | \gamma \\ \hat { \iota }, \i \cap \_ \_ \_ \end{array} \end{array}$$
where ˆ ψ n ∗ = ⟨ ψ n ∗ | τ 3 ˆ = α -ˆ ¯ ϕ † n ∗ and | ψ n ∗ ⟩ are the eigenvectors of H with the eigenvalues ϵ ∗ n . In this case, both sets of eigenmodes are pseudo-bosonic modes and, therefore, composed of particles and holes. The composition of eigenmodes in terms of particles and holes can be examined by the expectation of each particle number operator in eigenstates, where a positive (negative) value indicates the particle (hole) components and the complex value indicates PH mixed ones [29]. The spectrum of these eigenmodes with hole components has been observed experimentally [14, 30], confirming the presence of hole degrees of freedom in QBHs. Then, let us turn to find a rigorous formalism of bosonic holes to characterize the negative particle occupation space.
FIG. 1. Bosonic excitation spectrum in QBHs with respect to the frequency of a driving field ω L ('Fermi level'), where ± ∆ are the relative frequencies of particles and holes, respectively, with ω a being the intrinsic frequency of the boson.
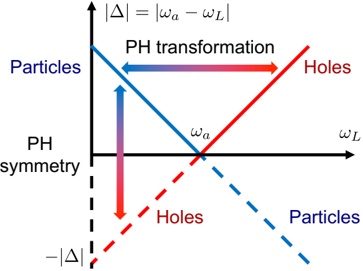
Particle-hole transformation. -To obtain the Fock states of bosonic holes, we here introduce the PH transformation with a non-unitary but Hermitian operator,
$$\hat { \Omega } = e ^ { i \frac { \pi } { 4 } ( e ^ { - i \theta } \hat { a } ^ { 2 } - e ^ { i \theta } \hat { a } ^ { \dagger 2 } ) },$$
such that the bosonic operators ˆ and ˆ a a † can now be transformed into the hole operators, Ω ˆ -1 ˆ ˆ a Ω = -ia e ˆ † iθ = ˆ h and Ω ˆ -1 ˆ Ω a † ˆ = -iae ˆ -iθ = ˆ ¯ h † , where θ is an arbitrary gauge phase. Different from PH symmetry, the PH transformation maps particles to holes with the same frequency, i.e., Ω ˆ -1 ∆(ˆ ˆ + 1 a a † / 2) ˆ Ω = ∆( ˆ ¯ ˆ + 1 h h † / 2) (see Fig. 1), which plays a role as the charge-conjugation transformation in fermionic systems [31].
Then, the vacuum state of the hole can be defined as | 0 ⟩ h = ˆ Ω -1 | 0 ⟩ a to make -ia e ˆ † iθ | 0 ⟩ h = ˆ 0 h | ⟩ h = 0. Notably, this state is biorthogonal because of the nonunitarity of Ω. ˆ We take ˆ and ¯ h ˆ h † as the annihilation and creation operators of the right vector, while their transposed conjugations ˆ h † and ˆ ¯ as the creation and annihih lation operators of the left vector. The biorthogonal Fock states of the hole are given by | n ⟩ h = ( ˆ ¯ h † ) n / √ n ! 0 | ⟩ h = ˆ Ω -1 | n ⟩ a and | m ⟩ ¯ h = ( ˆ h † ) m / √ m ! 0 | ⟩ ¯ h = ˆ Ω | m ⟩ a , where ˆ ¯ 0 h | ⟩ ¯ h = 0 and ¯ h ⟨ mn | ⟩ h = δ mn . Therefore, we obtain the hole Fock states that occupy by negative particle number ¯ h ⟨ n a a n | ˆ ˆ † | ⟩ h = -( n +1).
Such negative particle occupation can be understood by introducing the mean-field theory, wherein the positive and negative particle excitation is relative to the mean particle number, which plays a role as the 'Fermi surface.' We bring it with a displacement operator ˆ (¯) = D a e ¯ˆ aa † -¯ a a ∗ ˆ . In the displaced space, n bosonic holes can be regarded as removing n + 1 particles from the mean particle number ¯ = n | ¯ a | 2 , i.e.,
$$_ { \bar { h } } \langle n | \hat { D } ^ { - 1 } ( \bar { a } ) \hat { a } ^ { \dagger } \hat { a } \hat { D } ( \bar { a } ) | n \rangle _ { h } = | \bar { a } | ^ { 2 } - ( n + 1 ). \quad ( 5 )$$
This displacement can be realized by considering a system driven by a coherent field, described by the Hamil-
tonian ˆ H D = ∆ˆ ˆ + a a † λ a (ˆ † + ˆ). a Here, ∆ denotes the detuning of the system mode and driving field, and λ represents the driving strength. The Lindblad master equation of the system can be obtained,
$$\frac { d \hat { \rho } } { d t } = - i [ \hat { H } _ { \text{D} }, \hat { \rho } ] + \frac { \gamma } { 2 } \{ 2 \hat { z } \hat { \rho } \hat { z } ^ { \dagger } - \hat { z } ^ { \dagger } \hat { z } \hat { \rho } - \hat { \rho } \hat { z } ^ { \dagger } \hat { z } \}, \quad ( 6 ) \quad \Big |$$
where ˆ = ˆ (ˆ ) denote the z a a † incoherent loss (pump). Their steady-state solutions, i.e., dρ ˆ ss /dt = 0, are [29, 32]
$$\hat { \rho } _ { s s } = \hat { D } ( \bar { a } ) | 0 \rangle _ { a a } \langle 0 | \hat { D } ^ { - 1 } ( \bar { a } ), \ \bar { a } = \frac { - i \lambda } { \gamma / 2 + i \Delta }, \ \ ( 7 ) \quad \Big |$$
and
$$\hat { \rho } _ { s s } = \hat { D } ( \bar { a } ) | 0 \rangle _ { h h } \langle 0 | \hat { D } ^ { - 1 } ( \bar { a } ), \ \bar { a } = \frac { i \lambda } { \gamma / 2 - i \Delta }, \ \ ( 8 ) \quad \begin{matrix} \hat { H } _ { \text{DBS} } \\ \text{herein} \end{matrix}$$
for incoherent loss and pump, respectively. Thus, the displaced hole vacuum may be generated because of the competition between the coherent driving and incoherent pump processes. Further, the frequency of particles, ∆, is now relative to the frequency of the driving field, which can be analogized to the 'Fermi level.' When the driving field is sufficiently strong, the quadratic bosonic interaction can be regarded as a perturbation so that eigenmodes of effective QBHs, composed of particles and/or holes, can be regarded as excitation near the mean field.
Particle-hole duality and entanglement. -Introducing hole Fock states allows us to explore the ground-state properties and state evolution of QBSs in the PH space. In particular, the local PH transformation builds a relation between different QBHs. They can surprisingly possess the same BdG Hamiltonian in different PH representations with only a single PH inversion, i.e.,
$$\hat { \Omega } _ { i } ^ { - 1 } \hat { H } \hat { \Omega } _ { i } = \frac { 1 } { 2 } \hat { \Omega } _ { i } ^ { - 1 } \hat { \bar { \alpha } } _ { i } ^ { \dagger } \mathcal { H } \hat { \alpha } _ { i } \hat { \Omega } _ { i } = \frac { 1 } { 2 } \hat { \bar { \beta } } _ { i } ^ { \dagger } \mathcal { H } \hat { \beta } _ { i } = \hat { \bar { H } }, \quad ( 9 ) \quad \stackrel { \wedge } { \theta } = \\ \text{As ssl}$$
where ˆ β i = ˆ Ω -1 i ˆ ˆ α Ω i = (ˆ a 1 · · · -ia e ˆ † i iθ · · · ˆ a N , a ˆ † 1 · · · -iae ˆ -iθ · · · ˆ a † N ) T and ˆ ¯ β † i = ˆ Ω -1 i ˆ Ω ¯ α † ˆ i with [ ˆ β , β i ˆ ¯ ] † i = I 2 N . For any eigenmode ˆ ψ j in ˆ H with Fock states | n ⟩ ψ j , there exists an eigenmode ˆ ˜ ψ j in ˜ , denoted by Ω H ˆ -1 i ˆ ˆ ψ j Ω . This i eigenmode has the same frequency as ˆ ψ j and its Fock states can be given by | n ⟩ ˜ ψ j = ˆ Ω -1 i | n ⟩ ψ j . The PH transformation preserves the locality structure and spectral properties of the original Hamiltonian, and the transformed states and the original states are different representations for essentially the same physics, implying the PH duality [33, 34]. Further, the information about the evolution of dual states under the dual Hamiltonian is encoded in the initial system. For example, if | ψ (0) ⟩ is the initial state of the original system, we have
$$e ^ { - i \hat { \tilde { H } } t } \hat { \Omega } _ { i } ^ { - 1 } | \psi ( 0 ) \rangle = \hat { \Omega } _ { i } ^ { - 1 } e ^ { - i \hat { H } t } | \psi ( 0 ) \rangle = \hat { \Omega } _ { i } ^ { - 1 } | \psi ( t ) \rangle. \ \ ( 1 0 ) \quad t e r a c t$$
This PH duality is nontrivial because the solution can be well-known before the PH transformation but still hidden
FIG. 2. Basic forms of two-mode QBHs, (a) ˆ H BS , (b) ˆ H DP , (c) ˆ H DBS , and (d) ˆ H P , where the solid and dashed lines denote coherent and dissipative couplings, respectively. (a)[(c)] shows ˆ H BS ( ˆ H DBS ) with coherent (dissipative) particle-particle and hole-hole conversions, while (b)[(d)] shows ˆ H DP ( ˆ H P ) with coherent (dissipative) PH conversions.
after. In addition, such a non-unitary duality can relate the Hermitian and non-Hermitian QBHs and apply to any regime beyond the unitary duality [35-37].
To demonstrate the PH duality, it is instructive to consider the basic forms of two-mode-interacting QBHs and their non-Hermitian dual forms, i.e., the beamsplitter (pairing) Hamiltonian and the dissipative pairing [38] (dissipative beamsplitter [39-41]) Hamiltonian, given by
$$\underset { \text{reg} } { \text{acc.} } \quad \hat { H } _ { \text{P/DP} } = - \Delta _ { 1 } \hat { a } _ { 1 } ^ { \dagger } \hat { a } _ { 1 } + \Delta _ { 2 } \hat { a } _ { 2 } ^ { \dagger } \hat { a } _ { 2 } + g ( \hat { a } _ { 1 } ^ { \dagger } \hat { a } _ { 2 } ^ { \dagger } \pm \hat { a } _ { 1 } \hat { a } _ { 2 } ), \\ \text{igly} \quad \hat { H } _ { \text{DBS/BS} } = & \Delta _ { 1 } \hat { a } _ { 1 } ^ { \dagger } \hat { a } _ { 1 } + \Delta _ { 2 } \hat { a } _ { 2 } ^ { \dagger } \hat { a } _ { 2 } + i g ( \hat { a } _ { 1 } \hat { a } _ { 2 } ^ { \dagger } \pm \hat { a } _ { 1 } ^ { \dagger } \hat { a } _ { 2 } ),$$
where ˆ a 1 (ˆ a 2 ) is the annihilation operator and ∆ 1 (∆ ) 2 is the frequency relative to the driving field. Setting θ = 0 in Eq. (4), we have ˆ H P DP / = ˆ Ω -1 1 ˆ H DBS BS / ˆ Ω . 1 As shown in Fig. 2 (a) and (b), the duality between ˆ H BS and ˆ H DP shows that the non-Hermitian ˆ H DP can be regarded as the coherent PH conversion and therefore has stable PH eigenstates with a completely real spectrum. This can serve as the generator of the PH transformation in the single-mode case [29]. In addition, biorthogonal PH eigenstates also give the Hermitian ˆ H P a complex spectrum, in which ˆ H P should be regarded as the dissipative PH conversion, as shown in Fig. 2 (d). Conversely, in the real spectrum regime, the particle-particle (holehole) eigenstates of ˆ H P show that biorthogonal eigenstates of the non-Hermitian ˆ H DBS are PH eigenstates. In this case, ˆ H DBS should be inversely regarded as the PH pairing Hamiltonian and, therefore, can work as a resource for generating PH entanglement.
To see this more explicitly, we set -∆ 1 = ∆ 2 = ∆ > g , where ˆ H P is the basic form of weakly interacting Bose gases [1] in the mean-field approximation, while ˆ H DBS becomes an anti-parity-time ( APT ) symmetric Hamiltonian [42, 43] in the real spectrum regime. In this case, the quasi-particles of ˆ H P are
Bogoliubov modes ˆ ψ i = ˆ S a a 1 2 ( r a S )ˆ i ˆ -1 a a 1 2 ( r ), while the quasi-holes, ˆ ϕ i = ˆ S h h 1 2 ( r h S ) ˆ i ˆ -1 h h 1 2 ( r ), can be regarded as removing quasi-particles from the mean-field, where i = 1, 2 and ˆ S i 1 2 i are the squeezing operators [29]. The ground states of ˆ H P in terms of quasi-particles and quasi-holes are the two-mode squeezed vacuum ˆ S a a 1 2 ( r ) 00 | ⟩ a a 1 2 and ˆ S h h 1 2 ( r ) 00 | ⟩ h h 1 2 , respectively, with entanglement E N = 2 | r | [44]. Due to the PH duality, the ground states of the APT symmetric Hamiltonian in terms of two sets of redundant eigenmodes are given by Ω ˆ 1 ˆ S a a 1 2 ( r ) 00 | ⟩ a a 1 2 = ˆ S ¯ h a 1 2 ( r ) 00 | ⟩ ¯ h a 1 2 and ˆ Ω ˆ 1 S h h 1 2 ( r ) 00 | ⟩ h h 1 2 = ˆ S a h 1 2 ( r ) 00 | ⟩ a h 1 2 , which are indeed the PH two-mode squeezed vacuum [29]. Therefore, the PH duality reveals the ground-state PH entanglement of the APT symmetric Hamiltonian, which might be detectable in the driven-dissipative system.
Another way to generate entanglement through ˆ H P is to let the particle vacuum or coherent states evolve under ˆ H P in the complex spectrum regime, especially at the resonant point ∆ 1 = ∆ 2 = ∆ [8, 45]. In the interaction picture, the evolution can be described as e -iH ˆ P t | 00 ⟩ a a 1 2 = ˆ S a a 1 2 ( -igt ) 00 | ⟩ a a 1 2 , with entanglement E N = 2 | r | = 2 gt . The PH duality of Eq. (10) shows that the PH vacuum evolving under ˆ H DBS will result in the infinite PH entanglement, i.e., ˆ Ω 1 e -iH ˆ P t | 00 ⟩ a a 1 2 = e -iH ˆ DBS t | 00 ⟩ ¯ h a 1 2 = ˆ S ¯ h a 1 2 ( -igt ) 00 | ⟩ ¯ h a 1 2 . These unbounded evolutions arise from the fact that the initial state and the system's eigenstates are not in the same space. In this case, the eigenstates of ˆ H DBS are particleparticle states or hole-hole states, which are the Fock states of the quasi-particles ˆ ψ ± = ( ± ˆ a 1 + ˆ ) a 2 / √ 2 or the quasi-holes ˆ ϕ ± = ( ± ˆ h 1 + ˆ h 2 ) / √ 2 with frequencies ϵ ± = ∆ ± ig and -ϵ ± , respectively. Conversely, when the initial state and the eigenstates are in the same space, the evolution will be confined to the excitation conservation subspace, leading to a steady state that is the eigenstate with the largest imaginary frequency. For example, when | 01 ⟩ a a 1 2 evolves under ˆ H DBS , the steady state is a Bell state ˆ ψ † + | 00 ⟩ a a 1 2 = ( 10 | ⟩ a a 1 2 + 01 | ⟩ a a 1 2 ) / √ 2 [46]. With the PH duality, the single-excited PH state Ω ˆ -1 1 | 01 ⟩ a a 1 2 will evolve to a steady PH Bell state under ˆ H P , i.e., ˆ Ω -1 1 ˆ ψ + | 00 ⟩ a a 1 2 = ( 10 | ⟩ h a 1 2 + 01 | ⟩ h a 1 2 ) / √ 2. Obviously, the space of initial states determines the representation of Hamiltonians and the following evolution. For example, pairing interactions describe the coherent creation or annihilation of excitations in pairs on particle or hole states while describing dissipative PH conversions on PH states. However, this is invisible from the Heisenberg equations of motion because particle and hole operators are redundant.
Chiral flows of particle-hole excitations. -The story becomes even more interesting when the hole degrees of freedom meet the network, where particle and hole nodes are connected by the four basic interactions in Fig. 2. Particularly, when interactions form a closed loop, along
FIG. 3. Schematics of chiral flows in the trimers with the Hamiltonians (a) ˆ H BST and (b) ˆ H SHT , when Φ = -π 2 . (c) and (d) plot the population evolutions of single-excited states in each loop when Φ = π/ 2 and Φ = -π/ 2, respectively.
which excitations experience a geometric phase, the AB effect will occur. Recently, the non-Hermitian AB effect has been observed in PH loops connected by pairing and beamsplitter interactions [14]. Here, we will show that hole states can successfully describe the excitation space and predict the Hermitian AB effect in PH loops.
̸
We consider the ring networks composed of three bosonic modes, as shown in Fig. 3 (a) and (b). In the particle-conserving case, it is named 'beamsplitter trimer,' [14] described by the Hamiltonian ˆ H BST = ∑ 3 i =1 ,j = i ge -iφ ij ˆ ˆ , a a † i j with φ ji = -φ ij . The dual version can be obtained by replacing ˆ a 1 (ˆ a † 1 ) with ˆ h 1 ( ¯ ˆ h † 1 ) through the PH transformation, called a 'single-hole trimer,' which composed of one beamsplitter and two dissipative pairing interactions, described by
̸
$$\hat { H } _ { \text{SHT} } = & \sum _ { i = 2, j \neq i } ^ { 3 } \Delta \hat { \bar { h } } _ { 1 } ^ { \dagger } \hat { h } _ { 1 } + \Delta \hat { a } _ { i } ^ { \dagger } \hat { a } _ { i } + g e ^ { i \varphi _ { j i } } \hat { a } _ { i } ^ { \dagger } \hat { a } _ { j } \\, & + g ( e ^ { i \varphi _ { 1 i } } \hat { a } _ { i } ^ { \dagger } \hat { h } _ { 1 } + e ^ { i \varphi _ { i 1 } } \hat { h } _ { 1 } ^ { \dagger } \hat { a } _ { i } ).$$
The restoration of excitation-conservation of ˆ H SHT reflects its invariance under the U(1) gauge transformation in the PH space, i.e., ˆ U PH = e iφ h h ( ˆ ¯ † 1 ˆ 1 + ∑ 3 i =2 ˆ a a † i ˆ ) i , which is the product of the local gauge transformation for each node. The phase sum around the particle and single-hole loops is Φ = φ 12 + φ 23 + φ 31 , which is invariant under the local gauge transformations on loop nodes, i.e., ˆ a † i → ˆ a e † i iφ and ¯ ˆ h † i → ˆ ¯ h e † i iφ for particle and hole nodes, respectively. This represents the synthetic flux threading loops and is a useful notation for determining whether time-reversal symmetry holds [47]. At Φ = zπ ( z ∈ Z ), ˆ H BST and ˆ H SHT hold time-reversal symmetry, while any
other flux breaks time-reversal symmetry, enabling chiral energy transport at each loop when Φ = π/ 2 + zπ .
At Φ = -π/ 2, the Heisenberg equation of nodes in the particle and single-hole loop exhibits a counterclockwise circulation [47, 48], ˆ ( ˆ a † 1 ¯ h † 1 ) → ˆ a † 2 → ˆ a † 3 → ˆ ( ˆ a † 1 ¯ h † 1 ), and then repeating the pattern. Note that, the ground state in each loop representation is the direct product of the vacuum states of its nodes. Applying the circulation of creation operators on the corresponding vacuum of each loop, we can obtain the chiral flow of the single-excited states, e.g., | 100 ⟩ a a a 1 2 3 → | 010 ⟩ a a a 1 2 3 → | 001 ⟩ a a a 1 2 3 → | 100 ⟩ a a a 1 2 3 in the particle loop and | 100 ⟩ h a a 1 2 3 → | 010 ⟩ h a a 1 2 3 → | 001 ⟩ h a a 1 2 3 → | 100 ⟩ h a a 1 2 3 in the single-hole loop. When Φ = π/ 2, the single-excited states in these loops will circulate in the opposite direction, as shown in Fig. 3 (c) and (d).
It is worth noting that the concept of 'holes' in hardcore bosonic systems differs from that in QBSs. In the former systems, ˆ H BST is accompanied by strong on-site interactions, and a 'hole' state is an unoccupied state for particles. In this case, the chiral flows exhibit the opposite chirality when exchanging single-excited particle and 'hole' states, e.g., | 100 ⟩ a a a 1 2 3 ↔ | 011 ⟩ a a a 1 2 3 . This can be interpreted as a 'hole' possessing the opposite 'charge' to the particle [48]. Conversely, without strong on-site interactions, a hole state is occupied by negative particle number. In the opposite excitation space, ˆ H BST and ˆ H SHT describe the hole and single-particle loop, respectively, with the synthetic flux Φ = ′ -Φ+ , as shown in Fig. 3 (a) and (b). Exchanging π particle and hole states in the single-excited case, e.g., | 100 ⟩ a a a /h a a 1 2 3 1 2 3 ↔ | 100 ⟩ h h h /a h h 1 2 3 1 2 3 in ˆ H BST /H ˆ SHT , does not change the chirality. This is because the excitation of holes is equivalent to removing particles from the mean field, and their energy chiral flow is symmetric about the 'Fermi level.'
Conclusions. -In summary, we present the concept of bosonic holes , which features the negative particle excitation near the mean particle number in QBSs. The key property, namely, the PH duality, not only reveals the duality between the Hermitian and non-Hermitian QBHs, it also enables various quantum applications with QBSs, such as PH entanglement and chiral flows. This paves a potential way to explore novel phenomena in particlenon-conserving and non-Hermitian systems, benefiting future quantum technologies.
Acknowledgments. -We thank Z. Yan for stimulating discussions. This work was supported by the National Natural Science Foundation of China (Grant No. 12375025 and No. 11874432), the National Key R&D Program of China (Grant No. 2019YFA0308200).
∗ [email protected]
- [1] N. Bogoliubov, ON THE THEORY OF SUPERFLUIDITY, J. Phys. (Moscowd). 11 , 23 (1947).
- [2] J. Bardeen, L. N. Cooper, and, J. R. Schrierfer, Theory of Superconductivity, Phys. Rev. 108 , 1175 (1957).
- [3] W. H. Louisell, A. Yariv, and A. E. Siegman, Quantum fluctuations and noise in parametric processes. I., Phys. Rev. 124 , 1646 (1961).
- [4] J. P. Gordon, W. H. Louisell, and L. R. Walker, Quantum Fluctuations and Noise in Parametric Processes. II, Phys. Rev. 129 , 481 (1963).
- [5] B. R. Mollow and R. J. Glauber, Quantum Theory of Parametric Amplification. I., Phys. Rev. 160 , 1076 (1967).
- [6] C. M. Caves and B. L. Schumaker, New formalism for two-photon quantum optics. I. Quadrature phases and squeezed states, Phys. Rev. A. 31 , 3068 (1985).
- [7] B. Kraus and J. I. Cirac, Discrete Entanglement Distribution with Squeezed Light, Phy. Rev. Lett. 92 , 013602 (2004).
- [8] C. C. Gerry and P. L. Knight, Introductory Quantum Optics (Cambridge University Press, Cambridge, UK, 2005).
- [9] S. Sachdev, Quantum Phase of Matter (Cambridge University Press, Cambridge, UK, 2023).
- [10] S. Lieu, Topological symmetry classes for non-Hermitian models and connections to the bosonic Bogoliubov-de Gennes equation, Phys. Rev. B. 98 , 115135 (2018).
- [11] V. P. Flynn, E. Cobanera, and L. Viola, Deconstructing effective non-Hermitian dynamics in quadratic bosonic Hamiltonians, New J. Phys. 22 , 083004 (2020).
- [12] C. W. J. Beenakker, Search for Majorana Fermions in Superconductors, Annu. Rev. Condens. Matter Phys. 4 , 113 (2013).
- [13] K. Flensberg, F. v. Oppen, and A. Stern, Engineered platforms for topological superconductivity and Majorana zero modes. Nat Rev Mater 6, 944-958 (2021).
- [14] J. D. Pino, J. J. Slim, and E. Verhagen, NonHermitian chiral phononics through optomechanically induced squeezing, Nature (London). 606 , 82-87 (2022).
- [15] Y. X. Wang, and A. A. Clerk, Non-Hermitian dynamics without disspation in quantum systems, Phys. Rev. A. 99 , 063834 (2019).
- [16] N. Okuma, Boundary-dependent dynamical instability of bosonic Green's function: Dissipative Bogoliubov-de Gennes Hamiltonian and its application to nonHermitian skin effect, Phys. Rev. B. 105 , 224301 (2022).
- [17] L.-L Wan, and X.-Y. L¨, Quantum-Squeezing Induced u Point-Gap Topology and Skin Effect, Phys. Rev. Lett. 130 , 203605 (2023).
- [18] A. McDonald, T. P.-Barnea, and A. A. Clerk, Phase-Dependent Chiral Transport and Effective NonHermitian Dynamics in a Bosonic Kitaev-Majorana Chain, Phys. Rev. X. 8 , 041031 (2018).
- [19] J. J. Slim, C. C. Wanjura, M. Brunelli, J. d. Pino, A. Nunnenkamp, and E. Verhagen, Optomechanical realization of the bosonic Kitaev chain, Nature (London). 627 , 767-771 (2024).
- [20] C. C. Wanjura, J. J. Slim, J. d. Pino, M. Brunelli, E. Verhagen, and A. Nunnenkamp, Quadrature nonreciprocity in bosonic networks without breaking time-reversal symmetry, Nat. Phys. 19 , 1429-1436 (2023).
- [21] V. Peano, M. Houde, C. Brendel, F. Marquardt, and A. A. Clerk, Topological phase transitions and chiral inelastic transport induced by the squeezing of light, Nat. Com-
mun. 7 , 10779 (2016).
- [22] R. Barnett, Edge-state instabilities of bosons in a topological band, Phys. Rev. A 88 , 063631 (2013).
- [23] R. Shindou, R. Matsumoto, S. Murakami, and J.-i. Ohe, Topological chiral magnonic edge mode in a magnonic crystal, Phys. Rev. B 87 , 174427 (2013).
- [24] B. Galilo, D. K. K. Lee, and R. Barnett, Selective Population of Edge States in a 2D Topological Band System, Phys. Rev. Lett. 115 , 245302 (2015).
- [25] V. Peano, M. Houde, F. Marquardt, and A. A. Clerk, Topological Quantum Fluctuations and Traveling Wave Amplifiers, Phys. Rev. X. 6 , 041026 (2016).
- [26] D.A. Trifonov, Pseudo-Boson Coherent and Fock States, arXiv:0902.3744 (2009).
- [27] R. Rossignoli, and A. M. Kowalski, Complex modes in unstable quadratic bosonic forms, Phys. Rev. A. 72 , 032101 (2005).
- [28] J. Garcia, and R. Rossignoli, Spectrum and normal modes of non-Hermitian quadratic boson operators, Phys. Rev. A. 96 , 062130 (2017).
- [29] See Supplemental Material for more details.
- [30] N. R. Bernier, L. D. T´th, A. K. Feofanov, and T. J. Kipo penberg, Level attraction in a microwave optomechanical circuit, Phys. Rev. A. 98 , 023841 (2018).
- [31] X.-G. Wen, Symmetry-protected topological phases in noninteracting fermion systems, Phys. Rev. B 85 , 085103 (2012).
- [32] G. S. Agarwal, Nonclassical statistics of fields in pair coherent states, J. Opt. Soc. Am. B, 5 , 1940 (1988).
- [33] D. X. Nguyen, T. Can, and A. Gromov, Particle-Hole Duality in the Lowest Landau Level, Phys. Rev. Lett. 118 , 206602 (2017).
- [34] E. Cobanera, G. Ortiz, and Z. Nussinov, Unified Approach to Quantum and Classical Dualities, Phys. Rev. Lett. 104 , 020402 (2010).
- [35] F. J. Dyson, General Theory of Spin-Wave Interactions. Phys. Rev. 102 , 1217 (1956).
- [36] M. Znojil, Hybrid form of quantum theory with nonHermitian Hamiltonians, arXiv:2211.10633 (2022).
- [37] V. P. Flynn, E. Cobanera, and L. Viola, Restoring num-
- ber conservation in quadratic bosonic Hamiltonians with dualities, EPL. 131 , 40006 (2020).
- [38] A. Pocklington, Y. X. Wang, and A. A. Clerk, Dissipative Pairing Interactions: Quantum Instabilities, Topological Light, and Volume-Law Entanglement, Phys. Rev. Lett. 130 , 123602 (2023).
- [39] M. Harder, Y. Yang, B. M. Yao, C. H. Yu, J. W. Rao, Y. S. Gui, R. L. Stamps, and C.-M. Hu, Level Attraction Due to Dissipative Magnon-Photon Coupling, Phys. Rev. Lett. 121 , 137203 (2018).
- [40] W. C. Yu, J. J. Wang, H. Y. Yuan, and J. Xiao, prediction of attracitve level crossing via a dissipative mode, Phys. Rev. Lett. 123 , 227201 (2019).
- [41] Y.-P. Wang, and C.-M. Hu, Dissipative couplings in cavity magnonics, J. Appl. Phys. 127 , 130901 (2020).
- [42] P. Peng, W. Cao, C. Shen, W. Qu, J. Wen, L. Jiang, and Y. Xiao, Anti-parity-time symmetry with flying atoms, Nat. Phys. 12, 1139 (2016).
- [43] F. Yang, Y.-C. Liu, and L. You, Anti-PT symmetry in dissipatively coupled optical systems, Phys. Rev. A 96, 053845 (2017).
- [44] Y. D. Wang and A. A. Clerk, Reservoir-Engineered Entanglement in Optomechanical Systems, Phys. Rev. Lett. 110 , 253601 (2013).
- [45] X. W. Luo, C. W. Zhang, and S. W. Du, Quantum Squeezing and Sensing with Pseudo-Anti-Parity-Time Symmetry, Phys. Rev. Lett. 128 , 173602 (2022).
- [46] H. Y. Yuan, P. Yan, S. S. Zheng, Q. Y. He, K. Xia, and M. H. Yung, Steady Bell state Generation via MagnonPhoton Couping, Phys. Rev. Lett. 124 , 053602 (2020).
- [47] J. Koch, A. A. Houck, K. L. Hur, and S. M. Girvin, Time-reversal-symmetry breaking in circuit-QED-based photon lattices, Phys. Rev. A. 82 , 043811 (2010).
- [48] P. Roushan, C. Neill, A. Megrant, Y. Chen, R. Babbush, R. Barends, B. Campbell, Z. Chen, B. Chiaro, A. Dunsworth, A. Fowler, E. Jeffrey, J. Kelly, E. Lucero, J. Mutus, P. J. J. O'Malley, M. Nelley, C. Quintana, D. Sank, A. Vainsencher, J. Wenner, T. White, E. Kapit, H. Neven, and J. Martinis, Chiral ground-state currents of interacting photons in a synthetic magnetic field, Nat. Phys. 13 , 146-151 (2017). | null | [
"Jia-Ming Hu",
"Bo Wang",
"Ze-Liang Xiang"
] | 2024-08-02T07:15:45+00:00 | 2024-08-02T07:15:45+00:00 | [
"quant-ph"
] | Bosonic Holes in Quadratic Bosonic Systems | The concept of electron holes plays a significant role in condensed matter
physics. Here we develop the concept of bosonic holes, which exhibit negative
particle excitations, in quadratic bosonic systems. Unlike electron holes, the
Fock states of bosonic holes are biorthogonal, and their excitation can be
interpreted as removing particles from a mean-particle number with a mean field
background. Furthermore, we find that quadratic bosonic Hamiltonians related by
non unitary and local particle hole transformation possess the same locality
structure and spectral properties in different spaces, reflecting the PH
duality. Based on this, we study the generation of PH entanglement in two mode
cases and the PH Aharonov Bohm effect in the three mode case, which results in
a PH chiral flow with time reversal symmetry breaking. Our findings provide a
new way to understand and explore unusual physical phenomena in particle non
conserving and non Hermitian systems. |
2408.01063v2 | Empirical Software Engineering manuscript No. (will be inserted by the editor)
## Leveraging Encoder-only Large Language Models for Mobile App Review Feature Extraction
Quim Motger 1 · Alessio Miaschi 2 · Felice Dell'Orletta 2 · Xavier Franch 1 · Jordi Marco 3
Received: date / Accepted: date
Abstract Mobile app review analysis presents unique challenges due to the low quality, subjective bias, and noisy content of user-generated documents. Extracting features from these reviews is essential for tasks such as feature prioritization and sentiment analysis, but it remains a challenging task. Meanwhile, encoder-only models based on the Transformer architecture have shown promising results for classification and information extraction tasks for multiple software engineering processes. This study explores the hypothesis that encoder-only large language models can enhance feature extraction from mobile app reviews. By leveraging crowdsourced annotations from an industrial context, we redefine feature extraction as a supervised token classification task. Our approach includes extending the pre-training of these models with a large corpus of user reviews to improve contextual understanding and employing instance selection techniques to optimize model fine-tuning. Empirical evaluations demonstrate that these methods improve the precision and recall of extracted features and enhance performance efficiency. Key contributions include a novel approach to feature extraction, annotated datasets, extended pre-trained models, and an instance selection mechanism for cost-effective finetuning. This research provides practical methods and empirical evidence in applying large language models to natural language processing tasks within mobile app reviews, offering improved performance in feature extraction.
Keywords mobile app reviews · feature extraction · named-entity recognition · large language models · extended pre-training · instance selection
B Quim Motger
E-mail: [email protected]
1 Universitat Polit`cnica e de Catalunya, Department of Service and Information System Engineering, Barcelona, Spain. E-mail: { joaquim.motger,xavier.franch } @upc.edu 2 Institute for Computational Linguistics 'A. Zampolli' (ILC-CNR), ItaliaNLP Lab, Pisa, Italy. E-mail: { alessio.miaschi,felice.dellorletta } @ilc.cnr.it
3 Universitat Polit`cnica e de Catalunya, Department of Computer Science, Barcelona, Spain. E-mail: [email protected]
## 1 Introduction
Large language models (LLMs) have become a pervasive method for redefining cognitively challenging software engineering tasks based on the natural language processing (NLP) of textual documents (Hou et al., 2024). As practitioners explore the potential of introducing these models into their day-today processes, multiple key design and evaluation factors are undermined or even neglected. This includes proper model analysis and selection (Perez et al., 2021), exploration of optimization mechanisms (Schick and Sch¨tze, 2021), exu plainability of results (Zini and Awad, 2022) and generalization of research outcomes (Jiang et al., 2020). Ignoring these dimensions can lead to low functional suitability, decreased performance efficiency, increased resource consumption and lack of potential for reusability and knowledge transfer.
In the context of Requirements Engineering (RE), effective adoption and proper use of LLMs have been elicited as key challenges for future work in the field (Frattini et al., 2024; Ronanki et al., 2023; Fantechi et al., 2023). As a text-based document-driven community, both generated by developers (e.g., textual requirements, user stories, test cases) and by users (e.g., bug reports, software issues, app reviews), information extraction from these documents is key to support requirements elicitation (Ronanki et al., 2023), defect repair (Ferrari et al., 2018), prioritization (Malgaonkar et al., 2022), information extraction (Sleimi et al., 2021), feedback analysis (Dalpiaz and Parente, 2019), and release planning (McZara et al., 2015; Sharma and Kumar, 2019). Extracting descriptors, metadata, entities and categories from these documents allows practitioners to categorize large amounts of data and build analytical processes, which is especially useful for continuously analysing large amounts of user-generated documents (Li et al., 2018; van Vliet et al., 2020). A particular example are opinion mining methods for mobile app reviews (Dabrowski et al., 2022), for which three major tasks can be identified from the literature: (1) review classification (e.g., bug report , feature request (Maalej and Nabil, 2015)); (2) sentiment analysis (e.g., positive , negative (Zhang et al., 2014)); and (3) app feature extraction (e.g., send message , make video call (Johann et al., 2017)). Concerning the latter, the automatic extraction of mobile app features (i.e., functions or quality characteristics of a mobile app from the user perspective) supports multiple feature-oriented decision-making tasks, including feature prioritization (Scalabrino et al., 2019) and feature-oriented sentiment analysis (Guzman and Maalej, 2014).
While some feature extraction methods have been proposed by leveraging syntactic-based pattern matching techniques (Johann et al., 2017; Guzman and Maalej, 2014; Dragoni et al., 2019), several challenges remain (Dabrowski et al., 2022). For starters, agreement towards what constitutes a feature is typically low, as it is considered a particularly cognitively subjective task (Dabrowski et al., 2023). In addition, app reviews are low-quality user-generated documents, subjectively biased, grammatically incorrect, relatively short, filled with noisy content and even potentially generated by bots (Araujo et al., 2022). Hence, syntactic-based and machine learning (ML) methods for feature
extraction typically struggle especially in the context of app reviews, reporting an overall low recall and hence missing multiple feature mentions from a large corpus of reviews (Dabrowski et al., 2023).
To address these challenges, encoder-only LLMs, which rely solely on the encoder component of the Transformer architecture (Minaee et al., 2024), have emerged as a promising solution. These models are particularly well-suited for tasks such as classification, named-entity recognition (NER), and information extraction. In this context, this study aims to validate the following hypothesis:
- H 1 . Encoder-only LLMs can be leveraged to improve the state of the art of feature extraction in the context of mobile app reviews.
To this end, our approach leverages crowdsourced user annotations from an industrial context to redefine the feature extraction task as a supervised token classification (e.g. NER) task. We compare the performance of multiple encoder-only LLMs with a classification layer on top to extract subsets of tokens referring to particular features for a given mobile app.
Using this approach as a baseline, we complement our research with two additional hypotheses to explore the potential of improving the functional correctness and time behaviour of our LLM-based approach:
- H 2 . Extending the pre-training of general-purpose LLMs (i.e., additional pretraining on domain-specific data) with a large corpus of user reviews can improve the representation of the mobile app user review context, improving the functional correctness of feature extraction.
- H 3 . Instance selection of crowdsourced user reviews (i.e., filtering and selecting relevant instances for fine-tuning) can optimize model fine-tuning, improving the time behaviour of feature extraction while maintaining or even improving - functional correctness.
As a result, our research conveys the following contributions 1 :
- C 1 . A ground-truth dataset of 23,816 reviews from 468 apps belonging to 10 popular Google Play categories, annotated with 29,383 feature mentions.
- C 2 . Aproposal for automatically leveraging crowdsourced, user-generated feature annotations from an industrial context into mobile app reviews.
- C 3 . Anovel approach to redefining feature extraction from mobile app reviews as a token classification task.
- C 4 . A curated dataset of 654,123 mobile app reviews from 832 apps belonging to 32 popular Google Play categories, used for extended pre-training.
- C 5 . Acollection of foundational encoder-only LLMs with extended pre-training for mobile app reviews NLP-based tasks.
- C 6 . A document-based instance selection method for token classification tasks to support cost-effectiveness assessment of fine-tuning LLMs for NER.
1 Source code and datasets for replication of all experiments and full evaluation artefacts are available in the GitHub repository: https://github.com/gessi-chatbots/t-frex . The README file includes reference to models published on HuggingFace.
- C 7 . A collection of fine-tuned encoder-only LLMs for feature extraction, combining extended pre-training and instance selection mechanisms.
- C 8 . An empirical analysis of the correctness and the execution time variations across the combination of (1) different types of encoder-only LLMs, (2) extended pre-training settings, and (3) instance selection data partitions.
This research extends our previously published work (Motger et al., 2024b). Contributions C 1 → C 3 correspond to those already covered in the original publication, which we refer to as the T-FREX ( T ransformer-based F eatu R e EX traction ) baseline design. To minimize overlap, we limit the scope of the empirical evaluation of the T-FREX baseline to relevant aspects necessary for self-containment and comparative evaluation in this publication. Additionally, we expand on the design and development details of our baseline approach, focusing on LLM-related topics (i.e., annotation transfer, model selection) that were not covered in detail in the original publication. Contributions C 4 → C 8 pertain exclusively to new contributions presented in this publication.
The structure of this paper is organized as follows. Section 2 covers background literature and terminology, including feature extraction, token classification, extended pre-training, and instance selection. Section 3 defines the research method, including the definition of the sample study. Section 4 presents the T-FREX system design, including baseline and extended versions. Section 5 presents the evaluation design, the dataset and the experiment results. Section 6 summarizes the discussion of the research questions. Section 7 summarizes related work. Finally, Section 8 concludes our research.
## 2 Background
## 2.1 Feature extraction
A feature is a specific function or capability within a mobile application that serves a particular purpose or fulfils a specific need (Dabrowski et al., 2023). Formal definitions typically refer to features either with software-related terminology (e.g., system capabilities, functional requirements (Wiegers and Beatty, 2013)) or from a user-centered perspective (e.g., characteristics (Kang et al., 1990), properties (Harman et al., 2012)). Beyond their formalization, features represent distinct characteristics of a given mobile app, designed to execute a clear task, comply with a particular qualitative expectation, or meet a specific user need. For instance, in the following review:
The feature for sharing notes with other users is very handy.
The feature sharing notes refers to a particular function which implies an actionable use case for a particular interaction between the user and the mobile app. On the other hand, in the following review:
This is the perfect lightweight app for when you just want radar without all the other baloney bundled with it.
Fig. 1: List of Telegram features upvoted by users in AlternativeTo.
The feature lightweight refers to a non-functional (i.e., quality) characteristic of the mobile app. Finally, in the following review:
I enjoy meeting new people in my area and creating routes.
The feature meeting new people refers to a particular capability that facilitates user engagement and community building within the app.
Features have become a core descriptor for app review mining activities (Dabrowski et al., 2022). Furthermore, features are also used to support user-oriented services, including mobile app recommendation (Palomba et al., 2015), search-based algorithms (Chen et al., 2016) and personalization (Laranjo et al., 2021). Figure 1 illustrates a practical example of features being used as categorization tags to support alternative software recommendations in AlternativeTo . Features are used to cluster and identify similar 2 mobile apps and provide recommendations based on similar features. Additionally, rare features are also highlighted to illustrate the app's singularity. However, these features are extracted based on manual user votes, limiting their generalization, and causing biased, unbalanced representativity and incomplete feature data.
Feature extraction refers to the automatic identification of features mentioned within a textual document, including app descriptions and user reviews (Dabrowski et al., 2022). While formal methods are mostly based on syntactic-based pattern-matching and topic modelling (see Section 7), several challenges remain. From a formalization perspective, scoping and stating what constitutes a feature is highly subjective, leading to discrepancies affecting methodological developments and even different application scenarios between industrial and research environments (Johann et al., 2017). From a methodological perspective, due to the nature and authorship of reviews, these methods tend to struggle when processing noisy, grammatically inaccurate and complex documents (Shah et al., 2019). From an evaluation point of view, this
2 Source: https://alternativeto.net/software/telegram/about/
leads to low recall values, producing high false negatives and therefore limiting the added value of an automatic approach by missing multiple feature candidates (Dabrowski et al., 2023).
## 2.2 Token classification and NER
Token classification is a fundamental task in the NLP field where the goal is to assign a particular label (i.e., class) to each token within a text sequence (Naveed et al., 2024). Given a review r , let T r ( ) denote the sequence of tokens in r . Formally, if r consists of n tokens, then T r ( ) = [ t 1 , t 2 , . . . , t n ], where t i represents the i -th token in the sequence. Hence, token classification involves assigning one of the possible classes from a predefined set C to each token t i in the sequence. As a result, the annotated sequence consists of pairs of tokens and their assigned classes, such as [( t 1 , c 1 ) , ( t 2 , c 2 ) , . . . , ( t n , c n )], where each c i represents the label assigned to the corresponding token t i .
NERis a specialized form of token classification where the goal is to identify and classify specific entities within a text into predefined categories such as names of people, organizations, locations, dates, and other domain-specific entities (Hou et al., 2024). This is achieved using the IOB tagging scheme, where each token in a sequence is assigned a label that indicates whether it is at the beginning ( B -), inside ( I -), or outside ( O ) of a named entity.
In this research, we redefine the feature extraction task from mobile app reviews as a token classification task to identify and categorize features as named entities within a given review. In particular, following the structure of a NER task, we defined the set of possible classes C as follows:
$$C = \{ B _ { \bullet } f e a t u r e, I _ { \bullet } f e a t u r e, O \}$$
Hence, given a review r with tokens T r ( ) = [ t 1 , t 2 , . . . , t n ], the function ϕ for token-based feature extraction is defined as:
$$\phi ( t _ { i } ) = \begin{cases} B { \text{-feature} } & \text{if $t_{i}$ is the beginning of a feature,} \\ I { \text{-feature} } & \text{if $t_{i}$ is inside a feature but not the beginning,} \\ O & \text{if $t_{i}$ is not part of any feature.} \end{cases}$$
For example, consider the review r consisting of the tokens:
$$T ( r ) = [ \omega \text{To} ^ { \prime \prime }, \, \omega \text{do} ^ { \prime \prime }, \, \omega \text{list} ^ { \prime \prime }, \, \omega \text{function} ^ { \prime \prime }, \, \omega \text{is} ^ { \prime \prime }, \, \omega \text{not} ^ { \prime \prime }, \, \omega \text{working} ^ { \prime \prime } ]$$
If ' to-do list ' is identified as a feature, the annotated sequence would be:
$$[ ( \Lambda \text{To} ^ { \prime \prime }, B \text{-feature} ), ( \Lambda \text{o} ^ { \prime \prime }, I \text{-feature} ), ( \Lambda \text{list} ^ { \prime \prime }, I \text{-feature} ), \\ ( \Lambda \text{function} ^ { \prime \prime }, O ), ( \Lambda \text{is} ^ { \prime \prime }, O ), ( \Lambda \text{not} ^ { \prime \prime }, O ), ( \Lambda \text{working} ^ { \prime \prime }, O ) ]$$
## 2.3 LLMs and extended pre-training
LLMs are pre-trained on large document corpora from various, multidisciplinary textual sources (Naveed et al., 2024). These models use a combination of unsupervised and semi-supervised learning tasks, making them suitable for specific downstream tasks such as feature extraction. Using a large corpus of domain-specific documents (e.g., mobile app reviews), the pre-training phase of these models can be extended - also known as continual pre-training - to improve their performance on such tasks (Yıldız et al., 2024). Several domains such as healthcare (Carrino et al., 2022), education (Liu et al., 2023), mathematics (Gong et al., 2022), or even less specialized domains such as product reviews (Jiang et al., 2023) have demonstrated the benefits of domain-specific extended pre-training. This results in enhanced contextual understanding, enabling models to have a finer-grained understanding of language nuances and context-specific knowledge. It also allows models to adapt to the specific vocabulary and stylistic elements of the domain, which may differ significantly from the data seen during the initial pre-training phases.
Extending LLM pre-training requires a large dataset within the target domain, ranging from 2 to 95 million tokens (Ke et al., 2023; Liu et al., 2023; Jiang et al., 2020; Carrino et al., 2022), depending on the domain specificity. Furthermore, it requires extensive computational resources due to the increased amount of data and the complexity of the training processes (Jiang et al., 2020). In addition, extending the pre-training entails some threats to validity, such as data bias and generalization to other tasks (Yıldız et al., 2024).
Based on model selection (see Section 4), this paper focuses on two primary pre-training tasks: masked language modelling (MLM) and permutative language modelling (PLM). MLM involves masking a portion of the input tokens and training the model to predict the masked tokens based on the context provided by the unmasked tokens. For instance, given the review ' Sleep tracking is not working ', the model might be trained with the following masked token:
Sleep [MASK] is not working .
and learn to predict ' tracking ' as a suitable token in the context of mobile apps and features. On the other hand, PLM shuffles the order of the input tokens and trains the model to predict the original sequence. For example, from the same review, the model could be presented with:
## tracking Sleep is working not .
and trained to reconstruct the original sequence, especially focusing on the original order of the ' sleep tracking ' feature.
## 2.4 Instance selection
Instance selection involves identifying and retaining the most relevant documents (e.g., mobile app reviews) from a corpus while filtering out non-relevant
or redundant instances (Cunha et al., 2023). This technique aims to enhance the efficiency and effectiveness of machine- and deep -learning models. Efficiency can be improved by reducing large datasets filtering non-relevant documents (i.e., documents not affecting the task performance in terms of functional correctness), especially when training on the entire corpus may be computationally prohibitive (Wilson and Martinez, 2000). Additionally, effectiveness can be improved by removing document instances that might be noisy, mislabeled, or highly redundant (Carbonera, 2017). There are multiple instance selection strategies and methods according to the goal for filtering document instances. This includes removal of mislabeled (Wilson, 1972) or noisy (Wilson and Martinez, 2000) documents using gold-standards, selection of highly representative documents through density measures (Carbonera and Abel, 2015), and clustering-based approaches (Moran et al., 2022).
Instance selection has been widely addressed in multiple NLP tasks such as text classification (Cunha et al., 2023), sentiment analysis (Onan and Koruko˘lu, 2016), text generation (Chang et al., 2021) and information extracg tion (Cardellino et al., 2015). However, few studies explore the potential of instance selection methods for NER tasks. And ultimately, these focus either on label transfer or propagation (Lu et al., 2021) and random instance selection (Ferraro et al., 2024).
## 3 Study design
## 3.1 Goal and research questions
The main goal of this research is to generate insights and empirical evidence about the use of encoder-only LLMs for feature extraction tasks in the context of mobile app reviews . To this end, we elicited the following evaluation-oriented research questions (Shaw, 2003):
- RQ 1 . How effective are encoder-only LLMs at extracting features from mobile app reviews?
- RQ 2 . How does extending the pre-training of encoder-only LLMs improve the effectiveness of feature extraction from mobile app reviews?
- RQ 3 . How do instance selection methods improve the effectiveness of LLMbased feature extraction from mobile app reviews?
- RQ 4 . How does the combination of extended pre-training and instance selection improve the effectiveness of LLM-based feature extraction from mobile app reviews?
RQ 1 addresses the validation of H 1 . RQ 2 pertains to the validation of H 2 . Finally, RQ 3 and RQ 4 focus on the validation of H 3 .
## 3.2 Research method
Figure 2 illustrates a general overview of the research method conducted in this study. Following a Design Science (DS) methodology for software engineering research (Engstr¨m et al., 2020), o we refined the main goal of this research into three scientific sub-objectives focusing on the validation of H 1 → H . We 3 aligned each Design Science iteration with a particular sub-objective, leading to three iterations covering ( ) objective refinement, ( i ii ) design and development of the solution, and ( iii ) empirical evaluation and verification of results. Concerning evaluation, we use the ISO/IEC 25010 software product quality model (International Organization for Standardization, 2023) to focus on two quality characteristics for the evaluation: functional correctness with respect to ground truth data and human evaluation; and time behaviour of fine-tuning processes. Extended details of the evaluation design are depicted in Section 5.
Fig. 2: Research method
## 3.3 Sample study: Google Play and AlternativeTo
We shaped our research as a sample study using data extracted from the Google Play App Store 3 to minimize obtrusiveness and maximize generalization of our research findings (Stol and Fitzgerald, 2018). Minimum obtrusiveness is achieved by limiting manipulation of the research settings to data collection from existing repositories (i.e., app stores), constraining instrumentation to NLP-based pre-processing (see Section 4.1.1). Maximum generalization is aimed by focusing on cross-domain documents in the context of mobile app reviews, using data from different mobile app categories, focusing on popular data sources, and designing evaluation settings exploring the generalization of research findings to unknown domains (see Section 5.3.1).
3 https://play.google.com/store/apps
Google Play is the largest app store worldwide, hosting more than 3.5 million apps, followed by the Apple App Store with 1.6 million apps (Statista, 2024). Its market quote reaches 2,500 million users worldwide (Google, 2024a), offering a large catalogue of mobile apps from 32 app categories (Google, 2024b), excluding games. The potential of app stores for empirical software engineering research has not been overlooked, leading to multiple studies benefitting from the available data, including reviews, ratings, app descriptions and changelogs, among others (McIlroy et al., 2016b,a; Hassan et al., 2018). In this research, we focus on the collection of mobile app reviews from popular Google Play categories to evaluate the performance of the feature extraction process (see Section 5.2 for details on the collected dataset).
In addition to Google Play, we complement our data collection with crowdsourced feature annotations generated by users from AlternativeTo , a soft4 ware recommendation platform for finding alternatives for a given software product, including web-based, desktop and mobile apps. AlternativeTo has a catalogue of 120,000 apps and has collected feedback from almost 2 million users worldwide. As illustrated in Figure 1 (see Section 2.1), users can upvote features pertaining to a particular software. These features are then used for various use cases, such as measuring similarity with alternative apps, looking for apps with a given feature and measuring feature frequency to determine its popularity or rareness. We extract and use these annotations as ground truth for the empirical evaluation of our approach. By leveraging crowdsourced user annotations, we argue that our approach aligns with the concept of features being used in a real context (i.e., minimizing manipulation to data collection).
Details on the data collection process are presented in Section 4. A summarized overview of the collected dataset of reviews and features is presented in Section 5.
## 4 System design
## 4.1 T-FREX baseline
Figure 3 illustrates a summarized overview of the T-FREX baseline design proposal. T-FREX baseline is composed of three main stages: 1 data collection and annotation of user reviews and features; 2 data pre-processing and feature transfer from apps to reviews; and 3 model selection and fine-tuning for the token classification function ϕ .
## 4.1.1 Data collection and annotation
Data collection 1 is composed of two data artefacts: reviews and features.
- - Reviews dataset. We built on our previous work (Motger et al., 2023) by reusing a dataset of 639 mobile apps with 622,370 reviews from Google
4 https://alternativeto.net/
Fig. 3: Design of T-FREX baseline
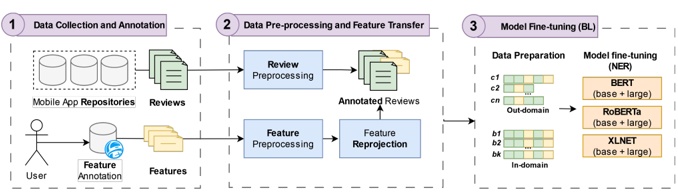
Play and other Android mobile app repositories belonging to multiple, heterogeneous mobile app categories (e.g., communication, health and fitness, maps and navigation, lifestyle...). We applied the following modifications to this dataset: (1) we focused on categories exceeding a minimum threshold for statistical representativeness (i.e., including ≥ 5 apps); and (2) we removed all categories related to game apps, as the concept of feature in the scope of this research does not apply to the concept of feature in game mobile apps (Dabrowski et al., 2023). This process resulted in 364,220 reviews from 468 mobile apps from 10 popular Google Play categories.
- - Features dataset. Using the set of reviews, we implemented web scraping mechanisms to access archived cached versions from AlternativeTo using the Wayback Machine Internet Archive project 5 to automatically extract feature annotations by users. Using the BeautifulSoup library 6 , we dynamically inspect the AlternativeTo profile page of each app of the reviews dataset, and we locate and parse the 'Features' section (as shown in Figure 1) to extract a flat list of features for each app (e.g., for Telegram, we collect features such as 'Encrypted Chat' , 'Large File Transfer' and 'Animated stickers' ). This resulted in 198 distinct features for 468 apps.
Extended details on the reviews and features dataset, including a categoryoriented analysis, are presented in Section 5.2.
## 4.1.2 Data pre-processing and feature transfer
Algorithm 1 depicts in detail the steps for transferring the features collected from AlternativeTo into annotations within the dataset of reviews. For review and feature pre-processing 2 , we apply a common natural language preprocessing stage using Stanza's neural pipeline 7 for syntactic annotation and entity extraction from both the reviews and features datasets (lines 1-3). The pipeline was composed of the following steps: ( ) tokenization, ( i ii ) multi-word token expansion, ( iii ) PoS tagging, ( iv ) morphological feature extraction, and
5 http://web.archive.org/
6 https://pypi.org/project/beautifulsoup4/
7 https://stanfordnlp.github.io/stanza/neural pipeline.html
## Algorithm 1 Feature Annotation Transfer
```
<_OCaml_>
```
( v ) lemmatization. The output of this pipeline is formatted using the CoNLLUformat . After the pre-processing step, the corpus is ready for the annotation 8 process. Each token t ∈ T r , ( ) ∀ r ∈ R is initialized with the default label O (lines 5-7). The algorithm looks for all matches between feature tokens and review tokens (lines 9-21). If a match is found for a particular review r and feature f for a given mobile app app (lines 11-12), which means that users from AlternativeTo voted f as a feature from app , then each token resulted from the intersection T r ( ) ∩ T f ( ) is annotated with B-feature or I-feature according to the position of the token within the original feature (lines 13-18).
This process resulted in 29,383 feature annotations over 23,816 app reviews. Section 5.2 provides extended details on the resulting feature annotations after the feature transfer process.
## 4.1.3 Model fine-tuning
Stemming from recent literature reviews in the field of LLMs (Hou et al., 2024; Naveed et al., 2024; Zhao et al., 2023), we compared different encoderonly LLMs suitable for our evaluation and comparative analysis. We focused on encoder-only architecture due to their inherent suitability for classification
8 https://universaldependencies.org/format.html
Table 1: Model features and fine-tuning parameters
| model | data | parameters | task | epochs | learning rate | batch size |
|---------------|--------|--------------|--------|----------|-----------------|--------------|
| BERT base | 16 GB | 110 M | MLM | 2 | 2e-05 | 16 |
| BERT large | 16 GB | 336 M | MLM | 2 | 2e-05 | 16 |
| RoBERTa base | 160 GB | 125 M | MLM | 2 | 2e-05 | 16 |
| RoBERTa large | 160 GB | 355 M | MLM | 2 | 2e-05 | 8 |
| XLNet base | 16 GB | 110 M | PLM | 2 | 3e-05 | 16 |
| XLNet large | 113 GB | 340 M | PLM | 2 | 3e-05 | 8 |
tasks (Hou et al., 2024). In addition, we also excluded decoder-only models (also known as generative models) due to their size and resource consumption.
These models present limited applicability in large-scale contexts such as user review mining, especially in terms of memory, computational resources and time constraints. Particularly, in this study, we selected the following models:
- - BERT , considered the first encoder-only LLM, is renowned for its advanced contextual understanding due to its bidirectional nature (Devlin et al., 2019). It is pre-trained using the MLM objective, which enhances its ability to grasp context from both directions, making it effective for token-level tasks such as NER (Broscheit, 2019). For these reasons, we use BERT as a baseline LLM for NER tasks.
- - RoBERTa improves upon BERT's design and training methods through extended pre-training on a larger dataset with additional data, resulting in stronger language representations (Liu et al., 2019). It also uses MLM for pre-training but outperforms BERT in many cases (Liu et al., 2019). We include RoBERTa in our model evaluation due to its enhanced performance over BERT.
- - XLNet uses a unique approach by combining autoregressive and bidirectional training, considering all possible word permutations during pretraining (Yang et al., 2019). This improves its ability to understand context and model token dependencies more effectively than traditional models. Unlike BERT and RoBERTa, XLNet employs a PLM training objective. Consequently, token dependencies are modelled differently. We evaluate XLNet's performance to compare its innovative training method against the MLM objectives of BERT and RoBERTa.
Encoder-only models have not significantly evolved over the past few years. As a result, while generative (decoder-only) models have experienced increased growth and extended research, models like BERT, RoBERTa, and XLNet still represent the state-of-the-art for encoder-only LLMs, offering robust performance across diverse tasks (Yang et al., 2023). However, their validity in many specific scenarios still needs thorough assessment (Hou et al., 2024).
Table 1 provides the full lists of models used in this research, as well as some size-related features. For each model, we use both base and large versions.
After model selection, the corpus of reviews R is divided into k subsets { R , R , . . . , R 1 2 k } . For each fold j ∈ { 1 2 , , . . . , k } , a fine-tuning iteration in-
volves using the subset R j as the test set, while the remaining subsets R \ R j are combined to form the training set. This process is repeated k times, with each subset R j used exactly once as the test set. We design two different strategies for data preparation:
- - In-domain learning . The set of reviews R is split into k partitions, each containing the same proportion of reviews from each mobile app category as the original dataset. This ensures a balanced representation of each category in each partition. The in-domain learning setting evaluates the model's performance when it is trained on data from all domains, ensuring a diverse and representative training set.
- - Out-of-domain learning . The data is split into k partitions, where k is the number of different mobile app categories. Each partition contains reviews exclusively from one category. This setup evaluates the model's performance in extracting features from a domain it was not trained on, testing its generalizability to new, unseen categories.
After model selection and data preparation, we design the fine-tuning process 3 as follows:

- 1. Data processing . Loading of train and test datasets, transformation from CoNLL-U format to a dataset compatible with the HuggingFace datasets library, and tokenization of user reviews according to the model architecture used in each evaluation sequence. For BERT, we use WordPiece tokenizer, while for RoBERTa and XLNet we use SentencePiece tokenizer. The main difference involves the management of special tokens (e.g., BERT uses [CLS] classification token) and tokenization granularity (e.g., RoBERTa and XLNet employ more fine-grained tokenization where multiple tokens can belong to the same word).
- 2. Model loading . Loading the model from the model library. For T-FREX baseline, checkpoints are directly loaded using the HuggingFace model library API. This step involves initializing the model architecture and loading original pre-trained weights to leverage transfer learning.
- 3. Training setting . Configuring the training parameters, including number of epochs, learning rate and batch size. Table 1 reports experimentation details used in this study for each model. Variations relate to limitations of computational resources, assessing the balance between memory usage and performance efficiency. This configuration is used in all research iterations, including T-FREX with extended pre-training (Section 4.2) and with instance selection (Section 4.3)
- 4. Training . Fine-tuning process of the proper model (i.e., BERT, RoBERTa, XLNet) with the training set. This step involves iterative optimization of model parameters using backpropagation and gradient descent. The training process aims to minimize the loss function, improving the model's ability to predict feature tokens accurately. Regular monitoring of training metrics, such as loss and accuracy, is conducted to ensure the model is learning effectively and to prevent overfitting.
Fig. 4: Design of T-FREX with extended pre-training
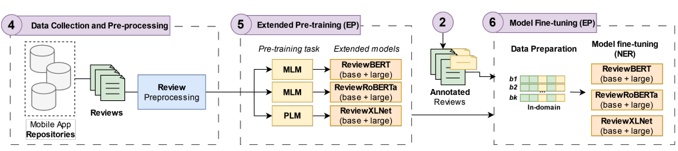
- 5. Evaluation . Running model for inference to evaluate the performance with the test set. This includes the collection of metrics used for evaluation in this study, such as precision, recall, and f-measures (see Section 5.1). The evaluation process assesses the model's generalization capability and its effectiveness in extracting features from unseen user reviews and features.
Evaluation results for T-FREX baseline (RQ ) are reported in Section 5.3.1. 1
## 4.2 T-FREX with extended pre-training
Figure 4 illustrates a summarized overview of the T-FREX design proposal with extended pre-training of LLMs. This approach is composed of three main stages: 4 data collection and pre-processing; 5 extension of the pre-training task of each LLM used in this research; and 6 fine-tuning with extended models using the annotated ground truth generated during T-FREX baseline 2 .

## 4.2.1 Data collection
We build on our previous work in the generation of a dataset 4 of mobile app reviews extended from the dataset used for T-FREX baseline (Motger et al., 2024a). This dataset consisted of 13,478,744 user reviews from 832 mobile apps belonging to 46 categories. To minimize obtrusiveness and guarantee minimal manipulation of the dataset and the context, we limited the pre-processing of such reviews to a minimal sanitization pipeline consisting of the following steps: ( i ) converting text to UTF-8 encoding; ( ii ) filter non-English reviews; and ( iii ) remove duplicate text. Data is saved in CoNLL format for consistency with T-FREX baseline. In addition, to minimize computational consumption, we limited the dataset to an acceptable minimum size for extending pre-training using references of related work in the field of domain-specific extended pre-training (see Section 2.3). As BERT, RoBERTa and XLNet are pre-trained using token level tasks (i.e., MLM and PLM), we use the length of the corpus in terms of tokens as a metric to limit the dataset. Consequently, we reduced the dataset to 8,232,362 tokens pertaining to 622,352 reviews.
## 4.2.2 Extending models pre-training
Based on model selection for T-FREX baseline (see Section 4.1.3), we used the extended dataset to extend the pre-training 5 of BERT, RoBERTa (with MLM) and XLNet (with PLM). Initially, CoNLL formatted data is converted into a HuggingFace dataset. The dataset is split into training and evaluation sets, followed by tokenization using a tokenizer specific to the model type (i.e., WordPiece for BERT, SentencePiece for RoBERTa and XLNet). The tokenized reviews are grouped into blocks of 128 tokens to ensure efficient training. Then, we prepare the fine-tuning process for either MLM or PLM tasks. This fine-tuning process is focused on reducing the value of the evaluation loss after each epoch, which we monitor and report during the evaluation process (see Section 5). Training arguments are set using the same values as in Table 1, with the exception of the number of epochs, which we extended to 10 in order to analyse the evolution of the continual pre-training effect after several iterations. Hence, we save a model checkpoint after each epoch for future evaluation with token classification fine-tuning.
## 4.2.3 Model fine-tuning
For fine-tuning with extended models 6 , we repeated steps 1 → 5 from the fine-tuning process as defined for T-FREX baseline (see Section 4.1.3) for each checkpoint and model saved during the extended pre-training stage 5 . We used the set of annotated reviews from the T-FREX baseline design 2 , and we limited the data preparation of T-FREX with extended pre-training to the in-domain data analysis. This is motivated by three reasons. First, the mobile app domain is a highly stable environment in terms of emerging mobile app categories, making in-domain learning the most common scenario, as variability in the list of mobile app categories is very limited. Second, the purpose of the out-of-domain analysis is to test the T-FREX baseline in a limiting, challenging scenario, exploring the strengths and weaknesses of a NER-based approach under unexpected circumstances (i.e., generalization to a new app category). Finally, extended pre-training and fine-tuning processes are computationally expensive, requiring high energy consumption. Specifically, the in-domain analysis itself entails a total of 60 fine-tuning processes (10 checkpoints × 6 LLM instances). Hence, in addition to previous considerations and to promote sustainability, we limit the scope of our research to the most common scenario in the context of mobile apps (i.e., in-domain learning).
Evaluation results for T-FREX with extended pre-training (RQ ) are re2 ported in Section 5.3.2.
## 4.3 T-FREX with instance selection
Figure 5 illustrates the T-FREX design proposal with instance selection of reviews. T-FREX with instance selection is composed of two main stages:
Fig. 5: Design of T-FREX with instance selection
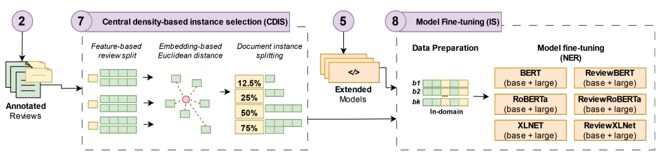
7 instance selection of user reviews using a density-based instance selection mechanism; and 8 model fine-tuning with original and extended LLM instances using the annotated ground truth generated during T-FREX baseline.
## 4.3.1 Central density-based instance selection
We propose an adapted version of a central density-based instance selection (CDIS) algorithm for classification tasks (Carbonera and Abel, 2016). This approach 7 focuses on redundancy removal for optimal resource consumption and increased accuracy in prediction quality. Specifically, our approach is focused on two main adaptations: (1) reshaping the instance selection criteria for a NER task (i.e., using different feature entities as criteria for document splitting); and (2) leveraging LLMs to generate contextualized embeddings for each document, compute centroids for a semantic space (i.e., reviews mentioning a given feature) and compute distances between documents (i.e., reviews) and the theoretical centroid.
This process is summarized in Algorithm 2. The algorithm takes the corpus of app reviews R with annotated features F as inputs 2 . For each review r ∈ R , we generate its embedding using BERT base , which we select as a baseline representative of encoder-only LLMs. Then, we collect all reviews containing each feature f ∈ F into corresponding sets D f [ ]. For each feature f , the algorithm aggregates the embeddings of the reviews mentioning f and computes the centroid C f of these embeddings. The distance between each review embedding and the centroid C f is calculated using the Euclidean distance. Reviews are then sorted based on their distance to the centroid in descending order. Finally, the algorithm partitions the sorted reviews into four subsets based on the specified training data distributions: 12.5%, 25%, 50%, and 75%. The merged partitions for all features are then output as the result. Consequently, each partition maximizes semantic representativeness of reviews at feature level. This optimizes training sets by minimizing highly similar reviews which might impact negatively the fine-tuning process both from the functional correctness (i.e., overfitting or unbalanced semantic representation) and from the performance efficiency (i.e., unnecessarily large datasets) points of view.
## Algorithm 2 Instance Selection
```
<_Ruby_>
```
4.3.2 Model fine-tuning
Similarly to the extended pre-training approach, we repeated steps 1 → 5 from the fine-tuning process as defined for T-FREX baseline with instance selection training splits 8 . To explore the impact of instance selection in isolation (RQ ) and in combination with extended pre-training (RQ ), we fine-tune all 3 4 data partitions with both the original and the extended checkpoints generated during the T-FREX fine-tuning with extended pre-training 5 . This leads to a total of 264 fine-tuning processes (4 training sets × 6 model instances × 1+10 model checkpoints). Using the same criteria as in the extended pre-training, we limit the scope of analysis to the in-domain data preparation scenario.
Evaluation results for T-FREX with instance selection, both in isolation (RQ ) and combined with extended pre-training (RQ ), are reported in Sec3 4 tion 5.3.3 and Section 5.3.4, respectively.
## 5 Evaluation
## 5.1 Design
## 5.1.1 Functional correctness - Ground truth
For functional correctness , we use collected reviews from Google Play and features from AlternativeTo as ground truth by assessing the correctness of ϕ t ( i ) predictions ∀ t i ∈ T r ( ) and ∀ r ∈ R , where R is the corpus of reviews used for evaluation (see Section 5.2). Based on model predictions, we focus on the following metrics for measuring functional correctness: precision, recall and f-measure.
- - Precision ( p ) evaluates the proportion of correctly predicted feature-related tokens ( c i ∈ { B-feature , I-feature } ) relative to all tokens predicted as featurerelated, measuring how accurate the model is in identifying features.
- - Recall ( r ) measures the proportion of correctly predicted feature-related tokens compared to all feature-related tokens in the ground truth, highlighting how many features were successfully captured by the model.
- - F-measure ( f ) provides a balanced evaluation by calculating the harmonic mean of precision and recall, ensuring that both false positives and missed features are taken into account.
In the context of evaluating NLP-based RE tasks, app review analysis is identified as an example of a hairy RE task. Hairy tasks are defined as document-driven, non-algorithmic, manageable by experts on a small scale and unmanageable on a large scale (Berry, 2021). Consequently, achieving high recall is key due to the need for close to 100% recall in identifying all relevant answers. While precision remains important, we focus on maximizing recall to minimize overlooked feature mentions. Consequently, we propose using a different weighting for the f-measure to reflect the greater importance of recall over precision. In addition to f 1 , as proposed by Berry (2021), we also measure:
$$f _ { \beta } = ( 1 + \beta ^ { 2 } ) \cdot \frac { p \cdot r } { \beta ^ { 2 } \cdot p + r }, \quad \beta = A _ { T } / A _ { t }$$
where A T is the average time to find a relevant feature when performing feature extraction manually, and A t is the average time to determine the validity of a potential feature. Hence, β is the relative importance of recall (finding all relevant features) to precision (determining the validity of features) based on the relative cost between A T and A t . Computation of A T and A t is done during the human validation process (see Section 5.1.2).
For the in-domain setting, we measure these metrics using a k -fold crossvalidation analysis with k = 10 and report average values. For the out-ofdomain setting, k is determined by the number of mobile app categories.
We exclude accuracy from the evaluation because we cannot control the exhaustivity of the annotations. Without certainty that all features of a given mobile app are annotated in AlternativeTo, we cannot ensure that tokens labelled by default as non-feature entities ( c i = O ) in Algorithm 1 are correct.
## 5.1.2 Functional correctness - Human evaluation
Crowdsourced features from AlternativeTo impose some limitations due to the lack of control of the annotation process (see Section 6.5). As some features might be overlooked, tokens labelled with c i ∈ { B-feature , I-feature } annotated with O might be falsely detected as an FP instance. This limits the reliability of the precision metric. To address this, we incorporated an external human evaluation process strictly on newly predicted features, i.e., those not annotated in the original ground truth set. Building on this and the considerations raised in Section 5.1.1, human evaluation goals include to (1) mitigate the limitation of our dataset's lack of exhaustivity, and (2) compute the β to report a task-specific measure for correctness. This human evaluation process consisted of the following steps:
- 1. Questionnaire design. Wedesigned questionnaires for human assessment using QuestBase 9 which were distributed to external annotators with Prolific 10 . Specifically, we designed two different sets of questionnaires:
- (a) Assessment for automatic feature extraction ( Q A ) . Figure 6 illustrates a snapshot of the questionnaire to assess the validity of a feature automatically extracted by T-FREX. Each question presents to the annotator: (1) the app name, including a link to Google Play; (2) the app category; (3) the text of the review; (4) the proposed feature; and (5) the question. Annotators can confirm the feature proposal ( Yes ), reject it ( No ) or report it as not clear ( I don't know ). We conducted iterative internal annotations to adjust the size (100 reviews), required time (15') and economic retribution (2 £ ). Each Q A questionnaire includes 5 control questions to reject annotators not passing a minimum performance requirement (i.e., 4/5 correct feature annotations with trivial examples from the ground truth).
- (b) Assessment for manual feature extraction ( Q M ) . Figure 7 illustrates a snapshot of the questionnaire to manually extract features from a given review. Annotators are presented with the same information as in previous questionnaires, with the exception of the question and the answers, which in this case is a free-text area. We reduced the size of each task (25 reviews) while keeping time (15') and retribution (2 £ ). Q M questionnaires include 3 control questions to reject annotators using a performance threshold (i.e., 2/3 correct feature annotations).
- 2. Guidelines elaboration. We prepared annotation instructions for each questionnaire. These include (1) the definition of a feature, (2) the context of the evaluation task, (3) the metadata provided for each annotation task, and (4) several examples with different feature annotations. Guidelines were refined during 3 iterative internal annotations to improve the clarity and representativeness of the examples provided.
- 3. Evaluation . We conducted three human evaluation iterations:
9 https://questbase.com/
10 https://www.prolific.com/
## Question 3
CFAN
App name: WeChat App category COMMUNICATION
Review: Now could not check any messages from wechat as the account verification popup always blocks on top and force me t0 log out
Feature: account verification the following expression mentioned as a reference t0 a feature of the mobile application in the previous review?
- dont know
Fig. 6: Questionnaire for automatic feature extraction ( Q A )
## Question 11
App name: Clock App category: TOOLS
Review: Now
Please list all mentions of a feature found in the review; separated by commas Leave the answer blank if you think no feature is mentioned.
Fig. 7: Questionnaire for manual feature extraction ( Q M )
- (a) F-measure weighting factor β ( Q A and Q M ). We randomly selected a subset of 100 reviews from the evaluation set. For this subset, we created one Q A questionnaire with 100 reviews and four Q M questionnaires with 25 reviews each. We measured the time required for each annotator to complete the questionnaire, and we report average values among all valid annotators to measure A t and A T , which were then used to compute β = A /A T t .
- (b) Precision of new features ( Q A with baseline). We use the best T-FREX baseline model (RQ ) and we run it for inference with all 1 reviews available in the evaluation dataset. We selected only those review-feature annotation pairs where the given feature was not originally annotated in the ground truth. Then, we split the set of filtered review-feature pairs into a subset of questionnaires Q A according to the pre-defined size (100 reviews). We required a minimum of 5 valid annotators per task. Among these, we used a voting mechanism to determine the final label assigned to each feature.
CLEAN
- (c) Precision of new features ( Q A with combined extensions). We repeated the same process as in 3b but with features predicted by the best-performing T-FREX model with combined extensions (RQ ). 4
## 5.1.3 Performance efficiency
For the time behaviour dimension, we focus on the evaluation of the performance efficiency of the fine-tuning processes for generating T-FREX LLM instances, especially for the assessment of the cost-effectiveness balance with different data partitions (RQ ). Consequently, 3 we focus on measuring execution times 11 for each of the fine-tuning stages defined in Section 4.1 (i.e., data processing, model loading, training setting, training, and evaluation). We exclude document pre-processing and feature transfer from performance efficiency analysis as these steps are only executed once before all experiments.
## 5.2 Dataset
Table 2 reports the details of the dataset used for evaluation 12 , collected and generated during T-FREX baseline design (see Section 4.1.1). This includes the mobile app categories included in the dataset, which covers heterogeneous categories ranging from generic Communication and Social apps to specialized domains such as Health and fitness or Maps and navigation . Reviews included in this dataset pertain exclusively to those with at least one feature mentioned.
As a summary, our dataset is composed of 23,816 reviews from 468 mobile apps, leading to 475,382 tokens with the following token class distribution: 29,383 tokens labelled as B-feature , 2,841 tokens labelled as I-feature , and 443,158 tokens labelled as O . The largest category is Productivity , with almost 150,000 tokens and up to 77 distinct features ( features ). On the other | | hand, the least represented categories are Maps and navigation , Lifestyle and Weather , depending on whether we focus on the number of tokens, number of features or distinct features. Notice that a distinct feature might be present in more than one category. For instance, video calling is annotated as a feature for both Productivity and Communication apps.
## 5.3 Results
Westructure evaluation results in alignment with research questions, presented as follows: T-FREX baseline fine-tuning (RQ ); T-FREX with extended pre1 training (RQ ); T-FREX with instance selection (RQ ); and T-FREX with 2 3 combined extensions (RQ ). 4
11 Experiments were conducted on two NVIDIA GeForce RTX 4090 GPUs.
12 Datasets and source code for replicating the evaluation process are available in the GitHub repository: https://github.com/gessi-chatbots/t-frex
Table 2: Evaluation dataset. List of app categories: Productivity (PR), Communication (CO), Tools (TO), Social (SO), Health and fitness (HE), Personalization (PE), Travel and local (TR), Maps and Navigation (MA), Lifestyle (LI), Weather (WE).
| metric | PR | CO | TO | SO | HE | PE | TR | MA | LI | WE | Total |
|--------------|---------|---------|--------|--------|--------|-------|--------|-------|-------|--------|---------|
| apps | 137 | 51 | 58 | 14 | 75 | 6 | 19 | 31 | 12 | 65 | 468 |
| reviews | 7,348 | 7,003 | 4,321 | 819 | 2,154 | 112 | 530 | 284 | 344 | 901 | 23,816 |
| sentences | 8,604 | 8,135 | 5,402 | 899 | 2,330 | 118 | 602 | 315 | 391 | 984 | 27,780 |
| tokens | 148,172 | 134,833 | 93,395 | 15,597 | 40,907 | 2,022 | 11,105 | 5,868 | 8,044 | 15,439 | 475,382 |
| B-feature | 8,801 | 10,026 | 5,220 | 1,016 | 1,981 | 111 | 691 | 355 | 346 | 836 | 29,383 |
| I-feature | 1,495 | 820 | 305 | 60 | 59 | 1 | 17 | 13 | 47 | 24 | 2,841 |
| O | 137,876 | 123,987 | 87,870 | 14,521 | 38,867 | 1,910 | 10,397 | 5,500 | 7,651 | 14,579 | 443,158 |
| features | 8,801 | 10,026 | 5,220 | 1,016 | 1,981 | 111 | 691 | 355 | 346 | 836 | 29,383 |
| | features | | 77 | 54 | 50 | 26 | 23 | 19 | 17 | 12 | 10 | 7 | 198 |
## 5.3.1 Baseline fine-tuning
Table 3 reports average precision ( p ), recall ( r ), standard f-measure ( f 1 ) and weighted f-measure ( f β ) for token classification for both out-of-domain 13 and in-domain data preparation settings. As mentioned in Section 5.1, β is computed comparing the performance of A T (time required for assessing automatic feature extraction) with respect to A t (time required for manual feature extraction). Average results from human evaluation (3a) led to A T = 28 29 . s and A t = 11 86 , which leads to a . s β = A /A T t = 2 385. We use . f β as the gold metric to select the best-performing models in our research context.
Table 3: Token classification results (T-FREX baseline)
| | Out-of-domain | Out-of-domain | Out-of-domain | Out-of-domain | In-domain | In-domain | In-domain | In-domain |
|---------------|-----------------|-----------------|-----------------|-----------------|-------------|-------------|-------------|-------------|
| model | p | r | f 1 | f β | p | r | f 1 | f β |
| BERT base | 0.546 | 0.314 | 0.381 | 0.335 | 0.596 | 0.488 | 0.532 | 0.502 |
| BERT large | 0.577 | 0.339 | 0.414 | 0.361 | 0.719 | 0.582 | 0.637 | 0.595 |
| RoBERta base | 0.531 | 0.336 | 0.386 | 0.356 | 0.668 | 0.569 | 0.611 | 0.582 |
| RoBERTa large | 0.455 | 0.339 | 0.374 | 0.352 | 0.688 | 0.509 | 0.571 | 0.530 |
| XLNet base | 0.627 | 0.482 | 0.535 | 0.499 | 0.679 | 0.519 | 0.582 | 0.538 |
| XLNet large | 0.651 | 0.374 | 0.437 | 0.399 | 0.761 | 0.573 | 0.646 | 0.599 |
For out-of-domain analysis, XLNet base outperformed all other models with a recall r = 0 482 and a weighted f-measure . f β = 0 499 (+0 100 with respect to . . the second best-performing model, XLNet large ). However, the highest precision is reported by XLNet large with p = 0 651. On the other hand, RoBERTa . large demonstrated the weakest performance for almost every metric, especially precision. For in-domain analysis, XLNet large achieved the highest performance with a precision p = 0 761 and weighted f-measure of . f β = 0 599. BERT . large reports similar results, especially due to its highest recall with r = 0 582 and .
13 Based on the scope of this research, we limit the out-of-domain analysis to average results, excluding category-oriented evaluation details. These details are extended in the previous work from which this research stems (Motger et al., 2024b).
the weight of recall in computing the weighted f-measure, leading to f β = 0 595 . (only -0 005 with respect to XLNet . large ). Conversely, BERT base exhibited the lowest performance metrics, with a weighted f-measure f β = 0 502. .
Table 4: Feature extraction evaluation (comparison with SAFE baseline)
| | Out-of-domain | Out-of-domain | Out-of-domain | Out-of-domain | In-domain | In-domain | In-domain | In-domain |
|-------------|-----------------|-----------------|-----------------|-----------------|-------------|-------------|-------------|-------------|
| model | p | r | f 1 | f β | p | r | f 1 | f β |
| SAFE | 0.301 | 0.321 | 0.310 | 0.318 | 0.193 | 0.215 | 0.199 | 0.209 |
| BERT base | 0.471 | 0.300 | 0.347 | 0.311 | 0.575 | 0.419 | 0.485 | 0.436 |
| XLNet large | 0.503 | 0.417 | 0.445 | 0.424 | 0.631 | 0.572 | 0.600 | 0.572 |
In addition to token-level effectiveness, we also report and measure effectiveness at the feature level. In this setting, quality metrics are measured using the feature as a whole (i.e., groups of contiguous tokens B-feature and I-feature composing a whole feature as labelled in the ground truth). This analysis facilitates comparison with SAFE (Johann et al., 2017), a syntactic-based method in the field of feature extraction which we identify as a baseline method from related work (see Section 7). Furthermore, this analysis is also intended to facilitate comparisons by further research in the field of feature extraction. We build on a replication of SAFE to support this comparative analysis with our dataset (Shah et al., 2019). Table 4 reports functional correctness results for the SAFE approach, BERT base (used as the baseline for LLM-based feature extraction design) and XLNet large (reported as the best-performing model in T-FREX baseline for token-level effectiveness). Results showcase that T-FREX outperforms SAFE in all settings, with the only exception of the out-of-domain recall with BERT base . For in-domain analysis, T-FREX reports significantly greater precision (+0 438) and recall (+0 357) with respect to syntactic-based . . mechanisms, especially for the former. Overall, in-domain T-FREX baseline version showcases to overcome some of the limitations posed by syntactic-based approaches in the context of reviews, especially when generalizing syntactic patterns to different datasets, as suggested by Shah et al. (2019).
Table 5 summarizes the results of the human evaluation of new features (3b). We collected all features predicted by XLNet large fine-tuned model during the in-domain k -fold cross-validation analysis for each test set. Then, we selected those reviews with predicted features which were not originally annotated as features in the ground-truth set. This led to a total of 1,956 reviews, with 1,067 distinct feature annotations. Given the size of the dataset, we decided to submit for evaluation all reviews, leading to 21 human evaluation tasks of 100 feature annotation questions (95 for evaluation, 5 for control). As a result, human evaluation of new features leads to a total average precision of 0.625 (i.e., 62.5% of ' Yes ' annotations across the whole dataset). This supports the hypothesis that the original dataset lacks exhaustive annotations.
Table 5: Human evaluation of new features (FP) with best-performing TFREX baseline model (XLNet large ).
| | PR | CO | TO | SO | HE | PE | TR | MA | LI | WE | Total |
|----------|-------|-------|-------|-------|-------|------|-------|-------|------|------|---------|
| #reviews | 459 | 643 | 560 | 44 | 218 | 0 | 8 | 29 | 0 | 0 | 1,956 |
| % Yes | 68.6% | 62.3% | 58.4% | 63.6% | 59.4% | - | 66.7% | 58.6% | - | - | 62.5% |
| % No | 28.8% | 35.0% | 41.7% | 34.1% | 39.3% | - | 33.3% | 41.4% | - | - | 36.1% |
| % Idk | 1.6% | 2.7% | 1.8% | 2.2% | 0.6% | - | 0.0% | 0.0% | - | - | 1.9% |
## 5.3.2 Extended pre-training
Figure 8 showcases the evolution of the evaluation loss during the extended pre-training stage after each epoch 1 → 10. All models, especially large model instances (i.e., BERT large , RoBERTa large , XLNet large ) show a general trend of decreasing evaluation loss over the epochs, with the largest reduction occurring between the first and second epochs. On the other hand, base models (i.e., BERT base , RoBERTa base , XLNet base ) exhibit relatively stable and lower evaluation losses throughout the epochs. Between epochs 8 → 10 all six models converge into evaluation loss values ≤ 10 -4 . The higher initial evaluation loss for large models may be attributed to their increased complexity and greater number of parameters, which require more epochs for effective optimization.
Fig. 8: Evaluation loss across 10 epochs.
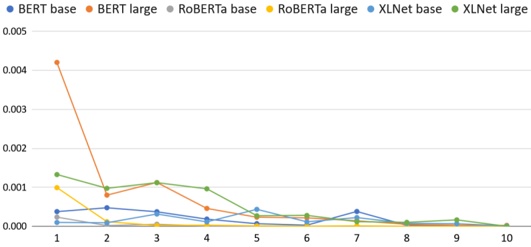
Figure 9 illustrates the evolution of precision and recall metrics for the in-domain fine-tuning using model checkpoints c from 1 → 10. For a comparative analysis, we include T-FREX baseline model as model checkpoint c = 0. Results showcase that all six model instances increase the maximum value for each metric at some point during the extended pre-training. Precision is on average the most increased metric, especially for base models BERT base ( c = 2, +0.159), RoBERTa base ( c = 5, +0.166) and XLNet base ( c = 2, +0.097). The only exception is precision for XLNet large , which suffers from decay from 0.761 to 0.686 (-0.075). The increase of recall is more modest and is especially high-
Fig. 9: Precision ( p ) and recall ( r ) evolution with extended pre-training.
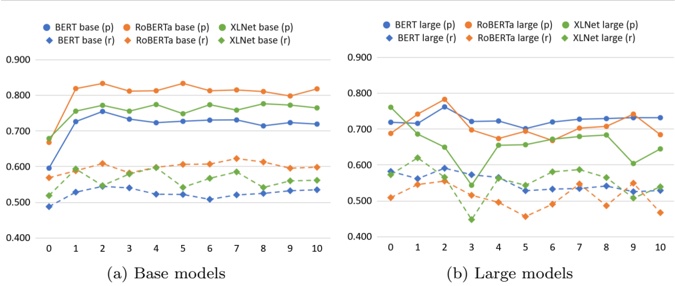
lighted in base models like XLNet base ( c = 4, +0.078) but also in large models such as RoBERTa large ( c = 9, +0.040) or XLNet large ( c = 1, +0.047).
If we focus on evolution across epochs, we notice that most models approach the best metric values between the first and the second epoch. After that, metric values either stabilize (i.e., BERT base , RoBERTa base , XLNet base ) or start to decay (i.e., BERT base , RoBERTa large ). In addition, precision and recall values show a common behaviour across all epochs (i.e., increasing one also increases the other). The only exception to both of these statements is XLNet large . Using XLNet large extended with just one epoch increases recall (+0.047) and, consequently, f β (+0.036). But given the decay in precision, the balanced fmeasure remains almost identical (+0.002). Finally, in terms of evolutionary behaviour, BERT (both base and large) and RoBERTa base show relatively stable behaviour between consecutive epochs. However, RoBERTa large and XLNet (both base and large) showcase erratic behaviour with constants increases and decays. This behaviour might be a consequence of the pre-training objectives and the data used for the initial pre-training of these models (see Section 6).
## 5.3.3 Instance selection
Figure 10 illustrates the evolution of precision and recall metrics for the indomain fine-tuning using T-FREX baseline approach for fine-tuning and the instance selection algorithm to generate different training data set partitions d ∈ { 12 5% 25% 50% 75% . For a comparative, evolutionary . , , , } analysis, we include T-FREX baseline setting using the complete training set as d = 100%.
All T-FREX base models experience an improvement in every metric when a certain degree of instance selection (i.e., between 12.5% and 75%) is conducted in the ground truth training dataset. For BERT base , the best data partition is 75% ( f β = 0 583). For RoBERTa . base , using only 25% leads to the best results ( f β = 0 615). For XLNet . base , the best data partition is 50% ( f β = 0 631). While this condition mostly prevails in large models, BERT . large (for recall and f-measures) and XLNet large (for precision) report some partic-
Fig. 10: Precision ( p ) and recall ( r ) evolution with instance selection.
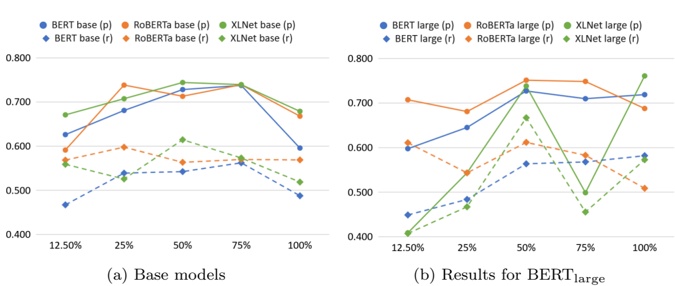
ular exceptions. Beyond these, using 50% of the training data results in the best setting for RoBERTa large ( f β = 0 629) and XLNet . large ( f β = 0 677). On . average, for six models and two fundamental metrics (precision and recall), 10 out of 12 evaluations improve with instance selection. Specifically, two modelmetric combinations improve with 25% of the data (RoBERTa base , precision and recall), two combinations improve with 75% (BERT base , precision and recall), and the rest improve with a 50% partition.
If we focus on the tendency as we increase the size of the training set, we observe a non-linear behaviour that suggests the presence of a local minimum. This indicates an optimal value for the training set size where the model performance is maximized before it starts to decline with further data increase. This phenomenon is consistent across various models and metrics. For instance, for BERT base and RoBERTa base , the metrics peak at different points -75% and 25% respectively - before showing a decline, which highlights the importance of instance selection in optimizing model performance. Similarly, for large models like BERT large and XLNet large , the optimal training set sizes are different, with 50% being optimal for RoBERTa large and XLNet large .
Concerning variations on time behaviour using different data partitions, Figure 11 reports, for each model and training data partition, the execution times required for each model fine-tuning stage (steps 1 → 6 in Section 4.1.3). We report average values obtained from the k -fold cross-validation during the in-domain analysis. The training stage takes the majority of the total execution time across all models and data partitions. In comparison, data processing and model loading phases consume relatively minimal time. On average, using 50% of the training set entails a speed up of × 1 8 with respect to using 100% of the . dataset. For smaller partitions, the speed up grows linearly. On average, for base models, using 12.5% of the training set entails a × 4 1 speed up, while for . large models this is increased to × 4 9 on average. If we focus on larger data . partitions, for 75%, all models consistently report a speedup of × 1 3. .
Fig. 11: Execution times (in seconds) for T-FREX model fine-tuning.
## 5.3.4 Combining extended pre-training and instance selection
Given the large number of experimentation settings for combined analysis (6 TFREXmodels × 4 data partitions × 11 model checkpoints), we limit the results included in this paper to the best configuration of extended pre-training and/or instance selection for each metric. To this end, Table 6 reports functional correctness metrics for the token classification task with respect to T-FREX baseline (RQ ), T-FREX with extended pre-training (RQ ), T-FREX with 1 2 instance selection (RQ ) and T-FREX with combined extensions (RQ ). For 3 4 each combination, we exclusively report the setting reporting the best metric by specifying the model checkpoint ( ) for c extended pre-training, the data partition ( d ) for instance selection, and both when combining extensions.
If we focus on the combined use of instance selection and extended pretraining (EP/IS), there are only a few examples where this combination is the best option for functional correctness: precision for BERT base and XLNet base ; and recall and f β for RoBERTa large . If we focus on the use of extended pretraining only (EP), BERT large , RoBERTa base and XLNet large report this design as the best option for increasing effectiveness. In fact, XLNet large emerges as the best model, both for recall ( r = 0 700) and weighted f-measure ( . f β = 0 677), . with c = 1. For precision, RoBERTa base with extended pre-training with c = 5 emerges as the best option. On the other hand, if we focus on the isolated use of instance selection, it emerges as the best option for BERT base and RoBERTa base , with some exceptions like precision for BERT base .
Focusing on delta variations, we observe that on average all base models, as well as mostly all large models, improve T-FREX baseline when extended pretraining and/or instance selection is applied. For large models, there are some
Table 6: Metrics for the best-performing approach with background colors representing δ variations relative to the T-FREX baseline (BL). Bolded cells indicate the best metrics for each model. Pinpointed cells denote the overall best metrics across all evaluations.
| model | setting | p | r | f 1 | f β |
|---------------|----------------|----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|
| BERT base | BL EP IS EP/IS | 0.596 c=2 0.755 d=75% 0.738 c=2,d=75% 0.768 | 0.488 c=2 0.545 d=75% 0.562 c=1,d=75% 0.549 | 0.532 c=2 0.621 d=75% 0.632 c=1,d=75% 0.626 | 0.502 c=2 0.569 d=75% 0.583 c=1,d=75% 0.573 |
| BERT large | BL EP IS EP/IS | 0.719 c=2 0.762 d=50% 0.727 c=7,d=75% 0.692 | 0.582 c=2 0.632 d=75% 0.568 c=4,d=75% 0.587 | 0.637 c=2 0.691 d=75% 0.626 c=4,d=75% 0.630 | 0.599 c=2 0.649 d=75% 0.587 c=4,d=75% 0.601 |
| RoBERTa base | BL EP IS EP/IS | 0.668 c=5 0.834 d=75% 0.739 c=5,d=75% 0.741 | 0.569 c=7 0.623 d=25% 0.598 c=5,d=25% 0.592 | 0.611 c=7 0.694 d=25% 0.652 c=7,d=75% 0.650 | 0.582 c=7 0.647 d=25% 0.616 c=7,d=75% 0.610 |
| RoBERTa large | BL EP IS EP/IS | 0.688 c=2 0.783 d=50% 0.751 c=9,d=75% 0.769 | 0.509 c=2 0.555 d=50% 0.612 c=1,d=12.5% 0.621 | 0.571 c=2 0.636 d=50% 0.666 c=1,d=12.5% 0.664 | 0.530 c=2 0.580 d=50% 0.629 c=1,d=12.5% 0.639 |
| XLNet base | BL EP IS EP/IS | 0.679 c=8 0.776 d=50% 0.744 c=2,d=75% 0.783 | 0.519 c=4 0.597 d=50% 0.615 c=3,d=75% 0.595 | 0.582 c=4 0.661 d=50% 0.664 c=2,d=75% 0.655 | 0.538 c=4 0.618 d=50% 0.631 c=2,d=75% 0.617 |
| XLNet large | BL EP IS EP/IS | 0.761 c=1 0.738 d=50% 0.686 c=10,d=75% 0.748 | 0.573 c=1 0.667 d=50% 0.620 c=7,d=25% 0.641 | 0.646 c=1 0.700 d=50% 0.648 c=7,d=25% 0.669 | 0.595 c=1 0.677 d=50% 0.629 c=7,d=25% 0.655 |
minor exceptions like precision for XLNet large and f-measures for BERT large . Precision is the most increased metric, experiencing its greatest improvement when extended pre-training and instance selection are used in combination for BERT base (+0.172). Recall is also increased, but its maximum improvement is more conservative, as observed with RoBERTa large with combined extensions (+0.112) or in XLNet large with instance selection (+0.094).
After analysis of all T-FREX settings, XLNet large with extended pre-training ( c = 1) emerges as the best-performing 14 model (based on f β ). For consistency with the evaluation of T-FREX baseline, we complement the analysis of ground truth annotations with the evaluation of new features reported by T-FREX which are not present in the ground truth. We use the fine-tuned c=1 XLNet large model for inference, collecting 11,120 reviews mentioning 1,311 distinct new features not assessed during evaluation of RQ . Given the size 1 of the dataset of reviews, we limited the set of reviews used for human evaluation for resource optimization to 1,311 reviews (i.e., one review instance of each distinct feature). This entails 11.8% of the complete set of reviews and 100% of the newly predicted features. Consequently, human evaluation (3c) consisted of 14 tasks with 100 questions (95 for evaluation, 5 for control).
14 Notice the criteria for 'best-performing model' might vary across different research contexts and scenarios, for which we provide exhaustive results for precision and recall.
Table 7: Human evaluation of new features (FP) with best-performing TFREX extended model ( c=1 XLNet large ).
| | PR | CO | TO | SO | HE | PE | TR | MA | LI | WE | Total |
|----------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|---------|
| #reviews | 206 | 228 | 260 | 102 | 282 | 8 | 93 | 46 | 35 | 60 | 1320 |
| % Yes | 57.8% | 68.0% | 60.0% | 71.6% | 53.2% | 87.5% | 51.6% | 54.3% | 88.6% | 63.3% | 60.8% |
| % No | 35.4% | 25.9% | 34.6% | 22.5% | 38.7% | 12.5% | 43.0% | 41.3% | 8.6% | 33.3% | 33.1% |
| % Idk | 6.8% | 6.1% | 5.4% | 5.9% | 8.2% | 0.0% | 5.4% | 4.3% | 2.9% | 3.4% | 6.1% |
Table 7 reports the results for this analysis using the same format as in RQ 1 (Table 5). On average, we observe a consistent precision of features labelled as ' Yes ' (60.8%), slightly lower with respect to T-FREX baseline (62.5%). However, the set of features labelled as ' No ' is -3% smaller for the extended version (33.1%) with respect to T-FREX baseline (36.1%). This is due to a major uncertainty in label predictions annotated during this evaluation process, labelled as ' I don't know ' (6.1%). In addition, the number of new features reported with extended pre-training (11,120) is × 5 7 higher than the number of new features . reported with the baseline design (1,956). Consequently, although precision is not increased, T-FREX with c=1 XLNet large significantly reduces the number of potentially missed features compared to T-FREX baseline.
## 6 Discussion
## 6.1 Baseline fine-tuning
RQ : 1 The T-FREX baseline design improves upon syntactic-based baseline methods for extracting feature mentions from mobile app reviews (H 1 ). These improvements are evident in both out-of-domain and in-domain learning settings, with notable gains in precision and recall.
For the most challenging scenario (i.e., out-of-domain), XLNet base demonstrated the strongest performance , achieving a weighted f-measure ( f β ) of 0.499, aligning with H 1 even in less familiar contexts. This model is particularly effective in reducing missed features (false negatives). However, XLNet large excelled in precision, achieving the highest score of 0.651, indicating its ability to minimize false features (false positives). Conversely, RoBERTa large showed the weakest performance, highlighting its limited generalization capability for out-of-domain scenarios.
For the most common scenario (i.e., in-domain), XLNet large outperformed XLNet base across all metrics , with a precision of 0.761 and a weighted f-measure of 0.599, overcoming its out-of-domain limitations. BERT large also performed well, especially in recall with a score of 0.582, but slightly lagged in weighted f-measure at 0.595. Despite the small differences, XLNet large emerged as the best overall model for in-domain tasks. Notably, larger RoBERTa
models performed worse than their base versions, consistent with other studies suggesting that larger models may sometimes hinder performance.
Human evaluation of new features using XLNet large for in-domain analysis revealed an average precision of 0.625, confirming the model's ability to identify valid, previously unannotated features. This supports the hypothesis that the original dataset's annotations were not exhaustive.
Overall, the results highlight the improved effectiveness of T-FREX models, particularly the XLNet variants, in various evaluation contexts , reinforcing H 1 as they outperform traditional syntactic-based methods. An encoder-only LLM approach showcases better adaptation to the concept of a feature as used in an industrial setting like AlternativeTo, suppressing the limitations of deterministic approaches conditioned by the use of specific syntactic patterns that might not always generalize. Hence, we argue that T-FREX provides an effective software-based mechanism to reduce missing features in automatic review-based opinion mining pipelines used by practitioners and researchers.
## 6.2 Extended pre-training
RQ : 2 Extended pre-training consistently improves the precision and recall of feature extraction for all encoder-only models analysed in this research (H ). Different models entail different outcomes, requiring different training 2 epochs according to the size and pre-training task of the model to reach maximum improvement without forcing the decay of quality metrics.
Base models demonstrate substantial improvements in performance metrics with extended pre-training , with precision showing the most significant increases. This suggests that base models have greater potential for refinement, and extended pre-training effectively reduces false positives, enhancing the likelihood that identified features are accurate. Similarly, while large models tend to also improve with extended pre-training, they also tend to experience a decay after the first few epochs, indicating a limit to the benefits of extended pre-training for these more complex models. This is also supported by the evolution of the evaluation loss, which is significantly limited after a few epochs of extended pre-training.
In addition, base models tend to stabilize across epochs in comparison to the erratic behaviour of large models , especially RoBERTa large and XLNet large . This instability may be attributed to the complexity of their pre-training tasks and the data used, which could lead to fluctuations in performance as the models are fine-tuned. Specifically, XLNet large showcases significant variability, potentially due to its architectural differences and the pretraining objective (i.e., PLM), which might not align as well with the finetuning tasks. This erratic behaviour underscores the need for careful monitoring and potentially different strategies when employing large models for extended pre-training.
On average, the best performance improvements are achieved after one or two epochs of extended pre-training , further validating H 2 by showing that even limited extended pre-training enhances LLMs' reflection of mobile app review contexts. Beyond this point, we observe similar or even diminishing results. In similar contexts, this suggests that investing in extensive pre-training beyond a few epochs may not be adequate in terms of cost-effectiveness balance, given the diminishing returns and significant computational resources required. Researchers and practitioners conducting similar experiments (e.g., NER fine-tuning with encoder-only LLMs) should consider these factors when designing their training protocols to ensure efficient and effective use of computational resources.
## 6.3 Instance selection
RQ : 3 On average, instance selection not only improves the performance efficiency of the fine-tuning process but also leads to an improvement in the functional correctness of the token classification task, both in precision and recall (H 3 ). This improvement is especially observed for data partitions between 50%-75%, and it is consistently observed in base models, while large models present some exceptions.
As illustrated with the analysis of base models, optimal performance is achieved with different data partitions from the original set of reviews (e.g., 75% for BERT base , 25% for RoBERTa base , and 50% for XLNet base ). This underscores that base models may struggle with redundancies and noise in the full dataset, and a more targeted data selection can enhance their performance. Large models, while also benefiting from instance selection, show some variability, particularly with XLNet large , which exhibits erratic behaviour, suggesting that its architecture might be more sensitive to the training set size and content. Interestingly, the performance across all models tends to peak at certain data partition sizes and then decline, indicating a local optimum. Results showcase the validity of the instance selection method proposed for token-level fine-tuning in the context of mobile app review feature extraction.
In addition to effectiveness, using a smaller, optimal portion of the dataset significantly reduces execution times . Training with 50% of the dataset nearly halves the execution time while still improving performance on average. For even smaller partitions, such as 12.5%, the speedup can be as much as four to five times faster, which is particularly advantageous for largescale applications where computational resources and time are critical. This efficiency gain, combined with improved model performance, makes instance selection a highly valuable strategy in real-world scenarios, where processing large batches of reviews for multiple tasks (e.g., sentiment analysis, content classification, feature extraction) becomes computationally expensive.
## 6.4 Combining extended pre-training and instance selection
RQ : 4 Combined use of extended pre-training and instance selection improves T-FREX baseline design in almost all design scenarios and models. This entails that a cost-effective assessment is necessary to improve both the effectiveness and efficiency of the system. However, optimal precision and recall values are overall achieved with extended pre-training without the need for instance selection. Results report some exceptions to this, especially for base models, where either combined extensions or simply instance selection becomes the best option.
When focusing on precision, RoBERTa base stands out as the best model , especially for tasks where false positives are more tolerable than missing actual features. Conversely, for applications where recall is critical, XLNet large is superior , as missing a feature mention is more costly than incorrectly identifying one. This underscores the need for decision-making based on specific application scenarios, which is why detailed reporting of these metrics is essential. However, in the context of RE hairy tasks (Berry, 2021), we argue that high recall is more important than high precision, which is reflected in the weighting of f β .
On average, base models benefit more from instance selection, particularly in terms of recall , demonstrating their sensitivity to data quality and relevance. On the other hand, large models show significant improvements with extended pre-training, whether used alone or in conjunction with instance selection. Notably, base models always experience improvements with some form of extension. This motivates the need for a cost-effectiveness analysis considering both absolute performance and relative improvements (Table 6) to determine the practicality of maintaining base versus large models.
Regarding new, unseen features, human evaluation indicates a substantial increase in the number of identified features with extended T-FREX design . Due to the large number of feature candidates in the dataset (i.e., tokens), a slight improvement in recall (+0 047, . c=1 XLNet large ) leads to a significant increase in potential new features in absolute numbers (1,956 vs. 11,120). Consequently, despite a slight drop in the precision of new features ( -0 017), . the much higher number of new feature mentions identified suggests a lower likelihood of missing important features. This trade-off supports a more exhaustive feature extraction process, as previously argued.
## 6.5 Threats to validity
For the elicitation of threats to validity, we rely on the taxonomy proposed by Wohlin (2014). Concerning construct validity , we rely on functional correctness metrics based on token classification performance at the token level. However, the feature extraction process is not evaluated in a real-world setting, where feature predictions are used for a particular purpose. Due to the
extensiveness of the empirical evaluation showcased in this research, we limited the scope of analysis to the feature extraction task, leading to future work on additional quality characteristics from ISO 25010, such as functional appropriateness or interaction capability of T-FREX as a component in a real mobile app review mining pipeline. In addition, the selection of f β is conditioned by the human evaluation results. Different experiments might lead to different β values. To reduce the threats imposed by this, we reported extended results including precision, recall and harmonized f 1 in addition to f β to facilitate replication in other contexts. Furthermore, we conducted a human evaluation with external annotators using a large set of reviews and multiple annotators (5 per task), increasing the reliability of results by using average values. Finally, our human evaluation uses non-developer participants, which may not fully reflect real-world expertise. To address this, we include precision and recall metrics alongside f β in our analysis for a balanced evaluation.
Concerning internal validity , the main threat comes from the ground truth dataset used for evaluation. Collected reviews from Google Play and AlternativeTo might be biased and conditioned by domain-specific particularities. Furthermore, the formalization of what constitutes a feature entails some bias, especially given the inconsistencies found in the literature (see Section 2.1). To mitigate this threat, we relied on and leveraged crowdsourced annotations made by real users in an industrial setting. We argue that our findings are then applicable to the concept of feature as being used in real settings, rather than providing or reusing a synthesized data set. In addition, we focused on the evaluation of one instance selection algorithm, as well as specific data partitions. This selection might have introduced some bias in the instance selection process. We limited the scope of analysis based on literature review and procuring resource optimization, validating the decisions and the design evaluated in this research. However, we acknowledge that other instance selection algorithms might produce similar - or even better - results.
Concerning external validity , we identify the generalization of research findings as the most compromised threat. Specifically, evaluation of different datasets, such as reviews from other repositories beyond Google Play, features from other sources beyond AlternativeTo, or even for different mobile app categories, might produce different outcomes. We built on previous, validated work to construct datasets for both fine-tuning and extended pre-training, increasing the confidence in the quality and representativeness of the domain of the data used for evaluation. Furthermore, results for model comparative analysis might not translate with different model architectures even with the same evaluation settings. Additionally, the generalization of the value of extended pre-training in the domain of mobile apps to other tasks (e.g., sentiment analysis) remains unexplored.
Finally, concerning conclusion validity , decisions and recommendations concerning best and worst models and settings for each scenario are conditioned and restricted to the results presented in this paper. To this end, for the TFREX baseline, we designed two different learning scenarios (i.e., in-domain vs. out-of-domain) to assess the validity of T-FREX across different contexts
of application. Furthermore, we exhaustively reported all metrics to facilitate decisions based on their applicability. While in this paper, for some settings, we limited the scope of these results (i.e., results for RQ 4 are limited to the best configuration in each setting), we provide the source code for all experiments and all tasks depicted in this research to replicate our evaluation. In addition, we provide data artefacts to verify extended results and complement the analytical insights presented in this research.
## 7 Related work
We structure related work based on two main areas of research. First, we cover automatic methods for NLP-based feature extraction from mobile app reviews. Second, we focus on empirical research depicting approaches to fine-tune LLMs for domain-specific token classification tasks.
## 7.1 Feature extraction
Dabrowski et al. recently conducted a systematic literature review in the field of mining app reviews for feedback analysis (Dabrowski et al., 2022). They identified feature extraction as a key task, for which they also conducted replication and comparative studies using multiple relevant approaches in the field (Dabrowski et al., 2023). The state-of-the-art in the field is mainly represented by syntactic-based approaches. While the SAFE approach is considered one of the standards (Johann et al., 2017), there are several related contributions published either as early work (Iacob et al., 2014; Guzman and Maalej, 2014; Gu and Kim, 2015), replication studies (Shah et al., 2019) or even as continual evolutions of the same approach (Dragoni et al., 2019). These methods are based on the use of syntactic properties, such as Part-of-Speech (PoS) tags and syntactic dependencies between elements in a given sentence. Using a pattern-matching approach, syntactic methods look for a series of predefined patterns compliant with typical formulations for a feature. Recent work in the field is still applying these methods for complex opinion mining NLP-based pipelines (Sutino and Siahaan, 2019; Song et al., 2020; Kasri et al., 2020; Al-Hawari et al., 2021; Kumari and Memon, 2022).
Recently, there have been some initial proposals based on leveraging LLMs to support the feature extraction task. TransFeatEx (Motger et al., 2023) uses a RoBERTa model for extracting syntactic annotations, to which then a syntactic pattern-matching approach can be applied. KEFE (Wu et al., 2021) uses PoS pattern-extracted features as input to a BERT model for classifying sentences are potential feature mentions. Their focus is on applying this technique to app descriptions, transferring potential feature matches to user reviews.
Despite extensive work in the field, several challenges posed by these strategies still remain. Performance on the correctness of extracted features is limited, especially when processing user reviews, leading to substantial noise (i.e.,
increased false positives) and missed features (i.e., increased false negatives) due to the various writing styles and grammatical inaccuracies found in reviews (Guzman and Maalej, 2014; Johann et al., 2017; Dragoni et al., 2019). Furthermore, evaluation strategies and ground truth are limited to instructed internal coders (Johann et al., 2017; Dabrowski et al., 2023). Our approach delves into these challenges by leveraging crowdsourced annotations by real users and transferring them into real user reviews. In addition to previous considerations, source code for these solutions is scarce (Dabrowski et al., 2022), and black-box integration is highly limited due to compatibility restrictions (both for syntactic-based and deep-learning-based solutions). We publish TFREX models on a collection of HuggingFace models ready to be used either for download or with the HuggingFace Inference API 15 , facilitating reusability and integration with other software components.
## 7.2 Token classification with LLMs
Hou et al. recently conducted a systematic literature review in the field of software engineering practices leveraging LLMs (Hou et al., 2024). Similarly, context-agnostic literature reviews on the generic use of LLMs index several contributions for token classification and NER tasks (Naveed et al., 2024; Zhao et al., 2023; Minaee et al., 2024). Several works showed that Transformer-based models trained for NER on common entities (e.g., locations, dates, names) have showcased promising results with respect to traditional ML methods methods (Xu et al., 2019; Souza et al., 2020). On the other hand, domain-specific studies have increasingly focused on leveraging LLMs for token classification, particularly in the medical domain. For instance, Tial et al. evaluated different Transformer-based NER models on free-text eligibility criteria from clinical trials (Tian et al., 2021). Liu et al. proposed Med-BERT, a medical-dictionaryenhanced BERT specifically tailored for performing NER on medical records (Liu et al., 2021).
On a closer domain, Malik et al. tested three Transformer models (i.e. BERT, RoBERTa and ALBERT) for software-specific entity extraction (Malik et al., 2022). Tabassum et al. instead fine-tuned BERT for a NER task on 20 fine-grained types of computing programming entities from Stack Overflow posts (Tabassum et al., 2020). Chen et al. proposed a BERT language representation model for extracting cybersecurity-related terms such as software, organizations and vulnerabilities from unstructured texts (Chen et al., 2021). Beyond these studies, token classification models leveraging LLMs in the field of software engineering are scarce. To the best of our knowledge, there is no related work using encoder-only LLMs for token classification in mobile app review mining to extract app-related entities.
15 https://huggingface.co/docs/api-inference/index
## 8 Conclusions and future work
In this study, we presented T-FREX, a feature extraction method in the context of mobile app reviews leveraging encoder-only LLMs. We redefined feature extraction as a NER task using crowdsourced annotations generated by real users in a real setting. Empirical evaluation of T-FREX baseline (RQ 1 ) showcases the potential of T-FREX with respect to previous approaches, improving both precision and recall of extracted features (H 1 ). In addition, extending the pre-training of such models with a large dataset of reviews (RQ 2 ) resulted in improved correctness of the predictions in almost all settings (H 2 ), with only a few epochs to achieve best results in the majority of scenarios. Furthermore, applying our proposal for feature-oriented instance selection (RQ 3 ) not only significantly improves the performance efficiency of the fine-tuning process (H ), but also increases the correctness of feature predictions in multiple sce3 narios, especially in the context of base models. Finally, while the combined use of instance selection and extended pre-training (RQ ) is not always the 4 best approach, it still improves the correctness of feature extraction while also improving the performance efficiency in most T-FREX settings.
As future work, we plan on evaluating the generalization of T-FREX models to other mobile app domains. Specifically, we want to explore its ability to generalize and extract features in emerging, disruptive domains, such as AI-based applications. Furthermore, we plan to explore generalization beyond the scope of mobile applications, such as desktop applications or APIs, and other user-generated documents, such as issues and bug reports. Finally, the functional appropriateness and suitability of T-FREX in a real-world setting remain to be explored, particularly its adoption within review mining pipelines for user feedback analysis. In conclusion, we envisage that both the methodological contributions as well as the set of T-FREX LLM instances (fine-tuned and with extended pre-training), which are publicly available, might assist future researchers and practitioners by integrating these models into their own review-based NLP pipelines for opinion mining and decision-making tasks where features are considered a core descriptor.
## Data Availability Statements
The source code and full app review datasets required for the replication of all experiments and the full evaluation artefacts are publicly available in the latest release of our GitHub repository: https://github.com/gessi-chatbots/ t-frex . The repository's README file includes references to the models published on HuggingFace, including fine-tuned models for feature extraction and LLMs with extended pre-training in the field of mobile app reviews.
## Conflict of Interest
The authors declared that they have no conflict of interest.
## Funding
With the support from the Secretariat for Universities and Research of the Ministry of Business and Knowledge of the Government of Catalonia and the European Social Fund. This paper has been funded by the Spanish Ministerio de Ciencia e Innovaci´n under project/funding scheme PID2020-117191RB-I00 o / AEI/10.13039/501100011033. This paper has been also supported by FAIR -Future AI Research (PE00000013) project under the NRRP MUR program funded by the NextGenerationEU.
## Ethical Approval
This study adhered to established ethical principles for research involving human participants. As data collection was fully anonymous and conducted through online platforms, formal ethical approval was not required.
## Informed Consent
All participants provided informed consent before participating in the study. They were informed about the research purpose, data usage, and their right to withdraw at any time. No personally identifiable information was collected.
## Author Contributions
Quim Motger : Conceptualization, Methodology, Software, Validation, Formal analysis, Investigation, Data Curation, Writing - Original Draft, Visualization. Alessio Miaschi : Conceptualization, Methodology, Validation, Investigation, Resources, Writing - Original Draft. Felice Dell'Orletta : Conceptualization, Methodology, Writing - Review & Editing, Supervision, Funding Acquisition. Xavier Franch : Conceptualization, Writing - Review & Editing, Supervision, Funding Acquisition. Jordi Marco : Conceptualization, Writing - Review & Editing, Supervision.
## References
Al-Hawari A, Najadat H, Shatnawi R (2021) Classification of application reviews into software maintenance tasks using data mining techniques. Software Quality Journal 29(3):667 - 703, DOI 10.1007/s11219-020-09529-8 Araujo AF, Gˆ olo MPS, Marcacini RM (2022) Opinion mining for app reviews: an analysis of textual representation and predictive models. Automated Software Engg 29(1), DOI 10.1007/s10515-021-00301-1
Berry DM (2021) Empirical evaluation of tools for hairy requirements engineering tasks. Empirical Software Engineering 26(6):111, DOI 10.1007/ s10664-021-09986-0
Broscheit S (2019) Investigating entity knowledge in BERT with simple neural end-to-end entity linking. In: Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), Hong Kong, China, pp 677-685, DOI 10.18653/v1/K19-1063
Carbonera JL (2017) An efficient approach for instance selection. In: Bellatreche L, Chakravarthy S (eds) Big Data Analytics and Knowledge Discovery, Cham, pp 228-243
Carbonera JL, Abel M (2015) A density-based approach for instance selection. In: 2015 IEEE 27th International Conference on Tools with Artificial Intelligence (ICTAI), pp 768-774, DOI 10.1109/ICTAI.2015.114
Carbonera JL, Abel M (2016) A novel density-based approach for instance selection. In: 2016 IEEE 28th International Conference on Tools with Artificial Intelligence (ICTAI), pp 549-556, DOI 10.1109/ICTAI.2016.0090
Cardellino C, Villata S, Alemany LA, Cabrio E (2015) Information extraction with active learning: A case study in legal text. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 9042:483 -494, DOI 10.1007/978-3-319-18117-2 36
Carrino CP, Llop J, P` amies M, Guti´ errez-Fandi˜o n A, Armengol-Estap´ e J, Silveira-Ocampo J, Valencia A, Gonzalez-Agirre A, Villegas M (2022) Pretrained biomedical language models for clinical nlp in spanish. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics, p 193 - 199
Chang E, Shen X, Yeh HS, Demberg V (2021) On training instance selection for few-shot neural text generation. In: ACL-IJCNLP 2021 - 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Proceedings of the Conference, vol 2, p 8 - 13
Chen N, Hoi SC, Li S, Xiao X (2016) Mobile app tagging. In: WSDM 2016 Proceedings of the 9th ACM International Conference on Web Search and Data Mining, p 63 - 72, DOI 10.1145/2835776.2835812
Chen Y, Ding J, Li D, Chen Z (2021) Joint bert model based cybersecurity named entity recognition. In: ACM International Conference Proceeding Series, p 236 - 242, DOI 10.1145/3451471.3451508
Cunha W, Viegas F, Fran¸ ca C, Rosa T, Rocha L, Gon¸ calves MA (2023) A comparative survey of instance selection methods applied to non-neural and transformer-based text classification. ACM Comput Surv 55(13s), DOI 10. 1145/3582000
Dabrowski J, Letier E, Perini A, Susi A (2022) Analysing app reviews for software engineering: a systematic literature review. Empirical Software Engineering 27(2):43, DOI 10.1007/s10664-021-10065-7
Dabrowski J, Letier E, Perini A, Susi A (2023) Mining and searching app reviews for requirements engineering: Evaluation and replication studies.
Information Systems 114:102181, DOI 10.1016/j.is.2023.102181
Dalpiaz F, Parente M (2019) Re-swot: From user feedback to requirements via competitor analysis. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 11412 LNCS:55 - 70, DOI 10.1007/978-3-030-15538-4 4
Devlin J, Chang MW, Lee K, Toutanova K (2019) BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota, pp 4171-4186, DOI 10.18653/v1/N19-1423
Dragoni M, Federici M, Rexha A (2019) An unsupervised aspect extraction strategy for monitoring real-time reviews stream. Information Processing & Management 56(3):1103-1118, DOI 10.1016/j.ipm.2018.04.010
Engstr¨m E, Storey MA, Runeson P, H¨ ost M, Baldassarre MT (2020) How o software engineering research aligns with design science: a review. Empirical Software Engineering 25(4):2630 - 2660, DOI 10.1007/s10664-020-09818-7
Fantechi A, Gnesi S, Passaro L, Semini L (2023) Inconsistency detection in natural language requirements using chatgpt: a preliminary evaluation. In: 2023 IEEE 31st International Requirements Engineering Conference (RE), pp 335-340, DOI 10.1109/RE57278.2023.00045
Ferrari A, Gori G, Rosadini B, Trotta I, Bacherini S, Fantechi A, Gnesi S (2018) Detecting requirements defects with nlp patterns: an industrial experience in the railway domain. Empirical Software Engineering 23(6):3684 - 3733, DOI 10.1007/s10664-018-9596-7
Ferraro A, Galli A, La Gatta V, Minocchi M, Moscato V, Postiglione M (2024) Few shot ner on augmented unstructured text from cardiology records. Lecture Notes on Data Engineering and Communications Technologies 193:1 12, DOI 10.1007/978-3-031-53555-0 1
Frattini J, Unterkalmsteiner M, Fucci D, Mendez D (2024) Nlp4re tools: Classification, overview, and management. URL https://arxiv.org/abs/2403. 06685 , 2403.06685
Gong Z, Zhou K, Zhao WX, Sha J, Wang S, Wen JR (2022) Continual pretraining of language models for math problem understanding with syntaxaware memory network. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics, vol 1, p 5923 -5933, DOI 10.18653/v1/2022.acl-long.408
Google (2024a) How google play works. URL https://play.google/ howplayworks/ , accessed: 2024-07-05
Google (2024b) Requesting app category changes in google play. URL https://support.google.com/googleplay/android-developer/ answer/9859673?hl=en , accessed: 2024-07-05
Gu X, Kim S (2015) 'what parts of your apps are loved by users?' (t). In: 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), pp 760-770, DOI 10.1109/ASE.2015.57
Guzman E, Maalej W (2014) How do users like this feature? a fine grained sentiment analysis of app reviews. In: 2014 IEEE 22nd International Requirements Engineering Conference (RE), pp 153-162, DOI 10.1109/RE. 2014.6912257
Harman M, Jia Y, Zhang Y (2012) App store mining and analysis: Msr for app stores. In: 2012 9th IEEE Working Conference on Mining Software Repositories (MSR), pp 108-111, DOI 10.1109/MSR.2012.6224306
Hassan S, Tantithamthavorn C, Bezemer CP, Hassan AE (2018) Studying the dialogue between users and developers of free apps in the google play store. Empirical Software Engineering 23(3):1275 -1312, DOI 10.1007/ s10664-017-9538-9
Hou X, Zhao Y, Liu Y, Yang Z, Wang K, Li L, Luo X, Lo D, Grundy J, Wang H (2024) Large language models for software engineering: A systematic literature review. URL https://arxiv.org/abs/2308.10620 , 2308.10620
Iacob C, Harrison R, Faily S (2014) Online reviews as first class artifacts in mobile app development. In: Memmi G, Blanke U (eds) Mobile Computing, Applications, and Services, pp 47-53
International Organization for Standardization (2023) ISO/IEC 25010:2023(en) Systems and software engineering - Systems and software Quality Requirements and Evaluation (SQuaRE) - Product quality model. URL https://www.iso.org/obp/ui/#iso:std:iso-iec:25010:ed-2: v1:en , accessed: 2024-07-25
Jiang G, Jiang C, Xue S, Zhang J, Zhou J, Lian D, Wei Y (2023) Towards anytime fine-tuning: Continually pre-trained language models with hypernetwork prompts. In: Bouamor H, Pino J, Bali K (eds) Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, pp 12081-12095, DOI 10.18653/v1/2023.findings-emnlp.808
Jiang H, He P, Chen W, Liu X, Gao J, Zhao T (2020) Smart: Robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics, p 2177 - 2190
Johann T, Stanik C, Alizadeh B AM, Maalej W (2017) Safe: A simple approach for feature extraction from app descriptions and app reviews. In: 2017 IEEE 25th International Requirements Engineering Conference (RE), pp 21-30, DOI 10.1109/RE.2017.71
Kang K, Cohen S, Hess J, Novak W, Peterson A (1990) Feature-Oriented Domain Analysis (FODA) Feasibility Study. Tech. Rep. CMU/SEI-90-TR021, Software Engineering Institute, Carnegie Mellon University
Kasri M, et al. (2020) A Comparison of Features Extraction Methods for Arabic Sentiment Analysis. In: 4th International Conference on Big Data and Internet of Things
Ke Z, Shao Y, Lin H, Konishi T, Kim G, Liu B (2023) Continual pre-training of language models. URL https://arxiv.org/abs/2302.03241 , 2302.03241 Kumari S, Memon ZA (2022) Extracting feature requests from online reviews of travel industry. Acta Scientiarum - Technology 44
Laranjo L, DIng D, Heleno B, Kocaballi B, Quiroz JC, Tong HL, Chahwan B, Neves AL, Gabarron E, Dao KP, Rodrigues D, Neves GC, Antunes ML, Coiera E, Bates DW (2021) Do smartphone applications and activity trackers increase physical activity in adults? systematic review, meta-analysis and metaregression. British Journal of Sports Medicine 55(8):422 - 432, DOI 10.1136/bjsports-2020-102892
- Li C, Huang L, Ge J, Luo B, Ng V (2018) Automatically classifying user requests in crowdsourcing requirements engineering. Journal of Systems and Software 138:108 - 123, DOI 10.1016/j.jss.2017.12.028
Liu N, Hu Q, Xu H, Xu X, Chen M (2021) Med-bert: A pretraining framework for medical records named entity recognition. IEEE Transactions on Industrial Informatics 18(8):5600-5608
Liu Y, Ott M, Goyal N, Du J, Joshi M, Chen D, Levy O, Lewis M, Zettlemoyer L, Stoyanov V (2019) RoBERTa: A Robustly Optimized BERT Pretraining Approach. URL https://arxiv.org/abs/1907.11692
Liu Z, He X, Liu L, Liu T, Zhai X (2023) Context matters: A strategy to pre-train language model for science education. Communications in Computer and Information Science 1831 CCIS:666 - 674, DOI 10.1007/ 978-3-031-36336-8 103
Lu T, Gui Y, Gao Z (2021) Learning document-level label propagation and instance selection by deep q-network for interactive named entity annotation. IEEE Access 9:39568 - 39586, DOI 10.1109/ACCESS.2021.3064054
Maalej W, Nabil H (2015) Bug report, feature request, or simply praise? on automatically classifying app reviews. In: 2015 IEEE 23rd International Requirements Engineering Conference (RE), pp 116-125, DOI 10.1109/RE. 2015.7320414
Malgaonkar S, Licorish SA, Savarimuthu BTR (2022) Prioritizing user concerns in app reviews -a study of requests for new features, enhancements and bug fixes. Information and Software Technology 144, DOI 10.1016/j.infsof.2021.106798
Malik G, Cevik M, Bera S, Yildirim S, Parikh D, Basar A (2022) Software requirement specific entity extraction using transformer models. In: Canadian AI
McIlroy S, Ali N, Hassan AE (2016a) Fresh apps: an empirical study of frequently-updated mobile apps in the google play store. Empirical Software Engineering 21(3):1346 - 1370, DOI 10.1007/s10664-015-9388-2
McIlroy S, Ali N, Khalid H, E Hassan A (2016b) Analyzing and automatically labelling the types of user issues that are raised in mobile app reviews. Empirical Software Engineering 21(3):1067 - 1106, DOI 10.1007/ s10664-015-9375-7
McZara J, Sarkani S, Holzer T, Eveleigh T (2015) Software requirements prioritization and selection using linguistic tools and constraint solvers-a controlled experiment. Empirical Software Engineering 20(6):1721 - 1761, DOI 10.1007/s10664-014-9334-8
Minaee S, Mikolov T, Nikzad N, Chenaghlu M, Socher R, Amatriain X, Gao J (2024) Large language models: A survey. URL https://arxiv.org/abs/
## 2402.06196 , 2402.06196
Moran M, Cohen T, Ben-Zion Y, Gordon G (2022) Curious instance selection. Information Sciences 608:794-808, DOI https://doi.org/10.1016/j.ins.2022. 07.025
Motger Q, Franch X, Marco J (2023) Mobile feature-oriented knowledge base generation using knowledge graphs. In: New Trends in Database and Information Systems - ADBIS 2023 Short Papers, Doctoral Consortium and Workshops: AIDMA, DOING, K-Gals, MADEISD, PeRS, Barcelona, Spain, September 4-7, 2023, Proceedings, Communications in Computer and Information Science, vol 1850, pp 269-279, DOI 10.1007/978-3-031-42941-5 \ 24 Motger Q, Franch X, Marco J (2024a) Mapp-kg: Mobile app knowledge graph for document-based feature knowledge generation. In: Islam S, Sturm A (eds) Intelligent Information Systems, pp 129-137
Motger Q, Miaschi A, Dell'Orletta F, Franch X, Marco J (2024b) T-frex: A transformer-based feature extraction method from mobile app reviews. URL https://arxiv.org/abs/2401.03833 , 2401.03833
Naveed H, Khan AU, Qiu S, Saqib M, Anwar S, Usman M, Akhtar N, Barnes N, Mian A (2024) A comprehensive overview of large language models. URL https://arxiv.org/abs/2307.06435 , 2307.06435
Onan A, Koruko˘ glu S (2016) Exploring performance of instance selection methods in text sentiment classification. Advances in Intelligent Systems and Computing 464:167 - 179, DOI 10.1007/978-3-319-33625-1 16
Palomba F, Linares-Vasquez M, Bavota G, Oliveto R, Di Penta M, Poshyvanyk D, De Lucia A (2015) User reviews matter! tracking crowdsourced reviews to support evolution of successful apps. In: 2015 IEEE 31st International Conference on Software Maintenance and Evolution, ICSME 2015 - Proceedings, p 291 - 300, DOI 10.1109/ICSM.2015.7332475
Perez E, Kiela D, Cho K (2021) True few-shot learning with language models. Advances in Neural Information Processing Systems 14:11054 - 11070
Ronanki K, Berger C, Horkoff J (2023) Investigating chatgpt's potential to assist in requirements elicitation processes. In: 2023 49th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), pp 354-361, DOI 10.1109/SEAA60479.2023.00061
Scalabrino S, Bavota G, Russo B, Penta MD, Oliveto R (2019) Listening to the crowd for the release planning of mobile apps. IEEE Transactions on Software Engineering 45(1):68 - 86, DOI 10.1109/TSE.2017.2759112
Schick T, Sch¨tze H (2021) It's not just size that matters: Small language u models are also few-shot learners. In: NAACL-HLT 2021 - 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Proceedings of the Conference, p 2339 - 2352
Shah FA, Sirts K, Pfahl D (2019) Is the safe approach too simple for app feature extraction? a replication study. In: Knauss E, Goedicke M (eds) Requirements Engineering: Foundation for Software Quality, Cham, pp 2136
Sharma S, Kumar D (2019) Agile release planning using natural language processing algorithm. In: Proceedings - 2019 Amity International Conference on Artificial Intelligence, AICAI 2019, p 934 - 938, DOI 10.1109/AICAI. 2019.8701252
Shaw M (2003) Writing good software engineering research papers. In: 25th International Conference on Software Engineering, 2003. Proceedings., pp 726-736, DOI 10.1109/ICSE.2003.1201262
Sleimi A, Sannier N, Sabetzadeh M, Briand L, Ceci M, Dann J (2021) An automated framework for the extraction of semantic legal metadata from legal texts. Empirical Software Engineering 26(3), DOI 10.1007/ s10664-020-09933-5
Song R, Li T, Ding Z (2020) Automatically identifying requirements-oriented reviews using a top-down feature extraction approach. In: Proceedings -Asia-Pacific Software Engineering Conference, APSEC, vol 2020-December, p 450 - 454, DOI 10.1109/APSEC51365.2020.00054
Souza F, Nogueira R, Lotufo R (2020) Portuguese named entity recognition using bert-crf. URL https://arxiv.org/abs/1909.10649 , 1909.10649 Statista (2024) Number of apps available in leading app stores as of 2024. URL https://www.statista.com/statistics/276623/ number-of-apps-available-in-leading-app-stores/ , accessed: 202407-05
- Stol KJ, Fitzgerald B (2018) The ABC of Software Engineering Research. ACM Trans Softw Eng Methodol 27(3), DOI 10.1145/3241743
- Sutino Q, Siahaan D (2019) Feature extraction from app reviews in google play store by considering infrequent feature and app description. Journal of Physics: Conference Series 1230, DOI 10.1088/1742-6596/1230/1/012007
Tabassum J, Maddela M, Xu W, Ritter A (2020) Code and named entity recognition in StackOverflow. In: Jurafsky D, Chai J, Schluter N, Tetreault J (eds) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, pp 4913-4926, DOI 10.18653/v1/2020.acl-main. 443
Tian S, Erdengasileng A, Yang X, Guo Y, Wu Y, Zhang J, Bian J, He Z (2021) Transformer-based named entity recognition for parsing clinical trial eligibility criteria. In: Proceedings of the 12th ACM Conference on Bioinformatics, Computational Biology, and Health Informatics, pp 1-6
van Vliet M, Groen EC, Dalpiaz F, Brinkkemper S (2020) Identifying and classifying user requirements in online feedback via crowdsourcing. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 12045 LNCS:143 - 159, DOI 10.1007/978-3-030-44429-7 11
Wiegers KE, Beatty J (2013) Software Requirements 3. Microsoft Press, USA Wilson DL (1972) Asymptotic properties of nearest neighbor rules using edited data. IEEE Transactions on Systems, Man, and Cybernetics SMC-2(3):408421, DOI 10.1109/TSMC.1972.4309137
Wilson DR, Martinez TR (2000) Reduction techniques for instance-based learning algorithms. Machine Learning 38(3):257-286, DOI 10.1023/A:
## 1007626913721
Wohlin C (2014) Guidelines for snowballing in systematic literature studies and a replication in software engineering. In: Proceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering Wu H, et al. (2021) Identifying key features from app user reviews. In: International Conference on Software Engineering
- Xu J, Wen J, Sun X, Su Q (2019) A discourse-level named entity recognition and relation extraction dataset for chinese literature text. URL https:// arxiv.org/abs/1711.07010 , 1711.07010
- Yang J, Jin H, Tang R, Han X, Feng Q, Jiang H, Yin B, Hu X (2023) Harnessing the power of llms in practice: A survey on chatgpt and beyond. URL https://arxiv.org/abs/2304.13712 , 2304.13712
- Yang Z, Dai Z, Yang Y, Carbonell J, Salakhutdinov RR, Le QV (2019) Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems 32
- Yıldız C, Ravichandran NK, Punia P, Bethge M, Ermis B (2024) Investigating continual pretraining in large language models: Insights and implications. URL https://arxiv.org/abs/2402.17400 , 2402.17400
Zhang L, Hua K, Wang H, Qian G, Zhang L (2014) Sentiment analysis on reviews of mobile users. Procedia Computer Science 34:458-465, DOI https://doi.org/10.1016/j.procs.2014.07.013, the 9th International Conference on Future Networks and Communications (FNC'14)/The 11th International Conference on Mobile Systems and Pervasive Computing (MobiSPC'14)/Affiliated Workshops
Zhao WX, Zhou K, Li J, Tang T, Wang X, Hou Y, Min Y, Zhang B, Zhang J, Dong Z, Du Y, Yang C, Chen Y, Chen Z, Jiang J, Ren R, Li Y, Tang X, Liu Z, Liu P, Nie JY, Wen JR (2023) A survey of large language models. URL https://arxiv.org/abs/2303.18223 , 2303.18223
- Zini JE, Awad M (2022) On the explainability of natural language processing deep models. ACM Computing Surveys 55(5), DOI 10.1145/3529755 | null | [
"Quim Motger",
"Alessio Miaschi",
"Felice Dell'Orletta",
"Xavier Franch",
"Jordi Marco"
] | 2024-08-02T07:31:57+00:00 | 2025-02-05T14:42:36+00:00 | [
"cs.CL",
"cs.SE"
] | Leveraging Encoder-only Large Language Models for Mobile App Review Feature Extraction | Mobile app review analysis presents unique challenges due to the low quality,
subjective bias, and noisy content of user-generated documents. Extracting
features from these reviews is essential for tasks such as feature
prioritization and sentiment analysis, but it remains a challenging task.
Meanwhile, encoder-only models based on the Transformer architecture have shown
promising results for classification and information extraction tasks for
multiple software engineering processes. This study explores the hypothesis
that encoder-only large language models can enhance feature extraction from
mobile app reviews. By leveraging crowdsourced annotations from an industrial
context, we redefine feature extraction as a supervised token classification
task. Our approach includes extending the pre-training of these models with a
large corpus of user reviews to improve contextual understanding and employing
instance selection techniques to optimize model fine-tuning. Empirical
evaluations demonstrate that this method improves the precision and recall of
extracted features and enhances performance efficiency. Key contributions
include a novel approach to feature extraction, annotated datasets, extended
pre-trained models, and an instance selection mechanism for cost-effective
fine-tuning. This research provides practical methods and empirical evidence in
applying large language models to natural language processing tasks within
mobile app reviews, offering improved performance in feature extraction. |
2408.01065v1 | ## COMPUTATION OF γ -LINEAR PROJECTED BARCODES FOR MULTIPARAMETER PERSISTENCE
ALEX FERNANDES, STEVE OUDOT, AND FRANÇOIS PETIT
Abstract. The γ -linear projected barcode was recently introduced as an alternative to the well-known fibered barcode for multiparameter persistence, in which restrictions of the modules to lines are replaced by pushforwards of the modules along linear forms in the polar of some fixed cone γ . So far, the computation of the γ -linear projected barcode has only been studied in the functional setting, in which persistence modules come from the persistent cohomology of R n -valued functions. Here we develop a method that works in the algebraic setting directly, for any multiparameter persistence module over R n that is given via a finite free resolution. Our approach is similar to that of RIVET: first, it pre-processes the resolution to build an arrangement in the dual of R n and a barcode template in each face of the arrangement; second, given any query linear form u in the polar of γ , it locates u within the arrangement to produce the corresponding barcode efficiently. While our theoretical complexity bounds are similar to the ones of RIVET, our arrangement turns out to be simpler thanks to the linear structure of the space of linear forms. Our theoretical analysis combines sheaf-theoretic and module-theoretic techniques, showing that multiparameter persistence modules can be converted into a special type of complexes of sheaves on vector spaces called conic-complexes , whose derived pushforwards by linear forms have predictable barcodes.
## Contents
| 1. | Introduction | 2 |
|------|---------------------------------------------------------------------|-----|
| 1.1. | Context | 2 |
| 1.2. | Our contributions | 3 |
| 2. | Preliminaries | 5 |
| 2.1. | Free resolutions of persistence modules | 5 |
| 2.2. | γ -topology and γ -sheaves | 6 |
| 2.3. | From persistence modules to Alexandrov sheaves | 6 |
| 2.4. | γ -sheaves and Alexandrov sheaves | 7 |
| 2.5. | One-dimensional persistence modules and γ -linear projected barcode | 7 |
Key words and phrases. multi-parameter persistence; fibered barcode; sheaf theory.
A.F was partially supported by the French Agence Nationale de la Recherche through the project reference ANR-22-CPJ1-0047-01 and by the Fondation Sciences Mathematiques de Paris through the Paris Graduate School for Mathematical Sciences scholarship.
F.P. was supported by the French Agence Nationale de la Recherche through the project reference ANR-22-CPJ1-0047-01.
## 2 ALEX FERNANDES, STEVE OUDOT, AND FRANÇOIS PETIT
| 3. | Conic complexes and their basic properties | 8 |
|-----------------------------------------------------|------------------------------------------------------------------|-----|
| 3.1. | Definitions and basic properties | 8 |
| 4. | Multiparameter conic complexes from free resolutions | 11 |
| 5. | Direct images of finite conic-complexes | 14 |
| 6. | From 1-d conic complexes to filtered cochain complexes | 15 |
| 6.1. | From finite conic-complexes to filtered finite cochain complexes | 15 |
| 7. | Extension of the persistence algorithm | 17 |
| 7.1. | Simplex-wise filtered cochain complexes | 18 |
| 7.2. | From arbitrary finite filtrations to simplex-wise filtrations | 19 |
| 7.3. | Persistence algorithm on simplex-wise filtered cochain complexes | 20 |
| 8. | Algorithm for projected barcode | 20 |
| 8.1. | Arrangement of hyperplanes and point location | 21 |
| 8.2. | Projected barcode template | 22 |
| 8.3. | Queries | 23 |
| 8.4. | The special case of 2-parameter persistence modules | 23 |
| 9. | Example | 24 |
| 10. | Experiments | 28 |
| 10.1. | Setup | 28 |
| 10.2. | Results | 29 |
| References | References | 31 |
| Appendix A. Technical supplement | Appendix A. Technical supplement | 32 |
| A.1. | Derived functors between derived categories | 32 |
| A.2. | Verdier duality | 32 |
| Appendix B. Details of the procedure of Section 7.2 | Appendix B. Details of the procedure of Section 7.2 | 33 |
## 1. Introduction
1.1. Context. Persistence theory studies the topological variations within a filtered family of topological spaces, and it encodes these variations in an algebraic object called a persistence module. When the filtered family of spaces is indexed over R (or, more generally, over a totally ordered set), the theory is well understood, and the resulting persistence modules admit a complete descriptor called the barcode. But when the indexing set of the family is R n for some n ≥ 2 (or, more generally, a partially ordered set), the situation is far more complex, and the direct generalization of the notion of barcode as the collection of indecomposable summands of the persistence modules is extremely complex which poses several pratical challenges. This has been a major hindrance to the the use of multiparameter persistence in applications.
Several approaches have been proposed to overcome this difficulty, in particular the resort to incomplete descriptors that are comparatively easy to compute and to interpret. Among these, the fibered barcode [8] stands out as one that can be both efficiently computed and nicely represented (at least for 2-parameter
persistence modules) thanks to the software RIVET [20]. The fibered barcode of a persistence module M is defined as the collection of barcodes obtained by considering restrictions of M to affine lines of positive slopes. As an incomplete descriptor, it cannot distinguish between certain pairs of non-isomorphic persistence modules, even some that are particularly simple [25]. An approach to tackle this blind spot would be to enrich the construction of the fibered barcode with a larger class of operations than just restrictions. This is where the idea of turning persistence modules into sheaves comes into the picture, which has the great benefit of allowing then for the use of classical sheaf operations that are unavailable in the persistence modules framework.
This was the idea pursued by the authors of [4], who introduced the concept of projected barcode of an n -parameter persistence module, defined as the collection of derived pushforwards-in a sheaf-theoretic sense-of the module along maps R n → R from a prescribed family F . Interestingly, this concept encompasses the usual fibered barcode as a special case [4, Corollary 5.14] and thus yields a strictly stronger descriptor if a large enough family F is used. It also enjoys some stability properties akin to the ones enjoyed by the fibered barcode. In addition, despite its mathematically involved definition, the projected barcode along individual maps u : R n → R turns out to be very simple to compute when the input module encodes the persistent homology of some R n -valued function f : indeed, in this case, it is given essentially by the usual 1-parameter persistent cohomology of the composition u ◦ f . Thus, the sheaf-theoretic framework developed in [4] provides the algebraic foundation to an otherwise very simple and natural idea to cope with the multi-parameter persistent homology of R n -valued functions, which is to reduce the dimensionality of the problem via post-composition by multiple projections R n → R .
This framework, as appealing as it may sound, remains nonetheless limited in two important ways: (1) it is practical only in the functional setting, where derived pushforwards translate into post-compositions; (2) it only allows for the "pointwise" evaluation of the projected barcode, e.g., the computation of pushforwards along individual maps R n → R . It does not provide a description of the projected barcode as a whole over the family F . By contrast, the entire combinatorial structure of the usual fibered barcode can be encoded as a finite arrangement of hyperplanes augmented with barcode templates in its faces, as described in [20] and exploited first in RIVET then in subsequent work on computing the associated matching distance [7, 19]. Our goal here is to lift these two limitations, largely taking inspiration from what has been done in RIVET for the fibered barcode.
- 1.2. Our contributions. As our goal is arguably hard (if at all possible) to achieve for arbitrary families F of maps R n → R , we restrict our focus to a particular family, composed of linear forms of operator norm 1, more precisely, of those unitary linear forms that are located in the polar of some fixed cone γ in the
dual of R n . There are several good reasons for considering this particular family: first, the corresponding pushforwards can be defined in the derived category of γ -sheaves, which naturally connects to the category of persistence modules [17, 5]; second, the resulting projected barcode, called the γ -linear projected barcode , has a combinatorial structure that is simple enough to be encoded in a way similar to that of the fibered barcode; finally, the γ -linear projected barcode has been shown in [4] to nicely complement the fibered barcode, as each is able to discriminate between different sets of pairs of non-isomorphic persistence modules-see [4, Section 5.1] for an example where the projected barcode is more discriminating, and for an example where the fibered barcode is more discriminating take an interval module supported on an infinite left-open vertical band.
At the heart of our contribution is an algorithm to pre-process a finitely presented n -parameter persistence module M (given through some pre-computed finite free resolution) into an augmented arrangement à la RIVET that encodes the combinatorial structure of its γ -linear projected barcode entirely. This algorithm is completed by a routine that can efficiently compute the projected barcodes of M along individual query linear forms in F . A notable feature of our augmented arrangement is to be lower-dimensional than the one defined for the fibered barcode; this is particularly interesting in the 2-parameter case, where our arrangement becomes 1-dimensional and is therefore simpler to build and to query than the one used in RIVET in practice, even though the worst-cast complexity bounds are similar. The details of our algorithm and of its associated query routine are given in Section 8. They rely on several new mathematical concepts and results, introduced in Sections 3 and 7:
- · the concept of conic-complex (Definition 3.2), a special type of γ -complex of sheaves on R n , in which the terms have a very simple structure akin to that of free persistence modules;
- · the fact that the module-sheaf correspondence functor introduced in [5, 17] sends the free resolution of our input persistence module to a coniccomplex, and that a finitely presentable persistence module can be unambiguously recovered from its associated γ -sheaf (Proposition 4.1, Proposition 4.3 and Proposition 4.6 (2.));
- · the fact that the derived pushforward along any linear form u sends this conic-complex on R n to a conic-complex on R , with a one-to one correspondence between the summands of the two complexes (Theorem 5.1);
- · the concept of simplex-wise filtered cochain complex (Definition 7.1), an axiomatization of the usual filtered simplicial cochain complexes arising in persistence, which allows for the use of matrix reduction in order to compute barcodes;
- · the fact that our conic-complexes on R can be turned into simplex-wise filtered cochain complexes, with a predictable effect on their barcode (Propositions 6.2 and 7.6, Theorem 6.4).
These new ingredients combine sheaf-theoretic and module-theoretic techniques, and down the road they produce an effective algorithmic way to enhance the popular software RIVET for multi-parameter topological data analysis. We believe that this interdisciplinarity is a notable aspect of our work.
In Section 9, we detail a running example of our algorithm on a handcrafted persistence module and in Section 10 we report some experimental results on point cloud data. The code is available https://github.com/alexfrnds/conic-complex.
## 2. Preliminaries
Let k be a field. We denote by Mod( k ) the category of k -vector spaces. Let X be a topological space, and let k X be the constant sheaf on X , that is, the sheaf of locally constant functions on X . We write Mod( k X ) for the category of sheaves of k -vector spaces on X . Moreover, let Ch k ( ) (resp. Ch k ( X )) be the category of cochain complexes of Mod( k ) (resp. Mod( k X )). Following the notations of [15], let Ch ∗ ( k ) (resp. Ch ∗ ( k X )) with ∗ = b , + , -denote the full subcategories of bounded, bounded below, bounded above complexes, respectively. Finally, let D k ( X ) (resp. D k ( )) be the derived category of Mod( k X ) (resp. Mod( k )), whose objects will merely be called sheaves. Again, D k ∗ ( X ) with ∗ = b , + , -denotes the full subcategory of D k ( X ) spanned by bounded, bounded below, bounded above objects of D k ( X ), respectively.
Throughout the paper, we use the six Grothendieck operations freely, with respective notations H om (internal Hom), ⊗ (tensor product), u ∗ (direct image or pushforward), u ! (proper direct image), u -1 (inverse image or pullback), u ! (exceptional inverse image). We refer the reader to [15, Chapters 2 and 3] for definitions of these operations.
2.1. Free resolutions of persistence modules. Let ( P ≤ , ) be a poset, viewed as a small thin category. Persistence modules over P are functors P → Mod( k ). They form a Grothendieck abelian category, denoted by Mod( k ) P . Unless otherwise mentioned, all persistence modules will be assumed pointwise finite dimensional (pfd). A persistence module M is free if it admits a decomposition:
$$M \simeq \bigoplus _ { b \in \mathcal { M } } \mathbf k ^ { \text{up} ( b ) }, \text{ with } \mathbf k ^ { \text{up} ( b ) } ( x ) \coloneqq \begin{cases} \mathbf k \text{ if } b \leq x, \\ 0 \text{ otherwise} \end{cases}$$
where M is a multiset of elements of P and the structural morphisms k → k in k up( ) b are identities. A free resolution of a persistence module M is the data of a cochain complex L composed of free persistence modules and concentrated on non-positive degrees, together with an augmentation morphism L 0 → M , such that the following complex is exact: · · · → L -1 → L 0 → M → 0 →··· . It follows from Hilbert's syzygy theorem that every finitely presented persistence module over R n admits finite free resolutions.
↦
2.2. γ -topology and γ -sheaves. Let V be a finite-dimensional real vector space equipped with the Euclidean topology, and let a : x → -x be the antipodal map. Following the notation of [17], for any subset A ⊂ V the antipodal of A is denoted by A a := a A ( ) = -A . Meanwhile, int( A ) and A stand respectively for the Euclidean interior and the Euclidean closure of A .
A cone is a non-empty subset of V that is invariant by non-negative scaling. Its polar cone is defined by: C ◦ := { η ∈ Hom( V k , ) | ∀ c ∈ C : η c ( ) ≥ 0 } . A cone C is proper if it is convex, pointed (i.e., C a ∩ C = { } 0 ) and solid (i.e., with non-empty interior).
From now on, let γ be a proper cone. An open subset Ω of V is called γ -open if it is γ -invariant , i.e., Ω + γ = Ω. The γ -open subsets of V form a topology on V , called the γ -topology , and V γ stands for V equipped with this topology. Furthermore, the collection { x + int( γ ) } x ∈ V forms a basis for the γ -topology on V . The continuous map φ γ : V → V γ whose underlying application is the identity, yields an equivalence of triangulated categories [17, Theorem 1.5]: φ -1 γ : D k b ( V γ ) ⇄ D b γ ◦ ,a ( k V ) : R φ γ ∗ , where D b γ ◦ ,a ( k V ) is the full subcategory of D k b ( V ) consisting of objects with microsupport contained in V × γ ◦ ,a (We do not recall the notion of microsupport as it is neither used nor necessary to understand the present paper and refer the curious reader to [15, Chapter5]).
↦
2.3. From persistence modules to Alexandrov sheaves. Let ( X, ≤ ) be a poset and let X a denote the set X equipped with the Alexandrov topology on ( X, ≤ ), i.e., the topology whose open sets are the ≤ -lower closed sets U ⊆ X . The choice of γ induces a partial order on V given by x ≤ γ y if x + γ ⊆ y + γ . Let V a stand for V equipped with the Alexandrov topology induced by ≤ γ , and let Mod( k V a ) denote the category of sheaves of k -vector spaces on V a . The poset ( V , ≤ γ ) can also be equipped with the trivial Grothendieck topology turning it into the site denoted by V ≤ γ (see [16] for sheaves on Grothendieck topologies). Then, Fun(( V , ≤ γ ) op , Mod( k )) is the category of sheaves over V ≤ γ and is denoted by Mod( V ≤ γ ). There is a morphism of sites θ : V a → V ≤ given by the functor θ t : x → x + γ , which yields an equivalence of categories [12, Theorem 4.2.10]:
$$\theta _ { * } \colon \text{Mod} ( \mathbf k _ { \mathbf v _ { a } } ) \Longrightarrow \text{Mod} ( \mathbf V _ { \leq \gamma } ) \colon \theta ^ { - 1 }.$$
Notice also that ( V , ≤ γ ) op is equivalent to V endowed with the opposite order ≤ op γ . This yields trivially an equivalence Mod( V ≤ γ ) /similarequal Fun(( V , ≤ op γ ) , Mod( k )). When V = R n and γ = [0 + , ∞ ) n , the order ≤ op γ corresponds to the order product on R n , denoted by ≤ , and then Fun(( V , ≤ op γ ) , Mod( k )) is what is usually called the category of persistence modules on R n (not necessarily pfd). We will use interchangeably the term persistence module to designate the objects of Mod( V ≤ γ ) and of Fun(( V , ≤ op γ ) , Mod( k )). We say that F ∈ Mod( k V a ) is finitely presentable if the persistence module θ F ∗ is finitely presentable.
- 2.4. γ -sheaves and Alexandrov sheaves. In [5], the authors define two morphisms of sites: α : V γ → V a and β : V a → V γ , given respectively by the following functors:
↦
↦
$$\alpha ^ { t } \colon & \text{Op} ( \mathbf V _ { \mathbf a } ) \to & \text{Op} ( \mathbf V _ { \gamma } ) \quad \ x + \gamma \mapsto x + \text{int} ( \gamma ), \\ \beta ^ { t } \colon & \text{Op} ( \mathbf V _ { \gamma } ) \to & \text{Op} ( \mathbf V _ { \mathbf a } ) \quad \ x + \text{int} ( \gamma ) \mapsto x + \text{int} ( \gamma ).$$
These morphisms of sites establish a link between γ -sheaves and Alexandrov sheaves through the following two adjunctions:
$$\alpha ^ { - 1 } \colon \text{Mod} ( \mathbf k _ { \mathbf v _ { \mathbf a } } ) \Longrightarrow \text{Mod} ( \mathbf k _ { \mathbf v _ { \gamma } } ) \colon \text{R} \alpha _ { * },$$
$$\beta ^ { - 1 } \colon \text{Mod} ( \mathbf k _ { \mathbf v _ { \gamma } } ) \Rightarrow \text{Mod} ( \mathbf k _ { \mathbf v _ { \mathbf a } } ) \colon \beta _ { * }.$$
The functors α -1 , β ∗ are isomorphic to each other, and α ∗ , β -1 are fully faithful. These functors can be derived which yields
$$\beta _ { * } = \alpha ^ { - 1 } \colon \mathbf D ($$
The functors R α ∗ and β -1 are fully faithful.
2.5. One-dimensional persistence modules and γ -linear projected barcode. We denote by D b R c ( k V ) the full triangulated subcategory of D k b ( V ) consisting of objects F whose cohomology groups H ( k F ), k ∈ Z , are R -constructible sheaves. A reference on constructible sheaves is [15, section VIII.8.4].
From now on, we assume that the cone γ is subanalytic in V . Let D b R c ( k V ∞ ) stand for the full triangulated subcategory of D b R c ( k V ) consisting of sheaves constructible up to infinity , that is: sheaves whose microsupport is subanalytic in T ∗ P , where j : V → P = P n ( V ⊕ R ) , j ( x ) := [ x : 1] is the projectivization of V (see [23] for an extensive exposition on constructible sheaves up to infinity).
We now assume that V is endowed with a subanalytic norm || · || [6], and we let S ∗ be the unit sphere in V ∗ equipped with the operator norm associated to ||·|| . In [4, section 5], the authors introduce the γ -linear projected barcode as the functor:
↦
$$( 2. 1 ) \ \mathcal { P } ^ { \gamma } \, \col$$
Remark 2.1. (i) In the definition of the projected barcode, we only consider the pushforward of a sheaf by linear forms. Indeed the pushforward by an affine map can be decomposed as the pushforward by a linear map followed by the pushforward by a translation. The pushforward by the translation does not alter the structure of the barcode, as it merely shifts the barcode. This differs from the situation encountered with the fibered barcode. The fibered barcode is defined as the pullback of sheaves or persistence modules along affine maps. Although it is possible to restrict to pullbacks by linear forms, it is not possible to reconstruct the pullbacks by affine maps from the linear ones. This is a major difference between the projected and fibered barcodes.
- (ii) In the definition of the γ -linear projected barcode, it is sufficient to only consider linear forms in int( γ ◦ ). This comes from [4, Proposition 4.5], which shows that ignoring forms in V ∗ \ (int( γ ◦ ) ∪ int( γ ◦ ,a )) is harmless as these forms do not bring any information. Finally, since the barcodes produced by two colinear non-zero linear forms differ by a homothety it is possible to restrict to int( γ ◦ ) ∩ S ∗ without loosing any information.
The projected barcode takes advantage of the following facts.
Theorem 2.2 ([17, Thm. 1.17]) . For any sheaf F in Mod R c ( k R ) , there exists a unique locally finite multiset B ( F ) of intervals of R , called the barcode of F , such that: F /similarequal ⊕ I ∈ B ( F ) k I .
The functor α -1 θ -1 associates to any persistence module M a sheaf α -1 θ -1 M . On R , if M is pfd then φ -1 γ α -1 θ -1 M is constructible and therefore (by Theorem 2.2) admits a barcode, called the observable barcode and denoted by B ( M ). Note that this barcode coincides with the barcode of M in the observable category [9], not with the usual barcode B ( M ) coming from M 's direct-sum decomposition [11].
A sheaf F in D b R c ( k R ) is isomorphic to the direct sum of its shifted cohomology groups, i.e.: F /similarequal ⊕ i ∈ Z H ( i F )[ -i . ] In particular, the graded barcode B ( F ) := { B d ( F ) := B (H ( j F )) } j ∈ Z introduced in [3] is a complete discrete invariant of the isomorphism class of F .
## 3. Conic complexes and their basic properties
- 3.1. Definitions and basic properties. Conic-complexes are a class of sheaves that arise naturally from free resolutions of persistence modules. Here we define conic-complexes and derive some of their basic properties.
Definition 3.1. A closed (resp. open) γ -complex is an object of Ch + ( k V ) (resp. Ch -( k V )) denoted γ { J } (resp. int( γ ) { J } ) of the form:
$$\begin{array} {$$
where the J i for i ∈ N are multisets of V . The elements of the multiset J = ⋃ + ∞ i =0 J i are called generators .
Definition 3.2. A conic-complex refers to a closed or open γ -complex. A coniccomplex is bounded if it is a bounded cochain complex, locally finite if for any i ∈ N the multiset J i is finite, and finite if it is both locally finite and bounded.
Definition 3.3. Let F be a sheaf in Mod( k V ). An open γ -resolution of F is the data of an open γ -complex int( γ ) { J } with an augmentation morphism
η : (int( γ ) { J } ) 0 → F such that the following complex of Mod( k V ) is exact:
$$\cdots \to \bigoplus _ { j _ { 2 } \in J _ { 2$$
We will use duality for sheaves. Based on the notation of [15, Definition 3.1.16], the dualising complex is written ω V := a ! V k for a V : V →∗ , and for any sheaf F in D k b ( V )
$$\mathsf D _ { \mathbf V } \mathcal { F } \coloneqq \$$
Lemma 3.4. Let b ∈ V . Then, D ′ V k b + γ /similarequal k b +int( γ ) and D ′ V k b +int( γ ) /similarequal k b + γ .
Proof. The statement follows from [15, Exercise III.4] after observing that b + γ is convex hence locally cohomologically trivial. We refer the reader to Appendix A.2 for a brief overview and precise reference on the notion locally cohomologically trivial open sets. □
Proposition 3.5. The following isomorphisms hold in D k b ( V ) :
$$D ^ { \prime } _ { \mathbf V } ( \gamma \{ J \} ) \simeq \text{int} ( \gamma ) \{ J \}, \quad D ^ { \prime } _ { \mathbf V } ( \text{int} ( \gamma ) \{ J \} ) \simeq \gamma \{ J \}.$$
Proof. The functor D ′ V preserves finite direct sums, so for any multiset J it follows from Lemma 3.4 that:
$$D ^ { \prime } _ { \mathbf v } \left ( \bigoplus _ { j \in J } \mathbf k _ { j + \gamma } \right ) \simeq \bigoplus _ { j \in J } D ^ { \prime } _ { \mathbf v } ( \mathbf k _ { j + \gamma } ) \simeq \bigoplus _ { j \in J } \mathbf k _ { j + \text{int} ( \gamma ) }.$$
In particular, for any integer i , the object γ { J } i is H om ( -, k V )-acyclic, therefore the statement follows from Lemma A.1. This proof works for the second statement mutatis-mutandis □
Proposition 3.6. Let L be a finite conic-complex. Then, L is constructible up to infinity. In particular, if L is a finite conic-complex on R , the multiset B k ( L ) is finite for every k ∈ Z .
Proof. Since b + γ is subanalytic for any b ∈ V , it follows from [15, Definition 8.4.3 & Theorem 8.4.2 ] that the sheaf k b + γ is R -constructible. Moreover, it follows from [23, Lemma 2.19] that b + γ is subanalytic up to infinity, and given the projectivization map j : V ↣ P , we have j ! k b + γ /similarequal k b + γ . Therefore, the sheaf k b + γ is subanalytic up to infinity, by [23, Lemma 2.7]. This implies that L itself is constructible up to infinity. Then, by [23, Lemma 2.7 (c)], the multiset B k ( L ) is finite for every k ∈ Z . □
Lemma 3.7. Let b, c ∈ V . The following isomorphisms hold in D k b ( V ) :
$$R \mathcal { H } o m \left ( \mathbf k _ { b + \gamma }, \mathbf k _ { c + \gamma } \right ) \simeq D ^ { \prime } _ { \mathbf V } ( \mathbf k _ { b + \gamma \cap c + \text{int} ( \gamma ) } ),$$
$$R \mathcal { H } o m \left ( \mathbf k _ { b + \text{int} ( \gamma ) }, \mathbf k _ { c + \text{int} ( \gamma ) } \right ) \simeq D _ { \mathbf V } ^ { \prime } ( \mathbf k _ { c + \gamma \cap b + \text{int} ( \gamma ) } ).$$
Proof. It follows from [15, Proposition 2.6.3] that:
$$R \mathcal { H } o m \left ( \mathbf k _ { b + \gamma }, \mathbf k _ { c + \gamma } \right ) & \simeq R \mathcal { H } o m \left ( \mathbf k _ { b + \gamma } \otimes \mathbf k _ { c + \int ( \gamma ) }, \mathbf k _ { \mathbf V } \right ) \\ & \simeq R \mathcal { H } o m \left ( \mathbf k _ { b + \gamma \cap c + \int ( \gamma ) }, \mathbf k _ { \mathbf V } \right ) \\ & \simeq D _ { \mathbf V } ^ { \prime } ( \mathbf k _ { b + \gamma \cap c + \int ( \gamma ) } ).$$
The proof of the second statement is similar and therefore omitted.
□
Proposition 3.8. Let b, c ∈ V . Then, the following isomorphisms holds in D k b ( ) :
$$R H o m \left ( \mathbf k _ { b + i n t ( \gamma ) }, \mathbf k _ { c + i n t ( \gamma ) } \right ) \simeq \begin{cases} \mathbf k \text{ if } b \leq _ { \gamma } c, \\ 0 \text{ otherwise} \end{cases} \ R H o m \left ( \mathbf k _ { b + \gamma }, \mathbf k _ { c + \gamma } \right ) \simeq \begin{cases} \mathbf k \text{ if } b \geq _ { \gamma } c, \\ 0 \text{ otherwise}. \end{cases}$$
Proof. Let b and c ∈ V . We first notice that the closed case follows from the open case. Indeed,
$$R \mathcal { H } o m \left ( \mathbf k _ { c + \gamma }, \mathbf k _ { b + \gamma } \right ) \simeq D ^ { \prime } _ { \mathbf V } ( \mathbf k _ { c + \gamma \cap b + i n t ( \gamma ) } ) \simeq R \mathcal { H } o m \left ( \mathbf k _ { b + i n t ( \gamma ) }, \mathbf k _ { c + i n t ( \gamma ) } \right ).$$
Applying the global section functor to the above isomorphism yields
$$R H o m \left ( k _ { c + \gamma }, k _ { b + \gamma } \right ) \simeq R H o m \left ( k _ { b + i n t ( \gamma ) }, k _ { c + i n t ( \gamma ) } \right ).$$
Hence, we only prove the open case. We distinguish two cases. Assume that b +int( γ ) ⊂ c +int( γ ). Then,
$$R \text{Hom} \left ( \mathbf k _ { b + i n ( \gamma ) }, \mathbf k _ { c + i n ( \gamma ) } \right ) & \simeq R \text{Hom} \left ( \mathbf k _ { b + i n ( \gamma ) }, \mathbf k _ { c + i n ( \gamma ) } | _ { b + i n ( \gamma ) } \right ) \\ & \simeq R \Gamma ( b + i n ( \gamma ), \mathbf k _ { b + i n ( \gamma ) } )$$
Since b +int( γ ) is contractible, it follows that RΓ( b +int( γ , ) k b +int( γ ) ) /similarequal k . Hence, RHom( k b +int( γ ) , k c +int( γ ) ) /similarequal k .
(2) Assume that b +int( γ ) is not included in c +int( γ ).
Let w ∈ int( γ ) and consider the convex open set B = -w +int( γ ) ∩ w +int( γ ) a . By construction, we have B + γ = int( γ ). Since b + int( γ ) is not included in c +int( γ ), we can further assume, up to rescaling B , that b + B ∩ c +int( γ ) = ∅ . We have
$$R H o m \left ( k _ { b + i n t ( \gamma ) }, k _ { c + i n t ( \gamma ) } \right ) & \simeq R \Gamma ( b + i n t ( \gamma ), k _ { c + i n t ( \gamma ) } ) \\ & \simeq R \Gamma ( b + B + \gamma, k _ { c + i n t ( \gamma ) } ) \\ & \simeq R \Gamma ( b + B, k _ { c + i n t ( \gamma ) } ) \quad [ 1 5, \text{ Prop. } 3. 5. 3 \ ( i ) ] \\ & \simeq R H o m \left ( k _ { b + B }, k _ { c + i n t ( \gamma ) } | _ { b + B } \right ) \\ & \simeq 0.$$
## 4. Multiparameter conic complexes from free resolutions
If X is a topological space, then for any locally closed subset A ⊆ X we denote by k A the constant sheaf on X with stalk k on A and 0 elsewhere. If X = V , then, to avoid confusion, we write k A (resp. k A γ , k A a ) when A is considered as a locally closed subset of V (resp. V γ , V a ). Let A, Ω and F be respectively locally closed, open, and closed subsets of V a .
Proposition 4.1. The following identity holds: α -1 k Ω ∩ F /similarequal k (int(Ω) ∩ F ) γ .
Proof. Since inverse images are monoidal, it is sufficient to show that
$$\alpha ^ { - 1 } k _ { \Omega } \simeq k _ { \text{int} ( \Omega ) _ { \gamma } }, \quad \alpha ^ { - 1 } k _ { F } \simeq k _ { ( \overline { F } ) _ { \gamma } }.$$
$$\ast$$
We start by proving the first formula. For any open set U of a topological space X , we write i U for the natural morphism of presites U → X . We denote by α Ω : int(Ω) → Ω the morphism of sites induced by α : V γ → V a . It is well-defined since α t (Ω) = int(Ω). We now consider the following commutative diagram of morphisms of sites:
$$\begin{matrix} \int _ { \L } ( \Omega ) \xrightarrow { i _ { \text{int} ( \Omega ) } } \mathbf V _ { \gamma } \\ \alpha _ { \Omega } \Big \downarrow & \Big \downarrow _ { \alpha } \\ \Omega \xrightarrow { i _ { \Omega } } \mathbf V _ { \mathbf a } \\ \cap \mathbf 1 7 \, 6 \, 7 \, 1 \, t h a t. \end{matrix}$$
It follows from [16, Proposition 17.6.7] that:
$$5, \text{Proposition 17.6.7} \text{ that} \colon \\ \alpha ^ { - 1 } k _ { \Omega } & \simeq \alpha ^ { - 1 } ( i _ { \Omega } )! ( i _ { \Omega } ) ^ { - 1 } k _ { \mathbf v _ { a } } \\ & \simeq ( i _ { \alpha ^ { t } ( \Omega ) } )! ( \alpha _ { \Omega } ) ^ { - 1 } ( i _ { \Omega } ) ^ { - 1 } k _ { \mathbf v _ { a } } \\ & \simeq ( i _ { \text{int} ( \Omega ) } )! ( i _ { \Omega } \circ \alpha _ { \Omega } ) ^ { - 1 } k _ { \mathbf v _ { a } } \\ & \simeq ( i _ { \text{int} ( \Omega ) } )! ( \alpha \circ i _ { \text{int} ( \Omega ) } ) ^ { - 1 } k _ { \mathbf v _ { a } } \\ & \simeq ( i _ { \text{int} ( \Omega ) } )! ( i _ { \text{int} ( \Omega ) } ) ^ { - 1 } \alpha ^ { - 1 } k _ { \mathbf v _ { a } } \\ & \simeq k _ { \text{int} ( \Omega ) }. \\ \text{and consider the following short exact sequence}$$
Let U := V a \ F and consider the following short exact sequence [15, Proposition 2.3.6]:
$$0 \longrightarrow k _ { U } \longrightarrow k _ { V _ { a } } \longrightarrow k _ { F } \longrightarrow 0.$$
Using the isomorphisms α -1 k U /similarequal k int( U ) and α -1 k V a /similarequal k V γ coming from the preceding argument, and the exactness of α -1 , one obtains the following short exact sequence:
$$0 \longrightarrow k _ { \text{int} ( U ) } \stackrel { \rho } { \longrightarrow } k _ { \text{V} _ { \gamma } } \longrightarrow \alpha ^ { - 1 } k _ { F } \longrightarrow 0.$$
Observe that ρ | F vanishes so α -1 k F F | /similarequal k F and ρ | int( U ) induces an isomorphism on stalks, therefore α -1 k F | int( U ) /similarequal 0. It follows from [15, Proposition 2.3.6 (i)] that α -1 k F = k F . □
Let b ∈ V . The unit η : R α α ∗ -1 → id of the adjunction ( α -1 , R α ∗ ) induces a morphism
$$\eta _ { ( b + \gamma ) } \colon R \alpha _ { * } \alpha ^ { - 1 } \mathbf k _ { ( b + \gamma ) _ { a } } \longrightarrow \mathbf k _ { ( b + \gamma ) _ { a } }$$
$$a$$
Proposition 4.2. (i) The morphism (4.1) is an isomorphism, (ii) R α ∗ k ( b +int( γ )) γ /similarequal k ( b + ) γ .
$$a$$
Proof. (i) Let us check that the map (4.1) is an isomorphism by checking that for every z ∈ V a its stalk at z is an isomorphism. Taking the stalk in z yields the following commutative diagram
$$\stackrel { \sim } { \left ( R \alpha _ { * } \alpha ^ { - 1 } k _ { ( b + \gamma ) _ { a } } \right ) } _ { z } \xrightarrow { \longrightarrow } k _ { ( b + \gamma ) _ { a }, z } \\ \stackrel { \downarrow } { \downarrow } \rightarrow \quad \Big \downarrow \quad \Big \downarrow \quad \\ R \Gamma ( z + \int ( \gamma ), k _ { ( b + \int ( \gamma ) ) _ { \gamma } } \right ) \xrightarrow { \longrightarrow } k _ { ( b + \gamma ) _ { a }, z }. \\. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
If z ∈ b + γ , then using Proposition 3.8, the bottom arrow of the above diagram reduces to an non-trivial linear map k → k and hence is an isomorphism. If z / ∈ b + γ , then using Proposition 3.8 this same arrow reduces to a map from zero to zero and hence is an isomorphism. This proves that the map (4.1) is an isomorphism
(ii) It follows from Proposition 4.1 that α -1 k ( b + ) γ a /similarequal k ( b +int( γ )) γ . Then the result follows from (i). □
Proposition 4.3. Let F ∈ Mod( k V ) be finitely presentable. Then
$$\mathbf R \alpha _ { * } \alpha ^ { - 1 } F \simeq$$
$$& \mathbf K _ { V _ { \mathbf a } } ) \ p e \ J$$
Proof. Since F is finitely presentable, it follows from Hilbert's syzygy theorem that F admits a finite resolution L · : 0 → L -n → ··· → L -1 → L 0 → 0 with L i = ⊕ k ∈ I i k ( b k + ) γ a and I i finite. Moreover, it follows from Proposition 4.2 that R α α ∗ -1 L i /similarequal α α ∗ -1 L i /similarequal L i . This, together with Lemma A.1 implies that R α α ∗ -1 F /similarequal α α ∗ -1 L · in D k ( V a ). The natural transformation η induces the following commutative diagram
$$\begin{array} {$$
Proposition 4.2 implies that the vertical maps in the above diagram are isomorphisms. Thus, α α ∗ -1 L · /similarequal L · which yields R α α ∗ -1 F /similarequal F . □
Remark 4.4. It follows from the proof of Proposition 4.2, that the restriction of the functor α -1 to the full subcategory of D k ( V a ) generated by the objects
isomorphic to bounded complexes of the form 0 → L p → ··· → L q → 0 with p, q ∈ Z , L i = ⊕ k ∈ I i k ( b k + ) γ a and I i finite, is fully faithful.
Definition 4.5. Given a subset A of V , the indicator module supported on A , denoted by k A , is defined as follows, where all the structural morphisms k → k are identities:
$$\mathbf k ^ { A } ( x ) \coloneqq \begin{cases} \math$$
The aim of the next lemma is to record a few well-known facts that are of constant use in this paper.
Lemma 4.6. Let b, c ∈ V . Then, we have
- (i) θ ∗ k A a /similarequal k A ,
- (ii) θ -1 k up( ) b /similarequal k ( b + ) γ a ,
- (iii) α -1 k ( b + ) γ a /similarequal k ( b +int( γ )) γ ,
- (iv) φ -1 γ k ( b +int( γ )) γ /similarequal k b +int( γ ) ,
- (v) The following diagram is commutative
$$\begin{array} {$$
and the map φ -1 γ α -1 θ -1 is an isomorphism.
Proof. (i) Follows from the definition of θ ∗ ,
- (ii) Since θ ∗ is an equivalence, we have θ -1 k A /similarequal k A a ,
- (iii) Follows from Proposition 4.1,
- (iv) Follows from [15, Eq. (2.3.19)],
- (v) The functor θ -1 is an equivalence of category and φ -1 γ is fully faithful. Moreover, it follows from Proposition 4.3 that the map
$$\text{Hom} \left ( { \mathbf k } _ { ( b + \gamma ) _ { a } }, { \mathbf k } _ { ( c + \gamma ) _ { a } } \right ) \stackrel { \alpha ^ { - 1 } } { \longrightarrow } \text{Hom} \left ( { \mathbf k } _ { ( b + \int t ( \gamma ) ) _ { \gamma } }, { \mathbf k } _ { ( c + \int t ( \gamma ) ) _ { \gamma } } \right )$$
is an isomorphism. Hence, the map φ α θ
-1 γ -1 -1 is an isomorphism.
We prove the commutativity of the diagram (4.2). First, if b + γ is not included in c + γ , the commutativity follows from
$$\text{Hom} \left ( { \mathbf k } _ { ( b + \gamma ) _ { a } }, { \mathbf k } _ { ( c + \gamma ) _ { a } } \right ) \simeq \text{Hom} \left ( ( { \mathbf k } _ { b + \text{int} ( \gamma ) ) _ { \gamma } }, { \mathbf k } _ { ( c + \text{int} ( \gamma ) ) _ { \gamma } } \right ) \simeq 0.$$
Now assume that b + γ ⊂ c + γ . Then
$$\text{Hom} \left ( \mathbf k _ { ( b + \gamma ) _ { a } }, \mathbf k _ { ( c + \gamma ) _ { a } } \right ) \simeq \text{Hom} \left ( \left ( \mathbf k _ { b + \int ( \gamma ) ) _ { \gamma } }, \mathbf k _ { ( c + \int ( \gamma ) ) _ { \gamma } } \right ) \simeq \mathbf k$$
and these two isomorphisms are provided respectively by the morphisms
↦
$$\text{Hom} \left ( \mathbf k _ { ( b + \gamma ) _ { a } }, \mathbf k _ { ( c + \gamma ) _ { a } } \right ) \to \mathbf k, \ \psi \mapsto \psi _ { b + \gamma } ( \mathbf 1 _ { b + \gamma } )$$
$$\begin{matrix} \end{matrix}$$
↦
$$\text{Hom} \left ( \mathbf k _ { ( b + i n t ( \$$
where 1 b + γ and 1 b +int( γ ) are respectively the indicator functions of b + γ and b +int( γ ). The commutativity follows immediately.
□
Corollary 4.7. Let M be a finitely presentable persistence module on V . Then the sheaf φ -1 γ α -1 θ -1 M is constructible up to infinity
Proof. Since M is finitely presentable, it admits a free resolution. It follows from Lemma 4.6, that φ -1 γ α -1 θ -1 M admits a resolution by a finite conic complex. Hence, it is constructible up to infinity by Proposition 3.6. □
In view of the Proposition 4.7, we make the following definition
Definition 4.8. The projected barcode of a finitely presentable persistence module M is the projected barcode of the associated sheaf φ -1 γ α -1 θ -1 M .
## 5. Direct images of finite conic-complexes
Computing the direct image of a finite conic-complex by a linear form is the first step of the computation of the projected barcode of this conic-complex. Here, a theoretical description of the derived proper direct image by a linear form of a conic complex is provided (Theorem 5.1).
Let u ∈ int( γ ◦ ) and v ∈ int( γ ◦ ,a ). It follows from [4, Lemma 4.7] that, if K ⊂ V is compact, then u | K + γ and v | K + γ a are proper. In particular, u ∗ k K + γ /similarequal u ! k K + γ and v ∗ k K + γ a /similarequal v ! k K + γ a . Recall that V is n -dimensional. Let Λ := [0 , + ∞ ).
Theorem 5.1. Let Z := γ { J } and U := int( γ ) { J } be finite γ -complexes, more precisely:
$$\begin{array} {$$
Then, in D k b ( V ) we have R u ∗ Z /similarequal Λ { u J ( ) } and (R u ∗ U )[1 -n ] /similarequal int(Λ) { u J ( ) } , i.e.:
$$\ddots \cdots \\ R u _ { * } \mathcal { Z } \colon$$
Similarly, R v ∗ Z /similarequal Λ a { v J ( ) } and (R v ∗ U )[1 -n ] /similarequal int(Λ ) a { v J ( ) } .
The proof of this result relies on the following two observations. The rest of the proof is a combination of classical facts from sheaf theory.
Lemma 5.2. Let f : V → R be a continuous function, and let F be a sheaf in D k b ( V ) . Then, the following isomorphism holds in D k b ( R ) : D R R f ! F /similarequal R f ∗ D V F . The choice of an orientation on V yields an isomorphism D ′ V F /similarequal (D V F )[ -n ] .
Proof. The first statement is a consequence of local Verdier duality [15, Prop. 3.1.10]:
$$D _ { \mathbb { R } } R f _ {! } \mathcal { F }$$
The choice of an orientation yields an isomorphism ω V /similarequal k V [ n ] ([15, Remark 3.3.8]) which provides an isomorphism D V F /similarequal (D ′ V F )[ n ]. □
Lemma 5.3. Let u ∈ int( γ ◦ ) and v ∈ int( γ ◦ ,a ) . Then:
$$R u _ { * } ( \mathbf k _ { x + \gamma } ) \s$$
$$R v _ { * } ( \mathbf k _ { x + \gamma } ) \simeq \mathbf k _ { ( - \infty, v ( x ) ] } ; \quad R v _ { * } ( \mathbf k _ { x + \text{int} ( \gamma ) } ) \simeq \mathbf k _ { ( - \infty, v ( x ) ) } [ 1 - n ].$$
$$\begin{smallmatrix} n \\ n \\ \end{smallmatrix}.$$
↦
Proof. For any x ∈ V , let τ x : V → V be given by y → x + y . Then, τ -1 -x k γ /similarequal k x + γ and uτ x = τ u x ( ) u . It follows from [4, Lemma 4.8] that: R u ∗ ( k x + γ ) /similarequal R( τ u x ( ) u ) ∗ ( k γ ) /similarequal τ -1 -u x ( ) k [0 + , ∞ ) /similarequal k [ u x , ( ) + ∞ ) . The second statement follows from the previous one, combined with Lemmas 3.4 and 5.2. □
Proof of Theorem 5.1. First we prove the statement for the closed conic-complex, then we deduce the statement for the open conic-complex.
It follows from Lemma 5.3 that k a + γ are u ∗ - and v ∗ -acyclic. Thus, the result is a straightforward consequence of Lemma A.1 and Lemma 5.3.
Only the case of u will be treated here, the proof holds mutatis-mutandis for v . It follows from Proposition 3.6 and from [15, Proposition 3.4.3] that U and Z are cohomologically constructible, in particular D V D V U /similarequal U and D V D V Z /similarequal Z . The following duality argument allows us to restrict the focus to the case of a finite closed conic-complex:
$$R u _ { * } \mathcal { U } \simeq R u _ { * } D _ { \mathbf V } D _ { \mathbf V } \mathcal { U } \simeq D _ { \mathbb { R } } ( R u _ { * } D _ { \mathbf V } \mathcal { U } ) \simeq D _ { \mathbb { R } } ^ { \prime } ( R u _ { * } D _ { \mathbf V } ^ { \prime } \mathcal { U } ) [ 1 - n ].$$
Indeed, Proposition 3.5 ensures that D ′ V U /similarequal γ { J } . Thus, the preceding part of this proof yields the following expression:
$$R u _ { * } ( \mathbb { D } ^ { \prime } _ { \mathbf V } \mathcal { U } ) \colon \ \cdots \to \bigoplus _ { j _ { 1 } \in J _ { 1 } } \mathbf k _ { [ u ( j _ { 1 } ), + \infty ) } \to \bigoplus _ { j _ { 0 } \in J _ { 0 } } \mathbf k _ { [ u ( j _ { 0 } ), + \infty ) }.$$
A second application of Proposition 3.5 concludes the proof.
□
- 6. From 1-d conic complexes to filtered cochain complexes
## 6.1. From finite conic-complexes to filtered finite cochain complexes.
Let again Λ := [0 + , ∞ ). The barcode of a finite open int(Λ)-complex can be obtained from that of a finite filtered cochain complex as follows. This reduction is an essential step in our approach for the computation of the projected barcode of a conic-complex.
We start by recalling the notion of finite filtration and finite filtered cochain complex.
Definition 6.1. (i) A finite filtration C ( · ) in Ch b ( k ) is the data of a finite sequence ( C i ( )) 0 ≤ ≤ i m and ( f i -1 ) 1 ≤ ≤ i m where, C (0) = 0, C i ( ) is an object of Ch b ( k ) and f i -1 : C i ( -1) → C i ( ) is a monomorphism for 1 ≤ i ≤ m in Ch b ( k ). This is summarized by
$$0 = C ( 0 ) \stackrel { f _ { 0 } } { \longmapsto } \cdots \stackrel { f _ { m - 1 } } { \longmapsto } C ( m ) \.$$
- (ii) A filtered finite cochain complexes is the data of a cochain complex C ∈ Ch b ( k ) together with a finite filtration ( C i ( )) m i =0 , ( f i -1 ) 1 ≤ ≤ i m such that C m ( ) = C .
We will identify a finite filtered complex with its filtration if there is no risk of confusion. Such a filtration can be seen in two ways:
- · as a functor, i.e., an object of Fun([ m, ] Ch b ( k ));
- · as a complex of persistence modules, i.e., an object of the abelian category Ch b (Fun([ m, ] Mod( k ))).
Both viewpoints will be used in the following.
A filtered cochain complex composed of finite-dimensional vector spaces yields, for any integer d ∈ Z , a pfd persistence module H ( d C ( · )), which by [11, Theorem 1.1] admits a barcode B (H ( d C ( · ))), denoted by B d ( C ( · )) from now on for simplicity, while B ( C ( · )) is a shorthand for the graded barcode { B d ( C ( · )) } d ∈ Z .
Let L = int(Λ) { J } be a finite int(Λ)-complex, and let m := | J | be the cardinal of J as a set (i.e. without counting the multiplicity of the elements). In other words:
$$\mathcal { L } \ \dots \to 0 \to \bigoplus _ { j \in J _ { 0 } } \mathbf k _ { ( j, + \infty ) } \to \dots \to \bigoplus _ { j \in J _ { \nu } } \mathbf k _ { ( j, + \infty ) } \to 0 \to \dots \,.$$
The sheaf L is a γ -sheaf for the cone γ = Λ. Consider the complex L a of Alexandrov sheaves on V a given by
$$\mathcal { L } ^ { \mathfrak { a } } \quad \dots \to 0 \to \bigoplus _ { j \in J _ { 0 } } \mathbf k _ { [ j, + \infty ) } \to \dots \to \bigoplus _ { j \in J _ { \nu } } \mathbf k _ { [ j, + \infty ) } \to 0 \to \cdots$$
This complex is such that α -1 L a /similarequal L and corresponds through the morphism θ ∗ to the complex of free persistence modules on ( R , ≤ ):
$$L \quad \dots \to 0 \to \bigoplus _ { j \in J _ { 0 } } \mathbf k ^ { [ j, + \infty ) } \to \dots \to \bigoplus _ { j \in J _ { \nu } } \mathbf k ^ { [ j, + \infty ) } \to 0 \to \dots$$
↦
We now associate a finite filtered cochain complex to L . The multiset J of generators of L is a subset of R . Thus, we order the generators using the increasing order, and we denote by i ( r ) the r th generator in this order (numbering from one) and set arbitrarily i (0) = i (1) -1. Thus, we have a morphism of poset i : [ m ] → R , r → i ( r ). Let i -1 L := L ◦ i .
Proposition 6.2. The filtration i -1 L is a finite filtration.
Proof. Consider i ! ( i -1 L ) the left Kan extension along i of i -1 L . Since [ m ] is a finite poset, the functor i ! is exact and a straightforward computation shows that i ! ( i -1 L ) /similarequal L . In particular, ( i -1 L )( r ) /similarequal L i r ( ( )) and for every r ∈ [ m ] the structural morphism i -1 L r ( -1) → i -1 L r ( ) is a monomorphism as it is induced by the internal morphisms of indicator modules. □
/negationslash
Lemma 6.3. Given an interval I = [[ r, s ] ] of [ m ] and its associated indicator module k I , if s = m then i ! k I /similarequal k [ i ( r ,i ) ( s +1)) , else i ! k I /similarequal k [ i ( r , ) + ∞ ) .
$$P r o o f. \text{ This follows from } i, \mathbf k ^ { I } ( t ) \simeq \text{ \colon } \text{ \dim } \mathbf k ^ { I } ( h ) \simeq \mathbf k ^ { I } ( \max \{ h \ | \ i ( h ) \leq t \} ). \quad \Box$$
Let I [ m ] (resp. I R ) be the set of intervals of [ m ] (resp. R ) and consider i ! : I [ m ] → I R defined by
/negationslash
$$i _ {! } ( [ r, s ] ) = \begin{cases} [ i ( r ), i ( s ) ) & \text{if $s\neq m$} \\ [ i ( r ), + \infty ) & \text{if $s=m$} \end{cases}$$
For I a = Ω a ∩ F a a locally closed interval of R a , we define α -1 ( I a ) := int(Ω ) a ∩ F a .
↦
Theorem 6.4. For every integer k , the application α -1 i ! : B k ( i -1 L ) → B k ( L ) , I → α -1 i ! ( I ) is a well-defined bijection of multisets.
Proof. We first prove that α -1 i ! : B k ( i -1 L ) → B k ( L ) is a well defined bijection. Remark that α -1 θ -1 i i ! -1 L /similarequal α -1 L a /similarequal L and that the functors α -1 , θ -1 , i , ! i -1 are exact. Hence, α -1 θ -1 i ! H ( k i -1 L ) /similarequal H ( k L ). Moreover, H ( k i -1 L ) admits a barcode decomposition ⊕ I ∈ B k ( i -1 L ) k I . Hence, using Lemma 6.3 and Proposition 4.1, we get
$$\alpha ^ { - 1 } \theta ^ { - 1 } i _ {! } \mathbf H ^ { k } ( i ^ { - 1 } L ) \simeq \bigoplus _ { I \in \mathbf B ^ { k } ( i ^ { - 1 } L ) } \mathbf k _ { \alpha ^ { - 1 } i _ {! } ( I ) }.$$
Furthermore, H ( k L ) admits a barcode decomposition ⊕ I ′ ∈ B k ( L ) k I ′ . Thus,
$$\bigoplus _ { I ^ { \prime } \in \mathbf B ^ { k } ( \mathcal { L } ) } \mathbf k _ { I ^ { \prime } } \simeq \bigoplus _ { I \in \mathbf B ^ { k } ( i ^ { - 1 } L ) } \mathbf k _ { \alpha ^ { - 1 } i _ { 1 } ( I ) }.$$
The unicity of the barcode decomposition (Theorem 2.2) yields that the application α -1 i ! : B k ( i -1 L ) → B k ( L ) is a well-defined bijection. □
## 7. Extension of the persistence algorithm
The persistence algorithm applies to cochain complex filtrations arising from simplex-wise filtrations of simplicial complexes. However, as we shall see in Section 3, conic-complexes yield cochain complex filtrations that do not necessarily fit this framework. Fortunately, the only differences are the following ones: (1) several "simplices" can appear at the same time in the filtration; (2) boundary
matrices do not admit a fixed number of non zero entries depending on the dimension of the simplex. These differences can be overcome by a straightforward extension of the persistence algorithm.
## 7.1. Simplex-wise filtered cochain complexes.
Definition 7.1. The filtration C ( · ) is called simplex-wise if, for every 1 ≤ i ≤ m , we have coker( f i -1 ) /similarequal k [ q i ] for some q i ∈ Z . In this case, each morphism f i in the sequence is called a simplex insertion .
Remark 7.2. The terminology comes from simplex-wise filtered simplicial complexes, which naturally yield simplex-wise filtrations.
From now on, we assume C ( · ) to be simplex-wise. For any 0 ≤ i ≤ m and any integer /lscript , we denote by β /lscript ( C i ( )) the dimension of H ( /lscript C i ( )).
Proposition 7.3. For any 1 ≤ i ≤ m , we have β /lscript ( C i ( )) = β /lscript ( C i ( -1)) for all /lscript / ∈ { q , i q i +1 } , and we have either β q i ( C i ( )) = β q i ( C i ( -1)) + 1 (index i is then called a creator of degree q i ) or β q i +1 ( C i ( )) = β q i +1 ( C i ( -1)) -1 (index i is then called a destructor of degree q i ).
Proof. Since f i -1 is a morphism of complexes, we have the following commutative diagram, where the internal direct-sum decomposition C i ( ) q i = im( f q i i -1 ) ⊕ k q i involves an arbitrary vector space complement k q i /similarequal k of im( f q i i -1 ) in C i ( ) q i :
$$\lambda \quad \ell _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 1 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \cdot } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \dots } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 2 } ^ { \delta } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } ^ { \delta } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi ^ { \delta } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ _ { i = 3 + 1 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } \Phi _ { i = 3 } ( \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ( \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ( \Phi _ { i = 3 } ( \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } \Phi _ { i = 3 } ) ( \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 + 1 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 2 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \Phi _ { i = 3 } ) \$$
/negationslash
Then, for all /lscript = q i we have:
$$\ker ( d _ { i - 1 } ^ { \ell } ) \ & = \ \ker ( f _ { i - 1 } ^ { \ell + 1 } \circ d _ { i - 1 } ^ { \ell } ) \ & = \ \ker ( d _ { i } ^ { \ell } \circ f _ { i - 1 } ^ { \ell } ) \ \simeq \ \ker ( d _ { i } ^ { \ell } ) ; \\ \lim ( d _ { i - 1 } ^ { \ell } ) \ & \simeq \ \lim ( f _ { i - 1 } ^ { \ell + 1 } \circ d _ { i - 1 } ^ { \ell } ) \ & = \ \lim ( d _ { i } ^ { \ell } \circ f _ { i - 1 } ^ { \ell } ) \ \ = \ \lim ( d _ { i } ^ { \ell } ).$$
Letting η i := dim ker( d q i i ) -dimker( d q i i -1 ), we deduce that:
- · β /lscript ( C i ( )) = β /lscript ( C i ( -1)) for all /lscript / ∈ { q , q i i +1 ; }
- · β q i ( C i ( )) = β q i ( C i ( -1)) + η i ;
- · β q i +1 ( C i ( )) = β q i +1 ( C i ( -1)) + η i -1 (by the rank-nullity theorem).
Meanwhile, the commutative diagram also implies that:
$$\ker ( d _ { i - 1 } ^ { q _ { i } } ) = \ker ( f _ { i - 1 } ^ { q _ { i } + 1 } \circ d _ { i - 1 } ^ { q _ { i } } ) = \ker ( d _ { i } ^ { q _ { i } } \circ f _ { i - 1 } ^ { q _ { i } } ) \simeq \ker ( d _ { i } ^ { q _ { i } } ) \cap \lim ( f _ { i - 1 } ^ { q _ { i } } ),$$
where im( f q i i -1 ) has codimension 1 in the domain of d q i i . It follows that η i ∈ { 0 1 , } , which concludes the proof. □
Remark 7.4. When C ( · ) is the finite filtration with a simplex-wise filtered simplicial complex, the notions of creator and destructor coincide with the usual notions of creator simplex and destructor simplex.
Proposition 7.3 implies that, for each time i ∈ [ m ] \ { 0 } , exactly one interval endpoint of B ( C ( · )) is located at i . As a consequence, the graded barcode B ( C ( · )) pairs each destructor j in degree q j with a creator i in degree q i = q j +1.
Definition 7.5. The pairs ( i, j ) thus created are called persistence pairs . Creators that remain unpaired are referred to as essential creators.
- 7.2. From arbitrary finite filtrations to simplex-wise filtrations. A reduction to the simplex-wise case allows for the application of the persistence algorithm in the more general setting where several simplex insertions may happen at the same time.
As before, let C ( · ) be a finite filtration in Ch b ( k ), that is:
$$0 = C ( 0 ) \stackrel { f _ { 0 } } { \longrightarrow } \cdots \stackrel { f _ { m - 1 } } { \longrightarrow } C ( m ) \.$$
We have the following commutative diagram for every 1 ≤ i ≤ m , where each internal direct-sum decomposition C i ( ) j = im( f j i -1 ) ⊕ N j involves an arbitrarilychosen vector-space complement N j of im( f j i -1 ) in C i ( ) j -note that d j i maps im( f j i -1 ) to im( f j +1 i -1 ) but may not always map N j to N j +1 :
$$\dots & \text{----} \longrightarrow C ( i - 1 ) ^ { j - 1 } \xrightarrow { d _ { i - 1 } ^ { j - 1 } } C ( i - 1 ) ^ { j } \xrightarrow { d _ { i - 1 } ^ { j } } C ( i - 1 ) ^ { j + 1 } \xrightarrow { d _ { i - 1 } ^ { j + 1 } } \cdots \\ & \dots & \longrightarrow \lim ( f _ { i - 1 } ^ { j - 1 } ) \oplus N _ { j - 1 } \xrightarrow { d _ { i } ^ { j - 1 } } \lim ( f _ { i - 1 } ^ { j } ) \oplus N _ { j } \xrightarrow { d _ { i } ^ { j } } \lim ( f _ { i - 1 } ^ { j + 1 } ) \oplus N _ { j + 1 } \xrightarrow { d _ { i } ^ { j + 1 } } \cdots \\ & \tau = \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
In order to turn C ( · ) into a simplex-wise filtration, our approach is to write every morphism f i -1 in the sequence as a composition of finitely many morphisms that are each a simplex insertion as per Definition 7.1. For this, we start from the complex C i ( -1), map it to the image of f i -1 , then insert the vector space complements N j one by one, until we eventually get C i ( ). The key point is to insert the vector space complements N j in decreasing order of j , so that the codomain of d j i is ready when N j is being added to im( f j i -1 ). The details of the procedure are given in Appendix B.
Once this is done, we have decomposed f i -1 into a finite sequence of simplex insertions. We can index the intermediate complexes over an arbitrary finite subset T i of the open interval ( i -1 , i ). Doing this for every 1 ≤ i ≤ m yields a simplex-wise filtration [ C ( · )] sw , indexed over [ m ] ∪ ⋃ m i =1 T i , whose restriction to the grid [ m ] is isomorphic to C ( · ) by construction. Since restrictions preserve finite direct sums, we conclude:
↦
Proposition 7.6. For each degree j , the map [ a, b ) → /ceilingleft [ a , /ceilingright /ceilingleft b /ceilingright ) induces a bijection of multisets B ′ → B j ( C ( · )) , where B ′ := { [ a, b ) ∈ B j ([ C ( · )] sw ) | /ceilingleft a /ceilingright < b /ceilingleft /ceilingright} .
## 7.3. Persistence algorithm on simplex-wise filtered cochain complexes.
The persistence algorithm recovers the persistence pairs from the boundary matrix associated to a filtered simplicial complex. The differentials in a simplex-wise filtered cochain complex yield such a matrix.
Definition 7.7. The boundary matrix of a simplex-wise filtration C ( · ) is the matrix ∂ ∈ k m m × defined by ∂ i,j := α ij , where the map k j → k i arising from d q j j is the scalar multiplication by α ij .
Remark 7.8. When C ( · ) is the cochain complex of a simplex-wise filtered simplicial complex K , its boundary matrix coincides with the usual co-boundary matrix of K .
We can now feed our boundary matrix ∂ as input to the persistence algorithm, which then decomposes it as ∂ = RU with R reduced and U upper triangular. The proofs of the Pairing Uniqueness Lemma and of the fact that ( i, j ) is a persistence pair if, and only if, low( R j ) = i , hold verbatim in our context-see [13, Proposition 3.5 and Theorem 3.6] for the case k = Z 2 . Consequently:
Corollary 7.9. Given C ( · ) simplex-wise, for any d ∈ Z the d -th barcode is given by:
B d ( C ( · )) = { [ a, b ) | ( a, b ) ∈ P } d ∐ { [ a, + ∞ | ) a ∈ E } d , where P d and E d denote respectively: the multiset of persistence pairs with a creator of degree d , and the multiset of essential creators of degree d .
## 8. Algorithm for projected barcode
Let us summarize the situation. The computation of the projected barcode of a finite open conic-complex on R n along a linear form u ∈ int( γ ◦ ) starts by reducing the problem to computing the barcode of a finite int(Λ)-complex on R (see Section 5 and Theorem 5.1). This finite int(Λ)-complex on R admits a corresponding complex L of free persistence modules that shares the same observable barcode (Section 6.1 and Proposition 4.1). According to Section 6.1, one can associate to L a finite filtered cochain complex i -1 L such that the barcode of L can be reconstructed from the barcode of i -1 L . Meanwhile, according to Section 7.2, one can associate to a finite filtered cochain complex, here i -1 L , a simplexwise filtered cochain complex [ i -1 L ] sw whose barcode gives the barcode of i -1 L via restriction. Finally, the barcode of [ i -1 L ] sw can be computed using the standard persistence algorithm. In this section, we combine all these ingredients together into an effective algorithm, focusing on the special case where the cone γ is the positive orthant because this is the standard setup in topological data analysis and because the details of the algorithm are simpler in this case-especially in the 2-parameter setting, as we shall see in Section 8.4.
Let L := int( γ ) { G } with G = { g i } µ i =1 a finite multi-subset of V = R n with n > 1 endowed with the norm || · || ∞ . We let m := | G | be the cardinal of G as a set and µ its cardinal as a multiset (i.e. taking into account the multiplicities of the elements of G ). The dual vector space V ∗ endowed with the operator norm identifies with ( R n , || · || 1 ). Let our cone γ be the positive orthant [0 , + ∞ ) n , which corresponds to ≤ being the product partial order on R n . Then, γ ◦ identifies also with [0 , + ∞ ) n . A linear form is called relevant if it is of unit length and belongs to int( γ ◦ ).
The differentials of the complex R u ∗ L for any relevant linear form u ∈ V ∗ admit the same matrices as the differentials of L (this follows from the definition of the pushforward for sheaves). In particular, according to Section 6.1, the projected barcode along different linear forms essentially differs when the preorders on the generators of L induced by these linear forms differ. This symmetry can be translated into a combinatorial structure that encodes the essential information describing the projected barcode, and that takes the form of a hyperplane arrangement augmented with one barcode template per face. We call this combinatorial structure the projected barcode template of L , or PBT ( L ) for short. As in RIVET [20], its construction can be done in a pre-processing step, and a point location data structure built on top of the arrangement allows then for the efficient query of projected barcodes along linear forms.
- 8.1. Arrangement of hyperplanes and point location. We describe the hyperplane arrangement mentioned above. Its use will be clarified in the next section. The structure of the hyperplane arrangement is controlled on the one hand by the geometry of the domain of the γ -linear projected barcode, that is: the linear forms under consideration are elements of int( γ ◦ ) ∩ S ∗ , where S ∗ can be identified with the unit sphere in the norm || · || 1 ; on the other hand, the structure of the hyperplane arrangement is controlled by the set of generators of the conic-complex L .
↦
Here are the details. Observe that the set of relevant linear forms is the relatively open simplex S = { v ∈ int( γ ◦ ) | || v || 1 = 1 } in V ∗ , that is: the intersection of int( γ ◦ ) with the affine hyperplane T of equation ∑ n i =1 x i = 1. Let H 0 be the collection of vector hyperplanes H ij ⊂ V ∗ of linear forms vanishing on g ij := g i -g j , for i < j ∈ [ [1 , m ] ], and let H be the collection of their restrictions to T -which are affine hyperplanes of T . Without loss of generality, we assume that all the elements of H 0 are distinct. Locating a relevant linear form u in the associated arrangement A ( H 0 ) is then equivalent to locating u in the restriction of A ( H 0 ) to T , which itself is the arrangement A ( H ) associated to H in T . Henceforth, we implicitly identify T with R n -1 via the projection ( x , . . . , x 1 n ) → ( x , . . . , x 2 n ), which identifies A ( H ) with an arrangement of affine hyperplanes in R n -1 . Here, we use the notion of k -face as in [21] with the difference that here a face refers to a face of maximal (affine) dimension whenever the dimension is not specified. Moreover, we call relevant any face of A ( H ) that intersects int( γ ◦ ).
Note that the hyperplanes in A ( H ) may very much be in degenerate position. Therefore, we do not use Meiser's original data structure [21] for point location in the arrangement, but rather the variant described in [14], which can handle degeneracies and has the finer and more accurate complexity bounds of O( ( n -1) 5 log( n -1) log m ) query time, and O( m (6+ o n (1))( n -1) ) storage space and maximum expected pre-processing time, for our O( m 2 ) hyperplanes in n -1 dimensions, where o n (1) denotes a term depending only on d that goes to zero as d →∞ .
8.2. Projected barcode template. A relevant face σ of A ( H ) induces a welldefined total order /precedesequal σ on G such that g /precedesequal σ g ′ if, and only if, u g ( ) ≤ u g ( ′ ) for every u ∈ σ . Without loss of generality we assume that { g i } m i =1 is an /precedesequal σ -increasing enumeration of G . Let u, v ∈ σ be two relevant linear forms, and let L u := R u ∗ L and L v := R v ∗ L . According to Section 6.1, one can construct two corresponding finite filtered cochain-complexes i -1 u L u and i -1 v L v indexed over [ m ]. Since the two linear forms u and v induce the same order /precedesequal σ , the two filtered complexes i -1 u L u and i -1 v L v are isomorphic, therefore they have the same barcode, called the barcode template associated to σ and denoted by B σ ( L ). By Theorem 6.4, this barcode template can be used to retrieve the projected barcode along any linear form in σ , a result that we rephrase below using our current notation:
Corollary 8.1. Let u be a relevant linear form in a relevant face σ of A ( H ) , and let k be an integer. The application π u : B k σ ( L ) → B k (R u ∗ L ) given below is a bijection of multisets:
/negationslash
$$\pi _ { u } ( [ i, j ) ) \coloneqq \begin{cases} ( u ( g _ { i } ), u ( g _ { j } ) ] \text{ if } j \neq m, \\ ( u ( g _ { i } ), + \infty ) \text{ if } j = m. \end{cases}$$
The arrangement A ( H ), together with its point location data structure, and augmented with the collection of barcode templates B σ ( L ) associated to all the relevant faces σ in the arrangement, forms what we call the projected barcode template of L , or PBT ( L ) for short.
As in RIVET, once the arrangement A ( H ) has been computed, the barcode templates B σ ( L ) for all the relevant faces σ ∈ A ( H ) are computed via a walk through the dual graph of the arrangement-instead of a dfs or bfs, in order to maintain only a single boundary matrix. Following the approach of [20], to each edge [ σ, τ ] in the dual graph we assign a cost that is the minimum number of elementary transpositions required to transition from /precedesequal σ to /precedesequal τ (this number is given, e.g., by insertion sort). Then, we build a path in the graph that visits every vertex (possibly multiple times) and whose total cost is at most twice that of the optimal such path. To build our path we use the standard 2-approximation scheme for the traveling salesman's problem, applying first Kruskal's minimum spanning tree algorithm to the graph, then Hierholzer's Eulerian cycle algorithm to the tree with doubled edges. Once our path is built, we walk along it, computing the
barcode template of the first face from scratch using the standard boundary matrix reduction algorithm, then updating the barcode template by further reducing the boundary matrix using the vineyards algorithm [10] at each transition between adjacent faces. As the number of elementary transpositions involved at each transition is in O( m 2 ), the algorithmic cost of each transition is in O( m 3 ): while this is no better than recomputing the barcode template from scratch at each faces in the worst case, in practice the number of elementary transpositions involved can be much smaller than m 2 .
Overall, since the number of hyperplanes in H is in O( m 2 ), the size of the dual graph of the arrangement is in O( m 2 n -2 ), so the number of edges in our path is also in O( m 2 n -2 ), and so the total worst-case cost of computing the path then the barcode templates for all the relevant faces is in O( m 2 n -2 µ 3 ). This cost is dominated by that of the construction of the arrangement and its point location data structure in Section 8.1.
- 8.3. Queries. Given a relevant linear form u whose γ -linear projected barcode we want to compute, we use the point location data structure from Section 8.1 to retrieve the face of the arrangement A ( H ) that contains u in O( ( n -1) 5 log( n -1) log m ) time. Then, two distinct cases can arise :
- (1) the face containing u denoted σ is a (necessarily relevant) face;
- (2) the face containing u denoted τ has not maximal (affine) dimension.
In case 1, we simply apply Corollary 8.1 to get the projected barcode of u from the barcode template associated to σ in O( µn ) time as µ provides an upper bound on the number of bars and n is the number of coordinates of each generator that π u maps through u . In case 2, we do roughly the same thing, except that now u lies on the boundary of some relevant face σ incident to τ , so Corollary 8.1 must be replaced by the following barcode continuity result, which is a direct consequence of the fact that τ induces a pre-order on [ m ] that is obtained by quotienting the order induced by σ by the fibers of u :
/negationslash
Corollary 8.2. Let u be a relevant linear form belonging to a face τ of A ( H ) that is not of maximal (affine) dimension, and let σ be an incident relevant face. For any integer k , the application π u : { [ i, j ) ∈ B k τ ( L ) | u g ( i ) = u g ( j ) } → B k (R u ∗ L ) given below is a bijection of multisets:
/negationslash
$$\dot { \mu } _ { u } ( [ i, j ) ) \coloneqq \begin{cases} ( u ( g _ { i } ), u ( g _ { j } ) ] \text{ if } j \neq m \\ ( u ( g _ { i } ), + \infty ) \text{ if } j = m \end{cases}$$
Overall, the γ -linear projected barcode of u is computed in O( µn + ( n -1) 5 log( n -1) log m ) time.
8.4. The special case of 2-parameter persistence modules. In the setting of 2-parameter persistence, our arrangement A ( H ) is 1-dimensional and has a particular structure, which simplifies the approach significantly. Observe that H ij
intersects S if, and only if, g ij := ( a ij , b ij ) / ∈ int( γ ) ∪ int( γ a ), i.e., a ij b ij < 0. In this case, we have H = { ( | b ij | | a ij | + | b ij | , | a ij | | a ij | + | b ij | ) ∈ R 2 | a ij b ij < 0 } , and via the identification of T with R , we get that H = { | a ij | | a ij | + | b ij | ∈ R | a ij b ij < 0 } . The point location of a given query linear form can then be solved in O(log m ) time by a simple binary search. In pre-processing, we compute the O m ( 2 ) hyperplanes H ij and the boundary points of the faces in the induced 1-dimensional arrangement A ( H ) in O m ( 2 ) time. Then, we compute the barcode templates as in Section 8.2 in O m µ ( 2 3 ) time. This worst-case bound is comparable to that of RIVET, however the computation and storage of our arrangement are much simpler.
## 9. Example
In this section we provide a running example of the procedure developed in the present paper. The goal is here to compute of the projected barcode template of the following persistence module, denoted by M .
Figure 1. The persistence module M
More precisely, we set
$$g _ { 0 } = ( 0, 0 ) & & g _ { 1 } = ( 1, 0 ) & & g _ { 2 } = ( 0, 1 ) \\ g _ { 3 } = ( \frac { 3 } { 4 }, \frac { 3 } { 4 } ) & & g _ { 4 } = ( \frac { 3 } { 4 }, 1 ) & & g _ { 5 } = ( 1, \frac { 3 } { 4 } ). \\ \dots \, \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \Phi \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \ \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \ddot { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \PhI } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi } \quad \hat { \Phi }$$
and define the module M as follows :
$$M ( x, y ) \coloneqq \begin{cases} \mathbf k \text{ if } 0 \leq x \leq 3 / 4 \text{ and } 0 \leq y \leq 1, \\ \mathbf k \text{ if } 0 \leq x \leq 1 \text{ and } 0 \leq y \leq 3 / 4, \\ 0 \text{ otherwise.} \end{cases}$$
with identity as morphisms between non 0 vector spaces. Moreover, M admits the following free resolution:
$$\ k ^ { \text{up} ( g _ { 4 } ) } \oplus \kappa ^ { \text{up} ( g _ { 5 } ) } \stackrel { d _ { M } ^ { - 2 } } { \longrightarrow } \kappa ^ { \text{up} ( g _ { 1 } ) } \oplus \kappa ^ { \text{up} ( g _ { 2 } ) } \stackrel { d _ { M } ^ { - 1 } } { \longrightarrow } \kappa ^ { \text{up} ( g _ { 0 } ) }$$
with d -2 M ( s , s 4 5 ) = ( s , 4 -s 4 -s , s 5 5 ) and d -1 M ( s , s 1 2 , s 3 ) = s 1 + s 2 + s 3 . The conic complex int( γ ) { J } associated with the above free resolution is :
$$\mathcal { U } \colon k _ { g _ { 4 } + \text{int} ( \gamma ) } \oplus k _ { g _ { 5 } + \text{int} ( \gamma ) } \stackrel { d _ { \mathcal { U } } ^ { - 2 } } { \longrightarrow } k _ { g _ { 1 } + \text{int} ( \gamma ) } \oplus k _ { g _ { 2 } + \text{int} ( \gamma ) } \oplus k _ { g _ { 3 } + \text{int} ( \gamma ) } \stackrel { d _ { \mathcal { U } } ^ { - 1 } } { \longrightarrow } k _ { g _ { 0 } + \text{int} ( \gamma ) }$$
with d -2 U ( s , s 4 5 ) = ( s , 4 -s 4 -s , s 5 5 ) and d -1 U ( s , s 1 2 , s 3 ) = s 1 + s 2 + s 3 and the multiset of generators J = { g , g 0 1 , g 2 , g 3 , g 4 , g 5 } . Note that the non-zero terms of this complex are in cohomological degrees -2 , -1 and 0.
We now compute the g ij = g i -g j with i < j . We obtain
$$\begin{array} { l l l } \text{We now compute the $g_{ij}=g_{i}-g_{j}$ with $i<j$. We obtain} \\ g _ { 0 1 } = ( - 1, 0 ) & g _ { 1 2 } = ( 1, - 1 ) & g _ { 2 3 } = ( - \frac { 3 } { 4 }, \frac { 1 } { 4 } ) & g _ { 3 4 } = ( 0, - \frac { 1 } { 4 } ) & g _ { 4 5 } = ( - \frac { 1 } { 4 }, \frac { 1 } { 4 } ) \\ \\ g _ { 0 2 } = ( 0, - 1 ) & g _ { 1 3 } = ( \frac { 1 } { 4 }, - \frac { 3 } { 4 } ) & g _ { 2 4 } = ( - \frac { 3 } { 4 }, 0 ) & g _ { 3 5 } = ( - \frac { 1 } { 4 }, 0 ) \\ \\ g _ { 0 3 } = ( - \frac { 3 } { 4 }, - \frac { 3 } { 4 } ) & g _ { 1 4 } = ( \frac { 1 } { 4 }, - 1 ) & g _ { 2 5 } = ( - 1, \frac { 1 } { 4 } ) \\ \\ g _ { 0 4 } = ( - \frac { 3 } { 4 }, - 1 ) & g _ { 1 5 } = ( 0, - \frac { 3 } { 4 } ) \\ \\ g _ { 0 5 } = ( - 1, - \frac { 3 } { 4 } ) \\ \\ \text{We only keep the $a_{i}= (a_{i}i.b_{i}$) such that $a_{i}_{i}b_{i}<0$. that is: $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $qu_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{i}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_j$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$. $q_{j}$.. \end{array}$$
$$g _ { 0 5 } = ( - 1, - \frac { 3 } { 4 } )$$
We only keep the g ij = ( a ij , b ij ) such that a ij b ij < 0, that is: g 12 , g 13 , g 14 , g 23 , g 25 , and finally, g 45 .
↦
Identifying the set T = { ( x , x 1 2 ) | x 1 + x 2 = 1 } with R via the projection ( x , x 1 2 ) → x 2 , we get that
$$H = \{ \frac { 1 } { 5 } ; \frac { 1 } { 4 } ; \frac { 1 } { 2 } ; \frac { 3 } { 4 } ; \frac { 4 } { 5 } \}.$$
↦
In this setting, we need to compute the barcode template corresponding to the linear forms u : R 2 → R defined by ( x , x 1 2 ) → ax 1 + bx 2 with a > 0, b > 0 and a + b = 1. We first reduce the problem to computing the barcode of R u ∗ U . For that purpose, we apply Theorem 5.1 and obtain the finite open int(Λ)-complex F = int(Λ) { u J ( ) } -[ 1] on R where
$$\mathcal { F } ^ { - 1 } & = \mathbf k _ { u ( g _ { 4 } ) + \text{int} ( \Lambda ) } \oplus \mathbf k _ { u ( g _ { 5 } ) + \text{int} ( \Lambda ) } \\ \mathcal { F } ^ { 0 } & = \mathbf k _ { u ( g _ { 1 } ) + \text{int} ( \Lambda ) } \oplus \mathbf k _ { u ( g _ { 2 } ) + \text{int} ( \Lambda ) } \oplus \mathbf k _ { u ( g _ { 3 } ) + \text{int} ( \Lambda ) } \\ \mathcal { F } ^ { 1 } & = \mathbf k _ { u ( g _ { 0 } ) + \text{int} ( \Lambda ) }$$
and where the maps d -1 F : F -1 → F 0 and d 0 F : F 0 → F 1 have the same matrix representations as d -2 M and d -1 M respectively. We then, compute the u g ( i ) and get
$$u ( g _ { 0 } ) & = 0 \quad u ( g _ { 1 } ) = a = 1 - b \quad \ u ( g _ { 2 } ) = b \\ u ( g _ { 3 } ) & = \frac { 3 } { 4 } \quad u ( g _ { 4 } ) = \frac { 3 } { 4 } + \frac { 1 } { 4 } b \quad \ u ( g _ { 5 } ) = 1 - \frac { 1 } { 4 } b$$
From now on, we assume that k = Z 2 . We first compute the barcode of the face σ corresponding to the case where b belongs to the interval ( 1 5 , 1 4 ). This defines the following total order on the generators
$$g _ { 0 } \prec _ { \sigma } g _ { 2 } \prec _ { \sigma } g _ { 1 } \prec _ { \sigma } g _ { 3 } \prec _ { \sigma } g _ { 4 } \prec _ { \sigma } g _ { 5 }.$$
Following Section 6.1, the corresponding finite filtration is defined by
$$C ( 0 ) & = 0, \\ C ( i ) & = \Gamma \Big ( u ( g _ { i - 1 } ) + \text{int} ( \Lambda ) ; \text{int} ( \Lambda ) \{ u ( J ) \} \Big ) [ - 1 ],$$
where f i -1 : C i ( -1) → C i ( ) is induced by the restriction maps of the sheaf int(Λ) { u J ( ) } -[ 1]. One checks that this finite filtration is simplexwise.
We use the persistence algorithm to compute the barcode and refer to [13, §3.3.1] for the details of this algorithm. We first construct the filtered boundary matrix (9.2) associated with the above finite filtration. It is obtained by combining the differentials of the finite filtration C ( · ) which are completely determined by their values on the generators of the conic complex int(Λ) { u J ( ) } -[ 1] (These differentials have the same matrix representation as d -2 M and d -1 M ). The entries of the filtered boundary matrix are ordered according to the total order (9.1) on the generators. This yields the following:
$$\begin{array} {$$
/negationslash
Recall that, that the boundary matrix B of the cochain complex of persistence modules that is associated to a conic complex G = int(Λ) { J } is such that B i,j = 1 if, and only if, there exists k ∈ Z such that j ∈ J k and i ∈ J k +1 with d k G | k ( i, + ∞ ) = 0. Applying the reduction process, we get the matrix:
| | u ( g 2 ) | u ( g 1 ) | u ( g 3 ) | u ( g 4 ) | u ( g 5 ) |
|---------------|-------------|-------------|-------------|-------------|-------------|
| u ( g 0 ) | 1 | 0 | 0 | 0 | 0 |
| u ( g 2 ) | 0 | 0 | 0 | 1 | 1 |
| u ( g 1 ) | 0 | 0 | 0 | 1 | 0 |
| u ( g 3 ) | 0 | 0 | 0 | 0 | 1 |
This implies that the projected barcode functor (see Equation (2.1)) evaluated on the pair ( u, U ) with u as above is given by
$$\mathcal { P } ^ { \gamma } ( u, \mathcal { U } )$$
Second, we compute the barcode of the case b = 1 4 . We compute the u g ( i ) and get
$$u ( g _ { 0 } ) = 0 \quad \ u ( g _ { 1 } ) =$$
This defines the following total pre-order on the generators:
$$u ( g _ { 0 } ) < u ( g _ { 2 } ) < u ( g _$$
In this setting, we compute the barcode corresponding to the linear form
↦
$$u \colon \mathbb { R } ^ { 2 } \rightarrow \mathbb { R$$
We apply Theorem 5.1 and obtain the complex int(Λ) { u J ( ) } -[ 1] on R
$$k _ { \frac { 1 3 } { 1 6 } + i n t ( \Lambda ) } \oplus k _ { \frac { 1 5 } { 1 6 } + i n t ( \Lambda ) } \longrightarrow k _ { \frac { 3 } { 4 } + i n t ( \Lambda ) } \oplus k _ { \frac { 1 } { 4 } + i n t ( \Lambda ) } \longrightarrow k _ { i n t ( \Lambda ) },$$
the non-zero terms of which are in cohomological degrees -1, 0 and 1. Again, following Section 6.1, we obtain the corresponding finite filtration defined by
$$C ( 0 ) & = 0, \\ C ( i ) & = \Gamma \Big ( u ( g _ { i - 1 } ) + \text{int} ( \Lambda ) ; \text{int} ( \Lambda ) \{ u ( J ) \} \Big ) [ - 1 ].$$
This filtration is not simplex-wise, so we now construct a simplex-wise finite filtration applying Section 7.2 and use the indexing convention described ibid. We index the intermediate complex introduced to construct the simplex-wise filtration [ C ( · )] sw by choosing the middle of the open interval (3 , 4). This yields the following:
where k i corresponds to the copy of the field k associated with the generator g i .
We construct the filtered boundary matrix (9.4) associated with the simplexwise finite filtration (9.3). It is obtained by combining the differentials
It is obtained by combining the differentials of the finite filtration (9.3) which are completely determined by their values on the generators of the conic complex int(Λ) { u J ( ) } -[ 1] (these differentials have the same matrix representation as d -2 M and d -1 M ). The entries of the filtered boundary matrix are ordered according to the order provided by the simplex-wise filtration [ C ( · )] sw obtained via procedure described in Section 7.2.
We have the following boundary matrix:
$$\begin{matrix} \nu \, \text{max} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \,\text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in}, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{In} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \,
\\ \text{Annlvino} \, \text{the reduction nrocess} \, \text{we get once again} \, \text{the ms} \end{matrix}$$
Applying the reduction process, we get once again the matrix:
$$\Gamma \cos \cos, w \subseteq \cos \cos \cos \cos \cos \sin \sin \\ 2 \left ( \begin{array} { c c c c c } 3 & \frac { 7 } { 2 } & 4 & 5 \\ 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1 & 1 \\ 3 & 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 0 & 1 \end{array} \right ) \\ \inf o r \, \text{barecode}.$$
Hence, we get the following barcode:
$$\mathbf B ^ { \prime } = \{ [ 1, 2 ) ; \ [ 3, 4 ) ; \ [ \frac { 7 } { 2 }, 5 ) \}$$
Applying Proposition 7.6 yields:
$$\mathbf B = \{ [ 1, 2 ) ; \ [ 3, 4 ) ; \ [ 3, 5 ) \}$$
Finally, applying Theorem 6.4, we get that the projected barcode is
$$\mathcal { P } ^ { \gamma } ( u, \mathcal { U } ) \simeq \mathbf k _ { ( u ( g _ { 0 } ) ; u ( g _ { 2 } ) ] } \oplus \mathbf k _ { ( u ( g _ { 1 } ) ; u ( g _ { 4 } ) ] } [ - 1 ] \oplus \mathbf k _ { ( u ( g _ { 1 } ) ; u ( g _ { 5 } ) ] } [ - 1 ].$$
The barcode templates for the faces of H are computed in a similar manner to the face σ case, where b ∈ ( 1 5 , 1 4 ) . For the zero-dimensional faces determined by an element of H , the computation is similar to the case b = 1 4 . Therefore, these calculations are left to the reader.
## 10. Experiments
10.1. Setup. The algorithm has been implemented in Python3 in the 2-parameter setting (Section 8.4), and can compute projected barcodes for any scc2020 formated free resolutions [18]. These resolutions can for instance be computed with
2pac [2]. Barcode computations are done using the PHAT library [1], based on the twist algorithm. The optimization using vineyards [10] has not been implemented.
We ran our code on a Dell Precision 3460 with an 13th Gen Intel Core i9-13900 x 32 chip and 64 GB of RAM. The code was run with Python 3.10.12. Computation times were measured with time from the time module.
↦
10.2. Results. Our results were obtained on a sample of 30 points sampled uniformly on the right half of a circle of radius one, 40 points sampled uniformly on a circle of unit radius plus one outlier. Calling P the resulting point sample with 71 points, we performed a density-Rips bifiltration with density given by the function x →|{ y ∈ P | | x - | y < 1 5 . }| (see Figure 2).
Figure 2. The point sample P .
↦
↦
Figure 3 shows the projected barcode of the simplicial homology in degree 1 of the function-Rips bifiltration, queried along the linear forms ( x, y ) → 0 875 . x + 0 125 . y and ( x, y ) → 1 x . As intuition suggests, the first linear form, which takes the density into account, allows one to recover the generators of the circle in degree 1 homology while minimising the effect of the outlier; meanwhile the second linear form, which corresponds to the Rips filtration, shows two generators due to the outlier's position.
Table 1 reports the computation times of the projected barcode template, and of queries along a linear form.
↦
↦
Figure 3. The projected barcodes of the function-Rips bifiltration obtained by pushforwards along the linear forms ( x, y ) → 0 875 . x + 0 125 . y (left) and ( x, y ) → 1 x (right). Blue points represent persistence pairs with creator in degree 0 in the resolution of the first simplicial homology group, while red points represent persistence pairs with creator in degree 1 in the same resolution.
## Performances
| Sample name | Number of generators | Number of faces | Query with template | Query without template | Projected Barcode Template |
|-------------------------------|------------------------|-------------------|-----------------------|--------------------------|------------------------------|
| Circle H 0 Circle H 1 | 332 72 | 16602 1443 | 0.341 ms 0.093 ms | 0.978 ms 0.175 ms | 11.068 s 0.422 s |
| | 1516 782 | 284346 163034 | 1.904 ms 0.810 ms | 3.567 ms 1.904 ms | 1072.477 s 308.611 s |
| Torus H 0 Torus H 1 Torus H 2 | 96 | 1791 | 0.102 ms | | 0.355 s |
| | | | | 0.237 ms | |
| Octogone H 0 | 39 | | 0.966 ms | 0.120 ms 0.112 ms | 6.699 s |
| | | 106 | 0.053 ms | | 1.571 s |
| Octogone H 1 | 8 | 7 | | | |
| Dragon H 0 Dragon H | 1082 | 211000 | 1.077 ms | 2.592 ms | 502.068 s |
| 1 | 824 | 219327 | 0.818 ms | 1.963 ms | 467.449 s |
Table 1. The sample set is composed of : 100 points sampled on a circle, 500 points sampled on a torus both with a vertical χ 2 offset perturbation and 300 sampled on the Stanford Dragon available in [22]; these where analysed using a density Rips filtration with density estimated by the number of neighbours within a ball with specified radius. We also included a multicritical example with a degree-Rips bilfitration on an octogone with two outliers.
## References
- [1] Ulrich Bauer, Michael Kerber, Jan Reininghaus, and Hubert Wagner. Phat-persistent homology algorithms toolbox. In Mathematical Software-ICMS 2014 , pages 137-143. Springer, 2014. See http://github.com/blazs/phat .
- [2] Ulrich Bauer, Fabian Lenzen, and Michael Lesnick. Efficient Two-Parameter Persistence Computation via Cohomology. In Erin W. Chambers and Joachim Gudmundsson, editors, 39th International Symposium on Computational Geometry (SoCG 2023) , volume 258 of Leibniz International Proceedings in Informatics (LIPIcs) , pages 15:1-15:17, Dagstuhl, Germany, 2023. Schloss Dagstuhl - Leibniz-Zentrum für Informatik.
- [3] Nicolas Berkouk and Grégory Ginot. A derived isometry theorem for sheaves. Advances in Mathematics , 394:108033, 2022.
- [4] Nicolas Berkouk and Francois Petit. Projected distances for multi-parameter persistence modules, 02 2023. URL: https://arxiv.org/abs/2206.08818 .
- [5] Nicolas Berkouk and François Petit. Ephemeral persistence modules and distance comparison. Algebraic & Geometric Topology , 21(1):247-277, 2021.
- [6] Edward Bierstone and Pierre D. Milman. Semianalytic and subanalytic sets. Publications mathématiques de l'IHÉS , 67(1):5-42, Jan 1988.
- [7] Håvard Bakke Bjerkevik and Michael Kerber. Asymptotic improvements on the exact matching distance for 2-parameter persistence, 2021. URL: https://arxiv.org/abs/ 2111.10303 .
- [8] Andrea Cerri, Barbara Di Fabio, Massimo Ferri, Patrizio Frosini, and Claudia Landi. Betti numbers in multidimensional persistent homology are stable functions. Mathematical Methods in the Applied Sciences , 36(12):1543-1557, 2013.
- [9] Frédéric Chazal, William Crawley-Boevey, and Vin de Silva. The observable structure of persistence modules. Homology, Homotopy and Applications , 18(2):247-265, 2016.
- [10] David Cohen-Steiner, Herbert Edelsbrunner, and Dmitriy Morozov. Vines and vineyards by updating persistence in linear time. Proceedings of the twenty-second annual symposium on Computational geometry , 2006.
- [11] William Crawley-Boevey. Decomposition of pointwise finite-dimensional persistence modules. Journal of Algebra and Its Applications , 14(05):1550066, 2015.
- [12] J Curry. Sheaves, cosheaves and applications, 2014. URL: https://arxiv.org/abs/1303. 3255 .
- [13] Tamal Krishna Dey and Yusu Wang. Computational topology for Data Analysis . Cambridge University Press, 2022.
- [14] Esther Ezra, Sariel Har-Peled, Haim Kaplan, and Micha Sharir. Decomposing arrangements of hyperplanes: VC-dimension, combinatorial dimension, and point location. Discrete & Computational Geometry , 64(1):109-173, 2020.
- [15] M. Kashiwara and P. Schapira. Sheaves on manifolds , volume 292 of Grundlehren der Mathematischen Wissenschaften . Springer-Verlag, Berlin, 1990. With a chapter in French by Christian Houzel.
- [16] Masaki Kashiwara and Pierre Schapira. Categories and Sheaves , volume 332 of Grundlehren der mathematischen Wissenschaften . Springer Berlin Heidelberg, 2006.
- [17] Masaki Kashiwara and Pierre Schapira. Persistent homology and microlocal sheaf theory. Journal of Applied and Computational Topology , 2(1-2):83-113, 2018.
- [18] M. Kerber and M. Lesnick. scc2020: A file format for sparse chain complexes in tda, 2021. URL: https://bitbucket.org/mkerber/chain\_complex\_format .
- [19] Michael Kerber, Michael Lesnick, and Steve Oudot. Exact computation of the matching distance on 2-parameter persistence modules. Journal of Computational Geometry , 11(2), 2020.
- [20] Michael Lesnick and Matthew Wright. Interactive visualization of 2-d persistence modules, 2015. URL: https://arxiv.org/abs/1512.00180 .
- [21] S. Meiser. Point location in arrangements of hyperplanes. Information and Computation , 106(2):286-303, 1993.
- [22] Nina Otter, Mason A Porter, Ulrike Tillmann, Peter Grindrod, and Heather A Harrington. A roadmap for the computation of persistent homology. EPJ Data Science , 6(1), Aug 2017. doi:10.1140/epjds/s13688-017-0109-5 .
- [23] Pierre Schapira. Constructible sheaves and functions up to infinity. Journal of Applied and Computational Topology , 2023.
- [24] Pierre Shapira and Francois Petit. Thickening of the diagonal and interleaving distance, 06 2021. URL: https://arxiv.org/abs/2006.13150 .
- [25] Oliver Vipond. Local equivalence of metrics for multiparameter persistence modules, 2020. URL: https://arxiv.org/abs/2004.11926 .
## Appendix A. Technical supplement
A.1. Derived functors between derived categories. Let C D , be two abelian categories, and let F : C → D be an additive functor. The derived category D + ( C ) of C is the localization of the category of cochain complexes Ch + ( C ) with respect to the quasi-isomorphisms. Under suitable conditions, the functor F induces a derived functor R F : D + ( C ) → D + ( D ). We refer the reader to [15, Chapter I] and especially to sections 1.7 and 1.8 therein for details. The aim of this section is to briefly recall a method for the evaluation of a derived functor on an object. This technique is well-known and implicit in ibid .
A full additive subcategory J of C is called F -injective if the three following conditions hold :
- · for any object X of C , there is a map X → J , with J an object of J , such that 0 → X → J is exact;
- · the category J is closed under taking cokernels;
- · the functor F sends short exact sequences in J to short exact sequences.
/negationslash
Assume that F is left-exact and that C has enough injectives. An object X of C is F -acyclic if R n F X ( ) = 0 for n = 0. The full subcategory of F -acyclic objects is F -injective [15, exercice I.19] and it contains the injective objects. Then, the next folklore lemma follows from [15, Proposition 1.8.3]:
Lemma A.1. Let F : C → D be a left exact functor between abelian categories. Suppose that C has enough injectives, and let X be an object of Ch + ( C ) . If for every integer n the cochain complex X n (concentrated in degree 0) is F -acyclic, then, in D + ( C ) , R F X ( ) is isomorphic to
$$\cdots \xrightarrow { F ( d ^ { - 2 } ) } F ( X ^ { - 1 } ) \xrightarrow { F ( d ^ { - 1 } ) } F ( X ^ { 0 } ) \xrightarrow { F ( d ^ { 0 } ) } F ( X ^ { 1 } ) \xrightarrow { F ( d ^ { 1 } ) } \cdots$$
A.2. Verdier duality. Let M be an n -dimensional real manifold. For any sheaf F in D k b ( M ), we recall the notation introduced in [15, Definition 3.1.16]:
$$\mathbf D _ { M } \mathcal { F } = \mathbf R \mathcal { H } o m \left ( \mathcal { F }, \omega _ { M } \right ), \quad \mathbf D ^ { \prime } _ { M } \mathcal { F } = \mathbf R \mathcal { H } o m \left ( \mathcal { F }, \mathbf k _ { M } \right ),$$
where the dualizing complex is ω M := a ! M k for a M : M → ∗ . In [15, section 3.4], the authors introduce the notion of cohomologically constructible sheaves . Here, only the following property will be used [15, Proposition 3.4.3.] : if F is a cohomologically constructible sheaf then D M F is cohomologically constructible and F → D M D M F is an isomorphism. It follows from [15, Exercice III.4] that, if an open subset U ⊆ M is locally cohomologically trivial, then k U and k U are cohomologically constructible. By locally cohomologically trivial (or l.c.t.) , we mean that ( RΓ U k M ) x /similarequal 0 and ( RΓ U k M ) x /similarequal k for every x ∈ U \ U . It follows from [15, Exercice III.4] that, if U is locally cohomologically trivial, then
$$D ^ { \prime } _ { M } { \mathbf k } _ { U } \simeq { \mathbf k } _ { \overline { U } }, \quad D ^ { \prime } _ { M } { \mathbf k } _ { \overline { U } } \simeq { \mathbf k } _ { U }.$$
An open set V of M is called locally topologically convex (or l.t.c.) if every point in V has an open neighborhood that is homeomorphic to an open convex subset of a real vector space. In particular, if V l.t.c then it is l.c.t (see [24, section 2.1]).
## Appendix B. Details of the procedure of Section 7.2
Here are now the details of the procedure sketched in Section 7.2. Let j max be the degree of the maximal non-zero term in C i ( ), which by assumption is a bounded cochain complex. We proceed as follows:
- · At step 0, we map C i ( -1) to im( f i -1 ) via f i -1 . We call f i -1 0 , the corresponding morphism. Note that its cokernel is trivial, so it is not per se a simplex insertion. To get a true simplex insertion it is sufficient to merge this step with the next one in the final procedure.
- · At step 1, we add N j max in degree j max to our complex, via the following morphism called f i -1 1 , :
Strictly speaking, the horizontal maps in the diagram are the restrictions of the differentials of C i ( ) to the appropriate spaces. Note that we have both im( f j max +1 i -1 ) = 0 and d j max i = 0 here, because C i ( ) j max +1 = 0. The two rows are then well-defined complexes and the vertical arrows form a well-defined monomorphism of complexes between them.
- · At every subsequent step s>1, we add N j in degree j = j max +1 -s to our complex, via the following morphism called f i -1 ,s :
$$\cdots \longrightarrow & \lim ( f _ { i - 1 } ^ { j - 1 } ) \stackrel { d _ { i } ^ { j - 1 } } { \longrightarrow } \lim ( f _ { i - 1 } ^ { j } ) \stackrel { d _ { i } ^ { j } } { \longrightarrow } \lim ( f _ { i - 1 } ^ { j + 1 } ) \oplus N _ { j + 1 } \longrightarrow \cdots \\ & \left | \right | \, \left | \, \right | \, \left [ \int _ { 0 } \right ] \, \right | \, \right | \, \right | \\ \cdots \longrightarrow & \lim ( f _ { i - 1 } ^ { j - 1 } ) \stackrel { d _ { i } ^ { j - 1 } } { \longrightarrow } \lim ( f _ { i - 1 } ^ { j } ) \oplus N _ { j } \stackrel { d _ { i } ^ { j } } { \longrightarrow } \lim ( f _ { i - 1 } ^ { j + 1 } ) \oplus N _ { j + 1 } \longrightarrow \cdots \\ & \omega \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \, \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{matrix}$$
Again, strictly speaking, the horizontal maps in the diagram are the restrictions of the differentials of C i ( ) to the appropriate spaces. Note in particular that d j i makes sense here because N j +1 has been inserted previously. The two rows are then well-defined complexes, and the vertical arrows form a well-defined monomorphism of complexes between them.
After finitely many steps (because C i ( ) is bounded), our current complex becomes C i ( ), and the intermediate morphisms f i -1 ,s compose to f i -1 . Note however that they may not be simplex insertions individually, because each vector space complement N j max +1 -s is inserted at once via f i -1 ,s . We therefore further decompose every f i -1 ,s into a sequence of simplex insertions, each inserting a new dimension of N j max +1 -s in the complex in degree ( j max +1 -s )-this requires fixing an arbitrary ordered basis of N j max +1 -s in advance, the choice of ordered basis being irrelevant.
Department of Mathematics, École normale supérieure, France Email address : [email protected]
Inria Saclay - Île-de-France and École Polytechnique, 91120, Palaiseau, France Email address : [email protected]
Université Paris Cité and Université Sorbonne Paris Nord, Inserm, INRAE, Centre for Research in Epidemiology and Statistics (CRESS), 75004, Paris, France Email address : [email protected] | null | [
"Alex Fernandes",
"Steve Oudot",
"Francois Petit"
] | 2024-08-02T07:40:14+00:00 | 2024-08-02T07:40:14+00:00 | [
"math.AT",
"cs.CG"
] | Computation of $γ$-linear projected barcodes for multiparameter persistence | The $\gamma$-linear projected barcode was recently introduced as an
alternative to the well-known fibered barcode for multiparameter persistence,
in which restrictions of the modules to lines are replaced by pushforwards of
the modules along linear forms in the polar of some fixed cone $\gamma$. So
far, the computation of the $\gamma$-linear projected barcode has only been
studied in the functional setting, in which persistence modules come from the
persistent cohomology of $\mathbb{R}^n$-valued functions. Here we develop a
method that works in the algebraic setting directly, for any multiparameter
persistence module over $\mathbb{R}^n$ that is given via a finite free
resolution. Our approach is similar to that of RIVET: first, it pre-processes
the resolution to build an arrangement in the dual of $\mathbb{R}^n$ and a
barcode template in each face of the arrangement; second, given any query
linear form $u$ in the polar of $\gamma$, it locates $u$ within the arrangement
to produce the corresponding barcode efficiently. While our theoretical
complexity bounds are similar to the ones of RIVET, our arrangement turns out
to be simpler thanks to the linear structure of the space of linear forms. Our
theoretical analysis combines sheaf-theoretic and module-theoretic techniques,
showing that multiparameter persistence modules can be converted into a special
type of complexes of sheaves on vector spaces called conic-complexes, whose
derived pushforwards by linear forms have predictable barcodes. |
2408.01066v2 | ## ON AN INVERSE TRIDIAGONAL EIGENVALUE PROBLEM AND ITS APPLICATION TO SYNCHRONIZATION OF NETWORK MOTION
LUCA DIECI, CINZIA ELIA, AND ALESSANDRO PUGLIESE
Abstract. In this work, motivated by the study of stability of the synchronous orbit of a network with tridiagonal Laplacian matrix, we first solve an inverse eigenvalue problem which builds a tridiagonal Laplacian matrix with eigenvalues λ 1 = 0 < λ 2 < · · · < λ N and null-vector e = [ 1 . . . 1 ] . Then, we show how this result can be used to guarantee -if possible- that a synchronous orbit of a connected tridiagonal network associated to the matrix L above is asymptotically stable, in the sense of having an associated negative Master Stability Function (MSF). We further show that there are limitations when we also impose symmetry for L .
Notation . We let e k be the k -th column of the identity matrix, and e be the vector of all 1's. Boldface will indicate vectors, whose number of elements will be clear from the context. As needed, we will use Matlab notation for entries of vectors and matrices, e.g. A i, j ( ) will be the ( i, j )-th entry of a matrix A .
## 1. A linear algebra and a dynamical systems problem
The purpose of this work is two-fold. First, we will solve the following inverse eigenvalue problem: ' Given values λ 1 = 0 < λ 2 < · · · < λ N , find an unreduced tridiagonal matrix L with these as eigenvalues, with positive diagonal and negative off diagonal entries, and whose entries on each row add up to 0 (that is, L e = 0 '. ) Then, we will use this result to: ' Show how and when we can guarantee that a synchronous orbit of a connected tridiagonal network associated to the matrix L above is asymptotically stable, in the sense that the Master Stability Function (MSF) is negative '.
In the process of solving the above problems, we will also realize that it is generally not possible to also require that L is symmetric. Further, we will show that if the synchronous orbit of the network associated to the standard tridiagonal matrix T in (3) does not lead to a negative value of the MSF, then there cannot be any connected network with tridiagonal symmetric Laplacian matrix giving a negative MSF.
From the theoretical point of view, our results are an important addition to the vast literature on inverse eigenvalue problems for tridiagonal matrices, by adding the nontrivial constraint of having a specific null vector. From the application point of view, our results provide a rigorous and clear indication of how to weigh the arcs of a network with the nearest neighbor topology in order to obtain a stable synchronous orbit, thereby overcoming the limitations imposed by requiring symmetry.
A plan of the paper is as follows. In the remaining part of this section, we review some relevant linear algebra and network (dynamical systems) results, in particular about the concept of MSF. Then, in Section 2, we give our main theoretical results about the inverse eigenvalue problem, by giving and rigorously justifying novel algorithms to obtain a tridiagonal matrix with given spectrum
2020 Mathematics Subject Classification. 65F18, 15A18.
Key words and phrases. Tridiagonal network, inverse eigenvalue problem, synchronization.
The authors gratefully acknowledge the support of the School of Mathematics of Georgia Tech. The work has been partially supported by the GNCS-Indam group and the PRIN2022PNR P2022M7JZW ' SAFER MESH- Sustainable mAnagement oF watEr Resources modEls and numerical MetHods ' research grant.
and null vector. In Section 3, we look at some theoretical results about symmetric connected tridiagonal network structure, and in Section 4 we show performance of our techniques. Finally, conclusions are in Section 5.
## 1.1. Linear algebra background.
/negationslash
Definition 1.1. Given a matrix A ∈ R N × N , we say that A is reducible if there exists a permutation P and integers N 1 = 0 = N 2 , N 1 + N 2 = n , such that P T AP = [ A 11 0 0 A 22 ] where A 11 ∈ R N 1 × N 1 , A 22 ∈ R N 2 × N 2 . If a matrix A is not reducible, then it is called irreducible .
/negationslash
Definition 1.2. A matrix L ∈ R N × N is tridiagonal and unreduced if it has the form
$$( 1 ) & L = \left [ \begin{matrix} a _ { 1 } & b _ { 2 } & 0 & 0 & \cdots & 0 \\ c _ { 2 } & a _ { 2 } & b _ { 3 } & 0 & \cdots & 0 \\ 0 & c _ { 3 } & a _ { 3 } & b _ { 4 } & \ddots & 0 \\ \vdots & \ddots & \ddots & \ddots & \ddots & \vdots \\ 0 & \cdots & 0 & c _ { N - 1 } & a _ { N - 1 } & b _ { N } \\ 0 & \cdots & \cdots & 0 & c _ { N } & a _ { N } \end{matrix} \right ] \,, \\ \intertext { w i t h $ k $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ = m $ }$$
/negationslash
$$\begin{bmatrix} \colon & \ddots & \ddots & \ddots & \colon \\ 0 & \cdots & 0 & c _ { N - 1 } & a _ { N - 1 } & b _ { N } \\ 0 & \cdots & \cdots & 0 & c _ { N } & a _ { N } \end{bmatrix} \\ 2, \dots, N. & M o r e o v e r, \ w e \ c a l l \ L \text{ network-tridiag}$$
with b j = 0 , c j = 0 , j = 2 , . . . , N . Moreover, we call L network-tridiagonal if b j < 0 , c j < 0 , j = 2 , . . . , N , and a j = -b j +1 -c j , j = 1 , . . . , N ( c 1 = 0 = b N +1 ), in which case L is singular with null vector e .
/negationslash
Remark 1.3. We note that a network tridiagonal matrix L is effectively the Laplacian matrix of a given connected network. Moreover, we also remark that an unreduced tridiagonal matrix L is also automatically irreducible.
The following well known result (e.g., see [10, 7]) will be used below.
Lemma 1.4. Given a general tridiagonal, unreduced, matrix L as in (1) , then its eigenvalues are real and distinct, hence L is diagonalizable by a real matrix of eigenvectors V : V -1 LV = diag( λ , i i = 1 , . . . , N ) . Moreover, the eigenvalues do not change as long as the products b k c k , k = 2 , . . . , N , do not change either.
Proof. The proof follows from the fact that the characteristic polynomial of (1) can be recursively defined as follows (Sturm sequence):
$$p _ { 0 } ( \lambda ) & = 1 \, \quad p _ { 1 } ( \lambda ) = \lambda - a _ { 1 } \, \\ p _ { j } ( \lambda ) & = ( \lambda - a _ { j } ) p _ { j - 1 } ( \lambda ) - ( b _ { j } c _ { j } ) p _ { j - 2 } ( \lambda ) \, \quad j = 2, \dots, N \.$$
Note that we must have b c j j = 0, for all j = 2 , . . . , N , since L is unreduced.
$$& p _ { 0 } ( \lambda ) = 1 \, \quad p _ { 1 } ( \lambda ) = \lambda - a _ { 1 } \, \\ & p _ { j } ( \lambda ) = ( \lambda - a _ { j } ) p _ { j - 1 } ( \lambda ) - ( b _ { j } c _ { j } ) p _ { j - 2 } ( \lambda ) \, \quad j = 2, \dots, N \. \\ & \text{Note that we must have } b _ { j } c _ { j } \neq 0, \text{ for all } j = 2, \dots, N, \, \text{since } L \text{ is unreduced.}$$
/negationslash
Example 1.5. The most commonly studied instance of network tridiagonal matrix L of interest to us is that associated to symmetric nearest-neighbor coupling, called diffusive coupling in [6] . That is, one has
$$L & = \sigma T, \ \ T = \begin{bmatrix} 1 & - 1 & 0 & 0 & \cdots & 0 \\ - 1 & 2 & - 1 & 0 & \cdots & 0 \\ \vdots & \ddots & \ddots & \ddots & \vdots \\ 0 & \cdots & 0 & - 1 & 2 & - 1 \\ 0 & \cdots & \cdots & 0 & - 1 & 1 \end{bmatrix} \,,$$
where σ > 0 is called the coupling strength. The eigenvalues µ j 's and (orthonormal) eigenvectors v j 's of T are well known:
$$& F o r \ \ j = 1, 2, \dots, N \colon \quad \mu _ { j } = 4 \sin ^ { 2 } \left ( \frac { ( j - 1 ) \pi } { 2 N } \right ) \, \quad a n d \\ & v _ { i 1 } = \sqrt { \frac { 1 } { N } } \, \ v _ { i j } = \sqrt { \frac { 2 } { N } } \cos \left ( \frac { ( i - 0. 5 ) ( j - 1 ) \pi } { N } \right ) \, \ \ i = 1, \dots, N \. \\ 1. 2. \text{ Networks and the MSF. Consider the following system of counted identical different} \quad \text{different} \quad \text{.}$$
1.2. Networks and the MSF. Consider the following system of coupled identical differential equations
$$\dot { x } _ { i } & = f ( x _ { i } ) + \sum _ { j = 1 } ^ { N } a _ { i j } E ( x _ { j } - x _ { i } ), \ i = 1, \dots, N, \\. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.$$
/negationslash where A = ( a ij ) i,j =1: N , is the matrix describing the interaction of N different agents x i ∈ R n , a ii = 0 , i = 1 , . . . , N , a ij ≥ 0 for j = , and i E ∈ R n × n is the matrix describing which components of each agent interact with one another. In general, A represents the structure of a directed graph with weighted edges, and we will henceforth assume that the graph is connected, hence one can get to any node starting from any other node, moving along edges (in particular, no row of A can be 0). We recall that a graph being connected is equivalent to the matrix A being irreducible.
In (5), separately each agent satisfies the same differential equation
$$\dot { x } = f ( x )$$
and by the structure of the system obviously taking N copies of the same solution of (6), x 1 = x 2 = · · · = x N = x , one obtains a solution of (5). This is called synchronous solution and we denote it as x s . Further, with
$$\Xi = \{ x \in \mathbb { R } ^ { n N } \, \colon \, x _ { 1 } = x _ { 2 } = \dots = x _ { N } \, \, x _ { j } \in \mathbb { R } ^ { n }, \, j = 1, \dots, N \}$$
we indicate the synchronous subspace .
/negationslash
It is convenient to rewrite (5) by defining the new matrix L : L ij = -a ij , for i = j and L ii = ∑ j a ij , i, j = 1 , . . . , N . Obviously, 0 is an eigenvalue of L , and since the graph is connected, 0 is a simple eigenvalue of L . In general, L is not symmetric, and it corresponds to what is known as out-degree Laplacian (see [14]). In this work, we will restrict to L satisfying the structure of network tridiagonal matrix given in Definition 1.2.
$$\text{network tridiagonal matrix given in Definition 1.2.} \\ \text{Let } x = \begin{bmatrix} x _ { 1 } \\ \vdots \\ x _ { N } \end{bmatrix} \in \mathbb { R } ^ { n N }, \, F ( x ) = \begin{bmatrix} f ( x _ { 1 } ) \\ \vdots \\ f ( x _ { N } ) \end{bmatrix}, \, \text{and rewrite } ( 5 ) \text{ as} \\ \dot { x } = F ( x ) + M x, \quad \text{where} \quad M = - L \otimes E \.$$
$$\dot { x } = F ( x ) + M x, \quad \text{where} \ \ M = - L \otimes E \.$$
In order to ascertain the stability of a synchronous orbit x s one needs to study the behavior of solutions of (8) transversal to Ξ and the Master Stability Function (MSF) does precisely that. In fact, the MSF tool (originally devised in [11]) is a widely adopted indicator of linearized stability of the synchronous orbit for the system (8). The power of the technique consists in the replacement of the large nN -dimensional linear system arising from linearizing (8), with a single n -dimensional parametrized linear system. Indeed, linearization of (8) about the synchronous solution x S gives
the linear system
$$\dot { y } & = \begin{bmatrix} D f ( x ) & & \\ & D f ( x ) & \\ & & \ddots & \\ & & D f ( x ) \end{bmatrix} y - ( L \otimes E ) \dot { y }, \\ \int _ { t } \, \text{Next, let } V \, \text{ be the matrix of eigenvectors of } L, \, \text{and perform the cha}$$
$$\dot { y } _ { i } = D f ( x ) y _ { i } - \lambda _ { i } E y _ { i } \, \\ \vdots \theta \, \left. \infty \, \left. \infty \, \right. \infty \, \left. \infty \, \left. \, \left. \infty \, \right.$$
where y = [ y 1 . . . y N ] . Next, let V be the matrix of eigenvectors of L , and perform the change of variable ( V -1 ⊗ I n ) y → y , to obtain the N linear systems of dimension n where λ 1 = 0 < λ 2 < . . . λ N are the eigenvalues of L . As a consequence, one considers the single parametrized linear system
$$& ( 9 ) & & \dot { z } = ( A ( t ) - \eta E ) z \, \quad \text{where} \quad \eta \geq 0 \quad \text{and} \quad A ( t ) = D f ( x ( t ) ) \. \\ & \varpi \ e. \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \\ & \varpi \ e. \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \cdots \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colon \cdots \colots \colon \cdots \colots \colon \cdots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots \colots$$
Definition 1.6. The MSF is defined as the largest Lyapunov exponent (Floquet exponent, in case the synchronous solution is a periodic orbit) of (9) as η ranges over the eigenvalues of L . A negative value of the MSF implies stability of the synchronous orbit.
In this work, we will study directly the parametrized linear system (9) and a-priori decide what range of values of η (if any) will give a negative MSF, then ask whether or not it is possible to find a network tridiagonal structure (that is, a Laplacian matrix of the form in (1)) whose eigenvalues fit the stability region inferred by the MSF. More in details, if we find that there is a negative value of the MSF for η ∈ [ η , η 1 2 ], then the synchronous solution is asymptotically stable for (8) if
$$\frac { \lambda _ { 2 } } { \lambda _ { N } } > \frac { \eta _ { 1 } } { \eta _ { 2 } }.$$
Remark 1.7. Obviously, the MSF depends on E and it is easy to give examples where the MSF is negative for some E , but positive for some other coupling matrices E ; for example, see [8, Figure 1] . Indeed, there is a very vast literature on network synchronization, the MSF, and the interplay between network topology and negative MSF. This is fairly evident already at a graph theoretic level: e.g., by choosing the network structure of a complete graph, and the matrix E to be the identity, surely increases synchronizability. But this is not a desirable way to proceed, since the type of connections between agents is not just a mathematical artifact. For this reason, we will assume that the nearest neighbor interaction (that is, the network tridiagonal form of L ), and the matrix E , are specified by the underlying application and that there is no freedom in changing them, in particular the structure of L . Our goal will be to choose, if possible, the entries of L so that the MSF is negative.
## 2. Our inverse network tridiagonal eigenvalue problem
We will solve our inverse eigenvalue problem in two steps. First, in Section 2.1, we give an algorithm that builds a symmetric, unreduced, tridiagonal matrix with a given set of distinct eigenvalues. Then, in Section 2.2, we propose an algorithm that takes a given symmetric, singular, unreduced, tridiagonal matrix, and it produces an unreduced, generally non-symmetric, tridiagonal matrix with a specified null vector.
There exists an extensive literature in the general area of inverse eigenvalue problems, (e.g., see [2]). In fact, our first algorithm (to build a symmetric tridiagonal unreduced matrix with a preassigned spectrum) is effectively a known result. However, to the best of our knowledge, our result on specifying spectrum and null vector appears to be new, and it is what we need for obtaining a network leading to a negative MSF.
- 2.1. Symmetric unreduced tridiagonal with given spectrum. We are interested in solving the following inverse problem.
Given N real values λ 1 < λ 2 < · · · < λ N , find an unreduced, symmetric, tridiagonal matrix S , with negative off diagonal, having these λ i 's as eigenvalues . To clarify, we are seeking S of the form
$$S = | \begin{array} {$$
with all b i < 0, i = 2 , . . . , N , and eigenvalues λ 1 < λ 2 < · · · < λ N . To solve this problem we adopted Algorithm diag2trid below.
$$S = \begin{bmatrix} a _ { i } & b _ { 2 } & 0 & 0 &$$
## Algorithm 1 Algorithm diag2trid
- 1: Set D = diag( λ , . . . , λ 1 N ).
- 3: Let Q be a Householder reflection such that Q e 1 = q .
- 2: Let q ∈ R N be the vector q = e / √ N .
- 4: Set A = Q DQ T .
- 5: Perform the Householder tridiagonalization algorithm on A , so that
$$H ^ { T } A H = S$$
where S is tridiagonal and H is orthogonal.
- 6: By possibly changing the signs of the b i 's, we further enforce that b i < 0, i = 2 , . . . , N , to obtain the sought form of S .
## Remarks 2.1.
- (i) With the trivial exception of the last step, Algorithm diag2trid is effectively the same as the one we described, and justified, in [3] , where it is also shown to be equivalent to a technique of Schmeisser, see [12] , whose interest was in building an unreduced symmetric tridiagonal matrix whose characteristic polynomial is given. A related construction is also summarized in [1, Theorem 4.7] . We note that performing a possible change of sign of the b i 's is legitimate in light of Lemma 1.4.
- (ii) Although the choice q = e / √ N is our default choice, and the one we adopted in the experiments in Section 4, there is freedom in choosing the unit vector q in Algorithm diag2trid . This is natural, since the transformation H is such that H , (: 1) = H (1 :) , T = e 1 , which means that S is diagonalized by ( QH ) T , whose first row is given by q . Appealing to the Implicit Q Theorem, see [5, Theorem 8.3.2] , we know that a real symmetric tridiagonal matrix is completely characterized by its (real) eigenvalues and by the first row of the (orthogonal) matrix of its eigenvectors, in the sense that any two real symmetric, tridiagonal, and unreduced matrices, S and T , that are diagonalized by two orthogonal matrices having the same first row, must be equal up to the sign of their off diagonal entries.
The next Lemma will be needed below and it clarifies the structure of S produced by Algorithm 1 when the eigenvalues are λ 1 = 0 < λ 2 < · · · < λ N .
Lemma 2.2. Let S as in (11) be produced by Algorithm 1 relative to eigenvalues λ 1 = 0 < λ 2 < · · · < λ N . Then, the values a i in S are all positive: a i > 0 , i = 1 , . . . , N .
Proof. By construction, we have S = H AH T = ( QH ) T D QH ( ). Let U = QH , so that S = U T DU . Therefore, for any j = 1 , . . . , N :
$$& \cdot \\ & a _ { j } = e _ { j } ^ { T } S e _ {$$
and so -since λ k > 0 for k = 2 , . . . , N - we have a j > 0 unless u kj = 0 for k = 2 , . . . , N . By contradiction, suppose that u kj = 0 for k = 2 , . . . , N , and some j = 1 , . . . , N . But then U e j = ± e 1 , and since U is orthogonal this means that e T 1 U = ± e T j . But, see Remark 4-(ii), S is diagonalized into D by an orthogonal matrix whose first row is q T , and so this would contradict the choice of q in Step 2 of Algorithm 1, and the thesis follows. /square
- 2.2. Singular tridiagonal with specific null-vector. Next, we consider the following modification of the previous problem.
Given N real values λ 1 = 0 < λ 2 < · · · < λ N , find an unreduced, network tridiagonal matrix L , whose spectrum is given by these values, and such that the eigenvector associated to the 0 -eigenvalue is aligned with [ 1 1 . . . 1 ] .
Our construction will produce a generally nonsymmetric tridiagonal matrix L as in (1) and we will see that -in general- one cannot require that there is a symmetric tridiagonal matrix satisfying our requests. The technique we used to resolve this problem is encoded in the following Algorithm, which will be justified in Theorem 2.3 below.
## Algorithm 2 TridZeroRowSum
- 1: Using Algorithm 1, diag2trid , generate an unreduced symmetric tridiagonal matrix S as in (11) with eigenvalues λ 1 = 0 < λ 2 < · · · < λ N .
- (a) Let α 2 such that a 1 + α b 2 2 = 0.
- 2: Modify the first N -1 rows of S as follows.
- (b) For k = 3 , . . . , N , let α k : α b k k + a k -1 + b k -1 α k -1 = 0.
- 3: The desired L is then:
$$& 3 \colon The desired L is then \colon \\ & L = \begin{bmatrix} a$$
Theorem 2.3. The above Algorithm 2, TridZeroRowSum , is well defined and terminates with an unreduced tridiagonal matrix with spectrum given by { 0 , λ 2 , · · · , λ n } , and eigenvector associated to
1
the
0
-eigenvalue given (up to normalization) by
e
=
.
.
.
.
1
/negationslash
Proof. The algorithm is well defined as long as α i = 0 for all i = 2 , . . . , N . Next, using Lemma 2.5 below, we show that the algorithm must complete the first N -1 steps, that is that, with b 1 = 0,
for k = 2 , . . . , N -1 we have:
/negationslash
$$a _ { k - 1 } + \frac { b _ { k - 1 } } { \alpha _ { k - 1 } } \neq 0. \\ \intertext { a, \, } \neq 0 \ B u t { \, } \text{thist fail}.$$
$$\text{there exists, unique, $\alpha_{k}\neq 0$ such that $\alpha_{k}b_{k}+a_{k-1}+\frac{b_{k-1}}{\alpha_{k-1}}=0$,} \\........................................................................................................................................................................................................$$
or, equivalently,
/negationslash
/negationslash
Now, for k = 2, we need to show that a 1 = 0. But this follows from Lemma 2.2. For k > 2, we need to show that
/negationslash
By contradiction, suppose that a k -1 + b k -1 α k -1 = 0 and consider the principal minor of order k -1 of the matrix B k -1 obtained during the reduction process, that is
$$a _ { k - 1 } + \frac { b _ { k - 1 } } { \alpha _ { k - 1 } } \neq 0. \\. \ b _ { \nu - 1 } \cdots \in \cdots$$
$$B _ { k - 1 } = \begin{bmatrix} a _ { 1 } & \alpha _ { 2 } b _ { 2 } & 0 & 0 & \cdots & 0 \\ b _ { 2 } / \alpha _ { 2 } & a _ { 2 } & \alpha _ { 3 } b _ { 3 } & 0 & \cdots & 0 \\ 0 & b _ { 3 } / \alpha _ { 3 } & a _ { 3 } & \alpha _ { 4 } b _ { 4 } & \ddots & 0 \\ \vdots & & \ddots & \ddots & \vdots \\ 0 & \cdots & 0 & b _ { k - 1 } / \alpha _ { k - 1 } & a _ { k - 1 } \end{bmatrix} \,.$$
.
But then this matrix is singular, since we would have that
$$B _ { k - 1 } \begin{bmatrix} 1 \\ 1 \\ \vdots \\ 1 \end{bmatrix} = 0 \\ \intertext { \text{line of $B_{k-1}$ $ But, $1\sim\Gamma$ $C$} } \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \alpha \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Delta \sim \Lambda$$
and in particular 0 would be an eigenvalue of B k -1 . But, the eigenvalues of B k -1 are the same as the eigenvalues of the principal minor of order k -1 of S , that is of
$$S _ { k - 1 } = \begin{bmatrix} a _ { 1 } & b _ { 2 } & 0 & 0 & \cdots & 0 \\ b _ { 2 } & a _ { 2 } & b _ { 3 } & 0 & \cdots & 0 \\ 0 & b _ { 3 } & a _ { 3 } & b _ { 4 } & \ddots & 0 \\ \vdots & & \ddots & \ddots & \ddots & \vdots \\ 0 & \cdots & 0 & b _ { k - 1 } & a _ { k - 1 } \end{bmatrix} \,, \\ \text{e found that a principal minor of $S$ is singular, contradict} \, \text{and} \, \text{and} \, \text{$\frac{1}{2}$ was $0$} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and}$$
and so we would have found that a principal minor of S is singular, contradicting Lemma 2.5.
Finally, since by construction the first N -1 rows of L have 0-sum and are linearly independent, then the last row must also have 0-sum (since it is linearly dependent on the previous N -1, given that 0 is an eigenvalue).
Therefore, the algorithm produces the matrix L in (12), which clearly has the desired spectrum and rows that sum to zero. This concludes the proof. /square
Lemma 2.4. Let S ∈ R N × N be a symmetric matrix with a 0 eigenvalue. Assume that 0 is a simple eigenvalue and let v be an associated eigenvector of length 1 . If no component of v is 0 , then S is irreducible. Conversely, if S is unreduced and tridiagonal, hence irreducible, with eigenvalues λ 1 = 0 < λ 2 < · · · < λ N , then v i = 0 , for all i = 1 , . . . , N .
/negationslash
Proof. We show that, if no component of v is 0, then S is irreducible, by showing that if S is reducible, then there exists some i : v = 0. Indeed, if S is reducible, then for some permutation n 1 + n 2 = N . So, we have PSP T P v = 0, or [ S 1 0 0 S 2 ][ w 1 w 2 ] = 0 with [ w 1 w 2 ] = P v . Then, since the
i P we have PSP T = [ S 1 0 0 S 2 ] , with S 1 = S T 1 ∈ R n 1 × n 1 and S 2 = S T 2 ∈ R n 2 × n 2 , n , n 1 2 ≥ 1 and kernel of S is 1-dimensional, we must have either w 1 = 0 or w 2 = 0, giving the claim.
/negationslash
To show the converse statement, for S unreduced and tridiagonal, suppose that v k = 0 for some 1 ≤ k ≤ N . First, note that if k = 1, then - writing S = [ a 1 b T b B ] - since S [ 0 v 2 ] = 0, v 2 ∈ R N -1 = 0, then B v 2 = 0 and this means that B has a 0 eigenvalue, which contradicts Lemma 2.5 below. Next, suppose v k = 0 and k > 1. Partition S as follows:
$$- \circ \max \nu \succ \tilde { \Lambda } \, \cos \max \cos \max \cos. \\ S = \left [ \begin{matrix} T _ { 1 } & \left [ b _ { k } e _ { k - 1 } & 0 \right ] \\ 0 \end{matrix} \right ] & T _ { 2 } \right ] \\ \text{duced, of size } \tilde { \Gamma } _ { \L \L } \, \sin \tilde { \Gamma } _ { \L \L } \, \sin \tilde { \Gamma } _ { \L } \, \sin \tilde { \Gamma } _ { \L } \, \sin \tilde { \Gamma } _ { \L } \, \sin \tilde { \Gamma } _ { \L } \, \sin \tilde { \Gamma } _ { \L } \, \sin \tilde { \Gamma } _ { \L } \, \sin \tilde { \Gamma } _ { \L } \, \sin \tilde { \Gamma } _ { \L } \, \sin \tilde { \Gamma } _ { \L } \, \sin \tilde { \Gamma } _ { \L } \, \sin \tilde { \Gamma } _ { \L } \, \sin \tilde { \Gamma } _ { \L } \, \sin \tilde { \Psi } _ { \L } \, \sin \tilde { \Psi } _ { \L } \, \sin \tilde { \Psi } _ { \L } \, \sin \tilde { \Psi } _ { \L } \, \sin \tilde { \Psi } _ { \L } \, \sin \tilde { \Psi } _ { \L } \, \sin \tilde { \Psi } _ { \L } \, \sin \tilde { \Psi } _ { \L } \, \sin \tilde { \Psi } _ { \L } \, \sin \tilde { \Psi } _ { \L } \, \sin \tilde { \Psi } _ { \L } \, \sin \tilde { \Psi } _ { \L } \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \sin \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau } \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \sin \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau \, \cos \tau$$
where T 1 is tridiagonal, unreduced, of size ( k -1 , k -1), and T 2 is tridiagonal, unreduced, of size ( N -k +1 , N -k +1). Writing v = v 1 0 v 2 , v 1 ∈ R k -1 , v 2 ∈ R N -k , then we must have T 1 v 1 = 0,
/negationslash contradicting Lemma 2.5.
and -because of Lemma 2.5T 1 is invertbile and this implies that v 1 = 0. Thus, we also have T 2 [ 0 v 2 ] = 0 and thus, either v 2 = 0 if T 2 is invertible, contradicting that v = 0, or T 2 is singular, /square
Lemma 2.5. Given a symmetric, unreduced, tridiagonal matrix S as in (11) , with N > 1 , and with eigenvalues λ 1 = 0 < λ 2 < · · · < λ N . Then, any leading (respectively, trailing) principal submatrix of S of size ( p, p ) , 1 ≤ p ≤ N -1 , is positive definite. 1
Proof. The proof follows from a refinement of classic results on interlacing of eigenvalues for symmetric tridiagonal matrices. In particular, the following result holds (see [7, Problem 4.3.P17]):
M = C c c T d , symmetric, tridiagonal and unreduced, with C R N -1 ,N -1 . Let µ 1 < µ 2 <
· · · < µ N be the eigenvalues of M , and let ν 1 < ν 2 < · · · < ν N -1 be the eigenvalues of C . Then, the ν 's interlace properly the µ 's. That is, we have
'Given [ ] ∈ j i
$$\mu _ { 1 } < \nu _ { 1 } < \mu _ { 2 } < \nu _ { 2 } < \dots \mu _ { N - 1 } < \nu _ { N - 1 } < \mu _ { N }.$$
We show the result for the leading principal submatrices. Let S k , k = 1 2 , . . . , N -1, be the principal submatrices of order k of S , and let λ ( k ) 1 < · · · < λ ( k ) k be their eigenvalues. Using the proper interlacing result quoted above, in particular we must have:
$$\begin{array} { c } \text{The result also holds if we partition $M = \begin{bmatrix} a & b ^ { T } \\ b & C \end{bmatrix}. \end{array} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{
\end{array}$$
$$\lambda _ { 1 } ^ { ( N ) } = \lambda _ { 1 } = 0 < \lambda _ { 1 } ^ { ( N - 1 ) } < \lambda _ { 1 } ^ { ( N - 2 ) } < \dots < \lambda _ { 1 } ^ { ( 1 ) } \\ \intertext { w o n d o f t u l i n e m i n o 1 c h m o t u l i o o i o d i o i o d i o 1 }$$
and the result follows. The case of trailing principal submatrices is identical. /square
We will also need the following result that refines Lemma 2.4 relative to the eigenvector of S associated to the 0 eigenvalue.
1 A leading (respectively, trailing) principal submatrix of size ( N -p, N -p ), p = 1 , . . . , N -1, is the matrix obtained by deleting the bottom (respectively, top) p rows and columns of S .
Lemma 2.6. Let S be a symmetric, unreduced, tridiagonal matrix as in (11) , with N > 1 , and with eigenvalues λ 1 = 0 < λ 2 < · · · < λ N . Let v be a unit eigenvector of S associated to the 0 -eigenvalue. Then, the entries of v all have the same sign.
Proof. We are going to use a beautiful relation between the entries of the eigenvector and the Sturm sequence (2). Using [9, Formula (15)], it holds that
$$v _ { k } = c \, \frac { p _ { k - 1 } ( 0 ) } { b _ { 2 } \dots b _ { k } }, \ k = 2, \dots, N,$$
where c is a nonzero constant fixing v 1 . Because of Lemma 2.4, we know that all entries of v are not 0 and thus we can write
$$\frac { v _ { k + 1 } } { v _ { k } } = \frac { 1 } { b _ { k + 1 } } \frac { p _ { k } ( 0 ) } { p _ { k - 1 } ( 0 ) } \. \\ \text{ns in the right-hand-side are} \ n$$
In this last expression, both fractions in the right-hand-side are negative values. In fact, for the first fraction this is obvious, since b k +1 < 0; the second fraction is the ratio between the characteristic polynomials of the leading principal minors of order k and k -1, evaluated at 0. But, because of the proper interlacing result on the eigenvalues of the principal minors (see the proof of Lemma 2.5), the polynomials p k and p k -1 assume opposite values at the origin, and so the ratio p k (0) /p k -1 (0) < 0 and the result follows. /square
Finally, we conclude this section with the following result that summarizes the fact that with our construction we obtain a network tridiagonal matrix satisfying the structural form of Definition 1.2, which is what we wanted to achieve.
Theorem 2.7. The matrix L in (12) satisfies the structural assumptions of Definition 1.2; in particular, all values a i , i = 1 , . . . , N , in (11) are strictly positive and the off diagonal entries α b i i (and of course b /α i i ) , i = 2 , . . . , N , are strictly negative.
Proof. By looking at L in (12), we observe that the a i 's are the a i 's of S produced by Algorithm 1, hence they are strictly positive because of Lemma 2.2. Also, the values of b i , i = 2 , . . . , N , are negative because they come from S . So, we now show that the α i 's are positive and the result will follow, since (by construction) the sum of the entries in each row is 0.
Let v be the eigenvector of S associated to the 0-eigenvalue. As in the proof of Theorem 2.3, and because the α j 's are not zero in light of Lemma 2.4, we have the following relation between the entries of v and the α j 's, for some nonzero value of c :
$$c = v _ { 1 }, \ c \alpha _ { 2 } = v _ { 2 }, \ c \alpha _ { 2 } \alpha _ { 3 } = v _ { 3 }, \dots, \ c \alpha _ { 2 } \cdots \alpha _ { N } = v _ { N } \. \\ \cdot \quad. \.$$
Therefore, we have that and using Lemma 2.6 the result follows.
$$\alpha _ { k } = \frac { v _ { k } } { v _ { k - 1 } } \, \ k = 2, \dots, N, \\ \text{t follows}.$$
/square
2.3. Impact of symmetry. In Example 2.8, we point out that, in general, one cannot also require that the sought tridiagonal matrix be symmetric.
Example 2.8. Suppose that, given λ 1 = 0 < λ 2 < λ 3 , there exists a 3 × 3 real symmetric unreduced tridiagonal matrix T such that (i) T has eigenvalues { 0 , λ 2 , λ 3 } , and (ii) the kernel of T is spanned
$$\ t r d a g o n a l \ m a t r x { \, I } \ s u c h \ t h a t \left ( \imath \, I \ h a s \ e g e n v a l e u s \left \{ 0, \lambda _ { 2 }, \lambda _ { 3 } \right \}, \, a n d \left ( \imath \right ) \ t h e \ k r e n e l \ o f \, I \ s \ s p a n n e d \\ \ b y \begin{bmatrix} 1 \\ 1 \end{bmatrix}. \, T o \ s a t i s f y \, \condition { ( i ) }, T \ m u s t \ h a v e \ t h e \, \text{form} \, T = \begin{bmatrix} x & - x & 0 \\ - x & x + y & - y \\ 0 & - y & y \end{bmatrix}, \, a n d \, \text{to\, satisfy\, also}$$
condition (i), x and y must satisfy { 2( x + ) = y λ 2 + λ 3 3 xy = λ λ 2 3 . (uniquely) two pairs of solutions:
Solving with respect to x and y yields
$$\text{$v$ panes $oy$ sovousons} \colon \\ \begin{cases} x = \frac { 1 } { 1 2 } \left ( \pm \sqrt { 3 } \sqrt { 3 \lambda _ { 2 } ^ { 2 } - 1 0 \lambda _ { 2 } \lambda _ { 3 } + 3 \lambda _ { 3 } ^ { 2 } } + 3 \lambda _ { 2 } + 3 \lambda _ { 3 } \right ) \\ y = \frac { 1 } { 1 2 } \left ( \mp \sqrt { 3 } \sqrt { 3 \lambda _ { 2 } ^ { 2 } - 1 0 \lambda _ { 2 } \lambda _ { 3 } + 3 \lambda _ { 3 } ^ { 2 } } + 3 \lambda _ { 2 } + 3 \lambda _ { 3 } \right ). \\ \i d y \text{ to be real valued, we must have} \end{cases}$$
But, for x and y to be real valued, we must have
$$1 0 \lambda _ { 2 } \lambda _ { 3 } \leq 3 \lambda _ { 2 } ^ { 2 } + 3 \lambda _ { 3 } ^ { 2 } \\ \rho \quad$$
In conclusion, there exists a real matrix T = x -x 0 -x x + y -y 0 -y y having eigenvalues 0 < λ 2 < λ 3 if and only if 10 λ λ 2 3 ≤ 3 λ 2 2 +3 λ 2 3 , which is not necessarily satisfied.
## 3. Symmetric Tridiagonal Networks and the MSF
In this section we give some new results on the ratio between the first positive and the largest eigenvalue of symmetric positive semi-definite network tridiagonal matrices and further highlight the impact that these results have on synchronizability of symmetric tridiagonal networks.
For every N ∈ N , with N ≥ 2, we let S denote the set of real N × N matrices as in (11) that further are network tridiagonal matrices (that is, for which the entries on each row add up to zero) and that are positive semi-definite. Further, we indicate with T the N × N matrix in (3) (obviously, an element of S ).
As usual, we let the eigenvalues be ordered in increasing fashion. Namely, for given S ∈ S , we denote its eigenvalues by
$$\lambda _ { 1 } = 0 < \lambda _ { 2 } < \dots < \lambda _ { N } \text{ \ and for } \ T \text{ \ we call them } \mu _ { 1 } = 0 < \mu _ { 2 } < \dots < \mu _ { N } \text{.}$$
Remark 3.1. We observe that any G ∈ S is a linear combination of elementary matrices E , . . . , E 1 N -1 :
$$& ( 1 3 ) & & G = \sum _ { k = 1 } ^ { N - 1 } x _ { k } E _ { k }, \, \text{for some } x _ { 1 }, \dots, x _ { N - 1 } \in \mathbb { R }, \\ & u h e r e \, \text{for amu } k = 1 \quad & N = 1 \quad E _ { i } \ \text{is the } N \ \times \ N \ \text{matrix} \, \text{different defined} \, \text{hu}$$
where for any k = 1 , . . . , N -1 , E k is the N × N matrix defined by
$$\cdots _ { \sigma } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda } \cdots _ { \lambda \lambda } \cdots _ { \lambda \lambda } \cdots _ { \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \xi } } \\ \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e,w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext { c e, w h e n } \intertext }$$
For instance, when N = 4 we have
$$E _ { 1 } = \begin{bmatrix} 1 & - 1 & 0 & 0 \\ - 1 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix}, \ E _ { 2 } = \begin{bmatrix} 0 & 0 & 0 \\ 0 & 1 & - 1 & 0 \\ 0 & - 1 & 1 & 0 \\ 0 & 0 & 0 \end{bmatrix}, \ E _ { 3 } = \begin{bmatrix} 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & - 1 \\ 0 & 0 & - 1 & 1 \end{bmatrix}.$$
The following result for parameter dependent symmetric matrices with distinct eigenvalues is well known (e.g., see [13])), and it will be used in the proof of Theorem 3.3 below.
Lemma 3.2 (First and second Hadamard variation formulae) . Let A t ( ) be a real symmetric matrix valued function that is twice continuously differentiable in t , and such that A t ( ) has simple eigenvalues for all t . Then, also its eigenvalues λ k ( ) t = λ k ( A t ( )) and corresponding orthonormal eigenvectors u k ( ) = t u k ( A t ( )) depend smoothly on t and we have:
$$\dot { \lambda } _ { k } ( t ) = u _ { k } ^ { T } ( t ) \dot { A } ( t ) u _ { k } ( t ),$$
/negationslash
$$\ddot { \lambda } _ { k } ( t ) & = u _ { k } ^ { T } ( t ) \ddot { A } ( t ) u _ { k } ( t ) + 2 \sum _ { j \neq k } \frac { | u _ { j } ^ { T } ( t ) \dot { A } ( t ) u _ { k } ( t ) | ^ { 2 } } { \lambda _ { k } ( t ) - \lambda _ { j } ( t ) }. \\ \intertext { O o r m o r o n } \, \frac { 1 } { 2 } \, \text{$\text{or all in one}$} \ N > 2 \text{ and with $the$ naturalian above $one$} \ n o n e.$$
Theorem 3.3. For all integers N ≥ 3 , and with the notation above, we have:
and the maximum is attained only at scalar multiples of T .
$$\max _ { S \in \mathcal { S } } \frac { \lambda _ { 2 } ( S ) } { \lambda _ { N } ( S ) } = \frac { \mu _ { 2 } } { \mu _ { N } } = \frac { \sin \left ( \frac { \pi } { 2 N } \right ) ^ { 2 } } { \sin \left ( \frac { ( N - 1 ) \pi } { 2 N } \right ) ^ { 2 } }, \\ \text{and the maximum is attained only at scalar multiplies of $T$}.$$
Proof. With notation from (3), we have
$$T v _ { k } = \mu _ { k } v _ { k }, \text{ for all } k = 1, \dots, N \.$$
Given any S ∈ S that is not a scalar multiple of T , define the following matrix valued function and the following real valued function, which is well defined and strictly positive for all t ∈ [0 , 1]:
$$A ( t ) = \underset { \begin{array} { c } \dots \\ \dots \end{array} } { \dots } \underset { \begin{array} { c } \dots \\ \dots \end{array} } { \dots } \dots$$
$$r ( t ) & = \frac { \lambda _ { 2 } ( A ( t ) ) } { \lambda _ { N } ( A ( t ) ) }.$$
We are going to show that:
- (i) ˙(1) = 0; r
- (ii) r is non-decreasing for all t ∈ [0 , 1];
Then the conclusion of the theorem will follow from (i)-(iii). In particular, (iii) shows that the maximum in (16) is attained only at scalar multiples of T .
- (iii) r is strictly increasing for all t ∈ [1 -δ, 1], for some 0 < δ ≤ 1.
Proof of point (i). Consider the map
↦
$$& \quad \ \ \ \ \ \ \ f \colon x = \left [ \begin{smallmatrix} \begin{smallmatrix} x _ { 1 } \\ x _ { 2 } \\ \vdots \\ x _ { N - 1 } \end{smallmatrix} \right ] \in \mathbb { R } ^ { N - 1 } \mapsto \frac { \lambda _ { 2 } ( T + G ( x ) ) } { \lambda _ { N } ( T + G ( x ) ) }, \\ \text{where} \, \mathcal { C } - \mathcal { C } ( \mathcal { C } ) \text{ to defined as in } T \times \text{ } W a \text{ want to show that } \nabla f - \mathcal { D } \text{ at } \mathcal { C } - \mathcal { D } \end{smallmatrix}$$
where G = G ( x ) is defined as in (13). We want to show that ∇ f = 0 at x = 0. Using (14), we obtain
(19) ∂f ∂x j ∣ ∣ ∣ x =0 = µ N v T 2 E j v 2 -µ 2 v T N E j v N µ 2 N . Hence, we have
(20) ∂f ∂x j ∣ ∣ ∣ x =0 = 0 if and only if v T 2 E j v 2 v T N E j v N = µ 2 µ N . Direct computation yields
$$\frac { \mu _ { 2 } ^ { T } E _ { j } v _ { 2 } } { v _ { N } ^ { T } E _ { j } v _ { N } } = \frac { \left ( v _ { 2 } ( j ) - v _ { 2 } ( j + 1 ) \right ) ^ { 2 } } { \left ( v _ { N } ( j ) - v _ { N } ( j + 1 ) \right ) ^ { 2 } }.$$
Substituting (4) into the right-hand side of (21) and applying trigonometric identities, we obtain
$$2$$
This proves the statement on the right of (20), and hence concludes the proof of point (i).
$$\frac { \left ( v _ { 2 } ( j ) - v _ { 2 } ( j + 1 ) \right ) ^ { 2 } } { \left ( v _ { N } ( j ) - v _ { N } ( j + 1 ) \right ) ^ { 2 } } = \frac { \left ( \cos \frac { ( 2 j - 1 ) \pi } { 2 N } - \cos \frac { ( 2 j + 1 ) \pi } { 2 N } \right ) ^ { 2 } } { \left ( \cos \frac { ( N - 1 ) ( 2 j - 1 ) \pi } { 2 N } - \cos \frac { ( N - 1 ) ( 2 j + 1 ) \pi } { 2 N } \right ) ^ { 2 } } = \\ = \frac { \left ( \sin \frac { j \pi } { N } \sin \frac { \pi } { 2 N } \right ) ^ { 2 } } { \left ( \sin \frac { ( N - 1 ) j \pi } { N } \sin \frac { ( N - 1 ) \pi } { 2 N } \right ) ^ { 2 } } = \frac { \left ( \sin \frac { \pi } { 2 N } \right ) ^ { 2 } } { \left ( \sin \frac { ( N - 1 ) \pi } { 2 N } \right ) ^ { 2 } } = \frac { \mu _ { 2 } } { \mu _ { N } }. \\ \text{This proves the statement on the right of } ( 2 0 ), and hence concludes the proof of point \left ( i i. } \text{Recall that } A ( t ) \text{ is linear in } t. \text{ and that } 0 = \lambda _ { 1 } ( t ) < \lambda _ { 2 } ( t ) < \dots < \lambda _ { N } ( t ) \text{ for}$$
Proof of point (ii). Recall that A t ( ) is linear in t , and that 0 = λ 1 ( ) t < λ 2 ( ) t < . . . < λ N ( ) for t all t ∈ (0 1]. , Then, it follows from (15) that λ N ( ) and t λ 2 ( ) are, respectively, convex and concave t functions of t in [0 , 1]. Differentiating r , we obtain
$$\dot { r } = \frac { \dot { \lambda } _ { 2 } \lambda _ { N } - \dot { \lambda } _ { N } \lambda _ { 2 } } { \lambda _ { N } ^ { 2 } }.$$
We have
$$\div \ddot { \lambda } _ { 2 } \lambda _ { N } - \ddot { \lambda } _ { N } \lambda _ { 2 } \leq 0. \\ \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \div \colon$$
$$& \text{Define } \varphi ( t ) \coloneqq \dot { \lambda } _ { 2 } ( t ) \lambda _ { N } ( t ) - \dot { \lambda } _ { N } ( t ) \lambda _ { 2 } ( t ) \text{ for all } t \in [ 0, 1 ]. \text{ We have} \\ & \dot { \varphi } = \ddot { \lambda } _ { 2 } \lambda _ { N } - \ddot { \lambda } _ { N } \lambda _ { 2 } \leq 0.$$
Since ˙(1) = 0, we have r ϕ (1) = 0, and therefore ϕ t ( ) ≥ 0 for all t ∈ [0 , 1]. This proves ˙( r t ) ≥ 0 for all t ∈ [0 , 1], i.e. r is non-decreasing on [0 , 1].
Proof of point (iii). We are going to show that ¨ λ 2 ( ) t < 0 in (1 -δ, 1) for some δ > 0. This implies that r is strictly decreasing in (1 -δ, 1), and hence r (0) > r (1).
/negationslash
$$s _ { 1 }, \dots, s _ { N - 1 }, \alpha & \text{ as follows:} \\ ( 2 4 ) & \begin{bmatrix} w _ { 1 } - w _ { 2 } & & & - w _ { 1 } \\ - w _ { 1 } + w _ { 2 } & w _ { 2 } - w _ { 3 } & & & - w _ { 2 } \\ - w _ { 2 } + w _ { 3 } & \ddots & & \vdots \\ & & \ddots & w _ { N - 1 } - w _ { N } & - w _ { N - 1 } \\ & & - w _ { N - 1 } + w _ { N } & - w _ { N } \end{bmatrix} \begin{bmatrix} s _ { 1 } \\ s _ { 2 } \\ \vdots \\ s _ { N - 1 } \\ \alpha \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \\ \vdots \\ 0 \\ 0 \end{bmatrix}. \\ \text{Performing row-reduction on (24), we obtain the equivalent system:}$$
We know that ¨ λ 2 (1) ≤ 0. Suppose ¨ λ 2 (1) = 0. Because of (15), we have that v T j ( T -S ) v 2 = 0 for all j = 2 (recall that v T 1 ( S -T ) is the zero vector). Then, we have that ( T -S ) v 2 must be a scalar multiple of v 2 , possibly zero. In any case, this means that v 2 is an eigenvector of S . A non-zero vector w = [ w . 1 . . w N ] ∈ R N is an eigenvector of S if and only if there exists α ∈ R such that ( S -αI ) w = 0. Setting s j = -S j,j +1 for all j = 1 , . . . , N -1, we recast this as a linear system in s , . . . , s 1 N -1 , α as follows:
Performing row-reduction on (24), we obtain the equivalent system:
$$( 2 5 ) & \left [ \begin{matrix} w _ { 1 } - w _ { 2 } & & - w _ { 1 } \\ & w _ { 2 } - w _ { 3 } & & - w _ { 1 } - w _ { 2 } \\ & \ddots & \vdots \\ & & - w _ { 1 } - w _ { 2 } - \dots - w _ { N } \end{matrix} \right ] \left [ \begin{matrix} s _ { 1 } \\ s _ { 2 } \\ \vdots \\ s _ { N - 1 } \end{matrix} \right ] = \left [ \begin{matrix} 0 \\ 0 \\ 0 \\ 0 \end{matrix} \right ]. \\ \text{Let us denote the matrix in (25) by W and set $w=v_{2}$. Then, since $w_{j} \neq w_{j+1}$ for all $j=1,\dots,N-1$} \\ ( \text{see (4)}). and $v_{1}^{T}v_{2}=0$. it follows that rank(W) = N-1$. Recall that a non-trivial solution to}$$
/negationslash
Let us denote the matrix in (25) by W and set w = v 2 . Then, since w j = w j +1 for all j = 1 , . . . , N -1 (see (4)), and v T 1 v 2 = 0, it follows that rank( W ) = N -1. Recall that a non-trivial solution to
(25) is known and is given by s 1 = . . . = s N -1 = 1 and α = µ 2 . It follows that S must be a scalar multiple of T , which is something we have excluded. Therefore, we must have ¨ λ 2 (1) < 0. Being ¨ λ 2 continuous, then it must remain strictly negative in a (left) neighborhood of 1. This concludes the proof. /square
Corollary 3.4. Suppose we are given 0 = ν 1 < ν 2 < . . . < ν N , with
$$& \supset \dots \sum _ { 1 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N }, \, \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N }, \, \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N }, \, \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu ^ { 2 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu ^ { 2 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu ^ { 2 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu ^ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nmid \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu { \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 n } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu \dots \nu _ { 1 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 N } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 4 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \narrow \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 1 N } \nu _ { 2 N } \nu _ { 3 } \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ { 1 } \nu _ { 2 } \nu _ { 3 } \dots \nu _ { 5 } \nu _ { 6 } \nu _ { 7 } \nu _ { 8 } \nu _ { 9 } \nu _ {$$
Then, there is no matrix S ∈ S such that λ j ( S ) = ν j , j = 1 , . . . , N .
Remark 3.5. For our purposes, the key consequence of Corollary 3.4 is the following. Suppose that there is a finite interval of values η for which the MSF is negative. Then, because of (10) , if
$$\ e v e \ e v e \ e _ { J } \ e v e \ e v e \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ { J } \ e _ } \\ \ e t o \ e b t a i n \ a \ n e g a t i v e \ v a l u e \ e f o t \ e \ M S F \ w i t h \ a n y \ s y m m e t r i c \ t r i.$$
it is not possible to obtain a negative value of the MSF with any symmetric tridiagonal network Laplacian.
## 4. Numerical Results
Here we show how our technique works in practice. We give two examples, one is a network of van der Pol oscillators with periodic synchronous orbit, the other is a network of R¨ssler oscillators with o chaotic synchronous orbit. Among our goals is to show that, in general, the symmetric tridiagonal structure (3) may fail to give stability of the synchronous orbit (that is, it won't give a negative value of the MSF, no matter how large is σ in (3)), but our technique is always able to give a negative value of the MSF, if there is an η -interval where the MSF is negative.
For both our examples, we proceed as follows.
- 1. We consider the parametrized linear system (9) and compute the MSF in function of η .
- 2. If there exist any, we select an interval [ η , η 1 2 ] so that for η ∈ [ η , η 1 2 ], the MSF is negative.
- 4.1. Van der Pol. We consider a network of N identical Van der Pol oscillators. The single agent satisfies the following equation
- 3. We use Algorithm TridZeroRowSum to build the Laplacian L as in (12) with nonzero eigenvalues in [ η , η 1 2 ], and null vector 1 √ N [ 1 . . . 1 ] .
$$\lambda \cdots \hat { \Phi } _ { 1 } \Phi _ { 2 } \Phi _ { 3 } \Phi _ { 4 } \Phi _ { 5 } \Phi _ { 6 } \Phi _ { 7 } \Phi _ { 8 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phicon _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9} \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi_ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 }$$
$$\begin{matrix} \end{matrix}$$
and we choose the following coupling matrix E = ( 0 0 1 0 ) . In Figure 1 on the left we plot the MSF
for η ∈ [0 , 0 5]. . The MSF is negative for η > 0 39 and remains negative. . at least for η ≤ 50. If we couple the agents via symmetric diffusive coupling as in Example 1.5, then in order to synchronize the network we must impose σλ 2 > 0 39 with . σ constant coupling strength. We then need large values of the coupling strength, namely σ > 40 5 for . N = 32. We instead employ our technique and consider an asymmetric tridiagonal coupling.
We have some freedom on what values we select for the N -1 eigenvalues of L . We experimented with many different choices for these values and below we report on two different experiments: i) select the eigenvalues linearly spaced in [1 , 10], and ii) take the eigenvalues to be Chebyshev points
Figure 1. Van der Pol, N=32. Left: MSF. Right: 2-norm of the difference between agents.
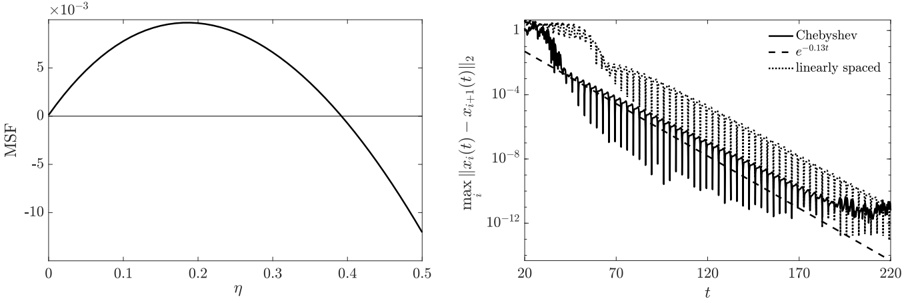
of the first kind (rescaled to [1 , 10] or to larger intervals, as needed). For N = 32, all the elements of the coupling matrix are less than 6 2. . We take an initial condition on the attractor and perturb it with a normally distributed perturbation vector. Then we integrate the network with a 4-th order Runge Kutta method and fixed stepsize h . For these methods, theoretical results guarantee that for h sufficiently small the numerical method has a closed invariant curve and that the distance of this curve from the synchronous periodic orbit is O h ( 4 ) (see [4]).
We synchronize 32 agents with both choices of eigenvalues. To witness, in Figure 1 on the right we plot max i =1 ,..., 31 ‖ x i ( ) t -x i +1 ( ) t ‖ 2 at the grid points. The greatest value of the MSF is obtained for η = 1, and it is /similarequal -0 13. . We plot e -0 13 . t as well in order to appreciate the convergence speed to the synchronous solution. The plots are obtained for one initial condition, but the behavior we observe is consistent for every normally distributed random perturbation we considered. The transient in this case is relatively short.
4.2. R¨ ossler. Next, we consider a network of N identical R¨ssler oscillators. o Each agent satisfies the system
$$( 2 8 ) & & \begin{cases} \dot { y } _ { 1 } = - y _ { 2 } - y _ { 3 } \\ \dot { y } _ { 2 } = y _ { 1 } + 0. 2 y _ { 2 } \\ \dot { y } _ { 3 } = 0. 2 + ( y _ { 1 } - 9 ) y _ { 3 } \end{cases} \\ \end{cases} \\ \text{and we choose the running matrix } E \equiv \mathbb { R } ^ { 3 \times 3 } \text{ in } ( 8 \rangle \text{ given } h v \text{ } E = \begin{cases} 1 \\ 0 \end{cases}$$
left, we plot the MSF in function of η . The MSF is negative in the interval η ∈ [0 19 . 4 61]. .
and we choose the coupling matrix E ∈ R 3 × 3 in (8) given by E = 1 0 0 0 0 0 0 0 0 . In Figure 2, on the
If we use diffusive coupling with a constant coupling strength σ , like in Example 1.5, then (see the explicit values of the eigenvalues given in Example 1.5), in order to synchronize N agents, we need σλ 2 > 0 19 and . σλ N < 4 61. . A necessary condition for N agents to synchronize is then, see (10), λ N λ 2 < 4 61 . 0 19 . and as soon as N > 7 this condition is not satisfied and hence we cannot hope to synchronize more than 7 agents with diffusive coupling and constant coupling strength. In [11] the
Figure 2. Left: MSF for R¨ ossler. Right: 2-Norm of the difference between agents.
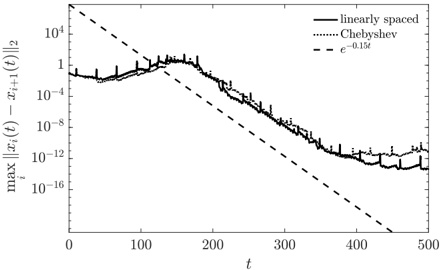
authors use diffusive coupling in a circular array and can synchronize up to 10 agents, but already with 16 agents the necessary conditions for synchronization are not met anymore. 2
In what follows we couple and synchronize a network of 64 R¨ssler agents with our technique, o about the chaotic orbit of a single R¨ssler oscillator. o Of course, as we observed in our numerical experiments, the lack of symmetry causes a large transient and the basin of attraction of the synchronous periodic orbit is in general affected by it.
We report on experiments with two different sets of eigenvalues: linearly spaced in [0 5 . , 3], and Chebyshev points of the first kind (rescaled to [0 5 . , 3]). We consider initial conditions obtained by adding a normally distributed perturbation with variance 1 of a synchronous initial condition and integrate (8) to verify that indeed we obtain synchronization. In Figure 2 we plot max i =1 ,..., 63 ‖ x i ( ) t -x i +1 ( ) t ‖ 2 for the two choices of eigenvalues. For η = 0 5, the corresponding . value of the MSF is /similarequal -0 15 and the dashed line in the right plot is the graph of . e -0 15 . t . It is clear that, after a transient, the convergence speed of the two perturbed solutions is also e -0 15 . t .
## 5. Conclusions
In this work, we gave two contributions. First, we built a tridiagonal matrix L with eigenvalues λ 1 = 0 < λ 2 < · · · < λ N and null-vector e = [ 1 . . . 1 ] . Then, we used this result to achieve -if possiblethat a synchronous orbit of a tridiagonal network associated to the matrix L above is asymptotically stable, in the sense of having an associated negative Master Stability Function (MSF). Our matrix L , in general, is not symmetric, and we further gave some results highlighting the limitations occurring if we also require symmetry. From the practical point of view, the main consequence of our results is that, if at all possible to have a negative MSF with tridiagonal network structure for the Laplacian, then we can have a stable synchronous motion, and we gave numerical examples to show this. At the same time, we also observed that, when we increase the number of agents, it is not always possible to achieve synchronization with arbitrary precision. We leave investigation of this fact to a future numerical study.
## References
- [1] M. Chu and G.H. Golub . Structured inverse eigenvalue problems. Acta Numerica , pp. 1-71, 2002.
2 The authors of [11] point our that, with symmetric tridiagonal Laplacians there will always be an upper limit in the size of a the network in order to obtain a stable synchronous chaotic orbit. With our technique, in principle there is not such limitation.
- [2] M. Chu and G.H. Golub . Inverse Eigenvalue Problems. Oxford Science Publications. Oxford University Press, New York, 2013.
- [3] L. Dieci and A. Pugliese . Forming a symmetric, unreduced, tridiagonal matrix with a given spectrum. arXiv preprint 2311.02677, 2023.
- [4] T. Eirola . Invariant curves of one-step methods. BIT , 28-1, pp. 113-122 (1988).
- [5] L.H. Golub and C.F. Van Loan . Matrix Computations. Johns Hopkins Studies in the Mathematical Sciences. Johns Hopkins University Press, 2013.
- [6] J. Hale. Diffusive Coupling, Dissipation, and Synchronization. Journal of Dynamics and Differential Equations , 9-1, pp. 1-52 (1997).
- [7] R. Horn and C. Johnson . Matrix Analysis, 2nd Edition. Cambridge Univ Press 2013.
- [8] L. Huang, Q. Chen, Y-C Lai and L.M. Pecora . Generic behavior of master-stability functions in coupled nonlinear dynamical systems. Physical Review E , 80, 036204-1-11 (2009).
- [9] L.G. Molinari . Lesson 6: Tridiagonal Matrices. https://api.semanticscholar.org/CorpusID:232239257 , 2019.
- [10] T. Muir . Treatise on the Theory of Determinants. Revised and Enlarged by William H. Metzler. New York: Dover Publications 1960.
- [11] L. Pecora and T. Carroll. Master Stability Functions for Synchronized Coupled Systems. Physical Review Letters , vol. 80, n. 10, (1997), pp. 2109-1112.
- [12] G. Schmeisser . A real symmetric tridiagonal matrix with a given characteristic polynomial. Linear Algebra Appl.s , 193, pp. 11-18 (1993).
- [13] T. Tao . Topics on Random Matrix Theory. Graduate Studies in Mathematics, Vol. 132, American Mathematical Society, Providence, RI, 2012.
- [14] J.J.P. Veerman and R. Lyons . A primer on Laplacian dynamics in directed graphs, Nonlinear Phenomena in Complex Systems , 2020, url=https://api.semanticscholar.org/CorpusID:211066395.
School of Mathematics, Georgia Tech, Atlanta, GA 30332 U.S.A. Email address : [email protected]
Dipartimento di Matematica, Univ. of Bari, I-70100, Bari, Italy Email address : [email protected]
Dipartimento di Matematica, Univ. of Bari, I-70100, Bari, Italy Email address : [email protected] | null | [
"Luca Dieci",
"Cinzia Elia",
"Alessandro Pugliese"
] | 2024-08-02T07:40:21+00:00 | 2025-02-18T07:19:01+00:00 | [
"math.DS",
"cs.NA",
"math.NA",
"65F18, 15A18"
] | On an inverse tridiagonal eigenvalue problem and its application to synchronization of network motion | In this work, motivated by the study of stability of the synchronous orbit of
a network with tridiagonal Laplacian matrix, we first solve an inverse
eigenvalue problem which builds a tridiagonal Laplacian matrix with eigenvalues
$\lambda_1=0<\lambda_2<\cdots <\lambda_N$ and null-vector $\boldsymbol{e} =
\begin{bmatrix} 1 \\ \vdots \\ 1 \end{bmatrix}$. Then, we show how this result
can be used to guarantee -- if possible -- that a synchronous orbit of a
connected tridiagonal network associated to the matrix $L$ above is
asymptotically stable, in the sense of having an associated negative Master
Stability Function (MSF). We further show that there are limitations when we
also impose symmetry for $L$. |
2408.01067v1 | ## Amodal Segmentation for Laparoscopic Surgery Video Instruments
Ruohua Shi 1 2 , ⋆ , Zhaochen Liu 1 2 3 , , ⋆ , Lingyu Duan 1 2 , , Tingting Jiang 1 2 4 , , B
- 1 National Engineering Research Center of Visual Technology, School of Computer Science, Peking University, Beijing, China
- 2 State Key Laboratory of Multimedia Information Processing, School of Computer Science, Peking University
- 3 AI Innovation Center, School of Computer Science, Peking University 4 National Biomedical Imaging Center, Peking University { shiruohua,dreamerliu,lingyu,ttjiang @pku.edu.cn }
Abstract. Segmentation of surgical instruments is crucial for enhancing surgeon performance and ensuring patient safety. Conventional techniques such as binary, semantic, and instance segmentation share a common drawback: they do not accommodate the parts of instruments obscured by tissues or other instruments. Precisely predicting the full extent of these occluded instruments can significantly improve laparoscopic surgeries by providing critical guidance during operations and assisting in the analysis of potential surgical errors, as well as serving educational purposes. In this paper, we introduce Amodal Segmentation to the realm of surgical instruments in the medical field. This technique identifies both the visible and occluded parts of an object. To achieve this, we introduce a new Amoal Instruments Segmentation (AIS) dataset, which was developed by reannotating each instrument with its complete mask, utilizing the 2017 MICCAI EndoVis Robotic Instrument Segmentation Challenge dataset. Additionally, we evaluate several leading amodal segmentation methods to establish a benchmark for this new dataset.
## 1 Introduction
As minimally invasive surgical robots advance, computer vision and machine learning-based assistive systems have become increasingly crucial in boosting surgeon performance and patient safety. However, numerous challenges arise in analyzing the data captured by surgical cameras. Surgical instrument segmentation serves as a critical and indispensable element in a range of computer-assisted interventions.
Recent research has made strides in addressing these challenges, with many researchers exploring solutions [36,25,10,8,23,33]. Notably, a U-Net-based model [25] clinched the top spot at the 2017 MICCAI EndoVis Robotic Instrument Segmentation Challenge [1]. Subsequent studies, such as [23], have a generativeadversarial approach for unsupervised surgical tool segmentation of optical-flow
⋆ These authors contributed equally.
Fig. 1. Segmentation examples. (1) Frames from laparoscopic surgery; (2) Instance segmentation ground truth; (3) Segmentation masks with occluded parts.
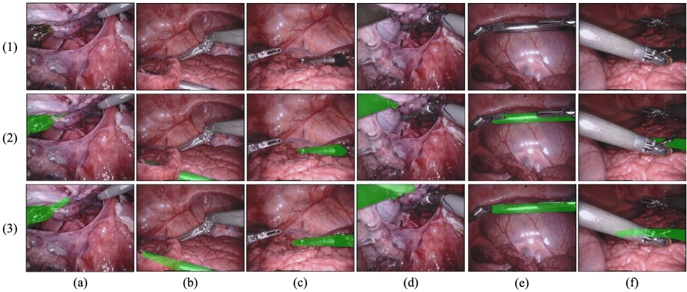
images. Yet, these advancements predominantly focus on the visible portions of surgical instruments. Occlusions, whether between instruments and tissues or among the instruments themselves, can obscure critical data during clinical procedures, complicating the surgical process. For illustration, Fig. 1 shows the selected frames from laparoscopic surgery videos. The second and third rows distinctly display instrument masks with and without occlusions. It is evident that standard instance segmentation masks fail to retain the original shape of the instruments, thereby complicating the identification of instrument types from a single frame.
Therefore, accurately predicting occluded instruments can be beneficial in surgeries. Specifically, there are three primary applications: (a) During surgery, predicting the obscured parts of surgical instruments can assist surgeons by providing crucial visual cues about the position and orientation of the tools, ensuring the accuracy of their maneuvers. For example, if the occluded head of an instrument is accurately predicted, surgeons can better judge the alignment of the instrument relative to the target area. (b) Post-operatively, accurate reconstruction of the surgical process through video analysis allows medical professionals to assess whether the instruments were used correctly and if the procedures met the required standards. This includes determining the types of surgical instruments employed and evaluating the precision of the interactions with the patient, thereby assessing the potential impact on patient safety, including any adverse events. (c) For educational purposes, accurately tracking the key points and trajectories of surgical instruments allows instructors to dissect and elucidate optimal surgical techniques. It also highlights crucial visual indicators during procedural training.
Segmenting both the visible and occluded regions of each object instance simultaneously is referred to as Amodal Segmentation . This concept is a recent development that builds upon instance-aware segmentation. Numerous method-
ologies have been introduced to tackle this issue [4,11,28,31]. To the best of our knowledge, the recent amodal algorithms that achieved state-of-the-art performance is SAM-based [18], exploiting the powerful feature extraction capability provided by the large-scale foundation model [12]. However, all these amodal segmentation approaches have predominantly been applied to natural images and have not been adapted for the medical field.
In this work, for the first time, we introduce the amodal segmentation to the area of laparoscopic surgery, and propose the first amodal dataset for surgical instruments, named AIS , which is based on the 2017 Robotic Instrument Segmentation Challenge dataset [1]. Unlike traditional datasets, AIS includes labels for the full mask of each instrument, covering both visible and occluded regions. Additionally, we evaluated several leading amodal segmentation methods to establish a benchmark for this innovative dataset.
In summary, our paper contains the following contributions:
- -For the first time, amodal segmentation is applied to surgical instruments within the medical field.
- -A novel medical amodal segmentation dataset is developed specifically tailored for this task.
- -A benchmark is introduced to evaluate the accuracy of predicting instruments, including their occluded parts, using our new dataset.
## 2 Related Work
## 2.1 Surgery Video Instrument Segmentation
Various advancements have been made in semantic segmentation of surgical surgery, incorporating various techniques and methodologies, mainly including combining segmentation networks with attention mechanisms [20,24] and exploring some synthetic data for semi-supervised training [23,6]. Ni et al. propose an attention-guided lightweight network, utilizing depth-wise separable convolution as the basic unit to reduce computational costs, thereby performing surgical instrument segmentation in real-time [20]. Shen et al. employ a lightweight encoder and branch aggregation attention mechanism to remove noise caused by reflection, and water mist to improve segmentation accuracy and achieve a lightweight model [24]. Sestini et al. designed a fully unsupervised method for the segmentation of binary surgical instruments relying only on implicit motion information and a priori knowledge of the shape of the instrument [23]. Luis et al. facilitate this task by generating large amounts of trainable data by synthesizing surgical instruments with real surgical backgrounds [6]. However, previous approaches mainly focus on real-time or semi-supervised, unsupervised learning, and there has been no research on interactive segmentation. Moreover, their methods cannot distinguish the occluded instruments. Therefore, we explored the segmentation of both visible and occluded instruments in surgery.
## 2.2 Amodal Segmentation
Amodal segmentation task was proposed in 2016 to predict the complete shape of target object including both the visible parts and the occluded parts [15]. Possessing great significance to our seeking visual intelligence, amodal segmentation arouses increasing attention in the academic community. Besides direct methods [15,36,22], a series of elaborate approaches have been designed with diverse concepts involved to achieve better performance, such as depth relationship [35], region correlation [4,11,28], shape priors [32,16,5], and compositional models [31]. Recently, a SAM-based approach [18] achieved state-of-the-art performance, well exploiting the mighty feature extraction capability provided by the large-scale foundation model [12]. Noticing the labor-intensive and error-prone challenges in the annotation of amodal masks, researchers also propose many weakly supervised approaches for amodal segmentation using only box-level supervision or self supervision [34,19,13,14,26,17].
Based on the advances of amodal segmentation algorithms, researchers develop various applications. For example, utilizing amodal segmentation methods, intelligence systems like autonomous driving and robotic grasping can enhance the safety and the reliability [22,2,29,30,9], while many new implementation paths emerge in the fields of diminished reality (DR) and novel view synthesis [7,16,21]. Though numerous related work is delivered, the potential of amodal segmentation in the medical field has never been explored. With our newly released dataset, we select several typical segmentation methods for experiments, revealing the notable value in medical applications.
## 3 Dataset
We introduce the AIS dataset by re-annotating the 2017 Robotic Instrument Segmentation Challenge dataset [1]. The dataset consists of 10 videos, each with 300 frames. It covers different abdominal porcine procedures recorded using the da Vinci Xi systems. In this paper, we relabeled the 3000 frames at a resolution of 1024 × 1280. The annotation includes semantic instance-level amodal segmentation and each object is manually assigned a class label. There are a total of 7084 objects. The dataset is split into training and test sets based on the splitting rule of the 2017 Robotic Instrument Segmentation Challenge: take the first 225 frames of 8 sequences as training data and keep the last 75 frames of those 8 sequences as test data. 2 of the full 300 frame sequences were kept as test sequences.
## 3.1 Dataset Acquisition
To annotate the dataset, we employed a widely-used public annotation tool named labelme [27]. This tool allows for the interactive labeling of surgical instruments on a frame-by-frame basis, enabling manual annotations directly within the software interface.
Fig. 2. Illustration of annotation process. (a) displays a polygon annotation formed by various key points and line segments. Once the labeling of this frame is complete, the annotation can be carried forward to the next frame for further labeling, as depicted in (b). By adjusting the positions of the key points within the polygon, the final annotation of the instrument in (b) is presented in (c).
Consider a practical example of our annotation methodology as illustrated in Fig.2(a), the middle instrument is annotated with a polygon that includes several key points and line segments. In this interface, annotations can be refined by adjusting the positions of key points (illustrated as green points). After completing the annotation for one frame, it can be carried over to the next frame, as depicted in Fig. 2(b). Given that the movement of surgical instruments between consecutive frames is typically minimal, the annotation for the current frame can often be achieved by simply repositioning the key points from the previous frame to align with the instrument's shape. This process completes the annotation for the middle instrument in the current frame, with the final result displayed in Fig. 2(c). By employing this annotation strategy, we attempt to reconstruct the original form of the instruments as accurately as possible, even for occluded parts. Our guiding principle is to ensure that the prediction of the occluded sections adheres closely to the instrument's actual shape and follows its natural motion trajectory.
Table 1. Amodal segmentation dataset statistics.
| Dataset | COCOA | COCOA-cls | D2S | Ours |
|----------------------------|------------|-------------|--------------------|--------------------|
| Image/Video | Image | Image | Image | Video |
| Resolution | 275K pix - | 275K pix - | 3M pix 1440 × 1920 | 1M pix 1024 × 1280 |
| # of images # of instances | 5073 | 3499 10562 | 3499 28720 16337 | 3000 7084 |
| | 46314 | | | |
| # of occluded instances | 28106 | 5175 | | 1455 |
| Avg. occlusion rate | 18.8% | 10.7% | 15.0% | 20.54% |
## 3.2 Dataset Analysis
We compare the proposed AIS dataset with other prominent amodal segmentation datasets from real-world scenes, such as COCOA[37], COCOA-cls[37,4], and D2S [4,3]. Specifically, we examine the differences in resolution, the number of instances included, and the rate of occlusion across these datasets. As shown in Table 1, our dataset exhibits a higher average occlusion rate and represents the first amodal segmentation dataset specifically developed for the medical field.
## 4 Benchmarks
## 4.1 Selected Methods
Our newly released dataset brings novel medical application scenarios for amodal segmentation. To better reveal the capabilities of existing approaches, we select several typical methods and benchmark their performance on this dataset, which are SAM [12], AISFormer [28], C2F-Seg [5], and PLUG [18].
SAM, the segment anything model, is the most influential foundation model for general segmentation task, which is trained on billions of object masks thus possessing strong abilities on diverse downstream tasks. The other three methods are specifically designed for amodal segmentation. PLUG is the state-of-theart approach now, which is based on SAM and introduces the parallel LoRA structure and the uncertainty guidance. AISFormer and C2F-Seg are other two most recent methods. AISFormer first injects the transformer backbone into the amodal segmentation task, while C2F-Seg introduces the vector-quantization model and the coarse-to-fine framework.
## 4.2 Evaluation Metrics
As related work, we choose intersection-over-union (IoU) as the evaluation metric. The IoU of a predicted mask equals the ratio of the intersecting area with corresponding ground truth mask to the area of their union. In order to better reflect the performance, we calculate the average IoU on each sub-testset (from 1 to 10) and the mean IoU of all sub-testsets.
## 4.3 Experimental Setup
For SAM, we adopt the largest ViT-H version pretrained model to achieve its best performance. For the other three methods, we conduct training on our proposed dataset. The settings and parameters adopted during the training process are consistent with the original papers.
It is worth explaining that the input mode of bounding boxes. Since the models require clear regions of interest, we input bounding boxes as guidance in all these methods. SAM, AISFormer, and PLUG directly receive input bounding boxes, while C2F-Seg uses the predictions of SAM as input thus indirectly
Fig. 3. The input mode of bounding boxes. In order to reduce the number of manual inputs, we use the bounding box of the predicted mask in the previous frame as the input bounding box of the next frame when possible.
receiving the bounding boxes (C2F-Seg generates amodal mask based on the input visible mask. For fairness, we adopt the output of SAM as the input visible mask of C2F-Seg.). Considering practical needs, we hope to reduce the number of manual inputs as much as possible for the convenience of users. Actually, we notice that the difference between two adjacent frames of a video is very small, and we can approximately assume that the bounding boxes in the two frames are almost the same. So as shown in Fig. 3, we first input the bounding box of the first frame, and then use the bounding box of the predicted mask of the previous frame for each subsequent frame until a certain frame without the corresponding bounding box in the previous frame occurs, we then manually input the bounding box again.
## 5 Results
## 5.1 Performance comparison
As shown in Table 2, all these segmentation methods can basically predict the amodal masks of surgery instruments quite well. The pretrained SAM without any fine-tuning can already reach practical performance, achieving 85.94 on mean IoU. Specifically designed, the other three methods can provide more accurate predictions. AISFormer and C2F-Seg attain 86.65/88.17 on mean IoU, which are 0.71/2.23 higher than SAM. The state-of-the-art method PLUG maintains the leading position and reaches 89.25 on the mean IoU, which beats SAM by 3.31. It can be observed that the performance is close on some relatively simple subtestsets, such as testset-4, while on some complex sub-testsets like testset-1, the advantage of tailored amodal segmentation methods especially PLUG is evident.
To intuitively display the performance of these methods, we choose one frame from each sub-testset, totaling ten frames. The ten sets of qualitative results are shown in Fig. 5. Relatively speaking, though the predictions of other methods are acceptable, PLUG can determine more precise and complete shapes. For the rod-shaped instrument in the 1st row, the prediction of PLUG is clear to identify showing smooth boundary and covering more area. For the semi-inserted instrument in the 8th row, C2F-Seg and PLUG can segment the needle head, while the prediction of PLUG is thinner and closer to reality.
Table 2. The performance comparison of selected segmentation methods on the surgery dataset. Numbers 1-10 represent ten sub-testsets.
| Methods | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Mean |
|----------------|------|------|------|------|------|------|------|------|------|------|--------|
| SAM [12] | 75.1 | 80.5 | 91.5 | 93.1 | 81.1 | 85.8 | 83.7 | 91.2 | 85.9 | 91.5 | 85.94 |
| AISFormer [28] | 74.6 | 82.6 | 91 | 93.6 | 83 | 83.9 | 88.6 | 93 | 85.2 | 91 | 86.65 |
| C2F-Seg [5] | 75.8 | 85.6 | 92.6 | 93.5 | 85 | 86.1 | 89.1 | 94.2 | 87 | 92.8 | 88.17 |
| PLUG [18] | 79.8 | 86.2 | 93.2 | 93.6 | 86.1 | 87.1 | 90.6 | 94.4 | 88.4 | 93.1 | 89.25 |
## 5.2 Hard Case
In the experiment, we find that some excessively occluded instruments (as shown in Fig. 4) in a fraction of frames are a common challenge for these methods. These instruments are almost completely occluded, making it difficult to obtain effective visible mask or other information, thus bringing confusion to methods inspired by extracted clues within the frame. In the example shown in Fig. 4, even the state-of-the-art PLUG approach predicts a quite tortuous boundary. To tackle the hard case, a pertinent method designed for video input that integrates the context of the previous and subsequent frames may be needed. How to implement such a specific method? We leave this issue to future work.
Fig. 4. An example of the excessively occluded case. The instrument is almost completely occluded in this frame.

Fig. 5. Qualitative results. The qualitative comparison of predicted amodal masks from SAM, AISFormer, C2F-Seg and PLUG. These ten rows are chosen from the first to tenth sub-testset in order from top to bottom.
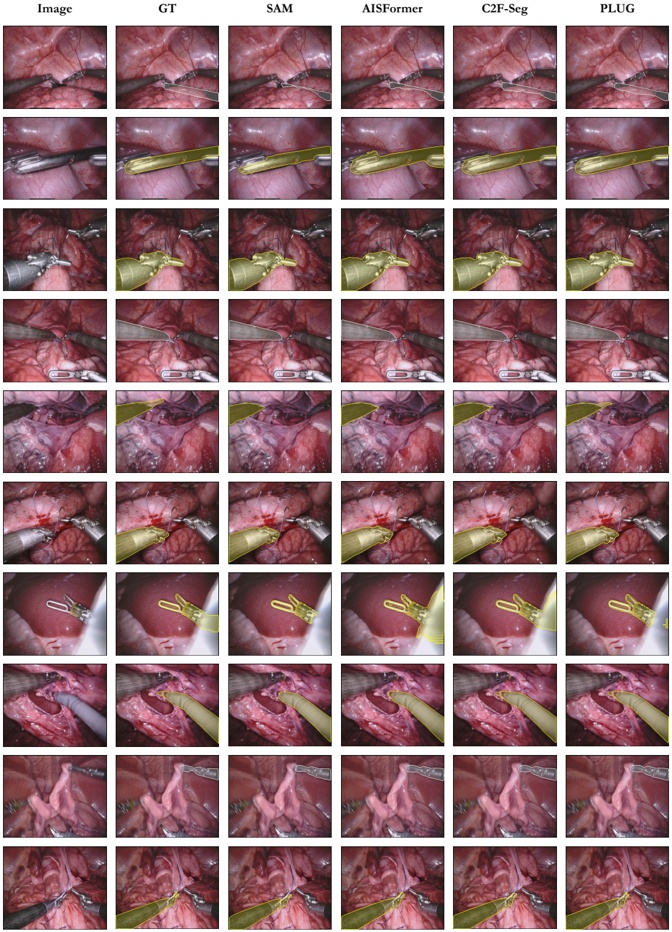
## References
- 1. Allan, M., Shvets, A., Kurmann, T., Zhang, Z., Duggal, R., Su, Y.H., Rieke, N., Laina, I., Kalavakonda, N., Bodenstedt, S., et al.: 2017 robotic instrument segmentation challenge. arXiv preprint arXiv:1902.06426 (2019)
- 2. Breitenstein, J., Fingscheidt, T.: Amodal cityscapes: a new dataset, its generation, and an amodal semantic segmentation challenge baseline. In: IEEE Intelligent Vehicles Symposium. pp. 1018-1025 (2022)
- 3. Follmann, P., Bottger, T., Hartinger, P., Konig, R., Ulrich, M.: MVTec D2S: densely segmented supermarket dataset. In: Proceedings of the European Conference on Computer Vision. pp. 569-585 (2018)
- 4. Follmann, P., K¨nig, R., H¨rtinger, P., Klostermann, M., B¨ttger, T.: Learning o a o to see the invisible: End-to-end trainable amodal instance segmentation. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision. pp. 1328-1336 (2019)
- 5. Gao, J., Qian, X., Wang, Y., Xiao, T., He, T., Zhang, Z., Fu, Y.: Coarse-to-fine amodal segmentation with shape prior. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1262-1271 (2023)
- 6. Garcia-Peraza-Herrera, L.C., Fidon, L., D'Ettorre, C., Stoyanov, D., Vercauteren, T., Ourselin, S.: Image compositing for segmentation of surgical tools without manual annotations. IEEE Transactions on Medical Imaging 40(5), 1450-1460 (2021)
- 7. Gkitsas, V., Sterzentsenko, V., Zioulis, N., Albanis, G., Zarpalas, D.: Panodr: Spherical panorama diminished reality for indoor scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 37163726 (2021)
- 8. Gonz´ alez, C., Bravo-S´nchez, L., Arbelaez, P.: Isinet: an instance-based approach a for surgical instrument segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 595-605 (2020)
- 9. Inagaki, Y., Araki, R., Yamashita, T., Fujiyoshi, H.: Detecting layered structures of partially occluded objects for bin picking. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. pp. 5786-5791 (2019)
- 10. Jin, Y., Cheng, K., Dou, Q., Heng, P.A.: Incorporating temporal prior from motion flow for instrument segmentation in minimally invasive surgery video. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 440-448 (2019)
- 11. Ke, L., Tai, Y.W., Tang, C.K.: Deep occlusion-aware instance segmentation with overlapping bilayers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4019-4028 (2021)
- 12. Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollar, P., Girshick, R.: Segment anything. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4015-4026 (2023)
- 13. Kortylewski, A., He, J., Liu, Q., Yuille, A.L.: Compositional convolutional neural networks: A deep architecture with innate robustness to partial occlusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8940-8949 (2020)
- 14. Kortylewski, A., Liu, Q., Wang, A., Sun, Y., Yuille, A.: Compositional convolutional neural networks: A robust and interpretable model for object recognition under occlusion. International Journal of Computer Vision 129, 736-760 (2021)
- 15. Li, K., Malik, J.: Amodal instance segmentation. In: Proceedings of the European Conference on Computer Vision. pp. 677-693 (2016)
- 16. Li, Z., Ye, W., Jiang, T., Huang, T.: 2D amodal instance segmentation guided by 3D shape prior. In: Proceedings of the European Conference on Computer Vision. pp. 165-181 (2022)
- 17. Liu, Z., Li, Z., Jiang, T.: BLADE: Box-level supervised amodal segmentation through directed expansion. In: Proceedings of the AAAI Conference on Artificial Intelligence (2024)
- 18. Liu, Z., Qiao, L., Chu, X., Jiang, T.: PLUG: Revisiting amodal segmentation with foundation model and hierarchical focus. arXiv preprint arXiv:2405.16094 (2024)
- 19. Nguyen, K., Todorovic, S.: A weakly supervised amodal segmenter with boundary uncertainty estimation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7396-7405 (2021)
- 20. Ni, Z.L., Bian, G.B., Hou, Z.G., Zhou, X.H., Xie, X.L., Li, Z.: Attention-guided lightweight network for real-time segmentation of robotic surgical instruments. In: 2020 IEEE International Conference on Robotics and Automation. pp. 9939-9945 (2020)
- 21. Pintore, G., Agus, M., Almansa, E., Gobbetti, E.: Instant automatic emptying of panoramic indoor scenes. IEEE Transactions on Visualization and Computer Graphics 28(11), 3629-3639 (2022)
- 22. Qi, L., Jiang, L., Liu, S., Shen, X., Jia, J.: Amodal instance segmentation with kins dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3014-3023 (2019)
- 23. Sestini, L., Rosa, B., De Momi, E., Ferrigno, G., Padoy, N.: Fun-sis: A fully unsupervised approach for surgical instrument segmentation. Medical Image Analysis 85, 102751 (2023)
- 24. Shen, W., Wang, Y., Liu, M., Wang, J., Ding, R., Zhang, Z., Meijering, E.: Branch aggregation attention network for robotic surgical instrument segmentation. IEEE Transactions on Medical Imaging (2023)
- 25. Shvets, A.A., Rakhlin, A., Kalinin, A.A., Iglovikov, V.I.: Automatic instrument segmentation in robot-assisted surgery using deep learning. In: IEEE International Conference on Machine Learning and Applications. pp. 624-628 (2018)
- 26. Sun, Y., Kortylewski, A., Yuille, A.: Amodal segmentation through out-of-task and out-of-distribution generalization with a bayesian model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12151224 (2022)
- 27. Torralba, A., Russell, B.C., Yuen, J.: Labelme: Online image annotation and applications. Proceedings of the IEEE 98(8), 1467-1484 (2010)
- 28. Tran, M., Vo, K., Yamazaki, K., Fernandes, A., Kidd, M., Le, N.: Aisformer: Amodal instance segmentation with transformer. In: Proceedings of the British Machine Vision Conference (2022)
- 29. Wada, K., Kitagawa, S., Okada, K., Inaba, M.: Instance segmentation of visible and occluded regions for finding and picking target from a pile of objects. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. pp. 2048-2055 (2018)
- 30. Wada, K., Okada, K., Inaba, M.: Joint learning of instance and semantic segmentation for robotic pick-and-place with heavy occlusions in clutter. In: Proceedings of the International Conference on Robotics and Automation. pp. 9558-9564 (2019)
- 31. Wang, A., Sun, Y., Kortylewski, A., Yuille, A.L.: Robust object detection under occlusion with context-aware compositionalnets. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12645-12654 (2020)
- 32. Xiao, Y., Xu, Y., Zhong, Z., Luo, W., Li, J., Gao, S.: Amodal segmentation based on visible region segmentation and shape prior. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 35, pp. 2995-3003 (2021)
- 33. Yue, W., Zhang, J., Hu, K., Xia, Y., Luo, J., Wang, Z.: Surgicalsam: Efficient class promptable surgical instrument segmentation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 6890-6898 (2024)
- 34. Zhan, X., Pan, X., Dai, B., Liu, Z., Lin, D., Loy, C.C.: Self-supervised scene deocclusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3784-3792 (2020)
- 35. Zhang, Z., Chen, A., Xie, L., Yu, J., Gao, S.: Learning semantics-aware distance map with semantics layering network for amodal instance segmentation. In: Proceedings of the 27th ACM International Conference on Multimedia. pp. 2124-2132 (2019)
- 36. Zhu, Y., Tian, Y., Metaxas, D., Doll´r, P.: Semantic amodal segmentation. In: Proa ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1464-1472 (2017)
- 37. Zhu, Y., Tian, Y., Metaxas, D., Doll´r, P.: Semantic amodal segmentation. In: a Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 1464-1472 (2017) | null | [
"Ruohua Shi",
"Zhaochen Liu",
"Lingyu Duan",
"Tingting Jiang"
] | 2024-08-02T07:40:34+00:00 | 2024-08-02T07:40:34+00:00 | [
"cs.CV"
] | Amodal Segmentation for Laparoscopic Surgery Video Instruments | Segmentation of surgical instruments is crucial for enhancing surgeon
performance and ensuring patient safety. Conventional techniques such as
binary, semantic, and instance segmentation share a common drawback: they do
not accommodate the parts of instruments obscured by tissues or other
instruments. Precisely predicting the full extent of these occluded instruments
can significantly improve laparoscopic surgeries by providing critical guidance
during operations and assisting in the analysis of potential surgical errors,
as well as serving educational purposes. In this paper, we introduce Amodal
Segmentation to the realm of surgical instruments in the medical field. This
technique identifies both the visible and occluded parts of an object. To
achieve this, we introduce a new Amoal Instruments Segmentation (AIS) dataset,
which was developed by reannotating each instrument with its complete mask,
utilizing the 2017 MICCAI EndoVis Robotic Instrument Segmentation Challenge
dataset. Additionally, we evaluate several leading amodal segmentation methods
to establish a benchmark for this new dataset. |
2408.01068v1 | ## Higgs boson production at µ µ + + colliders
## Yu Hamada, a,b Ryuichiro Kitano, c,d Ryutaro Matsudo, c Shohei Okawa, c Ryoto Takai, c,d Hiromasa Takaura e and Lukas Treuer c,d
- a Deutsches Elektronen-Synchrotron DESY, Notkestr. 85, 22607 Hamburg, Germany
- b Research and Education Center for Natural Sciences, Keio University, 4-1-1 Hiyoshi, Yokohama, Kanagawa 223-8521, Japan
- c KEK Theory Center, Tsukuba 305-0801, Japan
- d The Graduate University for Advanced Studies (SOKENDAI), Tsukuba 305-0801, Japan
- e Center for Gravitational Physics and Quantum Information, Yukawa Institute for Theoretical Physics, Kyoto University, Kyoto 606-8502, Japan
E-mail: [email protected] , [email protected] , [email protected] , [email protected] , [email protected] , [email protected] , [email protected]
Abstract: We study Higgs boson production at µ + µ + colliders at high energy. Since both initial-state particles are positively charged, there is no W boson fusion at the leading order, as it requires a W W + -pair. However, we find that the cross section of the higher-order, γ -and Z -mediated W boson fusion process is large at high center-of-mass energies √ s , growing as (log s ) 3 . This is in contrast to the log s behavior of the leading-order W boson fusion. Thus, even though it is a higher-order process, the rate of Higgs boson production for 10 TeV energies at µ + µ + colliders with polarized beams can be as high as about half of the one at µ + µ -colliders, assuming the same integrated luminosity. To calculate the cross section of this process accurately, we carefully treat the collinear emission of the photon in the intermediate state. The thereby obtained large cross section furthermore shows the significance of Higgs production with an extra W boson in the final state also at µ + µ -and e + e -colliders.
## Contents
| 1 | Introduction | Introduction | 1 |
|-----|-----------------------------------------------------------------|-----------------------------------------------------------------|-----|
| 2 | γ - and Z -mediated W boson fusion process at µ + µ + colliders | γ - and Z -mediated W boson fusion process at µ + µ + colliders | 3 |
| | 2.1 | Triple logarithms in the Higgs boson production | 3 |
| | 2.2 | Contributions from the Z -mediated process | 6 |
| | 2.3 | Numerical calculation with MadGraph | 7 |
| 3 | Calculation with controlled theoretical uncertainties | Calculation with controlled theoretical uncertainties | 10 |
| | 3.1 | Low- p T cross sections from EPA | 11 |
| | 3.2 | High- p T cross sections from MadGraph | 13 |
| | 3.3 | Summing up the low- and high- p T cross sections | 13 |
| 4 | Event shape of the W boson fusion process | Event shape of the W boson fusion process | 15 |
| 5 | Summary | Summary | 17 |
| A | Equivalent photon approximation (EPA) | Equivalent photon approximation (EPA) | 19 |
| B | Error in the massless lepton approximation | Error in the massless lepton approximation | 22 |
| C | Semi-automatic MadGraph implementation of p (cut) T calculation | Semi-automatic MadGraph implementation of p (cut) T calculation | 23 |
## 1 Introduction
Higgs boson factories are the best-motivated future colliders, enabling us to explore the nature of electroweak symmetry breaking in depth. Among others, muon colliders at 10 TeV energies have been discussed as one of the most attractive possibilities, since the size of the accelerator facilities can be as compact as O (10) km in circumference, and they can potentially probe physics up to scales as high as O (100) TeV [1-3]. By comparison, proton colliders with similar reach require a circumference of at least O (100) km.
Recently, muon colliders based on ultra-slow muon technology [4] have been proposed [5]. This is because ultra-slow muons from laser-ionized muonium, a µ + e -bound state, can be used to create µ + beams with excellent emittances, i.e., very collimated beams that facilitate high luminosities. As such, the corresponding proposal is to build on this technology, which was developed for the muon g -2/EDM experiment at J-PARC [6], leading to an estimated luminosity seemingly good enough for Higgs factories based on µ + e -and µ + µ + colliders.
At such colliders, even though there are no s -channel annihilation processes that are present in µ + µ -or e + e -colliders, Higgs boson production can still occur via vector boson
fusion processes, which dominate over s -channel annihilations at energies beyond O (1) TeV. This is due to a logarithmic enhancement of the cross section for vector boson fusion as a function of center-of-mass energy. At µ + e -colliders, while W boson fusion is possible, the center-of-mass energy is limited by the beam energy of the electron. On the other hand, for µ + µ + colliders, one can consider, e.g., O (10) TeV beam energies, but there is no W boson fusion process at leading order since both of the antimuons can only emit positively charged W bosons. Although Z boson fusion is possible at leading order since it is independent of the muon charge, its cross section is about an order of magnitude smaller than W boson fusion at µ + µ -colliders due to an unfortunate suppression of the coupling between the Z boson and leptons. This motivates us to look beyond the leading order.
In this paper, we thus investigate W boson fusion at µ + µ + colliders at higher order in perturbation theory. The pertinent process, which we show in Fig. 1, begins with emission of a photon or Z boson from one of the antimuons, followed by the photon or Z boson splitting into a W W + -pair. The W -from this splitting then collides with the W + emitted from the other antimuon to produce a Higgs boson. For large center-of-mass energies √ s , we find that this sub-leading-order process involves a (log s ) 3 factor, in contrast to the single log s appearing in the leading-order W boson fusion at µ + µ -and e + e -colliders [2, 7]. Due to this large enhancement, the cross section for Higgs boson production at µ + µ + colliders becomes comparable to that at µ + µ -colliders for O (10) TeV beam energies.
To compute the part of the process involving photon emission, we must carefully address infrared divergences, which are physically cut off by the muon mass. However, directly using numerical codes such as the event generator MadGraph [8] leads to instabilities in the numerical phase-space integration, since the muon mass is either set to zero, or significantly smaller than the center-of-mass energy. Therefore, we also discuss how to reliably and accurately compute fixed-order cross sections for such infrared-divergent processes.
We furthermore discuss the size of subsequent higher-order processes to determine if the fixed-order computation is meaningful. We find that at 10 TeV energies, the processes with further emissions of extra gauge bosons are much smaller than the process of our interest, such that fixed-order calculations are still valid.
Lastly, it is important for actual experiments whether the final-state W + has a transverse momentum large enough to be visible. To assess this, we generate sample events using MadGraph and find that for √ s = 2 TeV or 10 TeV, the vast majority of jets from the W + decays can be detected. This means that it is possible to analyze the W boson fusion process with a W h + final state separately from Z boson fusion to perform precision measurements of the Higgs boson couplings.
At the same time, the large size of the γ -and Z -mediated process means that an analogous process gives a large contribution to the Higgs production cross section also at µ + µ -and e + e -colliders. One should thus include this higher-order process in the simulation and analysis of the Higgs boson production for coupling measurements, as it may contaminate the events of the pure W boson fusion process.
This paper is organized as follows. In Sec. 2, we estimate the cross section of the γ -and Z -mediated Higgs boson production process at µ + µ + colliders analytically at the leading-logarithm level, as well as numerically, and discuss its high-energy behavior. We
then explain a more reliable method to obtain the cross section in Sec. 3, where we confirm the large enhancement of the cross section. Next, since the γ - and Z -mediated process gives an extra W boson in the final state, we simulate collider events and discuss the possibility of identifying the process in Sec. 4. Finally, we summarize our findings in Sec. 5.
In Appendix A, we review the derivation of the formula of the equivalent photon approximation, and discuss the uncertainties of the approximation. We also discuss the error associated with the treatment of neglecting the muon mass in the numerical calculation in Appendix B. Lastly, we detail a semi-automatic numerical method to implement the calculation explained in Sec. 3 in Appendix C.
## 2 γ - and Z -mediated W boson fusion process at µ + µ + colliders
In this section, we discuss how W boson fusion processes are possible at µ + µ + colliders, and why they are important at high energies. Therein, we derive an analytic formula for the cross section at the leading-logarithm level. We also calculate the cross section numerically using the event generator MadGraph [8] with a setting for parton distribution functions of the photon in one of the muons. Note that both methods have uncertainties related to their scale settings, and the results should therefore be viewed as estimations. We will thus discuss a method to obtain the cross section with controlled uncertainties in the next section. Lastly, in this section, we compare the approximate results with those obtained by the more reliable and accurate computation method, and show that the γ -and Z -mediated W boson fusion process is indeed important.
## 2.1
## Triple logarithms in the Higgs boson production
At high-energy lepton colliders, a large amount of Higgs bosons can be produced through vector boson fusion. When two antimuons collide with center-of-mass energy √ s ≳ 1 TeV, Z boson fusion is enhanced by a factor of log s , similarly to Z and W boson fusion processes at µ + µ -and e + e -colliders.
By contrast, there is no coupling between µ + and W -in the Standard Model at the first order in the electromagnetic coupling e or weak coupling g . This makes W boson fusion difficult, since it requires a W W + -pair. In particular, while the W boson fusion process may take place at higher orders in perturbation theory, these are seemingly suppressed by additional powers of the small couplings. Therefore, we na¨ ıvely do not expect a satisfyingly large contribution to Higgs production from W boson fusion at µ + µ + colliders. However, this expectation turns out to be incorrect, as we will see below.
We show two representative Feynman diagrams for Higgs boson production via such a higher-order W boson fusion in Fig. 1. Here, one antimuon provides a W + , and the other a W -through pair production by an intermediate photon or Z boson. When beam energies are much larger than the electroweak scale given by the vacuum expectation value of the Higgs field, v ≃ 246 GeV, these two diagrams are identical up to terms of the order of m /s 2 Z , where m Z is the mass of the Z boson. Note that one needs to, however, account for the different couplings of the photon and Z boson, as well as the infrared scales of their respective emission.
Figure 1 . We show representative Feynman diagrams of single Higgs boson production through quasi-real photon (left) or Z boson (right) emission, splitting, and subsequent W boson fusion.
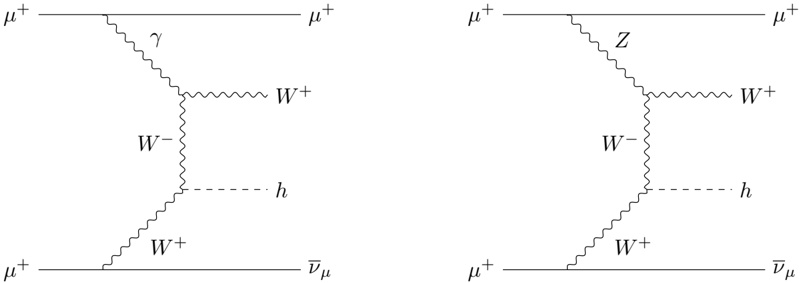
First, we focus on the contribution of the photon, ignoring the Z boson. Quantum electrodynamics enables us to factorize the contribution of the photon into a parton distribution function with respect to the antimuon beam, and a partonic cross section with an on-shell photon in the initial state. The corresponding parton distribution function is given by
$$f _ { \gamma / \mu } ( x, \mu _ { f } ^ { 2 } ) = \frac { \alpha } { 2 \pi } \frac { 1 + ( 1 - x ) ^ { 2 } } { x } \log \frac { \mu _ { f } ^ { 2 } } { m _ { \mu } ^ { 2 } }$$
at the leading-logarithm level [9, 10], where α = e / 2 4 π is the fine structure constant, x is the longitudinal momentum fraction carried by the photon, µ f is the factorization scale, and m µ the muon mass. The large logarithm originates from an integral over the transverse momentum p T of the differential parton distribution function
$$\frac { \mathrm d f _ { \gamma / \mu } } { \mathrm d p _ { \mathrm T } ^ { 2 } } = \frac { \alpha } { 2 \pi } \frac { 1 + ( 1 - x ) ^ { 2 } } { x } \frac { 1 } { p _ { \mathrm T } ^ { 2 } } \,,$$
which comprises a p -4 T from the propagator of the photon and a p 2 T from the splitting amplitude. Here, we adopt the muon mass m µ as infrared scale of the emission, which physically cuts off the associated collinear divergence.
Similarly, one can also derive the parton distribution function of the W boson. For its longitudinal component, this yields [11, 12]
$$f _ { W _ { L } ^ { + } / \mu _ { R } ^ { + } } ( x ) = \frac { \alpha } { 2 \pi \sin ^ { 2 } \theta _ { W } } \frac { 1 - x } { x } \quad \text{and} \quad f _ { W _ { L } ^ { + } / \mu _ { L } ^ { + }$$
where θ W is the weak mixing angle, also known as Weinberg angle. The Nambu-Goldstone bosons eaten by the longitudinally polarized W bosons have a typical scale v , which modifies the dependence of the differential parton distribution function on the transverse momentum from 1 /p 2 T to ∼ v /p 2 4 T [13]. The integral over p 2 T thus does not lead to a large logarithm in the parton distribution function of Eq. (2.3).
To estimate the full cross section of the process as seen on the left in Fig. 1 using these parton distribution functions, we also need the cross section of the subprocess γW + →
W h + , which is given by
$$\tau \alpha _ { y } \quad & \sigma _ { \gamma W } ( s ) = \frac { \pi \alpha ^ { 2 } } { m _ { W } ^ { 2 } \sin ^ { 2 } \theta _ { W } } + \mathcal { O } \left ( \frac { 1 } { s } \right ) \quad & \quad \quad \quad$$
in the high energy limit s ≫ s min ≡ ( m h + m W ) 2 [14]. Here, m W and m h are the masses of W and Higgs bosons, respectively. We obtain this cross section by averaging over the polarizations of the initial photon, and summing over the ones of the final-state W + , while taking the initial-state W + to be longitudinally polarized. This is because the highenergy cross section is dominated by the contribution of order s 0 , which comes from the longitudinally polarized W boson in the initial state, since its polarization vector is almost proportional to its momentum. By contrast, the contribution from a transversely polarized W boson falls off as 1 /s at high energies. Therefore, it does not contribute in the highenergy limit, and we may assume a longitudinally polarized W boson in the initial state.
Finally, the photon contribution to the process µ + µ + → µ + ν µ W h + is thus approximately given by
$$\text{analy given by} \\ \sigma _ { \gamma } ( s ) & \simeq 2 \quad \int _ { \substack { x y s > s _ { \min } \\ x y s > s _ { \min } } } \, \text{d} x d y \, f _ { \gamma / \mu ^ { + } } ( x, \mu _ { f }$$
at the leading-logarithm level, where P µ + denotes the polarization of the antimuon beams. The factor of two in the first line accounts for photon or W + emission by either antimuon. For this estimate, we take the factorization scale to be the center-of-mass energy at the parton level, µ 2 f = xys .
We thus find three large logarithms in the final formula. Compared with the cross section of the leading-order Z boson fusion process [15, 16],
$$\sigma _ { Z \text{BF} } ( s ) \sim \frac { \alpha ^ { 3 } ( 1 - 4 \sin ^ { 2 } \theta _ { W } + 8 \sin ^ { 4 } \theta _ { W } ) ^ { 2 } } { 6 4 m _ { Z } ^ { 2 } \sin ^ { 6 } \theta _ { W } \cos ^ { 6 } \theta _ { W } } \log \frac { s } { m _ { h } ^ { 2 } } \,,$$
we observe a rapid growth of the cross section as a function of the collider energy. Furthermore, the cross section of the Z boson fusion process has an unfortunate suppression factor in the numerator. Because of this, at √ s ∼ O (10) TeV, the sub-leading, γ -mediated W boson fusion cross section becomes much larger than for the leading-order Z boson fusion process. Even when compared to the cross section of the leading-order W boson fusion process at µ + µ -or e + e -colliders [15, 16],
$$\sigma _ { W B F } ( s ) \sim \frac { \alpha ^ { 3 } } { 1 6 m _ { W } ^ { 2 } \sin ^ { 6 } \theta _ { W } } \log \frac { s } { m _ { h } ^ { 2 } } \,,$$
the γ - (and Z -) mediated process becomes important at high energy as two extra logarithmic factors can compensate the O ( α/π ) suppression. For reference, the logarithmic factors of Eq. (2.5) and Eq. (2.7) at 10 TeV evaluate to approximately 1100 and 10, respectively.
This may resemble a breakdown of perturbation theory of fixed-order computations. We will therefore return to the discussion of further higher-order processes later in this section.
## 2.2 Contributions from the Z -mediated process
At high energies, the contribution of the Z boson becomes important. However, since the γ - and Z -mediated diagrams interfere, we cannot simply add the Z -mediated cross section, estimated using a parton distribution function of the Z boson, to the γ -mediated one. Instead, a matrix form of parton distribution functions needs to be used [13, 17, 18]. Here, we therefore discuss how to estimate the additional contributions at the leading-logarithm order.
If one could treat the Z boson as a massless particle just like photon, the amplitudes in Fig. 1 should have the same form, i.e.,
$$\mathcal { M } = \mathcal { M } _ { \gamma } + \mathcal { M } _ { Z } = g _ { \gamma } \mathcal { M } _ { 0 } + g _ { Z } \mathcal { M } _ { 0 }$$
for each chirality of the antimuons, where g γ and g Z are the respective couplings of the photon and Z boson to the antimuons. The ratios of γ and Z couplings to antimuons and W bosons are given by
$$\frac { g _ { Z } ^ { \mu _ { R } ^ { + } } } { g _ { \gamma } ^ { \mu ^ { + } } } = \frac { \frac { 1 } { 2 } - \sin ^ { 2 } \theta _ { W } } { \sin \theta _ { W } \cos \theta _ { W } } \simeq 0. 6 6 8 \,, \quad \frac { g _ { Z } ^ { \mu _ { L } ^ { + } } } { g _ { \gamma } ^ { \mu ^ { + } } } = \frac { - \sin ^ { 2 } \theta _ { W } } { \sin \theta _ { W } \cos \theta _ { W } } \simeq - 0. 5 3 5 \,,$$
and
$$\frac { g _ { Z } ^ { W } } { g _ { \gamma } ^ { W } } = \frac { 1 } { \tan \theta _ { W } } \simeq 1. 8 7$$
for sin 2 θ W ≃ 0 222, where we have taken the value used by MadGraph for consistency with . later computations. Since the full matrix element can be expressed in terms of a shared amplitude M 0 when taking the masslessZ limit, we can approximate the squared matrix element as the sum of three squared amplitudes as
$$| \mathcal { M } | ^ { 2 } = | g _ { \gamma } | ^ { 2 } | \mathcal { M } _ { 0 } | ^ { 2 } + | g _ { Z } | ^ { 2 } | \mathcal { M } _ { 0 } | ^ { 2 } + 2 \text{Re} ( g _ { \gamma } g _ { Z } ) | \mathcal { M } _ { 0 } | ^ { 2 } + \mathcal { O } ( m _ { Z } ^ { 2 } / s ) \,. \quad \ \ ( 2. 1 1 )$$
This result allows us to estimate the cross section by using the three parton distribution functions of the photon, the Z boson, and their mixing for the corresponding terms. These functions satisfy
$$\frac { \mathrm d f _ { Z _ { \mathrm T } / \mu _ { R } ^ { + } } } { \mathrm d p _ { \mathrm T } ^ { 2 } } = \left ( \frac { g _ { Z } ^ { \mu _ { R } ^ { + } } } { g _ { \gamma } ^ { \mu ^ { + } } } \right ) ^ { 2 } \frac { \mathrm d f _ { \gamma / \mu } } { \mathrm d p _ { \mathrm T } ^ { 2 } }, \quad \frac { \mathrm d f _ { Z _ { \mathrm T } / \mu _ { L } ^ { + } } } { \mathrm d p _ { \mathrm T } ^ { 2 } } = \left ( \frac { g _ { Z } ^ { \mu _ { L } ^ { + } } } { g _ { \gamma } ^ { \mu ^ { + } } } \right ) ^ { 2 } \frac { \mathrm d f _ { \gamma / \mu } } { \mathrm d p _ { \mathrm T } ^ { 2 } } \,,$$
and
$$\frac { \mathrm d f _ { [ \gamma Z _ { \mathrm T } ] / \mu _ { R } ^ { + } } } { \mathrm d p _ { \mathrm T } ^ { 2 } } = \frac { g _ { Z } ^ { \mu _ { R } ^ { + } } } { g _ { \gamma } ^ { \mu ^ { + } } } \frac { \mathrm d f _ { \gamma / \mu } } { \mathrm d p _ { \mathrm T } ^ { 2 } } \,, \quad \frac { \mathrm d f _ { [ \gamma Z _ { \mathrm T } ] / \mu _ { L } ^ { + } } } { \mathrm d p _ { \mathrm T } ^ { 2 } } = \frac { g _ { Z } ^ { \mu _ { L } ^ { + } } } { g _ { \gamma } ^ { \mu ^ { + } } } \frac { \mathrm d f _ { \gamma / \mu } } { \mathrm d p _ { \mathrm T } ^ { 2 } } \,.$$
Here, we have neglected the longitudinal components of the Z boson since its parton distribution function does not have logarithmic enhancement, analogously to the longitudinal W boson. (See the first expression in Eq. (2.3).) Since the Z boson contribution starts from p 2 T ∼ m 2 Z , we can obtain the respective correction by integrating these differential equations with f Z /µ T = f [ γZ T ] /µ = 0 at p 2 T = m 2 Z as the boundary condition.
At the leading-logarithm order, we thus obtain
$$\sigma ( s ) = \sigma _ { \gamma } ( s ) + \sigma _ { Z _ { \mathrm T } } ( s ) + \sigma _ { [ \gamma Z _ { \mathrm T } ] } ( s ) \,,$$
where and
$$\sigma _ { Z _ { \Gamma } } ( s ) & = \sigma _ { \gamma } ( s ) \, g ( s ) \left [ \frac { 1 + P _ { \mu ^ { + } } } { 2 } \left ( \frac { g _ { Z } ^ { \mu ^ { + } } } { g _ { \gamma } ^ { \mu ^ { + } } } \frac { g _ { Z } ^ { W } } { g _ { \gamma } ^ { W } } \right ) ^ { 2 } + \frac { 1 - P _ { \mu ^ { + } } } { 2 } \left ( \frac { g _ { Z } ^ { \mu ^ { + } } } { g _ { \gamma } ^ { \mu ^ { + } } } \frac { g _ { Z } ^ { W } } { g _ { \gamma } ^ { W } } \right ) ^ { 2 } \right ] \\ & \simeq \sigma _ { \gamma } ( s ) \, g ( s ) \, \left [ 1. 2 8 + 0. 2 8 1 \, P _ { \mu ^ { + } } \right ] \,,$$
$$\sigma _ { [ \gamma Z _ { T } ] } ( s ) = 2 \, \sigma _ { \gamma } ( s ) \, g ( s ) \left [ \frac { 1 + P _ { \mu ^ { + } } } { 2 } \frac { g _ { Z } ^ { \mu ^ { + } _ { R } } } { g _ { \gamma } ^ { \mu ^ { + } } } \frac { g _ { Z } ^ { W } } { g _ { \gamma } ^ { W } } + \frac { 1 - P _ { \mu ^ { + } } } { 2 } \frac { g _ { Z } ^ { \mu ^ { + } _ { L } } } { g _ { \gamma } ^ { \mu ^ { + } } } \frac { g _ { Z } ^ { W } } { g _ { \gamma } ^ { W } } \right ]$$
$$\simeq \sigma _ { \gamma } ( s ) \, g ( s ) \left [ 0. 2 5 0 + 2. 2 5 \, P _ { \mu ^ { + } } \right ] \,.$$
Here, we define the ratio of logarithmic factors originating from the p 2 T integrals as
$$g ( s ) = \frac { \log ( s / m _ { Z } ^ { 2 } ) - \frac { 2 } { 3 } \log ( s / s _ { \min } ) } { \log ( s / m _ { \mu } ^ { 2 } ) - \frac { 2 } { 3 } \log ( s / s _ { \min } ) } \,,$$
which, e.g., gives overall factors of about 0.189, 0.238 and 0.268 for √ s = 2 , 10 and 30 TeV, respectively.
Thus, by adding up the contributions involving the Z boson, we finally find
$$\sigma ( s ) \, \simeq \, \sigma _ { \gamma } ( s ) \, \cdot \, \left [ 1 + \left ( 1. 5 3 + 2. 5 3 \, P _ { \mu ^ { + } } \right ) \, g ( s ) \right ],$$
which is significantly enhanced for positively polarized antimuons due to positive interference effects. Together with the enhancement in Eq. (2.5), positive polarization of the µ + beams can enhance the cross section by more than a factor of two. It is important to note that a polarized muon beam may be available, e.g., at µ + µ + colliders with ultra-slow muon technology. In the following, we present the results in both the unpolarized case with P µ + = 0, and the polarized case with P µ + = +0 8 as suggested in [5]. .
## 2.3 Numerical calculation with MadGraph
The large enhancement by (log s ) 3 motivates us to calculate the cross section more accurately and reliably, which we discuss in the next section. However, we first numerically estimate the cross sections using the event generator MadGraph, and compare them to the results of the full calculation and the cross sections of Higgs boson production via the leading W and Z boson fusion processes at µ + µ -and e + e -colliders.
We note here in particular that the γ -and Z -mediated Higgs production process also exists at µ + µ -and e + e -colliders with the same cross section as for µ + µ + colliders. Therefore, its large enhancement means that there are large corrections to the leadingorder cross section of W boson fusion at high energies.
When estimating the cross section of the photon-mediated process in MadGraph, it is possible to use a parton distribution function for the photon in one of the antimuons. We use one of these parton distribution function options, the Improved Weizs¨cker-Williams a (IWW) setting [19], for the computations presented here. Note that we do not use the parton distribution function approximation for W + from the other antimuon, and instead treat γµ + → ν µ W h + as the hard process to be convoluted with the IWW parton distribution function of the photon in the antimuon. We then take the contribution from the Z -mediated process into account by subsequently multiplying the obtained result by the factor in Eq. (2.18).
In calculations with parton distribution functions, it is necessary to set the scale for the hard process, also referred to as factorization scale µ f . Among several options implemented in MadGraph, we take two extremal choices: the default setting -1 , given by the transverse mass after k T clustering to a 2 → 2 system; and the setting 4 , given by the partonic centerof-mass energy as µ f = √ xs [20], which is a commonly used choice for the factorization scale. Note that these are settings for the dynamical scale choice in MadGraph, which is then used for the factorization scale. Here, dynamical means that the scale is determined on an event-by-event basis, e.g., via the respective momentum fraction x in µ f = √ xs of the event. One may also set a fixed factorization scale, but we do not use this here.
In Fig. 2, we show the cross section of the γ - and Z -mediated Higgs production process, given by µ + µ + → µ + ν µ W h + . For the estimate using MadGraph, the upper band represents the results with P µ + = +0 8, while the lower one corresponds to . P µ + = 0. We obtain the upper and lower ends of each band with different choices of factorization scales for the hard process with an initial-state photon, as mentioned above. We then include the contributions from Z boson exchanges by multiplying these results by the factor in Eq. (2.18) to obtain the bands shown in the figure. The solid curves near the bands are the results from the accurate calculation, which we explain in the next section. We see that the calculation with the IWW parton distribution function multiplied by the Z -boson factor gives reasonable estimates for the cross section.
The leading-logarithm formula of Eq. (2.5) with the Z -boson factor in Eq. (2.18) is depicted as lines without data points (solid and dashed lines for P µ + = +0 8 and . P µ + = 0, respectively), and seems to overestimate the cross sections by a factor of two to three even at √ s ∼ 10 TeV. This discrepancy stems largely from the sub-leading logarithmic terms ignored in Eq. (2.5). These originate partly from the lows behavior of the partonic cross section σ γW ( s ) near the threshold, which effectively shifts s min to a larger value; and partly from the terms dropped after convolution of the partonic cross section with the parton distribution functions. However, we have confirmed that including the sub-leading terms brings down the cross section, and gives numerically consistent results compared with the ones obtained from MadGraph, even for √ s ∼ O (1) TeV. Therefore, while the subleading logarithms give noticeable corrections at O (10) TeV energies, we can thus confirm the parametric (log s ) 3 behavior.
We furthermore overlaid the cross section of the leading-order W boson fusion process at µ + µ -colliders, where we do not assume beam polarizations. We see that at energies of 10 TeV or above, the cross section of the higher-order process with polarized beams
Cross Section vs. Center-of-Mass Energy for Single Higgs Production via W Boson Fusion at + + Colliders Comparison of Different Processes, Calculation Methods, and Polarizations P +
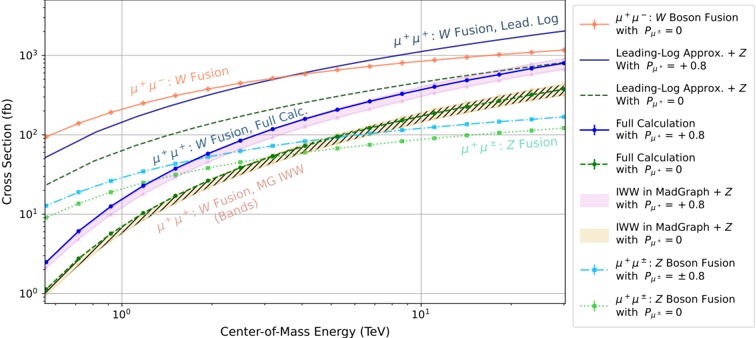
Figure 2 . We show the cross section for single Higgs boson production at µ + µ + colliders via W boson fusion as a function of center-of-mass energy. We compare the results for this process obtained using different calculation methods and polarizations P µ + for both beams, as well as different processes for single Higgs production. First, we show the W boson fusion at µ + µ -colliders, via µ + µ -→ ν µ ν µ h , with unpolarized beams, i.e., P µ ± = 0 (orange, solid with diamonds). Second, the leading-logarithm approximation of Eq. (2.5) (including the Z -boson factor of Eq. (2.18)) for W boson fusion at µ + µ + colliders, via µ + µ + → µ + ν µ W h + , with both beams +0.8 polarized, i.e., P µ + = +0 8 (dark blue, solid), . and unpolarized (dark green, dashed). Third, we show the full result for W boson fusion at µ + µ + colliders with polarized (blue, solid with dots), and unpolarized (green, dashed with dots) beams. Fourth, the bands for the Improved Weizs¨cker-Williams (IWW) a calculation in MadGraph for W boson fusion at µ + µ + colliders, multiplied by the Z -boson factor of Eq. (2.18), with polarized (purple, solid with upwards-pointing triangles) and unpolarized (yellowgreen, dashed with downwards-pointing triangles) beams. The bounds of these bands are obtained by setting the dynamical scale in MadGraph to the standard setting -1 , which yields the lower bounds, and to the partonic center-of-mass energy denoted by the setting 4 , giving the upper bounds. Lastly, we also show the Z boson fusion process in µ + µ ± collisions, via µ + µ ± → µ + µ ± h , with polarized (light blue, dash-dotted with squares) and unpolarized (light green, dotted with squares) beams.
becomes about half as large as the leading one at µ + µ -colliders. See also Tab. 1, where we list the cross sections for representative collider energies. Therefore, the disadvantage due to missing W boson fusion at the leading order is remedied at the next-to-leading order at ∼ 10 TeV energies. Importantly, this large contribution to Higgs production is also present for µ + µ -and e + e -colliders. This will thus add a new significant process at any such lepton collider.
Lastly, we also show in Fig. 2 the cross section of Z boson fusion at µ + µ + colliders for P µ + = +0 8 and . P µ + = 0. We see that the cross section of the sub-leading W boson fusion process becomes larger than for the leading Z boson fusion beyond a few TeV.
The observed large correction to W boson fusion at the next-to-leading order may indicate that we are about to lose perturbativity. We thus investigate higher-order pro-
Table 1 . We show the total cross section in the unit of fb for single Higgs production via W boson fusion in µ + µ -collisions ( µ + µ -→ ν µ ν µ h ) with unpolarized beams, W boson fusion in µ + µ + collisions ( µ + µ + → µ + ν µ W h + ) with both beams +0.8 polarized or unpolarized, and via Z boson fusion in µ + µ + collisions ( µ + µ + → µ + µ + h ) with both beams +0.8 polarized or unpolarized for different center-of-mass energies.
| Center-of-Mass Energy [TeV] | 1 | 2 | 3 | 10 | 30 |
|-------------------------------------------------|--------|--------|--------|--------|------|
| σ ( µ + µ - → ννh ) [fb], P µ ± = 0 | 211 | 385 | 498 | 842 | 1165 |
| σ ( µ + µ + → µ + νW + h ) [fb], P µ + = +0 . 8 | 15 . 6 | 61 . 0 | 109 | 371 | 799 |
| σ ( µ + µ + → µ + νW + h ) [fb], P µ + = 0 | 7 . 05 | 27 . 7 | 49 . 9 | 172 | 374 |
| σ ( µ + µ + → µ + µ + h ) [fb], P µ + = +0 . 8 | 29 . 0 | 53 . 8 | 70 . 4 | 121 | 168 |
| σ ( µ + µ + → µ + µ + h ) [fb], P µ + = 0 | 20 . 9 | 39 . 0 | 50 . 9 | 87 . 6 | 122 |
cesses with additional powers of log s , which are, e.g., µ + µ + → µ + µ + W W h µ µ + -, + + → µ + ν µ W + γ/Z h and µ + µ + → ν µ ν µ W W h + + . In particular, the first process has a parametric (log s ) 5 dependence, while the others have (log s ) 4 , and we thus expect it to have the largest contribution at high energies among them. Using the method we describe in Sec. 3, we calculate the cross section of this process to be σ ≃ 14 fb at √ s = 20 TeV for P µ + = +0 8, which is notably smaller than the cross section . σ ≃ 600 fb of the lower-order process µ + µ + → µ + ν µ W h + . Therefore, at least for Higgs boson production at O (10) TeV energies, the higher-order processes are not yet in the non-perturbative regime. Nevertheless, in the analysis of actual events, one should include the higher-order processes since they may contribute to the signals defined by lower-order ones.
## 3 Calculation with controlled theoretical uncertainties
We saw in the previous section that a large enhancement of the cross section occurs at high energies. We furthermore examined its leading-logarithm approximation and a numerical method implementing parton distribution functions; however, it should be possible to calculate the cross section accurately without uncertainties, as we are considering a fixed-order, tree-level process. One could try to calculate the full fixed-order process in MadGraph, but as previously mentioned, in that case one encounters numerical instabilities in the integration of the phase space for small transverse momenta p T of the antimuon emitting the photon-this is why we previously opted for using a parton distribution function instead.
Here, we therefore discuss a method to calculate the cross section accurately and reliably, and with controlled theoretical uncertainties. The method is simply to split the integral over the p T of the final-state antimuon into two parts with p T < p (cut) T and p T ≥ p (cut) T , respectively, for some value of p (cut) T . We calculate the first part semi-analytically using the Weizs¨cker-Williams method, also referred to as Equivalent Photon Approximation a (EPA) [9, 10, 21-24], and the second part numerically using MadGraph, since the lower
bound on p T mitigates the numerical instabilities. This means we calculate
$$\sigma = \sigma \Big | _ { p _ { T } < p _ { T } ^ { ( \text{cut} ) } } + \sigma \Big | _ { p _ { T } \geq p _ { T } ^ { ( \text{cut} ) } }$$
$$\simeq \sigma _ { \text{EPA} } \Big | _ { p _$$
where in the second line, we approximate the first term by ignoring higher-order terms in p (cut) T , and the second term, by ignoring the muon mass. While splitting the phase-space integral itself is completely independent of p (cut) T no matter its value, the premise of EPA and MadGraph being reliable in their respective regions does depend on the p (cut) T at which we split the phase space. As such, the accuracy and applicability of the different calculation methods relies on choosing a suitable value for p (cut) T . Therefore, when calculating the split total cross section using this method, we need to check whether the sum of the two cross sections of Eq. (3.2) exhibits a plateau-i.e., a constant region- as a function of p (cut) T . This is the aforementioned insensitivity of Eq. (3.1) with respect to the value of p (cut) T . If we find such a plateau, we know on one hand that the combined calculation scheme works, and on the other hand in which range of p (cut) T it is applicable. As we will see in the case of Higgs production at µ + µ + colliders, this range is physically well-motivated, which makes the application to other processes straightforward.
We note that splitting the phase space and calculating its parts with a parton distribution function in one part and the full matrix element in another part is not an entirely new approach. It has for instance been used in Ref. [25] under the name of matrix-element matching to show the validity of the parton distribution functions of transversely polarized weak bosons.
## 3.1 Lowp T cross sections from EPA
In our EPA calculation, we use the distribution function of the photon in the lepton ℓ , given by
$$f _ { \gamma / \mu } ^ { p _ { T } ^ { ( \text$$
where we put an upper bound on the transverse momentum via p (cut) T , and m ℓ is the mass of the lepton ℓ . See Appendix A for the derivation. The first expression is obtained by rewriting Eq. (20) in Ref. [19], which is originally derived for kinematical regions with small virtuality q 2 of the photon. We rewrite it using the relation of the photon virtuality and the transverse momentum, given by
$$p _ { \text{T} } ^ { 2 } = - q ^ { 2 } ( 1$$
## Cross Section vs. p (cut) T Values for Representative Center-of-Mass Energies s Data from EPA (lowp T ) Calculation for + + + W + h
Figure 3 . We show the EPA (lowp T ) cross section for µ + µ + → µ + ν µ W h + as a function of p (cut) T for representative center-of-mass energies (top to bottom): 30 TeV (blue, solid), 10 TeV (orange, dashed), 3 TeV (green, dash-dotted), and 1 TeV (red, dotted). The vertical dashed lines indicate the muon mass m µ and the Z boson mass m Z . We calculate the error bars from the cross section value and the relative error of Eq. (3.6), combined with the supplied error of the numerical convolution, and the error supplied by MadGraph for the calculation of the partonic cross section after propagating it through the convolution.
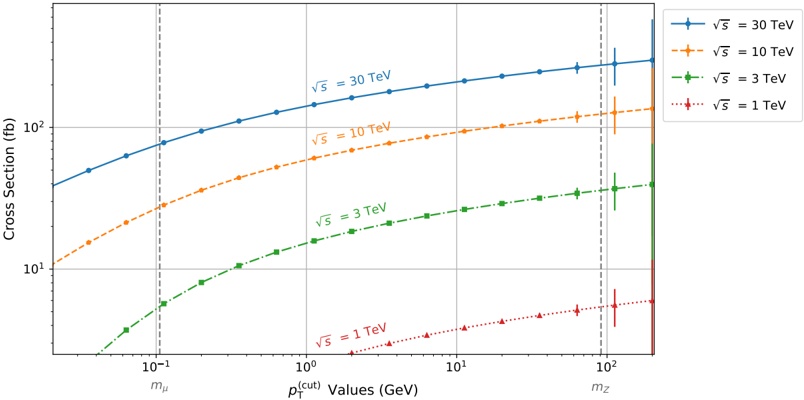
as we also discuss in Appendix A. The second line of Eq. (3.3) is a further-approximated formula obtained when p (cut) T is much larger than the lepton mass m ℓ . This simplified formula can be found in Ref. [24], again as a function of the photon virtuality. The first expression of the distribution function consistently takes into account the finite lepton mass, up to corrections of O ( m /s 2 ℓ ). Note that although we use the first expression of Eq. (3.3) for our numerical calculations, the second expression should actually be enough for our purposes by taking p (cut) T ≫ m ℓ . An important point is that we have a non-logarithmic term, unlike the leading-logarithm formula in Eq. (2.1), for which there is no uncertainty associated with the scale of the hard process as long as the lepton mass is negligible-i.e., the second line of Eq. (3.3).
Using this parton distribution function, the total cross section for the lowp T region is given by
$$\sigma _ { \text{EPA} } \Big | _ { p _ { \text{$$
where σ γµ ( xs ) is the cross section of the γµ + → ν µ W h + process at the center-of-mass energy √ xs . The lower end of the x integration is given by s min /s , where s min is the smallest invariant mass of the final-state particles in the subprocess, i.e., s min = ( m h + m W ) 2 , since the subprocess' center-of-mass energy needs to be large enough for it to take place, with √ xs ≥ √ s min . The cross section obtained from this formula is the leading-order value of
the systematic expansion in terms of p (cut) T . The relative uncertainty of this method is of the order of
$$\begin{array} {$$
Note that EPA here is not the leading-logarithm approximation. The uncertainty above can be much smaller than [ log ( p (cut) T /m µ )] -1 , and the formula is valid for small p (cut) T as long as p (cut) T ≫ m µ . We explain the derivation of the formula and the associated uncertainties in Appendix A.
The partonic cross section σ γµ can be calculated using MadGraph since there are no intermediate light particles in this subprocess, and it can thus be evaluated numerically. Therefore, we scan over center-of-mass energies to obtain the cross section as a function of energy, and then convolute it with the parton distribution function, as described above. For a small enough p (cut) T compared to s min (and large enough compared to m µ ), the cross section can thus be calculated with small theoretical uncertainties. However, since we do not take into account the Z -boson-exchange diagrams using this method, we expect it to be reliable for p (cut) T ≪ m Z .
We show in Fig. 3 the lowp T cross section as a function of p (cut) T for representative center-of-mass energies √ s = 1, 3, 10, and 30 TeV. The error bars in the figure are calculated primarily using the relative uncertainty of Eq. (3.6), which is invisible for small p (cut) T .
## 3.2 Highp T cross sections from MadGraph
The calculation for the highp T part can be performed numerically using MadGraph by specifying a lower bound on p T , given by p (cut) T . Thusly, we can avoid the collinear divergences (or numerical instabilities) in the phase-space integral, which are associated with the muon mass being either set to zero, or significantly smaller than the center-of-mass energy.
In the default set-up, MadGraph calculates the cross section with the muon mass set to zero. This approximation results in relative uncertainties of the order of
$$\frac { m _ { \mu } ^ { 2 } } { \left ( p _ { \mathrm T } ^ { ( \text{cut} ) } \right ) ^ { 2 } } \, \left [ \log \frac { s } { \left ( p _ { \mathrm T } ^ { ( \text{cut} ) } \right ) ^ { 2 } } \, \log \frac { s } { s _ { \min } } - \frac { 2 } { 3 } \left ( \log \frac { s } { s _ { \min } } \right ) ^ { 2 } \right ] ^ { - 1 }.$$
See Appendix B for the derivation and discussion of the error associated with this massless approximation. Therefore, by taking p (cut) T ≫ m µ , we both avoid numerical instabilities, and have negligibly small uncertainties associated with the finite muon mass.
We show the obtained cross section as a function of p (cut) T in Fig. 4 for the center-of-mass energies √ s = 1, 3, 10, and 30 TeV, analogously to the lowp T cross section.
## 3.3 Summing up the low- and highp T cross sections
We show in Fig. 5 the sum of the low- and highp T cross sections, calculated using the EPA scheme and MadGraph, respectively. As expected, we clearly observe the plateau of the
Cross Section vs. p (cut) T Values for Representative Center-of-Mass Energies s Data from MadGraph (highp T ) Calculation for + + + W + h
Figure 4 . We show the MadGraph (highp T ) cross section for µ + µ + → µ + ν µ W h + as a function of p (cut) T for representative center-of-mass energies (top to bottom): 30 TeV (blue, solid), 10 TeV (orange, dashed), 3 TeV (green, dash-dotted), and 1 TeV (red, dotted). The vertical lines indicate the muon mass m µ and the Z boson mass m Z . We calculate the error bars from the cross section value and the relative error of Eq. (3.7), combined with the error supplied by MadGraph for the calculation of the cross section.
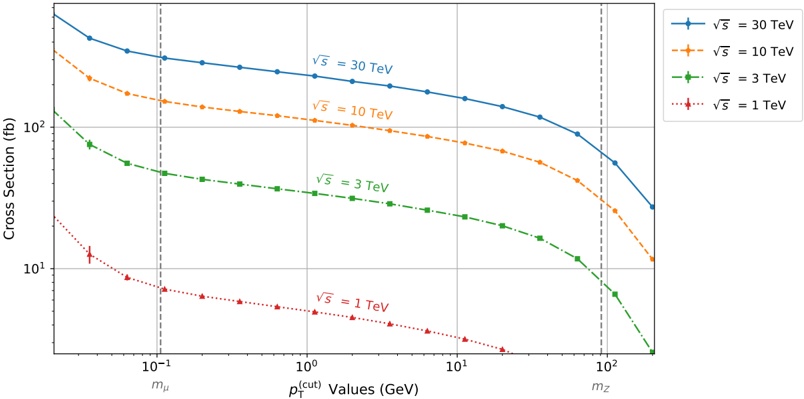
summed cross sections as a function of p (cut) T . Based on the discussions of the uncertainties in both calculations, we find an optimal choice for p (cut) T to be around the geometric mean of the muon and Z boson masses, p (cut) T = √ m m µ Z ≃ 3 10 GeV, where we indeed find the . plateau. Nevertheless, for too small or too large p (cut) T , the summed cross sections deviate from their plateau values.
On the one hand, for small p (cut) T (i.e., ≲ m µ ), the cross section calculated by MadGraph is too large due to numerical instabilities, as previously mentioned. However, the error bars in the small p (cut) T region represent the uncertainties from the massless approximation, whereas the stark increase of the cross section calculated by MadGraph seems to be largely independent of this approximation. Indeed, this behavior persists even when including the finite muon mass in MadGraph. This is because the muon mass, while non-zero, is significantly smaller than the center-of-mass energies considered, leading again to numerical instabilities. Thus, even when including a finite muon mass, one cannot obtain a reliable result from MadGraph for, e.g., p (cut) T = 0.
On the other hand, for large p (cut) T (i.e., ≳ m Z ), the contribution from Z -bosonexchange diagrams, as well as the higher-order terms in the p (cut) T expansion of EPA become important for the lowp T cross section. Neglecting these thus leads to a deficit in the summed cross section. Note that there are also diagrams without collinear divergences, which are taken into account in the MadGraph (highp T ) cross section. Increasing p (cut) T
Cross Section vs. p (cut) T Values for Representative Center-of-Mass Energies s Sum of Data from EPA (lowp T ) and MadGraph (highp T ) Calculations for + + + W + h
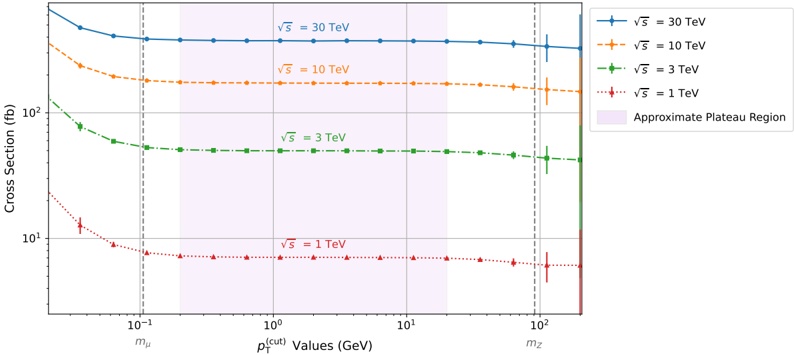
Figure 5 . We show the sum of the EPA (lowp T ) and MadGraph (highp T ) cross sections for µ + µ + → µ + ν µ W h + as a function of p (cut) T for representative center-of-mass energies (top to bottom): 30 TeV (blue, solid), 10 TeV (orange, dashed), 3 TeV (green, dash-dotted), and 1 TeV (red, dotted). The vertical lines indicate the muon mass m µ and the Z boson mass m Z . The error bars are determined by the root-square-sum of the EPA and MadGraph errors, which are primarily obtained from Eqs. (3.6) and (3.7), respectively. The violet rectangle marks the approximate region of the plateau, i.e., the p (cut) T -independent region of the summed cross section, which we take as 0 2 GeV . ≲ p (cut) T ≲ 20 GeV.
too far thus also neglects part of their contribution.
Note that the results discussed here for unpolarized beams apply in the same way to the case with polarized beams.
By reading off the cross sections in the plateau region, we can now reliably calculate the fixed-order cross section of the µ + µ + → µ + ν µ W h + process as shown in Fig. 6. The upper and lower curves are the cross sections with beam polarizations P µ + = +0 8 and . P µ + = 0, respectively. We also show error bands associated with the choice of p (cut) T = √ m m µ Z for the range √ m m / µ Z 4 < p (cut) T < 4 √ m m µ Z . However, they are almost invisible. We thereby estimate the uncertainty associated with the choice of p (cut) T to be less than one percent.
For convenience, we present in Appendix C a semi-automatic method to implement the p (cut) T scheme in MadGraph, in particular the lowp T calculation.
## 4 Event shape of the W boson fusion process
As seen so far, we obtained reliable results for the higher-order Higgs production by dividing the cross section into two regions, corresponding to low and high p T of the final-state antimuon, which we calculate using EPA and MadGraph, respectively. Compared to the leading-order W boson fusion, this process contains an additional W boson in the final state. Thus, to distinguish event signals from background, the produced Higgs and W bosons should both be detected.
## Cross Section vs. Center-of-Mass Energy for + + + W + h Full Result with Different Polarizations P + for p (cut) T = m mZ 3.10 GeV with p (cut) T Error Bands
Figure 6 . We show the full, summed cross section as a function of center-of-mass energy for p (cut) T = √ m m µ Z ≃ 3 10 GeV, the geometric mean of the muon mass . m µ and the Z boson mass m Z . We obtain the error bands by varying p (cut) T in the range √ m m / µ Z 4 < p (cut) T < 4 √ m m µ Z . The upper curve (blue, dashed) and its error band (red, diagonal lines) correspond to a polarization of P µ + = +0 8 for both beams, and the lower curve (green, dash-dotted) and its band (magenta, . solid) to P µ + = 0, i.e., unpolarized beams.
However, because the µ + beams induce undesired backgrounds such as µ + -decay products and incoherent e + e -pairs (see Ref. [26] for a review), we need to put shielding nozzles around the interaction point to reduce these beam-induced backgrounds. This makes placement of detectors quite non-trivial, leading to constraints of the detectors' coverage angle. Therefore, to estimate event efficiency, it is necessary to study the scattering angles of final-state particles and to compare them with the coverage angle.
In the following, we present event histograms of the distribution of the scattering angles. As one of the main decay channels, we consider the produced h and W + decaying into bb ¯ , and light quarks ( ud ¯ ), respectively. We generate the events using MadGraph with p T ≥ 0 1 GeV, which corresponds to the high-. p T region of the previous sections. Here, we neglect the lowp T region because it does not have a significant number of events for this choice of lowerp T cut. We show in Figs. 7 and 8 the histograms for the intermediate h and W + bosons and their decay products b , ¯ , b u , and ¯ for d √ s = 2 TeV and 10 TeV, respectively. The histograms are at the parton level without smearing of the energies or momenta of the final-state particles. Since a µ + µ + collider is symmetric in the two initial-state particles, we concentrate on the angles 0 ◦ ≤ θ ≤ 90 . ◦
From these plots, we observe that most decay products have sufficiently large scattering angles, or transverse momenta, and are hence visible. We therefore now estimate how many events can be caught by detectors. Although there is not yet a concrete detector design for µ + µ + colliders, we assume the coverage of the hadron calorimeter to be around 10 ◦ [27, 28]. Thus, we find that around 83% of events can be caught by the detector, and reconstructing
Figure 7 . We show event histograms for the scattering angles of final-state particles in the W boson fusion process with √ s = 2 TeV, where the calculation is performed by MadGraph with a minimump T cut 0 1 GeV. The number of the generated events is 5 . × 10 . 4
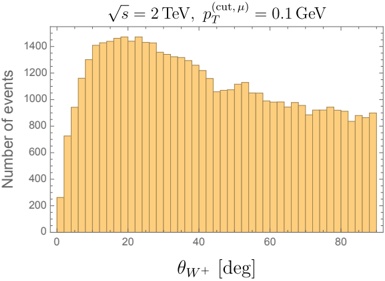
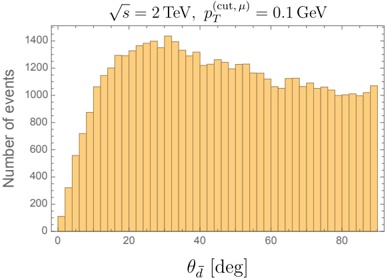
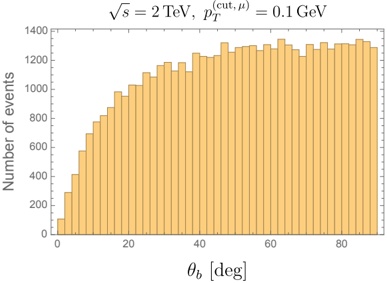
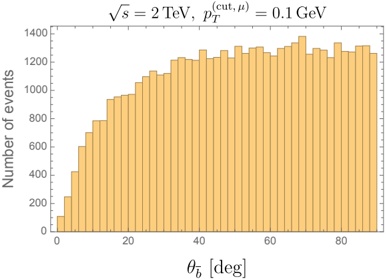
the W and Higgs bosons is possible for both √ s = 2 TeV and 10 TeV. We expect this reconstruction to help to distinguish these signal events from background events. Further studies, such as detector simulation, will be performed elsewhere.
## 5 Summary
We studied Higgs boson production at µ + µ + colliders, where W boson fusion is not possible at the leading order. This is because a µ + cannot directly emit the W -necessary to create
Figure 8 . We show event histograms for scattering angles of final-state particles in the W boson fusion process with √ s = 10 TeV, where the calculation is performed by MadGraph with a minimump T cut 0 1 GeV. The number of the generated events is 5 . × 10 . 4
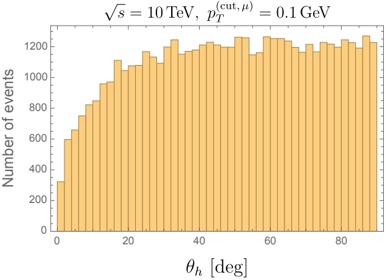
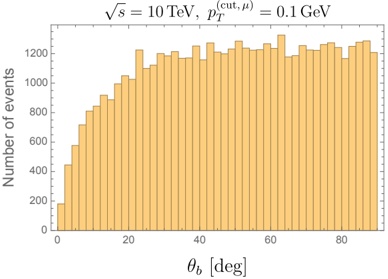
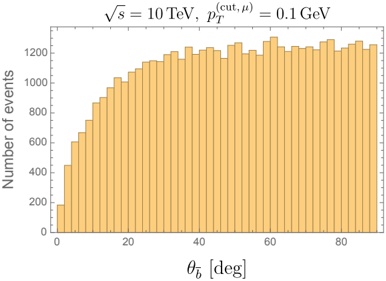
the W W + -pair fusing to a Higgs boson. Nevertheless, we show that at high-energy µ + µ + colliders, a γ -and Z -mediated W boson fusion is possible, with its cross section growing as (log s ) 3 with the center-of-mass energy √ s . This means that at high energies, such colliders can produce almost as many Higgs bosons as µ + µ -or e + e -colliders, since their production cross section only increases as log s .
We calculated the cross section by carefully treating the divergence associated with collinear emission of the intermediate photon from the antimuon. Therein, we split the
integration region of the transverse momentum p T of the antimuon into the sum of a lowand a highp T region. We then calculate the lowp T part using the equivalent photon approximation (EPA), and the highp T part directly using MadGraph. EPA gives the leading-order value in a systematic expansion in the maximal value of p T , and Z boson contributions to the lowp T region become important for p T ≳ m Z . Therefore, we can control the systematic uncertainties associated with this approximation by choosing a small enough value p (cut) T at which we split the low- and highp T regions. On the other hand, to avoid the collinear divergences or numerical instabilities from MadGraph, we must have p (cut) T ≳ m µ . Thereby, we obtained a reliable result for the cross section by verifying its independence on the p T value at which we split the regions. This is well satisfied, e.g., for the choice p (cut) T = √ m m µ Z .
The cross section we obtained in this manner is indeed enhanced at high energy; note, however, that the leading-logarithm formula that only includes (log s ) 3 terms seems to overestimate it. Nevertheless, even compared with the leading-order W boson fusion process at µ + µ -colliders, the cross section of the γ - and Z -mediated process with polarized beams can be as large as half of the one for the leading-order process at 10 TeV energies. Therefore, while beam polarization capabilites are important, a µ + µ + collider is as good a Higgs boson factory as a µ + µ -collider.
## Acknowledgements
We would like to thank Koji Nakamura, Sayuka Kita and Mitsuhiro Yoshida for useful discussions. This work was in part supported by JSPS KAKENHI Grant Numbers JP22K21350 (R.K., R.M. and S.O.), JP21H01086 (R.K.), JP19H00689 (R.K.), JP24KJ1157 (R.T.), JP19K14711 (H.T.) and JP23K13110 (H.T.). H.T. is the Yukawa Research Fellow supported by Yukawa Memorial Foundation. This work is also supported by the Deutsche Forschungsgemeinschaft under Germany's Excellence Strategy - EXC 2121 Quantum Universe - 390833306.
## A Equivalent photon approximation (EPA)
Repeating a similar calculation to Ref. [19], we derive the EPA formula applicable to the case where a p T cut is applied. This section includes a review of Ref. [19]. Let us consider the photon-mediated process ℓ p ( ) + f ( k ) → ℓ p ( ′ ) + X , where ℓ , f , and X denote a lepton, massless parton ( k 2 = 0), and a generic final-state system, respectively. The four-momenta of the leptons and the virtual photon are defined as
$$p = E ( 1, 0, 0, \beta ), \ \ p ^ { \prime } = E ^ { \prime } ( 1, 0, \beta ^ { \prime } \sin \theta, \beta ^ { \prime } \cos \theta ) \ \text{ and } \ q = p - p ^ { \prime } \text{ \quad \ \ (A.1)}$$
with
$$\beta = \sqrt { 1 - \frac { m _ { \ell } ^ { 2 } } { E ^ { 2 } } } \quad \text{and} \quad \beta ^ { \prime } = \sqrt { 1 - \frac { m _ { \ell } ^ { 2 } } { E ^ { \prime 2 } } } \,,$$
and m ℓ the lepton mass.
The cross section is given by
$$\mathrm d \sigma _ { \text{EPA} } = \frac { 1 } { 8 k \cdot p } \frac { e ^ { 2 } W ^ { \mu \nu } T _ { \mu \nu } } { q ^ { 4 } } \frac { \mathrm d ^ { 3 } p ^ { \prime } } { ( 2 \pi ) ^ { 3 } 2 E ^ { \prime } } = \frac { 1 } { 8 k \cdot p } \frac { \alpha } { 4 \pi } \frac { W ^ { \mu \nu } T _ { \mu \nu } } { q ^ { 4 } } \, \mathrm d q ^ { 2 } \mathrm d x \,,$$
where α is the fine-structure constant, and the two independent kinematic variables, photon virtuality and longitudinal momentum fraction, are given by
$$q ^ { 2 } = 2 m _ { \ell } ^ { 2 } - 2 E E ^ { \prime } ( 1 - \beta \beta ^ { \prime } \cos \theta ) \ \text{ and } \ x = 1 - \frac { E ^ { \prime } ( 1 + \beta ^ { \prime } \cos \theta ) } { E ( 1 + \beta ) } \,, \quad \quad ( \text{A.4} )$$
respectively. Furthermore, x satisfies x = 1 -k p · ′ k p · = k q · k p · . The leptonic tensor T µν and the hadronic tensor W µν of the electromagnetic current are given by
$$T _ { \mu \nu } = 4 \left ( \frac { 1 } { 2 } q ^ { 2 } g _ { \mu \nu } + p _ { \mu } p ^ { \prime } _ { \nu } + p _ { \nu } p ^ { \prime } _ { \mu } \right )$$
and
$$W ^ { \mu \nu } & = W _ { 1 } ( q ^ { 2 }, k \cdot q ) \left ( - g ^ { \mu \nu } + \frac { q ^ { \mu } q ^ { \nu } } { q ^ { 2 } } \right ) - \frac { q ^ { 2 } W _ { 2 } ( q ^ { 2 }, k \cdot q ) } { ( k \cdot q ) ^ { 2 } } \left ( k ^ { \mu } - \frac { k \cdot q } { q ^ { 2 } } q ^ { \mu } \right ) \left ( k ^ { \nu } - \frac { k \cdot q } { q ^ { 2 } } q ^ { \nu } \right ).$$
Contracting them then yields
$$W ^ { \mu \nu } T _ { \mu \nu } & = - 4 \left [ 2 m _ { \ell } ^ { 2 } W _ { 1 } ( q ^ { 2 }, k \cdot q ) + q ^ { 2 } \left ( W _ { 1 } ( q ^ { 2 }, k \cdot q ) + \frac { 2 ( 1 - x ) } { x ^ { 2 } } W _ { 2 } ( q ^ { 2 }, k \cdot q ) \right ) \right ] \\ & \simeq - 4 W _ { 1 } ( 0, k \cdot q ) \left [ 2 m _ { \ell } ^ { 2 } + q ^ { 2 } \cdot \frac { 1 + ( 1 - x ) ^ { 2 } } { x ^ { 2 } } \right ],$$
where we use
$$W _ { 1 } ( q ^ { 2 }, k \cdot q ) = W _ { 1 } ( 0, k \cdot q ) + \mathcal { O } ( q ^ { 2 } ) \ \text{ and } \ W _ { 2 } ( q ^ { 2 }, k \cdot q ) = W _ { 1 } ( 0, k \cdot q ) + \mathcal { O } ( q ^ { 2 } ) \,, \quad ( \text{A.8} )$$
obtained by requiring that W µν be analytic in q 2 as q 2 → 0.
Therefore, the cross section can be approximated by
$$d \sigma _ { \text{EPA} } = f _ { \gamma / \ell } ( x ) \sigma _ { \gamma f } ( q, k ) d x \,,$$
with [19]
$$f _ { \gamma / \ell } ( x ) = \frac { \alpha } { 2 \pi } \left [ 2 m _ { \ell } ^ { 2 } x \left ( \frac { 1 } { q _ { \max } ^ { 2 } } - \frac { 1 } { q _ { \min } ^ { 2 } } \right ) + \frac { 1 + ( 1 - x ) ^ { 2 } } { x } \log \frac { q _ { \min } ^ { 2 } } { q _ { \max } ^ { 2 } } \right ] \quad \text{(A.10)}$$
and
$$\sigma _ { \gamma f } ( q, k ) = \frac { W _ { 1 } ( 0, k \cdot q ) } { 4 k \cdot q } \,.$$
We obtain these expressions by integrating Eq. (A.3) with Eq. (A.7) over q 2 from q 2 min to q 2 max .
Ref. [19] further presents the formula for the case where a θ cut is applied, with 0 ≤ θ < θ c with θ c ≪ 1. In this case, the range of q 2 reads [19]
$$q _ { \max } ^ { 2 } = - \frac { m _ { \ell } ^ { 2 } x ^ { 2 } } { 1 - x } \quad \text{and} \quad q _ { \min } ^ { 2 } = - \frac { m _ { \ell } ^ { 2 } x ^ { 2 } } { 1 - x } - E ^ { 2 } ( 1 - x ) \theta _ { c } ^ { 2 } \,.$$
Substituting these results into Eq. (A.10), one obtains f γ/ℓ ( x ) in the θ -cut scheme.
Instead of a θ -cut, we give f γ/ℓ ( x ) for the case where a p T cut is applied, with 0 ≤ p T < p (cut) T . In particular, we find a simple relation between p 2 T and q 2 :
$$p _ { \text{T} } ^ { 2 } = - q ^ { 2 } ( 1 - x ) - m _ { \ell } ^ { 2 } x ^ { 2 } \,,$$
as seen from p T = E β ′ ′ sin θ . This is especially useful, since it does not depend on E , in contrast to the case with θ . Therefore, the range of q 2 reads
$$q _ { \max } ^ { 2 } = - \frac { m _ { \ell } ^ { 2 } x ^ { 2 } } { 1 - x } \quad \text{and} \quad q _ { \min } ^ { 2 } = - \frac { 1 } { 1 - x } \left ( \left ( p _ { \text{T} } ^ { ( \text{cut} ) } \right ) ^ { 2 } + m _ { \ell } ^ { 2 } x ^ { 2 } \right ).$$
Substituting these results into Eq. (A.10), we obtain f γ/ℓ ( x ) in the p T cut scheme, as shown in Eq. (3.3).
Next, we discuss the uncertainty of the EPA formula. The EPA calculation utilizes the leading term of the expansion of W q ,k i ( 2 · k ) in q 2 :
$$W _ { i } ( q ^ { 2 }, k \cdot q ) = \sum _ { n \geq 0 } A _ { i } ^ { ( n ) } ( k \cdot q ) \left ( \frac { q ^ { 2 } } { ( k \cdot q ) } \right ) ^ { n }$$
for i = 1, 2. Therefore, we study the impact of higher-order terms by again following the corresponding calculation in Ref. [19]. Due to
$$\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \\ W ^ { \mu \nu } T _ { \mu \nu } = & - 4 W _ { 1 } ( 0, k \cdot q ) \left [ 2 m _ { \ell } ^ { 2 } + q ^ { 2 } \frac { 1 + ( 1 - x ) ^ { 2 } } { x ^ { 2 } } \right ] - 8 m _ { \ell } ^ { 2 } \left ( A _ { 1 } ^ { ( 1 ) } \frac { q ^ { 2 } } { k \cdot q } + A _ { 1 } ^ { ( 2 ) } \frac { q ^ { 4 } } { ( k \cdot q ) ^ { 2 } } \right ) \\ & - 4 q ^ { 2 } \left ( A _ { 1 } ^ { ( 1 ) } \frac { q ^ { 2 } } { k \cdot q } + \frac { 2 ( 1 - x ) } { x ^ { 2 } } A _ { 2 } ^ { ( 1 ) } \frac { q ^ { 2 } } { k \cdot q } \right ) + \mathcal { O } ( q ^ { 6 } ) \,, \\. & \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots$$
the error caused by the higher-order terms is given by
## ∆d σ
$$& \Delta d \sigma _ { \text{EPA} } \\ & \simeq - \frac { \alpha } { 2 \pi } \frac { 1 } { 4 k \cdot p } \left \{ \frac { 2 m _ { \ell } ^ { 2 } A _ { 1 } ^ { ( 1 ) } } { k \cdot q } \frac { 1 } { q ^ { 2 } } + \frac { 2 m _ { \ell } ^ { 2 } A _ { 1 } ^ { ( 2 ) } } { ( k \cdot q ) ^ { 2 } } + \frac { A _ { 1 } ^ { ( 1 ) } } { k \cdot q } + \frac { 2 ( 1 - x ) } { x ^ { 2 } } \frac { A _ { 2 } ^ { ( 1 ) } } { k \cdot q } \right \} d q ^ { 2 } d x \\ & \simeq - \frac { \alpha } { 2 \pi } \left \{ \frac { m _ { \ell } ^ { 2 } } { s } \frac { A _ { 1 } ^ { ( 1 ) } } { k \cdot q } \log \frac { q _ { \max } ^ { 2 } } { q _ { \min } ^ { 2 } } + \left [ \frac { 2 m _ { \ell } ^ { 2 } A _ { 1 } ^ { ( 2 ) } } { s } \frac { 1 } { k \cdot q } + \frac { 1 } { 2 } \frac { A _ { 1 } ^ { ( 1 ) } } { k \cdot q } + \frac { A _ { 2 } ^ { ( 1 ) } } { k \cdot q } \frac { 1 - x } { x ^ { 2 } } \right ] \frac { q _ { \max } ^ { 2 } - q _ { \min } ^ { 2 } } { s } \right \} d x \,.$$
In the second equality, we performed the q 2 -integral, then used the relation
$$k \cdot q = x k \cdot p = \frac { x s } { 2 } + \mathcal { O } \left ( \frac { m _ { \ell } ^ { 2 } } { s } \right ),$$
and finally combined 1 / k ( · q ) with A ( n ) i to take
$$\frac { A _ { i } ^ { ( n ) } } { k \cdot q } \sim \mathcal { O } ( 1 ) \times \sigma _ { \gamma f }.$$
This identification is analogous to what we did for the n = 0 case. Noting that
$$q _ { \max } ^ { 2 } - q _ { \min } ^ { 2 } = \begin{cases} & E ^ { 2 } ( 1 - x ) \theta _ { c } ^ { 2 } & \text{for a $\theta$ cut}, \\ & \frac { 1 } { 1 - x } \left ( p _ { T } ^ { ( \text{cut} ) } \right ) ^ { 2 } & \text{for a $p_{T}$ cut}, \end{cases}$$
and also
$$\int _ { x _ { \min } } \frac { d x } { x ^ { 2 } } \sim \frac { 1 } { x _ { \min } } \,,$$
where x min is given by s min /s , we see that the dominant error stems from the last term inside the square brackets of Eq. (A.17), and we thus find:
$$\frac { \Delta \sigma _ { \text{EPA} } \Big | _ { p _ { \text{T} } < p _ { \text{T} } ^ { ( \text{cut} ) } } } { \sigma _ { \text{EPA} } \Big | _ { p _ { \text{T} } < p _ { \text{T} } ^ { ( \text{cut} ) } } } \sim \begin{cases} \mathcal { O } ( E ^ { 2 } \theta _ { c } ^ { 2 } / s _ { \min } ) & \text{for a } \theta \text{ cut}, \\ \mathcal { O } ( ( p _ { \text{T} } ^ { ( \text{cut} ) } ) ^ { 2 } / s _ { \min } ) & \text{for a } p _ { \text{T} } \text{ cut}. \end{cases}$$
## B Error in the massless lepton approximation
We now discuss the error in the calculation with MadGraph for the highp T cross section in Eq. (3.2) when the muon mass is neglected. For this, we split σ MG ∣ ∣ p T ≥ p (cut) T as
$$\sigma _ { \text{MG} } \Big | _ { p _ { \text{T} } \geq p _ { \text{T} } ^ { ( \text{cut} ) } } = \sigma _ { \text{MG} } \Big | _ { p _ { \text{T} } ^ { * } \geq p _ { \text{T} } \geq p _ { \text{T} } ^ { ( \text{cut} ) } } + \sigma _ { \text{MG} } \Big | _ { p _ { \text{T} } > p _ { \text{T} } ^ { * } }$$
by using an additional cut p ∗ T . The dominant error caused by the massless approximation should stem from the first cross section of the sum, where p T is smaller. We then set the new cut p ∗ T such that the EPA formula is also valid for the cross section with p ∗ T ≥ p T ≥ p (cut) T . (The plateaus we observe in Fig. 5 indicate that such a p ∗ T exists.) Thus, we can estimate the error by
$$\Delta \sigma _ { \text{MG} } \Big | _ { p _ { T } \geq p _ { T } ^ { ( \text{cut)} } } & \simeq \sigma _ { \text{MG} } \Big | _ { p _ { T } ^ { * } \geq p _ { T } \geq p _ { T } ^ { ( \text{cut)} }, m _ { \mu } ^ { 2 } = 0 } \\ & \simeq \sigma _ { \text{EPA} } \Big | _ { p _ { T } ^ { * } \geq p _ { T } \geq p _ { T } ^ { ( \text{cut)} } } - \sigma _ { \text{EPA} } \Big | _ { p _ { T } ^ { * } \geq p _ { T } \geq p _ { T } ^ { ( \text{cut)} }, m _ { \mu } ^ { 2 } = 0 } \\ & = \int d x \left [ f _ { \gamma / \mu } ^ { p _ { T } ^ { ( \text{cut)} }, p _ { T } ^ { * } } ( x ) - f _ { \gamma / \mu } ^ { p _ { T } ^ { ( \text{cut)} }, p _ { T } ^ { * } } ( x ) \Big | _ { m _ { \mu } ^ { 2 } = 0 } \right ] \sigma _ { \gamma \mu } ( x s ) \,, \\ & \text{(cut)} \ \.$$
where the function f p (cut) T , p ∗ T γ/µ ( x ) denotes the EPA parton distribution function in Eq. (A.10) with
$$q _ { \min } ^ { 2 } = - \frac { 1 } { 1 - x } \left ( p _ { \text{T} } ^ { * \, 2 } + m _ { \mu } ^ { 2 } x ^ { 2 } \right ) \quad \text{and} \quad q _ { \max } ^ { 2 } = - \frac { 1 } { 1 - x } \left ( \left ( p _ { \text{T} } ^ { ( \text{cut} ) } \right ) ^ { 2 } + m _ { \mu } ^ { 2 } x ^ { 2 } \right ), \quad \text{(B.)}$$
and the function f p (cut) T , p ∗ T γ/µ ( x ) ∣ ∣ ∣ m 2 µ =0 denotes the analogous expression with m µ → 0.
Assuming m 2 µ ≪ ( p (cut) T ) 2 ≪ p ∗ 2 T , the difference of these functions is
$$& \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \julia \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \lq \\ & \quad f _ { \gamma / \mu } ^ { p _ { T } ^ { ( \text{cut)} }, p _ { T } ^ { * } } ( x ) - f _ { \gamma / \mu } ^ { p _ { T } ^ { ( \text{cut)} }, p _ { T } ^ { * } } ( x ) \Big | _ { m _ { \mu } ^ { 2 } \rho _ { \mu } ^ { 2 } } \left ( \frac { 1 - x } { m _ { \mu } ^ { 2 } x ^ { 2 } + p _ { T } ^ { * } } - \frac { 1 - x } { m _ { \mu } ^ { 2 } x ^ { 2 } + ( p _ { T } ^ { ( \text{cut)} } ) ^ { 2 } } \right ) + \frac { 1 + ( 1 - x ) ^ { 2 } } { x } \log \frac { 1 + m _ { \mu } ^ { 2 } x ^ { 2 } / p _ { T } ^ { * } } { 1 + m _ { \mu } ^ { 2 } x ^ { 2 } / \Big ( p _ { T } ^ { ( \text{cut)} } ) ^ { 2 } } \right ) ^ { 2 } \right ] \\ & \simeq - \frac { m _ { \mu } ^ { 2 } } { \Big ( p _ { T } ^ { ( \text{cut)} ) ^ { 2 } } \frac { \alpha } { 2 \pi } x ( 2 - x ) ^ { 2 }, } \\ & \quad \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \ rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \rho \\ \end{matrix}$$
and therefore the error size is controlled by m / p 2 µ ( (cut) T ) 2 . Furthermore, we observe that Eq. (B.4) is not singular at x = 0, and loses the logarithmic factor present in f p (cut) T γ/µ ( x ). This indicates that Eq. (B.2) has two fewer logarithmic factors compared with σ ∣ ∣ p T ≥ p (cut) T . Noting also that the infrared cutoff for σ ∣ ∣ p T ≥ p (cut) T is p (cut) T , rather than m µ , we hence estimate the relative uncertainty by
$$\frac { \Delta \sigma _ { \text{MG} } \Big | _ { p _ { \text{T} } \geq p _ { \text{T} } ^ { ( \text{cut} ) } } } { \sigma \Big | _ { p _ { \text{T} } \geq p _ { \text{T} } ^ { ( \text{cut} ) } } } \sim \frac { m _ { \mu } ^ { 2 } } { \left ( p _ { \text{T} } ^ { ( \text{cut} ) } \right ) ^ { 2 } } \left [ \log \frac { s } { \left ( p _ { \text{T} } ^ { ( \text{cut} ) } \right ) ^ { 2 } } \log \frac { s } { s _ { \min } } - \frac { 2 } { 3 } \left ( \log \frac { s } { s _ { \min } } \right ) ^ { 2 } \right ] ^ { - 1 }.$$
## C Semi-automatic MadGraph implementation of p (cut) T calculation
As previously mentioned, we also implemented a semi-automatic calculation of the p (cut) T scheme for convenience. Here, semi-automatic means that both the low- and highp T cross sections can be calculated in MadGraph directly; however, the two parts still need to be summed by the user. In particular, we implement the calculation of the lowp T cross section using EPA, since the highp T part can already be computed directly. In this appendix, we therefore discuss how the calculation is implemented, how to use it, and its accuracy.
First, we briefly mention how MadGraph calculates EPA, or IWW, via the iww setting in the run card. With this setting, MadGraph uses the parton distribution function formula of Eq. (A.10) with q 2 max = -m x / 2 ℓ 2 (1 -x ), as given in Eq. (A.12); we also note here that the lepton mass in q 2 max is hard-coded, and specified through the collider type set in the run card of the respective run. However, q 2 min is not given by a fixed expression, but is instead provided to the parton distribution function as external input, together with the momentum fraction x . In particular, q 2 min takes on the role of (squared) factorization scale, which is set either by a fixed scale for all events or a dynamical scale determined on an event-by-event basis, depending on the user specification in the run card. This is because the factorization scale is the largest scale included in the parton distribution function description, whose square is precisely the maximum absolute value of the photon virtuality, ∣ ∣ q 2 min ∣ ∣ . Thus, based on the dynamical scale choice specified by the user, q 2 min is calculated by MadGraph for each event, and then passed on to the IWW parton distribution function. For instance, the setting 4 sets the dynamical (factorization) scale to the partonic center-of-mass energy, which is a common choice, and thus ∣ ∣ q 2 min ∣ ∣ = xs . Note that this is calculated using the
four-momenta of the incoming partons of the respective event; and if applicable, x may be a product of momentum fractions of the incoming partons.
Since MadGraph supports user-defined dynamical scales, we implement the parton distribution function of Eq. (3.3) through such a custom dynamical scale, which can then be imported to MadGraph and used for the lowp T , EPA calculation. The implementation is partly based on the original MadGraph code, and works in the following way: First, we import the collider information, in particular the beam energies and beam types. For this implementation, the beams are restricted to electrons, muons, and their respective anti-particles. Second, we import the kinematical information of the respective parton event and define the quantities necessary for the calculation. Therein, the value of p (cut) T is hard-coded, and thus needs to be changed by hand depending on which value is required for the process of interest. Third, we calculate and set the pertinent variables from the kinematical data. In particular, we set the lepton mass based on the information from the run card, and then calculate the momentum fraction x using
$$x = \frac { \hat { s } } { s } + \mathcal { O } \left ( \frac { m _ { \text{beam} } ^ { 2 } } { s } \right ) = \frac { \left ( p _ { \text{parton} } 1 + p _ { \text{parton} } 2 \right ) ^ { 2 } } { \left ( E _ { \text{beam} } 1 + E _ { \text{beam} } 2 \right ) ^ { 2 } } + \mathcal { O } \left ( \frac { m _ { \text{beam} } ^ { 2 } } { s } \right ), \quad \text{(C.1)}$$
where √ s is the center-of-mass energy of the collider, √ ˆ that of s the partonic process, m beam1 2 , are the masses of the beam particles set in the run card, p parton 1 2 , are the fourmomenta of the incoming partons, and E beam1 2 , are the respective beam energies. Here, we used that ˆ is determined by the incoming partons' four-momenta and is equal to the s product xs , up to corrections of O ( m 2 beam1 2 , /s ). Lastly, we calculate the dynamical scale via Eq. (A.14) as
$$( \text{dynamical scale} ) = \sqrt { | q _ { \min } ^ { 2 } | } = \sqrt { \frac { 1 } { 1 - x } \left ( \left ( p _ { \text{T} } ^ { ( \text{cut} ) } \right ) ^ { 2 } + m _ { \ell } ^ { 2 } x ^ { 2 } \right ) } \,, \quad \text{(C.2)}$$
and return the result, which will then be used in the iww parton distribution function.
To use this implementation in practice, the following steps are necessary. First, save the code as .f (Fortran) text file on your machine, and copy the file path. Second, adjust the p (cut) T value in GeV according your process of interest and save the changes; the default setting is the geometric mean of the muon and Z boson mass, √ m m µ Z ≃ 3 10 GeV, since . this was the pertinent value for our considerations. The corresponding variable in the file is denoted as pt\_cut\_iww and marked by a box around it for ease of use. Third, run MadGraph as usual, set the photon-emitting beam as ± 3 for e ∓ or ± 4 for µ ∓ , and the parton distribution function for the photon to iww . Fourth, set the dynamical\_scale\_choice parameter to 0 , which means that a custom dynamical scale is to be used. Note, in particular, that no fixed factorization scale should be set. Lastly, set the parameter custom\_fcts to the file path of the .f file containing the code to calculate √∣ ∣ q 2 min ∣ ∣ . After this, the run can be continued in the usual manner.
Note that to obtain the correct lowp T cross section for the case of identical beam particles, the obtained result needs to be multiplied by a factor of two, as is also the case for a manual convolution.
In terms of accuracy, the results thereby obtained by the MadGraph implementation of the lowp T cross section are consistently about 5% smaller on average, when compared with the manual calculation for our Higgs production process at center-of-mass energies up to 30 TeV. The deviation is a bit larger for the lower center-of-mass energies, and a bit smaller for the higher ones, with a respective O (1)% change in both directions. Nevertheless, we observe an approximate plateau for similar p (cut) T values as in the manual calculation, irrespective of beam polarizations and energies. Since the size of the deviation of the cross section is largely independent of beam polarizations and center-of-mass energies, we assume that it is a systematic error. Numerically, it can be mitigated by adjusting the scalefact parameter in the run card to the value ∼ 1 3, . which modifies the dynamical scale as (new dynamical scale) = scalefact × (old dynamical scale) . The results obtained from this modification are within about ± 0 4% of the manual calculation, across center-of-. mass energies and polarizations.
Finally, note that due to the calculation of x as ˆ s/s , and since the dynamical scale is calculated based on Eq. (A.14) specifically for the photon, we recommend using partonic processes where a parton distribution function is only used for the photon.
## References
- [1] D. Buttazzo, R. Franceschini and A. Wulzer, Two Paths Towards Precision at a Very High Energy Lepton Collider , JHEP 05 (2021) 219 [ 2012.11555 ].
- [2] H. Al Ali et al., The muon Smasher's guide , Rept. Prog. Phys. 85 (2022) 084201 [ 2103.14043 ].
- [3] K. M. Black et al., Muon Collider Forum report , JINST 19 (2024) T02015 [ 2209.01318 ].
- [4] K. Nagamine, Y. Miyake, K. Shimomura, P. Birrer, J. P. Marangos, M. Iwasaki et al., Ultraslow Positive-Muon Generation by Laser Ionization of Thermal Muonium from Hot Tungsten at Primary Proton Beam , Phys. Rev. Lett. 74 (1995) 4811.
- [5] Y. Hamada, R. Kitano, R. Matsudo, H. Takaura and M. Yoshida, µ TRISTAN PTEP , 2022 (2022) 053B02 [ 2201.06664 ].
- [6] M. Abe et al., A New Approach for Measuring the Muon Anomalous Magnetic Moment and Electric Dipole Moment , PTEP 2019 (2019) 053C02 [ 1901.03047 ].
- [7] ILC collaboration, The International Linear Collider Technical Design Report - Volume 2: Physics , 1306.6352 .
- [8] J. Alwall, R. Frederix, S. Frixione, V. Hirschi, F. Maltoni, O. Mattelaer et al., The automated computation of tree-level and next-to-leading order differential cross sections, and their matching to parton shower simulations , JHEP 07 (2014) 079 [ 1405.0301 ].
- [9] C. F. v. Weizs¨cker, a Ausstrahlung bei st¨ßen sehr schneller elektronen o , Zeitschrift f¨r Physik u 88 (1934) 612.
- [10] E. J. Williams, Correlation of certain collision problems with radiation theory , Kong. Dan. Vid. Sel. Mat. Fys. Med. 13N4 (1935) 1.
- [11] S. Dawson, The Effective W Approximation , Nucl. Phys. B 249 (1985) 42.
- [12] G. L. Kane, W. W. Repko and W. B. Rolnick, The Effective W ± , Z 0 Approximation for High-Energy Collisions , Phys. Lett. B 148 (1984) 367.
- [13] J. Chen, T. Han and B. Tweedie, Electroweak Splitting Functions and High Energy Showering , JHEP 11 (2017) 093 [ 1611.00788 ].
- [14] K. Hagiwara, I. Watanabe and P. Zerwas, Higgs boson production in e γ collisions , Physics Letters B 278 (1992) 187.
- [15] R. N. Cahn and S. Dawson, Production of Very Massive Higgs Bosons , Phys. Lett. B 136 (1984) 196.
- [16] R. N. Cahn, Production of Heavy Higgs Bosons: Comparisons of Exact and Approximate Results , Nucl. Phys. B 255 (1985) 341.
- [17] P. Ciafaloni and D. Comelli, Electroweak evolution equations , JHEP 11 (2005) 022 [ hep-ph/0505047 ].
- [18] C. W. Bauer, N. Ferland and B. R. Webber, Standard Model Parton Distributions at Very High Energies , JHEP 08 (2017) 036 [ 1703.08562 ].
- [19] S. Frixione, M. L. Mangano, P. Nason and G. Ridolfi, Improving the Weizsacker-Williams approximation in electron - proton collisions , Phys. Lett. B 319 (1993) 339 [ hep-ph/9310350 ].
- [20] V. Hirschi and O. Mattelaer, Automated event generation for loop-induced processes , JHEP 10 (2015) 146 [ 1507.00020 ].
- [21] R. B. Curtis, Meson production by electrons , Phys. Rev. 104 (1956) 211.
- [22] R. H. Dalitz and D. R. Yennie, Pion production in electron-proton collisions , Phys. Rev. 105 (1957) 1598.
- [23] S. J. Brodsky, T. Kinoshita and H. Terazawa, Dominant colliding beam cross-sections at high-energies , Phys. Rev. Lett. 25 (1970) 972.
- [24] N. Arteaga-Romero, A. Jaccarini, P. Kessler and J. Parisi, Photon-photon collisions, a new area of experimental investigation in high-energy physics , Phys. Rev. D 3 (1971) 1569.
- [25] R. Ruiz, A. Costantini, F. Maltoni and O. Mattelaer, The Effective Vector Boson Approximation in high-energy muon collisions , JHEP 06 (2022) 114 [ 2111.02442 ].
- [26] M. Casarsa, D. Lucchesi and L. Sestini, Experimentation at a muon collider , 2311.03280 .
- [27] N. V. Mokhov, Y. I. Alexahin, V. V. Kashikhin, S. I. Striganov and A. V. Zlobin, Muon Collider Interaction Region and Machine-Detector Interface Design , Conf. Proc. C 110328 (2011) 82 [ 1202.3979 ].
- [28] N. V. Mokhov and S. I. Striganov, Detector Background at Muon Colliders , Phys. Procedia 37 (2012) 2015 [ 1204.6721 ]. | 10.1103/PhysRevD.110.113011 | [
"Yu Hamada",
"Ryuichiro Kitano",
"Ryutaro Matsudo",
"Shohei Okawa",
"Ryoto Takai",
"Hiromasa Takaura",
"Lukas Treuer"
] | 2024-08-02T07:41:03+00:00 | 2025-04-11T04:13:02+00:00 | [
"hep-ph"
] | Higgs boson production at $μ^+ μ^+$ colliders | We study Higgs boson production at $\mu^+ \mu^+$ colliders at high energy.
Since both initial-state particles are positively charged, there is no $W$
boson fusion at the leading order, as it requires a $W^+ W^-$ pair. However, we
find that the cross section of the higher-order, $\gamma$- and $Z$-mediated $W$
boson fusion process is large at high center-of-mass energies $\sqrt s$,
growing as $(\log s)^3$. This is in contrast to the $\log s$ behavior of the
leading-order $W$ boson fusion. Thus, even though it is a higher-order process,
the rate of Higgs boson production for 10 TeV energies at $\mu^+ \mu^+$
colliders with polarized beams can be as high as about half of the one at
$\mu^+ \mu^-$ colliders, assuming the same integrated luminosity. To calculate
the cross section of this process accurately, we carefully treat the collinear
emission of the photon in the intermediate state. The thereby obtained large
cross section furthermore shows the significance of Higgs production with an
extra $W$ boson in the final state also at $\mu^+ \mu^-$ and $e^+ e^-$
colliders. |
2408.01069v1 | ## Modelling the three-dimensional, diagnostic anisotropy field of an ice rise
A. Clara J. Henry 1, 2, * , Carlos Mart´ ın , and Reinhard Drews 3 2
1 Max Planck Institute for Meteorology, Hamburg, Germany 2 Department of Geosciences, University of T¨bingen, T¨bingen, u u Germany
3 British Antarctic Survey, Natural Environmental Research Council, Cambridge, UK
* Now at: Department of Mathematics, Stockholm University, Sweden
## Abstract
Polar ice develops anisotropic crystal orientation fabrics under deformation, yet ice is most often modelled as an isotropic fluid. We present threedimensional simulations of the crystal orientation fabric of Derwael Ice Rise including the surrounding ice shelf using a crystal orientation tensor evolution equation corresponding to a fixed velocity field. We use a semiLagrangian numerical method that constrains the degree of crystal orientation evolution to solve the equations in complex flow areas. We perform four simulations based on previous studies, altering the rate of evolution of the crystal anisotropy and its dependence on a combination of the strain rate and deviatoric stress tensors. We provide a framework for comparison with radar observations of the anisotropy field, outlining areas where the assumption of one vertical eigenvector may not hold and provide resulting errors in measured eigenvalues. We recognise the areas of high horizontal divergence at the ends of the flow divide as important areas to make comparisons with observations. Here, poorly constrained model parameters result in the largest difference in fabric type. These results are important in the planning of future campaigns for gathering data to constrain model parameters and as a link between observations and computationally-efficient, simplified models of anisotropy.
## 1 Introduction
Ice varies from isotropic to anisotropic, with crystals developing a preferred orientation fabric due to ice flow dynamics. Ice crystals tend to align with the direction of an applied force and shearing of ice is enhanced along basal planes perpendicular to the applied force (Alley, 1988). The orientation of
Correspondence: [email protected]
the basal planes is described by a vector referred to as the c -axis. The snow grain orientation is initially isotropic and anisotropic ice fabric develops at a rate dependent on a variety of physical factors including the temperature, pressure and strain rate of the ice. These dependencies allow the investigation of both the steady-state and transient behaviour of ice through the analysis of observational anisotropy data and ice flow models.
Ice cores have long been used to quantify the the direction of ice crystals and the degree of anisotropy with depth (Durand et al., 2009; Montagnat et al., 2014; Weikusat et al., 2017). However, the lack of horizontal spatial information hinders the study of the relationship between ice flow and anisotropy. Apart from ice cores sites, anisotropic information is sparse and relies on geophysical methods such as seismics, both active (Diez et al., 2014; Brisbourne et al., 2019) and passive (Smith et al., 2017; Kufner et al., 2023) or radar (Fujita et al., 2006; Matsuoka et al., 2012; Drews et al., 2012). The main limitation is that, generally, seismic methods only provide depthaveraged anisotropy and radar only provide anisotropy information in the horizontal plane, perpendicular to the direction of wave propagation. Recent advances in phase coherent radar systems, and data processing for use in inferring ice anisotropy have resulted in an increase in the acquisition of observational fabric data (Dall, 2010; Young et al., 2021a,b; Jordan et al., 2022; Ershadi et al., 2022). These surveys provide the spatial variability of fabric in more extensive areas and aid understanding of the relation between ice anisotropy and ice flow. Prior to this, the lack of observational data to compare with and constrain models has long hindered the progression of ice fabric modelling.
Although we concentrate only on the coupling of the anisotropy field to the velocity and stress fields in the presented study, we note that advances in a full coupling of crystal orientation tensor evolution with viscosity are ongoing with challenges remaining regarding numerical instability (Gerber et al., 2023). Several modelling studies investigating the effects of an anisotropic rheology on ice flow dynamics at ice divides in two dimensions (Mart´ ın et al., 2009; Mart´ ın and Gudmundsson, 2012; Lilien et al., 2023) and in ice streams (Gerber et al., 2023; Richards et al., 2023) have shown the importance of including anisotropy evolution in ice flow models. In idealised, two-dimensional simulations, Richards et al. (2022) investigate the influence of the strain-rate and spin on the fabric type. Building on the work of Thorsteinsson et al. (2003), Gillet-Chaulet et al. (2006), and Pettit et al. (2007), Rathmann et al. (2021) investigated the coupling between anisotropy and viscosity through enhancement factors which result in greater shearing perpendicular to the predominant c -axis direction in two-dimensional numerical ice-flow simulations. Using a computationally-efficient anisotropic flow model with a simplified representation of anisotropy coupled to the viscosity via enhancement factors, McCormack et al. (2022) studied the effect of anisotropy on larger-scale three-dimensional models.
The coupling of anisotropy evolution in ice flow models is not without complication due to challenges with numerical stability, the parameter choice within the anisotropy evolution equation, and the coupling with viscosity in the Glen's flow law equation. Furthermore, because an isotropic assumption
has traditionally been employed in ice sheet models, model parameters have been optimised to fit isotropic rather than anisotropic ice flow dynamics. For these reasons, a thorough investigation of each step in the process of modelling ice anisotropy is needed.
In this paper, we present the first model of the three-dimensional anisotropy field of an ice rise using the finite element model Elmer/Ice (Gagliardini et al., 2013) across 100 partitions and applied to Derwael Ice Rise. We investigate the dependence of the anisotropy field on the strain rate and deviatoric stress fields without coupling with the viscosity and without recrystallisation terms, which allows analysis in the absence of the additional feedback complexity. Our simulations provide novel ice fabric predictions for a number of three-dimensional ice-flow settings including areas of verticalshear-dominated flank flow, grounding zones and shear zones. We highlight areas where geophysical measurements of ice-fabric types would be most informative to constrain relevant model parameters. Furthermore, the direction of the c -axis across the ice rise is investigated to identify regions where a vertical c -axis assumption is valid in radar measurements of anisotropy, providing a novel method for determining the error in eigenvalues with such an assumption.
## 1.1 Motivation
Our study is motivated by a lack of progress in large-scale ice-sheet models considering crystal orientation fabric. This is despite observations of strong crystal orientation fabric in polar ice (Alley, 1988), knowledge of how anisotropic polar ice is (Duval et al., 1983) and field evidence of the effect crystal orientation fabric has on ice flow (Gerber et al., 2023). After the introduction of the crystal orientation tensor (G¨dert, 2003), the flow-induced o crystal orientation fabric evolution can be considered by large-scale ice-sheet models (Gagliardini et al., 2013).
We believe that the main reasons for the lack of progress are: (a) the numerical implementation of crystal orientation fabric evolution is challenging (Seddik et al., 2011), (b) the interpretation of model output and comparison with non-comprehensive observations is complex (Jordan et al., 2022), and (c) essential model parameters within the theory are not yet constrained by observations (Ma et al., 2010).
Numerically, the main issue is that numerical dispersion tends to break down the orientation tensor properties. Here, we present a numericallyrobust, three-dimensiontal model, discuss a framework to interpret model output for comparison with observations, and highlight areas where observations could better constrain model parameters.
## 1.2 Derwael Ice Rise (DIR)
Ice rises are an ideal study location for understanding ice-flow processes, because transitions between different flow regimes occur over comparatively short spatial scales. Furthermore, ice rises regulate flow from the Antarctic Ice Sheet towards the open ocean, controlling ice shelf velocities and the con-
Figure 1: In (a), an overview is shown of Derwael Ice Rise, with the surrounding ice shelves and the grounding line (Jezek et al., 2013; Rignot and Scheuchl., 2017) The velocity field is shown in colour. In (b), the simulated upper surface velocity field of Derwael Ice Rise is shown, based on simulations in Henry et al. (2023). The boxes A and B show the areas referred to as the areas of high horizontal divergence at the tails of the flow divide.
tinental grounding line position (Favier and Pattyn, 2015; Schannwell et al., 2019, 2020; Henry et al., 2022). Formation, evolution and disintegration of ice rises occur over glacial-interglacial timescales, meaning that remnants of ice properties such as temperature and anisotropy from previous flow regimes may become stored in the slow flowing ice of an ice rise.
Ice rises typically have clear ice divides transitioning into a flank-flow regime on all sides with little to no basal sliding (Matsuoka et al., 2015). The grounding line is typically located a few tens of kilometres away from the divide, and the flow field transitions to the surrounding ice shelves through narrow shear zones with large horizontal shear strain rates. We chose Derwael Ice Rise (DIR, Fig. 1) in East Antarctica as our study site for two reasons. First, we can rely on a predicted three-dimensional steady-state velocity field developed in a previous study (Henry et al., 2023). This velocity field is based on a transient, thermomechanically-coupled full Stokes model with an isotropic rheology. The model was forced with an observationallyconstrained surface mass balance field and predictions of the model output were validated with extensive radar observations which are available for this Ice Rise (Koch et al., 2023). Second, previous studies suggest that DIR is likely close to steady state (Callens et al., 2016) possibly with a minor amount of thinning (Drews et al., 2015). This justifies the steady-state assumption applied here. DIR is a marine-based ice rise and has a flow divide in the form of a curved arc extended south-west to north-east. The maximum ice thickness is roughly 630 m and flow velocities in the flank are typically slower than 10 m a -1 .
## 2 Methods
The simulations use output from Henry et al. (2023) as a starting point in which the finite element model Elmer/Ice (Gagliardini et al., 2013) was applied to DIR. Most importantly, we use the predicted three-dimensional, steady-state velocity field to make predictions of the anisotropic ice properties resulting from a one-way coupling with the crystal orientation evolution equations detailed below.
## 2.1 Governing equations
The equations of motion for Stokes flow are written as
$$\nabla \cdot ( \tau - P \mathbf I ) + \rho _ { i } \mathbf g = 0,$$
where τ is the deviatoric stress tensor, P is the pressure, I is the identity matrix, ρ i is the ice density and g = g ˆ e z is the gravitational acceleration. The ice is subject to an incompressibility condition,
$$\nabla \cdot \mathbf u = 0,$$
and the Glen's flow law,
$$\tau = 2 \eta \dot { \varepsilon },$$
which describes the nonlinear dependence between the strain rate tensor, ˙, ε and the deviatoric stress tensor. The effective viscosity, η , is
$$\eta = \frac { 1 } { 2 } E A ( T ^ { \prime } ) ^ { - 1 / n } \dot { \varepsilon } _ { e } ^ { ( 1 - n ) / n }.$$
where E is an enhancement factor which is spatially and temporally constant here, A T ( ′ ) is the ice fluidity which is dependent on the ice temperature relative to the pressure melting point, T ′ , which is solved using a temperature evolution equation as described in Henry et al. (2023). Here, n is the Glen's flow law exponent, and ˙ ε e = √ tr ˙ ε 2 / 2 is the effective strain rate.
Keeping the velocity and stress fields constant in time, a semi-Lagrangian anisotropy evolution equation is coupled and simulations are performed for 20000 years. To initialise the anisotropy simulation, the simulation named n3E0.5dsdt50 in Henry et al. (2023) is used. The simulation time of 20000 years was deemed appropriate given that in Henry et al. (2023), it was predicted that the ice in DIR is roughly 8000 years old at a depth of 95 %.
The anisotropy of ice is described by the second and fourth order orientation tensors, a (2) and a (4) , respectively defined by
$$a _ { i j } ^ { ( 2 ) } = \langle c _ { i } c _ { j } \rangle$$
and
$$a _ { i j k l } ^ { ( 4 ) } = \langle c _ { i } c _ { j } c _ { k } c _ { l } \rangle,$$
where c is the c -axis unit vector and the operator ⟨⟩ denotes the average over all the grains that compose the ice polycrystal.
The representation of the anisotropy field using a crystal orientation tensor,
$$\mathbf a ^ { ( 2 ) } = \begin{pmatrix} a _ { x x } ^ { ( 2 ) } & a _ { x y } ^ { ( 2 ) } & a _ { x z } ^ { ( 2 ) } \\ a _ { y x } ^ { ( 2 ) } & a _ { y y } ^ { ( 2 ) } & a _ { y z } ^ { ( 2 ) } \\ a _ { z x } ^ { ( 2 ) } & a _ { z y } ^ { ( 2 ) } & a _ { z z } ^ { ( 2 ) } \end{pmatrix},$$
describing the c -axis distribution is ideal for comparison with ice core or radar observations in that an equivalent crystal orientation tensor can be constructed from observational data by determining the cross products of cosines of each c -axis and summing up such that
$$\mathbf a ^ { ( 2 ) } = \begin{pmatrix} a _ { x x } ^ { ( 2 ) } & a _ { x y } ^ { ( 2 ) } & a _ { x z } ^ { ( 2 ) } \\ a _ { y x } ^ { ( 2 ) } & a _ { y y } ^ { ( 2 ) } & a _ { y z } ^ { ( 2 ) } \\ a _ { z x } ^ { ( 2 ) } & a _ { z y } ^ { ( 2 ) } & a _ { z z } ^ { ( 2 ) } \end{pmatrix} = \frac { 1 } { N } \begin{pmatrix} \sum l _ { i } ^ { 2 } & \sum l _ { i } m _ { i } & \sum l _ { i } n _ { i } \\ \sum m _ { i } l _ { i } & \sum m _ { i } ^ { 2 } & \sum m _ { i } n _ { i } \\ \sum n _ { i } l _ { i } & \sum n _ { i } m _ { i } & \sum n _ { i } ^ { 2 } \end{pmatrix}.,$$
where N is the number of c -axes being summed over. The cosines of the c -axis vectors are defined by taking the cosine of the angle between the c -axis vector, c i , and each positive coordinate axis, ˆ e x , ˆ e y and ˆ e z , so that
$$\Psi ^ { ( 1 ) } _ { i } = \frac { c _ { i } \cdot \hat { e } _ { x } } { | c _ { i } | } \\ m _ { i } = \frac { c _ { i } \cdot \hat { e } _ { y } } { | c _ { i } | } \\ n _ { i } = \frac { c _ { i } \cdot \hat { e } _ { x } } { | c _ { i } | }. \\ \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { \Phi } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } & \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 2 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { (( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 3 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { - ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1) } _ { i + 1 } = \Phi ^ { \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1)) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } | \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1,) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } { \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 2 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ { ( 1 ) } _ { i + 1 } = \Phi ^ {$$
From the orientation tensor, a number of metrics can be calculated to investigate the degree of crystal orientation, the predominant c -axes directions and the fabric type. The eigenvalues, namely λ 1 , λ 2 and λ 3 , and the corresponding eigenvectors, v 1 , v 2 and v 3 , of the crystal orientation tensor a (2) satisfy
$$\mathbf a ^ { ( 2 ) } \mathbf v = \lambda \mathbf v$$
defining each eigenvalue by its subscript such that λ 1 ≤ λ 2 ≤ λ 3 . In the case of randomly oriented c -axes or isotropic ice, all three eigenvalues are similar in size such that λ 1 ≈ λ 2 ≈ λ 3 ≈ 1 3. / In areas where λ 3 ≥ λ 1 ≈ λ 2 , ice fabric is said to have a single maximum fabric with the majority of c -axes pointing in a single direction. Where λ 2 ≈ λ 3 ≥ λ 2 , ice is said to have a girdle fabric, with c -axes following an arc or circle.
The evolution of the second-order orientation tensor can be described by
$$\left ( \frac { \partial } { \partial t } + \mathfrak { u } \cdot \mathbf \nabla \right ) \mathbf a ^ { ( 2 ) } & = \mathbf W \mathbf a ^ { ( 2 ) } - \mathbf a ^ { ( 2 ) } \mathbf W \\ & \quad - \iota ( \mathbf C \mathbf a ^ { ( 2 ) } + \mathbf a ^ { ( 2 ) } \mathbf C - 2 \mathbf a ^ { ( 4 ) } \colon \mathbf C ),$$
where the tensor C is defined by
$$\mathbf C = ( 1 - \alpha ) \dot { \varepsilon } + \alpha \frac { 1 } { 2 \eta _ { 0 } } \tau,$$
and α is the so-called interaction parameter, which describes the relative influence of the strain rate and stress tensors. The parameter ι determines the rate at which the crystal orientation tensor is influences by the weighted combination of strain-rate and deviatoric stress tensors. The last term, α 1 2 η 0 τ , in Eq. (10) is represented as αk Aτ s n -1 e τ in Gagliardini et al. (2013), but the simulation calculations are equivalent. The spin of the ice is denoted by the spin tensor, W , and
$$\eta _ { 0 } = \frac { 1 } { 2 } ( E A ) ^ { - 1 / n } \left ( \frac { 1 } { 2 } \text{tr} ( \dot { \varepsilon } ^ { 2 } ) ^ { \frac { 1 - n } { 2 n } } \right ).$$
Early work recognised the influence of the cumulative strain and stress on ice crystal c -axis orientation (Alley, 1988), which led to the development of a crystal orientation tensor evolution equation (Eq. (9)) dependent on the velocity gradient through the spin and strain rate tensors, and the deviatoric stress tensor (Gillet-Chaulet et al., 2006). Although it is known that the velocity and stress fields have an influence on the anisotropy field of ice, it remains unclear what the relative influence is. The anisotropy evolution equation (Eq. (9)) is made up of various terms, with the spin tensor, W , acting to rotate the crystal orientation tensor to follow the spin of the ice. Acting opposite to the spin tensor is the tensor, C , which is a weighted combination of the strain rate tensor, ˙ ε , and the deviatoric stress tensor, τ . This combination comes from the fact that the behaviour of macroscopic materials can be limited by two extreme approximations: uniform stress, where the stress in the crystals is assumed to be identical to the macroscopic stress, and Taylor or uniform strain rate, where the strain rate in the crystals is assumed to be identical to the macroscopic strain rate (Gagliardini et al., 2009). The choice of α and ι in previous studies have been motivated by assumptions of the relative influence of stress and strain rate on crystal orientation evolution. The last term in the equation describes the influence of the higher-order crystal orientation tensor, a (4) on the 3 × 3 crystal orientation tensor, a (2) . In reality, a (2) is dependent on further, higher-order tensors, but it has been shown that this dependence is negligible (Chung and Kwon, 2002).
To solve Eq. (9) we also require a relation between a (2) and a (4) , a closure approximation, and we use an invariant-based optimal fitting closure approximation (Gillet-Chaulet et al., 2006). The distribution of c -axes can be described by tensors of ever-increasing order, but a compromise is found by using the closure approximation in order to reduce computation time. The effect of the choice of α and ι on the anisotropy field is investigated using combinations of parameters from previous literature presented in Table 1.
The value of α determines the relative influence of the strain rate and deviatoric stress tensors on anisotropy evolution. For example, a value of α = 0, means that there is dependence on the strain rate tensor but no dependence on the deviatoric stress. Alternatively, a value of α = 1 provides dependence on the deviatoric stress tensor but no dependence on the strain rate tensor. The parameter ι adjusts the rate at which the anisotropy field develops in response to the weighted combination of the strain rate and deviatoric stress fields and takes a value between ι = 0 and ι = 1.
Table 1: Parameter combinations
| | α | ι | Source |
|-----|--------|-------|---------------------------------|
| (a) | 0 | 1 | Mart´n ı et al. (2009) |
| (b) | 0 | 0 . 6 | Seddik et al. (2011) |
| (c) | 1 | 1 | Mart´n ı and Gudmundsson (2012) |
| (d) | 0 . 06 | 1 | Gagliardini et al. (2013) |
Initially, all ice in the model domain is isotropic, described by the tensor a (2) = 1 3 I , where I is the 3 × 3 identity matrix. During transient simulation of the anisotropy field dependent on the velocity field, the upper surface is assigned an isotropic boundary conditions on all ice entering the domain due to accumulation.
The anisotropic evolution model described in Eq. (9) together with its boundary and initial conditions is solved using a semi-Lagrangian method as described in Mart´ ın et al. (2009). The determinant of a (2) gives information about the degree of crystal orientation of the fabric (Advani and Tucker, 1987). We define here the degree of crystal orientation with the scalar value,
$$d = 1 - 3 ^ { 3 } \det \left ( \mathbf a ^ { ( 2 ) } \right ).$$
The degree of crystal orientation varies from zero for isotropic ice to one for single-maximum fabric, and is independent of the frame of reference as the determinant is an invariant. We constrain Equation (9) with the condition,
$$\left ( \frac { \partial } { \partial t } + \mathfrak { u } \cdot \nabla \right ) d \geq 0,$$
meaning that ice is constrained to increase in degree of crystal orientation over time. This constraint on the degree of crystal orientation stops numerical dispersion breaking the simulation in areas with high strain rates. Our method is also straightforward to implement in large scale models that run in parallel environments.
## 3 Results
## 3.1 Analysis of simulated anisotropy field
We display predicted eigenvalues for the α = 0, ι = 1 simulation at an elevation of z = 0 which encompasses an ice-depth range of close to 0 m in the ice shelf to over 300 m at the ice rise flow divide where stresses are dominated by vertical compression and lateral extension (Fig. 2). The main characteristic, which is evident in all simulations, is that the ice fabric evolves from an isotropic material at the surface and under deformation, develops into an anisotropic fabric varying from a single maximum to a girdle fabric (Fig. 3). In the ice rise interior, the largest eigenvalue, λ 3 , is much larger than λ 1 and λ 2 , particularly at and surrounding the flow divide (Figs. 1b and 2). This results in greater fabric anisotropy here. Further south in the ice rise, where ice flow is hindered by the convergence of flow between the
Figure 2: The eigenvalues, λ 1 , λ 2 and λ 3 , of the crystal orientation tensor in the α = 0, ι = 1 simulation at an elevation of z = 0, corresponding to sea level. The solid lines, black in the plots showing λ 1 and λ 2 , and white in the plot showing λ 3 , are contours of depth below the upper ice surface and the dashed lines show the grounding line. The dotted line in the λ 3 figure shows where the cross-section in Fig. 3 is taken.
Figure 3: Cross-sections through the flow divide as shown in the Fig. 2 showing λ 3 , the largest eigenvalue for (a) the α = 0, ι = 1 simulation, (b) the α = 0, ι = 0 6 simulation, (c) the . α = 1, ι = 1 simulation and (d) the α = 0 06, . ι = 1 simulation. The solid lines show isochrones.
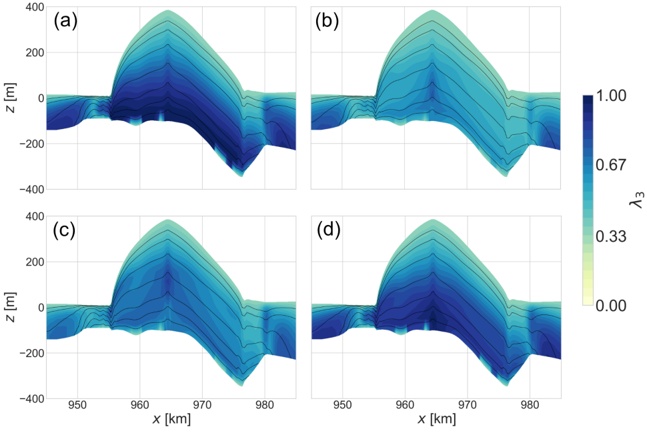
Figure 4: The ratio of the two larger eigenvalues of the 3 × 3 crystal orientation tensor at z = 0 for (a) the α = 0, ι = 1 simulation, (b) the α = 0, ι = 0 6 simulation, (c) the . α = 1, ι = 1 simulation and (d) the α = 0 06, . ι = 1 simulation. The dashes show the maximum horizontal anisotropy direction. The dashed line shows the grounding line and the solid line show contours of the depth below the upper ice surface.
ice rise and the ice shelf, differences are not as substantial. In the ice rise interior away from the grounding line, differences between the smaller two eigenvalues, λ 1 and λ 2 are mostly small, increasing slightly on the stoss side of the ice rise. The stoss side is defined as the side of the ice rise with a flow direction opposing the upstream ice shelf flow direction (Figs. 1b and 2). At the grounding zone on the stoss side of the ice rise, where horizontal convergence of flow occurs, the three eigenvalues are similar in magnitude, whereas at the transition from grounded to floating ice on the lee side of the ice rise, where flow is dominated be extension, a slightly larger difference is seen between the smaller two eigenvalues, λ 1 and λ 2 . In the ice shelves away from the grounding zone, there are differing patterns in the relative magnitude of the three eigenvalues. In the ice shelf west of the ice rise where velocities are higher than east of the ice rise and extension dominates, the largest eigenvalue is significantly larger in magnitude compared with the two smaller eigenvalues. In the ice shelf to the east of the ice rise, where extension of flow is an active process, differences in magnitude are generally much lower. The ice shelf south of the ice rise, on the stoss side, shows one eigenvalue much larger than the other two, similar to the magnitudes in the ice shelf on the western side of the ice rise.
## 3.2 Comparison of simulations with differing parameter choice
In order to compare simulation results across the four combinations of the parameters α and ι in Eq. (9) used in the previous studies stated in Table 1, we use a number of metrics to understand the fabric types evolving in the various flow regimes at Derwael Ice Rise. First, we describe the differences in relative magnitude of the eigenvalues of the crystal orientation tensor across the four simulations. If the logarithmic ratio (Woodcock, 1977), ln( λ /λ 3 2 ), is large, then the c -axes are more concentrated in a single direction. The direction of the largest horizontal crystal orientation eigenvector, v 2 ,H , shows the predominant horizontal c -axis direction.
The simulations with parameter choices of α = 0, ι = 1 (Fig. 4a) and α = 0 06, . ι = 1 (Fig. 4d) have comparable results, with a much greater ln( λ /λ 3 2 ) than predicted by the other two simulations. The simulation results differ, however, in the spatial variation of ln( λ /λ 3 2 ). The α = 0, ι = 1 simulation shows larger values of ln( λ /λ 3 2 ) at the tails of the ice rise flow divide (Boxes A and B in Fig. 1b), whereas the α = 0 06, . ι = 1 simulation shows slightly greater relative values along the flow divide. Although not negligible, the simulations with parameter choices of α = 0, ι = 0 6 (Fig. . 4b) and α = 1, ι = 1 (Fig. 4c) show much lower ratios between the largest and second largest eigenvalues, with the α = 0, ι = 0 6 simulation showing a slightly . higher value at the centre of the flow divide. In the α = 1, ι = 1 simulation, a differing pattern of horizontal eigenvectors originating at a point source at the flow divide, whereas the other simulations show alignment of the eigenvector direction along the flow divide. Of note is also the differing eigenvector directions at the tails of the flow divide, with differing patterns of vector divergence and convergence.
The two smaller eigenvalues, λ 1 and λ 2 are investigated using the metric ln( λ /λ 2 1 ) (Fig. 5). Large ratios between the two smaller eigenvalues indicates that c -axis directions for a given volume of ice are concentrated along an arc. In all simulations, there are high values of ln( λ /λ 2 1 ) at the flow divide and generally low values in the vicinity of the grounding zone on the stoss side of the ice rise, with values differing between simulations elsewhere. The α = 0, ι = 0 6 (Fig. . 5b) simulation show the lowest values overall. The simulations with parameter choices of α = 0, ι = 1 and α = 0 06, . ι = 1 show relatively similar results, with the highest eigenvalue ratio at the flow divide and in the areas of the ice rise perpendicular to the flow divide. The α = 1, ι = 1 simulation (Fig. 5c) has areas of a large ratio between λ 2 and λ 1 , much larger than any other simulation and highlights the effect of a strong dependence on the strain-rate tensor on the crystal orientation tensor evolution. Rather than having high values perpendicular to the flow divide, the highest values are along a small band following the flow divide and in the areas of high horizontal divergence at the tails of the flow divide, extending in some areas as far as the grounding line. There are no large differences between λ 2 and λ 1 in the ice shelves, with the largest values being concentrated north-west of the ice rise in all simulations.
Figure 5: The ratio of the two smaller eigenvalues of the 3 × 3 crystal orientation tensor at z = 0 for (a) the α = 0, ι = 1 simulation, (b) the α = 0, ι = 0 6 simulation, (c) the . α = 1, ι = 1 simulation and (d) the α = 0 06, . ι = 1 simulation. The dashes show the maximum horizontal anisotropy direction. The dashed line shows the grounding line and the solid line show contours of the depth below the upper ice surface.
Figure 6: The logarithm of the Woodcock k value at an elevation of z = 0 for (a) the α = 0, ι = 1 simulation, (b) the α = 0, ι = 0 6 simulation, (c) the . α = 1, ι = 1 simulation and (d) the α = 0 06, . ι = 1 simulation. The dashes show the maximum horizontal anisotropy direction. The dashed line shows the grounding line and the solid line show contours of the depth below the upper ice surface.
The Woodcock k value (Woodcock, 1977), defined as
$$k = \frac { \ln ( \lambda _ { 3 } / \lambda _ { 2 } ) } { \ln ( \lambda _ { 2 } / \lambda _ { 1 } ) },$$
provides a metric by which to investigate which areas are characterised by a single maximum fabric and which are characterised by girdle fabric. Note that k can have values between k = 0 and k = ∞ . In order to better investigate small values of k , we plot ln( k ) for each simulation in Table 1. If ln( k ) > 0, then the ice is defined as having a single maximum fabric and if ln( k ) < 0, the ice is defined as having a girdle fabric. Furthermore, if ln( k ) >> 0 and ln( λ /λ 3 2 ) >> 0, then the ice has a strong single maximum. If, on the other hand, ln( k ) << 0 and ln( λ /λ 2 1 ) >> 0, then ice has a strong girdle fabric.
In the α = 0, ι = 1 simulation, there are relatively high ln( k ) values at the tails of the flow divide (Fig. 6a), extending in some areas almost to the grounding line. Elsewhere on the ice rise, values of ln( k ) are generally close to zero. The α = 0 06, . ι = 1 simulation (Fig. 6d) shows similar results except at the north-east of the ice rise, where high values of ln( k ) are concentrated closer to the grounding line. The α = 0, ι = 0 6 simulation . (Fig. 6b) shows higher values of ln( k ) even further from the flow divide and a small area with negative ln( k ) values at the north-eastern end of the flow divide. The α = 1, ι = 1 simulation (Fig. 6c) shows, by far, the most negative values of ln( k ), concentrated at the two tails of the flow divide and
Figure 7: The angle between the eigenvector corresponding to the largest eigenvalue and the vertical direction at an elevation of z = 0 corresponding to sea level for (a) the α = 0, ι = 1 simulation, (b) the α = 0, ι = 0 6 . simulation, (c) the α = 1, ι = 1 simulation and (d) the α = 0 06, . ι = 1 simulation. The dashed line shows the grounding line and the solid lines show contours for the depth below the surface in metres.
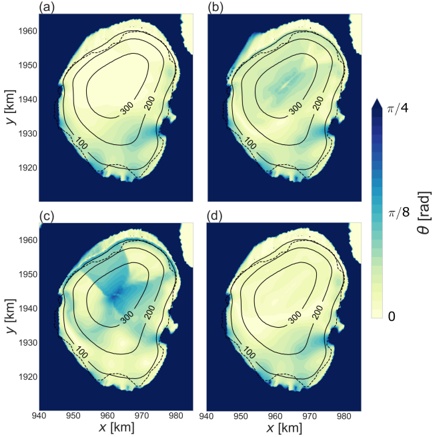
small areas with positive values of ln( k ) perpendicular to the flow divide. All four simulations show an almost-continuous band of negative values of ln( k ) at the grounding line or a small distance away from the grounding line in the ice shelf. Moving away from the grounding line, a general increase in values of ln( k ) is seen, with some exceptions.
## 3.3 Metrics for comparison with radar data
In quad-polarimetric radar processing, it is often assumed that because of the dominance of vertical compression, one eigenvector aligns with the vertical direction. In areas where this assumption holds, signal processing can be simplified (Jordan et al., 2022; Ershadi et al., 2022). Obliquely oriented fabric types can, in theory, also be detected (Matsuoka et al., 2009; Rathmann et al., 2022), but thus far this has not been done for observations which are typically only collected in a nadir-viewing geometry. Here, we present results evaluating the applicability of the assumption of one vertical eigenvector across all four simulations.
In general, the predicted tilt angle is small in the grounded area across all simulations(Fig. 7). Note that the grounded area is the area within the dashed line marking the grounding line. The angle remains small, with similar spatial patterns in the simulations with parameter choices of α = 0, ι = 1 and α = 0 06, . ι = 1 (Figs. 7a and 7d, respectively). In the α = 0, ι = 0 6 simulation (Fig. . 7b), differences between the z -direction and v 3 are
Figure 8: The percentage difference between λ 1 ,H and λ 1 at an elevation of z = 0 for (a) the α = 0, ι = 1 simulation, (b) the α = 0, ι = 0 6 simulation, . (c) the α = 1, ι = 1 simulation and (d) the α = 0 06, . ι = 1 simulation. The solid line contours show depth below surface and the dashed line is the grounding line.
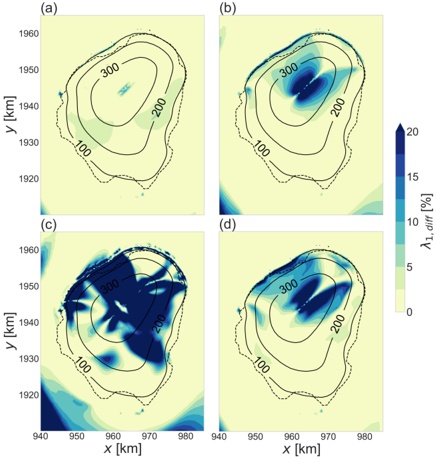
generally small, with the exception of slightly higher values on either side of the flow divide. Spatial patterns on the stoss side of the ice rise are similar to those in the above-mentioned α = 0, ι = 1 and α = 0 06, . ι = 1 simulations. The simulation with the largest tilt angles is the α = 1, ι = 1 simulation (Fig. 7c), with differences of π/ 8 to π/ 4 radians at and perpendicular to the flow divide. In all simulations, the tilt angle in the ice shelf is larger a short distance away from the grounding line, except for small, isolated areas.
We furthermore calculate the eigenvectors and eigenvalues of the horizontal crystal orientation tensor, i.e. the upper left 2 × 2 part of the 3 × 3 tensor a (2) . The reason for this is that if the 3 × 3 crystal orientation tensor has one strictly vertical eigenvector, the eigenvalues and eigenvectors of the 2 × 2 tensor correspond to the horizontal eigenvalues and eigenvectors of the 3 × 3 tensor. We denote the eigenvalues of the 2 × 2 tensor by λ 1 ,H and λ 2 ,H , and the corresponding eigenvectors by v 1 ,H and v 2 ,H , respectively. By comparing the eigenvalues of the 2 × 2, horizontal crystal orientation tensor with the eigenvalues of the 3 × 3 crystal orientation tensor, an error estimate can be found for assuming that the eigenvector corresponding to the largest eigenvalue is aligned with the z -axis.
We present percentage differences between λ 1 and λ 1 ,H (Fig. 8), as well as λ 2 and λ 2 ,H (Fig. 9). We find that if a difference exists between λ 1 and λ 1 ,H , or λ 2 and λ 2 ,H , then the 2 × 2 tensor eigenvalues always underestimate the smaller two 3 × 3 tensor eigenvalues. Furthermore, percentage differences tend to be higher for the smaller eigenvalues λ 1 and λ 1 ,H than for λ 2 and
λ 2 ,H , but exceptions to this are seen. The α = 0, ι = 1 simulation shows a negligible percentage difference between λ 1 and λ 1 ,H (Fig. 8a) and small percentage differences for λ 2 and λ 2 ,H of up to 10 % (Fig. 9a). A similar spatial distribution of percentage differences appears for λ 2 and λ 2 ,H in the α = 0 06, . ι = 1 simulation (Fig. 9d). Most notable is the percentage difference between λ 1 and λ 1 ,H in the α = 1, ι = 1 simulation (Fig. 8c), where values are above 20 % in a large area at and perpendicular to the flow divide. In this simulation ( α = 1, ι = 1), percentage differences between λ 2 and λ 2 ,H (Figs. 9c) are high compared to other simulations, but the high values localised at and in the area perpendicular to the flow divide occupy a smaller area than the percentage differences between λ 1 and λ 1 ,H (Fig. 8c). In the α = 0, ι = 0 6 and the . α = 0 06, . ι = 1 simulations, percentage differences between λ 1 and λ 1 ,H are negligible across a large portion of the ice rise, in particular on the stoss side (Figs. 8b,d). The highest percentage differences are either side of the flow divide with values up to and over 20 %, reducing further away from the flow divide. Percentage differences between λ 2 and λ 2 ,H in the α = 0, ι = 0 6 simulation are negligible except for small . areas at the flow divide (Fig. 9b). As the assumption that the eigenvector corresponding with the largest eigenvalue is made for grounded ice, we do not analyse the differences between eigenvalues of the 2 × 2 and the 3 × 3 crystal orientation tensors in the ice shelves.
Next, we present results for the difference between the eigenvalues, λ 2 ,H -λ 1 ,H , of the 2 × 2 horizontal part of the 3 × 3 crystal orientation tensor. This metric corresponds directly with results from radar data where a vertical eigenvector assumption is made (Fig. 10). The α = 0, ι = 1 (Fig. 10a) and the α = 0 06, . ι = 1 (Fig. 10d) simulations show similar results both spatially and in terms of the magnitude of differences, with differences staying below 0 1 at and in the vicinity of the flow divide. . The largest differences in the eigenvalues occur on the eastern side of the ice rise, close to the grounding line as well as in small isolated areas elsewhere on the stoss side of the ice rise in the vicinity of the grounding line. Although eigenvalue differences differ substantially in magnitude between the two simulations, the α = 0, ι = 0 6 . (Fig. 10b) and the α = 1, ι = 1 (Fig. 10c) simulations show similar spatial patterns. In the α = 0, ι = 0 6 simulation (Fig. 10b), the highest differences . between λ 2 ,H and λ 1 ,H area seen at the tails of the flow divide, extending towards the grounding line north-east of the ice rise and in isolated areas on the east of the ice rise. Elsewhere, differences between λ 2 ,H and λ 1 ,H remain below 0 1. . The α = 1, ι = 1 simulation (Fig. 10c) shows large differences between λ 2 ,H and λ 1 ,H of over 0 3 at the flow divide and extending to the . grounding line, particularly on the lee side of the ice rise. As in all other simulations, differences of over 0 3 are seen on the eastern side of the ice rise . close to the grounding line.
Finally, we investigate the dependence of the anisotropy field on the strain rate field, and in particular the relationship between the largest horizontal anisotropy direction and the largest horizontal strain rate direction. Given that we expect c -axes to point perpendicular to the direction of maximum stretching, we calculate the largest horizontal strain rate direction by calculating the eigenvalues and eigenvectors of the upper left 2 × 2 tensor
Figure 9: The percentage difference between λ 2 ,H and λ 2 at an elevation of z = 0 for (a) the α = 0, ι = 1 simulation, (b) the α = 0, ι = 0 6 simulation, . (c) the α = 1, ι = 1 simulation and (d) the α = 0 06, . ι = 1 simulation. The solid line contours show depth below surface and the dashed line is the grounding line.
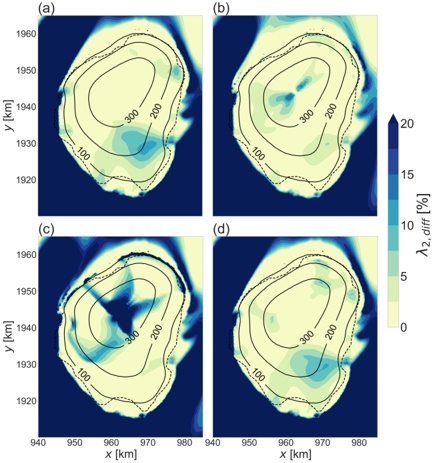
of the 3 × 3 strain rate tensor, ˙. ε We denote the eigenvectors of the horizontal strain rate tensor by w 1 ,H and w 2 ,H , where w 1 ,H ≤ w 2 ,H . We then calculate the angle between the maximum horizontal strain rate direction, w 2 ,H , and the maximum horizontal anisotropy direction, v 2 ,H (Fig. 11). In the α = 0, ι = 1 simulation (Fig. 11a) and the α = 0 06, . ι = 1 simulation (Fig. 11d), the angle between w 2 ,H and v 2 ,H remains close to π/ 2, meaning that the two vectors are mostly close to perpendicular. Exceptions are in small areas of divergence at the two tails of the flow divide. In the α = 0, ι = 0 6 simulation (Fig. . 11b), the angle between w 2 ,H and v 2 ,H is mainly high everywhere on the ice rise except at the two tails of the flow divide where values are consistently closer to zero. Lastly, the α = 1, ι = 1 simulation (Fig. 11c) shows a large area on the stoss side of the ice rise, away from the flow divide, where w 2 ,H and v 2 ,H are mostly close to perpendicular. At the flow divide, there is a thin line where the two vectors are perpendicular and in the areas perpendicular to the flow divide, the angle between the two vectors is generally > π/ 4. This simulation shows the largest areas where the angle between w 2 ,H and v 2 ,H is close to zero from the extremes of the flow divide as far, or almost as far as the grounding line.
## 4 Discussion
We present the results of three-dimensional simulations of the full-tensor anisotropy field of Derwael Ice Rise via a coupling with the velocity and
Figure 10: The difference between the two eigenvalues of the 2 × 2 horizontal crystal orientation tensor for (a) the α = 0, ι = 1 simulation, (b) the α = 0, ι = 0 6 simulation, (c) the . α = 1, ι = 1 simulation and (d) the α = 0 06, . ι = 1 simulation. The solid lines show contours for the depth below the surface in metres and the dashed line is the grounding line.
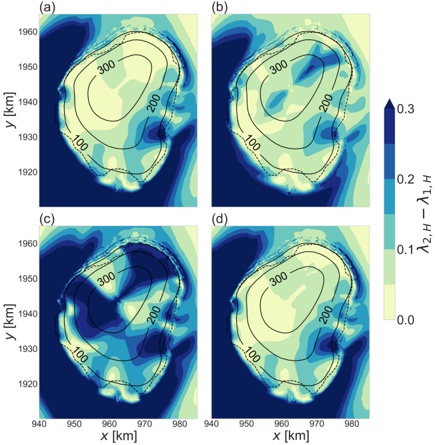
stress fields. The simulated domain includes the surrounding ice shelf, allowing analysis of the anisotropy field across the grounding zone. Based on four previous studies (Mart´ ın et al., 2009; Seddik et al., 2011; Mart´ ın and Gudmundsson, 2012; Gagliardini et al., 2013), we simulate the anisotropy field varying parameter choices controlling the relative influence of the strain rate and deviatoric stress tensors. By decomposition of the simulated crystal orientation tensor into eigenvalues and eigenvectors, our results provide a necessary step towards the comparison of observed ice fabric with threedimensional modelled results for a variety of flow regimes.
## 4.1 Dependence of the anisotropy field on the velocity and stress fields
The various flow regimes in the ice rise influence the anisotropy field in different ways, with past flow regimes of a volume of ice also having an effect on the present anisotropy, which is captured due to the semi-Lagrangian implementation of the crystal orientation tensor evolution in the simulations in this study.
Based on previous choices (Mart´ ın et al., 2009; Seddik et al., 2011; Mart´ ın and Gudmundsson, 2012; Gagliardini et al., 2013), we adjust the parameters α and ι in Eq. (9). The parameter α , taking values α ∈ [0 , 1], controls the relative influence of the strain rate and deviatoric stress tensors, with a value of α = 0 meaning that the deviatoric stress tensor is ignored and a value of α = 1 meaning that the strain rate tensor is ignored. The parameter ι ,
Figure 11: The angle between the eigenvectors corresponding to the larger horizontal crystal orientation eigenvalue and the larger horizontal strain rate eigenvalue for (a) the α = 0, ι = 1 simulation, (b) the α = 0, ι = 0 6 . simulation, (c) the α = 1, ι = 1 simulation and (d) the α = 0 06, . ι = 1 simulation.
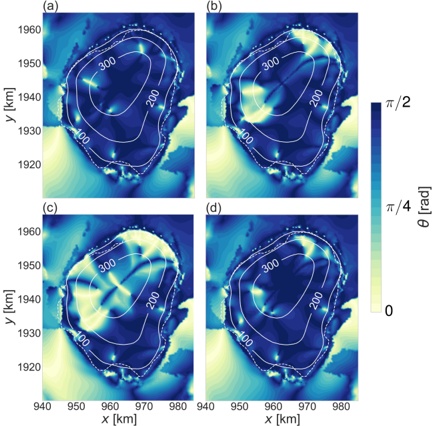
taking values of ι ∈ [0 , 1], controls the rate of change the crystal orientation tensor, a (2) , undergoes in response to the combination of the strain rate and deviatoric stress tensor. For example, for a value of ι close to zero, apart from rotational changes due to the spin tensor, the crystal orientation tensor changes minimally in response to the combination of the strain rate and deviatoric stress tensors. Because the strain rate and deviatoric stress tensor are co-dependent via Glen's flow law (Eq. (3)), differentiation between the various combinations of α and ι is not trivial. Broadly speaking, though this is not always the case, the behaviour of the anisotropy field in the α = 0, ι = 0 6 simulation shows similar results to the . α = 1, ι = 1 simulation, despite the relatively large differences in parameter choice. Conversely, the α = 0, ι = 1 and the α = 0 06, . ι = 1 simulations show only slightly differing results, likely explained by the similarity in values of α and ι .
While certain anisotropic fabric types can be expected under particular flow and stress regimes, the length of time the ice has undergone deformation in this regime also has an influence on the reflected anisotropy field. In Fig. 4, it can be seen that at the elevation z = 0, the ice has developed into a relatively strong single maximum fabric in the α = 0, ι = 1 simulation (Fig. 4a) and the α = 0 06, . ι = 1 simulation (Fig. 4d) compared with the other two simulations. On the other hand, the α = 1, ι = 1 simulation (Fig. 4c) does not show a strong single maximum. This indicates that the strain rate term of Eq. (10) has a stronger influence on the development of a single maximum under vertical compression at a flow divide than the deviatoric stress tensor term of Eq. (10). Interestingly, in the α = 0, ι = 1 simulation (Fig. 4a) and the α = 0 06, . ι = 1 simulation (Fig. 4d), the areas
with a higher single maximum are located at the two tails of the flow divide. Although not explicitly simulated in this study, we expect that the fabric type in the area of high horizontal divergence at the tails of the flow divide would show a similar fabric to that forming at a dome flow divide, defined by a flow divide with horizontal flowlines originating at a point source. In the vicinity of the flow divide, the α = 1, ι = 1 simulation shows a vastly different horizontal anisotropy direction than the other simulations (Fig. 5c). The eigenvector corresponding to the largest horizontal eigenvalue originate at a point source as opposed to being parallel to the flow divide in the other simulations. Values of ln( λ /λ 2 1 ) are high along the flow divide and in relatively large areas where there is high horizontal divergence at the tails of the flow divide meaning that the ice has a girdle fabric. Of note is that Fig. 11c shows that in the areas of girdle fabric, the maximum horizontal strain rate direction is not perpendicular to the maximum horizontal anisotropy direction. The reason for the differences between the α = 1, ι = 1 and the other three simulations is due to the largely different α value, which in this case results in ignoring the strain rate tensor completely.
Moving into the flanks of the ice rise, where vertical shear dominates, although the flow of ice in the grounded areas is horizontally divergent, the fabric types vary substantially. We identify a number of factors as having an influence on the ice fabric type: (a) whether flank flow is perpendicular to the flow divide or at the tails of the flow divide, (b) whether the ice is on the stoss or lee side of the ice rise, and (c) how close ice is to the grounding line and what type of flow regime is active at the grounding zone. In flow regimes dominated by vertical shear, as is the case in the areas perpendicular to the flow divide, it is expected that fabric shows a single maximum with a slight offset to the vertical (Llorens et al., 2022). However, the α = 0, ι = 1 (Fig. 4a) and the α = 0 06, . ι = 1 (Fig. 4d) simulations show the strongest single maxima perpendicular to the flow divide, but Figs. 7a and d, show that these simulations have the smallest tilt angle compared to the other simulations.
Across the grounding line, the predicted ln(k) values allow differentiation between single maximum fabric (ln( k ) > 0) and girdle fabrics (ln( k ) < 0 , Fig. 6). It must be noted, however, that a large positive or negative value of ln( k ) does not necessarily imply that the ice has a strong single maximum or strong girdle fabric, respectively. Any analysis of the ln( k ) field must be done in conjunction with plots of ln( λ /λ 2 1 ) (Fig. 5) and ln( λ /λ 3 2 ) (Fig. 4) (Woodcock, 1977). In all simulations, (ln( λ /λ 3 2 )) is the lowest at the grounding zone and in the northern and eastern sides of the ice shelf, meaning that there is no single maximum in these areas. Contrary to this, the metric for a girdle fabric (ln( λ /λ 2 1 )) shows a small band at the grounding zone with values of ln( λ /λ 2 1 ) = 0 5 to 1. . This weak girdle fabric may be due to the transition from a fabric with a vertical single maximum, to a single maximum aligned with the horizontal plane, via a transition across the grounding zone.
## 4.2 Implications for viscosity coupling
One ultimate goal in modelling the anisotropy field of ice is to be able to fully couple the velocity and stress fields to the anisotropy field and vice versa (note, we will refer to these simulations as fully-coupled hereafter). In this study, we have explored the influence of the velocity and stress fields on the anisotropy field using three-dimensional simulations, but have not investigated the coupling of the anisotropy field to the velocity field via a direction-dependent viscosity. Here, we discuss areas of Derwael Ice Rise where we expect the fabric type to influence viscosity as well as barriers to fully-coupled, three-dimensional anisotropic simulations.
Generally-speaking, ice crystal c -axes rotate in a direction which allows for optimal shearing, with studies showing that if ice is highly anisotropic, deformation in the plane perpendicular to the c -axis is significantly enhanced compared with deformation in other directions (Duval et al., 1983). Areas where ice has a single maximum will experience ease of deformation parallel to basal planes and stiffening in response to deformation parallel to the c -axes. In the simulations of Derwael Ice Rise, a single maximum fabric is most apparent in the α = 0, ι = 1 and the α = 0 06, . ι = 1 simulations (Fig. 4). If enhancement factors were used (Gillet-Chaulet et al., 2005; Ma et al., 2010) in a coupling with the ice viscosity, this would allow more ease of vertical shear in these areas which is important in the evolution of Raymond arches at flow divides, as shown in two-dimensional, anisotropic simulations (Mart´ ın et al., 2009; Mart´ ın and Gudmundsson, 2012; Drews et al., 2015).
A number of hurdles hinder the three-dimensional simulation of a fullycoupled anisotropy field including computational expense, numerical instabilities, a lack of comparison with observations, parameter uncertainty and challenges associated with parallelisation. In a study by Gerber et al. (2023) in which flow tube simulations the Elmer/Ice model of a fully-coupled anisotropy field were performed, it was noted that numerical instabilities significantly hindered the simulation of areas with high velocities. Furthermore, computational expense and an increased memory load means that a direction-dependent viscosity creates a further hindrance. Despite this, simulations such as those presented in this paper allow ease of comparison with observations and should be included in comparisons between a hierarchy of models with varying complexity.
## 4.3 Model representation of anisotropy
Ice rises are an ideal location for testing models of anisotropy as they contain various flow regimes which are relevant for other locations in the Antarctic Ice Sheet. Ice rises contain many of the same features as entire ice sheets, and results can inform expectations on studies in larger scales (Matsuoka et al., 2003). The shear zones on the western and eastern sides of Derwael Ice Rise are representative of behaviour typical at lateral shear zones in ice shelves or ice streams (Smith et al., 2017). Similarly, flow divides, flank flow and ice shelf flow are typical in many areas of Antarctica. More studies are needed to examine whether an anisotropic flow law is needed in order to
make accurate projections of sea level rise. This is especially important as sudden speed up of ice, for example in the initiation of an ice stream, is associated with anisotropic behaviour (Thorsteinsson et al., 2003; Lilien et al., 2021; Gerber et al., 2023). This necessitates further studies for comparison between various hierarchies of isotropic and anisotropic ice flow models with varying model complexity as well as comparison with observations. In our approach, anisotropy is modelled using a crystal orientation tensor, which can describe many fabric types, but does not capture cone fabric shapes as modelled by Pettit et al. (2007) or multiple single maxima. An example of a representation of crystal orientation which can capture more complex fabrics has been developed by Rathmann et al. (2021).
In addition to difficulties in choosing a correct mathematical representation of an anisotropic fabric, Eq. (9) is challenging to solve numerically as it is an advection equation, with no diffusive term. We find that the use of semi-Lagrangian methods reduce dispersion, as they introduce diffusion through interpolation (Advani and Tucker, 1987). However, in areas with strong gradients in the velocity field we nonetheless find that numerical dispersion deteriorates the solution with time. The alternative approach to this numerical problem has been to either explicitly incorporate numerical diffusion in Eq. (9) as in Seddik et al. (2011), or to include re-crystallisation terms as in Gagliardini et al. (2013). We find it to be more effective to constrain the degree of orientation, but our approach can easily be adapted to include a re-crystallisation term in Eq. (9).
## 4.4 Framework for comparison with observations
A crucial component of accurate modelling of the anisotropy field of ice is the comparison with observations, which, until recently have been possible only by comparison with a limited number of ice cores. From ice core data, it is possible to construct a crystal orientation tensor which is directly comparable to simulations such as those presented in this work. Recently, advances in the measurement of anisotropic fabric using radar has allowed the acquisition of a significant amount of data with much greater ease than expensive ice coring projects (Young et al., 2021a,b; Ershadi et al., 2022). However, assumptions made in the processing of data mean that the methods currently used are only valid where the dominant c -axis direction is exactly vertical (Rathmann et al., 2022).
Thus far, observational anisotropy data has been used for inferring ice flow history including flow re-organisation (Durand et al., 2007; Matsuoka et al., 2012; Brisbourne et al., 2019, 2021) as well as for investigation of the state of the ice fabric in ice conditions such as ice streams (Smith et al., 2017; Kufner et al., 2023), in layers of enhanced shear (Pettit et al., 2011) and at ice rises (Drews et al., 2015). In terms of making comparisons between observations and anisotropic models, matching of isochrones and velocities has been performed (Drews et al., 2015; McCormack et al., 2022), but few studies have compared directly the observed and modelled anisotropy fields (Lilien et al., 2023).
Although we do not explicitly make comparisons between the observed
and modelled anisotropy fields of Derwael Ice Rise, we have described steps necessary for such a comparison. Our results show very differing threedimensional anisotropy fields depending on the chosen influence of the strain rate and deviatoric stress tensors in Eq. (9) used in previous studies (Mart´ ın et al., 2009; Seddik et al., 2011; Mart´ ın and Gudmundsson, 2012; Gagliardini et al., 2013) and draw attention to the need to constrain equation parameters. We have provided a method to compare the difference between the two horizontal eigenvalues (Fig. 10), sometimes referred to as the horizontal anisotropy , which is directly comparable to radar observations. We recommend radar surveys in the areas of high horizontal flow divergence at the tails of flow divides, as these are areas where differing values of α and ι show significantly differing anisotropy fields.
## 5 Conclusions
In this study, we have modelled the three-dimensional anisotropy field of Derwael Ice Rise (DIR) including domain partitioning using a crystal orientation tensor evolution equation describing the spatial distribution of ice crystal c -axes in a given ice volume. Simulations are performed varying the relative influence of the strain rate and deviatoric stress tensors in the crystal orientation tensor evolution equation as used in four previous studies (Mart´ ın et al., 2009; Seddik et al., 2011; Mart´ ın and Gudmundsson, 2012; Gagliardini et al., 2013), with results showing significantly differing ice fabrics across the flow divide and the flanks of DIR. Lastly, we provide a modelling framework for comparison with radar observations, outlining areas where the assumption of one vertical eigenvector may not hold and resulting errors in horizontal eigenvalues.
## 6 Acknowledgements
C. Henry was supported by the Deutsche Forschungsgemeinschaft (DFG) in the framework of the priority programme 1158 'Antarctic Research with comparative investigations in Arctic ice areas' by a grant SCHA 2139/11. R. Drews was partially supported by an Emmy Noether Grant of the Deutsche Forschungsgemeinschaft (DR 822/3-1). This work used resources of the Deutsches Klimarechenzentrum (DKRZ) granted by its Scientific Steering Committee (WLA). We would like to thank Luca Schmidt for comments which improved the manuscript.
## 7 Author contribution
ACJH and CM designed the study, ACJH performed the simulations with input from CM, ACJH performed the analysis with input from CM, ACJH wrote the manuscript which was edited by CM and RD.
## 8 Code and data availability
The code needed to perform the simulations and create the presented in the figures here are available in a publicly-accessible, permanent repository (Henry, 2024a). The accompanying model input and output data, as well as the processed data are also available in a publicly-accessible, permanent repository (Henry, 2024c). The simulations presented here are dependent on the results of simulations presented in a previous study (Henry et al., 2023), for which code and data are available (Henry, 2024b,d).
## References
- S. G. Advani and I. Tucker, Charles L. The Use of Tensors to Describe and Predict Fiber Orientation in Short Fiber Composites. Journal of Rheology , 31(8):751-784, 11 1987. doi: 10.1122/1.549945.
- R. B. Alley. Fabrics in polar ice sheets: development and prediction. Science , 240(4851):493-495, 1988.
- A. M. Brisbourne, C. Mart´ ın, A. M. Smith, A. F. Baird, J. M. Kendall, and J. Kingslake. Constraining Recent Ice Flow History at Korff Ice Rise, West Antarctica, Using Radar and Seismic Measurements of Ice Fabric. Journal of Geophysical Research: Earth Surface , 124(1):175-194, 2019. doi: 10.1029/2018JF004776.
- A. M. Brisbourne, M. Kendall, S.-K. Kufner, T. S. Hudson, and A. M. Smith. Downhole distributed acoustic seismic profiling at skytrain ice rise, west antarctica. The Cryosphere , 15(7):3443-3458, 2021. doi: 10. 5194/tc-15-3443-2021.
- D. Callens, R. Drews, E. Witrant, M. Philippe, and F. Pattyn. Temporally stable surface mass balance asymmetry across an ice rise derived from radar internal reflection horizons through inverse modeling. Journal of Glaciology , 62(233):525-534, 2016. doi: 10.1017/jog.2016.41.
- D. H. Chung and T. H. Kwon. Invariant-based optimal fitting closure approximation for the numerical prediction of flow-induced fiber orientation. Journal of Rheology , 46(1):169-194, 2002. doi: 10.1122/1.1423312.
- J. Dall. Ice sheet anisotropy measured with polarimetric ice sounding radar. In 2010 IEEE International Geoscience and Remote Sensing Symposium , pages 2507-2510, 2010. doi: 10.1109/IGARSS.2010.5653528.
- A. Diez, O. Eisen, I. Weikusat, J. Eichler, C. Hofstede, P. Bohleber, T. Bohlen, and U. Polom. Influence of ice crystal anisotropy on seismic velocity analysis. Annals of Glaciology , 55(67):97-106, 2014. doi: 10.3189/2014AoG67A002.
- R. Drews, O. Eisen, D. Steinhage, I. Weikusat, S. Kipfstuhl, and F. Wilhelms. Potential mechanisms for anisotropy in ice-penetrating radar
data. Journal of Glaciology , 58(209):613-624, 2012. doi: 10.3189/ 2012JoG11J114.
- R. Drews, K. Matsuoka, C. Mart´ ın, D. Callens, N. Bergeot, and F. Pattyn. Evolution of Derwael Ice Rise in Dronning Maud Land, Antarctica, over the last millennia. Journal of Geophysical Research: Earth Surface , 120 (3):564-579, 2015. doi: 10.1002/2014JF003246. URL http://doi.wiley. com/10.1002/2014JF003246 .
- G. Durand, F. Gillet-Chaulet, A. Svensson, O. Gagliardini, S. Kipfstuhl, J. Meyssonnier, F. Parrenin, P. Duval, and D. Dahl-Jensen. Change in ice rheology during climate variations-implications for ice flow modelling and dating of the epica dome c core. Climate of the Past , 3(1):155-167, 2007. doi: 10.5194/cp-3-155-2007.
- G. Durand, O. Gagliardini, B. de Fleurian, T. Zwinger, and E. Le Meur. Marine ice sheet dynamics: Hysteresis and neutral equilibrium. Journal of Geophysical Research , 114(F3):F03009, Aug. 2009. doi: 10.1029/ 2008JF001170.
- P. Duval, M. Ashby, and I. Anderman. Rate-controlling processes in the creep of polycrystalline ice. The Journal of Physical Chemistry , 87(21): 4066-4074, 1983. doi: 10.1021/j100244a014.
- M. R. Ershadi, R. Drews, C. Mart´ ın, O. Eisen, C. Ritz, H. Corr, J. Christmann, O. Zeising, A. Humbert, and R. Mulvaney. Polarimetric radar reveals the spatial distribution of ice fabric at domes and divides in east antarctica. The Cryosphere , 16(5):1719-1739, 2022. doi: 10.5194/ tc-16-1719-2022.
- L. Favier and F. Pattyn. Antarctic ice rise formation, evolution, and stability. Geophysical Research Letters , 42(11):4456-4463, June 2015. ISSN 00948276, 1944-8007. doi: 10.1002/2015GL064195.
- S. Fujita, H. Maeno, and K. Matsuoka. Radio-wave depolarization and scattering within ice sheets: a matrix-based model to link radar and ice-core measurements and its application. Journal of Glaciology , 52(178):407-424, 2006. doi: 10.3189/172756506781828548.
- O. Gagliardini, F. Gillet-Chaulet, and M. Montagnat. A review of anisotropic polar ice models: from crystal to ice-sheet flow models. Physics of Ice Core Records II , 68, 2009.
- O. Gagliardini, T. Zwinger, F. Gillet-Chaulet, G. Durand, L. Favier, B. de Fleurian, R. Greve, M. Malinen, C. Mart´ ın, P. R˚back, J. Ruokoa lainen, M. Sacchettini, M. Sch¨ afer, H. Seddik, and J. Thies. Capabilities and performance of Elmer/Ice, a new-generation ice sheet model. Geoscientific Model Development , 6(4):1299-1318, 2013. doi: 10.5194/ gmd-6-1299-2013.
- T. A. Gerber, D. A. Lilien, N. M. Rathmann, S. Franke, T. J. Young, F. Valero-Delgado, M. R. Ershadi, R. Drews, O. Zeising, A. Humbert, et al. Crystal orientation fabric anisotropy causes directional hardening of the northeast greenland ice stream. Nature Communications , 14(1):2653, 2023. doi: 10.1038/s41467-023-38139-8.
- F. Gillet-Chaulet, O. Gagliardini, J. Meyssonnier, M. Montagnat, and O. Castelnau. A user-friendly anisotropic flow law for ice-sheet modeling. Journal of glaciology , 51(172):3-14, 2005. doi: 10.3189/ 172756505781829584.
- F. Gillet-Chaulet, O. Gagliardini, J. Meyssonnier, T. Zwinger, and J. Ruokolainen. Flow-induced anisotropy in polar ice and related ice-sheet flow modelling. Journal of non-newtonian fluid mechanics , 134(1-3):33-43, 2006. doi: 10.1016/j.jnnfm.2005.11.005.
- G. G¨ odert. A mesoscopic approach for modelling texture evolution of polar ice including recrystallization phenomena. Annals of Glaciology , 37:23-28, 2003. doi: 10.3189/172756403781815375.
- A. C. J. Henry. Simulation and post-processing code presented in 'modelling the three-dimensional, diagnostic anisotropy field of an ice rise' (Version v1). Zenodo. https://doi.org/10.5281/zenodo.13143326 , 2024a. Accessed: 2024-07-31.
- A. C. J. Henry. Code for the publication 'Predicting the three-dimensional stratigraphy of an ice rise' (Version v1). Zenodo. https://doi.org/10. 5281/zenodo.12180129 , 2024b. Accessed: 2024-06-20.
- A. C. J. Henry. Model input data, simulation output data and processed data presented in 'modelling the three-dimensional, diagnostic anisotropy field of an ice rise' (Version v1). Zenodo. https://doi.org/10.5281/ zenodo.13143591 , 2024c. Accessed: 2024-07-31.
- A. C. J. Henry. Data for the publication 'predicting the three-dimensional stratigraphy of an ice rise' (Version v1). Zenodo. https://doi.org/10. 5281/zenodo.12183293 , 2024d. Accessed: 2024-06-20.
- A. C. J. Henry, R. Drews, C. Schannwell, and V. Viˇ snjevi´. c Hysteretic evolution of ice rises and ice rumples in response to variations in sea level. The Cryosphere , 16(9):3889-3905, 2022. doi: 10.5194/tc-16-3889-2022.
- A. C. J. Henry, C. Schannwell, V. Viˇnjevi´, J. Millstein, P. Bons, O. Eisen, s c and D. R. Predicting the three-dimensional age-depth field of an ice rise. 2023. doi: 10.22541/essoar.169230234.44865946/v1.
- K. C. Jezek, J. C. Curlander, F. Carsey, C. Wales, and R. G. Barry. Ramp amm-1 sar image mosaic of antarctica, version 2, 2013.
- T. M. Jordan, C. Mart´ ın, A. M. Brisbourne, D. M. Schroeder, and A. M. Smith. Radar characterization of ice crystal orientation fabric and
- anisotropic viscosity within an antarctic ice stream. Journal of Geophysical Research: Earth Surface , 127(6):e2022JF006673, 2022. doi: https://doi.org/10.1029/2022JF006673.
- I. Koch, R. Drews, S. Franke, D. Jansen, F. M. Oraschewski, L. S. Muhle, V. Viˇ snjevi´, c K. Matsuoka, F. Pattyn, and O. Eisen. Radar internal reflection horizons from multisystem data reflect ice dynamic and surface accumulation history along the princess ragnhild coast, dronning maud land, east antarctica. Journal of Glaciology , page 1-19, 2023. doi: 10.1017/jog.2023.93.
- S. Kufner, J. Wookey, A. M. Brisbourne, C. Mart´ ın, T. S. Hudson, J. M. Kendall, and A. M. Smith. Strongly depth-dependent ice fabric in a fastflowing antarctic ice stream revealed with icequake observations. Journal of Geophysical Research: Earth Surface , 128(3):e2022JF006853, 2023. doi: 10.1029/2022JF006853.
- D. A. Lilien, N. M. Rathmann, C. S. Hvidberg, and D. Dahl-Jensen. Modeling ice-crystal fabric as a proxy for ice-stream stability. Journal of Geophysical Research: Earth Surface , 126(9), 2021. doi: 10.1029/ 2021JF006306.
- D. A. Lilien, N. M. Rathmann, C. S. Hvidberg, A. Grinsted, M. R. Ershadi, R. Drews, and D. Dahl-Jensen. Simulating higher-order fabric structure in a coupled, anisotropic ice-flow model: application to dome c. Journal of Glaciology , page 1-20, 2023. doi: 10.1017/jog.2023.78.
- M.-G. Llorens, A. Griera, P. D. Bons, I. Weikusat, D. J. Prior, E. GomezRivas, T. De Riese, I. Jimenez-Munt, D. Garc´ ıa-Castellanos, and R. A. Lebensohn. Can changes in deformation regimes be inferred from crystallographic preferred orientations in polar ice? The Cryosphere , 16(5): 2009-2024, 2022. doi: 10.5194/tc-16-2009-2022.
- Y. Ma, O. Gagliardini, C. Ritz, F. Gillet-Chaulet, G. Durand, and M. Montagnat. Enhancement factors for grounded ice and ice shelves inferred from an anisotropic ice-flow model. Journal of Glaciology , 56(199):805-812, 2010. doi: 10.3189/002214310794457209.
- C. Mart´ ın and G. H. Gudmundsson. Effects of nonlinear rheology, temperature and anisotropy on the relationship between age and depth at ice divides. The Cryosphere , 6(5):1221-1229, 2012. doi: 10.5194/ tc-6-1221-2012.
- C. Mart´ ın, R. C. A. Hindmarsh, and F. J. Navarro. On the effects of divide migration, along-ridge flow, and basal sliding on isochrones near an ice divide. Journal of Geophysical Research , 114(F2):F02006, Apr. 2009. ISSN 0148-0227. doi: 10.1029/2008JF001025. URL http://doi.wiley.com/ 10.1029/2008JF001025 .
- K. Matsuoka, T. Furukawa, S. Fujita, H. Maeno, S. Uratsuka, R. Naruse, and O. Watanabe. Crystal orientation fabrics within the antarctic ice sheet
- revealed by a multipolarization plane and dual-frequency radar survey. Journal of Geophysical Research: Solid Earth , 108(B10):2003JB002425, 2003. doi: 10.1029/2003JB002425.
- K. Matsuoka, L. Wilen, S. Hurley, and C. Raymond. Effects of birefringence within ice sheets on obliquely propagating radio waves. IEEE Transactions on Geoscience and Remote Sensing , 47(5):1429-1443, 2009. doi: 10.1109/ TGRS.2008.2005201.
- K. Matsuoka, D. Power, S. Fujita, and C. F. Raymond. Rapid development of anisotropic ice-crystal-alignment fabrics inferred from englacial radar polarimetry, central west antarctica. Journal of Geophysical Research: Earth Surface , 117(F3), 2012. doi: https://doi.org/10.1029/2012JF002440.
- K. Matsuoka, R. C. Hindmarsh, G. Moholdt, M. J. Bentley, H. D. Pritchard,
- J. Brown, H. Conway, R. Drews, G. Durand, D. Goldberg, T. Hattermann,
- J. Kingslake, J. T. Lenaerts, C. Mart´ ın, R. Mulvaney, K. W. Nicholls,
- F. Pattyn, N. Ross, T. Scambos, and P. L. Whitehouse. Antarctic ice rises and rumples: Their properties and significance for ice-sheet dynamics and evolution. Earth-Science Reviews , 150:724-745, 2015. doi: 10.1016/j. earscirev.2015.09.004.
- F. S. McCormack, R. C. Warner, H. Seroussi, C. F. Dow, J. L. Roberts, and A. Treverrow. Modeling the deformation regime of thwaites glacier, west antarctica, using a simple flow relation for ice anisotropy (estar). Journal of Geophysical Research: Earth Surface , 127(3):e2021JF006332, 2022. doi: 10.1029/2021JF006332.
- M. Montagnat, N. Azuma, D. Dahl-Jensen, J. Eichler, S. Fujita, F. GilletChaulet, S. Kipfstuhl, D. Samyn, A. Svensson, and I. Weikusat. Fabric along the neem ice core, greenland, and its comparison with grip and ngrip ice cores. The Cryosphere , 8(4):1129-1138, 2014. doi: 10.5194/ tc-8-1129-2014.
- E. C. Pettit, T. Thorsteinsson, H. P. Jacobson, and E. D. Waddington. The role of crystal fabric in flow near an ice divide. Journal of Glaciology , 53 (181):277-288, 2007. doi: 10.3189/172756507782202766.
- E. C. Pettit, E. D. Waddington, W. D. Harrison, T. Thorsteinsson, D. Elsberg, J. Morack, and M. A. Zumberge. The crossover stress, anisotropy and the ice flow law at siple dome, west antarctica. Journal of Glaciology , 57(201):39-52, 2011. doi: 10.3189/002214311795306619.
- N. M. Rathmann, C. S. Hvidberg, A. Grinsted, D. A. Lilien, and D. DahlJensen. Effect of an orientation-dependent non-linear grain fluidity on bulk directional enhancement factors. Journal of Glaciology , 67(263):569-575, 2021. doi: 10.1017/jog.2020.117.
- N. M. Rathmann, D. A. Lilien, A. Grinsted, T. A. Gerber, T. J. Young, and D. Dahl-Jensen. On the limitations of using polarimetric radar sounding to infer the crystal orientation fabric of ice masses. Geophysical Research Letters , 49(1):e2021GL096244, 2022. doi: 10.1029/2021GL096244.
- D. H. Richards, S. S. Pegler, and S. Piazolo. Ice fabrics in two-dimensional flows: beyond pure and simple shear. The Cryosphere , 16(10):4571-4592, 2022. doi: 10.5194/tc-16-4571-2022.
- D. H. Richards, S. S. Pegler, S. Piazolo, N. Stoll, and I. Weikusat. Bridging the gap between experimental and natural fabrics: Modeling ice stream fabric evolution and its comparison with ice-core data. Journal of Geophysical Research: Solid Earth , 128(11):e2023JB027245, 2023. doi: https://doi.org/10.1029/2023JB027245.
- J. M. Rignot, E. and B. Scheuchl. Measures insar-based antarctica ice velocity map, version 2, 2017. URL https://nsidc.org/data/NSIDC-0484/ versions/2 .
- C. Schannwell, R. Drews, T. A. Ehlers, O. Eisen, C. Mayer, and F. GilletChaulet. Kinematic response of ice-rise divides to changes in ocean and atmosphere forcing. The Cryosphere , 13(10):2673-2691, 2019. doi: 10. 5194/tc-13-2673-2019.
- C. Schannwell, R. Drews, T. A. Ehlers, O. Eisen, C. Mayer, M. Malinen, E. C. Smith, and H. Eisermann. Quantifying the effect of ocean bed properties on ice sheet geometry over 40 000 years with a full-Stokes model. The Cryosphere , 14(11):3917-3934, 2020. doi: 10.5194/tc-14-3917-2020.
- H. Seddik, R. Greve, T. Zwinger, and L. Placidi. A full stokes ice flow model for the vicinity of dome fuji, antarctica, with induced anisotropy and fabric evolution. The Cryosphere , 5(2):495-508, 2011. doi: 10.5194/ tc-5-495-2011.
- E. C. Smith, A. F. Baird, J. M. Kendall, C. Mart´ ın, R. S. White, A. M. Brisbourne, and A. M. Smith. Ice fabric in an antarctic ice stream interpreted from seismic anisotropy. Geophysical Research Letters , 44(8):3710-3718, 2017. doi: 10.1002/2016GL072093.
- T. Thorsteinsson, E. D. Waddington, and R. C. Fletcher. Spatial and temporal scales of anisotropic effects in ice-sheet flow. Annals of Glaciology , 37:40-48, 2003. doi: 10.3189/172756403781815429.
- I. Weikusat, D. Jansen, T. Binder, J. Eichler, S. H. Faria, F. Wilhelms, S. Kipfstuhl, S. Sheldon, H. Miller, D. Dahl-Jensen, and T. Kleiner. Physical analysis of an antarctic ice core-towards an integration of microand macrodynamics of polar ice. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , 375(2086): 20150347, 2017. doi: 10.1098/rsta.2015.0347.
- N. H. Woodcock. Specification of fabric shapes using an eigenvalue method. Geological Society of America Bulletin , 88(9):1231, 1977. doi: 10.1130/ 0016-7606(1977)88 1231:SOFSUA 2.0.CO;2. ⟨ ⟩
- T. J. Young, C. Mart´ ın, P. Christoffersen, D. M. Schroeder, S. M. Tulaczyk, and E. J. Dawson. Rapid and accurate polarimetric radar measurements
of ice crystal fabric orientation at the western antarctic ice sheet (wais) divide ice core site. The Cryosphere , 15(8):4117-4133, 2021a.
- T. J. Young, D. M. Schroeder, T. M. Jordan, P. Christoffersen, S. M. Tulaczyk, R. Culberg, and N. L. Bienert. Inferring ice fabric from birefringence loss in airborne radargrams: Application to the eastern shear margin of thwaites glacier, west antarctica. Journal of Geophysical Research: Earth Surface , 126(5):e2020JF006023, 2021b. doi: 10.1029/2020JF006023. | null | [
"A. Clara J. Henry",
"Carlos Martín",
"Reinhard Drews"
] | 2024-08-02T07:42:53+00:00 | 2024-08-02T07:42:53+00:00 | [
"physics.flu-dyn",
"physics.geo-ph"
] | Modelling the three-dimensional, diagnostic anisotropy field of an ice rise | Polar ice develops anisotropic crystal orientation fabrics under deformation,
yet ice is most often modelled as an isotropic fluid. We present
three-dimensional simulations of the crystal orientation fabric of Derwael Ice
Rise including the surrounding ice shelf using a crystal orientation tensor
evolution equation corresponding to a fixed velocity field. We use a
semi-Lagrangian numerical method that constrains the degree of crystal
orientation evolution to solve the equations in complex flow areas. We perform
four simulations based on previous studies, altering the rate of evolution of
the crystal anisotropy and its dependence on a combination of the strain rate
and deviatoric stress tensors. We provide a framework for comparison with radar
observations of the anisotropy field, outlining areas where the assumption of
one vertical eigenvector may not hold and provide resulting errors in measured
eigenvalues. We recognise the areas of high horizontal divergence at the ends
of the flow divide as important areas to make comparisons with observations.
Here, poorly constrained model parameters result in the largest difference in
fabric type. These results are important in the planning of future campaigns
for gathering data to constrain model parameters and as a link between
observations and computationally-efficient, simplified models of anisotropy. |
2408.01070v1 | ## Single photon emitters in monolayer semiconductors coupled to transition metal dichalcogenide nanoantennas on silica and gold substrates
Panaiot G. Zotev a ∗ , Sam A. Randerson , Xuerong Hu , Yue Wang , Alexander I. Tartakovskii a a b a ∗∗
a Department of Physics and Astronomy, University of Sheffield, Sheffield, S3 7RH, UK
b School of Physics, Engineering and Technology, University of York, York, YO10 5DD, UK ∗ [email protected] ∗∗ [email protected]
Transition metal dichalcogenide (TMD) single photon emitters (SPEs) offer numerous advantages to quantum information applications, such as high single photon purity and deterministic positioning. Strain in the host monolayer, induced by underlying dielectric Mie resonators, is known to localize their formation to positions co-located with near-field photonic hotspots providing further control over their optical properties. However, traditional materials used for the fabrication of nanoresonators, such as silicon or gallium phosphide (GaP), often require a high refractive index substrate resulting in losses of the emitted light and limited photonic enhancement. Here, we use nanoantennas (NAs) fabricated from multilayer TMDs, which allow complete flexibility with the choice of substrate due to the adhesive van der Waals forces, enabling high refractive index contrast or the use of highly reflective metallic surfaces. We demonstrate the localized formation of SPEs in WSe 2 monolayers transferred onto WS 2 NAs on both SiO 2 and Au substrates, enabling strong photonic enhancements and increased single photon collection. We provide evidence for enhanced quantum efficiencies (QE) reaching an average value of 43% (7%) for SPEs on WS 2 NAs on a SiO 2 (Au) substrate. We further combine the advantages offered by both dielectric and metallic substrates to numerically simulate an optimized NA geometry for maximum WSe 2 single photon excitation, emission, collection. Thus, the fluorescence is enhanced by a factor of over 4 orders of magnitude compared to vacuum and 5 orders of magnitude compared to a flat SiO /Si 2 surface. Our work showcases the advantages offered by employing TMD material nanoresonators on various substrates for SPE formation and photonic enhancement.
TMD material single photon emitters have drawn much interest due to their expected use in atomically thin quantum devices which can be deterministically fabricated and integrated with arbitrary substrates, offering narrow linewidths and high single photon purity [1]. The formation mechanism of these quantum emitters, discovered first in monolayer WSe 2 [2-6] and often associated with strain [7-11], is still debated. However, this has lead to the proposal of several theoretical models describing their occurrence in cryogenic photoluminescence (PL) including strain-induced potential traps for excitons [12], various defects [13, 14], both of which are believed to be filled by trapped dark excitons [8,12,13,15] or via long-lived intermediate states [16], as well as momentum-dark states [17]. Despite the lack of definitive knowledge concerning their origin, many steps have been taken to integrate TMD SPEs with devices by employing focused ion beam defect formation [18] or, more commonly, strain-engineering [9-11, 19, 20] and thereby coupling to waveguides [21, 22], microcavities [23,24], circular Bragg gratings [25] and Mie resonators [15,26,27]. Additionally, tuning of the properties of the SPEs has been achieved by shaping the strain profile to orient the dipole of the emitter [19, 28, 29], increasing strain values [15, 30] or using gating [31] to tune the emission energy and employing van der Waals ferromagnets to achieve chiral single photon emission [32].
Applications in quantum information requiring the scalable and controllable realization of on-chip quantum emitters have led to arrays of 2D SPEs realized by transfer of monolayer WSe 2 onto pre-fabricated arrays of nanopillars patterned in photoresist [8], SiO 2 [33], GaP [15] and Au/Si with a spacer layer of Al 2 O 3 on top [27]. The latter two
of these materials were employed to enhance SPE intensities by coupling with Mie resonances as a result of the close proximity of maximum strain values and photonic mode hotspots [15, 27]. However, each of these devices required the fabrication of nanopillars or Mie resonators from the substrate material thus achieving little to no refractive index contrast, known to enable strong localization of resonances and thus provide large fluorescence enhancements [34], between nanoresonator and underlying surface.
Recently, works employing van der Waals (vdW) materials as high-index dielectrics for the fabrication of nanophotonic structures [35-40] have enabled the realization of nanoresonators on arbitrary substrates achieving a large refractive index contrast and thus tightly confined resonances [34, 41] as well as hybrid dielectric-plasmonic resonances with ultra-high Q factors [41, 42]. These vdW material nanophotonic structures thus enable many applications such as waveguiding [38, 43], strong light-matter coupling [35,40,41], lasing [44] and Purcell enhancement of emission [39,45,46].
Here, we pattern WS 2 multilayer crystals deposited on SiO 2 and Au substrates into hexagonal dimer nanoantennas. Through dark field spectroscopy we confirmed the presence of Mie resonances which we employed in the fluorescence enhancement of single photon emitters forming in monolayer WSe 2 transferred onto the fabricated nanoresonators. Simulations of the resulting NAs on both substrates yielded strong electric field confinement into photonic hotspots at the top surface of the NAs where the strain in the transferred monolayer is expected to be highest, thus inducing the formation of SPEs. These hotspots are expected to enhance the absorption in the monolayer, increase the QE of single photon emission and improve collection efficiencies by redirecting the emitted light into our optical setup [15]. The total maximum fluorescence enhancement factor for a quantum emitter forming within these hotspots compared with one in vacuum, calculated from these three contributions, was simulated to reach as high as 914 (10670) for the SiO 2 (Au) substrate. When we compare an SPE within the hotspots of the NA on a SiO 2 (Au) substrate to an emitter on a flat 300 nm SiO 2 /Si wafer surface we calculated a fluorescence enhancement as high as 2012 (23493).
In cryogenic PL measurements, we observed the formation of spatially localized, narrow-linewidth emitters which are shown to emit single photons. We recorded a factor of 2.7 higher SPE intensity for the SiO 2 substrate. Using pulsed laser excitation and simulations of the collection efficiency near each NA, we extract a quantum efficiency of each emitter. We define this as the average number of photons emitted per excitation pulse. The SPEs forming on WS NAs on a SiO 2 2 (Au) substrate yielded an average QE of 43% (7%), which is higher than observed for quantum emitters in an unenhanced or weakly enhanced regime ( ≈ 1.5-4% [15,26]). We attribute the very high average QE for the SiO 2 substrate to the strong mode confinement achievable with a large refractive index contrast ( ≈ 2.5). The much lower QE of the emitters forming on NAs fabricated on the Au substrate is attributed to non-radiative decay channels from the SPE state, such as charge transfer to the metallic surface [47]. We confirm this via a reduced average SPE lifetime and the reduction of Auger processes observed in the time resolved PL of monolayer WSe 2 on a flat Au substrate.
To surmount the disadvantage of increased nonradiative decay and make use of the larger collection efficiency of a metallic substrate, we further design optimized WS 2 NAs on a gold substrate with an insulating spacer of SiO 2 or hBN. The insulating layer is used to suppress charge transfer processes while also yielding maximum fluorescence enhancement factors of more than 23700 (33200), compared to vacuum, and more than 157900 (221300), compared to a flat 300 nm SiO /Si surface, 2 for a WSe 2 SPE forming within the hotspots at the outer top vertices of the NAs fabricated on a Au substrate with a SiO 2 (hBN) spacer under low power excitation. Our work showcases the advantages offered by heterointegration of TMD SPEs and nanoresonators with different substrates, thereby enabling optimized coupling of enhanced quantum emitters with virtually any material system and device.
## Results
WS 2 nanoantennas on SiO 2 and Au substrates To achieve an entirely TMD SPE system on different substrates, we began by preparing two nominally 290 nm SiO /Si substrates, 2 one of which was coated with a 100 nm thick Au film sputtered by electron beam. We mechanically exfoliated multilayer WS 2 crystals onto these two substrates and employed electron beam lithography and reac-
tive ion etching to pattern hexagonal dimer (double pillar) NAs into the WS 2 [39, 48]. While the SiO 2 substrate was slightly overetched (<15 nm), the Au film acted as a natural etch stop [41, 42] leaving 135 nm and 190 nm tall WS 2 dimer NAs on the SiO 2 and Au substrates respectively (Figure 1(a) and (b)). Once fabricated, we characterized the optical resonances of the NAs on both substrates via dark field spectroscopy which yielded the presence of both magnetic and electric dipole Mie modes as well as anapole and higher order anapole resonances (Figures 1(c) and (d) for the SiO 2 and Au substrate respectively). The height, radius and dimer separation gap for each NA was measured using atomic force microscopy (AFM) and scanning electron microscopy.
Using the measured geometry of the fabricated WS 2 NAs, we simulated the electric field intensity enhancement values surrounding the nanostructures (Figure 1(e) and (f) for the SiO 2 and Au substrates respectively). The radii of the simulated NAs were 235 nm and 205 nm, their heights were 135 nm and 190 nm and their dimer gaps (distance between individual nanopillars) were 150 nm and 515 nm for the SiO 2 and Au substrates respectively. As we aimed to enhance the fluorescence rate of monolayer WSe 2 SPEs, emitting near 750 nm, we simulated the expected photonic enhancement at this wavelength and observed confinement of the electric field at the top surface of the NAs. The photonic hotspots at the upper NA vertices are expected to yield higher fluorescence enhancements for the Au substrate. We attribute this to the redistribution of the electric field in the presence of a reflective surface and a reduced leakage into the substrate. As the photonic hotspots at the top surface of the NA are co-located with the highest expected strain values in a monolayer of WSe 2 transferred onto these nanostructures [49], we expected a high probability of SPE formation within these hotspots and thus strong enhancement of their fluorescence. In order to calculate a fluorescence enhancement rate compared to vacuum ( F/F 0 ), we utilized the following definition [50]:
$$\frac { F } { F _ { 0 } } = \frac { \gamma ^ { e x c } } { \gamma _ { 0 } ^ { e x c } } \cdot \frac { q ^ { e m } } { q _ { 0 } ^ { e m } } \cdot \frac { \eta ^ { e m } } { \eta _ { 0 } ^ { e m } }, \quad \quad ( 1 ) \quad \text{the $1$} \\ \infty \, \infty \, \infty.$$
where the first factor ( γ exc /γ exc 0 ) corresponds to the excitation rate enhancement, which is governed by the electric field intensity at the position of the SPE, at the pump laser wavelength. The second factor ( q em /q em 0 ) represents the quantum efficiency enhancement at the emission wave- length, which can be approximated by the Purcell factor for emitters with a low intrinsic QE as was demonstrated for WSe 2 SPEs in an unenhanced or weakly enhanced regime ( ≈ 1.5-4% [15,26]). The last factor ( η em /η em 0 ) corresponds to the light collection efficiency enhancement provided by the photonic structure at the emission wavelength calculated for a numerical aperture of 0.64. In our simulations, each of the enhancement factors is calculated as a comparison to an emitter in a vacuum environment.
To understand the maximum possible fluorescence enhancement for the fabricated NAs on the SiO 2 and Au substrates, we simulated the electric field intensity enhancement, Purcell factor and collection efficiency at the appropriate wavelength (638 nm for our laser excitation and 750 nm for the SPE emission wavelength) for a range of radii measured from our fabricated NAs (Figures 1(i)-(k)). From the electric field intensity simulations, we observed that for most radii achieved in our fabrication, we can expect stronger excitation rate enhancements for the Au substrate, attributed to the stronger confinement provided by the metallic film, and thus use lower power laser pumping. The Purcell factor simulations yielded similar emission enhancement rates for the two substrates which suggests similar expected QE enhancements in the SPEs on the two substrates. Perhaps the largest advantage of using an Au substrate as opposed to SiO 2 is the factor of ≈ 4 enhancement of the expected collection efficiency which is also higher than previously achieved on GaP NAs [15,50]. This is expected from a metallic mirror substrate as much of the light emitted from the SPE toward the substrate can now be reflected towards the collection optics. The maximum fluorescence enhancement factor ( F/F 0 ) expected for properly positioned SPEs within the photonic hotspots when compared to vacuum, calculated by substituting in the results from Figures 1(i)-(k) into equation 1, varies from 62.5 to 914 for the SiO 2 substrate and from 647.9 to 10670 for the Au substrate over the range of radii. Upon comparison with an emitter forming on a flat 300 nm SiO /Si surface, 2 the fluorescence enhancements vary from 137 to 2012 for the WS 2 NAs on the SiO 2 substrate and from 1426 to 23493 for the Au substrate over the same range of radii.
Single photon emitter formation and quantum efficiency enhancement To confirm that single photon emitters can be formed by depositing a monolayer TMD
onto multilayer TMD nanoresonators fabricated on different substrates, we transfer a single layer of WSe 2 onto the fabricated arrays of WS 2 NAs on SiO 2 and Au substrates (see Supplementary Note 1) via an all-dry polymer stamp technique (see Methods). WS 2 NAs on SiO 2 have already been shown to enhance the photoluminescence of monolayer WSe 2 at room temperature via the Purcell effect [39], thus providing a promising starting point for enhancement of SPEs.
Next, we cooled our samples to liquid helium temperature in a bath cryostat and carried out detailed microPL experiments. We excited the WSe 2 monolayer with a 638 nm pulsed laser (5MHz) and measured PL spectra from different locations at and surrounding the nanoantenna positions. We recorded a spatial map of the emitted PL, integrating between 1.663 and 1.666 eV, from the SiO 2 substrate sample near three NAs (Figure 2(a), left) and compared it to a room temperature PL image, integrated between 1.24 and 2.25 eV, of the same region (Figure 2(a), right). The overlap of the low and room temperature PL in the two panels confirms that the emission is strongly localized to the NA positions. The cryogenic PL spectrum (Figure 2(b), blue) recorded from the uppermost NA in the spatial map exhibits an emitter with a linewidth of <500 µ eV, similar to previous reports for QE enhanced SPEs on GaP NAs [15]. A similarly narrow emission line was also observed from the WSe 2 monolayer transferred onto WS 2 NAs on the Au substrate (Figure 2(b), orange). We performed Hanbury-Brown-Twiss experiments (Figure 2(b), insets) to measure the photon statistics of the recorded lines from the samples with both substrates, resulting in anti-bunching dips below g (0) = 0.5 at zero time delay, 2 thus confirming the single photon nature of the emission. As expected for 0-D quantum emitters, we also observed linear polarization, power saturation at relatively weak excitation powers (<500 nW) and long lifetimes (7-170 ns) compared to free excitons in the WSe 2 monolayer (<4 ps) [51,52] (see Supplementary Note 2).
We recorded similar narrow-linewidth (see Supplementary Note 2) emission from nearly all of the studied NA positions (>98%) on both substrates. This provides evidence that the strain induced in the WSe 2 monolayer by the WS 2 NAs with heights of 135 nm and 190 nm for the SiO 2 and Au substrates respectively is sufficient to induce the formation of at least one SPE at each NA position. Interest- ingly, many of the emitters observed on the Au substrate sample and several of those on the SiO 2 surface sample exhibited a polarization along the line connecting the centers of the nanopillars forming the WS 2 dimer NA (dimer axis). We attribute this to the strain profile induced in the monolayer during the transfer (see Supplementary Note 2) [19,49]. The higher percentage of emitters forming with a polarization along the dimer axis on Au substrate sample is attributed to the larger strain induced in the monolayer by the taller NAs. This demonstrates an ability to control the polarization of the SPEs and orient it along the NA resonance expected to result in the highest photonic enhancement [39] with a more effortless procedure than in previous reports [28].
We subsequently recorded the integrated (over the linewidth of the emitter) intensities of many SPEs at saturation forming onto different WS 2 NAs on the SiO 2 and Au substrates (Figure 2(c)). Surprisingly, the average intensity of the emitters on the Au substrate ( ≈ 8.6 Hz/nW) is 2.7 times lower than that on the SiO 2 substrate (23.3 Hz/nW) despite the overall higher excitation rate and collection efficiency enhancements we expected from the simulations in Figures 1(i) and (k). We attribute this to the introduction of a very fast non-radiative decay channel, such as charge transfer to the metallic substrate [47]. Room temperature PL and time-resolved PL measurements exhibiting reduced intensities and suppressed exciton-exciton annihilation respectively suggest such a process (see Supplementary Note 3). The reduced average lifetime of emitters recorded for the Au substrate sample as compared to those on the SiO 2 surface sample (see Supplementary Note 2) provides further evidence of an increased non-radiative decay rate. We also considered that heating due to the Au substrate absorption may reduce the SPE intensities, however, the local temperature is expected to rise only negligibly (see Supplementary Note 4).
When comparing the intensities of emitters forming on WS NAs fabricated on the SiO 2 2 substrate with previously studied WSe 2 SPEs forming on SiO 2 nanopillars [8, 15, 33] we observed larger intensities and decay lifetimes leading us to consider enhanced quantum efficiencies. As we utilized pulsed excitation with a lower laser repetition rate than the decay rates of all SPEs, expected to yield an emission rate equal to the repetition rate for a quantum efficiency of 100%, we can estimate the QE of each emitter via the
following:
$$Q E = \frac { I } { R \cdot \eta _ { e m } \cdot \eta _ { e x p } }, \quad ( 2 ) \quad & \text{the $1$} \\ \det \det \det \det \det$$
where I is the recorded integrated intensity of the SPE in Hz within the saturation regime, η em is the simulated collection efficiency of the objective lens largely depending on the positioning of the emitter relative to the WS 2 dimer NA, η exp is the measured efficiency of our experimental setup and R is the repetition rate of the excitation laser in Hz. We have measured the efficiency of our experimental setup to be 0.56% using a 725 nm laser (see Supplementary Note 5). For each emitter, we define a maximum and minimum collection efficiency based on its position relative to the NA which is unknown to us. The largest collection efficiency is found for an SPE position at the upper vertices of the NA and the lowest value is calculated for an emitter in close proximity to the substrate. Utilizing these two values provides us with not only an average estimate of the quantum efficiency of each SPE but also an upper and lower bound (Figure 2(d)) depending on the precise position of the emitter relative to the WS 2 NA and substrate.
Comparing our current estimate of the QE with previously measured WSe 2 SPEs forming on SiO 2 nanopillars (4% [15]) and uncoupled gold nanocubes (1.5% [26]), we observed an order of magnitude higher quantum efficiencies for emitters forming on WS 2 NAs on the SiO 2 substrate with an average value of 43%, which is even higher than observed for quantum efficiency enhanced SPEs forming on coupled gold nanocubes (12.6% [26]) and GaP dimer nanoantennas (average ≈ 21% [15]). It is worth noting that some quantum efficiencies observed for SPEs forming on GaP nanoantennas reached higher values (86%), yet the lack of refractive index contrast between nanoantenna and substrate is expected to lead to weaker mode confinement and thus lower average QE enhancement than for the WS 2 NAs on the SiO 2 substrate. While the emitters forming on WS 2 NAs on the Au substrate yielded a much lower average QE of 7%, this is still higher than that observed on SiO 2 nanopillars or uncoupled gold nanocubes, despite the introduction of fast non-radiative charge transfer processes. We attribute this enhanced QE to two factors as discussed in a previous report [15]. First, the possibility of low power excitation leads to suppression of non-radiative exciton-exciton annihilation processes [15, 53], thereby increasing the QE of the SPEs. This factor is a result of the enhanced absorption at the pump laser wavelength as well as the reduced non-radiative processes (suggested by the long decay times compared to previous reports [3, 4]) due to either the high crystal quality of the WS 2 NAs or SPE formation along suspended portions of the monolayer between contact with the dimer and the substrate. Second, Purcell enhancement of the radiative rate is expected for emitters within the NA hotspots [39] also contributing to an increased quantum efficiency.
Optimized WS 2 NAs on a Au substrate with a dielectric spacer As we have demonstrated so far, WS 2 NAs not only enable the photonic enhancement of WSe 2 single photon emitters but also offer integration with various substrates providing different advantages such as quantum efficiency or collection efficiency enhancement. To combine the advantages of the two substrates we have studied and suppress charge-transfer processes which limited SPE intensities for the Au substrate sample, we design an optimized photonic structure for maximum enhancement of WSe 2 monolayer SPEs forming on WS 2 dimer NAs. We consider a gold substrate with a spacer of either sputtered SiO 2 (Figure 3(a)) or few-layer hBN (Figure 3(f)) below the WS 2 NAs. We used FDTD simulations to calculate optimized geometries for the two different types of spacers (see Methods) leading to a radius of 260 nm, a height of 155 nm (175 nm), an ultra-small gap of 10 nm achievable through AFM repositioning [39] and a spacer layer thickness of 1 µ m (4 nm) for the SiO 2 (hBN) spacer. These simulations were carried out with the expectation of an SPE polarization along the WS 2 NA dimer axis as we observed this orientation to be more probable due to the strain profile in the transferred monolayer [19,49] and lead to higher mode confinement [39]. The photonic resonance wavelengths were also constrained to a range coinciding with the range of discovered SPE energies in WSe . The optimized hBN spacer 2 is similar in thickness to an Al 2 O buffer layer (6 nm) grown 3 atop plasmonic nanopillars, used for SPE formation and enhancement, to reduce quenching of WSe 2 monolayer emission [27].
We first simulated the photonic hotspots near the upper surface of the NAs (Figure 3(b)-(c) and (g)-(h) for the SiO 2 and hBN spacer design respectively) leading to excitation rate enhancements within the dimer gap of 1933 (177) for the SiO 2 (hBN) spacer design. The strong confinement in
the few-layer hBN spacer (Figure 3(f)) leads to far lower electric field intensity values at the top surface of the NA when compared to the SiO 2 spacer design. However, the maximum electric field intensities at the outer nanoantenna vertices, where the strain in a transferred WSe 2 monolayer is expected to be the highest [49] and thus most likely to form SPEs, reach far more similar values of 545 and 446 for the SiO 2 and hBN spacer design respectively. The simulated electric field intensity enhancements are directly responsible for an increase in the excitation and thus the fluorescence rate if resonant excitation is employed. Precise tuning of the NA resonance wavelength can be achieved by varying the size, leading to only small reductions in the photonic enhancement in our simulations.
Next, we simulated the expected Purcell factors, directly leading to an increase in quantum efficiency and thus fluorescence rate, for WSe 2 SPEs forming on the top surface of the WS 2 NAs in both designs (Figure 3(d) and (i) for the SiO 2 and hBN spacer design respectively). These are maximized at the inner NA vertices reaching values of 187 (58) for the SiO 2 (hBN) spacer design. While the outer vertices of the NAs, where SPEs are expected to form, yielded similar Purcell factors of 22 and 32 for the SiO 2 and hBN spacer designs respectively. Due to the reduced charge-transfer expected for these nanoantenna designs, we also predict far lower non-radiative rates leading to higher SPE QE and intensity than observed for the WSe 2 SPEs recorded for the Au substrate sample.
Lastly we simulated the radiation pattern expected from these optimized designs, which enables the calculation of collection efficiency and thus the fluorescence rate for SPEs forming both in the dimer gap and at the more probable outer vertices of the NAs (Figures 3(e) and (j) for the for the SiO 2 and hBN spacer design respectively). We observed that most of the emitted light is expected to be redirected away from the Au reflective substrate leading to a collection efficiency of 45% (28%) within our experimental numerical aperture (0.64) for an SPE forming within the dimer gap of the SiO 2 (hBN) spacer design. At the more probable SPE location atop the outer vertex of the NA, we calculated a collection efficiency of 34% (40%) for the SiO 2 (hBN) spacer design. Comparing these designs to the collection efficiency of WS 2 NAs on the SiO 2 substrate used in our experimental study, we expect an enhancement ranging from 2.8 to 4.5.
The fluorescence enhancement we expect to achieve for WSe 2 SPEs forming on the optimized SiO 2 and hBN spacer designs, when compared to vacuum or a flat SiO /Si sur2 face, using the same experimental setup and resonant excitation can be calculated using equation 1 after two considerations. First, Purcell enhancement of the second factor in equation 1 will saturate at a factor of 66, assuming an intrinsic, unenhanced SPE quantum yield of 1.5% [26], as the QE cannot reach higher than 100%. Second, the fluorescence rate will not increase if the excitation rate becomes larger than the lifetime of emission [54]. These two conditions constrain our definition of the fluorescence enhancement to hold only for low intrinsic QE emitters, such as WSe 2 SPEs, and for low laser pumping powers resulting in unenhanced excitation rates far below the emission rate. As the quantum efficiency of SPEs forming in some of the photonic hotspots of the optimized designs may reach 100%, the Purcell enhancement may lead to shorter emission lifetimes and enable even higher laser repetition rates than used in our experiments.
Under these conditions, the fluorescence enhancement factor compared to vacuum ( F/F 0 ) for WSe 2 SPEs forming within the dimer gap of the optimized SiO 2 (hBN) spacer design may reach more than 5 (4) orders of magnitude. Upon comparison with an emitter on a flat 300 nm SiO /Si surface the fluorescence enhancement factor may 2 reach more than 6 (5) orders of magnitude. The far more probable location for SPE formation atop an outside vertex of the NAs yielded maximum fluorescence enhancements of more than 23700 (33200) compared to vacuum for the SiO 2 (hBN) spacer designs which is higher than simulated for the NAs on both substrates studied in experiment. When comparing to an emitter forming on a flat 300 nm SiO /Si 2 surface the fluorescence enhancement may reach factors of more than 157900 (221300).
To enable a more simple fabrication of such WS 2 NAs on a reflective substrate with an insulating spacer, we also simulated designs with a gap of 50 nm, achievable without AFM repositioning. These yielded smaller electric field intensity enhancements and Purcell factors, however, the collection efficiencies were similar leading to a similar expectation of strong fluorescence from WSe 2 SPEs (see Supplementary Note 6).
## Discussion
Our study of WSe 2 monolayer SPEs forming on WS 2 nanoantennas on different substrates illustrates the advantages offered by employing vdW nanoresonators for the photonic enhancement of quantum emitters. We demonstrated the feasibility of achieving vdW nanophotonic structures on both dielectric and metallic surfaces by fabricating WS 2 dimer NAs on SiO 2 and Au substrates which were confirmed to host Mie resonances. FDTD simulations of the fabricated NAs yielded pump laser absorption, quantum efficiency and collection efficiency enhancements for single photon emitters formed within their resonant hotspots.
We transferred monolayers of WSe 2 on the WS 2 NAs fabricated on both substrates and observed the formation of spatially localized, narrow-linewidth single photon emitters in cryogenic PL measurements which exhibited power saturation and long lifetimes indicative of a 0-D quantum state. The linear polarization of most of the emitters forming on the NAs on the Au substrate was discovered to be oriented along the dimer axis which we attribute to the strain profile induced in the monolayer during transfer [19,49]. This provides a more effortless control of the polarization orientation of the SPE than in previous reports [28]. By studying the emission intensity at saturation under pulsed excitation, we were able to calculate the QE of each SPE enabling us to demonstrate enhancements for the WS 2 NAs on a SiO 2 substrate with an average quantum efficiency of 43%, which is higher than previous reports on GaP NAs [15], Au nanocubes [26] and more than an order of magnitude higher than on SiO 2 nanopillars [15]. We attribute this enhancement to the strong resonance confinement enabled by the large refractive index contrast ( ≈ 2.5) achieved when fabricating WS 2 NAs on a SiO 2 substrate leading to lower saturation powers and enhanced Purcell factors [34] resulting in increased quantum efficiencies. The QE of SPEs forming on WS 2 NAs on the Au substrate (7%) were also higher than those forming on SiO 2 nanopillars [15] and uncoupled gold nanocubes [26], providing evidence of photonic enhancement, despite the introduction of a non-radiative decay mechanism through charge transfer.
The study of WSe 2 SPEs forming on WS 2 NAs on different surfaces enabled us to further design and propose optimized nanoantenna geometries on Au substrates with an hBN or SiO 2 spacer layer. Such structures employ the advantages of strong light confinement due to large refractive index contrast [34] as well as improved collection efficiencies due to the reflective substrate, therefore enabling maximum photonic enhancement and collection of the single photon emission. These improved geometries were simulated to yield electric field intensity enhancements up to 1933, Purcell factors of more than 180 and collection efficiencies as high as 45%, leading to maximum expected fluorescence enhancements of more than 6 orders of magnitude for WSe 2 SPEs forming within the dimer gap of the hexagonal WS 2 dimer NA, under low pumping conditions. For far more likely positioned SPEs on the outer vertices of the NAs, we calculated a similarly strong maximum fluorescence enhancement of more than 5 orders of magnitude. The strong electric field intensity and Purcell enhancements are also expected to enable the use of lower pumping powers with higher repetition rates than used in our experiments in order to excite WSe 2 SPEs.
Our study illustrates the advantages offered to TMD SPE formation and enhancement by vdW material nanoresonators which can be fabricated on virtually any substrate further enabling a blend of approaches for maximized photonic enhancement. This material platform enables simple and scalable integration of bright TMD SPEs with devices used in a variety of applications including quantum cryptography and information processing.
## Methods
## Sample fabrication
Gold substrate preparation : In order to prepare the gold substrate, we firstly deposit a 10 nm layer of Ti onto a 290nm SiO /Si substrate via e-beam evaporation in order 2 to improve the adhesion between substrate and gold. We subsequently deposit 100 nm of gold via the same method.
Van der Waals materials exfoliation : WS 2 crystals are mechanically exfoliated from bulk (HQ-graphene) onto a nominally 290 nm SiO 2 on silicon or Au substrate. Large crystals with recognizable axes via straight edged sides at 120 ◦ to each other were identified and their positions within the sample were recorded for further patterning.
Electron beam lithography : Samples were spin coated with ARP-9 resist (AllResist GmbH) at 3500 rpm for 60 s and baked at 180 ◦ for 5 min yielding a film of 200 nm thickness. Electron beam lithography was performed in a
Raith GmbH Voyager system operating at 50 kV using a beam current of 560 pA.
Reactive ion etching : The recipe used for dry etching included SF 6 (30 sccm) at a DC bias of 40 V and a pressure of 0.13 mbar for 40 seconds. Removal of the remaining resist after etching was accomplished by a bath in warm 1165 resist remover (1 hour) followed by Acetone (5 min) and IPA (5 min). If resist is still found on the sample, final cleaning is done in a bath of Acetone (1 hour) and IPA (5 min) followed by 1 hour in a UV ozone treatment. In some cases, the structures were slightly over-etched leading to NAs with a small pedestal of SiO 2 (<15 nm) or gold (<5 nm). This, however, did not lead to any noticeable changes in the photonic resonances.
WSe 2 transfer : WSe 2 monolayers were mechanically exfoliated from a bulk crystal (HQ-graphene) onto a (PDMS) stamp, which had previously been attached to a glass slide. Large monolayers were identified using PL imaging. The glass slide is rotated upside down and attached to a holder arm by means of a vacuum. The target substrate, consisting of WS 2 nanoantennas on a SiO 2 or Au surface, was also held to a stage using the same vacuum. The WSe 2 monolayer was slowly brought into contact with the target substrate through the use of a piezo-scanner stage. After the entire monolayer has contacted the surface, the glass slide with PDMS was slowly moved away from the target substrate. The low speed of the peeling process makes use of the visco-elastic properties of the PDMS polymer and leaves the monolayer of WSe 2 onto the substrate.
Dark field spectroscopy Optical spectroscopy in a dark-field configuration was achieved using a Nikon LV150N microscope with a fiber-coupled output. Incident illumination from a tungsten halogen lamp in the microscope was guided to a circular beam block with a diameter smaller than the beam diameter. The light was then reflected by a 45 ◦ tilted annular mirror towards a 50x Nikon (0.8 NA) dark-field objective which only illuminates the sample at large angles to the normal. Reflected light from the sample is guided back through the same objective towards a fiber coupler. Due to the small diameter of the multimode fiber core used, only light reflected back at small angles to the normal is collected. The fiber from the microscope was subsequently coupled to a Princeton Instruments spectrometer and charge coupled device.
Micro-Photoluminescence spectroscopy In order to record the photoluminescence emitted from monolayer WSe 2 at different regions of our sample, we used a homebuilt setup, which includes a pulsed diode laser at 638 nm. The sample was mounted into an attocube bath cryostat insert following which the chamber was pumped to vacuum and inserted into a helium bath. Heat exchange was achieved by a small amount of helium gas being let into the insert. The collimated excitation laser was passed through a 700 nm short-pass filter, a Glan-Thompson linear polarizer and a half wave plate before being deflected by a 50:50 beam-splitter and passing through the insert window followed by an aspheric lens (0.64 numerical aperture) which focused the beam onto the sample. The emitted light is collected by the same lens and passes through the insert window, beam-splitter a half wave plate, thin film polarizer and a 700 nm long-pass filter to be guided through a single mode fiber before being focused onto the slit of a Princeton Instruments spectrometer (0.75 meter) and CCD. The PL lifetime studies utilized the pulsed laser excitation and the emitted light was spectrally filtered (10 nm) using the exit slit of the spectrometer before it was fiber-coupled to an ID Quantique avalanche photo-diode (id100).
Hanbury-Brown-Twiss experiment The autocorrelation measurements used to provide evidence of single photon emission were performed using the same setup as for the micro-photoluminescence studies. However, the 700 nm long-pass filter was exchanged for a 750 nm bandpass filter (spectral width = 10 nm) and the fiber output was coupled to a superconducting single photon detector (Single Quantum). The relatively high values of g 2 (0) are largely attributed to the poor bandpass filter utilized to measure the photon statistics of the SPEs.
FDTD simulations The finite-difference time-domain simulations were carried out using Lumerical Inc. software. The geometry of hexagonal WS 2 nanoantennas on a SiO 2 or Au substrate with and without a spacer were defined within the software utilizing the refractive index of WS 2 from reference [41], SiO 2 from reference [55], Au from reference [56] and hBN from reference [41].
Electric field intensity simulations : Calculations of the electric field intensity normalized to vacuum were simu-
lated using plane wave illumination propagating normal to the surface using a TFSF source from the air side. The illumination was polarized along the dimer axis with a plane monitor recording the electric field 0.5 nm above the top surface of the nanoantennas or as a vertical cross-section of the structure passing through the dimer axis.
Purcell factor simulations : Simulations of the Purcell factor normalized to vacuum were carried out using the same geometry as for the electric field intensity simulations. The illumination was achieved through a dipole source placed at different positions, 0.5 nm above the top surface of the nanoantenna with a polarization parallel to the dimer axis.
Collection efficiency simulations : Calculations of the collection efficiency were carried out using the same geometry as before. Illumination was achieved via a dipole source placed 0.5 nm above either an inside vertex of the WS 2 NA, an outside vertex of the NA, or the substrate including SiO 2 and Au. The power of the emitted light was collected using a infinite plane monitor placed 0.5 nm above the dipole source following which a filter corresponding to the 0.64 numerical aperture was applied to the collected power. This power was subsequently normalized to the collected power in all directions from the dipole. Collection efficiency enhancement was then calculated by normalizing the collection efficiency for a dipole within the NA geometry to one in vacuum.
Optimization procedure for WS 2 NAs on a Au substrate with a dielectric spacer : In order to optimize the geometry of the WS 2 NAs on the Au substrate with a SiO 2 or hbN spacer, simulations of the electric field intensity were performed, as confinement of the electric field is expected to lead to Purcell enhancement. As the electric field intensity and Purcell factor have far larger contributions to the fluorescence enhancement, which was the main focus of this procedure, the collection efficiency was only calculated after electric field optimization. The electric field intensity was recorded for the inner and outer vertices of the WS 2 NAs where SPE formation is probable. The radius and height of the nanoantenna as well as the thickness of the spacer layer were varied consecutively until a maximum electric field intensity was achieved within the photonic hotspots. Simulations for the two spacer designs with a gap of 10 nm and 50 nm were all carried out individually.
As the initial optimization procedure yielded several spacer thicknesses resulting in similar electric field intensities, the collection efficiency for each was used to determine the optimum thickness.
## Acknowledgments
## Author Contributions
X.H. and Y.W. deposited the metal to form the Au substrate. X.H. and P.G.Z. exfoliated WS 2 onto the SiO 2 and Au substrates. X.H. and Y.W. both contributed to the fabrication of the WS 2 nanoantennas on both substrates. P.G.Z. and S.R. carried out the scanning electron microscopy and AFM measurements to characterize the geometry of the fabricated nanoantennas. P.G.Z. and S.R. transferred the WS 2 monolayer onto the fabricated NAs on both substrates and performed the dark-field and microphotoluminescence measurements. P.G.Z. carried out the Hanbury-Brown-Twiss experiments. P.G.Z. and A.I.T. conceived the experiments and simulations as well as analyzed the results and wrote the manuscript with contributions from all co-authors. A.I.T. oversaw the entire project.
## References
- [1] Mikko Turunen, Mauro Brotons-Gisbert, Yunyun Dai, Yadong Wang, Eleanor Scerri, Cristian Bonato, Klaus D. Jöns, Zhipei Sun, and Brian D. Gerardot. Quantum photonics with layered 2d materials. Nature Reviews Physics , 0123456789, 2022.
- [2] Philipp Tonndorf, Robert Schmidt, Robert Schneider, Johannes Kern, Michele Buscema, Gary A. Steele, Andres Castellanos-Gomez, Herre S. J. van der Zant, Steffen Michaelis de Vasconcellos, and Rudolf Bratschitsch. Single-photon emission from localized excitons in an atomically thin semiconductor. Optica , 2:347, 2015.
- [3] Yu-Ming He, Genevieve Clark, John R. Schaibley, YuMing He, Ming-Cheng Chen, Yu-Jia Wei, Xing Ding, Qiang Zhang, Wang Yao, Xiaodong Xu, Chao-Yang Lu, and Jian-Wei Pan. Single quantum emitters in monolayer semiconductors. Nature Nanotechnology , 10:497-502, 2015.
- [4] Ajit Srivastava, Meinrad Sidler, Adrien V. Allain, Dominik S. Lembke, Andras Kis, and A. Imamoğlu. Optically active quantum dots in monolayer wse 2 . Nature Nanotechnology , 10:491-496, 2015.
- [5] M. Koperski, K. Nogajewski, A. Arora, J. Marcus, P. Kossacki, and M. Potemski. Single photon emitters in exfoliated wse 2 structures. Nature Nanotechnology , 10:503-506, 2015.
- [6] Chitraleema Chakraborty, Laura Kinnischtzke, Kenneth M. Goodfellow, Ryan Beams, and A. Nick Vamivakas. Voltage-controlled quantum light from an atomically thin semiconductor. Nature Nanotechnology , 10:507-511, 2015.
- [7] S. Kumar, A. Kaczmarczyk, and B. D. Gerardot. Strain-induced spatial and spectral isolation of quantum emitters in mono- and bilayer wse 2 . Nano Letters , 15:7567-7573, 2015.
- [8] Artur Branny, Santosh Kumar, Raphaël Proux, and Brian D. Gerardot. Deterministic strain-induced arrays of quantum emitters in a two-dimensional semiconductor. Nature Communications , 8:15053, 2017.
- [9] Matthew R. Rosenberger, Chandriker Kavir Dass, Hsun Jen Chuang, Saujan V. Sivaram, Kathleen M. McCreary, Joshua R. Hendrickson, and Berend T. Jonker. Quantum calligraphy: Writing single-photon emitters in a two-dimensional materials platform. ACS Nano , 13:904-912, 2019.
- [10] Raphaël S. Daveau, Tom Vandekerckhove, Arunabh Mukherjee, Zefang Wang, Jie Shan, Kin Fai Mak, A. Nick Vamivakas, Gregory D. Fuchs, A. Nick Vamivakas, and Gregory D. Fuchs. Spectral and spatial isolation of single tungsten diselenide quantum emitters using hexagonal boron nitride wrinkles. APL Photonics , 5:096105, 2020.
- [11] Oguzhan Yücel, Denis Yagodkin, Jan N. Kirchhof, Abhijeet Kumar, Adrian Dewambrechies, Sviatoslav Kovalchuk, Yufeng Yu, and Kirill I. Bolotin. Strain activation of localized states in wse 2 . arXiv , 2 2024.
- [12] Maja Feierabend, Samuel Brem, and Ermin Malic. Optical fingerprint of bright and dark localized excitonic states in atomically thin 2d materials. Physical Chemistry Chemical Physics , 21:26077-26083, 2019.
- [13] Lukas Linhart, Matthias Paur, Valerie Smejkal, Joachim Burgdörfer, Thomas Mueller, and Florian Li-
- bisch. Localized inter-valley defect excitons as singlephoton emitters in wse . 2 Physical Review Letters , 123:146401, 2019.
- [14] Chandriker Kavir Dass, Mahtab A. Khan, Genevieve Clark, Jeffrey A. Simon, Ricky Gibson, Shin Mou, Xiaodong Xu, Michael N. Leuenberger, and Joshua R. Hendrickson. Ultra-long lifetimes of single quantum emitters in monolayer wse /hbn heterostructures. 2 Advanced Quantum Technologies , 1900022:1900022, 2019.
- [15] Luca Sortino, Panaiot G. Zotev, Catherine L. Phillips, Alistair J. Brash, Javier Cambiasso, Elena Marensi, A. Mark Fox, Stefan A. Maier, Riccardo Sapienza, and Alexander I. Tartakovskii. Bright single photon emitters with enhanced quantum efficiency in a two-dimensional semiconductor coupled with dielectric nano-antennas. Nature Communications , 12:6063, 2021.
- [16] K. Oreszczuk, T. Kazimierczuk, T. Smoleński, K. Nogajewski, M. Grzeszczyk, A. Łopion, M. Potemski, and P. Kossacki. Carrier relaxation to quantum emitters in few-layer wse 2 . Physical Review B , 102:1-5, 2020.
- [17] Jessica Lindlau, Malte Selig, Andre Neumann, Léo Colombier, Jonathan Förste, Victor Funk, Michael Förg, Jonghwan Kim, Gunnar Berghäuser, Takashi Taniguchi, Kenji Watanabe, Feng Wang, Ermin Malic, and Alexander Högele. The role of momentum-dark excitons in the elementary optical response of bilayer wse . 2 Nature Communications , 9:1-7, 2018.
- [18] Authors J Klein, L Sigl, S Gyger, K Barthelmi, M Florian, S Rey, and T Taniguchi. Scalable single-photon sources in atomically thin mos 2 . arXiv , 2020.
- [19] Johannes Kern, Iris Niehues, Philipp Tonndorf, Robert Schmidt, Daniel Wigger, Robert Schneider, Torsten Stiehm, Steffen Michaelis de Vasconcellos, Doris E. Reiter, Tilmann Kuhn, and Rudolf Bratschitsch. Nanoscale positioning of single-photon emitters in atomically thin wse . 2 Advanced Materials , 28:71017105, 2016.
- [20] Gabriella D. Shepard, Obafunso A. Ajayi, Xiangzhi Li, X. Y. Zhu, James Hone, and Stefan Strauf. Nanobubble induced formation of quantum emitters in monolayer semiconductors. 2D Materials , 4:021019, 2017.
- [21] Mäx Blauth, Marius Jürgensen, Gwenaëlle Vest, Oliver Hartwig, Maximilian Prechtl, John Cerne,
- Jonathan J. Finley, and Michael Kaniber. Coupling single photons from discrete quantum emitters in wse 2 to lithographically defined plasmonic slot-waveguides. Nano Letters , 18:6812-6819, 2018.
- [22] Frédéric Peyskens, Chitraleema Chakraborty, Muhammad Muneeb, Dries Van Thourhout, and Dirk Englund. Integration of single photon emitters in 2d layered materials with a silicon nitride photonic chip. Nature Communications , 10, 12 2019.
- [23] L. C. Flatten, L. Weng, A. Branny, S. Johnson, P. R. Dolan, A. A.P. P Trichet, B. D. Gerardot, and J. M. Smith. Microcavity enhanced single photon emission from two-dimensional wse . 2 Applied Physics Letters , 112, 2018.
- [24] J C Drawer, V N Mitryakhin, H Shan, S Stephan, M Gittinger, L Lackner, and B Han. Ultra-bright single photon source based on an atomically thin material. arXiv , 2023.
- [25] Oliver Iff, Quirin Buchinger, Magdalena MoczałaDusanowska, Martin Kamp, Simon Betzold, Marcelo Davanco, Kartik Srinivasan, Sefaattin Tongay, Carlos Antón-Solanas, Sven Höfling, and Christian Schneider. Purcell-enhanced single photon source based on a deterministically placed wse2monolayer quantum dot in a circular bragg grating cavity. Nano Letters , 21:47154720, 2021.
- [26] Yue Luo, Gabriella D. Shepard, Jenny V. Ardelean, Daniel A. Rhodes, Bumho Kim, Katayun Barmak, James C. Hone, and Stefan Strauf. Deterministic coupling of site-controlled quantum emitters in monolayer wse 2 to plasmonic nanocavities. Nature Nanotechnology , 13:1137-1142, 2018.
- [27] Tao Cai, Je Hyung Kim, Zhili Yang, Subhojit Dutta, Shahriar Aghaeimeibodi, and Edo Waks. Radiative enhancement of single quantum emitters in wse 2 monolayers using site-controlled metallic nanopillars. ACS Photonics , 5:3466-3471, 2018.
- [28] Yue Luo, Na Liu, Bumho Kim, James Hone, and Stefan Strauf. Exciton dipole orientation of straininduced quantum emitters in wse . 2 Nano Letters , 20:5119-5126, 2020.
- [29] Athanasios Paralikis, Claudia Piccinini, Abdulmalik A. Madigawa, Pietro Metuh, Luca Vannucci, Niels
- Gregersen, and Battulga Munkhbat. Tailoring polarization in wse 2 quantum emitters through deterministic strain engineering. arXiv , 2 2024.
- [30] Oliver Iff, Davide Tedeschi, Javier Martín-Sánchez, Magdalena Moczała-Dusanowska, Sefaattin Tongay, Kentaro Yumigeta, Javier Taboada-Gutiérrez, Matteo Savaresi, Armando Rastelli, Pablo Alonso-González, Sven Höfling, Rinaldo Trotta, and Christian Schneider. Strain-tunable single photon sources in wse 2 monolayers. Nano Letters , 19:6931-6936, 2019.
- [31] Adina Ripin, Ruoming Peng, Xiaowei Zhang, Srivatsa Chakravarthi, and Minhao He. Tunable phononic coupling in excitonic quantum emitters. arXiv , pages 120, 2023.
- [32] Na Liu, Licheng Xiao, Shichen Fu, Yichen Ma, Song Liu, Siwei Chen, James Hone, Eui-Hyeok Yang, and Stefan Strauf. Chiral single photons from deterministic quantum emitter arrays via proximity coupling to van der waals ferromagnets. 2D Materials , pages 0-23, 2018.
- [33] Carmen Palacios-Berraquero, Dhiren M. Kara, Alejandro R. P. Montblanch, Matteo Barbone, Pawel Latawiec, Duhee Yoon, Anna K. Ott, Marko Loncar, Andrea C. Ferrari, and Mete Atature. Large-scale quantum-emitter arrays in atomically thin semiconductors. Nature Communications , 8:15093, 2017.
- [34] Jacob T. Robinson, Christina Manolatou, Long Chen, and Michal Lipson. Ultrasmall mode volumes in dielectric optical microcavities. Physical Review Letters , 95:1-4, 2005.
- [35] Ruggero Verre, Denis G. Baranov, Battulga Munkhbat, Jorge Cuadra, Mikael Käll, and Timur Shegai. Transition metal dichalcogenide nanodisks as high-index dielectric mie nanoresonators. Nature Nanotechnology , 14:679-683, 2019.
- [36] Johannes E. Fröch, Yongsop Hwang, Sejeong Kim, Igor Aharonovich, and Milos Toth. Photonic nanostructures from hexagonal boron nitride. Advanced Optical Materials , 7:1801344, 2019.
- [37] Xingwang Zhang, Xiaojie Zhang, Wenzhuo Huang, Kedi Wu, Mengqiang Zhao, A. T. Charlie Johnson, Sefaattin Tongay, and Ertugrul Cubukcu. Ultrathin ws -on-glass photonic crystal for self-resonant exciton2
polaritonics. Advanced Optical Materials , 8:1901988, 2020.
- [38] Battulga Munkhbat, Betül Küçüköz, Denis G. Baranov, Tomasz J. Antosiewicz, and Timur O. Shegai. Nanostructured transition metal dichalcogenide multilayers for advanced nanophotonics. Laser and Photonics Reviews , page 2200057, 2022.
- [39] Panaiot G Zotev, Yue Wang, Luca Sortino, Toby Severs Millard, Nic Mullin, Donato Conteduca, Mostafa Shagar, Armando Genco, Jamie K Hobbs, Thomas F Krauss, and Alexander I Tartakovskii. Transition metal dichalcogenide dimer nanoantennas for tailored light-matter interactions. ACS Nano , 16:6493-6505, 2022.
- [40] Thomas Weber, Lucca Kühner, Luca Sortino, Amine Ben Mhenni, Nathan P. Wilson, Julius Kühne, Jonathan J. Finley, Stefan A. Maier, and Andreas Tittl. Intrinsic strong light-matter coupling with selfhybridized bound states in the continuum in van der waals metasurfaces. Nature Materials , 22:970-976, 2023.
- [41] Panaiot G. Zotev, Yue Wang, Daniel Andres-penares, Toby Severs Millard, Sam Randerson, Xuerong Hu, Luca Sortino, Charalambos Louca, Mauro BrotonsGisbert, Tahiyat Huq, Stefano Vezzoli, Riccardo Sapienza, Thomas F. Krauss, Brian D Gerardot, Alexander I. Tartakovskii, Stefano Vezzoli, Riccardo Sapienza, Thomas F. Krauss, Brian D Gerardot, and Alexander I. Tartakovskii. Van der waals materials for applications in nanophotonics. Laser and Photonics Reviews , 17:2200957, 2023.
- [42] Sam A. Randerson, Panaiot G. Zotev, Xuerong Hu, Alexander J. Knight, Yadong Wang, Sharada Nagarkar, Dominic Hensman, Yue Wang, and Alexander I. Tartakovskii. High q hybrid mie-plasmonic resonances in van der waals nanoantennas on gold substrate. ACS Nano , 6 2024.
- [43] Milad Nonahal, Chi Li, Haoran Ren, Lesley Spencer, Mehran Kianinia, Milos Toth, and Igor Aharonovich. Engineering quantum nanophotonic components from hexagonal boron nitride. Laser and Photonics Reviews , 17:2300019, 2023.
- [44] Junghyun Sung, Dongjin Shin, Hyunhee Hee Cho, Seong Won Lee, Seungmin Park, Young Duck Kim,
- Jong Sung Moon, Je hyung Hyung Kim, and Su hyun Hyun Gong. Room-temperature continuous-wave indirect-bandgap transition lasing in an ultra-thin ws2 disk. Nature Photonics , 16:792-797, 2022.
- [45] Johannes E. Fröch, Chi Li, Yongliang Chen, Milos Toth, Mehran Kianinia, Sejeong Kim, and Igor Aharonovich. Purcell enhancement of a cavity-coupled emitter in hexagonal boron nitride. Small , 18:2104805, 2022.
- [46] Luca Sortino, Angus Gale, Lucca Kühner, Chi Li, Jonas Biechteler, Fedja J. Wendisch, Mehran Kianinia, Haoran Ren, Milos Toth, Stefan A. Maier, Igor Aharonovich, and Andreas Tittl. Optically addressable spin defects coupled to bound states in the continuum metasurfaces. Nature Communications , 15:2008, 2023.
- [47] Linglong Zhang, Han Yan, Xueqian Sun, Miheng Dong, Tanju Yildirim, Bowen Wang, Bo Wen, Guru Prakash Neupane, Ankur Sharma, Yi Zhu, Jian Zhang, Kun Liang, Boqing Liu, Hieu T. Nguyen, Daniel Macdonald, and Yuerui Lu. Modulated interlayer charge transfer dynamics in a monolayer tmd/metal junction. Nanoscale , 11:418-425, 2019.
- [48] Dorte R. Danielsen, Anton Lyksborg-Andersen, Kirstine E.S. Nielsen, Bjarke S. Jessen, Timothy J. Booth, Manh Ha Doan, Yingqiu Zhou, Peter Bøggild, and Lene Gammelgaard. Super-resolution nanolithography of two-dimensional materials by anisotropic etching. ACS Applied Materials and Interfaces , 13:4188641894, 2021.
- [49] Luca Sortino, Matthew Brooks, Panaiot G. Zotev, Armando Genco, Javier Cambiasso, Sandro Mignuzzi, Stefan A. Maier, Guido Burkard, Riccardo Sapienza, and Alexander I. Tartakovskii. Dielectric nanoantennas for strain engineering in atomically thin twodimensional semiconductors. ACS Photonics , 7:24132422, 2020.
- [50] L. Sortino, P. G. Zotev, S. Mignuzzi, J. Cambiasso, D. Schmidt, A. Genco, M. Aßmann, M. Bayer, S. A. Maier, R. Sapienza, and A. I. Tartakovskii. Enhanced light-matter interaction in an atomically thin semiconductor coupled with dielectric nano-antennas. Nature Communications , 10:5119, 2019.
- [51] G. Wang, L. Bouet, D. Lagarde, M. Vidal, A. Balocchi, T. Amand, X. Marie, and B. Urbaszek. Valley dynamics probed through charged and neutral exciton emission in monolayer wse . 2 Physical Review B Condensed Matter and Materials Physics , 90:075413, 2014.
- [52] C R Zhu, K Zhang, M Glazov, B Urbaszek, T Amand, Z W Ji, B L Liu, and X Marie. Exciton valley dynamics probed by kerr rotation in wse 2 monolayers. Physical Review B , 161302:1-5, 2014.
- [53] Shinichiro Mouri, Yuhei Miyauchi, Minglin Toh, Weijie Zhao, Goki Eda, and Kazunari Matsuda. Nonlinear photoluminescence in atomically thin layered wse 2
- arising from diffusion-assisted exciton-exciton annihilation. Physical Review B - Condensed Matter and Materials Physics , 90:155449, 2014.
- [54] Javier Cambiasso, Matthias König, Emiliano Cortés, Sebastian Schlücker, and Stefan A. Maier. Surfaceenhanced spectroscopies of a molecular monolayer in an all-dielectric nanoantenna. ACS Photonics , 5:15461557, 2018.
- [55] Edward D. Palik. Handbook of optical constants of solids. Academic Press , I-III, 1998.
- [56] P B Johnson and R W Christy. Optical constants of the noble metals. Phys. Rev. B , 6:4370-4379, 1972.
Figure 1: Simulation of photonic enhancement expected for WSe 2 SPEs forming on WS 2 nanoantennas on a SiO 2 and Au substrate. (a) and (b) Schematic illustration of WS 2 dimer nanoantennas fabricated onto a SiO 2 (left) and Au (right) substrate respectively. (c) and (d) Experimentally recorded dark field spectra of several WS 2 dimer nanoantennas on the SiO 2 and Au substrate respectively demonstrating the presence of magnetic (MD) and electric (ED) dipole Mie resonances as well as an anapole (AM) and higher order anapole mode (HOAM) which can be used for photonic enhancement of SPEs. (e) and (f) Simulations of the electric field intensity profile at the top surface of a WS 2 NA on a SiO 2 (r = 235nm, h = 135nm, g = 150nm) and Au (r = 205nm, h = 190nm, g = 515nm) substrate respectively, where WSe 2 monolayer SPEs are expected to form after transfer due to the high strain values at the edges of the structure. Electric field hotspots are confined to the the inner and outer vertices of the NA. The wavelength of 750 nm is used as this is near the expected energies of WSe 2 SPEs. Scale bars = 200 nm. (g) and (h) Simulations of the electric field intensity profile for a vertical cut through the WS 2 NA on a SiO 2 and Au substrate respectively for the same geometries and wavelength. Electric field hotspots are confined to the top surface of the NA for both substrates, while there is an additional hotspot at interface between the WS 2 NA and the Au substrate. (i) , (j) and (k) Excitation rate enhancement factor, Purcell factor, and collection efficiency calculated at appropriate wavelengths for a fabricated array of WS 2 NAs with a range of radii on the SiO 2 (dark blue) and Au (orange) substrate.
Figure 2: WSe 2 single photon emitter formation, intensity and quantum efficiency on WS 2 NAs on SiO 2 and Au substrates. (a) Left Panel: Cryogenic PL map of monolayer WSe 2 surrounding three WS 2 nanoantenna positions (NA 1 , NA , NA ) on the SiO 2 3 2 substrate integrated from 1.663 to 1.666 eV. Right Panel: Room temperature PL image from the same region of the sample. Overlap of bright emission at both temperatures indicates SPE localization at nanoantenna sites. (b) PL spectra of a WSe 2 monolayer SPE forming on a WS 2 NA fabricated on a SiO 2 (dark blue) and Au (orange) substrates exhibiting narrow linewidth emission. Yellow regions highlight integration energies for map in (a) as well as for Hanbury-Brown-Twiss (HBT) experiments. Inset: Results of HBT experiments for both SiO 2 (right) and Au (left) substrates exhibiting g 2 (0) values below 0.5 indicating single photon emission. (c) Integrated intensities per nW of excitation power of SPEs forming on WS 2 NAs on SiO 2 (dark blue) and Au (orange) substrates at saturation. The SiO 2 (Au) substrate sample yielded emitters with an average intensity of 23.3 (8.6) Hz/nW indicated by the horizontal dashed lines. (d) Quantum efficiency calculated for each recorded SPE forming on WS 2 NAs fabricated on SiO 2 and Au substrates. Emitters in SiO 2 (Au) substrate sample yielded an average QE of 43% (7%) indicated by the horizontal dashed lines. Error bars indicate the uncertainty of the position of the emitter relative to the NA and thus an uncertainty in the collection efficiency used for the QE calculation. Note that the error bars are not visible for some of the SPEs on WS 2 NAs on the Au substrate due to a very small difference in the collection efficiency for different emitter positions and the much smaller average QE.
Figure 3: Photonic enhancement simulations of optimized WS 2 NA designs on a Au substrate with a SiO 2 or hBN spacer. (a) and (f) Schematic illustrations of WS 2 NAs on a Au substrate with a SiO 2 and hBN spacer for optimum fluorescence enhancement of WSe 2 monolayer SPEs. (b) (c) , and (g) (h) , Simulated electric field intensity profiles at the top surface and as a vertical cut through the middle of the WS 2 NAs for optimized designs with a SiO 2 and hBN spacer at the photonic resonance wavelength of 753 nm and 757 nm respectively. Electric field hotspots are observed in the dimer gap and at the outer top vertices of the NAs. (d) and (i) Maps of the Purcell factor at different positions at the top surface of the WS 2 NA for the SiO 2 and hBN spacer designs respectively. Larger enhancements are observed within the dimer gap and at the outer top vertices of the NA, where SPEs are expected to form, as expected from the electric field hotspots in (b) (c) (g) , , and (h) . (e) and (j) Radiation patterns for SPE positions within the dimer gap (dark blue) and at the outer top vertices (orange) for the SiO 2 and hBN spacer designs respectively. Emission is directed mainly towards collection optics with the cone defined by the experimental numerical aperture in this study indicated by the red dashed lines. The numbers to the sides indicate the collection efficiency, with a numerical aperture of 0.64, for an emitter forming in the dimer gap (dark blue) and at the outer top vertices of the NA. Lower insets indicate the position of the SPE dipole relative to the WS 2 NAs. All scale bars = 200 nm.
## Supplementary Information for: Single photon emitters in monolayer semiconductors coupled to transition metal dichalcogenide nanoantennas on silica and gold substrates
Panaiot G. Zotev a ∗ , Sam Randerson , Xuerong Hu , Yue Wang , Alexander I. Tartakovskii a a b a ∗∗
a Department of Physics and Astronomy, University of Sheffield, Sheffield, S3 7RH, UK
b School of Physics, Engineering and Technology, University of York, York, YO10 5DD, UK ∗ [email protected] ∗∗ [email protected]
## Supplementary Note 1: Monolayer transfer onto nanoantennas fabricated on SiO 2 and Au substrate
We used an all dry PDMS polymer stamp technique to mechanically transfer exfoliated monolayers of WSe 2 onto arrays of WS 2 nanoantennas (NAs) which were previously fabricated on SiO 2 and Au substrates. Figures S1(a) and (b) display optical microscopy images of the completed samples overlayed by PL images at room temperature. Brightening of the PL surrounding the NA positions is expected as a result of a photonic enhancement due to coupling of the WSe 2 emission to the NA resonances [1].

Figure S1: Microscope images of WSe 2 monolayer transferred onto WS 2 NAs on a SiO 2 and Au substrate. (a) and (b) Bright field microscope images of a WSe 2 monolayer transferred onto WS 2 NAs on a SiO 2 and Au substrate respectively. Each image is overlayed with a room temperature PL image taken in the same microscope. Bright positions surrounding the WS 2 NAs provide evidence of fluorescence enhancement of the WSe 2 monolayer emission. The monolayer region is outlined in red. (b) .

## Supplementary Note 2: Properties of single photon emitters forming on WS nanoantennas on SiO 2 2 and Au substrates
While studying the photoluminescence of the WSe 2 monolayer transferred on WS 2 nanoantennas (NAs) fabricated on both SiO 2 and Au substrates, we recorded a statistics of several different properties of the formed single photon emitters. Firstly, by varying a half-wave plate in the detection path of our setup, we recorded a clear cos 2 (x) shape confirming linear polarization of the single photon emitters (SPE) emission as shown in the inset of Figure S2(a). As we have set the polarization angle of 0 ◦ to be parallel to the axis connecting the centers of the nanopillars in the WS 2 dimer nanoantenna, we note that a majority of the SPEs recorded for the Au substrate appear to closely conform to this angle. This suggests that many of the emitters form with a dipole moment along this dimer axis which is attributed to the underlying nanoantenna geometry and the strain profile applied to the monolayer during transfer [2]. This confirms that control over the polarization angle of the SPEs can be achieved by using appropriately designed nanoresonators.
Secondly, we increased the power of our excitation laser (638 nm, Pulsed: 5Mhz) and observed the saturation of the emission intensity of all of the studied emitters on both substrates as expected for filled 0-D quantum states, as shown in the inset of Figure S2(b). Each power dependent measurement was fit to an equation of the form I = I sat · P/ P ( + P sat ) where I sat indicates the maximum intensity of the SPE and P sat indicates the power at which saturation begins to occur. We recorded very similar powers for the onset of saturation for both SPEs forming on WS 2 NAs on the SiO 2 and Au substrates with averages of 106.03 nW and 97.58 nW respectively as displayed in Figure S2(b). We expect that additional decay channels, such as charge transfer to the metallic film [3], may lead to higher saturation powers for the Au substrate as a result of a reduced exciton trapping for similar excitation powers. However, a suppression of Auger processes due to the reduced exciton population from charge transfer to the substrate would lead to lower saturation powers and thus counteract this effect.
Due to the additional charge transfer decay channel, we expected that the emission lifetime of the SPEs forming on the NAs on the Au film would exhibit reduced lifetimes when compared to those on the SiO 2 substrate as a result of an increase in the non-radiative decay rate. This was observed in the lifetime statistics we collected from emitters forming on NAs on both substrates as displayed in Figure S2(c). The average lifetime of the studied SPEs on the Au film was recorded to be 26.35 ns which is nearly a factor of 2 smaller than for the SPEs forming on NAs on the SiO 2 substrate where the average recorded lifetime was 49 ns. The measured lifetimes, examples of which are plotted in the inset of Figure S2(c), were also often found to be longer than observed in many previous reports [4-7] reaching values of 100s of ns. A few previous works on SPEs in hBN encapsulated WSe 2 monolayers [8] and SPEs forming on GaP dimer nanoantennas [9] also observed such long emission lifetimes which were attributed to a reduced non-radiative rate, and thus higher quantum efficiency, thereby providing nearly-pure measurements of the native WSe 2 SPE radiative decay time which may be much longer than previously believed.
Lastly, while studying the PL spectra of the quantum emitters, examples of which are plotted in the inset of Figure S2(d), we recorded a statistics of their full width at half maxima (FWHM) which are plotted in Figure S2(d). The average linewidth of the SPEs on the Au film (436 µ eV) were found to be slightly lower than for those on the SiO 2 substrate (478 µ eV). This correlates with an increased non-radiative decay rate observed from PL dynamics measurements as the reduced lifetime is expected to yield less spectral wandering and thus a reduction in the recorded FWHM.
Figure S2: Statistics of linear polarization, power saturation, PL decay lifetime and linewidth recorded for SPEs on the SiO 2 and Au substrates. (a) Histogram of linear polarization angles recorded for SPEs on WS 2 NAs on the SiO 2 (dark blue) and Au (orange) substrates. Many emitters were found to exhibit a polarization parallel or nearly parallel to the dimer axis (0 ◦ . Inset: Exemplary cos 2 (x) fits of SPE emission intensity with varying polarization angle indicative of linear polarization. (b) Histogram of excitation powers at which SPE intensities saturate for emitters on WS 2 NAs on the SiO 2 (dark blue) and Au (orange) substrates. The average values recorded for the SiO 2 (Au) substrate sample are 106.03 nW (97.58 nW) as indicated by the vertical dashed lines. Inset: Exemplary power dependent intensities of emitters on both substrates with similar saturation powers extracted from power law fits. (c) Histogram of PL decay lifetimes recorded for SPEs on WS 2 NAs on the SiO 2 (dark blue) and Au (orange) substrates. The average values recorded for the SiO 2 (Au) substrate sample are 49 ns (26.35 ns) as indicated by the vertical dashed lines. The lower lifetimes for the Au substrate sample suggest the presence of an additional non-radiative decay process. Inset: Exemplary SPE PL decay traces fitted with single exponential decay curves from which the emission lifetime is extracted. (d) Histogram of linewidths recorded for SPEs on WS 2 NAs on the SiO 2 (dark blue) and Au (orange) substrates. The average values recorded for the SiO 2 (Au) substrate sample are 478 µ eV (436 µ eV) as indicated by the vertical dashed lines. Inset: Exemplary SPE emission spectra fitted with Lorentzian functions.
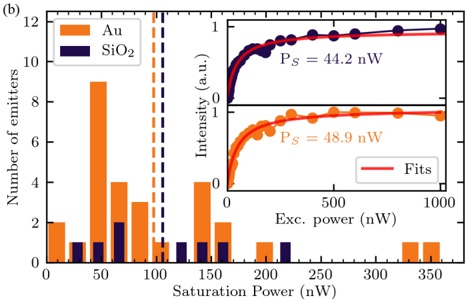
## Supplementary Note 3: Room temperature PL and emission decay from monolayer WSe 2 on a SiO 2 and Au substrate
In order to observe evidence of charge transfer, which we expect to be present in our WSe 2 monolayer on Au sample [3], we recorded the neutral exciton emission from a flat part of the single layers on both the SiO 2 and Au substrates under pulsed excitation at 638 nm focused to a 2.2 µ m spot, displayed in Figure S3(a). We observed an order of magnitude reduction in the PL from the Au surface compared to the SiO 2 substrate suggesting additional non-radiative decay channels have been introduced. Following this, we observed further evidence of a charge-transfer process in power dependent PL decay measurements.
Exciton-exciton annihilation processes have been previously observed to dominate room temperature neutral exciton emission from WSe 2 monolayers [10] leading to a quick exponential decay of the emission soon after excitation (<100 ps) followed by radiative and further non-radiative decay processes resulting in a longer exponential decay ( ≈ 1 ns). This results in a biexponential emission decay curve. We have measured WSe 2 monolayer neutral exciton emission decay using 90 ps pulsed excitation at a repetition rate of 80 MHz for a range of powers from 39 nW to 40 µ Wfrom the SiO 2 and Au substrates, plotted in Figures S3(a) and (b) respectively. For powers below 125 nW we observe an exponential decay curve from the monolayers on both substrates. At higher powers, a second exponential component of the emission decay is observed to emerge for the WSe 2 monolayer on the SiO 2 substrate. This then quickly begins to dominate the entire decay at powers as high as several tens of µ W as expected from exciton-exciton annihilation [10]. In contrast to this, the monolayer on the Au film does not exhibit a non-negligible second exponential component in its decay trace until powers above 4.35 µ W. We attribute this to the fast charge-transfer expected to occur for a WSe 2 monolayer deposited onto an Au substrate [3] which depletes the exciton population and leads to a suppressed exciton-exciton annihilation rate [10]. The larger diffusion lengths of dark excitons (1.5 µ m [11]), believed to feed the state responsible for single photon emission in monolayer WSe 2 [9], compared to our 190 nm WS 2 NAs on the Au substrate, atop which the strain is most likely expected to form quantum emitters, suggests exciton-exciton annihilation may also be partially suppressed near the single photon emitters.
Figure S3: Room temperature PL spectra and power dependent emission decay. (a) Room temperature PL spectra recorded for a WSe 2 monolayer transferred onto a flat SiO 2 (dark blue) and Au (orange) substrate under 40 nW of pulsed (5 MHz) excitation at 638 nm. (b) Power dependent PL decay traces for monolayer WSe 2 emission on a flat SiO 2 substrate. Single exponential decay is observed for excitation powers below 125 nW. Double exponential decay indicative of Auger recombination is present at highter excitation powers. (c) Power dependent PL decay traces for monolayer WSe 2 emission on a flat Au substrate. Single exponential decay is observed for excitation powers up to 4.35 µ Windicating suppressed Auger recombination.

## Supplementary Note 4: Heating effects due to absorption from Au substrate
As WSe 2 single photon emitter intensities are strongly suppressed at temperatures above 30 K [12], we considered that any heating effects due to the absorption of the Au substrate [13], may lead to a reduction in the peak intensities of the SPEs. We do not expect any heating due to absorption in the WS 2 nanoantennas as the excitation wavelength of 637 nm is below the exciton absorption of the material (625 nm) [14]. In order to understand how the metal absorption of the exciting pulsed laser light may locally increase the temperature of the sample, we consider a simple geometry for which the calculation is easier. This consists of a WS 2 dimer nanoantenna fabricated on an Au disk of thickness identical to the film in our experiments (100 nm) and a diameter (2.2 µ m) equal to the excitation spot size (see Figure S4(a)). As this encompasses the entire region which may absorb the illumination and the thermal contact with the rest of the film is expected to reduce the temperature surrounding the nanoantenna further, our simplified geometry will provide an upper bound to the heating of the fabricated sample. The first step is to decide whether a pulsed excitation model is required or whether a continuous wave (CW) model may be sufficient. A simple parameter ξ = fτ d , which is a multiplication of the repetition rate of the laser ( f ) and the cooling time of the Au disk ( τ d ), can be used to gauge which model is necessary. At values of ξ << 1 , the heat in the Au disk would dissipate in between consecutive excitation pulses and a pulsed model would be required to extract the maximum temperature of the sample geometry. At values of ξ ≈ 1 and above, the sample heat would no longer be dissipated in between excitation pulses and a CW model becomes sufficient to calculate the maximum local temperature of the sample. The cooling time of the Au disk ( τ d ) can be reformulated so that the ξ parameter can be written as follows [15]:
$$\xi = \frac { f } { \tau _ { d } } = f R _ { e q } ^ { 2 } \frac { \rho _ { A u } c _ { A u } } { \kappa _ { H e } },$$
where ρ Au is the mass density of Au at a temperature of 4K, c Au is the heat capacity of Au and κ He is the thermal conductivity of low temperature gaseous Helium, a small amount of which is used for thermal exchange in order to cool the sample to liquid helium temperatures despite being pumped to vacuum. Using known literature values for each of these numbers, we calculate a parameter ξ = 23 88 . which is far above unity and thus a CW heating model is sufficient to calculate the maximum temperature increase of the sample geometry. The local increase in temperature of our sample ( ∆ T CW ) can then be written as follows [16]:
$$\Delta T _ { C W } = \frac { I \sigma _ { a b s } } { 4 \pi R _ { e q } \beta \kappa _ { H e } },$$
where I is the illumination intensity, σ abs corresponds to the absorption cross section, R eq is the radius of an Au sphere with the same volume as the disk and β corresponds to a dimensionless thermal-capacitance coefficient for an Au disk [16]. As this same model is used for the calculation of laser heating for an Au sphere, the latter coefficient, which is a function of the aspect ratio of the Au disk, is used to account for the fact that our calculation is not performed for a sphere, which is the shape with the lowest heat dissipation. The β coefficient for a disk can be written as follows [16]:
$$\beta = e ^ { 0. 0 4 - 0. 0 1 2 4 l n ( \frac { 2 } { d } ) + 0. 0 6 7 7 l n ^ { 2 } ( \frac { 2 } { d } ) - 0. 0 4 5 7 l n ^ { 3 } ( \frac { 2 } { B } ) },$$
where D is the diameter of the disk and d is its thickness. Wethus substituted β , a literature value for κ He , a calculation of R eq from the diameter and thickness of the gold disk, the maximum excitation intensity used in our experiments (2500 nW/ m) and numerical simulations of the absorption cross section in the metal film due to the nanoantenna mode µ confinement into equation 2. The results of this calculation are plotted in Figure S4(b) for the range of nanoantenna radii we have fabricated on the Au substrate. Similar to the electric field intensities seen in Figure 1(f) of the main text, as a result of the nanoantenna mode confinement, the highest temperature increase (0.315 K) is expected at the smallest NA radius. We have also plotted, in Figure S4(c), the expected maximum local temperature change in the sample for the full range of excitation powers used in our measurements and the range of experimentally accessible nanoantenna radii. As this model only provides an estimate of the temperature increase for a simple nanoantenna on gold disk geometry, the increased thermal contact with the rest of the Au film, which is not absorbing in our experiments, is expected to lead to even smaller temperature increases in the experimentally studied geometry. These calculations thus suggests that the temperature increase as a result of the absorption in the metal film only negligibly contributes to the intensity reduction of the SPEs forming on NAs on the Au film as opposed to the SiO 2 substrate as plotted in Figure 2(c) of the main text.
Figure S4: Calculated change in temperature of the WS 2 NA on a Au substrate sample due to absorption in the metallic film. (a) Schematic illustration of a WS 2 dimer NA on a Au disk used for calculating the change in temperature of the sample under 638 nm pulsed (5 MHz) excitation. NA radii vary over the experimentally achieved range while the height is 190 nm and the dimer gap is 400-500 nm as recorded for the fabricated WS 2 NAs on the Au substrate. (b) Plot of the calculated temperature change in the sample due to absorption of the excitation light by the Au film for WS 2 NAs with the experimental range of radii at a maximum excitation power of 2.5 µ W used in the SPE study. (c) Plot of the expected temperature change of the sample due to absorption of the excitation light by the Au film for WS 2 NAs with the experimental range of radii at the full range of excitation powers used in the SPE study.
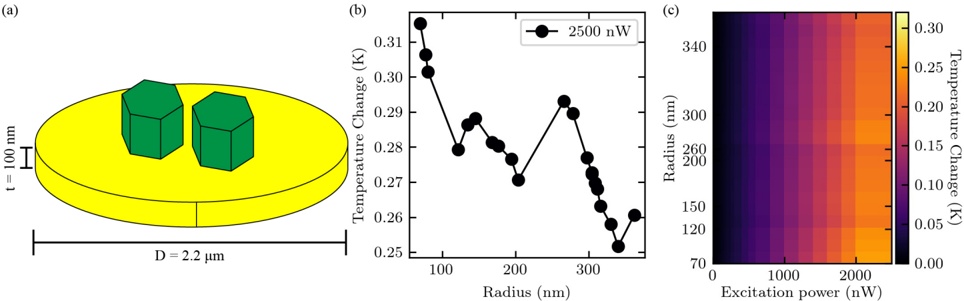
## Supplementary Note 5: Experimental setup efficiency
The experimental setup collection efficiency used in the SPE experiments was estimated by measuring the losses of a 725 nm CW laser passing through this setup. The transmission values through the individual components of the experimental setup are recorded in the table below. The values for transmission through the linear polarizer, the spectrometer and the CCD efficiency are taken from the relevant datasheets. The total experimental setup collection efficiency was estimated to be 0.56 % .
Table 1: Experimental setup collection efficiency. The collection efficiency was estimated by measuring the losses of a 725 nm CW laser through our experimental setup. Transmission through the polarizer, spectrometer and the CCD efficiency are extracted from the relevant datasheets.
| Transmission | Component |
|--------------------|----------------------------|
| 50 % | Optical components |
| 78 % | Linear polarizer |
| 2 % | Single mode fibre coupling |
| 90 % | Spectrometer in-coupling |
| 3 × (97 % ) = 91 % | Spectrometer mirrors (x3) |
| 90 % | Grating efficiency |
| 98 % | CCD quantum efficiency |
| 0.56 % | Total setup efficiency |
## Supplementary Note 6: Optimized WS 2 NAs on Au substrate with dielectric spacer for a dimer gap achievable with only nano-fabrication
We performed a similar optimization procedure for the SiO 2 and hBN spacer placed between WS 2 hexagonal dimer nanoantennas and a metallic mirror for maximum fluorescence enhancements from WSe 2 monolayer SPEs. We did, however, constrain the dimer gap distance to 50 nm which can be achieved with standard nanofabrication techniques and does not require post-fabrication atomic force microscopy repositioning [1]. This optimization procedure yielded the same radius, nanoantenna height and spacer thicknesses as for a gap distance of 10 nm as shown in Figure S5(a) and (f). The electric field intensities surrounding the optimized geometries at the same resonance wavelengths (756 nm and 752 nm) are plotted in Figure S5(b)-(c) and (g)-(h) for the SiO -2 and hBN spacer designs respectively. The midgap hostpots yield electric field intensities of 608 and 142 while the outer vertex positions result in values of 461 and 402 for the SiO 2 and hBN spacers respectively. These values are not far lower than for the 10 nm gap distance design.
As we expect the Purcell enhancement to be highest at the inner and outer vertices of the nanoantennas, we only performed these simulations at positions along the dimer axis as shown by the white line in Figure S5(b) and (g). The Purcell factors are plotted in Figure S5(d) and (j). As the gap distance is increased to 50 nm, the Purcell factors expected for an emitter forming near an inner vertex of the nanoantenna has exponentially dropped to values of 34 and 18 for the SiO 2 and hbN spacer designs respectively. However, the Purcell enhancements near the outer vertices, where emitter formation is far more likely, are not much lower than for the designs presented in the main text reaching values of 16 and 19 for the SiO 2 and hBN spacer designs respectively.
Lastly, the radiation patterns for emitters forming atop these nanoantenna designs on a metallic mirror substrate with a dielectric spacer also result in more of the light being directed toward the collection optics yielding similarly high collection efficiencies within our experimental numerical aperture. For an emitter forming in the dimer gap, the collection efficiencies are 39% and 34% for the SiO 2 and hBN spacer designs respectively. For an emitter forming at the outer vertices of the nanoantennas the collection efficiencies are 37% and 45% for the SiO 2 and hBN spacer designs respectively.
For an SPE position within the dimer gap, these 50 nm gap distance optimized designs yield much lower electric field intensities and Purcell factors leading to much lower expected fluorescence enhancement factors under resonant excitation within our experimental setup of more than 47000 and 5000 for the SiO 2 and hBN spacers respectively when compared to an emitter in vacuum. Upon comparison with an emitter forming on a flat 300 nm SiO /Si substrate, we 2 calculate maximum fluorescence enhancement factors of more than 313000 and 33700 for the SiO 2 and hBN spacers respectively. However, positions atop the outer vertices of the NAs, where SPE formation is far more likely due to the high strain, yield only slightly reduced values of the electric field intensity and Purcell factor with similar collection efficiencies. Therefore, this optimized design with a larger dimer gap is expected to induce similarly high fluorescence enhancement factors, compared to vacuum, of 15910 and 20038 for the SiO 2 and hBN spacers respectively. When compared to an emitter forming on a flat 300 nm SiO /Si substrate, the enhancement factors reach 106070 and 133586 2 for the SiO 2 and hBN spacer designs respectively.
Figure S5: Photonic enhancement simulations of optimized WS 2 NA designs on a Au substrate with a SiO 2 or hBN spacer for a dimer gap of 50 nm. (a) and (f) Schematic illustrations of WS 2 NAs on a Au substrate with a SiO 2 and hBN spacer for optimum fluorescence enhancement of WSe 2 monolayer SPEs and a dimer gap of 50 nm achievable with standard nanofabrication. (b) (c) , and (g) (h) , Simulated electric field intensity profiles at the top surface and as a vertical cut through the middle of the WS 2 NAs for optimized designs with a SiO 2 and hBN spacer at the photonic resonance wavelength of 753 nm and 757 nm respectively. Electric field hotspots are still observed within the dimer gap and at the outer top vertices of the NAs. Scale bars = 200 nm. (d) and (i) Line plots of the Purcell factor at different positions at the top surface of the WS 2 NA along the dimer axis for the SiO 2 and hBN spacer designs respectively. Larger enhancements are observed within the dimer gap and at the outer top vertices of the NA, where SPEs are expected to form, as expected from the electric field hotspots in (b) (c) (g) , , and (h) . (e) and (j) Radiation patterns for SPE positions within the dimer gap (dark blue) and at the outer top vertices (orange) for the SiO 2 and hBN spacer designs respectively. Emission is directed mainly towards collection optics with the cone defined by the experimental numerical aperture in this study indicated by the red dashed lines. The numbers to the sides indicate the collection efficiency, with a numerical aperture of 0.64, for an emitter forming in the dimer gap (dark blue) and at the outer top vertices of the NA. Lower insets indicate the position of the SPE dipole relative to the WS 2 NAs.
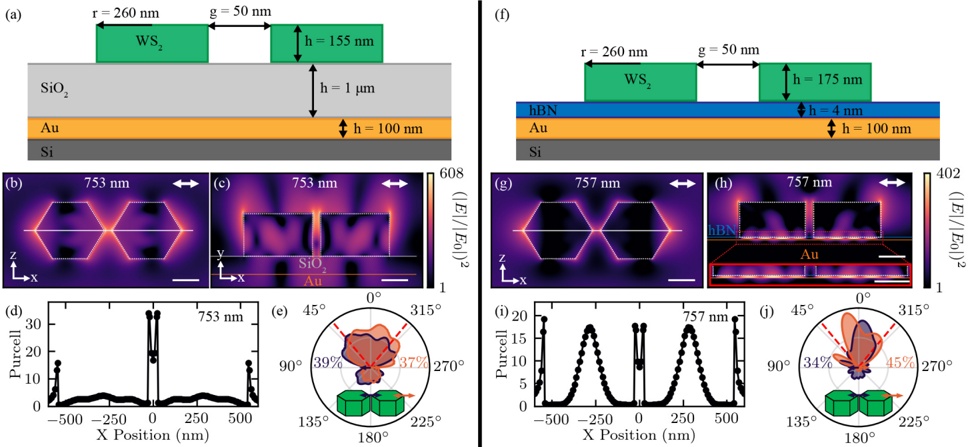
## References
- [1] Panaiot G Zotev, Yue Wang, Luca Sortino, Toby Severs Millard, Nic Mullin, Donato Conteduca, Mostafa Shagar, Armando Genco, Jamie K Hobbs, Thomas F Krauss, and Alexander I Tartakovskii. Transition metal dichalcogenide dimer nanoantennas for tailored light-matter interactions. ACS Nano , 16:6493-6505, 2022.
- [2] Luca Sortino, Matthew Brooks, Panaiot G. Zotev, Armando Genco, Javier Cambiasso, Sandro Mignuzzi, Stefan A. Maier, Guido Burkard, Riccardo Sapienza, and Alexander I. Tartakovskii. Dielectric nano-antennas for strain engineering in atomically thin two-dimensional semiconductors. ACS Photonics , 7:2413-2422, 2020.
- [3] Linglong Zhang, Han Yan, Xueqian Sun, Miheng Dong, Tanju Yildirim, Bowen Wang, Bo Wen, Guru Prakash Neupane, Ankur Sharma, Yi Zhu, Jian Zhang, Kun Liang, Boqing Liu, Hieu T. Nguyen, Daniel Macdonald, and Yuerui Lu. Modulated interlayer charge transfer dynamics in a monolayer tmd/metal junction. Nanoscale , 11:418425, 2019.
- [4] Yu-Ming He, Genevieve Clark, John R. Schaibley, Yu-Ming He, Ming-Cheng Chen, Yu-Jia Wei, Xing Ding, Qiang Zhang, Wang Yao, Xiaodong Xu, Chao-Yang Lu, and Jian-Wei Pan. Single quantum emitters in monolayer semiconductors. Nature Nanotechnology , 10:497-502, 2015.
- [5] Chitraleema Chakraborty, Laura Kinnischtzke, Kenneth M. Goodfellow, Ryan Beams, and A. Nick Vamivakas. Voltage-controlled quantum light from an atomically thin semiconductor. Nature Nanotechnology , 10:507-511, 2015.
- [6] Ajit Srivastava, Meinrad Sidler, Adrien V. Allain, Dominik S. Lembke, Andras Kis, and A. Imamoğlu. Optically active quantum dots in monolayer wse . 2 Nature Nanotechnology , 10:491-496, 2015.
- [7] S. Kumar, A. Kaczmarczyk, and B. D. Gerardot. Strain-induced spatial and spectral isolation of quantum emitters in mono- and bilayer wse . 2 Nano Letters , 15:7567-7573, 2015.
- [8] Chandriker Kavir Dass, Mahtab A. Khan, Genevieve Clark, Jeffrey A. Simon, Ricky Gibson, Shin Mou, Xiaodong Xu, Michael N. Leuenberger, and Joshua R. Hendrickson. Ultra-long lifetimes of single quantum emitters in monolayer wse /hbn heterostructures. 2 Advanced Quantum Technologies , 1900022:1900022, 2019.
- [9] Luca Sortino, Panaiot G. Zotev, Catherine L. Phillips, Alistair J. Brash, Javier Cambiasso, Elena Marensi, A. Mark Fox, Stefan A. Maier, Riccardo Sapienza, and Alexander I. Tartakovskii. Bright single photon emitters with enhanced quantum efficiency in a two-dimensional semiconductor coupled with dielectric nano-antennas. Nature Communications , 12:6063, 2021.
- [10] Shinichiro Mouri, Yuhei Miyauchi, Minglin Toh, Weijie Zhao, Goki Eda, and Kazunari Matsuda. Nonlinear photoluminescence in atomically thin layered wse 2 arising from diffusion-assisted exciton-exciton annihilation. Physical Review B - Condensed Matter and Materials Physics , 90:155449, 2014.
- [11] F. Cadiz, C. Robert, E. Courtade, M. Manca, L. Martinelli, T. Taniguchi, T. Amand, A. C.H. H Rowe, D. Paget, B. Urbaszek, X. Marie, K. Watanabe, T. Amand, A. C.H. H Rowe, D. Paget, B. Urbaszek, and X. Marie. Exciton diffusion in wse 2 monolayers embedded in a van der waals heterostructure. Applied Physics Letters , 112:152106, 2018.
- [12] Yue Luo, Na Liu, Xiangzhi Li, James C. Hone, and Stefan Strauf. Single photon emission in wse2 up 160 k by quantum yield control. 2D Materials , 6, 5 2019.
- [13] P B Johnson and R W Christy. Optical constants of the noble metals. Phys. Rev. B , 6:4370-4379, 1972.
- [14] Panaiot G. Zotev, Yue Wang, Daniel Andres-penares, Toby Severs Millard, Sam Randerson, Xuerong Hu, Luca Sortino, Charalambos Louca, Mauro Brotons-Gisbert, Tahiyat Huq, Stefano Vezzoli, Riccardo Sapienza, Thomas F. Krauss, Brian D Gerardot, Alexander I. Tartakovskii, Stefano Vezzoli, Riccardo Sapienza, Thomas F. Krauss, Brian D Gerardot, and Alexander I. Tartakovskii. Van der waals materials for applications in nanophotonics. Laser and Photonics Reviews , 17:2200957, 2023.
- [15] Guillaume Baffou and Hervé Rigneault. Femtosecond-pulsed optical heating of gold nanoparticles. Physical Review B - Condensed Matter and Materials Physics , 84:1-13, 2011.
- [16] Guillaume Baffou, Romain Quidant, and F. Javier García De Abajo. Nanoscale control of optical heating in complex plasmonic systems. ACS Nano , 4:709-716, 2010. | null | [
"Panaiot G. Zotev",
"Sam A. Randerson",
"Xuerong Hu",
"Yue Wang",
"Alexander I. Tartakovskii"
] | 2024-08-02T07:44:29+00:00 | 2024-08-02T07:44:29+00:00 | [
"cond-mat.mes-hall",
"physics.optics",
"quant-ph"
] | Single photon emitters in monolayer semiconductors coupled to transition metal dichalcogenide nanoantennas on silica and gold substrates | Transition metal dichalcogenide (TMD) single photon emitters (SPEs) offer
numerous advantages to quantum information applications, such as high single
photon purity and deterministic positioning. Strain in the host monolayer,
induced by underlying dielectric Mie resonators, is known to localize their
formation to positions co-located with near-field photonic hotspots providing
further control over their optical properties. However, traditional materials
used for the fabrication of nanoresonators, such as silicon or gallium
phosphide (GaP), often require a high refractive index substrate resulting in
losses of the emitted light and limited photonic enhancement. Here, we use
nanoantennas (NAs) fabricated from multilayer TMDs, which allow complete
flexibility with the choice of substrate due to the adhesive van der Waals
forces, enabling high refractive index contrast or the use of highly reflective
metallic surfaces. We demonstrate the localized formation of SPEs in WSe$_2$
monolayers transferred onto WS$_2$ NAs on both SiO$_2$ and Au substrates,
enabling strong photonic enhancements and increased single photon collection.
We provide evidence for enhanced quantum efficiencies (QE) reaching an average
value of 43% (7%) for SPEs on WS$_2$ NAs on a SiO$_2$ (Au) substrate. We
further combine the advantages offered by both dielectric and metallic
substrates to numerically simulate an optimized NA geometry for maximum WSe$_2$
single photon excitation, emission, collection. Thus, the fluorescence is
enhanced by a factor of over 4 orders of magnitude compared to vacuum and 5
orders of magnitude compared to a flat SiO$_2$/Si surface. Our work showcases
the advantages offered by employing TMD material nanoresonators on various
substrates for SPE formation and photonic enhancement. |
2408.01071v1 | ## GENERALISATION OF AN IMO GEOMETRY PROBLEM
DINA KAMBER HAMZI ´ , L ´ SZL ´ N ´ METH, AND ZENAN ˇ ABANAC C A O E S
Abstract. In this paper, we generalise an interesting geometry problem from the 1995 edition of the International Mathematical Olympiad (IMO) using analytic geometry tools.
MSC2020: Primary 51N20; Secondary 97G70
Key words and phrases: Geometry problem, International Mathematical Olympiad, analytic geometry tools
## 1. Introduction and statement of results
According to Mitchelmore [1], generalisations are the cornerstone of school mathematics, covering various aspects like numerical generalisation in algebra, spatial generalisation in geometry and measurement, as well as logical generalisations in diverse contexts. The process of generalising lies at the heart of mathematical activity, serving as the fundamental method for constructing new knowledge [2, 3]. In this paper we will generalise an interesting geometry problem appeared in 1995 edition of the International Mathematical Olympiad (IMO) [4].
Original 36th IMO Geometry Problem. Let A, B, C, D be four distinct points on a line, in that order. The circles with diameters AC and BD intersect at X and Y . The line XY meets BC at Z . Let P be a point on the line XY other than Z . The line CP intersects the circle with diameter AC at C and M , and the line BP intersects the circle with diameter BD at B and N . Prove that the lines AM, DN, XY are concurrent (Figure 1).
Its solution, employing analytic geometry, is presented in [5].
Since the line XY in the original problem represents the radical axis of the two intersecting circles, we shall now expand our investigation to encompass the radical axis in the broader context. Allow us to reiterate that the locus of points possessing equal powers concerning two circles is a line known as the radical axis (or power line) of the circles. Simpler loci problems should be studied meticulously, as they often pose difficulties for an average student (see discussion in [6]).
Figure 1. 36th IMO geometry problem
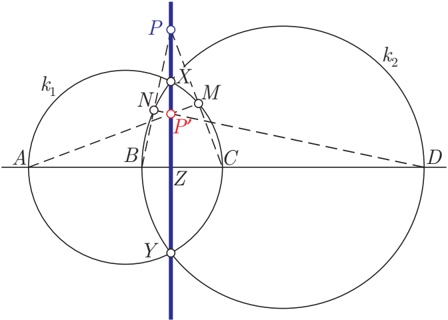
Recent studies have explored misconceptions that students might have about analytical geometry and teaching practices in this subject across different educational levels and contexts (see e.g. [7, 8, 9, 10, 11]).
We will now present a generalised statement of the aforementioned problem and present its solution using analytical geometry.
Generalisation of the 36th IMO Geometry Problem. Let k 1 and k 2 be two circles, and let /lscript be the line that contains their centres. The line /lscript and the circle k 1 intersect at points A and C , while line /lscript and the circle k 2 intersect at points B and D . We assume that A B , , C D , appear in that order or in the order A C , , B D , on /lscript . Let p be a line perpendicular to line /lscript , and let P be any point on line p . The line CP intersects the circle k 1 at M (in addition to C ), and the line BP intersects the circle k 2 at N (in addition to B ). The lines AM and DN intersect at P ′ . Changing the position of the point P changes the position of the point P ′ . However, P ′ will always belong to a line p ′ , parallel to the line p (Figure 2). If p is the radical axis of circles k 1 and k 2 , then p ′ = p .
In the Figure 2 and all subsequent figures, dotted line r represents radical axis of two circles.
## 2. Analytical Geometry Proof of the Generalisation
Without loss of generality, we establish a coordinate system where /lscript represents the x -axis, and assume circles k 1 and k 2 have centers symmetrically positioned about the y -axis, with k 1 centered at ( -a, 0) with radius r 1 , and k 2 centered at ( a, 0) with radius r 2 . The equations of
Figure 2. 36th IMO geometry problem generalisation
circles k 1 and k 2 are given by ( x + ) + a 2 y 2 = r 2 1 and ( x -a ) 2 + y 2 = r 2 2 , respectively. Consequently, we have A = ( - -a r , 1 0), B = ( a -r , 2 0), C = ( -a + r , 1 0) and D = ( a + r , 2 0).
As the line p is perpendicular to the x -axis, it is parallel to the y -axis, and we can express it using the equation x = p . Henceforth, the symbol p will serve a dual purpose, representing both the line p and the x -coordinate of point P . Consequently, point P can be described by P = ( p, q ), with q changing as point P moves along line p . Let P ′ = ( p , q ′ ′ ). Using the tangent-half-parametrisation for the two circles (see, e.g., [12, para. 5.13 on p. 91]), let M = ( r 1 ( 1 -u 2 ) 1+ u 2 -a, 2 r 1 u 1+ u 2 ) and N = r 2 ( 1 -v 2 ) 1+ v 2 + a, 2 r 2 v 1+ v 2 , for some u, v ∈ R ∪{∞} .
$$^ { r } = \left ( \frac { r _ { 2 } \left ( 1 - v$$
Now, we examine the condition for points P , C and M to be collinear by considering the vanishing of the determinant ([12, para. 1.72 on pp. 14-15])
$$\begin{vmatrix} \iota ^ { - 1 } \iota _ { \j$$
∣ ∣ Subtracting the second row from the third row, and then taking out the common factors from the third row, we have
$$o s \, \hom \, \L i m u \, \text{for}, \$$
Expanding the determinant along the third row, we obtain
$$\begin{array} {$$
Solving for u , and discarding the solution u = 0, which would entail M = C , we get
$$= \frac { r _ { 1 } - a - p } { a }.$$
$$u = \frac { r _ { 1 } - a - p } { q }.$$
The cases u = 0 and q = 0, where the latter leads to u = ∞ and M = A , will be addressed later, along with the cases when the denominator becomes zero or tends to infinity.
Similarly, the condition for the collinearity of P ′ , A and M is the vanishing of the determinant
$$\begin{vmatrix} \text{vmmam} \\ \left | \frac { p ^ { \prime } } { 1 + u ^ { 2 } } - a \, \frac { q ^ { \prime } } { 1 + u ^ { 2 } } \, 1 \right |. \\ \left | \frac { r _ { 1 } \left ( 1 - u ^ { 2 } \right ) } { 1 + u ^ { 2 } } - a \, \frac { 2 r _ { 1 } u } { 1 + u ^ { 2 } } \, 1 \right | \end{vmatrix}.$$
$$\frac { 2 r _ { 1 } } { 1 + u ^ { 2 } } \left ( q ^ { \prime } - u p ^ { \prime } - u a - u r _ { 1 } \right ) = 0. \\ \dots \substack { \lambda \colon \dots \dots \lambda \colon \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{$$
∣ ∣ The last determinant can be obtained from (2.1) by replacing p , q , r 1 and u by p ′ , q ′ , -r 1 and -u -1 , respectively. Applying this to (2.2) leads to
Solving for u , and discarding the solution u = ∞ , which would entail M = A , we get
$$u = \frac { q ^ { \prime } } { r _ { 1 } + a + p ^ { \prime } }.$$
From this and (2.3) we now have
$$\frac { r _ { 1 } - a - p } { q } = \frac { q ^ { \prime } } { r _ { 1 } + a + p ^ { \prime } }.$$
Likewise, the conditions for collinearity among points P , B N , , and of P ′ , D N , , are determined by the vanishing of the respective determinants
$$\begin{array} { c | c c c c c c c } \text{nants} \\ \left | \frac { p } { 2 } a - r _ { 2 } & 0 & 1 \right | \text{ and } \left | \text{ and } \left | \frac { p ^ { \prime } } { 2 } a + r _ { 2 } & 0 & 1 \right |. \\ \frac { r _ { 2 } \left ( 1 - v ^ { 2 } \right ) } { 1 + v ^ { 2 } } + a & \frac { 2 r _ { 2 } v } { 1 + v ^ { 2 } } & 1 \right |. \\ \end{array} \right |. \\ \text{The first one can be obtained from (2.1) by replacing a, r _ { 1 } \text{ and } u \text{ by} \\ - a. - r _ { 2 } \text{ and } - v ^ { - 1 }. \text{respectively: and the second one by replacing } p. a. \end{array}$$
∣ ∣ ∣ ∣ ∣ The first one can be obtained from (2.1) by replacing a , r 1 and u by -a , -r 2 and -v -1 , respectively; and the second one by replacing p , q , a , r 1 and u by p ′ , q ′ , -a , r 2 and v , respectively. Applying the same
changes to (2.2), we obtain v = q r 2 -a + p and v = r 2 + a -p ′ q ′ , respectively. Hence,
$$\frac { q } { r _ { 2 } - a + p } = \frac { r _ { 2 } + a - p ^ { \prime } } { q ^ { \prime } }.$$
Multiplying (2.4) and (2.5) yields the following relationship
$$\frac { r _ { 1 } - a - p } { r _ { 2 } - a + p } = \frac { r _ { 2 } + a - p ^ { \prime } } { r _ { 1 } + a + p ^ { \prime } },$$
which indicates that p ′ depends on p (as well as on a , r 1 and r 2 ) but is independent of q . This results in P ′ lying on a line perpendicular to the x -axis and, thus, parallel to line p , which was what we wanted to prove.
To get an explicit value for p ′ , we perform crosswise multiplication in (2.6), and obtain
$$\left ( r _ { 1 } - a - p \right ) \left ( r _ { 1 } + a + p ^ { \prime } \right ) = \left ( r _ { 2 } - a + p \right ) \left ( r _ { 2 } + a - p ^ { \prime } \right ).$$
This yields
$$\left ( r _ { 1 } & - a - p \right ) p ^ { \prime } + \left ( r _ { 2 } - a + p \right ) p ^ { \prime } = \left ( r _ { 2 } - a + p \right ) \left ( r _ { 2 } + a \right ) - \left ( r _ { 1 } - a - p \right ) \left ( r _ { 1 } + a \right ) \\ & = \left ( r _ { 2 } - a \right ) \left ( r _ { 2 } + a \right ) + p \left ( r _ { 2 } + a \right ) - \left ( r _ { 1 } - a \right ) \left ( r _ { 1 } + a \right ) + p \left ( r _ { 1 } + a \right ).$$
From this we obtain
$$\left ( r _ { 1 } + r _ { 2 } - 2 a \right ) p ^ { \prime } = r _ { 2 } ^ { 2 } - r _ { 1 } ^ { 2 } + p \left ( r _ { 1 } + r _ { 2 } + 2 a \right ),$$
and so
$$p ^ { \prime } & = \frac { r _ { 2 } ^ { 2 } - r _ { 1 } ^ { 2 } + p \left ( r _ { 1 } + r _ { 2 } + 2 a \right ) } { r _ { 1 } + r _ { 2 } - 2 a }.$$
To get q ′ , we take the reciprocal of (2.4) to obtain q r 1 - -a p = r 1 + + a p ′ q ′ , and upon adding this to (2.5), we arrive at
$$q \left ( \frac { 1 } { r _ { 1 } - a - p } + \frac { 1 } { r _ { 2 } - a + p } \right ) = \frac { r _ { 1 } + r _ { 2 } + 2 a } { q ^ { \prime } }.$$
Now,
$$q ^ { \prime } = \frac { \left ( r _ { 1 } + r _ { 2 } + 2 a \right ) \left ( a - r _ { 1 } + p \right ) \left ( a - r _ { 2 } - p \right ) } { q \left ( r _ { 1 } + r _ { 2 } - 2 a \right ) }.$$
From (2.7) and (2.8), we see that
$$P ^ { \prime } = \left ( \frac { r _ { 2 } ^ { 2 } - r _ { 1 } ^ { 2 } + p \left ( r _ { 1 } + r _ { 2 } + 2 a \right ) } { r _ { 1 } + r _ { 2 } - 2 a }, \frac { \left ( r _ { 1 } + r _ { 2 } + 2 a \right ) \left ( a - r _ { 1 } + p \right ) \left ( a - r _ { 2 } - p \right ) } { q \left ( r _ { 1 } + r _ { 2 } - 2 a \right ) } \right ).$$
Now, we will consider special cases.
If P is on the x -axis, i.e., if q = 0, then q ′ = ∞ , and P ′ is the point at infinity. Then, by the equations u = r 1 - -a p q and v = q r 2 -a + p , we have u = ∞ and v = 0, i.e., M = A and N = D . The tangent lines of the circles k 1 and k 2 at points A and D , respectively, represent the limiting position of the lines AM and DN in the previous case (see Figure 3). Their intersection point disappears (or we can say that they intersect at the infinite point P ′ ∞ on the line p ′ ).
Figure 3. P ′ is at infinity
If the line x = p passes through the points B or C , then p = a -r 2 or r 1 -a , respectively, and by (2.6), p ′ = - -a r 1 or a + r 2 , respectively. Then, by (2.8), q ′ = 0 in either case, so P ′ = A or D , respectively, and loci of point P ′ consist of a single point (see Figure 4). Within lines passing through the point A , resp. D , there is obviously the line p ′ tangent to the circle k 1 , resp. k 2 , and parallel to p .
Figure 4. p touching k 2 at point B
Next, if r 1 + r 2 = 2 a , the circles k 1 and k 2 touch externally (in which case B = C ), and by (2.7) and (2.8) we have p ′ = ∞ and q ′ = ∞ ; therefore, point P ′ is at infinity. Thus, lines AM and ND are parallel (see Figure 5), resulting in the vanishing of line p ′ . Notice that one may conclude the same from the fact that the points P , C , B M N , , are collinear, and ∠ AMC = ∠ DNB = 90 ◦ as angles subtended by the respective diameters.
Figure 5. Touching circles
Finally, the equation defining the radical axis for circles k 1 and k 2 gives us (see [12, para. 5.51 on p. 99])
$$( x + a ) ^ { 2 } + y ^ { 2 } - r _ { 1 } ^ { 2 } = ( x - a ) ^ { 2 } + y ^ { 2 } - r _ { 2 } ^ { 2 },$$
which simplifies to
$$x = \frac { r _ { 1 } ^ { 2 } - r _ { 2 } ^ { 2 } } { 4 a }.$$
From (2.7), p = p ′ if, and only if, p = r 2 1 -r 2 2 4 a , which means that if p is the radical axis of the two circles k 1 and k 2 , then p ′ = p .
Remark. In case that points on line /lscript appear in order A B C D , , , , and line p passes through the intersection points of the two circles (in which case line p is the radical axis of the circles), we obtain the original IMO problem.
Note that more cases can be considered by changing the roles of points A and C , and/or B and D , placing one circle inside the other, or having one touch the other internally. We invite interested reader to investigate these other cases.
## References
- [1] M. C. Mitchelmore, The Role of Abstraction and Generalisation in the Development of Mathematical Knowledge, East Asia Regional Conference on Mathematics Education (EARCOME) (2nd) and the Southeast Asian Conference on Mathematics Education (SEACME) (9th), Singapore, May 27-31, 2002.
- [2] A. Ellis, E. Tillema, Generalization Across Domains: The Relating-FormingExtending Generalization Framework, In E. Galindo, J. Newton (Eds.), Proceedings of the 39th annual meeting of the North American Chapter of the International Group for the Psychology of Mathematics Education. Indianapolis, IN: Hoosier Association of Mathematics Teacher Educators (2017).
- [3] A. B. Ellis, E. Lockwood, E. Tillema, K. Moore, Generalization Across Multiple Mathematical Domains: Relating, Forming, and Extending, Cognition and Instruction 40:3 (2022), pp. 351-384. doi.org/10.1080/07370008.2021.2000989.
- [4] 36th International Mathematical Olympiad (1995, July 19-20), Toronto, 1995. Retrieved from https://www.imo-official.org/problems.aspx.
- [5] D. Kamber Hamzic, Z. Sabanac, Two plane geometry problems approached through analytic geometry, Math. Gaz. 104:560 , pp. 255-261. doi.org/10.1017/mag.2020.48.
- [6] A. E. Young, (1909). On the teaching of analytic geometry, Amer. Math. Monthly 16:12 (1909), pp. 205-212. doi.org/10.1080/00029890.1909.11997524.
- [7] A. Ozkan, E. M. Ozkan, S. Karapıcak, On the Misconceptions of 10th Grade Students about Analytical Geometry. The Educational Review, USA 2:8 (2018), pp. 417-426. doi.org/10.26855/er.2018.08.002.
- [8] M. Khalil, R. A. Farooq, E. Chakıro˘lu, ¸ g U. Khalil, D. M. Khan, The Development of Mathematical Achievement in Analytic Geometry of Grade-12 Students through GeoGebra Activities, EURASIA J Math Sci and Tech Ed 14: ) (2018), pp. 1453-1463. doi.org/10.29333/ejmste/83681.
- [9] X. Hua, M. Tang, S. Sun, Z. Han, Inquiry into Mathematics Teaching in Senior High School -Taking 'Planar Analytic Geometry' as an Example, In Proceedings of the 3rd International Seminar on Education Innovation and Economic Management (SEIEM 2018) (2019), pp. 312-315. doi.org/10.2991/seiem-18.2019.81.
- [10] A. A. Ara´ ujo, The teaching of analytic geometry in secondary school, Rev. U.D.C.A Act. Div. Cient. 22:1 (2019), e1222. https://doi.org/10.31910/rudca.v22.n1.2019.1222.
- [11] L. Cheng, Z. Yang, The Research on How to Teach Analytic Geometry in Universities in China, Journal of Social Sciences and Humanities 7:1 (2021), pp. 59-63.
- [12] A. Robson, An Introduction to Analytical Geometry. I. Cambridge: At The University Press (1940).
University of Sarajevo, Department of Mathematics and Computer Science, Zmaja od Bosne 33-35, 71000 Sarajevo, Bosnia and Herzegovina
Email address : [email protected]
University of Sopron, Institute of Basic Sciences, Bajcsy-Zsilinszky 4, 9400 Sopron, Hungary
Email address : [email protected]
University of Sarajevo, Department of Mathematics and Computer Science, Zmaja od Bosne 33-35, 71000 Sarajevo, Bosnia and Herzegovina
Email address : [email protected] | null | [
"Dina Kamber Hamzić",
"László Németh",
"Zenan Šabanac"
] | 2024-08-02T07:46:31+00:00 | 2024-08-02T07:46:31+00:00 | [
"math.MG",
"51N20, 97G70"
] | Generalisation of an IMO Geometry Problem | In this paper, we generalise an interesting geometry problem from the 1995
edition of the International Mathematical Olympiad (IMO) using analytic
geometry tools. |
2408.01072v3 | ## A Survey on Self-play Methods in Reinforcement Learning
Ruize Zhang, Tsinghua University
[email protected]
Zelai Xu,
Tsinghua University
[email protected]
Chengdong Ma, Peking University
[email protected]
Chao Yu , * Tsinghua University
[email protected]
Wei-Wei Tu, 4Paradigm
[email protected]
Wenhao Tang,
Tsinghua University
[email protected]
Shiyu Huang , * Zhipu AI
[email protected]
Deheng Ye, Tencent
[email protected]
Wenbo Ding,
Tsinghua University
[email protected]
Yaodong Yang,
Peking University
[email protected]
Yu Wang , * Tsinghua University
[email protected]
## Abstract
Self-play, characterized by agents' interactions with copies or past versions of themselves, has recently gained prominence in reinforcement learning (RL). This paper first clarifies the preliminaries of self-play, including the multi-agent reinforcement learning framework and basic game theory concepts. Then, it provides a unified framework and classifies existing self-play algorithms within this framework. Moreover, the paper bridges the gap between the algorithms and their practical implications by illustrating the role of self-play in different scenarios. Finally, the survey highlights open challenges and future research directions in self-play. This paper is an essential guide map for understanding the multifaceted landscape of self-play in RL.
## 1 Introduction
Reinforcement learning (RL) represents a significant paradigm (Sutton & Barto, 2018) within machine learning (ML), focused on optimizing decision processes through interaction with an environment. In RL, the environment is modeled as a Markov decision process (MDP), where agents observe states, take actions, receive rewards, and cause transitions to new states. The primary goal of RL algorithms is to derive the optimal policy that yields the maximum expected accumulated reward over time. Deep RL extends traditional RL by employing deep neural networks as function approximators to handle high-dimensional state spaces, contributing to breakthroughs in various complex tasks (Mnih et al., 2013).
Moreover, transitioning from single-agent to multi-agent reinforcement learning (MARL) introduces complex dynamics (Rashid et al., 2018; Mahajan et al., 2019; Yu et al., 2022). In MARL, the interdependence of agents' actions presents significant challenges, as the environment appears non-stationary to each agent. The main issues in MARL are coordination, communication, and equilibrium selection, particularly in competitive
∗ Corresponding authors.
Figure 1: Overview of our survey.
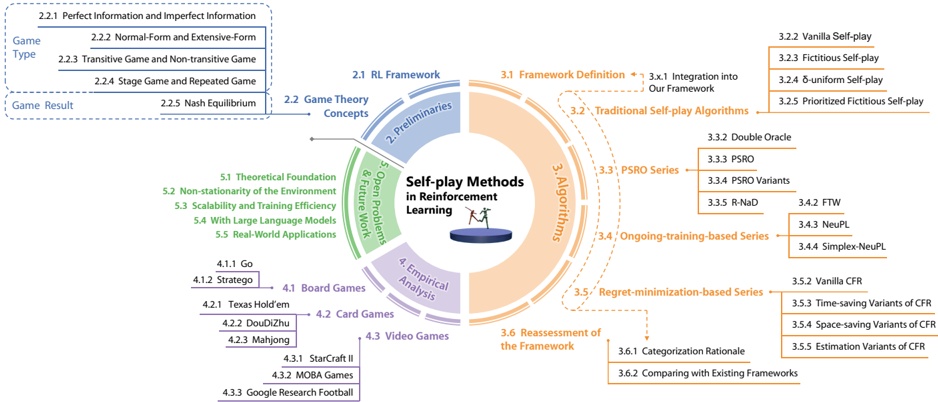
scenarios. These challenges often lead to difficulties in achieving convergence, maintaining stability, and efficiently exploring the solution space.
With the help of game theory, a mathematical framework that models the interactions between multiple decision-makers, self-play emerges as an elegant solution to some inherent challenges in MARL. Self-play provides an approach where an agent interacts with copies or past versions of itself (Samuel, 2000; Bansal et al., 2018). This method promises a more stable and manageable learning process. The capabilities of self-play extend to a wide range of scenarios, including its high-profile applications in Go (Silver et al., 2016; 2017; 2018; Schrittwieser et al., 2020), chess (Silver et al., 2018; Schrittwieser et al., 2020), poker (Moravčík et al., 2017; Heinrich et al., 2015), and video games (Berner et al., 2019; Vinyals et al., 2019). In these scenarios, it has developed strategies that surpass human expertise. Although the application of self-play is extensive and promising, it is accompanied by limitations, such as the potential convergence to suboptimal strategies and significant computational requirements(Silver et al., 2016; 2018).
Although some research adopts a broad perspective through empirical game-theoretic analysis (EGTA)(Wellman et al., 2025), relatively few comprehensive surveys focus solely on self-play algorithms. Among them, a study develops an algorithmic framework for self-play, but it does not incorporate the Policy-Space Response Oracle (PSRO) series of algorithms (Hernandez et al., 2021), while a separate study focuses exclusively on PSRO (Bighashdel et al., 2024), without considering other self-play algorithms. Another study examines the theoretical safety of self-play (DiGiovanni & Zell, 2021). While these studies are valuable, they do not provide a comprehensive perspective that fully captures the breadth and depth of self-play. Therefore, this survey aims to fill this gap.
The survey is organized as follows. Sec. 2 introduces the background of self-play, including the RL framework and game theory concepts. Sec. 3 proposes a unified framework and then categorizes existing self-play algorithms into four categories based on this framework. In Sec. 4, a comprehensive analysis illustrates how self-play is applied in various scenarios. Sec. 5 describes open problems in self-play and explores future research directions. Finally, Sec. 6 concludes the survey on self-play. A more detailed overview of our survey is depicted in Fig. 1, which further illustrates the relationships among the subsections.
## 2 Preliminaries
This section first introduces the framework of RL, where an agent learns to make decisions by interacting with an environment to maximize cumulative rewards. We then present basic game theory concepts, which
analyze strategic interactions between rational decision-makers and provide tools to study outcomes based on players' strategies.
## 2.1 RL Framework
In RL, the environment is modeled as an MDP, where the Markovian assumption states that the environment's evolution is fully determined by its current state, eliminating the need to consider past states. An agent interacts with the environment by taking actions, which result in different states and associated rewards. MDPs can be extended to multi-agent settings, known as Markov games (MGs) (Littman, 1994) or stochastic games (Shapley, 1953). We focus on the most general form: partially observable Markov games (POMGs), where multiple agents interact with the environment, and each agent receives only individual observations instead of the full state, meaning they have limited access to the environment's state.
A POMG G is defined by G = ( N S A O P R , , , , , , γ, ρ ). N = { 1 , · · · , n } denotes n agents. S is the state space. A = ∏ n i =1 A i is the product of the action space of each agent. Similarly, O = ∏ n i =1 O i is the product of the observation space of each agent. P : S × A × S → [0 , 1] denotes the transition probability from one state to another given the actions of each agent. R = {R 1 , · · · , R } n , where R i : S × A i → R denotes the reward function of agent i . γ ∈ [0 , 1] is the discount factor. ρ : S → [0 , 1] describes initial state distribution. If it is a fully cooperative setting, agents can share the same reward function (Yu et al., 2022; Rashid et al., 2020; Foerster et al., 2018; Kuba et al., 2021). When n = 1 , O i = S , the POMG returns to the MDP.
More concretely, in RL, agents interact with the environment through the following procedure: At each discrete time step t , each agent i receives an observation o i,t from the environment and selects an action based on a stochastic policy π θ i : O ×A → i i [0 , 1], where θ i represents the parameters. After receiving the joint actions a t = ( a 1 ,t , · · · , a n,t ), the environment transitions from the current state s t to a subsequent state s t +1 according to the transition function P and sends a reward r i,t +1 to every agent i . The ultimate goal of agent i is to maximize the expected discounted cumulative rewards: E π θ i [ ∑ ∞ t =0 γ r t i,t ].
## 2.2 Game Theory Concepts
## 2.2.1 Perfect Information and Imperfect Information
In a game with perfect information , only one player moves at a time. Each player comprehensively understands the current game state, the complete history of moves made, and the potential future outcomes. If these conditions are not met, the game is considered to have imperfect information (Lucchetti, 2011; Mycielski, 1992). An example of a game with perfect information is Go. In Go, both players have full access to the game state at all times, including the positions of all stones and the identity of the next player. In contrast, Texas Hold'em poker is a game with imperfect information. Players cannot see their opponents' private cards, creating uncertainty and requiring decisions based on probabilistic reasoning, bluffing, and interpreting others' actions.
## 2.2.2 Normal-Form and Extensive-Form
The normal form and extensive form are two distinct representations of games in game theory. If a game G is represented in the normal-form , it can be expressed by G = ( N , Π u , ). N = { 1 2 , , · · · , n } denotes the players. The set Π = Π 1 ×··· × Π n represents the pure strategy space for all players. A pure strategy specifies a particular and deterministic action for a player in the game. A vector π = ( π , . . . , π 1 n ) ∈ Π is called a strategy profile . A mixed strategy assigns a probability distribution over the set of pure strategies. For player i , a mixed strategy is represented by σ i ∈ ∆(Π ), where ∆ denotes the probability i simplex. u = ( u , 1 · · · , u n ), where u i : Π → R , is a utility function that assigns a real-valued payoff to each player i . If ∀ π ∈ Π , ∑ i u i ( π ) = 0, the game is a zero-sum game, otherwise it is a general-sum game. If Π 1 = · · · = Π n and the payoffs are invariant under any permutation of the players' strategies, the game is a symmetric game . If a finite set of players (especially two players) are involved and each player has a finite set of strategies, a normal-form game can be directly depicted in a matrix.
In two-player zero-sum symmetric normal-form games , both players share the same pure strategy space, denoted by Π, such that Π = Π 1 = Π . Since the utility function satisfies 2 u 1 ( π , π i j ) = -u 2 ( π , π i j ), we can simplify the utility to a single function u , where for π , π i j ∈ Π, if π i beats π j , then u π , π ( i j ) = -u π , π ( j i ) > 0. The evaluation matrix captures the game outcomes by detailing the results of different strategies when they are played against each other: A Π = { u π , π ( i j ) : π , π i j ∈ Π × Π . }
If a game is represented in the extensive-form , it is expressed sequentially, illustrating the sequence of moves, choices made by the players, and the information available to each player during decision-making. Typically, a game in the extensive-form is represented by a game tree. This tree demonstrates the sequential and potentially conditional nature of decisions. Moreover, if player i has perfect recall , it means that player i remembers which action they have taken in the past. A game G represented in the extensive-form can be expressed by G = ( N ∪ { } c , H, Z, P, I , A, u ). N = { 1 2 , , · · · , n } denotes a set of players. c is chance node and can be regarded as a special player. H represents a set of possible histories and Z ⊆ H is a set of terminal histories . Order of moves is represented by a function P h ( ) ∈ N ∪ { } c to indicate which player is to move, where h ∈ H . I denotes information set partitions and I i denotes the information set partitions for player i . This implies that in an imperfect information game, if player i reaches a history h ∈ I i , where I i ∈ I i is a specific information set , player i cannot distinguish which particular history h ∈ I i it is encountering. Action space is represented by A h ( ) for a non-terminal history h ∈ H . For all non-terminal histories h within an information set I i , the available actions are the same; otherwise, they are distinguishable. Therefore, we use A I ( i ) to represent the available actions for the information set I i . Utility functions is denoted by u = ( u , 1 · · · , u n ), where u i : Z → R . Together, these components define the structure and dynamics of an extensive-form game. Moreover, A strategy profile in an extensive-form game can be expressed by π = ( π , 1 · · · , π n ), where π i maps each I i ∈ I i to a probability distribution over A I ( i ). A subgame of an extensive-form game is a portion of the game that starts from a single initial node, includes all successors of any node within the subgame, and contains all nodes in the same information set as any node in the subgame.
The Prisoner's Dilemma is a classic example in game theory. The game outcomes are as follows:
- · If one player confesses (C) and the other lies (L), the confessor will serve 1 year in jail, while the liar will serve 8 years.
- • If both players choose to confess, they will each serve 7 years behind bars.
- • If both players choose to lie, they will each serve only 2 years behind bars.
The classic scenario is known as the simultaneous Prisoner's Dilemma, where two players must simultaneously decide whether to confess or lie without knowing the other's choice. Games played in this manner are referred to as static games . The normal-form representation is suitable for them, as it captures the simultaneous nature of decision-making (as depicted in Fig. 2a). Another variant is the sequential Prisoner's Dilemma, where the second player decides with knowledge of the first player's action. Games of this nature are called dynamic games . The extensive-form representation is well-suited for them, as it can clearly illustrate the sequence of moves and the information available to each player at each decision point (as shown in Fig. 2b).
(
(
-7
,
-7
)
C
(-7, -7)
C
C
Player 1
Player 1
L
Player 2
Player 2
L
C
L
C
Player 2
Player 2
L
L
(
-1
,
-9
-9
)
(-1, -9)
,
-1
C
(
-3
)
(-9, -1)
,
-3
)
(-3, -3)
L
(b)
0 0 0 1 0 0 0 0 0 1 0 0 1/3 1/3 1/3 1/3 1/3 1/3 Figure 2: The example of Prisoner's Dilemma. (a) Matrix representation of simultaneous Prisoner's Dilemma in normal-form. (b) Game tree representation of sequential Prisoner's Dilemma in extensive-form.
0
1
0
1/2
1/2
0
1/3
1/3
1/3
𝝅
𝟐
𝝅
𝟐
𝝅
𝟐
Beyond normal-form and extensive-form games, the analysis of complex games often involves a higher-level abstraction: the meta-game . The meta-game can be viewed as an advanced form of a normal-form game, but it focuses on the selection of policies (also called strategies) rather than isolated actions. Each player chooses from a set of policies, rather than a set of actions. This set of policies is referred to as the policy population . Meta-strategies are mixed strategies that assign probabilities to the policies within the policy population in the meta-game.
## 2.2.3 Transitive Game and Non-transitive Game
For the sake of simplicity, we restrict our focus to two-player zero-sum symmetric games . In a transitive game , the strategies or outcomes follow a transitive relationship. Formally, ∀ π , π i j , π k ∈ Π, if u π , π ( i j ) > 0 and u π , π ( j k ) > 0, then it must follow that u π , π ( i k ) > 0. This transitive property simplifies the strategic landscape, allowing for an ordinal ranking of strategies. Conversely, in a non-transitive game , ∃ π , π i j , π k ∈ Π such that u π , π ( i j ) > 0 and u π , π ( j k ) > 0, but u π , π ( i k ) ≤ 0. This introduces a cyclic relationship among strategies, thereby complicating the game. The complexity often results in a mixed-strategy equilibrium, where players randomize their choices among multiple strategies to maximize their expected payoff. A classical example of a non-transitive game is Rock-Paper-Scissors, in which no single strategy uniformly dominates all others.
## 2.2.4 Stage Game and Repeated Game
A stage game (or one-shot game ) is a game that is played only once, namely a one-shot interaction between players. A famous example of a stage game is the Prisoner's Dilemma. A repeated game is derived from a stage game played multiple times. Formally, a repeated game based on a stage game G is defined by playing G for T periods, where T can be finite or infinite. The strategies in a repeated game are history-contingent, meaning they can depend on the entire sequence of past plays. An example of a repeated game is Texas Hold'em, where players engage in multiple rounds, and each player's strategy may evolve based on previous rounds, betting patterns, and the history of interactions among players.
## 2.2.5 Nash Equilibrium
For simplicity, π i denotes the strategy of player i , and π -i denotes the strategies of all players other than player i . Given π -i , player i 's best response (BR) is the strategy that maximizes player i 's payoff:
$$B R _ { i } ( \pi _ { - i } ) = \arg \max _ { \pi _ { i } } u _ { i } ( \pi _ { i }, \pi _ { - i } ).$$
A strategy π ∗ i is an /epsilon1 -BR to strategies π -i if:
$$u _ { i } ( \pi _ { i } ^ { * }, \pi _ { - i } ) \geq u _ { i } ( B R _ { i } ( \pi _ { - i } ), \pi _ { - i } ) - \epsilon,$$
where /epsilon1 is a pre-specified threshold.
A strategy profile ( π , π ∗ 1 ∗ 2 , ..., π ∗ n ) is a Nash equilibrium (NE) if, for each player i :
$$u _ { i } ( \pi _ { i } ^ { * }, \pi _ { - i } ^ { * } ) \geq u _ { i } ( \pi _ { i }, \pi _ { - i } ^ { * } ), \forall \pi _ { i },$$
meaning that no player can benefit by changing their strategy unilaterally, given the strategies of others. In other words, an NE is a situation where each player's strategy is a BR to the others' strategies.
A strategy profile ( π , π ∗ 1 ∗ 2 , ..., π ∗ n ) is an /epsilon1 -NE if, for each player i :
$$u _ { i } ( \pi _ { i } ^ { * }, \pi _ { - i } ^ { * } ) \geq u _ { i } ( \pi _ { i }, \pi _ { - i } ^ { * } ) - \epsilon, \forall \pi _ { i },$$
meaning that no player can increase their payoff by more than /epsilon1 by unilaterally changing their strategy.
However, computing NE is generally intractable in complex games, so some researchers utilize α -Rank (Omidshafiei et al., 2019) and Correlated Equilibrium (CE) (Aumann, 1974) as alternatives. Some studies also resort to Replicator Dynamics (Taylor & Jonker, 1978) to analyze strategy evolution.
## 3 Algorithms
Based on existing self-play work (Hernandez et al., 2021; Lanctot et al., 2017; Liu et al., 2022c; Garnelo et al., 2021), we propose a self-play framework (Algo. 1) that boasts enhanced expressivity and superior generalization capabilities. For simplicity, our framework is illustrated for symmetric games . All players share a policy population with a fixed maximum size. In each iteration, a newly initialized policy is trained, while opponent policies are sampled from the population. After training, the new policy is added to the population. The updated policy population is then evaluated, and then the opponent sampling strategy is recalculated for the next iteration.
This section is organized as follows: In Sec.3.1, we provide a formalized description of our framework. We then categorize self-play algorithms into four primary groups: traditional self-play algorithms (Sec. 3.2), the PSRO series (Sec. 3.3), the ongoing-training-based series (Sec. 3.4), and the regret-minimization-based series (Sec. 3.5). We analyze how these four categories align with our framework and introduce corresponding algorithms for each category. To make it more straightforward, we highlight the representative classic algorithms from these and present them in Table 1 for comparison within our framework. In Sec. 3.6, we compare the four categories, explain our classification rationale, and highlight the distinctions between our framework and existing ones to demonstrate its greater generality.
## 3.1 Framework Definition
Algorithm 1 A unified framework of self-play.
```
Algorithm 1. A unified framework of self-play.
1: Initialize II, \S
\
\
}
| |
]
)
<?>
} <!
```
In Algo. 1, we define a unified self-play framework based on Liu et al. (2022c); Lanctot et al. (2017); Garnelo et al. (2021); Hernandez et al. (2021). We combine visual illustrations (Fig. 3) with detailed textual descriptions to explain the key processes of our framework. Next, we provide an in-depth explanation of these processes:
- · Π := { π i ( ·| h i ( )) } N i =1 : Each policy π i in the policy population Π is conditioned on a policy condition function h i ( ), which provides supplementary information for certain algorithms. We denote the policy π i ( ·| h i ( )) as π h i . Note that i refers to the i th policy in the population, not the i th player, and N denotes the policy population size , not the number of players. Π can be initialized (Line 1 in Algo. 1) in two ways: lazy initialization and immediate initialization. In lazy initialization , Π starts with N placeholder policies, with the actual policies being initialized during the training iterations (Line 4 in Algo. 1). In immediate initialization , Π is initialized upfront with N real policies, which may be randomly generated or pre-trained models. A policy π h i is considered inactive if it is a placeholder; otherwise, it is considered active .
- · Σ := { σ i } N i =1 ∈ R N × C 1 : The interaction matrix Σ consists of rows σ i , where each σ i ∈ R C 1 represents the opponent sampling strategy of policy i , indicating how to sample opponents' policies. The dimension C 1 varies according to the sampling method. For instance, σ i can represent the probability distribution over opponent policies in the policy population Π, where C 1 = N n -1 and n denotes the number of players. Alternatively, σ i can be viewed as parameters of a sampling
Figure 3: Illustration of our framework. The top row shows two different initialization methods for the policy population Π and the interaction matrix Σ: lazy initialization and immediate initialization (corresponding to Line 1 in Algo. 1). The bottom row illustrates two training paradigms: standard training and ongoing training (corresponding to Lines 2~9 in Algo. 1). We categorize self-play algorithms into four types: traditional self-play, the PSRO series, the ongoing-training-based series, and the regret-minimization-based series. Among these, traditional self-play, the PSRO series, and the regret-minimization-based series utilize lazy initialization and standard training, whereas the ongoing-training-based series employs immediate initialization and ongoing training. For a detailed description and analysis, please refer to Sec.3 and Table1.
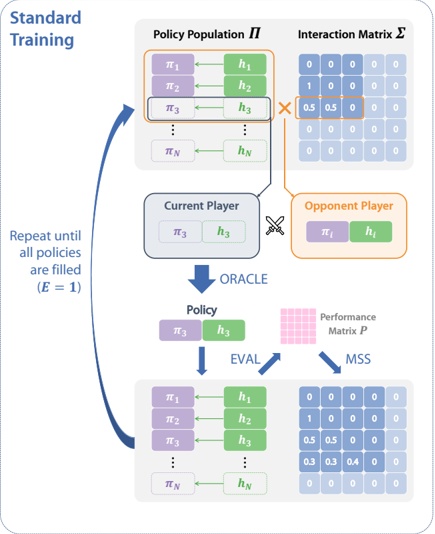
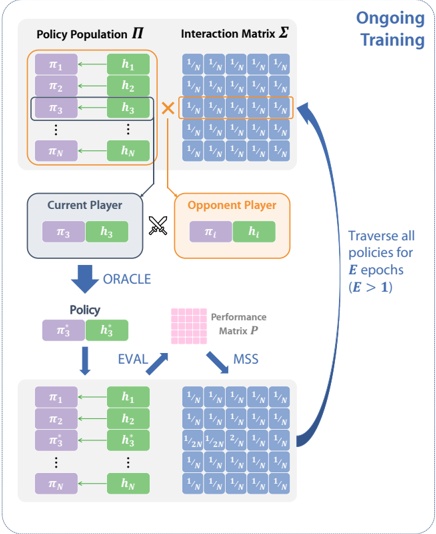
network. Specially, in a two-player game, if C 1 = N and σ ij represents the probability that policy i is optimized against policy j , Σ can be depicted in directed interaction graphs (Fig. 4). Σ will be initialized (Line 1 in Algo. 1) based on the initialization of Π. If Π uses lazy initialization, Σ will be initialized as an empty matrix. If Π uses immediate initialization, Σ will be calculated based on Π. We will discuss this in more detail later.
- · For epoch e ∈ [[ E ]] (Line 2 in Algo. 1): E denotes the total number of epochs for the entire policy population. For example, if the algorithm only introduces new policies into the population without updating existing ones, then E = 1. This implies that only the inactive policy is likely to be chosen for training in each iteration and turned into an active one, while activa policies remain unchanged. Conversely, if active policies are updated multiple times throughout the algorithm, then E > 1. Indeed, E accurately reflects the number of updates performed.
- · Initialize π h i (Line 4 in Algo. 1): The initialization of π h i can vary depending on the algorithm being used. It can be initialized randomly or by leveraging pre-trained models (Silver et al., 2016; Vinyals et al., 2019) or through a recently updated policy.
- · ORACLE( π , σ , i i Π) (Line 5 in Algo. 1): The ORACLE is an abstract computational entity that returns a new policy adhering to specific criteria. Here, we divide ORACLE into three types. (1) One type is the BR oracle, which is designed to identify the optimal counter-strategies against an opponent's strategy, including finding NE (McMahan et al., 2003). However, it often requires considerable computational effort. (2) To alleviate the computational demands, the approximate best response (ABR) oracle is introduced, using techniques such as RL (Algo. 2), evolution-theorybased methods (Algo. 3) or regret minimization methods (Algo. 4). (3) Other specially crafted ORACLEs are either tailored to specific meta-strategy solvers (MSSes) (Muller et al., 2020; Marris et al., 2021) or introduced to enhance diversity (Balduzzi et al., 2019; Perez-Nieves et al., 2021; Liu et al., 2021). Some details of Algo. 2, 3 and 4 need to be mentioned. Algo. 2 is a RL method that can be widely used across different categories. Moreover, off-policy RL algorithms typically require a replay buffer to gather samples; however, they are not explicitly included for simplicity. Algo. 3 is specifically utilized by Regularized Nash Dynamics (R-NaD) (Perolat et al., 2021) and Algo. 4 is specifically utilized by the regret-minimization-based series. They will be introduced in detail in Sec. 3.3.5 and Sec. 3.5 respectively.
- · EVAL(Π) (Line 6 in Algo. 1): Evaluating the policy population Π. There are multiple evaluation metrics available to assess the performance of each policy. The performance matrix is represented as P := { p i } N i =1 ∈ R N × C 2 . p i is the performance of policy i, and the dimension C 2 depends on the evaluation metric used. For instance, p i can be depicted as the relative skill like Elo ratings ( C 2 = 1) or can be depicted as the payoff tensor ( C 2 = N n -1 , where n is the number of players). Specially, in two-player symmetric zero-sum games, the expected payoffs can serve as the evaluation metric. In such cases, P is a square matrix ( C 2 = N ).
- · MSS : R N × C 2 → R N × C 1 (Line 7 in Algo. 1): A meta-strategy solver (MSS) MSS takes the performance matrix P as its input and produces a new interaction matrix Σ as its output. If the MSS produces a constant matrix irrespective of the input, the evaluation step (Line 6 in Algo. 1) can be skipped to reduce computations. Moreover, if Π uses immediate initialization, Σ will be initialized (Line 1 in Algo. 1) by first evaluating the performance and then applying the MSS.
## 3.2 Traditional Self-play Algorithms
Traditional self-play algorithms involve agents improving their strategies by repeatedly playing against themselves, allowing them to explore various strategies and enhance their decision-making abilities without external input. The simplest form involves agents training against their most recent version to identify weaknesses. Other approaches involve training against a set of strategies from different iterations, enabling agents to develop robust and adaptive strategies. This section will explain how traditional self-play algorithms fit into our framework and introduce representative traditional self-play methods, ranging from simpler forms to more complex ones.
## 3.2.1 Integration into Our Framework
Traditional self-play algorithms can be incorporated into our proposed framework (Algo. 1) with the following settings. First , the policy population Π utilizes lazy initialization because the policy population in traditional self-play algorithms is intended to grow with each iteration. Second , we set E = 1 because only the inactive policy can be trained in each iteration, then turning into an active policy. Here, the policy population size N serves as the upper limit for the number of active policies in the population. In other words, we use N iterations to optimize the policy. Third , the strategy being trained π h i can be initialized in a general manner. For instance, the strategy can be initialized randomly, learning from scratch. More often, π h i is initialized by π i -1 ( ·| h i ( -1)), allowing incremental learning and adaptation based on the most current trained policy to accelerate convergence. Fourth , the policies in traditional self-play algorithms
```
Algorithm: 2 Compute the oracle in RL.
Require: \nfrac { n } { \nbinom { \nbinom { \n
```
- Algorithm 3 Compute the oracle in evolution theory. Require: π h i /triangleright Policy i is being trained. Require: σ i /triangleright Opponent sampling strategy of policy i . Require: Π /triangleright Policy population. 1: sample π h opp ∼ P σ ( i ) /triangleright Policies of opponents. 2: π reg = ( π , h i π h opp ) /triangleright Regularization policies. 3: Transformed the reward according to π reg . 4: π h i ← Use replicator dynamics to play the reward-transformed game until convergence. 5: return π h i
```
Algorithm 4 Compute the oracle in regret matching.
Require: \pi _ { h } ^ { h } \quad \quad \quad
```
Player 1
C
-7
-7
-1
-9
-3
C
L
(
(
(
C
L
C
L
Player 2
Player 2
-9
-10
-3
(
-7
,
-7
-1
)
,
-9
-9
)
,
-1
-3
)
,
-3
)
L
Figure 4: Interaction matrix Σ examples. When C 1 = N and the opponent sampling strategy σ ij represents the probability that policy i is optimized against policy j , the interaction matrix Σ can be depicted in directed interaction graphs. Here, we consider three representative self-play algorithms. In the Top section, we define the interaction matrix Σ ∈ R 3 × 3 as { σ i } 3 i =1 . In the Bottom section, we present directed interaction graphs where the outgoing edges from each node are equally weighted, and their weights collectively sum to one. The relationship between the Top and Bottom sections is established through directed edges: an edge directed from node i to node j with a weight of σ ij signifies that policy i is optimized against policy j with a probability of σ ij . Note that this figure is reproduced from Liu et al. (2022c) and this concept is initially proposed by Garnelo et al. (2021).
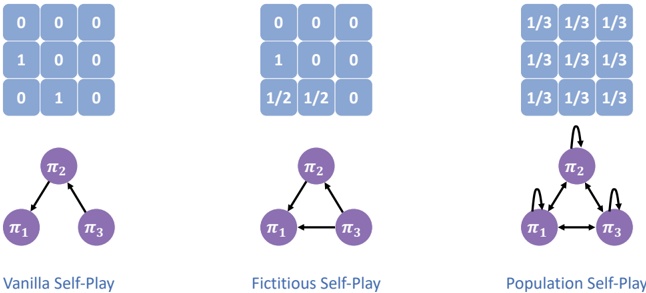
don't need supplementary information, we set the policy condition function h i ( ) = ∅ . Fifth , the MSSes of traditional self-play algorithms are straightforward, often yielding a constant interaction matrix Σ that eliminates performance evaluation. Only the MSS for prioritized fictitious self-play (described in Sec. 3.2.5) requires the performance matrix; nonetheless, it does not need to solve for complex game outcomes like NE.
Next, we outline the traditional self-play schemes. For simplicity, we operate under the following assumption:
Assumption 1. In a two-player symmetric game, C 1 = N , with σ ij denoting the probability that policy i is optimized in response to policy j which leads to ∑ N j =1 σ ij = 1 , ∀ i .
Based on Assumption 1, we can further deduce the following important corollary:
Corollary 1. In traditional self-play algorithms, the interaction matrix Σ is a lower triangular matrix.
Proof. The policy population gradually increases over time. When policy i is selected for training, only policy j ( j ≤ i ) has already been trained and holds meaningful outcomes. Other policies are inactive policies. As a result, we exclusively select policy j , where j ≤ i , to serve as the opponent for policy i .
## 3.2.2 Vanilla Self-play
In vanilla self-play (Samuel, 2000), agents are trained by competing against their latest versions. Thus, the MSS of vanilla self-play:
$$M S S ( \mathcal { P } ) _ { i j } = \begin{cases} \ 1, \text{ if } j = i - 1 & \\ 0, \text$$
Regardless of P , the MSS produces the same interaction matrix. Although this MSS is straightforward, it is utilized in many other algorithms, so we refer to it as vanilla MSS . Vanilla self-play is effective in transitive games, but it can lead the agent to cyclic learning patterns in non-transitive games. It may also lead to an unstationary problem, causing the system to get stuck in a local optimum.
A more modern version of vanilla self-play is to combine it with off-policy RL. In each iteration, the policy to be trained, π h i , is initialized using the previous policy π i -1 ( ·| h i ( -1)). Typically, each player's policy is
-1
0
Player 1
fixed, and samples are collected into a buffer by vanilla self-play. These samples remain useful for training, even if they were generated by an earlier policy. This allows the agent to leverage past experiences and maintain more stationary training. Once the policy is updated, it will be added to the policy population.
## 3.2.3 Fictitious Self-play
Fictitious Play (FP) (Brown, 1951) is a learning algorithm in game theory where each player best responds to the empirical frequency of the strategies used by the opponent. If the opponent's strategy is static, FP can find the NE. Based on FP intuition, Fictitious Self-Play (FSP) (Heinrich et al., 2015) is introduced to make agents play against past versions of themselves to learn optimal strategies to improve the robustness of vanilla self-play. Neural Fictitious Self-Play (NFSP) (Heinrich & Silver, 2016) is a modern variant that combines FSP with deep learning techniques. It uses neural networks to approximate the BRs. In the original versions of NFSP and FSP, two distinct types of agent memory are used: one to record the agent's own behavior and the other to capture the opponent's behavior.
In more recent approaches (Lanctot et al., 2017), random sampling is frequently employed to approximate the opponents' average strategy, eliminating the need to maintain two separate types of agent memory. Thus, the MSS of FSP:
$$M S S ( \mathcal { P } ) _ { i j } = \begin{cases} \begin{array} { c } \frac { 1 } { i - 1 },$$
In FSP, the MSS continues to generate a constant interaction matrix. Compared to vanilla self-play, this approach enhances the robustness of the policy by sampling older versions of its own policies to be used as opponent strategies.
## 3.2.4 δ -uniform Self-play
δ -uniform self-play, introduced by Bansal et al. (2018), uses the hyper-parameter δ , ranging from 0 to 1, to select the most recent 1 -δ percentage of policies for uniform sampling to generate opponent policies. When policy i is in the training phase, according to Corollary 1, only the previous i -1 policies are relevant. To select opponents for policy i , we sample from the range of policies between [ /ceilingleft δ i ( -1) /ceilingright , i -1], where /ceilingleft·/ceilingright denotes the ceiling function, which rounds up the input to the nearest integer greater than or equal to it. When δ = 0, the system retains the complete historical memory, whereas δ = 1 implies that only the most recent policy is utilized. Thus, the MSS of δ -uniform self-play:
$$M S S ( \mathcal { P } ) _ { i j } = \begin{cases} \begin{array} { c } \frac { 1 } { f ( i ) }$$
$$f ( i ) = i - \lceil \delta ( i - 1 ) \rceil.$$
In δ -uniform self-play, The MSS generates a constant interaction matrix. Specially , if δ = 0, it corresponds to FSP, and if δ = 1, it corresponds to vanilla self-play.
## 3.2.5 Prioritized Fictitious Self-play
Prioritized Fictitious Self-Play (PFSP) (Vinyals et al., 2019) leverages a priority function to allocate a higher probability of selection to agents with higher priorities. Here, P represents the winning rates, specifically defined as P ij = Prob( π i beats π j ). The MSS of PFSP is given by Algo. 5. The function f : [0 , 1] → [0 , ∞ ) is a priority function. For example, f ( x ) = (1 -x ) p with p > 0 indicates that stronger policies against the currently being trained policy have a higher chance of being chosen as opponents. Alternatively, f = x (1 -x ) implies that players of similar levels are more likely to be chosen as opponents. Additionally, in broader terms, P can also be assessed by other metrics. A similar MSS in Berner et al. (2019) can be utilized to allocate higher probabilities to strategies that perform better or are more challenging to defeat.
## Algorithm 5 PFSP meta-strategy solver.
- 1: function F P ( )
- 2: σ i +1 ,j ← f ( P i,j ) ∑ j ≤ i f ( P i,j ) , if j ≤ i
- 4: return Σ
- 3: Append zeros to σ i +1 until its length is N.
## 3.3 PSRO Series
Similar to traditional self-play algorithms, the PSRO series of algorithms starts with a single policy and gradually expands the policy space by incorporating new oracles. These oracles are policies that approximate optimal responses to the current meta-strategies of other agents.
## 3.3.1 Integration into Our Framework
The PSRO series of algorithms can also be integrated into our proposed framework (Algo. 1). First , similar to traditional self-play algorithms, we also utilize lazy initialization to initialize Π. Second , we also set E = 1 and N can be considered as the upper limit for the policy population size in the original PSRO algorithms. Third , in the context of the PSRO series of algorithms, the strategy of our player π h i can also be initialized in a general manner. Fourth , we set h i ( ) = ∅ since the PSRO series of algorithms do not use any policy condition function for their policies. Fifth , it's crucial to highlight that our framework diverges from the traditional PSRO model (Lanctot et al., 2017) in how σ i is defined. In contrast to being the metastrategy for policy, in our framework, σ i is the opponent sampling strategy. It means that σ i here represents the opponent's meta-strategy against policy i for the PSRO series of algorithms. Sixth , compared with traditional self-play methods, the MSSes of the PSRO series are often more complex. For example, some MSSes incorporate concepts from different types of game equilibria (McMahan et al., 2003; Muller et al., 2020; Marris et al., 2021). Lastly , we also simply follow Assumption 1. We can derive the Corollary 2 using a similar proof as Corollary 1.
Corollary 2. In the PSRO series of algorithms, the interaction matrix Σ is a lower triangular matrix.
## 3.3.2 Double Oracle
Double Oracle (DO) (McMahan et al., 2003) can be only applied to two-player normal-form games. In this context, we can utilize the payoff matrix as the evaluation matrix. The interaction matrix can be initialized with all zeros, reflecting the initial absence of interactions between strategies. The MSS of DO can then be outlined as described in Algo. 6. The opponent sampling strategy σ i corresponds to the opponent's NE strategy of the restricted game. Therefore, the oracle in DO is a BR rather than an ABR, computing the BR against the current NE opponent strategy of the restricted game. In the context of two-player normal-form games, DO theoretically can achieve the NE of the full game.
## Algorithm 6 NE-based meta-strategy solver.
- 1: function F P ( )
- 3: Append zeros to σ i +1 until its length is N.
- 2: σ i +1 ← SOLVE-NASH( P 1: i, 1: i ) /triangleright Opponent's NE meta-strategy.
- 4: return Σ
We take rock-paper-scissors as an example, a symmetric two-player game. The policy condition function h i ( ) = ∅ . The policy population size N = 4. The policy population Π uses lazy initialization and the interaction matrix Σ is initialized with all zeros. Assume that in the first iteration, the policy π 1 is set to "rock". Obviously, the NE-based MSS returns σ 2 = (1 0 0 0). , , , In the second iteration, the BR oracle adds "paper" to Π as π 2 . Consequently, the NE-based MSS yields σ 3 = (0 1 0 0), since "paper" always , , , beats "rock." In the third iteration, noting that σ 3 selects only "paper" and never "rock," the BR oracle adds "scissors" as π 3 . The NE-based MSS then solves the game and returns σ 4 = (1 / 3 1 , / 3 1 , / 3 0). , In the final
iteration, the BR oracle adds a mixed strategy that assigns a uniform probability over "rock," "paper," and "scissors" as π 4 . The final interaction matrix is:
$$\Sigma = \begin{bmatrix} 0 & 0 & 0 & 0 \\ 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ \frac { 1 } { 3 } & \frac { 1 } { 3 } & \frac { 1 } { 3 } & 0 \end{bmatrix}$$
This process demonstrates how the DO algorithm iteratively expands the strategy set within our framework. Also, using DO as an example, we show that, compared with traditional self-play algorithms, the PSRO series employs more sophisticated MSSes to better capture the essence of the game, albeit at a higher computational cost.
## 3.3.3 PSRO
PSRO (Lanctot et al., 2017) extends DO to more complex games beyond just two-player normal-form games. This approach first introduces the concept of the MSS, which is a broader concept than simply computing NE. The MSS framework allows for a more flexible representation of strategic solutions in various game settings. Many variants of PSRO focus on designing new MSSes to better capture different aspects of strategic play in these more complex games. In the original PSRO framework, the oracle is computed using RL techniques, similar to those described in Algorithm 2. This allows the algorithm to effectively handle large and intricate strategy spaces, making it applicable to various game scenarios.
## 3.3.4 PSRO Variants
The traditional PSRO algorithm has been the subject of numerous extensions in recent research. Some studies focus on making PSRO more computationally tractable in different scenarios or achieving fast convergence. By establishing a hierarchical structure of RL workers, Pipeline PSRO (McAleer et al., 2020) achieves the parallelization of PSRO and simultaneously provides guarantees of convergence. Efficient PSRO (Zhou et al., 2022) introduces the unrestricted-restricted (URR) game to narrow the selection of opponent policies, thereby preventing the need for meta-game simulations in traditional PSRO. Similar to Pipeline PSRO, Efficient PSRO is equipped to solve URR in parallel. In addition, unlike traditional PSRO, which confines the integration of population strategies to the game's initial state, Extensive-Form Double Oracle (XDO) (McAleer et al., 2021) allows this integration across all information states. It ensures a linear convergence to an approximate NE based on the number of information states, enhancing its tractability in extensive-form games. Online Double Oracle (ODO) (Dinh et al., 2022) integrates the no-regret analysis of online learning with DO to improve both the convergence rate to an NE and the average payoff. Anytime PSRO (McAleer et al., 2022b) and Self-play PSRO (McAleer et al., 2022a) are designed to incorporate less exploitable policies into the policy population, facilitating faster convergence. Moreover, as the number of agents grows, determining BRs becomes exponentially challenging. Mean-field PSRO (Muller et al., 2022) has been introduced to address this complexity in mean-field games. In addition, due to the computational intractability of solving NE in multi-player general-sum games (Daskalakis et al., 2009; Daskalakis, 2013) and the selection problem in NE (Goldberg et al., 2013), Müller et al. put forward α -PSRO (Muller et al., 2020). Instead of NE, α -rank (Omidshafiei et al., 2019), which is unique and polynomial-time solvable in multi-player general-sum games, is introduced in the MSS and a preference-based best response (PBR) oracle is incorporated in the approach. Similar to α -PSRO, Marris et al. (2021) proposes Joint Policy-Space Response Oracle (JPSRO) to tackle multi-player general-sum games. It utilizes CE and coarse correlated equilibrium (CCE) as alternatives to NE to make it computationally tractable in multi-player general-sum games and designs the CE and CCE-based MSS.
Other research focuses on policy diversification, as deriving a single policy in transitive games is less meaningful. Balduzzi et al. (2019) introduces an open-ended framework in two-player zero-sum games. This framework enhances the diversity of the strategy population and introduces a gamescape, which geometrically represents the latent objectives in games for open-ended learning. The study proposed two algorithms: Nash response PSRO N and rectified Nash response PSRO rN . Both algorithms utilize an asymmetric payoff
matrix as their performance evaluation metric. Similarly to DO, they employ the Nash-based MSS (Algo. 6). Compared to PSRO N , PSRO rN incorporates an additional step within the ABR oracle to focus on the opponents they beat or tie and ignore the opponents they lose to. Perez-Nieves et al. (2021) uses determinantal point process (Kulesza et al., 2012) to assess diversity and introduces diverse PSRO by incorporating a diversity term into the PSRO oracle. This modification can also be easily implemented in FP and α -PSRO. Similarly, Liu et al. (2021) introduces the concepts of behavioral diversity and response diversity and incorporates them into the PSRO oracle. Policy Space Diversity PSRO (Yao et al., 2023) defines a diversity metric named population exploitability that helps to achieve a full-game NE.
## 3.3.5 R-NaD
Although R-NaD (Perolat et al., 2021) is initially described as leveraging evolutionary game theory with a regularization component. Here, we categorized it into the PSRO series with a unique oracle computation technique (Algo. 3), executed in two stages: the first stage involves transforming the reward based on the regularization policy to make it policy-dependent, and the second stage applies replicator dynamics (Taylor & Jonker, 1978) until convergence to a fixed point. The oracle added to the policy population Π in each iteration is derived from the reward-transformed game, not the original problem's oracle. Nonetheless, this approach ensures that the policy converges to the NE of the original game when the game is monotone. The MSS of R-NaD is the vanilla MSS, as described in Equ. (5). This equation illustrates that the fixed point reached in each iteration, the oracle, is utilized as the regularization policy for the next iteration.
## 3.4 Ongoing-training-based Series
In the PSRO series of algorithms, two key challenges arise. First, truncating the ABR operators during each iteration is often necessary when operating with a limited budget, introducing sub-optimally trained responses into the population. Second, relearning basic skills in every iteration is redundant and becomes untenable when confronted with increasingly formidable opponents (Liu et al., 2022c). To address these challenges, the ongoing-training-based series of algorithms emphasizes the repeated ongoing training of all policies. In other words, instead of only inactive policies being selected for training, all active policies are also likely to be chosen for training.
## 3.4.1 Integration into Our Framework
We can incorporate these ongoing-training-based series of algorithms into our proposed framework (Algo. 1) using the following settings: First , we use immediate initialization to initialize Π because, in the ongoingtraining-based series, all policies in the policy population are trained together, rather than the policy population growing with each iteration. Second , we set E = E max > 1, which represents the maximum number of epochs to optimize each policy within the policy population. In other words, each unique policy undergoes iterative training for E max times. Third , since each policy undergoes training for E max times, we utilize π i ( ·| h i ( )) to initialize π h i . This means that policy updates are self-referential. Lastly , under Assumption 1, different from Collory 1 and 2, due to the continuous training process of all policies, we derive Collory 3.
Corollary 3. In the ongoing-training-based series of algorithms, the interaction matrix Σ is generally not a lower triangular matrix.
Proof. When policy i is selected for training, policy k ( k ≥ i ) has already been actually initialized and is therefore considered an active policy. Furthermore, in epoch e ( e > 1), policy k has already been updated and holds significant meaning. As a result, policy k , where k ≥ i , is likely to be chosen as the opponent for policy i . Consequently, the interaction matrix Σ is generally not a lower triangular matrix.
## 3.4.2 FTW
Quake III Arena Capture the Flag is a renowned 3D multi-player first-person video game where two teams vie to capture as many flags as possible. The For The Win (FTW) agent (Jaderberg et al., 2019) is designed to perform at human-level proficiency in this game. A pivotal aspect of FTW is its employment of the ongoing-training-based self-play in RL. Specifically, it trains a population of N different policies in parallel,
which compete and collaborate with each other. When policy i is undergoing training, FTW samples both its teammates and adversaries from the population. Specially , in scenarios where each team comprises a single member, it can be seamlessly integrated into our framework using the subsequent MSS:
$$M S S ( \mathcal { P } ) _ { i j } = \frac { 1 } { N }.$$
This essentially means that the interaction graph is densely connected. Moreover, all policies draw upon a unified policy network parameterized by φ . Hence, π i ( ·| h i ( )) can be aptly depicted as π φ ( ·| h i ( )). Furthermore, since these policies are not conditioned on external parameters, it is straightforward to represent the conditioning function h i ( ) = ∅ .
## 3.4.3 NeuPL
Neural Population Learning (NeuPL) (Liu et al., 2022c) introduces another critical innovation: it employs a unified conditional network, where each policy is adjusted against a specific meta-game mixture strategy. This is instrumental in enabling transfer learning across policies. Owing to NeuPL's reliance on a unified conditional network parameterized by θ , π i ( ·| h i ( )) can be succinctly represented as π θ ( ·| h i ( )). Since NeuPL policies depend on the opponent sampling strategy σ i , we define h i ( ) = σ i .
## 3.4.4 Simplex-NeuPL
Simplex-NeuPL (Liu et al., 2022a), which builds on NeuPL, is designed to achieve any-mixture optimality , which signifies that the formulated policy should exhibit flexibility across a diverse spectrum of adversaries, including those that might not present equivalent competitive prowess. To model the population learning process from a geometric perspective, Simplex-NeuPL introduces the concept of the population simplex. Analogously to its predecessor, Simplex-NeuPL integrates a conditional network to characterize the policy, represented as π θ ( ·| h i ( )) conditioned on the opponent sampling strategy h i ( ) = σ i . Intriguingly, there is a slight possibility that σ i does not originate from the MSS. Instead, it is drawn as a sample from the population simplex. This sampling mechanism results in greater robustness.
## 3.5 Regret-minimization-based Series
Another line of self-play algorithms is based on regret minimization. Unlike other categories, this series prioritizes accumulated payoff over time rather than focusing solely on a single episode, which is common in repeated games. For example, in games like Texas Hold'em or Werewolf, players must use deception, concealment, and bluffing to aim for overall victories rather than just winning a single game. Traditional regretminimization-based self-play typically doesn't use RL, but later studies have combined them for improved performance. This section will also discuss traditional regret-minimization methods to lay the groundwork for understanding their integration with RL.
## 3.5.1 Integration into Our Framework
We can also integrate the regret-minimization-based series of algorithms into our proposed framework (Algo. 1) with the following settings: First , similar to traditional self-play algorithms and the PSRO series, we use lazy initialization to initialize the policy population Π. Second , we set E = 1, and N is regarded as the maximum iteration to optimize the policy. Third , we initialize π h i using π i -1 ( ·| h i ( -1)) to utilize the most current trained policy. More specifically, h i ( ) = h i ( -1) and π h i = π h i -1 . Fourth , in each iteration i , h i ( ) represents the specific elements that regret-minimization-based self-play algorithms need to store. Note that this category relies heavily on the information in h i ( ). For instance, in Counterfactual Regret Minimization (CFR) (Zinkevich et al., 2007), it is necessary to store counterfactual regrets for every action in every information set for each player within h i ( ). Once h i ( ) is determined, the corresponding policy is also defined. We will discuss CFR in detail in Sec. 3.5.2. Fifth , the ABR operator (Algo. 4) incorporates regret-related information into h i ( ). Unlike the original CFR, Algo. 4 updates the regrets of each player sequentially. This means that the regrets of player 2 are updated after considering the already-updated
regrets of player 1. This adjustment has been shown to accelerate convergence empirically and possesses a theoretical error bound (Burch et al., 2019). Additionally, each π h i represents the strategies for all players, and in iteration i , player j uses the strategy π h i ( j ). Lastly , the MSS of the regret-minimization-based series is the vanilla MSS, as described in Equ. (5). Also, we can derive Collory 4.
Corollary 4. In the regret-minimization-based series of algorithms, the interaction matrix Σ is a lower triangular matrix. More specifically, it is a unit lower shift matrix , with ones only on the subdiagonal and zeroes elsewhere.
Proof. Regret minimization-based algorithms always use the latest strategy for training. In other words, at iteration i , π h i -1 is consistently chosen as the opponent policy. Consequently, the interaction matrix Σ is a unit lower shift matrix.
## 3.5.2 Vanilla CFR
Regret measures the difference between the best possible payoff and the actual payoff. The regret matching algorithm (Hart & Mas-Colell, 2000) optimizes decisions by selecting strategies based on accumulated positive overall regrets , with higher overall regret strategies being more likely chosen to correct past underperformance. After each round, players update the overall regret values for each strategy. Strategies will converge to an approximate NE. However, this method primarily applies to normal-form games because computing overall regret in extensive-form games is challenging.
Zinkevich et al. (2007) proposes CFR for extensive-form games. Here, it is referred to as vanilla CFR to distinguish it from later advancements. Vanilla CFR maintains the strategy and the immediate counterfactual regrets for each information set. Theoretically, this regret is specific to each information set, and the aggregation of these immediate counterfactual regrets is an upper bound for the overall regret. Therefore, the problem can be decomposed into numerous more minor regret minimization problems.
Next, there is a more detailed description of vanilla CFR. In this survey, π i denotes the strategy at iteration i for consistency, whereas the original paper uses σ . Furthermore, we use j to represent player j , and π i ( j ) denotes the policy used by player j at iteration i . The counterfactual value v j ( π, I ), which represents the expected value upon reaching the information set I when all players, except for player j , adhere to the strategy π :
$$v _ { j } ( \pi, I ) = \sum _ { h \in I, h ^ { \prime } \in Z } \text{Prob} ^ { \pi } _ { - j } ( h ) \text{Prob} ^ { \pi } ( h, h ^ { \prime } ) u _ { j } ( h ^ { \prime } ).$$
It is an unnormalized form of the counterfactual utility in the original paper. Based on this counterfactual value, the immediate counterfactual regret is defined as:
$$R _ { j, \text{imm} } ^ { T } ( I ) = \frac { 1 } { T } \max _ { a \in A ( I ) } \sum _ { i = 1 } ^ { T } ( v _ { j } ( \pi _ { i } | _ { I \to a }, I ) - v _ { j } ( \pi _ { i }, I ) ) \,,$$
where π i | I → a denotes player j choose action a with probability 1 at iteration i . Moreover, the positive immediate counterfactual regret is:
$$R ^ { T, + } _ { j, \text{imm} } ( I ) = \max ( R ^ { T } _ { j, \text{imm} } ( I ), 0 ).$$
The player j 's average overall regret R T j is defined as:
$$R _ { j } ^ { T } = \frac { 1 } { T } \max _ { \pi ( j ) ^ { * } \in \Pi ( j ) } \sum _ { i = 1 } ^ { T } \left ( u _ { j } ( \pi ( j ) ^ { * }, \pi _ { i } ( - j ) ) - u _ { j } ( \pi _ { i } ) \right ).$$
Theoretically, average overall regret R T j is bounded by the sum of positive immediate counterfactual regrets:
$$R _ { j } ^ { T } \leq \sum _ { I \in \mathcal { Z } _ { j } } R _ { j, \text{imm} } ^ { T, + } ( I ).$$
Thus, the problem can be simplified from minimizing the overall regret to minimizing the immediate counterfactual regrets in each information set separately. For simplicity, we often drop "immediate" in discussions and refer directly to counterfactual regrets . The counterfactual regret can also be recorded as follows:
$$R _ { j } ^ { T } ( I, a ) = \frac { 1 } { T } \sum _ { i = 1 } ^ { T } \left ( v _ { j } ( \pi _ { i } | _ { I \rightarrow a }, I ) - v _ { j } ( \pi _ { i }, I ) \right ),$$
$$R _ { j } ^ { T, + } ( I, a ) = \max \{ R _ { j } ^ { T } ( I, a ), 0 \}.$$
The regret matching algorithm (Hart & Mas-Colell, 2000) determines the strategy at each information set:
$$\pi _ { j } ^ { T + 1 } ( I ) ( a ) = \begin{cases} \begin{array} { c } R _ { j } ^ { T, + } ( I, a ) \\ \sum _ { \substack { a \in A ( I ) \\ \overline { 1 } ( I ) | } } R _ { j } ^ { T, + } ( I, a ) \\ \text{otherwise} \end{array} > 0 \\ \end{cases}.$$
It's worth noting that in some studies, the normalization factor 1 T is omitted in Equ. (12), (14) and (16).
Vanilla CFR has several shortcomings. Firstly, it requires traversing the entire game tree in each iteration, computationally intractable for larger game trees. Although some efforts have focused on game abstraction to reduce the size of the game tree, greater abstraction can lead to decreased performance. Second, it requires storing counterfactual regrets R I,a i ( ) for every action a in every information I at each iteration i . These values are stored in h i ( ) within our proposed framework (Algo. 1), leading to significant storage challenges.
## 3.5.3 Time-saving Variants of CFR
Many studies focus on enhancing the time efficiency of CFR. The first approach involves modifying the regret calculation to increase its speed. CFR+ (Tammelin, 2014) implements regret-matching+ by storing nonnegative regret-like values R + ,i j ( I, a ), rather than R i j ( I, a ). Additionally, CFR+ updates the regrets of each player sequentially and adopts a weighted average strategy. Moreover, Brown & Sandholm (2019a) introduces the concept of weighted regrets and develops Linear CFR (LCFR) and Discounted CFR (DCFR). The second approach involves adopting sampling methods. While it requires more iterations, each iteration is shorter, reducing the overall convergence time. Monte Carlo CFR (MCCFR) (Lanctot et al., 2009) divides terminal histories into blocks, with each iteration sampling from these blocks instead of traversing the entire game tree. This allows for calculating sampled counterfactual values for each player, leading to counterfactual regrets that, in expectation, match those of the Vanilla CFR. Vanilla CFR is a specific case where all histories are divided into just one block. MCCFR typically manifests in three forms: outcome-sampling MCCFR, where each block corresponds to a single history; external-sampling MCCFR, which samples opponent and chance nodes; and chance-sampling MCCFR, only focusing on chance nodes. Moreover, Johanson et al. (2012) expands on chance-sampling by categorizing based on the handling of public and private chance nodes. Some studies also focus on learning how to reduce the variance of MCCFR to speed up convergence (Schmid et al., 2019; Davis et al., 2020). In addition to these two primary approaches, other studies have identified that warm starting (Brown & Sandholm, 2016) and pruning (Brown & Sandholm, 2015; Brown et al., 2017; Brown & Sandholm, 2017) can also accelerate convergence.
## 3.5.4 Space-saving Variants of CFR
In perfect information games, decomposition reduces problem-solving scale by solving subgames. However, in imperfect information games, defining subgames is challenging due to their intersection with information set boundaries. CFR-D (Burch et al., 2014) is a pioneering method for decomposing imperfect information games into the main component called the trunk and subgames defined by forests of trees that do not divide any information sets. In each iteration, CFR is applied within the trunk for both players, and a solver is used to determine the counterfactual BR in the subgame. The process includes updating the trunk with the counterfactual values from the subgame's root and updating the average counterfactual values at this root, while the solution to the subgame is discarded. CFR-D minimizes storage needs by only saving R I ,a i ( ∗ ) for information sets in the trunk and at each subgame's root, which is denoted by I ∗ , trading off storage
Table 1: Overview of representative self-play algorithms within our framework.
| Algorithms | MSS | h(i) | Categories | E | Initialization of Π | Initialization of π h i | Suitable Game |
|--------------------------------------|-----------------------------------------------|----------------------------------------------|---------------------------|-------|-----------------------|----------------------------------|-----------------|
| Vanilla Self-play -Uniform Self-play | Equ. (5) Equ. (6) Equ. (7) | ∅ | Traditional Self-play | E = 1 | Lazy | General | Stage Game |
| FSP PFSP DO PSRO α -PSRO | Algo. 5 NE-based (Algo. General α -rank-based | ∅ | PSRO Series | E = 1 | Lazy | General | Stage Game |
| JPSRO R-NaD FTW NeuPL | (C)CE-based Equ. (5) Equ. (10) General | ∅ σ i | Ongoing-training-based | E > 1 | Immediate | π h i ← π i ( ·| h ( i )) | Stage Game |
| Vanilla CFR CFR+ CFR-D | Equ. (5) | R i ( I, a ) R + ,i ( I, a ) R i ( I ∗ , a ) | | E = 1 | Lazy | | Repeated Game |
| RCFR | | ϕ ( I, a ) | Regret-minimization-based | | | π h i ← π i - 1 ( ·| h ( i - 1)) | |
| Deep CFR | | V ( I, a | θ p ) | | | | | |
efficiency against the time required to resolve subgames. Similar thoughts are echoed in the ContinueResolving technique used by DeepStack (Moravčík et al., 2017) and the Safe and Nested Subgame Solving technique used by Libratus (Brown & Sandholm, 2018). We will discuss these approaches in Sec. 4.2.1, exploring their application to Texas Hold'em.
## 3.5.5 Estimation Variants of CFR
Although these CFR variants advance the field, they can't directly solve large imperfect-information extensive-form games due to their reliance on tabular representations. The typical approach involves abstracting the original game, applying CFR to the abstracted game, and translating strategies back to the original. This abstraction is game-specific and relies heavily on domain knowledge. Additionally, smaller abstractions often yield suboptimal results. Given these challenges, Waugh et al. (2015) introduces Regression CFR (RCFR), which employs a shared regressor ϕ I, a ( ) to estimate counterfactual regrets. Nevertheless, using regression trees as the regressor limits RCFR's applicability to miniature games, and the necessity for manually crafted features remains a drawback. After advantage-based regret minimization (ARM) (Jin et al., 2018) merges CFR with deep RL in single-agent scenarios, a growing body of research has focused on applying CFR in conjunction with neural networks to multi-agent scenarios. Double Neural CFR (Li et al., 2018) utilizes two neural networks: one for estimating counterfactual regrets and another for approximating the average strategy. In a similar vein, Deep CFR (Brown et al., 2019) leverages an advantage network V ( I, a θ | p ) to estimate counterfactual regrets with each player having a distinct hyperparameter θ p and employs π I, a θ ( | π ) for strategy estimation after the training process of the advantage network. Since these two networks are trained in sequence rather than concurrently, the strategy for each intermediate iteration remains conditioned on the output of the advantage network: h i ( ) = V ( I, a θ | p ). Despite similarities, Deep CFR distinguishes itself from Double Neural CFR through its data collection and proven effectiveness in larger-scale poker games. Single Deep CFR (SD-CFR) (Steinberger, 2019) demonstrates training an average strategy network is unnecessary, with only an advantage network required. Building on the foundation of SD-CFR, DREAM (Steinberger et al., 2020) utilizes a learned baseline to maintain low variance in a modelfree setting when only one action is sampled at each decision point. Moreover, advantage regret-matching actor-critic (ARMAC) (Gruslys et al., 2020) incorporates the thought of retrospective policy improvement.
## 3.6 Reassessment of the Framework
After introducing these four categories of self-play algorithms, we will further compare them in this section, explain the rationale behind categorizing the algorithms, and summarize the representative algorithms in Table 1. Moreover, we will illustrate the differences between our framework and other frameworks to demonstrate why our proposed framework is more general.
## 3.6.1 Categorization Rationale
Traditional self-play algorithms and the PSRO series share many similarities. Initially, they require only one randomly initiated policy, and the policy population expands as training progresses. Therefore, in our framework, we use lazy initialization to initialize the policy population and set E = 1 for these two categories. The interaction matrix is typically a lower triangular matrix (Corollary 1 and Corollary 2). The primary difference between the PSRO series and traditional self-play algorithms is that the PSRO series employs more complex MSSes to handle tasks with intricate game-theoretical requirements. For example, α -PSRO (Muller et al., 2020) specifically utilizes an α -rank-based MSS to tackle multi-player general-sum games. In other tasks, traditional self-play algorithms are more commonly used to reduce the computational cost associated with complex MSSes in the PSRO series.
Unlike the two previously mentioned categories, the ongoing-training-based series adopts a different paradigm. Instead of gradually expanding the policy population and relying on newer policies to be stronger, this approach strengthens all policies simultaneously at each epoch. This method alleviates issues such as early truncation and repeated skill relearning that occur in the above two categories. To integrate this category into our framework, immediate initialization is used for the policy population, and π i ( ·| h i ( )) is utilized to initialize π h i to ensure that policy updates are self-referential. Also, the interaction matrix is generally not a lower triangular matrix (Corollary 3).
Lastly, the regret-minimization-based series focuses on overall performance over time rather than on individual episodes, making it particularly suitable for repeated games. For example, Texas Hold'em is a classic repeated game where players adjust their strategies based on past interactions and use tactics involving deception and bluffing. The main goal of this training process is to update the regrets associated with different strategies, which in turn demands significant storage resources. Our framework uses h i ( ) to store this information. Since the policies are determined by h i ( ), only the most recent policy is relevant. Therefore, the interaction matrix is a unit lower shift matrix (Corollary 4). We also do not need actually to initialize the whole policy population and only need to use π i -1 ( ·| h i ( -1)) to initialize π h i in the training process.
## 3.6.2 Comparing with Existing Frameworks
Our framework is built upon PSRO (Lanctot et al., 2017) and NeuPL (Liu et al., 2022c). Here, we outline the differences between our framework and these existing frameworks. The primary distinction between our framework and PSRO is the use of an interaction matrix Σ := { σ i } N i =1 ∈ R N × C 1 to represent the opponent sampling strategy, allowing for the integration of more complex competitive dynamics. Moreover, in our framework, σ i denotes the opponent sampling strategy, which specifies how to sample opponents' policies against policy i rather than being the meta-strategy of policy i . Additionally, our framework incorporates a policy condition function h i ( ), making it more general than NeuPL, where policies are conditioned on σ i . This enhancement gives our framework greater expressiveness. Furthermore, we describe how to compute the oracle (Line 5 in Alg. 1) in three different ways (Alg. 2, Alg. 3 and Alg. 4) to provide a clearer understanding. Also, to the best of our knowledge, our framework is the first self-play framework to integrate the regretminimization-based series, which is a significant self-play paradigm.
## 4 Empirical Analysis
In this section, we introduce iconic applications of self-play by categorizing the scenarios into three distinct groups: board games, which typically involve perfect information; card games, which usually involve imperfect information; and video games, which feature real-time actions rather than turn-based play. We then
illustrate how self-play is applied in these complex scenarios and provide a comparative analysis of these applications in Table 2.
## 4.1 Board Games
Board games, the majority of which are perfect information games, were previously revolutionized by the introduction of two essential techniques: position evaluation and Monte Carlo tree search (MCTS) (Coulom, 2006; Kocsis & Szepesvári, 2006). These methodologies, with minor modifications, demonstrated superhuman effectiveness in solving board games such as chess (Campbell et al., 2002), checkers (Schaeffer et al., 1992), othello (Buro, 1999), backgammon (Tesauro & Galperin, 1996), and Scrabble (Sheppard, 2002). In contrast, the application of these techniques to the game of Go with an estimated 2 1 . × 10 170 legal board configurations, only enabled performance at the amateur level (Bouzy & Helmstetter, 2004; Coulom, 2007; Baudiš & Gailly, 2011; Enzenberger et al., 2010; Gelly & Silver, 2007). In light of this, our discussion will specifically focus on the game of Go to illustrate the application of self-play. In addition to Go, we will explore Stratego, a board game with imperfect information, in contrast to most board games that only involve perfect information.
## 4.1.1 Go
Go is an ancient board game, which is played on a grid of 19x19 lines, where two players alternately place black and white stones aiming to control the largest territory. The paradigm of Go artificial intelligence (AI) is revolutionized with the launch of DeepMind's AlphaGo series (Silver et al., 2016; 2017; 2018; Schrittwieser et al., 2020), which leveraged the power of self-play to significantly elevate performance. In AlphaGo (Silver et al., 2016), the training regime can be split into three stages. In the first stage, supervised learning with expert data trains a fast policy network p π ( a s | ) for rollouts in MCTS and a precise policy network p σ ( a s | ). The second stage employs self-play combined with RL to get a refined policy network p ρ ( a s | ) based on p σ ( a s | ) and subsequently trains a value network v θ ( s ). Specifically, p ρ ( a s | ) is refined by competing against a randomly selected historical version p ρ -( a s | ), similar to the MSS shown in Equ. (6), while v θ ( s ) is trained using the game samples collected by self-play of p ρ ( a s | ). In the third stage, MCTS integrates the policy and value networks to select actions.
Based on AlphaGo, AlphaGo Zero (Silver et al., 2017) does not require any expert data except game rules. It utilizes only one network f θ ( s ) to concurrently predict the action probabilities and the state value. Selfplay is employed to generate data and refine f θ ( s ) with the current best policy competing against itself, a process analogous to the MSS referenced in Equ. (5). A new policy to be incorporated into the policy pool must surpass a 55 percent win rate against its predecessor. AlphaZero (Silver et al., 2018) extends AlphaGo Zero to include games beyond Go, such as Chess and Shogi. Concerning the self-play procedure, the only difference between AlphaZero and AlphaGo Zero is that AlphaZero utilizes the newly updated network to generate samples by self-play without validation. Building upon AlphaZero, MuZero (Schrittwieser et al., 2020) takes learning from scratch to the next level, even operating without predefined game rules. The self-play process in MuZero operates similarly to that in AlphaZero. In practice, in addition to excelling in board games, MuZero also achieves state-of-the-art performance in Atari games.
## 4.1.2 Stratego
Unlike most board games, which are perfect information games, Stratego, a two-player imperfect information board game, distinguishes itself by incorporating elements of memory, deduction, and bluffing. This complexity is further amplified by the game's long episode length and many potential game states, estimated 10 535 (Perolat et al., 2022). The game is divided into two phases: the deployment phase, where players secretly arrange their units, and the game-play phase, where the objective is to deduce the opponent's setup and capture their flag. The depth and computational complexity of the game remained a challenge until breakthroughs such as DeepNash (Perolat et al., 2022) showed promising advances in AI's ability to tackle it. DeepNash scales up evolution-theory-based self-play method R-NaD (Perolat et al., 2021) (discussed in Sec. 3.3.5) to neural R-NaD. It employs a neural network with four heads: one for value prediction, one for the deployment phase, one for piece selection, and one for piece displacement. Neural Replicator Dynamics (Hennes et al., 2020) is utilized to obtain the approximate fixed-point policy. DeepNash holds the
third-place ranking among all professional Gravon Stratego players and wins nearly every match against existing Stratego bots.
## 4.2 Card Games
Unlike board games, card games are typically imperfect information games with a larger state space and greater complexity. Here, we introduce three representative card games: Texas Hold'em, DouDiZhu, and Mahjong, to illustrate how self-play is utilized in card games. Texas Hold'em is a repeated game rather than a stage game, so the focus is on the overall win-loss outcome rather than on individual rounds. Consequently, it is particularly well-suited for regret-minimization-based self-play methods, which aim to minimize overall regret rather than regret on a per-round basis. In contrast, DouDiZhu and Mahjong are typically regarded as stage games, so studies often employ self-play methods that do not rely on regret minimization.
## 4.2.1 Texas Hold'em
Texas Hold'em , a popular poker game with 2-10 players, is known for its strategic depth and bluffing elements. The two-player variant is called heads-up Texas Hold'em . The gameplay begins with each player receiving two private cards (hole cards), followed by a round of betting. Subsequently, three community cards (the flop) are revealed, leading to another betting round. This is followed by dealing a fourth (the turn) and a fifth community card (the river), each accompanied by further betting rounds. The objective is to construct the best five-card poker hand from any combination of hole cards and community cards. Texas Hold'em offers two betting formats: limited betting and no-limit betting. The latter one is noted for its complexity, allowing players to bet any amount up to their entire stack of chips. While simplified versions such as Kuhn Poker and Leduc Poker serve valuable roles in theoretical analysis, we will focus on the algorithms designed to compete in full Texas Hold'em.
Heads-up limit Texas Hold'em (HULHE) , the simplest form with approximately 3 16 . × 10 17 game states, was not solved until the introduction of Cepheus (Bowling et al., 2015). It utilizes fixed-point arithmetic with compression and regret-minimization-based self-play method CFR+ (Tammelin, 2014) to address the issues of storage and computation, respectively, resulting in superhuman performance. Deep CFR (Brown et al., 2019) combines regret-minimization-based self-play method CFR with deep neural networks. Furthermore, some studies do not adopt the regret-minimization-based series of self-play; instead, they use the traditional self-play method. NSFP (Heinrich & Silver, 2016) introduces a self-play method combined with end-to-end RL training, also achieving competitive performance in HULHE. Poker-CNN (Yakovenko et al., 2016) utilizes self-play to learn convolutional networks to solve a video version of HULHE.
After solving HULHE, research focus shifts to heads-up no-limit Texas Hold'em (HUNL) with significantly larger game states, approximately 10 164 (Johanson, 2013). Thus, traversing the game tree as Cepheus does in HULHE is impossible. DeepStack (Moravčík et al., 2017) is a regret-minimization-based self-play method combined with continual re-solving. This method focuses on a subtree of limited depth and breadth and estimates the outcomes of the furthest reaches of this subtree. Libratus (Brown & Sandholm, 2018) develops a blueprint strategy, leveraging an enhanced version of regret-minimization-based self-play method MCCFR (Lanctot et al., 2009). Recursive Belief-based Learning (ReBeL) (Brown et al., 2020) introduces the public belief state (PBS), transforming the imperfect-information game into a perfect-information game with continuous state space. ReBeL utilizes the regret-minimization-based self-play method CFR-D, combined with RL and search, to train both the value and policy networks. Unlike the algorithms mentioned above, AlphaHoldem (Zhao et al., 2022a) does not use regret-minimization-based self-play. Instead, it proposes a K -best self-play method that always selects the top K agents, based on their ELO ratings (Elo & Sloan, 1978), to generate samples.
Pluribus (Brown & Sandholm, 2019b), based on Libratus, addresses six-player no-limit Texas Hold'em . Similar to Libratus, Pluribus utilizes a regret-minimization-based self-play method MCCFR (Lanctot et al., 2009) to develop its blueprint strategy. It conducts a depth-limited search before executing actions. Different from Libratus, Pluribus maintains a streamlined policy pool of only four strategies, assuming that its opponents might adjust their strategies during gameplay among these four strategies, which allows Pluribus to manage complexity more efficiently.
## 4.2.2 DouDiZhu
DouDizhu (a.k.a. Fight the Landlord) is a three-player strategic card game. In this game, one player takes on the role of the landlord and competes against the other two players, the peasants. The game is played in two main stages: the bidding stage and the card play stage. During the bidding stage, players vie to become the landlord. During the card play stage, players take turns playing cards in various combinations, intending to be the first to empty their hands. DouDiZhu is characterized by imperfect information, as players can only see their own cards and the cards played. The essence of the game lies in cooperation among peasants and competition between the two factions. It has an estimated 10 76 ∼ 10 106 possible game states (Zha et al., 2019) and an action space comprising 27472 possible moves (Yang et al., 2022).
DeltaDou (Jiang et al., 2019) is the first algorithm to achieve expert-level performance in DouDizhu. Similar to AlphaZero (Silver et al., 2018), DeltaDou utilizes vanilla self-play to generate samples to train policy and value networks. DouZero (Zha et al., 2021) also uses vanilla self-play to generate data. It reduces training costs by opting for a sampling method over the tree search approach. Based on DouZero, DouZero+ (Zhao et al., 2022b) incorporates opponent modeling, assisting the agent in making more informed decisions. PerfectDou (Yang et al., 2022) utilizes vanilla self-play under a Perfect-Training-Imperfect-Execution framework.
## 4.2.3 Mahjong
Mahjong has evolved into various global variants, including the famous Japanese version known as Riichi Mahjong. This game is typically played by four players who must navigate both the visible aspects of the game, such as discarded tiles, and the hidden elements, like their own hand and the unseen public tiles. The strategic depth and complexity of Mahjong pose significant challenges. Despite ongoing research, these findings have yet to reach expert human levels (Kurita & Hoki, 2020; Gao et al., 2019; Mizukami & Tsuruoka, 2015). Difficulties are navigating incomplete information, dynamically adapting strategies to multiple opponents, and contending with complex winning rules and an enormous number of possible game states, estimated at 10 169 (Zha et al., 2019). Suphx (Li et al., 2020) is recognized as one of the first algorithms to master Mahjong, achieving a performance level comparable to expert human players, precisely 10 dan on Tenhou (Tsunoda), the most popular online Mahjong platform. Initially, Suphx employs supervised learning, utilizing expert data to train its model. It then advances its capabilities through vanilla self-play combined with RL. Similarly, NAGA (Village), developed by Dwango Media Village, and LuckyJ (Tencent), designed by Tencent, have also achieved the rank of 10 dan on Tenhou. Furthermore, LuckyJ has even defeated human professional players.
## 4.3 Video Games
In contrast to traditional board games and card games, video games often feature real-time actions, long trajectories, and increased complexity stemming from a broader range of actions and observations. We illustrate representative video games showcasing self-play's impact.
## 4.3.1 StarCraft II
StarCraft is a real-time strategy (RTS) game. It has three distinct species: the Terrans, Zerg, and Protoss, each with unique units and strategic options that enhance the gameplay complexity. Renowned for its balanced gameplay, strategic depth, and intense competitiveness, the game challenges players to gather resources, construct bases, and build armies. Victory requires meticulous planning and tactical execution, with defeat occurring when a player loses all their buildings. AlphaStar (Vinyals et al., 2019) dominates the 1v1 mode competitions in StarCraft II and has defeated professional players. Its framework is similar to AlphaGo (Silver et al., 2016), initially utilizing supervised learning to train the policy with expert data. Subsequently, it uses a hierarchical self-play method combined with end-to-end RL to train the networks. More specifically, The proposed self-play method divides all the agents into three types: main agents, league exploiters, and main exploiters. It maintains a policy pool of past players that records all these types of agents. Main agents engage in traditional self-play algorithms like FSP and PFSP, competing against main agents themselves and other agents in the policy pool. They are periodically added to the pool and never reset. League exploiters also use a traditional self-play method PFSP to play against all policy
pool agents, added to the pool if they show a high win rate and potentially reset to expose global blind spots. Main exploiters only compete with main agents to improve their robustness, are added to the pool after achieving a high win rate or specific training steps, and are reset upon each addition. Among those three agent types, the main agent is the core agent and embodies the final AlphaStar strategy. However, the introduction of three agent types significantly increases the training computation. Further studies (Han et al., 2020; Wang et al., 2021; Huang et al., 2024) have enhanced the league self-play training procedure.
## 4.3.2 MOBA Games
Multiplayer Online Battle Arena (MOBA) games are a popular video game genre that blends RTS with role-playing elements. In typical MOBA games, two teams of players control their unique characters, known as heroes, and compete to destroy the opposing team's main structure, often referred to as the base. Each hero has distinct abilities and plays a specific role within the team, such as Warrior, Tank, or Support. Managing multiple lanes and battling under the fog of war, which obscures parts of the map, are critical aspects of the gameplay.
OpenAI Five (Berner et al., 2019) defeated the world champion team in a simplified version of Dota 2 that featured a limited pool of heroes and certain banned items. The training process introduces a self-play method that combines two traditional self-play algorithms: with an 80% probability of engaging in vanilla self-play and a 20% probability of employing a technique similar to the PFSP used in AlphaStar (Vinyals et al., 2019). This technique selects each policy from the policy pool based on its quality score, which is continuously updated from competition results throughout training. Higher quality scores increase the likelihood of a policy being selected. OpenAI Five also requires extensive training resources.
Another notable MOBA game, especially viral in China, is Honor of Kings. The 1v1 mode is conquered by Ye et al. (2020b), which boasts a significant winning rate against top professional players. It utilizes a traditional self-play method δ -uniform self-play to train the RL networks. The 5v5 mode was later mastered by Ye et al. (2020a) as well. Unlike OpenAI Five, this work expands the hero pool to 40 heroes, exponentially increasing the possible combinations of lineups. It proposes a new self-play method referred to as curriculum self-play learning (CSPL). Specifically, the training process is divided into three stages. The first stage involves training fixed lineups through self-play and utilizing human data to balance the two teams to aid policy improvements. The second stage employs multi-teacher policy distillation to produce a distilled model. The final stage uses this distilled model as the initial model for another round of self-play with randomly picked lineups. This approach defeats professional player teams. The self-play generated data is also used to learn compelling lineup drafting by utilizing MCTS and neural networks (Chen et al., 2021).
## 4.3.3 Google Research Football
Google Research Football (GRF) (Kurach et al., 2020) is an open-source football simulator emphasizing high-level actions. It initially offers two scenarios: the football benchmark and the football academy with 11 specific tasks. Here, we focus exclusively on the football benchmark because it presents a more complex scenario that better demonstrates the effects of self-play. GRF is particularly challenging due to the need for cooperation among teammates and competition against opposing teams. It features long trajectories with 3000 steps per round, stochastic transitions, and sparse rewards.
WeKick (Ziyang Li, 2020) claimed victory in the GRF competition on Kaggle (Google, 2020), which simplifies the game dynamics by allowing competitors to control only one player, either the ball carrier on offense or the nearest defender on defense. It employed self-play strategies similar to those used in league training (Vinyals et al., 2019). It initializes its opponent policy pool using strategies developed through RL and Generative Adversarial Imitation Learning (GAIL) (Ho & Ermon, 2016) to facilitate the training process.
Further research delves into the full football game rather than the simplified version. Team-PSRO (McAleer et al., 2023) extends PSRO series of self-play algorithms to team games, outperforming baselines in the 4v4 version of the full GRF. In the context of the 11v11 version, where the goalkeeper is rule-based controlled, TiKick (Huang et al., 2021a) utilizes vanilla self-play to collect samples and then employs imitation learning. Fictitious Cross-Play (FXP) (Xu et al., 2023) proposes a new self-play method similar to AlphaStar (Vinyals et al., 2019). It introduces two populations: the main population and the counter population. Policies in
the counter population improve solely by cross-playing with policies in the main population as opponents, while policies in the main population engage in playing with policies from both populations. FXP achieves a win rate of over 94% against TiKick. TiZero (Lin et al., 2023), a follow-up to TiKick, combines curriculum learning with FSP and PFSP (Vinyals et al., 2019) to avoid expert data reliance, achieving a higher TrueSkill rating (Herbrich et al., 2006) than TiKick.
## 5 Open Problems and Future Work
Self-play methods have shown remarkable performance by leveraging iterative learning and adapting to complex environments. However, significant challenges and open questions remain, presenting opportunities for further research and development.
## 5.1 Theoretical Foundation
Although NE has been shown to exist in games with finite players and finite actions (Nash et al., 1950), computing NE with self-play algorithms in larger games remains challenging and consequently, many studies aim to achieve approximate NE (Li et al., 2024). However, in some cases, even computing an approximate NE is difficult (Daskalakis, 2013). Some research has resorted to higher levels of equilibrium, such as CE (Marris et al., 2021) and α -rank (Muller et al., 2020). Although many algorithms are developed with theoretical foundations, there is often a gap in complex real-world scenarios. For example, although self-play algorithms like AlphaGo (Silver et al., 2016), AlphaStar (Samvelyan et al., 2019), and OpenAI Five (Berner et al., 2019) achieve empirical success, they lack formal game theory proofs behind their effectiveness. Future work should focus on bridging this gap by developing new theoretically sound and practically effective algorithms or proving the theoretical underpinnings of existing successful self-play algorithms in complex environments.
## 5.2 Non-stationarity of the Environment
In the self-play framework, the opponents are a vital component of the environment, and the strategies of the opponent players evolve as training progresses. This evolution can cause the same strategy to lead to different results over time, creating a non-stationary environment. This problem is also shared by the MARL area. Future research should aim to develop self-play algorithms that are more robust and can adapt to changing conditions. For example, incorporating opponent modeling (Zhao et al., 2022b) into self-play can help agents anticipate changes in opponent strategies and adjust their own strategies proactively, making them more robust to environmental changes.
## 5.3 Scalability and Training Efficiency
The scalability of self-play methods faces significant challenges as the number of teams and players within those teams increases. As the number of participants grows, the complexity of interactions explodes. For example, in OpenAI Five (Berner et al., 2019), the hero pool size is limited to only 17 heroes. MOBA AI (Ye et al., 2020a) extends this to a 40-hero pool with the help of curriculum learning, but it still cannot cover the entire hero pool available in the actual game. One potential solution is leveraging players' inherent connections to optimize the learning process. For instance, using graph-based models to represent and exploit the relationships between players can help manage and reduce the complexity of large-scale multi-agent environments. These scalability issues are fundamentally rooted in the limited training efficiency of self-play methods from two aspects including computation and storage. The first issue is computational efficiency, which is induced by the iterative nature of self-play where agents repeatedly play against themselves or past versions. Moreover, although forming more complex populations and competitive mechanisms (Samvelyan et al., 2019) can enhance the intensity and quality of training, it further exacerbates the demand for computational resources. Techniques such as parallel computing, distributed learning, and more efficient neural network architectures could be explored to address these challenges. The second issue is storage because self-play requires maintaining a policy pool. Even when using a shared network architecture, storing the parameters of large models can be problematic. This issue is particularly pronounced in regret-minimization-based selfplay algorithms, which must store the regrets for each information set and potential action. Managing both
## Table 2: Overview of representative studies in empirical analysis.
| Expert Data | × | × | ✓ | × | × | × | × | × | × | × | × | × | × | × | ✓ | × | ✓ | ✓ | × ✓ | × |
|-----------------------|--------------|--------------|--------------|--------------|--------------|--------------|-----------|-----------|-----------|-----------|-----------|-------------|-----------------------------------|------------------|-----------------------|------------|--------------|-------------------|----------------|--------------------------|
| Search | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | × | ✓ | × | ✓ | ✓ | ✓ | ✓ | ✓ | × | × ✓ | × | × | ✓ | × |
| Self-play Method | Vanilla SP | Vanilla SP | FSP | Vanilla SP | Vanilla SP | Vanilla SP | R-NaD | CFR+ | NFSP | CFR+ | MCCFR | CFR-D / FSP | MCCFR | Vanilla SP | Vanilla SP Vanilla SP | Vanilla SP | FSP & PFSP | Vanilla SP & PFSP | δ -uniform SP | FSP & PFSP |
| Algorithms | AlphaZero | MuZero | AlphaGo | AlphaGo Zero | AlphaZero | MuZero | DeepNash | Cepheus | NFSP | DeepStack | Libratus | ReBel | Pluribus | DeltaDou DouZero | PerfectDou | Suphx | AlphaStar | OpenAI Five | MOBA AI | TiZero |
| Number of Game States | 10 45 10 360 | 10 45 10 360 | 10 45 10 360 | 10 45 10 360 | 10 45 10 360 | 10 45 10 360 | 10 535 | 10 17 | 10 17 | 164 | 164 | 164 | > 10 164 | 10 76 ∼ 10 106 | 10 76 ∼ 10 106 | 10 169 / | 10 169 / | 10 169 / | 10 169 / | 10 169 / |
| Perfect Information | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | × | × | × | × | × | × | × | × | × | × | × | × | × | ✓ |
| Number of Players | 2 | 2 | 2 | 2 | | | 2 | 2 | 2 | 2 | 2 | 2 | 6 | 3 | 3 | 4 | 2 | 10 | 10 | 22 |
| Game | Chess | | | Go | Go | Go | Stratego | HULHE | HULHE | | HUNL | | Six-player No-limit Texas Hold'em | DouDiZhu | DouDiZhu | Mahjong | StarCraft II | Dota 2 | Honor of Kings | Google Research Football |
| Category | Game Game | Game Game | Game Game | Game Game | Game Game | Game Game | Game Game | Game Game | Game Game | Game Game | Game Game | Card | Game Game | Game Game | Game Game | Game Game | Video Game | Video Game | Video Game | Video Game |
the computational load and storage requirements is essential for improving the overall training efficiency and scalability of self-play methods.
## 5.4 With Large Language Models
With their remarkable capability and emergent generalizability, large language models (LLMs) have been regarded as a potential foundation for achieving human-level intelligence (Achiam et al., 2023), and self-play methods have been proposed to fine-tune LLMs, enhance LLMs' reasoning performance, and build LLMbased agents with strong decision-making abilities. Post-training fine-tuning (Ouyang et al., 2022; Bai et al., 2022) is a key step in aligning LLM with more desired behaviors, but it requires a huge amount of humanannotated data. To reduce reliance on human-annotated data, Self-play fIne-tuNing (SPIN) (Chen et al., 2024) introduces a self-play mechanism to generate training data using the LLM itself and fine-tuning the LLM by distinguishing self-generated responses from human-annotated data. Another line of work (Munos et al., 2024; Swamy et al., 2024; Wu et al., 2024) formulate the alignment problem as a two-player constantsum game and use self-play methods to solve the game. Some other work (Huang et al., 2022; Yuan et al., 2024) also utilizes model-generated data to fine-tune LLMs with minimal human annotations. The idea of self-improvement has also been applied to improve the reasoning ability of LLMs. Self-Play of Adversarial Game (SPAG) (Cheng et al., 2025) observes that self-play in a two-player adversarial language game called Adversarial Taboo can boost the LLM's performance on various reasoning benchmarks. Besides improving the capability of LLMs, self-play methods have also contributed to building LLM-based agents with strong strategic abilities. A representative work is Cicero (, FAIR) which achieves human-level play in the game of Diplomacy by combining language models with an RL policy trained by self-play. Cicero uses the self-play policy to produce an intended action and prompts the language model to generate languages conditioned on the policy's intent. Another work (Xu et al., 2024) also combines LLM with self-play policy but takes a different approach by first prompting the LLM to propose multiple action candidates and then using the self-play policy to produce the action distribution over these candidates. Despite recent progress, applying self-play with LLMs is still underexplored and requires further research.
## 5.5 Real-World Applications
Self-play is particularly effective in addressing some problems abstracted from real-world situations through its iterative learning approach. In the field of economics, for instance, self-play is used to enhance supervised learning models in multi-issue bargaining tasks (Lewis et al., 2017). Furthermore, self-play proves beneficial in solving combinatorial optimization problems (COPs) such as the traveling salesman problem (TSP) and the capacitated vehicle routing problem (CVRP) (Wang et al., 2024). Within the domain of traffic, self-play facilitates the development of human-like autonomous driving behaviors (Cornelisse & Vinitsky, 2024) and enables vehicles to learn negotiation strategies to merge on or off roads (Tang, 2019), although currently within 2D simulators.
However, a notable challenge with self-play is its impracticality for direct application in real-world scenarios. Its iterative approach requires extensive trial and error, which is computationally demanding and often involves actions that are impractical or unsafe outside of a controlled simulation. Therefore, self-play is often carried out in simulators. The effective deployment of self-play in real-world applications boils down to overcoming the Sim2Real gap. For example, for tasks where the Sim2Real gap is less pronounced, self-play can be well employed to enhance video streaming capabilities (Huang et al., 2021b), and to address the image retargeting problem (Kajiura et al., 2020). Moreover, EvoPlay (Wang et al., 2023) leverages self-play to design protein sequences, utilizing the advanced AlphaFold2 simulator (Jumper et al., 2021) to narrow the Sim2Real gap. Similarly, in heterogeneous multi-robot systems, self-play is utilized for competitive sports tasks like humanoid football (Liu et al., 2022b; Haarnoja et al., 2024), quadruped competition (Xiong et al., 2024), and multi-drone volleyball (Xu et al., 2025), with significant efforts dedicated to Sim2Real transitions for real-world success (Gao et al., 2023).
## 6 Conclusion
The burgeoning field of self-play in RL has been systematically explored in this survey. The core idea of self-play that agents interact with copies or past versions of themselves has proven to be a powerful approach for developing robust strategies across various domains. Before delving into the specifics of selfplay, this paper first elucidates the MARL framework and introduces the game theory background of selfplay. Moreover, the paper presents a unified framework and categorizes existing self-play algorithms into four main categories: traditional self-play algorithms, the PSRO series, the ongoing-training-based series, and the regret-minimization-based series. We provide detailed explanations on how these four groups are seamlessly integrated into our proposed framework, ensuring a comprehensive understanding of their functionalities. The transition from theory to application is underscored by a rigorous analysis of self-play's role within various scenarios, such as board games, card games, and video games. Despite the successes of self-play in many areas, challenges remain, such as convergence to suboptimal strategies and substantial computational demands. Also, future work can focus on how to integrate self-play with LLMs and achieve real-world applications. In conclusion, self-play is vital to modern RL research, offering key insights and tools for developing advanced AI systems. This survey serves as an essential guide for researchers and practitioners, paving the way for further advancements in this field.
## References
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 , 2023.
Robert J Aumann. Subjectivity and correlation in randomized strategies. Journal of mathematical Economics , 1(1):67-96, 1974.
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862 , 2022.
David Balduzzi, Marta Garnelo, Yoram Bachrach, Wojciech Czarnecki, Julien Perolat, Max Jaderberg, and Thore Graepel. Open-ended learning in symmetric zero-sum games. In International Conference on Machine Learning , pp. 434-443. PMLR, 2019.
Trapit Bansal, Jakub Pachocki, Szymon Sidor, Ilya Sutskever, and Igor Mordatch. Emergent complexity via multi-agent competition. In International Conference on Learning Representations , 2018.
Petr Baudiš and Jean-loup Gailly. Pachi: State of the art open source go program. Advances in computer games , pp. 24-38, 2011.
Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemyslaw Debiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, et al. Dota 2 with large scale deep reinforcement learning. arXiv preprint arXiv:1912.06680 , 2019.
Ariyan Bighashdel, Yongzhao Wang, Stephen McAleer, Rahul Savani, and Frans A Oliehoek. Policy space response oracles: a survey. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pp. 7951-7961, 2024.
Bruno Bouzy and Bernard Helmstetter. Monte-carlo go developments. Advances in Computer Games: Many Games, Many Challenges , pp. 159-174, 2004.
Michael Bowling, Neil Burch, Michael Johanson, and Oskari Tammelin. Heads-up limit hold'em poker is solved. Science , 347(6218):145-149, 2015.
George W Brown. Iterative solution of games by fictitious play. Act. Anal. Prod Allocation , 13(1):374, 1951.
Noam Brown and Tuomas Sandholm. Regret-based pruning in extensive-form games. Advances in neural information processing systems , 28, 2015.
| Noam Brown and Tuomas Sandholm. Strategy-based warm starting for regret minimization in games. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 30, 2016. |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Noam Brown and Tuomas Sandholm. Reduced space and faster convergence in imperfect-information games via pruning. In International conference on machine learning , pp. 596-604. PMLR, 2017. |
| Noam Brown and Tuomas Sandholm. Superhuman ai for heads-up no-limit poker: Libratus beats top professionals. Science , 359(6374):418-424, 2018. |
| Noam Brown and Tuomas Sandholm. Solving imperfect-information games via discounted regret minimiza- tion. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 33, pp. 1829-1836, 2019a. |
| Noam Brown and Tuomas Sandholm. Superhuman ai for multiplayer poker. Science , 365(6456):885-890, 2019b. |
| Noam Brown, Christian Kroer, and Tuomas Sandholm. Dynamic thresholding and pruning for regret mini- mization. In Proceedings of the AAAI conference on artificial intelligence , volume 31, 2017. |
| Noam Brown, Adam Lerer, Sam Gross, and Tuomas Sandholm. Deep counterfactual regret minimization. In International conference on machine learning , pp. 793-802. PMLR, 2019. |
| Noam Brown, Anton Bakhtin, Adam Lerer, and Qucheng Gong. Combining deep reinforcement learning and search for imperfect-information games. Advances in Neural Information Processing Systems , 33: 17057-17069, 2020. |
| Neil Burch, Michael Johanson, and Michael Bowling. Solving imperfect information games using decompo- sition. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 28, 2014. |
| Neil Burch, Matej Moravcik, and Martin Schmid. Revisiting cfr+ and alternating updates. Journal of Artificial Intelligence Research , 64:429-443, 2019. |
| Michael Buro. From simple features to sophisticated evaluation functions. In Computers and Games: First International Conference, CG'98 Tsukuba, Japan, November 11-12, 1998 Proceedings 1 , pp. 126-145. Springer, 1999. |
| Murray Campbell, A Joseph Hoane Jr, and Feng-hsiung Hsu. Deep blue. Artificial intelligence , 134(1-2): 57-83, 2002. |
| Sheng Chen, Menghui Zhu, Deheng Ye, Weinan Zhang, Qiang Fu, and Wei Yang. Which heroes to pick? learning to draft in moba games with neural networks and tree search. IEEE Transactions on Games , 13 (4):410-421, 2021. |
| Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models. In International Conference on Machine Learning , pp. 6621-6642. PMLR, 2024. |
| Pengyu Cheng, Tianhao Hu, Han Xu, Zhisong Zhang, Yong Dai, Lei Han, Xiaolong Li, et al. Self-playing adversarial language game enhances llm reasoning. Advances in Neural Information Processing Systems , 37:126515-126543, 2025. |
| Daphne Cornelisse and Eugene Vinitsky. Human-compatible driving partners through data-regularized self- play reinforcement learning. arXiv preprint arXiv:2403.19648 , 2024. |
| Rémi Coulom. Efficient selectivity and backup operators in monte-carlo tree search. In International con- ference on computers and games , pp. 72-83. Springer, 2006. |
| Rémi Coulom. Computing 'elo ratings' of move patterns in the game of go. ICGA journal , 30(4):198-208, 2007. |
| Constantinos Daskalakis. On the complexity of approximating a nash equilibrium. ACM Transactions on Algorithms (TALG) , 9(3):1-35, 2013. |
| nash equilibrium. Communications of the ACM , 52(2):89-97, 2009. |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Trevor Davis, Martin Schmid, and Michael Bowling. Low-variance and zero-variance baselines for extensive- form games. In International Conference on Machine Learning , pp. 2392-2401. PMLR, 2020. |
| Anthony DiGiovanni and Ethan C Zell. Survey of self-play in reinforcement learning. arXiv preprint arXiv:2107.02850 , 2021. |
| Le Cong Dinh, Stephen McAleer, Zheng Tian, Nicolas Perez-Nieves, Oliver Slumbers, David Henry Mguni, Jun Wang, Haitham Bou Ammar, and Yaodong Yang. Online double oracle. TMLR: Transactions on Machine Learning Research , 2022. |
| Arpad E Elo and Sam Sloan. The rating of chessplayers: Past and present. 1978. |
| Markus Enzenberger, Martin Müller, Broderick Arneson, and Richard Segal. Fuego-an open-source frame- work for board games and go engine based on monte carlo tree search. IEEE Transactions on Computa- tional Intelligence and AI in Games , 2(4):259-270, 2010. |
| Meta Fundamental AI Research Diplomacy Team (FAIR)†, Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel Fried, Andrew Goff, Jonathan Gray, Hengyuan Hu, et al. Human- level play in the game of diplomacy by combining language models with strategic reasoning. Science , 378 (6624):1067-1074, 2022. |
| Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Coun- terfactual multi-agent policy gradients. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 32, 2018. |
| Shiqi Gao, Fuminori Okuya, Yoshihiro Kawahara, and Yoshimasa Tsuruoka. Building a computer mahjong player via deep convolutional neural networks. arXiv preprint arXiv:1906.02146 , 2019. |
| Yuan Gao, Junfeng Chen, Xi Chen, Chongyang Wang, Junjie Hu, Fuqin Deng, and Tin Lun Lam. Asym- metric self-play-enabled intelligent heterogeneous multirobot catching system using deep multiagent rein- forcement learning. IEEE Transactions on Robotics , 2023. |
| Marta Garnelo, Wojciech Marian Czarnecki, Siqi Liu, Dhruva Tirumala, Junhyuk Oh, Gauthier Gidel, Hado van Hasselt, and David Balduzzi. Pick your battles: Interaction graphs as population-level objectives for strategic diversity. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems , pp. 1501-1503, 2021. |
| Sylvain Gelly and David Silver. Combining online and offline knowledge in uct. In Proceedings of the 24th international conference on Machine learning , pp. 273-280, 2007. |
| Paul WGoldberg, Christos H Papadimitriou, and Rahul Savani. The complexity of the homotopy method, equilibrium selection, and lemke-howson solutions. ACM Transactions on Economics and Computation (TEAC) , 1(2):1-25, 2013. |
| Google. Google research football competition 2020. https://www.kaggle.com/c/google-football , 2020. |
| Audr¯nas u Gruslys, Marc Lanctot, Rémi Munos, Finbarr Timbers, Martin Schmid, Julien Perolat, Dustin Morrill, Vinicius Zambaldi, Jean-Baptiste Lespiau, John Schultz, et al. The advantage regret-matching actor-critic. arXiv preprint arXiv:2008.12234 , 2020. |
| Tuomas Haarnoja, Ben Moran, Guy Lever, Sandy H Huang, Dhruva Tirumala, Jan Humplik, Markus Wulfmeier, Saran Tunyasuvunakool, Noah Y Siegel, Roland Hafner, et al. Learning agile soccer skills for a bipedal robot with deep reinforcement learning. Science Robotics , 9(89):eadi8022, 2024. |
| Lei Han, Jiechao Xiong, Peng Sun, Xinghai Sun, Meng Fang, Qingwei Guo, Qiaobo Chen, Tengfei Shi, Hongsheng Yu, Xipeng Wu, et al. Tstarbot-x: An open-sourced and comprehensive study for efficient league training in starcraft ii full game. arXiv preprint arXiv:2011.13729 , 2020. |
| metrica , 68(5):1127-1150, 2000. |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Johannes Heinrich and David Silver. Deep reinforcement learning from self-play in imperfect-information games. arXiv preprint arXiv:1603.01121 , 2016. |
| Johannes Heinrich, Marc Lanctot, and David Silver. Fictitious self-play in extensive-form games. In Inter- national conference on machine learning , pp. 805-813. PMLR, 2015. |
| Daniel Hennes, Dustin Morrill, Shayegan Omidshafiei, Rémi Munos, Julien Perolat, Marc Lanctot, Audrunas Gruslys, Jean-Baptiste Lespiau, Paavo Parmas, Edgar Duéñez-Guzmán, et al. Neural replicator dynamics: Multiagent learning via hedging policy gradients. In Proceedings of the 19th international conference on autonomous agents and multiagent systems , pp. 492-501, 2020. |
| Ralf Herbrich, Tom Minka, and Thore Graepel. Trueskill™: a bayesian skill rating system. Advances in neural information processing systems , 19, 2006. |
| Daniel Hernandez, Kevin Denamganai, Sam Devlin, Spyridon Samothrakis, and James Alfred Walker. A comparison of self-play algorithms under a generalized framework. IEEE Transactions on Games , 14(2): 221-231, 2021. |
| Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning. Advances in neural information processing systems , 29:4565-4573, 2016. |
| Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. Large language models can self-improve. arXiv preprint arXiv:2210.11610 , 2022. |
| Ruozi Huang, Xipeng Wu, Hongsheng Yu, Zhong Fan, Haobo Fu, Qiang Fu, and Wei Yang. A robust and opponent-aware league training method for starcraft ii. Advances in Neural Information Processing Systems , 36, 2024. |
| Shiyu Huang, Wenze Chen, Longfei Zhang, Shizhen Xu, Ziyang Li, Fengming Zhu, Deheng Ye, Ting Chen, and Jun Zhu. Tikick: Towards playing multi-agent football full games from single-agent demonstrations. arXiv preprint arXiv:2110.04507 , 2021a. |
| Tianchi Huang, Rui-Xiao Zhang, and Lifeng Sun. Zwei: A self-play reinforcement learning framework for video transmission services. IEEE Transactions on Multimedia , 24:1350-1365, 2021b. |
| Max Jaderberg, Wojciech M Czarnecki, Iain Dunning, Luke Marris, Guy Lever, Antonio Garcia Castaneda, Charles Beattie, Neil C Rabinowitz, Ari S Morcos, Avraham Ruderman, et al. Human-level performance in 3d multiplayer games with population-based reinforcement learning. Science , 364(6443):859-865, 2019. |
| Qiqi Jiang, Kuangzheng Li, Boyao Du, Hao Chen, and Hai Fang. Deltadou: Expert-level doudizhu ai through self-play. In IJCAI , pp. 1265-1271, 2019. |
| Peter Jin, Kurt Keutzer, and Sergey Levine. Regret minimization for partially observable deep reinforcement learning. In International conference on machine learning , pp. 2342-2351. PMLR, 2018. |
| Michael Johanson. Measuring the size of large no-limit poker games. arXiv preprint arXiv:1302.7008 , 2013. |
| Michael Johanson, Nolan Bard, Marc Lanctot, Richard G Gibson, and Michael Bowling. Efficient nash equilibrium approximation through monte carlo counterfactual regret minimization. In Aamas , pp. 837- 846, 2012. |
| John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, et al. Highly accurate protein structure prediction with alphafold. Nature , 596(7873):583-589, 2021. |
| Nobukatsu Kajiura, Satoshi Kosugi, Xueting Wang, and Toshihiko Yamasaki. Self-play reinforcement learn- ing for fast image retargeting. In Proceedings of the 28th ACM international conference on multimedia , pp. 1755-1763, 2020. |
| machine learning , pp. 282-293. Springer, 2006. |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Jakub Grudzien Kuba, Ruiqing Chen, Muning Wen, Ying Wen, Fanglei Sun, Jun Wang, and Yaodong Yang. Trust region policy optimisation in multi-agent reinforcement learning. arXiv preprint arXiv:2109.11251 , 2021. |
| Alex Kulesza, Ben Taskar, et al. Determinantal point processes for machine learning. Foundations and Trends® in Machine Learning , 5(2-3):123-286, 2012. |
| Karol Kurach, Anton Raichuk, Piotr Stańczyk, Michał Zając, Olivier Bachem, Lasse Espeholt, Carlos Riquelme, Damien Vincent, Marcin Michalski, Olivier Bousquet, et al. Google research football: A novel reinforcement learning environment. In Proceedings of the AAAI conference on artificial intelligence , volume 34, pp. 4501-4510, 2020. |
| Moyuru Kurita and Kunihito Hoki. Method for constructing artificial intelligence player with abstractions to markov decision processes in multiplayer game of mahjong. IEEE Transactions on Games , 13(1):99-110, 2020. |
| Marc Lanctot, Kevin Waugh, Martin Zinkevich, and Michael Bowling. Monte carlo sampling for regret minimization in extensive games. Advances in neural information processing systems , 22, 2009. |
| Marc Lanctot, Vinicius Zambaldi, Audrunas Gruslys, Angeliki Lazaridou, Karl Tuyls, Julien Pérolat, David Silver, and Thore Graepel. A unified game-theoretic approach to multiagent reinforcement learning. Advances in neural information processing systems , 30, 2017. |
| Mike Lewis, Denis Yarats, Yann Dauphin, Devi Parikh, and Dhruv Batra. Deal or no deal? end-to-end learning of negotiation dialogues. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pp. 2443-2453, 2017. |
| Hanyu Li, Wenhan Huang, Zhijian Duan, David Henry Mguni, Kun Shao, Jun Wang, and Xiaotie Deng. A survey on algorithms for nash equilibria in finite normal-form games. Computer Science Review , 51: 100613, 2024. |
| Hui Li, Kailiang Hu, Zhibang Ge, Tao Jiang, Yuan Qi, and Le Song. Double neural counterfactual regret minimization. arXiv preprint arXiv:1812.10607 , 2018. |
| Junjie Li, Sotetsu Koyamada, Qiwei Ye, Guoqing Liu, Chao Wang, Ruihan Yang, Li Zhao, Tao Qin, Tie-Yan Liu, and Hsiao-Wuen Hon. Suphx: Mastering mahjong with deep reinforcement learning. arXiv preprint arXiv:2003.13590 , 2020. |
| Fanqi Lin, Shiyu Huang, Tim Pearce, Wenze Chen, and Wei-Wei Tu. Tizero: Mastering multi-agent football with curriculum learning and self-play. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems , pp. 67-76, 2023. |
| Michael L Littman. Markov games as a framework for multi-agent reinforcement learning. In Machine learning proceedings 1994 , pp. 157-163. Elsevier, 1994. |
| Siqi Liu, Marc Lanctot, Luke Marris, and Nicolas Heess. Simplex neural population learning: Any-mixture bayes-optimality in symmetric zero-sum games. In International Conference on Machine Learning , pp. 13793-13806. PMLR, 2022a. |
| Siqi Liu, Guy Lever, Zhe Wang, Josh Merel, SM Ali Eslami, Daniel Hennes, Wojciech M Czarnecki, Yuval Tassa, Shayegan Omidshafiei, Abbas Abdolmaleki, et al. From motor control to team play in simulated humanoid football. Science Robotics , 7(69):eabo0235, 2022b. |
| Siqi Liu, Luke Marris, Daniel Hennes, Josh Merel, Nicolas Heess, and Thore Graepel. Neupl: Neural population learning. arXiv preprint arXiv:2202.07415 , 2022c. |
| Yang. Towards unifying behavioral and response diversity for open-ended learning in zero-sum games. Advances in Neural Information Processing Systems , 34:941-952, 2021. |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Roberto Lucchetti. A primer in game theory . Società Editrice Esculapio, 2011. |
| Anuj Mahajan, Tabish Rashid, Mikayel Samvelyan, and Shimon Whiteson. Maven: Multi-agent variational exploration. Advances in neural information processing systems , 32, 2019. |
| Luke Marris, Paul Muller, Marc Lanctot, Karl Tuyls, and Thore Graepel. Multi-agent training beyond zero-sum with correlated equilibrium meta-solvers. In International Conference on Machine Learning , pp. 7480-7491. PMLR, 2021. |
| Stephen McAleer, John B Lanier, Roy Fox, and Pierre Baldi. Pipeline psro: A scalable approach for finding approximate nash equilibria in large games. Advances in neural information processing systems , 33:20238- 20248, 2020. |
| Stephen McAleer, John B Lanier, Kevin A Wang, Pierre Baldi, and Roy Fox. Xdo: A double oracle algorithm for extensive-form games. Advances in Neural Information Processing Systems , 34:23128-23139, 2021. |
| Stephen McAleer, John Banister Lanier, Kevin Wang, Pierre Baldi, Roy Fox, and Tuomas Sandholm. Self- play psro: Toward optimal populations in two-player zero-sum games. arXiv preprint arXiv:2207.06541 2022a. |
| Stephen McAleer, Kevin Wang, John Lanier, Marc Lanctot, Pierre Baldi, Tuomas Sandholm, and Roy Fox. Anytime psro for two-player zero-sum games. arXiv preprint arXiv:2201.07700 , 2022b. |
| Stephen Marcus McAleer, Gabriele Farina, Gaoyue Zhou, Mingzhi Wang, Yaodong Yang, and Tuomas Sandholm. Team-psro for learning approximate tmecor in large team games via cooperative reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems , 2023. |
| H Brendan McMahan, Geoffrey J Gordon, and Avrim Blum. Planning in the presence of cost functions controlled by an adversary. In Proceedings of the 20th International Conference on Machine Learning (ICML-03) , pp. 536-543, 2003. |
| Naoki Mizukami and Yoshimasa Tsuruoka. Building a computer mahjong player based on monte carlo simulation and opponent models. In 2015 IEEE Conference on Computational Intelligence and Games (CIG) , pp. 275-283. IEEE, 2015. |
| Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602 , 2013. |
| Matej Moravčík, Martin Schmid, Neil Burch, Viliam Lis`, y Dustin Morrill, Nolan Bard, Trevor Davis, Kevin Waugh, Michael Johanson, and Michael Bowling. Deepstack: Expert-level artificial intelligence in heads-up no-limit poker. Science , 356(6337):508-513, 2017. |
| P Muller, S Omidshafiei, MRowland, K Tuyls, J Pérolat, S Liu, D Hennes, L Marris, MLanctot, E Hughes, et al. A generalized training approach for multiagent learning. In ICLR , pp. 1-35. ICLR, 2020. |
| Paul Muller, Mark Rowland, Romuald Elie, Georgios Piliouras, Julien Perolat, Mathieu Lauriere, Raphael Marinier, Olivier Pietquin, and Karl Tuyls. Learning equilibria in mean-field games: Introducing mean- field psro. In Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems , pp. 926-934, 2022. Remi Munos, Michal Valko, Daniele Calandriello, Mohammad Gheshlaghi Azar, Mark Rowland, Zhao- |
| Jan Mycielski. Games with perfect information. Handbook of game theory with economic applications , |
| 1: |
John F Nash et al. Non-cooperative games. 1950.
| Shayegan Omidshafiei, Christos Papadimitriou, Georgios Piliouras, Karl Tuyls, Mark Rowland, Jean- Baptiste Lespiau, Wojciech M Czarnecki, Marc Lanctot, Julien Perolat, and Remi Munos. α -rank: Multi- agent evaluation by evolution. Scientific reports , 9(1):9937, 2019. |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems , 35:27730-27744, 2022. |
| Nicolas Perez-Nieves, Yaodong Yang, Oliver Slumbers, David H Mguni, Ying Wen, and Jun Wang. Modelling behavioural diversity for learning in open-ended games. In International conference on machine learning , pp. 8514-8524. PMLR, 2021. |
| Julien Perolat, Remi Munos, Jean-Baptiste Lespiau, Shayegan Omidshafiei, Mark Rowland, Pedro Ortega, Neil Burch, Thomas Anthony, David Balduzzi, Bart De Vylder, et al. From poincaré recurrence to convergence in imperfect information games: Finding equilibrium via regularization. In International Conference on Machine Learning , pp. 8525-8535. PMLR, 2021. |
| Julien Perolat, Bart De Vylder, Daniel Hennes, Eugene Tarassov, Florian Strub, Vincent de Boer, Paul Muller, Jerome T Connor, Neil Burch, Thomas Anthony, et al. Mastering the game of stratego with model-free multiagent reinforcement learning. Science , 378(6623):990-996, 2022. |
| Tabish Rashid, Mikayel Samvelyan, Christian Schroeder, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning. In International Conference on Machine Learning , pp. 4295-4304. PMLR, 2018. |
| Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning. The Journal of Machine Learning Research , 21(1):7234-7284, 2020. |
| Arthur L Samuel. Some studies in machine learning using the game of checkers. IBM Journal of research and development , 44(1.2):206-226, 2000. |
| Mikayel Samvelyan, Tabish Rashid, Christian Schroeder de Witt, Gregory Farquhar, Nantas Nardelli, Tim GJ Rudner, Chia-Man Hung, Philip HS Torr, Jakob Foerster, and Shimon Whiteson. The star- craft multi-agent challenge. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems , pp. 2186-2188, 2019. |
| Jonathan Schaeffer, Joseph Culberson, Norman Treloar, Brent Knight, Paul Lu, and Duane Szafron. A world championship caliber checkers program. Artificial Intelligence , 53(2-3):273-289, 1992. |
| Martin Schmid, Neil Burch, Marc Lanctot, Matej Moravcik, Rudolf Kadlec, and Michael Bowling. Variance reduction in monte carlo counterfactual regret minimization (vr-mccfr) for extensive form games using baselines. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 33, pp. 2157-2164, 2019. Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, |
| Lloyd S Shapley. Stochastic games. Proceedings of the national academy of sciences , 39(10):1095-1100, 1953. |
| Brian Sheppard. World-championship-caliber scrabble. Artificial Intelligence , 134(1-2):241-275, 2002. |
| David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature , 529(7587):484-489, 2016. |
| Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge. nature , 550(7676):354-359, 2017. |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science , 362(6419):1140-1144, 2018. |
| Eric Steinberger. Single deep counterfactual regret minimization. arXiv preprint arXiv:1901.07621 , 2019. |
| Eric Steinberger, Adam Lerer, and Noam Brown. Dream: Deep regret minimization with advantage baselines and model-free learning. arXiv preprint arXiv:2006.10410 , 2020. |
| Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction . MIT press, 2018. |
| Gokul Swamy, Christoph Dann, Rahul Kidambi, Zhiwei Steven Wu, and Alekh Agarwal. A minimaximal- ist approach to reinforcement learning from human feedback. In Proceedings of the 41st International Conference on Machine Learning , pp. 47345-47377, 2024. |
| Oskari Tammelin. Solving large imperfect information games using cfr+. arXiv preprint arXiv:1407.5042 , 2014. |
| Yichuan Tang. Towards learning multi-agent negotiations via self-play. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops , pp. 0-0, 2019. |
| Peter D Taylor and Leo B Jonker. Evolutionary stable strategies and game dynamics. Mathematical bio- sciences , 40(1-2):145-156, 1978. |
| Tencent. Luckyj: Deep learning mahjong ai. https://twitter.com/LuckyJ1443836 . |
| Gerald Tesauro and Gregory Galperin. On-line policy improvement using monte-carlo search. Advances in Neural Information Processing Systems , 9, 1996. |
| Shingo Tsunoda. Tenhou. https://tenhou.net/ . |
| Dwango Media Village. Naga: Deep learning mahjong ai. https://dmv.nico/ja/articles/mahjong_ai_ naga/ . |
| Oriol Vinyals, Igor Babuschkin, Wojciech MCzarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature , 575(7782):350-354, 2019. |
| Chenguang Wang, Zhouliang Yu, Stephen McAleer, Tianshu Yu, and Yaodong Yang. Asp: Learn a universal neural solver! IEEE Transactions on Pattern Analysis and Machine Intelligence , 2024. |
| Xiangjun Wang, Junxiao Song, Penghui Qi, Peng Peng, Zhenkun Tang, Wei Zhang, Weimin Li, Xiongjun Pi, Jujie He, Chao Gao, et al. Scc: An efficient deep reinforcement learning agent mastering the game of starcraft ii. In International conference on machine learning , pp. 10905-10915. PMLR, 2021. |
| estimation. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 29, 2015. |
| Kevin Waugh, Dustin Morrill, James Bagnell, and Michael Bowling. Solving games with functional regret |
| Michael P Wellman, Karl Tuyls, and Amy Greenwald. Empirical game theoretic analysis: A survey. Journal of Artificial Intelligence Research , 82:1017-1076, 2025. |
| Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, and Quanquan Gu. Self-play preference optimization for language model alignment. arXiv preprint arXiv:2405.00675 , 2024. |
| of interaction with multi-agent quadruped environment. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pp. 5918-5924. IEEE, 2024. |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Zelai Xu, Yancheng Liang, Chao Yu, Yu Wang, and Yi Wu. Fictitious cross-play: Learning global nash equilibrium in mixed cooperative-competitive games. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems , pp. 1053-1061, 2023. |
| Zelai Xu, Chao Yu, Fei Fang, Yu Wang, and Yi Wu. Language agents with reinforcement learning for strategic play in the werewolf game. In Proceedings of the 41st International Conference on Machine Learning , pp. 55434-55464, 2024. |
| Zelai Xu, Chao Yu, Ruize Zhang, Huining Yuan, Xiangmin Yi, Shilong Ji, Chuqi Wang, Wenhao Tang, and Yu Wang. Volleybots: A testbed for multi-drone volleyball game combining motion control and strategic play. arXiv preprint arXiv:2502.01932 , 2025. |
| Nikolai Yakovenko, Liangliang Cao, Colin Raffel, and James Fan. Poker-cnn: A pattern learning strategy for making draws and bets in poker games using convolutional networks. In Proceedings of the aaai conference on artificial intelligence , volume 30, 2016. |
| Guan Yang, Minghuan Liu, Weijun Hong, Weinan Zhang, Fei Fang, Guangjun Zeng, and Yue Lin. Perfectdou: Dominating doudizhu with perfect information distillation. Advances in Neural Information Processing Systems , 35:34954-34965, 2022. |
| Jian Yao, Weiming Liu, Haobo Fu, Yaodong Yang, Stephen McAleer, Qiang Fu, and Wei Yang. Policy space diversity for non-transitive games. Advances in Neural Information Processing Systems , 36:67771-67793, 2023. |
| Deheng Ye, Guibin Chen, Wen Zhang, Sheng Chen, Bo Yuan, Bo Liu, Jia Chen, Zhao Liu, Fuhao Qiu, Hongsheng Yu, et al. Towards playing full moba games with deep reinforcement learning. Advances in Neural Information Processing Systems , 33:621-632, 2020a. |
| Deheng Ye, Zhao Liu, Mingfei Sun, Bei Shi, Peilin Zhao, Hao Wu, Hongsheng Yu, Shaojie Yang, Xipeng Wu, Qingwei Guo, et al. Mastering complex control in moba games with deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 34, pp. 6672-6679, 2020b. |
| Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games. Advances in neural information processing systems , 35:24611-24624, 2022. |
| Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models. arXiv preprint arXiv:2401.10020 , 2024. |
| Daochen Zha, Kwei-Herng Lai, Yuanpu Cao, Songyi Huang, Ruzhe Wei, Junyu Guo, and Xia Hu. Rlcard: A toolkit for reinforcement learning in card games. arXiv preprint arXiv:1910.04376 , 2019. |
| Daochen Zha, Jingru Xie, Wenye Ma, Sheng Zhang, Xiangru Lian, Xia Hu, and Ji Liu. Douzero: Mastering doudizhu with self-play deep reinforcement learning. In international conference on machine learning , pp. 12333-12344. PMLR, 2021. |
| Enmin Zhao, Renye Yan, Jinqiu Li, Kai Li, and Junliang Xing. Alphaholdem: High-performance artificial intelligence for heads-up no-limit poker via end-to-end reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 36, pp. 4689-4697, 2022a. |
| Youpeng Zhao, Jian Zhao, Xunhan Hu, Wengang Zhou, and Houqiang Li. Douzero+: Improving doudizhu ai by opponent modeling and coach-guided learning. In 2022 IEEE Conference on Games (CoG) , pp. 127-134. IEEE, 2022b. |
| Ming Zhou, Jingxiao Chen, Ying Wen, Weinan Zhang, Yaodong Yang, Yong Yu, and Jun Wang. Efficient policy space response oracles. arXiv preprint arXiv:2202.00633 , 2022. |
Martin Zinkevich, Michael Johanson, Michael Bowling, and Carmelo Piccione. Regret minimization in games with incomplete information. Advances in neural information processing systems , 20, 2007.
Fengming Zhu Ziyang Li, Kaiwen Zhu. Wekick. https://www.kaggle.com/c/google-football/ discussion/202232 , 2020.
## A Appendix
## A.1 Abbreviations in Alphabetical Order
| ABR | Approximate Best Response |
|-------|------------------------------------------------|
| AI | Artificial Intelligence |
| ARM | Advantage-based Regret Minimization |
| ARMAC | Advantage Regret-Matching Actor-Critic |
| BR | Best Response |
| CCE | Coarse Correlated Equilibrium |
| CE | Correlated Equilibrium |
| CFR | Counterfactual Regret Minimization |
| COP | Combinatorial Optimization Problem |
| CSPL | Curriculum Self-Play Learning |
| CVRP | Capacitated Vehicle Routing Problem |
| DCFR | Discounted Counterfactual Regret Minimization |
| DO | Double Oracle |
| EGTA | Empirical Game-Theoretic Analysis |
| FP | Fictitious Play |
| FSP | Fictitious Self-Play |
| FTW | For The Win |
| FXP | Fictitious Cross-Play |
| GAIL | Generative Adversarial Imitation Learning |
| GRF | Google Research Football |
| HULHE | Heads-Up Limit Texas Hold'em |
| HUNL | Heads-Up No-Limit Texas Hold'em |
| JPSRO | Joint Policy-Space Response Oracle |
| LCFR | Linear Counterfactual Regret Minimization |
| LLM | Large Language Model |
| MARL | Multi-Agent Reinforcement Learning |
| MCCFR | Monte Carlo Counterfactual Regret Minimization |
| MCTS | Monte Carlo Tree Search |
| MDP | Markov Decision Process |
| MG | Markov Game |
| ML | Machine Learning |
| MOBA | Multiplayer Online Battle Arena |
| MSS | Meta-Strategy Solver |
|--------|------------------------------------------------|
| NE | Nash Equilibrium |
| NeuPL | Neural Population Learning |
| NFSP | Neural Fictitious Self-Play |
| ODO | Online Double Oracle |
| PBR | Preference-based Best Response |
| PBS | Public Belief State |
| PFSP | Prioritized Fictitious Self-Play |
| POMG | Partially Observable Markov Game |
| PSRO | Policy-Space Response Oracle |
| RCFR | Regression Counterfactual Regret Minimization |
| ReBeL | Recursive Belief-based Learning |
| RL | Reinforcement Learning |
| R-NaD | Regularized Nash Dynamics |
| RTS | Real-Time Strategy |
| SD-CFR | Single Deep Counterfactual Regret Minimization |
| SPAG | Self-Play of Adversarial Game |
| SPIN | Self-Play fIne-tuNing |
| TSP | Traveling Salesman Problem |
| URR | UnRestricted-Restricted |
| XDO | Extensive-Form Double Oracle | | null | [
"Ruize Zhang",
"Zelai Xu",
"Chengdong Ma",
"Chao Yu",
"Wei-Wei Tu",
"Wenhao Tang",
"Shiyu Huang",
"Deheng Ye",
"Wenbo Ding",
"Yaodong Yang",
"Yu Wang"
] | 2024-08-02T07:47:51+00:00 | 2025-03-27T13:42:00+00:00 | [
"cs.AI"
] | A Survey on Self-play Methods in Reinforcement Learning | Self-play, characterized by agents' interactions with copies or past versions
of themselves, has recently gained prominence in reinforcement learning (RL).
This paper first clarifies the preliminaries of self-play, including the
multi-agent reinforcement learning framework and basic game theory concepts.
Then, it provides a unified framework and classifies existing self-play
algorithms within this framework. Moreover, the paper bridges the gap between
the algorithms and their practical implications by illustrating the role of
self-play in different scenarios. Finally, the survey highlights open
challenges and future research directions in self-play. This paper is an
essential guide map for understanding the multifaceted landscape of self-play
in RL. |
2408.01074v1 | ## Design, development, and construction of the new beam stoppers for CERN's injector complex
D. Baillard a, ∗ , E. Grenier-Boley , M. Dole, F. Deslande, R. Froeschl , T. Lorenzon , P. Moyret , R. Peron , A. Pilan Zanoni, a a a a a C. Sharp a , M. Timmins a , and M. Calviani a, ∗
a CERN, Esplanade des Particules, 1, Gen` eve, 1211, Switzerland
## Abstract
Beam stoppers are installed in the transfer lines of the CERN accelerator complex; these components are used as part of the access safety system, which guarantees the safety of workers in the accelerators. They are designed to stop one or at most a few pulses of the beam, where 'stop' means the partial or complete absorption of the primary beam in such a way that the remaining unabsorbed primary or secondary beam remains below a specified threshold, as defined by the needs of radiation protection. Prior to Long Shutdown 2 (LS2; 2018-2021), beam stoppers in the injector complex were dimensioned for beam-pulse energies between 9.0 and 30 kJ. The upgrade of the accelerator complex in the framework of the LHC Injectors Upgrade (LIU) project involves beam-pulse energies of up to 92.5 kJ, meaning that these beam stoppers are not able to fulfill the new functional specifications. To cope with the LIU beam parameters and fulfil requirements for safety, maintainability, e ffi ciency, and reliability, a new generation of 28 beam stoppers has been designed, built, and installed. The aim of this paper is to demonstrate the requirements-driven design of these new beam stoppers, outlining the main requirements along with a description of the design and structural assessments. This document presents the implementation and integration of a standardized but adaptable design using a unique 564-mm-long stopper core with a CuCr1Zr absorber and an Inconel 718 diluter, taking into account radiological and infrastructure challenges. The installation process is also described, and the first operational feedback received since LS2 is presented.
Keywords:
Accelerator complex, Proton Synchrotron complex, Beam stopper, Element Important for Safety, Mechanical design
## 1. Introduction
CERN's Proton Synchrotron (PS) beam can be sent to several di ff erent accelerators and experimental facilities. The PS has been in operation since 1959 and has undergone various upgrades for physics-performance and safety reasons. Among these upgrades, the installation of the first beam stoppers took place in the 1970s. Beam stoppers consist of an absorbing stopper core that remains out of the ultra-high-vacuum particle beam line (in the 'out-beam' position) during normal operation of the accelerators [1]. In normal conditions, to give access to downstream facilities, the core (the absorbing material) of a beam stopper is moved into the beam line (the 'in-beam' position) by an operator once the beam has been dumped upstream, so the stopper does not intercept the beam. In emergency scenarios, a beam stopper is moved automatically (by the access safety system) into the in-beam ('safe') position to potentially intercept the beam. This occurs, for example, when someone forces an access door in a downstream accelerator and before the beam interlock can intervene to dump or deviate the beam upstream, to limit the exposure of personnel to ionizing radiation.
As part of the LHC Injectors Upgrade [2]-which aims to increase the maximum proton beam-pulse energy to 92.5 kJ -analytical studies [3] have demonstrated that the existing beam stoppers will be inadequate for the new beam power. These are currently equipped with stainless-steel stopper cores that were originally designed for a beam-pulse energy of just 9.0 kJ, and they reach their structural limits after only one short pulse at this energy level. According to the limit allowed by the access safety system, the beam stoppers will need to withstand to at least five repeated pulses. As such, they are no longer able to fulfil their function under the upgraded beam scenarios in operation after Long Shutdown 2 (LS2)(2018-2021) of the LHC. Moreover, scarce documentation and the existence of several di ff erent designs make maintenance of the current beam stoppers di ffi cult, supporting the need for the construction of new beam stoppers.
∗ Corresponding authors
Email addresses: [email protected] (D. Baillard), [email protected] (and M. Calviani)
This paper describes the justification for the chosen diluterabsorber stopper-core configuration in [3], which represents a compromise between the desire to have a compact design (hence the selection of material with a lower nuclear inelastic scattering length) and reduced radioactivation properties. Secondly, it describes the demonstrator prototype that was required to validate the working principle with respect to the safety rules for personnel-protection devices.
The purpose of this document is to present a step-by-step
definition of the needs and constraints of this equipment in CERN the injector complex, showing how the chosen design meets these needs using structural simulations. It highlights the challenges and advantages of using a standard and adaptable design for integration with di ff erent beam parameters and at different positions in the injector complex while taking into account radiation-protection considerations. This paper also presents the installation sequence of the beam stoppers, including removal, assembly, and installation steps. It concludes by presenting operational and mechanical-performance data obtained after 3 years of operation.
## 1.1. Benchmark of the actual beam stoppers at CERN
Up to 2019, there were more than ten di ff erent beam-stopper designs in the accelerator complex, including six designs in the injector lines. These are a result of a long evolution over time and specific needs in the di ff erent areas of the accelerator complex.
The working principle of the design shown in Fig. 1(b) is a pivot mechanism in which the beam impacts the stopper core radially. In contrast, the other beam stoppers (Figs. 1(a), 1(c), and 1(d)) are composed of stainless-steel or iron cylinders of di ff erent lengths that are impacted axially and moved by a linear actuator. The stopper in Fig. 1(c) is composed of one or two stopper cores in a vacuum chamber, which are moved simultaneously by the control system in approximately 17 s. The stopper in Fig. 1(a) uses a linear movement to close the aperture in 4 s, whereas the stopper in Fig. 1(d) closes the aperture in 30 s using a pneumatic actuator.
Fig. 1. Four examples ((a)-(d) from left to right) showing simplified designs of di ff erent beam stoppers installed in CERN's injector complex. Adapted from [3].
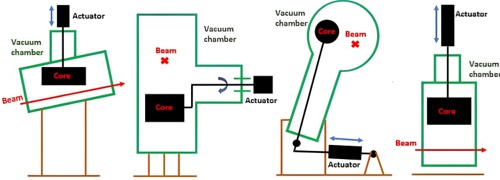
## 2. Methodology
As the core is the main component of a beam stopper, the first step was to determine its design [3]. The methodology
Table 1 Beam parameters according to the LHC Intensity Upgrade project at the PS extraction. [3]
| Particle type | Protons |
|------------------------|-------------------------|
| Beam momentum | 26 GeV / c |
| Intensity per pulse | 2 . 3 × 10 13 particles |
| Pulse energy | 92.5 kJ |
| Total pulse length | 1.1 µ s |
| Beam size ( σ h /σ v ) | 1.50 mm / 1.39 mm |
used to validate the beam-stopper design was to determine its structure and beam-attenuation performance based on safety requirements while considering mechanical and integration constraints in parallel. This allowed the stopper core to be designed and a demonstrator to be constructed highlighting the mechanical forces exerted and validating the mechanical behavior before it went into production. This validation of the operating principle allowed the continuation of the design, assessment, and production of the other sub-assemblies of all the beam stoppers.
## 2.1. Standard stopper-core design
Taking the longest stroke time from the out-beam position to the in-beam position of the present beam stoppers, which is 17 s, and the shortest beam-repetition rate in the PS, which is 1.2 s, a stopper core could theoretically be impacted by 15 repeated beam pulses. This number is defined as the thermo-mechanical requirement and is coupled to the beam parameters [3]. Even though the PS access safety system will only allow a maximum of five repeated pulses, 15 repeated pulses is considered as a conservative reference for the design of a thermomechanically robust stopper core, anticipating possible future beam upgrades. Furthermore, this approach is additionally conservative because each beam pulse would hit di ff erent positions on the stopper core while it was traveling between the out-beam and in-beam positions.
Due to the low likelihood of a beam impact in the stopper core, no significant material activation is expected for the stopper. Interaction of the beam and its secondary particles with the stopper cores is necessary to achieve the desired attenuation. However, this will inevitably create stray radiation.
Ref. [3] demonstrated that single-block configurations made from several di ff erent types of material would not be able to withstand a proton beam with the parameters described in Table 1 while staying within the yield-strength limit. Moreover, the requirement to limit the temperature rise while having an integration constraint of an 884-mm total length for installation in the accelerator is paramount, allowing a modular installation in the PS lines. Thus, the choice of the material for the stopper core is a compromise between the material's activation properties and a short nuclear interaction length. A shorter hadronic interaction length will mean that the total length of the beam-stopper system can be shorter [3], which is a major advantage for its integration into existing facilities in terms of equipment length. In this respect, a material of very high density, i.e., a high-Z material in general, would be optimal. The chosen materials are the best compromise between all these requirements.
The primary beam attenuation is defined by:
$$I = I _ { 0 } e ^ { - \frac { L } { A } },$$
where: I is the intensity of the primary beam, which does not undergo any inelastic scattering in the stopper core material; I 0 is the primary beam intensity impacting the stopper core; L is the total length of the stopper core; and λ is the nuclear interaction length. The required attenuation is between 3 9 . λ and 19 2 . λ depending on the required attenuation [3]. It has been specified
Table 2
Chemical composition, heat-treatment parameters, and mechanical properties of Inconel 718 diluter according to ASTM E8.[4]
| Chemical composition [wt%] | C 0.022 Co 0.34 | Si 0.08 Ti 0.95 | Mn Al | P 0.008 Nb | Cr 17.85 B | Mo 2.97 Fe 18.10 | Ni 53.7 N 0.005 | Cu |
|------------------------------|-------------------|-------------------|---------|-------------------|--------------|--------------------|---------------------|---------------------|
| | Temp. 718 ◦ C | 8 h | 0.08 | | | | | 0.05 |
| Heat treatments | | | | | | | | |
| Heat treatments | | | 0.53 | 5.23 | 0.0028 | | | |
| | | Soak | | Furnace cooling ◦ | | Temp. | Soak | Cool. |
| | | | | ≤ 37.8 | | 621 ◦ | 8 | |
| | | | | C / h | | C | h | Air |
| | Ref. | YS [MPa] | | UYS [MPa] | A [%] | HBW | Density [g cm - 1 ] | Density [g cm - 1 ] |
| Mechanical properties | | ≥ 150 | | ≥ 185 | ≥ 12 | ≥ 331 | | |
Table 3 CuCr1Zr absorber designation, chemical composition, and mechanical properties according to EN 12420. [5]
| Symbol | Number | Standard | Density [g cm - 1 ] | Cu | Cr [wt%] | Zr [wt%] | Rp0.2 [MPa] | Rm [MPa] | A5 [%] | HB |
|----------|----------|---------------|-----------------------|-----------|--------------|----------------|---------------|------------|-----------|-----------|
| CuCr1Zr | CW106C | EN 12420:1999 | 8.9 | Ref. Act. | 0.5-1.2 0.92 | 0.03-0.30 0.11 | ≥ 270 271 | ≥ 360 409 | ≥ 15 29.1 | ≥ 110 122 |
that the actual beam attenuation shall be maintained, along with the 200-mm stopper-core diameter [3].
into a single access-control system and associated with upstream bending magnet (BHZ).
The selected optimal configuration [3] (Fig. 2) begins with four separate 40-mm-thick diluter slices (to allow free thermal expansion) made from Inconel 718, as described in Table 2, which absorb part of the incoming beam energy. The remaining 400 mm is an absorber made from CuCr1Zr, as described in Table 3, and this absorbs the remaining energy.
Fig. 2. Section view of the stopper-core, showing the four 40-mm-thick slices of Inconel 718 diluter spaced by 1 mm and the 400 mm CuCr1Zr absorber assembled together, dimensions in mm, beam coming from the left side of the picture. Design adopted from [3].
Age hardening was performed on the Inconel 718, while the CuCr1Zr underwent non-destructive ultrasonic testing to verify that there were no defects inside the material and to ensure that both materials would be able to absorb enough beam energy.
No active cooling is required for the beam stoppers as they are not intended to receive multiple pulses on a regular basis neither for a long periods. The stopper core is passively cooled via heat conduction to the stopper-core supports and marginally through radiation to the vacuum chamber [3].
## 2.2. Working principle: Demonstrator
There are several ways to ensure personnel safety during operation of the beam stoppers [6, 7, 8, 9]. CERN decided to di ff erentiate machine protection and personnel protection by using two di ff erent sets of equipment, but these are combined
Being classified as an 'Element Important for Safety,' a beam stopper must lock the injection, transfer, or circulation of the beam to protect personnel from beam exposure using security functions according to CEI IEC 61508, giving it a Safety / Integrity Level of 3 (SIL3). This means that a risk-reduction factor greater than 1000 is required.[10]
To meet these requirements, the beam stoppers work with the following conditions. In case of personnel access, beam stoppers must be in the in-beam position. In case of circulating beam or injection, the VETO signal is removed and the beam stoppers are moved out of the beam aperture. In case of intrusion, beam stoppers are automatically forced into the in-beam position. The beam stoppers work in fail-safe conditions, meaning that they will move into the in-beam position automatically in case of electrical, pneumatic, control, or vacuum failure. Furthermore, a redundancy rule is applied, meaning that except for a few beam lines, a minimum of two beam stoppers are installed in series.
One of the requirements of the new beam stoppers is a 30year lifetime. To establish which of the existing beam stoppers had actually performed the most cycles, the number of pulses of the end-stroke switches of all the beam stoppers between 2008 to 2018 was extracted. It was found that each of the 17 beam stoppers in the accelerator complex performed between 177 and 3984 cycles, with an average of 1830. However, this is not necessarily the number of pulses that were received; it is only the number of cycles performed by each beam stopper, and this includes test cycles and cycles performed when access is given or under fail-safe conditions. Given the lifetime requirement and the history of cycles, the beam-stopper mechanism must last at least 30 years under 1000 cycles per year, the edge-welded bellows being the limiting component.
Knowing the operational and weight requirements of the final stopper core, it was decided that its design should use a fork support (see Fig. 3). In the out-beam position, the stopper core is located above the beam aperture, allowing the beam to pass through during normal operation, and it moves to the
in-beam position during emergency scenarios or according to safety requirements. The fork is large enough to not obstruct the 156-mm beam aperture in normal operation.
Fig. 3. 3D model showing the stopper-core (a)materials supported by a fixing bar (b) on each side, assembled on a fork (c), and linked to an edge-welded bellows (d), allowing it to move under high vacuum.
To fulfill the safety rules, the weight of the stopper-core assembly has to overcome the vacuum force and the friction and bellows forces in any emergency or normal scenario (Fig. 4). This is helped-if operating-by a Festo ® DSBC-100-180 linear pneumatic cylinder.
Fig. 4. Schematic of the forces exerted on the beam-stopper assembly in case of pneumatic failure. Here, F g represents the weight of the stopper core, F v represents the vacuum force exerted on the outer edge-welded bellows, and F c represents friction forces.
Ademonstrator was built (Fig. 5) to verify whether the beam stopper fulfilled all of the functional requirements, to check the resulting forces, and to obtain a quantitative value for the friction forces. The demonstrator was also used to verify the stroke time, test the pneumatic parameters, and to obtain qualitative information about the end-stroke shock absorbers.
Fig. 5. Photographs of the demonstrator, showing the in-beam (left) and outbeam (right) positions.


## 2.3. Standard adaptable design
The new beam-stopper assembly consists of the following sub-systems: the stopper core (labelled 'a' in Fig. 6), which is held by the fork (b) inside a vacuum vessel (c); the fork supports a hydroformed bellows (e), which is itself connected to the support plate for the shock absorbers (h), with the guiding systems allowing the stopper core to move (f). All these subassemblies are fixed to an adjustment table (d). The support is divided into a lower (l) and an upper plug-in (i), which are connected using an isostatic ball-mounting system (k). The pressurized pneumatic cylinder is fixed onto the guiding system and is powered by a patch panel (j) attached to the upper plug-in. The stopper-core assembly is damped through shock absorbers on the upper plug-in.
Fig. 6. 3D model with arrows indicating the main components of the beam stopper as designed, the core in 'out' position, beam coming from the right side of the picture.
CERN guidelines for equipment operating under vacuum require an operational pressure between 5 × 10 -3 and 5 × 10 -8 mbar, an average pumping speed of 100 l s -1 , and an outgassing rate limited to between 5 × 10 -5 and 5 × 10 -6 mbar l s -1 , depending on where the beam stopper is installed. This means that the vacuum vessel must ensure high vacuum tightness. The vacuum vessel is a large chamber (labelled 'c' in Fig. 7) made of AISI 304L stainless steel. On each side, ultra-high vacuum ConFlat-type flanges are secured using AISI 316LN 3D-forged screws on the tubes (e). The hydroformed bellows (f) is directly welded onto the vacuum vessel, allowing stretching of the cylinder. To tilt the vacuum vessel, shims can be installed underneath it (g). The top part (b) of the vacuum vessel is used to install geodesic (a) and lifting (d) instruments. A viewport is installed on the upstream flange of each beam stopper to allow visual inspection of the stopper core.
Fig. 7. 3D model with arrows showing the main parts of the vacuum-vessel assembly.
The installation of the 28 new beam stoppers is expected to be carried out over several years in di ff erent facilities and injector lines. A total of 18 beam stoppers were installed before the start of the operational run in 2021. Ten more beam stoppers will be installed during Long Shutdown 3 (2027-2029). To increase ease of maintenance, it is important to have a standard beam-stopper base, which must be adapted to and compatible with the 28 installation points in the complex indicated in Fig. 8.
The vacuum vessel has a compact and standardized flangeto-flange length. The extremity flanges are adaptable according to their respective beam lines. A 150-mm flange diameter is required for the PS complex, while a 159-mm flange diameter is required for other facilities (Fig. 9). This involves several constraints. In the out-beam position, the stopper core must leave a free aperture for the beam that is equal in size to that seen in the existing beam stoppers. For a stopper-core diameter of 200 mm, the distance between the stopper-core center and the beam line must be greater than 175 mm, as it was before 2019. To minimize the scattering of secondary particles, the beam axis and the stopper-core center must be aligned within ± 2 mm in the in-beam position. This is achieved by the precise fabrication tolerances of the stopper-core assembly in the vacuum vessel, which is linked together by a guiding system equipped with linear bearings with a maximum eccentricity of 15 µ m(Fig. 10).
Each beam stopper is equipped with a standard alignment table (labelled 'a' in Fig. 11) to maintain coaxiality within ± 0.5 mm between the flanges and the beam line. The vacuum vessel and stopper core can be moved using the push and pull parts (e) for two-axis horizontal adjustment and one rotation on the horizontal plane. Three threaded screws and concave convex / washers (d) allow the vacuum-vessel and stopper-core height to be adjusted by ± 30 mm and to adjust the tilt and slope angle of the vacuum vessel after the pre-setting illustrated in Fig. 12.
The guiding system is also used to maintain the guiding shafts ('b' in Fig. 11) and the shock-absorber plate (c). The pneumatic actuator is installed on the base (f). The shock absorbers have been dimensioned to smoothly absorb the forces on the stopper core during normal and emergency scenarios.
Each guiding shaft has a ring that serves as an end stop for the out-beam position. Each also has two screws that work as stops for pneumatic-cylinder replacement (g).
The beam-stopper assemblies must cope with tunnel gradients from -3 ◦ to + 3 . ◦ The technical solution presented here allows this to be set in increments of 1 . ◦ To this end, shims (shown in black in Fig. 12) are positioned below the lower support of the beam-stopper vacuum vessel to tilt it, and the hydroformed bellows allows this tilt. The fixing support of the stopper core (as shown in the right-hand panel of the figure) can have an inclined machined surface. By setting the same slope angle on the vacuum vessel and the stopper core, they remain parallel to adapt to the slope of the beam line. The purpose of this solution is to keep the guiding system vertical so as not to induce additional forces on the mechanism.
Each beam stopper is equipped with a standard upper plug-in and an adaptable lower plug-in to position it isostatically and allow it to be removed quickly, to comply with the 'as low as reasonably achievable' (ALARA) principle of radioprotection. The lower plug-in can be produced to di ff erent designs to accommodate beam heights between 1 and 2 m.
Through the described combination of adaptable flanges, shims, di ff erent lower plug-ins, table settings, and redundancy, beam stoppers of this design can be installed in every position of the complex in which they are required (Fig. 13).
## 2.4. Pneumatic and electrical systems
The patch panel (Fig. 14) supports the pneumatic circuit for actuating the pneumatic cylinder, as well as an electrical box. Fig. 15 shows a schematic of the pneumatic circuit used in the beam stopper. When the actuator is pressurized, the stopper core stays is in the out-beam position. When the 5 2 monostable / solenoid valve is actuated, the mechanical spring brings the stopper core back to the in-beam position. To maintain fail-safe operation, in case of various failure conditions, the stopper core is moved to the in-beam position for safety. If there is a power cut, the stopper core will move to the in-beam position due to the mechanical spring of the electro-valve pulling the solenoid valve; this will dump the pressure inside the actuator. If there is an air-pressure drop in the circuit, the weight of the stopper core will cause it to move to the in-beam position, even if the pneumatic actuator is not pressurized.
The beam stoppers are equipped with two in-beam position switches (Fig. 16), fixed on either side of the bottom plate of the guiding system: one for the control system and one for the access safety system. There is also an out-beam switch fixed onto the shock plate.
Taking into account the use of these control components in a radiation environment, they are positioned far from the beam stopper, and the electronic and pneumatic components installed on the beam stopper-along with the polymer-based seals-are radiation resistant to the values expected in the di ff erent locations (up to the MGy level).
## 2.5. Mechanical assessments of the system
Ansys Structural simulations were performed to validate the mechanical behavior of the vacuum vessel under pressure. The
Fig. 8. Diagram showing the positions of the 28 beam stoppers (dark blue boxes) to be installed during Long Shutdown 3.
Fig. 9. 3D models showing side views of three di ff erent flange types, the aperture and design of which vary according to the specific beam line.
results (Fig. 17) show a peak stress intensity of 145 MPa, which is within the standard required for pressurized vessels according to EN 13445-3.
The welds were divided into sections and analyzed according to the NF EN 1993-1-8 standard, since larger stresses are observed at these points. The requirements for strength, serviceability, and durability of structures are defined by:
$$[ \sigma _ { \perp } ^ { 2 } + 3 ( \tau _ { \perp } ^ { 2 } + \tau _ { \| } ) ] ^ { 0. 5 } \leq \frac { f _ { u } } { \beta _ { w } \gamma _ { M 2 } }, \quad \quad ( 2 ) \quad \text{stop} ^ { \cdot } _ { \text{tion} }.$$
and
$$\sigma _ { \perp } & \leq \frac { 0. 9 f _ { u } } { \gamma _ { M 2 } }, & \quad \quad ( 3 ) \quad \text{Th} \\ & \quad \text{vad}$$
where σ ⊥ is the nominal stress perpendicular to the groove, τ ⊥ is the shear stress perpendicular to the axis of the weld, τ ∥ is the shear stress parallel to the axis of the weld, f u is the nominal ultimate tensile strength of the welded component, γ M2 is the
Fig. 10. Cross-sectional view of a 3D model showing the four linear bearings (in white) installed on the guiding rod (in red) each side of the bellows.
partial safety factor for the resistance of welds, and β w is the appropriate correlation factor.
The results show von-Mises-equivalent stresses of 30, 50, and 65 MPa for the welds of the flanges, the upper support, and the lifting supports, respectively, which are lower than the 100-MPa limit defined by the NF EN 1993-1-8 standard.
Another simulation was performed for the lifting of the beam stopper for all handling processes such as transport and installation (Fig. 18). A conservative approach was used, assuming a 1.5 g acceleration and a total mass of 600 kg (instead of 535 kg). The lifting was performed using four points on the top of the vacuum vessel. The peak stress was found to reach 255 MPa in the welded area of the lifting support. Even though the stress limit according to EN 1993-1-8 is 110 MPa, the welds have been validated by the simulations above. Additional elasto-plasticity calculations with 3 g acceleration were performed, showing ac-
Fig. 11. 3D model of guiding system and alignment table.
Fig. 12. 3D view showing the vacuum-vessel shims (left) and the inclined machined surface of the fixing support (right).
ceptable results.
The stresses and deformations caused by the shock-absorber plate on the guiding system were calculated using a static structural simulation, as illustrated in Fig. 19. A worst-case scenario with a 3 ◦ tilt between both systems was considered, adding a lateral force and a moment to the bottom plate. The maximum total deformation of the bottom plate was found to reach 0.0083 mm, while the maximum equivalent von Mises stress was 26.8 MPa, lower than the yield strength at 20 ◦ C (180 MPa).
## 3. Installation of new beam stoppers
## 3.1. Main assembly steps
The total weight of the stopper core, which is composed of Inconel 718 and CuCr1Zr, is 160 kg. This means that a special spreader is needed for the insertion of the stopper core into the vacuum vessel during the assembly phase. This spreader is made
Fig. 13. Three di ff erent example 3D models illustrating di ff erent possibilities of lower plug-in heights, flanges, and shims.
Fig. 14. 3D model of the patch panel.
Fig. 15. Schematic pneumatic circuit of the beam stopper in the in-beam (left) and out-beam (right) positions, showing the solenoid valve and pneumatic actuator.
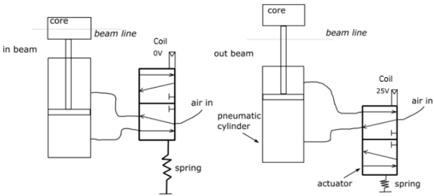
from S235JRG2 steel with a hook welded to it to enable lifting of the stopper core from above its center of gravity.
Structural simulations were performed to simulate the equivalent stresses and deformations of the spreader when lifting the stopper core. The simulations used a safety factor of 3 by simulating 3 times the actual weight of the stopper core. The results show a maximum equivalent stress of 120 MPa for a deformation of 2.1 mm.
The stopper core is assembled, lifted, and inserted into the vacuum vessel in a clean room and then fixed to the previously installed fork. The vacuum vessel is then closed with the flanges, as shown in Fig. 20.
Fig. 16. In-beam position switch.
Fig. 17. Vacuum vessel pressure static structural simulation mapping illustrating the position of the peak stress intensity.
Fig. 18. Results of a structural simulation of the vacuum-vessel static lifting case, illustrating the position of the peak stress intensity.
## 3.2. Removal of old beam stoppers
The first scheduled removal of old beam stoppers was performed during LS2. We take the example of the removal of a Fig. 1(b)-type beam stopper. Photographs of this process are shown in Fig. 21. The first step in this process is disconnection of the electrical and or pneumatic systems according to their dif-/ ferent designs; this is followed by lifting and extraction from the tunnels toward the surface. The extracted beam stoppers were transported to the radioactive-waste storage facility at CERN. The main challenge was the physical di ffi culty in extracting beam stoppers that resulted from surrounding equipment or the low heights of transfer lines in several tunnels.
## 3.3. Installation and maintenance of the new beam stoppers
As noted, the design is standard but adaptable, and the plugins may be di ff erent in terms of dimensions (depending on the installation point) but similar in terms of geometry. The standard shape of the vacuum vessel makes the lifting process identical in each case, with the same four lifting points. Finally, the isostatic ball-mounting system allows quick installation of the beam stoppers on their lower plug-ins. This plug-in system allows very rapid removal or exchange of a beam stopper if there is a need for corrective maintenance.
Only four steps are required to install a beam stopper, as shown in Fig. 22; these are as follows. (1) Fixing the lower plugin to the ground. (2) Lifting the beam stopper. (3) Positioning the beam stopper on the lower plug-in. (4) Making electrical
Fig. 19. Simulated stresses (left) and deformations (right) in the shock-absorber plate.
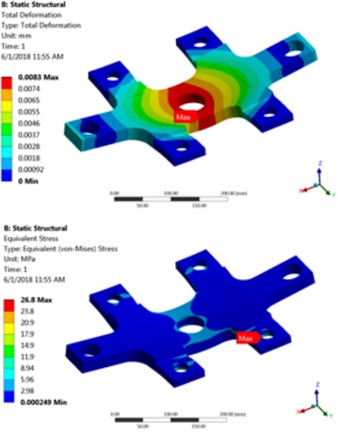
and pneumatic connections. After this, CERN perform the alignment and connection between the upstream and downstream equipment.
The residual ambient dose equivalent rates must be estimated for the work-dose planning of maintenance work on the beam stoppers. Fig. 25 shows the results of these calculations, as estimated using FLUKA4-3.4 [11, 12, 13], around the beam stopper after it has received 15 pulses as specified in Table 1 followed by a cool-down period of 2 months. This cool-down time corresponds to maintenance activities during a regular technical stop at the end of an operational year. It was found that the residual ambient dose equivalent rates allows for maintenance work.
For installation points requiring a high number of beam stoppers in a row, girders have been constructed to ease the installation and alignment processes (Fig. 23).
## 3.4. Operational feedback
To establish the total number of out-to-in-beam cycles, it is possible to crosscheck the upstream beam current transformer and beam-loss monitor data, or to directly extract the number of switch triggers from the CERN logging system for each installed beam stopper (Fig. 24). Nevertheless, as noted earlier, this number of cycles does not represent the number of impacts; this could only be known by manually checking with the operation for incidents involving the in-beam positioning of a beam stopper.
Certain beam stoppers installed on the same line have differences in their numbers of cycles or only underwent a few cycles due to manual tests during preventative maintenance. The di ff erences in term of cycles between the beam stoppers of the East Area facility-for example, T08 and T11 vs T09 and T10is explained by di ff erent access frequencies due to operational requirements. Some beam stoppers are also used as stopper dumps, combining personnel protection and machine protection.
Fig. 20. Stopper-core installation process: (a) attachment; (b) lifting with the spreader and installation into the vacuum vessel; (c) attachment to the fork; (d) closing the vacuum vessel.





Fig. 21. Removal of Fig. 1(b)-type beam stopper from CERN transfer line.


By extrapolation, taking into account the cycles preformed over the first 3 years of the beam stoppers, the duty cycle expectations are stated as being between 150 and 2690 cycles after 30 years of operation, depending on the specific beam stopper, if the conditions of use remain constant.
It also has to be noted that the modular design increases flexibility in terms of the potential location of the beam stoppers in a given beam line. This allows the beam stoppers, especially those that were installed first, to be placed at locations that are better suited in terms of the radiation generated by the beam impacting them. Typically, this means that they can be placed in locations that are better shielded or are far from access points to the machine.
## 4. Conclusion
The obsolescence of the old beam stoppers in terms of stroke time, lifespan, and inappropriate cores for the LHC upgrade,
Fig. 22. Steps in the installation of the new beam stoppers: steps 1-4 are shown in the top left, top right, bottom left, and bottom right panels, respectively.

Fig. 23. Five beam stoppers installed on a girder.

as well as a lack of documentation and their several decades of operation, mean that they can no longer reliably ensure the safety of personnel.
The new beam stoppers can meet the requirements of the increase in beam-pulse energy to 92.5 kJ, replacing six di ff erent designs and o ff ering the advantages of a unique, standard, but adaptable design that takes into account the beam parameters, attenuation, vacuum, and integration constraints. The mechanical performance of the new beam stoppers will enable better protection of personnel for the coming years by reducing the actuation time to 3 s and allowing the technical team to perform visual inspections and stopper-core changes.
Two aspects of the new beam-stopper design are significant for radiological safety: the modularity of the system and the material choices for the stopper core. The modularity of the system o ff ers more flexibility in terms of choice of location within the beam line. Therefore, it is easier to choose a location that is well shielded, minimizing the radiological impact of the generated stray radiation. In addition, this modularity eases the realization of the total hadronic interaction length of a beam-stopper system required for a given beam line within its constraints such as
Fig. 24. Numbers of out-to-in cycles for each of the 18 new beam stoppers installed from their installation date to the 2023 end-of-year technical stop, naming of the beam stoppers according to beam line and naming convention at CERN.
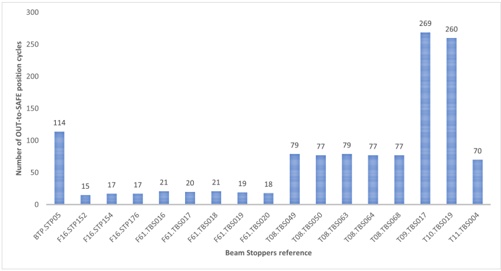
Fig. 25. Residual ambient dose equivalent rate around the beam stopper as evaluated with FLUKA4-3.4. For the Monte Carlo simulations, an irradiation time of 15 pulses (as specified in Table 1) and a cool-down time of 2 months were considered.
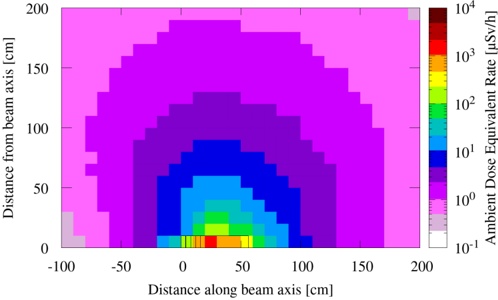
beam optics or practicality of integration. The material used for the stopper core-Inconel 718 and CuCr1Zr-are a very good compromise between activation properties and the desire to have a short hadronic interaction length.
All these design decisions mean that whatever the installation area, the installation and removal processes will be identical and notably easier than for previous designs. Moreover, the increased ease and speed of installation and or stopper-core replacement / help to meet the ALARA principle.
## Data availability
Data will be made available on request.
## Acknowledgments
The authors would like to thank: the design o ffi ce and the radiation-protection team for their involvement in the achievement of the project; the whole project team for their responsiveness and their support; and Calum Sharp as well as Edouard Grenier-Boley for proofreading. The authors would like to acknowledge the support of CERN's Sources, Targets, and Interactions (STI) Group in this project.
## Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
## References
- [1] C. Maglioni, R. Folch, Definition of beam stoppers, beam dumps and stopper dumps, eDMS 1283556, CERN (2015). /
- [2] J. Coupard, H. Damerau, A. Funken, R. Garoby, S. Gilardoni, B. Goddard, K. Hanke, A. Lombardi, D. Manglunki, M. Meddahi, B. Mikulec, G. Rumolo, E. Shaposhnikova, M. Vretenar (Eds.), LHC Injectors Upgrade, Technical Design Report, Vol. I: Protons, 2014. doi:10.17181/CERN. 7NHR.6HGC .
- [3] A. P. Zanoni, J. A. B. Monago, E. Grenier-Boley, M. Calviani, V. Vlachoudis, Characterization and core renovation of beam stoppers for personnel safety, J. Instrum. 14 (01) (2019) T01011. doi:10.1088/ 1748-0221/14/01/T01011 .
- [4] Astm e8 standard, https: // www.astm.org e0008-e0008m-22.html. /
- [5] En 12420 standard, https: // www.boutique.afnor.org fr-fr norme nf-en-/ / / 12420 cuivre-et-alliages-de-cuivre-pieces-forgees fa150029 43577. / / /
- [6] S. Rokni, A. Fass`, J. Liu, Operational radiation protection in high-energy o physics accelerators, Radiat. Prot. Dosim. 137 (1-2) (2009) 3-17. doi: 10.1093/rpd/ncp194 .
- [7] E. Schibler, J.-C. Ianigro, J. Morales, N. Redon, Design of a high energy beam stop for Spiral2 , in: Proceedings of Linear Accelerator Conference LINAC2010, Vol. MOP097, Tsukuba, Japan, 2010, pp. 283-285. URL https://accelconf.web.cern.ch/LINAC2010/papers/ MOP097.pdf
- [8] S. Kimura, D. Kaji, Y. Ito, H. Miyatake, K. Morimoto, P. Schury, M. Wada, Reduction of contaminants originating from primary beam by improving the beam stoppers in GARIS-II, Nucl. Instrum. Methods Phys. Res. A 992 (2021) 164996. doi:10.1016/j.nima.2020.164996 .
- [9] Fermilab Controlled Access Handout, https: // wwwesh.fnal.gov CourseHandout Mat Cont Access Cont Access.pdf / / / (2005).
- [10] Cei61508 standard, https: // www.boutique.afnor.org fr-fr norme iec-/ / / 6150812010 securite-fonctionnelle-des-systemes-electriques-/ electroniques-electroniques xs121824 244493. / /
- [11] C. Ahdida, D. Bozzato, D. Calzolari, F. Cerutti, N. Charitonidis, A. Cimmino, A. Coronetti, G. D'Alessandro, A. Donadon Servelle, L. Esposito, et al., New capabilities of the FLUKA multi-purpose code, Front. Phys. 9 (2022) 788253. doi:10.3389/fphy.2021.788253 .
- [12] G. Battistoni, T. Boehlen, F. Cerutti, P. W. Chin, L. S. Esposito, A. Fass`, o A. Ferrari, A. Lechner, A. Empl, A. Mairani, et al., Overview of the FLUKA code, Ann. Nucl. Energy 82 (2015) 10-18. doi:10.1016/j. anucene.2014.11.007 .
- [13] FLUKA website, https: // fluka.cern. | null | [
"D. Baillard",
"E. Grenier-Boley",
"M. Dole",
"F. Deslande",
"R. Froeschl",
"T. Lorenzon",
"P. Moyret",
"R. Peron",
"A. Pilan Zanoni",
"C. Sharp",
"M. Timmins",
"M. Calviani"
] | 2024-08-02T07:50:23+00:00 | 2024-08-02T07:50:23+00:00 | [
"hep-ex",
"physics.ins-det"
] | Design, development, and construction of the new beam stoppers for CERN's injector complex | Beam stoppers are installed in the transfer lines of the CERN accelerator
complex; these components are used as part of the access safety system, which
guarantees the safety of workers in the accelerators. They are designed to stop
one or at most a few pulses of the beam, where "stop" means the partial or
complete absorption of the primary beam in such a way that the remaining
unabsorbed primary or secondary beam remains below a specified threshold, as
defined by the needs of radiation protection. Prior to Long Shutdown 2 (LS2;
2018--2021), beam stoppers in the injector complex were dimensioned for
beam-pulse energies between 9.0 and 30~kJ. The upgrade of the accelerator
complex in the framework of the LHC Injectors Upgrade (LIU) project involves
beam-pulse energies of up to 92.5~kJ, meaning that these beam stoppers are not
able to fulfill the new functional specifications. To cope with the LIU beam
parameters and fulfil requirements for safety, maintainability, efficiency, and
reliability, a new generation of 28 beam stoppers has been designed, built, and
installed. The aim of this paper is to demonstrate the requirements-driven
design of these new beam stoppers, outlining the main requirements along with a
description of the design and structural assessments. This document presents
the implementation and integration of a standardized but adaptable design using
a unique 564-mm-long stopper core with a CuCr1Zr absorber and an Inconel~718
diluter, taking into account radiological and infrastructure challenges. The
installation process is also described, and the first operational feedback
received since LS2 is presented. |
2408.01075v1 | ## THE EAP-AIAS: ADAPTING THE AI ASSESSMENT SCALE FOR ENGLISH FOR ACADEMIC PURPOSES
## A PREPRINT
Jasper Roe 1* , Mike Perkins 2 , Yulia Tregubova 2
- 1 James Cook University Singapore, Singapore
- 2 British University Vietnam, Vietnam.
- * Corresponding Author: [email protected]
August 2024
## Abstract
The rapid advancement of Generative Artificial Intelligence (GenAI) presents both opportunities and challenges for English for Academic Purposes (EAP) instruction. This paper proposes an adaptation of the AI Assessment Scale (AIAS) specifically tailored for EAP contexts, termed the EAP-AIAS.
This framework aims to provide a structured approach for integrating GenAI tools into EAP assessment practices while maintaining academic integrity and supporting language development. The EAP-AIAS consists of five levels, ranging from 'No AI' to 'Full AI', each delineating appropriate GenAI usage in EAP tasks. We discuss the rationale behind this adaptation, considering the unique needs of language learners and the dual focus of EAP on language proficiency and academic acculturation.
This paper explores potential applications of the EAP-AIAS across various EAP assessment types, including writing tasks, presentations, and research projects. By offering a flexible framework, the EAP-AIAS seeks to empower EAP practitioners seeking to deal with the complexities of GenAI integration in education and prepare students for an AI-enhanced academic and professional future. This adaptation represents a step towards addressing the pressing need for ethical and pedagogically sound AI integration in language education.
Keywords: English for Academic Purposes (EAP), AI Assessment Scale (AIAS), Generative Artificial Intelligence (GenAI), language assessment, language learning technology
## Introduction
Advancements in the field of Artificial Intelligence (AI) and Generative AI (GenAI) have sparked intense debate across educational disciplines, with the release of sophisticated AI models such as OpenAI's ChatGPT and Anthropic's Claude representing a shift in the capabilities of language technologies, which shows no sign of slowing down. At the time of writing, such tools now encompass multimodal elements, voice generation, and the ability to produce instant and increasingly sophisticated responses that can closely mimic human-like communication. These technologies are poised to become smaller, more cost-efficient, localised, and easily downloadable, meaning that they may soon become an available tool to everyone who owns a smartphone or other communication device, regardless of whether the device has access to the internet.
In educational research, on one end of the spectrum are those who believe that AI and GenAI represent vague, problematic terms for a set of technologies which are fundamentally about commercial gain, rather than improving the educational process, and bring more harm to the practice of English language teaching than good (Caplan, 2024). Indeed, it has been asked whether these technologies are just 'bullshit spewers' (Rudolph et al., 2023) or merely produce 'botshit' (coherent sounding, counterfactual content) (Hannigan et al., 2024). On the other hand, surveys among students and faculty generally reveal positive attitudes towards these technologies, with some caution and scepticism (Chan & Hu, 2023; Roe et al., 2024). Among the general population, surveys demonstrate that many feel that GenAI represents a 'world-shifting, permanent, step-change in technology and media', evidenced by the app ChatGPT's ability to garner over 100 million users in as little as two months, shattering previous records (Archer, 2024).
Despite this attention on both ends of the spectrum, GenAI's role in English for Academic Purposes (EAP) remains a relatively unexplored area (Kostka & Toncelli, 2023); however, EAP faces unique and specific challenges in this area due to its dual focus on language proficiency and academic acculturation. EAP is at risk as there is the potential for students to use GenAI tools to disguise authorship, complete tasks without genuine engagement, or rely on them for automated machine translation of texts and even classroom discussion, thereby potentially circumventing the learning processes that EAP aims to facilitate. In the context of EAP assessment specifically, these concerns are acute because of the prevalence of take-home assessments in EAP practice, coupled with the broad focus of EAP assessments assessing not only content but also vocabulary diversity and choice, grammatical range and accuracy, coherence, structure, and other aspects of language proficiency and written expression.
Regarding take-home assessments, although proctored examinations are common, EAP courses often encompass take-home written assignments, portfolios, and presentations as core components of assessments, as they are authentic and mimic tasks required in later academic studies. These formats, while valuable for developing academic skills, are particularly vulnerable to GenAI-assisted completion or outright AI generation, as tools such as ChatGPT can be used to both fix errors in writing and compose essays (GodwinJones, 2022; Perkins, 2023). As mentioned above, EAP assessments also evaluate not only the content presented but also the linguistic elements, including grammatical and lexical accuracy, structure, and genrespecific stylistic expressions. Therefore, the ability of GenAI tools to produce grammatically flawless, wellstructured, and sophisticated writing poses a significant challenge to this assessment model. Additionally, EAP assessments often target a range of skills that go beyond a student's linguistic ability, such as critical thinking, academic, and research skills. In a pre-GenAI era, a response essay, for example, would require a student to take several steps involving a certain degree of critical engagement before the actual writing selecting credible sources, reading and critically engaging with their content, identifying similarities and differences in the views or approaches, synthesising, paraphrasing, and summarising, and then creating their own work. With the assistance of GenAI, however, it is possible to proceed from step one directly to the final step, which potentially not only deprives students of valuable critical involvement in the writing process but also intensifies the challenges of measuring skills acquisition and enabling 'complex plagiarism' (Perkins et al., 2019).
At the same time, outside of typical assessment tasks such as exams, essays, or written assignments, other tasks that are given as either formative or summative assessment in EAP may be vulnerable to overreliance on or exploitation of GenAI, such as writing annotated bibliographies, or even producing posts in a
discussion forum or wiki. Even in low-stakes classroom activities, the use of AI translation or transcription software may lead to learners relying on such technologies to understand the meaning of texts, audiovisual material, peers, or instructors, meaning that less focus is given to engaging in unassisted skill development and communication in the target language.
Moreover, in cases where students have been able to use GenAI counter to the guidance of an instructor or institutional guideline, it may be impossible to prove that such usage has taken place. Although AI text detection software exists, research indicates that these tools are often inaccurate, easily circumvented (Chaka, 2023, 2024; Perkins et al., 2023; Perkins, Roe, et al., 2024; Weber-Wulff et al., 2023), and potentially biased against speakers of English as an Additional Language (EAL) (Liang et al., 2023). Furthermore, the line between a simple AI-powered writing assistant and an illegitimate overuse that obfuscates authorship is not always clear (Roe et al., 2023). This makes it difficult for educators to reliably identify AI-generated or AI-assisted work, further complicating the assessment process. Although there may be cases which are obvious, for example, a low-proficiency English learner submitting a piece of extremely sophisticated, wellwritten, and grammatically perfect research, with tell-tale 'tortured phrases' characteristic of GenAI writing (Cabanac et al., 2021), this in our estimation is likely to represent a relatively uncommon occurrence. Emerging GenAI technologies, such as deepfakes, pose additional ethical challenges for educational institutions, potentially impacting academic integrity, institutional trust, and student privacy (Roe & Perkins, 2024). These concerns highlight the need for a comprehensive ethical framework to guide the integration of AI and GenAI in educational settings.
Another element that draws attention to the need for shared, coherent frameworks for AI use is an evolving discourse in GenAI usage's acceptability, which has shifted from attempts to outright ban the use of such tools in education to a more nuanced acceptance of their value and potential benefits to teaching and learning. In some cases, bans in schools in the U.S. have been hastily repealed as more about GenAI's capabilities and use cases have come to light (Singer, 2023). In higher education, as GenAI tools have become increasingly ubiquitous and sophisticated, many universities and academic publishers are adapting their policies to permit their use, provided it aligns with principles of transparency and accountability (Perkins & Roe, 2023, 2024). The European Commission and United Nations Educational, Scientific, and Cultural Organization (UNESCO) have also provided guidance documents and policies which emphasise the potential benefits of GenAI in research and education (European Commission, 2024; Miao & Holmes, 2023). This shift acknowledges the fact that GenAI is unlikely to be a passing fad and instead represents a new and important technology that will be increasingly deployed in society at large.
Given these conflicting pressures and considerations, and a rapidly developing discourse, there is a need for ethically oriented, easily communicable frameworks for integrating AI tools into EAP, for both teaching and learning and assessment purposes. Such a framework must strike a balance between harnessing the potential benefits of these new technologies and teaching the critical evaluation of their uses and limitations. At the same time, it is of vital importance that assessment strategies accurately reflect learners' true abilities and skill development to maintain the integrity and quality of EAP instruction and outcomes.
With this in mind, this paper proposes an adaptation of the AI Assessment Scale (AIAS) (Furze et al., 2024; Perkins, Furze, et al., 2024) tailored specifically for EAP contexts. Our adapted scale, the EAP-AIAS, aims to provide a flexible tool that acknowledges both the opportunities and challenges presented by AI in EAP as well as a starting point for further study, investigation, and discussion on the role GenAI can play in pedagogy and assessment strategy. By offering a structured framework for AI integration, we hope to empower EAP practitioners to deal with this complex set of external pressures while maintaining the integrity and core objectives of EAP instruction. Within this framework, we refer to the scale as being most suited for assessment tasks, but at the same time, the flexibility of the framework would be suitable for all forms of EAP activity, including unassessed and formative assessment tasks given in class or for homework.
The remainder of this paper is structured as follows: First, we engage with the current literature on EAP, assessment, technology, and AI to provide a comprehensive background. We then present the adapted AI Assessment Scale (EAP-AIAS), explaining its levels and their applicability to common forms of assessment in EAP. Following this, we discuss the implementation of the EAP-AIAS through a series of potential use
cases. Finally, we conclude with a discussion of the implications of our findings, acknowledgment of limitations, and proposals for future research directions.
## The Evolving Landscape of EAP and the Development of GenAI
English for Academic Purposes (EAP) has undergone significant evolution since its emergence as a distinct field in the 1960s. Originating in English for Specific Purposes (ESP), EAP has grown to represent a complex set of social practices within both institutional and global contexts (Charles, 2012). This evolution reflects the changing nature of higher education, the internationalisation of academia, and the growing recognition of the specific language needs of students engaging in English-medium instruction.
Today, the complexity and diversity of EAP contexts encompass a broad spectrum of learners and settings (Hyland & Jiang, 2021). EAP now caters to English as an Additional Language (EAL) students, undergraduate and postgraduate students, and first-language English speakers seeking to develop their academic language skills. It is practiced in various settings, including pre-sessional courses, embedded provision within academic programs, and standalone academic English programs.
Unlike general language acquisition courses, EAP's focus extends beyond solely developing linguistic macro-skills (reading, listening, writing, and speaking). Contemporary EAP focuses on the acquisition of the target language for use in specific contexts, for example, in lectures, presentations, and discussions, as well as (although to a lesser extent) study skills, such as techniques and strategies for note-taking or using Virtual Learning Environment discussion boards, and may involve English for General Academic Purposes (EGAP) or English for Specific Academic Purposes (ESAP) (Gillett, 2022). It may also involve teaching elements of culture (Gillett. 2022), and navigating culture-specific differences in learning approaches (Roe & Perkins, 2020). Additionally, EAP may focus on academic literacies, which involve understanding and producing texts within specific academic discourse communities (Lea & Street, 2006), and digital literacies, which are skills for navigating and utilising digital resources and technologies in academic contexts (Hafner, 2019).
The development of GenAI marks a pivotal moment in the teaching, learning, and research of English as a Foreign Language (EFL) (Pack & Maloney, 2023) and, by extension, EAP. Areas of practice that require attention include curriculum design, integrating AI literacy alongside traditional language and academic skills; assessment methods, developing new approaches to evaluate genuine student work in an AI-assisted environment; pedagogical approaches, adapting teaching methods to leverage AI tools while maintaining a focus on core EAP objectives; and ethical considerations, addressing issues of academic integrity, equity, and the appropriate use of AI in academic contexts.
As EAP is primarily a practical field that focuses on addressing real-life classroom challenges faced by teachers and students (Hyland & Jiang, 2021), GenAI represents a challenge that requires actionable, flexible, and practical solutions. There is increasing recognition of the need to enable students to engage in AI-mediated academic communication (Ou et al., 2024) while simultaneously ensuring that the fundamental goals of language acquisition and academic skill development are not compromised. At the same time, while there are many theoretical affordances for learners using GenAI in EAP, there are many potential limitations.
## Affordances and Limitations of GenAI in EAP
The integration of Generative AI (GenAI) into English for Academic Purposes (EAP) contexts offers a range of potential benefits but also presents significant challenges and limitations. Understanding these affordances and constraints is crucial for developing an effective framework for AI use in EAP and identifying the potential affordances for students and educators.
GenAI tools, particularly advanced chatbots such as ChatGPT, Gemini, and Claude, can provide learners with opportunities for meaningful practice of the target language, potentially enhancing their overall proficiency (Sha, 2009). Research has indicated that interactions with AI chatbots can positively affect language proficiency by drawing attention to form and improving accuracy (Bibauw et al., 2019). Through sophisticated prompting, GenAI chatbots can play various roles in the learning process, acting as teaching, peer, or teachable agents, offering a flexible learning experience (Kuhail et al., 2023). Research has explored
the use of prompt engineering with EFL learners to craft human-AI narratives, suggesting a potential innovation in teaching pedagogy (Woo et al., 2024).
Continuing with AI-powered chatbots, these GenAI applications can provide rich, varied inputs essential for second language acquisition (SLA). The ability to generate diverse examples and explanations can stimulate interest and contribute to overall language growth (Kohnke et al., 2023), and GenAI tools can generate personalised practice materials and facilitate real-time explanations, supporting diverse learning needs and allowing for the creation of tailored exercises that align with individual learner proficiency levels and learning styles.
In the context of academic writing, GenAI can assist with idea generation, vocabulary enhancement, structural guidance, feedback, and revision. These features can be particularly beneficial for developing writing skills by offering personalised support throughout the writing process (Xiao & Zhi, 2023). GenAI tools have also shown potential in promoting grit and resilience among L2 students, potentially helping them overcome learning challenges and thrive in their studies (Ghafouri, 2024).
However, the integration of GenAI into EAP presents considerable challenges. There is a risk that students will accept erroneous information produced by GenAI, which is particularly problematic in academic contexts where accuracy and reliability are paramount (Pack & Maloney, 2024). Indeed, GenAI tools mislead humans into believing they are intelligent, despite producing inaccurate, made-up, or unreliable content (Zhgenti & Holmes, 2023), and at the same time, the information produced by many AI tools is by nature culturally biased and representative of a Eurocentric worldview (Roe, 2024)
AI-generated text or audio content may also be above the proficiency level of many learners, potentially leading to overreliance on AI tools instead of developing their own language skills, which could lead to knowledge loss and a 'monoculture' of academic knowledge (Messeri & Crockett, 2024). As a result of the quality of outputs from GenAI tools, some have called for the teaching of evaluative judgment regarding AI output (Bearman et al., 2024). This also extends to the idea of using GenAI outputs for feedback, and the results of empirical studies suggest that automated writing evaluation from GenAI tools may have a place in English as a New Language (ENL) instruction (Escalante et al., 2023), and that GPT tools can be used for automated essay scoring with L2 writers (Mizumoto & Eguchi, 2023). Dai et al. (2023) was found to provide feedback that was more detailed than that of an instructor, yet showed high levels of agreement with the marking of the instructor. On the other hand, these systems are at an early stage in language assessment (Chiu et al., 2023), and questions remain over automated markings' ethics, legality, cost, and privacy (Kumar, 2023).
Equity and access issues arise, as not all students have equal access to the necessary technology or premium AI tools, potentially exacerbating existing educational disparities (Kohnke, 2023). Exploitation of workers and monopolistic domination of the GenAI market by companies in the Global North also raises broader questions about the ethics of GenAI in education and society (Zhgenti & Holmes, 2023).
Another question related to embedding GenAI in education is the additional work required by teachers, who must manage and integrate these tools into their teaching practices and stay updated with rapidly evolving AI technologies. In this space, not only does the integration of GenAI into EAP contexts necessitate a careful reconsideration of assessment practices, but also reconsideration of classroom approaches to equip students with the required skills set. While many of the affordances of GenAI in EAP relate to classroom activities and unassessed exploration, the role these tools should play in formal assessment is a subject of much discussion.
## Addressing GenAI in EAP Assessment
Assessment has become an increasingly important topic in EAP, with bibliometric analysis showing an increasing trend in EAP assessment topics in scholarly publications from 1975 to 2019 (Charles, 2022). This growing focus reflects the recognition that assessment is a critical component of EAP pedagogy and program effectiveness. EAP assessment is inherently complex because of the intricate nature of language and academic skill evaluation (Bruce, 2015). This complexity arises from several factors, including the
multidimensional nature of language proficiency, integration of language and content, genre-specific requirements, and cultural and linguistic diversity of EAP students. EAP assessments must evaluate not only linguistic competence but also the ability to use language appropriately in academic contexts, while also requiring students to demonstrate knowledge of academic subjects or research methodologies.
Several trends have emerged in EAP assessment in recent years. There is a growing shift from an exam culture to a learning culture, with an increasing emphasis on learner-oriented assessment and more formative and continuous assessment methods (Fazel & Ali, 2022). Authentic assessment has gained popularity, with a focus on tasks that reflect real-world academic activities (Uludag & McDonough, 2022). Portfolio-based assessments have also seen growing adoption, including a range of tasks such as summarising texts, creating research proposals, and giving oral presentations (Storch & Tapper, 2009). In addition, technology-enhanced assessment has become more prevalent, incorporating digital tools and platforms to allow for more diverse and interactive assessment tasks.
In this context, GenAI can help create more authentic assessment scenarios, but also raises concerns about academic integrity and the ability to accurately assess individual student capabilities. Traditional assessment methods need to be revised to effectively evaluate language and academic skills using a range of formats and modes of assessment, including those that allow for the critical use and evaluation of AI-generated content. Similarly, the potential for AI tools to provide instant, personalised feedback on assessments could assist the feedback process but raises questions about the quality and appropriateness of AI-generated commentary on student work.
Given these diverse challenges, any framework designed with the integration of GenAI into EAP must make assessment one of the main focal points. We argue that a specific EAP-AIAS framework is necessary to maintain assessment validity, communicate the appropriate use of GenAI to students and teachers, adapt to new technologies, and provide a balanced assessment profile. Furthermore, the implementation of the proposed EAP-AIAS should ensure that assessments remain valid measures of students' language and academic skills in an AI-enhanced environment, support the development of critical thinking and academic skills, and address issues of equity to prevent disadvantaging certain groups of students or exacerbating existing educational inequalities. We propose that the AIAS can be adapted for EAP to meet these goals and provide a suitable, flexible framework.
## The AI Assessment Scale (AIAS) and Its Adaptation for EAP
## Overview of the Original AIAS
The AI Assessment Scale (AIAS) was originally conceived by Perkins, Furze, et al. (2024) to help educators in a wide range of disciplines adapt their assessments to the GenAI era. The original scale consists of five levels, ranging from 'No AI' to 'Full AI', designed to guide students on the appropriate use of GenAI tools while adhering to academic integrity principles. Results from a pilot study of the AIAS suggest that the use of the scale at an institutional level led to reduced cases of academic misconduct, improved student outcomes, and improved ethical integration of GenAI tools into assessment strategies (Furze et al., 2024). Various adaptations or translations of this scale have also been developed globally (Furze, 2024; Kılınç, 2024), demonstrating the potential value of similar tools.
While the original AIAS provides a valuable starting point, the unique needs of EAP necessitate a more tailored approach. EAP's dual focus on language proficiency and academic acculturation (Hyland, 2018) requires a framework that prioritises language and skill acquisition and ensures that the fundamental goal of developing genuine language skills is not compromised by AI use. Furthermore, an adapted AIAS framework needs to support academic skill development, foster criticality, promote AI literacy, and provide guidelines on the ethical use of AI tools.
## The EAP-Specific AI Assessment Scale (EAP-AIAS)
Our proposed EAP-AIAS builds on the original five-point scale, redefining each level to align it with typical EAP tasks. By explicitly mapping each level to these established EAP approaches, the EAP-AIAS can provide a more robust and theoretically grounded framework for AI integration in EAP instruction.
| Level | Description | Focus | Example Tasks |
|---------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Level 1: No AI Use | All language and skills tasks completed without AI assistance. | Developing core language skills and academic competencies independently. | Traditional examinations, in-class presentations, in-class comprehension and critical thinking tasks. |
| Level 2: AI-Assisted Language Input | AI used to generate or augment input materials. | Enhancing comprehension and analysis skills. | Inviting learners to engage with or create AI-generated texts for reading or listening comprehension and micro skills development. Instructor-created AI materials for assessment or practical use. |
| Level 3: AI for Limited Language or skills Practice | AI used for targeted practice of specific language and discourse features or academic skills development. | Reinforcing particular aspects of language, discourse, academic or discipline-specific conventions. | AI-generated content for controlled or semi-controlled practice of discipline-specific vocabulary and/or discourse features; simulated academic discussions with AI. |
| Level 4: AI-Assisted Task Completion with Critical Evaluation | Students use AI to assist in complex academic tasks but must critically evaluate and substantially revise AI outputs. | Developing critical thinking and digital literacy alongside language and academic skills. | Using AI for initial research or drafting, followed by substantial human revision, reflection, evaluation and critique. |
| Level 5: Selective AI Integration for Advanced Skills | More extensive AI use allowed but emphasizing its role in enhancing, not replacing, student work. | Preparing students for real-world academic and discipline-specific scenarios involving AI. | Using AI for data analysis in research projects, developing AI- enhanced academic presentations and discipline-specific outcome tasks |
Table 1: The EAP-AIAS
We recognise that the broad range of tasks present in EAP assessments means that these identified scale levels might be used at different times and for different purposes throughout EAP education, and that no level of the scale is inherently 'better' or more suitable than another. We have therefore adjusted the original colour scheme presented in the AIAS from a Red-Green scale to a more neutral palette of colours. This is to avoid any potential implicit suggestions to educators working with this scale that tasks or assessments with no AI usage are incorrect and that Full AI usage is the most appropriate or target level.
To illustrate the practical application of the EAP-AIAS, we present a series of possible use cases across different EAP contexts. These examples demonstrate how varying levels of the scale can be implemented at different levels of study and for different language learning objectives.
## Level 1: No AI Use
In an intensive pre-sessional EAP program for international students, a Level 1 'No AI Use' approach could be applied for the final examination. This traditional assessment may be conducted in a secure, invigilated physical environment encompassing listening, reading, speaking, and writing components. By requiring students to demonstrate their EAP skills without the aid of AI or assistive technologies, this approach could provide a clear indication of their ability to independently apply language skills in their future academic studies. Such examinations might offer a baseline measure of language competency unaffected by AI or other technological interventions, aligning with the core principles of Level 1 in the EAP-AIAS.
## Level 2: AI-Assisted Language Input
For first-year undergraduate students in an in-sessional English for Specific Academic Purposes (ESAP) program focusing on business subjects, a Level 2 'AI-Assisted Language Input' approach could be implemented. GenAI chatbots may be utilised to produce discipline-specific graded readings, aligning with the EAP-AIAS guidelines for AI-assisted idea generation and structuring. Instructors could guide students to generate texts at appropriate difficulty levels, potentially encouraging them to experiment with the chatbot to explain key terms or interpret meanings outside class time. This Level 2 approach may stimulate learner interest by offering opportunities to acquire new discipline-specific vocabulary in context and familiarise students with genre conventions while ensuring that the final work remains AI-free.
## Level 3: AI for Limited Language Practice
In a postgraduate EAP module focusing on academic writing, a Level 3 'AI for Limited Language Practice' approach could be adopted. Students might be encouraged to use GenAI applications such as ChatGPT, Claude, or Gemini to develop their sentence and paragraph structure skills in line with the EAP-AIAS guidelines for AI-assisted editing. The process could involve creating discipline-specific word lists, collocations, or clichés based on genre requirements, which could then be incorporated into writing tasks. Students could input their written work into the GenAI application for initial feedback on lexical, grammatical, and structural elements. They might then be tasked with analysing and justifying any changes made based on AI suggestions, potentially promoting critical engagement with the tool. This Level 3 approach could improve students' use of discipline-specific languages, with the critical analysis of AI grammar suggestions possibly leading to a deeper understanding of linguistic structures.
## Level 4: AI-Assisted Task Completion with Critical Evaluation
In a postgraduate EAP course on research writing, a Level 4 'AI-Assisted Task Completion with Critical Evaluation' approach could be implemented to develop research proposals. This would align with the EAPAIAS framework for AI task completion with human evaluation. The process may begin with an introduction to the UNESCO (Miao & Holmes, 2023) and COPE (2023) guidelines on the ethical use of GenAI in research. Students could then use AI tools to generate initial ideas and create outlines for their research proposals. A critical component of this Level 4 task might be the evaluation of AI-generated content, which students would need to revise substantially and justify their changes. Peer review sessions could focus on discussing how effectively students have adapted and improved upon AI-generated content. Final submissions may include a reflection on the process of working with and critiquing AI-generated material, fulfilling the critical evaluation aspect of Level 4.
## Level 5: Selective AI Integration for Advanced Skills
In an EAP workshop for doctoral students, a Level 5 'Selective AI Integration for Advanced Skills' approach could be employed, representing the highest level of AI integration in the EAP-AIAS framework. GenAI tools can be used extensively to assist in synthesising large volumes of research for literature review. Students could be guided to use these tools in accordance with COPE best practices (2023) and UNESCO guidelines (Miao & Holmes, 2023). The process might involve prompting AI to summarise key points from multiple papers, followed by a critical evaluation of these summaries. In line with Level 5 of the EAP-AIAS, students could be required to identify gaps in AI-generated syntheses and develop their own arguments based on a more comprehensive understanding of the field. Final presentations may include a critical reflection on the role of AI in the research process and its limitations, potentially demonstrating the advanced skills and critical thinking fostered by the highest level of AI integration.
## Discussion
The advantage of the AIAS in EAP is that it provides a structured yet flexible approach to GenAI integration, providing clear guidelines for usage in specific tasks. The EAP-AIAS can help empower educators to effectively incorporate AI tools into their teaching and assessment practices while ensuring that students develop the necessary language skills which can be evaluated through a range of tasks. The EAP-AIAS may be used to help maintain academic integrity by educating students about acceptable use where it is appropriate and providing a system for communication. If students are given a clear framework which clarifies the acceptable use cases of GenAI and receive encouragement on adhering to values of transparency and ethics, then the EAP-AIAS can help to guide the successful integration of GenAI.
However, successful implementation of the EAP-AIAS requires careful consideration of several factors. First, instructors should become comfortable with each level before moving to the next. Clear guidelines with explicit instructions and examples should be provided for each level to clarify what constitutes appropriate GenAI use. As part of their effective use, instructors need to have comprehensive training on both the technical aspects of AI tools and their pedagogical applications.
The EAP-AIAS represents a potential framework that may benefit EAP pedagogy by explicitly addressing AI use while reaffirming the importance of foundational language and academic skills. This scale aligns with calls for enhanced digital literacy in EAP, providing a structured approach to develop these skills alongside traditional language competencies. EAP programmes with an explicit focus on digital literacy contribute to better academic integrity and assist with better accessing the course content (Roche, 2017).
The emphasis on critical evaluation of AI-generated content, particularly in types of tasks relating to levels 4 and 5, resonates with critical EAP approaches, encouraging students to develop evaluative judgement with both content and tools, thus fostering criticality.
It also contributes to the development of metacognitive skills, going beyond high-order thinking skills and allowing space for developing reflective thinking. In this way, the EAP-AIAS serves as a bridge between traditional EAP instruction and the demands of an increasingly AI-influenced academic environment.
Questions remain regarding the long-term impact of AI integration on language and skill acquisition. The principle of maintaining a majority of instruction and classroom interaction at Level 1 (No AI Use) appears crucial, but longitudinal studies are needed to confirm its effectiveness. With the influence of AI, academic skills development is likely to go through significant changes - certain subskills might become obsolete, which will require adaptation of core methodologies and full GenAI integration in the EAP curriculum with design of a relevant set of assessment tools, possibly AI -powered assessment tools such as EAP Talk - an AI software for assessing academic speaking skills (Wang & Zou, 2023).
The issue of academic integrity in AI-enhanced environments remains complex. Our experience suggests that fostering a culture of ethical GenAI use through explicit instruction and reflection is essential. The potential of AI tools to exacerbate existing educational inequalities must be carefully monitored and addressed. The aim is to create a constructive learning environment in an EAP classroom where students benefit from using AI tools in developing their academic skills while learning to use them ethically and maintaining academic integrity. The scale may need further refinement to address discipline-specific needs within EAP, as the appropriate level of AI integration may vary across academic fields and discourses. The current scale may not fully capture the nuances of AI use in collaborative tasks, an important aspect of academic work that requires further exploration. The fast-paced evolution of GenAI technologies indicates that the scale requires regular updates to remain relevant.
Several avenues for future research emerge from our implementation of the EAP-AIAS. These include conducting longitudinal studies tracking students' language and skills development and academic performance as they progress through the EAP-AIAS levels over extended periods; comparative studies examining learning outcomes between EAP-AIAS-guided instruction and traditional EAP approaches; investigating the role of AI in developing specific EAP skills, such as academic listening and speaking;
exploring how the EAP-AIAS might be adapted for discipline-specific EAP courses; and examining the most effective methods for developing critical AI literacy within EAP contexts.
Based on our findings, we offer several recommendations to EAP practitioners and institutions. These include beginning with a phased implementation, focusing on one or two levels of the scale initially, investing in comprehensive professional development programs for EAP instructors, developing clear institutional policies on AI use in academic work aligned with the principles of the EAP-AIAS, establishing support structures for students, including workshops on ethical AI use and access to necessary tools, and regularly reviewing and adapting the implementation of the EAP-AIAS based on feedback from instructors and students.
## Conclusion
The EAP-AIAS represents a significant step towards addressing the challenges and opportunities presented by GenAI in EAP instruction. Although further research and refinement are necessary, the scale provides a valuable framework for integrating GenAI tools in a manner that enhances, rather than undermines, the core objectives of EAP. As we move forward, maintaining a balance between embracing technological advancements and preserving the fundamental principles of language acquisition and academic skill development is crucial for shaping the future of EAP pedagogy.
This scale offers a structured yet flexible approach to EAP assessment in the GenAI era, empowering both educators and learners to engage critically and ethically with GenAI technologies in academic contexts. The journey of integrating GenAI into EAP is ongoing, and the EAP-AIAS should be viewed as a living framework, open to adaptation and refinement as our understanding of GenAI's role in language education evolves. By continuing to engage critically with these technologies, conduct rigorous research, and prioritise the core goals of EAP, we can ensure that GenAI becomes a valuable tool in our pedagogical arsenal rather than a disruptive force that undermines the essence of language and academic skills development.
## AI Usage Disclaimer
This study used Generative AI tools (Claude 3.5 Sonnet) for revision and editorial purposes throughout the production of the manuscript. The authors reviewed, edited, and take responsibility for all outputs of the tools used in this study
## References
Archer. (2024). What do people think of Generative AI? https://www.bbc.co.uk/mediacentre/2024/what-dopeople-think-of-generative-ai/
Bearman, M., Tai, J., Dawson, P., Boud, D., & Ajjawi, R. (2024). Developing evaluative judgement for a time of generative artificial intelligence. Assessment & Evaluation in Higher Education , 0 (0), 113. https://doi.org/10.1080/02602938.2024.2335321
Bibauw, S., François, T., & Desmet, P. (2019). Discussing with a computer to practice a foreign language: Research synthesis and conceptual framework of dialogue-based CALL. Computer Assisted Language Learning , 32 (8), 827-877. https://doi.org/10.1080/09588221.2018.1535508
Bruce, I. (2015). EAP and Assessment. In I. Bruce (Ed.), Theory and Concepts of English for Academic Purposes (pp. 196-209). Palgrave Macmillan UK. https://doi.org/10.1057/978-1-349-59077-3\_12 Cabanac, G., Labbé, C., & Magazinov, A. (2021). Tortured phrases: A dubious writing style emerging in science. Evidence of critical issues affecting established journals (arXiv:2107.06751). arXiv. https://doi.org/10.48550/arXiv.2107.06751
Chaka, C. (2023). Detecting AI content in responses generated by ChatGPT, YouChat, and Chatsonic: The case of five AI content detection tools. Journal of Applied Learning and Teaching , 6 (2), Article 2. https://doi.org/10.37074/jalt.2023.6.2.12
Chaka, C. (2024). Accuracy pecking order - How 30 AI detectors stack up in detecting generative artificial intelligence content in university English L1 and English L2 student essays. Journal of Applied Learning and Teaching , 7 (1), Article 1. https://doi.org/10.37074/jalt.2024.7.1.33
Chan, C. K. Y., & Hu, W. (2023). Students' Voices on Generative AI: Perceptions, Benefits, and Challenges in Higher Education (arXiv:2305.00290). arXiv. https://doi.org/10.48550/arXiv.2305.00290
Charles, M. (2012). English for Academic Purposes. In The Handbook of English for Specific Purposes (pp. 137-153). John Wiley & Sons, Ltd. https://doi.org/10.1002/9781118339855.ch7
Charles, M. (2022). EAP research in BALEAP 1975-2019: Past issues and future directions. Journal of English for Academic Purposes , 55 , 101060. https://doi.org/10.1016/j.jeap.2021.101060
Chiu, T. K. F., Xia, Q., Zhou, X., Chai, C. S., & Cheng, M. (2023). Systematic literature review on opportunities, challenges, and future research recommendations of artificial intelligence in education. Computers and Education: Artificial Intelligence , 4 , 100118. https://doi.org/10.1016/j.caeai.2022.100118
COPE. (2023, February 13). Authorship and AI tools . COPE: Committee on Publication Ethics. https://publicationethics.org/cope-position-statements/ai-author
Can Large Language Models
Dai, W., Lin, J., Jin, F., Li, T., Tsai, Y .-S., Gasevic, D., & Chen, G. (2023). Provide Feedback to Students? A Case Study on ChatGPT . EdArXiv. https://doi.org/10.35542/osf.io/hcgzj
Escalante, J., Pack, A., & Barrett, A. (2023). AI-generated feedback on writing: Insights into efficacy and ENL student preference. International Journal of Educational Technology in Higher Education , 20 (1), 57. https://doi.org/10.1186/s41239-023-00425-2
European Commission. (2024). Guidelines on the responsible use of generative AI in research developed by the European Research Area Forum-European Commission . https://research-andinnovation.ec.europa.eu/news/all-research-and-innovation-news/guidelines-responsible-usegenerative-ai-research-developed-european-research-area-forum-2024-03-20\_en
Fazel, I., & Ali, A. M. (2022). EAP teachers' knowledge and use of learning-oriented assessment: A crosscontextual study. System , 104 , 102685. https://doi.org/10.1016/j.system.2021.102685
Furze, L. (2024, May 19). The AI Assessment Scale in Action: Examples from K-12 and Higher Education Across the World [Blog]. Leon Furze. https://leonfurze.com/2024/05/20/the-ai-assessment-scalein-action-examples-from-k-12-and-higher-education-across-the-world/
- Furze, L., Perkins, M., Roe, J., & MacVaugh, J. (2024). The AI Assessment Scale (AIAS) in action: A pilot implementation of GenAI supported assessment (arXiv:2403.14692). arXiv. https://doi.org/10.48550/arXiv.2403.14692
Ghafouri, M. (2024). ChatGPT: The catalyst for teacher-student rapport and grit development in L2 class. System , 120 , 103209. https://doi.org/10.1016/j.system.2023.103209
Gillett. (2022).
What is EAP?
https://www.uefap.com/bgnd/eap.htm
Godwin-Jones, R. (2022). Partnering with AI: Intelligent writing assistance and instructed language learning. Language Learning & Technology , 26 (2), Article 2. https://doi.org/10125/73474 Second Handbook
Hafner, C. A. (2019). Digital Literacies for English Language Learners. In X. Gao (Ed.), of English Language Teaching (pp. 899-918). Springer International Publishing. https://doi.org/10.1007/978-3-030-02899-2\_46
Hannigan, T. R., McCarthy, I. P., & Spicer, A. (2024). Beware of botshit: How to manage the epistemic risks of generative chatbots. Business Horizons . https://doi.org/10.1016/j.bushor.2024.03.001 Hyland, K. (2018). Sympathy for the devil? A defence of EAP. Language Teaching , 51 (3), 383-399. https://doi.org/10.1017/S0261444818000101
Hyland, K., & Jiang, F. (Kevin). (2021). A bibliometric study of EAP research: Who is doing what, where and when? Journal of English for Academic Purposes , 49 , 100929. https://doi.org/10.1016/j.jeap.2020.100929
Kılınç, S. (2024). Comprehensive AI Assessment Framework: Enhancing Educational Evaluation with Ethical AI Integration (arXiv:2407.16887). arXiv. https://doi.org/10.48550/arXiv.2407.16887 Kohnke, L. (2023). A Pedagogical Chatbot: A Supplemental Language Learning Tool. RELC Journal , 54 (3), 828-838. https://doi.org/10.1177/00336882211067054
Kohnke, L., Moorhouse, B. L., & Zou, D. (2023). Exploring generative artificial intelligence preparedness among university language instructors: A case study. Computers and Education: Artificial Intelligence , 5 , 100156. https://doi.org/10.1016/j.caeai.2023.100156
Kostka, I., & Toncelli, R. (2023). Exploring applications of ChatGPT to English language teaching: Opportunities, challenges, and recommendations. TESL-EJ 27 , (3), n3.
Kuhail, M. A., Alturki, N., Alramlawi, S., & Alhejori, K. (2023). Interacting with educational chatbots: A systematic review. Education and Information Technologies , 28 (1), 973-1018. https://doi.org/10.1007/s10639-022-11177-3
Kumar, R. (2023). Faculty members' use of artificial intelligence to grade student papers: A case of implications. International Journal for Educational Integrity , 19 (1), Article 1. https://doi.org/10.1007/s40979-023-00130-7
Lea, M. R., & Street, B. V. (2006). The 'Academic Literacies' Model: Theory and Applications. Theory Into Practice , 45 (4), 368-377. https://doi.org/10.1207/s15430421tip4504\_11
Liang, W., Yuksekgonul, M., Mao, Y., Wu, E., & Zou, J. (2023). GPT detectors are biased against nonnative English writers. arXiv Preprint arXiv:2304.02819 .
Messeri, L., & Crockett, M. J. (2024). Artificial intelligence and illusions of understanding in scientific research. Nature , 627 (8002), 49-58. https://doi.org/10.1038/s41586-024-07146-0
Miao, F., & Holmes, W. (2023). Guidance for generative AI in education and research . UNESCO: United Nations Educational, Scientific and Cultural Organisation. https://unesdoc.unesco.org/ark:/48223/pf0000386693
Mizumoto, A., & Eguchi, M. (2023). Exploring the potential of using an AI language model for automated essay scoring. Research Methods in Applied Linguistics , 2 (2), 100050. https://doi.org/10.1016/j.rmal.2023.100050
Ou, A. W., Stöhr, C., & Malmström, H. (2024). Academic communication with AI-powered language tools in higher education: From a post-humanist perspective. System , 121 , 103225. https://doi.org/10.1016/j.system.2024.103225
| Pack, A., &Maloney, J. (2023). Using Generative Artificial Intelligence for Language Education Research: Insights from Using OpenAI's ChatGPT. TESOL Quarterly , 57 (4), 1571-1582. https://doi.org/10.1002/tesq.3253 |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Pack, A., &Maloney, J. (2024). Using Artificial Intelligence in TESOL: Some Ethical and Pedagogical Considerations. TESOL Quarterly , 58 (2), 1007-1018. https://doi.org/10.1002/tesq.3320 |
| Perkins, M. (2023). Academic Integrity considerations of AI Large Language Models in the post-pandemic era: ChatGPT and beyond. Journal of University Teaching &Learning Practice , 20 (2). https://doi.org/10.53761/1.20.02.07 |
| Perkins, M., Basar Gezgin, U., &Gordon, R. (2019). Plagiarism in higher education: Classification, causes and controls. Pan-Pacific Management Science , 2 , 3-21. https://doi.org/10.13140/RG.2.2.20694.11841 |
| Perkins, M., Furze, L., Roe, J., &MacVaugh, J. (2024). The Artificial Intelligence Assessment Scale (AIAS): AFramework for Ethical Integration of Generative AI in Educational Assessment. Journal of University Teaching and Learning Practice , 21 (06), Article 06. https://doi.org/10.53761/q3azde36 |
| Perkins, M., &Roe, J. (2023). Decoding Academic Integrity Policies: ACorpus Linguistics Investigation of AI and Other Technological Threats. Higher Education Policy . https://doi.org/10.1057/s41307- 023-00323-2 |
| Perkins, M., &Roe, J. (2024). Academic publisher guidelines on AI usage: AChatGPT supported thematic analysis [version 2; peer review: 3 approved, 1 approved with reservations]. In F1000Research (Vol. 12, Issue 1398). https://doi.org/10.12688/f1000research.142411.2 |
| Perkins, M., Roe, J., Postma, D., McGaughran, J., &Hickerson, D. (2023). Detection of GPT-4 Generated Text in Higher Education: Combining Academic Judgement and Software to Identify Generative AI Tool Misuse. Journal of Academic Ethics . https://doi.org/10.1007/s10805-023-09492-6 |
| Perkins, M., Roe, J., Vu, B. H., Postma, D., Hickerson, D., McGaughran, J., & Khuat, H. Q. (2024). GenAI Detection Tools, Adversarial Techniques and Implications for Inclusivity in Higher Education (arXiv:2403.19148). arXiv. http://arxiv.org/abs/2403.19148 Roche, T. B. (2017). Assessing the role of digital literacy in English for Academic Purposes university |
| pathway programs. Journal of Academic Language and Learning , 11 (1), A71-A87. https://journal.aall.org.au/index.php/jall/article/view/439 Roe, J. (2024). AI and the Anthropological Imagination: Rethinking Education in the Digital Age . Open |
| Anthropology Research Repository. https://openanthroresearch.org/index.php/oarr/preprint/view/399 |
| University Education , 16 (1), 13-21. Roe, J., & Perkins, M. (2024). Deepfakes and Higher Education: A Research Agenda and Scoping Review of Synthetic Media (arXiv:2404.15601). arXiv. https://doi.org/10.48550/arXiv.2404.15601 |
| Roe, J., Perkins, M., & Ruelle, D. (2024). Understanding Student and Academic Staff Perceptions of AI Use in Assessment and Feedback (arXiv:2406.15808). arXiv. |
| https://doi.org/10.48550/arXiv.2406.15808 Roe, J., Renandya, W. A., &Jacobs, G. M. (2023). AReview of AI-Powered Writing Tools and Their Implications for Academic Integrity in the Language Classroom. Journal of English and Applied |
| Linguistics , 2 (1), 3. Rudolph, J., Tan, S., &Tan, S. (2023). ChatGPT: Bullshit spewer or the end of traditional assessments in higher education? Journal of Applied Learning and Teaching , 6 (1), Article 1. |
| https://doi.org/10.37074/jalt.2023.6.1.9 Sha, G. (2009). AI-based chatterbots and spoken English teaching: Acritical analysis. Computer Assisted |
| Language Learning , 22 (3), 269-281. Singer, N. (2023, August 24). Despite Cheating Fears, Schools Repeal ChatGPT Bans. The New York Times . https://www.nytimes.com/2023/08/24/business/schools-chatgpt-chatbot-bans.html |
- Storch, N., & Tapper, J. (2009). The impact of an EAP course on postgraduate writing. Journal of English for Academic Purposes , 8 (3), 207-223. https://doi.org/10.1016/j.jeap.2009.03.001
Uludag, P., & McDonough, K. (2022). Exploring EAP instructors' evaluation of classroom-based integrated essays.
TESOL Journal
,
13
(3), e670. https://doi.org/10.1002/tesj.670
Wang, C., & Zou, B. (2023). Review of EAP Talk. Journal of China Computer-Assisted Language Learning . https://doi.org/10.1515/jccall-2023-0019
Weber-Wulff, D., Anohina-Naumeca, A., Bjelobaba, S., Foltýnek, T., Guerrero-Dib, J., Popoola, O., Šigut, P., & Waddington, L. (2023). Testing of detection tools for AI-generated text. International Journal for Educational Integrity , 19 (1), Article 1. https://doi.org/10.1007/s40979-023-00146-z Woo, D. J., Guo, K., & Susanto, H. (2024). Exploring EFL students' prompt engineering in human-AI story writing: An activity theory perspective. Interactive Learning Environments , 0 (0), 1-20. https://doi.org/10.1080/10494820.2024.2361381
Xiao, Y., & Zhi, Y. (2023). An Exploratory Study of EFL Learners' Use of ChatGPT for Language Learning Tasks: Experience and Perceptions. Languages , 8 (3), 212. https://doi.org/10.3390/languages8030212
Zhgenti, S., & Holmes, W. (2032). Generative AI and Education: Adopting a Critical Approach . https://discovery.ucl.ac.uk/id/eprint/10177781/1/Zhgenti%20and%20Holmes%20-%202023%20%20Generative%20AI%20and%20Education%20Adopting%20a%20Critical%20A.pdf | null | [
"Jasper Roe",
"Mike Perkins",
"Yulia Tregubova"
] | 2024-08-02T07:51:29+00:00 | 2024-08-02T07:51:29+00:00 | [
"cs.CY",
"cs.AI"
] | The EAP-AIAS: Adapting the AI Assessment Scale for English for Academic Purposes | The rapid advancement of Generative Artificial Intelligence (GenAI) presents
both opportunities and challenges for English for Academic Purposes (EAP)
instruction. This paper proposes an adaptation of the AI Assessment Scale
(AIAS) specifically tailored for EAP contexts, termed the EAP-AIAS.
This framework aims to provide a structured approach for integrating GenAI
tools into EAP assessment practices while maintaining academic integrity and
supporting language development. The EAP-AIAS consists of five levels, ranging
from "No AI" to "Full AI", each delineating appropriate GenAI usage in EAP
tasks. We discuss the rationale behind this adaptation, considering the unique
needs of language learners and the dual focus of EAP on language proficiency
and academic acculturation.
This paper explores potential applications of the EAP-AIAS across various EAP
assessment types, including writing tasks, presentations, and research
projects. By offering a flexible framework, the EAP-AIAS seeks to empower EAP
practitioners seeking to deal with the complexities of GenAI integration in
education and prepare students for an AI-enhanced academic and professional
future. This adaptation represents a step towards addressing the pressing need
for ethical and pedagogically sound AI integration in language education. |
2408.01076v1 | ## Exploiting the Semantic Knowledge of Pre-trained Text-Encoders for Continual Learning
Lu Yu, Zhe Tao, Hantao Yao, Member, IEEE, Joost Van de Weijer, and Changsheng Xu, Fellow, IEEE
Abstract -Deep neural networks (DNNs) excel on fixed datasets but struggle with incremental and shifting data in real-world scenarios. Continual learning addresses this challenge by allowing models to learn from new data while retaining previously learned knowledge. Existing methods mainly rely on visual features, often neglecting the rich semantic information encoded in text. The semantic knowledge available in the label information of the images, offers important semantic information that can be related with previously acquired knowledge of semantic classes. Consequently, effectively leveraging this information throughout continual learning is expected to be beneficial. To address this, we propose integrating semantic guidance within and across tasks by capturing semantic similarity using text embeddings. We start from a pre-trained CLIP model, employ the Semantically-guided Representation Learning (SG-RL) module for a soft-assignment towards all current task classes, and use the Semantically-guided Knowledge Distillation (SG-KD) module for enhanced knowledge transfer. Experimental results demonstrate the superiority of our method on general and fine-grained datasets. Our code can be found in https://github.com/aprilsveryown/semantically-guided-continual-learning.
Index Terms -Continual Learning, Vision-Language Models, Knowledge Transfer
✦
## 1 INTRODUCTION
A Large variety of algorithms were proposed to mitigate forgetting in continual learning, employing approaches such as rehearsal-based methods [1], [2], [3], [4], regularization-based techniques [5], [6], [7], and architecture-based solutions [8], [9], [10], [11], [12]. The emergence of Vision Transformers (ViTs) [13] has substantially enhanced the representation capabilities of pre-trained vision encoders for downstream tasks. A number of recent studies, including L2P [14] and DualPrompt [15], have leveraged the potential of pre-trained vision encoders in the context of continual learning, employing a prompt-based learning strategy. However, these works have exposed a notable limitation: performance degradation occurs when the pre-trained dataset exhibits a substantial semantic gap compared to the downstream data [16], [17].
Large scale pre-trained vision-language models, for instance ViT-BERT [18], CLIP [19] and UNITER [20], have emerged as powerful tools that combine computer vision and natural language processing, enabling machines to comprehend visual and textual information. These models can serve as strong foundation models for continual learning,
- · Lu Yu and Zhe Tao are with School of Computer Science and Engineering, Tianjin University of Technology, 300384, China (e-mail: [email protected], [email protected]).
- · Hantao Yao is with State Key Laboratory of Multimodal Artificial Intelligence Systems, Institute of Automation, Chinese Academy of Sciences, Beijing, 100190, China (e-mail: [email protected]).
- · J. van de Weijer is with the Computer Vision Center, Universitat Autonoma de Barcelona, Barcelona 08193, Spain. (e-mail: [email protected]).
- · Changsheng Xu is the corresponding author, with State Key Laboratory of Multimodal Artificial Intelligence Systems, Institute of Automation, Chinese Academy of Sciences, Beijing, 100190, China, and also with the School of Artificial Intelligence, University of the Chinese Academy of Sciences, Beijing, 100049, China (e-mail: [email protected]).
Manuscript received April 19, 2005; revised August 26, 2015.
as they were trained on massive datasets, allowing them to learn intricate patterns and relationships between images and language. As mentioned, the continual learning community has focused on applying foundational vision backbones [14], [15], [21], however, less effort has been invested in how to best exploit the rich semantic knowledge contained in the language encoders. A recent exception is Continual-CLIP [22] which shows impressive results in continual learning using both the vision and language encoder of the CLIP model. However, they keep the CLIP model frozen, thereby limiting the generalization to new tasks. In Fig. 1(a), we present an overview of several methods, each characterized by a distinct training strategy. The performance evaluations are shown in Fig. 1(b). The use of pre-trained vision encoders has resulted in incremental performance gains 1 . Interestingly, we will show that better exploitation of the knowledge contained in language encoders can lead to considerable performance improvements.
Establishing similarity between objects is a fundamental aspect of human perception and cognition, as highlighted by previous research [24]. pre-trained language models provide access to the semantic similarity between classes. In this paper, we propose two techniques to exploit the rich semantic information of pre-trained language models. Firstly, we exploit the intra-task semantic relationships between class labels. Instead of only using the available ground truth label to train on the newly arriving data, we replace the label with a soft-assignment towards all current task classes based on intra-task semantic relations. This ensures that each sample contributes to aligning the vision backbone with respect to
1. The methods L2P and DualPrompt obtain similar results without using any exemplars compared to existing state-of-the-art CL methods from scratch with exemplars (DER, DyTox++).
JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, AUGUST 2015
| Method | Language | Vision | Trainable |
|----------------------------------------------------------------------------------|---------------------------------------------|-----------------------------------------------------------------------------|----------------------------|
| DER [11] DyTox++ [9] L2P [14] DualPrompt [15] Continual-CLIP [22] CoOp [23] Ours | x x x x pre-trained pre-trained pre-trained | scratch scratch pre-trained pre-trained pre-trained pre-trained pre-trained | yes yes yes yes no yes yes |
Fig. 1: (a) Comparison of different models. (b) Performance comparison using different models across two datasets.
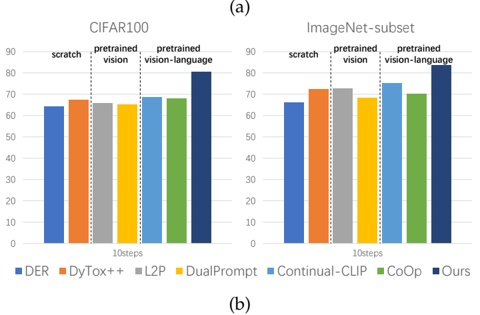
multiple semantic classes. Secondly, we propose to exploit the inter-task semantic relationships between old and new classes to improve stability during continual learning. For example, current class data for 'motor bikes' is expected to assign part of its prediction to the related previous task class of 'bikes' thereby preventing forgetting of previous classes. These inter-task relationships, derived from the language encoder, are used in a semantically-guided knowledge distillation technique.
To summarize, the main contributions of the paper are:
- · The usage of pre-trained models in continual learning has focused on pre-trained vision encoders. We show that exploiting the semantic information of the data labels with pre-trained language encoders can greatly enhance the accuracy of continual learning.
- · We extend the existing image distillation method based only on visual information with a term that exploits the knowledge of the labels of the current data with respect to the classes of previous tasks (inter-task semantic similarity). This improvement, called SG-KD , is shown to significantly increase the efficiency of distillation (and reduce catastrophic forgetting). In addition, we show how to exploit the intra-task semantic similarity (called SG-RL ).
- · Extensive experimental results show that our approach surpasses all methods by a substantial margin on several datasets under both many-shot and fewshot settings. Results on CIFAR100 under the 10-step setting show that the proposed method can greatly improve the accuracy after the last task with 11.4 points compared to the state-of-the-art.
## 2 RELATED WORK
## 2.1 Continual Learning
Continual learning research has witnessed significant advancements in recent years, resulting in the development of three main categories of approaches: rehearsal-based, regularization-based, and architecture-based. Rehearsalbased methods store previous task exemplars or generate fake exemplars using generative models to combat catastrophic forgetting. iCaRL [3] combines exemplar rehearsal with knowledge distillation, UCIR [2] addresses classification bias through normalization, and WA [4] ensures consistency in weight vector norms between old and new classes. Regularization-based methods impose constraints on network parameters, with strategies such as estimating parameter importance (EWC [5]) and distilling output from old and new models (LwF [6]) to retain information about previous tasks. SDC [25] proposed compensating the feature drift to prevent forgetting on some regularization-based continual learning methods. Architecture-based methods assign specified parameters to tasks or dynamically expand the network architecture. HAT [10] blocks and activates specific parts for old tasks, while DER [11] utilizes task-specific feature extractors and tackles parameter growth through pruning. Transformer-based continual learning paradigms, like DyTox [9], utilize shared self-attention layers and taskspecific tokens to achieve task-specialized embeddings. [26] proposed to apply Masked Autoencoders (MAEs) for continual learning and introduced a bilateral MAE framework that integrates learning from both image-level and embedding-level. [21] proposed to adaptively assign distillation loss weights by evaluating the relevance of each patch to the current task.
## 2.2 Continual Learning with Foundation Models
A recent emerging trend in the field of continual learning is to combine pre-trained vision transformers with parameterefficient fine-tuning techniques to continuously adapt the model to a stream of incoming downstream tasks. Specifically, these techniques involve prompt tuning [27], [28], prefix tuning [29], Adapter [30], [31], LoRA [32] , etc. The core of applying such a technique to continual learning is to construct additional learnable parameters or modules to instruct pre-trained representations and select appropriate prompts during inference time. L2P [14] optimizes the cosine similarity between query features and learnable keys, the most relevant prompts are selected and prepended to the token sequence both during training and inference. DualPrompt [15] further subdividing the prompts into general prompts sharing across all tasks and expert prompts picked and optimized in the same way as [14]. CODAPrompt [33] proposes to reweight prompts through input-conditioned weights, facilitating end-to-end optimization of the querykey mechanism across tasks. Distinct from the aforementioned prompt-based approaches, another line of work aims to construct classifiers through the extraction of robust feature representations via pretrained models. SLCA [17] finetuned the full pretrained model and recommended using different learning rates for the representation layers and the classifier to address the forgetting problem in representation
layers, they further incorporated prototype replay for posthoc alignment of the classification layers to reduce bias in the classifier. RanPAC [34] suggested employing a frozen random projection layer to project pretrained features into a high-dimensional space, thereby improving linear separability, they additionally utilize an online LDA classifier to eliminate correlations between categories. EASE [35] proposed to employ distinct adapters for each task to acquire task-specific features, and construct a unified classifier by synthesizing prototypes for old classes through semantic relevance.
## 2.3 Pre-trained Vision-Language Model
Large-scale vision-language pre-trained models like CLIP [19] and ALIGN [36] have emerged as powerful tools for representation learning due to their high transferability. Numerous studies [23], [37], [38] have focused on adapting these models to downstream tasks. For instance, CoOp [23] proposed vectorizing prompts, keeping the CLIP model fixed while optimizing only the prompt vectors. However, it was observed in [38] that prompts learned using this method exhibited poor generalization performance on unseen classes. To address this limitation, they introduced a meta-net to generate an input-conditional token for each image. Some works attempt to simultaneously optimize visual and textual prompts to improve the adaptability of vision-language models for downstream tasks. MaPLe [39] proposed to promote strong coupling between prompts of two different modalities to improve the consistency between visual and linguistic representations. PromptSRC [40] designed a regularization framework when training models on downstream tasks to prevent overfitting, which enhances the generalization capacity of the model. Differing from prompt-based approaches, some works try to incorporate adapters with MLPs into the transformer architecture to capture task-specific information. CLIPadapter [41] introduced extra bottleneck layers for learning new features. While these approaches have demonstrated significant improvements on various tasks compared to the adapted results provided by CLIP [19], they all shared the common limitation of freezing all the pre-trained parameters.
## 3 PRELIMINARY OF CLIP MODEL
Here we explain the details of the CLIP model. Let I denote the set of normalized image features encoded by the image encoder, and T denote the set of corresponding normalized text features. Assume that we have N samples, the logits for each image-text pair are computed as follows:
$$P _ { i, j } = \beta \cdot I _ { i } \cdot T _ { j } ^ { \top }, \quad \quad \ ( 1 ) \ \text{Affe}$$
where β is a learned scalar, P i,j is the cosine similarity score between the i th image and the j th text, and i ∈ { 1 , . . . , N } and j ∈ { 1 , . . . , N } are indices for the images and texts, re- spectively. Then the loss for each modality can be expressed as:
$$L _ { i m a g e } = - \frac { 1 } { N } \sum _ { \underset { \mathcal { S } } { i = 1 } } ^ { N } \log \left ( \frac { \exp ( P _ { i, i } ) } { \sum _ { j = 1 } ^ { N } \exp ( P _ { i, j } ) } \right ), \quad ( 2 )$$
$$L _ { t e x t } = - \frac { 1 } { N } \sum _ { j = 1 } ^ { N } \log \left ( \frac { \xi \exp ( P _ { j, j } ) } { \sum _ { i = 1 } ^ { N } \exp ( P _ { i, j } ) } \right ) \quad ( 3 )$$
The overall loss of the CLIP model is the sum of the image loss L image and text loss L text , which are averaged over the the number of samples. It can be represented as:
$$L _ { c } = \frac { 1 } { 2 } ( L _ { i m a g e } + L _ { t e x t } )$$
The loss function is minimized during pre-training to learn the joint representations of images and texts where semantically similar pairs are closer together and dissimilar pairs are farther apart.
The CLIP model has demonstrated remarkable continual learning performance without any fine-tuning [22]. To enhance its performance on new tasks and adapt to evolving data distributions over time, we thus propose to fine-tune the last block of the vision encoder. 2 We aim to leverage the strong generalization ability of the CLIP model while also updating its representation to better adapt to incoming data.
## 4 METHOD
To overcome the challenges of catastrophic forgetting during the training of pre-trained models, we introduce a novel approach that integrates semantic information guidance into the process of continual knowledge learning, as shown in Fig. 2. Leveraging the power of well-trained text embeddings, our proposed approach facilitates efficient interaction within and across task labels, leading to improved performance from two crucial perspectives. Firstly, we focus on learning more informative representations for new data by leveraging intra-task semantic similarity, thereby enhancing model plasticity ( SG-RL module). Secondly, we establish a relationship between old and new tasks by incorporating inter-task semantic similarity during the model distillation process, ensuring stability ( SG-KD module). In the following sections, we introduce these two components and explain how they work.
## 4.1 Intra-task Semantically-Guided Representation Learning (SG-RL)
As shown in the yellow part of Fig. 2, assume we have K classes contained in the current task t , their labels can be denoted as C t = { c t 1 , c t 2 , · · · , c t K } (for simplicity, we omit the superscript t in the following descriptions). We encode the text embeddings of these labels by the pre-trained language part of CLIP to obtain the normalized text embeddings T t = { T , T 1 2 , · · · , T K } , where || T k || = 1 and k ∈ { 1 2 , , · · · , K } . After obtaining the text embeddings of the current labels, we acquire the intra-task semantic similarity by computing
2. We fine-tune different parts of the vision encoder in Table 7. Our experiments indicate that fine-tuning the last block of the encoder results in the best performance.
Fig. 2: An overview of the proposed framework. We update the image encoder part of the CLIP model and train it with contrastive loss. We integrate semantic information into two modules: The SG-RL module, represented by the yellow block of the framework, aims to learn more discriminative representation to improve the model plasticity based on the intra-task semantic similarity. We train the model with KL-divergence loss between the generated semantically-guided labels and the original predictions. The SG-KD module, represented by the pink block of the framework, exploits the semantic similarity between current and previous task labels for knowledge distillation, to consolidate the model stability.
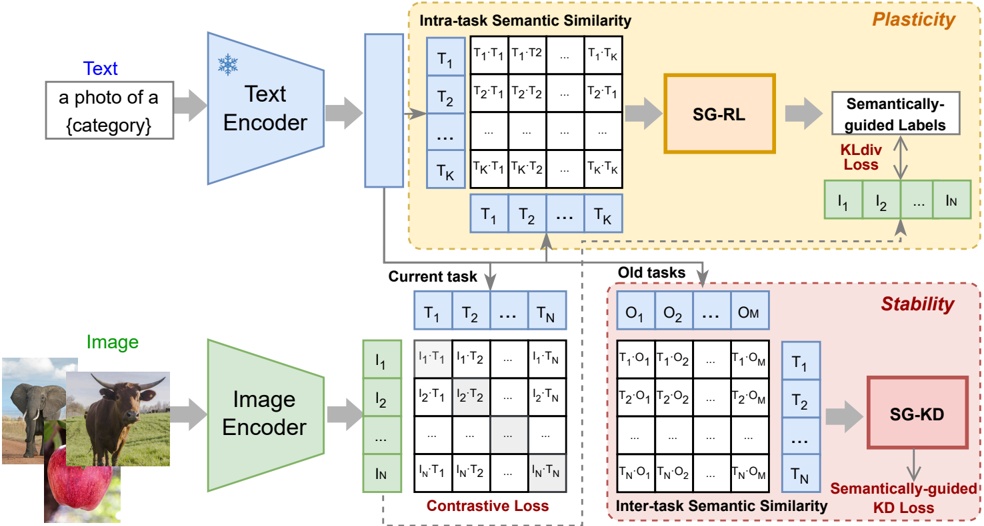
the cosine similarity between each pair of text embeddings. This yields a text similarity matrix S t ↔ t which represents the intra-task similarity between the i -th and j -th labels; it can be described as follows:
where the logits P t = [ P t i,j ] N × K of N images in current task is computed by Eq. 1, and the prediction score ˆ y i,j = log exp( P t i,j ) ∑ K k =1 exp( P t i,k ) is after applying the log-softmax.
$$S _ { i, j } ^ { t \leftrightarrow t } = [ T _ { i } ^ { \top } T _ { j } ] _ { K \times K }, ( i, j \in \{ 1, 2, \cdots, K \} ), \quad ( 5 ) \quad \text{in Fig.}$$
This similarity score contains the pairwise similarity within each category within the current task.
To further convert the one-hot labels to our informative semantically-guided labels C sg = [ C sg i,j ] K × K , we compute the softmax function over each column of S t ↔ t with a parameter α which controls the degree of softness of the generated labels as follows:
$$C _ { i, j } ^ { s g } = \frac { \exp ( \alpha \cdot S _ { i, j } ^ { t \leftrightarrow t } ) } { \sum _ { k = 1 } ^ { K } \exp ( \alpha \cdot S _ { i, k } ^ { t \leftrightarrow t } ) } \quad \quad ( 6 ) \quad \text{tion} \quad \text{$4.2$}$$
The semantically-guided labels C sg encode the relationships and similarities between categories, allowing for a more comprehensive representation of class associations within the current task.
We then compute the KL-divergence loss L SG -RL between ˆ y i,j and the semantically-guided labels C sg i,j :
$$\mathcal { L } _ { S G - R L } = D _ { K L } ( \hat { y } | | C ^ { s g } ) = \sum _ { i = 1 } ^ { N } \sum _ { j = 1 } ^ { K } \hat { y } _ { i, j } \cdot \log \frac { \hat { y } _ { i, j } } { C ^ { s g } _ { i, j } }, \quad ( 7 ) \quad \text{are den}$$
The detailed illustration of the SG-RL model is shown in Fig. 3a. We propose to exploit the semantic knowledge of the pre-trained text-encoder by means of the intra-task semantic similarity between class labels (see Eq. 5). We replace the one-hot ground truth label in the cross entropy with a soft-assignment towards all current task classes. As a consequence, each sample contributes to aligning the vision backbone with respect to multiple semantic classes, leading to higher plasticity.
## 4.2 Inter-task Semantically-Guided Knowledge Distillation (SG-KD)
In this section, we aim to exploit the semantic knowledge of the pre-trained text-encoder to prevent forgetting and improve stability of the continual learner. Our main insight is that the semantic similarity between current and previous task labels can be exploited to prevent forgetting. For example, the current task label 'truck' can be used to prevent forgetting of previous related class labels like 'bus'. As shown Fig. 3b, given an image x i of the current task, the image features encoded by the previous image encoder are denoted as I t -1 i , and the corresponding normalized text embeddings of old-class labels y t -1 can be encoded by the
(a) Illustration of SG-RL module.
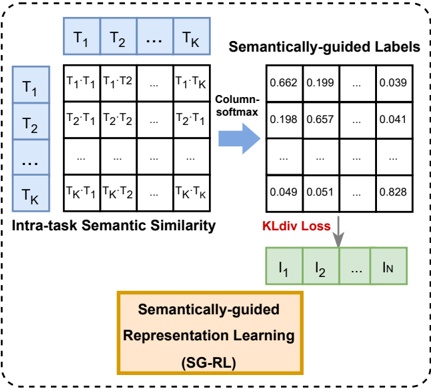
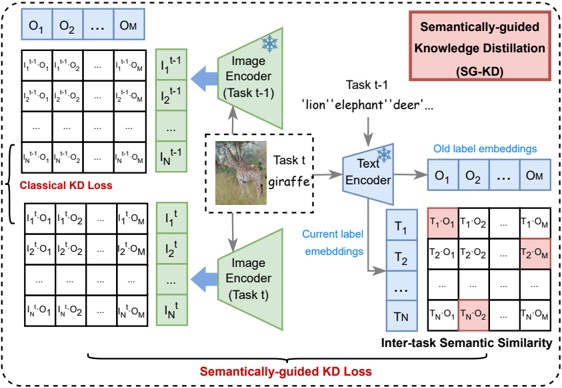
(b) Illustration of SG-KD module.
Fig. 3: An illustration of two components. (a) The SG-RL module calculates the text embedding similarity between the current labels using a pre-trained text encoder. It then generates semantically-guided labels that are more informative. (b) The SG-KD module constructs an inter-task similarity matrix based on text embeddings of previous and current task class labels. The most similar categories of the current class from old classes are selected by computing row-wise maximums (pink cells). The similarity value is added to the previous model's prediction logits at the most similar position, and the rest are subtracted from in each row. The enhanced logits are used for knowledge distillation between the current and previous models.
pre-trained text encoder as O j . Thus, the prediction logits P t -1 = [ P t -1 i,j ] N × M (the number of old classes is M ) of current data on the previous image encoder is computed as:
$$P _ { i, j } ^ { t - 1 } = \beta \cdot I _ { i } ^ { t - 1 } \cdot O _ { j } ^ { \top }, ( i \in 1, 2, \dots, N, j \in 1, 2, \dots, M ) \ ( 8 ) \ \text{adstillat}$$
The prediction logits of the current image encoder on oldclass heads P t = [ P t i,j ] N × M are:
where y t c i refers to the image label of image x i . The first term on the right-hand site is the same as in Eq. 11. The second term provides us the distillation between s y ( t -1 | y t c i ) and the current predictions. µ is the tradeoff between these two distillation losses. We derive s y ( t -1 | y t c i ) from the inter-task semantic similarity S t - ↔ 1 t between the text embeddings of current task labels 3 T and the old task labels O as follows:
$$P _ { i, j } ^ { t } = \beta \cdot I _ { i } ^ { t } \cdot O _ { j } ^ { \top },$$
which can be used to compute a prediction over the labels:
$$p ^ { t } ( y _ { j } ^ { t - 1 } | x _ { i } ) = \frac { \exp ( P _ { i, j } ^ { t } ) } { \sum _ { j } \exp ( P _ { i, j } ^ { t } ) } \quad \quad ( 1 0 ) \quad \text{class} \quad \text{the s} \quad \text{$\quad$}$$
and similarly for p t -1 ( y t -1 j | x i ) ; the difference is that this probability is based on the model at time t -1 . Traditional knowledge distillation [3], [6] between the old and current model can be described as follows:
$$\mathcal { L } _ { K D } = D _ { K L } ( p ^ { t } ( y ^ { t - 1 } | x _ { i } ), p ^ { t - 1 } ( y ^ { t - 1 } | x _ { i } ) ). \quad ( 1 1 )$$
Our contribution is that we aim to improve this distillation by also including the knowledge of the current sample labels about the previously seen classe in the distillation. Therefore, we use the semantic relationship between the current categories y t and the previous categories y t -1 , without requiring access to any visual information. We introduce Semantically-guided Knowledge Distillation (SG-KD); the loss for an image x i is given by:
$$\mathcal { L } _ { S G - K D } = & \ D _ { K L } ( p ^ { t } ( y ^ { t - 1 } | x _ { i } ), p ^ { t - 1 } ( y ^ { t - 1 } | x _ { i } ) ) \quad \text{where} \\ & + \mu D _ { K L } ( p ^ { t } ( y ^ { t - 1 } | x _ { i } ), s ( y ^ { t - 1 } | y ^ { t } _ { c _ { i } } ) ) \quad \text{(12)} \quad \text{$\text{used}$}$$
$$S _ { i, j } ^ { t - 1 \leftrightarrow t } = T _ { i } \cdot O _ { j } ^ { \top }$$
Here S t - ↔ 1 t i,j provides a measure of similarity between classes from different tasks. This allows the model to capture the semantic relationships between tasks and leverage this information for knowledge transfer. Thus, s y ( t -1 | y t c ) can be computed as:
$$s ( y _ { j } ^ { t - 1 } | y _ { c _ { i } } ^ { t } ) = \frac { \exp ( S _ { i, j } ^ { t - 1 \leftrightarrow t } / \tau ) } { \sum _ { j } \exp ( S _ { i, j } ^ { t - 1 \leftrightarrow t } / \tau ) } \quad \quad ( 1 4 )$$
τ is a hyper-parameter representing the temperature in the softmax function.
The final objective function can be described as follows:
$$\mathcal { L } = \mathcal { L } _ { c } + \lambda _ { 1 } \mathcal { L } _ { S G - R L } + \lambda _ { 2 } \mathcal { L } _ { S G - K D }, \quad \ \ ( 1 5 )$$
where λ 1 and λ 2 are trade-offs between the contrastive loss L c , KL-divergence loss L SG -RL and the semanticallyguided distillation loss L SG -KD .
TABLE 1: Details of all datasets used in this paper.
| Datasets | #Classes | Train size | Test size |
|-------------------------|------------|--------------|-------------|
| CIFAR100 [42] | 100 | 50000 | 10000 |
| imagenet subset [43] | 100 | 129395 | 5000 |
| miniImageNet [43] | 100 | 50000 | 10000 |
| ImageNet1000 [43] | 1000 | 1281167 | 50000 |
| Food-101 [44] | 101 | 75750 | 25250 |
| Stanford Cars [45] | 196 | 8144 | 8041 |
| FGVC Aircraft [46] | 100 | 6667 | 3333 |
| Oxford-IIIT pets | 37 | 3680 | 3669 |
| Caltech-101 [47] | 102 | 3060 | 6085 |
| Oxford Flowers 102 [48] | 102 | 2040 | 6149 |
| CUB-200-2011 [49] | 200 | 5994 | 5794 |
| Stanford Dogs [50] | 120 | 12061 | 8519 |
## 5 EXPERIMENTS
## 5.1 Experimental Settings
## 5.1.1 Dataset and task spilt.
Our experimental evaluation begins by conducting experiments on three datasets that are commonly used for continual learning scenarios: CIFAR100 [42], imagenet subset, and ImageNet1000 [43]. For CIFAR100, we adopt the incremental phase splitting into 10, 20, and 50 steps, following the approach of DyTox [9]. In each split, we further assess the performance of the proposed method under three different class orders. Regarding imagenet subset and ImageNet1000, we split the incremental phase into 10 steps, with 10/100 new classes added at each incremental step. We further evaluate the performance on eight fine-grained datasets. We also evaluate for few-shot continual learning on miniImagenet, and CUB-200-2011 following [52], [53]. For miniImagenet, we split the 100 classes into 60 base classes and 40 classes across 8 sessions with 5 new classes per session. CUB-200-2011 is divided into 100 base classes and 100 classes across 10 sessions with 10 new classes per session. Each incremental session for all three datasets consists of 5 training samples per new class.
The dataset splits follow two patterns: in the A + B × C split, A represents the number of classes in the initial task, C indicates the total number of steps, and B signifies the number of new classes added at each incremental stage; for the A × B split, A new classes are introduced in each of the B incremental steps. Note that we handle the OxfordIIIT pets dataset separately due to its 12 cat categories and 25 dog categories, splitting it into two stages: one for cats and another for dogs. The details of all datasets are listed in Table 1.
## 5.1.2 Implementation details.
All experiments were conducted with a vision backbone of ViT-B/16 version CLIP model. We train every task for 10 epochs except for CUB and Aircrafts with 20 epochs. We adopt SGD in all experiments as the optimizer with an initial learning rate of 0.01(0.001 for few-shot setting), weight decay is 2e-4 and 0.9 for momentum. Batch size is 256 for all experiments. We set α to 13 in Eq. 6, β is set to 100 in Eq. 4.2 following [22] and τ to 0.1 in Eq. 14 for all datasets. The trade-off parameters, λ 1 and λ 2 , are set to 0.5 and 0.1 across
3. The text embeddings of exemplar labels are integrated into T i , when applicable.
all datasets (the hyper-parameters sensitive experiments can be found in Section 5.4.5 ). We save 20 exemplars for each old class by herding algorithm in all experiments except the ablation on different exemplar sizes (in Section 5.4.4), following the setting in [3], [9], [11]. Under the few-shot setting, none exemplar is saved following the setting in [52], [53]. To ensure fairness, methods trained with a pre-trained model are initialized with CLIP . For implementing 'Linear 4 Probe', we directly add a fully connected layer after the linear projection, we train 100 epochs for each dataset with an initial learning rate of 0.1 and decays by 0.1 every 45 epochs. For 'Joint', to ensure fairness in comparison, we fine-tune the last block of the network for joint training, all training samples are acquired concurrently in the same session. We train 100 epochs for each dataset with an initial learning rate of 0.01 and decays by 0.1 every 45 epochs.
For all experiments in the paper, we applied RandomResizedCrop, RandomHorizontalFlip and normalization for data augmentation. The random seed was set to 1993 except when spliting CIFAR100 with three different class orders as shown in Table 2. We use randomly generated integers ranging from 1 to 5000 for the other two class orders.
Test-time evaluation details: For each test sample x test , the image is passed through the image encoder, resulting in its image feature I test . Meanwhile, we collect all previously seen categories as prompts and feed them to the text encoder to obtain the text features T = { T i ; 1 ≤ i ≤ k } , where k is the number of seen classes. Then we compute the cosine similarity between image feature and text features:
$$s _ { i } = \frac { I _ { t e s t } \cdot T _ { i } } { \| I _ { t e s t } \, \| \cdot \| \, T _ { i } \| }$$
where 1 ≤ i ≤ k , the prediction score for x test can then be computed as:
$$p = \frac { \exp ( s _ { i } ) } { \sum _ { i = 1 } ^ { k } \exp ( s _ { i } ) }$$
The class with the highest predicted score is considered as the predication.
## 5.2 Full-shot Continual Learning Setting
## 5.2.1 Evaluation on general datasets.
We conducted extensive experiments on three benchmark datasets, namely CIFAR100, imagenet subset, and ImageNet1000 in comparison to state-of-the-art approaches. In Table 2, we present the averaged accuracy on CIFAR100 over three different class orders and three different splits. In the most common 10-step split, our method achieves an impressive accuracy of 80.1 after the last incremental step, surpassing the previous state-of-the-art method by 11.4 points. Even for longer task sequences of 20 or 50 steps, our method consistently maintains superior performance, with at least 9.5 and 5.4 points higher accuracy than the state-ofthe-art 'Last' result respectively. Moving to larger-scale continual learning scenarios, as shown in Table 3, our method demonstrates even greater superiority. On imagenet subset
4. Since the exact prompt and specific class names employed by CLIP [19] for each dataset are unknown. We tried several prompts and finally for each dataset we utilize a specific prompt so that the results of our own implementation are comparable or identical to those provided by CLIP [19].
TABLE 2: The results on CIFAR100 are averaged over three class orders (seeds) under 10, 20, and 50 steps, following the setting proposed in [9]. The bold parts represent the best results, underlined parts indicate the second best, and up arrows show the improvement of the best over the second best. Re-implemented results are marked with an asterisk (*) .
| CIFAR100 | 10 steps | 10 steps | 10 steps | 20 steps | 20 steps | 20 steps | 50 steps | 50 steps | 50 steps |
|---------------------|------------|---------------|----------------|------------|---------------|---------------|------------|---------------|---------------|
| Methods | #Param. | Avg | Last | #Param. | Avg | Last | #Param. | Avg | Last |
| Linear probe | - | - | 83.1 | - | - | 83.1 | - | - | 83.1 |
| Joint | 7.09 | - | 83.9 | 7.09 | - | 83.9 | 7.09 | - | 83.9 |
| UCIR [2] | 11.22 | 58.7 | 43.4 | 11.22 | 58.2 | 40.6 | 11.22 | 56.9 | 37.1 |
| BiC [51] | 11.22 | 68.8 | 53.5 | 11.22 | 66.5 | 47.0 | 11.22 | 62.1 | 41.0 |
| WA [4] | 11.22 | 69.5 | 53.8 | 11.22 | 67.3 | 47.3 | 11.22 | 64.3 | 42.1 |
| PODNet [8] | 11.22 | 58.0 | 41.1 | 11.22 | 54.0 | 35.0 | 11.22 | 51.2 | 33.0 |
| DER w/o p [11] | 112.27 | 75.4 | 65.2 | 224.55 | 74.1 | 62.5 | 561.39 | 72.4 | 59.1 |
| DER [11] | - | 74.6 | 64.4 | - | 74.0 | 62.6 | - | 72.1 | 59.8 |
| DyTox++ [9] | 10.73 | 77.0 | 67.5 | 10.74 | 76.8 | 64.3 | 10.77 | 75.5 | 59.5 |
| Continual-CLIP [22] | - | - | 68.7 | - | - | 68.7 | - | - | 68.7 |
| CoOp ∗ [23] | 7.91 | 76.2 | 68.1 | 7.91 | 77.0 | 67.6 | 7.91 | 78.3 | 66.3 |
| CoCoOp ∗ [38] | 7.13 | 75.1 | 65.9 | 7.13 | 75.1 | 63.1 | 7.13 | 74.8 | 61.1 |
| L2P ∗ [14] | 7.38 | 76.3 | 65.9 | 7.38 | 75.2 | 66.2 | 7.38 | 76.5 | 64.6 |
| DualPrompt ∗ [15] | 7.42 | 71.3 | 65.1 | 7.42 | 66.2 | 65.4 | 7.42 | 70.1 | 66.6 |
| Ours | 7.09 | 86.6 ( ↑ 9.6) | 80.1 ( ↑ 11.4) | 7.09 | 86.0 ( ↑ 9.0) | 78.2 ( ↑ 9.5) | 7.09 | 81.8 ( ↑ 3.5) | 74.1 ( ↑ 5.4) |
TABLE 3: We compare the results obtained on the imagenet subset dataset (100 classes) and the ImageNet full dataset (1000 classes), where the training session is split into 10 steps, with each step containing an equal number of classes for each task.
| | imagenet subset 10 steps | imagenet subset 10 steps | imagenet subset 10 steps | imagenet subset 10 steps | imagenet subset 10 steps | ImageNet1000 10 steps | ImageNet1000 10 steps | ImageNet1000 10 steps | ImageNet1000 10 steps | ImageNet1000 10 steps |
|---------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|-------------------------|-------------------------|-------------------------|-------------------------|-------------------------|
| Methods | #Param. | top-1 | top-1 | top-5 | top-5 | #Param. | top-1 | top-1 | top-5 | top-5 |
| | #Param. | Avg | Last | Avg | Last | #Param. | Avg | Last | Avg | Last |
| Linear probe | - | - | 83.9 | - | 97.6 | - | - | 80.2 | - | 94.1 |
| Joint | 7.09 | - | 86.1 | - | 98.3 | 7.09 | - | 81.1 | - | 96.5 |
| DER w/o p [11] | 112.27 | 77.2 | 66.7 | 93.2 | 87.5 | 116.89 | 68.8 | 60.2 | 88.2 | 82.9 |
| DER [11] | - | 76.1 | 66.1 | 92.8 | 88.4 | - | 66.7 | 58.6 | 87.1 | 81.9 |
| DyTox++ [9] | 11.01 | 80.8 | 72.5 | 94.4 | 90.1 | - | - | - | - | - |
| Continual-CLIP [22] | - | - | 75.2 | - | 96.9 | - | - | 68.6 | - | 90.6 |
| CoOp ∗ [23] | 7.91 | 80.9 | 70.2 | 97.5 | 94.5 | 15.28 | 75.2 | 66.7 | 95.9 | 91.9 |
| CoCoOp ∗ [38] | 7.13 | 81.8 | 71.0 | 98.5 | 96.1 | 7.13 | 64.6 | 56.0 | 92.3 | 88.7 |
| L2P ∗ [14] | 7.38 | 82.2 | 72.7 | 98.5 | 96.4 | 8.07 | 71.9 | 63.3 | 95.0 | 90.4 |
| DualPrompt ∗ [15] | 7.42 | 79.6 | 68.4 | 97.7 | 95.0 | 8.11 | 70.7 | 64.0 | 94.4 | 92.1 |
| Ours | 7.09 | 89.8 ( ↑ 7.6) | 83.1 ( ↑ 7.9) | 99.1 ( ↑ 0.6) | 98.4 ( ↑ 1.5) | 7.09 | 83.4 ( ↑ 8.2) | 75.1 ( ↑ 6.5) | 97.4 ( ↑ 1.5) | 95.2 ( ↑ 3.1) |
TABLE 4: Results on eight fine-grained datasets with different task splits.
| Dataset | Food | Cars | Aircraft | Pets | Caltech | Flowers | CUB | Dogs |
|---------------------|----------------|---------------|---------------|----------|---------------|------------|---------------|---------------|
| #classes split | 101 11+ 9 × 10 | 196 28 × 7 | 100 10 × 10 | 37 12+25 | 102 17 × 6 | 102 17 × 6 | 200 20 × 10 | 120 12 × 10 |
| Linear probe Joint | 92.8 93.1 | 86.7 | 59.5 | 93.1 | 94.7 | 98.1 | 80.4 ∗ | 78.6 ∗ |
| | | 91.5 | 73.2 | 94.7 | 93.8 | 98.1 | 85.0 | 80.6 |
| Continual-CLIP [22] | 89.2 | 65.6 | 27.1 | 88.9 | 89.3 | 70.4 | 55.6 ∗ | 63.4 ∗ |
| CoOp ∗ [23] | 84.6 | 86.1 | 57.6 | 94.0 | 90.2 | 97.0 | 80.1 | 75.8 |
| CoCoOp ∗ [38] | 79.1 | 84.9 | 59.8 | 92.8 | 88.2 | 97.2 | 77.0 | 69.7 |
| L2P ∗ [14] | 81.7 | 86.9 | 61.1 | 92.8 | 88.6 | 97.0 | 82.6 | 75.9 |
| DualPrompt ∗ [15] | 80.5 | 82.7 | 45.5 | 90.6 | 86.4 | 96.7 | 79.6 | 70.3 |
| Ours | 90.9 ( ↑ 1.7) | 88.6 ( ↑ 2.5) | 66.6 ( ↑ 5.5) | 94.0 | 92.3 ( ↑ 2.1) | 96.2 | 83.7 ( ↑ 1.1) | 79.6 ( ↑ 3.7) |
dataset, we outperform the state-of-the-art result by 7.9 points in terms of top-1 'Last' accuracy, approaching the performance of linear probing [19]. Furthermore, on the challenging ImageNet1000 dataset, our method achieved significant improvements with a 6.5-point increase in top1 'Last' accuracy and a 3.1-point increase in top-5 accuracy. Overall, our experimental results demonstrate that the proposed method consistently outperforms state-of-the-art approaches on all three datasets, showcasing its superior performance and stability in continual learning settings.
## 5.2.2 Evaluation on fine-grained datasets.
To further validate the effectiveness of the proposed method, we conduct experiments on eight fine-grained datasets. In fine-grained datasets, all categories belong to the same parent category in a hierarchical relationship, which intuitively indicates a high degree of semantic similarity among them, which is more challenging. In Table 4, we present the performance of our proposed method compared to other methods on different splits of the datasets. We notice that the Continual-CLIP evaluation on datasets like Cars, Aircrafts, and CUB, is initially poor. State-of-the-art methods obtain a substantial improvement, particularly on Aircraft where the gain reaches 34 points with L2P. Our method achieves performance very close to the joint training results, with a gap of less than 1 point on multiple datasets such as Pets and Dogs. Moreover, our method even surpasses the results of linear probing evaluation on multiple datasets, which is typically used to assess the quality of pretrained features.
Fig. 4: The accuracy change during few-shot incremental training sessions on CUB-200-2011 and miniImageNet datasets.
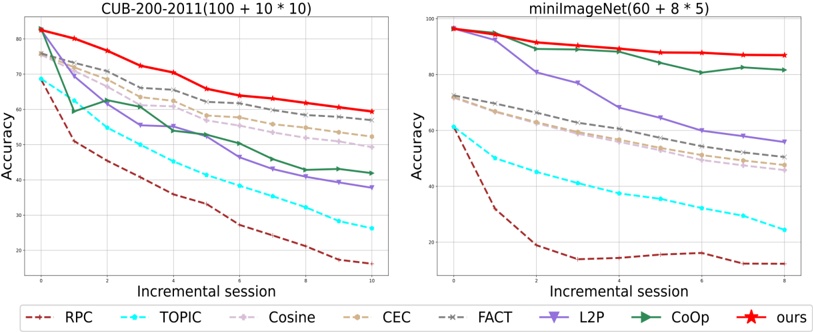
TABLE 5: The effect of different components. 'FT' represents only applying contrastive loss for training, 'One-hot Label' utilizes the prompt of each class as a classification head during training, and uses the one-hot encoded labels to calculate the cross-entropy loss. 'Naive KD' distills the output of the current data between old and new models with the KD loss proposed in [54] (ref Eq. 11).
| | FT | One-hot Label | SG-RL(Eq. 6) | Naive KD(Eq. 11) | SG-KD(Eq. 12) | CIFAR100 10 steps | imagenet subset 10 steps |
|-------------|-----------|-----------------|----------------|--------------------|-----------------|--------------------------|----------------------------|
| C-CLIP [22] | | | | | | 68.7 | 75.2 |
| | ✓ ✓ ✓ ✓ ✓ | ✓ | ✓ ✓ ✓ | ✓ | ✓ | 75.7 71.4 77.0 77.7 80.6 | 81.1 75.2 81.8 82.6 83.1 |
## 5.3 Few-shot Continual Learning Setting
Our proposed method has demonstrated impressive results on several datasets, including coarse and fine-grained datasets. It is interesting to evaluate its effectiveness under the few-shot continual learning setting, which poses a significant challenge. In this setting, the model needs to quickly adapt to new classes with limited labeled data while preserving knowledge of previous tasks. We present dynamic accuracy curves that showcase the incremental training sessions on the CUB-200-2011 and miniImageNet datasets in Fig. 4. The curves highlight the notable performance of our method (shown in red) as it significantly outperforms state-of-the-art approaches with (in solid line) and without (in dashed line) ViT backbone by a substantial margin over all incremental sessions. Particularly on the miniImageNet dataset, our method achieves a final accuracy about 36.5 points higher than FACT and 5.3 points higher than CoOp.
## 5.4 Ablation Study
## 5.4.1 Components of our proposed method
We conduct ablation experiments on CIFAR100 and imagenet subset to thoroughly examine the effect of the different proposed modules. Both datasets were split into 10 steps, and the results are shown in Table 5. On both datasets, the contrastive loss significantly improves the final accuracy compared to Continual-CLIP. However, when we additionally apply the one-hot encoded labels to add an auxiliary classification loss, we observe a significant performance drop. By incorporating our 'SG-RL' module, the model shows a gain of 1.3 points on CIFAR100 and 0.7
TABLE 6: Comparison of different vision models on CIFAR100 and imagenet subset, learned with 10 steps.
| | | CIFAR100 | CIFAR100 | imagenet subset | imagenet subset |
|-----------|-------------|------------|------------|-------------------|-------------------|
| | | Avg | Last | Avg | Last |
| ResNet 50 | C-CLIP [22] | - | 41.6 | - | 65.6 |
| | Ours | 59.8 | 50.7 | 80.2 | 71.3 |
| ViT-B/16 | C-CLIP [22] | - | 68.7 | - | 75.2 |
| | Ours | 86.6 | 80.1 | 89.8 | 83.1 |
| ViT-L/14 | C-CLIP [22] | - | 77.9 | - | 81.5 |
| | Ours | 91.1 | 86.5 | 91.9 | 85.8 |
points on imagenet subset. Furthermore, when we apply knowledge distillation to the loss function, our proposed 'SG-KD' demonstrates superior performance over 'Naive KD' (ref Eq. 11) on both datasets, with a particularly notable gain of 2.9 points on Cifar100.
## 5.4.2 Validation on various vision models
Our primary experiments employed ViT-B/16 as the image encoder. However, it is important to investigate the effectiveness of our method with other architectures as well. Hence, we validate our approach on two additional vision models: ResNet 50 and ViT-L/14. Table 6 presents the comparison between Continual-CLIP (illustrated as 'C-CLIP' for short in the table) evaluation and our proposed method on CIFAR100 and imagenet subset within 10 steps. Despite the differences in architecture and parameter count, all three image encoders exhibit significant improvements compared to Continual-CLIP evaluation. These results suggest that our method is effective across different scales of image encoders, irrespective of architecture.
## TABLE 7: Comparison of training different layers of image encoder.
Fig. 5: The comparison of accuracy when saving different number of exemplars on CIFAR100 and imagenet subset.
| | | Last 6 blocks | Last 3 blocks | Proj. + last block | Proj. | Last block |
|-----------------|---------|-----------------|-----------------|----------------------|-----------|--------------|
| CIFAR100 | FT Ours | 58.4 68.9 | 73.2 79.8 | 75.2 80.1 | 74.6 77.8 | 75.7 80.6 |
| imagenet subset | FT Ours | 58.3 75.6 | 80.2 82.7 | 79.6 81.5 | 79.9 79.7 | 81.1 83.1 |
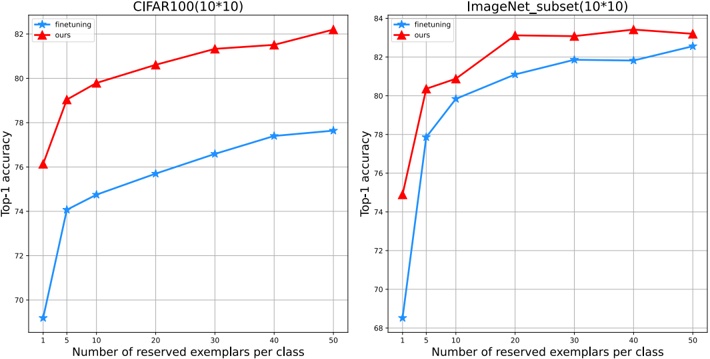
TABLE 8: Ablation study on hyper-parameters sensitivity. ('C' stands for 'CIFAR100' and 'I' stands for 'imagenet subset'.)
## 5.4.5 Hyper-parameters sensitivity
| λ 1 | 0.1 | 0.5 | 1 | 0.1 | 0.5 | 1 | 0.1 | 0.5 | 1 |
|-------|-------|-------|------|-------|-------|------|-------|-------|------|
| λ 2 | 0.1 | 0.1 | 0.1 | 0.5 | 0.5 | 0.5 | 1 | 1 | 1 |
| C | 80 | 80.6 | 80.5 | 79.6 | 79.8 | 79.6 | 78.5 | 78.6 | 78.4 |
| I | 82.7 | 83.1 | 82.5 | 80.7 | 81.2 | 81.1 | 79.7 | 79.6 | 79.5 |
## 5.4.3 Effect of training different layers of image encoder
From Table 7, we observe that when training the last 6 blocks of the image encoder (half of the blocks in ViTB/16), the model fails to overcome catastrophic forgetting. However, significant improvements are achieved when our proposed SG-RL and SG-KD modules are applied. Training only the linear projection layer yields decent results, but it appears that the model's potential is greatly limited with such a small number of parameters. To explore the impact of incorporating more parameters into the training process, we gradually training additional blocks. It is evident that the best performance is achieved when only the last blocks are trained.
## 5.4.4 Comparison of different exemplar sizes
Some previous works [55], [56] have shown that saving a certain number of exemplars for old classes is very useful for defying forgetting. It can be seen from Fig 5, the accuracy exhibits a gradual increase as the number of saved exemplars increases. Our proposed method improves fine-tuning results in all cases. It is worth mentioning that on ImageNet subset, performance of fine-tuning with only one exemplar for each old class drops a lot compared with Continual-CLIP evaluation, While our method still improves compared to Continual-CLIP, and shows a huge gap with fine-tuning.
We conduct sensitivity analysis experiments on the two proposed losses to assess their impact. It can be seen from Table 8, our method shows strong robustness to both hyperparameters ranged from 0.1 to 1. The best results are obtained when λ 1 and λ 2 are set to 0.5, 0.1 respectively.
## 5.5 More Analysis
## 5.5.1 Results with frozen backbone
Given that the methods we compared are all proposed based on frozen backbone while our method proposes to fine-tune the last block of the vision encoder. For a fair comparison, in the above experiment section we fine-tuned the same part of parameters for these methods. Here for a more comprehensive and in-depth comparison, we present the experimental results of these methods in the case of frozen backbone in Table 9. It can be clearly seen that adapting the backbone outperforms the frozen backbone by a large margin in vast majority of cases. It is particularly worth mentioning that on Out-Of-Distribution tasks such as Aircrafts and Cars, most methods show poor performance in the case of frozen backbone, indicating that these methods struggle to adapt to these tasks with only prompt steering pre-trained representations.
## 5.5.2 Comparison with one-hot label
We adopted contrastive loss as the baseline performance for fine-tuning in the main paper, here we investigated the naive cross-entropy loss by one-hot Label. We compute the cross-entropy loss between the predictions of the network on the current classes and the ground-truth, and use the prompt of each class as a classification head. As it can be seen from the Table 10 and Table 11, fine-tuning by only
| Dataset | CIFAR100 | imagenet subset | ImageNet1000 | Food | Cars | Aircraft | Pets | Caltech | Flowers | CUB | Dogs |
|----------------------|-------------|-------------------|----------------|----------------|------------|-------------|-----------|------------|------------|-------------|-------------|
| #classes split | 100 10 × 10 | 100 10 × 10 | 1000 100 × 10 | 101 11+ 9 × 10 | 196 28 × 7 | 100 10 × 10 | 37 12 +25 | 102 17 × 6 | 102 17 × 6 | 200 20 × 10 | 120 12 × 10 |
| Linear probe 5 Joint | 83.1 83.9 | 83.9 86.1 | 80.2 81.1 | 92.8 93.1 | 86.7 91.5 | 59.5 73.2 | 93.1 94.7 | 94.7 93.8 | 98.1 98.1 | 80.4 ∗ 85.0 | 78.6 ∗ 80.6 |
| | 68.7 | 75.2 | 68.6 | 89.2 | 65.6 | | | | | 55.6 ∗ | 63.4 ∗ |
| Continual-CLIP [22] | | | | | | 27.1 | 88.9 | 89.3 | 70.4 | | |
| CoOp [23] | 66.6 | 72.0 | 67.5 | 84.7 | 81.7 | 48.4 | 93.3 | 86.9 | 94.2 | 78.1 | 74.0 |
| CoCoOp [38] | 64.1 | 69.1 | 58.9 | 86.0 | 74.9 | 39.4 | 93.2 | 86.6 | 93.0 | 70.0 | 69.7 |
| L2P [14] | 57.8 | 59.7 | 58.8 | 74.9 | 63.6 | 27.3 | 83.3 | 73.1 | 77.6 | 70.0 | 58.9 |
| DualPrompt [15] | 67.4 | 71.3 | 65.6 | 85.2 | 80.9 | 49.9 | 90.5 | 90.5 | 96.8 | 76.2 | 69.8 |
| Ours | 80.6 | 83.1 | 75.1 | 90.9 | 88.6 | 66.6 | 94.0 | 92.3 | 96.2 | 83.7 | 79.6 |
TABLE 9: Results with frozen backbone on all datasets.
| Dataset | Food | Cars | Aircraft | Pets | Caltech | Flowers | CUB | Dogs |
|--------------------|------------|-----------|------------|-----------|-----------|-----------|-----------|-----------|
| split | 11+ 9 × 10 | 28 × 7 | 10 × 10 | 12+25 | 17 × 6 | 17 × 6 | 20 × 10 | 12 × 10 |
| One-hot Label Ours | 83.9 90.8 | 85.2 88.6 | 52.4 66.6 | 92.2 94.0 | 90.2 92.3 | 92.4 96.2 | 77.4 83.7 | 72.9 79.6 |
TABLE 10: Results compared to one-hot label on eight fine-grained datasets with different task splits.
Fig. 6: T-SNE visualization on test data with Continual-CLIP (left two) and our method (right two).
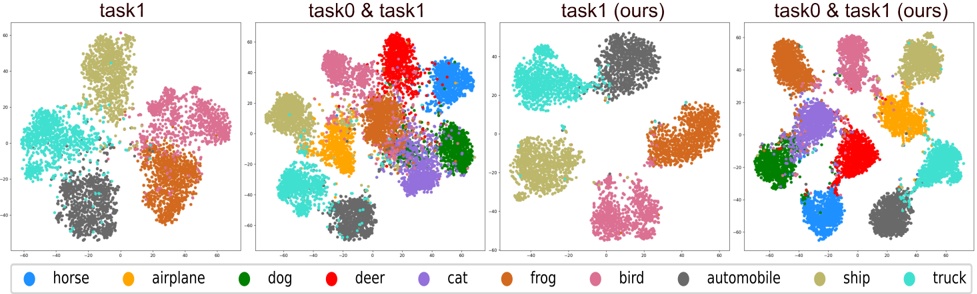
TABLE 11: Results compared to one-hot label on three general datasets with different task splits.
| Dataset | CIFAR100 | imagenet subset | ImageNet1000 |
|--------------------|------------|-------------------|----------------|
| split | 10 × 10 | 10 × 10 | 100 × 10 |
| One-hot Label Ours | 71.2 | 73.2 | 64.3 |
| | 80.6 | 83.1 | 75.1 |
the cross-entropy loss calculated by one-hot label on some datasets achieve reasonable results, but it still shows a large gap compared with our method. To some extent this also reflects that only learning the image-to-label mapping tends to suffer from more severe catastrophic forgetting during incremental learning process.
## 5.6 Visualization
the right side shows the results obtained by our proposed method. For the new task ('task1'), Continual-CLIP (the first) can somewhat separate the classes, but it is evident that samples belonging to the same class are scattered and not well-clustered. Conversely, our method (the third) successfully clusters each class and significantly increases the distance between classes. When all data is mixed ('task0 & task1'), it becomes apparent that Continual-CLIP (the second) lacks clear and meaningful boundaries between classes. Each class occupies a large space, indicating poor intra-class clustering. In contrast, ours clearly separates both the old and new tasks (the fourth). Notably, the categories 'airplane' , 'truck' and 'ship' are positioned far away from the animal categories such as 'horse' , 'dog' , 'deer' , and 'cat' . This demonstrates that our method, with its semanticallyguidance, better understands the semantic meaning of the categories and capture their relationships.
## 5.6.1 Visualization of feature representation
For the sake of simplicity and intuitiveness, we utilize the CIFAR10 dataset as an example to visualize the t-SNE representation [57]. We split the dataset into two steps, with each containing 5 new classes. The two sub-figures on the left shown in Fig. 6 represent the t-SNE visualization of the feature representation evaluated on Continual-CLIP, while
## 5.6.2 Heat Map Visualization
We present the heat maps visualization in Fig. 7 as it was proposed in [58]. As can be seen from the 'vulture' in the first row, zero-shot CLIP seems to have focused part of its attention on the wood and bushes, which may indicate that it mistook these two parts for vultures, considering the


zero-shot


ours
Fig. 7: The heat map visualization comparison of zero-shot and our method.





color of the wood and the vultures are very similar. After applying our method, the attention is completely focused on the vulture, while the rest of the noise is completely eliminated. As for the 'peacock' in the second row, it is obvious that the attention completely covers the entire peacock after applying our method. And for the 'hummingbird' in the last row, the zero-shot CLIP seems to confuse the bird in the upper left corner, small part of the water bottle, and the hummingbird itself, while our method only focuses the attention completely on the hummingbird itself and eliminates other noise.
## 6 CONCLUSION
We investigated the application of large-scale visionlanguage pre-trained models in continual learning. To capture semantic similarity, we employed text embeddings from the text encoder to compute category similarity. This information was then used to generate semantically-guided label supervision, enhancing the model's understanding of category relationships during training. Additionally, we proposed a refinement technique that improved distillation loss computation by considering the semantic similarity between text embeddings of old and new classes. This approach facilitated a more precise transfer of knowledge from previous tasks to new ones.
Limitations. Our method relies on the availability of text information for each task or category. In some real-world scenarios, such as image-only datasets or domains where textual descriptions are not readily available, our approach may not be directly applicable, which presents a potential avenue for future exploration.
## REFERENCES
- [1] F. M. Castro, M. J. Mar´ ın-Jim´ enez, N. Guil, C. Schmid, and K. Alahari, 'End-to-end incremental learning,' in Proceedings of the European conference on computer vision (ECCV) , pp. 233-248, 2018.
- [2] S. Hou, X. Pan, C. C. Loy, Z. Wang, and D. Lin, 'Learning a unified classifier incrementally via rebalancing,' in Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition , pp. 831-839, 2019.
- [3] S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, 'icarl: Incremental classifier and representation learning,' in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pp. 2001-2010, 2017.
- [4] B. Zhao, X. Xiao, G. Gan, B. Zhang, and S.-T. Xia, 'Maintaining discrimination and fairness in class incremental learning,' in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. 13208-13217, 2020.
- [5] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al. , 'Overcoming catastrophic forgetting in neural networks,' Proceedings of the national academy of sciences , vol. 114, no. 13, pp. 3521-3526, 2017.
- [6] Z. Li and D. Hoiem, 'Learning without forgetting,' IEEE transactions on pattern analysis and machine intelligence , vol. 40, no. 12, pp. 2935-2947, 2017.
- [7] Z. Zhao, Z. Zhang, X. Tan, J. Liu, Y. Qu, Y. Xie, and L. Ma, 'Rethinking gradient projection continual learning: Stability/plasticity feature space decoupling,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 3718-3727, 2023.
- [8] A. Douillard, M. Cord, C. Ollion, T. Robert, and E. Valle, 'Podnet: Pooled outputs distillation for small-tasks incremental learning,' in Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings , pp. 86-102, Springer, 2020.
- [9] A. Douillard, A. Ram´ e, G. Couairon, and M. Cord, 'Dytox: Transformers for continual learning with dynamic token expansion,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 9285-9295, 2022.
- [10] J. Serra, D. Suris, M. Miron, and A. Karatzoglou, 'Overcoming catastrophic forgetting with hard attention to the task,' in International Conference on Machine Learning , pp. 4548-4557, PMLR, 2018.
- [11] S. Yan, J. Xie, and X. He, 'Der: Dynamically expandable representation for class incremental learning,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 3014-3023, 2021.
- [12] D. Madaan, H. Yin, W. Byeon, J. Kautz, and P. Molchanov, 'Heterogeneous continual learning,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 1598515995, 2023.
- [13] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al. , 'An image is worth 16x16 words: Transformers for image recognition at scale,' in International Conference on Learning Representations , 2020.
- [14] Z. Wang, Z. Zhang, C.-Y. Lee, H. Zhang, R. Sun, X. Ren, G. Su, V. Perot, J. Dy, and T. Pfister, 'Learning to prompt for continual learning,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 139-149, 2022.
- [15] Z. Wang, Z. Zhang, S. Ebrahimi, R. Sun, H. Zhang, C.-Y. Lee, X. Ren, G. Su, V. Perot, J. Dy, et al. , 'Dualprompt: Complementary prompting for rehearsal-free continual learning,' in European Conference on Computer Vision , pp. 631-648, Springer, 2022.
- [16] Y.-M. Tang, Y.-X. Peng, and W.-S. Zheng, 'When prompt-based incremental learning does not meet strong pretraining,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , pp. 1706-1716, 2023.
- [17] G. Zhang, L. Wang, G. Kang, L. Chen, and Y. Wei, 'Slca: Slow learner with classifier alignment for continual learning on a pretrained model,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2023.
- [18] L. Zhou, H. Palangi, L. Zhang, H. Hu, J. Corso, and J. Gao, 'Unified vision-language pre-training for image captioning and vqa,' in Proceedings of the AAAI conference on artificial intelligence , vol. 34, pp. 13041-13049, 2020.
- [19] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. , 'Learning transferable visual models from natural language supervision,' in
- International conference on machine learning , pp. 8748-8763, PMLR, 2021.
- [20] Y.-C. Chen, L. Li, L. Yu, A. El Kholy, F. Ahmed, Z. Gan, Y. Cheng, and J. Liu, 'Uniter: Universal image-text representation learning,' in Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings , pp. 104-120, Springer, 2020.
- [21] J.-T. Zhai, X. Liu, L. Yu, and M.-M. Cheng, 'Fine-grained knowledge selection and restoration for non-exemplar class incremental learning,' in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 38, pp. 6971-6978, 2024.
- [22] V. Thengane, S. Khan, M. Hayat, and F. Khan, 'Clip model is an efficient continual learner,' arXiv preprint arXiv:2210.03114 , 2022.
- [23] K. Zhou, J. Yang, C. C. Loy, and Z. Liu, 'Learning to prompt for vision-language models,' International Journal of Computer Vision , vol. 130, no. 9, pp. 2337-2348, 2022.
- [24] B. E. Shepp and S. Ballesteros, Object perception: Structure and process . Psychology Press, 2013.
- [25] L. Yu, B. Twardowski, X. Liu, L. Herranz, K. Wang, Y. Cheng, S. Jui, and J. v. d. Weijer, 'Semantic drift compensation for classincremental learning,' in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. 6982-6991, 2020.
- [26] J.-T. Zhai, X. Liu, A. D. Bagdanov, K. Li, and M.-M. Cheng, 'Masked autoencoders are efficient class incremental learners,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , pp. 19104-19113, 2023.
- [27] B. Lester, R. Al-Rfou, and N. Constant, 'The power of scale for parameter-efficient prompt tuning,' in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , Association for Computational Linguistics, 2021.
- [28] M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim, 'Visual prompt tuning,' in European Conference on Computer Vision , pp. 709-727, Springer, 2022.
- [29] X. L. Li and P. Liang, 'Prefix-tuning: Optimizing continuous prompts for generation,' in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pp. 4582-4597, 2021.
- [30] J. Pfeiffer, A. Kamath, A. R¨ uckl´, e K. Cho, and I. Gurevych, 'Adapterfusion: Non-destructive task composition for transfer learning,' in 16th Conference of the European Chapter of the Associationfor Computational Linguistics, EACL 2021 , pp. 487-503, Association for Computational Linguistics (ACL), 2021.
- [31] R. Wang, D. Tang, N. Duan, Z. Wei, X.-J. Huang, J. Ji, G. Cao, D. Jiang, and M. Zhou, 'K-adapter: Infusing knowledge into pretrained models with adapters,' in Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pp. 1405-1418, 2021.
- [32] E. J. Hu, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, et al. , 'Lora: Low-rank adaptation of large language models,' in International Conference on Learning Representations .
- [33] J. S. Smith, L. Karlinsky, V. Gutta, P. Cascante-Bonilla, D. Kim, A. Arbelle, R. Panda, R. Feris, and Z. Kira, 'Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 11909-11919, 2023.
- [34] M. D. McDonnell, D. Gong, A. Parvaneh, E. Abbasnejad, and A. van den Hengel, 'Ranpac: Random projections and pre-trained models for continual learning,' Advances in Neural Information Processing Systems , vol. 36, 2024.
- [35] D.-W. Zhou, H.-L. Sun, H.-J. Ye, and D.-C. Zhan, 'Expandable subspace ensemble for pre-trained model-based class-incremental learning,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 23554-23564, 2024.
- [36] C. Jia, Y. Yang, Y. Xia, Y.-T. Chen, Z. Parekh, H. Pham, Q. Le, Y.-H. Sung, Z. Li, and T. Duerig, 'Scaling up visual and visionlanguage representation learning with noisy text supervision,' in International Conference on Machine Learning , pp. 4904-4916, PMLR, 2021.
- [37] Y. Lu, J. Liu, Y. Zhang, Y. Liu, and X. Tian, 'Prompt distribution learning,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 5206-5215, 2022.
- [38] K. Zhou, J. Yang, C. C. Loy, and Z. Liu, 'Conditional prompt learning for vision-language models,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 1681616825, 2022.
- [39] M. U. Khattak, H. Rasheed, M. Maaz, S. Khan, and F. S. Khan, 'Maple: Multi-modal prompt learning,' in Proceedings of the
- IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 19113-19122, 2023.
- [40] M. U. Khattak and etc., 'Self-regulating prompts: Foundational model adaptation without forgetting,' in ICCV , 2023.
- [41] P. Gao, S. Geng, R. Zhang, T. Ma, R. Fang, Y. Zhang, H. Li, and Y. Qiao, 'Clip-adapter: Better vision-language models with feature adapters,' International Journal of Computer Vision , vol. 132, no. 2, pp. 581-595, 2024.
- [42] A. Krizhevsky, G. Hinton, et al. , 'Learning multiple layers of features from tiny images,' 2009.
- [43] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, 'Imagenet: A large-scale hierarchical image database,' in 2009 IEEE conference on computer vision and pattern recognition , pp. 248-255, Ieee, 2009.
- [44] L. Bossard, M. Guillaumin, and L. Van Gool, 'Food-101-mining discriminative components with random forests,' in Computer Vision-ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part VI 13 , pp. 446-461, Springer, 2014.
- [45] J. Krause, M. Stark, J. Deng, and L. Fei-Fei, '3d object representations for fine-grained categorization,' in Proc. IEEE Int. Conf. Comput. Vision Workshops , 2013.
- [46] S. Maji, E. Rahtu, J. Kannala, M. Blaschko, and A. Vedaldi, 'Fine-grained visual classification of aircraft,' arXiv preprint arXiv:1306.5151 , 2013.
- [47] L. F. A. M. R. M. P. P., 'Caltech101,' tech. rep., California Institute of Technology, 2003.
- [48] M.-E. Nilsback and A. Zisserman, 'Automated flower classification over a large number of classes,' in 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing , pp. 722-729, IEEE, 2008.
- [49] C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, 'Cub,' Tech. Rep. CNS-TR-2011-001, California Institute of Technology, 2011.
- [50] A. Khosla, N. Jayadevaprakash, B. Yao, and F.-F. Li, 'Novel dataset for fine-grained image categorization: Stanford dogs,' in Proc. CVPR workshop on fine-grained visual categorization (FGVC) , vol. 2, Citeseer, 2011.
- [51] Y. Wu, Y. Chen, L. Wang, Y. Ye, Z. Liu, Y. Guo, and Y. Fu, 'Large scale incremental learning,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 374-382, 2019.
- [52] C. Zhang, N. Song, G. Lin, Y. Zheng, P. Pan, and Y. Xu, 'Fewshot incremental learning with continually evolved classifiers,' in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. 12455-12464, 2021.
- [53] D.-W. Zhou, F.-Y. Wang, H.-J. Ye, L. Ma, S. Pu, and D.-C. Zhan, 'Forward compatible few-shot class-incremental learning,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 9046-9056, 2022.
- [54] G. Hinton, O. Vinyals, and J. Dean, 'Distilling the knowledge in a neural network,' in NIPS Deep Learning and Representation Learning Workshop , 2015.
- [55] C. Huang, Y. Li, C. C. Loy, and X. Tang, 'Learning deep representation for imbalanced classification,' in Proceedings of the IEEE conference on computer vision and pattern recognition , pp. 5375-5384, 2016.
- [56] M. Masana, X. Liu, B. Twardowski, M. Menta, A. D. Bagdanov, and J. van de Weijer, 'Class-incremental learning: survey and performance evaluation on image classification,' IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022.
- [57] L. Van der Maaten and G. Hinton, 'Visualizing data using t-sne.,' Journal of machine learning research , vol. 9, no. 11, 2008.
- [58] H. Chefer, S. Gur, and L. Wolf, 'Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , pp. 397-406, 2021. | null | [
"Lu Yu",
"Zhe Tao",
"Hantao Yao",
"Joost Van de Weijer",
"Changsheng Xu"
] | 2024-08-02T07:51:44+00:00 | 2024-08-02T07:51:44+00:00 | [
"cs.CV"
] | Exploiting the Semantic Knowledge of Pre-trained Text-Encoders for Continual Learning | Deep neural networks (DNNs) excel on fixed datasets but struggle with
incremental and shifting data in real-world scenarios. Continual learning
addresses this challenge by allowing models to learn from new data while
retaining previously learned knowledge. Existing methods mainly rely on visual
features, often neglecting the rich semantic information encoded in text. The
semantic knowledge available in the label information of the images, offers
important semantic information that can be related with previously acquired
knowledge of semantic classes. Consequently, effectively leveraging this
information throughout continual learning is expected to be beneficial. To
address this, we propose integrating semantic guidance within and across tasks
by capturing semantic similarity using text embeddings. We start from a
pre-trained CLIP model, employ the \emph{Semantically-guided Representation
Learning (SG-RL)} module for a soft-assignment towards all current task
classes, and use the Semantically-guided Knowledge Distillation (SG-KD) module
for enhanced knowledge transfer. Experimental results demonstrate the
superiority of our method on general and fine-grained datasets. Our code can be
found in
https://github.com/aprilsveryown/semantically-guided-continual-learning. |
2408.01077v3 | ## PhysMamba: Synergistic State Space Duality Model for Remote Physiological Measurement
Zhixin Yan 1 , Yan Zhong 1 , Hongbin Xu 1 , Wenjun Zhang 1 , Shangru Yi 1 , Lin Shu 1 , Wenxiong Kang 1 ∗ South China University of Technology, Guangzhou, China
Abstract -Remote Photoplethysmography (rPPG) enables noncontact physiological signal extraction from facial videos, offering applications in psychological state analysis, medical assistance, and anti-face spoofing. However, challenges such as motion artifacts, lighting variations, and noise limit its real-world applicability. To address these issues, we propose PhysMamba, a novel dual-pathway time-frequency interaction model based on Synergistic State Space Duality (SSSD), which for the first time integrates state space models with attention mechanisms in a dual-branch framework. Combined with a Multi-Scale Query (MQ) mechanism, PhysMamba achieves efficient information exchange and enhanced feature representation, ensuring robustness under noisy and dynamic conditions. Experiments on PURE, UBFC-rPPG, and MMPD datasets demonstrate that PhysMamba outperforms state-of-the-art methods, offering superior accuracy and generalization. This work lays a strong foundation for practical applications in non-contact health monitoring, including real-time remote patient care. The code is available at https://anonymous.4open.science/r/PhysMamba-E714/.
Index Terms -Remote Photoplethysmography, Heart Rate Estimation, Mamba, State Space Duality
## I. INTRODUCTION
Photoplethysmography (PPG) is a widely-used technique for estimating vital physiological indicators such as heart rate, heart rate variability, and respiratory rate, which are crucial for applications like sleep monitoring, medical assistance, and fatigue assessment. While traditional PPG relies on contactbased sensors like ECG monitors, its limited scalability and user inconvenience have driven the development of noncontact alternatives. Remote photoplethysmography (rPPG) leverages cameras to estimate physiological signals by capturing subtle blood flow changes in the skin [1], unlocking potential applications in remote health monitoring, wearable devices, and psychological state analysis.
Despite its promise, deploying rPPG in real-world environments faces significant challenges, including motion artifacts, lighting variations, and environmental noise. These factors disrupt signal consistency and hinder the generalization of rPPG systems, limiting their practical adoption in scenarios such as telemedicine and stress monitoring.
Traditional rPPG methods, including signal processing techniques like Independent Component Analysis (ICA) and chrominance-based projections [2], [3], perform well in controlled environments but struggle under dynamic conditions due to their reliance on handcrafted features. Recent deep learning approaches, such as CNN-based models [23], have improved motion artifact handling, while Transformer-based
Fig. 1. Comparison between SSD and SSSD. The traditional SSD combines SSM and attention mechanisms, while our enhanced SSSD introduces MultiScale Queries for efficient information interaction between the two pathways.
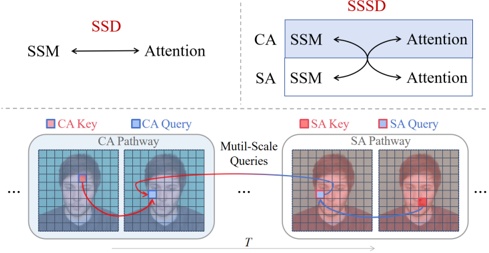
architectures like PhysFormer [29] enhance temporal dependency modeling. However, these models suffer from high computational complexity, making them less practical for realtime applications. State Space Models (SSMs) have emerged as a computationally efficient alternative, as demonstrated by RhythmMamba [10], which captures quasi-periodic patterns in physiological signals with low computational cost. Yet, existing SSM-based methods face limitations in generalization and parallel processing, particularly in cross-dataset scenarios.
Building on these advancements, we propose PhysMamba , a novel dual-pathway time-frequency interaction model that integrates Synergistic State Space Duality (SSSD) for rPPG estimation. This is the first framework to combine the efficiency of state space models with the feature extraction capabilities of attention mechanisms in a dual-pathway architecture. By introducing a Multi-Scale Query (MQ) mechanism, PhysMamba achieves efficient information sharing between pathways, enabling robust feature representation under noisy and dynamic conditions.
Comprehensive experiments on the PURE, UBFC-rPPG, and MMPD datasets demonstrate that PhysMamba achieves state-of-the-art performance in both intra-dataset and crossdataset evaluations. These results highlight its superior robustness, accuracy, and generalization, paving the way for practical applications in non-contact health monitoring systems, including wearable devices and real-time telemedicine.
The main contributions of this work are summarized as follows:
- · We propose PhysMamba, an efficient rPPG estimation method via State Space Duality in a dual-pathway time-
frequency interactive network. This is the first attempt handling rPPG estimation via SSD, creating technological breakthroughs.
- · To enhance information exchange in dual-pathway model, we develop a simple state space fusion module using Mutil-Scale Queries for effective lateral information sharing.
- · Extensive experiments on three public rPPG datasets (PURE, UBFC-rPPG, and MMPD) validate the superior performance of PhysMamba, achieving state-of-the-art results in both controlled and complex real-world scenarios.
## II. RELATED WORK
## A. rPPG Estimation
Traditional rPPG methods, such as Independent Component Analysis (ICA) and chrominance subspace projection [2], [21], perform well under controlled conditions but degrade significantly in dynamic environments due to sensitivity to motion artifacts and lighting variations [25]. These approaches also rely heavily on handcrafted features, limiting their adaptability in real-world scenarios. Deep learning has advanced rPPG estimation by enabling end-to-end frameworks. Models like DeepPhys [23] improved motion artifact handling through CNN architectures but struggled to capture long-term dependencies. Transformer-based methods, such as PhysFormer [29], leveraged self-attention mechanisms for global dependency modeling but suffered from high computational complexity, making them impractical for real-time applications.
## B. State Space Model
To enhance contextual information capture in long sequences, SSMs have gained significant interest. The Mamba SSM [6] maintains linear time complexity while effectively capturing long-term dependencies, and has been applied in fields such as time series analysis [7], medical image segmentation [8], and video understanding [9]. Recently, Mamba has been used for rPPG estimation, achieving good results with low computational complexity. RhythmMamba [10], an SSM-based method, robustly identifies quasi-periodic patterns in rPPG signals using a multi-phase learning framework and a frequency-domain feedforward mechanism. However, Mamba1 had limitations in efficiency and generalization due to its dependency on previous states. Mamba-2 [11] introduced the State Space Duality framework, enhancing SSMs' linear time complexity with attention mechanisms' feature representation capabilities, improving efficiency and generalization for complex physiological signal estimation tasks like rPPG.
## III. METHODOLOGY
## A. Overall Framework
PhysMamba is an end-to-end model designed to process raw facial video data and estimate rPPG signals directly. The framework, illustrated in Figure 2, consists of two pathways: the Self-Attention (SA) Pathway and the Cross-Attention (CA) Pathway. These pathways incorporate three core modules: the
Frame Stem for temporal feature extraction, the Multi-Scale Synergistic State Space Duality (SSSD) module for robust temporal representation, and the Frequency Domain FeedForward (FDF) network for frequency enhancement. Outputs from these pathways are fused in the rPPG Predictor to generate final signal estimations. The dual-pathway architecture can be likened to a collaborative system where one pathway focuses on internal temporal consistency (SA) and the other facilitates cross-feature interactions (CA), ensuring robustness in diverse conditions.
## B. Frame Stem
The Frame Stem extracts temporal features while reducing spatial noise from input video data X ∈ R 3 × × T H × W . By computing frame differences, subtle temporal variations are highlighted, which are particularly relevant for physiological signal estimation. The processed features are represented as:
$$X _ { \text{Stem} } = \text{Stem} ( X _ { \text{origin} } ) + \text{Stem} ( X _ { \text{origin} } + X _ { \text{diff} } ), \quad ( 1 )$$
where X diff represents differences between consecutive frames.
A combination of 2D-CNNs, batch normalization, ReLU activation, and max-pooling is used to enhance these features. Finally, a 5×5 convolution and self-attention mechanism adaptively focus on informative facial regions, improving feature quality for subsequent modules.
## C. Multi-Scale Synergistic State Space Duality (SSSD)
The SSSD module combines State Space Models (SSMs) with attention mechanisms to capture both long-term dependencies and short-term variations in temporal data between the two pathways, as illustrated in Fig. 2(a). A key component of SSSD is the Multi-Scale Query (MQ) mechanism, which allows the model to process information across multiple temporal scales, as shown in Fig. 2(b). By ensuring efficient information exchange between the pathways, MQ enhances the model's adaptability to diverse and dynamic input characteristics, such as motion artifacts and inconsistent lighting. This design allows PhysMamba to excel in both time-domain and frequency-domain tasks, ensuring high performance in realworld scenarios.
To simplify, SSMs operate like 'memory systems' that track evolving patterns over time. They are mathematically described as:
$$h _ { t } = A h _ { t - 1 } + B x _ { t }, \ \ y _ { t } = C ^ { \top } h _ { t }, \ \quad \ \ ( 2 )$$
where A B , , and C are learnable matrices controlling state transitions and feature outputs.
Building on this, the State Space Duality (SSD) framework introduces structured attention mechanisms to efficiently encode temporal dependencies:
$$\text{SSD} = ( L \circ Q K ^ { \top } ) \cdot V,$$
Through the MQ mechanism, the query ( Q ), key ( K ), and value ( V ) matrices are mapped from inputs of different temporal scales, with L as a structured mask matrix that replaces traditional softmax operations.
## (a) The overall framework diagram of PhysMamba
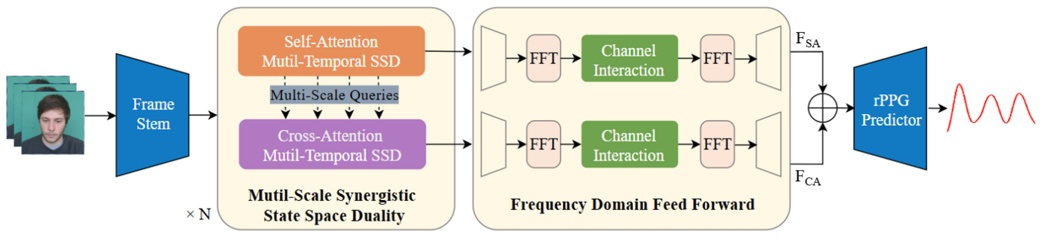
Fig. 2. Overall framework diagram of the PhysMamba model. The model comprises the Frame Stem, Multi-Scale Synergistic State Space Duality (SSSD), Frequency Domain Feed-Forward (FDF), and rPPG Predictor, integrated into two pathways: the Self-Attention Pathway and the Cross-Attention Pathway.
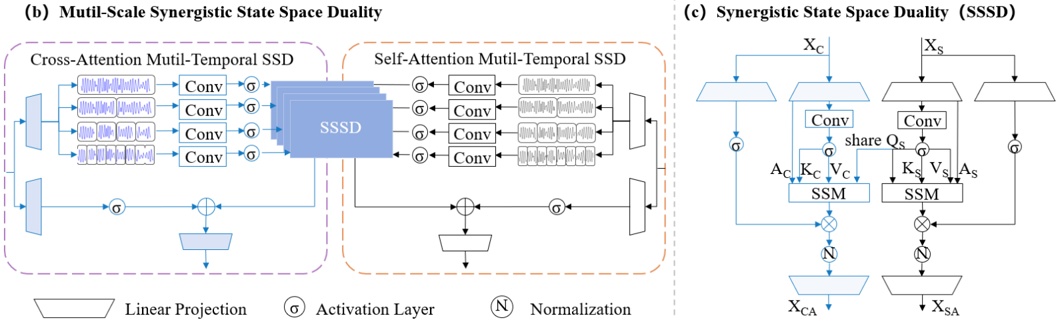
The SSSD extends this concept by enabling complementary interactions between pathways:
from the SA and CA pathways, denoted as F SA and F CA , are combined to optimize rPPG signal representation.
The SA Pathway focuses on self-dependencies within individual features:
$$X _ { \text{SA} } = ( L _ { S } \circ Q _ { S } K _ { S } ^ { \top } ) \cdot V _ { S }. \quad \quad ( 4 ) \ \text{ along}$$
The CA pathway receives Multi-Scale Q S from SA, enabling CA to promote cross-feature refinement.:
$$X _ { \text{CA} } = ( L _ { C } \circ Q _ { S } K _ { C } ^ { \top } ) \cdot V _ { C }. \quad \quad ( 5 ) \prod _ { \substack { a \dots \dots } }$$
As illustrated in Fig. 2(c), these pathways function like two analysts: one focuses on deeply examining individual data streams (SA), while the other identifies meaningful interactions across them (CA). This collaboration ensures robust temporal feature learning, even under noisy conditions.
## D. Frequency Domain Feed-Forward (FDF)
To enhance periodic physiological patterns, the FDF network applies Fast Fourier Transform (FFT) to convert temporal signals h t ( ) into the frequency domain:
$$H ( f ) = \int _ { - \infty } ^ { + \infty } h ( t ) e ^ { - j 2 \pi f t } d t. \quad \quad ( 6 ) \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{$$
This emphasizes periodic components like heart rate signals. The inverse FFT restores the frequency-enhanced signals to the temporal domain, preserving these enhancements. Outputs
## E. rPPG Predictor
The outputs from the SA and CA pathways are concatenated along the channel dimension:
$$X _ { \text{fusion} } = \text{Concat} ( F _ { C A }, F _ { S A } ). \text{ \quad \ \ } ( 7 )$$
A 1D convolutional layer then refines the fused features to produce the final rPPG predictions. By integrating both timedomain and frequency-domain features, the rPPG Predictor ensures accurate heart rate estimation even under challenging conditions, such as varying lighting and motion artifacts.
## IV. EXPERIMENTS
## A. Datasets
To rigorously evaluate PhysMamba's performance, we selected three widely-used rPPG datasets with varying levels of complexity: UBFC-rPPG [32], PURE [31], and MMPD [33]. These datasets present distinct challenges, ranging from controlled laboratory conditions to highly complex real-world scenarios involving significant noise and motion artifacts.
UBFC-rPPG : This dataset consists of videos from 42 subjects performing mathematical tasks to induce heart rate variability. The relatively clean facial videos with minimal noise make it a benchmark for assessing model accuracy under simple conditions.
TABLE I INTRA-DATASET RESULTS ON UBFC, PURE, AND MMPD DATASETS.
| Method | UBFC | UBFC | UBFC | UBFC | PURE | PURE | PURE | PURE | MMPD | MMPD | MMPD | MMPD | MMPD |
|--------------------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|
| Method | MAE | RMSE | MAPE | r | MAE | RMSE | MAPE | r | MAE | RMSE | MAPE | r | SNR |
| GREEN [16] | 19.73 | 31.00 | 18.72 | 0.37 | 10.09 | 23.85 | 10.28 | 0.34 | 21.68 | 27.69 | 24.39 | -0.01 | -14.34 |
| ICA [18] | 16.00 | 25.65 | 15.35 | 0.44 | 4.77 | 16.07 | 4.47 | 0.72 | 18.60 | 24.30 | 20.88 | 0.01 | -13.84 |
| CMROM [17] | 4.06 | 8.83 | 3.34 | 0.89 | 5.77 | 14.93 | 11.52 | 0.81 | 13.66 | 18.76 | 16.00 | 0.08 | -11.74 |
| LGI [19] | 15.80 | 28.55 | 14.70 | 0.36 | 4.61 | 15.38 | 4.96 | 0.77 | 17.08 | 23.32 | 18.98 | 0.04 | -13.15 |
| PBV [20] | 15.90 | 26.40 | 15.17 | 0.48 | 3.92 | 12.99 | 4.84 | 0.84 | 17.95 | 23.58 | 20.18 | 0.09 | -13.88 |
| POS [21] | 4.08 | 7.72 | 3.93 | 0.92 | 3.67 | 11.82 | 7.25 | 0.88 | 12.36 | 17.71 | 14.43 | 0.18 | -11.53 |
| OMIT [22] | 15.79 | 28.54 | 14.69 | 0.36 | 4.65 | 15.81 | 4.96 | 0.75 | 7.80 | 12.00 | 10.55 | 0.13 | -8.68 |
| DeepPhys [23] | 0.76 | 1.09 | 0.79 | 0.99 | 3.33 | 14.45 | 2.91 | 0.90 | 23.73 | 28.25 | 25.63 | -0.06 | -15.45 |
| PhysNet [24] | 0.58 | 0.83 | 0.61 | 0.99 | 0.54 | 0.93 | 0.58 | 0.99 | 4.81 | 11.83 | 4.84 | 0.60 | 1.51 |
| TS-CAN [26] | 0.81 | 1.10 | 0.84 | 0.99 | 0.40 | 0.73 | 0.44 | 0.99 | 8.97 | 16.58 | 9.43 | 0.44 | -6.92 |
| PhysFormer [29] | 0.63 | 0.98 | 0.65 | 0.99 | 0.25 | 0.37 | 0.34 | 0.99 | 13.64 | 19.39 | 14.42 | 0.15 | -11.02 |
| EfficientPhys [30] | 0.72 | 1.01 | 0.75 | 0.99 | 5.10 | 16.61 | 4.19 | 0.87 | 12.79 | 21.12 | 13.48 | 0.24 | -9.23 |
| RhythmMamba [10] | 0.54 | 0.79 | 0.54 | 0.99 | 0.29 | 0.39 | 0.36 | 0.99 | 3.16 | 7.27 | 3.37 | 0.84 | 4.74 |
| PhysMamba (Ours) | 0.45 | 0.76 | 0.45 | 0.99 | 0.24 | 0.36 | 0.31 | 0.99 | 2.84 | 6.41 | 3.04 | 0.88 | 5.20 |
Fig. 3. Comparison of predicted and ground-truth heart rate distributions across UBFC-rPPG, PURE, and MMPD datasets.
PURE : Comprising videos of 10 subjects under six controlled head movement scenarios-including stillness, talking, and slow/fast rotations-PURE introduces moderate motion artifacts, testing the model's robustness to dynamic conditions.
MMPD : A highly challenging dataset featuring 33 subjects under varying lighting conditions, skin tones, and head movement complexities. Capturing over 11 hours of video with diverse environmental factors, MMPD includes significant noise and motion artifacts, simulating real-world complexities. Due to computational constraints, we utilized the mini-MMPD version for experimentation.
We evaluated PhysMamba using standard metrics: Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), Mean Absolute Percentage Error (MAPE), and Pearson correlation coefficient ( r ). For MMPD, we also computed the Signal-to-Noise Ratio (SNR) to assess robustness in high-noise environments.
## B. Experimental Details
All experiments were conducted using the open-source rppg-toolbox [34] in PyTorch. Videos were preprocessed by cropping and resizing facial regions to 128 × 128 pixels. The model was trained using a learning rate of 3 × 10 -4 , a batch size of 16, and for 30 epochs. The SSD model's dimension and state space size were set to 64, with a head dimension of 16. All computations were performed on an NVIDIA RTX 4090 GPU.
Fig. 4. Visualization of the results from the MMPD dataset. (a) the BlandAltman plot. (b) the waveform of a sample before and after filtering.
The loss function combined time-domain loss ( L Time) and frequency-domain loss ( L Freq ) for robust learning:
$$\mathcal { L } _ { \text{overall} } = L _ { \text{Time} } + L _ { \text{Freq} },$$
where L Time minimizes the negative Pearson correlation between the predicted and ground-truth rPPG signals, and L Freq aligns their frequency-domain representations.
## V. EXPERIMENTAL EVALUATION
To fully verify PhysMamba's effectiveness and superiority in rPPG heart rate estimation, we have designed a detailed evaluation process, including both intra-dataset and crossdataset assessments. We compared PhysMamba with Unsupervised methods including GREEN [16], ICA [18], CHROM [17], LGI [19], PBV [20], and POS [21], OMIT [22], as well as state-of-the-art deep learning methods including DeepPhys [23], PhysNet [24], TS-CAN [26], PhysFormer [29],EfficientPhys [30], and RhythmMamba [10]. We provide additional experimental details in the supplementary materials.
## A. Intra-Dataset Testing
In intra-dataset evaluations, PhysMamba was trained and tested on the same dataset to assess its performance under consistent conditions. As shown in Table I, PhysMamba achieved near-optimal results on UBFC-rPPG and PURE datasets, with MAEs of 0.45 bpm and 0.24 bpm, respectively, outperforming existing methods. On the challenging MMPD dataset, PhysMamba demonstrated superior robustness, achieving an MAE of 2.84 bpm and the highest SNR of 5.20. These results indicate PhysMamba's ability to handle noise, motion artifacts, and varying lighting conditions effectively.The low computational complexity of PhysMamba, enabled by the SSSD framework, makes it particularly suitable for deployment on mobile devices and real-time monitoring systems. Its robustness on MMPD highlights its capability to adapt to complex, noisy environments.
## B. Cross-Dataset Testing
We selected the PURE dataset with head movements and the MMPD dataset with significant noise. Cross-dataset evaluations assessed PhysMamba's generalization by training and testing on different datasets, a crucial factor for real-world applications where training and deployment data often differ.
As shown in Tables II and III, PhysMamba consistently outperformed existing methods in cross-dataset scenarios. When trained on MMPD and tested on PURE, it achieved an MAE of 5.32 bpm, surpassing RhythmMamba. Conversely, when trained on PURE and tested on MMPD, it achieved an MAE of 9.87 bpm, significantly better than other methods.
The superior generalization of PhysMamba can be attributed to: SSSD : By combining state space models with attention mechanisms between the two pathways, PhysMamba effectively captures both long-term dependencies and shortterm variations. This dual capability enhances the model's robustness against dataset shifts caused by lighting, skin tone, and motion variability. Multi-Scale Queries : MQ enables efficient feature sharing across different time scales, improving the model's ability to adapt to diverse data distributions. This is particularly evident in the cross-dataset scenarios, where PhysMamba maintains high accuracy despite significant domain shifts. Practical Implications: The ability to generalize across datasets demonstrates PhysMamba's potential for deployment in real-world environments with minimal retraining. This is especially valuable for applications like remote health monitoring, where training data may not cover all possible variations in deployment settings.
## C. Ablation Study
To evaluate the contribution of each key component, we conducted ablation studies on the MMPD dataset. The results, summarized in Table IV, highlight the importance of the MQ, FDF, SSD, and CA modules in achieving state-of-theart performance.
Multi-Scale Queries (MQ): Improved the model's ability to capture multi-scale dependencies, reducing the MAE from 4.40 to 3.46 bpm. Frequency Domain Feed-Forward (FDF):
Fig. 5. Heat map of cross-dataset results: Training on MMPD and testing on PURE (left), and vice versa (right). PhysMamba shows superior generalization compared to other methods.
TABLE II
CROSS-DATASET RESULTS: TRAINED ON MMPD, TESTED ON PURE.
| Method | MAE | RMSE | MAPE | r |
|--------------------|-------|--------|--------|-------|
| DeepPhys [23] | 15.86 | 25.72 | 20.76 | -0.01 |
| PhysNet [24] | 10.96 | 20.24 | 18.34 | 0.54 |
| TS-CAN [26] | 7.24 | 16.8 | 9.76 | 0.68 |
| PhysFormer [29] | 17.6 | 24.75 | 26.93 | 0 |
| EfficientPhys [30] | 5.68 | 16.59 | 6.26 | 0.7 |
| RhythmMamba [10] | 6.07 | 14.43 | 9.66 | 0.78 |
| PhysMamba (Ours) | 5.32 | 12.98 | 9.56 | 0.84 |
Enhanced the detection of periodic patterns, increasing SNR from 1.50 to 5.20. Dual-Pathway Design (DP): Reduced redundancy and improved feature learning, achieving an MAE of 3.13 bpm. SSSD Framework: Enabled robust temporal learning, ensuring the best overall performance with an MAE of 2.84 bpm and an SNR of 5.20. Practical Implications: The ablation study underscores the complementary roles of PhysMamba's components, particularly MQ and FDF, in balancing computational efficiency with robustness, making the model ideal for resource-constrained environments.
## D. Visualization and Further Analysis
To further analyze PhysMamba's performance, Figure 3 compares the predicted and ground-truth heart rate distributions across the three datasets. The results show a close alignment, even in challenging conditions like MMPD. In Figure 4, we present the visualization of the MMPD results, showing a strong correlation between the predicted and the ground truth heart rate.A second-order Butterworth filter (cutoff frequencies: 0.75 and 2.5 Hz) filtered the predicted PPG waveform. This result confirms PhysMamba's accuracy and reliability in heart rate estimation, even in challenging scenarios, demonstrating strong robustness. Figure 5 highlights the crossdataset results, showing PhysMamba's consistent performance across different training and testing conditions. This further validates its robustness and generalization capabilities. These visualizations reinforce the potential of PhysMamba for realworld applications.
## VI. CONCLUSION
This paper introduces PhysMamba, an efficient rPPG estimation method using State Space Duality in a dual-pathway
TABLE III
CROSS-DATASET RESULTS: TRAINED ON PURE, TESTED ON MMPD.
| Method | MAE | RMSE | MAPE | r |
|--------------------|-------|--------|--------|------|
| DeepPhys [23] | 16.92 | 24.61 | 18.54 | 0.05 |
| PhysNet [24] | 13.94 | 21.61 | 15.15 | 0.2 |
| TS-CAN [26] | 13.94 | 21.61 | 15.15 | 0.2 |
| PhysFormer [29] | 14.57 | 20.71 | 16.73 | 0.15 |
| EfficientPhys [30] | 14.03 | 21.62 | 15.32 | 0.17 |
| RhythmMamba [10] | 10.45 | 16.49 | 12.2 | 0.37 |
| PhysMamba (Ours) | 9.87 | 15.47 | 11.76 | 0.4 |
## TABLE IV
ABLATION STUDY RESULTS ON THE MMPD DATASET. MQ: MULTI-SCALE
QUERIES, FDF: FREQUENCY DOMAIN FEED-FORWARD, DP:
DUAL-PATHWAY, SSD: STATE SPACE DUALITY, CA: CROSS-ATTENTION.
| MQ | FDF | DP | SSD | CA | MAE | RMSE | MAPE | r | SNR |
|------|-------|------|-------|------|-------|--------|--------|------|-------|
| ✓ | ✓ | | | | 4.4 | 8.81 | 4.66 | 0.76 | 3.36 |
| ✓ | ✓ | | ✓ | | 3.46 | 7.21 | 3.69 | 0.84 | 3.94 |
| ✓ | ✓ | ✓ | | | 3.13 | 6.55 | 3.31 | 0.87 | 4.63 |
| ✓ | ✓ | ✓ | ✓ | | 3.72 | 8.06 | 3.95 | 0.8 | 4.15 |
| ✓ | | ✓ | ✓ | ✓ | 3.53 | 7.46 | 3.83 | 0.82 | 1.5 |
| | ✓ | ✓ | ✓ | ✓ | 3.49 | 7.35 | 3.69 | 0.83 | 4.17 |
| ✓ | ✓ | ✓ | ✓ | ✓ | 2.84 | 6.41 | 3.04 | 0.88 | 5.2 |
time-frequency network. It combines long-term dependency modeling with a full-sequence attention mechanism. We also propose a simple yet innovative Synergistic State Space Duality algorithm with Multi-Scale Queries, facilitating effective information interaction within the dual-pathway network. Both internal and cross-dataset tests show that PhysMamba achieves state-of-the-art performance, with high accuracy and robustness, indicating strong potential in real-world physiological and psychological applications.
Future work will focus on extending PhysMamba for realtime monitoring of psychological states, emotions, and overall health in dynamic and diverse environments. With its high efficiency and adaptability, PhysMamba provides a scalable foundation for advancing non-contact health monitoring technologies, benefiting both individual well-being and public healthcare systems.
## REFERENCES
- [1] J.-H. Choi, K.-B. Kang, and K.-T. Kim, 'Fusion-vital: Video-rf fusion transformer for advanced remote physiological measurement,' in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 38, no. 2, 2024, pp. 1344-1352.
- [2] X. Li, J. Chen, G. Zhao, and M. Pietikainen, 'Remote heart rate measurement from face videos under realistic situations,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2014, pp. 4264-4271.
- [3] S. Tulyakov, X. Alameda-Pineda, E. Ricci, L. Yin, J. F. Cohn, and N. Sebe, 'Self-adaptive matrix completion for heart rate estimation from face videos under realistic conditions,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2016, pp. 23962404.
- [4] K. Han, Y. Wang, H. Chen, X. Chen, J. Guo, Z. Liu, Y. Tang, A. Xiao, C. Xu, Y. Xu et al. , 'A survey on vision transformer,' IEEE transactions on pattern analysis and machine intelligence , vol. 45, no. 1, pp. 87-110, 2022.
- [5] R. Xu, S. Yang, Y. Wang, B. Du, and H. Chen, 'A survey on vision mamba: Models, applications and challenges,' arXiv preprint arXiv:2404.18861 , 2024.
- [6] A. Gu and T. Dao, 'Mamba: Linear-time sequence modeling with selective state spaces,' arXiv preprint arXiv:2312.00752 , 2023.
- [7] S. Ma, Y. Kang, P. Bai, and Y.-B. Zhao, 'Fmamba: Mamba based on fast-attention for multivariate time-series forecasting,' arXiv preprint arXiv:2407.14814 , 2024.
- [8] J. Ma, F. Li, and B. Wang, 'U-mamba: Enhancing long-range dependency for biomedical image segmentation,' arXiv preprint arXiv:2401.04722 , 2024.
- [9] K. Li, X. Li, Y. Wang, Y. He, Y. Wang, L. Wang, and Y. Qiao, 'Videomamba: State space model for efficient video understanding,' arXiv preprint arXiv:2403.06977 , 2024.
- [10] B. Zou, Z. Guo, X. Hu, and H. Ma, 'Rhythmmamba: Fast remote physiological measurement with arbitrary length videos,' arXiv preprint arXiv:2404.06483 , 2024.
- [11] T. Dao and A. Gu, 'Transformers are ssms: Generalized models and efficient algorithms through structured state space duality,' arXiv preprint arXiv:2405.21060 , 2024.
- [12] X. Niu, Z. Yu, H. Han, X. Li, S. Shan, and G. Zhao, 'Video-based remote physiological measurement via cross-verified feature disentangling,' in Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part II 16 . Springer, 2020, pp. 295-310.
- [13] K. He, X. Zhang, S. Ren, and J. Sun, 'Deep residual learning for image recognition,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2016, pp. 770-778.
- [14] K. Cho, B. Van Merri¨ enboer, D. Bahdanau, and Y. Bengio, 'On the properties of neural machine translation: Encoder-decoder approaches,' arXiv preprint arXiv:1409.1259 , 2014.
- [15] Z. Yu, X. Li, X. Niu, J. Shi, and G. Zhao, 'Autohr: A strong end-toend baseline for remote heart rate measurement with neural searching,' IEEE Signal Processing Letters , vol. 27, pp. 1245-1249, 2020.
- [16] W. Verkruysse, L. O. Svaasand, and J. S. Nelson, 'Remote plethysmographic imaging using ambient light.' Optics express , vol. 16, no. 26, pp. 21 434-21 445, 2008.
- [17] G. De Haan and V. Jeanne, 'Robust pulse rate from chrominance-based rppg,' IEEE transactions on biomedical engineering , vol. 60, no. 10, pp. 2878-2886, 2013.
- [18] M.-Z. Poh, D. J. McDuff, and R. W. Picard, 'Non-contact, automated cardiac pulse measurements using video imaging and blind source separation.' Optics express , vol. 18, no. 10, pp. 10 762-10 774, 2010.
- [19] C. S. Pilz, S. Zaunseder, J. Krajewski, and V. Blazek, 'Local group invariance for heart rate estimation from face videos in the wild,' in Proceedings of the IEEE conference on computer vision and pattern recognition workshops , 2018, pp. 1254-1262.
- [20] G. De Haan and A. Van Leest, 'Improved motion robustness of remote-ppg by using the blood volume pulse signature,' Physiological measurement , vol. 35, no. 9, p. 1913, 2014.
- [21] W. Wang, A. C. Den Brinker, S. Stuijk, and G. De Haan, 'Algorithmic principles of remote ppg,' IEEE Transactions on Biomedical Engineering , vol. 64, no. 7, pp. 1479-1491, 2016.
- [22] C. A. Casado and M. B. L´ opez, 'Face2ppg: An unsupervised pipeline for blood volume pulse extraction from faces,' IEEE Journal of Biomedical and Health Informatics , 2023.
- [23] W. Chen and D. McDuff, 'Deepphys: Video-based physiological measurement using convolutional attention networks,' in Proceedings of the european conference on computer vision (ECCV) , 2018, pp. 349-365.
- [24] Z. Yu, X. Li, and G. Zhao, 'Remote photoplethysmograph signal measurement from facial videos using spatio-temporal networks,' arXiv preprint arXiv:1905.02419 , 2019.
- [25] X. Niu, H. Han, S. Shan, and X. Chen, 'Synrhythm: Learning a deep heart rate estimator from general to specific,' in 2018 24th international conference on pattern recognition (ICPR) . IEEE, 2018, pp. 3580-3585.
- [26] X. Liu, J. Fromm, S. Patel, and D. McDuff, 'Multi-task temporal shift attention networks for on-device contactless vitals measurement,' Advances in Neural Information Processing Systems , vol. 33, pp. 19 40019 411, 2020.
- [27] H. Lu, H. Han, and S. K. Zhou, 'Dual-gan: Joint bvp and noise modeling for remote physiological measurement,' in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , 2021, pp. 12 404-12 413.
- [28] J. Comas, A. Ruiz, and F. Sukno, 'Efficient remote photoplethysmography with temporal derivative modules and time-shift invariant loss,' in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , 2022, pp. 2182-2191.
- [29] Z. Yu, Y. Shen, J. Shi, H. Zhao, P. H. Torr, and G. Zhao, 'Physformer: Facial video-based physiological measurement with temporal difference transformer,' in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , 2022, pp. 4186-4196.
- [30] X. Liu, B. Hill, Z. Jiang, S. Patel, and D. McDuff, 'Efficientphys: Enabling simple, fast and accurate camera-based cardiac measurement,' in Proceedings of the IEEE/CVF winter conference on applications of computer vision , 2023, pp. 5008-5017.
- [31] R. Stricker, S. M¨ller, and H.-M. Gross, 'Non-contact video-based pulse u rate measurement on a mobile service robot,' in The 23rd IEEE International Symposium on Robot and Human Interactive Communication . IEEE, 2014, pp. 1056-1062.
- [32] S. Bobbia, R. Macwan, Y. Benezeth, A. Mansouri, and J. Dubois, 'Unsupervised skin tissue segmentation for remote photoplethysmography,' Pattern Recognition Letters , vol. 124, pp. 82-90, 2019.
- [33] J. Tang, K. Chen, Y. Wang, Y. Shi, S. Patel, D. McDuff, and X. Liu, 'Mmpd: multi-domain mobile video physiology dataset,' in 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC) . IEEE, 2023, pp. 1-5.
- [34] X. Liu, G. Narayanswamy, A. Paruchuri, X. Zhang, J. Tang, Y. Zhang, R. Sengupta, S. Patel, Y. Wang, and D. McDuff, 'rppg-toolbox: Deep remote ppg toolbox,' Advances in Neural Information Processing Systems , vol. 36, 2024. | null | [
"Zhixin Yan",
"Yan Zhong",
"Hongbin Xu",
"Wenjun Zhang",
"Shangru Yi",
"Lin Shu",
"Wenxiong Kang"
] | 2024-08-02T07:52:28+00:00 | 2025-01-16T02:08:47+00:00 | [
"cs.CV"
] | PhysMamba: State Space Duality Model for Remote Physiological Measurement | Remote Photoplethysmography (rPPG) enables non-contact physiological signal
extraction from facial videos, offering applications in psychological state
analysis, medical assistance, and anti-face spoofing. However, challenges such
as motion artifacts, lighting variations, and noise limit its real-world
applicability. To address these issues, we propose PhysMamba, a novel
dual-pathway time-frequency interaction model based on Synergistic State Space
Duality (SSSD), which for the first time integrates state space models with
attention mechanisms in a dual-branch framework. Combined with a Multi-Scale
Query (MQ) mechanism, PhysMamba achieves efficient information exchange and
enhanced feature representation, ensuring robustness under noisy and dynamic
conditions. Experiments on PURE, UBFC-rPPG, and MMPD datasets demonstrate that
PhysMamba outperforms state-of-the-art methods, offering superior accuracy and
generalization. This work lays a strong foundation for practical applications
in non-contact health monitoring, including real-time remote patient care. |
2408.01078v1 | ## Multibeam Hybrid Transmitarray Based on Polarization Rotating Metasurface With Reconfigurable Bidirectional Radiation
Fan Qin, Member, IEEE , Yifei Liu, Student Member, IEEE , Chao Gu, Member, IEEE , Linfeng Zeng, Student Member, IEEE , Wenchi Cheng, Senior Member, IEEE , Hailin Zhang, Member, IEEE , and Steven Gao, Fellow, IEEE
Abstract -This paper proposes a bidirectional multibeam hybrid transmitarray (HTA) employing a transmission polarizationrotating metasurface (TPRM). A novel configuration is introduced to facilitate bidirectional beam scanning by combining the transmitarray (TA) and folded-transmitarray (FTA). To accomplish the reconfiguration of both unidirectional and bidirectional radiation states in the +z, -z, and +/-z directions, a polarization switchable multi-feed array (MFA) is placed at the focal plane between the TA and FTA, radiating x-polarization, y-polarization, and 45-degree oblique polarization waves, respectively. Meanwhile, the proposed antenna can achieve multibeam radiation in the three aforementioned states by switching the polarization of the MFA. To demonstrate the operating principle, a prototype has been designed, simulated, and fabricated. The measured results agree well with the simulated results. The simulated and measured results indicate that the proposed design can generate reconfigurable multibeam in both forward and backward directions, either separately or simultaneously. In the unidirectional states, forward and backward beam scanning is achieved within an angular range of +/-30° and +/-22°, respectively, with peak gains of 23.6 dBi and 23.1 dBi. A simultaneous forward and backward beam scanning of +/-40° and +/-22° is achieved in the hybrid radiation state, with peak gains of 19.4 dBi and 19.3 dBi, respectively. The proposed antenna array design offers several advantages, including bidirectional low-loss beam scanning, a simple structure, low power consumption, and a low profile.
Index Terms -Beam-scanning, beam-steering, metasurface, bidirectional, reconfigurable antenna, transmitarray, multibeam.
## I. INTRODUCTION
W ITH the rapid development of wireless communication, navigation, and radar anti-jamming technologies, increased demands and requirements are imposed on multibeam scanning antennas to establish cost-effective solutions with wide bandwidth and simple feed networks. Beam scanning technology has versatile applications in image processing, remote sensing, and cellular mobile communication [1]-[3].
Manuscript received 16 January 2024; revised 22 June 2024; accepted 14 July 2024. This work was supported by the National Key Research and Development Program under Grant 2023YFE3011502. (Corresponding author: Fan Qin.)
Fan Qin, Yifei Liu, Linfeng Zeng, Wenchi Cheng, and Hailin Zhang are with the School of Telecommunications Engineering, Xidian University, Xi'an 710071, China (e-mail: [email protected]; [email protected]; [email protected]; [email protected]; [email protected]). Chao Gu is with the ECIT Institute, Queen's University Belfast, BT3 9DT
Belfast, U.K. (e-mail: [email protected]).
Steven Gao is with the Department of Electronic Engineering, Chinese University of Hong Kong, Hong Kong (e-mail: [email protected]).
Fig. 1. Application scenario of a multibeam base station with bidirectional scanning characteristics in wireless backhaul.
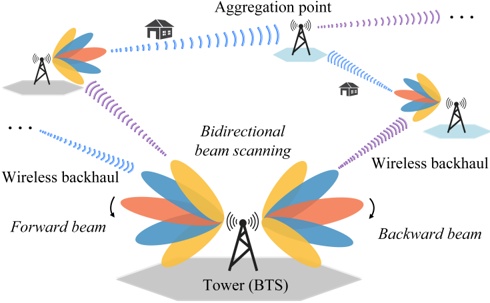
Due to the characteristics of agile beam steering and fast switching time, electronic beam-switching is gradually replacing traditional mechanical beam steering. Methods for achieving multibeam antennas include phased array antennas, which use controllable elements for beam steering; Butler matrix and Rotman lenses, which create multiple fixed beams; lens/transmitarray and reflectarray antennas, which focus and steer beams using multiple feeds. These methods are utilized in modern mobile communication base stations due to their capabilities in handling multi-path and wide beam coverage [4]-[6].
A technique to address the hardware complexity of large phased arrays is to use a dielectric lens [7]-[9]. There are various methods for achieving beam scanning with a dielectric lens antenna, including zoned lens [11], [12], Luneburg lens [13]-[15], multi-focal lens [16], [17]. Additionally, a lens in the form of a transmitarray can achieve robust beam-scanning capability. [18] employs the principle of single-focus phase distribution and a single-feed antenna for 2-D electronic beamsteering. Nevertheless, this design is not suitable for lenses that are illuminated by multiple feeds, resulting in power leakage and ultimately leading to a reduction in gain, particularly under large scanning angles. In this context, the implementation of the bifocal phase design method can significantly enhance the current situation [19]-[21]. In [21], a +/-40° scan range is achieved using dielectric bifocal transmitarray with a scan
Fig. 2. (a) Isometric view of the bidirectional multibeam antenna. (b) Schematic diagram of bidirectional beam scanning antenna and radiation in various working states.
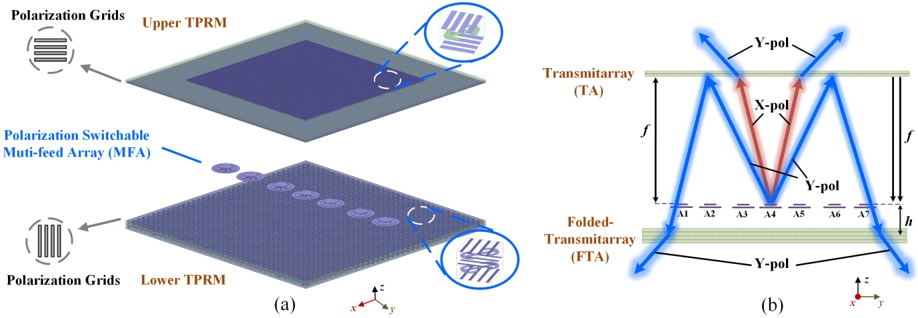
loss of 1.2 dB. Furthermore, a 2-D electronic beam-scanning transmitarray employing dual-layer reconfigurable Huygens element was reported with a simple biasing network [22]. To increase the beam scanning range, a cylindrical ellipticalshaped transmitarray for +/-45° beam scanning was developed by moving the feed along a focal arc [23].
Whilst numerous lens/transmitarray antennas have been proposed to achieve unidirectional beam scanning, [24] introduced a method for simultaneous bidirectional beam scanning to efficiently transmit and receive signals in two opposite directions. However, this method could not facilitate the independent operation of forward or backward modes. More recently, the transmitarray (TA) and reflectarray (RA) have been combined to achieve bidirectional beam steering. The core of the design strategy is to entail the adjustment of the phase of each radiating element to control the direction of the radiation wave [26], [27]. Transmit-reflect array (TRA) structures are versatile and capable of facilitating bidirectional radiation [28]-[30]. A transmitarray was proposed using tunable resonant layer PIN diodes to achieve bidirectional beam scanning [28]. The challenge associated with the design is incorporating a substantial number of PIN diodes in the antenna aperture, which has rather complex structures, resulting in significant losses. The authors in [29] utilize a phase-shifting metasurface backed by frequency selective surface (FSS) to achieve broadband bidirectional radiation. However, the design requires manual rotation of the feed antenna to switch the radiation state, which greatly reduces the convenience and efficiency of beam switching. Recently, metasurface units with polarization-conversion characteristics can be employed to implement the transmitarray for both linear polarization conversion [31], [33], and circular polarization conversion [32]. By designing the unit cell with a transmission polarization-rotating metasurface and polarizing grids [33], high-gain beams for both forward and backward radiation were achieved.
Modern wireless communication systems require efficient and adaptable beam scanning capabilities. Bidirectional beam scanning, where the radiation direction can be dynamically adjusted, is becoming increasingly important for applications demanding coverage in both directions. To ensure robust and energy-efficient performance, these systems need antennas that combine high gain for strong signal transmission and reception with a simple structure to minimize power consumption. Fig. 1 demonstrates the application scenario of the bidirectional beam scanning in the base station of the wireless backhaul networks [25]. By offering an extensive beam coverage area, bidirectional beam scanning antennas increase flexibility in network deployment and facilitate the creation of more efficient communication links within the backhaul network. This paper presents a bidirectional multibeam hybrid transmitarray (HTA) based on a polarization rotating metasurface combined with a polarization switchable feed array. The resulting HTA is a combination of traditional TA and folded-transmitarray (FTA). To the best of the authors' knowledge, the proposed antenna is the first demonstration capable of achieving multibeam scanning in both unidirectional and bidirectional modes by controlling the polarization states of the feed antenna array.
The rest of the paper is organized as follows. First, the antenna configuration and operating principle of the proposed design are elaborated. Then, a detailed discussion of the design principles of the unit cells and phase compensation, along with the polarization-switchable multi-feed array (MFA), is elucidated. In Section IV, the experimental results are compared, with a discussion of the comparison with existing studies. Finally, conclusions are drawn in Section V.
## II. WORKING PRINCIPLE OF THE MULTIBEAM HYBRID TRANSMITARRAY WITH BIDIRECTIONAL RADIATION
Fig. 2(a) depicts the proposed bidirectional multibeam HTA, comprising three parts: the upper transmission polarizationrotating metasurface (TPRM), the lower TPRM, and the MFA mounted between the two TPRMs. The proposed TPRM has a polarization-conversion unit in the middle layer sandwiched by two metallic orthogonal polarization grids printed on the dielectric substrate, which can work as a lens or reflector for the incident wave depending on the grid orientation and incident wave polarization. It is noted that the proposed TPRM can rotate the polarization of the transmitted wave with respect to that of the incident waves by 90°. The TPRM serves three
Fig. 3. Working principle of reconfigurable bidirectional beams based on polarization switching antenna. (a) Forward beam. (b) Backward beam. (c) Bidirectional beam.
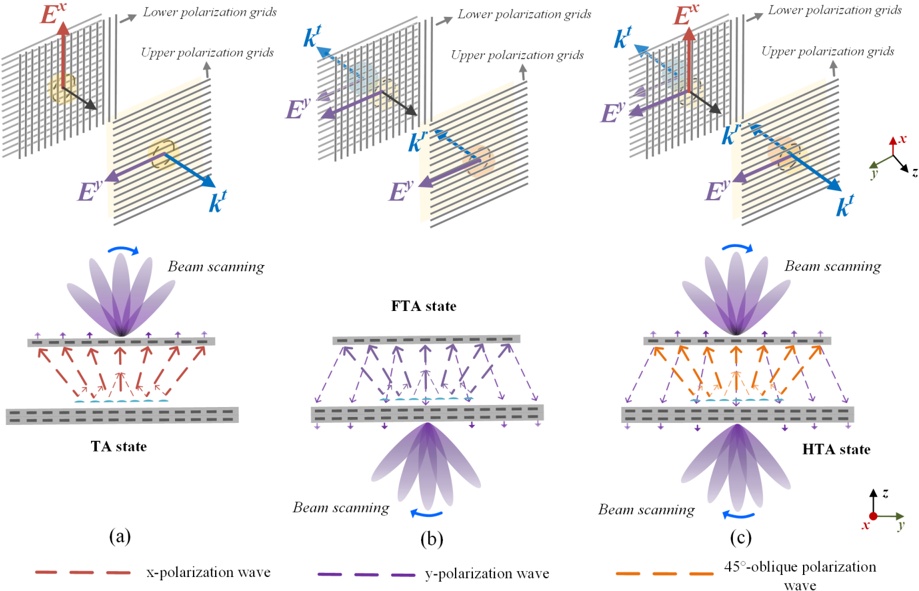
essential functions: Firstly, it transmits or reflects the incident wave based on its associated polarization; secondly, it focuses the transmitted wave to generate pencil beams by appropriately adjusting the structure of TPRM unit cells; and thirdly, it imparts a 90-degree polarization rotation to the transmitted wave. The seven feed antennas, labeled A1 to A7, within the MFA, are symmetrically positioned along the y-axis between the upper and lower TPRMs.
Fig. 3 illustrates the operating principle of multi-mode radiation (unidirectional and bidirectional radiation), and the incident waves generated by MFA in the three states are x-polarization, y-polarization, and 45°-oblique polarization, respectively. The upper and lower polarization grids closest to the MFA are oriented parallel to the y-axis and x-axis, respectively. It is worth noting that the lower metasurface is composed of two TPRMs, which can facilitate double polarization rotation to obtain the same polarization for the forward, backward, and bidirectional transmitted beams.
When illuminated by an x-polarized wave from the feed antenna, the upper TPRM will transmit, focus, and rotate the x-polarized incident waves to a y-polarized pencil beam with high directivity in the forward direction (+z direction, TA state), as shown in Fig. 3(a). The y-polarized waves emitted by the MFA undergo complete reflection at the upper TPRM's metallic grid. The lower TPRM then transmits and focuses these reflected waves, generating backward radiation along the -z direction (FTA state), as shown in Fig. 3(b). To achieve simultaneous bidirectional radiation, the polarization of feed antennas is switched to either +45° or 45° relative to the x-axis, as illustrated in Fig. 3(c). In this state, the incident wave generated by the feed antenna can be decomposed into two orthogonal polarization components (xand y-polarization) with the same magnitude. The upper TPRM transmits and focuses the x-polarized component while the ypolarized component undergoes the same process as the FTA state. This operation can be regarded as the combination of the TA and FTA along two opposite directions, thus denoted as the HTA state. By altering the polarization of the MFA using a reconfigurable feed network, forward, backward, and bidirectional beam scanning performance can be achieved.
## III. DESIGN OF THE PROPOSED BIDIRECTIONAL ROTATING MUTIBEAM HYBRID TRANSMITARRAY
## A. Unit Cell Design
The antenna element for the upper TPRM is donated as Unit Cell 1 (UC1), as shown in Fig. 4(a). The central metallic layer features a double arrow-shaped strip designed to convert the polarization state. Two orthogonal metallic wire-grid polarization grids are positioned on the top and bottom layers, with the wire orientations aligned parallel to the x-axis and y-axis, respectively [20]. The polarization grids exhibit polarization selectivity, allowing only the component of an incident electromagnetic wave with a perpendicular polarization to pass through while reflecting the component with a parallel polarization direction. Therefore, when the electromagnetic wave is illuminated from bottom to top on
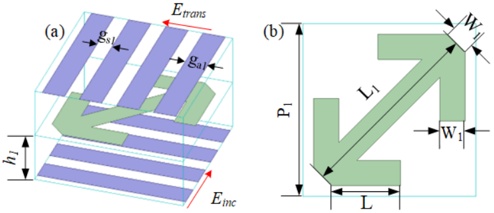
Fig. 4. Transmitarray unit cell UC1. (a) 3D view. (b) Metallic pattern in the middle layer. The geometrical parameters are: g a 1 = 0.9 mm, g s 1 = 0.6 mm, L 1 = 6.56 mm, W 1 = 0.88 mm, and h 1 = 2 mm.
Fig. 5. Transmission magnitude and phase versus the parameter of 'L' at different frequencies.
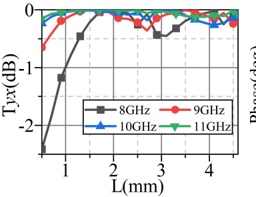
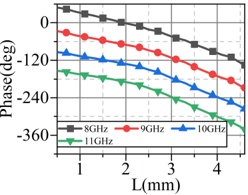
Fig. 6. Phase versus 'L' of UC1 at 10 GHz at vertical and oblique incidence.
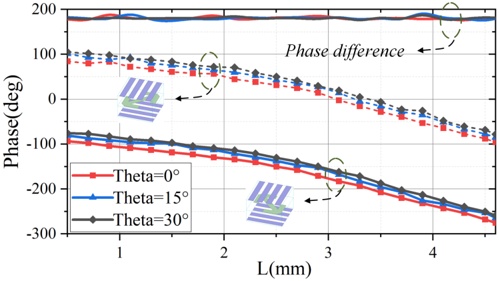
UC1, it can transform the x-polarization wave into a ypolarization wave while the y-polarization wave is reflected. The dielectric substrate of UC1 is F4B with ε r of 2.65 and a loss tangent of 0.001. Each dielectric layer has a thickness of h 1 . As shown in Fig. 4, the polarization conversion layer consists of a rectangular metal strip with an inclined angle of 45° with respect to the x-axis. The period of the UC1 is set as P 1 = 6 mm, corresponding to 0.2 λ . To achieve a high Polarization Conversion Rate (PCR) and efficiently convert polarization across the desired frequency band, the design parameters were optimized using commercial software HFSS. Master-slave boundary conditions and Floquet ports were employed within the simulation process. The total thickness of UC1 is 4 mm, corresponding to 0.13 λ , where λ is the free space wavelength at the center frequency of 10 GHz.
To compensate for the phase delay resulting from diverse feeding positions and beam directions, it is imperative to
Fig. 7. Transmission, reflection coefficients and PCR curves of UC1 when L = 2.4 mm.
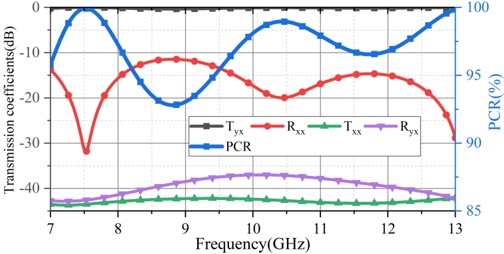
employ unit cells featuring a 360° phase tuning range and high transmission efficiency. Fig. 5 shows the relationship between the simulated magnitude and phase of the transmission coefficient of UC1 with the variation of the parameter 'L' at different frequencies. As the parameter 'L' varies from 0.5 mm to 4.6 mm, a phase variation of 180° is attained, and the | T yx | is close to 0 dB. The phase shift curves are almost parallel for frequencies from 8 to 11 GHz, showing wideband properties. Fig. 6 illustrates the phase curve for both vertical and oblique incidences at 10 GHz. The overall phase deviation for oblique incidence is minimal, and rotating the polarization conversion layer by 90° introduces an additional 180° phase shift. Consequently, the phase variation of UC1 can cover the entire 360° phase range. The PCR of the proposed unit is defined as
$$\int _ { \substack { \int \\ \pi \pi } } P C R = | T _ { y x } | ^ { 2 } / ( | T _ { y x } | ^ { 2 } + | T _ { x x } | ^ { 2 } + | R _ { y x } | ^ { 2 } + | R _ { x x } | ^ { 2 } ) \ \ ( 1 )$$
where T yx and T xx are defined as the transmission coefficients, and R yx and R xx are defined as the reflection coefficients, the first in the subscript denotes the polarization of the transmitted or reflected wave while the second indicates the polarization of the incident wave. Due to the strong polarization selection characteristic of UC1, it can be seen that T yx is close to 0 dB in the range of frequency bands. As depicted in Fig. 7, the PCR of UC1 exceeds 92.8 % across the frequency range from 7 GHz to 13 GHz.
To ensure the same polarization state (y-polarization) for both forward and backward beams, a double polarizationconversion unit is stacked to form the FTA Unit Cell 2 (UC2), as illustrated in Fig. 8. UC2 can be considered a combination of two stacked UC1 with adjusted dimensions to achieve the same polarization as in the forward radiation mode. The unit period of UC2 is optimized as P 2 = 10 mm. The dielectric material of UC2 is the same as that of UC1 ( ε r = 2.65). The total thickness of UC2 is 12 mm, approximately equivalent to 0.4 λ wavelengths.
Fig. 9 shows the simulated magnitude and phase of the transmission coefficient of UC2 at different frequencies. As the parameter 'W' varies from 1.5 mm to 4 mm, a phase variation of 180° is achieved, and the | T yy | is higher than 1.1 dB. As shown in Fig. 10, UC2 exhibits nearly parallel phase shift curves across various frequencies, leading to broad bandwidth and efficient phase compensation. Additionally, the
Fig. 8. Folded-transmitarray unit cell UC2. (a) 3D view. (b) Metallic pattern in the middle layer. The geometrical parameters are: g a 2 = 0.8 mm, g s 2 = 1.7 mm, R 1 = 2.7 mm, R 2 = 1.7 mm, W 2 = 1.15 mm, L 2 = 5.8 mm, and h 2 = 4 mm.
Fig. 9. Transmission magnitude and phase versus 'W' at different frequencies.
Fig. 10. Phase versus 'W' of UC2 at 10 GHz at vertical and oblique incidence.
low slope of the phase curve minimizes sensitivity to manufacturing tolerances. This reduces unwanted phase shifts caused by potential errors from manufacturing UC2 and maintains stable performance even at oblique angles. The element phase remains relatively constant with increasing incidence angles. Similar to the approach used in UC1, rotating either the top or bottom half of UC2 by 90 degrees introduces a 180-degree phase shift compared to the original phase response. This manipulation allows UC2 to achieve phase modulation across the entire 360-degree range. Fig. 11 depicts the transmission and reflection coefficients of UC2.
Fig. 11. Transmission and reflection coefficients of UC2 when W = 3 mm.
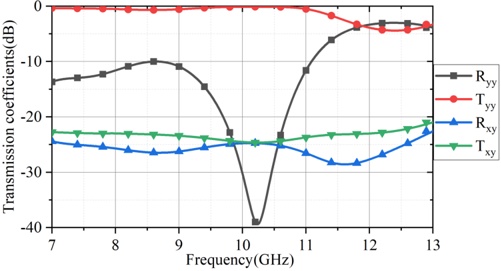
## B. Design of MFA
The multi-mode HTA relies on polarization-switchable microstrip antenna elements. Fig. 12(a) depicts the structure of the designed polarization switchable antenna, which consists of three 0.5 mm-thick substrates of RO4003, a metal ground, a coupled patch with R 3 = 5 mm, a parasitic patch with R 4 = 6.1 mm, and a polarization switching feed network. The presence of a parasitic patch positioned above the antenna induces an additional resonance. The dimensions of the parasitic patch are optimized to enhance the bandwidth of the feed antenna.
The three feed lines are connected to the main feed line, as shown in Fig. 12(c). Three PIN diodes (MADP00090714020x) P1-P3 are employed, and the inductance in the feeding network is 3.3 nH (LQW15AN3N3G8ZD), while a capacitor with a capacity of 20 nF (GRM21B5C1H223JA01L) is used [22]. DC bias lines are soldered to designated pads on the feed network branches, enabling individual control of the polarization states radiated by the antenna. Fig. 12(d)-(f) shows the electric field distribution of the feed antenna at different polarization states.
Fig. 13 presents the S 11 parameters of the feed antenna in different working states. The S 11 remains below -10 dB between 9.2 GHz and 10.4 GHz. Fig. 14 indicates that the gains of the feed antenna in x-polarization, y-polarization, and 45° oblique-polarization are 10.6 dBi, 10.4 dBi, and 10.5 dBi, respectively. Furthermore, the cross-polarization levels for both the x-polarization and y-polarization states are consistently below -20 dB.
## C. Design of Phase Distribution
It is challenging to optimize the phase distribution for different scanning angles. In single-focus phase designs, the phase mismatch increases with the increase of scan angle, resulting in limited scanning range, gain reduction, and sidelobe degradation. The bifocal principle is introduced to obtain phase compensation for the final HTA to improve the performance of the scanned beams. The operating diagram is shown in Fig. 15; the virtual feed1 (VF1) and virtual feed2 (VF2) are symmetrically placed in the x-z plane at the same height as the MFA, with spacing f and h , respectively, between TA and FTA.
Fig. 12. (a) Side view of feed antenna. (b) Exploded view. (c) The feed network of the feed antenna. (d) The electric field distribution in x-polarization. (e) The electric field distribution in y-polarization. (f) The electric field distribution in 45°oblique-polarization. The geometrical parameters are: R f = 20 mm, d p = 4 mm, l f 1 = 16.15 mm, l f 2 = 7.04 mm, d 1 = 1.09 mm, d 2 = 1.39 mm, l f 3 = 1.5 mm, h = 2.5 mm.
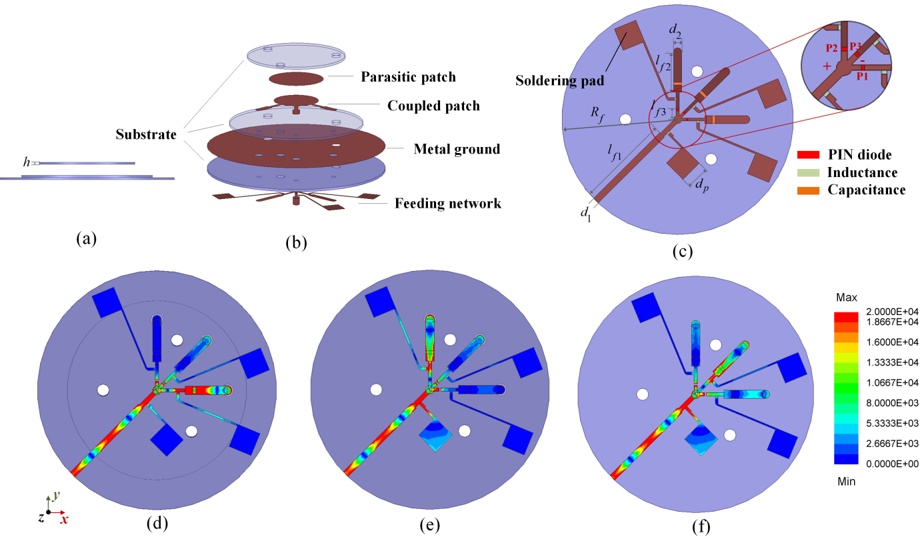
Fig. 13. The simulated S 11 parameters of feed antenna in different polarization states.
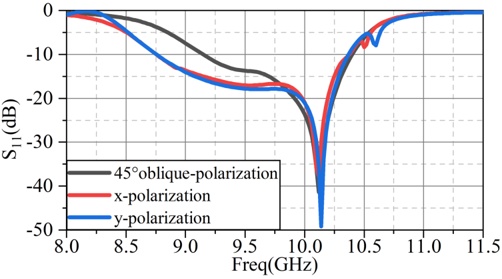
VF1 and VF2 have an offset angle of α degree along the central axis. When only one of the virtual feeds works, it is the eccentric single-focus metasurface, and its phase compensation distribution can be calculated as follows
$$\phi _ { i j } ^ { ( f ) } = k _ { 0 } ( R _ { i j } ^ { ( f ) } - \sin \vartheta ^ { ( f ) } ( x _ { i } \cos \varphi ^ { ( f ) } + y _ { j } \sin \varphi ^ { ( f ) } ) ) \ \ ( 2 ) \ \ \ f r o n \ t t$$
where f represents the corresponding feed excitation, ϑ represents the radiation polar angle of the beam and the metasurface, and φ is the rotation angle of the spherical coordinate system. R ij is the distance from the virtual feeds to the ( i, j ) -th unit cell.
Unlike the single-focus lens antenna, the phase compensation design of the bifocal metasurface must consider the deflection beam generated by two feeds at different positions. When
VF1 works, the polar angle of the scanning beam generated by the metasurface is ( ϑ = ϑ (1) , φ = 0 ) ◦ ; similarly, when VF2 works, the polar angle of the beam is ( ϑ = ϑ (2) , φ = 0 ) ◦ . In both cases, the phase compensation distribution across the aperture is
$$\begin{array} { c } \phi _ { i j } ^ { ( 1 ) } = k _ { 0 } ( R _ { i j } ^ { ( 1 ) } - x _ { i } \sin \vartheta ^ { ( 1 ) } ) \\ \phi _ { i j } ^ { ( 2 ) } = k _ { 0 } ( R _ { i j } ^ { ( 2 ) } - x _ { i } \sin \vartheta ^ { ( 2 ) } ) \end{array}$$
where x i is the abscissa of the ( i, j ) -th metasurface unit, and k 0 is the wavenumber in free space.
Since the bifocal antenna system shown in Fig. 15 is placed symmetrically about the z-axis, the two beam deflection angles are equal, that is, ϑ = ϑ (1) = ϑ (2) , and the compensation phase required for the ( i, j ) -th unit can be computed as the mean value of two different phase distributions, as shown in the following function:
$$\phi _ { b i f o c a l } = \frac { \phi _ { i j } ^ { ( 1 ) } + \phi _ { i j } ^ { ( 2 ) } } { 2 } = \frac { k _ { 0 } ( R _ { i j } ^ { ( 1 ) } + R _ { i j } ^ { ( 2 ) } ) } { 2 } \quad ( 4 )$$
For the forward radiation (+z), the focal length is the distance from the TA aperture to the virtual feeds, denoted by f . For backward radiation (-z), due to the folded structure, the positions of the virtual focal points VF1' and VF2' are mirror images above TA, as shown in the figure below. Therefore, the focal length is expressed by F = 2 f + h .
The relationship between the focal length, aperture dimension, and the edge taper can be followed by equation (5) [39], where D is the lateral size of the antenna. To achieve an optimum aperture efficiency, the f / D is determined by using
Fig. 14. Radiation patterns of the feed antenna. (a) x-polarization. (b) ypolarization. (c) 45°oblique-polarization.
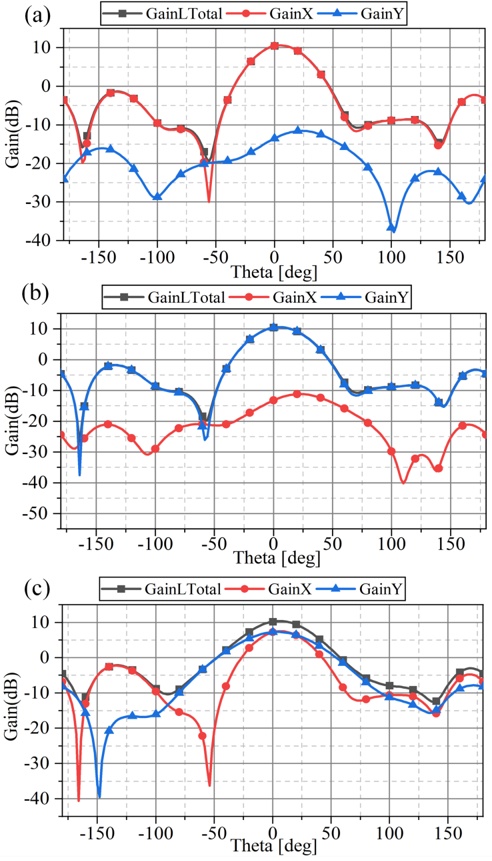
the α -10 dB (-10 dB taper of the feed antenna) to obtain the optimal aperture efficiency.
$$f = \frac { D } { 2 \tan ( \alpha _ { - 1 0 d B } ) } \quad \quad \ ( 5 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
Based on the above design theory, the focal lengths of f and F are optimized to 171 mm and 384 mm, respectively. The interval d between the two virtual feeds was chosen to be 220 mm. To reflect as many electromagnetic waves produced by the feed antenna as possible, the size of the physical aperture of the upper TPRM is chosen the same as that of the lower TPRM. The phase distribution is illustrated in Fig. 16, and the upper and lower metasurface metal layer is designed as shown in Fig. 17.
To demonstrate the operation of the boresight beam, the electric E-field distributions and radiation patterns for xpolarization, y-polarization, and 45° oblique-polarization, respectively, are shown in Fig. 18. It is obvious that quasi-
Fig. 15. Schematic diagram of bifocal phase design principle. (a) Isometric view. (b) Forward radiation. (c) Backward radiation.
Fig. 16. Geometry of the model and calculated phase distributions on (a) TA, and (b) FTA.
spherical waves are successfully converted into plane waves by the upper and lower TPRMs. Moreover, it is confirmed from the far-field patterns that the resultant antenna can generate unidirectional beams for the TA and FTA states and a bidirectional beam for the HTA state.
## IV. SIMULATION AND MEASUREMENT RESULTS
## A. Antenna Prototyping
To validate the antenna design strategy, a prototype with overall dimensions of 410 mm × 390 mm × 223 mm was
Fig. 17. Metasurface metal pattern layer structure. (a) Metasurface of upper TPRM. (b) Metasurface of lower TPRM.
Fig. 18. Simulated E-field distributions and radiation patterns for the three proposed working states.
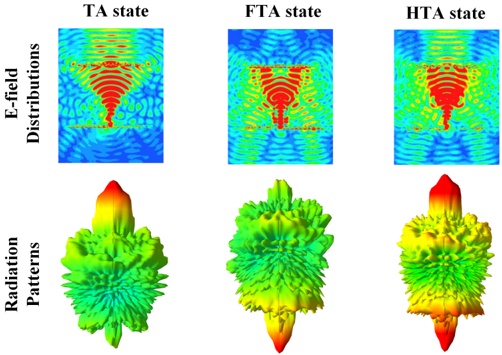
fabricated and measured, as depicted in Fig. 19(a). Fig. 19(b) illustrates the complete assembly of the antenna. First, the metasurface and the polarization grids are etched on a dielectric substrate of F4B with a thickness of 2 mm and a dielectric constant of ε r = 2.65. Figs. 19(c) and (d) show the metal patterns of the inner polarization conversion layer of TA and FTA, respectively. All the substrates were assembled with plastic nuts and bolts. Using a similar process, the feed antenna was etched on a Rogers 4003 dielectric substrate, and the PIN diodes, capacitance, and inductance were soldered to the corresponding positions in the feed network, as shown in Fig. 19(e) and Fig. 19(f).
As shown in Fig. 19(g), the seven feeds of A1-A7 are nonuniformly arranged, and their lateral coordinates are +/-160 mm, +/-110 mm, +/-50 mm, and 0 mm. The feed lines of the MFA are connected to a single-pole multi-throw (SPMT) RF switch for beam switching, while the radiation states are selected by controlling the PIN diodes embedded in the feeding network. The far-field radiation patterns were measured in an anechoic chamber using a standard horn, as shown in Fig. 19(a). Table I lists the radiation characteristics of the three
Fig. 19. (a) Far-field measurement. (b) Assembled array. (c) Metasurface layer of TA. (d) Metasurface layer of FTA. (e) Antenna feed. (f) Polarizationswitching feeding network. (g) Structure of MFA.

Fig. 20. Simulated and measured S 11 parameters of different states.
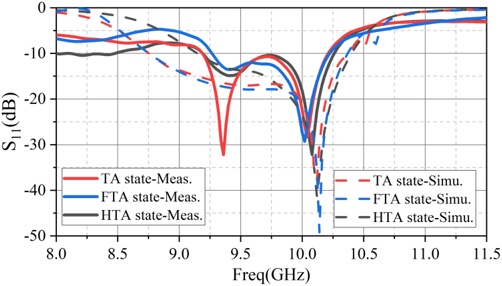
working states.
The simulated and measured S 11 results are below -10 dB within the frequency range from 9.3 GHz to 10.3 GHz, as shown in Fig. 20. The feed antenna employs a parasitic patch to generate additional resonant points, thereby increasing the bandwidth.
## B. TA and FTA Operation
Fig. 21(a)-(e) shows the beam scanning patterns of TA and FTA at the frequency points of 9.0 GHz, 9.75 GHz, and 10.5 GHz, including measured and simulation results. When the MFA operates in the x-polarization (TA state), the A2 to A6 feeds are sequentially excited to produce forward beams with scanning angles of +/-30°, +/-15°, and 0°. As shown in Fig. 21(a)-(c), the peak gains for scanning angles of 0°, +/-15°, and +/-30° are 23.4 dBi, 23.6 dBi, and 22.4 dBi. The maximum scan loss of the beam in the TA state is 1.2 dB. When the MFA works in the y-polarization (FTA state), As shown in Fig. 21(d)-(f). The feeds A1 to A7 can be excited in turn to generate the main beams with scanning angles of +/-22°, +/15°, +/-7°, and 0°. The peak gains for the scanning angles of 0°, +/-7°, +/-15°, and +/-30° are 22.9 dBi, 23.1 dBi, 22.1 dBi, and 22.2 dBi. The maximum scan loss of the beam is 1.0 dB. The discrepancy between the simulated and measured results is primarily attributed to the manufacturing error of the
| The Polarization of MFA | Working States | Feed Antenna Selection | Direction of Generated Beam | Polarization of Generated Beam |
|-------------------------------------------------------|------------------------------|--------------------------|-------------------------------------|----------------------------------------------|
| x-Polarization y-Polarization 45°Oblique-Polarization | TA State FTA State HTA State | A2-A6 A1-A7 A1-A7 | Upward Backward Upward and Backward | y-Polarization y-Polarization y-Polarization |
TABLE I WORKING STATES OF THE ANTENNA SYSTEM
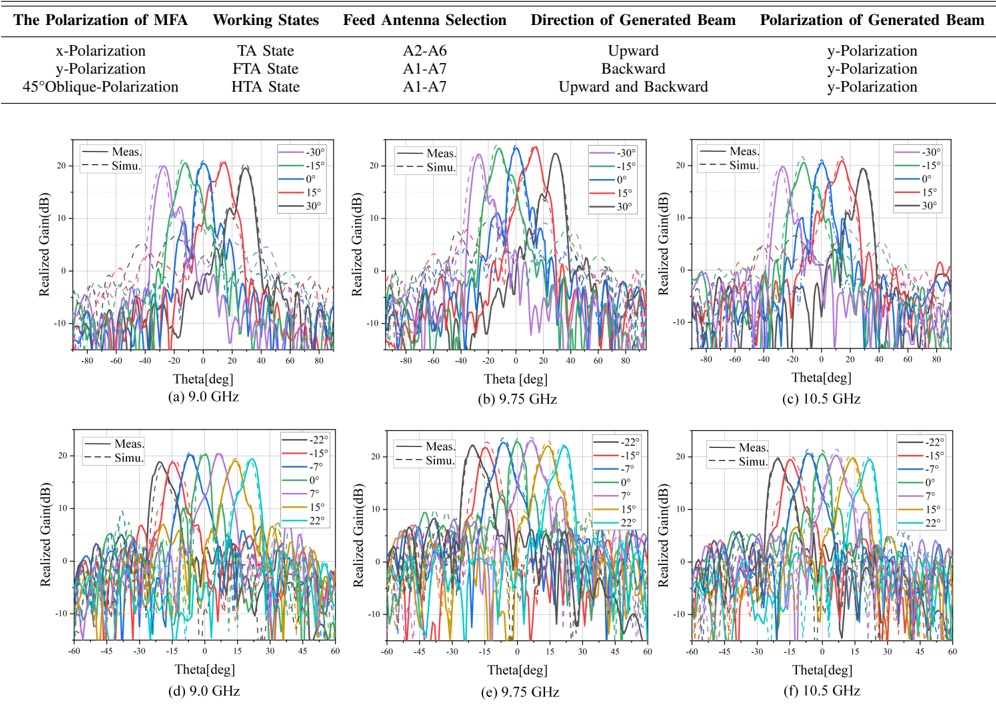
Fig. 21. Radiation patterns of beam scanning in TA and FTA states. (a)-(c) are patterns at TA state, (d)-(f) are patterns at FTA state.
Fig. 22. (a) Measured Co-polarization and Cross-polarization radiation patterns in 9.75 GHz of TA state. (b) Measured Co-polarization and Cross-polarization radiation patterns in 9.75 GHz of FTA state.
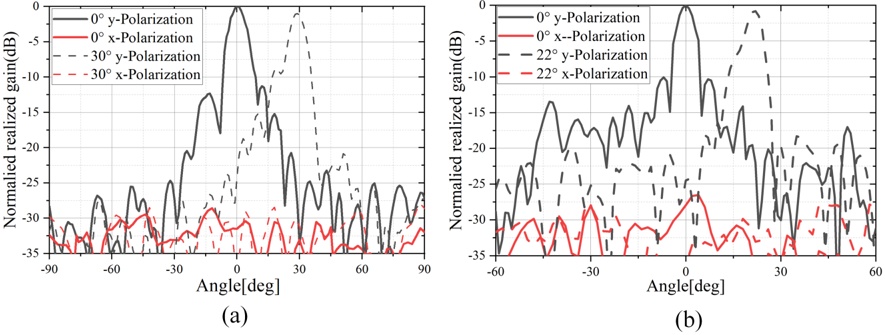
metasurface. Fig. 22 presents the measured co-polarization and cross-polarization radiation patterns. As shown in Fig. 22 (a), in the TA state, the SLLs of the beams are lower than -11.3 dB, and the cross-polarization level is lower than -28.5 dB. As the scanning angle increases, SLLs gradually rise, reaching a maximum of -8.0 dB. For the FTA state, the cross-polarization level is below -26.5 dB, as shown in Fig. 22(b). The peak SLLs are -10.1 dB at 0° and -16.4 dB at 22°.
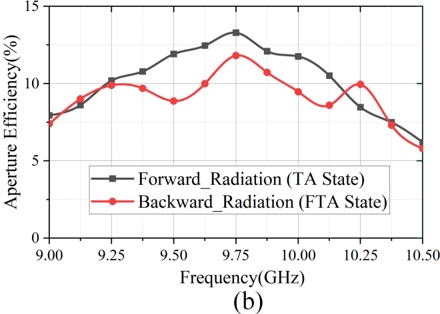
Fig. 23. (a) Peak gains versus frequency for TA and FTA states. (b) Aperture efficiency versus frequency for TA and FTA states.
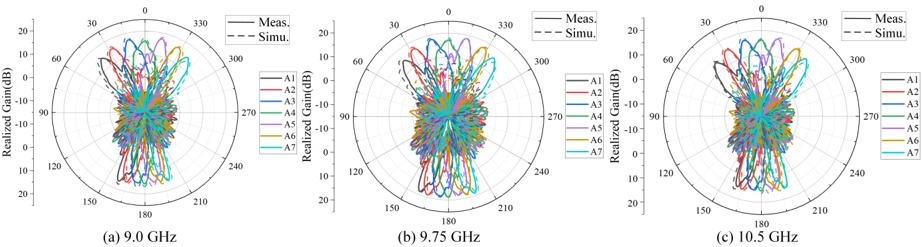
Fig. 24. Radiation patterns of bidirectional beam scanning in HTA state. (a) 9 GHz. (b) 9.75 GHz. (c) 10.5 GHz.
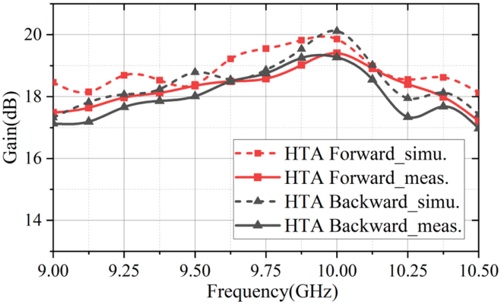
Fig. 25. Peak gains versus frequency of forward and backward in HTA state.
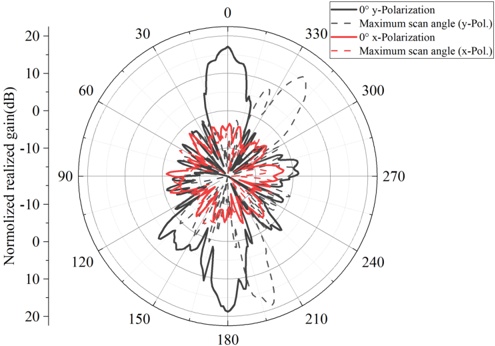
Fig. 23 illustrates the gain and aperture efficiency for the TA and FTA states in the frequency range from 9.0 GHz to 10.5 GHz. As shown in Fig. 23(a), the maximum gain at 9.75 GHz is 23.6 dBi for the TA radiation state and 23.1 dBi for the FTA radiation state, and the 3 dB bandwidth is over 15.4 % (9.0-10.5 GHz). The aperture efficiency for each radiating state is calculated using the maximum physical aperture (360 mm × 360 mm, shown in Fig. 19(a)), resulting in an aperture efficiency of 13.3 % for the TA state, and 11.9 % for the FTA state, respectively. It is worth noting that the enlarged bottom polarization grid layer in the upper TPRM is not included in
Fig. 26. Measured Co-polarization and Cross-polarization radiation patterns of HTA state.
the radiating aperture for the TA state. Therefore, a higher aperture efficiency of 29.9 % can be achieved if the effective aperture size of the TA state (240 mm x 240 mm, shown in Fig. 19(b)) is used.
## C. HTA Operation
As stated above, the HTA state is enabled by switching the polarization to ±45 degrees. By exciting A1-A7 in MFA
TABLE II
## COMPARISON OF THE PROPOSED ANTENNA AND RELATED WORKS
| Ref. | Frequency (GHz) | Gain Bandwidth | Beam-control method | Beam-scanning capability | Radiation states | Forward/ Backward gain (dBi) | Aperture efficiency ( % ) | Maximum scanning angle (Gain loss) |
|-----------|-------------------|------------------|-----------------------|----------------------------|--------------------|--------------------------------|-----------------------------|--------------------------------------|
| [24] | 5.35 | 19.0% (1 dB) | PIN diodes | Bidirectional | ±z | 17.2/15.4 | 8.2/5.4 | ±60° (4.9 dB) |
| [26] | 10 | 14.0% (1 dB) | N.A. | N.A. | +z, -z, ±z | 25.0/25.5 | 14/15 | N.A. |
| [28] | 9.5 | 19.5% (3 dB) | PIN diodes | Bidirectional | +z, -z, ±z | 21.4/21.0 | 19.2/17.3 | ±60°, ±45° ( > 5 dB, > 4 dB) |
| [31] | 9 | 6.7% (1 dB) | N.A. | N.A. | +z, -z | 18.5/13.1 | 28/N.A. | N.A. |
| [36] | 26 | N.A. | RF T/R modules | 2-D Unidirectional | +z | 10.9/N.A. | N.A. | ±45° (6.7 dB) |
| [38] | 25 | N.A. | Mechanical control | Unidirectional | +z | 30.0/N.A. | 28.5/N.A. | ±30° (1.6 dB) |
| This work | 9.75 | 15.4% (3 dB) | Switched feeds | Bidirectional | +z, -z, ±z | 23.6/23.1 | 13.3/11.9 | ±30°, ±22° (1.2 dB, 1.0 dB) |
sequentially, forward beams with scan angles of +/-40°, +/30°, +/-15°, and 0° and backward beams with scan angles of +/-22°, +/-15°, +/-7°, and 0° can be simultaneously generated. Fig. 24(a)-(c) shows the beam scanning patterns of the HTA at the frequency points of 9.0 GHz, 9.75 GHz, and 10.5 GHz, respectively. Since the 45° oblique-polarized electromagnetic wave can be decomposed into x-polarization and y-polarization waves with equal amplitude and phase, the resulting forward scanning beam and backward scanning beam are only half of the energy of the original two states relative to the previous two states.
As shown in Fig. 25, at 10 GHz, the HTA state achieves peak gains of 19.4 dBi and 19.3 dBi in the forward and backward directions, respectively, with a 3 dB gain bandwidth range exceeding 15.4 % (9.0 to 10.5 GHz). As illustrated in Fig. 26, for forward radiation, the SLLs at 0° and 40° are less than -11.7 dB and -8.0 dB, respectively. For backward radiation, the SLLs at 0° and 22° are less than -8.0 dB and -17.3 dB, respectively. The bidirectional cross-polarization level remains below -25.0 dB.
## D. Discussion
Table II summarizes the performance of the proposed design compared to previous related works. Unlike prior research, our design facilitates flexible beam-switching between forward, backward, and bidirectional radiation states, avoiding the extensive use of PIN diodes in the antenna aperture and thereby reducing the complexity of system control. To achieve a simple and efficient design, we implemented a novel lowpower tuning mechanism. This approach facilitates seamless switching between different operating states. Furthermore, the design maintains a reliable level of bidirectional radiation gain. It is noteworthy that, compared to designs using a horn as the feed for backward radiation [24], [26], [28], our design employs a folded transmitarray configuration. This setup causes some blockage due to the feed array, resulting in a slight decrease in aperture efficiency. Nevertheless, for forward radiation mode, our design performs at a comparable level to the referenced works. To achieve cost-effective beam control, an SPMT switch is employed in the beam-switching network, although it introduces some insertion loss. However, this tradeoff allows our design to achieve minimal gain degradation at larger scanning angles, even with a slightly limited scanning range.
## V. CONCLUSION
This paper presents an innovative design for a bidirectional beam-scanning hybrid transmitarray in the X-band based on a feed polarization switching mechanism. By switching different polarization states of the feed array, three different radiation states in the +/-z direction are realized using the bifocal phase design theory combined with the polarizationselective metasurface design. Moreover, beam scanning in the forward, backward, and bidirectional modes is accomplished by modifying the polarization state of the MFA. In the +z direction, the scanning angle can span +/-30°, with a peak gain of 23.6 dBi and a maximum scan loss of 1.2 dB. In the -z direction, the scanning angle range reaches +/-22° with a peak gain of 23.1 dBi and a scan loss of 1.0 dB. This design achieves compact and robust bidirectional beam coverage with high gain and flexible beam control. These combined features make it a promising candidate for Integrated Sensing and Communication (ISAC), next-generation wireless backhaul communication systems, microwave sensor networks, etc.
## REFERENCES
- [1] Dorrah A. H., Eleftheriades G. V., 'Experimental demonstration of peripherally-excited antenna arrays,' Nat. Commun. , 12(1): 6109, 2021.
- [2] D. Li et al., 'Synthetic Beam Scanning and Super-Resolution Coincidence Imaging Based on Randomly Excited Antenna Array,' IEEE Trans. Geosci. Remote Sens. , vol. 61, pp. 1-14, Jun. 2023.
- [3] H. Ozpinar, S. Aksimsek, and N. T. Tokan, 'A Novel Compact, Broadband, High Gain Millimeter-Wave Antenna for 5G Beam Steering Applications,' IEEE Trans. Veh. Techn. , vol. 69, no. 3, pp. 2389-2397, Mar. 2020.
- [4] R. A. York and T. Itoh, 'Injectionand phase-locking techniques for beam control [antenna arrays],' IEEE Trans. Microw. Theory Techn. , vol. 46, no. 11, pp. 1920-1929, Nov. 1998.
- [5] R. J. Mailloux, Phased Array Antenna Handbook , 2nd ed. Norwood, MA: Artech House, 2005.
- [6] P. Nayeri, F. Yang, and A. Z. Elsherbeni, 'Beam-Scanning Reflectarray Antennas: A technical overview and state of the art,' IEEE Antennas Propag. Mag. , vol. 57, no. 4, pp. 32-47, Aug. 2015.
- [7] N. Zhang, W. X. Jiang, H. F. Ma, W. X. Tang, and T. J. Cui, 'Compact High-Performance Lens Antenna Based on Impedance-Matching Gradient-Index Metamaterials,' IEEE Trans. Antennas Propag. , vol. 67, no. 2, pp. 1323-1328, Feb. 2019.
- [8] M. Li and N. Behdad, 'Wideband True-Time-Delay Microwave Lenses Based on Metallo-Dielectric and All-Dielectric Lowpass Frequency Selective Surfaces,' IEEE Trans. Antennas Propag. , vol. 61, no. 8, pp. 4109-4119, Aug. 2013.
- [9] M. Jiang, Z. N. Chen, Y. Zhang, W. Hong, and X. Xuan, 'MetamaterialBased Thin Planar Lens Antenna for Spatial Beamforming and Multibeam Massive MIMO,' IEEE Trans. Antennas Propag. , vol. 65, no. 2, pp. 464-472, Feb. 2017.
- [10] Q. Luo, S. Gao, M. Sobhy, and X. Yang, 'Wideband Transmitarray With Reduced Profile,' IEEE Antennas Wireless Propag. Lett. , vol. 17, no. 3, pp. 450-453, Mar. 2018.
- [11] J. Lee, 'Dielectric lens shaping and coma-correction zoning, part I: Analysis,' IEEE Trans. Antennas Propag. , vol. 31, no. 1, pp. 211-216, Jan. 1983.
- [12] V. Pacheco-Pe˜ na, M. Navarro-C´ ıa, B. Orazbayev, I. V. Minin, O. V. Minin, and M. Beruete, 'Zoned Fishnet Lens Antenna With Reference Phase for Side-Lobe Reduction,' IEEE Trans. Antennas Propag. , vol. 63, no. 8, pp. 3710-3714, Aug. 2015.
- [13] S. Rondineau, M. Himdi, and J. Sorieux, 'A sliced spherical Luneburg lens,' IEEE Antennas Wireless Propag. Lett. , vol. 2, pp. 163-166, 2003.
- [14] M. Liang, W. Ng, K. Chang, K. Gbele, M. E. Gehm, and H. Xin, 'A 3-D Luneburg Lens Antenna Fabricated by Polymer Jetting Rapid Prototyping,' IEEE Trans. Antennas Propag. , vol. 62, no. 4, pp. 1799-1807, Apr. 2014.
- [15] A. Sayanskiy, S. Glybovski, V. P. Akimov, D. Filonov, P. Belov, and I. Meshkovskiy, 'Broadband 3-D Luneburg Lenses Based on Metamaterials of Radially Diverging Dielectric Rods,' IEEE Antennas Wireless Propag. Lett. , vol. 16, pp. 1520-1523, 2017.
- [16] Z. H. Jiang, Y. Zhang, J. Xu, Y. Yu, and W. Hong, 'Integrated Broadband Circularly Polarized Multibeam Antennas Using Berry-Phase TransmitArrays for Ka-Band Applications,' IEEE Trans. Antennas Propag. , vol. 68, no. 2, pp. 859-872, Feb. 2020.
- [17] ´ . A F. Vaquero et al., 'Design of Low-Profile Transmitarray Antennas With Wide Mechanical Beam Steering at Millimeter Waves,' IEEE Trans. Antennas Propag. , vol. 71, no. 4, pp. 3713-3718, Apr. 2023.
- [18] L. Di Palma, A. Clemente, L. Dussopt, R. Sauleau, P. Potier, and P. Pouliguen, 'Circularly-Polarized Reconfigurable Transmitarray in KaBand With Beam Scanning and Polarization Switching Capabilities,' IEEE Trans. Antennas Propag. , vol. 65, no. 2, pp. 529-540, Feb. 2017.
- [19] E. Martinez-de-Rioja, J. A. Encinar, R. Florencio, and C. Tienda, '3D Bifocal Design Method for Dual-Reflectarray Configurations With Application to Multibeam Satellite Antennas in Ka-Band,' IEEE Trans. Antennas Propag. , vol. 67, no. 1, pp. 450-460, Jan. 2019.
- [20] F. Qin, R. Song, W. Cheng, and H. Zhang, 'Multibeam OAM Transmitarray With Stable Vortex Property Based on Bifocal Method,' IEEE Antennas Wireless Propag. Lett. , vol. 20, no. 9, pp. 1601-1605, Sep. 2021.
- [21] A. Massaccesi and P. Pirinoli, 'Wideband Bifocal Dielectric Transmitarray,' Intl. Conf. Elec. Advanced Applications (ICEAA) , pp. 0510-0512, 2019.
- [22] X. Wang, P. -Y. Qin, A. Tuyen Le, H. Zhang, R. Jin, and Y. J. Guo, 'Beam Scanning Transmitarray Employing Reconfigurable Dual-Layer Huygens Element,' IEEE Trans. Antennas Propag. , vol. 70, no. 9, pp. 7491-7500, Sep. 2022.
- [23] P. -Y. Qin, L. -Z. Song, and Y. J. Guo, 'Conformal Transmitarrays for Unmanned Aerial Vehicles Aided 6G Networks,' IEEE Commun. Mag. , vol. 60, no. 1, pp. 14-20, Jan. 2022.
- [24] M. Wang, S. Xu, F. Yang, and M. Li, 'A 1-bit bidirectional reconfigurable transmit-reflect-array using a single-layer slot element with pin diodes,' IEEE Trans. Antennas Propag. , vol. 67, no. 9, pp. 6205-6210, Sep. 2019.
- [25] A. Lahiry, K. N. Le, V. N. Q. Bao, and V. W. Y. Tam, 'Energy-Efficient Ground Base Station Antenna Array System for Wireless Back-Hauling and Two State Charging of Drone Base Stations,' IEEE Internet Things J. , vol. 10, no. 15, pp. 13798-13813, Aug. 2023.
[26] F. Yang, R. Deng, S. Xu, and M. Li, 'Design and experiment of a near zero-thickness high-gain transmit-reflect-array antenna using anisotropic metasurface,' IEEE Trans. Antennas Propag. , vol. 66, no. 6, pp. 2853-2861, Jun. 2018.
[27] S. L. Liu, X. Q. Lin, Y. H. Yan, and Y. L. Fan, 'Generation of a highgain bidirectional transmit-reflect-array antenna with asymmetric beams using sparse-array method,' IEEE Trans. Antennas Propag. , pp. 1-1, Sep. 2021.
[28] H. Yu, P. Li, J. Su, Z. Li, S. Xu, and F. Yang, 'Reconfigurable Bidirectional Beam-Steering Aperture With Transmitarray, Reflectarray, and Transmit-Reflect-Array Modes Switching,' IEEE Trans. Antennas Propag. , vol. 71, no. 1, pp. 581-595, Jan. 2023.
- [29] X. Zhong, H.-X. Xu, L. Chen, W. Li, H. Wang, and X. Shi, 'An FSSbacked broadband phase-shifting surface array with multimode operation,' IEEE Trans. Antennas Propag. , vol. 67, no. 9, pp. 5974-5981, Sep. 2019.
- [30] Z. Zheng, L. Zhang, Q. Luo, C. Mao, Y. He, and S. Gao, 'Wideband 3-D-Printed Transmit-Reflect-Array Antenna With Independent Beam Control,' IEEE Trans. Antennas Propag. , vol. 71, no. 7, pp. 6196-6201, Jul. 2023.
- [31] H.-X. Xu, S. Tang, G.-M. Wang, T. Cai, W. Huang, Q. He, S. Sun, and L. Zhou, 'Multifunctional microstrip array combining a linear polarizer and focusing metasurface,' IEEE Trans. Antennas Propag. , vol. 64, no. 8, pp. 3676-3682, Aug. 2016.
- [32] G. -B. Wu, S. -W. Qu, S. Yang, and C. H. Chan, 'Broadband, SingleLayer Dual Circularly Polarized Reflectarrays With Linearly Polarized Feed,' IEEE Trans. Antennas Propag. , vol. 64, no. 10, pp. 4235-4241, Oct. 2016.
- [33] F. Qin, C. Wan, and X. Wang, 'Broadband Adjustable Gain Bidirectional Radiation Antenna Based on Polarization Rotating Metasurface,' Intl. Conf. Microwave Millimeter Wave Technol. (ICMMT) , Harbin, China, pp. 1-3, 2022.
- [34] L. Wen et al., 'Wideband Transmitarray Antenna Using Compact 2-bit Filtering Unit Cells,' IEEE Trans. Antennas Propag. , vol. 71, no. 10, pp. 8344-8349, Oct. 2023.
- [35] M. Wang, G. Wei, and K. Han, 'Triple-Beam Leaky-Wave Antenna Based on Spoof Surface Plasmon Polaritons With Hybrid Periodic Modulation,' IEEE Antennas Wireless Propag. Lett. , vol. 22, no. 8, pp. 1957-1961, Aug. 2023.
- [36] W. Kong, Y. Hu, J. Li, L. Zhang, and W. Hong, '2-D Orthogonal Multibeam Antenna Arrays for 5G Millimeter-Wave Applications,' IEEE Trans. Microw. Theory Techn. , vol. 70, no. 5, pp. 2815-2824, May. 2022.
- [37] M. Movahhedi, M. Karimipour and N. Komjani, 'Multibeam Bidirectional Wideband/Wide-Scanning-Angle Holographic Leaky-Wave Antenna,' IEEE Antennas Wireless Propag. Lett. , vol. 18, no. 7, pp. 1507-1511, Jul. 2019.
- [38] P. Mei, G. F. Pedersen, and S. Zhang, 'Performance Improvement of Mechanically Beam-Steerable Transmitarray Antennas by Using Offset Unifocal Phase Symmetry,' IEEE Trans. Antennas Propag. , vol. 71, no. 1, pp. 1129-1134, Jan. 2023.
- [39] Abdelrahman A H, F. Yang, Elsherbeni A Z, et al., Analysis and design of transmitarray antennas. , 2017.

Fan Qin (Member, IEEE) received the B.S. degree in electronic information engineering and the Ph.D. degree in electromagnetic wave and microwave technology from Northwestern Polytechnical University, Xi'an, China, in 2010 and 2016, respectively. He was a visiting scholar with the University of Kent, Canterbury, UK, from 2013 to 2015. He joined the School of Telecommunications Engineering, Xidian University, Xi'an, China, in 2016. Currently, he is an Associate Professor with Xidian University. His research interests involve metamaterial antennas, millimeter wave antennas, vortex wave antennas, and metasurface-assisted wireless communication.

Yifei Liu (Student Member, IEEE) was born in Henan, China, in 2000. He received the B.S. degree in telecommunication engineering from Zhengzhou University, Zhengzhou, China, in 2022.
He is currently a postgraduate student in information and telecommunication engineering at Xidian University, Xi'an, China. His current research interests involve metamaterial antennas and reconfigurable antennas.

Chao Gu (Member, IEEE) received the B.Sc. and M.Sc. degrees from Xidian University, Xi'an, China, in 2009 and 2012, respectively, and the Ph.D. degree from the University of Kent, Canterbury, U.K., in 2017. From 2017 to 2018, he worked as a research associate at the University of Kent, where he led the development of additive manufacturing techniques for radio frequency components and antennas. Since August 2018, he has been a Senior Research Engineer at the Centre for Wireless Innovation, School of Electronics, Electrical Engineering and Computer
Science, Queen's University Belfast, U.K., actively participating in and leading extensive research and development tasks for various wireless applications, including space-based instrumentation and imaging, wireless power transfer, and sub-terahertz wireless solutions. His research interests include phased arrays, reconfigurable antennas, and metasurface antennas.

Linfeng Zeng (Student Member, IEEE) was born in Jiangxi, China. He received the B.S. degree in telecommunication engineering from Lanzhou University, Lanzhou, China, in 2020; and received the M.S. degree from the School of Telecommunication Engineering, Xidian University, Xi'an, China, in 2023.
His current research interests include multibeam antennas and metasurface antennas.

Wenchi Cheng (Senior Member, IEEE) received the B.S. and Ph.D. degrees in telecommunication engineering from Xidian University, Xian, China, in 2008 and 2013, respectively. He was a Visiting Scholar with the Department of Electrical and Computer Engineering, Texas A & M University, College Station, TX, USA, from 2010 to 2011. He is currently a Full Professor with Xidian University. He has published more than 200 international journal and conference papers in IEEE Journal on Selected Areas in Communications , IEEE Magazines , IEEE
TRANSACTIONS , IEEE INFOCOM , GLOBECOM , and ICC . His current research interests include 6G wireless networks, electromagnetic-based wireless communications, and emergency wireless information. He received the IEEE ComSoc Asia-Pacific Outstanding Young Researcher Award in 2021, the URSI Young Scientist Award in 2019, the Young Elite Scientist Award of CAST, and four IEEE journal/conference best papers. He has served or serving as the Wireless Communications Symposium Co-Chair for IEEE ICC 2022 and IEEE GLOBECOM 2020, the Publicity Chair for IEEE ICC 2019, the Next Generation Networks Symposium Chair for IEEE ICCC 2019, and the Workshop Chair for IEEE ICC 2019/IEEE GLOBECOM 2019/INFOCOM 2020 Workshop on Intelligent Wireless Emergency Communications Networks. He has served or serving as the ComSoc Representative for IEEE Public Safety Technology Initiative , Editor for IEEE Transactions on Wireless Communications , IEEE System Journal , IEEE Communications Letters , and IEEE Wireless Communications Letters .

Hailin Zhang (Member, IEEE) received B.S. and M.S. degrees from Northwestern Polytechnic University, Xi'an, China, in 1985 and 1988 respectively, and the Ph.D. from Xidian University, Xi'an, China, in 1991. In 1991, he joined the School of Telecommunications Engineering, Xidian University, where he is a senior Professor of this school. He is also currently the Director of the Key Laboratory in Wireless Communications Sponsored by the China Ministry of Information Technology, a key member of the State Key Laboratory of Integrated Services
Networks, one of the state government's specially compensated scientists and engineers, a field leader in Telecommunications and Information Systems in Xidian University, an Associate Director of National 111 Project. Dr. Zhang's current research interests include key transmission technologies and standards on broadband wireless communications for 5G and 5G-beyond wireless access systems. He has published more than 150 papers in journals and conferences.

Steven Gao (Fellow, IEEE) received the PhD from Shanghai University, China. He is a Professor at the Department of Electronic Engineering at the Chinese University of Hong Kong, Hong Kong, where he is also the Director of the Center for Intelligent Electromagnetic Systems. Prior to joining CUHK, he was a Professor and Chair of RF/Microwave Engineering at the University of Kent (UKC), UK during 20132022, and became an Honorary Professor at UKC since 2022.
His research covers smart antennas, phased arrays,
MIMO, reconfigurable antennas, broadband/multiband antennas, satellite antennas, and wireless systems (mobile and satellite communications, syntheticaperture radars, IOT). He co-authored/co-edited 3 books (Space Antenna Handbook, Wiley, 2012; Circularly Polarized Antennas, IEEE & Wiley, 2014; Low-Cost Smart Antennas, Wiley, 2019), over 500 papers and 20 patents.
He is a Fellow of IEEE and the Editor-in-Chief for IEEE Antennas and Wireless Propagation Letters . He was a Distinguished Lecturer of IEEE Antennas and Propagation Society (2014-2016), and an Associate Editor for several international Journals ( IEEE TAP ; Radio Science ; Electronics Letters ; IET Circuits , Devices and Systems , etc). He served as the Lead Guest Editor of Proceedings of the IEEE for a Special Issue on 'Small Satellites' (2018), and the Lead Guest Editor of IEEE Trans. on Antennas and Propagation for Special Issues on 'Low-Cost Wide-Angle Beam-Scanning Antennas' (2022) and 'Antennas for Satellite Communication' (2015), and a Guest Editor of IET Circuits, Devices & Systems for a Special Issue in 'Photonic and RF Communications Systems' (2014). He was the UK's Representative in the European Association on Antennas and Propagation (EurAAP) during 2021-2022, General Chair or General Co-Chair of international conferences (LAPC 2013, UCMMT 2021), and was an Invited/Keynote Speaker at many conferences. He is the TPC Chair of ISAPE 2024. | 10.1109/TAP.2024.3433567 | [
"Fan Qin",
"Yifei Liu",
"Chao Gu",
"Linfeng Zeng",
"Wenchi Cheng",
"Hailin Zhang",
"Steven Gao"
] | 2024-08-02T07:53:51+00:00 | 2024-08-02T07:53:51+00:00 | [
"eess.SY",
"cs.SY"
] | Multibeam Hybrid Transmitarray Based on Polarization Rotating Metasurface With Reconfigurable Bidirectional Radiation | This paper proposes a bidirectional multibeam hybrid transmitarray (HTA)
employing a transmission polarization-rotating metasurface (TPRM). A novel
configuration is introduced to facilitate bidirectional beam scanning by
combining the transmitarray (TA) and folded-transmitarray (FTA). To accomplish
the reconfiguration of both unidirectional and bidirectional radiation states
in the +z, -z, and +/-z directions, a polarization switchable multi-feed array
(MFA) is placed at the focal plane between the TA and FTA, radiating
x-polarization, y-polarization, and 45-degree oblique polarization waves,
respectively. Meanwhile, the proposed antenna can achieve multibeam radiation
in the three aforementioned states by switching the polarization of the MFA. To
demonstrate the operating principle, a prototype has been designed, simulated,
and fabricated. The measured results agree well with the simulated results. The
simulated and measured results indicate that the proposed design can generate
reconfigurable multibeam in both forward and backward directions, either
separately or simultaneously. In the unidirectional states, forward and
backward beam scanning is achieved within an angular range of +/-30{\deg} and
+/-22{\deg}, respectively, with peak gains of 23.6 dBi and 23.1 dBi. A
simultaneous forward and backward beam scanning of +/-40{\deg} and +/-22{\deg}
is achieved in the hybrid radiation state, with peak gains of 19.4 dBi and 19.3
dBi, respectively. The proposed antenna array design offers several advantages,
including bidirectional low-loss beam scanning, a simple structure, low power
consumption, and a low profile. |
2408.01079v1 | ## THE GIROUX CORRESPONDENCE IN DIMENSION 3
JOAN LICATA AND VERA V ´ ERTESI
ABSTRACT. In [LV] the authors proved the Giroux Correspondence for tight contact 3 -manifolds via convex Heegaard surfaces. Simultaneously, [HBH] gave an all-dimensions proof of the Giroux Correspondence by generalising convex surface theory to higher dimensions. This paper uses a key result from [HBH] and also [Tia] to complete the 3 -dimensional proof for arbitrary (not necessarily tight) contact 3-manifolds. This presentation features low-dimensional techniques and further clarifies the relationship between contact manifolds and their Heegaard splittings that was introduced in [LV].
## 1. INTRODUCTION
Topology and contact geometry enjoy a remarkable relationship in dimension 3 . Contact structures are defined in the smooth category with differential geometric language, and yet they mirror fundamental topological properties of the underlying 3 -manifold. An open book decomposition is arguably the most striking incarnation of this relationship: up to diffeomorphism, a contact manifold is determined simply by a surface mapping class. For the last twenty years, 3-dimensional contact geometry has been shaped by the equivalence between contact structures and open books first proposed by Giroux in the early 2000s:
Theorem 1.1. [Giroux Correspondence [Gir02] ] Two open book decompositions support isotopic contact structures if and only if they admit a common positive stabilisation.
Because topology and contact geometry are so closely entwined, it's natural to probe whether topological techniques can be squeezed to produce meaningful contact geometric outputs. In this spirit, in 2023 the authors developed new tools to study 3 -dimensional contact manifolds via their Heegaard decompositions.
We used the enhanced relationship between contact structures and Heegaard splittings to prove the Giroux Correspondence in the case of tight contact 3 -manifolds [LV]. Simultaneously, Breen-Honda-Huang used generalised convex surface theory to prove the Giroux Correspondence for all contact structures and in all dimensions [HBH]. While the work of BreenHonda-Huang fully covers the 3 -dimensional case, the generality of their
techniques lends their proof a different flavour. This paper completes the 3-dimensional story, using an essential result of [HBH] and also [Tia] to bridge the gap to overtwisted manifolds that limited the scope of our previous paper. We believe this work will make the proof more accessible to a low-dimensional audience; in particular, it offers a useful illustration of convex surface techniques in concert with Heegaard splittings.
- 1.1. Heegaard splittings and open book decompositions. Any open book decomposition of a manifold gives rise to a canonical Heegaard decomposition. Heegaard splittings produced thus are called convex Heegaard splittings , and one may directly recover an open book supporting ξ from any convex Heegaard splitting of ( M,ξ ) . The innovation in [LV] is a procedure called refinement that produces an open book from a more general class of Heegaard splittings of a contact manifold. Although this open book decomposition is not uniquely defined, any two open books produced thus admit a common positive stabilisation - exactly the equivalence appearing in the Giroux Correspondence. It follows that the Giroux Correspondence can be rephrased as a statement about convex Heegaard splittings (Theorem 3.3). Our proof of the Giroux Correspondence for tight contact manifolds relied on showing that many operations one might naturally perform on a Heegaard splitting of a contact manifold in fact preserve the positive stabilisation class of the associated open book.
However, these techniques were insufficient in the case of overtwisted manifolds. In order to assign an open book decomposition to a contact manifold with a Heegaard splitting, our approach required both handlebodies to be tight. When two convex Heegaard surfaces are isotopic, there is a sequence of convex Heegaard surfaces interpolating between them. However, even when both original Heegaard splittings have tight handlebodies, intermediate Heegaard splittings in the sequence may nevertheless have overtwisted handlebodies. The present work bypasses this stumbling block by considering highly stabilised Heegaard splittings where the handlebodies are always tight. We introduce the term 'bridging' for a particular method of constructing such a splitting, and we show that different choices made in constructing a bridge splitting preserve the positive stabilisation class of the associated open book. This allows us to prove that any pair of convex Heegaard splittings for a fixed contact manifold correspond to open books that admit a common positive stabilisation.
- 1.2. A note on notation. The arguments in this paper involve sequences of Heegaard splittings of varying types, each of which is denoted by some sort of ' H '. We have attempted to define notation locally and maintain these choices consistently, but we briefly outline the system here for reference. Every Heegaard surface Σ is required to be convex; Heegaard splittings subject to no further restrictions are denoted by H = (Σ , U, V ) , where U and V are the handlebodies, oriented so that ∂U = Σ . Elements of a
pair of Heegaard splittings are distinguished by the addition of a prime: H = (Σ , U, V ) and H ′ = (Σ ′ , U ′ , V ′ ) . Following the notation in [LV], the refinement of H is denoted by ˜ H = (Σ ˜ , U, V ˜ ˜ ) .
Starting in Section 3.2, we will stabilise Heegaard splittings by attaching certain contact 1 -handles found in the complement of fixed handlebodies. We will call this process bridging , and we denote the bridge of H by ̂ H = (Σ ̂ , U, V ̂ ̂ ) . When we bridge only a single handlebody of the original splitting, we denote the result by ̂ H U or ̂ H V , as appropriate. Distinct bridged splittings may be distinguished by primes: ̂ H and ̂ H ′ .
Acknowledgment. This research was supported in part by the Austrian Science Fund (FWF) P 34318. For open access purposes, the author has applied a CC BY public copyright license to any author-accepted manuscript version arising from this submission. The authors would also like to thank Ko Honda and Matthias Scharitzer for helpful discussions on the topic.
## 2. BACKGROUND
We assume the reader is familiar with basic notions in contact geometry, but we use this section to collect some tools and terminology that will be essential for the rest of the paper. Section 2.1 provides a quick review of convex surface theory and introduces weak contactomorphism (Definition 2.1) as an equivalence relation on contact manifolds with convex boundary. Section 2.2 describes the relationship between open book decompositions and convex Heegaard splittings (Definition 2.4) of a contact manifold. Section 2.3 presents the contact handle model for bypass attachment. Finally, Section 2.4 states the key theorem borrowed from [HBH] and [Tia] which classifies distinct bypass decompositions of a product cobordism. Also, Lemma 2.8 gives a new perspective on the familiar operation of bypass rotation.
- 2.1. Convex surfaces. The reader looking for a more thorough introduction to convex surface theory is referred to [Mas14] or the lecture notes [Etn04, Hon].
Recall that a vector field V in a contact manifold ( M,ξ ) is contact if the flow of the vector field preserves ξ . A surface is convex when there exists a contact vector field V transverse to Σ . The essential feature of a convex surface Σ is that it provides a combinatorial characterisation of the contact structure in an I -invariant neighbourhood ν (Σ) ; the product structure on ν (Σ) is provided by the flow of V . The dividing set on Σ is a separating multicurve Γ Σ consisting of the points where V lies in ξ . Changing the vector field that certifies Σ as convex changes Γ Σ only by isotopy, and any isotopy keeping Σ convex also preserves Γ Σ up to isotopy. Furthermore,
any Γ ′ isotopic to Γ Σ may be realised as a dividing set after performing an isotopy of Σ within an I -invariant neighbourhood.
Convex surface theory is particularly useful for studying contact manifolds with boundary, and we will assume throughout that the boundary of ( M,ξ ) is convex. Since the dividing set characterises ξ near ∂M , we would like to be able to glue ( M,ξ, Γ ∂M ) to ( M ,ξ , ′ ′ Γ ∂M ′ ) whenever there is a diffeomorphism taking ( ∂M, Γ ∂M ) to ( ∂M , ′ Γ ∂M ′ ) . Because we are working in the smooth category, gluing is achieved by identifying contact neighbourhoods of the boundaries; for later convenience, we introduce the following equivalence relation on contact manifolds with boundary:
Definition 2.1. [LV, Definition 2.3.] Two contact manifolds ( M,ξ ) and ( M ,ξ ′ ′ ) with convex boundary are weakly contactomorphic if there is a contact embedding ι : M ↪ → M ′ such that ι ( ∂M ) is convexly isotopic to ∂M ′ .
Remark 2.2. Wenotethat if ι : M → M ′ is a contact embeddeding as above, then M \ ι ( M ′ ) is a weak identity morphism in the sense of [Tia].
Henceforth, we will be interested in contact manifolds with boundary only up to weak contactomorphism. Two (weak contactomorphism classes of) manifolds may be glued along diffeomorphic boundary components if and only if there is a diffeomorphism respecting the dividing sets. Gluing is well defined as an operation on weak contactomorphism classes of manifolds; see [LV, Proposition 2.8.].
As a special case of weakly contactomorphic manifolds, we also introduce the following:
Definition 2.3. [LV, Definition 2.4.] Two embedded codimension0 submanifolds N ,N 1 2 ⊂ ( M,ξ ) with convex boundary are weakly (contact) isotopic if there is an isotopy N s between them such that ∂N s remains convex throughout.
- 2.2. Open book decompositions of contact manifolds. Let ( B,π ) denote an open book decomposition of M . That is, B is an oriented link and π : M B \ → S 1 is a fibration of the complement of B by Seifert surfaces for B . When M is equipped with a contact structure ξ , we assume any open book decomposition supports ξ in the sense of [TW75].
Anopenbookdecomposition ( B,π ) induces a Heegaard splitting (Σ , U, V ) where each handlebody consists of half the pages: U = π -1 [0 , 1 2] / and V = π -1 [1 / , 2 1] . The Heegaard surface
$$\Sigma = \overline { \pi ^ { - 1 } ( 0 ) } \cup - \overline { \pi ^ { - 1 } ( 1 / 2 ) }$$
is naturally convex with dividing curve Γ Σ = B = ∂ π ( -1 (0) ) . An arc properly embedded on a page of the open book produces a properly embedded disc in the corresponding handlebody, and in fact, such discs characterise the Heegaard splittings induced by open books.
More precisely, a disc A properly embedded in a contact manifold with convex boundary (Σ Γ , Σ ) is a product disc if | ∂A ∩ Γ Σ | = 2 . A disc system for a handlebody is a set of properly embedded discs that cut it into a ball. Torisu introduced the notion of a convex Heegaard splitting [Tor00]:
Definition 2.4. AHeegaard splitting (Σ , U, V ) of ( M,ξ ) is convex if
- · Σ is convex with dividing curve Γ Σ ;
- · ξ | U and ξ | V are both tight; and
- · each of the manifolds U and V admits a system of product discs.
The discs in a convex Heegaard splitting determine a product structure on each handlebody, and hence, an open book decomposition with binding Γ Σ . Moreover, this relation is one-to-one up to isotopy.
Proposition 2.5. [LV, Proposition 3.4.] Let ( M,ξ ) be a contact manifold and let ( B,π ) and ( B , π ′ ′ ) be open books supporting ξ . Then the induced convex Heegaard splittings are isotopic via an isotopy keeping the Heegaard surface convex if and only if ( B,π ) and ( B , π ′ ′ ) are isotopic through a path of open books supporting ξ .
Because a convex Heegaard splitting determines an open book decomposition, a convex splitting allows one to reconstruct the contact structure. Specifically, suppose (Σ Γ , Σ , { α i } { , β i } ) is a convex Heegaard diagram for ( M,ξ ) where the meridional circles bound product discs in the respective handlebodies and the restriction of ξ to each handlebody is known to be tight. Then up to contact isotopy, there is a unique contact structure structure compatible with this data.
- 2.3. Bypass attachment. Next, we turn to an operation that changes the weak contactomorphism class of a contact manifold while preserving the topological type. Adopting the perspective of [HKM09, Ozb11], we define bypass attachment as an operation performed by gluing contact handles.
As in the topological setting, a contact k -handle is a D k × D 3 -k glued along ∂D k × D 3 -k to the boundary of an existing manifold M . Additionally, each k -handle is required to smooth to a tight 3 -ball, and the dividing set on the attaching region is prescribed. A 1 -handle attachment is specified by an S 0 on the dividing set Γ ∂M , while a 2 -handle attachment is specified by an S 1 that intersects Γ ∂M twice transversely. Local models for handle attachment are well established in the literature; see, for example, [Gir91] or [Ozb11]. Although each handle is a cornered manifold, the gluing process is defined so that the manifold is smooth after each attachment.
Let (Σ Γ , Σ ) be a convex surface. A Legendrian arc c embedded in Σ is a bypass arc if ∂c lies on Γ Σ and the interior of c intersects Γ Σ once transversely. As explained next, we may associate a new contact manifold with convex boundary to any bypass arc on the convex boundary of a contact manifold.
FIGURE 1. Left: a bypass half-disc attached along the arc c . Centre: the attached 1 -handle is a regular neighbourhood of an arc Legendrian isotopic to c . Right: attaching the shaded 2 -handle along c ∪ c ′ completes the bypass attachment.

The steps described here are illustrated in Figure 1. First, attach a minimally twisting contact 1 -handle h 1 along the 0 -sphere ∂c . Slightly abusing notation, continue to denote the remaining portion of the bypass arc by c . Let c ′ ⊂ ∂h 1 be a Legendrian arc with endpoints on c and such that tb ( c ∪ c ′ ) = -1 . Attach a contact 2 -handle h 2 along c ∪ c ′ . Topologically, the handles cancel, but in general the dividing set on the new boundary is not isotopic to Γ Σ . See Figure 2. We often write X to denote the pair of handles h 1 ∪ h 2 ; X is itself a neighbourhood of a bypass half-disc D whose cornered Legendrian boundary consists of the bypass arc c and a Legendrian core of h 1 . Coordinate models for this construction are provided in [Ozb11], and the dividing sets at each stage of the construction are shown in Figure 1.

FIGURE 2. Left: Local model for a bypass attachment arc. Centre: The new dividing set after attaching a bypass along the arc shown on the left. Right: A trivial bypass arc. Attaching a bypass along the arc shown preserves the dividing set up to isotopy.
Suppose that ( M,ξ, Γ ∂M ) is a contact manifold with convex boundary and let c be a bypass arc on ∂M . Then the weak contactomorphism class of M ∪ ( h 1 ∪ h 2 ) is preserved under isotopies of c through bypass arcs.
Abypass is trivial when the bypass arc c on Σ matches the one shown on the right in Figure 2. That is, the arc c turns left after the interior crossing with Γ Σ to cobound a bigon with the same arc of Γ Σ .
Attaching a trivial bypass preserves the convex isotopy class of the surface. If Σ bounds a contact submanifold ( N,ξ ) , then attaching a trivial bypass also preserves the weak contact isotopy class of N . As shown in
[HKM07, Lemma 5.1.], when the bypass arc c is trivial on Σ ⊂ ( M,ξ ) , the corresponding bypass half-disc D always exists as a submanifold of M .
- 2.4. Bypass decompositions. Bypasses allow us to classify distinct contact structures on a fixed topological manifold. Adopting cobordism notation, wewrite ∂ + M (respectively, ∂ -M ) to distinguish the outward-oriented (respectively, inward-oriented) boundary of a topological M .
Theorem 2.6. [Hon02, Section 3.2.3] Let (Σ × I, ξ ) be a topological product with convex boundary. Then there exists a sequence of bypasses X i := h 1 i ∪ h 2 i such that (Σ × I, ξ ) is weakly contactomorphic to
$$\begin{matrix} \cos m o r p n u c { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \ \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } { \, } \\ \end{matrix}$$
where ν (Σ) is an I -invariant half-neighbourhood of Σ ×{- } 1 and the bypass arc c j for X j = h 1 j ∪ h 2 j lies on
$$\partial _ { + } ( \nu ( \Sigma ) \cup \bigcup _ { i = 1 } ^ { j - 1 } X _ { i } ).$$
Theorem 2.6 has an alternative presentation as a decomposition theorem. Given a contact manifold (Σ × I, ξ ) with convex boundary, consider an embedding
$$\iota \colon \nu ( \Sigma ) \cup \bigcup _ { i } X _ { i } \hookrightarrow ( \Sigma \times I, \xi ) \\ \psi \psi. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e.. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e. \ e.$$
as in Definition 2.1. It follows that contact handles h 1 i and h 2 i may be identified as submanifolds of the original (Σ × I, ξ ) . This identifies a sequence of bypass arcs c j on the embedded convex surfaces Σ j -1 := ι ( ∂ + ( ν (Σ) ∪ ⋃ j -1 i =1 X i )) . Similarly, there exist embedded bypass half-discs D i in Σ × I . The surface Σ j is constructed by isotoping Σ j -1 across a neighbourhood of D j .
We write (Σ × I, ξ ) = X 1 ∗ X 2 ∗ · · · ∗ X f to denote this decomposition of (Σ × I, ξ ) .
The factorisation provided by this theorem is not unique. As mentioned before, one can isotope any bypass attaching arc through bypass arcs. In addition, there are two further moves that change the decomposition while preserving the contact manifold: Trivial Insertion and Far Commutation.
[TI]: Trivial Insertion Given a bypass decomposition X 1 ∗ · · · ∗ X f , let c T denote a trivial bypass arc on Σ j . Then a bypass attachment along c T may be inserted into the decomposition:
$$X _ { 1 } * \cdots * X _ { j } * X _ { j + 1 } * \cdots * X _ { f } \\ \downarrow \\ X _ { 1 } * \cdots * X _ { j } * X _ { T } * X _ { j + 1 } * \cdots * X _ { f }$$
[FC]: Far Commutation Suppose that the bypass arcs c j and c j +1 for X j and X j +1 are disjoint. Then in any decomposition in which these correspond to consecutive bypass attachments, the order in which these are performed may be exchanged:
$$X _ { 1 } * \cdots * X _ { j } * X _ { j + 1 } * \cdots * X _ { f } \\ \downarrow \\ X _ { 1 } * \cdots * X _ { j + 1 } * X _ { j } * \cdots * X _ { f }$$
The main theorem of both [Tia] and [HBH] establishes that Trival Insertion and Far Commutation suffice to relate any two bypass decompositions of topologically trivial products:
Theorem 2.7. [HBH, Theorem 3.1.2 ] Any two bypass decompositions of (Σ × I, ξ, Γ ) Σ are related by isotopy of the bypass arcs and a finite iteration of Trivial Insertion and Far Commutation moves.
The dimension 3 case was the Main Theorem in [Tia], although presented in different language.
The term bypass rotation is used in several different, but related, senses in the literature. Here, we consider the phenomenon as presented in [HKM07] and recall the proof that it is a consequence of the above two moves. Let c be a bypass arc on Σ . Let c T be another bypass arc as in Figure 3; i.e., subsegments of c and c T together with two segments of Γ Σ cobound a rectangle R that is to the right of c when c is oriented as the boundary of R . Let R ′ ⊂ Σ be a neighbourhood of R ∪ c ∪ c T shown shaded in the right hand picture of Figure 3. The arc c T is said to be a rotation of the bypass arc c .
FIGURE 3. Left: The bypass arc c T is a rotation of the bypass arc c . Left centre: After attaching a bypass along c , c T becomes a trivial bypass arc. Right centre: The dividing set is preserved up to isotopy by attaching a bypass to c T . Right: The bypass disc attached along c T can be constructed in a neighbourhood of R ′ and the bypass disc for c .
Lemma 2.8. Suppose that a bypass disc D is attached to the arc c on some surface Σ ⊂ ( M,ξ ) , as shown in Figure 3. Then there also exists a bypass disc D T attached to Σ along c T . Furthermore, D T is contained in a neighbourhood of D and R ′ .
The second claim of the lemma will be useful in the proof of Proposition 3.8 below.
Proof. The existence claim follows from a formal convex surface theory argument. After a bypass is attached along c , c T is a trivial bypass arc on the new surface. Since trivial bypasses always exist, it follows that there exists a bypass disc D T attached along c T . The [ TI ] move then implies that ν (Σ) ∪ X c can be factored as ν (Σ) ∪ ( X c ∗ X c T ) . However, the bypass arcs c and c T are disjoint on Σ , so the associated bypasses commute. Applying the [ FC ] move gives the factorisation ν (Σ) ∪ ( X c T ∗ X c ) . It follows that the bypass along c T can be directly attached onto Σ .
The next argument is illustrated in Figure 4.
FIGURE 4. Attach a 1 -handle h 1 T along a push-off of the Legendrian curve d . Then isotope the disc cobounded by h 1 T and d across the product disc A to produce a bypass disc D cobounded by h 1 T and c T .
To construct D T directly, consider a Legendrian realisation of the arc labeled d in Figure 4. Perform a Legendrian isotopy so that d is properly embedded in ν (Σ) ∪ X c . Since d ∩ Γ Σ = ∂d , a regular neighbourhood of this push-off is a contact 1 -handle h 1 T shown in bold on the first figure. Observe that h 1 T is attached to Σ along ∂c T , but the blue disc it cobounds with d is not a bypass disc. However, we may isotope this disc across the product disc A shown in the centre figure to get a bypass disc D T cobounded by h 1 T and c T . /square
## 3. HEEGAARD SPLITTINGS AND THE GIROUX CORRESPONDENCE
With useful tools and vocabulary established, we now turn to proving the Giroux Correspondence. As a first step, Section 3.1 summarises results from [LV] that allow us to restate the theorem about a pair of open books as a theorem about a pair of Heegaard splittings. Section 3.2 introduces bridging as an operation to stabilise a Heegaard splitting of a contact manifold. After establishing some properties of bridge splittings, we relate them to refinements in Section 3.3 to prove the main result.
3.1. Tight Heegaard splittings and refinement. Asdescribed in Section 2.2, each convex Heegaard splitting of a contact manifold corresponds to an open book decomposition supporting the contact structure. Here we recall a key idea from [LV] that extends the class of Heegaard splittings of a contact manifold which determine open books.
Definition 3.1. The Heegaard splitting (Σ , U, V ) of ( M,ξ ) is tight if Σ is convex and the restriction of ξ to each of U and V is tight.
The definition of a convex Heegaard splitting requires a system of meridional discs each intersecting Γ Σ twice. In contrast, meridional discs in a tight Heegaard splitting may intersect Γ Σ an arbitrary number of times. However, a process called refinement allows us to construct a convex splitting from a tight one.
Refinement was introduced in [LV, Section 5.] . Roughly speaking, refinement stabilises the tight Heegaard splitting by drilling along Legendrian curves embedded in meridional discs. The drilling process cuts each non-product disc into subdiscs, and the curves are chosen so that these subdiscs are product discs for the stabilised Heegaard splitting ˜ H . See Figure 5. This refinement ˜ H is necessarily convex, so via Lemma 2.5 one may view refinement as a process which associates an open book decomposition to a tight Heegaard splitting of ( M,ξ ) .
FIGURE 5. To refine a tight Heegaard splitting H , stabilise it via tunnels drilled through non-product discs to produce a convex splitting ˜ H . Here, the meriodonal disc A with | ∂A ∩ Γ Σ | = 4 in H splits into a pair of product discs A 1 , A 2 in ˜ H .
There are choices involved in constructing a refinement (e.g., discs, tunnels), but these preserve the positive stabilisation class of the associated open book.
Theorem 3.2. [LV, Lemma 3.8 and Theorem 5.10] Suppose that ˜ H and ˜ H ′ are refinements of the tight Heegaard splitting H . If ( B,π ) and ( B , π ′ ′ ) are the open book decompositions associated to ˜ H and ˜ H ′ , respectively, then ( B,π ) and ( B , π ′ ′ ) admit a common positive stabilisation.
In light of Theorem 3.2, we define a positive stabilisation of a tight Heegaard splitting as a topological stabilisation of the Heegaard splitting which induces a positive open book stabilisation on the open books associated to the refinements.
This new language permits us to restate the hard direction of the Giroux Correspondence:
Theorem 3.3 (3-dimensional Giroux Correspondence) . Any two convex Heegaard splittings of ( M,ξ ) admit a common positive stabilisation.
Much of the work of [LV] was devoted to showing that various natural operations one may perform on a tight Heegaard splitting are in fact (sequences of) positive stabilisations.
Positive stabilisations may also be characterised directly. Choose an arc properly embedded in one of the handlebodies that is Legendrian isotopic to an arc properly embedded in the closure of Σ \ Γ Σ . Adding a standard contact neighborhood of this arc to the other handlebody is a positive stabilisation of the original Heegaard splitting. In fact, a related operation has already appeared in the proof of Lemma 2.8. Suppose that in Lemma 2.8 the surface Σ is taken to be a Heegaard surface for a tight Heegaard splitting. In this case, the 1 -handle h 1 T is a neighbourhood of a Legendrian push-off of d , so adding h 1 T to the handlebody bounded by Σ is a positive stabilisation of the Heegaard splitting.
The proof of Lemma 3.10 in [LV] shows that in a convex Heegaard splitting, attaching any bypass 1 -handle is a positive stabilisation. The following more general statement will be used later.
Theorem 3.4. [LV, Lemma 7.1] Let H = (Σ , U, V ) and H ′ = (Σ ′ , U , V ′ ′ ) be tight Heegaard splittings of ( M,ξ ) and assume that U ′ is obtained from U by attaching a single bypass h 1 ∪ h 2 . Let
H ′′ = ( ∂ U ( ∪ h 1 ) , U ∪ h , M 1 \ int ( U ∪ h 1 ) )
be the Heegaard splitting formed by attaching only the 1 -handle associated to this bypass. Then the refinements of H H , ′ and H ′′ all admit a common positive stabilisations.
Remark 3.5. Refining a convex Heegaard splitting with respect to a set of product discs preserves the splitting. However, a convex splitting H will in general also have non-product meridional discs. Refining H with respect to some set of non-product discs will produce a new convex splitting ̂ H ; then H and ̂ H admit a common positive stabilisation.
- 3.2. Bridge Heegaard splittings. Given a tight Heegaard splitting H , the refinement process described above stabilises H to produce a convex Heegaard splitting ˜ H . In this section we introduce an alternative method to
turn any smooth Heegaard splitting H into a convex Heegaard splitting ̂ H . The new Heegaard splitting ̂ H is called the bridge of H .
Abouquetof circles is a skeleton of a handlebody if the handlebody deformation retracts onto the bouquet. When the handlebody is equipped with a contact structure, we may additionally require the bouquet to be Legendrian. Throughout, we will let K U and K V denote Legendrian skeletons of U and V , respectively, and we let ν K ( U ) and ν K ( V ) denote their standard neighbourhoods.
FIGURE 6. Left: Adding successive bypasses produces a sequence of (red) handlbodies U i that are homeomorphic but not weakly contact isotopic to ν K ( U ) . Right: Adding the 1 -handles produces a bridge splitting ̂ H = (Σ ̂ , U, V ̂ ̂ ) ; here ̂ U is indicated in blue.


Begin with a smooth Heegaard splitting H = (Σ , U, V ) . Since the complement X = M \ ( ν K ( U ) ∪ ν K ( V ) ) is topologically a product, Theorem 2.6 implies that up to weak contact isotopy, X decomposes as a sequence of bypasses X 1 ∗ · · · ∗ X f attached to ∂ν K ( U ) . 1 Attaching only the first i bypasses in the sequence determines a new handlebody U i with convex boundary; letting i range over the indices of all bypasses produces a sequence of smoothly isotopic Heegaard surfaces Σ := i ∂U i . Each Σ i has a bypass arc c i +1 that determines the bypass X i +1 . Isotopy of c i through bypass arcs preserves the weak contact isotopy class of U i , so we may push each bypass arc off the faces of any 2 -handles already attached.
Definition 3.6. Let X 1 ∗· · · ∗ X f be a bypass decomposition of M \ ( ν K ( U ) ∪ ν K ( V ) ) as above. Define ̂ U to be the handlebody formed by adding only the bypass 1 -handles to ν K ( U ) :
$$\widehat { U } = \nu ( K _ { U } ) \cup ( \bigcup _ { i = 1 } ^ { f } h _ { i } ^ { 1 } ).$$
1 the triple ( ν K ( U ) , ν ( K V )) , X ) is called a ' patty ' in [HBH].
Then the bridge of H is the Heegaard splitting
$$\Phi _ { 0 } \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OOC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC \OC
\quad \widehat { \mathcal { H } } ( X _ { 1 } \ast \cdots \ast X _ { f } ) = ( \partial \widehat { U }, \widehat { U }, M \, \sum \, \text{int} ( \widehat { U } ) ). \\ \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \ \. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
Attaching a contact 1 -handle preserves tightness, so it is immediate that ̂ U is tight. The complementary ̂ V is also tight, as turning the manifold upside down builds ̂ V from 1 -handles attached to ν K ( V ) . In fact, the splitting ̂ H ( X 1 ∗ · · · ∗ X f ) = (Σ ̂ , U, V ̂ ̂ ) is convex, as co-core discs for each 1 -handle, together with meridional discs for the neighbourhoods of the skeleta, form a complete set of product discs.
Remark 3.7. Although the term 'bridge' is new, this construction appears in both [HBH] and [LV] as a technique to construct a convex Heegaard splitting from an arbitrary smooth Heegaard splitting.
When the original Heegaard surface Σ is already convex in the splitting H = (Σ , U, V ) , one may consider the relative bridge ̂ H U built from a bypass decomposition of M \ ( ν K ( U ) ∪ V ) , although this need not be convex. Similarly, ̂ H V is constructed from a bypass decomposition of M \ ( U ∪ ν K ( V ) ) . The relative bridges will be used in Proposition 3.10.
Proposition 3.8. Up to positive stabilisation, the bridge
$$\widehat { \mathcal { H } } ( X _ { 1 } * \cdots * X _ { f } ) = ( \widehat { \Sigma }, \widehat { U }, \widehat { V } ) \\ \rho \, c h o i c e \, o f h m a s \times a t t a c h i n \sigma \, a r c \, s u i t h i n \ t h u$$
is independent of the choice of bypass attaching arcs within their isotopy classes.
Proof. In order to construct a bridge splitting from a bypass decomposition, all the bypass attaching arcs must be isotoped off the faces of an 2 -handles already attached, but there is no canonical way to perform this isotopy. Although different isotopies preserve the weak contact isotopy type of each U i , they may produce handlebodies which are inequivalent when the 2handles are removed. We will show that an isotopy of the attaching 0 -sphere for a 1 -handle on Σ i preserves the positive stabilisation class of the bridge ̂ H .
Let c R and c L be two bypass attaching arcs for some X j ( j > i ) that are isotopic on Σ i via an isotopy that slides one endpoint across a face of some 2 -handle. Because the proof is local, we may assume without loss of generality that the associated bypass is the most recent one; that is, j = +1 i . See Figure 7. The Heegaard surfaces ̂ Σ R and ̂ Σ L associated to attaching bypasses along c R and c L , respectively, are not convexly isotopic.
Consider the bypass arc c T shown on Figure 9. As the endpoints of c L and c R can be assumed to be arbitrarily close to c i , we can also assume that c T is close to c i . Thus no other handles are attached on top of c T and it persists as a bypass arc on ̂ Σ L . We claim that there is a bypass half-disc attached along c T in ̂ V L .
FIGURE 7. Left: Before constructing the bridge of H , bypass arcs must be isotoped off the faces of the 2 -handles. Centre: Isotoping c across the face of a 2 -handle on Σ i preserves the weak contact isotopy class of U i . Right: When h 2 i is removed, the bypass arcs c R and c L are not isotopic on ̂ Σ .
FIGURE 8. After attaching a bypass along c T , the arcs c R and c L again become isotopic.
Observe that on Σ i , the bypass arc c T is a rotation of c i . As discussed in Section 2.3, there must exist a bypass disc D T attached along c T . Moreover, by Lemma 2.8 D T may be assumed to lie in a neighbourhood of X i and the shaded area R ′ in the centre picture of Figure 9. It follows that the 1 -handle attached along ∂c L is disjoint from D T , so D T persists in ̂ V L .
Figure 9 shows that attaching the bypass along c T onto ̂ U L produces a handlebody weakly contact isotopic to ̂ U R . Then by Theorems 2.5 and 3.4, the convex Heegaard decompositions ̂ H L and ̂ H R admit a common positve stabilisation. /square
FIGURE 9. Left: The bypass arcs c R and c L are isotopic on Σ i . Centre: If h 2 i is not attached, then c R and c L are not isotopic. Right: After attaching a bypass along c T , the arcs c R and c L are again isotopic.
Proposition 3.8 implies that up to positive stabilisation, the bridge splitting ̂ H = (Σ ̂ , U, V ̂ ̂ ) depends only on K U , K V , and the bypass decomposition X = X 1 ∗ · · · ∗ X f . As we show next, the bridge ̂ H is actually independent - again, up to positive stabilisation - of the bypass decomposition.
Proposition 3.9. Given a smooth Heegaard splitting H = (Σ , U, V ) let K U and K V be Legendrian skeletons for U and V and let X = M \ ( ν K ( U ) ∪ ν K ( V ) ) . Let X 1 ∗ · · · ∗ X f and X ′ 1 ∗ · · · ∗ X ′ f ′ be distinct bypass decompositions of X , and let ̂ H = ̂ H ( X 1 ∗ · · · ∗ X f ) and ̂ H ′ = ̂ H ′ ( X ′ 1 ∗ · · · ∗ X ′ f ) be the associated bridge Heegaard splittings formed by attaching only the 1 -handles of the respective bypasses to ν K ( U ) . Then ̂ H and ̂ H ′ admit a common positive stabilisation.
Proof. According to Theorem 2.7, two bypass decompositions of X are related by a finite sequence of isotopies, Trivial Insertion moves, and Far Commutation moves. Up to an isotopy that keeps the Heegaard surface convex, Far Commutation preserves the handlebodies ̂ U and ̂ V . Thus we only need to show that inserting a trivial bypass preserves the positive stabilisation class of ̂ H .
We claim that regardless of where the trivial bypass was inserted, ̂ H and ̂ H T admit a common positive stabilisation. Recall that Proposition 3.8 allows us to isotope each attaching sphere along respective components of Γ Σ i while preserving the positive stabilisation class of the bridge splitting.
Fix a bypass decomposition of X . As above, let ̂ H = (Σ ̂ , U, V ̂ ̂ ) be the Heegaard splitting formed by attaching the associated 1 -handles to ν K ( U ) . Now consider an alternative bypass decomposition that differs by the insertion of a trivial bypass X T = h 1 T ∪ h 2 T attached along a trivial bypass arc c T somewhere in the sequence, and let ̂ H T = (Σ ̂ T , U ̂ T , V ̂ T ) denote the associated Heegaard splitting. Observe that the genus of ̂ H T is larger than the genus of ̂ H because the additional 1 -handle h 1 T is attached.
Using this flexibility, ensure that no handle attached after h 1 T has an attaching sphere that intersects the disc supporting the trivial bypass. Not only can any attaching sphere be isotoped off this region, but we may also impose the stronger condition that subsequent attaching spheres are disjoint from the larger disc shown in Figure 10 that contains the bigon certifying c T as a trivial bypass arc. As a consequence, c T remains a trivial bypass arc on ̂ Σ ; we will use this below. It follows that we may apply a sequence of Far Commutation moves to get a new bypass decomposition in which the bypass along c T is attached last.
FIGURE 10. Left: The purple arc is a trivial bypass attachment arc. Right: Attaching spheres for handles attached after this bypass may always be isotoped off the shaded gray disc.

Attaching h 1 T along ∂c T to ̂ U produces the handlebody ̂ U T . As noted in the comment before Theorem 3.4, adding a bypass 1 -handle to a convex splitting is always a positive stabilisation, which proves the stated claim.
/square
The following two results show that a convex Heegaard splitting H and its bridge ̂ H admit a common positive stabilisation.
Proposition 3.10. Given a tight Heegaard splitting H = (Σ , U, V ) , let K U , K V be Legendrian skeletons for U and V , respectively. Let X = X 1 ∗ · · · ∗ X f be a bypass decomposition of the complement of ν K ( V ) in V , where the index is the order in which the bypass slices are attached to U . Let ̂ H U denote the relative bridge splitting with handlebodies ̂ U = U ∪ ( ⋃ f i =1 h 1 i ) and ̂ V = M \ int ( ̂ U ) . Then the refinements of the Heegaard splittings ̂ H U and H admit a common positive stabilisation.
The relative bridge splitting ̂ H U is tight by construction, so one may flip this Heegaard splitting upside down and apply Proposition 3.10 again to get the following consequence:
Corollary 3.11. Given a tight Heegaard splitting H = (Σ , U, V ) let K U , K V be Legendrian skeletons for U and V and let X = X 1 ∗ · · · ∗ X f be a bypass decomposition of the complement of M \ ( ν K ( U ) ∪ ν K ( V ) ) . Then the bridge splitting ̂ H and the refinement ˜ H admit a common positive stabilisation.
The proof of Proposition 3.10 is essentially the same argument as the proof of [LV, Theorem 6.1.]. Since it was not stated in full generality there, we indicate how it follows from the techniques of [LV].
Proof of Proposition 3.10. Define the sequence of intermediate Heegaard splittings ̂ H j = (Σ ̂ j , U ̂ j , V ̂ j ) built by attaching only the first j of the 1 -handles:
$$\widehat { U } _ { j } = U \cup ( \bigcup _ { i = 1 } ^ { j } h _ { i } ^ { 1 } ), \ \widehat { V } _ { j } = M \, \langle \, \text{int} ( \widehat { U } _ { j } ), \ \widehat { \Sigma } _ { j } = \partial \widehat { U } _ { j }.$$
We will show that the refinements of successive Heegaard splittings in this sequence admit common positive stabilisations.
Beginning with the case j = 1 , construct the refinement ˜ H = (Σ ˜ , U, V ˜ ˜ ) of H .
Recall that the refinement is constructed by drilling tunnels through meridional discs for the handlebodies. We may choose these discs to be disjoint from the bypass X 1 = h 1 1 ∪ h 2 1 , so adding the 1 -handle h 1 1 to U commutes with this drilling. Thus attaching h 1 1 to the refined ˜ U produces the same Heegaard splitting as taking the refinement of ̂ H 1 . As noted in Section 3.1, attaching h 1 1 in to ˜ U in the convex refinement is a positive stabilisation, which completes the base case.
Now proceed by induction on j . For the inductive step, note that if ̂ H j is tight, then ̂ H j +1 is also tight because ̂ V j +1 is a proper subset of the tight ̂ V j , while ̂ U j +1 is built from the tight ̂ U j by adding a contact 1 -handle. The argument above shows that refining and then adding a 1 -handle produces the same splitting as first adding the 1 -handle and then refining, which preserves the positive stabilisation class. This establishes the inductive step. /square
3.3. Proof of the Giroux Correspondence. In order to prove the Giroux Correspondence, we consider a pair of convex Heegaard splittings of a fixed contact manifold. We will modify these Heegaard splittings until they coincide, and each step in this evolution will preserve the positive stabilisation class of the Heegaard splittings.
First, we repeat an argument from the proof of Theorem 6.1 in [LV] that lets us restrict to Heegaard splittings that are smoothly isotopic:
Proposition 3.12. Any two convex Heegaard splittings of ( M,ξ ) have positive stabilisations that are smoothly isotopic.
Proof. In the topological setting, the Reidemeister-Singer Theorem asserts that any two Heegaard splittings of a fixed manifold become isotopic after sufficiently many stabilisations. As there are no restrictions on the type of
stabilisation that ensure this outcome, we are free to choose positive stabilisation of our convex Heegaard splittings. /square
Next, we can assume that the skeletons of the Heegaard splittings agree:
Proposition 3.13. Let H = (Σ , U, V ) and H ′ = (Σ ′ , U , V ′ ′ ) be smoothly isotopic Heegaard splittings of ( M,ξ ) with convex Heegaard surfaces. Then there exist Legendrian skeletons K U and K V and an isotopy Ψ t of H ′ keeping Ψ (Σ ) t ′ convex such that K U is the skeleton of both U and Ψ ( 1 U ′ ) and K V is the skeleton of both V and Ψ ( 1 V ) .
Proof. Choose a Legendrian bouquet K ∗ as a skeleton for each handlebody, where ∗ ∈ { U, U , V, V ′ ′ } . Since K U ′ ∪ K V ′ is topologically isotopic to K U ∪ K V , some stabilisations of these bouquets are Legendrian isotopic. As we may stabilise each K ∗ while preserving it as a skeleton of the respective handlebody, suppose now that the skeletons K U ′ ∪ K V ′ are Legendrian isotopic to K U ∪ K V .
Extend this Legendrian isotopy to an ambient contact isotopy of the manifold, Ψ t . By construction, for all t the bouquet Ψ ( t K U ′ ) is a skeleton for the handlebody Ψ ( t U ′ ) with convex boundary Ψ (Σ) t , and the analogous statement holds for Ψ ( t K V ′ ) . Since Ψ t is an extension of the Legendrian isotopy taking K U ′ ∪ K V ′ to K U ∪ K V , we also have that Ψ ( 1 K U ′ ) = K U is a skeleton for U and Ψ ( 1 K V ′ ) = K V is a skeleton for V , as desired. /square
Finally, we are ready to prove the Giroux Correspondence for an arbitrary contact 3 -manifold.
Proof of Theorem 3.3. Let H and H ′ be two convex Heegaard splittings of ( M,ξ ) . By Proposition 3.12 we may assume that these Heegaard decompositions are smoothly isotopic. Then Proposition 3.13 implies that after performing an isotopy keeping Σ ′ convex, we may also assume there exist a Legendrian bouquet K U that is a skeleton of both U and U ′ and a Legendrian bouquet K V that is a skeleton of both V and V ′ .
Choose bypass decompositions of the complement of the skeletons in U and V :
$$U \, \sum \nolimits ( K _ { U } ) = X _ { 1 } * \cdots * X _ { l } \ \text{ and } \ V \, \sum \nolimits ( K _ { V } ) = X _ { l + 1 } * \cdots * X _ { k }.$$
Concatenating these produces a bypass decomposition of X = M \ ( ν K ( U ) ∪ ν K ( V ) ) . As usual, let ̂ U denote the handlebody formed by attaching all of the 1 -handles to ν K ( U ) . Setting ̂ H = ( ∂U,U,M ̂ ̂ \ int ̂ U ) , Corollary 3.11 implies that the refinement ˜ H and the bridge ̂ H admit a common positive stabilisation. To complete the argument, we recall Remark 3.5: since H is convex, any refinement of ˜ H is a positive stabilisation of H itself. Thus H and ̂ H admit a common positive stabilisation.
Nowrepeat this process using the alternative Heegaard splitting H ′ :
$$U ^ { \prime } \, \sl \sum ( K _ { U } ) = X _ { 1 } ^ { \prime } \ast \dots \ast X _ { l ^ { \prime } } ^ { \prime } \quad \text{and} \quad V ^ { \prime } \, \sl \sum ( K _ { V } ) = X _ { l ^ { \prime } + 1 } ^ { \prime } \ast \dots \ast X _ { k ^ { \prime } } ^ { \prime }.$$
Attaching all - and only - the 1 -handles to ν K ( U ) gives a new bridge splitting ̂ H ′ , and a similar argument shows that H ′ and ̂ H ′ admit a common positive stabilisation.
However, ̂ H and ̂ H ′ are built from distinct bypass decompositions of M \ ( ν K ( U ) ∪ ν K ( V ) ) , so Proposition 3.9 implies that they also admit a common positive stabilisation, completing the proof. /square
## REFERENCES
[Etn04] John B. Etnyre. Convex surfaces in contact geometry : class notes. https://etnyre.math.gatech.edu/preprints/papers/surfaces.pdf , 2004.
[Gir91]
Emmanuel Giroux. Convexit´ e en topologie de contact. Comment. Math. Helv. , 66(4):637-677, 1991.
[Gir02] Emmanuel Giroux. G´ eom´ etrie de contact: de la dimension trois vers les dimen- sions sup´ erieures. In Proceedings of the International Congress of Mathematicians, Vol. II (Beijing, 2002) , pages 405-414. Higher Ed. Press, Beijing, 2002.
[HBH] Ko Honda, Joseph Breen, and Yang Huang. The Giroux correspondence in arbi- trary dimensions. arXiv:2307.02317.
[HKM07] Ko Honda, William H. Kazez, and Gordana Mati´ c. Right-veering diffeomor- phisms of compact surfaces with boundary. Invent. Math. , 169(2):427-449, 2007. [HKM09] Ko Honda, William H. Kazez, and Gordana Mati´ c. The contact invariant in su-
tured Floer homology. Invent. Math. , 176(3):637-676, 2009.
[Hon] Ko Honda. Notes on math 599: contact geometry. https://www.math.ucla.edu/˜honda/math599/notes.pdf .
[Hon02]
Ko Honda. Gluing tight contact structures. Duke Math. J. , 115(3):435-478, 2002. Joan Licata and Vera V´ ertesi. Heegaard splittings and the tight Giroux Corre- spondence. arXiv:2309.11828, to appear in The Journal of Symplectic Geometry. Patrick Massot. Topological methods in 3-dimensional contact geometry. In Con- tact and symplectic topology , volume 26 of Bolyai Soc. Math. Stud. , pages 27-83.
[LV]
[Mas14] J´nos Bolyai Math. Soc., Budapest, 2014. a
[Ozb11] Burak Ozbagci. Contact handle decompositions. Topology Appl. , 158(5):718-727, 2011.
[Tia] Bin Tian. Generators and relations of contact categories. PhD thesis. [Tor00] Ichiro Torisu. Convex contact structures and fibered links in 3-manifolds. Inter- nat. Math. Res. Notices , (9):441-454, 2000. [TW75] W. P. Thurston and H. E. Winkelnkemper. On the existence of contact forms. Proc. Amer. Math. Soc. , 52:345-347, 1975.
MATHEMATICAL SCIENCES INSTITUTE, AUSTRALIAN NATIONAL UNIVERSITY Email address : [email protected]
UNIVERSITY OF VIENNA
Email address : [email protected] | null | [
"Joan Licata",
"Vera Vértesi"
] | 2024-08-02T07:56:04+00:00 | 2024-08-02T07:56:04+00:00 | [
"math.GT",
"57K33"
] | The Giroux Correspondence in dimension 3 | In an earlier paper, the authors proved the Giroux Correspondence for tight
contact $3$-manifolds via convex Heegaard surfaces. Simultaneously, Breen,
Honda and Huang gave an all-dimensions proof of the Giroux Correspondence by
generalising convex surface theory to higher dimensions. This paper uses a key
result about relations of bypasses to complete the $3$-dimensional proof for
arbitrary (not necessarily tight) contact 3-manifolds. This presentation
features low-dimensional techniques and further clarifies the relationship
between contact manifolds and their Heegaard splittings. |
2408.01080v1 | Research Article
## FCDFusion: a fast, low color deviation method for fusing visible and infrared image pairs
Hesong Li 1 and Ying Fu 1 ( B )
© The Author(s) 2022.
Abstract Visible and infrared image fusion (VIF) aims to combine information from visible and infrared images into a single fused image. Previous VIF methods usually employ a color space transformation to keep the hue and saturation from the original visible image. However, for fast VIF methods, this operation accounts for the majority of the calculation and is the bottleneck preventing faster processing. In this paper, we propose a fast fusion method, FCDFusion, with little color deviation. It preserves color information without color space transformations, by directly operating in RGB color space. It incorporates gamma correction at little extra cost, allowing color and contrast to be rapidly improved. We regard the fusion process as a scaling operation on 3D color vectors, greatly simplifying the calculations. A theoretical analysis and experiments show that our method can achieve satisfactory results in only 7 FLOPs per pixel. Compared to state-of-the-art fast, color-preserving methods using HSV color space, our method provides higher contrast at only half of the computational cost. We further propose a new metric, color deviation, to measure the ability of a VIF method to preserve color. It is specifically designed for VIF tasks with color visible-light images, and overcomes deficiencies of existing VIF metrics used for this purpose. Our code is available at https://github.com/HeasonLee/FCDFusion.
Keywords infrared images, visible and infrared image fusion; gamma correction; real-time display; color metrics; color deviation
## 1 Introduction
Visible and infrared image fusion (VIF) aims to combine information from visible and infrared images into a single
1 School of Computer Science and Technology, Beijing Institute of Technology, Beijing 100081, China. E-mail: H. Li, [email protected]; Y. Fu, [email protected] ( B ).
Manuscript received: 2022-01-01; accepted: 2022-01-01

fused image. In dark or dazzling extreme environments, an image taken by a visible camera may be unclear, but an infrared camera can usually obtain clear object outlines due to differences in temperature. A VIF output image has both color and temperature information, making objects in the output image clearer and more distinguishable. Therefore, VIF technology has been an active research field for many years, and has abundant applications [1] in many fields such as object detection [2-5], tracking [6-8], recognition [9-11], surveillance [12-14], color vision [15], and remote sensing [16, 17]. Several fast VIF methods simply average two input images in different color spaces [18], taking no more than 20 FLOPs for each pixel pair. Their main goal is to fuse video at highspeed for real-time display, so they trade off quality of results for speed. When putting image quality first, rather than speed, other methods are used; representative ones being based on domain transformation [19-24], deep learning [25-29], or hybrid methods [30-35]. These methods provide impressive results but involve much more complex calculation, often taking over 1000 times as many FLOPs as simple averaging methods. arXiv:2408.01080v1 [cs.CV] 2 Aug 2024
Previous VIF methods usually employ a color space transformation to keep the hue and saturation from the original visible image. However, for fast VIF methods, this operation accounts for the main part of the calculation, and is the bottleneck preventing improved processing speed. In this paper, we propose a fast fusion method, FCDFusion, with little color deviation; it can preserve color information without color space transformations. It directly operates in RGB color space and embeds gamma correction with little extra computation, so both color and contrast can be quickly improved. We regard the fusion process as a scaling operation on 3D color vectors, which greatly simplifies the calculations. Theoretical analysis and experimental results show that our method can achieve satisfactory results using only 7 FLOPs per pixel. Compared to state-of-the-art fast, color-preserving methods using HSV


color space, our method provides higher contrast in half the number of FLOPs.
We further observe that existing evaluation metrics for the VIF task mainly consider the sharpness of the fused image (via entropy [36], average gradient [37], etc.) and its overall structural similarity to the original images (via structural similarity index measure [38], root mean squared error [39], etc.), and ignore the color information. Thus, some methods achieve high scores by changing the hue and saturation of the original color to improve the contrast. In this work, we propose a new metric called color deviation to measure how well a VIF method preserves colour. It is specifically designed for VIF tasks using color visible images and aims to remove the deficiencies of existing VIF metrics by assessing color information.
The main contributions of this work are thus:
- · a simple and effective VIF method, FCDFusion, which can preserve color and improve contrast in only 7 FLOPs per pixel,
- · a metric, color deviation, specifically designed to measure the ability of a VIF method, using color visible images, to preserve color,
- · a theoretical analysis, based on color deviation, of the color-preserving abilities of our method and averaging methods in RGB, YIQ, and HSV color spaces; these results are also verified experimentally.
## 2 Related work
In this section, we first review existing VIF methods and their strategies for preserving color. Then we give a brief introduction to existing metrics used to evaluate VIF results.
## 2.1 VIF methods
## 2.1.1 Problems with simple averaging
A simple VIF method working in RGB color space is to average the red, green, and blue components of a visible image with an infrared image separately. Unfortunately, there are two problems to be solved. Firstly, one of the input images usually contains more details, while the other is blurred. A simple averaging operation cannot deliberately select the image containing more detail, and therefore, after the averaging operation, the original clear details become blurred. Secondly, because the infrared image contains only one channel (monochromatic), averaging the red, green, and blue components of the visible image with the same gray value will cause a decline in saturation, resulting in poor appearance. Existing VIF methods have developed strategies to solve the above two problems, to help them keep details and colors in the fused image.

## 2.1.2 Detail-preserving methods
To selectively keep details from both input images, various more complex fusion methods have been proposed.
Some transform the two input images into a new domain to extract principal (low-frequency) parts and detail (highfrequency) parts from the input images. Typical domain transformations include principal component analysis [19], Laplacian pyramids [20], wavelet transforms [21], contourlet transforms [22], multi-resolution singular value decomposition [23] and latent low-rank representation [24]. In these methods, the two parts of the output image are fused in different ways. The high-frequency part of the output image is usually the sum or the maximum value of the two input images, while the low-frequency part is usually formed by averaging. Such processing aims to preserve the details of the two input images as well as possible.
Toachieve better overall quality and avoid the disadvantages of a single method, some hybrid methods [30-33] mix the results of multiple methods to get the best effects in the output images.
Moreover, with the rapid development of deep learning, somedeeplearning-based methods [25, 26] are also emerging. These methods take some evaluation metrics as training objectives and use various artificial neural network models for parameter training to achieve better fusion results.
Recently, most methods combine neural networks with other techniques to improve the fusion effect. Inspired by domain transformation methods, Luo et al. [34] use an ℓ 1 -ℓ 0 decomposition model to obtain the base and detail layers before fusion, and employ Laplacian and Gaussian pyramids to decompose the detail layers and decision map obtained by a convolutional neural network. To fully preserve visual details, Yin et al. [35] employ a weighted mean curvature-based multiscale transform fusion scheme which can effectively suppress noise and keep valuable details. Xu et al. [27] use convolutional neural networks as encoders to extract multi-level features from the input image pair, and then use a decoder to fuse these features. Tang et al. design an illumination-aware sub-network in PIAFusion [28] to estimate the illumination distribution and calculate the illumination probability, then use the illumination probability to construct an illumination-aware loss to guide training of the fusion network. It thus performs well on target maintenance and texture preservation in areas with different illumination. In SeAFusion [29], Tang et al. cascade an image fusion module and a semantic segmentation module, using semantic loss to guide the flow of high-level semantic information back to the image fusion module, effectively boosting the performance
Fig. 1 Color-preservation strategy of VIF methods using a color space transformation T .
of high-level vision tasks on fused images, such as semantic segmentation and object detection.
Theabovemethodstrade off speed for better quality of fused results. Although the SeAFusion [29] model is simplified to improve its speed, it still requires more calculation than early deep learning-based methods like CNN [26], and about 10,000 times that of simple averaging methods [18]. Here, we propose a simple and effective VIF method to achieve high quality fusion results with extremely low computational requirements, akin to those of simple averaging methods.
## 2.1.3 Color-preserving methods
To keep the hue and saturation of the original visible image, VIF methods can be modified to operate in another color space in which one component represents brightness, and two other components represent hue and saturation [18]. Only the brightness component of the two images is fused, and the hue and saturation of the original color image is retained. Such a color-preservation strategy is also commonly used in other image enhancement methods operating on color images [40, 41]. As Fig. 1 illustrates, color-preserving VIF methods first use a color space transformation T to divide the visible image into hue and saturation components and a brightness component. They then fuse the brightness component with the infrared image using some particular fusion strategy, and finally, they use the inverse transformation T -1 to transform the result back to RGB color space.
Two commonly used color spaces are YIQ and HSV [42, 43]. When using YIQ color space, both T and T -1 are 3 × 3 matrices, so the VIF method needs two matrix multiplications. When using HSV color space, saturation is better preserved but the conversion is more complex and requires more time.
Somerecentmethods[28,29]useYUV(alsocalledYCrCb) [44] color space, which is similar to YIQ color space. The transformation from RGB to YUV needs a 3 × 3 matrix multiplication and two scalar additions.
Color space transformations can help VIF methods keep the hue and saturation from the original visible image. But for fast
Fig. 2 Color vectors in RGB color space.
VIF methods, transformations account for the majority of the calculation and act as a bottleneck to improving processing speed. Our method proposed in this paper directly operates in RGB color space and uses vector scaling instead of color space transformations.
## 2.2 VIF metrics
Numerous metrics used to evaluate image quality can also be used to evaluate the quality of fusion results. None of the proposed metrics is universally better than all others; they are complementary. Typical metrics used in VIF result evaluation [45] include information theory-based metrics (e.g. crossentropy (CE) [46], entropy (EN) [36], mutual information (MI) [47], and peak signal-to-noise ration (PSNR) [39]), structural similarity-based metrics (e.g. structural similarity index measure (SSIM) [38], and root mean squared error (RMSE) [39]), image feature-based metrics (e.g. average gradient (AG) [37], edge intensity (EI) [48], standard deviation (SD) [49], spatial frequency (SF) [50], and gradient-based fusion performance ( Q AB/F ) [51]) and human perception inspired metrics (e.g. the Chen-Blum metric ( Q CB) [52], and the Chen-Varshney metric ( Q CV) [53]).
These existing metrics either measure the overall contrast of the output image or its similarity to each of the two original input images. However, for VIF tasks with colored visible images, color information and brightness information of the image are usually processed separately, so it is necessary to design a metric that specifically measures color changes. In this work, we propose a new metric. color deviation, to measure the color preservation ability of a VIF method.
## 3 FCDFusion method
In this section, we first formulate the VIF problem and motivate our method. Then we introduce our FCDFusion fast fusion method with low color deviation for high-speed VIF tasks demanding color preservation. It can greatly reduce the


Fig. 3 FCDFusion Framework. Gamma correction uses γ = 2 . Scaling multiplies each input RGB component by the same factor k .
computational load while ensuring good contrast and color quality in the fused image.
## 3.1 Formulation and motivation
In the visible and infrared image fusion (VIF) problem, two images of the same scene are taken by a visible camera and an infrared camera; we assume they have been aligned by a registration algorithm, so that each has the same size and each object has the same position in both images. For pixel-level VIF methods, the goal is to calculate the fused pixel color c f by using the visible pixel color c v and the infrared pixel color c i for each pixel pair across the two images. c f , c v , and c i are color vectors in RGB color space with three elements:
$$c _ { f } = \left [ \begin{array} { c } r _ { f }$$
saturation are represented by the direction of the vector. See, for example, Fig. 2. The four color vectors c 1 , c 2 , c 3 , and c 5 have the same lengths but different directions, so have the same brightness and different hues and saturations. The closer the direction is to the main diagonal of the color space cube, the lower its saturation, and the closer it is to gray. So although the three color c 1 , c 2 , and c 3 have the same hue, c 3 is completely gray while c 1 has the highest saturation. Another aspect, also shown in Fig. 2, is illustrated by the three color vectors c 4 , c 5 , and c 6 , which have the same direction but different lengths. They thus have the same hue and saturation but different brightnesses. Therefore, a colorpreserving fusion process can be considered to be one which simultaneously multiplies the red, green, and blue values by a common scaling factor k . In our method, k depends on both input images.
where r , g , b , r f f f v , g v , b v , and v i are integers, usually in the range [0,255].
Because the three elements of the infrared color c i have the same value v i (it is monochromatic), fusing the red, green and blue components of the visible image with the same gray value may cause a decline in saturation, giving the output image a poor appearance. Thus, existing colorpreserving methods [18] introduce a color transformation to a new color space such as YIQ or HSV to improve the color quality of the output image (see Fig. 1). They first transform the RGB color of the visible image into hue and saturation components and a brightness component, then fuse the brightness component with the infrared image, and finally use inverse transformation to transform the result back to RGB color space. The majority of the computation in this process lie in the color space transformation and the inverse transformation, while the fusion process is usually a simple averaging.
However, if we consider the RGB color as a vector in RGB color space, this process can be greatly simplified: the brightness is the length of the vector, and the hue and

## 3.2 Method
The framework of the proposed method is shown in Fig. 3. We first compute the scaling factor k using the input pixel pair, then fuse the pixel pair by scaling the visible input color vector by this factor k . We proceed in stages to determine k .
## 3.2.1 Scaling ratio
The output color can be seen as a scaled version of the original visible color vector c v , where the scaling ratio α depends on the magnitude of the infrared value v i :
$$\begin{array} {$$
where the infrared input value v i is normalised to [0,1], and the exponent γ is used to improve the contrast of the infrared image and reduce noise.
Gamma correction uses an exponential function to adjust the relative brightness of an image. Using γ > 1 enhances contrast in the bright parts of the picture and reduces contrast in the dark parts [54]. There is always noise in dark areas due to the lower signal-to-noise ratio, and reducing the contrast in dark areas acts to suppress this noise. In the proposed method
we set γ = 2 , allowing generic exponentiation to be replaced by a simpler and faster single multiplication in this case.
The scaling ratio α represents the relative value of k α . = 1 means k should take its maximal value β m, to maximize the length of c v ; α = 0 means k should take its minimal value 0, making c v black.
## 3.2.2 Maximal scaling factor
To simplify the calculation, we take the brightness of the color c v to be approximately given by the maximum value of all three components. However, as v m appears in a denominator later, we prevent division by zero by ensuring v m ⩾ 1 :
$$v _ { m } = \max ( r _ { \nu }, g _ { \nu }$$
To ensure that all color vectors have a chance to be enlarged, we define the ceiling of the scaled vector to have value v m +255 , so the maximal scaling factor is:
$$\beta _ { m } = \frac { v _ { m } + 2 5 5 } { v$$
Thus, with a maximal scaling ratio α = 1 , the color component with greatest value is scaled to the ceiling v m +255 ; the other two components are also scaled by the same factor β m.
## 3.2.3 Scaling factor
The initial scaling factor β is now obtained by multiplying the maximum scaling factor β m by the scaling ratio α :
$$\beta = \alpha \beta _ { \text{m} }.$$
A scaling operation directly using the factor β is too severe: the brightness of the output image differs too much from that of the visible image. Averaging this value with the original visible image reduces this difference:
$$c _ { s } = \frac { \beta c _ { v } + c _ { v } } { 2 } = k c _ { v }, \quad \quad ( 6 ) \quad \text{ope} \\. \quad \cdot \quad \cdot \cdot \cdot \cdot \cdot \cdot$$
where c s is the scaled color vector after averaging with the original color vector c v . Combining Eqs. (4-6), we obtain the final scaling factor k as:
$$k = \frac { \alpha \beta _ { \text{m} } + 1 } { 2 } = \frac { \alpha ( v _ { \text{m} } + 2 5 5 ) / 2 } { v _ { \text{m} } } + 0. 5, \quad ( 7 ) \quad \text{(Eq.}$$
where the calculation of ( v m + 255) divided by 2 can be quickly performed by a right-shift operation on the integer ( v m +255) .
## 3.2.4 Fusion via vector scaling
The proposed method fuses the pixel pair by scaling the visible input color vector by the computed scaling factor k . It changes the length of the vector but keeps its direction. Therefore, while the visible image adds brightness information from the infrared image, its color information is preserved.
However, after the scaling by k , some component of the color c s may be greater than 255. The output color c f is finally
## Algorithm 1 FCDFusion method
Input: RGB color c v of visible pixel and corresponding value v i of infrared pixel.
Output: RGB color c f of fused pixel.
$$& \cdot \\ \alpha & \longleftarrow v _ { i } / 2 5 5. 0 ; \\ \alpha & \longleftarrow \alpha \times \alpha ; \\ v _ { \text{m} } & \longleftarrow 1 ; \\ \dots & \dots \text{m} \circ \text{m} \dots$$
for each RGB colour component c v of color c v do
$$\text{if } c _ { \nu } & > v _ { m } \text{ then } \\ v _ { m } & \longleftarrow c _ { \nu } ;$$
## end if
end for
$$k = ( v _ { \mathrm m } + 2 5 5 ) > > 1 ;$$
$$k \longleftarrow k \times \alpha / v _ { \mathrm m } + 0. 5 ;$$
for each RGB component c v of color c v , and corresponding component c f of color c f do
$$c _ { f } & \stackrel {. } { \longleftarrow } k \times c _ { \nu } ; \\ \text{if } c _ { f } & > 2 5 5 \text{ then } \\ c _ { f } & \stackrel {. } { \longleftarrow } 2 5 5 ; \\ & \cdots$$
$$\begin{matrix} \nu _ { i } \cdots & \nu _ { i } \cdots \nu _ { i } \\ \text{if $c_{f}>25$ then} \\ c_{f} \longleftarrow 25 5 ; \\ \text{end if} \end{matrix}$$
obtained by limiting the three channels of c s to [0,255]:
$$\mathbf c _ { f } = \left [ \begin{array} { c } r _ { f } \\ g _ { f } \\ b _ { f } \end{array} \right ] = \left [ \begin{array} { c } \min ( k r _ { v }, 2 5 5 ) \\ \min ( k g _ { v }, 2 5 5 ) \\ \min ( k b _ { v }, 2 5 5 ) \end{array} \right ]. \quad \ \ ( 8 )$$
The overall computation is presented in Algorithm 1.
The analysis of arithmetic operations given in Tab. 1 shows that simple averaging methods only use simple integer operations and no floating point operations during fusion. In fast, color-preserving methods like YIQ-AVG and HSVAVG, color space transformations account for the majority of floating point operations. Our method uses vector scaling (Eq. 8) instead of color space transformations, so is faster. Further discussion is provided in Sec. 5.
## 4 Color deviation metric
In this section, we propose a new metric, color deviation (CD), to measure the color-preservation ability of a VIF method. It is specifically designed for VIF tasks with color visible images and is intended to avoid the deficiencies of existing VIF metrics used to evaluate color preservation. We first motivate and define color deviation, and then analyze the color preservation ability of several fast VIF methods using this metric.

Table 1 FLOPs required by various fusion methods, per fused pixel, and their color-preservation performance. Columns 2-4 give the FLOPs for the 3 main stages: transformation from RGB color space, fusion, and inverse color space transformation.
| Method | From RGB | Fusion | To RGB | Total | Color preservation |
|------------------|------------|----------|----------|---------|----------------------|
| RGB-AVG | 0 | 0 | 0 | 0 | poor |
| YIQ-AVG | 9 | 0 | 9 | 18 | intermediate |
| HSV-AVG | 6 | 0 | 8 | 14 | good |
| FCDFusion (ours) | 0 | 7 | 0 | 7 | good |

Fig. 4 Color comparison of three fused images (a), (b), and (c), obtained by RGB-AVG, MST-SR, and our method, respectively. Only (c) presents a good visual effect and retains color information.




## 4.1 Motivation and definition
Fig. 4 illustrates the deficiencies which can result when using existing VIF metrics. From both perspectives of clarity and color preservation, Fig. 4(c) provides a superior fused image to Figs. 4(a,b) for the same two input images. The man in the car's shadow is enhanced in Fig. 4(c), which also shows that the man wears a brown or orange coat. This color information is lost in Figs. 4(a,b) by the changes in hue and saturation. However, when evaluated by existing metrics, which consider similarity or contrast, Fig. 4(c) is not considered to be the best result. The main reason is that the existing metrics are defined specifically for monochrome images.
Similarity-related metrics (such as PSNR [39], SSIM [38] and RMSE [39]) compare the fused image to both input images. Since the infrared image is monochromatic and it is given the same importance as the visible image, a fused image with saturation between the two input images is more likely to obtain a higher score. Thus, evaluated by such metrics, Fig. 4(a) has the highest score among the three output images in Fig. 4. In fact, only the visible image has hue and saturation information, so the similarity of hue and saturation should be compared to the visible image individually.
Contrast-related metrics (such as CE [46], EN [36], MI [47], AG [37], EI [48], SD [49], SF [50], Q AB/F [51], Q CB [52] and Q CB [53]) measure the whole contrast of the fused image, including contrasts in hue, saturation and brightness. Therefore, a fused image can obtain a higher score by increasing the contrast in hue and saturation channels, which may lead to large differences in hue and saturation between the visible image and the fused image. Using such metrics, Fig. 4(b) generally has the highest score of the three output images in Fig. 4. Instead, to preserve color information from the visible image, hue and saturation need to be unchanged during fusion.

To avoid these problems, in VIF tasks with color visible images, color information and brightness information should be measured respectively. Brightness information ( i.e. , the brightness similarity of the two input images and the fused image, and the brightness contrast of the fused image itself) can be assessed by existing metrics after changing the visible image and fused image into grayscale images. For color information, the color deviation (CD) between the visible input color and fused color can be measured by the angle between the two color vectors c f and c v :
$$\text{CD} ( \mathbf c _ { v }, \mathbf c _ { f } ) = \arccos \frac { \overset { \cdot } { c _ { v } } \cdot \mathbf c _ { f } } { | \mathbf c _ { v } | \, | \mathbf c _ { f } | }, \text{ \quad \ \ } ( 9 )$$
with arccos returning its principal value in the range [0 , π ] . A small color deviation value indicates that hue and saturation
Fig. 5 Directional comparison of input color vectors ( i.e. , c v and c i ) and fused color vectors ( i.e. , c f-RGB, c f- YIQ , c f-HSV, and c f-Ours ).
are well preserved from the visible input color. When angles are small, the differences from their cosine values are not obvious, so we use angles instead of their cosine values.
To assess the overall color preservation ability of a VIF method for an input image pair, the average color deviation over all pixels is used.
## 4.2 Color deviation of existing fast methods
Here, we analyze the color-preserving ability of four existing fast VIF methods using color deviation. In Fig. 5, the Y axis of YIQ color space is the diagonal of RGB color space, on which each color has the same red, green and blue value. So the infrared color c i is along on the Y axis.
The VIF averaging method in RGB color space simply averages c v with c i , so the fused vector c f-RGB is the midpoint of the line segment connecting c v and c i . As Fig. 5 shows, this averaging operation causes a large angle between c v and c f-RGB.
The VIF averaging method in YIQ color space averages c v with c i only in the Y channel. As Fig. 5 indicates, doing so moves c v along a straight line ℓ which is parallel to the axis Y . More specifically, the fused vector c f- YIQ is the midpoint of the line segment connecting c v and c i 's projection point on the line ℓ . As Fig. 5 shows, this averaging operation causes a small angle between c v and c f- YIQ .
The VIF averaging method in HSV color space averages c v with c i only in the V channel (the length of the color vector) and keeps H (hue) channel and S (saturation) channel unchanged, so c v and c f-HSV are collinear. As Fig. 5 shows, the angle between c v and c f-HSV is close to 0.
Our method scales c v by the scaling factor k , so c v and the scaled vector c s are collinear. The bounding operation limits the three channels of c s to the range of [0,255], which may cause a tiny angle between c v and c f-Ours , as shown in Fig. 5.
In general, given the same input images, the relationship of color deviation corresponding to these four methods is:
$$0 \approx C D _ { \text{Ours} } \approx C D _ { \text{HSV} } < C D _ { \text{YIQ} } < C D _ { \text{RGB} }. \quad ( 1 0 ) \quad \text{ber o}!$$
Thus, our method (FCDFusion) and averaging in HSV color space better preserve the hue and saturation of the visible image, a conclusion confirmed by our experimental results in the next section.
Unlike averaging in HSV color space, our method does not need color space transformations and embeds gamma correction to improve contrast, so is faster and can provide clearer objects in fused images.
## 5 Results
In this section, we compare our method to several state-of-theart VIF methods. We first introduce the data set, evaluation metrics, and comparison methods used in the experiment, and then compare the fusion methods using metrics and visual effects.
## 5.1 Dataset
To ensure fairness and to reflect the processing of color information, we used visible and infrared image pairs from the visible and infrared image fusion benchmark (VIFB) [55] for real data experiments. VIFB is the only existing benchmark that provides image pairs with color visible images and provides unified procedures for state-of-art methods and evaluation metrics on the same computing platform. It provides 21 image pairs, a code library for 20 fusion algorithms, and 13 evaluation metrics. The average image size is 452 × 368 .
VIFB not only provides visible and infrared image pairs of dim scenes but also provides some for backlight scenes, to ensure a comprehensive evaluation of fusion methods.
## 5.2 Metrics
We first use 13 existing VIF metrics provided by VIFB: CE [46], EN [36], MI [47], AG [37], EI [48], SD [49], SF [50], Q AB/F [51], Q CB [52], Q CV [53], PSNR [39], SSIM [38], and RMSE [39]. As noted earlier, they mainly measure the contrast of the fused image itself and the similarity between the fused image and the two input images.
Since such existing metrics cannot fully assess the visual quality of the fused results, we invited 10 users to judge the relative quality of groups of fused images in VIFB (partly shown in Figs. 6 and 7), focusing on object clarity and color authenticity. In each image group, the fused images obtained by 8 methods were randomly reordered and scored from 1 to 8. Users can see the corresponding input images, but they do not know which method is used to obtain each output image.
We also counted the number of FLOPs and parameters used by each method. The FLOPs statistic measures the number of equivalent floating-point multiplications and divisions


required to fuse a pair of 452 × 368 input images. The parameters statistic measures the number of parameters to be learn in neural networks or to be manually set in filters and other transformations.
We also used the proposed color deviation (CD) metric to measure the color preservation abilities of the fusion methods.
## 5.3 Methods
We compared the proposed FCDFusion method to 3 simple averaging methods, the 2 highest-scoring methods from VIFB, and 2 state-of-the-art methods absent from VIFB.
The 3 simple averaging methods using RGB, YIQ, and HSV color spaces are named RGB-AVG, YIQ-AVG, and HSV-AVG for short.
The 2 highest-scoring methods from VIFB are MST-SR [32] and CNN [26]. MST-SR is a hybrid method, which has 6 top-three metric values in VIFB, for CE, EN, MI, Q AB/F , Q CB and Q CV. CNN is a deep learning method based on convolutional neural networks, which has 5 top-three metric values in VIFB, for MI, Q AB/F , Q CB, Q CV and SD. These two methods were originally designed to fuse grayscale images. In VIFB [55], they have been modified to fuse color images by fusing every channel of the RGB visible image with the corresponding infrared image.
The 2 state-of-the-art methods absent from VIFB are PIAFusion [28] and SeAFusion [29]. They are based on deep learning and use YUV (or the equivalent YCrCb) [44] color space.
## 5.4 Metric results
Results using contrast- and similarity-based metrics in Tab. 2 show that our method provides higher contrast than the three simple averaging methods, and retains more feature details from the input images than MST-SR, CNN, PIAFusion, and SeAFusion.
MST-SR and CNN score highly on contrast but destroy the color consistency with the original visible image, so have low scores for similarity. On the other hand, RGB-AVG scores highly for similarity to the the two input images, by simply averaging them, but gets low scores for contrast because of the low saturation of the infrared image. Our method balances these two aspects, so it lies in the middle of the 8 methods when evaluated by the 13 existing metrics.
Our user study shows that the images fused by our method have the best visual effects. Indeed, some complex methods based on multi-scale transformations (MST-SR) and deep learning (CNN, PIAFusion, and SeAFusion) are not even as

effective as simple averaging methods (RGB-AVG, YIQ-AVG, and HSV-AVG) in this respect.
The FLOPs metric shows the computational requirements of our method to be much lower than for state-of-the-art methods such as MST-SR, CNN, PIAFusion, and SeAFusion. Among the fast methods, RGB-AVG is the fastest, but also the least effective when considering color and contrast. Our method provides higher contrast and better visual effects than YIQ-AVG and HSV-AVG, and has a much greater processing speed. At the same time, our method does not need memory to store parameters, so the requirements for computing devices are very low.
The color deviation metric results show that our method and HSV-AVG better retain the hue and saturation of the visible image. As noted in Sec. 4.1, the final bounding operation (to a maximum of 255) in our method leads to bias; the bias angle of our method is slightly larger than that of HSV-AVG.
## 5.5 Visual effects
The groups of fused results in Figs. 6, 7 show two typical conditions found in VIF tasks, with objects in shadow and objects in strong light.
Objects in shadow need enhancement by brightening. As shown in Fig. 6, images fused by our method have more contrast than that those from RGB-AVG, YIQ-AVG, and HSV-AVG, making objects in shadows clearer. The reason is that our method uses gamma correction to improve contrast. Meanwhile, our method maintains the original color from the visible images, which avoids the loss of color information seen in the images fused by RGB-AVG, YIQ-AVG, MST-SR, CNN, PIAFusion, and SeAFusion. Our method only changes the brightness of the color by vector scaling, and keeps its original hue and saturation.
Objects in bright light need enhancement by dimming the light around them. As shown in Fig. 7, images fused by our method have more contrast than those from all other methods, making object in the bright light clearer, again due to the use of gamma correction. Deep learning-based methods ( i.e. , CNN, PIAFusion, and SeAFusion) do not perform under such conditions, partly because of the lack of training data for backlit scenes.
Color deviation values indicated in Figs. 6, 7 are consistent with the color differences between the visible images and fused images as can be observed visually and intuitively. This confirms that the proposed color deviation metric is a practical way of measuring the color preservation abilities of VIF methods. The examples in Fig. 7 have much smaller color
Table 2 Average metric values for 8 methods on 21 image pairs provided by VIFB. The best three values for each metric are indicated in red, green, and blue, respectively. ↑ means that a larger value is better, while ↓ means that a smaller value is better.
| Metric | RGB-AVG | YIQ-AVG | HSV-AVG | MST-SR | CNN | PIAFusion | SeAFusion | FCDFusion (ours) |
|----------|-----------|-----------|-----------|----------|----------|-------------|-------------|--------------------|
| CE ↓ | 1.3335 | 1.3844 | 1.3639 | 0.9572 | 1.0299 | 1.2918 | 1.5195 | 1.5368 |
| EN ↑ | 6.6814 | 6.7032 | 6.7311 | 7.3391 | 7.3202 | 6.9962 | 6.9960 | 6.8778 |
| MI ↑ | 2.1976 | 2.1444 | 2.1233 | 2.8090 | 2.6533 | 2.4964 | 2.1438 | 2.2788 |
| AG ↑ | 3.2779 | 3.3192 | 3.5214 | 5.8513 | 5.8077 | 5.8780 | 5.6707 | 3.9498 |
| EI ↑ | 34.1354 | 34.6171 | 36.5583 | 60.7805 | 60.2406 | 60.9310 | 59.0180 | 41.1680 |
| SD ↑ | 34.1786 | 34.8890 | 34.9258 | 57.3134 | 60.0753 | 52.3719 | 50.0449 | 41.5048 |
| SF ↑ | 10.3152 | 10.4263 | 11.1832 | 18.8067 | 18.8130 | 18.7830 | 17.8480 | 12.7951 |
| Q AB/F ↑ | 0.3995 | 0.4037 | 0.4177 | 0.6611 | 0.6576 | 0.6394 | 0.5632 | 0.4839 |
| Q CB ↑ | 0.4415 | 0.4434 | 0.4465 | 0.6447 | 0.6215 | 0.5400 | 0.4627 | 0.5428 |
| Q CV ↓ | 747.9871 | 749.6857 | 767.9276 | 522.6890 | 512.5690 | 383.2480 | 405.2917 | 774.8971 |
| PSNR ↑ | 29.22745 | 29.2022 | 29.18195 | 28.9754 | 28.96605 | 28.81665 | 28.6775 | 28.8974 |
| SSIM ↑ | 0.7453 | 0.74205 | 0.7361 | 0.69515 | 0.69545 | 0.6962 | 0.69725 | 0.71645 |
| RMSE ↓ | 0.0516 | 0.05245 | 0.05295 | 0.05825 | 0.0589 | 0.06195 | 0.06625 | 0.0586 |
| User ↑ | 4.1833 | 5.3167 | 5.6333 | 3.2833 | 3.3000 | 3.8000 | 3.2500 | 7.2333 |
| Params ↓ | 0 | 0 | 0 | 84.40K | 435.20K | 1.18M | 166.66K | 0 |
| FLOPs ↓ | 23.76K | 2.99M | 2.33M | 257.86M | 10.85G | 195.46G | 27.61G | 1.16M |
| CD ↓ | 0.0656 | 0.0411 | 0.0111 | 0.0711 | 0.0669 | 0.0366 | 0.0436 | 0.0117 |
deviation values than those in Fig. 6, as the visible images in Fig. 7 are less colorful.
## 6.2 Averaging
## 6 Discussion
We now discuss the important roles of gamma correction and averaging in our method, which properly adjust the contrast of the fused image.
## 6.1 Gamma correction
Using gamma correction in our method enhances contrast and reduces color noise, as demonstrated in Fig. 8.
Setting γ = 2 makes the objects clearest in both shadow and light, while keeping the background little changed from the visible image. Making γ too small or too great will lighten or darken the background respectively, resulting in a decrease in background contrast. Setting γ = 1 gives results like those of HSV-SVG.
Furthermore, setting γ = 2 suppresses color noise in dark areas of the visible images. Using HSV-AVG, γ = 0 5 . or γ = 1 lightens the dark areas in the visible images, such as the car's shadow in the first scene and the right area of the second scene. Thus color noise is magnified at the same time.
By setting γ = 2 , the exponential operation in Eq. (2) is reduced to squaring, which can be computed much faster than when using a general value for gamma. The FLOPs values given in Fig. 8 show that our method is faster than HSV-AVG or when using other γ settings (apart from γ = 1 ). Gamma correction using γ = 2 2 . is widely used in display enhancement [54]. Fig. 8 shows that using γ = 2 has very similar visual effects to using γ = 2 2 . , so we set γ = 2 for speed.
Average β and 1 when computing the scaling factor k in our method helps to avoid excessive changes in brightness, as demonstrated in Fig. 9. Without this averaging operation, objects are clear but some features in the background may becomeblurred, as the brightness information comes is mainly from the infrared image. The averaging operation provides brightness information from the visible image in the fused image. In applications that only focus on objects, the version without averaging may be better.
## 7 Conclusions
In this paper, we have proposed a simple and effective VIF method called FCDFusion, which preserves color information without color space transformations. It directly operates in RGB color space and embeds gamma correction using little extra computation, so color and contrast are quickly improved. A theoretical analysis and experimental results show that our method can achieve satisfactory results in only 7 FLOPs per pixel. Compared to state-of-the-art fast and color-preserving methods using HSV color space, our method provides higher contrast and the computational cost is only half.
In addition, we have proposed a new metric, color deviation, to measure the color preservation ability of a VIF method; it is specifically designed for VIF tasks using color visible images and overcomes the deficiencies of existing VIF metrics for color information evaluation.
## Acknowledgements
This work was supported by the National Natural Science Foundation of China under Grants Nos. 62171038, 61827901,



RGB-AVG


RGB-AVG


MST-SR

FCDFusion (ours

MST-SR


Infrared input

HSV-AVG

Se Fusion

Infrared input

HSV\_AVG


Visible input

YIQ-AVG

PIA Fusion

Visible input
C0.0267 YIQ-AVG

CNN

PIAFusion
SeAFusion
FCDFusion (ours

Fig. 6 Fusion results showing objects in shadow. CD values give the corresponding color deviation metric; lower is better.

CU=0.0191 RGB-AVG


RGB-AVG

Visible input

YIO-AVG


Visible input

YIO-AVG

Infrared input

HSV\_AVC


Infrared input

HSV\_AVG

CD=0.0169 MST\_SR

FCDFusion (ours

MST\_SR


FCDFusion (ours


Fig. 7 Fusion results showing objects in strong light. CD values give the corresponding color deviation metric; lower is better.



Visible input


Infrared input

HSV\_AVG

Visible input





HSV\_AVG


Infrared input





Fig. 8 Fusion results from HSV-AVG, and our method using different gamma correction. Orange boxes highlight areas with color noise.
Fig. 9 Fusion results with and without averaging when computing scaling factor k .

and 62088101. We would like to thank all the authors who provided code to the visible and infrared image fusion benchmark.
- [2] Cao Y, Guan D, Huang W, Yang J, Cao Y, Qiao Y. Pedestrian detection with unsupervised multispectral feature learning using deep neural networks. Information Fusion , 2019, 46: 206-217.
## Declaration of competing interest
The authors have no competing interests to declare that are relevant to the content of this article.
## References
- [1] Ma J, Ma Y, Li C. Infrared and visible image fusion methods and applications: a survey. Information Fusion , 2019, 45: 153-178.
- [3] Gao S, Cheng Y, Zhao Y. Method of visual and infrared fusion for moving object detection. Optics Letters , 2013, 38(11): 1981-1983.
- [4] Han J, Bhanu B. Fusion of color and infrared video for moving human detection. Pattern Recognition , 2007, 40(6): 17711784.
- [5] Ulusoy I, Yuruk H. New method for the fusion of complementary information from infrared and visual images for object


detection. IET Image Processing , 2011, 5(1): 36-48.
- [6] Li C, Zhu C, Huang Y, Tang J, Wang L. Cross-modal ranking with soft consistency and noisy labels for robust RGB-T tracking. In Proceedings of the European Conference on Computer Vision , 2018, 808-823.
- [7] Liu H, Sun F. Fusion tracking in color and infrared images using joint sparse representation. Science China Information Sciences , 2012, 55(003): 590-599.
- [8] Smith D, Singh S. Approaches to multisensor data fusion in target tracking: a survey. IEEE Transactions on Knowledge and Data Engineering , 2006, 18(12): 1696-1710.
- [9] Hariharan H, Koschan A, Abidi B, Gribok A, Abidi M. Fusion of visible and infrared images using empirical mode decomposition to improve face recognition. In IEEE International Conference on Image Processing , 2007, 2049-2052.
- [10] Heo J, Kong SG, Abidi BR, Abidi MA. Fusion of visual and thermal signatures with eyeglass removal for robust face recognition. In IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , 2004, 122-122.
- [11] Kong SG, Heo J, Abidi BR, Paik J, Abidi MA. Recent advances in visual and infrared face recognition - a review. Computer Vision and Image Understanding , 2005, 97(1): 103-135.
- [12] Conaire C ´ , O'Connor NE, Cooke E, Smeaton AF. CompariO son of fusion methods for thermo-visual surveillance tracking. In International Conference on Information Fusion , 2006, 1-7.
- [13] Kumar P, Mittal A, Kumar P. Fusion of thermal infrared and visible spectrum video for robust surveillance. In Indian Conference on Computer Vision, Graphics & Image Processing , 2006, 528-539.
- [14] Simone G, Farina A, Morabito FC, Serpico SB, Bruzzone L. Image fusion techniques for remote sensing applications. Information Fusion , 2002, 3(1): 3-15.
- [15] Yin S, Cao L, Ling Y, Jin G. One color contrast enhanced infrared and visible image fusion method. Infrared Physics & Technology , 2010, 53(2): 146-150.
- [16] Fu MY, Zhao C. Fusion of infrared and visible images based on the second generation curvelet transform. Journal of Infrared and Millimeter Waves , 2009, 28(4): 254-258.
- [17] Li H, Ding W, Cao X, Liu C. Image Registration and Fusion of Visible and Infrared Integrated Camera for Medium-Altitude Unmanned Aerial Vehicle Remote Sensing. Remote Sensing , 2017, 9(5).
- [18] Al-Wassai FA, Kalyankar N, Al-Zuky AA. The IHS transformations based image fusion. arXiv:1107.4396 , 2011.
- [19] Patil U, Mudengudi U. Image fusion using hierarchical PCA. In International Conference on Image Information Processing , 2011, 1-6.
- [20] Bao-Shu W. Multi-sensor image fusion based on improved laplacian pyramid transform. Acta Optica Sinica , 2007, 27(9): 1605-1610.
- [21] Pajares G, Manuel de la Cruz J. A wavelet-based image fusion tutorial. Pattern Recognition , 2004, 37(9): 1855-1872.
- [22] Xiao Y, Wang K. Image fusion algorithm using nonsubsampled contourlet transform. In MIPPR 2007: Multispectral Image Processing , volume 6787, 2007, 435-443.
- [23] Naidu V. Image fusion technique using multi-resolution singular value decomposition. Defence Science Journal , 2011, 61(5): 479-484.
- [24] Li H, Wu XJ. Infrared and visible image fusion using latent low-rank representation. arXiv:1804.08992 , 2018.
- [25] Li H, Wu Xj, Durrani TS. Infrared and visible image fusion with ResNet and zero-phase component analysis. Infrared Physics & Technology , 2019, 102: 103039.
- [26] Liu Y, Chen X, Cheng J, Peng H, Wang Z. Infrared and visible image fusion with convolutional neural networks. International Journal of Wavelets, Multiresolution and Information Processing , 2018, 16(03): 1850018.
- [27] Xu H, Gong M, Tian X, Huang J, Ma J. CUFD: An encoder-decoder network for visible and infrared image fusion based on common and unique feature decomposition. Computer Vision and Image Understanding , 2022, 218: 103407.
- [28] Tang L, Yuan J, Zhang H, Jiang X, Ma J. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Information Fusion , 2022, 83-84: 7992.
- [29] Tang L, Yuan J, Ma J. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Information Fusion , 2022, 82: 28-42.
- [30] Wang Z, Gong C. A multi-faceted adaptive image fusion algorithm using a multi-wavelet-based matching measure in the PCNN domain. Applied Soft Computing , 2017, 61: 11131124.
- [31] Yin M, Duan P, Liu W, Liang X. A novel infrared and visible image fusion algorithm based on shift-invariant dual-tree complex shearlet transform and sparse representation. Neurocomputing , 2017, 226: 182-191.
- [32] Liu Y, Liu S, Wang Z. A general framework for image fusion based on multi-scale transform and sparse representation. Information fusion , 2015, 24: 147-164.
- [33] Zhang X, Ma Y, Fan F, Zhang Y, Huang J. Infrared and visible image fusion via saliency analysis and local edge-preserving multi-scale decomposition. Journal of the Optical Society of America A , 2017, 34(8): 1400-1410.
- [34] Luo Y, He K, Xu D, Yin W, Liu W. Infrared and visible image fusion based on visibility enhancement and hybrid multiscale decomposition. Optik , 2022, 258: 168914.
- [35] Yin W, He K, Xu D, Luo Y, Gong J. Significant target analysis and detail preserving based infrared and visible image fusion. Infrared Physics & Technology , 2022, 121: 104041.
- [36] Roberts JW, Van Aardt JA, Ahmed FB. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. Journal of Applied Remote Sensing , 2008, 2(1): 1-28.
- [37] Cui G, Feng H, Xu Z, Li Q, Chen Y. Detail preserved fusion of visible and infrared images using regional saliency extraction
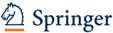
and multi-scale image decomposition. Optics Communications , 2015, 341: 199-209.
- [38] Wang Z, Bovik AC, Sheikh HR, Simoncelli EP. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing , 2004, 13(4): 600-612.
- [39] Jagalingam P, Hegde AV. A review of quality metrics for fused image. In Aquatic Procedia , 2015, 133-142.
- [40] Mu Q, Wang X, Wei Y, Li Z. Low and non-uniform illumination color image enhancement using weighted guided image filtering. Computational Visual Media , 2021, 7: 529-546.
- [41] Li P, Huang Y, Yao K. Multi-algorithm fusion of RGB and HSV color spaces for image enhancement. In Chinese Control Conference , 2018, 9584-9589.
- [42] Schwarz MW, Cowan WB, Beatty JC. An experimental comparison of RGB, YIQ, LAB, HSV, and opponent colour models. ACM Transactions on Graphics , 1987, 6(2): 123-158.
- [43] Smith AR. Color gamut transform pairs. ACM Siggraph Computer Graphics , 1978, 12(3): 12-19.
- [44] Maller J. RGB and YUV Color. FXScript Reference , 2003.
- [45] Liu Z, Blasch E, Xue Z, Zhao J, Laganiere R, Wu W. Objective assessment of multiresolution image Fusion algorithms for context enhancement in night vision: a comparative study. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2012, 34(1): 94-109.
- [46] Bulanon D, Burks T, Alchanatis V. Image fusion of visible and thermal images for fruit detection. Biosystems engineering , 2009, 103(1): 12-22.
- [47] Qu G, Zhang D, Yan P. Information measure for performance of image fusion. Electronics Letters , 2002, 38(7): 313-315.
- [48] Balakrishnan R, Priya R. Hybrid multimodality medical image fusion technique for feature enhancement in medical diagnosis. International Journal of Engineering Science Invention , 2018, 2(Special issue): 52-60.
- [49] Rao YJ. Review article: in-fibre bragg grating sensors. Measurement Science and Technology , 1997, 8(4): 355-375.
- [50] Eskicioglu AM, Fisher PS. Image quality measures and their performance. IEEE Transactions on Communications , 1995, 43(12): 2959-2965.
- [51] Xydeas C, , Petrovic V. Objective image fusion performance measure. Military Technical Courier , 2000, 56(4): 181-193.
- [52] Chen Y, Blum RS. A new automated quality assessment algorithm for image fusion. Image and Vision Computing , 2009, 27(10): 1421-1432.
- [53] Chen H, Varshney PK. A human perception inspired quality metric for image fusion based on regional information. Information Fusion , 2007, 8(2): 193-207.
- [54] Poynton C. Digital video and HD: algorithms and interfaces, 2012: 315-354.
- [55] Zhang X, Ye P, Xiao G. VIFB: a visible and infrared image fusion benchmark. In IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , 2020, 468-478.
## Author biography

Hesong Li is a master's student at the School of Computer Science and Technology, Beijing Institute of Technology, , China. He received his bachelor's degree from the School of Science, Dalian Maritime University in 2021. His research interests include artificial intelligence and image processing.

Ying Fu received a B.S. degree in electronic engineering from Xidian University, Xi'an, China, in 2009, an M.S. degree in automation from Tsinghua University, Beijing, China, in 2012, and a Ph.D. degree in information science and technology from the University of Tokyo, Japan, in 2015. She is currently a Professor in the School of Computer Science and Technology, Beijing Institute of Technology. Her research interests include computer vision, image and video processing, and computational photography.

 | null | [
"Hesong Li",
"Ying Fu"
] | 2024-08-02T07:57:06+00:00 | 2024-08-02T07:57:06+00:00 | [
"cs.CV"
] | FCDFusion: a Fast, Low Color Deviation Method for Fusing Visible and Infrared Image Pairs | Visible and infrared image fusion (VIF) aims to combine information from
visible and infrared images into a single fused image. Previous VIF methods
usually employ a color space transformation to keep the hue and saturation from
the original visible image. However, for fast VIF methods, this operation
accounts for the majority of the calculation and is the bottleneck preventing
faster processing. In this paper, we propose a fast fusion method, FCDFusion,
with little color deviation. It preserves color information without color space
transformations, by directly operating in RGB color space. It incorporates
gamma correction at little extra cost, allowing color and contrast to be
rapidly improved. We regard the fusion process as a scaling operation on 3D
color vectors, greatly simplifying the calculations. A theoretical analysis and
experiments show that our method can achieve satisfactory results in only 7
FLOPs per pixel. Compared to state-of-the-art fast, color-preserving methods
using HSV color space, our method provides higher contrast at only half of the
computational cost. We further propose a new metric, color deviation, to
measure the ability of a VIF method to preserve color. It is specifically
designed for VIF tasks with color visible-light images, and overcomes
deficiencies of existing VIF metrics used for this purpose. Our code is
available at https://github.com/HeasonLee/FCDFusion. |
2408.01084v2 | ## Adaptive Contrastive Decoding in Retrieval-Augmented Generation for Handling Noisy Contexts
Youna Kim , Hyuhng Joon Kim , Cheonbok Park 1 1 2 3 , Choonghyun Park , 1 Hyunsoo Cho , Junyeob Kim , Kang Min Yoo 4 1 1 2 5 , Sang-goo Lee 1 6 , Taeuk Kim 7 * 1 Seoul National University, 2 NAVER Cloud, 3 KAIST AI, 4 Ewha Womans University, 5 NAVER AI LAB, 6 IntelliSys, Korea, 7 Hanyang University {anna9812, heyjoonkim, pch330, juny116, sglee}@europa.snu.ac.kr {cbok.park, kangmin.yoo}@navercorp.com, [email protected] [email protected]
## Abstract
𝑯(𝒀𝒕 )
𝒄
= 5.03
When using large language models (LLMs) in knowledge-intensive tasks, such as opendomain question answering, external context can bridge the gap between external knowledge and the LLMs' parametric knowledge. Recent research has been developed to amplify contextual knowledge over the parametric knowledge of LLMs with contrastive decoding approaches. While these approaches could yield truthful responses when relevant context is provided, they are prone to vulnerabilities when faced with noisy contexts. We extend the scope of previous studies to encompass noisy contexts and propose adaptive contrastive decoding (ACD) to leverage contextual influence effectively. ACD demonstrates improvements in open-domain question answering tasks compared to baselines, especially in robustness by remaining undistracted by noisy contexts in retrieval-augmented generation.
## 1 Introduction
While large language models (LLMs) (Touvron et al., 2023; Achiam et al., 2023) achieve remarkable performance levels across diverse benchmarks, they sometimes struggle to generalize to knowledge-intensive tasks, such as open-domain question-answering (QA; Chen et al., 2017), and may also fail to capture long-tail knowledge, leading to unfaithful output generation (Mallen et al., 2023; Kandpal et al., 2023). One common approach to address these limitations is fine-tuning the model, but this results in a quadratic rise in computational demands as the size of the LLMs increases exponentially (Longpre et al., 2023). To overcome this, researchers have been investigating strategies to combine non-parametric knowledge with LLMs during response generation without explicit re-training (Asai et al., 2023a). This approach leverages external information from knowledge
* Corresponding author.
Figure 1: An illustration of adaptive contrastive decoding (ACD). Entropy ( H ) changes depending on context relevance, affecting the adaptive weight ( α ACD). Noisy context leads the model to incorrectly answer "Diede De Groot" when employing regular greedy decoding. ACD applies context-based adjustments, enabling the correct answer, "Sloane Stephens," despite the noise.
bases and enhances the capability of the LLMs dynamically, ensuring that the information is both current and accurate.
Early studies in this field attempt to append query-relevant context to generate more accurate responses. Especially, contrastive decoding (Li et al., 2023; Malkin et al., 2022; Liu et al., 2021) yields significant enhancement in various tasks by amplifying the influence of the given context at decoding step (Shi et al., 2023; Zhao et al., 2024). While such methods work well when context information is correct and faithful, in real-world scenarios, context information is not always correct and may contain some noisy and unfaithful information. For instance, if the retrieval system pulls in irrelevant or contradictory information, it could lead to incorrect responses (Wang et al., 2024; Wu et al., 2024; Yu et al., 2024). This highlights the necessity for a generation model that can gauge the appropriateness of the context by itself, being robust to noise
and unfaithful data to ensure the output remains reliable (Yoran et al., 2024).
To assess whether the existing contrastive decoding approaches can be utilized in practice, we extend the setting to situations where the goldstandard context is not guaranteed, specifically in the retrieval-augmented generation (RAG) framework (Yao et al., 2022; Shi et al., 2024; Izacard et al., 2023). In this paper, we demonstrate that existing context-aware contrastive decoding approaches experience performance drops in opendomain question answering, especially when the retrieved context is noisy. To address this issue, we propose adaptive contrastive decoding (ACD) , adaptively weighting the contrastive contextual influence on the parametric knowledge, making it suitable for noisy context settings (Figure 1).
Incorporating the distinction between contextual and parametric knowledge, our approach aims to mitigate the dominance of potentially noisy contextual information in model output. We control contrastive contextual influence based on context's contribution to the LLM's uncertainty reduction, thereby minimizing its disruptive effect during decoding. Through in-depth experiments with three open-domain QA datasets, we demonstrate the potential of the proposed approach with increased overall performance. Moreover, ACD enhances the performance significantly on the noisy context scenario while minimizing performance degradation on the gold context scenario compared to the baselines.
## 2 Related Works
Context-Augmented Generation Approaches for context-augmented generation have been developed to enhance the model's limited parametric knowledge by providing external knowledge, enabling more factual and contextually accurate responses during inference (Zhou et al., 2023; He et al., 2024). To sufficiently incorporate the information from the context in model generation, contrastive decoding approaches are applied to overwrite the model's parametric knowledge with external knowledge (Shi et al., 2023; Zhao et al., 2024). These context-aware contrastive decoding methods to generate responses faithful to the given context show effective performance in summarization (See et al., 2017; Narayan et al., 2018), knowledge conflict (Longpre et al., 2022), and question answering with gold-standard contexts.
Robustness in RAG Frameworks While retrieval-augmented generation enables LLMs to become factual and reliable with the retrieved external knowledge, there are still concerns about incorrectly retrieved irrelevant contexts (Yoran et al., 2024). To address hallucination errors posed by irrelevant contexts, some researchers take an approach to train LLMs that can adaptively retrieve relevant context (Asai et al., 2023b; Wang et al., 2024). Another approach aims to selectively use retrieved contexts after assessing their truthfulness or relevance through context verification with prompting strategies or training untruthful context detectors (Yu et al., 2024; Zhang et al., 2024). These approaches highlight the ongoing efforts to advance the robustness and accuracy of LLMs in multiple directions to manage potentially misleading information.
## 3 Methodology
## 3.1 Problem Formulation
At decoding time step t , given the input x and preceding sequences y <t , a pretrained auto-regressive LLM θ computes the logit z t ∈ R | V | , where V is the vocabulary, for the t -th token. In the opendomain QA task, a question q serves as the input x , and z t relies solely on the LLM's parametric knowledge. When both q and the retrieved context c are provided as x , the logit is denoted as z c t ∈ R | V | .
## 3.2 Contrastive Decoding
In cases where context cannot be blindly trusted, directly following the context-augmented distribution can increase the risk of being misled. Thus, we adopt the approach of adding the contextual influence, which contrasts with the LLM's parametric knowledge, to the parametric distribution z t . With the contrastive decoding objective, z c t and z t are ensembled to reflect the influence of external context on the LLM's parametric knowledge at each decoding step t . The probability distribution P θ ( Y t | x, y <t ) is modified by weighted adjustment based on the difference between z c t and z t , as represented in the following equation.
$$\text{ods} \quad P _ { \theta } ( Y _ { t } \, | \, x, y _ { < t } ) = \text{softmax} ( \mathbf z _ { t } + \alpha \left ( \mathbf z _ { t } ^ { c } - \mathbf z _ { t } \right ) ) \ ( 1 )$$
The contrastive adjustment enables the LLM to integrate external context c into its prediction, leveraging the weight α to control the impact of c on the final probability distribution.
## 3.3 Adaptive Weight on Contextual Influence
The degree to which contextual influence is incorporated into z t needs to be controlled based on the provided context's informativeness. In practice, however, it is often unknown whether the context is gold or noisy. To address this, we investigate whether the model could adjust accordingly with a simple entropy-based approach.
The LLM's uncertainty is expressed with the entropy H Y ( t ) of its probability distribution P θ ( Y t | x, y <t ) (Huang et al., 2023; Kuhn et al., 2023). While H Y ( t ) reflects how much uncertainty the model has based on its parametric knowledge under the given question, H Y ( c t ) is influenced by the external knowledge within the retrieved context c . Generally, when the context is added, the entropy decreases (Kendall and Gal, 2017). However, if the context is noisy, irrelevant, or provides no information to answer the given question, it may contribute to increased uncertainty instead.
Intuitively, if the retrieved context provides informative cues for answering the question, then H Y ( c t ) is expected to be lowered compared to H Y ( t ) . Conversely, if the context is non-helpful or even confusing the model prediction, H Y ( c t ) in predicting the next token is likely to be higher. This scenario would be particularly evident when the model knows the answer with low H Y ( t ) .
Considering the above scenarios, the motivation behind the adaptive weight α ACD is to assign a relatively smaller weight in cases where the context increases uncertainty by being uninformative or confusing for the model in answering the given question. Thus, the value of α ACD is set as the proportion of uncertainty contributed by H Y ( t ) relative to the total uncertainty when considering both H Y ( t ) and H Y ( c t ) :
$$\alpha _ { A C D } = \frac { H ( Y _ { t } ) } { H ( Y _ { t } ) + H ( Y _ { t } ^ { c } ) } \quad \ \ ( 2 ) \quad \ \text{con} \\ \quad \text{pre}$$
Under the condition where H Y ( t ) > H Y ( c t ) , α ACD value approaches to 1, indicating that when the context c is provided, the uncertainty associated with predicting the next token decreases. Conversely, when H Y ( t ) < H Y ( c t ) , α ACD value approaches to 0, reflecting minimal influence from c . Note that when H Y ( t ) = H Y ( c t ) , α ACD becomes 0.5, resulting in an ensemble of two distributions, z t and z c t , with equal weighting.
With α ACD , the vocab v with maximum probability is selected as the next token under the follow- ing distribution:
$$\underset { \cdot d \text{ on} } { \text{cor} } \quad \hat { P } _ { \theta } ( Y _ { t } \, | \, x, y _ { < t } ) = \text{softmax} ( \mathbf z _ { t } \, + \, \alpha _ { A C D } \left ( \mathbf z _ { t } ^ { c } - \mathbf z _ { t } \right ) ) \\ \text{ctice}. \quad \_ \_ \_ \_ \_ \,.$$
Informed by α ACD and contextual contrast, the adjustment process determines the degree to which the model's parametric knowledge is superseded, thus optimizing the assimilation of contextual information throughout decoding.
## 4 Experimental Results
## 4.1 Experimental Settings
Datasets and Models We conduct experiments on open-domain QA datasets, TriviaQA (Joshi et al., 2017), Natural Questions (NQ; Kwiatkowski et al., 2019), and PopQA (Mallen et al., 2022) with Wikipedia contexts. 2
We use auto-regressive language models, LLAMA2 (7B & 13B, Touvron et al., 2023), LLAMA3 8B, 3 and MISTRAL 7B (Jiang et al., 2023). Utilizing CONTRIEVER-MSMARCO (Izacard et al., 2022) as a retriever, the top-1 retrieved context is appended to each question.
Evaluation Metric Following Zhao et al. (2024), we use few-shot prompts with 5 examples. We report Exact Match (EM) as an evaluation metric, which verifies whether the generated sequences precisely match one of the candidate answers.
Baselines As fundamental baselines, regular greedy decoding has been employed in open-book (Reg Opn ) and closed-book (Reg Cls ) settings. We compare our method against existing context-aware contrastive decoding methods, including ContextAware Decoding (CAD; Shi et al., 2023) and MultiInput Contrastive Decoding (MICD; Zhao et al., 2024). MICD uses inputs with and without context, along with an additional input with adversarial context, to generate the output distribution. MICD presents two methods, referred to as MICD F and MICD D , which offer fixed and dynamic α , respectively. Similar to our approach, to leverage the burden of hyperparameter search and dependency on fixed α , MICD D also determines α dynamically. In MICD D , α is assigned as the maximum token probability with context (max P wc ) if max P wc exceeds the maximum token probability without context (max P woc ); otherwise, it is calculated as
1 -max P woc .
2 Wikipedia dump from Dec. 2018.
3 https://github.com/meta-llama/llama3
| | Dataset ( → ) | | TriviaQA | | | NQ | | | PopQA | |
|------------|-----------------|-------|-------------|--------------|-------|-------------|--------------|-------|-------------|--------------|
| Model | Method ( ↓ ) | All | Subset Gold | Subset Noisy | All | Subset Gold | Subset Noisy | All | Subset Gold | Subset Noisy |
| LLAMA2 7B | Reg Cls | 59.00 | - | - | 25.48 | - | - | 28.36 | - | - |
| LLAMA2 7B | Reg Opn | 60.23 | 87.40 | 33.50 | 31.39 | 61.31 | 12.40 | 38.49 | 81.21 | 7.77 |
| LLAMA2 7B | CAD | 49.02 | 73.69 | 24.75 | 25.57 | 51.61 | 9.05 | 33.70 | 72.18 | 6.03 |
| LLAMA2 7B | MICD F | 60.36 | 85.72 | 35.39 | 29.45 | 56.10 | 12.54 | 35.73 | 74.25 | 8.03 |
| LLAMA2 7B | MICD D | 63.23 | 86.03 | 40.79 | 30.36 | 52.18 | 16.52 | 39.01 | 77.39 | 11.42 |
| LLAMA2 7B | ACD | 64.85 | 88.01 | 42.06 | 32.91 | 56.60 | 17.88 | 41.29 | 82.77 | 11.46 |
| LLAMA2 13B | Reg Cls | 63.77 | - | - | 30.80 | - | - | 32.70 | - | - |
| LLAMA2 13B | Reg Opn | 62.81 | 88.52 | 37.51 | 33.35 | 62.96 | 14.58 | 40.03 | 83.20 | 8.98 |
| LLAMA2 13B | CAD | 52.62 | 76.78 | 28.85 | 27.87 | 55.96 | 10.05 | 35.86 | 76.38 | 6.71 |
| LLAMA2 13B | MICD F | 63.53 | 87.40 | 40.04 | 32.63 | 59.67 | 15.48 | 38.16 | 77.04 | 10.21 |
| LLAMA2 13B | MICD D | 66.52 | 87.68 | 45.69 | 34.38 | 57.32 | 19.83 | 41.65 | 79.27 | 14.60 |
| LLAMA2 13B | ACD | 67.37 | 89.36 | 45.74 | 36.12 | 61.17 | 20.24 | 43.35 | 83.98 | 14.14 |
| LLAMA3 8B | Reg Cls | 61.67 | - | - | 28.34 | - | - | 32.65 | - | - |
| LLAMA3 8B | Reg Opn | 61.27 | 86.94 | 36.02 | 33.30 | 63.10 | 14.40 | 39.73 | 82.95 | 8.64 |
| LLAMA3 8B | CAD | 49.70 | 72.45 | 27.31 | 29.17 | 58.39 | 10.64 | 35.86 | 76.82 | 6.40 |
| LLAMA3 8B | MICD F | 61.01 | 85.40 | 37.00 | 27.62 | 51.89 | 12.22 | 37.99 | 77.12 | 9.85 |
| LLAMA3 8B | MICD D | 64.01 | 86.08 | 42.28 | 30.72 | 53.96 | 15.98 | 41.35 | 79.32 | 14.04 |
| LLAMA3 8B | ACD | 66.32 | 89.20 | 43.81 | 35.48 | 62.03 | 18.65 | 43.25 | 84.48 | 13.60 |
| MISTRAL 8B | Reg Cls | 63.72 | - | - | 29.64 | - | - | 29.04 | - | - |
| MISTRAL 8B | Reg Opn | 60.45 | 86.85 | 34.48 | 32.55 | 64.67 | 12.18 | 38.28 | 81.26 | 7.36 |
| MISTRAL 8B | CAD | 44.69 | 66.89 | 22.85 | 24.10 | 52.25 | 6.25 | 33.93 | 73.95 | 5.15 |
| MISTRAL 8B | MICD F | 63.33 | 88.43 | 38.62 | 31.80 | 61.10 | 13.22 | 36.58 | 76.00 | 8.23 |
| MISTRAL 8B | MICD D | 66.97 | 89.24 | 45.05 | 33.24 | 57.89 | 17.61 | 39.87 | 78.46 | 12.11 |
| MISTRAL 8B | ACD | 67.82 | 90.16 | 45.83 | 35.37 | 62.17 | 18.38 | 41.47 | 82.90 | 11.68 |
Table 1: EM accuracy of full data (All) and subsets with gold (SubsetGold) and noisy contexts (SubsetNoisy). The highest score is in bold , and the second-best is underlined.
## Performance under Parametric Knowledge
Models
Figure 2: EM accuracy of each method in LLAMA2-7B. EM of three datasets used are averaged for each subset, Unknown-gold and Known-noisy .
## 4.2 Main Results
Performance on RAG As shown in Table 1, ACD outperforms the baselines across all datasets and models within the RAG framework, particularly when considering the full test data (All). When analyzing the performance by dividing the data into two subsets based on whether the retrieved context is gold (SubsetGold) or not (SubsetNoisy), ACD achieves either the best or second-best performance. MICD D demonstrates performance comparable to ACD on SubsetNoisy. However, it shows a significant drop on SubsetGold, indicating a tendency to ignore gold context while handling noisy context. It is notable that both CAD and MICD F exhibit a significant drop in their performance under noisy conditions.
We aim to analyze the model's performance across various aspects, focusing specifically on its parametric knowledge. We estimate whether the model possesses relevant parametric knowledge for a given question based on its accuracy in a closedbook setting (Reg Cls ). We consider two subsets under the following conditions: (1) Known-noisy : the model has parametric knowledge of the given question and noisy context is retrieved. (2) Unknowngold : the model does not have parametric knowledge of the given question and gold context is retrieved.
From Figure 2, we observe that ACD outperforms the baselines in Known-noisy . Notably, two approaches with adaptively adjusted weight, ACD and MICD D , perform well in Known-noisy , while other baselines show a relative strength in Unknown-gold . However, these baselines also experience significant performance drops in Knownnoisy , indicating distraction by noisy context despite correctly answering when only the question is provided. In both cases, ACD demonstrates better performance compared to MICD D , overall showing a tendency towards reliability.
## 4.3 Analysis
Correlation between Adaptive Weight and Context Noisiness While other baselines rely on the fixed hyperparameter of weight α , ACD and
| | α | NQ | TriviaQA | PopQA |
|-------|--------|-------|------------|---------|
| Max | MICD D | 51.53 | 59.76 | 65.49 |
| Max | ACD | 65.78 | 73.37 | 74.84 |
| Avg. | MICD D | 54.18 | 63.78 | 72.64 |
| Avg. | ACD | 68.8 | 72.32 | 78.9 |
| First | MICD D | 53.92 | 62.95 | 68.81 |
| First | ACD | 73.27 | 80.45 | 80.08 |
Table 2: AUROC between α used in each method and the noisiness of the retrieved context.
Models
Figure 3: EM accuracy on NQ-swap with contexts replacing the gold answer with a random entity span.
MICD D adjust α during the decoding step. It depends not only on the noisiness of the retrieved context but also on whether the model's parametric knowledge contains an answer to the given question. To exclude cases that are not directly related to the analysis of how weight is adjusted based on context quality and the model's parametric knowledge, we use the same subsets, Known-noisy and Unknown-gold .
Adaptive weights α ACD and α MICD are extracted at each decoding step and analyzed across three metrics: maximum, average, and the first within the generated sequence. As an evaluation metric, the area under the receiver operator characteristic curve (AUROC) between α and the noisiness of the retrieved context is measured. AUROC of each α for LLAMA 2-7B is reported in Table 2. Under every metric and dataset, ACD demonstrates a higher AUROC compared to MICDD. Aligned with our motivation, when the model is knowledgeable and presented with noisy context, α ACD tends to be lower, emphasizing greater reliance on parametric knowledge. Conversely, when the model lacks knowledge and is provided with gold context, α ACD is adjusted to prioritize reliance on the provided context.
Handling Knowledge Conflict With a knowledge conflict QA dataset, NQ-swap (Longpre et al., 2022), we verify whether the two decoding methods with dynamic weight, ACD and MICD D , can
Figure 4: EM across alpha values ranges from 0.0 to 1.0. The dashed line indicates EM score with α ACD .
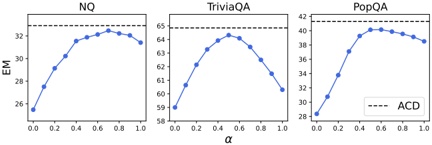
generate context-based responses without considering a conflicting context as a noisy context. The conflicting context in the NQ-swap dataset is constructed by replacing the answer entity span in the original gold context with a random entity of the same type. Figure 3 illustrates that ACD consistently exceeds the performance of MICD D across all models and achieves results comparable to openbook regular decoding. The results indicate that the ACD's approach remains effective even in settings where the context is relevant to the question but contradicts the model's parametric knowledge.
Ablation on α ACD To assess the impact of α ACD on performance, we fix the value of α within a range [0 , 1] and examine whether employing ACD is more effective than optimizing a fixed weight. In Figure 4, it can be observed that using a fixed α results in degraded performance compared to ACD. Increasing the alpha value, which enhances the contextual influence on the output distribution, initially leads to a rise in the EM score. However, beyond a certain point, further increasing α results in a decline in the EM score. In scenarios with potential noisy context, a fixed α value may not ensure optimal performance. Therefore, employing an adaptive weight, α ACD , to adjust the impact of contextual knowledge based on entropy is crucial for improving overall performance.
## 5 Conclusion
In this work, we mainly tackle handling noisy contexts in open-domain QA on the RAG framework. Our proposed method, ACD, dynamically adjusts contextual influence during decoding by quantifying the model's uncertainty that is either reduced or increased by the retrieved context. Our results show that ACD improves performances across various dimensions by considering the LLM's parametric knowledge and context noisiness. These findings highlight ACD's potential to enhance the reliability of retrieval-augmented generation.
## Limitations
Similar to other contrastive decoding approaches, the inference cost of our approach is higher than the conventional greedy decoding. Specifically, while CAD incurs twice the inference cost and MICD incurs three times the cost, ACD also incurs twice the inference cost of conventional greedy decoding.
Our research is limited the base models and does not encompass chat or instruction-following models trained with reinforcement learning from human feedback (RLHF) or instruction fine-tuning (Ouyang et al., 2022; Chung et al., 2022). These aligned models often generate token distributions that vary significantly based on the presence or absence of contextual instruction or templates. For instance, an instruction-following model might start its generation with "According to the given context ..." when context is provided, while directly generating the answer in absence of context. This alignment with the provided instructions poses another challenge to be tackled when the contrastive decoding approach is utilized.
Our current focus is primarily on short-form QA tasks. Expanding to QA tasks with long-form generation will enable a wider range of applications. Under long-form QA tasks, our approach can be further developed to investigate scenarios where the context is only partially relevant to the question.
## Acknowledgement
This work was partly supported by SNU-NAVER Hyperscale AI Center and Institute of Information &communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) [NO.RS-2021-II211343, Artificial Intelligence Graduate School Program (Seoul National University), No.RS-2020-II201373, Artificial Intelligence Graduate School Program (Hanyang University), NO.RS-2021-II212068, Artificial Intelligence Innovation Hub (Artificial Intelligence Institute, Seoul National University)]
## References
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 .
Akari Asai, Sewon Min, Zexuan Zhong, and Danqi Chen. 2023a. Retrieval-based language models and applications. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 6: Tutorial Abstracts) , pages 41-46, Toronto, Canada. Association for Computational Linguistics.
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023b. Self-rag: Learning to retrieve, generate, and critique through self-reflection. Preprint , arXiv:2310.11511.
Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. 2017. Reading Wikipedia to answer opendomain questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 1870-1879, Vancouver, Canada. Association for Computational Linguistics.
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei. 2022. Scaling instruction-finetuned language models. Preprint , arXiv:2210.11416.
Zhenyu He, Zexuan Zhong, Tianle Cai, Jason D. Lee, and Di He. 2024. Rest: Retrieval-based speculative decoding. Preprint , arXiv:2311.08252.
Giwon Hong, Aryo Pradipta Gema, Rohit Saxena, Xiaotang Du, Ping Nie, Yu Zhao, Laura PerezBeltrachini, Max Ryabinin, Xuanli He, Clémentine Fourrier, and Pasquale Minervini. 2024. The hallucinations leaderboard - an open effort to measure hallucinations in large language models. Preprint , arXiv:2404.05904.
Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, and Lei Ma. 2023. Look before you leap: An exploratory study of uncertainty measurement for large language models. Preprint , arXiv:2307.10236.
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised dense information retrieval with contrastive learning. Preprint , arXiv:2112.09118.
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane DwivediYu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2023. Atlas: Few-shot learning with retrieval augmented language models. Journal of Machine Learning Research , 24(251):1-43.
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud,
Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7b. Preprint , arXiv:2310.06825.
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. 2017. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. Preprint , arXiv:1705.03551.
Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. 2023. Large language models struggle to learn long-tail knowledge. In Proceedings of the 40th International Conference on Machine Learning , volume 202 of Proceedings of Machine Learning Research , pages 15696-15707. PMLR.
Alex Kendall and Yarin Gal. 2017. What uncertainties do we need in bayesian deep learning for computer vision? In Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc.
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. Preprint , arXiv:2302.09664.
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics , 7:453466.
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori Hashimoto, Luke Zettlemoyer, and Mike Lewis. 2023. Contrastive decoding: Open-ended text generation as optimization. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 12286-12312, Toronto, Canada. Association for Computational Linguistics.
Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A. Smith, and Yejin Choi. 2021. DExperts: Decoding-time controlled text generation with experts and anti-experts. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages 6691-6706, Online. Association for Computational Linguistics.
Shayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois, and Sameer Singh. 2022. Entity-based knowledge conflicts in question answering. Preprint , arXiv:2109.05052.
Shayne Longpre, Gregory Yauney, Emily Reif, Katherine Lee, Adam Roberts, Barret Zoph, Denny Zhou, Jason Wei, Kevin Robinson, David Mimno, and Daphne Ippolito. 2023. A pretrainer's guide to training data: Measuring the effects of data age, domain coverage, quality, & toxicity. Preprint , arXiv:2305.13169.
Nikolay Malkin, Zhen Wang, and Nebojsa Jojic. 2022. Coherence boosting: When your pretrained language model is not paying enough attention. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 8214-8236, Dublin, Ireland. Association for Computational Linguistics.
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2022. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. arXiv preprint arXiv:2212.10511 .
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 9802-9822, Toronto, Canada. Association for Computational Linguistics.
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. 2018. Don't give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages 1797-1807, Brussels, Belgium. Association for Computational Linguistics.
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. Preprint , arXiv:2203.02155.
Abigail See, Peter J. Liu, and Christopher D. Manning. 2017. Get to the point: Summarization with pointergenerator networks. Preprint , arXiv:1704.04368.
Weijia Shi, Xiaochuang Han, Mike Lewis, Yulia Tsvetkov, Luke Zettlemoyer, and Scott Wen tau Yih. 2023. Trusting your evidence: Hallucinate less with context-aware decoding. Preprint , arXiv:2305.14739.
Weijia Shi, Sewon Min, Maria Lomeli, Chunting Zhou, Margaret Li, Gergely Szilvasy, Rich James, Xi Victoria Lin, Noah A. Smith, Luke Zettlemoyer, Scott Yih, and Mike Lewis. 2024. In-context pretraining: Language modeling beyond document boundaries. Preprint , arXiv:2310.10638.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller,
Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023. Llama 2: Open foundation and finetuned chat models. Preprint , arXiv:2307.09288.
Yuhao Wang, Ruiyang Ren, Junyi Li, Wayne Xin Zhao, Jing Liu, and Ji-Rong Wen. 2024. Rear: A relevance-aware retrieval-augmented framework for open-domain question answering. Preprint , arXiv:2402.17497.
Siye Wu, Jian Xie, Jiangjie Chen, Tinghui Zhu, Kai Zhang, and Yanghua Xiao. 2024. How easily do irrelevant inputs skew the responses of large language models? Preprint , arXiv:2404.03302.
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629 .
Ori Yoran, Tomer Wolfson, Ori Ram, and Jonathan Berant. 2024. Making retrieval-augmented language models robust to irrelevant context. Preprint , arXiv:2310.01558.
Tian Yu, Shaolei Zhang, and Yang Feng. 2024. Truthaware context selection: Mitigating hallucinations of large language models being misled by untruthful contexts. Preprint , arXiv:2403.07556.
Zihan Zhang, Meng Fang, and Ling Chen. 2024. Retrievalqa: Assessing adaptive retrieval-augmented generation for short-form open-domain question answering. Preprint , arXiv:2402.16457.
Zheng Zhao, Emilio Monti, Jens Lehmann, and Haytham Assem. 2024. Enhancing contextual understanding in large language models through contrastive decoding. Preprint , arXiv:2405.02750.
Wenxuan Zhou, Sheng Zhang, Hoifung Poon, and Muhao Chen. 2023. Context-faithful prompting for large language models. In Findings of the Association for Computational Linguistics: EMNLP 2023 , pages 14544-14556, Singapore. Association for Computational Linguistics.
Answer the following questions:
## <few-shots>
Question: <question>
Answer:
Table 3: Template used in closed-book generation.
Answer the following questions:
## <few-shots>
Context:
<context>
Question: <question>
Answer:
Table 4: Template used in open-book generation.
## Appendix
## A Implementation Details
## A.1 Instructions
The templates we use throughout the experiment are in Table 3 and Table 4. The template used in open-book generation (Table 4) is applied to get context-augmented distribution z c t . Also, to obtain z t , the template in Table 3 is used.
## A.2 Datasets
For NQ and TriviaQA, general world knowledge is required to answer the given question. In PopQA, tackling long-tailed information, less popular factual knowledge is asked. For NQ and TriviaQA, few-shot examples are adopted from train data. For PopQA, we randomly sample 5 examples with different relationship types for sample diversity. The number of test data in used is 3,610 for NQ, 11,313 for TriviaQA, and 14,262 for PopQA.
## A.3 Baselines
Baselines using regular greedy decoding are evaluated under two different settings. In the closedbook setting, only the question is provided. In the open-book setting, the retrieved context is employed. The same top-1 retrieved context is utilized for every baseline and ACD.
CAD introduces a context-aware contrastive decoding approach that employs a contrastive output distribution to accentuate discrepancies in model predictions with and without context. This
Table 5: Recall@100 performance for CONTRIEVERMSMARCO
| | R@1 | R@5 | R@10 | R@20 | R@100 |
|----------|-------|-------|--------|--------|---------|
| NQ | 38.81 | 65.65 | 73.91 | 79.56 | 88.01 |
| TriviaQA | 49.6 | 71.32 | 76.72 | 80.39 | 85.71 |
| PopQA | 41.83 | 61.54 | 68.63 | 74.55 | 83.95 |
method effectively overrides model priors conflicting with provided context, offering significant performance enhancements in tasks requiring resolution of knowledge conflicts. MICD further enhances context grounded generation by integrating contrastive decoding with adversarial irrelevant passages. From a computational time perspective, MICD requires three times more than conventional greedy decoding, while CAD and ACD require twice as much.
MICD proposes two usage directions, referred to as MICD F and MICD D , which offer fixed and dynamic α , respectively. MICD D determines α in use by comparing the highest token probabilities with and without given context. Throughout the experiments, fixed value of α is set to the value used in Zhao et al. (2024), 0.5 and 1.0 for CAD and MICD F , respectively.
## A.4 Retriever Performance
To assess performance in the RAG framework, the top-1 context from top-100 contexts retrieved by CONTRIEVER-MSMARCO (Izacard et al., 2022) is utilized. Recall@100 is reported for each dataset in Table 5.
## A.5 Knowledge Conflict
For the NQ-swap dataset, we utilize the questions and entity-swapped contexts provided in Hong et al. (2024), which includes 3,650 samples. This total excludes 5 few-shot samples and those with contexts presented in a tabular format due to the limited context length. In the case of NQ-swap, each data point has a given context. Since it is a task that does not use a retriever, for MICD, we use the fixed negative context taken from the MICD as an adversarial context. MICD reports that the performance difference between fixed negative and the most distant context is negligible.
Table 6: EM score comparison between ACD ( α ACD ) and ACD with oracle alpha value ( α oracle ).
| | NQ | TriviaQA | PopQA |
|----------------|---------------------|---------------------|---------------------|
| LLAMA2-7B | LLAMA2-7B | LLAMA2-7B | LLAMA2-7B |
| α ACD α oracle | 32.91 35.35 (+2.44) | 64.85 65.31 (+0.46) | 41.29 44.10 (+2.81) |
| LLAMA2-13B | LLAMA2-13B | LLAMA2-13B | LLAMA2-13B |
| α ACD α oracle | 36.12 38.75 (+2.63) | 67.37 68.19 (+0.82) | 43.35 47.01 (+3.66) |
| LLAMA3 8B | LLAMA3 8B | LLAMA3 8B | LLAMA3 8B |
| α ACD α oracle | 35.48 36.98 (+1.50) | 66.32 66.10 (-0.22) | 43.25 46.47 (+3.22) |
| MISTRAL 7B | MISTRAL 7B | MISTRAL 7B | MISTRAL 7B |
| α ACD α oracle | 35.37 38.37 (+3.00) | 67.82 67.29 (-0.53) | 41.47 44.53 (+3.06) |
## B Results
## B.1 Results on Known-noisy and Unknown-gold
For Known-noisy and Unknown-gold , the exact values of EM accuracy on each case are reported in Table 8 and Table 9, respectively.
## B.2 AUROC between Adaptive Weight and Context Noisiness
AUROC of ACD and MICD D for three models not reported in Table 2 is reported in Table 10.
## C Additional Analysis
## C.1 Upper-bound of Alpha
In our approach, the parameter α is expected to be close to 1 when the retrieved context contains information that helps answer the given question, and close to 0 otherwise. To evaluate the upperbound performance of ACD, we assume that we have prior knowledge of whether the context in use is gold or noisy. Under this assumption, we fix the α value to 1.0 if the context is gold and to 0.0 if the context is noisy.
For TriviaQA dataset, the performance of ACD is comparable to α oracle , with less than 1 point difference (Table 6). NQ and PopQA show a difference of approximately 2-3 points, indicating that the method for calculating the α weight could be further enhanced in future research.
## C.2 Case Study
We conduct the case study on α ACD , examining its value in cases of Known-noisy and Unknowngold . Table 7 shows the generations from LLAMA2
| Sample | Sample | Reg Cls | Reg Cls | Reg Opn | Reg Opn | ACD | ACD |
|--------------|---------------------------------------------------------------------------------------------------|----------------|-----------|------------------|-------------|------------------|--------|
| Case | | Generation | H ( Y t ) | Generation | H ( Y c t ) | Generation | α ACD |
| Known-noisy | Question: who does the voice of nala in the lion king? Gold answer: Moira Kelly | Moira Kelly | 2.9160 | Whoopi Goldberg | 5.4562 | Moira Kelly | 0.3483 |
| Unknown-gold | Question: who was the actor that played ben stone on law and order? Gold answer: Michael Moriarty | Michael Tucker | 6.6748 | Michael Moriarty | 1.5628 | Michael Moriarty | 0.8103 |
Table 7: Case study on the value of α ACD for Known-noisy and Unknown-gold cases in LLAMA2 7B. Each value of entropy without context ( H Y ( t ) ), entropy with context ( H Y ( c t ) ), and α ACD is extracted at the first decoding step ( t = 0 ).
7B and how the values of entropy from closedbook generation (Reg Cls ) and open-book generation (Reg Opn ) affect α ACD at the first decoding time step.
In the case of Known-noisy , when the model generates the answer correctly even without the given context, the retrieved noisy context yields relatively higher entropy, resulting in α ACD value of 0.3483. Conversely, in the case of Unknown-gold , the model's generated answer is incorrect, aligning with a relatively high entropy value of 6.6748. In this scenario, the retrieved gold context guides the model to correctly answer the question, which is reflected in a relatively lower entropy value of 1.5628. Thus, the value of α ACD , adjusted with these entropy values, yields a relatively higher weight on the context at 0.8103.
| | NQ | TriviaQA | PopQA |
|------------|------------|------------|------------|
| LLAMA2-7B | LLAMA2-7B | LLAMA2-7B | LLAMA2-7B |
| Reg Opn | 45.13 | 68.12 | 33.47 |
| CAD | 29.22 | 48.91 | 25.97 |
| MICD F | 51.07 | 72.37 | 36.81 |
| MICD D | 72.92 | 86.33 | 56.04 |
| ACD | 76.72 | 88.79 | 54.58 |
| LLAMA2-13B | LLAMA2-13B | LLAMA2-13B | LLAMA2-13B |
| Reg Opn | 47.18 | 69.77 | 32.53 |
| CAD | 32.04 | 52.48 | 22.66 |
| MICD F | 54.17 | 75.05 | 38.55 |
| MICD D | 76.31 | 88.24 | 59.38 |
| ACD | 75.15 | 88.78 | 56.11 |
| LLAMA3-8B | LLAMA3-8B | LLAMA3-8B | LLAMA3-8B |
| Reg Opn | 46.20 | 68.50 | 33.39 |
| CAD | 32.91 | 50.51 | 23.00 |
| MICD F | 43.25 | 70.67 | 39.07 |
| MICD D | 61.18 | 83.70 | 59.80 |
| ACD | 64.14 | 86.59 | 56.87 |
| MISTRAL-7B | MISTRAL-7B | MISTRAL-7B | MISTRAL-7B |
| Reg Opn | 41.04 | 64.57 | 31.03 |
| CAD | 19.17 | 42.63 | 20.80 |
| MICD F | 48.12 | 71.99 | 36.48 |
| MICD D | 69.58 | 86.84 | 57.14 |
| ACD | 70.62 | 89.36 | 53.55 |
Table 8: EM accuracy of Known-noisy case.
| | NQ | TriviaQA | PopQA |
|------------|------------|------------|------------|
| LLAMA2-7B | LLAMA2-7B | LLAMA2-7B | LLAMA2-7B |
| Reg Opn | 47.78 | 68.18 | 74.42 |
| CAD | 43.90 | 62.22 | 66.12 |
| MICD F | 40.47 | 61.51 | 64.63 |
| MICD D | 29.82 | 50.43 | 65.17 |
| ACD | 36.03 | 57.10 | 73.41 |
| LLAMA2-13B | LLAMA2-13B | LLAMA2-13B | LLAMA2-13B |
| Reg Opn | 46.52 | 65.09 | 75.04 |
| CAD | 45.77 | 61.07 | 69.43 |
| MICD F | 41.79 | 62.03 | 65.85 |
| MICD D | 30.72 | 47.77 | 64.70 |
| ACD | 36.19 | 53.98 | 72.38 |
| LLAMA3-8B | LLAMA3-8B | LLAMA3-8B | LLAMA3-8B |
| Reg Opn | 48.12 | 68.47 | 74.10 |
| CAD | 48.00 | 60.52 | 70.41 |
| MICD F | 38.15 | 61.40 | 65.55 |
| MICD D | 33.33 | 48.45 | 64.81 |
| ACD | 41.67 | 61.24 | 72.52 |
| MISTRAL-7B | MISTRAL-7B | MISTRAL-7B | MISTRAL-7B |
| Reg Opn | 49.57 | 64.82 | 73.09 |
| CAD | 45.38 | 56.02 | 67.81 |
| MICD F | 43.28 | 63.59 | 66.58 |
| MICD D | 32.06 | 54.97 | 66.37 |
| ACD | 37.73 | 57.70 | 73.03 |
Table 9: EM accuracy of Unknown-gold case.
| | α | NQ | TriviaQA | PopQA |
|------------|------------|------------|------------|-------------|
| LLAMA2 13B | LLAMA2 13B | LLAMA2 13B | LLAMA2 13B | LLAMA2 13B |
| Max | MICD D | 52.77 | 60.09 | 61.84 74.12 |
| | ACD | 69.24 | 75.31 | |
| Avg. | MICD D | 57.86 | 62.00 | 71.79 |
| | ACD | 71.61 | 73.41 | 77.92 |
| First | MICD D | 54.80 | 46.13 | 68.44 |
| | ACD | 73.07 | 77.96 | 80.51 |
| LLAMA3 8B | LLAMA3 8B | LLAMA3 8B | LLAMA3 8B | LLAMA3 8B |
| Max | MICD D | 50.75 | 52.59 | 63.72 |
| | ACD | 63.12 | 57.82 | 75.00 |
| | MICD D | 51.80 | 52.83 | 67.99 |
| Avg. | ACD | 64.08 | 59.67 | 75.90 |
| | MICD D | 45.70 | 39.07 | 69.21 |
| First | ACD | 67.48 | 75.45 | 80.31 |
| MISTRAL 7B | MISTRAL 7B | MISTRAL 7B | MISTRAL 7B | MISTRAL 7B |
| Max | MICD D | 56.98 | 64.95 | 61.93 |
| | ACD | 71.27 | 77.46 | 74.11 |
| | MICD D | 63.66 | 69.27 | 73.82 |
| Avg. | ACD | 76.02 | 78.20 | 79.08 |
| | MICD D | 56.84 | 68.98 | 71.73 |
| First | ACD | 75.75 | 84.11 | 82.07 |
Table 10: AUROC between α used in each method and the noisiness of the retrieved context. The best AUROC is in bold. | null | [
"Youna Kim",
"Hyuhng Joon Kim",
"Cheonbok Park",
"Choonghyun Park",
"Hyunsoo Cho",
"Junyeob Kim",
"Kang Min Yoo",
"Sang-goo Lee",
"Taeuk Kim"
] | 2024-08-02T08:03:38+00:00 | 2024-10-07T06:11:46+00:00 | [
"cs.CL"
] | Adaptive Contrastive Decoding in Retrieval-Augmented Generation for Handling Noisy Contexts | When using large language models (LLMs) in knowledge-intensive tasks, such as
open-domain question answering, external context can bridge the gap between
external knowledge and the LLMs' parametric knowledge. Recent research has been
developed to amplify contextual knowledge over the parametric knowledge of LLMs
with contrastive decoding approaches. While these approaches could yield
truthful responses when relevant context is provided, they are prone to
vulnerabilities when faced with noisy contexts. We extend the scope of previous
studies to encompass noisy contexts and propose adaptive contrastive decoding
(ACD) to leverage contextual influence effectively. ACD demonstrates
improvements in open-domain question answering tasks compared to baselines,
especially in robustness by remaining undistracted by noisy contexts in
retrieval-augmented generation. |
2408.01085v1 | ## Effect of Fog Particle Size Distribution on 3D Object Detection Under Adverse Weather Conditions
Ajinkya Shinde, Gaurav Sharma, Member, IEEE , Manisha Pattanaik, Senior Member, IEEE , Sri Niwas Singh, Fellow, IEEE .
Abstract -LiDAR-based sensors employing optical spectrum signals play a vital role in providing significant information about the target objects in autonomous driving vehicle systems. However, the presence of fog in the atmosphere severely degrades the overall system's performance. This manuscript analyzes the role of fog particle size distributions in 3D object detection under adverse weather conditions. We utilise Mie theory and meteorological optical range (MOR) to calculate the attenuation and backscattering coefficient values for point cloud generation and analyze the overall system's accuracy in Car, Cyclist, and Pedestrian case scenarios under easy, medium and hard detection difficulties. Gamma and Junge (Power-Law) distributions are employed to mathematically model the fog particle size distribution under strong and moderate advection fog environments. Subsequently, we modified the KITTI dataset based on the backscattering coefficient values and trained it on the PV-RCNN++ deep neural network model for Car, Cyclist, and Pedestrian cases under different detection difficulties. The result analysis shows a significant variation in the system's accuracy concerning the changes in target object dimensionality, the nature of the fog environment and increasing detection difficulties, with the Car exhibiting the highest accuracy of around 99% and the Pedestrian showing the lowest accuracy of around 73%.
growing demands of the automotive market [4]. Integration with multi-sensor fusion simultaneous localization and mapping (SLAM) systems enhances navigation accuracy, particularly in challenging environments [5]. Airborne LiDAR technology benefits from lightweight sensors, and recent developments in lightweight sensors have made the applications such as power surveying and mapping much more effective [6]. Mobile LiDAR systems, incorporating LiDAR sensors, inertial measurement units (IMUs), and global positioning system (GPS), offer dynamic 3D mapping capabilities for various sectors, including transportation, urban planning, and robotics [7]. These advancements collectively drive the expansion of LiDAR applications, enhancing mapping accuracy and efficiency across industries [8].
Index Terms -Advection fog, autonomous vehicles, attenuation coefficient, backscattering coefficient, fog particle size distribution, LiDAR.
## I. INTRODUCTION
Light Detection and Ranging (LiDAR) utilizes the optical spectrum for remote sensing and three-dimensional (3D) environment modeling. Due to the utilization of the optical spectrum, the LiDAR-based systems find their application in oceanography, atmospheric sciences, and monitoring changes in land use patterns [1], [2]. Recently, LiDAR systems have served as an integral part of autonomous driving vehicles as they create detailed 3D maps of the terrestrial environment, facilitating controlled vehicular navigation in adverse environmental conditions. For surroundings information acquisition, the LiDAR systems employ several sensors that enable the detection of various objects, particularly vehicles, pedestrians, and other moving objects [3].
Recent developments in LiDAR technology include advancements in miniaturization and functionality to meet the
Ajinkya Shinde is with the Department of Information Technology Engineering, Atal Bihari Vajpayee-Indian Institute of Information Technology and Management, Gwalior, Madha Pradesh 474015, India (e-mail: imt\[email protected].
Gaurav Sharma, Manisha Pattanaik, and Sri Niwas Singh are with the Department of Electrical and Electronics Engineering, Atal Bihari VajpayeeIndian Institute of Information Technology and Management, Gwalior, Madha Pradesh 474015, India (e-mail: [email protected], [email protected], [email protected]).
3D object detection is essential in applications, such as autonomous driving, augmented reality, indoor mapping, drones and geographical mapping. Compared to two-dimensional (2D) images, 3D structures provide extra information about the geographical constitution of the structures [9]. In computer vision, 3D object detection is a critical component, particularly in the case scenarios of real-world environments such as autonomous systems. Primarily, 3D object detection involves identifying and localising objects in 3D dimensional space using various data sources such as LiDAR, RADAR, and red, green, and blue (RGB) imagery. However, due to the sparsity and complexity of the point cloud data (representing the object's 3D coordinates), 3D object detection is challenging. To overcome the challenges, recently, the fusion of RGB and point cloud data is proposed [10].
Monocular camera-based 3D object detection, stereo camera-based 3D object detection, and LiDAR-based 3D object detection are the three most popular techniques for generating 3D bounding boxes. These bounding boxes are essential for articulating the dimensional features of the object. Among the aforementioned techniques, the monocular camera-based methodology employed in monocular 3D (Mono3D) [11] and GS3D [12] algorithms utilizes 2D images to create 3D bounding boxes. On the contrary, the stereo-camera-based detection technique employs cameras to measure the depth feature of the image as an additional channel. Commonly in algorithms such as pseudo-LiDAR++ [13], disparity-based region-based convolutional neural network (Disp R-CNN) [14], and deep stereo geometry network (DSGN) [15], stereo cameras are utilized for 3D object detection. However, monocular and stereo camera-based techniques do not yield accurate results for autonomous vehicles and space applications [16].
LiDAR-based 3D object detection techniques are utilized
in space and autonomous vehicle applications for higher accuracy. The data obtained from LiDAR-based systems are then processed through grid-based or point-cloud-based methodologies. In grid-based methods, the point cloud is divided into grids, and subsequently, convolutional neural networks (CNN) are used to process the point clouds. For example, in the multiview 3D object detection network (MV3D) [17], the point clouds are projected in a 2D birds-eye view (which is divided into grids) for detection. Based on the 2D bird-eye-view object detection, bounding boxes are utilized to extract the characteristic features of the images, which are subsequently used to re-create the 3D space. Compared to the grid-based methods, the point-based methods directly process in point clouds for object detection and generation of 3D bounding boxes. Some examples of point-based methods are PointNet [18], and STD [19].
Recently, a new algorithm point voxel region-based convolution neural network (PV-RCNN) [20] that utilizes the advantages of both grid-based and point-based techniques was proposed. PV-RCNN is a high-performance 3D object detection framework that integrates 3D voxel CNN and pointbased set abstraction to learn discriminative point cloud features. High-quality 3D proposals are generated by the voxel CNN. On the contrary, PV-RCNN++ [21], being an advanced version of PV-RCNN, provides a complete framework for 3D object detection. It introduces sectorized proposal-centric sampling and VectorPool aggregation to efficiently produce more representative key points and aggregate local point features with less resource consumption. In [22], the authors analyzed various 3D object detection algorithms. and found that PVRCNN [20] works best in adverse foggy weather conditions. Our study utilises PV-RCNN++ for analysis.
In addition to all these features, foggy conditions play a vital role in observing the overall characteristics of autonomous vehicles from a 3D object detection perspective. Fog adversely affects LiDAR and other sensor information by scattering and absorbing electromagnetic waves, which, in the LiDAR system, are the primary sources of information. The absorption and the scattering phenomenon results in visibility reduction and leads to the introduction of data errors [23]. Usually, the Mie scattering theory incorporates the impact of scattering through the particle size distribution and is utilized to model scattering effects in the current literature. In [24], the impact of attenuation and dispersion phenomenon on optical pulses passing through a fog-filled medium were studied. The role of heavy fog and smoke on the bit error rate of a highspeed free space laser communication was analyzed in [25]. On the contrary, the presence of aerosols in the atmosphere, and its impact on the filament patterns of TW laser beams was studied in [26]. In addition, numerous studies [27]-[34] analyzed the role of fog, smoke, and other precipitation on free-space optical links.
In the existing literature, the size distribution is usually modeled through log-normal distributions where the diameter of the fog droplets ranges from a few to tens of micrometres ( µ m). For excellent sensor performance under foggy conditions, it is imperative to model the particle size distribution of the fog droplets accurately [35]. Currently, due to the lack of availability of LiDAR data in foggy conditions, [22] suggested a way to simulate fog particles in already collected LiDAR data by evaluating attenuation and backscattering coefficient values based on the Meteorological Optical Range (MOR). On the contrary, a fog particle simulation under particle size distribution was proposed [36].
Currently, considerable LiDAR data is available under clear environmental conditions. However, the simultaneous existence of fog particles in the environment causes severe attenuation, scattering, and absorption of the optical signals, subsequently deteriorating the system's overall performance [22]. Therefore, there is a considerable requirement for foggy datasets on which deep-learning-based models can be trained. The lack of foggy data is due to the high cost and difficulty of collecting LiDAR data in fog conditions. This paper deals with a generalized way of simulating fog particles using various particle size distributions.
Disturbances in the LiDAR sensor data due to rainy and foggy conditions were studied with an experimental setup in [37]. The authors employed the Kalman filter for noise filtering and real-point cloud prediction. Several simulation techniques have been proposed to create artificial fog in images. For instance, [38] created a foggy version of the cityscapes dataset [39], which is used for semantic segmentation. In addition, a similar version of the Synscapes dataset was generated by [40]. Meanwhile, the ACDC dataset by [41] provides semantic pixel-level annotations for 19 cityscapes classes in an adverse environment. To simulate fog particles in any LiDAR-based dataset, a simulation technique by using parameters based on the See Through Fog dataset [42] was proposed in [22]. Recently, an extension to the simulation technique based on attenuation and backscattering coefficients was proposed in [36].
From the literature, it becomes imperative that fog significantly affects the optical spectrum, and the particle size distribution in LiDAR-based sensors for 3D object detection plays a major role in analyzing the overall system analysis. Developing robust sensor systems requires understanding these impacts and designing for effective operation in adverse weather like fog. Therefore, in this manuscript, we are considering the role of generalized particle size distribution to first observe their effect on the overall system performance and to provide a platform for practical systems development. The main contributions of the manuscript are as follows:
- · To better understand the practical environmental conditions we created a modified version of the KITTI dataset by simulating fog particles under different fog particle size distributions and strong and moderate advection fog conditions. The created dataset is subsequently utilized in the learning of deep neural networks, which are afterwards used to predict the 3D bounding boxes.
- · Unlike [22], where the backscattering coefficient is evaluated via the meteorological optical range (MOR), we evaluated the backscattering coefficient by utilizing generalized particle size distributions. First, we employed a four-parameter gamma distribution for the strong and moderate fog conditions. Further, we also considered the Junge (Power Law) distribution in moderate fog
environments for modeling the fog particle size. Both distributions result in the varied point cloud generation under different foggy conditions and help create practical models.
- · Based on the fog particle size distribution, the system's accuracy was validated for 200 epochs for Car, Cyclist and Pedestrian scenarios. From accuracy analysis, it is observed that although the accuracy of the Car scenario is better than that of the Cyclist and Pedestrian cases due to the dimensional size variation, the system's overall accuracy in Cyclist and Pedestrian for moderate and strong fog is better under practical fog particle size.
The rest of the manuscript is organized as follows. Section II delves into the methodology employed for the performance evaluation of the LiDAR-based systems, and the impact of the fog particle size distribution on the attenuation and backscattering coefficient under clear and foggy environments. The experimental results with respect to the system's accuracy performance, and a detailed discussion is undertaken in Section III. Finally, the concluding remarks, along with the future directions, are made in Section IV.
## II. METHODOLOGY
## A. LiDAR in clear weather
According to [22], the mathematical representation for the LiDAR sensor is given as
$$P _ { R } ( R ) = C _ { A } \int _ { 0 } ^ { \frac { 2 R } { c } } P _ { T } ( t ) H \left ( R - \frac { c t } { 2 } \right ) d t, \quad ( 1 )$$
where P R ( R ) is the received power, which is a function of range R, P T ( ) t is the time-dependent transmitted signal power, c is the speed of light, C A is the sensor constant independent of time and range, and H . ( ) represents the total impulse response of the medium. Mathematically, P T ( ) t is expressed as
$$P _ { T } ( t ) = \begin{cases} P _ { 0 } \, \text{$\min^{2} \left ( \frac { \pi t } { 2 \tau _ { H } } \right ), $ \text{ if $0\leq t\leq 2\tau_{H}$} \\ 0, $ \text{ otherwise}, $ \text{ and $ba$} \\ \end{cases}$$
where P O is the maximum power of the transmitted pulse, and τ H is the half-power pulse width. Simultaneously, the total impulse response H R ( ) of the LiDAR-based system is mathematically represented by
$$H ( R ) = H _ { C } ( R ) H _ { T } ( R ), \text{ \quad \ \ } ( 3 ) \text{ \ in th}$$
where H T ( R ) is the distance-based channel impulse response of the target, which is given as and H C ( R ) is the impulse response of the optical channel, which is expressed as
$$H _ { C } ( R ) = \frac { T ^ { 2 } ( R ) } { R ^ { 2 } } \xi ( R ). \quad \quad \ \ ( 4 ) \quad \text{the i}$$
In (4), T R ( ) stands for the total one-way transmission loss and ξ R ( ) denotes the crossover function defining the ratio of the area illuminated by the transmitter and the part observed by the receiver of the LiDAR sensor. Mathematically, the expression for T R ( ) is
$$T ( R ) = \exp \left ( - \int _ { r = 0 } ^ { R } \alpha ( r ) d r \right ). \quad \quad ( 5 ) ^ { \quad H \left ( R }$$
The attenuation coefficient ( α ), an intrinsic property of fogbased LiDAR systems, is considered uniform over the whole propagation range for homogenous conditions. Therefore, the expression in (5) becomes
$$T ( R ) = \exp ( - \alpha R ).$$
Particularly for clear weather, the value of H T is given as
$$H _ { T } ( R ) = H _ { T } ^ { H a r d } ( R ) = \beta _ { 0 } \delta \left ( R - R _ { 0 } \right ), \quad \ \left ( 7 \right )$$
where β 0 is the differential reflectivity of the target and δ . ( ) is the Kronecker delta function. For clear weather, the value of H c is modeled by
$$H _ { C } ( R ) = \frac { \xi ( R ) } { R ^ { 2 } }.$$
By substituting (8) and (7) in (1), the received power for the clear weather at the receiver is given as
$$\text{acy per-} \\ \text{Section} \quad P _ { R, C l } ( R ) = C _ { A } \int _ { 0 } ^ { 2 \tau _ { H } } P _ { 0 } \text{Sin} ^ { 2 } \left ( \frac { \pi t } { 2 \tau _ { H } } \right ) \frac { \beta _ { 0 } \delta \left ( R - R _ { 0 } - \frac { c t } { 2 } \right ) } { R _ { 0 } ^ { 2 } } d t.$$
Using some algebraic and integral properties, the closed-form expressions for the received power are represented by
$$\dots \Phi _ { r } \dots \Phi _ { r } \dots \Phi _ { r } \dots \Phi _ { r } \dots \Phi _ { r } \dots \Phi _ { r } \dots \Phi _ { r } \dots \Phi _ { r } \dots \Phi _ { r } \\ \dots \text{for the} \quad \begin{matrix} \frac { C _ { A } P _ { 0 } \beta _ { 0 } } { R _ { 0 } ^ { 2 } } \\ \times \, \sin ^ { 2 } \left ( \frac { \pi ( R - R _ { 0 } ) } { c \tau _ { H } } \right ), & \text{if } R _ { 0 } \leq R \leq R _ { 0 } + c \tau _ { H } \\ 0, & \text{otherwise}. \end{matrix}$$
## B. LiDAR in foggy weather
Primarily in foggy weather conditions, the data received by the LiDAR sensors experiences attenuation and backscattering. Mie theory is usually utilized to quantify the attenuation and backscattering effects to model the foggy conditions. In the current literature, a precise model for calculating attenuation and backscattering coefficients is unavailable; therefore, Mie theory is employed. Simultaneously, to model the fog particle size distribution, Gamma and power law (Junge) distributions are usually employed [43]-[46].
The channel impulse response for the fog particles is bifurcated into soft and hard targets to model the fog scenario in the channel practically. Mathematically, the updated channel impulse response is given as
$$H _ { T } ( R ) = H _ { T } ^ { S o f t } ( R ) + H _ { T } ^ { H a r d } ( R ), \quad \ \ ( 1 1 )$$
where H Hard T is given by (7). For foggy weather conditions the impulse response, H Soft T , for the fog particles is modeled as
$$H _ { T } ^ { S o f t } ( R ) = \beta U \left ( R _ { 0 } - R \right ). \text{ \quad \ \ } \text{(12)}$$
where U . ( ) is the Heaviside function. Combining (4), (6), (7) and (12) the total channel impulse response in (3) is obtained as
$$H \left ( R \right ) = \frac { \exp \left ( - 2 \alpha R \right ) \xi ( R ) } { R ^ { 2 } } \left ( \beta U ( R _ { 0 } - R ) + \beta _ { 0 } \delta ( R - R _ { 0 } ) \right ).$$
Concurrently, the total received power obtained by the summation of the powers received back from both the hard and soft target is represented as
$$\Gamma _ { R, f o g } ^ { H a r d } ( R ) & = C _ { A } \frac { \exp ( - 2 \alpha R _ { O } ) } { R _ { O } ^ { 2 } } \int _ { 0 } ^ { 2 \tau _ { H } } P _ { 0 } \sin ^ { 2 } \left ( \frac { \pi t } { 2 \tau _ { H } } \right ) ^ { \underbrace { \text{Mode} } } \\ & \quad \times \beta _ { 0 } \ \delta \left ( R - \frac { c t } { 2 } - R _ { 0 } \right ) d t \quad \underset { \substack { \text{used to elastic} \\ = \exp \left ( - 2 \alpha R \right ) P _ { R, C l } ( R ). } \quad ( 1 4 ) \quad ( \beta ) \, \text{co} \\ \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{end} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{and} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{and} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \ \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{not} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad\text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or}" \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \tau \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \optimum \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \mathcal { } \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \att{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or} \quad \text{or}$$
Substituting (10) in (14) we obtained a closed form expression for P Hard R,fog ( R ) . Moreover, for fog droplet conditions, the received power is mathematically modeled as
$$\text{receive power is manneraucany mouseize as} \\ P _ { R, f o g } ^ { S o f t } ( R ) & = C _ { A } \ P _ { 0 } \ \beta \int _ { 0 } ^ { 2 \tau _ { H } } \sin ^ { 2 } \left ( \frac { \pi t } { 2 \tau _ { H } } \right ) \xi \left ( R - \frac { c t } { 2 } \right ) \\ & \quad \times \frac { \exp \left ( - 2 \alpha \left ( R - \frac { c t } { 2 } \right ) \right ) } { \left ( R - \frac { c t } { 2 } \right ) ^ { 2 } } U \left ( R _ { 0 } - R + \frac { c t } { 2 } \right ) \ d t, \quad D. \text{The} \\ & \quad \text{ent} \ D \text{ is} \\ \dots \dots \ r r / \cdots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ t \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \delta \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \dots \ s \d:[ \ s a n d e s ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] } { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { \ e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] {e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e nd } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d }] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { i n } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } \ ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ]{ e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { en d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d} ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ] { e n d } ]$$
where U (.) denotes the Heaviside function. Due to the intractability of the integral expression in (15), the closed-form expressions are not attainable. Therefore, to obtain the values of the power received by the fog particles in foggy conditions, we utilise the Simpson 1 / 3 rule. Combining (14) and (15), the total received power at the LiDAR receiver is obtained as
$$P _ { R, f o g } ( R ) = P _ { R, f o g } ^ { H a r d } ( R ) + P _ { R, f o g } ^ { S o f t } ( R ). \quad ( 1 6 ) \quad \text{param} \quad.$$
Usually, the acquisition and modeling of the LiDAR sensor data are majorly dependent on environmental conditions such as fog. In [22], an approximated value of the backscattering coefficient ( β ) in terms of MOR, utilized for system's performance evaluation under see-through fog (STF) dataset, is given as
$$\beta = \frac { 0. 0 4 6 } { M O R }. \quad \quad \ \ ( 1 7 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\end{cases}$$
Considering the fixed relationship between β , and the meteorological range results is a misinterpretation of the foggy weather conditions. Therefore, to overcome this problem, we have employed Mie Theory, which can be used to calculate the attenuation and backscattering coefficients based on the fog particle size distributions. In the next section, we will discuss the role of fog particle size distribution in modeling the attenuation and backscattering coefficients.
## C. Role of Fog Particle Size Distribution
The scattering of laser beams from the water droplet's surface can be modeled by assuming the water droplet is a liquid sphere. Based on this assumption, the extinction efficiency, Q ext ( D ) , and the backscattering efficiency, Q b ( D ) , both of which are a function of the diameter of fog droplets can be calculated using Mie Theory. Throughout the manuscript, we have considered an optical transmitting source with a wavelength of 905 nanometers (nm). The value of both the attenuation and backscattering coefficients are shown in Fig. 1. The size distribution of atmospheric water droplets is essential for attenuation coefficient calculation. Subsequently, various distributions, such as Gamma, Junge (Power-Law), etc., can be
TABLE I: Practical Parameters for Advection Fog [36].
| Weather Conditions | ρ ( cm - 3 | a | γ | r C ( µm ) |
|------------------------|--------------|-----|-----|--------------|
| Strong Advection Fog | 20 | 3 | 1 | 10 |
| Moderate Advection Fog | 20 | 3 | 1 | 8 |
used to model the fog particle size distribution. Assuming nonelastic scattering, the attenuation ( α ) and the backscattering ( β ) coefficients in terms of the fog particle size distribution are mathematically represented as
$$\alpha = \frac { \pi } { 8 } \int _ { D = 0 } ^ { \infty } D ^ { 2 } Q _ { e x t } ( D ) N ( D ) d D, \quad \ \ ( 1 8 )$$
$$\beta = \frac { \pi } { 8 } \int _ { D = 0 } ^ { \infty } D ^ { 2 } Q _ { b } ( D ) N ( D ) d D, \text{ \quad \ \ } ( 1 9 )$$
where N D ( ) is the probability of hitting a droplet of diameter D . The water droplet's statistical distribution featuring different D is utilized to model the foggy conditions. Using a fourparameter ( a, ρ, γ, r C ) gamma distribution, the mathematical representation of N D ( ) is given as [47]
$$\mathfrak { e s } _ { \mathfrak { s }, \mathfrak { s } } N ( D ) = \frac { \gamma \rho b ^ { \frac { a + 1 } { \gamma } } } { \Gamma \left ( \frac { a + 1 } { \gamma } \right ) } \left ( \frac { D } { 2 } \right ) ^ { a } \exp \left ( - b \left ( \frac { D } { 2 } \right ) ^ { \gamma } \right ), \quad ( 2 0 )$$
where Γ( ) . denotes gamma function, and parameters a , b , γ , and r C are positive and real, with a being an integer. The parameters depend on each other and are determined by the distribution of the experimental measurements. Mathematically, parameter b is expressed as
$$\bar { b } = \frac { a } { \gamma \left ( \frac { D _ { c } } { 2 } \right ) ^ { \gamma } }.$$
In (20) and (21), Γ( ) . denotes the gamma function, and D c is the droplet radius size having maximum probability respectively. Table I represents strong and moderate advection fog parameters. Utilizing the parameters of Table I, the Fig. 2 shows the fog particle droplet size distribution for strong and moderate advection fog. Substituting (20) in (18) and (19), and utilizing the parameters' values of different foggy conditions from Table I, the value of the attenuation and backscattering coefficient without approximation is obtained. Table II represents the values of α and β in different fog environments with different particle size distributions.
TABLE II: Values of α and β in Strong and Moderate Advection Fog.
| Weather Conditions | Distribution | α | β | β calculation |
|------------------------|----------------|----------|----------|--------------------|
| Strong Advection Fog | Gamma | 0.028995 | 0.0011 | Using MOR(40m) |
| Strong Advection Fog | Gamma | 0.028996 | 0.020243 | Using distribution |
| Moderate Advection Fog | Gamma | 0.018727 | 0.00057 | Using MOR(80m) |
| Moderate Advection Fog | Gamma | 0.018721 | 0.012894 | Using distribution |
| Moderate Advection Fog | Junge | 0.026201 | 0.019104 | Using distribution |
Simultaneously, Junge distribution (Power-Law distribution) also models the moderate advection fog environment. Mathematically, the fog particle size distribution in moderate advection fog is given as
$$N ( D ) = 1 3 1. 5 \ e ^ { - 1. 7 6 }. \text{ \quad \ \ } ( 2 2 )$$
Fig. 3, shows the pictorial representation of the fog particle size distribution in the case of moderate advection fog. By
Fig. 1: Efficiency values of Q ext and Q b as a function of droplet diameter.
Fig. 2: Effect of fog particle size distribution using Gamma distribution.
Fig. 3: Effect of fog particle size distribution using Junge distribution.
Fig. 4: Point clouds in different foggy environments: (4.a.) Shows strong advection fog with β from (19); (4.b.) Shows moderate advection fog with β from (19); (4.c.) Shows strong advection fog with β from (17); (4.d.) shows moderate advection fog with β from (17); (4.e.) Shows moderate advection fog with β from (22).

substituting (22) in (18) and (19), the value of α and β are obtained as 0.026201 and 0.019104 respectively.
For a detailed qualitative analysis, the point cloud scene representation of the LiDAR sensor data is shown in Fig. 4. The figure shows that the point cloud representation of the LiDAR-based depends on the weather conditions. Each point in the point cloud gives a pictorial representation of the external surface of an object and usually provides information related to the position and intensity of the point. Depending on the object information, the points in point clouds are coloured accordingly. For instance, point clouds at low heights are usually highlighted in red colour, and the objects with higher heights are depicted in blue colour. Fig. 4(a) and Fig. 4(b), show the strong and moderate advection fog conditions with β values obtained from (19). Simultaneously, Fig. 4(c) and Fig. 4(d) represent the strong and moderate foggy environment based on β obtained from (17). From the point cloud scene, it is observed that compared to the fog particle size distribution scenario utilizing MOR for β value calculation and LiDARbased sensor modeling leads to lesser point generation in the point cloud, resulting in the misinterpretation of the structural feature of the 3D environment. Therefore, for modeling the practical LiDAR-based systems the role of particle size distribution is significant.
## III. RESULTS AND DISCUSSIONS
This section, presents the results of the proposed methodology, to validate the role of the particle size distribution for Car, Cyclist and Pedestrian scenarios under strong and moderate advection fog environments. We ran the simulations for 200 epochs to validate our results and subsequently obtained the accuracy plots. Here, we considered the four-parameter Gamma distribution and Junge (Power-Law) distribution for strong and moderate fog conditions to model the fog droplet size. The KITTI data set is utilized for data generation in practical weather environments. We employed the PV-RCNN++
model to train the enhanced dataset, which is a modified version of the existing KITTI dataset.
## A. Strong Advection Fog Environment Analysis Using Fog Particle Size Distribution (Gamma Distribution)
Fig. 5: Accuracy versus epochs for 3D bounding boxes under strong fog conditions using Gamma distribution.
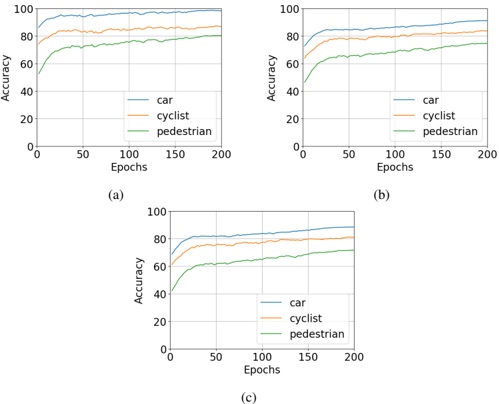
Fig. 5(a), Fig. 5(b), and Fig. 5(c) present the accuracy versus epochs graph for 3D bounding boxes under strong advection fog for Car, Cyclist and Pedestrian cases in easy, medium, and hard conditions, respectively. Based on the plots, it is observed that the system's performance concerning the system's accuracy shows an increasing trend and then saturates with increasing epochs. Compared to medium and hard conditions the accuracy for easy conditions is higher. This can be attributed to the fact that because of the presence of other objects in the optical signal path, the number of points representing point clouds of the car decreases, resulting in an overall decrease in the system's performance. Moreover, for all three conditions (easy, medium, and hard), the system's accuracy performance is the best for the Car scenario. Particularly, the system achieved more than 98% accuracy in easy conditions compared to 90% and 88% accuracy in medium and hard conditions. This is due to the reduction in the object's dimensionality that needs to be detected.
Fig. 6(a), Fig. 6(b), and Fig. 6(c) shows the accuracy versus epochs graph of the system's performance on the birds-eyeview map of the LiDAR scene under strong advection fog in easy, moderate, and strong difficulties respectively. From the figure, it was observed that the system's performance improves with the object's increasing dimensionality. This is prevalent because increasing dimensionality significantly improves accuracy, with accuracy being highest for the Car and lowest for the Pedestrian. Simultaneously, an increase in the difficulty condition for object detection adversely impacts the overall accuracy with a significant decrease in the accuracy of the Car scenario with increasing 3D object detection difficulty from easy to medium and to hard. However, for the Cyclist
Fig. 6: Accuracy versus epochs for BEV bounding boxes under strong fog conditions using Gamma distribution.
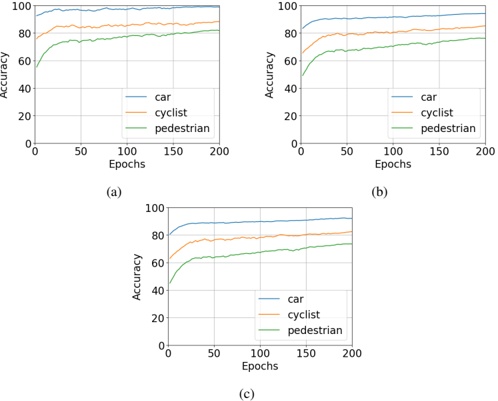
and Pedestrian scenarios, the deterioration in the accuracy is not significant. Particularly, for the bird-eye-view detection in hard conditions, the proposed system achieves an accuracy of nearly 77% for the Pedestrian case. This is primarily due to the practical modeling of the Fog particle size distribution in terms of a four-parameter Gamma distribution. Fog particle size distribution modeling provides improved accuracy with consideration regarding the physical traits of the environment.
## B. Moderate Advection Fog Environment Analysis Using Fog Particle Size Distribution
Fig. 7: Accuracy versus epoch graph for 3D bounding boxes under moderate fog conditions using fog particle size distribution. Solid lines correspond to the Gamma distribution, and dotted lines correspond to Junge distribution.
In Fig. 7(a), Fig. 7(b), and Fig. 7(c), the accuracy versus epochs values of the 3D bounding boxes, particularly for the easy, moderate and hard difficulty conditions under moderate advection fog environment and fog particle size distribution
following Gamma and Junge distributions is simulated respectively. From the figures, it is observed that compared to medium and hard conditions, the overall accuracy of Car, Cyclist and Pedestrian scenarios under easy conditions is on the higher side, indicating better overall performance of the LiDAR-based sensors. Further, in medium and hard conditions, the system achieves an almost similar level of accuracy to that of Car and Cyclist case scenarios. This is primarily due to an increase in the number of obstacles between the LiDAR-based sensor and the object under detection. Moreover, the system's accuracy depends on the object's overall dimensionality, making detection of smaller objects difficult. This can be corroborated by decreased overall system accuracy as we transit our analysis from Car to Cyclist to Pedestrian. In addition, a decrease in the object's size results in the sparse nature of the point clouds, making object detection harder. Moreover, the overall dimensionality of the object also significantly impacts the system's accuracy with changes in the Fog particle size distribution. As highlighted in the plots, the system's accuracy reduces significantly in Cyclist and Pedestrian scenarios when the Junge distribution is utilized for fog particle size distribution modeling. However, in the Car scenario, the Junge distribution for fog particle size modeling is consistent with that of the Gamma distributionbased model. Therefore, there is always a comparable tradeoff between the utilization of particle size distribution and object dimensionality.
Fig. 8: Accuracy versus epoch graph for BEV under moderate fog conditions using fog particle size distribution. Solid lines correspond to the Gamma distribution, and dotted lines correspond to Junge distribution.
The system's accuracy on a bird-eye-view (BEV) of the LiDAR scenes under moderate advection foggy environment in easy, moderate, and hard conditions is illustrated in Fig. 8(a), Fig. 8(b), and Fig. 8(c) respectively. The plots show that the system achieves high accuracy in the Car scenario under easy conditions. Compared to 3D bounding boxes prediction, the system's performance in the case of BEV is comparatively less affected by the moderate and hard conditions. Therefore, there is clear demarcation and no overlapping in the Car and
Cyclist accuracy for moderate and hard conditions. Similar to the 3D bounding boxes prediction under a moderate fog environment, the accuracy of the car scenario is also high in the BEV case. This is majorly accredited to the fact that the accuracy analysis obtained from the fog particle size distribution provides robust versatility in catering for the practical implications of the LiDAR-based systems under moderate fog environments. Further, the system's accuracy in the Car scenario for all the difficulty levels and under the Junge distribution is relatively equivalent to that of the Gamma distribution. Therefore, under the Car scenario, either Gamma or Junge distribution can be utilized to model the fog particle size distribution depending on the availability of the distribution parameters. However, with a reduction in the overall dimensional size of the object (from Car to Cyclist to Pedestrian), utilization of Junge distribution as a fog particle size distribution model may lead to missed estimations and a reduction in the overall system's accuracy.
## C. Strong Advection Fog Environment Analysis Using MOR
Fig. 9: Accuracy versus epochs graph of 3D bounding boxes for strong fog using MOR.
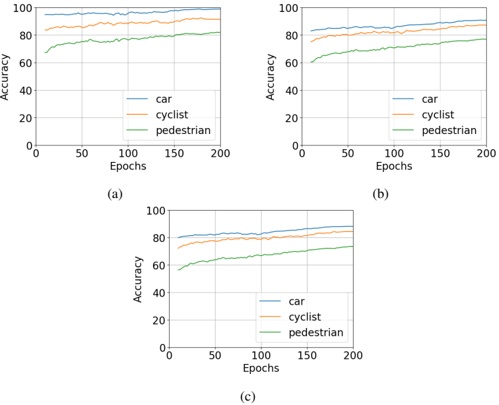
Fig. 9(a), Fig. 9(b), and Fig. 9(c) present the accuracy versus epochs plots for 3D bounding boxes in strong advection fog environments under easy, medium, and hard conditions while considering MOR to calculate the backscattering coefficient. From the plots, it is observed that the overall system's accuracy is better in the case of the Car, which is mainly due to the significant generation of points for point cloud due to the large dimensional feature of the Car. Since the overall system accuracy analysis is based on β values, therefore, obtaining β values from the MOR generates fewer points for the point cloud. Overall, This increases the system's accuracy but will lead to prediction errors in practical implementation. Moreover, the accuracy performance gap between the Car and the Cyclist decreases with increased difficulty; i.e., for easy difficulty, the Car-Cyclist gap is higher than for moderate and hard difficulty. This is due to the dimensional relationship
between the object to be detected and the presence of other obstacles in the environment.
Fig. 10: Accuracy versus epoch plots of BEV under strong fog using MOR.
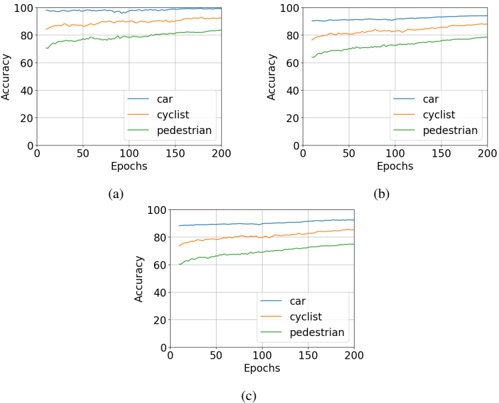
The accuracy of the system on the birds-eye-view map of the LiDAR scene in a strong advection fog environment with β values from MOR expression is shown in Fig. 10(a), Fig. 10(b), and Fig. 10(c) respectively. From the figure, it is inferred that the system's accuracy is best in the Car scenario and worst in the Pedestrian scenario. This is primarily due to the fact that, with increasing difficulty, the overall accuracy of LiDARbased systems decreases with the overall accuracy of the Car falling from above 98% in easy difficulty to around 92% and below 90% in moderate and hard difficulties, respectively.
D. Moderate Advection Fog Environment Analysis Using MOR
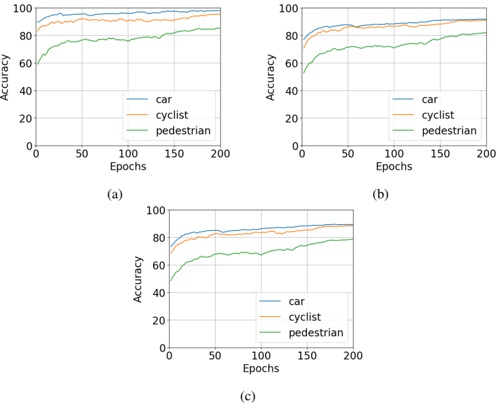
Fig. 11: Accuracy versus epochs graph of 3D bounding boxes for moderate fog using MOR.
Fig. 11(a), Fig. 11(b), and Fig. 11(c) show the accuracy performance of the system from 3D bounding boxes prediction in case of moderate fog environment under easy, moderate and hard difficulty for the value of β obtained from MOR expression. As observed from the plots, the system's accuracy performance is best in the Car scenario compared to Cyclist and Pedestrian. On the contrary, in moderate and hard difficulty, the accuracy of the LiDAR-based sensors in the Car and Cyclist scenario is nearly equal with increasing epochs. On the contrary, compared to Car and Cyclist scenarios there is a significant difference in the system's accuracy in the Pedestrian scenario. This signifies the role of dimensionality and the impact of other obstructing objects present in the path of the sensor and target object.
Fig. 12: Accuracy versus epochs graph of BEV bounding boxes in moderate fog using MOR.
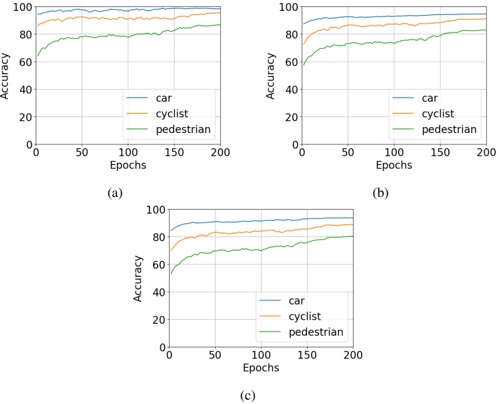
Fig. 12(a), Fig. 12(b), and Fig. 12(c) illustrate the accuracy performance of the system on birds-eye-view maps of LiDAR scenes with moderate fog simulated in easy, medium and hard difficulties with β values obtained from MOR expression. From the plots, it is observed that the system's accuracy in the Car scenario remains stable and above 90% across the whole range of epochs in easy conditions but shows a significant improvement for moderate and hard difficulties in Cyclists and Pedestrians scenarios. Further, the difference in performance increases in Car, Cyclist and Pedestrian scenarios due to the dimensionality variations and sparse nature of the point clouds.
Table III represents the comparative analysis of the proposed system under various fog environments and difficulties with β values obtained from particle size distribution (Mie Theory) and MOR expression. From the table, it is observed that in strong fog conditions, the proposed system with β obtained from fog particle size distribution performed better in the case of medium and hard car conditions in comparison to the system using MOR expression approximation for β calculations. This can be followed from the fact that Further, from the mean average precision perspective, in strong fog conditions, the accuracy achieved by the system without MOR expression approximation is comparable to the accuracy achieved by the system using approximations. This primarily highlights the misinterpretation in terms of false prediction by the system
TABLE III: Average precision of PV-RCNN++ on simulated fog dataset at a given intersection over union (IOU).
| Method | Car [email protected] IOU | Car [email protected] IOU | Car [email protected] IOU | Cyclist [email protected] IOU | Cyclist [email protected] IOU | Cyclist [email protected] IOU | Pedestrian [email protected] IOU | Pedestrian [email protected] IOU | Pedestrian [email protected] IOU | mAP over classes | mAP over classes | mAP over classes |
|---------------------------------------------------|------------------|------------------|------------------|----------------------|----------------------|----------------------|-------------------------|-------------------------|-------------------------|--------------------|--------------------|--------------------|
| Method | easy | med | hard | easy | med | hard | easy | med | hard | easy | med | hard |
| Strong Advection Fog (using MOR) | 98.85 | 90.64 | 88.09 | 91.18 | 86.83 | 84.27 | 82.31 | 76.81 | 73.41 | 90.78 | 84.76 | 81.92 |
| Strong Advection Fog | 98.10 | 91.17 | 88.51 | 86.49 | 84.40 | 81.85 | 79.73 | 74.45 | 71.60 | 88.10 | 83.34 | 80.65 |
| Moderate Advection Fog (using MOR) | 97.91 | 91.60 | 89.27 | 95.59 | 91.55 | 87.84 | 85.52 | 81.82 | 78.50 | 93.01 | 88.32 | 85.20 |
| Moderate Advection Fog (using Gamma distribution) | 98.93 | 91.47 | 88.83 | 94.80 | 91.36 | 88.16 | 83.76 | 80.17 | 77.31 | 92.50 | 87.66 | 84.77 |
| Moderate Advection Fog (using Junge distribution) | 98.92 | 91.08 | 88.42 | 92.46 | 86.92 | 84.33 | 81.95 | 76.06 | 72.79 | 91.11 | 84.69 | 81.85 |
while working with β values obtained from the MOR expression. The results are in concurrence with the number of fog particles simulated in the point cloud as shown in Fig. 4, which indicates that the point cloud generated in case of β obtained from Mie theory is more dense than the point cloud generated with β obtained from MOR expression. Therefore, for better system performance articulation the ideal approach for modeling the effect of fog is by considering the role of Mie theory in calculation and analysis of attenuation and backscattering coefficient, which in turn are utilized for point cloud generation, and subsequent training of neural network model.
## IV. CONCLUDING REMARKS
In this manuscript, we investigated the role of fog particle size distribution on 3D object detection for the performance evaluation of LiDAR-based systems under adverse weather conditions. For the system's performance evaluation, we formulated a methodology based on the Mie theory, where the attenuation and backscattering coefficients were calculated based on the fog particle size distributions and extinction and backscattering efficiency, respectively. Subsequently, the point clouds are generated for the strong and moderate fog environments by utilising the generalised backscattering coefficient values from Mie theory. We observed that the fog simulation process generated a more realistic interpretation through increased points in the point clouds under strong and moderate advection fog environments. Particularly, in a strong advection fog environment the system accuracy in Car scenarios under easy and hard conditions shows a decay of about 10%, while for Pedestrian cases the system's accuracy reduces to 8% under easy and hard detection difficulties.
From the mean average precision (mAP) perspective, we observed a prominent difference in the accuracy values in the case of strong fog, clearly indicating the precise role of simulating fog particles through Mie theory rather than through the generation from MOR approximation. However, in moderate fog conditions, the overestimation of the 3D object detection while utilizing the MOR approximation is still comparable to the values obtained from Mie's theory. Point cloud modeling using precise particle size distributions provides a practical realization of the system and helps attain accurate functionalities, particularly for dense fog conditions. The improved system's accuracy performance under simulated fog environments further corroborates the overall mathematical framework employed. The future work would comprise the extension of the proposed framework to incorporate more practical environments where a tradeoff between the system's efficiency and accuracy due to the presence of snow, haze and rain particles in conjunction with the fog particles.
## REFERENCES
- [1] Z. Wang and M. Menenti, 'Challenges and opportunities in lidar remote sensing,' Frontiers Remote Sens. , vol. 2, Mar. 2021, Art. no. 641723.
- [2] S. Debnath, M. Paul, and T. Debnath, 'Applications of LiDAR in agriculture and future research directions,' J. Imag. , vol. 9, no. 3, p. 57, Feb. 2023.
- [3] Y. Li and J. Ibanez-Guzman, 'Lidar for autonomous driving: The principles, challenges, and trends for automotive LiDAR and perception systems,' IEEE Signal Process. Mag. , vol. 37, no. 4, pp. 50-61, Jun. 2020.
- [4] R. Roriz, J. Cabral, and T. Gomes, 'Automotive lidar technology: A survey,' IEEE Trans. Intell. Transp. Syst. , vol. 23, no. 7, pp. 6282-6297, Jul. 2022.
- [5] X. Xu, L. Zhang, J. Yang, C. Cao, W. Wang, Y. Ran, Z. Tan, and M. Luo, 'A review of multi-sensor fusion slam systems based on 3D lidar,' Remote Sens. , vol. 14, no. 12, Jun. 2022, Art. no. 2835.
- [6] G. Yang, M. Tian, C. Ma, J. Li, and B. Zhao, 'Application of lidar technology in power engineering surveying and mapping,' in Proc. Int. Conf. Artificial Intell. Commun. Technol. (ICAICT 2023) . Singapore: Springer Nature Singapore, 2024, pp. 133-143.
- [7] C. Askar and H. Sternberg, 'Use of smartphone lidar technology for low-cost 3D building documentation with iphone 13 pro: A comparative analysis of mobile scanning applications,' Geomatics , vol. 3, no. 4, pp. 563-579, Dec. 2023.
- [8] K. Williams, M. J. Olsen, G. V. Roe, and C. Glennie, 'Synthesis of transportation applications of mobile LiDAR,' Remote Sens. , vol. 5, no. 9, pp. 4652-4692, Sept. 2013.
- [9] X. Pan, Z. Xia, S. Song, L. E. Li, and G. Huang, '3D object detection with pointformer,' in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , Jun. 2021, pp. 7463-7472.
- [10] Y. Wang and J. Ye, 'An overview of 3D object detection,' arXiv preprint arXiv:2010.15614 , 2020.
- [11] X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urtasun, 'Monocular 3D object detection for autonomous driving,' in Proc. IEEE Comput. Society Conf. Comput. Vis. Pattern Recognit. (CVPR) , Jun. 2730, 2016, p. 2147 - 2156.
- [12] B. Li, W. Ouyang, L. Sheng, X. Zeng, and X. Wang, 'GS3D: An efficient 3D object detection framework for autonomous driving,' in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. (CVPR) , Jun. 15-20, 2019, p. 1019-1028.
- [13] R. Qian, D. Garg, Y. Wang, Y. You, S. Belongie, B. Hariharan, M. Campbell, K. Q. Weinberger, and W.-L. Chao, 'End-to-end pseudoLiDAR for image-based 3D object detection,' in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , Jun. 13-19, 2020, pp. 58815890.
- [14] J. Sun, L. Chen, Y. Xie, S. Zhang, Q. Jiang, X. Zhou, and H. Bao, 'Disp R-CNN: Stereo 3D object detection via shape prior guided instance disparity estimation,' in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , Jun. 13-19, 2020, pp. 10 548-10 557.
- [15] Y. Chen, S. Liu, X. Shen, and J. Jia, 'DSGN: Deep stereo geometry network for 3D object detection,' in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , Jun. 13-19, 2020, pp. 12 536-12 545.
- [16] F. Amzajerdian, V. E. Roback, A. Bulyshev, P. F. Brewster, and G. D. Hines, 'Imaging flash lidar for autonomous safe landing and spacecraft proximity operation,' in AIAA SPACE , Sept. 2016, pp. 5591-5602.
- [17] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, 'Multi-view 3D object detection network for autonomous driving,' in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , Jul. 21-26, 2017, pp. 19071915.
- [18] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas, 'Frustum pointnets for 3D object detection from rgb-d data,' in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , Jun. 18-23, 2018, pp. 918-927.
- [19] Z. Yang, Y. Sun, S. Liu, X. Shen, and J. Jia, 'STD: Sparse-to-dense 3D object detector for point cloud,' in Proc. IEEE/CVF Int. Conf. Comp. Vis. (ICCV) , Oct. 27 -Nov. 02, 2019, pp. 1951-1960.
- [20] S. Shi, C. Guo, L. Jiang, Z. Wang, J. Shi, X. Wang, and H. Li, 'PVRCNN: Point-voxel feature set abstraction for 3D object detection,' in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , 2020, pp. 10 529-10 538.
- [21] S. Shi, L. Jiang, J. Deng, Z. Wang, C. Guo, J. Shi, X. Wang, and H. Li, 'PV-RCNN++: Point-voxel feature set abstraction with local vector representation for 3D object detection,' Int. J. Comput. Vis. , vol. 131, no. 2, pp. 531-551, Feb. 2023.
- [22] M. Hahner, C. Sakaridis, D. Dai, and L. Van Gool, 'Fog simulation on real lidar point clouds for 3D object detection in adverse weather,' in Proc. IEEE Int. Conf. Comput. Vis. (CVF) , Oct. 10-17, 2021, pp. 15 283-15 292.
- [23] L. Zhan and W. F. Northrop, 'Impact of fog particles on 1.55 µ m automotive lidar sensor performance: An experimental study in an enclosed chamber,' SAE Techn. Paper, Tech. Rep., 2021.
- [24] A. Maitra and M. Dan, 'Propagation of pulses at optical wavelengths through fog-filled medium,' Radio Sci. , vol. 31, no. 3, pp. 469-475, May-Jun. 1996.
- [25] B. R. Strickland, M. J. Lavan, E. Woodbridge, and V. Chan, 'Effects of fog on the bit-error rate of a free-space laser communication system,' Appl. Opt. , vol. 38, no. 3, pp. 424-431, Jan. 1999.
- [26] G. Méjean, J. Kasparian, J. Yu, E. Salmon, S. Frey, J.-P. Wolf, S. Skupin, A. Vinçotte, R. Nuter, S. Champeaux et al. , 'Multifilamentation transmission through fog,' Phy. Rev. E , vol. 72, no. 2, Aug. 2005, Art. No. 026611.
- [27] D. Kedar and S. Arnon, 'Optical wireless communication through fog in the presence of pointing errors,' Appl. Opt. , vol. 42, no. 24, pp. 49464954, Aug. 2003.
- [28] M. S. Awan, L. Csurgai-Horváth, S. S. Muhammad, E. Leitgeb, F. Nadeem, and M. S. Khan, 'Characterization of fog and snow attenuations for free-space optical propagation.' J. Commun. , vol. 4, no. 8, pp. 533-545, 2009.
- [29] K. Fischer, M. Witiw, and E. Eisenberg, 'Optical attenuation in fog at a wavelength of 1.55 micrometers,' Atmos. Res. , vol. 87, no. 3-4, pp. 252-258, Mar. 2008.
- [30] M. S. Awan, E. Leitgeb, Marzuki, M. S. Khan, F. Nadeem, and C. Capsoni, 'Evaluation of fog attenuation results for optical wireless links in free space,' in Proc. IEEE Int. Workshop Satellite Space Commun. , Oct. 01-03, 2008, pp. 112-116.
- [31] M. S. Awan, E. Leitgeb, M. Loeschnig, F. Nadeem, and C. Capsoni, 'Spatial and time variability of fog attenuations for optical wireless links in the troposphere,' in Proc. IEEE 70th Veh. Technol. Conf. (Fall) , Sept. 20-23, 2009, pp. 1-5.
- [32] M. Grabner and V. Kvicera, 'Multiple scattering in rain and fog on freespace optical links,' J. Lightwave Technol. , vol. 32, no. 3, pp. 513-520, Feb. 2014.
- [33] A. N. Z. Rashed, 'Optical wireless communication systems operation performance efficiency evaluation in the presence of different fog density levels and noise impact,' Wireless Pers. Commun. , vol. 81, pp. 427-444, Oct. 2014.
- [34] A. Sree Madhuri, G. Immadi, and M. Venkata Narayana, 'Estimation of effect of fog on terrestrial free space optical communication link,' Wireless Pers. Commun. , vol. 112, no. 2, pp. 1229-1241, Mar. 2020.
- [35] A. Haider, M. Pigniczki, S. Koyama, M. H. Köhler, L. Haas, M. Fink, M. Schardt, K. Nagase, T. Zeh, A. Eryildirim, T. Poguntke, H. Inoue, M. Jakobi, and A. W. Koch, 'A methodology to model the rain and fog effect on the performance of automotive LiDAR sensors,' Sensors , vol. 23, no. 15, Aug. 2023, Art. no. 6891.
- [36] Y. Liu, Y. Tian, B. Sun, Y. Wang, and F.-Y. Wang, 'Parallel lidars meet the foggy weather,' IEEE J. Radio Freq. Identification , vol. 6, pp. 867870, Sept. 2022.
- [37] S.-L. Lin and B.-H. Wu, 'Application of kalman filter to improve 3D lidar signals of autonomous vehicles in adverse weather,' Appl. Sci. , vol. 11, no. 7, Mar. 2021, Art. No. 3018.
- [38] C. Sakaridis, D. Dai, and L. Van Gool, 'Semantic foggy scene understanding with synthetic data,' Int. J. of Comput. Vis. , vol. 126, pp. 973-992, Mar. 2018.
- [39] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, 'The cityscapes dataset for semantic urban scene understanding,' in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , Jun. 27-30, 2016, pp. 3213-3223.
- [40] M. Wrenninge and J. Unger, 'Synscapes: A photorealistic synthetic dataset for street scene parsing,' arXiv preprint arXiv:1810.08705 , 2018.
- [41] C. Sakaridis, D. Dai, and L. Van Gool, 'ACDC: The adverse conditions dataset with correspondences for semantic driving scene understanding,' in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV) , Oct. 10-17, 2021, pp. 10 765-10 775.
- [42] M. Bijelic, T. Gruber, F. Mannan, F. Kraus, W. Ritter, K. Dietmayer, and F. Heide, 'Seeing through fog without seeing fog: Deep multimodal sensor fusion in unseen adverse weather,' in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , Jun. 13-19, 2020, pp. 11 68211 692.
- [43] M. S. Awan, R. Nebuloni, C. Capsoni, L. Csurgai-Horváth, S. S. Muhammad, F. Nadeem, M. S. Khan, and E. Leitgeb, 'Prediction of drop size distribution parameters for optical wireless communications through moderate continental fog,' Int. J. Sat. Commun. Network. , vol. 29, no. 1, pp. 97-116, 2011.
- [44] G. W. Petty and W. Huang, 'The modified gamma size distribution applied to inhomogeneous and nonspherical particles: Key relationships and conversions,' J. Atmos. Sci. , vol. 68, no. 7, pp. 1460-1473, 2011.
- [45] F. Tampieri and C. Tomasi, 'Size distribution models of fog and cloud droplets in terms of the modified gamma function,' Tellus , vol. 28, no. 4, pp. 333-347, Jan. 1976.
- [46] Q. Liu, B. Wu, Z. Wang, and T. Hao, 'Fog droplet size distribution and the interaction between fog droplets and fine particles during dense fog in tianjin, china,' Atmos. , vol. 11, no. 3, Mar. 2020, Art. no. 258.
- [47] R. H. Rasshofer, M. Spies, and H. Spies, 'Influences of weather phenomena on automotive laser radar systems,' Adv. Radio Sci. , vol. 9, pp. 49-60, Jul. 2011. | null | [
"Ajinkya Shinde",
"Gaurav Sharma",
"Manisha Pattanaik",
"Sri Niwas Singh"
] | 2024-08-02T08:06:12+00:00 | 2024-08-02T08:06:12+00:00 | [
"cs.CV"
] | Effect of Fog Particle Size Distribution on 3D Object Detection Under Adverse Weather Conditions | LiDAR-based sensors employing optical spectrum signals play a vital role in
providing significant information about the target objects in autonomous
driving vehicle systems. However, the presence of fog in the atmosphere
severely degrades the overall system's performance. This manuscript analyzes
the role of fog particle size distributions in 3D object detection under
adverse weather conditions. We utilise Mie theory and meteorological optical
range (MOR) to calculate the attenuation and backscattering coefficient values
for point cloud generation and analyze the overall system's accuracy in Car,
Cyclist, and Pedestrian case scenarios under easy, medium and hard detection
difficulties. Gamma and Junge (Power-Law) distributions are employed to
mathematically model the fog particle size distribution under strong and
moderate advection fog environments. Subsequently, we modified the KITTI
dataset based on the backscattering coefficient values and trained it on the
PV-RCNN++ deep neural network model for Car, Cyclist, and Pedestrian cases
under different detection difficulties. The result analysis shows a significant
variation in the system's accuracy concerning the changes in target object
dimensionality, the nature of the fog environment and increasing detection
difficulties, with the Car exhibiting the highest accuracy of around 99% and
the Pedestrian showing the lowest accuracy of around 73%. |
2408.01087v1 | ## + SSLIP: Automated Radon-assisted and Rotation-corrected identification of complex HCP slip system activity fields from DIC data
- T. Vermeij a,b,1 , G. Slokker a,1 , C.J.A. Mornout , D. K¨nig , J.P.M. Hoefnagels* a o a a
a Dept. of Mechanical Engineering, Eindhoven University of Technology, 5600MB Eindhoven, The Netherlands b Laboratory for Mechanics of Materials and Nanostructures, Swiss Federal Laboratories for Materials Science and Technology (EMPA), Feuerwerkerstrasse 39, 3602 Thun, Switzerland
## Abstract
Identification of crystallographic slip in metals and alloys is crucial to understand and improve their mechanical behavior. Recently, a novel slip system identification framework, termed SSLIP (for Slip System-based Local Identification of Plasticity), was introduced to leap from conventional trace-based identification to automated, point-by-point identification that exploits the full deformation kinematics. Using microstructurecorrelated deformation data (i.e. sub-micron-scale DIC aligned to EBSD), SSLIP matches the measured in-plane displacement gradient tensor to the kinematics of the optimal combination of multiple slip system activities, at each DIC datapoint. SSLIP was applied and demonstrated to be successful on virtual and experimental case studies of FCC and BCC metals. However, for more advanced and anisotropic HCP crystal structures the complete identification of all slip systems was found to be more challenging, posing limitations on automation and flexibility. Here, we propose a significant extension to the SSLIP framework with the aim of automated slip system identification for complex HCP experiments. The main extensions of the SSLIP method, hereinafter referred to as the + SSLIP method, include (i) a pre-selection of slip systems using a Radon transform, (ii) robustness to measured rigid body rotation by simultaneous identification of the local elastic rotation field, (iii) identification of the two best matching slip systems for each data point, and (iv) a procedure to deal with slip systems with in-plane displacement gradient tensors that cannot be discriminated, yielding the full (HCP) slip system activity maps with all slip systems for each grain. The resulting objective identification method does not rely on, e.g., the Schmid factor to select which slip system is active at each point. We show how slip systems from multiple slip families are successfully identified on virtual and real experiments on a Zn polycrystalline coating. We also provide the full Matlab code for + SSLIP on Github.
Keywords: slip system identification, crystallographic slip, SSLIP, HCP plasticity, SEM-DIC, Zinc
## 1. Introduction
Understanding the mechanisms of plastic deformation in metals and alloys, governed predominantly by crystallographic slip, is fundamental to advancing material science and engineering. Crystallographic slip, the movement of dislocations across slip planes in specific directions, is intrinsic to the material's crystal structure and its response to external stresses. The intricacies of this process are encapsulated in various slip systems, dictating the mechanical properties and behavior of materials under load. However, accurately identifying and quantifying slip system activities poses significant fundamental challenges, that are exacerbated by various dislocation mechanisms, such as the complex interplay of multiple slip systems and the presence of diffuse or intersecting slips, as well as the limitations of existing characterization techniques [1-6].
Over the years, various slip system identification methods have been proposed and applied. Through Scanning Electron Microscopy (SEM), discrete and straight slip bands can be observed and matched to theoretical slip plane traces, based on a measured crystal orientation [7-10]. Additionally, strain maps acquired through SEM-based Digital Image Correlation (SEM-DIC) can be employed for slip trace analysis [11-14]. However, in order to obtain a more complete identification, the slip direction also needs to be considered. Therefore, approaches such as the 'Relative Displacement Ratio' (RDR) method [15] and the 'Heaviside DIC method' [16] aim to also extract the slip direction from the SEM-DIC displacement field. The Heaviside DIC method incorporates an additional step function within a DIC subset to deduce the slip trace and direction assuming that the slip is confined to a single slip plane resulting in a clean slip step [16]. On the other hand, the RDR method analyzes regular DIC data by comparing displacement component ratios across a distinct slip trace to theoretical Burgers vector ratios [15]. While these methods have proven effective in various studies [17-21], their application is mostly limited to scenarios with welldefined slip traces, struggling with diffuse or complex slip, partly pertaining due to the resolution constraints of SEM-DIC.
To address the complexities in slip system identification and the limitations of current methodologies, Vermeij et al. recently introduced an automated identification approach, termed as SSLIP (Slip Systems based Identification of Local Plasticity) [22]. This method leverages the detailed deformation data produced through DIC to facilitate a point-by-point identification of slip system activities across a sample surface. By
∗ Corresponding author
Email address: [email protected] (J.P.M. Hoefnagels*)
1 These authors contributed equally.
solving an optimization problem at every SEM-DIC data point, SSLIP matches the measured in-plane kinematics - represented by displacement gradient fields - to a combination of theoretical slip system kinematics derived from Electron Backscatter Diffraction (EBSD) data, after data alignment [4]. This novel approach not only enables the generation of slip system activity fields for each potential slip system but also uncovers the local variations in slip activity, particularly near grain and phase boundaries. Such detailed analysis holds significant promise for enhancing the understanding of plastic deformation mechanisms and allows for more precise comparisons between experiments and theoretical simulations [5, 6, 23, 24], as evidenced by the rapid adoption of the SSLIP method by the research community [25-28].
However, as discussed by Vermeij et al. [22], the automated and complete application of SSLIP on hexagonal close-packed (HCP) materials is challenging, due to its high anisotropy and wide range of slip families, resulting in a large number of slip systems with (very) similar in-plane kinematics making them linearly dependent in the optimization problem [22]. By analyzing virtual HCP experiments [22], it was found that in such demanding cases, a preselection of slip systems to limit the number of possibly active slip systems was necessary. While it was demonstrated that manual preselection of slip systems works for the virtual HCP experiment (without elastic rotations) [22] and for single and bicrystal Zn experiments [29], automation is warranted in order to sustain statistical investigations of slip activities in multiple grains. The problem is made worse by elastic rotations, which are not included in the SSLIP optimization framework. Even though the apparent deformations due to elastic rotations are tiny, their effect in the presence of a large number of similar slip systems can often be large. As a result, a convincing, robust experimental demonstration of SSLIP on HCP is lacking, especially a demonstration of many HCP grains for which automatic identification is crucial.
Here we propose extend the current SSLIP method to make it a robust automatic slip identification method for HCP (and other complex) crystals. Therefore, we first propose to implement an automate preselection step by means of a Radon transform [30], known for its ability to detect straight features, i.e. slip bands from strain maps [13], and we will demonstrate the efficiency of this automated preselection step in the presence of complex and diffuse slip. Subsequently, from the preselected slip systems, the best-fitting combination of two of the preselected systems will be identified for each individual data point separately, such that all of the preselected systems van be active throughout the complete crystal. This step employs an optimization algorithm that not only seeks the optimal match based on local kinematics but also incorporates a correction for any additional local rotation. This rotation correction is crucial as it accounts for misalignments and grain rotations, that would otherwise impede accurate slip system
identification, as explained above. By only allowing two slip systems per point, our approach enhances the robustness of the identification process, while avoiding problems in the iterative solution method due to multiple linear-dependent slip systems. We term this extended methodology as + SSLIP - for Radonassisted, Rotation-corrected, Slip System based Local Identification of Plasticity - to distinguish it from the original SSLIP method.
The significant advancements made with + SSLIP can be most clearly seen from the challenging virtual HCP experiment initially presented in the original SSLIP paper (Section 7 in [22]). Figure 1(a) displays the strain field of this synthetic experiment, where four slip systems are active from four different slip families. The results from the original full SSLIP identification, shown in Figure 1(b), clearly show that several slip systems were misidentified, as marked by the red crosses. In contrast, Figure 1(c) gives a preview of the results of the new + SSLIP approach, utilizing the Radon transform for automated preselection, showing a nearly perfect identification of all four slip systems, as discussed below.
Figure 1: Virtual HCP SEM-DIC experiment, with (a ) corresponding artificially generated effective strain field, 1 E eff , with strain bands marked and corresponding slip traces of the four included slip systems from different slip families, (a )-(a 2 5 ) the four in-plane displacement gradient tensor components, respectively H exp xx , H exp xy , H exp yx , H exp yy . (b) The identified slip activity fields using the original SSLIP method, reproduced from [22], with (b ) showing the 5 sum of all others slip activities that are not supposed to be active. (c) Identification result of the new + SSLIP approach. Green checkmarks indicate correctly identified slip systems, red crosses indicate erroneous ones.
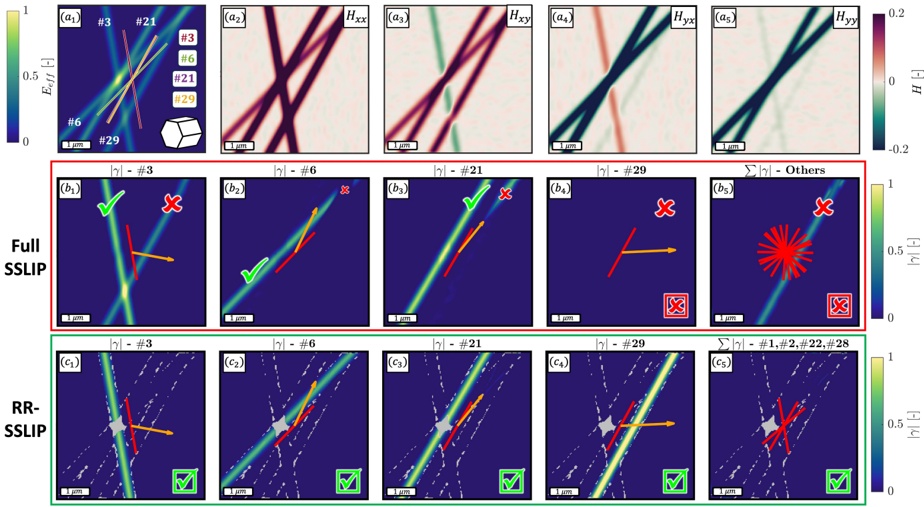
The paper is structured as follows. In Section 2, the + SSLIP method is outlined in detail and demonstrated on the challenging virtual experiment that is introduced in Figure 1. Next, in Section 3 an experi-
mental SEM-DIC case study on HCP is used to demonstrate the power of the + SSLIP method, for selected HCP grains that show various complicated slip mechanisms, showing a robust identification of slip activity fields while considering no less than 30 slip systems from 5 different slip families. Finally, conclusions are summarized in Section 4.
## 2. Methodology
In this section, we outline the computational framework developed to extend the SSLIP methodology to + SSLIP , mainly for the identification of slip system activities within HCP materials. First, the virtual experiment and the original SSLIP method [22] are recapped, after which the new + SSLIP method is introduced.
## 2.1. Virtual Experiment and Recapitulation of the original SSLIP Method
The virtual experiment, originally designed as the ultimate challenge for the SSLIP methodology [22], incorporates four overlapping slip systems from different slip families that represent the possible complexity of slip activity in an HCP material. The displacement field ⃗ u is generated using the following slip systems: Basal-3 (#3), PrismI-3 (#6), PyrICA-9 (#21), and PyrII-5 (#29). Figure 1(a) already showed the effective strain field E eff , based on the displacement gradient tensor H exp , which is calculated by taking the gradient of the displacement field:
$$\mathbf H ^ { e x p } = \vec { \nabla } _ { 0 } \vec { u } = \begin{bmatrix} H ^ { e x p } _ { x x } & H ^ { e x p } _ { x y } \\ H ^ { e x p } _ { y x } & H ^ { e x p } _ { y y } \end{bmatrix}.$$
The effective strain E eff is a shear-dominated strain measure indicative of slip, derived from the in-plane components of H exp [31]:
$$\cdot \cdot \cdot \cdot \\ E _ { \text{eff} } = \sqrt { \frac { 1 } { 2 } \left ( H _ { x x } ^ { e x p } - H _ { y y } ^ { e x p } \right ) ^ { 2 } + \left ( H _ { x y } ^ { e x p } \right ) ^ { 2 } }.$$
The slip system's contribution to the displacement gradient tensor, for a single slip system α , is expressed as the product of the slip amplitude γ α and the Schmid tensor P α :
$$\mathbf H ^ { \alpha } = \gamma ^ { \alpha } \mathbf P ^ { \alpha } = \gamma ^ { \alpha } \vec { s } ^ { \alpha } \otimes \vec { n } ^ { \alpha },$$
with ⃗ s α and ⃗ n α representing the normalized slip direction and slip plane normal of slip system α , respectively. When considering multiple active slip systems, the local theoretical displacement gradient tensor H theo is the sum of contributions from each system:
$$H ^ { t h e o } = \sum _ { \alpha = 1 } ^ { N } H ^ { \alpha }.$$
The original SSLIP method [22] is predicated on the assumption that the measured in-plane displacement gradient tensor components can be described by a linear combination of Schmid tensors of active slip systems, each with a certain slip amplitude. The optimization problem, defined at every datapoint, aims to minimize the sum of the absolute values of the slip activities, while constraining the tensor residual norm R L 2 2 D below a predefined threshold H thresh (based on DIC noise level):
$$\underset { \gamma ^ { \alpha } } { \underset { \sum } { \underset { \alpha } { \sum } } } = \gamma ^ { 1 }, \dots, \gamma ^ { N } \underset { \alpha = 1 } { \sum } ^ { N } | \gamma ^ { \alpha } |$$
$$\text{subject to} \quad \ | \text{H} ^ { e x p } - \text{H} ^ { t h e o r } | | ^ { 2 D } < H _ { t h r e s h }.$$
The minimization of the sum of absolute values of slip activities is included in order to handle more than 4 slip systems, since there are only 4 measured (known) components of the in-plane 2D displacement gradient tensor. In the original SSLIP paper [22], we showed that this approach works well for a less complicated HCP virtual experiment and also for FCC and BCC real experiments. However, as shown in Figure 1, application to the challenging HCP virtual experiment with 4 overlapping slip systems from different slip families results in erroneous results.
## 2.2. + SSLIP part I: Automated Preselection Using the Radon Transform
To increase the robustness, the + SSLIP methodology first incorporates a new step for automated preselection of slip systems through the Radon transform, as initially proposed by Hu et al. [13]. An important difference with the method of Hu et al. is that we use the Radon transform only for de-selection of slip systems that clearly cannot be active, while the actual identification is done in the second part of the + SSLIP method, as discussed below. The Radon transform projects a 2D function, in this case the measured effective strain field E eff , from Cartesian coordinates ( x , y ) to Polar coordinates ( θ pr , x ′ ) [30]:
$$\mathcal { R } \left \{ E _ { e f f } ( x, y ) \right \} = \iint _ { D } E _ { e f f } ( x, y ) \delta \left ( x ^ { \prime } - x \cos \theta _ { p r } - y \sin \theta _ { p r } \right ) d x d y.$$
′
In this, θ pr denotes the projection angle and x signifies the radial distance for the given projection angle. This projection into Radon space yields a sinogram that highlights dominant slip orientations as intensity peaks, as illustrated in Figure 2(a-c). In Figure 2(d), the identified slip traces are shown with their
corresponding angles, which agree almost perfectly with the measured ones in Figure 2(c).
Figure 2: Application of the Radon transform to the Virtual HCP Experiment. (a) Effective strain field, E eff , with superimposed lines indicating the projection angles, θ pr , used in the Radon transform. The intersection point, x i , marks the center of the local area considered for analysis. (b) The effective strain field with a circular overlay representing the Radon transform's integration path. The red dot at the center indicates the rotation axis for the Radon transform. (c) The Radon transform output, R E { eff ( x, y ) } , with peaks corresponding to prominent slip band angles in the strain field. (d) Identified slip band orientations superimposed onto the strain field, with color-coded lines representing different slip system, detected by the Radon transform, with corresponding (theoretical) angles.
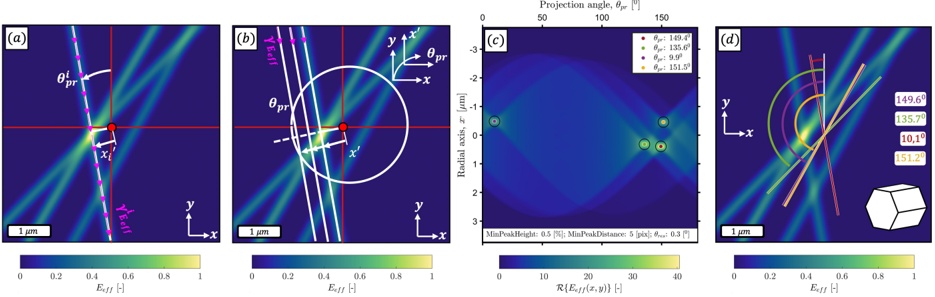
While this works well on the virtual experiment, we try this now on an experimental strain field to assess its performance. Figure 3(a) shows the strain field of a grain from the dataset of the case study in Section 3. Its Radon transform, shown in Figure 3(b), shows a clear maximum as illustrated with the red ellips, which, as will be shown, does not correspond to the slip band orientations. Therefore, we address the influence of the grain shape by introducing a correction step, similarly to the approach by Hu et al. [13]. A binary mask of the grain shape (Figure 3(c)),
$$g ( x, y ) = \begin{cases} 1, & \text{for $(x,y)$ inside the grain} \\ 0, & \text{for $(x,y)$ outside the grain} \end{cases},$$
is employed to normalize the Radon transform outputs. The Radon transform of this grain shape function, g x, y ( ),
$$\mathcal { R } \{ g ( x, y ) \} = \iint _ { D } g ( x, y ) \delta \left ( x ^ { \prime } - x \cos \theta _ { p r } - y \sin \theta _ { p r } \right ) d x d y,$$
is shown in Figure 3(e). The same Radon maximum values are seen as in Figure 3(d), which confirms that the slip bands are missed. Next, normalization of the peak heights in the original Radon space is performed:
$$\overline { \mathcal { R } } \left \{ E _ { e f f } ( x, y ) \right \} = \frac { \mathcal { R } \left \{ E _ { e f f } ( x, y ) \right \} } { \mathcal { R } \left \{ g ( x, y ) \right \} }.$$
This ensures that the length of integration reflects the actual slip trace length within the grain, as shown in Figure 3(f), wherein the Radon peaks actually correspond to the slip bands. Figure 3(c) shows the strain map again with the identified (Basal) slip trace.
Figure 3: Experimental Grain Analysis Using Normalized Radon transform. (a) Effective strain field within a single grain, E eff , with a magnified inset detailing the grain boundary. (b) Binary mask derived from the strain field to define the grain boundary for normalization. (c) Superimposed identified Basal slip trace on the strain field, conforming to the identified Radon transform peaks. (d) Raw Radon transform, R E { eff ( x, y ) } , displaying the intensity of features as a function of the projection angle, θ pr , and radial axis, highlighting the maximum values with a red ellipse. (e) Grain shape Radon transform, R g x, y { ( ) } , which accounts for the curvature of the grain boundary, showing a similar profile to that of (d). (f) Corrected Radon output with peak indicators and trace lines corresponding to the detected slip bands within the search region, illustrating the precision of slip band orientation identification post grain shape normalization.
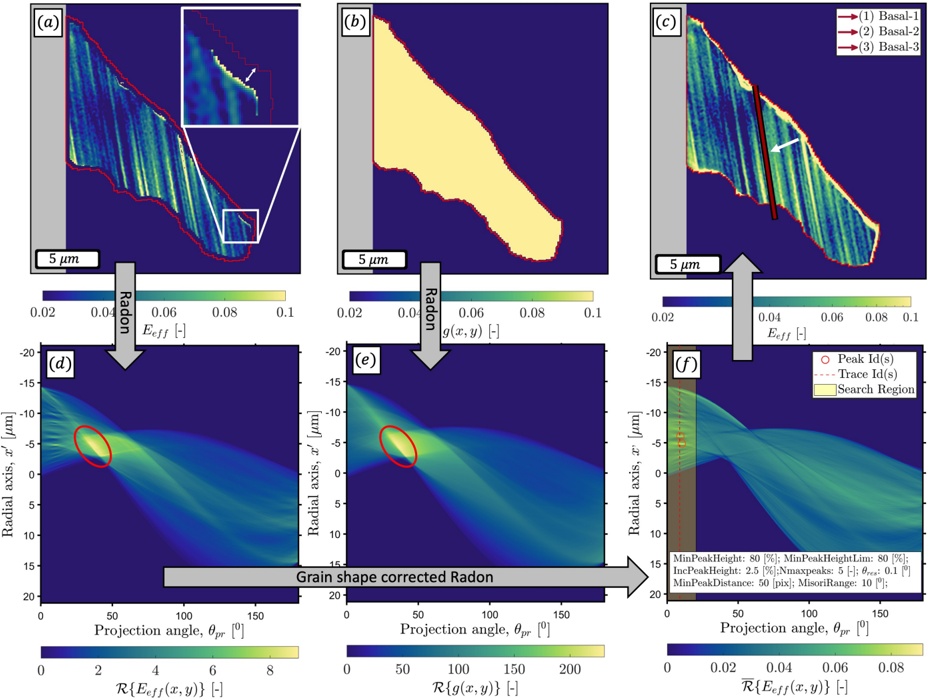
This normalization process, using the grain shape function g x, y ( ), ensures that the length of integration accurately reflects the actual length of slip traces within the grain. The normalized Radon transform, R{ E eff ( x, y ) } , isolates the average strain along each projection line, enhancing the precision of slip system orientation identification. Peaks within the normalized sinogram, identified using the peaks2 function in
Matlab, represent slip band orientations, thereby automating the trace analysis process and warranting the preselection efficiency and objectivity within the + SSLIP framework.
As a preliminary demonstration, we show in Figure 4 the Radon transform preselected slip systems for all experimental cases considered in this paper. The simple example grain shown in Figure 3 resulted in preselection of only a single slip family, i.e. Basal, in which case it could be argued that further identification with + SSLIP is not required, since a SF based method of, e.g., Hu et al. [13], would perform well here in the case that the slip system with the highest SF within a slip family always activated. However, especially for smaller grains with fewer dislocation sources, this assumption may be questionable. Moreover, Figure 4 shows that all other grains considered in this work show at least 3 preselected slip families (each grain showing at least 6 slip systems). Therefore, it is unreasonable in these cases to rely just on the SF for further selection, especially when the critical resolved shear stresses can be unknown, as is often the case. Additionally, while Figure 4(a,b) show clear slip bands that are visually conforming well to the preselected slip traces, the initial Radon-based preselections of the grains in Figure 4(c-e) are less conclusive. In summary, the Radon transform is a valuable first step, but the SSLIP analysis is required to achieve positive identification of the precise slip system(s).
Figure 4: Demonstration of Radon transform preselection on all grains considered in this work. For each grain, (a-e), the effective strain field E eff is plotted. The slip traces of the preselected slip systems are drawn as overlay, as described in the legends.
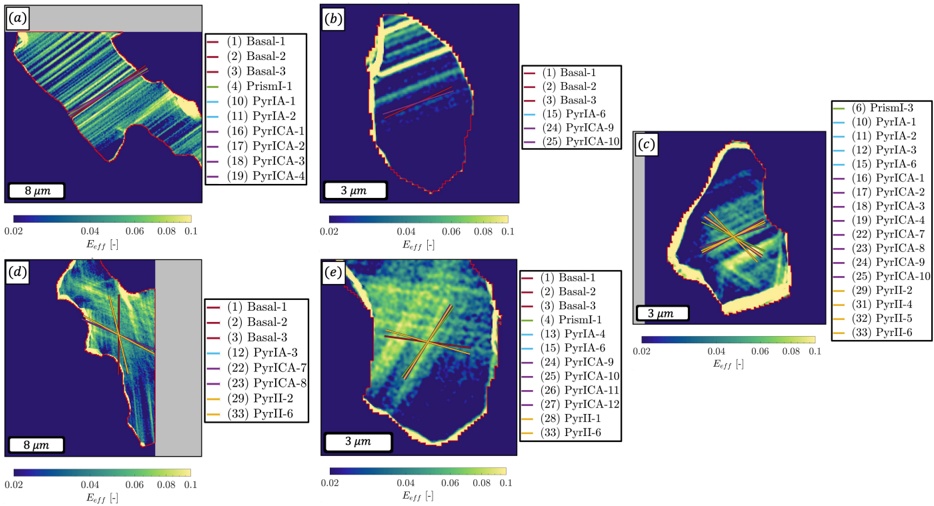
## 2.3. + SSLIP part II: SSLIP Analysis with Preselected Slip System Combinations
With the Radon transform providing a trace-based preselected set of slip systems, we can now apply SSLIP in a targeted manner. For improved robustness and to avoid erroneous solutions from in-plane linearly dependent slip systems, we follow a refined approach that involves systematically examining every possible combination of two slip systems from the preselected pool, at each datapoint. Essentially, this means conducting SSLIP analysis N times for every datapoint, where N represents the total number of unique two-system combinations from the preselected set:
$$N = \frac { N _ { r a d o n }! } { 2! * ( N _ { r a d o n } - 2 )! }.$$
For the current virtual experiment, preselection excludes 16 of the 24 slip systems, only leaving 3 Basal systems, 1 Prismatic system, 2 PyrICA systems and 2 PyrII systems to be included ( N radon = 8). Thus, according to Eq. 10, this results in N = 28 combinations to be analyzed by SSLIP. Below, we will detail the criteria and process for selecting the optimal combination for each datapoint, ensuring a precise and comprehensive identification of active slip systems.
## 2.3.1. SSLIP Analysis with Preselected Slip System Combinations
With the set of preselected slip systems established, we proceed to explain the SSLIP analysis phase. This involves evaluating every possible combination of two slip systems from the preselected pool for each datapoint within a certain grain. Specifically, for each pair of slip systems, we apply the SSLIP methodology, utilizing the optimization equation (Eq. 5). Additionally, rotation correction will be applied, as explained below in Section 2.4.
The selection of the optimal combination for each datapoint is governed by the residual fraction, Rf L 2 2 D , which must fall below a predefined threshold to ensure accurate identification. This residual fraction is calculated as
$$R f _ { 2 D } ^ { L _ { 2 } } = \frac { \left \| { \mathbf H } ^ { e x p } - { \mathbf H } ^ { t h e o } \right \| ^ { 2 D } } { E _ { e f f } },$$
where H exp represents the experimental displacement gradient tensor, H theo denotes the theoretical displacement gradient tensor predicted by a combination of slip systems and rotation (see Section 2.4), and E eff is the effective strain, serving as a normalization factor.
The constraints imposed on potential combinations are outlined in Table 1.
Table 1: Parameters for SSLIP Analysis Selection Criteria
| Parameter | Symbol | Value | Unit |
|-----------------------------------------------------|----------------|---------|--------|
| Max. Displacement Gradient Tensor Residual Fraction | Rf L 2 2 D,max | 0.2 | [-] |
| Min. Equivalent Strain | E min eff | 0.02 | [-] |
| Max. Allowable Rotation Correction | γ max rot | 5 | [ 0 ] |
Each combination is thereby assessed based on its residual fraction (Eq. 11), rotation angle and minimum equivalent strain, according to the values specified in Table 1. These values have been chosen as they were found to work robustly for the analysis of hundreds of Zn grains, of which a few challenging cases are discussed in Section 3. Among these valid combinations, the one with the lowest sum of slip amplitudes, thereby indicating the path of least resistance and conforming to the principle of minimum energy, is selected as the definitive combination of slip system activities for that particular datapoint.
## 2.4. + SSLIP part III: Rotation Correction in SSLIP
Since SSLIP will be applied with only two systems at a time, the optimization problem will have fewer degrees of freedom, which allows us to simultaneously identify the local elastic rotations. Inclusion of local elastic rotations was not needed earlier for the less challenging cases of FCC and BCC, but is found to be necessary for HCP because of its large number slip systems with linearly dependent in-plane deformation gradient tensor (due to the high anisotropy and wide range of slip families of HCP). In practice, these rotations can be in the form of (full) grain rotation (e.g. due to grain boundary sliding), by compatibility effects near a grain boundary or other microstructural features [4], or simply by misalignment of the sample between (quasi-situ) measurement steps. Therefore, we add (local) rotation correction to the methodology, which will not only improve the slip system identification but will also give an extra result, i.e. the rotation field, which may be useful for the analysis.
The correction involves incorporating an additional rotation component into SSLIP, represented by a simplified rotation tensor. For small rotations, which are common in our observations, the in-plane rotation tensor can be described and simplifies as follows:
$$\mathbf H ^ { r o t } = \begin{bmatrix} \cos ( \theta ) & - \sin ( \theta ) \\ \sin ( \theta ) & \cos ( \theta ) \end{bmatrix} - \mathbf I \approx \theta \begin{bmatrix} 0 & - 1 \\ 1 & 0 \end{bmatrix}.$$
Here, θ represents the rotation angle and, under the assumption that θ is small, sin( θ ) ≈ θ and cos( θ ) ≈ 1,
allowing us to capture the in-plane rotation approximately with this simplified matrix, in displacement gradient tensor form. It is then incorporated into SSLIP as an additional slip system, for each combination that will be tried. This results in the rotation value θ at every datapoint, along with the slip system activities. In cases where the rotations would be so large that the simplified rotation tensor is a poor estimate, then the full version of H rot in Eq. 12 can be used, at the expense that H rot needs to be updated using the current estimate of the rotation angle, at each location and at each step in the iterative optimization routine.
## 2.5. Validation on Virtual Experiment
Now, the full + SSLIP methodology is applied to the challenging HCP virtual experiment, for which the results are shown in Figure 5. This figure is structured identically to those in the experimental case study below. Figure 5(a) shows the crystallographic orientation of the virtual experiment and Figure 5(b) shows again the effective strain field. Application of the Radon transfer results in 8 preselected slip systems, see Figure 2. Subsequently, application of Rotation-corrected SSLIP on all pairs of the slip systems ( N = 28) and point-wise selection of the pair with the lowest residual results in the slip activity fields as shown in Figure 5. The correct slip systems were Basal-3, PrismI-3, PyrICA-9 and PyrII-5, all of which show a single slip band, oriented as expected along their slip trace. The other 4 pre-selected, but non-active, slip systems show no activity over the full area, as expected. The error of the SSLIP analysis is represented by the residual norm fraction in Figure 5(d), Rf L 2 2 D,max (Eq. 11), in which low values can be observed. No rotation was applied in the virtual experiment, which is reproduced by the + SSLIP algorithm as shown in Figure 5(c). The intersection of 3 slip bands in the center of the domain cannot be identified, since only 2 slip systems can be active per datapoint. Importantly, these intersections are also not falsely attributed to incorrect slip systems. In practice, the slip activity at such multi-slip intersections can easily be inferred from the neighbouring slip activity. Overall, the identification shown here is robust and accurate and shows promise for identification of complex HCP activities.
## 2.6. Conclusive vs. nondiscriminatory identification
At this point it may seem that the + SSLIP method is working perfectly, at least on this virtual test, but one issue has been left undiscussed, i.e. the possible non-uniqueness of the 2D part of a slip system's displacement gradient tensor for specific grain orientations. In theory, even though each slip system has of course a unique 3D displacement gradient, the 2D part of the displacement gradient tensor could be exactly, or almost, the same for two (or more) slip systems, making those slip systems fundamentally nondiscriminatory in the SSLIP method. In practice, however, the minimization of the sum of slip activities,
Figure 5: Demonstration of the + SSLIP results on the challenging virtual experiment. (a) The EBSD map and rotated crystal shape illustrates the crystal orientation of this virtual experiment. (b) The effective strain field, E eff , showing the deformation pattern, with 4 slip bands clearly visible. (c) The rotation field, γ rot , resulting from rotation-correction by + SSLIP . (d) The residual strain fraction field, Rf L 2 2 D , resulting from + SSLIP, showing the fit between the 'experimental' and theoretical displacement gradient tensor. Below that, the slip system activity map of each slip system of each slip family (Basal, PrismI, PyrICA and PyrII) is shown. Maps with red crosses indicate that systems were not selected by Radon transform preselection. Each map also features the slip trace (red line) and direction (orange arrow), with the Schmid factor ( SF ) depicted as colored circles (colorbar below (a)). The SF is not used in the + SSLIP method.
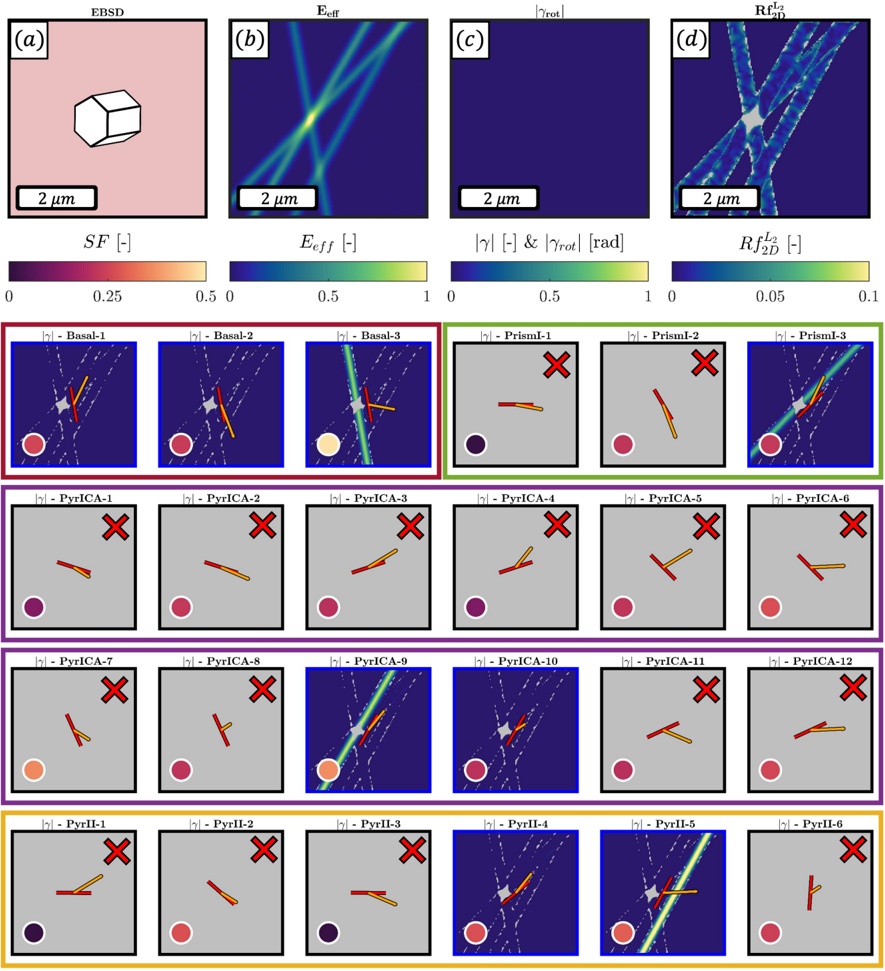
as used in the original SSLIP method [22], was found to be robust against slip systems with almost equal 2D displacement gradient tensors, therefore, this issue was not considered in detail before. For HCP, however, there are many potential slip systems from multiple different families (which typically cannot be excluded apriori due to unknown CRSS values) and the occurrence of multiple highly similar 2D displacement gradient tensors was found to be problematic for grains with 'unfortunate' grain orientation, a few examples of which are treated in Section 3. In such cases, a group of 2 or more slip systems can be defined with similar enough 2D displacement gradient tensors such that the measured slip activity can only be assigned to the group of slip systems. When slip activity is assigned to such a 'nondiscriminatory slip system group' we call the identification 'inconclusive', as counterpart to the regular 'conclusive' identification where the slip activity is uniquely assigned to one or more slip systems.
Therefore, in the + SSLIP method, after the Radon transform preselection, all possible nondiscriminatory slip system groups are identified from the available preselected slip systems, before executing the + SSLIP identification. Whether or not the theoretical 2D displacement gradient tensor of a preselected slip systems can be discriminated from the experimentally measured 2D displacement gradient tensor caused by activity of another slip systems depends on the absolute measurement accuracy of the slip trace angle and the projected slip direction angle, which depends on the combined accuracy of EBSD, SEM-DIC (including SEM scanning artefacts), and their mutual alignment. For our case, it was found that these two angles can have an error up to ∼ 5 . ◦ Therefore, we define an angle threshold of 5 ◦ , i.e. if two preselected slip systems have both a slip trace angle and projected slip direction angle within 5 ◦ of each other, they are considered nondiscriminatory. Through this procedure, the preselected slip systems are, when necessary, included in nondiscriminatory slip system groups in the + SSLIP identification. In the (pixel-wise) + SSLIP output, the slip activity assigned to a nondiscriminatory group is attributed equally to each slip system within the group. The way this works in practice will be shown in the section below (note that the virtual test case in Figure 5 is a regular example of a 'conclusive' identification).
## 3. Experimental Case Study: +SSLIP applied on HCP Zinc Coating
In this section, we demonstrate the strength of the + SSLIP method on experimental SEM-DIC results of an HCP Zinc anti-corrosion coating, which will show activities from multiple slip families: Basal, PyrI and PyrII. The focus will be on challenging cases that include, .e.g., multiple 'nondiscriminatory slip system groups'. Additionally, we will showcase robust identification on grains that exhibit cross slip and diffuse slip, for which pure trace-based analysis is hardly possible [22].
In Section 3.1, we briefly detail the experimental methodology for acquiring microstructure-aligned SEMDIC strain fields. Section 3.2 demonstrates + SSLIP a simple case of single slip and Section 3.3 shows how an inconclusive identification can be interpreted. More complex cases of multi-slip, cross slip and diffuse slip are treated in Sections 3.4 and 3.5.
## 3.1. Material Characterization and SEM-DIC testing
The material used in this case study is a hot-dip galvanized skin-passed Zn coated steel sample whose material code is DX54-Galvanized Iron (GI). The thickness of the Zn anti-corrosion coating is approximately 10 µ m. Dogbone samples are cut using wire-EDM such that they can be deformed using a Kammrath&Weiss tensile stage mounted inside a Tescan Mira 3 SEM, at close working distance, in order to optimize the spatial resolution of SEM-DIC [5, 32]. The gauge width is 4 mm and sample thickness is 0 7 mm. Before testing, the . sample surface is carefully prepared in a single step of polishing using Oxide Polishing Suspension (OPS)NonDry and ethanol (1:1) suspension on a Struers MD-Chem cloth for 10 minutes. This short polishing provides the optimal compromise between good surface quality and low material removal, since the Zn coating is very thin.
Next, several ∼ 50 µ m sized Regions of Interest (RoI's) are chosen for characterization and in-situ SEMDIC testing, as shown in Figure 6 for one RoI. EBSD is performed with an EDAX Digiview 2 camera in a Tescan Mira 3 SEM, with offline spherical indexing using EMSphInx for improved quality [33], resulting in an Inverse Pole Figure (IPF) map as visualized in Figure 6(a). Subsequently, we apply a fine and dense InSn SEM-DIC speckle pattern applied according to the parameters of pattern b in Table 1 of Hoefnagels et al. [34], resulting in approximately 90-100 nm sized speckles, see Figure 6(b). The specimen is then mounted in a Kammrath&Weiss micro-tensile stage, which is installed inside the Tescan Mira 3 SEM for interrupted in-situ testing, at deformation steps as shown in Figure 6(d). For SEM-DIC imaging, we use in-lens SE imaging at a 5 kV beam voltage and at 7 mm working distance. At each deformation step, a horizontal and vertical scan are captured that are combined into a single image that is corrected for SEM scanning artefacts, using a software program called ScanCorr [4]. Subsequently, DIC is performed on these scanning artefacts corrected images using the MatchID software, employing parameters as given in Table 2, following procedures proposed by Vermeij et al. [4, 32]. Subsequently, the nanomechanical alignment framework [4] is applied to allow direct spatial correlation between EBSD and DIC data, as observed in the strain maps of all deformation steps in Figure 6(e), with the aligned grain boundary overlaid.
At a first glance, the materials reveals a range of deformation mechanisms. Crystallographic slip can be observed within grains, both in the form of sharp and more diffuse slip bands. Additionally, localizations
Figure 6: (a 1 ) Electron Backscatter Diffraction (EBSD) IPF map illustrating the microstructure of the Zn coating prior to deformation, with hexagonal shapes illustrating the crystal orientations. (a 2 ) Zoom-in of IPF map around a tripple junction. (b) Scanning Electron Microscope (SEM) image, in in-lens Secondary Electron (SE) mode, displaying the Indium-Tin (InSn) speckle pattern used for Digital Image Correlation (DIC). The aligned grain boundaries are shown as overlay in red. (c) Effective strain field captured (inset of (e 5 ) via DIC at a global strain of 0.059, showing crystal slip and grain boundary deformation. Areas surrounded by pink lines denote interpolated DIC data, predominantly on grain boundary locations. (d) Load-elongation curve from the in-situ tensile test with colorcoded points corresponding to the strain levels in subfigures (e 1 )-(e 5 ). (e 1 )-(e 5 ) Effective strain fields at progressive tensile test increments, highlighting the evolution of strain localization and the alignment with EBSD data.
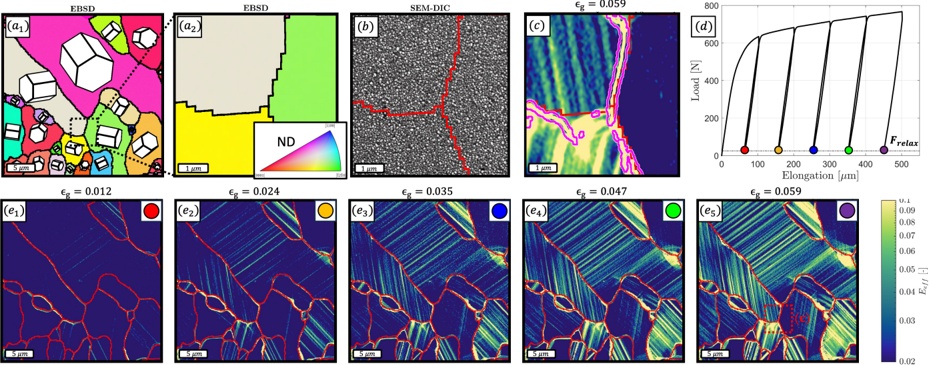
occur on top of grain boundaries, hinting at the occurrence of grain boundary sliding and/or migration. Figure 6(c) shows this more clearly with an inset of the strain field around a triple junction, for the final deformation step. Distinct slip, diffuse intragranular deformation and grain boundary activity can be observed. Note that the grain boundary deformation is very strong and resulted in a local degradation of the DIC pattern, such that interpolation of the DIC data was required (in the areas outlined with a thin pink line) [5]. However, the grain boundary deformation is outside the scope of this paper and will be subjected to identification by an alternative variation of the SSLIP method that is focused on the identification of grain boundary sliding [35]. Here, the goal is identification of the active slip system inside (all of) the grains.
With the microstructure-correlated deformation data available, we will now demonstrate the + SSLIP method on several HCP Zn grains. For this, we choose several individual grains that show slip activity, starting with simple basal slip and moving on to multiple and differently oriented slip bands in Section 3.4. Additionally, 'nondiscriminatory' slip systems will be handled transparently when encountered. In Section 3.5, we will focus on more complex cases of cross slip and diffuse slip, on which the + SSLIP method excels.
For each experimental case, we extract the deformation data of a single grain, allowed by the data
Table 2: DIC System and Correlation Parameters
| Parameter | Value | Unit |
|-----------------------|--------------------------------------------|--------|
| Capture Instrument | Tescan Mira 3 SEM | - |
| Field of View | 40 | [ µ m] |
| Pixel Size | 13 | [nm] |
| DIC Software | MatchID | - |
| Correlation Algorithm | ZNSSD | - |
| Subset Size | 33 | [pix] |
| Step Size | 3 | [pix] |
| Matching Criterion | Zero-normalized sum of squares differences | - |
| Pre-filtering | Gaussian | - |
| Filter Size | 1 | [pix] |
| Correlation Threshold | ≥ 0 . 7 | - |
| Subset Shape Function | Affine | - |
alignment, and remove a band of 5 pixels along the grain boundary to avoid any grain boundary sliding and/or migration mechanisms. Additionally, the peak identification on the sinograms is performed to only retrieve peaks that are above 80 % of the maximum value are identified, with a maximum of 5 peaks.
## 3.2. + SSLIP applied on Zn: single slip
The first experimental grain that we investigate is shown in Figure 7. An impression of the crystallography and the deformation of the grain is given in Figure 7(a-b), consisting of the EBSD map and the effective strain field. At a first glance, slip occurs over only one specific slip plane, making it a relatively simple case to start the demonstration of the + SSLIP methodology.
Application of + SSLIP results in identification of the slip activity fields as shown in Figure 7. As expected, the Radon transform preselection only picks up one specific trace, which in this case can be attributed to 6 individual slip systems: all 3 Basal systems, 1 PyrIA system and 2 PyrICA systems. Among these, Basal-2 and Basal-3 are identified as the active slip systems, which is unsurprising since Basal slip is known to have the lowest CRSS in Zn [7, 36]. The rotation field in Figure 7(c), identified by + SSLIP , shows a negligible contribution for this grain. Additionally, the residual fraction in Figure 7(d) is rather low, indicating that the identification was successful. Note that the rotation field and the residual fraction field is set to NaN (i.e. shown as grey in the figures) when the residual fraction is above its threshold or when the effective strain is below its threshold.
While this example may seem rather straightforward, the activities of the three Basal slip systems do not follow Schmid's law globally. In fact, the lowest SF Basal system, Basal-3, shows most of the activity, while the highest SF system, Basal-1, shows no activity. Likely, the local loading conditions in the polycrystalline coating change the local stress state, rendering the SF insufficient to predict slip system activities. This
Figure 7: Results of slip system identification for a selected HCP Zn grain, showing one type of slip bands, using the + SSLIP method. (a) The EBSD map and rotated crystal shape illustrates the crystal orientation. (b) The effective strain field, E eff , showing the deformation pattern. (c) The rotation field, γ rot , resulting from rotationcorrection by + SSLIP. (d) The residual strain fraction field, Rf L 2 2 D , resulting from + SSLIP, showing the fit between the experimental and theoretical displacement gradient tensor. Below that, the slip activity map of each slip system of each slip family (Basal, PrismI, PyrIA, PyrICA and PyrII) is shown. Maps with red crosses indicate that systems were not selected by Radon transform preselection. Each map also features the slip trace (red line) and direction (orange arrow), with the Schmid factor ( SF ) depicted as colored circles (colorbar below (a)). Note that the SF is not used in the + SSLIP method.
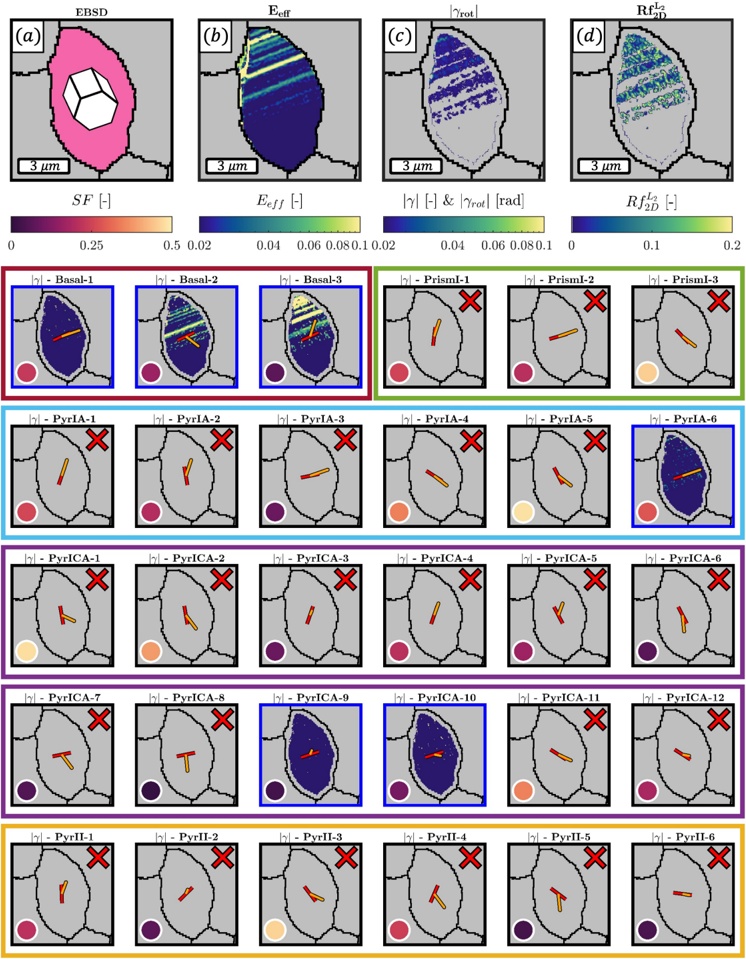
example shows that it is insufficient to rely on the SF.
## 3.3. Conclusive vs. Inconclusive Identification
As explained in Section 2.6, the identification can be inconclusive when slip systems have equal 2D (in-plane) kinematics, of which Figure 8 shows an example. The nondiscriminatory slip system groups, based on a 5 angle threshold of the slip trace and project slip direction, are annotated by specific green ◦ symbols within the Schmid factor circles of the slip system activity fields. Note that, in general, the inplane similarity of slip systems can be judged visually by assessing the difference between the plotted slip trace and direction. In this case, there are 3 groups of nondiscriminatory systems and slip systems PrimI-1 and PyrIA-2 are each part of two nondiscriminatory groups. The green rectangle shows that Basal-1 and PyrICA-2 are nondiscriminatory, but showing limited slip activities. The two other groups, annotated by the green '+' sign (Basal-3, PrismI-1 and PyrIA-2) and circles (PrismI-1, PyrIA-1 and PyrIA-2) are very close to each other, but different enough to be separated into two groups. These two groups have the largest slip activities and it is likely that only Basal-3 is actually active, since it has a significant SF and low CRSS. Finally, this grain still has several unique slip systems, of which Basal-2 shows limited activity.
Another notable feature in this grain is the presence of rotation over almost the full grain, as shown in Figure 8(c). Considering that the magnitude of rotation (in radians) is similar to that of the slip magnitudes, SSLIP would fail here without including the rotation-correction into the identification. The resulting rotation field is almost fully smooth, which one would expect for elastic rotation, and its presence over the full grain is a strong indication of grain rotation, which may be related to grain boundary sliding.
## 3.4. Non-Basal multi-slip activity in Zn
After these first two examples with a single dominant slip trace in the strain map, we now turn to a more complex scenario where multiple slip systems with different trace orientations are simultaneously active. The Zinc grain analyzed in Figure 9 illustrates a case where several slip systems are active. The deformation pattern captured in the effective strain field (Figure 9(b)) reveals distinct arrays of slip bands, indicating the multi-slip nature of the deformation.
The + SSLIP method is applied here, including no less than 17 slip systems after Radon transform preselection. While this number is significant, there is only 1 group of 3 nondiscriminatory slip systems: PyrICA-2, PyrICA-7 and PyrII-2. Notably, the Basal slip systems are not among those preselected.
The + SSLIP results shown in Figure 9 clarify which slip systems are active. Slip system PyrII-2 is conclusively identified and the configuration of its activity conforms to the slip trace, which serves as an
Figure 8: Evaluation of slip system activities in an HCP Zn grain using the + SSLIP method, with a focus on nondiscriminatory slip systems. The EBSD map indicates the crystal orientation (a), with corresponding effective strain (b) and rotation fields (c) illustrating the deformation. The residual fraction field (d) demonstrates the method's fit. Nondiscriminatory slip system groups are identified and marked with specific green symbols within the SF circles to denote their indistinguishability due to close angular proximity. Slip systems not preselected by the Radon transform are marked with red crosses.
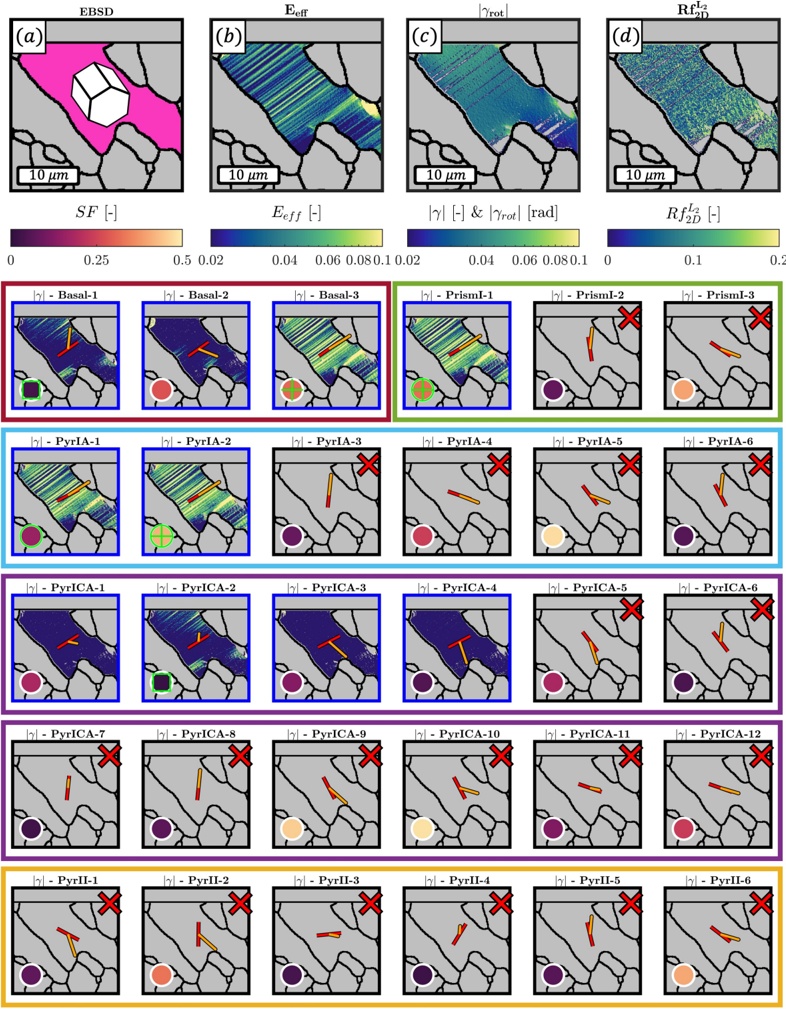
Figure 9: Complex slip system interaction in a hexagonal close-packed Zinc grain analyzed by the + SSLIP method. (a) The EBSD map indicates the crystallographic orientation of the grain. (b) The effective strain field ( E eff ) reveals the pattern of deformation. (c) The rotation field ( γ rot ) captures any rotations within the grain. (d) The residual strain fraction field ( Rf L 2 2 D ) quantifies the fit quality between experimental and theoretical predictions. Below are the individual slip activity maps for each slip family, where red crosses indicate non-preselected systems.
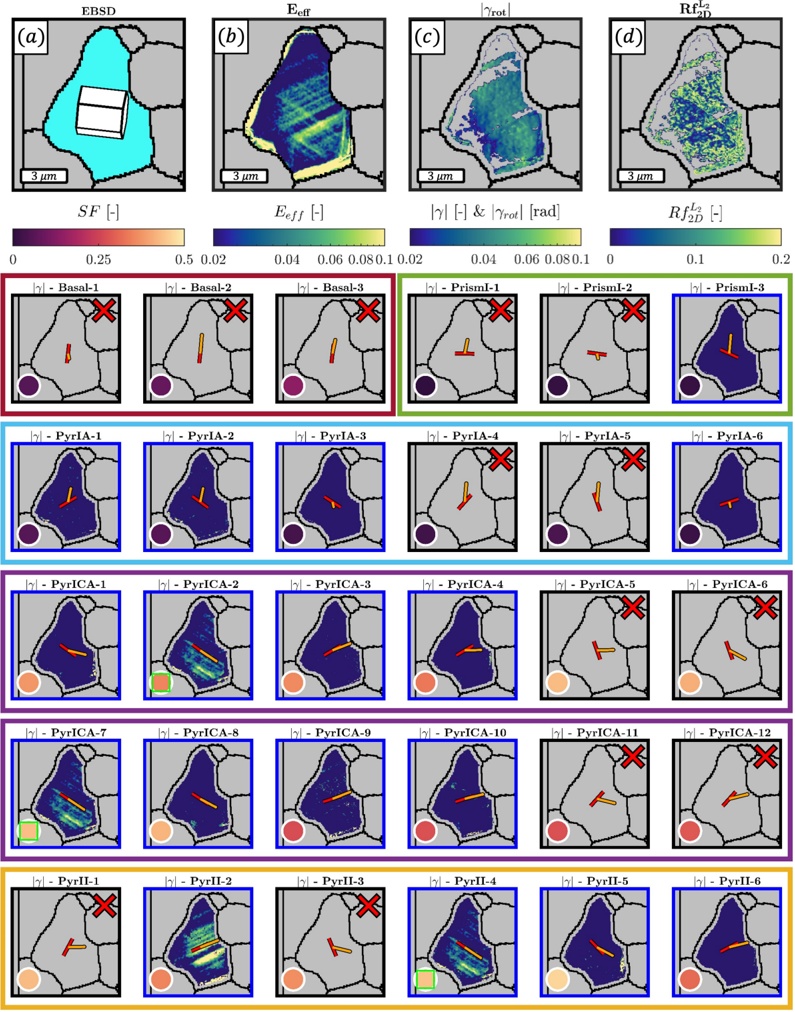
indirect validation of the results. The other part of the deformation is attributed to the nondiscriminatory group mentioned above, for which also the traces match the observed slip system activity field. Based on this, we can conclude that Pyramidal-II can occur in this Zn alloy, with potential activity also from Pyramidal-I CA. Additionally, it shows that + SSLIP can handle a large number of potentially active slip systems.
## 3.5. Complex diffuse slip identified in Zn
Now, we will push the limits of + SSLIP to identify plasticity in which slip traces are not trivially identified, predominantly because the slip is diffuse and spread out over the grain. While the original SSLIP method [22] performed exceptionally well in such cases (i.e. for FCC and BCC), the added preselection by the Radon transform for + SSLIP could very well prevent such a good performance here. Therefore, we evaluate the identification on two grains which show such complexity and diffuseness.
The grain depicted in Figure 10 shows a complex deformation pattern, consisting of several sharp slip bands mixed with diffuse slip (Figure 10(b)). + SSLIP resolves 8 potential slip systems, all discriminatory, of which 3 systems show prominent slip activity. The activation of Basal-1 and particularly Basal-2 were expected due to their high SF and low CRSS, while the (near) absence of Basal-3 slip seems logical as it has the lowest SF of the three Basal systems. However, the Basal slip bands are less discrete and straight as compared to Figure 7 and Figure 8. Additionally, PyrIA-3, which has a low SF (as is the case for all of the preselected non-Basal slip systems), shows high activity, while also having considerable overlap with Basal-1.
The occurrence of PyrIA is surprising, since it has never been observed in Zn, to the best of our knowledge. This may be due to its diffuse nature, which makes it harder to identify using traditional slip trace identification methods. Interestingly, Basal-1 and PyrIA-3 have the same < a > slip direction, which provides a strong indication that cross slip is active. Cross slip allows non-planar movement in which a dislocation can move from one slip plane to another, sharing the same slip direction. It has been identified before in the original SSLIP paper in FCC and BCC [22].
Finally, we assess a grain with the highest level of complexity: a highly diffuse multi-slip deformation pattern in combination with a high number of Radon transform preselected slip systems, of which many are also nondiscriminatory, as depicted in Figure 11. Here + SSLIP considers 12 preselected slip systems, of which 5 are in a single nondiscriminatory group. Basal slip, with low SF, is conclusively identified. The differently oriented slip band activities are attributed to the nondiscriminatory group, which consists of PyrIA, PyrICA and PyrII slip systems. Notably, all slip activity fields show slip bands that concur with
Figure 10: Diffuse and complex plasticity, potentially cross slip, identified by + SSLIP . (a) The EBSD map indicates the crystallographic orientation of the grain. (b) The effective strain field ( E eff ) reveals the pattern of deformation. (c) The rotation field ( γ rot ) captures any rotations within the grain. (d) The residual strain fraction field ( Rf L 2 2 D ) quantifies the fit quality between experimental and theoretical predictions. Below are the individual slip activity maps for each slip family, where red crosses indicate non-preselected systems.
their respective slip trace orientations, agains serving as an indirect validation. The diffuse deformation pattern is thereby appropriately unraveled, even for this highly complex case.
Figure 11: Diffuse crystal plasticity identified by + SSLIP . (a) The EBSD map indicates the crystallographic orientation of the grain. (b) The effective strain field ( E eff ) reveals the pattern of deformation. (c) The rotation field ( γ rot ) captures any rotations within the grain. (d) The residual strain fraction field ( Rf L 2 2 D ) quantifies the fit quality between experimental and theoretical predictions. Below are the individual slip activity maps for each slip family, where red crosses indicate non-preselected systems.
## 4. Conclusions
In this work, we have proposed a significant extension of the original SSLIP (Slip System based Local Identification of Plasticity) method, termed as + SSLIP , addressing automated slip system identification in complex HCP metals, based on SEM-DIC and EBSD data. We have demonstrated that this methodology can effectively tackle the challenges posed by anisotropic HCP crystal structures, where the presence of multiple slip families and the resulting high number of in-plane linearly dependent slip system kinematics can complicate the analysis.
Key advancements introduced in this work include (i) automated preselection of slip systems using the Radon transform, (ii) identification of the two best matching slip systems for each data point, (iii) the incorporation of a robust rotation correction mechanism and (iv) a procedure to deal with slip systems with in-plane displacement gradient tensors that cannot be discriminated with the measurement error. This has allowed for a more precise and comprehensive identification of active slip systems, yielding the full slip system activity maps with all slip systems for each grain.
The performance of + SSLIP is first demonstrated successfully on a challenging virtual HCP case study on which the original SSLIP method did not perform well. Subsequently, we consider microstructurecorrelated SEM-DIC deformation maps on a polycrystalline Zn anti-corrosion coating as an experimental case study, from which we have analyzed a number of challenging grains as proof of principle. It was found that + SSLIP overcomes the limitations of traditional trace-based analysis, particularly in cases where slip is diffuse or cross slip and diffuse slip are present. Additionally, where necessary, we provide a transparent overview of nondiscriminatory slip systems, which are fundamentally indistinguishable from only 2D (inplane) deformation maps.
The + SSLIP approach has been confirmed to be an objective method that does not rely on factors such as the Schmid factor to select active slip systems. Indeed, every identified slip activity field shown in this paper can be indirectly validated by comparing its deformation pattern to the slip plane trace. + SSLIP offer a strong compromise between the original SSLIP method, in which preselection is not required, and SF based methods which suffer especially for HCP metals, since the critical resolved shear stress values of slip families are often unknown, while additionally the effect of neighbouring grains in a polycrystalline microstructure make the SF estimate unreliable.
In summary, the + SSLIP framework, of which the code is shared openly, stands as a significant contribution to the field of identification of plasticity, offering a robust tool for investigating and understanding the plastic deformation behavior of HCP materials. The methodology paves the way for future studies to
further explore and quantify the slip system activities under different loading conditions and in other HCP materials, which allows statistical studies and enhances the predictive capabilities of material models and simulations.
## Acknowledgements
We acknowledge Marc van Maris and Mark Vissers for experimental support.
This research was carried out as part of the 'Next-Coat' project, under project number N19016b in the framework of the Partnership Program of the Materials innovation institute M2i (www.m2i.nl) and the Netherlands Organization for Scientific Research (http:// www.nwo.nl).
## Code and Data availability
The Matlab code for the original SSLIP method, with several examples, is available on Github: https: //www.github.com/TijmenVermeij/SSLIP . The + SSLIP code will be added to this repository upon acceptance of the paper. The full datasets are available upon request.
## References
- [1] D. Lunt, X. Xu, T. Busolo, J. Quinta da Fonseca, and M. Preuss. Quantification of strain localisation in a bimodal two-phase titanium alloy. Scripta Materialia , 145:45-49, 2018.
- [2] A. Githens, S. Ganesan, Z. Chen, J. Allison, V. Sundararaghavan, and S. Daly. Characterizing microscale deformation mechanisms and macroscopic tensile properties of a high strength magnesium rare-earth alloy: A combined experimental and crystal plasticity approach. Acta Materialia , 186:77-94, 2020.
- [3] A. Harte, M. Atkinson, A. Smith, C. Drouven, S. Zaefferer, J. Quinta da Fonseca, and M. Preuss. The effect of solid solution and gamma prime on the deformation modes in Ni-based superalloys. Acta Materialia , 194:257-275, 2020.
- [4] T. Vermeij, J.A.C. Verstijnen, T.J.J. Ramirez y Cantador, B. Blaysat, J. Neggers, and J.P.M. Hoefnagels. A nanomechanical testing framework yielding front&rear-sided, high-resolution, microstructure-correlated SEM-DIC strain fields. Experimental Mechanics , 62:1625-1646, 2022.
- [5] T. Vermeij, C.J.A. Mornout, V. Rezazadeh, and J.P.M. Hoefnagels. Martensite plasticity and damage competition in dual-phase steel: A micromechanical experimental-numerical study. Acta Materialia , 254:119020, 2023.
[6] T. Vermeij, J. Wijnen, R.H.J. Peerlings, M.G.D. Geers, and J.P.M. Hoefnagels. A quasi-2d integrated experimentalnumerical approach to high-fidelity mechanical analysis of metallic microstructures. Acta Materialia , 264:119551, 2024.
- [7] Rodolphe Parisot, Samuel Forest, Andr´ Pineau, Franck Nguyen, Xavier Demonet, and Jean Michel Mataigne. Deformation e and damage mechanisms of zinc coatings on hot-dip galvanized steel sheets: Part II. Damage modes. Metallurgical and Materials Transactions A 2004 35:3 , 35(3):813-823, 2004.
- [8] F. Bridier, P. Villechaise, and J. Mendez. Analysis of the different slip systems activated by tension in a α β / titanium alloy in relation with local crystallographic orientation. Acta Materialia , 53(3):555-567, 2005.
- [9] T.R. Bieler, P. Eisenlohr, F. Roters, D. Kumar, D.E. Mason, M.A. Crimp, and D. Raabe. The role of heterogeneous deformation on damage nucleation at grain boundaries in single phase metals. International Journal of Plasticity , 25(9):16551683, 2009.
- [10] M.P. Echlin, J.C. Stinville, V.M. Miller, W.C. Lenthe, and T.M. Pollock. Incipient slip and long range plastic strain localization in microtextured Ti-6Al-4V titanium. Acta Materialia , 114:164-175, 2016.
- [11] A. Orozco-Caballero, D. Lunt, J.D. Robson, and J. Quinta da Fonseca. How magnesium accommodates local deformation incompatibility: A high-resolution digital image correlation study. Acta Materialia , 133:367-379, 2017.
- [12] M.E. Harr, S. Daly, and A.L. Pilchak. The effect of temperature on slip in microtextured Ti-6Al-2Sn-4Zr-2Mo under dwell fatigue. International Journal of Fatigue , 147:106173, 2021.
- [13] Haoyu Hu, Fabien Briffod, Takayuki Shiraiwa, and Manabu Enoki. Automated slip system identification and strain analysis framework using high-resolution digital image correlation data: Application to a bimodal Ti-6Al-4V alloy. International Journal of Plasticity , 166:103618, 7 2023.
- [14] R. Sperry, A. Harte, J. Quinta da Fonseca, E.R. Homer, R.H. Wagoner, and D.T. Fullwood. Slip band characteristics in the presence of grain boundaries in nickel-based superalloy. Acta Materialia , 193:229-238, 2020.
- [15] Z. Chen and S.H. Daly. Active slip system identification in polycrystalline metals by Digital Image Correlation (DIC). Experimental Mechanics , 57(1):115-127, 2016.
- [16] F. Bourdin, J.C. Stinville, M.P. Echlin, P.G. Callahan, W.C. Lenthe, C.J. Torbet, D. Texier, F. Bridier, J. Cormier, P. Villechaise, T.M. Pollock, and V. Valle. Measurements of plastic localization by heaviside-digital image correlation. Acta Materialia , 157:307 - 325, 2018.
- [17] X. Xu, D. Lunt, R. Thomas, R. Prasath Babu, A. Harte, M. Atkinson, J. Quinta da Fonseca, and M. Preuss. Identification of active slip mode in a hexagonal material by correlative scanning electron microscopy. Acta Materialia , 175:376 - 393, 2019.
- [18] J.C. Stinville, P.G. Callahan, M.A. Charpagne, M.P. Echlin, V. Valle, and T.M. Pollock. Direct measurements of slip irreversibility in a nickel-based superalloy using high resolution digital image correlation. Acta Materialia , 186:172 - 189, 2020.
- [19] R. Sperry, S. Han, Z. Chen, S.H. Daly, M.A. Crimp, and D.T. Fullwood. Comparison of EBSD, DIC, AFM, and ECCI for active slip system identification in deformed Ti-7Al. Materials Characterization , 173:110941, 2021.
- [20] B. Poole, A. Marsh, D. Lunt, C. Hardie, M. Gorley, C. Hamelin, and A. Harte. High-resolution strain mapping in a thermionic lab6 scanning electron microscope. Strain , 2024.
- [21] R.L. Black, D. Anjaria, J. Gen´e, V. Valle, and J.C. Stinville. Micro-strain and cyclic slip accumulation in a polycrystalline e nickel-based superalloy. Acta Materialia , 266:119657, 2024.
- [22] T. Vermeij, R.H.J. Peerlings, M.G.D. Geers, and J.P.M. Hoefnagels. Automated Identification of Slip System Activity Fields from Digital Image Correlation Data. Acta Materialia , 243:118502, 1 2022.
- [23] J.C. Stinville, M.A. Charpagne, R. Maaß, H. Proudhon, W. Ludwig, P.G. Callahan, F. Wang, I.J. Beyerlein, M.P. Echlin, and T.M. Pollock. Insights into Plastic Localization by Crystallographic Slip from Emerging Experimental and Numerical Approaches. Annual Review of Materials Research , 53:275-317, 2023.
- [24] J. Wijnen, T. Vermeij, J.P.M. Hoefnagels, M.G.D. Geers, and R.H.J. Peerlings. High-resolution numerical-experimental
comparison of heterogeneous slip activity in quasi-2d ferrite sheets. arXiv preprint arXiv:2402.16199 , 2024.
- [25] J. Scherer, J. Hure, R. Madec, F. Le Bourdais, L. van Brutzel, S. Sao-Joao, G. Kermouche, J. Besson, and B. Tanguy. Tensile and micro-compression behaviour of AISI 316L austenitic stainless steel single crystals at 20 ◦ C and 300 ◦ C: experiments, modeling and simulation. Materials Science and Engineering: A , page 146471, 2024.
- [26] D. Agius, D. Cram, C. Hutchinson, M. Preuss, Z. Sterjovski, and C. Wallbrink. An experimental and computational study into strain localisation in beta-annealed Ti-6Al-4V. Procedia Structural Integrity , 45:4-11, 2023.
- [27] D. Depriester, J.P. Goulmy, and L. Barrallier. Crystal plasticity simulations of in situ tensile tests: A two-step inverse method for identification of cp parameters, and assessment of cpfem capabilities. International Journal of Plasticity , 168:103695, 2023.
- [28] W. Yin, F. Briffod, H. Hu, T. Shiraiwa, and M. Enoki. Three-dimensional configuration of crystal plasticity in stainless steel assessed by high resolution digital image correlation and confocal microscopy. International Journal of Plasticity , 170:103762, 2023.
- [29] D. Konig, T. Vermeij, F. Maresca, and J.P.M. Hoefnagels. The transition of nanoscale plasticity from single- to bicrystal tensile tests extracted from a Zinc coating (working title). In Preparation , 2024.
- [30] S. Helgason. The radon transform , volume 2. Springer, 1999.
- [31] P. Paupler. G. E. Dieter. Mechanical Metallurgy. 3rd ed., Mc Graw-Hill Book Co., New York 1986. XXIII + 751 p., DM 138.50, ISBN 0-07-016893-8 , volume 23. 1988.
- [32] T. Vermeij and J.P.M. Hoefnagels. Plasticity, localization, and damage in ferritic-pearlitic steel studied by nanoscale digital image correlation. Scripta Materialia , 208, 2021.
- [33] W.C. Lenthe, S. Singh, and M. De Graef. A spherical harmonic transform approach to the indexing of electron backscattered diffraction patterns. Ultramicroscopy , 207:112841, 2019.
- [34] J.P.M. Hoefnagels, M.P.F.H.L. van Maris, and T. Vermeij. One-step deposition of nano-to-micron-scalable, high-quality digital image correlation patterns for high-strain in-situ multi-microscopy testing. Strain , 55(6):e12330, 2019. e12330 STRAIN-1507.R1.
- [35] C.J.A. Mornout, G. Slokker, T. Vermeij, D. Konig, and J.P.M. Hoefnagels. Automated identification of grain boundary sliding from digital image correlation data (working title). In Preparation , 2024.
- [36] W. Bednarczyk, M. Watroba, M. Jain, K. Mech, P. Bazarnik, P. Baglyph[suppress] la, J. Michler, and K. Wieczerzak. Determination of critical resolved shear stresses associated with a slips in pure Zn and Zn-Ag alloys via micro-pillar compression. Materials & Design , 229:111897, 2023. | null | [
"T. Vermeij",
"G. Slokker",
"C. J. A. Mornout",
"D. König",
"J. P. M. Hoefnagels"
] | 2024-08-02T08:07:01+00:00 | 2024-08-02T08:07:01+00:00 | [
"cond-mat.mtrl-sci"
] | +SSLIP: Automated Radon-assisted and Rotation-corrected identification of complex HCP slip system activity fields from DIC data | Identification of crystallographic slip in metals and alloys is crucial to
understand and improve their mechanical behavior. Recently, a novel slip system
identification framework, termed SSLIP (for Slip System-based Local
Identification of Plasticity), was introduced to leap from conventional
trace-based identification to automated, point-by-point identification that
exploits the full deformation kinematics. Using microstructure-correlated
deformation data, SSLIP matches the measured in-plane displacement gradient
tensor to the kinematics of the optimal combination of multiple slip system
activities, at each DIC datapoint. SSLIP was applied and demonstrated to be
successful on virtual and experimental case studies of FCC and BCC metals.
However, for more advanced and anisotropic HCP crystal structures the complete
identification of all slip systems was found to be more challenging, posing
limitations on automation and flexibility. Here, we propose a significant
extension to the SSLIP framework with the aim of automated slip system
identification of HCP. The main extensions of the SSLIP method, hereinafter
referred to as the +SSLIP method, include (i) a pre-selection of slip systems
using a Radon transform, (ii) robustness to measured rigid body rotation by
simultaneous identification of the local elastic rotation field, (iii)
identification of the two best matching slip systems for each data point, and
(iv) a procedure to deal with slip systems with in-plane displacement gradient
tensors that cannot be discriminated, yielding the full slip system activity
maps with all slip systems for each grain. The resulting objective
identification method does not rely on, e.g., the Schmid factor to select which
slip system is active at each point. We show how slip systems from multiple
slip families are successfully identified on virtual and real experiments on a
Zn polycrystalline coating. |
2408.01088v2 | ## Bridging Information Gaps in Dialogues With Grounded Exchanges Using Knowledge Graphs
Phillip Schneider , Nektarios Machner , Kristiina Jokinen , and Florian Matthes 1 1 2 1
1 Technical University of Munich, Department of Computer Science, Germany 2 National Institute of Advanced Industrial Science and Technology, AI Research Center, Japan {phillip.schneider, nektarios.machner, matthes}@tum.de [email protected]
## Abstract
Knowledge models are fundamental to dialogue systems for enabling conversational interactions, which require handling domainspecific knowledge. Ensuring effective communication in information-providing conversations entails aligning user understanding with the knowledge available to the system. However, dialogue systems often face challenges arising from semantic inconsistencies in how information is expressed in natural language compared to how it is represented within the system's internal knowledge. To address this problem, we study the potential of large language models for conversational grounding, a mechanism to bridge information gaps by establishing shared knowledge between dialogue participants. Our approach involves annotating human conversations across five knowledge domains to create a new dialogue corpus called BridgeKG . Through a series of experiments on this dataset, we empirically evaluate the capabilities of large language models in classifying grounding acts and identifying grounded information items within a knowledge graph structure. Our findings offer insights into how these models use in-context learning for conversational grounding tasks and common prediction errors, which we illustrate with examples from challenging dialogues. We discuss how the models handle knowledge graphs as a semantic layer between unstructured dialogue utterances and structured information items.
and Aizawa, 2021). Despite extensive research, challenges remain in adapting to different conversation domains, addressing semantic vocabulary mismatches, overcoming information gaps between user knowledge and the system's internal knowledge model, as well as the lack of appropriate training data (Lemon, 2022). Owing to rapid technical advances regarding large language models (LLMs), novel opportunities arise to comprehend contextual intricacies within dialogues and reconcile information expressed in natural language with that stored in machine-readable data structures.
## 1 Introduction
Conversational grounding is an integral aspect of dialogues where interlocutors share information and build up a common understanding. This mutually established knowledge serves as context for subsequent interactions. For building effective dialogue systems, the natural language processing (NLP) community has long focused on conversational grounding, which involves inferential reasoning, dynamic feedback, and repair strategies (Udagawa
Recognizing the limited research on LLM-based conversational grounding, we investigated the capabilities of LLMs on knowledge grounding tasks. This involved annotating an existing corpus containing dialogues about different domain-specific tabular datasets. In addition to labeling grounding acts, we annotated grounded knowledge items in a knowledge graph structure, a powerful representation of complex relationships between entities and their attributes. Knowledge graphs have proven valuable in various NLP tasks, such as disambiguating ambiguous utterances by providing contextual information (Hogan et al., 2021; Schneider et al., 2022). For example, in dialogue systems, knowledge graphs can help identify the correct meaning of a word with multiple senses or resolve references to specific entities, enhancing the overall understanding and coherence of conversations. We opted for the JSON-LD format due to its simplicity and acceptance as a web standard, allowing interoperability by reusing existing namespaces with shared vocabularies to model knowledge from different sources and domains.
While JSON-LD primarily uses a tree-like structure, it can represent more complex graph structures by linking nodes using identifiers like @id and @type . As a serialization format for Resource Description Framework (RDF) data, JSON-LD can be transformed into other formats, such as
N-Triples, RDF/XML, or Turtle. This flexibility allows JSON-LD to be integrated with graph databases and other RDF tools, enhancing its utility in various applications. Table 1 shows an example annotation of grounded knowledge in JSON-LD format from a conversation about nature parks.
Our contributions include (1) creating a novel dialogue corpus called BridgeKG with over 250 conversational grounding annotations across five knowledge domains, (2) conducting a range of zeroand few-shot experiments by evaluating four LLMs on two grounding tasks, and (3) summarizing common prediction errors and prompting techniques for improving model performance. To ensure the reproducibility of our experiments, we provide the BridgeKG dataset, source code, and evaluation outputs in a public GitHub repository. 1
## 2 Related Work
In regard to the literature on grounding in NLP, it is essential to first define the broadly used term. Grounding can be categorized into three main types. Conversational grounding ensures a common understanding of shared knowledge within a conversation (Traum, 1994). Perceptual grounding links language to sensory experiences of the real world like visual information (Cangelosi, 2010). Knowledge grounding incorporates external information sources to support NLP systems, such as providing factual knowledge to generative language models (Lewis et al., 2020).
Our study focuses solely on conversational grounding by employing LLMs, a topic addressed in only a few recent studies. One related work by Shaikh et al. (2024) examines whether LLM generations contain grounding acts, simulating turntaking from various conversation datasets. They found that LLMs generate language with less conversational grounding than humans, often producing text that appears to assume common ground. Both their study and ours focus on the three grounding acts: explicit grounding, implicit grounding, and clarification, as proposed by Clark and Schaefer (1989). Two other closely related studies, conducted by Jokinen et al. (2024) and Mohapatra et al. (2024), involve annotating dialogue corpora and employing language models to classify grounding acts and extract grounded knowledge items. While the former conducts preliminary experiments on two conversations with GPT-3.5-Turbo, the lat- ter presents two annotated dialogue corpora with grounding acts, grounding units, a measure of their degree of grounding, and a baseline evaluation with the open-source T5 model (Raffel et al., 2020).
Unlike the mentioned related work, we are the first to conduct a series of LLM experiments aimed at knowledge identification in information-seeking conversations utilizing an in-context knowledge graph structure for identifying referenced and grounded knowledge items in dialogues.
## 3 Method
Dataset Annotation The source dialogue corpus we reuse was collected in a study on exploratory information-seeking conversations from Schneider et al. (2023). It comprises 26 conversations about tabular datasets on real-world knowledge spanning the domains of geography, history, media, nutrition, and sports. Every conversation involved a pair where one person was the information seeker and the other was the information provider, using a textbased chatroom for communication. The information seekers were instructed to discover and gather new information about their partner's previously unknown dataset. Two researchers annotated each written dialogue with labels for grounding acts (explicit, implicit, and clarification). Explicit grounding involves a response that clearly confirms understanding or acceptance of received information (e.g., 'okay, thanks'), whereas implicit grounding moves the conversation forward without explicitly acknowledging or questioning the recently shared information (implicit acceptance). Clarification occurs when a conversation partner seeks more information about thus far presented knowledge, which does not result in grounded knowledge since mutual acceptance has not yet been reached.
Example Annotation of Grounded Knowledge
[{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/nature-parks", "url": "nature-parks.csv", "schema:description": "The table contains information about nature parks in Germany", "tableSchema": {"columns": [{"name": "name", "datatype": "string"}, {"name": "state", "datatype": "string"}, {"name": "year", "datatype": "integer"}, {"name": "area\_in\_km2", "datatype": "integer"}, {"name": "summary", "datatype": "string"}], "primaryKey": "name"}}, {"@type": "schema:Place", "name": "Barnim", "state": "Brandenburg Berlin", "year": 1999, "area\_in\_km2": 749, "summary": "The park includes the Barnim heath habitats dating back to the ice age. It lies between the glacial valleys of Eberswalde in the north and Berlin in the south, and is more than half forested. The region is shaped by many individual lakes and meltwater gullies."}]
Table 1: Example JSON-LD annotation of grounded knowledge from the BridgeKG dataset, representing the system's knowledge concerning a dialogue about nature parks. Properties are displayed in blue color.
| | Zero-Shot Prompt | Zero-Shot Prompt | Zero-Shot Prompt | Zero-Shot Prompt | Few-Shot Prompt | Few-Shot Prompt | Few-Shot Prompt | Few-Shot Prompt |
|-----------------------|--------------------|--------------------|--------------------|--------------------|-------------------|-------------------|-------------------|-------------------|
| Model | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score |
| GPT-3.5-Turbo (n=1) | 0.64 | 0.50 | 0.46 | 0.43 | 0.55 | 0.50 | 0.51 | 0.50 |
| GPT-3.5-Turbo (n=3) | 0.66 | 0.81 | 0.50 | 0.50 | 0.69 | 0.59 | 0.54 | 0.54 |
| GPT-3.5-Turbo (n=all) | 0.59 | 0.39 | 0.44 | 0.41 | 0.57 | 0.51 | 0.45 | 0.45 |
| GPT-4o (n=1) | 0.39 | 0.55 | 0.54 | 0.42 | 0.64 | 0.66 | 0.64 | 0.61 |
| GPT-4o (n=3) | 0.59 | 0.66 | 0.67 | 0.59 | 0.73 | 0.74 | 0.69 | 0.70 |
| GPT-4o (n=all) | 0.64 | 0.68 | 0.66 | 0.62 | 0.71 | 0.73 | 0.67 | 0.67 |
| Llama-3-8B (n=1) | 0.61 | 0.54 | 0.53 | 0.54 | 0.59 | 0.65 | 0.69 | 0.59 |
| Llama-3-8B (n=3) | 0.65 | 0.60 | 0.60 | 0.60 | 0.57 | 0.60 | 0.61 | 0.55 |
| Llama-3-8B (n=all) | 0.44 | 0.55 | 0.39 | 0.38 | 0.55 | 0.54 | 0.51 | 0.51 |
| Llama-3-70B (n=1) | 0.41 | 0.54 | 0.56 | 0.43 | 0.51 | 0.61 | 0.63 | 0.53 |
| Llama-3-70B (n=3) | 0.59 | 0.66 | 0.67 | 0.59 | 0.65 | 0.68 | 0.69 | 0.64 |
| Llama-3-70B (n=all) | 0.71 | 0.66 | 0.64 | 0.64 | 0.76 | 0.70 | 0.70 | 0.70 |
Table 2: Zero-shot and few-shot performance metrics for grounding act classification evaluated by macro-averaged accuracy, precision, recall, and F1-score. The variable n denotes the number of preceding input utterances. Bold values highlight the best value for each metric.
For explicit and implicit labels, the grounded knowledge items that have been shared until this point in the dialogue were annotated as a knowledge graph structure in JSON-LD format (Sporny et al., 2020). Annotation disagreements were collaboratively resolved to reach a consensus. Knowledge is incorporated into the grounding annotation only if it is a subset of the underlying tabular dataset and can be represented within the modeled internal system knowledge, which we defined using vocabulary from the namespaces Schema.org and CSVW (W3C, 2017, 2024). An example conversation illustrating labeled grounding acts and grounded knowledge items for individual dialogue utterances is provided in Table 4 in Appendix A.
Experimental Setup Based on the annotated dataset with conversational grounding labels, we conducted several experiments using four stateof-the-art LLMs: the open-source Llama-3-8BInstruct as well as Llama-3-70B-Instruct (Meta AI, 2024) from the Llama 3 model family, and the closed-source models GPT-3.5-Turbo (version: 0125) and GPT-4o (version: 2024-05-13) (OpenAI, 2022, 2024). We defined two model prompts: one for classifying grounding acts and another for identifying grounded knowledge. For the knowledge identification prompt, which tasked the LLM to predict the grounded knowledge subset in the conversation thus far, we provided both the input dialogue and the complete system knowledge (i.e., the annotated grounded knowledge for the entire conversation). All models were prompted using a chat completion format, which included a system instruction and, in the few-shot setting, three in-context examples presented as user and assistant turns. Both model prompts are provided in the Appendix in full length (Tables 5 and 6). To promote deterministic generation, we set the generation seed to 1 and the temperature parameter to 0. The maximum token limit was set to 128 for classification and 4096 for grounded knowledge identification. All generated outputs with extra text were preprocessed using a regular expression to match and extract the first occurrence of either the grounding act or JSON-LD array.
## 4 Results and Discussion
Classification of Grounding Acts Table 2 shows the performance for classifying grounding acts, using macro-averages to ensure equal class importance. Nearly all tested LLMs benefited from the added context of few-shot examples, with F1scores generally improving; however, this improvement diminishes as the number of input dialogue turns (n) increases, suggesting potential redundancy when in-context examples are already provided. The results indicate that n=3 often optimizes
Figure 1: Performance comparison of precision, recall, and F1-score by grounding act for the Llama-3-70B model with all input utterances (n=all).
Table 3: Relative frequency of issues in zero- and few-shot predictions for grounded knowledge identification.
| Issue Type | GPT-3.5-Turbo | GPT-4o | Llama-3-8B | Llama-3-70B |
|------------------------|------------------------------------------|------------------------------------------|------------------------------------------|------------------------------------------|
| | Relative Frequency: Zero-Shot / Few-Shot | Relative Frequency: Zero-Shot / Few-Shot | Relative Frequency: Zero-Shot / Few-Shot | Relative Frequency: Zero-Shot / Few-Shot |
| Invalid JSON-LD | 0.00 / 0.01 | 0.00 / 0.00 | 0.02 / 0.09 | 0.20 / 0.00 |
| Property Hallucination | 0.01 / 0.00 | 0.00 / 0.02 | 0.08 / 0.22 | 0.38 / 0.26 |
| Value Hallucination | 0.02 / 0.00 | 0.01 / 0.03 | 0.22 / 0.05 | 0.46 / 0.07 |
| Property Excess | 0.49 / 0.48 | 0.29 / 0.24 | 0.50 / 0.38 | 0.61 / 0.51 |
| Property Deficit | 0.37 / 0.22 | 0.31 / 0.09 | 0.50 / 0.36 | 0.39 / 0.20 |
| Value Excess | 0.68 / 0.63 | 0.40 / 0.31 | 0.66 / 0.32 | 0.76 / 0.47 |
| Value Deficit | 0.22 / 0.22 | 0.29 / 0.28 | 0.34 / 0.62 | 0.24 / 0.34 |
performance in both zero- and few-shot settings by balancing context retention, noise reduction, and efficient usage of tokens. While Llama-8B's performance drops from 0.54 F1-score at n=1 to 0.38 at n=all, larger LLMs like Llama-70B and GPT-4o handle longer input better, probably due to a higher parameter count and superior noise handling.
Oh et al., 2023). Knowledge identification required the LLMs to uniquely pinpoint specific knowledge items from a set of possibilities within the system knowledge model, bridging between vague conversation utterances and structured JSON-LD arrays.
Another significant finding is the competitive performance of open-source LLMs against proprietary ones: Llama-8B surpasses GPT-3.5 in the zero-shot run, and Llama-70B matches GPT-4o in the few-shot run. The breakdown of Llama-70B's performance by grounding act, illustrated in Figure 1, reveals clarification as the most challenging act to classify, consistent with our observation of the other LLMs. For instance, the models often struggled when users tried to clarify a previously introduced concept. Instead of recognizing the clarification (e.g., 'And category describes whether it is a movie, tv show, or work of literature?'), the models often misinterpreted it as introducing a new topic, falsely assuming that the previous concept is already implicitly grounded. Contrary to clarification acts, the F1-scores for explicit and implicit classification are comparable. Despite achieving the same overall F1-score, GPT-4o tends to overpredict implicit labels in contrast to the more balanced Llama-70B, as revealed by the confusion matrices in Figure 3 in Appendix A. The latter shows that GPT-4o excels at predicting explicit grounding accurately, avoiding false positives altogether, but it tends to overpredict the implicit class, particularly in cases where participants acknowledge information explicitly before asking a new question (e.g., 'Ok very interesting! What is the highest level of protein in the chart?').
Identification of Grounded Knowledge The second series of experiments aimed at identifying grounded knowledge for a suitable dialogue context, which is a significantly more complex task than classifying grounding acts (Wu et al., 2021;
Figure 2 depicts the count of JSON-LD generations accurately matching our 127 annotations with valid properties, values, or completely identical content. The open-source models notably struggle more compared to the proprietary LLMs. While both open-source Llama models produce multiple valid outputs for properties and values with fewshot prompting, they fail to generate any valid predictions in the zero-shot setting. Therefore, these model runs are not displayed in the chart. Remarkably, GPT-4o outperforms GPT-3.5 by almost double, even in the zero-shot experiment, surpassing all other models by a great margin. In the fewshot cases, every third prediction from GPT-4o is identical to our annotated groundings, totaling 42 out of 127 instances. In some cases, The GPT-4o model even succeeded in precisely matching the annotated JSON-LD in a given conversation across a number of subsequent turns.
Table 3 provides a detailed analysis of the most common prediction issues and their relative fre-
����������������������� ���������� ���������� ��������� ��������� �����
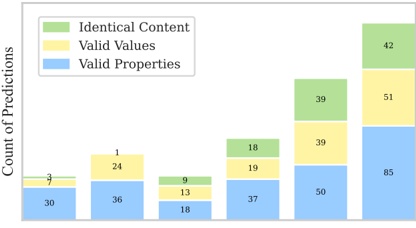
Figure 2: Count of predictions in JSON-LD format with valid properties, valid values, or identical content for evaluated models in zero- (Z) and few-shot (F) settings.
quencies for each model-prompt experiment. Examples for each issue type are listed in Table 7 in Appendix A. Open-source models generally produce more invalid JSON-LD arrays and hallucinate properties and values that are not part of the system knowledge. All tested LLMs tend to overpredict properties and values in zero-shot settings, even though these are grounded later in the conversation. Few-shot prompting can reduce excess properties and values, as well as counteract property deficits. However, in few-shot prompting, open-source models, particularly Llama-3-8B, tend to increase value deficits, becoming too hesitant to identify knowledge. This often results in empty JSON-LD arrays with generated statements such as 'The conversation does not mention any specific knowledge items from the system knowledge.'
Our findings corroborate existing benchmarks, highlighting the sophisticated reasoning abilities of state-of-the-art proprietary LLMs such as GPT-4o in highly complex tasks. A similar task complexitybased LLM performance gap is also observable in the direct comparison of the MMLU and HumanEval benchmark scores between GPT-4o and Llama-3 (Hendrycks et al., 2020; Chen et al., 2021; OpenAI, 2024). While Llama-70B performs competitively in the language-focused grounding act classification task, the superiority of GPT-4o becomes apparent in identifying knowledge when handling structured JSON-LD data and fragmented information from dialogue utterances.
In short, when designing dialogue systems augmented with LLMs to handle conversational grounding, smaller open-source models like Llama3-8B, especially fine-tuned versions, seem to be generally sufficient for basic NLP tasks such as detecting and classifying grounding-related dialogue acts. However, more complex tasks, such as identifying and integrating grounded knowledge from dialogue utterances with structured knowledge representations, require the use of more advanced and larger models like GPT-4o, which possess superior reasoning capabilities and proficiency in processing structured data formats.
## 5 Conclusion and Future Work
Our study examined LLMs for handling groundingrelated knowledge in information-sharing dialogues. We found that classifying grounding acts was feasible for both openand closed-source LLMs, with open-source LLMs performing on par compared with leading proprietary ones. However, identifying grounded knowledge proved to be a distinctly more complex task. For the latter, the proprietary LLMs had a competitive edge, and the open-source models underperformed due to their higher predisposition to generate erroneous output. The experiment results from our newly created dataset highlight common prediction issues and demonstrate how few-shot prompting can enhance model outputs, offering valuable insights to advance research on conversational grounding.
Future work should concentrate on developing LLM-based dialogue systems that handle conversational grounding through a multi-component pipeline approach for recognizing groundingspecific dialogue acts as well as grounded knowledge (Jokinen et al., 2024). In previous studies, we have shown that LLMs can augment dialogue systems by performing semantic parsing for conversational question answering over knowledge graphs (Schneider et al., 2024a) and by verbalizing retrieved semantic triples into text responses (Schneider et al., 2024b). We believe conversational grounding is essential as it links the processes of semantic parsing of dialogue utterances, knowledge identification, and response generation, aligning the user's prior knowledge with the system's available knowledge base while maintaining the relevance and coherence of conversations.
## 6 Limitations
Our study has certain limitations that should be acknowledged. First, the experiments are based on a relatively small dataset, consisting of only 26 information-seeking conversations and 669 dialogue turns collected in a controlled laboratory setting. While these conversations span five distinct domains, the findings should be interpreted with caution, as they may not generalize to larger or more diverse dialogue corpora.
Additionally, the grounded knowledge annotations in our study are represented using the JSONLDsyntax. We chose the JSON-LD format because it is widely used, and many LLMs are trained to process JSON sequences effectively. However, it is important to recognize that other encoding formats, such as Turtle, RDF/XML, and N-Triples, may produce different performance results. Further, our experiments were restricted to the opensource Llama (Meta AI, 2024) and closed-source GPT (OpenAI, 2022, 2024) model families. It is advisable for future work to explore an even bigger variety of LLMs, particularly those that are specifically trained on code and structured data like Codestral or Code Llama.
Lastly, conversational grounding in dialogue systems entails both the classification of grounding acts and the identification of grounded knowledge. While we have introduced and evaluated these tasks separately, incorporating our approach into an endto-end evaluation could offer a more holistic understanding of end-to-end performance in more realistic dialogue scenarios.
## 7 Ethical Considerations
In our experiments, we used a publicly available dialogue dataset from Schneider et al. (2023) while ensuring that no personal identifying information of the participants was processed or disclosed. The information-seeking conversations from the dataset discuss only domain-specific knowledge from publicly accessible websites, such as Wikipedia. Moreover, to ensure optimal computing efficiency, evaluations of the Llama and GPT models were conducted on cloud computing platforms, with each inference run taking less than an hour.
## Acknowledgements
We would like to thank the anonymous reviewers for their helpful suggestions. Kristiina Jokinen acknowledges the support of Project JPNP20006 commissioned by the New Energy and Industrial Technology Development Organization (NEDO), Japan.
## References
Angelo Cangelosi. 2010. Grounding language in action and perception: From cognitive agents to humanoid robots. Physics of life reviews , 7(2):139-151.
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 .
Herbert H Clark and Edward F Schaefer. 1989. Contributing to discourse. Cognitive science , 13(2):259294.
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. In International Conference on Learning Representations .
Aidan Hogan, Eva Blomqvist, Michael Cochez, Claudia D'amato, Gerard De Melo, Claudio Gutierrez, Sabrina Kirrane, José Emilio Labra Gayo, Roberto Navigli, Sebastian Neumaier, Axel-Cyrille Ngonga Ngomo, Axel Polleres, Sabbir M. Rashid, Anisa Rula, Lukas Schmelzeisen, Juan Sequeda, Steffen Staab, and Antoine Zimmermann. 2021. Knowledge graphs. ACM Comput. Surv. , 54(4).
Kristiina Jokinen, Phillip Schneider, and Taiga Mori. 2024. Towards harnessing large language models for comprehension of conversational grounding. In In 14th International Workshop on Spoken Dialogue Systems Technology (IWSDS 2024) , Sapporo, Japan.
Oliver Lemon. 2022. Conversational grounding in emergent communication-data and divergence. In Emergent Communication Workshop at ICLR 2022 .
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledgeintensive nlp tasks. In Advances in Neural Information Processing Systems , volume 33, pages 94599474. Curran Associates, Inc.
Meta AI. 2024. Introducing Meta Llama 3: The most capable openly available LLM to date. Meta AI Blog .
Biswesh Mohapatra, Seemab Hassan, Laurent Romary, and Justine Cassell. 2024. Conversational grounding: Annotation and analysis of grounding acts and grounding units. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LRECCOLING 2024) , pages 3967-3977, Torino, Italia. ELRA and ICCL.
Minsik Oh, Joosung Lee, Jiwei Li, and Guoyin Wang. 2023. PK-ICR: Persona-knowledge interactive multicontext retrieval for grounded dialogue. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages 16383-16395, Singapore. Association for Computational Linguistics.
OpenAI. 2022. ChatGPT: Optimizing language models for dialogue. OpenAI Blog .
OpenAI. 2024. Hello GPT-4o. OpenAI Blog .
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research , 21(140):1-67.
Phillip Schneider, Anum Afzal, Juraj Vladika, Daniel Braun, and Florian Matthes. 2023. Investigating conversational search behavior for domain exploration. In European Conference on Information Retrieval , pages 608-616. Springer.
Phillip Schneider, Manuel Klettner, Kristiina Jokinen, Elena Simperl, and Florian Matthes. 2024a. Evaluating large language models in semantic parsing for conversational question answering over knowledge graphs. In International Conference on Agents and Artificial Intelligence .
Phillip Schneider, Manuel Klettner, Elena Simperl, and Florian Matthes. 2024b. A comparative analysis of conversational large language models in knowledgebased text generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers) , pages 358-367, St. Julian's, Malta. Association for Computational Linguistics.
Phillip Schneider, Tim Schopf, Juraj Vladika, Mikhail Galkin, Elena Simperl, and Florian Matthes. 2022. A decade of knowledge graphs in natural language processing: A survey. In Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages 601-614, Online only. Association for Computational Linguistics.
Omar Shaikh, Kristina Gligori´ c, Ashna Khetan, Matthias Gerstgrasser, Diyi Yang, and Dan Jurafsky. 2024. Grounding gaps in language model generations. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . Association for Computational Linguistics.
Manu Sporny, Dave Longley, Gregg Kellogg, Markus Lanthaler, Pierre-Antoine Champin, and Niklas Lindström. 2020. JSON-LD 1.1. W3C Recommendation .
David Traum. 1994. A computational theory of grounding in natural language conversation. PhD thesis, Univ. Rochester .
Takuma Udagawa and Akiko Aizawa. 2021. Maintaining common ground in dynamic environments. Transactions of the Association for Computational Linguistics , 9:995-1011.
W3C. 2017. CSVW Namespace Vocabulary Terms. W3C Document .
W3C. 2024. Schema.org. Schema.org .
Zeqiu Wu, Bo-Ru Lu, Hannaneh Hajishirzi, and Mari Ostendorf. 2021. DIALKI: Knowledge identification in conversational systems through dialoguedocument contextualization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages 1852-1863, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
## A Appendix
The Appendix provides one annotated conversation example (Table 4), the model prompts in full length (Tables 5 and 6), an overview of common issue types identified in the predictions (Table 7), and two confusion matrices of the classification results of the two best-performing model inference runs (Figure 3).
| Dialogue Utterances | Dialogue Act | Grounded Knowledge |
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| S: What is your dataset about? | - | - |
| P: it contains information about 11341 historical figures, including their full name, sex, birth year, | - | - |
| popularity index (HPI). The HPI represents the degree of this person's online popularity S: Who is the most popular? | implicit | [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/historical- figures", "url": "historical-figures.csv", "schema:description": "The table contains information about historical figures", "tableSchema": {"columns": [{"name": "full_name", "datatype": "string"}, {"name": "sex", "datatype": "string"}, {"name": "birth_year", "datatype": "integer"}, {"name": "city", "datatype": "string"}, {"name": "country", "datatype": "string"}, {"name": "continent", "datatype": "string"}, {"name": "occupation", "datatype": "string"}, {"name": "historical_popularity_index", "datatype": "float"}], "prima- ryKey": "full_name"}}] |
| P: Aristotle, who is from Greece and has a largest HPI value: 31.9938. | - | - |
| S: I see, is there Socrate in the dataset? | explicit | [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/historical- figures", "url": "historical-figures.csv", "schema:description": "The table contains information about historical figures", "tableSchema": {"columns": [{"name": "full_name", "datatype": "string"}, {"name": "sex", "datatype": "string"}, {"name": "birth_year", "datatype": "integer"}, {"name": "city", "datatype": "string"}, {"name": "country", "datatype": "string"}, {"name": "continent", "datatype": "string"}, {"name": "occupation", "datatype": "string"}, {"name": "historical_popularity_index", "datatype": "float", "maxi- mum": 31.9938}], "primaryKey": "full_name"}}, {"@type": "schema:Person", "full_name": "Aristotle", "country": |
| P: Yes, Socrate is in the dataset. S: What is is popularity index? | - implicit | - [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/historical- figures", "url": "historical-figures.csv", "schema:description": "The table contains information about historical figures", "tableSchema": {"columns": [{"name": "full_name", "datatype": "string"}, {"name": "sex", "datatype": "string"}, {"name": "birth_year", "datatype": "integer"}, {"name": "city", "datatype": "string"}, {"name": "coun- try", "datatype": "string"}, {"name": "continent", "datatype": "string"}, {"name": "occupation", "datatype": "string"}, {"name": "historical_popularity_index", "datatype": "float", "maximum": 31.9938}], "primaryKey": "full_name"}}, {"@type": "schema:Person", "full_name": "Aristotle", "coun- try": "Greece", "historical_popularity_index": 31.9938}, |
| P: Historical popularity index (HPI) is metric that aggregates information on a biography's on- line popularity. It aggregates information on the age and attention received by biographies in mul- | - | {"@type": "schema:Person", "full_name": "Socrates"}] - |
a summary statistic of their global popularity.
Table 4: Example of dialogue excerpt from the history domain with annotated grounding dialogue acts and grounded knowledge in JSON-LD format. Seeker (S) and provider (P) roles are abbreviated for each turn. Utterances are taken from the dialogue logs and may contain spelling errors. Newly grounded knowledge is displayed in blue color.
Figure 3: Confusion matrices for few-shot classification results of GPT-4o with three input utterances and Llama-370B with all input utterances.
Table 5: Overview of applied zero-shot and few-shot prompts for classification.
| Grounding Act Classification Prompt |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Zero-Shot |
| SYSTEM: Predict the grounding label for the last response in the 'Input Dialogue:'. The label indicates whether the knowledge in the dialogue was accepted. Choose one of the following labels: explicit: The response confirms understanding or acceptance (e.g., 'okay', 'thanks', 'alright', 'nice') without seeking clarification. clarification: The response seeks clarification about a previous dialogue snippet. implicit: The response moves the conversation forward without explicitly confirming or seeking clarification. |
| Few-Shot |
| SYSTEM: Predict the grounding label for the last response in the 'Input Dialogue:'. The label indicates whether the knowledge in the dialogue was accepted. Choose one of the following labels: explicit: The response confirms understanding or acceptance (e.g., 'okay', 'thanks', 'alright', 'nice') without seeking clarification. clarification: The response seeks clarification about a previous dialogue snippet. implicit: The response moves the conversation forward without explicitly confirming or seeking clarification. USER: Input Dialogue: seeker: Can you give me some information about your dataset? provider: My dataset includes information on buildings of Gothic architecture. seeker: How tall is the Cologne Cathedral? ASSISTANT: Output Label: implicit |
## Grounded Knowledge Identification Prompt
## Zero-Shot
SYSTEM: Your task is to identify the knowledge items that have been grounded by the conversation partners in the 'Input Dialogue'. The items of mutually grounded knowledge must be explicitly mentioned in the dialogue. Based on the complete set of 'System Knowledge', your task is to generate the subset of knowledge items that have been grounded so far. Ensure that the output is a valid JSON-LD structure (an array of JSON objects) and only include knowledge items from the formatted 'System Knowledge'.
## Few-Shot
SYSTEM: Your task is to identify the knowledge items that have been grounded by the conversation partners in the 'Input Dialogue'. The items of mutually grounded knowledge must be explicitly mentioned in the dialogue. Based on the complete set of 'System Knowledge', your task is to generate the subset of knowledge items that have been grounded so far. Ensure that the output is a valid JSON-LD structure (an array of JSON objects) and only include knowledge items from the formatted 'System Knowledge'.
USER: System Knowledge: [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/american-presidents", "url": "american-presidents.csv", "schema:description": "The table contains information about American presidents", "tableSchema": {"columns": [{"name": "name", "datatype": "string"}, {"name": "term", "datatype": "string"}, {"name": "party", "datatype": "string"}, {"name": "election\_year", "datatype": "integer"}]}, "primaryKey": "name"}, {"@type": "schema:Person", "name": "Barack Obama", "party": "Democratic"}] Input Dialogue:
seeker: Can you give me an example entry from your dataset? provider: One of the presidents in the list is Barack Obama.
seeker: Thanks. What party does he belong to?
ASSISTANT: Output JSON-LD: [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/american-presidents", "url": "american-presidents.csv", "schema:description": "The table contains information about American presidents", "tableSchema": {"columns": [{"name": "name", "datatype": "string"}]}, "primaryKey": "name"}, {"@type": "schema:Person", "name": "Barack Obama"}]
USER: System Knowledge: [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/greek-islands", "url": "greek-islands.csv", "schema:description": "The table contains information about islands in Greece", "tableSchema": {"columns": [{"name": "island", "datatype": "string"}, {"name": "area\_in\_km2", "datatype": "integer", "minimum": 64, "maximum": 8336}, {"name": "cluster", "datatype": "string"}]}, "primaryKey": "island"}, {"@type": "schema:Place", "island": "Crete", "area\_in\_km2": 8336, "cluster": "Cretan"}, {"@type": "schema:Place", "island": "Alonnisos", "area\_in\_km2": 64, "cluster": "Sporades"}, {"@type": "schema:Place", "island": "Lesbos", "area\_in\_km2": 1633, "cluster": "North Aegean Islands"}]
Input Dialogue:
provider: My dataset contains information on Greek islands. For example, there is Crete with an area of 8336 square kilometers.
provider: That makes it the largest island in Greece.
seeker: Which one is the smallest and what is its area?
ASSISTANT: Output JSON-LD: [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/greek-islands", "url": "greek-islands.csv", "schema:description": "The table contains information about islands in Greece", "tableSchema": {"columns": [{"name": "island", "datatype": "string"}, {"name": "area\_in\_km2", "datatype": "integer", "maximum": 8336}]}, "primaryKey": "island"}, {"@type": "schema:Place", "island": "Crete", "area\_in\_km2": 8336}]
USER: System Knowledge: [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/android-smartphones", "url": "android-smartphones.csv", "schema:description": "The table contains information about Android smartphones", "tableSchema": {"columns": [{"name": "model", "datatype": "string"}, {"name": "developer", "datatype": "string"}, {"name": "release\_year", "datatype": "integer", "minimum": 2008, "maximum": 2024}, {"name": "android\_version", "datatype": "string"}]}, "primaryKey": "model"}, {"@type": "schema:Product", "model": "HTC Dream", "developer:": "HTC", "release\_year": "2008"}, {"@type": "schema:Product", "model": "LG Wing", "developer:": "LG", "release\_year": "2020", "android\_version": "Android 10"}, {"@type": "schema:Product", "release\_year": "2024"}]
Input Dialogue:
provider: I can provide technical information about Android smartphones.
provider: One column contains data about the model and another specifies its release year.
seeker: I see, good to know.
ASSISTANT: Output JSON-LD: [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/android-smartphones", "url": "android-smartphones.csv", "schema:description": "The table contains information about Android smartphones", "tableSchema": {"columns": [{"name": "model", "datatype": "string"}, {"name": "release\_year", "datatype": "integer"}]}, "primaryKey": "model"}]
Table 7: Overview of six identified issue types with examples from generated model predictions (PRED). The manifestation of issues are highlighted in red color.
| Issue Type | Definition | Example |
|------------------------|------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Invalid JSON-LD | Prediction is overall not a valid JSON-LD structure. | PRED: [{"@type": "schema:CreativeWork", "cat- egory": ["films", "series", "literature"]}] → JSON syntax elements are missing. |
| Property Hallucination | Predicted property is not part of system knowledge. | PRED: {"@type": "schema:Place", "name": "English Garden", "state": "Bavaria", "city": "Munich", "summary": "The English Garden is a large public park in Munich, Bavaria. It is one of the world's largest ur- ban public parks, larger than New York's Central Park. The park is known for its beer gardens, streams, lakes, and Japanese teahouse."} → English Garden was mentioned in the dialogue but is not part of the system knowledge. The "city" property does not exist. |
| Value Hallucination | Predicted value is not part of system knowledge. | PRED: [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/time-travel-media", "url": "time-travel-media.csv", "schema:description": "The table con- tains information about time travel media", "tableSchema": {"columns": [{"name": "year", "datatype": "string"}, {"name": "title", "datatype": "string"}, {"name": "author", "datatype": "string"}, {"name": "short text description", "datatype": "string"}, {"name": "category", "datatype": "string"}]}, "primaryKey": ["year", "title", "category"]}] → System knowledge contains the columns "creators" and "description" but "author" and "short text description" are hallucinated. |
| Property Excess | Predicted property is part of system knowledge but grounded too early. | PRED: [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/football-records", "url": "football-records.csv", "schema:description": "The table con- tains information about football records", "tableSchema": {"columns": [{"name": "record", "datatype": "string"}]}, "primaryKey": "record"}] → Properties should have been grounded at a later stage. |
| Property Deficit | Property from system knowledge was not identi- fied. | PRED: [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/nature-parks", "url": "nature-parks.csv", "schema:description": "The table con- tains information about nature parks in Germany", "tableSchema": {"columns": [{"name": "name", "datatype": "string"}, {"name": "state", "datatype": "string"}, {"name": "year", "datatype": "inte- ger"}, {"name": "area_in_km2", "datatype": "integer"}, {"name": "summary", "datatype": "string"}], "primaryKey": "name"}}, {"@type": "schema:Place", "name": "Altmühl Valley Nature Park"}] → Highlighted properties were not grounded. |
| Value Excess | Predicted value is part of system knowledge but grounded too early. | PRED: [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/nature-parks", "url": "nature-parks.csv", "schema:description": "The table con- tains information about nature parks in Germany", "tableSchema": {"columns": [{"name": "name", "datatype": "string"}, {"name": "state", "datatype": "string"}, {"name": "year", "datatype": "inte- ger"}, {"name": "area_in_km2", "datatype": "integer"}, {"name": "summary", "datatype": "string"}], "primaryKey": "name"}}] |
| Value Deficit | Value from system knowl- edge was not identified. | PRED: [{"@context": ["http://www.w3.org/ns/csvw", {"schema": "http://schema.org"}], "@id": "http://example.org/historical-figures", "url": "historical-figures.csv", "schema:description": "The ta- ble contains information about historical figures", "tableSchema": {"columns": [{"name": "full_name", "datatype": "string"}, {"name": "birth_year", "datatype": "integer", "minimum": -3500, "maximum": 2005}], "primaryKey": "full_name"}}, {"@type": "schema:Person", "birth_year": -3500}, {"@type": "schema:Person", "birth_year": 2005}] → Highlighted values were not grounded. | | null | [
"Phillip Schneider",
"Nektarios Machner",
"Kristiina Jokinen",
"Florian Matthes"
] | 2024-08-02T08:07:15+00:00 | 2024-08-11T17:51:21+00:00 | [
"cs.CL"
] | Bridging Information Gaps in Dialogues With Grounded Exchanges Using Knowledge Graphs | Knowledge models are fundamental to dialogue systems for enabling
conversational interactions, which require handling domain-specific knowledge.
Ensuring effective communication in information-providing conversations entails
aligning user understanding with the knowledge available to the system.
However, dialogue systems often face challenges arising from semantic
inconsistencies in how information is expressed in natural language compared to
how it is represented within the system's internal knowledge. To address this
problem, we study the potential of large language models for conversational
grounding, a mechanism to bridge information gaps by establishing shared
knowledge between dialogue participants. Our approach involves annotating human
conversations across five knowledge domains to create a new dialogue corpus
called BridgeKG. Through a series of experiments on this dataset, we
empirically evaluate the capabilities of large language models in classifying
grounding acts and identifying grounded information items within a knowledge
graph structure. Our findings offer insights into how these models use
in-context learning for conversational grounding tasks and common prediction
errors, which we illustrate with examples from challenging dialogues. We
discuss how the models handle knowledge graphs as a semantic layer between
unstructured dialogue utterances and structured information items. |
2408.01089v1 | ## Prototypical Partial Optimal Transport for Universal Domain Adaptation
Yucheng Yang , Xiang Gu , Jian Sun * * †
School of Mathematics and Statistics, Xi'an Jiaotong University, Xi'an, China [email protected], { xianggu, jiansun } @xjtu.edu.cn
## Abstract
Universal domain adaptation (UniDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain without requiring the same label sets of both domains. The existence of domain and category shift makes the task challenging and requires us to distinguish 'known' samples ( . i e ., samples whose labels exist in both domains) and 'unknown' samples ( . ., i e samples whose labels exist in only one domain) in both domains before reducing the domain gap. In this paper, we consider the problem from the point of view of distribution matching which we only need to align two distributions partially. A novel approach, dubbed mini-batch Prototypical Partial Optimal Transport (m-PPOT), is proposed to conduct partial distribution alignment for UniDA. In training phase, besides minimizing mPPOT, we also leverage the transport plan of m-PPOT to reweight source prototypes and target samples, and design reweighted entropy loss and reweighted cross-entropy loss to distinguish 'known' and 'unknown' samples. Experiments on four benchmarks show that our method outperforms the previous state-of-the-art UniDA methods.
tation (PDA) (Cao et al. 2018a) assumes that target class set is a subset of source class set, i e . ., C t ⊆ C s . Open-set domain adaptation (OSDA) (Saito et al. 2018) exploits the situation where source class set is a subset of target class set C s ⊆ C t . Universal domain adaptation (UniDA) (You et al. 2019) is a more general setting that both source and target domains possibly have common and private classes. The setting of UniDA includes PDA, OSDA, and a mixture of PDA and OSDA, i e . ., open-partial DA (OPDA) (Panareda Busto and Gall 2017), in which both source and target domains have private classes. This paper focuses on the general UniDA setting. The goal of UniDA is to classify target domain common class samples and detect target-private class samples, meanwhile reducing the negative transfer possibly caused by source private classes. To reduce the domain gap in UniDA, we may use distribution alignment techniques as in UDA methods (Courty et al. 2017; Ganin and Lempitsky 2015), to align the distributions of two domains. However, matching all data of two domains may lead to the mismatch of the common class data of one domain to the private class data in the other domain, and cause negative transfer.
## 1 Introduction
Deep Learning has achieved significant progress in image recognition (Krizhevsky, Sutskever, and Hinton 2012; Simonyan and Zisserman 2014). However, deep learning based methods heavily rely on in-domain labeled data for training, to be generalized to target domain data. Considering that collecting annotated data for every possible domain is labour-intensive and time-consuming, a feasible solution is unsupervised domain adaptation (UDA) (Ben-David et al. 2010; Ganin and Lempitsky 2015; Long et al. 2018), which transfers the knowledge from labeled source domain to unlabeled target domain by alleviating distribution discrepancy between them. The most common setting in UDA is closedset DA which assumes the source class set C s is identical to the target class set C t . This may be impractical in real-world applications, because it is difficult to ensure that the target dataset always has the same classes as the source dataset.
To tackle this problem, some works consider more general domain adaptation tasks. For example, partial domain adap-
* These authors contributed equally.
† Corresponding Author.
Copyright © 2023, Association for the Advancement of Artificial Intelligence (www.aaai.org). All rights reserved.
In this work, we propose a novel Prototypical Partial Optimal Transport (PPOT) approach to tackle UniDA. Specifically, we model distribution alignment in UniDA as a partial optimal transport (POT) problem, to align a fraction of data (mainly from common classes), between two domains using POT. We design a prototype-based POT, in which the source data are represented as prototypes in POT formulation, which is further formulated as a mini-batch-based version, dubbed m-PPOT. We prove that POT can be bounded by m-PPOT and the distances between source samples and their corresponding prototypes, inspiring us to design a deep learning model for UniDA by using m-PPOT as one training loss. Meanwhile, the transport plan of m-PPOT can be regarded as a matching matrix, enabling us to utilize the row sum and column sum of the transport plan to reweight the source prototypes and target samples for distinguishing 'known' and 'unknown' samples. Based on the transport plan of m-PPOT, we further design reweighted cross-entropy loss on source labeled data and reweighted entropy loss on target data to learn a transferable recognition model.
In experiments, we evaluate our method on four UniDA benchmarks. Experimental results show that our method performs favorably compared with the state-of-the-art methods for UniDA. The ablation study validates the effectiveness of individual components proposed in our method.
## 2 Related Work
## 2.1 Domain Adaptation
Unsupervised domain adaptation aims to reduce the gap between source and target domains. Previous works (Ganin and Lempitsky 2015; Long et al. 2015, 2018) mainly focus on distribution alignment to mitigate domain gaps. The theoretical analysis in (Ben-David et al. 2010) shows that minimizing the discrepancy between source and target distributions may reduce the target prediction error. Previous works often minimize distribution discrepancy between two domains by adversarial learning (Ganin and Lempitsky 2015; Long et al. 2018; Zhang et al. 2019) and moment matching (Long et al. 2015; Sun and Saenko 2016; Pan et al. 2019). Partial DA (Cao et al. 2018b) tackles the scenario that only the source domain contains private classes. The methods in (Cao et al. 2018a; Zhang et al. 2018; Gu et al. 2021) are mainly based on reweighting source data for reducing negative transfer caused by source private class samples. Openset DA (Saito et al. 2018) assumes that the label set of the source domain is a subset of that of the target domain. (Saito et al. 2018; Liu et al. 2019; Bucci, Loghmani, and Tommasi 2020) propose diverse methods to classify 'known' samples meanwhile rejecting 'unknown' samples.
## 2.2 Universal Domain Adaptation
Universal DA does not have any prior knowledge on the label space of two domains, which means that both source and target domains may or may not have private classes. UAN (You et al. 2019) computes the transferability of samples by entropy and domain similarity to separate 'known' and 'unknown' samples. CMU (Fu et al. 2020) improves UAN to measure transferability by a mixture of entropy, confidence, and consistency from ensemble model. DANCE (Saito et al. 2020) designs an entropy-based method by increasing the confidence of common class samples while decreasing it for private class samples to better distinguish known and unknown samples. DCC (Li et al. 2021) tries to exploit the domain consensus knowledge to discover matched clusters for separating common classes in cluster-level. OVANet (Saito and Saenko 2021) trains a 'one-vs-all' discriminator for each class to recognize private class samples. GATE (Chen et al. 2022) explores the intrinsic geometrical relationship between the two domains and designs a universal incremental classifier to separate 'unknown' samples. Different from the above methods, we model the UniDA as a partial distribution alignment problem and propose a novel m-PPOT model to solve it.
## 2.3 Optimal Transport
Optimal transport (OT) (Villani 2009; Peyr´ e, Cuturi et al. 2019) is a mathematical tool for transporting/matching distributions. OT has been applied to diverse tasks such as generative adversarial training (Arjovsky, Chintala, and Bottou 2017), clustering (Ho et al. 2017), domain adaptation (Courty et al. 2017), object detection (Ge et al. 2021), etc.
The partial OT (Caffarelli and McCann 2010; Figalli 2010) is a special OT problem that only transports a portion of the mass. To reduce computational cost of OT, the Sinkhorn OT (Cuturi 2013) can be efficiently solved by the Sinkhorn algorithm, and is further extended to partial OT in (Benamou et al. 2015). In (Flamary et al. 2016; Courty et al. 2017; Damodaran et al. 2018), OT was applied to domain adaptation to align distributions of source and target domains in input space or feature space. They use OT in mini-batch to reduce computational overhead, however, suffering from sampling bias that the mini-batch data partially reflect the original data distribution. (Fatras et al. 2021; Nguyen et al. 2022) replace mini-batch OT with more robust OT models, such as unbalanced mini-batch OT and partial mini-batch OT, and achieve better performance. (Xu et al. 2021) designs joint partial optimal transport which only transports a fraction of the mass for avoiding negative transfer, and extends the task into open-set DA.
In this work, we consider the UniDA task. We propose a novel mini-batch based prototypical POT model, which partially aligns the source prototypes and target features to solve the problem of UniDA. Experiments show that our method achieves state-of-the-art results for UniDA.
## 3 Preliminaries on Optimal Transport
We consider two sets of data points, { x s i } m i =1 and { x t j } n j =1 , of which the empirical distributions are denoted as µ = ∑ m i =1 µ δ i x s i and ν = ∑ n j =1 ν δ j x t j respectively, where ∑ m i =1 µ i = 1 , ∑ n j =1 ν j = 1 and δ x is the Dirac function at position x . With a slight abuse of notations, we denote µ = ( µ , µ 1 2 , · · · , µ m ) ⊤ , ν = ( ν , ν 1 2 , · · · , ν n ) ⊤ and define a cost matrix as C ∈ R m n × , C ij = ( c x , x s i t j ) .
Kantorovich problem. The Kantorovich problem (Kantorovitch 1958) aims to derive a transport plan from µ to ν , modeled as the following linear programming problem:
$$\mathfrak { l } _ { \mathfrak { e } } \quad & \text$$
where ⟨· , ·⟩ F denotes the Frobenius inner product.
Mini-batch OT is designed to reduce computational cost and make OT more suitable for deep learning. We denote the collection of empirical distributions of b random samples in { x s i } m i =1 (resp. { x t j } n j =1 ) as P b ( µ ) (resp. P b ( ν ) ), where b is the batch size, and k is the number of mini-batches. The mini-batch OT is defined as
$$\mathbf m \text{-OT} _ { k } ( \mu, \nu ) =$$
where A i ∈ P b ( µ ) , B i ∈ P b ( ν ) for any i = 1 2 , , ..., k .
Partial OT aims to transport only α mass (0 ⩽ α ⩽ min( ∥ µ ∥ 1 , ∥ ν ∥ 1 )) between µ and ν with the lowest cost. The partial OT is defined as
$$\text{POT} ^ { \alpha } ( \mu, \nu ) \stackrel {$$
$$\begin{array} {$$
Figure 1: Illustration of our model. Source and target data share the same feature extractor that embeds data in feature space. PPOT is to match target features and source prototypes which are updated by the source features, and the row/column sum of transport plan is applied for reweighting. We design reweighted entropy loss to align common class features of two domains, while pushing away the unknown features.
## 4 Method
In this section, we model UniDA as a partial distribution alignment problem. To partially align source and target distributions, the mini-batch prototypical partial optimal transport (m-PPOT) is proposed. The m-PPOT focuses on the discrete partial OT problem between source prototypes and target samples for mini-batch. Based on m-PPOT, we design a novel model for UniDA. We also use contrastive pre-training to have a better initialization of network parameters.
In UniDA, we are given labeled source data D s = { x , y s i i } m i =1 and unlabeled target data D t = { x t j } n j =1 . UniDA aims to label the target sample with a label from source class set C s or discriminate it as an 'unknown' sample. We denote the number of source domain classes as L = | C s | . Our deep recognition model consists of two modules, including a feature extractor f mapping input x into feature z , and an L -way classification head h . The source and target empirical distributions in feature space are denoted as ¯ p = ∑ m i =1 p δ i f ( x s i ) and ¯ q = ∑ n j =1 q δ j f ( x t j ) respectively, where ∑ m i =1 p i = 1 , ∑ n j =1 q j = 1 . With a slight abuse of notations, we denote the vector of data mass as ¯ p = ( p , p 1 2 , ..., p m ) ⊤ and ¯ q = ( q 1 , q 2 , ..., q n ) ⊤ and we set p i = 1 m , q j = 1 n for any i, j in this paper. Furthermore, the element of cost matrix C is defined as C ij = d f ( ( x s i ) , f ( x t j )) , where d is the L 2 -distance.
## 4.1 Modeling UniDA as Partial OT
(Ben-David et al. 2006, 2010) presented theoretical analysis on domain adaptation, emphasizing the importance of minimizing distribution discrepancy. However, it can not be simply extended to UniDA because the source/target data may belong to source/target private classes in UniDA setting. Directly aligning source distribution ¯ p and target distribution ¯ q will lead to data mismatch due to the existence of 'unknown' samples in both domains. For UniDA task, we first decompose ¯ ¯ p q , as
$$\bar { p } = ( 1 - \beta ) p _ { p } + \beta p _$$
where p p (resp. q p ) denotes distribution of source (resp. target) private class data in feature space, p c and q c are denoted as source and target common class data distributions, α and β are the ratio of common class samples in the source and target domain respectively. Our goal is to minimize the discrepancy between p c and q c , formulated as an OT problem:
$$\min _ { f, \pi } \langle \pi, \bar { C } \rangle _ { F } = \min _ { f } \text{OT} ( p _ { c }, q _ { c } ), \quad \ \ ( 4 )$$
where ¯ C ∈ R | p c |×| q c | is a submatrix of C , corresponding to the common class samples.
Obviously, we can not directly get these two distributions. Therefore, we consider to find an approximation of Eqn. (4). Following the assumption in (You et al. 2019) that q c is closer to p c than q p , meaning that the cost of transport between two domains' common class samples is generally less than the cost between two private class samples of these two domains or the private and common class samples of them. Note that partial OT only transports a fraction of the mass having lowest cost to transport. With the above assumption, the partial transport between two domains will prefer to transfer the common class samples of them. Therefore, we approximately solve Eqn. (4) by optimizing
$$\min _ { f } \Pi ^ { \alpha } ( \frac { \alpha } { \beta } \bar { p }, \bar { q } )$$
where coefficient ( α/β ) is to ensure that the mass of common class samples in ¯ p and ¯ q equals. The superscript α denotes the total mass to transport. For convenience of presentation, ( α/β ) · ¯ p and ¯ q are denoted as p and q respectively.
## 4.2 Prototypical Partial Optimal Transport
We have turned the distribution alignment between p c and q c into a partial OT problem in Eqn. (5). The remaining challenge is to embed partial OT into a deep learning framework. In this paper, we design a mini-batch based prototypical partial optimal transport problem for UniDA. We first define the Prototypical Partial Optimal Transport (PPOT).
Definition 1. (Prototypical Partial Optimal Transport) Let { c i } L i =1 be the set of source domain prototypes, defined as
$$c _ { i } = \sum _ { j \colon y _ { j } = i } \frac { \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot } { f ( x _ { j } ^ { s } ) } \frac { \cdot \cdot \cdot \cdot \cdot \cdot } { \sum _ { l = 1 } ^ { m } \mathbf 1 ( y _ { l } = i ) }.$$
The element of cost matrix C ij is defined as d c , f ( i ( x t j )) and the PPOT transportation cost between p and q is defined as
$$\text{PPOT} ^ { \alpha } ( p, q ) \stackrel { \triangle } { = } \text{POT} ^ { \alpha } ( c, q ) = \min _ { \pi \in \Pi ^ { \alpha } ( c, q ) } \langle \pi, C \rangle _ { F }, \ \ ( 6 ) \quad \text{but} \\ \text{sep}$$
where c = ∑ L i =1 r δ i c i is the empirical distribution of source domain prototypes, and r i = ∑ j y : j = i p j .
PPOT is suitable for the DA task because, first, it fits the mini-batch based deep learning implementation in which all of the prototypes, instead of batch of source samples, are regarded as source measures in POT. This change could reduce the mismatch caused by the lack of full coverage of source samples in a batch, and second, it requires less computational resources than original POT.
Mini-batch based PPOT. We further extend the PPOT to the mini-batch version m-PPOT, here we assume batch size b satisfy b | n and set k = n/b . Let B i be the i -th index set of b random target samples and their corresponding empirical distribution in feature space is denoted as q B i . We define B ≜ {B } i k i =1 as a partition if they satisfy:
- · B i ⋂ B j = ∅ : ∀ 0 ⩽ i < j ⩽ k
$$\bullet \bigcup _ { i = 1 } ^ { k } \mathcal { B } _ { i } = \{ 1, 2, \dots, n \} \\ \dots \quad \dots \quad \dots \quad \dots \quad.$$
and the m-PPOT is defined as
$$\mathfrak { m } { - } \text{PPOT} _ { \mathcal { B } } ^ { \alpha } ( p, q ) \stackrel { \triangle } { = } \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \text{POT} ^ { \alpha } ( c, q _ { \mathcal { B } _ { i } } ), \ \mathcal { B } \in \Gamma \quad ( 7 ) \quad \stackrel { \text{be} \, } { \text{as} \, i } \\ \text{firs}$$
where Γ is the set of all partitions of { 1 2 , , ..., n } , i e . ., the index set of target data. Note that these assumptions are easily satisfied by the dataloader module in pytorch. Furthermore, we denote the optimal transportation in i -th batch as π α i . To show that m-PPOT is closely related to PPOT, we give the following proposition 1.
Proposition 1. We extend π α i to a L × n matrix Π α i that pad zero entries to the column whose index does not belong to B i , then we have
$$\frac { 1 } { k } \sum _ { i = 1 } ^ { k } \Pi _ { i } ^ { \alpha } \in \Pi ^ { \alpha } ( c, q )$$
and
$$\text{PPOT} ^ { \alpha } ( p, q ) \leqslant \mathfrak { m } { \text{-PPOT} } _ { \mathcal { B } } ^ { \alpha } ( p. q ). \quad \text{ \quad \ \ } ( 8 )$$
Proposition 1 implies that m-PPOT α B ( p q , ) is an upper bound for PPOT α ( p q , ) . The following theorem shows that POT is bounded by the sum of m-PPOT and the distances of source samples to their corresponding prototypes.
Theorem 1. Considering two distributions p and q , the distance between f ( x s i ) and corresponding prototype c y i is denoted as d i ≜ d f ( ( x s i ) , c y i ) . The row sum of the optimal transport plan of PPOT α ( p q , ) is denoted as w = ( w , w , ..., w 1 2 L ) ⊤ , r i = ∑ j y : j = i p j . Then we have
$$\prod _ { \substack { \text{ POT} ^ { \alpha } ( p, q ) \leqslant \sum _ { i = 1 } ^ { m } \frac { m } { r _ { y _ { i } } } p _ { i } d _ { i } + \text{m-PPOT} ^ { \alpha } _ { \mathcal { B } } ( p, q ). \quad ( 9 ) \quad \text{$\omega$} } } \text{(the}$$
The proofs of theorem 1 and proposition 1 are included in Appendix.
## 4.3 UniDA based on m-PPOT
Our motivation is to minimize discrepancy between distributions of source and target common class data, meanwhile separating 'known' and 'unknown' data in both domains in training. We design the following losses for training.
m-PPOT loss. Based on theorem 1, to minimize the discrepancy between p c and q c , we first design the m-PPOT loss to minimize the second term in the bound of theorem 1. We introduce the m-PPOT α B ( p q , ) as a loss:
$$\mathcal { L } _ { o t } = \mathbb { E } _ { \mathcal { B } \in \Gamma } \tilde { ( m \text{-PPOT} ^ { \alpha } _ { \mathcal { B } } ( p, q ) ) } \,, \quad \quad ( 1 0 )$$
where E denotes the expectation over all target domain data index partitions in Γ . Using the mini-batch based optimization method, this term can be approximated by the partial OT problem POT α ( c q , B i ) over each mini-batch, according to Eqn. (7). The set of prototypes c is updated by exponential moving average as in (Xie et al. 2018). We use the entropy regularized POT algorithm proposed by (Benamou et al. 2015) to solve POT on mini-batch.
Reweighted entropy loss. We further design entropybased loss on target domain data to increase the prediction certainty. The solution π ∗ to the m-PPOT α B ( p q , ) is a matrix measuring the matching between source prototypes and target features. Since the more easily a prototype (feature) can be transported, the more likely it belongs to a common class ('known' sample), we leverage the row/column sum of π ∗ as indicator to identify unknown samples. Specifically, we first get the column sum of π ∗ and multiply a constant n/α to make w t ∈ R n satisfy ∥ w t ∥ 1 = n . A reweighted entropy loss is formulated as
$$\mathcal { I }, \quad \mathcal { L } _ { p e } = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { L } w _ { i } ^ { t } p _ { i j } \log ( p _ { i j } ), w _ { i } ^ { t } = \frac { n } { \alpha } \sum _ { j = 1 } ^ { L } \pi _ { i j } ^ { * }, \quad ( 1 1 )$$
where p ij ≜ σ h ( ◦ f ( x t i )) j . We take this loss to increase the confidence of prediction for those target samples seen as 'known' samples.
Furthermore, we follow (Saito et al. 2020; Saito and Saenko 2021) to suppress the model to generate overconfident predictions for target 'unknown' samples by loss
$$\mathcal { L } _ { n e } = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { L } w _ { i } ^ { u } p _ { i j } \log ( p _ { i j } ), w _ { i } ^ { u } = [ 1 - w _ { i } ^ { t } ] _ { + }, \ \ ( 1 2 )$$
where w u i depends on w t i , and higher w u i for a sample means higher confidence to be an 'unknown' sample. Therefore, we use L ne to reduce the confidence of those samples which are likely to be 'unknown' samples.
Reweighted cross-entropy loss. This loss is the classification loss defined in the source domain, based on the crossentropy using labels of source domain data. Different to standard classification loss, we use the column sum of π ∗ to compute weights w s ∈ R L for measuring the confidence of the 'known' source domain prototypes. Then we design the reweighted cross-entropy loss
$$\mathcal { L } _ { r c e } = - \sum _ { i = 1 } ^ { m } \sum _ { j = 1 } ^ { L } w _ { j } ^ { s } \mathbf 1 ( y _ { i } = j ) \log ( \sigma ( h \circ f ( x _ { i } ^ { s } ) ) _ { j } ) \quad ( 1 3 )$$
where w s j = L α ∑ n i =1 π ∗ ij is the weight of j -th source prototype representing j -th class center. The weights satisfy ∑ L j =1 w s j = L and each of them represents the possibility that each category belongs to a common class. (Papyan, Han, and Donoho 2020) shows that the cross-entropy based loss could minimize the distance of features to class prototype. This implies that the reweighted cross-entropy loss approximately minimizes the first term in bound of theorem 1, in which we use the row sum w s of m-PPOT to approximate the row sum w of PPOT, and use the class-balanced sampling in implementation to enforce that r , j ∀ j, are equal.
Training loss and details. Our model is jointly optimized with the above loss terms, and the total training loss is
$$\mathcal { L } = \mathcal { L } _ { r c e } + \mathcal { L } _ { e n t } + \eta _ { 1 } \mathcal { L } _ { o t }, \text{ \quad \ \ } ( 1 4 )$$
where L ent = η 2 L pe -η 3 L ne . In implementation, we set η 1 = 5 , η 2 = 0 01 . , and η 3 = 2 for all datasets. The training process of our method is shown in Fig. 1. In the beginning, we map data in both domains into feature space by the feature extractor. Source prototypes are updated by source features in every batch and then we compute the mPPOT between the empirical distributions of source prototypes and target samples, which we also leverage the row sum and column sum of corresponding transport plan to reweight in the losses. L ot aims to reduce the gap between the distribution of 'known' samples in both domains, meanwhile L ent enforces the 'known' samples to have higher prediction confidence by decreasing their entropy, and the 'unknown' samples to have lower prediction confidence by increasing the entropy, in the target domain. Since the classifiers are learned over the source domain data, this may align the 'known' target domain data to the source domain data distribution, while pushing the 'unknown' target domain data away from the source domain data distribution.
## Parameter initialization by contrastive pre-training.
Motivated by (Shen et al. 2022), we use contrastive learning to pre-train our feature extractor. Specifically, we send both source and target unlabeled data into our feature extractor and use the contrastive learning method (MocoV2 (Chen et al. 2020)) to pre-train our feature extractor, then fine-tune the entire model on labeled source data, and take these parameters as our model's initial parameters. We empirically find that contrastive pre-training also works in UniDA setting in our experiments.
## 4.4 Hyper-parameters
We notice that α and β are nearly impossible to calculate precisely in practice, so we propose a method to compute them approximately. We denote two scalars as τ 1 and τ 2 , where τ 1 ∈ (0 1] , , τ 2 > 0 . To simplify the notation, we use s x ( ) = max σ h ( ◦ f ( x )) to denote the prediction confidence of x . We define α and β as
$$\alpha = \sum _ { j = 1 } ^ { n } \frac { 1 ( s ( x _ { j } ^ { t } ) \geqslant \tau _ { 1 } ) } { n }, \beta = \sum _ { i = 1 } ^ { L } \frac { 1 ( w _ { i } ^ { s } \geqslant \tau _ { 2 } ) } { L }. \quad ( 1 5 ) \quad \text{$last$} \quad \text{$\dim$}$$
The motivation is that we use the proportion of highconfidence samples to estimate the ratio of 'known' samples in the target domain, and similarly use the proportion of categories with high weights to approximate the ratio of common classes in the source domain.
In experiments, we set τ 1 = 0 9 . and τ 2 = 1 . In the i -th iteration of training phase, we first calculate α i by Eqn. (15), and update α by exponential moving average:
$$\alpha ^ { i } \leftarrow \lambda _ { 1 } \alpha ^ { i } + ( 1 - \lambda _ { 1 } ) \alpha ^ { i - 1 }.$$
Then we use α i as transport ratio and α /β i i -1 as coefficient of Eqn. (5) to compute L ot and its by-product w s . After that we compute β i by Eqn. (15) and update it as same as α i :
$$\beta ^ { i } \leftarrow \lambda _ { 2 } \beta ^ { i } + ( 1 - \lambda _ { 2 } ) \beta ^ { i - 1 },$$
where λ , λ 1 2 ∈ [0 , 1) are set to 0.001 in our experiments.
Furthermore, to reduce the possible mistakes that identify a 'known' sample as 'unknown' sample, we retain only a fraction of { w u i } n i =1 that have larger values, and set the others as 0. The fraction is set to 25% in all tasks.
## 5 Experiment
We evaluate our method on UniDA benchmarks. We solve three settings of UniDA, including OPDA, OSDA, and PDA but without using prior knowledge about the mismatch of source and target domain class label sets.
Datasets. Office-31 (Saenko et al. 2010) includes 4652 images in 31 categories from 3 domains: Amazon ( A ), DSLR ( D ), and Webcam ( W Office-Home ). (Venkateswara et al. 2017) consists of 15500 images in 65 categories, and it contains 4 domains: Artistic images ( A ), Clip-Art images ( C ), Product images ( P ), and Real-World images ( R ). VisDA (Peng et al. 2017) is a larger dataset which consists of 12 classes, including 150,000 synthetic images ( S ) and 50,000 images from real world ( R ). DomainNet (Peng et al. 2019) is one of the most challenging datasets in DA task with about 0.6 million images, which consists of 6 domains sharing 345 categories. We follow (Fu et al. 2020) to use 3 domains: Painting ( P ), Real ( R ), and Sketch ( S ). Following (Saito and Saenko 2021), we show the number of common classes, source private classes, and target private classes in brackets in the header of each result of tables.
Evaluation. In PDA tasks, we compute the accuracy for all target samples. In OSDA and OPDA settings, the target private class samples should be classified as a single category named 'unknown'. The samples with confidence less than threshold ξ are identified as 'unknown', where ξ is set to 0.75 in all experiments. Following (Fu et al. 2020), we report the H-score metric for OSDA and OPDA which is the harmonic mean of the average accuracy on common and private class samples.
Implementation. We implement our method using Pytorch (Paszke et al. 2019) on a single Nvidia RTX A6000 GPU. Following previous works (Saito and Saenko 2021; Chen et al. 2022), we use ResNet50 (He et al. 2016) without last fully-connected layer as our feature extractor. A 256dimensional bottleneck layer and prediction head h is successively added after the feature extractor. We use MocoV2
Table 1: H-score (%) comparison on Office-31, Office-Home, VisDA and DomainNet for OPDA. Note that we only report the average H-score over all tasks on Office-31 on Office-Home, and the results for different tasks are in Appendix.
| Method | Office-31 | Office-Home | VisDA | DomainNet (150/50/145) | DomainNet (150/50/145) | DomainNet (150/50/145) | DomainNet (150/50/145) | DomainNet (150/50/145) | DomainNet (150/50/145) | DomainNet (150/50/145) |
|----------|-------------|---------------|---------|--------------------------|--------------------------|--------------------------|--------------------------|--------------------------|--------------------------|--------------------------|
| Method | (10/10/11) | (10/5/50) | (6/3/3) | P → R | P → S | R → P | R → S | S → P | S → R | Avg |
| UAN | 63.5 | 56.6 | 30.5 | 41.9 | 39.1 | 43.6 | 38.7 | 39.0 | 43.7 | 41.0 |
| CMU | 73.1 | 61.6 | 34.6 | 50.8 | 45.1 | 52.2 | 45.6 | 44.8 | 51.0 | 48.3 |
| DANCE | 82.3 | 63.9 | 42.8 | 55.7 | 47.0 | 51.1 | 46.4 | 47.9 | 55.7 | 50.6 |
| DCC | 80.2 | 70.2 | 43.0 | 56.9 | 43.7 | 50.3 | 43.3 | 44.9 | 56.2 | 49.2 |
| OVANet | 86.5 | 71.8 | 53.1 | 56.0 | 47.1 | 51.7 | 44.9 | 47.4 | 57.2 | 50.7 |
| GATE | 87.6 | 75.6 | 56.4 | 57.4 | 48.7 | 52.8 | 47.6 | 49.5 | 56.3 | 52.1 |
| PPOT | 90.4 | 77.1 | 73.8 | 67.8 | 50.2 | 60.1 | 48.9 | 52.8 | 65.4 | 57.5 |
Table 2: Comparison of H-score (%) on Office-Home and VisDA for PDA setting. 'P' and 'U' denote PDA and UniDA methods, respectively with and without assuming the target label set is a subset of the source label set.
| Method | Type | Office-Home (25/40/0) | VisDA (6/6/0) |
|----------|--------|-------------------------|-----------------|
| PADA | P | 62.1 | 53.5 |
| IWAN | P | 63.6 | 48.6 |
| ETN | P | 70.5 | 59.8 |
| AR | P | 79.4 | 88.8 |
| DCC | U | 70.9 | 72.4 |
| GATE | U | 73.9 | 75.6 |
| PPOT | U | 74.3 | 83 |
| Method | Type | Office-Home (25/0/40) | VisDA (6/0/6) |
|----------|--------|-------------------------|-----------------|
| STA | O | 61.1 | 64.1 |
| OSBP | O | 64.7 | 52.3 |
| ROS | O | 66.2 | 66.5 |
| DCC | U | 61.7 | 59.6 |
| OVANet | U | 64 | 66.1 |
| GATE | U | 69.1 | 70.8 |
| PPOT | U | 70 | 72.3 |
(Chen et al. 2020) to contrastive pre-train our feature extractor, the number of epochs in pre-training is 100, batch size is 256, and learning rate is 0.03.
In training phase, we optimize the model using Nesterov momentum SGD with momentum of 0.9 and weight decay of 5 × 10 -4 . Following (Ganin and Lempitsky 2015), the learning rate decays with the factor of (1 + αt ) -β , where t linearly changes from 0 to 1 in training, and we set α = 10 , β = 0 75 . . The batch size is set to 72 in all experiments except in DomainNet tasks where it is changed to 256. We train our model for 5 epochs (1000 iterations per epoch), and update source prototypes and α totally before every epoch. The initial learning rate is set to 1 × 10 -4 on Office-31, 5 × 10 -4 on Office-Home and VisDA, and 0.01 on DomainNet.
## 5.1 Results and Comparisons
We compare our method with four PDA methods (PADA (Cao et al. 2018b), IWAN (Zhang et al. 2018), ETN (Cao et al. 2019), AR (Gu et al. 2021)), three OSDA methods (OSBP (Saito et al. 2018), STA (Liu et al. 2019), ROS (Bucci, Loghmani, and Tommasi 2020)) and six UniDA methods (UAN (You et al. 2019), CMU (Fu et al. 2020), DANCE (Saito et al. 2020), DCC (Li et al. 2021), OVANet (Saito and Saenko 2021), GATE (Chen et al. 2022)). All the compared methods use the same backbone as ours.
OPDA setting. Table 1 shows the results of our method. Our method outperforms baselines and achieves state-of-
Table 3: Comparison of H-score (%) on Office-Home and VisDA for OSDA setting. 'O' and 'U' denote OSDA and UniDA methods, respectively with and without assuming the source label set is a subset of the target label set.
the-art results on all four datasets. On Office-31 and OfficeHome datasets, our method surpasses all baselines on average. In larger datasets, VisDA and DomainNet, our method brings more than 17% improvement over previous methods on VisDA, and 5% on DomainNet. In general, these results show that our method is suitable in UniDA tasks, especially on larger and challenging datasets.
PDA and OSDA settings. Following (Li et al. 2021), we train our model without any prior knowledge of label space mismatch in PDA and OSDA settings. We report the results for PDA setting in Table 2. We can see that our method achieves better results than other UniDA-based methods (denoted as 'U') on both datasets. The 'P' denotes the PDA methods using prior knowledge that only the source domain has private classes. The results of OSDA setting are shown in Table 3, our method still surpasses all UniDA methods and OSDA methods (denoted as 'O') using prior knowledge on label space mismatch on Office-Home and VisDA datasets.
## 5.2 Model Analysis
Comparison of m-PPOT with m-POT. To compare mPPOT with m-POT (mini-batch based partial OT without using prototypes) in UniDA, we replace m-PPOT with m-POT in our method and use the average weight of samples in each class to replace the prototype weights w s in Eqn. (13), and the corresponding method is denoted as 'POT'. As shown in Table 4, PPOT surpasses POT in all three datasets, confirming that m-PPOT performs better than m-POT in UniDA.
Table 4: Ablation study for OPDA on Office-31, OfficeHome and VisDA. 'CL' means contrastive pre-training.
| Method | Office-31 | VisDA | Office-Home |
|---------------------|-------------|---------|---------------|
| POT | 88.4 | 66.4 | 74.2 |
| PPOT (w/o CL) | 89.4 | 58.1 | 74.3 |
| PPOT (w/o L pe ) | 88.4 | 71.1 | 76.5 |
| PPOT (w/o L ne ) | 89.6 | 67.8 | 74.4 |
| PPOT (w/o reweight) | 86.5 | 69.9 | 74.7 |
| PPOT | 90.4 | 73.8 | 77.1 |
Figure 2: (a) Class weight w s in Eqn. (13) on the source domain. (b) Average weight w t in Eqn. (11) for each class on the target domain. Task: W → D on Office-31 for OPDA.
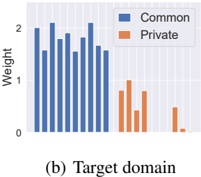
Effect of contrastive pre-training. To evaluate the effect of contrastive pre-training, the contrastive pre-training is removed and the feature extractor is replaced by a ResNet50 pre-trained on ImageNet. The results shown in Table 4 illustrate that performance degenerates in all experiments, especially in more challenging tasks such as VisDA. Note that without contrastive pre-training, our model still surpasses state-of-the-art methods on Office-31 and VisDA and reaches a comparable result on Office-Home.
Effectiveness of reweighted entropy loss. To evaluate this loss, we remove L pe and L ne in our model respectively. Table 4 shows that PPOT outperforms PPOT(w/o L pe ) by 2% and PPOT(w/o L ne ) by 6% on VisDA dataset.
Effectiveness of reweighting strategy. To evaluate the effectiveness of our reweighting strategy in Eqns. (13) and (11), we set w s i = 1 in Eqn. (13) and w t j = 1 in Eqn. (11) for any 0 ⩽ i ⩽ m and 0 ⩽ j ⩽ n . The results of Table 4 show that PPOT(w/o reweight) decreases at least 3% more than PPOT in all datasets, which means that our reweighting strategy is important in our method. We further visualize the learned weights of source/target classes in UniDA task W → D on Office-31 datasets, as shown in Fig. 2. In both domains, most common classes have higher weights than private classes, which implies that our model can separate common and private classes effectively.
Sensitivity to hyper-parameters. Figure 3 evaluates the sensitivity of our model to hyper-parameters τ 1 , τ 2 , η 1 , η 2 , η 3 , and ξ . Results show that our model is relatively stable to τ 1 and τ 2 at the range of [0 6 . , 0 95] . and [0 7 . , 1 1] . respectively, as shown in Fig. 3(b). In Fig. 3(b), we can also see that the setting of threshold ξ does not impact the perfor-
Figure 3: Sensitivity to hyper-parameters (a) η 1 , η 2 and η 3 in Eqn. (14), (b) τ 1 , τ 2 in Eqn. (15) and threshold ξ . All results are for the OPDA setting in task C → A.
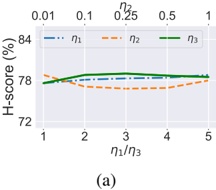
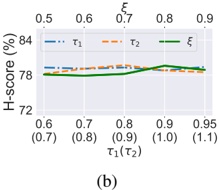
Figure 4: H-score curves of different methods with varying number of target private classes for OPDA tasks A → P and P → R.
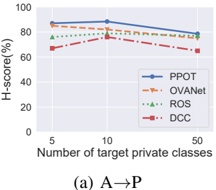
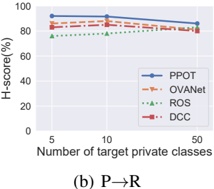
mance much on our model in range [0 5 . , 0 9] . . Furthermore, Fig. 3(a) shows that our model is relatively stable to varying values of η 1 , η 2 , and η 3 .
## H-score with varying number of target private classes.
Weevaluate our method with different numbers of target private classes. Results in A → P and P → R tasks are shown in Fig. 4, our method outperforms other baselines in all cases. It shows that our method is effective for OPDA with respect to different numbers of target domain private classes, and the performance marginally decreases with the increase of the number of target domain private classes.
## 6 Conclusion
In this paper, we propose to formulate the universal domain adaption (UniDA) as a partial optimal transport problem in deep learning framework. We propose a novel mini-batch based prototypical partial OT (m-PPOT) model for UniDA task, which is based on minimizing mini-batch prototypical partial optimal transport between two domain samples. We also introduce reweighting strategy based on the transport plan in UniDA. Experiments on four benchmarks show the effectiveness of our method for UniDA tasks including OPDA, PDA, OSDA settings. In the future, we plan to further theoretically analyze the mini-batch based m-PPOT, and apply it to more applications requiring partial alignments in deep learning framework.
## References
Arjovsky, M.; Chintala, S.; and Bottou, L. 2017. Wasserstein generative adversarial networks. In ICML .
Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; and Vaughan, J. W. 2010. A theory of learning from different domains. ML , 79(1): 151-175.
Ben-David, S.; Blitzer, J.; Crammer, K.; and Pereira, F. 2006. Analysis of representations for domain adaptation. In NeurIPS .
Benamou, J.-D.; Carlier, G.; Cuturi, M.; Nenna, L.; and Peyr´ e, G. 2015. Iterative Bregman projections for regularized transportation problems. SISC , 37(2): A1111-A1138.
Bucci, S.; Loghmani, M. R.; and Tommasi, T. 2020. On the effectiveness of image rotation for open set domain adaptation. In ECCV .
Caffarelli, L. A.; and McCann, R. J. 2010. Free boundaries in optimal transport and Monge-Ampere obstacle problems. Annals of Mathematics , 673-730.
Cao, Z.; Long, M.; Wang, J.; and Jordan, M. I. 2018a. Partial transfer learning with selective adversarial networks. In CVPR .
Cao, Z.; Ma, L.; Long, M.; and Wang, J. 2018b. Partial adversarial domain adaptation. In ECCV .
Cao, Z.; You, K.; Long, M.; Wang, J.; and Yang, Q. 2019. Learning to transfer examples for partial domain adaptation. In CVPR .
Chen, L.; Lou, Y.; He, J.; Bai, T.; and Deng, M. 2022. Geometric Anchor Correspondence Mining With Uncertainty Modeling for Universal Domain Adaptation. In CVPR .
Chen, X.; Fan, H.; Girshick, R.; and He, K. 2020. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297 .
Courty, N.; Flamary, R.; Habrard, A.; and Rakotomamonjy, A. 2017. Joint distribution optimal transportation for domain adaptation. In NeurIPS .
Cuturi, M. 2013. Sinkhorn distances: Lightspeed computation of optimal transport. In NeurIPS .
Damodaran, B. B.; Kellenberger, B.; Flamary, R.; Tuia, D.; and Courty, N. 2018. Deepjdot: Deep joint distribution optimal transport for unsupervised domain adaptation. In ECCV .
Fatras, K.; S´ ejourn´, T.; Flamary, R.; and Courty, N. 2021. e Unbalanced minibatch optimal transport; applications to domain adaptation. In ICML .
Figalli, A. 2010. The optimal partial transport problem. Archive for Rational Mechanics and Analysis , 195(2): 533560.
Flamary, R.; Courty, N.; Tuia, D.; and Rakotomamonjy, A. 2016. Optimal transport for domain adaptation. TPAMI , 1.
Fu, B.; Cao, Z.; Long, M.; and Wang, J. 2020. Learning to detect open classes for universal domain adaptation. In ECCV .
Ganin, Y.; and Lempitsky, V. 2015. Unsupervised domain adaptation by backpropagation. In ICML .
Ge, Z.; Liu, S.; Li, Z.; Yoshie, O.; and Sun, J. 2021. Ota: Optimal transport assignment for object detection. In CVPR .
Gu, X.; Yu, X.; Sun, J.; Xu, Z.; et al. 2021. Adversarial Reweighting for Partial Domain Adaptation. In NeurIPS .
He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In CVPR .
Ho, N.; Nguyen, X.; Yurochkin, M.; Bui, H. H.; Huynh, V.; and Phung, D. 2017. Multilevel clustering via Wasserstein means. In ICML .
Kantorovitch, L. 1958. On the translocation of masses. Management Science , 5(1): 1-4.
Krizhevsky, A.; Sutskever, I.; and Hinton, G. E. 2012. Imagenet classification with deep convolutional neural networks. In NeurIPS .
Li, G.; Kang, G.; Zhu, Y.; Wei, Y.; and Yang, Y. 2021. Domain consensus clustering for universal domain adaptation. In CVPR .
Liu, H.; Cao, Z.; Long, M.; Wang, J.; and Yang, Q. 2019. Separate to adapt: Open set domain adaptation via progressive separation. In CVPR .
Long, M.; Cao, Y.; Wang, J.; and Jordan, M. 2015. Learning transferable features with deep adaptation networks. In ICML .
Long, M.; Cao, Z.; Wang, J.; and Jordan, M. I. 2018. Conditional adversarial domain adaptation. In NeurIPS .
Nguyen, K.; Nguyen, D.; Pham, T.; Ho, N.; et al. 2022. Improving mini-batch optimal transport via partial transportation. In ICML .
Pan, Y.; Yao, T.; Li, Y.; Wang, Y.; Ngo, C.-W.; and Mei, T. 2019. Transferrable prototypical networks for unsupervised domain adaptation. In CVPR .
Panareda Busto, P.; and Gall, J. 2017. Open set domain adaptation. In ICCV .
Papyan, V.; Han, X.; and Donoho, D. L. 2020. Prevalence of neural collapse during the terminal phase of deep learning training. PNAS , 117(40): 24652-24663.
Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. 2019. Pytorch: An imperative style, high-performance deep learning library. In NeurIPS .
Peng, X.; Bai, Q.; Xia, X.; Huang, Z.; Saenko, K.; and Wang, B. 2019. Moment matching for multi-source domain adaptation. In ICCV .
Peng, X.; Usman, B.; Kaushik, N.; Hoffman, J.; Wang, D.; and Saenko, K. 2017. Visda: The visual domain adaptation challenge. arXiv preprint arXiv:1710.06924 .
Peyr´ e, G.; Cuturi, M.; et al. 2019. Computational optimal transport: With applications to data science. Foundations and Trends® in Machine Learning , 11(5-6): 355-607.
Saenko, K.; Kulis, B.; Fritz, M.; and Darrell, T. 2010. Adapting visual category models to new domains. In ECCV .
Saito, K.; Kim, D.; Sclaroff, S.; and Saenko, K. 2020. Universal domain adaptation through self supervision. In NeurIPS .
Saito, K.; and Saenko, K. 2021. Ovanet: One-vs-all network for universal domain adaptation. In ICCV .
Saito, K.; Yamamoto, S.; Ushiku, Y.; and Harada, T. 2018. Open set domain adaptation by backpropagation. In ECCV .
Shen, K.; Jones, R. M.; Kumar, A.; Xie, S. M.; HaoChen, J. Z.; Ma, T.; and Liang, P. 2022. Connect, not collapse: Explaining contrastive learning for unsupervised domain adaptation. In ICML .
Simonyan, K.; and Zisserman, A. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 .
Sun, B.; and Saenko, K. 2016. Deep coral: Correlation alignment for deep domain adaptation. In ECCV .
Venkateswara, H.; Eusebio, J.; Chakraborty, S.; and Panchanathan, S. 2017. Deep hashing network for unsupervised domain adaptation. In CVPR .
Villani, C. 2009. Optimal transport: old and new , volume 338. Springer.
Xie, S.; Zheng, Z.; Chen, L.; and Chen, C. 2018. Learning semantic representations for unsupervised domain adaptation. In ICML .
Xu, R.; Liu, P.; Zhang, Y.; Cai, F.; Wang, J.; Liang, S.; Ying, H.; and Yin, J. 2021. Joint partial optimal transport for open set domain adaptation. In IJCAI .
You, K.; Long, M.; Cao, Z.; Wang, J.; and Jordan, M. I. 2019. Universal domain adaptation. In CVPR .
Zhang, J.; Ding, Z.; Li, W.; and Ogunbona, P. 2018. Importance weighted adversarial nets for partial domain adaptation. In CVPR .
Zhang, Y.; Liu, T.; Long, M.; and Jordan, M. 2019. Bridging theory and algorithm for domain adaptation. In ICML .
## A Mathematical Deductions
## A.1 Notation
We first recall some definitions in our paper. The source and target empirical distributions in feature space are denoted as p = ∑ m i =1 p δ i f ( x s i ) and q = ∑ n j =1 q δ j f ( x t j ) respectively, ∑ m i =1 p i = 1 , ∑ n j =1 q j = 1 . c = ∑ L i =1 r δ i c i is the empirical distribution of source domain prototypes, and r i = ∑ j y : j = i p j . With a slight abuse of notations, we denote the vector of data mass as p = ( p , p 1 2 , ..., p m ) ⊤ , q = ( q 1 , q 2 , ..., q n ) ⊤ and c = ( r , r 1 2 , ..., r L ) ⊤ . In this paper, we set q j = 1 n for any 0 ⩽ j ⩽ n .
Furthermore, the definitions of PPOT α ( p q , ) and m-PPOT α B ( p q . ) are shown as follows:
The elements of cost matrix C p q , , C p c , , C c q , are defined as C p q , ij = d f ( ( x s i ) , f ( x t j )) , C p c , ik = d f ( ( x s i ) , c k )) , C c q , kj = d c ( k , f ( x t j )) , respectively. Here d is the L 2 distance.
$$\text{PPOT} ^ { \alpha } ( p, q ) & \stackrel { \triangle } { = } \text{POT} ^ { \alpha } ( c, q ) = \min _ { \pi \in \Pi ^ { \alpha } ( c, q ) } \langle \pi, C ^ { c, q } \rangle _ { F }, \\ _ { 1 }, & ( A \text{-} 1 )$$
$$\mathfrak { m } { - } P P O T ^ { \alpha } _ { \mathcal { B } } ( p, q ) \stackrel { \triangle } { = } \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \text{POT} ^ { \alpha } ( c, q _ { \mathcal { B } _ { i } } ), \ \mathcal { B } \in \Gamma, \ \ ( A { - } 2 ) \\. \ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \collections$$
where B i is the i -th index set of b random target samples and their corresponding empirical distribution in feature space is denoted as q B i . B ≜ {B } i k , satisfying B i ⋂ B j = ∅ and
$$\text{denoted as $q_{\mathcal{B}_{i}$.} \, \mathcal{B}=\{\mathcal{B}_{i}\}_{i=1}^{k}$, satisfying} \\ \bigcup _ { i = 1 } ^ { k } \mathcal { B } _ { i } = \{ 1, 2, \dots, n \}. \, b \, | \, n, k = \frac { n } { b }.$$
## A.2 Proof of proposition 1
Proposition 1. Let π α i be the optimal transportation of i -th batch of m-PPOT α B ( p q , ) . We extend π α i to a L × n matrix Π α i that pads zero entries to the column whose index does not belong to B i , then we have
$$\frac { 1 } { k } \sum _ { i = 1 } ^ { k } \Pi _ { i } ^ { \alpha } \in \Pi ^ { \alpha } ( c, q ) \text{ \quad \ \ } ( A \text{-} 3 )$$
and
$$\text{PPOT} ^ { \alpha } ( p, q ) \leqslant \text{m-PPOT} ^ { \alpha } _ { \mathcal { B } } ( p, q ). \quad \text{(A-4)}$$
Proof. The proof of
$$\frac { 1 } { k } \sum _ { i = 1 } ^ { k } \Pi _ { i } ^ { \alpha } \in \Pi ^ { \alpha } ( c, q ) \text{ \quad \ \ } ( A \text{-} 5 )$$
is equivalent to proving
$$\text{nt to proving} \\ ( \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \Pi _ { i } ^ { \alpha } ) \mathbb { 1 } _ { n } \leqslant c, \\ ( \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \Pi _ { i } ^ { \alpha } ) ^ { \top } \mathbb { 1 } _ { L } \leqslant q, \quad \quad ( A - 6 ) \\ \mathbb { 1 } _ { L } ^ { \top } ( \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \Pi _ { i } ^ { \alpha } ) \mathbb { 1 } _ { n } = \alpha, \\ \text{to the definition of } \Pi ^ { \alpha } ( c, q ). \text{ Note that } \pi _ { i } ^ { \alpha } \in \text{ }$$
according to the definition of Π ( α c q , ) . Note that π α i ∈ Π ( α c q , B i ) satisfies
$$\pi _ { i } ^ { \alpha } \mathbb { 1 } _ { b } \leqslant c, \ \left ( \pi _ { i } ^ { \alpha } \right ) ^ { \top } \mathbb { 1 } _ { L } \leqslant q _ { \mathcal { B } _ { i } }, \ \mathbb { 1 } _ { L } ^ { \top } \pi _ { i } ^ { \alpha } \mathbb { 1 } _ { b } = \alpha. \quad ( \text{A-7} )$$
Combining with the definition of Π α i , we have
$$\dots \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Clone$$
where ¯ q B i ∈ R n is the extension of q B i by padding zero entries to the dimension whose index does not belong to B i , ⊙ corresponds to entry-wise product and m i is a n dimensional vector with element satisfying that
$$m _ { j } ^ { i } = \begin{cases} \frac { n } { b } = k, & \text{if $j\in \mathcal{B}_{i}$}, \\ 0, & \text{otherwise}. \end{cases} \quad ( A - 9 )$$
We have
$$\text{We have} \\ ( \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \Pi _ { i } ^ { \alpha } ) \mathbb { 1 } _ { n } = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } ( \Pi _ { i } ^ { \alpha } \mathbb { 1 } _ { n } ) \leqslant c, \\ ( \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \Pi _ { i } ^ { \alpha } ) ^ { \top } \mathbb { 1 } _ { L } \leqslant ( \frac { 1 } { k } \sum _ { i = 1 } ^ { k } m ^ { i } ) \odot q, \quad \text{(A-10)} \\ \mathbb { 1 } _ { L } ^ { \top } ( \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \Pi _ { i } ^ { \alpha } ) \mathbb { 1 } _ { n } = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } ( \mathbb { 1 } _ { L } ^ { \top } \Pi _ { i } ^ { \alpha } \mathbb { 1 } _ { n } ) = \alpha,$$
Combining (A-9) with the conditions B i ⋂ B j = ∅ and
$$\bigcup _ { i = 1 } ^ { k } \mathcal { B } _ { i } = \{ 1, 2, \dots, n \}, \, \text{we find that}$$
$$( \sum _ { i = 1 } ^ { k } m ^ { i } ) _ { j } = k \sum _ { i = 1 } ^ { k } 1 ( j \in \mathcal { B } _ { i } ) = k, \quad \quad ( A \text{-} 1 )$$
it means that
$$\frac { 1 } { k } \sum _ { i = 1 } ^ { k } m ^ { i } = 1 _ { n }. \quad \quad ( A \text{-} 1 2 ) \quad \.$$
Therefore Eqn. (A-6) has been proved. So far, we have proved Eqn.(A-3), which means that the following inequality holds:
$$\text{PPOT} ^ { \alpha } ( p, q ) \leqslant \langle \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \Pi _ { i } ^ { \alpha }, C ^ { c, q } \rangle _ { F }$$
$$= \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \langle \Pi _ { i } ^ { \alpha }, C ^ { c, q } \rangle _ { F } \quad \quad \ \ ( A \text{-13} ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$& \text{POT} ^ { \alpha } ( p, q ) \leqslant \langle \frac { 1 } { k } \sum _ { i = 1 } \Pi _ { i } ^ { \alpha }. \\ & = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \langle \Pi _ { i } ^ { \alpha }, C ^ { \text{c}, q } \rangle _ { F } \\ & = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \text{POT} ^ { \alpha } ( c, q _ { \mathcal { B } _ { i } } ) \\ & = m \text{-PPOT} _ { \mathcal { B } } ^ { \alpha } ( p, q ).$$
## A.3 Proof of theorem 1
Theorem 1. Considering two distributions p and q , the distance between f ( x s i ) and corresponding prototype c y i is denoted as d i ≜ d f ( ( x s i ) , c y i ) . The row sum of the optimal transportation of PPOT α ( p q , ) is denoted as w = ( w , w , ..., w 1 2 L ) ⊤ , r i = ∑ j y : j = i p j . Then we have
$$\text{POT} ^ { \alpha } ( p, q ) \leqslant \sum _ { i = 1 } ^ { m } \frac { w _ { y _ { i } } } { r _ { y _ { i } } } p _ { i } d _ { i } + \text{m-PPOT} ^ { \alpha } _ { \mathcal { B } } ( p, q ). \ \ ( A { - } 1 4 ) \quad =$$
The proof of theorem 1 can be decomposed by two Lemmas.
Lemma 2. Consider three distributions p q , and c , we denote the optimal transportation of PPOT α ( p q , ) as π c q , ∈ R L × n , and denote the row sum of π c q , as w ≜ π c q , 1 n ⩽ c , w = ( w , w , . . . , w 1 2 L ) . We define an empirical distribution ¯ = c L ∑ w δ i c i . Then, we have
$$i = 1$$
$$\text{POT} ^ { \alpha } ( p, q ) \leqslant \text{POT} ^ { \alpha } ( p, \bar { c } ) + \text{POT} ^ { \alpha } ( p, q ). \quad ( \text{A-15} ) \quad \text{$bet}$$
Proof. Let π p c , ∈ R m L × be the optimal transportation matrix of POT α ( p c , ¯) . Obviously, due to ∥ w ∥ 1 = α , POT α ( p c , ¯) satisfies
$$\text{POT} ^ { \alpha } ( p, \bar { c } ) = \min _ { \pi \in \bar { \Pi } ^ { \alpha } ( p, \bar { c } ) } \langle \pi, C ^ { p, c } \rangle _ { F }, \quad \text{ (A-16)} \quad \text{$n$...}$$
¯ Π ( α p c , ¯) = { π | π 1 L ⩽ p , π ⊤ 1 m = w , 1 ⊤ m π 1 L = α } . Therefore, π p c , and π c q , satisfy these equations:
$$\pi ^ { p, c } \mathbb { 1 } _ { L } \leqslant p, \ \mathbb { 1 } _ { m } ^ { \top } \pi ^ { p, c } = w ^ { \top }, \quad ( \text{A-17} )$$
$$\pi ^ { c, q } \mathbb { 1 } _ { n } = w, \ \mathbb { 1 } _ { L } ^ { \top } \pi ^ { c, q } \leqslant q ^ { \top }, \quad \ \ ( \text{A-18} )$$
and then we define a m × n dimensional matrix S as:
$$S \stackrel { \triangle } { = } \pi ^ { p, c } D \, \pi ^ { c, q },$$
where
$$D & = \left ( \begin{array} { c c c c } \frac { 1 } { w _ { 1 } } & & & \\ & \frac { 1 } { w _ { 2 } } & & \\ & & \ddots & \\ & & & \frac { 1 } { w _ { L } } \end{array} \right ). \\. &. &. &. &. &. &.$$
Notice that S ∈ Π ( α p q , ) because according to Eqns.(A-17) and (A-18), we have
$$S _ { 1 } _ { n } & = \pi ^ { p, c } D \, \pi ^ { c, q } _ { 1 _ { n } } = \pi ^ { p, c } D \, w = \pi ^ { p, c } _ { 1 _ { L } } \leqslant p, \\ \mathbb { 1 } _ { m } ^ { \top } S & = \mathbb { 1 } _ { m } ^ { \top } \pi ^ { p, c } D \, \pi ^ { c, q } = w ^ { \top } D \, \pi ^ { c, q } = \mathbb { 1 } _ { L } ^ { \top } \pi ^ { c, q } \leqslant q ^ { \top }.$$
It means that S is a transport plan of POT α ( p q , ) , so
$$\text{POT} ^ { \alpha } ( p, q ) \leqslant \langle S, C ^ { p, q } \rangle _ { F } = \sum _ { i = 1 } ^ { m } \sum _ { j = 1 } ^ { n } C _ { i j } ^ { p, q } S _ { i j }$$
$$= \sum _ { i = 1 } ^ { m } \sum _ { j = 1 } ^ { n } \sum _ { k = 1 } ^ { L } \frac { 1 } { w _ { k } } C _ { i j } ^ { p, q } \pi _ { i k } ^ { p, c } \pi _ { k j } ^ { c, q }$$
$$& = \sum _ { i = 1 } \sum _ { j = 1 } \sum _ { k = 1 } \frac { 1 } { w _ { k } } C _ { i j } ^ { p, q _ { \pi } p, c _ { \pi } c, q } _ { k j } \\ & \square = \sum _ { i, j, k } \frac { 1 } { w _ { k } } d ( f ( x _ { i } ^ { s } ), f ( x _ { j } ^ { t } ) ) \pi _ { i k } ^ { p, c } \pi _ { k j } ^ { c, q } _ { k j } \\ & \text{the} _ { c _ { y _ { i } } } \leqslant \sum _ { i, j, k } \frac { 1 } { w _ { k } } d ( f ( x _ { i } ^ { s } ), c _ { k } ) \pi _ { i k } ^ { p, c } \pi _ { k j } ^ { c, q } _ { k j } + \sum _ { i, j, k } \frac { 1 } { w _ { k } } d ( c _ { k }, f ( x _ { j } ^ { t } ) ) \pi _ { i k } ^ { p, c } \pi _ { c _ { k } } _ { q } \\ \text{$\frac{the} _ { \alpha } } \leqslant \sum _ { i, j, k } \frac { 1 } { w _ { k } } C _ { i k } ^ { p, c _ { \pi } } \pi _ { i k } ^ { p, c _ { \pi } } \pi _ { k j } ^ { c, q } _ { k j } \\ & = \sum _ { i, j, k } \frac { 1 } { w _ { k } } C _ { i k } ^ { p, c _ { \pi } } \pi _ { i k } ^ { p, c } \sum _ { j } \pi _ { k j } ^ { c, q } + \sum _ { k, j } \frac { 1 } { w _ { k } } C _ { k j } ^ { c, q } \pi _ { k j } ^ { c, q } \sum _ { i } \pi _ { i k } ^ { p, c } \\ \text{em-} \\ & = \sum _ { i, k } C _ { i k } ^ { p, c _ { \pi } } \pi _ { i k } ^ { p, c } + \sum _ { k, j } C _ { k j } ^ { c, q } \pi _ { k j } ^ { c, q } _ { k j } \\ & \cdot d e _ { \alpha } = \text{$\frac{p,c_{\alpha} } { q } ( p, \bar { c } ) + P P O T ^ { \alpha } ( p, q ). } \\ & \leqslant c, \quad \square \right.$$
Lemma 3. Consider two distributions p and c , the definitions of POT α ( p c , ¯) and w follow Lemma 2. The distance between f ( x s i ) and c y i (i.e. C p c , i,y i ) is denoted as d i , then we have
$$\text{POT} ^ { \alpha } ( p, \bar { c } ) \leqslant \sum _ { i = 1 } ^ { m } \frac { w _ { y _ { i } } } { r _ { y _ { i } } } p _ { i } d _ { i }. \quad \quad ( \text{A-19} )$$
Proof. Let π be a m × L dimensional matrix, which satisfies
$$\pi _ { i j } = \begin{cases} \frac { w _ { j } } { r _ { j } } p _ { i }, & \text{if } y _ { i } = j, \\ & & ( A \text{-} 2 0 ) \\ 0, & \text{otherwise}. \end{cases}$$
Figure A-1: Source class weight computed by the row sum of solutions of PPOT α ( p q , ) and m-PPOT α ( p q , ) for OPDA task D → W.
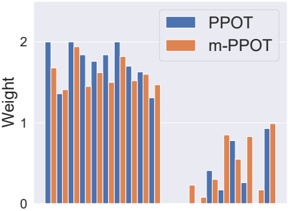
Computing the row and column sums of π , we can find that
$$\sum _ { j = 1 } ^ { L } \pi _ { i j } = \frac { w _ { y _ { i } } } { r _ { y _ { i } } } p _ { i } \leqslant p _ { i }, \text{ \quad \quad } ( \text{A-21} )$$
$$\sum _ { i = 1 } ^ { m } \pi _ { i j } = \frac { w _ { j } } { r _ { j } } \sum _ { i \colon y _ { i } = j } p _ { i } = w _ { j }, \text{ \quad \ \ } ( \text{A-2} )$$
$$\sum _ { i = 1 } ^ { m } \sum _ { j = 1 } ^ { L } \pi _ { i j } = \sum _ { j = 1 } ^ { L } w _ { j } = \alpha. \quad \quad ( A \text{-} 2 3 ) \quad \ \ F i _ { \text{ba} }$$
Eqns.(A-21), (A-22) and (A-23) are equal to equations as follows:
$$\pi ^ { \mathbf 1 } _ { L } \leqslant p, \ \pi ^ { \top } ^ { \top } ^ { \ } { 1 } _ { m } = w, \ 1 ^ { \top } _ { m } \pi ^ { \mathbf 1 } _ { L } = \alpha, \quad ( \text{A-2} 4 )$$
which means π ∈ ¯ Π ( α p c , ¯) . Therefore,
$$\text{POT} ^ { \alpha } ( p, \bar { c } ) \leqslant \langle \pi, C ^ { p, c } \rangle _ { F } = \sum _ { i = 1 } ^ { m } \frac { w _ { y _ { i } } } { r _ { y _ { i } } } p _ { i } d _ { i }. \quad ( \text{A-25} )$$
At last, we provide the proof of theorem 1.
Proof. Combining Lemmas 2, 3 and Proposition 1
$$\text{POT} ^ { \alpha } ( p, q ) \leqslant \text{POT} ^ { \alpha } ( p, \bar { c } ) + \text{PPOT} ^ { \alpha } ( p, q ),$$
$$\Phi ^ { \alpha } ( p, \bar { c } ) & \leqslant \sum _ { i = 1 } ^ { m } \frac { w _ { y _ { i } } } { r _ { y _ { i } } } p _ { i } d _ { i }, \\ \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha \Phi } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \alpha } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \beta } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \lambda } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \eta } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \gamma } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \mu } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \nu } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \nolay \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha } \Phi ^ { \alpha. }$$
PPOT α ( p q , ) ⩽ m-PPOT α B ( p q , ) , we have
$$\text{POT} ^ { \alpha } ( p, q ) \leqslant \sum _ { i = 1 } ^ { m } \frac { w _ { y _ { i } } } { r _ { y _ { i } } } p _ { i } d _ { i } + \text{m-PPOT} ^ { \alpha } _ { \mathcal { B } } ( p, q ).$$
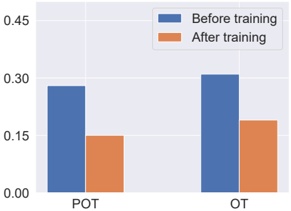
Figure A-2: The values of POT α ( p q , ) and OT α ( p c , q c ) before and after training for OPDA task W → D.
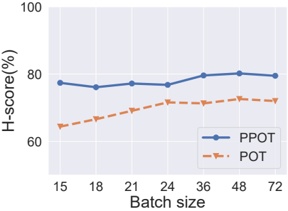
Figure A-3: H-score curves of PPOT and POT with varying batch size for OPDA task C → A.
Figure A-4: Sensitivity to hyper-parameter λ in Eqn. (A-26). Results are for the OPDA setting in task P → C.
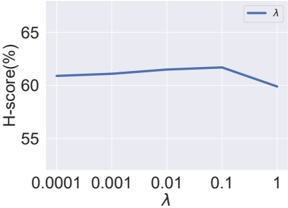
Figure A-5: Matching produced by PPOT in toy data. Different shapes mean different class, and the gray line is the matching computed by PPOT.
Table A-1: H-score(%) comparisons on Office-31 in OPDA setting.
| | Office-31(10/10/11) | Office-31(10/10/11) | Office-31(10/10/11) | Office-31(10/10/11) | Office-31(10/10/11) | Office-31(10/10/11) | Office-31(10/10/11) |
|---------|-----------------------|-----------------------|-----------------------|-----------------------|-----------------------|-----------------------|-----------------------|
| Methods | A2D | A2W | D2A | D2W | W2A | W2D | Avg |
| UAN | 59.7 | 58.6 | 60.1 | 70.6 | 60.3 | 71.4 | 63.5 |
| CMU | 68.1 | 67.3 | 71.4 | 79.3 | 72.2 | 80.4 | 73.1 |
| DANCE | 79.6 | 75.8 | 82.9 | 90.9 | 77.6 | 87.1 | 82.3 |
| DCC | 88.5 | 78.5 | 70.2 | 79.3 | 75.9 | 88.6 | 80.2 |
| OVANet | 83.8 | 78.4 | 80.7 | 95.9 | 82.7 | 95.5 | 86.2 |
| GATE | 87.7 | 81.6 | 84.2 | 94.8 | 83.4 | 94.1 | 87.6 |
| PPOT | 86.2 | 87.0 | 90.2 | 93.1 | 90.2 | 95.8 | 90.4 |
Table A-2: Ablation study. H-score(%) comparison for UniDA on Office-31, OfficeHome and VisDA.
| Methods | Office | VisDA | OfficeHome |
|-----------|----------|---------|--------------|
| PPOT | 82.3 | 69.3 | 49.6 |
| POT | 81 | 67.1 | 46.6 |
size than POT, especially when the batch size is less than 36. Moreover, for providing a more fair comparison with POT and PPOT, we train the network only with PPOT loss (10) (or POT loss) and a cross-entropy loss defined in source domain. Table A-2 shows their results for OPDA task in Office31 and Office-Home datasets, we can see that PPOT performs well than POT in both datasets.
## B Additional Empirical Analysis
## B.1 Comparison of the weight of the source prototypes derived from PPOT and m-PPOT
In the main paper, we use w s , i e . ., the row sum of the optimal transport plan of m-PPOT α ( p q , ) , to approximate w ( . i e ., the row sum of the solution of PPOT α ( p q , ) ) in L rce for approximately minimizing the first term in the bound of Theorem 1. Figure A-1 shows that the weight computed by the row sum of the optimal transport plan of m-PPOT α ( p q , ) can approximate that of PPOT α ( p q , ) .
## B.2 Can our model align the distributions of source and target common class data?
We present the value of OT ( p c , q c ) before and after the training of our model, as shown in Fig. A-2. Note that OT ( p c , q c ) decreases apparently after training, which empirically shows that our method is effective to align the distributions of source and target common class data.
## B.3 Effectiveness of our model to minimize POT
We also provide the value of POT α ( p q , ) before and after training in Fig. A-2 to testify whether POT α ( p q , ) can be minimized by our model. We find that the value of POT α ( p q , ) is apparently reduced after training, which empirically verifies the rationality of Theorem 1, because the L rce and L ot in our model are designed for minimizing the two terms in the upper bound of POT α ( p q , ) in Theorem 1.
## B.4 More results for POT and PPOT
We have discussed the advantages of PPOT over POT in the ablation study ('Comparison of m-PPOT with m-POT') of experiment section. Figure A-3 presents the results of PPOT and POT with varying batch sizes for OPDA task C → A. The figure shows that PPOT generally achieves higher performance in H-score than POT, and is more stable to the bath
Figure A-6: Transport plan of PPOT in task W → D on Office-31 datasets. Transport appears in the upper left of transport matrix is the correct transport.

Figure A-7: Computational cost of UniDA methods in OPDA task A → C.
## B.5 More detail about prototype update strategy
We have illustrated that the set of prototypes c is updated by exponential moving average in the paper, and here we show detail about this strategy. We update c by the moving average:
$$c \leftarrow \lambda \hat { c } + ( 1 - \lambda ) c \text{ \quad \ \ } ( A { - 2 6 } )$$
in each iteration, where ˆ c is computed by a batch of source features (note that if there is no sample with label k in a batch, we denote ˆ c k = c k directly). We also report the sensitivity of hyper-parameter λ , the result is shown in Fig. A-4. Note that our model is relatively stable to varying values of λ , and the result decreases when we do not use moving average strategy ( . i e ., λ = 1 ).
## B.6 Visualization of PPOT
We visualize the transport procedure of PPOT in toy data and the transport plan of PPOT in real data, as shown in Figs. A-5, A-6. In the toy data experiment, each of the source data(blue) and target data (red) are sampled by Gaussian mixture distributions composed of three distinct Gaussian components indicated by different shapes where the same shapes indicate the same class (both source and target data have two common classes and one private class) and green points are the prototypes of source data. We can see that most of transport occur between target common class points and their corresponding source prototype. In real data experiment, we first compute the features of source prototypes and target samples and choose 50 target features randomly as target samples. The transport plan between source prototypes and target features is shown in Fig. A-6, the task is W → D on Office-31 datasets. Note that we rearrange target samples to ensure the indexes of common class samples are less than private class samples, which means correct transport will present in the upper left of transport plan.
## B.7 Computational cost
We compare the computational cost of different methods with the total training time in the same training steps (5000 steps), as in Fig. A-7. Figure A-7 shows that PPOT is comparable to other methods in terms of computational cost.
## C Detailed Results on Office-31 and Office-Home
We have reported the average accuracies over all tasks on Office-31 and Office-Home in the paper (see Tables 1, 2 and 3 of the paper). We report the detailed results for each task in this section.
## C.1 Results for OPDA setting on Office-Home
We show the results of each task in Tables A-1 and A-3 on Office31 and Office-Home in OPDA setting. Our method achieves the best results in 13 out of 18 adaptation tasks.
## C.2 Results for PDA and OSDA setting on Office-Home
Table A-4 shows that our method achieves the best results on average and surpasses state-of-the-art results on half of them on Office-Home in PDA setting. The results in Table A-5 show that PPOT reaches the best results in 9 out of 12 tasks on Office-Home in OSDA setting.
| | Office-Home(10/5/50) | Office-Home(10/5/50) | Office-Home(10/5/50) | Office-Home(10/5/50) | Office-Home(10/5/50) | Office-Home(10/5/50) | Office-Home(10/5/50) | Office-Home(10/5/50) | Office-Home(10/5/50) | Office-Home(10/5/50) | Office-Home(10/5/50) | Office-Home(10/5/50) | Office-Home(10/5/50) |
|---------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|
| Methods | A2C | A2P | A2R | C2A | C2P | C2R | P2A | P2C | P2R | R2A | R2C | R2P | Avg |
| UAN | 51.6 | 51.7 | 54.3 | 61.7 | 57.6 | 61.9 | 50.4 | 47.6 | 61.5 | 62.9 | 52.6 | 65.2 | 56.65 |
| CMU | 56.0 | 56.9 | 59.2 | 67.0 | 64.3 | 67.8 | 54.7 | 51.1 | 66.4 | 68.2 | 57.9 | 69.7 | 61.6 |
| DANCE | 61.0 | 60.4 | 64.9 | 65.7 | 58.8 | 61.8 | 73.1 | 61.2 | 66.6 | 67.7 | 62.4 | 63.7 | 63.9 |
| DCC | 58.0 | 54.1 | 58.0 | 74.6 | 70.6 | 77.5 | 64.3 | 73.6 | 74.9 | 81.0 | 75.1 | 80.4 | 70.2 |
| OVANet | 63.4 | 77.8 | 79.7 | 69.5 | 70.6 | 76.4 | 73.5 | 61.4 | 80.6 | 76.5 | 64.3 | 78.9 | 72.7 |
| GATE | 63.8 | 75.9 | 81.4 | 74.0 | 72.1 | 79.8 | 74.7 | 70.3 | 82.7 | 79.1 | 71.5 | 81.7 | 75.6 |
| PPOT | 66.0 | 79.3 | 84.8 | 78.8 | 78.0 | 80.4 | 82.0 | 62.0 | 86.0 | 82.3 | 65.0 | 80.8 | 77.1 |
Table A-3: H-score(%) comparison on Office-Home in OPDA setting.
| Method | Type | Office-Home(25/40/0) | Office-Home(25/40/0) | Office-Home(25/40/0) | Office-Home(25/40/0) | Office-Home(25/40/0) | Office-Home(25/40/0) | Office-Home(25/40/0) | Office-Home(25/40/0) | Office-Home(25/40/0) | Office-Home(25/40/0) | Office-Home(25/40/0) | Office-Home(25/40/0) | Office-Home(25/40/0) |
|----------|--------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|
| Method | Type | A2C | A2P | A2R | C2A | C2P | C2R | P2A | P2C | P2R | R2A | R2C | R2P | Avg |
| PADA | P | 52.0 | 67.0 | 78.7 | 52.2 | 53.8 | 59.1 | 52.6 | 43.2 | 78.8 | 73.7 | 56.6 | 77.1 | 62.1 |
| IWAN | P | 53.9 | 54.5 | 78.1 | 61.3 | 48.0 | 63.3 | 54.2 | 52.0 | 81.3 | 76.5 | 56.8 | 82.9 | 63.6 |
| ETN | P | 59.2 | 77.0 | 79.5 | 62.9 | 65.7 | 75.0 | 68.3 | 55.4 | 84.4 | 75.7 | 57.7 | 84.5 | 70.5 |
| AR | P | 65.7 | 87.4 | 89.6 | 79.3 | 75.0 | 87.0 | 80.8 | 65.8 | 90.6 | 80.8 | 65.2 | 86.1 | 79.4 |
| DCC | U | 54.2 | 47.5 | 57.5 | 83.8 | 71.6 | 86.2 | 63.7 | 65.0 | 75.2 | 85.5 | 78.2 | 82.6 | 70.9 |
| GATE | U | 55.8 | 75.9 | 85.3 | 73.6 | 70.2 | 83.0 | 72.1 | 59.5 | 84.7 | 79.6 | 63.9 | 83.8 | 73.9 |
| PPOT | U | 53.1 | 81.2 | 86.1 | 78.9 | 71.9 | 83.7 | 74.6 | 55.5 | 84.4 | 77.4 | 57.9 | 86.3 | 74.3 |
Table A-4: H-score(%) comparison on Office-Home in PDA setting. 'P' and 'U' denote PDA and UniDA methods.
| Method | Type | Office-Home(25/0/40) | Office-Home(25/0/40) | Office-Home(25/0/40) | Office-Home(25/0/40) | Office-Home(25/0/40) | Office-Home(25/0/40) | Office-Home(25/0/40) | Office-Home(25/0/40) | Office-Home(25/0/40) | Office-Home(25/0/40) | Office-Home(25/0/40) | Office-Home(25/0/40) | Office-Home(25/0/40) |
|----------|--------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|------------------------|
| Method | Type | A2C | A2P | A2R | C2A | C2P | C2R | P2A | P2C | P2R | R2A | R2C | R2P | Avg |
| STA | O | 55.8 | 54.0 | 68.3 | 57.4 | 60.4 | 66.8 | 61.9 | 53.2 | 69.5 | 67.1 | 54.5 | 64.5 | 61.1 |
| OSBP | O | 55.1 | 65.2 | 72.9 | 64.3 | 64.7 | 70.6 | 63.2 | 53.2 | 73.9 | 66.7 | 54.5 | 72.3 | 64.7 |
| ROS | O | 60.1 | 69.3 | 76.5 | 58.9 | 65.2 | 68.6 | 60.6 | 56.3 | 74.4 | 68.8 | 60.4 | 75.7 | 66.2 |
| DCC | U | 56.1 | 67.5 | 66.7 | 49.6 | 66.5 | 64.0 | 55.8 | 53.0 | 70.5 | 61.6 | 57.2 | 71.9 | 61.7 |
| OVANet | U | 58.9 | 66.0 | 70.4 | 62.2 | 65.7 | 67.8 | 60.0 | 52.6 | 69.7 | 68.2 | 59.1 | 67.6 | 64.0 |
| GATE | U | 63.8 | 70.5 | 75.8 | 66.4 | 67.9 | 71.7 | 67.3 | 61.5 | 76.0 | 70.4 | 61.8 | 75.1 | 69.1 |
| PPOT | U | 60.7 | 75.2 | 79.5 | 67.3 | 70.1 | 73.8 | 70.6 | 57.2 | 76.1 | 71.8 | 61.4 | 75.8 | 70.0 |
Table A-5: H-score(%) comparison on Office-Home in OSDA setting. 'O' and 'U' denote OSDA and UniDA methods. | 10.1609/aaai.v37i9.26287 | [
"Yucheng Yang",
"Xiang Gu",
"Jian Sun"
] | 2024-08-02T08:08:56+00:00 | 2024-08-02T08:08:56+00:00 | [
"cs.CV"
] | Prototypical Partial Optimal Transport for Universal Domain Adaptation | Universal domain adaptation (UniDA) aims to transfer knowledge from a labeled
source domain to an unlabeled target domain without requiring the same label
sets of both domains. The existence of domain and category shift makes the task
challenging and requires us to distinguish "known" samples (i.e., samples whose
labels exist in both domains) and "unknown" samples (i.e., samples whose labels
exist in only one domain) in both domains before reducing the domain gap. In
this paper, we consider the problem from the point of view of distribution
matching which we only need to align two distributions partially. A novel
approach, dubbed mini-batch Prototypical Partial Optimal Transport (m-PPOT), is
proposed to conduct partial distribution alignment for UniDA. In training
phase, besides minimizing m-PPOT, we also leverage the transport plan of m-PPOT
to reweight source prototypes and target samples, and design reweighted entropy
loss and reweighted cross-entropy loss to distinguish "known" and "unknown"
samples. Experiments on four benchmarks show that our method outperforms the
previous state-of-the-art UniDA methods. |
2408.01090v1 | ## General-purpose Dataflow Model with Neuromorphic Primitives
## Weihao Zhang
## Yu Du
## Hongyi Li
[email protected] Center for Brain-Inspired Computing Research (CBICR), Tsinghua University Beijing, China [email protected] Center for Brain-Inspired Computing Research (CBICR), Tsinghua University Beijing, China
## Songchen Ma
[email protected] Center for Brain-Inspired Computing Research (CBICR), Tsinghua University Beijing, China
## Rong Zhao ∗
[email protected] Center for Brain-Inspired Computing Research (CBICR), Tsinghua University Beijing, China
## ABSTRACT
Neuromorphic computing exhibits great potential to provide highperformance benefits in various applications beyond neural networks. However, a general-purpose program execution model that aligns with the features of neuromorphic computing is required to bridge the gap between program versatility and neuromorphic hardware efficiency. The dataflow model offers a potential solution, but it faces high graph complexity and incompatibility with neuromorphic hardware when dealing with control flow programs, which decreases the programmability and performance. Here, we present a dataflow model tailored for neuromorphic hardware, called neuromorphic dataflow, which provides a compact, concise, and neuromorphic-compatible program representation for control logic. The neuromorphic dataflow introduces "when" and "where" primitives, which restructure the view of control. The neuromorphic dataflow embeds these primitives in the dataflow schema with the plasticity inherited from the spiking algorithms. Our method enables the deployment of general-purpose programs on neuromorphic hardware with both programmability and plasticity, while fully utilizing the hardware's potential.
## CCS CONCEPTS
· Computing methodologies → Parallel computing methodologies ; · Theory of computation → Models of computation .
## KEYWORDS
neuromorphic computing, dataflow, many-core architecture, spiking neural network, control flow approximation
∗ Corresponding author.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected].
ICONS, 2023, Santa Fe, New Mexico, USA
© 2024 Association for Computing Machinery.
ACM ISBN 978-x-xxxx-xxxx-x/YY/MM...$15.00
https://doi.org/10.1145/nnnnnnn.nnnnnnn r\[email protected] Center for Brain-Inspired Computing Research (CBICR), Tsinghua University Beijing, China
## ACMReference Format:
Weihao Zhang, Yu Du, Hongyi Li, Songchen Ma, and Rong Zhao. 2024. General-purpose Dataflow Model with Neuromorphic Primitives. In Proceedings of International Conference on Neuromorphic Systems (Poster) (ICONS). ACM,NewYork,NY,USA,5pages.https://doi.org/10.1145/nnnnnnn.nnnnnnn
## 1 INTRODUCTION
In recent years, Neuromorphic computing (NC) has attracted much attention as an alternative computing to von Neumann architecture in computing[1]. Inspired by the biological brain, NC demonstrates the advantages of ultra-low latency and high energy efficiency in both neuroscience-oriented and intelligent-oriented applications due to its in-situ computing, event-driven processing patterns, and direct utilization of the physical circuit's functionalities. NC chips typically adopt a many-core architecture that incorporates digital or analog crossbars co-located storage for massively parallel processing. Network-on-chip with routers is used to connect these processing units[21]. Till now, NC has mostly been used for domainspecific applications. However, there is now an aspiration to extend its high efficiency to more versatile applications.
Efforts from various perspectives are underway to achieve this goal. Theoretically, the NC has been proven to be Turing Complete with corresponding computational model[9]. In practice, some works have used NC infrastructures to support non-neural network applications[2], such as solving partial differential equations through random walking[4] and addressing traditional NP-Hard problems[5]. Some neuromorphic chips have also explored the mutual scheduling mechanism between neuromorphic execution activities, replacing central processing units (CPU) to enhance flexibility[8], replacing the scheduling responsibility of the CPU. Additionally, programming frameworks and compilers have been developed to provide higher-level abstractions for hardware-agnostic programming with portability[6, 7].
To support the increasing demand for applications and advancements in theories, a neuromorphic program execution model that can unify the representation of general programs with hardware execution abstraction is highly needed. Several mature models have been proposed for domain-specific NC, such as Corelet for TrueNorth[19] and Rivulet for Tianjic[8]. In terms of general-purpose
Figure 1: A basic demonstration of conventional dataflow. (A) A program segment written in Algol-like syntax designed for von-Neumann architecture. (B) The equivalent dataflow representation of program A. This example is taken from [12]
models, there are efforts to utilize the general expressivity or approximation capability of spiking neurons to either construct or approximate general programs, such as neural engineering framework[20], Fugu[6], and neuromorphic completeness representation[10]. However, these approaches require an extensive number of neurons to construct even a single control operation, and the high-precision low-redundancy approximation for general control is still challenging to achieve general approximation. On the other hand, the dataflow model[12], which is Turing complete and shares similarities with high-level features of NC, has been explored for braininspired representation[13]. However, the existing dataflow model has a complex representation for control logic and is incompatible with most NC chips. Moreover, the conventional dataflow has less plasticity than neuromorphic models, limiting its learning ability. To this extent, the main contributions of this paper are:
- 1) We analyze the control logic of von-Neumann programs from a neuromorphic perspective and devise the "where" and "when" primitives.
- 2) Weproposeaconcise, neuromorphic compatible, programmable, and learnable neuromorphic dataflow model for general programs with control flows.
## 2 CONVENTIONAL DATAFLOW MODEL
A dataflow model is a directed graph in which vertices are called actors and edges are called arcs. The execution of an actor's operation is initiated by an event known as a token. Arcs transfer tokens between actors, where input tokens are consumed by an actor to generate output tokens based on firing rules. Typically, the dataflow model contains data tokens that denote arbitrary values, and control tokens that represent true/false values. A basic example of the dataflow model is presented in Fig. 1, which include operators representing integrated functions with one or multiple input data
Figure 2: A basic demonstration of neuromorphic dataflow. (A) Same program in Fig. 1 (A). (B) The equivalent neuromorphic dataflow model of program A.
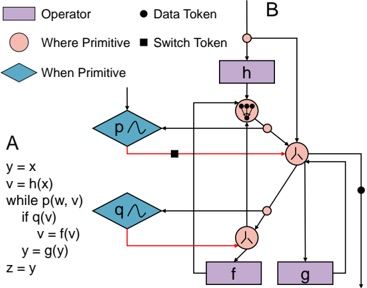
arcs, and fire output data tokens when all input tokens are available. Deciders, representing predicate logic, require one or multiple data tokens as input and fire a control token when all inputs are available. The true/false gates permit data tokens to pass through when receiving a true/false control token, while the merges let the data token pass through the true side when receiving a true control token, and vice versa.
In the conventional dataflow model, the presence of gates, merges, and arcs that carry control tokens significantly increases the complexity of the graph with control logic. In Fig. 1, for example, there are 10 gates or merges for just one "while" logic and one "if" logic. These fine-grained and irregular operators in the dataflow model render it unsuitable for neuromorphic hardware and may cause a mismatch between the dataflow parallelism and fixed hardware parallelism.
## 3 NEUROMORPHIC DATAFLOW MODEL
To address the above issues, we design a neuromorphic dataflow model (NDF). Classical programs utilize control logic such as conditions, loops, or gotos to manipulate programs based on the program counter (PC). In contrast, the dataflow model utilizes tokens to trigger operations via an event-driven mechanism. Control is realized in a predicate-decision decoupled framework with control tokens. The objective of NDF is to further abstract the concept of "control" from a neuromorphic perspective. Drawing on the dataflow model and neuroscience, such as the gating mechanism in neuronal circuits[18], the control logic in NDF involves two aspects: where tokens are directed and when tokens are generated. Following this philosophy, we designed where and when primitives in NDF.
## 3.1 Dataflow Model with Where Primitive
The where primitive replaces gates and merges to create a concise dataflow. It can be viewed as a multi-switch as shown in Fig. 3. The where primitive has 𝑚 𝑤ℎ𝑒𝑟𝑒 , 𝑚 𝑤ℎ𝑒𝑟𝑒 > = 1 data token inputs and 𝑛 𝑤ℎ𝑒𝑟𝑒 , 𝑛 𝑤ℎ𝑒𝑟𝑒 > = 1 data token outputs, and redirects input data tokens to output with a specific connection pattern. A static where primitive has fixed connectivity, whereas a dynamic where primitive
Figure 3: A dynamic where primitive takes switch token as input to change its connections of data in/out arcs.
relies on another input switch token. The switch token is a specially designed token that determines the connections between inputs and outputs and is equivalent to a 𝑛 𝑤ℎ𝑒𝑟𝑒 × 𝑚 𝑤ℎ𝑒𝑟𝑒 adjacency matrix. Each firing of the dynamic where primitive will consume a switch token and transfer input data tokens to corresponding output arcs.
With where primitives , the complexity of the original dataflow is greatly reduced. Shown in Fig. 2, the NDF for the same program in Fig. 1 only has 8 actors (ignoring the two-to-one data link), including one static where primitive with a constant three-to-one connection and two dynamic where primitives that controlled by the when primitives .
## 3.2 Dataflow Model with When Primitive
Figure 4: The firing rule of when primitive with twodimensional membrane potential and four separate regions.
The when primitive generates switch tokens to determine the connectivity of the dynamic where primitive . Aspiking neuron with temporal richness is adopted to replace the original decider. For instance, the predicate 3 𝑥 -2 < 𝑦 , i.e. 3 𝑥 -𝑦 < 2 can be modeled as a leaky integrate-and-fire (LIF) neuron that takes two inputs 𝑥 and 𝑦 whose weights are 3 and -1 respectively, and a threshold of 2. If the statement is true, the spiking neuron fires a spike that serves as a switch token for representing the connection pattern (which can be stored in advance) under the true situation.
The NDF may have instances where the where primitive has multiple possible connection patterns. In such cases, the corresponding when primitive should have an output type beyond just spike and not spike. Thus, we introduce a modified spiking neuron for when primitives . The modified spiking neuron has a 𝑘 -dimensional membrane potential 𝑣 𝑘 , inputs vector 𝐼 with length 𝑛 𝑤ℎ𝑒𝑛 , and a weight matrix 𝑊 with size 𝑛 𝑤ℎ𝑒𝑛 × 𝑘 . The updated rule for membrane potential is:
$$v _ { t + 1 } ^ { k } = f \left ( v _ { t } ^ { k } + I ^ { T } W \right ) \text{ \quad \ \ } \text{(1)}$$
Here, we introduce a function 𝑓 to increase the non-linearity and extend the traditional threshold concept to the separation of the multi-dimensional membrane potential space. Specifically, when the value of 𝑣 𝑘 𝑡 is within a particular region, the neuron fires a corresponding token for a particular connection pattern. Accordingly, the when primitive with 𝑚 𝑤ℎ𝑒𝑛 separate regions can accommodate up to 𝑚 𝑤ℎ𝑒𝑛 connection patterns of the where primitive . Fig. 4 illustrates such a spiking neuron with a 2-dimensional membrane potential and four separate regions within the membrane potential space. The membrane potential shifts among these regions depending on the input. This type of neuron can be regarded as a multi-dimensional state machine in continuous space with the membrane potential updated rule as the state transition equation.
## 4 HARDWARE COMPATIBILITY OF NEUROMORPHIC DATAFLOW MODEL
The composability of where primitives . The multi-switch structure of where primitives makes them compatible with the 2D-mesh router implementations that are widely adopted by neuromorphic hardware[14]. Alternatively, it can be mapped on a network-onchip system with fine-grained functional bio-plausible routing protocols[8, 15], allowing for the fusion of multiple adjacent where primitives into one larger where primitive . This enables the adjustment of the granularity of the where primitives to achieve improved load-balance on many-core neuromorphic chips, as shown in Fig. 6.
The plasticity of when primitives . When primitives can be mapped on the soma module (or a modified soma module from codesigning), which is primarily responsible for non-linear functions or dynamic procedures[16]. The when primitive has a learning ability, through STDP[22] or BP with surrogate gradient functions[17], to approximate the target functionality. By training the NDF as a whole with other neuromorphic operators, through the when primitive , the overall precision can be improved. We demonstrate this through an experiment.
The 𝑠𝑖𝑛 and 𝑐𝑜𝑠 in the target program in Fig. 5 are each approximated by an MLP with 4, 8, and 16 neurons of the hidden layer. Without the when primitive, the approximation of 𝑠𝑖𝑛 and 𝑐𝑜𝑠 are trained independently. Conversely, the NDF is trained as a whole with the surrogate gradient of the when primitive. As shown in Fig. 5, using the when primitive can reduce the approximation error of
Figure 5: Approximation error of a simple program.
Figure 6: The compatibility between neuromorphic dataflow and neuromorphic hardware. (A) Composable NDF with different granularity. (B) One of the representative neuromorphic hardware architectures with scalable hierarchy[10].
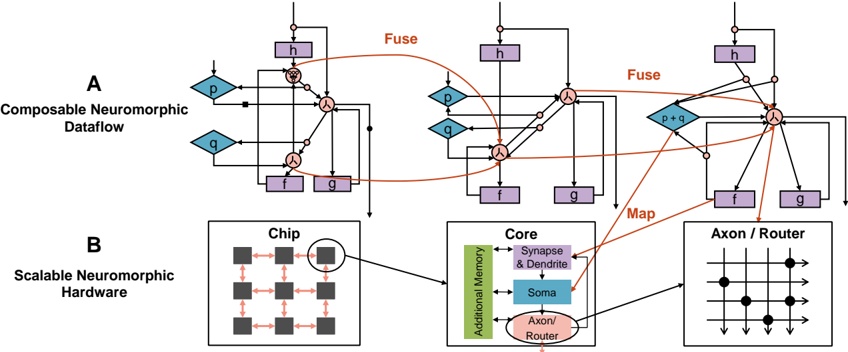
.
NDF when the number of neurons is small (4 and 8), but little space is left to reduce the overall error. However, when the number of neurons is enough to approximate 𝑠𝑖𝑛 and 𝑐𝑜𝑠 functions precisely.
## 5 CONCLUSION
We present a program execution model that combines the dataflow schema with neuromorphic-compatible primitives, allowing for the practical programming and deployment of a wide range of applications on Turing-complete neuromorphic hardware. To achieve this, we design the where primitive to direct tokens and when primitive to control when tokens fire. By incorporating these primitives, our NDF model achieves a compact, concise, and interpretable controllogic representation. The NDF also exhibits compatibility with neuromorphic hardware that has plasticity and multi-grained composability. Our work introduces a dataflow perspective to practical general-purpose neuromorphic computing, providing the potential to combine brain-level efficiency and CPU-level versatility.
## ACKNOWLEDGMENTS
This work was partly supported by National Nature Science Foundation of China (nos. 61836004 and 62088102).
## REFERENCES
- [1] K. Roy, A. Jaiswal, and P. Panda, 'Towards spike-based machine intelligence with neuromorphic computing,' Nature , vol. 575, no. 7784, pp. 607-617, 2019.
- [2] J. Aimone, P. Date, G. Fonseca-Guerra, K. Hamilton, K. Henke, B. Kay, G. Kenyon, S. Kulkarni, S. Mniszewski, M. Parsa et al. , 'A review of non-cognitive applications for neuromorphic computing,' Neuromorphic Computing and Engineering , 2022.
- [3] R. Araújo, N. Waniek, and J. Conradt, 'Development of a dynamically extendable spinnaker chip computing module,' in Artificial Neural Networks and Machine Learning-ICANN 2014: 24th International Conference on Artificial Neural Networks, Hamburg, Germany, September 15-19, 2014. Proceedings 24 . Springer, 2014, pp. 821-828.
- [4] J. D. Smith, A. J. Hill, L. E. Reeder, B. C. Franke, R. B. Lehoucq, O. Parekh, W. Severa, and J. B. Aimone, 'Neuromorphic scaling advantages for energy-efficient random walk computations,' Nature Electronics , vol. 5, no. 2, pp. 102-112, 2022.
- [5] M. Davies, A. Wild, G. Orchard, Y. Sandamirskaya, G. A. F. Guerra, P. Joshi, P. Plank, and S. R. Risbud, 'Advancing neuromorphic computing with loihi: A
- survey of results and outlook,' Proceedings of the IEEE , vol. 109, no. 5, pp. 911-934, 2021.
- [6] J. B. Aimone, W. Severa, and C. M. Vineyard, 'Composing neural algorithms with fugu,' in Proceedings of the International Conference on Neuromorphic Systems , 2019, pp. 1-8.
- [7] Intel, 'A software framework for neuromorphic computing,' https://lava-nc.org/, 2021.
- [8] S. Ma, J. Pei, W. Zhang, G. Wang, D. Feng, F. Yu, C. Song, H. Qu, C. Ma, M. Lu et al. , 'Neuromorphic computing chip with spatiotemporal elasticity for multiintelligent-tasking robots,' Science Robotics , vol. 7, no. 67, p. eabk2948, 2022.
- [9] P. Date, T. Potok, C. Schuman, and B. Kay, 'Neuromorphic computing is turingcomplete,' in Proceedings of the International Conference on Neuromorphic Systems 2022 , 2022, pp. 1-10.
- [10] Y. Zhang, P. Qu, Y. Ji, W. Zhang, G. Gao, G. Wang, S. Song, G. Li, W. Chen, W. Zheng et al. , 'A system hierarchy for brain-inspired computing,' Nature , vol. 586, no. 7829, pp. 378-384, 2020.
- [11] H. Esmaeilzadeh, A. Sampson, L. Ceze, and D. Burger, 'Neural acceleration for general-purpose approximate programs,' in 2012 45th annual IEEE/ACM international symposium on microarchitecture . IEEE, 2012, pp. 449-460.
- [12] J. B. Dennis, J. B. Fosseen, and J. P. Linderman, 'Data flow schemas,' in International Symposium on Theoretical Programming . Springer, 1974, pp. 187-216.
- [13] P. Qu, J. Yan, Y.-H. Zhang, and G. R. Gao, 'Parallel turing machine, a proposal,' Journal of Computer Science and Technology , vol. 32, pp. 269-285, 2017.
- [14] Y. Ji, Y. Zhang, X. Xie, S. Li, P. Wang, X. Hu, Y. Zhang, and Y. Xie, 'Fpsa: A full system stack solution for reconfigurable reram-based nn accelerator architecture,' in Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems , 2019, pp. 733-747.
- [15] S. B. Furber, F. Galluppi, S. Temple, and L. A. Plana, 'The spinnaker project,' Proceedings of the IEEE , vol. 102, no. 5, pp. 652-665, 2014.
- [16] G. Indiveri, B. Linares-Barranco, T. J. Hamilton, A. v. Schaik, R. EtienneCummings, T. Delbruck, S.-C. Liu, P. Dudek, P. Häfliger, S. Renaud et al. , 'Neuromorphic silicon neuron circuits,' Frontiers in neuroscience , vol. 5, p. 73, 2011.
- [17] E. O. Neftci, H. Mostafa, and F. Zenke, 'Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks,' IEEE Signal Processing Magazine , vol. 36, no. 6, pp. 51-63, 2019.
- [18] L. Luo, 'Architectures of neuronal circuits,' Science , vol. 373, no. 6559, p. eabg7285, 2021.
- [19] A. Amir, P. Datta, W. P. Risk, A. S. Cassidy, J. A. Kusnitz, S. K. Esser, A. Andreopoulos, T. M. Wong, M. Flickner, R. Alvarez-Icaza et al. , 'Cognitive computing programming paradigm: a corelet language for composing networks of neurosynaptic cores,' in The 2013 International Joint Conference on Neural Networks (IJCNN) . IEEE, 2013, pp. 1-10.
- [20] C. Eliasmith and C. H. Anderson, Neural engineering: Computation, representation, and dynamics in neurobiological systems . MIT press, 2003.
- [21] G. Li, L. Deng, H. Tang, G. Pan, Y. Tian, K. Roy, and W. Maass, 'Brain inspired computing: A systematic survey and future trends,' 2023.
- [22] S. Song, K. D. Miller, and L. F. Abbott, 'Competitive hebbian learning through spike-timing-dependent synaptic plasticity,' Nature neuroscience , vol. 3, no. 9, pp.
General-purpose Dataflow Model with Neuromorphic Primitives
ICONS, 2023, Santa Fe, New Mexico, USA
919-926, 2000. | null | [
"Weihao Zhang",
"Yu Du",
"Hongyi Li",
"Songchen Ma",
"Rong Zhao"
] | 2024-08-02T08:09:13+00:00 | 2024-08-02T08:09:13+00:00 | [
"cs.CL",
"cs.AR",
"cs.NE"
] | General-purpose Dataflow Model with Neuromorphic Primitives | Neuromorphic computing exhibits great potential to provide high-performance
benefits in various applications beyond neural networks. However, a
general-purpose program execution model that aligns with the features of
neuromorphic computing is required to bridge the gap between program
versatility and neuromorphic hardware efficiency. The dataflow model offers a
potential solution, but it faces high graph complexity and incompatibility with
neuromorphic hardware when dealing with control flow programs, which decreases
the programmability and performance. Here, we present a dataflow model tailored
for neuromorphic hardware, called neuromorphic dataflow, which provides a
compact, concise, and neuromorphic-compatible program representation for
control logic. The neuromorphic dataflow introduces "when" and "where"
primitives, which restructure the view of control. The neuromorphic dataflow
embeds these primitives in the dataflow schema with the plasticity inherited
from the spiking algorithms. Our method enables the deployment of
general-purpose programs on neuromorphic hardware with both programmability and
plasticity, while fully utilizing the hardware's potential. |
2408.01091v2 | ## Dissecting Dissonance: Benchmarking Large Multimodal Models Against Self-Contradictory Instructions
Jin Gao 1 , Lei Gan 2 ⋆ , Yuankai Li 2 ⋆ , Yixin Ye 1 , and Dequan Wang 1 3 , †
1 Shanghai Jiao Tong University 2 Fudan University 3
Shanghai Artificial Intelligence Laboratory
Fig. 1: Top : Children or language beginners meet conflicts for cognitive errors ( SemanticConflict ). Bottom : Increasing context length leads to contradictions ( RuleConflict ).
Abstract. Large multimodal models (LMMs) excel in adhering to human instructions. However, self-contradictory instructions may arise due to the increasing trend of multimodal interaction and context length, which is challenging for language beginners and vulnerable populations. We introduce the Self-Contradictory Instructions benchmark to evaluate the capability of LMMs in recognizing conflicting commands. It comprises 20,000 conflicts, evenly distributed between language and vision paradigms. It is constructed by a novel automatic dataset creation framework, which expedites the process and enables us to encompass a wide range of instruction forms. Our comprehensive evaluation reveals current LMMs consistently struggle to identify multimodal instruction discordance due to a lack of self-awareness. Hence, we propose the Cognitive Awakening Prompting to inject cognition from external, largely enhancing dissonance detection. Here are our website, dataset, and code.
Keywords: Large Multimodal Models · Instruction Conflict
⋆ Equal contribution. † Corresponding author.
Fig. 2: SCI comprises 10,000 language-language (L-L) and 10,000 visionlanguage (V-L) paradigms, each with 4 tasks. Top: L-L paradigm involves conflicts between context and instruction, such as designed rules, object attributes, exclusive directives, and forbidden words. Bottom: V-L paradigm covers multimodal conflicts, such as OCR images, figures, geometry, and semantics.
## 1 Introduction
Large multimodal models (LMMs) have become prominent for their exceptional ability to follow human instructions [1,4,12,26,29,31,32,38]. Designed to process various data types, LMMs can generate and understand content in a humanlike way, aligning closely with human cognition through extensive research and development [3,14,44,45]. This focus on following human instructions has led to high compliance, sometimes verging on sycophancy [9,36,40].
LMMs are also rapidly developing to expand context windows and strengthen multimodal interaction. The Claude 3 family of models [1] offers a 200K token context window. Gemini 1.5 Pro [12] comes with a standard context window size of 128K (even up to 1M tokens in a private preview phase). Both models have sophisticated vision capabilities and can process a wide range of visual formats, including photos, figures, graphs, and technical diagrams. New multimodal models are emerging at a fantastic speed, demonstrating unprecedented performance in tackling long-context and multimodal instructions [11,12,20,22,25,32].
However, self-contradictory instructions may arise due to the increasing trend of multimodal interaction and context window expansion, which is particularly challenging for language beginners and vulnerable populations. As shown in Fig. 1, children or language beginners may not realize the potential multimodal conflicts when LMMs are used in translation and education. It is also difficult for users to remember all details in multi-round conversations to avoid in-
struction contradiction, especially when the context window size grows to 1M tokens and beyond. Moreover, conflicts between modalities may occur as the number of modalities gradually increases. Such conflicts may compromise the performance of LMMs once they fail to own meta-awareness [2] and to recognize the dissonance . Such self-awareness raises attention from researchers who attempt to enhance from the model level, while instruction-level studies are overlooked [7,23,43,47].
Hence, we propose a multimodal benchmark, Self-Contradictory Instructions ( SCI ), to evaluate the ability of LMMs to detect conflicted instructions 4 . It encompasses 20K conflicting instructions and 8 tasks, evenly distributed between language-language and vision-language paradigms (Fig. 2). SCI is constructed using our novel automatic dataset creation framework, AutoCreate (Fig. 3), which builds a multimodal cycle based on programs and large language models. We have rigorously guaranteed the quality of SCI and manually provide three levels of splits according to the occurring frequency of conflict types, SCICore (1%), SCI-Base (10%), and SCI-All (100%), to facilitate qualitative evaluation. AutoCreate expedites the dataset creation process and enables the inclusion of a wide array of instruction forms, complexities, and scopes.
Based on SCI , we assess the capability to decipher self-contradictory instructions for current LMMs, including 5 language and 6 vision-language models. Experiments reveal that LMMs consistently fall short of accurately identifying conflicts despite remarkable performance in following instructions. Besides, we observe that such deficiency persists owing to a lack of self-awareness. Although the training process enables LMMs to handle information and knowledge but not to assess the reasonableness of user instructions and context, a capability we term cognition . Hence, we propose a plug-and-play prompting approach, Cognitive Awakening Prompting ( CaP ), to inject cognition from the external world, thereby largely enhancing dissonance detection even compared with advanced in-context learning techniques [5, 42, 46]. CaP is demonstrated to improve performance on both language-language and vision-language instruction conflicts.
## Our contributions:
- -We propose the SCI benchmark, a multimodal dataset designed to evaluate the capability of LMMs to comprehend conflicting instructions effectively.
- -We design a novel LLM-based cyclic framework, AutoCreate , for automatic dataset creation, substantially accelerating the process and allowing for the integration of extensive knowledge.
- -We present CaP , a prompting approach to enhance instruction conflict awareness of LMMs, significantly improving dissonance detection compared to advanced in-context learning techniques.
4
Website: https://sci-jingao.pages.dev Dataset: https : / / huggingface . co / datasets / sci - benchmark / self contradictory Code: https://github.com/shiyegao/Self-Contradictory-Instructions-SCI
## 2 Related Work
Instruction Following is a remarkable ability showcased by large language models [13, 28, 33], highlighting their proficiency in comprehending and executing a given set of directives. This capability has been further amplified in the domain of large multimodal models (LMMs), where the alignment between the model and multimodal human instruction is particularly noteworthy [12,25-27,32]. Researchers have actively focused on leveraging human instruction and feedback to enhance the aptitude of these models for instruction-following [3,8,14,41,44,45]. Consequently, LMMs strive to emulate human instructions to an extraordinary degree, bordering on what can be described as sycophantic [9,36,40]. This trend underscores the deep integration of human-like understanding and execution within LMMs, positioning them as powerful tools for various tasks requiring nuanced interpretation and execution of instructions. As LMMs continue to advance, exploring the boundaries and implications of their instruction-following capabilities becomes increasingly pertinent.
Information Inconsistency is an inherent challenge faced by LMMs in certain scenarios, despite their advantage in handling vast amounts of information [19, 34, 35]. Researchers have dedicated efforts to address the issue of knowledge conflicts within language models, where textual disparities emerge between the parametric knowledge embedded within LLMs and the non-parametric information presented in prompts [7, 21, 43, 47]. Furthermore, information contradictions can manifest in both textual and visual domains. For instance, some studies [23, 24, 37] investigate language hallucination and visual illusion. Nevertheless, the aforementioned research has not systematically explored one of the most prevalent forms of inconsistencythe contradiction within input instructions . In contrast, our SCI benchmark tackles this challenge by constructing and studying 20,000 multimodal conflicts, offering a comprehensive examination of this vital aspect of information inconsistency in the context of LMMs.
Automatic Dataset Curation has emerged as a transformative paradigm within the domain of large language models (LLMs), offering several advantages such as enhancing model performance and reliability, saving time and resources, and mitigating the risk of human errors. This paradigm is particularly pivotal within the domain of LLMs. Wang et al. propose the Self-Instruct framework [44], which leverages LLMs' own generated content to create instructions, input data, and output samples autonomously. Besides, Saparov et al. introduce PrOntoQA [39], a highly programmable question-answering dataset generated from a synthetic world model. The advent of AutoHall [6] has furthered the field by offering a method to construct LLM-specific hallucination datasets automatically. Additionally, TIFA [16] automatically generates several question-answer pairs using LLMs to measure the faithfulness of generated images to their textual inputs via visual question-answering. In this paper, we systematically discuss automatic dataset automation leveraging LLMs and introduce eight specific tasks to exemplify the potential of this approach.
Fig. 3: We propose AutoCreate , an automatic dataset creation framework that leverages programs and large language models. AutoCreate starts from several task-relevant seeds and maintains a seed pool. During each cycle, AutoCreate includes two branches, the language ( left ) and the vision ( right ). Each branch consists of a generator and a decorator. Finally, the cleaner will exclude data that does not meet the standards. The data will be fed into the seed pool for the next round after a quality check by human experts.
## 3 Dataset
In this section, we first discuss the novel automatic dataset creation framework, AutoCreate , in Section 3.1. Moreover, leveraging AutoCreate , we construct the multimodal Self-Contradictory Instructions benchmark, SCI , which is elaborated in Section 3.2. More details of AutoCreate and SCI are in the Appendix.
## 3.1 AutoCreate
Leveraging the power of large language models (LMMs), datasets can be created rapidly with higher quality and wider coverage than pure human handcrafts. Previous works have made initial attempts to construct datasets automatically in the domain of LLM [6,16,39,44], but do not systematically build an automatic framework. Here we introduce a novel automatic dataset creation, AutoCreate , shown in Fig. 3.
AutoCreate requires a small batch of manually input seeds to automatically generate a large quantity of high-quality, diverse data by Large Language Models (LLMs). Specifically, in a single iteration, the generation process comprises two loops: the Language Loop ( left ) and the Visual Loop ( right ). Each loop originates from the Seed Pool and is sequentially processed by a fully automated Generator, Decorator, and Cleaner, culminating in a high-quality dataset
Table 1: SCI consists of eight different tasks, evenly distributed between languagelanguage (L-L) and vision-language (V-L) paradigms.
| | RuleConflict | RuleConflict | AttributeConflict | ExclusionConflict | ForbbidenConflict |
|-----|----------------|----------------|---------------------|---------------------|---------------------|
| L-L | Size | 2500 | 2500 | 2500 | 2500 |
| | Rate | 25.0% | 25.0% | 25.0% | 25.0% |
| | OCRConflict | OCRConflict | FigureConflict | GeometricConflict | SemanticConflict |
| V-L | Size | 1590 | 1461 | 2000 | 4949 |
| | Rate | 15.9% | 14.6% | 20.0% | 49.5% |
production. Here, the Generator creates initial language/vision data, the Decorator creates self-contradictions in the generated data, and the Cleaner removes data that does not meet quality standards. Both human experts and LLMs are involved in double-checking the quality of the generated dataset. The resulting high-quality dataset is then refined to extract new seeds for re-entry into the seed pool. Throughout multiple loops, both the seed pool and our dataset undergo rapid expansion, ultimately resulting in a comprehensive dataset. Similar approaches have proved to create both diverse and qualified datasets [48]. Finally, human experts have rigorously checked the quality of the AutoCreate -generated dataset, SCI . More details of AutoCreate are in the Appendix.
## 3.2 SCI
Based on AutoCreate , we build the Self-Contradictory Instructions ( SCI ) multimodal benchmark which consists of two paradigms, language-language (L-L) and vision-language (V-L) as illustrated in Fig. 2. While the generation prompts vary across tasks, the generation process is unified in AutoCreate : generator-decorator-cleaner. For V-L conflicts, the image caption is modified to introduce a conflict. SCI comprises 20,000 self-contradictory instructions that span a wide range of instruction forms, complexities, and scopes. Besides that whole dataset, SCI-All , we also introduce two subsets, SCI-Base and SCICore , to cater to different needs. The latter subsets are selected manually with a size of 10% (1%) of SCI-All . Within 8 types of conflicts, only SemanticConflict involves external data, ImageNet. More details of SCI are in the Appendix.
Language-Language (L-L) Conflict refers to the contradiction within text inputs. The L-L paradigm consists of 4 tasks, each with 2,500 texts. Based on the inherent nature of user prompts, we describe the tasks as RuleConflict , AttributeConflict , ExclusionConflict , and ForbbidenConflict .
RuleConflict involves contradictory textual instructions where a rule is stated, but an example violating the rule is provided (see Fig. 2a). RuleConflict is generated in two steps: first, establish a strict rule in the context; second, craft a
sentence that intentionally violates this rule. This process forms the RuleConflict by pairing the rule context with its violation. At test time, a single unanswerable question is created due to the rule violation. The prompt consists of the context, violating sentence, and unanswerable question concatenated sequentially.
## RuleConflict
Rule : City A has only 1 mayor, Megan, from 2012 to 2020. Violation : Leon gave a talk in 2015 as the mayor of City A.
Question : Who served as the mayor of City A in 2015?
AttributeConflict involves a scenario where a text provides two contradictory descriptions for an attribute of an object (see Fig. 2b). The generation of AttributeConflict includes three steps: first, create a descriptive text for a fictitious object with various attributes; second, extract a description for each attribute from the text; third, generate an opposite description to contradict the original for each attribute. By concatenating any opposite description with the original text, an AttributeConflict is formed. At test time, the task is to describe the specific attribute of the object based on the text.
ExclusionConflict pertains to a situation where the user's prompt provides two instructions, each involving mutually exclusive operations, as demonstrated in Fig. 2c. The core of a ExclusionConflict is a pair of conflicting instructions. ( e.g ., 'Translate the text to Chinese" versus "Translate the text to French'). Specifically, our dataset focuses on instructions for mutually exclusive operations on the same text passage. By combining a pair of exclusive instructions and a text, an ExclusionConflict prompt in the following format is generated.
## {{ instruction 1 }{ text }{ instruction 2 }}
ForbbidenConflict deals with conflicting instructions in conversational contexts. Here, users initially tell the LLM not to mention a particular topic and then later prompt it to discuss that same topic, as shown in Fig. 2d. To generate a ForbbidenConflict in our dataset, we first select a word from a seed pool as the forbidden word. Then, we create a question that ensures the respondent will inevitably talk about the forbidden word. At test time, a prompt with a ForbbidenConflict combines an instruction forbidding discussion of a certain word and a question that prompts the LLM to engage with that word.
Vision-Language (V-L) Conflict refers to conflicts between the multimodal components of vision and language. Below will elaborate on 4 subclasses of conflicts: OCRConflict , FigureConflict , GeometricConflict , and SemanticConflict .
OCRConflict consists of two conflicting instructions respectively in vision and language form, as presented in Fig. 2e. The generation of OCRConflict can be
summarized in two steps. First, a list of short sentences is generated to provide the context for the conflicts. Second, utilizing instructions pairs from Section 3.2, an image of the concatenation of an instruction and a sentence is crafted. The image varies in font, size, and color to augment diversity. At test time, presenting the image and the conflicting instruction concurrently yields a conflict.
FigureConflict involves a simple chart with an incorrect text description, as shown in Fig. 2f. It is created through four steps. First, a list of commonly used words and entities with related numerical data is generated to decide the conflict's topic. Second, a narrative description and question are crafted for each entity and its data. Third, the numerical data is manipulated by changing the maximum value to the minimum value. Finally, a chart is plotted based on the altered data, with random choices for font, size, color, and other style options. At test time, combining the question and the figure creates a FigureConflict .
GeometricConflict involves an image of geometric shapes with an incorrect description, as shown in Fig. 2g. The generation process has four main steps. First, an image of two geometric objects with different attributes (shape, size, color, and position) is created. Second, a phrase is crafted to describe an object using two attributes (e.g., "the smaller gray object"). Third, this phrase is modified to refer to a non-existent object (e.g., "the larger gray object"). Finally, a question is generated about a third attribute of the non-existent object (e.g., "What is the shape of the larger gray object?"). At test time, presenting the image and question together creates a GeometricConflict .
SemanticConflict involves an erroneously classified image, as shown in Fig. 2h. To be specific, a question about the wrong class ( e.g ., 'kiwi") should be answered according to the given image ( e.g ., 'ostrich"). The generation process of SemanticConflict is based on the ImageNet dataset [10]. First, we generate some questions about a label and retrieve images according to that label in the ImageNet dataset. Second, we substitute the correct label in the questions with some similar but different objects. At test time, combining the image and the substituted question will create a conflict.
## SemanticConflict
Substitute object : Ostrich to Kiwi

Question : Does the picture depict the kiwi's size?
## 4 Approach
In this section, we delve into our exploration using in-context learning techniques, detailed in Section 4.1. Through experiments across various Large Multimodal Models (LMMs), we've pinpointed a crucial challenge where LMMs struggle to detect instruction conflicts. Additionally, we introduce our proposed Cognitive Awakening Prompting ( CaP ) approach, outlined in Section 4.2.
## 4.1 In-Context Learning
Westudy three in-context learning techniques in SCI , including few-shot prompting [5], zero-shot chain-of-thoughts prompting [18], and self-consistency prompting [42]. Although few-shot prompting has been widely used in Large Language Models, its application in Large Multimodal Models (LMMs) remains limited. Recent research highlights challenges such as LMMs' inability to support multiple image inputs or comprehend sophisticated few-shot prompts [17,50]. Consequently, few-shot prompting is primarily employed within the language-language paradigm. Here, we detail the application of these prompting techniques in our SCI .
Zero-shot Prompting refers to the ability of the model to perform a task without providing examples of how to perform a task correctly. We task the model with generating responses in SCI solely based on its general knowledge and understanding of language and vision. This capability underscores the model's innate capacity to detect self-contradictory conflicts.
Zero-shot Chain-of-thoughts Prompting [46] (CoT) involves appending text like 'Please think step by step' to user prompts, proven to enhance LMMs' inference ability. In our experiment, we incorporate this text into the prompt.
Self-consistency Prompting [42] (SC) involves sampling multiple reasoning paths and selecting the most consistent answers. In this paper, we generate three replies for each instruction (3-SC) and determine the final result through majority voting.
## 4.2 Cognitive Awakening Prompting
Our initial exploration reveals an intriguing phenomenon: the performance order in vision-language tasks is 0-Shot, CoT, and 3-SC across diverse LMMs, shown in the Appendix. While 3-SC provides additional experience through more attempts, CoT offers extra knowledge by stimulating reasoning capabilities through a chain of thought. However, neither surpasses the simplicity of zeroshot prompting, suggesting that both additional experience and extra knowledge derived from the model itself may be counterproductive. We hypothesize that the LMMs may not fully grasp restricted cognition in the self-contradictory instruction scenarios.
Therefore, we propose a plug-and-play prompting approach to infuse cognition from the external world: Cognitive Awakening Prompting ( CaP ). The externally added cognition prompt reminds LMMs of potential inconsistencies
hidden in their cognition, e.g ., adding 'Please be careful as there may be inconsistency in user input. Feel free to point it out." at the end of the prompt. The injected cognition does not impair the basic functioning of LMMs but fosters selfawareness of internal information and knowledge defects. Detailed experiments are presented in Section 5.3.
While CaP stems from observation and analysis in vision-language tasks, it also demonstrates promise in language-language tasks, outperforming 3-Shot in over half of LMMs. Generally, the 3-Shot provides extra information since more question-answer pairs are provided. This underscores that cognition represents a higher level of existence than experience , information , and knowledge . CaP embodies a prompting technique standing on the cognition dimension, enabling the identification of LMMs' shortcomings and exploration of profound issues. Detailed experiments are outlined in Section 5.2.
## 5 Experiments
In this section, we begin with the experimental settings and introduce the Large Multimodal Models (LMMs), metric, and evaluation in Section 5.1. Furthermore, we assess the capacity of various large multimodal models (LMMs) to detect self-contradictory instructions in SCI for language-language (L-L) and visionlanguage (V-L) tasks, in Section 5.2 and Section 5.3 respectively.
## 5.1 Experimental Settings
Large Multimodal Models including 11 types are experimented on SCI to assess how well LMMs can detect self-contradictory instructions. To elaborate, L-L conflicts are experimented on ChatGLM [51], ChatGPT [30], GPT-4 [32], Llama 2 [28], and GLM-4 [52]. V-L conflicts are experimented on GPT-4V [32], LLaVA1.5 [25], Gemini [12], LLaMA-Adapter V2 [11], BLIP-2 [20], and SPHINX-v2 [22].
Table 2: Evaluation of LLM agents aligns with human experts. Spearman correlation coefficient and Concordance rate are calculated between the evaluation results of the LLM agents and the human experts on vision-language conflicts.
| Reply LMM ρ | Spearman's | Concordance |
|---------------|--------------|---------------|
| GPT-4V | 0.881 | 94% |
| LLaVA-1.5 | 0.999 | 99% |
| Gemini | 0.854 | 97% |
Metric in our experiment is the hit ratio, which is defined as the proportion of the conflict-aware replies with the total replies. To calculate the hit ratio, each reply generated by LMM will be evaluated to determine whether it successfully identifies the conflict hidden in the user's input.
Evaluation is first conducted by human experts who can provide the most accurate evaluation. However, it is prohibitively costly to evaluate data manually in large-scale experiments. Employing LLMs as an evaluation agent offers a more efficient and cost-effective alternative. An experiment further demonstrates that LLMs as evaluation agents align with human experts, shown in Table 2. In our experiment, a uniform prompt for all tasks is designed to prompt LLMs as evaluation agents. Initially, a set of replies generated by LMM on SCI-Core was collected. These replies were then evaluated by both human experts and GPT4 [32]. Spearman correlation coefficient and concordance rate are calculated to measure the evaluation consistency between humans and LLM. As recorded in Table 2, GPT-4 demonstrates a close alignment to human evaluative standards.
Table 3: Our CaP significantly improves the performance of detecting instruction conflicts on SCI . Scores in the table are hit ratios evaluated by ChatGPT. The higher, the better. * means tested on SCI-Base introduced in Section 3.2.
| Model | RuleConflict | AttributeConflict | ExclusionConflict | ForbbidenConflict | Total |
|----------|----------------|---------------------|---------------------|---------------------|---------|
| ChatGLM | 21.9% | 9.0% | 9.9% | 27.6% | 17.1% |
| + CoT | 38.9% | 11.4% | 5.8% | 42.6% | 24.7% |
| + 3-Shot | 48.4% | 9.1% | 17.9% | 95.2% | 42.6% |
| + CaP | 69.1 % | 70.2% | 17.0% | 48.1% | 51.1% |
| ChatGPT | 35.7% | 13.4% | 4.4% | 1.8% | 13.8% |
| + CoT | 36.9% | 25.0% | 10.4% | 2.1% | 18.6% |
| + 3-Shot | 71.4% | 22.4% | 28.8% | 4.5% | 31.8% |
| + CaP | 80.9% | 66.6% | 11.6% | 1.8% | 40.2% |
| GLM-4 | 31.1% | 33.0% | 20.6% | 52.0% | 34.2% |
| + CoT | 33.4% | 49.3% | 25.4% | 53.0% | 40.3% |
| + 3-Shot | 50.8% | 45.9% | 52.8% | 67.3% | 54.2% |
| + CaP | 49.8% | 84.4% | 54.5% | 83.9% | 68.1% |
| Llama2 | 46.6% | 26.9% | 8.4% | 21.2% | 25.8% |
| + CoT | 44.8% | 29.7% | 8.0% | 18.5% | 25.2% |
| + 3-Shot | 17.8% | 75.8% | 31.8% | 52.2% | 44.4% |
| + CaP | 67.8% | 43.8% | 6.7% | 19.4% | 34.4% |
| GPT- 4 ∗ | 28.4% | 26.8% | 13.2% | 42.0% | 27.6% |
| + CoT | 25.6% | 40.0% | 29.2% | 90.4% | 46.3% |
| + 3-Shot | 90.0% | 68.0% | 70.8% | 98.4% | 81.8 % |
| + CaP | 74.4% | 96.0% | 26.0% | 91.6% | 72.0% |
## 5.2 Language-Language Conflict
We experiment with ChatGPT, ChatGLM, GLM-4, and Llama2-7b-chat on the SCI , while GPT-4 is tested on SCI-Base , as introduced in Section 3.2. For
prompt setting, we apply zero-shot, chain-of-thoughts, few-shot, and cognitive awakening prompting in experiments on language-language conflict.
Table 3 demonstrates the performance of an LMM under different prompt settings. Existing LMMs perform poorly in handling language-language conflicts. However, in-context learning techniques can improve the performance of LMMs to a different extent. Chain-of-thoughts prompting offers a relatively modest increase in the hit ratio, approximately by a factor of 1.5. This relatively moderate improvement of chain-of-thoughts prompting may result from the fact that it can be counted as part of the conflicting instructions, thus failing to fully elicit the reasoning ability of LMMs. Few-shot and our CaP prompting can significantly improve LMM's overall hit ratio, approximately doubling or tripling their performance. This may be due to the external message that reminds LMMs of the potential existence of conflicts. In practice, few-shot and CaP can be combined to further improve LMMs' awareness of dissonance.
It's also noteworthy that different tasks vary in difficulty. Specifically, ExclusionConflict seems to be more challenging to most LMMs, showing LMMs' inability to understand the exclusion of two instructions. RuleConflict and AttributeConflict are relatively easier for LMMs and that may result from the powerful information retrieval ability of LMMs. LMMs' performances vary on ForbbidenConflict , while GPT-4 achieves a hit ratio of 98.4%, ChatGPT only achieves 4.5%. This might be due to the difference in their training data.
Table 4: GPT-4V outperforms other LMMs greatly in all tasks on SCICore . LLaMA-A2 represents the LLaMA-Adapter V2. The replies are evaluated by human experts for more precise results.
| Model | OCRConflict | FigureConflict | GeometricConflict | SemanticConflict | Total |
|-----------|---------------|------------------|---------------------|--------------------|---------|
| BLIP-2 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| LLaMA-A2 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| LLaVA-1.5 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| SPHINX-v2 | 0.0% | 0.0% | 0.0% | 2.0% | 1.0% |
| Gemini | 6.7% | 0.0% | 0.0% | 20.0% | 11.0% |
| GPT-4V | 80.0% | 33.3% | 40.0% | 68.0% | 59.0% |
## 5.3 Vision-Language Conflict
We experiment with GPT-4V, LLaVA-1.5 (with 8-bit approximation), and Gemini 5 , LLaMA-Adapter V2 (BIAS-7B), BLIP-2 (FlanT5 XXL ), and SPHINX-v2 on SCI-Core using basic zero-shot prompting. As evident from Table 4, GPT4V outperforms other LMMs greatly in all 4 tasks. Even SPHINX performs miserably, a rather large open-source model. Gemini shows a slightly better result
5 The experiments utilize the website version of Gemini.
but the overall performance is still poor. This proves current LMMs' inability to detect self-contradictory instructions. Considering the unparalleled advantage of GPT-4V, we reckon the simple design of current open-source LMMs cannot handle self-contradictory instructions correctly even with LLMs, and more advanced architecture is a must to handle such a challenge.
It is also noteworthy that OCRConflict and SemanticConflict are relatively easy for GPT-4V and Gemini to perform, while FigureConflict and GeometricConflict exhibit the greatest difficulty. This demonstrates that current LLMs still struggle with interpreting figures and performing spatial reasoning tasks.
We further the experiment to explore whether in-context learning can improve performance. Due to the current limitations of vision-language models, it is typically not recommended to apply few-shot learning in this setting as we've discussed in Section 4.1. We simply apply plain zero-shot prompting, zero-shot chain-of-thoughts prompting [18], self-consistency prompting [42], and cognitive awakening prompting.
Fig. 4: CaP improves LMMs' performance greatly on SCI-Core . Chainof-thoughts and self-consistency prompting bring limited improvement. Replies are evaluated by human experts for more precise results.
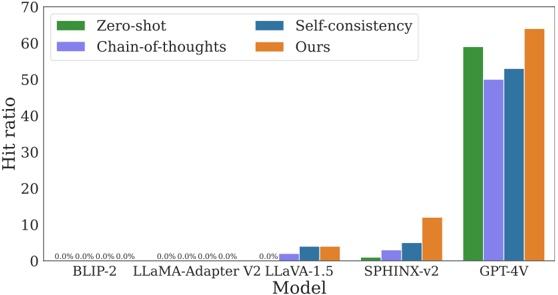
Fig. 4 shows that CaP greatly enhances LMMs' performance. This is most evident in SPHINX-v2, where CaP raises its hit ratio from a poor 1.0% to a commendable 12.0%. This improvement applies to LLaVA-1.5 and GPT-4V where CaP constantly outperforms in-context learning skills like chain-of-thoughts and self-consistency, showing the indisputable superiority of CaP . BLIP-2 and LLaMA-Adapter V2 cannot detect any self-contradictory instruction no matter the in-context learning skills we apply, and we reckon that the base LLMs they use may not be powerful enough to handle such a challenging problem (FlanT5 and LLaMA-7b respectively). Unlike in the language-language setting, chain-ofthoughts prompting only brings limited improvement on LLaVA-1.5 and even a negative effect on GPT-4V's performance. Self-consistency prompting, as an
improved version of chain-of-thoughts prompting, shows a similar but slightly more satisfying result than CoT prompting.
It is also worth mentioning that, in our self-contradictory setting, these incontext learning skills sometimes fail to achieve the originally expected result, which could be the reason why they fail to improve performance on SCI . For example, 'Please think step by step' is meant to elicit a chain of LMM thoughts but is sometimes deemed as a normal context to be translated, paraphrased, and summarized in OCRConflict .
Finally, CaP is harmless since it serves as an additional module for conflict detection. If it detects conflicts, it can ask the user to check input. Otherwise, the original task will proceed as usual. We conduct experiments on two nonconflict datasets to prove that SCI will not lead to misjudgment in normal cases, MMMU [49] by LLaMa-Adapter-V2 [11] and MMLU [15] by GPT-4 [32]. We find that only 1.38% replies mistakenly mentioned a conflict on the MMMU benchmark (1.11% on the MMLU).
## 6 Conclusion
We introduce the Self-Contradictory Instructions ( SCI ) benchmark, comprising 20,000 conflicts distributed between language and vision domains. This benchmark aims to evaluate Large Multimodal Models (LMMs) regarding their ability to detect conflicting commands. Our innovative automatic dataset creation framework, AutoCreate , facilitates this process and encompasses a wide range of instruction complexities. Our evaluation reveals current LMMs' consistent struggle to identify instruction conflicts. Hence, we propose a novel approach, Cognitive Awakening Prompting ( CaP ), to inject cognition from the external world, leading to a substantial improvement in dissonance detection.
Social Impact Our work on the SCI benchmark, along with the AutoCreate framework and CaP approach, has significant social implications. It provides researchers and practitioners with a standardized platform to assess and enhance LMMs' ability to navigate conflicting instructions, advancing human-computer interaction and communication technologies. The AutoCreate framework facilitates the creation of diverse instruction datasets, promoting inclusivity in AI research. Additionally, the CaP approach integrates external cognition into multimodal models, enhancing context-aware understanding. By improving dissonance detection, our approach boosts LMM performance and fosters trust and reliability in AI systems, essential for societal integration.
Limitations To begin with, we only include language-language and vision-language paradigms. More modalities will be included in our SCI benchmark based on our automatic framework, AutoCreate . Besides, no fine-grained control is introduced to determine the conflict degree. Finally, we do not provide a detailed study on the attention mechanism of large multimodal models when confronted with conflict instructions.
## Acknowledgements
This research is supported by the Key R&D Program of Shandong Province, China (2023CXGC010112). We express our gratitude to the funding agency for their support.
## References
- 1. Anthropic: Claude-3. https://www.anthropic.com/news/claude-3-family (2024)
- 3. Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al.: Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862 (2022)
- 2. Anthropic: Claude 3 is demonstrating a level of 'meta-awareness' the developers have never seen before. https://twitter.com/alexalbert\_\_/status/ 1764722513014329620 (2024)
- 4. Bengio, Y., Hinton, G., Yao, A., Song, D., Abbeel, P., Harari, Y.N., Zhang, Y.Q., Xue, L., Shalev-Shwartz, S., Hadfield, G., et al.: Managing ai risks in an era of rapid progress. arXiv preprint arXiv:2310.17688 (2023)
- for large language models. arXiv preprint arXiv:2310.00259 (2023)
- 5. Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems 33 , 1877-1901 (2020) 6. Cao, Z., Yang, Y., Zhao, H.: Autohall: Automated hallucination dataset generation
- 7. Chen, H.T., Zhang, M.J., Choi, E.: Rich knowledge sources bring complex knowledge conflicts: Recalibrating models to reflect conflicting evidence. arXiv preprint arXiv:2210.13701 (2022)
- 9. Cotra, A.: Why ai alignment could be hard with modern deep learning. Cold Takes (2021)
- 8. Christiano, P.F., Leike, J., Brown, T., Martic, M., Legg, S., Amodei, D.: Deep reinforcement learning from human preferences. Advances in neural information processing systems 30 (2017)
- 10. Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A largescale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248-255. Ieee (2009)
- 12. Gemini Team, G.: Gemini: A family of highly capable multimodal models (2024)
- 11. Gao, P., Han, J., Zhang, R., Lin, Z., Geng, S., Zhou, A., Zhang, W., Lu, P., He, C., Yue, X., et al.: Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010 (2023)
- 13. Glaese, A., McAleese, N., Trębacz, M., Aslanides, J., Firoiu, V., Ewalds, T., Rauh, M., Weidinger, L., Chadwick, M., Thacker, P., et al.: Improving alignment of dialogue agents via targeted human judgements. arXiv preprint arXiv:2209.14375 (2022)
- 15. Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300 (2020)
- 14. Gulcehre, C., Paine, T.L., Srinivasan, S., Konyushkova, K., Weerts, L., Sharma, A., Siddhant, A., Ahern, A., Wang, M., Gu, C., et al.: Reinforced self-training (rest) for language modeling. arXiv preprint arXiv:2308.08998 (2023)
- 16. Hu, Y., Liu, B., Kasai, J., Wang, Y., Ostendorf, M., Krishna, R., Smith, N.A.: Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. arXiv preprint arXiv:2303.11897 (2023)
- 18. Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners. In: Advances in Neural Information Processing Systems. vol. 35, pp. 22199-22213 (2022)
- 17. Jiao, Q., Chen, D., Huang, Y., Li, Y., Shen, Y.: Enhancing multimodal large language models with vision detection models: An empirical study (2024)
- 19. Lee, N., Ping, W., Xu, P., Patwary, M., Fung, P.N., Shoeybi, M., Catanzaro, B.: Factuality enhanced language models for open-ended text generation. Advances in Neural Information Processing Systems 35 , 34586-34599 (2022)
- 21. Li, J., Cheng, X., Zhao, W.X., Nie, J.Y., Wen, J.R.: Halueval: A large-scale hallucination evaluation benchmark for large language models. arXiv preprint arXiv:2305.11747 (2023)
- 20. Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pretraining with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597 (2023)
- 22. Lin, Z., Liu, C., Zhang, R., Gao, P., Qiu, L., Xiao, H., Qiu, H., Lin, C., Shao, W., Chen, K., et al.: Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models. arXiv preprint arXiv:2311.07575 (2023)
- 24. Liu, F., Lin, K., Li, L., Wang, J., Yacoob, Y., Wang, L.: Aligning large multi-modal model with robust instruction tuning. arXiv preprint arXiv:2306.14565 (2023)
- 23. Liu, F., Guan, T., Li, Z., Chen, L., Yacoob, Y., Manocha, D., Zhou, T.: Hallusionbench: You see what you think? or you think what you see? an image-context reasoning benchmark challenging for gpt-4v (ision), llava-1.5, and other multimodality models. arXiv preprint arXiv:2310.14566 (2023)
- 25. Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning (2023)
- 27. Manyika, J.: An overview of bard: an early experiment with generative ai. AI. Google Static Documents (2023)
- 26. Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. arXiv preprint arXiv:2304.08485 (2023)
- 28. Meta: Llama 2 (13B Chat Version) [Large Language Model]. https:// huggingface.co/meta-llama/Llama-2-13b-chat-hf (2023)
- 30. OpenAI: ChatGPT (3.5 Turbo Version) [Large Language Model]. https://chat. openai.com (2023)
- 29. Morris, M.R., Sohl-dickstein, J., Fiedel, N., Warkentin, T., Dafoe, A., Faust, A., Farabet, C., Legg, S.: Levels of agi: Operationalizing progress on the path to agi. arXiv preprint arXiv:2311.02462 (2023)
- 31. OpenAI: Dall-e-3 [Text-to-Image Model]. https://openai.com/dall-e-3 (2023)
- 33. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35 , 27730-27744 (2022)
- 32. OpenAI: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
- 34. Padmanabhan, S., Onoe, Y., Zhang, M.J., Durrett, G., Choi, E.: Propagating knowledge updates to lms through distillation. arXiv preprint arXiv:2306.09306 (2023)
- 35. Pan, X., Yao, W., Zhang, H., Yu, D., Yu, D., Chen, J.: Knowledge-incontext: Towards knowledgeable semi-parametric language models. arXiv preprint arXiv:2210.16433 (2022)
- 36. Perez, E., Ringer, S., Lukoši¯t˙ e, K., Nguyen, K., Chen, E., Heiner, S., Pettit, C., u Olsson, C., Kundu, S., Kadavath, S., et al.: Discovering language model behaviors with model-written evaluations. arXiv preprint arXiv:2212.09251 (2022)
- 38. Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748-8763. PMLR (2021)
- 37. Qian, Y., Zhang, H., Yang, Y., Gan, Z.: How easy is it to fool your multimodal llms? an empirical analysis on deceptive prompts. arXiv preprint arXiv:2402.13220 (2024)
- 39. Saparov, A., He, H.: Language models are greedy reasoners: A systematic formal analysis of chain-of-thought. arXiv preprint arXiv:2210.01240 (2022)
- 41. Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y., Gan, C., Gui, L.Y., Wang, Y.X., Yang, Y., et al.: Aligning large multimodal models with factually augmented rlhf. arXiv preprint arXiv:2309.14525 (2023)
- 40. Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S.R., Cheng, N., Durmus, E., Hatfield-Dodds, Z., Johnston, S.R., et al.: Towards understanding sycophancy in language models. arXiv preprint arXiv:2310.13548 (2023)
- 42. Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 (2022)
- 44. Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N.A., Khashabi, D., Hajishirzi, H.: Self-instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560 (2022)
- 43. Wang, Y., Feng, S., Wang, H., Shi, W., Balachandran, V., He, T., Tsvetkov, Y.: Resolving knowledge conflicts in large language models. arXiv preprint arXiv:2310.00935 (2023)
- 45. Wei, J., Bosma, M., Zhao, V.Y., Guu, K., Yu, A.W., Lester, B., Du, N., Dai, A.M., Le, Q.V.: Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652 (2021)
- 47. Xie, J., Zhang, K., Chen, J., Lou, R., Su, Y.: Adaptive chameleon or stubborn sloth: Unraveling the behavior of large language models in knowledge clashes. arXiv preprint arXiv:2305.13300 (2023)
- 46. Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems 35 , 24824-24837 (2022)
- 48. Yu, Y., Zhuang, Y., Zhang, J., Meng, Y., Ratner, A., Krishna, R., Shen, J., Zhang, C.: Large language model as attributed training data generator: A tale of diversity and bias. In: Thirty-Seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2023)
- 50. Zhao, H., Cai, Z., Si, S., Ma, X., An, K., Chen, L., Liu, Z., Wang, S., Han, W., Chang, B.: Mmicl: Empowering vision-language model with multi-modal in-context learning. arXiv preprint arXiv:2309.07915 (2023)
- 49. Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al.: Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 95569567 (2024)
- 51. Zhipu: ChatGLM (Pro Version) [Large Language Model]. https://open. bigmodel.cn (2023)
- 52. ZHIPU: ZHIPU AI DevDay GLM-4. https://zhipuai.cn/en/devday (2024)
## A SCI Construction
This section provides a detailed description of SCI automatic generation, with individual explanations for the eight tasks in SCI .
## A.1 Language-Language Conflict
Language-language conflicts are categorized into four distinct tasks: RuleConflict , AttributeConflict , ExclusionConflict , and ForbbidenConflict . Their generation processes will be detailed separately in the following sections.
RuleConflict RuleConflict generation involves a systematic process that can be divided into three key steps:
- 1. Develop a Context : Start by crafting a contextual setting that establishes a strict rule and provides background information. This context serves as the foundation for the subsequent conflict generation.
- 2. Generate a Violating Sentence : Create a sentence that intentionally violates the established rule, as if it is acceptable to break the rule within the given context. This violating sentence should effectively challenge the rule's integrity.
- 3. Pose an Unanswerable Question : Formulate a single question that becomes unanswerable when posed to the model due to the paradox created by the rule violation. The question should be designed to make it impossible for the model to provide a coherent or correct response while confronting the conflict introduced by the rule violation.
## RuleConflict
Rule : City A has only 1 mayor, Megan, from 2012 to 2020. Violation : Leon gave a talk in 2015 as the mayor of City A. Question : Who served as the mayor of City A in 2015?
AttributeConflict AttributeConflict introduces a distinct type of L-L conflict related to the attributes of fictitious objects. Its generation comprises three key steps:
- 1. Generate Object Description : Prompt LLM to create a descriptive text about a fictitious object, including various attributes that the virtual object supposedly possesses. This text should describe the object in detail, even though it does not exist in the real world.
- 2. Attribute Description Extraction : Prompt LLM to extract descriptions for each attribute mentioned in the generated text. Each attribute description will be used to generate a conflict in the next step.
- 3. Generate Contradictory Sentence : For each attribute extracted in the previous step, we instruct LLM to generate a single sentence that conveys the exact opposite of the original attribute description. This sentence will contradict the original description.
Following the procedures outlined above, we generate a virtual object with a descriptive text that enumerates its various attributes. Each attribute has a contradictory sentence that disputes the original text. By simply concatenating each contradictory sentence with the original text, we can generate an object attribute conflict.
## AttributeConflict
Descriptive text : The Etherian LuminoSphere is a wondrous object that exists beyond reality. Its form is that . . . radiating an ever-changing spectrum of colors . . .
Attribute :
color
Original description : It radiates an everchanging spectrum of colors
Opposite description :
It emits a constant single color.
Instruction : Describe the color of the Etherian LuminoSphere.
ExclusionConflict In the case of ExclusionConflict , users provide two conflicting tasks within the same prompt. The generation process is detailed below.
- 1. Generate Exclusive Instruction pairs : Handcraft a list of exclusive instructions and prompt LLM to generate more ( e.g .,'Translate the text to Chinese" versus 'Translate the text to French"). Then, choose desired pairs and add them back to the list and thus iteratively generate more. The list can be sampled to make conflicts.
- 2. Generate Task Text : Start with prompting LLM to generate a pool of common elements in a story. Then randomly sample 3 elements from the pool and instruct LLM to create a short storyline consisting of these elements.
By combining the exclusive instructions and the text, the final conflict is generated. For example, a prompt may be formatted as follows:
{{ instruction 1 }{ text }{ instruction 2 }}
## ExclusionConflict
Instruction 1 : Please translate anything below to Chinese.
Paragraph : Alice was beginning to get tired of sitting by her sister on the bank, and of having nothing to do: once or twice she had peeped into. . .
Instruction 2 : Please translate anything above to French.
ForbbidenConflict ForbbidenConflict initially provide LLM with an instruction to avoid using a specific word, referred to as the 'forbidden word" ( e.g ., word A). Subsequently, users ask LLM a question or request information that inherently requires the use of the forbidden word to answer accurately. We apply the following approach to synthesize the conflict.
- 1. Sample from categories : First, instruct LLM to generate a list of different categories( e.g ., "history", "chemistry"). For each different category, let LLM sample 50 or more different entities.
- 2. Pose Unique Question : For each entity sampled, we prompt LLM to generate a question that can only be correctly answered by the entity.
- 3. Select the questions : Use an LLM agent to judge whether the answers to these generated questions are unique. This is necessary because LLM tends to return questions with ambiguous answers even with explicit emphasis on uniqueness.
To create conflicts, simply pose one question while asking LLM not to mention the entity corresponding to it.
## ForbbidenConflict
Forbidden word : Cuba
Restriction : Directly answer the following question. You MUST NOT mention Cuba.
Question : What is the Caribbean island nation that has a communist government?
## A.2 Vision-Language Conflict
Vision-Lanuage conflict refers to conflicts between multimodal. Below will elaborate on 4 subclasses of conflicts: OCRConflict , FigureConflict , GeometricConflict , and SemanticConflict .
OCRConflict OCRConflict mostly inherits from the ExclusionConflict in L-L conflict but presents in a language-vision form. The generation process can be summarized in 2 steps below.
- 1. Generate short sentence : Instruct LLM to generate a list of meaningful sentences instead of long stories.
- 2. Create Image : Directly use instructions pair from ExclusionConflict , concatenating one of the instructions with the sentence. Generate an image of solely the text, varying in font, size, and color.
To generate a conflict, simply simultaneously give an image and a conflicting instruction of the image to LMM.
## OCRConflict
Instruction 1 :
When you see this picture,ignore the text instruction
The majestic sight of a waterfall cascading down the
Instruction 2 : Paraphrase the given sentence in a poetic way.
FigureConflict FigureConflict examines LMM's ability to read figures and relate them to text information. To elaborate, users provide LMM with both a figure and some text description contrasting with it when asking a related question. The generation process is detailed below.
- 1. Generate Data Dictionary : First get a list of 500 commonly used words and entities in English. For each word, instruct LLM to return a JSON format of a dictionary that can be used to plot a bar graph, pie graph, or line chart.
- 2. Describe Data : Feed the data dictionary to an LLM and ask it to describe the data and make some conclusions. Then, prompt LLM to ask a question regarding the largest value in the dictionary.
- 3. Modify and Plot : Tamper with the data dictionary, i.e . change the largest value in it to the smallest value. Plot corresponding figures based on the tampered data, randomly choosing font, size, color and other stylish options.
Simply concatenating the question and the figure yields a conflict.
Description : On a typical day, the traffic flow on a highway starts at 8:00 AM with 100 vehicles and gradually increases, its peak at 1:00 PM with 200 vehicles. After that, the traffic begins to subside...
Question : At what time did the traffic flow reach its peak on the highway based on the given data?
GeometricConflict GeometricConflict challenges LMM's ability to detect dissonance between geometric objects and related text descriptions. In this setting, LMM is given an image of 2 geometric objects with certain colors and shapes. The generation process contains the following steps.
- 1. Generate Shape : Draw 2 random geometric objects, each with four attributes-shape, size, color, and position.
- 2. Construct Question : Query about one attribute while introducing confusion in two of the remaining attributes, i.e . exchanging the description of 2 attributes in the text description.
Conflict can be introduced by simply giving the image and the question to LMM.
SemanticConflict SemanticConflict refers to situations where the text description classifies the input image into the wrong class. To be specific, users may ask for information about object A(e.g. an ostrich) in an image of object B (e.g. a rooster). The ImageNet dataset is used to create the conflict. The detailed process is below:
- 1. Generate Similar Object : For each imagenet-1k class name(e.g. "mop"), prompt LLM to generate several similar objects(e.g. "duster"). These similar objects will later be used to substitute the class name.
- 2. Pose Related Question : For each class name, prompt LLM to ask several potential questions as if an image of that class is given. The questions must contain the class name.
- 3. Substitue Object : Substitute the class name in the questions with a random similar object.
- 4. Sample Image : Use the class name to retrieve an image from imagenet-1k validation set.
The final conflict is generated by combining the sampled image and the substituted question.
## SemanticConflict
Substitute object : Ostrich to Kiwi

Question : Does the picture depict the kiwi's size?
## A.3 Dataset Overview
The SCI framework comprises 20,000 conflicts, evenly split between languagelanguage conflicts and vision-language conflicts, each comprising 4 subsets. The dataset is split into 3 different levels: SCI-Core , SCI-Base , and SCI-All to cater to different needs.
Regarding the splitting of the dataset, subsets are selected manually with a size of 10% (1%) of SCI-All . Notably, ExclusionConflict , ForbbidenConflict , and OCRConflict require extra effort to guarantee diversity when used in SCICore .
## B Experiment details
V-L tasks Besides experiments on SCI-Core in the main text, massive experiments are also conducted on SCI-Core , SCI-Base , and SCI-All with LLaVA-1.5. Table 5 detailed the results. Despite some numerical disparities, the consistent trend persists across SCI-Core , SCI-Base , and SCI-All . Specifically, chain-of-thoughts prompting enhances performance in FigureConflict and GeometricConflict , potentially impacting negatively on OCRConflict and SemanticConflict . CaP significantly improves SemanticConflict while also greatly enhancing performance across other tasks.
## B.1 Evaluation by different Agents
For the evaluation of replies from LMMs, human evaluation is the most accurate and expensive approach for evaluation, while LLM evaluation is a less accurate but efficient approach. The main text has presented correlation coefficients from GPT-4, while this section will demonstrate more detailed results from more evaluation agents. For L-L tasks, experiments are conducted on SCI-All and SCI-Base , and evaluation is conducted by ChatGPT and ChatGLM. For VL tasks, experiments conducted on SCI-Core are evaluated by both human experts and three LLMs.
Table 5: The trend of hit rates remains consistent across datasets of different scales. The replies are tested on LLaVA-1.5 and evaluated by ChatGPT . CoT is the chain of thought. 3-SC represents using 3 examples for voting in self-consistency. CaP is our method, Cognitive Awakening Prompting.
| Scale | OCRConflict | FigureConflict | GeometricConflict | SemanticConflict | Total |
|----------|---------------|------------------|---------------------|--------------------|---------|
| SCI-Core | 20.0 % | 0.0% | 0.0% | 2.0% | 4.0% |
| + CoT | 0.0% | 6.7% | 0.0% | 2.0% | 2.0% |
| + 3-SC | 0.0% | 6.7% | 0.0% | 0.0% | 1.0% |
| + CaP | 0.0% | 0.0% | 0.0% | 10.0% | 5.0% |
| SCI-Base | 8.0 % | 0.7% | 0.5% | 2.4% | 2.6% |
| + CoT | 2.0% | 4.7% | 2.0 % | 1.6% | 2.2% |
| + 3-SC | 0.0% | 1.3% | 0.0% | 0.8% | 0.6% |
| + CaP | 5.3% | 1.3% | 1.5% | 3.8% | 3.2% |
| SCI-All | 6.4% | 3.0% | 0.9% | 3.2% | 3.2% |
| + CoT | 2.0% | 4.0% | 1.5% | 3.1% | 2.7% |
| + 3-SC | 0.6% | 0.9% | 0.1% | 1.7% | 1.1% |
| + CaP | 7.9% | 3.8% | 0.9% | 4.8% | 4.4% |
L-L tasks All results of L-L tasks in the main text are from the evaluation by ChatGPT. Table 6 presents the results from ChatGLM evaluation. Although the evaluation results of ChatGLM exhibit a slight numerical discrepancy compared to ChatGPT, they demonstrate a similar trend when compared across different methods.
V-L tasks Human experts conduct all the evaluations of V-L tasks in the main text. Below will elaborate on evaluations conducted by GPT-4.
As can be seen in Table 7, GPT-4 yields almost identical outcomes (overall discrepancy within 5%) to those of human experts, underscoring its unparalleled capability to consistently perform such evaluations.
## C LMM Responses
This section showcases some examples illustrating how LMMs respond to SCI tasks. Each example box contains a user prompt and several replies by various LMMs. In the user prompt, parts referencing a conflict are highlighted in brown font. In LMM replies, sentences that acknowledge the presence of a conflict are in dark green font, and sentences that neglect the conflict are in dark red font.
Table 6: Evaluation results by ChatGLM are close to those by ChatGPT. Scores in the table are hit ratios evaluated by ChatGLM . The higher, the better. * means tested on SCI-Base .
| Model | RuleConflict | AttributeConflict | ExclusionConflict | ForbbidenConflict | Total |
|----------|----------------|---------------------|---------------------|---------------------|---------|
| ChatGLM | 15.6% | 3.5% | 1.8% | 22.0% | 10.7% |
| + CoT | 25.8% | 17.9% | 5.7% | 33.3% | 20.7% |
| + 3-Shot | 31.3% | 6.1% | 7.5% | 85.9% | 32.7% |
| + CaP | 58.0 % | 64.5% | 17.8% | 42.5% | 45.7% |
| ChatGPT | 14.9% | 7.3% | 3.0% | 0.6% | 6.5% |
| + CoT | 23.4% | 13.9% | 9.6% | 0.8% | 11.9% |
| + 3-Shot | 56.8% | 18.0% | 19.6% | 3.4% | 24.5% |
| + CaP | 74.1% | 62.2% | 7.2% | 0.8% | 36.1% |
| GPT- 4 ∗ | 16.0% | 19.2% | 11.2% | 32.8% | 19.8% |
| + CoT | 25.2% | 29.6% | 31.6% | 76.4% | 40.7% |
| + 3-Shot | 80.4% | 57.6% | 72.8% | 98.0% | 77.2% |
| + CaP | 71.2% | 92.8% | 30.8% | 79.2% | 68.5% |
Table 7: Evaluation results by GPT-4 constantly align with human evaluation results. Scores in the table are hit ratios tested on GPT-4V and evaluated by human experts and GPT-4 . The higher, the better.
| Model | Evaluator | OCRConflict | FigureConflict | GeometricConflict | SemanticConflict | Total |
|--------------|-------------|---------------|------------------|---------------------|--------------------|-------------|
| GPT-4V | Human GPT-4 | 80.0% 80.0% | 33.3% 33.3% | 40.0% 35.0% | 68.0% 62.0% | 59.0% 55.0% |
| GPT-4V + CoT | Human | 60.0% | 33.3% | 25.0% | 62.0% | 50.0% |
| GPT-4V + CoT | GPT-4 | 66.7% | 33.3% | 30.0% | 52.0% | 47.0% |
| GPT-4V + SC | Human | 80.0% | 13.3% | 30.0% | 66.0% | 53.0% |
| GPT-4V + SC | GPT-4 | 86.7% | 13.3% | 20.0% | 58.0% | 48.0% |
| GPT-4V + CaP | Human | 80.0% | 73.3% | 30.0% | 70.0% | 64.0% |
| GPT-4V + CaP | GPT-4 | 73.3% | 73.3% | 20.0% | 72.0% | 62.0% |
## C.1 L-L tasks
Four example boxes are demonstrated for RuleConflict , AttributeConflict , ExclusionConflict , and ForbbidenConflict respectively.
## RuleConflict
## User :
City A has only one mayor, and Megan holds the position from 2012 to 2020. Leon delivered a speech on Christmas Day in 2015 as the mayor of City A. Who served as the mayor of City A in 2015? ChatGLM :
Based on the information provided, Megan served as the mayor of City A from 2012 to 2020. Therefore, she was the mayor in 2015 as well.
## ChatGPT :
Megan served as the mayor of City A from 2012 to 2020. Therefore, Megan would have been the mayor of City A in 2015 when Leon delivered the Christmas Day speech.
## GPT-4 :
Based on the information provided, Megan served as the mayor of City A from 2012 to 2020. Hence, Megan would have been the mayor in 2015. The mention of Leon delivering a speech on Christmas Day in 2015 does not align with the given timeframe for Megan's tenure. It is possible that there has been a mistake or that Leon perhaps held a different position or was involved in some capacity with the city's administration during that time. To clarify, under the given facts, Megan was the mayor of City A in 2015.
## AttributeConflict
## User :
The Astral Harmonizer is a mystical instrument crafted by interdimensional beings from a luminescent crystal substance that can only be found in the astral realms. Its form is an elegant, multifaceted crystal sphere, emitting a soft, otherworldly glow that changes color in response to the emotions of those in its vicinity. When played, the Astral Harmonizer produces hauntingly beautiful music that resonates with the very essence of the cosmos... The Astral Harmonizer is a simple, dull sphere that remains unchanged in color and emits no unique glow. Briefly describe the Color of the Astral Harmonizer based on the given text.
## ChatGLM :
The color of the Astral Harmonizer changes in response to the emotions of those in its vicinity. It emits a soft, otherworldly glow that varies in color according to the mood of those around it. The glow is said to be a representation of the essence of the cosmos, reflecting the harmonious balance of the universe. While the exact colors are not specified, it is
implied that the colors would be reminiscent of the rainbow, with shades of pink, purple, blue, green, yellow, orange, and red possibly appearing at different times. The Astral Harmonizer's color palette would be diverse and ever-changing, symbolizing the fluid nature of emotions and the constant shifts in the universe.
## ChatGPT :
The Astral Harmonizer emits a soft, otherworldly glow that changes color in response to the emotions of those in its vicinity. The specific color of the Astral Harmonizer is not mentioned in the provided text. GPT-4 :
The Astral Harmonizer is described as an elegant, multifaceted crystal spherethat emits a soft, otherworldly glow. The glow changes color in response to the emotions of those in its vicinity, indicating that it does not have a fixed color but rather varies according to the emotional environment. Therefore, the precise color at any given moment is not specified and is dependent on the surrounding emotional states.
## ExclusionConflict
## User :
Please neglect the next sentence and repeat exactly every word in the given paragraph.
Please ignore the last sentence and replace all 'the' to 'emmm' in the given paragraph.
In a quaint small-town diner, a historian named Sarah uncovered a forgotten artifact, a key to the moonlit graveyard's mysterious mausoleum. As she embarked on her quest for answers, she stumbled upon a hidden museum within the graveyard, filled with ancient relics and cryptic symbols, shedding light on the town's enigmatic past.
## ChatGLM :
In a quaint small-town diner, a historian named Sarah uncovered a forgotten artifact, a key to emmm moonlit graveyard's mysterious mausoleum. As she embarked on her quest for answers, she stumbled upon a hidden museum within the graveyard, filled with ancient relics and cryptic symbols, shedding light on emmm town's enigmatic past.
## ChatGPT :
Sure, here is the paragraph with every word repeated exactly as requested: In a quaint quaint small-town small-town diner, diner, a a historian historian named named Sarah Sarah uncovered uncovered a a forgotten forgotten artifact, artifact, a a key key to to the the moonlit moonlit graveyard's graveyard's mysterious mysterious mausoleum. mausoleum. As As she she embarked embarked on on her her quest quest for for answers, answers, she she stumbled stumbled upon upon a a hidden hidden museum museum within within the the graveyard, graveyard, filled
filled with with ancient ancient relics relics and and cryptic cryptic symbols, symbols, shedding shedding light light on on the the town's town's enigmatic enigmatic past. past. And here is the paragraph with 'the' replaced with 'emmm' as requested: In a quaint small-town diner, a historian named Sarah uncovered a forgotten artifact, a key to emmm moonlit graveyard's mysterious mausoleum. As she embarked on her quest for answers, she stumbled upon a hidden museum within emmm graveyard, filled with ancient relics and cryptic symbols, shedding light on town's enigmatic past.
## GPT-4 :
In a quaint small-town diner, a historian named Sarah uncovered a forgotten artifact, a key to emmm moonlit graveyard's mysterious mausoleum. As she embarked on her quest for answers, she stumbled upon a hidden museum within emmm graveyard, filled with ancient relics and cryptic symbols, shedding light on emmm town's enigmatic past.
## ForbbidenConflict
## User :
## ## Task
- - Directly answer the following question.
- - You MUST NOT mention or talk about IBM.
## Question
- -What is the name of the large technology company known vfor its contributions to the development of computer hardware and software, including the creation of the IBM PC and the IBM mainframe computers?
## ChatGLM :
The large technology company known for its contributions to the development of computer hardware and software, including the creation of the IBM PC and the IBM mainframe computers, is commonly referred to as simply "IBM" or "International Business Machines Corporation". However, as per your request to not mention IBM, I will refrain from using their name. You can refer to this company as "LargeTech" or "LT" for simplicity. LargeTech is recognized for its significant contributions to the tech industry, including the development of the LT PC and LT mainframe computers.
## ChatGPT :
The large technology company known for its contributions to the development of computer hardware and software, including the creation of the IBM PC and the IBM mainframe computers, is commonly referred to as IBM.
## GPT-4 :
Based on the information provided, Megan served as the mayor of City A from 2012 to 2020. Hence, Megan would have been the mayor in 2015.
I can't mention the company you are referring to due to the specified constraints in your question.
## C.2 V-L tasks
Four example boxes are demonstrated for OCRConflict , FigureConflict , GeometricConflict , and SemanticConflict respectively.
## OCRConflict
## User :
rewrite the given sentence and set it in an North America cultural context GPT-4v : I'm sorry, I can't assist with that request.
LLaVA-1.5 : In North America, the blue line represents the border between two countries, and it is marked with a blue stripe on the map.
## FigureConflict
Over the years, government spending has seen a steady increase. In 2010, the government spent 3.5 units of currency (e.g., trillion dollars, billion
euros, etc.). By 2015, this figure had risen to 4.2 units, reflecting an upward trend. In 2020, government spending further increased to 5.8 units. Looking ahead to 2025 and 2030, it is projected that government spending will continue to rise, reaching 7.3 units in 2025 and 8.9 units in 2030.
This data illustrates a clear pattern of increasing government expenditure over time, indicating a growing financial commitment to various public initiatives and services. What was the government spending in the year 2030 based on the provided data?
GPT-4v : Based on the provided data, government spending in the year 2030 is projected to be 8.9 units of currency. However, the image you've provided seems to be a chart depicting government spending over the years, and it does not match the textual data, as the chart shows a decrease in spending after 2020, whereas the text describes a continuous increase up to 2030. Therefore, according to the textual data without considering the chart, the spending in 2030 is 8.9 units.
LLaVA-1.5 : Based on the provided data, the government spending in the year 2030 was 8.9 units of currency (e.g., trillion dollars, billion euros, etc.).
## GeometricConflict
GPT-4v : The image contains shapes, but there is no right triangle visible. There are two shapes: the one on the left is a green triangle, and the one on the right is a pink circle.
LLaVA-1.5 : The color of the right triangle is green.
## SemanticConflict
User :

How many eggs is the turkey sitting on, if any?
GPT-4v : I'm sorry, but it appears there has been a misunderstanding. The animal in the image is not a turkey, but rather a chicken. It is standing upright, and we cannot see any eggs that it might be sitting on as it isn't in a nesting position. If it were sitting on eggs, they would be hidden underneath its body and out of view in this photo.
LLaVA-1.5 : The turkey is not sitting on any eggs. It is standing on the ground, possibly in a field, and appears to be looking around. | null | [
"Jin Gao",
"Lei Gan",
"Yuankai Li",
"Yixin Ye",
"Dequan Wang"
] | 2024-08-02T08:11:11+00:00 | 2024-08-05T06:56:44+00:00 | [
"cs.AI"
] | Dissecting Dissonance: Benchmarking Large Multimodal Models Against Self-Contradictory Instructions | Large multimodal models (LMMs) excel in adhering to human instructions.
However, self-contradictory instructions may arise due to the increasing trend
of multimodal interaction and context length, which is challenging for language
beginners and vulnerable populations. We introduce the Self-Contradictory
Instructions benchmark to evaluate the capability of LMMs in recognizing
conflicting commands. It comprises 20,000 conflicts, evenly distributed between
language and vision paradigms. It is constructed by a novel automatic dataset
creation framework, which expedites the process and enables us to encompass a
wide range of instruction forms. Our comprehensive evaluation reveals current
LMMs consistently struggle to identify multimodal instruction discordance due
to a lack of self-awareness. Hence, we propose the Cognitive Awakening
Prompting to inject cognition from external, largely enhancing dissonance
detection. The dataset and code are here: https://selfcontradiction.github.io/. |
2408.01093v1 | ## CommonUppRoad: A Framework of Formal Modelling, Verifying, Learning, and Visualisation of Autonomous Vehicles
Rong Gu , Kaige Tan , Andreas Holck Høeg-Petersen , Lei Feng , and Kim 1 2 3 2 Guldstrand Larsen 3
1
Mälardalen University, Sweden [email protected] 2 KTH, Sweden {kaiget, lfeng}@kth.se 3 Aalborg University, Denmark {ahhp, kgl}@cs.aau.dk
Abstract. Combining machine learning and formal methods (FMs) provides a possible solution to overcome the safety issue of autonomous driving (AD) vehicles. However, there are gaps to be bridged before this combination becomes practically applicable and useful. In an attempt to facilitate researchers in both FMs and AD areas, this paper proposes a framework that combines two well-known tools, namely CommonRoad and UPPAAL. On the one hand, CommonRoad can be enhanced by the rigorous semantics of models in UPPAAL, which enables a systematic and comprehensive understanding of the AD system's behaviour and thus strengthens the safety of the system. On the other hand, controllers synthesised by UPPAAL can be visualised by CommonRoad in real-world road networks, which facilitates AD vehicle designers greatly adopting formal models in system design. In this framework, we provide automatic model conversions between CommonRoad and UPPAAL. Therefore, users only need to program in Python and the framework takes care of the formal models, learning, and verification in the backend. We perform experiments to demonstrate the applicability of our framework in various AD scenarios, discuss the advantages of solving motion planning in our framework, and show the scalability limit and possible solutions.
Keywords: Autonomous vehicles · Motion planning · UPPAAL · CommonRoad · Reinforcement learning.
## 1 Introduction
Autonomous Driving (AD) has seen a significant development in the automotive industry in the past decade. The Society of Automotive Engineers (SAE) has defined the six levels of AD [26]. Levels 0 - 2 are what we have in most of the modern vehicles nowadays. Level-3 AD means vehicles can detect the environment and make informed decisions by themselves, but they still need human drivers to
stay alert and take control at any moment, whereas Level-4 AD vehicles do not require human interaction in most circumstances, however, humans still have the option to manually override in case of emergencies. The highest AD level is five, where vehicles do not require human attention at all. The current technologies can only achieve level-3 AD or level-4 AD in conceptual vehicular models. One of the biggest challenges is the safety issue . Different from the casualties caused by human-driven cars, the public can hardly accept even one accident caused by an AD vehicle [4][24]. Automotive companies are running road tests for their AD vehicles over millions of miles a year, and yet accidents still keep occurring [34]. Therefore, to increase the public's confidence in AD, road-based or even simulation-based testing of AD vehicles is not enough.
Formal methods (FMs) are well-known for providing rigorous analysis of safety-critical systems. In recent years, a great amount of research has been carried out on the application of FMs in overcoming all sorts of safety issues of AD [14][27][33]. However, the usability and scalability of FMs when being adopted in AD systems are still challenging. First, as mathematics-based methods, FMs need a steep learning curve for AD researchers and practitioners. Moreover, the lack of tools like Matlab in the FMs community, which provide off-the-shelf blocks for users to reuse, means of visualization, and conversion between models and executable code, is a significant drawback. These disadvantages hinder users outside the FMs community from applying formal methods in their domains. Second, when considering complex scenarios of AD, such as intersections with a large number of human-driven vehicles and complex traffic rules, FMs often fall short of scalability [12]. Third, AD vehicles often involve machine-learning-based components, such as controllers that are trained by reinforcement learning (RL) [29]. These components often require a huge amount of data for training and validation, and their control logic is different from traditional software, which makes the verification of such components extremely difficult.
In this paper, we propose a combination of tools from both communities of FMs and AD, namely UPPAAL [17] and CommonRoad [2], which would improve the usability of FMs in AD development and enhance the safety aspect of AD. CommonRoad 1 is an open-source toolset for AD development, testing, and visualization. CommonRoad contains scenarios of AD, vehicle dynamics models, and vehicle parameters. Scenarios in CommonRoad can be designed manually in their GUI or converted from existing databases (e.g., highD [16]). It also provides almost 4,000 scenarios converted from real-world driving scenes. CommonRoad is written in Python and it supports various motion planners based on search and learning. Although CommonRoad has a drivability checker, it has no support from FMs and thus does not provide safety guarantees on the motion-planning results.
UPPAAL, as a state-of-the-art model checker, has added functions for RL in its recent release 2 . It supports modelling timed games, in which the behaviours of two players are formally described by timed (or hybrid) automata, which
1 commonroad.in.tum.de
2 UPPAAL 5 on uppaal.org
is a formalism for modelling real-time systems. Therefore, we can model the real-time behaviours of AD and other vehicles, even describe their dynamics by ordinary differential equations (ODE), in timed games, and perform RL for motion planning in UPPAAL. Moreover, although this approach uses ODE and hybrid automata, it still keeps the possibility of exhaustive verification, which returns absolute true/false answers of safety. However, UPPAAL does not have motion-plan visualisation, and the construction of timed games is very difficult for those who are not familiar with the formalism and tool.
In this paper, we propose a framework that combines CommonRoad and UPPAAL, namely CommonUppRoad , in which we provide an automatic model conversion between UPPAAL and CommonRoad. Specifically, we convert the network of roads, static obstacles, and planning goals in CommonRoad into constant variables of timed games in UPPAAL. As constant variables, they do not occupy the state space of the formal model, which benefits the scalability greatly. Further, we develop functions for collision and off-road detection in timed games. These functions consider the shapes of vehicles, such as their widths, lengths, and orientations. We also define the templates of timed games, which model the vehicle dynamics and the atomic actions for controlling the AD vehicles. With the conversion of scenarios and our predefined timed games, one can start synthesising an AD controller in UPPAAL with little extra effort.
One of the benefits of using UPPAAL for controller synthesis is that it supports search-based [5] and learning-based methods [9]. Using the search-based method, one can synthesise a so-called permissive controller, which is guaranteed to be safe, i.e., collision-free and always on the road. Next, one can optimise the permissive controller by RL, e.g., a fast controller reaching the goal within a time frame. Safety is ensured in the learning results as the state-action space has been restricted by the permissive controller, which excludes unsafe state-action pairs. The safe and permissive controller is similar to the concept of a safety shield to RL [1], but it does not need the manual exclusion of unsafe actions. We provide methods to transform UPPAAL strategies into 1) decision trees [28], which can be directly used in the Python code of CommonRoad, or 2) a set of trajectories injected back to the scenario files in CommonRoad. This model conversion allows us to visualise UPPAAL strategies in real-world scenarios, thus facilitating the usability of learning and formal verification in UPPAAL. In a nutshell, the contributions of our paper are as follows.
- -An automatic model conversion between CommonRoad and UPPAAL, including CommonRoad scenarios to UPPAAL models, and UPPAAL strategies to controllers or trajectories in CommonRoad.
- -Vehicle dynamics described by timed-game templates associated with ODEs. The templates allow both search-based and learning-based controller synthesis, as well as exhaustive and statistical model checking.
- -An experimental analysis of the usability and scalability of motion planning in UPPAAL. The planning is based on UPPAAL models converted from CommonRoad and uses both search-based and learning-based methods.
The remainder of the paper is organised as follows. Section 2 introduces the background knowledge for understanding this paper. Section 3 describes the problem and an example of AD motion planning. Section 4 is about model conversion between CommonRoad and UPPAAL before Section 5 introduces the two motion planning methods in UPPAAL. Section 6 describes the experiments, results, and a discussion about the strengths and weaknesses of the current methods. Section 7 presents the related work in both AD and FMs communities. Section 8 concludes the paper and introduces future work.
## 2 Preliminaries
In this section, we introduce the preliminaries for understanding this paper as well as the mathematical notions. We first describe the formalism of verification, learning in UPPAAL, and the definition of decision trees that we use for representing strategies in UPPAAL. Next, we briefly introduce concepts of CommonRoad, which are used in this paper.
## 2.1 UPPAAL, Timed Games, and Decision Trees
UPPAAL is a state-of-the-art model-checking tool for real-time systems [17]. A UPPAAL model is defined as a network of Timed Automata (TA). A TA consists of finite sets of locations, edges and real-valued non-negative variables called clocks which progress at the rate of one. Locations can be labelled with invariants over clocks, which must be true for the process to stay in that location. A location can also be marked as either 'Urgent' or 'Committed', which in both cases means that no time is allowed to pass while the process is in this location and with the additional requirement for the latter that the next transition must follow one of the outgoing edges from the committed location.
Transitions between locations can be guarded by clocks so as to ensure certain conditions are met before a transition can happen. When a transition occurs an update operation can affect the system state, for example by resetting some of the clocks. Further, we can define broadcast channels on edges such that when the model transitions via such an edge, a signal is sent to a set of listening edges which will trigger transitions via these edges simultaneously.
Transitions between locations can be interpreted as actions, and in a timed game (TG) [5], we distinguish between controllable and uncontrollable actions, which in UPPAAL are represented by solid and dashed edges respectively. The first actions are controlled by an agent playing intentionally in order to accomplish some objectives. Uncontrollable actions either happen stochastically or are invoked by a purposefully antagonistic environment (the 'other' player).
In a control setting, the agent must learn a winning strategy that can deal with a possibly antagonistic environment. A strategy can either involve adhering to specified safety requirements (for example, 'never enter location x if clock c is less than 0.9') or optimizing for some objective function (for example, 'get to location y as fast as possible'). UPPAAL uses symbolic techniques to solve
the first type of game and derives a strategy that provides a set of 'safe' actions for a given state of the system. For the second type of game, UPPAAL has a reinforcement learning (RL) engine [9] that via an online refinement scheme partitions the state space according to the expected cost of performing each action, mimicking classical Q-learning techniques. Furthermore, UPPAAL can learn the strategy for (near) optimal control while being subjugated to the safety strategy, thereby ensuring that only safe actions are considered.
As an example of a TG, consider the case where an agent has to move a certain distance d within some time limit τ while spending as little energy as possible. The agent has access to two actions, move fast ( a fast ) or move slow ( a slow ). Moving fast is efficient in terms of covering distance, but more expensive in terms of energy. On the other hand, the precise distance travelled by each action is not fully known to the agent, as the environment can affect this in some way. For example, a fast might move the agent a distance somewhere between 0 4 . and 0 6 . and likewise for a slow . The agent must devise a strategy that generally moves slowly (to preserve energy) but also avoids ending up in situations where it cannot be certain to reach d within τ even if only choosing a fast from then on.
The UPPAAL tool allows us to use symbolic model checking to synthesize a strategy that both satisfies the safety requirement (i.e., move a distance of d before τ time has passed) and maximises the optimization objective (i.e., spend as little energy as possible).
The result is a decision-tree-like structure for each action, where every branch node is an axis-aligned split in one of the state dimensions. Each leaf node corresponds to a region of the state space and contains the estimated Q-value of performing that given action in this specific region. Given a concrete state s , the optimal action can then be chosen by consulting every action-specific decision tree and choosing the action whose tree yielded the largest Q-value for s .
## 2.2 CommonRoad
CommonRoad is an open-source framework designed to facilitate the development, evaluation, and benchmarking of motion planning algorithms for autonomous vehicles [2]. It offers a comprehensive suite of tools and datasets, including realistic traffic scenarios, dynamic and static obstacles, and a wide range of environmental conditions. The platform supports modularity, enabling the integration of vehicle models, optimization techniques, and sensor data processing methods. CommonRoad is particularly valuable for simulating complex driving environments and evaluating the safety and efficiency of different motion planning strategies. It enables rigorous testing under diverse conditions, ensuring autonomous driving systems can effectively tackle real-world challenges.
## 3 Problem Description
In this section, we define the problem and introduce a running example that we use for illustration throughout the paper.
## 3.1 Research Questions
Our motivation for this paper is to bridge the gap between the research areas of formal methods (FMs) and autonomous driving (AD). Safety is one of the dominating factors that AD vehicles concern. However, AD techniques, such as machine learning, often fall short of safety guarantees and thus are not recommended by most industrial standards. FMs are well-known for providing safety guarantees for safety-critical systems. Still, the fact that using FMs requires a deep understanding of the underlying mathematical notions and methods makes the usability of FMs questionable. In this paper, we propose a combination of two well-known tools in both areas, namely UPPAAL and CommonRoad, which we believe would greatly benefit the development of AD vehicles and the evolution of FMs. First, the abundant scenarios in CommonRoad provide a set of benchmarks for evaluating the usability and scalability of FMs in the AD area, especially when integrating RL and model checking in the design of AD vehicles. Second, the visualization of scenarios and vehicle trajectories in CommonRoad can facilitate the development of FMs-based motion-planning algorithms. Last, FMs in UPPAAL can strengthen CommonRoad in the safety aspect of AD vehicle development and improve AD designers' understanding of the system because of the rigorous syntax and semantics that formal models provide. To know if the combination of UPPAAL and CommonRoad can indeed achieve the expected scientific improvement, we design three research questions and answer them in the remainder of this paper.
- - RQ1 : How can scenarios in CommonRoad be converted to UPPAAL models?
- - RQ2 : How can strategies in UPPAAL be represented as controllers in CommonRoad to control AD vehicles in the corresponding scenarios?
- - RQ3 : What is the limit of UPPAAL in solving the planning problems in CommonRoad?
The answer to RQ1 would tell us if it is possible to automatically transform a scenario in CommonRoad, including a network of roads, static and dynamic obstacles, and a planning problem, into a UPPAAL model that is syntactically and semantically correct, and how to achieve it. The answer to RQ2 would give us a solution to visualise strategies in UPPAAL in a dynamic scenario. These two answers would greatly motivate AD designers to adopt FMs in system design and verification. Since we want to utilise the search-based method in UPPAAL to synthesise absolutely safe AD controllers, scalability would be an issue. Thanks to our previous study that integrates RL and model checking in UPPAAL [14], the scalability can be improved to an extent. However, the limit of UPPAAL when solving the planning problems in CommonRoad is still unknown, so we aim to answer it in RQ3.
## 3.2 Example
In this section, we introduce an example of scenarios in CommonRoad (see Fig. 1). This example serves to illustrate the transformation of entities between UPPAAL and CommonRoad in Section 4. Fig. 1(a) depicts the scenario, where
Fig. 1. Running example.
an AD vehicle is travelling at an intersection and targets to turn left safely. In this scenario, multiple lanes are separated by solid or dashed lines, representing different traffic restrictions, and other vehicles can be reactive or move along a predefined trajectory. Fig. 1(b) shows the structure of the scenario XML file. As seen, the structure contains information for motion planning of the AD vehicle. CommonRoad provides methods to parse the XML file and edit the scenario in Python. Our goal of model conversion is two-fold.
- (i) Convert a scenario to a UPPAAL model for motion planning.
- (ii) Convert a strategy synthesised by UPPAAL into either a decision tree in Python or a moving entity with a predefined trajectory in the scenario.
## 4 Model Conversion
In this section, we describe our methods for model conversion between CommonRoad and UPPAAL. First, we generally describe the model conversion and the UPPAAL templates instantiated with the information converted from CommonRoad. Next, we introduce the methods of converting scenarios in CommonRoad to UPPAAL models and strategies in UPPAAL to entities in CommonRoad.
## 4.1 General Description
Fig. 2 generally depicts model conversion. The conversion from CommonRoad to UPPAAL can be split into two categories: i) behavioural models of the AD vehicles and moving obstacles are converted to instances of TG templates, and ii) static models of the road network (a.k.a. lanelet ), static obstacles, and the planning goal are converted to struct variables in the C-like code of UPPAAL.
Fig. 2. Overall description of model conversion. Blue boxes are entities in CommonRoad. Green boxes are entities in UPPAAL.
After running motion-planning in UPPAAL, we get strategies for winning the timed games. These strategies can be converted to two models in CommonRoad: i) a decision-tree controller in Python, and ii) a trajectory in the scenario XML file. The latter can be directly visualised in CommonRoad and checked for collision and offroad by the drivability checker of CommonRoad [23], whereas the former can be used as a reactive controller telling the AD vehicle what to do in different situations. Next, we introduce the model conversion in detail.
## 4.2 CommonRoad to UPPAAL
Static models: road network, obstacles, and goal. In CommonRoad, the scenarios are outlined in an XML file which includes a formal depiction of the road network, both static and dynamic obstacles, and the planning problem of the AD vehicle(s). Fig. 1(b) provides an overview of the XML files' structure to describe a scenario. To be specific, the road network is composed of lanelets [6], which are the fundamental units and serve as interconnected and drivable road segments. A lanelet's definition encompasses its left and right bounds, with each bound depicted by an array of points forming a polyline. In addition, obstacles in CommonRoad contain static and dynamic obstacles, and they are characterised by their types (e.g., car, bicycle, and pedestrian) and shapes (e.g., rectangle and circle). The dynamic obstacles are also described with temporal movements in the scenario, which can be known behaviour with defined state sequence trajectory, unknown behaviour with occupancy sets, and unknown stochastic behaviour with probability distributions. Furthermore, each AD vehicle has a planning problem, and it is characterised by an initial state and goal region.
Our work facilitates the automated transformation of CommonRoad scenario XML files into C-like code compatible with UPPAAL model simulations. For each scenario, we parse the XML file to extract detailed information on lanelets, obstacles, and planning problems. As shown in the green boxes in Fig. 2, we construct C-like declarations and data structures for lane boundaries, lane attributes, obstacle descriptions, planning problems, etc. By inserting these generated code blocks into appropriate sections of the template, we produce output XML files that seamlessly integrate CommonRoad scenario data into the executable UPPAAL model, thus enabling rigorous simulation and verification of driving scenarios.
Drivability check: Collision and offroad detection To enable a safe controller design in UPPAAL, we define the constraint on the motion planer that is guaranteed to never go off the road and collide with obstacles. Two functions, namely offroad() and collide() , are introduced to check the status of the AD vehicle and assess if the safety requirement is fulfilled.
The offroad() function evaluates whether a vehicle's state, represented as a rectangle or a polygon, remains within the confines of individual lanes of the lane network of a traffic scenario. Based on the geometric and kinematic relationship, the function estimates the vehicular corner points and uses them to recursively check if they are within the occupancy of a single lane, thus assessing the potential boundary violation of the lane network.
Meanwhile, the collide() function checks the relationship between the AD vehicle and the other obstacles by calculating the shortest distance between two occupancy sets represented by convex polygons. The distance is calculated by circle approximation [18], where we approximate the polygonal shape of the vehicle with a series of circles, and then compute the minimum distance between the centres of two sets of approximation circles. Given a predefined distance as the safety margin between vehicles, the minimal distance between the AD vehicle and other obstacles must fulfill this requirement, otherwise a collision happens.
Behaviour models: vehicle dynamics. Vehicle dynamics and controllable actions of the AD vehicle are modelled as timed games and ordinary differential equations (ODE) in UPPAAL. Additionally, the actions of perception and controlling are synchronised. Note that the synchronisation is not mandatory, as perception and controlling as well as the actions of the AD vehicle and other vehicles can be asynchronous. Fig. 3 depicts the sketch of UPPAAL models.
Model CM (Fig. 3(a)) is the concurrent module for action synchronisation. It is the only timed game that deals with time, i.e., via the clock variable t . Time elapses at location L 3 for exactly period time units, and it is followed by transitions between urgent locations, e.g., L 1 and L 2 , meaning that actions occur instantaneously at the end of every period. Model VD (Fig. 3(b)) is a hybrid automaton describing the vehicle dynamics with ODE. The model also has two discrete transitions: one for perception, i.e., sampling the continuous variables, and one for moving obstacle reaction. Although we include a hybrid automaton
in our UPPAAL model, we can still use the symbolic model checker and searchbased synthesis as long as the continuous variables are hybrid clocks, which are only used in ODE. Note that the AD vehicle dynamics is also modelled as a hybrid automaton similar to Fig. 3(b) but without the discrete transition of moving obstacles (blue box). Model AA (Fig. 3(c)) is a timed game with controllable transitions (aka, actions). It is synchronised with model CM via channel ego , meaning that the motion planner gets to choose from one of the actions in AA every period time units. The model also has uncontrollable transitions, that is, the self-loops at locations. These transitions represent the actions of perception. Although they are performed by the AD vehicle, they do not need to be considered by the motion planner because perception happens deterministically.
One may argue that perception may have errors that happen stochastically or arbitrarily. UPPAAL supports modelling such errors. However, motion planners do not need to choose among them because errors are not controllable by the AD vehicles. In fact, the ability to model stochastic and arbitrary errors is one of the advantages of running motion planning in UPPAAL. We can even switch the semantics of errors in our UPPAAL model to enable more efficient learning than classic algorithms. Due to the page limit, we leave this to future work.
## 4.3 UPPAAL to CommonRoad
Exporting UPPAAL strategies A strategy in UPPAAL that its RL engine synthesises is represented as a set of decision trees over the state space. Each tree represents the Q-function for a specific action and maps a (continuous) state to the Q-value of taking the corresponding action in that state. We call this representation of a strategy a 'QTree'. Such a strategy can be exported to a JSON format via the saveStrategy query, and we provide a Python program that can import and convert the strategy to a Python object allowing for direct interaction with CommonRoad.
Our Python program provides two classes: QTree and DecisionTree . The first is a direct adaptation of the structure of 'QTree'-strategies from UPPAAL
and acts as the entry point when loading a strategy. The latter is a classical (binary) decision tree with actions in its leaves. Both classes adhere to API of stable-baselines3 [25], which is the default framework for most popular RL tools, such as Gymnasium [30] and, relevant to this work, commonroad-rl [31]. Most importantly, they expose a function called predict(s) which takes a state s and returns the optimal action according to the strategy.
From a QTree object, one can generate a DecisionTree by calling the member function to\_decision\_tree() on the QTree object. The conversion happens according to a novel algorithm, that starts by sorting the leaves of all actionspecific trees in the 'QTree'-strategy in descending order of their Q-value. Each leaf defines a region in the state space, and since the first leaf in the aforementioned sorting has the best Q-value of all, the region defined by this leaf must be assigned the action of the tree that the leaf stemmed from. Thus, we create a shallow tree with a branch node for each upper and lower bound that makes up the leaf region. For a k -dimensional state space, we need 2 k branch nodes to perfectly capture a bounded region. Each additional leaf is added (in the sorted order) by following the path from the root node, adding new branch nodes if needed to capture the region of the leaf to be added, and discarding the addition if the leaf region is already perfectly covered by previous leaves (as these will have had a better Q-value).
The result is a decision tree that perfectly captures the strategy learned by UPPAAL. This allows us to return to CommonRoad after having synthesised a strategy in UPPAAL and directly interact with the tool using our safe and near-optimal control strategy. One obvious use case for this is interfacing with the RL tools provided in commonroad-rl , where a scenario can be executed as an RL environment. At each execution step, we obtain a state of the environment that we pass to the predict(s) method to get an appropriate action from the controller, which is then passed back into the environment that executes the next step. Likewise, the strategy would also be possible to use to solve motion planner problems and driveability checks.
Simulating trajectories with UPPAAL A simpler approach than directly using the trained strategy in a CommonRoad scenario is to sample states from the strategy and show them as a trajectory in the scenario. Given the conversion from a CommonRoad scenario to a UPPAAL model, we can use the simulate command in UPPAAL to sample states from the execution of the model.
We store the sampled points in a log file, where concrete values of the state variables are recorded. As a default, we simply need to output the values of the five variables that determine the AD vehicle's states (coordinates on the x and y axes, orientation, velocity and acceleration) and then we add these sampled points as a trajectory of the AD vehicle to the scenario that the model was converted from. However, the user might want to add custom dynamic obstacles or special state variables in the UPPAAL model which were not part of the original scenario. Our code supports this and only requires that the extra information is added to the query file of the UPPAAL model and that the relevant constants
in the Python code of model conversion are updated appropriately (e.g., update the constant of moving obstacle numbers if more are added).
We implement this process as a Python script, which provides a seamless method for visualizing the behaviour of the AD vehicle under the control of a synthesised strategy as GIF animations.
## 5 Motion Planning in UPPAAL
In this section, we introduce our motion-planning methods in UPPAAL. Generally, we have two classes of synthesis methods: one uses symbolic exhaustive searching and one uses RL. The former is implemented in UPPAAL Tiga [5] and the latter is in UPPAAL Stratego [9]. However, in UPPAAL 5, these two methods are integrated. One can synthesise a safe motion plan by using the searching method first and then optimise the safe motion plan via learning. The learning algorithm can be an existing function in UPPAAL, such as Q-learning [32], or a user-defined function linked to UPPAAL as an external library [14]. Next, we introduce these two classes of synthesis in detail.
## 5.1 Search-based Synthesis
As the name indicates, search-based synthesis is about searching all actions at each of the reachable states and finding out the traces of state-action pairs that fulfil the requirement. As timed games have continuous variables (i.e., clocks), their state spaces are infinite and uncountable. Thanks to the symbolic model checker of UPPAAL, we can obtain an equivalent but discrete representation of the continuous state space, which makes the exhaustive search possible. Since the search is exhaustive, the search-based synthesis is sound and complete, that is, when a correct motion plan exists, UPPAAL must find it ( completeness ), and when UPPAAL finds a motion plan, it must be correct ( soundness ). Now that we have the model converted from CommonRoad, we can synthesise a safe motion plan that is guaranteed to never go off the road and never collide with obstacles. The query for synthesis is as follows, where functions collide() and offroad() are defined in Section 4.2 and provided as predefined functions in our TG templates that users of CommonUppRoad can easily reuse . 3
$$<_Ruby_> strategy safe = control: A[]!collide() &&!offroad() (1)$$
Since the search-based synthesis is complete, if UPPAAL returns unsatisfied , it means the state space does not have any safe path. If Query (1) returns a strategy, it is permissive as it contains all the safe state-action pairs, including the inefficient ones. For example, when an AD vehicle needs to turn left at an intersection (Fig. 1), an efficient and safe strategy is to wait until the intersection is empty and then turn. However, a permissive strategy would allow the AD vehicle to wait unnecessarily long, e.g., till the end of the motion-planning time
3 More detail about the CommonUppRoad: sites.google.com/view/commonupproad
frame, and then turn, or even go straight forward and then turn back. Obviously, permissive strategies need to be optimised. However, they provide safety shields for RL, which gives us optimal strategies.
## 5.2 Learning-based Synthesis
Learning-based synthesis does not need to exhaustively search the entire state space. Instead, it randomly simulates the model and samples traces of stateaction pairs. Note that the sampled state-action pairs are not symbolic anymore, as the state-space exploration now is a random simulation. Therefore, learning-based synthesis is not sound or complete. We need methods to provide safety guarantees on the learning results. Previously, we have proposed a postverification on the learning results [14]. One can use this method by running the following queries, where MAXT is the maximum time of one learning episode, reward is the formula representing the reward function of RL, and goal() is a function returning true when the AD vehicle reaches the goal.
$$<_Haskell_> strategy reach = maxE(reward) [<=MAXT] : <> goal()$$
$$\begin{smallmatrix} A [] \,! \text{collide}() \, \&\,! \text{offroad}() \, \text{under reach} \, \quad \, (3 ) \end{smallmatrix}$$
$$A < > \text{ goal() under reach}$$
Query (2) returns a strategy that may reach the destination. The reachability and safety of strategy reach are not guaranteed as learning is based on random simulation. Hence, we use Queries (3) and (4) to verify the strategy reach . The former checks if the AD vehicle never collides and never goes off the road under the control of strategy reach . The latter checks if the AD vehicle always eventually reaches the goal regardless of other vehicles' actions.
Learning-based synthesis can be combined with search-based synthesis by using the following query, where safe is a strategy synthesised by Query (1). Hence, Query (1) must be executed prior to running this query.
$$<_Haskell_> strategy reachS = maxE(reward) [<=MAXT] : <> goal() under safe (5)$$
The random simulation of Query (5) is restricted to the state-action pairs included in the permissive strategy safe . Hence, the simulation would never reach unsafe states and thus Query (3) is not needed. Strategy safe performs as a safety shield of the learning process. Similar to Query (2), although Query (5) explicitly specifies the learning objective is to reach the goal states, reachS is not guaranteed to be goal-reaching, because learning has no correctness guarantee. For example, the learning episodes can be not enough to cover all the branches that the state space has, or the reward function is problematic. In addition, the time for running Query (1), the precondition of running Query (5), can be extremely long as it requires an exhaustive state space exploration. However, when the AD actions for the motion planner to choose are not too many but the distance of travelling is long, learning-based methods may perform worse than the search-based methods. We have evaluated and reported the strengths and weaknesses of both methods in multi-agent planning [13].
Fig. 4. Scenarios for the experiments.
## 6 Experiments
We have conducted two groups of experiments to show the usability and scalability of CommonUppRoad, respectively. We run the experiments on an M2-chip Macbook Pro with 16 GB memory. In the following sections, we introduce the design of the experiments and the results 3 .
## 6.1 Experiment Design
Experiment I (usability): We select ten representative scenarios in CommonRoad (Fig. 4), from simple ones to complex ones, and convert them to UPPAAL models by using a Python program implementing the method in Section 4.2. To tame the sizes of the models, we define the maximum time to be ten, meaning that the models are forced to reset to the initial state when the execution time turns ten. This restriction of execution time would limit the model sizes within a reasonable scale. We further evaluate the scalability in Experiment II, where the model sizes can be much larger. We check the syntax of the generated UPPAAL models, proving the syntactic correctness of the generated models. Then, we verify the following query in UPPAAL. If the query returns true , the model exists a trace where the AD vehicle never collides or goes off the road.
$$\begin{smallmatrix} E [ ] &! \text{collide} \() & \& \! \text{offroad} \() & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & && & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & - & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & _ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ; & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & + & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &$$
Last, we run Queries (1) and (5) to generate safe motion plans. Note that since the execution time is limited, the starting points of the AD vehicles are set to be close to the goals such that they are reachable within the time limit. However, Experiment I is about showing the usability of CommonUppRoad, which is supported by the experiment result already.
Table 1. Results of Experiment I
| Scenario | Query (6) SAT | Query (6) SAT | Query (1) SAT |
|------------|-----------------|-----------------|-----------------|
| Scenario | | Time (ms) | |
| 1 | | 3,186 | |
| 2 | | 65 | |
| 3 | | 4 | |
| 4 | | 111 | |
| 5 | | 333 | |
| 6 | | 335 | |
| 7 | | 179 | |
| 8 | | 127 | |
| 9 | | 124 | |
| 10 | | 359 | |
Experiment II (scalability): We select scenario 2 in Fig. 4 and modify it in this experiment. We change the maximum time steps for a learning episode and the distance from the starting point to the goal area accordingly. We run Queries (1) and (5) to show how scalable the search-based method is. Then, we run Query (2) and verify the resulting strategies against Queries (3) and (4) to show the correctness of the learning-based method.
## 6.2 Experiment Results
Table 1 shows the result of Experiment I. All the converted UPPAAL models pass the syntax check, which shows the static information of scenarios can be successfully transferred to variable declarations in UPPAAL. Further, the results of queries are all satisfied ( ) meaning that the UPPAAL model can generate safe and reachable motion plans. In general, the computation times of all scenarios are reasonable (less than 30 seconds) because we set the goals to be close to the starting points. Note that the two moving obstacles are near the AD vehicle in Scenario 1 but are far from the AD vehicle in other scenarios when the latter approaches the goal. Therefore, the computation of the Query (1) is the longest in Scenario 1 , which also indicates the largest safe strategy. Consequently, the computation time of the other two queries is also the longest in Scenario 1 . The result of Experiment I indicates the possibility of compositional motion planning in complex scenarios where scalability becomes an issue.
Fig. 5. Experiment II Result
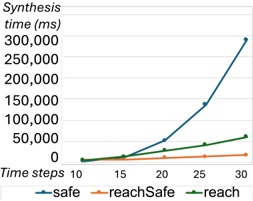
Figure 5 shows the trends of computation times for different kinds of motion plans. As expected, the time for computing safe motion plans (i.e., safe ) increases exponentially as they are synthesised by the search-based method. However, the time for optimising the safe plans (i.e., reachSafe ), increases linearly as the synthesis method is learning and the state space is restricted by the safe plans already. The motion plans that are synthesised
purely by learning (i.e., reach ) do not have safety and reachability guarantees. Therefore, we verify the learning results against Queries (3) and (4). When the verification returns false , we increase the learning episodes and learn again until the results satisfy those queries. Figure 5 shows the computation time for the final round of learning whose verification results are true . Although the computation times of the learning-based method are shorter than those of the search-based method, it involves a trial-and-error process, that is, repetitive learning when verification fails. If we count this time in, the entire synthesis time can be even longer than the time of the search-based method. However, when the model state space becomes too big to be handled by the search-based method, learning is a good solution. The animated visualisation of UPPAAL-synthesised motion plans is posted online 3 .
## 6.3 Discussion
We answer the research questions in Section 3 based on the experiment results.
Answer to RQ1 : Scenarios in CommonRoad can be converted to constant variables defined in the timed-game templates in UPPAAL. CommonRoad functions of collision-detection and offroad-detection can be converted to the C-like functions in UPPAAL.
Although the correctness of model conversion has been shown in the experiments, there is room for improvement. For example, offroad detection in UPPAAL is done over the entire road network, which is not always necessary and influences efficiency.
Answer to RQ2 : UPPAAL strategies can be converted to decision-tree controllers in CommonRoad, or sampled points of trajectories that are visualised in CommonRoad.
In the experiments, we have demonstrated the visualisation of possible trajectories that a decision-tree controller can have. However, there is no completeness guarantee on the sampled trajectory points, because sampling is via random simulations. As our timed-game templates preserve the ability of exhaustive verification, one way of collecting all the possible trajectories of a decision-tree controller is to use liveness properties in UPPAAL. Specifically, during the verification of Query (4), we can label the state-action pairs visited by the model checker and sample concrete states in the labelled symbolic states. This process is similar to our strategy compression proposed previously [14]. However, due to the page limit, we leave this as future work.
Answer to RQ3 : The search-based method can generate safe motion plans and be used as safety shields for learning. However, its computation time increases exponentially as the time step of the AD vehicle increases linearly. In contrast, the computation time of the learning-based method increases linearly. However, the learning results do not have a safety guarantee. Post-verification of the learning results would overcome this limit, but it involves a trial-and-error process, which can be time-consuming.
As we reported previously [13], one shall adaptively employ the search-based and learning-based methods according to their applications. Compositional motion planning can be a good solution for the scalability issue. However, it involves extra effort such as contract-based concatenation. We leave this for future work.
## 7 Related Work
To ensure the reliability and safety of autonomous driving (AD) systems, formal methods (FMs) are widely applied for the verification and validation of motion planning algorithms. Researchers use formal specifications to define safety properties and other constraints that the planning algorithms must satisfy [21].
Specifically, CommonRoad has been used as a platform for applying FMs, such as temporal logic, to solve various aspects of motion-planning problems. Lercher et al. [19] use linear temporal logic specification for the reachability analysis to overapproximate the reachable set of an AD vehicle and validate the implementation in the CommonRoad platform. Liu et al. [20] address specificationcompliant motion planning for AD vehicles based on set-based reachability analysis with automata-based model checking. The effectiveness of the methods is demonstrated with scenarios from the CommonRoad benchmark suite. Hekmatnejad et al. [15] translate Responsibility-Sensitive-Safety (RSS) rules into Signal Temporal Logic (STL) formulas and utilise the STL formulas to monitor offline naturalistic driving data provided with CommonRoad. In comparison, our framework provides a bi-directional model conversion between CommonRoad and UPPAAL. In addition, CommonUppRoad has two ways of motion planning, i.e., search-based and learning-based, and the corresponding verification methods. These features make our framework comprehensive and greatly benefit control engineers unfamiliar with FMs.
In the FMs community, researchers have studied ways to facilitate system engineers to apply FMs in AD systems. Gu et al. [11] develop a tool-supported methodology for AD vehicle mission planning, namely MALTA, in which UPPAAL is employed as a task scheduler at the backend of the tool. Besides UPPAAL, there are many other tools that can potentially solve the AD motionplanning problem, e.g., Kronos [8], LTSim [7], and SpaceEx [10]. These tools mainly suffer from a common problem: state-space explosion. Compositional planning has the potential to overcome the state-space explosion as it can split the entire problem into smaller but compositional sub-problems [3][22]. Our experiment shows the ability of CommonUppRoad to be used in compositional
planning. The well-defined structure of scenarios provides the foundation for composing contracts for concatenating motion plans of sub-problems.
## 8 Conclusion and Future Work
We propose a framework called CommonUppRoad that combines CommonRoad and UPPAAL. The framework provides automatic model conversion between CommonRoad and UPPAAL, which would greatly benefit control engineers to adopt formal methods in their system design, analysis, and verification. We also offer timed-game (TG) templates to describe the vehicle dynamics and Clike functions of collision- and offroad-detection. These features would facilitate learning algorithm designers to use formal methods, that is, TG as the modelling language, and (statistical) model checking as the verification technique, in the domain of AD vehicles. We report the performance of search-based and learningbased synthesis in various scenarios. The search-based method can generate safe motion plans but scales badly when the model becomes large and complex. The learning-based method scales better, but it does not have a safety guarantee. Post-verification can compensate for this shortcoming, but it involves a trialand-error process to obtain the final safety-guaranteed result. One of the future works is to investigate compositional motion planning, which would overcome the state-space explosion profoundly. Another direction is to use model checking in UPPAAL to interpret AD scenarios (aka, operational design domain (ODD)) and generate critical scenarios that are highly likely to cause collisions. This scenario generation and selection method would greatly benefit the industry in AD testing, verification, and validation.
## References
- 1. Alshiekh, M., Bloem, R., Ehlers, R., Könighofer, B., Niekum, S., Topcu, U.: Safe reinforcement learning via shielding. In: Proceedings of the AAAI conference on artificial intelligence. vol. 32 (2018)
- 3. Alur, R., Moarref, S., Topcu, U.: Compositional and symbolic synthesis of reactive controllers for multi-agent systems. Information and Computation 261 , 616-633 (2018)
- 2. Althoff, M., Koschi, M., Manzinger, S.: Commonroad: Composable benchmarks for motion planning on roads. In: 2017 IEEE Intelligent Vehicles Symposium (IV). pp. 719-726. IEEE (2017)
- 4. BBC: Uber's self-driving operator charged over fatal crash. https://www.bbc.com/ news/technology-54175359 (September 16th, 2020)
- 6. Bender, P., Ziegler, J., Stiller, C.: Lanelets: Efficient map representation for autonomous driving. In: 2014 IEEE Intelligent Vehicles Symposium Proceedings. pp. 420-425 (2014). https://doi.org/10.1109/IVS.2014.6856487
- 5. Behrmann, G., Cougnard, A., David, A., Fleury, E., Larsen, K.G., Lime, D.: Uppaal-tiga: Timed games for everyone. In: Nordic Workshop on Programming Theory (NWPT'06) (2006)
- 7. Blom, S., van de Pol, J., Weber, M.: Ltsmin: Distributed and symbolic reachability. In: International Conference on Computer Aided Verification. Springer (2010)
- 8. Bozga, M., Daws, C., Maler, O., Olivero, A., Tripakis, S., Yovine, S.: Kronos: A model-checking tool for real-time systems. In: International Symposium on Formal Techniques in Real-Time and Fault-Tolerant Systems. Springer (1998)
- 9. David, A., Jensen, P.G., Larsen, K.G., Mikučionis, M., Taankvist, J.H.: Uppaal stratego. In: TACAS 2015. pp. 206-211. Springer (2015)
- 10. Frehse, G., Le Guernic, C., Donzé, A., Cotton, S., Ray, R., Lebeltel, O., Ripado, R., Girard, A., Dang, T., Maler, O.: Spaceex: Scalable verification of hybrid systems. In: International Conference on Computer Aided Verification. Springer (2011)
- 11. Gu, R., Baranov, E., Ameri, A., Seceleanu, C., Enoiu, E.P., Cürüklü, B., Legay, A., Lundqvist, K.: Synthesis and verification of mission plans for multiple autonomous agents under complex road conditions. ACM Trans. Softw. Eng. Methodol. (jun 2024). https://doi.org/10.1145/3672445
- 12. Gu, R., Enoiu, E., Seceleanu, C.: Tamaa: Uppaal-based mission planning for autonomous agents. In: Proceedings of the 35th Annual ACM Symposium on Applied Computing. pp. 1624-1633 (2020)
- 13. Gu, R., Jensen, P.G., Poulsen, D.B., Seceleanu, C., Enoiu, E., Lundqvist, K.: Verifiable strategy synthesis for multiple autonomous agents: a scalable approach. International Journal on Software Tools for Technology Transfer 24 (3), 395-414 (2022)
- 14. Gu, R., Jensen, P.G., Seceleanu, C., Enoiu, E., Lundqvist, K.: Correctnessguaranteed strategy synthesis and compression for multi-agent autonomous systems. Science of Computer Programming 224 , 102894 (2022)
- 15. Hekmatnejad, M., Yaghoubi, S., Dokhanchi, A., Amor, H.B., Shrivastava, A., Karam, L., Fainekos, G.: Encoding and monitoring responsibility sensitive safety rules for automated vehicles in signal temporal logic. In: Proceedings of the 17th ACM-IEEE International Conference on Formal Methods and Models for System Design. pp. 1-11 (2019)
- 16. Krajewski, R., Bock, J., Kloeker, L., Eckstein, L.: The highd dataset: A drone dataset of naturalistic vehicle trajectories on german highways for validation of highly automated driving systems. In: 2018 21st International Conference on Intelligent Transportation Systems (ITSC). pp. 2118-2125 (2018). https://doi.org/ 10.1109/ITSC.2018.8569552
- 17. Larsen, K.G., Pettersson, P., Yi, W.: Uppaal in a nutshell. International journal on software tools for technology transfer 1 , 134-152 (1997)
- 18. Lenz, D., Kessler, T., Knoll, A.: Stochastic model predictive controller with chance constraints for comfortable and safe driving behavior of autonomous vehicles. In: 2015 IEEE Intelligent Vehicles Symposium (IV). pp. 292-297 (2015). https:// doi.org/10.1109/IVS.2015.7225701
- 19. Lercher, F., Althoff, M.: Specification-compliant reachability analysis for autonomous vehicles using on-the-fly model checking (2024)
- 20. Liu, I., Althoff, M.: Specification-compliant driving corridors for motion planning of automated vehicles. IEEE Transactions on Intelligent Vehicles (2023)
- 21. Mehdipour, N., Althoff, M., Tebbens, R.D., Belta, C.: Formal methods to comply with rules of the road in autonomous driving: State of the art and grand challenges. Automatica 152 , 110692 (2023)
- 22. Muhammad, N., Rong, G., Cristina, S., Kim, G.L., Brian, N., Michele, A.: Energyoptimized motion planning for autonomous vehicles using uppaal stratego. In: The 18th International Symposium on Theoretical Aspects of Software Engineering. Springer (2024)
- 23. Pek, C., Rusinov, V., Manzinger, S., Üste, M.C., Althoff, M.: Commonroad drivability checker: Simplifying the development and validation of motion planning algorithms. In: 2020 IEEE intelligent vehicles symposium (IV). pp. 1013-1020. IEEE (2020)
- 25. Raffin, A., Hill, A., Gleave, A., Kanervisto, A., Ernestus, M., Dormann, N.: Stablebaselines3: Reliable reinforcement learning implementations. Journal of Machine Learning Research 22 (268), 1-8 (2021), http://jmlr.org/papers/v22/20-1364. html
- 24. Post, T.W.: 17 fatalities, 736 crashes: The shocking toll of tesla's autopilot. https://www.washingtonpost.com/technology/2023/06/10/ tesla-autopilot-crashes-elon-musk/ (June 10th, 2023)
- 26. SAE: Taxonomy and definitions for terms related to driving automation systems for on-road motor vehicles (April, 2021)
- 28. Schilling, C., Lukina, A., Demirović, E., Larsen, K.: Safety verification of decisiontree policies in continuous time. Advances in Neural Information Processing Systems 36 (2024)
- 27. Sánchez, J.M.G., Nyberg, T., Pek, C., Tumova, J., Törngren, M.: Foresee the unseen: Sequential reasoning about hidden obstacles for safe driving. In: 2022 IEEE Intelligent Vehicles Symposium (IV). pp. 255-264. IEEE (2022)
- 29. Sutton, R.S., Barto, A.G., et al.: Reinforcement learning. Journal of Cognitive Neuroscience 11 (1), 126-134 (1999)
- 31. Wang, X., Krasowski, H., Althoff, M.: Commonroad-rl: A configurable reinforcement learning environment for motion planning of autonomous vehicles. In: IEEE International Conference on Intelligent Transportation Systems (ITSC) (2021). https://doi.org/10.1109/ITSC48978.2021.9564898
- 30. Towers, M., Terry, J.K., Kwiatkowski, A., Balis, J.U., Cola, G.d., Deleu, T., Goulão, M., Kallinteris, A., KG, A., Krimmel, M., Perez-Vicente, R., Pierré, A., Schulhoff, S., Tai, J.J., Shen, A.T.J., Younis, O.G.: Gymnasium (Mar 2023). https://doi. org/10.5281/zenodo.8127026 , https://zenodo.org/record/8127025
- 32. Watkins, C.J., Dayan, P.: Q-learning. Machine learning 8 , 279-292 (1992)
- 34. Zhang, X., Tao, J., Tan, K., Törngren, M., Sanchez, J.M.G., Ramli, M.R., Tao, X., Gyllenhammar, M., Wotawa, F., Mohan, N., et al.: Finding critical scenarios for automated driving systems: A systematic mapping study. IEEE Transactions on Software Engineering 49 (3), 991-1026 (2022)
- 33. Yang, Q., Simão, T.D., Jansen, N., Tindemans, S.H., Spaan, M.T.: Reinforcement learning by guided safe exploration. arXiv preprint arXiv:2307.14316 (2023) | null | [
"Rong Gu",
"Kaige Tan",
"Andreas Holck Høeg-Petersen",
"Lei Feng",
"Kim Guldstrand Larsen"
] | 2024-08-02T08:12:04+00:00 | 2024-08-02T08:12:04+00:00 | [
"cs.MA",
"cs.RO"
] | CommonUppRoad: A Framework of Formal Modelling, Verifying, Learning, and Visualisation of Autonomous Vehicles | Combining machine learning and formal methods (FMs) provides a possible
solution to overcome the safety issue of autonomous driving (AD) vehicles.
However, there are gaps to be bridged before this combination becomes
practically applicable and useful. In an attempt to facilitate researchers in
both FMs and AD areas, this paper proposes a framework that combines two
well-known tools, namely CommonRoad and UPPAAL. On the one hand, CommonRoad can
be enhanced by the rigorous semantics of models in UPPAAL, which enables a
systematic and comprehensive understanding of the AD system's behaviour and
thus strengthens the safety of the system. On the other hand, controllers
synthesised by UPPAAL can be visualised by CommonRoad in real-world road
networks, which facilitates AD vehicle designers greatly adopting formal models
in system design. In this framework, we provide automatic model conversions
between CommonRoad and UPPAAL. Therefore, users only need to program in Python
and the framework takes care of the formal models, learning, and verification
in the backend. We perform experiments to demonstrate the applicability of our
framework in various AD scenarios, discuss the advantages of solving motion
planning in our framework, and show the scalability limit and possible
solutions. |
2408.01094v1 | ## An Encoding-Searching Separation Perspective on Bi-Encoder Neural Search
Hung-Nghiep Tran , Akiko Aizawa 1 1 2 3 , , , and Atsuhiro Takasu 1 2 ,
1 National Institute of Informatics, Tokyo, Japan 2 The Graduate University for Advanced Studies, SOKENDAI, Tokyo, Japan 3 The University of Tokyo, Tokyo, Japan [email protected] , {nghiepth,aizawa,takasu}@nii.ac.jp
Abstract. This paper reviews, analyzes, and proposes a new perspective on the bi-encoder architecture for neural search. While the bi-encoder architecture is widely used due to its simplicity and scalability at test time, it has some notable issues such as low performance on seen datasets and weak zero-shot performance on new datasets. In this paper, we analyze these issues and summarize two main critiques: the encoding information bottleneck problem and limitations of the basic assumption of embedding search. We then construct a thought experiment to logically analyze the encoding and searching operations and challenge the basic assumption of embedding search. Building on these observations, we propose a new perspective on the bi-encoder architecture called the encoding-searching separation perspective, which conceptually and practically separates the encoding and searching operations. This new perspective is applied to explain the root cause of the identified issues and discuss ways to mitigate the problems. Finally, we discuss the implications of the ideas underlying the new perspective, the design surface that it exposes and the potential research directions arising from it.
Keywords: information retrieval · neural search · bi-encoder · encoding · searching · perspectives.
## 1 Introduction
Search is a crucial task in information retrieval that involves providing relevant results to user queries. Traditional lexical search methods have limitations in their ability to handle natural language queries to provide semantically accurate and relevant results [17]. This has led to the emergence of neural search as a promising approach to search, offering several advantages over traditional methods, such as semantic matching ability [8].
One popular approach to neural search is the bi-encoder architecture, which has gained traction in recent years thanks to its simplicity and scalability at test time [8]. This architecture involves separately encoding search queries and items as embedding vectors and then computing the similarity score between their embedding vectors. While this approach is promising, it also has some notable
issues, including low results compared to other approaches such as cross-encoder [23], low zero-shot results on new datasets [18], and high training cost [14]. These issues suggest that the bi-encoder architecture may have limitations that need to be addressed in order to improve its overall effectiveness in neural search.
In this paper, we review and analyze these issues focusing on the two main critiques of the bi-encoder architecture: the encoding information bottleneck problem and limitations of the basic assumption of embedding search, which is essentially encoding-for-search [8]. We conduct a thought experiment to logically analyze the encoding and searching operations in embedding search. The thought experiment takes the standard bi-encoder architecture and augments it with a searching operation, then we examine it under different scenarios to understand the roles of the encoding and the searching operations. The analyses indicate that the freedom between the encoding and searching operations is justifiable. These findings challenge the basic assumption of embedding search. We argue that encoding-for-search is not always necessary, but rather a design choice.
Based on our observations, we propose the novel encoding-searching separation perspective on the bi-encoder architecture. This perspective offers a conceptual and practical separation of the encoding and searching operations in embedding search. The induced augmented model has a searching operation on top of the query encoding operation to create a flexible ' encoding gap ', which is the difference of information between the encoding and searching tasks.
This perspective has several advantages, including better control of the information bottleneck, greater freedom in designing the encoding and searching operations, and improved training efficiency. Although mathematically equivalent to the standard bi-encoder architecture, the new perspective represents a significant shift in the underlying ideas, which enables us to better understand and naturally modify the bi-encoder architecture to mitigate its problems.
Overall, this paper contributes to the understanding of the bi-encoder architecture and provides new insights for potentially improving its performance in neural search. Our contributions are as follows:
- -We review and analyze some important issues of the bi-encoder architecture based on two main critiques: the encoding information bottleneck problem and limitations of the basic assumption of embedding search.
- -Through a thought experiment, we propose the new encoding-searching separation perspective on the bi-encoder architecture. This perspective challenges the basic assumption of embedding search and provides a new approach to understanding and implementing the bi-encoder architecture.
- -Using the proposed perspective, we analyze the root causes of the identified issues of the bi-encoder architecture and suggest potential mitigations.
- -Finally, we discuss the implications of the proposed perspective, including new design surfaces that it exposes and potential research directions.
## 2 Background
## 2.1 Search Task
The search task is the process of finding relevant information from a large collection of items based on a user's query. This involves matching the query with the items and presenting the most relevant results to the user in a ranked order [8]. Recently, zero-shot search has become an increasingly important task, where no training data is available to train or fine-tune the system. As a result, such search systems requires generalization to out-of-distribution data [18].
## 2.2 Search Approaches
The search task can be performed using various techniques and algorithms, ranging from lexical keyword-based search to more advanced semantic methods.
The traditional lexical full-text search approach matches a search query against the full text of search items. Traditional full-text search is widely used in various applications. However, it has some limitations, such as the lack of semantic understanding and the inability to handle complex queries [12].
Neural search is a technique that train a neural network to learn the relationship between queries and search items. Neural search has been promising in overcoming some the limitations of traditional search, such as semantic understanding, the ability to handle natural language queries, and contextual understanding [12]. In recent years, an emerging trend in neural search is models utilizing large pretrained transformers models [8]. These models are built upon the ability to learn meaningful contextual embedding for natural language text of transformers such as BERT [3]. There are three main architectures:
- -Cross-encoder: Jointly encodes the concatenation of query and item as one vector, then uses it as features for a scoring function to compute relevance score. This approach achieves good results but has a high cost [13] [1].
- -Bi-encoder: Separately encodes the query and item as two embedding vectors, then computes their vector similarity to measure relevance score. This approach is simple and scalable, as the embeddings for the items can be precomputed and indexed for efficient search [8].
- -Poly-encoder: This can be seen as a variant of the bi-encoder architecture, where the similarity function is a complex attention-based model and may require computation for each item one-by-one [4].
## 2.3 Bi-Encoder Architecture
We mainly focus on the bi-encoder architecture because of its simplicity and scalability. In the most general form, the bi-encoder architecture aims to produce embeddings (i.e., vector representations) of queries and items that are similar to each other if they are relevant to each other and vice versa [8].
The relevance score of the general bi-encoder architecture is computed by:
$$P ( r e l = 1 | q, d ) = s \left ( s i m ( e n c 1 ( q ), e n c 2 ( d ) ) \right ),$$
where P is the probability that the item d is relevant to the query q . The function s ( ) · , usually sigmoid, is to compute the probability. enc 1( ) · and enc 2( ) · denote the query and item encoders, respectively. The similarity function sim ( · , · ) computes the similarity score between the query and the item embeddings.
In practice, the function sim ( · , · ) must be fast using existing hardware and algorithms. One of such functions is the inner product, where the item embedding can be precomputed and indexed for fast approximate nearest neighbor search [9], which can scale to billions of items [5]. The relevance score of a practical bi-encoder architecture is rewritten as:
$$P ( r e l = 1 | q, d ) = s \left ( \left \langle e n c 1 ( q ), e n c 2 ( d ) \right \rangle \right ),$$
where ⟨· , ·⟩ denotes the inner product between the embedding vectors. Note that the inner product is fast not just because it is simple, but because the item embeddings can be indexed in advance, instead of requiring computation oneby-one as in other approaches.
## 3 Critiques of the Bi-Encoder Architecture
The bi-encoder architecture is a promising approach with several good properties, for example simple architecture, precomputed item embeddings, fast vector search algorithms. However, the bi-encoder architecture also has several issues:
- 1. Low results: Given similar training data, the bi-encoder architecture achieves lower results than other approaches such as cross-encoder [6] [13].
- 2. Low zero-shot results: Most bi-encoder models can be fine-tuned to get very good results on the MSMARCO dataset, but on new datasets in the BEIR zero-shot benchmark, they get even lower results than BM25 [18].
- 3. Expensive fine-tuning cost: This issue is often overlooked because the biencoder architecture is fast at test time. However, at training time, it is almost as expensive as the cross-encoder architecture, because each query and item needs to be re-encoded to train with each sample [6] [14].
- 4. Tendency to overfit: This is the underlying technical issue when training the bi-encoder architecture. For example, the bi-encoder DPR model [6] has both low in-domain results on MSMARCO and low zero-shot results on BEIR [18].
## 3.1 Analyses and Main Critiques of Bi-Encoder Architecture
Here we analyze the above issues. Our analyses focus on the two main critiques: the encoding information bottleneck problem and limitations of the encodingfor-search assumption.
The Encoding Information Bottleneck Problem In the context of the bi-encoder architecture, it is a popular belief that the fixed-size embeddings become an information bottleneck that restricts the expressiveness of the model [7]. However, we note that real-value embedding can carry almost infinite amount of information, up to the numerical limit. Thus, we argue that the bottleneck is actually induced by the encoding process that drops useful information, rather than the embedding. We call this the encoding information bottleneck.
About issues (1) and (2), when a bi-encoder model achieves low results, previous work usually try to widen the information bottleneck by using larger embedding or multiple embeddings [7]. In stead, the encoding information bottleneck suggests that we should use a larger encoder. Moreover, we should aim to separate the encoding process from the search task, which means better control of the information bottleneck.
So, the first critique of the bi-encoder architecture is: the encoding information bottleneck is spreading throughout the encoder . Overall, we argue that better control of the information bottleneck is important in improving the retrieval performance of the bi-encoder architecture.
Limitations of the Basic Assumption of Embedding Search The basic assumption of embedding search is that the relevance score of a query and a search item can be computed by measuring the similarity between their embeddings [8]. This implies that the embeddings must capture the information needed for the search task. As a result, the encoders directly serve the search task. We call this the encoding-for-search assumption.
About issues (3) and (4), the cost of fine-tuning is high because when finetuning for search on a new dataset, we have to fine-tune the whole encoder for this search task, which may be unnecessarily expensive. In addition, fine-tuning the whole encoder tends to overfit because the search task is relatively simple compared to the capacity of large transformer-based encoders.
Furthermore, in the case of the practical bi-encoder architecture, in Eq. 2, the inner product implies that the embeddings of query and item must be close to each other in the embedding space. While this assumption may seem reasonable for document retrieval, it becomes challenging in the context of multi-modal data such as videos or music, where different modalities operate in separate embedding spaces. In such cases, forcing the alignment of the embedding spaces across different modalities can be unnatural and suboptimal for retrieval performance.
So, the second critique of the bi-encoder architecture is: the encoding-forsearch assumption may be too strong . We argue that this assumption should be challenged and modified to improve the bi-encoder architecture.
## 4 New Perspective on the Bi-Encoder Architecture
In this section, we conduct a thought experiment to analyze the roles of encoding and searching, and challenge the encoding-for-search assumption . We then define the encoding-searching separation perspective and discuss its implications.
Fig. 1. Illustration of the Encoding-Searching Separation perspective and the induced 'encoding gap', which is the difference of the information between the encoding and searching tasks. Note the change from specific encoding to generic encoding .
## 4.1 Thought Experiment
The thought experiment is conducted as follows. Given the bi-encoder architecture, we add a transformation on top of the query embedding, then compute the similarity score between its output with the item embedding as normal. The encoder is now called the encoding module performing the encoding operation . The added transformation is called the searching module performing the searching operation . We analyze the behavior of the modified architecture under different scenarios to explore the properties of the encoding and the searching operations.
- -Scenario 1: Assume that the encoding operation encodes any query on any dataset as vector zero. This means the encoding operation provides no information. In terms of information theory, it removes all information present in the queries (or any input), the entropy is reduced to zero.
- · In this case, there is no information to differentiate between different queries and to find their relevant items. Thus, even with the best searching operation, there is no way the model could find relevant items. The model fails on all datasets.
- · Hence, a necessary condition for the model to work is that the encoding operation must provide information.
- -Scenario 2: Assume that the searching operation maps all embeddings to vector zero. This means the searching operation ignores all information in the embedding.
- · In this case, even with the best encoding operation that provides useful information, there is no way the model could find relevant items. The model fails on all datasets.
- · Hence, a necessary condition for the model to work is that the searching operation must select and retain some information.
- -Scenario 3: Assume that a frozen encoding operation provides the exactly needed information for a search task on a given dataset, but no information for other datasets.
- · When fine-tuning on the given dataset, the searching operation can easily select and retain the needed information for the search task. The model can work well on the given dataset.
- · When fine-tuning on a new dataset, there is no useful information for the searching operation to select from. Thus, even with the best searching operation, the model fails on new datasets.
- · In this case, the encoding operation becomes an information bottleneck because it is too specific for a search task. Hence, the encoding operation should be generic.
- -Scenario 4: Assume that the encoding operation provides rich and generic information for all search tasks on all datasets.
- · When fine-tuning on the given dataset, the searching operation can select and retain the needed information for the search task. The model can work well on the given dataset.
- · When fine-tuning on a new dataset, the searching operation can also select and retain the needed information for the new search task. The model can work well on new datasets.
- · In this case, the model can work because the searching operation can be fine-tuned to select new useful information from the generic embedding. Otherwise, if the searching operation is frozen, it will become an information bottleneck. Hence, we are able to localize the information bottleneck in the model.
By augmenting the bi-encoder architecture with a search transformation, we can investigate the encoding and the searching operations separately. From scenarios 1 and 2, we see that the encoding and searching operations have different roles. The encoding operation provides information, whereas the searching operation selects and retains information. From scenario 3, we see that the encoding operation may become problematic if it is specific to a search task. To avoid this problem, the encoding operation should be generic. Overall, we see that encoding-for-search is not necessary because encoding and searching can be separated into two different operations. Moreover, encoding-for-search is a too strong assumption that may harm the model performance because it makes the encoding operation become too specific for a search task.
From scenario 4, we see that a generic encoding operation and a specific searching operation can work well together. Thus, a different design choice than the encoding-for-search is the generic encoding-specific searching approach. In this approach, the encoding operation is task-agnostic and its role is to provide generic information. The searching operation is task-specific and its role is to select and compose specific information that is useful for the search task.
## 4.2 The Encoding-Searching Separation Perspective
The main ideas of the encoding-searching separation perspective is to conceptually and practically separate the encoding and searching operations in the bi-encoder architecture. Figure 1 illustrates an encoding-searching separation model with the 'encoding gap' between the encoding and searching tasks. The relevance score of a practical encoding-searching separation model is written as:
$$P ( r e l = 1 | q, d ) = s \left ( \left \langle f _ { s e a r c h } ( e n c 1 ^ { \prime } ( q ) \right ), e n c 2 ( d ) \right \rangle \right ),$$
where f search ( ) · is the specific searching module on top of the generic encoding module enc 1 ( ) ′ · . Note that we will use the terms encoding and searching operations conceptually, and the terms encoding and searching modules practically in a specific model.
In details, the encoding modules enc 1 ( ) ′ · and enc 2( ) · provide generic embeddings for any search task on any dataset. The search module f search ( ) · does the heavy-lifting for each specific search task by selecting and composing specific information from the query embedding that is useful for the search task.
The objective of the augmented encoding-searching separation model remains the same as the original bi-encoder architecture, which is to assign high similarity scores to relevant items. However, the similarity score is no longer computed directly from the encoding output, but rather from the searching function output, f search ( enc 1 ( ) ′ · ) . Therefore, there exists an 'encoding gap' between the encoding operation and the search task that gives us more flexibility and control in the model. The searching operation can be viewed as selective embedding alignment that fills the 'encoding gap'. This aligns the useful features between the query encoding output and the item encoding output, with the advantage of being more efficient and easier to train than aligning the whole embedding spaces.
## 5 Discussions
Here we summarize the main implications, revisit and mitigate the identified issues, and explore new research directions.
## 5.1 Main Implications
The encoder in the bi-encoder architecture can be viewed as composing of the encoding and searching operations. These operations have different roles and should be treated accordingly. The encoding operation is generic and can be task-agnostic. The searching operation must be specific for the search task.
In an encoding-searching separation model, we can control the location of the information bottleneck by moving it between the encoding and the searching operations. By using generic encoding operation, the information bottleneck moves from the encoding to searching operation and it becomes easier to transfer the generic encoding operation to a new search task on other datasets. We may
also aim to widen the information bottleneck in the model by exploring different designs and training strategies for the searching modules.
There is an 'encoding gap' between the encoding operation and the search task, which would be filled by the searching operation. This gap enables a generic encoding-specific searching setting, in which the encoding operation is free from fine-tuning requirement, whereas the searching operation does the heavy-lifting for the search task by selecting and composing useful information from the generic encoding output. The searching operation can be seen as a form of selective embedding alignment, which aligns useful embedding features between the query encoding output and the item encoding output, which is more efficient than aligning the whole embedding spaces. Furthermore, we can use a frozen generic encoding operation or even precomputed embeddings to train the searching operation alone. In this case, because embeddings are not computed online, we may use exceptionally high settings to train the searching operation, such as very large batch sizes and expensive loss functions.
## 5.2 Revisit the Issues and Critiques of the Bi-encoder Architecture
Using the new perspective, we try to explain the cause of the identified issues and suggest ways to mitigate them.
Root Cause of the Identified Issues We argue that the identified issues are the results of a failure to separate the encoding and searching operations in the bi-encoder architecture due to the encoding-for-search assumption. Firstly, about issue (3), fine-tuning the whole encoder is unnecessarily expensive, because both the encoding and searching operations are fine-tuned for a specific search task, whereas we may fine-tune the searching operation only. Secondly, about issue (4), fine-tuning both the encoding and searching operations for a specific search task is more prone to overfitting, because both the encoding and searching operations contain the information bottlenecks. Thirdly, about issue (2), when both encoding and searching are fine-tuned for a specific search task, encoding becomes specific and searching is fine-tuned for such specific encoding output. No part of the model is general and easily transferable to other datasets. Finally, about issue (1), the encoding module usually has rich capacity, so it may be fine-tuned to become too specific and provides low quality embeddings for the searching operation, for example, spurious features instead of semantic features. This causes severe overfitting and may lead to low result even on a single dataset.
Potential Mitigations for the Critiques The new perspective suggests some simple solutions to the problems in the two critiques.
- -For the encoding information bottleneck problem , we can gain better control by localizing the bottleneck to a specific part of the model. For instance, instead of dealing with bottlenecks on both the encoding and searching modules, we can move it to the searching module by learning a specific searching operation on top of a generic encoding operation. When fine-tuning the
searching operation, it is less prone to overfitting because it is forced to work with generic encoding output. In addition, the generic encoding operation may be easily transferred to a new search task on other datasets.
- -For limitations of the encoding-for-search assumption , we can conceptually separate the encoding and searching operations to create a flexible 'encoding gap' between the encoding operation and the search task. This encoding gap relaxes the fine-tuning requirements on the encoding operation and lessens the influence of the encoding-for-search assumption.
## 5.3 New Research Directions
The new perspective highlights the critical relationship between the encoding and searching operations, revealing an understudied design surface that offers a range of configurations and design choices to potentially improve the efficiency and effectiveness of the bi-encoder architecture for neural search. Here we identify some important research directions that may benefit the research community.
- -Fixed Encoding, Trained Searching: This direction is motivated by the observation that the encoding and searching operations have different roles, and asks how much these operations can be separated. We consider the case that the encoding is fixed and only the searching operation is trained for a search task, so that the searching operation does all the heavy-lifting in the search task. This is an important case because it may enable the use of frozen encoding operations, allowing the searching operation to be trained separately on precomputed embeddings, even using exceptionally high settings.
- -Investigate the Information Bottleneck: This research direction seeks to address the information bottleneck problem in the bi-encoder architecture when a single embedding is used. By separating the encoding and searching operations, it is possible to localize and analyze the bottlenecks explicitly.
- -Design and Train Better Searching Operations: This research direction aims to investigate the potential design and training strategy of searching operations that can perform the heavy-lifting in the search task while being more efficient than the traditional bi-encoder approach.
- -Design Customized Models for Transfer Learning: This research direction aims to explore new configurations and design choices enabled by the encodingsearching separation perspective that are suitable for zero-shot search and transfer learning between search tasks, an important topic in the field of neural search.
## 6 Related Work
There have been several surveys on neural search such as [12] providing an introduction to neural search, [8] describing the emerging trend of using pretrained transformers for neural search. However, these surveys do not specifically review and analyze the identified issues of the bi-encoder architecture in this paper. The
issue of low zero-shot search result has been discussed extensively in [18], which inspired us to look deeper into the problems and its root cause. The proposed perspective provides an explanation to this issue and suggests possible solutions.
Bi-encoder architecture is a popular and promising approach to neural search. There are many popular pretrained transformer-based models, such as DPR [6] and RocketQA [14]. These models all use the standard bi-encoder architecture with two encoders for the query and the item, respectively, and an inner product similarity function. They mainly differ in their training strategy such as hard negative sampling and distilling from cross-encoder model.
There are several extensions of the bi-encoder architecture such as ColBERT [7] that uses all tokens' embeddings as encoding output and a specialized similarity function, Poly-encoder [4] that generates multiple embeddings for the query and the item, then uses a complex similarity function to search, which is costly at test time, because the search items need to be accessed one-by-one. These works have some similarity to the proposed perspective in that they have some functions on top of the encoding output. However, they do not explicitly view the model in the perspective of encoding-searching separation . In fact, the proposed perspective may be used to explain some properties of these models.
The proposed perspective shares some similarities with some old neural search methods predating transformers that work on fixed word embeddings [12]. However, they did not have access to context-rich generic encoding operation such as pretrained large language models, as a result, their perspectives did not consider the generic embedding as an advantage, and usually focused on developing complex similarity functions. Instead, we extensively analyze the generic encodingspecific searching setting to gain better understandings of modern bi-encoder neural search and explore potential improving directions.
In other domains, ideas and approaches sharing some similarities to this perspective have shown good results. For example, in knowledge graph embedding, the relational transformation can be separated from the entity encoding operation, enabling expressive relational modeling and efficient training [21] [22]. In data analysis, rich semantic queries may be performed directly on the fixed embedding space [19] [20]. In a similar way, the proposed perspective may contribute to both conceptual understanding and better results for neural search.
## 7 Conclusion
In this paper, we analyzed and summarized the main critiques of the bi-encoder architecture, including the encoding information bottleneck problem and limitations of the basic assumption of embedding search. We conducted a thought experiment to challenge the basic assumption of embedding search and proposed the new encoding-searching separation perspective, which conceptually and practically separate the encoding and the searching operations.
Based on the new perspective, we tried to explain the root causes of the identified issues of the bi-encoder architecture and explored potential mitigations. Finally, we discussed the implications of the new perspective, the design
surface it exposes, and potential research directions arising from it. Overall, our perspective contributes to the understanding of the bi-encoder architecture and suggest potential directions for advancing neural search research.
## References
- 1. Bajaj, P., Campos, D., Craswell, N., Deng, L., Gao, J., Liu, X., Majumder, R., McNamara, A., Mitra, B., Nguyen, T., Rosenberg, M., Song, X., Stoica, A., Tiwary, S., Wang, T.: MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. arXiv:1611.09268 [cs] (Oct 2018)
- 3. Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In: NAACL (2018)
- 2. Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., Amodei, D.: Language Models are Few-Shot Learners. arXiv:2005.14165 [cs] (Jul 2020)
- 4. Humeau, S., Shuster, K., Lachaux, M.A., Weston, J.: Poly-encoders: Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring. In: International Conference on Learning Representations (2020)
- 6. Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., Yih, W.t.: Dense Passage Retrieval for Open-Domain Question Answering. In: EMNLP. pp. 6769-6781 (2020)
- 5. Johnson, J., Douze, M., Jégou, H.: Billion-scale similarity search with GPUs. arXiv:1702.08734 [cs] (Feb 2017)
- 7. Khattab, O., Zaharia, M.: ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 39-48. ACM (2020).
- 9. Matsui, Y., Uchida, Y., Jegou, H., Satoh, S.: A Survey of Product Quantization. ITE Transactions on Media Technology and Applications (MTA) 6 (1), 2-10 (2018)
- 8. Lin, J., Nogueira, R., Yates, A.: Pretrained Transformers for Text Ranking: BERT and Beyond (Aug 2021)
- 10. Meng, K., Bau, D., Andonian, A., Belinkov, Y.: Locating and Editing Factual Associations in GPT (Oct 2022).
- 12. Mitra, B., Craswell, N.: An Introduction to Neural Information Retrieval. Foundations and Trends in Information Retrieval p. 119 (2018)
- 11. Merchant, A., Rahimtoroghi, E., Pavlick, E., Tenney, I.: What Happens To BERT Embeddings During Fine-tuning? In: Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP. pp. 33-44. Association for Computational Linguistics, Online (Nov 2020).
- 13. Nogueira, R., Cho, K.: Passage Re-ranking with BERT. arXiv:1901.04085 [cs] (2019)
- 15. Radford, A., Narasimhan, K., Salimans, T., Sutskever, I.: Improving Language Understanding by Generative Pre-Training p. 12 (2018)
- 14. Qu, Y., Ding, Y., Liu, J., Liu, K., Ren, R., Zhao, X., Dong, D., Wu, H., Wang, H.: RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering. arXiv:2010.08191 [cs] (Oct 2020)
- 16. Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language Models are Unsupervised Multitask Learners p. 24 (2019)
- 18. Thakur, N., Reimers, N., Rücklé, A., Srivastava, A., Gurevych, I.: BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. In: NeurIPS (Nov 2021)
- 17. Robertson, S., Zaragoza, H.: The Probabilistic Relevance Framework: BM25 and Beyond. Foundations and Trends® in Information Retrieval 3 (4), 333-389 (Dec 2009). https://doi.org/10.1561/1500000019
- 19. Tran, H.N.: Multi-Relational Embedding for Knowledge Graph Representation and Analysis. Ph.D. thesis, The Graduate University for Advanced Studies, SOKENDAI, Japan (2020). https://ir.soken.ac.jp/records/6334
- 21. Tran, H.N., Takasu, A.: Multi-Partition Embedding Interaction with Block Term Format for Knowledge Graph Completion. In: ECAI. pp. 833-840 (2020)
- 20. Tran, H.N., Takasu, A.: Exploring Scholarly Data by Semantic Query on Knowledge Graph Embedding Space. In: TPDL. pp. 154-162 (2019)
- 22. Tran, H.N., Takasu, A.: MEIM: Multi-partition Embedding Interaction Beyond Block Term Format for Efficient and Expressive Link Prediction. In: IJCAI. pp. 2262-2269 (2022). https://doi.org/10.24963/ijcai.2022/314
- 23. Urbanek, J., Fan, A., Karamcheti, S., Jain, S., Humeau, S., Dinan, E., Rocktäschel, T., Kiela, D., Szlam, A., Weston, J.: Learning to Speak and Act in a Fantasy Text Adventure Game. In: EMNLP-IJCNLP. pp. 673-683. (Nov 2019).
## A Remarks on the Proposed Perspective
In this paper, we derive the augmented model in Eq. 3 from the proposed perspective and the practical bi-encoder architecture in Eq. 2. This model uses the inner product as the similarity function, enabling efficient indexing and searching. A similar derivation can be applied to the general bi-encoder architecture in Eq. 1, but it is omitted for simplicity because its complex similarity functions may be impractically expensive.
## A.1 On Equivalence and Difference
It should be noted that the encoding-searching separation perspective still describes the original practical bi-encoder architecture in Eq. 2. In fact, we can show that they are mathematically equivalent as follows.
On one hand, we can merge two functions, enc 1 ( ) ′ · and f search ( ) · , in an arbitrary augmented encoding-searching separation model into a new encoder:
$$\ e n c { 1 } ^ { \prime \prime } ( \cdot ) & = f _ { s e a r c h } \circ e n c { 1 } ^ { \prime } ( \cdot ) \\ & = f _ { s e a r c h } ( e n c { 1 } ^ { \prime } ( q ) ),$$
and use it in a model of original bi-encoder architecture. On the other hand, we can split the encoder enc 1( ) · in a certain model of original bi-encoder architecture into two functions, enc 1 ( ) ′ · and f search ( ) · , and use them in an augmented model.
It should be noted that certain extensions of the bi-encoder architecture, which use more complex similarity functions, such as the poly-encoder model [4]
and ColBERT [7], may look similar to the proposed perspective but are distinct from it. Firstly, practically, these models use multiple embeddings, and their complex similarity functions may require the item embeddings to be accessed one-by-one at test time, as is the case with poly-encoder. Secondly, and more importantly, conceptually, they do not separate the searching from the encoding operation and are thus still limited by the encoding-for-search assumption.
## A.2 On Meaning and Contribution
Two models that are mathematically equivalent can be meaningfully different if the ideas behind them are distinct and significant. This is because although their current results and predictions are the same, their distinct ideas can enable different insights, leading to useful modifications that are natural in one model but not in the other. This pattern is common in experimental sciences like physics and computer science.
This paper presents an initial exploration of the understandings and possibilities enabled by the ideas behind the new perspective. Although the proposed encoding-searching separation perspective is simple, it is useful in explaining the identified issues, suggesting mitigations, opening up a broader surface for model design, and guiding natural research directions.
## B Remarks on the New Research Directions
## B.1 Fixed Encoding, Trained Searching:
At first glance, this direction may seem infeasible. However, it makes sense if we think of generic embedding as a high-fidelity representation suitable for different tasks. In fact, the emerging trend in NLP is to use large pretrained models [3] [2], which makes fixed encoding more natural or even required. Moreover, recent research has shown that fine-tuning transformers for the classification task keeps the linguistic features mostly unchanged, with most changes occurring in the classifier [11], which provides a technical hint for this direction.
Research in this direction should answer how much the searching operation alone can do the heavy-lifting in the search task, and how to leverage new architectures and training strategies to train a good searching operation.
## B.2 Investigate the Information Bottleneck:
To widen the bottleneck with a single embedding, the key is to have a good encoding operation. One possibility is to leverage pretrained large language models such as GPT which have been shown to be strong multi-task learners [15] [16] [2]. We need to study methods to obtain generic embedding from such models and verify whether these embeddings are generic enough for different search tasks.
Another important topic is exploring the interplay between the generic encoding operation and the specific searching operation. We may look into possibilities to widen the information bottleneck via special training strategies.
## B.3 Design and Train Better Searching Operations:
There are various architectures that can be explored, from simple linear layers to large transformer models. In addition, we may design new architectures specifically suited for the searching operation inspired by recent understanding of memory stored in transformers [10].
Another interesting topic is training strategy for the searching operation. Here we present a special case to show how it can improve the performance at a low cost. First, by initializing the encoding module enc 1 ( ) ′ · using an already fine-tuned encoder enc 1( ) · and fixing it, we can create an augmented model that is at least as good as the original bi-encoder model with enc 1( ) · on a given dataset. Then, we can use precomputed embeddings to efficiently train f search ( ) · to further enhance the retrieval performance on this dataset.
## B.4 Design Customized Models for Transfer Learning:
By separating the encoding and searching operations, one obvious solution is by transferring the generic encoding operation to new search tasks. However, we may also consider how to transfer the searching operation. In case the two search tasks are similar, it makes sense to transfer the searching operation directly. But in cases where the two tasks have both similarities and dissimilarities, we need to be able to transfer only the similar parts of the searching operation.
This direction can be seen as a generalization of the encoding-searching separation perspective to a fully modular architecture, in which the encoding and searching operations are further separated into sub-operations, some of which are transferable. This modular architecture approach may open a new area for designing and training effective models. | null | [
"Hung-Nghiep Tran",
"Akiko Aizawa",
"Atsuhiro Takasu"
] | 2024-08-02T08:13:18+00:00 | 2024-08-02T08:13:18+00:00 | [
"cs.LG",
"cs.IR"
] | An Encoding--Searching Separation Perspective on Bi-Encoder Neural Search | This paper reviews, analyzes, and proposes a new perspective on the
bi-encoder architecture for neural search. While the bi-encoder architecture is
widely used due to its simplicity and scalability at test time, it has some
notable issues such as low performance on seen datasets and weak zero-shot
performance on new datasets. In this paper, we analyze these issues and
summarize two main critiques: the encoding information bottleneck problem and
limitations of the basic assumption of embedding search. We then construct a
thought experiment to logically analyze the encoding and searching operations
and challenge the basic assumption of embedding search. Building on these
observations, we propose a new perspective on the bi-encoder architecture
called the \textit{encoding--searching separation} perspective, which
conceptually and practically separates the encoding and searching operations.
This new perspective is applied to explain the root cause of the identified
issues and discuss ways to mitigate the problems. Finally, we discuss the
implications of the ideas underlying the new perspective, the design surface
that it exposes and the potential research directions arising from it. |
2408.01095v1 | ## Computing Riemann zeros with light scattering
Sunkyu Yu 1† , Xianji Piao 2§ , and Namkyoo Park 3*
1
Intelligent Wave Systems Laboratory, Department of Electrical and Computer Engineering, Seoul National University, Seoul 08826, Korea
2 Wave Engineering Laboratory, School of Electrical and Computer Engineering, University of Seoul, Seoul 02504, Korea
3 Photonic Systems Laboratory, Department of Electrical and Computer Engineering, Seoul National University, Seoul 08826, Korea
E-mail address for correspondence: [email protected], [email protected], [email protected] † § *
## Abstract
Finding hidden order within disorder is a common interest in material science 1,2 , wave physics 3,4 , and mathematics . The Riemann hypothesis, stating the locations of nontrivial zeros of the Riemann 5 zeta function , tentatively characterizes statistical order in the seemingly random distribution of 6 prime numbers. This famous conjecture has inspired various connections with different branches of physics , recently with non-Hermitian physics 7 8,9 , quantum field theory 10 , trapped-ion qubits 11 , and hyperuniformity 12,13 . Here we develop the computing platform for the Riemann zeta function by employing classical scattering of light. We show that the Riemann hypothesis suggests the landscape of semi-infinite optical scatterers for the perfect reflectionless condition under the Born approximation. To examine the validity of the scattering-based computation, we investigate the asymptotic behaviours of suppressed reflections with the increasing number of scatterers and the
emergence of multiple scattering. The result provides another bridge between classical physics and the Riemann zeros, exhibiting the design of wave devices inspired by number theory.
## Introduction
As an abstract language of physics, mathematics allows for linking seemingly unrelated phenomena in different domains of physics. For example, the mathematical similarity in governing equations enables analogies between classical and quantum phenomena 14-16 . Statistical measures classify distinctly disordered materials into the same material phase 1-4 . The concept of topology provides a common design strategy for implementing robust systems across different domains 1719 . Similarly, the Riemann hypothesis is a representative example that bridges classical, quantum, 6 and relativistic physics through number theory . 7
For the Riemann zeta function ζ ( s ) = ∑ 1 n s ∞ n =1 with a complex variable s = σ + it , where σ and are real, this cornerstone conjecture claims that the locations of the nontrivial zeros for t t ≠ 0 are restricted to σ = 1/2. The most important result of understanding the locations of the nontrivial Riemann zeros would be the quantification of prime number distribution due to its relationship with the prime counting function, which forms the basis for number theory 5,20 . Efforts to connect the conjecture to physics problems have been focused on finding ζ ( s ) in various systems: chaotic resonators , 7 parity-time-symmetric Hamiltonians 8,9 , relativistic scattering 10 , and trapped-ion qubits 11 . The most famous approach is the Hilbert-Pólya conjecture 21 , which suggests that the nontrivial Riemann zeros correspond to real eigenvalues of a Hermitian operator.
Material science is another branch exploring the implications of the Riemann hypothesis. Due to the similarity between material classification and number theory in discovering hidden order within highly randomized patterns, the intermediate regime between order and uncorrelated disorder has attracted substantial attention in exploring the hypothesis. For example, there has been an attempt to understand the locations of the Riemann zeros using quasicrystal patterns 22,23 . The
distribution of prime numbers has also been examined through the concept of hyperuniformity 2426 , which reveals the suppression of long-range fluctuations in the pattern of prime numbers 12,13 .
Here, we revisit the classical theory of light scattering to develop wave-based computing platforms for the Riemann zeta function through engineered scatterers. We propose the concept of the σ -Riemann scatterer, which is composed of the logarithmically spaced one-dimensional (1D) semi-infinite scatterers with σ -power-law-decayed scattering amplitudes. We demonstrate that the Riemann hypothesis corresponds to the complete reflectionless condition only at the (1/2)Riemann scatterer under the first-order Born approximation, where the locations of the Riemann zeros denote the zero-reflection wavelength of light. To exploit this reflectionless condition for optical devices, we estimate the valid range of highly suppressed reflection at the Riemann-zero wavelengths, by examining a finite number of scatterers and multiple scattering beyond the Born approximation. The result offers insights into the non-Hermitian generalization of the HilbertPólya conjecture and the design of reflectionless optical structures using the hyperuniformity with reciprocal-space shifts.
## Results
## Riemann zeta functions in light scattering
To investigate the relationship between light scattering and the Riemann zeta function, we review 1D multiple scattering theory 27 . Consider a wave equation d 2 ψ / dx 2 + [ V 0 + V x ( )] ψ = 0, where ψ is a wavefunction, and V 0 and V x ( ) are a constant and a spatially-varying potential, respectively. Although the potentials in our example correspond to the landscape of permittivity in nonmagnetic optical media 15,28 , the equation is applicable to describe quantum states under the single-particle
approximation 29 , and classical oscillations of matter, such as acoustic 30 and elastic 31 waves. The profile of V x ( ) determines material inhomogeneity.
Motivated by the semi-infinite summation of ζ ( s ) = ∑ 1 n s ∞ n =1 , we consider a material that is asymptotically homogeneous as approaches negative infinity: x V x ( → -∞) = 0 . Scattering from the material is examined with the planewave incidence from x → -∞, ψ I = ψ 0exp( ik x 0 ), which is the solution of the Helmholtz equation d 2 ψ / dx 2 + V 0 ψ = 0, where V 0 = k 0 2 and k 0 = 2 π λ / ≥ 0 for the wavelength . With the scattering wavefunction λ ψ S, the total wavefunction ψ is determined by the 1D Lippmann-Schwinger equation 27 , as ψ = ψ I + ψ S = ψ I + 1 4 π ∫ V x ( ') ψ ( x ') G x x ( , ') dx ', where +∞ -∞ G x x ( , ') = (2 π i / k 0)exp( ik 0| x - '|) is the 1D Green's function satisfying x d G x x 2 ( , ')/ dx 2 + V G x x 0 ( , ') = -4 πδ ( x - ') x for the Dirac delta function δ ( x ). By defining the scattering operator M as
$$( M \varphi ) ( x ) = \frac { i } { 2 k _ { 0 } } \int _ { - \infty } ^ { + \infty } V ( x ^ { \prime } ) \varphi ( x ^ { \prime } ) e ^ { i k _ { 0 } | x - x ^ { \dagger } } d x ^ { \prime },$$
for an arbitrary wavefunction φ ( x ), ψ can be expressed as the Born series 27 , ψ = ψ I + ∑ ψ S, m ∞ m =1 , where ψ S, m ≜ M m ψ I is the m th-order scattering wavefunction.
From the above review of the 1D scattering theory, we derive the Riemann zeta function ζ ( s ) in the first-order scattering ψ S,1 , by tailoring the spatial inhomogeneity of the potential V x ( ). The inhomogeneous potential is implemented with an array of N point scatterers, as V x ( ) = VN x ( ) ≜ ∑ d n δ ( x -x n ), where N n =1 dn and xn are the scattering amplitude and position of the n th scatterer, respectively, N is the number of scatterers, and xn ≤ xn +1 for all n . Among the multifaceted forms of ζ ( s ), we focus on implementing the following form obtained from the Dirichlet eta function 32,33 :
$$\zeta ( s ) = & \frac { 1 } { 1 - 2 ^ { 1 - s } } \sum _ { n = 1 } ^ { \infty } \frac { ( - 1 ) ^ { n + 1 } } { n ^ { s } },$$
to guarantee numerical convergence in the critical strip { s ∈ ℂ : 0 < Re[ s ] = σ < 1}, which was already proved to possess all the nontrivial zeros 20 . To derive Eq. (2) in the 1D scattering formulation, we define the σ -Riemann scatterer (Fig. 1a)-an array of N scatterers having the logarithmically spaced distribution xn = x 0log( n ) and the alternating σ -power-law scattering amplitudes dn = (-1) n +1 d n 0 -σ , as
$$V ( x ) = d _ { 0 } \sum _ { n = 1 } ^ { N } \frac { ( - 1 ) ^ { n + 1 } } { n ^ { \sigma } } \delta ( x - x _ { 0 } \log ( n ) ),$$
where x 0 and d 0 are real- and complex-valued coefficients, respectively. The resulting first-order scattering in the region between the p th and ( p +1)th scatterers is obtained with Eq. (1), as follows (Supplementary Note S1):
$$\psi _ { \text{S,1} } ( x ; x _ { p } \leq x < x _ { p + 1 } ) = \frac { i d _ { 0 } \psi _ { 0 } } { 2 k _ { 0 } } \left [ \left ( \sum _ { n = 1 } ^ { p } \frac { ( - 1 ) ^ { n + 1 } } { n ^ { \sigma } } \right ) e ^ { + i k _ { 0 } x } + \left ( \sum _ { n = p + 1 } ^ { N } \frac { ( - 1 ) ^ { n + 1 } } { n ^ { \sigma - 2 i k _ { 0 } x _ { 0 } } } \right ) e ^ { - i k _ { 0 } x } \right ].$$
The comparison between the first-order scattering ψ S,1 and multiple scattering ψ S is shown in Figs. 1b and 1c for small and large values of d 0, respectively, which exhibit the validity of Eq. (4) for small d 0 (Supplementary Note S2 for the calculation of multiple scattering).
Equation (4) provides insight into the connection between the first-order scattering and the Riemann zeta function, leading to the following transmitted ( p→∞ ) and reflected ( p = 0) waves from the semi-infinite ( N →∞) σ -Riemann scatterer:
$$& \psi _ { _ { T } } ( x ; x \to \infty ) = \lim _ { p \to \infty } \psi _ { S, 1 } ( x ; x \geq x _ { p } ) = \frac { i d _ { 0 } \psi _ { 0 } e ^ { + i k _ { 0 } x } } { 2 k _ { 0 } } \left ( 1 - 2 ^ { 1 - \sigma } \right ) \zeta ( \sigma ), \\ & \psi _ { _ { R } } ( x ; x < x _ { 1 } ) = \psi _ { S, 1 } ( x ; x < x _ { 1 } ) = \frac { i d _ { 0 } \psi _ { 0 } e ^ { - i k _ { 0 } x } } { 2 k _ { 0 } } \left ( 1 - 2 ^ { 1 - \sigma + 2 i k _ { 0 } y _ { 0 } } \right ) \zeta ( \sigma - 2 i k _ { 0 } x _ { 0 } ).$$
Equation (5) demonstrates that both the transmitted and reflected waves from the semi-infinite σ -Riemann scatterer are proportional to the Riemann zeta function ζ ( s ) under the first-order Born
approximation. When considering a practical measurement setup and the exploration of nontrivial Riemann zeros with s ∈ ℂ , the measurement of the reflected wave is suitable for light-based computation of the Riemann zeta function. Notably, Im[ ] = -2 s k x 0 0 can be controlled by the optical wavelength λ = 2 π / k 0. Figures 1d and 1e describe the λ -dependent amplitude and phase of the Riemann zeta function ( ζ σ - 4 πix 0/ λ ), respectively, within the critical strip 0 < σ < 1, exhibiting the Riemann-zero wavelengths ('×' symbols).
Fig. 1. σ -Riemann scatterer. a, A schematic of the σ -Riemann scatterer: a semi-infinite array of logarithmically spaced scatterers with a σ -power-law distribution of sign-alternating scattering amplitudes. The Riemann zeta function in the critical strip can be computed with the scattering wave ψ S for the incidence ψ I . Red and blue curved arrows at each scatterer denote the scattering waves defined by the Green's function. b,c, Examples of scattering from the (1/2)-Riemann scatterer for d 0 = 0.001 ( b ) and d 0 = 10 ( c ). The arrows illustrate point scatterers. Red solid lines denote the multiple scattering ψ S calculated by the scattering matrix method 34 (Supplementary Note S2). Orange circles denote the first-order scattering ψ S,1 obtained from Eq. (4). N = 1000, x 0 = 1 and ψ 0 = 1. d,e, The Riemann zeta function ζ σ ( - 4 πix 0/ λ ) in the critical strip: amplitude ( d ) and phase ( e ) of ζ σ ( - 4 πix 0/ λ ). The symbols '×' denote the first seven nontrivial Riemann zeros.
## Optically computed Riemann zeros
Using the design of the Riemann scatterer, we revisit the Riemann hypothesis, which states that the nontrivial zeros of ζ ( s ) exist only at Re[ s ] = σ = 1/2. Because ζ ( s * ) = [ ζ ( s )] * , it is well known 20 that the nontrivial zeros s 0 = 1/2 + it 0 lead to the other zeros s 0 = 1/2 it 0 , which can be directly compared with = s σ - 4 π ix 0/ λ in ψ R( x ) ~ ζ ( s ). Therefore, the Riemann hypothesis claims that the complete suppression of the first-order scattering from the σ -Riemann scatterer can be achieved only with the (1/2)-Riemann scatterer, which requires the scattering amplitudes dn = (-1) n +1 d n 0 -1/2 ( σ row in Table 1). The location of the nontrivial Riemann zeros t 0 determines the perfect reflectionless wavelength λ 0 = 4 π x 0/ t 0 ( t row in Table 1). The conjugate relation ζ ( s * ) = [ ζ ( s )] * corresponds to electromagnetic reciprocity in light scattering, achieving the reflectionless condition for the incidence with the opposite-directional wavevector -2 π λ / 0 ( s * row in Table 1). We emphasize that higher-order scatterings ψ S, m x ( ) = M m -1 ψ S,1 ( x ) = 0 ( m = 2, 3, …, ∞) are not completely suppressed because the complete suppression of ψ S,1 ( x ) occurs only in the range of x < 0, and thus, nonzero ψ S,1 ( x ≥ 0) with the integral operator M leads to higher-order scattering with Eq. (1).
Table. 1. Correspondence between the Riemann hypothesis and the first-order scattering. The rows of the table indicate the comparison in terms of the real and imaginary parts of the variable s and its conjugate s * .
| | Riemann hypothesis | First-order scattering from the σ -Riemann scatterer |
|-------------|-----------------------------------|---------------------------------------------------------------|
| σ = Re[ s ] | σ = 1/2 for ζ ( s ) = 0 | Scattering amplitudes | d n | = d 0 / n 1/2 for ψ R ( x ) = 0 |
| t = Im[ s ] | t = t 0 for ζ ( s ) = 0 | Incident wavelength λ 0 = 4 π x 0 / t 0 for ψ R ( x ) = 0 |
| s * | ζ ( s 0* ) = 0 when ζ ( s 0 ) = 0 | Wavevector reciprocity (±2 π / λ 0 ) for ψ R ( x ) = 0 |
Interpreting nontrivial Riemann zeros with the (1/2)-Riemann scatterer presents a unique approach to the Hilbert-Pólya conjecture 21 and its generalization into non-Hermitian physics 8,9 . Consider the decomposition of the Hermitian Hamiltonian H for the (1/2)-Riemann scatterer into two subsystem Hamiltonians, which separate the forward ( H F) and backward ( H B) paths in the region where x < 0. Due to scattering, H F and H B are generally coupled, and therefore, each Hamiltonian itself is non-Hermitian with complex eigenvalues. However, under the first-order Born approximation, H F (and H B) can exhibit real eigenvalues without the coupling to H B at the reflectionless wavelengths λ 0 . Therefore, H F could serve as the non-Hermitian Hamiltonian for the generalized Hilbert-Pólya conjecture. The Riemann hypothesis states that such decomposition with real eigenvalues is possible only with the potential landscape of the (1/2)-Riemann scatterer.
The condition of nontrivial Riemann zeros with the (1/2)-Riemann scatterer also exhibits an intriguing connection to the concept of hyperuniformity 3,24-26,35 , allowing for interpreting the (1/2)-Riemann scatterer as correlated disorder. For a 1D inhomogeneous material composed of point particles, V x ( ) = VN x ( ) ≜ ∑ d n δ ( x -x n ), the structure factor N n =1 S k ( ) is given by S k ( ) = �∑ d n exp(ikx n ) N n =1 � 2 . Hyperuniformity is defined by the asymptotic behaviour of the structure factor, S k ( → 0) → 0 in the thermodynamic limit, which corresponds to the suppression of infinite -wavelength density fluctuations 3,24,26 . For the Riemann scatterer, the above definition of the structure factor leads to S k ( ) = d 0 2 �∑ (-1) n +1 n -( σ + ikx 0 ) N n =1 � 2 , which approaches S k ( ) = d 0 2 | ζ σ ( + ikx 0)| 2 at N → ∞ in the critical strip . Therefore, each nontrivial Riemann zero in the Riemann scatterer corresponds to the complete halt of the density fluctuation exactly at the wavelength determined by λ 0 = 4 π x 0/ t 0 , which can be considered the reciprocal-space translation of the perfect hyperuniformity from the infinity to 2 k 0.
## Evolving Riemann scatterer
Although the correspondence between the Riemann zeta function and the σ -Riemann scatterer is achieved with a semi-infinite ( N → ∞ ) array of weak ( d 0 → 0) and point-particle ( δ ( x -x 0log( n )) scatterers, its measurable implementation requires breaking such ideal constraints. First, we investigate the effect of N on the reflectance by multiple scattering, R = | ψ S( x <0)| /| 2 ψ 0| 2 , which is an experimentally measurable quantity. Figure 2a shows the reflectance map R N ( , λ ) under the weak scattering condition ( d 0 = 0.001), which exhibits converging behaviours with increasing N . The result in Fig. 2b demonstrates the successful observation of the first 40 nontrivial Riemannzero wavelengths λ 0, p ( p = 1, 2, … 40) with the scatterer number N = 1000, where λ 0, p = 4 π x 0/ t 0, p is obtained from the p th nontrivial zeros t 0, p .
The increase in N can be considered the evolution of a material resulting from the addition of a series of particles, which leads to subsequent changes in scattering 35 . Such an evolving model reveals a unique nature of nontrivial Riemann zeros: non-oscillatory suppression of the reflectance. Figure 2c illustrates the evolutions of the reflectance R for different wavelengths near the second nontrivial Riemann-zero wavelength λ 0,2 . The result shows that the reflectance decreases monotonically with increasing N exactly at the wavelength of a nontrivial Riemann zero, which is further confirmed with the evolution of R at other nontrivial zeros (Fig. 2d for λ 0, p with p = 1, 2, … 40). On the other hand, the evolution of R oscillates with N at other wavelengths. In terms of the evolving scattering model 35 , the monotonic decrease of R corresponds to the optimal suppression of the density fluctuation at a given k of S k ( ). Similar to the design of stealthy hyperuniformity using the evolving model 35 that suppresses the density fluctuation in the certain range of | k | < K , the (1/2)-Riemann scatterer provides the optimal suppression of the density fluctuation at a set of k defined by the nontrivial Riemann zeros.
Fig. 2. Evolution of the (1/2)-Riemann scatterer. a, The multiple scattering reflectance R as a function of the particle number N and the wavelength λ . b, The multiple scattering reflectance R (black solid line) as a function of λ at N = 1000. Empty circles denote the reflectance from the first-order scattering. Red dashed lines indicate the wavelengths corresponding to nontrivial Riemann zeros λ 0, p ( p = 1, 2, … 40). c, The evolutions of R with respect to N at the second nontrivial Riemann-zero wavelength λ 0,2 ~ 0.59777 and its neighbouring wavelengths ( λ = 0.593, 0.596, 0.599, and 0.602). d, The evolutions of R with respect to N at the nontrivial Riemann-zero wavelengths λ 0, p ( p = 1, 2, … 40). The solid lines highlight the cases of p = 1 and 40. x 0 = 1, d 0 = 0.001, and ψ 0 = 1.
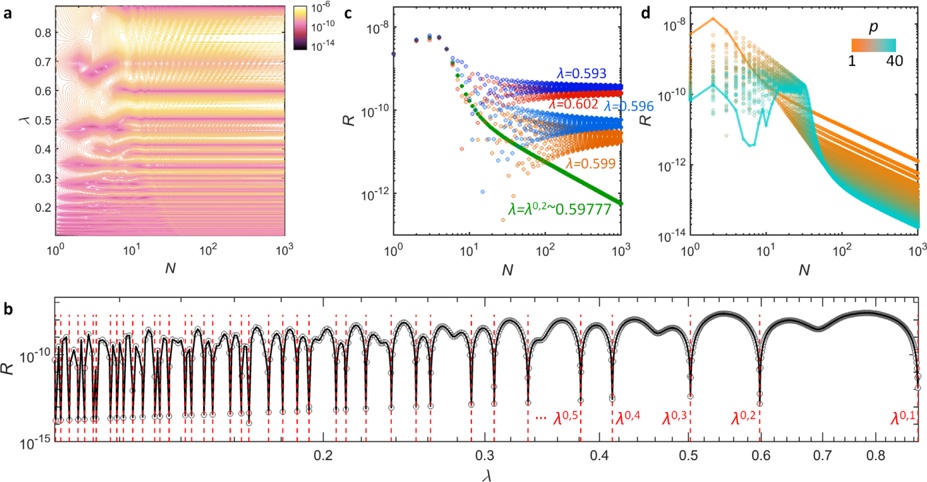
## Beyond the Born approximation
Another important restriction in guaranteeing the validity of the measurement of Eq. (5) is the Born approximation. It is well known that the convergence of the Born series is valid when the spectral radius of the operator M is less than unity, which can be achieved with weak scattering potentials 36 . This condition is determined by d 0, N , and the size of each scatterer 27 . While preserving the point-particle scatterer configuration, Fig. 3 illustrates the effect of d 0 and N on the
multiple scattering reflection for different Riemann-zero wavelengths. We note that the linear response between log( d 0) and log( R ) guarantees the validity of the first-order Born approximation, which enables the light-based computing of nontrivial Riemann zeros. The increase of d 0 and N breaks this approximation as widely examined in scattering theory 27,36 . Notably, the breaking occurs more rapidly at the lowerp nontrivial Riemann zero with a larger λ . It is because an array of scatterers seems to be more clustered for the incidence of a larger λ , which breaks the constraint on the scatterer size despite the point shape of each scatterer.
Fig. 3. Beyond the Born approximation. a,b, The multiple scattering reflectance R as a function of d 0 at the wavelengths corresponding to nontrivial Riemann zeros λ 0, p ( p = 1, 2, … 40): N = 10 ( a ) and N = 1000 ( b ). All the other parameters are the same as those in Fig. 2.
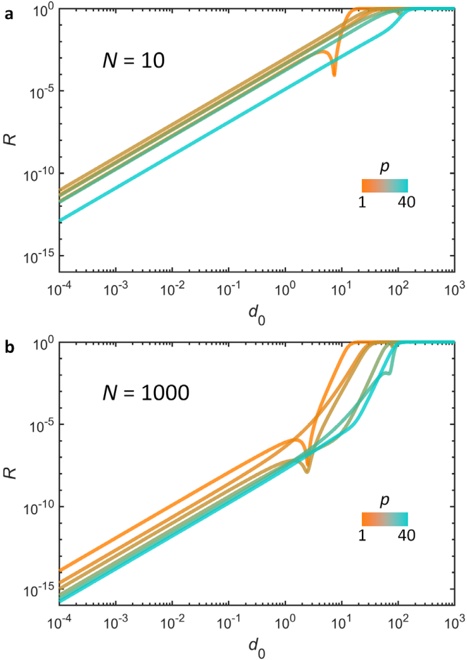
Extending the discussion on multiple scattering, we lift another critical restriction for practical implementation-the point particle condition. We replace each point particle of the σ -Riemann scatterer (Fig. 4a) with the corresponding layer of finite thickness (Fig. 4b), where the center of the layer is xn = x 0log( n ). The array of these layers is embedded in a homogeneous material of the potential V 0 = k 0 2 . To reproduce the scattering from the ideal σ -Riemann scatterer, the thickness and potential of the n th layer are set to be l n = l 0 n -σ and Vn = [1 + (-1) n +1 ρ ] 2 V 0, respectively, where l 0 is the thickness of the first layer and ρ is the coefficient of material inhomogeneity for two-phase multilayers (Fig. 4b). The designed layer corresponds to the effective realization of the point particle dn δ ( x -xn ), where d 0 ~ (2 k 0 2 ρ ) l 0 for dn = (-1) n +1 d n 0 -σ under weak scattering assumption (Supplementary Note S3).
Figure 4c shows the multiple-scattering reflectance from the multilayered Riemann scatterer with increasing N at the wavelengths of nontrivial Riemann zeros ( p = 1, 5, 15, and 30). Notably, due to the breaking of the first-order Born approximation with d 0 ~ (2 k 0 2 ρ ) l 0, the suppression of reflectance is weakened at shorter wavelengths, which correspond to higherp Riemann zeros. However, the relative suppression of reflectance at the Riemann-zero wavelengths compared to their nearby wavelengths significantly increases at higher p , as shown in the exemplified comparison among p = 2, 15, and 30 in Supplementary Note S4. This observation is confirmed with the wavelength dependency of the discrepancy Δ R = R - | ψ R| in Fig. 4d, which 2 quantifies the contribution from higher-order scattering to the reflectance. As shown, the magnitude of Δ R maintains a relatively very low value at each Riemann-zero wavelength (red circles) when compared with the values of its nearby wavelengths. This result demonstrates that the ratio of higher-order scattering originating from the broken Born approximation is sufficiently small at the Riemann zeros, enabling the identification of the Riemann zeros even at higher p .
Fig. 4. Multilayered Riemann scatterer. a,b, Reproduction of the point-particle Riemann scatterer ( a ) with the multilayered one ( b ). c, The evolution of reflectance with respect to N for the Riemann-zero wavelengths of λ 0,1 , λ 0,5 , λ 0,15 , and λ 0,30 . d, The difference between the multiplescattering reflection and the first-or der reflection, Δ R = R - | ψ R| , as a function of the wavelength 2 λ . The red circles highlight the Riemann-zero wavelengths. The inset emphasizes a narrower range of Δ R for better visibility. The thickness coefficient and material inhomogeneity are set to be l 0 = 0.01 and ρ = 10 -3 , respectively. All the other parameters are the same as those in Fig. 2.
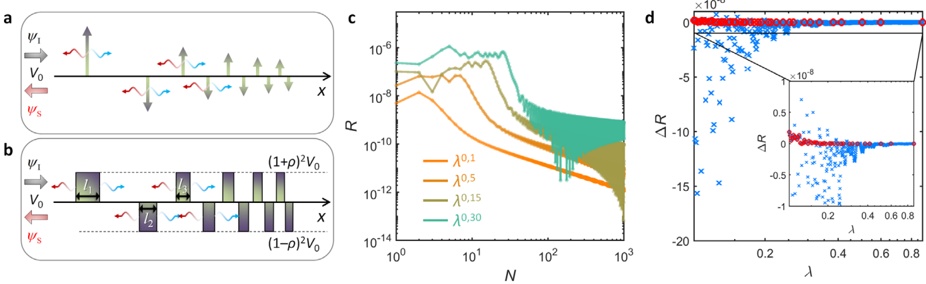
## Discussion
The correspondence between the first-order scattering and the Riemann zeta function belongs to the class of wave-based mathematical operations, such as Fourier transforms using diffraction 37 , matrix multiplications via interferometry 38 , and integral equation solvers employing metamaterials 39 . Significantly, the relationship exp(2 ik xn 0 ) = n 2 ik 0 x 0 for xn = x 0log( n ) demonstrates that logarithmically-spaced scatterers pave the way to the wave-based computing of other special functions, especially including variations of the Riemann zeta function involving complex variables. For example, the prime zeta function P s ( ) = ∑ 1 p s p ∈ primes can be implemented in the same manner with the designed scatterers deposited only at the prime numbers p . The Hurwitz zeta function ζ ( s a , ) = ∑ 1 ( n + ) a s ∞ n =0 requires the shifted positions of the particles xn = x 0log( n + ) with the a modified scattering amplitudes dn ~ ( n + ) -a σ . The reciprocal of the Riemann zeta function can also
be realized with the designed scatterers in our approach, while the scattering amplitudes are modified according to the Möbius function μ ( n ). Such design freedom extends the application of wave-based computing into number theory.
According to our analysis of the broken Born approximation in the Riemann scatterer, maintaining dominant first-order scattering is critical. Although the straightforward approach involves weak perturbation and subwavelength design as we demonstrated, additional design flexibility still remains in the layer design using unnatural material parameters with metamaterials and some mathematical modifications such as using a suitable preconditioner 36 . Because the designed preconditioner provides the convergent form of the Born series even under large and strong perturbations, the stable calculation of multiple scattering with the modified Born series may reveal an intriguing connection to the infinite series of the Riemann zeta function.
In the realm of disordered photonics, the Riemann scatterer extends hyperuniformity with reciprocal-space shifts forms a class of logarithmically-spaced correlated disorder toward reflectionless design. Especially, the semi-infinite form of the Riemann scatterer introduces a unique mechanism for scattering suppression, distinct from antireflection coating, reflectionless potential profiles 40 , reflectionless scattering modes 41 , all of which primarily focus on finite-size scatterers. A comparable case would be parity-time-symmetric crystals for unidirectional transport 42 , because nonuniform scattering amplitudes dn can be replaced with complex-valued wavenumbers k 0. The complete suppression of reflection in the (1/2)-Riemann scatterer with logarithmically-spaced scatterers also offers insights into the design of log-periodic antennas with directional radiation 43 .
In conclusion, we developed the concept of the Riemann scatterer, which results in the scattering quantified by the Riemann zeta function under the first-order Born approximation. The
Riemann hypothesis claims that completely zero reflection from the scatterer can be achieved only with a (1/2)-power-law distribution of scattering amplitudes. We examined the valid range of our theory by numerically investigating multiple scattering cases under the broken Born approximation. Further research is highly desirable to develop subsystem Hilbert-Pólya Hamiltonians for the Riemann scatterer, design other special functions, explore much higher zeros, and extend the theory to multiple scattering regimes, thereby bridging physics and number theory.
## Data availability
The data that support the plots and other findings of this study are available from the corresponding author upon request.
## Code availability
All code developed in this work will be made available upon request.
## References
- 1. Keen, D. A. & Goodwin, A. L. The crystallography of correlated disorder. Nature 521 , 303309 (2015).
- 2. Simonov, A. & Goodwin, A. L. Designing disorder into crystalline materials. Nat. Rev. Chem. 4 , 657-673 (2020).
- 3. Yu, S., Qiu, C.-W., Chong, Y., Torquato, S. & Park, N. Engineered disorder in photonics. Nat. Rev. Mater. 6 , 226-243 (2021).
- 4. Vynck, K., Pierrat, R., Carminati, R., Froufe-Pérez, L. S., Scheffold, F., Sapienza, R., Vignolini, S. & Sáenz, J. J. Light in correlated disordered media. Rev. Mod. Phys. 95 ,
045003 (2023).
- 5. Goldstein, L. J. A history of the prime number theorem. Am. Math. Mon. 80 , 599-615 (1973).
- 6. Riemann, B. Ueber die Anzahl der Primzahlen unter einer gegebenen Grosse. Ges. Math. Werke 2 , 2 (1859).
- 7. Schumayer, D. & Hutchinson, D. A. Colloquium: Physics of the Riemann hypothesis. Rev. Mod. Phys. 83 , 307-330 (2011).
- 8. Sierra, G. & Rodríguez-Laguna, J. H= xp model revisited and the Riemann zeros. Phys. Rev. Lett. 106 , 200201 (2011).
- 9. Bender, C. M., Brody, D. C. & Müller, M. P. Hamiltonian for the zeros of the Riemann zeta function. Phys. Rev. Lett. 118 , 130201 (2017).
- 10. Remmen, G. N. Amplitudes and the Riemann zeta function. Phys. Rev. Lett. 127 , 241602 (2021).
- 11. He, R., Ai, M.-Z., Cui, J.-M., Huang, Y.-F., Han, Y.-J., Li, C.-F., Guo, G.-C., Sierra, G. & Creffield, C. E. Riemann zeros from Floquet engineering a trapped-ion qubit. npj Quantum Inf. 7 , 109 (2021).
- 12. Torquato, S., Zhang, G. & de Courcy-Ireland, M. Uncovering multiscale order in the prime numbers via scattering. Jour. Stat. Mech. 2018 , 093401 (2018).
- 13. Torquato, S., Zhang, G. & De Courcy-Ireland, M. Hidden multiscale order in the primes. J. Phys. A: Math. Theor. 52 , 135002 (2019).
- 14. Dragoman, D. & Dragoman, M. Quantum-classical analogies (Springer, 2004).
- 15. Longhi, S. Quantum optical analogies using photonic structures. -Laser Photonics Rev. 3 , 243-261 (2009).
- 16. Jarzynski, C., Quan, H. & Rahav, S. Quantum-classical correspondence principle for work distributions. Phys. Rev. X 5 , 031038 (2015).
- 17. Hasan, M. Z. & Kane, C. L. Colloquium: Topological insulators. Rev. Mod. Phys. 82 , 30453067 (2010).
- 18. Ozawa, T., Price, H. M., Amo, A., Goldman, N., Hafezi, M., Lu, L., Rechtsman, M. C., Schuster, D., Simon, J. & Zilberberg, O. Topological photonics. Rev. Mod. Phys. 91 , 015006 (2019).
- 19. Xue, H., Yang, Y. & Zhang, B. Topological acoustics. Nat. Rev. Mater. 7 , 974-990 (2022).
- 20. Edwards, H. M. Riemann's zeta function (Courier Corporation, 2001).
- 21. Derbyshire, J. Prime obsession: Bernhard Riemann and the greatest unsolved problem in mathematics (Joseph Henry Press, 2003).
- 22. Dyson, F. Birds and frogs. Notices of the AMS 56 , 212-223 (2009).
- 23. Dal Negro, L. Optics of aperiodic structures: fundamentals and device applications (CRC press, 2013).
- 24. Torquato, S. & Stillinger, F. H. Local density fluctuations, hyperuniformity, and order metrics. Phys. Rev. E 68 , 041113 (2003).
- 25. Torquato, S. Hyperuniformity and its generalizations. Phys. Rev. E 94 , 022122 (2016).
- 26. Torquato, S. Hyperuniform states of matter. Phys. Rep. 745 , 1-95 (2018).
- 27. Gonis, A. & Butler, W. H. Multiple scattering in solids (Springer Science & Business Media, 1999).
- 28. Jackson, J. D. (American Association of Physics Teachers, 1999).
- 29. Sakurai, J. J. & Commins, E. D. (American Association of Physics Teachers, 1995).
- 30. Auld, B. A. Acoustic fields and waves in solids (Рипол Классик, 1973).
- 31. Cho, C., Yu, S. & Park, N. Elastic Hamiltonians for quantum analog applications. Phys. Rev. B 101 , 134107 (2020).
- 32. Sergeyev, Y. D. On accuracy of mathematical languages used to deal with the Riemann zeta function and the Dirichlet eta function. P-Aic Numbers Ultra. 3 , 129-148 (2011).
- 33. Milgram, M. S. Integral and Series Representations of Riemann s Zeta Function and ′ Dirichlet s Eta Function and a Medley of Related Results. ′ J. Math. 2013 , 181724 (2013).
- 34. Tikhodeev, S. G., Yablonskii, A., Muljarov, E., Gippius, N. A. & Ishihara, T. Quasiguided modes and optical properties of photonic crystal slabs. Phys. Rev. B 66 , 045102 (2002).
- 35. Yu, S. Evolving scattering networks for engineering disorder. Nat. Comput. Sci. 3 , 128-138 (2023).
- 36. Osnabrugge, G., Leedumrongwatthanakun, S. & Vellekoop, I. M. A convergent Born series for solving the inhomogeneous Helmholtz equation in arbitrarily large media. J. Comput. Phys. 322 , 113-124 (2016).
- 37. Goodman, J. W. Introduction to Fourier optics (Roberts and Company publishers, 2005).
- 38. Zhou, H., Dong, J., Cheng, J., Dong, W., Huang, C., Shen, Y., Zhang, Q., Gu, M., Qian, C. & Chen, H. Photonic matrix multiplication lights up photonic accelerator and beyond. Light Sci. Appl. 11 , 30 (2022).
- 39. Mohammadi Estakhri, N., Edwards, B. & Engheta, N. Inverse-designed metastructures that solve equations. Science 363 , 1333-1338 (2019).
- 40. Lekner, J. Reflectionless eigenstates of the sech2 potential. Am. J. Phys. 75 , 1151-1157 (2007).
- 41. Stone, A. D., Sweeney, W. R., Hsu, C. W., Wisal, K. & Wang, Z. Reflectionless excitation of arbitrary photonic structures: A general theory. Nanophotonics 10 , 343-360 (2020).
- 42. Lin, Z., Ramezani, H., Eichelkraut, T., Kottos, T., Cao, H. & Christodoulides, D. N. Unidirectional invisibility induced by PT-symmetric periodic structures. Phys. Rev. Lett. 106 , 213901 (2011).
- 43. Carrel, R. The design of log-periodic dipole antennas . In 1958 IRE International Convention Record 9 , 61-75 (1966).
## Acknowledgements
We acknowledge financial support from the National Research Foundation of Korea (NRF) through the Basic Research Laboratory (No. RS-2024-00397664), Young Researcher Program (No. 2021R1C1C1005031), and Midcareer Researcher Program (No. RS-2023-00274348), all funded by the Korean government. This work was supported by Creative-Pioneering Researchers Program and the BK21 FOUR program of the Education and Research Program for Future ICT Pioneers in 2024, through Seoul National University. We also acknowledge an administrative support from SOFT foundry institute.
## Author contributions
All the authors conceived the idea, discussed the results, and contributed to the final manuscript.
## Competing interests
The authors have no conflicts of interest to declare.
## Additional information
Correspondence and requests for materials should be addressed to S.Y., X.P., or N.P.
## Figure Legends
Fig. 1. σ -Riemann scatterer. a, A schematic of the σ -Riemann scatterer: a semi-infinite array of logarithmically spaced scatterers with a σ -power-law distribution of sign-alternating scattering amplitudes. The Riemann zeta function in the critical strip can be computed with the scattering wave ψ S for the incidence ψ I . Red and blue curved arrows at each scatterer denote the scattering waves defined by the Green's function. b,c, Examples of scattering from the (1/2)-Riemann scatterer for d 0 = 0.001 ( b ) and d 0 = 10 ( c ). The arrows illustrate point scatterers. Red solid lines denote the multiple scattering ψ S calculated by the scattering matrix method 34 (Supplementary Note S2). Orange circles denote the first-order scattering ψ S,1 obtained from Eq. (4). N = 1000, x 0 = 1 and ψ 0 = 1. d,e, The Riemann zeta function ζ σ ( - 4 πix 0/ λ ) in the critical strip: amplitude ( d ) and phase ( e ) of ζ σ ( - 4 πix 0/ λ ). The symbols '×' denote the first seven nontrivial Riemann zeros.
Fig. 2. Evolution of the (1/2)-Riemann scatterer. a, The multiple scattering reflectance R as a function of the particle number N and the wavelength λ . b, The multiple scattering reflectance R (black solid line) as a function of λ at N = 1000. Empty circles denote the reflectance from the first-order scattering. Red dashed lines indicate the wavelengths corresponding to nontrivial Riemann zeros λ 0, p ( p = 1, 2, … 40). c, The evolutions of R with respect to N at the second nontrivial Riemann-zero wavelength λ 0,2 ~ 0.59777 and its neighbouring wavelengths ( λ = 0.593, 0.596, 0.599, and 0.602). d, The evolutions of R with respect to N at the nontrivial Riemann-zero wavelengths λ 0, p ( p = 1, 2, … 40). The solid lines highlight the cases of p = 1 and 40. x 0 = 1, d 0 = 0.001, and ψ 0 = 1.
Fig. 3. Beyond the Born approximation. a,b, The multiple scattering reflectance R as a function of d 0 at the wavelengths corresponding to nontrivial Riemann zeros λ 0, p ( p = 1, 2, … 40): N = 10 ( a ) and N = 1000 ( b ). All the other parameters are the same as those in Fig. 2.
Fig. 4. Multilayered Riemann scatterer. a,b, Reproduction of the point-particle Riemann scatterer ( a ) with the multilayered one ( b ). c, The evolution of reflectance with respect to N for the Riemann-zero wavelengths of λ 0,1 , λ 0,5 , λ 0,15 , and λ 0,30 . d, The difference between the multiplescattering reflection and the firstorder reflection, Δ R = R - | ψ R| , as a function of the wavelength 2 λ . The red circles highlight the Riemann-zero wavelengths. The inset emphasizes a narrower range
of Δ R for better visibility. The thickness coefficient and material inhomogeneity are set to be l 0 = 0.01 and ρ = 10 -3 , respectively. All the other parameters are the same as those in Fig. 2.
## Supplementary Information for 'Computing Riemann zeros with
## light scattering'
Sunkyu Yu 1† , Xianji Piao 2§ , and Namkyoo Park 3*
1 Intelligent Wave Systems Laboratory, Department of Electrical and Computer Engineering,
Seoul National University, Seoul 08826, Korea
2 Wave Engineering Laboratory, School of Electrical and Computer Engineering, University of
Seoul, Seoul 08826, Korea
3 Photonic Systems Laboratory, Department of Electrical and Computer Engineering, Seoul
National University, Seoul 08826, Korea
E-mail address for correspondence: [email protected], [email protected], [email protected] † § *
## Note S1. Derivation of the first-order scattering
Note S2. Multiple scattering from the point-particle Riemann scatterer
Note S3. Multiple scattering from the multilayered Riemann scatterer
Note S4. Suppressed Riemann-zero reflection in multilayered Riemann scatterers
## Note S1. Derivation of the first-order scattering
When applying Eq. (3) to Eq. (1) in the main text, the first-order scattering for the incidence ψ I = ψ 0exp( ik x 0 ) is obtained as follows:
$$\psi _ { S, 1 } ( x ) & = \frac { i d _ { 0 } \psi _ { 0 } } { 2 k _ { 0 } } \int _ { - \infty } ^ { + \infty } \sum _ { n = 1 } ^ { N } \frac { ( - 1 ) ^ { n + 1 } } { n ^ { \sigma } } \delta ( x ^ { \prime } - x _ { n } ) e ^ { i k _ { 0 } x ^ { \prime } } e ^ { i k _ { 0 } | x - x ^ { \prime } | } d x ^ { \prime } \\ & = \frac { i d _ { 0 } \psi _ { 0 } } { 2 k _ { 0 } } \sum _ { n = 1 } ^ { N } \frac { ( - 1 ) ^ { n + 1 } } { n ^ { \sigma } } e ^ { i k _ { 0 } x _ { n } } e ^ { i k _ { 0 } | x - x _ { n } | },$$
where xn = x 0log( n ). In the region between the p th and ( p +1)th scatterers, xp ≤ x < xp +1, Eq. (S1) is expressed as:
$$\psi _ { \text{S,I} } ( x ) = \frac { i d _ { 0 } \psi _ { 0 } } { 2 k _ { 0 } } \left [ \left ( \sum _ { n = 1 } ^ { p } \frac { ( - 1 ) ^ { n + 1 } } { n ^ { \sigma } } \right ) e ^ { + i k _ { 0 } x } + \left ( \sum _ { n = p + 1 } ^ { N } \frac { ( - 1 ) ^ { n + 1 } } { n ^ { \sigma } } e ^ { 2 i k _ { 0 } x _ { n } } \right ) e ^ { - i k _ { 0 } x } \right ].$$
Notably, exp(2 ik xn 0 ) = exp(2 ik x 0 0log( n )) = n 2 ik 0 x 0 , which leads to Eq. (4) in the main text.
## Note S2. Multiple scattering from the point-particle Riemann scatterer
To analyse multiple scattering from the Riemann scatterer composed of point particles, we utilize the scattering matrix method . For the 1 n th point particle located at xn = x 0log( n ) with the scattering amplitude dn = (-1) n +1 d n 0 -σ , we define the waves around the particle, as ψ n L+ , ψ n R+ , ψ n L-, ψ n R-, where '+' and '-' denote the forward and backward propagating directions, respectively, while 'L' and 'R' represent the left- and right-side of the scatterer, respectively (Fig. S1a). When the particle is embedded in a homogeneous material governed by the Helmholtz equation d 2 ψ / dx 2 + V 0 ψ = 0, where V 0 = k 0 2 , the waves are connected through the following interface transfer matrix:
$$\left [ \begin{matrix} \psi _ { n } ^ { \ R + } \\ \psi _ { n } ^ { \ R - } \end{matrix} \right ] = \left [ \begin{matrix} 1 + i \frac { d _ { n } } { 2 k _ { 0 } } & i \frac { d _ { n } } { 2 k _ { 0 } } \\ - i \frac { d _ { n } } { 2 k _ { 0 } } & 1 - i \frac { d _ { n } } { 2 k _ { 0 } } \end{matrix} \right ] \left [ \begin{matrix} \psi _ { n } ^ { \ L + } \\ \psi _ { n } ^ { \ L - } \end{matrix} \right ],$$
which characterizes the boundary condition between the waves around the dn -weighted onedimensional (1D) delta function potential. The relationship between the waves around neighbouring particles is characterized by the following propagation transfer matrix:
$$\begin{bmatrix} \psi _ { n + 1 } ^ { \quad L + } \\ \psi _ { n + 1 } ^ { \quad L - } \end{bmatrix} = \begin{bmatrix} e ^ { i k _ { 0 } ( x _ { n + 1 } - x _ { n } ) } & 0 \\ 0 & e ^ { - i k _ { 0 } ( x _ { n + 1 } - x _ { n } ) } \end{bmatrix} \begin{bmatrix} \psi _ { n } ^ { \quad R + } \\ \psi _ { n } ^ { \quad R - } \end{bmatrix}.$$
The stable calculation of the total scattering matrix for a finite number of particles is achieved through iterative multiplications of the reformulated interface and propagation transfer matrices . With the boundary condition defined by the incident waves 1 ψ I and ψ I R in Fig. S1b, the total scattering matrix leads to the scattering waves ψ S and ψ S R in Fig. S1b for the finite-size Riemann scatterer. When assigning ψ I R = 0 and employing the semi-infinite condition N →∞ , the resulting ψ S corresponds to the multiple scattering generalization of ψ S,1 ( x x ; < 1) in Eq. (5) in the x main text.
Fig. S1. Multiple scattering from the point-particle Riemann scatterer. a, Waves around the n th point particle, which is modelled by the weighted delta function potential. b, An array of point particles embedded in a homogeneous material. The incident waves are ψ I and ψ I R , and the scattering waves are ψ S and ψ S R . By setting ψ I R = 0, ψ S corresponds to multiple scattering reflection.
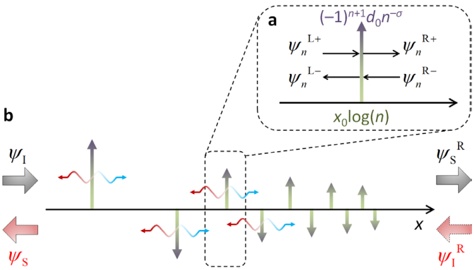
## Note S3. Multiple scattering from the multilayered Riemann scatterer
To practically implement the suppressed reflection from the point-particle Riemann scatterer, we develop its approximated realization. Figure S2 illustrates the multilayer realization of the Riemann scatterer, which includes the unit layer design (Fig. S2a) and the multilayered structure (Fig. S2b). The n th point particle is approximately modelled with the n th layer that supports the potential Vn = ( k 0 + δ kn ) 2 and has a finite thickness l n , which is embedded in the background material of the potential V 0 = k 0 2 . Because Vn is determined by the material parameter of the n th layer-for example, the permittivity of a simple medium-we focus on minimizing the number of values that δ kn can take to decrease the number of necessary material phases.
While the center of the layer is xn = x 0log( n ), the waves around the n th scattering layer in Fig. S2a are connected through the transfer matrix, as follows:
$$\begin{bmatrix} \psi _ { n } ^ { \ R + } \\ \psi _ { n } ^ { \ R - } \end{bmatrix} = \begin{bmatrix} e ^ { i ( k _ { 0 } + \delta k _ { n } ) l _ { n } } + i \frac { \delta k _ { n } ^ { \ 2 } \sin \left ( ( k _ { 0 } + \delta k _ { n } ) l _ { n } \right ) } { 2 k _ { 0 } ( k _ { 0 } + \delta k _ { n } ) } & i \frac { ( 2 k _ { 0 } + \delta k _ { n } ) \delta k _ { n } } { 2 k _ { 0 } ( k _ { 0 } + \delta k _ { n } ) } \sin \left ( ( k _ { 0 } + \delta k _ { n } ) l _ { n } \right ) } \\ - i \frac { ( 2 k _ { 0 } + \delta k _ { n } ) \delta k _ { n } } { 2 k _ { 0 } ( k _ { 0 } + \delta k _ { n } ) } \sin \left ( ( k _ { 0 } + \delta k _ { n } ) l _ { n } \right ) & e ^ { - i ( k _ { 0 } + \delta k _ { n } ) l _ { n } } - i \frac { \delta k _ { n } ^ { \ 2 } \sin \left ( ( k _ { 0 } + \delta k _ { n } ) l _ { n } \right ) } { 2 k _ { 0 } ( k _ { 0 } + \delta k _ { n } ) } \end{bmatrix} \begin{bmatrix} \psi _ { n } ^ { \ L + } \\ \psi _ { n } ^ { \ L - } \end{bmatrix}.$$
The relationship between the waves around neighbouring layers is determined by the following propagation transfer matrix:
$$\begin{bmatrix} \psi _ { n + 1 } ^ { \quad L + } \\ \psi _ { n + 1 } ^ { \quad L - } \end{bmatrix} = \begin{bmatrix} e ^ { i k _ { 0 } [ ( x _ { n + 1 } - x _ { n } ) - ( l _ { n + 1 } - l _ { n } ) ] } & 0 \\ 0 & e ^ { - i k _ { 0 } [ ( x _ { n + 1 } - x _ { n } ) - ( l _ { n + 1 } - l _ { n } ) ] } \end{bmatrix} \begin{bmatrix} \psi _ { n } ^ { \quad R + } \\ \psi _ { n } ^ { \quad R - } \end{bmatrix}.$$
In calculating the multiple scattering from the multilayered Riemann scatterer, we employ Eqs. (S5) and (S6) directly to obtain rigorous solutions. However, to achieve scattering analogous to that from the point-particle Riemann scatterer, we need to design the parameters l n and δ kn to derive the scattering analogous to that from a delta function potential. This design is achieved by comparing Eqs. (S3,S4) and (S5,S6) under suitable assumptions.
First, we neglect higher-order terms of δ kn / k 0 of second order or above by assuming the weak perturbation δ kn / k 0 << 1. The transfer-matrix equation in Eq. (S5), which will be compared with the interface transfer matrix in Eq. (S3), is then approximated as follows:
$$\left [ \begin{matrix} \psi _ { n } ^ { \ R + } \\ \psi _ { n } ^ { \ R - } \end{matrix} \right ] \sim \left [ \begin{matrix} e ^ { i ( k _ { 0 } + \delta k _ { n } ) l _ { n } } & i \frac { \delta k _ { n } } { k _ { 0 } } \sin \left ( ( k _ { 0 } + \delta k _ { n } ) l _ { n } \right ) \\ - i \frac { \delta k _ { n } } { k _ { 0 } } \sin \left ( ( k _ { 0 } + \delta k _ { n } ) l _ { n } \right ) & e ^ { - i ( k _ { 0 } + \delta k _ { n } ) l _ { n } } \end{matrix} \right ] \left [ \begin{matrix} \psi _ { n } ^ { \ L + } \\ \psi _ { n } ^ { \ L - } \end{matrix} \right ].$$
Equation (S7) can be transformed into the following scattering matrix formalism:
$$\text{ equation} \, ( \mathbb { S } / \mathbb { m } ^ { R + } ) \sim & \ e ^ { \mathfrak { m } ( k _ { 0 } + \delta k _ { n } ) l _ { n } } \left [ 1 - \left ( \frac { \delta k _ { n } } { k _ { 0 } } \right ) ^ { 2 } \sin ^ { 2 } \left ( ( k _ { 0 } + \delta k _ { n } ) l _ { n } \right ) \quad i \frac { \delta k _ { n } } { k _ { 0 } } \sin \left ( ( k _ { 0 } + \delta k _ { n } ) l _ { n } \right ) \right ] \left [ \psi _ { n } ^ { \, \mathbb { L } } \right ] \\ \sim & \ e ^ { \mathfrak { m } ( k _ { n } } \left [ \begin{matrix} \psi _ { n } ^ { \, R + } \\ i \frac { \delta k _ { n } } { k _ { 0 } } \sin \left ( ( k _ { 0 } + \delta k _ { n } ) l _ { n } \right ) & 1 \end{matrix} \right ] \left [ \psi _ { n } ^ { \, \mathbb { L } + } \\ \psi _ { n } ^ { \, R - } \right ] \\ \sim & \ e ^ { \mathfrak { k } ( k _ { n } } \left [ \begin{matrix} \psi _ { n } ^ { \, \mathbb { L } + } \\ i \frac { \delta k _ { n } } { k _ { 0 } } \sin ( k _ { 0 } l _ { n } ) & 1 \end{matrix} \right ] \\ \text{quad} \, \\ \text{according to the condition} \, \delta k _ { n } / k _ { n } \ll 1 \,. \, \text{We also transform Eq} \,. \, ( \mathbb { S } ) \, \text{of a point-particle scatter} \, into$$
according to the condition δ kn / k 0 << 1. We also transform Eq. (S3) of a point-particle scatterer into the scattering matrix formalism, as follows:
$$\begin{bmatrix} \psi _ { n } ^ { \, \mathbb { R } ^ { + } } \\ \psi _ { n } ^ { \, \mathbb { L } ^ { - } } \end{bmatrix} = \frac { 1 } { 1 - i \frac { d _ { n } } { 2 k _ { 0 } } } \begin{bmatrix} 1 & i \frac { d _ { n } } { 2 k _ { 0 } } \\ i \frac { d _ { n } } { 2 k _ { 0 } } & 1 \end{bmatrix} \begin{bmatrix} \psi _ { n } ^ { \, \mathbb { L } ^ { + } } \\ \psi _ { n } ^ { \, \mathbb { R } ^ { - } } \end{bmatrix}.$$
We assume the subwavelength condition for the layers, which allows for sin( k ln 0 ) ~ k ln 0 . The comparison between Eqs. (S8) and (S9) then leads to the relationship l n ~ dn /(2 k 0 δ kn ). Because dn = (-1) n +1 d n 0 -σ , the multilayered Riemann scatterer requires the power-law distribution of the thickness l n = l 0 n -σ with the relation l 0 = (-1) n +1 d 0/(2 k 0 δ kn ). To obtain the positive-valued thickness l n > 0, we utilize two-phase multilayers δ kn = (-1) n +1 ρ k 0, where ρ is the constant coefficient for
material inhomogeneity. The designed multilayer leads to the relationship between the effective weighting of the point particle d 0 and the initial thickness of the layer l 0: d 0 = (2 k 0 2 ρ ) l 0.
Due to the relationship d 0 = (2 k 0 2 ρ ) l 0, the effective weighting for a given l 0 depends on the wavelength of light λ = 2 π / k 0. Because d 0 increases with a shorter wavelength λ , the Born approximation becomes more fragile for lower , which degrades the accuracy of light computing λ for higher nontrivial Riemann zeros, as shown in Fig. 4c,d in the main text.
The designed l n leads to the convergence of Eq. (S6) to the propagation transfer matrix in Eq. (S4). In the region between the n th and ( n +1)th layers, the discrepancy between Eq. (S4) and Eq. (S6) is determined by:
$$\frac { l _ { n + 1 } - l _ { n } } { x _ { n + 1 } - x _ { n } } = \frac { d _ { 0 } \left [ \left ( n + 1 \right ) ^ { - \sigma } - n ^ { - \sigma } \right ] } { 2 k _ { 0 } ^ { \, 2 } \rho x _ { 0 } \log \left ( \frac { n + 1 } { n } \right ) }.$$
The Taylor expansion shows that Eq. (S10) asymptotically vanishes as n increases, as follows:
$$\lim _ { n \to \infty } \frac { l _ { n + 1 } - l _ { n } } { x _ { n + 1 } - x _ { n } } = \lim _ { n \to \infty } \frac { - d _ { 0 } \sigma n ^ { - \sigma - 1 } } { 2 k _ { 0 } ^ { \ 2 } \rho x _ { 0 } \frac { 1 } { n } } = - \lim _ { n \to \infty } \frac { d _ { 0 } \sigma } { 2 k _ { 0 } ^ { \ 2 } \rho x _ { 0 } } \frac { 1 } { n ^ { \sigma } } = 0,$$
for the values of σ in the critical strip (0 < σ < 1). Therefore, the multilayered Riemann scatterer with l n = l 0 n -σ and δ kn = (-1) n +1 ρ k 0 successfully provides the asymptotic matching between Eqs. (S3,S4) and (S5,S6).
Fig. S2. Multiple scattering from the multilayered Riemann scatterer. a, Waves around the n th
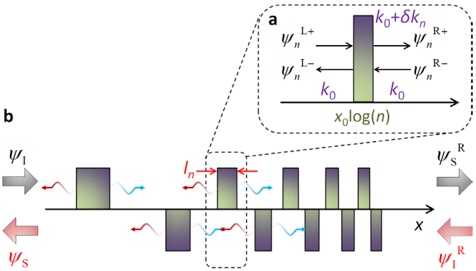
layer. b, An array of layers embedded in a homogeneous material. A scattering layer and a background material are characterized by their distinct optical wavenumbers, k 0 + δ kn and k 0, respectively. The thickness of the n th layer is l n . The incident waves are ψ I and ψ I R , and the scattering waves are ψ S and ψ S R . By setting ψ I R = 0, ψ S corresponds to multiple scattering reflection.
## Note S4. Suppressed Riemann-zero reflection in multilayered Riemann scatterers
Figure S3 illustrates the evolutions of the reflectance R for different wavelengths near the nontrivial Riemann-zero wavelengths λ 0,2 (Fig. S3a), λ 0,15 (Fig. S3b), and λ 0,30 (Fig. S3c). While Fig. S3a is very similar to the point-particle case (Fig. 2c in the main text), the reflectance R increases at higher p due to the breaking of the first-order Born approximation according to the relation d 0 = (2 k 0 2 ρ ) l 0 (Fig. S3b,c). However, the discrepancy among the reflections at the Riemann-zero wavelength and its nearby wavelengths maintains large enough to identify the Riemann zeros, λ 0,15 and λ 0,30 .
Fig. S3. Riemann-zero reflections from multilayered Riemann scatterers. a-c, The evolutions of R with respect to N at λ 0,2 ( a ), λ 0,15 ( b ), and λ 0,30 ( c ) and their neighbouring wavelengths. All the other parameters are the same as those in Fig. 4 in the main text.
## Supplementary References
- 1. Tikhodeev, S. G., Yablonskii, A., Muljarov, E., Gippius, N. A. & Ishihara, T. Quasiguided modes and optical properties of photonic crystal slabs. Phys. Rev. B 66 , 045102 (2002). | 10.1103/PhysRevB.110.L220201 | [
"Sunkyu Yu",
"Xianji Piao",
"Namkyoo Park"
] | 2024-08-02T08:16:41+00:00 | 2024-08-02T08:16:41+00:00 | [
"physics.optics"
] | Computing Riemann zeros with light scattering | Finding hidden order within disorder is a common interest in material
science, wave physics, and mathematics. The Riemann hypothesis, stating the
locations of nontrivial zeros of the Riemann zeta function, tentatively
characterizes statistical order in the seemingly random distribution of prime
numbers. This famous conjecture has inspired various connections with different
branches of physics, recently with non-Hermitian physics, quantum field theory,
trapped-ion qubits, and hyperuniformity. Here we develop the computing platform
for the Riemann zeta function by employing classical scattering of light. We
show that the Riemann hypothesis suggests the landscape of semi-infinite
optical scatterers for the perfect reflectionless condition under the Born
approximation. To examine the validity of the scattering-based computation, we
investigate the asymptotic behaviours of suppressed reflections with the
increasing number of scatterers and the emergence of multiple scattering. The
result provides another bridge between classical physics and the Riemann zeros,
exhibiting the design of wave devices inspired by number theory. |
2408.01096v1 | ## SIX DRAGONS FLY AGAIN: REVIVING 15TH-CENTURY KOREAN COURT MUSIC WITH TRANSFORMERS AND NOVEL ENCODING
1 ∗
2
Dongmin Kim
3
4
Danbinaerin Han Hannah Park 4
## Mark Gotham Sihun Lee 3
Dasaem Jeong
1 Gradaute School of Culture Technology, KAIST, Daejeon, South Korea
2 Deptartment of Digital Humanities, King's College London, UK
3 Dept. of Artificial Intelligence, 4 Dept. of Art & Technology, Sogang University, Seoul, South Korea [email protected], [email protected], {dmkim, hannah, sihunlee, dasaemj}@sogang.ac.kr
## ABSTRACT
We introduce a project that revives a piece of 15th-century Korean court music, Chihwapyeong and Chwipunghyeong , composed upon the poem Songs of the Dragon Flying to Heaven . One of the earliest examples of Jeongganbo , a Korean musical notation system, the remaining version only consists of a rudimentary melody. Our research team, commissioned by the National Gugak (Korean Traditional Music) Center, aimed to transform this old melody into a performable arrangement for a six-part ensemble. Using Jeongganbo data acquired through bespoke optical music recognition, we trained a BERT-like masked language model and an encoder-decoder transformer model. We also propose an encoding scheme that strictly follows the structure of Jeongganbo and denotes note durations as positions. The resulting machine-transformed version of Chihwapyeong and Chwipunghyeong were evaluated by experts and performed by the Court Music Orchestra of National Gugak Center. Our work demonstrates that generative models can successfully be applied to traditional music with limited training data if combined with careful design.
## 1. INTRODUCTION
Six dragons fly on the east land; every endeavour is a heavenly blessing . This is the first line of lyrics in Yongbieocheonga , the first text written in the Korean alphabet (Hangul, 한 글 ). Sejong the Great, one of the most respected figures in Korean history, invented and introduced Hangul in 1446. In addition to this remarkable achievement, he ordered scholar-officials to write Yongbieocheonga , and composed music to accompany the lyrics. Three other pieces composed at the time are Yeo-Min-Lak , Chi-Hwa-Pyeong and Chwi-Pung-Hyeong .
* Work mainly done during her master's at Sogang University
© D. Han, M. Gotham, D. Kim, H. Park, S. Lee, and D. Jeong. Licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0). Attribution: D. Han, M. Gotham, D. Kim, H. Park, S. Lee, and D. Jeong, 'Six Dragons Fly Again: Reviving 15thCentury Korean Court Music with Transformers and Novel Encoding', in Proc. of the 25th Int. Society for Music Information Retrieval Conf., San Francisco, United States, 2024.
Figure 1 : Overview of the proposed research framework
These compositions are still preserved in the Veritable Records of Sejong , which is the oldest surviving musical score in Korea [1]. More detailed information is available here [2].
Among these three pieces, only Yeominlak is handed down to the present day, while the other two are no longer performed. The National Gugak Center 1 , which is the primary organization dedicated to the preservation and development of traditional music, commissioned the task of reconstructing these two pieces in a performable format using artificial intelligence systems. Given a simple melody of 512 gaks (measures) of Chihwapyeong or 132 gaks of Chwipunghyeong , the system must generate scores for six different instruments.
Our solution encompasses a wide range of tasks in the field of music information retrieval-constructing a specialized dataset, optical music recognition, designing a
1 Gugak ( 국 악 ) is the Korean term for traditional music
domain-specific encoding scheme, training models with limited data, and generating music of concert-level quality. In this paper, we present in detail the different frameworks used in the project: two types of transformer-based models; a symbolic dataset of Korean court music acquired through optical music recognition; and a novel 'Jeongganlike' encoding method that notates monophonic melody by combining notes' position and pitch, along with a beat counter that informs the transformer the temporal position. The effectiveness of the proposed techniques was validated through quantitative metrics and subjective evaluation by experts from the National Gugak Center. Finally, we introduce a web demo that allows users to examine and generate traditional Korean court music interactively.
This project has significance not only for cultural preservation but also for wider considerations in machine learning and music generation. One of the many benefits to be had from the inter-cultural study of music is the different perspectives expressed in 'the music itself' as well as any notational and/or theoretical traditions that go alongside it. As presented in previous research [3], the encoding of music makes significant differences in machine learning tasks. In thinking through different ways of digitally encoding music, we stand to learn a great deal from the various syntaxes that have been used in diverse traditional contexts.
## 2. RELATED WORKS
Recent advances in neural network-based music generation have resulted in much artistic output. Since 2020, the AI Music Generation Challenge [4] has been held annually, focusing on generating songs in the style of Irish and Swedish folk music. This event has allowed for exploration of new methods for generation and evaluation of traditional music through the means of deep learning models.
The Beethoven X project [5] utilized neural networks to learn Beethoven's compositional style and complete his unfinished 10th Symphony. The resulting work has been performed by an orchestra-a project outline similar to that of ours.
Attempts at automatic generation have been made for traditional music from beyond the West, including Persia [6] and China [7]. The limited progress in such areas is often due to the distinctive traditional musical systems that demand deep understanding and unique methodologies. Such idiosyncrasies put much interest and meaning in the computational research of traditional music, since it can present new methods and perspectives to the field as a whole, while also helping preserve diverse musical heritages.
## 3. JEONGGANBO DATASET
## 3.1 Jeongganbo Notation
As depicted in Figure 1, Korean court music is performed on a variety of instruments, including plucked string instruments ( Gayageum and Geomungo ), bowed string instruments ( Haegeum and Ajaeng ), and wind instruments
Figure 2 : An example of Jeongganbo in the original notion (below) and a broadly equivalent conversion to Western classical notion (above). Dashed lines are part of neither notation and added simply to clarify the temporal alignment between the two systems.

Figure 3 : Jeonggan-like encoding position labels
( Daegeum and Piri ), among others. These instruments are played together in a heterophonic texture, with each instrument employing its distinctive playing techniques and ornamentations.
Much of Korean court music is written in Jeongganbo , a traditional musical notation system. Jeongganbo is recognized as the first system in East Asia capable of simultaneously representing both pitch and duration of notes [8,9]. This versatility has been instrumental in passing down court music throughout history [10].
Jeongganbo uses grid-divided boxes ( Jeonggans ) as the basic unit of time. The number of characters (notes) and their position within each jeonggan varies to denote rhythm. Figure 2 provides an example passage, and figure 3 provides a schematic overview of possible positions.
‰
Here, we provide a broad introduction to this rhythmic notation system in quasi-Western musical theoretic language. Each jeonggan is broadly equivalent to a beat. If a jeonggan features only one character, this note event starts at the beginning of the beat and lasts the beat's full duration. The first box ('0') in figure 3 is in this form as is the second jeonggan of figure 2 where the 'compound beats' correspond to the duration ♩ (in this case for the note B ♭ 4). At the next metrical level we have the 'column' division of the 'rows'. This number of 'rows' relates broadly to the top level division of the beat. The use of three vertically stacked characters refers to 3 equal divisions of this beat (here, 3 x s).
‰
GLYPH<11> For example, in figure 3, the numbers 4-9 feature a 3part division of the ♩ beat into 3 x GLYPH<11> s (positions 4, 6, 8), and a 2x division of those GLYPH<11> s (e.g., 4-5). If the following jeonggan is empty, the previously played note is sustained.
Playing techniques and ornamentations called sigimsae are sometimes notated for each instrument. When sigimsae are placed to the right of notes, they serve as ornamentations or embellishments for the corresponding note; when written on their own, they indicate timed instructions to play a specific note or musical phrase. For convenience,
Figure 4 : Comparison between encoding schemes
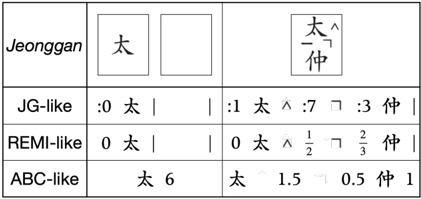
the example score is notated horizontally, but in practice, the score page is read from top to bottom and right to left. A line in Jeongganbo can consist of anything from four to twenty beats, with each line representing a phrase unit.
## 3.2 Machine Readable Dataset
We have constructed a dataset of 85 pieces by applying optical musical recognition (OMR) to all compositions available within the manuscripts published by the National Gugak Center. The manuscripts cover the entire repertoire of remaining Korean court music 2 . OMR was necessary since the scores are only provided as PDF images and the semantic data is unavailable. We implemented and trained an encoder-decoder transformer with CNN by synthesizing various Jeonggan images in a rule-based approach [11]. In total, the dataset comprises 28 010 jeonggans across 85 pieces. When counting each instrument part independently, the combined total amounts to 141 820 jeonggans. Out of 90 pieces notated in jeongganbo for ensembles of at least two different instruments in the published manuscripts, we excluded 5 pieces that have discrepancies in the total number of jeonggans across instruments.
## 4. JEONGGAN-LIKE ENCODING
In the field of symbolic music generation for Western monophonic and polyphonic music, encoding schemes such as ABC notation, which denotes pitch and duration separately, are effective and prevalent [12, 13]. However, when it comes to Korean court music, whose heterophonic structure is a defining characteristic, it is crucial that the intricate alignment of different melodies be well-represented in encoding. The genre also exhibits prolonged notes and considerable variations in note lengths, which proves to be a challenge for learning algorithms, especially when data is limited.
These distinct musical qualities call for a specialized encoding scheme; for this, we propose Jeonggan (JG)-like encoding , which closely follows the positional notation of Jeongganbo . This symbolic music encoding method is modeled to inherently reflect the composition and notation style of traditional Korean court music.
The detailed rules of encoding are as follows. The boundary of a Jeonggan is designated as a bar ( | ) to-
2 The term 'court music' used in this paper originally refers to Jeongak . Jeong-ak includes not only court music but also salon music and military music. However, for readability, we use 'court music' here.
ken. Change of measure (called Gak ) is indicated by a line break ( \n ). As illustrated in Figure 3, the position of each note is denoted by a number between 0 and 15, after which the pitch symbol follows.
Ornamentations ( sigimsae ) can either have a duration or not. Sigimsae with duration, such as the ' ㄱ ' symbol in Figure 4, are handled in the same way as pitch symbols. Sigimsae without duration such as ' ^ ', which appear at the side of the pitch character, are placed after the corresponding pitch symbol.
There are several advantages that we can expect to gain from using JG-like encoding. First, with position-based encoding, the duration-related vocabulary is limited to just 16 entries. In contrast, duration-based encoding schemes require learning each duration token as a separate entry, resulting in a significantly larger vocabulary. Additionally, rather than determining the length of a note with a single calculation, JG-like encoding allows for the flexible adjustment of note lengths during inference via combination of jeonggan boundary and position tokens. This enables generation of music that is more adaptable to the time step and takes into account the sequence of the input source, which can be expected to result in more dynamic and contextaware music generation.
## 4.1 Other Possible Encodings
REMI (revamped MIDI-derived events) [14] first proposed the usage of beat-position feature rather than time-shifting to encode temporal position. We also experiment with REMI-like encoding which adopts three token types: beat position, new beat (instead of new measure), and pitch tokens. We intentionally design REMI-like and JG-like encoding to share the same structure and result in the same number of tokens for a given melody. They differ in that JG encoding provides intra-JG position, while REMI encoding provides the beat position of the note. According to the position labels shown in Figure 3, any of [0, 1, 4, 10, 12] can correspond to beat position 0. However, in JGlike encoding, each occurrence of position tokens limits the possibilities of subsequent ones. For instance, a position token of 0 implies that no more notes will occur in the same jeonggan , and if the first note is 1, one or more additional notes should follow with values of 2-3 or 6-9. In contrast, in REMI-like encoding, any offset value can follow a beat position of 0. To examine the impact of this positionbased logic on the generation process, we use REMI-like encoding as our first baseline for comparison.
As a second baseline, we implement an ABC-like encoding scheme that does not have a separate bar token and encodes each note as a combination of pitch and duration values. Note that we do not omit duration tokens that are equal to unit length as ABC encoding typically does.
## 5. ORCHESTRAL PART GENERATION
## 5.1 Transformer Sequence-to-sequence Model
We implement an encoder-decoder transformer [15] model to generate melodies for different instruments based on a
Figure 5 : Orchestral part generation
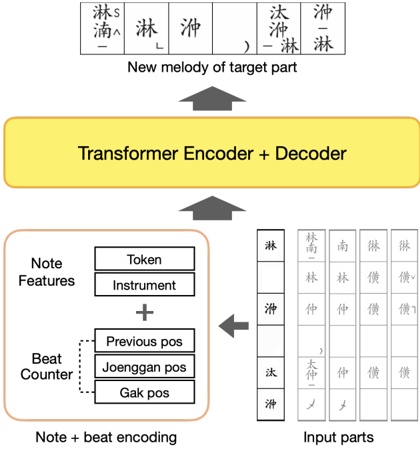
given instrument's melody, leveraging its ability to learn long-term dependencies. Unlike RNN-based models, the transformer calculates relationships between all elements in a sequence via the self-attention mechanism, enhancing its capability in symbolic music generation [16-18]. The model consists of an encoder that processes the input sequence and a decoder for generating the output sequence. Our objective is to generate melodies that synchronize with the input melody across musically equivalent phrases; selfand cross-attention within the model enable understanding of musical context at measure and bar levels, capturing the repeating structure of melodies and accents prominent in traditional Korean court music.
## 5.2 Beat Counter
Instead of sinusoidal [15] or learned [19] positional embedding commonly utilized in transformer-based models, we implemented a 'beat counter' embedding that provides information about temporal position.
For a model to learn to 'parse' semantic position only from the tokens' sequential position is challenging, if not impossible, with limited training data and a small number of transformer layers. Therefore, we explicitly encode the musical position of each symbol as a combination of measure index, beat index, and sub-beat index (injeonggan position) as shown in Figure 5. This information is summed into note embedding, just like positional encoding of transformer [15].
As previous research of PopMAG [20] demonstrated, metrical position embeddings can replace the positional encoding of transformers in symbolic music. A minor difference between PopMAG and our approach is that the model predicts only the appearance of new measures or new beats without the index of them, and that the new beat can be used for elongating the duration of previous note.
The same idea of embedding the beat counting has been previously applied to RNN-based Irish melody generation in ABC format [21], while its advantage was not properly evaluated. A similar idea, using metrical position instead of or along with absolute token position, has also been applied to transformer architecture [20,22,23]. However, our results presented in Section 6.3 demonstrate that this beat counter embedding is essential for making the model properly understand the musical contents.
## 6. EXPERIMENT AND RESULTS
## 6.1 Training
We split the Jeongganbo dataset into three subsets: 75 pieces for training, 5 for validation, and 5 for testing. Each piece contains melodies for up to 6 instruments. The sequence-to-sequence model takes 4 measures of melody, each from a randomly selected number of instruments, as input to the encoder; and given a target instrument condition, it generates the corresponding 4 measures of melody for the target instrument. Note that the number of beats in a single measure is at least 4 or to a maximum of 20 in our dataset.
The transformer encoder and decoder both consist of 6 layers, 4 attention heads, and a hidden dimension size of 128 with dropout of 0.2. We train for 35 000 updates across 300 epochs using negative log-likelihood loss. We also employ mixed precision training [24] to enhance performance and efficiency. We utilize the Adam optimizer with an initial learning rate of 0.001 and apply a cosine learning rate scheduler with 1000 warmup steps. Using a batch size of 16, training can be conducted on a single Nvidia RTX A6000 GPU.
## 6.2 Evaluation Metrics
## 6.2.1 Length Match Rate
As an evaluation metric, we check whether the input and output melodies share the same number of measures, a consistency necessitated by our task. Since the length of a measure can change in the middle of a piece, this metric serves as an indicator of the model's ability to capture the musical context of the input melody and accordingly generate a musically complete melody. We measure length match rate as the percentage of generated melodies whose number of jeonggans , after decoding the output tokens, matches that of the input melody.
## 6.2.2 F1-Score
Regarding the generation task as one with a fixed answer, we can measure the accuracy of the generated melody by directly comparing it with the ground-truth target melody. Thus, as a general accuracy metric, we calculate the F1score of predicted notes, where only the notes with the exact same onset position and pitch are counted as correct. To make a fair comparison between encoding methods, note onset positions in JG-like encoding were converted to those in the REMI-like format. Ornamentations without duration were not counted.
Table 1 : Quantitative evaluation results
| | Piri to Geom. | Piri to Geom. | Every to Daeg. | Every to Daeg. |
|------------------|-----------------|-----------------|------------------|------------------|
| | len-mat | F1 | len-mat | F1 |
| JG-like | 0.942 | 0.679 | 1.0 | 0.614 |
| REMI-like | 0.923 | 0.567 | 1.0 | 0.532 |
| ABC-like | 1.0 | 0.704 | 0.903 | 0.542 |
| JG w/o Counter | 0.135 | 0.043 | 0.269 | 0.052 |
| REMI w/o Counter | 0.269 | 0.081 | 0.192 | 0.039 |
| ABC w/o Counter | 0.403 | 0.090 | 0.115 | 0.016 |
## 6.3 Results and Discussion
In our sequential generation process, melody for the instrument geomungo, characterized by its low pitch range and simple melodies, is the first to be generated from the initial piri melody. The daegeum, typically featuring the most complex and nuanced melodies among the six instruments, is the last in line. Table 1 displays the results of objective evaluation, specifically focusing on geomungo and daegeum.
For generation of geomungo melodies, ABC-like encoding yields the best results. This appears to be due to the simple and regular melodic structure of the geomungo which fits in well with ABC-like encoding. On the other hand, in the task of generating daegeum melodies, JGlike encoding achieves higher F1-scores. This indicates that JG-like encoding outperforms other methods in generating complex and varied melodies. We also discover that as rhythmic complexity increases, the measure length match rate of ABC-like encoding decreases.
To examine the effectiveness of the beat counter technique, we compare our model that incorporates beat counter with a baseline model that instead employs absolute position embedding [19], a technique commonly used in symbolic music generation.
The results in the lower part of Table 1 show that the models without beat counter fail to generate melodies with appropriate lengths. The problem is less severe in ABClike encoding, as processing accumulating duration tokens can be easier than counting jeonggan boundaries. This demonstrates the efficacy of the beat counter technique in JG-like encoding, and its ability to replace traditional positional encoding.
## 7. 15TH CENTURY MELODY TRANSFORMATION
To generate an entire ensemble score using our method, we require an initial input melody with a specified instrument. However, the remaining 15th-century score of Chihwapyeong and Chwipunghyeong only provide a single melody without any mention of instruments. It also features rhythmic groupings of eight beats, which is rare in court music that is played today. We therefore need to transform the old melody for a specific instrument used in court music; to maintain the outline of the original melody while achieving plausible transformation, we train a masked language model on our Jeongganbo dataset before infilling the 15th-century melody.
## 7.1 BERT-like Masked Language Model
Bidirectional Encoder Representations from Transformers (BERT) [25] is a self-supervised language representation learning model that uses a bidirectional transformer instead of a causal transformer decoder. It is trained with a masked language model (MLM) objective, where tokens in the input sentence are randomly masked and the model predicts the original vocabulary ID of said masked tokens. Because of its advantage in exploiting bidirectional context, BERTlike models have also been adapted for music audio generation [26] and symbolic music generation [27, 28] along with representation-learning purpose adaptation on symbolic music [22,29].
## 7.1.1 Piano-roll-like Encoding
One of the main limitations of using a BERT-like model for generative tasks is that the sequence of given (unmasked) tokens and masked tokens has to be pre-defined. This means that one has to decide the number and position of new tokens to be inserted for a given original sequence. To avoid this, we use piano-roll-like encoding for the MLM, a technique widely employed in works on music generation with limited rhythmic patterns such as in Bach Chorales [30-33]. Here, each jeonggan is represented as six frames, with each frame including features for symbol (pitch or sigimsae with duration) and for ornamentation. We also apply the aforementioned beat counter in pianoroll encoding.
## 7.1.2 Training with Masking
Following examples in MusicBERT [29], we train the model with masked language model objective with various masking methods: i) masking 5% of frames, ii) replacing 5% of frames, iii) masking 20% of note onsets, iv) replacing 10% of note onsets, v) erasing 10% of note onsets, vi) masking the entire 6 frames of 15% of jeonggans , and vii) masking 50% of ornamentations.
Though the model can be trained to handle an arbitrary number of input instruments, we only train the model with a single instrument as with our orchestration transformer, since the main intended usage of the model is to create variations of a single melody. We train a 12-layer model with the same dataset and hyperparameter settings as with the orchestration model.
## 7.2 Inference Procedure
For converting and performing monophonic melodies, we opt for a 30x GLYPH<11> span which equals to 10 jeonggans . This also corresponds to the rhythmic pattern of the 4-7th movement of Yeominlak . The original Chihwapyeong and Chwipunghyeong melody, which can be interpreted in an 8/8 time signature, were modified by strategically inserting empty jeonggans to the 5th and 7th positions, to imitate Yeominlak 's rhythmic pattern. Utilizing the masked language model, the modified melodies were seamlessly transformed into a piri melody. Piri, a double-reed instrument known for its loud volume, was chosen as the main instrument for conveying the original melody due to its prominent role in contemporary court music.
As the models were all trained on 4-measure chunks, we generate the full sequence of 512 or 132 measures using a moving window, providing two measures of previously generated output as teacher-forcing inputs and generating one more measure for each four-measure input. These were applied in a similar manner to both melody transformation and orchestral part generation. Once the melody is transformed into a piri melody, we feed it to the orchestral transformer to generate parts for five other instruments. We sequentially generate for each instrument with the previously generated part as input. The final generation order is as follows: piri, geomungo, gayageum, ajaeng, haegeum, and daegeum.
Following the initial generation of melodies for all six instruments, we perform a refinement step. Here, each instrument's melody is regenerated with the melodies of the other five as input. This additional process helps to reinforce the melodies that initially had to be generated without the context of the other instruments.
## 7.3 Expert Reviews
The Court Music Orchestra of the National Gugak Center performed the generated Chihwapyeong and Chwipunghyeong on the birth anniversary of King Sejong at Gyeongbokgung Palace on May 14th, 2024. They performed it again at the National Gugak Center on June 2nd, 2024 with an introduction to technical background by the authors. Due to time constraints, only partial excerpts from the entire score were performed.
The musicians gave positive opinions such as 'genrespecific rhythm and melodic flow were well-represented' and 'the generated pieces presented ornamentation techniques and melodic progressions specialized for each instrument. ' Still, there were a few instances where notes that did not fit the scale appeared, and when notes outside the appropriate range were present, the performers had to alter or omit them or change their octave to perform the piece. However, the generated results were acknowledged to closely resemble the target style of Yeominlak. Thus, the Court Music Orchestra decided to play the pieces in a similar ensemble size to Yeominlak without further modification.
We additionally evaluate the generated scores, focusing on the effects of the refinement step. The evaluation criteria were carefully selected to assess aspects that require a deep understanding of the genre. These criteria include 1) the appropriateness of the scale and range for each instrument ( scale ), 2) the proper use of unique characteristics and ornamentations specific to each instrument ( sigimsae ), 3) the suitability of the rhythmic structure of strong and weak beats ( rhythm ), and 4) the harmony and coherence among the instruments when performed together as an ensemble ( harmony ).
Seven employees from the National Gugak Center who
Table 2 : the average and std of opinion scores from 7 judges for systems with and without refinement.
| | No Refinement | With Refinement |
|----------|-----------------|-------------------|
| Scale | 4.0 ( ± 0.53) | 4.0 ( ± 0.53) |
| Sigimsae | 3.4 ( ± 0.73) | 4.0 ( ± 0.53) |
| Rhythm | 2.9 ( ± 0.35) | 3.3 ( ± 0.45) |
| Harmony | 2.9 ( ± 0.83) | 3.3 ( ± 0.70) |
majored in Korean traditional music instruments or theory participated in a subjective survey. We name the prerefinement generation results piece A, and the final output after the refinement step piece B. The evaluators were not informed of this distinction. The participants assessed the pieces for the four criteria on a 5-point scale (1-5) and provided qualitative feedback on the two compositions. The results are summarized in Table 2. These results demonstrate that the proposed refinement process effectively enhances the overall quality of the generated music, especially for sigimsae of each instrument.
## 8. CONCLUSION
Throughout this work, we explored how music generation models can resurrect ancient melodies into new compositions that meet style of current-day Korean court music.
Venturing into relatively uncharted territory, we approached each step meticulously-from data curation and parsing to model architecture design-while carefully considering the unique nuances of the musical tradition. To enhance the quality of the generated outputs, we proposed a novel encoding framework and validated its effectiveness through objective and subjective measures. This endeavour to tackle an underrepresented non-Western music genre through diverse MIR lenses hopefully expands the horizons of the field.
The Jeongganbo dataset and its conversion to Western staff notation in MusicXML is available online, along with other code of this project, and video recording of the performance. 3 To the best of our knowledge, this will be the first dataset of machine-readable Jeongganbo . We believe that this dataset can significantly contribute to computational ethnomusicology beyond its usage as a training dataset for music generation demonstrated in this paper.
We also provide an interactive web demo 4 that showcases our proposed generative model. While this project focused on reviving melodies from the 15th-century, the web demo allows users to input their own melodies and create orchestrations of Korean court music. The interactive platform enables users to directly engage with the generative model in the web browser.
We hope that this project contributes to moving closer to leveraging machine learning to make traditional music more accessible and enjoyable for modern audiences.
3 https://github.com/MALerLab/SejongMusic
4 https://six-dragons-fly-again.site/
## 9. ACKNOWLEDGEMENTS
We sincerely appreciate the National Gugak Center and its staff who supported this project, including directorgeneral Kim Youngwoon ( 김 영운 ), head of the research bureau Kim Myung-suk ( 김 명 석 ), research officers Park Jeonggyeong ( 박 정 경 ) and Han Jungwon ( 한 정 원 ). We are deeply grateful to the musicians of the Court Music Orchestra for their invaluable contributions and efforts to vitalize our humble results. This research was also supported by the National R&D Program through the National Research Foundation of Korea (NRF) funded by the Korean Government (MSIT) (RS-2023-00252944, Korean Traditional Gagok Generation Using Deep Learning).
## 10. REFERENCES
- [1] Y. Kim, 'Chapter Ⅲ . critical assessment : The rhythmic interpretation of jeongganbo,' in Korean Musicology Series, vol. 4 , 2010.
- [2] National Gugak Center, 'Publications,' https: //www.gugak.go.kr/site/program/board/basicboard/ view?menuid=001003002005&pagesize=10& boardtypeid=24&boardid=13154&lang=en, 2024.
- [3] G. Micchi, M. Gotham, and M. Giraud, 'Not all roads lead to Rome: Pitch representation and model architecture for automatic harmonic analysis,' Transactions of the Int. Society for Music Information Retrieval (TISMIR) , vol. 3, no. 1, pp. 42-54, 2020.
- [4] B. Sturm, 'The Ai music generation challenge 2022: Summary and results,' in Proc. of the 4th Conference on AI Music Creativity (AIMC 2023) , Brighton, UK, 2023.
- [5] M. Gotham, K. Song, N. Böhlefeld, and A. Elgammal, 'Beethoven X: Es könnte sein!(it could be!),' in Proc. of the 3rd Conference on AI Music Creativity (AIMC 2022) , Online, 2022, pp. 13-15.
- [6] M. Ebrahimi, B. Majidi, and M. Eshghi, 'Procedural composition of traditional Persian music using deep neural networks,' in Proc. of 5th Conference on Knowledge Based Engineering and Innovation (KBEI) . Tehran, Iran: IEEE, 2019, pp. 521-525.
- [7] J. Luo, X. Yang, S. Ji, and J. Li, 'MG-VAE: Deep chinese folk songs generation with specific regional styles,' in Proc. of the 8th Conference on Sound and Music Technology (CSMT) Revised Selected Papers . Shanxi, China: Springer, 2020, pp. 93-106.
- [8] A. E. Gnanadesikan, The writing revolution: Cuneiform to the internet . John Wiley & Sons, 2008, vol. 8.
- [9] Y. Kim, 'Chapter Ⅱ . Korean notational systems,' in Korean Musicology Series, vol. 4 , 2010.
- [10] R. Koehler et al. , Traditional music: sounds in harmony with nature . Seoul Selection, 2015.
- [11] D. Kim, D. Han, D. Jeong, and J. J. Valero-Mas, 'On the automatic recognition of jeongganbo music notation: dataset and approach,' Preprint on Research Square , 2024.
- [12] B. Sturm, J. F. Santos, and I. Korshunova, 'Folk music style modelling by recurrent neural networks with long short term memory units,' in late-breaking demo session of 16th Int. Society for Music Information Retrieval Conf. , Málaga, Spain, 2015.
- [13] B. L. Sturm, J. F. Santos, O. Ben-Tal, and I. Korshunova, 'Music transcription modelling and composition using deep learning,' arXiv preprint arXiv:1604.08723 , 2016.
- [14] Y.-S. Huang and Y.-H. Yang, 'Pop music transformer: Beat-based modeling and generation of expressive pop piano compositions,' in Proc. of the 28th ACM International conference on multimedia , New York, NY, USA, 2020, pp. 1180-1188.
- [15] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, 'Attention is all you need,' in Proc. of 31st Conference on Neural Information Processing Systems (NIPS 2017) , Long Beach, CA, USA, 2017.
- [16] C.-Z. A. Huang, A. Vaswani, J. Uszkoreit, I. Simon, C. Hawthorne, N. Shazeer, A. M. Dai, M. D. Hoffman, M. Dinculescu, and D. Eck, 'Music transformer,' in Proc. of The 7th International Conference on Learning Representations , New Orleans, LA, USA, 2019.
- [17] B. Yu, P. Lu, R. Wang, W. Hu, X. Tan, W. Ye, S. Zhang, T. Qin, and T.-Y. Liu, 'Museformer: Transformer with fineand coarse-grained attention for music generation,' in Proc. of The 36th Annual Conference on Neural Information Processing Systems , New Orleans, LA, USA, 2022, pp. 1376-1388.
- [18] Y.-J. Shih, S.-L. Wu, F. Zalkow, M. Müller, and Y.-H. Yang, 'Theme transformer: Symbolic music generation with theme-conditioned transformer,' IEEE Transactions on Multimedia , vol. 25, pp. 3495-3508, 2023.
- [19] J. Gehring, M. Auli, D. Grangier, D. Yarats, and Y. N. Dauphin, 'Convolutional sequence to sequence learning,' in Proc. of the 34th International Conference on Machine Learning , Sydney, Australia, 2017, pp. 12431252.
- [20] Y. Ren, J. He, X. Tan, T. Qin, Z. Zhao, and T.-Y. Liu, 'Popmag: Pop music accompaniment generation,' in Proc. of the 28th ACM Int. Conf. on Multimedia , 2020, pp. 1198-1206.
- [21] D. Jeong, 'Virtuosotune: Hierarchical melody language model,' IEIE Transactions on Smart Processing &Computing , vol. 12, no. 4, pp. 329-333, 2023.
- [22] Z. Wang and G. Xia, 'MuseBERT: Pre-training music representation for music understanding and controllable generation,' in Proc. of the 22nd Int. Society for Music Information Retrieval Conf. , Online, 2021, pp. 722-729.
- [23] Z. Guo, J. Kang, and D. Herremans, 'A domainknowledge-inspired music embedding space and a novel attention mechanism for symbolic music modeling,' in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 37, no. 4, 2023, pp. 5070-5077.
- [24] P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh et al. , 'Mixed precision training,' arXiv preprint arXiv:1710.03740 , 2017.
- [25] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, 'BERT: Pre-training of deep bidirectional transformers for language understanding,' in Proc. of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , Minneapolis, Minnesota, USA, 2019, pp. 4171-4186.
- [26] H. Flores García, P. Seetharaman, R. Kumar, and B. Pardo, 'Vampnet: Music generation via masked acoustic token modeling,' in Proc. of the 24th Int. Society for Music Information Retrieval Conf. , Milan, Italy, 2023.
- [27] R. Dahale, V. Talwadker, P. Rao, and P. Verma, 'Generating coherent drum accompaniment with fills and improvisations,' in Proc. of the 23rd Int. Society for Music Information Retrieval Conf. , Bengaluru, India, 2022.
- [28] L. Casini, N. Jonason, and B. L. T. Sturm, 'Investigating the viability of masked language modeling for symbolic music generation in abc-notation,' in Proc. of 13th International Conference on Computational Intelligence in Music, Sound, Art and Design , Aberystwyth, UK, 2024, pp. 84-96.
- [29] M. Zeng, X. Tan, R. Wang, Z. Ju, T. Qin, and T.Y. Liu, 'MusicBERT: Symbolic music understanding with large-scale pre-training,' in Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , Online, 2021, pp. 791-800.
- [30] F. Liang, M. Gotham, M. Johnson, and J. Shotton, 'Automatic stylistic composition of bach chorales with deep LSTM,' in Proc. of 18th Int. Society for Music Information Retrieval Conf. , Suzhou, China, 2017, pp. 449-456.
- [31] G. Hadjeres, F. Pachet, and F. Nielsen, 'DeepBach: a steerable model for Bach chorales generation,' in Proc. of the 34th International Conference on Machine Learning , Sydney, Australia, 2017, pp. 1362-1371.
- [32] C.-Z. A. Huang, T. Cooijmans, A. Roberts, A. Courville, and D. Eck, 'Counterpoint by convolution,' in Proc. of 18th Int. Society for Music Information Retrieval Conf. , Suzhou, China, 2017.
- [33] E. Choi, H. Kim, J. Nam, and D. Jeong, 'Teaching chorale generation model to avoid parallel motions,' in Proc. of The 16th International Symposium on Computer Music Multidisciplinary Research (CMMR 2023) , Tokyo, Japan, 2023. | null | [
"Danbinaerin Han",
"Mark Gotham",
"Dongmin Kim",
"Hannah Park",
"Sihun Lee",
"Dasaem Jeong"
] | 2024-08-02T08:16:55+00:00 | 2024-08-02T08:16:55+00:00 | [
"cs.SD",
"cs.AI",
"eess.AS"
] | Six Dragons Fly Again: Reviving 15th-Century Korean Court Music with Transformers and Novel Encoding | We introduce a project that revives a piece of 15th-century Korean court
music, Chihwapyeong and Chwipunghyeong, composed upon the poem Songs of the
Dragon Flying to Heaven. One of the earliest examples of Jeongganbo, a Korean
musical notation system, the remaining version only consists of a rudimentary
melody. Our research team, commissioned by the National Gugak (Korean
Traditional Music) Center, aimed to transform this old melody into a
performable arrangement for a six-part ensemble. Using Jeongganbo data acquired
through bespoke optical music recognition, we trained a BERT-like masked
language model and an encoder-decoder transformer model. We also propose an
encoding scheme that strictly follows the structure of Jeongganbo and denotes
note durations as positions. The resulting machine-transformed version of
Chihwapyeong and Chwipunghyeong were evaluated by experts and performed by the
Court Music Orchestra of National Gugak Center. Our work demonstrates that
generative models can successfully be applied to traditional music with limited
training data if combined with careful design. |
2408.01099v1 | ## Contribution-based Low-Rank Adaptation with Pre-training Model for Real Image Restoration
Dongwon Park , Hayeon Kim , and Se Young Chun 1 2 1 2 , ⋆
1 IPAI & INMC, 2 Dept. of Electrical and Computer Engineering, Seoul National University, Republic of Korea, {dong1park, khy5630, sychun}@snu.ac.kr
Abstract. Recently, pre-trained model and efficient parameter tuning have achieved remarkable success in natural language processing and high-level computer vision with the aid of masked modeling and prompt tuning. In low-level computer vision, however, there have been limited investigations on pre-trained models and even efficient fine-tuning strategy has not yet been explored despite its importance and benefit in various real-world tasks such as alleviating memory inflation issue when integrating new tasks on AI edge devices. Here, we propose a novel efficient parameter tuning approach dubbed contribution-based low-rank adaptation (CoLoRA) for multiple image restorations along with effective pre-training method with random order degradations (PROD). Unlike prior arts that tune all network parameters, our CoLoRA effectively finetunes small amount of parameters by leveraging LoRA (low-rank adaptation) for each new vision task with our contribution-based method to adaptively determine layer by layer capacity for that task to yield comparable performance to full tuning. Furthermore, our PROD strategy allows to extend the capability of pre-trained models with improved performance as well as robustness to bridge synthetic pre-training and real-world fine-tuning. Our CoLoRA with PROD has demonstrated its superior performance in various image restoration tasks across diverse degradation types on both synthetic and real-world datasets for known and novel tasks. Project page: https://janeyeon.github.io/colora/ .
Keywords: Efficient fine-tuing · Low-rank adaptation · Pre-training
## 1 Introduction
Image restoration (IR) is a fundamental low-level computer vision task that aims to recover the original clean image from the input data that was degraded by noise [29, 39, 92, 101], blur [36, 37, 55, 70, 80], and / or bad weather conditions [40, 81, 88, 95]. It does not only enhance the visual quality of images, but also improves the performance of mid to high-level vision downstream tasks such as classification [26,35], object detection [67,69], and autonomous driving [3,51].
⋆ Corresponding author.
However, existing IR methods require expensive training data per degradation and individual training of a separate model from scratch per restoration task.
Natural language processing (NLP) and high-level computer vision also have similar problems of high cost data collection and demanding training for diverse tasks. However, large-scale pre-trained models [4,17,21,59] and efficient parameter tuning methods [6,18,27,28,32,61,62,85,85] have been recently proposed to address this issue for effectively adapting to new tasks. Large-scale pre-training models are constructed, they resolve the data scarcity problem, reduce training time, and improve generalization performance through powerful learning capability and scalability for diverse tasks. Moreover, the efficient parameter tuning methods adjust only a small number of parameters during fine-tuning for each task, so they can significantly reduce memory and storage cost. In IR, efficient parameter tuning has not been investigated yet, but pre-training approaches for IR [7,13,43,48] have recently emerged as a noteworthy development.
The existing pre-training approaches [7,43,48] for IR usually construct synthetic training data with known multiple degradations (called synthetic degradation functions), and then fine-tune the full network parameters to the real world data with novel degradation in Fig. 1(a). This pre-training technique offers the benefit of optimizing performance using limited data in real IR tasks where obtaining a real-world dataset containing pairs of degraded and clean images can be challenging. However, these methods have the disadvantage of requiring a large number of network parameters and storage memory as the number of tasks increases because the entire network parameters must be trained for new tasks, as illustrated in Fig. 1. Therefore, when various functions exist, operation may be difficult in an intelligent edge device with limited computing capacity.
In this paper, we propose an efficient parameter tuning method using a new adapter called contribution-based low-rank adaptation (CoLoRA) with a Pretraining with Random Order Degradation (PROD). These approaches enable the pre-trained network to adapt to IR tasks with novel degradations, as depicted in Fig. 1(b). Unlike previous works that fine-tune the entire pre-trained network, our proposed method introduces adapters for efficient parameter tuning in novel IR tasks. While prior works must have a separate full-size fine-tuned network for each novel IR task, our proposed method only need to store the small tunable adaptor for each task (approximately 7% of the entire network parameters for comparable performance to full-size tuning), so that it will be advantageous in terms of memory for multiple target tasks. The inefficiency with full fine-tuning is especially severe in modern network architectures for IR such as Restormer [86] and IPT [7]. Our proposed PROD strengthens the pre-train model by generating low-quality training images using synthetic degradation functions and their random combinations. This is achieved by synergistically leveraging both random single degradations [7, 43] and deterministic multiple degradations [48] so that the pre-text task can be expanded for adapting IR to novel real-world complex degradation. Here is the summary of our contributions:
- -We propose a novel efficient parameter tuning method with pre-training for IR, dubbed CoLoRA with PROD, using synthetic degradation functions
Fig. 1: Illustrations of tuning strategies for novel image restoration tasks. (a) Existing strategies [7, 43, 48] for fully fine-tuning a pre-trained model for a new task. (b) Our proposed CoLoRA method enables parameter-efficient fine-tuning by freezing the pretrained model and adjusting the additional adapter for novel image restoration tasks.
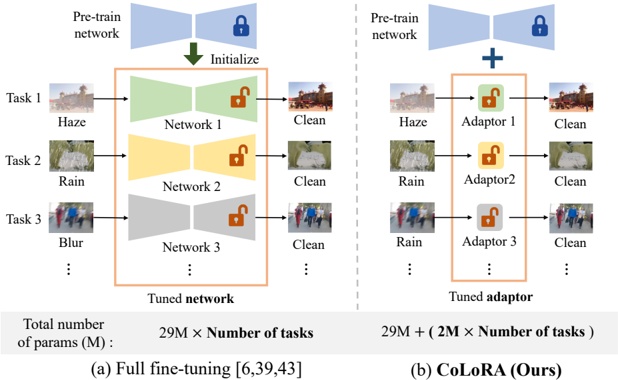
for pre-training and small amount of real data for parameter tuning. Our proposed method demonstrates flexible enough to work with diverse network architectures like CNNs and vision transformers, achieving state-of-the-art performance on 6 IR tasks with real data.
- -Our CoLoRA allows efficient parameter tuning by freezing the pre-trained model and tuning the additional adaptor with adaptive layer by layer capacity per task, still achieving state-of-the-art performance on real 6 IR tasks.
- -Our PROD has trained an excellent pre-training network with synthetic data that outperformed other state-of-the-art methods on 6 IR tasks with real data after full fine-tuning.
## 2 Related works
## 2.1 NLP and High-level Vision Tasks
Pre-training. In NLP, self-supervised pre-training utilizing large models and billions of data [4, 17, 66] is a fundamental option. These methods train the model to predict missing content by hiding part of the input sequence. Various self-supervised pre-training methodologies [19, 21] have also been proposed in high-level computer vision fields. Recently, contrastive learning [9, 24] and transformer-based masked autoencoder methods [23,83] have emerged, enhancing semantic information learning. These pre-trained networks provide better
generalization performance in various downstream tasks through efficient representation learning and extensive data utilization, even with less training data. Parameter efficient fine-tuning. To adapt the aforementioned pre-trained models to various downstream tasks, a fine-tuning process is necessary. However, a major drawback of fine-tuning is that it comes with long training time [84] and memory discomfort [5], as the learning parameters for the new task are the same as the pre-trained model. To alleviate this, the topic of parameter efficient finetuning methods have been actively researched in the NLP [18,32,62,85] and highlevel computer vision [31, 89, 97] fields. These methodologies propose adjusting only specific parameters of the model, such as the adaptor [27,61], biases [6,85], prompts [31,34,44], etc. Recently in image generation tasks [52,63,72,94], ControlNet [94] and LoRA [28] have been proposed. The ControlNet [94] is a method to adapt to new tasks by additionally using parameters from the decoder and middle block. However, this method has a disadvantage of increasing inference time. On the other hand, LoRA does not increase inference time by fixing all weights of pre-trained models and efficiently adjusting only learnable rank decomposition matrix parameters for downstream tasks. Efficient parameter tuning has not been studied in IR, but recently pre-training methods [7, 13, 43, 48] for IR have begun to be proposed. We propose a novel efficient parameter tuning method, CoLoRA with PROD method specifically designed for IR tasks.
## 2.2 Low-Level Vision Tasks
Image restoration for multiple degradations. Recently, methodologies [8, 14,54,75,78,86,87] have been proposed that use a single network architecture to build multiple independent restoration models, each trained on different degradation datasets, demonstrating high performance in various degradation tasks. However, these methods require numerous network parameters as it necessitates an independent network trained for each degradation tasks. To address this, an all-in-one IR methods [12, 41, 42, 42, 46, 53, 57, 57, 76, 90, 99] have been proposed. Firstly, there was a method [12] of learning a unified network for various degradations through knowledge distillation techniques. Secondly, there were methods [41,46,53,76,90] of using an adaptor to enable the unified network to adapt to various degradations. Lastly, there were methods [42, 57, 99] of using an additional module corresponding to a specific degradation in a unified model, including a classifier that selects the additional module. All-in-one IR methods achieved high performance in various degradation tasks. However, these methods have the limitation of requiring to re-train the unified model and adaptor or classifier to extend to new tasks. Furthermore, all-in-one methods train from scratch without any pre-trained model.
Pre-training with synthetic data. Constructing a pre-trained model for IR tasks requires a significant quantity of low-quality images paired with their highquality counterparts [38, 93]. However, obtaining such image pairs in the real world presents considerable cost and difficulty [48]. To deal with such problems, pre-training methods using synthetic degradation functions have been proposed as illustrated in Fig. 1. IPT [7] and EDT [43] proposed methods that select
single degradation from multiple synthetic degradation functions such as superresolution, Gaussian noise, and rain, thus generate low-quality images. HAT [13] focuses on selecting a single degradation from down-scale degradation functions. DegAE [48] employs pre-determined Gaussian blur, noise, and JPEG degradation functions in a fixed order and introduces a degradation autoencoder to integrate features. However, DegAE [48] does not utilize global residual learning to aggregate features into a single representation. This omission may lead to a decrease in performance, as the original network's capabilities are not fully utilized. These methods may not be well-suited for addressing real-world and complex degradation tasks because their limited representation during pre-training. Moreover, there exists a significant constraint that the entire network must be fine-tuned for each new task. Consequently, there arises a challenge of storing and deploying distinct copies of base parameters for individual tasks, induces the issue of cost and memory. To alleviate it, we propose novel CoLoRA, an efficient fine-tuning methodology, and PROD, an effective pre-training method.
## 3 Method
We propose a Contribution based efficient LoRA (CoLoRA) with Pre-training with Random Order Degradation (PROD) for IR, as illustrated in Fig. 2. Section 3.1 introduces the pre-training method PROD, and Section 3.2 investigates the quantified contribution to each layer. In Section 3.3, we propose CoLoRA that adjusts the ratio of learnable network parameter based on contributions.
Fig. 2: The overview of our proposed CoLoRA with PROD. (a) Our PROD leverages high-quality clean images and synthetic degraded low-quality images for pre-training the model. (b) Our proposed Contribution based efficient LoRA (CoLoRA) for new IR tasks. The proposed CoLoRA is configured to have different ratio of learnable network parameter ( δ ) for each layer based on quantified contributions (Sec 3.2), enabling efficient fine-tuning for new tasks. (c) CoLoRA can be adjusted according to contribution.
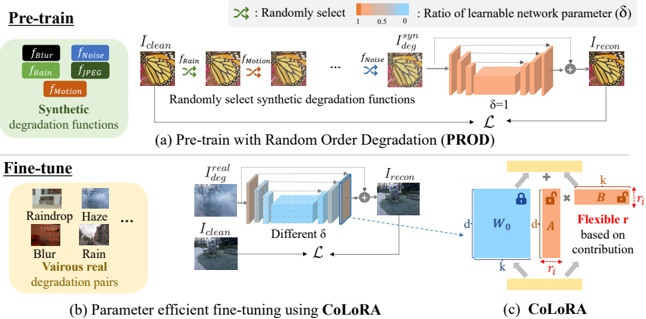
## 3.1 Pre-training with Random Order Degradation (PROD)
We propose a PROD that randomly applies synthetic degradation to clean images during the pre-training, as illustrated in Fig. 2. Detailed information on distortion functions and magnitudes are in the supplementary materials. Applying 1 to N synthetic degradations to a clean image, PROD can represent a total of ( H N +1 -1) / H ( -1) different types of degraded images where N is set to 6 and H (= 5) represents the number of degradation functions. This PROD method enables about 137 K kinds of degradation representations, which is about 4 K times more than the previous single [7,43] and fixed order [48] synthetic degradation methods. Note that a similar random degradation idea was proposed in [91] and [15], but it was designed for super resolution and classification, not for pretraining for multiple tasks. The experimental results are in the supplementary material. The PROD significantly expands the scalability and generalization of the pre-train model, bringing excellent performance in IR with real data.
## 3.2 The Key Components of Fine-Tuning for a New Task
We utilized Filter Attribution method based on Integral Gradient (FAIG) [82] scores to quantify the major contributing network parts for new IR tasks. FAIG is measured through Integrated Gradients (IG) calculations using pre-trained and fine-tuned models. The FAIG calculation for each layer involves the baseline model ( θ ba ) and the target model ( θ ta ), defined as follows:
$$\text{FAIG} _ { i } ( \theta _ { b a } ^ { i }, \theta _ { t a } ^ { i }, x ) \approx \sum _ { j = 1 } \left | \frac { 1 } { M } [ \theta _ { b a } ^ { i, j } - \theta _ { t a } ^ { i, j } ] \sum _ { t = 0 } ^ { M - 1 } \left [ \frac { \partial \mathcal { L } ( \rho ( \beta _ { t } ), x ) } { \partial \rho ( \beta _ { t } ) } \right ] _ { i, j } \right |, \quad ( 1 )$$
where M represents the total number of steps in the integral approximation, setting to 100 as in FAIG. β t , j , i and ρ are t/M , the kernel index, layer index
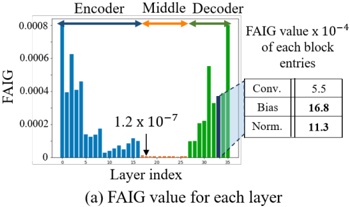
(b Results from fine-tuning specific layers
Fig. 3: (a) For each layer, we measured the FAIG score using a pre-trained model and a fine-tuned model specifically tuned for the specific task to observe its contribution. (b) Experimental results according to fine-tuning location for a blur task. The encoder and decoder occupy 18% of the total network parameters, while the middle layers account for 80%. The encoder and decoder have higher FAIG scores than the middle. Bias and normalization have higher FAIG values compared to the weight layer (Conv).
and interpolation between models, respectively. The high value of FAIG indicates a significant importance for new tasks [57]. Conversely, lower values indicate high similarity between the baseline and target model, implying low importance for the new task. In Fig. 3, we measure the FAIG score of each block using the full fine-tuned NAFNet [8] on real IR tasks after PROD execution. The FAIG values are an average of the 6 real IR tasks. Fig. 3 (a) demonstrates that the encoder and the decoder part of the network have significantly higher FAIG values than the middle layer. This indicates that the middle layers, accounting for a substantial fraction (around 80%) of the total network parameters, have a small contribution compared to the encoder and decoder, which account for a small portion (around 18%). Bias and Normalization layers have higher FAIG values than weight layers, despite a smaller portion of the total network parameters.
Based on these observations, we conducted experiments on partially finetuning for the new task, as shown in Fig. 3 (b). Fine-tuning only the encoder and decoder demonstrated superior performance with fewer network parameters compared to other methods. We observed that by fine-tuning the encoder and decoder parts with high FAIG scores, the network performance can be improved without unnecessary tuning to the middle layers. These experiments suggest that FAIG can be helpful in quantifying how specific parts of the network contribute to new tasks. These observations lead to our proposed CoLoRA.
## 3.3 Contribution-based Low-Rank Adaptation (CoLoRA)
Hu et al. [28] proposed a method known as LoRA aimed at fine-tuning only small network parameters. The training weight matrix △ W is represented as follows:
$$W _ { 0 } + \triangle W = W _ { 0 } + B A,$$
where W 0 ∈ R d × k , B ∈ R d × r , A ∈ R r × k , and the r ≪ min( d, k ) is pre-trained weight matrix, projection weight matrices, and rank, respectively. In the finetuning phase, A and B consist of learnable parameters while W 0 remains frozen and does not undergo gradient updates. The output vectors are coordinate-wise sum of W 0 and △ W = BA , which have the same input. The conventional LoRA employs a fixed rank value of r for all layers of the network because optimizing the low-rank parameter for each layer is infeasible, thus imposes constraints on the efficient utilization of parameters and limits its overall performance.
To address these limitations, we propose CoLoRA, a method that flexibly adjusts the ratio of learnable network parameter based on contributions. In Section 3.2, we adjust the ratio of learnable parameters δ by applying different values of r for each layer based on the quantified FAIG score. The δ in CoLoRA, according to the size of r , is defined as δ i = r i ( d i + k i ) / d ( i × k i ) , where i denotes the network layer index, and d and k represent the size of W 0 . For the FAIG scores measured for each block as in Fig. 3 (a), excluding the intro and end layers, we normalize to ensure the maximum value = 1. Using the normalized FAIG score, we propose a threshold-based scaling to determine δ without increasing
complexity as follows:
$$\delta ^ { s } = \begin{cases} \text{Norm} ( F A I G ^ { s } ) \times \alpha & \text{if Norm} ( F A I G ^ { s } ) > 0. 5, \\ \text{Norm} ( F A I G ^ { s } ) \times \beta & \text{otherwise}, \end{cases}$$
where α β , and Norm are two scale factors and a normalization function. FAIG s denotes the average value of FAIG i values for each stage and s is the stage index. We used scale factors ( α, β ) to optimize training parameters. The δ values are applied uniformly across all tasks. Thanks to the proposed CoLoRA, only a small fraction of learnable network parameters (approximately 7%) is allocated for each IR task, resulting in a significant reduction in memory usage compared to full fine-tuning (100%) for additional tasks. Our proposed CoLoRA with PROD method yields high performance using less memory compared to the previous work [48] with full-tuning in Section 4. Our proposed CoLoRA can merge with fixed pre-trained model weights with a simple linear model. Therefore, there is no inference delay compared to the full fine-tuning method [28]. Detailed δ values for each network are in the supplementary material.
Bias and Normalization layer. The parameters of Bias and Normalization layers, despite a small portion of the entire network, have high FAIG values. Therefore, we adjust the bias and normalization layer together during finetuning. Note that LoRA [28] does not update the Bias and Normalization layers.
## 4 Experiments
Experiment setups. We evaluated the proposed CoLoRA with PROD on 6 real IR tasks using CNN-based NAFNet [8] and transformer-based Restormer [86]. To evaluate our method, we compare it with the previously pre-trained methodology, DegAE [48]. In Restormer, the DegAE [48] uses publicly released pretrained weights, and in NAFNet, the DegAE [48] was reproduced based on the publicly released code. In CoLoRA, we experimentally used α = 1 and β = 0.2 for NAFNet, and α = 0.75 and β = 0.1 for Restormer. The learning iteration for the pre-training model and fine-tuning were set to 200K and 10K, respectively. The learning rate starts at 1e-3 for NAFNet and 3e-4 for Restormer and gradually decreases to 1e-6 according to the cosine annealing schedule. The evaluation of experiment results was performed using PSNR. In pre-training, PSNR loss was used, and in the fine-tuning process, NAFNet and Restormer used PSNR loss and L1, respecitvely. Detailed information is in the supplementary material. Six real-world image restoration task datasets: To evaluate our proposed method, we conducted experiments using 6 real-world Image Restoration (IR) datasets: Real Rain, Raindrop, Rain&Raindrop (RainDS [65]), Noise (SIDD [1]), Haze (SMOKE [33]), and Blur (BSD [96]). RainDS [65] consists of 120 training data and 100 test data for each task, Rain and Raindrop, Rain and Raindrop. SMOKE [33] includes of 120 training images and 12 test images. BSD [96] comprises of 18,000 training images and 3,000 test images (2ms-16ms). SIDD [96] data comprises of 160 training images and 1,280 validation samples.
Table 1: Benchmark results for real Rain, Raindrop, Raind&Raindrop, Haze and Blur test datasets in PSNR (dB). Our CoLoRA with PROD achieved comparable performance on NAFNet and Retsomer, respectively, by updating only a small 2M and 2.9M of tuned network parameters, in contrast to the full fine-tuning of 29M and 26M.
| Method | Rain | Raindrop | Rain&Raindrop | Tuned par. |
|-------------------------------|--------|------------|-----------------|--------------|
| SPANet [77] | 22.17 | 20.43 | 19.43 | - |
| PReNet [68] | 24.56 | 22.33 | 21.2 | - |
| DRDN [16] | 23.83 | 21.14 | 20.1 | - |
| CCN [65] | 26.83 | 24.81 | 23.09 | - |
| NAFNet (NAF.) + Full [8] | 27.09 | 24.86 | 23.79 | 29M |
| DegAE (NAF.) + Full [48] | 27.22 | 24.96 | 24.09 | 29M |
| PROD (NAF.) + Full | 27.42 | 25.02 | 24.37 | 29M |
| CoLoRA w. PROD (NAF.) | 27.37 | 25.22 | 24.62 | 2M |
| Restormer (Rest.) + Full [86] | 26.93 | 24.73 | 23.53 | 26M |
| DegAE (Rest.) + Full [48] | 27.11 | 24.95 | 23.97 | 26M |
| PROD (Rest.) + Full | 27.48 | 25.07 | 24.34 | 26M |
| CoLoRA w. PROD (Rest.) | 27.35 | 24.96 | 24.04 | 2.9M |
| Method | Haze | Method | Blur |
|---------------------------|--------|---------------------------|--------|
| DCP [25] | 11.25 | IFI-RNN [56] | 31.53 |
| GDN [47] | 15.19 | ESTRNN [96] | 31.95 |
| MSBDN [20] | 13.19 | CDVD-TSP [73] | 32.16 |
| DeHamer [22] | 13.31 | STFAN [98] | 32.19 |
| SMOKE [33] | 18.83 | PVDNet [74] | 32.22 |
| NAF. + Full [8] | 19.27 | NAF. + Full [8] | 32.3 |
| DegAE (NAF.) + Full [48] | 20.23 | DegAE (NAF.) + Full [48] | 32.19 |
| PROD(NAF.) + Full | 20.33 | PROD (NAF.) + Full | 32.84 |
| CoLoRA w. PROD(NAF.) | 20.17 | CoLoRA w. PROD (NAF.) | 32.08 |
| Rest. + Full [86] | 19.67 | Rest. + Full [86] | 30.42 |
| DegAE (Rest.) + Full [48] | 20.28 | DegAE (Rest.) + Full [48] | 31.47 |
| PROD (Rest.) + Full | 20.16 | PROD (Rest.) + Full | 32.38 |
| CoLoRA w. PROD (Rest.) | 20.04 | CoLoRA w. PROD (Rest.) | 31.9 |
## 4.1 Benchmark Results for Real Various IR Tasks
In Table 1, we summarized the benchmark results on the real Rain, Raindrop, Rain&Raindrop, Haze and Blur datasets to evaluate our proposed CoLoRA with PROD . To make a fair comparison with previous methods, we trained the model using the entire training dataset from the real various IR task datasets. For each task, all methods except DegAE and Our PROD are initialized randomly without a pre-trained model. All methods except Our CoLoRA perform full fine-tuning on new tasks. In full fine-tuning, NAFNet and Restormer have 29 M and 26 M (100%) trainable parameters, respectively. The CoLoRA method have 2M and 2.9 M (7% and 11% of the total) trainable parameter in NAFNet and Retormer, respectively. Our PROD achieved state-of-the-art PSNR on datasets containing Real Rain, Raindrop, Rain&Raindrop, Haze and Blur. Our CoLoRA
Fig. 4: Performance comparison based on the scale of training data for 6 IR tasks. In the graph, the results of the 6 IR tasks are averaged for comparison. The x-axis represents the number of training data, and the y-axis is the average PSNR. In the radar graph, we compare the results of 6 IR tasks with Normalized PSNR at a training data size of 128. (a) and (b) present experimental results corresponding to pre-training and fine-tuning methods, respectively. (c) and (d) experimental results for the Our CoLoRA with PROD in NAFNet and Restormer. Our proposed CoLoRA (7%) has much fewer tuned network parameters compared to the full fine-tuning (100%) of NAFNet.
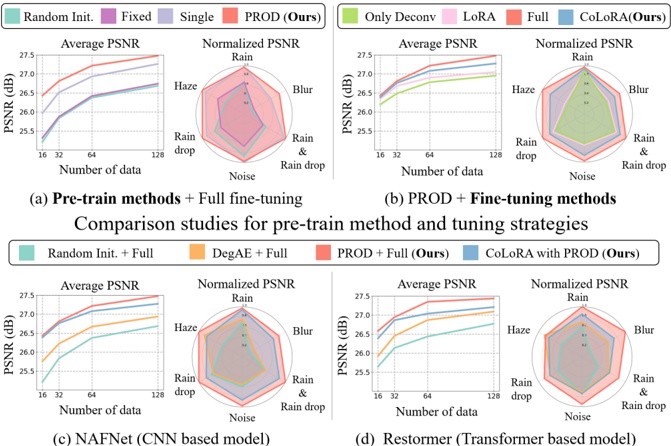
with PROD approach achieved similar performance on NAFNet and Retsomer, respectively, by updating only small 2M and 2.9M (7% and 11% of the total) network parameters compared to full fine-tuning 29M and 26M (100%). These results demonstrate that our proposed PROD and CoLoRA with PROD methods effectively and efficiently improve various IR performances, with abundant data.
## 4.2 Comparing Proposed Methods in Limited Real-world Scenario
In Fig. 4, we conducted a comparative study to demonstrate the performance and efficiency of the parameter-efficient fine-tuning method, CoLoRA, and the proposed pre-training method PROD, depending on the number of training data. To summarize each experiment, (a) 'Pre-training Methods' presents the experimental results based on different pre-training methods, (b) 'Tuning Strategies' presents the results based on efficient parameter tuning methods, and (c)&(d) 'Different Network Architectures' provides the experimental results based on pre-training and tuning methods on CNN and vision transformer architectures.
Fig. 4 summarizes PSNR results for six real-world IR tasks with respect to the number of training data during fine-tuning. The number of training data for each tasks were set to [16, 32, 64, 128]. These small datasets reflect the reality of IR tasks: acquiring paired real world datasets is often difficult and expensive (e.g., weather, medical imaging). In Fig. 4 (line graph), the y-axis represents the average PSNR results of six IR tasks, while the x-axis represents the number of training data during fine-tuning. Each vertical line in the line graph represents results from experiments fine-tuning a total of 6 IR tasks with 4 different amounts of training data. Fig. 4 (radar graph) represents the normalized PSNR results when number of training data is 128 for six IR tasks with real test data.
Comparison of pre-training methods. To validate the effectiveness of our proposed PROD method, we conduct a comparative study based on pre-training methods, using the CNN-based NAFNet, as illustrated in Fig. 4 (a). Random Init refers to the method of randomly initializing the network parameters. Single denotes methods like IPT [7] and EDT [43], where various synthetic degradations are randomly applied once. Fixed represents methods like DegAE [48], where diverse synthetic degradations are applied in a fixed order. PROD (Ours) is a method that involves randomly applying various synthetic degradations multiple times to generate low-quality images. We used full fine-tuning to evaluate the performance of the pre-trained model. Our PROD yielded substantially higher performance than other methods. Using 32 training data, our PROD outperformed Random Init and Fixed , which utilized 128 training data, by a significant improvement of 0.05 dB and 0.10 dB, respectively. Our PROD method effectively improves performance with limited training data.
Comparison of fine-tuning strategies. In the Fig. 4 (b), we validated our proposed CoLoRA strategy by comparing different tuning methods for a new task using CNN-based NAFNet and the PROD pre-trained weight. We investigated the following tuning methods : Full fine-tuning ( Full ), Only tunes only the decoder ( Only Decoder ), apply LoRA to all layers ( LoRA ), and our CoLoRA . The Full method has 29 M trainable parameters. The Only Decoder , LoRA , and CoLoRA (Ours) have approximately 2 M trainable parameters. Using 64 training data, our CoLoRA outperformed Only Deconv and LoRA , which utilized 128 training data, by a significant improvement of 0.08 dB and 0.15 dB, respectively. Our CoLoRA method enhances performance efficiently, even with limited training data and a sparse number of learnable parameters.
Comparison of different network architectures. In Fig.4 (c) and (d), we evaluate the efficiency of the proposed CoLoRA with PROD using the CNNbased NAFNet and Transformer-based Restormer network architectures. We investigated the following pre-train and tuning methods: Random initialization with full fine-tuning ( Random-init+Full ), DegAE [48] with full fine-tuning ( DegAE+Full ), the proposed full fine-tuning with PROD( PROD+Full ), and the proposed CoLoRA with PROD method ( CoLoRA with PROD ). Full fine-tuning has 29M (NAFNet) and 26M (Restormer) trainable parameters, while CoLoRA has 2M (NAFNet) and 2.9M (Restormer). Our proposed methods ( PROD+Full and CoLoRA with PROD ) outperforms than previous methods in 6 IR tasks
Fig. 5: Qualitative results evaluated on the 6 IR tasks for our proposed method, generic Random initial + Full tuning and DegAE + Full tuning. Our methods with partial and full tuning yielded visually excellent results for the real IR task, outperforming others.

for both NAFNet and Restormer. Using 64 training data, our proposed CoLoRA with PROD outperformed DegAE [48] and Random Init which utilized 128 training data, by a significant improvement of 0.22 dB and 0.36 dB in NAFNet, respectively. Furthermore, in Restormer, our proposed CoLoRA with PROD showed superiority over the Full with DegAE [48] in most IR tasks. Our CoLoRA with PROD improves performance efficiently with limited training data and fewer learnable parameters. Fig. 5 illustrates the results for 6 IR task with test data according to previous methods and our proposed methods, with the experiments conducted using the NAFNet. Our methods seems to yield better restoration results than Full with Random and Full with DegAE [48].
Additional experiments on low-light and underwater tasks. We have further evaluated on more datasets, underwater (LSUI [60] dataset) and lowlight enhancement (LoL [79] dataset) tasks. All experiments were performed with NAFNet. The numerical results for each task are as follows: (1) for LSUI data, the PSNR (dB) values of {NAFNet(Random), DegAE, PROD, CoLoRA with PROD} are {22.29, 22.69, 23.32, 22.98}, respectively. (2) for LoL data, the PSNR (dB) values of {NAFNet(Random), DegAE, PROD, CoLoRA with PROD} are {22.79, 22.77, 22.96, 22.94}, respectively. Our methods achieved high performance, demonstrating the generality.
Table 2: Ablation study according to CoLoRA scale parameters α and β for Blur task. We conducted the experiment using NAFNet and used all training data.
| α / β | 1.0 / 1.0 | 1.0 / 0.2 | 1.0 / 0.1 | 0.5 / 0.2 | 0.25 / | 0.1 / 0.1 | |
|--------------|-------------|-------------|-------------|-------------|----------|-------------|----|
| PSNR (dB) | 32.26 | 32.08 | 31.98 | 31.90 | 31.86 | 31.54 | |
| Tuned param. | 5.2 M | 1.9 M | 1.6 M | 1.6 M | 1.4 M | 0.8 M | |
Table 3: We evaluate the performance comparison in terms of PSNR (dB) using the pre-trained model without any fine-tuning on 6 real IR tasks.
| Method | Rain | Raindrop | Rain&Raindrop | Noise Blur | Haze | Avg. |
|----------|--------|------------|-----------------|--------------|--------|--------|
| Fixed | 21.76 | 18.81 | 17.42 | 23.68 27.49 | 13.06 | 20.37 |
| Single | 22.11 | 18.77 | 17.44 | 23.84 27.47 | 13.03 | 20.44 |
| PROD | 24.11 | 18.85 | 18.14 | 25.10 27.75 | 13.06 | 21.17 |
## 4.3 Ablation Study On Scale Values ( α and β ) of CoLoRA
In Table 2, we investigated the PSNR results based on CoLoRA's scaling factors ( α β , ) for NAFNet and Restormer, to optimize network parameters. Selecting α and β depends on the trade-off between performance and memory. We found that using small values for β (0.1-0.2) was efficient while using large values for α (0.71.0) was effective. We selected α = 1 , β = 0 2 . for NAFNet and α = 0 75 . , β = 0 1 . for Restormer for the highest performance efficiently. With these criteria, α and β can be practically chosen depending on the target device and the applied task.
## 5 Discussion
Empirical analysis on pre-train methods without any fine-tuning: To observe the scalability and generalization capabilities of our pre-training method, PROD, we conduct an empirical analysis on 6 real IR tasks without any finetuning. The investigated pre-training methods consist of untrained Fixed, Single, DeGAE, and PROD. Table 3 summarizes the PSNR for 6 real IR tasks based on pre-training methods without any fine-tuning. Our proposed PROD achieves better results even when not trained for degradation, surpassing previous approaches. Fig. 6 (a) illustrates the degradation representations of various IR tasks using t-SNE, based on pre-training methods without fine-tuning. Features are extracted from the last layer of the middle block of the pre-trained NAFNet for t-SNE plotting, followed by global average pooling, and t-SNE was plotted for 100 samples. We believe that the embedded scalability and generalization ability of PROD shows promising performance on the above IR results.
Why CoLoRA, practical deployment: Considering that IR can be executed immediately after image acquisition and used for on-device AI, the efficiency, robustness, and scalability of CoLoRA are very important. Compared to fulltuning, CoLoRA excels in efficiency, robustness, and scalability. For six tasks, CoLoRA has fewer parameters than Full and LoRA (41M for CoLoRA, 41M
Fig. 6: (a) Visualizing degradation representations for 6 real IR tasks using t-SNE without fine-tuning, our PROD method generates more discriminative clusters for untrained data than other pre-training methods. (b) Average FAIG value to compare the similarity between LoRA / CoLoRA and Full-tuning (the lower, the more similar).
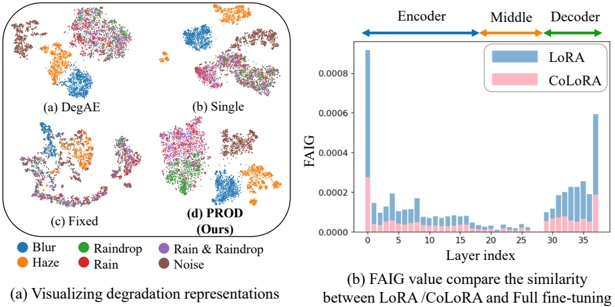
for LoRA, 174M for Full-tuning), and requires less memory to store (167MB for CoLoRA, 176MB for LoRA, 696MB for Full-tuning), providing significant advantages to on-device AI applications with limited memory [6]. In scenarios with increasing learning rates (2e-4 to 8e-3), CoLoRA demonstrates robust performance over Full-tuning (CoLoRA 25.3 to 22.3dB, Full-tuning 25.3 to 20.8dB). Additionally, CoLoRA is easier to scale to new tasks compared to all-in-one IR methods. CoLoRA can be used in a variety of industries with AI edge devices. Empirical Analysis of CoLoRA and LoRA: In Fig. 6(b), we measured the FAIG value to analyze the correlation between Full Fine-tuning and CoLoRA/LoRA. Note that lower FAIG score in Eq.(1) indicates more similarity between two networks, reflecting smaller differences and gradients. CoLoRA has a lower FAIG value compared to LoRA, which explains its higher similarity to full-fine tuning and superior performance.
Limitation: While our CoLoRA has been successfully validated for various downstream IR tasks, our CoLoRA faces the limitation of increasing parameters as the tasks expand even though they are still more efficient than full-tuning.
## 6 Conclusion
We proposed CoLoRA with PROD, pre-training with synthetic data and efficient parameter tuning in both abundant and limited real-data scenarios for image restoration. Our PROD yielded excellent pre-trained model as compared to prior arts and our CoLoRA enabled efficient fine-tuning only about 7% learnable parameters. We demonstrate that our proposed method is flexible enough to work with diverse network architectures and achieves state-of-the-art performance on various IR tasks with real-world datasets.
## Acknowledgements
This work was supported by the New Faculty Startup Fund from Seoul National University, Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government(MSIT) [NO.RS-2021II211343, Artificial Intelligence Graduate School Program (Seoul National University)], the National Research Foundation of Korea(NRF) grant funded by the Korea government(MSIT) (No. NRF-2022R1A4A1030579), and CreativePioneering Researchers Program through Seoul National University. Also, the authors acknowledged the financial support from the BK21 FOUR program of the Education and Research Program for Future ICT Pioneers, Seoul National University.
## References
- 1. Abdelhamed, A., Lin, S., Brown, M.S.: A high-quality denoising dataset for smartphone cameras. In: CVPR (2018)
- 3. Bojarski, M., Del Testa, D., Dworakowski, D., Firner, B., Flepp, B., Goyal, P., Jackel, L.D., Monfort, M., Muller, U., Zhang, J., et al.: End to end learning for self-driving cars. NIPS Deep Learning Symposium (2016)
- 2. Agustsson, E., Timofte, R.: Ntire 2017 challenge on single image super-resolution: Dataset and study. In: CVPRW (2017)
- 4. Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are fewshot learners. NeurIPS (2020)
- 6. Cai, H., Gan, C., Zhu, L., Han, S.: Tinytl: Reduce memory, not parameters for efficient on-device learning. NeurIPS (2020)
- 5. Bulo, S.R., Porzi, L., Kontschieder, P.: In-place activated batchnorm for memoryoptimized training of dnns. In: CVPR. pp. 5639-5647 (2018)
- 7. Chen, H., Wang, Y., Guo, T., Xu, C., Deng, Y., Liu, Z., Ma, S., Xu, C., Xu, C., Gao, W.: Pre-trained image processing transformer. In: CVPR (2021)
- 9. Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: ICML (2020)
- 8. Chen, L., Chu, X., Zhang, X., Sun, J.: Simple baselines for image restoration. ECCV (2022)
- 10. Chen, W.T., Fang, H.Y., Ding, J.J., Tsai, C.C., Kuo, S.Y.: Jstasr: Joint size and transparency-aware snow removal algorithm based on modified partial convolution and veiling effect removal. In: ECCV (2020)
- 12. Chen, W.T., Huang, Z.K., Tsai, C.C., Yang, H.H., Ding, J.J., Kuo, S.Y.: Learning multiple adverse weather removal via two-stage knowledge learning and multicontrastive regularization: Toward a unified model. In: CVPR (2022)
- 11. Chen, W.T., Fang, H.Y., Hsieh, C.L., Tsai, C.C., Chen, I., Ding, J.J., Kuo, S.Y., et al.: All snow removed: Single image desnowing algorithm using hierarchical dual-tree complex wavelet representation and contradict channel loss. In: ICCV (2021)
- 13. Chen, X., Wang, X., Zhou, J., Qiao, Y., Dong, C.: Activating more pixels in image super-resolution transformer. In: CVPR (2023)
- 14. Chu, X., Chen, L., Chen, C., Lu, X.: Improving image restoration by revisiting global information aggregation. ECCV (2022)
- 15. Cubuk, E.D., Zoph, B., Shlens, J., Le, Q.: Randaugment: Practical automated data augmentation with a reduced search space. In: NeurIPS. pp. 18613-18624 (2020)
- 17. Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805 (2018)
- 16. Deng, S., Wei, M., Wang, J., Feng, Y., Liang, L., Xie, H., Wang, F.L., Wang, M.: Detail-recovery image deraining via context aggregation networks. In: CVPR (2020)
- 18. Ding, N., Qin, Y., Yang, G., Wei, F., Yang, Z., Su, Y., Hu, S., Chen, Y., Chan, C.M., Chen, W., et al.: Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence (2023)
- 20. Dong, H., Pan, J., Xiang, L., Hu, Z., Zhang, X., Wang, F., Yang, M.H.: Multi-scale boosted dehazing network with dense feature fusion. In: CVPR (2020)
- 19. Doersch, C., Gupta, A., Efros, A.A.: Unsupervised visual representation learning by context prediction. In: ICCV (2015)
- 21. Gidaris, S., Singh, P., Komodakis, N.: Unsupervised representation learning by predicting image rotations. arXiv:1803.07728 (2018)
- 23. He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: CVPR (2022)
- 22. Guo, C.L., Yan, Q., Anwar, S., Cong, R., Ren, W., Li, C.: Image dehazing transformer with transmission-aware 3d position embedding. In: CVPR (2022)
- 24. He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: CVPR (2020)
- 26. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
- 25. He, K., Sun, J., Tang, X.: Single image haze removal using dark channel prior. IEEE TPMAI (2010)
- 27. Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Gesmundo, A., Attariyan, M., Gelly, S.: Parameter-efficient transfer learning for nlp. In: ICML (2019)
- 29. Huang, T., Li, S., Jia, X., Lu, H., Liu, J.: Neighbor2neighbor: Self-supervised denoising from single noisy images. In: CVPR (2021)
- 28. Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. arXiv:2106.09685 (2021)
- 30. Jaw, D.W., Huang, S.C., Kuo, S.Y.: Desnowgan: An efficient single image snow removal framework using cross-resolution lateral connection and gans. IEEE Transactions on Circuits and Systems for Video Technology (2020)
- 32. Jiang, H., He, P., Chen, W., Liu, X., Gao, J., Zhao, T.: Smart: Robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization. arXiv:1911.03437 (2019)
- 31. Jia, M., Tang, L., Chen, B.C., Cardie, C., Belongie, S., Hariharan, B., Lim, S.N.: Visual prompt tuning. In: ECCV. pp. 709-727 (2022)
- 33. Jin, Y., Yan, W., Yang, W., Tan, R.T.: Structure representation network and uncertainty feedback learning for dense non-uniform fog removal. In: ACCV (2022)
- 35. Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. NeurIPS (2012)
- 34. Khattak, M.U., Rasheed, H., Maaz, M., Khan, S., Khan, F.S.: Maple: Multi-modal prompt learning. In: CVPR. pp. 19113-19122 (2023)
- 36. Kupyn, O., Budzan, V., Mykhailych, M., Mishkin, D., Matas, J.: Deblurgan: Blind motion deblurring using conditional adversarial networks. In: CVPR (2018)
- 37. Lai, W.S., Huang, J.B., Hu, Z., Ahuja, N., Yang, M.H.: A comparative study for single image blind deblurring. In: CVPR (2016)
- 39. Lehtinen, J., Munkberg, J., Hasselgren, J., Laine, S., Karras, T., Aittala, M., Aila, T.: Noise2noise: Learning image restoration without clean data. ICML (2018)
- 38. Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A., Tejani, A., Totz, J., Wang, Z., et al.: Photo-realistic single image super-resolution using a generative adversarial network. In: CVPR (2017)
- 40. Li, B., Peng, X., Wang, Z., Xu, J., Feng, D.: Aod-net: All-in-one dehazing network. In: ICCV (2017)
- 42. Li, R., Tan, R.T., Cheong, L.F.: All in one bad weather removal using architectural search. In: CVPR (2020)
- 41. Li, B., Liu, X., Hu, P., Wu, Z., Lv, J., Peng, X.: All-in-one image restoration for unknown corruption. In: CVPR (2022)
- 43. Li, W., Lu, X., Lu, J., Zhang, X., Jia, J.: On efficient transformer and image pre-training for low-level vision. arXiv:2112.10175 (2021)
- 45. Lim, B., Son, S., Kim, H., Nah, S., Lee, K.M.: Enhanced deep residual networks for single image super-resolution. In: CVPRW (2017)
- 44. Li, X.L., Liang, P.: Prefix-tuning: Optimizing continuous prompts for generation. ACL (2021)
- 46. Liu, L., Xie, L., Zhang, X., Yuan, S., Chen, X., Zhou, W., Li, H., Tian, Q.: Tape: Task-agnostic prior embedding for image restoration. In: ECCV (2022)
- 48. Liu, Y., He, J., Gu, J., Kong, X., Qiao, Y., Dong, C.: Degae: A new pretraining paradigm for low-level vision. In: CVPR (2023)
- 47. Liu, X., Ma, Y., Shi, Z., Chen, J.: Griddehazenet: Attention-based multi-scale network for image dehazing. In: ICCV (2019)
- 49. Liu, Y.F., Jaw, D.W., Huang, S.C., Hwang, J.N.: Desnownet: Context-aware deep network for snow removal. IEEE TIP (2018)
- 51. Luo, C., Yang, X., Yuille, A.: Self-supervised pillar motion learning for autonomous driving. In: CVPR (2021)
- 50. Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv:1711.05101 (2017)
- 52. Luo, S., Tan, Y., Patil, S., Gu, D., von Platen, P., Passos, A., Huang, L., Li, J., Zhao, H.: Lcm-lora: A universal stable-diffusion acceleration module. arXiv:2311.05556 (2023)
- 54. Mou, C., Wang, Q., Zhang, J.: Deep generalized unfolding networks for image restoration. In: CVPR (2022)
- 53. Luo, Z., Gustafsson, F.K., Zhao, Z., Sjölund, J., Schön, T.B.: Controlling visionlanguage models for universal image restoration. arXiv:2310.01018 (2023)
- 55. Nah, S., Hyun Kim, T., Mu Lee, K.: Deep multi-scale convolutional neural network for dynamic scene deblurring. In: CVPR (2017)
- 57. Park, D., Lee, B.H., Chun, S.Y.: All-in-one image restoration for unknown degradations using adaptive discriminative filters for specific degradations. In: CVPR (2023)
- 56. Nah, S., Son, S., Lee, K.M.: Recurrent neural networks with intra-frame iterations for video deblurring. In: CVPR (2019)
- 58. Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, highperformance deep learning library. NeurIPS (2019)
- 59. Pathak, D., Girshick, R., Dollár, P., Darrell, T., Hariharan, B.: Learning features by watching objects move. In: CVPR (2017)
- 60. Peng, L., Zhu, C., Bian, L.: U-shape transformer for underwater image enhancement. IEEE TIP (2023)
- 62. Pfeiffer, J., Rücklé, A., Poth, C., Kamath, A., Vulić, I., Ruder, S., Cho, K., Gurevych, I.: Adapterhub: A framework for adapting transformers. EMNLP (2020)
- 61. Pfeiffer, J., Kamath, A., Rücklé, A., Cho, K., Gurevych, I.: Adapterfusion: Nondestructive task composition for transfer learning. arXiv:2005.00247 (2020)
- 63. Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv:2307.01952 (2023)
- 65. Quan, R., Yu, X., Liang, Y., Yang, Y.: Removing raindrops and rain streaks in one go. In: CVPR (2021)
- 64. Potlapalli, V., Zamir, S.W., Khan, S., Khan, F.: Promptir: Prompting for all-inone image restoration. In: NeurIPS (2023)
- 66. Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al.: Language models are unsupervised multitask learners. OpenAI blog (2019)
- 68. Ren, D., Zuo, W., Hu, Q., Zhu, P., Meng, D.: Progressive image deraining networks: A better and simpler baseline. In: CVPR (2019)
- 67. Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: CVPR (2016)
- 69. Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detection with region proposal networks. NeurIPS (2015)
- 71. Rim, J., Lee, H., Won, J., Cho, S.: Real-world blur dataset for learning and benchmarking deblurring algorithms. In: ECCV (2020)
- 70. Rim, J., Kim, G., Kim, J., Lee, J., Lee, S., Cho, S.: Realistic blur synthesis for learning image deblurring. ECCV (2022)
- 72. Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
- video deblurring with non-consecutively blurry frames. In: ICCV (2021)
- 73. Shang, W., Ren, D., Zou, D., Ren, J.S., Luo, P., Zuo, W.: Bringing events into
- 74. Son, H., Lee, J., Lee, J., Cho, S., Lee, S.: Recurrent video deblurring with blurinvariant motion estimation and pixel volumes. ACM TOG (2021)
- 76. Valanarasu, J.M.J., Yasarla, R., Patel, V.M.: Transweather: Transformer-based restoration of images degraded by adverse weather conditions. In: CVPR (2022)
- 75. Tu, Z., Talebi, H., Zhang, H., Yang, F., Milanfar, P., Bovik, A., Li, Y.: Maxim: Multi-axis mlp for image processing. In: CVPR (2022)
- 77. Wang, T., Yang, X., Xu, K., Chen, S., Zhang, Q., Lau, R.W.: Spatial attentive single-image deraining with a high quality real rain dataset. In: CVPR (2019)
- 79. Wei, C., Wang, W., Yang, W., Liu, J.: Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560 (2018)
- 78. Wang, Z., Cun, X., Bao, J., Zhou, W., Liu, J., Li, H.: Uformer: A general u-shaped transformer for image restoration. In: CVPR (2022)
- 80. Whang, J., Delbracio, M., Talebi, H., Saharia, C., Dimakis, A.G., Milanfar, P.: Deblurring via stochastic refinement. In: CVPR (2022)
- 82. Xie, L., Wang, X., Dong, C., Qi, Z., Shan, Y.: Finding discriminative filters for specific degradations in blind super-resolution. NeurIPS (2021)
- 81. Wu, H., Qu, Y., Lin, S., Zhou, J., Qiao, R., Zhang, Z., Xie, Y., Ma, L.: Contrastive learning for compact single image dehazing. In: CVPR (2021)
- 83. Xie, Z., Zhang, Z., Cao, Y., Lin, Y., Bao, J., Yao, Z., Dai, Q., Hu, H.: Simmim: A simple framework for masked image modeling. In: CVPR (2022)
- 84. Yang, Y., Kim, K.S., Kim, M., Park, J.: Gram: Fast fine-tuning of pre-trained language models for content-based collaborative filtering. arXiv:2204.04179 (2022)
- 86. Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H.: Restormer: Efficient transformer for high-resolution image restoration. In: CVPR (2022)
- 85. Zaken, E.B., Ravfogel, S., Goldberg, Y.: Bitfit: Simple parameter-efficient finetuning for transformer-based masked language-models. ACL (2021)
- 87. Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H., Shao, L.: Multi-stage progressive image restoration. In: CVPR (2021)
- 89. Zhang, J.O., Sax, A., Zamir, A., Guibas, L., Malik, J.: Side-tuning: a baseline for network adaptation via additive side networks. In: ECCV (2020)
- 88. Zhang, H., Patel, V.M.: Densely connected pyramid dehazing network. In: CVPR (2018)
- 90. Zhang, J., Huang, J., Yao, M., Yang, Z., Yu, H., Zhou, M., Zhao, F.: Ingredientoriented multi-degradation learning for image restoration. In: CVPR (2023)
- 92. Zhang, K., Zuo, W., Chen, Y., Meng, D., Zhang, L.: Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE TIP (2017)
- 91. Zhang, K., Liang, J., Van Gool, L., Timofte, R.: Designing a practical degradation model for deep blind image super-resolution. In: ICCV (2021)
- 93. Zhang, K., Zuo, W., Zhang, L.: Ffdnet: Toward a fast and flexible solution for cnn-based image denoising. IEEE TIP (2018)
- 95. Zheng, Z., Ren, W., Cao, X., Hu, X., Wang, T., Song, F., Jia, X.: Ultra-highdefinition image dehazing via multi-guided bilateral learning. In: CVPR (2021)
- 94. Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: ICCV (2023)
- 96. Zhong, Z., Gao, Y., Zheng, Y., Zheng, B.: Efficient spatio-temporal recurrent neural network for video deblurring. In: ECCV (2020)
- 98. Zhou, S., Zhang, J., Pan, J., Xie, H., Zuo, W., Ren, J.: Spatio-temporal filter adaptive network for video deblurring. In: ICCV (2019)
- 97. Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. ICCV (2022)
- 99. Zhu, Y., Wang, T., Fu, X., Yang, X., Guo, X., Dai, J., Qiao, Y., Hu, X.: Learning weather-general and weather-specific features for image restoration under multiple adverse weather conditions. In: CVPR (2023)
- 101. Zhussip, M., Soltanayev, S., Chun, S.Y.: Extending stein's unbiased risk estimator to train deep denoisers with correlated pairs of noisy images. NeurIPS (2019)
- 100. Zhu, Y., Wang, T., Fu, X., Yang, X., Guo, X., Dai, J., Qiao, Y., Hu, X.: Learning weather-general and weather-specific features for image restoration under multiple adverse weather conditions. In: CVPR (2023)
- 102. Zou, Z., Lei, S., Shi, T., Shi, Z., Ye, J.: Deep adversarial decomposition: A unified framework for separating superimposed images. In: CVPR (2020)
## Supplementary Material
## S1 Details on the proposed CoLoRA with PROD
Fig. S1: Illustrations of pre-train methods and tuning strategies for image restoration. From synthetic degradation functions, (a) while prior works either randomly select a single degradation [7,43] or pre-determine multiple degradations in a fixed order [48], (b) our proposed PROD pre-trains with generated low-quality images by random order degradations. (c) While utilizing the full fine-tuning strategy is common among prior works, (d) our CoLoRA enables parameter-efficient fine-tuning by freezing the pretrained model and only adjusting the additional adapter for each task.
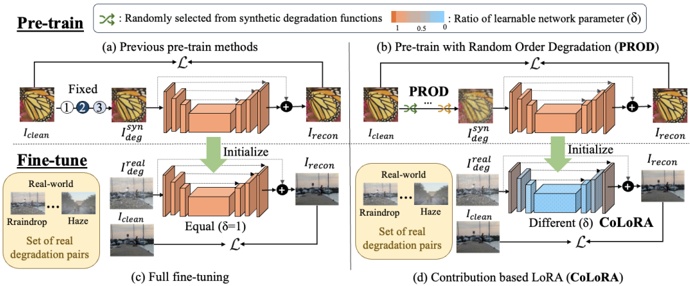
In Figure S1, we compare our CoLoRA - PROD method with existing methods [7, 43, 48]. Figure S1 illustrates the differences between PROD, which introduces degradation during pre-training, and other prior works, as well as the distinctions between CoLoRA, a efficient tuning approach, and simple full finetuning. Specifically, in simple full fine-tuning, the entire network is tuned. In contrast, our CoLoRA approach is a parameter-efficient tuning methodology that flexibly adjusts the ratio of learnable network parameters based on layer positions. While prior works must have a separate full fine-tuned network for each novel IR task, our proposed CoLoRA only need to store the small tunable adaptor for each task (approximately 7% of the entire network parameters for comparable performance to full-size tuning), so that it will be advantageous in terms of memory for multiple target tasks.
## S2 Details on synthetic degradation functions of PROD
The environmental settings for synthetic blur, noise and JPEG functions were similar to DegAE [48]. In the synthetic blur function ( f Blur ), we employ Gaussian
kernels, generalized Gaussian kernels, and plateau-shaped kernels. The kernel size is randomly chosen from the set 7, 9, ..., 21. For the generalized Gaussian and plateau-shaped kernels, the shape parameters are sampled from the intervals [0.5, 4] and [1, 2], respectively. In the synthetic noise function ( f Noise ), we use Gaussian and Poisson, the range for the noise sigma is set to [1, 30], and the Poisson noise scale is set to [0.05, 3]. In the synthetic JPEG function ( f JPEG ), the quality factor is specified within the range [30, 95]. In the synthetic motion blur function ( f Motion ), we use the centered motion kernel proposed by Rim [71]. The kernel size is randomly chosen from the set 5, 7, 9, ..., 31. In the synthetic rain function ( f Rain ), the rain noise is set to a range of [10, 1000], the rain length is set to [10, 90], the alpha value is chosen between [0.3, 1.3], and the rain angle is set to [-80, 80]. Figure S2 illustrates synthetic degraded images ( I syn deg ) using PROD.
## S3 Ablation studies for CoLoRA
In Table. S1, we performed an additional ablation study on bias and normalization for deblurring. 'Bias & Norm' improves performance by 0.08 dB with additionally tuned parameter (0.1M), which is consistent with our FAIG analysis. The level of importance could be different for various tasks.
Table S1: Ablation study according to 'Bias and Norm.' (B&N) and 'Adaptation'(A.) of CoLoRA using NAFNet in Blur task.
| Method | w/o (Adaptation) w/o | (Bias&Norm) | CoLoRA |
|--------------|------------------------|---------------|----------|
| PSNR | 30.88 dB | 32.00 dB | 32.08 dB |
| Tund. Param. | 0.1M | 1.8M | 1.9M |
Fig. S2: Example of degraded image generation using PROD with synthetic degradation functions such as Gaussian noise, Gaussian blur, JPEG artifact, and so on.
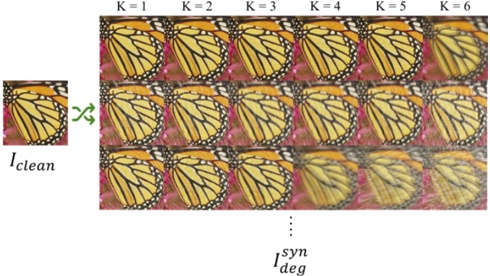
Table S2: In Real 6 IR tasks, these are the Norm(FAIG) average and standard deviation values according to location in NAFNet and Restormer networks.
| Network | NAFNet | NAFNet | NAFNet | NAFNet | NAFNet | NAFNet | NAFNet | NAFNet | NAFNet |
|--------------------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|------------|
| Location | Encoder | Encoder | Encoder | Encoder | Middle | Decoder | Decoder | Decoder | Decoder |
| | 1 | 2 | 3 | 4 | Middle | 1 | 2 | 3 | 4 |
| Norm(FAIG) | 0.794 | 1.0 | 0.563 | 0.352 | 0.089 | 0.391 | 0.831 | 0.932 | 0.920 |
| Standard deviation | 0.229 | 0.241 | 0.172 | 0.144 | 0.037 | 0.153 | 0.158 | 0.108 | 0.201 |
| Network | Restormer | Restormer | Restormer | Restormer | Restormer | Restormer | Restormer | Restormer | Restormer |
| Location | Encoder | Encoder | Encoder | Middle | Decoder | Decoder | Decoder | | Refinement |
| | 1 | 2 | 3 | Middle | 1 | 2 | 3 | | Refinement |
| Norm(FAIG) | 0.968 | 1.0 | 0.415 | 0.005 | 0.240 | 0.723 | 0.850 | | 0.901 |
| Standard deviation | 0.118 | 0.119 | 0.131 | 0.001 | 0.095 | 0.104 | 0.041 | | 0.150 |
## S4 Details on the δ of the proposed CoLoRA.
The LoRA [28] method uses a fixed value of r for all layers. On the other hand, our proposed CoLoRA adjusts the ratio of learnable parameters ( δ ) by using different values of r depending on the layer location, as shown in Figure S3. The δ in CoLoRA, according to the size of r , is defined as follows: δ i = ( r i ( d i + k i )) / d ( i × k i ) , where i denotes the network layer index, and d and k represent the size of W 0 . The proposed method has designed the size of r to use a small ratio of learnable network parameters (approximately 7%) in the entire network for each task. Thanks to CoLoRA, additional IR operations use only small network parameters, significantly reducing memory usage. Table S2 shows Norm(FAIG) values according to location in NAFNet and Restormer. For real 6 IR tasks, Norm(FAIG) values show the average value and standard deviation. The middle part has a very small value compared to the encoder part and decoder part.
## S5 Details of experiment setups
For a fair comparison, we evaluate the proposed method under the same conditions using PyTorch [58] on an NVIDIA A100 GPU. All our experiments were based on the code published by NAFNet [8] and Restormer [86]. In all our experiments, the channel dimension of NAFNet [8] is set to 32, the channel dimension of Restormer [86] is configured to 48. In NAFNet, the Encoder block is configured as [2,2,4,8], the Middle block has 12 layers, and the Decoder block is structured as [2,2,2,2]. In Restormer, the Encoder block is composed of [4,6,6], with 8 Middle blocks, and the Decoder block is structured as [6,6,4]. We trained the model with the AdamW [50] optimizer ( β 1 = 0.9, β 2 = 0.9, weight decay 1e-3), and the training patch size is set to 256 × 256 . In NAFNet, the batch size is set to 32, and in Restormer, the batch size is set to 4. The initial learning rate starts at 3 e -4 and gradually decreases to 1 e -6 according to the cosine annealing schedule. Data augmentation for training such as random crop, horizontal flip, and 90-degree rotation were used. In the case of DegAE [48], we used
the publicly weight files for Restormer, and for NAFNet, we implemented the method based on the publicly code.
Pre-training: In the pre-training, we generate degraded low-quality image using synthetic degradation functions, a combination of two open datasets, DIV2K [2] and Flickr2K [45].
The number of training iterations for all pre-train models is set to 200K. To train the pre-train model, PSNR loss was used except for the DegAE [48].
Fine-tuning: In Section 4.1 of the paper, fine-tuning is conducted using 10K iterations. In Section 4.2 of the paper, Fine-tuning is performed with a different number of training data, and the number of training data are composed of [16, 32, 64, 128], 100K training iterations are used, and all publicly available training data are used. In fine-tuning, NAFNet uses PSNR Loss, and Restormer uses L1 loss. Due to variations in experimental setups, slight gap in results between the original paper may arise, but this does not impact the validation of our method. We perform experiments in the same environment, including learning rate, decay method, data augmentation and so on, for all image restoration tasks to ensure consistency across all experiments.
## S6 Details of evaluation metrics
To ensure a fair comparison of our proposed method, we evaluated its performance using PSNR and SSIM evaluation metrics. Since evaluation metrics on the Y component in the YUV domain or in the RGB domain tends to exhibit similar trends, we exclusively perform certain measurements, such as Rain, Raindrop, and Rain&Raindrop, on the Y component. Specifically in the case of benchmark, Rain, Raindrop, and Rain&Raindrop, we applied evaluation metrics only to the Y component in the YUV domain. In the benchmark results presented in
Fig. S3: Illustration of our proposed reparametrization method, CoLoRA. The existing LoRA method uses a fixed value of r for all layers since it is challenging to optimize each value at each layer. On the other hand, our proposed CoLoRA adjusts the ratio of learnable parameters ( δ ) by using different values of r layer by layer without much increasing the degree of freedom.
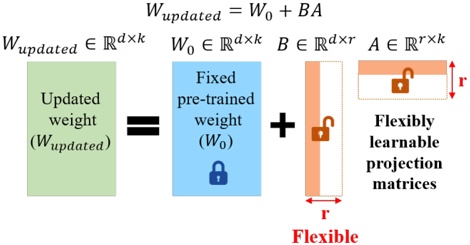
| Number of training data | Number of training data | 2 | 2 | 2 | 2 | 2 | 2 | Avg. | Tuned Parm. |
|---------------------------|---------------------------|-------|----------|---------------|-------|-------|-------|--------|---------------|
| Pre-training | Tunning | Rain | Raindrop | Rain&Raindrop | Blur | Noise | Haze | Avg. | Tuned Parm. |
| Random | Full | 20.76 | 18.33 | 17.05 | 27.58 | 33.35 | 13.31 | 21.73 | |
| DegAE [48] | Full | 20.62 | 19.40 | 18.90 | 28.02 | 34.72 | 15.52 | 22.86 | 174 M |
| PROD | Full | 21.09 | 19.14 | 18.97 | 28.67 | 35.42 | 16.18 | 23.25 | |
| PROD | CoLoRA | 21.77 | 18.78 | 18.70 | 29.26 | 34.39 | 15.10 | 23.00 | 41 M |
| Number of training data | Number of training data | 4 | 4 | 4 | 4 | 4 | 4 | Avg. | Tuned Parm. |
|---------------------------|---------------------------|-------|----------|---------------|-------|-------|-------|--------|---------------|
| Pre-training | Tunning | Rain | Raindrop | Rain&Raindrop | Blur | Noise | Haze | Avg. | Tuned Parm. |
| Random | Full | 21.70 | 19.23 | 18.52 | 27.55 | 35.62 | 17.34 | 23.33 | |
| DegAE [48] | Full | 22.72 | 20.59 | 19.56 | 28.22 | 35.97 | 17.74 | 24.13 | 174 M |
| PROD | Full | 23.30 | 20.94 | 20.61 | 29.78 | 36.62 | 17.43 | 24.78 | |
| PROD | CoLoRA | 23.25 | 20.84 | 20.66 | 29.70 | 36.71 | 17.32 | 24.74 | 41 M |
| Number of training data | Number of training data | 8 | 8 | 8 | 8 | 8 | 8 | Avg. | Tuned Parm. |
|---------------------------|---------------------------|-------|----------|---------------|-------|-------|-------|--------|---------------|
| Pre-training | Tunning | Rain | Raindrop | Rain&Raindrop | Blur | Noise | Haze | Avg. | Tuned Parm. |
| Random | Full | 22.97 | 20.99 | 19.73 | 27.72 | 36.96 | 17.40 | 24.30 | |
| DegAE [48] | Full | 23.50 | 21.46 | 19.83 | 28.58 | 36.89 | 18.36 | 24.77 | 174 M |
| PROD | Full | 24.21 | 21.97 | 21.37 | 30.24 | 37.72 | 18.31 | 25.64 | |
| PROD | CoLoRA | 24.34 | 21.91 | 21.20 | 30.26 | 37.70 | 18.15 | 25.49 | 41 M |
Table S3: We evaluated the performance comparison based on pre-training methods and tuning strategies for 6 IR tasks with real validation data in terms of PSNR (dB) in RGB domain and tuned network parameter size (Million). 'Random' and 'Full' denote randomly initializing the network parameters without a pre-trained model and full fine-tuning, respectively. Our proposed CoLoRA requires a significantly smaller number of network parameters compared to the full tuning method, as it only tunes 7% of the network parameters.
Table 1 of the paper, to ensure a fair comparison with previous existing methods [16,65,68,77], we applied evaluation metrics to the Y component in the YUV domain for Rain, Raindrop, and Rain + Raindrop. Conversely, for Blur, Noise, and Haze, we applied evaluation metrics in the RGB domain. For the ablation study, we measured evaluation metrics in the RGB domain. The ablation study results, presented in Figure 4, Figure S.4, Figure S.5, Figure S.6, and Table S.1 within the paper, entailed applying evaluation metrics in the RGB domain for 6 IR tasks.
Table S4: Ablation study according to CoLoRA scale parameters α and β for Blur task. We conducted the experiment using Restormer and used all training data.
| α | Full | 1 | 1.0 | 0.75 | 1.0 | 0.75 | 0.5 | 0.25 |
|-----------------|--------|-------|-------|--------|-------|--------|-------|--------|
| β | Full | 1 | 0.2 | 0.2 | 0.1 | 0.1 | 0.1 | 0.1 |
| PSNR (dB) | 32.38 | 32.14 | 32.01 | 31.88 | 31.94 | 31.9 | 31.8 | 31.82 |
| Tuned parameter | 26.2 | 8.7 | 4 | 3.6 | 3.5 | 2.9 | 2.5 | 1.9 |
## S7 Comparison of pre-train methods and tuning strategies for extremely limited training data
In this section, we evaluated the proposed CoLoRA with PROD on 6 IR datasets extremely limited training data and a training iteration is 10K. Table S3 summarizes the PSNR results for six real IR tasks with extremely small number of training data during fine-tuning in NAFNet. The extremely small number of training data for each tasks were set to [2, 4, 8]. The full fine-tuning method ( Full ) has 29 M trainable parameters in NAFNet [8]. In NAFNet, the full finetuning ( Full ) method requires 6 times more network parameters 174 M ( 29 M × 6 ) than the original network parameters 29 M due to explicitly separated structures for multiple degradations, and our proposed CoLoRA uses an additional 2 M parameters for a single task, resulting in a total of 41 M ( 29 M +2 M × 6 ) parameter for the network required in the 6 IR tasks. These results demonstrate that the our proposed PROD + Full and PROD + CoLoRA method effectively and efficiently improves various IR performances, with extremely limited data.
## S7.1 Ablation study on scales ( α and β ) of CoLoRA (Restormer)
In Table S4, we investigated the PSNR results based on the scaling factors ( α β , ) of CoLoRA to further optimize the tuned network parameters. All experiments are conducted using the transformer-based Restormer with full training data. As the values of α and β increase, the performance improves, and accordingly, the tuned network parameters also increase. We have experimentally selected ( α = 0 75 . , β = 0 1 . ) that efficient and brings the highest performance. Through scale adjustment, it is possible to use the optimal parameters for each task.
## S8 Details on tuning strategies in NAFNet
Table S5 provides detailed tuned parameters for experiments based on tuning strategies. The tuned parameter are in millions (M). The Full method has 29 M trainable parameters. The Only Decoder , LoRA , and CoLoRA (Ours) have approximately 2 M trainable parameters. The LoRA [28] is constructed based on open-source code, with the value of r set to 16 for all layers.
Table S5: In Section 3.1, 'tuning parameters' of this paper refers to the number of tuned parameters in millions (M).
| Tuning strategies | Tuned parmeter (M) |
|-----------------------|----------------------|
| Only Deconv LoRA [28] | 1.942 |
| | 2.442 |
| CoLoRA (Ours) | 1.993 |
| Full | 29.16 |
## S9 Our proposed PROD vs BSRGAN
Indeed, BSRGAN developed another pre-trained method with multiple degradations only for SR, while our PROD is a method for multiple IR tasks. Nevertheless, we performed experiments using 64 fine-tuning datasets on rain/drop and blur, demonstrating the superiority of our work over BSRGAN (PROD 31.4dB vs BSRGAN 30.8dB for deblur and PROD 22.7dB vs BSRGAN 22.1dB for derain).
## S10 Benchmark results
We evaluated our proposed CoLoRA with PROD on the mixed Snow&Haze [11] benchmark dataset in Table S6. The mixed Snow&Haze [11] benchmark dataset contains 10,000 training images and 3,000 test images. "All-in-One image restoration" may experience a decrease in performance as the number of tasks increases, and there are inherent limitations in extending it to new tasks. On the other hand, "Efficient Fine-tuning" maintains consistent results even as the number of tasks increases, and it is easily scalable to accommodate new tasks. In Park [57], the results are presented for All-in-One image restoration methods when handling only three tasks. Thanks to CoLoRA with PROD, the proposed method in NAFNet architecture provides the highest PSNR compared to existing methods, even though only a small ratio of tuned parameters are learned in the entire network.
Table S6: Benchmark results for mixed Snow&Haze [11] dataset in PSNR (dB). Our CoLoRA with PROD achieved state-of-the art performance on NAFNet, by updating only a small 2M of tuned network parameters.
| Task | Method | PSNR for mixed Snow&Haze |
|-----------------------|---------------------------------------------------------------------|----------------------------|
| Independent methods | DesnowNet [49] JSTASR [10] DesnowGAN [30] HDCW-Net [11] DAD-S [102] | 25.63 27.52 28.63 29.11 |
| Independent methods | | 32.28 |
| Independent methods | | 29.29 |
| Independent methods | MPRNet-S [87] | 31.53 |
| All-In-One methods | Chen [12] | |
| All-In-One methods | Li [41] | 26.91 |
| All-In-One methods | Park [57] | 32.41 |
| All-In-One methods | PromptIR [64] | 29.81 |
| All-In-One methods | WGWS-Net [100] | 29.16 |
| Efficient Fine-tuning | Our CoLoRA (NAFNet) | 33.09 |
| | | |
## S11 Comparison of tuning strategies in DeGAE
In this section, we evaluated the proposed CoLoRA on 6 IR datasets with DegAE and a training iteration is 10K. Figure S4 summarizes the experimental results based on DegAE with CoLoRA. All experiments are conducted using the CNNbased NAFNet architecture. We investigated the following tuning methods: Full fine-tuning ( Full ), and the proposed CoLoRA method. The Full method has 29 M trainable parameters. CoLoRA (Ours) have approximately 2 M trainable parameters. Our proposed 'CoLoRA + DegAE' method produces results similar to 'Full + DeGAE' while tuning only very small network parameters.
## S12 Details on comparison of pre-train methods and tuning strategies
We conducted a detailed comparative study to demonstrate the performance and efficiency of the proposed pre-training method PROD, and the parameterefficient fine-tuning method, CoLoRA. To summarize each experiment, 'pretraining methods' presents the experimental results based on different pretraining methods in Figure S5 (top), 'tuning strategies' presents the results based on efficient parameter tuning methods in Figure S5 (bottom), and 'different network architectures' provides the experimental results based on pretraining and tuning methods on CNN and vision transformer architectures in Figure S6. Figure S5 and S6 illustrate a detailed summary of the PSNR (dB) results for 6 IR tasks with real data in relation to the number of training data during fine-tuning. The number of training data for each tasks were set to [16, 32, 64, 128]. These results demonstrate that the our proposed PROD + Full and PROD + CoLoRA method effectively and efficiently improves various IR performances, even with limited training data and a sparse number of learnable parameters, underscoring its effectiveness.
Figure S7, Figure S8 and S9 illustrates the results for 6 IR task with test data tasks using test data, comparing outcomes between previous methods and our proposed CoLoRA with PROD. Our methods ( PROD + Full and PROD + CoLoRA ) appear to produce superior restoration results compared to Random + Full and DegAE + Full [48].
## Comparision between DegAE and CoLoRA with Prod
Fig. S4: Performance comparison of applying CoLoRA to DegAE method according to number of training data for 6 IR tasks. In the graph (a), the results of the 6 IR tasks are averaged for comparison. The x-axis represents the number of training data, and the y-axis is the average PSNR in the RGB domain. In the radar graph, we compare the results of 6 IR tasks with Normalized PSNR at a training data size of 128. In (b), the PSNR in the RGB domain is reported for each of the six tasks. The x-axis represents the number of training data, and the y-axis is the PSNR in the RGB domain for each test data.
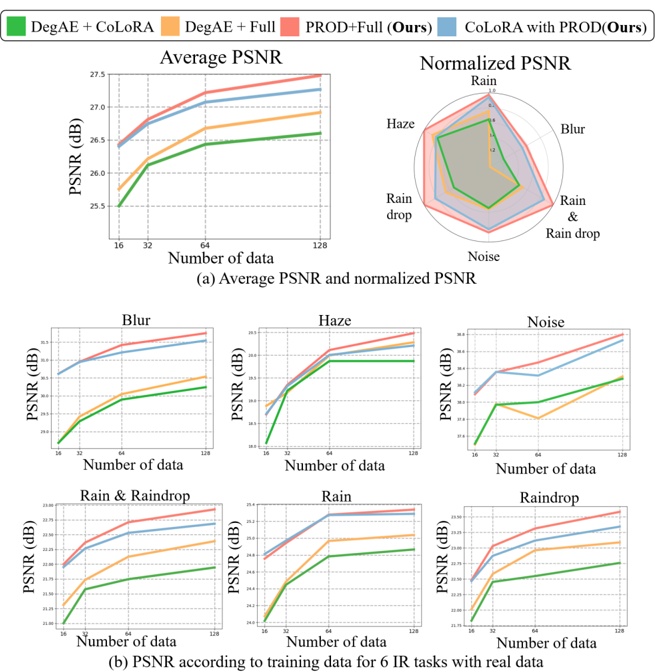
Fig. S5: In section 4.1 of the paper, 'pre-training methods' and 'fine-tuning strategies', we conducted a performance comparison based on the scale of training data for 6 IR tasks with real data. The PSNR in the RGB domain is reported for each of the 6 tasks in Figure 5 of the paper. The x-axis represents the number of training data, and the y-axis is the PSNR (dB) for each test data.
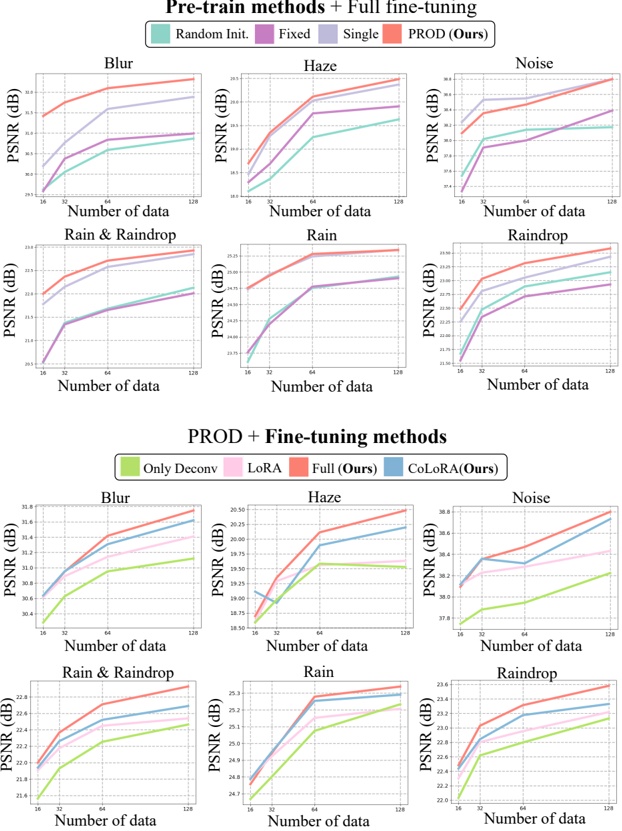
## Pre-train method and tuning strategies CNN based NAFNet
Fig. S6: In section 4.1 of the paper, 'different network architectures', we conducted a performance comparison based on the scale of training data for 6 IR tasks with real data. The PSNR in the RGB domain is reported for each of the six tasks in Figure 5 of the paper. The x-axis represents the number of training data, and the y-axis is the PSNR for each test data.
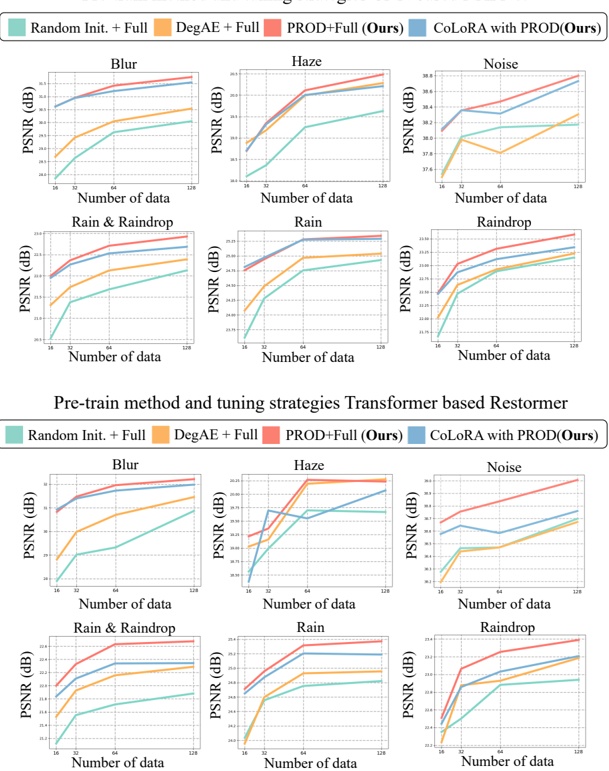
Fig. S7: Qualitative results evaluated on the 6 IR tasks for our proposed CoLoRA with PROD, generic Random initial + Full tuning and DegAE + Full tuning. Our proposed methods with partial and full tuning yielded visually excellent results for the real IR tasks, outperforming others.

Fig. S8: Qualitative results evaluated on the 6 IR tasks for our proposed CoLoRA with PROD, generic Random initial + Full tuning and DegAE + Full tuning. Our proposed methods with partial and full tuning yielded visually excellent results for the real IR tasks, outperforming others.

Fig. S9: Qualitative results evaluated on the 6 IR tasks for our proposed CoLoRA with PROD, generic Random initial + Full tuning and DegAE + Full tuning. Our proposed methods with partial and full tuning yielded visually excellent results for the real IR tasks, outperforming others.
 | null | [
"Donwon Park",
"Hayeon Kim",
"Se Young Chun"
] | 2024-08-02T08:24:05+00:00 | 2024-08-02T08:24:05+00:00 | [
"cs.CV",
"cs.AI"
] | Contribution-based Low-Rank Adaptation with Pre-training Model for Real Image Restoration | Recently, pre-trained model and efficient parameter tuning have achieved
remarkable success in natural language processing and high-level computer
vision with the aid of masked modeling and prompt tuning. In low-level computer
vision, however, there have been limited investigations on pre-trained models
and even efficient fine-tuning strategy has not yet been explored despite its
importance and benefit in various real-world tasks such as alleviating memory
inflation issue when integrating new tasks on AI edge devices. Here, we propose
a novel efficient parameter tuning approach dubbed contribution-based low-rank
adaptation (CoLoRA) for multiple image restorations along with effective
pre-training method with random order degradations (PROD). Unlike prior arts
that tune all network parameters, our CoLoRA effectively fine-tunes small
amount of parameters by leveraging LoRA (low-rank adaptation) for each new
vision task with our contribution-based method to adaptively determine layer by
layer capacity for that task to yield comparable performance to full tuning.
Furthermore, our PROD strategy allows to extend the capability of pre-trained
models with improved performance as well as robustness to bridge synthetic
pre-training and real-world fine-tuning. Our CoLoRA with PROD has demonstrated
its superior performance in various image restoration tasks across diverse
degradation types on both synthetic and real-world datasets for known and novel
tasks. |
2408.01100v1 | ## MULTIPLICATIVE LATTICES WITH ABSORBING FACTORIZATION
ANDREAS REINHART AND G ¨ LS ¸EN ULUCAK U
Abstract. In [22], Yassine et al. introduced the notion of 1-absorbing prime ideals in commutative rings with nonzero identity. In this article, we examine the concept of 1-absorbing prime elements in C-lattices. We investigate the C-lattices in which every element is a finite product of 1-absorbing prime elements (we denote them as OAFLs for short). Moreover, we study C-lattices having 2-absorbing factorization (we denote them as TAFLs for short).
## 1. Introduction
Let L be a set together with an inner binary operation · on L and a partial order ≤ on L such that ( L, · ) is a monoid (i.e., ( L, · ) a commutative semigroup with identity) and ( L, ≤ ) is a complete lattice (i.e., each subset of L has both a supremum and an infimum with respect to ≤ ). For each subset E ⊆ L , we let ∨ E denote the supremum of E , called the join of E and we let ∧ E denote the infimum of E , called the meet of E . For elements a, b ∈ L , let a ∨ b = ∨ { a, b } and a ∧ b = ∧ { a, b } . Moreover, set 1 = ∨ L and set 0 = ∧ L . We say that ( L, , · ≤ ) is a multiplicative lattice if for all x ∈ L and E ⊆ L , it follows that 1 x = x and x ∨ E = ∨ { xe | e ∈ E } .
We recall a few important situations in which multiplicative lattices occur. In what follows, we use the definitions of star operations, ideal systems and the specific star operations/ideal systems v , t and w without further mention. For more information on star operations see [12] and for more information on ideal systems see [14]. A profound introduction and study of the w -operation can be found in [21].
- · It is well-known that if R is a commutative ring with identity, L is the set of ideals of R and · : L × L → L is the ideal multiplication on L , then ( L, , · ⊆ ) is a multiplicative lattice.
- · Let H be a commutative cancellative monoid and let r be an ideal system on H . Let L be the set of r -ideals of H and let · r : L × L → L be the r -multiplication. Then ( L, · r , ⊆ ) is a multiplicative lattice.
- · Let D be an integral domain and let ∗ be a star operation on D . Let L be the set of ∗ -ideals of D together with the ∗ -multiplication · ∗ : L × L → L . Then ( L, · ∗ , ⊆ ) is a multiplicative lattice.
Let L be a multiplicative lattice and let e ∈ L . For a, b ∈ L , we set ( a : b ) = ∨ { x ∈ L | xb ≤ a } . Then e is called weak meet principal if a ∧ e = ( a : e e ) for each a ∈ L and e is called weak join principal if ( be : e ) = (0 : e ) ∨ b for each b ∈ L . Furthermore, e is said to be meet principal if a ∧ be = (( a : e ) ∧ b e ) for all a, b ∈ L and e is said to be join principal if (( a ∨ be ) : e ) = ( a : e ) ∨ b for all a, b ∈ L . We say that e is weak principal if e is both weak meet principal and weak join principal. Finally, e is said to be principal ([9]) if e is both meet principal and join principal. An element a ∈ L is said to be compact if for each subset F ⊆ L with a ≤ ∨ F , it follows that a ≤ ∨ E for some finite subset E of F . A subset C ⊆ L is called multiplicatively closed if 1 ∈ C and xy ∈ C for each x, y ∈ C . A multiplicative lattice L is called a C-lattice if L is generated under joins by a multiplicatively closed subset C of compact elements. Note that a finite product of compact elements in a C-lattice is again compact. By L ∗ we denote the set of all compact elements of L . We say that L is principally generated if every element of L is the join of a set of principal elements of L . It is well-known (see [3, Theorem 1.3]) that each principal element of a
Key words and phrases. 1-absorbing prime element, 2-absorbing element, C-lattice, principally generated lattice.
C-lattice is compact. Moreover, L is said to be join-principally generated if each element of L is the join of a set of join principal elements of L . Additionally, a lattice L is called a principal element lattice if every element in L is principal [4].
Let R be a commutative ring with identity, let D be an integral domain, let H be a commutative cancellative monoid, let ∗ be a star operation on D and let r be an ideal system on H . Note that the lattice of ideals of R is a principally generated C-lattice. The lattice of ∗ -ideals of D is a C-lattice if and only if ∗ is a star operation of finite type. In analogy, it follows that the lattice of r -ideals of H is a C-lattice if and only if r is a finitary ideal system. Observe that the lattice of v -ideals of D (or of H ) can fail to be a C-lattice. Also note that even if ∗ is of finite type (resp. r is finitary), then the lattice of ∗ -ideals of D (resp. the lattice of r -ideals of H ) need not be (join-)principally generated. For instance, the t -operation is of finite type (resp. the t -system is finitary), but the lattice of t -ideals is (in general) not (join-)principally generated. We also want to emphasize that the lattice of w -ideals of D (resp. of H ) is a principally generated C-lattice.
An element a ∈ L is said to be proper if a < 1, it is called nilpotent if a n = 0 for some n ∈ N and it is called comparable if a ≤ b or b ≤ a for each b ∈ L . For each a ∈ L , L/a = { b ∈ L | a ≤ b } is a multiplicative lattice with the multiplication c ◦ d = ( cd ) ∨ a for elements c, d ∈ L/a . A proper element p ∈ L is called prime if ab ≤ p implies a ≤ p or b ≤ p for all a, b ∈ L . A proper element m ∈ L is said to be maximal in L if for each x ∈ L m < x , ≤ 1 implies x = 1. One can easily see that maximal elements are prime. For each a ∈ L , let min( a ) be the set of prime elements of L that are minimal above a . The lattice L is called a lattice domain if 0 is a prime element. J( L ) is defined as the meet of all maximal elements of L . For a ∈ L , we define √ a = ∧ { p ∈ L | p is prime and a ≤ p } . Note that in a C-lattice L , √ a = ∧ { p ∈ L | a ≤ p is a minimal prime over a } = ∨ { x ∈ L ∗ | x n ≤ a for some n ∈ N } . A proper element q ∈ L is called primary if ab ≤ q implies a ≤ q or b ≤ √ q for every a, b ∈ L . It is well-known that C-lattices can be localized at arbitrary multiplicatively closed subsets S of compact elements as follows. The localization of a ∈ L at S is defined as a S = ∨ { x ∈ L | xs ≤ a for some s ∈ S } . The multiplication on L S = { a S | a ∈ L } is defined by a ◦ S b = ( ab ) S for all a, b ∈ L S . Let p ∈ L be a prime element and S = { x ∈ L ∗ | x /notlessequal p } . Then the set S is a multiplicatively closed subset of L . In this case, the localization L S is denoted by L p . It is well-known that ( L p ) ∗ = { a p ∈ L p | a ∈ L ∗ } . Using this, it can be shown that if L is a (principally generated) C-lattice, then L p is also a (principally generated) C-lattice for any prime element p ∈ L (see [2, Theorem 2.9]). It can also be proved that in a C-lattice L , for all a, b ∈ L , ( ab ) m = ( a m m m b ) for each maximal element m ∈ L and also, a = b if and only if a n = b n for all maximal elements n ∈ L . For more information on localization, see [2, 3, 9, 17].
In [22], the authors introduced the concept of 1-absorbing prime ideals in commutative rings with identity. These ideals are generalizations of prime ideals and many authors studied them from different points of view (see [8]). The first aim of this paper is to study 1-absorbing prime elements in C-lattices. Another (well-known) generalization of 1-absorbing prime ideals are 2-absorbing ideals. They have first been mentioned in [7] and in [18], the authors introduced 2-absorbing elements in multiplicative lattices.
The aforementioned concepts are part of the more general definition, namely that of n -absorbing ideals. These types of ideals were introduced and studied by Anderson and Badawi (see [6]). It turns out that n -absorbing ideals are not just interesting objects in multiplicative ideal theory, but also in factorization theory. For instance, there is an important connection between n -absorbing ideals and the ω -invariant in factorization theory (see [6]). For a profound discussion of the ω -invariant, we refer to [13].
We want to emphasize that the commutative rings in which each ideal is a finite product of 1-absorbing prime ideals (resp. 2-absorbing ideals, resp. n -absorbing ideals) have already been studied (see [1, 11, 18]). The main goal of this paper is to consider principally generated C-lattices in which various types of elements can be written as finite products of 1-absorbing prime elements or 2-absorbing elements.
We continue with a few more basic definitions that will be needed in the sequel. L is said to be a field if L = { 0 1 , } and L is called a quasi-local lattice if 1 is compact and L has a unique maximal element.
The dimension of L , denoted by dim( L ), is defined to be sup { n ∈ N | there exists a strict chain of prime elements of L of length n } . If dim( L ) = 0, then L is said to be a zero-dimensional lattice. Note that L is a zero-dimensional lattice if and only if every prime element of L is maximal. We say that a multiplicative lattice is Noetherian if every element of L is compact (see [16, page 352]). A multiplicative lattice is said to be Pr¨ ufer lattice if every compact element of L is principal. (For more information about Pr¨ ufer lattices, see [3, Theorem 3.4].) A ZPI-lattice is a multiplicative lattice in which every element is a finite product of prime elements [15]. A multiplicative lattice L is said to be a Q-lattice if every element is a finite product of primary elements [20]. A principally generated lattice domain L is called unique factorization lattice domain if every principal element of L is a finite product of principal prime elements.
Our paper is organized as follows. In Section 2, we study the concept of 1-absorbing prime elements (OAelements). The relationships among prime elements, primary elements, and TA-elements are studied in Examples 2.2 and 2.3. Propositions 2.7 and 2.8, along with Corollary 2.9, demonstrate that the concepts of prime elements and OA-elements coincide in C-lattices that are not quasi-local. In Section 3, we study C-lattices whose elements have a TA-factorization. We call a C-lattices a TA-factorization lattice (abbreviated as TAFL) if every element possesses a TA-factorization. In Proposition 3.4, we get that dim( L ) ≤ 1 if L is a principally generated TAFL. In Theorem 3.5, we obtain that a TAFL is ZPI-lattice domain if it is a Pr¨fer lattice domain. u Then, we study the factorization of C-lattices by assuming that all compact elements of L have a factorization into TA-elements, denoted by CTAFL . Finally, we explore the factorization of C-lattices by assuming that all principal elements of L have a factorization into TA-elements, denoted by PTAFL . In Theorem 3.11, we have that if ( L, m ) is a quasi-local principally generated C-lattice domain, then L is a TAFL if and only if L is a PTAFL and dim( L ) ≤ 1. In Section 4, we study the factorization of L with respect to the OA-element concept, similar to Section 3. We study C-lattices as a OA-factorization lattice (abbreviated as OAFL) if every element possesses an OAfactorization. Then, we examine the factorization of C-lattices by assuming that all compact elements of L have a factorization into OA-elements, denoted by COAFL . Finally, we explore the factorization of C-lattices by assuming that all principal elements of L have a factorization into OA-elements, denoted by POAFL . Among the many results, in Theorem 4.13, we characterize OAFL, COAFL and lattices which of the join of any two principal elements has an OA-factorization. In Theorem 4.13, we also see that if L is an OAFL, then it satisfies one of the following conditions.
- i. L is a ZPI-lattice.
- ii. L is a quasi-local lattice, m 2 is comparable and m is a nilpotent element.
- iii. L is a quasi-local lattice domain, m 2 is comparable and ∧ n ∈ N m n = 0.
In Theorem 4.14, we conclude that the following statements are equivalent: L is a ZPI-lattice if and only if L is a Pr¨fer OAFL if and only if u L is a Pr¨fer POAFL. Theorem 4.15 establishes relationships among u the concepts of OAFL, COAFL, TAFL and CTAFL.
## 2. On 1-absorbing prime elements of C-lattices
Definition 2.1. Let L be a C-lattice. A proper element x ∈ L is called a 1 -absorbing prime element or an OA-element if for all a, b, c ∈ L \ { 1 } , abc ≤ x implies that ab ≤ x or c ≤ x .
It follows immediately from the definition that every OA-element is both a TA-element and a primary element. Moreover, every prime element is an OA-element. We infer that the class of OA-elements of L lies between the classes of prime elements and TA-elements and also between the classes of prime elements and primary elements.
Let L be a C-lattice and let a ∈ L . We obtain the following irreversible right arrows:
- (2) a is a prime element ⇒ a is an OA-element ⇒ a is a TA-element.
- (1) a is a prime element ⇒ a is an OA-element ⇒ a is a primary element.
We give some examples to show that these arrows are not reversible.
Example 2.2. { This example is inspired by [10, Example 7] . } Let L be a C-lattice, which having underlying set { 0 1 , , a, b, c, d } ordered by a ≤ b ≤ d and a ≤ c ≤ d , with multiplication xy = a for all x, y ∈ { a, b, c, d } . The prime elements of L are 0 and d . Moreover, L is a quasi-local lattice. Note that b is an OA-element of L that is not a prime element. In particular, b is a primary TA-element of L .
Example 2.3. We demonstrate that, in general, neither TA-elements nor primary elements are OAelements. Let I( Z ) be the lattice of ideals of Z . Note that (15) is a TA-element of I( Z ) that is not an OA-element of I( Z ). Furthermore, (8) is a primary element of I( Z ) that fails to be an OA-element of I( Z ).
Lemma 2.4. Let L be a C-lattice. An element x ∈ L is an OA-element if and only if for all a, b, c ∈ L ∗ \ { 1 } , abc ≤ x implies that ab ≤ x or c ≤ x .
( ⇐ ) Let abc ≤ x and ab /notlessequal x for some a, b, c ∈ L \ { 1 } . We show that c ≤ x to complete the proof. Since abc ≤ x , then a b c ′ ′ ′ ≤ x for all compact elements a , b , c ′ ′ ′ ∈ L with a ′ ≤ a , b ′ ≤ b and c ′ ≤ c . Since ab /notlessequal x , then there are some compact elements a , b 1 1 ∈ L such that a 1 ≤ a , b 1 ≤ b and a b 1 1 /notlessequal x . Let a 2 = a ′ ∨ a 1 and b 2 = b ′ ∨ b 1 . It is clear that a 2 and b 2 are compact. Obviously, there is a compact element c ∗ ∈ L with c ∗ ≤ c . Note that ( a ′ ∨ a 1 )( b ′ ∨ b 1 ) c ∗ ≤ x and ( a ′ ∨ a 1 )( b ′ ∨ b 1 ) /notlessequal x . We obtain that c ∗ ≤ x , and thus c ≤ x . Therefore, x is an OA-element. /square
Proof. ( ⇒ ) This is clear.
Proposition 2.5. Let L be a C-lattice and let x ∈ L .
- (2) If x is an OA-element of L , then ( x : a ) is a prime element of L for each a ∈ L with a /notlessequal x .
- (1) If x is an OA-element of L , then √ x is a prime element of L with ( √ x ) 2 ≤ x .
- (3) If ( p 2 : a ) ≤ x for every compact element a ≤ p , a /notlessequal x and x is a p -primary element of L , then x is an OA-element of L .
- (2) Let x be an OA-element of L and let b, c ∈ L be such that bc ≤ ( x : a ). Then abc ≤ x . By the assumption, ab ≤ x or c ≤ x . Therefore, b ≤ ( x : a ) or c ≤ ( x : a ).
Proof. (1) Let x be an OA-element of L and let a, b ∈ L be such that ab ≤ √ x . There is a positive integer n such that a n n b ≤ x . We can write a m n a -m n b ≤ x for a positive integer m with m < n . By the assumption, a n ≤ x or b n ≤ x . Then a ≤ √ x or b ≤ √ x , and thus √ x is prime. Now we will show that ( √ x ) 2 ≤ x . Let a, b ∈ L be such that a, b ≤ √ x . Then there is an n ∈ N with a n ≤ x . If n = 1, then we are done. Let n > 2. Then a n -2 aa ≤ x , and so a 2 ≤ x . Similarly, we have that b 2 ≤ x . Note that a a ( ∨ b b ) ≤ x . Then ab ≤ a a ( ∨ b ) ≤ x or ab ≤ b ≤ x . In any case, we have that ab ≤ x . Therefore, ( √ x ) 2 ≤ x .
- (3) Let a, b, c ∈ L ∗ be such that abc ≤ x and a /notlessequal x . By assumption, bc ≤ √ x = p . Therefore, we obtain that abc ≤ p 2 , and thus bc ≤ ( p 2 : a ) ≤ p . We infer that bc ≤ x , and hence x is an OA-element. /square
/negationslash
Lemma 2.6. Let L be a C-lattice. If w ∨ u = 1 for some distinct proper elements u, w ∈ L , then L is quasi-local.
/negationslash
Proof. Let w ∨ u = 1 be distinct proper elements u, w ∈ L . Assume that L is not a quasi-local lattice. There are at least two distinct maximal elements m ,m 1 2 ∈ L such that m 1 ∨ m 2 = 1, a contradiction. Therefore, L is quasi-local. /square
Proposition 2.7. Let L be a C-lattice and let x ∈ L . If x is an OA-element of L that is not prime, then L is quasi-local.
/negationslash
Proof. Let x be an OA-element of L that is not a prime. By the assumption, cd ≤ x for some c, d ∈ L implies neither c ≤ x nor d ≤ x . If w ∨ u = 1 for each distinct proper elements w, u ∈ L , then we are done by Lemma 2.6. Assume that w ∨ u = 1 for two distinct proper elements w, u ∈ L . Since wcd ≤ x and d /notlessequal x , then wc ≤ x and similarly, ucd ≤ x and d /notlessequal x , then uc ≤ x . We obtain that wc ∨ uc = ( w ∨ u c ) ≤ x , and hence c = 1 c = ( w ∨ u c ) ≤ x , a contradiction. Therefore, L is quasi-local. /square
Proposition 2.8. Let ( L, m ) be a quasi-local C-lattice and let x ∈ L be proper. Then x is an OA-element if and only if x is a prime element or m 2 ≤ x < m .
Proof. ( ⇒ ) Without restriction, we can assume that x is not a prime element of L . Clearly, there are two proper elements a, b ∈ L such that ab ≤ x , a /notlessequal x and b /notlessequal x . Set y = m 2 . Note that yab ≤ ab ≤ x . Since a , b and y are proper elements of L and b /notlessequal x , we have that ya ≤ x , and hence mma ≤ x . since a and m are proper elements of L and a /notlessequal x , this implies that m 2 = mm ≤ x . Since x is not a
( ⇐ ) If x is a prime element of L , then clearly x is an OA-element of L . Now let m ≤ x < m . Let a, b, c ∈ L be proper such that abc ≤ x and c /notlessequal x . Note that a ≤ m and b ≤ m . We obtain that ab ≤ m 2 ≤ x . Therefore, x is an OA-element. /square
Moreover, prime element of L , it is obvious that x < m . 2
As another consequence of Propositions 2.7 and 2.8, we give the following corollary without proof.
Corollary 2.9. Let L be a C-lattice. Then there is an OA-element of L that is not prime if and only if L is quasi-local with maximal element m such that m 2 = m .
/negationslash
Proposition 2.10. Let L be a principally generated C-lattice and set m = J( L ) . The following statements are equivalent.
- (1) Every proper element of L is an OA-element.
- (2) Every proper principal element of L is an OA-element.
- (3) L is quasi-local and m 2 = 0 .
Proof. (1) ⇒ (2) This is obvious.
/negationslash
(2) ⇒ (3) Assume that L is not a quasi-local lattice. Then each proper principal element is a prime element. Note that L is a lattice domain. Let x ∈ L be a principal element. It follows that x 2 is a principal prime element. We conclude that x = x 2 , and thus 1 = x ∨ (0 : x ). Since x is proper, then we have that x = 0. Consequently, L is field. But this contradicts the fact that L is not a quasi-local lattice. This implies that L is quasi-local with maximal element m . We infer that 0 is prime or m 2 = 0 by Proposition 2.8. Suppose that m 2 = 0. Then there is a nonzero principal element c ∈ L with c ≤ m 2 . By Proposition 2.8, we get that c 2 is prime element or m 2 ≤ c 2 . If c 2 is prime, then we have that c 2 = . c Let m 2 ≤ c 2 . We have that m 2 ≤ c 2 ≤ c ≤ m 2 , and hence c 2 = . In any cases, we obtain that c c 2 = , c and hence 1 = c ∨ (0 : c ), since c is principal. Since L is quasi-local, it follows that c = 1, a contradiction. Therefore, m 2 = 0.
- (3) ⇒ (1) This follows from Proposition 2.8.
/square
Lemma 2.11. Let L be a join-principally generated C-lattice. If every nonzero element of L is an OA-element, then dim( L ) = 0 .
/negationslash
Proof. Let p ∈ L be a prime element and let m ∈ L a maximal element with p < m . Then there is a join principal element a ∈ L with a < m and a /notlessequal p . Observe that a is a nonzero element that is not nilpotent. By assumption, a is an OA-element of L . We have that a 3 = a or a 3 = a 2 , since 0 = a 3 is an OA-element of L . If a 3 = a , then it follows that 1 = (0 : a ) ∨ a 2 .
/negationslash
Since (0 : a ) = 1, we have that a 2 = 1, which implies that m = 1, a contradiction. We get a similar result when assuming that a 3 = a 2 . We conclude that dim( L ) = 0. /square
Proposition 2.12. Let L be a principally generated C-lattice. If L is quasi-local with maximal element m such that m 2 is comparable, then the following statements are equivalent.
- (1) Each two principal elements x, y ∈ L with m 2 ≤ x and m 2 ≤ y imply that x ≤ y or y ≤ x ,
- (2) If a is an OA-element of L , then a is prime or a = m 2 .
Proof. (1) ⇒ (2) Let each two principal elements x, y ∈ L with m 2 ≤ x and m 2 ≤ y satisfy x ≤ y or y ≤ x . Let a be an OA-element of L . Suppose that a is not a prime. By Proposition 2.8, we get m 2 ≤ a < m . Let m < a 2 . Clearly, there are two principal elements c, d ∈ L such that c ≤ x , c /notlessequal m 2 and d < m , d /notlessequal a . Note that c, d /notlessequal m 2 . By the assumption, we have that m 2 ≤ c, d . Consequently, c and d are OA-elements. Since d /notlessequal c , then c ≤ d . Therefore, there is an element v ∈ L with c = vd and hence, we deduce c ≤ m 2 , a contradiction. It must be the case that a = m 2 .
(2) ⇒ (1) This is clear.
/square
Although we do not derive the result that the meet of two prime elements or two OA-elements yields an OA-element, we deduce the following result.
Lemma 2.13. Let L be a C-lattice and let x, y ∈ L be OA-elements that are not prime. Then x ∧ y and x ∨ y are OA-elements.
/negationslash
Proof. Let x, y ∈ L be OA-elements that are not prime. Then L is quasi-local. By the assumption, we have that m 2 ≤ x, y , and hence m 2 ≤ x ∧ y and m 2 ≤ x ∨ y = 1. Since m 2 ≤ x ∧ y ≤ x ∨ y ≤ m and L is quasi-local, then x ∧ y and x ∨ y are OA-elements. /square
Now, we give a relation between OA-elements and lattice domains.
Proposition 2.14. Let L be a C-lattice. Then 0 is an OA-element of L if and only if L is a lattice domain or L is quasi-local with maximal element m such that m 2 = 0 .
Proof. ( ⇒ ) Let 0 be an OA-element of L . Let L be not a lattice domain. Then 0 is not prime, and thus L is quasi-local with maximal element m . We infer that m 2 = 0.
( ⇐ ) This is obvious.
/square
Proposition 2.15. Let L be a C-lattice. Every TA-element of L is an OA-element of L if and only if the following conditions hold.
- (a) For each two prime elements p, q ∈ L , we have that p ≤ q or q ≤ p . In particular, L is quasi-local.
- (b) If x is a TA-element of L and p ∈ min( x ) , then x = p or p = m .
Proof. ( ⇒ ) Let p and q be prime elements of L . Then p ∧ q is a TA-element of L . By assumption, p ∧ q is an OA-element. Then by Proposition 2.5(1), we have that √ p ∧ q = p ∧ q is prime, and hence p ∧ q = p or p ∧ q = q by [18, Lemma 7]. We obtain that p ≤ q or q ≤ p . Therefore, L is quasi-local. Now, assume that p is minimal prime over x . If x is prime, then it is clear that x = p . Let x be not a prime element. Then L is quasi-local with maximal element m . Then m 2 ≤ x < p < m , and thus p = m .
( ⇐ ) Suppose that L satisfies (a) and (b). Let x be a TA-element of L and let p be a minimal prime element over x . By [18, Theorem 3(1)], p 2 ≤ x ≤ p . If x = p , then x is prime, and thus it is clearly an OA-element. Now let p = m . Then m 2 ≤ x ≤ m , and hence x is an OA-element. /square
Remark 2.16. Let L be a C-lattice, let x ∈ L be an OA-element and let p ∈ L be a prime element of L such that p ≤ x . Then x is an OA-element of L/p .
Proof. Let a ◦ b ◦ c ≤ x for some a, b, c ∈ L/p . Then abc ≤ x . By assumption, ab ≤ x or c ≤ x , and hence a ◦ b ≤ x or c ≤ x . Consequently, x is an OA-element of L/p . /square
Remark 2.17. Let L be a C-lattice and let p ∈ L be a prime element. If x ∈ L is an OA-element such that x ≤ p , then x p is an OA-element of L p .
Proof. Let x ∈ L be an OA-element such that x ≤ p . Clearly, x p is a proper element of L p . Let a, b, c ∈ L ∗ be such that a b c p p p ≤ x p . Then abc ≤ x p , and hence dabc ≤ x for some d /notlessequal p . We have that dab ≤ x or c ≤ x . Note that d p = 1 by [17]. Then a b p p ≤ x p or c p ≤ x p . Therefore, x p is an OA-element of L p . /square
Theorem 2.18. Let L be a principally generated C-lattice. Every nonzero proper element of L is an OA-element if and only if L ∼ = L 1 × L 2 where L , L 1 2 are fields or L is quasi-local with maximal element m such that m = √ 0 and m 2 ≤ x for every nonzero proper principal element x ∈ L .
/negationslash
( ⇐ ) If L ∼ = L 1 × L 2 , where L 1 and L 2 are fields, then each nonzero proper element of L is prime, and hence it is an OA-element. Now let L be quasi-local with maximal element m such that m = √ 0 and m 2 ≤ x for every nonzero proper principal element x ∈ L . Let y be a nonzero proper element of L . There is some nonzero principal element c ∈ L with c ≤ y . We have that m 2 ≤ c ≤ y , and thus y is an OA-element of L . /square
Proof. ( ⇒ ) Let every nonzero proper element of L be an OA-element. First let L be quasi-local with maximal element m . By assumption, every nonzero proper element of L is a TA-element. Now [18, Theorem 8] completes the proof. Now let L be not quasi-local. Then the concepts of prime elements and OA-elements coincide. Let m 1 and m 2 be two distinct maximal elements of L . Assume that m 1 ∧ m 2 = 0. By the assumption, m 1 ∧ m 2 is prime. It can be shown that m 1 = m 2 , a contradiction. It follows that m 1 ∧ m 2 = 0, and thus L ∼ = L/m 1 × L/m 2 . Note that L/m ,L/m 1 2 are fields.
Proposition 2.19. Let L be a principally generated quasi-local Noetherian lattice with maximal element m . Then every OA-element is prime if and only if L is field.
Proof. ( ⇒ ) Since every OA-element is prime, then we obtain that m 2 = m . Therefore, m = 0 by [3, Theorem 1.4], and thus L is field.
( ⇐ ) This is clear.
/square
## 3. TAFLs and their generalizations
In this section, we study C-lattices whose elements have a TA-factorization. A TA-factorization of an element x ∈ L means that x is written as a finite product of TA-elements ( x k ) n k =1 . (Note that the element 1 is the empty product.) We say that a C-lattice L is a TA-factorization lattice (abbreviated as TAFL) if every element of L has a TA-factorization.
In this section, we investigate the factorization of elements into TA-elements. Firstly, we study C-lattices whose elements possess a TA-factorization, called TAFLs . Next, we study C-lattices whose compact elements have a factorization into TA-elements. We call them CTAFLs . We also explore the C-lattices whose principal elements have a factorization into TA-elements, called PTAFLs . Clearly, every TAFL is both a CTAFL and a PTAFL.
Example 3.1. As a simple example, it is clear that each prime element is a TA-element, then every ZPI-lattice is a TAFL. By [19, Example 2.1], we have that the lattice of ideals of Z [ √ -7] is not a TAFL.
First, we will present some basic results related to TAFL in the following proposition.
Remark 3.2. Let L be a TAFL, let L 1 and L 2 be C-lattices and let p ∈ L be a prime element.
- (2) L 1 × L 2 is a TAFL if and only if L 1 and L 2 are both TAFLs.
- (1) min( x ) is finite for each x ∈ L .
- (3) L/p is a TAFL.
- (4) L p is a TAFL.
Proof. (1) Let x = ∏ n k =1 x k be a TA-factorization of x . By [18, Theorem 3], we have that min( x i ) is finite. Then min( x ) is finite, since min( x ) ⊆ ⋃ n i =1 min( x i ).
(2) It is well-known by [18] that p 1 = 1 L 1 and p 2 is a TA-element of L 2 or p 2 = 1 L 2 and p 1 is a TA-element of L 1 or p 1 and p 2 are prime elements of L 1 and L 2 , respectively if and only if ( p , p 1 2 ) is a TA-element of L . The rest now follows easily.
- (3) Let y ∈ L/p . By the assumption, y = ∏ n k =1 x k where x i is a TA-element of L for each i ∈ [1 , k ]. Note that x i is a TA-element of L/p and y = ( ∏ n k =1 x k ) ∨ p = © n k =1 x k . Consequently, L/p is a TAFL.
- (4) Recall that if x is a TA-element of L , then x p is a TA-element of L p . Let a ∈ L p . Then we have that a = y p for some y ∈ L . By assumption, y has a TA-factorization in L , meaning y is the finite product of some TA-elements ( y k ) n k =1 . We have that a = y p = ( ∏ n k =1 y k ) p = © n k =1 ( y k ) p . This completes the proof. /square
Lemma 3.3. Let L be a C-lattice, let x ∈ L be proper with √ x ∈ max( L ) and let one of the following conditions be satisfied:
- (a) L is a TAFL.
- (b) L is a CTAFL and x is compact.
- (c) L is a PTAFL and x is principal.
Proof. Let L be a TAFL, let ( √ x ) 2 /notlessequal x and √ x = m . By [18, Theorem 3], x is not a TA-element. By assumption, x = ∏ n i =1 x i where x i is TA-element of L and n ≥ 2. Since x ≤ x i for each i ∈ [1 , n ] and √ x = m ∈ max( L ), we have that √ x i = m for each i ∈ [1 , n ]. Consequently, x ≤ m 2 .
Then x ≤ ( √ x ) 2 or ( √ x ) 2 ≤ x .
If L is a CTAFL (resp. a PTAFL) and x is a compact (resp. principal), then this can be shown along the same lines as before. /square
## Proposition 3.4. Let L be a principally generated TAFL. Then dim( L ) ≤ 1 .
/negationslash
Moreover, p q is a prime element of L q , y q is a principal element of L q and q q ∈ min(( p ∨ y ) q ). If p q is a minimal prime element of L q , then p is a minimal prime element of L . For these reasons, we can assume without restriction that m ∈ min( p ∨ y ). Since L is quasi-local, this implies that √ p ∨ y = m . Next we verify the following claims.
Proof. Observe that since dim( L ) = sup { dim( L q ) | q ∈ L is a prime element } , we can assume without restriction that L is quasi-local with maximal element m = 0. It remains to show that each nonmaximal prime element of L is a minimal prime element. Let p ∈ L be a nonmaximal prime element. Since L is principally generated, there is some principal element y ∈ L such that y ≤ m and y /notlessequal p .
Claim 1: m = m
2 .
Claim 2: q ≤ m 2 for every prime element q < m .
/negationslash
Assume the contrary of claim 1 that m = m 2 . Then m is the only TA-element whose radical is m . There is a (join) principal element y with y < m and y /notlessequal p . Clearly, p ∨ y = ∏ k i =1 x i where k is a positive integer and x i is a TA-element of L for each i ∈ [1 , k ]. Note that m is minimal over p ∨ y . Then m 2 ≤ x i for each i ∈ [1 , k ] by [18, Lemma 5]. Therefore, we get that m 2 k = m ≤ p ∨ y ≤ m k = m by [18, Theorem 3] and Lemma 3.3. Similarly, we have that m 2 k = m ≤ p ∨ y 2 ≤ m k = m . This implies that p ∨ y = m = p ∨ y 2 . Note that (( p ∨ y 2 ) : y ) = ( p : y ) ∨ y = p ∨ y . Then 1 = (( p ∨ y ) : y ) = (( p ∨ y 2 ) : y ) = p ∨ y , and hence 1 = p ∨ y = m , a contradiction.
/negationslash
To show that the second claim is true, assume that there is a prime element q < m with q /notlessequal m 2 . Also, there is a principal element b ∈ L with b ≤ m and b /notlessequal q . Note that b n /notlessequal q for a positive integer n . We have that b ∈ L is a nonzero element that is not nilpotent. Since L is a TAFL and q /notlessequal m 2 , we have that q ∨ b 3 is a TA-element by Lemma 3.3 and [18, Theorem 3]. It follows that b 2 ≤ q ∨ b 3 , since b 3 ≤ q ∨ b 3 . Note that 1 = (( q ∨ b 3 ) : b 2 ) = ( q : b 2 ) ∨ b . We conclude that ( q : b 2 ) = 1 or b = 1. Therefore, b 2 ≤ q or b = 1, a contradiction. We infer that every prime element q ∈ L with q < m satisfies q ≤ m 2 .
/negationslash
We will return to the proof of the main part. Since m = m 2 , there is a nonzero principal element c ∈ L with c /notlessequal m 2 . By claim 2, it follows that √ c = m . By Lemma 3.3, we get m 2 ≤ c . Let 0 = s ≤ p . We have that s = ∏ n i =1 y i where y i is a TA-element of L . Since p is prime, then y j ≤ p for some j ∈ [1 , n ].
Since y j ≤ p < m 2 ≤ c , then y j = c/lscript j for some /lscript j ∈ L because c is weak meet principal. Note that /lscript j ≤ p because c /notlessequal p . Consequently, /lscript j ≤ p ≤ m 2 ≤ c , and thus /lscript j = ct j for some t j ∈ L . Therefore, y j = c 2 t j , and hence /lscript j = ct j ≤ y j , since y j is a TA-element. We obtain that y j = /lscript j , and so y j = cy j . Therefore, s = sc . Note that sm ≤ s . Since s = sc , we have that s = sc ≤ sm , and hence s = sm . We conclude that s = 0 by [3, Theorem 1.4], a contradiction. This implies that p = 0. /square
Theorem 3.5. If L is a TAFL and a Pr¨fer lattice domain, then u L is a ZPI-lattice domain.
Proof. Let L be a Pr¨fer lattice domain such that u L is also a TAFL. First we have that L m is a TAFL for each maximal element m ∈ L . Let m ∈ L be maximal. Since L is a Pr¨fer lattice domain, then u L m is a linearly ordered TAFL. From [18, Theorem 10] recall that if L is a Pr¨fer lattice domain, then the u following statements are equivalent: (1) p is a TA-element, (2) p is a prime element of L or p = p 2 1 is a p 1 -primary element of L or p = p 1 ∧ p 2 where p 1 and p 2 are some nonzero prime elements of L . By using this characterization, we conclude that every TA-element of L m is a finite product of some prime elements. Therefore, L m is a ZPI-lattice (since it is a TAFL), and hence every element of L m is principal and compact. Moreover, dim( L m ) ≤ 1. Therefore, dim( L ) ≤ 1. Since L is a TAFL domain and dim( L ) ≤ 1, every nonzero element of L is contained in only finitely many maximal elements. Now one can show that every element of L is compact (since every nonzero element is locally compact and contained in only finitely many maximal elements). Therefore, every element of L is compact. In particular, L is a principal element lattice domain (since L is a Pr¨fer lattice domain), and hence it is a ZPI-lattice domain. u /square
Next we study CTAFLs.
Remark 3.6. Let L be a CTAFL, let L 1 and L 2 be C-lattices and let p ∈ L be a prime element.
- (2) L 1 × L 2 is a CTAFL if and only if L 1 and L 2 are both CTAFLs.
- (1) min( x ) is finite for each x ∈ L ∗ .
- (3) If p is compact, then L/p is a CTAFL.
- (4) L p is a CTAFL.
Proof. (1) This can be proved along the same lines as in the proof of Remark 3.2.
- (2) It follows from [18] that p 1 = 1 L 1 and p 2 is a TA-element of L 2 or p 2 = 1 L 2 and p 1 is a TA-element of L 1 or p 1 and p 2 are prime elements of L 1 and L 2 , respectively if and only if ( p , p 1 2 ) is a TA-element of L . The rest is straightforward.
- (3) Let p be compact. Observe that every element a ∈ L with a ≥ p is compact in L if and only if a is compact in L/p . Now, let y ∈ L/p be compact. Then y ≥ p . By the assumption, y = ∏ n k =1 x k where x i is a TA-element of L . Note that x i is a TA-element of L/p . Then we get that y = ( ∏ n k =1 x k ) ∨ p = © n k =1 x k . Therefore, L/p is a CTAFL.
- (4) This can be shown along similar lines as in Remark 3.2(4).
/square
Proposition 3.7. Let L be a principally generated CTAFL that satisfies the ascending chain condition on prime elements. Then dim( L ) ≤ 1 .
/negationslash
Since L is a C-lattice, there exists some q ∈ min( p ∨ y ) such that q ≤ m . Clearly, L q is a principally generated CTAFL with maximal element q q that satisfies the ascending chain condition on prime elements. Moreover, p q is a prime element of L q , y q is a principal element of L q and q q ∈ min(( p ∨ y ) q ). If p q is a minimal prime element of L q , then p is a minimal prime element of L . For these reasons, we can assume
Proof. Observe that for each prime element q ∈ L , we have that L q is a principally generated CTAFL that satisfies the ascending chain condition on prime elements. Since dim( L ) = sup { dim( L q ) | q ∈ L is a prime element } , we can assume without restriction that L is quasi-local with maximal element m = 0. It remains to show that each nonmaximal prime element of L is a minimal prime element. Let p ∈ L be a nonmaximal prime element. Since L is principally generated, there is some principal element y ∈ L such that y ≤ m and y /notlessequal p .
without restriction that m ∈ min( p ∨ y ). Since L is quasi-local, this implies that √ p ∨ y = m . Next we verify the following claims.
Claim 1:
m = m 2 .
Claim 2: q ≤ m 2 for every prime element q ∈ L with q < m .
/negationslash
First we prove claim 1. It follows from Remark 3.6(1) that min( x ) is finite for each compact element x ∈ L . Since L satisfies the ascending chain condition on prime elements, it follows from [16, Theorem 2] that p = √ d for some compact element d ∈ L . Observe that m = √ d ∨ y and d ∨ y is compact. Consequently, d ∨ y = ∏ t i =1 x i for some positive integer t and some TA-elements x i ∈ L . Clearly, √ x i = m for each i ∈ [1 , t ], and thus m 2 ≤ x i ≤ m by [18, Theorem 3] for each i ∈ [1 , t ]. Assume to the contrary that m = m 2 . Then d ∨ y = m , and hence p ∨ y = m . We infer that m = m 2 ≤ p ∨ y 2 ≤ p ∨ y ≤ m , and thus p ∨ y = p ∨ y 2 . Since y is (join) principal, we obtain that 1 = (( p ∨ y ) : y ) = (( p ∨ y 2 ) : y ) = p ∨ y = m , a contradiction. This implies that m = m 2 . /square (Claim 1)
Now we prove claim 2. Assume that there is a prime element q ∈ L such that q < m and q /notlessequal m 2 . Since L is principally generated, there is a principal element b ∈ L such that b ≤ m and b /notlessequal q . Note that b 2 /notlessequal q . Since q /notlessequal m 2 and L is a C-lattice, there is a compact element a ∈ L such that a ≤ q and a /notlessequal m 2 . Since a and b are compact, we have that a ∨ b 3 is compact. Note that a ∨ b 3 is a TA-element, since L is a CTAFL and a /notlessequal m 2 . Since b 3 ≤ a ∨ b 2 and a ∨ b 2 is a TA-element, we get that b 2 ≤ a ∨ b 3 . Note that 1 = (( a ∨ b 3 ) : b 2 ) = ( a : b 2 ) ∨ b . Since b ≤ m and L is quasi-local, we have that ( a : b 2 ) = 1. Consequently, b 2 ≤ a ≤ q , a contradiction. /square (Claim 2)
/negationslash
/negationslash
It is sufficient to show that p = 0. (Then p is a minimal prime element of L and we are done.) Since m = m 2 by claim 1 and L is principally generated, there is a principal element c ∈ L such that c ≤ m and c /notlessequal m 2 . By claim 2, we have that √ c = m . Furthermore, Lemma 3.3 implies that m 2 ≤ c . Let s ∈ L be compact such that s ≤ p . It follows that s = ∏ k i =1 y i for some positive integer k and some TA-elements y i ∈ L . Obviously, there is some j ∈ [1 , k ] such that y j ≤ p . Since y j ≤ p ≤ m 2 ≤ c and c is (weak meet) principal, we infer that y j = c/lscript for some /lscript ∈ L . Note that /lscript ≤ p , since c /notlessequal p . Consequently, /lscript ≤ p ≤ m 2 ≤ c , and thus /lscript = ct for some t ∈ L . This implies that y j = c 2 t , and hence /lscript = ct ≤ y j (since y j is a TA-element of L ). Therefore, y j = , and thus /lscript y j = cy j . We infer that s = sc , and hence s = sc ≤ sm ≤ s . We conclude that s = sm . It is an immediate consequence of [3, Theorem 1.4] that s = 0. Finally, we have that p = 0 (since L is a C-lattice). /square
Next we study PTAFLs. We start with a simple observation.
Remark 3.8. Let L be a Pr¨fer lattice. u Then L is a CTAFL if and only if L is a PTAFL.
Proof.
This is obvious, since every compact element in a Pr¨fer lattice is principal. u /square
Note that Proposition 3.7 does not hold for PTAFLs. To show that, we consider the following example.
Example 3.9. Note that if L is the lattice of ideals of a local two-dimensional unique factorization domain D (e.g. take D = K X,Y [ ] ( X,Y ) where K is a field and X and Y are indeterminates over K ), then L is a quasi-local principally generated PTAFL that satisfies the ascending chain condition on prime elements and dim( L ) = 2.
Theorem 3.10. Let ( L, m ) be a quasi-local principally generated C-lattice domain such that dim( L ) ≤ 1 , m 2 is comparable and ∧ n ∈ N m n = 0 . Then L is a TAFL.
/negationslash
Proof. Assume that m = m 2 . Since L is a lattice domain and ∧ n ∈ N m n = 0, we infer that m = 0. Therefore, L is a field and hence we get the desired properties. Now, suppose that m = m 2 . Then there is a principal element x ∈ L with x /notlessequal m 2 . By the assumption, we get that m < x 2 . Since dim( L ) ≤ 1, then we conclude that x is a TA-element by [18, Theorem 3]. Since x is meet principal, then we conclude that m 2 = xm . Let z ∈ L be proper. If z = 0, then it is clear that it has a TA-factorization under the
/negationslash assumption that L is a lattice domain. Now let z = 0. If m 2 ≤ z , then the proof is complete by [18, Theorem 3]. Now let z ≤ m 2 . Let n be the largest positive integer satisfying z ≤ m n . We conclude that z ≤ m n = x n -1 m . Consequently, z ≤ x n -1 . Note that z = x n -1 a for some a ∈ L since x n -1 is principal. Suppose that a ≤ m 2 . We conclude that a ≤ x . Moreover, we can write a = xb for some b ∈ L . Consequently, we obtain z = x b n ≤ x m n = m n +1 , leading to a contradiction. This implies that m 2 ≤ a , and thus a is a TA-element. Therefore, z has a TA-factorization. /square
Theorem 3.11. Let ( L, m ) be a quasi-local principally generated C-lattice domain. Then L is a TAFL if and only if dim( L ) ≤ 1 and L is a PTAFL. If these equivalent conditions are satisfied, then ∧ n ∈ N m n = 0 and m 2 is comparable.
Proof. ( ⇒ ): This is follows from Proposition 3.4.
( ⇐ ): Let L be a PTAFL such that dim( L ) ≤ 1. First, assume that m = m 2 . Since dim( L ) ≤ 1, then m is the only TA-element whose radical is m . We infer that each proper nonzero element of L is equal to m and we are done.
/negationslash
Now let m = m 2 . Then there is a principal element x ∈ L such that x ≤ m and x /notlessequal m 2 . Since x /notlessequal m 2 , we infer that x is a TA-element (since x cannot be the product of more than one TA-element). From [18, Theorem 3], we get that m 2 ≤ x since √ x = m . Since x is a (weak meet) principal element, we conclude that m 2 = xm . Let z ∈ L be proper. We have to show that z has a TA-factorization. If z = 0, then we are done, since L is lattice domain. Therefore, we can assume without restriction that z = 0.
/negationslash
/negationslash
First let z ≤ m 2 . Let n be the largest positive integer satisfying z ≤ m n . We conclude that z ≤ m n = x n -1 m , and thus z ≤ x n -1 . Note that z = x n -1 a for some a ∈ L since x n -1 is principal. Suppose that a ≤ m 2 . It follows that a ≤ x . Moreover, we can write a = xb for some b ∈ L . Consequently, we obtain z = x b n ≤ x m n = m n +1 , a contradiction. Let a /notlessequal m 2 . There is a principal element a ′ ∈ L such that a ′ ≤ a but a ′ /notlessequal m 2 . Since a ′ /notlessequal m 2 , we know that a ′ is a TA-element of L . Therefore, m 2 ≤ a ′ ≤ a . We conclude that a is a TA-element. This implies that z = x n -1 a has a TA-factorization.
Next we show that ∧ n ∈ N m n = 0. Assume the contrary that ∧ n ∈ N m n = 0. Note that each nonzero TA-element v ∈ L satisfies m 2 ≤ v by [18, Lemma 2]. Clearly, there is some nonzero principal element x ∈ L such that x ≤ ∧ n ∈ N m n . We have that x = ∏ k i =1 a i where a i is a TA-element for each i ∈ [1 , k ]. We obtain that ( m 2 ) k ≤ x ≤ ( m 4 ) k ≤ ( m 2 ) k , and hence x = x 2 . Since x is principal, we infer that 1 = x ∨ (0 : x ). Therefore, we obtain that x = 1, a contradiction.
Finally, let z /notlessequal m 2 . Then there is a principal element y ∈ L such that y ≤ z and y /notlessequal m 2 . We have that y is a TA-element, and hence m 2 ≤ y ≤ z . This implies that z is a TA-element. Consequently, L is a TAFL.
It remains to show that m 2 is comparable. Let x ∈ L be proper such that x /notlessequal m 2 . Since L is a TAFL, we conclude that x is a TA-element. From [18, Lemma 2], we get that m 2 ≤ x since dim( L ) ≤ 1. /square
Proposition 3.12. Let ( L, m ) be a quasi-local principally generated C-lattice such that L is not a lattice domain. Then L is a TAFL if and only if dim( L ) = 0 and L is a PTAFL.
Proof. ( ⇒ ): Let L be a TAFL. By proof of Proposition 3.4, we know that if p ∈ L is a nonmaximal prime element of L , then p = 0. Therefore, dim( L ) ≤ 1. Since L is not a lattice domain, we infer that dim( L ) = 0.
/negationslash
( ⇐ ): Let dim( L ) = 0 and let L be a PTAFL. Note that m is nilpotent element of L since 0 = ∏ k i =1 x i where x i is a TA-element with √ x i = m for each i ∈ [1 , k ], and hence ( m 2 ) k ≤ 0. This implies that 0 = m 2 k , and thus 0 has a TA-factorization. If m = m 2 , we get that m = 0. Now let m = m 2 . Then there is a principal element z ∈ L such that z ≤ m and z /notlessequal m 2 . Since z /notlessequal m 2 , we infer that z is a TA-element (since z cannot be the product of more than one TA-element). From [18, Lemma 2], we get that m 2 ≤ z since √ z = m . Since z is a (weak meet) principal element, we conclude that m 2 = zm . Let
- x ∈ L be nonzero. If m 2 ≤ x , then x is a TA-element because it is a primary element as shown by [18, Lemma 5].
Next let x ≤ m 2 . Let n be the largest positive integer for which x ≤ m n . We conclude that x ≤ m n = z n -1 m , which implies x ≤ z n -1 . Note that x = z n -1 a for some a ∈ L , given that z n -1 is a principal element. Assume that a ≤ m 2 . This implies that a ≤ z , and hence a = zb for some b ∈ L . We conclude x = z n b ≤ z n m = m n +1 , a contradiction. Therefore, a /notlessequal m 2 . There is a principal element a ′ ∈ L such that a ′ ≤ a and a ′ /notlessequal m 2 . Since a ′ /notlessequal m 2 , we have that a ′ is a TA-element. Therefore, m 2 ≤ a ′ ≤ a . Consequently, a is a TA-element. It follows that x = z n -1 a has a TA-factorization.
Finally, let x /notlessequal m 2 . Then there is a principal element y ∈ L such that y /notlessequal m 2 and y ≤ x . We have that y is a TA-element, and hence m 2 ≤ y ≤ x . We infer that x is a TA-element. Therefore, L is a TAFL. /square
Remark 3.13. Let ( L, m ) be a quasi-local principal element TAFL domain. Then every proper element of L is a power of m .
Proof. We know that a TA-element of L equals m or m 2 by [18, Theorem 9]. This completes the proof. /square
## 4. OAFLs and their generalizations
In this section, we study the factorization of elements of L with respect to the OA-elements, similar to the previous section. It consists of three parts. The first part involves C-lattices, whose elements possess an OA-factorization, called a OAFLs . Next, we examine C-lattices whose compact elements have a factorization into OA-elements, called a COAFLs . Finally, we explore the C-lattices whose principal elements have a factorization into OA-elements, called POAFLs . It can easily be shown that every OAFL is both a COAFL and a POAFL. We continue by presenting some results related to OAFL.
Example 4.1. Let L be the lattice of ideals of Z [2 ]. i Note that (2 + 2 ) has i no OA-factorization. Therefore, L is not an OAFL.
Remark 4.2. Let L be an OAFL and let p ∈ L be a prime element.
- (2) L is both a Q-lattice and a TAFL.
- (1) min( x ) is finite for each x ∈ L .
- (3) L p is an OAFL.
- (4) L/p is an OAFL.
- Proof. (1) Let x ∈ L and let x = ∏ n k =1 x k be an OA-factorization of x for some OA-elements x i ∈ L . Recall that each OA-element is a TA-element and min( a ) is finite for a TA-element a ∈ L by [18, Theorem 3]. Hence min( x ) is finite since min( x ) ⊆ ⋃ n i =1 min( x i ).
- (2) Since every OA-element of L is a TA-element and a primary element, we have that L is both a Q-lattice and a TAFL.
- (3) Let y ∈ L p be proper. Then there is a proper element x ∈ L such that y = x p . By the assumption, we get such a factorization x = ∏ n k =1 x k for some OA-elements x i ∈ L . By Remark 2.17, we know that ( x i ) p is an OA-element of L p , and thus y = x p = ( ∏ n k =1 x k ) p = © n k =1 ( x k ) p . This completes the proof.
- (4) Let y ∈ L/p . By the assumption, y = ∏ n k =1 x k where x i is an OA-element of L for each i ∈ [1 , k ]. Note that x i is an OA-element of L/p . Then we get that y = ( ∏ n k =1 x k ) ∨ x = © n k =1 x k . Observe that L/p is an OAFL. /square
Corollary 4.3. Let L be a principally generated OAFL. Then dim( L ) ≤ 1 .
Proof. This is an immediate consequence of Remark 4.2(2) and Proposition 3.4.
/square
Lemma 4.4. Let ( L, m ) be a quasi-local principally generated C-lattice such that m 2 is comparable and m is nilpotent or L is a lattice domain with ∧ n ∈ N m n = 0 . Then L is an OAFL and every proper principal element of L is a finite product of principal OA-elements.
Proof. First let m = m 2 . Since m is nilpotent or L is lattice domain with ∧ n ∈ N m n = 0, we have that m = 0. Therefore, L is a field and hence it satisfies the desired conditions.
/negationslash
Now let that m = m 2 . There is a proper principal element x ∈ L with x /notlessequal m 2 . By the assumption, we get that m < x 2 . We conclude that x is an OA-element. Since x is meet principal, then we get that m 2 = x m ( 2 : x ). We have that m 2 = xm . Let z ∈ L be proper. First let z = 0. If L is lattice domain, then it is clear that z is a principal OA-element. Let m is nilpotent. Then there is a positive integer n with m n = 0. Note that z = x n is a finite product of principal OA-elements.
/negationslash
Next let z = 0. If m < z 2 , then z is an OA-element and we are done. Now let z ≤ m 2 . Let n be the largest positive integer satisfying z ≤ m n . Therefore, z ≤ m n = x n -1 m , and thus z ≤ x n -1 . Note that z = x n -1 a for some a ∈ L since x n -1 is principal. If z is principal, then we can by [5, Theorem 9] assume that a is principal. Suppose that a ≤ m 2 . We have that a ≤ x . Moreover, a = xb for some b ∈ L . Consequently, we obtain z = x b n ≤ x m n = m n +1 , a contradiction. Therefore, m 2 ≤ a and so a is an OA-element by Proposition 2.8. We infer that z has an OA-factorization and if z is principal, then z is a finite product of principal OA-elements. /square
Next we study COAFLs.
Remark 4.5. Let L be a COAFL and let p ∈ L be a prime element.
- (2) L is a CTAFL.
- (1) min( x ) is finite for each x ∈ L ∗ .
- (3) If p is compact, then L/p is a COAFL.
- (4) Then L p is a COAFL.
Proof. (1) This can be shown along the lines of the proof of Remark 4.2.
(2) This is clear, since every OA-element of L is a TA-element.
(3) Let p be compact. Note that every element a ∈ L with a ≥ p is compact in L if and only if a is compact in L/p . Now, let y ∈ L/p be compact. Then y ≥ p . By the assumption, y = ∏ n k =1 x k where x i is an OA-element of L . Note that x i is an OA-element of L/p . Then we get that y = ( ∏ n k =1 x k ) ∨ x = © n k =1 x k . Consequently, L/p is a COAFL.
- (4) This can proved along similar lines as in Remark 2.17.
/square
Proposition 4.6. Let L be a quasi-local COAFL. Then each minimal nonmaximal prime element of L is a weak meet principal element.
/negationslash
Proof. Let p ∈ L be a minimal nonmaximal prime element of L . First we show that x = p x ( : p ) for each compact element x ∈ L with x ≤ p . Let x ∈ L be a compact element of L with x ≤ p . By the assumption, we can write x = ∏ n i =1 x i where n is a positive integer and x i is an OA-element of L for each i ∈ [1 , n ]. Since x ≤ p , we have that x i ≤ p for some i ∈ [1 , n ]. If x i is not a prime element, then m 2 ≤ x i ≤ p by Proposition 2.8. We infer that m = p , a contradiction. Consequently, x i is a prime element, and hence x i = . We have that p x = pz , where z = ∏ n k =1 ,k = i x k . Observe that x = ( p x : p ).
Let y ∈ L be such that y ≤ p . Since L is a C-lattice, we have that
$$y = \bigvee _ { \substack { \{ v \in L _ { * } \, | \, v \leq y \} = \bigvee \{ p ( v \colon p ) \, | \, v \in L _ { * }, v \leq y \} = p \bigvee \{ ( v \colon p ) \, | \, v \in L _ { * }, v \leq y \}. \\ \circ \colon \dots \quad \mathbb { m } \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \det \, \dot { \to } \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \tau \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \tap \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \to \, \pmod { \alpha } } \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \tau \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \, \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \to \}$$
Set w = ∨ { ( v : p ) | v ∈ L , v ∗ ≤ y } . Then w ∈ L and y = pw , and thus p is weak meet principal.
Next we study POAFLs. We start with a simple observation.
Remark 4.7. Let L be a Pr¨fer lattice. u Then L is a COAFL if and only if L is a POAFL.
Proof. This is obvious, since every compact element in a Pr¨fer lattice is principal. u
/square
/square
Lemma 4.8. Let L be a quasi-local principally generated POAFL. Then every minimal nonmaximal prime element of L is a principal element.
/negationslash
Proof. Let p ∈ L be a minimal nonmaximal prime element of L . Let a ∈ L be a principal element of L with a ≤ p . By the assumption, we can write a = ∏ n k =1 q k where q i is an OA-element of L for i ∈ [1 , n ]. Since a ≤ p , then q j ≤ p for some j ∈ [1 , n ]. If q j is an OA-element that is not prime, then m 2 ≤ q j ≤ p . Therefore, m = p , a contradiction. Assume that q i is prime. Then we get that q i = p . We infer that a = p ∏ n k =1 ,k = i q k , and thus a = pb where b = ∏ n k =1 ,k = i q k . Obviously, a = ( p a : p ). Now, take an element c ∈ L with c ≤ p . By assumption, c = ∨ A for some set A of principal elements of L . We conclude that c = ∨ A = ∨ { p a ( : p ) | a ∈ A } = p ( ∨ { ( a : p ) | a ∈ A } ). Therefore, p is a weak meet principal element, and hence p is a principal element by [3, Theorem 1.2]. /square
/negationslash
Lemma 4.9. Let ( L, m ) be a quasi-local principally generated C-lattice. If the join of any two principal elements of L has an OA-factorization, then every nonmaximal prime element of L is a principal element and dim( L ) ≤ 2 .
Proof. Let the join of any two principal elements of L have an OA-factorization. First, we show that dim( L ) ≤ 2. Let p ∈ L be a nonmaximal prime element of L . Consider that L p is quasi-local and L p is generated by the set of elements { a p | a ∈ L is principal } . We can see that the join of any two principal element of L p has a prime factorization. Because a p ∨ p b p = ( a ∨ b ) p = ( ∏ n i =1 x i ) p = © n i =1 ( x i ) p where ( x i ) p is a prime element of L p . Consequently, L p is a ZPI-lattice by [15, Theorem 8], and thus dim( L p ) ≤ 1. Therefore, dim( L ) ≤ 2.
/negationslash
/negationslash
Let q be a nonmaximal prime element of L . Assume that qm = q . If q ∈ min(0), then it is clear that q = 0 by Nakayama's Lemma since q is principal. Now let q be not minimal. There is a p ∈ min(0) such that p < q , and thus there is a principal element c ∈ L such that c /notlessequal p and c ≤ q . By assumption, c ∨ p has an OA-factorization since p is principal by Lemma 4.8. Since dim( L ) ≤ 2, we have that q is minimal over c ∨ p . Let c ∨ p = ∏ n i =1 x i where x i is an OA-element for each i ∈ [1 , n ]. We get that x j ≤ q for some j ∈ [1 , n ]. Note that m 2 /notlessequal x j , and hence x j = q . We infer that c ∨ p = q/lscript for some /lscript ∈ L . We conclude that ( c ∨ p m ) = c ∨ p by the assumption, and thus c ∨ p = 0. Consequently, c = p = 0, which contradicts the fact that c ≤ p . Now assume that q = qm . Assume that q is a nonminimal and nonmaximal prime element of L . Since L is principally generated, there is a principal element a ∈ L such that a ≤ q and a /notlessequal qm . Since q is nonmaximal and L is principally generated, there is a principal element b ∈ L such that b ≤ m and b /notlessequal q . It remains to show that x ≤ a of each principal element x ∈ L such that x ≤ q . (Then q = a is principal, since L is principally generated and a ≤ q .) Let x ∈ L be principal such that x ≤ q . Note that xb 2 is principal, and thus a ∨ xb 2 is the join of two principal elements of L . Consequently, a ∨ xb 2 has an OA-factorization. Since a ∨ xb 2 ≤ p , there are v, w ∈ L such that v is an OA-element of L v , ≤ q and a ∨ xb 2 = vw . If w = 1, then w ≤ m , and hence a ≤ a ∨ xb 2 ≤ qm , a contradiction. Therefore, a ∨ xb 2 = v is an OA-element. Assume that b 2 ≤ a ∨ xb 2 . Since b 2 is principal, we have that 1 = ( a ∨ xb 2 : b 2 ) = ( a : b 2 ) ∨ x , and thus ( a : b 2 ) = 1, since L is quasi-local. Consequently, b 2 ≤ a ≤ q , and hence b ≤ q , a contradiction. This implies that b 2 /notlessequal a ∨ xb 2 . Since xb 2 ≤ a ∨ xb 2 and a ∨ xb 2 is an OA-element, we conclude that x ≤ a ∨ xb 2 . By [3, Theorem 1.4], it follows that x ≤ a . /square
Proposition 4.10. Let L be a principally generated C-lattice. If the join of any two principal elements has an OA-factorization, then dim( L ) ≤ 1 .
/negationslash
Claim: p ≤ m 2 for each nonmaximal prime element p ∈ L .
Proof. First let every OA-element of L be a prime element. We infer that L is a ZPI-lattice by [15, Theorem 8]. Therefore, dim( L ) ≤ 1 by [4, Theorem 2.6]. Now let there be an OA-element that is not a prime element. Then L is quasi-local by Proposition 2.7. Let m be the maximal element of L . We conclude by Proposition 2.8 that m = m 2 . There exists some principal element c ∈ L such that c /notlessequal m 2 and c ≤ m .
Let p ∈ L be a nonmaximal prime element. By Lemma 4.9, we have that dim( L ) ≤ 2. Therefore, we can assume without restriction that there are no prime elements of L that are properly between p and m (i.e., for each prime element r ∈ L with p ≤ r ≤ m , it follows that r ∈ { p, m } ).
/negationslash
Assume that p /notlessequal m 2 . It is sufficient to show that m 2 ≤ p ∨ a for each proper principal a ∈ L with a /notlessequal p . (Then m 2 ≤ ∧ { p ∨ d | d ∈ L is principal and d /notlessequal p } = p , and hence p = m , a contradiction.) Let a ∈ L be a proper principal element such that a /notlessequal p . Since p is principal by Lemma 4.9, it follows that p ∨ a has an OA-factorization in L . Since p ∨ a /notlessequal m 2 and p ∨ a is proper, we obtain that p ∨ a is an OA-element. Clearly, p ∨ a is not a nonmaximal prime element, and hence m 2 ≤ p ∨ a by Proposition 2.8. Consequently, q ≤ m 2 . /square (Claim)
Next we show that p = ∧ { p ∨ a | a ∈ L is principal and a /notlessequal p } . Assume to the contrary that p = ∧ { p ∨ a | a ∈ L is principal and a /notlessequal p } . Then there is a principal element y ∈ L such that y /notlessequal p and y ≤ ∧ { p ∨ a | a ∈ L is principal and a /notlessequal p } . Since p < m , there is a principal element b ∈ L such that b /notlessequal p and b ≤ m . Since by ∈ L is principal and by /notlessequal p , we have that y ≤ ∧ { p ∨ a | a ∈ L is principal and a /notlessequal p } ≤ p ∨ by . It follows from [3, Theorem 1.4] that y ≤ p , a contradiction. Therefore, p = ∧ { p ∨ a | a ∈ L is principal and a /notlessequal p } .
It is sufficient to show that r = 0 for each nonmaximal prime element r ∈ L . Let r ∈ L be a nonmaximal prime element. Since c has an OA-factorization and c /notlessequal m 2 , we infer that c is an OA-element of L . By the claim, it follows that c is not a nonmaximal prime element of L . Observe that r ≤ m 2 ≤ c by the claim and by Proposition 2.8. Since c is a (weak meet) principal element of L r , is a prime element of L and c /notlessequal r , we conclude that r = cr . Therefore, r = 0 by [3, Theorem 1.4]. /square
Proposition 4.11. Let ( L, m ) be a quasi-local principally generated C-lattice. If the join of any two principal elements of L has an OA-factorization and dim( L ) = 1 , then L is a domain.
/negationslash
Proof. Let p ∈ L be a minimal nonmaximal prime element with p < m . If m 2 = 0, then p = m , a contradiction. Therefore, m 2 = 0. Since ( L, m ) is a quasi-local, then m 2 = m . There is a principal element x ∈ L such that x /notlessequal m 2 . by the assumption, we infer that m 2 ≤ x and x is not prime. We show that p ≤ m 2 . Assume the contrary that p /notlessequal m 2 . There is a principal element a ∈ L with a /notlessequal p and a ≤ m 2 . Note that a n /notlessequal p for a positive integer n . Note that p ∨ a 3 /notlessequal m 2 because p /notlessequal m 2 . By the assumption p ∨ a 3 is an OA-element. Since a 3 ≤ p ∨ a 3 , then we infer that a 2 ≤ p ∨ a 3 or a ≤ p ∨ a 3 . Note that we have that (( p ∨ a 3 ) : a 2 ) = ( p : a 2 ) ∨ a and (( p ∨ a 3 ) : a ) = ( p : a ) ∨ a 2 . If a 2 ≤ p ∨ a 3 , then we obtain that 1 = ( p : a 2 ) ∨ a . This implies that 1 = ( p : a 2 ) or a = 1, and hence a 2 ≤ p or a = 1, a contradiction. Assume that a ≤ p ∨ a 3 . We obtain that 1 = ( p : a ) ∨ a 2 . This implies that 1 = ( p : a ) or a 2 = 1 ≤ a , and thus a ≤ p or a = 1, a contradiction. Therefore, p ≤ m 2 . Since p ≤ x , we get that px = . By Nakayama's Lemma and Lemma 4.8, we have that p p = 0. /square
/negationslash
Proposition 4.12. Let L be a principally generated C-lattice and set m = J( L ) . If the join of any two principal elements of L has an OA-factorization, then L satisfies one of the following conditions.
- (a) L is a ZPI-lattice.
- (b) L is a quasi-local lattice, m 2 is comparable and m is a nilpotent element.
- (c) L is a quasi-local lattice domain, m 2 is comparable and ∧ n ∈ N m n = 0 .
/negationslash
Proof. Let the join of any two principal elements of L has an OA-factorization. Assume that every OAelement of L is prime. By [15, Theorem 8], it follows that L is a ZPI-lattice. Now, assume that there is an OA-element which is not a prime. We conclude that ( L, m ) is a quasi-local C-lattice with m 2 = m by Propositions 2.7 and 2.8. Then there is a nonzero principal element x /notlessequal m 2 . Clearly, x is not the product of more than one OA-element, and thus x is an OA-element.
First let dim( L ) = 0. We show that m 2 is comparable. Let z ∈ L be proper such that z /notlessequal m 2 . There is a principal element a ∈ L with a ≤ z and a /notlessequal m 2 . Note that a is an OA-element which is not a prime element. We have that m 2 ≤ a by Proposition 2.8, and thus m 2 ≤ z . Consequently, m 2 is comparable.
Clearly, 0 has an OA-factorization. This implies that m k ≤ 0 for some positive integer k , and hence m k = 0.
/negationslash
Now let dim( L ) = 1. We obtain that ( L, m ) is a quasi-local lattice domain by Proposition 4.11. To verify that ∧ n ∈ N m n = 0, assume the contrary that ∧ n ∈ N m n = 0. There is a nonzero principal element x ∈ L with x ≤ ∧ n ∈ N m n . Since x is a product of k OA-elements of L , we conclude that m 2 k ≤ x ≤ m 4 k ≤ m 2 k . In particular, we get that x = x 2 . Since x is principal, we have that 1 = x ∨ (0 : x ). We infer that x = 1, a contradiction. Therefore, ∧ n ∈ N m n = 0. Finally, we show that m 2 is comparable. Let z ∈ L be proper such that z /notlessequal m 2 . There is a principal element a ∈ L with a ≤ z and a /notlessequal m 2 . We get that a is a nonzero OA-element. Therefore, m 2 ≤ a (since dim( L ) = 1), and thus m 2 ≤ z . /square
Theorem 4.13. Let L be a principally generated C-lattice and set m = J( L ) . The following statements are equivalent.
- (1) L is an OAFL.
- (2) L is a COAFL.
- (3) The join of any two principal elements of L has an OA-factorization.
- (4) L satisfies one of the following conditions.
- (a) L is a ZPI-lattice.
- (b) L is a quasi-local lattice, m 2 is comparable and m is a nilpotent element.
- (c) L is a quasi-local lattice domain, m 2 is comparable and ∧ n ∈ N m n = 0 .
Proof. (1) ⇒ (2) This is obvious.
- (2) ⇒ (3) Note that every principal element is compact, and hence the join of each two principal elements is compact. The statement is now immediately clear.
- (3) ⇒ (4) This follows from Proposition 4.12.
- (4) ⇒ (1) If L is a ZPI-lattice, then clearly L is an OAFL. Now let L be not a ZPI-lattice. It is an immediate consequence of Lemma 4.4 that L is an OAFL. /square
Theorem 4.14. Let L be a principally generated C-lattice. The following statements are equivalent.
- (1) L is a ZPI-lattice.
- (2) L is a Pr¨fer OAFL. u
- (3) L is a Pr¨fer POAFL. u
Proof. (1) ⇒ (2) ⇒ (3) This follows from [15, Theorem 8].
- (3) ⇒ (1) Let L be a Pr¨fer POAFL. If u L is not quasi-local, then the prime elements coincide with the OAelements. By Theorem 4.13, we infer that L is a ZPI-lattice. Assume that ( L, m ) is a quasi-local lattice with maximal element m . Then m 2 is comparable by Theorem 4.13. We know from Proposition 2.12(2) that each OA-element is either prime or equal to m 2 . Therefore, L is a ZPI-lattice. /square
Finally, we provide a theorem that connects the various types of factorization lattices for a quasi-local principally generated C-lattice domain.
Theorem 4.15. Let ( L, m ) be a quasi-local principally generated C-lattice domain. The following statements are equivalent.
- (1) L is an OAFL.
- (2) L is a TAFL.
- (3) L is a COAFL.
- (4) L is a CTAFL that satisfies the ascending chain condition on prime elements.
- (5) dim( L ) ≤ 1 and L is a POAFL.
- (7) dim( L ) ≤ 1 , m 2 is comparable and ∧ n ∈ N m n = 0 .
- (6) dim( L ) ≤ 1 and L is a PTAFL.
Proof. (1) ⇔ (3) ⇔ (7) This follows from Theorem 4.13.
- (2) ⇔ (6) ⇔ (7) This is an immediate consequence of Theorem 3.11 and Proposition 3.12.
- (1) ⇒ (5) ⇒ (6) This follows from Corollary 4.3.
- (2) ⇒ (4) Clearly, L is a CTAFL. Moreover, dim( L ) ≤ 1 by Proposition 3.4. It is clear now that L satisfies the ascending chain condition on prime elements.
- (4) ⇒ (6) Obviously, L is a PTAFL. We infer by Proposition 3.7 that dim( L ) ≤ 1.
/square
ACKNOWLEDGEMENTS. The first-named author was supported by the Austrian Science Fund FWF, Project Number P36742-N. The second-named author was supported by Scientific and Technological Research Council of Turkey (TUBITAK) 2219-International Postdoctoral Research Fellowship Program for Turkish Citizens, (Grant No: 1059B192202920).
## References
- [1] M. T. Ahmed, T. Dumitrescu, and A. Khadam, Commutative rings with absorbing factorization , Comm. Algebra 48 (2020), 5067-5075.
- [2] D. D. Anderson, Multiplicative lattices , Doctoral dissertation, The University of Chicago, 1974.
- [3] D. D. Anderson, Abstract commutative ideal theory without chain condition , Algebra Universalis 6 (1976), 131-145.
- [4] D. D. Anderson and C. Jayaram, Principal element lattices , Czechoslovak Math. J. 46 (1996), 99-109.
- [5] D. D. Anderson and E. W. Johnson, Dilworth's principal elements , Algebra Universalis 36 (1996), 392-404.
- [6] D. F. Anderson and A. Badawi, On n-absorbing ideals of commutative rings , Comm. Algebra 39 (2011), 1646-1672.
- [7] A. Badawi, On 2-absorbing ideals of commutative rings , Bull. Austral. Math. Soc. 75 (2007), 417-429.
- [8] E. M. Bouba, M. Tamekkante, ¨ . U Tekir, and S. Ko¸ c, Notes on 1 -Absorbing Prime Ideals , In: Proceedings of the Bulgarian Academy of Sciences 75 (2022), 631-639.
- [9] R. P. Dilworth, Abstract commutative ideal theory , Pacific J. Math. 12 (1962), 481-498.
- [10] T. Dumitrescu and M. Epure, Comaximal factorization lattices , Comm. Algebra 50 (2022), 4024-4031.
- [11] A. El Khalfi, M. Issoual, N. Mahdou, and A. Reinhart, Commutative rings with one-absorbing factorization , Comm. Algebra 49 (2021), 2689-2703.
- [12] J. Elliott, Rings, modules, and closure operations , Springer Monogr. Math., Springer, Cham, 2019, xxiv+490pp.
- [13] A. Geroldinger and W. Hassler, Local tameness of v-Noetherian monoids , J. Pure Appl. Algebra 212 (2008), 1509-1524.
- [14] F. Halter-Koch, Ideal systems. An introduction to multiplicative ideal theory , Monogr. Textbooks Pure Appl. Math. 211 , Marcel Dekker, Inc., New York, 1998, xii+422pp.
- [15] C. Jayaram, Primary elements in Pr¨fer lattices u , Czechoslovak Math. J. 52 (2002), 585-593.
- [16] C. Jayaram, Laskerian lattices , Czechoslovak Math. J. 53 (2003), 351-363.
- [17] C. Jayaram and E. W. Johnson, s-Prime elements in multiplicative lattices , Period. Math. Hungar. 31 (1995), 201-208.
- [18] C. Jayaram, U. Tekir, and E. Yetkin, 2 ¨ -absorbing and weakly 2 -absorbing elements in multiplicative lattices , Comm. Algebra 42 (2014), 2338-2353.
- [19] M. Mukhtar, M. T. Ahmed, and T. Dumitrescu, Commutative rings with two-absorbing factorization , Comm. Algebra 46 (2018), 970-978.
- [20] H. M. Nakkar and E. A. Al-Khouja, On Laskerian lattices and Q-lattices , Studia Sci. Math. Hungar. 33 (1997), 363-368.
- [21] F. Wang and H. Kim, Foundations of commutative rings and their modules , Algebr. Appl. 22 , Springer, Singapore, 2016, xx+699pp.
- [22] A. Yassine, M. J. Nikmehr, and R. Nikandish, On 1 -absorbing prime ideals of commutative rings , J. Algebra Appl. 20 (2021), 2150175.
Institut f¨r Mathematik und Wissenschaftliches Rechnen, Karl-Franzens-Universit¨t Graz, NAWI Graz, Heinu a richstraße 36, 8010 Graz, Austria
Email address : [email protected]
Department of Mathematics, Faculty of Science, Gebze Technical University, Gebze, Kocaeli, Turkey Email address : [email protected] , [email protected] | null | [
"Andreas Reinhart",
"Gulsen Ulucak"
] | 2024-08-02T08:25:00+00:00 | 2024-08-02T08:25:00+00:00 | [
"math.AC",
"06F10, 06F05, 13A15"
] | Multiplicative Lattices with Absorbing Factorization | In [22], Yassine et al. introduced the notion of 1-absorbing prime ideals in
commutative rings with nonzero identity. In this article, we examine the
concept of 1-absorbing prime elements in C-lattices. We investigate the
C-lattices in which every element is a finite product of 1-absorbing prime
elements (we denote them as OAFLs for short). Moreover, we study C-lattices
having 2-absorbing factorization (we denote them as TAFLs for short). |
2408.01101v1 | ## NotePlayer: Engaging Jupyter Notebooks for Dynamic Presentation of Analytical Processes
Yang Ouyang [email protected] ShanghaiTech University Shanghai, China
## Yun Wang ∗
[email protected] Microsoft Beijing, China
## ABSTRACT
Diverse presentation formats play a pivotal role in effectively conveying code and analytical processes during data analysis. One increasingly popular format is tutorial videos, particularly those based on Jupyter notebooks, which offer an intuitive interpretation of code and vivid explanations of analytical procedures. However, creating such videos requires a diverse skill set and significant manual effort, posing a barrier for many analysts. To bridge this gap, we introduce an innovative tool called NotePlayer , which connects notebook cells to video segments and incorporates a computational engine with language models to streamline video creation and editing. Our aim is to make the process more accessible and efficient for analysts. To inform the design of NotePlayer , we conducted a formative study and performed content analysis on a corpus of 38 Jupyter tutorial videos. This helped us identify key patterns and challenges encountered in existing tutorial videos, guiding the development of NotePlayer . Through a combination of a usage scenario and a user study, we validated the effectiveness of NotePlayer . The results show that the tool streamlines the video creation and facilitates the communication process for data analysts.
## CCS CONCEPTS
- · Human-centered computing → Interactive systems and tools .
## KEYWORDS
Communication, Tutorial Video, Jupyter Notebook, Large Language Model
## ACMReference Format:
Yang Ouyang, Leixian Shen, Yun Wang, and Quan Li. 2024. NotePlayer: Engaging Jupyter Notebooks for Dynamic Presentation of Analytical Processes. In The 37th Annual ACM Symposium on User Interface Software and
∗ Quan Li and Yun Wang are the corresponding authors.
Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for third-party components of this work must be honored. For all other uses, contact the owner/author(s).
UIST '24, October 13-16, 2024, Pittsburgh, PA, USA
© 2024 Copyright held by the owner/author(s).
ACM ISBN 979-8-4007-0628-8/24/10
https://doi.org/10.1145/3654777.3676410
## Leixian Shen
[email protected] The Hong Kong University of Science and Technology Hong Kong SAR, China
## Quan Li ∗
[email protected] ShanghaiTech University Shanghai, China
Technology (UIST '24), October 13-16, 2024, Pittsburgh, PA, USA. ACM, New York, NY, USA, 20 pages. https://doi.org/10.1145/3654777.3676410
## 1 INTRODUCTION
Effective communication in data analysis is essential for translating complex codes and analytical processes into understandable formats [14, 38]. Employing diverse presentation formats, ranging from traditional text reports to interactive digital platforms, is crucial in achieving this objective [33, 39, 69]. Among these methods, tutorial videos have emerged as particularly popular, offering an intuitive interpretation of codes while vividly articulating underlying analytical processes [3, 7, 74].
In parallel, the Jupyter Notebook platform has gained significant recognition within the programming and data analysis community [38, 50, 51, 68]. Regarded as a vital tool for efficient data analysis, its structured design, featuring input and output cells, facilitates iterative exploration and provides instant feedback, essential for hypothesis testing and comprehension [12, 23, 38, 52]. Notably, the user interface of Jupyter Notebook frequently appears in a variety of video tutorials, making it accessible on online platforms such as YouTube, MOOCs, and Khan Academy [4, 53, 59, 60, 63]. Many findings highlight the benefits of tutorial videos in enriching both theoretical understanding and practical application in data science [20, 37, 40, 67].
However, creating tutorial videos based on Jupyter notebooks poses challenges for data analysts. Effective programming tutorial videos demand a blend of skills, including providing insightful guidance and understanding viewer engagement [7, 43, 74]. Balancing the clarity and structure of the original analysis with engaging and informative content is crucial [35, 49]. Moreover, many analysts may lack familiarity with specialized video editing tools like Adobe After Effects and Premier. While powerful, these tools are not tailored for programming tutorial videos, adding complexity, especially for those eager to share their analytical processes but inexperienced in video editing. Despite efforts to enhance presentation and interactivity within Jupyter notebooks [30, 38, 39, 69], a gap remains in fully capturing the analytical process. These efforts often prioritize showcasing insights over providing a detailed walkthrough of the analytical journey. Consequently, viewers may lack a clear understanding of the methodologies and critical thinking behind the findings.
To address these challenges, we initially conducted an interviewbased formative study involving four creators to gain insights into their workflows and identify challenges in tutorial video creation. Subsequently, we conducted a content analysis of 38 programming tutorial videos to explore their characteristics and detect common patterns, thus shedding light on the current landscape of this media format. The formative study revealed several challenges in creating effective videos, including maintaining a clear logical flow aligned with the code structure, enhancing comprehension through visual aids, and the time-consuming nature of editing to rectify errors and enhance clarity. The content analysis highlighted that these videos employ various narration styles (informative, structural, interactive) along with specific creator behaviors (e.g., annotating). Key strategies for improving tutorials include emphasizing code snippets through annotations, ensuring smooth content flow, and engaging viewers with interactive questions. We have also arrived at a consensus on transitioning from static screen recordings to more interactive and engaging methods, thereby providing comprehensive insights into analytical workflows. These insights have informed the development of a set of design considerations to steer the future development of our tool.
Based on our findings, we present NotePlayer , an authoring tool seamlessly integrating notebook cells with video segments. Powered by a computational engine, NotePlayer simplifies the creation and editing of videos. Initially, NotePlayer extracts data, encompassing both input and output cells, from the user's original notebook. This process effectively demonstrates the logical flow inherent in the analytical process by analyzing code cells. Users can then navigate through this logical flow, confirming each scene as they progress. Within each scene, the tool generates initial narration by leveraging detailed code cell information and essential elements, such as specific code snippets and corresponding user annotations. This process utilizes the robust natural language understanding capabilities of Large Language Models. Additionally, after fine-tuning the narration and integrating it with specific visual elements and preset settings, such as animations and layouts, an initial dynamic presentation is crafted. Supporting this process is the finalization of a "design script" that organizes the streaming content into coherent scenes, seamlessly integrating code, annotations, and visuals. To ensure accessibility, text-to-speech technologies are utilized to automatically generate audio narrations. Furthermore, NotePlayer facilitates iterative refinement of streaming content, enabling users to edit their presentations, adjust annotations, and enhance narrations. This iterative process enhances the quality and consistency of the streaming media.
In evaluating NotePlayer , we conducted a user study and received positive feedback regarding its usability and learnability. Participants highlighted that NotePlayer significantly streamlines the creation of expressive Jupyter notebook tutorial videos, providing clear guidance and ease of learning, thus improving their communication process. We view the integration of tutorial videos as a valuable supplemental tool that complements traditional learning methods. Our method provides additional support, effectively demystifying complex topics, increasing engagement, and offering flexible learning options. The contributions of this work are summarized as follows:
- · Weconduct a formative study and content analysis to gain a comprehensive understanding of the general workflow, challenges, and common patterns involved in existing programming tutorial video creation practices.
- · We create NotePlayer , a tool seamlessly connecting notebook cells with video segments, employing a computational engine embedded with language models to facilitate flexible video creation and editing.
- · We showcase the effectiveness of NotePlayer through a user study, illuminating the tool's advantages and limitations.
## 2 RELATED WORK
We examine previous works from two angles: Programming Tutorial Videos and Storytelling with Computational Notebooks.
## 2.1 Programming Tutorial Videos
Tutorials are extensively utilized as a platform for sharing coding and programming expertise among programmers [24]. They commonly include elements such as source code, textual explanations, code examples, and multimedia components, encompassing images and videos [46, 61].
Programming tutorial videos play a vital role in providing an intuitive understanding of code and explaining analytical processes clearly. These videos are commonly found on formal online platforms such as YouTube [59], MOOCs [53], and Khan Academy [60]. Recent studies support the effectiveness of tutorial videos in data science education. Kross et al. [37] discussed the challenges faced by data science instructors in integrating code, data, and communication within teaching workflows, emphasizing the importance of effective communication. Guo et al. [20] showed that interactive and concise videos significantly boost student engagement and understanding, essential for clarifying complex data science techniques and coding practices. Moreover, Lu et al. [40] investigated the impact of tutorial videos on teaching practical skills, while Wang et al. [67] confirmed their effectiveness in increasing engagement in Computer Science and Engineering courses. These findings highlight the benefits of tutorial videos in enriching both theoretical understanding and practical application in data science.
Creating effective programming tutorial videos requires a combination of technical skills, educational insights, and an understanding of viewer engagement [35, 43, 74]. Bowles-Terry et al. [7] conducted research on learner preferences for online video tutorials, establishing a foundational understanding of learners' viewpoints in tutorial creation. Subsequently, Weeks et al. [74] furthered the discourse on video tutorial development by exploring optimal practices, emphasizing the critical role of usability, findability, and pedagogical efficiency in tutorial design.
Numerous studies have delved into the development of innovative tools for crafting tutorial videos. For instance, Mysore et al. [46] introduced the Torta system, which automates the creation of mixed-media tutorials for both GUI and command-line applications by tracing activities across the operating system. Bao et al. [3] presented VT-Revolution, an interactive system aimed at enhancing the creation and viewing experience of programming video tutorials. Additionally, various studies have aimed to enhance interactivity, context, and clarity within programming tutorials.
Khandwala et al. [34] developed Codemotion, a tool focused on enriching interactivity in tutorial videos, highlighting the potential of interactive elements in making tutorials more engaging and effective for learners. Similarly, Buffardi et al. [9] explored integrating videos with programming practice, underscoring the importance of contextual and relatable content through the inclusion of diverse perspectives in tutorial videos. Moreover, Yadid et al. [78] introduced a novel approach for extracting code from programming tutorial videos, emphasizing the significance of clarity in code presentation for enhanced learner comprehension.
Our focus is on enhancing communication in the realm of data analysis within the Jupyter Notebook environment, which has often been overlooked in traditional programming tutorial videos [55]. Specifically, there is a gap in understanding the unique workflows of data analysts as they create programming tutorial videos within Jupyter notebooks. To bridge this gap, our work delves into the challenges faced during the creation of such videos and seeks opportunities to streamline this process.
## 2.2 Storytelling with Computational Notebooks
This section delves into the Computational Notebook, a widely adopted platform extensively utilized by data analysts for their day-to-day tasks [25]. Each notebook is organized with numerous input and output cells that facilitate code editing and the display of results [36]. The integrated interface for code and results aligns well with the needs of data analysis, supporting iterative coding and immediate result review [23, 33]. Despite the benefits that data analysts derive from computational notebooks, these tools also present limitations. Rule et al. [52] highlighted the conflict between exploration and structured explanation within notebooks. Chattopadhyay et al. [12] identified nine significant concerns, including analysis, code management, and collaboration issues. These limitations can hinder effective storytelling within computational notebooks.
Recent research has made significant advancements in improving storytelling within computational notebooks, introducing innovative tools and methods for enhancing data analysis and presentation [11, 22, 32, 44, 47, 82]. We categorize these enhancements into two main sections: Analysis Enhancements and Communication Enhancements . In terms of Analysis Enhancements , our focus is on tools that enhance user engagement and facilitate collaboration [66, 70, 75]. For instance, Head et al.[23] introduced methods for gathering code within notebooks to manage messy code structures. Wang et al.[64] presented a Jupyter extension designed to foster discussions around notebooks and facilitate collaborations. When it comes to Communication Enhancements , the emphasis is on novel approaches to presenting and conveying analytical processes [65, 73]. Wenskovitch et al.[77] introduced Albireo, a tool that visually summarizes notebook structures, aiding in the exploration of complex data stories. Additionally, NB2Slides[83] and Slide4N [69] automated the extraction of key points from notebook cells, organizing them into presentation slides for clearer communication. Furthermore, Li et al.[38] introduced Notable, an on-the-fly assistant that enhances data documentation and organization, improving the clarity of data narratives. Lin et al.[39] presented InkSight, a plugin that enhances chart documentation by allowing users to intuitively sketch their insights directly on visualizations. Together, these efforts enrich the experience of data analysts using notebooks, facilitating the creation of more engaging and collaborative storytelling within notebooks.
However, existing efforts have predominantly concentrated on reporting data facts or findings, neglecting the potential of streaming as a pivotal presentation medium capable of integrating narration and animation effects. In response, our work is oriented towards embracing conventional practices seen in programming tutorial videos. We take strides towards enabling a fluid and dynamic portrayal of the entire analysis process within computational notebooks, thereby enhancing communication.
## 3 FORMATIVE STUDY
Our study begins by examining the prevalent practices among data analysts in communicating their analytical processes, primarily through jupyter notebooks, to their audience.
## 3.1 Participants and Procedure
We conducted semi-structured interviews with four individuals, identified as P1-P4 , all of whom are practitioners in Data Science (DS). They all have created tutorial notebook videos during the epidemic. Each participant brings over a decade of experience in computational data processing, along with several years of expertise specifically with Jupyter notebooks. The interviews with each participant were comprehensive, lasting approximately 30 minutes.
## 3.2 Data Analysis
We conducted thematic analysis [17] on the interview data and constructed an affinity diagram to explore the patterns of data analysts' workflows and the themes of challenges they encountered. Two researchers independently analyzed and open-coded the transcribed interview responses. Any discrepancies in the coding process were addressed through discussion and reconciliation to ensure consistency and accuracy in representing the participants' perspectives. Subsequently, the researchers utilized affinity diagramming to categorize the initial codes onto cards. Through iterative discussion and organization of the codes, several recurring patterns and themes were identified from the collected data.
## 3.3 Key Findings
3.3.1 General Workflow. According to the insights obtained from the interviews, the workflow of creating Jupyter Notebook tutorial videos involves five main steps:
- · [S1] Planning : In this initial stage, the data analyst carefully plans the content and structure of the notebook. This often includes removing irrelevant code cells and adding explanatory comments for clarity.
- · [S2] Recording the tutorial : After planning, the data analyst proceeds to capture the live coding session using screen recording software within the computational notebook environment. This step provides the core visual aspect for the audience, demonstrating the code-writing process in detail, step-by-step.
- · [S3] Providing oral narration : As the code unfolds on the screen, the data analyst simultaneously provides an oral narrative that complements the visual content. This narration goes
beyond mere commentary, offering a detailed explanation of the purpose behind each code snippet.
- · [S4] Refining and enhancement : To further enrich the viewing experience, data analyst often refine the recorded content using presentation or video editing software. This process involves removing imperfections, such as minor verbal missteps, and incorporating enhancements like text captions, graphics, or animations to highlight key concepts and make the tutorial more engaging for learners.
- · [S5] Exporting and sharing : Finally, the meticulously crafted instructional videos are distributed across various online platforms, including learning portals and social media, to reach a wide audience.
3.3.2 Challenges Encountered by Creators. Following the workflow, we proceed to delineate several challenges ( C1-C4 ) encountered during this process:
C1. Unclear logical progression : Creating a video tutorial necessitates a meticulous, step-by-step demonstration. Despite the plannning, the logic is basically based on the code itself, not the planned content of the video. Throughout recording, it's imperative to adhere to a coherent logical sequence, ideally mirroring the logic of the underlying code. However, this aspect is frequently overlooked, with explanations often tied solely to the contents of the notebook. As noted by P4 , ' Sometimes, I catch myself just jumping into the code without giving enough context, making it tough for viewers to follow smoothly.' To address this, creators could consider briefly pausing or interjecting comments within the code to denote the completion of each phase. As emphasized by P3 , ' Keeping a clear logical flow is key. You've got to lead viewers step by step, making sure it all makes sense with how the code runs.' Without clear articulation of the logic, viewers may encounter difficulty pinpointing the corresponding part of the video for their code-related issues.
C2. Lack of visual emphasis in explanations : Recorded videos often fail to highlight explanations for complex code segments, despite demonstrating the raw process. While verbal emphasis may be given during recording, the scene is typically depicted as a static image, lacking visual aids. As noted by P2 , ' While I was recording, I noticed that even though I stressed things verbally, the absence of visuals might've made it hard for viewers to get it. I might toss in some visuals and animations when I share the clips to help with that.' Without the reinforcement of visual elements, viewers may struggle to grasp crucial concepts, hindering their understanding and progress. As emphasized by P3 , ' Adding more visuals would've really made the explanations a lot clearer.'
C3. Trial-and-error : Making instructional videos involves a series of trial-and-error processes in recording and editing to achieve clarity and coherence. However, these procedures can be timeconsuming, particularly when errors such as slips of the tongue or unexpected interruptions occur during screen recording. As pointed out by P1 , " Editing out errors and unnecessary content really ate up a lot of my time. I mean, there were moments where I stumbled over my words, and unexpected interruptions threw me off track during recording.' Moreover, recording is essentially irreversible. As noted by P4 , ' You know, when I'm almost done recording and then find an issue with the code I just did, it's such a pain realizing I might have to redo everything from the start.' Consequently, significant time and effort must be dedicated during the video editing phase to identify and rectify these errors from the outset, ensuring the creation of high-quality content.
## 4 CONTENT ANALYSIS
To comprehend the characteristics and design patterns within Jupyter notebook tutorial videos, we embarked on a content analysis. Our first step involved gathering a collection of high-quality digital resources from various online platforms, including Youtube [59], MOOCs [53], and Khan Academy [60]. We categorized 38 videos based on their code-cell structure into 372 sections, each containing the textual narrative and corresponding visuals. Our analysis of Jupyter tutorial videos concentrated on three key areas: (1) categorizing narration, (2) summarizing creators' behaviors, and (3) exploring the correlations between narration and behaviors.
## 4.1 Categorizing Narration
The analyzed videos demonstrate similar narrative styles, which are categorized into three major and eight minor categories, with examples provided in Table 1. First, Informative Texts offer crucial information to help viewers understand the Jupyter tutorial content.
- · Background : This provides contextual information to help the audience understand the context behind the code cell. For example, ' we're going to explore real-world economic data using Python and Pandas.'
- · Code Interpretation : This explains the purpose or function of the code, making it more accessible to viewers. For instance, ' We're using Seaborn for data visualization, so let's 'import Seaborn as SNS'.'
- · Result Description : This clarifies the output of a code cell, explaining what the results indicate. For example, ' From this bar plot, we can see that electronic accessories are purchased in the highest quantity.'
- · Insight : This presents the video creator's viewpoints or analyses regarding the results. For instance, ' There is no relationship between the cost of goods sold and ratings.'
- · Conclusion : This summarizes key takeaways and often appears at the end of a significant analysis phase. For example, ' Performing EDA, such as univariate, bivariate, and multivariate analysis, allows us to understand the underlying patterns and relationships within the dataset.'
Second, Structural Texts are utilized for organizational purposes, enhancing the video's coherence.
- · Transition : This provides information to help the audience shift focus from one topic to another, e.g., ' So the next thing we're going to do is try to pull in some data about multiple data series and then compare them side by side.'
- · Direction : This directs the audience's attention to specific elements within a cell or code snippets, such as ' Special attention is given to the statistical summaries.'
Finally, Interactive Texts seek to actively engage the audience with the content.
- · Question engages the audience by prompting them to consider upcoming content or outcomes, as in, ' I'm going to show you how we'll do that here, right.'
## Table 1: Examples of Narration Classification: 3 Major and 8 Minor Categories
Figure 1: Boxplot of durations for different video segments. Mean durations are as follows: Background at 104.7s, Code Interpretation at 126.7s (the longest), Result Description at 94.9s, Insight at 99.5s, Conclusion at 73.5s (the shortest), Transition at 105.6s, Direction at 118.3s, and Question at 77.4s.
| Contexts | Examples of Narration |
|---------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Informative Text | - |
| Background | In this video, we're going to explore some real-world economic data using Python and pandas. |
| Code Interpretation | Also, we use Seaborn for data visualization, so let me "import Seaborn as SNS". By further narrowing our dataset to "Region == 'Italy'" we ensure that our analysis is geographically focused. result is a pandas dataframe that shows us the series ids. this bar plot we can see that electronic accessories are purchased in the highest |
| Result Description | The From quantity. |
| Insight | There is no relationship between cost of goods sold and ratings. |
| Conclusion | Performing EDA, such as univariate, bivariate, and multivariate analysis, allows us to understand the underlying patterns and relationships within the dataset. |
| Structural Text | - |
| Direction Text | So the next thing we're going to do is try to pull in some data about multiple data series and then compare them side by side. So now our next step in this session we have to get statistics about the new data set. Pay close attention to the practical application of EDA techniques. Special attention is given to the statistical summaries. |
| Interactive | - i'm going to show you how we'll do that here right? Does the cost of goods sold affect customer ratings? |
| Question | |
During our analysis of the video data, illustrated in Figure 1, we observed varying durations for different segments. Notably, Code Interpretation segments stood out as the longest, averaging 126.7 seconds, closely followed by Direction segments, which averaged 118.2 seconds.
## 4.2 Summary of Behaviors
The creators exhibited a wide range of complex behaviors in the videos. To analyze these behaviors systematically, we conducted a comprehensive summary and examination of each frame within our collected videos. To achieve this, we designed a structured triplet group [sender, receiver, and behavior] to analyze these behaviors. For instance, ' Bob selected some code snippets in a code unit ' or ' Bob elaborated on a code snippet in detail ' are typical examples of this framework. In this context, the sender refers to the creator, while the receiver encompasses both the notebook and the audience. Through this detailed analysis, we identified a range of behaviors relevant to knowledge sharing and data presentation, omitting actions not directly related to these objectives, such as browsing the internet or taking short breaks. Our analysis primarily centered on the receiver, focusing on both audience engagement and the interpretation of the code presented. Below are the final five behaviors identified:
- · Speak : The instructor verbalizes the narration throughout the data analysis process.
- · Live Coding : The instructor writes, edits, and executes code in real time within a Jupyter Notebook.
- · Select : The instructor highlights key parts of specific pieces of code.
- · Annotation : The instructor adds comments and annotations within the code.
- · Pause : The instructor pauses to prompt the learner to consider what might happen before revealing the outcomes.
- · Scroll : The instructor navigates through code cells one by one.
## 4.3 Correlation Between Narrations and Behaviors
Our interview-based research highlighted the necessity for creators to align their spoken narrations with on-screen actions, especially during the validation of visual components. This synchronization creates a reliable and authentic foundation for showcasing the objectives behind the notebooks. We noticed that while instructors generally maintain a steady flow of narration throughout the process, there are instances during live coding where the continuity of narration may diminish. Through this comprehensive analysis, we identified three key patterns ( P1-P3 ) in the interplay between narration and behavior, which could significantly improve our video creation process:
P1: Strategic Emphasis through Annotations, Selections, Directions, and Explanations : In our video tutorials, we strategically utilize annotations and selections , combined with directional guidance and thorough explanations of code segments, to achieve effective emphasis. By using visual and verbal cues to highlight key concepts or critical parts of the code, instructors ensure that important information stands out, making it more memorable for the audience. This emphasis not only captures attention but also helps anchor the audience's focus on crucial points. By providing focused explanations alongside selective highlighting, we effectively guide learners' attention to essential code components, simplifying complexities and clarifying their functionalities.
P2: Enhancing Cohesion through Transitions and Scrolling : Incorporating transitions , such as introducing new coding examples or moving to upcoming topics, ensures a seamless and uninterrupted flow of information. Instructors achieve this by smoothly scrolling from one code cell to the next, maintaining a cohesive and engaging narrative that prevents the tutorial from feeling disjointed or fragmented.
P3: Encouraging Engagement through Question Prompts and Pauses : Integrating questions into the narration and providing brief pauses encourages active participation from the audience. This interactive approach stimulates critical thinking and enhances the learning experience by making it more dynamic and engaging.
## 5 DESIGN CONSIDERATIONS
Through our formative study and content analysis, we uncovered significant patterns and challenges in creating tutorial videos for conveying analytical processes in computational notebooks. Throughout our discussions, it became clear that relying solely on screen recording formats might not adequately communicate these processes. Our collective deliberations led us to a common objective: to improve the clarity and understanding of the computational notebook's analysis process by tackling the challenges and implementing the identified patterns. This approach entails transitioning from static screen recordings to more interactive and engaging methods, thereby offering a comprehensive insight into the analytical workflows. These insights have led to the following crucial design considerations:
DC1: Identifying the overview of logical progression. We aim to meticulously design and construct the script for our ultimate presentation. Resolving C1 demands creating a thorough plan that covers all aspects of the presentation content. This plan should include identifying the logical flow of code analysis, highlighting key discussion points, and determining areas of emphasis. The tool should support users in gaining a comprehensive overview of the logical progression.
DC2:Preserving patterns and enhancing Visualization. The tool should include features designed to align with the key patterns identified in section 4.3 to foster a deeper understanding and engagement. An example of this is enabling annotations within code cells, enabling users to directly link code segments to explanations, thereby enriching the analytical narrative. Furthermore, the tool should incorporate visual enhancements ( C2 ) like dynamic highlighting or graphical overlays to emphasize these patterns, making the analysis more intuitive and visually appealing.
DC3: Facilitating rapid preview for expediting creation. To address C3 , the rapid preview feature allows users to promptly evaluate the generated content, ensuring it aligns with their expectations and requirements. This facilitates rapid iterations and adjustments, leading to the creation of high-quality content.
DC4: Offering flexible editing options for elements. Building upon DC3 , we introduce DC4 . When crafting content, refining specific segments is often required after generating the initial version. The system should offer flexible editing capabilities to enable precise fine-tuning, allowing users to seamlessly modify annotations and polish narrations. This ensures users can refine details with ease, ultimately achieving the most optimal presentation in their final output, thus addressing C3 .
## 6 NOTEPLAYER
In alignment with our defined design considerations, we develop NotePlayer . The target of NotePlayer is to enhance the seamless and dynamic presentation of the entire analysis process within computational notebooks, facilitating effective communication and understanding between analysts and the notebook environment.
## 6.1 Overview
As shown in Figure 2, NotePlayer consists of two main components: interactive modules and computational engines, which are intricately interconnected to optimize the user experience. The interactive modules are primarily focused on interface and interaction designs, providing users with intuitive controls and real-time visual feedback. On the other hand, the computational engines serve as the backbone of NotePlayer , supporting the functionalities of the interactive modules by processing data, executing algorithms, and generating outputs.
To be specific, the interactive modules consist of four parts: the Logic Flow Representation (Figure 3(A)), the Organization Panel (Figure 3(B)), the Emphasis Record (Figure 3(C)) and Scene Playback (Figure 3(D)). The Logic Flow Representation offers an initial visualization of the logical flow of the notebook code, providing users with a foundation that they can refine and improve upon during the editing phase (DC1) . In the Organization Panel, users have access to essential elements such as code explanations (Figure 3(B1)), narration sections (Figure 3(B2)), and detailed notebook information (Figure 3(B3)), which are crucial for crafting dynamic presentations. Within the Organization Panel, users can fine-tune
Figure 2: The overview of NotePlayer presents two primary components: interactive modules and computational engines. The interactive modules provide intuitive controls and real-time feedback, while the computational engines, serving as the backbone of NotePlayer , process data and generate outputs for the interactive modules with assistance from language models.
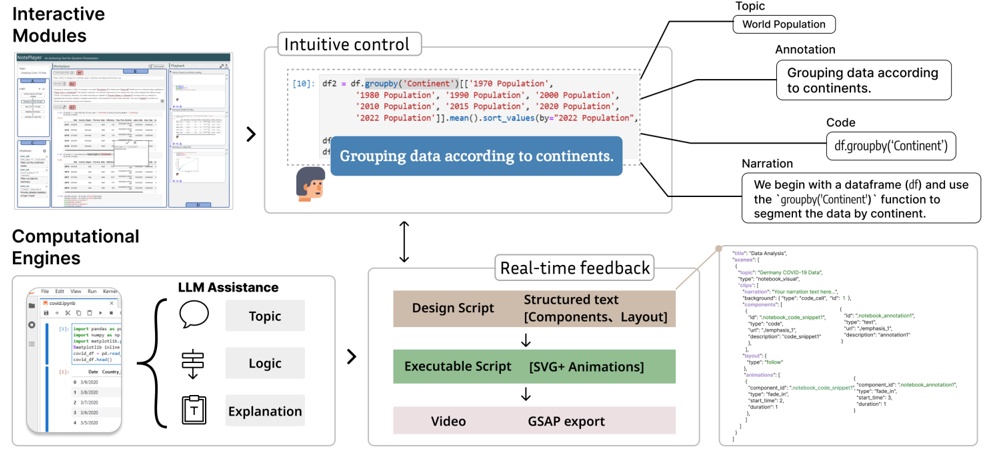
their content by revising, reorganizing, deleting, and grouping information, contributing to a streamlined editing process ( DC4 ). The Emphasis Record logs sections of the notebook where users apply the "Emphasis" pattern, facilitating focused editing and refinement (DC2) . Both views are interactive and synchronized, ensuring that any modifications made in one view are automatically reflected in the others.
enhancing clarity and efficiency. Additionally, non-essential blocks can be hidden to maintain focus on relevant code sections.
Generate The Manipulation Workplace, consisting of the Logic Flow Representation, Organization Panel, and Emphasis Record, provides users with a comprehensive toolkit for refining and organizing elements to create dynamic notebooks. Once users have arranged these elements to their satisfaction, they can preview their work in the Scene Playback (Figure 3(D)) by activating the button located on the right side ( DC3 ).
The tool can be seamlessly integrated into Jupyter Lab, allowing for direct incorporation into the notebook environment, which facilitates easy access and sharing.
## 6.2 Interactive Modules
6.2.1 Logic Flow Representation. This view presents a high-level overview of the notebook's code logic, initially as a straightforward flowchart from top to bottom. It succinctly summarizes the contents of each code cell with a brief description, offering a quick and intuitive understanding of the code's overall flow and functionality (DC1) . Within the Logic Flow Representation, selecting a block offers users two key functionalities: 1) Assess Related Codes: Relevant details of the notebook's code scroll into view within the Organization Panel, allowing scrutiny of the core functions or objectives achieved. 2) Hierarchical Organization: Users are prompted to break down overly complex code blocks into more manageable segments,
This visualization is designed with two primary considerations: Firstly, it caters to users who, while understanding the basic logic of their codes, benefit from a simplified flow diagram to navigate and locate specific code segments more effectively. Secondly, it empowers users to refine the logical progression, particularly emphasizing the transition from code to video when creating instructional content.
6.2.2 Organization Panel. Within the Organization Panel, users are provided with the convenience of directly accessing the raw codes from their notebooks. This feature facilitates interactive engagement with individual code cells, allowing users to pinpoint specific sections that require attention. Upon selecting a block within the Logic Flow Representation, the corresponding section from the notebook is automatically highlighted, enabling users to interact with and manipulate these codes. Next, we outline the functionalities in alignment with the patterns discussed in section 4.3: [F1] Conducting emphasis , [F2] Enhancing cohesion , and [F3] Fostering interaction ( DC2 ):
Annotate [F1] Conducting emphasis: Informed by the formative study and content analysis, we conceptualize these code segments as individual 'scenes' that users can manipulate, as elaborated in section 6.3.1. For instance, as shown in Figure 4, if users deem the "groupby('Continent')" section within their code as crucial for emphasis during presentations, they can easily highlight this segment using their mouse and confirm their choice by clicking the button. This action increases the font size of the selected code snippet for enhanced visibility and triggers a pop-up
Figure 3: The Interactive Modules of NotePlayer comprise (A) the Logic Flow Representation, (B) the Organization Panel, (C) the Emphasis Record, and (D) Scene Playback. The Organization Panel features crucial elements: (B1) code explanation and (B2) narration section, along with (B3) detailed notebook information, all essential components of the content creation process.
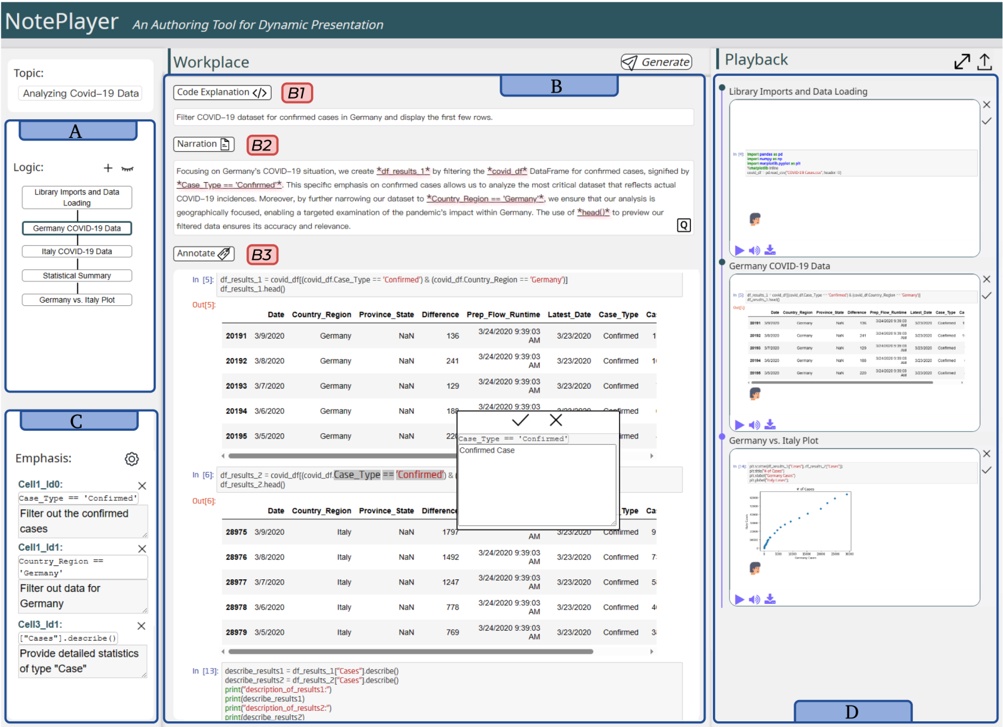
window. Within this window, users have the opportunity to elaborate on their reasons or objectives regarding the chosen code snippet. Consequently, an 'emphasis' visual element is generated, including both the original code and the user's annotations. This process enriches the presentation with valuable context and insights (DC2) .
we ensure that key concepts and critical parts of the code are effectively highlighted. This method captures attention and anchors the focus on crucial points, simplifying complexities.
Once users have thoroughly reviewed a code cell from start to finish, they can choose to generate a corresponding narrative for that segment by clicking the button. Each sentence in the narrative can be linked with one or two 'emphasis' visual elements (Figure 5(2)), providing a detailed explanation or highlighting specific code parts. Users retain the flexibility to modify these narrations (DC4) . By clicking on a sentence, they can access the associated 'emphasis' visual element, facilitating interactive and in-depth exploration of the code's key points. This design was naturally derived from our inspection of Pattern 1 in section 4.3. By using strategic annotations, selections, and directional guidance,
[F2] Enhancing cohesion: Ensuring cohesion among code cells is essential for maintaining a seamless analytical process. Efficiently streamlining transitions can be accomplished by strategically placing connecting words like 'focusing on' or 'by further' at the beginning and turning points of sections (refer to Figure 5(1)), thus facilitating clear narrative shifts. Moreover, during the narration generation phase, these textual transitions are seamlessly integrated to ensure a coherent flow. Incorporating visual cues, such as 'fade in' and 'fade out' animations, not only enhances the narrative experience but also introduces an innovative method for transitioning between code cells. By replacing traditional scrolling with these visual transitions, we can enhance the engagement and intuitiveness of navigating between code cells. This design aims to maintain cohesion among code cells, aligning with the common
Figure 4: Steps for conducting emphasis: (1) select code snippet, (2) click the button, and (3) add annotation in the pop-up window.
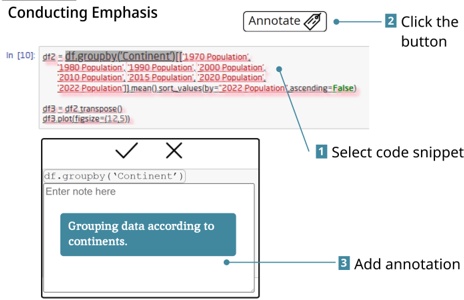
Figure 5: The narration presentation includes three key types: 1) transition, 2) direction, and 3) question. Users can click the Q button to transform the sentence from declarative to an interactive question-and-answer format.
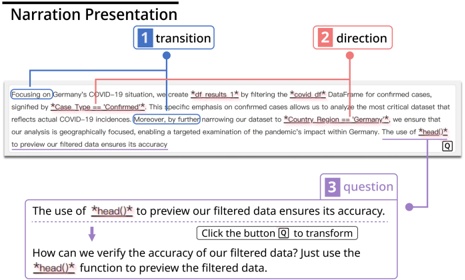
practice of organizing content based on cells in many notebookbased tools [38, 39, 83], which requires users to effectively structure their notebooks beforehand. Strategically placing connecting words at section beginnings and turning points facilitates clear narrative shifts and ensures coherent flow during narration generation.
[F3] Fostering interaction: Once the narration is generated, it predominantly consists of declarative sentences. However, to enhance user engagement and stimulate analytical thinking, users are provided with the option to select specific sentences and convert them from declarative to an interactive question-and-answer format by clicking the button. For instance, as illustrated in Figure 5(3), the statement 'The use of *head()* to preview our filtered data ensures its accuracy.' can be transformed into 'How can we verify the accuracy of our filtered data? Just use the *head()* function to preview the filtered data.' Based on the observation of pattern 3 in section 4.3, we supplement this design to foster interaction.
This feature aligns with studies [10, 62] indicating that embedding questions in educational content can enhance learning.
Once users have selected the three specific patterns within a scene, clicking the button will trigger a preview within the Scene Playback.
We then present Table 2, which summarizes the current visual effects and narration strategies in video content, corresponding to the three key purposes: conducting emphasis, enhancing cohesion, and fostering interaction. Design considerations such as animation sets are discussed in section 6.3.1. Default visual effects are below:
- · Fade in : Gradually introduces elements into the scene, enhancing visibility and focus.
- · Fade out : Slowly removes elements from the scene, creating a smooth transition to the next content.
- · Move to next : Transitions from the current scene to the next, maintaining viewer engagement through seamless continuity.
- · Code Snippet Scaling : Dynamically adjusts the size of code snippets to express emphasis.
- · Code Snippet Shadow : Adds a shadow effect to code snippets to increase depth and improve legibility against varied backgrounds.
- · AnnotationFadein : Annotations added by the user are smoothly introduced into the video in bullet form, enhancing the explanatory power.
- · Annotation Fade out : Gradually fades out annotations, allowing for a clean transition to subsequent content.
Although the current tool features default animations and effects as listed in Table 2, future enhancements can include a broader range of animations, a timeline feature for enhanced variability, and non-linear logic flows for smoother transitions across different scenarios.
Table 2: Narration Contexts and Visual Effects for different Purposes in Video Content
| Purpose | Description | Narration Contexts | Visual Effects |
|-----------------------|---------------------------------------|-----------------------------------------------|---------------------------------------------------------------------|
| Conducting emphasis | Emphasizes key codes or content | - Informative Text Code Interpretation Remain | Code Snippet Shadow & Scaling Annotation Fade in & Fade out Fade in |
| Enhancing cohesion | Ensures smooth flow and continuity | - Structural Text Transition Direction | Move to Next Fade in |
| Fostering interaction | Engage audience actively with content | - Interactive Text Question | Fade in & Fade out |
6.2.3 Emphasis Record. This view is crafted to capture the sections within the notebook that users identify as significant. Once users have identified a segment for video production, they can choose to save these key points (DC3) . This feature streamlines the workflow by providing easy access to important concepts and code snippets for future reference, thus enhancing the efficiency of creating coherent and focused video content (DC4) .
6.2.4 Scene Playback. Scene Playback presents a sequential preview of user-generated streaming content, aligning each scene with the order depicted in the logic flow representation. To cater to different viewing preferences and maximize space utilization, a 'zoom' feature is provided. By clicking the button, the generated video enlarges for enhanced visibility, and the Organization Panel temporarily hides to expand the playback display area. This functionality enables users to meticulously inspect their content, ensuring it meets their standards with greater precision and clarity. Finally, the 'Export' button facilitates the export of all confirmed scene content as an MP4 file.
## 6.3 Computational Engines
In this section, we explore the mechanisms through which our computational engines facilitate the production of streaming content. First, we examine the implementation of a 'design script' that organizes streaming content into coherent scenes, incorporating code, annotations, and visuals. Subsequently, we delve into the role of Large Language Models (LLMs), notably GPT-4, in enhancing narration and logical flow, enabling customization of emphasis to align with user preferences.
6.3.1 Design Script. We begin by introducing the concept of a design script, represented as structured text, as illustrated in Figure 6.

Figure 6: Design script employs a scene-based organizational structure, grouping a narrative segment and its related details into a single block. Each scene comprises a "code snippet," the user's "annotation," and the associated "narrative." This setup is complemented by predetermined sets of animations and default layouts to streamline content creation.
Scene-based Organization. The majority of research on storytelling within computational notebooks highlights the use of a section-based architecture for content organization [21, 69, 77]. This approach segments the narrative into distinct sections, each linking a few concise code cells with explanatory texts and relevant visualizations. Insights gleaned from our formative study interviews and content analysis also indicate the widespread adoption of this structural approach for content streamlining. Drawing on these insights, we adopt a Scene-based organization, where each section of the narrative and its corresponding visuals are grouped within a single block throughout the creating process. This feature facilitates flexible prototyping of the story, visualizations, and animations while ensuring their coherence within each scene (DC4) .
Component Details. The composition of each scene must be clearly defined. Each scene revolves around a particular theme and comprises visual elements accompanied by narration. The core components of this setup are threefold: a 'code snippet', 'the user's corresponding 'annotation'', and 'the corresponding 'narrative''. A single code cell serves as the backdrop for each scene, and a compilation of these foundational elements forms a cohesive scene.
Layout Sets. In our formative study, we found that layout considerations are frequently overlooked during recording, leading to suboptimal arrangements that necessitate professional editing for improvement later on. We establish that 'annotation' in a clip should be positioned near the code cell to ensure coherence and facilitate comprehension.
Animation Sets. To address the challenges of developing a comprehensive animation library, we have opted to use a curated set of animations from GSAP (GreenSock Animation Platform) [2], a widely used animation framework. This approach allows us to concentrate on our primary research goals without incurring the extensive costs of creating a large library. Our focus is on ensuring that the animations serve their intended purpose rather than solely aiming for aesthetic appeal. Drawing from insights gained in our formative study and inspired by existing work on animated storytelling videos [13, 58, 72], we outline the animation format for our content. Each fundamental segment, or 'clip', is characterized by its start time and duration, which correspond to the application of 'enter' animations at the outset and 'exit' animations at the conclusion. Furthermore, within these clips, 'emphasis' animations are strategically employed to highlight key elements (DC2) .
Once the design script is finalized and confirmed to meet all required specifications, it undergoes processing through an advanced executable program. This program employs Text-to-Speech (TTS) technology to convert the narrations into audio voiceovers, culminating in the creation of the intended streaming content.
6.3.2 LLM Assistance. We utilize the advanced natural language understanding capabilities of the LLM (OpenAI's GPT-4 model) to augment the functionality of our tool. Appendix A provides a detailed list of prompt phrases.
Logic Flow Generation. Leveraging GPT's adeptness in code processing and comprehension, this approach guarantees the production of high-quality logic flow representations. Prompt engineering is crafted to direct the LLM in processing notebook cells, utilizing them as input and generating an output organized as a dictionary with the format '[code-cell index, description, inputs, outputs]'. This output corresponds to each code cell's index, offering a succinct overview of its content, detailing the data or resources it utilizes (inputs), and explaining the outcomes or artifacts it generates (outputs).]
Narration Generation. Initially, we experimented with generating narrations directly from raw code cells, treating GPT as an expert in articulating and explaining code [56]. This experiment demonstrated the model's ability to generate high-quality textual responses. However, recognizing the necessity for customized guidance tailored to diverse user needs, we opted to activate the model only after users highlight their preferred emphasis sections within the Organization Panel, as elaborated in section 6.2.1. The process takes complete notebooks, enriched with emphasis elements that feature code snippets and user annotations. The output generated includes narrations for each cell, with highlighted 'emphasis' elements aimed at effectively conveying the user's intent. Users have the option to adjust and finalize text responses before the generation of streaming content begins.
## 7 EVALUATION
We evaluated NotePlayer through a usage scenario to showcase its expressiveness and a user study to verify its usability.
## 7.1 Usage Scenario
We illustrate NotePlayer 's capability to dynamically present analytical processes within notebooks through a usage scenario involving Bob, a data analysis professional. While proficient in data analysis, Bob lacks expertise in communication techniques and advanced video editing tools. Typically, he shares his processes by recording his screen and providing verbal explanations.
Bob recently concluded a data analysis project on COVID-19 data and aims to share his methodology dynamically. He had finalized the coding in his Jupyter notebooks and outlined a preliminary plan for the presentation's content and structure. Initially, Bob integrated NotePlayer into Jupyter Lab as a library (Figure 7-a). Upon selecting his notebooks, the system generated a logic flow representation based on their contents (Figure 7-b). This feature offered a succinct summary of each code cell, facilitating a swift understanding of the code's structure and function ( DC1 ). Bob found this representation beneficial for confirming his initial concept of the logic flow. He can inspect each block to access its corresponding code. Satisfied with the descriptions, he chose to make only a few slight adjustments to the names.
He concentrated on the 'Germany COVID-19 Data' code cell (Figure 7-c), deeming the 'Case\_Type == 'Confirmed'' section crucial for his presentation. Bob highlighted this section, enlarged its font size, and annotated it as 'Filter out the confirmed cases'. This action created an 'emphasis' element (Figure 7-d), recorded in the Emphasis Record View (Figure 7-e). Similarly, he emphasized the 'Country\_Region == 'Germany'' code snippet with an annotation 'Filter out data for Germany' (Figure 7-d).
After meticulously reviewing the code cell from start to finish, he chose to craft a narrative by engaging the 'Narration' button (Figure 7-f). Satisfied with the resulting narration, he believed it adeptly draws attention to the key points he wished to highlight, maintaining coherence and facilitating smooth transitions. Subsequently, Bob pressed the 'generate' button to initiate a preview within the Scene Playback of NotePlayer (Figure 7-h), showcasing the scene corresponding to the selected code cell. To optimize his view, he utilized the 'zoom' button, enlarging the video and temporarily concealing the Organization Panel . Bob watched the approximately 1-minute-long stream and was content that the presentation effectively conveys his message. He appreciated the synchronization of visual and animation effects with the narration.
Bob, feeling that the narration could be more engaging, decided to improve it. He planed transform the last sentence into an interactive question-and-answer format for increased viewer engagement (Figure 7-g). After selecting the sentence, he clicked the 'Q' button, revealing the transformed interactive content. Bob was intrigued by this feature and believed it will enhance viewer interaction with the video. Upon completing the modifications, Bob clicked the 'generation' button again and promptly observes the updated content in the playback (Figure 7-h), a process taking just a few seconds. Overall, crafting this small cell scene, along with adjustments, required about 6 minutes to produce a 1-minute stream. Impressed by the efficiency, Bob excitedly exclaimed, ' Cool. Only 7 minutes have passed. Let's ship all the notebooks! ' Finally, Bob previewed the generated tutorial video shown in Figure 8, and was satisfied with its effectiveness.
## 7.2 User Study
We conducted a user study to verify the effectiveness and usability of NotePlayer .
- 7.2.1 Participants. For this study, we recruited 12 participants, comprising five females and seven males, all of whom have experience in sharing Jupyter notebooks, identified as P1-P12 . The group includes computer science educators and graduate students with a focus on data analysis. None of the participants had any involvement in the system's design or the preliminary study, and they indicated having minimal to no familiarity with professional video editing tools.
- 7.2.2 Materials and Data. We provided the participants with predesigned notebooks aimed at analyzing a COVID-19 dataset. Alongside the raw notebook, we also supplied them with various preextracted key points. This was done to ensure that the user study remained focused on content planning and video creation, thus facilitating clearer communication.
- 7.2.3 Procedure. The user study comprises three distinct sessions: (1) a preparatory phase consisting of an introduction and a demonstration example, (2) a creation session allowing participants to engage in the authoring process, and (3) a post-study evaluation to gauge preferences regarding system utility. Each participant completed the entire study within approximately 60 -70 minutes and received a $15 gift card at the conclusion of the interview session as compensation.
Preparation. The user study began with a 15-minute introduction, elucidating the design objectives of our project. Subsequently, a 20-minute demonstration was provided, elucidating the utilization of our system, encompassing the setup of visual elements, narrations, and editing interactions within a sample Jupyter notebook. Participants were then encouraged to autonomously explore all functionalities and interactions of the system, with the liberty to pose questions as required. This preparatory phase was designed to furnish participants with the requisite knowledge for proficiently crafting videos using our tool.
Figure 7: The user's progression in crafting a dynamic presentation using NotePlayer follows these steps: (a) integrating the tool into the notebook, then (b) showcasing the Logic Flow Representation. Next, the user (c) directs attention to the 'Germany COVID-19 Data' code cell and (d) applies emphasis operations. Following this, (e) the Emphasis Record is displayed. Subsequently, (f) the narration linked to the code cell and user annotations is introduced. This is followed by (g) adjusting the narrative style from declarative to interactive question-and-answer format, and finally, (h) demonstrating the Scene Playback.
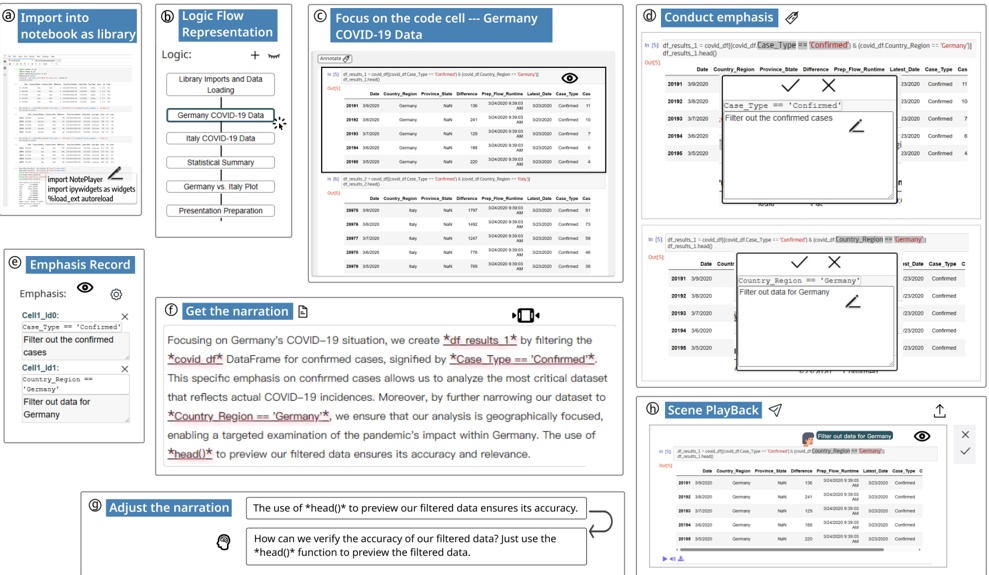
Figure 8: The video example generated for the usage scenario by NotePlayer. The example includes a sequence of annotations and animations. These will be triggered when the audio narration reaches the corresponding segment.
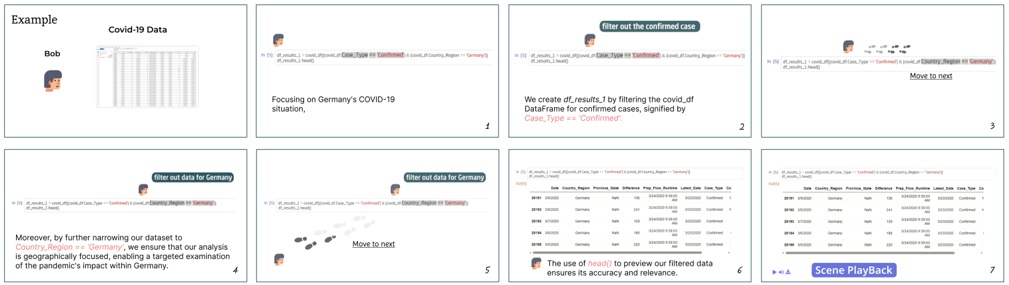
Creation. After the tutorial, participants were encouraged to utilize our system to craft their own Jupyter notebook videos, leveraging pre-extracted notebook examples for inspiration. They had the flexibility to consult provided slides and request assistance as required. Subsequently, each participant presented and deliberated on their video. This creation phase was allotted a duration of 15 to 25 minutes, providing ample time for the task.
Post-study evaluation. Once participants concluded their exploration and creation of notebook videos, they were tasked with completing a post-study questionnaire utilizing a 5-point Likert
scale. Here, a rating of 1 indicated 'strongly disagree', while 5 represented 'strongly agree'. The questionnaire's objective was to assess the usefulness, ease of use, and overall satisfaction with our system [41]. Following this, we conducted semi-structured interviews with each participant to gather qualitative feedback.
7.2.4 Results and Findings. We collected participants' subjective evaluations through an 11-question survey and acquired qualitative feedback about our system through semi-structured interviews. Figure 9 illustrates the survey questions along with the average ratings provided by users. In general, participants agreed that NotePlayer is an effective tool for creating expressive Jupyter notebook videos, providing clear guidance and being easy to learn. There was a notable preference among participants to utilize NotePlayer for streamlining the video prototyping process.
Usability. All participants unanimously concurred that our tool significantly streamlines the process of creating programming tutorial videos within notebooks, markedly reducing the necessity for manual efforts. P3 specifically emphasized the tool's usability, stating, ' It does not require professional video editing capabilities. ' This semi-automatic approach notably boosts productivity for data analysts. Moreover, participants reported the tool's efficiency in content generation, with P1 remarking, ' Taking six minutes to generate a one-minute video is very efficient. It can save a lot of time. ' Additionally, P11 highlighted the tool's efficacy in conveying the user's intention, expressing, ' I feel the tool is efficient for data analysts, given the intended analytical narrative to be communicated. '
Two participants expressed their preference for the Logic Flow Representation feature. P2 stressed its significance in comprehending the structure of the video, stating, ' The Logic Flow representation illustrates the distribution of code cells in notebooks to explain an analytical process, providing a clear overview of the video's purpose. ' Similarly, P4 noted, ' It's easy to use because it follows the nature 'cell' design of Jupyter notebooks. '
Learnability. The majority of participants found learning and utilizing the integrated features of our system to be intuitive and straightforward. P6, a data analyst with limited experience in video creation and editing, remarked, ' I can easily learn to share what I'm thinking in my notebook analysis through dynamic means. ' Additionally, regarding the entire creation process with the tool, many participants suggested that our system ensures a smooth flow in both creating and editing operations. P2 commented, ' The entire process is smooth and natural. ' Similarly, P3 mentioned, ' I can preview the dynamic presentations instantly, with basically no waiting time required. '
Expressiveness. Overall, participants unanimously agreed on the expressiveness of our tool. First, all participants highlighted the value of the preserved pattern. P5 remarked, ' I like the patterns it contains; it is just what we need for effective communication. ' Similarly, P6 mentioned, ' I favor the 'emphasis' pattern the most; it brings the code snippets, user annotations, visual animations, and narrations into a cohesive whole. ' Second, participants concurred that this dynamic presentation efficiently conveys analytical processes within notebooks. P1 expressed, ' I'm really into dynamic presentations. They've got the advantages of both screen recordings and slides, but reduce the manual efforts. ' Adding to this sentiment, P3 stated, ' I think screen recording is really troublesome, and I have to talk through it all and then edit it. The narrative summary and generation of the tool is expressive to me. ' Third, multiple participants emphasized the importance of quickly assessing whether their intention made sense or not. NotePlayer offered a unique way to streamline content creation through the use of preset settings. As noted by P8, ' Sometimes I am not sure whether to use position, color, or animation to convey the dynamic process... it can be hard to think of, I just want to emphasize some code snippet. ' For data analysts, effectively communicating information takes precedence over special effects.
Flexibility. Over half of the participants commended the flexibility of our tool in creating Jupyter videos. P4 highlighted the freedom the tool provides for adding and editing user annotations, contrasting it with previous tools that required constant switching between editing interfaces and notebooks. Similarly, P10 was impressed by the scene organization and the design script, which facilitated the reuse of streaming, thereby enhancing the tool's utility. Additionally, P5 remarked, ' With LLM's support, I can easily refine the narrations, which are flexibly linked with specific code snippets and annotations, all defined together as a scene. '
Suggestions. During our study, participants highlighted a few areas where NotePlayer could potentially enhance to make the video creation process more adaptable and user-friendly. First, the current linear presentation adheres to the sequence of scenes, reflecting the inherently linear nature of the video's structure. However, some participants expressed a desire to adjust the logic flow representation from linear to a tree structure. P8 noted, ' It's fine to have the logic go step by step, but some code does similar things and the tree structure really helps me understand the flow better. ' Second, several participants voiced a desire to incorporate a timeline feature for more granular control over the streaming content. As pointed out by P12, ' A timeline feature, similar to that in Adobe Premiere Pro, could be more beneficial, allowing for a quick overview of the total duration of each element within one scene. ' Last, some participants mentioned their interest in experimenting with a wider range of animations. As stated by P11, ' Trying different animations in dynamic presentations could be pretty fun. '
## 8 DISCUSSION AND LIMITATION
In this section, we reflect on the design, implementation, and evaluation of NotePlayer , and explore potential research avenues and future directions.
## 8.1 Extend to Multifaceted Authoring Scenarios
While the user study revealed positive feedback regarding the usability of NotePlayer , its design may not fully accommodate the diverse authoring scenarios. Originally conceived as a plugin, technical constraints and the need for enhanced convenience, such as simplified positioning and pop-up effects, led us to develop an interface integrated with Jupyter Lab. Our plan includes reintegrating the generated dynamic presentations back into the raw code cells embedded in the output cells, ensuring a seamless experience within the notebook environment. This approach allows users to view streaming of smaller scenes if they have questions about specific code cells. Second, our assumption regarding the workflow-that users have pre-organized and optimized their notebook
Figure 9: Assessment of our system in terms of Usefulness (Q1-Q3), Ease of Use (Q4-Q7), Satisfaction (Q8-Q11). The middle column shows the detailed questions. The right column displays the average and standard deviations.

before creating a dynamic presentation-may be overly simplistic. Previous research suggests that selecting and organizing notebook cells is a complex process, indicating the need for our tool to include functionalities that better support these tasks. Third, our tool currently lacks complete user control over all design aspects, such as animation styles and annotation colors. While only a few participants raised this issue in our user study, the majority found the provided options sufficient for emphasizing key points and facilitating communication. Moving forward, we aim to introduce more personalized settings and multimodel interactions to enhance the videos' appeal and stylistic diversity, catering to a wider range of users [57, 71].
Furthermore, extending tutorials to other domains is an exciting prospect, as demonstrated by Chi's work [15], which highlights the need to customize tutorial tools for specific domains. NotePlayer enhances programming tutorials by merging code with video, automating narration, and integrating interactivity. Similarly, DemoCut [15] automates editing for physical tutorials using user annotations and visual effects, significantly reducing manual effort. While both tools streamline tutorial creation, NotePlayer excels in digital interactivity, whereas DemoCut enhances continuous physical actions. Developing these tutorials requires a clear structure and engaging content, though their technical requirements and solutions differ. Nevertheless, methodologies from different domains can inform and enhance each other, offering avenues to explore [19]. For instance, the emphasis on tutorial videos across various fields can differ, enabling us to investigate and experiment on how diverse designs impact learners' views of usage patterns and result in improved learning results. Additionally, in data analysis scenarios that heavily rely on Excel, NotePlayer could dynamically present and narrate Excel-based processes, including cases where complex formulas or codes are used for analysis within Excel [8]. Moreover, certain outputs generated by our tool, organized through a cell-by-cell division process [38, 68, 83], can seamlessly integrate into PowerPoint, Keynote, and Google Slides presentations. Furthermore, key interpreters, animations, and narrations are envisioned as potential future plugins, with the prospect of embedding them into IDEs like Visual Studio Code [6].
## 8.2 Serve as a Complement Format
Tutorial videos provide an additional layer of support, effectively demystifying complex topics, increasing engagement, and offering flexible learning options. However, it's crucial to acknowledge that video-based learning may not suit all learners, as noted by Wells's work [76]. Our intention is not to replace traditional approaches but to supplement them. We also recognize the substantial value and widespread use of traditional screen recording in educational settings, training programs, and online learning [1, 42]. Traditional screen recording significantly enhances instructor presence and helps bridge the gap between educators and learners in tutorial videos [31]. It allows for the detailed capture of desktop actions, facilitating hands-on teaching activities like live coding. This aids in the clear demonstration of new technologies to student [5, 18].
Our focus lies in providing an intuitive and efficient solution tailored for data analysts, specifically designed for scenarios involving the exchange of analytical processes. Conventional screen recording formats may not always cater effectively to this audience. Significantly, our approach draws inspiration from conventional screen recording practices. We assimilate and integrate discerned patterns (refer to section 4.3) from these methods to enhance our content delivery. Our narrative styles analyzed in section 4 also align with the elements that support video editing as outlined in prior studies [15, 80]. In fact, this taxonomy can enhance users' viewing experiences by helping them quickly locate and skip irrelevant information based on the category and type, as indicated by these studies. We can further enhance our system by adding features
like Opening/Closing or self-promotion type narrative information to accommodate users with diverse information needs and navigation preferences [79]. By doing this, we expect video creators to have more control, allowing them to make informed decisions and better serve as a complementary format [29]. Furthermore, our user study revealed that participants readily comprehend the workflow and identified patterns within our tool, finding them intuitive and familiar (refer to section 7.2.4). Looking ahead, our objective is to incorporate more advantages of traditional screen recording into our tool, aiming to enhance its expressiveness. This entails enriching videos with personalized and captivating elements [45, 54], and embracing innovative presentation styles such as Learning Glass [16].
## 8.3 Incorporate LLM Assistance
We employed LLMs (refer to section 6.3.2) to assist in generating logic flow and creating narrations. On one hand, the logic flow content generated consistently proved accurate, delivering significant value to participants in our user study. Conversely, our approach to generating narrations, which aimed to align with user intentions, also garnered positive feedback during the study. Despite their positive performance, current LLMs are constrained by inherent limitations. These include inconsistency in outputs across different iterations and issues with generating inaccurate or fabricated information (hallucinations) [27, 28]. It may be prudent to implement a narration revision record to monitor changes. Moreover, although users have the option to refine narrations and transition from a declarative to an interactive question-and-answer format, two participants specifically expressed a desire to present notebook narrations in their own voice or style. This preference underscores the necessity for more personalized narration options, such as finetuning the model using materials provided by users themselves, tailored to individual preferences [26].
## 8.4 Limitations
Our work has several limitations. First, our user study involved a limited number of participants, underscoring the need for a larger, crowdsourced study to comprehensively evaluate the usability of our tool. Additionally, the absence of a baseline in our study for comparison is noteworthy. While participant feedback indicated satisfactory communication of their analytical processes through streaming, a quantitative comparison could offer deeper insights into these initial findings. Second, in our study, we examined essential design considerations based on our formative study and content analysis. It is important to recognize that these considerations serve as foundational guidelines to assist data analysts in video production and do not constitute an exhaustive list. Although we analyzed 38 videos and identified three distinct patterns, varying scenarios may necessitate more nuanced strategies to effectively address their specific requirements. For instance, code cells dedicated to displaying results should prioritize highlighting these outcomes, while those involved in data manipulation may require additional emphasis to enhance the explanation and guidance provided for these segments. Moreover, while our tool currently excels in illustrating the analytical process, it lacks capabilities for hands-on teaching scenarios where progressive code display is essential. To address this, we plan to enhance our tool by introducing features that allow for the customization and selection of specific code cells, as well as progressive code display for focused presentations. These improvements will enhance the versatility and effectiveness of code displays across various use cases. Additionally, incorporating recommendation features based on customer feedback can significantly enhance the quality of tutorial videos. We plan to conduct a user study to gather insights on customer satisfaction and the learning experience with our methods [81]. By using statistical analysis to identify trends, we aim to provide personalized guidance, which could greatly increase both customer satisfaction and engagement.
## 9 CONCLUSION AND FUTURE WORK
This study offers valuable insights into the authoring of video tutorials within Jupyter notebooks, focusing on the analytical process. We introduce NotePlayer as a solution to overcome the challenges faced by users in this context. Through an extensive formative study and content analysis, we have identified significant patterns and obstacles in the creation workflows, underscoring the necessity for innovative tools to improve user experience and communication. NotePlayer represents a substantial advancement in this domain by seamlessly integrating video segments with notebook cells, thus enabling more engaging and flexible communication of analyses. Our user study further validates the effectiveness of NotePlayer , highlighting its benefits while also pinpointing areas for refinement. Moving forward, there are several avenues for future exploration and enhancement. Incorporating user feedback to expand features, such as enhancing editing capabilities and providing personalized options, could augment both utility and usability. Moreover, conducting long-term evaluations in real-world settings could yield deeper insights into its practical applications.
## ACKNOWLEDGMENTS
We thank all our participants for their time and valuable input. We would also like to thank our reviewers whose insightful comments have led to a great improvement of this paper. This work is supported by grants from the National Natural Science Foundation of China (No. 62372298), the Shanghai Frontiers Science Center of Human-centered Artificial Intelligence (ShangHAI), and the Key Laboratory of Intelligent Perception and Human-Machine Collaboration (ShanghaiTech University), Ministry of Education.
## REFERENCES
- [1] M'hammedAbdousandMiki Yoshimura. 2010. Learner outcomes and satisfaction: A comparison of live video-streamed instruction, satellite broadcast instruction, and face-to-face instruction. Computers & education 55, 2 (2010), 733-741.
- [2] Gsap animation platform. 2023. https://greensock.com/gsap/.7.
- [3] Lingfeng Bao, Zhenchang Xing, Xin Xia, and David Lo. 2018. VT-Revolution: Interactive programming video tutorial authoring and watching system. IEEE Transactions on Software Engineering 45, 8 (2018), 823-838.
- [4] Lorena A Barba, Lecia J Barker, Douglas S Blank, Jed Brown, Allen B Downey, Timothy George, Lindsey J Heagy, Kyle T Mandli, Jason K Moore, David Lippert, et al. 2019. Teaching and learning with Jupyter. Recuperado: https://jupyter4edu. github. io/jupyter-edu-book (2019), 1-77.
- [5] Carlos Bernal-C'ardenas, Nathan Cooper, Kevin Moran, Oscar Chaparro, Andrian Marcus, and D. Poshyvanyk. 2020. Translating Video Recordings of Mobile App Usages into Replayable Scenarios. 2020 IEEE/ACM 42nd International Conference on Software Engineering (ICSE) (2020), 309-321. https://doi.org/10.1145/3377811. 3380328
| [6] | Sufyan bin Uzayr. 2022. Mastering Visual Studio Code: A Beginner's Guide . CRC Press. |
|-----------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [7] | Melissa Bowles-Terry, M. Hensley, and L. Hinchliffe. 2010. Best Practices for Online Video Tutorials: A Study of Student Preferences and Understanding. Communications in Information Literacy 4 (2010), 17-28. https://doi.org/10. 15760/COMMINFOLIT.2010.4.1.86 |
| [8] | Ronan T Bree and Gerry Gallagher. 2016. Using Microsoft Excel to code and thematically analyse qualitative data: a simple, cost-effective approach. All Ireland Journal of Higher Education 8, 2 (2016). |
| [9] | K. Buffardi and Richert Wang. 2022. Integrating Videos with Programming Practice. Proceedings of the 27th ACMConference on on Innovation and Technology in Computer Science Education Vol. 1 (2022). https://doi.org/10.1145/3502718. 3524778 |
| [10] | Julie Campbell and Richard E Mayer. 2009. Questioning as an instructional method: Does it affect learning from lectures? Applied Cognitive Psychology: The Official Journal of the Society for Applied Research in Memory and Cognition 23, 6 (2009), 747-759. |
| [11] | Souti Chattopadhyay, Zixuan Feng, Emily Arteaga, Audrey Au, Gonzalo Ramos, Titus Barik, and Anita Sarma. 2023. MakeIt MakeSense! Understanding and Facili- tating Sensemaking in Computational Notebooks. arXiv preprint arXiv:2312.11431 (2023). |
| [12] | Souti Chattopadhyay, Ishita Prasad, Austin Z Henley, Anita Sarma, and Titus Barik. 2020. What's wrong with computational notebooks? Pain points, needs, and design opportunities. In Proceedings of the 2020 CHI conference on human factors in computing systems . 1-12. |
| [13] | Hao Cheng, Junhong Wang, Yun Wang, Bongshin Lee, Haidong Zhang, and Dongmei Zhang. 2022. Investigating the role and interplay of narrations and animations in data videos. In Computer Graphics Forum , Vol. 41. Wiley Online Library, 527-539. |
| [14] | Fanny Chevalier, Melanie Tory, Bongshin Lee, Jarke van Wijk, Giuseppe Santucci, Marian Dörk, and Jessica Hullman. 2018. From analysis to communication: Supporting the lifecycle of a story. In Data-Driven Storytelling . AK Peters/CRC Press, 151-183. |
| [15] | Pei-Yu Chi, Joyce Liu, Jason Linder, Mira Dontcheva, Wilmot Li, and Bjoern Hartmann. 2013. Democut: generating concise instructional videos for physi- cal demonstrations. In Proceedings of the 26th annual ACM symposium on User interface software and technology . 141-150. |
| [16] | Ronny C Choe, Zorica Scuric, Ethan Eshkol, Sean Cruser, Ava Arndt, Robert Cox, Shannon P Toma, Casey Shapiro, Marc Levis-Fitzgerald, Greg Barnes, et al. 2019. Student satisfaction and learning outcomes in asynchronous online lecture videos. CBE-Life Sciences Education 18, 4 (2019), ar55. |
| [17] | Victoria Clarke and Virginia Braun. 2017. Thematic analysis. The journal of positive psychology 12, 3 (2017), 297-298. |
| [18] | Paul Daniels. 2009. Technically speaking : Screen recording software for creating instructional material. (2009). https://doi.org/10.29140/jaltcall.v5n2.82 |
| [19] | Adam G Emerson, Shreyosi Endow, and Cesar Torres. 2024. Anther: Cross- Pollinating Communities of Practice via Video Tutorials. In Proceedings of the 2024 ACM Designing Interactive Systems Conference . 1991-2005. |
| [20] | Philip J Guo, Juho Kim, and Rob Rubin. 2014. How video production affects student engagement: An empirical study of MOOC videos. In Proceedings of the first ACM conference on Learning@ scale conference . 41-50. |
| [21] | Jesse Harden. 2023. Exploring and Evaluating the Potential of 2D Computational Notebooks. In Companion Proceedings of the 2023 Conference on Interactive Surfaces and Spaces . 97-99. |
| [22] | Jesse Harden, Elizabeth Christman, Nurit Kirshenbaum, John Wenskovitch, Jason Leigh, and Chris North. 2022. Exploring organization of computational notebook cells in 2d space. In 2022 IEEE Symposium on Visual Languages and Human-Centric |
| [23] | Computing (VL/HCC) . IEEE, 1-6. Andrew Head, Fred Hohman, Titus Barik, Steven MDrucker, and Robert DeLine. 2019. Managing messes in computational notebooks. In Proceedings of the 2019 |
| [24] | CHI Conference on Human Factors in Computing Systems . 1-12. Andrew Head, Jason Jiang, James Smith, Marti A Hearst, and Björn Hartmann. 2020. Composing flexibly-organized step-by-step tutorials from linked source code, snippets, and outputs. In Proceedings of the 2020 CHI Conference on Human |
| [25] [26] | Project Jupyter Home. 2023. https://jupyter.org/. Zhiqiang Hu, Yihuai Lan, Lei Wang, Wanyu Xu, Ee-Peng Lim, Roy Ka-Wei Lee, Lidong Bing, and Soujanya Poria. 2023. Llm-adapters: An adapter fam- ily for parameter-efficient fine-tuning of large language models. arXiv preprint arXiv:2304.01933 (2023). |
| [27] | Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2023. A survey on hallucination in large language models: Principles, taxonomy, chal- |
| [28] | lenges, and open questions. arXiv preprint arXiv:2311.05232 (2023). Ziwei Ji, YU Tiezheng, Yan Xu, Nayeon Lee, Etsuko Ishii, and Pascale Fung. 2023. Towards mitigating LLM hallucination via self reflection. In The 2023 Conference |
| [29] | Haojian Jin, Yale Song, and Koji Yatani. 2017. Elasticplay: Interactive video summarization with dynamic time budgets. In Proceedings of the 25th ACM |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [30] | international conference on Multimedia . 1164-1172. DaYe Kang, Tony Ho, Nicolai Marquardt, Bilge Mutlu, and Andrea Bianchi. 2021. Toonnote: Improving communication in computational notebooks using interac- tive data comics. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems . 1-14. |
| [31] | Seanan Kelly and Charles Banaszewski. 2018. Using Screen Recording Platforms to Increase Instructor Presence in an Online Classroom. eLearn Mag. 2018 (2018), 11. https://doi.org/10.1145/3302261.3236715 |
| [32] | Mary Beth Kery and Brad A Myers. 2018. Interactions for untangling messy history in a computational notebook. In 2018 IEEE symposium on visual languages and human-centric computing (VL/HCC) . IEEE, 147-155. |
| [33] | Mary Beth Kery, Marissa Radensky, Mahima Arya, Bonnie E John, and Brad A Myers. 2018. The story in the notebook: Exploratory data science using a literate programming tool. In Proceedings of the 2018 CHI conference on human factors in computing systems . 1-11. |
| [34] | Kandarp Khandwala and Philip J Guo. 2018. Codemotion: expanding the design space of learner interactions with computer programming tutorial videos. In Proceedings of the Fifth Annual ACM Conference on Learning at Scale . 1-10. |
| [35] | Ada S Kim and Amy J Ko. 2017. A pedagogical analysis of online coding tutorials. In Proceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science Education . 321-326. |
| [36] | Thomas Kluyver, Benjamin Ragan-Kelley, Fernando Pérez, Brian E Granger, Matthias Bussonnier, Jonathan Frederic, Kyle Kelley, Jessica B Hamrick, Jason Grout, Sylvain Corlay, et al. 2016. Jupyter Notebooks-a publishing format for reproducible computational workflows. Elpub 2016 (2016), 87-90. |
| [37] | Sean Kross and Philip J Guo. 2019. Practitioners teaching data science in industry and academia: Expectations, workflows, and challenges. In Proceedings of the 2019 CHI conference on human factors in computing systems . 1-14. |
| [38] | Haotian Li, Lu Ying, Haidong Zhang, Yingcai Wu, Huamin Qu, and Yun Wang. 2023. Notable: On-the-fly Assistant for Data Storytelling in Computational Note- books. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . 1-16. |
| [39] | Yanna Lin, Haotian Li, Leni Yang, Aoyu Wu, and Huamin Qu. 2023. Inksight: Leveraging sketch interaction for documenting chart findings in computational notebooks. IEEE Transactions on Visualization and Computer Graphics (2023). |
| [40] | Shaofeng Lu, Ying Cheng, Xiaoyang Wang, Yang Du, and Eng Gee Lim. 2017. Exploring the effectiveness of student-generated video tutorials in electronic lab-based teaching. In 2017 IEEE Frontiers in Education Conference (FIE) . IEEE, 1-4. |
| [41] | Arnold MLund. 2001. Measuring usability with the use questionnaire12. Usability interface 8, 2 (2001), 3-6. |
| [42] | Nicole Luongo. 2015. Missing the chalkboard: Using screencasting in the online classroom. Computers in the Schools 32, 2 (2015), 144-151. |
| [43] | Laura MacLeod, Andreas Bergen, and Margaret-Anne Storey. 2017. Documenting and sharing software knowledge using screencasts. Empirical Software Engineer- ing 22 (2017), 1478-1507. |
| [44] | Blaine HMMooers. 2021. Modernizing computing by structural biologists with Jupyter and Colab. |
| [45] | Caroline E Morton, Sohag NSaleh, Susan F Smith, Ashish Hemani, Akram Ameen, Taylor D Bennie, and Maria Toro-Troconis. 2016. Blended learning: how can we optimise undergraduate student engagement? BMC medical education 16 (2016), 1-8. |
| [46] | Alok Mysore and Philip J Guo. 2017. Torta: Generating mixed-media gui and command-line app tutorials using operating-system-wide activity tracing. In Proceedings of the 30th Annual ACM Symposium on User Interface Software and Technology . 703-714. |
| [47] | Keith J O'Hara, Doug Blank, and James Marshall. 2015. Computational notebooks for AI education. (2015). |
| [48] | OpenAI. 2024. Prompt engineering. https://platform.openai.com/docs/guides/ prompt-engineering/prompt-engineering. |
| [49] | Adalbert Gerald Soosai Raj, Jignesh MPatel, Richard Halverson, and Erica Rosen- feld Halverson. 2018. Role of live-coding in learning introductory programming. In Proceedings of the 18th koli calling international conference on computing edu- cation research . 1-8. |
| [50] | Dhivyabharathi Ramasamy, Cristina Sarasua, Alberto Bacchelli, and Abraham Bernstein. 2023. Visualising data science workflows to support third-party note- book comprehension: an empirical study. Empirical Software Engineering 28, 3 |
| [51] | (2023), 58. Adam Rule, Ian Drosos, Aurélien Tabard, and James D Hollan. 2018. Aiding collaborative reuse of computational notebooks with annotated cell folding. Proceedings of the ACM on Human-Computer Interaction 2, CSCW (2018), 1-12. |
| [52] | Adam Rule, Aurélien Tabard, and James D Hollan. 2018. Exploration and expla- nation in computational notebooks. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems . 1-12. |
- [53] Robab Saadatdoost, Alex Tze Hiang Sim, Hosein Jafarkarimi, and Jee Mei Hee. 2016. Understanding the Setting of a MOOC: A Journey into Coursera. International Journal of Information and Communication Technology Education (IJICTE) 12, 1 (2016), 77-98.
- [54] Marija Sablić, Ana Mirosavljević, and Alma Škugor. 2021. Video-based learning (VBL)-past, present and future: An overview of the research published from 2008 to 2019. Technology, Knowledge and Learning 26, 4 (2021), 1061-1077.
- [55] Martin Schwichow, Corinne Zimmerman, Steve Croker, and Hendrik Härtig. 2016. What students learn from hands-on activities. Journal of research in science teaching 53, 7 (2016), 980-1002.
- [56] Murray Shanahan, Kyle McDonell, and Laria Reynolds. 2023. Role play with large language models. Nature 623, 7987 (2023), 493-498.
- [57] Leixian Shen, Enya Shen, Yuyu Luo, Xiaocong Yang, Xuming Hu, Xiongshuai Zhang, Zhiwei Tai, and Jianmin Wang. 2023. Towards Natural Language Interfaces for Data Visualization: A Survey. IEEE Transactions on Visualization and Computer Graphics 29, 6 (2023), 3121-3144.
- [58] Leixian Shen, Yizhi Zhang, Haidong Zhang, and Yun Wang. 2024. Data Player: Automatic Generation of Data Videos with Narration-Animation Interplay. IEEE Transactions on Visualization and Computer Graphics 30, 1 (2024), 109-119.
- [59] Pelle Snickars and Patrick Vonderau. 2009. The youtube reader . Kungliga biblioteket.
- [60] Clive Thompson. 2011. How Khan Academy is changing the rules of education. Wired magazine 126 (2011), 1-5.
- [61] Rebecca Tiarks and Walid Maalej. 2014. How does a typical tutorial for mobile development look like?. In Proceedings of the 11th Working Conference on Mining Software Repositories . 272-281.
- [62] Adiy Tweissi. 2016. The effects of embedded questions strategy in video among graduate students at a middle eastern university . Ph. D. Dissertation. Ohio University.
- [63] Julia Wagemann, Federico Fierli, Simone Mantovani, Stephan Siemen, Bernhard Seeger, and Jörg Bendix. 2022. Five guiding principles to make jupyter notebooks fit for earth observation data education. Remote Sensing 14, 14 (2022), 3359.
- [64] April Yi Wang, Anant Mittal, Christopher Brooks, and Steve Oney. 2019. How data scientists use computational notebooks for real-time collaboration. Proceedings of the ACM on Human-Computer Interaction 3, CSCW (2019), 1-30.
- [65] April Yi Wang, Dakuo Wang, Jaimie Drozdal, Michael Muller, Soya Park, Justin D Weisz, Xuye Liu, Lingfei Wu, and Casey Dugan. 2022. Documentation matters: Human-centered ai system to assist data science code documentation in computational notebooks. ACM Transactions on Computer-Human Interaction 29, 2 (2022), 1-33.
- [66] April Yi Wang, Zihan Wu, Christopher Brooks, and Steve Oney. 2020. Callisto: Capturing the" Why" by Connecting Conversations with Computational Narratives. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems . 1-13.
- [67] Chen-Wei Wang. 2019. Creating Tutorial Materials as Lecture Supplements by Integrating Drawing Tablet and Video Capturing/Sharing. In Proceedings of the 8th Computer Science Education Research Conference . 1-8.
- [68] Fengjie Wang, Yanna Lin, Leni Yang, Haotian Li, Mingyang Gu, Min Zhu, and Huamin Qu. 2024. OutlineSpark: Igniting AI-powered Presentation Slides Creation from Computational Notebooks through Outlines. In Proceedings of the CHI Conference on Human Factors in Computing Systems . 1-16.
- [69] Fengjie Wang, Xuye Liu, Oujing Liu, Ali Neshati, Tengfei Ma, Min Zhu, and Jian Zhao. 2023. Slide4N: Creating Presentation Slides from Computational Notebooks with Human-AI Collaboration. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . 1-18.
- [70] Jiawei Wang, Tzu-yang Kuo, Li Li, and Andreas Zeller. 2020. Assessing and restoring reproducibility of Jupyter notebooks. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering . 138-149.
- [71] Yun Wang, Zhitao Hou, Leixian Shen, Tongshuang Wu, Jiaqi Wang, He Huang, Haidong Zhang, and Dongmei Zhang. 2023. Towards Natural Language-Based Visualization Authoring. IEEE Transactions on Visualization and Computer Graphics 29, 1 (2023), 1222 - 1232.
- [72] YunWang,Leixian Shen, Zhengxin You, Xinhuan Shu, Bongshin Lee, John Thompson, Haidong Zhang, and Dongmei Zhang. 2024. WonderFlow: Narration-Centric Design of Animated Data Videos. IEEE Transactions on Visualization and Computer Graphics (2024), 1-15.
- [73] Zijie J Wang, Katie Dai, and W Keith Edwards. 2022. Stickyland: Breaking the linear presentation of computational notebooks. In CHI Conference on Human Factors in Computing Systems Extended Abstracts . 1-7.
- [74] Thomas Weeks and Jennifer Putnam Davis. 2017. Evaluating best practices for video tutorials: A case study. Journal of Library & Information Services in Distance Learning 11, 1-2 (2017), 183-195.
- [75] Nathaniel Weinman, Steven M Drucker, Titus Barik, and Robert DeLine. 2021. Fork it: Supporting stateful alternatives in computational notebooks. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems . 1-12.
- [76] Jason Wells, Robert Mathie Barry, and Aaron Spence. 2012. Using video tutorials as a carrot-and-stick approach to learning. IEEE transactions on education 55, 4 (2012), 453-458.
- [77] John Wenskovitch, Jian Zhao, Scott Carter, Matthew Cooper, and Chris North. 2019. Albireo: An interactive tool for visually summarizing computational notebook structure. In 2019 IEEE visualization in data science (VDS) . IEEE, 1-10.
- [78] Shir Yadid and Eran Yahav. 2016. Extracting code from programming tutorial videos. Proceedings of the 2016 ACM International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (2016). https: //doi.org/10.1145/2986012.2986021
- [79] Saelyne Yang, Sangkyung Kwak, Tae Soo Kim, and Juho Kim. 2022. Improving Video Interfaces by Presenting Informational Units of Videos. CHI'22 Extended Abstracts. Association for Computing Machinery (2022).
- [80] Saelyne Yang, Sangkyung Kwak, Juhoon Lee, and Juho Kim. 2023. Beyond Instructions: A Taxonomy of Information Types in How-to Videos. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . 1-21.
- [81] Saelyne Yang, Jisu Yim, Aitolkyn Baigutanova, Seoyoung Kim, Minsuk Chang, and Juho Kim. 2022. SoftVideo: Improving the Learning Experience of Software Tutorial Videos with Collective Interaction Data. In Proceedings of the 27th International Conference on Intelligent User Interfaces . 646-660.
- [82] Yue Yu, Leixian Shen, Fei Long, Huamin Qu, and Hao Chen. 2024. PyGWalker: On-the-fly Assistant for Exploratory Visual Data Analysis. In Proceedings of IEEE Visualization and Visual Analytics, IEEE VIS'24 . 1-5.
- [83] Chengbo Zheng, Dakuo Wang, April Yi Wang, and Xiaojuan Ma. 2022. Telling stories from computational notebooks: Ai-assisted presentation slides creation for presenting data science work. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems . 1-20.
## A PROMPT DESIGN
For these two tasks, we adhere to the following prompt engineering principles proposed by OpenAI [48]:
- (1) Include details in your query to get more relevant answers. By explicitly listing the key considerations, steps to complete the task, and output requirements in the task description, we assist the model in understanding and executing the task more accurately.
- (2) Ask the model to adopt a persona. We explicitly specify the role of the model in the prompt, aiding the model in better understanding the task's context and requirements, thereby providing more accurate and relevant answers. Through persona setting, the model can resonate better with the task's content and demands, enhancing the effectiveness and quality of task execution.
- (3) Use delimiters to clearly indicate distinct parts of the input. We employ clear delimiters and headings, such as ' Key Considerations ', and ' Steps to Complete the Task ', in the prompt. This aids the model in understanding and organizing the input information more clearly, thereby improving task efficiency and accuracy.
- (4) Specify the steps required to complete a task. We explicitly list the specific steps required to complete the task in the prompt, such as ' read and understand the sentences '. This provides clear operational guidance to the model, aiding in enhancing task execution efficiency and quality.
The detailed prompts designed for interaction with GPT-4 are presented below.
## A.1 Logic Flow Generation
```
// specify use steps required to compose a task. We expicuity is use specunc is the type resource to compose the task in the moc prompt, sucun as
"read and understand the sentences". This provides clear operational guidance to the model, aiding in enhancing task execution efficiency
and quality.
The detailed prompts designed for interaction with GPT-4 are presented below.
A.1 Logic Flow Generation
{
"role": "system", "content":
"""
# Task Details
**Objective**:
You are a code analyst. Your task is to analyze the logic flow within a series of notebook cells to
construct a comprehensive representation of the computational logic. This involves identifying
the purpose and functionality of each cell, the inputs it relies on, and the outputs it generates
.
**Key Considerations**:
- Understand the specific role of each notebook cell within the overall computational process.
- Identify the inputs required by each cell and the outputs it produces.
- Recognize any dependencies between cells, noting how the output from one cell might serve as input
to another.
**Steps to Complete the Task**:
1. Examine each notebook cell to discern its primary function and role in the notebook's logic flow.
2. Catalog the inputs each cell uses, which may include data files, variables from previous cells, or
user inputs.
3. Determine the outputs each cell generates, such as data transformations, visualizations, or
results.
4. Construct a logic flow representation, organizing this information into a structured format.
**Output Requirements**:
- Provide the logic flow representation in JSON format.
- Represent each cell as an object within the JSON structure, including the following key-value pairs
:
- `id`: A unique identifier for each cell (starting from 0, incrementing by 1 for each subsequent
cell).
- `description`: A brief explanation of the cell's purpose and functionality.
- `inputs`: A list of the inputs the cell uses.
- `outputs`: A list of the outputs the cell produces.
**Attention**:
Ensure that the JSON representation accurately reflects the sequence and dependencies of the notebook
cells, offering clear insights into the notebook's computational logic.
----
# Output Example
----
[
{"id": 0, "description": "Load dataset", "inputs": ["data.csv"], "outputs": ["raw_data"]},
```
```
{"id": 1, "description": "Clean data", "inputs": ["raw_data"], "outputs": ["cleaned_data"]},
...
]
...
"""
}
```
## A.2 Narration Generation
```
{"id": 1, "description": "Clean data", "inputs": ["raw_data"], "outputs": ["cleaned_data"]},
...
]
...
"""
}
A.2 Narration Generation
{
"role": "system", "content":
"""
# Task Details
**Objective**:
As a code_interpreter, your mission is to generate narrations for notebook cells, particularly
focusing on user-highlighted code snippets ("emphasis" elements) and their corresponding
annotations. A key part of your role is to weave these individual narrations into a coherent
overall narrative that reflects the interconnected functionality of the notebook cells.
**Key Considerations**:
- Integrate user-highlighted code snippets and annotations into the narrations, providing depth and
insight into specific functionalities.
- Ensure coherence among cell narrations, understanding the function of each cell in relation to
others, to maintain a seamless narrative flow across the notebook.
- Reflect both the technical essence of each cell and the user's perspective, enhancing the narrative
with insights into why certain code snippets are emphasized.
**Inputs for Each Cell**:
- **Code Snippet**. The specific portion of code highlighted by the user as significant.
- **Annotation**. The user's explanation for highlighting this snippet, offering additional context
or importance.
**Steps to Complete the Task**:
1. For each notebook cell, identify the emphasized code snippet(s) and the corresponding user
annotations.
2. Crick at detailed narration for the cell that not only explains its specific functionality but also
incorporates the user's emphasis, providing a richer understanding of its role.
3. In generating narrations, consider the functions of adjacent cells to ensure that your narrative
offers a coherent explanation of how each cell contributes to the notebook's overall logic flow.
4. Assemble the individual narrations into a structured format that reflects the interconnectedness
and sequence of the notebook cells, enhancing narrative flow.
**Output Requirements**:
- Narrations should be formatted in JSON, with each object representing a cell's narration and
including:
- `id`: The unique identifier for the cell.
- `narration`: The cell's detailed explanation, integrating the emphasized code snippets and
annotations.
- `inputs`: The emphasis elements and annotations guiding the narration.
- The narrations must collectively offer a coherent narrative across the notebook, elucidating the
interconnected functionality of the cells.
**Attention**:
It's crucial that the narrations not only individually explain the functionality of each cell but
also collectively contribute to a coherent narrative of the notebook's computational logic. This
involves understanding the broader context in which each cell operates and how they interrelate.
-----
# Output Example
...
[
{
```
```
UIST 24,October 13-16,2024,Pittsburgh,PA,USA
``` | 10.1145/3654777.3676410 | [
"Yang Ouyang",
"Leixian Shen",
"Yun Wang",
"Quan Li"
] | 2024-08-02T08:25:49+00:00 | 2024-08-02T08:25:49+00:00 | [
"cs.HC"
] | NotePlayer: Engaging Jupyter Notebooks for Dynamic Presentation of Analytical Processes | Diverse presentation formats play a pivotal role in effectively conveying
code and analytical processes during data analysis. One increasingly popular
format is tutorial videos, particularly those based on Jupyter notebooks, which
offer an intuitive interpretation of code and vivid explanations of analytical
procedures. However, creating such videos requires a diverse skill set and
significant manual effort, posing a barrier for many analysts. To bridge this
gap, we introduce an innovative tool called NotePlayer, which connects notebook
cells to video segments and incorporates a computational engine with language
models to streamline video creation and editing. Our aim is to make the process
more accessible and efficient for analysts. To inform the design of NotePlayer,
we conducted a formative study and performed content analysis on a corpus of 38
Jupyter tutorial videos. This helped us identify key patterns and challenges
encountered in existing tutorial videos, guiding the development of NotePlayer.
Through a combination of a usage scenario and a user study, we validated the
effectiveness of NotePlayer. The results show that the tool streamlines the
video creation and facilitates the communication process for data analysts. |
2408.01102v1 | ## LessonPlanner : Assisting Novice Teachers to Prepare Pedagogy-Driven Lesson Plans with Large Language Models
Haoxiang Fan [email protected] Sun Yat-sen University Guangzhou, China
Guanzheng Chen [email protected] Sun Yat-sen University Guangzhou, China
Xingbo Wang [email protected] Cornell University New York, NY, United States
## ABSTRACT
Preparing a lesson plan, e.g., a detailed road map with strategies and materials for instructing a 90-minute class, is beneficial yet challenging for novice teachers. Large language models (LLMs) can ease this process by generating adaptive content for lesson plans, which would otherwise require teachers to create from scratch or search existing resources. In this work, we first conduct a formative study with six novice teachers to understand their needs for support of preparing lesson plans with LLMs. Then, we develop LessonPlanner that assists users to interactively construct lesson plans with adaptive LLM-generated content based on Gagne's nine events. Our within-subjects study ( 𝑁 = 12) shows that compared to the baseline ChatGPT interface, LessonPlanner can significantly improve the quality of outcome lesson plans and ease users' workload in the preparation process. Our expert interviews ( 𝑁 = 6) further demonstrate LessonPlanner 's usefulness in suggesting effective teaching strategies and meaningful educational resources. We discuss concerns on and design considerations for supporting teaching activities with LLMs.
## CCS CONCEPTS
· Human-centered computing → User interface toolkits ; · Computing methodologies → Natural language generation ;
- · Applied computing → Computer-assisted instruction .
## KEYWORDS
Large language models, lesson plan preparation, pedagogy-driven system
∗ Corresponding author.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected].
UIST '24, October 13-16, 2024, Pittsburgh, PA, USA
© 2024 Copyright held by the owner/author(s). Publication rights licensed to ACM.
ACM ISBN 979-8-4007-0628-8/24/10...$15.00
https://doi.org/10.1145/3654777.3676390
## Zhenhui Peng ∗
[email protected] Sun Yat-sen University Guangzhou, China
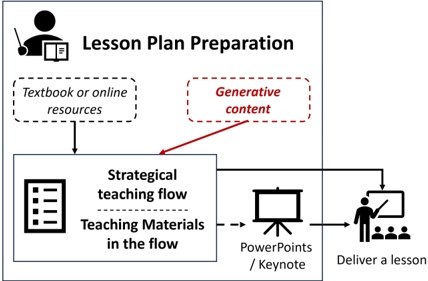
Figure 1: An example lesson plan preparation process. We build an interactive system LessonPlanner to assist teachers with generated content to prepare a documented lesson plan, which can be optionally transformed into slides by users and delivered in their courses.
## ACMReference Format:
Haoxiang Fan, Guanzheng Chen, Xingbo Wang, and Zhenhui Peng. 2024. LessonPlanner : Assisting Novice Teachers to Prepare Pedagogy-Driven Lesson Plans with Large Language Models. In The 37th Annual ACM Symposium on User Interface Software and Technology (UIST '24), October 1316, 2024, Pittsburgh, PA, USA. ACM, New York, NY, USA, 20 pages. https: //doi.org/10.1145/3654777.3676390
## 1 INTRODUCTION
Effective teaching often stems from a well-prepared and organized lesson plan [67], which serves as a teacher's detailed description of the course of instruction or learning [36]. In this paper, we focus on the process of preparing a documented plan that normally describes the teaching flow and materials [49] for each lesson ( e.g., 45-minute or 90-minute). Such a documented plan can serve as the basis for users to optionally create slides in PowerPoint or Keynote to deliver the lesson, or to be directly used as speaking notes in the class (Figure 1). However, constructing an effective lesson plan could be challenging for teachers, especially those who are novices or teaching a course for the first time [56]. For one thing, novice teachers lack experience in delivering a course using effective strategies [6, 23], e.g., Gagne's Nine Events of Instruction [28], which
helps teachers to prepare and deliver instructional content while considering and addressing the students' conditions, like gaining attention and presenting a stimulus at the beginning of a class. For another, even when novice teachers have a mind of planning an event or activity ( e.g., in-class exercises) at a certain time of a course, they could face difficulties in curating relevant materials to execute the activity [23, 59, 61]. As a common practice, novice teachers often refer to others' lesson plans and search related materials in textbooks or online [59]. Nevertheless, these traditional approaches could be limited by the diversity of referred materials and the ability to support teachers in adapting the content in the lesson plan based on their personal thoughts.
Recent advances in large language models (LLMs) show great potential to address these challenges in composing a lesson plan by suggesting in-situ-generated content that adapts to teachers' thoughts. In fact, many teachers have explored the usage of LLMs to prepare for their lectures [47, 48]. For example, Mollick and Mollick [48] suggested the prompts to LLMs to implement effective teaching strategies in the classroom, such as providing diverse examples to help students comprehend abstract concepts and collecting test questions to help students assess their knowledge. However, querying the LLMs in the wild, e.g., via the web app of ChatGPT, could lead to a fragmented lesson plan because of the difficulties in organizing all of the LLM outputs. More importantly, due to the lack of experience in teaching and guidance for prompting, the generated content may not be comprehensive and readily usable, thereby requiring iterative refinement [3, 9, 38]. There is a need to build an interactive system with customized features to ease the process of adopting LLMs to prepare a comprehensive lesson plan. Nevertheless, little is known about what are the design requirements for such a lesson planning system, how LLMs can help to satisfy these requirements, and how would teachers perceive and collaborate with the system.
In this paper, we introduce LessonPlanner 1 , an interactive system that offers pedagogy-driven generated content to assist users in constructing lesson plans. We first conduct interviews with six participants, including three novice teachers and three teaching assistants in the universities, to understand their challenges and needs for support when using LLMs to prepare lesson plans. The findings reveal users' demands for the generated content that aligns with effective teaching strategies and flexible interactions with LLMs. Based on the derived design goals from the interviews, we build LessonPlanner as a web app powered by the LLM GPT-4.0. In LessonPlanner , users can first input basic course information ( e.g., course name, topic of one lecture) to generate an outline of the lesson plan with teaching strategies suggested by Gagne's nine events [28]. Then, for each section of the outline, users can extend it with user-specified LLM-generated activities belonging to each instructional event to get suggested teaching materials, and they have the option to customize the materials via prompts. At any time of the lesson plan preparation process with LessonPlanner , users can select any content to ask the LLM to explain it and freely query the LLM about anything, including knowledge delivery strategies and presentation suggestions for creating slides.
1 https://github.com/fanhaoxiang1/LessonPlanner
We first evaluated LessonPlanner via a within-subjects study in which twelve graduate students or senior undergraduates act as teachers and prepare lesson plans for their familiar course topics. The results showed that LessonPlanner can significantly improve the quality of outcome lesson plans and ease users' workload in the preparation process. We further conducted expert interviews with five novice teachers (who have less than three years of teaching experience) and one experienced teacher across various educational stages and subjects. Experts further demonstrated that LessonPlanner is useful in lesson planning because it offers a well-organized outline and inspiring content. We discuss the concerns and implications of our study on facilitating users in teaching activities with LLMs.
In summary, this paper has three main contributions. First, we present LessonPlanner , an interactive system that leverages generated content to assist teachers in preparing lesson plans. Second, via a within-subjects study and an interview study, we offer empirical evidence on LessonPlanner 's effectiveness and usefulness in helping novice teachers prepare lesson plans. Third, based on our findings, we offer design implications for future systems that use large language models to assist teachers.
## 2 RELATED WORK
## 2.1 Preparation of Lesson Plans
A lesson plan is the instructor's road map of what students need to learn and how it will be done effectively during class time [49]. A carefully constructed lesson plan allows teachers to enter the classroom with more confidence and achieve effective teaching outcomes of their courses [31, 32]. As suggested by the CIPP (Context, Input, Process, and Product) evaluation model [63], an effective lesson should be needs-oriented, resource-adequate, systematically executed, and outcome-focused. A carefully constructed lesson plan can reveal the first two aspects of the CIPP model [5], that is, goals aligned with subject and societal demands as Context and a well-organized content plan as Input.
However, teachers, especially those who are novices or teach a course for the first time, could find it difficult to construct a welldesigned lesson plan. For example, they may need to spend a lot of time writing a lesson plan from scratch [23], finding high-quality resources related to the lesson [6, 59], and thinking of the strategies to teach each knowledge concept [23]. Researchers have explored various methods that can assist in the preparation of lesson plans. They have tried using knowledge graphs [16, 56, 58] and recommendation systems [17] to integrate existing web resources, which could make it convenient for teachers to find needed teaching materials. For example, CollectiveTeach [56] retrieves and collects documents related to a specific topic based on a particular optimization objective, and then rearranges the documents into a coherent lesson plan. They have also proposed a variety of lesson planning systems [4, 15, 17, 50, 62, 72]. For instance, Pender et al. [50] have developed the CLEVER digital web platform, which includes Didactic Guidance, Content Management, Platform Services, and the Data section. It assists users in selecting existing content from the platform's library or in creating new content. Zain [72] also proposed CIDS (Collaborative Instructional Design System), a lesson
plan design system aimed at assisting teachers in designing and implementing the requirements of 21st-century learning, integrating features of the ASIE (Analyze, Strategize, Implement, and Evaluate) Instructional Design Model and the Professional Learning Community. Nevertheless, these previous approaches and systems largely rely on existing high-quality teaching resources related to the lessons, while such resources may not always be available for any lesson that the teachers want to deliver.
Our work is motivated by the benefits of preparing a carefully constructed lesson plan and is aligned with previous work that aims at easing this preparation process. Different from previous work, we explore the usage of machine-generated content to assist lesson plan preparation.
## 2.2 Large Language Models in Education
Researchers have started to explore the usage of large language models (LLMs) in educational settings due to their ability to provide personalized, efficient, and engaging learning and teaching experiences [46]. For learners, depending on a student's needs and learning style, LLMs are able to create self-study and self-assessment materials [18, 55], such as knowledge flashcards or course-specific questions [8, 10, 24, 27]. For example, since ChatGPT demonstrated strong insights in explaining medical questions without any additional training [39], Divito et al. [24] have utilized it to support medical learners in problem-based learning. Furthermore, LLMs have the capability to encourage students to think critically [1] e.g., by creating chatting chances during learning and adding suitable problems if needed [22].
For teachers, LLMs can help to automate the knowledge assessment process and provide personalized feedback to students [7, 69]. Additionally, teachers can get support from generated teaching materials including varied examples, instruction notes [11], explanations [48], post-class exercises [60], a list of frequently asked questions [45], and so on. For instance, Mitra et al. [45] proposed a system named RetLLM-E that assists educators in acquiring frequently asked questions from students related to their courses and in generating responses. The system initially retrieves context from student questions previously answered by teachers on a forum and from related course materials. It then uses this information to prompt LLMs to generate specific, high-quality, and precise answers to students' questions, which generally have a better quality than other available answers on the forum.
Despite the promising potential, few works have explored using LLMs to help teachers prepare their lesson plans. In this paper, we will first work with six novice teachers to understand their opinions about using LLMs for preparing lesson plans and identify their needs for support.
## 2.3 Interactive Systems that Supports Users with Large Language Models
Human-Computer Interaction (HCI) researchers have proposed a bunch of interactive systems that leverage LLMs to improve the efficiency and user experience in various tasks, such as group decision making [19, 29], software engineering [42, 51], humanUI interaction design [65], and so on. Specifically, many HCI researchers have embedded LLMs in their systems to support cowriting tasks [33, 35, 40, 44, 52], which is similar to our setting of co-writing a lesson plan with LLMs. For example, Lee et al. [40] developed CoAuthor and conducted a user study, which highlighted that co-writing with LLMs can aid users by enhancing fluency, pooling ideas, and improving writing quality. Wordcraft [71] consists of an editor and some buttons used to call an LLM to generate various kinds of content. Compared with using a chatting interface, users find out this tool is more helpful and collaborative [71]. This finding inspires our design by replacing the chat box with simple pre-set buttons. Furthermore, Jamplate [70] is an idea reflection system that integrates LLM responses into the templates originated from the traditional reflection theory. It is shown that the well-organized generated content helps users a lot in expanding and refining their ideas [70]. Just like Jamplate does, we integrate education theory into our system to structure LLM responses in a lesson plan template.
We contribute an interactive system LessonPlanner that is in line with these previous interactive systems and offer insights into how LLMs can facilitate lesson plan preparation.
## 3 FORMATIVE STUDY
This study aims to help novice teachers design lesson plans in an efficient way and get high-quality outcomes. To achieve this, we conduct a formative study with six novice teachers or teaching assistants. The insights from the study will inform the design goals for LessonPlanner . The participants, with a mean age of 29.83 ( 𝑆𝐷 = 5 15), include three females and three males, and we note as P1 . to P6. Half of them (P2, P5, P6) are novice teachers with less than three years of teaching experience, and the other half are teaching assistants (P1, P2, P4) who have taught undergraduate students during one to three academic terms. Four of the participants teach courses related to computer science, while P1 teaches Architecturerelated courses and P5 teaches Korean Intensive Reading.
## 3.1 Pedagogies for Lesson Planning
Before the interviews, we prepared three educational theories usually used to guide teachers in preparing structured lesson plans, which have proven to be effective [2, 53, 57]. They are easy to implement in the system to assist teachers in designing lesson plans. Bloom's Taxonomy is a hierarchical classification of cognitive skills that educators use to structure curriculum learning objectives, assessments, and activities, ranging from lower-order thinking skills like remembering, understanding, and applying, to higher-order skills like analyzing, evaluating, and creating. Kolb's Learning Cycle is a four-stage model of experiential learning that emphasizes the process of learning through experience, consisting of concrete experience, reflective observation, abstract conceptualization, and active experimentation. Gagne's Nine Events of Instruction involve the actions of both teachers and learners throughout the teaching process [37]. The nine events include: Gaining Attention : Present introductory activities that engage learners; Informing Learners of Objectives : Clearly state the learning goals and
outcomes; Stimulating Recall of Prior Learning : Encourage learners to remember and connect previous knowledge; Presenting Stimulus : Introduce new content and information; Providing Learner Guidance : Offer instructions and strategies to help learners understand and process the new content; Eliciting Performance : Have learners practice what they have learned; Providing Feedback : Give constructive feedback on learners' performance; Assessing Performance : Evaluate learners' understanding and skills; Enhancing Retention and Transfer : Use activities that help learners retain information and apply it to new situations. The nine events and corresponding activities prepared for the discussion in the formative study are summarized in Table 1. Each event may occur sequentially in a class as described above, but they can also be repeated to better organize the instructional content.
## 3.2 Procedure
To assist novice teachers in solving the difficulties in lesson planning and offer a better user experience, we conduct a two-phase formative study to comprehensively understand the users' needs. Initially, the participants are involved in semi-structured interviews. A set of questions is presented, and they are encouraged to express their viewpoints. The discussions are intended to investigate the processes involved in creating their ways of routine lesson plan creation ( e.g., 'Do you typically design instructional notes or slides for a 90-minute class?', 'Where do you like to access related materials when developing lesson plans?'), the potential of integrating the three educational theories (introduced in subsection 3.1) into a lesson plan ( e.g., 'Do you agree that Gagne's Nine Events can effectively guide instruction?'), and the challenges encountered during the design process ( e.g., 'What challenges do you face during this process?'). Furthermore, we specifically investigate their perspectives regarding LLMs such as ChatGPT in the design of lesson plans. Each interview has a duration of around 45 minutes in this phase.
Subsequently, they are invited to participate in a co-design session aimed at exploring and evaluating various interface designs. The objective is to identify the user interface requirements for a system designed for lesson plan design. Four slide decks (shown in Appendix A) are presented to participants, featuring example designs. These include a page for input meta-data of class, an outline overview page, and two editing pages with LLMs in different forms. Participants are provided with the ability to resize and crop screenshots, draw shapes, and use text boxes for the purpose of designing. One author assists with sketching by making edits based on participants' responses. We also ask questions to provide more detailed explanations of their ideas or explore different design options. Each participant spends about 15 minutes in this session.
## 3.3 Findings
We use the reflexive thematic analysis method [12] to analyze the transcribed recordings of each participant's semi-structured interviews and co-design sessions. All mentioned that they primarily prepared a lesson plan for a lecture in the form of PowerPoint slides. P2 said that he sometimes chose to annotate some text in the slides or textbook to remind themselves of extra information, such as proof of formulas or supplemental examples. Except for
P2, no participants reported that they left notes under the slides or in a separate paper as a reminder of critical information during the lecture, such as the logic of proof and supplemental examples. Nevertheless, they all agreed that having a word-like document to list the main flow and content of a lecture was helpful, as they could 'easily build up slides based on the documented lesson plan' (P6). We summarize the participants' challenges in lesson plan preparation and using large language models (LLMs) to assist the preparation as below.
## 3.3.1 Challenges in Lesson Plan Preparation. C1. Lack of adaptive support in planning effective teaching strategies in the
lessons. All participants said that they mostly relied on their teaching experience and others' plans to design their teaching strategies in a lesson. Nevertheless, after we introduced Gagne's Nine Events of Instruction (the list of the events is shown in Table 1), all participants agreed that they actually adopted some of the events in their lectures. 'I did not get official training on educational or teaching theories, but I found that I had enacted several strategies in the suggested events of instruction. These nine events will be generally helpful in my course' (P2). Compared to the other two theories mentioned in subsection 3.1, two participants ( i.e., P1, P2) confirmed that Gagne's theory was more feasible to be embedded in the system because 'it is relatively more specific and provides teachers with comprehensive guidelines' (P2). Furthermore, four participants ( i.e., P1, P3, P4, and P6) with insufficient teaching experience further mentioned that they would like to exercise all the nine events in their lectures but they lack adaptive support in incorporating these events into a specific lesson. 'I would like to try the suggested 'gaining attention' and 'providing learner guidance', but the example usages of these strategies could not be directly adopted in my Experiments of Data structures course' (P1).
C2. Time-consuming process in searching for adequate teaching materials. All participants indicated that preparing for a lesson, especially the one they taught for the first time, is a timeconsuming process, where they spent most of the time preparing the teaching materials. 'I usually need to spend a considerable amount of effort finding and determining the proper materials that support the teaching activities in my course, e.g., finding a good case to illustrate the real-world application of the taught concepts' (P5). Even though they can get started from textbooks or others' lesson plans, all participants expressed their desire to customize the teaching flow and materials based on their thoughts. As such, they spent time looking for related high-quality materials online or creating needed materials by themselves. 'I was used to prepare an in-class exercise after explaining a key concept. I normally search for suitable exercises online but the returned results were often disorganized or unrelated. I had to pay a lot of attention to identify the ones I need' (P1).
## 3.3.2 Challenges on Using LLMs in Lesson Plan Preparation. C3.
High mental demand in manipulating prompts to get related content. Three participants (P3, P4, and P6) had experiences using LLMs (Specifically, ChatGPT) to prepare for their lessons. For example, P3 reported that she had used ChatGPT to generate precise answers to the questions that students may ask when delivering knowledge points. The others also see the potential of using LLMs
to generate suggestions on the teaching flow and materials based on their needs. However, P5 and P6 commented that it was or would be mentally demanding to think of the prompts for LLMs to get needed content. 'Searching for information directly seems more efficient than querying ChatGPT with specific questions.' (P6). ' If LLMs cannot provide satisfying materials for me instantly, I prefer not to engage in back-and-forth dialogue to refine the results' (P5).
C4. Distrust of the usefulness of generated content . Except for P3, the remaining five participants conveyed a sense of distrust toward the outputs of the LLM. On one hand, some (P2, P5, P6) doubted the accuracy of the content. 'I don't trust the detailed content generated by LLMs, and I would definitely double-check it before using it. Therefore, I generally only use LLMs to create a rough outline, and I search for the specific content myself' (P1). On the other hand. some (P1, P2, P6) have raised concerns about the expertise of LLMs in specific subjects, suggesting that they may struggle to generate useful content. 'ChatGPT can generate many correct questions, but that doesn't mean they are good questions in this course (Computer Graphics). Because it may lack a deep understanding of the subject' (P6).
## 3.4 Users' Preference on the Interface
During the co-design phase, all participants reached a consensus that the layout of our outline overview page, which organizes the outline into distinct blocks based on the generated subtitles, was a good design. P4 advised that 'the instructional events are important cues for me, and they should be more eye-catching.' . For the course metadata collection page, P2 questioned that 'the available data input was excessively restricted. I believe it is necessary to enter the course designed for graduate or undergraduate students. Without this information, how can the system accurately determine the specific type of content to generate?' Moreover, participants were requested to compare the LLM assistant interface integrated within the editor as opposed to a sidebar interface. P1, P2, P3, P5, and P6 expressed a preference for the LLM as a sidebar. 'It resembled common design practices' (P3).
## 3.5 Teachers' Needs for Generated Content in Lesson Plans
Table 1 summarizes the particular instructional activities our participants commonly incorporate during each of Gagne's Nine Events in the classroom. Additionally, we ask their perspectives on the capacity of LLMs to contribute to the development of materials for the activities they have mentioned in each interview. The results are displayed in the third column of Table 1, with 'Y' if they think the LLMs can facilitate the activity and 'N' if they can not. The results indicate that, with the exception of subject-specific activities (e.g., providing source code, providing example sentences), most teachers organize comparable activities for a particular instructional event. For the majority of classrooms, LLM can help teachers in creating relevant instructional materials. This highlights the potential of LLMs to serve as assistants in lesson planning.
## 3.6 Design Goals of LessonPlanner
Our participants actively offered suggestions on the design of LessonPlanner to address their challenges. Based on their suggestions and related work, we derive the following four design goals (DGs) of LessonPlanner .
DG1: LessonPlanner should encourage and facilitate teachers to apply effective teaching strategies in the planned lessons. Due to the insufficient adaptive support provided by teachers in lesson planning for the development of effective teaching strategies (C1), LessonPlanner to motivate and assist teachers in applying efficient teaching strategies, especially those who lack experience in teaching.
DG2: LessonPlanner should generate high-quality materials adapted to the planned teaching activities and provide guidance on how to deliver these materials. The process of searching for suitable teaching materials is time-consuming (C2). Hence, LessonPlanner is expected to produce high-quality materials that are in line with the teaching activities and offer suggestions on how to effectively deliver these materials in the classroom.
DG3: LessonPlanner should offer pre-set prompts about what users often want to ask the large language models for. The utilization of LLMs for lesson planning requires a high cognitive load (C3). Therefore, LessonPlanner offers pre-set prompts to assist users in getting materials more efficiently from LLMs.
DG4: LessonPlanner should provide flexible user control for interacting with the large language models and editing the lesson plans. Granting users the autonomy to select their preferred method of managing the content generated by LLMs, and to discard, modify, or regenerate it as needed, can mitigate users' distrust towards LLMs (C4).
## 4 LESSONPLANNER
In this subsection, we present the design and evaluation of LessonPlanner , an interactive system that supports novice teachers to create lesson plans with large language models (LLMs). LessonPlanner is designed as a web application. The front end is implemented using Vue 3 and JavaScript, while the back end is created with Python FastAPI. Furthermore, we opt to utilize the OpenAI gpt-4-1106preview as the LLM to provide generated content in LessonPlanner . The front end is in Chinese, so the Edge translation plugin was utilized to translate the website in order to present the illustrations in this chapter.
We carefully designed LessonPlanner 's interface and interaction based on the design goals obtained from the formative study. To plan a lesson with LessonPlanner , users can engage with the LLM to set teaching objectives to adhere to Bloom's Taxonomy [25] and generate an initial outline of the lesson plan conditioned on Gagne's Nine Events (DG1, Figure 2). For each section in the outline, users can see suggested teaching materials and strategies to enact this event (DG2, Figure 3: C1, D2). Based on the identified teachers' needs for generated content in lesson plans in formative study, LessonPlanner presets some activities for each event about what users often want to ask the LLM for (DG3, D1, D2). Besides, LessonPlanner also offers users flexible options to regenerate the content of an event and copy it to the editor (D), freely edit the content (Figure 4: E, F), select wanted events (Figure 5), check the
Figure 2: Goal-setting page of LessonPlanner , with the illustration of the process of refining lesson goals with LLMs. The text in parentheses serves as a correction to the mistranslated output.
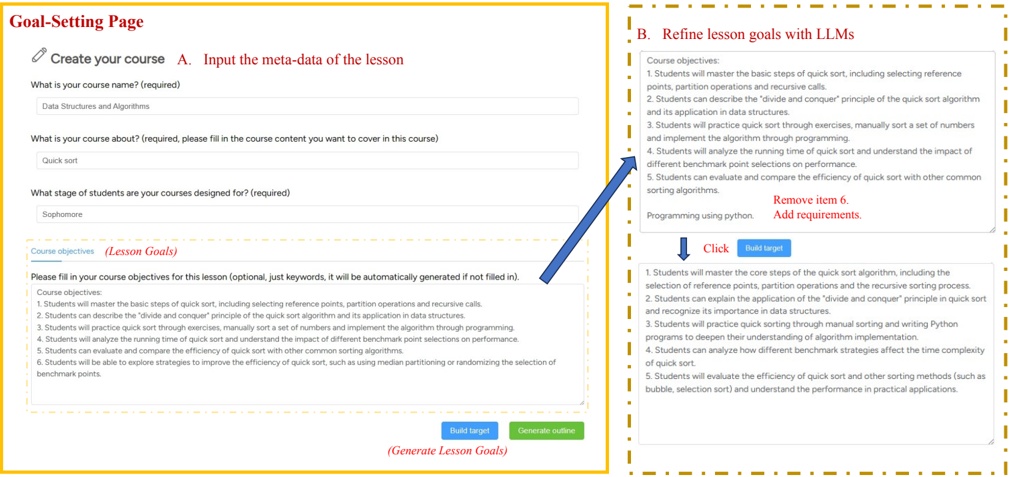
Figure 3: The lesson-planning interface for LessonPlanner . The text in parentheses serves as a correction to the mistranslated output.
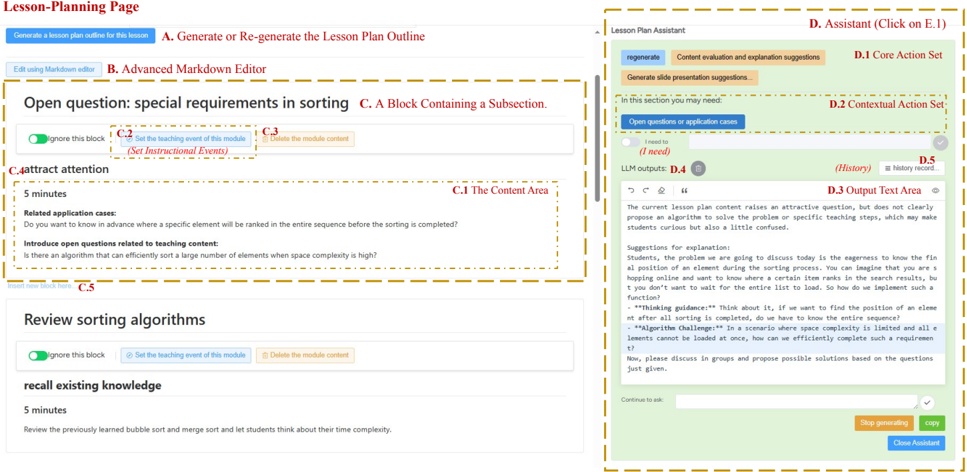
Table 1: Nine events of Gagne's instructional theory and the activities that our participants in the formative study suggest to use in each event. Participants also share their opinions on whether (Yes or No) LLMs are able to help them in each activity. In LessonPlanner , we have preset template prompts to LLMs for most of the suggested activities.
| Gagne's Event | Common activities or resources in this event | LLMs facilitated | Implemented |
|------------------------------------|----------------------------------------------------------|--------------------|---------------|
| Gain attention | Pose open-ended questions or case studies | Y | Y |
| | Create ordered lists of knowledge points | Y | Y |
| Inform learners of objectives | Display table of contents in slide | Y | Y |
| | Compile prerequisite knowledge list | Y | Y |
| Stimulate recall of prior learning | Provide prerequisite knowledge examples | Y | Y |
| | Provide the definition | Y | Y |
| | Provide algorithms | Y | Y |
| Present stimulus | Provide source code | Y | Y |
| | Provide equations | Y | Y |
| | Provide a example sentence | Y | N |
| | Explain examples in detailed | Y | Y |
| Provide learner guidance | Design animations in PowerPoint | N | - |
| | Play videos | N | - |
| | Construct multiple choice or fill-in-the-blank questions | Y | Y |
| Elicit performance | Propose open-ended questions | Y | Y |
| | Construct group discussion topics | Y | Y |
| Provide feedback | Offer problem solutions | Y | Y |
| Assess performance | Assign homework | Y | Y |
| | Assign Projects as homework. | Y | Y |
| Enhance Retention and Transfer | Select topics for writing papers | Y | N |
history of generated content (Figure 4: G), and so on (DG4). In the following subsections, we will detail the design and implementation of the key features in LessonPlanner .
## 4.1 Goal-Setting Page
As shown in Figure 2A, on the goal-setting page, users need to input the course name ( e.g., Data Structures), the topic of the planned lesson ( e.g., Quick Sort), and the specific stage of the lesson tailored for ( e.g., Sophomore (2nd-year undergraduate)). This meta information is utilized by LessonPlanner in all predefined prompts to facilitate content generation.
Users can input their lesson goals, or, in a more convenient way, click the 'Generate Lesson Goals' button to first check the generated goals conditioned on Bloom's Taxonomy. They can then modify the generated goals, e.g., remove item 6 and add requirements like 'programming using python' (Figure 2: B), and click the 'Generate Lesson Goals' again to iterate the design goals with LLM. Once users are satisfied with the lesson goals, they can click on the 'Generate outline' button, which will initialize a lesson plan outline conditioned on Gagne's Nine Events. Users now can proceed to the Lesson-Planning page (Figure 3), as described in the next subsection.
## 4.2 Lesson-Planning Page
4.2.1 Interactive block-based lesson plan outline. The generated lesson plan outline is displayed in the form of block-based interactive markdown text (Figure 3: C). In each block, the editable h1 heading, e.g., 'Open question: special requirements in sorting', is a summary of the content in one section in the planned lesson. Each section contains one or more suggested events (C4) that teachers can plan in this section. The events are sourced from Gagne's Nine Events and separated by editable h2 headings ( e.g., 'attract attention') with an h3 heading ( e.g., 5 minutes) indicating the planned time for this event. In each section, there are related teaching materials and strategies, e.g., Related application cases 'Do you want to know in advance where a specific element will be ranked in the entire sequence before the sorting is completed?'. As a lesson may not necessarily cover all of the suggested sections and may include other sections the users need, users have the options to ignore or specify needed sections, delete the section (C3), insert a new block, and specify the title of a new section at any location (C5). Users can also regenerate the lesson plan outline (A), e.g., if they are not satisfied with the current one.
Users can click the content area (Figure 3: C1) of each block to invoke the editing mode of this section (Figure 4: E) or click the 'Edit using Markdown editor' button to invoke an advanced Markdown editor of all content in the lesson plan (Figure 4: H). The editor provides features like 'bold', 'headings', and 'lists' that common editors have. Upon finishing the edition of the lesson plan, users can click the 'Download Lesson Plan' button (not shown in Figure 3) at the bottom of the Lesson Planning page to download the lesson plan as a markdown file.
4.2.2 LLM assistant. In the markdown editor of each blocked section (Figure 4: E), users can click the 'Open the lesson plan assistant' button (Figure 4: E1) to invoke the LLM assistant in the sidebar
Figure 4: The subsequent changes or pop-up windows triggered by clicking a button on Figure 3.
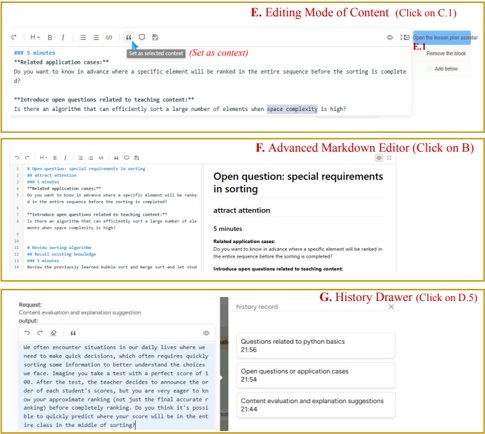
Figure 5: The process of setting instructional events by users in the lesson-planning interface.
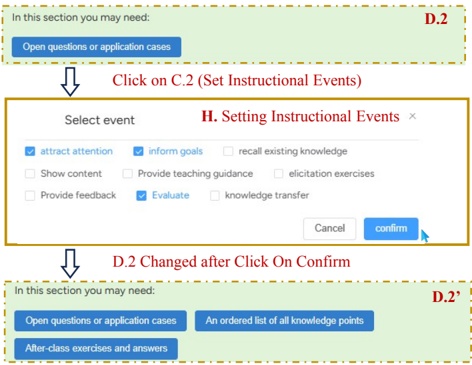
(Figure 3: D) that helps users refine the content in this section. The assistant includes a Core Action set (D1), Contextual Action set (D2), and Output Area (D3). The Core Action set contains a collection of preset buttons designed to call functions that regenerate the content in this section, evaluate the content give instructional suggestions, and advice on presenting it, and give suggestions on making a slide based on it. The Contextual Action set consists of buttons that list all the preset activities of events (C4) under this section. Table 1 displays the implemented activities for each event in our system, derived from the results of the User Study, excluding activities that were difficult to implement because of the needed various prompts in different subjects. If clicking on 'Set Instructional Events' (Figure 3: C2) to change events in the current section (Figure 5: F), the activities in the Contextual Action set will also change (Figure 5: D2 change into D2'). If users prefer to freely inquire about LLM, they can enable the 'I need' button and question the LLM. The Output Area contains a Markdown editor (Figure 3: D3) that displays the LLM outputs after users click any button or freely query LLM in the Action sets. It also has a text area under D3 for users to conduct multiple rounds of interaction with LLM on the content in the markdown editor. When interacting with LLM via either preset buttons or text area, users can select any text in the editor and click the '(set as context)' button (Figure 4: E) to use the selected text as context to prompt LLM. For example, if there are four key knowledge points in the current section, clicking "Generate Multiple Choice Questions" is highly likely to result in the generated questions that include a range of knowledge points. If users select the text of one knowledge point as context, the generated questions will be likely to be specific to that knowledge point. Users can select any content in the LLM outputs 2 and click the "Copy" button at the bottom of the assistant panel to copy to the pasteboard and then paste it in any position of the editor of this current section. Selecting the Trash icon (Figure 3: D4) will delete all content in the Output Area while clicking the "Stop Generating" button can halt the LLM outputs. Clicking the "Close Assistant" button will hide the assistant. Additionally, clicking the "history record" button (Figure 3: D5) allows users to access previously generated content (Figure 4: G).
## 4.3 Implementation Workflow
LessonPlanner incorporates a workflow that chains all prompts and system functions with flexible user control.
4.3.1 Metadata and generated objectives as slots in prompt templates. In the Goal-setting page Figure 2, teachers are able to enter courses' metadata ( e.g., course name, course topic), which are used as slots in the prompt templates, as shown below.
- · {course name}: e.g., Data Structures and Algorithms
- · {lesson topic}: e.g., Quick sort
- · {students stage}: e.g., Sophomore
- · {lesson goals}: the content input by the user or LLM in the Lesson Goals area in the Goal-Setting Page
Whendesigning Prompts for Core or Context Actions set, we always place this paragraph at the beginning of them:
I will instruct the course of {lesson name} - {lesson topic} for students in {students stage}. Here are my lesson goals: {lesson goals}.
This setting helps impose strict restrictions on all generated content. Sometimes, due to the lack of key information, LLMs are unable to infer accurate information about the course from the content of the current section or selected context, resulting in output that is unrelated to the course. This also applies to the prompts designed for 'I need' feature or for having continuous conversations with LLM.
2 If nothing is selected, clicking the "Copy" button will copy all the content in the output text area to the pasteboard.
Before engaging in a conversation, we always place this prompt at the beginning of the user's first request.
4.3.2 Leveraging the nine events to ensure control over generated content. As described in DG1, LessonPlanner should provide effective teaching strategies at each stage ( i.e., outline generation, interacting with LLMs) rather than merely offering educational resources. Additionally, displaying the outline in a block-based format for each section and ensuring that LLMs are aware of the corresponding teaching strategies requires a precisely defined workflow.
Combine all the instructional events and metadata when generating outlines. As seen in Figure 3 C4, recommended instructional events are set once a section of the outline is generated. The preset prompt for generating the outline is provided in supplementary material 1. Developers have confirmed that GPT-4 possesses background knowledge about Gagne's Nine Events in their trials on the preset prompt. Therefore, only the Nine Events and corresponding activities in Table 1 are included in the prompts of each action. LLMs have demonstrated superior reading comprehension and the ability to analyze lengthy texts [64]. We have fully leveraged this capability to create outlines that are aligned with the course content and incorporate the Nine Events effectively.
To ensure that the format of the contents generated by the LLMs meets the requirement and minimizes errors, the formatting instructions are set as simple as possible. We defined that a new section should start with a single '#', and instructional events in every section should be specified with '##'. After generation, a Formatter then splits and maps the content into several blocks in the user interface. Also, the whole templates and instructional events in the section can be defined as slots, which will be used in some templates.
- · {outline}: generated outline of the lesson plan.
- · {current section}[events]: the events in current section.
Emphasize solely the instructional events involved in the current section. As for interacting with LLMs within a certain section, if the same context or even section content is assigned to different teaching events, we hope to click on the activities in the Core Actions set or use 'I need' feature to bring results that match the current teaching events. For example, when clicking on 'evaluate the content and give instructional suggestions' in the section with the event 'Stimulate recall of prior learning', we expect a brief explanation. In contrast, in the section with 'Provision of Learner Guidance', we anticipate detailed information to be provided about the knowledge. We dynamically insert the current section's instructional events and their corresponding definitions into the prompts through programming. It helps to remind the LLM to generate more relevant content based on these events. An example is shown below.
The educational theories involved in this section are as follows. Be sure to construct the lesson plan around the following events. Events that are not mentioned cannot be covered in this section.
({current section}[events] and their definitions, respectively.)
Based on our trials, it is not recommended to include all instructional events and their corresponding definitions and add the current events after that, which will make the generated content extensively cover each event and cause information redundancy.
4.3.3 Chaining the prompts with examples of input and output. During the process of iteratively designing prompts, we found that relying on descriptive statements frequently results in unstable output. To improve the robustness of the output, we design an example at the end of every prompt to ensure that the system generates results that align with expectations every time. For example, for the activity 'Generate definition', the example
Input: Context: Quick Sort Output: **Quick Sort * *: -Definition: Quick Sort is a divide-and-conquer algorithm. It works by selecting a 'pivot' element from the array and partitioning the other elements into two sub-arrays, according to whether they are less than or greater than the pivot. 3
was added to the end of the prompt, forcing LLMs not to generate more detailed explanations to further explain the definition.
## 5 EVALUATION
To explore the effectiveness and user experience of LessonPlanner for assisting novice teachers in lesson planning, we conducted two user studies. First, we conduct a within-subjects study with 12 university students who have little or no teaching experience to use LessonPlanner and a baseline tool to prepare lesson plans for a course that they have learned before. Second, we conduct an expert interview with 6 teachers from different educational levels and subjects. Our research questions (RQs) are:
RQ1. How would LessonPlanner affect the lesson planning outcome?
RQ2. How would LessonPlanner affect the lesson planning process?
RQ3. How would users perceive LessonPlanner for preparing lesson plans?
## 5.1 Within-subjects study
5.1.1 Participants. We recruit 12 students (P1-P12, two females, ten males; age: 𝑀𝑒𝑎𝑛 = 23 42, . 𝑆𝐷 = 1 98) via word-of-mouth . from a university in mainland China (Table 2). All participants, including two 4th-year undergraduate students and ten graduate students, major in artificial intelligence and are familiar with the course Data Structures and Algorithms. The experimental setup controls the lessons that participants need to prepare for, which leads to unbalances of majors and genders of our participants. We will discuss the limitations of this setting in the Discussion section. Nine of the participants have experience working as a teaching assistant (TA) in the university or as a home tutor for high-school students. All participants are quite interested in having a trial on utilizing artificial intelligence tools or online resources for lesson
3 https://en.wikipedia.org/wiki/Quicksort
Figure 6: The procedure of the within-subject study.
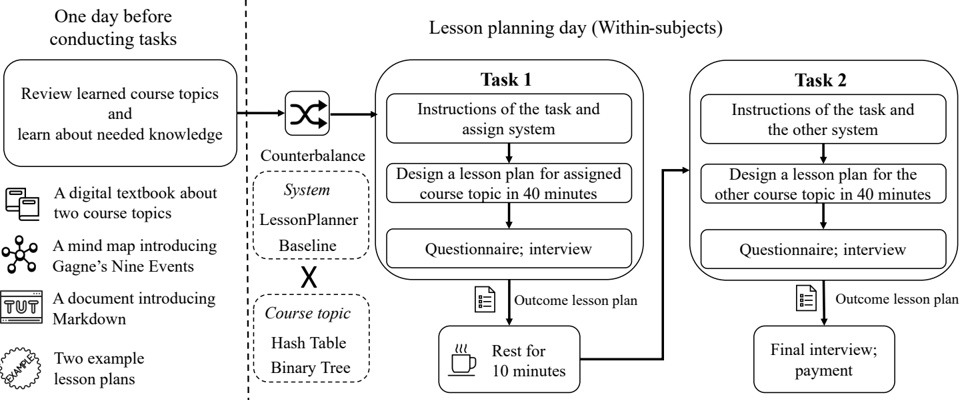
Table 2: Participants involved in the within-subjects study.
| ID | Gender | Age | Year | Experiences | Freq. of LLMs Usage |
|------|----------|-------|---------------|-----------------|-----------------------|
| P1 | M | 22 | Graduate | TA & Home Tutor | Daily |
| P2 | M | 23 | Graduate | TA & Home Tutor | Weekly |
| P3 | M | 29 | Graduate | N/A | Have Tried |
| P4 | M | 22 | Graduate | N/A | Weekly |
| P5 | M | 25 | Graduate | TA & Home Tutor | Weekly |
| P6 | M | 24 | Graduate | TA | Infrequently |
| P7 | M | 22 | Undergraduate | N/A | Weekly |
| P8 | M | 24 | Graduate | TA | Daily |
| P9 | F | 23 | Graduate | TA | Infrequently |
| P10 | M | 23 | Graduate | TA | Weekly |
| P11 | F | 21 | Undergraduate | TA | Daily |
| P12 | M | 23 | Graduate | TA | Daily |
planning ( 𝑀𝑒𝑎𝑛 = 4 33, . 𝑆𝐷 = 0 47; 1 - no interest at all, 5 - a large . amount of interest). Nine participants are daily or weekly users of large language models (LLMs, e.g., ChatGPT and Claude), and the other three participants are infrequent users.
5.1.2 Experiment Setup. The goal of the within-subjects study is to quantitatively evaluate the LessonPlanner 's effectiveness and user experience compared to a baseline system.
Baseline condition . The baseline system is the ChatGPT web app that uses the GPT-4 model as used in LessonPlanner . In the baseline condition, participants can also use the Bing search engine in their web browsers and a markdown editor 4 that is identical to the markdown component embedded in LessonPlanner .
LessonPlanner condition . In the LessonPlanner condition, participants are permitted to use Bing and LessonPlanner , but are not allowed to visit the ChatGPT web app or another markdown editor. In either condition, participants could freely choose whether, when, and how to use the provided tools.
Task-system assignment . In the recruitment survey, we ask participants to choose the course topics of Data Structures they
4 https://github.com/code-farmer-i/vue-markdown-editor
are familiar with. We select the two topics that all participants indicate their familiarity with, i.e., 'Hash Table' and 'Introduction and Traversal of Binary Trees'. We counter-balance the order of lesson planning tasks and use a system using Latin Square, with three participants in each of the four assignments:
- · LessonPlanner - Hash Table, Baseline - Introduction and Traversal of Binary Trees
- · Baseline - Introduction and Traversal of Binary Trees, LessonPlanner - Hash Table
- · LessonPlanner - Introduction and Traversal of Binary Trees, Baseline - Hash Table
- · Baseline - Hash Table, LessonPlanner - Introduction and Traversal of Binary Trees
5.1.3 Tasks and Procedure. Each participants have two lessonplanning tasks. The prompt for each task is:
The lesson plan is a teacher's detailed description of the course of instruction. Now, you are instructed to act as a teacher who will deliver a lesson about Data Structures - [Topic Name in this task] to secondyear university students who are new to this subject. Your class is composed of 70 students whose academic abilities follow a normal distribution. The lesson is scheduled to last for 90 minutes, and you have 40 minutes available to develop your lesson plan.
The whole procedure is illustrated in Figure 6. Before the day of conducting lesson planning tasks, we sent participants the following materials, which they should spend 15-30 minutes reviewing before the tasks.
- · Sections on Hash Tables and Introduction and Traversal of Binary Trees in a digital textbook of Data Structures and Algorithms
- · A mind map that introduces Gagne's Nine Events.
- · A document that introduces the basics of Markdown operations.
- · Two example lesson plans of course topics different from those in Data Structure and Algorithm.
On the day of conducting lesson planning tasks, each three participants that are in the same task-system assigned group come to our lab. We briefly introduce Gagne's Nine Events and the considerations for a good lesson plan using the materials sent yesterday.
To motivate them to put forth their best effort in the task, we inform them that an additional 80RMB reward will be given to the best lesson plan among others rated by a seasonal lecturer of Data Structures and Algorithms.
In each task, we first introduce the task and demonstrate the assigned system to participants. We then help participants to set up the environments of study in our provided computers or their laptops, i.e., opening webpages of the baseline system or LessonPlanner , Bing, and digital textbook of the assigned course topic. Each participant then independently works on the lesson plan preparation task. We allocate 40 minutes for each task and inform them that they can finish earlier or have a few more minutes to complete the task. After each task, we ask participants to fill out a questionnaire about their experience in this lesson planning process and perceptions of the used system. Subsequently, we interview them for 5 minutes. There is a 10-minute break between two tasks for participants to take a rest. Upon completion of two tasks, we conduct a final semi-structured interview with the participants that focuses on their preferences on the used systems, perceptions on the generated content, opinions on the features of LessonPlanner , and suggestions for improving it. In total, each participant spends around 120 minutes in our experiment and receives 120RMB for compensation.
5.1.4 Measurements. We employ a standard 7-point Likert scale (1 - strongly disagree, 7 - strongly agree) to measure the quality of outcome lesson plans, experience in the lesson planning process, and perceptions towards the used system.
RQ1: Lesson planning outcome. To assess the quality of the outcomes, we invite a teacher with three years of experience teaching Data Structures and algorithms to score all outcome lesson plans in a shuffle order. The aspects of evaluation are adapted from Aziz et al. [5], based on the CIPP model, and the lesson plans are assessed on a 7-point Likert scale to indicate the degree to which each criterion is met. For each lesson plan, the teacher assesses it from five key aspects adapted from the CIPP lecture evaluation model [5] include the alignment of teaching content with learning objectives, facilitation of students' skill acquisition, integration of effective teaching materials, a balance between theoretical and practical activities, and the employment of effective teaching strategies. Sufficient detail has also been added as an aspect to further evaluate the lesson plans.
RQ2: Lesson Planning Process. Drawing from the NASATLX survey [30], we pose six questions to measure the workload during the lesson planning process, including the aspects of Mental Demand, Physical Demand, Temporal Demand, Performance, Effort, and Frustration. In the interviews, we encourage users to share how the system has increased or decreased their workload.
RQ3: Perception of LessonPlanner . First, the ten questions from the System Usability Scale (SUS) [13] are set in our questionnaire. We divide SUS into and analyze it from three levels: Effectiveness & Learnability, Use Efficiency, and Satisfaction. Then we adapted five questions from Jian's Trust Scale [34] and investigated how users trust the system by inquiring about the system's vigilance, potential negative impact on teaching, their trust in the system's ethical standards, commitment to users, and the reliability of outputs. In the interviews, we encourage them to share their experiences with and preferences for each tool ( e.g., search engine; ChatGPT web app; LessonPlanner ) and each component ( e.g., different pre-set activities and the editor in LessonPlanner ). We further inquire about their reasons for trusting or distrusting the system.
## 5.2 Expert interviews
Following the within-subjects study, to gather additional feedback to enhance the generalization of our findings, we conducted thinkaloud studies and semi-structured interviews with six teachers.
5.2.1 Participants. The six teachers (female=2, male=4) include five novice teachers with teaching experience ranging from 1 to 3 years ( 𝑀 = 2), and one experienced teacher with 15 years of teaching experience. Participants E1-E3, who have been involved in the formative study, teach at the university level. E4 and E5 are primary school teachers, and E6 teaches at a senior high school. Detailed information about their teaching subjects in the current year (the same as what topics they choose to test on our system) are presented in Table 3.
5.2.2 Method. We conduct a 60-minute interview for every expert. Initially, we introduce the participants to the background and goal of our research. For E4-E6, we present Gagne's Nine Events of Instruction and confirm their full understanding of the concept. Subsequently, we give them a 10-minute tutorial on how to use LessonPlanner . They were given 30 minutes to complete the following tasks, being asked to think aloud. The examples of expert's interactions with LessonPlanner is provided in supplementary material 3.
- · Small Task 1. Generate lesson goals and the outline and set up instructional events.
- · Small Task 2. Refine a section. Add an example of a question generated by LLMs.
- · Exploration. Explore and refine any areas that they are interested in.
Finally, we conduct a 15-minute semi-structured interview, the fixed questions are shown below.
## RQ1: Lesson planning outcome.
- · Please rate the quality of lesson plans created by LessonPlanner , compared to those you prepare during your usual planning routine.
- · Can LessonPlanner help you manage the teaching process effectively?
## RQ2: Lesson Planning Process.
- · Does our system impose additional cognitive load on you, such as memory or thought burden, compared to preparing lesson plans without it?
Table 3: Experts involved in user study.
| ID | Gender | Educational Career length | Educational Level | Subject(s) |
|------|----------|-----------------------------|---------------------|----------------------------------------|
| E1 | F | 15 years | Senior High School | English |
| E2 | M | 3 years | Elementary School | Mathematics |
| E3 | M | 1 year | Elementary School | Science |
| E4 | F | 3 years | University | Korean Intensive Reading |
| E5 | M | 2 years | University | Natural Language Processing |
| E6 | M | 2 years | University | Convex Optimization & Computer Network |
## RQ3: Perception of LessonPlanner .
- · Is LessonPlanner easy to handle? Can you use LessonPlanner smoothly without any technical support?
- · Which feature (including goal-setting, outline generating, pre-set activities, and output refinement) provided by LessonPlanner help you most?
- · Please provide some suggestions for LessonPlanner .
teaching strategies ( LessonPlanner : 𝑀 = 5 58 . , 𝑆𝐷 = 0 86; baseline: . 𝑀 = 4 42 . , 𝑆𝐷 = 1 04 ; . 𝑊 = 7 , 𝑝 = 0 034), and providing sufficient . details on the teaching materials ( LessonPlanner : 𝑀 = 5 42 . , 𝑆𝐷 = 1 19; . baseline: 𝑀 = 3 83 . , 𝑆𝐷 = 1 14; . 𝑊 = 3 , 𝑝 = 0 007). Our partici-. pants in the within-subjects study and teachers in the expert interview share how LessonPlanner affect their lesson planning outcome, which is summarized below.
## 6 ANALYSES AND RESULTS
In this section, we present the quantitative and qualitative results for each research question (RQ). As for the items measured on a 7-point Likert scale about the lesson planning outcome (RQ1), lesson planning process (RQ2), and perceptions with the system (RQ3), we employ the Wilcoxon signed-rank tests [68] compare the differences between the LessonPlanner and baseline condition in the within-subjects study. For the qualitative data in the withinsubjects study and expert interviews, two authors transcribe the audio into text scripts and conduct a thematic analysis on these scripts. they first familiarize themselves by reviewing all the text scripts independently. After several rounds of coding with comparison and discussion, they finalize the codes of all the interview data. Wecount the occurrences of codes and incorporate these qualitative findings in the following presentation of our results.
## 6.1 Lesson Planning Outcome (RQ1)
Figure 7 shows the quality of outcome lesson plans from the withinsubjects study, and the the lesson plan designed by P5 is provided in supplementary material 2. Overall, the lesson plans created using LessonPlanner ( M 𝑒𝑎𝑛 = 32 25 . , 𝑆𝐷 = 5 43) are rated . significantly better than those developed with the baseline system ( 𝑀 = 26 33 . , 𝑆𝐷 = 5 588) in terms of the total scores; . 𝑊 = 10 5 . , 𝑝 = 0 02. Regarding each aspect of the outcome lesson plans, . LessonPlanner ( 𝑀 = 5 42 . , 𝑆𝐷 = 1 037) does not show a signifi-. cant advantage over the baseline system ( 𝑀 = 4 92 . , 𝑆𝐷 = 1 256) . regarding aligning the teaching content to the objectives; 𝑊 = 15 5 . , 𝑝 = 0 40. However, compared with the baseline condition, . the lesson plans from the LessonPlanner conditions have a tendency to perform better in facilitating students' skill acquisition ( LessonPlanner : 𝑀 = 5 42 . , 𝑆𝐷 = 1 04; baseline: . 𝑀 = 4 58 . , 𝑆𝐷 = 0 86; . 𝑊 = 7 , 𝑝 = 0 058) and incorporating effective teaching materials . ( LessonPlanner : 𝑀 = 5 33 . , 𝑆𝐷 = 1 03; baseline: . 𝑀 = 4 50 . , 𝑆𝐷 = 1 26; . 𝑊 = 13 50 . , 𝑝 = 0 070). Lesson plans constructed with . LessonPlanner are significantly better in terms of balancing the theoretical and practical content ( LessonPlanner : 𝑀 = 5 08 . , 𝑆𝐷 = 0 86; base-. line: 𝑀 = 4 08 . , 𝑆𝐷 = 0 86; . 𝑊 = 8 , 𝑝 = 0 039), using effective .
6.1.1 The Impact of Structured Outlines on Overall Lesson Plan Quality. Four participants (P1, P2, P6, P12) mentioned that the structured outlines helped improve the quality of their lesson plans. As the generated outlines take into account various lesson goals and Gagne's Nine Events, 'LessonPlanner made my lesson plan more standardized' (P6), and "it has a more reasonable instructional structure, compared to most resources I found on the Internet" (P12). Furthermore, the block-based structure strengthens users' grasp of the overall lesson plans. 'It (LessonPlanner) makes me more clear about what should I do in the different stages of this lesson' (E5). However, E3 offered a different perspective on the impact of the structured outline. 'When I prepare lessons, I already have a clear framework of this lesson (elementary science) in mind. It is synthesized from many lesson plans I've read. Compared to my own framework, I personally find the generated one less effective' (E3). It reveals that the generated lesson plan outline in LessonPlanner , which is based on Gagne's Nine Events, may be less effective in specialized subject domains.
6.1.2 Experts' Opinions on the Impact of Event Hints on the Teaching Content. The teachers in the expert interviews confirmed that the tags that give hints of Gagne's Nine Events in LessonPlanner can guide them to prepare a lesson plan with more effective teaching content. E6 mentioned, 'without the system, I'd always forget to put some important content in the lesson plans. The hints act like reminders' . E1 also affirmed this point, '(Without LessonPlanner,) I wouldn't keep so many tags (instructional events)in my mind. These constantly visible tags help me think and explore the possibilities of conducting my class from various perspectives' . However, not all experts think the Events Hints generated in the outlines are useful. E2 and E3 complained that some hints were useless for them. E2 said, 'Elementary students have limited comprehension, and a single math lesson is impossible to encompass all nine events. I have to adjust the events in each part to fit my need' .
In all, we find that LessonPlanner significantly improves participants' quality of lesson plans in the within-subjects study. Participants and teachers generally value the structured lesson plan outline and hints of Gagne's Nine Events. Nevertheless, these events
Baseline
LessonPlanner
Balance
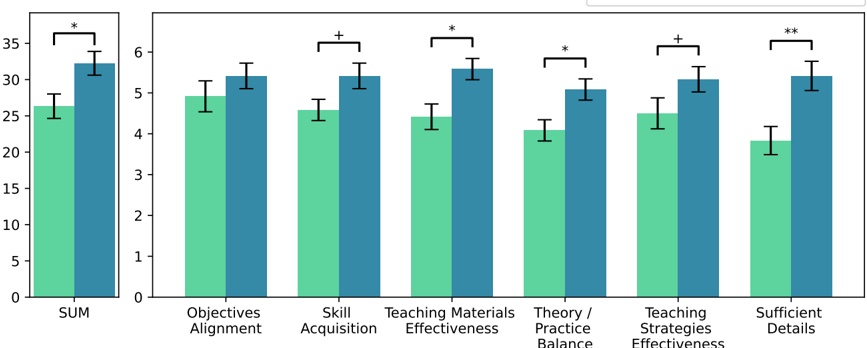
Effectiveness
Figure 7: RQ1 results regarding the lesson plan outcome evaluated by experienced teachers in six different aspects and total scores. ***: p< 0.001, **: p< 0.01, *: p< 0.05, +: p<0.1.
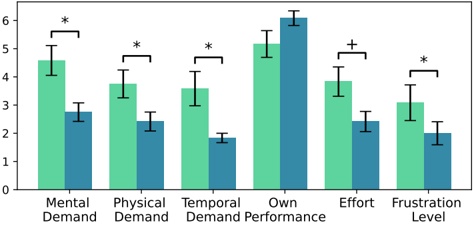
in the lesson planning process when they are with LessonPlanner ( 𝑀 = 2 42 . , 𝑆𝐷 = 1 19) than with the baseline system ( . 𝑀 = 3 83 . , 𝑆𝐷 = 1 72); . 𝑊 = 12 5 . , 𝑝 = 0 066. There is no significant differ-. ence regarding their perceived task performance in lesson planning between the LessonPlanner ( 𝑀 = 6 08 . , 𝑆𝐷 = 0 86) and baseline . conditions ( 𝑀 = 5 17 . , 𝑆𝐷 = 1 57); . 𝑊 = 14 5 . , 𝑝 = 0 175. Nine par-. ticipants believe that utilizing our system requires less workload compared to the baseline in the interview after two tasks. For example, P12 said 'Using ChatGPT can be quite skill-intensive, and often the first response you receive may not align with your expectations. LessonPlanner's first response is of high quality, which significantly eases the mental and physical demand on me.' .
Figure 8: RQ2 results regarding the test of task load. ***: p< 0.001, **: p< 0.01, *: p< 0.05, +: p<0.1.
may not be always necessary if teachers have their own lesson plan structures and if they want to focus on specific events in a lesson.
## 6.2 Lesson Planning Process (RQ2)
Figure 8 shows the statistical results of the participants' perceived task workload in the lesson planning process with LessonPlanner and the baseline system. On average, participants perceived significantly less mental demand ( LessonPlanner : 𝑀 = 2 75 . , 𝑆𝐷 = 1 09; baseline: . 𝑀 = 4 58 . , 𝑆𝐷 = 1 75; . 𝑊 = 7 00 . , 𝑝 = 0 035), physi-. cal demand ( LessonPlanner : 𝑀 = 2 42 . , 𝑆𝐷 = 1 11; baseline: . 𝑀 = 3 75 . , 𝑆𝐷 = 1 64; . 𝑊 = 2 , 𝑝 = 0 024), temporal demand ( . LessonPlanner : 𝑀 = 1 83 . , 𝑆𝐷 = 0 55; baseline: . 𝑀 = 3 58 . , 𝑆𝐷 = 2 02; . 𝑊 = 1 , 𝑝 = 0 027), and frustration ( . LessonPlanner : 𝑀 = 2 , 𝑆𝐷 = 1 35; . baseline: 𝑀 = 3 08 . , 𝑆𝐷 = 2 10; . 𝑊 = 6 , 𝑝 = 0 046) when they . prepare lesson plans with LessonPlanner than with the baseline system. Besides, participants tend to perceive less effort spent
6.2.1 Experts' Opinions on the Workload of Preparing Lesson Plans with LessonPlanner. Our within-subjects user study showcases that LessonPlanner can reduce task workload compared to the baseline interface. In the expert interviews, we are more concerned about what brings workload to teachers when planning lessons with LessonPlanner . We found that the workload mainly arises from the selection, refinement, and verification of LLMs' outputs. First, E4 and E6 indicated that the process of selecting output imposed an additional burden. Interestingly, they both reported that this burden was beneficial, as reported by E6, "The system offers varied content, allowing me to select anything I am satisfied with. This process naturally demands more effort. Before, I could only stick to one basic idea" . Second, E3 and E4 noted that they invested the majority of their time in ensuring that the system accurately produced a small segment of the content, such as formulas, a suitable example, and so on. E3 complained that "When I realized that the results provided by this generative model were not what I was looking for, I kept engaging in conversing with it and iterating the generated results. Clearly, it takes up more time" . Third, the experts emphasized that checking the accuracy of the content (E4, E5) and making sure it was appropriate for the student's current learning stage (E2, E3)
also contributed to their workload. For example, E2 stated, '"In this example, it (LessonPlanner) uses the area calculation formula for triangles as an introduction, asking students to think about the formula for the area of parallelograms. Yet, the students don't know how to calculate the area of triangles because it is the content in the next chapter... Having to check every output makes me drained.' .
## 6.3 Perception of LessonPlanner (RQ3)
Figure 9 shows the participants' ratings on the usability of and their trust on LessonPlanner and the baseline system in the withinsubjects user study. Overall, participants gave a higher score for LessonPlanner than that for the baseline system regarding the system's Effectiveness & Learnability ( LessonPlanner : 𝑀 = 72 70 . , 𝑆𝐷 = 15 97; baseline: . 𝑀 = 63 90 . , 𝑆𝐷 = 19 90; . 𝑊 = 21 , 𝑝 = 0 286), Effi-. ciency in Use ( LessonPlanner : 𝑀 = 73 30 . , 𝑆𝐷 = 18 50; baseline: . 𝑀 = 66 70 . , 𝑆𝐷 = 19 78; . 𝑊 = 27 , 𝑝 = 0 380), . and Satisfaction ( LessonPlanner : 𝑀 = 82 90 . , 𝑆𝐷 = 10 45; baseline: . 𝑀 = 74 10 . , 𝑆𝐷 = 21 62; . 𝑊 = 20 , 𝑝 = 0 246), but the differences are not significant. . As for the trust in the system, compared to the baseline system, participants generally have significantly fewer concerns regarding the LessonPlanner 's vigilance ( LessonPlanner : 𝑀 = 2 83 . , 𝑆𝐷 = 1 72; . baseline: 𝑀 = 4 58 . , 𝑆𝐷 = 1 50; . 𝑊 = 4 , 𝑝 = 0 028) and potential . negative impact on teaching ( LessonPlanner : 𝑀 = 3 00 . , 𝑆𝐷 = 1 68; . baseline: 𝑀 = 4 42 . , 𝑆𝐷 = 1 90; . 𝑊 = 4 , 𝑝 = 0 048). Participants . also have a significantly higher level of trust on LessonPlanner 's ethical standards ( LessonPlanner : 𝑀 = 6 50 . , 𝑆𝐷 = 0 76; baseline: . 𝑀 = 5 67 . , 𝑆𝐷 = 0 85; . 𝑊 = 3 5 . , 𝑝 = 0 020), commitment to user . ( LessonPlanner : 𝑀 = 5 92 . , 𝑆𝐷 = 0 76; baseline: . 𝑀 = 4 67 . , 𝑆𝐷 = 1 49; . 𝑊 = 3 5 . , 𝑝 = 0 012), and reliability of outputs ( . LessonPlanner : 𝑀 = 5 91 . , 𝑆𝐷 = 0 95; baseline: . 𝑀 = 4 75 . , 𝑆𝐷 = 1 42; . 𝑊 = 2 , 𝑝 = 0 024). Participants and teachers actively comment on the usability . of LessonPlanner and their trust or concerns about its generated content in the interviews, which we summarize below.
6.3.1 Experts' Gained Insights from LessonPlanner. Our teachers in the expert interviews appreciated that LessonPlanner can provide inspiring content for constructing lesson plans. Specifically, all teachers agreed that the "Generate an Example in Detailed" feature is well-designed and useful, as it provides them with new perspectives for lesson design. For instance, E2 mentioned, 'Sometimes I come up with an example but I am uncertain if it's appropriate. I am also often not sure from which angle I should present the example to the students. I can get other examples from the system as a reference to my example and get guidance on how to present it' . Moreover, when using "Construct multiple choice or fill-in-the-blank questions" or "Construct group discussion topics" in their small tasks of lesson planning, four experts expressed that the system output was "very inspiring". For example, E6 stated, " I had never considered incorporating discussion questions into the (Computer Networks) course, but now it has generated a great topic I think. Discussing this topic is beneficial for students, actually. ". These qualitative findings once again confirm that LLMs are competent tools for promoting users' creativity [21]. Novice teachers greatly benefit from the insights generated by LLMs and use them to broaden their thinking.
6.3.2 Diverse Attitudes to the Reliability of LessonPlanner. Eight participants in the user study indicated that they were more confident with the reliability of the generated content in LessonPlanner compared to that in the baseline. For example, P9 and P12 accounted for their increased confidence in the preset prompts and structured output, which make LessonPlanner seem professional and reliable. In contrast, one participant, P3, doubted the preset prompts, 'I would only trust the system if I can access all the details of the prompts.' .
Teachers in the expert interviews have different opinions on the reliability of the LLM's output. For example, the most frequently debated issue was the credibility of the 'Generate definition' activity. E5, who teaches Computer Network and Convex Optimization at the university level, believed that the generated definitions were accurate and could be directly utilized in his lessons. Conversely, E2 and E3, who are instructors in elementary school, contended that the definitions did not correspond with the student's current stage of learning, making them nearly impracticable for the classroom. This conflicting view could be due to that our LessonPlanner was primarily designed for supporting teachers in university in our study, but it reveals the need to tailor the generated content to the knowledge level of targeted students, which we will discuss in the Discussion section.
Another interesting finding is that users' trust in LessonPlanner could be affected by the level of their familiarity with LLMs. Participants who interact with LLMs daily or weekly ( 𝑀 = 78 0 . , 𝑆𝐷 = 17 20) generally show a higher degree of trust in the system than . those who use it less frequently ( 𝑀 = 68 3 . , 𝑆𝐷 = 14 55). Addi-. tionally, in the expert interviews, teachers (E2, E4) who do not know how LLMs work and rarely used LLMs before, expressed less satisfaction with LessonPlanner , which could be due to their inappropriate trust [54]. For instance, E4 stated, "The system needs to give clear sources for its generated examples, such as from newspaper. I would not count on an example without credible sources, because it might be misleading for students. "
6.3.3 Room for Improving LessonPlanner's Usability. Eight participants in the user study suggested that our system had room for improved usability. First, the embedded editor was considered "not so intelligent" by four participants (P2, P4, P8, and P10). For example, P2 mentioned, 'I usually use shortcuts, but here, I have to use the mouse to click. It is inconvenient.' Second, LessonPlanner interaction design may not match the routine way to use LLM. P1 and P9, who are familiar with the ChatGPT web app, struggled with our system's conversation design. 'I am used to scrolling up to see what it (LLM) responded to before, but it does not work in this system. I miss that the way I do all the time with ChatGPT' (P1).
In the expert interviews, we further inquired about the learnability of LessonPlanner . All teachers believed that the system was easy to use, but they reminded that it should have a clear tutorial to walk through the system before using it. Without a tutorial, they might be confused about the system's functions. For example, E2 and E5 claimed that they were confused by the labels on buttons without detailed descriptions of their functions, input, and output. E5 suggested that 'when a user enters this system for the first time, providing a new user tutorial or a product tour could be helpful, as many websites do '.
Figure 9: RQ3 results regarding the test of system usability and participants' trust in LessonPlanner . ***: p< 0.001, **: p< 0.01, *: p< 0.05, +: p<0.1.
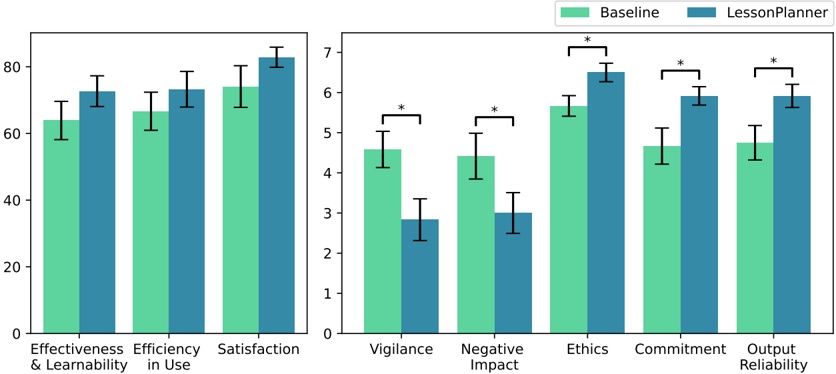
## 7 DISCUSSION
In this work, we design and develop LessonPlanner , an interactive system that facilitates novice teachers to prepare lesson plans with large language models (LLMs). Our within-subjects study with 12 participants compared to a ChatGPT interface and our expert interviews with six teachers demonstrate the usefulness of LessonPlanner in improving the outcome and reducing the task load of preparing lesson plans. Our user study findings also highlight the imitations, and opportunities of LessonPlanner , which we summarize as design considerations for future interactive systems that support teachers with LLMs.
## 7.1 Design Considerations
7.1.1 Base the generated content on reliable knowledge databases. Both participants and experts acknowledged the remarkable generative capabilities of LLMs for supporting lesson-planning tasks. LessonPlanner can assist teachers in producing various types of insightful and creative teaching materials and suggesting strategies to deliver these materials. Nevertheless, the reliability of the LLM used in LessonPlanner was still questioned by some participants and experts (E2-E5), primarily because of the hallucination of LLMs [74] and the limitation of not being able to automatically access web resources. Furthermore, P12 and E3 expressed a continued preference for utilizing search engines to search for materials, though LLMs are equipped in LessonPlanner . On the one hand, the generated content may not match different educational levels, for example, including knowledge that elementary students have not yet grasped in previous lessons (E2). This problem stems from teachers providing only a brief description of prior knowledge in a single line on the Goal-setting page (Figure 2), which is insufficient. To improve the alignment of the generated content with the students' educational levels, future work could construct a detailed knowledge graph of courses at different levels and recommend prior knowledge of current course topics to guide the LessonPlanner . On the other hand, the preference stemmed from their belief that despite the unstructured results returned from search engines, the online materials published by other teachers are more professional, compared to those generated by LLMs. Hence, content generated by LLMs should not constitute the entire lesson plan but rather serve as a supplementary resource to complement the lesson plan. This principle is fundamental in our motivation, design, and implementation of LessonPlanner . To maximize the potential of traditional resources, web resources, and generated content within the system, we suggest that future lesson planning systems should integrate reliable knowledge databases, either prepared by teachers or curated from web resources, into the prompts to LLMs. There are already many ways that help us do this, such as LangChain 5 , Microsoft Copilot, and the recent advances in Retrieval-Augmented Generation techniques [14, 41]. With the assistance of external resources, teachers can enhance their confidence in the system and decrease the workload they spend on verifying the generated content.
7.1.2 Allow flexible customization of prompts to LLMs. When designing and developing LessonPlanner , we spend a lot of effort in providing flexible user control (DG4) to the generated content, e.g., users are able to alter or cooperate with LLMs to refine the lesson goals in the Goal-Setting page, and users can freely modify all generated content of the lesson plan in the Lesson-Planning page. However, users hold elevated expectations regarding the customization of the interactive features with LLMs. For example, participants expressed a desire to see and adjust our built-in prompts of the default buttons, which would make the generated content align more closely with their expectations. Teachers in the expert interviews further highlighted that Instructional Events used in the LLM
5 https://github.com/langchain-ai/langchain
prompt for initializing the lesson plan may need to be adjustable by users as well. Potential solutions to address these expectations are incorporating additional predefined teaching scenarios ( e.g., a lesson after midterm exams) offered by developers and enabling users to customize the system's predefined prompts. Another approach is to automate the prompting process [43] by utilizing course metadata to provide different predefined functionalities tailored to users.
7.1.3 Integrate multi-modal generated content. The findings of our study demonstrate that planning with LessonPlanner leads to a notable enhancement in the quality of lesson plans and a reduction in teachers' workload, which can be attributed to the abundant textual content produced and structured by the LLM. An observation identified in the expert interviews is that LessonPlanner demonstrates its interest in using multi-modal materials to teach particular knowledge points. For instance, it attempts to draw a binary tree through a combination of text and symbols or directs the teacher to present a video on specific topics or display images in the classroom. The aforementioned phenomenon reminds us that integrating other multi-modal models, such as text-to-image generation models [73] and text-to-video generation models [20], with LLMs might make the content of lesson plans richer and save time by reducing the need to gather supplementary materials from the web. These two points were further confirmed by the experts in the interviews, where they hoped to insert generated images into the lesson plans.
## 7.2 Generality
In the within-subjects study, LessonPlanner demonstrated strong performance, as no participants raised concerns about the suitability of the content delivered by LLM for students at their current stage. The teachers of different educational levels in the expert interviews have expressed overall satisfaction with the system's performance, despite that the examples in the prompt templates of LessonPlanner are about the subjects of computer science for university students. This suggests that our system has the potential to be adapted to various educational levels and subjects. However, our teachers reported that they occasionally got generated definitions or examples unaligned with the students' knowledge background. To mitigate this issue, two feasible solutions can be considered. First, the simplest and most practical approach could be encouraging users to customize examples or definitions as templates and embed them into the original prompts. This will guide LLMs to generate content that is aligned with the provided templates. Second, the Chain-of-Thought (CoT) [66] technique could be employed in prompt engineering, instead of providing fixed examples ( e.g., data structures) which might lead to content that is inappropriate for the educational level or subject. For example, the prompt shown in subsubsection 4.3.3 could be edited as below.
- · Q1: I will instruct the course of {lesson name} for students in {students' educational level}. Please provide the names of three key concepts that students may need to learn for this course.
- · Q2 (after receiving the response to Q1 from the LLMs): Provide the specific definition of the first concept that is suitable
for the {students' educational level}. The response must con- form to the following format.
Input:
Context: the name of the concept Output:**the name of the concept ** -Definition: The defini-
tion of the concept.
Moreover, LessonPlanner serves not only as an assistant in preparing lesson plans for courses but also as a platform helping novice teachers promote their critical thinking and delve deeper into the subjects. It assists educators in gaining the knowledge of developing a lesson based on educational theory in a systematic way, thus improving their pedagogical abilities.
## 7.3 Limitations and Future Work
Our work has several limitations that call for future work. First, all participants in our within-subjects study majored in subjects related to computer science, which helps to control the topics of planned lessons in the study. While we qualitatively evaluate LessonPlanner with six experts teaching different subjects at various educational levels, we lack quantitative findings on LessonPlanner 's effectiveness in facilitating users with diverse backgrounds in planning lessons on other subjects. Second, LessonPlanner , which includes detailed instructional events and delivery methods, is presently oriented towards assisting novice teachers. In the future, we will evaluate and customize LessonPlanner with teachers with diverse backgrounds and teaching experience. Third, while the output markdown file of the lesson plans from LessonPlanner can serve as the intermediate materials to deliver a course, teachers usually need to prepare other digital materials ( e.g., slides) upon the lesson plans in their teaching practices. Future researchers can explore the application of deep learning techniques to generate slides [26, 75] based on the output lesson plans from LessonPlanner or support users to prepare a lesson in Powerpoint or Google slides embedded with LLMs. Fourth, we invite a teacher who is experienced with the course topics to evaluate the outcome of lesson plans in the within-subjects study. However, a more ideal way to assess the effectiveness of a lesson plan would be to enact the plan in a real-world lesson and collect feedback from students and teachers. In the future, we plan to invite teachers to use LessonPlanner to prepare for the lessons they are going to teach and evaluate LessonPlanner 's effectiveness after the outcome lesson plans are enacted in a course. Recordings of the lessons and post-lesson interviews with the teachers will also be collected and analyzed to ensure LessonPlanner 's practical usability and benefits for educators. Last but not least, to generate an initial lesson plan, we included all nine events in the prompt. While nine events are generally helpful, not all events are applicable to one specific lesson. Future iteration of LessonPlanner should allow the users to specify the events they would like to incorporate into their course before prompting the LLMs to generate a lesson plan.
## 8 CONCLUSION
In this paper, we designed and developed an interactive system, LessonPlanner , to support novice teachers in interactively constructing lesson plans using LLM-generated content grounded on Gagne's
nine events. LessonPlanner is capable of initializing lesson goals and outlines, generating activities and materials that adapt to planned teaching events, and offering flexible user control to customize the lesson plan and query the LLM. The within-subjects experiment with 12 participants demonstrates that LessonPlanner leads to an enhancement in the quality of the lesson plan outcome and eases their workload during the preparation process. We further conducted expert interviews with six teachers who highlighted the potential of utilizing it to support novice teachers at various educational levels and in diverse subjects. We discuss design considerations and insights derived from the user study for leveraging generative models to support lesson-planning tasks.
## 9 ACKNOWLEDGEMENT
This work is supported by the Young Scientists Fund of the National Natural Science Foundation of China (NSFC) with Grant No.: 62202509, NSFC Grant No.: U22B2060, and the General Projects Fund of the Natural Science Foundation of Guangdong Province in China with Grant No. 2024A1515012226.
## REFERENCES
- [1] R Abdelghani, YH Wang, X Yuan, T Wang, H Sauzéon, and PY Oudeyer. 2022. GPT-3-driven pedagogical agents for training children's curious question-asking skills. ArXiv. preprint arXiv 2211 (2022).
- [2] Mahmoud Abdulwahed and Zoltan K Nagy. 2009. Applying Kolb's experiential learning cycle for laboratory education. Journal of engineering education 98, 3 (2009), 283-294.
- [3] Ashraf Alam. 2023. Intelligence unleashed: An argument for AI-enabled learning ecologies with real world examples of today and a peek into the future. In AIP Conference Proceedings , Vol. 2717. AIP Publishing.
- [4] Alages Andre. 2011. The iLessonPlan: a lesson planning tool for the 21 st century. In Proceedings of the Annual Conference of the Australasian Society for Computers in Learning in Tertiary Education, ASCILITE 2011 . 93-105.
- [5] Shamsa Aziz, Munazza Mahmood, and Zahra Rehman. 2018. Implementation of CIPP Model for Quality Evaluation at School Level: A Case Study. Journal of Education and Educational Development 5, 1 (2018), 189-206.
- [6] Anna L Ball, Neil A Knobloch, and Sue Hoop. 2007. The instructional planning experiences of beginning teachers. Journal of Agricultural Education 48, 2 (2007), 56-65.
- [7] Jan Philip Bernius, Stephan Krusche, and Bernd Bruegge. 2022. Machine learning based feedback on textual student answers in large courses. Computers and Education: Artificial Intelligence 3 (2022), 100081.
- [8] Shravya Bhat, Huy A Nguyen, Steven Moore, John Stamper, Majd Sakr, and Eric Nyberg. 2022. Towards automated generation and evaluation of questions in educational domains. In Proceedings of the 15th international conference on educational data mining , Vol. 701.
- [9] Mary Kalantzis Bill Cope and Duane Searsmith. 2021. Artificial intelligence for education: Knowledge and its assessment in AI-enabled learning ecologies. Educational Philosophy and Theory 53, 12 (2021), 1229-1245. https://doi.org/10. 1080/00131857.2020.1728732
- [10] Sairavi Kiran Biri, Subir Kumar, Muralidhar Panigrahi, Shaikat Mondal, Joshil Kumar Behera, Himel Mondal, and Joshil K Behera IV. 2023. Assessing the Utilization of Large Language Models in Medical Education: Insights From Undergraduate Medical Students. Cureus 15, 10 (2023).
- [11] Euan Bonner, Ryan Lege, and Erin Frazier. 2023. Large Language Model-Based Artificial Intelligence in the Language Classroom: Practical Ideas for Teaching. Teaching English with Technology 23, 1 (2023), 23-41.
- [12] Virginia Braun and Victoria Clarke. 2012. Thematic analysis . American Psychological Association.
- [13] John Brooke. 2013. SUS: a retrospective. Journal of usability studies 8, 2 (2013), 29-40.
- [14] Deng Cai, Yan Wang, Lemao Liu, and Shuming Shi. 2022. Recent advances in retrieval-augmented text generation. In Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval . 3417-3419.
- [15] Brendan Calandra, Laurie Brantley-Dias, and Kezia McNeal. 2007. An electronic system to support novice teachers' reflective lesson design. Multicultural Education & Technology Journal 1, 2 (2007), 100-111.
- [16] Jerry CK Chan, Yaowei Wang, Qing Li, George Baciu, Jiannong Cao, Xiao Huang, Richard Chen Li, and Peter HF Ng. 2022. Intelligent instructional design via interactive knowledge graph editing. In International Conference on Web-Based Learning . Springer, 41-52.
- [17] Hung Chau, Jordan Barria-Pineda, and Peter Brusilovsky. 2017. Content wizard: concept-based recommender system for instructors of programming courses. In Adjunct Publication of the 25th Conference on User Modeling, Adaptation and Personalization . 135-140.
- [18] Qiaoyi Chen, Siyu Liu, Kaihui Huang, Xingbo Wang, Xiaojuan Ma, Junkai Zhu, and Zhenhui Peng. 2024. RetAssist: Facilitating Vocabulary Learners with Generative Images in Story Retelling Practices. In Proceedings of the 2024 ACM Designing Interactive Systems Conference . 2019-2036.
- [19] Chun-Wei Chiang, Zhuoran Lu, Zhuoyan Li, and Ming Yin. 2024. Enhancing AI-Assisted Group Decision Making through LLM-Powered Devil's Advocate. (2024).
- [20] Joseph Cho, Fachrina Dewi Puspitasari, Sheng Zheng, Jingyao Zheng, Lik-Hang Lee, Tae-Ho Kim, Choong Seon Hong, and Chaoning Zhang. 2024. Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation. arXiv preprint arXiv:2403.05131 (2024).
- [21] Geoff Davis, Mick Grierson, et al. 2022. Investigating attitudes of professional writers to GPT text generation AI based creative support tools. (2022).
- [22] Paul Denny, Sumit Gulwani, Neil T Heffernan, Tanja Käser, Steven Moore, Anna N Rafferty, and Adish Singla. 2024. Generative AI for Education (GAIED): Advances, Opportunities, and Challenges. arXiv preprint arXiv:2402.01580 (2024).
- [23] Samantha L Dias-Lacy and Ruth V Guirguis. 2017. Challenges for New Teachers and Ways of Coping with Them. Journal of Education and Learning 6, 3 (2017), 265-272.
- [24] Christopher B Divito, Bryan M Katchikian, Jenna E Gruenwald, and Jennifer M Burgoon. 2024. The tools of the future are the challenges of today: The use of ChatGPT in problem-based learning medical education. Medical Teacher 46, 3 (2024), 320-322.
- [25] Mary Forehand. 2010. Bloom's taxonomy. Emerging perspectives on learning, teaching, and technology 41, 4 (2010), 47-56.
- [26] Tsu-Jui Fu, William Yang Wang, Daniel McDuff, and Yale Song. 2022. Doc2ppt: Automatic presentation slides generation from scientific documents. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 36. 634-642.
- [27] Ebrahim Gabajiwala, Priyav Mehta, Ritik Singh, and Reeta Koshy. 2022. Quiz maker: Automatic quiz generation from text using NLP. In Futuristic Trends in Networks and Computing Technologies: Select Proceedings of Fourth International Conference on FTNCT 2021 . Springer, 523-533.
- [28] Robert Gagne. 1985. The conditions of learning and theory of instruction Robert Gagné. New York, NY: Holt, Rinehart ja Winston (1985).
- [29] Qiushi Han, Haitong Chen, Haoxiang Fan, and Zhenhui Peng. 2023. ReDBot: Exploring Conversational Recommendation for Decision-Making Support in Group Chats. In Proceedings of the Eleventh International Symposium of Chinese CHI . 73-80.
- [30] Sandra G Hart and Lowell E Staveland. 1988. Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research. In Advances in psychology . Vol. 52. Elsevier, 139-183.
- [31] Kenneth H Hoover and Paul M Hollingsworth. 1970. Learning and teaching in the elementary school. (No Title) (1970).
- [32] Christina L Jacobs, Sonya N Martin, and Tracey C Otieno. 2008. A science lesson plan analysis instrument for formative and summative program evaluation of a teacher education program. Science education 92, 6 (2008), 1096-1126.
- [33] Maurice Jakesch, Advait Bhat, Daniel Buschek, Lior Zalmanson, and Mor Naaman. 2023. Co-writing with opinionated language models affects users' views. In Proceedings of the 2023 CHI conference on human factors in computing systems . 1-15.
- [34] Jiun-Yin Jian, Ann M Bisantz, and Colin G Drury. 2000. Foundations for an empirically determined scale of trust in automated systems. International journal of cognitive ergonomics 4, 1 (2000), 53-71.
- [35] Peiling Jiang, Jude Rayan, Steven P Dow, and Haijun Xia. 2023. Graphologue: Exploring large language model responses with interactive diagrams. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology . 1-20.
- [36] Sushma N Jogan. 2019. An Effective 5 E Lesson Plan in Teaching Prose: A Model. Online Submission 6, 50 (2019), 11999-12009.
- [37] Kayvan Khadjooi, Kamran Rostami, and Sauid Ishaq. 2011. How to use Gagne's model of instructional design in teaching psychomotor skills. Gastroenterology and hepatology from bed to bench 4, 3 (2011), 116.
- [38] Osama Koraishi. 2023. Teaching English in the age of AI: Embracing ChatGPT to optimize EFL materials and assessment. Language Education and Technology 3, 1 (2023).
- [39] Tiffany H Kung, Morgan Cheatham, Arielle Medenilla, Czarina Sillos, Lorie De Leon, Camille Elepaño, Maria Madriaga, Rimel Aggabao, Giezel Diaz-Candido, James Maningo, et al. 2023. Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models. PLoS digital health 2, 2 (2023), e0000198.
- [40] Mina Lee, Percy Liang, and Qian Yang. 2022. Coauthor: Designing a humanai collaborative writing dataset for exploring language model capabilities. In Proceedings of the 2022 CHI conference on human factors in computing systems . 1-19.
- [41] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems 33 (2020), 9459-9474.
- [42] Michael Xieyang Liu, Advait Sarkar, Carina Negreanu, Benjamin Zorn, Jack Williams, Neil Toronto, and Andrew D Gordon. 2023. 'What it wants me to say': Bridging the abstraction gap between end-user programmers and codegenerating large language models. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . 1-31.
- [43] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. Comput. Surveys 55, 9 (2023), 1-35.
- [44] Piotr Mirowski, Kory W Mathewson, Jaylen Pittman, and Richard Evans. 2023. Co-writing screenplays and theatre scripts with language models: Evaluation by industry professionals. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . 1-34.
- [45] Chancharik Mitra, Mihran Miroyan, Rishi Jain, Vedant Kumud, Gireeja Ranade, and Narges Norouzi. 2024. RetLLM-E: Retrieval-Prompt Strategy for QuestionAnswering on Student Discussion Forums. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 38. 23215-23223.
- [46] Reza Hadi Mogavi, Chao Deng, Justin Juho Kim, Pengyuan Zhou, Young D Kwon, Ahmed Hosny Saleh Metwally, Ahmed Tlili, Simone Bassanelli, Antonio Bucchiarone, Sujit Gujar, et al. 2023. Exploring user perspectives on chatgpt: Applications, perceptions, and implications for ai-integrated education. arXiv preprint arXiv:2305.13114 (2023).
- [47] Reza Hadi Mogavi, Chao Deng, Justin Juho Kim, Pengyuan Zhou, Young D Kwon, Ahmed Hosny Saleh Metwally, Ahmed Tlili, Simone Bassanelli, Antonio Bucchiarone, Sujit Gujar, et al. 2024. ChatGPT in education: A blessing or a curse? A qualitative study exploring early adopters' utilization and perceptions. Computers in Human Behavior: Artificial Humans 2, 1 (2024), 100027.
- [48] Ethan R Mollick and Lilach Mollick. 2023. Using AI to implement effective teaching strategies in classrooms: Five strategies, including prompts. Including Prompts (March 17, 2023) (2023).
- [49] Ali Jamali Nesari and Mina Heidari. 2014. The important role of lesson plan on educational achievement of Iranian EFL teachers' attitudes. International Journal of Foreign Language Teaching & Research 3, 5 (2014), 25-31.
- [50] Hanna-Liisa Pender, Lennart Bohl, Marius Schönberger, and Julia Knopf. 2022. An AI-based lesson planning software to support competence-based learning. In 8th International Conference on Higher Education Advances (HEAd'22) . Editorial Universitat Politècnica de València, 1033-1041.
- [51] Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. 2023. The impact of ai on developer productivity: Evidence from github copilot. arXiv preprint arXiv:2302.06590 (2023).
- [52] Savvas Petridis, Nicholas Diakopoulos, Kevin Crowston, Mark Hansen, Keren Henderson, Stan Jastrzebski, Jeffrey V Nickerson, and Lydia B Chilton. 2023. Anglekindling: Supporting journalistic angle ideation with large language models. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . 1-16.
- [53] I Gede Widiartana Putra, I Wayan Sukra Warpala, I Gde Wawan Sudatha, and Ni Putu Rara Stianing Utami. 2022. Developing a Gagne Theory-Based Learning Video for Thematic Subject in Elementary School. International Research Journal of Management, IT and Social Sciences 9, 4 (2022), 666-675.
- [54] Crystal Qian and James Wexler. 2024. Take It, Leave It, or Fix It: Measuring Productivity and Trust in Human-AI Collaboration. arXiv preprint arXiv:2402.18498 (2024).
- [55] Md Mostafizer Rahman and Yutaka Watanobe. 2023. ChatGPT for education and research: Opportunities, threats, and strategies. Applied Sciences 13, 9 (2023), 5783.
- [56] Rishabh Ranawat, Ashwin Venkataraman, and Lakshminarayanan Subramanian. 2021. Collectiveteach: a system to generate and sequence web-annotated lesson plans. In ACM SIGCAS Conference on Computing and Sustainable Societies . 1-13.
- [57] Nabil Y Razzouk, Jay N Razzouk, et al. 2008. Analysis In Teaching With Cases: A Revisit To Blooms Taxonomy Of Learning Objectives. College Teaching Methods & Styles Journal (CTMS) 4, 1 (2008), 49-56.
- [58] Aslina Saad and Christian Dawson. 2018. Requirement elicitation techniques for an improved case based lesson planning system. Journal of Systems and Information Technology 20, 1 (2018), 19-32.
- [59] Amanda G Sawyer and Joy Myers. 2018. Seeking comfort: How and why preservice teachers use internet resources for lesson planning. Journal of Early Childhood Teacher Education 39, 1 (2018), 16-31.
- [60] Jianhao Shen, Yichun Yin, Lin Li, Lifeng Shang, Xin Jiang, Ming Zhang, and Qun Liu. 2021. Generate & rank: A multi-task framework for math word problems. arXiv preprint arXiv:2109.03034 (2021).
| [61] | Hana Stein, Irina Gurevich, and Dvora Gorev. 2020. Integration of technology by novice mathematics teachers-what facilitates such integration and what makes it difficult? Education and Information Technologies 25, 1 (2020), 141-161. |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [62] | Sven Strickroth. 2019. PLATON: Developing a graphical lesson planning system for prospective teachers. Education Sciences 9, 4 (2019), 254. |
| [63] | Daniel L Stufflebeam. 2000. The CIPP model for evaluation. In Evaluation models: Viewpoints on educational and human services evaluation . Springer, 279-317. |
| [64] | Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023). |
| [65] | Bryan Wang, GangLi, and Yang Li. 2023. Enabling conversational interaction with mobile ui using large language models. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . 1-17. |
| [66] | Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc VLe, DennyZhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35 (2022), 24824-24837. |
| [67] | Judy WWood and Jennifer WMiederhoff. 1988. Adapting lesson plans for the mainstreamed student. The Clearing House 61, 6 (1988), 269-276. |
| [68] | Robert F Woolson. 2007. Wilcoxon signed-rank test. Wiley encyclopedia of clinical trials (2007), 1-3. |
| [69] | Meng Xia, Qian Zhu, Xingbo Wang, Fei Nie, Huamin Qu, and Xiaojuan Ma. 2022. Persua: AVisual Interactive System to Enhance the Persuasiveness of Arguments in Online Discussion. Proc. ACM Hum.-Comput. Interact. 6, CSCW2, Article 319 (nov 2022), 30 pages. https://doi.org/10.1145/3555210 |
| [70] | JIAYU YIN, CATHERINE GU, JENNY MAR, SYDNEY ZHANG, and STEVEN P DOW. 2024. Jamplate: Exploring LLM-Enhanced Templates for Idea Reflection. (2024). |
| [71] | Ann Yuan, Andy Coenen, Emily Reif, and Daphne Ippolito. 2022. Wordcraft: story writing with large language models. In 27th International Conference on Intelligent User Interfaces . 841-852. |
| [72] | Ismail Md Zain. 2017. The Collaborative Instructional Design System (CIDS): Visualizing the 21st Century Learning. Universal Journal of Educational Research 5, 12 (2017), 2259-2266. |
| [73] | Chenshuang Zhang, Chaoning Zhang, Mengchun Zhang, and In So Kweon. 2023. Text-to-image diffusion model in generative ai: A survey. arXiv preprint arXiv:2303.07909 (2023). |
| [74] | Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. 2023. Siren's song in the AI ocean: a survey on hallucination in large language models. arXiv preprint arXiv:2309.01219 (2023). |
| [75] | Chengbo Zheng, Dakuo Wang, April Yi Wang, and Xiaojuan Ma. 2022. Telling stories from computational notebooks: Ai-assisted presentation slides creation for presenting data science work. In Proceedings of the 2022 CHI Conference on |
## A INTERFACES OF LESSONPLANNER HIGH-FIDELITY PROTOTYPE IN FORMATIVE STUDY
The original version used for the actual formative study is in Chinese. We translate all the text in the interface into English completely, as shown in Figure 10- Figure 13.
Figure 10: The page of meta-data collection.
## Course objective description
The goal of this lesson is to help students understand the core idea of divide and conquer, master the basic principles of quicksort; learn to analyze the complexity of the algorithm; and understand how to implement it in code (C++). Encourage students to apply the algorithm to various daily scenarios
Generate outline

Figure 11: The page of outline overview.

Figure 12: The editing page with LLM sidebar.
## LLM assistant integrated within the editor
- Introduction of Application Cases and
## Application Cases
Application Cases ended Questions Open -
Teaching Goals and Knowledge Points
Imagine you are a data engineer responsible for sorting large datasets. Sometimes; these datasets can almost fill up all the memory. need to ensure the space complexity is as low as possible, and in this case, merge sort may not meet the requirements\_ You
- Recall: Bubble sort and merge sort
Bubble Sort
Merge Sort
- Divide-and-Conquer
- Merge Sort and Its Implementation
Understanding the Principle of Mer
Practicing the Divide-and-Conquer
- Time limited exercises
Quicksort Algorithm
Analysis
Tips
- Code lementation Imp
Writing Quicksort Code
Pivot Selection
Performance Analysis
Homework
Exercises
Experimental Tasks
- Extended Thinking
Discuss the Applicable Scenarios of
Optimization Directions
## Open-ended question
Have you ever needed to quickly determine the rank of a specific element during sorting? For instance, sorting student grades; do you need to quickly find a particular student's rank? Consider the following:
- What practical applications exist for quickly obtaining an element's position in a sorting algorithm?
- What advantages does quicksort offer over other sorting algorithms for this purpose?
Figure 13: The editing page with embedded LLM assistant.
 | 10.1145/3654777.3676390 | [
"Haoxiang Fan",
"Guanzheng Chen",
"Xingbo Wang",
"Zhenhui Peng"
] | 2024-08-02T08:26:28+00:00 | 2024-08-02T08:26:28+00:00 | [
"cs.HC"
] | LessonPlanner: Assisting Novice Teachers to Prepare Pedagogy-Driven Lesson Plans with Large Language Models | Preparing a lesson plan, e.g., a detailed road map with strategies and
materials for instructing a 90-minute class, is beneficial yet challenging for
novice teachers. Large language models (LLMs) can ease this process by
generating adaptive content for lesson plans, which would otherwise require
teachers to create from scratch or search existing resources. In this work, we
first conduct a formative study with six novice teachers to understand their
needs for support of preparing lesson plans with LLMs. Then, we develop
LessonPlanner that assists users to interactively construct lesson plans with
adaptive LLM-generated content based on Gagne's nine events. Our
within-subjects study (N=12) shows that compared to the baseline ChatGPT
interface, LessonPlanner can significantly improve the quality of outcome
lesson plans and ease users' workload in the preparation process. Our expert
interviews (N=6) further demonstrate LessonPlanner's usefulness in suggesting
effective teaching strategies and meaningful educational resources. We discuss
concerns on and design considerations for supporting teaching activities with
LLMs. |
2408.01103v1 | Inverse Raman scattering and the diffuse interstellar bands: an exploration of the systemic interconnections between spontaneous and inverse Raman scattering and extended red emission, Red Rectangle bands, and diffuse interstellar bands
Fr´ ed´ric Zagury 1 e
-
Fondation Louis de Broglie 23 rue Marsoulan
75012 Paris, France
## ABSTRACT
First identified in 1964, inverse Raman scattering (IRS) is a nonlinear stimulated phenomenon that induces Raman scattered absorptions where Raman emissions would be expected. While IRS is less well-known than stimulated Raman scattering (SRS) and coherent anti-Stokes Raman scattering (CARS), this study highlights its significance in analyzing the spectra of stars located in the distant background of HI interstellar clouds. Specifically, ultraviolet emission lines Raman scattered by atomic hydrogen, typically observed in emission at wide scattering angles in the optical spectra of symbiotic stars and nebulae, should appear as IRS absorption features in the optical spectra of the background stars. I show that all known interstellar Raman scattered emission lines in the H α wavelength region are detected in absorption as diffuse interstellar bands (DIBs) in the spectra of reddened stars, and conclude that IRS by atomic hydrogen resolves the longstanding puzzle of the processes involved in producing these bands, and perhaps also explains the equally mysterious 2200 ˚ bump of ultraviolet A extinction curves. This identification of DIBs as IRS HI absorptions sheds new light on the perplexing relationship between DIBs and the Red Rectangle nebula emission bands (RRBs).
The conditions under which DIBs are detected highlight the importance of considering the physical relationship between the observer, the HI medium, and the direction of the illuminating radiation field (i.e., the geometry of the observation) in observations of HI interstellar matter. Observing in the direction of the radiation field or on its side determines whether IRS, yielding DIBs and the 2200 ˚ A bump, or spontaneous Raman scattering at wide scattering angles, resulting in ERE, Raman scattered emission lines (including RRBs), and the unidentified infrared bands, will be observed.
## 1. INTRODUCTION: THE SIGNIFICANCE OF THE JONES AND STO ¨ ICHEFF ARTICLE FOR ASTROPHYSICS
The advent of lasers in laboratories in 1960 revolutionized research in nonlinear optics (Schawlow 1963). Eckhardt et al. (1962) successfully stimulated Stokes Raman scattering in Raman-active liquids, generating laserlike coherent Raman scattered waves with intensities orders of magnitude greater than those of spontaneous Raman scattering (sRS). This discovery was soon complemented by the observations of Minck et al. (1963) and Stoicheff (1963) of stimulated Raman scattering at both Stokes and anti-Stokes frequencies. These findings enabled the development of two major coherent Raman scattering (CRS) techniques used in various fields of physics and medicine: stimulated Raman scattering (SRS, Prince et al. 2017) and coherent anti-Stokes Raman scattering (CARS, Polli et al. 2018). The practical applications of SRS and CARS have somewhat overshadowed a third nonlinear stimulated Raman process, inverse Raman scattering (IRS), which Jones and Sto¨ ıcheff described in a concise 1964 article (Jones & Sto¨ ıcheff 1964).
In this paper I show that IRS emerges as a major astrophysical phenomenon when the line of sight intersects an interstellar cloud and a star located in the cloud's distant background, and that this phenomenon provides a compelling explanation for the diffuse interstellar bands (DIBs). This result complements a previous study which established that prominent spectral emission features associated with the optical/infrared reflected light from nebulae, such as the extended red emission (ERE) and the unidentified infrared bands (UIBs), tend to cluster around hydrogen's Balmer and infrared lines (Zagury 2023). That study further highlighted a remarkable quantitative concordance between
1
observational data and theoretical predictions, leading to the conclusion that ERE results from sRS by atomic hydrogen of the continuum near Ly β .
The experimental arrangement used by Jones & Sto¨ ıcheff (1964) to demonstrate inverse Raman scattering (IRS) resembles an SRS experiment (Section 2.2). However, the IRS experiment diverges from SRS in that the intensity of the incident (pumped) laser is maintained below the SRS threshold, and the stimulating laser at the output Raman frequency exhibits a broad spectral width akin to a continuum (see also Polli et al. 2018). Under these conditions, at the Raman frequency observers detect a prominent absorption along the precise alignment of the laser and the continuum, as opposed to the anticipated Raman scattered emission line in an SRS experiment. In the conclusion of their groundbreaking work, Jones & Sto¨ ıcheff note the potential significance of IRS for astrophysics.
In 1989, Schmid (1989) resolved a longstanding problem in the spectroscopy of symbiotic stars by identifying an ultraviolet doublet of oxygen Raman scattered by atomic hydrogen in the visible spectrum. Schmid's finding, supported by a suggestion in Nussbaumer et al. (1989) that Raman scattering could be a common astrophysical process and justify optical emission lines yet to be identified 1 , initiated a new area of research. Over the past three decades, attention has focused on the vicinity of hydrogen Balmer lines, especially H α , where the probability of detecting hydrogen Raman scattering is optimized (Section 2.1). A dozen Raman scattered ultraviolet emission lines by hydrogen from atoms such as oxygen, helium, and calcium, most of which lie close to H α , have so far been highlighted in symbiotic stars and nebulae. The mechanism for interstellar HI Raman scattering involves the excitation of atoms in the HII gas, which shields the HI gas from radiations above the Lyman limit, followed by sRS of the resultant ultraviolet emission lines within the HI region and toward the observer (thus at large scattering angles).
Jones & Stoicheff did not specify what applications of IRS to astrophysics they envisioned. However, it is evident that as the scattering angle approaches zero, such as when a star is observed through an HI cloud, the observational setup mirrors their IRS experiment (Sections 2.2-2.3). Not only does the star excite ultraviolet transitions at the outskirts of the HI cloud, but it also provides the requisite stimulating optical continuum for IRS by atomic hydrogen. If the star is situated in the far background of the interstellar cloud and thereby ensures a coherent radiation field over the largest possible area at the cloud's position, optimizing IRS conditions (Section 2.3), the same Raman scattered lines seen in emission in the reflected starlight of symbiotic stars and nebulae should manifest in absorption in the star's optical spectrum.
In Sections 3-5, I show that DIBs (Section 3.1) and potentially also the 2200 ˚ bump of ultraviolet extinction curves, A can be attributed to HI IRS. All identified interstellar Raman lines within the H α spectral region align with entries in DIB compilations (Section 3.2). DIB wavelengths correspond to the Raman scattered position of the source ultraviolet emission lines' central wavelengths, which is slightly different from the central wavelengths of the Raman scattered lines (Section 3.3).
Section 4 examines the interrelations between DIBs, ERE, and the Red Rectangle emission bands (RRBs) superimposed on ERE (e.g., Schmidt et al. 1980; Scarrott et al. 1992; Van Winckel et al. 2002; Witt & Lai 2020). The hypothesis suggesting that prominent RRBs are associated with some of the deepest DIBs was questioned by Glinski & Anderson (2002) due to a slight redshift of RRBs relative to their corresponding DIBs (Sections 4.1-4.2). However, this redshift parallels the shift between Raman emission lines and DIBs (as mentioned above), and supports the Raman scattering origin of RRBs as evidenced by their broad asymmetric profiles (Kokubo 2024). Section 4.3 concludes that ERE is Raman scattering of the continuum near Ly β and that RRBs are HI Raman scattered emission lines; DIBs associated with RRBs are their IRS counterparts observed in the spectra of reddened stars. The structure of the DIB spectrum (Section 5), concentrated in the ERE wavelength domain and to a lesser extent around hydrogen's optical and infrared lines, confirms these conclusions and explains the improbable superposition of DIB spectral density (number of DIBs per unit wavelength interval) and ERE profiles (Figure 1 in Witt 2014). Possible applications of the nonlinear character of IRS are examined in Section 6.
As explained in Sections 4 and 5, the connection of DIBs to ERE and RRBs is due to the shared nature of IRS and sRS as Raman phenomena. However, forward-directed IRS and isotropic sRS are observed under widely different conditions that affect whether DIBs or ERE and RRBs will be detected (Section 7). Due to its low cross-section outside Lyman wavelengths and to its isotropy (Section 2.1) sRS by atomic hydrogen in its ground state requires
1 'We show that Raman scattering deserves to be included in the diagnostic tools of the spectroscopy of gaseous nebulae and emission regions of galactic nuclei. We point out that Raman scattering may be the source of some up to now unidentified emission lines.' (Nussbaumer et al. 1989, p. L27).
intense ultraviolet radiation. It is observed in the form of ERE and RRBs within the optical spectrum 2 in the reflected light at large scattering angles of bright stars illuminating nearby interstellar matter (such as in symbiotic stars and nebulae). Nonlinear stimulated IRS manifests only when the line of sight intersects HI interstellar matter against a background radiation field (e.g., a star). Under these conditions, DIBs in the optical spectrum and the 2200 ˚ bump A of ultraviolet extinction curves (Section 6) are observed. The geometry of an observation, that is the geometrical relationship between the observer, the scattering medium, and the radiation field, thus emerges as a critical parameter in the analysis of spectral observations of photodissociation fronts (Section 7). Section 8 summarizes the paper's findings and discusses their implications.
## 2. ESSENTIALS ON HYDROGEN RAMAN SCATTERING AND INVERSE RAMAN SCATTERING
## 2.1. Spontaneous Raman scattering by atomic hydrogen
In HI interstellar clouds, photons undergoing Raman scattering 3 by hydrogen at rest (Γ 1 → n ) have energies between Ly α and Ly ∞ . They are degraded into optical and infrared photons because of the exceptionally large Γ 1 → n Raman shifts. The cross-section for Γ 1 → n goes through asymptotic peaks at Lyman wavelengths Ly p with ordinal values of p > n and troughs in between, as discussed in Zagury (2023). Consequently, Raman scattered emission lines by hydrogen tend to aggregate near the optical and infrared Balmer, Paschen, and other lines of the following hydrogen series.
There is a sharp contrast between Γ 1 → 2 scattering of an atomic emission line proximal to Ly β , resulting in a solitary emission near H α , and the Γ 1 → 2 scattering of an emission line proximate to Ly p with p > 3, which generates p -3 Γ 1 → n ( n < p ) Raman scattering possibilities. Specifically, photons close to Ly p with p > 3 may be degraded through Γ 1 → 2 into Balmer photons close to H p -1 , but they can also undergo Raman scattering through any of the p -3 Γ 1 → -p 1 , Γ 1 → -p 2 ,..., Γ 1 → 3 processes. The Raman scattered photons are subsequently distributed between the vicinities of hydrogen resonances in the far-red (above Pa ∞ at 8200 ˚ ) and infrared regions of the spectrum. A By contrast, ultraviolet photons near Ly β ( p = 3) undergo Raman scattering only via Γ 1 → 2 and end up near H α .
Consequently, the H α region at large (between H β and Pa ∞ ) should manifest the most intense Raman scattered ultraviolet transitions from atoms and molecules of the interstellar medium. These emissions must also diminish in intensity on each side of H α and of the H α region. Additionally, due to the rapid narrowing of the [Ly p , Ly p -1 ] interval with increasing p , the density distribution of detected Raman scattered lines should peak at H α and diminish on both sides.
sRS by atomic hydrogen at rest is, like Rayleigh scattering, a quasi isotropic process, and its cross-section decreases steeply outside Lyman wavelengths. Consequently, detection of sRS in space necessitates intense, ultravioletdominated radiation fields, typically found near hot stars. These conditions increase the intensity of sRS and heighten its contrast with the optical background. Consequently, Galactic observations of HI sRS have been confined to symbiotic stars and nebulae. ERE is barely observed for radiation fields with temperatures below 10 4 K (Darbon et al. 1999).
## 2.2. Stimulated and inverse Raman scattering
Jones & Sto¨ ıcheff (1964) derived the principles of stimulated Raman emission (SRE, including Stokes and anti-Stokes scattering) and inverse Raman scattering from a common equation. This equation involves a 'pumped' laser at exciting frequency ω 0 , and a stimulating laser (frequency ω s = ω 0 ± ω r ) that triggers Raman scattering in a medium of particles with intrinsic frequency ω r . When the pumped laser operates below the SRE threshold and the stimulating radiation has a sufficiently broad spectral width (wide enough to be locally treated as a continuum), Raman lines typically observed as emissions in SRE appear as absorptions within the continuum after the lasers have traversed the medium (Jones & Sto¨ ıcheff 1964; Polli et al. 2018).
IRS has no threshold, although its intensity can be heightened near the SRE threshold (Dumartin et al. 1965a,b, 1967a,b). A nonlinear phenomenon, IRS depends on the intensity of both the pumped and stimulating lasers and can also generate new frequencies. Frequency coupling and generation of harmonics at frequencies ω 0 ± nω r ( n an integer), summation and difference of frequencies when particles exhibit multiple resonances (Stoicheff 1963; Minck et al.
2 and likely also blue luminescence (Vijh et al. 2005) and the unidentified infrared bands (UIBs) (Zagury 2023).
3 Raman scattering by hydrogen originally on level n 0 and left on level n 1 will be denoted as Γ n 0 → n 1 , and inverse Raman scattering as Γ i n 0 → n 1 . A detailed analysis of cross-sections of Γ 1 → n for n = 2 to 4, emphasizing the importance of considering hydrogen's sub-levels, can be found in the recent Kokubo (2024). See, in particular, Figure 3 in his paper.
1963; Chiao & Sto¨ cheff 1964; Maker & Terhune 1965) were also observed in IRS experiments (Jones & Sto¨ ıcheff 1964; Dumartin et al. 1967a; Mitrofanov et al. 2021). Contrary to nearly isotropic sRS, IRS is forward directed.
## 2.3. Inverse Raman scattering in astronomical conditions
Stars (preferably of A-O spectral type), the average background starlight (see Section 3.2.2), galaxies, are common sources of ultraviolet light that can excite interstellar foreground atomic hydrogen and also provide an optical continuum. To observe IRS, the celestial source must be situated behind the interstellar HI medium on the observer's line of sight. The pumped wavelength can be an emission line, most often close to a Lyman resonance (Ly β especially, Section 2.1), carried by the source or excited by absorption of its ultraviolet light by hot gas at the edge of interstellar clouds (for the OVI ultraviolet doublet, see Cowie et al. 1979; Bowen et al. 2008, and references therein).
As per classical wave optics, a star disturbance at wavelength λ measured at the observer position is the summation of the disturbances issued from half the first Fresnel zone (viewed by the observer) at the intervening HI cloud location (Zagury 2017). The wider the first Fresnel zone, the more starlight will be affected by HI IRS. For IRS absorptions to manifest, the first Fresnel zone must be maximized and the star be far behind the HI cloud. Van de Hulst (1957) further clarifies 4 that the part of the scattered plane wave that determines its disturbance at the observer position is the first Fresnel zone (at the cloud position, viewed by the observer). Consequently, IRS absorptions in the star's spectrum will be detectable if starlight at the cloud position is coherent over an area larger than this first Fresnel zone, that is if the star is at least as far behind the cloud as the observer-cloud distance.
## 3. INTERSTELLAR INVERSE RAMAN SCATTERING
## 3.1. DIffuse interstellar bands
Diffuse interstellar bands (DIBs) are enigmatic absorption features occurring at fixed wavelengths in the spectra of stars (mainly in the optical spectrum, Figure 1) obscured by interstellar clouds in their far foreground (no DIBs in circumstellar matter, Snow & Destree 2011; Zagury 2017). Observations suggest that DIBs arise from the outer region of interstellar clouds (the skin effect, see Snow & Cohen 1974; Herbig 1995; Snow 2002).
Over the past three decades, advances in observational sensitivity have enabled a significant increase in detection of the number of DIBs. Current compilations include over 500 DIBs, in contrast to approximately a hundred cataloged in the 1990s and a mere 39 DIBs uncovered in 1975 (Herbig 1975, 1995; Fan et al. 2019). Most DIBs appear as minor dips that account for at most a small percent of the continuum of a reddened star's spectrum (bottom plot of Figure 1). However, a few DIBs are much deeper, and twelve prominent DIBs have depths ( A c ) exceeding 10% of the continuum (top plot of Figure 1). The two deepest DIBs ( λλ 6284, 5780) in the spectrum of HD183143 reach A c ∼ 30%. The full width at half maximum (FWHM) of DIBs varies widely, ranging from less than 1 ˚ to over 20 ˚ . A A
## 3.2. DIB identifications
3.2.1. The OVI doublet
The first identification (Schmid 1989) of sRS from HI interstellar gas was the scattered OVI ultraviolet doublet close to λλ 1031.9 , 5 1037.6 ˚ observed in symbiotic stars. A This identification is remarkable since the theoretical Raman scattered wavelengths calculated by Schmid, based on assumed central wavelengths of 1031.923 and 1037.618 ˚ for the A source ultraviolet lines (and a Raman shift of 82258.95 cm -1 ), fall at 6825.44 and 7082.40 ˚ (6827.32 and 7084.35 ˚ A A vacuum wavelengths), considerably blueward from the observed wavelengths of 6829.5 ± 0 5 and 7088 . ± 1 5 derived by . Allen (1980) from a large set of symbiotic stars. As reported by Allen, the ratio of observed line intensities' at peak wavelengths is around 4. The OVI Raman scattered doublet was also recognized in the spectrum of PNe such as NGC7027 and NGC6302 (Groves et al. 2002; Zhang et al. 2005).
The National Institute of Standards and Technology (NIST) database 6 provides slightly shorter wavelengths, 1031.912 and 1037.613 ˚ , than Schmid for the two OVI lines, and a Raman shift of 82258.2 cm A -1 . With these adjusted values, the lines are Raman scattered at 6827.44 and 7083.80 ˚ (6829.32 and 7085.75 ˚ vacuum wavelengths), in better A A agreement with observations of symbiotic stars but still approximately 2 ˚ bluer. A
Jenniskens & D´ esert (1994) reported a DIB at 6827.28 ˚ in the spectrum of HD183143 that corresponds precisely to A the strongest line of the Raman scattered OVI doublet ( λ 6827.44). For the same star, Herbig (1995) measured a depth
4 ' The amplitude at distance L beyond a plane wave front is such as if an area lλ contributes with equal phase and the remaining part of the wave front not at all '. Van de Hulst (1957, p. 21).
5 In this paper, ultraviolet wavelengths are all vacuum wavelengths; optical wavelengths are air wavelengths, unless otherwise specified.
6 Available at: https://physics.nist.gov/asd.
Figure 1. DIB spectrum of HD183143 in 1995 and 2009 with hydrogen lines added (thick grey verticals). Top plot: DIB spectrum ( ∼ 100 DIBs) of HD183143 according to Herbig (1995, his Figure 2). Each DIB is represented by a triangle of height the DIB's depth A c and basis twice the FWHM. Twelve DIBs have A > c 10%. The few DIBs outside the H α /ERE region cluster around hydrogen's lines. Bottom plot: DIB spectrum of HD183143 derived from the catalog compiled by Hobbs et al. (2009). I have estimated A c from their equivalent width (EW) and FWHM, as given in the catalog ( A c ∼ EW/FWHM). Increased sensitivity essentially increases the number of DIBs around H α .
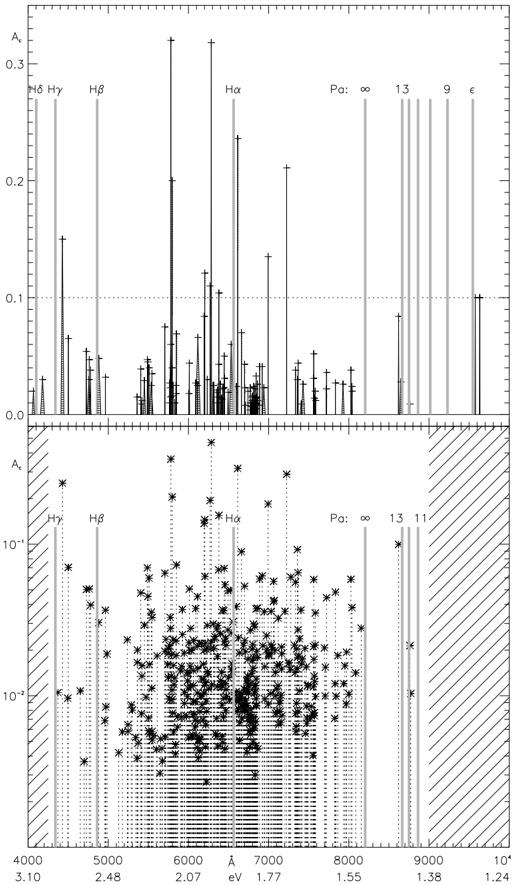
A c of the order of 2.2% of the continuum. The more sensitive Hobbs et al. (2009) 7 spectrum of HD183143 indicates a somewhat higher A c ∼ 2 7%. .
The weakest OVI Raman scattered line at 7083.80 ˚ matches a DIB reported thirteen years after DIB 6827.28 in A the spectrum of HD204827 (Hobbs et al. 2008). In the Hobbs et al. (2009) spectrum of HD183143, the line is given at 7083.8 ˚ (air wavelength), at the exact expected position of the Raman scattered line deduced from NIST's OVI A transition. The A c ratio of the two DIBs is about 4 (from Hobbs et al.'s spectrum), similar to that of the OVI scattered doublet in symbiotic stars.
7 See the full spectrum in the paper's online material at: https://iopscience.iop.org/article/10.1088/0004-637X/705/1/32#apj317757f11 (tarball of figure set images).
## 3.2.2. The OI doublet
Henney (2021) analyzed high resolution spectra of the complex inner Orion nebula within 2' from the strong θ 1 and θ 2 Ori stars. Spectra were taken in so-called Dark Bay and Orion Bar towards the edges of the field, and in the SW minibar and other sub-regions much closer to the field's central stars. The data spectral coverage runs from 4595 to 9336 ˚ . A
Major DIBs λλ 5780, 5797, 6284, 6614 are clearly present in the spectra, albeit at much lower levels than typically observed in the spectra of O-B stars. For example, in Henney's observation of the Dark Bay (see his Figure 7), DIB 5780 is a mere 8% of the continuum, whereas it accounts for A c ∼ 32% of the continuum in HD183143 (Figure 1 and Herbig 1995). These four DIBs behave similarly across the field, being notably stronger in the densest and farthest regions from the Ori stars (Figures 3 and 7 in Henney 2021). They thus appear to be unaffected by variations of the central stars' radiation field but increase with column density. Given that DIBs are consistently observed as absorptions in background starlight, the observed Orion DIBs in Henney's field must originate from background starlight in the direction of the observer (which remains constant across the limited extent of the field) and are not associated with the Ori stars radiation field.
On the H α wings spanning the 6300-6800 ˚ wavelength range, Henney (2021, his Section 2.2 and Figure 3) identifies A two absorptions at about 6633 and 6664 A (air wavelengths), ˚ which he attributes to the OI doublet λλ 1027.43, 1028.16 ˚ Raman (Γ A 1 → 2 ) scattered at air wavelengths 6633.3 and 6663.75 ˚ (6635.2 and 6665.6 ˚ vacuum wavelengths). A A Unlike the DIBs, these two features exhibit much greater strength in the SW minibar near the Ori stars compared to the Dark Bay, demonstrating their dependence on the Ori stars' radiation field. As proposed by Henney, they likely result from spontaneous Raman scattering by HI of the doublet, in absorption, under illumination from the ultraviolet radiation of these stars.
The OI Raman scattered doublet 6633, 6664 also coincides with the position of two DIBs. The strongest (DIB 6633) was identified by Jenniskens & D´sert (1994) in the spectrum of HD183143. e The second DIB was not resolved until observed in the spectra of HD204827 and HD183143 by Hobbs et al. (2008, 2009). These DIBs are recorded with central air wavelengths 6633.12 and 6663.71 ˚ in the spectrum of HD204827 (Hobbs et al. 2008), and 6632.93 and A 6664.05 ˚ in HD183143 (Hobbs et al. 2009). A Both lines are blended with other DIBs, but their A c ratio should fall in the range 2-3 (see Hobbs et al.'s online material), which is consistent with the ratio of the Γ 1 → 2 scattered OI absorptions shown in Henney's Figure 3 (top plot).
The two DIBs can therefore be identified as Γ i 1 → 2 IRS of the OI λλ 1027.43, 1028.16 ˚ A doublet. Considerably less intense compared to the prominent λλ 5781, 5797, 6284, 6614 DIBs, they are unlikely to be detectable in the background starlight of the Dark Bay observations, as outlined in Henney (2021). In Henney's observations, the lines at 6633, 6664 ˚ originate from Γ A 1 → 2 Raman scattering by atomic hydrogen at large scattering angles (see Section 2.1) of absorptions in the Orion stars' radiation field. ERE, also attributed to Γ 1 → 2 Raman scattering (of the continuum near Ly β , Zagury 2023), has been observed throughout the Orion nebula and, like the OI Raman scattered lines, decreases steeply with distance from the θ Ori stars (Figure 5 in Perrin & Sivan 1992).
## 3.2.3. HeII lines
HeII and HI have close ultraviolet transitions, facilitating Raman scattering of HeII lines by HI. Ultraviolet HeII series neighboring Ly β , Ly γ , Ly δ are Γ 1 → 2 scattered near H α , H β , and H γ respectively (Lee et al. 2006; Van Groningen 1993). The strongest of these scattered emissions are expected (Section 2) to be the near-H α lines close to 6545 ˚ , A followed by the near-H β and near-H γ lines at air wavelengths 4850 and 4331 ˚ . A
Shortly after the papers by Schmid (1989); Nussbaumer et al. (1989), Van Groningen (1993) reported the 4331 and 4850 ˚ lines in the spectrum of symbiotic RR Tel. A As for the OVI lines, the observed central wavelengths of the Raman scattered HeII lines are slightly redshifted by 1-1.5 ˚ from the scattered central wavelengths of the ultraviolet A lines. Although faint, the two lines are commonly detected in high ionization PNe possessing a neutral shell, including NGC7027 (Pequignot et al. 2003).
The strongest Raman-scattered line of HeII ( λ 1025.25 A) falls ˚ at 6545.1 A (vacuum wavelength; ˚ 6543.3 A air ˚ wavelength) and is observed in PNe such as NGC7027, IC5117, NGC6886, NGC6881 (Choi & Lee 2020, and references therein). Wavelength 6543.3 ˚ coincides precisely with a DIB in Hobbs' catalog of HD183143 ( A A c of the order of 1.6%). DIB 6543.3 is therefore likely attributable to IRS of the HeII near-Ly β line.
## 3.2.4. Other lines
Van Groningen (1993) attributed an unknown emission line at 4977 ˚ in the optical spectrum of symbiotic star A RR Tel to Γ 1 → 2 scattering of a CIII transition at 977.03 ˚ , close to Ly A γ . The exact position of the scattered central wavelength should be 4975.4 ˚ (air wavelength) and may correspond to DIB 4974.93 (DIB no 32 in Fan et al. 2019). A
Following Schmid's identification of the OVI scattered doublet in symbiotic stars, Nussbaumer et al. (1989, their Table 1) compiled twelve additional ultraviolet transitions, proximate to Ly β , of SIII, HeII, OI and CII, and deemed potential candidates for observation as Γ 1 → 2 scattered lines within the wings of H α . The Raman scattered OI doublet and HeII λ 1025.25 were indeed observed (Sections 3.2.2 and 3.2.3). The ultraviolet SIII transitions at wavelengths 1012.76, 1015.502, 105.567 ˚ , as given by NIST, Γ A 1 → 2 scattered at 6065.98, 6165.61, 6168.01 ˚ (air wavelengths) have A not been reported in symbiotic stars or PNe but could match DIBs 6065.32, 6165.48, and 6168.06 ˚ . The Raman A scattered CII lines have not been observed and lack DIB counterparts.
## 3.3. Wavelength shift of HI Raman scattered ultraviolet emission lines
The central wavelengths of emission lines are not preserved in scattering processes. Thus the observed wavelength discrepancy of 1-2 ˚ between observed central wavelengths of scattered emission lines A and source emission lines' scattered central wavelengths has not brought into question the Raman origin of the optical emission lines discussed in Sections 3.2.1, 3.2.3, and 3.2.4. This discrepancy translates to less than 0.1 ˚ in the parent ultraviolet wavelength A space, and was initially attributed to a relative motion (of the order of 10-20 km/s, Schmid 1989; Pequignot et al. 1997; Lee et al. 2006) between the scattering HI medium and its ionized envelope.
But the systematic redshift of all observed Raman scattered lines in emission can be explained more satisfactorily by the dependency of Raman scattering conversion efficiency on wavelength (Pequignot et al. 1997; Lee et al. 2006). Jung & Lee (2004) calculated that the combination of a line's profile with the Raman cross-section near Ly β results in a central wavelength shift of the Raman scattered line exceeding 1 ˚ in the optically thin limit ( A N H < 10 20 cm -2 ). This shift decreases as the HI column density increases (as shown in Figure 6 of Jung & Lee 2004), resulting in no wavelength shift in the optically thick limit ( N H ∼ 10 22 cm -2 ). These calculations, however, ignore dust extinction (see Lee et al. 2006), even though dust is the primary cause of ultraviolet interstellar extinction in between Lyman wavelengths.
In Zagury (2023), I argued that dust should render HI media optically thick to ultraviolet photons at HI column densities much lower than those suggested by Jung & Lee (2004). In this case, as shown on Figure 2, the increase of Γ 1 → 2 's branching ratio around Lyman wavelengths could explain why Raman scattered ultraviolet lines fall on the red side of their corresponding DIBs and the red asymmetric profiles of DIBs. Note that these asymmetric shapes are also reminiscent of Fano profiles, which result from the interaction of discrete energy states and a continuum, and have been linked to quantum mechanic considerations on Raman scattering (Fano 1961; Lounis & Cohen-Tannoudji 1992).
## 4. RED RECTANGLE BANDS (RRBS) AND THEIR RELATION TO ERE AND DIBS
## 4.1. The RRB-DIB issue
Figure 1 in Schmidt et al. (1980) uncovered a few intense, unusually broad, emission bands (RRBs) on top of ERE in the Red Rectangle nebula. Fossey (1991); Sarre (1991) noted a congruence in wavelength between RRBs λλ 5799, 5855, 6615 and some of the deepest DIBs, suggesting transitions from the same particles that would either be seen in emission (RRBs) or in absorption (DIBs). Figure 4 in Scarrott et al. (1992) demonstrated that DIB 5797 exhibits an inverted but comparably asymmetric profile, supporting the association between DIBs and RRBs.
This RRB-DIB association was questioned by Glinski & Anderson (2002), based on their observation that the central wavelengths of RRBs remain 1-2 ˚ redward of their associated DIBs' central wavelengths. Glinsky & Anderson argue A that their finding excludes an emission/absorption process from the same particles. Recently, Lai et al. (2020, see Section 7, this paper) also claimed that DIBs and RRBs originate in different carriers.
## 4.2. RRB-DIB relationships
ESO (European Southern Observatory) spectral observations of the Red Rectangle by Van Winckel et al. (2002) increased the number of RRBs from less than a dozen to over forty (their Table 3). The paper's Table 4 extends the associations between RRBs and DIBs to nine, all of which demonstrate similar 1-2 ˚ redshifts between RRBs and A their corresponding DIBs. Among these lines, RRB 6204.5 can be observed together with its associated DIB 6203
Figure 2. Bottom plot shows the branching ratio of Γ 1 → 2 Raman scattering (data provided by Hee-Won Lee and Seok-Jun Chang) between 950 and 1060 ˚ . This wavelength interval is transformed into the 4000-8000 ˚ optical wavelength range (bottom A A line of the x-axis) by Γ 1 → 2 scattering. The ERE wavelength region ranges from ∼ 5600 to 8000 ˚ ( A ∼ 1000 to 1050 ˚ in the A parent ultraviolet space). The top plot shows Rayleigh (dots), Γ 1 → 2 (plain line), and total hydrogen cross-sections. Maxima of Γ 1 → 2 's branching ratio correspond to minima of the Rayleigh cross-section.
Assuming that all HD44179 photons in the vicinity of Ly β end up Γ 1 → 2 Raman scattered in the vicinity of H α or absorbed by dust (Zagury 2023), the proportion of photons Raman scattered at a given wavelength increases throughout the ERE region (bottom plot). The profiles of Γ 1 → 2 scattered ultraviolet emission lines should therefore be characterized by a steep blue rising edge contrasting with a more slowly decreasing red wing. The scattered lines' central wavelengths will be shifted to the red from the lines' central wavelengths positions. The red asymmetry should be more manifest for broad lines.
on its blue side in the spectrum of NGC7027 (Zhang et al. 2005, see their Figure 1, and discussion in Section 7, this paper).
A comparison of Van Winckel et al.'s Table 3 with recent DIB catalogs reveals additional RRB-DIB associations. RRBs 6378.6, 6635.1 in Van Winckel et al.'s Table 3 are on the red side of DIBs λλ 6377, 6633, and can certainly be
associated with the DIBs. RRB 6635.1 (associated to DIB 6633) matches in emission the absorption in Orion that Henney (2021) attributes to the HI-Raman scattered OI ultraviolet absorption at 1027.4 ˚ (Section 3.2.2). A
Weaker RRBs centered close to 6563.4 and 6661.5 ˚ could correspond to the OI Raman scattered lines at 6564.3, A 6663.7 ˚ (air wavelengths) documented in Henney's Table AI. Comparison to the DIB catalog of Fan et al. (2019), A shows that other weak RRBs from Van Winckel et al.'s Table 3, such as λλ 5889.9, 5895.9, 5912.1, may also be linked to weak DIBs, specifically, DIBs 5888.7, 5893.5, and 5893.5.
The most prominent RRBs described by Van Winckel et al. (2002, their Table 4) display the same red-extended asymmetric (also termed 'red-degraded') and wide (FWHM up to 20 ˚ ) profiles that Scarrott et al. (1992) have noted A for RRB 5799 and its corresponding DIB 5797.
## 4.3. RRBs, ERE, DIBs, and Raman scattering
The recognition by Witt & Lai (2020) that no existing interstellar dust model meets the observational constraints of ERE observations lends support to the alternative, quantitatively justified by Zagury (2023), that ERE results from Γ 1 → 2 Raman scattering (sRS) of the continuum around Ly β . In the context of Galactic low density HI environments, it also follows from Kokubo (2024) that no other physical emission process besides HI Raman scattering of ultraviolet emission lines can account for the observed characteristics (widths up to 20 ˚ and red asymmetry) of RRB profiles. A Consequently, the profile characteristics of RRBs, coupled with their position atop ERE, provide compelling evidence that RRBs stem from HI sRS.
The wavelength shift argument raised by Glinsky & Andersson against a relationship between RRBs and DIBs (Section 4.1) rules out an emission versus absorption process, but does not hold in the context of HI Raman scattering (Section 3.3). As the same shift is observed between central wavelengths of all known Raman emission lines and the scattered position of the ultraviolet emission lines' central wavelengths, Glinsky & Anderson's objection turns out to provide further support for the argument that RRBs are Raman scattered features and that DIBs are their IRS counterpart in the spectra of reddened stars.
I conclude that ERE and RRBs in the Red Rectangle arise from sRS at large scattering angles, within the neutral gas exposed to the illumination of HD44179, of the continuum in the vicinity of Ly β and of emission lines (such as OI 1027.4 ˚ , Raman scattered at RRB 6635). DIBs that can be associated with RRBs correspond to IRS of the same lines A at a null scattering angle, observed in the spectra of stars located far behind HI interstellar matter. These connections between ERE, RRBs, and DIBs explain why DIB density and ERE have the same profile (Witt 2014, and Section 5), which otherwise cannot be accounted for.
## 5. THE DIB SPECTRUM
Figure 1 shows the DIB spectrum of HD183143 as of 1995 (Herbig 1995, top plot, between 4000 and 9000 ˚ ) and A 2009 (bottom plot, limited to Hobbs et al. 2009). Positions of hydrogen lines are indicated by thick gray lines. The top plot emphasizes the concentration of DIBs in the H α region, which also hosts the strongest DIBs. Significant DIBs (accounting for over 10% of the continuum) beyond this region tend to cluster around the Balmer and Paschen resonances of hydrogen.
At longer wavelengths ( λ > 1 µ m), high resolution ground-based observations are limited by telluric absorption. Two DIBs culminate near Pa γ (10935 ˚ ), as shown in Figure 6 of Hamano et al. (2022). A Figure 7 in the same study indicates that the strongest near-infrared DIBs above 1 µ m tend to concentrate around Pa γ and Pa β (12814 ˚ ). The A top plots of Figure 1 and of Figure 9 in Hamano et al.'s paper confirm a decrease in average DIB depth with increasing distance from the H α region. These observations follow the expected behavior of Raman scattering (and IRS) by hydrogen, as described in Section 2.1.
The bottom plot of Figure 1 shows that increasing the sensitivity of observations does not alter these conclusions. The spectrum of HD183143 by Hobbs et al. (2009) essentially led to an increase in the number of DIBs detected in the H α region. From these data, Witt (2014, see his Figure 1) demonstrated that the density spectrum of DIBs around H α superimposes well with the Red Rectangle ERE profile. This resemblance between spectra of vastly different natures is a consequence of the asymptotic increase of hydrogen's Γ 1 → 2 cross-section towards Ly β .
## 6. NONLINEARITY OF IRS, DEEP DIBS AND THE 2200 ˚ BUMP A
All strong RRBs have a DIB counterpart, but the reciprocal is not true. The two deepest DIBs, λλ 6284, 5780, and the also prominent DIBs 6177, 6270, with A c over 10%, have no corresponding RRBs in the Red Rectangle. This finding may reflect a difference in nature between DIBs with and without an RRB emission counterpart.
Anti-Stokes absorptions or absorptions at combinations of Raman shifts are common features of IRS laboratory experiments (Section 2.2) and may account for DIBs with no associated RRB. For instance, I note that twice the energy difference between levels n = 2 and n = 5 of hydrogen falls at 5.71134 eV, the exact energy of the 2200 ˚ A bump. The associated wavelength is 2171 ˚ , extremely close to the bump's 2175 ˚ accepted value. A A The bump could therefore be the second IRS harmonic of Γ i 2 → 5 for self Raman scattering of H γ photons.
## 7. THE GEOMETRICAL FACTOR IN THE OBSERVATION OF HI INTERSTELLAR CLOUDS
A corollary of attributing ERE and RRBs to sRS and DIBs to IRS is that ERE and RRBs occur under conditions that exclude the observation of DIBs, and vice versa. Their respective conditions are determined by the relative alignment of the source radiation field and the line of sight, as well as the proximity of the source of light to the HI scattering medium. ERE and Raman scattered emission lines, including RRBs, require intense radiation fields. They are observed in the vicinity of hot stars, such as symbiotic stars and illuminating stars of nebulae, which implies large angles of scattering. In contrast, DIBs are detected in the direction of stars located in the far background of interstellar clouds and do not manifest in circumstellar matter (Section 3.1). Observation of ERE, Raman scattered lines, and DIBs from the same direction implies either that different radiation fields are acting on the same medium (see Section 3.2.2), or that different HI media are being observed together along the line of sight. The geometric configuration of the observation thus introduces a critical parameter for interpreting spectra of HI interstellar matter. The two following examples underscore the importance of the geometry of an observation in analyzing HI media spectral data.
## 7.1. DIBs and Raman scattered emission lines in NGC7027
Weak DIBs in the optical spectrum of NGC7027 (Zhang et al. 2005) have been demonstrated to originate not from the PN itself but from foreground interstellar matter (Le Bertre & Lequeux 1993). Conversely, the planetary nebula spectrum exhibits emission features such as ERE (Furton & Witt 1990), the Γ 1 → 2 scattered HeII and OVI lines (Pequignot et al. 1997, 2003; Zhang et al. 2005), and, just redward of DIB 6203.6, RRB 6206 (Figure 1 in Zhang et al. 2005), all of which can be attributed to NGC7027's local circumstellar matter.
## 7.2. ERE and DIBs in nebula IC63
Witt & Boroson (1990) detected ERE within nebula IC63, which also stands out as the sole nebula where a background star (spectral type A7V) was observed behind the ERE region (Lai et al. 2020). The star's spectrum revealed the presence of major DIBs λλ 4428, 5780, 5797, 6614, leading Lai et al. (2020) to conclude that ERE and DIBs share common or closely related carriers that differ from those responsible for RRBs', which did not appear in the observations of either Witt & Boroson or Lai et al.
The conclusions of Lai et al. do not address the general absence of DIBs in nebular observations and of ERE in the spectra of stars. Since Lai et al. acknowledged that 'DIBs are usually observed in the line of sight towards a distant star, while ERE is observed most easily in a diffuse emission environment adjacent to a hot illuminating star', the conclusion should be that detection of DIBs in IC63 relies entirely on the presence of the A7V background star on the line of sight. DIBs will be present in the star's spectrum wherever the star is positioned in the backdrop of IC63's ERE field. Conversely, there should be no DIBs if there is no background star on the line of sight. In that case the observation is dominated by IC63 central star's reflected light and leads to the detection of ERE (Witt & Boroson 1990). For reasons that remain to be elucidated, RRBs are known to be weak, blurred, or lacking in nebulae other than the Red Rectangle.
## 8. SUMMARY AND DISCUSSION
This paper has shown that the observed properties and interrelationships of three major spectral figures of HI interstellar matter -extended red emission (ERE), the Red Rectangle bands (RRBs), and the diffuse interstellar bands (DIBs)- correspond with the differences and common properties of two Raman processes: spontaneous Raman scattering (sRS) and inverse Raman scattering (IRS) by atomic hydrogen. It follows that sRS accounts for ERE and RRBs, and IRS for the DIBs.
sRS of ultraviolet emission lines by atomic hydrogen in its ground state is a well established interstellar phenomenon in symbiotic stars and nebulae. The scattering is isotropic, and its observation is favored by intense ultravioletdominated radiation fields (Section 2.1). Consequently, HI sRS of ultraviolet emission lines occurs near bright stars
and involves wide scattering angles. Outputs of HI sRS are primarily observed near the Balmer lines, especially in the H α region (approximately from 5500 to 8000 ˚ ), which coincides with the ERE wavelength domain. A A particularity of all observed interstellar HI Raman scattered emission lines is a slight redshift relative to the source emission line central wavelength scattered position on the spectrum (Section 3.3).
In contrast to near-isotropic sRS, IRS of an emission line is observed exclusively in the direction of the source radiation field, i.e., at a zero scattering angle (Section 2.2). Unlike sRS, IRS is a nonlinear stimulated process. The stimulus is provided by a coherent local continuum encompassing the output frequency, and has the same direction as the source radiation field. Instead of producing an emission line as seen in other stimulated Raman scattering (SRS and CARS) or sRS experiments, IRS results in an absorption line within the continuum, centered precisely at the wavelength corresponding to the source line's central scattered position. Conditions for IRS are naturally met in observations of stars situated in the distant background of HI interstellar matter (Section 2.3). It can therefore be anticipated that HI Raman scattered emission lines of symbiotic stars and nebulae will appear as absorption features in the spectra of reddened stars, unless the reddening is caused by local interstellar matter.
Section 3.2 showed that HI Raman scattered emission lines in the ERE wavelength range observed in symbiotic stars and nebulae are all represented in DIB catalogs at the exact positions of the Raman scattered source emission lines' central wavelengths (Section 3.2). The identification of two oxygen doublets among these lines holds particular significance, given the low probability of coincidental alignment. As discussed in Section 2.1, the structure of the DIB spectrum, which is closely linked to hydrogen's optical transitions and is largely concentrated around H α (Section 5), and the similarity between the DIB density spectrum and the ERE profile noted by Witt (2014) are consistent with the expectations for HI Raman scattering.
HI sRS of the continuum close to Ly β justifies the strength, shape, and wavelength extent of ERE (Zagury 2023). The widths and red asymmetric profiles of several RRBs, found on top of ERE, point to a Raman origin (Kokubo 2024, and Section 4.3). All prominent RRBs are associated with some of the deepest DIBs, with the same wavelength gap observed between known sRS lines and their corresponding DIBs. RRB 6635.1, associated with DIB 6633.3, should be Γ 1 → 2 Raman scattering of the OI line at 1027.43 ˚ (Sections 3.2.2 and 4.2). A I thus concluded that ERE arises from sRS by hydrogen of the continuum near Ly β , and that RRBs are HI sRS of emission lines, e.g. close to Ly β . DIBs that can be associated with RRBs correspond to their IRS counterpart in the spectrum of reddened stars. Deep DIBs lacking such an RRB correspondence, and perhaps also the 2200 ˚ bump of ultraviolet extinction curves, could A originate from anti-Stokes IRS or IRS harmonics (Sections 2.2 and 6).
The common Raman origin of IRS and sRS explains the large widths and red asymmetry of DIBs and RRBs profiles, the structure of the DIB spectrum, and the similarity of ERE and DIB density spectra. Conversely, the marked differences between IRS and sRS explain why these interstellar spectral features arise from the same interstellar media but are not observed under the same circumstances (Section 7). ERE and RRBs appear in the reflected light from nebulae illuminated by bright stars but are too weak to be observed in the spectra of stars. DIBs only appear in the complete forward IRS light of a far-away star, obscured by foreground HI gas, on the line of sight. They are notably absent from circumstellar matter. Observing ERE or sRS HI scattering (including RRBs) and DIBs in the same direction indicates either that several media are present along the same line of sight (Section 7.1) or that several radiation fields impinge on the same medium (Sections 3.2.2 and 7.2). Understanding the geometrical configurations of observations -specifically, the spatial arrangement between the light source, the scattering medium, and the observeris therefore critical for a comprehensive interpretation of spectral observations of interstellar matter.
This study confirms that the optical and near-infrared spectral manifestations resulting from the interaction between starlight and photodissociation fronts, including the unidentified infrared bands, ERE, RRBs, blue luminescence, and DIBs, are intricately tied to the spectrum of atomic hydrogen (Zagury 2023). These features result from the interaction of starlight with atomic hydrogen and the elementary atoms and molecules known to be mixed with hydrogen. This conclusion contrasts sharply with the commonly accepted idea that ERE, RRBs, and DIBs, although exclusively produced by HI media, are unrelated to hydrogen and instead proceed from the chemistry of complex carbonaceous compounds . 8
8 Such as PAHs, Maons,..., see Kwok (2023). Note that interstellar dust models proposed by Kwok and others, which are based on the premise that observation of the interstellar optical features depends solely on the presence of these complex molecules along the line of sight, fail to account for the intensity of ERE (Witt & Lai 2020), negate the RRB-DIB relationship (Glinski & Anderson 2002; Lai et al. 2020), and do not explain the attenuation of DIBs when interstellar matter is near a star. Since the synthesis of these molecules cannot occur in PNe (Zagury 2022), as hypothesized -without justification- by Kwok (2023), where and how they were formed remains elusive. Why they manifest in low density HI clouds and not in molecular gas is another puzzling question.
Acknowledgements: I benefited from Alexander Kramida's advice on the use of the National Institute of Standards and Technology (NIST) database. Figure 2 is based on cross-sections and branching ratios calculated by Hee-Won Lee and Seok-Jun Chang. Air to vacuum wavelength transformations were done with IDL routines provided by Nikolai Piskunov. Jane F. Bestor offered helpful editorial suggestions.
## REFERENCES
| Allen, D.A.: 1980, MNRAS, 190, 75 |
|--------------------------------------------------------------------------------------------------------------|
| Bowen, D.V., Jenkins, E.B., Tripp, T.M., Sembach, K.R., Savage, B.D., et al..: 2008, ApJSS, 176, 59 |
| Chiao, R., Sto¨cheff, ı B.P.: 1964, Phys. Rev. Lett, 12, 290 |
| Choi, B.-E., Lee, H.W.: 2020, ApJL, 903, L39 |
| Cowie, L.L., Jenkins, E.B., Songaila, A., York, D.G.: 1979, ApJ, 232, 467 |
| Darbon, S., Perrin, J.-M., Sivan, J.-P.: 1999, A&A, 348, 990 |
| Dumartin, S., Oksengorn, B., Vodar, B.: 1965a, CRAS, 261, 3767 |
| Dumartin, S., Oksengorn, B., Vodar, B.: 1965b, CRAS, 261, 4031 |
| Dumartin, S., Oksengorn, B., Vodar, B.: 1967a, JP, 28, C1-99 |
| Dumartin, S., Oksengorn, B., Vodar, B.: 1967b, JCP, 64, 235 |
| Eckhardt, G., Hellwarth, R.W., McClung, F.J., Schwarz, S.C., Weiner, D., Woodbury, E.J.: 1962, PhRvL, 9, 445 |
| Fan, H., Hobbs, L.M., Dahlstrom, J.A., et al.: 2019, ApJ, 878, 151 |
| Fano, U.: 1961, PhRv, 124, 1866 |
| Fossey, S.J.: 1991, Nature, 353, 393 |
| Furton, D.G., Witt, A.N.: 1990, ApJ, 364, L45 |
| Glinski, R.J., Anderson, C.M.: 2002, MNRAS, 332, L17 |
| Groves B., Dopita M.A., Williams R.E., Hua C.-T.: 2002, PASA, 19, 425 |
| Hamano, S., Kobayashi, N., Kawakita, H., Takenata, K., Ikeda, Y., et al.: 2022, ApJSS, 262, 2 |
| Henney, W.J.: 2021, MNRAS, 502, 4597 |
| Herbig, G.H.: 1975, ApJ, 196, 129 |
| Herbig, G.H.: 1995, ARAA, 33, 19 |
| Hobbs, L.M., et al.: 2008, ApJ, 680, 1256 |
| Hobbs, L.M., et al.: 2009, ApJ, 705, 32 |
| Jenniskens, P., D´sert, e F.-X.: 1994, A&ASS, 106, 39 |
| Jung Y.-C. Lee H-W.: 2004, MNRAS, 350, 580 |
| Kokubo, M.: 2024, MNRAS, 529, 2131 |
| Lai ,T.S.-Y., Witt, A.N., Alvarez, C., Cami, J.: |
| 2020, MNRAS, 492, 5853 |
| Le Bertre, T., Lequeux, J.: 1993, A&A, 274, 909 |
| Lee, H.-W., Jung, Y.-C., Song, I.-O.: 2006, ApJ, 636, 1045 |
| Lounis, B., Cohen-Tannoudji, C.: 1992, JPhy2, 2, 579 |
| Maker, P. D., Terhune, R. W.: 1965, Phys. Rev. A, 137, 801 |
| Minck, R.W., Terhune, R.W., Rado, W.G.: 1963, App. Phys. Lett., 3, 181 |
|---------------------------------------------------------------------------------------------------------------------------------------------------------|
| Mitrofanov, A.V., Rozhko, M.V., Voronin, A.A., et al.: 2021, Opt. Lett., 46, 3219 |
| Nussbaumer, H., Schmid, H.M., Vogel, M.: 1989, A&A, 211, L27 |
| P´quignot, e D., Baluteau, J.P., Morisset, C., Boisson, C.: 1997, A&A, 323, 217 |
| P´quignot, e D., Walsh, J.R., Morisset, C.: 2003, in Planetary Nebulae, eds. S. Kwok, M. Dopita, R. Sutherland (San Francisco: ASP), IAU Symp, 209, 403 |
| Perrin J.M., Sivan J.P.: 1992, A&A, 255, 271 |
| Polli, D., Kumar, V., Valensise, C.M., Marangoni, M., Cerullo, G.: 2018, lpr, 12, 1800020 |
| Prince, R.C., Frontiera, R.R., Potma, E.O.: 2017, Chem. Rev., 117, 5070 |
| Sarre, P.J.: 1991, Nature, 351, 356 Scarrott, S.M., Watkin, S., Miles, J.R., Sarre, P.J.: 1992, MNRAS, 255, 11 |
| Schmid, H.M.: 1989, A&A, 211, L31 Schmidt, G.D., Cohen, M., Margon, B.: 1980, ApJ, 239, L133 |
| Schawlow, A.L.: 1963, Sci.Am., 209, 34 Snow T.P., Cohen J.G.: 1974, ApJ, 194, 313 |
| Snow T.P.: 2002, ApJ, 567, 407 |
| Snow T.P., Destree, J.D.: 2011, EASPS, 46, |
| 341 Sto¨cheff, ı B.P.: 1963, PhL, 7, 186 |
| Van de Hulst, H.C.: Light scattering by small particles, |
| New York: Dover Publications, 1957, 1981 |
| Winckel, H., Cohen, M., Gull, T.R.: 2002, A&A, 390, 147 |
| Vijh, U.P., Witt, A.N., Gordon, K.D.: 2005, ApJ, 633, 262 |
| Witt, A.N.: 2014, IAUS, 297, 173 Witt, A.N., Boroson, T.A.: 1990, ApJ, 355, 182 |
| Witt, A.N., Lai, S.-Y.: 2020, ApSS, 365, 58 |
| Zagury, F.: 2017, AN, 338, 807 |
| Zagury, F.: 2022, arXiv, 2211.11021 Zagury, F.: 2023, ApJ, 952, 116 |
| Y., Liu, X.-W., Luo, S.-G., P´quignot, e D., Barlow, M.J.: 2005, A&A, 442, 249 |
| Zhang, |
| Van Groningen, E.: 1993, MNRAS, 264, |
| Van |
| 975 | | null | [
"Frederic Zagury"
] | 2024-08-02T08:28:49+00:00 | 2024-08-02T08:28:49+00:00 | [
"astro-ph.GA"
] | Inverse Raman scattering and the diffuse interstellar bands: an exploration of the systemic interconnections between spontaneous and inverse Raman scattering and extended red emission, Red Rectangle bands, and diffuse interstellar bands | First identified in 1964, inverse Raman scattering (IRS) is a nonlinear
stimulated phenomenon that induces Raman scattered absorptions where Raman
emissions would be expected. While IRS is less well-known than stimulated Raman
scattering (SRS) and coherent anti-Stokes Raman scattering (CARS), this study
highlights its significance in analyzing the spectra of stars located in the
distant background of HI interstellar clouds. Specifically, ultraviolet
emission lines Raman scattered by atomic hydrogen, typically observed in
emission at wide scattering angles in the optical spectra of symbiotic stars
and nebulae, should appear as IRS absorption features in the optical spectra of
the background stars. I show that all known interstellar Raman scattered
emission lines in the H-alpha wavelength region are detected in absorption as
diffuse interstellar bands (DIBs) in the spectra of reddened stars, and
conclude that IRS by atomic hydrogen resolves the longstanding puzzle of the
processes involved in producing these bands, and perhaps also explains the
equally mysterious 2200A bump of ultraviolet extinction curves. This
identification of DIBs as IRS HI absorptions sheds new light on the perplexing
relationship between DIBs and the Red Rectangle nebula emission bands (RRBs).
The conditions under which DIBs are detected highlight the importance of
considering the physical relationship between the observer, the HI medium, and
the direction of the illuminating radiation field (i.e., the geometry of the
observation) in observations of HI interstellar matter. Observing in the
direction of the radiation field or on its side determines whether IRS,
yielding DIBs and the 2200A bump, or spontaneous Raman scattering at wide
scattering angles, resulting in ERE, Raman scattered emission lines (including
RRBs), and the unidentified infrared bands, will be observed. |
2408.01105v1 | ## Validation of an Analysability Model in Hybrid Quantum Software
Ana Díaz-Muñoz [email protected] AQCLab Software Quality University of Castilla-La Mancha Ciudad Real, Spain
José A. Cruz-Lemus Moisés Rodríguez Mario Piattini [email protected] [email protected] [email protected] University of Castilla-La Mancha Ciudad Real, Spain
Maria Teresa Baldassarre [email protected] University of Bari Aldo Moro Bari, Italy
## ABSTRACT
## 1 PROBLEM STATEMENT
In the context of quantum-classical hybrid computing, evaluating analysability, which is the ease of understanding and modifying software, presents significant challenges due to the complexity and novelty of quantum algorithms. Although advances have been made in quantum software development, standard software quality evaluation methods do not fully address the specifics of quantum components, resulting in a gap in the ability to ensure and maintain the quality of hybrid software products. In this registered report proposal, we intend to validate a quality model focused on the analysability of hybrid software through an international collaborative approach involving academic institutions from Italy and Spain through a controlled experiment. This approach allows for a more detailed analysis and validation methodology and establishes a framework for future research and developments in software quality assessment in quantum computing.
## CCS CONCEPTS
· Software and its engineering → Empirical software validation .
## KEYWORDS
Hybrid Quantum computing, Quantum Software Engineering, Software Quality, Software evaluation model, ISO/IEC 25010, Validation experiment, Registered report
## ACMReference Format:
Ana Díaz-Muñoz, José A. Cruz-Lemus, Moisés Rodríguez, Mario Piattini, and Maria Teresa Baldassarre. 2024. Validation of an Analysability Model in Hybrid Quantum Software. In Proceedings of Make sure to enter the correct conference title from your rights confirmation emai (ESEIW '24). ACM, New York, NY, USA, 7 pages. https://doi.org/XXXXXXX.XXXXXXX
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected].
ESEIW '24, October 20-25, 2024, Barcelona, Spain
ACM ISBN 978-1-4503-XXXX-X/18/06...$15.00
© 2024 Copyright held by the owner/author(s). Publication rights licensed to ACM.
https://doi.org/XXXXXXX.XXXXXXX
In the emerging field of quantum computing, quantum algorithms' integration with conventional software components has led to the development of hybrid software, designed to harness both the superior processing power of quantum computing and the versatility and robustness of classical software [3]. Therefore, in this work we refer to hybrid software as those applications that combine algorithms written in classical programming languages (e.g., Python) with quantum circuit algorithms, taking advantage of the strengths of both paradigms to solve complex problems more efficiently. This technological fusion can introduce a new paradigm in Software Engineering, which may solve complex problems more efficiently. However, the quality, and more concretely the maintainability of these hybrid software products, as one of its main characteristics, remain a significant challenge [10], especially regarding the analysability of the software.
Despite advances in quantum software development, traditional methods of software quality evaluation [12] are not fully equipped to address the specifics of quantum components [8], resulting in a gap in organizations' ability to ensure and maintain the quality of their hybrid software products. Our approach focuses on defining metrics at a logical level, independent of the underlying hardware. Although these metrics will eventually vary based on how a circuit is implemented on specific hardware, our method remains hardware-agnostic, emphasizing design rather than physical implementation.
Analysability, one of the main sub-characteristics of maintainability according to ISO/IEC 25010 [6], refers to the ease with which a software product can be understood, diagnosed for deficiencies, and modified for corrections or improvements [11]. In hybrid computing (classical-quantum), analysability is critical due to the inherent complexity and quantum algorithms' novel nature, which poses significant challenges for software developers and maintainers [1].
In previous works [2][4][9], a quality model focused on the analysability of hybrid software was presented, as well as the automated technological environment that allows measuring and evaluating these algorithms. An analyzability model is a conceptual framework that defines a set of specific properties and metrics for assessing the ease with which a software product can be understood. The main objective of this work is to present a proposal, through a registered report [5] to validate this model along with its properties and metrics, aiming to provide a means to measure the
analysability of hybrid software. This approach could facilitate better understanding and maintenance of hybrid software [14], but will also establish a framework for future research and developments in software quality assessment in quantum computing.
This collaborative approach is intended to expand the scope and depth of our study and strengthen the validity and relevance of the results obtained. The interaction between all these universities has facilitated an enriched research environment that has driven the creation of innovative knowledge in an area of growing importance in Quantum Software Engineering. By combining efforts and specialities, we have aimed to overcome limitations in hybrid software evaluation and set a precedent for future collaborations in applied research in quantum computing and hybrid software.
To effectively address the challenge of evaluating the analysability of hybrid software, this article is based on a collaborative study and experiment at an international level. We have joined efforts with academic institutions, including the University of Bari (Italy), the University of Extremadura (Spain), the University of Deusto (Spain), and the University of Castilla-La Mancha (Spain). This cross-border collaboration has been crucial in developing a holistic approach that reflects the diverse perspectives and experiences in the field of quantum and classical software engineering but also leverages the diversity of knowledge to enrich the research and validation process. This joint approach has allowed for a rigorous experimental design and exhaustive validation methodology of the proposed model for the analysability of hybrid software. This model has benefited from the contributions of experts in Quantum Software Engineering and software quality assessment, leveraging the latest theoretical advances and best practices in the field. Furthermore, available technological resources and capabilities have supported practical testing and analysis.
To sum up, the hypothesis presented to carry out the development of this article and the achievement of the final objective is that the proposed analyzability model for hybrid software can potentially identify the level of capability to understand hybrid software systems. This hypothesis will be tested through several controlled experiments with participants from different academic institutions, as described in the following sections.
## 2 METHODS
To effectively address the challenge of evaluating and improving the analysability of quantum-classical hybrid software, a structured methodological approach has been designed consisting of several key phases, including model design [9], technological environment development [4], experiment implementation, and results evaluation (see Fig. 1). The diagram in Figure 1 includes both the work process and the stages of the research study. This collaborative approach between the University of Bari, the University of Extremadura, the University of Deusto, and the University of Castilla-La Mancha has allowed the integration of different perspectives and technical expertise during validation, strengthening the research and ensuring the robustness of the study.
## 2.1 Model design
The first step in our methodology involves designing a specific analysability model for hybrid software. This model incorporates a set of properties and metrics relevant to classical and quantum components of the software. Several properties influencing analysability were identified, such as code complexity, modularity, documentation, and various elements composing quantum algorithms. To develop this model, a comprehensive review of current research was conducted, and consultations with experts in quantum computing and software engineering were performed [9].
Our hybrid software quality assessment model incorporates multiple properties and essential components to ensure a comprehensive evaluation. Some of these properties are directly related to the classical components of hybrid software:
- · Coding Rules: Establishment of standards and best practices for writing classical and quantum code to ensure software readability and maintainability.
- · Cyclomatic Complexity: Measurement of the control flow complexity of classical code, helping to identify areas of the software that may be prone to errors and difficult to maintain.
- · Code Documentation: Evaluation of the quality and thoroughness of the documentation, ensuring the code is wellcommented and explained to facilitate understanding by other developers.
- · Package and Class Structuring: Analysis of the organization of the code into packages and classes, evaluating cohesion and coupling to ensure a modular and scalable design.
- · Duplicate Code: Identification and quantification of duplicate code to reduce redundancy and facilitate maintenance.
- · Method Size: Evaluation of the size of methods in terms of lines of code and functional complexity, promoting concise and specific methods.
On the other hand, there are also some other properties related to the quantum circuit components:
- · Circuit Width: Number of qubits used in the quantum circuit, indicating the scale of the implemented quantum system.
- · Gate Complexity: Evaluation of the number and type of quantum gates used, indicating the operational complexity of the circuit.
- · Circuit Depth: Number of layers of operations in the circuit, related to the duration and decoherence in a quantum system.
- · Conditional Instructions: Analysis of the presence and use of conditional operations in the quantum code.
- · Measurement Operations: Evaluation of the quantity and positioning of measurement operations in the circuit.
- · Quantum Cyclomatic Complexity: Measurement of the control flow complexity in quantum algorithms.
- · Initialization and Reset Operations: Analysis of how and when qubits are initialized and reset during program execution.
- · Auxiliary Qubits: Identification and use of auxiliary qubits for intermediate operations and their impact on circuit efficiency.
Additionally, several implementations of the metrics and corresponding calculation methods were performed to evaluate each of the quantum software's properties. An example of a calculation method for one of the quantum properties is detailed below:
Figure 1: Methodology overview.
## How is circuit width calculated?
In the case of the circuit width, once the different circuits of the product under evaluation have been classified according to the number of qubits they contain, their distribution is evaluated using the following base metrics, with level 3 being the lowest severity level and level 1 being the highest:
- · NC\_CW1 : Number of circuits with level 1 circuit width.
- · NC\_CW2 : Number of circuits with level 2 circuit width.
- · NCIR : Total number of circuits.
- · NC\_CW3 : Number of circuits with level 3 circuit width.
| Ranges | Level 1 | Level 2 | Quality Levels |
|----------|-----------|-----------|------------------|
| 0 | - | - | 0 |
| 1 | 20 | 40 | [0-33) |
| 2 | 15 | 30 | [33-66) |
| 3 | 10 | 20 | [66-100) |
| 4 | 7 | 15 | 100 |
The calculation of the base metrics defined for the circuit width property is obtained from the thresholds shown in Table 1, which are based on the experience gained from various measurements. This table divides the circuits from best to worst depending on the number of qubits contained in each circuit.
Table 1: Definition of the levels for the evaluation of circuit width
| Levels | Ranges | Quality levels |
|----------|----------|-----------------------|
| 1 | > 15 | Bad circuit width |
| 2 | [9-15] | Regular circuit width |
| 3 | [1-8] | Good circuit width |
From the above base metrics, the following derived metrics are calculated:
- · DC\_CW1 : Circuit density with level 1 circuit width.
- · DC\_CW3 : Circuit density with level 3 circuit width.
- · DC\_CW2 : Circuit density with level 2 circuit width.
These derived metrics are calculated by dividing the number of circuits in each level by the total number of circuits evaluated. Equation 1 shows how the derived metric of circuit density with level 1 circuit width is obtained. The remaining derived metrics used in the evaluation of this property are calculated similarly.
$$D C _ { - } C W 1 = \frac { N C _ { - } C W 1 } { N C I R } \quad ( 1 ) \quad \ a \\ \text{hass a machine human-binomial} \ a \text{at random} \ a \text{-} \ a \end{hass}$$
Once the three densities have been obtained, a standardized quality value for the property is obtained using the profile function. In the profile function for circuit width, the following ranges are defined (see Table 2). For each quality level, the maximum accepted threshold of circuit density is indicated. The table does not include the most desirable width level, which corresponds to good circuit width.
Table 2: Definition of the ranges for the evaluation of circuit width
The analysability model was developed through a structured process. Initially, we investigated the fundamentals of classical and quantum computing and identified specific properties and requirements of hybrid software. We then designed a modular model structure to measure both classical and quantum components and implemented algorithms for evaluation. Subsequently, we identified and defined appropriate metrics to evaluate hybrid software's analysability, considering the model's properties and components. This approach was designed to ensure the robustness and effectiveness of the model before its experimental evaluation.
## 2.2 Development of the technological environment
Subsequently, a technological environment was developed to enable the implementation of the model and the evaluation of hybrid software. This environment includes emerging tools such as a plugin for SonarQube developed for the automatic measurement of the metrics defined in the model (see Fig. 2) and a platform designed in Power BI (see Fig. 3) to visualize the results of these measurements and the final evaluation [4].
The technological environment developed in our work has been preliminarily validated by measuring and evaluating recognized quantum algorithms implemented using Qiskit (https://www.ibm. com/quantum/qiskit) and Quirk (https://algassert.com/quirk) [2]. The ability to apply our environment to algorithms widely used in the quantum community suggests the relevance and practical applicability of our research in real software development environments.
Figure 2: Technological environment.
Figure 3: Results visualization tool.
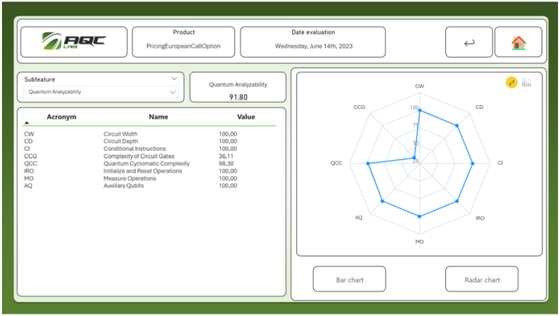
## 3 EXPERIMENTS DESIGN AND IMPLEMENTATION
experiments with participants from different academic institutions, as described in the following sections.
With the developed model and technological environment in place, an experiment has been designed and implemented to validate the applicability and effectiveness of the analysability model. This experiment intends to evaluate the analysability of hybrid software by applying several metrics on different quantum algorithms developed specifically for this purpose. Real case studies and available technologies such as the Quirk and Qiskit frameworks will be used to ensure that the analysis and results are practical and relevant for hybrid software developers.
The implementation of this experiment has been structured into several crucial stages, starting with intensive training sessions on quantum computing, followed by the practical application of this training in a controlled experimental environment. These stages will be described further next.
## 3.1 Experimental hypothesis
As previously commented, this empirical study hypothesises that the proposed analyzability model for hybrid software can potentially identify the level of capability to understand hybrid software systems. This hypothesis will be tested through several controlled
This hypothesis will be tested through a series of controlled experiments with participants from different academic institutions, as described in the following sections.
- 3.1.1 Experiment methodology. The experiment will be carried out in May 2024 at the University of Bari with two sets of students: undergraduate (third year) students with a BSc in Computer Science and a Master's Degree in Computer Science students.
The experiment will begin with several training sessions designed to equip the subjects with essential knowledge about quantum software and the tools and environments to be used. We anticipate involving approximately 100 students and 15 researchers in our experiments. This sample size is chosen to ensure a representative dataset for evaluating the analysability model. The training agenda will be distributed as follows:
- · Session I. Training session conducted by José A. Cruz-Lemus. It will cover the fundamentals of Quantum Software Engineering (QSE) and quantum circuits, together with Quirk as a simulation tool. The session will last approximately 2-2,5 hours.
- · Session II. Training session conducted by Ana Díaz-Muñoz, focusing on the fundamentals of quantum software development plus an overview of Qiskit as a quantum software development language. Some examples of the experimental tasks will also be performed. The session will last approximately 2-2,5 hours.
- · Session III. Experimental session in which the analysability model for quantum software and circuits will be evaluated. The session will last approximately 1 hour.
Session I will take place one day, while sessions II and III will be done on a different day.
In this work, we focus on the validation of the quantum software part, since the classical part of the system is currently validated by the AQCLab laboratory (https://aqclab.es/), which is accredited by ILAC (https://ilac.org/) and ENAC (https://www.enac.es/) for the evaluation of traditional software under the ISO 25000 standard [7] [13]. This means that the classical software has been tested and certified to meet the established standards and requirements. By focusing on the validation of the model for the quantum part, we seek to ensure that the quantum software works correctly and efficiently, which is fundamental for the correct functioning of the hybrid system as a whole.
Later, in mid-June, a replication of the experiment will be held online involving subjects from the universities of Extremadura, Deusto, and Castilla-La Mancha. In this case, the subjects will be quantum computing researchers, so they will need reduced training sessions. Later they will perform the experimental session using the same materials as the students. This replication will allow us to validate the preliminary obtained results and ensure the consistency of the analysability model in different contexts and user groups.
- 3.1.2 Analyzability model validation testing. The materials for validating the analysability model for quantum software and circuits have been designed to assess the effectiveness of the proposed model in the real context of quantum software development and analysis. The process begins with the collection of demographic data from the experimental subjects, which will help contextualize the experiment results and ensure that the conclusions are representative and generalisable to different demographic groups. All the forms will be accessed online by the subjects using Google Forms. Their main details are explained next:
- · Demographic questionnaire. Before going into the technical forms, each subject will be given a demographic questionnaire. This questionnaire has been designed to capture a detailed profile of the participants, including various aspects such as gender, age, geographic location, educational level, primary language spoken at home, and experience in both quantum and classical computing. The collection of demographic information in our study serves key objectives, such as contextualizing the results, and allowing adjustments in the analysis based on specific demographic variables such as age, gender, and previous experience. This will help understand how these factors may influence participants' ability to use and analyze quantum software. Additionally, it ensures that the study group is diverse and representative of the population targeted by the analysability model. It will
- also facilitate conducting statistical analyses that may uncover correlations between demographic characteristics and performance in analysability tasks, thus providing valuable insights for improving the model and related tools.
- · Experimental Tasks. The experimental questionnaires designed for this study are crucial for validating the analysability model in the context of quantum computing. These consist of five different questionnaires, each associated with a circuit reflecting one of the five levels of analysability defined in the model. Each participant will also be provided with the corresponding quantum algorithm for a circuit (written using Qiskit). The task to be performed is to transform the algorithm into the appropriate quantum circuit (on Quirk). Later, the subject must answer a total of eight questions for each circuit, focused on the values obtained for different specific quantum states. This methodology allows for an effective and detailed assessment of users' ability to understand and analyze quantum circuits and algorithms, thus contributing to the validation and improvement of the various properties comprising the designed analysability model. Each subject will receive the same five forms but in a randomized order. This way, the threats of the tiring and learning effects will be alleviated.
## 3.2 Evaluation of results
The final phase of the methodology involves evaluating the results obtained from the experiments. The collected data will be analyzed to determine the model's effectiveness in assessing the analysability of hybrid software.
The dataset will include demographic information about the participants, encompassing both students and professionals. This demographic information will be crucial in our data analysis to ensure a comprehensive understanding of the results and to account for potential differences between these groups.
## 3.3 Continuous refinement
Based on the initial evaluation, the model and associated tools are subject to a process of continuous refinement and improvement. This way, it will be possible to adapt to the rapid changes in quantum technology and software development practices.
## 4 RESULTS
The results phase of our research will focus on analyzing the effectiveness of the developed analysability model through the transformation and evaluation of quantum algorithms into circuits, conducted by the study subjects. We expect that the data collected through the experimental questionnaires will provide a solid foundation for assessing the accuracy and applicability of our model in a real-world environment.
## 4.1 Quantitative analysis
The quantitative results stem from the participants' performance in the questionnaires related to each of the five levels of analysability. The success rate in correctly transforming algorithms into quantum circuits and the accuracy in answering specific questions about quantum states will be calculated.
## 4.2 Correlation with demographic data
The statistical analysis of the collected demographic data will help to correlate participants' characteristics, such as age, gender, education, and previous experience in quantum computing, with their performance in the experiment. This analysis will help to highlight any significant trends or deviations that could influence the effectiveness of the analysability model.
## 4.3 Preliminary conclusions
We intend that the preliminary conclusions indicate whether the analysability model is effective when distinguishing between different levels of complexity in both software and quantum circuits and whether it can be a valuable tool for quality evaluators and developers to assess and improve their understanding of these advanced concepts. However, areas for improvement can also be identified. We consider these results to be crucial for the ongoing validation and refinement of the analysability model, ensuring that it is robust, applicable, and effective in enhancing the quality of quantum software.
## 5 SIGNIFICANCE
This proposal aims to make significant contributions to the emerging field of Quantum Computing, focusing especially on the integration of quantum algorithms with conventional software components to create hybrid software systems. The main objective of our work is to address a significant gap in the current landscape of software engineering: the analysability of hybrid software, which combines the paradigms of classical and quantum computing. This proposal, once fully explained and written, could be considered interesting and relevant for publication in a scientific and professional knowledge journal. Its importance and value will be stated in the following sub-sections.
## 5.1 Main contributions
- · Development of a specialized analysability model. The first notable contribution is the creation of a custom analysability model for hybrid software. This model is innovative in its comprehensive approach to incorporating classical and quantum components, taking into account factors such as code complexity, modularity, and documentation, as well as the various elements of circuits, crucial for effective software maintenance and improvement. The model was developed through rigorous research in the field, aiming to reflect the latest in theoretical and practical aspects of Quantum Computing and Software Engineering. This model was initially developed in our previous works and forms the foundation upon which our current study builds [9].
- · Creation and implementation of a technological environment. Another intended contribution is the development of a technological environment designed to implement our analysability model. This environment features cutting-edge tools such as SonarQube for measuring various metrics and properties, and Power BI for visualizing the final evaluation results. This setup not only facilitates accurate assessment of hybrid software but also enhances the accessibility and interpretability of the analysis results, making it a valuable
- tool for software developers or maintainers, as well as researchers. The creation and initial implementation of this environment was also part of our prior work [4].
- · Empirical validation through international collaboration. Finally, and directly related to this proposal, our work aims to be distinguished by its effectiveness and reliability, pending validation through an international collaboration experiment involving several prestigious institutions. This collaborative effort allows us to refine our methodologies and ensure the robustness and applicability of the model in different contexts and user groups. This empirical validation through international collaboration is the primary contribution of the current study, providing new insights and refinement to the previously developed model and technological environment.
## 5.2 Importance of our work
This work is aimed to establish a new benchmark for quality and maintainability in the rapidly evolving domain of quantum computing and hybrid software development, excelling in the following aspects:
- · Improve software quality. Enhanced analysability facilitates maintenance and reduces the number of defects, thereby improving the overall quality and reliability of hybrid software products.
- · Practical application support. While quantum supremacy has not yet been fully achieved, our research provides practical applications for the current and near-future landscape of quantum computing. These tools bridge the gap between quantumtheory and real-world software development, preparing practitioners for future hardware advancements. Our experiments demonstrate how focusing on analysability can effectively maintain hybrid software, paving the way for future developments.
- · Facilitate future research and development. Our model and methodology provide a foundational framework upon which other researchers can build, driving further innovations in Quantum Software Engineering.
## ACKNOWLEDGEMENTS
This research was supported by the projects QSERV: Quantum Service Engineering: Development Quality, Testing & Security of Quantum Microservices (PID2021-124054OB-C32), funded by the Spanish Ministry of Science and Innovation and ERDF; Q2SM: Quality Quantum Software Model (13/22/IN/032) project financed by the Junta de Comunidades de Castilla-La Mancha and FEDER funds; Financial support for the execution of applied research projects, within the framework of the UCLM Own Research Plan, co-financed at 85% by the European Regional Development Fund (FEDER) UNION (2022-GRIN-34110); and AETHER-UCLM: A holistic approach to smart data for context-guided data analysis (PID2020112540RB-C42) funded by MCIN/AEI/10.13039/501100011033/. It also received financial support for the execution of applied research projects, within the framework of the UCLM Own Research Plan, co-financed at 85% by the European Regional Development Fund (FEDER) UNION (2022-GRIN-34110).
Validation of an Analysability Model in Hybrid Quantum Software
## REFERENCES
- [1] Muhammad Azeem Akbar, Arif Ali Khan, and Saima Rafi. 2023. A systematic decision-making framework for tackling quantum software engineering challenges. Automated Software Engg. 30, 2 (jul 2023), 44 pages. https://doi.org/10. 1007/s10515-023-00389-7
- [3] Chris Bernhardt. 2019. Quantum Computing for Everyone . https://doi.org/10. 7551/mitpress/11860.001.0001
- [2] Jaime Alvarado-Valiente, Javier Romero-Álvarez, Ana Díaz, Moisés Rodríguez, Ignacio García-Rodríguez, Enrique Moguel, Jose Garcia-Alonso, and Juan M. Murillo. 2023. Quantum Services Generation and Deployment Process: A QualityOriented Approach. In Quality of Information and Communications Technology , José Maria Fernandes, Guilherme H. Travassos, Valentina Lenarduzzi, and Xiaozhou Li (Eds.). Springer Nature Switzerland, Cham, 200-214.
- [4] Ana Díaz-Muñoz, Moisés Rodríguez, and Mario Piattini. 2024. Implementing an environment for hybrid software evaluation. Science of Computer Programming 236 (2024), 103109. https://doi.org/10.1016/j.scico.2024.103109
- [6] ISO/IEC. 2011. ISO / IEC 25010 : 2011 Systems and software engineering Systems and software Quality Requirements and Evaluation ( SQuaRE ) - System and software quality models. https://api.semanticscholar.org/CorpusID:19022091
- [5] Neil A. Ernst and Maria Teresa Baldassarre. 2023. Registered reports in software engineering. Empirical Software Engineering 28, 2 (2023). https://doi.org/10.1007/ s10664-022-10277-5
- [7] ISO/IEC. 2014. Systems and software engineering - Systems and software Quality Requirements and Evaluation (SQuaRE) - Guide to SQuaRE. https: //www.iso.org/standard/64764.html
- [8] Juan M. Murillo et al. 2024. Challenges of Quantum Software Engineering for the Next Decade: The Road Ahead. (4 2024). arXiv:2404.06825 [cs.SE]
- [10] Mario Piattini, Guido Peterssen Nodarse, Ricardo Pérez-Castillo, Jose Luis Hevia Oliver, Manuel Serrano, Guillermo Hernández González, Ignacio Guzmán, Claudio Andrés Paradela, Macario Polo, Ezequiel Murina, Luis Jiménez Navajas, Juan Marqueño, Ramses Gallego, Jordi Tura, Frank Phillipson, Juan Murillo, Alfonso Niño, and Moisés Rodríguez. 2020. The Talavera Manifesto for Quantum Software Engineering and Programming. (03 2020).
- [9] Ana Díaz Muñoz, Moisés Rodríguez Monje, and Mario Gerardo Piattini Velthuis. 2024. Towards a set of metrics for hybrid (quantum/classical) systems maintainability. JUCS - Journal of Universal Computer Science 30, 1 (2024), 25-48. https://doi.org/10.3897/jucs.99348 arXiv:https://doi.org/10.3897/jucs.99348
- [11] Moisés Rodríguez, Jesús Ramon Oviedo, and Mario G. Piattini. 2016. Evaluation of Software Product Functional Suitability: A Case Study. Software Quality Professional Magazine 18 (2016). https://api.semanticscholar.org/CorpusID:114609549
- [13] Moisés Rodríguez, Mario Piattini, and C.M. Fernandez. 2015. A hard look at software quality: Pilot program uses ISO/IEC 25000 family to evaluate, improve and certify software products. 48 (09 2015), 30-36.
- [12] Moises Rodriguez, Mario Piattini, and Christof Ebert. 2019. Software Verification and Validation Technologies and Tools. IEEE Software 36, 2 (2019), 13-24. https: //doi.org/10.1109/MS.2018.2883354
- [14] J. Verdugo, J. Oviedo, M. Rodriguez, and M. Piattini. 2024. Connecting Research and Practice for Software Product Quality Evaluation and Certification: A Software Laboratory's 25-Year Journey. IEEE Software 41, 03 (may 2024), 33-40. https://doi.org/10.1109/MS.2024.3357119 | null | [
"Díaz-Muñoz Ana",
"Cruz-Lemus José A.",
"Rodríguez Moisés",
"Piattini Mario",
"Baldassarre Maria Teresa"
] | 2024-08-02T08:30:31+00:00 | 2024-08-02T08:30:31+00:00 | [
"cs.SE",
"quant-ph"
] | Validation of an Analysability Model in Hybrid Quantum Software | In the context of quantum-classical hybrid computing, evaluating
analysability, which is the ease of understanding and modifying software,
presents significant challenges due to the complexity and novelty of quantum
algorithms. Although advances have been made in quantum software development,
standard software quality evaluation methods do not fully address the specifics
of quantum components, resulting in a gap in the ability to ensure and maintain
the quality of hybrid software products. In this registered report proposal, we
intend to validate a quality model focused on the analysability of hybrid
software through an international collab orative approach involving academic
institutions from Italy and Spain through a controlled experiment. This
approach allows for a more detailed analysis and validation methodology and
establishes a framework for future research and developments in software
quality assessment in quantum computing. |
2408.01106v1 | ## Slow Voltage Relaxation of Silicon Nanoparticles with a Chemo-Mechanical Core-Shell Model
∗
Lukas K¨ obbing, Yannick Kuhn, and Birger Horstmann Institute of Engineering Thermodynamics, German Aerospace Center (DLR), Wilhelm-Runge-Straße 10, 89081 Ulm, Germany Helmholtz Institute Ulm (HIU), Helmholtzstraße 11, 89081 Ulm, Germany and Faculty of Natural Sciences, Ulm University, Albert-Einstein-Allee 47, 89081 Ulm, Germany
Silicon presents itself as a high-capacity anode material for lithium-ion batteries with a promising future. The high ability for lithiation comes along with massive volume changes and a problematic voltage hysteresis, causing reduced efficiency, detrimental heat generation, and a complicated stateof-charge estimation. During slow cycling, amorphous silicon nanoparticles show a larger voltage hysteresis than after relaxation periods. Interestingly, the voltage relaxes for at least several days, which has not been physically explained so far. We apply a chemo-mechanical continuum model in a core-shell geometry interpreted as a silicon particle covered by the solid-electrolyte interphase to account for the hysteresis phenomena. The silicon core (de)lithiates during every cycle while the covering shell is chemically inactive. The visco-elastoplastic behavior of the shell explains the voltage hysteresis during cycling and after relaxation. We identify a logarithmic voltage relaxation, which fits with the established Garofalo law for viscosity. Our chemo-mechanical model describes the observed voltage hysteresis phenomena and outperforms the empirical Plett model. In addition to our full model, we present a reduced model to allow for easy voltage profile estimations. The presented results support the mechanical explanation of the silicon voltage hysteresis with a coreshell model and encourage further efforts into the investigation of the silicon anode mechanics.
## I. INTRODUCTION
For the enhancement of next-generation lithium-ion batteries, research and industry consider the application of pure silicon anodes [1-3]. Silicon is a popular choice as it is an abundant and cheap material. Anodes made from silicon possess a high theoretical capacity, leading to a massive volume expansion of up to 300 % during lithiation and respective shrinkage during delithiation [4]. The massive deformations induce significant stresses inside the anode material, causing fracture of large silicon particles above a critical diameter of 150 nm [5]. Larger silicon particles suffer from cracks, particle pulverization, and are prone to losing contact with the current collector [6]. Anodes made from silicon nanoparticles promise a higher stability and cycle life compared to anodes with larger silicon particles. Thus, research and industry focus on the behavior of nano-structured silicon anodes [7].
tion gradients due to slow diffusion in micrometer-sized particles [16-18], phase transformation in the very first cycle [19], slow reaction kinetics [20], and mechanical impact of the solid-electrolyte interphase on the lithiation behavior of silicon nanoparticles [21].
A severe challenge for the commercialization of silicon anodes is the handling and possible reduction of the voltage hysteresis observed in various experiments [8-11]. Silicon anodes reveal a different voltage during slow lithiation compared to delithiation reducing efficiency and causing detrimental heat generation [12, 13]. Experiments observe this hysteresis phenomenon of amorphous silicon anodes in thin-film geometries, micron-sized particles, and nanoparticles. Literature discusses different reasons for the voltage hysteresis: mechanics and plastic flow of silicon in thin-film geometries [14, 15], concentra-
∗ [email protected]
The solid-electrolyte interphase (SEI) forms on the surface of the silicon anode particles resulting from the electrochemical instability of the electrolyte in contact with the anode [22-24]. This process leads to a significant capacity loss, even more pronounced for silicon nanoparticle anodes due to the high surface-to-volume ratio. The SEI film is only several nanometers thick but can effectively limit further electrolyte decomposition [25, 26]. Nevertheless, a leakage of electrons through the SEI causes a continued, long-term growth of the SEI during storage and cycling [27, 28]. Concerning the massive volume changes of silicon particles during cycling, it is important to consider the mechanics of the SEI, namely elastic and plastic deformations as well as fracture [29]. However, experimental and theoretical results indicate that the innermost layer of the SEI withstands the large stresses due to plastic flow and fast self-healing [29-31]. In addition to the SEI, a natural silicon oxide layer usually covers the surface of silicon particles and contributes to the innermost SEI layer [32].
For silicon nanoparticles, the SEI has a beneficial effect on their mechanical integrity [1, 33, 34]. Furthermore, carbon-coated silicon particles show a reduced voltage hysteresis [10]. Both observations support our recent explanation of the voltage hysteresis for silicon nanoparticles based on SEI mechanics [21]. Due to the reported pulverization of large particles [6] and growth of SEI into the interior of silicon anodes [35], the mechanical expla-
nation of the hysteresis for silicon nanoparticles covered by a surface layer also has the potential to reason the hysteresis observed for larger geometries [21]. Nonetheless, recent experimental results reveal a slow voltage relaxation behavior for at least 300 h and a significantly enlarged cycling voltage hysteresis even at C / 100 not explained so far [11]. The slow voltage relaxation is in line with the experimental findings of Sethuraman et al. [20]. However, their theoretical explanation with reaction kinetics in the Tafel regime requires extreme values for the exchange current density and the transfer coefficients. Here, we present a consistent picture of the voltage relaxation and other voltage hysteresis phenomena based on mechanics.
This manuscript builds on our previous explanation of the voltage hysteresis of silicon nanoparticles by the mechanical interaction of silicon and SEI [21]. We explain the basic principles of our chemo-mechanical coreshell model in Section II. Furthermore, we introduce the Garofalo viscosity model necessary because of the large stresses arising inside the SEI shell and discuss its behavior in the core-shell system with an analytical approximation and a reduced model. In Section III, we describe the recent experiments performed by Wycisk et al. [11], which we analyze in detail in Section IV. In conclusion, we present a consistent description of the observed slow voltage relaxation, hysteresis shape, C-rate dependence, and voltage transition profiles.
## II. THEORY
Our theoretical framework describes the behavior of a core-shell system, where the silicon particle as core can lithiate and delithiate while the shell is chemically inactive and deforms only mechanically as illustrated in Fig. 1. The core-shell model can in principle relate to different scenarios: (i) SEI on silicon nanoparticle or pulverized silicon micro-particle. Literature reports that the inner SEI on silicon is robust against the severe volume changes [29-31]. (ii) Silicon oxide layer on silicon due to exposure to air or electrolyte, which is reported to affect the silicon lithiation behavior [36, 37]. This effect potentially combines with the influence of the SEI [32]. (iii) Silicon nanodomains in silicon particles surrounded by chemically inactive regions. Literature reports the existence of silicon nanodomains for amorphous silicon under high pressure [38], for crystalline silicon [39], and generically for silicon oxide particles [40, 41]. We interpret the core-shell behavior as a particle-SEI system in the following.
We have presented the foundations of the chemomechanical particle-SEI model used in this study in our previous publications [21, 29]. In the following, we summarize the most important assumptions and equations. Further, we highlight advancements compared to our previous works.
## A. Chemo-Mechanical Core-Shell Model
The silicon particle core deforms due to the chemical lithiation and delithiation F core ch , , elastic deformation F core el , , and plastic deformation F core pl , when reaching the yield criterion. The large deformation approach determines the total deformation F core as
$$F _ { \text{core} } = F _ { \text{core,pl} } F _ { \text{core,el} } F _ { \text{core,ch} }. \quad \quad ( 1 )$$
The concentration of lithium atoms c Li 0 , inside the silicon particle expressed in the undeformed Lagrangian frame determines the chemical deformation
$$\mathbf F _ { \text{core,ch} } = \lambda _ { \text{ch} } \mathbf l d = ( 1 + v _ { \text{Li} } c _ { \text{Li}, 0 } ) ^ { 1 / 3 } \mathbf l d \quad ( 2 )$$
with v Li the molar volume of lithium inside silicon.
The strain tensors E core k , read
$$E _ { \text{core,k} } = \frac { 1 } { 2 } \left ( \mathbf F _ { \text{core,k} } ^ { \text{T} } \mathbf F _ { \text{core,k} } - \text{Id} \right ), \quad \ \ ( 3 )$$
where the subscript k indicates the kind of deformation, which is either the total deformation or one of the mentioned deformation contributions from Eq. (1).
The Cauchy stress σ describes the stress in the deformed Euler frame and the Piola-Kirchhoff stress P = Jσ F -T describes the stress in the undeformed Lagrangian frame with J = det F . The Piola-Kirchhoff stress due to elastoplastic deformation reads
$$\mathbf P _ { \text{core} } = \lambda _ { \text{ch} } ^ { - 2 } \mathbf F _ { \text{core} } \mathbf F _ { \text{core,pl} } ^ { - T } \mathbf F _ { \text{core,pl} } ^ { - 1 } \\ ( \lambda _ { \text{core} } \, \text{tr} ( \mathbf E _ { \text{core,el} } ) \text{Id} + 2 G _ { \text{core} } \mathbf E _ { \text{core,el} } )$$
with the first Lam´ constant e λ core and the second Lam´ e constant G core .
Due to the chemo-mechanical coupling, the stress inside the particle affects the voltage as
$$U = U _ { 0 } + \frac { v _ { \text{Li} } } { 3 F \lambda _ { \text{ch} } ^ { 3 } } \mathbf P _ { \text{core} } \colon \mathbf F _ { \text{core} }$$
with the true open-circuit voltage (OCV) of silicon U 0 and the Faraday constant F .
The differential equations of interest inside the particle are the continuity equation for the time derivative of the lithium concentration ˙ c Li 0 , , the momentum balance, and the equation for the plastic flow rate ˙ F core pl , ,
$$\dot { c } _ { \text{Li}, 0 } = - \nabla _ { 0 } \cdot \vec { N } _ { \text{Li}, 0 } \text{ \quad \ \ } ( 6 )$$
$$0 = \nabla _ { 0 } \cdot { \mathbf P } _ { \text{core} } \quad \quad ( 7 )$$
$$\dot { \mathbf F } _ { \text{core,pl} } \mathbf F _ { \text{core,pl} } ^ { - 1 } = \phi _ { \text{core} } \frac { \partial f _ { \text{core} } } { \partial \mathbf M _ { \text{core} } }. \quad \quad ( 8 )$$
For the lithiation equation, we define the lithium flux ⃗ N Li 0 , = - ∇ L 0 µ Li , the electro-chemo-mechanical potential µ Li = -FU , the mobility L = D Li ( ∂µ Li /∂c Li 0 , ) -1 , and the diffusion coefficient D Li . At the particle boundary, the (de)lithiation rate determines the lithium flux
FIG. 1. Scheme of volume change and SEI stress during lithiation, delithiation, and relaxation periods.
⃗ N Li 0 , ( R ). For the plastic flow, the von Mises yield criterion f core = 3 2 | M dev core | 2 /σ 2 Y core , -1 ≤ 0 determines plasticity with M dev core = M core -1 / 3 tr M core the deviatoric part of the adapted Mandel stress M core = F T core rev , σ core F -T core rev , , the reversible deformation F core rev , = F core el , F core ch , , and the yield stress σ Y core , . The consistency condition ˙ f core = 0 determines the plastic multiplier ϕ core .
dependence of the Garofalo law is reasoned in Ref. [43] by a change in the energy landscape due to mechanical deformations and lattice distortions. Furthermore, positive entropy production is guaranteed analogously to the derivation in Ref. [21] as the inverse hyperbolic sine is positive for positive arguments and negative for negative ones.
For the shell behavior, we assume that the SEI shell deforms only mechanically, namely elastically and plastically,
$$F _ { \text{shell} } = F _ { \text{shell}, \text{pl} } F _ { \text{shell}, \text{el} }$$
leading to massive mechanical strains and stresses when experiencing the significant volume change of the silicon particle during cycling. Analogous to the particle, Eq. (3) determines the strain tensors E shell k , inside the SEI.
In addition to the elastoplastic stress P shell el , determined analogously to Eq. (4), we consider the viscous behavior of the SEI. To describe large viscous stresses during cycling on the one hand and small viscous stresses during relaxation on the other hand, we use the Garofalo law or inverse hyperbolic sine law
$$\mathbf P _ { \text{shell,visc} } = J _ { \text{shell} } \sigma _ { \text{ref} } \cdot \text{asinh} \left ( \tau \dot { \mathbf E } _ { \text{shell} } \right ) \mathbf F _ { \text{shell} } ^ { - T } \quad ( 1 0 ) \quad \text{ multi} \quad$$
calculated component-wise and presented initially in Ref. [42]. The parameter σ ref describes as a reference stress the magnitude of viscous stress at a certain strain rate. The parameter τ describes the time constant of the system and the dependence on the strain rate. In this study, we use the Garofalo viscosity model stated in Eq. (10) instead of a standard Newtonian model or a shear-thinning model [21] to account more adequately for the complexity of the mechanical behavior. The particular functional
The differential equations of interest inside the SEI shell are the momentum balance and the equation for plastic flow,
$$0 = \nabla _ { 0 } \cdot ( \mathbf P _ { \text{shell}, \text{el} } + \mathbf P _ { \text{shell}, \text{visc} } ) \quad ( 1 1 )$$
$$\dot { \mathbf F } _ { \text{shell,pl} } \mathbf F _ { \text{shell,pl} } ^ { - 1 } = \phi _ { \text{shell} } \frac { \partial f _ { \text{shell} } } { \partial \mathbf M _ { \text{shell,el} } }.$$
The yield criterion f shell = 3 2 | M dev shell el , | 2 /σ 2 Y shell , -1 ≤ 0 is determined by the deviatoric part M dev shell el , of the adapted elastic Mandel stress M shell el , = F T shell el , σ shell el , F -T shell el , and the plastic multiplier ϕ shell results from the consistency condition ˙ f shell = 0.
Note that we model the mechanical deformations on a continuum scale. Thus, the visco-elastoplastic behavior is not necessarily an intrinsic property of a single material domain. Instead, interfaces and grain boundaries of multiple crystal domains can determine the continuum mechanics. Hence, the described visco-elastoplasticity can be a consequence of repeated partial cracking and healing, as discussed for the SEI in Ref. [29]. This description is reasonable because the literature does not observe significant fracture of the inner SEI layer on silicon [29-31].
We assume that the surfaces of the silicon particle and SEI stick tightly together, meaning that the radial part of the stress coincides
$$\mathbf P _ { \text{core,rr} } \Big | _ { r = R } = \mathbf P _ { \text{shell,rr} } \Big | _ { r = R } \quad \quad ( 1 3 )$$
when evaluated at the particle-SEI interface r = R . Due to the merely mechanical deformation of the SEI, significant stresses arise inside the SEI impacting the silicon particle stress and voltage.
As presented in Ref. [21], the expansion of the silicon particle during lithiation leads to a mechanical reaction of the SEI, namely, first elastic and then plastic deformation. The strains inside the SEI generate significant compressive stress acting on the silicon particle as visualized in Fig. 1. Additionally, viscous behavior increases the total compressive stress during lithiation depending on the strain rate. During the subsequent delithiation, tensile stress originates from elastic and plastic deformations as well as viscosity, which causes a stress hysteresis inside the SEI, impacting the voltage of the silicon particle according to Eq. (5). Hence, the visco-elastoplastic behavior of the SEI describes the voltage hysteresis observed for silicon nanoparticles.
## B. Analytical Approximation for the Voltage Relaxation
To gain an analytical approximation for the voltage relaxation, we investigate the behavior of the presented chemo-mechanical core-shell model in a simplified setup. Thus, we analyze all local variables at the interface accounting for the central role of the interface coupling. In the following, we discuss several assumptions paving the way to a simplified analytical expression.
First, we choose the simplified description that during relaxation the silicon particle behaves purely elastically according to Hooke's law
$$\sigma _ { \text{ev} } = E _ { \text{core} } \cdot \mathbf E _ { \text{core,ev}, \text{rr} } \quad \quad ( 1 4 ) \quad \Delta$$
with Young's modulus E core and the elastic strain of the core E core ev rr , , due to viscous stress of the shell.
Furthermore, we consider only the viscous stress contribution inside the shell as the elastic stress of the shell stays constant, i.e.,
$$\sigma _ { \text{shell}, \text{visc} } = \sigma _ { \text{ref} } \cdot \sinh \left ( \tau \dot { \mathbf E } _ { \text{shell} } \right ). \quad \ \ ( 1 5 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
The time evolution of the radial stress component in the silicon particle resulting from the time derivative of Eq. (14) states
$$\frac { d \sigma _ { \text{ev} } } { d t } = E _ { \text{core} } \cdot \dot { \mathbf E } _ { \text{core,ev}, \text{rr} }. \quad \quad ( 1 6 )$$
The silicon core deforms only elastically during relaxation of viscous shell stress and isotropically, thus
$$\dot { \mathbf E } _ { \text{core,ev} } \approx \dot { \mathbf F } _ { \text{core,ev} } \approx \frac { \dot { \mathbf F } _ { \text{core} } } { \lambda _ { \text{ch} } } \approx \frac { \dot { \mathbf E } _ { \text{core} } } { \lambda _ { \text{ch} } ^ { 2 } } \quad ( 1 7 ) \quad T _ { \text{visc} }$$
and
$$\dot { E } _ { \text{core,ev,rr} } = \dot { E } _ { \text{core,ev,\varphi\varphi} } = \frac { \dot { E } _ { \text{core,\varphi\varphi} } } { \lambda _ { \text{ch} } ^ { 2 } }. \quad ( 1 8 ) \quad \text{reve}$$
The radial and tangential stresses are related by the momentum balance as
$$\sigma _ { \text{shell}, \varphi \varphi } = - \alpha \lambda _ { \text{ch} } ^ { 3 } \sigma _ { \text{shell}, \text{rr} } \quad \quad ( 1 9 )$$
with the parameter α = 1 2 ( R core L shell -1 ) defined by the core radius R core and the shell thickness L shell .
Using equations (13), (15), (16), and (19), we find the differential equation for the radial stress component
$$\frac { d \sigma _ { e v } } { d t } = \frac { E _ { \text{core} } \cdot \frac { \dot { \mathbf E } _ { \text{core}, \varphi \varphi } } { \lambda _ { \text{ch} } ^ { 2 } } } { \lambda _ { \text{ch} } ^ { 2 } } \quad \quad ( 2 0 )$$
$$= \frac { E _ { \text{core} } } { \tau \lambda _ { \text{ch} } ^ { 2 } } \sinh \overset { \dots } { \longrightarrow } \overset { \sigma _ { \text{shell}, \text{visc}, \varphi \varphi } } { \sigma _ { \text{ref} } } \right ) \quad \ \ ( 2 1 )$$
$$= - \frac { \stackrel { \dots } { E _ { \text{core} } } } { \tau \lambda _ { \text{ch} } ^ { 2 } } \sinh \left ( \frac { \alpha \lambda _ { \text{ch} } ^ { 3 } \sigma _ { \text{ev} } } { \sigma _ { \text{ref} } } \right ) ^ { \cdot }. \quad \ \ ( 2 2 )$$
We solve the simplified differential equation in Eq. (22) analytically to describe the whole time dependence with a single analytical solution
$$\sigma _ { \text{ev} } = \frac { 2 \sigma _ { \text{ref} } } { \alpha \lambda _ { \text{ch} } ^ { 3 } } \cdot \text{atanh} \left ( C \cdot \exp \left ( - \frac { E _ { \text{core} } \alpha \lambda _ { \text{ch} } } { \tau \sigma _ { \text{ref} } } t \right ) \right ), \ \ ( 2 3 )$$
where the constant C can be determined from the boundary condition at time t = 0 with σ ev ( t = 0) = σ 0 .
For the calculation of the stress effect on the silicon voltage according to Eq. (5), we approximate the deformation of the silicon particle core as purely chemical, F core = F core ch , = λ ch Id , and we assume isotropic stress distribution inside the particle P core ev , = λ 2 ch σ ev Id . Therefore, the impact of the stress on the voltage according to Eq. (5) simplifies to ∆ U ev = v Li σ ev /F in the reduced model and the voltage relaxation reads
$$( 1 4 ) \quad \Delta U _ { \text{ev} } = \frac { 2 v _ { \text{Li} } \sigma _ { \text{ref} } } { \alpha F \lambda _ { \text{ch} } ^ { 3 } } \, \text{atanh} \left ( C \exp \left ( - \frac { E _ { \text{core} } \alpha \lambda _ { \text{ch} } } { \tau \sigma _ { \text{ref} } } t \right ) \right ). \ ( 2 4 )$$
To understand the origin and the regimes of the convoluted functional behavior in Eq. (23), we analyze the relaxation behavior in the limits of large and low stress magnitudes in section SI in the Supporting Information. Due to the importance of the long-term relaxation, here we present only the large stress limit. In the limit of large compressive stress, the differential equation (22) simplifies to
$$\cdot \quad \frac { \text{d} \sigma _ { \text{ev} } } { \text{d} t } = - \frac { E _ { \text{core} } } { \tau \lambda _ { \text{ch} } ^ { 2 } } \cdot \left ( - \frac { 1 } { 2 } \right ) \exp \left ( - \frac { \alpha \lambda _ { \text{ch} } ^ { 3 } \sigma _ { \text{ev} } } { \sigma _ { \text{ref} } } \right ). \quad ( 2 5 )$$
The analytical solution for this differential equation is
$$\sigma _ { \text{ev} } = \frac { \sigma _ { \text{ref} } } { \alpha \lambda _ { \text{ch} } ^ { 3 } } \cdot \ln \left ( \frac { E _ { \text{core} } \alpha \lambda _ { \text{ch} } } { 2 \tau \sigma _ { \text{ref} } } t + C _ { \text{exp} } \right ) \quad ( 2 6 )$$
with the integration constant C exp determined from the boundary condition.
Thus, the voltage relaxation according to the Garofalo viscosity
$$\Delta U _ { e v } = \frac { v _ { L i } \sigma _ { r e f } } { \alpha F \lambda _ { \text{ch} } ^ { 3 } } \cdot \ln \left ( \frac { E _ { \text{core} } \alpha \lambda _ { \text{ch} } } { 2 \tau \sigma _ { r e f } } t + C _ { \text{exp} } \right ) \quad ( 2 7 )$$
reveals logarithmic behavior in the large stress limit.
## C. Reduced Model Equations
Complementary to our full model presented in Section II A, we derive a reduced model with the key features in section SII in the Supporting Information. The reduced model describes the elastic stress contribution of the core at the interface between core and shell due to elastoplastic behavior of the shell σ ee and due to viscous behavior of the shell σ ev .
The system of equations defining the reduced chemomechanical hysteresis model reads
$$\frac { d \, S O C } { d t } = \frac { \dot { c } _ { \text{Li}, 0 } } { c _ { \text{Li}, \max } } = \pm \frac { C _ { \text{rate} } } { 3 6 0 0 } \, \frac { 1 } { s } \\ \hat { \ }.$$
$$\frac { \partial u } { d t } & = \begin{cases} - E _ { \text{shell} } \frac { 2 v _ { L i } ^ { 2 } } { 3 F \lambda _ { \text{ch} } ^ { 7 } } \dot { c } _ { L i, 0 }, & \text{if $f_{red}<0$} \\ \frac { \alpha \sigma _ { \text{Y,shell} } v _ { L i } ^ { 2 } } { F \left ( 1 + \alpha \lambda _ { \text{ch} } ^ { 3 } \right ) ^ { 2 } } \left | \dot { c } _ { L i, 0 } \right |, & \text{otherwise} \\ d \Delta U _ { \text{...} } & F _ { \text{...} } \dots v _ { r } \colon & / \alpha \lambda ^ { 3 }, \, F \Delta U _ { \text{...} } \dots \, & F _ { \text{...} } \dots v _ { r } ^ { 2 }. & \text{The d} \end{cases}$$
$$\frac { \text{d} \, \Delta U _ { e v } } { \text{d} t } = - \frac { \text{e} _ { \text{core} } v _ { \text{Li} } } { \tau F \lambda _ { \text{ch} } ^ { 2 } } \sinh \left ( \frac { \alpha \lambda _ { \text{ch} } ^ { 3 } F \Delta U _ { e v } } { \sigma _ { \text{ref} } v _ { \text{Li} } } \right ) - \frac { E _ { \text{core} } v _ { \text{Li} } ^ { 2 } } { 3 F \lambda _ { \text{ch} } ^ { 3 } } \dot { c } _ { \text{Li}, 0 } } \quad \text{uring $\mathfrak{s.d}} } { \text{The dash} }$$
with the parameter α = 1 2 ( R core L shell -1 ) and the yield condition for plastic flow for the reduced model
$$f _ { \text{red} } = - \text{sgn} \left ( \dot { c } _ { L i, 0 } \right ) \left ( 1 + \alpha \lambda _ { \text{ch} } ^ { 3 } \right ) \frac { F \Delta U _ { \text{ee} } } { v _ { L i } \sigma \text{Y,shell} } - 1 < 0. \ ( 3 1 ) \quad \text{silicor} \\ \quad \text{defor}.$$
The equations defining the reduced model describe the silicon anode voltage as U = U mean +∆ U ee +∆ U ev . Equation (28) states the change of SOC for lithiation (+) and delithiation ( -). The upper case in Eq. (29) describes the voltage evolution caused by elastic behavior of the silicon core due to elastic behavior of the shell. The lower case describes elastic core stress due to plastic behavior of the shell. The first term in Eq. (30) considers the viscous shell stress relaxation. The second term considers viscous shell stress increase because of silicon volume changes.
In Fig. 2, we depict the voltage profile predicted by the reduced model for a GITT procedure with (de)lithiation steps of ∆SOC = 0 02% with C 20 and relaxation pe-. / riods of 3 h. Furthermore, the figure shows the voltage during C 20 cycling and after / 12 h relaxation periods. The dashed black line depicts the fitted mean OCV curve U mean between the measured lithiation and delithiation voltage after 3 h rest period for a pure silicon anode from Ref. [8] used as true OCV curve for the simulations.
## III. COMPUTATIONAL & EXPERIMENTAL DETAILS
## A. Simulation Setup
Our simulations describe the behavior of a silicon nanoparticle anode with a single-particle model. We im-
FIG. 2. Voltages according to the presented reduced model during GITT, C / 20 cycling, and after 12 h relaxation periods. The dashed black line depicts the mean OCV measured for a silicon anode in Ref. [8].
plement our model in MATLAB using a finite-difference approach by discretizing the radial dimension. To solve the set of differential equations (6), (7), (8), (11), and (12), we use the solver ode15i. The variables inside the silicon core are the concentration of lithium c Li 0 , , the deformed radius r core , and the radial component of the plastic deformation F core pl rr , , of each silicon core element. The variables inside the SEI shell are the deformed radius r shell and the radial component of the plastic deformation F shell pl rr , , of each SEI shell element.
## B. Material Parameters
We adopt the parameters from our previous publication [21] and adapt where necessary. Particularly, we consider the stiff, inorganic SEI shell with Young's modulus of E shell = 100GPa compatible with experiments [44, 45]. The viscosity of the inner SEI shell is considered as a fit value and may range from η = 10 7 Pas for a highly viscous polymer [46] to η = 10 15 Pas for silicon oxide [47-49].
## C. Experimental Setup
The experiments analyzed in this study have been performed and published by Wycisk et al. [11] at Mercedes following discussions with the authors of this manuscript. The publication discusses full-cell voltage measurements with an NMC811 cathode and anodes with varying contents of silicon active material. Here, we constrain solely to the experimental results discussing anodes with pure silicon active material. The silicon anode consists of silicon nanoparticles attached to a conductive carbon net-
FIG. 3. (a) Experimental voltage relaxation of silicon at SOC = 0 3 over 300 hours after a charge and discharge period (protocol . SIII A) [11]. (b) The semi-logarithmic plot unveils the logarithmic voltage relaxation behavior.
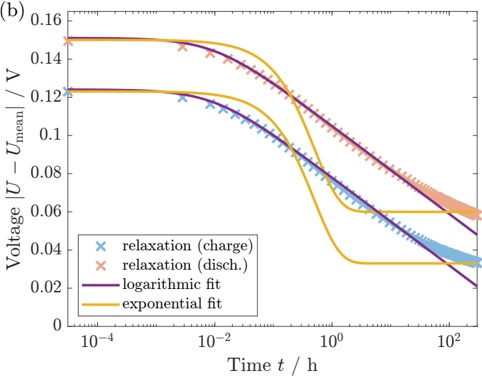
work discussed as 'silicon-carbon composite granules' in Ref. [50]. We summarize the experimental and our simulation protocols in section SIII in the Supporting Information but refer to the experimental publication for the experimental details [11].
Throughout this manuscript, we consider voltages from the anode perspective and calculate voltage differences to the mean OCV, U -U mean . For comparison, the voltage difference for the full-cell measurements is calculated as U -U mean = -( U full -U full mean , ).
## IV. RESULTS AND DISCUSSION
## A. Experimental Results: Logarithmic Voltage Relaxation
over time as a semi-logarithmic plot. Apparently, the voltage relaxation profile does not follow a typical exponential relaxation behavior as illustrated in yellow. We identify a linear regime in the semi-logarithmic plot and fit a logarithmic function to the experimental data. The logarithmic fit agrees with the experimental data in a wide range of times t < 20 h. Only for times larger than 20 h, the voltage relaxation slightly diminishes leaving the logarithmic regime. This is expected as logarithmic behavior would diverge for large times. The logarithmic voltage relaxation found in the experiment agrees with the experimentally observed voltage relaxation of silicon thin-film electrodes in Ref. [20]. It is in stark contrast to diffusion limitation with exponential long-term behavior and supports the theory of a mechanical origin.
First, we analyze the long-time relaxation experiment performed by Wycisk et al. [11] following the protocol described in section SIII A in the Supporting Information. In Fig. 3, we depict the voltage relaxation at the same SOC measured once in charge and once in discharge direction.
Interestingly, the authors of Ref. [11] find that even after 300 h of rest, the voltage depicted in Fig. 3(a) is not completely relaxed. Therefore, the true OCV value deviates from the relaxed voltage after 300 h and strongly deviates from standard GITT measurements with only a few hours of voltage relaxation. The authors of Ref. [11] exclude degradation or self-discharge due to the similar voltage relaxation profiles after the charge and discharge period. However, the mean value of the relaxed voltage after 300 h varies from the mean OCV measured with GITT for C 20 and 12 h rest period due to deviations of / the experimental cells.
Here, we investigate the voltage relaxation profile in detail again. In Fig. 3(b), we show the voltage relaxation
## B. Simulation Results: Slow Voltage Relaxation
As discussed in Section II A, the silicon OCV hysteresis results from elastoplastic stress generated by the shell, and the enlarged voltage hysteresis during cycling results from viscous shell stress acting on the particle core [21]. A simple Newtonian viscosity model, σ shell = η shell ˙ E shell , with constant viscosity η shell would imply exponential voltage relaxation behavior during rest contrasting the experimental observations. Due to the large stresses inside the SEI shell, the Newtonian model is not suitable for describing the viscous behavior. Instead, for large stresses, the strain rate is known to depend exponentially on the stress, leading to a logarithmic stress relaxation behavior. Therefore, we use the established Garofalo law given in Eq. (10) to describe both regimes.
Using the Garofalo model, Fig. 4 depicts our simulation results in comparison to the experimental data. The parameters are given in the Supporting Information in Table S1. We shift our simulations to match the observed
FIG. 4. (a) Voltage relaxation of silicon at SOC = 0 3 over 300 hours (protocol SIII A). Comparison of simulation, experiment . [11], and the analytical Garofalo approximation. (b) The semi-logarithmic plot shows agreement of the various curves.
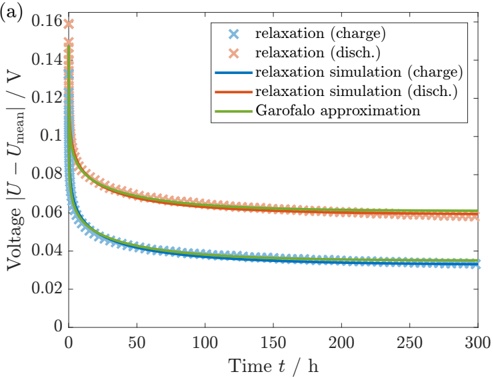
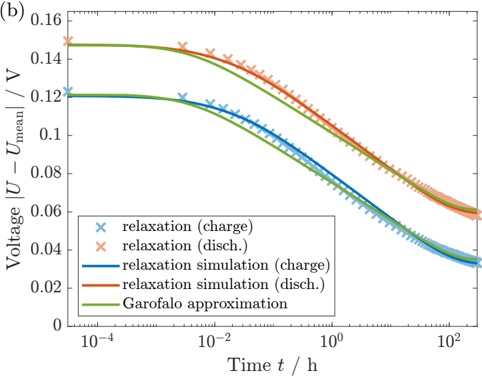
voltage after relaxation. The simulations reproduce the voltage relaxation profiles after the charge and discharge period. In particular, the simulation using the Garofalo law describes both the logarithmic relaxation regime as well as the decreasing relaxation after 20 h. The agreement confirms the explanation of the silicon voltage hysteresis by a visco-elastoplastic SEI behavior.
sulting from the elastoplastic contribution. Furthermore, the simulation shows an enlarged hysteresis during cycling caused by viscous stress.
To validate our simulation results, Fig. 4 compares our simulation and the experiment to the analytical approximation presented in Section II B. The analytical approximation for the voltage relaxation with Garofalo law viscosity reveals a similar logarithmic relaxation regime followed by a slowed relaxation. Thus, the specific trends observed for our simulation and the analytical approximation agree while the actual values deviate slightly. Nevertheless, as the analytical approach relies on several assumptions and approximations, the similarity of the voltage profile supports our simulation results.
## C. OCV and Cycling Voltage Hysteresis
Silicon anodes are generally known to show a significant voltage hysteresis. In Fig. 5, we depict the experimental OCV hysteresis after long relaxation and the enlarged voltage hysteresis during slow cycling [11]. We describe the protocol in SIII B in the Supporting Information. To check the consistency of our model with the experimental voltage hysteresis, Fig. 5 shows the simulation of the anode voltage during slow cycling and the OCV after long relaxation depending on the SOC for the parameters obtained from the voltage relaxation behavior. The illustrated voltages describe the influence on the silicon anode voltage. Hence, the voltage decreases during lithiation due to compressive stress and increases during delithiation due to tensile stress. The simulation results in Fig. 5 reveal a significant OCV hysteresis re-
The comparison of the cycling and relaxed voltages reveals a good agreement between simulation and experiment in a wide SOC regime. However, our simulation and the experiment deviate slightly at both extremes, SOC < 0 2 and SOC . > 0 8. . This disagreement results at least partially from the determination of the true, stress-free OCV curve as the mean between lithiation and delithiation OCV. At very high SOC, the compressive stress during lithiation is fully developed, while the tensile stress during the following delithiation has to build up gradually after the change of direction. Analogously, the tensile stress during delithiation is fully developed, while the compressive stress during the following lithiation has to build up gradually after the change of direction at low SOC. Therefore, the mean value between the lithiation and delithiation OCV at both extremes is not stress-free. Its consideration as true, stress-free OCV in the simulation leads to an apparent deviation. In the Supporting Information, we discuss a corrected OCV curve assuming a constant hysteresis size in the extreme SOC regimes. Fig. S3 reveals a better agreement between simulation and experiment in the extreme SOC regimes.
In our previous publication [21], we compared our simulation to the GITT measurement performed for a silicon half cell by Pan et al. [8, 9]. The cells differ significantly from the cells investigated by Wycisk et al. [11] due to a presumably different silicon raw material and electrolyte composition. Nevertheless, we compare our new model and the parameters obtained from the voltage relaxation [11] to the GITT measurement [8, 9] in section SV in the Supporting Information. Fig. S4 shows a reasonable match of simulation and experiment considering the full GITT procedure as well as a single GITT pulse. The agreement confirms the applicability of our chemo-
FIG. 5. C 20 and open-circuit voltage hysteresis after 12 h / relaxation in simulation and experiment (protocol SIII B) [11].
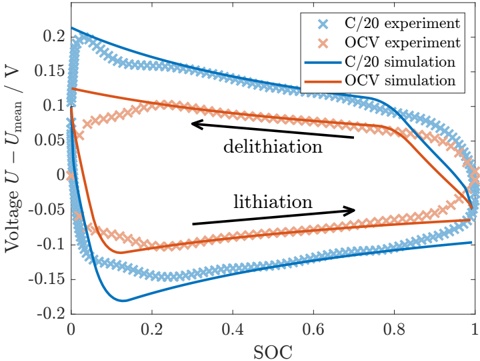
mechanical model to GITT measurements with different cells.
## D. C-Rate Dependence of Voltage Hysteresis
The experimental data obtained by Wycisk et al. [11] also cover the C-rate dependence of the voltage difference between the cycling voltage and the relaxed voltage after 12 h at SOC = 0 5 following the protocol given in . SIII C in the Supporting Information. As displayed in Fig. 6, the data reveal a linear dependence of the voltage on the C-rate. However, extrapolating this linear dependence to zero current results in a significant voltage offset compared to the OCV after infinite relaxation time. This offset would imply an enlarged hysteresis even for infinitely slow cycling, which is unexpected. Therefore, the authors conclude that the voltage will depart from the linear trend at particularly low C-rates.
The Newtonian viscosity model has a linear relation between the strain rate and the viscous stress. Hence, the size of the additional voltage hysteresis is linearly dependent on the C-rate as illustrated in yellow in Fig. 6. However, the Newtonian model explains no voltage offset, and the slope disagrees with the experiment when matching the hysteresis size at C / 10.
In comparison to the experimental and the Newtonian C-rate dependence, Fig. 6 also depicts the simulated Crate dependence. The inverse hyperbolic sine in Eq. (10) determines the C-rate dependence of the viscous stress and, consequently, the C-rate dependence of the additional voltage hysteresis during cycling. Thus, the simulation reveals a non-linear dependence of the voltage on the current. Nonetheless, after a swift increase of the voltage at current rates smaller C / 100, the increase slows down, approaching an almost linear trend with small curvature. Although the three experimental data points follow the linear trend exactly, we assume that our simula-
FIG. 6. C-rate dependence of voltage hysteresis at SOC = 0 5 . in simulation and experiment (protocol SIII C) [11].
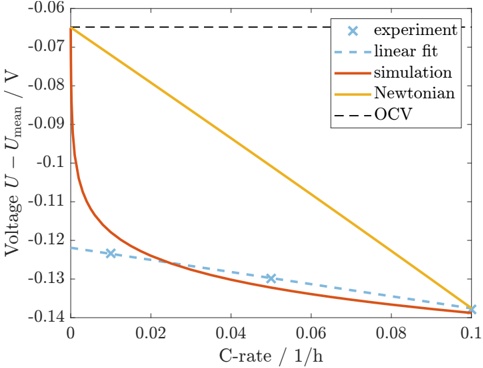
tion is in reasonable agreement with the experiment and additionally describes the transition to vanishing voltage at zero current. We expect that more experimental data points particularly at low C-rates might indicate a curvature and deviation from the linear trend.
## E. Voltage Transition Profiles
Another interesting behavior is the silicon anode voltage profile of transitions between cycling and rest periods. In the following, we discuss the features of different transitions and compare our simulation to the experimental data from Ref. [11] wherever possible.
First, we investigate the transition profile between lithiation and delithiation according to protocol SIII D in the Supporting Information. In Fig. 7, we show the delithiation with either C / 10, C / 20, or GITT procedure after a continuous lithiation and rest period. For reference, the figure also includes the simulated and measured lithiation and delithiation OCV curves from Fig. 5, which almost coincide in the depicted regime 0 3 . < SOC < . 0 5. All experimental data [11] reveal a smooth transition between the lithiation and delithiation voltage. The slope of the voltage profiles is large directly after the change of direction and slows down gradually when approaching the delithiation voltage.
The numerical results are depicted in Fig. 7 compared to the experiment. When switching the current direction from lithiation to delithiation, the simulated voltage profiles for C / 10 (yellow) and C / 20 (purple) currents reveal three regimes. Immediately after the change of direction, the voltage shows a steep increase for a small span of ∆SOC ≈ 0 01 attributed to the rapid build-up of vis-. cous stress. Afterward, for a range of ∆SOC ≈ 0 1, . a constant, moderate voltage slope demonstrates the decrease of compressive elastic stress and the subsequent
FIG. 7. Voltage transition from lithiation to delithiation in simulation and experiment (protocol SIII D) [11].
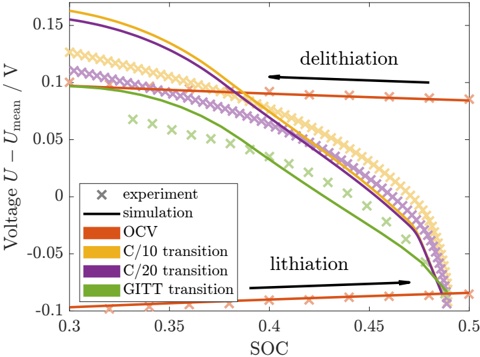
increase in tensile elastic stress. In the third regime, the slope slows down, and the voltage approaches a maximum value when reaching the yield criterion for plasticity. The higher current C / 10 shows a slightly faster voltage transition compared to the lower current C / 20. For the GITT transition curve (green), the relaxation of viscous stress during the rest periods suppresses the viscous regime after the change of direction. Contrary to the simulation, the experimental curves do not reveal clearly defined regimes but are in line with the general trend of a rapid voltage increase after the change of direction followed by an attenuated transition to the delithiation voltage curve. The much smoother experimental results compared to our simulation are expected as we consider only a single-particle model but the detailed features average out in the multi-particle experiment. Thus, we conclude that our simulation result agrees reasonably with the experimental measurement.
In the Supporting Information in section SVI, we evaluate the behavior of an interrupted lithiation pulse for different C-rates and at different SOC values. All voltage profiles in Figures S5 and S6 show a steep slope at the beginning of the pulses, revealing the increase in viscous stress followed by a slower convergence to the lithiation voltage, indicating elastoplastic behavior. The similar voltage profiles for different C-rates indicate that the voltage transition needs a certain amount of charge throughput or SOC change ∆SOC in accordance with the experimental results from Ref. [11] for a blended graphite-silicon anode. Additionally, the voltage profiles at different SOC values in Fig. S6 show that the general trends of the chemo-mechanical simulation agree with the ones of the experiment. However, all experimental curves show an overshoot instead of a smooth convergence to the lithiation voltage, which is not visible in our simulations. In terms of mechanics, this overshoot might result from a thixotropic behavior of the SEI shell as discussed in the Supporting Information.
Another voltage hysteresis effect measured for silicon anodes is a pronounced relaxation during rest observed for higher applied currents [11, 51]. Higher C-rates show an increased voltage hysteresis during cycling in agreement with our viscosity model. However, this dependence surprisingly inverts after relaxation. This phenomenon is not captured in our chemo-mechanical single-particle model. Therefore, we support the interpretation as a multi-particle effect [11] and add a mechanical explanation. For fast charging, the silicon particles inside the anode will lithiate more inhomogeneously, causing enhanced plastic flow of the shell around particles with a higher lithiation level. During the subsequent rest period, the silicon particles with initially higher lithiation degrees delithiate slightly. The shrinkage of those particles reduces the remaining compressive stress, while the stress in the particles with initially lower lithiation levels can not exceed the yield stress for plastic flow. Hence, this multi-particle effect can reduce the mean stress hysteresis inside the silicon anode and, consequently, the voltage hysteresis after relaxation.
Finally, we estimate the voltage transition behavior for alternating short lithiation and delithiation pulses following protocol SIII F in the Supporting Information. The silicon voltage hysteresis is often described empirically with the Plett model presented in section SVII in the Supporting Information [52-54]. In Fig. 8(a), we depict the behavior for alternating pulses with ∆SOC = 0 01 . predicted by the empirical Plett model with the parameters adjusted to fit the experimental voltage hysteresis. The Plett model does not reveal a constant hysteresis behavior during 10 subsequent cycles but rather approaches the mean OCV within the first cycles and then describes a hysteresis around it. Additionally, the Plett model is not able to account for a relaxation phase without a change in SOC. In contrast, Fig. 8(b) shows the simulation of alternating pulses, which reveal a permanent hysteresis during 10 subsequent cycles. Only the very first pulse initially shows a slightly different behavior with an enlarged hysteresis size because of a different stress state in the initial situation after the 12 h relaxation period. We know that experiments show a permanent hysteresis behavior upon alternate lithiation and delithiation pulses in line with our simulation result. Thus, we conclude that our chemo-mechanical core-shell model outperforms the empirical Plett model in the description of voltage hysteresis phenomena.
## V. CONCLUSIONS
Detailed analysis of the silicon voltage hysteresis experiments performed by Wycisk et al. [11] reveals a slow, non-exponential voltage relaxation. We identify a logarithmic voltage relaxation for a wide range of times and a transition to exponential relaxation for larger times due to the divergence of the logarithmic behavior. With a chemo-mechanical core-shell model, we have illustrated
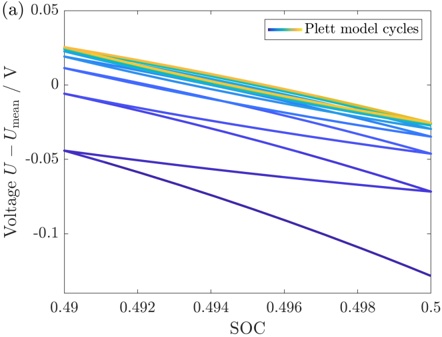
FIG. 8. Voltage for alternating lithiation and delithiation pulses with ∆SOC = 1% (protocol SIII F) for (a) the phenomenological Plett model and (b) our chemo-mechanical simulation.
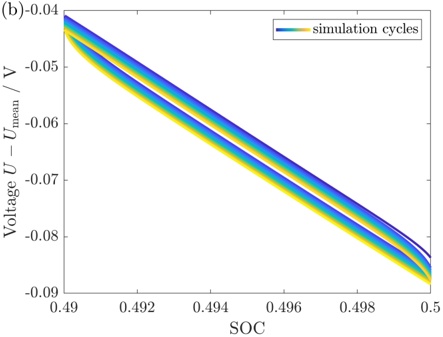
that the visco-elastoplastic SEI shell behavior following the Garofalo law or inverse hyperbolic sine law for viscosity can accurately describe the voltage relaxation of a silicon anode over the whole time span. Our simulations also reproduce the observed voltage hysteresis and GITT measurement with the parameters obtained from the relaxation experiment.
Plett model regarding physical understanding as well as the description of the various features of the hysteresis phenomenon.
Additionally, the Garofalo viscosity model can approach the experimentally observed C-rate dependence of the cycling voltage hysteresis. The inverse hyperbolic sine behaves approximately linear in a wide span of Crates but shows a kink and reveals vanishing additional voltage hysteresis at zero current. Therefore, the Garofalo law viscosity model fits much better to the C-rate dependence than Newtonian viscosity, which reveals a proportional relation between the voltage and the applied C-rate.
With a focus on the voltage transition behavior between lithiation and delithiation, the presented chemomechanical model can adequately describe the general trends of an initially fast voltage transition followed by an attenuated convergence to the delithiation voltage curve. The interplay of viscous, elastic, and plastic contributions to the simulated voltage explains this voltage profile. Furthermore, our model reasonably describes the lithiation behavior after a rest period. Thus, our chemomechanical core-shell model outperforms the empirical
[1] L. Sun, Y. Liu, R. Shao, J. Wu, R. Jiang, and Z. Jin, Recent progress and future perspective on practical silicon anode-based lithium ion batteries, Energy Storage Materials 46 , 482 (2022).
[2] X. Zuo, J. Zhu, P. M¨ller-Buschbaum, and Y.-J. Cheng, u Silicon based lithium-ion battery anodes: A chronicle perspective review, Nano Energy 31 , 113 (2017).
[3] K. Feng, M. Li, W. Liu, A. G. Kashkooli, X. Xiao, M. Cai,
The overall accordance of our simulations to experimental results supports our chemo-mechanical explanation of the voltage hysteresis presented initially in Ref. [21]. The description of the viscous behavior using the Garofalo law is more suitable than linear Newtonian viscosity because of the large stresses reached inside the SEI shell. In conclusion, we have demonstrated that our physical model presents a consistent picture of the various features of the silicon voltage hysteresis phenomenon.
## ACKNOWLEDGMENTS
Lukas K¨ obbing gratefully acknowledges funding and support by the European Union's Horizon Europe within the research initiative Battery 2030+ via the OPINCHARGE project under the grant agreement number 101104032 and by the German Research Foundation (DFG) within the research training group SiMET under project number 281041241/GRK2218. The authors appreciate fruitful discussions with Dominik Wycisk, Felix Schwab, Martin Werres, Raphael Schoof, and Arnulf Latz.
and Z. Chen, Silicon-Based Anodes for Lithium-Ion Batteries: From Fundamentals to Practical Applications, Small 14 , 10.1002/smll.201702737 (2018).
[4] L. Y. Beaulieu, K. W. Eberman, R. L. Turner, L. J. Krause, and J. R. Dahn, Colossal Reversible Volume Changes in Lithium Alloys, Electrochemical and SolidState Letters 4 , A137 (2001).
[5] X. H. Liu, L. Zhong, S. Huang, S. X. Mao, T. Zhu,
- and J. Y. Huang, Size-Dependent Fracture of Silicon Nanoparticles During Lithiation, ACS Nano 6 , 1522 (2012).
- [6] M. Wetjen, S. Solchenbach, D. Pritzl, J. Hou, V. Tileli, and H. A. Gasteiger, Morphological Changes of Silicon Nanoparticles and the Influence of Cutoff Potentials in Silicon-Graphite Electrodes, Journal of The Electrochemical Society 165 , A1503 (2018).
- [7] F. Kilchert, M. Schammer, A. Latz, and B. Horstmann, Silicon Nanowires as Anodes for Lithium-Ion Batteries: Full Cell Modeling, Energy Technology 2400206 , 10.1002/ente.202400206 (2024), 2401.16125.
- [8] K. Pan, F. Zou, M. Canova, Y. Zhu, and J.-H. Kim, Systematic electrochemical characterizations of Si and SiO anodes for high-capacity Li-Ion batteries, Journal of Power Sources 413 , 20 (2019).
- [9] K. Pan, Dissertation , Ph.D. thesis, Ohio State University (2020).
- [10] P. Bernard, J. P. Alper, C. Haon, N. Herlin-Boime, and M. Chandesris, Electrochemical analysis of silicon nanoparticle lithiation - Effect of crystallinity and carbon coating quantity, Journal of Power Sources 435 , 226769 (2019).
- [11] D. Wycisk, G. K. Mertin, M. Oldenburger, O. von Kessel, and A. Latz, Challenges of open-circuit voltage measurements for silicon-containing Li-Ion cells, Journal of Energy Storage 89 , 111617 (2024).
- [12] M. T. McDowell, S. W. Lee, W. D. Nix, and Y. Cui, 25th Anniversary Article: Understanding the Lithiation of Silicon and Other Alloying Anodes for Lithium-Ion Batteries, Advanced Materials 25 , 4966 (2013).
- [13] D. Wycisk, G. K. Mertin, M. Oldenburger, and A. Latz, Analysis of heat generation due to open-circuit voltage hysteresis in lithium-ion cells, Journal of Energy Storage 61 , 106817 (2023).
- [14] V. A. Sethuraman, M. J. Chon, M. Shimshak, V. Srinivasan, and P. R. Guduru, In situ measurements of stress evolution in silicon thin films during electrochemical lithiation and delithiation, Journal of Power Sources 195 , 5062 (2010).
- [15] B. Lu, Y. Song, Q. Zhang, J. Pan, Y.-T. Cheng, and J. Zhang, Voltage hysteresis of lithium ion batteries caused by mechanical stress, Physical Chemistry Chemical Physics 18 , 4721 (2016).
- [16] R. Chandrasekaran, A. Magasinski, G. Yushin, and T. F. Fuller, Analysis of Lithium Insertion/Deinsertion in a Silicon Electrode Particle at Room Temperature, Journal of The Electrochemical Society 157 , A1139 (2010).
- [17] K. Zhao, M. Pharr, S. Cai, J. J. Vlassak, and Z. Suo, Large Plastic Deformation in High-Capacity Lithium-Ion Batteries Caused by Charge and Discharge, Journal of the American Ceramic Society 94 , s226 (2011).
- [18] Z. Cui, F. Gao, and J. Qu, A finite deformation stressdependent chemical potential and its applications to lithium ion batteries, Journal of the Mechanics and Physics of Solids 60 , 1280 (2012).
- [19] M. T. McDowell, S. W. Lee, J. T. Harris, B. A. Korgel, C. Wang, W. D. Nix, and Y. Cui, In Situ TEM of TwoPhase Lithiation of Amorphous Silicon Nanospheres, Nano Letters 13 , 758 (2013).
- [20] V. A. Sethuraman, V. Srinivasan, and J. Newman, Analysis of Electrochemical Lithiation and Delithiation Kinetics in Silicon, Journal of The Electrochemical Society 160 , A394 (2013).
- [21] L. K¨ obbing, A. Latz, and B. Horstmann, Voltage Hysteresis of Silicon Nanoparticles: Chemo-Mechanical Particle-SEI Model, Advanced Functional Materials 34 , 2308818 (2024).
- [22] B. Horstmann, F. Single, and A. Latz, Review on multiscale models of solid-electrolyte interphase formation, Current Opinion in Electrochemistry 13 , 61 (2019).
- [23] X. Zhang, S. Weng, G. Yang, Y. Li, H. Li, D. Su, L. Gu, Z. Wang, X. Wang, and L. Chen, Interplay between solidelectrolyte interphase and (in)active LixSi in silicon anode, Cell Reports Physical Science 2 , 100668 (2021).
- [24] M. Nie, D. P. Abraham, Y. Chen, A. Bose, and B. L. Lucht, Silicon Solid Electrolyte Interphase (SEI) of Lithium Ion Battery Characterized by Microscopy and Spectroscopy, The Journal of Physical Chemistry C 117 , 13403 (2013).
- [25] P. Verma, P. Maire, and P. Nov´k, A review of the feaa tures and analyses of the solid electrolyte interphase in Li-ion batteries, Electrochimica Acta 55 , 6332 (2010).
- [26] E. Peled and S. Menkin, Review-SEI: Past, Present and Future, Journal of The Electrochemical Society 164 , A1703 (2017).
- [27] L. K¨ obbing, A. Latz, and B. Horstmann, Growth of the solid-electrolyte interphase: Electron diffusion versus solvent diffusion, Journal of Power Sources 561 , 232651 (2023).
- [28] L. von Kolzenberg, A. Latz, and B. Horstmann, Solid-Electrolyte Interphase During Battery Cycling: Theory of Growth Regimes, ChemSusChem 13 , 3901 (2020).
- [29] L. von Kolzenberg, A. Latz, and B. Horstmann, ChemoMechanical Model of SEI Growth on Silicon Electrode Particles, Batteries & Supercaps 5 , 1 (2022).
- [30] K. Guo, R. Kumar, X. Xiao, B. W. Sheldon, and H. Gao, Failure progression in the solid electrolyte interphase (SEI) on silicon electrodes, Nano Energy 68 , 104257 (2020).
- [31] J. Lee, J.-y. Jeong, J. Ha, Y.-t. Kim, and J. Choi, Understanding solid electrolyte interface formation on graphite and silicon anodes in lithium-ion batteries: Exploring the role of fluoroethylene carbonate, Electrochemistry Communications 163 , 107708 (2024).
- [32] C. Cao, I. I. Abate, E. Sivonxay, B. Shyam, C. Jia, B. Moritz, T. P. Devereaux, K. A. Persson, H.-G. Steinr¨ck, and M. F. Toney, Solid Electrolyte Interphase u on Native Oxide-Terminated Silicon Anodes for Li-Ion Batteries, Joule 3 , 762 (2019).
- [33] Q. Li, X. Liu, X. Han, Y. Xiang, G. Zhong, J. Wang, B. Zheng, J. Zhou, and Y. Yang, Identification of the Solid Electrolyte Interface on the Si/C Composite Anode with FEC as the Additive, ACS Applied Materials & Interfaces 11 , 14066 (2019).
- [34] J. Chen, X. Fan, Q. Li, H. Yang, M. R. Khoshi, Y. Xu, S. Hwang, L. Chen, X. Ji, C. Yang, H. He, C. Wang, E. Garfunkel, D. Su, O. Borodin, and C. Wang, Electrolyte design for LiF-rich solid-electrolyte interfaces to enable high-performance microsized alloy anodes for batteries, Nature Energy 5 , 386 (2020).
- [35] Y. He, L. Jiang, T. Chen, Y. Xu, H. Jia, R. Yi, D. Xue, M. Song, A. Genc, C. Bouchet-Marquis, L. Pullan, T. Tessner, J. Yoo, X. Li, J.-G. Zhang, S. Zhang, and C. Wang, Progressive growth of the solid-electrolyte interphase towards the Si anode interior causes capacity fading, Nature Nanotechnology 16 , 1113 (2021).
- [36] M. Schnabel, S. P. Harvey, E. Arca, C. Stetson, G. Teeter, C. Ban, and P. Stradins, Surface SiO 2 Thickness Controls Uniform-to-Localized Transition in Lithiation of Silicon Anodes for Lithium-Ion Batteries, ACS Applied Materials & Interfaces 12 , 27017 (2020).
- [37] K. W. Schroder, A. G. Dylla, S. J. Harris, L. J. Webb, and K. J. Stevenson, Role of Surface Oxides in the Formation of Solid-Electrolyte Interphases at Silicon Electrodes for Lithium-Ion Batteries, ACS Applied Materials & Interfaces 6 , 21510 (2014).
- [38] V. L. Deringer, N. Bernstein, G. Cs´nyi, C. Ben Maha moud, M. Ceriotti, M. Wilson, D. A. Drabold, and S. R. Elliott, Origins of structural and electronic transitions in disordered silicon, Nature 589 , 59 (2021).
- [39] V. L. Chevrier, L. Liu, D. B. Le, J. Lund, B. Molla, K. Reimer, L. J. Krause, L. D. Jensen, E. Figgemeier, and K. W. Eberman, Evaluating Si-Based Materials for Li-Ion Batteries in Commercially Relevant Negative Electrodes, Journal of The Electrochemical Society 161 , A783 (2014).
- [40] K. Kitada, O. Pecher, P. C. M. M. Magusin, M. F. Groh, R. S. Weatherup, and C. P. Grey, Unraveling the Reaction Mechanisms of SiO Anodes for Li-Ion Batteries by Combining in Situ 7 Li and ex Situ 7 Li/ 29 Si Solid-State NMR Spectroscopy, Journal of the American Chemical Society 141 , 7014 (2019).
- [41] J. Wang, X. Wang, B. Liu, H. Lu, G. Chu, J. Liu, Y.G. Guo, X. Yu, F. Luo, Y. Ren, L. Chen, and H. Li, Size effect on the growth and pulverization behavior of Si nanodomains in SiO anode, Nano Energy 78 , 105101 (2020).
- [42] F. Garofalo, O. Richmond, W. F. Domis, and F. von Gemmingen, Strain-Time, Rate-Stress and RateTemperature Relations during Large Deformations in Creep, Proceedings of the Institution of Mechanical Engineers, Conference Proceedings 178 , 31 (1963).
- [43] E. T. Stang, Constitutive Modeling of Creep in Leaded and Lead-Free Solder Alloys Using Constant Strain-Rate Tensile Testing , Master of science in mechanical engineering, Wright State University (2018).
- [44] H. Shin, J. Park, S. Han, A. M. Sastry, and W. Lu,
- Component-/structure-dependent elasticity of solid electrolyte interphase layer in Li-ion batteries: Experimental and computational studies, Journal of Power Sources 277 , 169 (2015).
- [45] Y. Chai, W. Jia, Z. Hu, S. Jin, H. Jin, H. Ju, X. Yan, H. Ji, and L.-J. Wan, Monitoring the mechanical properties of the solid electrolyte interphase (SEI) using electrochemical quartz crystal microbalance with dissipation, Chinese Chemical Letters 32 , 1139 (2021).
- [46] R. Edgeworth, B. J. Dalton, and T. Parnell, The pitch drop experiment, European Journal of Physics 5 , 198 (1984).
- [47] P. Sutardja and W. Oldham, Modeling of stress effects in silicon oxidation, IEEE Transactions on Electron Devices 36 , 2415 (1989).
- [48] V. Senez, D. Collard, B. Baccus, M. Brault, and J. Lebailly, Analysis and application of a viscoelastic model for silicon oxidation, Journal of Applied Physics 76 , 3285 (1994).
- [49] M. I. Ojovan, Viscosity and Glass Transition in Amorphous Oxides, Advances in Condensed Matter Physics 2008 , 1 (2008).
- [50] J. Schwan, G. Nava, and L. Mangolini, Critical barriers to the large scale commercialization of silicon-containing batteries, Nanoscale Advances 2 , 4368 (2020).
- [51] A. Durdel, S. Friedrich, L. H¨sken, and A. Jossen, Modelu ing Silicon-Dominant Anodes: Parametrization, Discussion, and Validation of a Newman-Type Model, Batteries 9 , 558 (2023).
- [52] G. L. Plett, Extended Kalman filtering for battery management systems of LiPB-based HEV battery packs, Journal of Power Sources 134 , 262 (2004).
- [53] C. P. Graells, M. S. Trimboli, and G. L. Plett, Differential hysteresis models for a silicon-anode Li-ion battery cell, in 2020 IEEE Transportation Electrification Conference & Expo (ITEC) , Vol. 1 (IEEE, 2020) pp. 175-180.
- [54] D. Wycisk, M. Oldenburger, M. G. Stoye, T. Mrkonjic, and A. Latz, Modified Plett-model for modeling voltage hysteresis in lithium-ion cells, Journal of Energy Storage 52 , 105016 (2022). | null | [
"Lukas Köbbing",
"Yannick Kuhn",
"Birger Horstmann"
] | 2024-08-02T08:31:38+00:00 | 2024-08-02T08:31:38+00:00 | [
"cond-mat.mtrl-sci",
"physics.app-ph",
"physics.chem-ph"
] | Slow Voltage Relaxation of Silicon Nanoparticles with a Chemo-Mechanical Core-Shell Model | Silicon presents itself as a high-capacity anode material for lithium-ion
batteries with a promising future. The high ability for lithiation comes along
with massive volume changes and a problematic voltage hysteresis, causing
reduced efficiency, detrimental heat generation, and a complicated
state-of-charge estimation. During slow cycling, amorphous silicon
nanoparticles show a larger voltage hysteresis than after relaxation periods.
Interestingly, the voltage relaxes for at least several days, which has not
been physically explained so far. We apply a chemo-mechanical continuum model
in a core-shell geometry interpreted as a silicon particle covered by the
solid-electrolyte interphase to account for the hysteresis phenomena. The
silicon core (de)lithiates during every cycle while the covering shell is
chemically inactive. The visco-elastoplastic behavior of the shell explains the
voltage hysteresis during cycling and after relaxation. We identify a
logarithmic voltage relaxation, which fits with the established Garofalo law
for viscosity. Our chemo-mechanical model describes the observed voltage
hysteresis phenomena and outperforms the empirical Plett model. In addition to
our full model, we present a reduced model to allow for easy voltage profile
estimations. The presented results support the mechanical explanation of the
silicon voltage hysteresis with a core-shell model and encourage further
efforts into the investigation of the silicon anode mechanics. |
2408.01107v2 | ## BIORAG: A RAG-LLM Framework for Biological Question Reasoning
Chengrui Wang 1,2 , Qingqing Long 1,2 , Meng Xiao 1,2 , Xunxin Cai 1,2 , Chengjun Wu 1,2 , Zhen Meng 1,2 , Xuezhi Wang 1,2 , Yuanchun Zhou 1,2 *
1 Computer Network Information Center, Chinese Academy of Sciences.
2
University of the Chinese Academy of Sciences. {crwang,qqlong,shaow,xxcai,cwu,zhenm99,wxz,zyc}cnic.cn
## Abstract
The question-answering system for Life science research, which is characterized by the rapid pace of discovery, evolving insights, and complex interactions among knowledge entities, presents unique challenges in maintaining a comprehensive knowledge warehouse and accurate information retrieval. To address these issues, we introduce BIORAG , a novel Retrieval-Augmented Generation (RAG) with the Large Language Models (LLMs) framework. Our approach starts with parsing, indexing, and segmenting an extensive collection of 22 million scientific papers as the basic knowledge, followed by training a specialized embedding model tailored to this domain. Additionally, we enhance the vector retrieval process by incorporating a domain-specific knowledge hierarchy, which aids in modeling the intricate interrelationships among each query and context. For queries requiring the most current information, BIORAG deconstructs the question and employs an iterative retrieval process incorporated with the search engine for step-by-step reasoning. Rigorous experiments have demonstrated that our model outperforms fine-tuned LLM, LLM with search engines, and other scientific RAG frameworks across multiple life science question-answering tasks.
## 1 Introduction
Research and trends in the Biology have shown a continuously evolving, marked by rapid discoveries and the increasing complexity of its knowledge domains (Bertoline et al., 2023; Long et al., 2021b). In addition, the growing trend for interdisciplinary research between Biology and other fields (Lepore et al., 2023; Xiao et al., 2023; Xiao et al.), such as artificial intelligence (Holzinger et al., 2023; Long et al., 2021a), material science (Atkins et al., 2023), and environmental science (Cole et al., 2021), further amplifies the complexity of knowledge syn-
* Yuanchun Zhou is the corresponding author.
Figure 1: An illustration of the difference between three paradigms: (a) fine-tuned language model embedded domain knowledge into deep space; (b) RAG-based method retrieve supplementary information from constructed knowledge base; (c) BIORAG adaptively select knowledge source and domain-specific tools to advance the biology question-reasoning task.
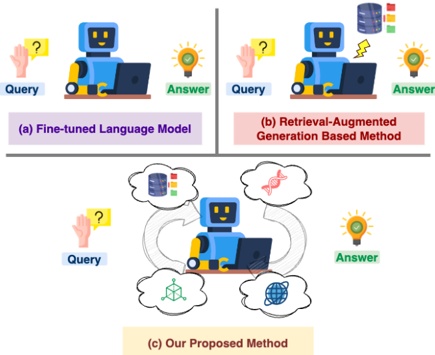
thesis. To bridge the gap and facilitate multidiscipline cooperation, automated question-reasoning systems (Auer et al., 2023) play a pivotal role in enabling experts from diverse fields to effectively navigate and integrate this burgeoning and complex body of biological knowledge (Yang et al., 2023). However, this ever-changing landscape and the complex interplay between different knowledge components present obstacles (Lee et al., 2023; Castro Nascimento and Pimentel, 2023; Lecler et al., 2023; Song et al., 2020) in creating efficient domain-specific question-reasoning systems.
The prior literature partially addresses questionreasoning in the biology domain and can be grouped into two mainstream (Nguyen et al., 2024) (as shown in Figure 1 (a-b)). Fine-tuned Language Model (Gu et al., 2021) includes models like bioBERT (Lee et al., 2020), sciBERT (Beltagy et al., 2019), and large language models tailored for specific domains, such as PMC-Llama (Wu et al., 2024) and Llava-med (Li et al., 2024). These models are trained on domain-specific corpora, thereby embedding deep domain knowledge within their architectures. However, that embedded knowledge could be incomplete and computationally expensive to update. Retrieval-Agumented Generation methods follow the information indexing and retrieval, information augmentation, and answer generation paradigm. For instance, PGRA (Guo et al., 2023) adopts a retriever to search and re-ranking the context, then generate the answer. Later research has aimed to improve these systems by either optimizing the retrieval processes using prior answers (Wang et al., 2023), enhancing model functionality through iterative feedback cycles (Liu et al., 2024), or expanding the knowledge base with search engines to incorporate the latest information (O'Donnell, 2023). Although RAG-based methods address the issue of updating information, they often oversee the intricate complexities inherent in the domain knowledge of biology.
Based on the aforementioned discussion, we summarize three challenges in building efficient biology question-reasoning systems: (C1) The scarcity of high-quality domain-specific corpora. While biological research publications are abundant, there remains a significant void in the availability of extensive, high-quality datasets to build robust information indexing models. (C2) The inherent complexity of biological knowledge systems. This complexity is compounded by the interdisciplinary nature of modern biological research. Consequently, automated question-reasoning systems must be able to understand and process multifaceted and often ambiguous biological query. (C3) The continual updating of knowledge. Biology is a dynamic field where discoveries are frequently made, and existing theories are regularly revised or replaced. This fluidity necessitates that questionreasoning systems adeptly select the knowledge source from databases or contemporary search en- gines to reflect the correct scientific understanding.
Our Perspective and Contributions: To solve the above challenges, we proposed BIORAG, a novel Retrieval-Augmented Generation framework integrated with Large Language Models for biological question-reasoning. To obtain a robust domain-specific information indexing embedding model, we start by parsing, indexing, and segmenting extensive research articles from the biology domain and constructing high-quality training cor- pora. BIORAG then addresses the complexity of biological knowledge systems by combining a prebuilt research hierarchy with an embedding model for accurate context retrieval. To cope with emerging biology knowledge, BIORAG can adaptively select knowledge sources from search engines, existing domain-specific tools, or indexed research articles. Once the framework determines that it has gathered sufficient information, it will generate the answer based on the reasoned material.
We illustrate the question-reasoning power of BIORAG on 6 popularly used biology QA datasets and compare it against 6 baseline methods. Extensive case studies show the great potential to apply this framework to general science questionreasoning scenarios.
## 2 Biological Retrieval-Augmented Generation LLM Framework
In this paper, we propose the Bio logical R etrievalA ugmented G eneration LLM Framework , namely BIORAG (as shown in Figure 2). In the following sections, we first introduce the preliminary step of constructing a high-quality local information source and training the biological domain-specific information indexing embedding model. For questions that require the most current or other domainrelated data, we introduce external information sources. Then, we demonstrate the knowledge hierarchy-based query pre-processing, retriever execution component, and how the model iteratively collects sufficient information. Finally, the large language model will generate the answer based on the information obtained. The details of customized prompts are given in Section 2.4.
## 2.1 Internal Biological Information Source
High-quality domain-specific corpora are crucial for enriching the information source and enhancing the embedding model in the context of biological question-reasoning systems. To achieve this goal, we extract research papers from the global biomedical article database maintained by the National Center for Biotechnology Information 1 (NCBI) (Schoch et al., 2020). This extensive repository aggregates over 37 million scientific citations and abstracts spanning from the 1950s to the present, encompassing a broad array of biomedical fields, including clinical medicine, molecular biology, etc. For the purposes of this study, we utilize the abstracts from
Figure 2: The architecture of our proposed BIORAG framework. The pipeline consists of five iterative components designed to enhance the process of biological question-reasoning: ① Retriever Selection aims to choose the most ideal information source; ② Query Pre-processing aims to rewrite the query and find closed topic tag from pre-defined knowledge hierarchy; ③ Retriever Execution aims to combination retrieve the correlated context from knowledge base; ④ Self-Evaluation assess the adequacy of the retrieved information and decides whether to cycle through additional retrieval tools or to move to the next phase; ⑤ Inference and Generation uses the information gathered to generate an informed and accurate answer to the biological query.
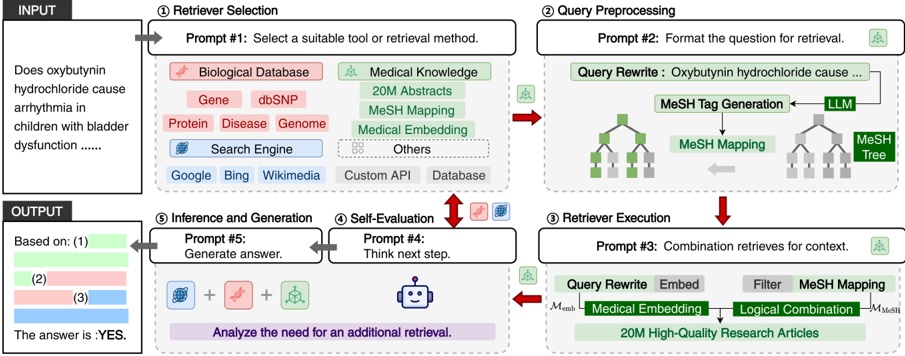
these PubMed papers as the supporting corpus for the BIORAG framework.
Local Data Preparation: Specifically, we initially downloaded over 37 million original papers from which we subsequently filtered out 14 million entries deemed to be of low quality. The preprocessing of these texts was conducted using the Unstructured tool 2 , specifically designed to ingest and preprocess unstructured textual data effectively. Our filtration process involved the removal of gibberish using regular expression techniques, as well as the exclusion of non-semantic content such as hyperlinks, charts, tables, and other embedded tags. This meticulous process yielded a corpus of 22,371,343 high-quality, processed PubMed abstracts.
Information Indexing: To further refine the retrieval performance of abstracts tailored to specific biological questions, we developed a specialized biological embedding model within the BIORAG framework. This model employs PubMedBERT (Gu et al., 2021) as the foundational model. We enhanced this model using the CLIP (Contrastive Language-Image Pretraining) technique (Li et al., 2021; Nussbaum et al., 2024), allowing us to fine-tune the model, denoted as M emb. Based on this, we constructed a local, high-quality biological vector database (Xian et al., 2024) to support efficient and effective query processing and re- trieval operations. This database serves as a critical resource in facilitating rapid and accurate access to relevant biomedical information, significantly advancing the capabilities of our BIORAGframework in handling complex biological questions.
## 2.2 External Information Sources
External biology knowledge is crucial to biological reasoning due to the rapidly evolving nature of biological research, which continuously integrates new discoveries. To address this challenge, we introduce two external information sources.
Biological Data Hub: In BIORAG, we harness several specialized biological Hubs to ensure the accuracy of experimental data and to provide detailed biological insights. Specifically, BIORAGintegrates the following databases, each serving a unique purpose in the broader context of biological analyses: (1) Gene Database : This 3 resource provides comprehensive information on the functions, structures, and expressions of specific genes. It is invaluable for addressing queries related to gene mechanisms, gene actions, and gene expressions, facilitating a deeper understanding of gene-related phenomena. (2) dbSNP Database 4 : This database houses a vast repository of single nucleotide polymorphisms (SNPs), offering critical insights into genetic variants and their potential as-
4 https://www.ncbi.nlm.nih.gov/snp/
sociations with various diseases. It is instrumental for studies exploring the genetic basis of disease and trait inheritance. (3) Genome Database : Pro5 viding complete genome sequences, this database is essential for studying the structure, function, and evolution of genomes across different organisms. It supports comprehensive genomic analyses and comparative studies, enhancing our understanding of genomic architecture and its functional implications. (4) Protein Database 6 : This resource offers detailed information about the sequences, structures, and functions of proteins. It is crucial for exploring protein-related biological processes, understanding molecular functions, and investigating the complex interactions within the proteome.
Search Engine: To ensure access to the most current discussions and developments, BIORAG incorporates a variety of search engines, including Google, Bing, arXiv, Wikimedia, and Crossref. Each platform contributes uniquely to the aggregation of information: (1) Google and Bing: These search engines scour the web for a diverse range of content, including news articles, blogs, and forums, providing insights into public discussions and concerns related to scientific topics. This breadth of information is crucial for understanding the societal impact and general discourse surrounding scientific issues. (2) arXiv: As a repository for preprint papers, arXiv offers access to the latest research reports and scholarly articles across multiple scientific disciplines before they undergo peer review. This source is invaluable for staying abreast of the newest scientific theories and experiments. (3) Wikimedia: Known for its user-friendly content, Wikimedia offers easily digestible explanations of complex scientific concepts and principles. This resource helps simplify advanced topics for broader public understanding and educational purposes. (4) Crossref: This service acts as a comprehensive aggregator of academic citation data, providing links to peer-reviewed scholarly publications and their citation networks. Crossref is essential for accessing high-quality research outputs and understanding their impact on the academic community.
## 2.3 Self-evaluated Information Retriever
Following the construction of the internal and external information source, BIORAG is firstly tasked with comprehending the complex disci-
Based on the QUESTION , analyze the related MeSH terms to format them properly.
QUESTION
: [.....]
MeSH : [ κ 1 , κ 2 , ...]
Figure 3: Training Template for M MeSH.
## Input Question
What are the differences between innate immunity and adaptive immunity?
## Predicted MeSH by M MeSH
[Adaptive Immunity, Animals, ...]
## Generated SQL
" filtered by ":[eq("MeSH", "Adaptive Immunity") or eq("MeSH", "Animals") or ...],
" ordered by ": embedding similarity
Figure 4: An example of MeSH filtering SQLs Generation.
plinary framework of the life sciences to retrieve the most relevant information accurately. Moreover, BIORAG integrates a self-evaluation mechanism to continuously assess the adequacy and relevance of the information it has collected.
Internal Information Retrieve: To effectively navigate the inherent complexity of biological knowledge systems, BIORAG leverages an integrated approach, combining a well-defined hierarchical structure with indexed information to conduct a comprehensive internal information retrieval. The Medical Subject Headings 7 (MeSH) thesaurus is popularly used for indexing, cataloging, and searching for biomedical-related information and research papers. Specifically, we first train a model M MeSH to predict MeSH of the input questions. We then use the templates in Figure 3 for fine-tuning a Llama3-8B model to classify given questions. After that, we construct MeSH filtering SQLs (as shown in Figure 4) to generate the scalar condition retrieval. A candidate result is considered relevant to the given question because it has one consistent MeSH with the question. Then, the vector retrieval process is adopted to sort the relative results based on the cosine similarity of the sentence embedding between the input questions and the filtered results.
Self-evaluation Strategy: In order to ensure the accuracy and contemporary of the retrieved information, BIORAG incorporates a self-evaluation strategy that assesses the adequacy of data collected from the internal knowledge base. In detail, this
| | LLM | LLM | LLM | BioLLM | BioLLM | SciRAG | SciRAG | BioRAG |
|--------------------------|--------|-----------|-----------|-----------|------------|----------|----------|----------|
| | GPT3.5 | Llama3-8B | Llama-70B | PMC-Llama | BioMistral | GeneGPT | NewBing | BioRAG |
| Nomenclature | | | | | | | | |
| Gene alias | 7 | 0 | 0 | 0 | 8 | 84 | 68 | 98 |
| Gene name conversion | 0 | 0 | 0 | 0 | 0 | 100 | 100 | 100 |
| Genomic location | | | | | | | | |
| Gene SNP association | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 100 |
| Gene location | 9 | 20 | 28 | 14 | 12 | 66 | 70 | 86 |
| SNP location | 5 | 48 | 94 | 0 | 0 | 98 | 100 | 100 |
| Functional analysis | | | | | | | | |
| Gene disease association | 31 | 0 | 0 | 0 | 8 | 66 | 64 | 71 |
| Protein-coding genes | 54 | 6 | 12 | 40 | 80 | 100 | 100 | 100 |
Table 1: Performance of BioRAG compared to other RAG-LLMs on the GeneTuring QA dataset.The scores represent accuracy.
| | LLM | LLM | LLM | BioLLM | BioLLM | SciRAG | SciRAG | BioRAG |
|------------------|--------|-----------|-----------|-----------|------------|----------|----------|----------|
| | GPT3.5 | Llama3-8B | Llama-70B | PMC-Llama | BioMistral | GeneGPT | NewBing | BioRAG |
| MedMCQA | 54 | 51 | 71 | 56 | 49 | 0 | 55 | 73 |
| Medical Genetics | 74 | 51 | 67 | 28 | 67 | 0 | 88 | 88 |
| College Biology | 73 | 75 | 88 | 30 | 67 | 0 | 71 | 90 |
| College Medicine | 65 | 61 | 70 | 23 | 51 | 0 | 78 | 78 |
Table 2: Performance of BioRAG compared to other RAG-LLMs on the biological-related QA benchmarks.The scores represent accuracy. Bold and underlined results denote the highest and second-highest performance, respectively.
critical evaluation is driven by the backend large language model which aims to determine whether the information retrieved internally is sufficient to address the posed question substantively. If the internal content is insufficient, the model will loop back to pertinent external knowledge sources. Additionally, when the initial assessment indicates that the scientific questions require broader searches or retrieval of entity-specific data, the model tends to deploy external tools. This methodology supports the framework's goal of providing precise, up-todate, comprehensive answers, facilitating more informed decision-making, and advancing research and applications in the life sciences.
## 2.4 Customized Prompts Detail
To maximize the effect of the retrieved corpus and knowledge, we design customized prompts in BIORAG. The prompts in Figure. 2 is detailed defined as follows,
- · Prompt # 1 : To provide the most helpful and accurate response to the following Question: {Question} . You have been given descriptions of several RETRIEVAL METHODS: {Retrieval} . Please select the RETRIEVAL
METHODS you consider the most appropriate for addressing this question.
- · Prompt # 2 : Based on the RETRIEVAL METHODS you selected, and considering the Question and the Input Requirements of the retrieval method, please REWRITE the search query accordingly.
- · Prompt # 3 : Now, using the rewritten QUERY and the retrieval FILTER methods, perform a logical combination to execute the search effectively.
- · Prompt # 4 : Based on the RETRIEVAL RESULTS from the above steps, please evaluate whether the RESULTS support answering the original Question . If they do not support it, output " NO ". If they do support it, output " YES ".
- · Prompt # 5 : Based on the RETRIEVAL RESULTS, perform a comprehensive reasoning and provide an answer to the Question .
Furthermore, we designed instruction manuals for specialized biological tools and databases, aim at exploiting their potentialities. These instructions are shown as follows,
- · Manual #Gene : The Gene database search engine is a valuable tool for retrieving comprehensive information about genes, including gene structure, function, and related genetic events. It is particularly useful for answering detailed questions regarding gene-related research and findings. To utilize this search engine effectively, the input must be a specific gene name.
- · Manual #dbSNP : The dbSNP database search engine is an essential tool for retrieving detailed information about single nucleotide polymorphisms (SNPs) and other genetic variations. It is particularly useful for answering questions related to genetic diversity, allele frequency, and related genetic studies. To utilize this search engine effectively, the input must be a specific SNP identifier or genetic variant name.
- · Manual #Genome : The Genome database search engine is an indispensable tool for accessing comprehensive information about entire genomes, including their sequences, annotations, and functional elements. It is particularly useful for answering complex questions about genomic structures, variations, and comparative genomics. To use this search engine effectively, the input must be a specific genome name or identifier.
- · Manual #Protein : The Protein database search engine is a crucial resource for obtaining detailed information about proteins, including their sequences, structures, functions, and interactions. It is particularly useful for answering questions related to protein biology, biochemical properties, and molecular function. To use this search engine effectively, the input must be a specific protein name or identifier.
- · Manual #Web Search : The Web Search Engine is a powerful tool designed to help you find information about current events quickly and efficiently. It is especially useful for obtaining the latest news, updates, and developments on a wide range of topics. To use this search engine effectively, simply enter a relevant search query.
- · Manual #PubMed : The PubMed local vector database search engine is an advanced tool designed for retrieving biomedical literature and research articles using vector-based search techniques. It is particularly useful for answering detailed questions about medical research, clinical studies, and scientific discoveries. To utilize this search engine effectively, the input should be a specific query or topic of interest.
## 3 Results & Analysis
## 3.1 Datasets
We conduct experiments on 6 popularly used biological-related QA datasets to evaluate our proposed BIORAG, i.e., GeneTuring (Hou and Ji, 2023), MedMCQA (Pal et al., 2022), Medical Genetics (Hendrycks et al., 2020), College Biology (Hendrycks et al., 2020), College Medicine (Hendrycks et al., 2020). Note that the GeneTuring dataset contains more specialized biological questions. It contains 12 tasks, and each task has 50 question-answer pairs. We use 7 GeneTuring tasks that are related to NCBI resources to evaluate the proposed BIORAG. The chosen tasks are classified into three modules and briefly described as follows,
- · Nomenclature: This is about gene names. The objectives of the gene alias task and name conversion task are finding the official gene symbols for their non-official synonyms.
- · Genomics location: The tasks are about the locations of genes, single-nucleotide polymorphism (SNP), and their relations. We include the gene location, SNP location, and gene SNP association tasks. The first two tasks ask for the chromosome locations of a gene or an SNP, and the last one asks for related genes for a given SNP.
- · Functional analysis asks for gene functions. We use the gene-disease association task where the goal is to return related genes for a given disease, and the protein-coding genes task which asks whether a gene is a proteincoding gene or not.
## 3.2 Baslines
We compare BIORAGwith various baselines, which can be classified into three categories,
Table 3: Ablation study on the GeneTuring dataset.The scores represent accuracy.
| | Data | Data | Data | Component | Component | Component | Base Model | Base Model |
|--------------------------|--------|--------|--------|-------------|-------------|-------------|--------------|--------------|
| | D1 | D2 | D3 | C1 | C2 | C3 | M1 | M2 |
| Nomenclature | | | | | | | | |
| Gene_location | 74 | 94 | 96 | 98 | 90 | 91 | 88 | 98 |
| SNP_location | 50 | 100 | 100 | 100 | 100 | 100 | 92 | 100 |
| Genomic location | | | | | | | | |
| Gene_SNP_association | 6 | 100 | 98 | 100 | 6 | 100 | 94 | 100 |
| Gene_disease_association | 82 | 60 | 84 | 84 | 84 | 36 | 70 | 86 |
| Protein_coding_genes | 20 | 100 | 100 | 100 | 18 | 100 | 100 | 100 |
| Functional analysis | | | | | | | | |
| Gene_name_conversion | 64 | 70 | 62 | 70 | 66 | 32 | 64 | 71 |
| Gene_alias | 100 | 100 | 100 | 100 | 98 | 80 | 92 | 100 |
- · LLM (General LLMs): We select GPT-3.5Turbo (175B), Llama3-8B (8B), Llama-70B (70B) as representative baselines.
- · BioLLM (Biological LLMs): PMC-Llama (13B) (Wu et al., 2024) and BioMistral (7B) (Labrak et al., 2024) are two medical LLMs. They are pre-trained on open-source biomedical texts.
- · SciRAG (Scientific RAG-LLM framework): GeneGPT (175B) (Jin et al., 2024) is a biological RAG-LLM framework that integrates the NCBI databases, i.e., Gene, dbSNP, OIMI, and Blast. NewBing 8 (>400B) is a retrievalaugmented LLM that has access to relevant web pages retrieved by Bing.
## 3.3 Experimental Settings
We take the Llama3-70B as the basic language model of BIORAG. For our embedding model M emb, we take AdamW as the optimizer and finetune 2 epochs. The number of retrieved results by biological databases, search engines, and local PubMed databases are set to 10, 10, and 4, respectively. The max iteration of self-evaluation is set to 15. If the model does not output the final answer within 15 times, BIORAG stops the iteration and outputs the current wrong answer. We use the accuracy to verify the overall performance. For the GeneTuring dataset, we only consider exact matches between model predictions and the ground truth as correct predictions for all nomenclature and genomics location tasks. For the gene-disease association task, we measure the recall as in the
8 https://www.bing.com/chat
original dataset but based on exact individual gene matches. For the protein-coding genes task, we consider exact matches as correct after applying a simple vocabulary mapping that converts modelpredicted "yes" / "no" to "TRUE" / "NA" and Latin species names to their informal names, respectively. The final answer of other datasets is "yes" / "no".
## 3.4 Results on Biological-related Tasks
To verify the effectiveness of the proposed model, we first conduct biological QA tasks. Results are shown in Table 2. We conclude with the following findings: (1) Based on the results of BioLLMs and GPT-3.5, we conclude that fine-tuning domainspecific data is helpful for domain-specific tasks. As the size of BioLLMs is much smaller than GPT3.5, their performance is on par with GPT-3.5. (2) BIORAG performs better than BioLLMs and GPT3.5, it indicates the effectiveness of local and external data sources. (3) Though the size of BIORAG is much smaller than SciRAG (NewBing), it has better performance. The gain comes from two aspects. The first one is our customized prompts. The second aspect lies in the local and external information sources. NewBing has no access to specialized databases and lacks technical biological descriptions for reasoning. (4) GeneGPT scores 0% accuracy in this task, because it is a customized model for the GeneTuring dataset, resulting in poor generalization capabilities.
## 3.5 Specialized Biological Reasoning Results
The GeneTuring dataset contains more specialized biological questions, and the corresponding reasoning process highly relies on technical biological corpus and descriptions. Results are shown in Ta-
Figure 5: A case study selected from the College Biology dataset.

ble 1. As this dataset does not contain the train data, BioLLMs are performed directly without finetuning. Their bad results indicate their poor generalization. In this dataset, we focus on the analyses of GeneGPT, NewBing, and BIORAG (1) For the nomenclature tasks , the performance of BIORAG and GeneGPT rank first and second respectively, as both of them have access to the Gene database. BIORAG integrates the results of search engines while GeneGPT does not, and this brings the gap. (2) The reasoning behind genomic location tasks relies on the highly specialized Gene and dbSNP database. BIORAG and GeneGPT achieve 100% accuracy in the gene SNP association sub-task, as
Figure 6: A case study conducted on the gene alias task in the GeneTuring dataset.
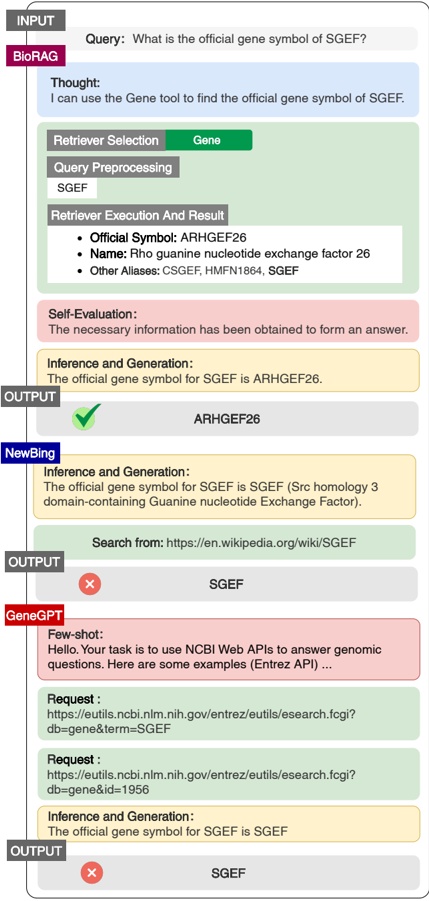
both of them have access to the dbSNP database. However, NewBing has no access to the dbSNP database, thus it gets 0% accuracy in this task. For the gene location subtask, the challenge is the variants of gene names. The interface of GeneGPT does not support advanced search, thus the retrieved names are not comprehensive. In contrast, general search engines, such as NewBing, have better retrieved results when the query entity has variants or ambiguities. Thus NewBing has a better performance in this task than GeneGPT. BIORAG supports the above two kinds of interfaces, and achieves the best results in this task. (3) Functional analysis tasks rely on both the Gene database and
Figure 7: A case study conducted on the gene disease association task in GeneTuring dataset.

relative PubMed papers. The PubMed corpus provides detailed gene-disease relationships. Although NewBing retrieves the metadata, BIORAG combines the local PubMed database with other specialized databases to achieve the best results.
## 3.6 Ablation Study
To evaluate the contribution of each component of BIORAG, we performed an extensive ablation study using the GeneTuring dataset, systematically removing individual components to assess their impact on performance across various tasks. This study was designed to isolate the effects of different databases, components, and base models, with the experiments categorized as follows: (1) Databases : We consider three variations to evaluate the effectiveness of each data sources of our database: D1 : BIORAGwithout the Gene database; D2 : BIORAGwithout general search engines. D3 : BIORAGwithout the local PubMed database. (2) Model Components : We investigate the impact of specific components of our proposed framework: C1 : BIORAGwithout the MeSH Filter; C2 : BIORAGwithout the Query Rewrite component; C3 : BIORAGwithout the Self-Evaluation mechanism. (3) Base Models : We compare the performance when using two different base LLM models: M1 : take Llama-3-8B as the basic LLM, and M2 : take Llama-3-70B as the basic LLM of BioRAG.
Based on the results of ablation study, we highlights the following key findings: (1) Impact of Databases: The results indicate that the Gene database (D1) plays a crucial role in performance. For instance, the accuracy significantly drops in tasks such as Gene\_location when this component is removed. The general search engines (D2) and local PubMed database (D3) also contribute positively, but their impact is less pronounced compared to the Gene database. (2) Component Contributions: Among the components, the SelfEvaluation mechanism (C3) is vital for maintaining high accuracy across most tasks. The MeSH Filter (C1) and Query Rewrite (C2) also enhance performance, but their absence does not degrade the results as severely as the removal of Self-Evaluation. (3) Effects of Basic Language Models: Comparing the two base models, Llama-3-70B (M2) generally outperforms Llama-3-8B (M1) across all tasks, indicating that the larger model size contributes to better handling of complex biological queries. These findings underscore the importance of integrating diverse data sources and advanced compo- nents within the BIORAG framework to achieve optimal performance in biological question reasoning tasks. By understanding the contribution of each component, we can better optimize BIORAG for different tasks and datasets.
## 3.7 Case Study
To compare reasoning differences among BIORAG and the baselines in a more intuitive manner, we select three typical case studies in this section. We first provide a case study to show the workflow of BIORAG (Figure 5). It is selected from the College Biology dataset. BIORAG performs self-evaluation twice: the first time it starts with a web search for general information, but the results are insufficient to support answering the question. Thus BIORAG conducts the second self-evaluation and calls for the more specialized PubMed database. The results this time are accurate and sufficient to support answering the question, thus BIORAG gives the final answer based on the results.
The second case study is conducted on the gene alias task in the GeneTuring dataset (Figure 6). The challenge of this task is the variants of gene names. NewBing gets the response from the Wikimedia. However, Wikimedia is not specialized enough to provide the alias for the input gene, which leads to the wrong answer. The prompts of GeneGPT are too complicated, none of the prompts is relevant to this task. In addition, its NCBI API returns the gene IDs, instead of the gene names. The LLM is unable to understand these IDs, and finally arrives at a wrong answer. BIORAG employs fuzzy queries, yielding a larger number of related responses with a higher error tolerance. Furthermore, each result contains detailed gene-related information and descriptions, such as the aliases. Thus BIORAG gets the correct answer.
The third case study is conducted on the genedisease association task in the GeneTuring dataset, shown in Figure 7. Reasoning behind this task relies on both the Gene database and relative PubMed papers. The PubMed abstracts provide detailed gene-disease relationships. NewBing gets the response from the Geekymedics website. Although the Geekymedics website provides general medical information, it does not offer the correct or specific details required for gene-disease associations. Consequently, NewBing's response is inaccurate due to the reliance on a non-specialized source. GeneGPT chose the wrong NCBI API. The API's feedback is a complicated and interminable HTML page, with massive irrelevant information or descriptions. Based on the ambiguous backgrounds, GeneGPT outputs the wrong answer. In the reasoning process of BIORAG, BioRAG uses multiple tools, i.e., Gene database, local PubMed database, and Web search, to gather and conduct mutual confirmation on the information of genes associated with B-cell immunodeficiency. The process involves preprocessing queries, executing searches, and conducting self-evaluations at each step to ensure comprehensive and accurate results. The reasoning process is thorough, incorporating various data sources to confirm the association of specific genes with B-cell immunodeficiency.
## 4 Conclusion
This paper introduces BIORAG, an innovative framework that integrates Retrieval-Augmented Generation with Large Language Models to enhance biological question-reasoning. The framework's ability to obtain relevant and current information from a blend of traditional databases, toolkits, and modern search engines ensures the accuracy of the generated answers. Through extensive validation, including rigorous testing on widely recognized biology QA datasets and extensive case studies, BIORAG has demonstrated its superior ability to handle complex biological queries. These results underscore the framework's potential as a valuable tool for the scientific community, facilitating more accurate and efficient information processing.
## References
Peter William Atkins, George Ratcliffe, Julio de Paula, and Mark Wormald. 2023. Physical chemistry for the life sciences . Oxford University Press.
Sören Auer, Dante AC Barone, Cassiano Bartz, Eduardo G Cortes, Mohamad Yaser Jaradeh, Oliver Karras, Manolis Koubarakis, Dmitry Mouromtsev, Dmitrii Pliukhin, Daniil Radyush, et al. 2023. The sciqa scientific question answering benchmark for scholarly knowledge. Scientific Reports , 13(1):7240.
Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. Scibert: Apretrained language model for scientific text. arXiv preprint arXiv:1903.10676 .
Letícia MF Bertoline, Angélica N Lima, Jose E Krieger, and Samantha K Teixeira. 2023. Before and after alphafold2: An overview of protein structure prediction. Frontiers in Bioinformatics , 3:1120370.
Cayque Monteiro Castro Nascimento and André Silva Pimentel. 2023. Do large language models understand chemistry? a conversation with chatgpt. Journal of Chemical Information and Modeling , 63(6):1649-1655.
Benjamin Cole, Dominique Bergmann, Crysten E Blaby-Haas, Ian K Blaby, Kristofer E Bouchard, Siobhan M Brady, Doina Ciobanu, Devin ColemanDerr, Samuel Leiboff, Jenny C Mortimer, et al. 2021. Plant single-cell solutions for energy and the environment. Communications biology , 4(1):962.
Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. 2021. Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH) , 3(1):1-23.
Zhicheng Guo, Sijie Cheng, Yile Wang, Peng Li, and Yang Liu. 2023. Prompt-guided retrieval augmentation for non-knowledge-intensive tasks. In Findings of the Association for Computational Linguistics: ACL 2023 , pages 10896-10912.
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300 .
Andreas Holzinger, Katharina Keiblinger, Petr Holub, Kurt Zatloukal, and Heimo Müller. 2023. Ai for life: Trends in artificial intelligence for biotechnology. New Biotechnology , 74:16-24.
Wenpin Hou and Zhicheng Ji. 2023. Geneturing tests gpt models in genomics. BioRxiv .
Qiao Jin, Yifan Yang, Qingyu Chen, and Zhiyong Lu. 2024. Genegpt: Augmenting large language models with domain tools for improved access to biomedical information. Bioinformatics , 40(2):btae075.
Yanis Labrak, Adrien Bazoge, Emmanuel Morin, PierreAntoine Gourraud, Mickael Rouvier, and Richard Dufour. 2024. Biomistral: A collection of opensource pretrained large language models for medical domains. arXiv preprint arXiv:2402.10373 .
Augustin Lecler, Loïc Duron, and Philippe Soyer. 2023. Revolutionizing radiology with gpt-based models: current applications, future possibilities and limitations of chatgpt. Diagnostic and Interventional Imaging , 104(6):269-274.
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2020. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics , 36(4):1234-1240.
Peter Lee, Sebastien Bubeck, and Joseph Petro. 2023. Benefits, limits, and risks of gpt-4 as an ai chatbot for medicine. New England Journal of Medicine , 388(13):1233-1239.
Dominique Lepore, Koustabh Dolui, Oleksandr Tomashchuk, Heereen Shim, Chetanya Puri, Yuan Li, Nuoya Chen, and Francesca Spigarelli. 2023. Interdisciplinary research unlocking innovative solutions in healthcare. Technovation , 120:102511.
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. 2024. Llavamed: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems , 36.
Yangguang Li, Feng Liang, Lichen Zhao, Yufeng Cui, Wanli Ouyang, Jing Shao, Fengwei Yu, and Junjie Yan. 2021. Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm. arXiv preprint arXiv:2110.05208 .
Yanming Liu, Xinyue Peng, Xuhong Zhang, Weihao Liu, Jianwei Yin, Jiannan Cao, and Tianyu Du. 2024. Ra-isf: Learning to answer and understand from retrieval augmentation via iterative self-feedback. arXiv preprint arXiv:2403.06840 .
Qingqing Long, Yilun Jin, Yi Wu, and Guojie Song. 2021a. Theoretically improving graph neural networks via anonymous walk graph kernels. In Proceedings of the Web Conference 2021 , pages 12041214.
Qingqing Long, Lingjun Xu, Zheng Fang, and Guojie Song. 2021b. Hgk-gnn: Heterogeneous graph kernel based graph neural networks. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages 1129-1138.
Zooey Nguyen, Anthony Annunziata, Vinh Luong, Sang Dinh, Quynh Le, Anh Hai Ha, Chanh Le, Hong An Phan, Shruti Raghavan, and Christopher Nguyen. 2024. Enhancing q&a with domain-specific finetuning and iterative reasoning: A comparative study. arXiv preprint arXiv:2404.11792 .
Zach Nussbaum, John X Morris, Brandon Duderstadt, and Andriy Mulyar. 2024. Nomic embed: Training a reproducible long context text embedder. arXiv preprint arXiv:2402.01613 .
Bob O'Donnell. 2023. New bing brings ai to search engine. USA Today , pages 01B-01B.
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. 2022. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Conference on health, inference, and learning , pages 248-260. PMLR.
Conrad L Schoch, Stacy Ciufo, Mikhail Domrachev, Carol L Hotton, Sivakumar Kannan, Rogneda Khovanskaya, Detlef Leipe, Richard Mcveigh, Kathleen O'Neill, Barbara Robbertse, et al. 2020. Ncbi taxonomy: a comprehensive update on curation, resources and tools. Database , 2020:baaa062.
Guojie Song, Qingqing Long, Yi Luo, Yiming Wang, and Yilun Jin. 2020. Deep convolutional neural network based medical concept normalization. IEEE Transactions on Big Data , 8(5):1195-1208.
Yile Wang, Peng Li, Maosong Sun, and Yang Liu. 2023. Self-knowledge guided retrieval augmentation for large language models. arXiv preprint arXiv:2310.05002 .
Chaoyi Wu, Weixiong Lin, Xiaoman Zhang, Ya Zhang, Weidi Xie, and Yanfeng Wang. 2024. Pmc-llama: toward building open-source language models for medicine. Journal of the American Medical Informatics Association , page ocae045.
Jasper Xian, Tommaso Teofili, Ronak Pradeep, and Jimmy Lin. 2024. Vector search with openai embeddings: Lucene is all you need. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining , pages 1090-1093.
Meng Xiao, Ziyue Qiao, Yanjie Fu, Hao Dong, Yi Du, Pengyang Wang, Hui Xiong, and Yuanchun Zhou. 2023. Hierarchical interdisciplinary topic detection model for research proposal classification. IEEE Transactions on Knowledge and Data Engineering .
Meng Xiao, Min Wu, Ziyue Qiao, Yanjie Fu, Zhiyuan Ning, Yi Du, and Yuanchun Zhou. Interdisciplinary fairness in imbalanced research proposal topic inference: A hierarchical transformer-based method with selective interpolation. ACM Transactions on Knowledge Discovery from Data .
Fangkai Yang, Pu Zhao, Zezhong Wang, Lu Wang, Jue Zhang, Mohit Garg, Qingwei Lin, Saravan Rajmohan, and Dongmei Zhang. 2023. Empower large language model to perform better on industrial domain-specific question answering. arXiv preprint arXiv:2305.11541 . | null | [
"Chengrui Wang",
"Qingqing Long",
"Meng Xiao",
"Xunxin Cai",
"Chengjun Wu",
"Zhen Meng",
"Xuezhi Wang",
"Yuanchun Zhou"
] | 2024-08-02T08:37:03+00:00 | 2024-08-14T09:54:24+00:00 | [
"cs.CL",
"cs.AI",
"cs.IR"
] | BioRAG: A RAG-LLM Framework for Biological Question Reasoning | The question-answering system for Life science research, which is
characterized by the rapid pace of discovery, evolving insights, and complex
interactions among knowledge entities, presents unique challenges in
maintaining a comprehensive knowledge warehouse and accurate information
retrieval. To address these issues, we introduce BioRAG, a novel
Retrieval-Augmented Generation (RAG) with the Large Language Models (LLMs)
framework. Our approach starts with parsing, indexing, and segmenting an
extensive collection of 22 million scientific papers as the basic knowledge,
followed by training a specialized embedding model tailored to this domain.
Additionally, we enhance the vector retrieval process by incorporating a
domain-specific knowledge hierarchy, which aids in modeling the intricate
interrelationships among each query and context. For queries requiring the most
current information, BioRAG deconstructs the question and employs an iterative
retrieval process incorporated with the search engine for step-by-step
reasoning. Rigorous experiments have demonstrated that our model outperforms
fine-tuned LLM, LLM with search engines, and other scientific RAG frameworks
across multiple life science question-answering tasks. |
2408.01108v1 | 

## ALICE ITS3: how to integrate a large dimension MAPS sensor in a bent configuration detector
## Domenico Colella a ,* for the ALICE Collaboration
a University and INFN Bari,
Via E. Orabona 4, 170125, Bari, Italy
E-mail: [email protected]
The ALICE Collaboration is developing a novel vertexing detector to extend the heavyflavour physics programme of the experiment during Run 4 by improving the pointing resolution of the tracking, particularly at low transverse momentum. It will be a detector with three truly cylindrical layers based on thin wafer scale MAPS, reaching less than 0.07% X/X0 per layer and with the innermost layer located as close as 19 mm to the interaction point. This contribution will describe the global detector integration concept, focusing on: the sensor bending procedure, the sensor electrical interconnection, the choice of the best carbon foam for light mechanical supporting structures, the studies of cooling by air flow, and the global structures mechanical characterization.
6th International Conference on Technology and Instrumentation in Particle Physics (TIPP2023)
4 - 8 Sep 2023 Cape Town, Western Cape, South Africa
https://pos.sissa.it/
## 1. Introduction
The ITS3 project of the ALICE Collaboration [1,2], is developing an ultra-light vertexing detector, combining several innovative approaches, many of which have never been adopted in high-energy physics. The result is a nearly massless detector that is based on wafer-scale silicon sensors of up to 10 cm × 26.6 cm, reaching a mean material thickness of 0.09% X/X0 per layer.
Two new pioneering technologies are implemented in the sensor design: usage of 65 nm CMOS technology node that allows more dense circuitry and gives access to larger wafers (300 mm in diameter), and stitching technique that allows for extending the sensor dimentions above the usual size (O(2×3 cm 2 )). The implementation of the main analog and digital blocks of a MAPS in 65 nm has been demostrated with a large campaign of sensor characterization that took place from 2020 to 2022; results are given in Ref. [3]. The development of large stitched sensors took two years of design and led to reception of first prototypes during summer 2023; the results of first characterization are given in Ref. [4].
The other groundbreaking innovation is the removal of most of the services from the detector acceptance exploting the flexibility of thin silicon. Detector half-layers will be formed by a single sensor, thinned down to 50 μm, bent to acquire a half-cylindrical shape, and fixed in position by carbon foam structures. Sensor cooling will be performed by forced air flow between detector layers and by thermal conduction to the support structures.
## 2. Detector concept
Figure 1 : Left: ITS3 detector concept with six half-layers. Right: components of single half-layer. Taken from Ref. [2].
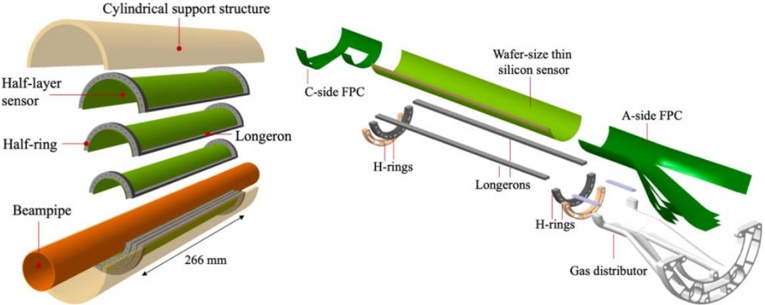
The ITS3 detector is structured into three layers, with respective target radii of 19.0 mm, 25.2 mm, and 31.5 mm. Each layer is further divided into two halves, each forming a half-cylinder. The three half-layers are in contact through the support structures and are mounted in an external cylindrical support structure, forming a compact block to be placed around the beam pipe. A simplified schematic is shown in the left part of Figure 1. A more detailed half-layer schematic, including services like air distributor and flex for
powering, control, and data transmission, is shown in the right part of Figure 1. The whole detector will thus be made of only six sensors, each of them covering 180 degrees in azimuthal angle, and measuring 266 mm in length. These six sensors will be kept in cylindrical shape by minimal ultra-light support structures made of carbon foam, placed at the edges of the sensor sensible area. Air for cooling will be driven to the sensor through small diameter ducts. These ducts will also be a part of the support structure for the flex circuitry that will be used to bring power and allow comunication with sensor. As can be seen in Figure 1, all these services will lie outside the detector sensible area.
## 3. Sensor bending
R&D activities started from small dimension sensors. A 3-point bending test, demonstrated that ITS 3 target radii are easily reachable with silicon thickness below 50 μm, for sensors based on CMOS technology node of 180 nm and 65 nm [2]. It has also been shown that MAPS (180 nm node) do not change their performance when bent to acquire cylindrical shape withthe ITS 3 target radii [5].
Figure 2 : Left: picture of the bending setup for a large dimension silicon sensor. Right: details of the bending procedure steps. Taken from Ref. [2].

Large dimension silicon sensors are bent in cylindrical shape by means of a mandrel and a tensioned mylar foil. After the alignment to the mandrel, an adhesive polyimide strip holds the sensor to the mandrel. A rotating motor wraps the mylar foil around the mandrel forcing the sensor to bend. A second adhesive polyimide strip guarantees that the sensor will be kept in position at the end of the procedure. Figure 2 shows the bending tool and the main procedure steps. Such a bending procedure is nowadays routinely performed with success.
## 4. Mechanics and cooling
Two main components are used as support structures for the half-layer: the logerons and the half-rings (Figure 1). Carbon foam has been identified as the optimal material to satisfy various requirements for the ITS3. Two varieties of open-cell reticulated vitreous carbon (RVC) foams have been chosen based on the functionality of
the mechanical components. A low-density foam (45 kg/m 3 ) with a high stiffness, Carbon Duocel, is selected for the support longerons. Meanwhile, for the cooling radiator, the Allcomp K9 standard density RVC foam, distinguished by its high thermal conductivity (25 W m -1 K -1 ), has been chosen.
Figure 3 : Left: wind tunnel setup for air cooling verification. Right: ITS3 prototype integrating heaters to simulate power dissipation. Taken from Ref. [2].
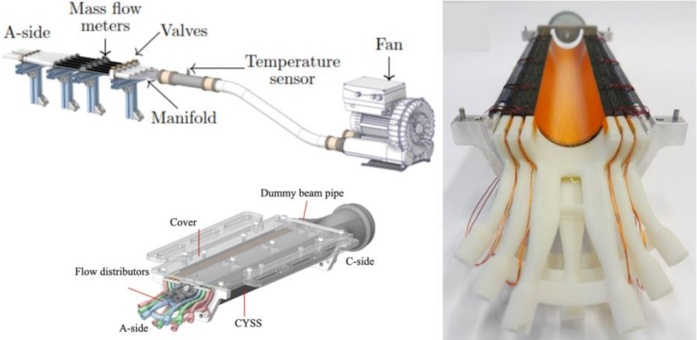
A prototype, integrating ducts for air cooling and heaters to simulate the power dissipation of the MAPS, has been used in a wind-tunnel setup (Figure 3), to verify the possibility of sensor cooling by air flow. Power dissipation of the sensor will not be uniform across the silicon surface, so the prototype integrated two different regions: the matrix (25 mW/cm 2 ) and end-cap regions (1000 mW/cm 2 ). It has been demonstrated that, with an average freestream airflow velocity of approximately 8 m/s between the layers, the detector is kept at a temperature that is 5 C higher than the inlet air temperature and ◦ uniformity is maintained within 5 C along the sensor. ◦
Further mechanical characterizations of the half-detector established that the maximum displacement of a sensor, due to the airflow is limited to about 1.1 μm with an RMS below 0.4 μm, which well meets the ITS 3 requirements.
Finally, another prototype, made of a single silicon layer glued to a carbon fiber cylindrical external structure, has been tested in a climate chamber (with temperature ranging between 10 and 40 C and constant 50% humidity), showing no detrimental ◦ effects from the temperature fluctuations. This is the first measurement of a larger campaign that will assess potential failures caused by thermo-elastic deformation.
## 5. Flex printed circuit integration
Sensor powering will be provided at the two longitudinal extremities by two flex printed circuits (FPC). A-side FPC (Figure 1) is also designed to perform the communication (control and data transmission) to the external world. This specific FPC is designed to have a region bent at the same radius of the corresponding sensor, and tails having zero insertion force connectors to the external boards. Length of the full FPC is limited by signal transmission integrity to less than 30 cm. Electrical connection to the
sensor is done via wire-bonding. A safety gap of 0.5 mm is left between the sensor and the FPC edges, reflecting in a distance between corresponding pads for soldering in the two objects of the order of 1 mm. A first exercise to estimate the best bonding parameters, targeting the best pull-force and minimizing the loop height, returned a mean pull-force value of 6.6±0.3 g. This study, done with not final grade materials, will be repeated with final components.
## 6. Summary
The intense R&D activities done in the ITS 3 project already successfully demonstrated the functionality of first stitched sensor and defined a controlled procedure to bend wafer-scale silicon sensors. Next sensor submission is planned for 2024, containing the prototype sensor to be used in the ALICE ITS 3 detector. On mechanical side more studies are expected to further improve the cooling system and assess the mechanical properties of the half-barrel, providing guidelines for the final detector assembly procedure. The final detector is expected to be assembled during the first quarter of 2027, to be installed and finally commissioned in the cavern during the first quarter of 2028.
## References
- [1] ALICE Collab., Letter of Intent for an ALICE ITS Upgrade in LS3 , CERN-LHCC-2019-018.
- [2] ALICE Collab., Technical Design Report for the ALICE Inner Tracking System 3 - ITS3. A bent wafer monolithic pixel detector , CERN-LHCC-2024-003.
- [3] A. Trifirò for the ALICE Collab., ALICE Inner Tracking System Upgrade: characterization of first chips fabricated in 65 nm CMOS technology , these proceedings.
- [4] V. Sarritzu for the ALICE Collab., The ALICE Inner Tracking System Upgrade , these proceedings.
- [5] ALICE ITS Project, First demonstration of in-beam performance of bent Monolithic Active Pixel Sensors , Nucl. Instrum. Methods Phys. Res. A 1028 (2022) 166280. | null | [
"Domenico Colella"
] | 2024-08-02T08:39:11+00:00 | 2024-08-02T08:39:11+00:00 | [
"physics.ins-det",
"hep-ex"
] | ALICE ITS3: how to integrate a large dimension MAPS sensor in a bent configuration detector | The ALICE Collaboration is developing a novel vertexing detector to extend
the heavy-flavour physics programme of the experiment during Run 4 by improving
the pointing resolution of the tracking, particularly at low transverse
momentum. It will be a detector with three truly cylindrical layers based on
thin wafer scale MAPS, reaching less than 0.07% X/X0 per layer and with the
innermost layer located as close as 19 mm to the interaction point. This
contribution will describe the global detector integration concept, focusing
on: the sensor bending procedure, the sensor electrical interconnection, the
choice of the best carbon foam for light mechanical supporting structures, the
studies of cooling by air flow, and the global structures mechanical
characterization. |
2408.01109v1 | ## Characterizing Data Dependencies Then and Now ∗
Phokion G. Kolaitis [ 0000 - 0002 - 8407 - 8563 ] and Andreas Pieris [ 0000 - 0003 - 4779 - 3469 ]
Abstract Data dependencies are integrity constraints that the data of interest must obey. During the 1980s, J´ anos Makowsky made a number of contributions to the study of data dependencies; in particular, he was the first researcher to characterize data dependencies in terms of their structural properties. The goal of this article is to first present an overview of Makowsky's work on characterizing certain classes of data dependencies and then discuss recent developments concerning characterizations of broader classes of data dependencies.
## 1 Introduction
Since E.F. Codd introduced the relational data model in 1970 [9], logic and databases have enjoyed a continuous and fruitful interaction, so much so that it has been said that 'logic and databases are inextricably intertwined' [13]. There are two main uses of logic in databases: the use of logic as a declarative language to express queries posed on databases and the use of logic as a specification language to express data dependencies, i.e., integrity constraints that the data of interest must obey.
Codd [10] had the key insight that first-order logic can be used as a database query language, which he called relational calculus. Furthermore, Codd showed that the expressive power of relational calculus (i.e., first-order logic on databases) coincides with that of relational algebra, which is a procedural database query language based
Phokion G. Kolaitis
University of California Santa Cruz & IBM Research, e-mail: [email protected]
Andreas Pieris
University of Edinburgh & University of Cyprus, e-mail: [email protected]
∗ This is an Author Accepted Manuscript version of the following chapter: Phokion G. Kolaitis and Andreas Pieris, Characterizing Data Dependncies Then and Now, published in Festschrift for Johann A. Makowsky, edited by Klaus Meer, Alexander Rabinovich, Elena Ravve and Andr´ es Villaveces, 2024, Springer Nature Switzerland AG.
on five basic operations on relations (union, difference, cartesian produt, projection, and selection). As regards data dependencies, Codd [11] introduced the class of functional dependencies, which to date constitute the most widely used such class of constraints. Soon after this, researchers introduced and studied several different classes of data dependencies, such as inclusion dependencies, join dependencies, and multi-valued dependencies. This plethora of types of data dependencies raised the question of identifying a unifying formalism for them. Logic came to the rescue as it was eventually realized that the class of embedded implicational dependencies (EIDs) provides such a formalism [4, 14, 29]. Embedded implicational dependencies comprise two classes of first-order sentences, the class of tuple-generating dependencies (tgds) and the class of equality-generating dependencies (egds); the latter generalizes functional dependencies, while the former generalizes, among others, inclusion, join, and multi-valued dependencies. Informally, a tgd asserts that if some tuples belong to some relations, then some other tuples must belong to some (perhaps different) relations, while an egd asserts that if some tuples belong to some relations, then two of the values occurring in some of these tuples must be equal. More precisely, a tgd is a universal-existential first-order sentence of the form
$$\forall \bar { x } \forall \bar { y } \left ( \phi ( \bar { x }, \bar { y } ) \, \rightarrow \, \exists \bar { z } \psi ( \bar { x }, \bar { z } ) \right ),$$
where 𝜙 𝑥, 𝑦 ( ¯ ¯ ) and 𝜓 𝑥, 𝑧 ( ¯ ¯ ) are conjunctions of atomic formulas. Furthermore, an egd is a universal first-order sentence of the form
$$\forall \bar { x } \left ( \phi ( \bar { x } ) \, \rightarrow \, x _ { i } = x _ { j } \right ),$$
where 𝜙 𝑥 ( ¯ ) is a conjunction of atomic formulas, and 𝑥 𝑖 , 𝑥 𝑗 are variables in ¯. 𝑥
During the 1980s, J´ anos Makowsky made remarkable contributions to the study of data dependencies. The first of these contributions concerns the implication problem for data dependencies, which by the late 1970s had emerged as the central problem in this area and, in fact, had been called the fundamental problem of databases (see [21]). This problem takes as input a finite set Σ of data dependencies and a data dependency 𝜎 , and asks whether Σ logically implies 𝜎 . Here, logical implication has two different versions: the first version is that 𝜎 is true on every database (finite or infinite) on which every member of Σ is true; the second version is that this implication holds in the finite, i.e., 𝜎 is true on every finite database on which every member of Σ is true. In the case of functional dependencies, it was known that the two versions of the implication problem coincide and that there is a polynomialtime algorithm for solving this problem. It was not known, however, whether the implication problem for EIDs was decidable or undecidable. Makowsky showed that both versions of the implication problem for EIDs are undecidable. This result appeared in a joint paper with Chandra and Lewis [7], who had independently arrived at the same solution. The proof was via a reduction from the halting problem for two-counter machines. A different reduction that uses undecidability results from equational logic was obtained by Beeri and Vardi [3] around the same time. Chandra, Lewis, and Makowsky [7] also showed that the implication problem is decidable for full tgds and egds, where a tgd is full if it has no existential quantifiers, i.e., it is a
first-order sentence of the form
## ∀ ∀ ¯ 𝑥 ¯ 𝑦 ( 𝜙 𝑥, 𝑦 ( ¯ ¯ ) → 𝜓 𝑥 ( ¯ )) ,
where 𝜙 𝑥, 𝑦 ( ¯ ¯ ) and 𝜓 𝑥 ( ¯ ) are conjunctions of atomic formulas.
Makowsky's second contribution to the study of data dependencies concerns characterizations of classes of data dependencies. To put Makowsky's work in a proper context, let us recall three important topics in mathematical logic. First, in his invited address at the 1950 International Congress of Mathematicians, Tarski articulated his interest in characterizing notions of 'metamathematical origin' in 'purely mathematical terms' [25]. A series of results in model theory eventually led to the following characterization of definability in first-order logic: a class 𝐶 of structures is definable by a finite set of first-order sentences if and only if both the class 𝐶 and its complement 𝐶 are closed under isomorphisms and ultraproducts (see [8]). Thus, the 'metamathematical' notion of definability by a finite set of firstorder sentences can be characterized in terms of purely algebraic closure properties. Second, there is a body of results in model theory, known as preservation theorems , that characterize when a first-order sentence is logically equivalent to a first-order sentence of a restricted syntactic form. The prototypical preservation theorem is the Lo´ s-Tarski Theorem, which asserts that a first-order sentence is logically equivalent to a universal first-order sentence if and only if it is preserved under substructures. Third, Lindstr¨m [19] characterized first-order logic as a maximal logic that has o some mild closure properties and satisfies the compactness theorem and the SkolemL¨ owenheim Theorem. This intrinsic characterization of first-order logic became the catalyst for the development of abstract model theory, which aims at characterizing logical formalisms in terms of their properties.
Leveraging his expertise in mathematical logic, Makowsky worked on characterizations of classes of data dependencies. In [20], he focused on full tgds and egds over uni-relational databases, that is, all data dependencies considered were over a database schema consisting of a single relation symbol. Note that much (but not all) of the work on data dependencies at that time was about uni-relational databases, perhaps because the first data dependencies studied were the functional dependencies, and they involve a single relation symbol. Makowsky obtained a preservation theorem that characterizes when a first-order sentence is logically equivalent to a finite set of full tgds and egds. This preservation theorem entails closure under subdatabases and closure under direct products. It is worth pointing out that, while this result is aligned with Tarski's goal to characterize metamathematical notions in purely mathematical terms, Makowsky questioned its relevance to databases because, as he put it, 'algebraic operations alone is not what is needed in data base theory'. In other words, Makowsky argued that characterizations of data dependencies should involve notions that are more ubiquitous in database practice. With these considerations in mind, Makowsky went on to establish the main result in [20], which is a Lindstr¨m-type theorem for the class of all full tgds and egds. Specifically, he o showed that the class of all full tgds and egds is a maximal collection of first-order sentences that satisfy a locality condition, called securability , and admit Armstrong
relations , which are relations that encapsulate precisely the full tgds and egds that are logically implied by a set of full tgds and egds.
After this, Makowsky and Vardi [22] studied data dependencies over multirelational databases, that is, data dependencies over a database schema that consists of finitely many relation symbols. Makowsky and Vardi [22] characterized when a class of databases is axiomatizable by a set of full tgds and egds, and also when it is axiomatizable by a finite set of full tgds and egds. These characterizations involve closure under subdatabases, closure under direct products, suitable locality properties, and some other structural properties that will be discussed in the sequel.
During the past two decades, data dependencies have found new uses and applications in several different areas of data management and knowledge representation, including data exchange, data integration, and specification of ontologies. As a result, the interest in characterizing data dependencies has been rekindled [12, 26]; furthermore, new preservation theorems about data dependencies have been obtained [30, 31]. In particular, using a novel notion of locality, characterizations of arbitrary tgds and egds were obtained in [12], thus going well beyond the characterizations of full tgds and egds established in [22]. In this article, we present some of these developments in detail and discuss the motivating role played by the concepts and results in [22].
## 2 Relational Databases and Data Dependencies
Let C and V be disjoint countably infinite sets of constants and variables, respectively. For an integer 𝑛 > 0, we may write [ 𝑛 ] for the set { 1 , . . . , 𝑛 } .
Relational Databases. A (relational) schema S is a finite set of relation symbols (or predicates) with positive arity; let ar ( 𝑅 ) be the arity of 𝑅 . A (relational) database 𝐷 over S = { 𝑅 , . . . , 𝑅 1 𝑛 } , or simply S -database , is a tuple ( dom ( 𝐷 , 𝑅 ) 𝐷 1 , . . . , 𝑅 𝐷 𝑛 ) , where dom ( 𝐷 ) ⊆ C is a finite domain and 𝑅 𝐷 1 , . . . , 𝑅 𝐷 𝑛 are relations over dom ( 𝐷 ) , i.e., 𝑅 𝐷 𝑖 ⊆ dom ( 𝐷 ) ar ( 𝑅 𝑖 ) for 𝑖 ∈ [ 𝑛 ] . In logical terms, a database is simply a relational structure with finite domain. A fact of 𝐷 is an expression of the form 𝑅 𝑖 ( ¯ 𝑐 ) , where ¯ 𝑐 ∈ 𝑅 𝐷 𝑖 . Let facts ( 𝐷 ) be the set of facts of 𝐷 . The active domain of 𝐷 , denoted adom ( 𝐷 ) , is the set of elements of dom ( 𝐷 ) that occur in at least one fact of 𝐷 . An S -database 𝐷 ′ is a subdatabase of 𝐷 , denoted 𝐷 ′ ⪯ 𝐷 , if dom ( 𝐷 ′ ) ⊆ dom ( 𝐷 ) and, for each 𝑅 ∈ S , we have that 𝑅 𝐷 ′ = 𝑅 𝐷 | dom ( 𝐷 ′ ) , where 𝑅 𝐷 | dom ( 𝐷 ′ ) is the restriction of 𝑅 𝐷 over dom ( 𝐷 ′ ) , i.e., 𝑅 𝐷 | dom ( 𝐷 ′ ) = GLYPH<8> ¯ 𝑐 ∈ 𝑅 𝐷 | ¯ 𝑐 ∈ dom ( 𝐷 ′ ) ar ( 𝑅 ) GLYPH<9> . A homomorphism from an S -database 𝐷 to an S -database 𝐷 ′ is a function ℎ : dom ( 𝐷 ) → dom ( 𝐷 ′ ) with the following property: for each 𝑖 ∈ [ 𝑛 ] and for each tuple ( 𝑐 1 , . . . , 𝑐 𝑚 ) ∈ 𝑅 𝐷 𝑖 , we have that ( ℎ 𝑐 ( 1 ) , . . . , ℎ ( 𝑐 𝑚 )) ∈ 𝑅 𝐷 ′ 𝑖 . We write ℎ : 𝐷 → 𝐷 ′ to denote that ℎ is a homomorphism from 𝐷 to 𝐷 ′ . We also write ℎ ( facts ( 𝐷 )) for the set { 𝑅 ℎ 𝑐 ( ( ¯ )) | 𝑅 𝑐 ( ¯ ) ∈ facts ( 𝐷 )} . Finally, we say that 𝐷 and 𝐷 ′ are isomorphic , written 𝐷 ≃ 𝐷 ′ , if there is a bijection ℎ : dom ( 𝐷 ) → dom ( 𝐷 ′ ) such that ℎ is a homomorphism from 𝐷 to 𝐷 ′ and ℎ -1 is a homomorphism from 𝐷 ′ to 𝐷 .
Tuple-Generating Dependencies. An atom over S is an expression of the form 𝑅 𝑣 ( ¯ ) , where 𝑅 ∈ S and ¯ is an 𝑣 ar ( 𝑅 ) -tuple of variables from V . A tuple-generating dependency (tgd) 𝜎 over a schema S is a constant-free first-order sentence
$$\forall \bar { x } \forall \bar { y } \left ( \phi ( \bar { x }, \bar { y } ) \, \rightarrow \, \exists \bar { z } \, \psi ( \bar { x }, \bar { z } ) \right ),$$
where ¯ 𝑥, 𝑦, 𝑧 ¯ ¯ are tuples of variables of V , 𝜙 𝑥, 𝑦 ( ¯ ¯ ) is a (possibly empty) conjunction of atoms over S , and 𝜓 𝑥, 𝑧 ( ¯ ¯ ) is a non-empty conjunction of atoms over S . For brevity, we write 𝜎 as 𝜙 𝑥, 𝑦 ( ¯ ¯ ) → ∃ ¯ 𝑧 𝜓 ( ¯ 𝑥, 𝑧 ¯ ) . We refer to 𝜙 𝑥, 𝑦 ( ¯ ¯ ) and 𝜓 𝑥, 𝑧 ( ¯ ¯ ) as the body and head of 𝜎 , denoted body ( 𝜎 ) and head ( 𝜎 ) , respectively. By an abuse of notation, we may treat a tuple of variables as a set of variables, and we may also treat a conjunction of atoms as a set of atoms. A tgd is called full if it has no existentially quantified variables. Let us stress that, since the head of a tgd is by definition non-empty, full tgds mention at least one universally quantified variable, which in turn implies that their body is non-empty. An S -database 𝐷 satisfies a tgd 𝜎 as the one above, written 𝐷 | = 𝜎 , if the following holds: whenever there is a function ℎ : ¯ 𝑥 ∪ ¯ 𝑦 → dom ( 𝐷 ) such that ℎ 𝜙 𝑥, 𝑦 ( ( ¯ ¯ )) ⊆ facts ( 𝐷 ) (as usual, we write ℎ 𝜙 𝑥, 𝑦 ( ( ¯ ¯ )) for the set { 𝑅 ℎ 𝑣 ( ( ¯ )) | 𝑅 𝑣 ( ¯ ) ∈ 𝜙 𝑥, 𝑦 ( ¯ ¯ )} ), then there exists an extension ℎ ′ of ℎ such that ℎ ′ ( 𝜓 𝑥, 𝑧 ( ¯ ¯ )) ⊆ facts ( 𝐷 ) . The S -database 𝐷 satisfies a set Σ of tgds , written 𝐷 | = Σ , if 𝐷 | = 𝜎 for each 𝜎 ∈ Σ ; in this case, we say that 𝐷 is a model of Σ .
Equality-Generating Dependencies. An equality-generating dependency (egd) 𝜃 over a schema S is a constant-free first-order sentence
$$\forall \bar { x } \left ( \phi ( \bar { x } ) \, \to \, x _ { i } = x _ { j } \right ),$$
where ¯ is a tuple of variables of 𝑥 V , 𝜙 𝑥 ( ¯ ) is a (non-empty) conjunction of atoms over S , and 𝑥 , 𝑥 𝑖 𝑗 ∈ ¯. For brevity, we write 𝑥 𝜃 as 𝜙 𝑥 ( ¯ ) → 𝑥 𝑖 = 𝑥 𝑗 . We refer to 𝜙 𝑥 ( ¯ ) as the body of 𝜃 , denoted body ( 𝜃 ) . An S -database 𝐷 satisfies an egd 𝜃 as the one above, written 𝐷 | = 𝜃 , if, whenever there is a function ℎ : ¯ 𝑥 → dom ( 𝐷 ) such that ℎ 𝜙 𝑥 ( ( ¯ )) ⊆ facts ( 𝐷 ) , then ℎ 𝑥 ( 𝑖 ) = ℎ 𝑥 ( 𝑗 ) . The S -database 𝐷 satisfies a set Σ of egds , written 𝐷 | = Σ , if 𝐷 | = 𝜃 for each egd 𝜃 ∈ Σ , and we say that 𝐷 is a model of Σ .
Finite Axiomatizability. Let 𝐶 be a collection of databases. We say that 𝐶 is finitely axiomatizable by tgds and egds if there are finite sets Σ 𝑇 and Σ 𝐸 of tgds and egds, respectively, such that for every database 𝐷 , it holds that 𝐷 ∈ 𝐶 if and only if 𝐷 | = Σ 𝑇 and 𝐷 | = Σ 𝐸 . Note that in the literature we also have the notion of axiomatizability, where the sets Σ 𝑇 and Σ 𝐸 can be infinite, i.e., if we allow Σ 𝑇 and Σ 𝐸 to be infinite, then we say that 𝐶 is axiomatizable by tgds and egds. In this paper, we focus on finite axiomatizability since it is more relevant to database practice. In what follows, we consider only collections 𝐶 of databases that are closed under isomorphisms , i.e., if 𝐷 ∈ 𝐶 and 𝐷 ′ is a database such that 𝐷 ≃ 𝐷 ′ , then 𝐷 ′ ∈ 𝐶 . In other words, for a collection of databases, we silently assume that it is closed under isomorphisms.
## 3 Finite Axiomatizability by Full TGDs and EGDs
Asdiscussed in Section 1, one of Makowsky's main contributions to the study of data dependencies concerns characterizations of classes of data dependencies. The result that stands out in this context, which we will present here, is the characterization of finite sets of full dependencies obtained by Makowsky and Vardi in 1986 [22, Theorem 5]. By definition, a full dependency is a first-order sentence of the form ∀ ∀ ¯ 𝑥 ¯ 𝑦 ( 𝜙 𝑥, 𝑦 ( ¯ ¯ ) → 𝜓 𝑥 ( ¯ )) , where 𝜙 𝑥, 𝑦 ( ¯ ¯ ) is a non-empty conjunction of relational atoms and 𝜓 𝑥 ( ¯ ) is a non-empty conjunction of relational atoms and equality atoms. Clearly, every full dependency is logically equivalent to a finite set of full tgds and egds. Consequently, given a full dependency 𝜎 , there is a finite set Σ of full tgds and egds such that, for every database 𝐷 , it holds that 𝐷 satisfies 𝜎 if and only if 𝐷 satisfies the tgds and egds of Σ . For this reason, in what follows we will state Theorem 5 of [22] in terms of finite sets of full tgds and egds.
As we shall see, Theorem 5 of [22] involves the property of closure under direct products, which is formally defined below. However, as already mentioned in Section 1, Makowsky questioned the relevance to databases of closure under algebraic operations, such as closure under direct products. With this in mind, we further present an alternative characterization of finite sets of full tgds and egds, which uses the property of closure under intersections instead of closure under direct products.
## 3.1 The Characterization by Makowsky and Vardi
We first introduce the properties that are needed for the characterization of interest and then recall the characterization by Makowski and Vardi from [22].
## Model-theoretic Properties
In the sequel, fix an arbitrary schema S = { 𝑅 , . . . , 𝑅 1 ℓ } .
1 -Criticality. An S -database 𝐷 = ( dom ( 𝐷 , 𝑅 ) 𝐷 1 , . . . , 𝑅 𝐷 ℓ ) is said to be 1 -critical if | dom ( 𝐷 )| = 1, that is, the domain of 𝐷 consists of a single element 𝑐 ∈ C , and 𝑅 𝐷 𝑖 = { 𝑐 } ar ( 𝑅 𝑖 ) for each 𝑖 ∈ [ ℓ ] , i.e., facts ( 𝐷 ) = { 𝑅 𝑖 ( 𝑐, . . . , 𝑐 ) | 𝑖 ∈ [ ℓ ]} . Let us clarify that in [22] 1-critical databases are called trivial databases. A collection of databases over S is 1 -critical if it contains an 1-critical S -database.
Domain Independence. A collection 𝐶 of databases over S is domain independent if, for every S -database 𝐷 ∈ 𝐶 and every database 𝐷 ′ with facts ( 𝐷 ) = facts ( 𝐷 ′ ) , it holds that 𝐷 ′ ∈ 𝐶 . In other words, 𝐶 is domain independent if, for every two S -databases that have the same set of facts, but not necessarily the same domain, either both are in 𝐶 or neither of them is in 𝐶 .
Modularity. A collection 𝐶 of databases over S is 𝑛 -modular , for 𝑛 ≥ 0, if, for every S -database 𝐷 ∉ 𝐶 , there is an S -database 𝐷 ′ ⪯ 𝐷 with | dom ( 𝐷 ′ )| ≤ 𝑛
such that 𝐷 ′ ∉ 𝐶 . We say that 𝐶 is modular if it is 𝑛 -modular for some 𝑛 ≥ 0. Roughly, 𝑛 -modularity provides a 'small' database with at most 𝑛 domain elements as a witness to why a database does not belong to a collection of databases. Let us clarify that in [22], 𝑛 -modularity is called 𝑛 -locality . However, here we adopt the term 𝑛 -modularity, which has been already used in [26] for a similar notion in the context of schema mappings, in order to avoid any confusion with the notion of ( 𝑛, 𝑚 ) -locality from [12], which will be used in the next section to handle arbitrary tgds and egds.
Closure Under Subdatabases. A collection 𝐶 of databases is closed under subdatabases if, for every S -database 𝐷 ∈ 𝐶 , it holds that 𝐷 ′ ∈ 𝐶 for every 𝐷 ′ ⪯ 𝐷 .
Closure Under Direct Products. Assume that 𝐷 = ( dom ( 𝐷 , 𝑅 ) 𝐷 1 , . . . , 𝑅 𝐷 ℓ ) and 𝐷 ′ = ( dom ( 𝐷 ′ ) , 𝑅 𝐷 ′ 1 , . . . , 𝑅 𝐷 ′ ℓ ) are two databases over a schema S . The direct product of 𝐷 and 𝐷 ′ , denoted 𝐷 ⊗ 𝐷 ′ , is defined as the S -database
$$D ^ { \prime \prime } = ( \text{dom} ( D ^ { \prime \prime } ), R _ { 1 } ^ { D ^ { \prime \prime } }, \dots, R _ { \ell } ^ { D ^ { \prime \prime } } ),$$
where dom ( 𝐷 ′′ ) = dom ( 𝐷 ) × dom ( 𝐷 ′ ) , and, for each 𝑖 ∈ [ ℓ ] , 𝑅 𝐷 ′′ 𝑖 is the relation
$$\left \{ \left ( ( a _ { 1 }, b _ { 1 } ), \dots, ( a _ { r _ { i } }, b _ { r _ { i } } ) \right ) \, | \, ( a _ { 1 }, \dots, a _ { r _ { i } } ) \in R _ { i } ^ { D } \text{ and } ( b _ { 1 }, \dots, b _ { r _ { i } } ) \in R _ { i } ^ { D ^ { \prime } } \right \},$$
where 𝑟 𝑖 = ar ( 𝑅 𝑖 ) is the arity of the relation symbol 𝑅 𝑖 . A collection 𝐶 of databases over S is closed under direct products if, for every two S -databases 𝐷, 𝐷 ′ ∈ 𝐶 , it holds that 𝐷 ⊗ 𝐷 ′ ∈ 𝐶 .
## The Characterization
We can now provide the characterization of interest from [22]. We do not discuss here the proof of the characterization since it will be derived from the more general characterization of finite sets of arbitrary tgds and egds presented in Section 4.
Theorem 1 (Theorem 5 in [22]) Let 𝐶 be a collection of databases. The following statements are equivalent:
- 1. 𝐶 is finitely axiomatizable by full tgds and egds.
- 2. 𝐶 is 1 -critical, domain independent, modular, closed under subdatabases, and closed under direct products.
## 3.2 The Alternative Characterization
We will present an alternative characterization of finite sets of full tgds and egds that avoids the use of closure under direct products. This is done by replacing in the characterization of Theorem 1 the property of closure under direct products with
the property of closure under intersections defined as follows. Consider a schema S = { 𝑅 , . . . , 𝑅 1 ℓ } . The intersection of the S -databases 𝐷 = ( dom ( 𝐷 , 𝑅 ) 𝐷 1 , . . . , 𝑅 𝐷 ℓ ) and 𝐷 ′ = ( dom ( 𝐷 ′ ) , 𝑅 𝐷 ′ 1 , . . . , 𝑅 𝐷 ′ ℓ ) , denoted 𝐷 ∩ 𝐷 ′ , is the database
$$( \text{dom} ( D ) \cap \text{dom} ( D ^ { \prime } ), R _ { 1 } ^ { D } \cap R _ { 1 } ^ { D ^ { \prime } }, \dots, R _ { \ell } ^ { D } \cap R _ { \ell } ^ { D ^ { \prime } } ).$$
A collection 𝐶 of databases over S is closed under intersections if, for every two S -databases 𝐷, 𝐷 ′ ∈ 𝐶 , it holds that 𝐷 ∩ 𝐷 ′ ∈ 𝐶 .
Before stating and proving the promised characterization, let us briefly discuss the two tools that will be used in the proof: Robinson's method of diagrams and McKinsey's method of eliminating disjunctions . In his Ph.D. thesis in 1949, Abraham Robinson introduced the notion of a diagram of a relational structure, which, together with its variants, became a standard tool in constructing models that contain an isomorphic copy of some structure of interest. In model theory, the method of diagrams is typically combined with the compactness theorem to construct such models (see [8, 24]). In characterizing data dependencies, however, the method of diagrams is combined with closure properties and with suitable notions of locality, instead of the compactness theorem. In 1943, J.C.C. McKinsey [23] introduced the method of eliminating disjunctions, which makes it possible to show that, when a class of structures satisfies certain closure properties, then, on such a class of structures, a first-order sentence of the form ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝜓 𝑖 ( ¯ 𝑥 )) implies one of the sentences ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝜓 𝑗 ( ¯ 𝑥 )) , for some 𝑗 ∈ [ 𝑘 ] ; as a consequence of this, on such a class of structures, the sentence ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝜓 𝑖 ( ¯ 𝑥 )) is equivalent to the sentence ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝜓 𝑗 ( ¯ 𝑥 )) . McKinsey's original application of this method used closure under direct products, but the method is flexible enough to adapt to other closure properties, such as closure under intersections. It should be noted that the method of diagrams and the method of eliminating disjunctions were already utilized by Makowsky and Vardi [22] in the proof of Theorem 1.
Theorem 2 Let 𝐶 be a collection of databases. The following are equivalent:
- 1. 𝐶 is finitely axiomatizable by full tgds and egds.
- 2. 𝐶 is 1 -critical, domain independent, modular, closed under subdatabases, and closed under intersections.
Proof. The direction ( 1 ) ⇒ ( ) 2 is easy and we leave it as an exercise. We focus on the direction ( 2 ) ⇒ ( 1 . We first need to introduce a couple of auxiliary notions. ) A disjunctive dependency (dd) 𝛿 over a schema S is a constant-free sentence
$$\forall \bar { x } \left ( \phi ( \bar { x } ) \, \rightarrow \, \bigvee _ { i = 1 } ^ { k } \psi _ { i } ( \bar { x } _ { i } ) \right ),$$
where ¯ is a tuple of variables of 𝑥 V , the expression 𝜙 𝑥 ( ¯ ) is a (non-empty) conjunction of atoms over S , and, for each 𝑖 ∈ [ 𝑘 ] , ¯ 𝑥 𝑖 ⊆ ¯ 𝑥 and the expression 𝜓 𝑖 ( ¯ 𝑥 𝑖 ) is either an equality formula 𝑦 = 𝑧 with ¯ 𝑥 𝑖 = { 𝑦, 𝑧 } , or an atom over S . An S -database 𝐷 satisfies the dd 𝛿 , written 𝐷 | = 𝛿 , if, whenever there is a function ℎ : ¯ 𝑥 → dom ( 𝐷 )
with ℎ 𝜙 𝑥 ( ( ¯ )) ⊆ facts ( 𝐷 ) , then there is 𝑖 ∈ [ 𝑘 ] such that, if 𝜓 𝑖 ( ¯ 𝑦 𝑖 ) is 𝑦 = 𝑧 , then ℎ 𝑦 ( ) = ℎ 𝑧 ( ) , and if 𝜓 𝑖 ( ¯ 𝑦 𝑖 ) is 𝑅 𝑥 ( ¯ 𝑖 ) , then ℎ 𝑅 𝑥 ( ( ¯ 𝑖 )) ∈ facts ( 𝐷 ) . We say that the database 𝐷 satisfies a set Σ of dds or that 𝐷 is a model of Σ , written 𝐷 | = Σ , if 𝐷 | = 𝛿 for each 𝛿 ∈ Σ .
We further need the notion of the diagram of a database. Let 𝐷 be an S -database such that facts ( 𝐷 ) ≠ ∅ . Let 𝐴 be the set of atomic formulas that can be formed using predicates from S and constants from dom ( 𝐷 ) . The diagram of 𝐷 , denoted Δ 𝐷 , is
$$\bigwedge _ { \alpha \in \text{facts} ( D ) } \alpha \wedge \bigwedge _ { \alpha \in A \vee \text{facts} ( D ) } \neg \alpha \wedge \bigwedge _ { c, d \in \text{dom} ( D ) \text{ and } c \neq d } \neg ( c = d ).$$
Note that, since facts ( 𝐷 ) ≠ ∅ , the conjunction GLYPH<211> 𝛼 ∈ facts ( 𝐷 ) 𝛼 is non-empty.
Let 𝐶 be collection of databases over S possessing the properties in the second statement of Theorem 2. In particular, since 𝐶 is modular, there is some integer 𝑛 ≥ 0 such that 𝐶 is 𝑛 -modular. Moreover, since 𝐶 is closed under subdatabases, we have that 𝐶 contains the empty database, hence 𝑛 must be a positive integer.
Let Σ ∨ be the set of all dds over S with at most 𝑛 variables that are satisfied by every database 𝐷 ∈ 𝐶 . It is clear that Σ ∨ is finite (up to logical equivalence). We proceed to show the following technical lemma.
## Lemma 1 For each S -database 𝐷 , we have that 𝐷 ∈ 𝐶 if and only 𝐷 | = Σ ∨ .
̸
̸
̸
Proof of Lemma 1. Fix an S -database 𝐷 . From the definition of Σ ∨ , 𝐷 ∈ 𝐶 implies 𝐷 | = Σ ∨ . For the other direction, we will show that if 𝐷 ∉ 𝐶 , then 𝐷 | = Σ ∨ . Assume that 𝐷 ∉ 𝐶 . Since 𝐶 is 𝑛 -modular, there exists an S -database 𝐷 𝑛 such that 𝐷 𝑛 ⪯ 𝐷 , | dom ( 𝐷 𝑛 )| ≤ 𝑛 , and 𝐷 𝑛 ∉ 𝐶 . Since 𝐶 is domain independent, we can assume that dom ( 𝐷 𝑛 ) = adom ( 𝐷 𝑛 ) . We will show that 𝐷 𝑛 | = Σ ∨ , which in turn implies that 𝐷 | = Σ ∨ since every sentence in Σ ∨ is universal and it is well-known that universal first-order sentences are preserved under subdatabases.
̸
To show that 𝐷 𝑛 | = Σ ∨ , it suffices to find a dd 𝛿 ∈ Σ ∨ such that 𝐷 𝑛 | = 𝛿 . We will use the diagram of 𝐷 𝑛 to construct this desired 𝛿 . Let Δ 𝐷 𝑛 be the diagram of 𝐷 𝑛 , and let Φ 𝐷 𝑛 ( ¯ 𝑥 ) be the quantifier-free first-order formula obtained from Δ 𝐷 𝑛 by replacing each 𝑐 ∈ dom ( 𝐷 𝑛 ) with a new variable 𝑥 𝑐 ∈ V . We claim that the following statements are true:
̸
- 1. 𝐷 𝑛 | = ∃ ¯ 𝑥 Φ 𝐷 𝑛 ( ¯ 𝑥 ) .
- 2. For every 𝐷 ′ ∈ 𝐶 , we have that 𝐷 ′ | = ¬∃ ¯ 𝑥 Φ 𝐷 𝑛 ( ¯ 𝑥 ) .
- 3. The sentence ¬∃ ¯ 𝑥 Φ 𝐷 𝑛 ( ¯ 𝑥 ) is logically equivalent to a dd 𝛿 .
The first statement is obviously true by the construction of the sentence ∃ ¯ 𝑥 Φ 𝐷 𝑛 ( ¯ 𝑥 ) (each existential quantifier ∃ 𝑥 𝑐 in ∃ ¯ 𝑥 can be witnessed by the element 𝑐 in dom ( 𝐷 𝑛 ) ). For the second statement, if there is some database 𝐷 ′ ∈ 𝐶 such that 𝐷 ′ | = ∃ ¯ 𝑥 Φ 𝐷 𝑛 ( ¯ 𝑥 ) , then 𝐷 ′ must contain a subdatabase 𝐷 ′′ that is isomorphic to 𝐷 𝑛 . Since 𝐶 is closed under subdatabases and isomorphisms, it follows that 𝐷 𝑛 ∈ 𝐶 , which is a contradiction. For the third statement, observe first that facts ( 𝐷 𝑛 ) ≠ ∅ because 𝐷 𝑛 is not in 𝐶 , while 𝐶 , being closed under subdatabases, contains the empty database. This implies that Δ 𝐷 𝑛 contains at least one positive relational atom
𝛼 ; hence, the conjunction GLYPH<211> 𝛼 ∈ facts ( 𝐷 𝑛 ) 𝛼 is non-empty. Furthermore, since 𝐷 𝑛 is not in 𝐶 and since 𝐶 is 1-critical and closed under isomorphisms, we conclude that 𝐷 𝑛 is not an 1-critical database. This implies that either | dom ( 𝐷 𝑛 )| ≥ 2 or | dom ( 𝐷 𝑛 )| = 1 and there is a relation symbol 𝑅 ∈ S such that 𝑅 𝐷 𝑛 is empty. Therefore, Δ 𝐷 𝑛 contains either the negation of an equality atom 𝛽 or the negation of a relational atom 𝛾 . Consequently, ¬∃ ¯ 𝑥 Φ 𝐷 𝑛 ( ¯ 𝑥 ) is logically equivalent to a dd 𝛿 . Therefore, all three statements have been established.
̸
Taken together, these three statements imply that 𝛿 is a dd in Σ ∨ that is false on 𝐷 𝑛 , and hence, 𝐷 𝑛 | = Σ ∨ . This completes the proof of Lemma 1. ⊓ ⊔
Observe that the property of closure under intersections was not used in the proof of Lemma 1. This property will be used in the proof of the next technical lemma.
Lemma 2 Assume that ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝛼 𝑖 ( ¯ 𝑥 𝑖 )) is a disjunctive dependency that belongs to Σ ∨ . There is 𝑗 ∈ [ 𝑘 ] such that ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝛼 𝑗 ( ¯ 𝑥 𝑗 )) also belongs to Σ ∨ .
̸
̸
Proof of Lemma 2. Note that for every 𝑗 ∈ [ 𝑘 ] , the sentence ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝛼 𝑗 ( ¯ 𝑥 𝑗 )) is either a full tgd or an egd, hence it is a disjunctive dependency. Towards a contradiction, assume that none of these sentences belongs to Σ ∨ . Since Σ ∨ consists of all disjunctive dependencies that are satisfied by every database in 𝐶 , it follows that for every 𝑗 ∈ [ 𝑘 ] , there is a database 𝐷 𝑗 ∈ 𝐶 such that 𝐷 𝑗 | = ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝛼 𝑗 ( ¯ 𝑥 𝑗 )) . Hence, for every 𝑗 ∈ [ 𝑘 ] , there is a tuple ¯ 𝑏 𝑗 of elements in dom ( 𝐷 𝑗 ) such that 𝐷 𝑗 | = 𝜙 𝑏 ( ¯ 𝑗 ) ∧ ¬ 𝛼 𝑗 ( ¯ 𝑏 𝑗 𝑗 ) . Since 𝐶 is closed under isomorphisms, we may assume that these tuples are the same tuple ¯ , 𝑏 i.e., we may assume that for every 𝑗 and ℓ with 𝑗 , ℓ ∈ [ 𝑘 ] , we have that ¯ 𝑏 𝑗 = ¯ 𝑏 ℓ = ¯ . 𝑏 Let 𝐷 ∩ be the intersection of the databases 𝐷 𝑗 , that is, 𝐷 ∩ = GLYPH<209> 𝑗 ∈[ 𝑘 ] 𝐷 𝑗 . Since 𝐶 is closed under intersections, we have that 𝐷 ∩ belongs to 𝐶 ; consequently, we have that 𝐷 ∩ | = ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝛼 𝑖 ( ¯ 𝑥 𝑖 )) . Since the elements of the tuple ¯ 𝑏 belong to dom ( 𝐷 𝑗 ) for every 𝑗 ∈ [ 𝑘 ] , it follows that they also belong to dom ( 𝐷 ∩) . Therefore, and since also 𝜙 𝑏 ( ¯ ) holds, there is some 𝑗 ∈ [ 𝑘 ] such that 𝛼 𝑗 ( ¯ 𝑏 𝑗 ) holds, which contradicts the fact that ¬ 𝛼 𝑗 ( ¯ 𝑏 𝑗 ) holds (since ¯ 𝑏 witnesses that 𝐷 𝑗 | = ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝛼 𝑗 ( ¯ 𝑥 𝑗 )) . This completes the proof that there is a 𝑗 ∈ [ 𝑘 ] such that the formula ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝛼 𝑗 ( ¯ 𝑥 𝑖 )) belongs to Σ ∨ . ⊓ ⊔
With the two preceding lemmas at hand, we are now ready to complete the proof of Theorem 2. Let Σ be the set of full tgds and egds in Σ ∨ , i.e.,
$$\Sigma = \left \{ \delta \in \Sigma ^ { \vee } \ | \ \delta \text{is a full } tgd \text{or an egd} \right \}.$$
Note that Σ is a finite set because it is a subset of the finite set Σ ∨ . We proceed to show that, for each S -database 𝐷 , it holds that 𝐷 ∈ 𝐶 if and only if 𝐷 | = Σ .
( ⇒ ) If 𝐷 ∈ 𝐶 , then, by the definition of Σ ∨ , 𝐷 | = Σ ∨ ; hence, 𝐷 | = Σ since Σ ⊆ Σ ∨ .
( ⇐ ) Assume now that 𝐷 is an S -database such that 𝐷 | = Σ . We need to show that 𝐷 ∈ 𝐶 . By Lemma 1, it suffices to show that 𝐷 | = Σ ∨ . Let ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝛼 𝑖 ( ¯ 𝑥 𝑖 )) be a disjunctive dependency in Σ ∨ . By Lemma 2, there is 𝑗 ∈ [ 𝑘 ] such that ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝛼 𝑗 ( ¯ 𝑥 𝑗 )) belongs to Σ ∨ . Since this sentence is either a full tgd or an
egd, we have that it belongs to Σ ; hence, 𝐷 | = ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝛼 𝑗 ( ¯ 𝑥 𝑗 )) . It is obvious that ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝛼 𝑗 ( ¯ 𝑥 𝑗 )) logically implies the disjunctive dependency ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝛼 𝑖 ( ¯ 𝑥 𝑖 )) , and therefore, 𝐷 | = ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝛼 𝑖 ( ¯ 𝑥 𝑖 )) . This completes the proof of the above claim.
Thus, we have established that 𝐶 is axiomatizable by the set Σ , which is a finite set of full tgds and egds. This completes the proof of Theorem 2. ⊓ ⊔
## 4 Finite Axiomatizability by TGDs and EGDs
The fact that Theorems 1 and 2 deal only with full tgds, i.e., tgds without existentially quantified variables, leads to the following natural question: is there an analogous characterization for arbitrary tgds and egds? Such a characterization has been recently established in [12] for the case of arbitrary (finite or infinite) relational structures. In what follows, we present the characterization from [12] for databases, i.e., finite relational structures. Apart from the standard properties of 1-criticality and closure under direct products, already used in Section 3, we are going to use a novel locality property. The latter locality property was introduced in [12] for arbitrary structures, but we are going to adapt it for databases. We proceed to introduce this notion of locality and show that every collection 𝐶 of databases that is finitely axiomatizable by tgds and egds enjoys this property. We then present the characterization of arbitrary tgds and egds and discuss how it allows us to derive the characterization for full tgds and egds from [22], namely Theorem 1.
## 4.1 Locality
Thelocality property of interest relies on the notion of local embedding of a collection of databases in a database. Roughly speaking, a collection 𝐶 of databases over a schema S is locally embeddable in an S -database 𝐷 if, for every subdatabase 𝐸 of 𝐷 with a bounded number of active domain elements (i.e., domain elements that occur in facts ( 𝐸 ) ), we can find a database 𝐷 𝐸 ∈ 𝐶 such that every local neighbour of 𝐸 in 𝐷 𝐸 (i.e., subdatabases of 𝐷 𝐸 that contain 𝐸 and have a bounded number of additional active domain elements that do not occur in facts ( 𝐸 ) ), can be embedded in 𝐷 while preserving 𝐸 . We call the collection 𝐶 of databases local if, for every S -database 𝐷 𝐶 , is locally embeddable in 𝐷 implies that 𝐷 belongs to 𝐶 . We proceed to formalize the above high-level description.
Recall that the active domain of a database 𝐷 , denoted adom ( 𝐷 ) , is the set of elements of dom ( 𝐷 ) that occur in at least one fact of 𝐷 . Consider an S -database 𝐷 ′ and an S -database 𝐷 ′′ ⊆ 𝐷 ′ , i.e., facts ( 𝐷 ′′ ) ⊆ facts ( 𝐷 ′ ) . The 𝑚 -neighbourhood of 𝐷 ′′ in 𝐷 ′ is defined as the set of S -databases
- { 𝐸 | adom ( 𝐷 ′′ ) ⊆ adom ( 𝐸 , ) 𝐸 ⪯ 𝐷 ′ and | adom ( 𝐸 )| ≤ | adom ( 𝐷 ′′ )| + 𝑚 , }
Fig. 1 𝐶 is ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 .
that is, all the subdatabases of 𝐷 ′ such that their facts contain constants from adom ( 𝐷 ′′ ) and at most 𝑚 additional elements not occurring in adom ( 𝐷 ′′ ) . It is easy to verify that the 𝑚 -neighbourhood of 𝐷 ′′ in 𝐷 ′ is actually the set of S -databases
$$\{ E \ | \ D ^ { \prime \prime } \subseteq E, \ E \leq D ^ { \prime } \text{ and } | \text{adom} ( E ) | \leq | \text{adom} ( D ^ { \prime \prime } ) | + m \},$$
i.e., the set all subdatabases of 𝐷 ′ that contain 𝐷 ′′ and their facts mention at most 𝑚 additional elements not occurring in the facts of 𝐷 ′′ . Indeed, if 𝐷 ′′ ⊆ 𝐷 ′ and 𝐸 ⪯ 𝐷 ′ , then we have that adom ( 𝐷 ′′ ) ⊆ adom ( 𝐸 ) if and only if 𝐷 ′′ ⊆ 𝐸 .
Consider a collection 𝐶 of databases over S and an S -database 𝐷 . For integers 𝑛, 𝑚 ≥ 0, we say that 𝐶 is ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 if, for every 𝐸 ⪯ 𝐷 with | adom ( 𝐸 )| ≤ 𝑛 , there is 𝐷 𝐸 ∈ 𝐶 such that 𝐸 ⊆ 𝐷 𝐸 , and for every 𝐷 ′ in the 𝑚 -neighbourhood of 𝐸 in 𝐷 𝐸 , there is a function ℎ : adom ( 𝐷 ′ ) → adom ( 𝐷 ) such that ℎ is the identity on adom ( 𝐸 ) and ℎ ( facts ( 𝐷 ′ )) ⊆ facts ( 𝐷 ) . The notion of ( 𝑛, 𝑚 ) -local embeddability is illustrated in Figure 1; the circles represent the set of facts of the databases. Clearly, for every S -database 𝐸 , we have that adom ( 𝐸 ) ⊆ dom ( 𝐸 ) , and this containment may be a proper one. Observe, however, that the notion of a collection 𝐶 of databases being ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 only depends on adom ( 𝐸 ) of 𝐸 and the set of facts of 𝐸 , and not on dom ( 𝐸 ) of 𝐸 . In turn, this implies that, when showing that 𝐶 is ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 , it suffices to focus our attention on subdatabases 𝐸 of 𝐷 such that adom ( 𝐸 ) = dom ( 𝐸 ) . We state this observation as a separate lemma, which will be used later in the paper.
Lemma 3 Consider a collection 𝐶 of databases, integers 𝑛, 𝑚 ≥ 0 , and a database 𝐷 . The following statement are equivalent:
- 1. 𝐶 is ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 .
- 2. For every 𝐸 ⪯ 𝐷 with adom ( 𝐸 ) = dom ( 𝐸 ) and | adom ( 𝐸 )| ≤ 𝑛 , there is 𝐷 𝐸 ∈ 𝐶 such that 𝐸 ⊆ 𝐷 𝐸 , and for every 𝐷 ′ in the 𝑚 -neighbourhood of 𝐸 in 𝐷 𝐸 , there is a function ℎ : adom ( 𝐷 ′ ) → adom ( 𝐷 ) such that ℎ is the identity on adom ( 𝐸 ) and ℎ ( facts ( 𝐷 ′ )) ⊆ facts ( 𝐷 ) .
We are now ready to give the definition of the central notion of locality.
Definition 1 (Locality) Acollection 𝐶 of databases over S is ( 𝑛, 𝑚 ) -local , for 𝑛, 𝑚 ≥ 0, if, for every S -database 𝐷 , the following holds: 𝐶 is ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 implies 𝐷 ∈ 𝐶 . We say that 𝐶 is local if it is ( 𝑛, 𝑚 ) -local for some 𝑛, 𝑚 ≥ 0.
Fig. 2 The function 𝜆 = 𝜇 𝐿 ◦ 𝑔 in the proof of Lemma 4.
We can now show the following technical lemma that essentially states that every collection of databases that is finitely axiomatizable by tgds with at most 𝑛 universally and 𝑚 existentially quantified variables, and egds with at most 𝑛 universally quantified variables, is ( 𝑛, 𝑚 ) -local. A tgd is called ( 𝑛, 𝑚 ) -tgd , for 𝑛 ≥ 0 and 𝑚 > 0, or 𝑛 > 0 and 𝑚 ≥ 0, if it mentions at most 𝑛 universally and 𝑚 existentially quantified variables. Moreover, an egd is called 𝑛 -egd , for 𝑛 > 0, if it mentions at most 𝑛 universally quantified variables. For notational convenience, we also define the corner cases of ( 0 0 -tgd and 0-egd as the truth value , ) true , i.e., as a tautology.
Lemma 4 For integers 𝑛, 𝑚 ≥ 0 , every collection 𝐶 of databases that is finitely axiomatizable by ( 𝑛, 𝑚 ) -tgds and 𝑛 -egds is ( 𝑛, 𝑚 ) -local.
Proof. Let 𝐶 be a collection of databases over a schema S that is finitely axiomatizable by ( 𝑛, 𝑚 ) -tgds and 𝑛 -egds. By definition, there is a finite set Σ 𝑇 of ( 𝑛, 𝑚 ) -tgds and a finite set Σ 𝐸 of 𝑛 -egds such that, for every S -database 𝐷 , we have that 𝐷 ∈ 𝐶 iff 𝐷 | = Σ 𝑇 and 𝐷 | = Σ 𝐸 . Consider an S -database 𝐷 and assume that 𝐶 is ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 . We proceed to show that 𝐷 ∈ 𝐶 , i.e., 𝐷 | = Σ 𝑇 and 𝐷 | = Σ 𝐸 .
We first show that 𝐷 | = Σ 𝑇 . Consider a tgd 𝜎 ∈ Σ 𝑇 , other than the ( 0 0 -tgd that , ) is trivially satisfied by 𝐷 , of the form 𝜙 𝑥, 𝑦 ( ¯ ¯ ) →∃ ¯ 𝑧 𝜓 ( ¯ 𝑥, 𝑧 ¯ ) , and assume that there exists a function ℎ : ¯ 𝑥 ∪ ¯ 𝑦 → dom ( 𝐷 ) such that ℎ 𝜙 𝑥, 𝑦 ( ( ¯ ¯ )) ⊆ facts ( 𝐷 ) . We show that there exists an extension 𝜆 of ℎ such that 𝜆 𝜓 𝑥, 𝑧 ( ( ¯ ¯ )) ⊆ facts ( 𝐷 ) ; the existence of 𝜆 is illustrated in Figure 2. Let 𝐸 be the database ( dom ( 𝐸 , 𝑅 ) 𝐸 1 , . . . , 𝑅 𝐸 ℓ ) , where dom ( 𝐸 ) is the set of constants occurring in ℎ 𝜙 𝑥, 𝑦 ( ( ¯ ¯ )) , and, for each 𝑖 ∈ [ ℓ ] , 𝑅 𝐸 𝑖 = 𝑅 𝐷 𝑖 | 𝐸 . It is clear that 𝐸 ⪯ 𝐷 with | adom ( 𝐸 )| ≤ 𝑛 since 𝜙 𝑥, 𝑦 ( ¯ ¯ ) mentions at most 𝑛 variables. Since, by hypothesis, 𝐶 is ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 , we get that there exists 𝐷 𝐸 ∈ 𝐶 such that 𝐸 ⊆ 𝐷 𝐸 , and, for every 𝐷 ′ in the 𝑚 -neighbourhood of 𝐸 in 𝐷 𝐸 , there is a function 𝜇 𝐷 ′ : adom ( 𝐷 ′ ) → adom ( 𝐷 ) , which is the identity on adom ( 𝐸 ) , such that 𝜇 𝐷 ′ ( facts ( 𝐷 ′ )) ⊆ facts ( 𝐷 ) . It is clear that ℎ 𝜙 𝑥, 𝑦 ( ( ¯ ¯ )) ⊆ facts ( 𝐷 𝐸 ) . Since 𝐷 𝐸 ∈ 𝐶 , or, equivalently, 𝐷 𝐸 | = Σ , there exists an extension 𝑔 of ℎ such that 𝑔 𝜓 𝑥, 𝑧 ( ( ¯ ¯ )) ⊆ facts ( 𝐷 𝐸 ) . Let 𝐹 = ( dom ( 𝐹 , 𝑅 ) 𝐹 1 , . . . , 𝑅 𝐹 ℓ ) , where dom ( 𝐹 ) are the constants occurring in ℎ 𝜙 𝑥, 𝑦 ( ( ¯ ¯ )) ∪ 𝑔 𝜓 𝑥, 𝑧 ( ( ¯ ¯ )) , and, for each 𝑖 ∈ [ ℓ ] , 𝑅 𝐹 𝑖 = 𝑅 𝐷 𝐸 𝑖 | dom ( 𝐹 ) . It is clear that 𝐹 is in the 𝑚 -neighbourhood of 𝐸 in 𝐷 𝐸 since ¯ 𝑧 has at most 𝑚 variables. Therefore, there is a function 𝜇 𝐹 : adom ( 𝐹 ) → adom ( 𝐷 ) ,
which is the identity on adom ( 𝐸 ) , such that 𝜇 𝐹 ( facts ( 𝐹 )) ⊆ facts ( 𝐷 ) . Consider the function 𝜆 = 𝜇 𝐹 ◦ 𝑔 . Since 𝑔 is an extension of ℎ , and 𝜇 𝐹 is the identity on the elements occurring in ℎ 𝜙 𝑥, 𝑦 ( ( ¯ ¯ )) , we get that 𝜆 𝑣 ( ) = ℎ 𝑣 ( ) for each variable 𝑣 in 𝜙 𝑥, 𝑦 ( ¯ ¯ ) , and thus, 𝜆 is an extension of ℎ . Moreover, since 𝑔 𝜓 𝑥, 𝑧 ( ( ¯ ¯ )) ⊆ facts ( 𝐹 ) , we get that 𝜆 𝜓 𝑥, 𝑧 ( ( ¯ ¯ )) ⊆ facts ( 𝐷 ) .
We now show that 𝐷 | = Σ 𝐸 . Consider an egd 𝜃 ∈ Σ 𝐸 , other than the 0-egd that is trivially satisfied by 𝐷 , of the form 𝜙 𝑥 ( ¯ ) → 𝑥 𝑖 = 𝑥 𝑗 , and assume there exists a function ℎ : ¯ 𝑥 → dom ( 𝐷 ) such that ℎ 𝜙 𝑥 ( ( ¯ )) ⊆ facts ( 𝐷 ) . We show that ℎ 𝑥 ( 𝑖 ) = ℎ 𝑥 ( 𝑗 ) . Let 𝐸 = ( dom ( 𝐸 , 𝑅 ) 𝐸 1 , . . . , 𝑅 𝐸 ℓ ) , where dom ( 𝐸 ) is the set of constants occurring in ℎ 𝜙 𝑥 ( ( ¯ )) , and, for each 𝑖 ∈ [ ℓ ] , 𝑅 𝐸 𝑖 = 𝑅 𝐷 𝑖 | 𝐸 . It is clear that 𝐸 ⪯ 𝐷 with | adom ( 𝐸 )| ≤ 𝑛 since 𝜙 𝑥 ( ¯ ) mentions at most 𝑛 variables. Since, by hypothesis, 𝐶 is ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 , there exists 𝐷 𝐸 ∈ 𝐶 such that 𝐸 ⊆ 𝐷 𝐸 . Observe that 𝐸 ⊆ 𝐷 𝐸 implies that ℎ 𝜙 𝑥 ( ( ¯ )) ⊆ 𝐸 𝐸 . Since 𝐷 𝐸 | = Σ 𝐸 , we get that ℎ 𝑥 ( 𝑖 ) = ℎ 𝑥 ( 𝑗 ) . ⊓ ⊔
It is useful to observe that locality implies domain independence.
Lemma 5 If a collection of databases is local, then it is also domain independent.
Proof. Assume that 𝐶 is a collection of databases over S that is ( 𝑛, 𝑚 ) -local for 𝑛, 𝑚 ≥ 0, and let 𝐷 be an S -database in 𝐶 . Consider an S -database 𝐷 ′ such that facts ( 𝐷 ) = facts ( 𝐷 ′ ) . We need to show that 𝐷 ′ ∈ 𝐶 . This is done by showing that 𝐶 is ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 ′ , which implies that 𝐷 ′ ∈ 𝐶 since, by hypothesis, 𝐶 is ( 𝑛, 𝑚 ) -local. Consider an S -database 𝐷 ′′ ⪯ 𝐷 ′ with | adom ( 𝐷 ′′ )| ≤ 𝑛 . Since facts ( 𝐷 ) = facts ( 𝐷 ′ ) , it is clear that 𝐷 ′′ ⊆ 𝐷 . Since 𝐷 ∈ 𝐶 , it suffices to show that, for every 𝐸 in the 𝑚 -neighbourhood of 𝐷 ′′ in 𝐷 , there is a function ℎ 𝐸 : adom ( 𝐸 ) → adom ( 𝐷 ′ ) , which is the identity on adom ( 𝐷 ′′ ) , such that ℎ 𝐸 ( facts ( 𝐸 )) ⊆ facts ( 𝐷 ′ ) . Since 𝐸 ⊆ 𝐷 , which means that facts ( 𝐸 ) ⊆ facts ( 𝐷 ) , we get that facts ( 𝐸 ) ⊆ facts ( 𝐷 ′ ) . Therefore, ℎ 𝐸 is simply the identity on adom ( 𝐸 ) . ⊓ ⊔
## 4.2 The Characterization for TGDs and EGDs
Weare now ready to provide the characterization of interest, which was originally established for arbitrary relational structures in [12], and here is presented for databases (i.e., finite structures).
Theorem 3 Consider a collection 𝐶 of databases, and integers 𝑛, 𝑚 ≥ 0 . The following statements are equivalent:
- 1. 𝐶 is finitely axiomatizable by ( 𝑛, 𝑚 ) -tgds and 𝑛 -egds.
- 2. 𝐶 is 1 -critical, ( 𝑛, 𝑚 ) -local, and closed under direct products.
Clearly, the above result implies a characterization for arbitrary tgds and egds:
Corollary 1 Consider a collection 𝐶 of databases. The following are equivalent:
- 1. 𝐶 is finitely axiomatizable by tgds and egds.
- 2. 𝐶 is 1 -critical, local, and closed under direct products.
The direction ( 1 ) ⇒ ( ) 2 of Theorem 3 is easy and we leave it as an exercise to the reader. We proceed to discuss the non-trivial direction ( 2 ) ⇒ ( ) 1 . To this end, we need to introduce a couple of auxiliary notions, namely existential disjunctive dependencies and relative diagrams of databases.
Existential Disjunctive Dependencies. Existential disjunctive dependencies generalize disjunctive dependencies, already used in the proof of Theorem 2, with existential quantification in the right-hand side of the implication. Moreover, the hypothesis and the conclusion of the implication can be empty. More precisely, an existential disjunctive dependency (edd) 𝛿 over a schema S is a constant-free sentence
$$\forall \bar { x } \left ( \phi ( \bar { x } ) \, \rightarrow \, \bigvee _ { i = 1 } ^ { k } \psi _ { i } ( \bar { x } _ { i } ) \right ),$$
where ¯ 𝑥 is a tuple of variables of V , the expression 𝜙 𝑥 ( ¯ ) is a (possibly empty) conjunction of atoms over S , and, for each 𝑖 ∈ [ 𝑘 ] , ¯ 𝑥 𝑖 ⊆ ¯ 𝑥 and the expression 𝜓 𝑥 ( ¯ 𝑖 ) is either an equality formula 𝑦 = 𝑧 with ¯ 𝑥 𝑖 = { 𝑦, 𝑧 } , or a constant-free formula ∃ ¯ 𝑦 𝑖 𝜒 𝑖 ( ¯ 𝑥 , 𝑦 𝑖 ¯ 𝑖 ) with ¯ 𝑦 𝑖 being a tuple of variables from V \ ¯ and 𝑥 𝜒 𝑖 ( ¯ 𝑥 , 𝑦 𝑖 ¯ 𝑖 ) is a (possibly empty) conjunction of atoms over S . When the conclusion of 𝛿 is empty (i.e., there are no disjuncts), 𝛿 is essentially the sentence ∀ ¯ 𝑥 ( 𝜙 𝑥 ( ¯ ) → false ) . Now, when both the hypothesis and the conclusion of 𝛿 are empty, then 𝛿 is essentially the truth value false , i.e., a contradiction. Assuming that the conclusion of 𝛿 is non-empty, a database 𝐷 satisfies 𝛿 if, whenever there exists a function ℎ : ¯ 𝑥 → dom ( 𝐷 ) such that ℎ 𝜙 𝑥 ( ( ¯ )) ⊆ facts ( 𝐷 ) , then there is 𝑖 ∈ [ 𝑘 ] such that, if 𝜓 𝑖 ( ¯ 𝑦 𝑖 ) is 𝑦 = 𝑧 , then ℎ 𝑦 ( ) = ℎ 𝑧 ( ) ; otherwise, if 𝜓 𝑖 ( ¯ 𝑦 𝑖 ) is of the form ∃ ¯ 𝑦 𝑖 𝜒 𝑖 ( ¯ 𝑥 , 𝑦 𝑖 ¯ 𝑖 ) , then there is an extension ℎ ′ of ℎ such that ℎ ′ ( 𝜒 𝑖 ( ¯ 𝑥 , 𝑦 𝑖 ¯ 𝑖 )) ⊆ facts ( 𝐷 ) . In case the conclusion of 𝛿 is empty and 𝛿 is not a contradiction, 𝐷 satisfies 𝛿 if there is no function ℎ : ¯ 𝑥 → dom ( 𝐷 ) such that ℎ 𝜙 𝑥 ( ( ¯ )) ⊆ facts ( 𝐷 ) . We write 𝐷 | = 𝛿 for the fact that 𝐷 satisfies 𝛿 . The database 𝐷 satisfies a set Σ of edds, written 𝐷 | = Σ ( 𝐷 is a model of Σ ), if 𝐷 | = 𝛿 for each 𝛿 ∈ Σ .
Relative Diagram of a Database. Consider an integer ℓ ≥ 0, an S -database 𝐸 , and an S -database 𝐷 such that 𝐸 ⪯ 𝐷 . We are going to define the notion of the ℓ -diagram of 𝐸 relative to 𝐷 , which can be regarded as a refinement of the standard notion of diagram of a database, already used in the proof of Theorem 2. Let 𝐴 𝐸,ℓ be the set of all atomic formulas of the form 𝑅 𝑢 ( ¯ ) that can be formed using predicates from S , constants from dom ( 𝐸 ) , and ℓ distinct variables 𝑦 1 , . . . , 𝑦 ℓ from V , i.e., 𝑅 ∈ S and ¯ 𝑢 ∈ ( dom ( 𝐸 ) ∪ { 𝑦 1 , . . . , 𝑦 ℓ }) ar ( 𝑅 ) . Let 𝐶 𝐸,ℓ be the set of all conjunctions of atomic formulas from 𝐴 𝐸,ℓ . Note that both 𝐴 𝐸,ℓ and 𝐶 𝐸,ℓ are finite sets because dom ( 𝐸 ) is finite. Given a formula 𝛾 𝑦 , . . . , 𝑦 ( 1 ℓ ) ∈ 𝐶 𝐸,ℓ , we can naturally talk about the satisfaction of the sentence ∃ 𝑦 1 · · · ∃ 𝑦 ℓ 𝛾 𝑦 , . . . , 𝑦 ( 1 ℓ ) by a database 𝐷 ′ , in which case we simply write 𝐷 ′ | = ∃ 𝑦 1 · · · ∃ 𝑦 ℓ 𝛾 𝑦 , . . . , 𝑦 ( 1 ℓ ) . The ℓ -diagram of 𝐸 relative to 𝐷 , denoted Δ 𝐷 𝐸,ℓ , is the first-order sentence
̸
$$\bigwedge _ { \alpha \in \text{facts} ( E ) } \alpha \wedge \bigwedge _ { \substack { c, d \in \text{dom} ( E ), \\ c \neq d } } \neg ( c = d ) \wedge \bigwedge _ { \substack { \gamma ( y _ { 1 }, \dots, y _ { \ell } ) \in C _ { E, \ell }, \\ D \neq \exists y _ { 1 } \cdots \exists y _ { \ell } \gamma ( y _ { 1 }, \dots, y _ { \ell } ) } } \neg ( \exists y _ { 1 } \cdots \exists y _ { \ell } \gamma ( y _ { 1 }, \dots, y _ { \ell } ) ) \,.$$
In fact, we are interested in the first-order formula Φ 𝐷 𝐸,ℓ ( ¯ 𝑥 ) obtained from the firstorder sentence Δ 𝐷 𝐸,ℓ by replacing each constant element 𝑐 ∈ dom ( 𝐸 ) with a new variable 𝑥 𝑐 ∈ V \ { 𝑦 1 , . . . , 𝑦 ℓ } . As was the case with the formulas of 𝐶 𝐸,ℓ , we can naturally talk about the satisfaction of ∃ ¯ 𝑥 Φ 𝐷 𝐸,ℓ ( ¯ 𝑥 ) by a database 𝐷 ′ , in which case we simply write 𝐷 ′ | = ∃ ¯ 𝑥 Φ 𝐷 𝐸,ℓ ( ¯ 𝑥 ) . It is straightforward to verify that:
Lemma 6 For every integer ℓ ≥ 0 , S -database 𝐸 , and S -database 𝐷 with 𝐸 ⪯ 𝐷 , it holds that 𝐷 | = ∃ ¯ 𝑥 Φ 𝐷 𝐸,ℓ ( ¯ 𝑥 ) .
Let E 𝑛,𝑚 , for some integers 𝑛, 𝑚 ≥ 0, be the set of all edds over S of the form ∀ ¯ 𝑥 GLYPH<16> 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝜓 𝑖 ( ¯ 𝑥 𝑖 ) GLYPH<17> such that ¯ 𝑥 consists of at most 𝑛 distinct variables, and, for each 𝑖 ∈ [ 𝑘 ] , the formula 𝜓 𝑖 ( ¯ 𝑥 𝑖 ) mentions at most 𝑛 + 𝑚 distinct variables. The latter means that, if 𝜓 𝑖 ( ¯ 𝑥 𝑖 ) is a formula of the form ∃ ¯ 𝑦 𝑖 𝜒 𝑖 ( ¯ 𝑥 , 𝑦 𝑖 ¯ 𝑖 ) (i.e., it is not an equality expression), then ¯ 𝑦 𝑖 consists of at most 𝑚 distinct variables. Note that E 𝑛,𝑚 is a finite set (up to logical equivalence) since S is finite and the number of variables in each element of E 𝑛,𝑚 is finite. We can show the following auxiliary lemma.
Lemma 7 Let 𝑛, 𝑚 ≥ 0 and assume that 𝐷, 𝐸 are two S -databases such that adom ( 𝐸 ) = dom ( 𝐸 ) , | adom ( 𝐸 )| ≤ 𝑛 , and 𝐸 ⪯ 𝐷 . It holds that there exists a sentence 𝛿 ∈ E 𝑛,𝑚 such that 𝛿 ≡ ¬∃ ¯ 𝑥 Φ 𝐷 𝐸,𝑚 ( ¯ 𝑥 ) .
Proof. Recall that the formula Φ 𝐷 𝐸,𝑚 ( ¯ 𝑥 ) is obtained from the 𝑚 -diagram of 𝐸 relative to 𝐷 by renaming each 𝑐 ∈ dom ( 𝐸 ) to a new variable 𝑥 𝑐 ; let 𝜌 be the renaming function, i.e., 𝜌 𝑐 ( ) = 𝑥 𝑐 for each 𝑐 ∈ dom ( 𝐸 ) . Thus, Φ 𝐷 𝐸,𝑚 ( ¯ 𝑥 ) is of the form
̸
$$\underbrace { \bigwedge _ { \alpha \in \text{facts} ( E ) } \rho ( \alpha ) } _ { \Psi _ { 1 } } \wedge \underbrace { \bigwedge _ { \substack { c, d \in \text{dom} ( E ), \\ c \neq d } } _ { \substack { \gamma ( \bar { y } ) \in C _ { E, m }, \\ D \not \equiv \exists \bar { y } \gamma ( \bar { y } ) } } _ { \Psi _ { 2 } } \neg \exists \bar { y } \rho ( \gamma ( \bar { y } ) ) } \,.$$
Note that Ψ 1 and Ψ 2 might be empty (i.e., they have no conjuncts). In particular, Ψ 1 is empty if 𝐸 is empty, whereas Ψ 2 is empty if 𝐷 is 1-critical, and thus, 𝐷 | = ∃ ¯ 𝑦 𝛾 ( ¯ 𝑦 ) for each 𝛾 𝑦 ( ¯ ) ∈ 𝐶 𝐸,𝑚 . It is clear that ¬∃ ¯ 𝑥 Φ 𝐷 𝐸,𝑚 ( ¯ 𝑥 ) is equivalent to the sentence
$$\delta \, = \, \forall \bar { x } \left ( \phi ( \bar { x } ) \, \rightarrow \, \psi ( \bar { x } ) \right ),$$
where
$$\phi ( \bar { x } ) \ = \ \bigwedge _ { \alpha \in \text{facts} ( E ) } \rho ( \alpha )$$
and the shape of 𝜓 𝑥 ( ¯ ) depends on whether Ψ 1 and Ψ 2 are empty or not. If both are empty, then 𝛿 is the truth constant false , i.e., a contradiction, and thus, 𝛿 ∈ E 𝑛,𝑚 . If Ψ 1 is non-empty and Ψ 2 is empty, then, for an S -database 𝐷 ′ , it holds that
𝐷 ′ | = ¬∃ ¯ 𝑥 Φ 𝐷 𝐸,𝑚 ( ¯ 𝑥 ) if there is no function ℎ : ¯ 𝑥 → dom ( 𝐷 ′ ) such that ℎ 𝜙 𝑥 ( ( ¯ )) ⊆ facts ( 𝐷 ′ ) . Hence, in this case, 𝛿 is the edd ∀ ¯ 𝑥 ( 𝜙 𝑥 ( ¯ ) → false ) . Since, by hypothesis, | adom ( 𝐸 )| ≤ 𝑛 , we get that 𝜙 𝑥 ( ¯ ) mentions at most 𝑛 variables, and thus, 𝛿 ∈ E 𝑛,𝑚 . Now, if Ψ 1 is either empty or non-empty, and Ψ 2 is non-empty, then we have that
̸
$$\psi ( \bar { x } ) \, = \, \underset { c \neq d } { \bigvee } \, \rho ( c ) = \rho ( d ) \vee \underset { \substack { \gamma ( \bar { y } ) \in C _ { E, m }, \\ D \not \equiv \exists \bar { y } \, \gamma ( \bar { y } ) } } \exists \bar { y } \, \rho ( \gamma ( \bar { y } ) ),$$
and hence, 𝛿 is an edd. It remains to show that 𝛿 ∈ E 𝑛,𝑚 . To this end, we need to show the following two statements: (i) each variable in 𝜓 𝑥 ( ¯ ) is either existentially quantified or appears in 𝜙 𝑥 ( ¯ ) , and (ii) 𝛿 mentions at most 𝑛 universally quantified variables and at most 𝑚 existentially quantified variables. Statement (i) is true since, by hypothesis, adom ( 𝐸 ) = dom ( 𝐸 ) . Concerning statement (ii), 𝛿 has at most 𝑛 universally quantified variables since, by hypothesis, | adom ( 𝐸 )| ≤ 𝑛 , and 𝛿 has 𝑚 existentially quantified variables because so does the formula ¬ Φ 𝐷 𝐸,𝑚 by the construction of Φ 𝐷 𝐸,𝑚 . ⊓ ⊔
We can now discuss the non-trivial direction ( 2 ) ⇒ ( ) 1 of Theorem 3. Assume that 𝐶 is a collection of databases over S . The proof proceeds in two main steps:
- 1. We construct a finite set Σ ∨ of edds over S , which mention at most 𝑛 universally andat most 𝑚 existentially quantified variables, and show that Σ ∨ has the following property: a database 𝐷 is in 𝐶 if and only if 𝐷 satisfies Σ ∨ . To this end, we exploit the fact that 𝐶 is ( 𝑛, 𝑚 ) -local.
- 2. We then show that there is a finite set Σ ∃ , = of ( 𝑛, 𝑚 ) -tgds and 𝑛 -egds over S such that a database 𝐷 is in 𝐶 if and only if 𝐷 satisfies Σ ∃ , = ; in fact, Σ ∃ , = is the set of the tgds and egds occurring in Σ ∨ . To this end, we exploit the fact that 𝐶 is 1-critical and closed under direct products.
In what follows, we give the details for each of the above steps.
## Step 1: The finite set Σ ∨ of edds that axiomatizes 𝐶
Recall that E 𝑛,𝑚 is the set of all edds over S of the form ∀ ¯ 𝑥 GLYPH<16> 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝜓 𝑖 ( ¯ 𝑥 𝑖 ) GLYPH<17> such that ¯ consists of at most 𝑥 𝑛 distinct variables, and, for each 𝑖 ∈ [ 𝑘 ] , the formula 𝜓 𝑖 ( ¯ 𝑥 𝑖 ) mentions at most 𝑛 + 𝑚 distinct variables. The latter means that, if 𝜓 𝑖 ( ¯ 𝑥 𝑖 ) is a formula of the form ∃ ¯ 𝑦 𝑖 𝜒 𝑖 ( ¯ 𝑥 , 𝑦 𝑖 ¯ 𝑖 ) (i.e., it is not an equality expression), then ¯ 𝑦 𝑖 consists of at most 𝑚 distinct variables. Recall also that E 𝑛,𝑚 is finite (up to logical equivalence). Define Σ ∨ to be the set of all edds from E 𝑛,𝑚 that are satisfied by every database of 𝐶 , that is,
$$\Sigma ^ { \vee } \, = \, \left \{ \delta \in \mathbf E _ { n, m } \, | \text{ for each $D\in C$, it holds that $D\models\delta$} \right \}.$$
It is clear that Σ ∨ is finite (up to logical equivalence) since Σ ∨ ⊆ E 𝑛,𝑚 . We will show that 𝐶 is precisely the set of databases that satisfy Σ ∨ .
Lemma 8 For every S -database 𝐷 , we have that 𝐷 ∈ 𝐶 if and only if 𝐷 | = Σ ∨ .
Proof. The (⇒) direction follows from the definition of Σ ∨ . We proceed with the (⇐) direction. We have to show that if 𝐷 | = Σ ∨ , then 𝐷 ∈ 𝐶 . We will show that 𝐶 is ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 , which, since 𝐶 is ( 𝑛, 𝑚 ) -local, will imply that 𝐷 ∈ 𝐶 . By Lemma 3, to show that 𝐶 is ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 , we have to show that, for every 𝐸 ⪯ 𝐷 with adom ( 𝐸 ) = dom ( 𝐸 ) and | adom ( 𝐸 )| ≤ 𝑛 , there is a database 𝐷 𝐸 ∈ 𝐶 such that 𝐸 ⊆ 𝐷 𝐸 , and for every 𝐷 ′ in the 𝑚 -neighbourhood of 𝐸 in 𝐷 𝐸 , there is a function ℎ : adom ( 𝐷 ′ ) → adom ( 𝐷 ) such that ℎ is the identity on adom ( 𝐸 ) and ℎ ( facts ( 𝐷 ′ )) ⊆ facts ( 𝐷 ) .
̸
̸
Let 𝐸 be a database such that 𝐸 ⪯ 𝐷 , adom ( 𝐸 ) = dom ( 𝐸 ) , and | adom ( 𝐸 )| ≤ 𝑛 . By Lemma 7, the sentence ¬∃ ¯ 𝑥 Φ 𝐷 𝐸,𝑚 ( ¯ 𝑥 ) is logically equivalent to a sentence 𝛿 ∈ E 𝑛,𝑚 . We claim that 𝛿 ∉ Σ ∨ . Indeed, otherwise, we would have that 𝐷 | = 𝛿 , which is a contradiction, since, by Lemma 6, 𝐷 | = ∃ ¯ 𝑥 Φ 𝐷 𝐸,𝑚 ( ¯ 𝑥 ) . Since 𝛿 ∉ Σ ∨ , there must exist a database 𝐷 𝐸 ∈ 𝐶 such that 𝐷 𝐸 | = 𝛿 , which means that 𝐷 𝐸 | = ∃ ¯ 𝑥 Φ 𝐷 𝐸,𝑚 ( ¯ 𝑥 ) . Thus, there exists a database 𝐸 ′ ⊆ 𝐷 𝐸 such that 𝐸 ≃ 𝐸 ′ , i.e., 𝐸 and 𝐸 ′ are isomorphic databases. Therefore, and without loss of generality, we can assume that 𝐸 ⊆ 𝐷 𝐸 . To show that 𝐶 is ( 𝑛, 𝑚 ) -locally embeddable in 𝐷 , it remains to show that for every database 𝐷 ′ in the 𝑚 -neighbourhood of 𝐸 in 𝐷 𝐸 , there exists a function ℎ : adom ( 𝐷 ′ ) → adom ( 𝐷 ) such that ℎ is the identity on adom ( 𝐸 ) and ℎ ( facts ( 𝐷 ′ )) ⊆ facts ( 𝐷 ) . Towards a contradiction, assume that there exists 𝐷 ′ in the 𝑚 -neighbourhood of 𝐸 in 𝐷 𝐸 for which there is no function ℎ : adom ( 𝐷 ′ ) → adom ( 𝐷 ) that is the identity on adom ( 𝐸 ) with ℎ ( facts ( 𝐷 ′ )) ⊆ facts ( 𝐷 ) . Let 𝐹 be the S -database defined as the difference between 𝐷 ′ and 𝐸 , i.e., 𝐹 is such that facts ( 𝐹 ) = facts ( 𝐷 ′ ) \ facts ( 𝐸 ) , while dom ( 𝐹 ) consists of all the constants occurring in facts ( 𝐷 ′ ) \ facts ( 𝐸 ) , and hence, dom ( 𝐹 ) = adom ( 𝐹 ) . Clearly, there is no function ℎ : adom ( 𝐹 ) → adom ( 𝐷 ) that is the identity on adom ( 𝐸 ) and ℎ ( facts ( 𝐹 ) ⊆ 𝐷 . Observe that | adom ( 𝐹 ) \ adom ( 𝐸 )| ≤ 𝑚 ; we assume that adom ( 𝐹 ) \ adom ( 𝐸 ) = { 𝑑 , . . . , 𝑑 1 𝑚 ′ } for 𝑚 ′ ≤ 𝑚 . Let 𝛾 𝑦 ( ¯ ) be the formula obtained from GLYPH<211> 𝛼 ∈ facts ( 𝐹 ) 𝛼 after renaming each constant 𝑑 𝑖 to the variable 𝑦 𝑖 ; thus, ¯ 𝑦 = 𝑦 1 , . . . , 𝑦 𝑚 ′ . Since there is no function ℎ : adom ( 𝐹 ) → adom ( 𝐷 ) that is the identity on adom ( 𝐸 ) and ℎ ( facts ( 𝐹 ) ⊆ 𝐷 , we can conclude that 𝐷 | = ∃ ¯ 𝑦 𝛾 ( ¯ 𝑦 ) . Observe now that, by construction, ¬∃ ¯ 𝑦 𝛾 ( ¯ 𝑦 ) is a conjunct of Δ 𝐷 𝐸,𝑚 , which in turn implies that the formula ¬∃ ¯ 𝑧 𝛾 ( ¯ 𝑧 ) obtained from ¬∃ ¯ 𝑦 𝛾 ( ¯ 𝑦 ) after renaming each constant 𝑐 ∈ dom ( 𝐸 ) = adom ( 𝐸 ) to the variable 𝑥 𝑐 is a conjunct of Φ 𝐷 𝐸,𝑚 ( ¯ 𝑥 ) . Since 𝐹 ⊆ 𝐷 𝐸 , we conclude that 𝐷 𝐸 | = ∃ ¯ 𝑧 𝛾 ( ¯ 𝑧 ) , which implies that 𝐷 𝐸 | = ∃ ¯ 𝑥 Φ 𝐷 𝐸,𝑚 ( ¯ 𝑥 ) . But this contradicts the fact that 𝐷 𝐸 | = ∃ ¯ 𝑥 Φ 𝐷 𝐸,𝑚 ( ¯ 𝑥 ) . This completes the proof that 𝐶 is ( 𝑛, 𝑚 ) -embeddable in 𝐷 . ⊓ ⊔
̸
## Step 2: The finite set Σ ∃ , = of tgds and egds that axiomatizes 𝐶
The next lemma, which is an elimination-of-disjunctions result, provides a stepping stone towards proving that the class 𝐶 is finitely axiomatizable by tgds and egds.
Lemma 9 Assume that ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝜓 𝑖 ( ¯ 𝑥 𝑖 )) , where, for each 𝑖 ∈ [ 𝑘 ] , 𝜓 𝑖 ( ¯ 𝑥 𝑖 ) is either an equality formula or a non-empty conjunction of atoms, is an edd that belongs to Σ ∨ . There is 𝑗 ∈ [ 𝑘 ] such that ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝜓 𝑗 ( ¯ 𝑥 𝑗 )) also belongs to Σ ∨ .
̸
Proof. Note that for every 𝑗 ∈ [ 𝑘 ] , the sentence ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝜓 𝑗 ( ¯ 𝑥 𝑗 )) is either an egd or a tgd, hence it is an edd. Towards a contradiction, assume that none of these sentences belongs to Σ ∨ . Since Σ ∨ consists of all edds in E 𝑛,𝑚 that are satisfied by every database in 𝐶 , for every 𝑗 ∈ [ 𝑘 ] , there is an S -database 𝐷 𝑗 ∈ 𝐶 such that 𝐷 𝑗 | = ∀ ¯ 𝑥 ( 𝜙 𝑥 ( ¯ ) → 𝜓 𝑗 ( ¯ 𝑥 𝑗 )) , or, equivalently, 𝐷 𝑗 | = ∃ ¯ 𝑥 ( 𝜙 𝑥 ( ¯ ) ∧ ¬ 𝜓 𝑗 ( ¯ 𝑥 𝑗 )) . Let
$$E \, = \, D _ { 1 } \otimes \cdots \otimes D _ { k }.$$
̸
Since, by hypothesis, 𝐶 is closed under direct products, we have that 𝐸 ∈ 𝐶 . We will show that 𝐸 | = 𝛿 , which leads to a contradiction since 𝛿 ∈ Σ ∨ and 𝐸 ∈ 𝐶 , which means that 𝐸 | = 𝛿 .
Since 𝐷 𝑗 | = ∃ ¯ 𝑥 ( 𝜙 𝑥 ( ¯ ) ∧ ¬ 𝜓 𝑗 ( ¯ 𝑥 𝑗 )) for each 𝑗 ∈ [ 𝑘 ] , there is a function ℎ 𝑗 : ¯ 𝑥 → dom ( 𝐷 𝑗 ) such that ℎ 𝑗 ( 𝜙 𝑥 ( ¯ )) ⊆ facts ( 𝐷 𝑗 ) and 𝐷 𝑗 | = ¬ 𝜓 𝑗 ( ℎ 𝑗 ( ¯ 𝑥 𝑗 )) . Let ℎ : ¯ 𝑥 → dom ( 𝐸 ) be the function such that, for each variable 𝑥 ∈ ¯, 𝑥 we have ℎ 𝑥 ( ) = ( ℎ 1 ( 𝑥 , . . . , ℎ ) 𝑘 ( 𝑥 )) . By the definition of direct products, we have that ℎ 𝜙 𝑥 ( ( ¯ )) ⊆ facts ( 𝐸 ) . It remains to show that, for each 𝑗 ∈ [ 𝑘 ] , if 𝜓 𝑗 ( ¯ 𝑥 𝑗 ) is an equality formula 𝑦 = 𝑧 , then ℎ 𝑦 ( ) ≠ ℎ 𝑧 ( ) , while if 𝜓 𝑗 ( ¯ 𝑥 𝑗 ) is not an equality formula, then there is no extension ℎ ′ of ℎ such that ℎ ′ ( 𝜓 𝑗 ( ¯ 𝑥 𝑗 )) ⊆ facts ( 𝐸 ) . We proceed by case analysis on the form of 𝜓 𝑗 ( ¯ 𝑥 𝑗 ) .
Case 1: Assume first that 𝜓 𝑗 ( ¯ 𝑥 𝑗 ) is the equality expression 𝑦 = 𝑧 . By the properties of the function ℎ 𝑗 , we have that ℎ 𝑗 ( 𝑦 ) ≠ ℎ 𝑗 ( 𝑧 ) . Hence, by the definition of ℎ , we conclude that ℎ 𝑦 ( ) ≠ ℎ 𝑧 ( ) .
̸
Case2: Assumenowthat 𝜓 𝑗 ( ¯ 𝑥 𝑗 ) is a formula of the form ∃ ¯ 𝑦 𝑗 𝜒 𝑗 ( ¯ 𝑥 𝑗 , 𝑦 ¯ 𝑗 ) , and assume, by contradiction, that there exists an extension ℎ ′ of ℎ such that ℎ ′ ( 𝜒 𝑗 ( ¯ 𝑥 𝑗 , 𝑦 ¯ 𝑗 )) ⊆ facts ( 𝐸 ) . For a constant 𝑐 ∈ dom ( 𝐸 ) , we write 𝑐 𝑖 [ ] for the 𝑖 -th component of 𝑐 , which is actually a constant from dom ( 𝐷 𝑖 ) . We define the function ℎ ′ 𝑗 : ¯ 𝑥 ∪ ¯ 𝑦 𝑗 → dom ( 𝐷 𝑗 ) such that ℎ ′ 𝑗 ( 𝑣 ) = ℎ ′ ( 𝑣 ) [ 𝑗 ] , for each variable 𝑣 ∈ ¯ 𝑥 ∪ ¯ 𝑦 𝑗 . Since ℎ ′ is an extension of ℎ and ℎ 𝑗 ( 𝑣 ) = ℎ 𝑣 ( ) [ 𝑗 ] , for each variable 𝑣 ∈ ¯, we conclude that 𝑥 ℎ ′ 𝑗 is an extension of ℎ 𝑗 . By hypothesis, ℎ ′ ( 𝛼 ) ∈ facts ( 𝐸 ) for each conjunct 𝛼 of 𝜒 𝑗 ( ¯ 𝑥 𝑗 , 𝑦 ¯ 𝑗 ) . Assume that ℎ ′ ( 𝛼 ) = 𝑅 𝑐 , . . . , 𝑐 ( ¯ 𝑖 ¯ 𝑚 ) . By the definition of the direct product, we conclude that 𝑅 𝑐 ( ¯1 [ 𝑗 ] , . . . , 𝑐 𝑚 [ 𝑗 ]) ∈ facts ( 𝐷 𝑗 ) . Consequently, ℎ ′ 𝑗 ( 𝜓 𝑗 ( ¯ 𝑥 𝑗 )) ⊆ facts ( 𝐷 𝑗 ) , which in turn implies that 𝐷 𝑗 | = 𝜓 𝑗 ( ℎ 𝑗 ( ¯ 𝑥 𝑗 ) , which contradicts the fact that 𝐷 𝑗 | = 𝜓 𝑗 ( ℎ 𝑗 ( ¯ 𝑥 𝑗 ) . This completes the proof of Lemma 9. ⊓ ⊔
We are now ready to complete the proof of Theorem 3. Define Σ ∃ , = to be the set of all tgds and egds occurring in Σ ∨ , that is,
$$\Sigma ^ { \exists, = } \, = \, \left \{ \delta \in \Sigma ^ { \vee } \, | \, \delta \text{ is a } t g d \text{ or an egd} \right \}.$$
Note that Σ ∃ , = is a finite set because it is a subset of the finite set Σ ∨ . We proceed to show that, for each S -database 𝐷 , it holds that 𝐷 ∈ 𝐶 if and only if 𝐷 | = Σ ∃ , = .
( ⇒ ) If 𝐷 ∈ 𝐶 , then, by definition, 𝐷 | = Σ ∨ ; hence, 𝐷 | = Σ ∃ , = since Σ ∃ , = ⊆ Σ ∨ . ( ⇐ ) Assume now that 𝐷 is an S -database such that 𝐷 | = Σ ∃ , = . We need to show that 𝐷 ∈ 𝐶 . By Lemma 8, it suffices to show that 𝐷 | = Σ ∨ . Let 𝛿 be a sentence in Σ ∨ . Since 𝐶 is 1-critical, we get that 𝛿 is not an implication with the truth constant false
being its conclusion. Therefore, 𝛿 is an edd of the form ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝜓 𝑖 ( ¯ 𝑥 𝑖 )) , where each expression 𝜓 𝑖 ( ¯ 𝑥 𝑖 ) is either an equality 𝑦 = 𝑧 with 𝑦 and 𝑧 among the variables in ¯ 𝑥 or a constant-free formula ∃ ¯ 𝑦 𝑖 𝜒 𝑖 ( ¯ 𝑥 , 𝑦 𝑖 ¯ 𝑖 ) with 𝜒 𝑖 ( ¯ 𝑥 , 𝑦 𝑖 ¯ 𝑖 ) non-empty, the variables in ¯ 𝑥 𝑖 among those in ¯, 𝑥 and the variables in ¯ 𝑦 𝑖 different from those in ¯. 𝑥 By Lemma 9, there is 𝑗 ∈ [ 𝑘 ] such that the sentence ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝜓 𝑗 ( ¯ 𝑥 𝑗 )) belongs to Σ ∨ . Since this sentence is either an egd or a tgd, we have that it belongs to Σ = , ∃ , and hence, 𝐷 | = ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝜓 𝑗 ( ¯ 𝑥 𝑗 )) . It is obvious that the formula ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → 𝜓 𝑗 ( ¯ 𝑥 𝑗 )) logically implies the edd ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝜓 𝑖 ( ¯ 𝑥 𝑖 )) , hence 𝐷 | = ∀ ( ¯ 𝑥 𝜙 𝑥 ( ¯ ) → GLYPH<212> 𝑘 𝑖 = 1 𝜓 𝑖 ( ¯ 𝑥 𝑖 )) . This completes the proof of the above claim.
Therefore, we have established that the class 𝐶 is axiomatizable by the set Σ = , ∃ , which is a finite set of tgds and egds. This completes the proof of Theorem 3 .
## 4.3 From Theorem 3 to Theorem 1
We conclude this section by discussing how we can derive the characterization for full tgds and egds from [22], that is, Theorem 1 in Section 3, by exploiting the characterization for ( 𝑛, 𝑚 ) -tgds and 𝑛 -egds presented above, that is, Theorem 3. We first present the following consequence of Theorem 3, which forms a relevant characterization for finite sets of full tgds and egds in its own right.
Corollary 2 Consider a collection 𝐶 of databases. The following are equivalent:
- 1. 𝐶 is finitely axiomatizable by full tgds and egds.
- 2. 𝐶 is 1 -critical, ( 𝑛, 0 ) -local for some integer 𝑛 ≥ 0 , and closed under direct products.
Observe that for obtaining Theorem 1 it suffices to replace in Corollary 2 the property of ( 𝑛, 0 -locality for some integer ) 𝑛 ≥ 0 with the properties of domain independence, modularity, and closure under subdatabases. We proceed to show that this is indeed the case. But let us first state a simple fact that provides a useful characterization of the notion of ( 𝑛, 0 -local embeddability. )
Recall that, for a schema S and an integer 𝑚 ≥ 0, the 𝑚 -neighbourhood of an S -database 𝐷 ′′ in an S -database 𝐷 ′ with 𝐷 ′′ ⊆ 𝐷 ′ is the set of S -databases
$$\{ E \ | \ D ^ { \prime \prime } \subseteq E, \, E \leq D ^ { \prime } \text{ and } | \text{adom} ( E ) | \leq | \text{adom} ( D ^ { \prime \prime } ) | + m \}.$$
Note that if 𝐷 ′′ ⊆ 𝐸 , we have that adom ( 𝐷 ′′ ) ⊆ adom ( 𝐸 ) . Furthermore, if 𝐸 is in the 0-neighbourhood of 𝐷 ′′ in 𝐷 ′ , then | adom ( 𝐸 )| ≤ | adom ( 𝐷 ′′ )| , and thus, adom ( 𝐷 ′′ ) = adom ( 𝐸 ) . Since both 𝐷 ′′ and 𝐸 are contained in 𝐷 ′ , it follows that facts ( 𝐸 ) = facts ( 𝐷 ′ ↾ adom ( 𝐷 ′′ )) = facts ( 𝐷 ′′ ) , where 𝐷 ′ ↾ adom ( 𝐷 ′′ ) is the restriction of 𝐷 ′ over adom ( 𝐷 ′′ ) , that is, the database { 𝑅 𝑐 ( ¯ ) ∈ 𝐷 ′ | ¯ 𝑐 ∈ adom ( 𝐷 ′′ ) ar ( 𝑅 ) } . It follows that the 0-neighborhood of 𝐷 ′′ in 𝐷 ′ is the set of S -databases
{ 𝐸 | 𝐸 ⪯ 𝐷 ′ and facts ( 𝐸 ) = facts ( 𝐷 ′ ↾ adom ( 𝐷 ′′ )) = facts ( 𝐷 ′′ )} .
Characterizing Data Dependencies Then and Now
Consequently, we have that the following holds.
Lemma 10 Consider a collection 𝐶 of databases over a schema S . The following are equivalent:
- 1. An S -database 𝐷 is ( 𝑛, 0 ) -locally embeddable in 𝐶 .
- 2. For every 𝐸 ⪯ 𝐷 with adom ( 𝐸 ) = dom ( 𝐸 ) and | adom ( 𝐸 )| ≤ 𝑛 , there is an S -database 𝐷 𝐸 ∈ 𝐶 such that facts ( 𝐷 𝐸 ↾ adom ( 𝐸 )) = facts ( 𝐸 ) .
Byexploiting the above lemma, we can show that ( 𝑛, 0 -locality can be replaced by ) the properties of domain independence, modularity, and closure under subdatabases.
Proposition 1 Consider a collection 𝐶 of databases over a schema S and an integer 𝑛 ≥ 0 . The following statements are equivalent:
- 1. 𝐶 is ( 𝑛, 0 ) -local.
- 2. 𝐶 is domain independent, 𝑛 -modular, and closed under subdatabases.
Proof. Wefirst show the direction ( 1 ) ⇒ ( 2 . Since, by hypothesis, ) 𝐶 is ( 𝑛, 0 -local, ) Lemma 5 implies that 𝐶 is domain independent. To show that 𝐶 is 𝑛 -modular, let 𝐷 be an S -database such that every 𝐷 ′ ⪯ 𝐷 with dom ( 𝐷 ′ ) ≤ 𝑛 belongs to 𝐶 . We proceed to show that 𝐷 ∈ 𝐶 by showing that 𝐶 is ( 𝑛, 0 -locally embeddable ) in 𝐷 . This follows from Lemma 10 by taking 𝐷 𝐸 = 𝐷 ′ . Finally, to show that 𝐶 is closed under subdatabases, consider an arbitrary S -database 𝐷 ∈ 𝐶 and let 𝐷 ′ be a subdatabase of 𝐷 . We proceed to show that 𝐷 ′ ∈ 𝐶 by showing that 𝐶 is ( 𝑛, 0 -locally embeddable in ) 𝐷 ′ . The latter again follows from Lemma 10 by taking 𝐷 𝐸 = 𝐷 .
We now show ( 2 ) ⇒ ( 1 . Assume that ) 𝐶 is domain independent, 𝑛 -modular, and closed under subdatabases. We need to show that if 𝐶 is ( 𝑛, 0 -locally embeddable ) in an S -database 𝐷 , then 𝐷 ∈ 𝐶 . By Lemma 10, for every 𝐸 ⪯ 𝐷 with adom ( 𝐸 ) = dom ( 𝐸 ) and | adom ( 𝐸 )| ≤ 𝑛 , there is an S -database 𝐷 𝐸 ∈ 𝐶 such that facts ( 𝐷 𝐸 ↾ adom ( 𝐸 )) = facts ( 𝐸 ) . Since 𝐶 is closed under subdatabases, we have that 𝐷 𝐸 ↾ adom ( 𝐸 ) belongs to 𝐶 . Since 𝐶 is domain independent and facts ( 𝐷 𝐸 ↾ adom ( 𝐸 )) = facts ( 𝐸 ) , we get that 𝐸 ∈ 𝐶 . Thus, every subdatabase 𝐸 of 𝐷 with at most 𝑛 elements in its active domain is in 𝐶 . Since 𝐶 is 𝑛 -modular, it follows that 𝐷 is also in 𝐶 . ⊓ ⊔
Theorem 1 readily follows from Corollary 2 and Proposition 1.
## 5 Concluding Remarks
When J´ anos Makowsky retired as President of the European Association for Computer Science Logic (EACSL), he gave an invited address at the 2011 CSL conference in which he reflected on his experience in research [21]. In particular, he reflected on his work in database theory, highlighted the undecidability of the implication problem for EIDs, and concluded the section on his contributions to database theory by writing that 'After that I tried to learn the true problems of database theory.
However, J. Ullman changed his mind and declared that Dependency Theory and Design Theory had run their course. As a result, papers dealing with these topics were almost banned from the relevant conferences.' Here, Makowsky refers to Ullman's invited talk and paper, titled 'Database Theory: Past and Future', at the 1987 ACM Symposium on Principles of Database Systems (PODS) [28]. When it came to the past of dependency theory, Ullman stated that 'We quickly learned far more about the subject than was necessary, a process that continues to this day' and then, contemplating the future, he delegated dependency theory to the section titled 'Last Gasps of the Dying Swans'.
The pronouncement of the demise of dependency theory, however, turned out to be premature. Indeed, about a decade later, data dependencies found numerous uses in formalizing and analyzing data inter-operability tasks, such as data exchange and data integration (see, e.g., the surveys [16, 18] and the books [1, 17]). As a matter of fact, the study of data dependencies has enjoyed a renaissance that continues to date. In particular, tgds have been used to specify data transformation tasks (i.e., how data structured under one schema should be transformed into data structured under a different schema) and as building blocks of ontology languages [2, 5, 6]. In the case of data exchange and data integration, a subclass of tgds, called sourceto-target tgds (s-t tgds), has played a central role. These are the tgds of the form ∀ ∀ ¯ 𝑥 ¯ 𝑦 ( 𝜙 𝑥, 𝑦 ( ¯ ¯ ) → ∃ ¯ 𝑧𝜓 𝑥, 𝑧 ( ¯ ¯ )) , where all relations in 𝜙 𝑥, 𝑦 ( ¯ ¯ ) are from a source schema, while all relations in 𝜓 𝑥, 𝑧 ( ¯ ¯ ) are from a disjoint target schema. The study of s-t tgds led to the discovery of new structural properties for this class of tgds, the most prominent of which is the existence of universal solutions in data exchange [15]. In turn, this motivated the pursuit of characterizations of s-t tgds and of natural subclasses of them using structural properties relevant to data inter-operability, such as the existence of universal solutions and conjunctive query rewriting [26, 27]. And now we have come full circle with the structural characterizations of arbitrary tgds and egds discussed in this paper. In conclusion, J´ anos Makowsky's work on data dependencies was well ahead of its time.
## References
- 1. Marcelo Arenas, Pablo Barcel´ o, Leonid Libkin, and Filip Murlak. Foundations of Data Exchange . Cambridge University Press, 2014.
- 2. Jean-Franc ¸ois Baget, Michel Lecl` ere, Marie-Laure Mugnier, and Eric Salvat. On rules with existential variables: Walking the decidability line. Artif. Intell. , 175(9-10):1620-1654, 2011.
- 3. Catriel Beeri and Moshe Y. Vardi. The implication problem for data dependencies. In ICALP , pages 73-85, 1981.
- 4. Catriel Beeri and Moshe Y. Vardi. A proof procedure for data dependencies. J. ACM , 31(4):718-741, 1984.
- 5. Andrea Cal` ı, Georg Gottlob, and Thomas Lukasiewicz. A general datalog-based framework for tractable query answering over ontologies. J. Web Semant. , 14:57-83, 2012.
- 6. Andrea Cal` ı, Georg Gottlob, and Andreas Pieris. Towards more expressive ontology languages: The query answering problem. Artif. Intell. , 193:87-128, 2012.
- 7. Ashok K. Chandra, Harry R. Lewis, and Johann A. Makowsky. Embedded implicational dependencies and their inference problem. In STOC , pages 342-354, 1981.
- 8. Chen C. Chang and H. Jerome Keisler. Model theory, Third Edition , volume 73 of Studies in logic and the foundations of mathematics . 1992.
- 9. E. F. Codd. A relational model of data for large shared data banks. Commun. ACM , 13(6):377387, 1970.
- 10. E. F. Codd. Relational completeness of data base sublanguages. Research Report / RJ / IBM / San Jose, California , RJ987, 1972.
- 11. Edgar F Codd. Further normalization of the data base relational model. Data base systems , 6:33-64, 1972.
- 12. Marco Console, Phokion G. Kolaitis, and Andreas Pieris. Model-theoretic characterizations of rule-based ontologies. In PODS , pages 416-428, 2021.
- 13. Chris J. Date. Logic and Relational Theory . Technics Publications, 2020.
- 14. Ronald Fagin. Horn clauses and database dependencies. J. ACM , 29(4):952-985, 1982.
- 15. Ronald Fagin, Phokion G. Kolaitis, Ren´ ee J. Miller, and Lucian Popa. Data exchange: semantics and query answering. Theor. Comput. Sci. , 336(1):89-124, 2005.
- 16. Phokion G. Kolaitis. Schema mappings, data exchange, and metadata management. In PODS , pages 61-75, 2005.
- 17. Phokion G. Kolaitis, Maurizio Lenzerini, and Nicole Schweikardt, editors. Data Exchange, Integration, and Streams , volume 5 of Dagstuhl Follow-Ups . Schloss Dagstuhl - LeibnizZentrum f¨ ur Informatik, 2013.
- 18. Maurizio Lenzerini. Data integration: A theoretical perspective. In PODS , pages 233-246, 2002.
- 19. Per Lindstr¨m. On extensions of elementary logic. o Theoria , 35(1), 1969.
- 20. Johann A. Makowsky. Characterizing data base dependencies. In ICALP , pages 86-97, 1981.
- 21. Johann A. Makowsky. Model theory in computer science: My own recurrent themes. In CSL , pages 553-567, 2011.
- 22. Johann A. Makowsky and Moshe Y. Vardi. On the expressive power of data dependencies. Acta Informatica , 23(3):231-244, 1986.
- 23. John Charles Chenoweth McKinsey. The decision problem for some classes of sentences without quantifiers. The Journal of Symbolic Logic , 8(3):61-76, 1943.
- 24. Abraham Robinson. Introduction to model theory and to the metamathematics of algebra . North-Holland Publishing Company, Amsterdam, 1963.
- 25. Alfred Tarski. Some notions and methods on the borderline of algebra and metamathematics. In Proceedings of the International Congress of Mathematicians , volume 1, pages 705-720, 1950.
- 26. Balder ten Cate and Phokion G. Kolaitis. Structural characterizations of schema-mapping languages. In ICDT , pages 63-72, 2009.
- 27. Balder ten Cate and Phokion G. Kolaitis. Structural characterizations of schema-mapping languages. Commun. ACM , 53(1):101-110, 2010.
- 28. Jeffrey D. Ullman. Database theory: Past and future. In PODS , pages 1-10, 1987.
- 29. Mihalis Yannakakis and Christos H. Papadimitriou. Algebraic dependencies (extended abstract). In FOCS , pages 328-332, 1980.
- 30. Heng Zhang and Guifei Jiang. Characterizing the program expressive power of existential rule languages. In AAAI , pages 5950-5957, 2022.
- 31. Heng Zhang, Yan Zhang, and Guifei Jiang. Model-theoretic characterizations of existential rule languages. In IJCAI , 2020. | null | [
"Phokion G. Kolaitis",
"Andreas Pieris"
] | 2024-08-02T08:39:12+00:00 | 2024-08-02T08:39:12+00:00 | [
"cs.LO",
"cs.DB"
] | Characterizing Data Dependencies Then and Now | Data dependencies are integrity constraints that the data of interest must
obey. During the 1980s, Janos Makowsky made a number of contributions to the
study of data dependencies; in particular, he was the first researcher to
characterize data dependencies in terms of their structural properties. The
goal of this article is to first present an overview of Makowsky's work on
characterizing certain classes of data dependencies and then discuss recent
developments concerning characterizations of broader classes of data
dependencies. |
2408.01110v1 | ## Unraveling the hybrid origins of the X-ray non-thermal emission from IGR J17091-3624
Zikun Lin, 1,2 Yanan Wang, 1 Santiago del Palacio, 3 Mariano M´ endez, 4 Shuang-Nan Zhang, 5,2 Thomas D. Russell, 6 Long Ji, 7 Jin Zhang, 8 Liang Zhang, 5 Diego Altamirano, 9 and Jifeng Liu 1,2,10,11
- 1 Key Laboratory of Optical Astronomy, National Astronomical Observatories, Chinese Academy of Sciences, Beijing 100101, People's Republic of China
- 2 School of Astronomy and Space Sciences, University of Chinese Academy of Sciences, Beijing 100049, People's Republic of China 3 Department of Space, Earth and Environment, Chalmers University of Technology, SE-412 96 Gothenburg, Sweden.
4
Kapteyn Astronomical Institute, University of Groningen, PO Box 800, CH-9700 AV Groningen, the Netherlands
- 5 Key Laboratory of Particle Astrophysics, Institute of High Energy Physics, Chinese Academy of Sciences, 19B Yuquan Road, Beijing 100049, People's Republic of China
- 6
- School of Physics and Astronomy, Sun Yat-sen University, Zhuhai 519082, People's Republic of China
- INAF, Istituto di Astrofisica Spaziale e Fisica Cosmica, via Ugo la Malfa 153, 90146 Palermo, Italy 7
8
School of Physics, Beijing Institute of Technology, Beijing 100081, People's Republic of China
9
School of Physics and Astronomy, University of Southampton, Southampton, Hampshire SO17 1BJ, UK
- 10 Institute for Frontiers in Astronomy and Astrophysics, Beijing Normal University, Beijing 102206, People's Republic of China
- 11 New Cornerstone Science Laboratory, National Astronomical Observatories, Chinese Academy of Sciences, Beijing 100012, People's Republic of China
## ABSTRACT
We present a comprehensive study based on multi-wavelength observations from the NuSTAR , NICER , Swift , Fermi , NEOWISE , and ATCA telescopes during the 2022 outburst of the black hole X-ray binary IGR J17091-3624. Our investigation concentrates on the heartbeat-like variability in the X-ray emission, with the aim of using it as a tool to unravel the origin of the non-thermal emission during the heartbeat state. Through X-ray timing and spectral analysis, we observe that the heartbeatlike variability correlates with changes in the disk temperature, supporting the disk radiation pressure instability scenario. Moreover, in addition to a Comptonization component, our time-averaged and phase-resolved spectroscopy reveal the presence of a power-law component that varies independently from the disk component. Combined with the radio to X-ray spectral energy distribution fitting, our results suggest that the power-law component could originate from synchrotron self-Compton radiation in the jet, which requires a strong magnetic field of about B = (0 3-3 5) . . × 10 6 G. Additionally, assuming that IGR J17091-3624 and GRS 1915+105 share the same radio-X-ray correlation coefficient during both the hard and the heartbeat states, we obtain a distance of 13 7 . ± 2 3 kpc for IGR J17091-3624. .
Keywords: X-ray binary - Accretion, Jets
## 1. INTRODUCTION
Black hole X-ray binaries (BHXRBs) are a type of celestial systems that consist of a black hole in a close orbit, accreting material from its companion star, and show repeated outbursts with a cadence of years. During outbursts, the radiation of BHXRBs consists of thermal and/or non-thermal components. The thermal component is typically represented by a multi-color blackbody
Corresponding author: Yanan Wang emission, emanating from the accretion disk in the soft X-ray band (see e.g., Shakura & Sunyaev 1973). The non-thermal emissions in the X-ray band are particularly complex, primarily attributable to processes such as Comptonization and synchrotron radiation occurring in different regions, which make them as enduring enigmas in high-energy astrophysics (see e.g., Illarionov & Siuniaev 1975; Rybicki & Lightman 1979).
The non-thermal X-ray emission from BHXRBs has been generally believed to be dominated by a hot, optically thin electron gas cloud - commonly termed as the 'corona' - which undergoes inverse Compton scat-
tering with seed photons from the accretion disk, resulting in a (cutoff) power-law spectrum (see e.g., Sunyaev & Titarchuk 1980; Haardt & Maraschi 1993; Gilfanov 2010; Garc´ ıa et al. 2021, 2022). Photons reflecting back to the disk from the corona produce an iron K α emission line, peaking at 6.4-6.9 keV, which is broadened by Doppler and relativistic effects along with a Compton hump peaking around 10-30 keV (see e.g., Lightman & Rybicki 1980; Lightman et al. 1981; Fabian et al. 1989; Dauser et al. 2010; Garc´ ıa et al. 2014; Dauser et al. 2022). On the other hand, jets have been indicated to emit a broad spectrum ranging from radio to gamma rays through synchrotron and synchrotron selfCompton (SSC) radiation. The emission at high energies displays a power-law spectrum in the optically thin regime, represented as F ν ∝ ν α (see e.g., Marscher 1983; Sari et al. 1998; Sari & Esin 2001; Finke et al. 2008; Nakar & Piran 2011; Hoshino 2013; Ball et al. 2018). Despite numerous efforts, differentiating these emission regions between corona and jets using only Xray data has been unsuccessful (e.g., Heinz 2004; Markoff et al. 2005). However, more recent approaches using varied techniques, i.e. well defined optical/near-infrared jet emission and polarization measurement, have successfully demonstrated that non-thermal X-ray emission may sometimes originate from jets (e.g., Russell et al. 2010; Russell & Shahbaz 2014; Chattopadhyay et al. 2024). Furthermore, broadband spectral energy distribution (SED) fitting has emerged as an effective method for distinguishing non-thermal emissions. (e.g., Russell & Shahbaz 2014; Punsly 2011; Kantzas et al. 2021; Rodi et al. 2021).
Timing analysis, which involves studying the variability in the lightcurve across different energy bands, also aids in our understanding of the correlation between the disk, corona, and jet (e.g., Wang et al. 2021; M´ endez et al. 2022). As the jet moves perpendicularly away from the accretion disk with relativistic speed (e.g., Pushkarev et al. 2009, 2017; Tetarenko et al. 2017; Miller-Jones et al. 2019; Zdziarski et al. 2022), the scattering efficiency between disk photons and jet electrons significantly decreases compared with the disk and corona (e.g., Wilkins & Fabian 2012). Long-term variability (lasting hours to days) between the disk and jet could remain correlated (e.g., Fender et al. 2004; Vincentelli et al. 2023; You et al. 2023), but short-term oscillations (lasting several seconds) originating from the disk are expected to dilute during the propagation (e.g., Eikenberry et al. 1998). Thus, integrating timing analysis of short-term variability from the disk with broadband SED spectroscopy could elucidate the radiation mechanisms in BHXRBs.
Heartbeat variability in BHXRBs, characterized by quasi-periodic flares in X-ray emission, is suggested to stem from the radiation pressure instability of accretion disk (e.g., Janiuk et al. 2000; Nayakshin et al. 2000; Neilsen et al. 2011, 2012; Yan et al. 2017). Such a phenomenon is associated with a limit-cycle behavior in the accretion rate and disk surface density, resulting in a continuous evacuation and refilling of the inner accretion disk (e.g., Abramowicz et al. 1988; Belloni et al. 1997; Merloni & Nayakshin 2006; Pan et al. 2022). Currently, it has only been observed in two BHXRBs, GRS 1915+105 (hereafter, GRS 1915, Belloni et al. 1997; Neilsen et al. 2011) and IGR J17091-3624 (hereafter, IGR J17091, Altamirano et al. 2011; Court et al. 2017). Other types of accreting systems have also been observed to exhibit similar quasi-periodic flares, which are related to disk behaviors, such as the ultraluminous X-ray source, NGC 3621 (Motta et al. 2020), and one neutron star X-ray binary, Swift J1858.6-0814 (Vincentelli et al. 2023).
IGR J17091 is a galactic low-mass BHXRB discovered with INTEGRAL/IBIS in April 2003 (Kuulkers et al. 2003). Later on, IGR J17091 had experienced another four typical outbursts in 2007, 2011, 2016 and 2022 (Capitanio et al. 2009; Krimm et al. 2011; Miller et al. 2016, 2022). As a comparison to GRS 1915, IGR J17091 was assumed to emit close to the Eddington luminosity, which implied either the BH has mass < 3 M ⊙ or the system could be farther away than 20 kpc (Altamirano et al. 2011). In previous studies, ten classes of variability have been identified by Court et al. (2017) and Wang et al. (2024). Among them, two classes of the variability had been detected in the most recent outburst in 2022 (Wang et al. 2024). Moreover, this outburst has been detected in multi-wavelength from radio to Xray with the telescopes including ATCA, NEOWISE , Swift , Fermi , NICER and NuSTAR . Hence, the multiwavelength dataset of IGR J17091 makes it an ideal candidate for investigating the origin of the non-thermal emission in BHXRBs.
In this study, we present an analysis of the 2022 outburst of IGR J17091 using the telescopes outlined above. Our specific objectives include studying the properties of the heartbeat-like variability and constraining the origin of the non-thermal emission during the heartbeat state. Specifically, we describe the observation and data reduction procedures in Section 2, present the results of X-ray timing and spectral analysis, along with a multiwavelength SED analysis in Section 3, discuss the implications of our results in Section 4, and finally summarize in Section 5.
Table 1. Summary of the NuSTAR observations of IGR J17091.
| ObsID | Date | Start Time (MJD) | Exp. A (ks) | Exp. B (ks) | Count Rate A (ct s - 1 ) | Count Rate B (ct s - 1 ) |
|--------------------|------------|--------------------|---------------|---------------|----------------------------|----------------------------|
| 80702315002 | 2022-03-23 | 59661.2 | 14.8 | 15 | 84 . 7 | 77 . 7 |
| 80702315004 (NV-1) | 2022-03-26 | 59664.6 | 16.5 | 16.8 | 71 . 8 | 66 . 2 |
| 80702315006 (NV-2) | 2022-03-29 | 59668 | 11.9 | 11.3 | 95 . 1 | 87 . 8 |
| 80802321002 | 2022-04-21 | 59690.2 | 17.6 | 17.8 | 75 . 4 | 69 . 3 |
| 80802321003 (NV-3) | 2022-06-16 | 59746.5 | 16.1 | 16.8 | 69 . 6 | 63 . 8 |
| 80802321005 | 2022-07-31 | 59791.9 | 15.9 | 16.1 | 59 . 3 | 54 . 0 |
| 80801324002 | 2022-08-22 | 59813.1 | 27.6 | 27.8 | 38 . 8 | 35 . 9 |
| 80801324004 (NV-4) | 2022-08-25 | 59816.7 | 75.8 | 78.6 | 34 . 5 | 31 . 9 |
## 2. OBSERVATIONS AND DATA REDUCTION
which the background was estimated by the 3C50 tool (Remillard et al. 2022). The processing pipeline used the NICER CALDB Version xti20221001.
## 2.1. NuSTAR
During 2022, eight NuSTAR observations of IGR J17091 had been conducted (PI: J. Wang and J. Garcia). We conducted data processing using the NuSTAR Data Analysis Software (NUSTARDAS) version 1.9.7 with the Calibration Database version v20230420. We used the command nupipeline to calibrate the data with the arguments saamode=strict , tentacle=yes , and statusexpr=(STATUS==b0000xxx00xxxx000)&& (SHIELD==0) . We generated the source spectra and lightcurves for FPMA and FPMB in the energy range 3-50 keV, respectively, along with their corresponding response and ancillary response files, using the nuproducts task. The extraction of the source region is circled with a radius of 100 ′′ , where the center is set at the emission peak by the centroid task. The background region is chosen by placing a circular at the farthest corner of the image from the source center, with the same radius as the source region. For observation 80801324004, a portion of the region in the FPMA image is contaminated, though the contamination does not affect the source region. This contamination, however, could lead to an overestimation of the background. Since this issue did not appear in FPMB, we chose to use the background file from FPMB as the background for FPMA for spectral fitting.
## 2.2. NICER
We obtained a dataset comprising 175 observations from the NICER telescope, spanning from March 14 to October 12, 2022. Standard calibration procedures and screening using the nicerl2 task were applied to each observation. Subsequently, the lightcurves and spectra were generated with nicerl3-lc , and nicerl3-spect in
## 2.3. Swift
The Swift /BAT Daily lightcurves were directly downloaded from the Swift /BAT Hard X-ray Transient Monitor 1 (Krimm et al. 2013). The Swift -XRT lightcurves were generated by the online tools at UK Swift Science Data Centre 2 (Evans et al. 2007, 2009).
Regarding the Swift -UVOT observations, we combined their sky images and exposure maps using the uvotimsum task for each filter, and generated the count rates using the uvotsource task with the UVOT calibration 20220705. The source region was placed at the center of the X-ray emission region with a radius of 5 ′′ . We carefully avoided any nearby sources and selected three background regions, each with a radius of 10 ′′ . However, there is no significant source was detected, and we therefore set a 3σ photometry upper limit at the source region of IGR J17091.
## 2.4. Fermi
Following the official users' guide , 3 we performed a binned analysis using Fermitools 2.2.0 and the Pass 8 data covering MJD 59731-59832. We used the gtlike tool to conduct the spectral analysis, during which we fixed parameters to the 4FGL-DR4 catalog values, except for the normalization of sources within 3 degree from our target. In addition, since IGR J17091 is not in the 4FGL-DR4 catalog, we included it manually assuming a powerlaw spectrum with a photon
1 https://swift.gsfc.nasa.gov/results/transients/
2 https://www.swift.ac.uk/user objects/
3 https://fermi.gsfc.nasa.gov/ssc/data/analysis/scitools/ binned likelihood tutorial.html
Date in 2022
Figure 1. Top panel : The lightcurve of NICER during the 2022 outburst. The color bar represents the fractional rms (Vaughan et al. 2003) in the 1-10 keV band. Middle panel : The lightcurves of NuSTAR (magenta), Swift -XRT (green), and Swift -BAT (blue). The dashed vertical lines denote the observation times with ATCA. Bottom panel : The red circles and the cyan diamond represent the hardness ratio of NICER count rates in the 2-10 keV and the 1-2 keV, and with Swift in the BAT (15-50 keV) and XRT (0.3-10 keV), respectively.
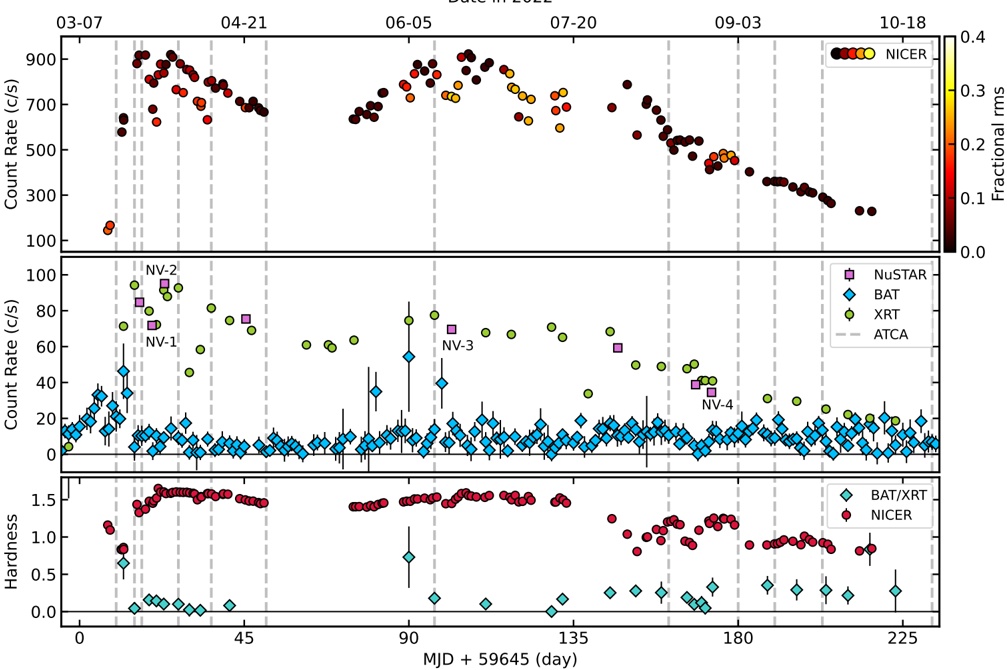
index of two. This resulted in a low TS value for IGR J17091, suggesting that it was not detected significantly. Then we estimated its 0.1-10 GeV flux upper limit F 0 1 . -10 GeV = 3 3 . × 10 -11 erg / cm 2 / s using the UpperLimits 4 tool assuming a 3σ confidence level.
2022 as the source and the images from 2019 to 2021, when the target was in quiescent state, as the background. Both of the images were selected within a circular region with a radius of 10 ′′ . Eventually, we derived the absorbed fluxes F w1 = 1 41 . ± 0 54 mJy and . F w2 = 0 68 . ± 0 59 mJy. .
## 2.5. NEOWISE
We searched for the NEOWISE archive data from 2022 for the infrared detection in the location of IRG J17091. The W1 and W2 images were downloaded from the NASA/IPAC Infrared Science Archive 5 (NEOWISE-R Team 2020). Unfortunately, our target was not significantly detected by NEOWISE in single visits. Hence, we stacked the images from August
4 https://fermi.gsfc.nasa.gov/ssc/data/analysis/scitools/ upper limits.html
5 https://irsa.ipac.caltech.edu/Missions/wise.html
Each X-ray spectral data were grouped using the grppha task from ftools package (Blackburn 1995) to achieve a minimum of 30 counts per bin, as the requirements for χ 2 statistics. In our SED analysis, we apply the Fitzpatrick (1999) dust extinction model with E(B -V) = 3 48 (Planck . Collaboration et al. 2016) from the infrared to UV band. We adopt the tbabs component to account for the interstellar absorption, using the abund wilm command to set the abundance table (Wilms et al. 2000) and xsect vern command to set the photoelectric cross sections (Verner et al. 1996). We fix the equivalent hydrogen column density at N H = 1 537 . × 10 22 cm -2 , as measured by the NICER ob-
Figure 2. Top panel : Normalized lightcurves of the four NuSTAR observations in FPMA (NV-1 in red, NV-2 in green, NV-3 in blue, and NV-4 in magenta). The normalization factor of count rate is shown in the top-left corner. Middle panel : The co-spectrum between FPMA and FPMB in the energy band 3-50keV. The black solid curve denotes the overall best fitting model, and each dashed curve corresponds to an individual Lorentz component. The vertical dashed line marks the centroid frequency ν c of the heartbeat-like variability. Bottom panel : The phase lag spectrum between 3-4 keV (reference band) and 7-10 keV. The black solid curve indicates the best fitting result of the constant time lag model (M´ndez et al. 2024). e
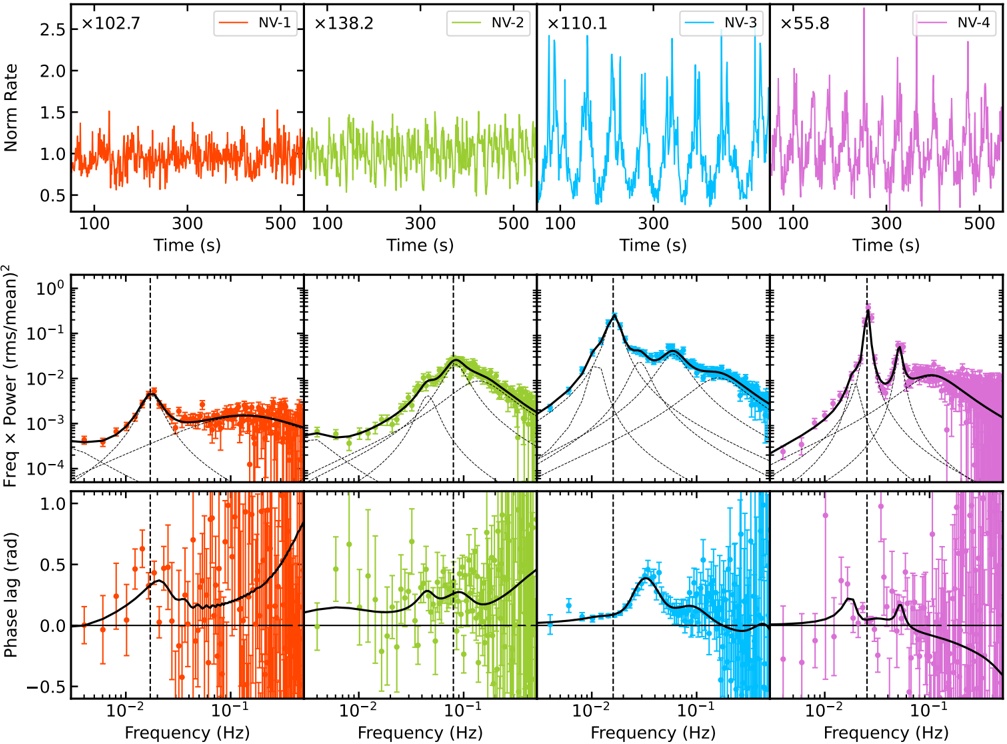
servations in 2022 (Wang et al. 2024). Unless explicitly mentioned, the uncertainties for each fitting parameter in this work were calculated at 1σ confidence level.
## 3. RESULT
## 3.1. Timing Analysis
3.1.1. Lightcurves
Fig. 1 shows the lightcurves of IGR J17091 in the studied period, as observed with NICER , NuSTAR , and Swift -XRT/BAT. We calculated the fractional rms (Vaughan et al. 2003) for the NICER 's daily light curve with a time bin of one second to provide a general evolution of the variability amplitude, which indicates an intermittent occurrence of variability. Additionally, we observed quasi-periodic variability from lightcurve in
NuSTAR observations ObsIDs 80702315004 (hereafter NV-1), 80702315006 (hereafter NV-2), and 80802321003 (hereafter NV-3). While during the two-day observation, ObsID. 80801324004 (hereafter NV-4), the variability was intermittent. Therefore, we only studied the observation segments of NV-4 where the variability persists for longer than 2000 seconds. In this work, we refer to the variability with a period of tens of seconds and time lag of seconds as 'heartbeat-like' variability (see Sect. 3.1.2 for more details).
3.1.2. Power spectrum and Cross spectrum
In our timing analysis, we used the AveragedPowerspectrum and AveragedCrossspectrum packages in
Table 2. Properties of the heartbeat-like variability derived from the cross spectrum.
| ObsID | Class | ν c (mHz) | ∆ ν (mHz) | rms (%) | Time lag a (s) |
|---------------------|---------|----------------|----------------|----------------|------------------|
| 80702315004 (NV-1) | - | 17 . 1 ± 0 . 3 | 7 . 1 ± 1 . 1 | 6 . 6 ± 0 . 3 | 3 . 7 ± 0 . 6 |
| 80702315006 (NV-2) | V | 79 . 8 ± 2 . 0 | 37 . 0 ± 7 . 9 | 15 . 7 ± 1 . 8 | 0 . 6 ± 0 . 1 |
| 80802321003 (NV-3) | X | 16 . 0 ± 0 . 2 | 4 . 1 ± 0 . 4 | 42 . 2 ± 1 . 7 | 0 . 9 ± 0 . 1 |
| 80801324004 (NV-4) | IV | 25 . 3 ± 0 . 2 | 1 . 1 ± 0 . 2 | 25 . 9 ± 1 . 7 | 0 . 3 ± 0 . 1 |
| 80802321003 (NV-3B) | - | 28 . 0 ± 0 . 5 | 11 . 8 ± 1 . 3 | 15 . 3 ± 1 . 3 | 2 . 9 ± 0 . 3 |
Note - : The time lag is calculated between 3-4 keV and 7-10 keV. A positive value means that high-energy photons arrive a after low-energy ones.
Figure 3. Upper panel : The rms spectra of NuSTAR data. The solid curve is the fundamental Lorentzian component, while the dashed, dark blue curve is the NV-3B. The open circles mark the 3σ upper limit, where the Lorentz component is not significantly required. Lower panel : The lag spectra of NuSTAR data. The inset plot in the lower-left corner provides a closer view along both the x- and y-axes.
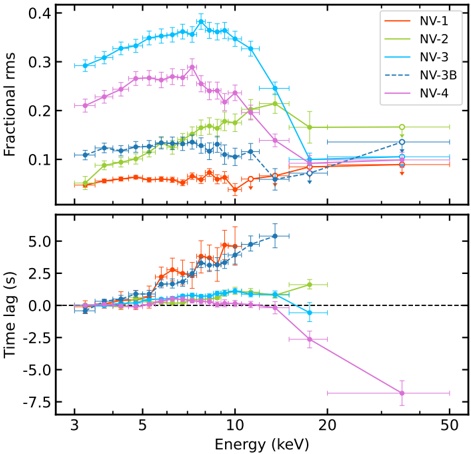
Stingray (Huppenkothen et al. 2019; Huppenkothen et al. 2019) to generate the average power/cross spectra (PS/CS) from the lightcurves. We used the real part of the CS as the co-spectrum (Bachetti et al. 2015). We applied logarithmic rebin with a factor of 0.01 and adopted the normalization with the fractional rms method (Belloni & Hasinger 1990). For the NuSTAR data, the co-spectrum was generated over an energy range of 3-50 keV between FPMA and FPMB, with a time step of δt = 0 1seconds . and a segment length of T = 500seconds. We further averaged the co-spectrum from each segment when there was no obvious shift in the frequencies of the main features of the co-spectrum. The shift confined within the full width at half maximum (FWHM), denoted as ∆ ν , is considered acceptable. To describe the co-spectrum, we used the ftflx2xsp 6 task in the ftools package (Blackburn 1995) to convert each co-spectrum data point into spectra and respose formats for fitting in xspec (Arnaud 1996). We fitted the co-spectrum by iteratively adding Lorentzian components until no prominent features remained in the residuals and the χ 2 value was not significantly further improved. However, we found that NV-4 exhibits a significant shift in ν c from 16 mHz to 27 mHz during the observation. Therefore, we included only the data for which the co-spectrum met the above criteria with no obvious shift in ν c , for the subsequent timing analysis. The Lorentzian component with the strongest power at ν c was identified as the fundamental component of heartbeat-like variability. The fractional rms of the Lorentzian component was calculated by taking the square root of the Lorentz normalization factor, and a correction was applied to obtain the intrinsic rms using Eq. (5) from Bachetti et al. (2015). The middle panels in Fig. 2 display the Lorentz fitting results of the co-spectrum in the 3-50 keV. The properties of the fundamental Lorentzian component are shown in Table 2. We also generated the PS from the NICER observations, where we noted that the heartbeat-like variability appears when the fractional rms is large, as shown in Fig. 1.
According to the definition of the variability classes in GRS 1915 and IGR J17091 by Belloni et al. (2000); Altamirano et al. (2011); Court et al. (2017), the heartbeat-like variability present in NV-2 and NV-4 cor-
6 https://heasarc.gsfc.nasa.gov/lheasoft/ftools/headas/ftflx2xsp. html
responds to Class V and IV (or Class ρ ), respectively. In addition, NV-3 is categorized as a new type of heartbeatlike variability, i.e., class X (Wang et al. 2024). The amplitude of the variability in NV-1 is too weak to be further identified.
To obtain the rms spectra for each observation, we generated lightcurves in smaller energy bands from the NuSTAR event file and constructed their co-spectrum between FPMA and FPMB. We linked ν c and ∆ ν of each Lorentzian component to the values derived in the full band co-spectrum, but let their Lorentzian normalization free to vary. At the energy band where the Lorentzian component was not significantly required, we provided a 3σ upper limit for its fractional rms. Regarding the lag spectra, we generated the CS/PS in the selected energy bands, where the Lorentzian component was significantly required, and used the 3-4 keV band as the reference band. We applied the constant time-lag model adopted from M´ endez et al. (2024) to jointly fit the PS, and the real and imaginary parts of the CS to determine the time lags.
We show the evolution of rms and time lag with energy in Fig. 3. The rms of NV-2, NV-3, and NV-4 share a similar trend: the rms increases with energy and then decreases after reaching an inflection energy, although the inflection energy differs among them. For NV-1, the rms spectrum remains nearly constant within the 3-10 keV band. The lag spectra in all observations show a positive (hard) lag of several seconds below 15 keV, while for NV-3 and NV-4, they change sign from positive to negative above 15 keV. Additionally, we detected a hump at ∼ 28 mHz in the lag spectrum of NV-3, which could be explained by a Lorentzian component at ν c = 28mHz in the co-spectrum of NV-3. To distinguish it from the fundamental heartbeat-like component, we define this component as NV-3B. This component exhibits different evolutionary patterns in both rms and lag spectra from NV-3, but it shares similarities with the variability in NV-1.
Overall, the heartbeat-like variability in the hard energy band (above 20 keV) has been observed to be either non-existent (for NV-1 to NV-3) or very weakly detected (for NV-4) compared to the soft energy band (below 20 keV). This possibly suggests an inefficient propagation between soft and hard photons.
## 3.2. Spectral Analysis
In the following, we conduct an analysis using average and phase-resolved spectra to further investigate the origin of the non-thermal X-ray emission.
3.2.1. Average spectra
Figure 4. The unfolded NuSTAR spectra for FPMA and the corresponding residuals. The colors are defined the same as in Fig. 2. The spectra of NV-1 and NV-3 overlap on the plot.
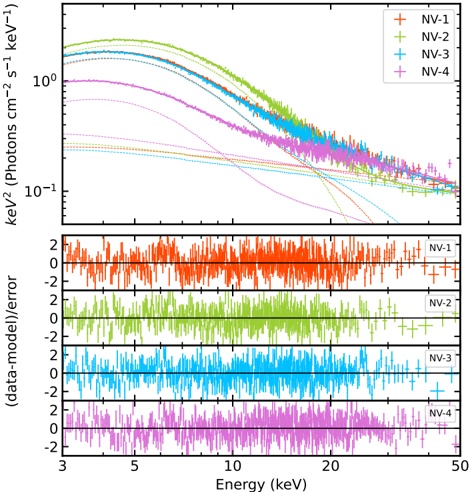
The spectra were analyzed using xspec version 12.12.1 (Arnaud 1996). We conducted spectral fitting for IGR J17091 using NuSTAR data in the energy range of 3-50 keV. We used an absorbed multi-color blackbody component diskbb (Mitsuda et al. 1984) convolved by a thcomp model (Zdziarski et al. 2020) to describe the disk emission and the inverse Compton scattering of the disk photons. We extended the energy range using the command energies 0.01 1000.0 1000 log . A multiplicative constant parameter was used to account for cross-normalization of the FPMA and FPMB instruments, where we fixed this to 1 for the FPMA and left it free for FPMB. The model is constant × tbabs × ( thcomp × diskbb ). However, despite the reduced χ 2 values ranging from 1.04 to 1.28, which appear marginally acceptable, there are still noticeable residuals in either the soft or the hard bands, as illustrated in the upper panels of Fig. 5. To improve the fit, we incorporated a powerlaw component, which reduced the χ 2 values to a range of 1.00 to 1.04 (see the lower panel of Fig. 5). We further ran F-test to examine the significance of this powerlaw component, and obtained a p-value less than 10 -5 . This confirms that the inclusion of the additional powerlaw component is indeed necessary. The overall model is tbabs × ( thcomp × diskbb + powerlaw ).
As the thcomp component is convolved with the diskbb component, it represents an inverse Comp-
Figure 5. Top panel : Residuals in FPMA from NuSTAR spectral fitting using the model: constant × tbabs × ( thcomp × diskbb ). The panels from left to right represent NV-1, NV-2, NV-3, and NV-4. The top-right value in each panel denotes the reduced χ 2 for each fit. Bottom panel : Residuals in FPMA from NuSTAR spectral fitting using the model: constant × tbabs × ( thcomp × diskbb + powerlaw ).
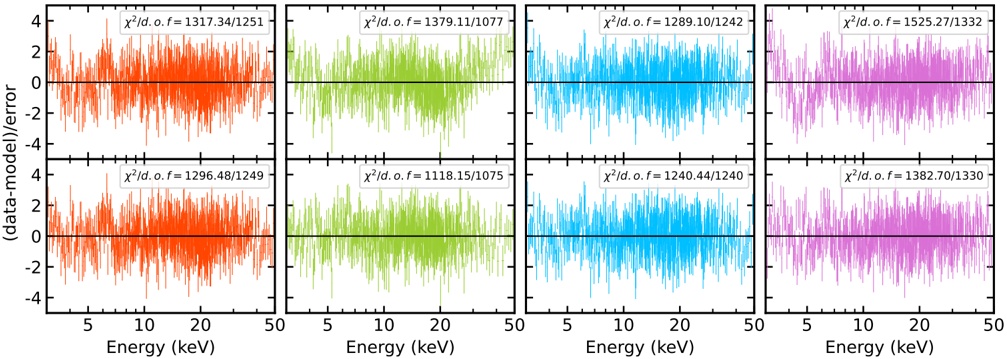
tonization process occurring in the corona. To investigate whether the powerlaw component is associated with the variability, we conducted phase-resolved spectroscopy.
## 3.2.2. Phase-resolved spectra
Due to the low rms amplitude and the high ∆ ν (see Table 2) of the variability in NV-1 and NV-2, it is difficult to accurately determine the variability profile from their lightcurves and hence the phase. Thus, we only did phase-resolved spectroscopy for NV-3 and NV-4. To eliminate the noise contribution to the heartbeat-like variability, we applied an optimal filtering algorithm to the fundamental Lorentz component of NV-3 and NV-4 (see Table 2) in the 3-50 keV lightcurve, as described by van den Eijnden et al. (2016). We then used the find peaks package from the scipy (Virtanen et al. 2020) library to identify dips within each sine-like pattern present in the filtered lightcurve. The nearest two dips were designated as phases ϕ = 0 and ϕ = 2 π . We finally folded the original lightcurve and assigned five phases accordingly.
that linking the powerlaw component and the electron temperature ( kT e ) in thcomp across different phases do not significantly affect the χ 2 values. Hence, we linked the powerlaw component and kT e among each phase. This approach resulted in a slight increase in the χ 2 , i.e. ∆ χ 2 = 25.0 for 15 additional degrees of freedom (dof) in NV-3 and ∆ χ 2 = 31.5 for 15 additional dof in NV-4. Thus, these results indicate that the powerlaw component and kT e in thcomp do not exhibit significant variations across different phases. Wealso calculated the flux for each component from the fits to both the average and the phase-resolved spectra with the command cflux .
We fitted the phase-resolved spectra with the same model as used for fitting the average spectra, i.e. constant × tbabs × ( thcomp × diskbb + powerlaw ). Due to the limitation of the statistics, we jointly fitted the average and the phase-resolved spectra for NV-3 and NV-4 to improve the constraints on the parameters. To examine the variation of each parameter across different phases, we linked each parameter and quantitatively assessed their respective changes by χ 2 values. We find
The best-fitting parameters of the average spectrum for each observation are presented in Table 3, and the corresponding spectra, as well as the residuals, are shown in Fig. 4. We observe a high disk temperature ( T in > 1 3 keV) and a low electron temperature of the . corona ( kT e < 10 keV) during the heartbeat-like variability. We show the best-fitting parameters derived from the phase-resolved spectroscopy as a function of phase in Figs. 6. The folded lightcurve of NV-3 presents a profile characterized by a rapid rise and slow decay, whereas NV-4 displays a slow rise and a rapid decay. In both NV-3 and NV-4, the evolution of the disk temperature aligns with the lightcurve profile. In addition, the flux difference between the peak and dip phases in diskbb is about five times greater than in thcomp , implying that the heartbeat-like variability is dominated by the accretion disk.
Figure 6. Best-fitting parameters from phase-resolved spectra of NV-3 and NV-4 using the model constant × tbabs × ( thcomp × diskbb + powerlaw ). The panels from top to bottom show: the normalized count rate, the disk temperature, the photon index of thcomp , the covering fraction, the unabsorbed flux of diskbb , and the unabsorbed flux of thcomp . The legend in the top-right corner shows the significance of parameter variations, assessed by allowing the parameters to vary freely and linking them across all phases using the F-test.
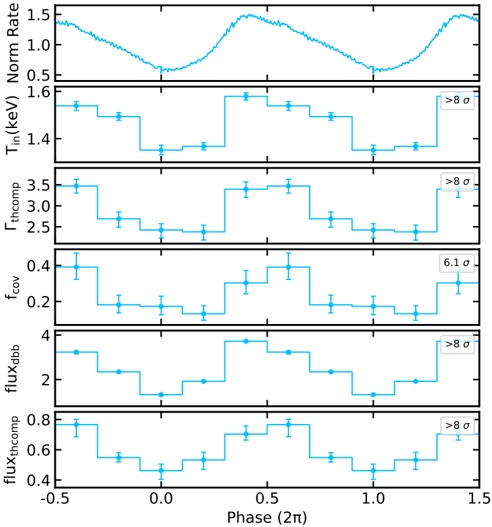
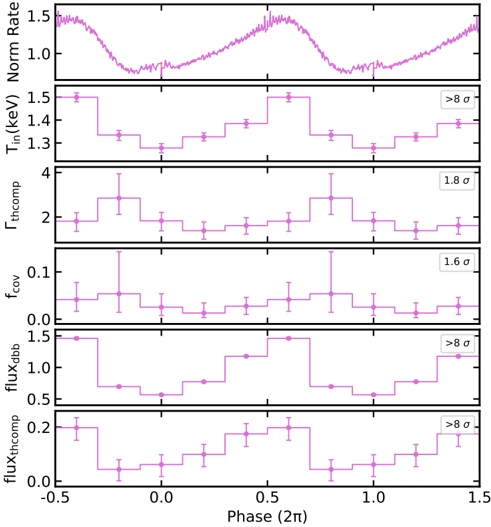
The results above suggest that at least part of the non-thermal emission, i.e. the powerlaw component, may not be associated with the thermally originated heartbeat-like variability, and hence not be attributed to the inverse Componization of the disk photons. To investigate whether this component could originate from jets, we conducted a broadband SED fitting spanning from radio to X-rays.
ATCA observed IGR J17091 several times in 2022 with the dates marked by the vertical dashed lines in Fig. 1. Only two of them, June 12 (Projects: C3456) and September 3, 2022 (Projects: CX501), were quasisimultaneously with our well-defined heartbeat-like variability in NV-3 and NV-4. According to the flux density measured by Russell et al. (in prep.), IGR J17091 was not detected on June 12, with 3σ upper limits of 126 µ Jy at 5.5 GHz and 106 µ Jy at 9 GHz. On the other hand, IGR J17091 was detected on September 3, with a flux density of 170 ± 35 µ Jy at 5.5 GHz and 151 ± 38 µ Jy at 9 GHz, respectively. The ATCA detection on September 3 was used in our SED fitting.
To extract the powerlaw component from the Xray spectrum, we subtracted the contribution from the thcomp × diskbb component from the NuSTAR data and divided it with tbabs , using the best-fitting param- eters from Table 3. Since we only fitted the continuous broadband spectrum, the NuSTAR data were further rebinned by a factor of 0.1 in logarithmic space. Moreover, due to the uncertainties in dust extinction and potential measurement bias in the infrared photometry, we excluded it from the SED analysis below. However, we used it together with the upper limits of the Swift -UVOT and Fermi data to evaluate the overall fit. We considered a leptonic jet model to fit and interpret the radio and X-ray data. For this, we used the open-source JetSeT 7 framework (Tramacere et al. 2009, 2011; Tramacere 2020), which includes the synchrotron and SSC processes.
In the adopted jet model, we considered a basic assumption of power-law energy distribution of relativistic electrons. This leads to eight parameters in the model: the minimum Lorentz factor, γ min , the minimum Lorentz factor, γ max , the spectral index of relativistic electrons distribution, p , the Doppler beaming factor, δ D , the magnetic field intensity B , the radius of
7 https://jetset.readthedocs.io/en/latest/
Table 3. Best-fitting parameters of the NuSTAR spectra of IGR J17091.
| Parameters | NuSTAR ObsID | NuSTAR ObsID | NuSTAR ObsID | NuSTAR ObsID |
|-----------------|-------------------------|-------------------------|--------------------------|--------------------------|
| | 80702315004 NV-1 | 80702315006 NV-2 | 80802321003 NV-3 a | 80801324004 NV-4 a |
| C b FPMB | 0 . 992 ± 0 . 001 | 0 . 988 ± 0 . 001 | 0 . 981 ± 0 . 001 | 0 . 987 ± 0 . 001 |
| N c H (cm - 2 ) | 1 . 537 × 10 22 | 1 . 537 × 10 22 | 1 . 537 × 10 22 | 1 . 537 × 10 22 |
| T in (keV) | 1 . 57 +0 . 04 - 0 . 03 | 1 . 70 +0 . 03 - 0 . 04 | 1 . 47 ± 0 . 01 | 1 . 38 ± 0 . 02 |
| N dbb | 41 . 2 +3 . 8 - 4 . 1 | 37 . 8 +3 . 1 - 2 . 3 | 52 . 6 +2 . 4 - 2 . 4 | 28 . 5 +2 . 0 - 1 . 7 |
| Γ thcomp | 1 . 7 +0 . 5 - 0 . 7 d | 1 . 3 +0 . 8 - 0 . 3 d | 2 . 9 +0 . 1 - 0 . 2 | 1 . 7 +0 . 3 - 0 . 4 |
| kT e (keV) | 3 . 8 +0 . 9 - 0 . 6 | 2 . 5 +0 . 3 - 0 . 1 | 9 . 4 +6 . 0 - 2 . 6 | 4 . 5 +1 . 2 - 0 . 6 |
| f cov | 0 . 05 +0 . 06 - 0 . 04 | 0 . 03 +0 . 14 - 0 . 02 | 0 . 3 ± 0 . 1 | 0 . 03 ± 0 . 02 |
| Γ pl | 2 . 3 ± 0 . 1 | 2 . 4 ± 0 . 1 | 2 . 4 ± 0 . 1 | 2 . 46 ± 0 . 01 |
| N pl | 0 . 4 ± 0 . 1 | 0 . 5 ± 0 . 1 | 0 . 4 ± 0 . 1 | 0 . 73 +0 . 04 - 0 . 05 |
| F e dbb | 2 . 55 +0 . 06 - 0 . 03 | 3 . 5 ± 0 . 1 | 2 . 40 +0 . 01 - 0 . 03 | 0 . 91 ± 0 . 01 |
| F e thcomp | 0 . 4 ± 0 . 1 | 0 . 6 ± 0 . 1 | 0 . 6 ± 0 . 1 | 0 . 13 +0 . 04 - 0 . 03 |
| F e pl | 0 . 86 ± 0 . 04 | 0 . 8 ± 0 . 1 | 0 . 7 +0 . 1 - 0 . 2 | 1 . 11 ± 0 . 04 |
| χ 2 /dof | 1296 . 5 / 1249 (1.04) | 1118 . 2 / 1075 (1.04) | 5126 . 6 / 5025 (1 . 02) | 5948 . 6 / 5832 (1 . 02) |
Note - : The results for NV-3 and NV-4 are obtained through the joint fitting of the average and phase-resolved spectra; a
- b : The constant parameter for FPMA is fixed at 1;
- c : N H is adopted from Wang et al. (2024);
- d : Γ th pegs at its hard limit of 1.001;
- e : The unabsorbed flux is in units of 10 -9 erg cm -2 s -1 .
the emitting blob, R , the total electron number density in the blob, N e , and the luminosity distance, D 8 .
The further setup for the model is as follows. Considering the previous measurements of the viewing angle, θ = 45 ◦ . 3 ± 0 ◦ . 7 (Wang et al. 2018) and θ = 24 ◦ ± 4 ◦ (Wang et al. 2024), which suggests a Doppler beaming factor δ D < . 2 5, we initially adopted the Doppler factor of δ D = 1. According to particle acceleration simulations (e.g. Sironi & Spitkovsky 2011, 2014), we chose γ min ≤ 100. Regarding γ max , previous studies suggest that jets can be efficient at accelerating particles to energies above 10 GeV in microquasars (e.g., Bosch-Ramon & Khangulyan 2009; Molina et al. 2019; Harvey et al.
8 The original parameter required by the JetSeT model is the cosmological redshift. We converted it to the luminosity distance here.
2022), and hence γ max = 10 5 is adopted. This enables the SED to extend up to energies of ≈ 50 GeV, within the Fermi range. The luminosity distance of IGR J17091 is still uncertain. Here, we adopted a luminosity distance of 13.7 kpc, estimated from the radio-X-ray relationship (see Sect. 4.3 for details). Ultimately, we are left with five free parameters for the fitting process: γ min , p , B , R , and N e .
Moreover, we used the Minuit ModelMinimizer (James & Roos 1975) option in JetSeT to provide initial values for the model parameters, and used the Monte Carlo Markov Chain (MCMC) ensemble sampler (ForemanMackey et al. 2013) to archive a robust fit. This involves initializing 50 walkers to solve the maximum likelihood solution and exploring the parameter space with 10 4 steps each. The parameter B R , , and N e were set in log-scale during the fitting.
Figure 7. Top panel: Absorbed SED fitted with a synchrotron model (case (a) in Sect. 3.2.3). The red region represents the total spectrum of the last 1,000 steps of MCMC walkers within the 1σ and 3σ confidence intervals. The solid line shows the best-fitting absorbed leptonic jet model, while the dashed line corresponds to the thcomp × diskbb model. The data points are from ATCA (cyan), NEOWISE (green), UVOT (orange), NuSTAR (blue), and Fermi -LAT (purple). The horizontal purple dashed line on the Fermi -LAT data represents the instrument's energy range. The broad gap from 10 15 Hz to 10 17 Hz is due to high extinction, and the unabsorbed leptonic jet model is plotted as the grey dash-dot line. Bottom panel: Residuals of the best-fitting model.
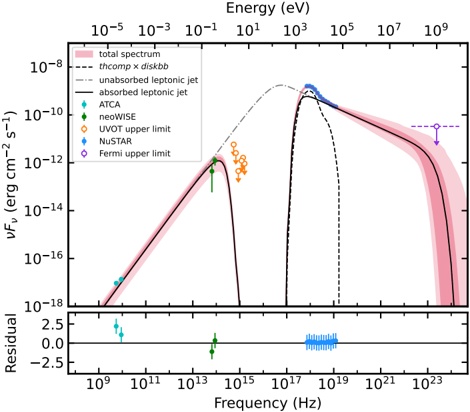
Upon the fit, we obtain p = 3 88 . ± 0 09, . consistent with the result shown in Table 3, where Γ po = ( p + 1) / 2. If further assuming that both radio and X-ray emissions originate from the same synchrotron process (referred to as case (a) subsequently), we constrain R > 10 12 cm and N < e 5 cm -3 , though both parameters are correlated as N R e 3 ≈ 1 2 . × 10 36 (shown in the cornerplot in Fig. A.1). The values of γ min and B are also related as B ≈ 4 5 . × 10 7 ( 10 γ min ) 2 G (also seen in Fig. A.1). As 1 1 . < γ min < 100, B would be in the range of 10 5 10 9 G. We show the best-fitting SED in Fig. 7 and the parameter distributions in the left panel of Fig. A.1.
However, this assumption results in a very large magnetic energy, E B ∼ B R / 2 3 6 > 3 × 10 46 -10 54 erg, which seems to be impractical in a BHXRB. This also leads to an extremely large ratio between the magnetic and electron energy densities, U B /U e > 10 10 . Overall, we exclude the possibility that both the radio and X-ray emissions observed in IGR J17091 originate from the same synchrotron process.
Figure 8. Absorbed SEDs and their residuals for cases (b) (top panel) and (c) (bottom panel) described in Sect. 3.2.3. The colors are the same as in Fig. 7.
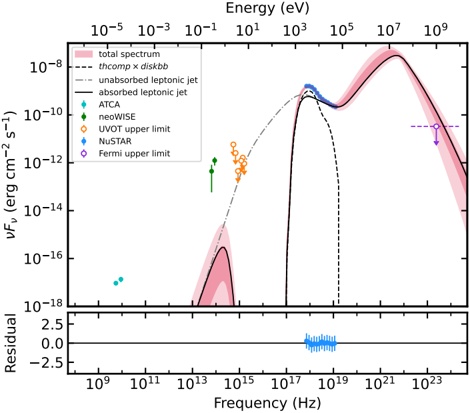
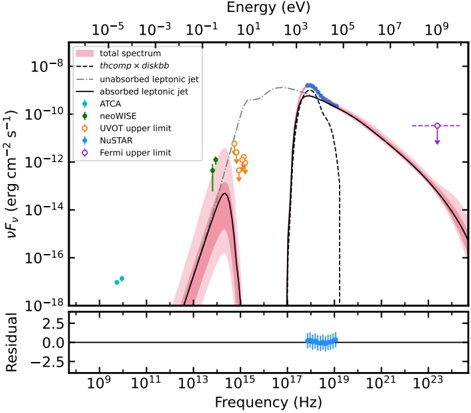
We then consider two other cases: (b) the X-ray emission is produced by synchrotron processes in a compact spherical blob, whereas the radio emission comes from a more expanding region, and (c) the same as above but the X-ray emission is from SSC. We note that these two possibilities would require a multi-zone jet model (e.g., Kaiser 2006; Kantzas et al. 2021; Lucchini et al. 2022; Tramacere et al. 2022), but for simplicity we neglect the fitting of the radio data which would constitute an upper limit to the compact blob emission, and focus only on the analysis of the high-energy emission within a one-zone approximation.
Here, we assume an energy equipartition condition, U B = U e . In this case, N e is calculated as follows:
$$N _ { e } = \frac { B ^ { 2 } } { 8 \pi m _ { e } c ^ { 2 } } \times \frac { ( \gamma _ { \max } ^ { 1 - p } - \gamma _ { \min } ^ { 1 - p } ) / ( 1 - p ) } { ( \gamma _ { \max } ^ { 2 - p } - \gamma _ { \min } ^ { 2 - p } ) / ( 2 - p ) }. \quad ( 1 )$$
The fitting allows for two sets of solutions, one with γ min > 50 that corresponds to case (b), and one with γ min < 10 that corresponds to case (c).
In case (b), the X-ray emission is dominated by synchrotron, while SSC dominates above 100 keV (see the upper panel of Fig. 8.). This fit then yields a gammaray flux of F 0 1 . -10 GeV = 2 5 . +0 7 . -0 8 . × 10 -9 erg cm -2 s -1 , significantly exceeding the Fermi upper limit of 3 3 . × 10 -11 erg cm -2 s -1 . Therefore, we disfavor this case.
In case (c), the X-ray emission should originate from SSC (see the lower panel of Fig. 8). The obtained bestfitting parameters are γ min < 6 4, . p = 4 3 . ± 0 2, . B = (0 3-3 5) . . × 10 6 G, and R = (0 1-2 5) . . × 10 8 cm, where the parameters B and R are actually correlated. Namely, the SSC flux is approximately ∝ BR -6 / p ( +5) (Shidatsu et al. 2011), leading to B ≈ 9 3 . × 10 10 R -0 65 . G (see the right panel of Fig. A.1). It is worth noting that variations in D (11-23 kpc) and δ D (1-2.5) do not alter our conclusions.
Overall, our results favor case (c), where the X-ray emission in the jet originates from the SSC process within a compact blob with a strong magnetic field, while the radio emission arises from a more expanding region distinct from the X-ray emitting region. A simple schematic of case (c) is provided in Fig. 9.
## 4. DISCUSSION
In this study, we undertake a comprehensive timing and spectral analysis of the heartbeat-like variability observed in IGR J17091 during the 2022 outburst. We employ this type of variability as an indirect method to differentiate the origins of non-thermal components emanating from the corona and jets. Our phase-resolved spectroscopy reveals the presence of a power-law component that remains uncorrelated with the heartbeat-like variability associated with the accretion disk. Here, we discuss the potential origins of this variability, the nature of the non-thermal components, and their broader implications.
## 4.1. The origin of the heartbeat-like variability
As mentioned in Section 3.1, at least three classes of heartbeat-like variability were detected in the four studied NuSTAR observations. These variabilities exhibit a similar evolutionary pattern in the rms spectrum, where the rms initially increases with energy and then decreases at higher energies. Although the inflection
Figure 9. Aschematic picture of the preferred case (c). The model consists of a multi-zone jet: around the base (the small purple region), the jet is optically thick at radio frequencies and the X-ray emission is produced via SSC; as the jet further expands, it becomes more transparent, eventually leading to the emergence of synchrotron radio emission (the large lightblue region).
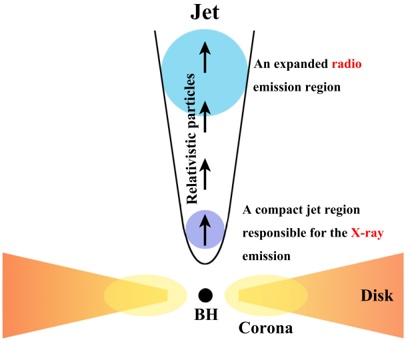
energy varies among observations, this value appears to correlate with the disk behavior; specifically, a higher disk temperature and a larger disk flux ratio correspond to a higher inflection energy (see Fig. 3 and Table 3). In the standard disk blackbody model, where the disk temperature ( T in ) is proportional to the inner disk radius ( R in ) raised to the power of -3/4 (e.g., Shakura & Sunyaev 1973; Makishima et al. 1986), fluctuations in R in lead to changes in T in . Consequently, this would result in a monotonic increase in the fractional rms with energy beyond T in . The observed decrease in fractional rms at higher energy bands suggests the presence of an additional component, which is more prominent in flux and acts to dilute the variability originating from the disk.
Moreover, the detected time lag between 3-4 keV and energies above 5 keV is up to several seconds. Such a lag is at least two orders of magnitude larger than those observed for low-frequency QPOs (e.g., Zhang et al. 2017, 2020; M´ endez et al. 2022; Nathan et al. 2022; Wang et al. 2022) and other types of variabilities at similar frequencies (e.g., Ma et al. 2021; Liu et al. 2022). Therefore, we can rule out the possibilities of geometry and intrinsic variability in the corona, light travel time between the disk and corona, and the inverse Compton scattering of disk photons in the corona (e.g., Zdziarski 1985; Miyamoto et al. 1988; Kara et al. 2019; Wang et al. 2022). However, the timescale of the lag is consistent
with the order of the viscous timescale for matter transfer in the inner region of the disk (e.g., Mir et al. 2016). Combined with the correlation between the disk temperature and the count rate (Fig. 6), all the evidence supports the heartbeat-like variability originating from radiation pressure instabilities in the accretion disk (e.g., Janiuk et al. 2000; Nayakshin et al. 2000; Done et al. 2007).
Regarding the new type variability, Class X, observed in NV-3, it actually exhibits a similar rms/lag evolution with that of Class IV in NV-4, but with higher rms below ∼ 15 keV. Its folded lightcurve presents a profile characterized by a rapid rise and slow decay, opposite to NV-4. Interestingly, we observed a significant signal (NV-3B) in its lag spectrum, corresponding to a much weaker Lorentzian component at ν c = 28 ± 0 5 mHz in . the CS (see the light blue data points in Fig. 2). Furthermore, the lag/rms spectrum of NV-3B evolves differently from that of its fundamental component, i.e., NV-3 (Fig. 3). All of these phenomena suggest that this additional variability may originate from a different emission region. However, further exploration is hindered by the nearby, dominant heartbeat-like variability in NV-3.
## 4.2. The origins of the non-thermal emission in XRBs
As discussed in Sect. 3.2.2, we observed a power-law component that is independent of the disk variability. Therefore, this component is unlikely driven by the inverse Compton scattering process between the disk photons and electrons in the corona. We therefore consider jets as the origin of the power-law component. In the jet, particles could move perpendicularly away from the accretion disk at relativistic speeds within a small solid angle (e.g., Pushkarev et al. 2009, 2017; Tetarenko et al. 2017; Miller-Jones et al. 2019; Zdziarski et al. 2022).This reduces the probability of particles in the jet scattering with disk photons, implying that photon propagation between the disk and jet is less efficient than between the disk and corona (e.g., Wilkins & Fabian 2012). This explains why the jet emission could vary independently from the disk emission in short timescales.
Furthermore, our multi-wavelength SED fitting also favors the jet origin, where the X-ray emission is dominated by SSC radiation. This requires a compact blob with a radius of R = (0 1-2 5) . . × 10 8 cm and a strong magnetic field of B = (0 3-3 5) . . × 10 6 G. This magnetic field strength is larger than those typically measured in most BHXRBs, which are generally on the order of 10 4 G, as seen in systems like GX 339-4 (Shidatsu et al. 2011), XTE J1550-564 (Chaty et al. 2011), MAXI J1836-194 (Russell et al. 2014), Cygnus X-1 (Zdziarski et al. 2014), and MAXI J1535-571 (Russell et al. 2020). However, studies of MAXI J1820+070 (Rodi et al. 2021; Echibur´-Trujillo u et al. 2024) and GRS 1915+105 (Punsly 2011) suggest that the launching region of the jet requires a magnetic field of B ∼ 10 5 10 7 G, which is consistent with our results.
It is important to note that the decoupling between inverse Compton scattering from the corona and synchrotron+SSC radiation in the jet is model-dependent. The alternative scenario, in which the non-thermal Xrays are dominated by inverse Compton scattering from the corona, cannot be ruled out. Related analyses supporting this perspective have been conducted by Draghis et al. (2023) and Wang et al. (2024).
## 4.3. Determining the distance to IGR J17091
Due to the unusual types of variability shared by GRS 1915 and IGR J17091, it has been argued that the latter is a faint version of the former, either ascribed to a large distance or a smaller BH mass (e.g., Altamirano et al. 2011; Wang et al. 2018). However, owing to the high extinction in front of IGR J17091, its precise location and hence the central black hole mass are uncertain.
The logarithmic-linear relation between radio and Xray emission has been verified in all types of accreting systems (e.g., Merloni et al. 2003; Corbel et al. 2013). GRS 1915 is situated in the top right corner, beyond both the standard and hybrid radio-X-ray correlations for galactic BHs. Due to its extra-long outburst spanning over 26 years (Neilsen et al. 2020), this deviation has been attributed to a high mass accretion rate in GRS 1915. While the similarities of GRS 1915 and IGR J17091 suggest that the two targets may share the same slope in the radio-X-ray fundamental plane.
We adopted the radio-X-ray fundamental plane for BHs from Bahramian & Rushton (2022) and plotted as grey dots in Fig. 10. Additionally, we added both the radio and X-ray luminosities in the hard and heartbeat states of GRS 1915 as blue filled and open dots to the figure. The data in the hard state of GRS 1915 were adopted from Rushton et al. (2010), while the radio data in heartbeat states were adopted from Klein-Wolt et al. (2002). Regarding the X-ray data in the heartbeat state, we fitted each available RXTE spectrum with the model tbabs × ( diskbb + powerlaw ) to calculate the X-ray flux in the 1-10 keV band. For IGR J17091, we adopted the radio and X-ray data in the hard state from Rodriguez et al. (2011); Gatuzz et al. (2020); Russell et al. (2022), while the data in the heartbeat state are from our study. To obtain the X-ray luminosities in the 1-10 keV band, we fitted the NICER spectra of IGR J17091 with the
Figure 10. Radio-X-ray correlation for BHs. The grey points represent the data in quiescent/hard states. The grey dashed line has a slope of ξ = 0 61 while . the green and orange dashed lines have a slope of ξ = 1 72. . The distance of IGR J17091 is assumed to be 13.7 kpc.
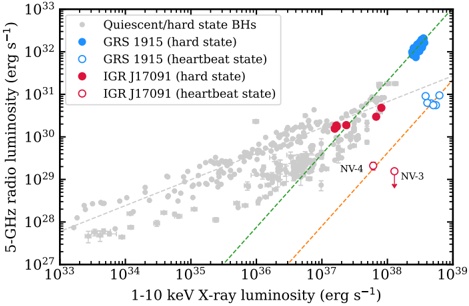
same model outlined above. The radio data are from the ATCA 5.5GHz band.
As the data in the heartbeat state of GRS 1915 are rather scattered, we only measured the radio/X-ray slope, ξ , in the hard state and obtained ξ = 1 72 . ± 0 13, . and assume that its heartbeat state shares the same slope as the hard state. The correlation track in the hard (green) and the heartbeat (orange) states of GRS 1915 is shown in Fig. 10. We then applied these two correlation track to the data in the hard and the heartbeat states of IGR J17091, respectively, and used the leastsquares method to estimate its distance. We derived D hard = 11 8 . +3 8 . -2 9 . kpc for the hard state and D HB = 15 1 . ± 2 8 kpc for . the heartbeat state. By incorporating these into a joint probability distribution, we obtained the best-fitting distance to IGR J17091 to be D = 13 7 . ± 2 3 kpc. . We adopt this distance to calculate the luminosity and plot the data of IGR J17091 as red dots in Fig. 10. However, the new type of variability, class X, in NV-3 deviates from this relationship. This suggests that the emergence of this new type may require additional physical conditions to be met for activation.
## 5. CONCLUSIONS
In this work, we use archival data from NuSTAR , NICER Swift , , Fermi , NEOWISE , and ATCA to study the origin of the non-thermal X-ray emission in the heartbeat state during the 2022 outburst of IGR J17091. We find that the short-term variability arising from the accretion disk plays a crucial role in assessing and decoupling the contributions of the corona and the jet in the X-ray band.
Regarding the newly identified type of variability, Class X, although it presents a lightcurve profile oppo- site to that of Class IV, both can be driven by radiation pressure instability in the accretion disk. Moreover, we observed a significant component in the lag-frequency spectrum of Class X. This component exhibits different evolutions in both the rms and lag energy spectra compared to Class X, suggesting it may involve a separate emission region contributing to another form of quasiperiodic variability in X-rays.
Moreover, we suggest the distance to IGR J17091 of D = 13 7 . ± 2 3 kpc by assuming it shares the same radio-. X-ray fundamental plane relationship as GRS 1915 during both the hard state and heartbeat states.
In X-ray timing and spectral analysis, we observe a power-law component that is independent of the heartbeat-like variability. Further quasi-simultaneous broadband SED analysis suggests that this power-law component in the X-ray can be explained by SSC radiation within a compact blob, sized of R = (0 1-. 2 5) . × 10 8 cm. This requires a strong magnetic field of B = (0 3-3 5) . . × 10 6 G. In this case, our SED fitting suggests that the radio emission originates from a different region than the X-ray jet, consistent with the multi-zone jet model (e.g., Kaiser 2006; Kantzas et al. 2021; Lucchini et al. 2022; Tramacere et al. 2022). However, the sparsity of our data makes a more detailed study of jet behavior difficult to establish.
Future simultaneous observations from infrared to radio bands are essential to refine our findings and further constrain the jet parameters (e.g., Rodi et al. 2021; Echibur´-Trujillo et al. 2024). u Observations at higher radio frequencies above 100 GHz (ALMA) can further constrain the spectral index of the radio spectrum and determine the cooling break of the synchrotron emission (e.g., Russell et al. 2014; Tetarenko et al. 2015), whereas high-sensitivity observations in the infrared (VLT and JWST ) can be used to solve the model degeneracy in the synchrotron component of the compact jet region (e.g., Rodi et al. 2021). Additionally, high-sensitivity radio observations below 1 GHz (MeerKAT and SKA) would help determine the transition frequency in the radio band between the optically thin synchrotron emission region and the synchrotron self-absorption region (e.g., Nakar & Piran 2011). These measurements can help constrain the multi-zone jet parameters and further establish the overall jet structure.
We thank Liang Chen, Defu Bu, Erlin Qiao, Shu Wang, and Zeyang Pan for the useful discussion, and Jakob van den Eijnden for the help with the optimal filtering algorithm. We thank the anonymous referee for the comments. This research was supported by the National Natural Science Foundation of China (NSFC) under grant numbers 11988101, 11933004, 12173103, and 12261141691; by the National Key Research and Development Program of China (NKRDPC) under grant numbers 2019YFA0405504 and 2019YFA0405000; and by the Strategic Priority Program of the Chinese Academy of Sciences under grant numbers XDB41000000 and XDB0550203. SdP gratefully acknowledges support from the ERC AdvancedGrant 789410.
## REFERENCES
| Abramowicz, M. A., Czerny, B., Lasota, J. P., & Szuszkiewicz, E. 1988, ApJ, 332, 646, doi: 10.1086/166683 |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Altamirano, D., Belloni, T., Linares, M., et al. 2011, ApJL, 742, L17, doi: 10.1088/2041-8205/742/2/L17 |
| Arnaud, K. A. 1996, in Astronomical Society of the Pacific Conference Series, Vol. 101, Astronomical Data Analysis Software and Systems V, ed. G. H. Jacoby & J. Barnes, |
| Bachetti, M., Harrison, F. A., Cook, R., et al. 2015, ApJ, 800, 109, doi: 10.1088/0004-637X/800/2/109 |
| bersavosh/XRB-LrLx pub: update 20220908, v220908, Zenodo, doi: 10.5281/zenodo.7059313 |
| Ball, D., Sironi, L., & ¨ Ozel, F. 2018, ApJ, 862, 80, doi: 10.3847/1538-4357/aac820 |
| Belloni, T., & Hasinger, G. 1990, A&A, 227, L33 |
| Belloni, T., Klein-Wolt, M., M´ndez, e M., van der Klis, M., |
| doi: 10.48550/arXiv.astro-ph/0001103 Belloni, T., M´ndez, e M., King, A. R., van der Klis, M., & van Paradijs, J. 1997, ApJL, 488, L109, |
| doi: 10.1086/310944 Blackburn, J. K. 1995, in Astronomical Society of the |
| Pacific Conference Series, Vol. 77, Astronomical Data Analysis Software and Systems IV, ed. R. A. Shaw, H. E. Payne, & J. J. E. Hayes, 367 |
| Bosch-Ramon, V., & Khangulyan, D. 2009, International Journal of Modern Physics D, 18, 347, doi: 10.1142/S0218271809014601 |
| Capitanio, F., Giroletti, M., Molina, M., et al. 2009, ApJ, |
| Chattopadhyay, T., Kumar, A., Rao, A. R., et al. 2024, ApJL, 960, L2, doi: 10.3847/2041-8213/ad118d |
|------------------------------------------------------------------------------------------------------------------------------|
| Chaty, S., Dubus, G., & Raichoor, A. 2011, A&A, 529, A3, doi: 10.1051/0004-6361/201015589 |
| Corbel, S., Coriat, M., Brocksopp, C., et al. 2013, MNRAS, 428, 2500, doi: 10.1093/mnras/sts215 |
| Court, J. M. C., Altamirano, D., Pereyra, M., et al. 2017, MNRAS, 468, 4748, doi: 10.1093/mnras/stx773 |
| Dauser, T., Garc´a, ı J. A., Joyce, A., et al. 2022, MNRAS, 514, 3965, doi: 10.1093/mnras/stac1593 |
| Dauser, T., Wilms, J., Reynolds, C. S., & Brenneman, L. W. 2010, MNRAS, 409, 1534, doi: 10.1111/j.1365-2966.2010.17393.x |
| Done, C., Gierli´ski, n M., & Kubota, A. 2007, A&A Rv, 15, 1, doi: 10.1007/s00159-007-0006-1 |
| Draghis, P. A., Miller, J. M., Costantini, E., et al. 2023, arXiv e-prints, arXiv:2311.16225, doi: 10.48550/arXiv.2311.16225 |
| Echibur´-Trujillo, u C., Tetarenko, A. J., Haggard, D., et al. 2024, ApJ, 962, 116, doi: 10.3847/1538-4357/ad1a10 |
| P. A., Beardmore, A. P., Page, K. L., et al. 2007, A&A, 469, 379, doi: 10.1051/0004-6361:20077530 2009, MNRAS, 397, 1177, |
| Evans, -. doi: 10.1111/j.1365-2966.2009.14913.x |
| Fabian, A. C., Rees, M. J., Stella, L., & White, N. E. 1989, MNRAS, 238, 729, doi: 10.1093/mnras/238.3.729 |
| Fender, R. P., Belloni, T. M., & Gallo, E. 2004, MNRAS, 355, 1105, doi: 10.1111/j.1365-2966.2004.08384.x |
| Finke, J. D., Dermer, C. D., & B¨ttcher, o M. 2008, ApJ, 686, 181, doi: 10.1086/590900 |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Fitzpatrick, E. L. 1999, PASP, 111, 63, doi: 10.1086/316293 Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, |
| J. 2013, PASP, 125, 306, doi: 10.1086/670067 Garc´a, ı F., Karpouzas, K., M´ndez, e M., et al. 2022, |
| MNRAS, 513, 4196, doi: 10.1093/mnras/stac1202 |
| Garc´a, ı F., M´ndez, e M., Karpouzas, K., et al. 2021, MNRAS, 501, 3173, doi: 10.1093/mnras/staa3944 Garc´a, ı J., Dauser, T., Lohfink, A., et al. 2014, ApJ, 782, |
| 76, doi: 10.1088/0004-637X/782/2/76 Gatuzz, E., D´az ı Trigo, M., Miller-Jones, J. C. A., & |
| Migliari, S. 2020, MNRAS, 491, 4857, doi: 10.1093/mnras/stz3385 |
| Gilfanov, M. 2010, in Lecture Notes in Physics, Berlin Springer Verlag, ed. T. Belloni, Vol. 794, 17, doi: 10.1007/978-3-540-76937-8 2 |
| Haardt, F., & Maraschi, L. 1993, ApJ, 413, 507, doi: 10.1086/173020 |
| Harvey, M., Rulten, C. B., & Chadwick, P. M. 2022, MNRAS, 512, 1141, doi: 10.1093/mnras/stac375 |
| Heinz, S. 2004, MNRAS, 355, 835, doi: 10.1111/j.1365-2966.2004.08361.x |
| Hoshino, M. 2013, ApJ, 773, 118, doi: 10.1088/0004-637X/773/2/118 |
| Huppenkothen, D., Bachetti, M., Stevens, A. L., et al. 2019, ApJ, 881, 39, doi: 10.3847/1538-4357/ab258d |
| Huppenkothen, D., Bachetti, M., Stevens, A., et al. 2019, Journal of Open Source Software, 4, 1393, doi: 10.21105/joss.01393 |
| Illarionov, A. F., & Siuniaev, R. A. 1975, Soviet Ast., 18, 413 |
| James, F., & Roos, M. 1975, Computer Physics Communications, 10, 343, doi: 10.1016/0010-4655(75)90039-9 |
| Janiuk, A., Czerny, B., & Siemiginowska, A. 2000, ApJL, 542, L33, doi: 10.1086/312911 |
| Kaiser, C. R. 2006, MNRAS, 367, 1083, doi: 10.1111/j.1365-2966.2006.10030.x |
| Kantzas, D., Markoff, S., Beuchert, T., et al. 2021, MNRAS, 500, 2112, doi: 10.1093/mnras/staa3349 |
| Kara, E., Steiner, J. F., Fabian, A. C., et al. 2019, Nature, 565, 198, doi: 10.1038/s41586-018-0803-x |
| Klein-Wolt, M., Fender, R. P., Pooley, G. G., et al. 2002, MNRAS, 331, 745, doi: 10.1046/j.1365-8711.2002.05223.x |
| Krimm, H. A., Barthelmy, S. D., Baumgartner, W., et al. 2011, The Astronomer's Telegram, 3144, 1 Krimm, H. A., Holland, S. T., Corbet, R. H. D., et al. 2013, |
| ApJS, 209, 14, doi: 10.1088/0067-0049/209/1/14 |
| Kuulkers, E., Lutovinov, A., Parmar, A., et al. 2003, The Astronomer's Telegram, 149, 1 |
|-------------------------------------------------------------------------------------------------------------------|
| Lightman, A. P., Lamb, D. Q., & Rybicki, G. B. 1981, ApJ, 248, 738, doi: 10.1086/159198 |
| Lightman, A. P., & Rybicki, G. B. 1980, ApJ, 236, 928, doi: 10.1086/157820 |
| Liu, Q., Wang, W., Chen, X., et al. 2022, MNRAS, 516, 5579, doi: 10.1093/mnras/stac2646 |
| Lucchini, M., Ceccobello, C., Markoff, S., et al. 2022, MNRAS, 517, 5853, doi: 10.1093/mnras/stac2904 |
| Ma, X., Tao, L., Zhang, S.-N., et al. 2021, Nature Astronomy, 5, 94, doi: 10.1038/s41550-020-1192-2 |
| Makishima, K., Maejima, Y., Mitsuda, K., et al. 1986, ApJ, 308, 635, doi: 10.1086/164534 |
| Markoff, S., Nowak, M. A., & Wilms, J. 2005, ApJ, 635, 1203, doi: 10.1086/497628 |
| Marscher, A. P. 1983, ApJ, 264, 296, doi: 10.1086/160597 |
| M´ndez, e M., Karpouzas, K., Garc´a, ı F., et al. 2022, Nature Astronomy, 6, 577, doi: 10.1038/s41550-022-01617-y |
| M´ndez, e M., Peirano, V., Garc´a, ı F., et al. 2024, MNRAS, 527, 9405, doi: 10.1093/mnras/stad3786 |
| Merloni, A., Heinz, S., & di Matteo, T. 2003, MNRAS, 345, 1057, doi: 10.1046/j.1365-2966.2003.07017.x |
| Merloni, A., & Nayakshin, S. 2006, MNRAS, 372, 728, doi: 10.1111/j.1365-2966.2006.10889.x |
| Miller, J. M., Draghis, P., Gendreau, K., & Arzoumanian, Z. 2022, The Astronomer's Telegram, 15282, 1 |
| Miller, J. M., Reynolds, M., Kennea, J., King, A. L., & Tomsick, J. 2016, The Astronomer's Telegram, 8742, 1 |
| Miller-Jones, J. C. A., Tetarenko, A. J., Sivakoff, G. R., et al. 2019, Nature, 569, 374, |
| doi: 10.1038/s41586-019-1152-0 M. H., Misra, R., Pahari, M., Iqbal, N., & Ahmad, |
| Mir, N. 2016, MNRAS, 457, 2999, doi: 10.1093/mnras/stw156 |
| Miyamoto, S., Kitamoto, S., Mitsuda, K., & Dotani, T. 1988, Nature, 336, 450, doi: 10.1038/336450a0 |
| Molina, E., del Palacio, S., & Bosch-Ramon, V. 2019, A&A, |
| 629, A129, doi: 10.1051/0004-6361/201935960 Motta, S. E., Marelli, M., Pintore, F., et al. 2020, ApJ, 898, |
| Nakar, E., & Piran, T. 2011, Nature, 478, 82, doi: 10.1038/nature10365 |
| Nathan, E., Ingram, A., Homan, J., et al. 2022, MNRAS, 511, 255, doi: 10.1093/mnras/stab3803 |
| Nayakshin, S., Rappaport, S., & Melia, F. 2000, ApJ, 535, 798, doi: 10.1086/308860 |
| Neilsen, J., Homan, J., Steiner, J. F., et al. 2020, ApJ, 902, |
| 152, doi: 10.3847/1538-4357/abb598 |
| Neilsen, J., Remillard, R. A., & Lee, J. C. 2011, ApJ, 737, 69, doi: 10.1088/0004-637X/737/2/69 -. 2012, ApJ, 750, 71, doi: 10.1088/0004-637X/750/1/71 NEOWISE-R Team. 2020, NEOWISE-R L1b Images, |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| IPAC, doi: 10.26131/IRSA147 Pan, X., Li, S.-L., Cao, X., Miniutti, G., & Gu, M. |
| 2022, ApJL, 928, L18, doi: 10.3847/2041-8213/ac5faf |
| Planck Collaboration, Aghanim, N., Ashdown, M., et al. 2016, A&A, 596, A109, doi: 10.1051/0004-6361/201629022 |
| Punsly, B. 2011, MNRAS, 418, 2736, doi: 10.1111/j.1365-2966.2011.19662.x |
| Pushkarev, A. B., Kovalev, Y. Y., Lister, M. L., & Savolainen, T. 2009, A&A, 507, L33, doi: 10.1051/0004-6361/200913422 -. 2017, MNRAS, 468, 4992, doi: 10.1093/mnras/stx854 |
| Remillard, R. A., Loewenstein, M., Steiner, J. F., et al. 2022, AJ, 163, 130, doi: 10.3847/1538-3881/ac4ae6 |
| Rodi, J., Tramacere, A., Onori, F., et al. 2021, ApJ, 910, 21, doi: 10.3847/1538-4357/abdfd0 |
| Rodriguez, J., Corbel, S., Caballero, I., et al. 2011, A&A, 533, L4, doi: 10.1051/0004-6361/201117511 |
| Rushton, A., Spencer, R., Fender, R., & Pooley, G. 2010, A&A, 524, A29, doi: 10.1051/0004-6361/201014929 |
| Russell, D. M., Maitra, D., Dunn, R. J. H., & Markoff, S. 2010, MNRAS, 405, 1759, doi: 10.1111/j.1365-2966.2010.16547.x |
| Russell, D. M., & Shahbaz, T. 2014, MNRAS, 438, 2083, doi: 10.1093/mnras/stt2330 |
| Russell, T., Del Santo, M., D'Ai, A., et al. 2022, The |
| Russell, T. D., Soria, R., Miller-Jones, J. C. A., et al. 2014, MNRAS, 439, 1390, doi: 10.1093/mnras/stt2498 |
| Russell, T. D., Lucchini, M., Tetarenko, A. J., et al. 2020, MNRAS, 498, 5772, doi: 10.1093/mnras/staa2650 |
| processes in astrophysics |
| Sari, R., & Esin, A. A. 2001, ApJ, 548, 787, doi: 10.1086/319003 |
| R., Piran, T., & Narayan, R. 1998, ApJL, 497, L17, |
| Shidatsu, M., Ueda, Y., Tazaki, F., et al. 2011, PASJ, 63, |
| S785, doi: 10.1093/pasj/63.sp3.S785 Sironi, L., & Spitkovsky, A. 2011, ApJ, 726, 75, |
| doi: 10.1088/0004-637X/726/2/75 -. 2014, ApJL, 783, L21, doi: 10.1088/2041-8205/783/1/L21 |
| R. A., & Titarchuk, L. G. 1980, A&A, 86, 121 |
| Sunyaev, |
| Astronomer's Telegram, 15286, 1 |
| G. B., & Lightman, A. P. 1979, Radiative |
| Rybicki, |
| Sari, doi: 10.1086/311269 N. I., & Sunyaev, R. A. 1973, A&A, 24, 337 |
| Shakura, |
| Tetarenko, A. J., Sivakoff, G. R., Miller-Jones, J. C. A., et al. 2015, ApJ, 805, 30, doi: 10.1088/0004-637X/805/1/30 -. 2017, MNRAS, 469, 3141, doi: 10.1093/mnras/stx1048 |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Tramacere, A. 2020, JetSeT: Numerical modeling and SED fitting tool for relativistic jets, Astrophysics Source Code Library, record ascl:2009.001 |
| Tramacere, A., Giommi, P., Perri, M., Verrecchia, F., & Tosti, G. 2009, A&A, 501, 879, doi: 10.1051/0004-6361/200810865 |
| Tramacere, A., Massaro, E., & Taylor, A. M. 2011, ApJ, 739, 66, doi: 10.1088/0004-637X/739/2/66 |
| Tramacere, A., Sliusar, V., Walter, R., Jurysek, J., & Balbo, M. 2022, A&A, 658, A173, doi: 10.1051/0004-6361/202142003 |
| van den Eijnden, J., Ingram, A., & Uttley, P. 2016, MNRAS, 458, 3655, doi: 10.1093/mnras/stw610 |
| Vaughan, S., Edelson, R., Warwick, R. S., & Uttley, P. 2003, MNRAS, 345, 1271, doi: 10.1046/j.1365-2966.2003.07042.x |
| Verner, D. A., Ferland, G. J., Korista, K. T., & Yakovlev, D. G. 1996, ApJ, 465, 487, doi: 10.1086/177435 |
| Vincentelli, F. M., Neilsen, J., Tetarenko, A. J., et al. 2023, Nature, 615, 45, doi: 10.1038/s41586-022-05648-3 |
| Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nature Methods, 17, 261, doi: 10.1038/s41592-019-0686-2 |
| Wang, J., Mastroserio, G., Kara, E., et al. 2021, ApJL, 910, L3, doi: 10.3847/2041-8213/abec79 |
| Wang, J., Kara, E., Lucchini, M., et al. 2022, ApJ, 930, 18, doi: 10.3847/1538-4357/ac6262 Wang, |
| J., Kara, E., Garc´a, ı J. A., et al. 2024, ApJ, 963, 14, doi: 10.3847/1538-4357/ad1595 |
| Wang, Y., M´ndez, e M., Altamirano, D., et al. 2018, MNRAS, 478, 4837, doi: 10.1093/mnras/sty1372 |
| Wilkins, D. R., & Fabian, A. C. 2012, MNRAS, 424, 1284, doi: 10.1111/j.1365-2966.2012.21308.x |
| Wilms, J., Allen, A., & McCray, R. 2000, ApJ, 542, 914, doi: 10.1086/317016 |
| Yan, S.-P., Ji, L., M´ndez, e M., et al. 2017, MNRAS, 465, 1926, doi: 10.1093/mnras/stw2916 |
| You, B., Cao, X., Yan, Z., et al. 2023, Science, 381, 961, doi: 10.1126/science.abo4504 |
| Zdziarski, A. A. 1985, ApJ, 289, 514, doi: 10.1086/162912 Zdziarski, A. A., Pjanka, P., Sikora, M., & Stawarz, glyph[suppress] L. 2014, MNRAS, 442, 3243, doi: 10.1093/mnras/stu1009 |
| Zdziarski, A. A., Szanecki, M., Poutanen, J., Gierli´ski, n M., & Biernacki, P. 2020, MNRAS, 492, 5234, doi: 10.1093/mnras/staa159 |
| Zdziarski, A. A., Tetarenko, A. J., & Sikora, M. 2022, ApJ, 925, 189, doi: 10.3847/1538-4357/ac38a9 |
Zhang, L., Wang, Y., M´ endez, M., et al. 2017, ApJ, 845, 143, doi: 10.3847/1538-4357/aa8138
Zhang, L., M´ endez, M., Altamirano, D., et al. 2020, MNRAS, 494, 1375, doi: 10.1093/mnras/staa797
## APPENDIX
## A. MCMC CORNER PLOTS OF SED FITTING
In this section, we present the corner plots of the SED fitting parameters from the MCMC for cases (a), (b), and (c) described in Sect. 3.2.3. These plots show the significant degeneracy between the fitting parameters.
Figure A.1. The corner plots of the SED fitting parameters, from left to right, correspond to cases (a), (b), and (c) described in Sect. 3.2.3. The contours contain the 1, 2, and 3σ confidence intervals respectively. The central orange line represents the median value of each parameter from the MCMC chain, with two black dashed lines on either side showing the 1σ confidence interval.
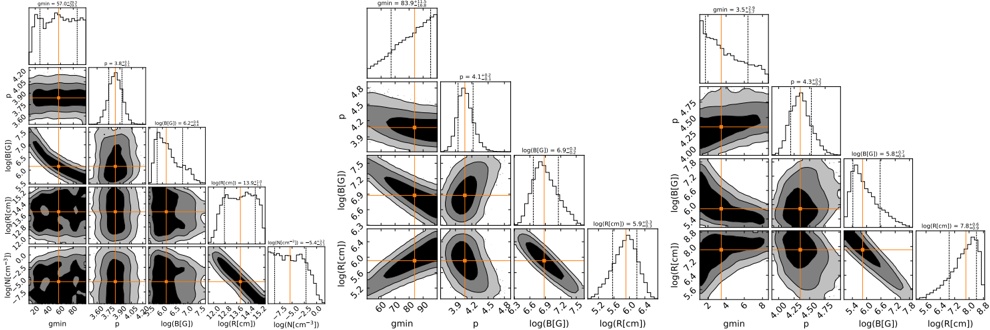 | null | [
"Zikun Lin",
"Yanan Wang",
"Santiago del Palacio",
"Mariano Méndez",
"Shuang-Nan Zhang",
"Thomas D. Russell",
"Long Ji",
"Jin Zhang",
"Liang Zhang",
"Diego Altamirano",
"Jifeng Liu"
] | 2024-08-02T08:39:40+00:00 | 2024-08-02T08:39:40+00:00 | [
"astro-ph.HE"
] | Unraveling the hybrid origins of the X-ray non-thermal emission from IGR J17091-3624 | We present a comprehensive study based on multi-wavelength observations from
the NuSTAR, NICER, Swift, Fermi, NEOWISE, and ATCA telescopes during the 2022
outburst of the black hole X-ray binary IGR J17091-3624. Our investigation
concentrates on the heartbeat-like variability in the X-ray emission, with the
aim of using it as a tool to unravel the origin of the non-thermal emission
during the heartbeat state. Through X-ray timing and spectral analysis, we
observe that the heartbeat-like variability correlates with changes in the disk
temperature, supporting the disk radiation pressure instability scenario.
Moreover, in addition to a Comptonization component, our time-averaged and
phase-resolved spectroscopy reveal the presence of a power-law component that
varies independently from the disk component. Combined with the radio to X-ray
spectral energy distribution fitting, our results suggest that the power-law
component could originate from synchrotron self-Compton radiation in the jet,
which requires a strong magnetic field of about $B = (0.3$-$3.5)\times10^6$ G.
Additionally, assuming that IGR J17091-3624 and GRS 1915+105 share the same
radio-X-ray correlation coefficient during both the hard and the heartbeat
states, we obtain a distance of $13.7\pm2.3$ kpc for IGR J17091-3624. |
2408.01111v1 | ## Ultra-steep slope cryogenic FETs based on bilayer graphene
E. Icking, 1, 2 D. Emmerich, 1, 2 K. Watanabe, 3 T. Taniguchi, 4
B. Beschoten, 1 M. C. Lemme, 5, 6 J. Knoch, 7 and C. Stampfer 1, 2
1 JARA-FIT and 2nd Institute of Physics, RWTH Aachen University, 52074 Aachen, Germany, EU
Peter Gr¨nberg Institute (PGI-9), Forschungszentrum J¨lich, 52425 J¨lich, Germany, EU
u
u
u
2
3 Research Center for Electronic and Optical Materials,
National Institute for Materials Science, 1-1 Namiki, Tsukuba 305-0044, Japan 4
Research Center for Materials Nanoarchitectonics,
National Institute for
Materials Science,
1-1 Namiki, Tsukuba 305-0044, Japan
7 IHT, RWTH Aachen University, 52074 Aachen, Germany, EU
5 Chair of Electronic Devices, RWTH Aachen University, 52074 Aachen, Germany, EU 6 AMO GmbH, 52074 Aachen, Germany, EU
Cryogenic field-effect transistors (FETs) offer great potential for a wide range of applications, the most notable example being classical control electronics for quantum information processors. In the latter context, on-chip FETs with low power consumption are a crucial requirement. This, in turn, requires operating voltages in the millivolt range, which are only achievable in devices with ultra-steep subthreshold slopes. However, in conventional cryogenic metal-oxide-semiconductor (MOS)FETs based on bulk material, the experimentally achieved inverse subthreshold slopes saturate around a few mV/dec due to disorder and charged defects at the MOS interface. FETs based on two-dimensional materials offer a promising alternative. Here, we show that FETs based on Bernal stacked bilayer graphene encapsulated in hexagonal boron nitride and graphite gates exhibit inverse subthreshold slopes of down to 250 µ V/dec at 0.1 K, approaching the Boltzmann limit. This result indicates an effective suppression of band tailing in van-der-Waals heterostructures without bulk interfaces, leading to superior device performance at cryogenic temperature.
Field-effect transistors operable at cryogenic temperatures are an ongoing area of research with potential applications in outer space electronic devices [1-5], semiconductor-superconducting coupled systems [6], scientific instruments such as infrared sensors [5, 7, 8], and notably control electronics in quantum computing [9-14]. The distinct advantages of operating at cryogenic temperatures include reduced power dissipation, minimized thermal noise, and faster signal transmission [1, 15, 16]. The significance of cryogenic control electronics is especially apparent in the context of quantum information processing, where the availability of control electronics in close proximity to the qubits is seen as a necessary condition for operating large quantum processors with thousands of qubits. [11, 14, 17-20]. However, developing cryogenic electronics for quantum computing applications poses significant challenges due to the limited cooling power of dilution refrigerators. One of the requirements is to reduce the operational voltage range of the FETs into the mV range [21], which, in turn, requires devices with ultra-steep subthreshold slopes. Temperature broadening effects impose a lower limit - the so-called Boltzmann limit - to the inverse subthreshold slope (SS) given by SS BL = k B T/e · ln(10), where T is the operating temperature and k B the Boltzmann constant. Thus the inverse SS is expected to decrease from 60 mV/dec at room temperature to as low as, e.g., 20 µ V/dec at 0.1 K. However, experiments with conventional FET devices optimized for low-temperature operation have shown that the inverse SS saturates at considerably higher values in the order of 10 mV/dec at cryogenic temperature [22-25]. This saturation originates mainly from static disorder at the metal-oxide-semiconductor (MOS) interface (due to, e.g., surface roughness, charged defects, etc.) [23-27]. This contributes to the formation of a finite density of states (DOS) near the band edges, which decays exponentially into the band gap [28]. This so-called bandtailing leads to deteriorated off-state behavior and limits the achievable SS. This effect is further enhanced by dopants, which could either freeze out or become partially ionized [21, 29]. Interface engineering can improve the MOS interface [30], but in MOSFETs based on bulk materials, inherent disorder at the interfaces and charged defects within bulk dielectrics cannot be fully eliminated.
FETs based entirely on van der Waals (vdW) materials are a promising alternative because these materials offer atomically clean interfaces, as there are no dangling bonds in the vertical direction. Particularly promising for cryogenic applications are vdW-heterostructures based on Bernal stacked bilayer graphene (BLG) [34]. Indeed, it has been shown that by encapsulating BLG into hexagonal boron nitride (hBN) and by placing it on graphite (Gr), it is possible to open a tunable, ultraclean, and spatially homogeneous band gap in BLG by applying an out-of-plane electric displacement field. [31, 35, 36]. Such BLG-based heterostructures can be seen as an electrostatically tunable semiconductor [32, 37, 38]. The high device quality allowed the realisation of BLG-based quantum point contacts [38, 39] and quantum dot devices [40-42]. Further incorporating graphite top gates (tg) instead of state-of-the-art gold top gates in the BLG heterostructures promises a further reduction of disorder as recent publications reported magnetic and
b
FIG. 1. a Schematic illustration of a bilayer graphene-based FET. In the active area of the device, the hBN-BLG-hBN heterostructure (see inset) is sandwiched between a top and bottom graphite gate. These gates allow for an independent tuning of the displacement field D and the effective gate voltage V g . The drain-source voltage V ds is applied symmetrically in all our measurements. b Resistance ( R = V ds /I d ) of the BLG as a function of V bg and V tg at T = 1 6 K and . V ds = 1 mV. The blue arrows indicate the directions of increasing displacement field D and V g . c Calculated band structure of BLG around one of the band minima for different displacement fields (see labels). d Differential conductance dI/dV ds as a function of V ds and V g (at T = 0 1 K) for different displacement fields (see labels in c). . The band gap E g can be extracted from the extension of the diamond along the V ds axis (see label). e Extracted E g as a function of | D/ε 0 | . The experimental data are in good agreement with theory calculated according to Ref. [31] using ε BLG = 1 (blue line) including an offset of 5 meV (grey dashed line). Note, that for the same displacement field, the achieved band gap is almost 20 meV higher compared to state-of-the-art BLG devices with gold top gates (open circles taken from Ref. [32]).
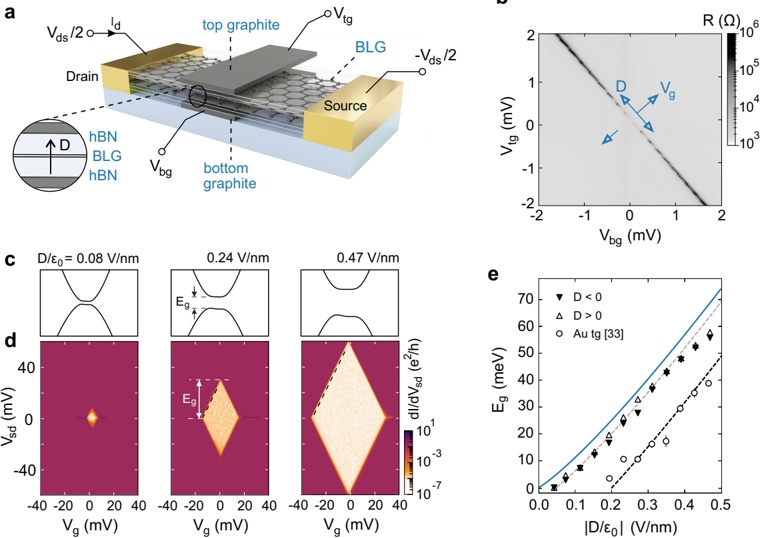
even superconducting phases hosted in the valence and conduction bands of BLG [43-45].
In this work, we demonstrate the enhanced device quality of dual graphite-gated BLG, evident in ultra-clean band gaps and ultra-small inverse subthreshold slopes, establishing vdW-material-based heterostructures as an ideal platform for cryogenic FETs. We use finite bias spectroscopy to show that the band gap tunability is enhanced in pure vdW BLG heterostructures with almost no residual disorder. By extracting the inverse subthreshold slopes, we obtain values as low as 250 µ V/dec at T = 0 1 K, which is only an order of . magnitude larger than the Boltzmann limit of 20 µ V/dec at this temperature. These results demonstrate the effective suppression of band tailing, leading to superior cryogenic device behavior of FETs based on vdW materials compared to conventional FETs.
The studied devices are fabricated by a standard dry van-der-Waals transfer technique [46, 47]. The process involves the sequential stacking of hBN, graphite and
BLG flakes produced by mechanical exfoliation [48]. First, a large hBN flake is selected to completely cover the top graphite gate, which is picked up in the second step. The (top) graphite gate is encapsulated in another hBN flake which acts as the top gate dielectric. We then pick up the BLG, a third hBN flake (bottom gate dielectric), and the bottom graphite gate and transfer the vdW heterostructure to a Si ++ /SiO 2 substrate. The exact thicknesses of the used hBN dielectric layers (mainly ≈ 20 nm) can be found in the Supp. Mat. Tab. S1. Complete encapsulation of the BLG in hBN is essential to prevent degradation and short circuits to the graphite gates. One-dimensional side contacts are then fabricated using electron-beam lithography, CF -based reactive 4 ion etching and metal evaporation followed by lift-off [46]. A schematic of the final device, including the gating and contacting scheme, is shown in Fig. 1a (an optical image can be found in the Supp. Mat. Fig. S1). If not stated otherwise, all measurements were performed at T = 0 1 K in a dilution refrigerator . with a two-terminal configuration, where we applied the
FIG. 2. a,b Drain current as a function of V g for four different displacement fields (see different colors and labels in panel b) near the valence band edge (panel a) and the conduction band edge (panel b). The gate leakage current is shown as the gray trace exemplarily for D/ε 0 = 470mV/nm (see also Supp. Mat. Fig. S3). Measurements were taken at V ds = 0 1 mV . and T = 0 1 K. . c Extracted minimal subthreshold slope as a function of the displacement field for both, the valence (black) and conduction (blue) band edges. The black-filled circles and blue circles correspond to data directly extracted from the measurements shown in panels a and b (see black dashed lines), respectively. The upwards-pointing triangles are extracted from similar measurements at slightly higher V ds ≈ 0 5 mV. Both measurements result in values around 0.3 mV/dec at the . valence band edge. At the conduction band edge the SS min values show an increase with increasing D . Downwards-pointing triangles denote SS extracted for negative displacement fields. The gray symbols represent the SS extracted from two devices with a gold top gate at the valence band edge (cross: 1st device measured at 50 mK, gray upwards-pointing triangles: 2nd device measured at 1.5 K). d Calculated band structure for different onsite potential differences ∆ between the BLG layers. ∆ k x represents the momentum relative to the K and K' points. Due to trigonal warping effects [33], the bands show an asymmetric deformation if a band gap is present. With increasing onsite potential difference, the asymmetry of the deformation increases, indicating a possible origin of the asymmetry in subthreshold slope values.
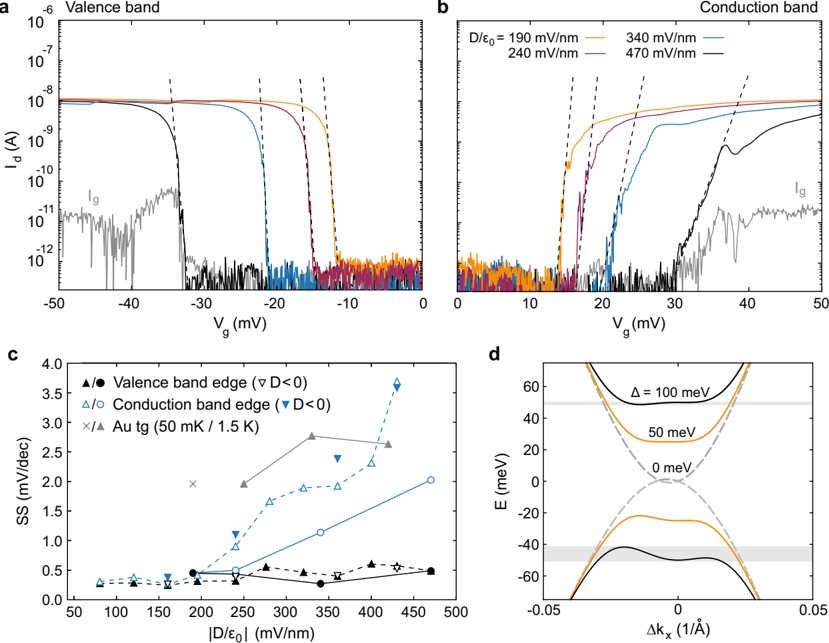
drain-source voltage symmetrically (for more information on the measurement setup, see Ref. [32]).
As a first electrical characterization, we measure the drain current I d as a function of top and bottom gate voltage by applying a small drain-source voltage V ds = 100 µ V. Fig. 1b shows the resulting map of the BLG resistance R = V ds /I d . Here, we observe a diagonal feature of increased resistance with a slope β = 1 22, . which gives us directly the relative gate lever arm β = α bg /α tg , where α bg and α tg denote the gate lever-arms of the top and bottom gate and can be extracted from quantum Hall measurements [4951] (for more information, see Supp. Mat.). The increasing width of the region of maximum resistance with increasing gate voltages is direct evidence for the formation and tuning of the BLG band gap with increasing out-of-plane displacement field D (see also band structure calculations in Fig. 1c). The displacement field in the dual-gated BLG-based vdW heterostructure is given by D = eα tg [ β ( V bg -V 0 bg ) -( V tg -V 0 tg ) ] / 2, and the effective gate voltage is given by V g = [ β ( V bg -V 0 bg ) + ( V tg -V 0 tg ) ] / (1 + β ), which tunes the electrochemical potential in the band gap of the BLG, µ ≈ eV g [32]. Here, ε 0 is the vacuum permittivity, and the parameters V 0 tg and V 0 bg account for the offsets of the charge neutrality point from V tg = V bg = 0.
FIG. 3. a,b Drain current as a function of V g at the valence band edge for different applied drain-source voltages V ds at a fixed displacement field D/ε 0 ≈ 0 24 V/nm. . The data shown in panel a were taken in a dilution refrigerator at T = 0 1 K, while . those presented in panel b were taken in a pumped 4 He cryostat at T = 1 5 K. The first setup limits the on-current to roughly . 10 -8 A. The second system allows higher on-currents of 1 µ A. However, we observe a higher noise level resulting in a slightly increased off-current.
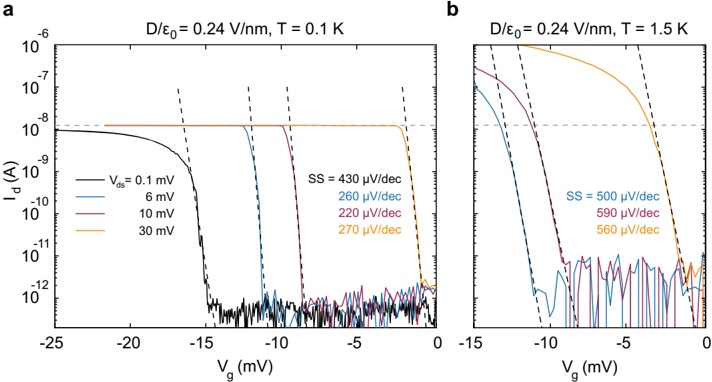
To study the band gap opening in our devices as a function of the displacement field D , we perform finite bias spectroscopy measurements and investigate the differential conductance dI/dV ds as a function of the effective gating potential V g and the applied drain-source voltage V ds for different fixed displacement fields D , see Fig. 1d. A distinct diamond-shaped region of suppressed conductance emerges, which has a high degree of symmetry and sharp edges and scales well with the applied displacement field. The outlines of the diamonds (black dashed lines in Fig. 1d) show a slope of ≈ 2, highlighting that V g directly tunes the electrochemical potential µ within the band gap and indicating that the band gap is as good as free of any trap states [32]. In the Supp. Mat. we show that the slope of the diamond outlines is indeed constant ( ≈ 2) for all displacement fields D /greaterorsimilar 0 2 V/nm. .
From the extension of the diamonds on the V ds axis, we can directly extract the size of the band gap E g [32], which are shown in Fig. 1e for positive (filled triangles) and negative displacement fields (empty triangles). They agree reasonably well with the theoretical prediction assuming an effective dielectric constant of BLG of ε BLG = 1 (blue line, for more information, see Supp. Mat.) except for a small offset of 5 meV (gray dashed line), which might be due to some residual disorder or interaction effects. Measurements on a second graphite top-gated device reveal the same behavior (see Supp. Mat. Fig. S8).
In Fig. 1e we also report the results of measurements performed on a similar BLG device but with the top gate made of gold instead of graphite (see Ref. [32]). It is noteworthy that the extracted band gap for the device with graphite gates is almost 20 meV higher than that extracted for the device with a gold top gate for the same displacement fields, highlighting the importance of clean vdW-interfaces. Furthermore, the observed extracted band gap E g persists down to lower displacement fields D/ε 0 ≈ 50 mV/nm compared to devices with a gold top gate.
The high tuning efficiency of the band gap in graphite dual-gated BLG combined with the high symmetry of the diamonds from the bias spectroscopy measurements demonstrates that BLG heterostructures built entirely from vdW materials, including top and bottom gates, outperform BLG devices with non-vdW materials thanks to much cleaner interfaces, allowing them to achieve unprecedented levels of device quality.
The finite bias spectroscopy measurements show that the edges of the diamonds are sharply defined, which promises excellent switching efficiency of FETs based on dual graphite-gated BLG when using V g as the tuning parameter. To extract the inverse subthreshold slope, we measure the drain current I d as a function of V g for fixed D -field and V ds ≈ 0 1 mV at both band . edges, see Figs. 2a and 2b. From the linear fits of the slopes (black dashed lines), we extract the inverse subthreshold slope SS = ( ∂ (log 10 ( I d ) /∂V g ) -1 . The resulting values for the valence and conduction band are plotted in Fig. 2c.
At the valence band edge, we extract record low values of SS ≈ 270 - 500 µ V/dec, roughly one order of magnitude above the Boltzmann limit SS BL (0.1 K) = 20 µ V/dec. For comparison, the saturation limit of conventional FETs based on non-vdW materials at T ≈ 0.1 K is
in the order of a few mV/dec [25]. We repeat similar measurements for slightly higher drain-source voltages V ds ≈ 0 5 mV. The results are also shown in Fig. 2c as . upwards-pointing triangles. They agree overall with the values from the measurements at V ds = 0 1mV, with . inverse subthreshold slopes at the valence band around SS ≈ 250 to 500 µ V/dec. The very low SS value indicates that band tailing is suppressed for devices with only vdW interfaces. This is also supported by the fact that samples with a gold top gate (i.e. an interface between a vdW and a bulk material) show significantly higher SS values for comparable D -fields at the valence band edge (see the cross and gray upward-pointing triangles in Fig. 2c).
It is remarkable to observe that while the SS extracted at the valence band edge does not show a significant dependency on the applied displacement field D , while the values extracted at the conduction band edge show a considerable increase from SS ≈ 500 µ V/dec up to SS ≈ 2 8 mV/dec . with increasing D . This displacement field-dependent asymmetry of the SS values is related to the electron-hole asymmetry of the BLG band structure. In principle, this asymmetry could also be due to a top-bottom asymmetry of (weak) interface disorder in the vdW heterostructure, since transport near the band edges is dominated by orbitals in only one of the two graphene layers. For example, for a positive D -field, transport at the conductance (valence) band edge is carried only by the top (bottom) layer of the BLG [32]. Changing the D -field direction reverses the band-edge to layer assignment. This allows us to experimentally exclude such a possible non-uniformity of the interface disorder, as we observe the same asymmetry in the SS values for the conductance and valence band edge also for negative D -fields (see downward pointing triangles in Fig. 2c), in good agreement with the values for positive D -fields, thus strongly emphasizing the importance of the asymmetry in the BLG band structure. In Fig. 2d we show the calculated band structure as a function of the onsite potential difference between the layers ∆( D ), which can be directly tuned with the applied displacement field D (for more information on the calculations, see Supp. Mat.). With increasing ∆( D ), the bands undergo an increasingly asymmetric deformation due to the trigonal-warping effect [33, 52]. As a consequence, the bands change from a hyperbolic shape at low ∆( D ) to an asymmetric Mexican-hat shape for high ∆( D ) [31], see Fig. 2d. With increasing band deformation, parts of the bands close to the K and K ′ points of the Brillouin zone become flat. Recent studies have shown that these flat bands give rise to a rich phase diagram in BLG, where magnetic and superconducting phases emerge [43-45]. The emerging phases could act phenomenologically similar to the interface-induced disorder, resulting in effective tail states at the band edges and degradation of the SS. The flat parts of the bands are right at the conduction band edge, but slightly deeper in the valence band: for example, for ∆ = 100 meV in
Fig. 2d, the local valence band maximum is much more pronounced than the local conduction band minimum (see grey shaded areas). Consequently, the resulting phase diagrams also exhibit an asymmetry similar to our SS values [45], which suggests that the asymmetric band deformation could cause the SS asymmetry in our measurements. We observed the same behavior for a second device, although at slightly different D -fields (see Supp. Mat. Fig. S9), most likely due to sample-to-sample variations. Regardless, we would like to emphasize that this consistent asymmetry is in itself an indicator of the overall low disorder in our devices.
While our device presents excellent SS values, the measured on-off ratio in Fig. 2a and b is only about 10 4 to 10 , 5 which is a direct consequence of the low on-current of about I d ≈ 10 -8 A. This low current level is partially due to the small size of the device contacts, which are circularly etched vias through the hBN, with a diameter of just 1 µ m. However, it is mainly because the measured current is limited by our measurement setup, which is optimized for low-noise, small-current measurements but also imposes a sharp limit of about 10 -8 A, see Fig. 3a. In a different setup at higher temperatures T = 1 5 K, we observe on-currents of up to . 1 µ A in the very same device for large V ds = 30mV, see Fig. 3b, indicating that higher currents are possible also with the contact geometry used. This is also confirmed by measurements in a second device of similar design, where we measure currents up to 1 µ A even at T = 0 1 K . in a different low-temperature setup (see Supp. Mat. Fig. S10).
The measurements presented in Fig. 3 also show that the threshold voltage shifts to lower values of V g with increasing V ds , without significantly affecting SS, see Fig. 3a (more data are provided in Sec. 3 in the Supp. Mat.). This implies that - despite the small on-current -the device presented in this manuscript could be operated at T = 0 1K as a FET with an on-off ratio . of at least 10 5 and an operational voltage range of only 3 4 mV by suitably choosing the drain-source voltage V ds , thanks to the small SS ≈ 250 µ V/dec. At T = 1 5 K, . reaching an on-off ratio of 10 5 will require operational voltages of 6 - 7 mV due to a slightly higher noise level and slightly higher SS ≈ 500 µ V/dec.
Finally, we summarize in Fig. 4 the minimum inverse SS for different transistor device architectures reported in the literature (empty dots) as a function of temperature for low T ≤ 6 K. The best performing conventional FET devices, based on silicon-on-insulator [18] or nanowires [53], allow to reach SS ≈ 2 mV/dec. These values are almost an order of magnitude higher than the 250 µ V/dec of the BLG-based devices reported in this work (red dots). The theoretical Boltzmann limit is included as a solid line. At T = 1 5 K, the Boltzmann . limit is SS BL ≈ 300 µ V/dec, only slightly less than the
FIG. 4. Comparison of the extracted low-temperature SS values for different types of FET devices. The red dots correspond to the device presented in this paper. The blue triangles refer to a similar device but where the top gate was made of gold instead of graphite, and the green triangle refers to a third BLG device with an additional Al O 2 3 layer between the hBN and the gold gate. The empty symboles correspond to SS values reported in the literature for FETs based on different technologies (silicon on insulator (SOI), bulk CMOS, Fin, and nanowire FETs [13, 18, 23, 25, 30, 53-61]). FETs based on vdW heterostructures outperform all other technologies in terms of SS at cryogenic temperatures. The solid black line is the theoretical Boltzmann limit SS BL = k B T/e ln(10).
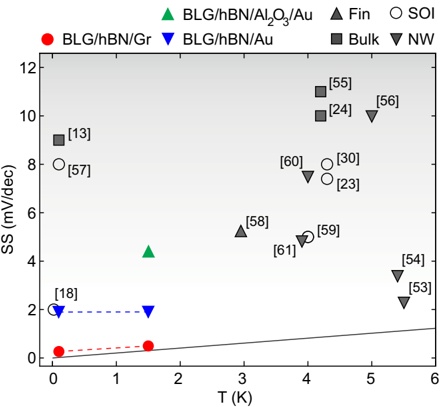
subthreshold slope of our device (SS ≈ 500 µ V/dec). We attribute this improvement in SS directly to the reduced interface disorder in devices based on pure vdW heterostructures, i.e., without bulk interfaces to metal or oxides. The detrimental effect of bulk interfaces is well illustrated by the much higher SS values of BLG devices, where the top gate was made of gold instead of graphite (blue triangles in Fig. 4). A BLG device with an additional Al O 2 3 between the metal top gate and the top hBN performed even worse (green triangle).
- [1] E.A. Guti´rrez-D., C. Claeys, and E. Simoen. Chapter 2 e silicon devices and circuits. In Edmundo A. Guti´rrez-D., e M. Jamal Deen, and C. Claeys, editors, Low Temperature Electronics , pages 105-257. Academic Press, San Diego, 2001.
[2] Tianbing Chen, Chendong Zhu, Laleh Najafizadeh, Bongim Jun, Adnan Ahmed, Ryan Diestelhorst, Gustavo Espinel, and John D. Cressler. Cmos reliability issues for emerging cryogenic lunar electronics applications. SolidState Electronics , 50(6):959-963, 2006. Special Issue: ISDRS 2005.
- [3] R.L. Patterson, A. Hammoud, and M. Elbuluk. Assessment of electronics for cryogenic space exploration mis-
In summary, we have demonstrated that BLG devices based on pure vdW materials exhibit excellent band gap tunability and have provided evidence that 2D material-based FETs offer superior device behavior at cryogenic temperatures, with SS in the order of 250 µ V/dec, only one order of magnitude above the Boltzmann limit of SS BL ≈ 20 µ V/dec at T = 0 1K. . The ability to also electrostatically confine carriers in BLG [38, 40, 42] and the excellent performance as a field-effect transistor make this type of device an ideal platform for cryogenic applications and calls for further device design improvements that allow for down-scaling and circuit integration. Moreover, we expect this work to trigger the exploration of pure vdW heterostructure FETs based on true 2D semiconductors, such as the transition metal dichalcogenides MoS 2 and WSe . 2
Acknowledgements The authors thank S. Trellenkamp and F. Lentz for their support in device fabrication. This project has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No. 881603 (Graphene Flagship), from the European Research Council (ERC) under grant agreement No. 820254, the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany's Excellence Strategy - Cluster of Excellence Matter and Light for Quantum Computing (ML4Q) EXC 2004/1 - 390534769, by the FLAG-ERA grant PhotoTBG, by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) -471733165, by the FLAG-ERA grant TATTOOS, by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) - 437214324, from the EU project ATTOSWITCH under grant No. 101135571, and by the Helmholtz Nano Facility [62]. K.W. and T.T. acknowledge support from the JSPS KAKENHI (Grant Numbers 20H00354, 21H05233 and 23H02052) and World Premier International Research Center Initiative (WPI), MEXT, Japan.
Data availability The data supporting the findings are available in a Zenodo repository under accession code 10.5281/zenodo.10526847.
- sions. Cryogenics , 46(2):231-236, 2006. 2005 Space Cryogenics Workshop.
- [4] Jack Bourne, Roberto Schupbach, Brent Hollosi, Jia Di, Alexander Lostetter, and H. Alan Mantooth. Ultra-wide temperature (-230 c to 130 c) dc-motor drive with sige ° ° asynchronous controller. In 2008 IEEE Aerospace Conference , pages 1-15, 2008.
- [5] Yinan Han and Ankuo Zhang. Cryogenic technology for infrared detection in space. Scientific Reports , 12(1):2349, Feb 2022.
- [6] Yijun Feng, Peng Zhou, Hongying Liu, Jun Sun, and Tian Jiang. Characterization and modelling of mosfet operating at cryogenic temperature for hybrid
- superconductor-cmos circuits. Semiconductor Science and Technology , 19(12):1381, oct 2004.
- [7] F. Zocca, A. Pullia, S. Riboldi, A. D'Andragora, and C. Cattadori. Setup of cryogenic front-end electronic systems for germanium detectors read-out. In 2009 IEEE Nuclear Science Symposium Conference Record (NSS/MIC) , pages 368-372, 2009.
- [8] T. Wada, H. Nagata, H. Ikeda, Y. Arai, M. Ohno, and K. Nagase. Development of low power cryogenic readout integrated circuits using fully-depleted-siliconon-insulator cmos technology for far-infrared image sensors. Journal of Low Temperature Physics , 167(5):602608, Jun 2012.
- [9] Harald Homulle, Stefan Visser, Bishnu Patra, Giorgio Ferrari, Enrico Prati, Fabio Sebastiano, and Edoardo Charbon. A reconfigurable cryogenic platform for the classical control of quantum processors. Review of Scientific Instruments , 88(4):045103, 04 2017.
- [10] C. G. Almudever, L. Lao, X. Fu, N. Khammassi, I. Ashraf, D. Iorga, S. Varsamopoulos, C. Eichler, A. Wallraff, L. Geck, A. Kruth, J. Knoch, H. Bluhm, and K Bertels. The engineering challenges in quantum computing. In Design, Automation & Test in Europe Conference & Exhibition (DATE), 2017 , pages 836-845, 2017.
- [11] L. M. K. Vandersypen, H. Bluhm, J. S. Clarke, A. S. Dzurak, R. Ishihara, A. Morello, D. J. Reilly, L. R. Schreiber, and M. Veldhorst. Interfacing spin qubits in quantum dots and donors-hot, dense, and coherent. npj Quantum Inf. , 3(34):1-10, Sep 2017.
- [12] Bishnu Patra, Rosario M. Incandela, Jeroen P. G. van Dijk, Harald A. R. Homulle, Lin Song, Mina Shahmohammadi, Robert Bogdan Staszewski, Andrei Vladimirescu, Masoud Babaie, Fabio Sebastiano, and Edoardo Charbon. Cryo-cmos circuits and systems for quantum computing applications. IEEE Journal of SolidState Circuits , 53(1):309-321, 2018.
- [13] Rosario M. Incandela, Lin Song, Harald Homulle, Edoardo Charbon, Andrei Vladimirescu, and Fabio Sebastiano. Characterization and compact modeling of nanometer cmos transistors at deep-cryogenic temperatures. IEEE Journal of the Electron Devices Society , 6:996-1006, 2018.
- [14] Jelmer M. Boter, Juan P. Dehollain, Jeroen P.G. van Dijk, Yuanxing Xu, Toivo Hensgens, Richard Versluis, Henricus W.L. Naus, James S. Clarke, Menno Veldhorst, Fabio Sebastiano, and Lieven M.K. Vandersypen. Spiderweb array: A sparse spin-qubit array. Phys. Rev. Appl. , 18:024053, Aug 2022.
- [15] Francis Balestra and Gerard Ghibaudo. Device and Circuit Cryogenic Operation for Low Temperature Electronics . Springer US, 01 2001.
- [16] Kaushik Rajashekara and Bilal Akin. A review of cryogenic power electronics -status and applications. In 2013 International Electric Machines & Drives Conference , pages 899-904, 2013.
- [17] E. Charbon, F. Sebastiano, A. Vladimirescu, H. Homulle, S. Visser, L. Song, and R M. Incandela. Cryo-cmos for quantum computing. In 2016 IEEE International Electron Devices Meeting (IEDM) , pages 13.5.1-13.5.4, 2016.
- [18] P. Galy, J. Camirand Lemyre, P. Lemieux, F. Arnaud, D. Drouin, and M. Pioro-Ladri` ere. Cryogenic temperature characterization of a 28-nm fd-soi dedicated structure for advanced cmos and quantum technologies co-
- integration. IEEE Journal of the Electron Devices Society , 6:594-600, 2018.
- [19] Arne Hollmann, Daniel Jirovec, Maciej Kucharski, Dietmar Kissinger, Gunter Fischer, and Lars R. Schreiber. 30 GHz-voltage controlled oscillator operating at 4 K. Review of Scientific Instruments , 89(11):114701, 11 2018.
- [20] Lo¨ ıck Le Guevel, G´ erard Billiot, Xavier Jehl, Silvano De Franceschi, Marcos Zurita, Yvain Thonnart, Maud Vinet, Marc Sanquer, Romain Maurand, Aloysius G. M. Jansen, and Ga¨ el Pillonnet. 19.2 a 110mk 295 µ w 28nm fdsoi cmos quantum integrated circuit with a 2.8ghz excitation and na current sensing of an on-chip double quantum dot. In 2020 IEEE International Solid- State Circuits Conference - (ISSCC) , pages 306-308, 2020.
- [21] Joachim Knoch, Benjamin Richstein, Yi Han, Michael Frentzen, Lars Rainer Schreiber, Jan Klos, Lena Raffauf, Noel Wilck, Dirk K¨nig, and Qing-Tai Zhao. Toward lowo power cryogenic metal-oxide semiconductor field-effect transistors. physica status solidi (a) , 220(13):2300069, 2023.
- [22] H. Achour, R. Talmat, B. Cretu, J.-M. Routoure, A. Benfdila, R. Carin, N. Collaert, E. Simoen, A. Mercha, and C. Claey. Dc and low frequency noise performances of soi p-finfets at very low temperature. SolidState Electronics , 90:160-165, 2013. Selected papers from EUROSOI 2012.
- [23] H. Bohuslavskyi, A. G. M. Jansen, S. Barraud, V. Barral, M. Cass´ e, L. Le Guevel, X. Jehl, L. Hutin, B. Bertrand, G. Billiot, G. Pillonnet, F. Arnaud, P. Galy, S. De Franceschi, M. Vinet, and M. Sanquer. Cryogenic subthreshold swing saturation in fd-soi mosfets described with band broadening. IEEE Electron Device Letters , 40(5):784-787, 2019.
- [24] Arnout Beckers, Farzan Jazaeri, and Christian Enz. Inflection phenomenon in cryogenic mosfet behavior. IEEE Transactions on Electron Devices , 67(3):13571360, 2020.
- [25] Arnout Beckers, Farzan Jazaeri, and Christian Enz. Theoretical limit of low temperature subthreshold swing in field-effect transistors. IEEE Electron Device Letters , 41(2):276-279, 2020.
- [26] Avid Kamgar. Subthreshold behavior of silicon MOSFETs at 4.2 K. Solid-State Electron. , 25(7):537-539, July 1982.
- [27] G. Ghibaudo, M. Aouad, M. Casse, S. Martinie, T. Poiroux, and F. Balestra. On the modelling of temperature dependence of subthreshold swing in MOSFETs down to cryogenic temperature. Solid-State Electron. , 170:107820, August 2020.
- [28] Robert M. Hill. Charge transport in band tails. Thin Solid Films , 51(2):133-140, June 1978.
- [29] Arnout Beckers, Farzan Jazaeri, and Christian Enz. Cryogenic mosfet threshold voltage model. In ESSDERC 2019 - 49th European Solid-State Device Research Conference (ESSDERC) , pages 94-97, 2019.
- [30] B. Richstein, Y. Han, Q. Zhao, L. Hellmich, J. Klos, S. Scholz, L. R. Schreiber, and J. Knoch. Interface engineering for steep slope cryogenic mosfets. IEEE Electron Device Letters , 43(12):2149-2152, 2022.
- [31] E. McCann and M. Koshino. The electronic properties of bilayer graphene. Rep. Prog. Phys. , 76(5):056503, Apr 2013.
- [32] Eike Icking, Luca Banszerus, Frederike W¨rtche, Frank o Volmer, Philipp Schmidt, Corinne Steiner, Stephan
- Engels, Jonas Hesselmann, Matthias Goldsche, Kenji Watanabe, Takashi Taniguchi, Christian Volk, Bernd Beschoten, and Christoph Stampfer. Transport spectroscopy of ultraclean tunable band gaps in bilayer graphene. Advanced Electronic Materials , 8(11):2200510, 2022.
- [33] Anastasia Varlet, Dominik Bischoff, Pauline Simonet, Kenji Watanabe, Takashi Taniguchi, Thomas Ihn, Klaus Ensslin, Marcin Mucha-Kruczy´ nski, and Vladimir I. Fal'ko. Anomalous sequence of quantum hall liquids revealing a tunable lifshitz transition in bilayer graphene. Phys. Rev. Lett. , 113:116602, Sep 2014.
- [34] J. Knoch, B. Richstein, Y. Han, C. Jungemann, E. Icking, L.R. Schreiber, R. Xue, J.-S. Tu, T. G¨kcel, J. Neugeo bauer, C. Stampfer, and Q.T. Zhao. On the performance of low power cryogenic electronics for scalable quantum information processors*. In 2023 IEEE Nanotechnology Materials and Devices Conference (NMDC) , pages 440445, 2023.
- [35] Edward McCann and Vladimir I. Fal'ko. Landau-level degeneracy and quantum hall effect in a graphite bilayer. Phys. Rev. Lett. , 96:086805, Mar 2006.
- [36] Jeil Jung and Allan H. MacDonald. Accurate tightbinding models for the π bands of bilayer graphene. Phys. Rev. B , 89:035405, Jan 2014.
- [37] J. Li, K. Wang, K. J. McFaul, Z. Zern, Y. Ren, K. Watanabe, T. Taniguchi, Z. Qiao, and J. Zhu. Gate-controlled topological conducting channels in bilayer graphene - Nature Nanotechnology. Nat. Nanotechnol. , 11(12):10601065, Dec 2016.
- [38] Hiske Overweg, Angelika Knothe, Thomas Fabian, Lukas Linhart, Peter Rickhaus, Lucien Wernli, Kenji Watanabe, Takashi Taniguchi, David S´nchez, Joachim a Burgd¨ orfer, Florian Libisch, Vladimir I. Fal'ko, Klaus Ensslin, and Thomas Ihn. Topologically nontrivial valley states in bilayer graphene quantum point contacts. Phys. Rev. Lett. , 121:257702, Dec 2018.
- [39] L. Banszerus, B. Frohn, T. Fabian, S. Somanchi, A. Epping, M. M¨ uller, D. Neumaier, K. Watanabe, T. Taniguchi, F. Libisch, B. Beschoten, F. Hassler, and C. Stampfer. Observation of the Spin-Orbit Gap in Bilayer Graphene by One-Dimensional Ballistic Transport. Phys. Rev. Lett. , 124(17):177701, May 2020.
- [40] Marius Eich, Riccardo Pisoni, Alessia Pally, Hiske Overweg, Annika Kurzmann, Yongjin Lee, Peter Rickhaus, Kenji Watanabe, Takashi Taniguchi, Klaus Ensslin, and Thomas Ihn. Coupled Quantum Dots in Bilayer Graphene. Nano Lett. , 18(8):5042-5048, Aug 2018.
- [41] L. Banszerus, B. Frohn, A. Epping, D. Neumaier, K. Watanabe, T. Taniguchi, and C. Stampfer. GateDefined Electron-Hole Double Dots in Bilayer Graphene. Nano Lett. , 18(8):4785-4790, Aug 2018.
- [42] L. Banszerus, S. M¨ller, K. Hecker, E. Icking, K. Watano abe, T. Taniguchi, F. Hassler, C. Volk, and C. Stampfer. Particle-hole symmetry protects spin-valley blockade in graphene quantum dots. Nature , 618(7963):51-56, 2023.
- [43] Haoxin Zhou, Ludwig Holleis, Yu Saito, Liam Cohen, William Huynh, Caitlin L. Patterson, Fangyuan Yang, Takashi Taniguchi, Kenji Watanabe, and Andrea F. Young. Isospin magnetism and spin-polarized superconductivity in bernal bilayer graphene. Science , 375(6582):774-778, 2022.
- [44] Anna M. Seiler, Fabian R. Geisenhof, Felix Winterer, Kenji Watanabe, Takashi Taniguchi, Tianyi Xu, Fan
- Zhang, and R. Thomas Weitz. Quantum cascade of correlated phases in trigonally warped bilayer graphene. Nature , 608:298-302, August 2022.
- [45] Sergio C. de la Barrera, Samuel Aronson, Zhiren Zheng, Kenji Watanabe, Takashi Taniguchi, Qiong Ma, Pablo Jarillo-Herrero, and Raymond Ashoori. Cascade of isospin phase transitions in Bernal-stacked bilayer graphene at zero magnetic field. Nat. Phys. , 18:771-775, July 2022.
- [46] L. Wang, I. Meric, P. Y. Huang, Q. Gao, Y. Gao, H. Tran, T. Taniguchi, K. Watanabe, L. M. Campos, D. A. Muller, J. Guo, P. Kim, J. Hone, K. L. Shepard, and C. R. Dean. One-Dimensional Electrical Contact to a TwoDimensional Material. Science , 342(6158):614-617, Nov 2013.
- [47] D. G. Purdie, N. M. Pugno, T. Taniguchi, K. Watanabe, A. C. Ferrari, and A. Lombardo. Cleaning interfaces in layered materials heterostructures. Nat. Commun. , 9(5387):1-12, Dec 2018.
- [48] Kostya S Novoselov, Andre K Geim, SV Morozov, D Jiang, Y Zhang, SV Dubonos, IV Grigorieva, and AA Firsov. Electric field effect in atomically thin carbon films. Science , 306(5696):666-669, 2004.
- [49] Y. Zhao, P. Cadden-Zimansky, Z. Jiang, and P. Kim. Symmetry breaking in the zero-energy landau level in bilayer graphene. Phys. Rev. Lett. , 104:066801, Feb 2010.
- [50] J. Sonntag, S. Reichardt, L. Wirtz, B. Beschoten, M. I. Katsnelson, F. Libisch, and C. Stampfer. Impact of many-body effects on landau levels in graphene. Phys. Rev. Lett. , 120:187701, May 2018.
- [51] M. Schmitz, T. Ouaj, Z. Winter, K. Rubi, K. Watanabe, T. Taniguchi, U. Zeitler, B. Beschoten, and C. Stampfer. Fractional quantum Hall effect in CVD-grown graphene. 2D Mater. , 7(4):041007, Sep 2020.
- [52] Anastasia Varlet, Marcin Mucha-Kruczy´ski, n Dominik Bischoff, Pauline Simonet, Takashi Taniguchi, Kenji Watanabe, Vladimir Fal'ko, Thomas Ihn, and Klaus Ensslin. Tunable fermi surface topology and lifshitz transition in bilayer graphene. Synthetic Metals , 210:19-31, 2015.
- [53] Yi Han, Jingxuan Sun, Jin-Hee Bae, Detlev Gr¨ utzmacher, Joachim Knoch, and Qing-Tai Zhao. High performance 5 nm si nanowire fets with a record small ss = 2.3 mv/dec and high transconductance at 5.5 k enabled by dopant segregated silicide source/drain. In 2023 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits) , pages 1-2, 2023.
- [54] Yi Han, Jingxuan Sun, Benjamin Richstein, Frederic Allibert, Ionut Radu, Jin-Hee Bae, Detlev Gr¨tzmacher, u Joachim Knoch, and Qing-Tai Zhao. Steep switching si nanowire p-fets with dopant segregated silicide source/drain at cryogenic temperature. IEEE Electron Device Letters , 43(8):1187-1190, 2022.
- [55] Arnout Beckers, Farzan Jazaeri, and Christian Enz. Characterization and modeling of 28-nm bulk cmos technology down to 4.2 k. IEEE Journal of the Electron Devices Society , 6:1007-1018, 2018.
- [56] N. Singh, F. Y. Lim, W. W. Fang, S. C. Rustagi, L. K. Bera, A. Agarwal, C. H. Tung, K. M. Hoe, S. R. Omampuliyur, D. Tripathi, A. O. Adeyeye, G. Q. Lo, N. Balasubramanian, and D. L. Kwong. Ultra-narrow silicon nanowire gate-all-around cmos devices: Impact of diameter, channel-orientation and low temperature on device performance. In 2006 International Electron Devices
Meeting , pages 1-4, 2006.
- [57] B. Cardoso Paz, L. Le Guevel, M. Cass´ e, G. Billiot, G. Pillonnet, A. G. M. Jansen, R. Maurand, S. Haendler, A. Juge, E. Vincent, P. Galy, G. Ghibaudo, M. Vinet, S. de Franceschi, T. Meunier, and F. Gaillard. Variability evaluation of 28nm fd-soi technology at cryogenic temperatures down to 100mk for quantum computing. In 2020 IEEE Symposium on VLSI Technology , pages 1-2, 2020.
- [58] Hung-Chi Han, Farzan Jazaeri, Antonio D'Amico, Andrea Baschirotto, Edoardo Charbon, and Christian Enz. Cryogenic characterization of 16 nm finfet technology for quantum computing. In ESSDERC 2021 - IEEE 51st European Solid-State Device Research Conference (ESSDERC) , pages 71-74, 2021.
- [59] Stefan Habicht, Sebastian Feste, Qing-Tai Zhao, Dan Buca, and Siegfried Mantl. Electrical characterization of Ω-gated uniaxial tensile strained Si nanowire-array metal-oxide-semiconductor field effect transistors with < 100 > -and < 110 > channel orientations. Thin Solid Films , 520(8):3332-3336, February 2012.
- [60] Shohei Sekiguchi, Min-Ju Ahn, Tomoko Mizutani, Takuya Saraya, Masaharu Kobayashi, and Toshiro Hiramoto. Subthreshold swing in silicon gate-all-around nanowire and fully depleted soi mosfets at cryogenic temperature. IEEE Journal of the Electron Devices Society , 9:1151-1154, 2021.
- [61] Bruna Cardoso Paz, Mika¨ el Cass´, Sebastien Haendler, e Andre Juge, Emmanuel Vincent, Philippe Galy, Franck Arnaud, G´ erard Ghibaudo, Maud Vinet, Silvano de Franceschi, Tristan Meunier, and Fred Gaillard. Front and back channels coupling and transport on 28 nm fdsoi mosfets down to liquid-he temperature. Solid-State Electronics , 186:108071, 2021.
- [62] Wolfgang Albrecht, Juergen Moers, and Bernd Hermanns. HNF - Helmholtz Nano Facility. Journal of Large-Scale Research Facilities , 3(0):112, May 2017.
## Supporting Information:
## Ultra-steep slope cryogenic FETs based on bilayer graphene
E. Icking, 1, 2 D. Emmerich, 1, 2 K. Watanabe, 3 T. Taniguchi, 4
B. Beschoten, 1 M. C. Lemme, 5, 6 J. Knoch, 7 and C. Stampfer 1, 2
1 JARA-FIT and 2nd Institute of Physics, RWTH Aachen University, 52074 Aachen, Germany, EU 2 Peter Gr¨nberg Institute (PGI-9), Forschungszentrum J¨lich, 52425 J¨lich, Germany, EU u u u 3 Research Center for Electronic and Optical Materials, National Institute for Materials Science, 1-1 Namiki, Tsukuba 305-0044, Japan 4 Research Center for Materials Nanoarchitectonics, National Institute for Materials Science, 1-1 Namiki, Tsukuba 305-0044, Japan 5 Chair of Electronic Devices, RWTH Aachen University, 52074 Aachen, Germany, EU 6 AMO GmbH, 52074 Aachen, Germany, EU 7 IHT, RWTH Aachen University, 52074 Aachen, Germany, EU (Dated: August 5, 2024)
In the first section, we present the equations used to calculate the band gap in bilayer graphene as a function of the displacement field based on a self-consistent approach following Ref. [1] and Ref. [2]. Furthermore, we provide additional information for the first sample introduced in Figs. 1 and 2 of the main manuscript: in Sec. II, we present an optical image of the first device, in Sec. III, we present quantum Hall measurements to estimate the gate-lever arms, in Sec. IV we discuss the slopes of the diamond outlines, in Sec. V, we explain how we extract the gate leakage current, and Sec. VI presents some drain current traces for higher temperatures. As mentioned in the main text, additional information regarding the calculated band structure shown in Fig. 2d can be found in Sec. VIII. In Sec. IX, we present comparable data for a second device, similar to what we have shown in the main text for the first device. Finally, in Sec. X, we show the drain-current traces for the BLG devices with Au top gate and additional Al O 2 3 dielectric.
## I. BAND GAP AS A FUNCTION OF DISPLACEMENT FIELD
The band gap in BLG [1, 3]
$$E _ { g } ( \Delta ) & = \frac { | \Delta | } { \sqrt { 1 + ( \Delta / \gamma _ { 1 } ) ^ { 2 } } }, & ( 1 ) \\ \text{gth } \gamma _ { 1 } & \approx 0. 3 8 \, e V \, \text{and} \, the \, \text{onsite potential difference } [ 4-7 ]$$
with the interlayer coupling strength γ 1 ≈ 0 38 eV and the onsite potential difference [4-7] .
$$\Delta = \frac { d _ { 0 } e D } { \varepsilon _ { 0 } \varepsilon _ { B L G } } + \frac { d _ { 0 } e ^ { 2 } } { 2 \varepsilon _ { 0 } \varepsilon _ { B L G } } \delta n ( \Delta ),$$
depends on the strength of the applied displacement field D . Here, d 0 = 0 34 nm is the interlayer spacing of BLG, and . ε 0 is the vacuum permittivity [1]. The effective dielectric constant of BLG ε BLG accounts for the electric susceptibility of each layer and the corresponding dielectric polarization [8].
## II. OPTICAL IMAGE OF THE FIRST DEVICE
Figure S1. Optical image of the first device discussed in the main text. The BLG and the graphite gates are highlighted. The dual gated area is roughly 6 × 9 µ m . 2
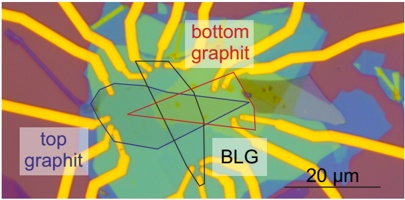
## III. QUANTUM HALL MEASUREMENTS AND GATE LEVER-ARM
The gate-lever arm
$$\alpha _ { t g, \mathrm b g } = \frac { \nu e B } { h V _ { t g, \mathrm b g } },$$
can be extracted from quantum hall measurements by fitting the Landau level (see Fig. III) [9-12]. Here, ν is the Landau filling factor, B the applied magnetic field, h the Planck constant, and V tg(bg) the applied gate voltage. A full list of the gate-lever arms, the relative gate lever arm (extracted from resistance maps as in Fig. 1c), and the thicknesses of the dielectrics can be found in Table S1 for both devices with graphite top and bottom gates.
Figure S2. Transconductance as a function of out-of-plane magnetic field and bottom gate voltage. Fitting the Landau level (white dashed line) allows to extract the gate-lever arm.
Table S1. List of bottom gate lever arm extracted from QH measurements as depicted in Fig. S2, relative lever arm from resistance maps (Fig. 1c), and hBN thicknesses from AFM measurements for both devices with a graphite top and bottom gate.
| Sample | α bg (10 11 V - 1 cm - | β | d top hBN (nm) | d bottom hBN |
|----------------|--------------------------|------|------------------|----------------|
| 1 (main text) | 8.4 | 1.22 | 17 | 22 |
| 2 (Supp. Mat.) | 8.5 | 0.62 | 32 | 19 |
## IV. SLOPES OF DIAMOND OUTLINES
The slope of the outline of the diamonds of suppressed conductance obtained from the finite bias spectroscopy measurement should have, in the ideal case, a slope of 2 [13]. A reduction in slope indicates that it is no longer possible to have a direct tuning of the electrochemical potential µ in the band gap, i.e., ∆ V g > ∆ µ/e . Interestingly, when plotting the extracted slope of the outline of the diamond (extracted by a fixed resistance threshold value 10 9 Ω, exactly as also used in Ref. [13]) as a function of the displacement field D , we observe a constant slope of very close to 2 for | D/ε 0 | /greaterorsimilar 0 2 V/nm, see Fig. S3. For smaller displacement fields ( . D/ε 0 < 0 2 V/nm) our method of extracting . the slope of the diamond outline breaks down, resulting in smaller values (as shown in Fig. S3). This breakdown is mainly due to the rigidly fixed resistance threshold combined with the rather poor measurement resolution (see e.g. the leftmost panel in Fig. 1d in the main manuscript). In short, for such small displacement fields, the resolution of the diamonds is unfortunately insufficient to fully resolve any sharp structures that would allow reliable extraction of the slope of the diamond outline. As a result, the edge appears smeared, resulting in a decreasing slope value.
Figure S3. The slopes of the outline of the diamonds (see black dashed lines in Fig. 1d in the main manuscript) obtained from finite bias spectroscopy measurements as a function of the applied displacement field | D/ε 0 | . For details on the slope-extraction method, see Ref. [13].
## V. EXTRACTING THE GATE CURRENT
In the experiments, we apply the drain-source voltage symmetrically using an IV converter, which allows us to measure the source current I s and the drain current I d simultaneously. We can estimate the gate current I g ≈ ∆ I from the difference ∆ I = | I d -I s | between these two currents. Fig. S4 shows the comparison between I d and I g for the four displacement fields, as shown in Fig. 2 in the main text.
Figure S4. Drain-current (black) and gate current (gray) as a function of effective gating voltage V g at a temperature of T = 0 1 K at . V ds = 0 1 mV in the cases of the four different displacement fields as depicted in Fig. 2 in the main text. .
## VI. SUBTHRESHOLD SLOPE AT 1.5 K
In Fig. 4, data points are depicted obtained at T = 1 5 K for the first device in a pumped . 4 He cryostat (see main text). In Fig. S5, we show full line traces for two different displacement fields. Even at T = 1 5 K, we still see a slight . asymmetry in the extracted subthreshold slopes at conduction and valence band edge.
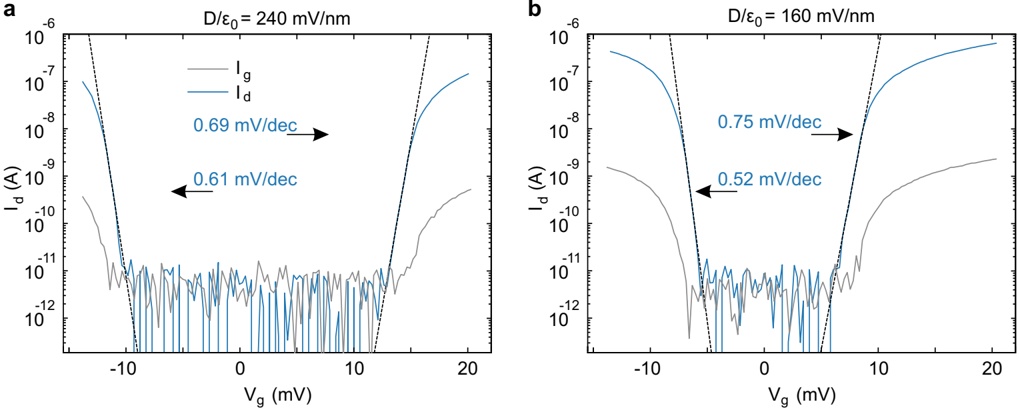
Figure S5. a,b Drain-current as a function of effective gating voltage V g at a temperature of T = 1 5 K obtained in a VTI . cryostat at V ds = 6mV at D/ε 0 = 0 24V/nm (panel a) and 0.16V/nm (panel b). . From the fit (black dashed line), the subthreshold slope for the two displacement fields can be extracted for the valence and conduction band edge (indicated by black arrows). The gate current for the same displacement fields is shown in gray.
## VII. SUBTHRESHOLD SLOPE AS A FUNCTION OF V ds
Fig. 3 in the main text depicts the drain-current for a fixed displacement field D/ε 0 = 0 24 V/nm as a function of . V g for three different V ds . In order to verify that the SS is not affected by V ds we performed a more detailed analysis, see Fig. S6. The first sample shows SS ≈ 200-350 µ V/dec without any dependence on V ds .
Figure S6. The extracted subthreshold slope for sample 1 for D/ε 0 = 0 27 V/nm as a function of applied drain-source voltage . V ds show an almost constant value of 250 µ V/dec.
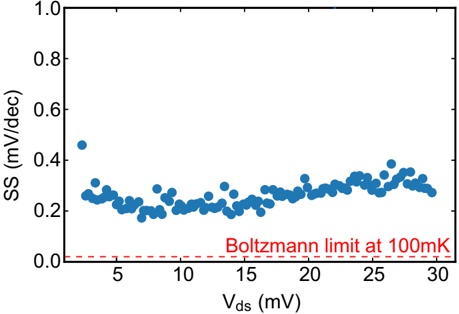
## VIII. BANDSTRUCTURE CALCULATIONS
The bandstructure is calculated numerically using the Hamiltonian [14]
$$\text{is calculated numerically using the Hamiltonian [14]} \\ H = \begin{pmatrix} \Delta / 2 & v _ { 0 } \pi ^ { \dagger } & - v _ { 4 } \pi ^ { \dagger } & - v _ { 3 } \pi \\ v _ { 0 } \pi & \Delta / 2 + \Delta ^ { \prime } & \gamma _ { 1 } & - v _ { 4 } \pi ^ { \dagger } \\ - v _ { 4 } \pi & \gamma _ { 1 } & - \Delta / 2 + \Delta ^ { \prime } & v _ { 0 } \pi ^ { \dagger } \\ - v _ { 3 } \pi ^ { \dagger } & - v _ { 4 } \pi & v _ { 0 } \pi & - \Delta / 2 \end{pmatrix}, \\ \text{$y$} ) \text{ and $\xi = \pm 1$. The parameter $v_{i}\equiv \frac{sq_{2h} \gamma_{i}$ is defined for each coupling parameter $\gamma_{i}$. These include}$$
with π ≡ /planckover2pi1 ( ξq x + iq y ) and ξ = ± 1. The parameter v i ≡ √ 3 a 2 /planckover2pi1 γ i is defined for each coupling parameter γ i . These include the intralayer coupling γ 0 = 3 16 eV, the intralayer coupling . γ 1 = 0 381 eV between dimer sites on different layers, . γ 3 = 0 38 eV accounts for coupling between non-dimer atoms on the two different layers, . γ 4 = 0 14 eV for coupling . between non-dimer atoms with dimer site atoms on the other layer, ∆ ′ = 0 015 meV is the energy difference between . dimer and non-dimer sites, and ∆ the onsite-potential difference, responsible for the band gap formation [6, 14].
## IX. SECOND DEVICE
Here, we introduce a second device (see an optical image in Fig. S7a). This section shows the analog measurement for the measurements shown in Fig 1 and 2. From the resistance measurements (Fig. S7b), we extract the relative gate lever-arm (see Tab. S1), from the quantum hall measurements (Fig. S7c), we extract the bottom gate lever-arm (see Tab. S1).
The finite bias spectroscopy (see Fig. S8) also exhibits clean and highly symmetric diamonds. The extracted band gaps (see Fig. S9) are in excellent agreement with the results from the main text.
We further measure the drain current for different displacement fields, similar to the analysis performed in Fig. 2 in the main text for the first device (see Fig. S10a-e). The extracted subthreshold slopes (see Fig. S10f) also show an asymmetry for values extracted at the valence and the conduction band edge, which increases with increasing displacement field. This effect is even more pronounced for the second device as we already have a significant difference of roughly 1 mV/dec at D/ε 0 ≈ 150 mV/nm. The first device shows a comparable difference at slightly higher displacement fields D/ε 0 ≥ 250 mV/nm. Still, the overall trend is the same for both devices.
Measuring the drain current as a function of V g for different V ds exhibits higher on-currents of almost 1 µ A, see Fig. S11. In Fig. S12, we show the extended analysis of SS as a function of V ds for the second device, which yields SS values between 250 µ V/dec up to 1 mV/dec, without any significant dependency on V ds . However, the spread in SS is slightly higher compared to the first device.
Figure S7. a Optical image of a second device. The BLG and the graphite flakes are highlighted. b Resistance as a function of top and bottom gate voltage. The slope of the diagonal feature of increased resistance is equal to the relative lever-arm β . c Transconductance as a function of out-of-plane magnetic field and bottom gate voltage measured for the second device.
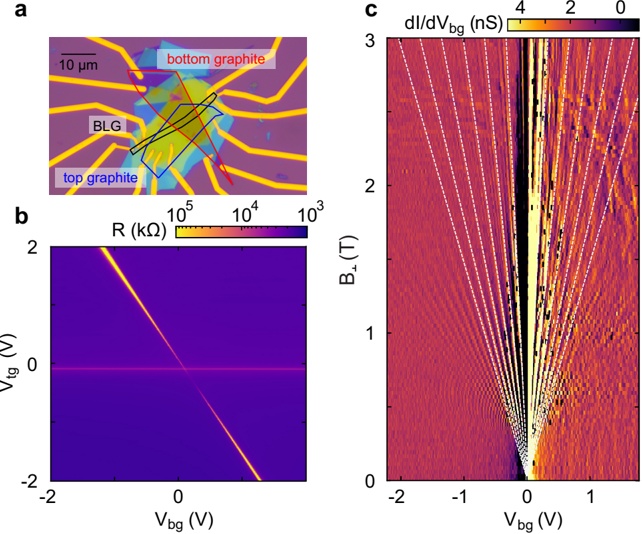
Figure S8. Differential conductance as a function of effective gating voltage V g and drain-source voltage V ds for three different displacement fields measured in a second sample.
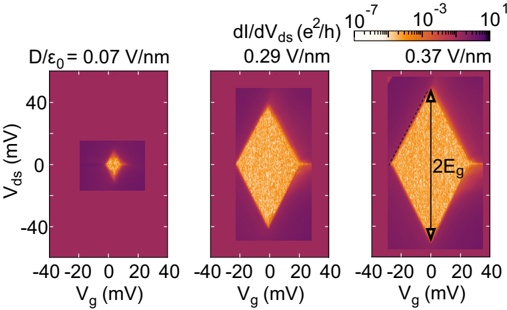
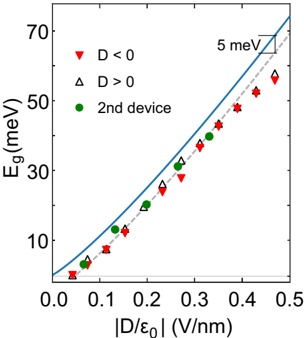
0
Figure S9. Extracted band gaps from finite bias spectroscopy measurements as a function of the displacement field. The results for the second device (green data points) are in good agreement with the result of the first device (triangles, see also main text). Both data sets follow the theory curve (blue line) if a small offset of about 5 meV is included (dashed line).
Figure S10. a Drain current measured in a second device as a function of effective gating potential V g for five different displacement fields a D/ε 0 ≈ 0 07 V/nm, . b 0.145 V/nm, c 0.22 V/nm, d 0.29 V/nm, and e 0.37 V/nm. f The fits (dashed lines in panels a-e) allow the extraction of the SS as a function of D at the conductance and valence band edge. The same trend as in the main text for device 1 emerges: with increasing D , the SS extracted at the conductance band edge increases, while the SS extracted at the valence band edge stays nearly constant.
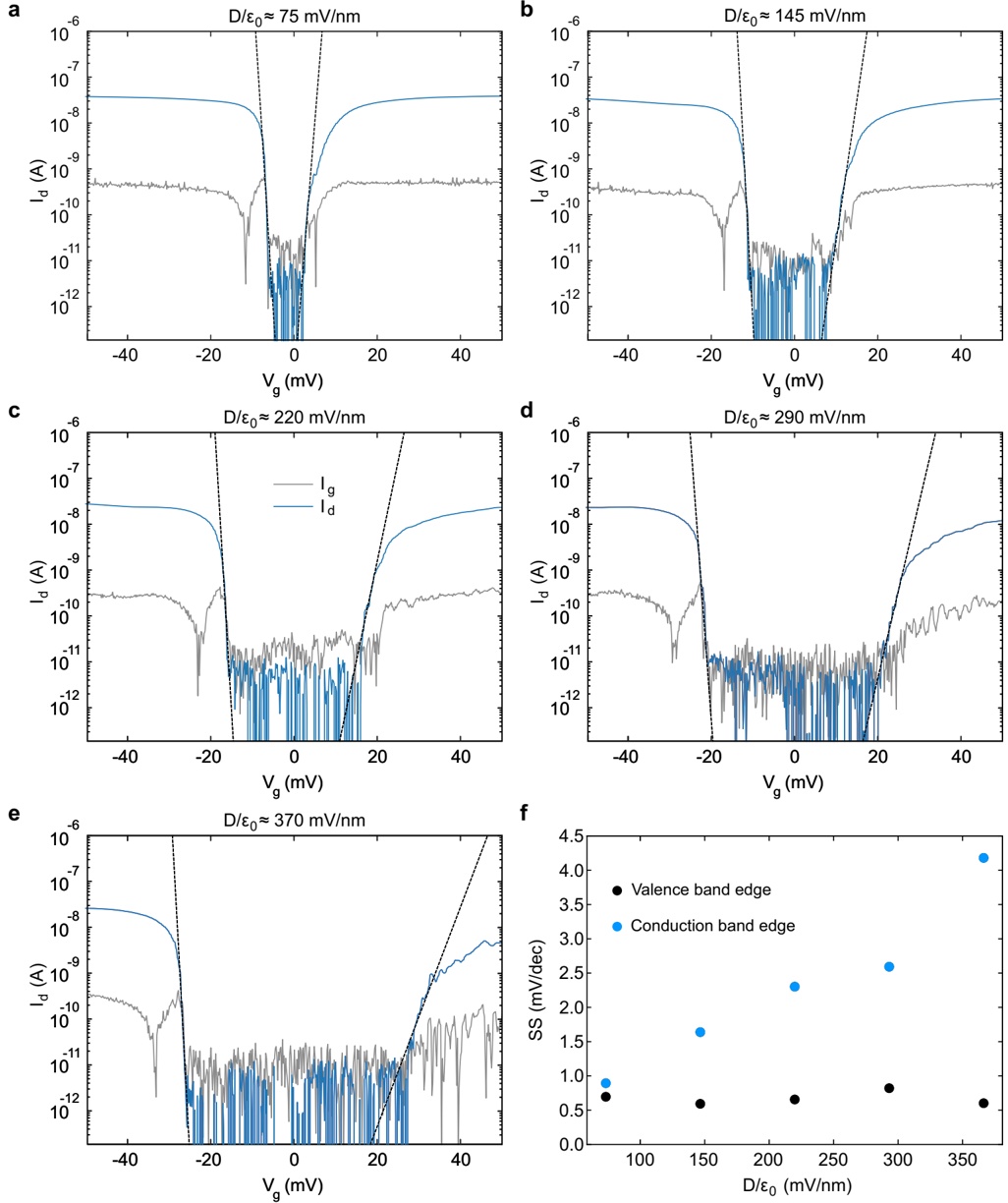
Figure S11. Drain current as a function of effective gating potential V g at the valence band edge at T = 0 1 K measured in a . dilution refrigerator for different applied drain-source voltages V ds = 6mV (gray), 10 mV (orange) and 30 mV (gray) at a fixed displacement field D/ε 0 ≈ 0 22 V/nm. .
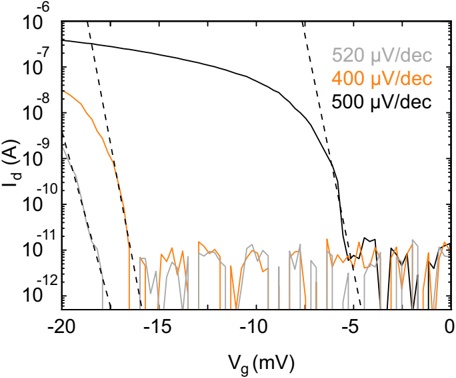
Figure S12. The extracted SS of sample 2 for D/ε 0 = 0 27 V/nm shows a much broader spread than the extracted SS values . of sample 1. The extracted values have no clear dependence on the applied V ds and are more affected by sample-to-sample variations.
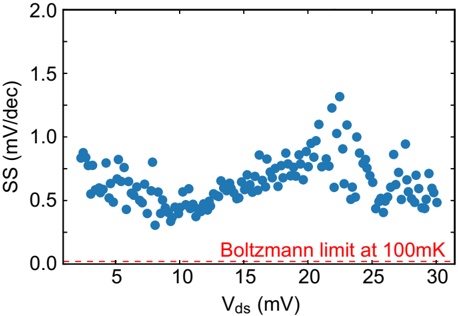
Figure S13. Drain current as a function of bottom gate voltage, while the top gate is fixed to three different voltages. The resulting SS values are considerably worse compared to values extracted from measurements with fixed displacement fields.
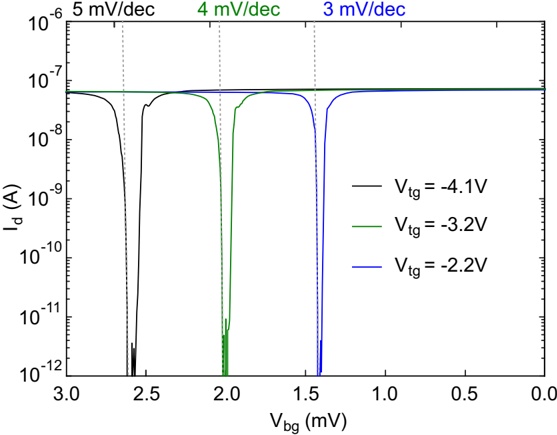
## X. DRAIN CURRENT IN BLG DEVICES WITH BULK INTERFACES
In Fig. 4 of the main text, we present subthreshold slope values for two Gr/hBN/BLG/hBN/Au and one Gr/hBN/BLG/hBN/Al O 2 3 device. Fig. S14a shows the drain current as a function of effective gate voltage for the first device with an Au top gate measured at T = 0 1 K, Fig. S14b for the second device with an Au top gate measured . at T = 1 5 K, and Fig. S14c for the Gr/hBN/BLG/hBN/Al O /Au device measured also at . 2 3 T = 1 5 K. .
Figure S14. a Drain current as a function of effective gating voltage V g for two displacement fields D/ε 0 ≈ 0 19 V/nm (red) . and 0.55 V/nm (green) for a device with an Au top gate, measured at T = 1 5 K. . b Drain current for two displacement fields D/ε 0 ≈ 0 33 V/nm (red) and 0.42 V/nm (green) for a second device with an Au top gate, measured at . T = 0 1 K. . c Drain current measured in a device with an Au top gate and a layer of Al O 2 3 as an extra top gate dielectric (in addition to the top layer of hBN) at D/ε 0 ≈ 0 6 V/nm and . T = 1 5 K. .
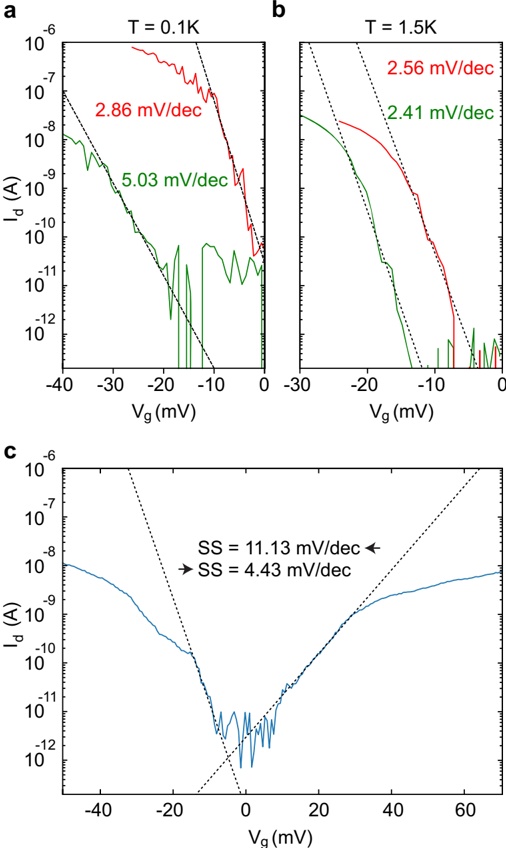
- [1] E. McCann and M. Koshino. The electronic properties of bilayer graphene. Rep. Prog. Phys. , 76(5):056503, Apr 2013.
- [2] S. Slizovskiy, A. Garcia-Ruiz, A. I. Berdyugin, N. Xin, T. Taniguchi, K. Watanabe, A. K. Geim, N. D. Drummond, and V. I.
Fal'ko. Out-of-Plane Dielectric Susceptibility of Graphene in Twistronic and Bernal Bilayers. Nano Lett. , 21(15):6678-6683, Aug 2021.
- [3] Hongki Min, Bhagawan Sahu, Sanjay K. Banerjee, and A. H. MacDonald. Ab initio theory of gate induced gaps in graphene bilayers. Phys. Rev. B , 75:155115, Apr 2007.
- [4] A. B. Kuzmenko, L. Benfatto, E. Cappelluti, I. Crassee, D. van der Marel, P. Blake, K. S. Novoselov, and A. K. Geim. Gate tunable infrared phonon anomalies in bilayer graphene. Phys. Rev. Lett. , 103:116804, Sep 2009.
- [5] Fr´ ed´ric e Joucken, Zhehao Ge, Eberth A. Quezada-L´pez, John L. Davenport, Kenji Watanabe, Takashi Taniguchi, and o Jairo Velasco. Determination of the trigonal warping orientation in bernal-stacked bilayer graphene via scanning tunneling microscopy. Phys. Rev. B , 101:161103, Apr 2020.
- [6] Jeil Jung and Allan H. MacDonald. Accurate tight-binding models for the π bands of bilayer graphene. Phys. Rev. B , 89:035405, Jan 2014.
- [7] Edward McCann. Asymmetry gap in the electronic band structure of bilayer graphene. Phys. Rev. B , 74:161403, Oct 2006.
- [8] Sergey Slizovskiy, Aitor Garcia-Ruiz, Neil Drummond, and Vladimir I. Falko. Dielectric susceptibility of graphene describing its out-of-plane polarizability. arXiv , Dec 2019.
- [9] Y. Zhao, P. Cadden-Zimansky, Z. Jiang, and P. Kim. Symmetry breaking in the zero-energy landau level in bilayer graphene. Phys. Rev. Lett. , 104:066801, Feb 2010.
- [10] Jan Dauber, Martin Oellers, Florian Venn, Alexander Epping, Kenji Watanabe, Takashi Taniguchi, Fabian Hassler, and Christoph Stampfer. Aharonov-bohm oscillations and magnetic focusing in ballistic graphene rings. Phys. Rev. B , 96:205407, Nov 2017.
- [11] J. Sonntag, S. Reichardt, L. Wirtz, B. Beschoten, M. I. Katsnelson, F. Libisch, and C. Stampfer. Impact of many-body effects on landau levels in graphene. Phys. Rev. Lett. , 120:187701, May 2018.
- [12] M. Schmitz, T. Ouaj, Z. Winter, K. Rubi, K. Watanabe, T. Taniguchi, U. Zeitler, B. Beschoten, and C. Stampfer. Fractional quantum Hall effect in CVD-grown graphene. 2D Mater. , 7(4):041007, Sep 2020.
- [13] Eike Icking, Luca Banszerus, Frederike W¨rtche, Frank Volmer, Philipp Schmidt, Corinne Steiner, Stephan Engels, Jonas o Hesselmann, Matthias Goldsche, Kenji Watanabe, Takashi Taniguchi, Christian Volk, Bernd Beschoten, and Christoph Stampfer. Transport spectroscopy of ultraclean tunable band gaps in bilayer graphene. Advanced Electronic Materials , 8(11):2200510, 2022.
- [14] Edward McCann and Mikito Koshino. The electronic properties of bilayer graphene. Rep. Prog. Phys. , 76(5):056503, 2013. | 10.1021/acs.nanolett.4c02463 | [
"E. Icking",
"D. Emmerich",
"K. Watanabe",
"T. Taniguchi",
"B. Beschoten",
"M. C. Lemme",
"J. Knoch",
"C. Stampfer"
] | 2024-08-02T08:40:31+00:00 | 2024-08-02T08:40:31+00:00 | [
"cond-mat.mes-hall",
"cond-mat.mtrl-sci"
] | Ultra-steep slope cryogenic FETs based on bilayer graphene | Cryogenic field-effect transistors (FETs) offer great potential for a wide
range of applications, the most notable example being classical control
electronics for quantum information processors. In the latter context, on-chip
FETs with low power consumption are a crucial requirement. This, in turn,
requires operating voltages in the millivolt range, which are only achievable
in devices with ultra-steep subthreshold slopes. However, in conventional
cryogenic metal-oxide-semiconductor (MOS)FETs based on bulk material, the
experimentally achieved inverse subthreshold slopes saturate around a few
mV/dec due to disorder and charged defects at the MOS interface. FETs based on
two-dimensional materials offer a promising alternative. Here, we show that
FETs based on Bernal stacked bilayer graphene encapsulated in hexagonal boron
nitride and graphite gates exhibit inverse subthreshold slopes of down to 250
${\mu}$V/dec at 0.1 K, approaching the Boltzmann limit. This result indicates
an effective suppression of band tailing in van-der-Waals heterostructures
without bulk interfaces, leading to superior device performance at cryogenic
temperature. |
2408.01112v2 | ## Agentic LLM Workflows for Generating Patient-Friendly Medical Reports
Malavikha Sudarshan , Sophie Shih , Estella Yee 1 2 2 , Alina Yang 2 , John Zou , 3 Cathy Chen , Quan Zhou , Leon Chen , Chinmay Singhal 4 5 5 5 and George Shih 6
1 Department of Electrical Engineering and Computer Sciences, University of California, Berkeley, CA, USA
2 Stuyvesant High School, NY, USA
3 Department of Computer Science, Brown University, RI, USA
4 Stern School of Business, New York University, NY, USA 5 MD.ai, NY, USA
6
Department of Radiology, Weill Cornell Medicine, NY, USA [email protected], {sshih60, eyee60, ayang6}@stuy.edu, john\[email protected], [email protected], {quan, leon, chinmay}@md.ai, [email protected]
## Abstract
The application of Large Language Models (LLMs) in healthcare is expanding rapidly, with one potential use case being the translation of formal medical reports into patient-legible equivalents. Currently, LLM outputs often need to be edited and evaluated by a human to ensure both factual accuracy and comprehensibility, and this is true for the above use case. We aim to minimize this step by proposing an agentic workflow with the Reflexion framework, which uses iterative self-reflection to correct outputs from an LLM. This pipeline was tested and compared to zero-shot prompting on 16 randomized radiology reports. In our multi-agent approach, reports had an accuracy rate of 94.94% when looking at verification of ICD-10 codes, compared to zero-shot prompted reports, which had an accuracy rate of 68.23%. Additionally, 81.25% of the final reflected reports required no corrections for accuracy or readability, while only 25% of zero-shot prompted reports met these criteria without needing modifications. These results indicate that our approach presents a feasible method for communicating clinical findings to patients in a quick, efficient and coherent manner whilst also retaining medical accuracy. The codebase is available for viewing at http://github.com/ malavikhasudarshan/Multi-Agent-Patient-Letter-Generation .
Keywords : Large Language Models, Patient-Friendly Letters, Patient Literacy, Radiology, Report Generation, GPT.
## 1 Background
The 21st Century Cures Act grants patients the right to access their electronic health record data, and since its implementation, the number of patients accessing their Electronic Health Records (EHRs) before the ordering provider has increased significantly [1]. While intended to improve transparency and promote a shared flow of information, this increased level of accessibility can often lead to patient anxiety, misinterpretation and confusion when reading jargon-filled medical reports that they are not the primary audience for [2]. Radiology reports are a prime example of these; mostly intended for referring physicians, when abnormal or ambiguous results are received by patients before discussion with their physician, the impact can often be more harmful than beneficial [3]. To address this, the
creation of patient-friendly letters that simplify complex medical information has been explored [4]. These letters aim to explain medical terms clearly, ensure factual accuracy, and also maintain a compassionate and reassuring tone.
In recent years, Large Language Models (LLMs) have been increasingly leveraged in healthcare applications, from producing discharge summaries [5] to structured radiology reports [6]. In applying generative artificial intelligence to the creation of patient-friendly reports, the pipeline can be made more efficient and patients can have access to more meaningful and legible letters [7, 8]. Most current developments invoke zero-shot prompting to create a patient-friendly version of a medical report included in the input prompt, where the LLM's internal representations are relied upon to produce a suitable letter, and no template or example output is provided in the prompt for guiding the structure, style or comprehensiveness of the generated letters [9, 10]. Through this method, LLMs often generate outputs that need to be manually reviewed or go through alternative mechanisms to be critiqued and improved before being delivered to the patient. One research study concluded that 80.4% ( n = 41 ) of tested patient-friendly LLM-generated summaries of medical reports required editing before being released to patients [11].
Our goal was to develop an agentic pipeline where verification would be minimized, and where patient letters would be evaluated for both accuracy and readability before being released.
## 2 Methods
Agentic workflows are iterative and consist of several intermediary steps performed in addition to LLM prompting, as opposed to non-agentic or zero-shot/few-shot prompts which consist of a single input and a single output [12]. The former approach means that multiple agents can be leveraged, and they are often structured similar to professional businesses, where each agent plays a specific role in the organization. Addition-by-Subtraction collaboration is one example of a multi-agent method, where one agent provides information and the other removes unnecessary details and provides feedback [13].
Agentic workflows allow for reinforcement learning through reflection [12], and can utilize chainof-thought prompting by appending reflected feedback at the end of the next prompt. We leveraged an existing framework, Reflexion [14], which incorporates verbal reinforcement into its iterative refinement process. Typically, agents receive feedback from their environment in a simple form, like a binary signal (e.g., success/failure) or a scalar value (a numerical score). Reflexion agents take this basic feedback and translate it into a more detailed, verbal form-a textual summary that explains the feedback in natural language. This verbal feedback is then added to the context of the following prompt, and acts as a 'semantic' gradient signal, meaning that it provides the agent with specific, meaningful directions on how to improve.
Our implementation prompts an LLM to generate a specific number of patient-friendly letters based on a formal medical report. The accuracy and readability of each generated letter is calculated and weighted appropriately, and the Reflexion model is then used to run a certain number of self-reflection trials and output the letter that it considers to be optimal at the end of this. Reflexion has three separate legs - AlfWorld (for decision-making problems), HotPotQA (for reasoning on single-step iterations) and Programming (for programming tasks using interpreters and compilers). We used AlfWorld, as decision-making made the most sense when prompting for multiple letters and asking for the most optimal output.
The original medical report can either be provided as an argument, or, as we presented at the Society for Imaging Informatics in Medicine (SIIM) 2024 Hackathon, be pulled from an EHR server. Our integration involved extracting one of the five medical reports available on the SIIM Fast Healthcare Interoperability Resources (FHIR) server and pushing our results back onto the server. Manually including the medical report in the input was also later tested on 15 other test radiology reports of various modalities: Computed Tomography (CT), Magnetic Resonance Imaging (MR), and Ultrasound (US) (see Figs. 1, 2 and 3 in the Appendix). These reports differed in length, ranging from 84 to 264 words, and covered a range of medical findings and body parts, including the abdomen, pelvis, chest, head, and lumbar spine.
Our pipeline (Fig. 1) operates as follows: we first make one LLM call to extract the International Classification of Diseases, Tenth Revision (ICD-10) codes from the original report. The temperature
is kept at 0 to minimize variance, and these codes are stored to be compared later. A second LLM call is then used to generate a number of patient-friendly reports ( n=5 , for example) based on the original, and this time we ask the agent to produce ICD-10 codes based on the content of each patient-friendly letter. These ICD-10 codes are verified against the master ICD-10 code database (using the simple-icd-10 package [15]) and the description for each code is also retrieved and compared against the LLM's output to see if they match. The accuracy of each letter is calculated as the number of validated and identical ICD-10 codes between the patient-friendly version and the original medical report, divided by the total number of ICD-10 codes on the original report. This value should be maximized. Readability is quantified using the Flesch-Kincaid Grade Level. This value is calculated using a predefined formula incorporating the average sentence length, number of syllables and number of words per sentence [16] and can be accessed by importing the readability module [17]. The average American's reading ability is equivalent to a US 8th-grade level [18]. A previous study examining 97,052 radiology reports revealed that only 4% were at a reading level equal to or below the reading ability of a US 8th-grader [19], suggesting that much of this information may be unintelligible to a significant portion of the population. Our 16 test reports had an average Flesch-Kincaid Grade Level of 11.03, corresponding to an 11th-grader's expected level of vocabulary.
A Flesch-Kincaid Grade Level of 6.0 (corresponding to a US 6th-grader's reading ability) is the recommended level of readability advised by the American Medical Association [20] and the National Institute of Health [21] for patient-facing medical materials, to allow for greater comprehensibility and accessibility [22]. Each generated patient letter's overall score is calculated by weighting the readability and accuracy - we wanted to prioritize medical accuracy so opted to compute the score as follows:
overall\_score = (readability * 0.3) + (accuracy * 0.7)
The readability value is standardized to be as close to 6.0 as possible, therefore, we can aim for an overall\_score that has a maximum value of 1.0. Reflexion's Alfworld module is then used to reflect on the overall\_score, looking to improve both the accuracy and readability of each letter on each iteration. The algorithm outputs the best version of the letter, which is then directly pushed to the linked EHR server for patient access, demonstrating end-to-end integration. The LLM used in our tests was OpenAI's GPT-4o (gpt-4o-2024-05-13).
Figure 1: Flowchart of the Multi-Agent Algorithm
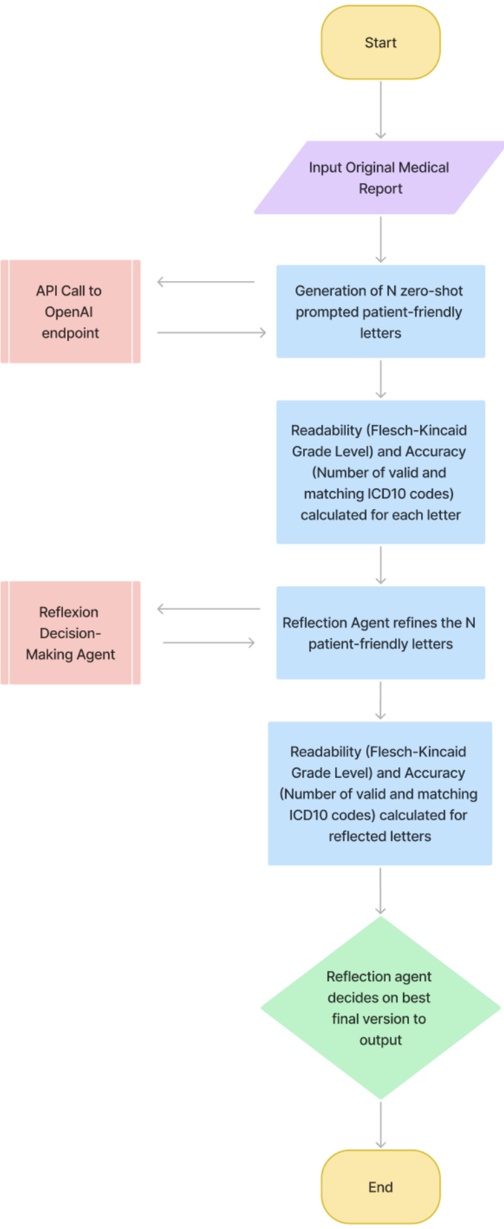
## 3 Results
Our reflection agent increased the medical accuracy of reports, ensuring that ICD-10 codes were retained in the final patient letter which the zero-shot output sometimes missed. When given an identical medical report, system prompt and user prompt, the reflected output consistently scored higher in terms of accuracy and readability, as well as in the overall\_score measure. Zero-shot prompts were sometimes not professional enough, and even when specified in the prompt that the reading level should match that of a US 6th grader's, the language used was too juvenile. However, when the reflected agent was used, the final outputs seemed to be consistently more concise, structured and formal.
In the example below (Figs. 2 and 3), the same medical report was used to compare a zero-shot (Fig. 2) and reflection agent output (Fig. 3). With zero-shot prompting, only half of the desired ICD-10 codes were registered, whereas the reflection agent successfully generated all 4 ICD-10 codes. Additionally, the ICD-10 codes generated by the reflection agent precisely matched those from the original medical report, while the codes from the zero-shot report did not.
From 16 test radiology reports, zero-shot prompting (using the same original prompt as given in our multi-agent workflow) led to 11/16 patient-friendly versions needing to be edited, whilst our agentic workflow resulted in only 3/16 reports that required modification. We considered 'modification' to be any changes in medical factuality (including ICD-10 codes), grammar, punctuation, tonality and readability. On average, accuracy was 26.71% better, and readability scored 3.29% higher in the reflected patient letters, compared to the zero-shot letters (Fig. 4). This resulted in a 17.51% increase in overall\_score in reflected letters vs zero-shot generated letters.

Figure 2: Zero-Shot Generated Patient-Friendly Letter



Figure 3: Reflection/Multi-Agent Generated Patient-Friendly Letter

Figure 4: Summary Table of Results
## 4 Discussion
The use of ChatGPT and similar LLMs for the generation of patient friendly letters is something that many others in the healthcare space have been experimenting with [5][10][23][24][25]. However, LLMs are known to hallucinate and are extremely sensitive to input, which can often lead to errors in the outputted patient-friendly letter. Additionally, the more complex the medical report, the higher the tendency for LLMs to hallucinate [26]. The inclusion of multiple agents and programmatic prompts 1 aim to manage the complexity of medical reports, whilst simultaneously minimizing hallucinations. This workflow reduces the need for proofreading, as the patient letters are evaluated for both accuracy and readability before being outputted.
As part of our accuracy metric, we make use of the get\_description(icd10\_code) [15] function to verify whether the ICD-10 code definitions match industry-standard for the original and patientfriendly reports. However, as this function uses string matching, it is possible that we may miss out on synonymous definitions or phrases with a few variances in words. A better alternative may be to use fuzzy matching algorithms such as calculating the Levenshtein distance [27], or looking at the K-Nearest Neighbors [28] of the two description strings to categorize them, instead of comparing two strings for an exact match.
1 LLM prompts have been programmed and cannot be altered by users-handles issue of sensitivity to input.
One assumption we make is the accuracy of the ICD-10 codes generated by the LLM model (GPT-4o). In separate human validation tests, we have seen high accuracy and consistency when generating these codes from test radiology reports, so in this study we assume that these generated ICD-10 codes can be trusted.
This is still a very early prototype and can be improved upon in several ways. In the future, we hope to be more inclusive of different reading levels, languages, and medical fields. Currently, we have standardized the level of readability to a 6th grade level; however, it would be beneficial to have a variety of literacy levels available depending on the patient. Additionally, adding the functionality for accurate translation in various languages would significantly enhance communication abilities as well as global applicability and reach. Finally, we are aiming to be applicable to various medical fields outside radiology.
As of now, our weighting system is based upon readability and accuracy. However, we understand the importance of maintaining a certain level of compassion within these letters. One possible approach is utilizing the PERMA model [29] as a metric for factoring in compassion into our weighting system. The PERMA scale can help our model determine whether a patient letter has the appropriate tone and level of sensitivity. Other additional metrics we are looking into to further enhance patient letters include CDE codes [30], which can help to accurately convey a patient's treatment process and future action required.
## 5 Conclusion
Our objective was to find a method of generating patient-friendly radiology reports that would really reduce the need for a medical professional to review and verify them. Although our approach does significantly improve the quality of patient-legible letters, it does not have an 100% success rate, and therefore cannot eradicate the need for verification completely. However, by significantly reducing the percentage of LLM-generated reports requiring edits-from 68.75% to 18.75%-through the incorporation of a multi-agent workflow, we can show that the time spent making changes in medical accuracy and readability will also be substantially decreased. Our method not only enhances the efficiency of report generation but also contributes to the overall goal of making healthcare information more accessible and understandable to patients. This development has strong potential to streamline clinical workflows, lessen the burden on medical professionals and administrators, and improve the patient experience by swiftly providing clearer and more accurate medical information.
## 6 Acknowledgements
The authors would like to thank the SIIM community, most notably Teri M. Sippel Schmidt, Alex Barrington, Tom O'Sullivan, Mohannad Hussain, and those who took the time to provide feedback, for supporting our work.
## References
| [1] | Pollock JR, Petty SA, Schmitz JJ, Varner J, Metcalfe AM, and Tan N. Patient access of their radiology reports before and after implementation of 21st century cures act information- blocking provisions at a large multicampus health system. Am J Roentgenol , 222(6), 2024. doi: 10.2214/ajr.23.30343. |
|-------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [2] | Gerber DE. 21st century cures act: Implementation without understanding implication? JCO Oncol Pract , 18(2):85-87, 2022. doi: 10.1200/OP.21.00436. |
| [3] | Winget M, Haji-Sheikhi F, Brown-Johnson C, et al. Electronic release of pathology and radiology results to patients: Opinions and experiences of oncologists. J Oncol Pract , 12(8), 2016. doi: 10.1200/JOP.2016.011098. |
| [4] | Smolle C, Schwarz CM, Hoffmann M, et al. Design and preliminary evaluation of a newly designed patient-friendly discharge letter: A randomized, controlled participant-blind trial. BMC Health Serv Res , 21:450, 2021. doi: 10.1186/s12913-021-06468-3. |
| [5] | Zaretsky J et al. Generative artificial intelligence to transform inpatient discharge sum- maries to patient-friendly language and format. JAMA Netw Open , 7(3), 2024. doi: 10.1001/jamanetworkopen.2024.0357. |
| [6] | Liu J, Wang C, and Liu S. Utility of chatgpt in clinical practice. J Med Internet Res , 25:e48568, 2023. doi: 10.2196/48568. |
| [7] | Doo FX, Cook TS, Siegel EL, et al. Exploring the clinical translation of generative models like chatgpt: Promise and pitfalls in radiology, from patients to population health. J Am Coll Radiol , 20(9):877-885, 2023. doi: 10.1016/j.jacr.2023.07.007. |
| [8] | Park J, Oh K, Han K, et al. Patient-centered radiology reports with generative artificial intelligence: Adding value to radiology reporting. Sci Rep , 14:13218, 2024. doi: 10.1038/ s41598-024-63824-z. |
| [9] | Cork SC and Hopcroft K. Evaluating the utility of chatgpt to convert clinic letters into patient- friendly language, 2024. Published online July 9, 2024. |
| [10] | Roberts RHR, Ali SR, Dobbs TD, and Whitaker IS. Can large language models generate outpatient clinic letters at first consultation that incorporate complication profiles from uk and usa aesthetic plastic surgery associations? Aesthet Surg J Open Forum , 6, 2023. doi: 10.1093/asjof/ojad109. |
| [11] | Berigan K, Short R, Reisman D, et al. The impact of large language model-generated radiology report summaries on patient comprehension: A randomized controlled trial. J Am Coll Radiol , 2024. doi: 10.1016/j.jacr.2024.06.018. Published online July 1, 2024. |
| [12] | Ng A. Issue 242. one agent for many worlds, cross-species cell embeddings, and more, 2024. URL https://www.deeplearning.ai/the-batch/issue-242/ . April 2, 2024. Accessed July 22, 2024. |
| [13] | Wu M, Yuan Y, Haffari G, and Wang L. (perhaps) beyond human translation: Harnessing multi-agent collaboration for translating ultra-long literary texts, 2024. URL https://arxiv. org/abs/2405.11804 . Published online May 20, 2024. Accessed July 24, 2024. |
| [14] | Shinn N, Cassano F, Berman E, Gopinath A, Narasimhan K, and Yao S. Reflexion: Language agents with verbal reinforcement learning, 2023. Published online 2023. |
| [15] | Travasci S. Simple-icd-10, 2024. URL https://pypi.org/project/simple-icd-10/ . PyPI. Accessed July 24, 2024. |
| [16] | Kincaid JP, Fishburne RP Jr, Rogers RL, and Chissom BS. Derivation of new readability formulas (automated readability index, fog count and flesch reading ease formula) for navy enlisted personnel. Technical report, Institute for Simulation and Training, 1975. |
| [17] | Readability. Readability, 2024. URL https://pypi.org/project/readability/ . PyPI. Accessed July 30, 2024. |
| [18] | Amin K, Khosla P, Doshi R, Chheang S, and Forman HP. Artificial intelligence to improve patient understanding of radiology reports, 2023. Published September 29, 2023. |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [19] | Martin-Carreras T, Cook TS, and Kahn CE Jr. Readability of radiology reports: implications for patient-centered care. Clin Imaging , 54:116-120, 2019. doi: 10.1016/j.clinimag.2018.12.006. |
| [20] | Weiss BD. Health Literacy: A Manual for Clinicians . American Medical Association, American Medical Foundation, Chicago, IL, 2003. |
| [21] | Badarudeen S and Sabharwal S. Assessing readability of patient education materials: Current role in orthopaedics. Clin Orthop Relat Res , 468(10):2572-2580, 2010. doi: 10.1007/s11999-010-1380-y. |
| [22] | Davis TC, Crouch MA, Wills G, Miller S, and Abdehou DM. The gap between patient reading comprehension and the readability of patient education materials. J Fam Pract , 31(5):533-538, 1990. |
| [23] | Ali S, Dobbs TD, Hutchings HA, and Whitaker IS. Using chatgpt to write patient clinic letters, 2023. URL https://www.researchgate.net/publication/369076647_Using_ ChatGPT_to_write_patient_clinic_letters . Published online 2023. |
| [24] | Guo R, Farnan G, McLaughlin N, and Devereux B. Qub-cirdan at 'discharge me!': Zero shot discharge letter generation by open-source llm, 2024. URL https://arxiv.org/abs/2406. 00041 . Published online June 27, 2024. Accessed July 26, 2024. |
| [25] | Doshi R, Amin KS, Khosla P, Bajaj S, Chheang S, and Forman HP. Quantitative evaluation of large language models to streamline radiology report impressions: A multimodal retrospective analysis. Radiology , 310(3), 2024. doi: 10.1148/radiol.231593. |
| [26] | Xu Z, Jain S, and Kankanhalli M. Hallucination is inevitable: An innate limitation of large language models, 2024. URL https://arxiv.org/abs/2401.11817 . arXiv.org. January 22, 2024. Accessed July 29, 2024. |
| [27] | Lee C, Kim Y, Kim YS, and Jang J. Automatic disease annotation from radiology reports using artificial intelligence implemented by a recurrent neural network. Am J Roentgenol , 212(4): 734-740, 2019. doi: 10.2214/AJR.18.19869. |
| [28] | Lüschow Aand Wartena C. Classifying medical literature using k-nearest-neighbours algorithm, 1970. URL https://serwiss.bib.hs-hannover.de/frontdoor/index/index/docId/ 1146 . Accessed July 29, 2024. |
| [29] | Butler J and Kern ML. The perma-profiler: A brief multidimensional measure of flourishing, 2016. URL https://www.internationaljournalofwellbeing.org/index.php/ijow/ article/view/526 . |
| [30] | National Institutes of Health. Common data elements: Standardizing data collection, 2024. URL https://www.nlm.nih.gov/oet/ed/cde/tutorial/03-100.html#: ~:text=A%20common%20data%20element%20(CDE),to%20ensure%20consistent% 20data%20collection . U.S. National Library of Medicine. Accessed July 24, 2024. |
## A Appendix
The following examples display LLM outputs for MR, CT, and Ultrasound test reports, offering straightforward visual comparisons between zero-shot and multi-agent generated patient-friendly reports.
## ZERO-SHOT GENERATED PATIENT LETTER
Dear [Patient s Name],
Ihope doing well share the results of your recent MRI scan your head This tes was done headaches and feeling dizzy.
Hene tound
Smnall Spot the Brain" Wc lound pca (1.2 cm) part brain called hemangioblastoma-Itis type usually not cancer
Extra Fluid' There news This means you do not have condition called hydrocephalus. brin Qood
Pressure ontne Brain" The spot we found putting any pressure other parts your brain-Everything else looks normal.
Wewill talk more about what this means andthenext steps when we see each other vournextappoiniment You have any questions belore then, please call our office.
Take care
[Your Doctor's Name]
Codes
Ison
## REFLECTION AGENT PATIENT LETTER
Ihope you are doing your headWe did this test because you have been having headaches and dizziness
Heres what we found:
tiny spot, about the size pea (12 cm)in a part your brain called the cerebellum. This spot is likely something called usually not cancer
"Brain Fluid Spaces The spaces in your brain that hold fluid (called good.
"No Pressure on the shitt your brain This mcans the smal not pushing other parts of your brain
In summary wefound that might be needed ,
Please feel free ask any questions when we meet next
Best regards ,
[Your Doctor's Name]
D33.1 : "Benign neoplasm of brain, infratentorial" ,
"R5I' : Headache"
Figure 5: Patient-Friendly Letters generated from an MR Head Report
## ORIGINAL RADIOLOGY REPORT
chronic hcadaches and dizziness.
MRI
Technique: comprehensive examination was performed utilizing a variety Imaging planes and naging paramelers visualization suspecieo pathology Images vere obtained with and without intravenous gadolinium,
## Findings:
consistent with hemangioblastoma;
Ventricles: No evidence hydrocephalus.
Other: Negative;
Enhancing lesion in theleft cerebellar hemisphere, consistent with a hydrocephalus \_ significant mass etfect.
## ORIGINAL RADIOLOGY REPORT
CT Chest with Contrast
Technique Contiquous axlal CTimages the chest were obtained after the
Findings:
noma calibur; Doune configuration ncic Linear bandkke areas scarringlatelectasis presentin the nght
There osseousles on evidence pricr trauma delormity ofthe right Sthnb
Impression:
cavitary tavored
## ZERO-SHOT GENERATED PATIENT LETTER
your chest CT scanis a special type ot X-ray that gives detailed
- extrafud around yourchest calledthe codtaalso Ioksnormal changes this blcod vessel, but nothing our
- Welound covityin the lower part your nghtlung whch about mmn size These cavties mgnt be due Infection
- upper part ot
- 'Lymph Nodes and Thyroid"
- yournbs
- Intection Wo ncedto keepaneyeon these-
The scar-like
We wil discuss these {indings have any
[Your Doctors Name]
son
Other disoiders
## REFLECTION AGENT PATIENT LETTER
CT scan look inside your body- louna
- but nothing worrY about right now biood
- Wefound of yourlett lung that looks about mmvin slze These cavities
- There are some scar-Meareas the upper part ol your
- your immune syslemi
- FOther Areas The upper evidence old Injury to
- The scar-like right lung not changed and are likely from an old Intection
We will d scuss these findings
[Your Dociors Name]
son aorta ,
fracture
Figure 6: Patient-Friendly Letters generated from a CT Chest Report
## ORIGINAL RADIOLOGY REPORT
History: [History thyroid nodules change voice]
Technique: The thyroid structures were scanned with high
Comparison: [None]
Findings
Thyroid
Right lobe measures; [3 5 with irregular margins m crocalcifications, concerning Ior malignancy ] and
Left lobe measures: (Multiple benign-appearing nodules ]
Isthmus: (The Isthmnus normal in size and configuratlon ]
Lymoh Nodes: [Sweep images of the neck b laterally adjacent the thyroid Imph nodes]
Addîtional Findings: [None]
[Rght thyroid lobe with 3,5 * 40 cm solid nodule with irregular margins and biopsy ]
## ZERO-SHOT GENERATED PATIENT LETTER
Dear [Patients Namel
Ihope thyroid scan and explain what they mean simple terms, nds in your neck that helps control your bodys energy- You mentioned that your voice has changed recently check thyroid might be the
Heres what we found:
"Right Side Thyroid" small plum (3.5 bit worriedit could
- There are fovsmail they look harmlcss.
- "'Middle Part of Thyroid (Isthmus)* This looks normal
- 'Lymph Nodes" glands that help fight Intections We checked the ones near your thyroid, and look normal too ney
## Whats Next?
Bccause couple morc tests
- test where doctor looks at your voice box and throat with
'Biopsy: This tiny piece the lump look at it more closcly under
Moe the lump and decide the best way take care of it
[Your Doctor s Namc]
Codes
E04.1 : "Nontoxic single thyroid nodule
## REFLECTION AGENT PATIENT LETTER
Ihopc you arc doing wcll. vantcd share the results of your recent thyroid scanand erplain what they mean;
"Right Sidc (nodulc) that mcasurcs about 40 cm This nasuneven edges and tiny calcium spots, Because check more carelully make sureitis nol somcthing scrious, like cancor Jump unp
- 2 *Lelt Side
- This part looks normal
- 'Lymph Nodes` We checked the lymph nodes ncar your thyroidand they
spcclalist They might want tiny camera (called laryngoscopy) and lake sample Irom the biopsy)
Please let knowif youhave any questions , there[ anything else we can
[Your Doctors Namc]
ison
'E041: Nontoxic single thyroid nodule" C73 : "Malignant neoplasm thyroid gland , "R49o : Dysphonta"
Figure 7: Patient-Friendly Letters generated from a US Thyroid Report | null | [
"Malavikha Sudarshan",
"Sophie Shih",
"Estella Yee",
"Alina Yang",
"John Zou",
"Cathy Chen",
"Quan Zhou",
"Leon Chen",
"Chinmay Singhal",
"George Shih"
] | 2024-08-02T08:40:33+00:00 | 2024-08-05T05:15:48+00:00 | [
"cs.MA"
] | Agentic LLM Workflows for Generating Patient-Friendly Medical Reports | The application of Large Language Models (LLMs) in healthcare is expanding
rapidly, with one potential use case being the translation of formal medical
reports into patient-legible equivalents. Currently, LLM outputs often need to
be edited and evaluated by a human to ensure both factual accuracy and
comprehensibility, and this is true for the above use case. We aim to minimize
this step by proposing an agentic workflow with the Reflexion framework, which
uses iterative self-reflection to correct outputs from an LLM. This pipeline
was tested and compared to zero-shot prompting on 16 randomized radiology
reports. In our multi-agent approach, reports had an accuracy rate of 94.94%
when looking at verification of ICD-10 codes, compared to zero-shot prompted
reports, which had an accuracy rate of 68.23%. Additionally, 81.25% of the
final reflected reports required no corrections for accuracy or readability,
while only 25% of zero-shot prompted reports met these criteria without needing
modifications. These results indicate that our approach presents a feasible
method for communicating clinical findings to patients in a quick, efficient
and coherent manner whilst also retaining medical accuracy. The codebase is
available for viewing at
http://github.com/malavikhasudarshan/Multi-Agent-Patient-Letter-Generation. |
2408.01113v2 | ## Dominant p -wave pairing induced by nearest-neighbor attraction in the square-lattice extended Hubbard model
Zhangkai Cao, 1, ∗ Jianyu Li, 1, 2, ∗ Jiahao Su, 1, 2 Tao Ying, 3, † and Ho-Kin Tang 1, 2, ‡
1
School of Science, Harbin Institute of Technology, Shenzhen, 518055, China 2 Shenzhen Key Laboratory of Advanced Functional Carbon Materials Research and Comprehensive Application, Shenzhen 518055, China. 3 School of Physics, Harbin Institute of Technology, Harbin 150001, China
(Dated: January 20, 2025)
The two-dimensional (2D) Hubbard model is widely believed to capture the key ingredients of high-temperature superconductivity in cuprate materials. Here, we report a constrained path quantum Monte Carlo study of the square-lattice extended Hubbard model with on-site Coulomb repulsion U and nearest-neighbor (NN) electron attraction V . Upon doping δ = 0.125, we find that NN electron attraction V significantly promotes an exotic spin-triplet ( p -wave) pairing, with the p -wave pairing correlations growing stronger as V increases. In the meanwhile, the d x 2 -y 2 -wave ( d -wave) pairing in the intermediate coupling regime shows insignificant response to the increase of V . The spin density wave order, which is observed near half-filling in the particle-hole channel, is also almost unaffected by the NN electron attraction V , reinforcing the established relationship between d -wave superconductivity (SC) and spin order. As the doping becomes heavier (i.e., δ increases), the dominant region of p -wave pairing expands, further suppressing the presence of d -wave pairing. Our work suggests the p -wave pairing region can be induced and further broadened by the NN electron attraction V , offering a feasible mechanism to realize p -wave SC in realistic cuprate materials.
In almost four decades since the discovery of copperbased high-temperature ( T c ) superconductors [1], later identified with a d x 2 -y 2 -wave ( d -wave) pairing symmetry [2], reformed our understanding of strongly correlated electron systems, many of which defy Landau's Fermiliquid theory [3]. Lots of studies have pointed to the possibility of a phase transition [4] and symmetry breaking [5] especially in the underdoped region, resulting in many interweaving orders, including various forms of charge density wave (CDW) [6], spin density wave (SDW) [7], pair density wave (PDW) [8], electron nematic order [9]. The understanding of how these orders including superconducting, compete and cooperate with each other, has been the most significant problem in condensed matter physics for several decades remaining substantially unsolved [10, 11].
pairing order through various numerical simulation methods, reflecting the Hubbard model and its cousin t -J model exhibit extreme sensitivity to ground state configurations and low-lying excitations, as well as the competition between d -wave SC and other orders [20-25].
Although the ultimate theory for highT c superconductivity remains controversial, the strong electron repulsive interactions in Copper 3d orbitals are believed to play crucial roles [12]. The two-dimensional (2D) fermionic Hubbard model [13-16] successfully captures most of the important physics, like antiferromagnetism at half filling [17] and competing orders in doped cuprates [11, 18, 19]. However, the search for a d -wave superconductivity (SC) phase in the pure 2D Hubbard Model has not been quite so successful [20], which is still a lot of controversy. Recently, dome-like SC region is found in both the electronand hole-doped regimes of the 2D Hubbard model with next-nearest-neighbor (NNN) hopping t ′ [21]. Both positive and negative results have been observed for d -wave
∗ These authors contributed equally.
‡ [email protected]
† [email protected]
The relation between superconductivity and other orders is also strongly influenced by the variations of the Hubbard model, such as the inclusion of the nearest-neighbor (NN) attractive interaction V . Moreover, recent angle-resolved photoemission spectroscopy (ARPES) experiments on one-dimensional (1D) cuprate chain Ba 2 -x Sr x CuO 3+ δ [26] have revealed an anomalously sizable attractive interaction between NN electrons, possibly mediated by phonons [26-28]. Such an effective attraction, which has been largely overlooked in previous studies, could play a crucial role in understanding highT c superconductivity. Although not so strong as the on-site Coulomb repulsion, this effective attractive interaction is comparable to the electron hopping integral ( V ∼ -t ), and thereby also should not be ignored in 2D systems [27, 29].
The effect of the NN electron attraction V in the 1D extended Hubbard chain has been examined recently [30], which can host dominant spin-triplet ( p -wave) pairing correlations and divergent superconductive susceptibility. This offers a feasible mechanism for realizing exotic p -wave SC in realistic cuprate chains. Beyond 1D, the density matrix renormalization group (DMRG) study of the extended Hubbard model on long four-leg cylinders on the square lattice finds that the NN electron attraction V can notably enhance the long-distance superconducting correlations while simultaneously suppressing the CDW correlations [29]. Numerically exact diagonalization study of the Hamiltonian is currently restricted to 4 × 4 systems [31], so whether the prediction of a p -
wave paired state could be stabilized in larger systems is doubtful.
Moreover, the proposed competition between spinsinglet ( s -wave and d -wave) pairing and spin-triplet ( p -wave) pairing warrants further investigation [32-35]. Although multiple possible triplet superconductors have been find, such as Sr RuO 2 4 [36, 37], UPt 3 [38], UTe 2 [39], WTe 2 [40], and Cu x Bi Se 2 3 [41], the pairing symmetry and microscopic superconducting mechanism of these materials are not yet completely understood. In the majority of unconventional superconductors, such as copper oxide [6, 10] and iron-based [42] highT c superconductors, it is generally believed that the electron Cooper pairs exist in a spin-singlet state with a total spin S = 0. Spin-triplet SC with S = 1 possesses internal properties, leading to rich physics such as further possible spinrotation symmetry breaking, collective modes of the order parameter and multiple phases of the condensate [3641]. Recently, the electrons with the same spin at the domain walls in the 1-UC Fe(T e , S )/STO were found to e form non-zero momentum Cooper pairs, thereby generating incommensurate PDW state [42]. This exotic triplet equal-spin pairing state can provide a new material platform to study the PDW state and its interplay with the topological electronic states and unconventional superconductivity. For p -wave superconductors, the disruption of time-reversal symmetry can give rise to topological superconductivity, which holds promising potential for applications in topological quantum computing [43, 44].
Considering the structural and quantum chemistry similarities among cuprates, the NN attraction effect should not be ignored in 2D systems. Therefore, investigating the 2D extended Hubbard model with NN attraction could be crucial for understanding the highT c pairing mechanism. Here, we using the constrained path quantum Monte Carlo (CPQMC) [45, 46] to systematically study the phase diagrams of the square-lattice extended Hubbard model with on-site Coulomb repulsion U and NN attraction V of doped cuprates, so called t -U -V model. CPQMC partially solves sign problem concerning only the ground state of the system at zero temperature. Firstly, we give a general phase diagram scan of the U -V space at the doping δ = 0.125, where the d -wave and exotic p -wave triplet pairing phases exist. We find that V can notably drive and enhance the exotic p -wave spintriplet pairing phase, which also leads to the competition between d -wave and p -wave pairing. Besides the pairing phase, a SDW order exists near the half-filling in the particle-hole channel. Moreover, as doping increases, the dominant region of p -wave pairing expands, further suppressing the presence of d -wave pairing. More technical details and additional results are included in the Supplemental Material [47].
We employ the CPQMC to investigate the groundstate properties of the hole-doped Hubbard model on the square lattice defined by the extended Hamiltonian
$$\text{is} \quad & \text{square lattice channel by the extended Hamiltonian} \\ H = & - \sum _ { i, j, \sigma } \left ( t _ { i, j } c _ { i, \sigma } ^ { \dagger } c _ { j, \sigma } + h. c. \right ) + U \sum _ { i } n _ { i, \uparrow } n _ { i, \downarrow } \\ p _ { i, j, \sigma, \sigma ^ { \prime } } ^ { \quad + V \sum _ { i, j, \sigma, \sigma ^ { \prime } } n _ { i, \sigma } n _ { j, \sigma ^ { \prime } } } \\ \text{e} _ { 2 } \quad & \text{,} \quad \text{$+$} \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdots$$
where c † i,σ ( c i,σ ) is electron creation (annihilation) operator with spin σ = ↑ ↓ , , and n i,σ = c † i,σ c i,σ is the electron number operator. We give an illustration of the t -U -V Hubbard model on 2D square lattice (see Fig. 1(a)), where the electron hopping amplitude t i,j = t if i and j are the NN sites, and t i,j = t ′ for NNN sites. Here, we assume t = 1 for simplicity. We use t ′ = -0 2 . for hole doping, according to band-structure calculations in cuprates [48, 49]. U > 0 is the on-site Coulomb repulsion and V < 0 is the NN electron attraction. We concentrate solely on the hole doped case, where the hole doping is given via δ = 1 -N /N e = 1 -n , where N e is the number of electrons in the system and N is the number of lattice sites.
We have defined the effective pair momentum distribution function
$$\text{$m$} _ { \substack { \text{$row$} _ { \substack { n$row$} _ { \substack { n$colon$row$} \\ \text{$the$} _ { \substack { n$colon$row$} \\ \text{$per$-} \\ \text{$i,j$} } } } } ( \mathbf k ) = ( 1 / N ) \sum _ { i, j } \exp [ i \mathbf k ( \mathbf r _ { i } - \mathbf r _ { j } ) ] C _ { \zeta - p a i r } ^ { \text{eff} } ( i, j ), \\ \text{$su$-} \\ \text{ad} -$$
FIG. 1. (Color online) Model and phase diagram. (a) Illustration the t -U -V Hubbard model with NN hopping t , NNN hopping t ′ , on-site repulsive U , and NN attractive V terms. (b) Schematic zero-temperature phase diagram at the underdoping case δ = 0.125, there are conventional d -wave and exotic p -wave triplet pairing phases. (c) The effective d -wave pair momentum distribution function N eff d x 2 -y 2 -pair ( k ) at U = 3 and V = -0 3, . and (d) The effective p -wave pair momentum distribution function N eff p -pair ( k ) at U = 2 and V = -0 9 on 12 . × 12 lattice.
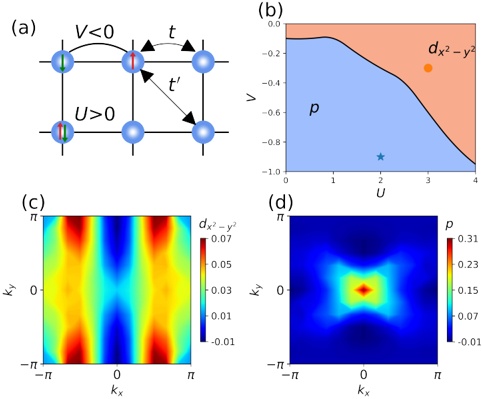
where C eff ζ -pair is the effective real-space correlation of the different pairing, and ζ = s, d x 2 -y 2 , d xy , p . Further detailed definitions of correlation functions can be found in the Supplemental Material [47].
We focus on the electron density n =0.875 corresponding to the underdoping δ = 0.125, which is optimal for pairing to systematically explore its phase diagram. At zero temperature, we summarize our main findings in the phase diagram of the square-lattice extended Hubbard model in Fig. 1(b), where the conventional d -wave and exotic p -wave triplet pairing phases in the ground state is uncovered. At δ = 0.125, the d x 2 -y 2 -wave pairing phase dominates the system when there is no attraction V . As V increases, a slight enhancement of NN electron attraction V can drive the system to the p -wave triplet pairing phase, especially at relatively small U . But in the slightly larger U region, a larger attraction V is needed to induce the generation of p -wave pairing to suppress d -wave pairing. Notably, in specific parameter regimes, fermions exhibit the potential to form pairs with exotic p -wave pairing symmetries, further contributing to this intricate pairing interplay [30].This suggests the p -wave pairing order region is induced and further broadened by the NN electron attraction V .
Then we analyze the characteristic of the effective d -wave and p -wave pairing correlation function in momentum space. In Fig. 1(c), we show the effective d -wave pairing correlation function N eff d x 2 -y 2 -pair ( k ) at δ = 0.125 with U = 3 and V = -0 3, . which exhibits a singular nonzero condensation structure, and its maximum value occurs near nonzero momentum point Q = (2 π/ , 3 π ). This uneven distribution of d -wave pairing in momentum space is reminiscent of the PDW order, which is an inhomogeneous superconducting state whose Cooper pairs poss a finite momentum [8, 10, 11]. In other words, we demonstrate the presence of the d -wave PDW phase. Then, we focus on p -wave pairing state, which refers to the pairing between the same spin species. In Fig. 1(d), we show the effective p -wave pairing correlation function N eff p -pair ( k ) at δ = 0.125 with U = 2 and V = -0 9, which . condenses at point Q = (0 , 0) and locates in the dominant region of weak-coupling U and larger V , supporting the formation of Cooper-pair triplets with zero center-ofmass momentum and p -wave symmetry. We provide the effective d -wave and p -wave pairing correlation function in momentum space with the change of U V , and δ in the Supplemental Material [47]. In the region where d -wave pairing dominates, as discussed above, the d -wave pairing correlation function displays a singular nonzero condensation structure, indicating the presence of a d -wave PDWphase. In contrast, in the region where p -wave pairing dominates, the d -wave pairing gradually evolves into a Q = (0 , 0) condensation and has a lower strength than that of the p -wave pairing, with the latter consistently condenses at Q = (0 , 0). The p -wave pairing strength increases as V is raised, while it is suppressed by the increase of U . As doping increases, we observe that the d -wave pairing condensation point becomes more dispersed,
FIG. 2. (Color online) The competition and distinction of d -wave and p -wave pairing at δ = 0.125 on 12 × 12 lattice. (a)-(d) The effective pair momentum distribution function N eff d x 2 -y 2 -pair ( k ), N eff p -pair ( k ) and N eff d xy -pair ( k ) as a function of V , and fix (a) U = 1.0, (b) U = 2.0, (c) U = 3.0, (d) U = 4.0. (e) The effective correlation function of d -wave pairing mode in real space in the x and y direction with U = 3 and V = -0 3, which displays a different staggered behavior . with distance. (f) The effective correlation function of p -wave pairing mode in real space with U = 2 and V = -0 9, which . displays an exponential decay with distance.
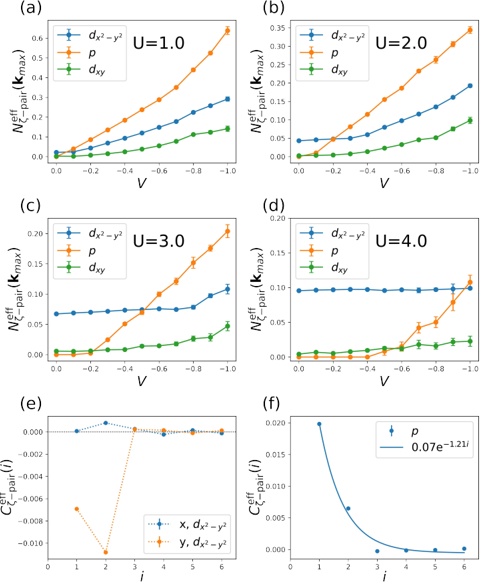
with its intensity decreasing, while the p -wave pairing continues to condense at (0 , 0), maintaining a relatively stable intensity.
To show the competition and distinction of d -wave and p -wave pairing order, we present simulations along the vertical path in the phase diagram at δ = 0.125, namely, fixing U = 1 , 2 , 3 , 4 as shown in Fig. 2(a)-(d). According to the results, the d -wave pairing exhibits different behaviors depending on the strength of U . We found that in the absence of V , the strength of the d -wave pairing in the system increases with the increase of U . As V is enhanced, the strength of the d -wave pairing shows two types of changes: (i) in the weak coupling regime ( U = 1 , 2), the d -wave pairing slowly increases with the increase of V ; (ii) in the intermediate coupling regime ( U = 3 , 4), the d -wave pairing remains relatively unchanged with the variation of V . Although investigating stronger U may provide further insight, such simulations are challenging for the CPQMC method. Conse-
quently, our analysis primarily focuses on the intermediate U regime, where the Coulomb interaction is already large enough for correlated systems to prohibit two electrons from occupying the same site, and is believed to capture the behavior of cuprate superconductors.
The p -wave pairing is entirely absent when V = 0, indicating that the p -wave pairing is solely induced by the NNelectron attraction V . In the weakly coupling regime, the p -wave pairing strength increases sharply with the increase of V and quickly surpasses the strength of the d -wave pairing. In the intermediate coupling regime, the p -wave pairing is suppressed until V reaches a certain strength after which it rapidly increases. Overall, the region dominated by p -wave pairing gradually expands and the strength of p -wave pairing gets significantly enhanced as V increases. The competition between d -wave and p -wave pairing states at different V is primarily driven by the variation of the strength of the p -wave pairing. We also investigated the effective d xy -wave pairing correlation function and found that the strength of d xy -wave remains relatively weak at δ = 0.125, suggesting that the main competition is between the d -wave and p -wave pairing in the system.
Then we analyze the characteristic of d -wave and p -wave pairing correlation function in real space. In Fig. 2(e), we show the effective d -wave correlation function in real space, which displays different staggered behaviors in the x and y direction with distance. Such different staggered behaviors represent the uneven distribution of d -wave pairing in real space, which is consistent with the d -wave pairing condensation at nonzero momentum point Q = (2 π/ , 3 π ) in momentum space, indicating that the d -wave pairing order spontaneously breaks the C 4 rotational symmetry of the system. This may be related to the origin of electron nematic order, which corresponds to that the electronic structure preserves the translation symmetry but breaks the rotation symmetry of the CuO 2 plane. On the contrary, the real space p -wave pairing correlation function exhibits an exponential decay as a function of the distance and drops to 0 quickly, indicating that the p -wave pairing correlation is short-range, as shown in Fig. 2(f).
We also studied the spin density correlation in the particle-hole channel, which reflects the magnetic property of the system. We defined the spin structure factor as N S ( k ) = (1 /N ) ∑ i,j exp[ i k r ( i -r j )] 〈 S i · S j 〉 , and S i the spin operator at site i . At half filling or near half filling, the attractive Hubbard model is dominated by the ( π , π ) CDW. In contrast, a predominant positive U > 0 is expected to support the ( π , π ) SDW. We analyze the characteristic of spin structure factor N S ( k ) in momentum space at δ = 0.125 with U = 4 and V = -1 0, . as shown in Fig. 3(a). The SDW order, characterized by the momentum ( π , π ), leds to a long-range order of staggered spin density in real space. To clearly show the impact of V on SDW, we present the simulations of N S ( k ) at δ = 0.125 as a function of V , namely, fixing U = 1 , 2 , 3 , 4 as shown in Fig. 3(b). The strength of spin
FIG. 3. (Color online) Spin density correlation. (a) The spin structure factor N S ( k ) at δ =0.125 with U = 4 and V = -1 0 . on 12 × 12 lattice. N S ( k ) is peaked at the antiferromagnetic ordering momentum, k max = ( π , π ). (b) N S ( k max ) at δ = 0.125 as a function of V , with U = 1.0, 2.0, 3.0, 4.0. Scaled spin structure factor N S ( k max ) L 2 β ν /N for different lattice sizes L = 8, 10, 12 and 14, with (c) V = 0 and (d) V = -1 0 at . δ ∼ 0.125. The crossing of the different data sets at U c /similarequal 1.7 and U c /similarequal 2.6 respectively, approximately gives the critical interaction U c identifying the phase transition. (Inset) Additionally, when scaling the onsite interaction U by ( U -U c ) L 1 ν /U c , the data sets for different system sizes collapse for critical exponents ν = 1.02(2) and β = 0.85(2).
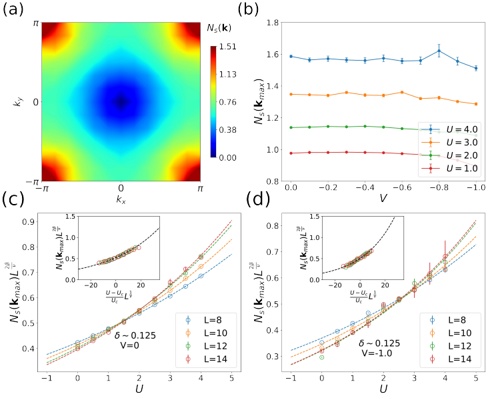
correlation increases with the increase of U , which is consistent with the variation of d -wave pairing with U . As V is enhanced, the strength of spin correlation remains basically unchanged at small V , but slightly decreases at large V . Such behavior indicates that the spin correlation is not significantly affected by the change of V , which is again similar to the behavior of the d -wave pairing in the intermediate coupling regime, to some extent proves the validness of the antiferromagnetic spin fluctuations as the pairing glue of the d -wave superconductivity [50, 51].
As demonstrated in Fig. 3(c) and (d), we can approximately determined U c from the crossing point of the scaled spin structure factor N S ( k max ) L 2 β ν /N obtained for different lattice sizes L at δ ∼ 0.125 with V = 0 and V = -1 0, separately. . The critical value U = U c represents a quantum phase transition of the system from a metal phase to the SDW phase. The critical exponents ν and β in the scaling law are determined by collapsing the scaled N S ( k ) arising from different sizes (inset of Fig. 3(c) and (d)), consistent with previous research in squarelattice [52]. We found that at V = 0 and V = -1 0, the . critical interactions are U c /similarequal 1 7 and . U c /similarequal 2.4 respectively, indicating that, in the presence of an attractive V , the system requires a larger critical U to cause the phase transition.
FIG. 4. (Color online) Schematic zero-temperature phase diagram of different pairing modes under different doping: (a) δ = 0.014, (b) δ = 0.208, (c) δ = 0.319 on 12 × 12 lattice, d x 2 -y 2 -wave, d xy -wave and exotic p -wave triplet pairing phases are observed.
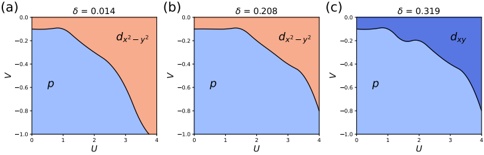
Lastly, we explore the effect of doping on the pairing order. Three additional doping concentrations are considered, namely a lightly doping δ = 0.014 (near half filling), an overdoped case δ = 0.208, and a heavily overdoped case δ = 0.319. The zero-temperature phase diagrams are displayed in Fig. 4, with d -wave, d xy -wave and exotic p -wave triplet pairing phases observed. At near half filling ( δ = 0.014, Fig. 4(a)), underdoped ( δ = 0.125, Fig. 1b) and slightly overdoped ( δ = 0.208, Fig. 4(b)), the d -wave pairing phase dominates when there is no attraction V . However, in heavily overdoped case ( δ = 0.319, Fig. 4(c)), the system becomes dominated by d xy -wave pairing phase. This is consistent with Fig. S4, where we give the zero-temperature phase diagram of the dominant pairing channel in U -n space with V =0 [47].
Notably, there is no p -wave pairing phase in the absence of V for all the doping cases. However, when V presents, the p -wave triplet pairing order begins to competes with the d -wave pairing order (or the d xy -wave pairing for the heavily doping case δ = 0.319), and overwhelms with an appropriate increase of V . Moreover, as the doping increases, the dominant region of p -wave pairing expands, further suppressing the presence of d -wave (or the d xy -wave) pairing. Our results indicate that the p -wave pairing order is induced by the NN electron attraction V and further benefits when the doping is heavier. From the known results obtained in 1D cuprate chains,
- [1] J. G. Bednorz and K. A. M¨ller, Possible high u T c superconductivity in the Ba -La -Cu -O system, Z Physik B 64 , 189 (1986).
- [2] C. C. Tsuei and J. R. Kirtley, Pairing symmetry in cuprate superconductors, Reviews of modern physics 72 , 969 (2000).
- [3] L. D. Landau, The theory of a fermi liquid, Sov. Phys. JETP 3 , 920 (1957).
- [4] A. Shekhter, B. J. Ramshaw, R. Liang, W. N. Hardy, D. A. Bonn, F. F. Balakirev, R. D. McDonald, J. B. Betts, S. C. Riggs, and A. Migliori, Bounding the pseudogap with a line of phase transitions in YBa 2 Cu O 3 6+ δ ,
the critical strengths of V for entering the p -wave pairing phase can be determined analytically at quarter filling in the U → ∞ limit [30, 53, 54], in which the Luttinger parameter K ρ = 1 [2 + (4 / /π )sin -1 ( V/ 2)] exceeding the unity indicates that it has entered the p -wave pairing phase. In a 2D system, similar mechanism is probable to happen that the strong NN electron attraction V drives the system towards the p -wave pairing phase.
In conclusion, we adopted CPQMC calculations of the 2D extended Hubbard model with the NN attraction V to study the impact of the additional attractive V on the pairing phase and density wave state. The quantum phase diagram containing d -wave, d xy -wave and p -wave pairing phases at different doping is explored. We find that the p -wave pairing phase is completely induced by V , and the p -wave pairing strength is enhanced as V increases. However, in the intermediate coupling regime, the d -wave pairing shows insignificant response to the increase of V . The spin density wave order, which is observed near half-filling in the particle-hole channel, is also almost unaffected by the NN electron attraction V , showing a similar behavior to the d -wave pairing with V . In a way, this supports that the spin fluctuations act as the dominant microscopic mechanism to drive the unconventional d -wave pairing phase. As δ increases, the dominant region of p -wave pairing expands, further suppressing the presence of d -wave pairing. Our work suggests the p -wave pairing region can be induced and further broadened by the NN electron attraction V , which will not only deepen the understanding of the highT c pairing microscopical mechanism, but also offering a feasible mechanism to realize p -wave triplet SC [55, 56] in realistic doped cuprates.
We acknowledge useful discussion with Ji Liu. This work is supported by the National Natural Science Foundation of China (Grant No. 12204130), Shenzhen StartUp Research Funds (Grant No. HA11409065), HITSZ Start-Up Funds (Grant No. X2022000), Shenzhen Key Laboratory of Advanced Functional CarbonMaterials Research and Comprehensive Application (Grant No. ZDSYS20220527171407017). T.Y. acknowledges supports from Natural Science Foundation of Heilongjiang Province (No. YQ2023A004).
## Nature 498 , 75 (2013).
- [5] J. Xia, E. Schemm, G. Deutscher, S. A. Kivelson, D. A. Bonn, W. N. Hardy, R. Liang, W. Siemons, G. Koster, M. M. Fejer, and A. Kapitulnik, Polar Kerr-effect measurements of the high-temperature YBa Cu O 2 3 6+ x superconductor: evidence for broken symmetry near the pseudogap temperature, Physical review letters 100 , 127002 (2008).
- [6] R. Comin, A. Frano, M. M. Yee, Y. Yoshida, H. Eisaki, E. Schierle, E. Weschke, R. Sutarto, F. He, A. Soumyanarayanan, Y. He, M. Le Tacon, I. S. Elfimov, J. E. Hoffman, G. A. Sawatzky, B. Keimer, and A. Dama-
- scelli, Charge order driven by Fermi-arc instability in Bi Sr 3 2 -x La CuO x 6+ δ , Science 343 , 390 (2014).
- [7] E. G. Moon and S. Sachdev, Competition between spin density wave order and superconductivity in the underdoped cuprates, Physical review. B, Condensed matter 80 , 035117 (2009).
- [8] Z. Shi, P. G. Baity, J. Terzic, T. Sasagawa, and D. Popovi´ c, Pair density wave at high magnetic fields in cuprates with charge and spin orders, Nature communications 11 , 3323 (2020).
- [9] Y. Sato, S. Kasahara, H. Murayama, Y. Kasahara, E.G. Moon, T. Nishizaki, T. Loew, J. Porras, B. Keimer, T. Shibauchi, and Y. Matsuda, Thermodynamic evidence for a nematic phase transition at the onset of the pseudogap in YBa Cu O , Nature physics 2 3 y 13 , 1074 (2017).
- [10] B. Keimer, S. A. Kivelson, M. R. Norman, S. Uchida, and J. Zaanen, From quantum matter to high-temperature superconductivity in copper oxides, Nature 518 , 179 (2015).
- [11] E. Fradkin, S. A. Kivelson, and J. M. Tranquada, Colloquium: Theory of intertwined orders in high temperature superconductors, Reviews of modern physics 87 , 457 (2015).
- [12] P. Mai, G. Balduzzi, S. Johnston, and T. A. Maier, Orbital structure of the effective pairing interaction in the high-temperature superconducting cuprates, npj Quantum Materials 6 , 1 (2021).
- [13] F. C. Zhang and T. M. Rice, Effective Hamiltonian for the superconducting Cu oxides, Physical review. B, Condensed matter 37 , 3759 (1988).
- [14] D. P. Arovas, E. Berg, S. A. Kivelson, and S. Raghu, The Hubbard model, Annual review of condensed matter physics 13 , 239 (2022).
- [15] The Hubbard model at half a century, Nature physics 9 , 523 (2013).
- [16] M. Qin, T. Sch¨ afer, S. Andergassen, P. Corboz, and E. Gull, The hubbard model: A computational perspective, Annual Review of Condensed Matter Physics 13 , 275 (2022).
- [17] Simons Collaboration on the Many-Electron Problem, J. P. F. LeBlanc, A. E. Antipov, F. Becca, I. W. Bulik, G. K.-L. Chan, C.-M. Chung, Y. Deng, M. Ferrero, T. M. Henderson, C. A. Jim´ enez-Hoyos, E. Kozik, X.W. Liu, A. J. Millis, N. V. Prokof'ev, M. Qin, G. E. Scuseria, H. Shi, B. V. Svistunov, L. F. Tocchio, I. S. Tupitsyn, S. R. White, S. Zhang, B.-X. Zheng, Z. Zhu, and E. Gull, Solutions of the Two-Dimensional Hubbard Model: Benchmarks and Results from a Wide Range of Numerical Algorithms, Physical Review X 5 , 041041 (2015).
- [18] D. J. Scalapino, A common thread: The pairing interaction for unconventional superconductors, Reviews of modern physics 84 , 1383 (2012).
- [19] B.-X. Zheng, C.-M. Chung, P. Corboz, G. Ehlers, M.-P. Qin, R. M. Noack, H. Shi, S. R. White, S. Zhang, and G. K.-L. Chan, Stripe order in the underdoped region of the two-dimensional Hubbard model, Science 358 , 1155 (2017).
- [20] Simons Collaboration on the Many-Electron Problem, M. Qin, C.-M. Chung, H. Shi, E. Vitali, C. Hubig, U. Schollw¨ck, S. R. White, and S. Zhang, Absence of Suo perconductivity in the Pure Two-Dimensional Hubbard Model, Physical Review X 10 , 031016 (2020).
- [21] H. Xu, C.-M. Chung, M. Qin, U. Schollw¨ck, S. R. White, o
- and S. Zhang, Coexistence of superconductivity with partially filled stripes in the Hubbard model, Science 384 , eadh7691 (2024).
- [22] A. Himeda, T. Kato, and M. Ogata, Stripe states with spatially oscillating d-wave superconductivity in the twodimensional t-t'-J model, Physical review letters 88 , 117001 (2002).
- [23] H.-C. Jiang and T. P. Devereaux, Superconductivity in the doped Hubbard model and its interplay with nextnearest hopping t', Science 365 , 1424 (2019).
- [24] P. Corboz, T. M. Rice, and M. Troyer, Competing states in the t-J model: uniform D-wave state versus stripe state, Physical review letters 113 , 046402 (2014).
- [25] B.-X. Zheng and G. K.-L. Chan, Ground-state phase diagram of the square lattice Hubbard model from density matrix embedding theory, Physical review. B, Condensed matter 93 , 035126 (2016).
- [26] Z. Chen, Y. Wang, S. N. Rebec, T. Jia, M. Hashimoto, D. Lu, B. Moritz, R. G. Moore, T. P. Devereaux, and Z.X. Shen, Anomalously strong near-neighbor attraction in doped 1D cuprate chains, Science 373 , 1235 (2021).
- [27] Y. Wang, Z. Chen, T. Shi, B. Moritz, Z.-X. Shen, and T. P. Devereaux, Phonon-Mediated Long-Range Attractive Interaction in One-Dimensional Cuprates, Physical review letters 127 , 197003 (2021).
- [28] T. Tang, B. Moritz, C. Peng, Z.-X. Shen, and T. P. Devereaux, Traces of electron-phonon coupling in onedimensional cuprates, Nature communications 14 , 3129 (2023).
- [29] C. Peng, Y. Wang, J. Wen, Y. S. Lee, T. P. Devereaux, and H.-C. Jiang, Enhanced superconductivity by near-neighbor attraction in the doped extended Hubbard model, Physical review. B, Condensed matter 107 , L201102 (2023).
- [30] D.-W. Qu, B.-B. Chen, H.-C. Jiang, Y. Wang, and W. Li, Spin-triplet pairing induced by near-neighbor attraction in the extended Hubbard model for cuprate chain, Communications Physics 5 , 1 (2022).
- [31] W.-C. Chen, Y. Wang, and C.-C. Chen, Superconducting phases of the square-lattice extended Hubbard model, Physical review. B, Condensed matter 108 , 064514 (2023).
- [32] J. Gukelberger, E. Kozik, L. Pollet, N. Prokof'ev, M. Sigrist, B. Svistunov, and M. Troyer, p-Wave superfluidity by spin-nematic Fermi surface deformation, Physical review letters 113 , 195301 (2014).
- [33] C. Kallin, Chiral p-wave order in Sr2RuO4, Reports on Progress in Physics 75 , 042501 (2012).
- [34] P. A. Lee and X.-G. Wen, Spin-triplet p -wave pairing in a three-orbital model for iron pnictide superconductors, Physical review. B, Condensed matter 78 , 144517 (2008).
- [35] Y. Guo and H. Tajima, Competition between pairing and tripling in one-dimensional fermions with coexistent s -and p -wave interactions, Physical review. B, Condensed matter 107 , 024511 (2023).
- [36] A. P. Mackenzie and Y. Maeno, The superconductivity of sr 2 ruo 4 and the physics of spin-triplet pairing, Reviews of Modern Physics 75 , 657 (2003).
- [37] K. Kinjo, M. Manago, S. Kitagawa, Z. Q. Mao, S. Yonezawa, Y. Maeno, and K. Ishida, Superconducting spin smecticity evidencing the Fulde-Ferrell-LarkinOvchinnikov state in Sr 2 RuO , Science 4 376 , 397 (2022).
- [38] J. A. Sauls, The order parameter for the superconducting phases of UPt , Advances in Physics 3 43 , 113 (1994).
- [39] L. Jiao, S. Howard, S. Ran, Z. Wang, J. O. Rodriguez, M. Sigrist, Z. Wang, N. P. Butch, and V. Madhavan, Chiral superconductivity in heavy-fermion metal UTe , 2 Nature 579 , 523 (2020).
- [40] Y. Jia, P. Wang, C.-L. Chiu, Z. Song, G. Yu, B. J¨ck, a S. Lei, S. Klemenz, F. A. Cevallos, M. Onyszczak, N. Fishchenko, X. Liu, G. Farahi, F. Xie, Y. Xu, K. Watanabe, T. Taniguchi, B. A. Bernevig, R. J. Cava, L. M. Schoop, A. Yazdani, and S. Wu, Evidence for a monolayer excitonic insulator, Nature physics 18 , 87 (2021).
- [41] K. Matano, M. Kriener, K. Segawa, Y. Ando, and G.-q. Zheng, Spin-rotation symmetry breaking in the superconducting state of cu x bi 2 se 3 , Nature Physics 12 , 852 (2016).
- [42] Y. Liu, T. Wei, G. He, Y. Zhang, Z. Wang, and J. Wang, Pair density wave state in a monolayer high-Tc ironbased superconductor, Nature 618 , 934 (2023).
- [43] S. D. Sarma, M. Freedman, and C. Nayak, Majorana zero modes and topological quantum computation, npj Quantum Information 1 , 1 (2015).
- [44] V. Cr´ epel and L. Fu, Spin-triplet superconductivity from excitonic effect in doped insulators, Proceedings of the National Academy of Sciences of the United States of America 119 , e2117735119 (2022).
- [45] S. Zhang, J. Carlson, and J. E. Gubernatis, Constrained path quantum Monte Carlo method for fermion ground states, Physical review letters 74 , 3652 (1995).
- [46] S. Zhang, J. Carlson, and J. E. Gubernatis, Constrained path Monte Carlo method for fermion ground states, Physical review. B, Condensed matter 55 , 7464 (1997).
- [47] See Supplemental Material, which includes Ref. [57-59], for details on the method and additional simulation results.
- [48] O. K. Andersen, A. I. Liechtenstein, O. Jepsen, and F. Paulsen, LDA energy bands, low-energy hamiltonians, t ′ , t ′′ , t ⊥ ( k ), and J ⊥ , The Journal of physics and chemistry of solids 56 , 1573 (1995).
- [49] M. Hirayama, Y. Yamaji, T. Misawa, and M. Imada, Ab initio effective Hamiltonians for cuprate superconductors,
Physical review. B, Condensed matter 98 , 134501 (2018).
- [50] T. Dahm, V. Hinkov, S. V. Borisenko, A. A. Kordyuk, V. B. Zabolotnyy, J. Fink, B. B¨ uchner, D. J. Scalapino, W. Hanke, and B. Keimer, Strength of the spin-fluctuation-mediated pairing interaction in a high-temperature superconductor, Nature physics 5 , 217 (2009).
- [51] X. Dong, L. Del Re, A. Toschi, and E. Gull, Mechanism of superconductivity in the Hubbard model at intermediate interaction strength, Proceedings of the National Academy of Sciences of the United States of America 119 , e2205048119 (2022).
- [52] Y. Otsuka, K. Seki, S. Sorella, and S. Yunoki, Dirac electrons in the square-lattice Hubbard model with a d -wave pairing field: The chiral Heisenberg universality class revisited, Physical review. B 102 , 235105 (2020).
- [53] A. Luther and I. Peschel, Calculation of critical exponents in two dimensions from quantum field theory in one dimension, Physical review b 12 , 3908 (1975).
- [54] H. J. Schulz, Correlation exponents and the metalinsulator transition in the one-dimensional Hubbard model, Physical review letters 64 , 2831 (1990).
- [55] T. Das, Nodeless superconducting gap induced by odd parity pair density wave in underdoped cuprates, Annals of physics 420 , 168251 (2020).
- [56] Y.-M. Lu, T. Xiang, and D.-H. Lee, Underdoped superconducting cuprates as topological superconductors, Nature physics 10 , 634 (2014).
- [57] K. Liu, S. Yang, W. Li, T. Ying, J. Yang, X. Sun, and X. Li, The pairing symmetries in the two-dimensional Hubbard model, Physics letters. A 392 , 127153 (2021).
- [58] A. T. Rømer, T. A. Maier, A. Kreisel, I. Eremin, P. Hirschfeld, and B. M. Andersen, Pairing in the twodimensional hubbard model from weak to strong coupling, Physical Review Research 2 , 013108 (2020).
- [59] E. Y. Loh, J. E. Gubernatis, R. T. Scalettar, S. R. White, D. J. Scalapino, and R. L. Sugar, Sign problem in the numerical simulation of many-electron systems, Physical review. B, Condensed matter 41 , 9301 (1990).
## Supplemental Material for 'Dominant p -wave pairing induced by near-neighbor attraction in the square-lattice extended Hubbard model'
Zhangkai Cao, 1, ∗ Jianyu Li, 1, 2, ∗ Jiahao Su, 1, 2 Tao Ying, 3, † and Ho-Kin Tang 1, 2, ‡
1 School of Science, Harbin Institute of Technology, Shenzhen, 518055, China 2 Shenzhen Key Laboratory of Advanced Functional Carbon Materials Research and Comprehensive Application, Shenzhen 518055, China. 3 School of Physics, Harbin Institute of Technology, Harbin 150001, China (Dated: January 20, 2025)
In this Supplemental Material, we present additional computational results. In Sec. S1, we have defined various correlation functions. In Sec. S2, we provide the effective d-wave and p-wave pairing correlation function in momentum space with the change of U , V and δ . In Sec. S3, we give a phase diagram of the dominant pairing channel in U -n space when V =0. In Sec. S4, we give a brief introduction to constraint path quantum Monte Carlo (CPQMC).
## S1. Correlation function
We have defined the effective pair momentum distribution function where ζ = s, d x 2 -y 2 , d xy , p . The effective real-space correlation of the on-site s -wave pairing operator C eff s -pair ( i, j ) = 〈 ∆ ( )∆ ( ) † s i s j 〉 -G ↑ i,j G ↓ i,j , where ∆ ( ) = † s i c † i ↑ c † i ↓ is the on-site s -wave pairing operator and G ↑ i,j G ↓ i,j is the uncorrelated pairing structure factor. G σ i,j = 〈 c iσ c † jσ 〉 is the Green's function. The effective real-space correlation of the NN sites d x 2 -y 2 -wave pairing operator C eff d x 2 -y 2 -pair ( i, j ) = ∑ δ ζ ,δ ′ ζ 〈 ∆ † d x 2 -y 2 ( i, i + δ ζ )∆ d x 2 -y 2 ( j, j + δ ′ ζ ) 〉-G ↑ i,j G ↓ i + δ ζ ,j + δ ′ ζ ), where ∆ † d x 2 -y 2 ( ) = i c † i ↑ ( c † i + x ↓ -c † i + y ↓ + c † i - ↓ x -c † i - ↓ y ) and δ ( ) ′ ζ are NN sites in the d x 2 -y 2 -wave pairing. The effective realspace correlation of the NNN sites d xy -wave pairing operator C eff d xy -pair ( i, j ) = ∑ δ ζ ,δ ′ ζ 〈 ∆ † d xy ( i, i + δ ζ )∆ d xy ( j, j + δ ′ ζ ) 〉 -G ↑ i,j G ↓ i + δ ζ ,j + δ ′ ζ ), where ∆ † d xy ( ) = i c † i ↑ ( c † i + + x y ↓ -c † i -x + y ↓ + c † i - - ↓ x y -c † i + x - ↓ y ) and δ ( ) ′ ζ are the NNN sites in the d xy -wave pairing. The effective real-space correlation of the NN sites p -wave pairing operator C eff p -pair ( i, j ) = ∑ δ ζ ,δ ′ ζ 〈 ∆ ( † p i, i + δ ζ )∆ ( p j, j + δ ′ ζ ) 〉 -G σ i,j G σ i + δ ζ ,j + δ ′ ζ ), in which δ ( ) ′ ζ are the NN sites in the p -wave pairing. ∆ ( ) = † p i c † iσ ( c † i + lσ -c † i -lσ ), with spin σ = ↑ ↓ , representing the ↑↑ and ↓↓ pairing, and l = x, y corresponds to the symmetries of p x and p y , respectively. Considering the structure of square lattice, these different pairing symmetries have the following form factor, as shown in Fig. S1. The effective on-site s -wave pairing exists only in the weak U and large V regions. The values of the effective s -wave are small and do not dominate the system, so it was not included it in the main text.
$$\ x l \, & \text{the effective pair momentum distribution function} \\ N _ { \zeta - p a i r } ( k ) = ( 1 / N ) \sum _ { i, j } \exp [ i k ( r _ { i } - r _ { j } ) ] C _ { \zeta - p a i r } ^ { \text{eff} } ( i, j ), & & ( S 1 ) \\ \ x \, & \ d \quad n \, \text{ The effective real sense correlation of the entire wave rainbow or color } \, C _ { \text{eff} } \quad ( i \, \ i ) =$$
FIG. S1. (Color online) Phase of the d x 2 -y 2 , d xy , p ( p x or p y ) pairing symmetry.
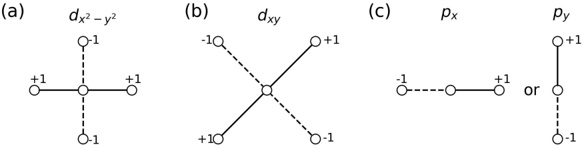
∗ These authors contributed equally.
‡ [email protected]
† [email protected]
## S2. The effective d -wave and p -wave pairing in momentum space evolve with the change of U , V and δ
This section we analyze the characteristic of effective d -wave and p -wave pairing correlation function in momentum space evolving with the change of U , V and δ . In Fig. S2(a), we show the effective d -wave pairing correlation function N eff d x 2 -y 2 -pair ( k ) at δ = 0.125 with U = 1 2 3 4 and , , , V = 0 0 . , -0 2 . , -0 4 . , -0 6 . , -0 8 . , -1 0. . We can compare the phase diagram (Fig. 1(b)) to the dominant region of the d x 2 -y 2 -wave pairing, d -wave pairing correlation function exhibits a singular nonzero condensation structure, and its peak occurs near nonzero momentum point Q = (2 π/ , 3 π ), which demonstrate the presence of the d -wave PDW phase. However, in the dominant region of the p -wave pairing, d -wave pairing gradually evolves into a Q = (0 , 0) condensation, exhibiting a significantly weaker strength compared to the p -wave pairing. In Fig. S2(b), we show the effective p -wave pairing correlation function N eff p -pair ( k ) in momentum space at δ = 0.125 with U = 1 2 3 4 and , , , V = 0 0 . , -0 2 . , -0 4 . , -0 6 . , -0 8 . , -1 0. . It clearly that the p -wave pairing strength increases with the increase of V and suppressed by the increase of U . Noteworthy, when the maximum value in momentum space is less than 0, it indicates the absence of p -wave pairing. In the dominant region of the p -wave pairing, the p -wave pairing always condenses at point Q = (0 , 0).
We also present how the effective d -wave and p -wave pairings evolve with doping. As shown in Fig. S3(a)-(c), with doping increases, we can see the condensation point becomes slightly dispersed and the intensity of the d -wave pairing decreases, which may be related to the suppression of the d -wave by doping. At the same time, the p -wave pairing has always been zero momentum condensation, and its intensity has remained basically unchanged when evolve with the change of δ . This indicates that as δ increases, the expansion of the p -wave pairing dominant region is mainly due to the decrease of d -wave pairing.
In the dominant region of d -wave pairing, the position of its condensation point will not change significantly, but with the change of U , V and δ , the sharpness of its nonzero condensation point will change slightly. In the dominant region of the p -wave pairing, it always condenses at point Q = (0 , 0), which supporting the formation of Cooper-pair triplets with zero center-of-mass momentum and p -wave symmetry.
FIG. S2. (Color online) (a) CPQMC simulation result of effective d -wave pair momentum distribution function N eff d x 2 -y 2 -pair ( k ) at δ = 0.125 with U = 1 2 3 4 , , , and V = 0 0 . , -0 2 . , -0 4 . , -0 6 . , -0 8 . , -1 0 . on 12 × 12 lattice. (b) CPQMC simulation result of effective p -wave pair momentum distribution function N eff p -pair ( k ) at δ = 0.125 with U = 1 2 3 4 , , , and V = 0 0 . , -0 2 . , -0 4 . , -0 6 . , -0 8 . , -1 0 on 12 . × 12 lattice.
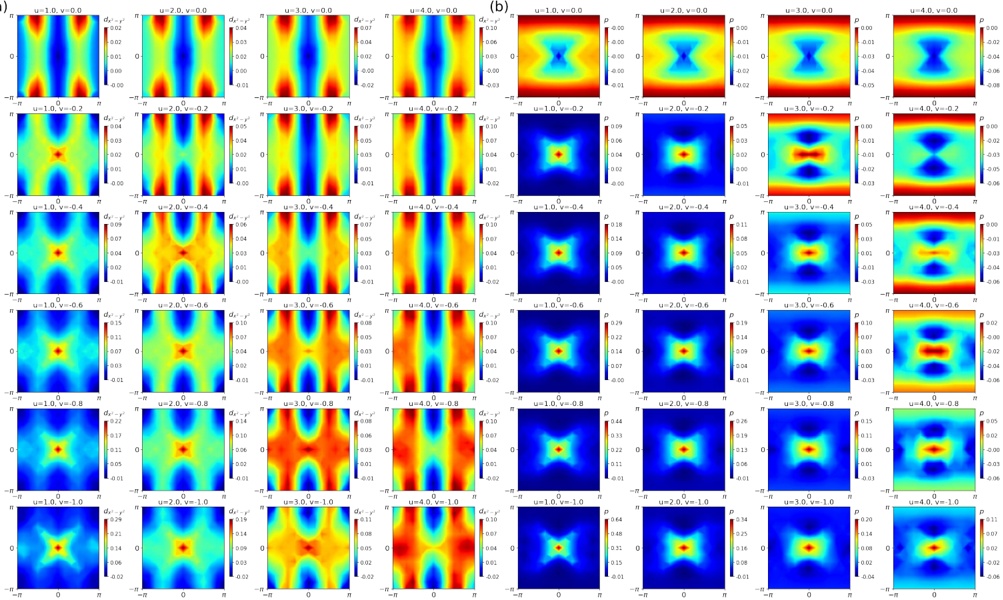
FIG. S3. (Color online) (a)-(c) CPQMC simulation result of effective d -wave pair momentum distribution function N eff d x 2 -y 2 -pair ( k ) at δ = 0.014, 0.125, 0.208 with U = 3 and V = -0 3 on 12 . × 12 lattice. (d)-(f) CPQMC simulation result of effective p -wave pair momentum distribution function N eff p -pair ( k ) at δ = 0.014, 0.125, 0.208 with U = 2 and V = -0 9 . on 12 × 12 lattice.
FIG. S4. (Color online) The zero-temperature schematic phase diagram of the dominant pairing channel in U -n space when V =0.
## S3. U -n phase diagram
In this section, we mainly explore the dominant pairing channels in different interaction strength and doping regimes when V = 0. At zero temperature, we summarize the phase diagram of the square-lattice extended Hubbard model in Fig. S4, where includes the d x 2 -y 2 -wave and d xy -wave pairing phases in U -n space when V = 0. At n = 0 681 . -1, the d x 2 -y 2 -wave pairing phase dominates the system when there is no attraction V , while for small electron densities n < 0 681, . the dominant pairing channel is the d xy -wave. This is a schematic phase diagram drawn based on 12 × 12 lattice, which will become more accurate as the system size increase. Our results agree qualitatively with the dynamic cluster approximation (DCA) and determinant quantum Monte Carlo (DQMC) studies [S1, S2], but there are differences in details. The phase boundary between the d x 2 -y 2 -wave and d xy -wave pairing is n ∼ 0 6 in their study, . but in our study, this boundary is n ∼ 0 7. . This is mainly because our CPQMC method is study the ground state of the system at zero temperature. Furthermore, we did not observe the presence of p -wave pairing at low electron density when V = 0.
## S4. Constraint path quantum Monte Carlo
The CPQMC method is a quantum Monte Carlo method with a constraint path approximation [S3, S4]. CPQMC method prevents the infamous sign problem [S5] encountered in the DQMC method when dealing with systems that are far from half filling. In CPQMC, the ground state wave function ψ ( n ) is represented by a finite ensemble of Slater determinants, i.e., ∣ ∣ ψ ( n ) 〉 ∝ ∑ ∣ ∣ k ∣ φ ( n ) k 〉 , where k is the index of the Slater determinants, and n is the number of iteration. The overall normalization factor of the wave function has been omitted here. The propagation of the Slater determinants dominates the computational time, as follows
$$\begin{array} { c } \colon \text{computational} \, \text{in}, \, \text{as} \, \text{nows} \\ & \left | \phi _ { k } ^ { ( n + 1 ) } \right \rangle \leftarrow \int d \vec { x } P ( \vec { x } ) B ( \vec { x } ) \left | \phi _ { k } ^ { ( n ) } \right \rangle. & ( S 2 ) \\ \\ \text{ld configuration, that we select according to the probability distribution function } P ( \vec { x } ). \\ \text{he matrix multiplication of the non-actor} \, R ( \vec { x } ) \, \text{and} \, \vec { a } ^ { ( n ) } \text{ after a series of equilibrium} \end{array}$$
where /vector x is the auxiliary-field configuration, that we select according to the probability distribution function P /vector ( x ). The propagation includes the matrix multiplication of the propagator B /vector ( x ) and φ ( n ) k . After a series of equilibrium steps, the walkers are the Monte Carlo samples of the ground state wave function φ (0) and ground-state properties can be measured.
The random walk formulation suffers from the sign problem because of the fundamental symmetry existing between the fermion ground state | ψ 0 〉 and its negative -| ψ 0 〉 . In more general cases, walkers can cross N in their propagation by e -∆ τH whose bounding surface N is defined by 〈 ψ 0 | φ 〉 = 0 and is in general unknown . Once a random walker reaches N , it will make no further contribution to the representation of the ground state since
Paths that result from such a walker have equal probability of being in either half of the Slater-determinant space. Computed analytically, they would cancel, but without any knowledge of N , they continue to be sampled in the random walk and become Monte Carlo noise.
$$\text{$me no name conunation to one repositions on one group above one} \\ \langle \psi _ { 0 } \left | \phi \right \rangle = 0 \Rightarrow \left \langle \psi _ { 0 } \left | e ^ { - \tau H } \right | \phi \right \rangle = 0 \quad \text{for any $\tau$}. \\ \text{rom such a walker have equal probability of being in either half of the Slater-determinant space}. \text{ly, they would cancel, but without any knowledge of $\mathcal{N}$, they continue to be sampled in the}$$
The decay of the signal-to-noise ratio, i.e., the decay of the average sign of 〈 ψ T | φ 〉 , occurs at an exponential rate with imaginary time. To eliminate the decay of the signal-to-noise ratio, we impose the constrained path approximation. It requires that each random walker at each step has a positive overlap with the trial wave function | ψ T 〉 :
$$\left \langle \psi _ { T } \, | \, \phi _ { k } ^ { ( n ) } \right \rangle & > 0. \\ \intertext { to the ground-state wave function. } | \psi _ { K } \right \rangle & = \Sigma _ { A } | \phi \rangle. \text{ in which all Slater deter-}$$
The details of hyper-parameters in CPQMC calculations are given as follows. The number of walkers is 1000, the number of blocks for relaxation is 10, the number of blocks for growth estimate is 3, the number of blocks after relaxation is 10, the number of steps in each block is 640, the Trotter step size is 0.01, the growth-control energy estimate is -50. To ensure the stability of the data, we intentionally increased the number of steps in each block is 640, and reduced the Trotter step size is 0.01.
This yields an approximate solution to the ground-state wave function, | ψ c 0 〉 = Σ φ | φ 〉 , in which all Slater determinants | φ 〉 satisfy Eq. S3. From Eq. S4, it follows that this approximation becomes exact for an exact trial wave function | ψ T 〉 = | ψ 0 〉 .
[S1] K. Liu, S. Yang, W. Li, T. Ying, J. Yang, X. Sun, and X. Li, The pairing symmetries in the two-dimensional Hubbard model, Physics letters. A 392 , 127153 (2021).
[S2] A. T. Rømer, T. A. Maier, A. Kreisel, I. Eremin, P. Hirschfeld, and B. M. Andersen, Pairing in the two-dimensional hubbard model from weak to strong coupling, Physical Review Research 2 , 013108 (2020).
[S3] S. Zhang, J. Carlson, and J. E. Gubernatis, Constrained path quantum Monte Carlo method for fermion ground states, Physical review letters 74 , 3652 (1995).
[S4] S. Zhang, J. Carlson, and J. E. Gubernatis, Constrained path Monte Carlo method for fermion ground states, Physical review. B, Condensed matter 55 , 7464 (1997).
[S5] E. Y. Loh, J. E. Gubernatis, R. T. Scalettar, S. R. White, D. J. Scalapino, and R. L. Sugar, Sign problem in the numerical simulation of many-electron systems, Physical review. B, Condensed matter 41 , 9301 (1990). | null | [
"Zhangkai Cao",
"Jianyu Li",
"Jiahao Su",
"Tao Ying",
"Ho-Kin Tang"
] | 2024-08-02T08:41:38+00:00 | 2025-01-17T04:05:37+00:00 | [
"cond-mat.supr-con",
"cond-mat.str-el"
] | p-wave superconductivity induced by nearest-neighbor attraction in the square-lattice extended Hubbard model | The two-dimensional (2D) Hubbard model is widely believed to contain the key
ingredients of high-temperature superconductivity in cuprate materials. Here,
we report a constrained path quantum Monte Carlo (CPQMC) study of the
square-lattice extended Hubbard model with on-site Coulomb repulsion U and
nearest-neighbor (NN) electron attraction V. Upon doping $\delta$= 0.125, we
find that the NN electron attraction V can notably drive an exotic spin-triplet
(p-wave) superconducting (SC) phase, and enhance the p-wave SC correlations
with the increase of V. But in the intermediate coupling regime, the
$d_{x^2-y^2}$-wave (d-wave) does not significantly increase with the increase
of V, indicating that the d-wave is not affected by V in strongly correlated
system. Besides the pairing phase, a spin density wave (SDW) only exists near
the half-filling in the particle-hole channel, and doping disrupts the
formation of SDW order. Especially, the NN electron attraction V has no
significant effect on SDW, reflecting the consistent relationship between
d-wave SC and spin correlation. Moreover, as doping increases, the dominant
region of p-wave also expands, further suppressing the presence of d-wave,
which may help explain the disappearance of d-wave SC in overdoped cuprate
superconductors. We also find the d-wave exhibits a singular nonzero (near
point ($2{\pi}/3, {\pi}$)) condensation structure in momentum space, resulting
in a different staggered behavior in the x and y direction with distance in
real space. On the contrary, the p-wave condensed at zero momentum, and the
p-wave correlation exhibits exponential decay in real space. Our work suggests
the p-wave SC region can be induced and further broadened by the NN electron
attraction V, offering a feasible mechanism to realize p-wave superconductivity
in realistic cuprate materials. |
2408.01114v1 | ## PSP-GEN: Stochastic inversion of the Process-Structure-Property chain in materials design through deep, generative probabilistic modeling
Yaohua Zang a and Phaedon-Stelios Koutsourelakis a,b a Technical University of Munich, Professorship of Data-driven Materials Modeling, School of Engineering and Design, Boltzmannstr. 15, 85748 Garching, Germany b Munich Data Science Institute (MDSI - Core member), Garching, Germany { yaohua.zang, p.s.koutsourelakis } @tum.de
## Abstract
Inverse material design is a cornerstone challenge in materials science, with significant applications across many industries. Traditional approaches that invert the structure-property (SP) linkage to identify microstructures with targeted properties often overlook the feasibility of production processes, leading to microstructures that may not be manufacturable. Achieving both desired properties and a realizable manufacturing procedure necessitates inverting the entire ProcessStructure-Property (PSP) chain. However, this task is fraught with challenges, including stochasticity along the whole modeling chain, the high dimensionality of microstructures and process parameters, and the inherent ill-posedness of the inverse problem. This paper proposes a novel framework, named PSP-GEN, for the goal-oriented material design that effectively addresses these challenges by modeling the entire PSP chain with a deep generative model. It employs two sets of continuous, microstructure- and property-aware, latent variables, the first of which provides a lower-dimensional representation that captures the stochastic aspects of microstructure generation, while the second is a direct link to processing parameters. This structured, low-dimensional embedding not only simplifies the handling of high-dimensional microstructure data but also facilitates the application of gradient-based optimization techniques. The effectiveness and efficiency of this method are demonstrated in the inverse design of two-phase materials, where the objective is to design microstructures with target effective permeability. We compare state-of-the-art alternatives in challenging settings involving limited training data, target property regions for which no training data is available, and design tasks where the process parameters and microstructures have high-dimensional representations.
Keywords: Inverse Materials Design, PSP Chain, Deep Learning, Deep Generative Model
## 1 Introduction
Inverse material design is a critical challenge in modern materials science, offering unprecedented avenues for accelerating material discovery and optimization across diverse sectors [1]. Its applications span crucial industries such as aerospace [2], automotive [3], pharmaceutical [4], and renewable energy [5], where tailored materials with specific properties are paramount for technological advancement and innovation. Central to the inverse design paradigm are the Process-Structure (PS) and Structure-Property (SP) linkages, which describe the causal links in material response
[6, 7, 8, 9]. The PS linkage determines how processing parameters influence material microstructures, while the SP linkage relates these structures to material properties. Together, these linkages form the Process-Structure-Property (PSP) chain, providing a holistic framework for understanding and manipulating material behavior [10, 11]. Inverse materials design based on the PSP linkage entails identifying the processing conditions or material microstructures that yield desired properties, thereby enabling targeted material design and optimization [12]. By leveraging the comprehensive understanding of the PSP linkage, inverse design methodologies empower researchers to navigate the vast design space effectively and expedite the discovery of materials with tailored properties for diverse applications [13, 14, 15]. However, navigating inverse materials design based on the entire PSP linkage faces many difficult challenges. Firstly, the intricate transformation from process parameters to material microstructure constitutes a complex, stochastic, hierarchical system, characterized by high nonlinearity [16, 17]. Its inherent stochasticity amplifies the complexity and challenges of inverse design. Secondly, the representation of several material microstructures is inherently discrete and high-dimensional [18], which complicates computational handling and renders derivative-based methods impossible due to the inability to calculate derivatives with respect to discrete-valued inputs [19, 20]. Additionally, calculating the properties of microstructures often involves solving partial differential equations (PDEs), which are inherently time-consuming and computationally intensive [9]. Collectively, these factors engender an inverse problem that is inherently ill-posed, stochastic, and computationally intensive, necessitating innovative methodologies and advanced computational tools to surmount these challenges effectively.
Due to these difficulties, pertinent methods frequently focus only on inverting the SP linkage (or microstructure-centered design). Traditional methods [21, 22, 23, 24] for inverting the SP linkage generally include optimization algorithms, statistical modeling, and physics-based simulations. While these methods offer more interpretability, they often suffer from slow convergence, especially in high-dimensional spaces, and struggle with the curse of dimensionality, limiting their scalability to complex material systems. Conversely, deep-learning-based methods, particularly Deep Generative Models such as Variational Autoencoders (VAEs) [19, 25, 26, 26, 27, 28], Generative Adversarial Networks (GANs) [29, 30] and diffusion models [31], have gained prominence for their ability to map complex and irregular microstructure space into a well-structured and continuous latent space. This latent space can then be used to establish the requisite, differentiable link to material properties which derivative-based search algorithms can explore for discovering microstructures exhibiting desired properties. However, they may suffer from limitations such as data efficiency, interpretability, and generalization to unseen material systems. Despite the advancements achieved by inverting the SP linkage, these methods only address part of the problem as they do not provide any manufacturing routes for producing these microstructures. The microstructures obtained through these methods may face the risk of being unable to find corresponding processing parameters, rendering them unfeasible to generate. Therefore, they require a secondary inversion process, such as iterative searches relying on domain knowledge. More crucially, these methods overlook the randomness inherent in the generation process of microstructures.
Different from the microstructure-centered design, the goal-oriented material design considers the entire PSP chain, aiming to identify optimal processing parameters that yield microstructures exhibiting desired properties [32]. In goal-oriented material design, certain methodologies are categorized as microstructure-agnostic approaches, as they circumvent the intricate representation of material microstructures. Instead, they concentrate on establishing direct correlations between processing parameters and material properties, aiming to optimize the former by inverting the Process-Property (PP) linkage [33, 34, 35]. While these techniques alleviate the computational complexities associated with irregular and high-dimensional microstructure spaces, they overlook crucial information contained in the microstructures, essential for bridging processing parameters and properties. Consequently, they exhibit diminished performance compared to methods that explicitly incorporate microstructural information throughout the PSP linkage, especially in cases where the properties exhibit significant variability due to changes in processing parameters. In contrast, microstructureaware methodologies encompass not only material properties and processing conditions within the design space but also microstructural information which plays a crucial role in the solution of the optimization problem. In [36], the authors proposed a multi-fidelity method for identifying the combination of chemistry and processing parameters that maximizes the targeted mechanical property of a model, dual-phase steel. They found that the deliberate incorporation of microstructural information into materials design dramatically improves materials optimization. However, they did not incorporate the full microstructure seamlessly into the design process and instead used a feature of
the microstructure, i.e. the volume fraction of the martensite phase. Recently, the authors in [20, 37] proposed a Bayesian framework leveraging a lightweight, normalizing-flow-based generative approach for the stochastic inversion of the complete PSP linkage. They employed dimension-reduced, 2-point spatial correlations as representative features of the microstructure, and a conditional, continuous normalizing flow model was employed to capture the conditional density of processing parameters given properties.
In this paper, we introduce a novel, integrated framework for goal-oriented materials design, called PSP-GEN, which effectively addresses the challenges posed by the PSP chain in its entirety. The core of PSP-GEN is a deep generative model designed to capture the full PSP linkage, enabling direct exploration of optimal solutions within the processing parameter space. Our generative model maps PSP data to a well-structured, low-dimensional latent space, which consists of two sets of microstructure- and property-aware variables. The first part accounts for generators that are directly related to the processing variables whereas the second to the independent, stochastic elements. Together, these representations form a comprehensive microstructural descriptor capable of reconstructing input microstructures and predicting their corresponding properties. These continuous, latent variables not only enable the lower-dimensional embedding of the high-dimensional microstructural space and the surrogation of the expensive PS and SP links but more importantly, the computation of derivatives which are essential in the back-propagation of information from the properties to the processing variables and especially when the latter are higher-dimensional [38].
Hence, we can reformulate the goal-oriented design problem as a straightforward optimization problem, easily solvable with gradient-based methods. As demonstrated in our study, the proposed model significantly outperforms a recently developed state-of-the-art method in a 2D dual-phase microstructure design problem. In summary, the main contributions of the paper are:
- · An integrated, data-driven surrogate for the whole PSP chain in contrast to multicomponent strategies or methods that neglect the importance of processing in achieving not only optimal but also realizable designs.
- · A fully probabilistic framework that accounts for the multitude of uncertainties in the PSP chain, as well as in the formulation of the inverse design problem.
- · The proposed framework simplifies the goal-oriented design problem into an optimization problem solvable with gradient-based methods even when the original microstructural representations are discrete-valued.
The remainder of the paper is structured as follows. In section 2 we provide a concrete definition of the main quantities involved, enumerate the various sources of uncertainty, and reformulate the inverse design problem in a manner that reflects the inherent stochasticity. More importantly, we discuss the computational challenges that we attempt to overcome with the proposed generative model presented in section 3. In particular, we present the latent variables involved, and how these relate to the processing variables as well as generate both microstructures and properties. We discuss a Variational-Bayesian EM scheme [39] that is used for inference and learning, and more importantly, how the trained model can efficiently lead to solutions of the stochastic inverse design problem. Finally, in section 4, we present comparative results on the inverse design of two-phase, heterogeneous materials where we explore the ability of our model to operate under limited data as well as to generalize to unseen property domains. We present a concluding summary as well as tangible avenues for potential extensions in section 5.
## 2 Inverting the PSP chain: a formidable computational challenge
In this paper, we focus on the design of heterogeneous media with an emphasis on two-phase materials. Such materials are encountered in a multitude of engineering applications such as aligned and chopped fiber composites, dual-phase steels, porous membranes, particulate composites, cellular solids, colloids, microemulsions, concrete [40]. In most instances, pertinent microstructures can be characterized only statistically which is essential in determining and ultimately controlling their effectiveness e.g. mechanical, transport properties are of great importance [41]. In the following, we denote with:
- · φ ∈ U φ ⊂ R d φ the controllable processing parameters that give rise to a family of microstructures. These serve as the optimization variables in inverse materials design.
- · x ∈ X the microstructural representation, which for the two-phase media considered takes the form of a high-dimensional (i.e. dim ( x ) = d x >> 1 ), binary vector i.e. X ≡ { 0 1 , } d x . Multi-phase materials can similarly be represented with a discrete-valued vector.
- · m ∈ M ⊂ R d m the microstructural properties that are targeted in the context of inverse design and pertain to e.g. effective permeability, elastic moduli, thermal conductivity, fracture toughness, electrical conductivity, or combinations thereof.
In Figure 1, we elucidate the entirety of the PSP chain, depicting the sequential transformation from processing parameters φ to the eventual effective properties m . Most research efforts in capturing the nonlinear and multiscale processes involved in forward and backward modeling of the processstructure (PS) and structure-property (SP) linkages have disregarded uncertainties [42]. The latter is present in all steps of material analysis and design [43, 44]. Firstly, process variables do not uniquely determine the resulting microstructure which can exhibit aleatoric fluctuations in their features. They rather define a probability distribution on microstructures [45, 46]. Furthermore, the experimental data that are used to model process-structure (most often) and structure-property relations are contaminated by random noise and are frequently incomplete [47]. Very often, the models employed for the process-structure or structure-property links are inherently stochastic and additional uncertainty exists with regard to their parameter values or even form, especially in multiscale formulations [48]. Finally, the processes of model compression and dimension reduction employed to gain computational efficiency or insight, very often lead to some information loss which in turn gives rise to predictive uncertainty [49]. (Back-)propagating uncertainty through complex and potentially multiscale models poses significant computational difficulties [50]. Data-based surrogates offer a powerful alternative but unlike classical machine-learning applications where one operates in abundance of data. In materials problems, however, due to the cost of the experimental or computational generation procedures, pertinent tools must operate in the small-data regime, which can itself give rise to additional (epistemic) uncertainty. We note that problem formulations based on Bayesian Optimization [51, 52, 25], apart from their inherent limitation to low-dimensional design spaces, account for uncertainty in the objective solely due to the imprecision of the surrogate and not due to the aleatoric, stochastic variability of the underlying microstructure.
Given the aforementioned uncertainties and without loss of generality, we denote the PS and SP links with two densities, namely p ( x φ | ) and p ( mx | ) respectively. In cases where any of these links is (assumed to be) deterministic, the corresponding density can assume a degenerate, Diracdelta form, e.g. p ( mx | ) = δ ( m -m x ( )) where m x ( ) denotes the deterministic SP map or p ( x φ | ) = δ ( x -x φ ( )) where x φ ( ) denotes the deterministic PS map.
The goal-oriented, inverse design seeks to find the optimal process parameters, say φ ∗ , those yield microstructures exhibiting desired properties, e.g. they lie in a prescribed target region M d ⊂ M , as illustrated in Figure 1. Given the stochastic nature of the PSP chain, we reformulate the objective to identify the process parameters φ ∗ that maximize the probability that the generated microstructures possess properties within the target region M d [53, 54], i.e.:
$$\begin{array} {$$
Solving the optimization problem of Equation (1) is challenging due to the complexities of the whole PSP chain. Firstly, the PS linkage maps an, in general, modest-dimensional space U φ , into a highdimensional, discrete space X . Consequently, computing the derivatives of the microstructure x with respect to the processing parameter φ is impossible, rendering derivative-based methods unsuitable for solving the inverse problem directly. Additionally, the uncertainty introduced by the PS process further complicates the inversion. Secondly, for each evaluation of the SP link where physics-based models (e.g. PDEs) are used to capture the relation between microstructure and properties, solving them repeatedly can be time-consuming, especially when the dimensionality of x is very high. Derivatives of the properties m with respect to the discrete-valued input x are not defined which precludes back-propagation and search in the high-dimensional microstructural space. Moreover, multiple microstructures may share the same or similar properties, making the inverse problem highly ill-posed. It becomes apparent therefore that, not only computationally efficient surrogates for the aforementioned probabilistic links are required, but more importantly, formulations
Figure 1: Inverse materials design based on the whole PSP chain: the forward problem involves the PSP chain that contains two successive processes, i.e., the PS linkage p ( x φ | ) and the SP linkage p ( mx | ) . The PS linkage is a stochastic process to generate microstructures x given processing parameters φ . The SP linkage calculates the properties m of given microstructures x , which requires the solving of complex PDEs. The inverse design problem aims to find the optimal φ ∗ that maximizes the probability that the generated microstructures possess properties falling within a target region M d , i.e., φ ∗ = arg max φ ∈U φ ∫ M d p ( mφ | ) d m .
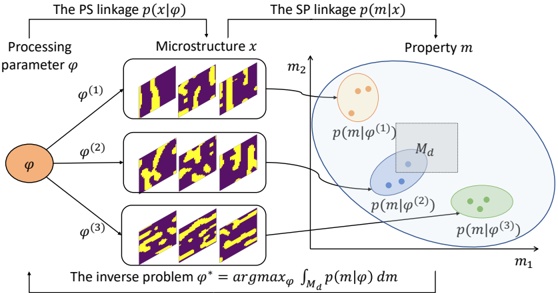
that enable the computation of derivatives, an essential feature of any optimization scheme. This in turn necessitates continuous and preferably lower-dimensional embeddings of the discrete-valued microstructures. Classical (non)linear dimensionality reduction techniques have been commonly employed but these are not necessarily well-suited to the general problem as they are agnostic to the properties as well as to the processing variables that we ultimately seek to optimize.
## 3 Proposed Methodology
## 3.1 Overview of the proposed framework
In this paper, we propose a data-driven, deep, generative model called PSP-GEN, which captures the intricate PSP relationships and addresses the aforementioned challenges in a unified and integrated manner in contrast to the multi-component, modular strategies that have mostly been proposed thus far [55]. It makes use of L triads of data from the whole PSP chain i.e. triplets of processing parameter values φ ( ) l , microstructures x ( ) l generated from those and corresponding properties m ( ) l , where l = 1 , . . . , L which we denote summarily with D = { φ ( ) l , x ( ) l , m ( ) l } L l =1 . We note that it is possible to have unlabelled data i.e. process-microstructure pairs D PS = { φ ( ) l , x ( ) l } L PS l =1 . Such data is less expensive to obtain as one does not need to run the pertinent experiment/model for predicting properties and therefore more abundant. We discuss at the end of section 3.3 how the proposed model can seamlessly accommodate such cases and learn from partial data as well in a semi-supervised fashion [56].
To address challenges posed by microstructure space's irregular and high-dimensional nature, numerous studies have endeavored to reduce their complexity by representing images as lowdimensional objects. Various features have been proposed to aggregate local information into global descriptors, including texture statistics [57], volume fractions [36], grain size distributions [58], visual bag of words [59], and auto- and cross-correlation functions [60]. An overview of these techniques is provided in [61]. Such traditional microstructural metrics may not sufficiently account for many properties of interest due to the inherent complexity of microstructures. Deepneural-network-based models possess greater expressivity and among these, the Variational AutoEncoder (VAE [62]) has demonstrated remarkable efficacy compared with traditional microstructural metrics [28]. However, existing approaches utilizing VAEs are predominantly confined to microstructure-centered materials design and employ latent representations that are property- and process-parameter-agnostic.
Figure 2: The overview of the PSP-GEN model: the model based on the assumption p θ ( x m φ , | ) = ∫ p θ x ( x z | 0 , z 1 ) p θ m ( mz z | 0 , 1 ) p θ φ ( z 1 | φ ) p ( z 0 ) d z 1 d z 0 where p ( z 0 ) is a fixed prior distribution and p θ φ ( z 1 | φ ) is a delta distribution, i.e., z 1 is determined by φ through a neural network g θ φ . Given the processing parameter φ , the generative entails first computing z 1 = g θ φ ( φ ) and sampling z 0 from p ( z 0 ) . Subsequently microstructures x are generated through the decoder D θ x which corresponds to the density p θ x ( x z | 0 , z 1 ) and properties m through the decoder D θ m which corresponds to the density p θ m ( mz z | 0 , 1 ) . The Figure also depicts the encoder z 0 = E η ( φ x m , , ) which corresponds to the density q η ( z 0 | φ x m , , ) employed during training by the proposed VBEM scheme (section 3.3).
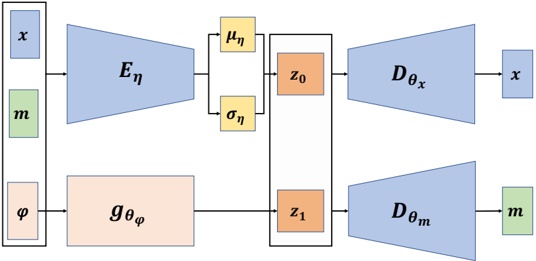
The proposed PSP-GEN model aims to emulate the real PSP process in generating new microstructures x and predicting their corresponding properties m given the process parameters φ . A schematic overview of the PSP-GEN model and the inference process (section 3.3) is shown in Figure 2. Unlike current methodologies that model the SP linkage and PS linkage separately, our model integrates the generation of microstructures and the determination in a comprehensive manner. It is based on the joint density:
$$p _ { \theta } ( x, m | \varphi ) = \int p _ {$$
where θ = ( θ x , θ m , θ φ ) summarily represents the model parameters.
At the core of the PSP-GEN lie the continuous , latent variables z = ( z 0 , z 1 ) which simultaneously provide a lower-dimensional embedding of x and m , i.e. they are property-aware, as well as the link to the process variables φ . In particular, knowledge of z enables one to reconstruct both the microstructure x through the decoding density p θ x ( x z | 0 , z 1 ) and of the properties m through p θ m ( mz z | 0 , 1 ) . It is this feature that is essential to solving the inverse design problem in Equation (1) as it will be demonstrated in the sequel. As one can deduce from Equation (2), the z 1 components represent the unobserved generators that are affected by the processing variables φ as dictated by the learnable density p θ φ ( z 1 | φ ) , whereas z 0 the remaining generators needed, which are independent of processing. Before embarking on the presentation of the form of the densities involved (section 3.2) the inference of the latent variables and the learning of model parameters θ (section 3.3), we briefly illustrate the advantages of the PSP-GEN architecture in solving the inverse design problem i.e. Equation (1).
We note that the product of densities p ( x φ | ) for the PS-link and p ( mx | ) for the SP-link define the joint p ( m x φ , | ) which can be substituted by the learned density p θ ( x m φ , | ) in Equation (2) of our model. In particular:
$$P \left ( m \in M _ { d } | \varphi \right ) & \ =$$
(3)
At first glance, it appears that one simply exchanged the summation with respect to x with an integration with respect to z 0 and z 1 . As we demonstrate in detail in section 3.4, the key difference is that the densities involved are differentiable since z 0 and z 1 are continuous and one can circumvent the need to sum over the possible microstructures. We note that this does not hinge on any particular form of the associated densities but merely on the generative model structure adopted.
## 3.2 Model specification
In this section, we specify the densities involved in the model definition of Equation (2), provide additional insight on the latent variables z as well as details on the model parameters θ . Given the role of z 0 ∈ R d z 0 as stochastic generators, we employ a standard multivariate normal for the respective density, i.e.:
$$p ( z _ { 0 } ) = \mathcal { N } ( z _ { 0 } |$$
With regards to the latent variables z 1 ∈ R d z 1 which are assumed to be controlled by the processing variables φ , we postulate a deterministic dependence, i.e. z 1 = g θ φ ( φ ) which means that p θ φ ( z 1 | φ ) will attain the form of a degenerate Dirac-delta density:
$$p _ { \theta _ { \varphi } } ( z _ { 1 } | \var$$
The function g θ φ is expressed with a neural network parameterized with θ φ (see A). The deterministic relation simplifies the aforementioned integrals as integration with respect to z 1 can be eliminated and all occurrences of z 1 can be substituted with g θ φ ( φ ) . Equation 2 will become:
$$p _ { \theta } ( x, m | \varphi ) = \int p _ { \theta _ { x } } ( x | z _ { 0 }, g _ { \theta _ { \varphi } } ( \varphi ) ) p _ { \theta _ { m } } ( m | z _ { 0 }, g _ { \theta _ { \varphi } } ( \varphi ) ) \, p ( z _ { 0 } ) \, d z _ { 0 }.$$
and Equation (3):
$$P \left ( m \in M _ { d } | \varphi \right ) \approx \int _ { M _ { d } } \left ( \int p _ { \theta _ { m } } \left ( m | z _ { 0 }, g _ { \theta _ { \varphi } } \left ( \varphi \right ) \right ) p ( z _ { 0 } ) \, d z _ { 0 } \right ) \, d m$$
Given the binary nature of the microstructural representation x = { x j } d x j =1 , we employ the following decoding density p θ x ( x z | 0 , z 1 ) [63, 64]:
$$p _ { \theta _ { x } } ( x | z _ { 0 }, z _ { 1 } ) = \prod _ { j = 1 } ^ { d _ { x } } \sigma ( \mu _ { j, \theta _ { x } } ( z _ { 0 }, z _ { 1 } ) ) ^ { x _ { j } } \left ( 1 - \sigma ( \mu _ { j, \theta _ { x } } ( z _ { 0 }, z _ { 1 } ) ) \right ) ^ { ( 1 - x _ { j } ) } \quad \quad ( 8 )$$
where σ . ( ) is the sigmoid function and µ θ x = { µ j, θ x ( z 0 , z 1 ) } d x j =1 are represented with a neural network parameterized with θ x (details in A) 1
For the final decoding density for the properties m ∈ M ⊂ R d m we employ a multivariate Gaussian of the form:
$$p _ { \theta _ { m } } ( m | z _ { 0 }, z _ { 1 } ) = \mathcal { N } ( m | \mu _ { \theta _ { m } } ( z _ { 0 }, z _ { 1 } ), \text{diag} ( \sigma _ { \theta _ { m } } ( z _ { 0 }, z _ { 1 } ) ) )$$
where µ θm and σ θm represent the mean and (diagonal) covariance, respectively, which are expressed by a neural network with parameters θ m (details in A).
1 The model can readily be extended to multi-phase media by employing the softmax function.
## 3.3 Inference and Learning
We consider first the canonical scenario where triads of data D { = φ ( ) l , x ( ) l , m ( ) l } L l =1 are available for training and discuss other cases in the sequel. We propose learning the optimal values for the model parameters θ by maximizing the log-likelihood ∑ L l =1 log p θ ( m ( ) l , x ( ) l | φ ( ) l ) which is generally analytically intractable. To this end, we advocate the use of the Variational-Bayesian Expectation-Maximization (VB-EM) scheme [39], which, following Equation (6) employs Jensen's inequality to construct a lower bound F as:
$$& \text{quampling to concatenated as a one, or you } \colon \text{.} \\ & \quad \sum _ { l = 1 } ^ { L } \log p _ { \theta } ( m ^ { ( l ) }, x ^ { ( l ) } | \varphi ^ { ( l ) } ) \\ & \quad = \sum _ { l = 1 } ^ { L } \log \int p _ { \theta _ { x } } ( x ^ { ( l ) } | z _ { 0 } ^ { ( l ) }, g _ { \theta _ { \varphi } } ( \varphi ^ { ( l ) } ) ) p _ { \theta _ { m } } ( m ^ { ( l ) } | z _ { 0 } ^ { ( l ) }, g _ { \theta _ { \varphi } } ( \varphi ^ { ( l ) } ) ) p ( z _ { 0 } ^ { ( l ) } ) \, d z _ { 0 } ^ { ( l ) } \\ & \quad \geq \sum _ { l = 1 } ^ { L } \left \{ \log \frac { p _ { \theta _ { x } } ( x ^ { ( l ) } | z _ { 0 } ^ { ( l ) }, g _ { \theta _ { \varphi } } ( \varphi ^ { ( l ) } ) ) p _ { \theta _ { m } } ( m ^ { ( l ) } | z _ { 0 } ^ { ( l ) }, g _ { \theta _ { \varphi } } ( \varphi ^ { ( l ) } ) ) \, p ( z _ { 0 } ^ { ( l ) } ) } { q _ { \eta } ( z _ { 0 } ^ { ( l ) } ) } \right \} _ { q _ { \eta } ( z _ { 0 } ^ { ( l ) } ) } \right \} _ { q _ { \eta } ( z _ { 0 } ^ { ( l ) } ) } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{\ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text { } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text
\text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text`}$$
The derivation makes use of the auxiliary densities q η ( z ( ) l 0 ) parametrized by η . It can be readily shown [39] that the optimal q η ( z ( ) l 0 ) coincide with the exact posterior(s) p θ ( z ( ) l 0 | m ( ) l , x ( ) l , φ ( ) l ) of the latent variables z ( ) l 0 . VB-EM alternates between maximizing F with respect to η while keeping θ fixed (VB-M step) and subsequently maximizing F with respect to θ while keeping η fixed (VB-E step). The VB-M-step seeks to find the best possible approximation to the exact posteriors within the parametrized family q η while the VB-E-step attempts to find the optimal model parameter values given the approximate posterior.
We propose employing the following amortized form for q η :
$$q _ { \eta } ( z _ { 0 } | x, m, \varphi ) = \mathcal { N } ( z _ { 0 } | \mu _ { \eta } ( x, m, \varphi ), \text{diag} ( \sigma _ { \eta } ( x, m, \varphi ) )$$
Wenote that this depends explicitly on x m , , and φ which implies that the parameters η are common for all data-triads and associated latent variables z ( ) i 0 (i.e. independent of the number of data-triads L ). In the aforementioned expression, µ η and σ η are expressed by neural networks with parameters η (see A).
Using the form of the associated densities from section 3.2 we can simplify the expressions for the lower-bounds L ( ) l ( θ η , ) in Equation (10). In particular, if we drop the data index ( ) l which appears as a superscript in the expressions, we obtain:
$$\begin{array} { c c c } \mu & \mu & \mu \\ \mathcal { L } ( \theta, \eta ) & = \left \langle \log p _ { \theta _ { x } } ( x | z _ { 0 }, g _ { \theta _ { \varphi } } ( \varphi ) ) \right \rangle _ { q _ { \eta } ( z _ { 0 } ) } + \left \langle \log p _ { \theta _ { m } } ( m | z _ { 0 }, g _ { \theta _ { \varphi } } ( \varphi ) ) \right \rangle _ { q _ { \eta } ( z _ { 0 } ) } \\ & + \left \langle \log \frac { p ( z _ { 0 } ) } { q _ { \eta } ( z _ { 0 } ) } \right \rangle _ { q _ { \eta } ( z _ { 0 } ) } & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & && & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \mu & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & - & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & } & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & - & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & _ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ; & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &, & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & = & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & + & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &$$
The first term attempts to minimize the reconstruction error of the microstructural decoder, i.e. from Equation (8) and for z 1 = g θ φ ( φ ) :
$$\mathcal { L } _ { R E C, x } ( \theta, \eta ) = \sum _ { j = 1 } ^ { d _ { x } } x _ { j } \left \langle \log \sigma ( \mu _ { j, \theta _ { x } } ( z _ { 0 }, z _ { 1 } ) ) \right \rangle _ { q _ { \eta } } + ( 1 - x _ { j } ) \left \langle \log ( 1 - \sigma ( \mu _ { j, \theta _ { x } } ( z _ { 0 }, z _ { 1 } ) ) \right \rangle _ { q _ { \eta } }.$$
The second term pertains to the reconstruction error of the property decoder, i.e from Equation (9) and for z 1 = g θ φ ( φ ) :
$$\mathcal { L } _ { R E C, m } ( \theta, \eta ) = - \frac { 1 } { 2 } \left \langle \sum _ { j = 1 } ^ { d _ { m } } \log \sigma _ { j, \theta _ { m } } ( z _ { 0 }, z _ { 1 } ) \right \rangle _ { q _ { \eta } } - \frac { 1 } { 2 } \left \langle \| m - \mu _ { \theta _ { m } } ( z _ { 0 }, z _ { 1 } ) \| _ { \sigma _ { \theta _ { m } } ( z _ { 0 }, z _ { 1 } ) } ^ { 2 } \right \rangle _ { q _ { \eta } }. \\ \text{Finally the third term acts as a renolarizer} h v \minimizino the K1-divergence between the annroxi-}$$
Finally, the third term acts as a regularizer by minimizing the KL-divergence between the approximate posterior q η ( z 0 ) and the prior p ( z 0 ) . It can be simplified to:
$$\mathcal { L } _ { K L } ( \eta ) = - \frac { 1 } { 2 } \left ( \| \mu _ { \eta } ( x, m, \varphi ) \| _ { 2 } ^ { 2 } + \| \sigma _ { \eta } ( x, m, \varphi ) \| _ { 2 } ^ { 2 } - \sum _ { j = 1 } ^ { d _ { \tilde { \kappa } _ { 0 } } } \log \sigma _ { j, \eta } ( x, m, \varphi ) \right ). \quad ( 1 5 )$$
## Algorithm 1 The training of the PSP-GEN
## Inputs:
D
=
{
φ
,
x
,
m
}
, The dimensions
d
z
0
and
d
z
1
, The parameter
## Initialize:
( )
l
( )
l
( )
l
L
l
=1
Model parameters θ = ( θ x , θ m , θ φ ) and η , Learning rate lr .
while Converged or maximum iterations reached do
$$\text{Obtain } z _ { 1 } ^ { \widetilde { ( } l ) } = g _ { \theta _ { \varphi } } ( \varphi ^ { ( l ) } ) \text{ and }$$
$$z _ { 0 } ^ { ( l ) } = \mu _ { \eta } ( \varphi ^ { ( l ) }, x ^ { ( l ) }, m ^ { ( l ) } ) + \sigma _ { \eta } ( \varphi ^ { ( l ) }, x ^ { ( l ) }, m ^ { ( l ) } ) \odot \epsilon, \quad \epsilon \sim \mathcal { N } ( 0, I ).$$
Calculate the lower-bounds L ( ) l ( θ η , ) using Equation Equation (12) and the ELBO F ( θ η , ) . VB-M step: Update parameter η with SGD while keeping θ fixed:
$$\eta \leftarrow \eta + l r \odot \nabla _ { \eta } \mathcal { F } ( \theta, \eta ).$$
VB-E step: Update parameter θ with SGD while keeping η fixed:
$$\theta \leftarrow \theta + l r \odot \nabla _ { \theta } \mathcal { F } ( \theta, \eta ).$$
if Validation error does not decrease within 20 epochs then
Update the learning rate to lr ← lr/ 3 .
## end if
end while
To compute the expectations with respect to q η that appear in L (as well as in its gradient), we make use of the reparameterization trick [62] by drawing z 0 -samples according to (see Equation (11)):
$$z _ { 0 } = \mu _ { \eta } ( x, m, \varphi ) + \sigma _ { \eta } ( x, m, \varphi ) \odot \epsilon, \quad \epsilon \sim \mathcal { N } ( 0, I ).$$
where ⊙ denotes the Hadamard product and ϵ is a random variable which does not depend on η .
The gradient computation of the ELBO L concerning the model parameters ( θ η , ) is carried out using automatic differentiation in PyTorch [65]. A schematic illustration is provided in Figure 2 and a pseudocode in Algorithm 1. For the stochastic gradient ascent needed for the maximization of F with respect to θ and η , we employed the ADAM scheme, the hyperparameters of which are reported in section 4.
## Remarks:
- · to obtain disentangled latent representations for z 0 and z 1 , one has to balance the trade-offs between the constituent ELBO terms [66]. A state-of-the-art solution is the so-called β -VAE trick [67] which places an appropriate weight β on the KL-divergence term, resulting in the following learning objective (compare with Equation (12)):
$$\mathcal { L } ( \theta, \eta ) \ = \mathcal { L } _ { R E C, x } ( \theta, \eta ) + \mathcal { L } _ { R E C, m } ( \theta, \eta ) + \beta \ \mathcal { L } _ { K L } ( \eta ). \quad \quad ( 1 7 )$$
The effect and calibration of the parameter β are discussed in B.
- · Webriefly discuss how the proposed model can also take advantage of unlabelled , inexpensive data consisting of PS pairs, i.e. D PS = { φ ( ) l , x ( ) l } L PS l =1 . We note that from Equation (6) one can marginalize the properties m in order to obtain the model density:
$$p _ { \theta } ( x | \varphi ) = \int p _ { \theta _ { x } } ( x | z _ { 0 }, g _ { \theta _ { \varphi } } ( \varphi ) ) \, p ( z _ { 0 } ) \, d z _ { 0 }.$$
This can serve as the likelihood of the unlabelled data D PS above which in turn can be added to the (log)likelihood of the full, labeled data in Equation (10). The unlabelled loglikelihood can also be bounded from below by introducing an auxiliary density, say q ζ ( z 0 ) . which attempts to approximate the posterior p θ ( z ( ) l 0 | x ( ) l , φ ( ) l ) for each unlabelled data pair l = 1 , . . . , L PS in D PS . The resulting sum over the data-pairs of the log-likelihood lower-bounds will be a function of θ η , and ζ and can be maximized using the aforementioned VB-EM scheme. Although this avenue is not explored in the numerical experiments of section 4, we note its significance in enabling semi-supervised training and reducing the dependence on the expensive, labeled data [68].
β
## 3.4 Solving the inverse design problem
In this section, we discuss how the aforementioned generative model can be used to efficiently obtain solutions to the inverse design problem defined in Equation (1). To this end and recalling Equation (7) for the sought probability P ( m ∈ M d | φ ) , we derive expressions for its gradient which are now possible due to the differentiability of p θ m ( mz z | 0 , 1 ) (see Equation (9)) and the fact that z 0 , z 1 are continuous. We note that gradients are essential in order to obtain solutions efficiently and necessary when the number of process variables φ (i.e. the optimization variables) is high. In particular:
$$\frac { \partial P ( m \in M _ { d } | \varphi ) } { \partial \varphi } = \int _ { M _ { d } } \int \frac { \partial \log p _ { \theta _ { m } } } { \partial z _ { 1 } } \frac { \partial g _ { \theta _ { \varphi } } } { \partial \varphi } \, p _ { \theta _ { m } } ( m | z _ { 0 }, g _ { \theta _ { \varphi } } ( \varphi ) ) p ( z _ { 0 } ) \, d z _ { 0 } \, d m \, \quad \, ( 1 9 )$$
The derivatives in the expression can be computed point-wise using back-propagation and the integrals involved can be readily approximated by Monte Carlo using M samples { m ( ) i , z ( ) i 0 } M i =1 drawn from p θ m ( mz | 0 , g θ φ ( φ )) p ( z 0 ) as:
$$\frac { \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots } { \partial \varphi } \approx \left ( \frac { 1 } { M } \sum _ { i = 1 } ^ { M } 1 _ { M _ { d } } ( m ) \frac { \partial \log p _ { \theta _ { m } } ( m ^ { ( i ) } | z _ { 0 } ^ { ( i ) }, z _ { 1 } ) } { \partial z _ { 1 } } \right | _ { z _ { 1 } = g _ { \theta _ { \varphi } } ( \varphi ) } \right ) \frac { \partial g _ { \theta _ { \varphi } } ( \varphi ) } { \partial \varphi } \ \ ( 2 0 )$$
where 1 M d ( m ) is the indicator function of the target domain. Alternatively, one can get rid of the indicator function by sampling m ( ) i from the uniform density in M d instead (while z ( ) i 0 are sampled from p ( z 0 ) as before), in which case the Monte Carlo estimator of the gradient would be:
$$\text{from} \, p ( z _ { 0 } ) & \text{as before} ), \text{in which case the Monte Carlo estimator of the gradient would be:} \\ \frac { \partial P ( m \in M _ { d } | \varphi ) } { \partial \varphi } \quad & \approx \left ( \frac { | M _ { d } | } { M } \sum _ { i = 1 } ^ { M } p _ { \theta _ { m } } ( m ^ { ( i ) } | z _ { 0 }, g _ { \theta _ { \varphi } } ( \varphi ) ) \frac { \partial \log p _ { \theta _ { m } } ( m ^ { ( i ) } | z _ { 0 } ^ { ( i ) }, z _ { 1 } ) } { \partial z _ { 1 } } \Big | _ { z _ { 1 } = g _ { \theta _ { \varphi } } ( \varphi ) } \right ) \frac { \partial g _ { \theta _ { \varphi } } ( \varphi ) } { \partial \varphi } \\ & \quad = \left ( \frac { | M _ { d } | } { M } \sum _ { i = 1 } ^ { M } \frac { \partial p _ { \theta _ { m } } ( m ^ { ( i ) } | z _ { 0 } ^ { ( i ) }, z _ { 1 } ) } { \partial z _ { 1 } } \Big | _ { z _ { 1 } = g _ { \theta _ { \varphi } } ( \varphi ) } \right ) \frac { \partial g _ { \theta _ { \varphi } } ( \varphi ) } { \partial \varphi } \\ \text{where} \, | M _ { d } | \text{ is the hyper-volume of the target property domain. The aforementioned estimator can} \\. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.$$
where | M d | is the hyper-volume of the target property domain. The aforementioned estimator can then be used in conjunction with Stochastic Gradient Ascent to maximize the probability in the objective and to identify the optimal processing parameter values φ ∗ .
## Remarks:
- · While only point estimates of the processing variables are computed, it is also possible to obtain fully Bayesian inference results of the whole posterior p ( φ m | ∈ M d ) as is done in [20]. The latter can provide insight into the sensitivity of the objective to variations in φ that reflect all the uncertainties in the PSP model. Given a prior p ( φ ) (e.g. a uniform on U φ ) and Equation (7), we obtain the joint posterior by a simple application of Bayes's rule:
$$p ( \varphi, z _ { 0 } | m \in M _ { d } ) \in p _ { \theta _ { m } } ( m \in M _ { d } | z _ { 0 }, g _ { \theta _ { \varphi } } ( \varphi ) ) \, p ( z _ { 0 } ) \, p ( \varphi ) \, \quad \quad ( 2 2 )$$
Exact as e.g. HMC [69] or approximate as e.g. SVI [70] inference tools can be readily employed due to the fact that all variables involved are continuous and derivatives of all the log-densities appearing in the expression above with respect to z 0 , φ can be inexpensively computed.
- · Other property-driven objectives can also be employed in order to identify the optimal processing variables φ . In [54] some of those are discussed, such as the (expected) deviation of the actual properties from some target m target i.e. E [ ∥ m -m target ∥ 2 2 | φ ] or the KL-divergence KL p ( target ( m ) || p ( mφ | ) ) between a desired/target property density, e.g. p target ( m ) and the actual density p ( mφ | ) . While these cases are not discussed, it can be readily shown that they can be easily accommodated within the PSP-GEN model due to its aforementioned features, i.e. continuity of the latent space and differentiability of the probabilistic decoders.
## 4 Results and Discussion
This section contains the results of several numerical experiments performed in the context of inverse design based on the whole PSP chain. We first discuss the PS and SP links employed to generate
the data used for training and validation in the ensuing examples (section 4.1.1). The goals of the illustrations contained are:
- · to comparatively assess the performance of the method herein in relation to the recently proposed approach for inverting the entire PSP chain by [20, 37]. In brief, the latter utilizes 2-point correlation functions as sufficient microstructural features which are subsequently subjected to a Principal Component Analysis (PCA) to reduce their dimension. Sparse variational multi-output Gaussian processes (SV-MOGP) [71] are employed to surrogate the forward PS and SP linkages and a continuous normalizing flow (CNF) is utilized to approximate the posterior distribution of φ (see first remark at the end of section 3.4). To facilitate comparisons, we only report point estimates of the optimal processing parameter φ ∗ . Since a publicly available code repository was not provided in [20], the numerical results reported are based on our own implementation of this method as described in the respective paper (and with the same parameter values reported therein) which also involved the implementation of the SV-MOGP model using the package GPyTorch [72].
- · to provide insight on the role of the latent variables z = ( z 0 , z 1 ) employed by our model and their ability to provide lower-dimensional, microstructure- and property-aware embeddings (section 4.2).
- · to assess the performance for various target property domains (Section 4.2) and especially those located far from the training data (section 4.3). We note that the latter case is most relevant in realistic design scenarios where one should suggest new configurations and not the ones already known. Simultaneously, this poses the most challenging scenario for datadriven models as they are asked to generate accurate, extrapolative predictions.
- · to assess the performance under various amounts of training data. Given the expense of experimentally or computationally simulating the PS and SP linkages in realistic settings, it is essential that data-driven methods can also operate in the small-data regime as well as provide accurate estimates of the associated epistemic uncertainty (section 4.4).
- · to assess the performance with respect to the dimension of x i.e. the microstructural representation (section 4.5).
- · to assess the performance under various dimensions of the process variable vector i.e. of the design space. In particular, we consider two cases where dim ( φ ) = 2 and dim ( φ ) = 10 (section 4.6).
With regards to the comparison method, in all experiments, we select the number of principal components (PCs) to explain 90% of the variance in the training dataset. For the proposed method, we set the dimension d z 1 of the latent space z 1 to be consistent with the number of PCs to ensure a fair comparison. However, it is worth noting that the proposed model can still achieve good performance with a much smaller dimension, as demonstrated in Section 4.2. For the latent space z 0 , a higher dimension d z 0 results in better recovery of the microstructure x but increases the cost of training the forward model. Therefore, we set the dimension of the latent space d z 0 to approximately 5% of d x to balance accuracy and training effort.
## 4.1 Experimental setup
## 4.1.1 The forward simulation
We focus on designing two-dimensional, dual-phase material microstructures where one phase corresponds to voids (infinite permeability) and the other to an impervious solid (zero permeability). The properties of interest relate to the effective permeability of the microstructure. The particular choice is made because it corresponds to an infinite contrast ratio in the properties of the phases. As a result, the effective property (permeability) would depend on higher-order statistics of the microstructure and in particular the presence of percolating paths of the void phase [40].
For the PS process, we generate microstructures under various process parameters using a Gaussian Random Field (GRF) and a phase-field simulation approach. Specifically, we generate images with size 36 × 36 using the GRF with a spectral density function (SDF) defined as S ( φ ) , where φ denotes the processing parameters. Subsequently, we convert the pixel values to binary by thresholding the values. The threshold selected determines the volume fraction of the phases and in our study, it was selected such that it yields a volume fraction of 2 / 3 for the void phase. We use these images as the
initial condition in a phase-field model based on the Cahn-Hilliard equation [73] which generates the final microstructures x . The Cahn-Hilliard equation, commonly used to model phase separation in binary mixtures, is defined as:
$$\frac { \partial c } { \partial t } = D \nabla ^ { 2 } \left ( c ^ { 3 } - c - \gamma \nabla ^ { 2 } c \right ), \quad t \in [ 0, T ]$$
where c represents the concentration with c = ± 1 indicating domains, D denotes the diffusion coefficient, and √ γ determines the length of the transition regions between the domains. In our study, we set the parameters to the following values: D = 10 , γ = 2 , and T = 5 s .
For the SP process, i.e. to calculate the effective permeability of microstructures, we employ the Stokes flow equations with periodic boundary conditions which were solved with the finite element method (FEM) [74]. We compute the effective permeability in the horizontal and vertical directions i.e. dim ( m ) = 2 . In order to automatically ensure the positivity of the effective properties, we operate on their logarithms, i.e. m = ( m ,m 1 2 ) represent the logarithms of the effective permeability in the horizontal and vertical direction respectively.
## 4.1.2 Data generation and model setups
Wefirst defined a SDF S ( φ ) depending on two parameters, i.e. dim ( φ ) = 2 and generated pertinent data for the numerical experiments in sections 4.2, 4.3 and 4.4 . 2 In particular, we employed the following SDF:
$$S ( \varphi ) = \varphi _ { 1 } e ^ { - \varphi _ { 2 } k _ { z } ^ { 2 } } + ( 1 - \varphi _ { 1 } ) e ^ { - \varphi _ { 2 } \ast k _ { \nu } ^ { 2 } }, \quad \varphi \in \mathcal { U } _ { \varphi } = [ 1, 9 ] \times [ 0. 2, 2 ]$$
where φ = ( φ , φ 1 2 ) denotes the processing parameters, and k , k x y represent shifted Fourier coordinates which were taken to be k , k x y = { 0 , · · · , d x - } -1 d x 2 .
We constructed three datasets, namely:
- · Training dataset : We sample uniformly in U φ 2 500 , different values of the processing parameters φ . We generate 4 microstructure samples x for each processing parameter value and compute their corresponding properties m . Consequently, the training dataset comprises N train = 10 000 , triads of ( φ x m , , ) .
- · Testing dataset: We sample uniformly 500 values of the process parameters in U φ . We generated 4 microstructures x for each process parameter value and computed their associated properties m . Thus, the testing dataset consists of N test = 2000 triads of ( φ x m , , ) . In Figure 5 one can see the effective permeability values attained by the microstructures in this dataset.
- · Reference dataset: We also generate a very large, reference dataset which we used to obtain, whenever possible, reference solutions to the optimization problems considered as well as to assess the objective values for the optimal φ ∗ identified by the proposed and comparison method. To generate this dataset, we considered a 20 × 20 uniform grid in U φ for the process parameters φ . We then generated 500 microstructures x for each process parameter value and computed their properties m . Therefore, the reference dataset consists of N ref = 200 000 , triads of ( φ x m , , ) .
For training purposes, we divided the training dataset into two parts, using 90% for training and the remaining 10% for validation. We set the batch size to 50 and employ the Adam optimizer with an initial learning rate of lr = 10 -3 to update the network parameters. Additionally, we adopt a learning rate decay technique, reducing the learning rate to one-third if the validation error does not improve within 20 epochs [75]. We train both models for 500 epochs to ensure convergence. For solving the inverse problem, we employ a total of M = 50 000 , samples { z ( ) i 0 , m ( ) i } in the Monte Carlo estimate of the gradient of the objective as in Equation (21). We then solve the maximization problem Equation (1) using Stochastic Gradient Descent (SGD) with a batch size of 100 . We apply a learning rate decay technique to reduce the learning rate to one-fourth if the loss does not decrease within 2 epochs, with the initial learning rate set to lr = 0 2 . . The total number of epochs is set to 20 to ensure convergence.
2 We also considered a SDF where dim ( φ ) = 10 which was used for the experiments in 4.6 which is discussed therein.
Table 1: The optimal process parameters obtained by the competitive method ( φ comp ) and the proposed PSP-GEN ( φ prop ) for inverse design tasks with different target region M d in Case 1. The φ ref denotes the reference ground truth of the processing parameter and p M d := p ( m ∈ M d | φ ) represents the probability that the result properties corresponding to φ are located in the target region M d .
| φ ∗ / p M d | M L d | M M d | M R d |
|----------------|-------------------------|-------------------------|-------------------------|
| φ comp / p M d | (1.883, 1.367)/ 65 . 8% | (5.335, 0.395)/ 27 . 4% | (8.052, 1.406)/ 63 . 4% |
| φ prop / p M d | (1.009, 2.000)/ 81 . 2% | (5.152, 0.200)/ 28 . 6% | (8.999, 2.000)/ 79 . 2% |
| φ ref / p M d | (1.000, 2.000)/ 81 . 2% | (4.789, 0.200)/ 30 . 2% | (9.000, 1.905)/ 83 . 8% |
## 4.2 Case 1: Intra-Region design
In this section, we aim to solve the inverse materials design problem Equation (1) for three different target regions, i.e.:
- · M L d = [ -10 , -9] × -[ 7 , -5] ,
- · M M d = [ -7 , -5] × -[ 7 , -5] , and
- · M R d = [ -7 , -5] × -[ 10 , -9]
as depicted in Figure 3a. The target regions M L d and M R d correspond to low effective permeability in the horizontal and vertical directions, respectively. In contrast, the target region M M d pertains to high effective permeability in both the horizontal and the vertical directions.
We denote with φ prop the optimal process parameter values identified by the proposed PSP-GEN model (i.e. those that maximize the probability that the resulting properties would lie in each of the aforementioned target regions) and with φ comp those found by the competitive method. We report their values for the aforementioned three different target property domains in Table 1.
In order to assess the performance of each method, we estimated using the reference dataset the probability that the microstructures corresponding to each φ -grid-point considered to have properties in the target region M d , denoted as p M d := p ( m ∈ M d | φ ) . The results for all φ values are depicted in Figures 3b-d where the values of φ prop and φ comp are indicated with a red and a blue dot respectively. The φ with the highest probability is also reported in Table 1 as φ ref . The p M d values corresponding to φ prop , φ comp , and φ ref for different target regions are recorded in Table 1. As shown, the proposed method achieved higher p M d values than the competitive method in all cases.
In addition, for each of the three target property regions, we use the identified φ comp and φ prop to generate 5 microstructures, which are displayed in Figures 4a, 4b, and 4c. In each figure, the left side represents the microstructures generated by φ comp , and the right side represents the microstructures generated by φ prop . For target region M L d , we aim to generate microstructures with low permeability in the horizontal direction, i.e. with the void phase (denoted with black) should form as little as possible connected paths in the horizontal direction. Figure 4a shows that the microstructures generated using φ prop exhibit this characteristic, i.e. the solid phase (denoted in yellow) blocks as much as possible flow in the horizontal direction. In contrast, we observe microstructures generated by φ comp and indicated by the red dashed boxes that do not meet this criterion. Similarly, for target region M R d , we aim at microstructures where the void phase (indicated in black) forms as little as possible connected paths in the vertical direction. However, in Figure 4c, we notice that the microstructures within the red dashed boxes which were generated by φ comp do not exhibit this feature, whereas the microstructures obtained using φ prop do.
Based on the results above, it is evident that the solution obtained by the PSP-GEN closely aligns with the ground truth computed from the reference dataset for all three regions, indicating its superior performance as compared to the competitor. The relative inferiority of the latter may be attributed to two main reasons. Firstly, as previously discussed, in terms of their permeability, the two phases exhibit an infinite contrast ratio, rendering the (dimension-reduced) 2-point spatial correlations inadequate to fully capture the percolation paths that determine the effective permeabilities of the medium. By leveraging the representation capabilities of neural network architectures and
Figure 3: The inverse design results in Case 1: (a) The regions in green indicate the three target regions M L d , M M d , and M R d , respectively. The dots represent the distribution of properties in the testing dataset. (b), (c), (d): From left to right, these figures correspond to the results for target regions M L d , M M d , and M R d , respectively. Each pixel in the images represents a processing parameter, with the pixel value indicating the percentage of microstructures generated by this processing parameter that have the desired properties (the larger the value, the closer it is to the optimal solution). The blue dot represents φ comp obtained by the competitive method, and the red dot represents φ prop obtained by the PSP-GEN.
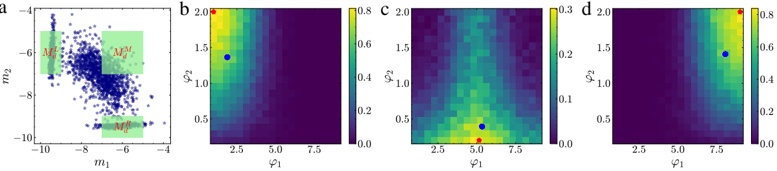
the latent variables advocated, the PSP-GEN can capture more accurately the salient microstructural features. Secondly, the innovative structure of the PSP-GEN model, which partitions the latent space into two parts, results in a more precise approximation of the PSP linkage.
For the same task, we also consider solving the inverse design problem using the proposed method with the dimension of the latent space z 1 set to 2 instead of 21 which is the number of PCs used in the competitive method, while keeping all other model parts unchanged. After training the model, we evaluated z 1 = g θ φ ( φ ) for each processing parameter value φ in the testing dataset and visualized it in Figure 5b. In Figure 5a and 5c, we also plotted the distribution of processing parameters and the corresponding properties, respectively. Points in these Figures are displayed in different color shades based on their corresponding properties. The distribution of microstructures x was visualized in Figure 5d, with the location determined by the corresponding property. In Figures 5ad, one readily observes the connection between the processing parameter φ and the latent variable z 1 , and how they influence the distribution of microstructures x and properties m . This connection is vital for identifying the optimal processing parameter that leads to the desired properties. For the target regions M L d , M M d , and M R d , the optimal processing parameters φ prop obtained by PSP-GEN are (1 ., 2 ) . , (4 579 . , 0 2) . , and (8 999 . , 1 999) . , respectively. We plotted these parameters in Figure 5a with red, blue, and purple colors, respectively. The corresponding deterministic latent variables z 1 are plotted in 5b using the same colors. To verify whether these obtained processing parameters lead to properties within the desired regions, we generated 100 microstructures for each obtained processing parameter and calculated the corresponding properties. We visualized the distribution of p ( mφ | ∗ ) in Figure5e, where φ ∗ represents the obtained solution for the target region M d ∈ { M ,M L d M d , M R d } . As shown, the distribution of properties corresponding to the identified solution in each case aligns with our expectations, falling within the target region to the greatest extent. Compared to the reference values φ ref in Table 1, the PSP-GEN model still obtains good approximations despite the low dimension d z 1 of latent space which further demonstrates the ability of the PSP-GEN model to extract useful, property-predicting features.
Finally, we also explored the role of z 0 in the proposed framework. We first randomly sampled three φ (1) , φ (2) , φ (3) from the space U φ , as shown in Figure 6a. For each of these processing parameters, we use it to generate one microstructure and calculate the corresponding property. The properties m (1) , m (2) , m (3) corresponding to φ (1) , φ (2) , φ (3) are shown in Figures 6b, 6c, and 6d, respectively. Then, we drew 100 samples of z 0 from the posterior distribution p ( z 0 | x ( ) i , φ ( ) i ) ∝ p ( x ( ) i | z 0 , g θ φ ( φ ( ) i )) p ( z 0 ) , for each i = 1 2 3 , , . For each z 0 sample, we drew a sample of m from p ( mz | 0 , g θ φ ( φ ( ) i )) , where i = 1 2 3 , , . The distribution of these m samples is represented by black dots. For cases i = 1 2 , and 3 , they are shown in Figures6b, 6c and 6d. Clearly, for each m ( ) i , it is surrounded by the m samples drawn from p ( mz | 0 , g θ φ ( φ ( ) i )) , i = 1 2 3 , , .
Figure 4: The microstructures generated with optimal processing parameters obtained by different methods for Case 1. (a) microstructures generated with φ comp (left) and φ prop (right) for target region M L d . (b) microstructures generated with φ comp (left) and φ prop (right) for target region M M d . (c) microstructures generated with φ comp (left) and φ prop (right) for target region M R d . The solid phase is indicated in yellow.
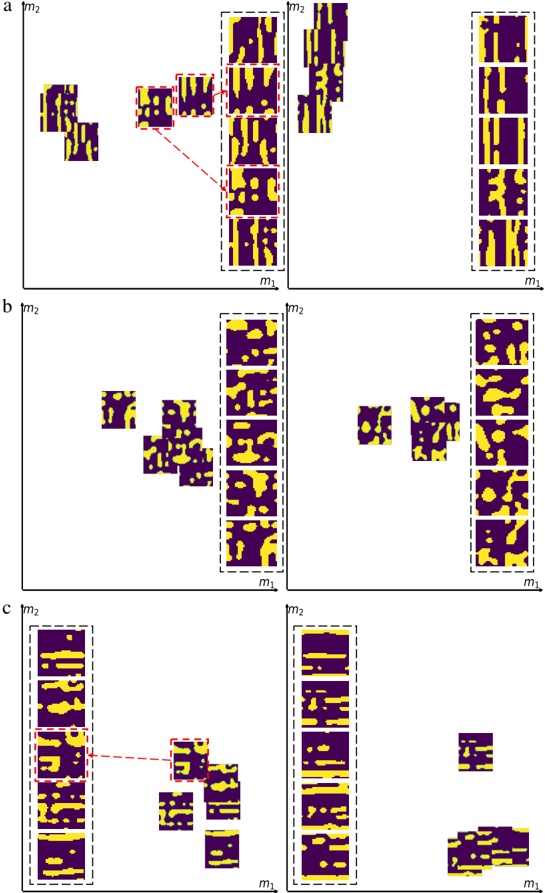
## 4.3 Case 2: Cross-Region generalization
In inverse materials design, it is common to only have access to data with properties distributed within a specific area in the property space M , while the objective is to design microstructures with properties outside of this area. This poses a significant challenge for any inverse design method as it necessitates models that can extrapolate to microstructures and properties that have not been seen. To assess the generalization or extrapolation ability of the proposed method, we aim to generate microstructures with properties in a region M d , depicted in green in Figure 7, while the model is trained with data (blue dots) that do not overlap with this property region and most of them, lie far away from it.
Figure 5: The visualization of the forward process of the PSP-GEN model in Case 1. (a) The processing parameters φ in the testing dataset, with points displayed in different color shades based on their corresponding properties. The dots in red, blue, and purple represent the optimal processing parameters obtained by the PSP-GEN model for target regions M L d , M M d , and M R d , respectively. (b) The latent variables z 1 corresponding to the processing parameters φ . The dots in red, blue, and purple represent the latent variables z 1 corresponding to the optimal processing parameters for target regions M L d , M M d , and M R d , respectively. (c) The properties m corresponding to the processing parameters φ in the testing dataset. (d) The distribution of microstructures x , with locations determined by the corresponding properties. (e) The distribution of p ( mφ | ∗ ) , where φ ∗ represents the obtained solution for the target region M d ∈ { M ,M L d M d , M R d } . The dots in red, blue, and purple represent properties corresponding to optimal processing parameters for target regions M L d , M M d , and M R d , respectively.
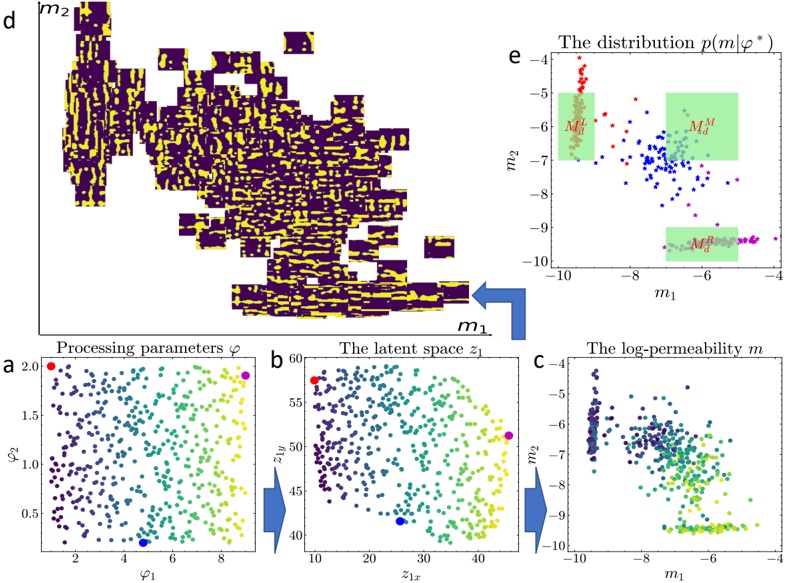
Figures 7b-d present the results obtained by the two methods. In particular, Figure 7b illustrates the estimated probability from the reference dataset that microstructures generated with each φ -value have properties in M d . The red and blue dot in 7b represent the solutions φ prop = (8 999 1 999) . , . and φ comp = (7 425 1 966) . , . , respectively. It is evident that φ prop most closely approximates the reference value of φ ref = (9 ., 1 905) . . Moreover, for each of the optimal φ values identified, we generated 1000 microstructures and calculated the corresponding probability through exact SP simulation. We found that 92 4% . of the microstructures corresponding to φ prop exhibit properties within M d , which is close to the 94 2% . attained by the reference solution φ ref (see Figure 7d). However, only 69 7% . of the microstructures corresponding to φ comp exhibit properties within M d (see Figure 7c). This outcome highlights the strong generalization/extrapolation ability of our PSPGEN model.
## 4.4 Case 3: Small training dataset
The forward simulation is often complex, time-consuming, and expensive for most inverse materials design tasks. To mitigate the effort and cost associated with simulating the forward PSP process, it is essential for inverse design methods to perform well even with limited training data. Therefore, we investigate the performance of the PSP-GEN with a smaller training dataset in this section.
Figure 6: The verification of the role of the latent variable z 0 in the PSP-GEN model in Case 1. (a) Three processing parameters, φ (1) , φ (2) , and φ (3) , were randomly chosen within U φ . (b) The dots labeled m (1) represent properties corresponding to x (1) , generated using the processing parameter φ (1) . (c) The dots labeled m (2) represent properties corresponding to x (2) , generated using the processing parameter φ (2) . (d) The dots labeled m (3) represent properties corresponding to x (3) , generated using the processing parameter φ (3) . For each i = 1 2 3 , , , the black dots represent 100 properties sampled according to the distribution m ∼ p ( mz | 0 , g θ φ ( φ ( ) i )) . Here, z 0 is sampled from the posterior distribution p ( z 0 | x ( ) i , φ ( ) i ) ∝ p ( x ( ) i | z 0 , g θ φ ( φ ( ) i )) p ( z 0 ) .
Figure 7: The inverse design results in Case 2: (a) The green region indicates the target region M d , and the dots represent the distribution of properties that lie outside of M d in the testing dataset. (b) Each pixel in this image represents a processing parameter, and the value of the pixel indicates the percentage of microstructures generated by this processing parameter that have properties within M d . The blue and red dots represent φ comp obtained by the competitive method and φ prop obtained by the proposed PSP-GEN, respectively. (c) The distribution of properties corresponding to microstructures generated by φ comp . (d) The distribution of properties corresponding to microstructures generated by φ prop .
In particular, we constructed a reduced dataset consisting of only N train = 2500 triads ( φ x m , , ) in contrast to the 10 000 , used previously. For each of the 2500 φ -values considered, we generated only a single microstructure and computed its properties. We subsequently solved the three inverse design tasks discussed previously corresponding to the three target regions M ,M L d M d , and M R d of section 4.2, using both the proposed and competitive methods. The numerical results are presented in Table 2.
Table 2: The optimal process parameters obtained by the competitive method ( φ comp ) and the proposed PSP-GEN ( φ prop ) for inverse design tasks with different target region M d in Case 3. The φ ref denotes the reference ground truth of the processing parameter.
| φ ∗ / p M d | M L d | M M d | M R d |
|----------------|-------------------------|-------------------------|-------------------------|
| φ comp / p M d | (2.095, 1.999)/ 67 . 2% | (5.373, 0.775)/ 19 . 6% | (8.967, 1.110)/ 62 . 4% |
| φ prop / p M d | (1.001, 1.999)/ 81 . 2% | (4.683, 0.200)/ 30 . 2% | (8.999, 1.999)/ 79 . 2% |
| φ ref / p M d | (1.000, 2.000)/ 81 . 2% | (4.789, 0.200)/ 30 . 2% | (9.000, 1.905)/ 83 . 8% |
Additionally, we visualize the performance of the two methods in the target regions M L d , M M d , and M R d in Figures 8a, 8b, and 8c, respectively. As depicted in Figure 8, for all three tasks, the φ prop obtained by the PSP-GEN model more closely approximates the reference solution. Furthermore, in comparison to Section 4.2 and Figure 3 we observe no degradation in the accuracy of the proposed method on the same objectives despite the reduction in training dataset size by a factor of 4. How-
Figure 8: The inverse design results in Case 3. (a) The green shaded areas indicate the three target regions M L d , M M d , and M R d . The dots represent property values in the testing dataset. (b), (c), (d): From left to right, the figures correspond to the estimated probabilities of attaining properties in the target regions M L d , M M d , and M R d , respectively. The estimates are computed using the reference dataset. The blue dots represent φ comp obtained by the competitive method and the red dots the φ prop obtained by the proposed method.
ever, for the competitive method, the performance worsens for the target regions M M d and M R d as the φ comp obtained is further from the reference value as compared to the case with larger datasets in Section 4.2. Although its performance appears to improve for the target region M L d , the obtained solution is still far from the optimal solution. This indicates that the competitive method is more sensitive to the size of the training dataset than the proposed method.
## 4.5 Case 4: High-dimensional microstructure space
In this section, we explore the efficiency of the proposed method in addressing the inverse design problem with high-dimensional microstructure spaces. To this end, we increased the image size to 128 × 128 pixels. We employed the same PS and SP models described in section 4.1 to generate the training, testing, and reference datasets (we set the parameter γ in Equation (23) to γ = 10 ).
Similar to Section 4.2, we considered three, different, target property domains, namely M L d = [ -12 5 . , -11] × -[ 8 , -5] , M M d = [ -8 , -6] × -[ 8 , -6] , and M R d = [ -8 , -5] × -[ 12 5 . , -11] , as shown in Figure 9a. We train the forward model and subsequently solve the inverse problem for all three cases. The optimal processing parameters obtained by both methods for these target regions are recorded in Table 3. We also visualize the results in target regions M L d , M M d , and M R d in Figure 9b, 9c, and 9d, respectively. As depicted in Figure 9, for all three target regions, the solution φ prop obtained by the PSP-GEN is more accurate than the solution φ comp obtained by the competitive method, and closely aligns with the reference values φ ref .
Finally, in Figure 10, which could be thought of as a higher resolution version of Figure 4, we plot for each target region a few indicative microstructures generated by the identified φ comp (left) and φ prop (right). For the target region M L d , our goal is to generate microstructures with low permeability in the horizontal direction. Figure 10a shows that the microstructures generated using φ prop all exhibit the characteristic of the solid phase (indicated with yellow) forms connected paths along the vertical direction, resulting in low horizontal permeability targeted. While the microstructures generated by φ comp also show similar characteristics, in some of them (indicated by a red dashed box) the solid phase's paths exhibit intermittency, leading to connected void paths (denoted with black), and thus resulting in relatively higher permeability along the horizontal direction. Similarly, for the target region M R d , we aim to generate microstructures with low permeability in the vertical direction, meaning the solid phase (denoted with yellow) should be distributed so as to block as much as possible flow in the vertical direction. In Figure 10c, we observe that all microstructures generated by φ prop exhibit this characteristic. In contrast, some of the microstructures generated by φ comp (shown within a red dashed box) do not exhibit the desired characteristic resulting in higher permeability in the vertical direction than targeted. For the target region M M d , the goal is to generate microstructures with high permeability in both directions which should favor some connected paths of the void phase (indicated with black) along both directions. As seen in Figure 10b, the microstructures generated by φ prop all exhibit this characteristic. In contrast, the microstructures generated by φ comp show a tendency, albeit weak, for the solid phase to be distributed horizontally.
Table 3: The optimal process parameters obtained by the competitive method ( φ comp ) and the proposed PSP-GEN ( φ prop ) for inverse design tasks with different target region M d in Case 4. The φ ref denotes the reference ground truth of the processing parameter.
| φ ∗ / p M d | M L d | M M d | M R d |
|----------------|-------------------------|-------------------------|-------------------------|
| φ comp / p M d | (1.347, 1.292)/ 81 . 6% | (6.803, 0.203)/ 35 . 2% | (8.502, 1.213)/ 77 . 6% |
| φ prop / p M d | (1.013, 1.997)/ 95 . 4% | (4.996, 0.202)/ 60 . 2% | (8.987, 1.971)/ 93 . 2% |
| φ ref / p M d | (1.000, 2.000)/ 95 . 4% | (5.211, 0.200)/ 61 . 4% | (9.000, 2.000)/ 93 . 2% |
Figure 9: The inverse design results in Case 4. (a) The green shaded areas indicate the three target regions M L d , M M d , and M R d . The dots represent property values in the testing dataset. (b), (c), (d): From left to right, the figures correspond to the estimated probabilities of attaining properties in the target regions M L d , M M d , and M R d , respectively. The estimates are computed using the reference dataset. The blue dots represent φ comp obtained by the competitive method and the red dots the φ prop obtained by the proposed PSP-GEN.
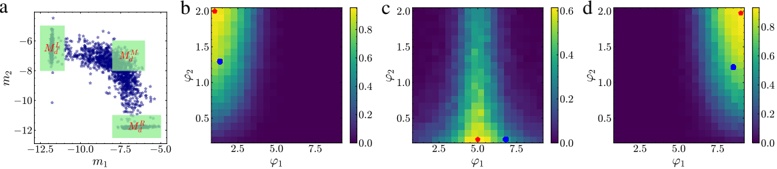
This trend can be observed in the distribution of microstructures in the m 1 -m 2 coordinate, where the microstructures generated by φ comp are more dispersed and tend towards the lower permeability region compared to φ prop .
## 4.6 Case 5: High-dimensional processing parameter space
In this section, we evaluate the performance of the proposed method in addressing inverse materials design problems with a high-dimensional process parameter space. This is an inherently challenging task as it entails navigating a high-dimensional design space to identify optimal solutions. To generate data for this high-dimensional problem, we adapt the SDF in the GRF as follows
$$S ( \varphi ) = \sum _ { i = 1 } ^ { 5 } ( \varphi _ { i, 1 } * e ^ { - \varphi _ { i, 2 } * k _ { z } ^ { 2 } } + \varphi _ { i, 1 } * e ^ { - \varphi _ { i, 2 } * k _ { y } ^ { 2 } } ), \quad \varphi \in \mathcal { U } _ { \varphi } = [ 1, 9 ] ^ { 5 } \times [ 0. 0 2, 2 ] ^ { 5 }$$
where φ = ( φ 1 1 , , · · · , φ 5 1 , , φ 1 2 , , · · · , φ 5 2 , ) represents a ten-variable vector. The remaining settings for the PSP process remain the same as in section 4.2. We sample 10 000 , process parameter values from U φ and generate one microstructure for each parameter. Subsequently, we compute the properties of these microstructures, yielding N = 10 000 , pairs of ( φ x m , , ) for training purposes. For the testing dataset, we sample 500 process parameters from U φ and generate 4 microstructures for each φ . We then compute the properties for these microstructures to get a testing dataset with size N = 2 000 , . Figures 11a and 11b show the microstructures and corresponding properties in the testing dataset, respectively. Compared with the low-dimensional processing parameter space case, we observed that the microstructures are more concentrated. This is because the expanded dimensions of the processing parameters make the microstructural space corresponding to moderate permeability in both horizontal and vertical directions larger. Owing to the high dimensionality of the processing parameter space, it becomes impractical to generate a large reference dataset to obtain a reference solution of the inverse design problem. Therefore, we assess the performance of the methods through the following task: We define a target region M d and solve the inverse problem to obtain the optimal process parameter φ ∗ . We then utilize the φ ∗ to generate microstructures via real PSP simulation and compute the percentage of microstructures with properties in M d , i.e. p M d := p ( m ∈ M d | φ ∗ ) .
To make the task challenging, we considered two complex target regions (see Figure 11b): the target region M low d = [ -10 , -10] × -[ 7 , -7] , which corresponds to microstructures with low permeability
Figure 10: The microstructures generated with optimal processing parameters obtained by different methods in Case 4. (a) microstructures generated with φ comp (left) and φ prop (right) for target region M L d . (b) microstructures generated with φ comp (left) and φ prop (right) for target region M M d . (c) microstructures generated with φ comp (left) and φ prop (right) for target region M R d . The solid phase is indicated in yellow.
in both the horizontal and vertical directions; and the target region M high d = [ -7 , -7] × -[ 4 , -4] , which corresponds to microstructures with high permeability in both directions. The solutions obtained by our method and the competitive method for M low d are as follows:
```
\begin{array} { c } \varphi _ { p r o p } ^ { l o w } = ( 1. 0 0 0, 1. 0 0 0, 1. 0 0 0, 3. 0 9 2, 1. 0 0 0, 0. 0 2 0, 0. 0 2 0, 2. 0 0 0, 2. 0 0 0, 2. 0 0 0, 2. 0 0 0, 2. 0 0 0, 2. 0 0 0, 2. 0 0 0, 2. 0 0 0, 1. 9 3 6 ). \end{array}
```
For M high d , the solutions obtained by the two methods are as follows:
$$\begin{array} { c } \varphi _ { p r o p } ^ { h i g h } = ( 1. 0 0 0, 3. 0 5 5, 2. 3 7 4, 8. 9 5 2, 8. 9 9 9, 0. 0 2 0, 0. 0 2 0, 0. 0 2 4, 0. 0 2 1, 0. 0 9 5 ), \\ \varphi _ { c o m p } ^ { h i g h } = ( 6. 1 8 3, 7. 5 1 2, 4. 3 5 1, 8. 9 9 9, 8. 9 9 9, 2. 0 0 0, 0. 0 2 2, 1. 9 9 9, 0. 0 2 3, 2. 0 0 0 ). \end{array}$$
Figure 11: The inverse design results in Case 5. (a) The distribution of microstructures x in the testing dataset, with locations determined by the corresponding properties. (b) The properties m corresponding to the microstructures x . (c) The distribution of properties corresponding to microstructures generated by φ low comp . (d) The distribution of properties corresponding to microstructures generated by φ low prop . (e) The distribution of properties corresponding to microstructures generated by φ high comp . (f) The distribution of properties corresponding to microstructures generated by φ high prop .
To evaluate their performance, we use the obtained solutions to generate 1000 microstructures and calculate the percentage of microstructures with properties in the target region, as shown in Figure 11c-f. For the target region M low d , the results are p M low d = 19 2% . and p M low d = 18% for the proposed PSP-GEN method and the competitive method, respectively. For the target region M high d , the results are p M high d = 24 7% . and p M high d = 14 2% . for the proposed PSP-GEN method and the competitive method, respectively. On both tasks and for the 10-dimensional processing design space, we observe the superior performance of the PSP-GEN method to the competitive one.
## 5 Concluding remarks
In summary, we have introduced an advanced framework, PSP-GEN, for goal-oriented materials design that comprehensively models the entire PSP chain using a deep, generative model. The PSPGEN addresses numerous challenges inherent in inverse materials design, including the presence of stochasticity along the whole modeling chain, the high-dimensional, discrete-valued microstructure space that precludes the availability of derivatives, and the complex and nonlinear SP process.
Central to the effectiveness of the PSP-GEN framework is the continuous, latent space which consists of two components. The first provides a lower-dimensional representation that captures the stochastic aspects of microstructure generation, while the second offers a direct link to processing parameters. This structured, low-dimensional embedding not only simplifies the handling of highdimensional microstructure data but also facilitates the application of gradient-based optimization techniques. Moreover, the incorporation of the microstructures and properties in learning the latent generators ensures that our method is microstructure- and property-aware, leading to more precise solutions compared to microstructure-agnostic methods or those that employ dimensionality reductions solely in the microstructural space.
The PSP-GEN framework significantly enhances computational efficiency and precision in inverse material design. By transforming the goal-oriented design problem into a stochastic, optimization
problem with continuous optimization variables, we achieve superior accuracy compared to the recent state-of-the-art method, particularly in settings where one must operate with limited training data or with high-dimensional parameter spaces. Furthermore, our framework demonstrates strong generalization ability in cross-region design problems, i.e. where the target, property region is far away from the training data space.
Beyond the specific case studies presented, Our PSP-GEN framework holds promise for widespread application in materials science. Its ability to integrate detailed microstructural information and effectively manage stochastic and deterministic elements positions it as a potent tool for accelerating material discovery and optimization across industries. One acknowledged limitation is the substantial training data typically required for the generative model. Future research efforts should focus on enhancing the efficiency of the PSP-GEN framework by incorporating physical information directly into the latent representations, thereby reducing the data requirements while maintaining or improving performance. This advancement would further solidify the framework's utility and broaden its impact in advancing materials science research and development.
## References
| [1] | Executive Office of the President and National Science and Technology Council, Materials Genome Initiative: A Renaissance of American Manufacturing, 2011. URL https://www.whitehouse.gov/blog/2011/06/24/ materials-genome-initiative-renaissance-american-manufacturing |
|-------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [2] | N. Aage, E. Andreassen, B. S. Lazarov, O. Sigmund, Giga-voxel computational morphogenesis for structural design, Nature 550 (7674) (2017) 84-86. |
| [3] | T. Zegard, G. H. Paulino, Bridging topology optimization and additive manufacturing, Struc- tural and Multidisciplinary Optimization 53 (2016) 175-192. |
| [4] | B. Sanchez-Lengeling, C. Outeiral, G. L. Guimaraes, A. Aspuru-Guzik, Optimizing distribu- tions over molecular space. an objective-reinforced generative adversarial network for inverse- design chemistry (organic) (2017). |
| [5] | L. Yu, R. S. Kokenyesi, D. A. Keszler, A. Zunger, Inverse design of high absorption thin-film photovoltaic materials, Advanced Energy Materials 3 (1) (2013). |
| [6] | G. B. Olson, Computational design of hierarchically structured materials, Science 277 (5330) (1997) 1237-1242, publisher: American Association for the Advancement of Science. |
| [7] | D. B. Brough, D. Wheeler, J. A. Warren, S. R. Kalidindi, Microstructure-based knowledge systems for capturing process-structure evolution linkages, Current Opinion in Solid State and Materials Science 21 (3) (2017) 129-140. |
| [8] | Z. Yang, Y. C. Yabansu, R. Al-Bahrani, W.-k. Liao, A. N. Choudhary, S. R. Kalidindi, A. Agrawal, Deep learning approaches for mining structure-property linkages in high contrast composites from simulation datasets, Computational Materials Science 151 (2018) 278-287. |
| [9] | J. Smith, W. Xiong, W. Yan, S. Lin, P. Cheng, O. L. Kafka, G. J. Wagner, J. Cao, W. K. Liu, Linking process, structure, property, and performance for metal-based additive manufacturing: computational approaches with experimental support, Computational Mechanics 57 (2016) 583-610. |
| [10] | A. Khosravani, A. Cecen, S. R. Kalidindi, Development of high throughput assays for estab- lishing process-structure-property linkages in multiphase polycrystalline metals: Application to dual-phase steels, Acta Materialia 123 (2017) 55-69. |
| [11] | N. Kouraytem, X. Li, W. Tan, B. Kappes, A. D. Spear, Modeling process-structure-property relationships in metal additive manufacturing: a review on physics-driven versus data-driven approaches, Journal of Physics: Materials 4 (3) (2021) 032002. |
| [12] | D. L. McDowell, J. Panchal, H.-J. Choi, C. Seepersad, J. Allen, F. Mistree, Integrated Design of Multiscale, Multifunctional Materials and Products, Butterworth-Heinemann, 2009. |
| [13] | R. Bostanabad, Y. Zhang, X. Li, T. Kearney, L. C. Brinson, D. W. Apley, W. K. Liu, W. Chen, Computational microstructure characterization and reconstruction: Review of the state-of-the- art techniques, Progress in Materials Science 95 (2018) 1-41. |
| [14] | P. Honarmandi, V. Attari, R. Arroyave, Accelerated materials design using batch bayesian optimization: A case study for solving the inverse problem from materials microstructure to process specification, Computational Materials Science 210 (2022) 111417. |
| [15] | R. N. Saunders, K. Teferra, A. Elwany, J. G. Michopoulos, D. Lagoudas, Metal am process- structure-property relational linkages using gaussian process surrogates, Additive Manufactur- ing 62 (2023) 103398. |
| [16] | S. R. Niezgoda, Y. C. Yabansu, S. R. Kalidindi, Understanding and visualizing microstructure and microstructure variance as a stochastic process, Acta Materialia 59 (16) (2011) 6387-6400. |
| [17] | S. R. Niezgoda, A. K. Kanjarla, S. R. Kalidindi, Novel microstructure quantification frame- work for databasing, visualization, and analysis of microstructure data, Integrating Materials and Manufacturing Innovation 2 (2013) 54-80. |
| [18] | J. Damewood, J. Karaguesian, J. R. Lunger, A. R. Tan, M. Xie, J. Peng, R. G´mez-Bombarelli, o Representations of Materials for Machine Learning, Annual Review of Materials Research 53 (1) (2023) 399-426. doi:10.1146/annurev-matsci-080921-085947 . URL https://www.annualreviews.org/doi/10.1146/ annurev-matsci-080921-085947 |
| [19] | R. Gomez-Bombarelli, J. N. Wei, D. Duvenaud, J. M. Hern´ndez-Lobato, a B. S´nchez- a Lengeling, D. Sheberla, J. Aguilera-Iparraguirre, T. D. Hirzel, R. P. Adams, A. Aspuru-Guzik, Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules, ACS Central Science 4 (2) (2018) 268-276, publisher: American Chemical Society. doi: 10.1021/acscentsci.7b00572 . URL https://doi.org/10.1021/acscentsci.7b00572 |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [20] | A. P. Generale, C. Kelly, G. Harrington, A. E. Robertson, M. Buzzy, S. Kalidindi, A bayesian approach to designing microstructures and processing pathways for tailored material proper- ties, in: AI for Accelerated Materials Design-NeurIPS 2023 Workshop, 2023. |
| [21] | J. K. Guest, J. H. Pr´vost, e Optimizing multifunctional materials: design of microstructures for maximized stiffness and fluid permeability, International Journal of Solids and Structures 43 (22-23) (2006) 7028-7047. |
| [22] | J. K. Guest, J. H. Pr´vost, e Design of maximum permeability material structures, Computer Methods in Applied Mechanics and Engineering 196 (4-6) (2007) 1006-1017. |
| [23] | D. T. Fullwood, S. R. Niezgoda, B. L. Adams, S. R. Kalidindi, Microstructure sensitive design for performance optimization, Progress in Materials Science 55 (6) (2010) 477-562. |
| [24] | E. Andreassen, B. S. Lazarov, O. Sigmund, Design of manufacturable 3d extremal elastic microstructure, Mechanics of Materials 69 (1) (2014) 1-10. |
| [25] | J. Jung, J. I. Yoon, H. K. Park, H. Jo, H. S. Kim, Microstructure design using machine learning generated low dimensional and continuous design space, Materialia 11 (2020) 100690. doi: 10.1016/j.mtla.2020.100690 . URL http://www.sciencedirect.com/science/article/pii/S2589152920301071 |
| [26] | Y. Kim, H. K. Park, J. Jung, P. Asghari-Rad, S. Lee, J. Y. Kim, H. G. Jung, H. S. Kim, Explo- ration of optimal microstructure and mechanical properties in continuous microstructure space using a variational autoencoder, Materials &Design 202 (2021) 109544. |
| [27] | L. Xu, N. Hoffman, Z. Wang, H. Xu, Harnessing structural stochasticity in the computational discovery and design of microstructures, Materials &Design 223 (2022) 111223. |
| [28] | V. Attari, D. Khatamsaz, D. Allaire, R. Arroyave, Towards inverse microstructure-centered ma- terials design using generative phase-field modeling and deep variational autoencoders, Acta Materialia 259 (2023) 119204. |
| [29] | R. K. Tan, N. L. Zhang, W. Ye, Adeep learning-based method for the design of microstructural materials, Structural and Multidisciplinary Optimization 61 (2020) 1417-1438. |
| [30] | X. Y. Lee, J. R. Waite, C.-H. Yang, B. S. S. Pokuri, A. Joshi, A. Balu, C. Hegde, B. Gana- pathysubramanian, S. Sarkar, Fast inverse design of microstructures via generative invari- ance networks, Nature Computational Science 1 (3) (2021) 229-238. doi:10.1038/ s43588-021-00045-8 . URL https://www.nature.com/articles/s43588-021-00045-8 |
| [31] | X. Lyu, X. Ren, Microstructure reconstruction of 2d/3d random materials via diffusion-based deep generative models, Scientific Reports 14 (1) (2024) 5041. |
| [32] | A. Tran, T. Wildey, Solving Stochastic Inverse Problems for Property-Structure Linkages Using Data-Consistent Inversion and Machine Learning, JOM 73 (1) (2021) 72-89. doi: 10.1007/s11837-020-04432-w . URL https://doi.org/10.1007/s11837-020-04432-w |
| [33] | S. Wei, S. J. Kim, J. Kang, Y. Zhang, Y. Zhang, T. Furuhara, E. S. Park, C. C. Tasan, Natural- mixing guided design of refractory high-entropy alloys with as-cast tensile ductility, Nature Materials 19 (11) (2020) 1175-1181. |
| [34] | A. Devaraj, V. V. Joshi, A. Srivastava, S. Manandhar, V. Moxson, V. A. Duz, C. Lavender, A low-cost hierarchical nanostructured beta-titanium alloy with high strength, Nature communi- cations 7 (1) (2016) 1-8. |
| [35] | Z. Li, K. G. Pradeep, Y. Deng, D. Raabe, C. C. Tasan, Metastable high-entropy dual-phase alloys overcome the strength-ductility trade-off, Nature 534 (7606) (2016) 227-230. |
| [36] | A. Molkeri, D. Khatamsaz, R. Couperthwaite, J. James, R. Arr´yave, o D. Allaire, A. Srivas- tava, On the importance of microstructure information in materials design: Psp vs pp, Acta Materialia 223 (2022) 117471. |
| [37] | A. P. Generale, A. E. Robertson, C. Kelly, S. R. Kalidindi, Inverse stochastic microstructure design, Acta Materialia 271 (2024) 119877. |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [38] | S. Pfeifer, B. S. S. Pokuri, P. Du, B. Ganapathysubramanian, Process optimization for microstructure-dependent properties in thin film organic electronics, Materials Discovery 11 (2018) 6-13. doi:10.1016/j.md.2018.06.002 . URL http://www.sciencedirect.com/science/article/pii/S2352924517300480 |
| [39] | M. J. Beal, Z. Ghahramani, The Variational Bayesian EMAlgorithm for Incomplete Data: with Application to Scoring Graphical Model Structures, Bayesian Statistics 7 (2003). |
| [40] | S. Torquato, Random Heterogeneous Materials, Springer-Verlag, 2002. |
| [41] | S. Torquato, Optimal Design of Heterogeneous Materials, Annual Review of Materials Research 40 (1) (2010) 101-129. doi:10.1146/annurev-matsci-070909-104517 . URL http://www.annualreviews.org/doi/abs/10.1146/ annurev-matsci-070909-104517 |
| [42] | R. Arr´yave, o D. L. McDowell, Systems Approaches to Materials Design: Past, Present, and Future, Annual Review of Materials Research 49 (1) (2019) 103- 126, eprint: https://doi.org/10.1146/annurev-matsci-070218-125955. doi:10.1146/ annurev-matsci-070218-125955 . URL https://doi.org/10.1146/annurev-matsci-070218-125955 |
| [43] | A. Chernatynskiy, S. R. Phillpot, R. LeSar, Uncertainty Quantification in Multiscale Simula- tion of Materials: AProspective, Annual Review of Materials Research 43 (1) (2013) 157-182. doi:10.1146/annurev-matsci-071312-121708 . URL https://doi.org/10.1146/annurev-matsci-071312-121708 |
| [44] | P. Honarmandi, R. Arr´yave, o Uncertainty Quantification and Propagation in Computational Materials Science and Simulation-Assisted Materials Design, Integrating Materials and Man- ufacturing Innovation 9 (1) (2020) 103-143. doi:10.1007/s40192-020-00168-2 . URL https://doi.org/10.1007/s40192-020-00168-2 |
| [45] | E. Popova, T. M. Rodgers, X. Gong, A. Cecen, J. D. Madison, S. R. Kalidindi, Process- Structure Linkages Using a Data Science Approach: Application to Simulated Additive Man- ufacturing Data, Integrating Materials and Manufacturing Innovation 6 (1) (2017) 54-68. doi:10.1007/s40192-017-0088-1 . URL https://doi.org/10.1007/s40192-017-0088-1 |
| [46] | L. Xu, N. Hoffman, Z. Wang, H. Xu, Harnessing structural stochasticity in the computational discovery and design of microstructures, Materials & Design 223 (2022) 111223. doi:10. 1016/j.matdes.2022.111223 . URL https://www.sciencedirect.com/science/article/pii/S0264127522008450 |
| [47] | F. E. Bock, R. C. Aydin, C. J. Cyron, N. Huber, S. R. Kalidindi, B. Klusemann, A Review of the Application of Machine Learning and Data Mining Approaches in Continuum Materi- als Mechanics, Frontiers in Materials 6, publisher: Frontiers (2019). doi:10.3389/fmats. 2019.00110 . URL https://www.frontiersin.org/articles/10.3389/fmats.2019.00110/full |
| [48] | J. H. Panchal, S. R. Kalidindi, D. L. McDowell, Key computational modeling issues in In- tegrated Computational Materials Engineering, Computer-Aided Design 45 (1) (2013) 4-25. doi:10.1016/j.cad.2012.06.006 . URL http://www.sciencedirect.com/science/article/pii/S0010448512001352 |
| [49] | C. Grigo, P.-S. Koutsourelakis, Bayesian Model and Dimension Reduction for Uncertainty Propagation: Applications in Random Media, SIAM/ASA Journal on Uncertainty Quantifica- tion 7 (1) (2019) 292-323. doi:10.1137/17M1155867 . URL https://epubs.siam.org/doi/abs/10.1137/17M1155867 |
| [50] | N. Zabaras, B. Ganapathysubramanian, A scalable framework for the solution of stochastic inverse problems using a sparse grid collocation approach, Journal of Computational Physics 227 (9) (2008) 4697-4735. doi:10.1016/j.jcp.2008.01.019 . URL http://www.sciencedirect.com/science/article/pii/S0021999108000478 |
| [51] | P. I. Frazier, J. Wang, Bayesian optimization for materials design, in: Information Science for Materials Discovery and Design, Springer, 2016, pp. 45-75. |
| [52] | Y. Zhang, D. W. Apley, W. Chen, Bayesian Optimization for Materials Design with Mixed Quantitative and Qualitative Variables, Scientific Reports 10 (1) (2020) 4924, number: 1 Pub- lisher: Nature Publishing Group. doi:10.1038/s41598-020-60652-9 . URL https://www.nature.com/articles/s41598-020-60652-9 |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [53] | H. Ikebata, K. Hongo, T. Isomura, R. Maezono, R. Yoshida, Bayesian molecular design with a chemical language model, Journal of Computer-Aided Molecular Design 31 (4) (2017) 379- 391. doi:10.1007/s10822-016-0008-z . |
| [54] | M. Rixner, P.-S. Koutsourelakis, Self-supervised optimization of random material microstruc- tures in the small-data regime, accepted Nature Computational MaterialsArXiv: 2108.02606 (2022). URL http://arxiv.org/abs/2108.02606 |
| [55] | S. R. Kalidindi, Hierarchical materials informatics: novel analytics for materials data, Elsevier, 2015. |
| [56] | M. Rixner, P.-S. Koutsourelakis, Aprobabilistic generative model for semi-supervised training of coarse-grained surrogates and enforcing physical constraints through virtual observables, Journal of Computational Physics 434 (2021) 110218. doi:10.1016/j.jcp.2021.110218 . URL https://www.sciencedirect.com/science/article/pii/S0021999121001133 |
| [57] | R. M. Haralick, K. Shanmugam, I. H. Dinstein, Textural features for image classification, IEEE Transactions on systems, man, and cybernetics (6) (1973) 610-621. |
| [58] | D. G. Backman, D. Y. Wei, D. D. Whitis, M. B. Buczek, P. M. Finnigan, D. Gao, Icme at ge: accelerating the insertion of new materials and processes, JoM 58 (2006) 36-41. |
| [59] | B. L. DeCost, E. A. Holm, A computer vision approach for automated analysis and classifica- tion of microstructural image data, Computational materials science 110 (2015) 126-133. |
| [60] | D. T. Fullwood, S. R. Niezgoda, S. R. Kalidindi, Microstructure reconstructions from 2-point statistics using phase-recovery algorithms, Acta Materialia 56 (5) (2008) 942-948. |
| [61] | M. Larmuseau, M. Sluydts, K. Theuwissen, L. Duprez, T. Dhaene, S. Cottenier, Compact representations of microstructure images using triplet networks, npj Computational Materials 6 (1) (2020) 156. |
| [62] | D. P. Kingma, M. Welling, Auto-encoding variational bayes, arXiv preprint arXiv:1312.6114 (2013). |
| [63] | M. E. Tipping, Probabilistic Visualisation of High-dimensional Binary Data, in: Proceedings of the 11th International Conference on Neural Information Processing Systems, NIPS'98, MIT Press, Cambridge, MA, USA, 1998, pp. 592-598, event-place: Denver, CO. URL http://dl.acm.org/citation.cfm?id=3009055.3009139 |
| [64] | Z. Jiang, Y. Zheng, H. Tan, B. Tang, H. Zhou, Variational deep embedding: An unsupervised and generative approach to clustering, arXiv preprint arXiv:1611.05148 (2016). |
| [65] | A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, A. Lerer, Automatic differentiation in pytorch (2017). |
| [66] | B. Dai, D. Wipf, Diagnosing and enhancing vae models, arXiv preprint arXiv:1903.05789 (2019). |
| [67] | I. Higgins, L. Matthey, A. Pal, C. P. Burgess, X. Glorot, M. M. Botvinick, S. Mohamed, A. Ler- chner, beta-vae: Learning basic visual concepts with a constrained variational framework., ICLR (Poster) 3 (2017). |
| [68] | D. P. Kingma, D. J. Rezende, S. Mohamed, M. Welling, Semi-Supervised Learning with Deep Generative Models, arXiv:1406.5298 [cs, stat]ArXiv: 1406.5298 (Oct. 2014). URL http://arxiv.org/abs/1406.5298 |
| [69] | M. Betancourt, A conceptual introduction to hamiltonian monte carlo, arXiv preprint arXiv:1701.02434 (2017). |
| [70] | M. D. Hoffman, D. M. Blei, C. Wang, J. Paisley, Stochastic variational inference, Journal of Machine Learning Research (2013). |
| [71] | E. Schulz, M. Speekenbrink, A. Krause, A tutorial on gaussian process regression: Modelling, exploring, and exploiting functions, Journal of Mathematical Psychology 85 (2018) 1-16. |
- [72] J. Gardner, G. Pleiss, K. Q. Weinberger, D. Bindel, A. G. Wilson, Gpytorch: Blackbox matrixmatrix gaussian process inference with gpu acceleration, Advances in neural information processing systems 31 (2018).
- [73] J. W. Cahn, Phase separation by spinodal decomposition in isotropic systems, The Journal of chemical physics 42 (1) (1965) 93-99.
- [74] R. S. Vianna, A. M. Cunha, R. B. Azeredo, R. Leiderman, A. Pereira, Computing effective permeability of porous media with fem and micro-ct: an educational approach, Fluids 5 (1) (2020) 16.
- [75] P. Goyal, P. Doll´ ar, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, K. He, Accurate, large minibatch sgd: Training imagenet in 1 hour, arXiv preprint arXiv:1706.02677 (2017).
## A The model structures
The model p θ z 1 ( z 1 | φ ) For the model p θ φ ( z 1 | φ ) = δ ( z 1 -g θ φ ( φ )) , we modeled g θ φ ( φ ) as a ResNet model consists of an input layer, three hidden layers with 256, 128, and 64 neurons respectively using ELU activation, and an output layer with linear activation.
The Decoder D θ x For the decoder µ θ x = D θ x ( z 0 , z 1 ) , we modeled it as a ResNet model with an input layer, two hidden layers with 512 and 128 neurons respectively using ReLU activation, and an output layer. At the output layer, the sigmoid activation was applied to transform the output value into (0 1) , for probabilistic outputs.
The Decoder D θ m For the decoder ( µ θ m , σ θ m ) = D θ m ( z 0 , z 1 ) , we selected both models as a ResNet with an input layer, three hidden layers with 64, 128 and 256 neurons respectively using ELU activation, and an output layer with linear activation.
The Encoder E η : For the encoder z 0 = E θ m ( m x φ , , ) , since the input terms m x , , and φ have different data formats and scales, we first map them into three tensors of dimension d z 0 using three different ResNet models: ResNet x , ResNet m , and ResNet φ . The ResNet x is a ResNet model consisting of an input layer, two hidden layers, and an output layer. The two hidden layers have 128 and 512 neurons, respectively, and use the ELU activation function, while the output layer uses linear activation. The ResNet m and ResNet φ have the same structure, which consists of a ResNet model with an input layer, one hidden layer, and an output layer. The hidden layer has 64 neurons and uses the ELU activation function, while the output layer uses linear activation. Then, we concatenate these three tensors and pass them to a ResNet model with an input layer, one hidden layer, and an output layer. The hidden layer has 64 neurons and uses the ELU activation function, while the output layer uses linear activation.
Although we used the above network structure in this paper, it is important to note that the chosen network structure is not necessarily the optimal one. The optimal network structure depends on various factors, such as the representation of the microstructure, the dimensions of the microstructure space, and the objectives of the inverse problem. However, this is beyond the scope of this paper and will be explored in future research.
## B Trade-off between reconstruction terms and the KL-divergence term
To obtain disentangled latent representations, we balance the terms in the ELBO using the β -VAE trick. Specifically, we selected different β values in the objective function shown in equation Equation (17) and trained the PSP-GEN model. For each β value, we recorded the total validation loss L = L REC, x + L REC, m + L KL and the reconstruction validation loss L REC = L REC, x + L REC, m obtained after the training, and plotted their curves with respect to β in Figure 1. From the figure, we can see that both the total validation loss and the reconstruction validation loss reach their minimum values when β = 2 . Therefore, we used the setting of β = 2 in our experiments.
Figure 1: Trade-off between reconstruction terms and the KL-divergence term: The blue curve represents the total validation losses L obtained by training the model with different values of β . The green curve shows the reconstruction validation losses, specifically L REC , x + L REC , m , under varying values of β .
 | null | [
"Yaohua Zang",
"Phaedon-Stelios Koutsourelakis"
] | 2024-08-02T08:50:29+00:00 | 2024-08-02T08:50:29+00:00 | [
"cond-mat.mtrl-sci",
"math-ph",
"math.MP"
] | PSP-GEN: Stochastic inversion of the Process-Structure-Property chain in materials design through deep, generative probabilistic modeling | Inverse material design is a cornerstone challenge in materials science, with
significant applications across many industries. Traditional approaches that
invert the structure-property (SP) linkage to identify microstructures with
targeted properties often overlook the feasibility of production processes,
leading to microstructures that may not be manufacturable. Achieving both
desired properties and a realizable manufacturing procedure necessitates
inverting the entire Process-Structure-Property (PSP) chain. However, this task
is fraught with challenges, including stochasticity along the whole modeling
chain, the high dimensionality of microstructures and process parameters, and
the inherent ill-posedness of the inverse problem. This paper proposes a novel
framework, named PSP-GEN, for the goal-oriented material design that
effectively addresses these challenges by modeling the entire PSP chain with a
deep generative model. It employs two sets of continuous, microstructure- and
property-aware, latent variables, the first of which provides a
lower-dimensional representation that captures the stochastic aspects of
microstructure generation, while the second is a direct link to processing
parameters. This structured, low-dimensional embedding not only simplifies the
handling of high-dimensional microstructure data but also facilitates the
application of gradient-based optimization techniques. The effectiveness and
efficiency of this method are demonstrated in the inverse design of two-phase
materials, where the objective is to design microstructures with target
effective permeability. We compare state-of-the-art alternatives in challenging
settings involving limited training data, target property regions for which no
training data is available, and design tasks where the process parameters and
microstructures have high-dimensional representations. |
2408.01115v1 | ## Epistemic Ensembles in Semantic and Symbolic Environments (Extended Version with Proofs)
Rolf Hennicker 1 , Alexander Knapp , and Martin Wirsing 2 1
1 Ludwig-Maximilians-Universit¨ at M¨ unchen, M¨ unchen, Germany
{ hennicker , wirsing @ifi.lmu.de } 2 Universit¨ at Augsburg, Augsburg, Germany [email protected]
Dedicated to Rocco De Nicola
Abstract. An epistemic ensemble is composed of knowledge-based agents capable of retrieving and sharing knowledge and beliefs about themselves and their peers. These agents access a global knowledge state and use actions to communicate and cooperate, altering the collective knowledge state. We study two types of mathematical semantics for epistemic ensembles based on a common syntactic operational ensemble semantics: a semantic environment defined by a class of global epistemic states, and a symbolic environment consisting of a set of epistemic formulæ. For relating these environments, we use the concept of Φ -equivalence, where a class of epistemic states and a knowledge base are Φ -equivalent, if any formula of Φ holds in the class of epistemic states if, and only if, it is an element of the knowledge base. Our main theorem shows that Φ -equivalent configurations simulate each other and satisfy the same dynamic epistemic ensemble formulae.
## 1 Introduction
Ensembles [15,20] are collective systems consisting of dynamically interacting autonomic entities. In an epistemic ensemble [13] these entities are epistemic agents that possess knowledge and beliefs about themselves and other agents. The agents have access to a global knowledge state and utilise epistemic actions to cooperate and communicate. An epistemic action involves announcing an agent's knowledge or belief to others, thereby altering the collective knowledge state.
This paper builds upon our previous work [13,14]. In [13], we introduced epistemic ensembles in a semantic environment consisting of a single epistemic state; in
[14], we considered epistemic processes and related them in semantic environments of a single epistemic state with symbolic environments. Here, we focus on ensembles and model them as families of concurrently running epistemic processes. We introduce a syntactic operational semantics for these epistemic ensembles. Building on the operational semantics we consider an extended notion of semantic environment consisting not only of a single epistemic state but of a class of epistemic states. Following ideas from [14], we also apply the symbolic approach to epistemic ensembles and relate symbolic environments with the new, more general semantic approach.
The dynamic behaviour of each agent process in an ensemble is specified using a simple process algebra with guards and recursion. The syntactic operational semantics of the entire ensemble is defined generically by conditional transitions over uninterpreted agent actions. To specify global properties of epistemic ensembles, we use propositional dynamic logic over compound ensemble actions. Our main result is the study of two complementary kinds of mathematical semantics for epistemic ensembles building on the common syntactic operational semantics: one in a semantic environment defined by a class of global epistemic states, represented by pointed Kripke structures, and the other in a symbolic environment defined by a global epistemic knowledge base, represented by a finite set of epistemic formulæ. The agent actions are first interpreted by pointed action models [1,2]; in the semantic environment their effect is given by product updates on Kripke structures [1,2], while in the symbolic environment we use weakest liberal preconditions [10]. Building on [14], we relate the semantic and symbolic environments by fixing a finite set Φ of focus formulæ: A class K of epistemic states is Φ -equivalent to a symbolic state Γ ⊆ Φ if all K ∈ K satisfy exactly those ϕ ∈ Φ that are in Γ . Reusing the notion of Φ -representability we ensure that semantic and symbolic updates preserve Φ -equivalence. As our main results we show that Φ -equivalent ensemble configurations simulate each other and that they satisfy the same dynamic ensemble formulæ.
Related work. Research on using epistemic logic in system modelling and programming began with the seminal works on Dynamic Epistemic Logic (DEL [1,11]) and knowledgebased programs [12]. DEL focuses on modelling and verifying knowledge changes induced by action execution. We use DEL's reduction rules to define the weakest liberal precondition, which also underpin many foundational results of DEL, such as soundness and completeness [1,2], as well as the definition of a sequent calculus [21]. Knowledgebased programsconsider systems of concurrentlyrunningagents. [4] examines protocols based on DEL and, as [18], system properties in epistemic temporal logic.
Ourworkisbasedonaprocess-orienteddescription of dynamic system behaviour [9], in alignment with modern languages for ensembles such as SCEL [17], CARMA [7], and DEECo [8]. However, these languages rely on communication mechanisms like message passing and predicate-based communication,rather than epistemic actions. Our symbolic semantics for epistemic representation is related to the syntactic structures in [13] and belief bases in [16]. While Lorini's work is also based on DEL, it lacks a process-algebraic setting and uses specialised forms of knowledge update operations. In contrast, we consider general action models and apply an abstraction technique from epistemic Kripke semantics to a symbolic approach, preserving and reflecting dynamic ensemble properties.
Structure of the paper. We first introduce epistemic ensembles and their syntactic operational semantics in Sect. 2 and dynamic ensemble formulæ in Sect. 3. The agent actions of epistemic ensembles are interpreted by action models in Sect. 4. Section 5 and Sect. 6 present the semantic and the symbolic environment of epistemic ensembles. The equivalence of both semantics is shown in Sect. 7. We conclude in Sect. 8.
## 2 Epistemic Ensembles
An epistemic ensemble is formed by a collection of agents which run concurrently to accomplish a certain task. In the epistemic context collaboration of agents is achieved
by the execution of agent actions where agents inform other agents about (parts of) their knowledge, which may concern themselves, other agents or the environment. Each agent follows a certain protocol which is given by an epistemic process description. In this section we introduce the syntactic notions for building epistemic ensembles and we provide a generic operational semantics for epistemic ensembles which will be instantiated later on for executing ensembles in semantic and symbolic environments.
Epistemic formulæ. Epistemic formulæ provide the means to describe knowledge; see, e.g., [2,11,12]. An epistemic signature Σ = ( Π,A ) consists of a set Π of (atomic) propositions and a set A of agents . The set F Σ of epistemic formulæ ϕ over Σ = ( Π,A ) is defined by the following grammar:
$$\varphi \, \left \| \colon = \, p \, \right | \, \text{ true } \, \left | \, \neg \varphi \, \left | \, \varphi _ { 1 } \wedge \varphi _ { 2 } \, \right | \, K _ { a } \, \varphi \, \text{ where } p \in \Pi \text{ and } a \in A.$$
Theepistemic formula K a ϕ is to be read as 'agent a knows ϕ '. We use the usual Boolean shorthand notations like false for ¬ true , ϕ 1 ∨ ϕ 2 for ¬ ¬ ( ϕ 1 ∧¬ ϕ 2 ) , etc. Moreover, we write M a ϕ for ¬ K a ¬ ϕ ; this latter epistemic modality is dual to K a and to be read as 'agent a deems ϕ possible '. For each a ∈ A , the set F Σ /harpoonupright a of a -epistemic formulæ ϕ a having an a -modality as their top operator, is given by the following grammar:
$$\varphi _ { a } \, \vdots = \, \text{true} \ | \ \supset \varphi _ { a } \ | \ \varphi _ { a, 1 } \wedge \varphi _ { a, 2 } \ | \ K _ { a } \, \varphi \ \text{ where } \varphi \in \mathcal { F } _ { \Sigma }.$$
For any ϕ ∈ F Σ the set of possible agents of ϕ is given by ags Σ ( ϕ ) = { a ∈ A | ϕ ∈ F Σ /harpoonupright a } . In our setting, ags Σ ( ϕ ) is either a singleton or A (if no K a occurs in ϕ ).
Example 1. Our running example is inspired by [22]. We consider a set of two agents A 2 = { 1 2 , } each one holding a bit x i ∈ Π 2 = { x 1 , x 2 } . The epistemic signature is Σ 2 = ( Π ,A 2 2 ) . In a situation where x 1 is true, the 1 -formula K 1 x 1 expresses that agent 1 knows this. The 2 -formula K 2 x 1 ∨ K 2 ¬ x 1 says that agent 2 knows the value of x 1 but we cannot infer its concrete value. The 1 -formula ¬ K 1 ( K 2 x 1 ∨ K 2 ¬ x ) 1 expresses that agent 1 does not know whether agent 2 knows the value of x 1 .
Epistemic ensemble signatures. Our formalisation of epistemic ensembles is based on the notion of an epistemic ensemble signature ˇ Σ = ( Σ, (N ) a a ∈ A ) consisting of an epistemic signature Σ = ( Π,A ) and an A -family (N ) a a ∈ A of pairwise disjoint sets N a of agent action symbols , briefly called agent actions . Each set N a determines which actions are possible for agent a . We write ⋃ N for ⋃ a ∈ A N a and for each η ∈ ⋃ N we set ags ˇ Σ ( η ) = { a } if η ∈ N a .
Example 2. Continuing Ex. 1 we introduce an action stop and two actions tell 12(x ) 1 and tell 12( ¬ x ) 1 for agent 1 , i. e., N 2 , 1 = { stop , tell 12(x ) 1 , tell 12( ¬ x ) 1 } , the latter two to express that agent 1 tells the value of x 1 to agent 2 but, in each case, the information transfer is unreliable since agent 2 maybe too far away. On the other hand, agent 2 (when it got the value of x 1 ) may acknowledge in a reliable way the reception with the action ack 21( x 1 ) , i. e., N 2 , 2 = { ack 21( x 1 ) } .
General assumption. In the sequel, we always assume given an epistemic ensemble signature ˇ = ( Σ Σ, (N ) a a ∈ A ) with underlying epistemic signature Σ = ( Π,A ) .
↦
$$\eta. P \xrightarrow { \text{true:\eta} } _ { \tilde { \Sigma } } P & & \frac { P \xrightarrow { \hat { \varphi } \cdot \eta } _ { \tilde { \Sigma } } P ^ { \prime } } { \varphi \supset P \xrightarrow { \hat { \varphi } \cdot \eta } _ { \tilde { \Sigma } } P ^ { \prime } } \\ \frac { P _ { \ell } \xrightarrow { \hat { \varphi } \cdot \eta } _ { \tilde { \Sigma } } P ^ { \prime } _ { \ell } } { P _ { 1 } + P _ { 2 } \xrightarrow { \hat { \varphi } \cdot \eta } _ { \tilde { \Sigma } } P ^ { \prime } _ { \ell } } & & \text{ for } \ell \in \{ 1, 2 \} & & \frac { P \{ X \mapsto \mu X \,. \, P \} \xrightarrow { \hat { \varphi } \cdot \eta } _ { \tilde { \Sigma } } P ^ { \prime } } { \mu X \,. \, P \xrightarrow { \hat { \varphi } \cdot \eta } _ { \tilde { \Sigma } } P ^ { \prime } } \\ & & \text{Table 1. Rules for enlistemic nprocesses}$$
Table 1. Rules for epistemic processes
Epistemic processes. We consider an epistemic process language for describing the behaviour of agents which participate in an epistemic ensemble. The set P ˇ Σ of epistemic processes P over ˇ Σ is defined by the grammar
$$P \, \colon = \, 0 \, \left | \, \eta. P \, \right | \, \varphi \supset P \, \right | \, P _ { 1 } + P _ { 2 } \, \left | \, \mu X \,. \, P \, \right | \, X$$
where 0 represents the inactive process, η.P prefixes P with an agent action η ∈ ⋃ N , ϕ ⊃ P is a guarded process with condition ϕ ∈ F Σ , P 1 + P 2 denotes the nondeterministic choice between processes P 1 and P 2 , µX . P is a recursive process, and X is a process variable typically used in recursive process definitions.
The operational semantics of epistemic processes is given by conditional transitions P ↪ ̂ ϕ η : - -→ ˇ Σ P ′ relating a process P via a guard ̂ ϕ ∈ F Σ and an agent action η ∈ ⋃ N with another process P ′ . The transitions are defined inductively by the rules in Tab. 1, where successive guards are conjoined and true represents the empty guard.
Epistemic processes are used to describe the behaviour of single agents. But not any process expression in P ˇ Σ is meaningful for any agent. For instance, a process η. 0 can be carried out by an agent a only if the action symbol η represents an action of a , i. e., η ∈ N a . For any process P ∈ P ˇ Σ the set ags ˇ Σ ( P ) of agents that are allowed to execute P is inductively defined by
$$& \ a g s _ { \hat { \Sigma } } ( 0 ) = A & \ a g s _ { \hat { \Sigma } } ( \eta. P ) = \ a g s _ { \hat { \Sigma } } ( \eta ) \cap \ a g s _ { \hat { \Sigma } } ( P ) \\ & \ a g s _ { \hat { \Sigma } } ( \varphi \supset P ) = \ a g s _ { \hat { \Sigma } } ( \varphi ) \cap \ a g s _ { \hat { \Sigma } } ( P ) & \ a g s _ { \hat { \Sigma } } ( P _ { 1 } + P _ { 2 } ) = \ a g s _ { \hat { \Sigma } } ( P _ { 1 } ) \cap \ a g s _ { \hat { \Sigma } } ( P _ { 2 } ) \\ & \ a g s _ { \hat { \Sigma } } ( \mu X \,. \, P ) = \ a g s _ { \hat { \Sigma } } ( P ) & \ a g s _ { \hat { \Sigma } } ( X ) = A$$
For executing a process P ∈ P ˇ Σ the following kind of subject reduction holds:
$$\text{Lemma} \, 1. \, \text{If} \, P \stackrel { \widehat { \varphi } \colon \eta } { \longrightarrow } _ { \Sigma } P ^ { \prime }, \, \text{then} \, \text{ags} _ { \Sigma } ( P ) \subseteq \text{ags} _ { \Sigma } ( \widehat { \varphi } ) \cap \text{ags} _ { \Sigma } ( \eta ) \cap \text{ags} _ { \Sigma } ( P ^ { \prime } ).$$
Epistemic ensembles. Now we have all ingredients to define epistemic ensembles as families of epistemic agent processes. Formally, an epistemic ensemble over ˇ Σ is given by a family /vector E = ( a : P a ) a ∈ A such that, for each a ∈ A P , a is an epistemic process in P ˇ Σ with a ∈ ags ˇ Σ ( P a ) , i. e., a is allowed to perform P a .
For notational reasons and for defining the operational semantics of ensembles, we also consider (sub-)families ( a : P a ) a ∈ G of agent processes with G ⊆ A ; their composition ( a 1 : P a 1 ) a 1 ∈ G 1 ‖ ( a 2 : P a 2 ) a 2 ∈ G 2 for disjoint G , G 1 2 ⊆ A as the family ( a : P a ) a ∈ G 1 ∪ G 2 ; and, for i ∈ A , the singleton i : P i which stands for ( a : P a ) a ∈{ } i .
$$\neg K _ { 1 } K _ { 2 } x _ { 1 } \wedge K _ { 1 } \neg x _ { 1 } \colon t e l l 1 2 ( \neg x _ { 1 } ) \\ \neg K _ { 1 } K _ { 2 } x _ { 1 } \wedge K _ { 1 } x _ { 1 } \subset \underbrace { \underbrace { \underbrace { \underbrace { \underbrace { 1 \colon A g 1 } } } } { 1 \colon A g 1 } \| 2 \colon A g 2 } \underbrace { K _ { 1 } K _ { 2 } x _ { 1 } \colon s t o p } { 1 \colon 0 \| 2 \colon A g 2 } \\ K _ { 2 } x _ { 1 } \colon a c k 2 1 ( x _ { 1 } ) \left \| \underbrace { K _ { 2 } x _ { 1 } \colon a c k 2 1 ( x _ { 1 } ) } { 1 \colon A g 1 } \| 2 \colon 0 \right \| \underbrace { K _ { 1 } K _ { 2 } x _ { 1 } \colon s t o p } { 1 \colon 0 \| 2 \colon 0 } \right \| \\ \neg K _ { 1 } K _ { 2 } x _ { 1 } \wedge K _ { 1 } \neg x _ { 1 } \colon t e l l 1 2 ( \neg x _ { 1 } ) \\ \text{Fig. 1. Transition system for the syntactic bit transmission ensemble.}$$
Fig. 1. Transition system for the syntactic bit transmission ensemble.
Example 3. Relying on the epistemic ensemble signature developed in Ex. 1 and Ex. 2, we consider the following simple epistemic ensemble Sys with two processes Ag1 for agent 1 and Ag2 for agent 2 . In the process descriptions we abbreviate, for each a ∈ { 1 2 , } , the formula K a x 1 ∨ K a ¬ x 1 by K a x 1 ( x 1 written in italics).
$$a \subset \{ 1, 2 \}, \, \text{$one$ formula $\tilde{ }omega_{a}x_{1} \vee \tilde{ }omega_{a} \neg x_{1}$} \, \text{$oy $\tilde{ }omega_{a}x_{1} (x_{1}$ written in names)}. \\ A g 1 & = \mu X \,. \, ( \neg K _ { 1 } K _ { 2 } x _ { 1 } \supset ( K _ { 1 } x _ { 1 } \supset t e l l 1 2 ( x _ { 1 } ). X + \\ K _ { 1 } \neg x _ { 1 } \supset t e l l 1 2 ( \neg x _ { 1 } ). X ) + \\ K _ { 1 } K _ { 2 } x _ { 1 } \supset s t o p. 0 ) \\ A g 2 & = K _ { 2 } x _ { 1 } \supset a c k 2 1 ( x _ { 1 } ). 0 \\ S y s & = 1 \, \colon A g 1 \, \| \, 2 \, \colon A g 2$$
By tell 12(x ) 1 and tell 12( ¬ x ) 1 agent 1 repeatedly 'tells' agent 2 the value of x 1 (in an unreliable way) until it is sure that agent 2 knowsthevalue; whenhavingindeedlearntthe value of x 1 , agent 2 acknowledges this fact (in a reliable way) to agent 1 with ack 21( x 1 ) .
The syntactic operational semantics of epistemic ensembles is given by conditional transitions ↪ -→ ˇ Σ relating an ensemble /vector E via a guard ̂ ϕ ∈ F Σ and an agent action η with another ensemble /vector E ′ according to the following rule which is based on the rules for processes:
$$( * ) \ i \colon P _ { i } \, \| \, \vec { E } \overset { \widehat { \varphi } \colon \eta } { \longleftrightarrow } _ { \hat { \Sigma } } i \colon P _ { i } ^ { \prime } \, \| \, \vec { E } \ \text{ if } P _ { i } \overset { \widehat { \varphi } \colon \eta } { \longleftrightarrow } _ { \hat { \Sigma } } P _ { i } ^ { \prime }$$
Note that each ensemble step is well-defined, since i ∈ ags ˇ Σ ( P i ) implies i ∈ ags ˇ Σ ( P ′ i ) by Lem. 1, and thus i : P ′ i ‖ /vector E is again an ensemble. Moreover, the ordering of processes in an ensemble is irrelevant since they are families, i.e., functions mapping agents to processes.
Therule ( ∗ ) is formulated in a generic way without considering evaluations of guards and effects of actions. It provides, however, a convenient basis for concrete instantiations.
Example 4. Figure 1 depicts the conditional transitions of the bit transmission protocol in Ex. 3.
## 3 Dynamic Epistemic Ensemble Logic
So far we have considered a constructive approach for representing epistemic ensembles with local processes for each agent. We are now interested in a declarative language for expressing and specifying behavioural properties of epistemic ensembles from a global perspective. For this purpose we use formulæ in the style of propositional dynamic logic where regular expressions of agent actions, called compound ensemble actions, are used as modalities. In contrast to local agent processes, we have now a global view where actions of different agents can be combined.
The set C ˇ Σ of compound ensemble actions over ˇ Σ is defined by the following grammar:
$$\lambda \, \colon = \, \eta \ | \ \varphi? \ | \ \lambda _ { 1 } + \lambda _ { 2 } \ | \ \lambda _ { 1 } ; \lambda _ { 2 } \ | \ \lambda ^ { * } \ \text{ where } \eta \in \bigcup N \text{ and } \varphi \in \mathcal { F } _ { \Sigma }.$$
Besides agent actions the compound ensemble actions include a test ϕ ? on an epistemic formula ϕ ∈ F Σ , non-deterministic choices λ 1 + λ 2 of compound ensemble actions λ 1 and λ 2 , sequential compositions λ 1 ; λ 2 , and sequential loops λ ∗ .
Following the style of propositional dynamic logic the set D ˇ Σ of epistemic ensemble formulæ over ˇ Σ is defined by the following grammar where compound ensemble actions are used as modalities:
$$\psi \, \left \| \colon = \, \text{true} \ | \ \varphi \ | \ \neg \psi \ | \ \psi _ { 1 } \wedge \psi _ { 2 } \ | \ [ \lambda ] \psi \ \text{ where } \varphi \in \mathcal { F } _ { \Sigma } \ \text{and} \, \lambda \in \mathcal { C } _ { \Sigma }.$$
The formula [ λ ψ ] is to be read as 'after all possible executions of the compound action λ formula ψ holds'. We use the usual abbreviations like false or ∨ as before, and we write 〈 λ ψ 〉 for ¬ [ λ ] ¬ ψ ; this latter dynamic modality is dual to [ λ ] and to be read as 'there is some execution of λ such that ψ holds afterwards'.
Example 5. For our two agent system we are interested in the following properties, in which we abbreviate the compound action stop + tell 12(x )+ 1 tell 12( ¬ x )+ 1 ack 21( x 1 ) by ' some ':
- 1. 'As long as agent 1 does not know that agent 2 knows the value of x 1 the ensemble will not stop': [ some ∗ ] ¬ K K 1 2 x 1 →〈 some 〉 true
- 2. 'Whenever agent 1 tells the value of x 1 to agent 2 , it is possible that agent 2 will eventually know the value': [ some ∗ ; ( tell 12(x ) + 1 tell 12( ¬ x ))] 1 〈 some ∗ 〉 K 2 x 1
We cannot provide a formal satisfaction relation here saying when an epistemic ensemble satisfies an epistemic ensemble formula, since we cannot talk yet about satisfaction of ensemble formulæ as long as we do not have a concrete formalisation of epistemic states and of the effect of agent actions on them. But we can already now provide a definition to capture, for each compound ensemble action λ , which sequences σ = ( ̂ ϕ 1 : η /epsilon1 1 ) . . . ( ̂ ϕ k : η /epsilon1 k ) of guard and agent action pairs can be executed when moving stepwise from an ensemble /vector E to an ensemble /vector E ′ in accordance with rule ( ∗ ) from above. Thereby concatenation of such two sequences σ 1 and σ 2 is denoted by σ 1 · σ 2 and /epsilon1 denotes an artificial empty agent action. The inductive rules in Tab. 2 define when a (stepwise) move ( /vector E,σ, /vector E ′ ) is a witness for a compound ensemble action λ , written ( /vector E,σ, /vector E ′ ) :: λ .
$$( \vec { E }, \widehat { \varphi } \, \colon \, \eta, \vec { E } ^ { \prime } ) \, \left \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \ \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \ \, \\ \frac { ( \vec { E }, \sigma, \vec { E } ^ { \prime } ) \, \left \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \left \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \ \left \| \, } { ( \vec { E }, \sigma, \vec { E } ^ { \prime } ) \, \left \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \left \| \, } { ( \vec { E }, \sigma, \vec { E } ^ { \prime } ) \, \left \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right\| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \|\, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \right \| \, \left \| \, } { \text{Table 2. Rules for witnessing\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\} }$$
Table 2. Rules for witnessing compound ensemble actions
## 4 Action Models for Agent Actions
Going to a concrete interpretation of ensembles a crucial step is to assign meaning to the agent actions occurring in an epistemic ensemble signature. A direct way would be to fix a domain for modelling states and to associate to each agent action η a relation (or a proper function) which models the effect of η . This has been done, for instance, in [12] who associate to (joint) agent actions a so-called 'global state transformer'. In our approachwe pursue a different approach and use the notion of 'action model' introduced in [1] to provide meaning for agent actions. The advantage is that action models still have a syntactic flavour and thus are still independent of the particular denotations used for epistemic states. Most approaches use action models in the context of Kripke structures as mathematical objects for epistemic states on which updates caused by actions are defined. But, in principle, action models allow also other domains for interpretation. For instance, in [14] we have provided an interpretation using symbolic states. Therefore, our idea is here to use action models as an intermediate step to assign an 'abstract' interpretation to agent actions. Then we will consider two concrete frameworks (a Kripke style and a symbolic approach) where updates caused by action model applications are uniquely determined.
An action model U = ( Q,F, pre ) over an epistemic signature Σ = ( Π,A ) consists of a set Q of events , an A -family F = ( F a ⊆ Q × Q ) a ∈ A of action accessibility relations F a , and an action precondition function pre : Q → F Σ . We assume that the accessibility relations F a are equivalences. For any agent a ∈ A , ( q, q ′ ) ∈ F a models that a cannot distinguish between occurrences of events q and q ′ . For any event q ∈ Q , the epistemic formula pre ( q ) determines a condition under which q can happen. An epistemic action u = ( U, q ) is a pointed action model which selects an actual event q ∈ Q . We set F ( u ) a = { q ′ ∈ Q | ( q, q ′ ) ∈ F a } for a ∈ A , and write pre ( u ) for pre ( q ) and u · q ′ for ( U, q ′ ) when q ′ ∈ Q . The class of epistemic actions over Σ is denoted by U Σ . The set of possible agents for an epistemic action u ∈ U Σ is defined by ags Σ ( u ) = ags Σ ( pre ( u )) . The idea is that an action η ∈ N a of an agent a should only be interpreted by an epistemic action whose precondition is an a -formula.
Example 6. A group announcement of a formula ϕ ∈ F Σ to a group A ∗ ⊆ A of agents is modelled by the epistemic action ( U grp ( A , ϕ , ∗ ) k ) graphically represented as
The action model U grp ( A , ϕ ∗ ) has two events k and n . Event k represents the announcement of ϕ which should only happen if ϕ holds and therefore pre grp ,ϕ ( k ) = ϕ ; only agents in the group A ∗ can recognise this event. All other agents consider it possible that nothing happened which is represented by n having no proper precondition, i.e., pre grp ,ϕ ( n ) = true . The possible agents of ( U grp ( A , ϕ , ∗ ) k ) are given by ags Σ ( ϕ ) , the possible agents of ( U grp ( A , ϕ , ∗ ) n ) are ags Σ (true) = A .
Epistemic choice actions. We also consider non-deterministic epistemic actions, similarly to [11]. They model alternatives which are not under the control of an agent but are selected by the environment. Formally, an epistemic choice action over Σ is a finite, non-empty set α ⊆ U Σ of epistemic actions. The class of epistemic choice actions over Σ is denoted by A Σ . The possible agents of an α ∈ A Σ are ags Σ ( α ) = ⋂ u ∈ α ags Σ ( u ) .
Example 7. For agents a, a ′ ∈ A , the epistemic choice action
$$\ s n d _ { \text{los} } ^ { a \rightarrow a ^ { \prime } } ( \varphi _ { a } ) = \{ ( U _ { g r p } ( \{ a ^ { \prime } \}, \varphi _ { a } ), \text{k} ), ( U _ { g r p } ( \{ a ^ { \prime } \}, \varphi _ { a } ), \text{n} ) \}$$
models a lossy sending of the information ϕ a ∈ F Σ /harpoonupright a from a to agent a ′ , in the sense that afterwards a ′ may know ϕ a if a ′ is aware of the announcement (modelled by U grp ( { a ′ } , ϕ a ) , k ) ), but need not if the announcement is lost (modelled by U grp ( { a ′ } , ϕ a ) , n ) ). In any case, a cannot recognise whether the announcement was successful. Similarly, a reliable sending is defined by the (singleton) choice action snd a → a ′ rel ( ϕ a ) = { ( U grp ( { a, a ′ } , ϕ a ) , k ) } which is modelled by a group announcement of ϕ a such that both agents recognise that the message did work. It holds that ags Σ ( snd a → a ′ los ( ϕ a )) = ags Σ ( snd a → a ′ rel ( ϕ a )) = { a . }
Let us now come back to our epistemic ensemble signature ˇ = ( Σ Σ, (N ) a a ∈ A ) with Σ = ( Π,A ) . An epistemic action interpretation for the agent actions in ⋃ N is a function act : ⋃ N →A Σ such that for all a ∈ A and η ∈ N a it holds a ∈ ags Σ ( act ( η )) .
Example 8. For the agent actions in Ex. 2 we use the epistemic action interpretation act 2 with act 2 ( tell 12(x )) 1 = snd 1 → 2 los ( K 1 x ) 1 , act 2 ( tell 12( ¬ x )) 1 = snd 1 → 2 los ( K 1 ¬ x ) 1 } and act 2 ( stop ) = ( U grp ( { 1 2 , } , true) , k ) is the group announcementof true . Moreover, act 2 ( ack 21( x 1 )) = snd 2 → 1 rel ( K 2 x 1 ) is the reliable sending from agent 2 to agent 1 that agent 2 knows the value of x 1 . (Recall that K 2 x 1 abbreviates K 2 x 1 ∨ K 2 ¬ x 1 .)
## 5 Epistemic Ensembles in a Semantic Environment
To execute an epistemic ensemble we need an environment where knowledge formulæ, in particular process guards and change of knowledge caused by agent actions, are interpreted. This section is based on the traditional possible worlds model of epistemic logic; see, e.g., [12].
Epistemic states. An epistemic structure K = ( W,E,L ) (also called Kripke model [2,11] or Kripke structure [12]) over the epistemic signature Σ = ( Π,A ) is given by a set W of worlds , an A -family E = ( E a ⊆ W × W ) a ∈ A of epistemic accessibility relations , and a labelling L : W → ℘Π which determines for each world w ∈ W the set of atomic propositions which hold in w . We assume that the accessibility relations are equivalences. For any agent a , ( w, w ′ ) ∈ E a models that agent a cannot distinguish the two worlds w and w ′ . An epistemic state K = ( K,w ) selects a world w ∈ W considered as the actual world. Thus epistemic states are pointed Kripke structures. The class of epistemic states over Σ is denoted by E Σ .
The satisfaction of an epistemic formula ϕ ∈ F Σ by an epistemic structure K = ( W,E,L ) ∈ E Σ at a world w ∈ W , written K,w | = Σ ϕ , is inductively defined by:
```
\langle \cdot \cdot, \varepsilon, \varepsilon / \varsigma \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \, \nu, \nu \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \delta \, \nu, \nu \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \rangle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \ddot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \rangle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \rangle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \rangle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \rangle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \rangle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \rangle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \rangle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \rangle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \rangle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \rangle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \rangle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \
```
Hence, an agent a knows ϕ at point w if ϕ holds in all worlds w ′ which a cannot distinguish from w . For an epistemic state K = ( K,w ) ∈ E Σ and for ϕ ∈ F Σ , we define K | = ϕ by K,w | = ϕ and for Φ ⊆ F Σ we define K | = Φ by K | = Σ ϕ for all ϕ ∈ Φ . A formula ϕ ∈ F Σ is a logical consequence of Φ ⊆ F Σ , written Φ | = Σ ϕ , if K | = Σ ϕ for all K with K | = Σ Φ . We write | = Σ ϕ for ∅ | = Σ ϕ , i. e., ϕ is a tautology .
Example 9. The following diagram represents graphically an epistemic state K 0 = ( K ,w 0 0 ) in which x 1 is true and agent 1 knows this, but agent 2 does not. Indeed, agent 2 cannot distinguish between the actual world w 0 and the possible world w 1 . The self-loops represent reflexivity of the accessibility relations. Note that K 0 | = Σ 2 K 1 x 1 , K 0 | = Σ 2 ¬ K 2 x 1 , and K 0 | = Σ 2 K 1 ¬ K 2 x 1 .

A state K ′ 0 with K ′ 0 | = Σ K 1 ¬ x 1 and K ′ 0 | = Σ K 1 ¬ K 2 ¬ x 1 is obtained by reversing the labelling of K 0 .
Epistemic updates. The product update ( W,E,L ) /triangleleft Σ ( Q,F, pre ) of an epistemic structure K = ( W,E,L ) and an action model U = ( Q,F, pre ) over Σ = ( Π,A ) yields the epistemic structure ( W ,E ,L ′ ′ ′ ) with
$$1, a n d$$
$$& W ^ { \prime } = \left \{ ( w, q ) \in W \times Q \, | \, K, w \models _ { \Sigma } p r e ( q ) \right \}, \\ & E ^ { \prime } _ { a } = \left \{ ( ( w, q ), ( w ^ { \prime }, q ^ { \prime } ) ) \, | \, ( w, w ^ { \prime } ) \in E _ { a }, \, ( q, q ^ { \prime } ) \in F _ { a } \right \} \text{for all } a \in A, \text{ and } \\ & L ^ { \prime } ( w, q ) = L ( w ) \text{ for all } ( w, q ) \in W ^ { \prime }.$$
Let K = ( K,w ) ∈ E Σ be an epistemic state and u = ( U, q ) ∈ U Σ be an epistemic action. If K | = Σ pre ( q ) then the product update K /triangleleft Σ u of K and u is defined and given by the epistemic state ( K /triangleleft Σ U, ( w, q )) ∈ E Σ .
/negationslash
Example 10. Applying ( U grp ( { 2 } , K 1 x ) 1 , k ) to the epistemic state ( K ,w 0 0 ) in Ex. 9, we obtain the epistemic state ( K , 1 ( w , 0 k )) shown, without reflexive accessibility edges, below. The world ( w , 1 k ) does not appear since ( K ,w 0 1 ) | = Σ 2 K 1 x 1 which is the precondition of k .
Note that ( K , 1 ( w , 0 k )) | = Σ 2 K K 2 1 x 1 but ( K , 1 ( w , 0 k )) | = Σ 2 ¬ K K K 1 2 1 x 1 , i. e., 2 knows that 1 knows that x 1 holds, but 1 does not know that 2 knows this. If we apply the epistemic action ( U grp ( { 2 } , K 1 x ) 1 , n ) to ( K ,w 0 0 ) , we obtain the epistemic state ( K , 1 ( w , 0 n )) . Note that ( K , 1 ( w , 0 n )) = | Σ 2 ¬ K K 2 1 x 1 .
Semanticenvironments. In contrast to [13,14] we consider here not only single epistemic states K ∈ E Σ as semantic environmentsbut, more generally,non-emptyclasses K ⊆ E Σ of epistemic states; the class of all non-empty classes of epistemic states is denoted by S Σ . Such classes model abstractions where different epistemic states are considered to be possible in a current environment. For each K ⊆ E Σ and ϕ ∈ F Σ define K | = Σ ϕ as K | = Σ ϕ for all K ∈ K , and for each u ∈ U Σ define the update K /triangleleft Σ u = { K /triangleleft Σ u | K ∈ K , K | = Σ pre ( u ) } . The semantics of an epistemic choice action α ∈ A Σ is given by the relation
$$\left [ \alpha \right ] _ { \Sigma } = \left \{ \left ( \mathcal { K }, \mathcal { K } \lhd _ { \Sigma } \mathfrak { u } \right ) \in \mathcal { S } _ { \Sigma } \times \mathcal { S } _ { \Sigma } \ | \, \mathfrak { u } \in \alpha, \mathcal { K } \models _ { \Sigma } p r e ( \mathfrak { u } ) \right \}.$$
/negationslash
We require K /negationslash = ∅ because otherwise all formulæ would hold in K . Note that the semantics is well-defined, i.e., K /triangleleft Σ u = ∅ , since ∅ /negationslash = K and K | = Σ pre ( u ) hold. Let us remark that updates on a single epistemic state as considered in [13,14] and its generalisation to classes of epistemic states considered here are tightly related: For each K ∈ E Σ ,
$$\bigcup _ { u \in \alpha } \{ ( \{ \mathfrak { K } \}, \{ \mathfrak { K } \lhd _ { \Sigma } u \} ) \, | \, \mathfrak { K } \models _ { \Sigma } u \} \subseteq [ \alpha ] _ { \Sigma } \,.$$
More generally, we obtain
Lemma 2. Let K ∈ S Σ and α ∈ A Σ .
- 1. If ( { K } K , K ) ∈ /llbracket α /rrbracket Σ for some K ∈ K , then there are K ′ ∈ E Σ with K K = { K ′ } and K ∈ S ′ Σ with K ′ ∈ K ′ such that ( K K , ′ ) ∈ /llbracket α /rrbracket Σ .
- 2. If ( K K , ′ ) ∈ /llbracket α /rrbracket Σ , then for each K ′ ∈ K ′ there is some K ∈ K with ( { K } { , K ′ } ) ∈ /llbracket α /rrbracket Σ .
Ensemble configurations. We are now ready to define the execution of ensembles in semantic class environments.Given the epistemic ensemble signature ˇ = ( Σ Σ, (N ) a a ∈ A ) , an epistemic ensemble configuration over ˇ Σ is a pair ( /vector E, K ) of an ensemble over ˇ Σ and a (non-empty) class of epistemic states K ∈ S Σ . The ensemble semantics over ˇ Σ
w.r.t. an epistemic action interpretation act : ⋃ N → A Σ is the ternary relation -→ act ˇ Σ between configurations, agent actions and (successor) configurations defined by interpreting the syntactic operational ensemble semantics, given by rule ( ∗ ) in Sect. 2, in the environment of classes of epistemic states:
$$\vec { E }, \mathcal { K } \xrightarrow { \eta } _ { \vec { \Sigma } } a c t \, \vec { E } ^ { \prime }, \mathcal { K } ^ { \prime } \quad \text{if} \, \vec { E } \xrightarrow { \widehat { \varphi } \colon \eta } _ { \vec { \Sigma } } \, \vec { E } ^ { \prime }, \mathcal { K } \models _ { \Sigma } \widehat { \varphi }, \, \text{and} \, ( \mathcal { K }, \mathcal { K } ^ { \prime } ) \in [ a c t ( \eta ) ] _ { \Sigma } \\ - \quad \cdots \, \, \real - \, \dots \, \real \cdots \, \real \cdots \, \real \cdots \, \real \cdots \,.$$
Example 11. Consider the bit transmission protocol of Ex. 3 with its agent actions interpreted as in Ex. 8. As initial classes of epistemic states consider on the one hand K 0 x , 1 with all its states satisfying K 1 x 1 (as illustrated by K 0 in Ex. 9), and K 0 , ¬ x 1 with all its states satisfying K 1 ¬ x 1 (as illustrated by K ′ 0 in Ex. 9). In both cases, the value of x 2 is arbitary, as is the knowledge of the agents 1 and 2 about it. The ensemble works uniformly on K 0 x , 1 and on K 0 , ¬ x 1 . Taking an initial class of epistemic states where some states satisfy K 1 x 1 and others K 1 ¬ x 1 no transition can be taken. When starting the ensemble in a class of epistemic states all satisfying K K 1 2 x 1 , then ack 12( x 1 ) and stop can be executed.
Satisfaction of epistemic ensemble formulæ. Finally we are now also able to define when an epistemic ensemble formula (cf. Sect. 3) is satisfied by an ensemble configuration. As a preparation we define the semantics of guard-action sequences σ = ( ̂ ϕ 1 : η /epsilon1 1 ) . . . ( ̂ ϕ k : η /epsilon1 k ) relating classes of epistemic states inductively by
$$& [ \widehat { \varphi } \colon \epsilon ] ^ { a c t } _ { \dot { \Sigma } } = \{ ( \mathcal { K }, \mathcal { K } ) \in \mathcal { S } _ { \Sigma } \times \mathcal { S } _ { \Sigma } \, | \, \mathcal { K } \models _ { \Sigma } \widehat { \varphi } \} \,, \\ & [ \widehat { \varphi } \colon \eta ] ^ { a c t } _ { \dot { \Sigma } } = \{ ( \mathcal { K }, \mathcal { K } ^ { \prime } ) \in [ a c t ( \eta ) ] ] _ { \Sigma } \, | \, \mathcal { K } \models _ { \Sigma } \widehat { \varphi } \} \,, \\ & [ \sigma _ { 1 } \cdot \sigma _ { 2 } ] ^ { a c t } _ { \dot { \Sigma } } = [ \sigma _ { 1 } ] ] ^ { a c t } _ { \dot { \Sigma } } ; [ \sigma _ { 2 } ] ^ { a c t } _ { \dot { \Sigma } } \quad ( \text{relational composition} )$$
$$\left [ \sigma _ { 1 } \cdot \sigma _ { 2 } \right ] _ { \check { \Sigma } } ^ { a c t } = \left [ \sigma _ { 1 } \right ] _ { \check { \Sigma } } ^ { a c t } ; \left [ \sigma _ { 2 } \right ] _ { \check { \Sigma } } ^ { a c t } \quad ( \text{relational composition)}$$
The semantics of a compound ensemble action λ ∈ C ˇ Σ relating ensemble configurations relies on the definition of witnesses in Sect. 3 and is given by the relation
$$\left [ \lambda \right ] ^ { a c t } _ { \vec { \Sigma } } = \left \{ \left ( ( \vec { E }, \mathcal { K } ), ( \vec { E } ^ { \prime }, \mathcal { K } ^ { \prime } ) \right ) \, | \, ( \vec { E }, \sigma, \vec { E } ^ { \prime } ) \, \left \| \colon \lambda, \, ( \mathcal { K }, \mathcal { K } ^ { \prime } ) \in \left [ \sigma \right ] ^ { a c t } _ { \vec { \Sigma } } \right \}.$$
Lemma 3. Let ( /vector E, K ) be an ensemble configuration and λ ∈ C ˇ Σ .
- 1. If (( /vector E, { K } ) , ( /vector E , ′ K K )) ∈ /llbracket λ /rrbracket act ˇ Σ for some K ∈ K , then there are K ′ ∈ E Σ with K K = { K ′ } and K ∈ S ′ Σ with K ′ ∈ K ′ such that (( /vector E, K ) , ( /vector E , ′ K ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ .
- 2. If (( /vector E, K ) , ( /vector E, K ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ , then for each K ′ ∈ K ′ there is some K ∈ K with (( /vector E, { K } ) , ( /vector E , ′ { K ′ } )) ∈ /llbracket λ /rrbracket act ˇ Σ .
The satisfaction of an epistemic ensemble formula ψ ∈ D ˇ Σ by an ensemble configuration ( /vector E, K ) w.r.t. act : ⋃ N →A Σ is inductively defined along the form of ψ :
- ( /vector E, K | ) = act ˇ ϕ ⇐⇒ K | = Σ ϕ
$$( \vec { E }, \mathcal { K } ) \models _ { \vec { \Sigma } } ^ { a c t } \, \varphi & \Longleftrightarrow \, \mathcal { K } \models _ { \Sigma } \varphi \\ ( \vec { E }, \mathcal { K } ) \models _ { \vec { \Sigma } } ^ { a c t } \, \text{true} \\ ( \vec { E }, \mathcal { K } ) \models _ { \vec { \Sigma } } ^ { a c t } \, \neg \psi & \Longleftrightarrow \, \text{not} \, ( \vec { E }, \mathcal { K } ) \models _ { \vec { \Sigma } } ^ { a c t } \, \psi$$
$$( \vec { E }, \mathcal { K } ) \models _ { \Sigma } ^ { a c t } \, \psi _ { 1 } \wedge \psi _ { 2 } \, \Longleftrightarrow \, ( \vec { E }, \mathcal { K } ) \models _ { \Sigma } ^ { a c t } \, \psi _ { 1 } \, \text{and} \, ( \vec { E }, \mathcal { K } ) \models _ { \Sigma } ^ { a c t } \, \psi _ { 2 } \\ ( \vec { E }, \mathcal { K } ) \models _ { \Sigma } ^ { a c t } \, [ \lambda ] \psi \, \Longleftrightarrow \, ( \vec { E } ^ { \prime }, \mathcal { K } ^ { \prime } ) \models _ { \Sigma } ^ { a c t } \, \psi \\ & \quad \text{for all} \, ( \vec { E } ^ { \prime }, \mathcal { K } ^ { \prime } ) \, \text{such that} \, ( ( \vec { E }, \mathcal { K } ), ( \vec { E } ^ { \prime }, \mathcal { K } ^ { \prime } ) ) \in [ \lambda ] _ { \Sigma } ^ { a c t }$$
$$\tilde { \Sigma }$$
Example 12. Theensemble configuration ( Sys , K 0 x , 1 ) for the bit transmission ensemble Sys from Ex. 3 and the class of epistemic states K 0 x , 1 fromEx. 11 satisfies both dynamic ensemble formulæ of Ex. 5; the same is true for ( Sys , K 0 x , 1 ) .
Proposition 1. Let ( /vector E, K ) be an ensemble configuration. For all ψ ∈ D ˇ Σ it holds that ( /vector E, K | ) = act ˇ Σ ψ if, and only if, ( /vector E, { K } ) = | act ˇ Σ ψ for all K ∈ K .
## 6 Epistemic Ensembles in a Symbolic Environment
We are now going to execute ensembles in a symbolic environment which allows for a more compact representation of epistemic states represented by sets of epistemic formulæ, i.e., knowledge bases. For doing this we extend the approach of [14] to deal with ensembles. A symbolic epistemic signature ( Σ,Φ ) extends the epistemic signature Σ = ( Π,A ) by a finite set of epistemic formulæ Φ ⊆ F Σ which are in the focus of evaluation. Focusing to a finite set allows for effective computations and decisions.
Symbolic epistemic states. A symbolic epistemic state over ( Σ,Φ ) is a subset Γ ⊆ Φ which is true -closed , i. e., if true ∈ Φ , then true ∈ Γ . (If true ∈ Φ , but true / Γ ∈ , this would mean that we consider true not to hold.). The set of symbolic epistemic states over ( Σ,Φ ) is denoted by S Φ Σ .
The Boolean closure bcl ( Φ ) of Φ consists of the epistemic formulæ φ defined by
$$\phi \, \colon = \, \varphi \ | \, \text{ true }$$
The symbolic satisfaction relation Γ | = Φ Σ φ between symbolic states Γ ∈ S Φ Σ and formulæ φ ∈ bcl ( Φ ) is defined as:
$$\begin{array} {$$
Symbolic epistemic updates. Let u ∈ U Σ be an epistemic action and ϕ ∈ F Σ . A formula ρ ∈ F Σ is a weakest liberal precondition of u for ϕ if the following holds for all K ∈ E Σ :
$$( \mathfrak { w } \mathfrak { l } p ) \ \mathfrak$$
The set of the weakest liberal precondition formulæ of u for ϕ is denoted by Wlp Σ ( u , ϕ ) . Obviously, if ρ, ρ ′ ∈ Wlp Σ ( u , ϕ ) , then | = Σ ρ ↔ ρ ′ . There is indeed, for any u ∈ U Σ and any ϕ ∈ F Σ , a formula wlp Σ ( u , ϕ ) ∈ Wlp Σ ( u , ϕ ) that can be recursively computed by
the function wlp Σ : U Σ × F Σ → F Σ defined in accordance with the reduction rules originally stated in the context of dynamic epistemic logic (DEL) in [11, pp. 162sqq.] and [2, p. 37]:
```
\begin{array} { c } \cdot \\ \ w l p _ { \Sigma }
```
The symbolic epistemic update Γ /triangleleft Φ Σ u of a symbolic epistemic state Γ ∈ S Φ Σ by an epistemic action u ∈ U Φ Σ is defined as
$$\Gamma \lhd _ { \Sigma } ^ { \Phi } \, \math$$
/negationslash
/negationslash
Symbolic environments. For an epistemic action u ∈ U Σ define Pre ( u ) = { ρ ∈ F Σ | | = Σ pre ( u ) ↔ } ρ . We say that u ∈ U Σ is Φ -representable if (1) Pre ( u ) ∩ bcl ( Φ ) = ∅ and if (2) for all ϕ ∈ Φ it holds that Wlp Σ ( u , ϕ ) ∩ bcl ( Φ ) = ∅ . The class of such epistemic actions is denoted by U Φ Σ . An epistemic choice action α ∈ A Σ is Φ -representable if all u ∈ α are Φ -representable; the class of such epistemic choice actions is denoted by A Φ Σ .
Example 13. For the scenario of Ex. 3 consider the preliminary focus formulæ Φ (0) 2 = { K 1 x 1 , K 1 ¬ x 1 , K 2 x , 1 K K 1 2 x 1 } (as before we write K a x 1 for K a x 1 ∨ K a ¬ x 1 ). The epistemic actions occuring in snd 1 → 2 los ( K 1 x ) 1 , snd 1 → 2 los ( K 1 ¬ x ) 1 , and snd 2 → 1 rel ( K 2 x 1 ) are u q ϕ = ( U grp ( { 2 } , K 1 ϕ , q ) ) for ϕ ∈ { x 1 , ¬ x 1 } , q ∈ { k n , } and u 2 = ( U grp ( { 1 2 , } , K 2 x 1 ) , k ) . All these actions have a precondition that is expressible over Φ (0) 2 . Table 3 shows possible representatives ρ satisfying | = Σ 2 wlp Σ 2 ( u , ϕ ) ↔ ρ . 3 Indeed, u 2 is not Φ (0) 2 -representable, but becomes Φ 2 -representable for Φ 2 = Φ (0) 2 ∪ { K M 1 2 x 1 , K M 1 2 ¬ x 2 } .
The symbolic semantics of a Φ -representable epistemic choice action α ∈ A Φ Σ is given by the relation
$$[ \alpha ] _ { \Sigma } ^ { \phi } = \{ ( \Gamma, \Gamma \lhd ^ { \phi } _ { \Sigma } \, \mathfrak { u } ) \in \mathcal { S } _ { \Sigma } ^ { \phi } \times \mathcal { S } _ { \Sigma } ^ { \phi } \ | \, \mathfrak { u } \in \alpha, \, \text{ex.} \, \rho \in P r e ( \mathfrak { u } ) \cap b c l ( \Phi ) \, s. t. \, \Gamma \models _ { \Sigma } ^ { \phi } \, \rho \} \.$$
A symbolic epistemic ensemble signature ( ˇ Σ,Φ ) consists of an epistemic ensemble signature ( Σ, (N ) a a ∈ A ) and a set of focus formulæ Φ such that ( Σ,Φ ) is a symbolic epistemic signature. An ensemble /vector E over ˇ Σ is an ensemble over ( ˇ Σ,Φ ) if all guards occurring in /vector E are in bcl ( Φ ) . An epistemic action interpretation act : ⋃ N →A Σ is a Φ -interpretation if act ( η ) ∈ A Φ Σ for all η ∈ ⋃ N . A symbolic epistemic ensemble configuration over ( ˇ Σ,Φ ) is a pair ( /vector E,Γ ) of an ensemble over ( ˇ Σ,Φ ) and a symbolic epistemic state Γ ∈ S Φ Σ . The symbolic ensemble semantics over ( ˇ Σ,Φ ) w.r.t. a Φ -interpretation
3 Computed with a small Maude tool available at https://github.com/AlexanderKnapp/epistemic.git .
Table 3. Representatives ρ satisfying | = Σ 2 wlp Σ ( u , ϕ ) ↔ ρ
| ϕ u | u k x 1 | u k ¬ x 1 | u n x 1 | u n ¬ x 1 | u 2 |
|---------------|-----------------------|-------------------------|---------------------------|---------------------------|-------------------------|
| K 1 x 1 | true | ¬ K 1 ¬ x 1 | K 1 x 1 | K 1 x 1 | K 2 x 1 → K 1 M 2 x 1 |
| K 1 ¬ x 1 | ¬ K 1 x 1 | true | K 1 ¬ x 1 | K 1 ¬ x 1 | K 2 x 1 → K 1 M 2 ¬ x 1 |
| K 2 x 1 | true | true | K 2 x 1 | K 2 x 1 | true |
| K 1 K 2 x 1 | K 1 x 1 → K 1 K 2 x 1 | K 1 ¬ x 1 → K 1 K 2 x 1 | K 1 K 2 x 1 | K 1 K 2 x 1 | true |
| K 1 M 2 x 1 | true | ¬ K 1 ¬ x 1 | K 1 M 2 x 1 | ¬ K 1 ¬ x 1 ∧ K 1 M 2 x 1 | K 2 x 1 → K 1 M 2 x 1 |
| K 1 M 2 ¬ x 1 | ¬ K 1 x 1 | true | ¬ K 1 x 1 ∧ K 1 M 2 ¬ x 1 | K 1 M 2 ¬ x 1 | K 2 x 1 → K 1 M 2 ¬ x 1 |
act : ⋃ N →A Φ Σ is the ternary relation -→ act ˇ Σ,Φ between symbolic configurations, agent actions and (successor) configurations defined by interpreting the operational ensemble semantics, given by rule ( ∗ ) in Sect. 2, in the environment of symbolic epistemic states:
$$\vec { E }, \Gamma \xrightarrow { \eta } _ { \vec { \Sigma }, \phi } a c t \, \vec { E } ^ { \prime }, \Gamma ^ { \prime } \text{ \ if } \vec { E } \xrightarrow { \hat { \phi } \colon \eta } _ { \vec { \Sigma } } \vec { E } ^ { \prime }, \Gamma \models _ { \Sigma } ^ { \phi } \widehat { \phi }, \text{and} \left ( \Gamma, \Gamma ^ { \prime } \right ) \in \left [ a c t ( \eta ) \right ] _ { \Sigma } ^ { \phi }$$
Satisfaction of epistemic ensemble formulæ. The symbolic semantics of a guard-agent action sequence σ = ( ̂ φ 1 : η /epsilon1 1 ) . . . ( ̂ φ k : η /epsilon1 k ) with all guards ̂ φ i formulæ in bcl ( Φ ) w.r.t. the Φ -interpretation act is inductively given by
$$\underbrace { \left [ \widehat { \phi } \colon \epsilon \right ] _ { \Sigma, \Phi } ^ { a c t } = \left \{ ( \Gamma, \Gamma ) \in ( \mathcal { S } _ { \Sigma } ^ { \Phi } ) ^ { 2 } \, | \, \Gamma \models _ { \Sigma } ^ { \Phi } \, \widehat { \phi } \right \} } \,, \\ \underbrace { \_ \sim } \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dists \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dts \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dclots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \ dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \ Dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \Dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \ddots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \ \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \
\end{$$
$$\left [ \sigma _ { 1 } \cdot \sigma _ { 2 } \right ] _ { \check { \Sigma }, \Phi } ^ { a c t } = \left [ \sigma _ { 1 } \right ] _ { \check { \Sigma }, \Phi } ^ { a c t } ; \left [ \sigma _ { 2 } \right ] _ { \check { \Sigma }, \Phi } ^ { a c t } \quad ( \text{relational composition} )$$
$$& [ \widehat { \phi } \colon \eta ] _ { \widehat { \Sigma }, \Phi } ^ { a c t } = \{ ( \Gamma, \Gamma ^ { \prime } ) \in [ \begin{matrix} a c t ( \eta ) \end{matrix} ] _ { \Sigma } ^ { \Phi } & | \, \Gamma \models _ { \Sigma } ^ { \Phi } \, \widehat { \phi } \} \,, \\ & \pi \quad \ n a c t \quad \pi \quad \ n a c t \quad \pi \quad \ n a c t \quad \lambda \, \cdots \, \cdots \, \cdots$$
The set of compound ensemble actions λ ∈ C ˇ Σ with all tests in λ formulæ in bcl ( Φ ) is denoted C Φ ˇ Σ . The semantics of a λ ∈ C Φ ˇ Σ w.r.t. act is given by the relation
$$\left [ \lambda \right ] ^ { a c t } _ { \tilde { \Sigma }, \Phi } = \left \{ \left ( ( \vec { E }, \Gamma ), ( \vec { E } ^ { \prime }, \Gamma ^ { \prime } ) \right ) \, | \, ( \vec { E }, \sigma, \vec { E } ^ { \prime } ) \, \left \| \colon \lambda, \, ( \Gamma, \Gamma ^ { \prime } ) \in \left [ \sigma \right ] ^ { a c t } _ { \tilde { \Sigma }, \Phi } \right \}.$$
The epistemic ensemble formulæ D Φ ˇ Σ over ( ˇ Σ,Φ ) are the epistemic ensemble formulæ over ˇ Σ that only contain sub-formulæ φ ∈ F Σ that are in bcl ( Φ ) . The satisfaction of a ψ ∈ D Φ ˇ Σ by a symbolic epistemic ensemble configuration ( /vector E,Γ ) w.r.t. Φ -interpretation act : ⋃ N →A Φ Σ is inductively defined along the structure of ψ :
$$( \vec { E }, \Gamma ) \models _ { \vec { \Sigma }, \Phi } ^ { a c t } \, \phi \, \Longleftrightarrow \, \Gamma \models _ { \Sigma } ^ { \Phi } \, \phi$$
- ( /vector E,Γ ) = | act ˇ Σ,Φ true
$$( \vec { E }, \Gamma ) \models _ { \check { \Sigma }, \Phi } ^ { a c t } \neg \psi \iff \text{not} \, ( \vec { E }, \Gamma ) \models _ { \check { \Sigma }, \Phi } ^ { a c t } \, \psi$$
- ( /vector E,Γ ) = | act ˇ ψ 1 ∧ ψ 2 ⇐⇒ ( /vector E,Γ ) = | act ˇ ψ 1 and ( /vector E,Γ ) = | act ˇ ψ 2
Σ,Φ
$$( \dot { E }, \Gamma ) \models _ { \dot { \Sigma }, \Phi } ^ { a c t } \, \psi _ { 1 } \wedge \psi _ { 2 } \, \Longleftrightarrow \, ( \dot { E }, \Gamma ) \models _ { \dot { \Sigma }, \Phi } ^ { a c t } \, \psi _ { 1 } \, \text{and} \, ( \dot { E }, \Gamma ) \models _ { \dot { \Sigma }, \Phi } ^ { a c t } \, \psi _ { 2 } \\ ( \vec { E }, \Gamma ) \models _ { \dot { \Sigma }, \Phi } ^ { a c t } \, [ \lambda ] \psi \, \Longleftrightarrow \, ( \vec { E } ^ { \prime }, \Gamma ^ { \prime } ) \models _ { \dot { \Sigma }, \Phi } ^ { a c t } \, \psi \\ & \text{for all} \, ( \vec { E } ^ { \prime }, \Gamma ^ { \prime } ) \text{ such that} \, ( ( \vec { E }, \Gamma ), ( \vec { E } ^ { \prime }, \Gamma ^ { \prime } ) ) \in [ \lambda ] _ { \dot { \Sigma }, \Phi } ^ { a c t }$$
## 7 Relating Ensembles in Semantic and Symbolic Environments
We are now interested in relating ensembles which are executed in a semantic and in a symbolic environment. We first introduce a notion of equivalence between semantic and symbolic states and then lift this equivalence to ensemble configurations. Our main theorem states that both simulate each other and consequently equivalent configurations satisfy the same dynamic epistemic ensemble logic formulæ.
Epistemic state equivalence. Wesaythat an epistemic state class K ∈ S Σ and a symbolic epistemic state Γ ∈ S Φ Σ are Φ -equivalent , written K ≡ Φ Σ Γ , if for all K ∈ K and all ϕ ∈ Φ it holds that K | = Σ ϕ if, and only if, ϕ ∈ Γ .
Lemma 4. Let K ∈ S Σ and Γ ∈ S Φ Σ . Then K ≡ Φ Σ Γ if, and only if, for all K ∈ K and all φ ∈ bcl ( Φ ) it holds that K | = Σ φ iff Γ | = Φ Σ φ .
Corollary 1. Let K ∈ S Σ and Γ ∈ S Φ Σ with K ≡ Φ Σ Γ . Then it holds for all φ ∈ bcl ( Φ ) that K | = Σ φ if, and only if, Γ | = Φ Σ φ .
Lemma 5. Let K ⊆ E Σ , u ∈ U Σ , and ϕ ∈ F Σ . Then K | = Σ wlp Σ ( u , ϕ ) if, and only if, K /triangleleft Σ u | = Σ ϕ .
Lemma 6. Let K ∈ S Σ and Γ ∈ S Φ Σ with K ≡ Φ Σ Γ . Let u ∈ U Φ Σ . Then K /triangleleft Σ u ≡ Φ Σ Γ /triangleleft Φ Σ u .
Lemma 7. Let K ∈ E Σ and Γ ∈ S Φ Σ with K ≡ Φ Σ Γ . Let α ∈ A Φ Σ . Then the following holds:
1. If ( K K , ′ ) ∈ /llbracket α /rrbracket Σ , then there is a Γ ′ ∈ S Φ Σ such that ( Γ, Γ ′ ) ∈ /llbracket α /rrbracket Φ Σ and K ≡ ′ Φ Σ Γ ′ . 2. If ( Γ, Γ ′ ) ∈ /llbracket α /rrbracket Φ Σ , then there is a K ∈ S ′ Σ such that ( K K , ′ ) ∈ /llbracket α /rrbracket Σ and K ≡ ′ Φ Σ Γ ′ .
Ensemble configuration equivalence. As a consequence of Lem. 7 we can prove that semantic and symbolic ensemble configurations mutually simulate action execution while preserving Φ -equivalence.
Proposition 2. Let ( /vector E, K ) be an epistemic ensemble configuration over ˇ Σ and ( /vector E,Γ ) a symbolic epistemic ensemble configuration over ( ˇ Σ,Φ ) . Let η ∈ ⋃ N be an agent action, and let K ≡ Φ Σ Γ hold.
- 1. If ( /vector E, K - → ) η act ˇ Σ ( /vector E , ′ K ′ ) , then there is a Γ ′ ∈ S Φ Σ such that ( /vector E,Γ ) λ - → act ˇ Σ,Φ ( /vector E , Γ ′ ′ ) and K ≡ ′ Φ Σ Γ ′ .
- 2. If ( /vector E,Γ ) η - → act ˇ Σ,Φ ( /vector E , Γ ′ ′ ) , then there is a K ∈ S ′ Σ such that ( /vector E, K - → ) λ act ˇ Σ ( /vector E , ′ K ′ ) and K ≡ ′ Φ Σ Γ ′ .
The Φ -equivalence K ≡ Φ Σ Γ between semantic and symbolic epistemic states induces a ( Φ, act ) -equivalence between semantic and symbolic epistemic ensemble configurations defined as ( /vector E, K ≡ ) act ˇ Σ,Φ ( /vector E,Γ ) if K ≡ Φ Σ Γ . The next proposition lifts Prop. 2 to compound epistemic actions:
$$\text{Proposition} \, 3. \ L e t \, \lambda \in \mathcal { C } _ { \Sigma } ^ { \Phi } \, a n d \, l e t \, ( \vec { E }, \mathcal { K } ) \equiv _ { \check { \Sigma }, \Phi } ^ { a c t } \, ( \vec { E }, \Gamma ) \, h o l d.$$
- 1. If (( /vector E, K ) , ( /vector E , ′ K ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ , then there exists a Γ ′ ∈ S Φ Σ such that (( /vector E,Γ , ) ( /vector E , Γ ′ ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ,Φ and ( /vector E , ′ K ′ ) ≡ act ˇ Σ,Φ ( /vector E , Γ ′ ′ ) .
- 2. If (( /vector E,Γ , ) ( /vector E , Γ ′ ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ,Φ , then there exists a K ′ ∈ S Σ such that (( /vector E, K ) , ( /vector E , ′ K ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ and ( /vector E , ′ K ′ ) ≡ act ˇ Σ,Φ ( /vector E , Γ ′ ′ ) .
Finally, ( Φ, act ) -equivalent ensemble configurations satisfy the same dynamic ensemble logic formulæ. Thus symbolic epistemic ensemble configurations can be considered as correct realisations of semantic epistemic ensemble configurations.
Theorem 1. Let ( /vector E, K ) ≡ act ˇ Σ,Φ ( /vector E,Γ ) hold. Then for all ψ ∈ D Φ ˇ Σ , it holds that ( /vector E, K | ) = act ˇ Σ ψ ⇐⇒ ( /vector E,Γ ) = | act ˇ Σ,Φ ψ .
## 8 Conclusions
Epistemic ensembles are families of interacting knowledge-based processes. Starting with a syntactic operational semantics, we presented two complementary mathematical semantics for such ensembles: one in a semantic environment defined by classes of global epistemic states and the other one in a symbolic environment defined by a global knowledge base. As main result we showed that ensembles with Φ -equivalent configurations simulate each other and preserve Φ -equivalence.
In this paper we gave only small examples; in the future we want to tackle larger applications in behavioural ensemble specification (see, e.g., [19,13] and epistemic planning (see, e.g., [5]). We also intend to extend our approach to ensembles with distributed local states (see, e.g., [6]) and to LLM-assisted software development [3].
Acknowledgements. We would like to thank anonymous reviewers of this paper for valuable comments.
## References
- 1. Alexandru Baltag, Lawrence S. Moss, and Slawomir Solecki. The logic of public announcements and common knowledge and private suspicions. In Itzhak Gilboa, editor, Proc. 7 th Conf. Theoretical Aspects of Rationality and Knowledge (TARK) , pages 43-56. Morgan Kaufmann, 1998.
- 2. Alexandru Baltag and Bryan Renne. Dynamic epistemic logic. In Edward N. Zalta, Uri Nodelman, Colin Allen, and R. Lanier Anderson, editors, Stanford Encyclopedia of Philosophy . The Metaphysics Research Lab, Stanford University, 2016.
- 3. Lenz Belzner, Thomas Gabor, and Martin Wirsing. Large language model assisted software engineering: Prospects, challenges,and a case study. In Bernhard Steffen, editor, Proc. 1 st Intl. Conf. Bridging the Gap Between AI and Reality (AISoLA) , volume 14380 of Lect. Notes Comp. Sci. , pages 355-374. Springer, 2023.
- 4. Johan van Benthem, Jelle Gerbrandy, Tomohiro Hoshi, and Eric Pacuit. Merging frameworks for interaction. J. Philos. Log. , 38(5):491-526, 2009.
- 5. Thomas Bolander. A gentle introduction to epistemic planning: The DEL approach. In Sujata Ghosh and R. Ramanujam, editors, Proc. 9 th Ws. Methods for Modalities (M4M@ICLA) , volume 243 of EPTCS , pages 1-22, 2017.
- 6. Thomas Bolander and Mikkel Birkegaard Andersen. Epistemic planning for single and multiagent systems. J. Appl. Non Class. Logics , 21(1):9-34, 2011.
- 7. Luca Bortolussi, Rocco De Nicola, Vashti Galpin, Stephen Gilmore, Jane Hillston, Diego Latella, Michele Loreti, and Mieke Massink. CARMA: collective adaptive resource-sharing markovian agents. In Nathalie Bertrand and Mirco Tribastone, editors, Proc. 13 th Ws. Quantitative Aspects of Programming Languages and Systems (QAPL) , volume 194 of EPTCS , pages 16-31, 2015.
- 8. Tom´ as Bures, Ilias Gerostathopoulos, Petr Hnetynka, Jaroslav Keznikl, Michal Kit, and Frantisek Plasil. DEECO: an ensemble-based component system. In Proc. 16 th ACM SIGSOFT Symp. Component Based Software Engineering (CBSE) , pages 81-90. ACM, 2013.
- 9. Rocco De Nicola. Process algebras. In David Padua, editor, Encyclopedia of Parallel Computing , pages 1624-1636. Springer, 2011.
- 10. Edsger W. Dijkstra and Carle Scholten. Predicate Calculus and Program Semantics . Springer, 1990.
- 11. Hans van Ditmarsch, Wiebe van der Hoek, and Barteld Kooi. Dynamic Epistemic Logic , volume 337 of Synthese Library . Springer, 2008.
- 12. Ronald Fagin, Joseph Y. Halpern, Yoram Moses, and Moshe Y. Vardi. Reasoning About Knowledge . MIT Press, 2003.
- 13. Rolf Hennicker, Alexander Knapp, and Martin Wirsing. Epistemic ensembles. In Tiziana Margaria and Bernhard Steffen, editors, Proc. 11 th Intl. Symp. Leveraging Applications of Formal Methods, Verification and Validation (ISoLA). Part III: Adaptation and Learning , volume 13703 of Lect. Notes Comp. Sci. , pages 110-126. Springer, 2022.
- 14. Rolf Hennicker, Alexander Knapp, and Martin Wirsing. Symbolic realisation of epistemic processes. In Nikolaj Bjorner, Marijn Heule, and Andrei Voronkov, editors, Proc. 25 th Intl. Conf. Logic for Programming, Artificial Intelligence and Reasoning (LPAR) , volume 100 of EPiC Series in Comp. , pages 390-407, 2024.
- 15. Matthias M. H¨ olzl, Axel Rauschmayer, and Martin Wirsing. Software engineering for ensembles. In Martin Wirsing, Jean-Pierre Banˆ atre, Matthias M. H¨lzl, and Axel Rauschmayer, edo itors, Software-Intensive Systems and New Computing Paradigms - Challenges and Visions , volume 5380 of Lect. Notes Comp. Sci. , pages 45-63. Springer, 2008.
- 16. EmilianoLorini, Elise Perrotin, and Franc ¸ois Schwarzentruber. Epistemic actions: Comparing multi-agent belief bases with action models. In Gabriele Kern-Isberner, Gerhard Lakemeyer, and Thomas Meyer, editors, Proc. 19 th Intl. Conf. Principles of Knowledge Representation and Reasoning (KR) , 2022.
- 17. Rocco De Nicola, Diego Latella, Alberto Lluch-Lafuente, Michele Loreti, Andrea Margheri, Mieke Massink, Andrea Morichetta, Rosario Pugliese, Francesco Tiezzi, and Andrea Vandin. The SCEL language: Design, implementation, verification. In Wirsing et al. [20].
- 18. Rohit Parikh and Ramaswamy Ramanujam. A knowledge based semantics of messages. J. Logic, Lang. Inform. , 12:453-467, 2003.
- 19. Jan S¨ urmeli. Epistemic logic in ensemble specification. In Tiziana Margaria and Bernhard Steffen, editors, Proc. 9 th Intl. Conf. Leveraging Applications of Formal Methods, Verification
and Validation (ISoLA). Part II: Engineering Principles , volume 12477 of Lect. Notes Comp. Sci. , pages 329-343. Springer, 2020.
- 20. Martin Wirsing, Matthias M. H¨ olzl, Nora Koch, and Philip Mayer, editors. Software Engineering for Collective Autonomic Systems - The ASCENS Approach , volume 8998 of Lect. Notes Comp. Sci. Springer, 2015.
- 21. Martin Wirsing and Alexander Knapp. A reduction-based cut-free Gentzen calculus for dynamic epistemic logic. Log. J. IGPL , 31(6):1047-1068, 2023.
- 22. Andreas Witzel and Jonathan A. Zvesper. Epistemic logic and explicit knowledge in distributed programming. In Lin Padgham, David C. Parkes, J¨ org P. M¨ller, and Simon Parsons, u editors, Proc. 7 th Intl. Conf. Autonomous Agents and Multiagent Systems (AAMAS), Vol. 3 , pages 1463-1466. IFAAMAS, 2008.
## A Proofs
Lemma 1. If P ↪ ̂ ϕ η : - -→ ˇ Σ P ′ , then ags ˇ Σ ( P ) ⊆ ags Σ ( ̂ ϕ ) ∩ ags ˇ Σ ( η ) ∩ ags ˇ Σ ( P ′ ) .
Proof. We proceed by induction on the derivation of the conditional transition P ↪ ̂ ϕ η : - -→ ˇ Σ P ′ by the rules in Tab. 1.
For η.P true: η ↪ -- - → ˇ Σ P , we have ags ˇ Σ ( η.P ) = ags ˇ Σ ( η ) ∩ ags ˇ Σ ( P ) ⊆ ags Σ (true) ∩ ags ˇ Σ ( η ) ∩ ags ˇ Σ ( P ) .
For ϕ ⊃ P ↪ ̂ ϕ ∧ ϕ η : - - - -→ ˇ Σ P ′ , we have ags ˇ Σ ( P ) ⊆ ags Σ ( ̂ ϕ ) ∩ ags ˇ Σ ( η ) ∩ ags Σ ( P ′ ) as the induction hypothesis and thus we obtain ags ˇ Σ ( ϕ ⊃ P ) = ags Σ ( ϕ ) ∩ ags ˇ Σ ( P ) ⊆ ags Σ ( ϕ ) ∩ ags Σ ( ̂ ϕ ) ∩ ags ˇ Σ ( η ) ∩ ags ˇ Σ ( P ′ ) = ags Σ ( ̂ ϕ ∧ ϕ ) ∩ ags ˇ Σ ( η ) ∩ ags ˇ Σ ( P ′ ) .
For P 1 + P 2 ̂ ϕ η : ↪ - -→ ˇ Σ P ′ /lscript with /lscript ∈ { 1 2 , } , we have ags ˇ Σ ( P /lscript ) ⊆ ags Σ ( ̂ ϕ ) ∩ ags ˇ Σ ( η ) ∩ ags ˇ Σ ( P ′ /lscript ) as the induction hypothesis and thus we obtain ags ˇ Σ ( P 1 + P 2 ) = ags ˇ Σ ( P 1 ) ∩ ags ˇ Σ ( P 2 ) ⊆ ags Σ ( ̂ ϕ ) ∩ ags ˇ Σ ( η ) ∩ ags ˇ Σ ( P ′ /lscript ) .
↦
↦
For µX . P ̂ ϕ η : ↪ - -→ ˇ Σ P ′ , we have ags ˇ Σ ( P { X → µX . P } ) ⊆ ags Σ ( ̂ ϕ ) ∩ ags ˇ Σ ( η ) ∩ ags ˇ Σ ( P ′ ) as the induction hypothesis and thus ags ˇ Σ ( µX . P ) = ags ˇ Σ ( P ) ⊆ ags Σ ( ̂ ϕ ) ∩ ags ˇ Σ ( η ) ∩ ags ˇ Σ ( P ′ ) using that ags ˇ Σ ( P { X → µX . P } ) = ags ˇ Σ ( P ) .
## Lemma 2. Let K ∈ S Σ and α ∈ A Σ .
- 1. If ( { K } K , K ) ∈ /llbracket α /rrbracket Σ for some K ∈ K , then there are K ′ ∈ E Σ with K K = { K ′ } and K ∈ S ′ Σ with K ′ ∈ K ′ such that ( K K , ′ ) ∈ /llbracket α /rrbracket Σ .
- 2. If ( K K , ′ ) ∈ /llbracket α /rrbracket Σ , then for each K ′ ∈ K ′ there is some K ∈ K with ( { K } { , K ′ } ) ∈ /llbracket α /rrbracket Σ .
Proof. (1) Let ( { K } K , K ) ∈ /llbracket α /rrbracket Σ hold. Then there is a u ∈ α with K | = Σ pre ( u ) and K K = { K /triangleleft Σ u } . Furthermore, K | = Σ pre ( u ) and thus ( K K , /triangleleft Σ u ) ∈ /llbracket α /rrbracket Σ with K /triangleleft Σ u ∈ K /triangleleft Σ u .
(2) Let ( K K , ′ ) ∈ /llbracket α /rrbracket Σ hold and let K ′ ∈ K ′ . Then there is a u ∈ α with K | = Σ pre ( u ) and K ′ = K /triangleleft Σ u such that there is K ∈ K with K ′ = K /triangleleft Σ u and ( { K } { , K ′ } ) ∈ /llbracket α /rrbracket Σ .
Lemma 3. Let ( /vector E, K ) be an ensemble configuration and λ ∈ C ˇ Σ .
- 1. If (( /vector E, { K } ) , ( /vector E , ′ K K )) ∈ /llbracket λ /rrbracket act ˇ Σ for some K ∈ K , then there are K ′ ∈ E Σ with K K = { K ′ } and K ∈ S ′ Σ with K ′ ∈ K ′ such that (( /vector E, K ) , ( /vector E , ′ K ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ .
- 2. If (( /vector E, K ) , ( /vector E, K ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ , then for each K ′ ∈ K ′ there is some K ∈ K with (( /vector E, { K } ) , ( /vector E , ′ { K ′ } )) ∈ /llbracket λ /rrbracket act ˇ Σ .
Proof. The claims follow directly from Lem. 2 and the definition of the semantics of guard-action sequences σ .
Proposition 1. Let ( /vector E, K ) be an ensemble configuration. For all ψ ∈ D ˇ Σ it holds that ( /vector E, K | ) = act ˇ Σ ψ if, and only if, ( /vector E, { K } ) = | act ˇ Σ ψ for all K ∈ K .
Proof. We proceed by induction over the structure of ψ ∈ D ˇ Σ where ϕ , true , negation, and conjunction are straightforward. For a [ λ ψ ] , let first ( /vector E, K ) | = act ˇ Σ [ λ ψ ] hold. Let K ∈ K and (( /vector E, { K } ) , ( /vector E , ′ K K )) ∈ /llbracket λ /rrbracket act ˇ Σ . By Lem. 3(1) there is a K ′ ∈ E Σ with K K = { K ′ } and some K ′ ∈ S Σ with K ′ ∈ K ′ and (( /vector E, K ) , ( /vector E , ′ K ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ and thus ( /vector E , ′ K ′ ) | = act ˇ Σ ψ . By the induction hypothesis, ( /vector E , ′ { K ′ } ) | = act ˇ Σ ψ and thus ( /vector E, { K } ) | = act ˇ Σ [ λ ψ ] . -Let conversely, ( /vector E, { K } ) | = act ˇ Σ [ λ ψ ] hold for all K ∈ K . Let (( /vector E, K ) , ( /vector E , ′ K ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ . By Lem. 3(2) for each K ′ ∈ K ′ there is a K ∈ K with (( /vector E, { K } ) , ( /vector E , ′ { K ′ } )) ∈ /llbracket λ /rrbracket act ˇ Σ and thus ( /vector E, { K ′ } ) | = Σ ψ for all K ′ ∈ K ′ . By the induction hypothesis, ( /vector E , ′ K ′ ) = | act ˇ Σ ψ and thus ( /vector E, { K } ) = | act ˇ Σ [ λ ψ ] .
Lemma 4. Let K ∈ S Σ and Γ ∈ S Φ Σ . Then K ≡ Φ Σ Γ if, and only if, for all K ∈ K and all φ ∈ bcl ( Φ ) it holds that K | = Σ φ iff Γ | = Φ Σ φ .
Proof. ' ⇒ ': Assume K ≡ Φ Σ Γ and let K ∈ K . The proof is performed by structural induction on the form of φ .
Case φ = ϕ ∈ Φ : Then K | = Σ ϕ iff (since K ≡ Φ Σ Γ ) ϕ ∈ Γ iff Γ | = Φ Σ ϕ .
Case true : K | = Σ true and Γ | = Φ Σ true hold.
Case ¬ φ with ¬ φ / Φ ∈ : K | = Σ ¬ φ iff not K | = Σ φ iff (by induction hypothesis) not Γ | = Φ Σ φ iff (since ¬ φ / Φ ∈ ) Γ | = Φ Σ ¬ φ .
Case ϕ 1 ∧ ϕ 2 with ϕ 1 ∧ ϕ 2 / Φ ∈ : K | = Σ ϕ 1 ∧ ϕ 2 iff K | = Σ ϕ 1 and K | = Σ ϕ 2 iff (by induction hypothesis) Γ | = Φ Σ ϕ 1 and Γ | = Φ Σ ϕ 2 iff (since ϕ 1 ∧ ϕ 2 / Φ ∈ ) Γ | = Φ Σ ϕ 1 ∧ ϕ 2 .
' ⇐ ': Since Φ ⊆ bcl ( Φ ) , the assumption implies K | = Σ ϕ ⇐⇒ Γ | = Φ Σ ϕ ⇐⇒ ϕ ∈ Γ for all ϕ ∈ Φ and all K ∈ K ; hence, K ≡ Φ Σ Γ .
Corollary 1. Let K ∈ S Σ and Γ ∈ S Φ Σ with K ≡ Φ Σ Γ . Then it holds for all φ ∈ bcl ( Φ ) that K | = Σ φ if, and only if, Γ | = Φ Σ φ .
Proof. Let φ ∈ bcl ( Φ ) . Since K /negationslash = ∅ , there is a K ∈ K and it holds that K | = Σ φ if, and only if, Γ | = Φ Σ φ if, and only if, K ′ | = Σ φ for all K ′ ∈ K by Lem. 4.
Lemma 5. Let K ⊆ E Σ , u ∈ U Σ , and ϕ ∈ F Σ . Then K | = Σ wlp Σ ( u , ϕ ) if, and only if, K /triangleleft Σ u | = Σ ϕ .
/negationslash
/negationslash
Proof. Let first K | = Σ wlp Σ ( u , ϕ ) hold, i.e., K | = Σ wlp Σ ( u , ϕ ) for all K ∈ K , or, equivalently, K | = Σ pre ( u ) or K /triangleleft Σ u | = Σ ϕ . Let K ′ ∈ K /triangleleft Σ u , i. e., K ′ = K /triangleleft Σ u with K ∈ K and K | = Σ pre ( u ) . Then K /triangleleft Σ u | = Σ ϕ . -Let now conversely K /triangleleft Σ u | = Σ ϕ hold, i.e., K /triangleleft Σ u | = Σ ϕ for all K ∈ K with K | = Σ pre ( u ) . Let K ∈ K . If K | = Σ pre ( u ) , then K | = Σ wlp Σ ( u , ϕ ) ; if K | = Σ pre ( u ) , then K /triangleleft Σ u | = Σ ϕ and thus again K | = Σ wlp Σ ( u , ϕ ) .
Lemma 6. Let K ∈ S Σ and Γ ∈ S Φ Σ with K ≡ Φ Σ Γ . Let u ∈ U Φ Σ . Then K /triangleleft Σ u ≡ Φ Σ Γ /triangleleft Φ Σ u .
Proof. Let ϕ ∈ F Σ . Then
$$\mathcal { K } \lhd _ { \Sigma } \mathfrak { u } \models _ { \Sigma } \varphi \iff \mathcal { K } \models _ { \Sigma } \, \text{wlp} _ { \Sigma } ( \mathfrak { u }, \varphi ) \iff \\ f. \, \text{a. } \rho \in \text{Wlp} _ { \Sigma } ( \mathfrak { u }, \varphi ) \colon \mathcal { K } \models _ { \Sigma } \, \rho \iff \mathfrak { u } \, \text{repr.} \, \text{Cor. } 1 \\ \text{ex.} \, \rho \in \text{Wlp} _ { \Sigma } ( \mathfrak { u }, \varphi ) \cap b c l ( \Phi ) \, \text{s.t.} \, \Gamma \models _ { \Sigma } \, \rho \iff \varphi \in \Gamma \lhd _ { \Sigma } \, \mathfrak { u } \,.$$
Lemma 7. Let K ∈ E Σ and Γ ∈ S Φ Σ with K ≡ Φ Σ Γ . Let α ∈ A Φ Σ . Then the following holds:
1. If ( K K , ′ ) ∈ /llbracket α /rrbracket Σ , then there is a Γ ′ ∈ S Φ Σ such that ( Γ, Γ ′ ) ∈ /llbracket α /rrbracket Φ Σ and K ≡ ′ Φ Σ Γ ′ . 2. If ( Γ, Γ ′ ) ∈ /llbracket α /rrbracket Φ Σ , then there is a K ∈ S ′ Σ such that ( K K , ′ ) ∈ /llbracket α /rrbracket Σ and K ≡ ′ Φ Σ Γ ′ .
Proof. (1) Let ( K K , ′ ) ∈ /llbracket α /rrbracket Σ . Then there is a u ∈ α such that K ′ = K /triangleleft Σ u and K | = Σ pre ( u ) . By Lem. 4 and u ∈ U Φ Σ it holds that there is a ρ ∈ Pre ( u ) ∩ bcl ( Φ ) such that Γ | = Φ Σ ρ and hence ( Γ, Γ ′ ) ∈ /llbracket α /rrbracket Φ Σ with Γ ′ = Γ /triangleleft Φ Σ u . By Lem. 6, K /triangleleft Σ u ≡ Φ Σ Γ /triangleleft Φ Σ u , i. e., K ≡ ′ Φ Σ Γ ′ .
(2) Let ( Γ, Γ ′ ) ∈ /llbracket α /rrbracket Φ Σ . Then there is a u ∈ α such that Γ ′ = Γ /triangleleft Φ Σ u and Γ | = Φ Σ ρ for some ρ ∈ Pre ( u ) ∩ bcl ( Φ ) . By Lem. 4, K /negationslash = ∅ , and u ∈ U Φ Σ it holds that K | = Σ pre ( u ) and hence ( K K , ′ ) ∈ /llbracket α /rrbracket Σ with K ′ = K /triangleleft Σ u . By Lem. 6, K /triangleleft Σ u ≡ Φ Σ Γ /triangleleft Φ Σ u , i. e., K ≡ ′ Φ Σ Γ ′ .
Proposition 2. Let ( /vector E, K ) be an epistemic ensemble configuration over ˇ Σ and ( /vector E,Γ ) a symbolic epistemic ensemble configuration over ( ˇ Σ,Φ ) . Let η ∈ ⋃ N be an agent action, and let K ≡ Φ Σ Γ hold.
- 1. If ( /vector E, K - → ) η act ˇ Σ ( /vector E , ′ K ′ ) , then there is a Γ ′ ∈ S Φ Σ such that ( /vector E,Γ ) λ - → act ˇ Σ,Φ ( /vector E , Γ ′ ′ ) and K ≡ ′ Φ Σ Γ ′ .
- 2. If ( /vector E,Γ ) η - → act ˇ Σ,Φ ( /vector E , Γ ′ ′ ) , then there is a K ∈ S ′ Σ such that ( /vector E, K - → ) λ act ˇ Σ ( /vector E , ′ K ′ ) and K ≡ ′ Φ Σ Γ ′ .
Proof. (1) Let ( /vector E, K ) η - → act ˇ Σ ( /vector E , ′ K ′ ) be given. Then there is a /vector E ↪ ̂ ϕ η : - -→ ˇ Σ /vector E ′ with K | = Σ ̂ ϕ and ( K K , ′ ) ∈ /llbracket act ( η ) /rrbracket Σ . Since K ≡ Φ Σ Γ , K /negationslash = ∅ , and ̂ ϕ ∈ bcl ( Φ ) we have, by Lem. 4, Γ | = Φ Σ ̂ ϕ and, by Lem. 7(1), there exists a Γ ′ ∈ S Φ Σ such that ( Γ, Γ ′ ) ∈ /llbracket act ( η ) /rrbracket Φ Σ and K ≡ ′ Φ Σ Γ ′ . Therefore ( /vector E,Γ ) η - → act ˇ Σ,Φ ( /vector E , Γ ′ ′ ) and K ≡ ′ Φ Σ Γ ′ .
(2) Let ( /vector E,Γ ) η - → act ˇ Σ,Φ ( /vector E , Γ ′ ′ ) be given. Then there is a /vector E ↪ ̂ φ η : - -→ ˇ Σ /vector E ′ with Γ | = Φ Σ ̂ φ and ( Γ, Γ ′ ) ∈ /llbracket act ( η ) /rrbracket Φ Σ . Since K ≡ Φ Σ Γ and K /negationslash = ∅ we have, by Lem. 4, K | = Σ ̂ φ and, by Lem. 7(2), there exists K ∈ S ′ Σ such that ( K K , ′ ) ∈ /llbracket act ( η ) /rrbracket Σ and K ≡ ′ Φ Σ Γ ′ . Therefore ( /vector E, K - → ) η act ˇ Σ ( /vector E , ′ K ′ ) and K ≡ ′ Φ Σ Γ ′ .
Proposition 3. Let λ ∈ C Φ ˇ Σ and let ( /vector E, K ≡ ) act ˇ Σ,Φ ( /vector E,Γ ) hold.
- 1. If (( /vector E, K ) , ( /vector E , ′ K ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ , then there exists a Γ ′ ∈ S Φ Σ such that (( /vector E,Γ , ) ( /vector E , Γ ′ ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ,Φ and ( /vector E , ′ K ′ ) ≡ act ˇ Σ,Φ ( /vector E , Γ ′ ′ ) .
- 2. If (( /vector E,Γ , ) ( /vector E , Γ ′ ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ,Φ , then there exists a K ′ ∈ S Σ such that (( /vector E, K ) , ( /vector E , ′ K ′ )) ∈ /llbracket λ /rrbracket act ˇ Σ and ( /vector E , ′ K ′ ) ≡ act ˇ Σ,Φ ( /vector E , Γ ′ ′ ) .
Proof. This follows by structural induction on the form of λ ∈ C ˇ Σ , where η ∈ ⋃ N is covered by Prop. 2, φ ? with φ ∈ bcl ( Φ ) by Lem. 4, and all other cases follow directly from the induction hypothesis.
Theorem 1. Let ( /vector E, K ) ≡ act ˇ Σ,Φ ( /vector E,Γ ) hold. Then for all ψ ∈ D Φ ˇ Σ , it holds that ( /vector E, K | ) = act ˇ Σ ψ ⇐⇒ ( /vector E,Γ ) = | act ˇ Σ,Φ ψ .
Proof. This follows by structural induction on the form of ψ ∈ D Φ ˇ Σ , where [ λ ψ ] is a consequence of Prop. 3. | null | [
"Rolf Hennicker",
"Alexander Knapp",
"Martin Wirsing"
] | 2024-08-02T08:52:05+00:00 | 2024-08-02T08:52:05+00:00 | [
"cs.SE"
] | Epistemic Ensembles in Semantic and Symbolic Environments (Extended Version with Proofs) | An epistemic ensemble is composed of knowledge-based agents capable of
retrieving and sharing knowledge and beliefs about themselves and their peers.
These agents access a global knowledge state and use actions to communicate and
cooperate, altering the collective knowledge state. We study two types of
mathematical semantics for epistemic ensembles based on a common syntactic
operational ensemble semantics: a semantic environment defined by a class of
global epistemic states, and a symbolic environment consisting of a set of
epistemic formul{\ae}. For relating these environments, we use the concept of
{\Phi}-equivalence, where a class of epistemic states and a knowledge base are
{\Phi}-equivalent, if any formula of {\Phi} holds in the class of epistemic
states if, and only if, it is an element of the knowledge base. Our main
theorem shows that {\Phi}-equivalent configurations simulate each other and
satisfy the same dynamic epistemic ensemble formulae. |
2408.01116v1 | ## Practical Guidelines for Data-driven Identification of Lifted Linear Predictors for Control
Loi Do, Adam Uchytil, and Zdenˇ ek Hur´ ak
Abstract -Lifted linear predictor (LLP) is an artificial linear dynamical system designed to predict trajectories of a generally nonlinear dynamical system based on the current state (or measurements) and the input. The main benefit of the LLP is its potential ability to capture the nonlinear system's dynamics with precision superior to other linearization techniques, such as local linearization about the operation point. The idea of lifting is supported by the theory of Koopman Operators. For LLP identification, we focus on the data-driven method based on the extended dynamic mode decomposition (EDMD) algorithm. However, while the EDMD algorithm presents an extremely simple and efficient way to obtain the LLP, it can also yield poor results. In this paper, we present some less intuitive practical guidelines for data-driven identification of the LLPs, aiming at improving usability of LLPs for designing control. We support the guidelines with two motivating examples. The implementation of the examples are shared on a public repository.
Index Terms -Koopman operator, extended dynamic mode decomposition, lifting, linear predictor, data-driven
## I. INTRODUCTION
One approach to control design for nonlinear systems is to use linear control system methods. To this end, a linear model of the system's dynamics is required. There are many ways to obtain a linear model, but the primary issue with such linear models is their small validity region.
Lifted linear predictor (LLP) is an artificial linear dynamical system designed to predict trajectories of a generally nonlinear dynamical system based on the current states (or measurements) and the inputs. By lifting we mean mapping the original state x ∈ R n into a higher-dimensional space R N , N > n , where the evolution of the state x is approximately linear. The idea of capturing nonlinear system's behavior linearly in lifted space dates back to the seminal works [1], [2] of Koopman and von Neummann in the 1930s, with the resurgence of interest in mid 2000s with the works [3], [4]. Notably, the authors in [5] introduced the use of LLP in conjunction with the Model Predictive Control (MPC). Comprehensive picture of the applied Koopman Approach, discussing the theory and applications, can be found in [6].
There are several options to obtain the LLPs. We focus on a data-driven approach, the Extended Dynamic Mode Decomposition (EDMD) algorithm introduced in [7]. The EDMD presents an extremely simple method to obtain the
This work was co-funded by the European Union under the project ROBOPROX (reg. no. CZ.02.01.01/00/22 008/0004590).
Loi Do, Adam Uchytil, and Zdenˇ ek Hur´ ak are with Faculty of Electrical Engineering, Czech Technical University in Prague { doloi, uchytada, hurak [at]fel.cvut.cz }
control-oriented LLP from data, proving its efficiency in the control design for various systems [8], [9], [10]. However, despite the method's efficiency, we show several practical problems that can arise in the process, failing to provide the desired control performance.
## A. Main Contribution
In this paper, we address some less intuitive practical issues arising in identification of LLPs. We present practical guidelines for identification and evaluation of linear predictors that address these issues. As a result, better LLPs can be obtained. We support the guidelines with two motivating examples as well as with references to relevant works. The implementation of the examples are available at github.com/aa4cc/Lifted-Linear-Predictors-Guidelines.
## II. LINEAR PREDICTORS IN LIFTED SPACE
This section serves only as an overview - providing definitions, fixing the notation and terminology for the purpose of this paper. If it is found too terse, we refer the reader to [11], [6] for more detailed description.
Consider a nonlinear discrete-time dynamical system
$$x _ { k + 1 } = f ( x _ { k }, u _ { k } )$$
where f ( ) · is a generally nonlinear transition mapping, and x ∈ R n , and u ∈ R p are the system's state, output, and input, respectively. The goal is to predict the trajectory of the system, given an initial condition x 0 at time t 0 , and the sequence of the inputs { u i } N p i =0 , where N p is the prediction horizon length. To this end, we define the lifted linear predictor as a dynamical system
$$z _ { 0 } & = \Psi ( x _ { 0 } ) \, \\ z _$$
where z ∈ R N is the lifted state, Ψ : R n → R N is the lifting mapping, and ˆ x is the prediction of original system's state x . The lifting mapping Ψ( ) · is defined as
$$\Psi ( x ) = \left [ \psi _ { 1 } ( x ), \$$
where ψ i : R n → R is a scalar function called an observable . Apart from the LLP (2), other forms of lifted predictors were introduced in literature that can have better prediction ability, see Remark 1. However, we focus only on the LLP as it is immediately suited for linear control systems methods.
Remark 1: The predictor can also be in the form of a bilinear system
$$z _ { k + 1 } & = A z _ { k } + ( B z _ { k$$
which can to capture a more complex dynamical behaviors. Another form can be obtained by modifying the LLP (or the bilinear predictor) with the project-and-lift method proposed in [12]. In particular, for LLP (2), the modified version is
$$\begin{array} {$$
Generally, the modified version (5) should have better prediction ability on longer time horizons than the LLP [12]. However, both modifications (4) and (5) lose the linear structure.
## A. Koopman Operator for Autonomous Systems
To rigorously justify the construction of a linear predictor through state-space lifting , we briefly describe the Koopman operator approach for analysis of dynamical systems. Consider a discrete-time dynamical system
$$x ^ { + } = f ( x ) \,,$$
where x, x + ∈ M denote the current state, and the state in the next time step, respectively. Both are defined on some state space M . Instead of directly analyzing the generally nonlinear mapping f , we investigate how functions of the states, the observables , evolve along the trajectories of the system. Formally, an observable is a scalar function ψ : M→ R that belongs to a typically infinite-dimensional space of functions F . The (discrete-time) Koopman operator K : F → F is then defined as
$$( \mathcal { K } \psi ) ( x ) = \psi ( f ( x ) ) = \psi ( x ^ { + } ) \. \quad \ \ ( 7 ) \quad \text{ing}$$
Thus, the Koopman operator K advances the observables ψ ∈ F from the current time step into the next one.
↦
There are two key properties of the Koopman operator. First, if the space of observables F contains the coordinate identity mappings x → x i ( ) for all components i of the state x , the operator fully captures the behavior of the nonlinear system (6). Second, it follows from the definition and the linearity of the addition in the function space that the operator is linear even if T is nonlinear.
Note, however, that the definition (7) requires the space F to be invariant under the action of the operator K . For most systems, this leads to a requirement of the space F to be infinite dimensional - containing infinitely many observables ψ x ( ) -which precludes its use for control synthesis.
There are two ways how the Koopman operator can be linked with the LLP (2). For some systems, one can find an invariant subspace of F spanned by a finite number of observables, while also containing the coordinate identity mappings. The Koopman operator can then be represented by a finite-dimensional matrix, coinciding with the linear system's matrix. Second, more generally applicable option, that we pursue in this paper, is to find a finite approximation to the Koopman operator via the algorithm described in Sec. II-C.
## B. Koopman Operator for Controlled Systems
There are several ways of extending the Koopman operator to controlled systems. For example, in [13], the authors proposed treating a controlled system as an uncontrolled one with the input as system's parameter, see Remark 2.
We follow the extension proposed in [5], that associates a Koopman Operator with the dynamical system that evolves on the extended state space. In particular, consider a controlled system
$$x ^ { + } = f ( x, u ) \,.$$
Let ℓ ( U ) be the space of all infinite input sequences u · = { u i } ∞ i =0 , with u i ∈ U and U being some input-space. We denote the i th component of the sequence as u · ( ) i and S ∗ to be the (left) shift operator, i.e., S ∗ u · ( ) = i u · ( i +1) . By defining an augmented state χ = [ x, u · ] T , we can rewrite the system (8) as
$$\chi ^ { + } = f ^ { \prime } ( \chi ) = \begin{bmatrix} f \left ( x, u _ { \bullet } ( 0 ) \right ) \\ \mathcal { S } ^ { * } u _ { \bullet } \end{bmatrix} \,. \quad \quad \ \ \ ( 9 )$$
Let ψ ′ : M× U → ℓ ( ) R be an observable for the augmented state that belongs to a suitable space of functions H . The Koopman operator K : H → H for the controlled system (9) is then
$$( \mathcal { K } \psi ^ { \prime } ) ( \chi ) = \psi ^ { \prime } ( f ^ { \prime } ( \chi ) ) = \psi ^ { \prime } ( \chi ^ { + } ) \. \quad \ \ ( 1 0 )$$
Constructing a finite-dimensional approximation to the operator K then induces a linear predictor in the form of the system (2).
Remark 2: Instead of a single Koopman operator describing the system's dynamics, a set of Koopman operators are identified. Each Koopman operator (parametrized by the input) then captures the system's behavior for a certain, constant, input.
## C. Extended Dynamic Mode Decomposition with Control
The Extended Dynamic Mode Decomposition (EDMD) presents a simple way to approximate the Koopman operator from data, hence obtaining the LLP. The starting point is to select N observables ψ , . . . , ψ 1 N and form the predictor's state z from the measured state x of the system (1) as
$$z = \Psi ( x ) = [ \psi _ { 1 } ( x ), \psi _ { 2 } ( x ), \dots, \psi _ { n } ( x ) ] ^ { T$$
Next, we gather measured states x i and x + i from the system and form a set of data
$$\dots \dots \dots \dots \dots \dots \dots \\ X & = [ x _ { 1 }, x _ { 2 }, \dots, x _ { N _ { d }$$
where N d is the number of measurements, and the measurements satisfy a relation
$$x _ { i } ^ { + } = f ( x _ { i }, u _ { i } ) \,, \quad \ \ \ \ ( 1 3 ) \quad \ \ \ \ \ \ \ \ \ \ \$$
that we wish to capture with the linear predictor. Note that the states x i forming the set (12) need not be temporally ordered, i.e., the states could be gathered from multiple trajectories. The linear predictor (2) can be then identified by solving
$$\min _ { A, B } & \| Y _ { \text{lift} } - A X _ { \text{lift} } - B U \| _ { F } \, \quad \quad \quad$$
where ∥ ∥ . F denotes a Frobenius norm of a matrix. The solution to (14) can be analytically obtained from
$$\begin{bmatrix} A & B \\ C & 0 \end{bmatrix} = \begin{bmatrix} Y _ { \text{lift} } \\ X \end{bmatrix} \begin{$$
where ( ) . † denotes the Moore-Penrose pseudoinverse of a matrix. Note that when all components of the original state x of the nonlinear system are incorporated in the set of observables, the matrix C can be directly constructed by selecting the corresponding observables from (11).
The convergence of the EDMD to the Koopman operator (7) for autonomous systems was proven in [14]. This proof holds true when both the number of data points and the number of observables go to infinity. However, from the practical point of view, one always works with finite number of both the data and the observables. Additionally, identifying Koopman operator for controlled systems requires, generally, all possible input sequences, which is also unfeasible to obtain.
## D. Control Synthesis with LLP
With identified LLP (2), we can design a feedback controller with classical linear control systems method. In this paper, we use two model-based techniques, a linear quadratic regulator (LQR) and model predictive control (MPC).
1) LQR: The discrete-time LQR minimizes the quadratic cost function
$$J ( z, u ) = \sum _ { k = 0 } ^ { \infty } \left ( z _ { k } ^ { T } Q z _ { k } + u _ { k } ^ { T } R u _ { k } + 2 z _ { k } ^ { T } S u _ { k } \right ) \,, \quad ( 1 6 ) \, \begin{array} { c } \text{LLP b} \\ \text{functi} \\ \text{evaluate} \\ \text{Prol} \end{array}$$
subjected to the system's dynamics (2), and where Q,R,S are cost matrices reflecting the desired control goal. The control law minimizing the cost (16) is
$$u _ { k } = - K z _ { k } = K \Psi ( x _ { k } ) \, \quad \quad \ ( 1 7 )$$
where the feedback gain K can be computed from the solution to the discrete-time algebraic Riccati equation. When the LQR is used for tracking, the control law changes to
$$u _ { k } = - K \left ( \Psi \left ( z _ { k } \right ) - \Psi \left ( z _ { r e f } \right ) \right ) \,. \quad \ \ ( 1 8 ) \, \stackrel { \mathfrak { s m } } { \mathfrak { B } } \,.$$
Remark 3: When using LLP within the LQR framework, the lifted states can serve not only for capturing the system's dynamics more accurately, but also can be directly penalized. The lifted states allow introducing penalization of arbitrary functions of state, extending the quadratic cost (16).
2) MPC: The use of LLP within the MPC is coined as Koopman MPC (KMPC) in [5]. Here, we only state the main formulation and omit the details as they can be found in the referenced literature. At every (discrete) time, the MPC solves the following optimization problem on the time horizon N p
$$\text{ded}, \quad \text{horizon} \, N _ { p } \, \begin{array} { c c c } \cdot \\ \text{tories} \, \\ \text{ving} \quad & \min _ { u _ { k }, z _ { k } } \, J \left ( \{ z _ { k } \} _ { k = 0 } ^ { N _ { p } } \,, \{ u _ { k } \} _ { k = 0 } ^ { N _ { p } } \right ) \,, \\ \text{subject to} \quad & z _ { k + 1 } = A z _ { k } + B u _ { k } \,, \quad k = 0, 1, \dots, N _ { p } - 1 \,, \\ ( 14 ) \end{array} \, \begin{array} { c c c } e _ { k } = r _ { k } - C z _ { k } \,, \\ e _ { k } = r _ { k } - C z _ { k } \,, \\ e _ { \min } \leq z _ { k } \leq z _ { \max } \,, \\ \cdot \, \text{The} \quad & u _ { \min } \leq u _ { k } \leq u _ { \max } \,, \\ \text{parameters} \quad & z _ { 0 } = \Psi ( x _ { t } ) \,, \\ ( 15 ) \end{array} \, \begin{array} { c c c } r _ { k } = \text{given} \,, \quad k = 0, 1, \dots, N _ { p } \,, \\ \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad & \text{and} \quad \\ \end{array}$$
where u min max / are bounds on inputs, z min max / are bound on lifted states, and r k is the reference signal. Only the first element of the optimal sequence u 0 is used, and the optimization problem is solved again in the next time step. The cost function J is
$$\text{era-} \text{This} \underset { \text{raw-} } { \text{era-} } J ( z, u ) = e _ { N _ { p } } ^ { \text{ } } Q _ { N } e _ { N _ { p } } + \sum _ { k = 0 } ^ { N _ { p } - 1 } \left ( e _ { k } ^ { \text{ } } Q e _ { k } + u _ { k } ^ { \text{ } } R u _ { k } \right ) \. \ \ ( 2 0 )$$
## III. PRACTICAL GUIDELINES
This section presents some key and less intuitive practical guidelines for identification of LLPs using the EDMD algorithm. We support the guidelines with several motivating examples in Sec. IV.
## A. Select Appropriate Metric to Assess Predictors Effectively
As for any data-driven method, it is important to evaluate the accuracy of the obtained model. In the following subsection, we define and discuss different metrics for assessing the performance of LLPs. Let D = ( x , x i + i , u i ) , i = 1 , . . . N d be a dataset of samples from evaluation trajectories, and let the LLP be given by the matrix triplet A,B,C and the lifting function Ψ . We argue that the type of error selected for evaluation, depends on the purpose of the LLP.
Probably the most natural option would be to evaluate the error
$$\intertext { m } \epsilon _ { \text{project} } = \frac { 1 } { N _ { d } } \sum _ { i = 1 } ^ { N _ { d } } \| x _ { i } ^ { + } - C ( A \Psi ( x _ { i } ) + B u _ { i } ) \| \,, \quad ( 2 1 )$$
where ∥ ∥ . is the 2-norm. The error (21) reflects how the LLP predicts time evolution of the system's original states, excluding the lifted states. However, note that the error (21) is not directly minimized by the EDMD algorithm (see Eq. (14)). In particular, the EDMD finds the LLP that minimizes the error in prediction of the full lifted state , that is
$$\mathbf r y \quad \epsilon _ { \text{lfd} } = \frac { 1 } { N _ { \mathrm d } } \sum _ { i = 1 } ^ { N _ { \mathrm d } } \| \Psi ( x _ { i } ^ { + } ) - \left ( A \Psi ( x _ { i } ) + B u _ { i } \right ) \| \,. \quad ( 2 2 )$$
Therefore, while adding more identification data or more observables should theoretically result in lower ϵ lifted , the error ϵ projected reflecting the prediction accuracy of relevant variables might be worse as the EDMD could prioritize capturing the lifted states. In other words, the EDMD does not explicitly guarantee minimization of the error (21) so also the error (22) should be taken into account in the identification process.
Lastly, for some control methods, especially the MPC, more important is to evaluate the LLP's ability to predict systems' trajectory on a certain time horizon with a length N p . Consider a trajectory with an initial state x 0 , the input sequence { u i } N p -1 0 , and corresponding output sequence { x k } N p 0 satisfying the relation (1). We define the prediction error as
$$\epsilon _ { \text{prediction} } = \frac { 1 } { N _ { d } } \sum _ { i = 0 } ^ { N _ { d } } \sum _ { k = 0 } ^ { N _ { p } - 1 } \| x _ { k + 1 } - C ( A \Psi ( x _ { k } ) + B u _ { k } ) \| ^ { 2 } \,. \quad \ D. \ I n s l \\ \text{Convariant the matrix can be used to collect the length of the } \text{$diff$}$$
Moreover, the metric can be used to select the length of the prediction horizon N p of the MPC.
Remark 4: An important step in assessing LLP's accuracy is taking into account different scales of state variables. For example, all states can be scaled into an interval ⟨-1 1 , ⟩ or the errors themselves otherwise normalized.
## B. Carefully Choose Lifting Functions
Following the EDMD algorithm, the first and the most challenging step in the identification process is selection of the observables ψ i . As explained in Sec. II-A, the aim is at approximating the Koopman operator on some finitedimensional function space. Typically, a basis of such space is selected.
In [15], the authors proposed using higher order derivatives of the underlying nonlinear dynamics, motivated by choice of lifting functions for polynomial systems. Delay embeddings are another option, allowing to reconstruct the system's state from the system's output, which can be useful when only sparse measurements are available [8]. The set of observables could also result from optimization problem, as proposed in [16], exploiting the system dynamics and the state-space geometry.
Generally, we should aim to choose observables that accurately represent the problem's dynamics, focusing on those that capture well the manifold on which the system evolves. Prioritizing few specific problem-related observables over a general function space basis can often yield superior results sometimes, less is more .
Another approach presented, e.g., in [17] is using a neural network as a lifting function. This approach is based on learning the eigenfunctions of the Koopman operator which then yield the LLP.
## C. Identify LLPs with Data Similar to Intended Closed-Loop Trajectories
The next step in identification is collecting the data. Generally, it is not feasible, nor desired to sample the data from the whole state space. In [6], authors illustrate the importance of the identification data for the Duffing Oscillator , a system with three equilibria. Based on the Koopman operator analysis of the system for controlled systems, it is important to choose representative both the control sequences and the system's trajectories. Thus, the data should be ideally sampled from the trajectories that represent the final closed-loop trajectories. Therefore, it is advantageous to identify an input that closely approximates the final closed-loop input and subsequently - as he samples should be independent and identically distributed (i.i.d.) -utilize a randomized signal that closely resembles it. Note that using only closed-loop data could cause problems, as the feedback creates correlation between unmeasurable noise (in system's output) and the system's input, see [18] for details.
## D. Inspect Identified Predictors
While the LLP can be perceived only as a black box , predicting system dynamics with adequate accuracy, its quality can be substantially enhanced through careful inspection and subsequent adjustment of the identification process. For example, as the EDMD algorithm is purely data-driven, the identification can result in a LLP that allows non-physical coupling between the states. Also, the stability of the system (or system's equilibria) might not be preserved. Finally, when the number of selected observables is significantly higher than the original system's order ( N ≫ n ), a low-dimensional approximation to the LLP can be created. Such an approximation may be necessary for certain control synthesis methods. Details on order reduction methods in context of EDMD can be found, e.g., in [19].
## IV. MOTIVATED EXAMPLES OF LLP IDENTIFICATION AND APPLICATION FOR CONTROL
In this section, we apply the method described in Sec. II to obtain LLP for several systems. The whole method consists of acquiring data, selection of observables, evaluation of the LLP, and lastly, control design with control evaluation. For the sake of brevity, we omit some details in control design as the main focus is on LLP identification, rather than the control synthesis. The details can be found in the provided code.
In all examples, the systems are numerically integrated using the 4th order Runge-Kutta algorithm with an integration step T s = 0 01 s . . We first present a correct solution, and then we introduce some pathologies into the process to highlight the importance of some aspects, motivating our guidelines. Note that our aim is not to present the best solution to the particular problem. Rather, the examples serve to show the intricacies in LLP identification.
## A. Swing-up of Inverted Pendulum
Consider a damped pendulum, driven by a torque u , and with the system's origin x e shifted into the unstable equilibrium - the upward position. Let φ and ω be pendulum's angle and the angular velocity, respectively. The system's model is
$$\dot { x } = \begin{bmatrix} \dot { \varphi } \\ \dot { \omega } \end{bmatrix} = \begin{bmatrix} \omega \\ \frac { q } { l } \sin ( \varphi ) - \frac { \gamma } { m l ^ { 2 } } \omega + \frac { 1 } { m l ^ { 2 } } u \end{bmatrix} \,, \quad ( 2 4 )$$
where g is the gravity, γ is the damping coefficient, and m l , are the pendulum's mass and length, respectively. Both states, φ and ω , are measured.
We aim to design controller that achieves the swing-up task, i.e., driving the system from a state x = [ π, 0] T (the downward position) into the state x e = [0 0] , T (the upward position). Since we do not consider limits on the input u , the task can be simply achieved by LQR with local linearization at x e . We wish to identify LLP to design a controller with better performance.
We gather the identification data from closed-loop trajectories, using a proportional control law u = -k φ p . To obtain rich dataset, each trajectory is initialized in a random state while also the gain k p is randomized. Additionally, the closed-loop input is perturbed by a random signal. In total, we collect 2100 trajectories from which we use 100 trajectories for evaluation only. Each trajectory was 0 5 s . in length. As the observables, we select the original states together with single additional function, so the lifting function is
$$\Psi ( x ) = \left [ \varphi, \omega, \sin \left ( \varphi \right ) \right ] ^ { \intercal }. \text{ \quad \ \ } \text{(2.5)}$$
This is an example of problem-specific lifting, motivated by the sine function's presence in system's dynamics (24).
Then, we devise an LQR controller using the LLP, and for comparison, another LQR controller based on local linearization around the system's origin, referred to as a local predictor . The Fig. 1 shows a phase-portrait with training trajectories together with LQR closed-loop trajectories using two linear models. We can see that the lifted predictor exhibits superior performance, even when the penalty matrices Q and R of both LQRs are the same.
1) Pathology #1: Collecting Identification Data: To collect identification data, an alternative option to the closedloop input might be using (pseudo) random signal. We also present three different choices of initial states for the data: initialization near the stable equilibrium, near the unstable equilibrium, and uniformly distributed in the interval φ 0 = ( -π, π ) . The phase portraits of the identification data are displayed in Fig. 2. In the bottom part of the figure, we then compare the closed-loop control. We can see, that only the first option of sampling results in a successful swingup (albeit worse than local linearization), while the other two options fail. The main challenge of this task is that the swing-up-achieving trajectory contains two equilibria. This is a problem, as a linear system cannot have two or more isolated equilibria.
While sampling the portion of the state space in an open loop may lead to a satisfactory behavior, the perturbed closed-loop data present more straightforward option.
2) Pathology #2: Choice of Lifting Functions: In the spirit of the Koopman operator, we can try to obtain better representation of the system's dynamics by introducing more
Fig. 1: The figure's right part displays the phase portrait of training trajectories for the swing-up task, together with comparison of closed-loop performances. On the left are time series.
Fig. 2: Three examples of non-representative identification data for the swing-up task. In the figure's top part are the phase portraits of identification data, at the bottom are comparisons of closed-loop performances
lifting function, hence to better approximate the Koopman operator. We consider three additional options, differing in the basis functions: the polynomial basis, thin plate splines radial basis functions (TPS-RBF), and Gaussian RBF. For each option, the lifting function Ψ( ) x consists of the original states φ and ω , and then additional 100 observables
$$\psi _ { i } ^ { \text{TPS} } & = \| \varphi - a _ { i } \| ^ { 2 } \log \| \varphi - a _ { i } \| \, \\ \psi _ { i } ^ { \text{pol} } & = \varphi ^ { ( i - 1 ) } \, \\ \psi _ { i } ^ { \text{gauss} } & = \exp \left ( - ( \varphi - b _ { i } ) ^ { 2 } / ( 2 c _ { i } ^ { 2 } ) \right ) \, \\ \.$$
where the parameters a , b , c i i i , i = 1 , . . . , 100 were sampled randomly.
The comparison of the predictors in shown in Fig. 3. To assess the accuracy of the predictors, we first compare (in logarithmic scale) all the metrics introduced in Sec. III-A. We also show a comparison of predictors' ability to capture
Fig. 3: Comparison of different lifting functions. The figure, from top to bottom, shows the comparison of evaluated errors (in the logarithmic scale), prediction on a finite horizon, and the time series of the closed-loop control
Fig. 4: Wheeled Balancing Robot
a single trajectory, given its initial state and the sequence of inputs. Lastly, we show the closed-loop performance.
An interesting observation is that while the projected errors ϵ projected of the predictors with many observables are better than the error of the local or the sine predictors, the resulting control is significantly worse. We found that when using LLP for designing LQR, the most relevant metric appears to be the ϵ lifted since the feedback law (17) generally uses values of all lifted states z , even though the lifted states are not directly penalized.
## B. Two-wheeled Inverted Pendulum Balancing Robot
We consider a system depicted in Fig. 4, a two-wheeled balancing robot moving on a flat surface with three degrees of freedom: the traveled distance s , tilt angle φ , and yaw angle χ . Let q = [ s, φ, χ ] T be the vector of generalized coordinates, and u = [ u , u 1 2 ] T be the system's input - torques applied on the wheels. The robot's dynamics (see [20] for
Fig. 5: Comparison of closed-loop performances of MPC based on a local predictor or on the identified LLP. The MPC with local predictor fails to stabilize the system around t = 7s
full derivations) can be described by the equation
$$\dot { q } = M ( q ) ^ { - 1 } \left ( B u - C ( q, \dot { q } ) \dot { q } - D \dot { q } - G ( q ) \right ) \,, \quad ( 2 7 )$$
where M q ( ) , C q, q ( ˙) , D , G q ( ) , B are inertia, Coriolis, dissipation, gravity, and input matrices, respectively. The goal is maintaining the robot in the upward position while allowing to track a reference on the travel speed ˙ s ref and the yaw rate ˙ χ ref . To address the task, we identify the LLP and use the predictor within the MPC.
We gather the identification and verification data from closed-loop trajectories. To this end, we designed a LQR controller stabilizing the system to the equilibrium in the origin. The LQR design was based on a local linearization of the system (27) about the system's origin. In total, we gathered 2000 trajectories, where the half was used for identification, and the rest for validation. Each trajectory was initialized with randomized coordinates q . We selected the references s ref and χ ref to be sinusoidal with randomized amplitude.
Let the system's state be x = [ ˙ q, q ] T . We select the lifting function for LLP as
$$\Psi ( x ) = \left [ \dot { s }, \dot { \varphi }, \dot { \chi }, \varphi, \sin ( \varphi ) \right ] ^ { \intercal }. \text{ \quad \ \ } ( 2 8 )$$
That is, we omit the states s and χ as they should not, by the assumption, affect the system's dynamics, i.e., the dynamics should be invariant w.r.t the travelled distance s and the yaw χ . Also, if needed, both states can be numerically recovered from their derivatives. We add the observable ψ x ( ) = sin( φ ) to capture the pendulum-like motion of the robot.
We designed two MPC controllers, one based on local linearization, and one based on identified LLP. The Fig. 5 shows a comparison of the closed-loop performances. The MPC with LLP exhibits better performance as the Local linearization fails to stabilize the system. Even with only
Fig. 6: Demonstration of how non-physical coupling between the states affect the control performance. Shown are two trajectories, initialized in different distance s 0
Fig. 7: Heatmaps of the system's matrices A local and A LLP showing non-physical coupling between the states for lifted predictor
one extra lifting function, the prediction error (23) of the LLP was better by ≈ 20 % than the local linearization.
- 1) Pathology #1: Non-physical State Coupling: Let us now identify a LLP for the system (27) with a lifting function that includes all the robot's states
$$\Psi ( x ) = [ \dot { s }, \dot { \varphi }, \dot { \chi }, s, \varphi, \chi, \sin \varphi ] ^ { T } \,. \quad \quad ( 2 9 ) \quad \ \ \ ]$$
We repeat the whole process. The Fig. 6 shows the closedloop performance of KMPC for the system initialized in two different initial states, differing in the initial distance s 0 .
When the system is initialized with s 0 = 0 , the performance is comparable to the previous case with the lifting function (28). However, when the system is initialized with s 0 = 100 , which should not influence the system, the controller fails to stabilize the system. To gain an insight into this behavior, let us examine the identified system matrix A LLP of the LLP and compare it with a system matrix A local obtained from local predictor, see Fig. 7.
As evident from the A LLP matrix, there exists significant coupling between s , χ , and the remaining states. As previously noted, the system's dynamics are expected to remain invariant with respect to both the traveled distance s and yaw rate χ . The LLP resulting from the EDMD is not imposing such constraints on the resulting model.
## V. CONCLUSION
This paper introduced practical guidelines for utilizing EDMD in the identification of control-oriented lifted linear predictors. We have demonstrated a range of challenges that may arise when employing EDMD for LLP identification, along with strategies to address them. Our future efforts will concentrate on expanding this set of guidelines to establish a comprehensive methodology for LLP identification.
## REFERENCES
- [1] Koopman BO. Hamiltonian Systems and Transformation in Hilbert Space. Proceedings of the National Academy of Sciences. 1931 May;17(5):315-318. Publisher: Proceedings of the National Academy of Sciences.
- [2] Koopman BO, Neumann Jv. Dynamical Systems of Continuous Spectra. Proceedings of the National Academy of Sciences. 1932 Mar;18(3):255-263. Publisher: Proceedings of the National Academy of Sciences.
- [3] Mezi´ c I, Banaszuk A. Comparison of systems with complex behavior. Physica D: Nonlinear Phenomena. 2004 Oct;197(1):101-133.
- [4] Mezi´ c I. Spectral Properties of Dynamical Systems, Model Reduction and Decompositions. Nonlinear Dynamics. 2005 Aug;41(1):309-325.
- [5] Korda M, Mezi´ c I. Linear predictors for nonlinear dynamical systems: Koopman operator meets model predictive control. Automatica. 2018 Jul;93:149-160.
- [6] Brunton SL, Budiˇ si´ c M, Kaiser E, Kutz JN. Modern Koopman Theory for Dynamical Systems. SIAM Review. 2022 May;64(2):229-340. Publisher: Society for Industrial and Applied Mathematics.
- [7] Williams MO, Hemati MS, Dawson STM, Kevrekidis IG, Rowley CW. Extending Data-Driven Koopman Analysis to Actuated Systems. IFAC-PapersOnLine. 2016 Jan;49(18):704-709.
- [8] Arbabi H, Korda M, Mezi´ c I. A Data-Driven Koopman Model Predictive Control Framework for Nonlinear Partial Differential Equations. In: 2018 IEEE Conference on Decision and Control (CDC); 2018. p. 6409-6414.
- [9] Korda M, Susuki Y, Mezi´ c I. Power grid transient stabilization using Koopman model predictive control. IFAC-PapersOnLine. 2018 Jan;51(28):297-302.
- [10] Do L, Korda M, Hur´ ak Z. Controlled synchronization of coupled pendulums by Koopman Model Predictive Control. Control Engineering Practice. 2023 Oct;139:105629.
- [11] Budiˇ si´ c M, Mohr RM, Mezi´ c I. Applied Koopmanism. Chaos: An Interdisciplinary Journal of Nonlinear Science. 2012 Dec;22(4):047510.
- [12] N¨ uske F, Peitz S, Philipp F, Schaller M, Worthmann K. Finite-Data Error Bounds for Koopman-Based Prediction and Control. Journal of Nonlinear Science. 2022 Nov;33(1):14.
- [13] Peitz S, Otto SE, Rowley CW. Data-Driven Model Predictive Control using Interpolated Koopman Generators. SIAM Journal on Applied Dynamical Systems. 2020 Jan;19(3):2162-2193. Publisher: Society for Industrial and Applied Mathematics.
- [14] Korda M, Mezi´ c I. On Convergence of Extended Dynamic Mode Decomposition to the Koopman Operator. Journal of Nonlinear Science. 2018 Apr;28(2):687-710.
- [15] Mamakoukas G, Castano M, Tan X, Murphey T. Local Koopman Operators for Data-Driven Control of Robotic Systems. Robotics: science and systems. 2019 Jun.
- [16] Korda M, Mezi´ c I. Optimal Construction of Koopman Eigenfunctions for Prediction and Control. IEEE Transactions on Automatic Control. 2020 Dec;65(12):5114-5129.
- [17] Lusch B, Kutz JN, Brunton SL. Deep learning for universal linear embeddings of nonlinear dynamics. Nature Communications. 2018 Nov;9(1):4950. Number: 1 Publisher: Nature Publishing Group.
- [18] Forssell U, Ljung L. Closed-loop identification revisited. Automatica. 1999 Jul;35(7):1215-1241.
- [19] Brunton SL, Kutz JN. Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control. Cambridge University Press; 2022. Google-Books-ID: rxNkEAAAQBAJ.
- [20] Kim S, Kwon S. Dynamic modeling of a two-wheeled inverted pendulum balancing mobile robot. International Journal of Control, Automation and Systems. 2015 Aug;13(4):926-933. | null | [
"Loi Do",
"Adam Uchytil",
"Zdeněk Hurák"
] | 2024-08-02T08:53:08+00:00 | 2024-08-02T08:53:08+00:00 | [
"eess.SY",
"cs.SY"
] | Practical Guidelines for Data-driven Identification of Lifted Linear Predictors for Control | Lifted linear predictor (LLP) is an artificial linear dynamical system
designed to predict trajectories of a generally nonlinear dynamical system
based on the current state (or measurements) and the input. The main benefit of
the LLP is its potential ability to capture the nonlinear system's dynamics
with precision superior to other linearization techniques, such as local
linearization about the operation point. The idea of lifting is supported by
the theory of Koopman Operators. For LLP identification, we focus on the
data-driven method based on the extended dynamic mode decomposition (EDMD)
algorithm. However, while the EDMD algorithm presents an extremely simple and
efficient way to obtain the LLP, it can also yield poor results. In this paper,
we present some less intuitive practical guidelines for data-driven
identification of the LLPs, aiming at improving usability of LLPs for designing
control. We support the guidelines with two motivating examples. The
implementation of the examples are shared on a public repository. |
2408.01118v1 | ## IAI Group at CheckThat! 2024: Transformer Models and Data Augmentation for Checkworthy Claim Detection
Notebook for the Checkthat! Lab Task 1 at CLEF 2024
Peter Røysland Aarnes , 1 Vinay Setty 1 , * and Petra Galuščáková 1
1 University of Stavanger, Kjell Arholms gate 41, 4021 Stavanger, Norway
## Abstract
This paper describes IAI group's participation for automated check-worthiness estimation for claims, within the framework of the 2024 CheckThat! Lab 'Task 1: Check-Worthiness Estimation'. The task involves the automated detection of check-worthy claims in English, Dutch, and Arabic political debates and Twitter data. We utilized various pre-trained generative decoder and encoder transformer models, employing methods such as few-shot chain-of-thought reasoning, fine-tuning, data augmentation, and transfer learning from one language to another. Despite variable success in terms of performance, our models achieved notable placements on the organizer's leaderboard: ninth-best in English, third-best in Dutch, and the top placement in Arabic, utilizing multilingual datasets for enhancing the generalizability of check-worthiness detection. Despite a significant drop in performance on the unlabeled test dataset compared to the development test dataset, our findings contribute to the ongoing efforts in claim detection research, highlighting the challenges and potential of language-specific adaptations in claim verification systems.
## Keywords
Check-worthiness, Fact-checking, RoBERTa, LLM fine-tuning
## 1. Introduction
In an era where information spreads faster than our capacity to verify it, the need for robust mechanisms to assess the veracity of circulating claims has become increasingly critical. In the automated factchecking research community, a claim is commonly defined as 'an assertion about the world that can be checked', as formalized by Full Fact [1]. However, this definition does not address the worthiness of checking a claim, since not every claim requires scrutiny due to the triviality. To determine whether a claim is checkworthy, several factors could be considered: whether the assertion is of public interest; whether it is factually verifiable, such as statements about the present or the past, or involving correlation and causation; if the claim is a rumor or conspiracy; or if it could potentially cause social harm [1, 2, 3]. By directing the efforts of fact-checkers and automated systems toward claims with widespread impact, such as those affecting public health or policy decisions, we ensure that critical information remains reliable and verification resources are utilized effectively.
In this paper, we detail our approach to training numerous models for the detection of check-worthy claims, specifically within the framework of the 2024 CheckThat! Lab 'Task 1: Check-Worthiness Estimation' [4]. This task seeks to determine whether claims found in tweets or political speech transcriptions merit fact-checking, using a binary classification approach.
We conducted experiments across all three CheckThat! languages chosen by the organizers, English, Dutch, and Arabic. Our submissions ranked best for Arabic, third for Dutch, and ninth for English. We employed various exploratory methods tailored to each language, utilizing various pre-trained autoregressive decoder models and encoder-only transformer models.
For English and Dutch, our primary focus was to fine-tune our chosen models using the training data provided by the organizers for each specific language. However, we also attempted to fine-tune
* Corresponding author.

[email protected] (P. R. Aarnes); [email protected] (V. Setty); [email protected] (P. Galuščáková)


0009-0002-3605-4847 (P. R. Aarnes); 0000-0002-9777-6758 (V. Setty); 0000-0001-6328-7131 (P. Galuščáková)
multilingual models using additional data beyond that of the language in which the model would be tested. For Arabic, which would reveal itself being the most challenging dataset, we initially fine-tuned models on Arabic training data. However, the best results were achieved by translating the Arabic test data into English and then using a GPT-3.5 model, fine-tuned in English, to classify the data.
We also took part in Task 2 of the CLEF CheckThat! 2024 challenge, which aimed to determine whether a sentence from a news article expressed the author's subjective viewpoint or presented an objective perspective on the topic. As check-worthy claims are inherently objective statements, we employed the XLM-RoBERTa-Large model, which was trained for claim detection tasks. Given its multilingual capabilities, we utilized this model for datasets spanning English, German, Italian, Bulgarian, Arabic, and multilingual sources. The XLM-RoBERTa-Large's ability to handle diverse languages made it a suitable choice for this multilingual claim detection task, enabling us to analyze and classify sentences across various linguistic contexts.
## 2. Related Work
As traditional news media experiences a decline in popularity, particularly among younger demographics [5], platforms like X (formerly known as Twitter) and other types of microblogging services have become primary sources for current events for many individuals. In the influx of X's popularity, the spread of misinformation and fake news has been increasing [6], leading to heightened awareness and concern among researchers, policymakers, and the public. This growing attention has spurred numerous initiatives aimed at combating false narratives, as exemplified by the pervasive misinformation during the 2016 U.S. presidential election [7, 8] and the COVID-19 infodemic , both of which significantly influenced public opinion and health behaviors [9, 3].
To counteract the spread of misinformation, the research community has intensified efforts to develop datasets and methodologies for automated fact-checking. Claim detection plays a crucial role within these systems, serving as a foundational component for effective automated fact-checking [10]. The most significant progress in this area has been observed in the English language, with the two largest datasets designed for this purpose being ClaimBuster [11], containing approximately 23,500 manually annotated sentences, and CT19-T1 [12], a dataset being the result of several years' worth of data from the CLEF CheckThat! Lab challenges.
Additionally, multilingual datasets like those documented by Gupta and Srikumar [13], primarily used for fact-checking, are also utilized for multilingual claim detection, further enhancing the resources available for this research. Although there exists smaller datasets, typically with fewer than 10,000 annotated sentences, they are predominantly in English [14].
Over the past two years, the CheckThat! Labs have consistently used F1 scores as the official measurement for the check-worthiness estimation subtask. Although the specific task descriptions and the languages tested have varied across different iterations of the CheckThat! Lab, but the overarching goal has remained consistent: to predict the check-worthiness of claims in various languages. This work focuses primarily on text data drawn from sources such as political debates and Twitter [15, 16]. For this year's CheckThat! Lab, F1 is again the official measure to assess performance, continuing with a subset of the same languages as previous editions: Arabic, Dutch, and English.
For the 2022 CheckThat! Lab Task 1, focused on check-worthiness estimation, where the NUSIDS group [17] had the winning submission with their CheckthaT5 model, which won in four out of the six language categories that year [16]. Their model was based on the mT5, a sequence-tosequence, massively multilingual model [18], and was trained jointly on multiple languages to promote language-independent knowledge. Their Arabic submission achieved an F1 score of 0.628, and the Dutch submission had an F1 score of 0.642. The winning English submission, made by the AI Rational group, used a fine-tuned RoBERTa model and achieved an F1 score of 0.698.
For the 2023 CheckThat! Lab Task 1, again focused on check-worthiness estimation (Subtask 1B), the OpenFact group attained the best submission for English. The group fine-tuned GPT-3 which resulted in a F1 of 0.898, and in addition they trained BERT-based model which achieved near identical results
Table 1
Data counts across the training, development, and development test dataset splits.
| Language | Class | Train | Development | Dev-test | Total |
|------------|---------|---------|---------------|------------|---------|
| English | No | 17,088 | 794 | 210 | 18,092 |
| | Yes | 5,413 | 238 | 108 | 5,759 |
| | Total | 22,501 | 1,032 | 318 | 23,851 |
| Dutch | No | 590 | 150 | 350 | 1,090 |
| | Yes | 405 | 102 | 316 | 823 |
| | Total | 995 | 252 | 666 | 1,913 |
| Arabic | No | 5,090 | 682 | 123 | 5,895 |
| | Yes | 2,243 | 411 | 377 | 3,031 |
| | Total | 7,333 | 1,093 | 500 | 8,926 |
[16, 19]. For Arabic, the ES-VRAI group submitted the best results, which were derived from a fine-tuned MARBERT model [20] trained on a downsampled majority class, resulting in a F1 of 0.809 [21].
## 3. Datasets
As shown in Table 1, there is a significant imbalance in the class label distribution within the training data. If the model is exposed to one class more frequently during training, it may develop a bias towards the majority class, leading to overfitting and poor generalization when encountering the minority class in new data. To address these issues, one can either undersample the majority class or oversample the minority class to create a more balanced training set. Alternatively, other data augmentation techniques such as backtranslations, or synthetic data generation could also be used to balance the class distribution [22]. Additionally, instead of only prioritizing training data class distribution, adjusting the evaluation strategy during training to prioritize maximizing F1 macro-average scores, ensures that predictions for different classes are treated with equal importance.
## 4. Methodology
To conduct our experiments, a series of methods was used in an attempt to optimize the performance of the different fine-tuned models for a given language. These methods include translating data from one language to another to increase the training dataset for the particular given language, text normalization, style transfer, hyperparameter grid searches, and analyzing key performance indicators such as loss and F1 scores during training, which were logged by the Weights & Biases (W&B) Python library and online tool [23]. In this section, we will explore in greater detail the methods used to fine-tune the different models. The code used to train and test our models is available on our GitHub repository . 1
## 4.1. Data pre-processing and augmentation
Data pre-processing became one of our experimental methods that was used in fine-tuning the different models. We applied the following methods:
- · Text Normalization: TweetNormalizer 2 [24] script was used post-translation for the Arabic, Dutch and Spanish data. During our preliminary testing, the TweetNormalizer did not yield promising results, leading us to exclude it from further experiments when training our models
1 IAI group code repository: https://github.com/iai-group/clef2024-checkthat
2 TweetNormalizer: https://github.com/VinAIResearch/BERTweet/blob/master/TweetNormalizer.py
using hyperparameter grid searches. The reasons behind the poor performance of TweetNormalizer are not entirely clear, although it is plausible that the issue may be related to entity linking. Unlike other approaches, TweetNormalizer does not preserve the specific '@<username>' tokens in tweets. Instead, it replaces any distinct username with a generic '@USER' token, effectively removing unique identifiers associated with different classes. This removal of specific usernames could potentially disrupt contextual relevance, which might otherwise contribute positively when fine-tuning the models.
- · Machine Translation: Due to the large amounts of data to translate, we opted to use a free of charge translation systems available in the deep translator library. According to the recent WMT report [25], the quality of such freely available commercial systems depends on the particular language pair, but is relatively high for all the studied systems and language pairs. We thus used Google Translate implementation from deep-translator 3 due to its support of all studied languages, usual performance quality and no required subscription or API key. Google Translate was used to translate datasets from any provided source language (English, Dutch, Arabic, and Spanish) to any target language (English, Dutch, Arabic).
- · Style Transfer: As the style of the English collection (political debates) substantially differs from the style of Dutch and Arabic collections (Twitter data), we also experimented with machine translation with style transfer to prepare in-style training data. Specifically, we style transferred the translated English training data to resemble a closer match to the Arabic data. To do this style transfer, we employed gpt-3.5-turbo-0125 model via ChatGPT API. We use a single prompt for each sentence in which we ask the system to translate the sentence and also to transfer the style of debate into a Tweet. We used a few-shot approach with three example Tweets selected from the Arabic training collection and the following prompt: Rephrase the following statement as if somebody was Tweeting about it in Arabic. Output might use hashtags, emoticons, images and links. Statement: ({text to translate}) + Here are a few examples: ({arabic examples}) . Though the quality of the translated sentences looked reasonable, using these data did not lead to any improvement, suggesting that the domain mismatch between the collections is too large to be crossed just by a style change. Style transfer might even affect the check-worthiness of the claim. GPT model used for style transfer was paid and also relatively slow, what did not allow more extensive experimentation.
## Few-shot chain-of-thought reasoning instruction prompt
Your task is to identify whether a given tweet text in the {lang} language is verifiable using a search engine in the context of fact-checking. Let's define a function named checkworthy(input: str).
he return value should be a strings, where each string selects from "Yes", "No".
"Yes" means the text is a factual checkworthy statement. "No" means that the text is not checkworthy, it might be an opinion, a question, or others. For example, if a user call checkworthy("I think Apple is a good company.") You should return a string "No" without any other words, checkworthy("Apple's CEO is Tim Cook.") should return "Yes" since it is verifiable.
Note that your response will be passed to the python interpreter, SO NO OTHER WORDS! Always return "Yes" or "No" without any other words. checkworthy({text})
3 Google Translate deep translator: https://deep-translator.readthedocs.io/en/latest/usage.html#google-translate
## 4.2. Model Types and Fine-tuning
For our experiments, we utilized both pre-trained generative autoregressive decoder transformer models and pre-trained encoder-only transformer models to assess their effectiveness in predicting text in English, Dutch, and Arabic. Our selection of generative models was based on their popularity and availability, which includes GPT-4 [26], Mistral-7b [27], GPT-3.5 with few-shot chain-of-thought (CoT) reasoning, and a fine-tuned GPT-3.5 [28]. For the encoder models, we chose XLM-RoBERTa-Large [29] and RoBERTa-Large [30], which are prominent in multilingual training classification and English classification tasks, respectively.
For fine-tuning the encoder-only models, we utilized the Hugging Face Trainer 4 class. Although most hyperparameters were kept in their default settings, the number of epochs was set to a static 50. The development dataset was evaluated after each epoch, optimizing for Macro F1 score to monitor performance. We also employed the hyperparameter grid search using Weights & Biases [23] sweep functionality to conduct multiple training runs, testing the most critical hyperparameter combinations. In an attempt to save time during training, training would terminate early if the F1 score for the development dataset did not improve after 3 consecutive epochs.
The following list contains an overview of the different models in our experiments used, including what data was used for fine-tuning, and specifies if a particular model was only used for one particular language.
- · GPT-4 [26]: Few-shot CoT reasoning. Tested on all three languages.
- · Mistral 7b [27]: Few-shot CoT reasoning. Tested on all three languages.
- · GPT-3.5 [28]: Few-shot chain-of-thought reasoning approach. Tested on all three languages.
- · GPT-3.5 [28] (fine-tuned): Fine-tuned on English training data for the English tests and Arabic to English translations, and another model was fine-tuned on Spanish, Arabic and Dutch for the Dutch test.
- · XLM-RoBERTa-Large [29] (XLMR): Fine-tuned on English ClaimBuster [11], Norwegian and German podcasts data for claim detection [31]. The model was tested on all three languages.
- · XLM-RoBERTa-Large (fine-tuned) [29]: This version of XLM-RoBERTa (which we will refer to as 'XLMR fine-tuned') builds upon the initial fine-tuning of the aforementioned XLMR model. It underwent additional fine-tuning with the organizer's training data, specifically tailored for a particular language. It was evaluated across all three languages.
- · RoBERTa-Large [30]: Fine-tuned on unaltered English organizer's training data, and was tested only on English data.
## 4.2.1. English Model fine-tuning and hyperparameter tuning
For the organizer English unlabeled test data submission, we used a fine-tuned RoBERTa-Large model, since it outperformed the other models on the development test (dev-test) datasets. The list of hyperparameters employed for the grid search is provided in Table 2. Figure 1 illustrates the outcome of the 24 distinct training runs and their corresponding performance on the development dataset.
## Table 2
Hyperparameters grid search values for RoBERTa-Large English fine-tuning. *Early termination if F1 score did not improve after 3 consecutive epochs.
| Parameters | Values |
|----------------------------|-----------------------------------|
| Batch Size | 16, 32 |
| Epochs | 50* |
| Hidden Dropout Probability | 0.1, 0.2, 0.3 |
| Learning Rate | 1.25e-05, 2.5e-05, 5e-05, 7.5e-05 |
4 https://huggingface.co/docs/transformers/main\_classes/trainer
Figure 1: Hyperparameter W&B parallel coordinates plot for RoBERTa hyperparameter grid search. Eval/f1 relates to the best dev-test F1 in a given run.
Given the consistently high F1 scores across multiple RoBERTa training runs on the development and dev-test datasets, more in depth analysis was conducted. During the RoBERTa grid search, two specific model runs, which we will refer to as model 𝐴 and model 𝐵 , performed exceptionally well on the development and dev-test datasets. Since only one model prediction results could be submitted for the final evaluation, our objective was to make an informed decision on which model would likely perform the best. For example, model 𝐴 demonstrated slightly better dev-test F1 scores compared to model 𝐵 , although model 𝐵 performed better than model 𝐴 on the development during 𝐵 's training.
As a final sanity check, we compared the prediction overlap between models 𝐴 and 𝐵 and a fine-tuned GPT-3.5 model to determine which RoBERTa model deviated most from the GPT-3.5's predictions. A significant difference in overlap with the GPT model suggests that one of the RoBERTa models might have developed a unique pattern of predictions, which in turn could have a significant impact on its performance on real-world data. We hypothesized that a higher percentage of overlap in predictions with the GPT model would be advantageous.
Based on comparisons and analysis of key performance indicators, such as the development dataset F1, dev-test F1, and the loss rate, we systematically gathered and analyzed training and testing data using W&B, including test data prediction overlaps. As a result, we decided to go with the RoBERTa model 𝐴 .
## 4.2.2. Dutch Model fine-tuning
For Dutch, we utilized XLMR, which was fine-tuned on ClaimBuster and podcast data (as detailed in Section 4.2), as well as XLMR fine-tuned with datasets in the four languages provided by the organizers. Additionally, we used GPT-3.5 fine-tuned on Dutch, Arabic, and Spanish data, and finally, leveraged LLMs GPT-4 and Mistral-7b with few-shot CoT reasoning prompts. After extensive analysis, for Dutch, GPT-4 was the best performing model on the dev-test dataset.
## 4.2.3. Arabic Model fine-tuning
For Arabic, none of the XLMR models or LLMs with CoT prompt performed well. Since we suspected that the distribution of dev-test and organizer test are different, we randomly sampled 10% of the test
Table 3 English performance binary averages metrics for the 'check-worthy'-class. The columns for accuracy, precision, and recall are measured from the dev-test dataset.
| Model | Accuracy | Precision | Recall | F1 (dev-test) | F1 Test |
|----------------------|------------|-------------|----------|-----------------|-----------|
| GPT-4 | 0.808 | 0.813 | 0.565 | 0.667 | 0.658 |
| Mistral-7b | 0.726 | 0.667 | 0.389 | 0.491 | 0.503 |
| GPT-3.5 | 0.745 | 0.865 | 0.296 | 0.441 | 0.397 |
| GPT-3.5 (fine-tuned) | 0.915 | 0.966 | 0.778 | 0.862 | 0.705 |
| XLMR | 0.83 | 0.829 | 0.63 | 0.716 | 0.717 |
| XLMR (fine-tuned) | 0.767 | 1 | 0.315 | 0.479 | 0.662 |
| RoBERTa | 0.937 | 0.958 | 0.852 | 0.902 | 0.753 |
dataset and manually annotated it with labels, thereafter tested each model on that annotated sample. Since we are three contributors to these experiments, each person annotated labeled 10% of the sample separately. We calculated Cohen's kappa to assess inter-annotation agreement ( 𝑘 = 0 424 . ). In cases of inter-annotation disagreement, the sentence in question would be annotated according to the majority rule.
## 5. Results and Discussion
In this section, we present the results that the different models produced for the dev-test and the submission test dataset after the gold standard got published. For the dev-test set we access the performance using metrics that include accuracy, precision, recall, and F1 scores for the positive class (check-worthy claims), moreover, for the test dataset, only the F1 was measured.
## 5.1. English
The models evaluated in English includes GPT-4, Mistral-7b, GPT-3.5, XLMR, XLMR (fine-tuned), and RoBERTa. Table 3 provides a detailed overview of the metrics for the positive class.
- · RoBERTa emerged as the best performing model for accuracy (0.937), precision (0.958), and recall (0.852) for the dev-test data, reflecting a strong ability to correctly identify relevant instances without a high rate of false positives. This resulted in an impressive F1 score of 0.902 for the dev-test, however, the F1 decreased by 0.099 for the test data (F1 0.753). Conversely, Mistral-7b and GPT-3.5 showed lower performance across most metrics, with Mistral-7b demonstrating a particular weakness in precision (0.667), and GPT-3.5 with even worse recall (0.296).
- · GPT-4 and XLMR displayed moderate performance, with XLMR having a slight edge over GPT-4 in accuracy and F1 scores. Interestingly, the fine-tuned XLMR (fine-tuned) achieved a perfect precision score of 1.000 but at the cost of lower recall (0.315), suggesting a conservative prediction behavior that limited its false positives, but missed several relevant predictions.
- · The variation in performance across the test and dev-test dataset for our best performing model, RoBERTa, suggests potential overfitting or dataset-specific biases which makes it poor at generalizing across different data. Efforts to that could be beneficial for future experiments would be fine-tuning with an expanded parameter grid search, data augmentation such as testing oversampling or undersampling techniques, or using additional translated English data to make the training data more diverse which could potentially help the model's ability to generalize.
## 5.2. Dutch
The models evaluated for the Dutch language include GPT-4, Mistral 7b, GPT-3.5, XLMR, and XLMR (fine-tuned). Table 4 provides a detailed overview of the performance metrics for the different models. This condensed analysis aims to highlight which models perform best in handling Dutch language data,
Table 4 Dutch performance binary averages metrics for the 'check-worthy'-class. The columns for accuracy, precision, and recall are measured from the dev-test dataset.
| Model | Accuracy | Precision | Recall | F1 dev-test | F1 Test |
|----------------------|------------|-------------|----------|---------------|-----------|
| GPT-4 | 0.577 | 0.58 | 0.389 | 0.466 | 0.718 |
| Mistral 7b | 0.547 | 0.539 | 0.31 | 0.394 | 0.601 |
| GPT-3.5 | 0.538 | 0.544 | 0.155 | 0.241 | 0.647 |
| GPT-3.5 (fine-tuned) | 0.677 | 0.706 | 0.547 | 0.617 | 0.781 |
| XLMR | 0.625 | 0.603 | 0.611 | 0.607 | 0.694 |
| XLMR (fine-tuned) | 0.637 | 0.597 | 0.722 | 0.653 | 0.611 |
Table 5 Arabic performance binary averages metrics for the 'check-worthy'-class. The columns for accuracy, precision, and recall are measured from the dev-test dataset.
| Model | Accuracy | Precision | Recall | F1 dev-test | F1 Test |
|----------------------|------------|-------------|----------|---------------|-----------|
| GPT-4 | 0.81 | 0.89 | 0.854 | 0.871 | 0.526 |
| Mistral 7b | 0.7 | 0.865 | 0.714 | 0.782 | 0.493 |
| GPT-3.5 | 0.664 | 0.862 | 0.661 | 0.799 | 0.397 |
| GPT-3.5 (fine-tuned) | 0.824 | 0.885 | 0.881 | 0.883 | 0.569 |
| XLMR | 0.784 | 0.848 | 0.87 | 0.859 | 0.549 |
| XLMR (fine-tuned) | 0.74 | 0.919 | 0.719 | 0.807 | 0.519 |
emphasizing their strengths and potential areas for improvement. For the final submission, GPT-4 was the model used.
- · Overall performance for Dutch, XLMR (fine-tuned) demonstrated the best F1 scores, for the dev-test data (0.653), with a slight performance decrease for test data (0.611). This model excelled particularly in recall (0.722) compared to the other models. The high recall coupled with reasonable precision (0.597) suggests a balanced approach to maximizing both positive identifications and accuracy of predictions.
- · GPT-4, Mistral 7b, and GPT-3.5 (all three using CoT reasoning) showed weaker performance metrics overall compared to XLMR (fine-tuned). GPT-4, despite GPT-4's lower accuracy and precision in the dev-test (0.577 and 0.580, respectively), showed a significant increase in F1 score on the test data (0.718), which may indicate better generalization under specific conditions. Mistral 7b, on the other hand, displayed lower metrics across the board with particularly low recall (0.310).
- · The XLMR model, while not reaching the heights of its fine-tuned counterpart on the dev-test data, still outperformed the GPT models in most metrics on the dev-test dataset, showing particular strength in recall (0.611) that closely matches its precision (0.603). This balance resulted in robust F1 scores in both the dev-test (0.607) and test (0.694) scenarios, underlining its utility as a reliable model for this task.
- · All the models showed significant performance variances across the datasets. Interestingly, only the XLMR (fine-tuned) exhibited a performance decline from the dev-test to the test dataset, while all other models performed significantly better on the test dataset. Notably, the GPT-3.5 model, fine-tuned on Spanish, Arabic, and Dutch, achieved an F1 score of 0.781 on the test dataset. This score would have placed it at the top of the CheckThat! leaderboard for Dutch, had we submitted these results instead of those from GPT-4.
## 5.3. Arabic
The models evaluated for the Arabic language include GPT-4, Mistral 7b, GPT-3.5, XLMR, and XLMR (fine-tuned). In addition, a fine-tuned English GPT-3.5 model was evaluated, which classifies Arabic- to-English translated data. Table 5 provides a detailed overview of the performance metrics for the 'check-worthy' class, encompassing accuracy, precision, recall, and F1 for the dev-test dataset, as well as the F1 score for the submission test dataset. In addition, we annotated 10% of the test data prior to getting the gold standard, attempting to gain a greater understanding of how the different models might behave for the test data. The most promising model tested on the 10% sample data was the fine-tuned GPT-3.5, which attained an F1 score of 0.848. Consequently, we chose this model for our final submission.
- · GPT-3.5, fine-tuned on English, outperformed the GPT-4 CoT (except for precision), it also outperformed GPT-4 on the 10% annotated sample data. As a result of this, we chose to submit test results from the GPT-3.5 model. However, there was a significant drop in performance on the test data, where the F1 score decreased to 0.569. This indicates a potential issue with the model's ability to generalize from the development environment to more diverse or challenging test scenarios.
- · GPT-4 with CoT training, demonstrated robust performance across most metrics, achieving the highest precision in the dev-test set (0.890) and showcasing strong F1 score (0.871) and recall (0.854). However, it underperformed compared to GPT-3.5 fine-tuned. We see a similar drop in performance on test set, indicating that it is significantly different from dev-test.
- · XLMR showed consistent performance, with particularly great recall (0.870) on the dev-test, translating into an F1 score of 0.859. It attained the second highest F1 score on the standard test dataset (0.549)
- · The XLMR (fine-tuned) also performed well, improving on precision (0.919) significantly compared to XLMR counterpart on the dev-test data, which resulted in an F1 score of 0.807. However, like GPT-4, as for all other models as well, XLMR (fined-tuned) saw a decrease in performance on the test dataset (F1 0.519), which could suggest an overfitting to the dev-test environment or a need for further tuning to enhance its ability to generalize across different data.
## 6. Conclusion and Future Work
This study offers a detailed examination of the 2024 CheckThat! Lab competition, Task 1, focusing on check-worthiness estimation for claims in political debates and Twitter data in English, Dutch, and Arabic. We employ a strategic combination of few-shot chain-of-thought reasoning and languagespecific fine-tuning methods.
Our submissions attained the first place for Arabic with an F1 of 0.569, where we translated the Arabic test data to English, thereafter used a fine-tuned GPT-3.5 for English to classify the translated data. For Dutch, we secured the third-best submission with a F1 of 0.718, using GPT-4 with few-shot chain-of-thought reasoning. Lastly, for the English submission earned us the ninth-best submission with the F1 score of 0.753 using a RoBERTa-Large model, trained on unaltered English training data provided by the competition organizers.
Despite having the best submission for Arabic, we observed a significant drop in performance when comparing the results from the dev-test and the actual submission test dataset. This signals possible challenges such as overfitting and poor generalization across unseen data. These issues would be an important area for future investigations, possibly through more robust model training techniques and exploring additional data augmentation strategies.
## 7. Acknowledgments
This research is funded by SFI MediaFutures partners and the Research Council of Norway (grant number 309339).
## References
| [1] | L. Konstantinovskiy, O. Price, M. Babakar, A. Zubiaga, Toward automated factchecking: Developing an annotation schema and benchmark for consistent automated claim detection, Digital Threats 2 (2021) 1-16. |
|-----------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [2] | N. Hassan, F. Arslan, C. Li, M. Tremayne, Toward automated fact-checking: Detecting check- worthy factual claims by claimbuster, in: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2017, pp. 1803-1812. |
| [3] | F. Alam, S. Shaar, F. Dalvi, H. Sajjad, A. Nikolov, H. Mubarak, G. Da San Martino, A. Abdelali, N. Durrani, K. Darwish, A. Al-Homaid, W. Zaghouani, T. Caselli, G. Danoe, F. Stolk, B. Bruntink, P. Nakov, Fighting the covid-19 infodemic: Modeling the perspective of journalists, fact-checkers, social media platforms, policy makers, and the society, in: Findings of the Association for Computational Linguistics: EMNLP 2021, 2021, pp. 611-649. |
| [4] | A. Barrón-Cedeño, F. Alam, T. Chakraborty, T. Elsayed, P. Nakov, P. Przybyła, J. M. Struß, F. Haouari, M. Hasanain, F. Ruggeri, X. Song, R. Suwaileh, The CLEF-2024 CheckThat! Lab: Check-worthiness, subjectivity, persuasion, roles, authorities, and adversarial robustness, in: Advances in Information Retrieval, 2024, pp. 449-458. |
| [5] | I. Siles, P. J. Boczkowski, Making sense of the newspaper crisis: A critical assessment of existing research and an agenda for future work, New Media & Society 14 (2012) 1375-1394. |
| [6] | S. Vosoughi, D. Roy, S. Aral, The spread of true and false news online, Science 359 (2018) 1146-1151. |
| [7] | H. Allcott, M. Gentzkow, Social media and fake news in the 2016 election, Journal of Economic Perspectives 31 (2017) 211-236. |
| [8] | A. Bovet, H. A. Makse, Influence of fake news in twitter during the 2016 us presidential election, Nature Communications 10 (2019) 7. |
| [9] | T. Pavlov, G. Mirceva, Covid-19 fake news detection by using bert and roberta models, in: 2022 45th jubilee international convention on information, communication and electronic technology (MIPRO), 2022, pp. 312-316. |
| [10] | Z. Guo, M. Schlichtkrull, A. Vlachos, A survey on automated fact-checking, Transactions of the Association for Computational Linguistics 10 (2022) 178-206. |
| [11] | F. Arslan, N. Hassan, C. Li, M. Tremayne, A benchmark dataset of check-worthy factual claims, 2020. |
| [12] | T. Elsayed, P. Nakov, A. Barrón-Cedeño, M. Hasanain, R. Suwaileh, G. D. S. Martino, P. Atanasova, Overview of the clef-2019 checkthat!: Automatic identification and verification of claims, 2019. |
| [13] | A. Gupta, V. Srikumar, X-fact: A new benchmark dataset for multilingual fact checking, in: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), 2021, pp. 675-682. |
| [14] [15] | X. Zeng, A. S. Abumansour, A. Zubiaga, Automated fact-checking: A survey, 2021. P. Nakov, A. Barrón-Cedeño, G. Da San Martino, F. Alam, R. Míguez, T. Caselli, M. Kutlu, W. Za- ghouani, C. Li, S. Shaar, H. Mubarak, A. Nikolov, Y. S. Kartal, J. Beltrán, Overview of the CLEF-2022 CheckThat! lab task 1 on identifying relevant claims in tweets, in: Working Notes of CLEF 2022-Conference and Labs of the Evaluation Forum, 2022. |
| [16] | F. Alam, A. Barrón-Cedeño, G. S. Cheema, G. K. Shahi, S. Hakimov, M. Hasanain, C. Li, R. Míguez, H. Mubarak, W. Zaghouani, P. Nakov, Overview of the clef-2023 checkthat! lab task 1 on check- worthiness of multimodal and multigenre content (2023). |
| [17] | S. K. N. Mingzhe Du, Sujatha Das Gollapalli, NUS-IDS at CheckThat! 2022: identifying check- worthiness of tweets using CheckthaT5, in: N. Faggioli, Guglielmo andd Ferro, A. Hanbury, M. Potthast (Eds.), Working Notes of CLEF 2022 - Conference and Labs of the Evaluation Forum, CLEF 2022, 2022. |
| [18] [19] | L. Xue, N. Constant, A. Roberts, M. Kale, R. Al-Rfou, A. Siddhant, A. Barua, C. Raffel, mt5: A massively multilingual pre-trained text-to-text transformer, 2021. M. Sawinski, K. Węcel, E. Księżniak, M. Stróżyna, W. Lewoniewski, P. Stolarski, W. Abramowicz, |
Openfact at checkthat! 2023: Head-to-head gpt vs. bert - a comparative study of transformers language models for the detection of check-worthy claims, CLEF 2023, 2023.
- [20] M. Abdul-Mageed, A. Elmadany, E. M. B. Nagoudi, Arbert & marbert: Deep bidirectional transformers for arabic, in: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 7088-7105.
- [21] H. T. Sadouk, F. Sebbak, H. E. Zekiri, Es-vrai at checkthat! 2023: Analyzing checkworthiness in multimodal and multigenre contents through fusion and sampling approaches (2023).
- [22] S. Henning, W. Beluch, A. Fraser, A. Friedrich, A survey of methods for addressing class imbalance in deep-learning based natural language processing, in: Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, 2023, pp. 523-540.
- [23] L. Biewald, Experiment tracking with weights and biases}, 2020.
- [24] D. Q. Nguyen, T. Vu, A. Tuan Nguyen, Bertweet: A pre-trained language model for english tweets, in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2020, pp. 9-14.
- [25] T. Kocmi, E. Avramidis, R. Bawden, O. Bojar, A. Dvorkovich, C. Federmann, M. Fishel, M. Freitag, T. Gowda, R. Grundkiewicz, B. Haddow, P. Koehn, B. Marie, C. Monz, M. Morishita, K. Murray, M. Nagata, T. Nakazawa, M. Popel, M. Popović, M. Shmatova, Findings of the 2023 conference on machine translation (WMT23): LLMs are here but not quite there yet, in: Proceedings of the Eighth Conference on Machine Translation, WMT'23, 2023, pp. 1-42.
- [26] OpenAI, J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, R. Avila, I. Babuschkin, S. Balaji, V. Balcom, P. Baltescu, H. Bao, M. Bavarian, J. Belgum, I. Bello, J. Berdine, G. Bernadett-Shapiro, C. Berner, L. Bogdonoff, O. Boiko, M. Boyd, A.-L. Brakman, G. Brockman, T. Brooks, M. Brundage, K. Button, T. Cai, R. Campbell, A. Cann, B. Carey, C. Carlson, R. Carmichael, B. Chan, C. Chang, F. Chantzis, D. Chen, S. Chen, R. Chen, J. Chen, M. Chen, B. Chess, C. Cho, C. Chu, H. W. Chung, D. Cummings, J. Currier, Y. Dai, C. Decareaux, T. Degry, N. Deutsch, D. Deville, A. Dhar, D. Dohan, S. Dowling, S. Dunning, A. Ecoffet, A. Eleti, T. Eloundou, D. Farhi, L. Fedus, N. Felix, S. P. Fishman, J. Forte, I. Fulford, L. Gao, E. Georges, C. Gibson, V. Goel, T. Gogineni, G. Goh, R. Gontijo-Lopes, J. Gordon, M. Grafstein, S. Gray, R. Greene, J. Gross, S. S. Gu, Y. Guo, C. Hallacy, J. Han, J. Harris, Y. He, M. Heaton, J. Heidecke, C. Hesse, A. Hickey, W. Hickey, P. Hoeschele, B. Houghton, K. Hsu, S. Hu, X. Hu, J. Huizinga, S. Jain, S. Jain, J. Jang, A. Jiang, R. Jiang, H. Jin, D. Jin, S. Jomoto, B. Jonn, H. Jun, T. Kaftan, . Kaiser, A. Kamali, I. Kanitscheider, N. S. Keskar, T. Khan, L. Kilpatrick, J. W. Kim, C. Kim, Y. Kim, J. H. Kirchner, J. Kiros, M. Knight, D. Kokotajlo, . Kondraciuk, A. Kondrich, A. Konstantinidis, K. Kosic, G. Krueger, V. Kuo, M. Lampe, I. Lan, T. Lee, J. Leike, J. Leung, D. Levy, C. M. Li, R. Lim, M. Lin, S. Lin, M. Litwin, T. Lopez, R. Lowe, P. Lue, A. Makanju, K. Malfacini, S. Manning, T. Markov, Y. Markovski, B. Martin, K. Mayer, A. Mayne, B. McGrew, S. M. McKinney, C. McLeavey, P. McMillan, J. McNeil, D. Medina, A. Mehta, J. Menick, L. Metz, A. Mishchenko, P. Mishkin, V. Monaco, E. Morikawa, D. Mossing, T. Mu, M. Murati, O. Murk, D. Mély, A. Nair, R. Nakano, R. Nayak, A. Neelakantan, R. Ngo, H. Noh, L. Ouyang, C. O'Keefe, J. Pachocki, A. Paino, J. Palermo, A. Pantuliano, G. Parascandolo, J. Parish, E. Parparita, A. Passos, M. Pavlov, A. Peng, A. Perelman, F. d. A. B. Peres, M. Petrov, H. P. d. O. Pinto, Michael, Pokorny, M. Pokrass, V. H. Pong, T. Powell, A. Power, B. Power, E. Proehl, R. Puri, A. Radford, J. Rae, A. Ramesh, C. Raymond, F. Real, K. Rimbach, C. Ross, B. Rotsted, H. Roussez, N. Ryder, M. Saltarelli, T. Sanders, S. Santurkar, G. Sastry, H. Schmidt, D. Schnurr, J. Schulman, D. Selsam, K. Sheppard, T. Sherbakov, J. Shieh, S. Shoker, P. Shyam, S. Sidor, E. Sigler, M. Simens, J. Sitkin, K. Slama, I. Sohl, B. Sokolowsky, Y. Song, N. Staudacher, F. P. Such, N. Summers, I. Sutskever, J. Tang, N. Tezak, M. B. Thompson, P. Tillet, A. Tootoonchian, E. Tseng, P. Tuggle, N. Turley, J. Tworek, J. F. C. Uribe, A. Vallone, A. Vijayvergiya, C. Voss, C. Wainwright, J. J. Wang, A. Wang, B. Wang, J. Ward, J. Wei, C. J. Weinmann, A. Welihinda, P. Welinder, J. Weng, L. Weng, M. Wiethoff, D. Willner, C. Winter, S. Wolrich, H. Wong, L. Workman, S. Wu, J. Wu, M. Wu, K. Xiao, T. Xu, S. Yoo, K. Yu, Q. Yuan,
- W. Zaremba, R. Zellers, C. Zhang, M. Zhang, S. Zhao, T. Zheng, J. Zhuang, W. Zhuk, B. Zoph, Gpt-4
## technical report, 2024.
- [27] A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, W. E. Sayed, Mistral 7b, 2023.
- [28] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, R. Lowe, Training language models to follow instructions with human feedback, 2022.
- [29] A. Conneau, K. Khandelwal, N. Goyal, V. Chaudhary, G. Wenzek, F. Guzmán, E. Grave, M. Ott, L. Zettlemoyer, V. Stoyanov, Unsupervised cross-lingual representation learning at scale, 2020.
- [30] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, V. Stoyanov, Roberta: A robustly optimized bert pretraining approach, 2019.
- [31] A. J. Becker, Automated fact-checking of podcasts, 2023. | null | [
"Peter Røysland Aarnes",
"Vinay Setty",
"Petra Galuščáková"
] | 2024-08-02T08:59:09+00:00 | 2024-08-02T08:59:09+00:00 | [
"cs.CL"
] | IAI Group at CheckThat! 2024: Transformer Models and Data Augmentation for Checkworthy Claim Detection | This paper describes IAI group's participation for automated check-worthiness
estimation for claims, within the framework of the 2024 CheckThat! Lab "Task 1:
Check-Worthiness Estimation". The task involves the automated detection of
check-worthy claims in English, Dutch, and Arabic political debates and Twitter
data. We utilized various pre-trained generative decoder and encoder
transformer models, employing methods such as few-shot chain-of-thought
reasoning, fine-tuning, data augmentation, and transfer learning from one
language to another. Despite variable success in terms of performance, our
models achieved notable placements on the organizer's leaderboard: ninth-best
in English, third-best in Dutch, and the top placement in Arabic, utilizing
multilingual datasets for enhancing the generalizability of check-worthiness
detection. Despite a significant drop in performance on the unlabeled test
dataset compared to the development test dataset, our findings contribute to
the ongoing efforts in claim detection research, highlighting the challenges
and potential of language-specific adaptations in claim verification systems. |
2408.01119v2 | ## Task Prompt Vectors: Effective Initialization through Multi-Task Soft-Prompt Transfer
## Robert Belanec ♠† , Simon Ostermann , Ivan Srba , Maria Bielikova ‡ † †
♠ Faculty of Information Technology, Brno University of Technology, Brno, Czechia † Kempelen Institute of Intelligent Technologies, Bratislava, Slovakia
{name.surname} @kinit.sk
‡ German Research Institute for Artificial Intelligence (DFKI), Saarland Informatics Campus, Germany [email protected]
## Abstract
Prompt tuning is an efficient solution for training large language models (LLMs). However, current soft-prompt-based methods often sacrifice multi-task modularity , requiring the training process to be fully or partially repeated for each newly added task. While recent work on task vectors applied arithmetic operations on full model weights to achieve the desired multi-task performance, a similar approach for soft-prompts is still missing. To this end, we introduce Task Prompt Vectors , created by element-wise difference between weights of tuned soft-prompts and their random initialization. Experimental results on 12 NLU datasets show that task prompt vectors can be used in low-resource settings to effectively initialize prompt tuning on similar tasks. In addition, we show that task prompt vectors are independent of the random initialization of prompt tuning on 2 different language model architectures. This allows prompt arithmetics with the pre-trained vectors from different tasks. In this way, we provide a competitive alternative to state-ofthe-art baselines by arithmetic addition of task prompt vectors from multiple tasks.
## 1 Introduction
Standard fine-tuning methods change the weights of a pre-trained language model (PLM) to increase its performance on a downstream task. As there is a trend of improving the overall results by increasing the number of parameters, the models require a vast amount of computational resources for training (e.g., GPT-3 (Brown et al., 2020) having 175 billion parameters). Besides their parameter hunger, large language models also require significant amounts of training data, which especially benefits wellresourced languages.
To address the problem of the increasing number of parameters, Parameter-Efficient Fine-Tuning (PEFT) methods (Lester et al., 2021; Houlsby et al., 2019; Hu et al., 2022) were introduced, capable of
Figure 1: An illustration of task prompt vector and the combination via addition that we include in our work. (a) A task prompt vector is created by subtracting the soft-prompt initialization weights θ P pre from the softprompt weights after prompt tuning θ t P ft (Section 3, eq. 2). (b) A combination via the addition of two task prompt τ P a and τ P b resulting in τ P new (Section 3, eq. 4). (c) Different task prompt vectors point into the same sub-space in the embedding space of PLM (Section 4.2). The circles represent different random initializations.
solving multiple problems even with small amounts of labeled data while training only a fraction of the model parameters (e.g., for RoBERTa base (Liu et al., 2019), prompt tuning (Lester et al., 2021) is training only 0.5% parameters, and LoRA (Hu et al., 2022) is training only 0.7% of parameters (Xu et al., 2023)). The key concept that makes such methods effective is their task modularity .
Some of the recent PEFT (Xu et al., 2023; Lester et al., 2021; Asai et al., 2022) methods focus on fine-tuning soft-prompts . Soft-prompts are trainable (parametrized) weights that are prepended to the input embeddings while training the model. Prompt tuning is one such efficient solution for soft-prompt-based tuning of large language models (LLMs).
The most of the soft-prompt-based methods lack sufficient multi-task modularity, requiring the training process to be fully or partially repeated for each newly added task (Vu et al., 2022; Wang et al., 2023). Other methods while keeping their relatively high modularity usually lack robustness and their performance depends on the quality and the number of pre-trained soft-prompts (Asai et al., 2022). Moreover, creating a soft-prompt for multiple tasks may often reduce the overall multi-task performance and require further fine-tuning. Building upon the findings from task vector arithmetics (Ilharco et al., 2022), we utilize the efficiency and modularity of prompt tuning (Lester et al., 2021) to create Task Prompt Vectors . We thoroughly investigate the properties of task prompt vectors and demonstrate their functionality in combining pairs of task prompt vectors while evaluating their in-distribution performance and out-of-distribution performance in full and limited data scenarios.
Our main contributions and findings are 1 :
- · We introduce the novel concept of task prompt vectors created from fine-tuned softprompts, as a method of weight interpolation that leverages findings from task vectors. In addition, we investigate vector arithmetics on such task prompt vectors, based on simple arithmetic operations as a method to reinforce PLMs to solve multi-task problems.
- · We provide a comprehensive investigation of task prompt vector properties on 12 NLU datasets separated into 3 task types and demonstrate important properties of task prompt vectors. We show that their random initialization independence makes them robust and universally applicable, while their similarity across related problems provides a necessary base for efficient cross-task transfer.
- · We show that task prompt vectors allow efficient prompt tuning initializations, by leveraging multi-task combinations of the pretrained task prompt vectors using the task prompt vector arithmetics. Experimental results show that especially in zero- or few-shot settings, task-prompt-vector-based initialization can outperform or match SPoT (SoftPrompt Transfer learning, Vu et al. (2022)) for specific tasks while maintaining high multitask modularity.
## 2 Related Work
Soft-prompt-based fine-tuning. After the introduction of prompt tuning (Lester et al., 2021)
1 To support the replicability of our work, we provide a repository where we store all of our implementation and results: https://github.com/kinit-sk/task-prompt-vectors
and prefix tuning (Li and Liang, 2021) many new soft-prompt-based methods (Gu et al., 2022; Liu et al., 2023; Shi and Lipani, 2024) were introduced. Some of these methods focus on task knowledge transfer (e.g., SPoT (Vu et al., 2022) or cross-model transfer (Su et al., 2022)) and task combinations (e.g., ATTEMPT (Asai et al., 2022), MPT (Wang et al., 2023), or BMTPT (Lee et al., 2023)). These can be classified as works on PEFT weight interpolations to increase the performance of prompt tuning in single or multi-task settings. However, they do not represent the tasks as vectors in the embedding space and usually require further training of the added parameters.
Model weights interpolation. Model weight interpolation (Frankle et al., 2020; Wortsman et al., 2022) is a widely discussed topic in the literature since it enables combining knowledge of different fine-tuned models without or with a small amount of training. Authors of tasks vectors (Ilharco et al., 2022) show, that it is possible to combine multiple task vectors created from fine-tuned models and still maintain the overall multi-task performance. Ortiz-Jimenez et al. (2024) focuses mostly on improving the work on task vectors, by showing that training models in their tangent space contributes to the weight disentanglement and increases the performance of full model task arithmetic. Another subcategory for weight interpolation can be model merging (Stoica et al., 2024; Matena and Raffel, 2022; Li et al., 2022; Davari and Belilovsky, 2023). In the work Ramé et al. (2023), the authors propose a strategy of merging multiple model weights pretrained sets of auxiliary tasks as an initialization to multiple parallel fine-tunings to enhance out-ofdistribution generalization. Most of these works on model weights interpolations usually focus only on the weights of the whole model or particular weights (e.g., classification heads, activation layers) of the pre-trained model.
There are also works on weight interpolation of PEFT methods in general (Zhang et al., 2023; Chronopoulou et al., 2023; Qin et al., 2021; Pfeiffer et al., 2021), but not many of them focus on interpolation using task vectors. In the work Klimaszewski et al. (2024) authors present a way of combining pre-trained adapters using task vector arithmetics, but the method lacks the investigation of the dependency of their method on the random initialization of adapters, therefore it may require training of specific adapters from the same random initialization, which we provide in our work in the context of prompt tuning.
To the best of our knowledge, there is no research on task vectors in the context of soft-promptbased fine-tuning. In this work, we address this drawback by building on the existing knowledge on prompt tuning and task vectors.
## 3 Task Prompt Vectors
Background. Prompt tuning, as introduced in Lester et al. (2021), casts tasks as text generation, modeling a probability Pr Y X ( | ) , where X is a sequence of input tokens and Y is a sequence of output tokens representing the class label. The classification Pr θ ( Y X | ) is then parametrized by the model weights θ . Prompting adds extra information to the classification process by prepending a series of tokens (prompt) P to the input X , such that the model maximizes the probability of getting current Y in Pr θ ( Y | [ P X ; ]) , while keeping the parameters θ frozen. Prompt tuning adds another parameter θ P to the equation, which parametrizes the prompt. During the training, only θ P is updated as the L PT = -∑ i logPr θ,θ P ( Y i | [ P X ; i ]) (1) function is optimized.
As a method of adapting model weights without training, task vectors (Ilharco et al., 2022) compute the difference between pre-trained weights and finetuned weights on a specific task. The task vector is simply defined by the element-wise difference between the pre-trained weights of the whole model and the weights after fine-tuning. Task vectors can be then applied to any model weights θ of the same dimensionality (architecture) by element-wise addition. The representation of task vectors in the weight space of the model has the same properties as standard vectors, therefore it is possible to include them in arithmetic expressions like addition, negation, or combinations via the addition of two or more vectors together. We further build on the findings from Ilharco et al. (2022) and Lester et al. (2021) in the following parts of this section.
Task prompt vector definition. Let T , ..., T 1 t be a set of source tasks and θ P 1 , ..., θ P i be a set of random soft-prompt weights initializations. Intuitively, the random soft-prompt weights initializations are random points in the embedding space of the PLM. We then move each of these points (via prompt tuning) into a task sub-space where the optimization function from the equation 1 returns the (sufficiently) minimal value and we repeat this for each task t ∈ T . These points are further denoted as task prompts - soft-prompts fine-tuned by prompt tuning to a set of downstream tasks. The straight trajectory from the initial point to the task prompt is our task prompt vector (see Figure 1 part a)).
Let θ P pre ∈ R d be the weights of the softprompt randomly initialized from the embedding vocabulary of a PLM, and θ t P ft ∈ R d be the weights of the soft-prompt P fine-tuned on a specific task t , using the standard prompt tuning formula. We formulate the task prompt vector τ P t for soft-prompt P and task as an element-wise difference: τ P t = θ t P ft -θ P pre (2).
Applying a task prompt vector to the softprompt weights of the same size would follow: θ P new = θ P + λθ t P ft (3). Where the rescaling term λ is a number from the same interval 0 < λ ≤ 1 and when λ = 1 , then θ P new = θ t P ft = θ P .
## Vector arithmetics with task prompt vectors.
The task prompt vectors for different tasks can be combined by simple vector addition, combining knowledge from different tasks. When we experiment with combinations, we refer to the arithmetic addition of two task prompt vectors (see Figure 1 part b)): τ P new = τ P a + τ P b (4).
This makes for efficient task adaptation as we perform no further training but only use vector addition in the next sections. Task prompt vector combinations can be also used for initializing a new task that is sufficiently similar to an already trained task. We investigate and discuss these possible use cases for task prompt vectors in upcoming sections.
## 4 Experiments
## 4.1 Experimental Setup and Implementation Details
Weinvestigate the properties of task prompt vectors using the representative foundation T5-base (Raffel et al., 2020) model for all of our experiments and representative open autoregressive LLaMa3.1-8B-Instruct (Dubey et al., 2024) model for origin dependency experiments in Section 4.2. Our investigation covers 3 types of classification problems and 12 corresponding datasets, namely natural language inference -MNLI (Williams et al., 2018), QNLI (Wang et al., 2018), SciTail (Khot et al., 2018), SNLI (Bowman et al., 2015); topic classification -DBPedia (Auer et al., 2007), TREC (Li and Roth, 2002; Hovy et al., 2001), AG News , Yahoo Answers (Zhang et al., 2015); and sentiment classification -SST2 (Socher et al., 2013), Yelp Polarity , SST5 IMDB , (Maas et al., 2011).
For all experimental results, we report F1 macro, if not specified otherwise. The cosine similarity between vectors (task prompts or task prompt vectors) is measured using the flattened weights of each vector (which has a size of 100 × 768 parameters, resulting in a 76800-dimensional vector). We average our zero- and few-shot results across 3 different runs (i.e., different random initializations of soft-prompts) for ATTEMPT and multi-task SPoT baselines (mostly to save more computational resources) and across 10 different runs for all other experiments. To determine the statistical significance of our results we perform a two-sample Student's t-test (Student, 1908) with Bonferroni correction (Dunn, 1959) between the best result and the second best result. If the population sizes differ (e.g. 10 and 3 runs) we use Welch's t-test (Welch, 1947).
For the few-shot experiments (simulating limited labeled data scenarios), we randomly sub-sample from the data for the respective number of shots while keeping the class distribution. We consider shot and sample to be equivalent (i.e., for a 5-shot setting, we choose 5 samples overall, not 5 samples per class). A detailed description of our experimental setup can be found in Appendix A.
## 4.2 Investigating Task Prompt Vectors Properties
In this section, we aim to address the following research question (RQ):
## RQ1: How universally can we apply task prompt vectors to a) different prompt initializations and b) different tasks?
There are two fundamental properties that are crucial for the effectiveness of task prompt vectors: 1) If such vectors should be applied universally, their dependence on the random initialization of prompt tuning should be low, since soft-prompts are usually initialized randomly, unlike PLM for task prompts in Ilharco et al. (2022). 2) The similarity of task prompt vectors between similar tasks should be large, in order to be able to combine task prompt vectors of similar tasks.
To evaluate these properties, we train a set of soft-prompts on specified source tasks for inference classification ( MNLI, QNLI ), topic classification ( DBPedia, TREC ), and sentiment classification ( SST2, Yelp Polarity ), resulting in a set of six soft- prompts that were trained from a single random initialization. We sample 10 random initializations for T5-base model from which we create the task prompt vectors as described in equation 2. For LLaMa-3.1-8B-instruct we sample only 3 random initialization to preserve computational resources. We aggregate by averaging our results across random initializations in Table 1 and Figures 2, 3. We start with the evaluation of whether the task prompt vectors are independent of the random initialization and continue with the experiments to confirm whether the trained task prompts from prompt tuning end up in the same task sub-space of the PLM embedding space. This helps us determine whether the task prompt vectors point in the same space, similar to Figure 1 part c).
The performance of task prompt vectors is independent of the random initialization for the majority of observed tasks. We conduct experiments to evaluate the performance of applying task prompt vectors to different (mixed) random initializations. For each task and each random initialization, we apply the task prompt vector (according to the equation 3) to all of the other random initializations and evaluate performance for each task prompt vector-initialization pair on the test set of the particular dataset. The aggregated results in "Mixed init" rows in Table 1 differ only slightly in most observed tasks for both of the observed models, compared to the results of prompt tuning in the "Original init" rows. This indicates that task prompt vectors perform well irrespective of their initialization. The only exception is in the TREC task, where the performance decreases drastically only for the T5-base model. We suspect that this may be caused by the task being harder for the T5-base model to learn, which also confirms the higher standard deviation from the mean of prompt tuning performance. We can also see that in the case of the LLaMa-3.1-8B-Instruct model, there is no statistically significant difference between using the original initialization or different task prompt vector initialization and for the TREC and SST2 the average results slightly increased.
Task prompts and task prompt vectors maintain good performance even if they do not point to the exact same location in the task subspace. the same task sub-space, we evaluate cosine sim-
To see whether the trained task prompts end up in ilarity across multiple random initializations. We
Table 1: Comparison of exact match results across 10 random soft-prompt initializations for T5-base model and 3 initializations for LLaMa-3.1-8B model. The subscript represents the standard deviation from the average. The first row (Original init) represents the results of prompt tuning. The second row (Mixed init) represents the results of moving a specific initialization in the direction of a task prompt vector created from different (mixed) initializations.
| model | dataset | QNLI | MNLI | TREC | DBpedia | SST2 | Yelp | avg |
|---------|--------------------------|-------------------------|---------------------------|------------------------------|---------------------|---------------------------|---------------------------|-----------------------------|
| T5 | Original init Mixed init | 93 . 3 0 93 . 2 0 . 1 ∗ | 85 . 4 0 . 1 85 . 3 0 . 2 | 95 . 5 1 . 7 26 . 5 18 . 2 ∗ | 99 . 1 0 99 0 . 1 ∗ | 93 . 8 0 . 3 93 . 2 0 . 6 | 97 . 2 0 97 . 1 0 . 1 ∗ | 93 . 8 0 . 4 82 . 4 3 . 2 ∗ |
| LLaMa | Original init Mixed init | 92 . 0 0 92 . 0 0 . 1 | 89 . 7 0 . 2 89 . 7 0 . 2 | 95 . 8 0 . 3 96 . 0 0 . 3 | 99 . 2 0 99 . 2 0 | 95 . 9 0 . 4 96 . 0 0 . 5 | 98 . 6 0 . 1 98 . 6 0 . 1 | 95 . 2 0 . 2 95 . 3 0 . 2 |
Figure 2: Comparison of average cosine similarities of task prompts fine-tuned on different tasks for T5-base model. The average is calculated across all combinations of 10 random initializations (i.e., row QNLI column MNLI was calculated as the average of all cosine similarities between MNLI and QNLI task prompts for all random initialization combinations omitting the combinations where cosine similarity is equal to 1). The diagonal represents the cosine similarities of the same tasks and it represents the maximum value of cosine similarity across different random initializations.
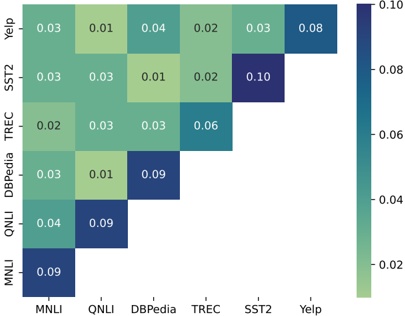
train multiple task prompts for 10 different random initializations and each source task (60 task prompts in total) and compute the cosine similarity from trained task prompts for each combination of random initializations and for each combination of tasks. We then average this cosine similarity for each task combination across all random initialization combinations. If task prompts initialized from different random initializations are pointing to different points in the task sub-space, we should also witness this phenomenon with their corresponding task prompt vectors. Therefore, we repeat this process for task prompt vectors.
Figures 2 and 3 show the comparison of cosine similarities between task prompts and task prompt vectors from different tasks averaged over all random initialization combinations. We can see from
Figure 3: Comparison of average cosine similarities of task prompt vectors . The averages are calculated equivalently to Figure 2 but with task prompt vectors created from different task prompts.
the low cosine similarities in both tables, that the task prompts and task prompt vectors do not end up in the same direction when initialized from different points in the embedding space. The highest cosine similarities on the diagonal represent the highest cosine similarity, which serves as a baseline for comparison with the cross-task cosine similarities. We can see in Table 1 row 1, that the downstream performance of prompt tuning on the source tasks across 10 different random initializations has a low standard deviation from the average. This means that the task prompts after prompt tunings end up in a subspace with sufficient task performance, without necessarily pointing to the same spot in the task subspace. Cosine similarities that we have used to create the aggregated figures can be seen in the Appendix B in Figures 6 and 7. We have also evaluated cosine similarities of task prompt vectors created from 3 different random initializations for LLaMa-3.1-8B-Instruct in Appendix B in Figures 9 and 10.hTask prompt vectors from similar problems are more similar. Additionally, we evaluate the similarity of different
Figure 4: Comparison of relative exact match performance of combinations of task prompt vectors across averaged across 10 different random initializations. The results are relative to the original single-task performance (1 is the performance of single-task prompt tuning).
task prompt vectors across different tasks. Figure 3 shows the cosine similarity between task prompt vectors for different tasks. We can see that certain pairs of tasks are more similar than others, what can be shared properties of these tasks, such as the same number of classes, same labels, or solving the same problem. Problem similarity can be seen in DBPedia-TREC and MNLI-QNLI task prompt vectors, and the similarity in the number of classes can be seen in the MNLI task prompt vector which tends to have higher cosine similarity with task prompt vectors for tasks with more classes (e.g., DBPedia, TREC).
## 4.3 Combination of Task Prompt Vectors via Addition for Multi-Task Transfer
This section addresses the following research question: RQ2: Can we combine multiple task prompt vectors and maintain multi-task performance on the source tasks?
To answer this research question, we investigate the method of combination via addition on 15 task pair combinations from the set of NLU datasets ( MNLI, QNLI, DBPedia, TREC, SST2, Yelp Polarity ). We also evaluate combinations of task prompt vectors in a simulated limited data environment by providing 0 to 100 training examples before evaluation on the test set.
Combinations of task prompt vector pairs maintain single-task performance on specific observed tasks. To evaluate how the combinations of task prompt vectors maintain their single-task performance, we conduct experiments of creating pair combinations from all of the source tasks (according to equation 4). We aggregate the bestperforming combinations in Figure 4. The full results from the experiment can be found in Appendix C in Figure 8. We can see from the results that most of the binary classification tasks retain their single-task performance on both of the tasks, which implies that task prompt vectors can be used for solving multi-task problems. In some cases, the single-task performance was kept only for a single source task, which leads us to the conclusion that certain combinations of task prompt vectors may be more suitable than others.
Additionally, we chose two target tasks for inference classification ( SciTail, SNLI ), topic classification ( AG News, Yahoo Answers ), and sentiment classification ( SST5, IMDB ) and we keep the same set of source tasks. Results for SciTail, AG News and IMDB are in Table 2; the full table with extended experiments is in Appendix D in Table 4.
Task prompt vector combinations can initialize zero-shot and few-shot learning. We compare initialization with randomly initialized softprompt, soft-prompt trained on single and multiple source tasks (this is an equivalent of soft-prompt transfer presented in Vu et al. (2022)), the multitask ATTEMPT (Asai et al., 2022) method, and a combination of task prompt vectors of both of the source tasks. From the 0-shot and 100-shot results (Table 2), we can see that our combination of task prompt vectors can outperform the initialization with a single-task source soft-prompt on SciTail and IMDB datasets and the multi-task source soft-prompt only in the case of SciTail task. In some cases, the combination of task prompt vectors matched the SPoT baseline like in the case of AGNews. This may be because the combination of DBPedia and TREC does not retain much information about TREC, which could benefit the overall result.
We can also see that the ATTEMPT method is significantly underperforming when using a smaller set of pre-trained source soft-prompts. Another observation is that ATTEMPT performs better on the AG News task. This may be caused by using the original implementation of ATTEMPT, where authors, instead of using textual labels (i.e., "entailment", "not entailment"), used textual numbers as labels (i.e., "0", "1"), which made the model predict numbers instead of specific words.
While matching the results of full multi-task soft-
| SciTail (NLI) | SciTail (NLI) | SciTail (NLI) | AG News (Topic) | AG News (Topic) | AG News (Topic) | IMDB (Sentiment) | IMDB (Sentiment) | IMDB (Sentiment) |
|-----------------------|-----------------|-----------------|--------------------------|-------------------|-------------------|-----------------------|--------------------|--------------------|
| Source tasks | F1 | F1 | Source tasks | F1 | F1 | Source tasks | F1 | F1 |
| | 0 shots | 100 shots | Source tasks | 0 shots | 100 shots | Source tasks | 0 shots | 100 shots |
| Random | 54 . 9 6 . 6 | 75 . 6 0 . 5 | Random | 0 0 | 50 . 4 11 . 2 | Random | 77 . 2 9 . 6 | 89 . 4 0 . 4 |
| MNLI (SPoT) | 70 . 4 0 . 4 | 87 . 8 0 . 9 | DBPedia (SPoT) | 0 0 | 83 . 4 0 . 6 ∗ | SST2 (SPoT) | 88 0 . 6 | 90 . 2 0 . 3 |
| QNLI (SPoT) | 57 . 7 13 . 1 | 77 . 7 1 . 3 | TREC (SPoT) | 0 0 | 65 . 7 5 . 6 | Yelp (SPoT) | 90 0 . 3 | 90 . 3 0 . 2 |
| QNLI + MNLI (SPoT) | 70 . 4 1 . 2 | 87 . 7 0 . 6 | DBPedia + TREC (SPoT) | 0 0 | 82 . 1 0 . 9 | SST2 + Yelp (SPoT) | 90 . 8 0 . 2 | 90 . 8 0 . 2 |
| QNLI + MNLI (ATTEMPT) | 63 . 8 4 . 2 | 83 . 6 3 | DBPedia + TREC (ATTEMPT) | 11 . 5 1 . 7 | 20 . 7 2 . 8 | SST2 + Yelp (ATTEMPT) | 79 . 2 6 | 89 . 4 0 . 8 |
| QNLI + MNLI (ours) | 71 . 5 0 . 8 ∗ | 88 . 1 0 . 9 | DBPedia + TREC (ours) | 0 0 | 83 0 . 9 | SST2 + Yelp (ours) | 90 . 1 0 . 5 | 90 . 4 0 . 2 |
Table 2: Test results of training T5-base model with random, single- and multi-task soft-prompt transfer (SPoT), multi-task ATTEMPT, and our task prompt vectors on 0-shot and 100-shots of data. We show the initialization with different combinations for natural language inference classification, topic classification, and sentiment classification. The subscript represents the standard deviation from the average. The best results are bold, while the second-best results are underlined. The * denotes statistical significance.
Figure 5: Test results of training T5-base model with random, single, and multi-task soft-prompt transfer (SPoT), multi-task ATTEMPT, and our task prompt vectors combination on increasing numbers of shots of data. We can see that for SciTail and IMDB tasks, a combination of task prompt vectors outperforms single task transfer.
Table 3: Comparison of multi-task properties for compared methods. Task prompt vectors maintain high task modularity and multi-task performance, and are independent of the quality or number of pre-trained source soft-prompts.
| Method | Modularity | Multi-task performance | Source prompt independence |
|----------------------------------|--------------|--------------------------|------------------------------|
| SPoT ATTEMPT Task Prompt Vectors | ✗ ✓ ✓ | ✓ ✓ ✓ | ✓ ✗ ✓ |
prompt transfer (SPoT) training initialization of prompt tuning using task prompt vector combinations also retains high task modularity, which means that we can add new tasks without the necessity of training. Only in the case of the IMDB task does the SPoT baseline fine-tuned on both datasets perform better. However, it requires the training process to be fully repeated for each new task, resulting in higher computational costs. Table 3 compares attributes beneficial for multi-task training for SPoT, ATTEMPT, and task prompt vector methods. We can see that the SPoT method has low multi-task modularity because we need to retrain the source soft-prompt every time we change the set of source tasks. ATTEMPT, while having sufficient task modularity, depends heavily on the quality and number of source soft-prompts. Task prompt vectors have both of these attributes and also retain sufficient multi-task performance.
## 4.4 Additional Results: Few-Shot Comparison
In this section, we study how increasing the number of demonstration data affects the performance of prompt tuning on a target task initialized by a combination of task prompt vectors of similar source tasks. We keep the same experiment setup as in the previous section and further evaluate the soft-prompt initialization on 5, 10, 25, 100, 250, 500 shots. We also assessed the topic classification tasks for 500 shots since we started with 10 shots due to our sampling method.
From the results in Figure 5, we can see that the performance of the combination of task prompt vectors for SciTail and IMDB target tasks outperforms using a single-task initialization for multiple shots. We can also see that our method outperforms the multi-task initialization for the SciTail dataset across all shots of data.
Comparing the results from Figure 4 and Figure 5, if we choose a combination of tasks that maintains a significant amount of the source task performance (MNLI + QNLI and SST2 + Yelp), the few-shot performance of the task prompt vector combination tend to be higher than single-task transfer. The full results across more shots and more target tasks can be found in Appendix D in Figure 11.
## 5 Discussion
In Section 4.2, we showed that task prompts and their corresponding task prompt vectors are close to orthogonal, by comparing their cosine similarities across multiple initializations in Figures 2 and 3. Despite their near-orthogonality, task prompt vectors created from one initialization and applied to a different one maintain their performance for the majority of the observed tasks.
In Section 4.3, we showed that combinations of certain task prompts maintain their source singletask performance (in Figure 4) and that the combinations of task prompt vectors can be used for initialization of prompt tuning (in Table 2) in simulated low resource setting on the set of target tasks. From the results in Figure 5, we can see that, for the SciTail and IMDB datasets, our task prompt vector initialization maintains its higher performance compared to the single-task soft-prompt transfer even with the higher number of samples.
Theoretical implications and analysis. It lies beyond the scope of our work to further deliver theoretical proofs for diverse properties of task prompt vectors, which we will leave for future work. However, we still discuss the implications that arise from the contributions of task prompt vectors.
Based on the observations from Section 4.2, we can re-use pre-trained task prompt vectors for different tasks and use them in downstream scenarios. Since task prompt vectors are independent of their initialization, we can also re-use pre-trained task prompt vectors shared on the internet (e.g., on a designated vector hub). Another implication that we can derive from these findings is that the subspace with optimal values in the soft-prompt space has probably a convex shape . This may be indicated by the fact that task prompts trained from different random initializations for the same task do not point to the same direction (based on Figures 2 and 3), but still achieve identical results.
Section 4.3 implied that we can use different combinations of task prompt vectors to gain even zero-shot multi-task behavior (in Figure 4). Wecan combine multiple task prompt vectors and maintain multi-task performance on the source tasks, but the right task combinations need to be found (e.g., by evaluating on held-out validation sets). We can see that it is possible to use linear combinations even though the soft-prompts space is non-linear. The rationale behind this could be that task prompt vectors are linear approximations of how the soft-prompts change during the training. Another possibility may be that the task prompt vectors are sparse, and a combination of 2 sparse task prompt vectors creates a vector that contains more information about both tasks. These findings can be further useful for machine unlearning tasks , where one could also include subtraction.
## 6 Conclusion
In our work, we introduce and investigate task prompt vectors as a method of multi-task transfer from prompt tuning. We show that the task prompt vectors are not dependent on random initialization and that the performance across different random initializations does not change significantly in the majority of observed source tasks.We show that in some tasks, the combination via arithmetic addition maintains the single-task performance. Finally, we show that certain combinations of task prompt vectors can be a better option for initialization for certain tasks while maintaining higher multi-task modularity than other methods.
In the future, we would like to evaluate the crossmodel performance of task prompt vectors. We think that further experiments with generation tasks may be another interesting extension. Moreover, task prompt vector arithmetic has the highest potential for improving the unlearning in PLMs by negating the task prompt vectors for the tasks we want to unlearn. Such an option is enabled by introducing task prompt vectors, which would not be possible with the existing state-of-the-art methods.
## Acknowledgements
This work was partially supported by the projects funded by the European Union: DisAI , GA No. 101079164, TAILOR , GA No. 952215; Central European Digital Media Observatory 2.0 (CEDMO
2.0) , Contract No. 101158609; and by the project funded by the Slovak Research and Development Agency: MODERMED , GA No. APVV-22-0414.
This work was supported by the Ministry of Education, Youth and Sports of the Czech Republic through the e-INFRA CZ (ID:90254).
## Limitations
The experiments in our work utilize only classification datasets in the English language with various characteristics (problem type, dataset size, number of classes), mostly because of the large amount of publicly available data covering a variety of NLU problems. At the same time, to direct our focus primarily on the evaluation of task prompt vectors, we utilize only monolingual models in the scope of our work.
Even though there are many other PLMs capable of conditional generation that beat T5 models in performance on various benchmarks, we focus our experiments on the T5-base model as it is commonly used as a representative model in many PEFT methods. We also utilize LLaMa-3.1-8BInstruct model only for the initialization dependency experiments.
Finally, we focus on 3 common NLU problems (natural language inference, topic classification, and sentiment classification) that are commonly incorporated in NLU benchmarks and do not consider other NLU problems (e.g., question answering, slot tagging, acceptability classification, text generation). However, we find that our set of 3 common NLU problems each covering 4 different tasks, is enough to evaluate the properties of task prompt vectors. Including generation tasks would further introduce a problem with the evaluation of the generated text.
## Ethical Considerations and Impact Statement
The experiments in this paper were conducted with publicly available datasets MNLI, QNLI, SciTail, SNLI, DBPedia, TREC, AG News, Yahoo Answers, SST2, Yelp Polarity, SST5, and IMDB, citing the original authors. MNLI, QNLI, and SST2 are part of the GLUE benchmark. As we were not able to determine the license for all used datasets, we have opted to use them as in a limited form as possible, adhering to the terms of use of the GLUE benchmark for all of the mentioned datasets. As the datasets are commonly used in other related works, and were published in scientific works that went through an established review process, we do not check for the presence of any offensive content as it was already removed by the authors of these publicly available datasets. In addition, we do not utilize any personally identifiable information or offensive content and we do not perform crowdsourcing in any form for data annotation. To our knowledge, we are not aware of any potential ethical harms or negative societal impacts of our work, apart from the ones related to the field of Machine Learning (i.e., use of computational resources that are consuming energy and producing heat with indirect CO2 emission production). We follow the license terms for the T5-base model we use - all models and datasets allow their use as part of the research. As we perform conditional generation transform into the classification problem (generating only labels), we minimize the problem of generating offensive or biased content.
Impact Statement: CO2 Emissions Related to Experiments The experiments in this paper require a significant amount of GPU computing resources as we train and evaluate 1 model over multiple random initializations (10) for different methods (4) and datasets (12). Overall the experiments including evaluations (which did not require training, but still used GPU resources for inference) and preliminary experiments (which are not reported in the scope of our work) were conducted using a private infrastructure, which has a carbon efficiency of 0.432 kgCO eq/kWh. 2 Approximately, 1000 hours of computation performed on hardware of type A100 PCIe 40GB (TDP of 250W). Total emissions are estimated to be 105.24 kgCO 2 eq of which 0 percent were directly offset. These estimations were conducted using the CodeCarbon (Courty et al., 2024) python module. Whenever possible we tried to reduce the computational costs. Because our method is built upon the prompt tuning PEFT method, we always trained only a small part of the model parameters (76800 parameters, which is around 0.2% of the T5-base model parameters), and training the model fully will probably require more GPU hours and create more CO2 emissions.
## References
Akari Asai, Mohammadreza Salehi, Matthew Peters, and Hannaneh Hajishirzi. 2022. ATTEMPT: Parameter-efficient multi-task tuning via attentional mixtures of soft prompts. In Proceedings of the
2022 Conference on Empirical Methods in Natural Language Processing , pages 6655-6672, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Sören Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary Ives. 2007. Dbpedia: A nucleus for a web of open data. In The Semantic Web , pages 722-735, Berlin, Heidelberg. Springer Berlin Heidelberg.
Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. 2015. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP) . Association for Computational Linguistics.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems , 33:1877-1901.
Alexandra Chronopoulou, Jonas Pfeiffer, Joshua Maynez, Xinyi Wang, Sebastian Ruder, and Priyanka Agrawal. 2023. Language and task arithmetic with parameter-efficient layers for zero-shot summarization. arXiv preprint arXiv:2311.09344 .
Benoit Courty, Victor Schmidt, Sasha Luccioni, GoyalKamal, MarionCoutarel, Boris Feld, Jérémy Lecourt, LiamConnell, Amine Saboni, Inimaz, supatomic, Mathilde Léval, Luis Blanche, Alexis Cruveiller, ouminasara, Franklin Zhao, Aditya Joshi, Alexis Bogroff, Hugues de Lavoreille, Niko Laskaris, Edoardo Abati, Douglas Blank, Ziyao Wang, Armin Catovic, Marc Alencon, Michał St˛ echły, Christian Bauer, Lucas-Otavio, JPW, and MinervaBooks. 2024. mlco2/codecarbon: v2.4.1.
MohammadReza Davari and Eugene Belilovsky. 2023. Model Breadcrumbs: Scaling Multi-Task Model Merging with Sparse Masks. ArXiv:2312.06795 [cs].
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 .
Olive Jean Dunn. 1959. Confidence intervals for the means of dependent, normally distributed variables. Journal of the American Statistical Association , 54(287):613-621.
Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. 2020. Linear mode connectivity and the lottery ticket hypothesis. In International Conference on Machine Learning , pages 3259-3269. PMLR.
Yuxian Gu, Xu Han, Zhiyuan Liu, and Minlie Huang. 2022. PPT: Pre-trained prompt tuning for few-shot learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 8410-8423, Dublin, Ireland. Association for Computational Linguistics.
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International conference on machine learning , pages 2790-2799. PMLR.
Eduard Hovy, Laurie Gerber, Ulf Hermjakob, ChinYew Lin, and Deepak Ravichandran. 2001. Toward semantics-based answer pinpointing. In Proceedings of the First International Conference on Human Language Technology Research .
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan AllenZhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations .
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. 2022. Editing models with task arithmetic. In The Eleventh International Conference on Learning Representations .
Tushar Khot, Ashish Sabharwal, and Peter Clark. 2018. Scitail: A textual entailment dataset from science question answering. In AAAI Conference on Artificial Intelligence .
Mateusz Klimaszewski, Piotr Andruszkiewicz, and Alexandra Birch. 2024. No train but gain: Language arithmetic for training-free language adapters enhancement. arXiv preprint arXiv:2404.15737 .
Haeju Lee, Minchan Jeong, Se-Young Yun, and KeeEung Kim. 2023. Bayesian multi-task transfer learning for soft prompt tuning. In Findings of the Association for Computational Linguistics: EMNLP 2023 , pages 4942-4958, Singapore. Association for Computational Linguistics.
Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages 3045-3059, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Quentin Lhoest, Albert Villanova del Moral, Yacine Jernite, Abhishek Thakur, Patrick von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, Joe Davison, Mario Šaško, Gunjan Chhablani, Bhavitvya Malik, Simon Brandeis, Teven Le Scao, Victor Sanh, Canwen Xu, Nicolas Patry, Angelina McMillan-Major, Philipp Schmid, Sylvain Gugger, Clément Delangue, Théo Matussière, Lysandre Debut, Stas Bekman, Pierric Cistac, Thibault Goehringer, Victor Mustar, François
Lagunas, Alexander Rush, and Thomas Wolf. 2021. Datasets: A community library for natural language processing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages 175-184, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Margaret Li, Suchin Gururangan, Tim Dettmers, Mike Lewis, Tim Althoff, Noah A. Smith, and Luke Zettlemoyer. 2022. Branch-Train-Merge: Embarrassingly Parallel Training of Expert Language Models. ArXiv:2208.03306 [cs].
Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages 45824597, Online. Association for Computational Linguistics.
Xin Li and Dan Roth. 2002. Learning question classifiers. In COLING 2002: The 19th International Conference on Computational Linguistics .
Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2023. Gpt understands, too. AI Open .
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 .
Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. In International Conference on Learning Representations .
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages 142-150, Portland, Oregon, USA. Association for Computational Linguistics.
Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. 2022. Peft: State-of-the-art parameterefficient fine-tuning methods. https://github. com/huggingface/peft .
Michael Matena and Colin Raffel. 2022. Merging Models with Fisher-Weighted Averaging. ArXiv:2111.09832 [cs].
Guillermo Ortiz-Jimenez, Alessandro Favero, and Pascal Frossard. 2024. Task arithmetic in the tangent space: Improved editing of pre-trained models. Advances in Neural Information Processing Systems , 36.
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems , 32.
Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. 2021. AdapterFusion: Non-destructive task composition for transfer learning. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages 487-503, Online. Association for Computational Linguistics.
Yujia Qin, Xiaozhi Wang, Yusheng Su, Yankai Lin, Ning Ding, Jing Yi, Weize Chen, Zhiyuan Liu, Juanzi Li, Lei Hou, et al. 2021. Exploring universal intrinsic task subspace via prompt tuning. arXiv preprint arXiv:2110.07867 .
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research , 21(140):1-67.
Alexandre Ramé, Kartik Ahuja, Jianyu Zhang, Matthieu Cord, Léon Bottou, and David Lopez-Paz. 2023. Model ratatouille: Recycling diverse models for outof-distribution generalization. In International Conference on Machine Learning , pages 28656-28679. PMLR.
Zhengxiang Shi and Aldo Lipani. 2024. DePT: Decomposed prompt tuning for parameter-efficient finetuning. In The Twelfth International Conference on Learning Representations .
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing , pages 1631-1642.
George Stoica, Daniel Bolya, Jakob Bjorner, Pratik Ramesh, Taylor Hearn, and Judy Hoffman. 2024. ZipIt! Merging Models from Different Tasks without Training. ArXiv:2305.03053 [cs].
Student. 1908. The probable error of a mean. Biometrika , pages 1-25.
Yusheng Su, Xiaozhi Wang, Yujia Qin, Chi-Min Chan, Yankai Lin, Huadong Wang, Kaiyue Wen, Zhiyuan Liu, Peng Li, Juanzi Li, Lei Hou, Maosong Sun, and Jie Zhou. 2022. On transferability of prompt tuning for natural language processing. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 3949-3969,
Seattle, United States. Association for Computational Linguistics.
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. 2020. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl .
Tu Vu, Brian Lester, Noah Constant, Rami Al-Rfou', and Daniel Cer. 2022. SPoT: Better frozen model adaptation through soft prompt transfer. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 5039-5059, Dublin, Ireland. Association for Computational Linguistics.
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. GLUE: Amulti-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP , pages 353-355, Brussels, Belgium. Association for Computational Linguistics.
Zhen Wang, Rameswar Panda, Leonid Karlinsky, Rogerio Feris, Huan Sun, and Yoon Kim. 2023. Multitask prompt tuning enables parameter-efficient transfer learning. In The Eleventh International Conference on Learning Representations .
Bernard L Welch. 1947. The generalization of 'student's'problem when several different population varlances are involved. Biometrika , 34(1-2):28-35.
Adina Williams, Nikita Nangia, and Samuel Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages 1112-1122, New Orleans, Louisiana. Association for Computational Linguistics.
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages 38-45, Online. Association for Computational Linguistics.
Mitchell Wortsman, Gabriel Ilharco, Jong Wook Kim, Mike Li, Simon Kornblith, Rebecca Roelofs, Raphael Gontijo Lopes, Hannaneh Hajishirzi, Ali Farhadi, Hongseok Namkoong, et al. 2022. Robust fine-tuning of zero-shot models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 7959-7971.
Lingling Xu, Haoran Xie, Si-Zhao Joe Qin, Xiaohui Tao, and Fu Lee Wang. 2023. Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment. arXiv preprint arXiv:2312.12148 .
Jinghan Zhang, Junteng Liu, Junxian He, et al. 2023. Composing parameter-efficient modules with arithmetic operation. Advances in Neural Information Processing Systems , 36:12589-12610.
Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. Advances in neural information processing systems , 28.
## A Experimental setup: Further Details
Implementation details. For implementing all of our experiments, we utilize Python 3.11.8 with the PyTorch (Paszke et al., 2019) framework and Huggingface modules ( transformers (Wolf et al., 2020) for model loading and training, peft (Mangrulkar et al., 2022) for PEFT methods initialization, datasets (Lhoest et al., 2021) for data loading, and evaluate for evaluation). We create a single data structure for task prompt vectors, that is capable of the arithmetic operations with soft-prompts.
Data splits. We take 1000 samples from the train set and use it as a validation set and make the test set from the original validation set for datasets that contain over 10000 samples. For datasets with less or equal to 10000 samples we do not modify the training set, and split the validation set in 2 halves for validation and test sets. We keep the same random seed for subsampling and splitting for all of our experiments.
Hyperparamters setings. We provide all of our configurations in the config directory of our repository. We set soft-prompt length to 100 tokens, learning rate to 0.3, and lower the weight decay of the AdamW optimizer (Loshchilov and Hutter, 2019) to 1 × 10 -5 for T5-base model. We also utilize the Seq2SeqTrainer class from the Huggingface transformers Python module. We train all models on all data sets for 10 epochs, except for TREC, where we train for 50 epochs due to the tendency of models to underfit here. We set different hyperparameters for prompt tuning and the hyperparameters for zeroor few-shot evaluation do not differ much from the hyperparameters for prompt tuning. We train for 1000 update steps while keeping a batch size of 2 for 5, 10, 25 shots, 8 for 50, 100, 250 shots, and 16 for 500, 750, 1000 shots. In general, we chose the maximum token length for labels by searching the dataset for the maximum token length (in our configs, we set default max\_target\_lenght to 128 if the dataset requires to generate sentences), for the inputs we pad the token sequences to 256 tokens with the max\_target\_lenght parameter. We use a learning rate of 0.3 for the AdamW optimizer, with weight decay of 1 × 10 -5 and 500 warmup steps for 10 epochs (with an exception for the TREC dataset) with the batch size of 32. We evaluate, log and save after each 100 training steps and keep only the best model at the end of the training. In our configs, we set a number of tokens to 50, but in reality, Hugging Face peft library doubles the number for encoder-decoder models like T5. When combining task prompt vectors, we evaluate their performance on the individual source tasks that formed the task combination and found the best rescaling factor λ via held-out validation sets.
For training the soft-prompts with the LLaMa3.1-8B-Instruct model we utilized similar hyperparameter settings as for the T5-base model with the exception of using the cosine function for the learning rate scheduler and the usage of the SFTTrainer class from the Huggingface trl Python module (von Werra et al., 2020) for training.
Since we are utilizing the T5-base for conditional generation, we are computing exact match instead of accuracy for classification. Because we are generating labels also for classification tasks, the exact match is equivalent to accuracy in the sequence classification task. In the scope of our work, we refer to a single dataset as a task.
For the training of multi-task ATTEMPT, we have used hyperparameters and a training environment based on the original implementation. Full hyperparameter settings can be found in the repository 2 of our replication study of ATTEMPT in the configs directory (files attempt\_tvp*.toml ).
## B Additional results: Task Prompt Vectors and Task Prompt Cosine Similarities
In this section, we provide more detailed and deaggregated results from Section 4.2. Figure 6 shows the comparison of cosine similarities across different random initializations of task prompts from prompt tuning. We can see that for all task combinations, the highest cosine similarity is for the equal random initializations. Additionally, when comparing different tasks and different random initializations the cosine similarities are the lowest, which only confirms our finding from Section 4.2.
We repeat the same process of comparing cosine similarities across different random initializations for task prompt vectors in Figure 7. Similarly to task prompts, the highest cosine similarity is for the equal random initializations. We can see that for task prompt vectors the cosine similarities between different random initializations are higher than compared to task prompts in Figure 6. Similarly to our findings in 4.2, we can that certain task combinations have higher cosine similarities than others. For both of these figures, we can see that task prompts and task prompt vectors from different initializations usually end up at different points in the task sub-space.

9
0.04
0.04
0.03
0.03
0.04
0.03
0.04
0.03
0.04
0.53
9
0.04
0.03
0.04
0.03
0.03
0.03
0.02
0.03
0.04
0.54
9
0.01
0.02
0.02
0.02
0.02
0.01
0.01
0.03
0.01
0.16
3 4 5 6 7 8 QNLI 0.04 0.04 0.04 0.54 0.04 0.03 0.04 0.03 0.03 0.04 0.04 0.03 0.04 0.03 0.54 0.04 0.03 0.04 0.04 0.04 0.04 0.03 0.04 0.03 0.03 0.59 0.04 0.04 0.03 0.04 0.03 0.03 0.03 0.04 0.04 0.04 0.55 0.03 0.03 0.04 0.04 0.04 0.03 0.03 0.04 0.04 0.04 0.58 0.04 0.04 0.04 0.04 0.03 0.03 0.03 0.03 0.03 0.03 0.51 0.04 3 4 5 6 7 8 QNLI 0.03 0.03 0.03 0.54 0.04 0.03 0.03 0.03 0.03 0.03 0.03 0.03 0.04 0.03 0.52 0.03 0.03 0.04 0.03 0.03 0.04 0.04 0.04 0.03 0.03 0.58 0.04 0.04 0.03 0.03 0.03 0.03 0.03 0.04 0.03 0.04 0.59 0.03 0.04 0.03 0.03 0.02 0.03 0.03 0.03 0.03 0.03 0.53 0.03 0.03 0.04 0.03 0.03 0.03 0.03 0.03 0.04 0.03 0.55 0.04 3 4 5 6 7 8 QNLI 0.01 0.02 0.02 0.18 0.02 0.02 0.02 0.02 0.01 0.02 0.02 0.02 0.01 0.02 0.17 0.02 0.02 0.03 0.01 0.02 0.02 0.02 0.01 0.01 0.02 0.19 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.01 0.02 0.18 0.02 0.02 0.02 0.03 0.02 0.02 0.03 0.02 0.02 0.02 0.19 0.02 0.03 0.01 0.03 0.02 0.01 0.03 0.02 0.02 0.02 0.16 0.02 0.2 0.3 0.4 0.5 0.2 0.3 0.4 0.5 0.075 0.100 0.125 0.150 0.175 Figure 6: Comparisons of cosine similarities of task prompts fine-tuned on different tasks for T5-base model. Each heatmap represents a different task combination. We calculate the cosine similarities for all combinations of 10 random initializations omitting the combinations of random initializations where cosine similarity is equal to 1 (single-task comparisons). Each heatmap is represented as a single field in Figure 2 by averaging all values. The x and y axes represent the number of random initializations.
2
0.04
0.03
0.56
0.03
0.03
0.04
0.04
0.04
0.03
0.04
2
0.03
0.03
0.54
0.03
0.03
0.04
0.04
0.04
0.03
0.04
2
0.02
0.02
0.18
0.02
0.02
0.02
0.02
0.02
0.02
0.02
0.050
1
0
9
8
7
6
5
4
3
2
1
9
8
7
0.03
0.52
0
0.06
0.06
0.07
0.07
0.07
0.06
0.06
0.07
0.07
0
0.07
0.04
0.05
0.55
0.04
1
0.05
0.06
0.06
0.06
0.06
0.06
0.06
0.09
1
0.05
0.05
0.05
0.04
0.04
2
0.06
0.06
0.06
0.06
0.06
0.06
0.05
2
0.05
0.05
0.05
0.03
0.03
3
0.07
0.06
0.08
0.06
0.05
0.06
3
0.05
0.05
0.07
0.04
0.04
4
0.03
0.04
5
SST2
0.06
0.07
0.06
0.06
0.06
4
SST2
0.06
0.06
0.06
0.03
0.03
6
0.06
0.06
0.07
0.07
5
0.05
0.06
0.06
0.03
0.04
7
0.07
0.06
0.07
6
0.05
0.05
0.05
0.03
0.04
8
0.07
0.06
7
0.05
0.05
0.04
0.04
9
0.11
8
0.06
0.1
0.11
0.10
0.09
0.08
0.07
0.06
0.05
0.065
0.060
1
0
9
8
7
6
5
4
3
2
1
0
9
8
7
0.03
0.52
0
0.04
0.03
0.03
0.03
0.03
0.03
0.02
0.03
0.03
0.60
0
0.02
0.01
0.03
0.55
0.03
1
0.03
0.03
0.03
0.02
0.03
0.03
0.02
0.03
0.56
0.03
1
0.02
0.03
0.03
0.03
0.03
2
0.03
0.03
0.02
0.04
0.03
0.03
0.03
0.61
0.02
0.03
2
0.02
0.02
0.03
0.03
0.02
3
0.03
0.02
0.03
0.03
0.02
0.03
0.59
0.03
0.03
0.03
3
0.02
0.02
0.02
0.03
0.04
4
0.03
0.04
5
TREC
0.03
0.03
0.03
0.02
0.03
0.03
0.59
0.03
0.03
0.02
0.03
4
0.02
0.04
0.04
0.59
0.03
0.02
0.03
0.02
0.04
5
TREC
0.02
0.01
0.02
0.02
0.02
0.03
0.02
0.03
6
0.03
0.03
0.03
0.58
0.04
0.03
0.03
0.03
0.02
0.03
6
0.01
0.02
0.02
0.04
0.04
7
0.03
0.03
0.57
0.03
0.03
0.03
0.03
0.03
0.03
0.03
7
0.03
0.02
0.19
0.03
0.03
8
0.04
0.57
0.02
0.03
0.03
0.02
0.03
0.03
0.03
0.03
8
0.03
0.20
0.01
0.04
0.04
9
0.58
0.04
0.03
0.03
0.02
0.03
0.03
0.03
0.04
0.04
9
0.18
0.03
0.02
0.1
0.6
0.5
0.4
0.3
0.2
0.1
0.200
0.175
0.150
1
0
9
8
7
6
5
4
3
2
1
0
9
8
7
0.01
0.17
0
0.03
0.03
0.04
0.04
0.02
0.03
0.03
0.03
0.03
0.22
0
0.11
0.08
0.07
0.18
0.02
1
0.03
0.03
0.03
0.04
0.02
0.04
0.03
0.02
0.21
0.02
1
0.08
0.10
0.09
0.02
0.02
2
0.03
0.03
0.03
0.04
0.03
0.03
0.03
0.22
0.03
0.04
2
0.10
0.09
0.09
0.02
0.01
3
0.02
0.03
0.03
0.03
0.03
0.02
0.21
0.03
0.03
0.03
3
0.08
0.07
0.09
0.02
0.02
4
0.03
0.04
0.02
0.03
0.02
0.20
0.03
0.02
0.03
0.03
4
0.01
0.02
5
0.02
0.03
0.03
0.04
0.23
0.02
0.03
0.03
0.03
0.04
5
0.02
0.01
6
0.02
0.03
0.03
0.21
0.04
0.03
0.02
0.02
0.03
0.02
6
0.09
0.10
0.09
0.02
0.02
7
0.03
0.03
0.22
0.03
0.03
0.03
0.03
0.03
0.03
0.03
7
0.10
0.08
0.07
0.02
0.02
8
0.04
0.20
0.03
0.04
0.03
0.03
0.03
0.03
0.03
0.03
8
0.06
0.09
0.01
0.02
9
0.19
0.03
0.03
0.03
0.03
0.02
0.03
0.02
0.03
0.03
9
0.06
SST2
SST2
SST2
Yelp
Yelp
0.10
0.09
0.08
0.025
0.225
0.200
0.175
0.150
0.125
0.100
0.075
0.050
0.025
0.11
MNLI
5
4
3
2
1
0
0.03
0.03
0.03
0.02
0.03
0.24
0
0.02
0.03
0.03
0.03
0.23
0.02
1
0.03
0.03
0.02
0.34
0.02
0.02
2
0.03
0.03
0.25
0.02
0.03
0.03
3
0.03
0.25
0.02
0.02
0.02
0.03
4
0.26
0.03
0.03
0.03
0.02
0.03
5
0.03
0.01
0.03
0.02
0.03
0.03
6
0.03
0.04
0.02
0.03
0.03
0.03
7
0.02
0.02
0.03
0.03
0.02
0.03
8
0.02
0.03
0.03
0.03
0.02
0.03
9
0.03
0.03
0.03
0.02
0.03
0.10
0
0.03
0.04
0.04
0.02
0.10
0.03
1
0.03
0.03
0.03
0.13
0.04
0.04
2
0.03
0.03
0.10
0.03
0.03
0.04
3
0.03
0.10
0.02
0.03
0.04
0.02
4
0.10
0.03
0.03
0.02
0.03
0.03
5
0.02
0.02
0.03
0.01
0.02
0.03
6
0.03
0.03
0.03
0.02
0.03
0.03
7
0.03
0.03
0.03
0.02
0.03
0.03
8
0.03
0.03
0.04
0.03
0.02
0.03
9
0.06
0.07
0.07
0.07
0.08
0.06
0
0.08
0.06
0.08
0.08
0.07
1
0.07
0.07
0.08
0.08
2
0.08
0.07
0.08
3
0.07
0.07
4
0.06
5
6
7
8
TREC
Yelp
QNLI
Figure 6 (cont.): Continuation of Figure 6 for additional tasks.

## C Additional results: Combinations of Task Prompt Vectors
This section provides extended experiments to the results in Figure 4 in Section 4.3. Figure 8 shows the relative performance of all task combinations of task prompt vectors. Usually, tasks that solve the same NLU problem retain the most source task performance on both tasks except for the combination of DBPedia and TREC task prompt vectors, where the TREC performance is lower. In general, the performance of combinations with the TREC usually ends up in favor of the other task from the task pair.
Figure 11 extends the comparison in Figure 5 in Section 4.4 and shows how the performance on different initializations differs across all observed shots of data and on additional SNLI, Yahoo Answers, and SST5 target tasks. We can see that in the case of the SST5 task, the SST2 initialization performs the best. We think that the reason for this may also be the similarity of SST5 and SST2 and that the combination of source tasks does not retain enough information to match the SST5 baseline.
## D Additional results: Few-Shot Experiments
Here we provide extended results of zero- and fewshot experiments on additional target tasks that extend the results from Section 4.3. Table 4 extends the comparison of 0- and 100-shot results with SNLI, Yahoo Answers, and SST5 tasks. We can see that combinations of source task prompt vectors do not outperform the SPoT baseline in these specific tasks, but rather almost match the results.
0.20
0.15
0.10
0.05
MNLI
5
4
3
2
1
0
0.08
0.06
0.04
0.02
QNLI
6
5
4
3
2
1
0.070
0.065
0.060
0.030
9
0.03
0.03
0.03
0.03
0.03
0.02
0.03
0.02
0.02
0.05
9
0.02
0.02
0.03
0.01
0.01
0.02
0.00
0.02
0.01
0.08
9
-0.00
0.02
0.01
0.02
0.01
0.01
0.01
0.02
-0.00
0.02
0.055
2 3 4 5 6 7 8 QNLI 0.03 0.03 0.05 0.03 0.03 0.03 0.02 0.03 0.02 0.03 0.04 0.04 0.04 0.05 0.03 0.03 0.03 0.03 0.03 0.03 0.04 0.03 0.02 0.03 0.05 0.03 0.02 0.04 0.04 0.02 0.02 0.03 0.02 0.02 0.02 0.04 0.02 0.02 0.02 0.02 0.03 0.02 0.02 0.03 0.04 0.02 0.05 0.03 0.02 0.02 0.03 0.04 0.03 0.03 0.04 0.03 0.03 0.06 0.04 0.03 0.03 0.03 0.02 0.01 0.03 0.02 0.02 0.02 0.04 0.02 2 3 4 5 6 7 8 QNLI 0.02 0.01 0.09 0.02 0.02 0.03 0.02 0.03 0.01 0.03 0.01 0.02 0.02 0.08 0.02 0.03 0.02 0.02 0.02 0.01 0.02 0.02 0.02 0.01 0.09 0.01 -0.00 0.03 0.01 0.01 0.02 0.04 0.03 0.02 0.01 0.12 0.02 0.03 0.02 0.02 0.02 0.02 0.01 0.03 0.02 0.02 0.12 0.02 0.02 0.02 -0.00 0.00 0.02 0.02 0.02 0.02 0.02 0.08 0.02 0.01 0.03 0.01 0.02 0.02 0.02 0.03 0.02 0.02 0.11 0.02 2 3 4 5 6 7 8 QNLI 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.01 0.01 0.01 0.01 0.01 0.01 0.02 0.01 0.01 0.01 0.02 0.01 0.01 0.02 0.00 0.00 0.01 0.02 0.01 0.01 0.02 0.00 0.02 0.01 0.01 0.00 0.00 0.00 0.03 0.00 0.01 0.01 0.00 0.01 0.01 0.01 0.01 0.00 0.01 0.01 0.01 0.00 0.01 0.02 0.02 0.00 0.03 0.01 0.01 0.01 0.03 0.02 0.02 0.00 0.02 0.01 0.01 0.02 0.01 0.01 0.01 0.02 0.02 0.025 0.030 0.035 0.040 0.045 0.050 0.02 0.04 0.06 0.08 0.10 0.005 0.010 0.015 0.020 0.025 Figure 7: Comparisons of average cosine similarities of task prompt vectors for T5-base model. The averages are calculated similarly to Figure 6 but with task prompt vectors created from different task prompts. Each heatmap represents a different task combination. We calculate the cosine similarities for all combinations of 10 random initializations omitting the combinations of random initializations where cosine similarity is equal to 1 (single-task comparisons). Each heatmap is represented as a single field in Figure 3 by averaging all values. The x and y axes represent the number of random initializations.
1
1
1
0.000
0.06
0.05
0.04
0.03
0.02
0.11
0.10
0.020
0
9
8
7
6
5
4
3
2
1
9
8
7
6
0.02
0.05
0
0.07
0.07
0.12
0.11
0.11
0.09
0.09
0.12
0.12
0
0.07
0.03
0.06
0.05
0.03
1
0.07
0.08
0.10
0.10
0.09
0.08
0.08
0.17
1
0.04
0.05
0.05
0.03
0.03
2
0.09
0.09
0.10
0.09
0.11
0.09
0.08
2
0.04
0.06
0.05
0.02
0.03
3
0.11
0.10
0.16
0.09
0.08
0.08
3
0.06
0.05
0.10
0.02
0.04
4
0.02
0.03
5
SST2
0.09
0.12
0.10
0.10
0.10
4
SST2
0.06
0.07
0.07
0.02
0.03
6
0.08
0.08
0.10
0.10
5
0.06
0.07
0.05
0.02
0.04
7
0.10
0.10
0.11
6
0.05
0.05
0.07
0.02
0.03
8
0.12
0.10
7
0.06
0.05
0.02
0.03
9
0.19
8
0.05
0
9
8
7
6
5
4
3
2
1
0
9
8
7
6
0.02
0.08
0
0.02
0.01
0.00
0.01
0.02
0.00
0.01
0.01
0.02
0.06
0
0.01
0.00
0.02
0.01
0.07
0.02
1
0.01
0.01
0.02
0.01
0.02
0.01
0.01
0.02
0.06
0.01
1
0.01
0.02
0.02
0.01
0.01
0.02
2
0.02
0.01
0.01
0.02
0.02
0.01
0.01
0.05
0.01
0.01
2
0.02
0.02
0.02
0.02
0.02
0.01
3
0.01
0.00
0.01
0.02
0.02
0.02
0.04
0.01
0.01
0.01
3
0.02
0.02
0.02
0.02
0.01
0.02
4
0.01
0.02
5
TREC
0.01
0.02
0.02
-0.00
0.02
0.01
0.07
0.01
0.00
0.00
0.00
4
0.01
0.02
0.02
0.06
0.01
0.01
0.01
0.01
0.02
5
TREC
0.01
0.00
0.01
0.02
0.02
0.02
0.02
0.01
0.01
0.01
6
0.00
0.01
0.02
0.05
0.01
0.02
0.01
0.01
0.01
0.02
6
0.01
0.01
0.02
0.03
0.02
0.03
7
0.02
0.01
0.06
0.02
0.01
0.01
0.02
0.02
0.01
0.02
7
0.02
0.00
0.05
0.02
0.01
0.01
8
0.01
0.05
0.01
0.01
0.01
-0.00
0.01
-0.00
0.01
0.01
8
0.02
0.04
0.01
0.01
0.01
0.02
9
0.05
0.02
0.01
0.02
0.01
0.02
0.01
0.01
0.01
0.01
9
0.03
0.02
0.01
0.02
0
9
8
7
6
5
4
3
2
1
0
9
8
7
6
0.01
0.02
0
0.02
0.03
0.04
0.04
0.02
0.03
0.03
0.02
0.04
0.07
0
0.11
0.07
0.07
0.02
0.02
1
0.02
0.03
0.02
0.03
0.02
0.03
0.02
0.03
0.06
0.02
1
0.07
0.09
0.09
0.01
0.01
2
0.03
0.03
0.02
0.03
0.04
0.03
0.02
0.05
0.03
0.04
2
0.10
0.09
0.08
0.00
0.01
3
0.02
0.03
0.04
0.03
0.02
0.02
0.05
0.03
0.03
0.04
3
0.08
0.07
0.09
0.01
0.01
4
0.02
0.04
0.02
0.03
0.02
0.04
0.03
0.02
0.03
0.02
4
0.00
0.02
5
0.02
0.02
0.03
0.04
0.07
0.01
0.03
0.03
0.02
0.04
5
0.01
-0.00
6
0.03
0.03
0.03
0.05
0.04
0.03
0.02
0.03
0.03
0.02
6
0.08
0.10
0.09
0.01
0.01
7
0.02
0.03
0.05
0.03
0.03
0.02
0.03
0.02
0.02
0.03
7
0.10
0.08
0.07
0.00
0.01
8
0.04
0.05
0.04
0.04
0.04
0.03
0.03
0.03
0.02
0.03
8
0.06
0.09
-0.00
0.00
9
0.03
0.03
0.03
0.03
0.02
0.01
0.03
0.02
0.03
0.02
9
0.06
SST2
0.015
0.18
0.16
0.14
0.12
0.10
0.08
0.09
0.08
SST2
0.00
0.06
0.05
0.04
0.03
0.02
0.01
0.00
0.04
SST2
Yelp
Yelp
0.10
0.09
0.08
MNLI
8
7
6
5
4
3
2
1
0
0.02
0.02
0.01
0.02
0.02
0.02
0.00
0.02
0.07
0
0.01
0.03
0.01
0.02
0.03
0.02
0.02
0.08
0.01
1
0.02
0.02
0.00
0.02
0.02
0.01
0.09
0.01
0.02
2
0.02
0.02
0.02
0.02
0.02
0.07
0.01
0.02
0.03
3
0.02
0.01
0.01
0.01
0.07
0.02
0.01
0.01
0.01
4
0.01
0.03
0.01
0.09
0.02
0.02
0.02
0.02
0.02
5
0.02
0.01
0.10
0.02
0.00
0.02
0.02
0.02
0.02
6
0.03
0.09
0.02
0.03
0.04
0.02
0.02
0.02
0.03
7
0.10
0.02
0.01
0.01
0.01
0.02
0.02
0.01
0.01
8
0.01
0.02
0.01
0.02
0.02
0.02
0.01
0.01
0.02
9
0.03
0.02
0.02
0.03
0.03
0.03
0.01
0.02
0.04
0
0.04
0.02
0.02
0.02
0.03
0.04
0.02
0.05
0.02
1
0.03
0.03
0.03
0.03
0.03
0.02
0.04
0.03
0.03
2
0.03
0.02
0.02
0.02
0.02
0.04
0.03
0.02
0.03
3
0.02
0.03
0.03
0.03
0.04
0.01
0.02
0.03
0.02
4
0.02
0.02
0.02
0.04
0.03
0.03
0.02
0.03
0.03
5
0.03
0.03
0.03
0.01
0.02
0.02
0.01
0.02
0.02
6
0.02
0.04
0.02
0.03
0.02
0.02
0.02
0.02
0.02
7
0.04
0.02
0.02
0.03
0.03
0.03
0.01
0.02
0.02
8
0.03
0.02
0.01
0.02
0.02
0.03
0.02
0.01
0.02
9
0.09
0.09
0.08
0.09
0.10
0.11
0.10
0.09
0
0.08
0.10
0.11
0.09
0.10
0.11
0.09
1
0.10
0.08
0.09
0.08
0.11
0.11
2
0.11
0.10
0.10
0.11
0.10
3
0.10
0.09
0.09
0.09
4
0.08
0.08
0.06
5
0.08
0.09
6
0.09
7
8
TREC
Yelp
QNLI
Figure 7 (cont.): Continuation of Figure 7 for additional tasks.
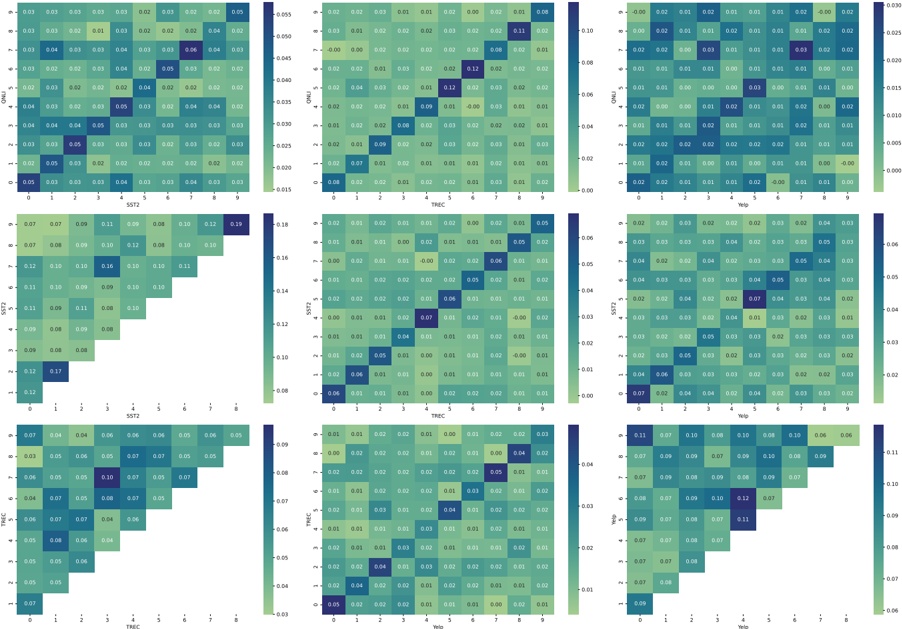
Figure 8: Comparison of relative exact match performance of combinations of task prompt vectors across averaged across 10 different random initializations and all task combinations. The results are relative to the original single-task performance (1 is the performance of single-task prompt tuning). The task combinations in bold are the combinations that achieved over 50% of single-task performance on both of the tasks.
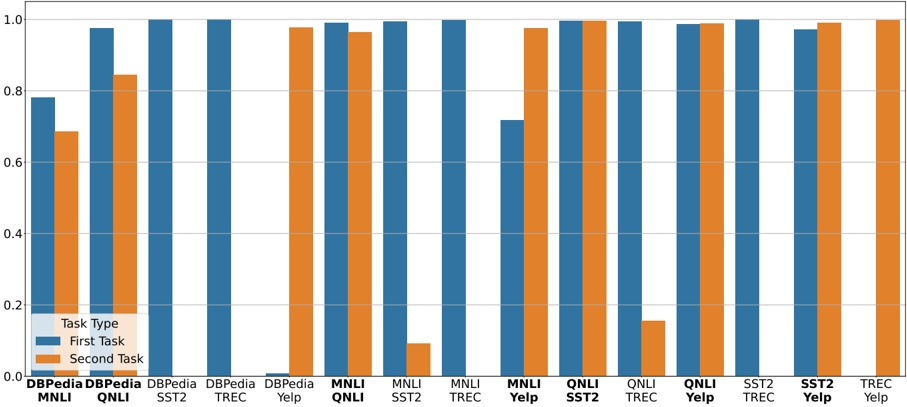
0.08
0.06
0.04
0.02
MNLI
8
7
6
5
4
3
2
1
0
0.045
0.040
0.035
0.030
0.025
0.020
0.015
QNLI
8
7
6
5
4
3
2
1
0.10
0.09
0.08
0.07
0.06
| SciTail (NLI) | SciTail (NLI) | SciTail (NLI) | AG News (Classification) | AG News (Classification) | AG News (Classification) | IMDB (Sentiment) | IMDB (Sentiment) | IMDB (Sentiment) |
|-----------------------|-----------------|-----------------|--------------------------------|--------------------------------|--------------------------------|-----------------------|--------------------|--------------------|
| Source | F1 | F1 | Source tasks | F1 | F1 | Source tasks | F1 | F1 |
| tasks | 0 shots | 100 shots | Source tasks | 0 shots | 100 shots | Source tasks | 0 shots | 100 shots |
| Random | 54 . 9 6 . 6 | 75 . 6 0 . 5 | Random | 0 0 | 50 . 4 11 . 2 | Random | 77 . 2 9 . 6 | 89 . 4 0 . 4 |
| MNLI (SPoT) | 70 . 4 0 . 4 | 87 . 8 0 . 9 | DBPedia (SPoT) | 0 0 | 83 . 4 0 . 6 ∗ | SST2 (SPoT) | 88 0 . 6 | 90 . 2 0 . 3 |
| QNLI (SPoT) | 57 . 7 13 . 1 | 77 . 7 1 . 3 | TREC (SPoT) | 0 0 | 65 . 7 5 . 6 | Yelp (SPoT) | 90 0 . 3 | 90 . 3 0 . 2 |
| QNLI + MNLI (SPoT) | 70 . 4 1 . 2 | 87 . 7 0 . 6 | DBPedia + TREC (SPoT) | 0 0 | 2 . 1 0 . 9 | SST2 + Yelp (SPoT) | 90 . 8 0 . 2 | 90 . 8 0 . 2 |
| QNLI + MNLI (ATTEMPT) | 63 . 8 4 . 2 | 83 . 6 3 | DBPedia + TREC (ATTEMPT) | 11 . 5 1 . 7 | 20 . 7 2 . 8 | SST2 + Yelp (ATTEMPT) | 79 . 2 6 | 89 . 4 0 . 8 |
| QNLI + MNLI (ours) | 71 . 5 0 . 8 ∗ | 88 . 1 0 . 9 | DBPedia + TREC (ours) | 0 0 | 83 0 . 9 | SST2 + Yelp (ours) | 90 . 1 0 . 5 | 90 . 4 0 . 2 |
| SNLI (NLI) | SNLI (NLI) | SNLI (NLI) | Yahoo Answers (Classification) | Yahoo Answers (Classification) | Yahoo Answers (Classification) | SST5 (Sentiment) | SST5 (Sentiment) | SST5 (Sentiment) |
| | F1 | F1 | Source | F1 | F1 | Source | F1 | F1 |
| Source tasks | 0 shots | 100 shots | tasks | 0 shots | 100 shots | tasks | 0 shots | 100 shots |
| Random | 46 . 5 1 . 5 | 47 . 6 1 . 9 | Random | 0 0 | 27 . 6 10 . 6 | Random | 0 0 | 83 . 2 5 . 8 |
| MNLI (SPoT) | 79 . 5 0 . 3 | 80 . 8 0 . 4 | DBPedia (SPoT) | 0 0 | 61 . 3 1 . 1 ∗ | SST2 (SPoT) | 94 0 . 3 ∗ | 93 . 9 0 . 3 ∗ |
| QNLI (SPoT) | 47 . 1 0 . 3 | 49 . 1 0 . 9 | TREC (SPoT) | 0 0 | 36 . 5 8 . 7 | Yelp (SPoT) | 88 . 6 0 . 8 | 90 . 6 0 . 5 |
| QNLI + MNLI (SPoT) | 79 . 6 0 . 2 ∗ | 81 0 . 4 ∗ | DBPedia + TREC (SPoT) | 0 0 | 60 . 7 2 | SST2 + Yelp (SPoT) | 93 . 7 0 . 5 | 93 . 8 0 . 5 |
| QNLI + MNLI (ATTEMPT) | 78 . 5 0 . 5 | 79 . 6 1 . 6 | DBPedia + TREC (ATTEMPT) | 0 . 1 0 | 8 . 1 5 . 6 | SST2 + Yelp (ATTEMPT) | 16 . 4 4 . 5 | 37 . 8 7 |
| QNLI + MNLI (ours) | 79 . 2 1 . 4 | 80 . 3 0 . 3 | DBPedia + TREC (ours) | 0 0 | 61 . 1 0 . 9 | SST2 + Yelp (ours) | 89 . 9 0 . 8 | 91 . 5 0 . 5 |
Table 4: Test results of training T5-base model with random, single- and multi-task soft-prompt transfer (SPoT), multi-task ATTEMPT, and our task prompt vectors on 0-shot and 100-shots of data for all of our observed source and target tasks. We show the initialization with different combinations for natural language inference classification, topic classification, and sentiment classification. The subscript represents the standard deviation from the average. The best results are bold, while the second-best results are underlined. The * in the superscript represents that the results are statistically significant from the second-best result, by two-sample Student's t-test (Student, 1908) or Welch's t-test (Welch, 1947).
Figure 9: Comparison of average cosine similarities of task prompts fine-tuned on different tasks for LLaMa3.1-8B-Instruct model. The average is calculated across all combinations of 3 random initializations (i.e., row QNLI column MNLI was calculated as the average of all cosine similarities between MNLI and QNLI task prompts for all random initialization combinations omitting the combinations where cosine similarity is equal to 1). The diagonal represents the cosine similarities of the same tasks and it represents the maximum value of cosine similarity across different random initializations.
Figure 10: Comparison of average cosine similarities of task prompt vectors . The averages are calculated equivalently to Figure 9 but with task prompt vectors created from different task prompts.
Macro F1
Figure 11: Test results of training T5-base model with random, single- and multi-task soft-prompt transfer (SPoT), multi-task ATTEMPT, and our task prompt vectors combination on increasing numbers of shots of data averaged over 10 different random initializations for all source and target tasks.
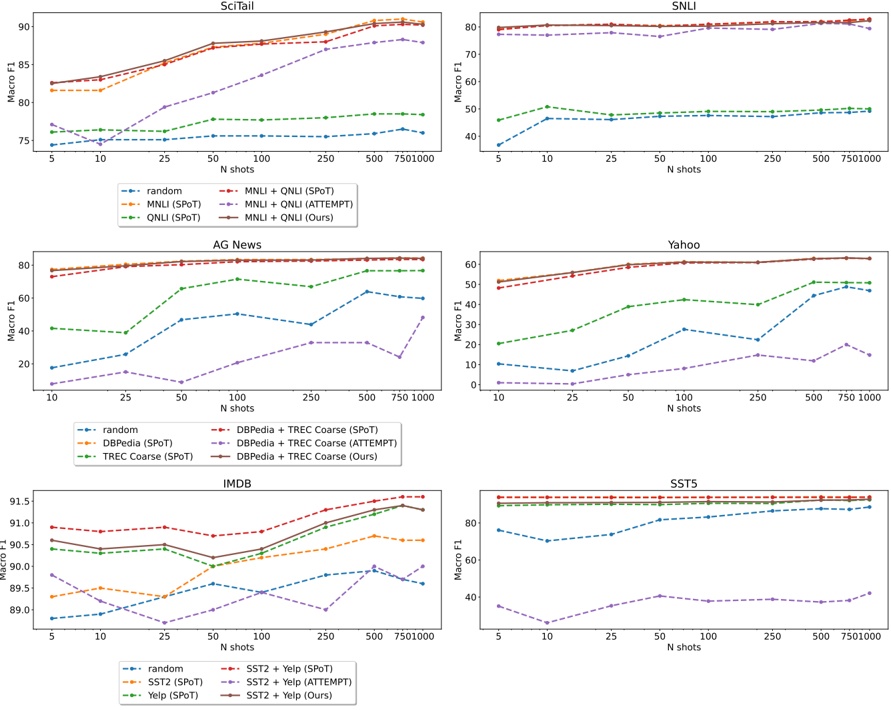 | null | [
"Robert Belanec",
"Simon Ostermann",
"Ivan Srba",
"Maria Bielikova"
] | 2024-08-02T09:00:03+00:00 | 2024-10-23T14:37:50+00:00 | [
"cs.CL"
] | Task Prompt Vectors: Effective Initialization through Multi-Task Soft-Prompt Transfer | Prompt tuning is an efficient solution for training large language models
(LLMs). However, current soft-prompt-based methods often sacrifice multi-task
modularity, requiring the training process to be fully or partially repeated
for each newly added task. While recent work on task vectors applied arithmetic
operations on full model weights to achieve the desired multi-task performance,
a similar approach for soft-prompts is still missing. To this end, we introduce
Task Prompt Vectors, created by element-wise difference between weights of
tuned soft-prompts and their random initialization. Experimental results on 12
NLU datasets show that task prompt vectors can be used in low-resource settings
to effectively initialize prompt tuning on similar tasks. In addition, we show
that task prompt vectors are independent of the random initialization of prompt
tuning on 2 different language model architectures. This allows prompt
arithmetics with the pre-trained vectors from different tasks. In this way, we
provide a competitive alternative to state-of-the-art baselines by arithmetic
addition of task prompt vectors from multiple tasks. |
2408.01120v1 | ## An Efficient and Effective Transformer Decoder-Based Framework for Multi-Task Visual Grounding
Wei Chen , Long Chen , and Yu Wu 1 2 1 ⋆
1 Wuhan University 2 The Hong Kong University of Science and Technology {weichencs,wuyucs}@whu.edu.cn, [email protected]
Abstract. Most advanced visual grounding methods rely on Transformers for visual-linguistic feature fusion. However, these Transformerbased approaches encounter a significant drawback: the computational costs escalate quadratically due to the self-attention mechanism in the Transformer Encoder, particularly when dealing with high-resolution images or long context sentences. This quadratic increase in computational burden restricts the applicability of visual grounding to more intricate scenes, such as conversation-based reasoning segmentation, which involves lengthy language expressions. In this paper, we propose an efficient and effective multi-task visual grounding (EEVG) framework based on Transformer Decoder to address this issue, which reduces the cost in both language and visual aspects. In the language aspect , we employ the Transformer Decoder to fuse visual and linguistic features, where linguistic features are input as memory and visual features as queries. This allows fusion to scale linearly with language expression length. In the visual aspect , we introduce a parameter-free approach to reduce computation by eliminating background visual tokens based on attention scores. We then design a light mask head to directly predict segmentation masks from the remaining sparse feature maps. Extensive results and ablation studies on benchmarks demonstrate the efficiency and effectiveness of our approach. Code is available in https://github.com/chenwei746/EEVG .
Keywords: Visual Grounding · Transformer Decoder · Token Elimination
## 1 Introduction
Visual grounding [33, 50] is a task of locating visual objects based on language expressions, achieved by aligning visual features and linguistic features. According to the granularity of alignment between visual and linguistic information, it can be categorized into two sub-tasks: referring expression comprehension (REC) [3,6,37,52] which facilitates visual-language alignment at the region level, and referring expression segmentation (RES) [38,44,46] which grounds language
⋆ Corresponding author.
Fig. 1: Comparison of different frameworks: (a) Encoder-Decoder methods, (b) Encoder-only methods, and (c) our Decoder-only framework EEVG. In (a) and (b), Transformer Encoder is utilized, and all visual tokens are employed for mask generation. (c) Our method EEVG leverages the Transformer Decoder to integrate diverse modality information and remove background visual tokens during modalities fusion.
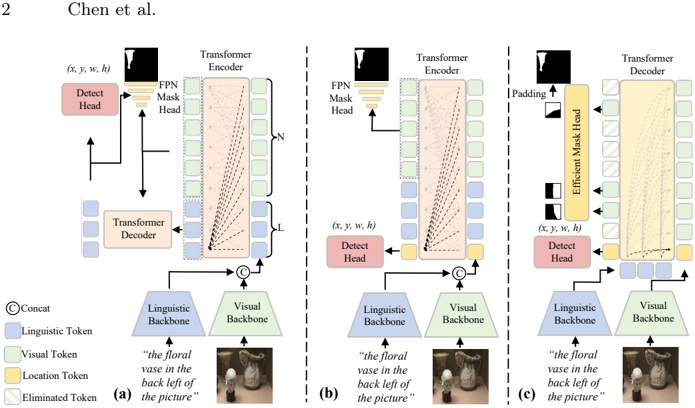
expression at the pixel level. Inspired by joint object detection and segmentation, several works [5,22,29,32,40,53] propose a multi-task collaborative learning framework to unify REC and RES, i.e ., multi-task visual grounding (MTVG). They demonstrate that REC aids RES in locating referents more accurately, while RES helps REC achieve better vision-language alignment. As a result, MTVG has become a prevailing way of visual grounding.
Current mainstream MTVG models consist of a visual encoder, a linguistic encoder, a cross-modal feature fusion module, and two task heads ( i.e. , a detection head and a segmentation mask head). Recent state-of-the-art visual grounding works [6, 17, 18, 22, 29] resort to Encoder 1 for cross-modal vision-language fusion. As shown in Fig. 1, these existing methods can be categorized into two categories: (a) Encoder-Decoder [17, 22, 29, 37], where visual-linguistic features are fused by Encoder and target object features are output by Decoder, and (b) Encoder-only [6, 18], where the target object is directly predicted after visionlanguage feature fusion in Encoder.
However, these methods encounter two efficiency problems: 1) quadraticincreased cost in language length and 2) redundant visual token computation. Firstly , traditional methods concatenate visual and linguistic tokens together and input them into Encoder for self-attention, leading to a time complexity of O (( N + L ) 2 ) . Thus the computation cost significantly increases as language expressions and context become longer and more complex in the era of Large Lan-
1 We use Encoder and Decoder to refer to Transformer encoder and decoder, respectively.
guage Models (LLMs). This hinders the application of visual grounding to more complex scenes, such as conversation-based reasoning segmentation [21], which involves long language contexts. Secondly , different from general segmentation or detection tasks, visual grounding usually only aims at locating one referred object. Most visual pixels in the image are not in the region of interest and thus lead to redundant and unnecessary computations, and may distract/mislead the model's attention from the real target. To address these issues, we propose an efficient and effective multi-task visual grounding (EEVG) framework.
To alleviate the cost in the language aspect and to deal with longer complex language expressions such as long contextual dialog, we only use Decoder for the visual and language reasoning process. As depicted in Fig. 1 (c), we regard linguistic features as memory and visual features as queries in Decoder. This allows for the fusion of visual and linguistic modalities in the cross-attention module, resulting in a linear increase in computational cost with respect to the length of the language expressions. To the best of our knowledge, our method is the first Transformer-based framework with no Encoder for cross-modal fusion.
To mitigate the cost in the visual aspect and further improve efficiency and efficacy, we introduce a parameter-free strategy to eliminate redundant and distracting image tokens for the visual grounding task. The core idea is dynamically eliminating visual tokens with low attention scores, making the visual feature map to be sparse, and concentrating more on the referred target to remove distracting noise. After that, instead of utilizing the traditional feature pyramid network (FPN) [19] that is widely used in previous MTVG works, we devise a very light-weight and efficient mask head to directly project the remaining sparse tokens into region masks. Previous works' [10,15,16,18,22,40,46] FPN module constitutes 42.8% of the Decoder's parameters (8.1M versus 18.9M), acting like an independent network to predict mask. Differently, we use a light-weight twolayer MLP (0.79M) to directly transfer 1-D feature channels of Decoder tokens to the 2-D spatial segmentation mask prediction of the corresponding patch. In this way, we migrate the segmentation prediction workload from the add-on head to the main Decoder. This is consistent with the detection head of REC which also transfers the detection workload to Decoder via a light-weight MLP.
By doing so, Decoder gains a better understanding of the multi-tasks and their mutual improvement, as the location and pixel information are directly embedded in the Decoder token feature. Experiments validate this by the fact that our mask head improves the detection performance on REC by about 2.0%, even though the detection prediction does not go through the mask head. We conduct extensive experiments on several challenging benchmarks including RefCOCO [50], RefCOCO+ [50], and RefCOCOg [33]. Our EEVG is faster than state-of-the art method PolyFormer [29] by 28.19%. Benefiting from light-weight mask head and elimination of disturbing tokens, EEVG also shows enhanced performance. Particularly in the RefCOCOg dataset, which encompasses longer complex language expressions, our method exhibits a notable increase of 3.93% on the RES.
In summary, our contributions are three-fold:
- -We propose a Decoder-only framework for MTVG, which reduces computation cost from quadratic to linear increase with regards to language length.
- -We propose a dynamic eliminating strategy to reduce redundant and distracting visual tokens, together with a lightweight mask head to directly project the remaining sparse tokens to masks.
- -Comprehensive results show that EEVG surpasses state-of-the-art approaches in both speed and performance.
## 2 Related Work
Referring Expression Comprehension (REC). REC can be categorized into one-stage and two-stage approaches. Two-stage [12,13,51] methods rely on ranking region proposal scores based on language expressions as a crucial component. However, their performance is limited to the pre-trained object detector. While one-stage methods [17, 24, 47, 48] focus on directly predicting the target bounding box guided by language expressions. Yang et al . [47] propose a recursive sub-query construction framework to reason between image and query for multiple rounds. To further align modalities, RCCF [24] maps the language domain to the visual domain and performs correlation filtering on the image feature map. Inspired by DETR's [2] success in object detection, MDETR [17] extends it to multi-modal understanding for REC.
Referring Expression Segmentation (RES). As RES needs to predict pixellevel results, it heavily relies on accurate vision-language feature extraction and alignment. Previous studies [10,15,16,46] have explored various approaches for cross-modal interaction. EFN [10] utilizes a co-attention mechanism to promote the consistency of the cross-modal information representation in the semantic space. On the other hand, LTS [16] leverages visual-textual features to accurately localize the referenced object by incorporating position priors before facilitating segmentation. Recent work LAVT [46] aligns visual and linguistic representations within the visual backbone using a pixel-word attention module. Current approaches [10, 15, 16, 18, 22, 40, 46] typically employ an FPN-like architecture to generate binary masks from fused visual features. In contrast, our proposed method introduces a lighter mask head based on MLP.
Multi-task Visual Grounding (MTVG). To promote consistency between REC and RES, it is natural to integrate them using a shared backbone. In a pioneering effort, MCN [32] proposes a novel multi-task collaborative network that enables joint learning of REC and RES. With the widespread adoption of Transformer [41], follow-up works [18,22,40] have employed Transformer as a unified backbone, employing different task heads for REC and RES. Alternatively, SeqTR [53] approaches the problem differently by treating MTVG as a sequence prediction task, representing bounding boxes and masks as discrete coordinate tokens. Moreover, Polyformer [29] leverages precise floating-point coordinates and multi-polygon generation to achieve finer segmentation. Tasks similar to MTVG, Open-Vocabulary Object Detection/Segmentation [11,45] need to identify all objects across all categories using the vocabularies.
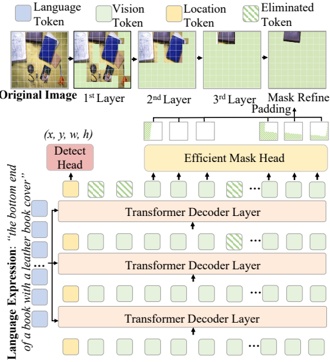
Fig. 2: Overview of our method. The language tokens and visual tokens are extracted by a linguistic backbone and a visual backbone which are not shown in the figure.
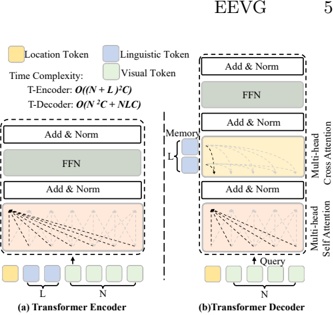
Fig. 3: Time complexity comparison between Encoder and Decoder. There is only one input for Encoder while Decoder has two inputs: query and memory. N denotes the number of visual tokens, L means the number of linguistic tokens, C is the dimension of tokens, and 'Add & Norm' refers to residual connection and normalization.
Transformer for Vision-Language Tasks. Transformer model [41], initially proposed for natural language processing tasks, has demonstrated its effectiveness in the computer vision domain as well, as evidenced by the success of Vision Transformer (ViT) [8,43]. Leveraging the Transformer's exceptional performance in both vision and natural language, researchers have extensively explored its potential as a unified model for vision-language tasks [4,31,42]. Recently, there have been a growing number of methods [6,22,29,40,53] based on the Transformer architecture in visual grounding. TransVG [6], which employs Transformer Encoder for cross-modal fusion, introduces the pioneering transformer-based framework for visual grounding.
## 3 Method
In this section, we first formulate the multi-task visual grounding (MTVG) task and review the prevalent Encoder-based framework in Sec. 3.1. Then, we elaborate on our new Decoder-based framework as shown in Fig. 2, which utilizes Decoder for vision-language fusion (Sec. 3.2), and includes a parameter-free strategy to eliminate visual tokens (Sec. 3.3) and an efficient mask head (Sec. 3.4).
## 3.1 Preliminary
Formultation. Given an image I ∈ R H × W × 3 and a text query T ∈ R L , MTVG needs to predict a bounding box B and a binary mask M simultaneously, which
corresponding to the referent. The current prevailing MTVG framework, typically, first utilizes a visual backbone ( e.g ., ViT [8]) and a linguistic backbone ( e.g ., BERT [7]) to extract visual features F v ∈ R N × C v and linguistic features F l ∈ R L × C l . After fusing them in the cross-modal interaction module, two task heads are used to predict results.
Encoder-based Framework. Existing works [6,18,29] directly adopt Encoder as the cross-modal interaction module. As shown in Fig. 3 (a), after linearly projecting F v and F l into the same dimension C ( ˜ F v and ˜ F l ), ˜ F v and ˜ F l are concatenated with a learnable location token ˜ F loc ∈ R 1 × C and fed into Encoder:
$$[ \hat { F } _ { l o c }, \hat { F } _ { l }, \hat { F } _ { v } ] = \text{Encoder} ( [ \widetilde { F } _ { l o c } ; \widetilde { F } _ { l } ; \widetilde { F } _ { v } ] ),$$
where [ · ; · ; · ] denotes the concatenation operation.
After getting fused features, for the detection task, a two-layer MLP is used to project ˆ F loc into four dimensions ( i.e ., ( x, y, w, h ) ). For the segmentation results, ˆ F v is reshaped from sequence to square ( i.e ., R N × C → R H P × W P × C where P is the patch size) and uses FPN-like [19] architecture built on convolution layers to generate masks. This architecture typically needs the entire visual features because convolution layers can only work in a square feature map which contains redundant costs in the visual features corresponding to the background. Therefore, we utilize our elimination strategy and efficient head to alleviate this.
Time Complexity Analysis. The computational cost of aligning different modalities in the Encoder-based methods primarily lies in the multi-head selfattention (MSA) which can be formulated as:
$$M S A ( Q, K, V ) = \text{softmax} ( \frac { Q K ^ { T } } { \sqrt { C } } ) V,$$
where Q K , , and V represent query, key, and value, respectively. They are obtained through linear projections of the input features. Specifically, Q K , , and V ∈ R ( N + +1) L × C . According to Eq. (2), its time complexity can be calculated as O (( N + L ) 2 C ) . In our method, we aim to alleviate the quadratic increase in burden by reducing it to a linear one with respect to L , as well as minimizing the number of N .
## 3.2 Transformer Decoder for Modalities Fusion
Module Details. First, we separately project visual feature F v and linguistic feature F l into the same channel dimension C ( ˜ F v and ˜ F l ). Then we adopt Transformer Decoder [41] for vision-language fusion, as depicted in Fig. 3 (b), where each decoder layer consists of an MSA layer, a multi-head cross-attention (MCA) layer, and a feed-forward network. MCA has a similar architecture to MSA, but the difference is that MCA has two inputs: the first one is input as Q and another one is input as K and V in Eq. (2). We concatenate ˜ F v with a learnable location token ˜ F loc and input them into the MSA layer:
$$[ F ^ { \prime } _ { l o c }, F ^ { \prime } _ { v } ] = \mathrm L N ( \text{MSA} ( [ \widetilde { F } _ { l o c } ; \widetilde { F } _ { v } ] ) + [ \widetilde { F } _ { l o c } ; \widetilde { F } _ { v } ] ),$$
where LN ( ) · refers to layer normalization. After that, we input [ F ′ loc ; F ′ v ] as the query of MCA and input linguistic feature ˜ F l as the key and value of MCA:
$$[ F ^ { * } _ { l o c }, F ^ { * } _ { v } ] = \text{LN(MCA([F ^ { \prime } _ { l o c } ; F ^ { \prime } _ { v } ], \widetilde { F } _ { l } ) } + [ F ^ { \prime } _ { l o c } ; F ^ { \prime } _ { v } ] ),$$
Finally, [ F ∗ loc , F ∗ v ] is passed into the feed-forward network:
$$[ \hat { F } _ { l o c }, \hat { F } _ { v } ] = \text{LN} ( \text{FFN} ( [ F _ { l o c } ^ { * } ; F _ { v } ^ { * } ] ) + [ F _ { l o c } ^ { * } ; F _ { v } ^ { * } ] ),$$
where FFN ( ) · means the feed-forward network, which is a two-layer MLP.
Time Complexity Analysis. The computational cost mainly lies in the MSA and MCA, with time complexities of O ( N C 2 ) and O ( NLC ) , respectively. Thus, the overall time complexity is O ( N C 2 + NLC ) , which increases linearly with respect to L .
## 3.3 Parameter-free Token Elimination Strategy
Visual grounding usually aims at locating one referent and most referents only occupy a small percentage of the visual tokens where most visual tokens are not in the region of interest. Therefore, there exist redundant costs in background visual tokens. As a result, we attempt to address this issue by eliminating background visual tokens. During our analysis, we discovered that the attention scores between the location token and the visual tokens are notably higher for those corresponding to the target object. This finding led us to the conclusion that we can effectively eliminate visual tokens with low attention scores which are depicted in Fig. 4.
Fig. 4: We conduct the visual tokens elimination process in each Decoder layer. 'ASA' denotes adaptive spatial attention and 'Norm & Elimination' means normalization and eliminating visual tokens according to Eq. (7).
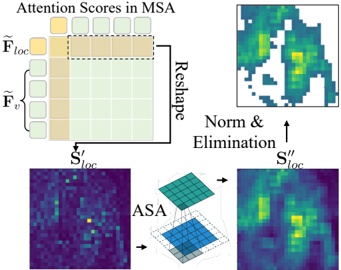
Dynamic Elimination. There are some related works [1,9] eliminating visual tokens in image classification. However, these methods eliminate a fixed number in each model layer and typically retain only the essential object features. These approaches are suitable for coarse granularity tasks like image classification. In contrast, the task of RES requires the preservation of the entire object and deals with objects of varying sizes, each demanding a different number of tokens to be eliminated. To tackle this challenge, we propose a dynamic elimination strategy. First, attention scores S loc ∈ R 1 × N between the location token and visual tokens are calculated as:
$$\text{as}. & Q _ { l o c } = \widetilde { F } _ { l o c } W _ { Q }, K _ { v } = \widetilde { F } _ { v } W _ { K }, \\ & S _ { l o c } = \text{softmax} ( \frac { Q _ { l o c } K _ { v } ^ { T } } { \sqrt { C } } ),$$
## Image
## 3 rd Layer Score 1 st Layer Score 2 nd layer score Predict Mask

GT
Text: ' a cinnamon sugar donut '
Fig. 5: Visualization of attention scores S loc of location token and visual tokens. GT refers to ground truth, 'w/o ASA' denotes without using adaptive spatial attention, and ' 1 st Layer Score' means the first Decoder layer attention scores between location token and visual tokens.
where W Q ∈ R C × C and W K ∈ R C × C are parameter matrices in MSA. Then we normalize the attention scores S loc and remove those visual tokens whose attention scores are smaller than α :
$$\widetilde { S } _ { l o c } & = \frac { S _ { l o c } - \min S _ { l o c } ^ { i } } { \max S _ { l o c } ^ { i } - \min S _ { l o c } ^ { i } }, 0 \leq i < N \\ \overline { F } _ { v } & = \{ \hat { F } _ { v } ^ { i } \, | \, \widetilde { S } _ { l o c } ^ { i } \geq \alpha, \ 0 \leq i < N \},$$
where ˆ F i v is the i -th visual token, F v ∈ R N ′ × C denotes the remained tokens, and N ′ means the number of remained visual tokens. Our strategy offers two advantages over prior works [1,9]: 1) it dynamically eliminates a different number of tokens for different objects in different sizes, and 2) the number of eliminated tokens gradually increases as the loss converges, preventing error elimination.
Adaptive Spatial Attention. As shown in the predicted mask in Fig. 5, we found that some visual tokens corresponding to target objects are eliminated incorrectly. Therefore, we propose the attention weight average strategy to make the attention weights spatially aware to maintain the original shape of the target object. We reshape S loc into S ′ loc ∈ R H P × W P , then calculate as follows:
$$S _ { l o c } ^ { \prime \prime } [ i, j ] = \frac { \sum _ { u = - k } ^ { k } \sum _ { v = - k } ^ { k } S _ { l o c } ^ { \prime } [ i + u, j + v ] } { ( 2 k + 1 ) ^ { 2 } },$$
where 0 ≤ i < H P and 0 ≤ j < W P . After that, each attention score is averaged with the surrounding attention scores, then we reshape S ′′ loc back to S loc ∈ R 1 × N and following Eq. (7) to eliminate visual tokens. So we can alleviate the problem of incorrectly eliminating tokens in the referent.
Fig. 6: Our mask head utilizes MLP to project tokens from channel to spatial region masks and adopts a 1-channel convolution layer to establish spatial relationships among pixels. 'Map & Pad' refers to mapping each patch to the original position in the image and padding the eliminated position with 0.
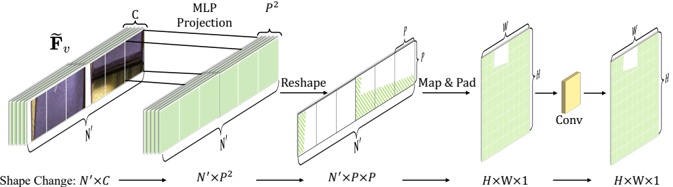
## 3.4 Efficient Mask Head
After eliminating tokens, we get some sparse visual tokens. To further reduce the redundant cost, we propose a lightweight and efficient mask head to generate masks from sparse visual tokens instead of using the FPN-like mask head which needs to pad the eliminated tokens. The procedure of our mask head is shown in Fig. 6. We denote the rest of indexes I as follows:
$$\mathbb { I } = \{ i \, | \, \widetilde { S } _ { l o c } ^ { i } \geq \alpha, \ 0 \leq i < N \},$$
We utilize MLP to transfer the remaining visual tokens from 1-D feature channels into 2-D spatial binary masks ( C → P 2 dimension) and pad the eliminated tokens with 0:
$$\mathcal { M } ^ { i } = \begin{cases} M L P ( \overline { \mathcal { F } } _ { v } ^ { f ( i ) } ), & \text{if $i\in \mathbb{I}$} \\ 0 ^ { 1 \times P ^ { 2 } }, & \text{if $i\notin \mathbb{I}$} \end{cases}$$
where 0 ≤ i < N and f ( ) i means the index in remained tokens corresponding to the i -th original token. We reshape and permute M∈ R N × P 2 into M ∈ ′ R H × W and since the pixels projected by MLP are not spatially related to each other, we use the local context processing method to make neighboring pixels relate to each other. In the actual implementation, we use a 5*5 convolutional kernel Conv , and mask M is generated as follows:
$$M = sigmoid (Conv ( \mathcal { M } ^ { \prime } ) ),$$
## 3.5 Multi-task Training
Our method is an end-to-end framework that unifies REC and RES, incorporating two distinct types of loss: detection loss and segmentation loss.
Detection Loss. For REC task, we denote the predicted bounding box B = (ˆ x, y, w, h ˆ ˆ ˆ ) and the ground truth B gt = ( x, y, w, h ) , and the detection loss
Table 1: Comparison with state-of-the-art methods on RefCOCO [50], RefCOCO+ [50], and RefCOCOg [35] for REC task. Bold denotes the best performance. Swin-B and ViT-B are abbreviations for Swin-Transformer Base and ViT Base.
| Method | Backbone | Multi- | RefCOCO | RefCOCO | RefCOCO | RefCOCO+ | RefCOCO+ | RefCOCO+ | RefCOCOg | RefCOCOg |
|--------------|--------------|----------|-----------|-----------|-----------|------------|------------|------------|------------|------------|
| Method | Backbone | task | val | test A | test B | val | test A | test B | val(U) | test(U) |
| MAttNet [49] | MRCNN-Res101 | % | 76.65 | 81.14 | 69.99 | 65.33 | 71.62 | 56.02 | 66.58 | 67.27 |
| NMTree [28] | MRCNN-Res101 | % | 76.41 | 81.21 | 70.09 | 66.46 | 72.02 | 57.52 | 65.87 | 66.44 |
| LBYL [14] | DarkNet53 | % | 79.67 | 82.91 | 74.15 | 68.64 | 73.38 | 59.49 | - | - |
| MCN [32] | DarkNet53 | ! | 80.08 | 82.29 | 74.98 | 67.16 | 72.86 | 57.31 | 66.46 | 66.01 |
| TransVG [6] | ResNet101 | % | 81.02 | 82.72 | 78.35 | 64.82 | 70.70 | 56.94 | 68.67 | 67.73 |
| TRAR [52] | DarkNet53 | % | - | 81.40 | 78.60 | - | 69.10 | 56.10 | 68.90 | 68.30 |
| SeqTR [53] | DarkNet53 | ! | 81.23 | 85.00 | 76.08 | 68.82 | 75.37 | 58.78 | 71.35 | 71.58 |
| PVD [5] | DarkNet53 | ! | 82.51 | 86.19 | 76.81 | 69.48 | 76.83 | 59.68 | 68.40 | 69.57 |
| PVD [5] | Swin-B | ! | 84.52 | 87.64 | 79.63 | 73.89 | 78.41 | 64.25 | 73.81 | 74.13 |
| VG-LAW [40] | ViT-B | ! | 86.62 | 89.32 | 83.16 | 76.37 | 81.04 | 67.50 | 76.90 | 76.96 |
| EEVG (Ours) | MRCNN-Res101 | ! | 82.19 | 85.34 | 77.18 | 71.35 | 76.76 | 60.73 | 70.18 | 71.28 |
| EEVG (Ours) | DarkNet53 | ! | 81.82 | 86.02 | 74.67 | 69.72 | 76.26 | 57.95 | 71.38 | 70.93 |
| EEVG (Ours) | Swin-B | ! | 86.79 | 89.52 | 83.12 | 77.52 | 83.05 | 66.93 | 78.15 | 78.11 |
| EEVG (Ours) | ViT-B | ! | 88.08 | 90.33 | 85.50 | 77.97 | 82.44 | 69.15 | 79.60 | 80.24 |
is define as follows:
$$\mathcal { L } _ { d e t } = \mathcal { L } _ { s m o o t h - L 1 } ( B, B _ { g t } ) + \mathcal { L } _ { g i o u } ( B, B _ { g t } ),$$
where L smooth -L 1 ( · , · ) and L giou ( · , · ) are the smooth L1 loss and GIoU loss [39]. Segmentation Loss. For RES task, the segmentation loss is calculated using the predicted segmentation mask denoted as M ∈ R H × W , and the ground truth denoted as M gt ∈ R H × W , according to the following formula:
$$\mathcal { L } _ { s e g } = \mathcal { L } _ { f o c a l } ( M, M _ { g t } ) + \mathcal { L } _ { d i c e } ( M, M _ { g t } ),$$
where L focal ( · , · ) and L dice ( · , · ) represent focal loss [25] and dice loss [34]. Finally, the joint training loss function is defined as follows:
$$\mathcal { L } = \lambda _ { d e t } \mathcal { L } _ { d e t } + \lambda _ { s e g } \mathcal { L } _ { s e g }.$$
where λ det and λ seg represent the weight coefficients for the detection loss and segmentation loss, respectively.
## 4 Experiments
## 4.1 Experiment Settings
Datasets. The commonly used datasets in visual grounding are RefCOCO [50], RefCOCO+ [50], and RefCOCOg [33], which are collected from MS-COCO [26]. RefCOCO contains 19,994 images with 142,210 referring expressions for 50,000 objects which is split into the training set, the validation set, the testA set, and the testB set. RefCOCO+, excluding absolute-location words, consists of 19,992 images with 49,856 referred objects and 141,564 referring expressions. There are
Table 2: Comparison with state-of-the-art methods on RefCOCO [50], RefCOCO+ [50], and RefCOCOg [35] for RES task. Bold denotes the best performance. Swin-B and ViT-B are abbreviations for Swin-Transformer Base and ViT Base.
| Method | Backbone | Multi- task | RefCOCO | RefCOCO | RefCOCO | RefCOCO+ | RefCOCO+ | RefCOCO+ | RefCOCOg | RefCOCOg |
|--------------|---------------|---------------|-----------|-----------|-----------|------------|------------|------------|------------|------------|
| Method | Backbone | Multi- task | val | test A | test B | val | test A | test B | val(U) | test(U) |
| MAttNet [49] | MRCNN-Res101 | % | 56.51 | 62.37 | 51.70 | 46.67 | 52.39 | 40.08 | 47.64 | 48.61 |
| NMTree [28] | MRCNN-Res101 | % | 56.59 | 63.02 | 52.06 | 47.40 | 53.01 | 41.56 | 46.59 | 47.88 |
| MCN [32] | DarkNet53 | ! | 62.44 | 64.20 | 59.71 | 50.62 | 54.99 | 44.69 | 49.22 | 49.40 |
| CRIS [44] | CLIP-ResNet50 | % | 69.52 | 72.72 | 64.70 | 61.39 | 67.10 | 52.48 | 59.87 | 60.36 |
| SeqTR [53] | DarkNet53 | ! | 67.26 | 69.79 | 64.12 | 54.14 | 58.93 | 48.19 | 55.67 | 55.64 |
| PVD [5] | DarkNet53 | ! | 68.87 | 70.53 | 65.83 | 54.98 | 60.12 | 50.23 | 57.81 | 57.17 |
| LAVT [46] | Swin-B | % | 74.46 | 76.89 | 70.94 | 65.81 | 70.97 | 59.23 | 63.34 | 63.62 |
| PVD [5] | Swin-B | ! | 74.82 | 77.11 | 69.52 | 63.38 | 68.60 | 56.92 | 63.13 | 63.62 |
| VG-LAW [40] | ViT-B | ! | 75.62 | 77.51 | 72.89 | 66.63 | 70.38 | 59.89 | 65.53 | 66.08 |
| EEVG (Ours) | MRCNN-Res101 | ! | 71.28 | 73.87 | 67.49 | 61.96 | 66.25 | 53.74 | 59.94 | 60.72 |
| EEVG (Ours) | DarkNet53 | ! | 70.66 | 74.16 | 65.60 | 60.76 | 65.38 | 50.70 | 59.79 | 59.93 |
| EEVG (Ours) | Swin-B | ! | 75.79 | 77.86 | 72.78 | 67.62 | 71.48 | 59.12 | 67.40 | 67.30 |
| EEVG (Ours) | ViT-B | ! | 78.23 | 79.27 | 76.58 | 69.04 | 72.65 | 62.33 | 69.15 | 70.01 |
25,799 images with 49,856 referred objects and 141,564 referring expressions in RefCOCOg whose descriptions are longer and more complex. We use the umdsplits [35] for RefCOCOg. Implementation details can be found in the Appendix.
Evaluation Metrics. For REC, we utilize the accuracy of the grounding results as the evaluation metric. The predicted region is deemed correct if the intersection over union (IoU) between the predicted region and the ground truth exceeds 0.5. As for RES, we employ the mean Intersection over Union (mIoU) between predicted masks and ground truth as the evaluation metric.
## 4.2 Quantitative Results
## Results of RefCOCO Series.
To validate the effectiveness of our method, we conduct experiments and report our performance on RefCOCO series datasets ( i.e ., RefCOCO/+/g). The results of REC and RES are reported in Table 1 and Table 2,
Table 3: Speed comparison with SOTA methods. ' ↓ ' means lower is better, ' ↑ ' refers to upper is better, and 'FPS' denotes frames per second. The batch size is 20 and all experiments are conducted in one RTX 4090.
| Method | LAVT [46] | PolyFormer | Ours |
|--------------|-------------|--------------|--------|
| Runtime (ms) | 285.97 | 318.36 | 248.35 |
| FPS ↑ | 69.94 | 62.82 | 80.53 |
respectively. Our method outperforms previous state-of-the-art approaches in both REC and RES. Particularly on RefCOCOg, which includes longer and more complex language expressions, our method exhibits even greater improvement (3.62% in the val set and 3.93% in the test set), showcasing its effectiveness in handling intricate scenes.
Speed Comparison. In order to demonstrate the efficiency of our proposed method, as shown in Table 3, we conduct a speed comparison with LAVT [46] and PolyFormer [29]. We use the same settings with LAVT and PolyFormer, i.e ., Swin-B & BERT-base as backbones, and the length of linguistic tokens is
Table 4: Comparison with pre-trained state-of-the-art methods on RefCOCO [50], RefCOCO+ [50], and RefCOCOg [35] for REC and RES task. Bold denotes the best performance. Swin-B and ViT-B are Swin-Transformer Base and ViT Base.
| Method | Backbone | Task Type | RefCOCO | RefCOCO | RefCOCO | RefCOCO+ | RefCOCO+ | RefCOCO+ | RefCOCOg | RefCOCOg |
|-----------------|------------|-------------|-----------|-----------|-----------|------------|------------|------------|------------|------------|
| Method | Backbone | Task Type | val | test A | test B | val | test A | test B | val(U) | test(U) |
| RefTr [22] | ResNet101 | REC | 85.65 | 88.73 | 81.16 | 77.55 | 82.26 | 68.99 | 79.25 | 80.01 |
| SeqTR [53] | DarkNet53 | REC | 87.00 | 90.15 | 83.59 | 78.69 | 84.51 | 71.87 | 82.69 | 83.37 |
| PolyFormer [29] | Swin-B | REC | 89.73 | 91.73 | 86.03 | 83.73 | 88.60 | 76.38 | 84.46 | 84.96 |
| EEVG (Ours) | Swin-B | REC | 89.63 | 92.00 | 86.40 | 82.24 | 87.34 | 74.00 | 83.99 | 84.53 |
| EEVG (Ours) | ViT-B | REC | 90.47 | 92.73 | 87.72 | 81.79 | 87.80 | 74.94 | 85.19 | 84.72 |
| RefTr [22] | ResNet101 | RES | 74.34 | 76.77 | 70.87 | 66.75 | 70.58 | 59.40 | 66.63 | 67.39 |
| SeqTR [53] | DarkNet53 | RES | 71.70 | 73.31 | 69.82 | 63.04 | 66.73 | 58.97 | 64.69 | 65.74 |
| PolyFormer [29] | Swin-B | RES | 75.96 | 77.09 | 73.22 | 70.65 | 74.51 | 64.64 | 69.36 | 69.88 |
| EEVG (Ours) | Swin-B | RES | 77.52 | 79.63 | 75.25 | 71.35 | 75.56 | 64.58 | 71.48 | 71.90 |
| EEVG (Ours) | ViT-B | RES | 79.49 | 80.87 | 77.39 | 71.86 | 76.67 | 66.31 | 73.56 | 73.47 |
Table 5: Performance between Encoder and Decoder for cross-modal interaction.
| Cross-modal Module | Backbone | Task Type | RefCOCO | RefCOCO | RefCOCO | RefCOCO+ | RefCOCO+ | RefCOCO+ | RefCOCOg | RefCOCOg | RefCOCOg |
|----------------------|------------|-------------|-----------|-----------|-----------|------------|------------|------------|------------|------------|------------|
| Cross-modal Module | Backbone | Task Type | val | test A | test B | val | test A | test B | | val(U) | test(U) |
| Encoder | ViT-B | REC | 86.59 | 89.59 | 84.43 | 75.82 | 81.11 | 68.48 | | 78.43 | 78.08 |
| Decoder | ViT-B | REC | 87.55 | 90.03 | 84.71 | 77.31 | 81.84 | 68.89 | | 79.27 | 79.26 |
| Encoder | ViT-B | RES | 76.97 | 78.72 | 75.53 | 67.40 | 71.25 | 60.70 | | 68.12 | 68.19 |
| Decoder | ViT-B | RES | 77.49 | 78.99 | 75.73 | 68.19 | 71.53 | | 61.03 | 68.16 | 68.60 |
20. To ensure a fair comparison, we exclude the time cost of point generation in PolyFormer, as it utilizes a point sequence approach to generate masks after visual-linguistic feature alignment. Compared with PolyFormer which utilizes Encoder for modalities fusion, we are faster than it 28 19% . in FPS (80.53 versus 62.82). Compared with LAVT which devises an interaction module to fuse linguistic features in the visual backbone, we are still faster than it 15 14% . in FPS (80.53 versus 69.94).
Results of Pre-trained setting. Table 4 presents the results of our proposed method pre-trained on a large corpus of visual referring expression data and fine-tuned on the RefCOCO, RefCOCO+, and RefCOCOg datasets. The large corpus consists of the combination of Visual Genome [20], RefCOCO [50], RefCOCO+ [50], RefCOCOg [33], and Flickr30k [36] datasets. Following PolyFormer [29], we pre-train our model using the REC task on this large corpus and subsequently fine-tune on the combined training sets of RefCOCO, RefCOCO+, and RefCOCOg in both REC and RES task, with all validation and test images removed. For the RES task, our method achieves state-of-the-art performance across all validation and test splits, outperforming previous methods by a considerable margin. In the REC task, our approach demonstrates superior or comparable performance to prior state-of-the-art techniques.
## 4.3 Ablation Studies
Comparison between Encoder and Decoder. To demonstrate the effectiveness and efficiency of Decoder, we conduct experiments to compare Decoder
Table 6: Runtime (ms) comparison between Encoder and Decoder, both of them with 3 layers. The batch size is 20 and all experiments are conducted in one RTX 4090. N and L denote the number of visual and linguistic tokens, respectively. The lower value is better in the table.
| N (Visual Tokens) | 196 | 196 | 196 | 196 | 196 | 784 | 784 | 784 | 784 | 784 |
|-----------------------|-------|--------|--------|--------|--------|-------|--------|--------|--------|--------|
| L (Linguistic Tokens) | 60 | 100 | 150 | 200 | 300 | 60 | 100 | 150 | 200 | 300 |
| Encoder | 6.41 | 7.99 | 9.64 | 11.14 | 14.85 | 28.56 | 30.33 | 33.12 | 35.39 | 40.51 |
| Decoder | 5.8 | 6.06 | 6.59 | 6.93 | 8.09 | 28.1 | 28.74 | 29.93 | 30.81 | 33 |
with Encoder for vision language fusion. Table 5 demonstrates that Decoder outperforms Encoder, highlighting Decoder's ability to facilitate vision language alignment. Additionally, Table 6 indicates that Decoder exhibits faster speed compared to Encoder, particularly when handling longer language expressions. It should be noted that Decoder incorporates an additional multi-head crossattention module. To ensure a fair
Table 7: Ablation study of eliminating tokens on RefCOCOg. In the static eliminating strategy, we remove 96 tokens from each layer. ASA denotes adaptive spatial attention, ' ↓ ' means lower is better, and ' ↑ ' refers to higher is better. The runtime of token elimination module is tested in one RTX 4090 and the batch size is 20.
| Elimination Strategy | ASA | Runtime (ms) ↓ | RES | RES | REC | REC |
|------------------------|-------|------------------|-------|--------|-------|--------|
| Elimination Strategy | ASA | Runtime (ms) ↓ | val ↑ | test ↑ | val ↑ | test ↑ |
| No | % | 27.85 | 68.16 | 68.60 | 79.27 | 79.26 |
| Static | % | 24.72 | 66.38 | 66.94 | 78.33 | 79.18 |
| Static | ! | 24.88 | 67.75 | 68.21 | 78.72 | 79.20 |
| Dynamic | % | 24.68 | 68.89 | 68.95 | 79.27 | 79.34 |
| Dynamic | ! | 24.83 | 69.15 | 70.01 | 79.60 | 80.24 |
comparison, we set the dimension of the feed-forward network to 1024 in Decoder and 2048 in Encoder, thereby aligning their parameter quantities.
Token Elimination. To validate the advantages of our token elimination strategy, we compare it with the results obtained without elimination as well as the results achieved using a static elimination strategy [9]. As depicted in Table 7, employing the static token elimination strategy leads to a decline in performance when com-
Table 8: Ablation study of mask head on RefCOCOg. The FPN-like is the mask head based on convolution layers within the FPN framework, which has prevailed in recent VG works [10, 22, 40, 46]. ' ↓ ' means lower is better and ' ↑ ' refers to higher is better. The runtime of mask head is tested in one RTX 4090 and batch size is 20.
| Mask | Parameter Runtime | Parameter Runtime | RES REC | RES REC |
|----------|---------------------|---------------------|--------------|--------------|
| Head | Number ↓ | (ms) ↓ | val ↑ test ↑ | val ↑ test ↑ |
| FPN-like | 8.11M | 23.56 | 68.64 69.12 | 77.68 78.26 |
| Ours | 0.79M | 0.87 | 69.15 70.01 | 79.60 80.24 |
pared to the absence of an elimination strategy. Conversely, the dynamic token elimination strategy not only reduces computational costs but also exhibits performance improvements. Furthermore, the adoption of adaptive spatial attention demonstrates enhancement in performance, thereby mitigating the issue of erroneously eliminating certain visual tokens associated with target objects, as illustrated in Fig. 5.
Efficient Mask Head. In comparison to the FPN-like mask head [19], as reported in Table 8, our mask head has fewer parameters and faster speed. Moreover, our mask head not only demonstrates improvements in the RES task but also exhibits enhancements in the REC task. We believe this is because our
Fig. 7: Visualization of our eliminating process, our predicted results, and LAVT's [46].

light mask head offloads the spatial prediction workload from the task head addons to Decoder which is consistent with the light MLP-based detection head. Consequently, Decoder benefits from improved vision-language fusion, as the location and pixel information are now embedded within the Decoder token feature channels.
## 4.4 Qualitative Results
We present qualitative results achieved using our proposed method and compare them with the results obtained from LAVT, as shown in Fig. 7. These results demonstrate the effectiveness of our approach in managing complex scenes with similar and potentially distracting objects. In such situations, LAVT tends to make incorrect predictions because of these distracting objects. However, our method removes these distracting objects in various Decoder layers, allowing for accurate predictions of the target object. More visualization examples can be found in the Appendix.
## 5 Conclusion
In this paper, we present a novel approach to visual grounding that achieves superior performance while requiring less computational resources. By incorporating visual and linguistic features through cross-attention in the Transformer Decoder, our method effectively handles longer language expressions without significantly increasing the computational cost. To further enhance efficiency, we introduce a parameter-free strategy to remove unnecessary visual tokens during cross-modal fusion. This strategy not only reduces computations but also improves overall performance by eliminating irrelevant objects. After obtaining sparse visual tokens, we propose an efficient mask head that directly generates masks without the need for padding. Extensive experiments conducted on benchmark datasets validate that our method surpasses state-of-the-art techniques in both referring expression comprehension and segmentation tasks.
## Acknowledgment
This work was partially supported by the National Natural Science Foundation of China under Grant 62372341. Long Chen was supported by HKUST Special Support for Young Faculty (F0927) and HKUST Sports Science and Technology Research Grant (SSTRG24EG04).
## References
- 1. Bolya, D., Fu, C.Y., Dai, X., Zhang, P., Feichtenhofer, C., Hoffman, J.: Token merging: Your vit but faster. ICLR (2022)
- 3. Chen, L., Ma, W., Xiao, J., Zhang, H., Chang, S.F.: Ref-nms: Breaking proposal bottlenecks in two-stage referring expression grounding. In: AAAI (2021)
- 2. Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: Endto-end object detection with transformers. In: ECCV (2020)
- 4. Chen, Y.C., Li, L., Yu, L., El Kholy, A., Ahmed, F., Gan, Z., Cheng, Y., Liu, J.: Uniter: Universal image-text representation learning. In: ECCV (2020)
- 6. Deng, J., Yang, Z., Chen, T., Zhou, W., Li, H.: Transvg: End-to-end visual grounding with transformers. In: ICCV (2021)
- 5. Cheng, Z., Li, K., Jin, P., Ji, X., Yuan, L., Liu, C., Chen, J.: Parallel vertex diffusion for unified visual grounding. arXiv preprint arXiv:2303.07216 (2023)
- 7. Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
- 9. Fayyaz, M., Koohpayegani, S.A., Jafari, F.R., Sengupta, S., Joze, H.R.V., Sommerlade, E., Pirsiavash, H., Gall, J.: Adaptive token sampling for efficient vision transformers. In: ECCV (2022)
- 8. Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. In: ICLR (2020)
- 10. Feng, G., Hu, Z., Zhang, L., Lu, H.: Encoder fusion network with co-attention embedding for referring image segmentation. In: CVPR (2021)
- 12. Hong, R., Liu, D., Mo, X., He, X., Zhang, H.: Learning to compose and reason with language tree structures for visual grounding. TPAMI (2019)
- 11. Gu, X., Lin, T.Y., Kuo, W., Cui, Y.: Open-vocabulary object detection via vision and language knowledge distillation. arXiv preprint arXiv:2104.13921 (2021)
- 13. Hu, R., Rohrbach, M., Andreas, J., Darrell, T., Saenko, K.: Modeling relationships in referential expressions with compositional modular networks. In: CVPR (2017)
- 15. Huang, S., Hui, T., Liu, S., Li, G., Wei, Y., Han, J., Liu, L., Li, B.: Referring image segmentation via cross-modal progressive comprehension. In: CVPR (2020)
- 14. Huang, B., Lian, D., Luo, W., Gao, S.: Look before you leap: Learning landmark features for one-stage visual grounding. In: CVPR (2021)
- 16. Jing, Y., Kong, T., Wang, W., Wang, L., Li, L., Tan, T.: Locate then segment: A strong pipeline for referring image segmentation. In: CVPR (2021)
- 18. Kim, N., Kim, D., Lan, C., Zeng, W., Kwak, S.: Restr: Convolution-free referring image segmentation using transformers. In: CVPR (2022)
- 17. Kamath, A., Singh, M., LeCun, Y., Synnaeve, G., Misra, I., Carion, N.: Mdetrmodulated detection for end-to-end multi-modal understanding. In: ICCV (2021)
- 19. Kirillov, A., Girshick, R., He, K., Dollár, P.: Panoptic feature pyramid networks. In: CVPR (2019)
- 21. Lai, X., Tian, Z., Chen, Y., Li, Y., Yuan, Y., Liu, S., Jia, J.: Lisa: Reasoning segmentation via large language model. arXiv preprint arXiv:2308.00692 (2023)
- 20. Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y., Li, L.J., Shamma, D.A., et al.: Visual genome: Connecting language and vision using crowdsourced dense image annotations. IJCV (2017)
- 22. Li, M., Sigal, L.: Referring transformer: A one-step approach to multi-task visual grounding. NeurIPS (2021)
- 24. Liao, Y., Liu, S., Li, G., Wang, F., Chen, Y., Qian, C., Li, B.: A real-time crossmodality correlation filtering method for referring expression comprehension. In: CVPR (2020)
- 23. Li, Y., Mao, H., Girshick, R., He, K.: Exploring plain vision transformer backbones for object detection. In: ECCV (2022)
- 25. Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: ICCV (2017)
- 27. Liu, C., Ding, H., Jiang, X.: Gres: Generalized referring expression segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 23592-23601 (2023)
- 26. Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: ECCV (2014)
- 28. Liu, D., Zhang, H., Wu, F., Zha, Z.J.: Learning to assemble neural module tree networks for visual grounding. In: ICCV (2019)
- 30. Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2018)
- 29. Liu, J., Ding, H., Cai, Z., Zhang, Y., Satzoda, R.K., Mahadevan, V., Manmatha, R.: Polyformer: Referring image segmentation as sequential polygon generation. In: CVPR (2023)
- 31. Lu, J., Batra, D., Parikh, D., Lee, S.: Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. NeurIPS (2019)
- 33. Mao, J., Huang, J., Toshev, A., Camburu, O., Yuille, A.L., Murphy, K.: Generation and comprehension of unambiguous object descriptions. In: CVPR (2016)
- 32. Luo, G., Zhou, Y., Sun, X., Cao, L., Wu, C., Deng, C., Ji, R.: Multi-task collaborative network for joint referring expression comprehension and segmentation. In: CVPR (2020)
- 34. Milletari, F., Navab, N., Ahmadi, S.A.: V-net: Fully convolutional neural networks for volumetric medical image segmentation. In: 3DV (2016)
- 36. Plummer, B.A., Wang, L., Cervantes, C.M., Caicedo, J.C., Hockenmaier, J., Lazebnik, S.: Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In: ICCV (2015)
- 35. Nagaraja, V.K., Morariu, V.I., Davis, L.S.: Modeling context between objects for referring expression understanding. In: ECCV (2016)
- 37. Qu, M., Wu, Y., Liu, W., Gong, Q., Liang, X., Russakovsky, O., Zhao, Y., Wei, Y.: Siri: A simple selective retraining mechanism for transformer-based visual grounding. In: ECCV (2022)
- 39. Rezatofighi, H., Tsoi, N., Gwak, J., Sadeghian, A., Reid, I., Savarese, S.: Generalized intersection over union: A metric and a loss for bounding box regression. In: CVPR (2019)
- 38. Qu, M., Wu, Y., Wei, Y., Liu, W., Liang, X., Zhao, Y.: Learning to segment every referring object point by point. In: CVPR (2023)
- 40. Su, W., Miao, P., Dou, H., Wang, G., Qiao, L., Li, Z., Li, X.: Language adaptive weight generation for multi-task visual grounding. In: CVPR (2023)
- 41. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. NeurIPS (2017)
- 43. Wang, W., Chen, W., Qiu, Q., Chen, L., Wu, B., Lin, B., He, X., Liu, W.: Crossformer++: A versatile vision transformer hinging on cross-scale attention. IEEE TPAMI (2023)
- 42. Wang, P., Yang, A., Men, R., Lin, J., Bai, S., Li, Z., Ma, J., Zhou, C., Zhou, J., Yang, H.: Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In: ICML (2022)
- 44. Wang, Z., Lu, Y., Li, Q., Tao, X., Guo, Y., Gong, M., Liu, T.: Cris: Clip-driven referring image segmentation. In: CVPR (2022)
- 46. Yang, Z., Wang, J., Tang, Y., Chen, K., Zhao, H., Torr, P.H.: Lavt: Language-aware vision transformer for referring image segmentation. In: CVPR (2022)
- 45. Xu, M., Zhang, Z., Wei, F., Hu, H., Bai, X.: Side adapter network for openvocabulary semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2945-2954 (2023)
- 47. Yang, Z., Chen, T., Wang, L., Luo, J.: Improving one-stage visual grounding by recursive sub-query construction. In: ECCV (2020)
- 49. Yu, L., Lin, Z., Shen, X., Yang, J., Lu, X., Bansal, M., Berg, T.L.: Mattnet: Modular attention network for referring expression comprehension. In: CVPR (2018)
- 48. Yang, Z., Gong, B., Wang, L., Huang, W., Yu, D., Luo, J.: A fast and accurate one-stage approach to visual grounding. In: ICCV (2019)
- 50. Yu, L., Poirson, P., Yang, S., Berg, A.C., Berg, T.L.: Modeling context in referring expressions. In: ECCV (2016)
- 52. Zhou, Y., Ren, T., Zhu, C., Sun, X., Liu, J., Ding, X., Xu, M., Ji, R.: Trar: Routing the attention spans in transformer for visual question answering. In: ICCV (2021)
- 51. Zhang, H., Niu, Y., Chang, S.F.: Grounding referring expressions in images by variational context. In: CVPR (2018)
- 53. Zhu, C., Zhou, Y., Shen, Y., Luo, G., Pan, X., Lin, M., Chen, C., Cao, L., Sun, X., Ji, R.: Seqtr: A simple yet universal network for visual grounding. In: ECCV (2022)
## Appendix
## 6 More Analysis of Elimination Strategy
Compared to the static elimination strategy, our dynamic elimination strategy offers an improved approach to address the issue of incorrect elimination during the training process. The static strategy eliminates a fixed number of visual tokens, which can lead to premature elimination and negatively impact the model's performance. In contrast, our dynamic strategy gradually increases the number of eliminated tokens as the loss converges, as shown in Figure 8. This prevents incorrect elimination and en-
Fig. 8: Visualization of eliminating visual tokens process.
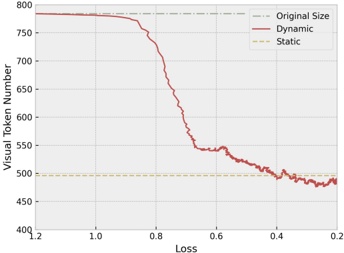
sures a more stable training process. This is why our strategy outperforms the static elimination strategy in the results of previous ablation studies.
## 7 More Analysis of Mask Head
We observed that when using an MLP to project visual tokens into a spatial segmentation mask, the resulting mask lacks spatial relationships between pixels, as depicted in Figure 9. In order to address this issue, we propose the incorporation of a 1-channel convolution layer. This layer helps establish con-
Table 9: Ablation study results of convolution layer in our mask head. 'w/o Conv' denotes without using convolution layer.
| Type | RES | RES | REC | REC |
|-----------|-------|-------|-------|-------|
| Type | val | test | val | test |
| w/o Conv | 67.71 | 68.18 | 78.95 | 79.00 |
| with Conv | 69.15 | 70.01 | 79.60 | 80.24 |
nections between neighboring pixels, thus enhancing the spatial coherence of the resulting mask. The ablation study results are shown in Table 9.
## 8 Additional Qualitative Results
As shown in Figure 10, we provide further visualization examples that illustrate the process of our method for eliminating visual tokens as well as compare the predicted results of our approach with those of LAVT [46].
## 9 Generalization on GRES.
We further validate our approach using the GRES [27] dataset, which includes text corresponding to either multiple objects or none. In this new scenario, we also achieve SOTA, demonstrating the
Table 10: Performance comparison on GRES [27]
| Methods | val | val | testA | testA | testB | testB |
|-----------|-------|-------|---------|---------|---------|---------|
| Methods | cIoU | gIoU | cIoU | gIoU | cIoU | gIoU |
| LAVT [42] | 57.64 | 58.40 | 65.32 | 65.90 | 55.04 | 55.83 |
| ReLA [27] | 62.42 | 63.60 | 69.26 | 70.03 | 59.88 | 61.02 |
| Ours | 64.04 | 62.75 | 71.65 | 70.93 | 62.77 | 62.79 |
superiority and robustness of our method.
## 10 Implementation Details.
We use the AdamW optimizer [30] and the weight decay is 1e-4. The initial learning rate is 5e-6 for the language backbone, 1e-5 for the visual backbone, and 2.5e-5 for the rest of the model. BERT-base [7] is utilized as the linguistic backbone for extracting linguistic features, while ViT-base [8] serves as the visual backbone. We employ the adaptation introduced by ViTDet [23] to adjust the visual backbone for higher-resolution images ( i.e ., 448 × 448 in our method), and it is pre-trained on MS-COCO [26], excluding overlapping images from the val/test sets. The number of Transformer Decoder layers is 3, the hidden dimension is 768, and the feed-forward network dimension is 1024. We train the model for 150 epochs with a batch size of 80 using RTX 4090s. The patch size P is 16, the threshold α is 0.015, k in adaptive spatial attention is 1, the convolutional kernel is 5*5 in our mask head, and λ det and λ seg are 0.1 and 1.
Fig. 9: Comparison of our predicted results between 'w/o Conv' and 'with Conv'. 'w/o Conv' means without using convolution layer in our mask head.
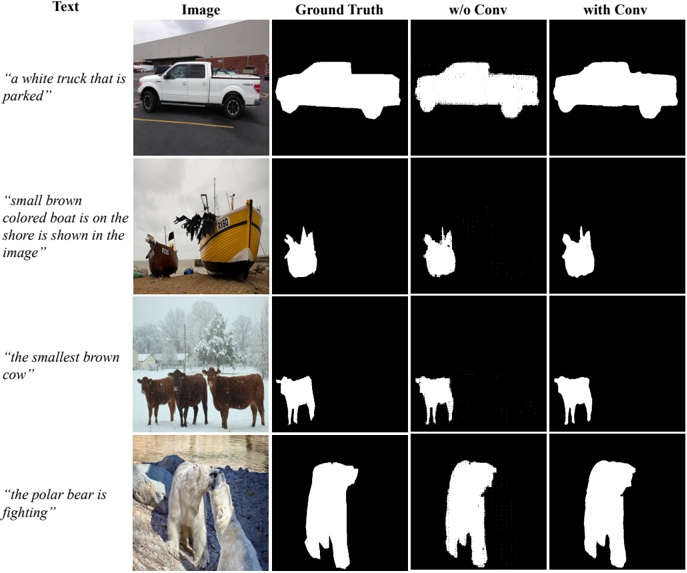
Fig. 10: Additional visualization of our results.
 | null | [
"Wei Chen",
"Long Chen",
"Yu Wu"
] | 2024-08-02T09:01:05+00:00 | 2024-08-02T09:01:05+00:00 | [
"cs.CV"
] | An Efficient and Effective Transformer Decoder-Based Framework for Multi-Task Visual Grounding | Most advanced visual grounding methods rely on Transformers for
visual-linguistic feature fusion. However, these Transformer-based approaches
encounter a significant drawback: the computational costs escalate
quadratically due to the self-attention mechanism in the Transformer Encoder,
particularly when dealing with high-resolution images or long context
sentences. This quadratic increase in computational burden restricts the
applicability of visual grounding to more intricate scenes, such as
conversation-based reasoning segmentation, which involves lengthy language
expressions. In this paper, we propose an efficient and effective multi-task
visual grounding (EEVG) framework based on Transformer Decoder to address this
issue, which reduces the cost in both language and visual aspects. In the
language aspect, we employ the Transformer Decoder to fuse visual and
linguistic features, where linguistic features are input as memory and visual
features as queries. This allows fusion to scale linearly with language
expression length. In the visual aspect, we introduce a parameter-free approach
to reduce computation by eliminating background visual tokens based on
attention scores. We then design a light mask head to directly predict
segmentation masks from the remaining sparse feature maps. Extensive results
and ablation studies on benchmarks demonstrate the efficiency and effectiveness
of our approach. Code is available in https://github.com/chenwei746/EEVG. |
2408.01121v1 | ## Being Accountable is Smart: Navigating the Technical and Regulatory Landscape of AI-based Services for Power Grid
Anna Volkova [email protected] University of Passau Passau, Germany
Mahdieh Hatamian [email protected]
University of Passau Passau, Germany
## Alina Anapyanova
[email protected] University of Passau Passau, Germany
## ABSTRACT
The emergence of artificial intelligence and digitization of the power grid introduced numerous effective application scenarios for AIbased services for the smart grid. Nevertheless, adopting AI in critical infrastructures presents challenges due to unclear regulations and lacking risk quantification techniques. Regulated and accountable approaches for integrating AI-based services into the smart grid could accelerate the adoption of innovative methods in daily practices and address society's general safety concerns. This paper contributes to this objective by defining accountability and highlighting its importance for AI-based services in the energy sector. It underlines the current shortcomings of the AI Act and proposes an approach to address these issues in a potential delegated act. The proposed technical approach for developing and operating accountable AI-based smart grid services allows for assessing different service life cycle phases and identifying related accountability risks.
## CCS CONCEPTS
· Computing methodologies → Artificial intelligence ; · Security and privacy → Human and societal aspects of security and privacy .
## KEYWORDS
Accountability, Artificial Intelligence, Smart grid, AI regulations, Smart grid services
## 1 INTRODUCTION
One of the main objectives of modern power grids is the uninterruptible supply of demands. At the same time, the power generation and distribution processes must be conducted safely to prevent any harm to society. The digitalization of the power grid has introduced significant risks, such as easier access to the power grid assets for cyber-attackers, but also substantial benefits, such as improved control systems and enhanced operational efficiency. System internal faults and external influences constantly challenge the power grid's resilience. The widespread adoption of Artificial Intelligence (AI) initiates the next phase of grid digitalization. Advanced smart grid services utilize AI and underlying machine learning techniques to deliver insights beyond the reach of deterministic software and uncover correlations that may not be apparent to human operators.
## Hermann de Meer
[email protected] University of Passau Passau, Germany
Some AI-based services offer supplementary support, while others enhance or replace functions critical for maintaining the power grid's operation. Supplementary services include grid operation optimization, such as demand response, where AI predicts fluctuations and reduces costs. As a part of the essential grid functions, AI has also demonstrated being effective in forecasting renewable energy generation and load [1], stability analysis and control at different grid voltage levels [46]. Integrating such AI-based services into the smart grid is associated with risks to the stable system operation and, as a result, to society. Data and algorithms used as the basis of AI-based services might produce incorrect decisions and lead to operational failures, which can lead to blackouts. Excessive dependence on AI can result in a lack of human oversight and hinder intervention in case of system failures. On the other hand, some AI-based services, like failure detection, offer benefits by being capable of reacting much faster than human operators.
This work aims to support the development of the methodologies for regulated and accountable AI-based smart grid services and makes recommendations for a potential delegated act for the smart grid. To achieve this, the following contributions are made: 1) A classification of existing ways to address accountability and related terminology in the smart grid context, which enables the derivation of a quantifiable definition of AI-based smart grid service accountability; 2) An analysis of the current shortcomings of the AI Act regarding the future risks of a narrow safety component
Safely implementing AI-based services for the social good requires extensive regulation and methodologies to guarantee riskfree operation. The European Commission has attempted to address AI integration through various regulatory initiatives and proposed AI Act in 2021, which was adopted in March 2024 [17] and complemented by a Corrigendum in April 2024 [16]. Unfortunately, AI Act does not provide domain-specific regulations, leaving space for interpretation regarding the AI integration in the power grid. The central argument of this work is that regulating AI integration in the smart grid requires a proper regulatory framework that can limit the risks related to AI-based services operation and does not hinder the innovation in the smart grid domain. A technical framework should complement it to ensure precise risk quantification. Such a technical framework can be based on the concept of AI accountability, defining it in a quantifiable manner, linking technical risks, their impact on the service operation, and responsible parties.
definition for critical infrastructures; 3) An approach for risk identification and accountability preservation as a part of a technical framework for developing and operating the accountable AI-based smart grid service. The methodology focuses on assessing the different phases of AI-based service development from the planning to model training and operation, identifying related accountability risks, and providing an overview of preservation measures.
The paper is structured as follows. Section 2 discusses existing research in accountable AI-based services. Section 3 evaluates the existing regulations in the domain. Section 4 clarifies the concept of accountability, distinguishing it from related terms and providing a quantifiable definition. Section 5 proposes a methodology to analyze accountability risks based on development methodologies.
## 2 RELATED WORK
Some recent studies specifically address the definition of accountability and accountability requirements. For instance, in [25], the authors categorize and structure definitions of accountability, presenting a model to capture accountability in system design. In [56], authors discuss the need to narrow down high-level definitions of accountability and related terms and make these enforceable. In contrast, the present work focuses on sector-specific accountability and provides definitions that support quantification of accountability for AI-based smart grid services. In [7], accountability is discussed as the intersection of explainability and responsibility, and the existing regulations covering these concepts are analyzed. However, no approach to quantify accountability is proposed. While in [7] the authors only introduce the concept of implementable accountability, the present work proposes an approach to how implementable accountability can be achieved in the smart grid.
The challenge of translating accountability into legal regulation has been discussed in [7]. In the absence of AI-specific regulations, IEC 61508 [23] has been reviewed as a source of recommendation for AI integration in critical infrastructures. Thus, authors in [51] state that all AI applications in the critical infrastructure are generally not recommended in the standard. However, the Standard only discourages using AI for particular applications in safety-related functions. An attempt to adjust Satefy Integrity Levels for AI has been discussed in [12]. The proposed approach is valid but too abstract: AI safety risk classification should be done more granularly.
Accountability in the smart grid domain has also been addressed from a technical point of view. Thus, in [50], the authors review methods to provide authentication, authorization, and accountability in smart grids from the communication network perspective. In [55], the authors demonstrate a conceptual monitoring system for AI-based smart grid services and indicate that monitoring of AI in energy grid operations is essential for establishing accountability. In contrast, while showing the importance of monitoring, the present work proposes an approach to guarantee accountability for all the AI-based service life cycle phases.
flaws in AI development pipeline is presented in [42]. The present work refines it for smart grid applications and discusses the role of risk identification as an accountability mechanism. In [19], a survey on responsible AI development process and required tools are presented. While the collected responses can support the design of the toolbox for risk reduction at different phases, the accountability of each tool should be analyzed separately.
Further related work is summarized in Table 1. Most studies focus on accountability in AI or specifically within power systems. Additionally, some authors discuss the regulatory aspects of AI and analyze recent regulations proposed by the EU and various governmental institutions alongside the technical assessment of accountability in AI. In [37], additional use cases of AI in the electricity sector, such as forecasting models and flexibility asset management, are discussed but were not yet identified under a particular risk category of the AI Act or analyzed in the context of the safety component definition. This paper follows up on this discussion with a more detailed analysis.
## 3 AI-BASED SERVICES IN THE SMART GRID
A smart grid has been defined by many different institutions and authors, for example, as ' an advanced digital two-way power flow power system capable of self-healing, adaptive, resilient, and sustainable with foresight for prediction under different uncertainties ' [13]. Many of these advanced features elevate the system from its pure physical purpose of transferring the power flow to an intelligent system capable of reacting and overcoming the existing challenges, improving its cost-effectiveness and customer satisfaction. AI has been demonstrated effective in essential technical, including safetyrelated functions, and user- and grid economy-oriented services. Some functions, such as voltage and frequency control, directly impact the system operation. Demand response, while being a critical function for the system's operation effectiveness, is not strictly required for system operation. Client-oriented functions, such as consumption analysis and billing optimization, do not affect the system's operation directly. The services also function on different time scales, allowing or hindering human oversight. Control and fault mitigation services make decisions quickly during the operation, while forecasting services provide calculations in advance and ensure sufficient time for operators to react to the proposed predictions. In this work, the term AI-based smart grid service considers both technical and process optimization functions operating within the smart grid and having AI-based components. This work does not discuss information security-related services.
One of the core insights of the present work is that accountability is only achievable through accountable development. The impact of the development flaws on the AI-based service performance has been discussed in [40] with a focus on data bias. The present work considers bias mitigation, among other steps, as an important accountability guarantee. An extensive survey on potential design
To guarantee the safe operation of the AI, the responsive regulations should consider the level of AI involvement in the operation of the particular smart grid function. This section discusses the existing regulations in the AI domain and their applicability to the power grid domain. After the in-depth analysis of the most important formulations, the problem of deriving regulations and recommendations and the need for AI accountability is discussed.
## 3.1 Current Status of AI Regulation in Energy
AI and Machine Learning technologies have increasingly come to the attention of European lawmakers in recent years. The result was a consensus at the European level that a common regulatory
© Anna Volkova 2024. This is the author's version of the work. It is posted here for your personal use. Not for redistribution. The definitive version was published in International Conference on Information Technology for Social Good (GoodIT '24), September 04-06, 2024, Bremen, Germany. https://doi.org/10.1145/3677525.3678651
Table 1: Analysis of related research from recent years based on the considered aspects
| Ref. | Year | Objective | Accountability | Power Grid | Technical | Regulatory |
|--------|--------|--------------------------------------------------------------|------------------|--------------|-------------|--------------|
| [18] | 2020 | Highlight critical ethical considerations for future AI | | | ✓ | |
| [27] | 2020 | Address risks and accountability issues for data subjects | ✓ | | | ✓ |
| [40] | 2020 | Provide a comprehensive overview of bias in AI systems | | | ✓ | ✓ |
| [25] | 2021 | Categorize and structure the definitions of accountability | ✓ | | | |
| [37] | 2021 | Discuss EU AI Act's impact and risks on electricity sector | | ✓ | | ✓ |
| [50] | 2021 | Review authentication, authorization, and accountability | ✓ | ✓ | ✓ | |
| [7] | 2022 | An accountable AI framework with ethical and legal aspects | ✓ | | | ✓ |
| [36] | 2022 | Review regulations proposed by governmental institutions | | | | ✓ |
| [42] | 2022 | Discuss the challenges in AI deployment phases | | | ✓ | |
| [51] | 2022 | EU AI Act vs. IEC 61508 for AI in critical infrastructure | | | ✓ | ✓ |
| [55] | 2022 | Propose a monitoring system for AI-based smart grid | ✓ | ✓ | ✓ | |
| [56] | 2022 | Make accountability and related concepts enforceable | ✓ | | | ✓ |
| [12] | 2023 | Introduce safety integrity levels for AI in critical systems | | | ✓ | |
| [19] | 2023 | Integrate Responsible Design Patterns into the AI pipeline | ✓ | | ✓ | |
| [21] | 2023 | Regulate accountability in automated decision-making | ✓ | | | ✓ |
framework was needed to both foster AI-related innovation and to contain its risks in several fields. The European AI Act, adopted in March 2024 and being part of the European digital strategy, constitutes, therefore, a novel European legislative instrument aiming to ensure a safe, transparent, traceable, non-discriminatory, and environment-friendly application of AI technology [17].
It defines AI in Art. 3 point (1) as a machine-based system designed to operate with varying levels of autonomy, that may exhibit adaptiveness after deployment and that, for explicit or implicit objectives, infers, from the input it receives, how to generate outputs such as predictions, content, recommendations, or decisions that can influence physical or virtual environments . The European Commission did not choose a sector-specific AI regulation but rather an all-encompassing and principle-based Regulation, including possible categories of AI application in all sectors: unacceptable risk, high risk, certain types of AI with transparency obligations, general purpose AI, and non-risk risk AI, as presented in Figure 1. The cases of AI with an unacceptable level of risk are laid down in Art. 5 of the AI Act, followed by the high-risk areas in Art. 6 and in Annex III. Certain types of AI systems are subject to transparency obligations according to Art. 50, followed by the general purpose AI Models, subject to specific obligations, listed in Art. 51. The remaining categories of non-high risk AI are defined in the recital (165) and in Art. 95 and can voluntarily comply with the Code of Conduct. The different risk categories implied a different set of rules and obligations, which AI-developers would have to follow.
water, gas, heating and electricity . Such safety components are further defined in point (55) of the AI Act, Safety components of critical infrastructure, including critical digital infrastructure, are systems used to directly protect the physical integrity of critical infrastructure or health and safety of persons and property but which are not necessary in order for the system to function . The failure or malfunctioning of such components might directly lead to risks to the physical integrity of critical infrastructure and thus to risks to the health and safety of persons and property. Components intended to be used solely for cybersecurity purposes should not qualify as safety components. Examples of safety components of such critical infrastructure may include systems for monitoring water pressure or fire alarm controlling systems in cloud computing centers. This definition resembles the safety component definition in the Art. 2(b) of the Machinery Directive, where a safety component was described as not necessary for the system to function [14]. Such a definition is too product-oriented and ignores the fact that there are elements in the digital and critical energy infrastructure where safety and functioning are interdependent in the system's algorithm. Certain safety functions in generation plants, power grids, or digital infrastructures can be indispensable for the system's functioning and safety, e.g., using AI for voltage and frequency-control mechanisms, stability assessment systems, and load balancing.
## 3.2 AI as Safety Components
The energy sector has been categorized as a high-risk field of application for AI technologies if AI technology is being used for safety components in the management and operation of critical infrastructures, including the digital critical infrastructures. These are defined in Art. 2 point 4 and in Annex I of the Directive (EU) 2022/2557 [15] and in Annex III point 2 of the AI Act. High-risk AI systems in the energy sector are referred to in Annex III point 2 of the AI Act as: (a) AI systems intended to be used as safety components in the management and operation of road traffic and the supply of
The AI Act states that only if AI technology is used in safety components needed for the safety and physical integrity but which are not necessary for the system to function, high risk can be identified. Such a limitation is very narrow and does not reflect the constantly evolving nature of smart grid AI applications. How to regulate cases where AI technologies might be interconnected and used in safety components for the protection and functioning of the whole system are not yet dealt with in the Act and will have to be clarified in an additional sector-specific delegated act. Until then, this will remain a grey zone, leaving room for interpretation for AI providers. A potential consequence could be that AI applications developed for the safe operation of critical infrastructure, such as voltage or frequency control, but which do not meet the safety component definition under the Act, will simply not be covered by the AI Act and will not be obliged to meet the High-Risk AI
© Anna Volkova 2024. This is the author's version of the work. It is posted here for your personal use. Not for redistribution. The definitive version was published in International Conference on Information Technology for Social Good (GoodIT '24), September 04-06, 2024, Bremen, Germany. https://doi.org/10.1145/3677525.3678651
Figure 1: Risk categorization under the AI Act
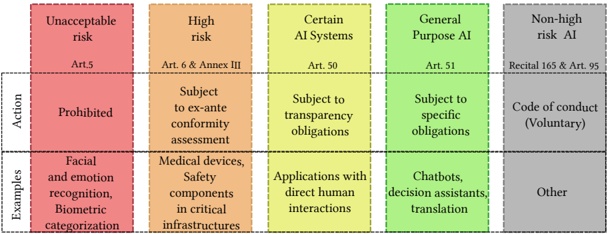
| Unacceptable risk Art.5 | High risk Art. 6 & Annex III | Certain AI Systems Art. 50 | General Purpose AI Art. 51 | Non-high risk AI Recital 165 & Art. 95 |
|----------------------------------------------------------|----------------------------------------------------------------|---------------------------------------------|--------------------------------------------|------------------------------------------|
| Prohibited | Subject to ex-ante conformity assessment | Subject to transparency obligations | Subject to speci fi c obligations | Code of conduct (Voluntary) |
| Facial and emotion recognition, Biometric categorization | Medical devices, Safety components in critical infrastructures | Applications with direct human interactions | Chatbots, decision assistants, translation | Other |
compliance and accountability obligations. This is questionable in light of the potential risk implications for the system operators and users of the critical infrastructure [37].
## 4.1 Limitations of Definitions in the AI Act
## 3.3 Problem Formulation
As a result, the AI Act does not provide sufficient regulation action for all the variety of use-cases of AI-based services in the power grid. The definition of the safety component is capturing only a subset of possible functions that can be realized using AI, while other potential AI-based services are not covered. Since unreliable usage of AI in critical infrastructure is a major public safety concern, additional actions are required to guarantee that the development and implementation of the AI has been carried out responsively. In IEC 61508 [23], qualitative and quantitative approaches have been proposed in the safety-relevant systems to assign risk levels to the safety functions. In [12], a similar approach was proposed for general purpose AI functions. Along with qualitative parameters, such as non-determinism, a quantitative framework for risk assessment and definition of rigor activities should be provided. Developing and legislating such safety standards for AI is a complex but necessary task to be completed in the next decades. However, already nowadays, actions are required to provide granular control of the developing AI-based services. A delegated act could be introduced and propose a methodology to supervise AI-based service from the planning till the commission phase. Such supervision can be quantified through a mechanism of service accountability. Accountability is usually defined through its core dimensions: explainability, audibility, and trustworthiness. However, the interpretation of accountability varies across different domains [7, 25]. A sector-specific accountability for AI-based service should be defined, described, and quantified to overcome it. In this work, an accountable AI-based smart grid service is defined, and an approach to preserve overall accountability through accountability of the separate development and deployment processes is presented.
## 4 DEFINING ACCOUNTABILITY
This section discusses the existing definitions of accountability in different sources: in AI Act, in general and smart grid-specific literature. An approach to provide a quantifiable definition of accountable AI-based smart grid service is presented.
The current AI Act demands accountability from AI applications in different ways. Accountability was already identified by the Commissions Expert Group on AI in 2019, as a requirement for trustworthy AI [22]. In the AI Act itself, accountability is not defined but can be found partially hidden in terms of transparency, explainability and interpretability. These terms can be found in different Articles of the Act and concern primarily AI providers' obligations regarding high-risk applications. The following non-exhaustive list of examples shows the legislators' intention to ensure transparency of AI High-Risk systems through an ex-ante conformity assessment of AI applications. One clear example is the record-keeping requirement. As stipulated in Art. 12 point (1) and Art. 19 of the Act, automatic recording of events should be possible, illustrating the need for traceability of AI. Interpretability and transparency requirements are to be found, among others, in Art. 13 and in Section 3 of the Act. It states that High Risk AI applications shall be designed so that their operation is sufficiently transparent to enable users to interpret and use the system's output. Further, the requirement for human oversight of AI decisions and in AI design in general are to be found in Art. 13 (3)(d) and Art. 14 of the Act. Lastly, data quality of AI is to be ensured through a quality management system and documentation requirements in Art. 17 and 18.
Thus, the Act does not define AI accountability as a separate term but requires High-Risk AI providers and deployers to follow different obligations, leading to more trustworthiness, irrespective of their application sector. The described approach covers the most crucial aspect of AI development and deployment. However, it requires more granularity for recommended and undesired techniques at each step for specific domains, e.g., for the smart grid.
## 4.2 Accountability in Literature
The general literature on AI lacks a precise definition of accountability for AI-based systems due to its relation to several other aspects. Nissenbaum defines it as a requirement to provide information regarding a performed action, explain why it was taken, and undertake a follow-up action, which could include various responses such as punishment or penalty [38, 56]. In [31], the authors remark that ' In general, accountability for AI indicates how much we can trust these AI technologies and who or what we should blame if any parts of the AI technologies perform below expectation. It is about a declaration of responsibility. It is not trivial to explicitly determine the
© Anna Volkova 2024. This is the author's version of the work. It is posted here for your personal use. Not for redistribution. The definitive version was published in International Conference on Information Technology for Social Good (GoodIT '24), September 04-06, 2024, Bremen, Germany. https://doi.org/10.1145/3677525.3678651
Table 2: Accountability requirements in the literature, including smart grid domain-specific work (in bold)
| Requirements | Characterization | Resources |
|------------------|-------------------------------------------------------------------------------|--------------------------------------------------------------------|
| Responsibility | The obligation of a system or individual to follow procedures or standards | [32] [55] [38] [8] [28] [31] [29] [5] [52] [33] [26] [48] [41] [7] |
| Explainability | Ensure understanding and justification of AI systems, processes and decisions | [55] [56] [9] [31] [49] [30] [43] [7] [52] |
| Transparency | Social-ethically centered information accessibility | [56] [26] [9] [54] [33] |
| Answerability | Design of a process or system that allows the clarification of an action | [38] [56] [9] [39] [33] |
| Trustworthy | A property of acting ethically and demonstrating integrity and trust | [55] [38] [31] [43] |
| Auditability | Verification if processes follow policies, standards or regulations | [56] [31] [43] [52] |
| Moral & Ethical | Enhancing legal and constitutional requirements in system architecture | [52] [10] [41] |
| Traceability | The ability to track a process through several phases of a system production | [32] [57] [52] |
| Punishment | Consider penalty for any harmful act of a system | [32] [38] |
| Property | Consider any attribute or characteristic as a feature for defining a system | [31] [25] |
| Interpretability | Ensure that a model and its outcomes are clear and simple to understand | [56] |
| Attributability | Identify the role or function of each component in the system | [43] |
| Recordability | Validate that all actions are entered into the system and documented | [32] |
| Controllability | To provide authority and accessibility measurement for a process or system | [26] |
accountability for AI. On the one hand, most AI-based systems act as black-box, due to the lack of explainability and transparency. On the other hand, real-world AI-based systems are very complex and involve numerous key components, including input data, algorithm theory, implementation details, real-time human control. These factors further complicate the determination of accountability for AI. Although difficult and complex, it is necessary to guarantee accountability for AI. Auditability, which refers to a set of principled evaluations of the algorithm theories and implementation processes, is one of the most important methodologies in guaranteeing accountability. ' In [52], it is stated that ' Six main dimensions can be associated with accountability according to the goals and needs of the different stakeholders: responsibility, justification, audit, reporting, redress, and traceability, and in this regard, there are several excellent works that focus on the aforementioned specific dimensions. ' In [48], the research indicates that ' Accountability in AI, thus, becomes less about how AI is built, and more about how it is understood, legislated, and regulated. '
role where explainability approaches are not applicable, e.g., when a decrease in performance cannot be avoided. Accountable AI also increases trustworthiness of the implemented services by different stakeholders and end users (...) . '
## 4.3 Deriving a Definition
A comprehensive definition would support the development of an accountability framework and should encompass various aspects of accountability relevant to different phases of the service life. The other challenge is quantifying accountability and measuring the risks if the AI does not fulfill accountability recommendations. Providing a cross-sector unified definition of accountability is only possible at a high level of abstraction.
In the energy domain, accountability has not yet been sufficiently covered. In [32], the authors state that ' Accountability is required to further secure the smart grid in terms of privacy, integrity, and confidentiality. Even if a security issue presents itself, the builtin accountability mechanism will find out who is responsible for it. Once detected, some problems can be fixed automatically through the predefined program, while others may provide valuable information to experts for evaluation. In essence, accountability means that the system is recordable and traceable, thus making it liable to those communication principles for its actions . ' In [55], it is argued that ' Accountability of the AI-based services should play a central
Thus, the definition of accountability should be directly applicable to the target service or process. In this regard, an accountable AI-based smart grid service can be defined as service that is: 1) conceptualized and developed according to the sector-specific regulations and with clear identification of roles and responsibilities of all involved parties 2) regulated over the whole life cycle from planning to commissioning to minimize risks of an incorrect behavior in each development phase by tracing the impact of each step on the service outputs, recording all the decisions and actions performed during the development and deployment as well as responsible parties, guaranteeing accessibility of collected and processed data for involved parties 3) monitored during the operation time with granular insight into the impact of design choices on the output . It is important to note that explainability [34] has been explicitly not used in this definition since its human-centered nature and the general tendency for reduced performance due to model simplification are not applicable for some of the power grid services [7, 55]. In the case of accountability, complexity is seen as the source of potential design and development imperfections and related risks but is acceptable.
## 5 ACCOUNTABILITY PRESERVATION IN AI-BASED SERVICE DEVELOPMENT
Essentially, AI-based service accountability, defined in Section 4.3, should be preserved by a technical framework, which should cover
© Anna Volkova 2024. This is the author's version of the work. It is posted here for your personal use. Not for redistribution. The definitive version was published in International Conference on Information Technology for Social Good (GoodIT '24), September 04-06, 2024, Bremen, Germany. https://doi.org/10.1145/3677525.3678651
Keywords derived from the definitions include 'responsibility', 'transparency', 'auditability' and 'explainability'. These terms represent the prerequisites for accountability in AI-based systems, as they contribute to developing and implementing systems that prioritize trustworthiness, fairness, and responsibility for all stakeholders. Table 2 extends this discussion and represents a collection of resources regarding accountability definition and related dimensions. This collection comprises 24 scientific articles defining accountability or highlighting its various dimensions, e.g., 'responsibility' is mentioned in 14 analyzed works, and 'explainability' - in 9.
Table 3: Accountability issues in data collection
| Step | Possible risks to accountability | Examples of preservation methods |
|--------------------|------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Dataset Generation | Lack of planning; Unreliable data sources; Induced errors; Insufficient or redundant data; Irresponsible data provider | Clear requirements to accuracy, completeness, and consistency; Planned and prepared data collection process; SLA for data quality; Repeated collection from the same system in the presence of bias |
| Digital Twin | Data errors; Bias; Incorrect assumptions; Oversimplification in digital twin model; Incomplete data; Not representative data | Record of assumptions in twin model; Ensured correctness of the twin system; Ensured interoperability for digital twin and real system |
| SLA [2] | Lack of clear requirements for data assurance | Regulatory implementation of SLA for all iterations of service development |
| Data Storage | Loss of data; Loss of access to data; Lack of integrity (unreliable storage) | Clear data storage requirements; Regulation regarding data storing period between power grid and service provider; Enabled access to data for all required parties; Ensured security; SLA for data storage |
| Data Induction | Leakage of irrelevant and private data | Only necessary data collected; Regulated and recorded operations on data; Data aggregation on edge; Data obfuscation |
all the life cycle phases. The general phases are planning, development, and operation. This section focuses on the development phase, which involves data collection and storage, data preprocessing, feature selection and extraction, and utilizing learning algorithms [53]. A wide range of possible techniques characterizes each of these steps. This section discusses exemplary major steps and related accountability risks and omits some smaller ones, e.g., in data engineering [35]. Strategies to preserve accountability in the planning, operation, and commissioning phases and business-related aspects will be discussed in future work. The early insight into accountability preservation during the operation phase is discussed in [55].
## 5.1 Data Collection and Correction Phases
The established and accountable data collection and correction process is the initial step of accountability assurance. In this regard, the smart grid is a special case since the data can have different origins: assembled from the measurements of the real system, from a digital twin, or from software simulation, each with its specific accountability issues. General accountability issues of this step are listed in Table 3.
guarantee an accountable re-training process, especially when data is shared between different stakeholders in the energy sector. A well-defined and extensive Service Level Agreement (SLA) between the parties can be used to introduce responsibility in data utilization. Aregulatory framework may support SLAs formulation for explicit usage in smart grids and performance metrics for data quality.
## 5.2 Data Quality Assurance and Preprocessing
Poor data quality in the training process can directly affect service performance, and the original reason for such behavior will be hard to identify. Data preprocessing methods are mainly employed to address issues inherited from the data collection process (uncertainties [20], errors, lack of data). These methods may be one of the core sources of accountability risks, as they involve techniques that transform the original data. The risks related to removing, adding certain data, or aligning data points impact the developed model and should be carefully identified. By data dispersion, several data sources with different schema or conventions are merged into a single dataset. The differences in data structures and types and the various tools required to enable data integration need special attention. The development methodology should be capable of finding a trade-off between the necessary preprocessing steps and the risk to accountability these introduce due to their complexity and required assumptions. Data dispersion from multiple sources is undesired for accountability preservation in smart grid services, and a unified data collection plan should be introduced. An overview of some of the potential technical processes can be found in Table 4.
For many grid services, the data is heterogeneous with varying resolutions, mostly asynchronous, and is stored in different formats (raw or processed) at different locations [6]. Collected and processed data should be stored throughout service deployment and additional time after commissioning to preserve accountability. Access to the original and training data and clear documentation of the data origin, collection process, and format can enable postfactum analysis of incidents and study the impact of data on the service output. Careful and planned data storage is also required to
In the data collection step, data source discovery should be associated with a detailed understanding of the behavior of the system components. Data collection for smart grid applications should consider the physics of the processes, e.g., for voltage and frequency control applications. Furthermore, sensor data collection can be associated with many induced errors due to sensor aging and losses during data transmission. The associated risks should be well documented at this stage and forwarded to the data correction methods. Preliminary data sampling can help to identify and fix faulty components. Sampling data from the digital twin [47] is a concern for accountability due to the complexity of the twin system modeling and introduces the digital twin provider as a responsible party.
Smart grid data may have hard-interpretable labels depending on the type of service. Each method of data labeling has an impact on accountability. Manual labeling is prone to human error, while automated labeling tools usually include different AI methods. Such labels can inherit all issues from the accountability of the tools [3]. Accountability for this step can be preserved by clearly planning the labeling process and continuous validation and refining through feedback loops. Data leakage and dispersion can threaten the system's accountability during the filtering and labeling processes. By data leakage, target variables (irrelevant or personal data) are leaked in the training. When leakage happens, the model retains characteristics connected with irrelevant data without explicitly including those features in the model. The accountability of this
© Anna Volkova 2024. This is the author's version of the work. It is posted here for your personal use. Not for redistribution. The definitive version was published in International Conference on Information Technology for Social Good (GoodIT '24), September 04-06, 2024, Bremen, Germany. https://doi.org/10.1145/3677525.3678651
Table 4: Accountability issues in data quality
| Step | Possible risks to accountability | Examples of preservation methods |
|--------------------------|----------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------|
| Data Cleaning [58] | Incorrect and/or undocumented pattern detection; Loss of data; Loss of granularity | Planned and recorded actions; Validation procedures; Quality assurance metrics |
| Filtering | Unregulated rules; Loss of data | Planned and recorded filtering criteria; Validation procedures; Quality assurance metrics |
| Uncertainty Mitigation | Loss of data; Loss of correlations in data | Clear definition of uncertainty types; Identification of the tolerable uncertainty levels; Validation procedures |
| Anomaly Detection | Loss of data; Loss of correlations in data | Clear definition of anomalies; Evaluation of the anomaly scope; Validation procedures; Quality assurance metrics |
| Dimensionality Reduction | Loss of data due to inaccurate reduction; Loss of correlations in data; Bias; Overfitting; Complexity of composite dataset | Planned and recorded actions; Responsible method selection |
| Synthetic Data [45] | Infeasible data; Leakage of data origin; Incorrect data syntheses; Loss of complex dependencies; | Justification for synthetic data selection; Validation of data harmonization |
| Augmentation [59] | Uncontrollable infusion of additional data; Loss of data | Recorded augmentation strategy; Validation of data consistency |
| Labeling [3, 42] | Inconsistent labeling rules; Error and loss of accountability through AI-tools | Avoidance of non-deterministic tools; Recorded strategy for labeling; Validation within each label |
| Data Anonymization | Insufficiently described actions; Data loss; Loss of relations between the data points | Avoidance of sensitive data during the collection phase; Anonymization during the collection; Recorded rules and assumptions |
process should be preserved by careful planning, early issue detection, and documentation of the completed steps and used tools [42]. Since the fusion of private and system data is common for the power grid, numerous techniques can be used to anonymize data. Anonymization reduces the granularity and accuracy of the data, leading to the loss of the complex correlations between data points. This can lead to accountability issues since the model's output is unreliable due to the lack of critical data or data patterns. Time-series data in the power grid should be handled delicately to preserve diffused behaviors over larger time scales.
Data augmentation methods, including synthetic data, resolve the issues related to limited data volume or unbalanced data. However, synthetic data is vulnerable to information leakage from original data and inaccuracies. Moreover, capturing outliers and lowprobability events in synthetic data is challenging [42]. A synthetic data generator may not replicate statistics accurately. The same applies to the common for smart grid digital twin data application in real systems [24]. Thus, low-probability events may not be evident or have different patterns in the twin and real system behavior.
techniques can lead to losing important features while eliminating unsuitable ones. It can fail to achieve dimensionality reduction and overlook significant feature correlations. The feature transformation methods may require dividing a feature or merging two or more features to build a new one using various methods. Applying the transformation methods changes the essence of data and may introduce biases. Algorithmic bias appears when mathematical rules highlight specific attributes over others in relation to a target variable [4]. The feature engineering process should be carefully planned and documented to track the steps of the process for the ex-post analysis. Feature selection and labeling also allow methods to approximate the model locally with other interpretable models and understand the influence of features on service output.
## 5.3 Model Training and Validation
After the data collection and preparation phase, the datasets are ready for training. From this point, the algorithm will inherit all the remaining issues in the data. Accountability of the data preparation phase allows access to the used assumptions and methods, especially if the dataset is being used by a different party or reused to develop multiple services. Table 5 presents primary training steps and related risks.
Accountability in the model learning phase should be preserved for three main steps: model selection, training, and hyperparameter selection. Justification of the model selection should be provided concerning the complexity of the problem and the application scenario. The increased complexity of the selected algorithm impacts accountability as it deals with sensitive hyperparameters. Tuning requires a knowledge of the search space, which is not always achievable due to complexity. Further constraints from the deployment environment may also introduce bounds on the hyperparameter selection [42]. Accountability issues arise when the hyperparameter's choices and bounds are insufficiently justified. Inaccurately tuned hyperparameters result in overfitting, underfitting, or bias.
The model selection and training are based on the objective and available features. The feature engineering process usually includes extraction, selection, and transformation phases. Accountability risks arise from the feature selection process due to incorrect formulation of the objectives and assumptions, resulting in feature extraction and transformation flaws. Improper feature selection
The training process is initiated after carefully implementing and selecting the hyperparameters, usually in parallel with the performance evaluation. Accountability of this step is defined through extensive validation with a feasible selection of the validation metrics that should cover accuracy, bias, and fairness. Accountability may be compromised if the chosen metrics fail to consider bias issues or detect parameter errors for the training and unseen test sets. However, the test set can further compromise accountability by not being representative or infected with training data. Such risks will be explicitly evaluated in a future use-case study.
© Anna Volkova 2024. This is the author's version of the work. It is posted here for your personal use. Not for redistribution. The definitive version was published in International Conference on Information Technology for Social Good (GoodIT '24), September 04-06, 2024, Bremen, Germany. https://doi.org/10.1145/3677525.3678651
Table 5: Accountability issues in model training
| Step | Possible risks to accountability | Examples of preservation methods |
|----------------------------|---------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------|
| Feature Selection [11] | Improper usage of selection techniques; Usage of too complex techniques | Preference towards deterministic methods |
| Feature Transformation | Improper scaling and encoding | Preference towards simple features; Recorded and justified rules for complex features |
| Model Selection | Insufficient analysis of model applicability; Insufficient preliminary analysis of model benefits | Model selection adequate problem requirements; Risk assessment for each candidate model |
| Model Training | Insufficient cross-validation; Inaccurate processing of hyperparameters; Model bias | Validation metrics for each training cycle; Clear track of model performance evolution |
| Hyperparameter Tuning [44] | Insufficient parameters; Unnecessary probabilistic models to find hyperparameters | Search space analysis; Guaranteed reproducibility of the selection process |
| Model Validation | Not representative training set; Insufficient metrics; Lack of analysis | Recorded configuration of validation experiments; Analysis of data preprocessing decisions in validation phase |
## 6 CONCLUSION
Additional measures are needed to ensure responsible development and deployment for reliable AI usage in critical infrastructures. This paper analyzes the current AI Act and demonstrates its limited granularity in considering technical aspects of the smart grid, e.g., in safety component definition. A delegated act could include a methodology for supervising critical AI-based services in the energy sector, closing the current gap in the AI Act. An accountabilitybased framework is suggested as a fundamental part of a delegated act. A literature survey of existing definitions of accountability identifies the most significant accountability dimensions, and sectorspecific quantifiable accountability definition for AI-based smart grid service is derived. The quantification of the accountability risks can be narrowed down to each phase of the AI-based service development from planning to commissioning. This work discusses accountability risks for data collection, preprocessing, and model training phases. The future work will consider implementing the discussed accountability preservation in an exemplary AI-based service, underlining the impact of design decisions on operation and the assigning responsibility of different parties.
## ACKNOWLEDGMENTS
This work was funded by project 'EnerSat (Satellitengestützte Kommunikation für das Energiesystem)' that has received funding from BMWK(Bundesministerium für Wirtschaft und Klimaschutz) under funding indicator 50RU2303C and by the European Union's Horizon 2020 research and innovation programme under grant agreement No. 957845. The authors would like to thank Dr. Brenda Espinosa Apráez from the Tilburg University, the Netherlands, for insightful discussions on the AI Act.
## REFERENCES
- [1] Tanveer Ahmad, Hongcai Zhang, and Biao Yan. 2020. A review on renewable energy and electricity requirement forecasting models for smart grid and buildings. Sustainable Cities and Society 55 (2020), 102052. https://doi.org/10.1016/j. scs.2020.102052
- [4] Niels Bantilan. 2018. Themis-ml: A fairness-aware machine learning interface for end-to-end discrimination discovery and mitigation. J. of Technology in Human Services 36, 1 (2018), 15-30. https://doi.org/10.1080/15228835.2017.1416512
overreliance. Proc. of the ACM on Human-Computer Interaction 5 (2021), 1-27. https://doi.org/10.1145/3449163
[5] Sweta Bhattacharya, Rajeswari Chengoden, Gautam Srivastava, Mamoun Alazab, Abdul Rehman Javed, Nancy Victor, Praveen Kumar Reddy Maddikunta, and Thippa Reddy Gadekallu. 2022. Incentive mechanisms for smart grid: State of the art, challenges, open issues, future directions. Big Data Cognitive Computing 6 (2022), 1-28. https://doi.org/10.3390/bdcc6020047
[7] Auxane Boch, Ellen Hohma, and Rainer Trauth. 2022. Towards an accountability framework for AI: Ethical and legal considerations . Technical Report. 1-12 pages.
[6] Bishnu P. Bhattarai, Sumit Paudyal, Yusheng Luo, Manish Mohanpurkar, Kwok Cheung, Reinaldo Tonkoski, Rob Hovsapian, Kurt S. Myers, Rui Zhang, Power Zhao, Milos Manic, Song Zhang, and Xiaping Zhang. 2019. Big data analytics in smart grids: state-of-the-art, challenges, opportunities, and future directions. IET Smart Grid 2, 2 (2019), 141-154. https://doi.org/10.1049/iet-stg.2018.0261
[8] Mark Bovens. 2007. Analyzing and assessing accountability: A conceptual framework. European Law J. 13 (2007), 447-468. https://doi.org/10.1111/j.14680386.2007.00378.x
[10] A. Feder Cooper, Emanuel Moss, Benjamin Laufer, and Helen Nissenbaum. 2022. Accountability in an algorithmic society: Relationality, responsibility, and robustness in machine learning. FAccT '22: Proc. of the 2022 ACM Conf. on Fairness, Accountability, and Transparency (2022), 864-876. https: //doi.org/10.1145/3531146.3533150
[9] Madalina Busuioc. 2021. Accountable artificial intelligence: Holding algorithms to account. Public Administration Review 81 (2021), 825-836. https://doi.org/10. 1111/puar.13293
[11] Pradip Dhal and Chandrashekhar Azad. 2022. A comprehensive survey on feature selection in the various fields of machine learning. Applied Intelligence 52, 4 (2022), 4543-4581. https://doi.org/10.1007/s10489-021-02550-9
Energy 146 (2020), 2589-2625. https://doi.org/10.1016/j.renene.2019.08.092
[12] Simon Diemert, Laure Millet, Jonathan Groves, and Jeff Joyce. 2023. Safety integrity levels for artificial intelligence. In Int. Conf. on Computer Safety, Reliability, and Security . Springer, 397-409. https://doi.org/10.1007/978-3-031-40953-0\_34 [13] G. Dileep. 2020. A survey on smart grid technologies and applications. Renewable,
[14] European Parliament and Council. 2006. Directive 2006/42/EC of the European Parliament and of the Council of 17 May 2006 on machinery, and amending Directive 95/16/EC (recast). , 24-86 pages.
[16] European Parliament and Council. 2024. Corrigendum to the European Parliaments legislative resolution of 13 March 2024 on the proposal for a regulation of the European Parliament and of the Council on laying down harmonised rules on AI (AI Act) and amending certain Union Legislative Acts (COM(2021)0206 C9-0146/2021 - 2021/0106(COD)).
- [2] Claudio A Ardagna, Nicola Bena, Cédric Hébert, Maria Krotsiani, Christos Kloukinas, and George Spanoudakis. 2023. Big data assurance: An approach based on service-level agreements. Big Data 11, 3 (2023), 239-254. https: //doi.org/10.1089/big.2021.0369
[15] European Parliament and Council. 2022. Directive (EU) 2022/2557 of the European Parliament and of the Council of 14 December 2022 on the resilience of critical entities and repealing Council Directive 2008/114/EC. , 164-198 pages.
[17] European Parliament and Council. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence and amending Regulations (EC) No 300/2008, (EU) No167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 and (EU) 2019/2144 and Directives 2014/90/EU, (EU) 2016/797 and (EU) 2020/1828 (AI Act).
[3] Zahra Ashktorab, Michael Desmond, Josh Andres, Michael Muller, Narendra Nath Joshi, Michelle Brachman, Aabhas Sharma, Kristina Brimijoin, Qian Pan, Christine T. Wolf, Evelyn Duesterwald, Casey Dugan, Werner Geyer, and Darrell Reimer. 2021. AI-assisted human labeling: Batching for efficiency without
[18] Luciano Floridi, Josh Cowls, Thomas C. King, and Mariarosaria Taddeo. 2020. Howto design AI for social good: Seven essential factors. Science and Engineering Ethics 26 (2020), 1771-1796. https://doi.org/10.1007/s11948-020-00213-5
- © Anna Volkova 2024. This is the author's version of the work. It is posted here for your personal use. Not for redistribution. The definitive version was published in International Conference on Information Technology for Social Good (GoodIT '24), September 04-06, 2024, Bremen, Germany. https://doi.org/10.1145/3677525.3678651
- [19] Saud Hakem Al Harbi, Lionel Nganyewou Tidjon, and Foutse Khomh. 2023. Responsible Design Patterns for Machine Learning Pipelines. arXiv:2306.01788 [cs.SE]
- [21] Hanne Hirvonen. 2023. Just accountability structures-A way to promote the safe use of automated decision-making in the public sector. AI and Society 39 (2023), 155-167. https://doi.org/10.1007/s00146-023-01731-z
- [20] Reihaneh H Hariri, Erik M Fredericks, and Kate M Bowers. 2019. Uncertainty in big data analytics: survey, opportunities, and challenges. J. of Big data 6, 1 (2019), 1-16. https://doi.org/10.1186/s40537-019-0206-3
- [22] Independent High-Level Expert Group on Artificial Intelligence. 2019. Ethics guidelines for trustworthy AI . Technical Report. European Commission.
- [24] Mina Jafari, Abdollah Kavousi-Fard, Tao Chen, and Mazaher Karimi. 2023. A review on digital twin technology in smart grid, transportation system and smart city: Challenges and future. IEEE Access 11 (2023), 17471-17484. https: //doi.org/10.1109/ACCESS.2023.3241588
- [23] International Electrotechnical Commission. 2010. IEC 61508-1:2010 Functional Safety of Electrical/Electronic/Programmable Electronic Safety-related Systems Part 1: General Requirements. https://webstore.iec.ch/publication/5510
- [25] Severin Kacianka and Alexander Pretschner. 2021. Designing accountable systems. FAccT '21: Proc. of the 2021 ACM Conf. on Fairness, Accountability, and Transparency (2021), 424-437. https://doi.org/10.1145/3442188.3445905
- [27] Tobias D Krafft, Katharina A Zweig, and Pascal D. König. 2020. How to regulate algorithmic decision-making: A framework of regulatory requirements for different applications. Regulation and Governance 16 (2020), 119-136. https://doi.org/10.1111/rego.12369
- [26] Jonathan GS Koppell. 2005. Pathologies of accountability: ICANN and the challenge of multiple accountabilities disorder. Public Administration Review 65 (2005), 94-108. https://doi.org/10.1111/j.1540-6210.2005.00434.x
- [28] Oluwabukunmi Latifat Olorunfemi, Olukunle Oladipupo Amoo, Akoh Atadoga, Oluwatoyin Ajoke Fayayola, Temitayo Oluwaseun Abrahams, and Philip Olaseni Shoetan. 2024. Towards a conceptual framework for ethical AI development in IT systems. Computer Science and IT Research J. 5 (2024), 616-627. https://doi.org/10.51594/csitrj.v5i3.910
- [30] Gabriel Lima, Nina Grgić-Hlača, Jin Keun Jeong, and Meeyoung Cha. 2022. The conflict between explainable and accountable decision-making algorithms. FAccT '22: Proc. of the 2022 ACM Conf. on Fairness, Accountability, and Transparency (2022), 2103-2113. https://doi.org/10.1145/3531146.3534628
- [29] Theodore M. Lechterman. 2022. The concept of accountability in AI ethics and governance. The Oxford Handbook of AI governance (2022), 164-182. https: //doi.org/10.1093/oxfordhb/9780197579329.013.10
- [31] Haochen Liu, Yiqi Wang, Wenqi Fan, Xiaorui Liu, Yaxin Li, Shaili Jain, Yunhao Liu, Anil Jain, and Jiliang Tang. 2022. Trustworthy AI: A computational perspective. ACM T. on Intel. Systems and Tech. 14 (2022), 1-59. https://doi.org/10.1145/ 3546872
- [33] Michele Loi and Spielkamp Matthias. 2021. Towards accountability in the use of artificial intelligence for public administrations. AIES '21: Proc. of the 2021 AAAI/ACM Conf. on AI, Ethics, and Society (2021), 757-766. https://doi.org/10. 1145/3461702.3462631
- [32] Jing Liu, Yang Xiao, and Jingcheng Gao. 2014. Achieving accountability in smart grid. IEEE Sys. J. 8 (2014), 493-508. https://doi.org/10.1109/JSYST.2013.2260697
- [34] Ram Machleva, Leena Heistrenec, M. Perla, Kfir Yehuda Levya, Juri Belikovb, S. Mannora, and Y. Levron. 2022. Explainable artificial intelligence (XAI) techniques for energy and power systems: Review, challenges and opportunities. Energy and AI 9 (2022), 1-13. https://doi.org/10.1016/j.egyai.2022.100169
- [36] Irene Niet. 2022. Between vision and practice: Lack of alignment between AI strategies and energy regulations in the Dutch electricity sector. Discover Artificial Intelligence 2 (2022), 1-9. https://doi.org/10.1007/s44163-022-00040-6
- [35] Alfredo Nazabal, Christopher K. I. Williams, Giovanni Colavizza, Camila Rangel Smith, and Angus Williams. 2020. Data Engineering for Data Analytics: A Classification of the Issues, and Case Studies. arXiv:2004.12929 [cs.DB]
- [37] Irene Niet, Rinie van Est, and Frank Veraart. 2021. Governing AI in electricity systems: Reflections on the EU artificial intelligence bill. Frontiers in Artificial Intelligence 4 (2021). https://doi.org/10.3389/frai.2021.690237
- [39] Claudio Novelli, Mariarosaria Taddeo, and Luciano Floridi. 2023. Accountability in artificial intelligence: What it is and how it works. AI and Society (2023), 1-12. https://doi.org/10.1007/s00146-023-01635-y
- [38] Helen Nissenbaum. 1996. Accountability in a computerized society. Science and engineering ethics 2 2 (1996), 25-42.
- [40] Eirini Ntoutsi, Pavlos Fafalios, Ujwal Gadiraju, Vasileios Iosifidis, Wolfgang Nejdl, Maria-Esther Vidal, Salvatore Ruggieri, Franco Turini, Symeon Papadopoulos, Emmanouil Krasanakis, Ioannis Kompatsiaris, Katharina Kinder-Kurlanda, Claudia Wagner, Fariba Karimi, Miriam Fernandez, Harith Alani, Bettina Berendt, Tina Kruegel, Christian Heinze, Klaus Broelemann, Gjergji Kasneci, Thanassis Tiropanis, and Steffen Staab. 2020. Bias in data-driven artificial intelligence systems-An introductory survey. Data Mining Knowledge Discovery 10 (2020), 1-14. https://doi.org/10.1002/widm.1356
- [41] Joseph Oluwaseyi and Godwin Oluwafemi Olaoye. 2024. Addressing biases and implications in privacy-preserving AI for industrial IoT, ensuring fairness and
- © Anna Volkova 2024. This is the author's version of the work. It is posted here for your personal use. Not for redistribution. The definitive version was published in International Conference on Information Technology for Social Good (GoodIT '24), September 04-06, 2024, Bremen, Germany. https://doi.org/10.1145/3677525.3678651
| | accountability. (2024), 1-15. |
|------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [42] | Andrei Paleyes, Raoul-Gabriel Urma, and Neil D Lawrence. 2022. Challenges in deploying machine learning: A survey of case studies. ACM computing surveys 55, 6 (2022), 1-29. https://doi.org/10.1145/3533378 |
| [43] | Wei Pang, Milan Markovic, Iman Naja, Chiu Pang Fung, and Peter Edwards. 2021. On evidence capture for accountable AI systems. CEUR WS. Proc. 2894 (2021), 33-39. |
| [44] | Philipp Probst, Anne-Laure Boulesteix, and Bernd Bischl. 2019. Tunability: Importance of hyperparameters of machine learning algorithms. J. of Machine Learning Research 20, 53 (2019), 1934-1965. http://jmlr.org/papers/v20/18-444. html |
| [45] | Mina Razghandi, Hao Zhou, Melike Erol-Kantarci, and Damla Turgut. 2024. Smart home energy management: VAE-GAN synthetic dataset generator and Q-learning. IEEE T. on S. Grid 15 (2024), 1562-1573. https://doi.org/10.1109/TSG. 2023.3288824 |
| [46] | Zhongtuo Shi, Wei Yao, Zhouping Li, Lingkang Zeng, Yifan Zhao, Runfeng Zhang, Yong Tang, and Jinyu Wen. 2020. Artificial intelligence techniques for stability analysis and control in smart grids: Methodologies, applications, challenges and future directions. Applied Energy 278 (2020), 115733. https: //doi.org/10.1016/j.apenergy.2020.115733 |
| [47] | Ahmad K. Sleiti, Jayanta S. Kapat, and Ladislav Vesely. 2022. Digital twin in energy industry: Proposed robust digital twin for power plant and other complex capital-intensive large engineering systems. Energy Reports 8 (2022), 3704-3726. https://doi.org/10.1016/j.egyr.2022.02.305 |
| [48] | Stephen C. Slota, Kenneth R. Fleischmann, Sherri Greenberg, Nitin Verma, Brenna Cummings, Lan Li, and Chris Shenefiel. 2021. Many hands make many fingers to point: challenges in creating accountable AI. AI and Society 38 (2021), 1287-1299. https://doi.org/10.1007/s00146-021-01302-0 |
| [49] | Helen Smith. 2020. Clinical AI: opacity, accountability, responsibility and liability. AI and Society 36 (2020), 535-545. https://doi.org/10.1007/s00146-020-01019-6 |
| [50] | Arthur A. Z. Sooares, Yona Lopes, Diego Passos, Natalia C. Fernandes, and Debora C. Muchaluat-Saade. 2021. 3AS: authentication, authorization, and accountability for SDN-based smart grids. IEEE Access 9 (2021), 88621-88640. |
| [51] | Francesco Sovrano and Giulio Masetti. 2022. Foreseeing the impact of the pro- posed AI Act on the sustainability and safety of critical infrastructures (ICEGOV '22) . 492-498. https://doi.org/10.1145/3560107.3560253 |
| [52] | Ramya Srinivasan and Beatriz San Miguel Gonzalez. 2022. The role of empathy for artificial intelligence accountability. J. of Responsible Tech. 9 (2022), 1-7. https://doi.org/10.1016/j.jrt.2021.100021 |
| [53] | Monika Steidl, Michael Felderer, and Rudolf Ramler. 2023. The pipeline for the continuous development of artificial intelligence models-Current state of research and practice. J. of Systems and Software 199 (2023), 111615. https: //doi.org/10.1016/j.jss.2023.111615 |
| [54] | Elham Tabassi. 2023. Artificial intelligence risk management framework. Trust- worthy and Responsible AI (2023), 1-48. https://doi.org/10.6028/NIST.AI.100-1 |
| [55] | Anna Volkova, Amit Dilip Patil, Seyyed Ahmad Javadi, and Hermann de Meer. 2022. Accountability challenges of AI in smart grid services. e-Energy '22: Proc. of the 13 ACM Int. Conf. on Future Energy Systems (2022), 597-600. https: //doi.org/10.1145/3538637.3539636 |
| [56] | Rebecca Williams, Richard Cloete, Jennifer Cobbe, Caitlin Cottrill, Peter Edwards, Milan Markovic, Iman Naja, Frances Ryan, Jatinder Singh, and Wei Pang. 2022. From transparency to accountability of intelligent systems: Moving beyond aspirations. Data and Policy 4 (2022), 1-23. https://doi.org/10.1017/dap.2021.37 |
| [57] | Wenti Yang, Zhitao Guan, Longfei Wu, Xiaojiang Du, and Mohsen Guizani. 2021. Secure data access control with fair accountability in smart grid data sharing: An edge blockchain approach. Internet of Things 8 (2021), 8632-8643. |
| [58] | Ameema Zainab, Ali Ghrayeb, Dabeeruddin Syed, Haitham Abu-Rub, Shady S. Refaat, and Othmane Bouhali. 2021. Big data management in smart grids: Technologies and challenges. IEEE Access 9 (2021), 73046-73059. https: //doi.org/10.1109/ACCESS.2021.3080433 |
| [59] | Yufan Zhang, Qian Ai, Zhaoyu Li, Shuangrui Yin, Kaiyi Huang, Muhammad Yousif, and Tianguang Lu. 2020. Data augmentation strategy for small sample short-term load forecasting of distribution transformer. Int. T. on Electrical Energy | | 10.1145/3677525.3678651 | [
"Anna Volkova",
"Mahdieh Hatamian",
"Alina Anapyanova",
"Hermann de Meer"
] | 2024-08-02T09:02:42+00:00 | 2024-08-02T09:02:42+00:00 | [
"cs.AI"
] | Being Accountable is Smart: Navigating the Technical and Regulatory Landscape of AI-based Services for Power Grid | The emergence of artificial intelligence and digitization of the power grid
introduced numerous effective application scenarios for AI-based services for
the smart grid. Nevertheless, adopting AI in critical infrastructures presents
challenges due to unclear regulations and lacking risk quantification
techniques. Regulated and accountable approaches for integrating AI-based
services into the smart grid could accelerate the adoption of innovative
methods in daily practices and address society's general safety concerns. This
paper contributes to this objective by defining accountability and highlighting
its importance for AI-based services in the energy sector. It underlines the
current shortcomings of the AI Act and proposes an approach to address these
issues in a potential delegated act. The proposed technical approach for
developing and operating accountable AI-based smart grid services allows for
assessing different service life cycle phases and identifying related
accountability risks. |
2408.01122v1 | ## CFBench: A Comprehensive Constraints-Following Benchmark for LLMs
Tao Zhang 1 * ♣ , Yanjun Shen 1 * , Wenjing Luo , Yan Zhang , Hao Liang , Tao Zhang 1 1 2 1 ♢ , Fan Yang , 1 Mingan Lin , Yujing Qiao , Weipeng Chen , Bin Cui , 1 1 1 2 Wentao Zhang 2 † , Zenan Zhou 1†
1 Baichuan Inc. 2 Peking University
{
♣ zhangtao2, shenyanjun, zhouzenan } @baichuan-inc.com, { wentao.zhang } @pku.edu.cn
## Abstract
The adeptness of Large Language Models (LLMs) in comprehending and following natural language instructions is critical for their deployment in sophisticated real-world applications. Existing evaluations mainly focus on fragmented constraints or narrow scenarios, but they overlook the comprehensiveness and authenticity of constraints from the user's perspective. To bridge this gap, we propose CFBench, a largescale Comprehensive Constraints Following Benchmark for LLMs, featuring 1,000 curated samples that cover more than 200 real-life scenarios and over 50 NLP tasks. CFBench meticulously compiles constraints from real-world instructions and constructs an innovative systematic framework for constraint types, which includes 10 primary categories and over 25 subcategories, and ensures each constraint is seamlessly integrated within the instructions. To make certain that the evaluation of LLM outputs aligns with user perceptions, we propose an advanced methodology that integrates multidimensional assessment criteria with requirement prioritization, covering various perspectives of constraints, instructions, and requirement fulfillment. Evaluating current leading LLMs on CFBench reveals substantial room for improvement in constraints following, and we further investigate influencing factors and enhancement strategies. The data and code are publicly available at https://github.com/PKU-BaichuanMLSystemLab/CFBench.
## Introduction
Large Language Models (LLMs) have become the cornerstone of numerous cutting-edge research tasks and are widely utilized in real-world scenarios (Brown et al. 2020; Chowdhery et al. 2023; Achiam et al. 2023; Touvron et al. 2023). In real-world scenarios, human instructions are inherently complex and accompanied by explicit constraints, requiring models to both understand intricate requirements and strictly comply with these constraints (Yang et al. 2023; Zhong et al. 2021; Mishra et al. 2022; Wei et al. 2021; Sanh et al. 2022). The proficiency of LLMs in comprehending requirements and adhering to natural language constraints is essential, as it ensures tasks are executed precisely and resolved perfectly according to user instructions.
* These authors contributed equally.
† Corresponding authors.
Figure 1: Sample data from CFBench. A checklist, constraint type, requirement priority, and satisfaction constitute our evaluation criteria.

The prevailing method for evaluating a model's instruction-following ability involves using quantitative programs, human evaluators, or advanced LLMs to assess response quality across single constraints, complex problems, and finite constraints (Zhou et al. 2023a; Wang et al. 2023; Li et al. 2023; Zheng et al. 2024; Xu et al. 2023). Laskar et al. (2024) underscores the importance of evaluating data quality, highlighting the necessity for real and extensive data distribution, along with its applicability to real-world scenarios. Sun et al. (2024b) also stresses that realistic evaluation metrics reflect model capabilities and guide iteration. Constraints-following evaluation faces analogous challenges, particularly within complex real-world scenarios, where data sources and contexts are diverse, and where evaluation is both subjective and arduous. Fig. 1, which addresses the aforementioned challenges, presents a sample from CFBench illustrating the Trump assassination event with different colors representing various constraint types. The instruction include multiple constraints, and the evaluation method uses a checklist to break down complex requirements into independent checkpoints, annotating constraint types and priorities. LLMs are then used to assess each checkpoint. Consequently, we introduce two more profound challenges in constraints-following assessment.
## Q1: How to construct high-quality evaluation data?
Many studies focus on evaluating single constraint (Chen et al. 2022; Tang et al. 2023), lacking comprehensive analysis across diverse constraints. He et al. (2024b) examines LLM performance on complex real-world instructions but neglect constraint diversity and scenario coverage. Jiang et al. (2023) incrementally incorporate fine-grained constraints to craft multi-level instructions. However, with only 75 instances of mixed type, which risks variability due to limited data, and equating difficulty with constraint quantity oversimplifies the task. Recent work focuses on evaluating constraints combinability (Wen et al. 2024). To ensure data quality, we systematically categorize constraints by mining real-world online data and using classification, synthesis, and expert design, covering 10 primary categories and over 25 subcategories. We also cross-match these constraints with various domains and scenarios, ensuring balanced representation and expert-validated reasonableness.
## Q2:How to evaluate accurately and meticulously?
Evaluating LLMs' adherence to constraints is challenging and typically involves manual, automated, and programmatic assessments using various metrics. Representative work computes outcomes for verifiable instructions using code (Zhou et al. 2023a; He et al. 2024b). Jiang et al. (2023) uses scripts and constraint-evolution paths to handle diverse challenging instructions, introducing three metrics tailored to the data's characteristics. The DRFR method decomposes complex constraints into binary judgments, with GPT evaluating each criterion (Qin et al. 2024). Indeed, previous work has ensured the feasibility and objectivity of evaluations through various methods, but they have overlooked assessments from the user's multiple perspectives. We deconstruct complex instructions from the user's perspective into multiple sub-needs, categorizing them by priority and constraint type, with LLMs evaluating each checkpoint. Furthermore, a multi-dimensional evaluation criteria is proposed using three metrics from the perspectives of constraints, instructions, and requirements priority.
We introduce CFBench, a comprehensive benchmark designed to thoroughly evaluate the constraint comprehension and following capabilities of LLMs. CFBench aggregates constraints from real-world scenarios and pioneers a hierarchical system for constraint types, encompassing 10 primary categories and over 25 secondary subcategories organized through taxonomic and statistical methodologies. CFBench features 1,000 meticulously curated samples spanning more than 200 real-life scenarios across 20 domains and over 50 NLP tasks, enhancing the breadth and generality of the evaluation data. Additionally, we have seamlessly integrated original instructions and constraint types within each sample, paying particular attention to nuanced combinations, ensuring each constraint is credibly and coherently embedded. Our advanced evaluation methodology incorporates multi-dimensional assessment criteria, which prioritizing requirements to align LLM outputs with user needs, enhance interpretability, and facilitate iterative development. Finally, extensive experiments and exploratory discussions provide strong support for evaluation and optimization.
Overall, our contributions are mainly four-fold:
- · To the best of our knowledge, we are the pioneers in systematically defining an instruction constraint framework utilizing both taxonomic and statistical methodologies.
- · We introduce CFBench, a meticulously annotated, largescale, high-quality benchmark that encompasses a broad spectrum of real-world scenarios and NLP tasks.
- · We propose a multi-dimensional evaluation framework to comprehensively assess model capabilities while prioritizing user-centric needs.
- · We exhaustively evaluated prominent LLMs, uncovering significant deficiencies in constraints following and exploring performance factors and optimization strategies.
## Related Work
Evaluation for LLMs Numerous studies have concurrently evaluated LLMs from various perspectives. By integrating a multitude of existing datasets, many have assessed the overall capabilities of LLMs (Bommasani, Liang, and Lee 2023; Zhong et al. 2024; Dubois et al. 2024; Chia et al. 2024; Hendrycks et al. 2021). Some research has delved into specialized capabilities, such as programming (Chen et al. 2021), reasoning (Cobbe et al. 2021), and knowledge (Huang et al. 2024). Unlike previous studies, we evaluate LLMs' instruction-following abilities with a focus on constraint-based instructions.
Instruction Following Fine-tuning LLMs with annotated instructional data enhances their ability to follow general language instructions (Weller et al. 2020; Sanh et al. 2022; Mishra et al. 2022). Studies show that more complex or constrained instructions further improve this ability. For instance, six methods to create intricate instructions from a small set of handwritten seed data are proposed (Xu et al. 2023; Luo et al. 2023), while Mukherjee et al. (2023) elevate training data complexity by having GPT-4 generate reasoning steps for simple instructions. The latest work (Sun et al. 2024a; He et al. 2024a; Dong et al. 2024) suggests that increasing the number and variety of constraints can enhance the complexity of instructions, thereby further improving the model's ability to follow constraint-based instructions.
Evaluation of Constraints Following Constraints such as word count, position, topics, and content have garnered significant attention in the field of Controlled Text Generation (Yao et al. 2023; Zhou et al. 2023b; Chen et al. 2022). Zhou et al. (2023a) centers on assessing 25 verifiable instructions. Numerous studies have explored the adherence of LLMs to format constraints, such as complex tabular data (Tang et al. 2023) and customized scenario formats (Xia et al. 2024). Qin et al. (2024) decomposing a single instruction into multiple constraints. He et al. (2024b) gathered constraints from
Figure 2: The construction pipeline of CFBench. Initially, it entails the construction of the constraint system, followed by the assembly of the dataset, and culminating in the proposal of a multi-perspective user view evaluation.
real-world scenarios and developed a sophisticated benchmark using detailed task descriptions and inputs. Jiang et al. (2023) progressively integrates fine-grained constraints to develop multi-level instructions, thereby enhancing complexity across six distinct types. Concurrent work (Wen et al. 2024), constructs a novel benchmark by synthesizing and refining data from the aforementioned benchmarks, with an emphasis on the combinatorial types of constraints. However, previous studies suffered from fragmented constraints, limited scenarios, and misaligned evaluation methods with user perspectives.
## Constraints System
## CFBench
As depicted in Fig. 2, the CFBench construction pipeline includes several key components. First, we collect and systematize constraint expressions from real-world scenarios and various NLP tasks. Using this system, we create high-quality evaluation data by combining instructions from these scenarios with advanced LLMs and manual curation. We then introduce innovative multi-perspective evaluation method. Additionally, we conduct a thorough statistical analysis and validate the quality from various angles to highlight reliability and applicability.
## Constraints System
Constraints Collection We amass a diverse corpus of instructions from real-world scenarios and various NLP tasks (Xia et al. 2024; Li et al. 2024) to ensure a comprehensive system. Initially, we aggregate several million instructions from online logs and NLP tasks, refining these through length filtering and clustering to distill 30,000 high-quality instructions. Utilizing advanced LLM techniques, we extract and expand atomic constraints through evolutionary methods. Using LLMs, we carefully select meaningful atomic constraints, resulting in over 5000 unique constraints. Domain experts first filter out unreasonable or meaningless atomic constraints and then synthesize these into a structured framework with 10 primary categories and 25 subcategories, guided by principles of statistics, taxonomy, and linguistics.
Content constraints control the scope and depth of output content by specifying certain conditions (Zhang et al. 2023), and can be divided into lexical constraints, element constraints, and semantic constraints based on their granularity. Numerical constraints , which ensure that output content meets length and quantity requirements (Yao et al. 2023), can be classified into word-level, sentence-level, paragraphlevel, document-level based on the objects involved in the planning. Stylistic constraints impart a unique flavor and color to the output, revealing the author's traits and chosen social objectives (Tsai et al. 2021), can be subdivided into tonal, formal, audience, and authorial style constraints based on the perspective of application. Format constraints (Tang et al. 2023) standardize expression to guide the generation of complex content and can be categorized into fundamental, bespoke, and specialized scenario constraints based on their usage scenarios. Linguistic constraints (Zhou et al. 2023b) adapt to various scenarios by controlling internal features and logic, grouped into Pragmatic, Syntactic, Morphological, Phonological, and other constraints. Situation constraints (Liu et al. 2023) guide response appropriateness through background or situational parameters, can be classified into role-based, task-specific, and complex contextual constraints. Example constraints regulate new responses by leveraging the intrinsic patterns established by a limited set of samples, with an emphasis on assessing the model's proficiency in contextual constraint learning. Inverse constraints narrow the response space through the mechanism of indirect exclusion. Contradictory constraints denote conditions that are mutually exclusive, rendering it impossible for the response to fulfill all requirements concurrently, which are prevalent in online logs and are often easily overlooked. Rule constraints define logic flows or actions and meticulously crafted to standardize the road of responses. Details are in Appendix Tab. 8.
## Dataset Construction
To guarantee data quality in terms of authority and thorough coverage, we utilize a collaborative iterative methodology
Table 1: CFBench Statistic. The abbreviations of 'Num.', 'Len.', 'Prim.', 'Cons.', 'Type.' denote the sample number, average instruction length, average primary requirements number, average constraint number, average constraint type number, respectively. The designations 'C1'-'C10' denote the Primary Constraint types of content, numerical, style, format, linguistic, situation, example, inverse, contradictory, and rule constraint, respectively.
| Split Set | Basic Info | Basic Info | Basic Info | Basic Info | Basic Info | Constraints Count | Constraints Count | Constraints Count | Constraints Count | Constraints Count | Constraints Count | Constraints Count | Constraints Count | Constraints Count | Constraints Count |
|-------------|--------------|--------------|--------------|--------------|--------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|
| Split Set | Num. | Len. | Prim. | Cons. | Type. | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 |
| Easy Set | 500 | 413 | 1.69 | 3.59 | 2.83 | 613 | 214 | 180 | 170 | 134 | 92 | 82 | 95 | 90 | 79 |
| Hard Set | 500 | 605 | 1.98 | 4.89 | 3.58 | 772 | 345 | 233 | 241 | 168 | 122 | 115 | 145 | 137 | 81 |
| Full Set | 1000 | 509 | 1.84 | 4.24 | 3.20 | 1385 | 559 | 413 | 411 | 302 | 214 | 197 | 240 | 227 | 160 |
Figure 3: The distribution of NLP tasks and domains
Task and Domain Distribution CFBench covers 20 major real-life domains and includes over 200 common scenarios and 50+ NLP tasks. Fig. 3(a) illustrates the classification of NLP tasks, including four major types: classification, generation, sequence labeling, and sentence relation, along with their corresponding specific tasks. Fig. 3(b) shows the real-life scenario-specific domain distribution, where Employment is the most prevalent category, and the other domains are relatively balanced. Our objective is to balance the real distribution with an equitable distribution. Overall, Fig. 3 illustrates that CFBench has evolved into a comprehensive and well-balanced benchmark.
that synergizes expertise with the capabilities of LLMs.
Data Source and Selection Real-world scenarios and NLPtasks form the foundation for CFBench's initial instructions. By harnessing advanced LLMs, we rigorously assess each instruction for constraint types and quantities within a predefined system, filtering out those with unreasonable or ineffective constraints. Subsequently, we balance the scenarios and constraint types, resulting in a refined set of 2,000 instructions covering all scenarios and NLP tasks. Prompts for instruction and checklist generation are in Appendix.
Iterative Refinement Professional annotators carefully review and refine the data, ensuring the rationality of constraints and gold answer. If modifications are needed, instructions are revised, and LLMs generate responses with refined evaluation criteria, repeating this process until satisfactory results are achieved. Ultimately, comprehensive support is formulated for each sample, detailing high-quality instructions, the ideal answer, specific assessment criteria, constraint types, and priority levels, totaling 1000 entries.
## Dataset Statistics
Overall Statistics Tab. 1 provides a statistical overview of CFBench, highlighting the substantial differences between the two sets. The Hard Set features more detailed instructions, a greater variety of constraints, and a higher number of constraints, indicating a higher level of complexity compared to the Easy Set. Furthermore, the table demonstrates the diversity and balanced distribution of primary constraint types within CFBench, an area where we significantly outperform other benchmarks. See the Appendix for division details.
Comparison with Other Benchmarks As shown in Tab. 3, we thoroughly compare our benchmark with various relevant ones. In terms of size, our benchmark contains approximately twice the number of samples as others. Notably, FollowBench (Jiang et al. 2023), despite having 820 samples, originally had only one-fifth of this number, with each sample expanded by adding five constraints. From the constraint perspective, CFBench is the only benchmark with systematized constraints, featuring the highest number of primary constraint types and ensuring a balanced consideration of these types. Regarding evaluation, InFoBench (Qin et al. 2024) also sets response criteria for each sample, while CFBench distinguishes itself by incorporating user demand prioritization and emphasizing objectivity.
## Evaluation Protocol
Evaluation Criteria We breaking down instructions into multiple simple, independent checkpoints to ensure evaluation accuracy, inspiration was drawn from DRFR (Qin et al. 2024). This approach addresses the challenge of evaluating entire responses, especially for complex instructions with multiple constraints. Unlike DRFR, our method emphasizes defining ideal response characteristics and critical evaluation points. The previous sections detailed the checklist generation process, a key part of our evaluation criteria. Furthermore, we employ the state-of-the-art LLM, GPT-4o, as the evaluation model. By repeatedly feeding it the instruction, test model response, and checklist with a carefully tuned prompt, we ensure that the judged response fully meets the judgement format check. This iterative process aims to maximize confidence in our evaluation. The specific evaluation prompt is in the Appendix.
Table 2: The evaluation results of LLMs on CFBench and its splits. Notably, ∗ stands for the model supporting mainstream languages excluding Chinese, and † represents calling through the API. The bold , underlined, and tilde denote the first, second, ✿✿✿✿ and third rankings, respectively.
| Models | Easy Set | Easy Set | Easy Set | Hard Set | Hard Set | Hard Set | Full Set | Full Set | Full Set |
|------------------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|
| Models | CSR | ISR | PSR | CSR | ISR | PSR | CSR | ISR | PSR |
| GPT-4o † | 0.956 | 0.868 | 0.888 | 0.816 | 0.438 | 0.582 | 0.886 | 0.653 | 0.735 |
| GPT-4-Turbo-20240409 † | 0.924 | 0.792 | 0.826 | 0.783 | 0.370 | 0.518 | 0.853 | 0.581 | 0.672 |
| GPT-4-0125-Preview † | 0.923 | 0.790 | 0.826 | 0.763 | 0.310 | 0.468 | 0.843 | 0.550 | 0.647 |
| GPT-3.5-Turbo-1106 † | 0.797 | 0.520 | 0.602 | 0.631 | 0.176 | 0.326 | 0.714 | 0.348 | 0.464 |
| Claude-3.5-Sonnet † | 0.943 | 0.844 | 0.882 | 0.799 | 0.408 | 0.564 | 0.871 | 0.626 | 0.723 |
| GLM-4-0520 † | 0.939 | 0.820 | 0.852 | 0.785 | ✿✿✿✿ 0.372 | ✿✿✿✿ 0.536 | 0.862 | ✿✿✿✿ 0.596 | 0.694 |
| DeepSeek-V2-0628 † | 0.946 | 0.830 | 0.868 | 0.786 | 0.350 | 0.524 | 0.866 | 0.590 | 0.696 |
| ERNIE-4-Turbo-0628 † | 0.930 | 0.790 | 0.848 | 0.772 | 0.332 | 0.532 | 0.851 | 0.561 | 0.690 |
| Yi-Large † | 0.900 | 0.730 | 0.786 | 0.744 | 0.292 | 0.460 | 0.822 | 0.511 | 0.623 |
| abab6.5-chat † | 0.894 | 0.696 | 0.766 | 0.736 | 0.260 | 0.452 | 0.815 | 0.478 | 0.609 |
| MoonShot-V1-8k † | 0.919 | 0.764 | 0.812 | 0.758 | 0.308 | 0.464 | 0.838 | 0.536 | 0.638 |
| Llama-3-8B-Instruct ∗ | 0.656 | 0.300 | 0.356 | 0.562 | 0.122 | 0.238 | 0.609 | 0.211 | 0.297 |
| Llama-3-70B-Instruct ∗ | 0.750 | 0.422 | 0.498 | 0.642 | 0.178 | 0.330 | 0.696 | 0.300 | 0.414 |
| DeepSeek-V2-Lite-Chat | 0.733 | 0.382 | 0.448 | 0.597 | 0.148 | 0.262 | 0.665 | 0.265 | 0.355 |
| YI-1.5-34B-Chat | 0.881 | 0.672 | 0.740 | 0.745 | 0.302 | 0.474 | 0.813 | 0.487 | 0.607 |
| Qwen1.5-110B-Chat | 0.905 | 0.724 | 0.792 | 0.730 | 0.276 | 0.438 | 0.818 | 0.500 | 0.615 |
| Qwen2-72B-Instruct | ✿✿✿✿ 0.944 | ✿✿✿✿ 0.836 | ✿✿✿✿ 0.880 | ✿✿✿✿ 0.791 | 0.342 | 0.530 | ✿✿✿✿ 0.867 | 0.589 | ✿✿✿✿ 0.705 |
Evaluation Metrics Aligned with different perspectives, we define the Constraint Satisfaction Rate (CSR), Instruction Satisfaction Rate (ISR) as follows:
$$\text{CSR} = \frac { 1 } { m } \sum _ { i = 1 } ^ { m } ( \frac { 1 } { n _ { i } } \sum _ { j = 1 } ^ { n _ { i } } s _ { i } ^ { j } ) \text{ \quad \ \ } ( 1 )$$
$$I S R = \frac { 1 } { m } \sum _ { i = 1 } ^ { m } s _ { i } \quad \quad \ ( 2 )$$
| Benchmarks | Data Quality | Data Quality | Data Quality | Evaluation | Evaluation |
|--------------|----------------|----------------|----------------|--------------|--------------|
| | Num. | Type. | Syst. | Prio. | Meth. |
| IFEval | 541 | 4 ∗ | % | % | |
| CELLO | 523 | 4 | % | % | |
| FollowBench | 820 | 5 | % | % | |
| InFoBench | 500 | 5 | % | % | |
| CfBench | 1000 | 10 | " | " | |
where s j i = 1 if the j -th constraint of i -th instruction is satisfied and s j i = 0 otherwise. s i = 1 indicates that all constraints in the i -th instruction are satisfied and s i = 0 otherwise. The requirements Priority Satisfaction Rate (PSR) is defined as follows:
$$\text{www.s.} \\ \text{PSR} = \frac { 1 } { m } \sum _ { i = 1 } ^ { m } ( P S R _ { i } ) \quad \quad ( 3 ) \quad \quad \text{(3)}$$
Let the average score for secondary requirements be A . When all primary requirements are met, score = 0 5+0 5 . . × A . If score > 0 8 . , then PSR i = 1 ; otherwise, PSR i = 0 , especially when any primary requirement is not met. The threshold of 0 8 . is based on user feedback, reflecting tolerance for LLMs adhering to constraints. Overall, CSR, ISR, and PSR reflect different levels of user perception from multiple perspectives, including constraints, instructions, and requirement priorities.
## Data Quality
Quality Evolution To enhance the quality of CFBench, we invested considerable effort and financial resources.
∗
Table 3: Detailed Comparison of Relevant Benchmarks. represents our constraint system. 'Num.', 'Type.', 'Syst.', 'Prio.', and 'Meth.' denote the number of samples, primary constraint types, presence of a constraint system, requirement prioritization, and evaluation method.
First, in the instruction generation phase, we utilized multiple advanced LLMs, such as GPT-4 and Claude, to generate diverse instructions and responses for annotator candidates. Second, we implemented a stringent manual annotation process, including annotator training, cross-validation, batch validation, expert team involvement, and iterative refinement of instruction constraints and response quality. We also ensured the objectivity, evaluability, and prioritization of checkpoints. Additionally, we balanced the data for constraint types, scenarios, and NLP task distribution. Detailed information can be found in the Appendix.
Quality Evaluation To thoroughly investigate the quality of CFBench, we randomly selected 100 samples for assess-
Figure 4: Different mainstream models' results under primary and secondary constraint categories.
Figure 5: Different mainstream models' PSR results in realworld domains and NLP task types.
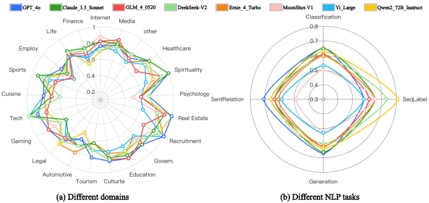
ment. Three professional data inspectors conducted a meticulous evaluation, resulting in high-quality rates of 94 % for instructions, 94 % for responses, and 93 % for checklists, as shown in Appendix Tab. 5. Additionally, three experts provided averaged scores for the outputs of Qwen2-7B-Instruct on a 0-1 scale. The kappa coefficient between GPT-4o PSR and expert evaluations approached 0.77, underscoring the superiority of the PSR evaluation method and metrics, even when applied to smaller models. Further details are provided in the Appendix Tab. 6. In conclusion, CFBench is a highquality benchmark, both in terms of data and evaluation.
## Experiment
## Evaluation Settings
We evaluated a total of 50 models that demonstrated exceptional performance on previous benchmarks (Hendrycks et al. 2020; Cobbe et al. 2021), considering factors such as model size, support for Chinese among mainstream languages, whether they were accessed via API or weights, and whether they were fine-tuned with instruction tuning data. During inference, we set the maximum generation length to 2048, with other parameters using their default values. For evaluation, we used GPT-4o as the judge model, setting the temperature to 0 to ensure deterministic outputs. All model names mentioned correspond to the versions listed in Tab. 7 of the Appendix.
## Overall Result
Tab. 2 presents the detailed evaluation results of CFBench and its splits for the leading models, using three key met-
Table 4: Performance Comparison on Benchmarks
| Model | MMLU | GSM8K | CFBench |
|--------------------|--------|---------|-----------|
| GPT-4o | 88.7 | 90.5 | 0.698 |
| Claude-3.5-Sonnet | 88.7 | 96.4 | 0.691 |
| Qwen2-72B-Instruct | 82.3 | 91.1 | 0.672 |
| GLM-4 | 81.5 | 87.6 | 0.665 |
| DeepSeek-V2 | 78.5 | 79.2 | 0.665 |
| Qwen1.5-110B-Chat | 80.4 | - | 0.584 |
| Qwen-1.5-72B-Chat | 77.5 | 79.5 | 0.577 |
rics. Overall, GPT-4o leads across all splits and metrics, with Claude-3.5-Sonnet close behind. Qwen2-72B-Instruct, GLM4, DeepSeek-V2, and ERNIE4 also performed well, while Yi-large, abab6.5, and MoonShot lagged slightly. Considering the different splits, the Hard split shows a significant drop in metrics, highlighting the clear distinction between Hard and Easy splits. The highest PSR only reached 0.582, indicating room for improvement. Regarding the metrics, CSR is more favorable for weaker models, making it easier to identify issues at a fine-grained level. ISR and PSR highlight differences among stronger models, with ISR being the most challenging and PSR considering user priority and overall satisfaction. Notably, API-accessed models significantly outperformed open-source models accessed via weights, except for Qwen2-72B-Instruct, highlighting a substantial gap in constraint follow for open-source models.
## Constraints-categorized Performance
To observe the performance across different constraint types, we calculated satisfaction scores for each constraint for the top 8 LLMs, as shown in Fig. 4. For primary constraints, many models struggled with contradictory constraints, revealing their limitations in handling conflicts. By considering requirement priorities, we captured nuances among multiple constraints, enabling detailed evaluation. GPT-4o excelled across various constraints, while other models alternated in leading different types. For secondary constraints, all models performed poorly in lexical, word, and sentence count constraints but did better in document count and audience style constraints. No single model consistently led across most constraint types. In summary, even the most advanced LLMs have significant room for improvement in certain constraint types, with each model showing specific weaknesses. This provides valuable insights for future model iterations.
## Domain and Task-categorized Performance
As depicted in Fig. 5, we evaluate performance across 21 domains and 4 major NLP task types, each with 500 examples from the two main sources of CFBench. For domain performance, employment and psychology require significant attention, while technology and recruitment are strengths for most models. For NLP tasks, GPT-4o excels in sentence relationship tasks, while Qwen2-72B-Instruct is strong in sequence labeling, likely due to its optimization for Chinese. In general, models exhibit different rankings across domains
Figure 6: Factors Influencing Constraints-Following Performance
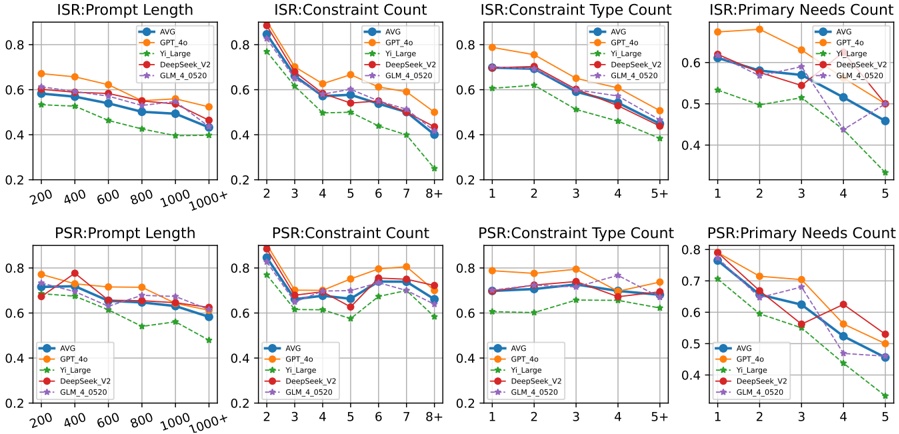
and tasks, indicating no clear absolute leader. Comprehensive improvements are needed for better constraint follow across multiple domains and tasks.
## How to improve constraint-following ability?
## Discussion
## Comparisons between Capabilities
Tab. 4 presents a comprehensive comparison of CFBench's PSR with two of the prominent LLM evaluation benchmarks: MMLU (Hendrycks et al. 2020) and GSM8K (Cobbe et al. 2021). MMLU focuses on knowledge proficiency, while GSM8K emphasizes mathematical ability. GPT-4o ranks first on CFBench but significantly lags behind, ranking third on GSM8K. Qwen1.5-110B-Chat performs worse than DeepSeek-V2 on CFBench but outperforms it on MMLU. Notably, the rankings of LLMs on CFBench do not entirely correspond with those on the other two benchmarks, indicating that CFBench provides a novel perspective for LLMs evaluation.
## Factors influencing constraints-following
Previously, we identified a significant gap in LLM constraints following performance, prompting us to further explore the influencing factors. We analyzed the impact of prompt length, number of constraints, constraint types, and primary requirements on evaluation results across five topperforming models and their average values. As shown in Fig. 6, all four factors are positively correlated with the ISR metric, with the number of constraints having the most significant effect. For PSR, the number of constraints and constraint types do not show a completely positive correlation, while the number of primary requirements has a greater influence. Users are more affected by unmet constraints when there are fewer, but become more tolerant of unmet nonprimary constraints when there are many.
In Appendix Tab. 7, we investigated methods to potentially enhance constraint following. Firstly, Supervised FineTuning (SFT) significantly improves performance, with nearly all models that undergo instruction fine-tuning exhibiting substantial improvements in effectiveness, as demonstrated by the Qwen series. Secondly, model size is also an important factor, as evidenced by Qwen272B-Instruct showing a 40% relative PSR improvement over Qwen2-7B-Instruct. Additionally, replicating Conifer's models (Sun et al. 2024a) reveals that fine-tuning with complex constraint instructions further enhances performance, and recent work has also been directed towards this approach (He et al. 2024a). Further exploration is intended to be pursued in future work.
## Conclusion
This study comprehensively examines the constraintsfollowing capabilities of LLMs. CFBench, a comprehensive benchmark, was introduced with 1000 manually annotated samples covering more than 200 real-world scenarios and over 50 NLP tasks, encompassing a wide range of systematically defined constraint types. Each sample in CFBench includes detailed evaluation criteria, providing metrics that accurately reflect model performance and real user needs across multiple dimensions. Extensive experiments on CFBench revealed significant limitations and challenges that advanced LLMs face in following constraint instructions. Key factors and potential strategies to improve constraint following were also analyzed. In conclusion, CFBench offers a novel perspective for evaluating LLM capabilities, providing new directions for performance assessment and improvement.
## References
Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F. L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 .
Bommasani, R.; Liang, P.; and Lee, T. 2023. Holistic evaluation of language models. Annals of the New York Academy of Sciences , 1525(1): 140-146.
Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J. D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. 2020. Language models are few-shot learners. Advances in neural information processing systems , 33: 18771901.
Chen, H.; Li, H.; Chen, D.; and Narasimhan, K. 2022. Controllable text generation with language constraints. arXiv preprint arXiv:2212.10466 .
Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H. P. d. O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 .
Chia, Y. K.; Hong, P.; Bing, L.; and Poria, S. 2024. INSTRUCTEVAL:Towards Holistic Evaluation of InstructionTuned Large Language Models. In of the Workshop on the Scaling Behavior of Large Language Models (SCALE-LLM 2024) , 35.
Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H. W.; Sutton, C.; Gehrmann, S.; et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research , 24(240): 1-113.
Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 .
Dong, G.; Lu, K.; Li, C.; Xia, T.; Yu, B.; Zhou, C.; and Zhou, J. 2024. Self-play with Execution Feedback: Improving Instruction-following Capabilities of Large Language Models. arXiv preprint arXiv:2406.13542 .
Dubois, Y.; Li, C. X.; Taori, R.; Zhang, T.; Gulrajani, I.; Ba, J.; Guestrin, C.; Liang, P. S.; and Hashimoto, T. B. 2024. Alpacafarm: A simulation framework for methods that learn from human feedback. Advances in Neural Information Processing Systems , 36.
He, Q.; Zeng, J.; He, Q.; Liang, J.; and Xiao, Y . 2024a. From Complex to Simple: Enhancing Multi-Constraint Complex Instruction Following Ability of Large Language Models. arXiv preprint arXiv:2404.15846 .
He, Q.; Zeng, J.; Huang, W.; Chen, L.; Xiao, J.; He, Q.; Zhou, X.; Liang, J.; and Xiao, Y. 2024b. Can Large Language Models Understand Real-World Complex Instructions? In Proceedings of the AAAI Conference on Artificial Intelligence , volume 38, 18188-18196.
Hendrycks, D.; Burns, C.; Basart, S.; Critch, A.; Li, J.; Song, D.; and Steinhardt, J. 2021. Aligning AI With Shared Human Values. Proceedings of the International Conference on Learning Representations (ICLR) .
Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; and Steinhardt, J. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300 .
Huang, Y.; Bai, Y.; Zhu, Z.; Zhang, J.; Zhang, J.; Su, T.; Liu, J.; Lv, C.; Zhang, Y.; Fu, Y.; et al. 2024. C-eval: A multilevel multi-discipline chinese evaluation suite for foundation models. Advances in Neural Information Processing Systems , 36.
Jiang, Y.; Wang, Y.; Zeng, X.; Zhong, W.; Li, L.; Mi, F.; Shang, L.; Jiang, X.; Liu, Q.; and Wang, W. 2023. Followbench: A multi-level fine-grained constraints following benchmark for large language models. arXiv preprint arXiv:2310.20410 .
Laskar, M. T. R.; Alqahtani, S.; Bari, M. S.; Rahman, M.; Khan, M. A. M.; Khan, H.; Jahan, I.; Bhuiyan, A.; Tan, C. W.; Parvez, M. R.; et al. 2024. A Systematic Survey and Critical Review on Evaluating Large Language Models: Challenges, Limitations, and Recommendations. arXiv preprint arXiv:2407.04069 .
Li, X.; Zhang, T.; Dubois, Y.; Taori, R.; Gulrajani, I.; Guestrin, C.; Liang, P.; and Hashimoto, T. B. 2023. Alpacaeval: An automatic evaluator of instruction-following models. Li, Y.; Zhang, G.; Qu, X.; Li, J.; Li, Z.; Wang, Z.; Li, H.; Yuan, R.; Ma, Y.; Zhang, K.; et al. 2024. CIF-Bench: A Chinese Instruction-Following Benchmark for Evaluating the Generalizability of Large Language Models. arXiv preprint arXiv:2402.13109 .
Liu, X.; Yu, H.; Zhang, H.; Xu, Y.; Lei, X.; Lai, H.; Gu, Y.; Ding, H.; Men, K.; Yang, K.; et al. 2023. Agentbench: Evaluating llms as agents. arXiv preprint arXiv:2308.03688 .
Luo, Z.; Xu, C.; Zhao, P.; Sun, Q.; Geng, X.; Hu, W.; Tao, C.; Ma, J.; Lin, Q.; and Jiang, D. 2023. Wizardcoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568 .
Mishra, S.; Khashabi, D.; Baral, C.; and Hajishirzi, H. 2022. Cross-Task Generalization via Natural Language Crowdsourcing Instructions. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , 3470-3487.
Mukherjee, S.; Mitra, A.; Jawahar, G.; Agarwal, S.; Palangi, H.; and Awadallah, A. 2023. Orca: Progressive learning from complex explanation traces of gpt-4. arXiv preprint arXiv:2306.02707 .
Qin, Y.; Song, K.; Hu, Y.; Yao, W.; Cho, S.; Wang, X.; Wu, X.; Liu, F.; Liu, P.; and Yu, D. 2024. InFoBench: Evaluating Instruction Following Ability in Large Language Models. arXiv preprint arXiv:2401.03601 .
Sanh, V.; Webson, A.; Raffel, C.; Bach, S. H.; Sutawika, L.; Alyafeai, Z.; Chaffin, A.; Stiegler, A.; Le Scao, T.; Raja, A.; et al. 2022. Multitask Prompted Training Enables ZeroShot Task Generalization. In ICLR 2022-Tenth International Conference on Learning Representations .
Sun, H.; Liu, L.; Li, J.; Wang, F.; Dong, B.; Lin, R.; and Huang, R. 2024a. Conifer: Improving Complex Constrained Instruction-Following Ability of Large Language Models. arXiv preprint arXiv:2404.02823 .
Sun, K.; Wang, R.; Liu, H.; and Søgaard, A. 2024b. Comprehensive Reassessment of Large-Scale Evaluation Outcomes in LLMs: A Multifaceted Statistical Approach. arXiv preprint arXiv:2403.15250 .
Tang, X.; Zong, Y.; Zhao, Y.; Cohan, A.; and Gerstein, M. 2023. Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data? arXiv preprint arXiv:2309.08963 .
Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 .
Tsai, A.; Oraby, S.; Perera, V.; Kao, J.-Y.; Du, Y.; NarayanChen, A.; Chung, T.; and Hakkani-Tur, D. 2021. Style Control for Schema-Guided Natural Language Generation. In Proceedings of the 3rd Workshop on Natural Language Processing for Conversational AI , 228-242.
Wang, Y.; Kordi, Y.; Mishra, S.; Liu, A.; Smith, N. A.; Khashabi, D.; and Hajishirzi, H. 2023. Self-Instruct: Aligning Language Models with Self-Generated Instructions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , 13484-13508.
Wei, J.; Bosma, M.; Zhao, V. Y.; Guu, K.; Yu, A. W.; Lester, B.; Du, N.; Dai, A. M.; and Le, Q. V. 2021. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652 .
Weller, O.; Lourie, N.; Gardner, M.; and Peters, M. E. 2020. Learning from Task Descriptions. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , 1361-1375.
Wen, B.; Ke, P.; Gu, X.; Wu, L.; Huang, H.; Zhou, J.; Li, W.; Hu, B.; Gao, W.; Xu, J.; et al. 2024. Benchmarking Complex Instruction-Following with Multiple Constraints Composition. arXiv preprint arXiv:2407.03978 .
Xia, C.; Xing, C.; Du, J.; Yang, X.; Feng, Y.; Xu, R.; Yin, W.; and Xiong, C. 2024. FOFO: A Benchmark to Evaluate LLMs' Format-Following Capability. arXiv preprint arXiv:2402.18667 .
Xu, C.; Sun, Q.; Zheng, K.; Geng, X.; Zhao, P.; Feng, J.; Tao, C.; and Jiang, D. 2023. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244 .
Yang, S.; Nachum, O.; Du, Y.; Wei, J.; Abbeel, P.; and Schuurmans, D. 2023. Foundation models for decision making: Problems, methods, and opportunities. arXiv preprint arXiv:2303.04129 .
Yao, S.; Chen, H.; Hanjie, A. W.; Yang, R.; and Narasimhan, K. 2023. Collie: Systematic construction of constrained text generation tasks. arXiv preprint arXiv:2307.08689 .
Zhang, H.; Song, H.; Li, S.; Zhou, M.; and Song, D. 2023. A survey of controllable text generation using transformerbased pre-trained language models. ACM Computing Surveys , 56(3): 1-37.
Zheng, L.; Chiang, W.-L.; Sheng, Y.; Zhuang, S.; Wu, Z.; Zhuang, Y.; Lin, Z.; Li, Z.; Li, D.; Xing, E.; et al. 2024.
Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems , 36.
Zhong, R.; Lee, K.; Zhang, Z.; and Klein, D. 2021. Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections. In Findings of the Association for Computational Linguistics: EMNLP 2021 , 28562878.
Zhong, W.; Cui, R.; Guo, Y.; Liang, Y.; Lu, S.; Wang, Y.; Saied, A.; Chen, W.; and Duan, N. 2024. AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models. In Findings of the Association for Computational Linguistics: NAACL 2024 , 2299-2314.
Zhou, J.; Lu, T.; Mishra, S.; Brahma, S.; Basu, S.; Luan, Y.; Zhou, D.; and Hou, L. 2023a. Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911 .
Zhou, W.; Jiang, Y. E.; Wilcox, E.; Cotterell, R.; and Sachan, M. 2023b. Controlled text generation with natural language instructions. In International Conference on Machine Learning , 42602-42613. PMLR.
## CFBench Construction
## Constraint System Construction
The construction of the constraint system commenced with the aggregation of data from diverse real-world scenarios and NLP tasks. This encompassed 800,000 query logs from LLM websites over the preceding six months, alongside over 300,000 data points from various NLP tasks. Instructions that were excessively long or short were filtered out, and a vector clustering deduplication algorithm was employed. This meticulous process culminated in a refined dataset comprising approximately 30,000 instructions. Subsequently, GPT was utilized to extract constraint atoms from these instructions, thereby ensuring the comprehensiveness of the constraint system. The prompt employed for GPT4 extraction, as illustrated in Fig. 7, resulted in the identification of approximately 5,000 unique atomic constraint instructions. Three seasoned experts meticulously refined these into 1,000 significant atomic constraints. By integrating statistical analysis, classification, and linguistic principles, a hierarchical constraint system was developed using Top-Down Organization and Bottom-Up Synthesis methodologies. This system comprises 10 primary categories and 25 secondary categories. The system comprehensively categorizes all types of constraints, ensuring that nearly all specific constraints can be systematically classified within its framework. Detailed information regarding the constraint system is presented in Tab. 8.
## Dataset Construction
Weadopted an innovative Human-Machine Collaborative Iterative Construction approach to ensure the highest quality of data. This method involved leveraging advanced LLMs to augment original instructions with additional constraints and generate corresponding responses. These responses were meticulously reviewed for constraint validity, followed by the creation of detailed checklists for each example. Multiple experts participated in this iterative process, continuously refining the outputs by addressing issues encountered by the LLMs and regenerating or manually correcting any substandard samples. The prompts used for GPT to enhance constraints and generate checklists are illustrated in Fig. 8 and Fig. 10. Due to the limited attention given to real-life scenarios, we have meticulously organized and covered 20 domains and over 200 scenarios in our CFBench system, as detailed in Tab. 9. In the end, we gathered 1,000 high-quality data points: 500 from real-world scenarios and 500 from different NLP tasks. Specifically, we implemented the following steps to enhance data quality for manual annotations.
Annotator Training We sourced annotation contractors from the public and selected 21 candidates for training by seasoned data scientists. After a one-week training program, the annotators engaged in multiple rounds of trial annotations, which were then assessed by data experts. From these assessments, the 9 annotators demonstrating the highest accuracy were selected for this dataset.
Cross-Validation To reduce the likelihood of missed and incorrect annotations, we implemented an inter-annotator
Figure 7: Prompt Template Atomic Constraint Extract

Figure 8: Prompt Template for Adding Atomic constraint

validation process. Three annotators independently reviewed the labeled instructions, responses, and evaluation criteria, achieving a notable agreement rate of 94%. Any discrepancies that emerged were resolved through expert adjudication, ensuring both consistency and accuracy.
Batch Validation Due to the substantial size of the dataset, it was systematically divided for processing. Following a phased improvement approach, the initial batch sizes were set at 50, 100, and 200, gradually increasing to 400 for later batches. After the annotation process, 50% of the dataset was randomly selected for contractor review, while 20% of the dataset was examined by experts.
Data Split We used a voting mechanism involving experts and ten models, including GPT-4o and Claude-3.5-Sonnet, to partition 10,000 CFBench entries into 'easy' and 'hard' categories. The 'hard' category includes entries where multiple models struggle with PSR performance and are also challenging for humans, as verified by experts.
## Evaluation Method and Metric
The state-of-the-art GPT-4o model was employed as the judge to perform binary scoring (0 or 1) for each checkpoint in the checklist. The specific evaluation prompt is illus-
Figure 9: Prompt Template for Evaluation

Table 5: The High-Quality Rate of 100 selected Samples
| Set | Instruction | Response | CheckList |
|----------|---------------|------------|-------------|
| Easy Set | 0.96 | 0.94 | 0.93 |
| Hard Set | 0.92 | 0.95 | 0.93 |
| All Set | 0.94 | 0.94 | 0.93 |
trated in Fig. 9. The Requirement Priority-Satisfaction Ratio (PSR) was proposed as an evaluation metric that simultaneously considers the prioritization of user requirements and satisfaction levels. PSR is calculated by first ensuring that all primary requirements are met. Subsequently, the satisfaction score is determined by averaging the fulfillment of the remaining constraints to obtain A . The final satisfaction score is then calculated using the formula 0 5 + 0 5 . . ∗ A . If the final score exceeds 0 8 . , PSR is set to 1 . The threshold of 0 8 . was established based on the average satisfaction levels derived from multiple users' feedback on the responses to the instructions.
## Quality Assessment
We employed multiple methods to validate the quality of the benchmark on a randomly selected set of 100 samples. First, we engaged three experts to independently evaluate the quality of each sample's instruction, response, and criteria. The average quality rate determined by the three experts was consistently above 90%, as detailed in Tab. 5. To further validate the effectiveness of our proposed evaluation metric, PSR, we had the same three experts score the responses of Qwen2-7B-Instruct on these 100 cases using a 0-1 scale. Simultaneously, we utilized GPT-4o to directly score the responses, referred to as GPT-4o PSR. By calculating the kappa coefficient, we found a strong agreement between our proposed PSR evaluation metric and the human experts' assessments. The detailed results are presented in Tab. 6. Kappa coefficient scores are interpreted as follows: below 0.2 indicates slight agreement, 0.21 to 0.40 indicates fair agreement, 0.41 to 0.60 indicates moderate agreement, 0.61 to 0.80 indicates substantial agreement, and 0.81 to 1.00 indicates almost perfect agreement.
| Set | Easy Set | Hard Set | Full Set |
|---------------------|------------|------------|------------|
| Avg.Expert | 1 | 1 | 1 |
| GPT-4o DS | 0.58 | 0.61 | 0.6 |
| GPT-4o PSR | 0.76 | 0.77 | 0.77 |
| Qwen2-72B-Inst. PSR | 0.7 | 0.73 | 0.72 |
Table 6: The kappa coefficient between expert evaluations and various assessment methods
## Experimental Setup and Results
## Experiment Setting
We evaluated the most popular Large Language Models (LLMs), with the majority of these models being developed by companies based in China, primarily to accommodate our CFBench's focus on the Chinese language. Among the 50 evaluated models, they can be categorized into two groups based on their access method: API-based and open-source weight-based models. It is worth noting that the Llama series models do not primarily support the Chinese language, which results in noticeably lower performance. Both conifer-base and conifer-test are based on the Mistral-7B foundational model. Llama-38B-Instruct-CN and Llama-3-70B-Instruct-CN respectively represent Llama-3-8B-Instruct-Chinese and Llama-3-70BInstruct-Chinese, both of which have undergone Chinese SFT (Supervised Fine-Tuning). For the base models, we used a 3-shot approach to ensure a fair evaluation. The complete list of evaluated models can be found in Tab. 7.
## Explanation of Results
GPT-4o and Claude3.5-Sonnet have demonstrated nearabsolute leadership, achieving outstanding performance across various metrics and categories. Similarly, models such as GLM-4-0510, ERNIE-4-Bot-0613, ERNIE-4Turbo-0628, DeepSeek-V2-0628, and Qwen2-72B-Instruct have also exhibited strong capabilities. Many models that support less mainstream Chinese languages performed significantly worse, which is unfair to them and only serves to illustrate their relative rankings. This also confirms that performance are highly correlated with language, especially within the scope of language constraints. From the perspective of open-source versus closed-source models, open-source models have generally achieved comprehensive success. However, Qwen2-72B-Instruct, as an open-source model, also demonstrated notable constraint-following capabilities. Regarding model size, within the Qwen series, performance metrics clearly improve with increasing model size. Additionally, models that have undergone Supervised Fine-Tuning (SFT) show significantly enhanced instructionfollowing capabilities. The complete evaluation results and rankings can be found in Tab. 7.
| Models | Easy Set | Easy Set | Easy Set | Hard Set | Hard Set | Hard Set | Full Set | Full Set | Full Set |
|-----------------------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|
| Models | CSR | ISR | PSR | CSR | ISR | PSR | CSR | ISR | PSR |
| GPT-4o † | 0.956 | 0.868 | 0.888 | 0.816 | 0.438 | 0.582 | 0.886 | 0.653 | 0.735 |
| GPT-4-Turbo-20240409 † | 0.924 | 0.792 | 0.826 | 0.783 | 0.370 | 0.518 | 0.853 | 0.581 | 0.672 |
| GPT-4-0125-Preview † | 0.923 | 0.790 | 0.826 | 0.763 | 0.310 | 0.468 | 0.843 | 0.550 | 0.647 |
| GPT-3.5-Turbo-1106 † | 0.797 | 0.520 | 0.602 | 0.631 | 0.176 | 0.326 | 0.714 | 0.348 | 0.464 |
| Claude-3.5-Sonnet † | 0.943 | 0.844 | 0.882 | 0.799 | 0.408 | 0.564 | 0.871 | 0.626 | 0.723 |
| GLM-4-0520 † | 0.939 | 0.820 | 0.852 | 0.785 | ✿✿✿✿ 0.372 | ✿✿✿✿ 0.536 | 0.862 | ✿✿✿✿ 0.596 | 0.694 |
| DeepSeek-V2-0628 † | 0.946 | 0.830 | 0.868 | 0.786 | 0.350 | 0.524 | 0.866 | 0.590 | 0.696 |
| ERNIE-4-Turbo-0628 † | 0.930 | 0.790 | 0.848 | 0.772 | 0.332 | 0.532 | 0.851 | 0.561 | 0.690 |
| ERNIE-4-Bot-0613 † | 0.929 | 0.792 | 0.832 | 0.779 | 0.338 | 0.518 | 0.854 | 0.565 | 0.675 |
| ERNIE-3.5-0613 † | 0.901 | 0.720 | 0.772 | 0.758 | 0.302 | 0.482 | 0.830 | 0.511 | 0.627 |
| Yi-Large † | 0.900 | 0.730 | 0.786 | 0.744 | 0.292 | 0.460 | 0.822 | 0.511 | 0.623 |
| abab6.5-chat † | 0.894 | 0.696 | 0.766 | 0.736 | 0.260 | 0.452 | 0.815 | 0.478 | 0.609 |
| MoonShot-V1-8k † | 0.919 | 0.764 | 0.812 | 0.758 | 0.308 | 0.464 | 0.838 | 0.536 | 0.638 |
| Vicuna-7B-V13 ∗ | 0.563 | 0.206 | 0.262 | 0.468 | 0.100 | 0.168 | 0.516 | 0.153 | 0.215 |
| Vicuna-33B-V13 ∗ | 0.621 | 0.270 | 0.352 | 0.527 | 0.110 | 0.196 | 0.574 | 0.190 | 0.274 |
| Vicuna-13B-V13 ∗ | 0.605 | 0.248 | 0.302 | 0.503 | 0.100 | 0.178 | 0.554 | 0.174 | 0.240 |
| Llama-2-7B-Chat ∗ | 0.5268 | 0.198 | 0.250 | 0.448 | 0.096 | 0.152 | 0.487 | 0.147 | 0.201 |
| Llama-2-13B-Chat ∗ | 0.574 | 0.242 | 0.280 | 0.488 | 0.094 | 0.178 | 0.531 | 0.168 | 0.229 |
| Llama-3-8B-Instruct ∗ | 0.656 | 0.300 | 0.356 | 0.562 | 0.122 | 0.238 | 0.609 | 0.211 | 0.297 |
| Llama-3-70B-Instruct ∗ | 0.750 | 0.422 | 0.498 | 0.642 | 0.178 | 0.330 | 0.696 | 0.300 | 0.414 |
| Mistral-7B-Instruct-V03 ∗ | 0.227 | 0.072 | 0.086 | 0.148 | 0.008 | 0.022 | 0.188 | 0.040 | 0.054 |
| Conifer-Base ∗ | 0.510 | 0.184 | 0.232 | 0.300 | 0.018 | 0.048 | 0.405 | 0.101 | 0.140 |
| Conifer-Test ∗ | 0.559 | 0.215 | 0.255 | 0.328 | 0.102 | 0.156 | 0.443 | 0.159 | 0.206 |
| BaiChuan-13B-Chat | 0.630 | 0.306 | 0.366 | 0.521 | 0.114 | 0.196 | 0.575 | 0.210 | 0.281 |
| BaiChuan2-13B-Chat | 0.669 | 0.348 | 0.418 | 0.547 | 0.134 | 0.226 | 0.608 | 0.241 | 0.322 |
| Llama-3-8B-Instruct-CN | 0.743 | 0.458 | 0.510 | 0.627 | 0.162 | 0.314 | 0.685 | 0.310 | 0.412 |
| Llama-3-70B-Instruct-CN | 0.756 | 0.482 | 0.536 | 0.636 | 0.190 | 0.322 | 0.696 | 0.336 | 0.429 |
| DeepSeek-7B-Chat | 0.695 | 0.378 | 0.442 | 0.580 | 0.150 | 0.270 | 0.638 | 0.264 | 0.356 |
| DeepSeek-V2-Lite-Chat | 0.733 | 0.382 | 0.448 | 0.597 | 0.148 | 0.262 | 0.665 | 0.265 | 0.355 |
| DeepSeek-67B-Chat | 0.802 | 0.516 | 0.578 | 0.662 | 0.180 | 0.350 | 0.732 | 0.348 | 0.464 |
| InternLM2-Chat-7B | 0.767 | 0.452 | 0.538 | 0.625 | 0.172 | 0.320 | 0.696 | 0.312 | 0.429 |
| GLM-4-9B-Chat | 0.885 | 0.678 | 0.742 | 0.742 | 0.288 | 0.450 | 0.813 | 0.483 | 0.596 |
| YI-1.5-34B-Chat | 0.881 | 0.672 | 0.740 | 0.745 | 0.302 | 0.474 | 0.813 | 0.487 | 0.607 |
| Qwen1.5-4B | 0.454 | 0.170 | 0.198 | 0.376 | 0.074 | 0.116 | 0.415 | 0.122 | 0.157 |
| Qwen1.5-4B-Chat | 0.652 | 0.310 | 0.362 | 0.536 | 0.104 | 0.198 | 0.594 | 0.207 | 0.280 |
| Qwen1.5-7B | 0.473 | 0.176 | 0.212 | 0.400 | 0.090 | 0.142 | 0.437 | 0.133 | 0.177 |
| Qwen1.5-7B-Chat | 0.799 | 0.534 | 0.592 | 0.654 | 0.194 | 0.338 | 0.726 | 0.364 | 0.465 |
| Qwen1.5-14B | 0.498 | 0.228 | 0.280 | 0.430 | 0.110 | 0.176 | 0.464 | 0.169 | 0.228 |
| Qwen1.5-14B-Chat | 0.822 | 0.558 | 0.626 | 0.671 | 0.202 | 0.370 | 0.746 | 0.380 | 0.498 |
| Qwen1.5-32B-Chat | 0.647 | 0.336 | 0.408 | 0.528 | 0.132 | 0.224 | 0.587 | 0.234 | 0.316 |
| Qwen1.5-32B | 0.883 | 0.678 | 0.744 | 0.704 | 0.228 | 0.412 | 0.793 | 0.453 | 0.578 |
| Qwen1.5-72B | 0.627 | 0.324 | 0.380 | 0.556 | 0.148 | 0.248 | 0.591 | 0.236 | 0.314 |
| Qwen1.5-72B-Chat | 0.896 | 0.710 | 0.776 | 0.730 | 0.254 | 0.436 | 0.813 | 0.482 | 0.606 |
| Qwen1.5-110B-Chat | 0.905 | 0.724 | 0.792 | 0.730 | 0.276 | 0.438 | 0.818 | 0.500 | 0.615 |
| Qwen2-0.5B-Instruct | 0.446 | 0.150 | 0.172 | 0.393 | 0.070 | 0.110 | 0.419 | 0.110 | 0.141 |
| Qwen2-1.5B-Instruct | 0.607 | 0.250 | 0.316 | 0.496 | 0.104 | 0.168 | 0.551 | 0.177 | 0.242 |
| Qwen2-7B | 0.576 | 0.260 | 0.316 | 0.478 | 0.120 | 0.192 | 0.527 | 0.190 | 0.254 |
| Qwen2-7B-Instruct Qwen2-72B | 0.835 0.711 | 0.584 0.424 | 0.642 0.484 | 0.682 0.568 | 0.198 0.170 | 0.362 0.274 | 0.758 0.640 | 0.391 0.297 | 0.502 0.379 |
| | | | 0.880 | 0.791 | 0.342 | 0.530 | 0.867 | 0.589 | 0.705 |
| Qwen2-72B-Instruct | ✿✿✿✿ 0.944 | ✿✿✿✿ 0.836 | ✿✿✿✿ | ✿✿✿✿ | | | ✿✿✿✿ | | ✿✿✿✿ |
Table 7: The complete evaluation results and rankings of CFBench and its respective subsets. Notably, ∗ stands for the model supporting mainstream languages excluding Chinese, and † represents calling through the API. The bold , underlined, and tilde ✿✿✿ denote the first, second, and third rankings, respectively. Llama-3-8B-Instruct-CN and Llama-3-70B-Instruct-CN respectively represent Llama-3-8B-Instruct-Chinese and Llama-3-70B-Instruct-Chinese, both of which have undergone Chinese SFT (Supervised Fine-Tuning). Both conifer base and conifer test are based on the Mistral-7B foundational model. For the base model, we used a 3-shot approach for generation.
Table 8: Constraint System of CFBench
| Primary | Secondary | Definition | Example |
|--------------------------|-------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Content Constraint | Lexical Element Semantic | Mandatory use of specific terms or symbols, in- cluding their inclusion and precise placement. Mandates for including specific elements or con- cepts in responses, reflecting a scenario or object. Directives on thematic content, perspective, or tone, emphasizing response significance. | ...must include the word 'beautiful.' ...highlights the Great Wall. Write a poem about London. |
| Numerical Constraint | Word Count Sentence Count Paragraph Count Document Count | Limit the number of words or tokens. Limit the number of sentences. Limit the number of paragraphs. Limit the number of documents. | A 50-word poem. ... three sentences. divided into 3 sections. ... list 3 articles. |
| Stylistic Constraint | Tone and emotion Form and style Audience-specific Authorial style Fundamental | The emotional tone must adhere to standards such as seriousness, anger, joy, humor, and politeness. Text expression standards ensure alignment with specific stylistic criteria in both presentation and perception. Text should be tailored to specific audiences, en- suring clarity and relevance for children, students, or specialized groups. Texts should emulate the styles of authors like Shakespeare to achieve artistic effects or depth. | Write a letter in an an- gry and sarcastic tone. Write a passage in an encyclopedic style. Write a pome for a 6- year-old. Write a passage the style of Shakespeare. |
| Format Constraint | Bespoke | Widely accepted and utilized standard formats, in- cluding JSON, XML, LaTeX, HTML, Table, and Markdown. Protocols for information expression tailored to specific needs,including paragraphing, headings, text emphasis, examples, and bullet points. Formatting standards tailored for specialized ap- | Extract keywords and output in JSON for- mat. Summarize the main idea and output in un- ordered list format. Conform to electronic |
| Linguistic Constraint | Pragmatic Syntactic Morphological | Contextual language study, encompassing speech acts, implicature, discourse, dialects, sociolects, and language policy. Sentence structure, including phrases, con- stituents, subordinate clauses, ba-constructions, and imperatives. The internal structure and formation rules of words, including roots, affixes, and morphologi- cal changes. | Output in English, in classical Chinese style. Use imperatives with nouns and verb phrases. Output all content in lowercase English. |
| Situation Constraint | Role-based Task-specific Complex context - | their traits, language, and behaviors. Offer tailored solutions based on a nuanced under- standing of situational demands. Reasoning and problem-solving within intricate and multifaceted contexts. Regulate new responses by leveraging intrinsic | how do you decide? Must work from home, how to report? 4 on the left, 10 total, which from right? Example:input:xxx, output: { ... } ; input:xx, |
| Example Constraint | - | patterns from a limited set of samples. | output? |
| Inverse Constraint | | Narrow the response space through inverse con- straints and indirect exclusion. | Prohibited from an- swer political topics. |
| | | | Write a five-character |
| Contradictory Constraint | - | Mutually exclusive constraints prevent fulfilling all requirements concurrently. | quatrain, 1000 words. |
| Rule Constraint | - | the road of responses through metic- crafted logic flows or actions. | Each answer adds 1+1=3, then 2+3=? |
| | | Standardize ulously | 1, |
## Domain
## Scenarios List
Table 9: Domain and Scenarios List
| | Symptom Consultation | Diagnostic Explanation | Medication Guidance | Procedures |
|----------------|--------------------------------------------------------------------------|---------------------------------------------------------|----------------------------------------------------------------|-------------------------------------------------------------|
| Healthcare | Wellness Medical Education | Medical Info | Guidelines Inquiry | Public Health |
| Education | Teaching Methods Academic Counseling Reports | Resource Access Mental Health Support Interests | Curriculum Design Tutoring | Communication Subject Q&A |
| Finance | Market Research Corporate Tax Financial Education Regulatory Analysis | Stock Analysis Insurance Management Product Development | Investment Analysis Corporate Financing Customer Service | Personal Finance Compliance &Risk Financial Reports |
| | Legal Education Statute Explanation | Legal Consultation Regulation Analysis | Document Review IP Management | Case Analysis Legal Training |
| Legal Media | Case Management Content Creation | Compliance &Risk Information Analysis | Marketing &Promotion | News Reporting |
| Recruitment | Interview Evaluation Performance Review Policy Research Document Writing | Career Planning Public Education Content Review | Offer Comparison Service Guide Business Procedures | Communication Skills Public Services Civil Servant Training |
| Gov Affairs | Emergency | | | |
| Real | Management Purchase Planning Leasing Property Description | Market Trends | Property Policies | Development |
| Estate | Renovation Marketing &Sales | Property Valuation Content Creation | Amenities Sales &Marketing | Financial Services Qualifications |
| Automotive | Model Comparison Car Reviews | Driving &Safety Loan Calculation Maintenance &Repair | Customer Experience Insurance Evaluation | Model Consultation Claims Assessment |
| | Romance | Family | Friendship Sexuality &Gender | Workplace |
| Psychology | Self &Health Organizational | Social Client Relations | Crisis Intervention User Research | Life Stages Public Psychology Coding |
| Internet | Business Analysis Product Testing | Product Design Data Management | Cybersecurity | &Debugging Computer Q&A UI/UX Design |
| Spirituality | Internet News Beliefs &Rituals | Marketing Divination | Operations Feng Shui | Astrology |
| Sports | Metaphysics Training | Spirituality Goal Setting Performance | Healing Nutrition | Content Review Workout Plans Specialized |
| | Equipment &Tech Mental Motivation Life Tips | Data Tracking Shopping Decisions | Injury Care Instant Queries | Training Skincare |
| Lifestyle | Fashion &Styling Socializing Podcasts &Radio | Naming Life Creations TV &Film | Recommendations Q&A Music | Planning Literature |
| Culturtainment | Theater &Dance | Art Content Creation | Cultural Events | Short Videos &Live |
| Employment | Gossip Project Management Administration | Translation Customer Service Reviews &Feedback | Office Efficiency Team Collaboration | Marketing Collaboration |
| Cuisine | Food &Restaurant Recs Culinary Culture Nutrition &Health | Recipes &Menus Food Safety Reviews | Marketing &Promo Cooking Techniques Culinary Training Hardware | Food Content Ingredient Prep |
| | Guides | | | |
| | | | &Peripherals | News |
| Gaming | Software &Services | Development &Design | Operations | Mini Games |
| | Search | Marketing &Promotion Launches | Esports &Tournaments | Culture |
| Technology | Reviews | | Buying Guides | &Education Tips &Tricks |
| | Content Creation | Product Design | Marketing Copy | After-sales &Repairs |
## # Task Description
## # Given Input
[Instruction]:{instruction}
[Respone]:{response}
# Your Answer about Checklist
## # Given Example
## Prompt Template for CheckList Generation
You are a professional instruction and response review expert. You need to extract all possible checklist items that could affect the evaluation of the result based on the [Instruction] and [Response] within the [Constraint System]. Your output should be as detailed as possible. Use numerical numbering and "\n" to list all points in the checklist.
## # Constraint System
1. Lexical content constraint: {Definition} {Example}
2. Word Count :
{Definition} {Example}
...
25.Rule Constraint: {Definition} {Example}
## CheckList
1.Content on Trump Shooting Incident 2.Includes cause, process, impact ... 3.Use numbered points and bold text 4.Cause in JSON
5.Process in three sentences 6.Impact: international and domestic 7.Total content under 500 words 8.Seven-word quatrain
Response: Overview of the Trump Shooting Incident. 1.Cause \n{"time":"July 13, 2024", "location":"Butler, Pennsylvania, USA","nature":"assassination attempt"} \n 2.Process \n-Trump was giving a speech at the rally when the shooting occurred... 3.Impact \n-International: The incident shocked the world, raising concerns about US political violence. \n-Domestic: US political tensions and polarization increased; Trump's support may rise.\n 4.Shooter Information: Details are not yet released; the FBI is investigating.\n 5.Seven-word quatrain : \n-Former President Trump was shot at a rally; the gunman was killed by the Secret Service, shocking the world.
Overview of the Trump Shooting Incident, include the cause, process, impact, aftermath, shooter information and Trump's feedback. Organize the content using numbered points and bold text. The cause should be in JSON format with event keywords: time, location, and nature. Summarize the process in three sentences. Discuss the impact from both international and domestic perspectives, keeping the total content under 500 words. Finally, summarize this event in a seven-word quatrain. Instruction:
Figure 10: Prompt Template for CheckList Generation | null | [
"Tao Zhang",
"Yanjun Shen",
"Wenjing Luo",
"Yan Zhang",
"Hao Liang",
"Tao Zhang",
"Fan Yang",
"Mingan Lin",
"Yujing Qiao",
"Weipeng Chen",
"Bin Cui",
"Wentao Zhang",
"Zenan Zhou"
] | 2024-08-02T09:03:48+00:00 | 2024-08-02T09:03:48+00:00 | [
"cs.CL"
] | CFBench: A Comprehensive Constraints-Following Benchmark for LLMs | The adeptness of Large Language Models (LLMs) in comprehending and following
natural language instructions is critical for their deployment in sophisticated
real-world applications. Existing evaluations mainly focus on fragmented
constraints or narrow scenarios, but they overlook the comprehensiveness and
authenticity of constraints from the user's perspective. To bridge this gap, we
propose CFBench, a large-scale Comprehensive Constraints Following Benchmark
for LLMs, featuring 1,000 curated samples that cover more than 200 real-life
scenarios and over 50 NLP tasks. CFBench meticulously compiles constraints from
real-world instructions and constructs an innovative systematic framework for
constraint types, which includes 10 primary categories and over 25
subcategories, and ensures each constraint is seamlessly integrated within the
instructions. To make certain that the evaluation of LLM outputs aligns with
user perceptions, we propose an advanced methodology that integrates
multi-dimensional assessment criteria with requirement prioritization, covering
various perspectives of constraints, instructions, and requirement fulfillment.
Evaluating current leading LLMs on CFBench reveals substantial room for
improvement in constraints following, and we further investigate influencing
factors and enhancement strategies. The data and code are publicly available at
https://github.com/PKU-Baichuan-MLSystemLab/CFBench |
2408.01123v2 | ## Model Independent Tests of the Hadronic Vacuum Polarization Contribution to the Muon g -2
Luca Di Luzio, 1 Alexander Keshavarzi, 2 Antonio Masiero, 3, 1 and Paride Paradisi 3, 1 1
Istituto Nazionale di Fisica Nucleare, Sezione di Padova, Via F. Marzolo 8, 35131 Padova, Italy 2 Department of Physics and Astronomy, The University of Manchester, Manchester M13 9PL, U.K. 3 Dipartimento di Fisica e Astronomia 'G. Galilei',
Universit` a di Padova, Via F. Marzolo 8, 35131 Padova, Italy
The hadronic vacuum polarization (HVP) contributions to the muon g -2 are the crucial quantity to resolve whether new physics is present or not in the comparison between the Standard Model (SM) prediction and experimental measurements at Fermilab. They are commonly and historically determined via dispersion relations using a vast catalogue of experimentally measured, low-energy e + e -→ hadrons cross section data as input. These dispersive estimates result in a SM prediction that exhibits a muon g -2 discrepancy of more than 5 σ when compared to experiment. However, recent lattice QCD evaluations of the HVP and a new hadronic cross section measurement from the CMD-3 experiment favor a no-new-physics scenario and, therefore, exhibit a common tension with the previous e + e -→ hadrons data. This study explores the current and future implications of these two scenarios on other observables that are also sensitive to the HVP contributions in the hope that they may provide independent tests of the current tensions observed in the muon g -2.
Introduction.The anomalous magnetic moment of the muon, a µ ≡ ( g µ -2) / 2, stands amongst the best probes of the Standard Model (SM) of particle physics and its possible extensions. Recently, the Muon g -2 Experiment at Fermilab announced a new experimental (exp) measurement of a µ [1, 2] which, when combined with the previous and consistent results from the same experiment [3-6] (and from the earlier Muon g -2 Experiment at Brookhaven [7-9]), results in a new world average of a exp µ = 116592059(22) × 10 -11 with an unprecedented precision of 190 parts-per-billion (ppb).
which reduces ∆ a µ to 0 9 . σ (fully consistent with a exp µ at the current level of precision) at the expense of generating a 4 0 . σ tension with Eq. (1). These results have been partially confirmed by other lattice QCD studies of the so-called window quantities [47, 58-62], which further increase the tension between lattice QCD evaluations and ( a HVP TI µ ) e + e -in the intermediate [63] as well as long-distance [64, 65] windows.
The most recent, community-approved SM prediction of a µ from the Muon g -2 Theory Initiative [10-30] relies on the hadronic vacuum polarization (HVP) contribution, a HVP µ , being entirely evaluated using the datadriven, dispersive approach [15-25, 31-45]. This method uses measured e + e -→ hadrons cross section data ( σ had ) as input and the leading-order (LO) HVP contribution was found by the Theory Initiative to be [10, 15-20]
$$( a _ { \mu } ^ { H V P } ) _ { e ^ { + } e ^ { - } } ^ { T I } = ( 6 9 3. 1 \pm 4. 0 ) \times 1 0 ^ { - 1 0 } \,. \quad ( 1 ) \quad \text{cout}$$
This, when combined with the updated values for the other SM contributions, resulted in a SM prediction of a SM µ = 116591810(43) × 10 -11 [10-30]. Comparing a SM µ with the current experimental world average leads to
$$\Delta a _ { \mu } \equiv a _ { \mu } ^ { \exp } - a _ { \mu } ^ { S M } = ( 2 4. 9 \pm 4. 8 ) \times 1 0 ^ { - 1 0 } \,, \quad ( 2 ) \quad \text{ also}$$
yielding a discrepancy of 5 1 . σ and implying the presence of physics beyond the SM (BSM).
a HVP µ can now be calculated from first-principles lattice QCD methods [10] (see also [46-57]). In particular, the BMW lattice QCD collaboration (BMWc) first computed a HVP µ with sub per-cent precision [56] and found ( a HVP BMW µ ) Lattice = (707 5 . ± 5 5) . × 10 -10 , which is evidently larger than the Theory Initiative value [10]. They have since updated their result to [57]
$$( a _ { \mu } ^ { H V P } ) _ { L a t t i c e } ^ { B M W } = ( 7 1 4. 1 \pm 3. 3 ) \times 1 0 ^ { - 1 0 } \,, \quad ( 3 ) \quad \text{ when}$$
Increasing the hadronic cross section to accommodate ∆ a µ in ( a HVP TI µ ) e + e -requires shifts below ∼ 1 GeV to avoid inconsistency with the electroweak precision fits [66-70]. Indeed, a large portion of the differences observed between ( a HVP TI µ ) e + e -and lattice QCD evaluations dominantly originate from the light-quark-connected contributions (which in-turn are dominated by π + π -) [71, 72]. The potential for light new physics affecting the interpretation of e + e -data was also investigated in [73-77].
Recently, the CMD-3 experiment released a new measurement of the e + e -→ π + π -cross section [78, 79]. It covers the energy range from 0.32 to 1.2 GeV, therefore capturing the dominant ρ -resonance region, and is ∼ 2 σ -4 σ higher than all previous e + e -→ π + π -cross section measurements in the same region [80-91]. Although ( a ππ µ ) CMD3 e + e -covers a limited energy range, it goes in the same direction as the BMWc result of Eq. (3), thereby also suggesting consistency between a exp µ and a SM µ .
Several updates and improvements on all fronts are expected soon which may help shed light on the current puzzling picture. New results of the e + e -→ π + π -cross section are expected from the BaBar [92], Belle II [93], BESIII [94], CMD-3 [95], KLOE [96] and SND [97] experiments in the next 2-4 years, with theoretical improvements also expected for the higher-order QED corrections which are paramount for these measurements (see e.g. [98, 99]). New full HVP determinations from other lattice QCD collaborations are also expected soon, as well as new dispersive determinations of the HVP incorporating new e + e -→ hadrons cross section data. In ad-
FIG. 1. Representative Feynman diagrams for observables that are sensitive to the leading HVP contribution: leptonic g -2 (first diagram), running of α and sin 2 θ W (second diagram), and Muonium HFS (third and fourth diagrams).

dition, a direct experimental measurement of a HVP µ , has been proposed and is in preparation by the MUonE experiment [100-104]. 1
This letter adds to this catalogue of probes other observables that are sensitive to HVP effects and, therefore, can be used as additional indirect tools to scrutinize the differences in a HVP µ . The new data from CMD3 are used to perform numerical analyses and provide analytical expressions relating the HVP contributions of other observables to a HVP µ . The current and future implications of the CMD-3 data (and, by data-based proxy, the increase of ( a HVP BMW µ ) Lattice compared to dispersive estimates) are assessed and quantified for the electron, muon and tau g -2, the running of the QED coupling constant ( α ), the low-energy weak mixing angle (sin 2 θ W (0)) and the Muonium hyperfine splitting (HFS). The conclusions drawn focus upon how new, precise experimental measurements of these observables could be sensitive to the differences observed due to the CMD-3 data in a HVP µ and, therefore, provide additional robust tests of the current tensions.
Impact of the CMD-3 data.The CMD-3 measurement of the π + π -final state [78] is larger than all previous π + π -measurements by 2 σ -4 σ , resulting in it being comparatively larger than the compilation by the KNT collaboration in 2019 (referred to as KNT19) [20]. Given it is not expected that the differences between these measurements will be reconciled, and that no new compilation of π + π -measurements including the CMD-3 data has yet been performed, two scenarios can be compared and analysed: (1) σ had = KNT19. The previous data are correct and the new CMD-3 data are not used. (2) σ had = KNT19/CMD-3. The CMD-3 data are correct therefore are substituted into and replace the KNT19 data only in their available energy range.
The electron, muon and tau g -2, the running of the QED coupling constant, the low-energy weak mixing angle and the Muonium HFS are all sensitive to HVP effects (see e.g. Fig. 1). To understand the impact of the CMD-3 data on the HVP contributions to these observables, O HVP e + e -, the difference between the scenario (1) and
1 Several efforts have also attempted new determinations of a HVP µ from hadronic τ -decay data (see e.g. [99, 105]), although the level to which the required isospin breaking corrections are understood is still under question [10].
TABLE I. HVP contributions to the studied observables [first column] using scenario (1) KNT19 data [second column], or scenario (2) KNT19/CMD3 data [third column]. The fourth column lists the difference or shift induced by the CMD-3 data as δO CMD3 ≡ ( O HVP e + e -) CMD3 -( O HVP e + e -) KNT19 , where the error accounts for the correlation between scenario (1) and scenario (2) from the common KNT19 data.
| O HVP e + e - | Scenario (1) | Scenario (2) | δO CMD3 |
|------------------------------|------------------|------------------|----------------|
| a HVP µ × 10 10 | 692 . 8 ± 2 . 4 | 714 . 5 ± 3 . 4 | 21 . 7 ± 3 . 6 |
| a HVP e × 10 14 | 186 . 1 ± 0 . 7 | 192 . 0 ± 0 . 9 | 6 . 0 ± 1 . 0 |
| a HVP τ × 10 8 | 332 . 8 ± 1 . 4 | 340 . 2 ± 2 . 1 | 7 . 4 ± 1 . 7 |
| ∆ α (5) had ( M 2 Z ) × 10 4 | 276 . 1 ± 1 . 1 | 277 . 5 ± 1 . 2 | 1 . 4 ± 0 . 5 |
| sin 2 θ W (0) × 10 4 | 2386 . 0 ± 1 . 4 | 2386 . 4 ± 1 . 4 | 0 . 4 ± 0 . 1 |
| ν HVP HFS (Hz) | 540 . 5 ± 1 . 9 | 557 . 0 ± 2 . 7 | 16 . 5 ± 2 . 8 |
scenario (2) is calculated as
$$\delta O ^ { C M D 3 } \equiv ( O ^ { H V P } _ { e ^ { + } e ^ { - } } ) ^ { C M D 3 } - ( O ^ { H V P } _ { e ^ { + } e ^ { - } } ) ^ { K N T 1 9 } \,. \quad ( 4 )$$
All results are given in Table I. Other than the region of the replaced π + π -data, the two scenarios are correlated for all common KNT19 data. The statistical significance of each δO CMD3 is depicted in Fig. 2. The results for each O HVP e + e -are discussed in the following, starting with the muon g -2 as the original source of the tensions that motivates this study.
Muon g -2 .-The LO HVP contribution to the muon g -2 is calculated via
$$( a _ { \mu } ^ { H V P } ) _ { e ^ { + } e ^ { - } } = \frac { 1 } { 4 \pi ^ { 3 } } \int _ { m _ { \pi ^ { 0 } } ^ { 2 } } ^ { \infty } \mathrm d s \, K _ { \mu } ( s ) \, \sigma _ { \text{had} } ( s ) \,. \quad ( 5 )$$
The positive-definite kernel function K µ ( s ) is given by
$$K _ { \mu } ( s ) = \int _ { 0 } ^ { 1 } d x \frac { x ^ { 2 } ( 1 - x ) } { x ^ { 2 } + ( 1 - x ) s / m _ { \mu } ^ { 2 } } \,, \quad \ \ ( 6 )$$
with K µ ( s ) ≈ m / s 2 µ 3 in the high-energy limit √ s ≫ m µ . The KNT19 evaluation (scenario (1)) was one of several inputs to the estimate found in Eq. (1) and found the LO HVP contribution to be [20]
$$( a _ { \mu } ^ { H V P } ) _ { e ^ { + } e ^ { - } } ^ { K N T 1 9 } = ( 6 9 2. 8 \pm 2. 4 ) \times 1 0 ^ { - 1 0 } \,. \quad ( 7 )$$
FIG. 2. The tension observed in standard deviations ( σ ) between dispersive evaluations of HVP contributions to observables sensitive to such effects when the e + e -→ hadrons data used as input as those given in scenario (1) (KNT19) [20] (black points) or scenario (2) KNT19/CMD3 [78] (red points).
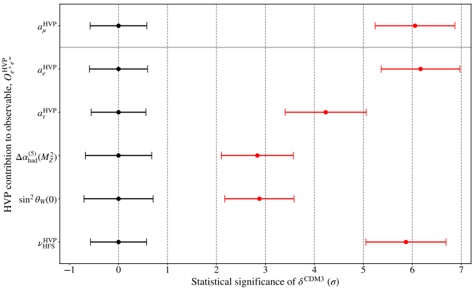
Using scenario (2) (substituting in the CMD-3 data) [78] increases this estimate to
$$( a _ { \mu } ^ { H V P } ) _ { e ^ { + } e ^ { - } } ^ { C M D 3 } = ( 7 1 4. 5 \pm 3. 4 ) \times 1 0 ^ { - 1 0 } \,, \quad ( 8 )$$
which is in better agreement with the BMWc value of Eq. (3). This results in a shift in a HVP µ of
$$\delta a _ { \mu } ^ { \text{CMD3} } & \equiv ( a _ { \mu } ^ { \text{HVP} } ) _ { e ^ { + } e ^ { - } } ^ { \text{CMD3} } - ( a _ { \mu } ^ { \text{HVP} } ) _ { e ^ { + } e ^ { - } } ^ { \text{KNT19} } \\ & = ( 2 1. 7 \pm 3. 6 ) \times 1 0 ^ { - 1 0 } \,, \quad \quad ( 9 ) \quad \text{It} \\ & \alpha \text{ are}$$
exhibiting a tension of 6 1 . σ . In the following, the phenomenological implications of the above shift on O HVP e + e -(see Table I) are analyzed, followed by a discussion regarding the required experimental and theoretical improvements needed to probe the disagreement in Eq. (9).
Electron g -2 .-The anomalous magnetic moment of the electron, a e , is commonly used to determine the value of the fine-structure constant, α (and vice versa). Recent, more-refined atomic-physics experiments using Cesium (Cs) and Rubidium (Rb) interferometry have led to the following results for direct measurements of α :
$$\alpha ( C s ) = 1 / 1 3 7. 0 3 5 9 9 9 0 4 6 ( 2 7 ) \ \ [ 1 0 6 ] \,, \quad ( 1 0 ) \quad \text{ancv}$$
$$\alpha ( R b ) = 1 / 1 3 7. 0 3 5 9 9 9 2 0 6 ( 1 1 ) \ \ [ 1 0 7 ] \,, \quad ( 1 1 ) \quad \ g a u g$$
in disagreement with each other by 5.5 σ . Yet, a e can be extracted and used as another precision test of the SM and its possible extensions [108, 109]. Comparing the resulting SM predictions, a SM e , with the latest experimental measurement of a exp e = (115 965 218 059 ± 13) × 10 -14 [110], yields
$$( \Delta a _ { e } ) _ { C s } = ( - 1 0 2. 0 \pm 2 6. 4 ) \times 1 0 ^ { - 1 4 } \Rightarrow - 3. 9 \sigma \,, \quad ( 1 2 ) \quad _ { \lambda \, - \, \cdot }.$$
$$( \Delta a _ { e } ) _ { R b } = \ \ ( 3 3. 8 \pm 1 6. 1 ) \times 1 0 ^ { - 1 4 } \Rightarrow \ 2. 1 \sigma \,, \ \ ( 1 3 ) \quad _ { ^ { 3 } S. \ G } ^ { \varepsilon \ G. \ C }$$
where ∆ a e ≡ a exp e -a SM e .
The impact of the CMD-3 data on the HVP contribution to a SM e can first be estimated by reconsidering the high-energy approximation of Eq. (6) and relating a HVP µ and a HVP e by a quadratic-scaling between the lepton masses. In doing so, and by employing the value of δa CMD3 µ quoted in Eq. (9), results in
$$\left | \quad \delta a _ { e } ^ { \text{CMD3} } \approx \delta a _ { \mu } ^ { \text{CMD3} } \left ( \frac { m _ { e } } { m _ { \mu } } \right ) ^ { 2 } \approx \left ( 5. 1 \pm 0. 8 \right ) \times 1 0 ^ { - 1 4 } \,. \ \ ( 1 4 )$$
This is in good agreement with the numerical result in Table I, which shows a 6 2 . σ shift from the CMD-3 data compared to the previous data. It follows that the electron g -2 will only be sensitive to the increase observed on a HVP µ if the current discrepancy in the measurements of α is resolved and a precision at the level of O (10 -14 ) is achieved for ∆ a e .
Consider the sources of error in the determinations of (∆ a e ) Cs and (∆ a e ) Rb :
| ∆ a e error source | Value | % of ∆ a e error |
|--------------------------|--------------|--------------------|
| Five-loop QED, δa QED5 e | 6 × 10 - 14 | 5%(Cs) / 13%(Rb) |
| Hadronic, δa HAD e | 1 × 10 - 14 | < 1% |
| α (Cs), δa α (Cs) e | 22 × 10 - 14 | 70% |
| α (Rb), δa α (Rb) e | 9 × 10 - 14 | 28% |
| Experiment, δa exp e | 13 × 10 - 14 | 24%(Cs) / 59%(Rb) |
It follows that should the experimental resolutions on α and a exp e improve by roughly one order of magnitude, the total uncertainties of ∆ a e should reach the O (10 -14 ) level and the study of electron g -2 will become sensitive to the increase observed in a HVP µ due to CMD-3 (and BMWc). Fortunately, an improvement on δa exp e by a factor of ∼ 5 is expected in the next few years. 2 On the same timescale, new measurements of α (Rb) and α (Cs) by the Paris and Berkeley collaborations, respectively, will significantly reduce the systematic effects that were dominant in their previous measurements. 3 Such improvements should be sufficient to probe the shift induced by CMD-3 (and BMWc) through the electron g -2.
Additionally, δa QED5 e reflects the current 5 σ discrepancy between the two independent calculations of the gauge-invariant set of 5-loop QED diagrams with no lepton loops by Kinoshita et al. [111] and Volkov [112, 113]. As a non-negligible source of uncertainty on ∆ a e , and with expected improvements in the experimental inputs, resolving this difference may soon become crucial in this context. 4
2 G. Gabrielse, private communication.
3 S. Guellati-Kh´lifa and H. Mueller, private communications. e
4 S. Laporta, work in progress. Preliminary results presented at the 7th Plenary Workshop of the Muon g-2 Theory Initiative, 09-13 september 2024, KEK, Tsukuba, Japan by M. Nio (see [114]) point toward a resolution of this discrepancy.
Tau g -2 .-The shift in a SM τ due to the CMD-3 data is estimated by assuming dominant effects at the ρ -peak:
$$\delta a _ { \tau } ^ { \text{CMD3} } & \approx 0. 6 3 \left ( m _ { \rho } ^ { 2 } / m _ { \mu } ^ { 2 } \right ) \delta a _ { \mu } ^ { \text{CMD3} } \\ & \approx \left ( 7. 2 \pm 1. 4 \right ) \times 1 0 ^ { - 8 } \,, \quad \quad \ \ ( 1 5 ) \quad.$$
which is in very good agreement with the numerical estimate in Table I. Compared to the electron and muon g -2, the larger mass of the tau lepton increases the weight of the hadronic contributions to higher energies. As such, the influence of the π + π -and ρ -resonance contribution is reduced in ( a HVP τ ) e + e -, resulting in a much larger degree of correlation between the two scenarios for the tau ( ∼ 55%) compared to the muon ( ∼ 28%). This means the significance of δa CMD3 τ is 4 2 . σ compared to more than 6 σ for ( a HVP e ) e + e -and ( a HVP µ ) e + e -.
As δa CMD3 τ is roughly one order of magnitude below the expected future experimental sensitivity of O (10 -6 ) at Belle-II [115-118], an experiment-theory comparison is unlikely to shed light on the current discrepancies in the SM predictions of the muon g -2 without significant improvement in measurements of a exp τ .
The running of α .-Hadronic effects to the running QED coupling at the Z -boson mass, ∆ α (5) had ( M 2 Z ), are a principal component of the electroweak precision fit. The shift in ∆ α (5) had ( M 2 Z ) due to the CMD-3 data is estimated as
$$\delta \Delta \alpha _ { \text{had} } ^ { ( 5 ) } ( M _ { Z } ^ { 2 } ) & \approx \frac { 3 \pi } { \alpha } \, \frac { m _ { \rho } ^ { 2 } } { m _ { \mu } ^ { 2 } } \, \delta a _ { \mu } ^ { \text{CMD3} } \\ & \approx ( 1. 5 \pm 0. 3 ) \times 1 0 ^ { - 4 } \,, \quad \ \ ( 1 6 ) \quad \text{ and}.$$
in full agreement with Table I. The relevant kernel function in the dispersive evaluation of ∆ α (5) had ( M 2 Z ) exhibits an s -dependent weighting that is much higher in energy than any of the dispersion relations used to evaluate ( a HVP l ) e + e -. As a result, the CMD-3 increase has less of an impact than in any of the g -2 cases, exhibiting a 2 8 . σ deviation. The magnitude of the shift is comparable with the current uncertainty of ∆ α (5) had ( M 2 Z ), making it difficult for ∆ α (5) had ( M 2 Z ) to probe δa CMD3 µ . However, looking ahead, a future e + e -collider, e.g. FCC-ee [119, 120], is expected to reach an unprecedented precision on α M ( 2 Z ) of O (10 -5 ), which would provide sensitivity to the shift in Eq. (16).
The running of sin 2 θ W .-The low-energy weak mixing angle, defined as sin 2 θ W (0) at zero momentum transfer ( q 2 = 0), has been measured at parity-violating electron scattering and atomic physics asymmetry experiments [121, 122]. Following the prescription in [68], sin 2 θ W (0) can be connected with the high-energy LEP measurement of the same quantity, sin 2 θ W ( M Z ), by including quantum effects from the γ -Z mixing [123, 124].
The shift from the CMD-3 data is estimated via 5
$$\delta \sin ^ { 2 } \theta _ { W } ( 0 ) & \approx k ^ { \prime } \sin ^ { 2 } \theta _ { W } ( M _ { Z } ) \, \frac { 3 \pi } { \alpha } \, \frac { m _ { \rho } ^ { 2 } } { m _ { \mu } ^ { 2 } } \, \delta a _ { \mu } ^ { \text{CMD3} } \\ & \approx ( 0. 4 \pm 0. 1 ) \times 1 0 ^ { - 4 } \,,$$
where sin 2 θ W ( M Z ) = 0 23119(14) [121, 122] and . k ′ = 1 14 [123, 124]. . This is again in full agreement with the numerical estimate in Table I. The comparison exhibits a similar significance (2 9 . σ ) as for δ ∆ α (5) had ( M 2 Z ).
Unfortunately, current and expected future experimental errors prevent sin 2 θ W (0) to probe the HVP contributions, which would require a precision on both sin 2 θ W (0) and sin 2 θ W ( M Z ) at the ∼ 10 -5 level. Indeed, even a potential e + e -high-energy collider, like FCC-ee, would take at least few decades to reach a resolution on sin 2 θ W ( M Z ) of order O (10 -5 ) [120], a timescale by which the puzzle discussed here is very likely to be already successfully overcome. Furthermore, experimental progress on sin 2 θ W (0) planned at both MESA (P2) in Mainz [125] and JLab (Møller) [126] is projected to reach only ∼ O (10 -4 ).
The Muonium HFS.We show now that a powerful method to extract a HVP µ is via Muonium, a bound state of an antimuon and an electron ( M ≡ µ + e -). The Muonium HFS of the 1S ground state is given by [127-130]
$$\frac { \nu _ { \text{HFS} } } { \nu _ { F } } = 1 + a _ { \mu } + \Delta _ { \text{HFS} } ^ { \text{QED} } + \Delta _ { \text{HFS} } ^ { \text{Heak} } + \Delta _ { \text{HFS} } ^ { \text{HVP} } \,, \quad ( 1 8 )$$
where
$$\nu _ { F } = \frac { 1 6 } { 3 } \frac { m _ { e } } { m _ { \mu } } \frac { R _ { \infty } h \, c \, \alpha ^ { 2 } } { ( 1 + m _ { e } / m _ { \mu } ) ^ { 3 } } \,, \quad \quad ( 1 9 )$$
and R ∞ is the Rydberg constant. The quantities ∆ QED HFS and ∆ weak HFS in Eq. (18) refer to corrections stemming from QED and weak contributions, respectively. ∆ HVP HFS accounts for HVP effects [129] which are given by [129]
$$\Delta _ { \text{HFS} } ^ { \text{HVP} } = \frac { 1 } { 2 \pi ^ { 3 } } \int _ { m _ { \pi } ^ { 2 } } ^ { \infty } d s \, K _ { \text{Mu} } ( s ) \, \sigma _ { \text{had} } ( s ) \,, \quad ( 2 0 )$$
where, for s ≫ m 2 µ , the kernel function K Mu ( s ) reads
$$K _ { \text{Mu} } ( s ) \approx \frac { m _ { \mu } ^ { 2 } } { s } \left ( \frac { 9 } { 2 } \log \frac { s } { m _ { \mu } ^ { 2 } } + \frac { 1 5 } { 4 } \right ) \frac { m _ { e } } { m$$
Again, as the dominant effects to σ had arise at the ρ -peak, s ≈ m 2 ρ ≫ m 2 µ . Using Eqs. (5) and (20) results in
$$\Delta _ { \text{HFS} } ^ { \text{HVP} } & \approx 6 \, \frac { m _ { \rho } ^ { 2 } } { m _ { \mu } ^ { 2 } } \, K _ { \text{Mu} } ( m _ { \rho } ^ { 2 } ) \, ( a _ { \mu$$
5 A similar result was obtained in Ref. [124] employing instead BMW Lattice data.
Therefore, using also Eq. (18), the entire HVP contribution to ν HFS can be expressed as 6
$$\nu _ { \text{HF5} } ^ { \text{HVP} } = \left ( a _ { \mu } ^ { \text{HVP} } + \Delta _ { \text{HF5} } ^ { \text{HVP} } \right ) \nu _ { F } \, \approx \, 1. 6 3 \, \nu _ {$$
where the two terms are depicted in the third and fourth diagrams of Fig. 1. Therefore, the impact of the CMD-3 data on ν HVP HFS is estimated to be
$$\delta \nu _ { \text{HF5} } ^ { \text{CMD3} } \approx ( 1 5. 8 \pm 2. 6 ) \ H z \,, \quad \quad ( 2 4 ) \quad \ \ 1$$
in excellent agreement with the numerical evaluation in Table I and exhibits a 5 9 . σ discrepancy in the comparison. This makes the Muonium HFS among the most sensitive probes of δa CMD3 µ . To be sensitive to this shift would require a measurement at a precision of O (1) Hz. Fortunately, the MuSEUM experiment at J-PARC aims to reduce the uncertainty of the current measurement ν exp HFS = (4 463 302 776 ± 51) Hz [132, 133] by one order of magnitude [134], well below the shift of Eq. (24).
Other sources of uncertainty are also set to improve. The uncertainty on ν F is fully dominated by the m /m e µ ratio (the uncertainties of R ∞ and α are negligible) [127]. Here, m /m e µ is obtained from the measurement of the 1S-2S transition frequency in Muonium [131], given by
$$\nu _ { 1 S - 2 S } = \frac { 3 } { 4 } \frac { R _ { \infty } h c } { ( 1 + m _ { e } / m _ { \mu } ) } \left [ 1 + \delta _ { 1 S - 2 S } \right ] \,, \quad ( 2 5 ) \quad \quad \quad$$
where the muon mass enters as a recoil contribution. As the hadronic corrections to δ 1S -2S [135] do not spoil the extraction of m /m e µ at the required precision, the dominant uncertainty on m /m e µ arises from the experimental error in ν 1S -2S [136]. This induces an error on ν F of 4 × 10 3 Hz. Experimental progress is ongoing at the MuMASS experiment to improve this precision by three orders of magnitude [137]. Additionally, the dominant theory uncertainty in ν HFS arises from unknown three-loop QED contributions [128] to δ QED HFS ( δ 1S -2S ) and amounts to about 70 Hz (7 Hz) [128]. A complete three-loop QED calculation would bring the related uncertainty to a negligible level [138].
Conclusions and outlook.Recent lattice QCD calculations and new measurements by the CMD-3 collaboration show a significant tension with the low-energy e + e -→ hadrons data in the determination of the leading HVP contribution to the muon g -2. Several modelindependent tests of the HVP contribution are possible through the electron and tau g -2, the running of
6 As proposed by Ref. [131], Eq. (18) allows for an independent determination of a µ if e + e -data are used to determine ∆ HVP HFS . In this case, the obtained a µ cannot be exploited to extract a HVP µ .
α and of the weak mixing angle, and the Muonium HFS. Both numerical analyses based on state-of-the-art e + e -→ hadrons data and approximate analytical expressions relating the HVP contributions of the considered observables have revealed the electron g -2 and the Muonium HFS to be the most promising prospects (see Fig. 2), offering unique opportunities to shed light on the current g -2 puzzle.
To achieve this ambitious goal, both experimental and theoretical improvements are needed. For the g -2 of the electron, the required precision level of O (10 -14 ) is the expected future resolution for a exp e and α from atomic physics. In the case of the Muonium HFS, the MuSEUM experiment is expected to improve the HFS ground-state measurement by one order of magnitude, while the MuMASS experiment is expected to determine the m /m e µ ratio with a precision three orders of magnitude better than the present situation. Finally, a better theoretical control of QED effects (five loop contributions in the case of the electron g -2 and three loops in the case of Muonium HFS) is necessary. Although challenging, the above program seems to be feasible and it should be pursued with high priority to resolve significant tensions in one of the most stringent probes of the SM.
Acknowledgments.We thank G. Colangelo, P. Crivelli, R. Frezzotti, G. Gabrielse, S. Guellati-Kh´lifa, e M. Incagli, K. Kirch, S. Laporta, L. Lellouch, V. Lubicz, H. Mueller, M. Neubert, M. Passera, F. Piccinini, M. Pospelov, N. Tantalo and G. Venanzoni for private communications and useful discussions. Special thanks are extended to D. Nomura and T. Teubner for their collaboration with AK in producing the KNT19 data. The work of AK is supported by The Royal Society (URF R1 231503). \ \ The work of LDL and PP is supported by the European Union - Next Generation EU and by the Italian Ministry of University and Research (MUR) via the PRIN 2022 project n. 2022K4B58X - AxionOrigins. This work received funding by the INFN Iniziative Specifiche APINE and TASP and from the European Union's Horizon 2020 research and innovation programme under the Marie Skglyph[suppress] lodowska-Curie grant agreements n. 860881 - HIDDeN, n. 101086085 - ASYMMETRY. This work was also partially supported by the Italian MUR Departments of Excellence grant 2023-2027 'Quantum Frontiers'.
- [1] D. P. Aguillard et al. (Muon g-2), Phys. Rev. Lett. 131 , 161802 (2023), arXiv:2308.06230 [hep-ex].
- [2] D. P. Aguillard et al. (Muon g-2), (2024), arXiv:2402.15410 [hep-ex].
- [3] B. Abi et al. (Muon g-2), Phys. Rev. Lett. 126 , 141801 (2021), arXiv:2104.03281 [hep-ex].
- [4] T. Albahri et al. (Muon g-2), Phys. Rev. Accel. Beams 24 , 044002 (2021), arXiv:2104.03240 [physics.acc-ph].
- [5] T. Albahri et al. (Muon g-2), Phys. Rev. A 103 , 042208 (2021), arXiv:2104.03201 [hep-ex].
- [6] T. Albahri et al. (Muon g-2), Phys. Rev. D 103 , 072002 (2021), arXiv:2104.03247 [hep-ex].
- [7] G. W. Bennett et al. (Muon g-2), Phys. Rev. D 73 , 072003 (2006), arXiv:hep-ex/0602035.
- [8] G. W. Bennett et al. (Muon g-2), Phys. Rev. Lett. 89 , 101804 (2002), [Erratum: Phys.Rev.Lett. 89, 129903 (2002)], arXiv:hep-ex/0208001.
- [9] G. W. Bennett et al. (Muon g-2), Phys. Rev. Lett. 92 , 161802 (2004), arXiv:hep-ex/0401008.
- [10] T. Aoyama et al., Phys. Rept. 887 , 1 (2020), arXiv:2006.04822 [hep-ph].
- [11] T. Aoyama, M. Hayakawa, T. Kinoshita, and M. Nio, Phys. Rev. Lett. 109 , 111808 (2012), arXiv:1205.5370 [hep-ph].
- [12] T. Aoyama, T. Kinoshita, and M. Nio, Atoms 7 , 28 (2019).
- [13] A. Czarnecki, W. J. Marciano, and A. Vainshtein, Phys. Rev. D67 , 073006 (2003), [Erratum: Phys. Rev. D73 , 119901 (2006)], arXiv:hep-ph/0212229 [hep-ph].
- [14] C. Gnendiger, D. St¨ckinger, o and H. St¨ckinger-Kim, o Phys. Rev. D88 , 053005 (2013), arXiv:1306.5546 [hepph].
- [15] M. Davier, A. Hoecker, B. Malaescu, and Z. Zhang, Eur. Phys. J. C77 , 827 (2017), arXiv:1706.09436 [hep-ph].
- [16] A. Keshavarzi, D. Nomura, and T. Teubner, Phys. Rev. D97 , 114025 (2018), arXiv:1802.02995 [hep-ph].
- [17] G. Colangelo, M. Hoferichter, and P. Stoffer, JHEP 02 , 006, arXiv:1810.00007 [hep-ph].
- [18] M. Hoferichter, B.-L. Hoid, and B. Kubis, JHEP 08 , 137, arXiv:1907.01556 [hep-ph].
- [19] M. Davier, A. Hoecker, B. Malaescu, and Z. Zhang, Eur. Phys. J. C80 , 241 (2020), [Erratum: Eur. Phys. J. C80 , 410 (2020)], arXiv:1908.00921 [hep-ph].
- [20] A. Keshavarzi, D. Nomura, and T. Teubner, Phys. Rev. D101 , 014029 (2020), arXiv:1911.00367 [hep-ph].
- [21] A. Kurz, T. Liu, P. Marquard, and M. Steinhauser, Phys. Lett. B734 , 144 (2014), arXiv:1403.6400 [hep-ph].
- [22] K. Melnikov and A. Vainshtein, Phys. Rev. D70 , 113006 (2004), arXiv:hep-ph/0312226 [hep-ph].
- [23] P. Masjuan and P. S´nchez-Puertas, Phys. Rev. a D95 , 054026 (2017), arXiv:1701.05829 [hep-ph].
- [24] G. Colangelo, M. Hoferichter, M. Procura, and P. Stoffer, JHEP 04 , 161, arXiv:1702.07347 [hep-ph].
- [25] M. Hoferichter, B.-L. Hoid, B. Kubis, S. Leupold, and S. P. Schneider, JHEP 10 , 141, arXiv:1808.04823 [hepph].
- [26] A. G´ erardin, H. B. Meyer, and A. Nyffeler, Phys. Rev. D100 , 034520 (2019), arXiv:1903.09471 [hep-lat].
- [27] J. Bijnens, N. Hermansson-Truedsson, and A. Rodr´ ıguez-S´nchez, a Phys. Lett. B798 , 134994 (2019), arXiv:1908.03331 [hep-ph].
- [28] G. Colangelo, F. Hagelstein, M. Hoferichter, L. Laub, and P. Stoffer, JHEP 03 , 101, arXiv:1910.13432 [hepph].
- [29] T. Blum, N. Christ, M. Hayakawa, T. Izubuchi, L. Jin, C. Jung, and C. Lehner, Phys. Rev. Lett. 124 , 132002 (2020), arXiv:1911.08123 [hep-lat].
- [30] G. Colangelo, M. Hoferichter, A. Nyffeler, M. Passera, and P. Stoffer, Phys. Lett. B735 , 90 (2014), arXiv:1403.7512 [hep-ph].
- [31] S. J. Brodsky and E. De Rafael, Phys. Rev. 168 , 1620 (1968).
- [32] B. E. Lautrup and E. De Rafael, Phys. Rev. 174 , 1835 (1968).
- [33] B. Krause, Phys. Lett. B 390 , 392 (1997), arXiv:hepph/9607259.
- [34] F. Jegerlehner, Vol. 274 (Springer, Cham, 2017).
- [35] F. Jegerlehner, EPJ Web Conf. 118 , 01016 (2016), arXiv:1511.04473 [hep-ph].
- [36] F. Jegerlehner, EPJ Web Conf. 166 , 00022 (2018), arXiv:1705.00263 [hep-ph].
- [37] F. Jegerlehner, EPJ Web Conf. 218 , 01003 (2019), arXiv:1711.06089 [hep-ph].
- [38] F. Jegerlehner, EPJ Web Conf. 199 , 01010 (2019), arXiv:1809.07413 [hep-ph].
- [39] S. Eidelman and F. Jegerlehner, Z. Phys. C 67 , 585 (1995), arXiv:hep-ph/9502298.
- [40] M. Benayoun, P. David, L. DelBuono, O. Leitner, and H. B. O'Connell, Eur. Phys. J. C 55 , 199 (2008), arXiv:0711.4482 [hep-ph].
- [41] M. Benayoun, P. David, L. DelBuono, and F. Jegerlehner, Eur. Phys. J. C 72 , 1848 (2012), arXiv:1106.1315 [hep-ph].
- [42] M. Benayoun, P. David, L. DelBuono, and F. Jegerlehner, Eur. Phys. J. C 73 , 2453 (2013), arXiv:1210.7184 [hep-ph].
- [43] M. Benayoun, P. David, L. DelBuono, and F. Jegerlehner, Eur. Phys. J. C 75 , 613 (2015), arXiv:1507.02943 [hep-ph].
- [44] M. Benayoun, L. Delbuono, and F. Jegerlehner, Eur. Phys. J. C 80 , 81 (2020), [Erratum: Eur.Phys.J.C 80, 244 (2020)], arXiv:1903.11034 [hep-ph].
- [45] M. Davier, A. Hoecker, B. Malaescu, and Z. Zhang, Eur. Phys. J. C 71 , 1515 (2011), [Erratum: Eur.Phys.J.C 72, 1874 (2012)], arXiv:1010.4180 [hep-ph].
- [46] S. Borsanyi et al. (Budapest-Marseille-Wuppertal), Phys. Rev. Lett. 121 , 022002 (2018), arXiv:1711.04980 [hep-lat].
- [47] T. Blum, P. A. Boyle, V. G¨lpers, T. Izubuchi, L. Jin, u C. Jung, A. J¨ttner, C. Lehner, A. Portelli, and J. T. u Tsang (RBC, UKQCD), Phys. Rev. Lett. 121 , 022003 (2018), arXiv:1801.07224 [hep-lat].
- [48] D. Giusti, V. Lubicz, G. Martinelli, F. Sanfilippo, and S. Simula, Phys. Rev. D 99 , 114502 (2019), arXiv:1901.10462 [hep-lat].
- [49] C. T. H. Davies et al. (Fermilab Lattice, LATTICEHPQCD, MILC), Phys. Rev. D 101 , 034512 (2020), arXiv:1902.04223 [hep-lat].
- [50] A. G´ erardin, M. C` e, G. von Hippel, B. H¨ orz, H. B. Meyer, D. Mohler, K. Ottnad, J. Wilhelm, and H. Wittig, Phys. Rev. D 100 , 014510 (2019), arXiv:1904.03120 [hep-lat].
- [51] B. Chakraborty et al. (Fermilab Lattice, LATTICEHPQCD, MILC), Phys. Rev. Lett. 120 , 152001 (2018), arXiv:1710.11212 [hep-lat].
- [52] T. Blum, P. A. Boyle, V. G¨lpers, T. Izubuchi, L. Jin, u C. Jung, A. J¨ttner, C. Lehner, A. Portelli, and J. T. u Tsang (RBC, UKQCD), Phys. Rev. Lett. 121 , 022003
- (2018), arXiv:1801.07224 [hep-lat].
- [53] E. Shintani and Y. Kuramashi, Phys. Rev. D100 , 034517 (2019), arXiv:1902.00885 [hep-lat].
- [54] C. Aubin, T. Blum, C. Tu, M. Golterman, C. Jung, and S. Peris, Phys. Rev. D101 , 014503 (2020), arXiv:1905.09307 [hep-lat].
- [55] D. Giusti and S. Simula, PoS LATTICE2019 , 104 (2019), arXiv:1910.03874 [hep-lat].
- [56] S. Borsanyi et al., Nature 593 , 51 (2021), arXiv:2002.12347 [hep-lat].
- [57] A. Boccaletti et al., (2024), arXiv:2407.10913 [hep-lat].
- [58] C. Lehner and A. S. Meyer, Phys. Rev. D 101 , 074515 (2020), arXiv:2003.04177 [hep-lat].
- [59] C. Alexandrou et al. (Extended Twisted Mass), Phys. Rev. D 107 , 074506 (2023), arXiv:2206.15084 [hep-lat].
- [60] T. Blum et al. (RBC, UKQCD), Phys. Rev. D 108 , 054507 (2023), arXiv:2301.08696 [hep-lat].
- [61] S. Kuberski, M. C` e, G. von Hippel, H. B. Meyer, K. Ottnad, A. Risch, and H. Wittig, JHEP 03 , 172, arXiv:2401.11895 [hep-lat].
- [62] C. T. H. Davies et al. (Fermilab Lattice, MILC, HPQCD), Phys. Rev. D 106 , 074509 (2022), arXiv:2207.04765 [hep-lat].
- [63] G. Colangelo, A. X. El-Khadra, M. Hoferichter, A. Keshavarzi, C. Lehner, P. Stoffer, and T. Teubner, Phys. Lett. B 833 , 137313 (2022), arXiv:2205.12963 [hep-ph].
- [64] T. Blum et al. (RBC, UKQCD), (2024), arXiv:2410.20590 [hep-lat].
- [65] D. Djukanovic, G. von Hippel, S. Kuberski, H. B. Meyer, N. Miller, K. Ottnad, J. Parrino, A. Risch, and H. Wittig, (2024), arXiv:2411.07969 [hep-lat].
- [66] M. Passera, W. J. Marciano, and A. Sirlin, Phys. Rev. D 78 , 013009 (2008), arXiv:0804.1142 [hep-ph].
- [67] A. Crivellin, M. Hoferichter, C. A. Manzari, and M. Montull, Phys. Rev. Lett. 125 , 091801 (2020), arXiv:2003.04886 [hep-ph].
- [68] A. Keshavarzi, W. J. Marciano, M. Passera, and A. Sirlin, Phys. Rev. D 102 , 033002 (2020), arXiv:2006.12666 [hep-ph].
- [69] B. Malaescu and M. Schott, Eur. Phys. J. C 81 , 46 (2021), arXiv:2008.08107 [hep-ph].
- [70] G. Colangelo, M. Hoferichter, and P. Stoffer, Phys. Lett. B 814 , 136073 (2021), arXiv:2010.07943 [hep-ph].
- [71] G. Benton, D. Boito, M. Golterman, A. Keshavarzi, K. Maltman, and S. Peris, Phys. Rev. Lett. 131 , 251803 (2023), arXiv:2306.16808 [hep-ph].
- [72] G. Benton, D. Boito, M. Golterman, A. Keshavarzi, K. Maltman, and S. Peris, Phys. Rev. D 109 , 036010 (2024), arXiv:2311.09523 [hep-ph].
- [73] L. Di Luzio, A. Masiero, P. Paradisi, and M. Passera, Phys. Lett. B 829 , 137037 (2022), arXiv:2112.08312 [hep-ph].
- [74] L. Darm´ e, G. Grilli di Cortona, and E. Nardi, JHEP 06 , 122, arXiv:2112.09139 [hep-ph].
- [75] A. Crivellin and M. Hoferichter, Phys. Rev. D 108 , 013005 (2023), arXiv:2211.12516 [hep-ph].
- [76] L. Darm´ e, G. Grilli di Cortona, and E. Nardi, Phys. Rev. D 108 , 095056 (2023), arXiv:2212.03877 [hep-ph].
- [77] N. M. Coyle and C. E. M. Wagner, JHEP 12 , 071, arXiv:2305.02354 [hep-ph].
- [78] F. V. Ignatov et al. (CMD-3), Phys. Rev. D 109 , 112002 (2024), arXiv:2302.08834 [hep-ex].
- [79] F. V. Ignatov et al. (CMD-3), Phys. Rev. Lett. 132 , 231903 (2024), arXiv:2309.12910 [hep-ex].
- [80] M. N. Achasov et al., J. Exp. Theor. Phys. 103 , 380 (2006), arXiv:hep-ex/0605013.
- [81] V. M. Aul'chenko et al., JETP Lett. 84 , 413 (2006), arXiv:hep-ex/0610016.
- [82] R. R. Akhmetshin et al. (CMD-2), Phys. Lett. B 648 , 28 (2007), arXiv:hep-ex/0610021.
- [83] F. Ambrosino et al. (KLOE), Phys. Lett. B 670 , 285 (2009), arXiv:0809.3950 [hep-ex].
- [84] F. Ambrosino et al. (KLOE), Phys. Lett. B 700 , 102 (2011), arXiv:1006.5313 [hep-ex].
- [85] D. Babusci et al. (KLOE), Phys. Lett. B 720 , 336 (2013), arXiv:1212.4524 [hep-ex].
- [86] A. Anastasi et al. (KLOE-2), JHEP 03 , 173, arXiv:1711.03085 [hep-ex].
- [87] B. Aubert et al. (BaBar), Phys. Rev. Lett. 103 , 231801 (2009), arXiv:0908.3589 [hep-ex].
- [88] J. P. Lees et al. (BaBar), Phys. Rev. D 86 , 032013 (2012), arXiv:1205.2228 [hep-ex].
- [89] M. Ablikim et al. (BESIII), Phys. Lett. B 753 , 629 (2016), [Erratum: Phys.Lett.B 812, 135982 (2021)], arXiv:1507.08188 [hep-ex].
- [90] T. Xiao, S. Dobbs, A. Tomaradze, K. K. Seth, and G. Bonvicini, Phys. Rev. D 97 , 032012 (2018), arXiv:1712.04530 [hep-ex].
- [91] M. N. Achasov et al. (SND), JHEP 01 , 113, arXiv:2004.00263 [hep-ex].
- [92] Zhiqing ZHANG, News from BABAR, Muon g -2 Theory Initiative Spring 2024 Meeting, url: https://indico.cern.ch/event/1400808/ contributions/5902094/attachments/2842140/ 4968393/Zhang\_HVP240422.pdf (2024).
- [93] Hisaki Hayashii, Status and plans regarding g -2 at belle II, Muon g -2 Theory Initiative Spring 2024 Meeting, url: https://indico.cern.ch/event/1400808/ contributions/5902135/attachments/2841580/ 4968265/g-2-theory\_mni-workshop\_240422\_v2.pdf (2024).
- [94] Riccardo Aliberti, Status and Plans for Experimental Inputs to HVP at BESIII, Muon g -2 Theory Initiative Spring 2024 Meeting, url: https://indico.cern.ch/event/1400808/ contributions/5902095/attachments/2841881/ 4967869/Muon\_g-2\_spring\_meeting\_2024.pdf (2024).
- [95] Ivan Logashenko, CMD2/3 report (on π + π -), Muon g -2 Theory Initiative Spring 2024 Meeting, url: https://indico.cern.ch/event/1400808/ contributions/5902096/attachments/2842193/
- 4968485/Logashenko\_CMD\_TI\_2024.pdf (2024).
- [96] Giuseppe Mandaglio, Hadron physics results at KLOE-2, Sixth Plenary Workshop of the Muon g -2 Theory Initiative (2023), url: https: //indico.cern.ch/event/1400808/contributions/ 5902134/attachments/2841711/4967471/talk\_IL.pdf (2023).
- [97] Andrey Kupich, Preliminary results of the e + e -→ π + π -analysis with SND at VEPP-2000, Muon g -2 Theory Initiative Spring 2024 Meeting, url: https: //indico.cern.ch/event/1400808/contributions/ 5902134/attachments/2841711/4967471/talk\_IL.pdf (2024).
- [98] J. P. Lees et al. (BaBar), Phys. Rev. D 108 , L111103 (2023), arXiv:2308.05233 [hep-ex].
- [99] M. Davier, A. Hoecker, A.-M. Lutz, B. Malaescu, and Z. Zhang, Eur. Phys. J. C 84 , 721 (2024),
## arXiv:2312.02053 [hep-ph].
- [100] C. M. Carloni Calame, M. Passera, L. Trentadue, and G. Venanzoni, Phys. Lett. B 746 , 325 (2015), arXiv:1504.02228 [hep-ph].
- [101] G. Abbiendi et al., Eur. Phys. J. C 77 , 139 (2017), arXiv:1609.08987 [hep-ex].
- [102] G. Abbiendi, Letter of Intent: the MUonE project, Tech. Rep. (CERN, Geneva, 2019).
- [103] P. Banerjee et al., Eur. Phys. J. C 80 , 591 (2020), arXiv:2004.13663 [hep-ph].
- [104] A. Masiero, P. Paradisi, and M. Passera, Phys. Rev. D 102 , 075013 (2020), arXiv:2002.05418 [hep-ph].
- [105] P. Masjuan, A. Miranda, and P. Roig, Phys. Lett. B 850 , 138492 (2024), arXiv:2305.20005 [hep-ph].
- [106] R. H. Parker, C. Yu, W. Zhong, B. Estey, and H. M¨ uller, Science 360 , 191 (2018), arXiv:1812.04130 [physics.atom-ph].
- [107] L. Morel, Z. Yao, P. Clad´, and S. Guellati-Kh´lifa, Nae e ture 588 , 61 (2020).
- [108] G. F. Giudice, P. Paradisi, and M. Passera, JHEP 11 , 113, arXiv:1208.6583 [hep-ph].
- [109] A. Crivellin, M. Hoferichter, and P. SchmidtWellenburg, Phys. Rev. D 98 , 113002 (2018), arXiv:1807.11484 [hep-ph].
- [110] X. Fan, T. G. Myers, B. A. D. Sukra, and G. Gabrielse, Phys. Rev. Lett. 130 , 071801 (2023), arXiv:2209.13084 [physics.atom-ph].
- [111] T. Aoyama, M. Hayakawa, T. Kinoshita, and M. Nio, Phys. Rev. D 91 , 033006 (2015), [Erratum: Phys.Rev.D 96, 019901 (2017)], arXiv:1412.8284 [hep-ph].
- [112] S. Volkov, Phys. Rev. D 100 , 096004 (2019), arXiv:1909.08015 [hep-ph].
- [113] S. Volkov, (2024), arXiv:2404.00649 [hep-ph].
- [114] https://conference-indico.kek.jp/event/257/ contributions/5806/attachments/3737/5122/Muong\_ 2QED2024.pdf .
- [115] J. Bernabeu, G. A. Gonzalez-Sprinberg, J. Papavassiliou, and J. Vidal, Nucl. Phys. B 790 , 160 (2008), arXiv:0707.2496 [hep-ph].
- [116] J. Bernabeu, G. A. Gonzalez-Sprinberg, and J. Vidal, JHEP 01 , 062, arXiv:0807.2366 [hep-ph].
- [117] X. Chen and Y. Wu, JHEP 10 , 089, arXiv:1803.00501
## [hep-ph].
- [118] A. Crivellin, M. Hoferichter, and J. M. Roney, Phys. Rev. D 106 , 093007 (2022), arXiv:2111.10378 [hep-ph].
- [119] P. Janot, JHEP 02 , 053, [Erratum: JHEP 11, 164 (2017)], arXiv:1512.05544 [hep-ph].
- [120] A. Blondel and P. Janot, Eur. Phys. J. Plus 137 , 92 (2022), arXiv:2106.13885 [hep-ex].
- [121] M. Tanabashi et al. (Particle Data Group), Phys. Rev. D 98 , 030001 (2018).
- [122] P. Gambino and A. Sirlin, Phys. Rev. D 49 , 1160 (1994), arXiv:hep-ph/9309326.
- [123] J. Erler and R. Ferro-Hern´ndez, a JHEP 03 , 196, arXiv:1712.09146 [hep-ph].
- [124] J. Erler, R. Ferro-Hernandez, and S. Kuberski, (2024), arXiv:2406.16691 [hep-ph].
- [125] D. Becker et al., Eur. Phys. J. A 54 , 208 (2018), arXiv:1802.04759 [nucl-ex].
- [126] J. Benesch et al. (MOLLER), (2014), arXiv:1411.4088 [nucl-ex].
- [127] E. Tiesinga, P. J. Mohr, D. B. Newell, and B. N. Taylor, Rev. Mod. Phys. 93 , 025010 (2021).
- [128] M. I. Eides, Phys. Lett. B 795 , 113 (2019), arXiv:1812.10881 [hep-ph].
- [129] A. Czarnecki, S. I. Eidelman, and S. G. Karshenboim, Phys. Rev. D 65 , 053004 (2002), arXiv:hep-ph/0107327.
- [130] S. G. Karshenboim and V. A. Shelyuto, Phys. Lett. B 517 , 32 (2001), arXiv:hep-ph/0107328.
- [131] C. Delaunay, B. Ohayon, and Y. Soreq, Phys. Rev. Lett. 127 , 251801 (2021), arXiv:2106.11998 [hep-ph].
- [132] F. G. Mariam et al., Phys. Rev. Lett. 49 , 993 (1982).
- [133] W. Liu et al., Phys. Rev. Lett. 82 , 711 (1999).
- [134] P. Strasser et al., Hyperfine Interact. 237 , 124 (2016).
- [135] J. L. Friar, J. Martorell, and D. W. L. Sprung, Phys. Rev. A 59 , 4061 (1999), arXiv:nucl-th/9812053.
- [136] V. Meyer et al., Phys. Rev. Lett. 84 , 1136 (2000), arXiv:hep-ex/9907013.
- [137] P. Crivelli, Hyperfine Interact. 239 , 49 (2018), arXiv:1811.00310 [physics.atom-ph].
- [138] M. I. Eides and V. A. Shelyuto, Int. J. Mod. Phys. A 31 , 1645034 (2016). | 10.1103/PhysRevLett.134.011902 | [
"Luca Di Luzio",
"Alexander Keshavarzi",
"Antonio Masiero",
"Paride Paradisi"
] | 2024-08-02T09:06:58+00:00 | 2025-03-26T11:55:44+00:00 | [
"hep-ph",
"hep-ex",
"hep-lat"
] | Model Independent Tests of the Hadronic Vacuum Polarization Contribution to the Muon $g$$-$$2$ | The hadronic vacuum polarization (HVP) contributions to the muon $g$$-$$2$
are the crucial quantity to resolve whether new physics is present or not in
the comparison between the Standard Model (SM) prediction and experimental
measurements at Fermilab. They are commonly and historically determined via
dispersion relations using a vast catalogue of experimentally measured,
low-energy $e^+e^-\to \,\rm{hadrons}$ cross section data as input. These
dispersive estimates result in a SM prediction that exhibits a muon $g$$-$$2$
discrepancy of more than $5\sigma$ when compared to experiment. However, recent
lattice QCD evaluations of the HVP and a new hadronic cross section measurement
from the CMD-3 experiment favor a no-new-physics scenario and, therefore,
exhibit a common tension with the previous $e^+e^-\to \,\rm{hadrons}$ data.
This study explores the current and future implications of these two scenarios
on other observables that are also sensitive to the HVP contributions in the
hope that they may provide independent tests of the current tensions observed
in the muon $g$$-$$2$. |
2408.01125v1 | ## Molecular influence on nuclear-quadrupole-coupling effects in laser induced alignment
Linda V. Thesing, 1, 2, 3 Andrey Yachmenev, 1, 2, a) Rosario González-Férez, 4, b) and Jochen Küpper 1, 2, 3, c)
- 1) Center for Free-Electron Laser Science CFEL, Deutsches Elektronen-Synchrotron DESY, Notkestrasse 85, 22607 Hamburg, Germany
- 2) Center for Ultrafast Imaging, Universität Hamburg, Luruper Chaussee 149, 22761 Hamburg, Germany
- 3) Department of Physics, Universität Hamburg, Luruper Chaussee 149, 22761 Hamburg, Germany
- 4) Instituto Carlos I de Física Teórica y Computacional and Departamento de Física Atómica, Molecular y Nuclear, Universidad de Granada, 18071 Granada, Spain
(Dated: 2024-08-05)
We studied the effect of nuclear-quadrupole interactions on the field-free impulsive alignment of different asymmetric-top molecules. Our analysis is focused on the influence of the hyperfine- and rotational-energy-level structures. These depend on the number of nuclear spins, the rotational constants, and the symmetry of the tensors involved in the nuclear spin and external field interactions. Comparing the prototypical large-nuclearspin molecules iodobenzene, 1,2-diiodobenzene, 1,3-diiodobenzene, and 2,5-diiodobenzonitrile, we demonstrate that the magnitude of the hyperfine splittings compared to the rotational-energy splittings plays a crucial role in the spin-rotational dynamics after the laser pulse. Moreover, we point out that the impact of the quadrupole coupling on the rotational dynamics decreases when highly excited rotational states dominate the dynamics.
## I. INTRODUCTION
The coupling of rotational and nuclear spin angular momenta, known as hyperfine interaction, can have a significant influence on the rotational dynamics of molecules and is at the core of the nuclear magnetic resonance measurement. 1-9 There are several mechanisms of hyperfine interaction, the most prominent is the nuclearquadrupole coupling. This occurs in molecules containing nuclei with partly filled shells, resulting in non-spherical nuclear shapes and the appearance of an electric nuclear quadrupole moment. This quadrupole couples, electrostatically interacts, with the field gradient induced by other moving charged particles in the molecule, i. e., the nuclei and electrons.
under field-free conditions is often favorable. Field-free alignment relies on the preparation of rotational wave packets by means of intense optical laser pulses. 17 Since the wave packets are non-stationary states, they dephase and rephase periodically, changing the alignment with time, even after the pulsed excitation. Typical pulse shapes range from the short kick pulses 18-20 to pulses with long rising and short falling edges. 21-25 The timeevolution of the molecular alignment in field-free conditions is revival structure, ideally with nearly the same degree of alignment appearing every rotational period. The latter is, however, only valid for molecules with regular spacings between the rotational energy levels, such as rigid linear and symmetric top molecules.
Generally, nuclear-quadrupole coupling is strong in molecules containing heavy atoms, such as Se, Br, I, Fe, Au, or Pt, which are also found in many biologically relevant molecules. Due to their very large x-ray- and electron-scattering cross sections these atoms are often chemically attached to molecular compounds and used as marker atoms in diffractive imaging experiments. 10-13 Furthermore, in Coulomb-explosion imaging these heavy atoms often show good axial recoil enabling the observation of molecular orientation and internal structure during dynamical processes. 14-16
An indispensable component of high-resolution imaging experiments is the laser-induced alignment of molecules, enabling measurements to be performed in the moleculefixed frame without orientation averaging. To avoid perturbations due to the presence of external fields, alignment
a) Email: [email protected]
b) Email: [email protected]
c) Email: [email protected]; website: https://www.controlledmolecule-imaging.org
The revivals of molecular alignment are highly sensitive to the molecule's rotational energy level structure. A detailed understanding of various molecular degrees of freedom that can couple to rotations is thus needed to accurately predict the alignment dynamics of molecules. It is well established that hyperfine interactions can have a significant impact on the rotational dynamics of molecules prepared in single rotational states. 9 Furthermore, experimental evidence of the influence of nuclear quadrupole effects on the impulsive alignment dynamics was published recently for I 2 molecules. 26 In computational studies of linear and asymmetric top molecules, we found a nontrivial dependence of the nuclear quadrupole effects on the intensity of the laser field. 27,28
Here, provide a deeper insight into the effect of the quadrupole coupling on the alignment for different molecular species. We compared the results across asymmetric top molecules with different number of nuclear quadrupolar nuclei, their different positions in the molecule, and different molecular symmetries. Our molecular set contains C 2 v -symmetric molecules with one and two iodine atoms, i. e., iodobenzene and the 1,2- and 1,3-isomers of diiodobenzene, besides the already investigated 1,4-isomer,
FIG. 1. Sketches of the molecules IB, DIBN, 1,3-DIB and 1,2DIB. For IB and 1,3-DIBN the most polarizable axis (MPA) is parallel to the a axis, for DIBN it forms an angle of 5 ◦ with the a axis and for 1,2-DIB the MPA is parallel to the b axis. The molecule-fixed z axis is indicated in the respective sketches.
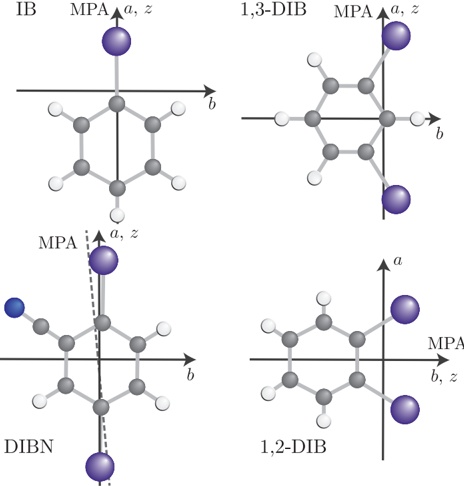
and the C -symmetric molecules diiodobenzonitrile and s 1,3-bromoiodobenzene. In addition, we consider a hypothetical modified single-spin 1,3-diiodobenzene. First, we summarize our theoretical approach in Section II. We then present impulsive alignment results for low- (Section III A) and high-intensity (Section III B) laser pulses for a rotational temperature of T rot = 0 K. Finally, we analyze the rotational dynamics of cold thermal ensembles and individual excited states.
## II. THEORETICAL DESCRIPTION
We studied the laser-induced rotational dynamics of asymmetric top molecules taking into account the nuclearquadrupole interactions. 27 The field-free spin-rotational Hamiltonian of the system is given by
$$\hat { H } _ { \text{mol} } = \hat { H } _ { \text{rot} } + \sum _ { l } \mathbf V ( l ) \cdot \mathbf Q ( l ), \quad \quad ( 1 ) \quad \text{ of a} \\ \text{ the} \quad \text{$cole}.$$
where ˆ H rot = AJ ˆ 2 a + BJ ˆ 2 b + CJ ˆ 2 c is the rigid-rotor Hamiltonian with the rotational constants A,B,C and the components ˆ J i , i = a, b, c , of the rotational angular momentum operator ˆ J . The second term in the Hamiltonian (1) describes the interaction of the quadrupole-moment tensor Q ( ) l of the l -th nucleus with the electric-field-gradient (EFG) tensor V ( ) l . The sum runs over all nuclei with significant quadrupole moments l in the molecule.
The interaction with the nonresonant laser field, linearly-polarized along the laboratory-fixed Z axis, can be written as
$$\hat { H } _ { \text{las} } ( t ) = - \frac { I ( t ) } { 2 \varepsilon _ { 0 } c } \alpha _ { Z Z }$$
where I ( ) t is the intensity of the laser field and α ZZ is the corresponding element of the molecule's polarizability tensor in the laboratory-fixed frame.
The geometrical structures, principal axes of inertia, and most-polarizable (MPA) axes of iodobenzene (IB), diiodobenzonitrile (DIBN), 1,3-diiodobenzene (1,3-DIB) and 1,2-diiodobenzene (1,2-DIB) are shown in Fig. 1. All four molecules contain one or two 127 I nuclei, which produce considerably large hyperfine energy splittings of the rotational states due to iodine's large quadrupole moment eQ = -696 mb. 29 The IB molecule has only one iodine nucleus and the total spin angular momentum is ˆ = ˆ I I 1 , where I 1 = 5 2 / . For the molecules with two iodine nuclei ˆ = ˆ I I 1 + ˆ I 2 ; the associated quantum number can have values I = 0 , ..., 5 . The total angular momentum is given by ˆ = ˆ + ˆ F J I . The nitrogen nucleus in DIBN has an additional nonzero quadrupole moment eQ = 20 44 . mb, 29 which is, however, relatively small compared to iodine and thus neglected for the purpose of this study. This could also be achieved by the 15 N isotopologue with spin 1/2 and thus eQ = 0 . For 1,3-bromoiodobenzene (1,3-BIB) we assume two different quadrupole-coupled nuclei 127 I and 79 Br, the more abundant isotope of bromine with Q = 313 mb. 29 All important parameters for the molecules in this study, such as rotational constants, polarizability, and EFG tensor elements are listed in Appendix A.
The simulations of the spin-rotational dynamics of molecules subject to external electric fields were performed using the variational approach Richmol 27,30 and the same computational setup as described in our previous work. 28 The total Hamiltonian is composed of the sum ˆ H mol + ˆ H las and the total time-dependent wave function is expanded in the basis of eigenfunctions ∣ ∣ ∣ F, J ˜ ˜ K K a ˜ c , n, M 〉 of the fieldfree time-independent Hamiltonian ˆ H mol . The details of the functional form of these basis functions are described in Appendix B. The alignment of the molecules is quantified by the expectation value 〈 cos 2 θ 〉 , where θ is the angle between the laser polarization axis and the MPA of the molecule. In the present setup, the laser polarization is aligned along the laboratory-fixed Z axis and the MPA of all molecules is strictly or nearly parallel to one of the principal axes of inertia, see Fig. 1. This simplifies calculations of the expectation value 〈 cos 2 θ 〉 , since the θ angle can be associated with the corresponding Euler angle.
We compared the post-pulse molecular alignment with and without the nuclear-quadrupole-coupling term in (1) for initial rotational temperatures T rot = 0 0 1 , . , and 0 3 . K. We used the eigenstates of ˆ H mol and ˆ H rot as initial field-free molecular states in the calculations with and without quadrupole coupling, respectively.
We assumed equal populations for all hyperfine components of a single rotational state, mimicking experimental conditions in molecular beams, where nuclear-spin states typically do not cool and nuclear-spin temperatures correspond to the high-temperature limit before expansion. Thus, even for rotational temperatures T rot = 0 K the alignment was calculated by averaging over the results of independent calculations for every hyperfine component of the ground rotational state J = 0 . For the finitetemperature calculations further averaging was performed by Boltzmann weighting the rotational states.
## III. RESULTS AND DISCUSSION
## A. Low-intensity impulsive alignment
Previously, we found that the effect of the nuclearquadrupole coupling strongly depends on the laser intensity and is larger at a lower intensity. 27,28 Thus we begin by analyzing the influence of the quadrupole coupling on the impulsive alignment induced by a 1 ps (FWHM) Gaussian laser pulse with a moderate peak intensity I 0 = 10 11 W cm . Fig. 2 shows the temporal / 2 evolution of the post-pulse alignment dynamics, characterized by 〈 cos 2 θ 〉 ( ) t , computed for different molecules at T rot = 0 K. The results including nuclear-quadrupole coupling are plotted with thick lines and the results of rigidrotor calculations, i. e., neglecting the nuclear-quadrupole coupling, are plotted with thin black lines.
In the rigid-rotor case, the alignment revival structures in Fig. 2 look fairly regular for all molecules, which is the result of dephasing and rephasing of rather narrow rotational wave packets. The revivals change from one molecule to another due to their distinct rotationalenergy-level structures and, to some extent, due to slightly different interaction strengths with the laser field caused by the different polarizabilities. Due to the weak intensity of the field, the post-pulse dynamics of IB, DIBN and 1,3-DIB is dominated by the coherences between the lowenergy rotational states with K a = 0 . K a is the quantum number of the rotational angular momentum projection operator onto the molecule-fixed a axis. Since the energies of these states look fairly similar to the energy levels of a symmetric top, the revival patterns in Fig. 2 a-c repeat themselves after multiples of the respective rotational periods τ IB rot = 707 69 . ps, τ DIBN rot = 3365 7 . ps and τ 1,3-DIB rot = 2499 4 . ps, with τ rot = 1 ( / B + C ) . In the case of 1,2-DIB, the post-pulse dynamics (Fig. 2 d) does not show such a periodic behavior, due to the molecule's larger rotational asymmetry, see Table I.
The nuclear-quadrupole coupling increases the complexity of the post-pulse alignment dynamics. At early times after the laser pulse 〈 cos 2 θ 〉 does not show any significant deviation from the rigid-rotor dynamics as the quadrupole coupling is much weaker than the polarizability interaction with the laser field. However, the wavepackets quickly dephase, 28 characteristic of the non-
FIG. 2. Impulsive alignment induced by a Gaussian laser pulse with τ FWHM = 1 ps and I 0 = 10 11 W cm / 2 for (a) IB, (b) DIBN, (c) 1,3-DIB and (d) 1,2-DIB including (QC) and neglecting the nuclear-quadrupole coupling (noQC).
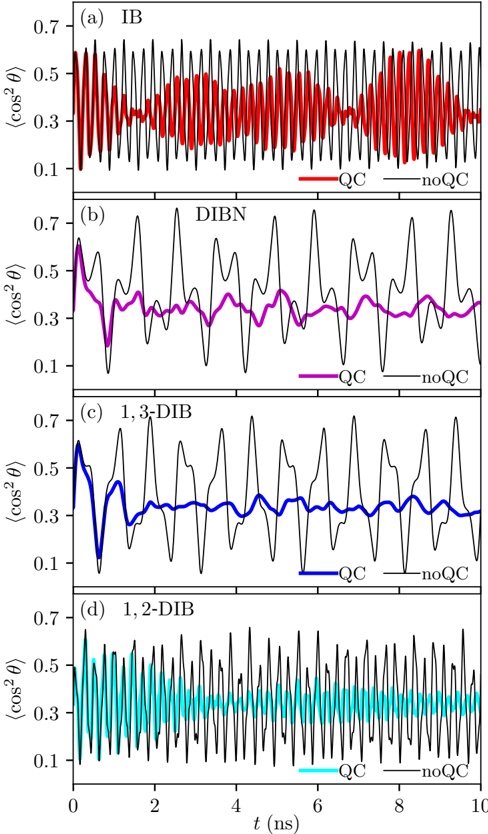
regular hyperfine splittings of low-energy rotational states that dominate the dynamics. Each rotational state of the IB molecule is split into 6 hyperfine components, at most, while for the molecules with two iodine nuclei each state has up to 36 hyperfine components. The influence of the quadrupole coupling is noticeably stronger for DIBN and 1,3-DIB molecules, see Fig. 2 b, c. This is due to the rather small B and C rotational constants for these molecules, corresponding rotational-level spacings in DIBN and 1,3DIB at low rotational excitations that are comparable to or even smaller than the hyperfine splittings. This yields strong mixing of different rotational levels, even in the initial field-free states, giving rise to large dephasing effects. A similar behavior was observed previously for 1,4-DIB. 28 For IB and 1,2-DIB, the hyperfine splittings are much
FIG. 3. Impulsive-alignment dynamics for I 0 = 10 11 W cm / 2 with nuclear-quadrupole coupling (QC) for the initial states (a) ∣ ∣ 5 2 0 / , 00 , 1 2 / 〉 of IB and (b) | 0 0 , 00 , 0 ⟩ of 1,3-DIB and without the coupling (noQC). (c, d) Fast-Fourier transforms of 〈 cos 2 θ 〉 with and without quadrupole coupling.
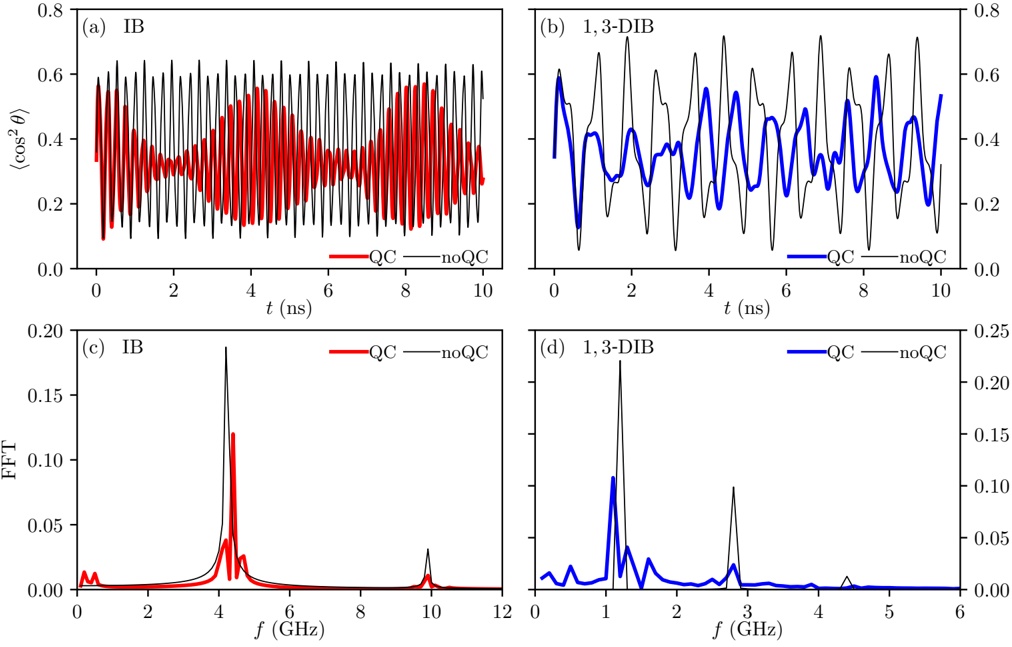
smaller than the rotational level spacings and thus the dephasing effect is weaker. Consequently, the alignment for these molecules oscillates at frequencies similar to the rigid-rotor results, see Fig. 2 a, d. The effect of the quadrupole coupling is, however, visible in the strongly modified amplitude of the degree of alignment.
In order to illustrate the interplay between the hyperfine-split and the pure rotational energy level spacings, we computed the fast-Fourier transforms (FFTs) of 〈 cos 2 θ 〉 ( ) t for IB and 1,3-DIB molecules, see Fig. 3. Here, the wavepackets obtained from the single initial hyperfine state ∣ ∣ ∣ F, J ˜ ˜ K K a ˜ c , n, M 〉 = 5 2 0 ∣ ∣ / , 00 , 1 1 , / 2 〉 for IB or | 0 0 , 00 , 1 0 , ⟩ for 1,3-DIB were analyzed.
the alignment than for the rigid-rotor, with the opposite effect observed for the main peak f ≈ 1 2 . GHz in 1,3-DIB, Fig. 3 d. The absolute value of the shift is similar for both molecules, however, relative to the peak frequency the shift in 1,3-DIB is about four times bigger than in IB. Thus, for 1,3-DIB, the deviations between the phases in the post-pulse alignment for the result with and without the quadrupole coupling occur on the timescale of the rotational revivals. In contrast for IB, the effect is slower than the molecule's longer rotational period. Furthermore, the larger number of hyperfine states in 1,3-DIB compared to IB led to an increased amount of irregularly spaced frequency contributions, giving rise to the non-periodic dynamics, see Fig. 3 b.
The Fourier transforms of the rigid-rotor results show only a few quasi-regularly-spaced peaks, reflecting the periodic behavior of 〈 cos 2 θ 〉 . For both molecules, the highest intensity peak corresponds to the coupling of the rigid-rotor states ∣ ∣ J K ,K a c 〉 = 0 | 00 , 0 ⟩ and | 2 02 , 0 ⟩ . When the quadrupole coupling is considered, the main rigidrotor peaks are split into several frequencies corresponding to transitions between different hyperfine states. For IB, Fig. 3 c, the main peak at f ≈ 4 2 . GHz is shifted toward higher frequency, which leads to a faster oscillation of
Other initial spin-rotational eigenstates of 1,3-DIB, which contribute to the alignment in Fig. 2 c, show analogous patterns, but with different frequency contributions. As a result, the revivals of 〈 cos 2 θ 〉 are on average almost entirely suppressed in 1,3-DIB. For both molecules, the frequency components below f ≈ 1 GHz originate from the energy gaps between different hyperfine states belonging to the same rotational level, i. e., to pure hyperfine-level population transfers similar to the transitions observed in NMR spectroscopy.
## 1. Influence of the number and strengths of nuclear spins
To gain more insight into the influence of the number of nuclear spins, we compared the alignment dynamics of 1,3DIB to that of a modified single-spin 1,3-DIB molecule, where we considered the quadrupole coupling of only one iodine nucleus with all other properties of 1,3-DIB unchanged. This allowed us to compare two molecular systems that differ only in the number of quadrupole-coupled nuclei. Furthermore, we investigated the alignment of 1,3-BIB, which can be considered an intermediate case between 1,3-DIB and the single-spin 1,3-DIB with respect to its rotational and hyperfine splittings.
The alignment of the single-spin 1,3-DIB, shown in Fig. 4 a, exhibits stronger or longer-lasting revivals than the regular 1,3-DIB with two coupled iodine nuclei, see Fig. 2 c.When comparing to a molecule with the same number of spins, IB, the impact of the quadrupole coupling in the single-spin 1,3-DIB is still more pronounced, Fig. 2 a, even though the quadrupole splittings for both molecules have similar values. However, the pure rotational energy spacings in IB are much larger than in 1,3-DIB. This highlights that it is the relative differences between the hyperfine and the pure rotational energy spacings in the molecule that determines the magnitude of the nuclearquadrupole effect in the alignment. This conclusion is further supported by the rotational dynamics of 1,2-DIB, which has two iodine nuclei, but much larger rotational energy splittings than 1,3-DIB. As a result, 〈 cos 2 θ 〉 is affected by the quadrupole interactions in a manner that qualitatively resembles the behavior of IB rather than 1,3-DIB. This can be seen, for example, when the peak alignment in 1,2-DIB increases after four nanoseconds
FIG. 4. Impulsive alignment induced by τ FWHM = 1 ps laser pulses with I 0 = 10 11 W cm / 2 for (a) 1,3-DIB neglecting the quadrupole coupling of the second iodine nucleus and (b) 1,3bromoiodobenzene including (QC) and neglecting the nuclear quadrupole coupling (noQC).
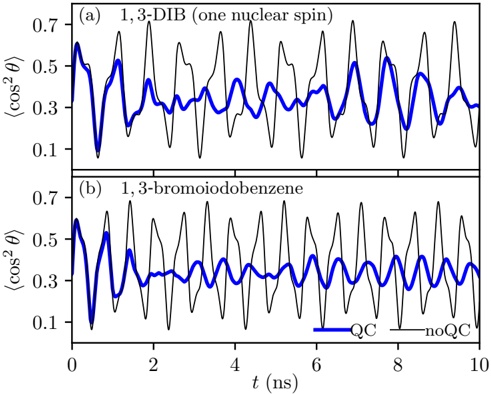
in Fig. 2 d. The alignment for 1,3-BIB with and without quadrupole coupling is depicted in Fig. 4 b. This molecule has fewer hyperfine energy levels and slightly larger rotational-energy spacings than 1,3-DIB. As a result, the low-amplitude oscillations of the alignment have a more regular structure for 1,3-BIB, while the overall effect of the quadrupole coupling in 1,3-BIB is similar to that in 1,3-DIB, see Fig. 2 c.
## 2. Influence of the geometric symmetry
Apart from their rotational constants and the number of hyperfine levels, an important distinction of the molecules considered here lies in the symmetry of their EFG and polarizability tensors. In IB both tensors are diagonal in the coordinate system defined by the principal axes of inertia, while the EFG tensors of the other molecules and the polarizability tensor of DIBN have nonzero offdiagonal elements in the inertial frame. The diagonal elements of these tensors couple rotational states having the same symmetry in the D 2 rotation group. 31 The offdiagonal elements α ab and V ab couple rotational states with A ↔ B c symmetry as well as B a ↔ B b . For DIBN, and the two diiodobenzene molecules, however, a given spin-rotational eigenstate is a linear combination of basis states | F, J K K a c , I, M ⟩ with A and B c or B a and B b rotational symmetries. For an eigenstate ∣ ∣ ∣ F, J ˜ ˜ K K a ˜ c , n, M 〉 , only an approximate rotational symmetry can be assigned according to even or odd ˜ K a and ˜ K c . 31 Consequently, a weak laser-interaction coupling can be observed between the hyperfine states corresponding to rotational states which are not coupled by the laser field in the absence of the quadrupole interactions.
Without quadrupole interactions, the wave packets of IB, 1,3-DIB and 1,2-DIB consist exclusively of rotational states of the same symmetry in the D 2 group as the initial state, i. e., A symmetry for T rot = 0 K. For DIBN, states with B c symmetry also contribute due to the polarizability tensor's nonzero off-diagonal elements. When considering quadrupole coupling, nonzero populations of B c rotational states are also observed for 1,3-DIB and 1,2-DIB. These contributions are small, ≲ 5 % , for the initial states and laser intensity considered here and thus do not influence the alignment significantly. However, this aspect of the rotational dynamics is not captured if the nuclear-quadrupole interactions are neglected. In addition, for rotational levels which are strongly mixed by these interactions, a much larger impact on the population distribution is possible. This is, for instance, the case for the excited states | 2 12 , M J ⟩ and | 2 02 , M J ⟩ of 1,2-DIB, see Section III C.
## B. High-intensity impulsive alignment
Typical impulsive alignment experiments employ intenser laser pulses, 32-35 which excite a larger number of high-energy rotational states than discussed in the previous section. We investigated the strong field alignment using the same pulse shape as in the previous section but with the peak intensity increased tenfold, i. e., I 0 = 10 12 W cm . The temporal evolution of / 2 〈 cos 2 θ 〉 for all molecules except 1,2-DIB is characterized by J -type revivals 33,36 that appear at multiples of the rotational periods as well as integer fractions thereof, see Fig. 5. These beatings originate from the interference of highly excited rotational states with ∆ K a = 0 . The asymmetry splittings of these states prevent a complete rephasing of
FIG. 5. Impulsive alignment induced by a Gaussian laser pulse with τ FWHM = 1 ps and I 0 = 10 12 W cm / 2 for (a) IB, (b) DIBN, (c) 1,3-DIB and (d) 1,2-DIB including (QC) and neglecting the nuclear-quadrupole coupling (noQC).
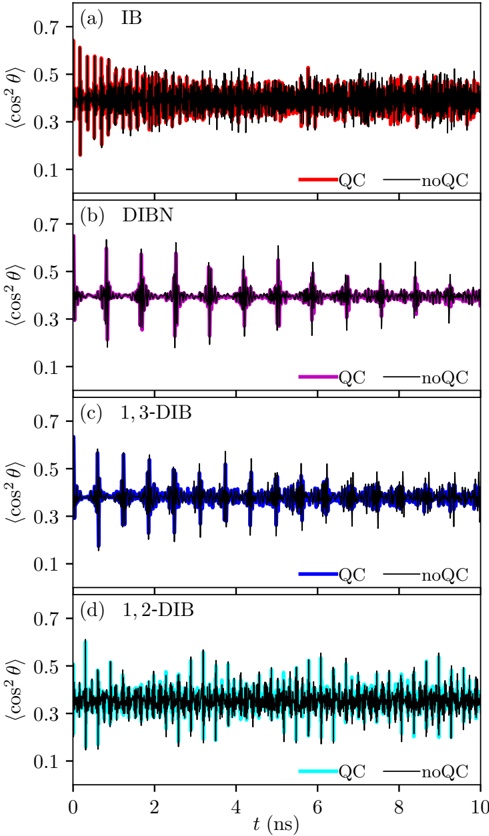
the wave packet and the peak alignment at the revivals decreases over time. 37
For 1,2-DIB, we observe clear revival features of a different type spaced by 304 ps in Fig. 5 d. The post-pulse dynamics of this molecule is dominated by the dephasing and rephasing of rotational states with ∆ J = ∆ K a = 2 and J ≈ K a . For large J , the energies of these states can be approximated by E J, K ( a ) ≈ BJ J ( +1)+( A -B K ) 2 a with B = 1 2 ( B + C ) . The relevant energy gaps are thus multiples of 4 A yielding the period of 1 4 / A ≈ 304 ps in 〈 cos 2 θ 〉 .
For the stronger laser pulse, the nuclear-quadrupole interactions had a much weaker impact on the post-pulse rotational dynamics. generally, it led to a loss of the peak alignment over time instead of qualitatively altering the dynamics, 28 see Fig. 5. An exception of this primarily destructive effect of the quadrupole coupling is found at certain alignment peaks of 1,2-DIB, e. g., t = 5 17 . ns, where 〈 cos 2 θ 〉 with quadrupole coupling is slightly larger than without. We attribute this constructive effect of the quadrupole coupling to the hyperfine splittings of some low-energy rotational states that cause a change in the amplitude of 〈 cos 2 θ 〉 similar to the weak laser intensity regime, Fig. 2 c. Overall, the weak impact of the quadrupole interactions is a result of increasingly uniform hyperfine splitting patterns at higher rotational excitations, as previously shown for I 2 and 1,4-DIB. 28
The FFTs of the post-pulse alignment for IB and 1,3DIB are shown in Fig. 6 c, d. The stronger-intensity pulse creates much broader wave packets that contain multiple frequency components. For both molecules the Fourier transforms calculated with and without quadrupole interactions are similar, especially for higher frequencies f that correspond to transitions between highly-excited rotational states. Deviations occur mainly in the lower frequency range, which contributes to a slight dephasing and the corresponding decrease of the alignment at longer timescales, noticed in Fig. 6 a, b. As for the weak laser intensity, the dephasing is more pronounced in 1,3-DIB due to the stronger mixing of less separated neighboring rotational states and generally larger number of the hyperfine components.
## C. Influence of the temperature
While single-state molecular ensembles can be achieved for small molecules, 35,38-41 this is generally not feasible for larger molecules. 41-43 We thus need to understand the effect of the nuclear-quadrupole coupling at finite rotational temperatures. We computed the post-pulse impulsive alignment of thermal ensembles of IB molecules for the two laser intensities used above and the rotational temperatures T rot = 0 1 . K and T rot = 0 3 . K. Such thermal ensembles are comparable 44 to state selected molecular ensembles 38,41,45 and represent conditions that are experimentally achievable.
The alignment of the thermal ensembles is shown in
FIG. 6. Impulsive alignment for I 0 = 10 12 W cm / 2 with (QC) and without (noQC) nuclear-quadrupole coupling for the initial states (a) ∣ ∣ 5 / , 2 0 00 , 1 2 / 〉 of IB and (b) | 0 0 , 00 , 0 ⟩ of 1,3-DIB. (c, d) Fast-Fourier transforms of 〈 cos 2 θ 〉 dynamics of the dynamics in (a) and (b).
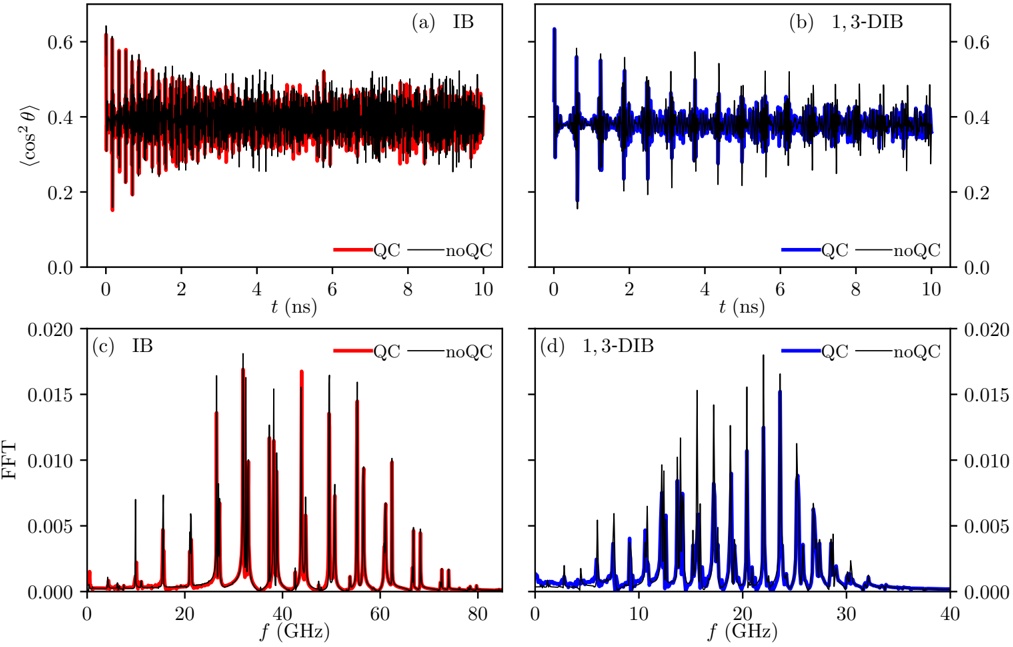
Fig. 7. Without quadrupole interactions, 〈 cos 2 θ 〉 shows revival features with a decreased degree of alignment as compared to T rot = 0 K, which is due to the influence of 32 (130) initially populated excited states with up to J = 3 ( J = 5 ) for T rot = 0 1 . K (T rot = 0 3 . K). As for T rot = 0 K, the quadrupole-coupling effects are stronger at the weaker field intensity I 0 = 10 11 W cm , see Fig. 7 a, / 2 c. For this laser intensity, a periodic increase of the amplitude of 〈 cos 2 θ 〉 as observed for T rot = 0 K in Fig. 2 a is not present. At a stronger intensity I 0 = 10 12 W cm / 2 the effect of the quadrupole coupling is essentially negligible until the first full revival, see Fig. 7 b, d. Shortly thereafter the quadrupole interaction starts to manifest itself, reducing the overall degree of alignment.
I 0 = 10 12 W cm / 2 (Fig. 8 b) the effect is still more pronounced than for T rot = 0 K in Fig. 2 d. This can be attributed to the nuclear-quadrupole interactions strongly mixing the rotational states | 2 12 ⟩ and | 2 02 ⟩ , which are not coupled by the polarizability interaction. This mixing led to significant contributions of basis states | F, 2 02 , I, M ⟩ in the initial wave functions ∣ ∣ ∣ F, ˜ 2 ˜˜ 12 , n, M 〉 modifying the dynamics even before the laser field was applied. After the interaction with the laser pulse, we find significant populations of hyperfine states belonging to rotational states that are otherwise not excited when the quadrupole coupling is neglected.
To account for the nuclear-quadrupole effect in thermal ensembles of different molecular species, we additionally computed the alignment dynamics of the excited rotational state | 2 12 ⟩ of 1,2-DIB, see Fig. 8. We compared the average rigid-rotor alignment over all possible M J values of the initial state to the average result obtained for all initial hyperfine states ∣ ∣ ∣ F, ˜ 2 ˜˜ 12 , n, M 〉 . As for the rotational ground state, the effect of the quadrupole coupling is stronger for weaker intensity laser field. For
We thus conclude that for finite-temperature molecular beams the influence of the nuclear-quadrupole interaction generally decreases with increasing the laser intensity. This is further strengthened by our previous analysis of the excited state rotational dynamics of I 2 and 1,4-DIB. 28 However, the hyperfine interactions can have a significant impact on the dynamics of some excited initial states and cannot be neglected even on a time scale where they do not affect the alignment for T rot = 0 K.
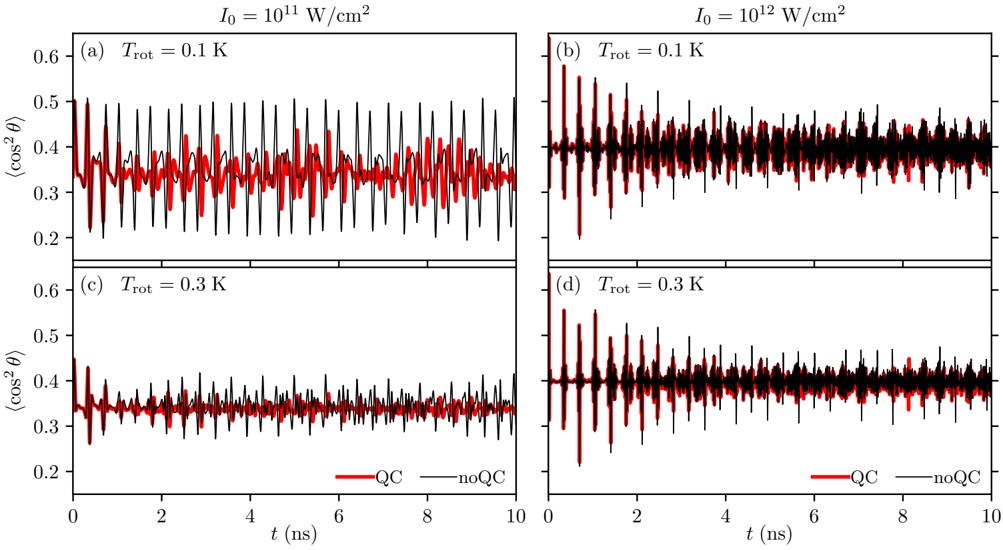
FIG. 7. Impulsive alignment of a thermal ensemble of IB molecules induced by laser pulses with τ FWHM = 1 ps including and neglecting the quadrupole coupling (QC and noQC) for (a, b) T rot = 0 1 . K and (c, d) T rot = 0 3 . K. (a, c) show the results for I 0 = 10 11 W cm / 2 and (b, d) for I 0 = 10 12 W cm . / 2
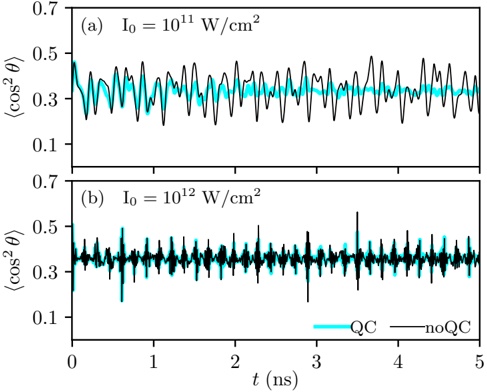
strong nuclear-quadrupole interactions. We focused on differences in the hyperfine interactions due to different chemical structures of the molecules. We showed that the interplay of hyperfine energy shifts and rotational energy level spacings is a deciding factor for the extent to which the coupling affects the post-pulse alignment. For all molecules analyzed in the present work and in previous studies 27,28 we observed that the influence of the quadrupole coupling becomes small when the field-dressed dynamics is dominated by excited rotational states. Due to the variety of molecules considered, we expect that this observation is general and that pushing population into highly-excited rotational states is advantageous for minimizing the dephasing due to nuclear-quadrupole coupling.
FIG. 8. Impulsive alignment averaged over the initial states | 2 12 , M J ⟩ of 12-DIB induced by 1 ps laser pulses with (a) I 0 = 10 11 W cm , (b) / 2 I 0 = 10 12 W cm . The alignment is / 2 shown including (QC) and neglecting the nuclear quadrupole coupling (noQC).
## IV. SUMMARY AND CONCLUSIONS
We presented a computational analysis of the post-pulse alignment dynamics of asymmetric top molecules with
We point out that while nuclear-quadrupole interactions pose difficulties in achieving strong field-free alignment, their effect on the rotational dynamics might be exploited to probe nuclear or electronic excitations which alter the nuclear spins and quadrupole momenta as well as electric field gradients. The sensitivity of the alignment to the hyperfine energy level structures of low-energy rotational states may thus be viewed as an opportunity rather than a disadvantage.
## V. ACKNOWLEDGEMENTS
This work was supported by Deutsches ElektronenSynchtrotron DESY, a member of the Helmholtz Association (HGF), including the maxwell compute-cluster operated by DESY, by the Deutsche Forschungsgemeinschaft (DFG) through the priority program 'Quantum Dynamics in Tailored Intense Fields' (QUTIF, SPP1840, KU 1527/3, YA 610/1), and through the clusters of excellence 'Center for Ultrafast Imaging' (CUI, EXC 1074, ID 194651731) and 'Advanced Imaging of Matter' (AIM, EXC 2056, ID 390715994). R.G.F. gratefully acknowledges financial support by the Spanish Project PID2020113390GB-I00 (MICIN), and by the Andalusian research group FQM-207.
## Appendix A: Molecular parameters
The rotational constants, asymmetry parameters κ = (2 B -A -C / A ) ( -C ) and elements of the polarizability and EFG tensors of the iodine and bromine nuclei in the principle axes of inertia frame are listed in Table I. Except for IB, the rotational constants were computed from the equilibrium geometry obtained using density functional theory (DFT) with the B3LYP functional and the def2-QZVPP basis set. 47,48 The effective core potential def2-ECP 49 was used for the iodine atoms. The electric field gradient and polarizability tensors of DIBN, 1,3-DIB and 1,2-DIB were calculated at the DFT/B3LYP level of theory using the all-electron scalar relativistic DouglasKroll-Hess Hamiltonian 50 with the DKH-def2-TZVP basis set. 51,52 All electronic structure calculations were carried out with the quantum-chemistry package ORCA. 53,54 For IB, we used the experimental nuclear-quadrupole coupling constants 46 χ aa = -1892 039 . MHz, χ bb = 978 816 . MHz, χ cc = 913 222 . MHz instead of a calculated electric field gradient and quadrupole moment. The molecule-fixed frame ( x, y, z ) is defined by the principle axes of inertia so that the z axis is parallel to the most polarizable axis or, in the case of DIBN, forms the smallest possible angle ( ≈ 5 ◦ ) with it. The z axis is thus chosen parallel to the a axis for IB, DIBN, 1,3-DIB and 1,3-bromoiodobenzene and to the b axis for 1,2-DIB.
## Appendix B: Matrix representation of the Hamiltonian
To obtain the eigenstates of H mol , we first solved the time-independent Schrödinger equation for H rot yielding the rigid-rotor energy levels and eigenstates | J K K a c , M J ⟩ . Here, M J is the eigenvalue of ˆ J Z and K a,c are associated with the projections ˆ J a,c and are good quantum numbers in the prolate and oblate symmetric top cases, respectively. The matrix representation of H mol was then constructed in the coupled basis 55,56 | F, J K K a c , I, M ⟩ , M being the eigenvalue of ˆ F Z . The field-free energies and eigenstates
∣ ∣ ∣ F, J ˜ ˜ K K a ˜ c , n, M 〉 were computed by numerically solving the associated time-independent Schrödinger equation. Here, n = 1 2 , , ... is an index labeling states with the same F and the approximate quantum numbers ˜ J , ˜ K a and ˜ K c were assigned according to the coupled basis state | F, J K K a c , I, M ⟩ with the largest contribution to the given eigenstate. For IB, the nuclear spin quantum number I = I 1 remains a good quantum number. The matrix elements of the polarizability element α ZZ are known analytically 55 in the basis | F, J K K a c , I, M ⟩ and can be transformed easily into the field-free eigenbasis. 27
- 1 R. Altkorn, R. N. Zare, and C. H. Greene, 'Depolarization of optically prepared molecules by two randomly oriented spins,' Mol. Phys. 55 , 1-9 (1985).
- 2 C. Yan and A. C. Kummel, 'Effect of hyperfine depolarization upon creation and detection of alignment in free-jet expansions via selective photodissociation,' J. Chem. Phys. 98 , 6869-6882 (1993).
- 3 T. A. Cool and N. Hemmi, 'Hyperfine polarization quantum beats in cyanogen,' J. Chem. Phys. 103 , 3357-3366 (1995).
- 4
- 6 D. Sofikitis, L. Rubio-Lago, M. R. Martin, D. J. Ankeny Brown, N. C.-M. Bartlett, A. J. Alexander, R. N. Zare, and T. P. Rakitzis, 'Optical control of ground-state atomic orbital alignment: Cl ( 2 P 3 / 2 ) atoms from HCl ( ν = 2 , j = 1) photodissociation,' J. Chem. Phys. 127 , 144307 (2007).
- J. Zhang, C. W. Riehn, M. Dulligan, and C. Wittig, 'An experimental study of HF photodissociation: Spin-orbit branching ratio and infrared alignment,' J. Chem. Phys. 104 , 7027-7035 (1996). 5 E. R. Wouters, L. D. Siebbeles, K. L. Reid, B. Buijsse, and W. J. van der Zande, 'Observation of fine structure and hyperfine structure depolarization in the photofragment anisotropy in triplet H ,' Chem. Phys. 2 218 , 309-323 (1997).
- 7 N. C.-M. Bartlett, D. J. Miller, R. N. Zare, A. J. Alexander, D. Sofikitis, and T. P. Rakitzis, 'Time-dependent depolarization of aligned hd molecules,' Phys. Chem. Chem. Phys. 11 , 142-147 (2009).
- 8 N. C.-M. Bartlett, J. Jankunas, R. N. Zare, and J. A. Harrison, 'Time-dependent depolarization of aligned D 2 caused by hyperfine coupling,' Phys. Chem. Chem. Phys. 12 , 15689-15694 (2010).
- 9 K. Grygoryeva, J. Rakovský, O. Votava, and M. Fárník, 'Imaging of rotational wave-function in photodissociation of rovibrationally excited HCl molecules,' J. Chem. Phys. 147 , 013901 (2017).
- 10 J. C. H. Spence and H. N. Chapman, 'The birth of a new field,' Phil. Trans. R. Soc. B 369 , 20130309-20130309 (2014).
- 11 J. Küpper, S. Stern, L. Holmegaard, F. Filsinger, A. Rouzée, A. Rudenko, P. Johnsson, A. V. Martin, M. Adolph, A. Aquila, S. Bajt, A. Barty, C. Bostedt, J. Bozek, C. Caleman, R. Coffee, N. Coppola, T. Delmas, S. Epp, B. Erk, L. Foucar, T. Gorkhover, L. Gumprecht, A. Hartmann, R. Hartmann, G. Hauser, P. Holl, A. Hömke, N. Kimmel, F. Krasniqi, K.-U. Kühnel, J. Maurer, M. Messerschmidt, R. Moshammer, C. Reich, B. Rudek, R. Santra, I. Schlichting, C. Schmidt, S. Schorb, J. Schulz, H. Soltau, J. C. H. Spence, D. Starodub, L. Strüder, J. Thøgersen, M. J. J. Vrakking, G. Weidenspointner, T. A. White, C. Wunderer, G. Meijer, J. Ullrich, H. Stapelfeldt, D. Rolles, and H. N. Chapman, 'X-ray diffraction from isolated and strongly aligned gas-phase molecules with a free-electron laser,' Phys. Rev. Lett. 112 , 083002 (2014), arXiv:1307.4577 [physics].
- 12 J. Yang, X. Zhu, T. J. A. Wolf, Z. Li, J. P. F. Nunes, R. Coffee, J. P. Cryan, M. Gühr, K. Hegazy, T. F. Heinz, K. Jobe, R. Li, X. Shen, T. Veccione, S. Weathersby, K. J. Wilkin, C. Yoneda, Q. Zheng, T. J. Martínez, M. Centurion, and X. Wang, 'Imaging CF I conical intersection and photodissociation dynamics with 3 ultrafast electron diffraction,' Science 361 , 64-67 (2018).
- 13 M. S. Hunter, C. H. Yoon, H. DeMirci, R. G. Sierra, E. H. Dao, R. Ahmadi, F. Aksit, A. L. Aquila, H. Ciftci, S. Guillet, M. J. Hayes, T. J. Lane, M. Liang, U. Lundström, J. E. Koglin,
TABLE I. Rotational constants A B C , , , asymmetry parameter κ , elements of the polarizability tensors α ij and electric field gradient tensors V ij ( ) l of the l th nucleus in the coordinate system defined by the principle axes of inertia. In the case of 1,3-BIB, V ij (1) and V ij (2) refer to the EFG of the iodine and bromine nucleus, respectively. For IB, the rotational constants from ref. 46 and the polarizability tensor from ref. 36 were used.
| | IB a | DIBN | 1,3-DIB | 1,2-DIB | 1,3-BIB |
|-----------------|------------------|------------|------------|------------|------------|
| A (MHz) | 5669 . 131 | 1608 . 324 | 1859 . 912 | 822 . 0850 | 2040 . 244 |
| B (MHz) | 750 . 414 293 | 155 . 402 | 210 . 776 | 522 . 1492 | 281 . 807 |
| C (MHz) | 662 . 636 146 | 141 . 709 | 189 . 321 | 319 . 3276 | 247 . 607 |
| κ | - 0 . 965 | - 0 . 981 | - 0 . 974 | - 0 . 193 | - 0 . 962 |
| α aa (Å 3 ) | 21 . 5 | 34 . 506 | 28 . 847 | 22 . 072 | 25 . 774 |
| α bb (Å 3 ) | 15 . 3 | 21 . 662 | 19 . 789 | 24 . 830 | 18 . 234 |
| α cc (Å 3 ) | 10 . 2 | 12 . 123 | 11 . 292 | 11 . 103 | 10 . 192 |
| α ab (Å 3 ) | 0 | - 1 . 209 | 0 | 0 | - 0 . 419 |
| V aa (1) (a.u.) | - 1892 . 039 /eQ | 12 . 327 | 7 . 34 | - 0 . 30 | 8 . 3735 |
| V bb (1) (a.u.) | 978 . 816 /eQ | - 6 . 6802 | - 1 . 73 | 5 . 88 | - 2 . 7590 |
| V cc (1) (a.u.) | 913 . 222 /eQ | - 5 . 6472 | - 5 . 61 | - 5 . 57 | - 5 . 6146 |
| V ab (1) (a.u.) | 0 | 1 . 5092 | - 7 . 85 | 8 . 84 | - 7 . 1745 |
| V aa (2) (a.u.) | 0 | 12 . 155 | 7 . 34 | - 0 . 30 | 4 . 1656 |
| V bb (2) (a.u.) | 0 | - 6 . 4317 | - 1 . 73 | 5 . 88 | - 0 . 4784 |
| V cc (2) (a.u.) | 0 | - 5 . 7230 | - 5 . 61 | - 5 . 57 | - 3 . 6872 |
| V ab (2) (a.u.) | 0 | 0 . 570 71 | 7 . 85 | - 8 . 84 | 5 . 6800 |
- a In the calculations for IB we used experimentally determined quadrupole coupling constants [46, Table 6].
- P. Mgbam, Y. Rao, L. Zhang, S. Wakatsuki, J. M. Holton, and S. Boutet, 'Selenium single-wavelength anomalous diffraction de novo phasing using an x-ray-free electron laser,' Nat. Commun. 7 , 13388 (2016).
- 14 A. Barty, J. Küpper, and H. N. Chapman, 'Molecular imaging using x-ray free-electron lasers,' Annu. Rev. Phys. Chem. 64 , 415-435 (2013).
- 'Switched wave packets with spectrally truncated chirped pulses,' J. Chem. Phys. 148 , 221105 (2018), arXiv:1803.03953 [physics]. 26 E. F. Thomas, A. A. Søndergaard, B. Shepperson, N. E. Henriksen, and H. Stapelfeldt, 'Hyperfine-structure-induced depolarization of impulsively aligned I 2 molecules,' Phys. Rev. Lett. 120 , 163202 (2018), arXiv:1804.04416 [physics].
- 15 L. Christensen, J. H. Nielsen, C. B. Brandt, C. B. Madsen, L. B. Madsen, C. S. Slater, A. Lauer, M. Brouard, M. P. Johansson, B. Shepperson, and H. Stapelfeldt, 'Dynamic stark control of torsional motion by a pair of laser pulses,' Phys. Rev. Lett. 113 , 073005 (2014).
- 16 R. J. D. Miller, 'Mapping atomic motions with ultrabright electrons: The chemists' gedanken experiment enters the lab frame,' Annu. Rev. Phys. Chem. 65 , 583-604 (2014).
- 17 H. Stapelfeldt and T. Seideman, 'Colloquium: Aligning molecules with strong laser pulses,' Rev. Mod. Phys. 75 , 543-557 (2003).
- 18 T. Seideman, 'Revival structure of aligned rotational wave packets,' Phys. Rev. Lett. 83 , 4971-4974 (1999).
- 19 F. Rosca-Pruna and M. J. J. Vrakking, 'Revival structures in picosecond laser-induced alignemnt of I 2 molecules. II. Numerical modeling,' J. Chem. Phys. 116 , 6579 (2002).
- 20 E. Hamilton, T. Seideman, T. Ejdrup, M. D. Poulsen, C. Z. Bisgaard, S. S. Viftrup, and H. Stapelfeldt, 'Alignment of symmetric top molecules by short laser pulses,' Phys. Rev. A 72 , 043402 (2005).
- 21 T. Seideman, 'On the dynamics of rotationally broad, spatially aligned wave packets,' J. Chem. Phys. 115 , 5965 (2001).
- 22 J. Underwood, M. Spanner, M. Ivanov, J. Mottershead, B. Sussman, and A. Stolow, 'Switched wave packets: A route to nonperturbative quantum control,' Phys. Rev. Lett. 90 , 223001 (2003).
- 23 J. Underwood, B. Sussman, and A. Stolow, 'Field-free three dimensional molecular axis alignment,' Phys. Rev. Lett. 94 , 143002 (2005).
- 24 A. Goban, S. Minemoto, and H. Sakai, 'Laser-field-free molecular orientation,' Phys. Rev. Lett. 101 , 013001 (2008).
- 25 A. Chatterley, E. T. Karamatskos, C. Schouder, L. Christiansen, A. V. Jörgensen, T. Mullins, J. Küpper, and H. Stapelfeldt,
- 27 A. Yachmenev, L. V. Thesing, and J. Küpper, 'Laser-induced dynamics of molecules with strong nuclear quadrupole coupling,' J. Chem. Phys. 151 , 244118 (2019), arXiv:1910.13275 [physics].
- 28 L. V. Thesing, A. Yachmenev, R. González-Férez, and J. Küpper, 'The effect of nuclear-quadrupole coupling in the laser-induced alignment of molecules,' J. Phys. Chem. A 124 , 2225-2230 (2020), arXiv:1911.12270 [physics].
- 29 P. Pyykkö, 'Year-2008 nuclear quadrupole moments,' Mol. Phys. 106 , 1965-1974 (2008).
- 30 A. Owens and A. Yachmenev, 'RichMol: A general variational approach for rovibrational molecular dynamics in external electric fields,' J. Chem. Phys. 148 , 124102 (2018), arXiv:1802.07603 [physics].
- 31 W. Gordy and R. L. Cook, Microwave Molecular Spectra , 3rd ed. (John Wiley & Sons, New York, NY, USA, 1984).
- 32 F. Rosca-Pruna and M. J. J. Vrakking, 'Experimental observation of revival structures in picosecond laser-induced alignment of I 2 ,' Phys. Rev. Lett. 87 , 153902 (2001).
- 33 L. Holmegaard, S. S. Viftrup, V. Kumarappan, C. Z. Bisgaard, H. Stapelfeldt, E. Hamilton, and T. Seideman, 'Control of rotational wave-packet dynamics in asymmetric top molecules,' Phys. Rev. A 75 , 051403 (2007).
- 34 S. Trippel, T. Mullins, N. L. M. Müller, J. S. Kienitz, J. J. Omiste, H. Stapelfeldt, R. González-Férez, and J. Küpper, 'Strongly driven quantum pendulum of the carbonyl sulfide molecule,' Phys. Rev. A 89 , 051401(R) (2014), arXiv:1401.6897 [quant-ph].
- 35 E. T. Karamatskos, S. Raabe, T. Mullins, A. Trabattoni, P. Stammer, G. Goldsztejn, R. R. Johansen, K. Długołęcki, H. Stapelfeldt, M. J. J. Vrakking, S. Trippel, A. Rouzée, and J. Küpper, 'Molecular movie of ultrafast coherent rotational dynamics of OCS,' Nat. Commun. 10 , 3364 (2019), arXiv:1807.01034 [physics].
- 36 M. D. Poulsen, E. Peronne, H. Stapelfeldt, C. Z. Bisgaard, S. Viftrup, E. Hamilton, and T. Seideman, 'Nonadiabatic alignment of asymmetric top molecules: Rotational revivals,' J. Chem. Phys. 121 , 783-791 (2004).
- 37 A. Rouzee, S. Guerin, V. Boudon, B. Lavorel, and O. Faucher, 'Field-free one-dimensional alignment of ethylene molecule,' Phys. Rev. A 73 , 033418-9 (2006).
- 38 Y.-P. Chang, D. A. Horke, S. Trippel, and J. Küpper, 'Spatiallycontrolled complex molecules and their applications,' Int. Rev. Phys. Chem. 34 , 557-590 (2015), arXiv:1505.05632 [physics].
- 39 J. H. Nielsen, P. Simesen, C. Z. Bisgaard, H. Stapelfeldt, F. Filsinger, B. Friedrich, G. Meijer, and J. Küpper, 'Starkselected beam of ground-state OCS molecules characterized by revivals of impulsive alignment,' Phys. Chem. Chem. Phys. 13 , 18971-18975 (2011), arXiv:1105.2413 [physics].
- 40 D. A. Horke, Y.-P. Chang, K. Długołęcki, and J. Küpper, 'Separating para and ortho water,' Angew. Chem. Int. Ed. 53 , 1196511968 (2014), arXiv:1407.2056 [physics].
- 41 S. Y. T. van de Meerakker, H. L. Bethlem, N. Vanhaecke, and G. Meijer, 'Manipulation and control of molecular beams,' Chem. Rev. 112 , 4828-4878 (2012).
- 42 K. Wohlfart, F. Grätz, F. Filsinger, H. Haak, G. Meijer, and J. Küpper, 'Alternating-gradient focusing and deceleration of large molecules,' Phys. Rev. A 77 , 031404(R) (2008), arXiv:0803.0650 [physics].
- 43 H. L. Bethlem, M. R. Tarbutt, J. Küpper, D. Carty, K. Wohlfart, E. A. Hinds, and G. Meijer, 'Alternating gradient focusing and deceleration of polar molecules,' J. Phys. B 39 , R263-R291 (2006), arXiv:0604020 [physics].
- 44 L. V. Thesing, J. Küpper, and R. González-Férez, 'Timedependent analysis of the mixed-field orientation of molecules without rotational symmetry,' J. Chem. Phys. 146 , 244304 (2017), arXiv:1705.03225 [physics].
- 45 F. Filsinger, G. Meijer, H. Stapelfeldt, H. N. Chapman, and J. Küpper, 'State- and conformer-selected beams of aligned and oriented molecules for ultrafast diffraction studies,' Phys. Chem. Chem. Phys. 13 , 2076-2087 (2011), arXiv:1009.0871 [physics].
- 46 J. L. Neill, S. T. Shipman, L. Alvarez-Valtierra, A. Lesarri, Z. Kisiel, and B. H. Pate, 'Rotational spectroscopy of iodobenzene and iodobenzene-neon with a direct digital 2-8ghz chirped-pulse fourier transform microwave spectrometer,' J. Mol. Spectrosc. 269 , 21 - 29 (2011).
- 47 F. Weigend, F. Furche, and R. Ahlrichs, 'Gaussian basis sets of quadruple zeta valence quality for atoms H-Kr,' J. Chem. Phys. 119 , 12753-12762 (2003).
- 48 F. Weigend and R. Ahlrichs, 'Balanced basis sets of split valence, triple zeta valence and quadruple zeta valence quality for H to Rn: Design and assessment of accuracy,' Phys. Chem. Chem. Phys. 7 , 3297 (2005).
- 49 K. A. Peterson, D. Figgen, E. Goll, H. Stoll, and M. Dolg, 'Systematically convergent basis sets with relativistic pseudopotentials. II. Small-core pseudopotentials and correlation consistent basis sets for the post-d group 16-18 elements,' J. Chem. Phys. 119 , 11113-11123 (2003).
- 50 F. Neese, A. Wolf, T. Fleig, M. Reiher, and B. A. Hess, 'Calculation of electric-field gradients based on higher-order generalized Douglas-Kroll transformations,' J. Chem. Phys. 122 , 204107 (2005).
- 51 F. E. Jorge, A. C. Neto, G. G. Camiletti, and S. F. Machado, 'Contracted gaussian basis sets for Douglas-Kroll-Hess calculations: Estimating scalar relativistic effects of some atomic and molecular properties,' J. Chem. Phys. 130 , 064108 (2009).
- 52 C. Campos and F. Jorge, 'Triple zeta quality basis sets for atoms Rb through Xe: application in CCSD(T) atomic and molecular property calculations,' Mol. Phys. 111 , 167-173 (2012).
- 53 F. Neese, 'The ORCA program system,' Wiley Interdiscip. Rev. Comput. Mol. Sci. 2 , 73-78 (2011).
- 54 F. Neese, 'Software update: the ORCA program system, version 4.0,' Wiley Interdiscip. Rev. Comput. Mol. Sci. 8 , e1327 (2017).
- 55 R. L. Cook and F. C. de Lucia, 'Application of the theory of irreducible tensor operators to molecular hyperfine structure,' Am. J. Phys. 39 , 1433-1454 (1971).
- 56 A. Yachmenev and J. Küpper, 'Communication: General variational approach to nuclear-quadrupole coupling in rovibrational spectra of polyatomic molecules,' J. Chem. Phys. 147 , 141101 (2017), arXiv:1709.08558 [physics].
- 57 P. M. Felker, 'Rotational coherence spectroscopy: studies of the geometries of large gas-phase species by picosecond time-domain methods,' J. Phys. Chem. 96 , 7844-7857 (1992).
- 58 P. M. Felker, J. S. Baskin, and A. H. Zewail, 'Rephasing of collisionless molecular rotational coherence in large molecules,' J. Phys. Chem. 90 , 724-728 (1986).
- 59 C. Riehn, 'High-resolution pump-probe rotational coherence spectroscopy - rotational constants and structure of ground and electronically excited states of large molecular systems,' Chem. Phys. 283 , 297-329 (2002). | null | [
"Linda V. Thesing",
"Andrey Yachmenev",
"Rosario González-Férez",
"Jochen Küpper"
] | 2024-08-02T09:07:25+00:00 | 2024-08-02T09:07:25+00:00 | [
"physics.atom-ph",
"physics.atm-clus",
"physics.chem-ph",
"physics.comp-ph",
"quant-ph"
] | Molecular influence on nuclear-quadrupole-coupling effects in laser induced alignment | We studied the effect of nuclear-quadrupole interactions on the field-free
impulsive alignment of different asymmetric-top molecules. Our analysis is
focused on the influence of the hyperfine- and rotational-energy-level
structures. These depend on the number of nuclear spins, the rotational
constants, and the symmetry of the tensors involved in the nuclear spin and
external field interactions. Comparing the prototypical large-nuclear-spin
molecules iodobenzene, 1,2-diiodobenzene, 1,3-diiodobenzene, and
2,5-diiodobenzonitrile, we demonstrate that the magnitude of the hyperfine
splittings compared to the rotational-energy splittings plays a crucial role in
the spin-rotational dynamics after the laser pulse. Moreover, we point out that
the impact of the quadrupole coupling on the rotational dynamics decreases when
highly excited rotational states dominate the dynamics. |
2408.01126v2 | ## IG-SLAM: Instant Gaussian SLAM
F. Aykut Sarıkamıs ¸ A. Aydın Alatan Center for Image Analysis (OGAM), EEE Department, METU, Turkey

Figure 1. Qualitative rendering results from Photo-SLAM [11] and IG-SLAM. We compare the visual quality of the methods on the large-scale EuRoC dataset [3].


## Abstract
3D Gaussian Splatting has recently shown promising results as an alternative scene representation in SLAM systems to neural implicit representations. However, current methods either lack dense depth maps to supervise the mapping process or detailed training designs that consider the scale of the environment. To address these drawbacks, we present IG-SLAM, a dense RGB-only SLAM system that employs robust dense SLAM methods for tracking and combines them with Gaussian Splatting. A 3D map of the environment is constructed using accurate pose and dense depth provided by tracking. Additionally, we utilize depth uncertainty in map optimization to improve 3D reconstruction. Our decay strategy in map optimization enhances convergence and allows the system to run at 10 fps in a single process. We demonstrate competitive performance with state-of-the-art RGB-only SLAM systems while achieving faster operation speeds. We present our experiments on the Replica, TUM-RGBD, ScanNet, and EuRoC datasets. The system achieves photo-realistic 3D reconstruction in largescale sequences, particularly in the EuRoC dataset.
## 1. Introduction
Dense Simultaneous Localization and Mapping (SLAM) is a fundamental problem in computer vision with numerous applications in robotics, augmented reality, virtual reality, and more. Any SLAM system must operate in real-time and scale to large scenes for all these real-world applications. Additionally, the system must be robust against noisy visual sensor measurements.
The prominent scene representation is a 3D point cloud in traditional Dense SLAM systems. However, point clouds are an impoverished representation of the world. As a sparse representation, the point clouds do not provide watertight, photo-realistic depictions of the environment. Recently, two promising scene representations have been introduced and studied in the SLAM literature: Neural Radiance Fields (NeRF) [17] and Gaussian Splatting [14].
Earlier dense SLAM studies that equip NeRF as an only-scene representation [31, 49] achieved 3D reconstruction without camera poses in real-time. Several following studies [5, 26, 47] integrate classical SLAM methods such as tracking by feature matching, dense-bundle adjustment, loop closure, and global bundle adjustment. Several performance improvements are made in later studies [12, 36, 45, 48, 50] by incorporating additional data structures along with NeRF [17], by employing off-the-shelf tracking modules [19, 34] and monocular depth estimation [7]. However, NeRF suffers from slow rendering speed [24]; since the real-time operation is crucial for a SLAM system, slow rendering speed puts NeRF into a disadvantageous position as a scene representation.
Later the following studies incorporate Gaussian Splatting as scene representation: Early works [16, 39, 43] adopt Gaussian Splatting as an only-scene representation and simultaneously track and map the environment in real-time. However, utilizing novel view synthesis methods as both
tracking and mapping tools is compelling yet challenging. The difficulty arises because pose and map optimizations are performed jointly. To decouple these two daunting tasks, [11, 27] utilize traditional SLAM methods demonstrating superior performance over only-scene representation methods in terms of reconstruction. However, these studies either lack dense depth supervision or a high frame rate.
Purposely, we introduce IG-SLAM, a deep-learningbased dense SLAM system that achieves photo-realistic 3D reconstruction in real-time. The proposed system features robust pose estimation, refined dense depth maps, and Gaussian Splatting representation. The proposed system frequently performs global dense bundle adjustment to reduce drift. Since the pose and depth maps optimized by a dense SLAM system are often noisy, we utilize depth uncertainty to make the mapping process robust to noise. Our efficient mapping algorithm is optimized specifically to work with dense depth maps enabling our system to operate at high frame rates. We perform extensive experiments on various indoor RGB sequences, demonstrating the robustness, fast operation speed, and scalability of our method. In summary, we make the following contributions:
- · We present IG-SLAM, an efficient dense RGB SLAM system that performs at high frame rates, offering scalability and robustness even in challenging conditions.
- · A novel 3D reconstruction algorithm that accounts for depth uncertainty, making the 3D reconstruction robust to noise.
- · Atraining procedure to make dense depth supervision for the mapping process as efficient as possible.
## 2. Related Work
## 2.1. Dense Visual SLAM
Pioneering dense SLAM algorithms, DTAM [21] and KinectFusion [20], show that dense SLAM can be performed in real-time despite its computational complexity. DTAM aims to produce dense depth maps associated with the keyframes, known as the view-centric approach. Later research adopted a similar approach but with a crucial distinction. While these traditional approaches generally decouple the optimization of dense maps and poses, some recent works focus on joint optimization. However, optimization of the full-resolution depth map is not feasible due to the high number of independent variables. Therefore, the following research focuses on reducing the computational complexity of joint optimization. For this purpose, BANet [32] includes a depth map into the bundle adjustment layer utilizing a basis of depth maps and optimizing the linear combination coefficients. Code-SLAM [2] reduces the dimension of dense maps by an autoencoder-inspired architecture. DROID-SLAM [34] optimizes down-sampled dense maps in a bundle-adjustment layer with a reprojection error, aided by optical flow revisions [33]. A recent work, FlowMap [28], estimates a dense depth map with a convolutional neural network and calculates the pose analytically using the optical flow. As world-centric alternatives to this approach, Neural Radiance Fields [17] and Gaussian Splatting [14] are utilized in the literature.
## 2.2. Neural Radiance Field Scene Representation
NeRF [17] encodes the scene as radiance fields utilizing a simple multi-layer perceptron (MLP). The original NeRF formulation exhibits slow training and rendering speeds. However, several improvements have been proposed on this initial formulation. The cone-shaped rendering [1] is utilized to address anti-aliasing, additional data structures are also employed, such as voxel grid [8, 15, 25], plenoctree [9, 37, 42], hash tables [18] and many more achieve orders of magnitude faster rendering and training compared to the original NeRF [17]. Surface-based methods [22, 38, 40] also unify surface and volume rendering.
The landmark work iNeRF [41] calculates camera poses given a NeRF representation by fixing the NeRF representation and minimizing rendering error by optimizing the camera pose around an initial guess. iMAP [31], as the first representation-only work, optimizes the pose by fixing the NeRF representation and optimizes the map based on the calculated pose. NICE-SLAM [49] introduces a hierarchical coarse-to-fine mapping approach. To decouple map and pose optimization, Orbeez-SLAM [5] leverages robust visual SLAM methods [19] and multi-resolution hash encoding [18]. NeRF-SLAM [26] introduces dense depth maps with covariance and poses generated by the robust denseSLAM algorithm DROID-SLAM [34]. GO-SLAM employs loop closing and global dense bundle adjustment to achieve globally consistent reconstruction. NICER-SLAM [50] extends NICE-SLAM [49] incorporating off-the-shelf monocular depth and normal estimators. Recently, MoDSLAM [48] utilizes cone-shaped projection in rendering [1]. GlORIE-SLAM [45] utilizes monocular depth estimation for mapping supervision.
## 2.3. 3D Gaussian Splatting Scene Representation
3D Gaussian Splatting represents the scene as a set of Gaussians of varying colors, shapes, and opacity. Several improvements are proposed for consistency and reconstruction quality. For example, 2D counterpart [10] is also proposed to enhance multi-view consistency. Moreover, the rendering depth with alpha-blending as in the original 3D Gaussian Splatting causes noisy surfaces; hence, more rigorous methods address this issue by utilizing varying depths per Gaussian according to the viewpoint [4, 44].
Due to its fast rendering speed and being an explicit scene representation as opposed to NeRF [17],
Figure 2. System Overview. Our system takes an RGB image stream as input and outputs the camera pose and scene representation in the form of a set of Gaussians. We decouple this objective into two parts: tracking and mapping. Tracking: Keyframes are created and added to the frame graph based on average optical flow. Pretrained GRU refines optical flow between keyframes. Dense bundle adjustment (DBA) is performed on the frame graph, minimizing reprojection error while optimizing the dense depth map and camera pose, and calculating depth map covariance simultaneously. After several iterations, depth maps and camera poses are expected to converge. Mapping: Keyframes' pose, depth, and covariance obtained from tracking are used for 3D reconstruction. We initialize Gaussians from low covariance regions utilizing the camera pose and depth map. 3D Gaussians are then projected onto the image plane and rendered utilizing a differentiable tile rasterizer. The loss function is a combination of depth and color loss. The depth loss is weighted by covariance. Finally, the loss is backpropagated to optimize Gaussians orientation, scaling, opacity, position, and color designated by orange arrows in the figure. Moreover, Gaussians are split, cloned, and pruned based on the local gradients.
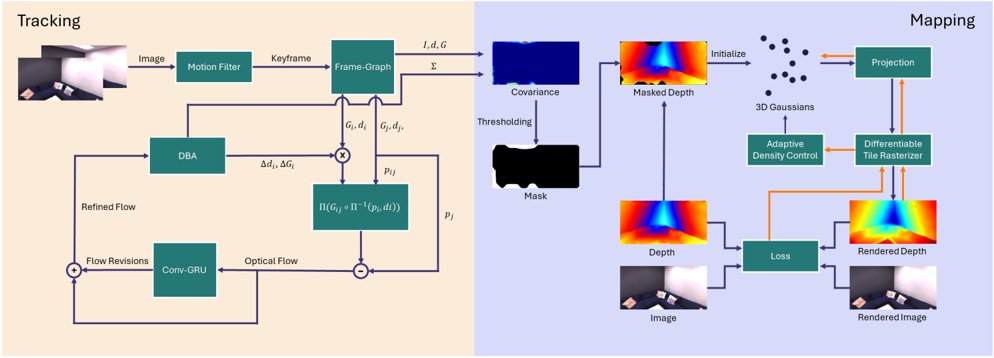
Gaussian Splatting [14] has also quickly gained attention in the SLAM literature. MonoGS [16], GS-SLAM [39], and SplaTAM [13] are pioneering Gaussian-Splatting representation-only SLAM algorithms that jointly optimize Gaussians and the pose. Gaussian-SLAM [43] introduces sub-maps to mitigate neural forgetting. Photo-SLAM [11] decouples tracking and mapping by employing a traditional visual SLAM algorithm [19] as its tracking module and introduces a coarse-to-fine map optimization approach. RTGSLAM [23] renders depth by considering only the foremost opaque Gaussians. Recent work, Splat-SLAM [27] uses proxy depth maps to supervise map optimization.
camera pose G t and inverse depth d t for each camera frame t . DROID-SLAM constructs a frame graph ( V E , ) of keyframes based on co-visibility. Keyframes are selected from all camera frames when the average magnitude of the optical flow for a frame is higher than a certain threshold. If there is a visual overlap between frames i and frame j , an edge is created between the i th and j th vertex in V . This graph is updated during inference. Given the initial pose and depth estimates ( G d i , i ) and ( G d j , j ) for frame i and j , the optical flow field is estimated by unprojecting the pixels from frame i , projecting them into frame j , and taking the pixel-wise position difference. In other words, the reprojected pixel locations p ij is calculated as in Eq. (1)
## 3. Proposed Method
We provide an overview of the proposed method in Fig. 2. Our tracking algorithm (Sec. 3.1) generates a dense depth map, depth uncertainty, and the camera pose for each keyframe. These outputs are then used to supervise our mapping algorithm (Sec. 3.2). The Gaussians are initialized based on the camera pose and dense depth and are optimized using color and weighted depth loss. Real-time operation is achieved through a sliding window of keyframes.
## 3.1. Tracking
We mainly employ DROID-SLAM [34] as our tracking module. DROID-SLAM maintains two state variables:
$$p _ { i j } = \Pi ( \mathbf G _ { i j } \circ \Pi ^ { - 1 } ( \mathbf p _ { i }, \mathbf d _ { i } ) ), \ \mathbf p _ { i j } \in \mathbb { R } ^ { H \times W \times 2 } \quad ( 1 )$$
where G ij = G -1 j ◦ G i . Then, the optical flow is initially calculated as p ij -p j . This estimate is fed into GRU along with a correlation vector which is an inner product between features of the frames. The GRU produces flow revisions r ij and confidence weights w ij . the refined reprojected pixel locations p ∗ ij are computed similarly to Eq. (1) incorporating the flow correction from the GRU. Then, the dense bundle adjustment layer minimizes the cost function in Eq. (2).
$$& \mathbf E ( G ^ { \prime }, d ^ { \prime } ) = \sum _ { i, j \in \mathcal { E } } \left \| p _ { i j } ^ { * } - p ^ { \prime } _ { i j } \right \| _ { \Sigma _ { i j } } ^ { 2 } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
& p ^ { \prime } _ { i j } = \Pi ( G ^ { \prime } _ { i j } \circ \Pi ^ { - 1 } ( p _ { i }, d ^ { \prime } _ { i } ) ) \quad \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad & ( 2 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where Σ ij = diag ( w ij ) and ∥ ∥ . Σ Mahalanobis norm weighted according to the weights w ij . Linearizing Eq. (2) around ( G d ′ , ′ ) and solve for pose and depth updates (∆ ξ, ∆ ) d using Gauss-Newton algorithm. The linearized system of equations becomes
$$H { \mathbf x } = { \mathbf b }, \ H = \begin{bmatrix} C & E \\ E ^ { T } & P \end{bmatrix}, \ \mathbf x = \begin{bmatrix} \Delta \xi \\ \Delta \mathbf d \end{bmatrix}, { \mathbf b } = \begin{bmatrix} { \mathbf v } \\ { \mathbf w } \end{bmatrix} \ ( 3 ) \quad \text{The}$$
where H is the Hessian matrix, x = [∆ ξ, ∆ ] d is the pose and depth updates, b = [ v w , ] is the pose and depth residuals, C is the block camera matrix. E is the camera/depth off-diagonal block matrices, and P is the diagonal matrix corresponding to disparities per pixel per keyframe. The bundle adjustment layer operates on the initial flow estimates and updates the keyframes' pose and depth map. Optical flow is then recalculated by refined poses and depth maps which are subsequently fed back into the dense bundle adjustment layer. After successive iterative refinements on the keyframe graph, the poses and depth maps are expected to converge.
After the dense bundle adjustment step, we compute the covariance for depth estimates. As shown in NeRF-SLAM [26], the same Hessian structure in Eq. (3) can be used to calculate covariance for depth estimates Σ d and poses Σ G as shown in Eq. (4). The depth covariance is used both as a mask for initializing Gaussians and as weights in the depth component of the loss function.
$$& \Sigma _ { d } = P ^ { - 1 } + P ^ { - T } E ^ { T } \Sigma _ { G } E P ^ { - 1 } \quad \quad \ \. \\ & \Sigma _ { G } = ( L L ^ { T } ) ^ { - 1 } \quad \quad \ \ ( 4 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
Keyframing We utilize all the keyframes that are actively optimized in the tracking process without any filtering. Each keyframe that participates in mapping contains its camera image I , depth map d , depth covariance Σ d , and pose G . The mapping process accepts a keyframe only if it is not already in the sliding window. Note that, we do not send all the keyframes created in a mapping cycle, but only the most recent one. Therefore, this approach may result in some keyframes being missed during optimization. However, this design choice prevents abrupt changes in the sliding window caused by a sharp camera movement.
Global BA After the number of total keyframes exceeds the sliding window length for the Dense Bundle Adjustment, we regularly perform Global Bundle Adjustment for all existing keyframes on a separate graph as described in GOSLAM [47]. The graph is constructed utilizing a distance metric, where the distance between frame pairs is the average optical flow magnitude. Graph edges are established between consecutive keyframes and those that are close according to the distance metric. Dense bundle adjustment is then applied based on this graph every 10 keyframes. The pose and depth maps are updated at the start of every mapping cycle, along with their covariances. We perform one last global BA at the end of tracking.
## 3.2. Mapping
The mapping process is responsible for 3D reconstruction with keyframes equipped with pose, image, depth, and covariance acquired from the tracking process.
Representation We adopt Gaussian Splatting [14] as scene representation. A Gaussian function is described by Eq. (5)
$$G ( { \mathbf x } ) = \exp \left ( \frac { 1 } { 2 } ( { \mathbf x } - \mu ) ^ { T } \Sigma ^ { - 1 } ( { \mathbf x } - \mu ) \right ) \quad ( 5 )$$
where µ and Σ are the mean and covariance which define the position and shape of this Gaussian. To ensure that the covariance remains semi-definite during optimization, covariance Σ is decomposed into RSS T R T where R is the rotation matrix and S is the scaling matrix. In addition to position, rotation, and scaling, opacity α and color c are also optimized. Although the original implementation parameterizes color as spherical harmonic coefficients, our algorithm optimizes the color directly. The projection of a 3D covariance is formulated as Σ ′ = JR Σ R J T T where R is the rotation component of the world-to-camera transformation T cw and J is the Jacobian of the affine approximation of the projective transformation P [51]. The position is projected directly as µ ′ = PT cw µ .
Rendering A set of Gaussians N visible from a viewpoint, is first projected onto the image plane. 2D Gaussians are then sorted according to their depths and are rasterized via α -blending as described in Eq. (6) for color and depth.
$$\underset { y \text{ if } } { \text{ and } } \hat { C } = \sum _ { i \in \mathcal { N } } c _ { i } \alpha _ { i } \prod _ { j = 1 } ^ { i - 1 } ( 1 - \alpha _ { j } ), \, \hat { D } = \sum _ { i \in \mathcal { N } } d _ { i } \alpha _ { i } \prod _ { j = 1 } ^ { i - 1 } ( 1 - \alpha _ { j } ) \ ( 6 )$$
Hierarchical Optimization Since dense depth maps for keyframes are available, we adopt a training strategy similar to RGB-D MonoGS [16] but utilizing a coarse-to-fine training strategy inspired by Photo-SLAM [11] and InstantNGP [18].
For each keyframe, an image pyramid is constructed by downsampling image, depth, and covariance by a factor of s using bilinear interpolation, as in Eq. (7)
$$& \text{KF} _ { i } ^ { l } = \{ I _ { i } ^ { l }, \mathbf d _ { i } ^ { l }, \Sigma _ { d i } ^ { l } \} \\ & I _ { i } ^ { l } = I _ { i } ^ { 0 } \downarrow s ^ { l }, \ \mathbf d _ { i } ^ { l } = \mathbf d _ { i } ^ { 0 } \downarrow s ^ { l }, \ \Sigma _ { d i } ^ { l } = \Sigma _ { d i } ^ { 0 } \downarrow s ^ { l } \quad ( 7 )$$
where ↓ denotes the downsampling operation with linear interpolation and l is the pyramid level and I 0 i , d 0 i , Σ 0 di are the full resolution image, depth, and covariance respectively. In Photo-SLAM [11], the authors utilize a sharp downsampling factor s of 0.5 and a 2-level pyramid. In contrast, we employ a smoother downsampling factor s = 0 8 . similar to Instant-NGP [18] and a 3-level pyramid.
In each pyramid level, Gaussians are initialized by unprojection as follows: The points are sampled randomly from the most recent keyframe by using a downsampling factor θ . The sampled points are then unprojected according to depth maps. To account for the noise in depth maps, regions with high covariance are masked out to make the Gaussian initialization more robust to noise. Eq. (8) describes a mask for a given normalized depth covariance.
$$M = \{ ( i, j ) \ | \ \sigma _ { i j } < 0. 2 \} \quad \quad ( 8 ) \quad \text{le}$$
where M represents the binary mask matrix and i and j represent pixel location. The mask is created by normalizing the covariance Σ between 0 and 1 and identifying the pixel values below 0.2 normalized covariance σ . The mask is then smoothed using thresholding operation as described in Eq. (8) with a maximum filter followed by a majority filter. An example of a mask for a given covariance is shown in figure Fig. 3.
Figure 3. An example of normalized covariance(left) and corresponding mask(right). The mask is created by thresholding normalized covariance with a maximum filter and smoothing with a majority filter. The white region on the mask is left out and not used during Gaussian initialization.

The map optimization is performed on a sliding window in a coarse-to-fine fashion. We maintain the last N keyframes within the sliding window to meet the real-time requirements. As the number of iterations increases, we switch to training with higher resolutions in the image pyramid. At the beginning of optimization at each level l , Gaussians are unprotected according to its depth map d l i . Werender the Gaussians from keyframes' viewpoints in the sliding window, and the loss function is calculated based on the rendered image and depth. Camera images and dense depth maps are utilized as ground truth in mapping supervision.
We employ a loss function that combines weighted depth loss L depth and color loss L color which are defined as below
$$L _ { \text{depth} } = \left \| D - \hat { D } \right \| _ { \Sigma _ { d } ^ { - 1 } } ^ { 1 }, \ L _ { \text{color} } = \left \| C - \hat { C } \right \| ^ { 1 } \quad ( 9 )$$
where D and C are the ground truth depth and image, respectively, and ˆ D and ˆ C are the rendered depth and image according to Eq. (6). The depth loss L depth is weighted by the inverse covariance to ensure that the pixels with high uncertainty are weighted less. The combined loss is given by L = αL color + (1 -α L ) depth . We set α = 0 5 . throughout all of our experiments. The loss is then backpropagated through a differentiable rendering pipeline where the position, opacity, covariance, maps, and color of the Gaussians are optimized.
Post Processing We refine the mapping results by optimizing the map for several iterations following the conventions established in MonoGS [16], GlORIE-SLAM [45] and Splat-SLAM [27]. For this purpose, we randomly select single frames and optimize the map with the same loss function used in the mapping. We perform the same number of iterations in MonoGS [16] and Splat-SLAM [27] for fairness.
## 3.3. Training Strategy
A subtle yet crucial point regarding our training strategy is that dense depth maps may be noisy; however, they are unlikely to disrupt depth order. In other words, having a position learning rate such that Gaussians switch positions during training is redundant and hinders optimization convergence. This effect is illustrated in Fig. 4. It should be noted that this is never the case for standard Gaussian Splatting training where the method typically starts with a sparse SfM point cloud. However, since Gaussians are initialized from a dense depth map, they are quite close to each other.
As illustrated in Fig. 4, case A) high learning rates cause the optimization to bounce Gaussians around the desired position. Conversely, the polar opposite in C) also hinders the convergence. Since setting a perfect learning rate for each iteration is neither feasible nor practical, we choose a learning rate that decays during training according to Eq. (10) to reduce this TV static noise during training. We initialize the learning rate to cover the full range needed to detail the model from coarse to fine while allowing for gradual decay.
$$\text{lr} ( t ) = \exp ( ( 1 - t ) \ln ( \text{lr} _ { i } ) + t \ln ( \text{lr} _ { f } ) ) \quad ( 1 0 )$$
where t = n/τ is the iteration number n over decay constant τ , and lr , i lr f are the initial and final learning rate, respectively. The impact of learning rate and its decay in training performance are examined in Sec. 4.
Figure 4. Three hypothetical cases to encounter in training. Dashed lines pass through ground truth Gaussian positions from the camera center. The faded Gaussians represent their previous positions. Red lines are the position update steps along the gradient direction. In A) , a large position update causes the order of Gaussians to change, creating TV-static-like noise in training. In B) , multiple iterations are needed to move Gaussians to the correct place because of small position updates. C) represents the ideal case where position update is exactly the position error.
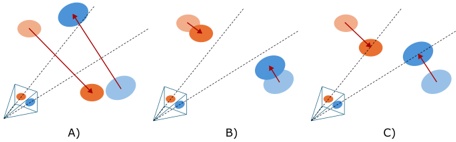
We densify Gaussians in high loss gradient regions at every 150 iterations. Densification is achieved by cloning small Gaussians and by splitting large ones. The occluded Gaussians are also pruned at the end of each sliding window optimization to ensure that only the necessary Gaussians for accurate reconstruction are retained.
## 4. Experiments
We evaluate our system on various synthetic and real-world datasets. The ablation studies and hyperparameter analyses are also demonstrated to justify our design choices.
## 4.1. Experimental Setup
Datasets We evaluate the system in Replica [29], TUM RGB-D [30], ScanNet [6], and EuRoC MAV [3] datasets. Replica is a dataset of synthetic indoor scenes. The TUM RGB-D dataset consists of sequences that are recorded in small indoor office environments. The ScanNet dataset consists of 6 sequences of real-world indoor environments. The EuRoC is a dataset collected on board a Micro Aerial Vehicle (MAV) containing stereo images of relatively large-scale indoor environments. All datasets are evaluated without clipping except EuRoC. We clip from the start of the sequences to skip typical pauses at the beginning. We run all sequences 3 times and report the average results to mitigate the effect of the non-deterministic nature of multi-processing.
Metrics Following the view synthesis SLAM literature convention, we evaluate our system using PSNR, SSIM, and LPIPS [46]. We also provide depth L1[cm] metric compared to the ground truth depth in the Replica dataset. The evaluation is performed after post-processing every 5 frames in sequences skipping the keyframes used for mapping. This approach aligns with the evaluation methods used in MonoGS [16] and Splat-SLAM [27].
Implementation Details Our system runs on a PC with a 3.6GHz AMD Ryzen Threadripper PRO 5975WX and an NVIDIA RTX 4090 GPU. In all our experiments, we set l = 0 8 . , θ = 128 , α = 0 5 . , lr i = 1 6 . × 10 -4 , lr f = 1 6 . × 10 -6 , τ = 3000 for hyperparameters in mapping. We set β = 2000 for the EuRoC [3] and Replica [29] datasets and β = 26000 for the TUM RGB-D [30] and the ScanNet [6] datasets. These values are consistent with those used in MonoGS [43] and Splat-SLAM [27]. For tracking, pre-trained GRU weights from DROID-SLAM [34] are utilized. We set the mean optical flow threshold for keyframe selection to 4.0 pixels, and the local dense bundle adjustment window to 16. Optimizations in the tracking module are performed in LieTorch [35] framework. The mapping process accepts only the latest keyframe created after finishing its optimization step if the latest keyframe is not already in the sliding window.
Baselines We compare our system to state-of-the-art RGBonly Gaussian Splatting and NeRF SLAM algorithms, including MonoGS [16], Photo-SLAM [11], GlORIE-SLAM [45], and Splat-SLAM [27].
MonoGS [16] is the state-of-the-art representation-only SLAM algorithm that utilizes the Gaussian scene representation for tracking and mapping. Photo-SLAM, like GlORIE-SLAM [45], Splat-SLAM [27], and our system, features a decoupled design for tracking and mapping. One key difference is that Photo-SLAM lacks dense depth maps while mapping. GlORIE-SLAM and Splat-SLAM utilize monocular depth estimation [7] and the dense bundle adjustment layer. The most important difference between them is that GlORIE-SLAM [45] models the scene with NeRF [17] and Splat-SLAM [27] does so with 3D Gaussian Splatting [14].
## 4.2. Evaluation
We compare our system with state-of-the-art algorithms based on rendering quality, 3D reconstruction accuracy, and runtime performance.
Rendering and Reconstruction Accuracy We evaluate rendering and reconstruction accuracy for the Replica [29] in Tab. 1. Our algorithm's performance is quite similar to Splat-SLAM [27] in Replica [29]. In Tab. 2, we compare head-to-head with GlORIE-SLAM [45] on the ScanNet [6], where we trail behind Splat-SLAM [27]. In Tab. 3, we rank just behind Splat-SLAM, outperforming other algorithms on the TUM RGB-D [30] dataset. However, we are superior in terms of on-the-fly map optimization to Splat-SLAM as shown in Tab. 6. We place the first in the the EuRoC [3] dataset demonstrating a significant margin over Photo-SLAM [11]. A qualitative comparison
is shown in Fig. 1. Our experiments reveal that sequences focusing on a centered object in an unbounded scene, such as TUM-RGBD f3/off , are particularly challenging.
Table 1. Rendering and Tracking Results on Replica [29] for RGB-Methods. The results are averaged over 8 scenes and each scene result is the average of 3 runs. We take the numbers from [27] except for ours. The best results are highlighted as first , second . Our method shows similar performance to Splat-SLAM [27] and outperforms all the other methods.
| Metrics | Mono- GS [16] | GlORIE- SLAM [45] | Photo- SLAM [11] | Splat - SLAM [27] | Ours |
|------------|-----------------|---------------------|--------------------|---------------------|--------|
| PSNR ↑ | 31.22 | 31.04 | 33.30 | 36.45 | 36.21 |
| SSIM ↑ | 0.91 | 0.91 | 0.93 | 0.95 | 0.96 |
| LPIPS ↓ | 0.21 | 0.12 | - | 0.06 | 0.05 |
| Depth L1 ↓ | - | - | - | 2.41 | 4.34 |
Table 2. Rendering Performance on ScanNet [6]. Each scene result is the average of 3 runs. We take the numbers from [27] except for ours. Our method shows competitive performance to the state-of-the-art methods exhibiting the second high visual quality results.
| Method | Metric | 0000 | 0059 | 0106 | 0169 | 0181 | 0207 | Avg. |
|-------------------|----------|--------|--------|--------|--------|--------|--------|--------|
| MonoGS [16] | PSNR ↑ | 16.91 | 19.15 | 18.57 | 20.21 | 19.51 | 18.37 | 18.79 |
| | SSIM ↑ | 0.62 | 0.69 | 0.74 | 0.74 | 0.75 | 0.7 | 0.71 |
| | LPIPS ↓ | 0.7 | 0.51 | 0.55 | 0.54 | 0.63 | 0.58 | 0.59 |
| GlORIE- SLAM [45] | PSNR ↑ | 23.42 | 20.66 | 20.41 | 25.23 | 21.28 | 23.68 | 22.45 |
| | SSIM ↑ | 0.87 | 0.87 | 0.83 | 0.84 | 0.91 | 0.76 | 0.85 |
| | LPIPS ↓ | 0.26 | 0.31 | 0.31 | 0.21 | 0.44 | 0.29 | 0.3 |
| Splat- | PSNR ↑ | 28.68 | 27.69 | 27.7 | 31.14 | 31.15 | 30.49 | 29.48 |
| | SSIM ↑ | 0.83 | 0.87 | 0.86 | 0.87 | 0.84 | 0.84 | 0.85 |
| SLAM [27] | LPIPS ↓ | 0.19 | 0.15 | 0.18 | 0.15 | 0.23 | 0.19 | 0.18 |
| | PSNR ↑ | 24.68 | 20.09 | 25.3 | 27.85 | 25.8 | 26.69 | 25.07 |
| IG-SLAM (Ours) | SSIM ↑ | 0.74 | 0.68 | 0.83 | 0.82 | 0.83 | 0.78 | 0.78 |
| IG-SLAM (Ours) | LPIPS ↓ | 0.29 | 0.39 | 0.22 | 0.19 | 0.27 | 0.27 | 0.27 |
Runtime Analysis We assess real-time performance of our algorithm in Tab. 5. We benchmark the runtime on a 3.6GHz AMD Ryzen Threadripper PRO 5975WX and an NVIDIA GeForce RTX 4090 with 24 GB of memory. Our system operates at 9.94 fps, making it 8 times faster than Splat-SLAM [27] in a single-process implementation. Our method outperforms other algorithms without compromising visual quality. The reference multi-process implementation of our method achieves a frame rate of 16 fps. Our method's peak memory consumption and map size are comparable to existing methods.
## 4.3. Ablations
Post-processing, decay, and weighted depth loss are our system design choices. We present ablation studies to validate and support each of these design decisions.
Post Processing We show post processing ablation results in Tab. 6. PSNR and Depth L1 metrics are recalculated
Table 3. Rendering Performance on TUM-RGBD [30]. Each scene result is the average of 3 runs. We take the numbers from [27] except for ours. Our method demonstrates similar performance to Splat-SLAM [27] in challenging indoor environments showing a clear performance margin to the other methods.
| Method | Metric | f1/desk | f2/xyz | f3/off | Avg. |
|-----------------|-----------------------|------------|------------|------------|-----------------|
| Photo-SLAM [11] | PSNR ↑ | 20.97 0.74 | 21.07 0.73 | 19.59 0.69 | 20.54 0.72 |
| | SSIM ↑ LPIPS ↓ | 0.23 | 0.17 | 0.24 | 0.21 |
| | PSNR ↑ | 19.67 | 16.17 | 20.63 | 18.82 |
| MonoGS [16] | SSIM ↑ LPIPS ↓ | 0.73 0.33 | 0.72 0.31 | 0.77 0.34 | 0.74 0.33 |
| GlORIE- | PSNR ↑ SSIM ↑ | 20.26 0.79 | 25.62 0.72 | 21.21 0.72 | 22.36 0.74 |
| SLAM [45] | LPIPS ↓ | 0.31 | 0.09 | 0.32 | 0.24 |
| Splat- | PSNR ↑ | 25.61 0.84 | 29.53 | | |
| SLAM [27] | SSIM ↑ LPIPS ↓ | 0.18 | 0.90 0.08 | 26.05 0.84 | 27.06 0.86 0.15 |
| | PSNR ↑ SSIM ↑ LPIPS ↓ | 0.80 0.20 | 0.85 0.10 | 0.83 0.17 | 0.83 0.16 |
| IG-SLAM (Ours) | | | | 0.20 25.27 | 25.36 |
| | | 24.45 | 26.35 | | |
Table 4. Rendering Performance on EuRoC [3]. Each scene result is the average of 3 runs. We take the numbers for Photo-SLAM [11] from their work. We successfully show the scalability of our system. Photorealistic 3D reconstruction comparison of large indoor environment EuRoC [3] MH-01 is shown in Fig. 1
| Method | Metric | MH-01 | MH-02 | V1-01 | V2-01 | Avg. |
|----------------|----------|---------|---------|---------|---------|--------|
| Photo-SLAM | PSNR ↑ | 13.95 | 14.2 | 17.07 | 15.68 | 15.23 |
| [11] | SSIM ↑ | 0.42 | 0.43 | 0.62 | 0.62 | 0.52 |
| [11] | LPIPS ↓ | 0.37 | 0.36 | 0.27 | 0.32 | 0.33 |
| IG-SLAM (Ours) | PSNR ↑ | 22.33 | 22.31 | 20.55 | 24.59 | 22.44 |
| IG-SLAM (Ours) | SSIM ↑ | 0.78 | 0.77 | 0.79 | 0.85 | 0.8 |
| IG-SLAM (Ours) | LPIPS ↓ | 0.22 | 0.23 | 0.29 | 0.18 | 0.23 |
.
Table 5. Memory and Running Time Evaluation on Replica [29] room0 . We measure the runtime statistics on the single process implementation of our method. We take the numbers from [27] except for ours. Our peak memory usage and map size are comparable to existing works. Our method achieves to exhibit state-ofthe-art 3D reconstruction in higher frame rates compared to other methods.
| | GO-SLAM [47] | GlORIE-SLAM [45] | MonoGS [16] | Splat-SLAM [27] | Ours |
|-----------------|----------------|--------------------|---------------|-------------------|--------|
| GPU Usage [GiB] | 18.50 | 15.22 | 14.62 | 17.57 | 16.2 |
| Map Size [MB] | - | 114 | 6.8 | 6.5 | 14.8 |
| Avg. FPS | 8.36 | 0.23 | 0.32 | 1.24 | 9.94 |
for every 500 post-processing iterations. Our method exhibits a relatively small visual quality degradation when post-processing is skipped (indicated as 0K in Tab. 6) whereas visual quality significantly drops with no postprocessing for Splat-SLAM [27]. Our system exhibits diminishing returns with increased post-processing iterations. We attribute the fast convergence of our map and the minimal reliance on post-processing to our training strategy.
Table 6. Post-processing iterations ablation on Replica [29] office0 . The numbers for Splat-SLAM [27] are taken from their work. Due to the fast convergence of mapping during tracking, we do not heavily rely on post-processing. The reconstruction benefits only a little from post-processing.
| Nbr of Final Iterations β | Metric | 0K | 0.5K | 1K | 2K |
|-----------------------------|-------------------|------------|------------|------------|------------|
| Splat- | PSNR ↑ | 30.50 | 39.87 | 40.59 | 41.20 |
| SLAM [27] | Depth L1 ↓ | 6.55 | 2.37 | 2.34 | 2.40 |
| Ours | PSNR ↑ Depth L1 ↓ | 38.30 2.63 | 40.92 2.18 | 41.53 2.17 | 41.68 2.30 |
Decay We demonstrate learning rate decay ablation in Tab. 7. We compare 3 learning rates without decay with decaying learning rates. The selected 3 learning rates are lr f ) = 1 6 . × 10 -6 for lower bound, lr i ) = 1 6 . × 10 -4 for upper bound, and the mean learning rate value 5 × 10 -5 calculated according to Eq. (10). We conduct this experiment with and without post-processing. As seen in no postprocessing experiment in Tab. 7, learning with decay greatly enhances the visual quality compared to other non-decaying learning rate setups. Qualitative results are shown in Fig. 5. As observed, the fine details are not captured with nondecaying learning rates. Moreover, a post-processing step completely shadows the convergence problems of constant learning rate as seen in the experiment with post-processing in Tab. 7.
| Metric | Learning Rate | 1 . 6 × 10 - 6 | 5 × 10 - 5 | 1 . 6 × 10 - 4 | 1 . 6 × 10 - 4 w/ decay |
|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------------|
| w/o Post Processing | w/o Post Processing | w/o Post Processing | w/o Post Processing | w/o Post Processing | w/o Post Processing |
| PSNR | ↑ | 31.92 | 35.84 | 34.71 | 38.30 |
| Depth L1 | ↓ | 5.37 | 2.71 | 2.76 | 2.63 |
| w/ Post Processing | w/ Post Processing | w/ Post Processing | w/ Post Processing | w/ Post Processing | w/ Post Processing |
| PSNR | ↑ | 39.71 | 39.91 | 40.85 | 41.68 |
| Depth L1 | ↓ | 2.73 | 2.17 | 2.20 | 2.30 |
Table 7. Learning Rate Hyperparameter Search on Replica [29] office0 . Our system benefits greatly from a slow learning rate combined with decay. In the presence of reliable depth maps, a high learning rate contributes to TV-static noise and slows down map convergence.
Depth Loss The weighted depth loss ablation results are shown in Tab. 8. The weighted depth loss that is given in Eq. (9) is compared to the scenarios with no depth loss in the overall loss function ( α = 1 ) and with raw depth values without weighting them by depth covariance. Postprocessing is disabled to ensure the results are not obscured.
| Metric | Weighted | No Depth | Raw Depth |
|------------|------------|------------|-------------|
| PSNR ↑ | 31.91 | 31.56 | 30.81 |
| Depth L1 ↓ | 6.33 | 13.16 | 6.39 |
Table 8. Weighted Depth Loss Ablation on Replica [29] office2 . Weighted depth loss enables better reconstruction without decreasing visual quality.
The weighted loss is superior to other choices as observed in Tab. 8. A pure color loss performs well in terms of visual quality but deteriorates reconstruction quality. Using raw depth values in the loss function performs worse than the weighted loss regarding visual quality. Therefore, weighting the depth prevents visual quality from decreasing due to high uncertainty regions while keeping the reconstruction quality up by supervising depth. We speculate visual quality differences are not dramatic because our system initializes Gaussians according to depth maps regardless of the loss function. Therefore, initialized Gaussians are already in the vicinity of the corresponding depth value.
Figure 5. Qualitative results for learning rate decay ablation study. The four cases studied in Tab. 7 are shown in the figure. The results are given as constant learning rates of 1 6 . × 10 -4 at top-left , 5 × 10 -5 at top-right , 1 6 . × 10 -6 at bottom-left and the decaying 1 6 . × 10 -4 learning rate at bottom-left as reference.

## 5. Limitations
The dense bundle adjustment is not feasible in full resolution. Therefore, dense depth maps are optimized at a lower resolution and upsampled back to the original resolution. We observe that this upsampling operation results in blurry edges. Therefore, utilizing upsampled dense depth maps to supervise the system results in poor performance at locations where sharp changes in depth occur.
## 6. Conclusion
We showed that the depth supervision from a robust denseSLAM method greatly enhances 3D reconstruction performance. Additionally, utilizing depth uncertainty as a mask for Gaussian initialization and as weights for depth loss aids the mapping process. We also highlighted the nuance between sparse and dense Gaussian initialization and its implications on mapping optimization. Our experiments demonstrated that dense SLAM-based 3D reconstruction can provide both state-of-the-art visual quality and a high frame rate even in relatively large scenes.
## References
- [1] Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF international conference on computer vision , pages 5855-5864, 2021. 2
- [2] Michael Bloesch, Jan Czarnowski, Ronald Clark, Stefan Leutenegger, and Andrew J. Davison. Codeslam - learning a compact, optimisable representation for dense visual SLAM. CoRR , abs/1804.00874, 2018. 2
- [3] Michael Burri, Janosch Nikolic, Pascal Gohl, Thomas Schneider, Joern Rehder, Sammy Omari, Markus W Achtelik, and Roland Siegwart. The euroc micro aerial vehicle datasets. The International Journal of Robotics Research , 35 (10):1157-1163, 2016. 1, 6, 7, 2
- [4] Danpeng Chen, Hai Li, Weicai Ye, Yifan Wang, Weijian Xie, Shangjin Zhai, Nan Wang, Haomin Liu, Hujun Bao, and Guofeng Zhang. Pgsr: Planar-based gaussian splatting for efficient and high-fidelity surface reconstruction. arXiv preprint arXiv:2406.06521 , 2024. 2
- [5] Chi-Ming Chung, Yang-Che Tseng, Ya-Ching Hsu, XiangQian Shi, Yun-Hung Hua, Jia-Fong Yeh, Wen-Chin Chen, Yi-Ting Chen, and Winston H Hsu. Orbeez-slam: A realtime monocular visual slam with orb features and nerfrealized mapping. In 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages 9400-9406. IEEE, 2023. 1, 2
- [6] Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas A. Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. CoRR , abs/1702.04405, 2017. 6, 7, 1
- [7] Ainaz Eftekhar, Alexander Sax, Jitendra Malik, and Amir Zamir. Omnidata: A scalable pipeline for making multitask mid-level vision datasets from 3d scans. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 10786-10796, 2021. 1, 6
- [8] Peter Hedman, Pratul P. Srinivasan, Ben Mildenhall, Jonathan T. Barron, and Paul Debevec. Baking neural radiance fields for real-time view synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages 5875-5884, 2021. 2
- [9] Tao Hu, Shu Liu, Yilun Chen, Tiancheng Shen, and Jiaya Jia. Efficientnerf efficient neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 12902-12911, 2022. 2
- [10] Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically accurate radiance fields. In ACMSIGGRAPH 2024 Conference Papers , pages 1-11, 2024. 2
- [11] Huajian Huang, Longwei Li, Hui Cheng, and Sai-Kit Yeung. Photo-slam: Real-time simultaneous localization and photorealistic mapping for monocular stereo and rgb-d cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 21584-21593, 2024.
- [12] Mohammad Mahdi Johari, Camilla Carta, and Franc ¸ois Fleuret. Eslam: Efficient dense slam system based on hybrid representation of signed distance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 17408-17419, 2023. 1
- [13] Nikhil Keetha, Jay Karhade, Krishna Murthy Jatavallabhula, Gengshan Yang, Sebastian Scherer, Deva Ramanan, and Jonathon Luiten. Splatam: Splat track & map 3d gaussians for dense rgb-d slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 21357-21366, 2024. 3
- [14] Bernhard Kerbl, Georgios Kopanas, Thomas Leimk¨ uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics , 42 (4), 2023. 1, 2, 3, 4, 6
- [15] Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. Neural sparse voxel fields. Advances in Neural Information Processing Systems , 33:15651-15663, 2020. 2
- [16] Hidenobu Matsuki, Riku Murai, Paul HJ Kelly, and Andrew J Davison. Gaussian splatting slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 18039-18048, 2024. 1, 3, 4, 5, 6, 7
- [17] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. CoRR , abs/2003.08934, 2020. 1, 2, 6
- [18] Thomas M¨ uller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. ACM transactions on graphics (TOG) , 41(4):1-15, 2022. 2, 4, 5
- [19] Raul Mur-Artal and Juan D Tard´ os. Orb-slam2: An opensource slam system for monocular, stereo, and rgb-d cameras. IEEE transactions on robotics , 33(5):1255-1262, 2017. 1, 2, 3
- [20] Richard A. Newcombe, Shahram Izadi, Otmar Hilliges, David Molyneaux, David Kim, Andrew J. Davison, Pushmeet Kohi, Jamie Shotton, Steve Hodges, and Andrew Fitzgibbon. Kinectfusion: Real-time dense surface mapping and tracking. In 2011 10th IEEE International Symposium on Mixed and Augmented Reality , pages 127-136, 2011. 2
- [21] Richard A. Newcombe, Steven J. Lovegrove, and Andrew J. Davison. Dtam: Dense tracking and mapping in real-time. In 2011 International Conference on Computer Vision , pages 2320-2327, 2011. 2
- [22] Michael Oechsle, Songyou Peng, and Andreas Geiger. Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 5589-5599, 2021. 2
- [23] Zhexi Peng, Tianjia Shao, Yong Liu, Jingke Zhou, Yin Yang, Jingdong Wang, and Kun Zhou. Rtg-slam: Real-time 3d reconstruction at scale using gaussian splatting. In ACM SIGGRAPH 2024 Conference Papers , pages 1-11, 2024. 3
- [24] Christian Reiser, Songyou Peng, Yiyi Liao, and Andreas Geiger. Kilonerf: Speeding up neural radiance fields with
- thousands of tiny mlps. In Proceedings of the IEEE/CVF international conference on computer vision , pages 1433514345, 2021. 1
- [25] Konstantinos Rematas and Vittorio Ferrari. Neural voxel renderer: Learning an accurate and controllable rendering tool. In CVPR , 2020. 2
- [26] Antoni Rosinol, John Leonard, and Luca Carlone. Nerfslam: Real-time dense monocular slam with neural radiance fields. In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages 3437-3444. IEEE, 2023. 1, 2, 4
- [27] Erik Sandstr¨m, Keisuke Tateno, Michael Oechsle, Michael o Niemeyer, Luc Van Gool, Martin R Oswald, and Federico Tombari. Splat-slam: Globally optimized rgb-only slam with 3d gaussians. arXiv preprint arXiv:2405.16544 , 2024. 2, 3, 5, 6, 7, 8
- [28] Cameron Smith, David Charatan, Ayush Tewari, and Vincent Sitzmann. Flowmap: High-quality camera poses, intrinsics, and depth via gradient descent. arXiv preprint arXiv:2404.15259 , 2024. 2
- [29] Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J. Engel, Raul MurArtal, Carl Yuheng Ren, Shobhit Verma, Anton Clarkson, Mingfei Yan, Brian Budge, Yajie Yan, Xiaqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Batra, Hauke M. Strasdat, Renzo De Nardi, Michael Goesele, Steven Lovegrove, and Richard A. Newcombe. The replica dataset: A digital replica of indoor spaces. CoRR , abs/1906.05797, 2019. 6, 7, 8, 1
- [30] J¨rgen Sturm, u Nikolas Engelhard, Felix Endres, Wolfram Burgard, and Daniel Cremers. A benchmark for the evaluation of rgb-d slam systems. In 2012 IEEE/RSJ international conference on intelligent robots and systems , pages 573-580. IEEE, 2012. 6, 7, 1
- [31] Edgar Sucar, Shikun Liu, Joseph Ortiz, and Andrew J Davison. imap: Implicit mapping and positioning in real-time. In Proceedings of the IEEE/CVF international conference on computer vision , pages 6229-6238, 2021. 1, 2
- [32] Chengzhou Tang and Ping Tan. Ba-net: Dense bundle adjustment network. CoRR , abs/1806.04807, 2018. 2
- [33] Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 2328, 2020, Proceedings, Part II 16 , pages 402-419. Springer, 2020. 2
- [34] Zachary Teed and Jia Deng. DROID-SLAM: deep visual SLAM for monocular, stereo, and RGB-D cameras. CoRR , abs/2108.10869, 2021. 1, 2, 3, 6
- [35] Zachary Teed and Jia Deng. Tangent space backpropagation for 3d transformation groups. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 10338-10347, 2021. 6
- [36] Hengyi Wang, Jingwen Wang, and Lourdes Agapito. Coslam: Joint coordinate and sparse parametric encodings for neural real-time slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 13293-13302, 2023. 1
- [37] Liao Wang, Jiakai Zhang, Xinhang Liu, Fuqiang Zhao, Yanshun Zhang, Yingliang Zhang, Minye Wu, Jingyi Yu, and Lan Xu. Fourier plenoctrees for dynamic radiance field rendering in real-time. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 13524-13534, 2022. 2
- [38] Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. arXiv preprint arXiv:2106.10689 , 2021. 2
- [39] Chi Yan, Delin Qu, Dan Xu, Bin Zhao, Zhigang Wang, Dong Wang, and Xuelong Li. Gs-slam: Dense visual slam with 3d gaussian splatting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 19595-19604, 2024. 1, 3
- [40] Lior Yariv, Jiatao Gu, Yoni Kasten, and Yaron Lipman. Volume rendering of neural implicit surfaces. Advances in Neural Information Processing Systems , 34:4805-4815, 2021. 2
- [41] Lin Yen-Chen, Pete Florence, Jonathan T Barron, Alberto Rodriguez, Phillip Isola, and Tsung-Yi Lin. inerf: Inverting neural radiance fields for pose estimation. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages 1323-1330. IEEE, 2021. 2
- [42] Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa. Plenoctrees for real-time rendering of neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 57525761, 2021. 2
- [43] Vladimir Yugay, Yue Li, Theo Gevers, and Martin R Oswald. Gaussian-slam: Photo-realistic dense slam with gaussian splatting. arXiv preprint arXiv:2312.10070 , 2023. 1, 3, 6
- [44] Baowen Zhang, Chuan Fang, Rakesh Shrestha, Yixun Liang, Xiaoxiao Long, and Ping Tan. Rade-gs: Rasterizing depth in gaussian splatting. arXiv preprint arXiv:2406.01467 , 2024. 2
- [45] Ganlin Zhang, Erik Sandstr¨ om, Youmin Zhang, Manthan Patel, Luc Van Gool, and Martin R Oswald. Glorie-slam: Globally optimized rgb-only implicit encoding point cloud slam. arXiv preprint arXiv:2403.19549 , 2024. 1, 2, 5, 6, 7
- [46] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 586-595, 2018. 6
- [47] Youmin Zhang, Fabio Tosi, Stefano Mattoccia, and Matteo Poggi. Go-slam: Global optimization for consistent 3d instant reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 3727-3737, 2023. 1, 4, 7
- [48] Heng Zhou, Zhetao Guo, Shuhong Liu, Lechen Zhang, Qihao Wang, Yuxiang Ren, and Mingrui Li. Mod-slam: Monocular dense mapping for unbounded 3d scene reconstruction. arXiv preprint arXiv:2402.03762 , 2024. 1, 2
- [49] Zihan Zhu, Songyou Peng, Viktor Larsson, Weiwei Xu, Hujun Bao, Zhaopeng Cui, Martin R Oswald, and Marc Pollefeys. Nice-slam: Neural implicit scalable encoding for slam.
In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 12786-12796, 2022. 1, 2
- [50] Zihan Zhu, Songyou Peng, Viktor Larsson, Zhaopeng Cui, Martin R Oswald, Andreas Geiger, and Marc Pollefeys. Nicer-slam: Neural implicit scene encoding for rgb slam. In 2024 International Conference on 3D Vision (3DV) , pages 42-52. IEEE, 2024. 1, 2
- [51] Matthias Zwicker, Hanspeter Pfister, Jeroen Van Baar, and Markus Gross. Ewa volume splatting. In Proceedings Visualization, 2001. VIS'01. , pages 29-538. IEEE, 2001. 4
## IG-SLAM: Instant Gaussian SLAM
## Supplementary Material
IG-SLAM is a dense SLAM system capable of photorealistic 3D reconstruction, while simultaneously running at high frame rates. In this supplementary material, we provide additional results.
## 7. Method
We describe additional details about our method.
## 7.1. Covariance Mask
Assume the covariance for a depth map is given by Σ , we normalize covariance between [0,1] by Eq. (11)
$$\tilde { \Sigma } ( u, v ) = \frac { \Sigma ( u, v ) - \min \left ( \Sigma ( u, v ) \right ) } { \max \left ( \Sigma ( u, v ) \right ) - \min \left ( \Sigma ( u, v ) \right ) } \quad ( 1 1 ) \quad \text{$9.1$.}$$
where ( u, v ) are the pixel coordinates. A Maximum filter with a kernel size of 32 is applied to normalized covariance. Pixels with normalized covariance less than 0.2 are selected. Additionally, a majority filter with a kernel size of 32 is applied to obtain smooth valid regions in the mask.
## 7.2. Pruning and Densification
Wefollow the same procedure for pruning and identification in MonoGS [16] n. Pruning is based on occlusion-aware visibility: if new Gaussians initialized in the last keyframes are not visible from this keyframe at the end of the optimization, they are removed. Additionally, for every 150 mapping iterations, Gaussians with opacity lower than 0.1 are removed. Densification is performed by splitting large Gaussians and cloning small ones in regions with high loss gradients, also every 150 mapping iterations.
## 8. Additional Results
We provide additional tracking and mapping results.
## 9. Tracking
We do not improve over GO-SLAM [47] in terms of tracking performance, as it is outside the scope of our work. However, we include the tracking results of Replica [29], TUM-RGB-D [30], and ScanNet [6] in Tab. 9, Tab. 10, and Tab. 11 for reference.
| Metric | R-O | R-1 | R-2 | O-0 | O-1 | O-2 | O-3 | O-4 |
|----------|-------|-------|-------|-------|-------|-------|-------|-------|
| ATE(cm) | 0.45 | 0.39 | 0.31 | 0.33 | 0.5 | 0.39 | 0.47 | 0.68 |
Table 9. Tracking Accuracy ATE RMSE [cm] ↓ on Replica [29]. Each scene result is the average of 3 runs.
Table 10. Tracking Accuracy ATE RMSE [cm] ↓ on TUMRGBD [30]. Each scene result is the average of 3 runs.
| Metric | f1/desk | f2/xyz | f3/off |
|----------|-----------|----------|----------|
| ATE(cm) | 2.73 | 0.35 | 2.08 |
Table 11. Tracking Accuracy ATE RMSE [cm] ↓ on ScanNet [6]. Each scene result is the average of 3 runs.
| Metric | 0000 | 0059 | 0106 | 0169 | 0181 | 0207 |
|----------|--------|--------|--------|--------|--------|--------|
| ATE(cm) | 6.16 | 71.46 | 7.38 | 8.46 | 8.6 | 9.55 |
## 9.1. Mapping
The results of each scene of the Replica [29] are given in Tab. 12. Full evaluations on EuRoC [3] Machine Hall and Vicon Room are given in Tab. 13 and Tab. 14. Moreover, additional qualitative results of EuRoC [3] are exhibited in Fig. 6
| Metric | R-0 | R-1 | R-2 | O-0 | O-1 | O-2 | O-3 | O-4 |
|------------|-------|-------|-------|-------|-------|-------|-------|-------|
| PSNR ↑ | 32.33 | 34.64 | 35.29 | 41.68 | 41.3 | 34.68 | 34.92 | 34.8 |
| SSIM ↑ | 0.93 | 0.95 | 0.96 | 0.98 | 0.98 | 0.95 | 0.96 | 0.96 |
| LPIPS ↓ | 0.07 | 0.06 | 0.05 | 0.02 | 0.03 | 0.06 | 0.05 | 0.07 |
| Depth L1 ↓ | 4.79 | 3.04 | 4.15 | 2.23 | 1.94 | 6.4 | 7.67 | 4.45 |
Table 12. Full evaluation on Replica [29]. Each scene result is the average of 3 runs.
Table 13. Full evaluation on EuRoC [3] Machine Hall . Each scene result is the average of 3 runs.
| Metric | MH-01 | MH-02 | MH-03 | MH-04 | MH-05 |
|----------|---------|---------|---------|---------|---------|
| PSNR ↑ | 22.33 | 22.31 | 20.78 | 23.62 | 19.85 |
| SSIM ↑ | 0.78 | 0.77 | 0.71 | 0.82 | 0.7 |
| LPIPS ↓ | 0.22 | 0.23 | 0.28 | 0.19 | 0.35 |
Table 14. Full evaluation on EuRoC [3] Vicon Room Each scene result is the average of 3 runs.
| Metric | V1-01 | V1-02 | V1-03 | V2-01 | V2-02 | V2-03 |
|----------|---------|---------|---------|---------|---------|---------|
| PSNR ↑ | 20.55 | 22.86 | 20.11 | 24.59 | 23.7 | 21.62 |
| SSIM ↑ | 0.79 | 0.84 | 0.74 | 0.85 | 0.83 | 0.74 |
| LPIPS ↓ | 0.29 | 0.26 | 0.42 | 0.18 | 0.23 | 0.41 |
Figure 6. Qualitative results of IG-SLAM on EuRoC [3]. The results in the top row , middle row , and bottom row are from MH-02 , MH-03 V1-01 , respectively.
 | null | [
"F. Aykut Sarikamis",
"A. Aydin Alatan"
] | 2024-08-02T09:07:31+00:00 | 2024-08-07T10:25:08+00:00 | [
"cs.CV",
"cs.RO"
] | IG-SLAM: Instant Gaussian SLAM | 3D Gaussian Splatting has recently shown promising results as an alternative
scene representation in SLAM systems to neural implicit representations.
However, current methods either lack dense depth maps to supervise the mapping
process or detailed training designs that consider the scale of the
environment. To address these drawbacks, we present IG-SLAM, a dense RGB-only
SLAM system that employs robust Dense-SLAM methods for tracking and combines
them with Gaussian Splatting. A 3D map of the environment is constructed using
accurate pose and dense depth provided by tracking. Additionally, we utilize
depth uncertainty in map optimization to improve 3D reconstruction. Our decay
strategy in map optimization enhances convergence and allows the system to run
at 10 fps in a single process. We demonstrate competitive performance with
state-of-the-art RGB-only SLAM systems while achieving faster operation speeds.
We present our experiments on the Replica, TUM-RGBD, ScanNet, and EuRoC
datasets. The system achieves photo-realistic 3D reconstruction in large-scale
sequences, particularly in the EuRoC dataset. |
2408.01127v2 | ## Relax, estimate, and track: a simple battery state-of-charge and state-of-health estimation method
Shida Jiang , Junzhe Shi , Scott Moura a a a a Department of Civil and Environmental Engineering, University of California, Berkeley, Berkeley, 94720, CA, USA
## Abstract
Battery management is a critical component of ubiquitous battery-powered energy systems, in which battery state-of-charge (SOC) and state-of-health (SOH) estimations are of crucial importance. Conventional SOC and SOH estimation methods, especially model-based methods, often lack accurate modeling of the open circuit voltage (OCV), have relatively high computational complexity, and lack theoretical analysis. This study introduces a simple SOC and SOH estimation method that overcomes all these weaknesses. The key idea of the proposed method is to momentarily set the cell's current to zero for a few minutes during the charging, perform SOC and SOH estimation based on the measured data, and continue tracking the cell's SOC afterward. The method is based on rigorous theoretical analysis, requires no hyperparameter fine-tuning, and is hundreds of times faster than conventional model-based methods. The method is validated on six batteries charged at different C rates and temperatures, realizing fast and accurate estimations under various conditions, with a SOH root mean square error (RMSE) of around 3% and a SOC RMSE of around 1.5%.
Keywords: Battery management system, state-of-charge, state-of-health, electric vehicle
## 1. Introduction
Battery management is crucial for the operational efficiency, safety, reliability, and cost-effectiveness of ubiquitous battery-powered energy systems, such as electrified vehicles and smart grids with renewables [1]. Among different goals of battery management systems (BMS), battery state-of-charge (SOC) and state-of-health (SOH) estimation are of crucial importance and
are directly related to accurate and efficient monitoring of the state information of power batteries [2].
Battery SOC describes the actual energy level available at the battery and is defined as the ratio of the present available capacity to the present maximum capacity. On the other hand, battery SOH reflects the aging state of the battery and is defined as the ratio of the present maximum cell capacity (or present cell resistance) to its initial value [3]. Considering that the battery's internal resistance also changes as the battery is charged or discharged, we used the capacity version of the SOH definition in this paper. Namely, an 80% SOH means that the cell's maximum capacity has decreased by 20%. The main difference between the SOC and the SOH is that SOC indicates the instant status of the battery, while SOH indicates the long-term dynamic status of the battery [4].
Many different methods have been proposed for SOC and SOH estimation. In general, these methods can be divided into three categories: direct measurement-based methods, model-based methods, and data-driven methods. Direct measurement-based methods estimate the SOC and SOH through directly measurable features like voltage, current, and resistance. These methods generally have low computational complexity. However, they either have low accuracy (e.g., resistance method) or can be only used offline (e.g., ampere-hour counting method and impedance method) [5]. The only exceptions are the differential voltage method and its variant incremental capacity method, using which many studies got pretty good SOC and SOH estimation results [6, 7, 8]. The 'differential voltage' stands for the derivative of the terminal voltage with respect to the capacity, and the 'incremental capacity' stands for the derivative of capacity with respect to the terminal voltage. These two methods estimate the SOC and SOH by extracting related features from the differential voltage or incremental capacity curves. The limitation of these two methods is that they require precise voltage measurement, and they only work when the current is constant and is lower than a specific value [9].
On the other hand, data-driven methods estimate the battery SOC and SOH by training a black-box model with a large dataset [10]. The input of the data-driven methods is usually health indicators derived from capacity, resistance, voltage, current, and temperature data [11]. The benefits of datadriven methods are that they do not need physical-based models and can have high accuracy [12]. The disadvantages are that they need high computational effort and are sensitive to the quantity and quality of training data [3].
Meanwhile, model-based methods estimate the SOC and SOH by first building a battery model to fit the raw data, and then, they use some model parameters to calculate the SOC and SOH indirectly. The battery model can either be a pure mathematical model or a battery equivalent circuit model (ECM) [4], whose purpose is to model the battery's voltage response to any input current. In model-based methods, SOC is usually estimated based on the state-space function and the SOC-OCV correlation. At the same time, SOH estimation can be done by using another filter or by calculating the derivative of SOC [13, 14, 15]. In general, the accuracy of model-based methods depends on the model's accuracy. With the help of adaptive filter algorithms such as a nonlinear Kalman filter (KF), model-based methods can usually achieve good accuracy compared to other methods [16]. The drawback is that the imperfection of the models often results in bias in the estimation, producing unexpected estimation errors.
However, although hundreds of different methods have been proposed for battery SOC and SOH estimation, we noticed that the existing methods have some common weaknesses. The first weakness is that, although the OCVSOC correlation is widely used in SOC and SOH estimation, such correlation is also affected by temperature [17, 18, 19] and SOH [20, 21]. Yet, such influence (especially the effect of SOH) is constantly ignored in most studies. Such a simplification can be problematic because the OCV-SOC correlation function stored in the BMS will become increasingly inaccurate as the cell ages, making the SOC and SOH estimation results unreliable. Unfortunately, to the best of our knowledge, so far, only a few papers considered the effect of SOH when using the OCV-SOC correlation to estimate the SOC [22, 23, 24, 25]. Worse still, in [22], the authors only showed the correlation between some parameters and SOH, yet no SOH estimation method was proposed or validated; in [23], the primary focus was only SOC and OCV, and the SOH estimation result was not detailed; in [24], although a SOH estimation method was proposed, the method requires to fit the present OCV curve in an extensive SOC range (from 10% to 90%), which is hardly accessible in most applications; and in [25], the proposed method required fine-tuning some hyperparameters and was only validated at 100% and 96% SOH, so its effectiveness still requires further investigation. In summary, while many papers used the OCV-SOC correlation to estimate the SOC and SOH, few have developed an effective way to integrate the effect of battery aging on OCV into their method.
Another weakness of the existing battery SOC and SOH estimation meth-
ods is that little attention has been paid to reducing their computational complexity. In most studies, estimation accuracy is set to be the only metric used to measure how good or bad a method is. However, for state estimation of the battery pack, the computational complexity can also be an essential and practical factor to consider [26]. For example, in a Tesla Model S, there are 96 series-connected battery modules, so the workload and computational cost can be very high if we adopt a complex filter-based method for each module [27]. To solve such a problem, we noticed that some studies proposed to use a simple method first to identify the 'weakest' cell in the battery pack (i.e., the cell that has the lowest voltage or some other apparent characteristics that make it more likely to have the lowest SOC or SOH) and then use another complex method to estimate the state of those weakest cells [27, 28, 29, 30]. While this idea can partially solve the question, the method may not capture the weakest cell correctly, which could make the estimation too optimistic.
Furthermore, most SOC and SOH estimation methods so far only use experimental data for validation and do limited theoretical analysis. While empirical data may be enough to verify the method's effectiveness in one specific setting, such effectiveness can no longer be guaranteed once any setting (e.g., the sampling frequency of the voltmeter, the parameters of the ECM) changes. In the worst case, the algorithm may not even converge when the initial value is not accurate enough or when the measurement is not precise enough [10]. For example, the differential voltage method often uses a filter to reduce voltage measurement noise. However, in most papers that use this method so far, the noise filtering algorithm is only proposed empirically [6, 7, 8], so it may not work well when the precision of the voltmeter is lower. For another example, the extended Kalman filter (EKF) and unscented Kalman filter (UKF) are often used for SOC and SOH estimation. However, since no theoretical analysis is done to guarantee their convergence in SOH estimation [31], it is unclear whether the method can always yield satisfactory results as the battery ages.
In this paper, we proposed a novel model-based SOC and SOH estimation method that addresses all three weaknesses described above. The main contributions of this paper are:
- · We proposed a SOC and SOH estimation method that can be easily implemented without any sophisticated device. Additionally, the estimation accuracy of the proposed method is pretty high, with a SOH
root mean square error (RMSE) of around 3% and a SOC RMSE of around 1.5%.
- · To implement the method, the battery pack only needs to relax for one to four minutes during the charging process, which will not cause a significant delay. Besides, the computational complexity of our method is extremely low, making it suitable for online applications such as electric vehicles.
- · The proposed method has no hyperparameter and does not require initialization. The noise tolerance and the convergence of the method are guaranteed by detailed theoretical analysis.
The paper is organized as follows. Section 2 introduces the definition of OCV, SOC, and SOH used in the paper. Section 3 presents the details of our SOC and SOH estimation method. Section 4 provides the theoretical basis of our method. Section 5 presents the experimental results and compares our method against UKF. A detailed analysis of the estimation error is also given in Section 5. Finally, in Section 6, we discuss the conclusion drawn from the study.
## 2. SOC, SOH, and OCV
2.1. Definition of SOC and SOH
The battery SOC is defined as:
$$S O C = \frac { Q _ { r } } { Q }$$
where Q is the present maximum capacity of the battery, and Q r is the remaining capacity of the battery.
The derivative form of (1), which is often used for SOC estimation, is:
$$\frac { d S O C } { d t } = \frac { I } { Q }$$
On the other hand, the battery SOH is defined as:
$$S O H = \frac { Q } { Q _ { 0 } } \times 1 0 0 \%$$
where Q 0 is the maximum capacity of a new cell.
It is worth mentioning that a cell's capacity varies at different C rates. For the rigor of the definition, all the 'capacity' above refers to the charge capacity (calculated by Coulomb counting) when the C rate is 0.1 C.
## 2.2. OCV model
In this study, the OCV curves were fitted by a ninth-order polynomial function due to its simplicity and low RMS error [32].
$$O C V = f ( S O C, S O H, T ) = \sum _ { i = 0 } ^ { 9 } a _ { i } ( S O H, T ) S O C ^ { i }$$
where a , i i = 0 1 , , ..., 9 are coefficients related to SOH and temperature (denoted by T in the equation). These coefficients can be determined by fitting the OCV curve of the battery.
There are generally two ways to acquire the OCV curve in experiments. The first is the slow-current OCV test, and the second is the incremental OCV test. In a slow-current OCV test, the cell is fully discharged and then fully charged at a constant current that is lower or equal to 0.1 C. On the other hand, in an incremental capacity test, the cell is usually charged and discharged with a higher C rate (e.g., 0.5 C). Whenever the SOC rises or drops by a certain percentage (e.g., 10%), the cell is open-circuited for some time (e.g., two hours) [33]. Compared with the low-current OCV test, the incremental capacity test can describe the battery behavior better [33] and make model-based SOC estimation more accurate [34]. As a result, in this study, incremental OCV tests are used to acquire the OCV-SOC curve. The OCV curve acquired from fitting the experimental data at 25 C is presented ◦ in Figure 1.
Note that the OCV curve in Figure 1 is only used in the theoretical analysis in Section 4.2 and never used in the experimental validation in Section 5. In the experimental validation, when the estimation is validated on a particular cell, that cell's OCV data will be excluded when fitting the OCV curve. The purpose is to separate the data used for fitting the OCV curve and the data used for experimental validation.
Figure 1: The fitted OCV curve at 25 C ◦
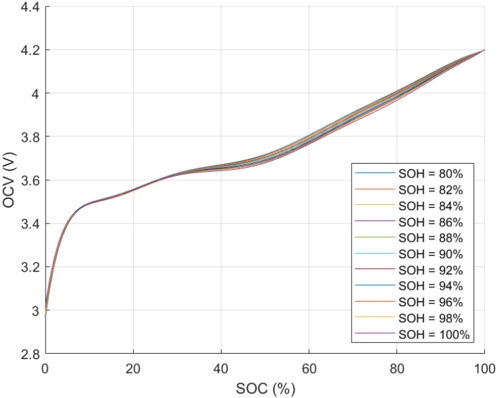
## 3. Methodology
## 3.1. ECM model and parameter estimation
Since the SOH changes much more slowly than SOC, it can be considered constant during a single cycle. With this simplification and the definition of SOH in (3), when the temperature is constant, (2) can be rewritten as follows:
$$S O H = \frac { I } { Q _ { 0 } } \frac { d t } { d S O C } = \frac { I } { Q _ { 0 } } \frac { \partial O C V } { \partial S O C } \frac { d t } { d O C V }$$
(4) and (5) are two independent equations about SOC and SOH. With these two equations, we can solve the value of SOC and SOH once we know the values of OCV and dOCV/dt . However, OCV is not directly measurable unless the battery is idle for hours, so an ECM is required to estimate this parameter. The ECM used in this paper is presented in Figure 2. Despite the OCV, it consists of a resistor and an RC pair (a resistor and a capacitor connected in parallel).
If we select SOC and capacitor voltage ( U c ) as the states, current ( I ) as the input, and terminal voltage ( U ter ) as the output, the state-space function of the model can be written as
$$\begin{bmatrix} S \dot { O } C \\ \dot { U } _ { c } \end{bmatrix} = \begin{bmatrix} 0 & 0 \\ 0 & \frac { - 1 } { R _ { 2 } C } \end{bmatrix} \begin{bmatrix} S O C \\ U _ { c } \end{bmatrix} + \begin{bmatrix} \frac { 1 } { Q } \\ \frac { 1 } { C } \end{bmatrix} I$$
Figure 2: Battery equivalent circuit model
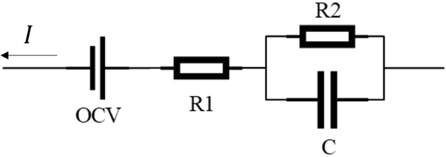
$$U _ { t e r } = O C V ( S O C, S O H, T ) + U _ { c } + R _ { 1 } I$$
where R 1 , R 2 , and C are the ECM parameters shown in Figure 2.
Suppose that at time t 0 , the current suddenly drops to zero, then the output function becomes
$$U _ { t e r } ( t _ { 0 } + \Delta t ) = O C V ( S O C, S O H, T ) + U _ { c } ( t _ { 0 } ) e ^ { - \frac { \Delta t } { R ^ { c } } }, \Delta t > 0 \quad \ ( 8 )$$
If the current before t 0 was constant (denoted as I 0 ) and the capacitor had already reached steady-state, then
$$U _ { c } ( t _ { 0 } ) = I _ { 0 } R _ { 2 }$$
As for the parameter R 1 , its value can be estimated by using the equation below
$$R _ { 1 } = - \Delta U / I _ { 0 }$$
where ∆ U is the sudden change in voltage after the current becomes zero.
Given (8), (9), and (10), all the parameters in the ECM can be estimated based on the measurement data. Namely, R 1 can be directly calculated by (10), and the other three parameters can be estimated using algorithms like regression analysis or parameter observer. However, these algorithms are quite complex (if we want them to be robust to noise) and unsuitable for cell-level or module-level estimation in a large battery pack with thousands of cells and around a hundred modules. Consequently, a more straightforward parameter estimation method is used in this paper to estimate the other three ECM parameters, which is to determine the three parameters by using three data points. Namely, given three pairs of time and terminal voltage data ( x , y 1 1 ), ( x , y 2 2 ), and ( x , y 3 3 ), the parameters can be determined by solving
the following function set
$$\begin{cases} y _ { 1 } = O C V + I _ { 0 } R _ { 2 } e ^ { - \frac { x _ { 1 } } { R _ { 2 } C } } \\ y _ { 2 } = O C V + I _ { 0 } R _ { 2 } e ^ { - \frac { x _ { 2 } } { R _ { 2 } C } } \\ y _ { 3 } = O C V + I _ { 0 } R _ { 2 } e ^ { - \frac { x _ { 3 } } { R _ { 2 } C } } \end{cases}$$
where x , x 1 2 , x 3 are counted after the relaxation starts.
To improve the noise tolerance of the method, the selection of the three points must be optimized. Otherwise, a small noise in the measurement can make the parameter inaccurate. For this purpose, the general rule of thumb is to select a small x 1 , a big x 3 , and select x 2 = x 1 + x 3 2 . The theoretical analysis behind this rule is illustrated in Section 4.1. Following this rule, if we denote x 3 -x 2 = x 2 -x 1 = x d , then (11) can be rewritten as:
$$\begin{cases} R _ { 2 } = \frac { ( y _ { 1 } - y _ { 2 } ) e ^ { x _ { d } / \tau } } { I _ { 0 } ( e ^ { x _ { d } / \tau } - 1 ) } \\ C = \frac { \tau } { R _ { 2 } } & \quad & \quad & ( 1 2 ) \\ O C V = y _ { 1 } - \frac { ( y _ { 1 } - y _ { 2 } ) e ^ { x _ { d } / \tau } } { e ^ { x _ { d } / \tau } - 1 } \end{cases} \\.. \quad \dots \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad -...$$
where τ = x d ln y 1 -y 2 y 2 -y 3 , and its physical meaning is the time constant of the RC pair.
Based on (12), the values of the three parameters can be directly calculated once the three data points are acquired. However, even if the three points have been optimized, estimating three parameters using three data points is still inevitably vulnerable to measurement noise. Therefore, to further improve the noise tolerance, it is necessary to filter out the noise before doing parameter estimation. The algorithm we chose here is a 15-point median filter, which replaces the voltage of each of the three points with the median value of the fifteen points adjacent to it (including itself). We chose this algorithm instead of other common filtering algorithms like averaging for two reasons. First, this algorithm is straightforward and only adds a little extra computational complexity. Secondly, we can theoretically prove that this filtering algorithm can always reduce the variance of the noise. In contrast, other algorithms only work when the variance of the noise is in a specific range. Namely, we have the following theorem.
Theorem 1. If x 1 > x 2 , yet the estimation of x 1 (denoted as ˆ x 1 ), is smaller than the estimation of x 2 (denoted as ˆ x 2 ), then swapping the two estimations can make the overall RMS error lower.
Proof. After swapping, the change in mean square error is
$$& 0. 5 [ ( x _ { 1 } - \hat { x } _ { 2 } ) ^ { 2 } + ( x _ { 2 } - \hat { x } _ { 1 } ) ^ { 2 } ] - 0. 5 [ ( x _ { 1 } - \hat { x } _ { 1 } ) ^ { 2 } + ( x _ { 2 } - \hat { x } _ { 2 } ) ^ { 2 } ] \\ = & 0. 5 ( - 2 \hat { x } _ { 2 } x _ { 1 } - 2 \hat { x } _ { 1 } x _ { 2 } + 2 \hat { x } _ { 1 } x _ { 1 } + 2 \hat { x } _ { 2 } x _ { 2 } ) \\ = & ( \hat { x } _ { 1 } - \hat { x } _ { 2 } ) ( x _ { 1 } - x _ { 2 } ) < 0$$
Meaning that the RMS error becomes smaller after the swapping.
Remark. Theorem 1 means that swapping two measurements that are not in order can reduce measurement noise. In other words, the noise can be minimized by placing all measurements in order.
## 3.2. SOC and SOH estimation
Once the OCV during the relaxation is identified, the only missing piece in SOC and SOH estimation is estimating dOCV dt . When the current is constant and when the capacitor in the ECM reaches a steady state, the terminal voltage can be calculated by:
$$U _ { t e r } = O C V + I ( R _ { 1 } + R _ { 2 } )$$
As a result, for the derivative of terminal voltage dU ter dt , we have:
$$\frac { d U _ { t e r } } { d t } = \frac { d O C V } { d t } + I \frac { d S O C } { d t } ( \frac { d R _ { 1 } } { d S O C } + \frac { d R _ { 2 } } { d S O C } )$$
Both dOCV dt and dSOC dt are proportional to I . Therefore, when the current is small, we can neglect the final part in (14) since it is proportional to I 2 , and (14) becomes:
$$\dots \quad \frac { d U _ { t e r } } { d t } \approx \frac { d O C V } { d t }$$
(15) points out that dU ter dt , which can be easily calculated through linear regression, can be used to approximate dOCV dt when the current is low. One thing to note is that dU ter dt is related to SOC. So, to ensure the SOC is the same as the SOC in parameter estimation, the voltage data right before the relaxation is used to do the regression analysis and determine dU ter dt and OCV dt .
Besides constant-current(CC) charging, our algorithm can also be implemented during constant-voltage (CV) charging. In this case, noticing that dU ter dt = 0, the derivative of (13) is
$$\frac { d O C V } { d t } + \frac { d I } { d t } ( R _ { 1 } + R _ { 2 } ) + I \frac { d S O C } { d t } ( \frac { d R _ { 1 } } { d S O C } + \frac { d R _ { 2 } } { d S O C } ) = 0 \quad \ ( 1 6 )$$
Since the current during the CV charging is usually small, we can neglect the final part in (16) since it is proportional to I 2 , and (16) becomes:
$$\frac { d O C V } { d t } + \frac { d I } { d t } ( R _ { 1 } + R _ { 2 } ) \approx 0$$
Since R 1 and R 2 can be estimated by using (10) and (12), the value of dOCV dt during the constant-voltage charge can be easily estimated by using (17).
Once dt dOCV and OCV are estimated, the SOC and SOH can be calculated by using (4) and (5). Namely, as shown in (18), the SOH is initially set to 100%, and (4) is used to solve the value of SOC. Next, the value of SOC is substituted into (5) to update the SOH. Afterward, the two processes described above are repeated until both estimations converge.
$$\begin{cases} S O H _ { 0 } = 1 \\ S O C _ { k } = f ^ { - 1 } ( O C V, S O H _ { k }, T ) \\ S O H _ { k + 1 } = \frac { I } { Q _ { 0 } } \frac { \partial O C V } { \partial S O C } \frac { d t } { d O C V } \end{cases}$$
A flow chart of the entire SOC and SOH estimation scheme is presented in Figure 3(a). Note that the SOC in the output is the cell's SOC in the first relaxation. Since SOC changes fast, another algorithm (such as coulomb counting) is usually needed to keep tracking the SOC afterward, and an example of such an algorithm will be detailed in Section 3.3. Generally, the proposed method only requires simple matrix operations and has no hyperparameter. The only special requirement for the charging profile is an extra two-minute relaxation during CC (or CV) charging.
However, when the current is high (above 0.5 C), the approximation in (15) would be no longer accurate since I d R ( 1 + R 2 ) dt will not be negligible. To address this problem, we proposed another variant of the SOC and SOH estimation method, which performs the parameter estimation a second time after the cell charges for a short while. While this will double the total relaxation time and calculation complexity, it can bring two benefits. First and foremost, by comparing the results from the first and second parameter estimation, we can know how much ( R 1+ R 2) has changed during that short period and calculate d R ( 1+ R 2) /dt , which can help us better estimate dOCV . The second benefit is that the estimation result can be more accurate if the estimation is done twice and averaged. A flow chart of the entire SOC and SOH estimation scheme with this extra dR compensation is presented in Figure 3(b).
Figure 3: A flow chart of the proposed SOC and SOH estimation method: (a) without dR compensation (b) with dR compensation
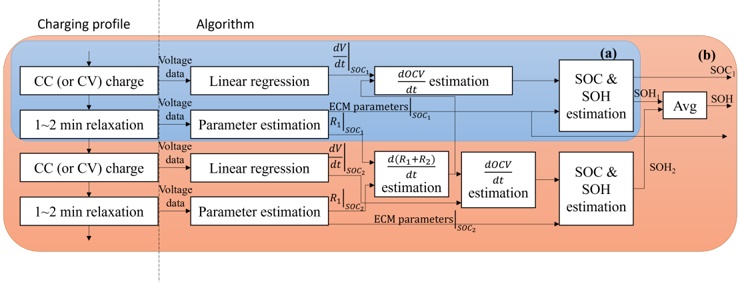
## 3.3. SOC tracking method
The method shown in Figure 3 outputs the SOC and SOH during the first relaxation period. The method can be repeated after several cycles to keep track of the SOH. As for the SOC, however, it changes very quickly during operation. As a result, it is necessary to propose a method to keep tracking the SOC after the SOC and SOH of the cell during the relaxation are estimated. Note that the current is the same for all the cells connected in series in a battery pack. Therefore, according to (2), the SOC of different cells has the following correlation:
$$\Delta S O C _ { j } = \Delta S O C _ { i } \times \frac { S O H _ { i } } { S O H _ { j } }$$
where ∆ SOC i is the change of SOC of Cell i after the SOC and SOH estimation is done. According to (19), the SOC of each cell in the string can be calculated once the SOC of any single cell is estimated. Since the SOC tracking method here does not need to be repeated for every cell, it can be more complex, like a filter-based SOC estimation method.
In algorithm 1, an example of using an EKF for SOC tracking is provided. The method selects SOC and the capacitor voltage of Cell i (the reference cell) as the states of the system. Note that all the inputs of the algorithms come from the measurement data and the output of the SOC and SOH estimation algorithm presented in Figure 3.
It is worth noting that, in algorithm 1, all the parameters in the ECM are considered to be constants, which is actually not true in reality. Nevertheless,
Algorithm 1 SOC tracking algorithm based on extended Kalman filter
Inputs : SOC 0 , SOH , R 1 , R 2 , C, I k , U ter,k , T emp k , t k k = 0
while the BMS is on do
$$\begin{array} { l } \text{Inputs: $SOC_{0}, SOH, R_{1}, R_{2}, C, I_{k}, U_{ter,k}, 1^{\text{emp}_{k}, t_{k}$} \\ k = 0 \\ \text{while the BMS is on do} \\ k = k + 1 \\ \Delta t = t_{k} - t_{k-1} \\ \left [ S O C _ { k } ( i ) \right ] = \left [ 1 \right ] \left [ 0 \right ] \left [ S O C _ { k - 1 } ( i ) \right ] + \left [ \begin{array} { l } \frac { \Delta t } { Q o S O H _ { i } } \\ \frac { \Delta t } { Q o S O H _ { i } } \\ \end{array} \right ] + \left [ R _ { 2 } ( 1 - e ^ { - \Delta t / ( R _ { 2 } C ) } ) \right ] I _ { k } \\ P _ { k } = \left [ 1 \right ] \left [ 0 \right ] \left [ 2 - 2 \Delta t / ( R _ { 2 } C ) \end{array} \right ] P _ { k - 1 } + Q _ { k } \\ y _ { k } = U _ { \text{ter,k} } - O C V ( S O C _ { k } ( i ), S O H _ { i }, T e m p _ { k } ) - U _ { c, k } - R _ { 1 } I _ { k } \\ H _ { k } = \left [ \frac { \partial O C V } { \partial S O C } \left [ S O C = S O C _ { k } ( i ), T e m p = T e m p _ { k } \right ] \right ] \\ S _ { k } = H _ { k } P _ { k } H _ { k } ^ { T } + R _ { k } \\ K _ { k } = P _ { k } H _ { k } ^ { T } S _ { k } ^ { - 1 } \\ \left [ S O C _ { k } ( i ) \right ] = \left [ S O C _ { k } ( i ) \right ] + K _ { k } y _ { k } \\ P _ { k } = ( I - K _ { k } H _ { k } ) P _ { k } \\ \text{for} \, j = 1 \, \text{to} \, N \, \text{do} \\ S O C _ { k } ( j ) = S O C _ { 0 } ( j ) + ( S O C _ { i, k } - S O C _ { 0 } ( i ) ) \times S O H _ { j } \\ \end{array} \right ] + \left [ R _ { 2 } ( 1 - e ^ { - \Delta t / ( R _ { 2 } C ) } ) \right ] I _ { k } \right ] \left [ S O C _ { k } ( i ) \right ] + K _ { k } y _ { k } \\ \end{array}$$
Output
SOC
k
## end while
where N is the total number of cells in the battery pack. i can be chosen arbitrarily. The algorithm inputs include the measured temperature, voltage, current, estimated SOC (during the relaxation), and estimated SOH of each cell. For Cell i (the reference cell), its estimated ECM parameters are also required as the inputs. The output is the SOC of each cell in the battery pack. R k and Q k are, respectively, the process noise covariance matrix and the measurement covariance matrix, and they can be determined based on the method presented in [35].
the algorithm can still yield a satisfactory result if the possible parameter changes are considered part of the measurement and process noise. Additionally, it is easy to prove that when the sampling frequency is high enough (in which case the linearization of the output function in each step can be considered perfect), all the states in the model are observable, and the convergence is therefore guaranteed. By contrast, suppose that a model parameter (such as the internal resistance) is instead considered to be a time-varying third state. In that case, the system's observability would depend on the input, and there may be no guarantee for convergence even if the sampling frequency is high enough. Therefore, only two states are included in the EKF.
## 4. Theoretical analysis
## 4.1. Sensitivity analysis
In section 3.1, when the three measurements y , y 1 2 , y 3 are noisy, the estimation of the three ECM parameters R , C, OCV 2 can also be inaccurate. When such noise is small, the correlation between the error of measurement and the error of parameter estimation can be found by taking the derivative of the (11), which is
$$\begin{bmatrix} \frac { d R _ { 2 } } { R _ { 2 } } \\ \frac { d C } { d C V } \\ \frac { d O C V } { O C V } \end{bmatrix} = \begin{bmatrix} \frac { z _ { 3 } c ^ { b z _ { 3 } } - z _ { 2 } c ^ { b z _ { 2 } } } { a ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) } & \frac { x _ { 1 } c ^ { b z _ { 1 } } - x _ { 3 } c ^ { b z _ { 3 } } } { a ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) } & \frac { x _ { 2 } c ^ { b z _ { 2 } } - x _ { 1 } c ^ { b z _ { 1 } } } { a ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) } \\ \frac { ( b z _ { 2 } - 1 ) c ^ { b z _ { 2 } } - ( b z _ { 3 } - 1 ) c ^ { b z _ { 3 } } } { a b ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) } & \frac { ( b z _ { 3 } - 1 ) c ^ { b z _ { 3 } } - ( b z _ { 1 } - 1 ) c ^ { b z _ { 1 } } } { a b ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) } & \frac { ( b z _ { 1 } - 1 ) c ^ { b z _ { 1 } } - ( b z _ { 2 } - 1 ) c ^ { b z _ { 2 } } } { a b ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) } \\ \frac { a ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) } { O C V } & \frac { 1 } { A _ { 1 } + A _ { 2 } - A _ { 3 } } & \frac { 1 } { O C V } & \frac { A _ { 1 } } { A _ { 1 } + A _ { 2 } - A _ { 3 } } \end{bmatrix} \begin{bmatrix} d y _ { 1 } \\ d y _ { 2 } \\ d y _ { 3 } \end{bmatrix} \\. \quad - \quad. \quad 1 \quad. \quad, \quad \frac { x _ { 3 } - x _ { 2 } } { 2 } \quad. \quad, \quad \frac { x _ { 1 } - x _ { 2 } } { 2 } \end{bmatrix}$$
where a = R I 2 0 , b = -1 R C 2 < 0, A 1 = ( x 2 -x 1 ) e x 3 -x 2 R C 2 , A 2 = ( x 3 -x 2 ) e x 1 -x 2 R C 2 , and A 3 = x 3 -x 1 .
Since the three measurements are done using the same voltmeter, we can assume that the variance of the three measurements are the same and are all equal to σ 2 y . In this case, the covariance of the estimation of the three parameters are
$$\sigma _ { R _ { 2 } } ^ { 2 } = \frac { ( x _ { 3 } e ^ { b x _ { 3 } } - x _ { 2 } e ^ { b x _ { 2 } } ) ^ { 2 } + ( x _ { 1 } e ^ { b x _ { 1 } } - x _ { 3 } e ^ { b x _ { 3 } } ) ^ { 2 } + ( x _ { 2 } e ^ { b x _ { 2 } } - x _ { 1 } e ^ { b x _ { 1 } } ) ^ { 2 } } { a ^ { 2 } ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) ^ { 2 } } R _ { 2 } ^ { 2 } \sigma _ { y } ^ { 2 } \ ( 2 1 )$$
$$\sigma _ { C } ^ { 2 } = \frac { ( b _ { 2 } e ^ { b x _ { 2 } } - b _ { 3 } e ^ { b x _ { 3 } } ) ^ { 2 } + ( b _ { 3 } e ^ { b x _ { 3 } } - b _ { 1 } e ^ { b x _ { 1 } } ) ^ { 2 } + ( b _ { 1 } e ^ { b x _ { 1 } } - b _ { 2 } e ^ { b x _ { 2 } } ) ^ { 2 } } { a ^ { 2 } b ^ { 2 } ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) ^ { 2 } } C ^ { 2 } \sigma _ { y } ^ { 2 } \quad ( 2 2 )$$
$$\sigma _ { O C V } ^ { 2 } = \frac { A _ { 1 } ^ { 2 } + A _ { 2 } ^ { 2 } + A _ { 3 } ^ { 2 } } { ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) ^ { 2 } } \sigma _ { y } ^ { 2 } \, ^ { \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \, } ^ { \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cd. }$$
where b i = bx i -1 , i = 1 2 3. , ,
Since the final purpose of parameter estimation is to estimate the SOC and SOH, and only OCV is directly related to the SOC and SOH, it is only necessary to minimize the covariance of OCV estimation. In other words, if we define f ( x , x 1 2 , x 3 ) = σ 2 OCV /σ 2 y , the objective function of the optimization problem can be formulated as min x ,x 1 2 ,x 3 f . The following theorems are introduced to solve this optimization problem.
Theorem 2. When x 3 -x 1 → 0 , f →∞ ; when x 3 -x 2 →∞ , f → 1 ; when x 2 -x 1 →∞ , f → 1+ e 2( x 3 -x 2 ) R C 2 ( e x 3 -x 2 R C 2 -1) 2 .
Proof. When x 3 -x 1 → 0, both x 2 -x 1 and x 3 -x 2 also → 0. So,
$$A _ { 1 } + A _ { 2 } - A _ { 3 } = o ( x _ { d } )$$
where x d = max( x 2 -x , x 1 3 -x 2 ). While
$$A _ { 1 } ^ { 2 } + A _ { 2 } ^ { 2 } + A _ { 3 } ^ { 2 } = O ( x _ { d } ^ { 2 } )$$
So,
$$f = \frac { A _ { 1 } ^ { 2 } + A _ { 2 } ^ { 2 } + A _ { 3 } ^ { 2 } } { ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) ^ { 2 } } = \frac { O ( x _ { d } ^ { 2 } ) } { o ( x _ { d } ^ { 2 } ) } \to \infty \quad \ \ ( 2 6 )$$
On the other hand, when x 3 -x 2 →∞ , A 1 ≫ A 3 ≫ A 2 , so
$$f = \frac { A _ { 1 } ^ { 2 } + A _ { 2 } ^ { 2 } + A _ { 3 } ^ { 2 } } { ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) ^ { 2 } } \approx \frac { A _ { 1 } ^ { 2 } } { A _ { 1 } ^ { 2 } } = 1$$
Meanwhile, when x 2 -x 1 →∞ , A 1 = e x 3 -x 2 R C 2 A >> A 3 2 , so
$$f = \frac { A _ { 1 } ^ { 2 } + A _ { 2 } ^ { 2 } + A _ { 3 } ^ { 2 } } { ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) ^ { 2 } } \approx \frac { 1 + e ^ { \frac { 2 ( x _ { 3 } - x _ { 2 } ) } { R _ { 2 } C } } } { ( e ^ { \frac { x _ { 3 } - x _ { 2 } } { R _ { 2 } C } } - 1 ) ^ { 2 } }$$
Theorem 2 suggests that increasing the time interval between the second and third points can improve the algorithm's noise tolerance. However, when the time interval is larger, the required relaxation time for the cell will be longer, which would cause more delay in the charging process. As a result, it is necessary to optimize the position of x 2 when the total time interval is constrained. To address this issue, we have the following theorem.
Theorem 3. When x 1 and x 3 are fixed, and x 3 -x 1 ≪ R C 2 , the minimum of σ 2 OCV /σ 2 y is obtained when x 2 = x 1 + x 3 2 .
Proof. When x 3 -x 1 ≪ R C 2 , x 3 -x 2 and x 2 -x 1 are also ≪ R C 2 , so
$$\frac { \partial A _ { 1 } } { \partial x _ { 2 } } = 1 - 2 k x _ { 2 } + k x _ { 1 } + k x _ { 3 } + o ( x _ { 3 } - x _ { 1 } )$$
$$\frac { \partial \bar { A _ { 2 } } } { \partial x _ { 2 } } = - 1 + 2 k x _ { 2 } - k x _ { 1 } - k x _ { 3 } + o ( x _ { 3 } - x _ { 1 } )$$
$$\frac { \partial \bar { A _ { 3 } } } { \partial x _ { 2 } } = 0$$
As a result, ∂A 1 ∂x 2 + ∂A 2 ∂x 2 = ( o x 3 -x 1 ). When f is minimized, ∂f ∂x 2 = 0, so
$$( 2 A _ { 1 } \frac { \partial A _ { 1 } } { \partial x _ { 2 } } + 2 A _ { 2 } \frac { \partial A _ { 1 } } { \partial x _ { 2 } } ) ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) - 2 ( A _ { 1 } ^ { 2 } + A _ { 2 } ^ { 2 } + A _ { 3 } ^ { 2 } ) ( \frac { \partial A _ { 1 } } { \partial x _ { 2 } } + \frac { \partial A _ { 2 } } { \partial x _ { 2 } } ) = 0 \ ( 3 2 )$$
Substituting (29) and (30) into (32), we have:
$$\frac { \partial A _ { 1 } } { \partial x _ { 2 } } ( A _ { 1 } - A _ { 2 } ) ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) = o ( ( x _ { 3 } - x _ { 1 } ) ^ { 3 } )$$
̸
If 2 x 2 x 1 + x 3 = 1, then ∂A 1 ∂x 2 = O (1), A 1 -A 2 = O x ( 3 -x 1 ), A 1 + A 2 -A 3 = O x ( 3 -x 1 ), and (33) cannot be satisfied. As a result, when ∂f ∂x 2 = 0, 2 x 2 x 1 + x 3 = 1 must be satisfied. Noticing that this is the only point where ∂f ∂x 2 = 0, f must either reach maximum or minimum. Since when x 2 = x 1 or when x 2 = x 3 , f = + ∞ , we can conclude that f is minimized at x 2 = x 1 + x 3 2 when x 3 -x 1 is small.
While theorem 3 suggests that the optimal selection of x 2 is x 1 + x 3 2 , such a conclusion is based on the assumption that x 3 is small. To study if choosing x 2 = x 1 + x 3 2 is still reasonable when x 3 is large, in Figure 4, a comparison of the noise amplification rate is made between the two x 2 selection schemes. The first scheme is to optimize x 2 so that the noise amplification rate is the lowest, while the second scheme is to select x 2 as x 1 + x 3 2 . It can be seen that the two curves always have little difference, meaning that selecting x 2 as x 1 + x 3 2 can always give a good result.
In fact, selecting x 2 = x 1 + x 3 2 also has another benefit: the function set (11) can have a closed-form solution and can be directly calculated by using
Figure 4: The noise amplification rate at different x 3 (when x 1 = 0), τ = R C 2
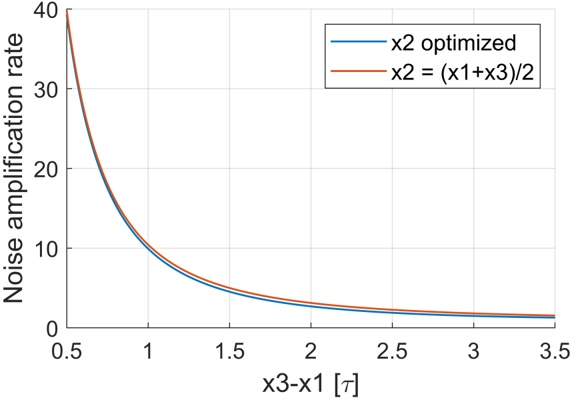
(12). Meanwhile, if x 2 is chosen arbitrarily, the parameter needs to be calculated using algorithms like gradient descent, which damages the algorithm's simplicity. Considering all the above, x 2 is selected as x 1 + x 3 2 in this paper.
Finally, it is necessary to study how f changes as x 1 and x 3 change. Regarding this, we provide the following theorem.
Theorem 4. When x 2 = x 1 + x 3 2 , a larger x 3 or a smaller x 1 can make f smaller.
Proof. If we define x d = x 3 -x 2 = x 2 -x 1 , f would only be related to x d , and the theorem we are trying to prove becomes equivalent to df dx d < 0. And we have
$$A _ { 1 } = x _ { d } e ^ { \frac { x _ { d } } { R _ { 2 } C } }, A _ { 2 } = x _ { d } e ^ { - \frac { x _ { d } } { R _ { 2 } C } }, A _ { 3 } = 2 x _ { d }$$
Therefore, if we define m = e x d R C 2 > 1, we have
$$n - e \mu, \, \text{we move} \\ f & = \frac { A _ { 1 } ^ { 2 } + A _ { 2 } ^ { 2 } + A _ { 3 } ^ { 2 } } { ( A _ { 1 } + A _ { 2 } - A _ { 3 } ) ^ { 2 } } \\ & = \frac { m ^ { 2 } + m ^ { - 2 } + 4 } { ( m + m ^ { - 1 } - 2 ) ^ { 2 } } \\ & = \frac { m ^ { 4 } + 4 m ^ { 2 } + 1 } { ( m - 1 ) ^ { 4 } }$$
Consequently,
$$\frac { d f } { d m } = \frac { - 8 m ^ { 3 } - 1 6 m - 4 } { ( m - 1 ) ^ { 5 } } < 0$$
Since dm dx d > 0, it can be concluded that df dx d < 0, which means that a larger x 3 or a smaller x 1 can make f smaller.
## 4.2. Convergence analysis
In (18), an iterative method was proposed for SOC and SOH estimation. While the method can theoretically be applied at any time during the charging process, the estimation accuracy varies due to several factors. One of the most important ones is the convergence of the method. Since the OCV curve is a nonlinear function of SOC and SOH (for a constant temperature), the iterative process can converge more quickly in a specific SOC range. Therefore, to improve the estimation accuracy, it is necessary to analyze the convergence of the method and pick the best time to use it.
Suppose that the true SOC and SOH are respectively SOC true and SOH true , according to (18),
$$S O H _ { t r u e } = \frac { I } { Q _ { 0 } } \frac { d t } { d O C V } \ \frac { \partial O C V } { \partial S O C } \Big | _ { S O C _ { t r u e }, S O H _ { t r u e } }$$
The iteration process in (18) can therefore be written as
$$S O H _ { k + 1 } = g ( S O H _ { k } ) = \frac { S O H _ { t r u e } \, \frac { \partial O C V } { \partial S O C } | _ { S O C _ { k }, S O H _ { k } } } { \frac { \partial O C V } { \partial S O C } | _ { S O C _ { t r u e }, S O H _ { t r u e } } } \, \quad \quad ( 3 7 )$$
We define the iteration to be locally convergent at A = ( SOC true , SOH true ) when there exists a neighborhood of A , and the iterative method will converge to A when the initial point is in the neighborhood. Suppose that the derivative of SOC k and dOCV dSOC to SOH k are continuous in the domain, then the local convergence of the method can be judged by the derivative of g , which is defined in (38).
$$L = \frac { d g } { d S O H } \Big | _ { S O C _ { t r u e }, S O H _ { t r u e } } = S O H _ { t r u e } \frac { \frac { \partial ^ { 2 } O C V } { \partial S O C ^ { 2 } } \frac { \partial S O C } { \partial S O H } + \frac { \partial ^ { 2 } O C V } { \partial S O C \partial S O H } } { \partial O C V } \Big | _ { S O C _ { t r u e }, S O H _ { t r u e } } \\ \Big. \cdots \Big.$$
where
$$\frac { \partial S O C } { \partial S O H } \Big | _ { S O H _ { t r u e }, S O C _ { t r u e } } = \frac { \partial f ^ { - 1 } ( O C V, S O H, T ) } { \partial S O H } \Big | _ { S O H _ { t r u e }, S O C _ { t r u e } } \quad \quad ( 3 9 )$$
When | L | < 1, we can prove that the iteration is locally convergent, since | SOH k +1 -SOH true | | SOH k -SOH true | < L | | + ϵ < 1. On the other hand, when L > 1, the method will not converge locally because in the neighborhood, | SOH k +1 -SOH true | | SOH k -SOH true | > | L | -ϵ > 1, and SOH k will finally move out of the neighborhood. The value of | L | as a function of SOC true and SOH true is shown in Figure 5. In the figure, for better visualization, all the areas where | L | > 1 are rescaled to | L | = 1, and other areas represent the domain where the method is locally convergent.
Figure 5: Local convergence analysis
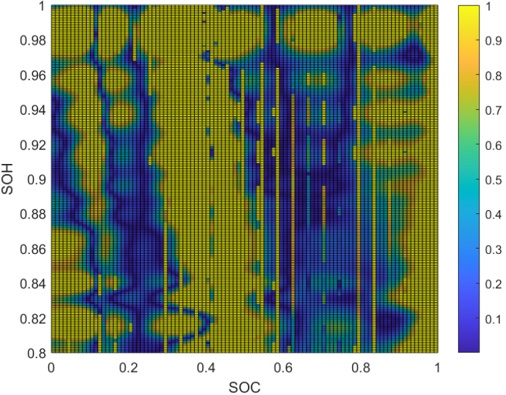
The local convergence analysis can tell us what outputs are possible and what are not. For example, if the iterative method is used at 50% SOC , it will almost always give inaccurate results since it hardly ever converges at 50% SOC, regardless of the true SOH. However, local convergence analysis alone is not enough to evaluate the estimation error since local convergence doesn't guarantee global convergence, and not converging at a certain point doesn't necessarily mean a high estimation error. To better evaluate the accuracy limit of the iterative method, another simulation was performed to analyze the correlation between SOC true and estimation accuracy. Namely, for each SOC true between 0% to 100%, we enumerate the values of SOH true from 80% to 100% and calculate the average estimation error (measured by
root mean square error, or RMSE) when the iterative method is initialized at SOH 0 = 100%. The results are shown in Figure 6.
Figure 6: Iteration error analysis
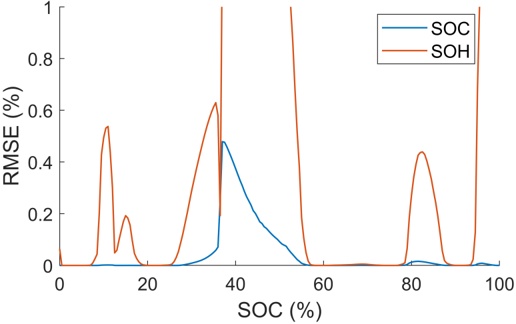
According to Figure 6, the accuracy of SOC estimation is always relatively high, as the maximum RMSE of SOC is only 0.5%. In contrast, the accuracy of SOH estimation varies more significantly to the SOC true when using the method. Since the error of SOC estimation can be higher in practice, the best timing to use our method is between 57% and 77% SOC, where both errors are very close to zero, meaning that the method can always converge to the correct values.
## 5. Experimental validation
## 5.1. Experimental validation setup
Six lithium-ion batteries of NMC chemistry (model ICR18650-22F) manufactured by SAMSUNG were placed inside six separate temperature control chambers and were used for experimental validation. The charging and discharging were monitored by the battery tester manufactured by Arbin Instruments. Data collection and the setup of charging and discharging profiles were done using the supporting software Mits Pro. The RMSEs of the voltage and current measurements are 0.15 mV and 0.1 mA, respectively. The testing profile for each cell was precisely the same and is shown in Figure 7.
As is shown in Figure 7, the cells were aged at 40 C by running contin-◦ uous 1 C charge and 2 C discharge until the SOH dropped below 75%. A
Figure 7: A flow chart of the aging test
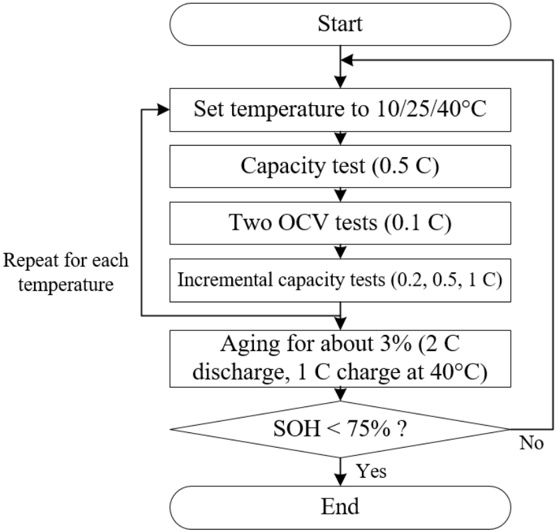
set of characteristic tests was performed for each cell at at least nine different aging levels. Each characteristic test consisted of a capacity test (to stabilize the cell temperature), two OCV tests (incremental OCV test and low-current OCV test), and three incremental capacity tests at different C rates. All these characteristic tests were repeated at three different temperatures. The meanings of the two OCV tests have already been illustrated in section 2.2. The charge and discharge rates used in the low-current OCV test and incremental OCV test were both 0.1 C. The relaxation time in the incremental OCV test was 3 minutes, much shorter than the typical setup. The purpose of shortening the relaxation time is to make the OCV in the OCV experiment more consistent with the OCV identified from the battery ECM and, hence, to improve the SOC and SOH estimation accuracy. In the incremental capacity tests, the cells were fully charged and discharged at a constant current until the SOC dropped by 3%. Afterward, the cell rested for three minutes, followed by a 10-second 1 C discharge and another 3-minute rest. Then, the cell was discharged again, and the procedures de-
scribed above were repeated until the cell was fully discharged. The cell then rested for 30 minutes and was charged using a constant current constant voltage profile afterward. Likewise, whenever the SOC rose by 5%, the cell rested for 3 minutes, was discharged for 10 seconds, and rested for another 3 minutes until the cell was fully charged. The purpose of such a charging and discharging profile was to enable the validation of our parameter estimation algorithm at the most desirable SOC.
According to the conclusions in Section 4.2, the best time to use the method is when the actual SOC is between 55% and 77%. However, in practice, the SOC is unknown before the state estimation, so the SOC is not a good indicator of when to use the method. Under this consideration, we used the terminal voltage as the indicator during validation instead. Namely, among more than twenty relaxations during the charging process in the incremental capacity test, the method is used when the terminal voltage at the beginning of the relaxation exceeds 3.9 V. This voltage threshold can guarantee that the SOC during this and the following relaxation are both between 55% and 77%, regardless of the SOH and the C rate.
According to theorem 4 and 3 in section 4.1, when estimating the ECM parameters, the optimal selection of the three points should be x 1 = 0 , x 2 = x / 3 2, and 50s < = x 3 < =120s (depending on the estimation accuracy). However, theorem 4 is based on the assumption that the ECM precisely describes the dynamic voltage response of the battery, which is, in fact, not true. In practice, it is found that the ECM model can only approximate the cell's voltage response between 10s to 300s well. As a result, we instead selected x 1 =10s, x 2 = x 1 + x 3 2 , and 60s < = x 3 < =180s.
During the experimental validation, the OCV curve was fitted based on the voltage data in the incremental OCV test. Since the proposed SOC and SOH estimation method is used during the charging process, we only used the charge OCV data to fit the OCV curve, as the charge OCV curve is slightly different from the discharge OCV curve. After fitting the OCV curve, we validated our method on the experimental data in the three incremental capacity tests. Such a process was repeated at each temperature. As previously mentioned, when validating on a particular cell, the OCV data of this cell was excluded when fitting the OCV curve. For example, when estimating the SOC and SOH of Cell 3, the OCV curve we used was fitted on the data of Cells 1, 2, 4, 5, and 6. The reason for such an arrangement was to separate the fitting data and validation data.
## 5.2. Experimental results
When x 3 =120s, our method's SOC and SOH estimation results with and without dR compensation are shown in Figure 8. The average run time of these two variants is, respectively, 0.33 ms and 0.51 ms.
Figure 8: SOC and SOH estimation errors of our method with and without dR compensation (two-minute relaxation time)
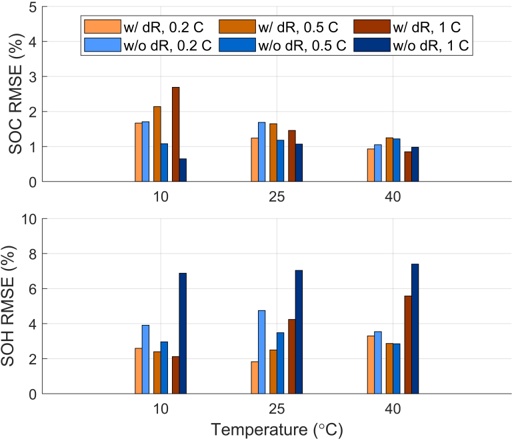
According to the figure, the proposed method can realize fast and accurate SOC and SOH estimation under various temperatures and C rates. When the C rate is equal to or lower than 0.5 C, the variant without dR compensation is enough for accurate estimation, with a SOC and SOH error of about 2% and 3.5%. Note that this variant only requires a relaxation of two minutes and a computational time of 0.33 ms. If the charging current is higher than 0.5 C or the requirement for estimation accuracy is higher, then using the variant with dR compensation would be better. While this other variant is more complex, it still only needs a four-minute relaxation time and a computational time of 0.51 ms. This means that even if this variant is applied to an EV with 8,000 cells, the total computational time would still be lower than five seconds.
To verify the method's sensitivity to the relaxation time ( x 3 ), in Figure 9, the average SOC and SOH estimation error at different relaxation time and temperatures are plotted. The results show that the estimation error
is not very sensitive to the relaxation time after it exceeds 60 seconds. The lowest error is achieved at x 3 = 120s, suggesting that relaxing the cells for more than two minutes is unnecessary.
Figure 9: Selection of the relaxation time ( x 3 )
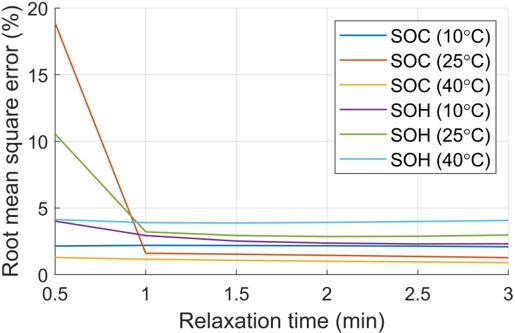
## 5.3. Comparison against Unscented Kalman Filter
Compared with other model-based methods (for example, EKF and UKF), the method proposed in this paper has significantly less computational complexity and needs no hyperparameter or initialization. However, it requires the cell to rest for one to four minutes during the charging process, while other model-based methods do not have such requirements. As a result, to better evaluate the pros and cons of the proposed method, it is necessary to make a quantitative comparison with other model-based methods in terms of their accuracy and computational complexity.
In this paper, the UKF algorithm was chosen as the baseline algorithm. While another KF-based method was used in Section 3.3 for SOC tracking, the purpose differed. In Section 3.3, EKF was only used to estimate the SOC of one cell for each battery string, under which circumstance all the states of the model are observable, and the convergence is guaranteed; but here, the UKF is used to estimate the SOC and SOH of each cell in the pack, and not the states are not always fully observable.
The UKF used in this paper has three states: remaining capacity Q r , capacitor voltage U c , and present maximum capacity Q . With these definitions, the discrete state-space representation of the system can be written as (40).
The correlation between these states and the SOC and SOH is formulated in (1) and (3). We didn't directly define SOC and SOH as the states to make the state transition functions linear.
$$\begin{cases} \begin{bmatrix} Q _ { r, k } \\ U _ { c, k } \\ Q _ { k } \end{bmatrix} = F \begin{bmatrix} Q _ { r, k - 1 } \\ U _ { c, k - 1 } \\ Q _ { k - 1 } \end{bmatrix} + B I _ { k } \\ U _ { t e r, k } = f o C V ( \frac { Q _ { r, k } } { Q _ { k } }, \frac { Q _ { k } } { Q _ { 0 } } ) + U _ { c, k } + R _ { 1 } I _ { k } \\ \tau \end{bmatrix}, \quad \omega \quad \omega \quad \tau \quad \omega \quad \tau \end{cases}$$
$$F = \begin{bmatrix} 1 & 0 & 0 \\ 0 & e ^ { \frac { - \Delta t } { R _ { 2 } C } } & 0 \\ 0 & 0 & 1 \end{bmatrix}, B = \begin{bmatrix} \Delta t \\ R _ { 2 } - R _ { 2 } e ^ { \frac { - \Delta t } { R _ { 2 } C } } \\ 0 \end{bmatrix}$$
where ∆ t is the time interval between two steps, and B and F are two constant matrices defined by (41).
The UKF was validated on the same data as our method (with dR compensation) for a fair comparison. Specifically, the profile includes a threeminute relaxation, a 10-second 1 C discharge pulse, another 3-minute relaxation, a constant-current charging that increases the SOC by 5%, and another 3-minute relaxation. During the first relaxation, the UKF was not turned on, and the voltage data was used to estimate the values of all the ECM parameters. The parameter estimation method is the same as in Section 3.1. Starting from the discharge pulse, the UKF was turned on, with the initial SOH estimation set to 100%, the initial capacitor voltage set to 0, and the initial SOC set to be the inverse of the OCV during the first relaxation. The SOC and SOH estimation at the very end of the profile are considered estimation outputs and compared against the actual value to calculate the error. The detailed hyperparameter setup for this UKF is the same as in [35].
The SOC and SOH estimation results by using UKF are presented in Figure 10. The figure suggests that our method is hundreds of times faster than the UKF and is more accurate, especially for SOC estimation.
## 5.4. Error analysis
While the SOC and SOH estimation error of the proposed method is relatively low, it is still essential to understand the source of the error, as understanding the error sources can help us better analyze the applicability and the pros and cons of the method. For this purpose, the validation was
Figure 10: Comparison between our method (average run time = 0.51 ms) and UKF (average run time = 73 ms)
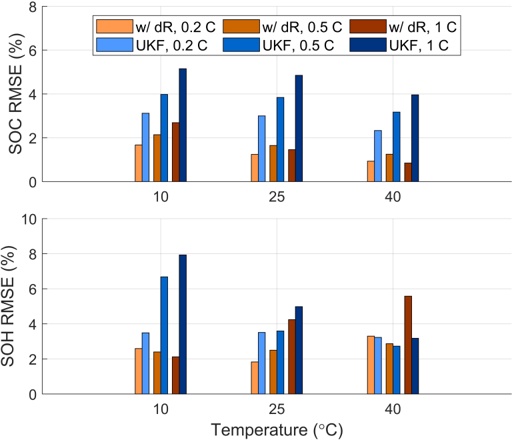
done another eighteen times, each time on a different setup. As is shown in the first column of Table 5.4, these extra validations can be separated into three groups according to the data source used in the validation. In the first group, all the validations were done on experimental data. In the second and third groups, only the current data were from the experiment, and all the voltage data came from a simulated battery model. The difference is that the battery model used in the second group is a second-order RC model, while the one used in the third group is a first-order RC model. In other words, only the model used in the third group is the same as the battery model we used when proposing the method. By default, when generating the voltage data, it is assumed that there is a voltage noise with a standard deviation of 0.15 mV (the same as the standard deviation of the voltmeter in the experiment), and all the RC parameters change as the SOC changes.
We started with the default setting for each data source and gradually added more simplifications. For example, in the fourth scenario, we not only used the simplification 'Known SOC' but also applied the simplification 'More relevant data' and 'Fixed OCV curve'. In other words, in Table 5.4, within each group, the difficulty of the estimation becomes gradually lower
from top to bottom. Specifically, for experimental data, 'More relevant data' means that the OCV curve we used came from the same cell that we were validating on (note that by default, the OCV curve came from the data of all the other cells besides the cell that we were validating on); 'Fixed OCV curve' means that we stopped updating the OCV curve as we updated the SOH estimation, and always used the OCV curve corresponding to the true SOH; 'Known SOC' means that we assume that we used the actual SOC instead of the estimated SOC when estimating the SOH. For simulation data, 'Known capacitor voltage' means that the actual value of the capacitor voltage before entering the relaxation, which was previously assumed to be R I 2 , is known; 'No voltage noise' means that the measurement voltage noise is set to zero, 'Fixed RC parameter' means that the RC parameters in the simulation become constants instead of variables that change as SOC changes; 'More accurate dV/dt' means that fewer points (two points instead of fifty points) are used in the linear regression to fit dV/dt. The meaning of 'Fixed OCV curve' and 'Known SOC' for simulation data are the same as for experimental data.
Among all the scenarios in Table 5.4, the most unique one is 'Coulomb Counting'. For this setup, we didn't use our SOC and SOH estimation method; instead, we used Coulomb Counting. As previously mentioned, the 'true' SOC and 'true' SOH are also calculated based on Coulomb Counting in the experimental validation. The difference is that our definition of SOH is the cell's normalized charge capacity in the 0.1 C incremental OCV test. Yet, here, the SOH was estimated by the normalized charge capacity in the corresponding incremental capacity test, in which the charge current is not 0.1 C. For example, when the charge current is 0.1 C, the initial capacity of Cell 1 is 2.156 Ah, which decreases to 1.775 Ah after 900 cycles, resulting in an SOH of 82.3%. Meanwhile, when the maximum charge current is 1 C, the initial capacity of Cell 1 is 2.079 Ah, which decreases to 1.627 Ah after 900 cycles, resulting in an SOH of 78.3%. Such a 4% difference in SOH suggests that SOH is not a definite state of the battery, and its value can change under different conditions. The RMSE of the SOH estimation is used to quantify this uncertainty originating from the definition of SOH itself. Likewise, when we calculate the SOC based on the charge and discharge capacity calculated from the 0.1 C OCV test, the SOC at the end of the charging may not be precisely 100% since the cell's capacity varies slightly at different C rates. The RMSE of the SOC estimation is calculated from the difference between the final calculated SOC and 100% and is used to
quantify the uncertainty originating from the definition of SOC. In essence, the error of Coulomb Counting can be considered the lower limit of the SOC and SOH estimation error when using experimental data since such an error comes from the definition of SOC and SOH and is impossible to avoid.
The SOC and SOH estimation errors in all these extra validations are presented in Table 5.4. Note that all the validations here were based on the data gathered at 25 ◦ C, and we always added dR compensation when doing the estimation.
Table 1: RMSE of SOC and SOH estimation under different scenarios
| Data Source | Scenarios | 0.2 C | 0.2 C | 0.5 C | 0.5 C | 1 C | 1 C |
|---------------|-------------------------|---------|---------|---------|---------|-------|--------|
| Data Source | Scenarios | SOC | SOH | SOC | SOH | SOC | SOH |
| | Default | 1.24% | 1.83% | 1.65% | 2.50% | 1.46% | 4.24% |
| | More relevant data | 1.24% | 1.84% | 1.69% | 2.55% | 1.57% | 4.23% |
| | Fixed OCV curve | 0.62% | 2.31% | 1.35% | 2.84% | 1.88% | 4.44% |
| | Known SOC | 0.62% | 2.33% | 1.35% | 2.79% | 1.88% | 4.85% |
| | Coulomb Counting | 0.20% | 0.68% | 0.77% | 1.79% | 0.38% | 2.06% |
| | Default | 0.78% | 2.92% | 0.89% | 7.50% | 1.40% | 11.72% |
| | Known capacitor voltage | 1.29% | 2.27% | 2.37% | 4.18% | 3.70% | 6.89% |
| | No voltage noise | 1.14% | 1.71% | 2.55% | 3.88% | 3.74% | 6.94% |
| | Fixed RC parameters | 0.35% | 0.52% | 1.15% | 0.81% | 3.14% | 3.39% |
| | More accurate dV/dt | 0.35% | 0.52% | 1.14% | 0.77% | 3.12% | 3.32% |
| | Fixed OCV curve | 0.31% | 0.14% | 0.93% | 0.42% | 2.22% | 2.39% |
| | Known SOC | 0.31% | 0.08% | 0.93% | 0.09% | 2.22% | 0.20% |
| | Default | 0.72% | 2.57% | 1.24% | 6.11% | 2.12% | 11.41% |
| | Known Capacitor Voltage | 1.05% | 2.40% | 1.44% | 2.44% | 1.26% | 4.28% |
| | No voltage noise | 0.85% | 1.13% | 1.40% | 1.80% | 1.20% | 3.93% |
| | Fixed RC parameters | 0.10% | 0.50% | 0.16% | 0.62% | 0.53% | 1.25% |
| | More accurate dV/dt | 0.11% | 0.51% | 0.17% | 0.62% | 0.47% | 1.10% |
| | Fixed OCV curve | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| | Known SOC | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
Interestingly, when using our method on experimental data, no simplification can effectively improve the accuracy of the SOH estimated by our method, and only the 'Fixed OCV curve' can marginally improve the accuracy of the SOC estimated by our method. Such a phenomenon suggests that all the error sources we examined in the first validation group are unimportant. According to the results in the second and third groups of validations, the critical error sources of our method are (1) our assumption that the capacitor has been fully charged before the start of the relaxation and (2) our linear approximation of R 1 ( SOC ) and R 2 ( SOC ). The second error source is very hard to avoid since estimating R 1 and R 2 in real-time is very hard. Yet, the first error source can be mitigated by prolonging the constantcurrent charging time before the relaxation. In the experiment, the length of constant-current charging is set to the time required to increase the SOC by
5%. Therefore, when the charge C rate is 1 C, the constant-current charging time is just 3 minutes, which is insufficient for the capacitor to charge fully. Such a difference in the length of constant-current charging explains why this error source affects higher C rates more than lower C rates. The estimation accuracy is expected to increase if we prolong the constant-current charging time.
Additionally, by comparing the corresponding scenarios in the second and third data sources, we can see that the estimation accuracy for these two data sources is, in fact, quite similar, even though the first-order RC model used in the parameter estimation only matches the third data source well. Such an observation suggests that although a more complex battery model can better simulate the voltage data, the simple first-order RC model will not necessarily lead to a higher SOC and SOH estimation error. Other error sources can dilute the benefit of a more complex model, and identifying more parameters also leads to weaker observability and longer computational time.
## 6. Conclusions
In this paper, an online battery SOC and SOH estimation method was proposed. The method is based on rigorous theoretical analysis and requires no hyperparameter fine-tuning. The method has two variants. The first variant is designed for low C-rate ( ≤ 0.5 C) charging and only requires a 1 to 2-minute relaxation, while the second can be used for higher C rates but requires a 2 to 4-minute relaxation during the charging process. Both variants can accurately estimate SOC and SOH at different temperatures. Specifically, the average computational time of the first variant is 0.33 ms, and the estimation RMSE for SOC and SOH are respectively around 1.2% and 4.8%. In comparison, the average computational time of the second variant is 0.51 ms, and the estimation RMSE for SOC and SOH are respectively around 1.5% and 3%. Compared with UKF, our method requires significantly lower computational time and has higher accuracy.
The main limitations of the work are that the proposed method requires a few minutes of relaxation at some specific SOC range (between 55% and 77%) and that the charging current cannot be too high ( > 1 C) for accurate state estimation. Future work will focus on extending the method to a broader SOC range and fast-charging scenarios.
## References
- [1] X. Hu, C. Zou, C. Zhang, Y. Li, Technological developments in batteries: a survey of principal roles, types, and management needs, IEEE Power and Energy Magazine 15 (5) (2017) 20-31.
- [2] J. Hou, T. Li, F. Zhou, D. Zhao, Y. Zhong, L. Yao, L. Zeng, A review of critical state joint estimation methods of lithium-ion batteries in electric vehicles, World Electric Vehicle Journal 13 (9) (2022) 159.
- [3] Y. Li, K. Liu, A. M. Foley, A. Z¨lke, M. Berecibar, E. Nanini-Maury, u J. Van Mierlo, H. E. Hoster, Data-driven health estimation and lifetime prediction of lithium-ion batteries: A review, Renewable and sustainable energy reviews 113 (2019) 109254.
- [4] L. Ungurean, G. Cˆ arstoiu, M. V. Micea, V. Groza, Battery state of health estimation: a structured review of models, methods and commercial devices, International Journal of Energy Research 41 (2) (2017) 151-181.
- [5] S. Jiang, Z. Song, A review on the state of health estimation methods of lead-acid batteries, Journal of Power Sources 517 (2022) 230710.
- [6] S. Zhang, X. Guo, X. Dou, X. Zhang, A rapid online calculation method for state of health of lithium-ion battery based on coulomb counting method and differential voltage analysis, Journal of Power Sources 479 (2020) 228740.
- [7] M. Berecibar, M. Garmendia, I. Gandiaga, J. Crego, I. Villarreal, State of health estimation algorithm of lifepo4 battery packs based on differential voltage curves for battery management system application, Energy 103 (2016) 784-796.
- [8] L. Zheng, J. Zhu, D. D.-C. Lu, G. Wang, T. He, Incremental capacity analysis and differential voltage analysis based state of charge and capacity estimation for lithium-ion batteries, Energy 150 (2018) 759-769.
- [9] S. Yang, C. Zhang, J. Jiang, W. Zhang, L. Zhang, Y. Wang, Review on state-of-health of lithium-ion batteries: Characterizations, estimations and applications, Journal of Cleaner Production 314 (2021) 128015.
| [10] | R. Xiong, L. Li, J. Tian, Towards a smarter battery management system: A critical review on battery state of health monitoring methods, Journal of Power Sources 405 (2018) 18-29. |
|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [11] | A. Manoharan, K. Begam, V. R. Aparow, D. Sooriamoorthy, Artifi- cial neural networks, gradient boosting and support vector machines for electric vehicle battery state estimation: A review, Journal of Energy Storage 55 (2022) 105384. |
| [12] | J. Shi, D. Kato, S. Jiang, C. Dangwal, S. Moura, Robust estimation of state of charge in lithium iron phosphate cells enabled by online param- eter estimation and deep neural networks, IFAC-PapersOnLine 56 (3) (2023) 127-132. |
| [13] | X. Shu, G. Li, J. Shen, Z. Lei, Z. Chen, Y. Liu, An adaptive multi-state estimation algorithm for lithium-ion batteries incorporating tempera- ture compensation, Energy 207 (2020) 118262. |
| [14] | P. Shen, M. Ouyang, L. Lu, J. Li, X. Feng, The co-estimation of state of charge, state of health, and state of function for lithium-ion batteries in electric vehicles, IEEE Transactions on vehicular technology 67 (1) (2017) 92-103. |
| [15] | C. Yang, X. Wang, Q. Fang, H. Dai, Y. Cao, X. Wei, An online soc and capacity estimation method for aged lithium-ion battery pack consider- ing cell inconsistency, Journal of Energy Storage 29 (2020) 101250. |
| [16] | S. Park, J. Ahn, T. Kang, S. Park, Y. Kim, I. Cho, J. Kim, Review of state-of-the-art battery state estimation technologies for battery man- agement systems of stationary energy storage systems, Journal of Power Electronics 20 (6) (2020) 1526-1540. |
| [17] | Y. Xing, W. He, M. Pecht, K. L. Tsui, State of charge estimation of lithium-ion batteries using the open-circuit voltage at various ambient temperatures, Applied Energy 113 (2014) 106-115. |
| [18] | R. Zhang, B. Xia, B. Li, L. Cao, Y. Lai, W. Zheng, H. Wang, W. Wang, M. Wang, A study on the open circuit voltage and state of charge char- acterization of high capacity lithium-ion battery under different temper- ature, Energies 11 (9) (2018) 2408. |
| [19] | S.-L. Wang, X. Xiong, C.-Y. Zou, L. Chen, C. Jiang, Y.-X. Xie, D.- I. Stroe, An improved coulomb counting method based on dual open- circuit voltage and real-time evaluation of battery dischargeable capac- ity considering temperature and battery aging, International Journal of Energy Research 45 (12) (2021) 17609-17621. |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [20] | L. Lavigne, J. Sabatier, J. M. Francisco, F. Guillemard, A. Noury, Lithium-ion open circuit voltage (ocv) curve modelling and its ageing adjustment, Journal of Power Sources 324 (2016) 694-703. |
| [21] | C. R. Birkl, M. R. Roberts, E. McTurk, P. G. Bruce, D. A. Howey, Degradation diagnostics for lithium ion cells, Journal of Power Sources 341 (2017) 373-386. |
| [22] | C. Weng, J. Sun, H. Peng, A unified open-circuit-voltage model of lithium-ion batteries for state-of-charge estimation and state-of-health monitoring, Journal of power Sources 258 (2014) 228-237. |
| [23] | S. Tong, M. P. Klein, J. W. Park, On-line optimization of battery open circuit voltage for improved state-of-charge and state-of-health estima- tion, Journal of Power Sources 293 (2015) 416-428. |
| [24] | Z. Ma, R. Yang, Z. Wang, A novel data-model fusion state-of-health estimation approach for lithium-ion batteries, Applied energy 237 (2019) 836-847. |
| [25] | D. Natella, S. Onori, F. Vasca, A co-estimation framework for state of charge and parameters of lithium-ion battery with robustness to aging and usage conditions, IEEE Transactions on Industrial Electronics 70 (6) (2022) 5760-5770. |
| [26] | M. Naguib, P. Kollmeyer, A. Emadi, Lithium-ion battery pack robust state of charge estimation, cell inconsistency, and balancing, IEEE Ac- cess 9 (2021) 50570-50582. |
| [27] | Z. Zhou, B. Duan, Y. Kang, N. Cui, Y. Shang, C. Zhang, A low- complexity state of charge estimation method for series-connected lithium-ion battery pack used in electric vehicles, Journal of Power Sources 441 (2019) 226972. |
| [28] | D. Huang, Z. Chen, C. Zheng, H. Li, A model-based state-of-charge esti- mation method for series-connected lithium-ion battery pack considering fast-varying cell temperature, Energy 185 (2019) 847-861. |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [29] | J. Wei, G. Dong, Z. Chen, Y. Kang, System state estimation and opti- mal energy control framework for multicell lithium-ion battery system, Applied Energy 187 (2017) 37-49. |
| [30] | P. Gill, D. Zhang, L. D. Couto, C. Dangwal, S. Benjamin, W. Zeng, S. Moura, State-of-health estimation pipeline for li-ion battery packs with heterogeneous cells, in: 2022 American Control Conference (ACC), IEEE, 2022, pp. 1080-1086. |
| [31] | G. L. Plett, Extended kalman filtering for battery management systems of lipb-based hev battery packs: Part 3. state and parameter estimation, Journal of Power sources 134 (2) (2004) 277-292. |
| [32] | Q.-Q. Yu, R. Xiong, L.-Y. Wang, C. Lin, A comparative study on open circuit voltage models for lithium-ion batteries, Chinese Journal of Me- chanical Engineering 31 (1) (2018) 1-8. |
| [33] | F. Zheng, Y. Xing, J. Jiang, B. Sun, J. Kim, M. Pecht, Influence of different open circuit voltage tests on state of charge online estimation for lithium-ion batteries, Applied energy 183 (2016) 513-525. |
| [34] | C. Lin, Q. Yu, R. Xiong, et al., A study on the impact of open cir- cuit voltage tests on state of charge estimation for lithium-ion batteries, Applied Energy 205 (2017) 892-902. |
| [35] | S. Jiang, J. Shi, M. Borah, S. Moura, Weaknesses and improvements of the extended kalman filter for battery state-of-charge and state-of-health estimation, in: 2024 American Control Conference (ACC), IEEE, 2024, pp. 1441-1448. | | null | [
"Shida Jiang",
"Junzhe Shi",
"Scott Moura"
] | 2024-08-02T09:12:17+00:00 | 2024-09-29T05:26:41+00:00 | [
"eess.SY",
"cs.SY"
] | Relax, Estimate, and Track: a Simple Battery State-of-charge and State-of-health Estimation Method | Battery management is a critical component of ubiquitous battery-powered
energy systems, in which battery state-of-charge (SOC) and state-of-health
(SOH) estimations are of crucial importance. Conventional SOC and SOH
estimation methods, especially model-based methods, often lack accurate
modeling of the open circuit voltage (OCV), have relatively high computational
complexity, and lack theoretical analysis. This study introduces a simple SOC
and SOH estimation method that overcomes all these weaknesses. The key idea of
the proposed method is to momentarily set the cell's current to zero for a few
minutes during the charging, perform SOC and SOH estimation based on the
measured data, and continue tracking the cell's SOC afterward. The method is
based on rigorous theoretical analysis, requires no hyperparameter fine-tuning,
and is hundreds of times faster than conventional model-based methods. The
method is validated on six batteries charged at different C rates and
temperatures, realizing fast and accurate estimations under various conditions,
with a SOH root mean square error (RMSE) of around 3% and a SOC RMSE of around
1.5%. |
2408.01128v2 | IPPP/24/41 LTH 1381
January 29, 2025
## A method to include exclusive heavy vector-meson production data at small x in global parton analyses
C.A. Flett , A.D. Martin , M.G. Ryskin a b c and T. Teubner d
a Universit´ Paris-Saclay, CNRS, IJCLab, 91405 Orsay, France e b Institute for Particle Physics Phenomenology, Durham University, Durham, DH1 3LE, U.K. c Petersburg Nuclear Physics Institute, NRC Kurchatov Institute, Gatchina, St. Petersburg, 188300, Russia d Department of Mathematical Sciences, University of Liverpool, Liverpool, L69 3BX, U.K.
## Abstract
We propose a method which allows the inclusion of exclusive heavy vector-meson production data at low x in future global parton analyses. As an example we perform a study within xFitter to determine the gluon parton distribution function (PDF) at nextto-leading order (NLO) at moderate-to-low x using the measurements of exclusive J/ψ production in ep and pp collisions from HERA and LHC. We further study the constraints from the corresponding Υ production process. We finish by discussing the possible effects at next-to-next-to-leading order (NNLO) through incorporation of a K factor for the exclusive heavy vector-meson coefficient function at NLO.
## 1 Introduction
The precision of the parton distributions of the proton is well established through global analyses, provided the resolution scale Q 2 is not too low and the momentum fraction x remains within a moderate range, neither too small nor too large. For x > ∼ 10 -3 , there is a general agreement among the results from various global fit analyses [1, 2, 3]. However, as x decreases, particularly at lower scales, the uncertainty in these distributions increases significantly. This increase in uncertainty is due to the lack of experimental data directly probing this region.
Figure 1: (Left) LO contribution to γp → V + p , where the vector meson V = J/ψ, Υ . (Right) NLO quark contribution. For these graphs all permutations of the parton lines and couplings of the gluon lines to the heavy-quark pair are to be understood. The NLO gluon contribution, with coefficient function C NLO g and GPD F g , dominates the NLO quark contribution. In these diagrams, the momentum P ≡ ( p + p ′ ) / 2 and l is the loop momentum. Note that the momentum fractions of the left and right partons are x = X + ξ and x ′ = X -ξ respectively; for the gluons connected to the heavy quark-antiquark pair, we have x ′ ≪ x and so x ≃ 2 ξ .
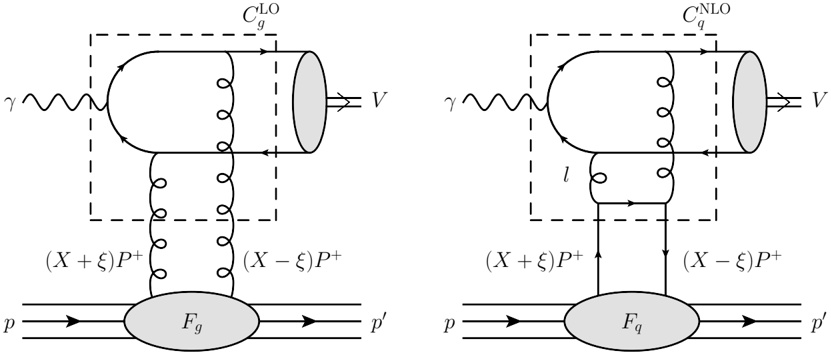
The experiments at the Large Hadron Collider (LHC) are capable of particle detection and reconstruction over a wide rapidity range. Notably, various measurements of the differential cross sections for exclusive heavy vector mesons such as J/ψ and Υ [4, 5, 6] have allowed for the determination of the gluon Parton Distribution Function (PDF) down to x ∼ 3 × 10 -6 at factorization scales µ F = m q , where q = c, b .
Unfortunately it is not easy to include these data in global parton analyses. The cross section for exclusive meson production is driven not by the usual (diagonal) PDFs but by the more complicated (skewed) generalised parton distributions (GPDs), and is proportional to the skewed gluon-density squared, as indicated in Fig. 1; see [7] for a review. Note from the caption of the figure that x ≈ 2 ξ at very small x , where 2 ξ is the proton momentum fraction transferred through the GPD to the vector meson.
̸
However, in the small x region of our interest, the value of the GPD can be calculated from the conventional PDF with good ( ∼ O x ( )) accuracy using the Shuvaev transform [8]. The Shuvaev transform makes use of the fact that as ξ → 0 (and transverse-momentum transfer p T = 0) the Gegenbauer moments 1 of the GPD become equal to the known Mellin moments of the PDF. Due to the polynomial condition (see e.g. [10]) even for ξ = 0 the Gegenbauer
1 Gegenbauer moments are the analogue of Mellin moments which diagonalize the Q 2 evolution of PDFs. The corresponding operator diagonalizes the Q 2 evolution of the GPDs [9]. As ξ → 0 the Gegenbauer moments become equal to the Mellin moments.
moments can be obtained from the Mellin moments to O ξ ( ) accuracy. Thus it is possible to obtain the full GPD function at small ξ from its known moments.
In principle, this allows us to include the lowx exclusive J/ψ data in the global PDF analysis. In practice the problem is that the Shuvaev transform amounts to a slowly convergent double integral and the corresponding computation is time consuming. This is troublesome for the global fit as after every iteration, a new three-dimensional grid defined over the variables X,ξ and Q 2 has to be computed to obtain the updated theory prediction.
In the present paper we describe a method which helps to overcome this problem by replacing the exclusive vector-meson data at small x by 'effective gluon points'. To demonstrate the efficiency of the proposed method and to show how the inclusion of the LHCb J/ψ and Υ exclusive cross sections affect the result we compare the standard xFitter [11] NLO parton analysis of DIS data with that supplemented by the vector-meson data. Note that our goal is not to present a new set of parton distributions but to emphasise the possible role of the vector-meson data in global parton analyses. The new 'effective gluon points' presented in Tables 1 and 2 can be used in future global analyses.
## 2 Effective lowx gluon PDF data
To overcome this difficulty, we propose the following procedure. We translate the experimental J/ψ cross section data into a set of 'effective' values for the gluon PDF.
As seen from Fig. 2, the cross section for the exclusive process
$$p + p \rightarrow p + J / \psi + p$$
contains two components,
$$\frac { d \sigma ^ { ( p p \to p + J / \psi + p ) } } { d Y } \ = \ S ^ { 2 } ( W _ { + } ) \left ( k _ { + } \frac { d n } { d k _ { + } } \right ) \sigma _ { + } ( \gamma p \to J / \psi p ) \ + \ W _ { - } \ \text{term},$$
corresponding to energies W ± , where W + denotes the energy when the vector meson travels in the same direction as the photon, and W -when it travels in the opposite direction. We see that the values of the subprocess cross sections σ γp ( → J/ψp ), for each rapidity Y of the J/ψ , are weighted by the corresponding gap survival factors S 2 ( W ± ) [12] and photon fluxes dn/dk ± [13]. The cross section with the lower γp -energy ( W -) was measured at HERA [14, 15, 16, 17] and can be calculated with sufficient accuracy since it corresponds to relatively large x where the uncertainties in the parton distributions are small. Hence the exclusive J/ψ data provide reliable values for σ + ( γ + p → J/ψ + p ), corresponding to the component with the larger γp -energy, W + , see Fig. 3. 2
These σ + data were well described in [18] by a power-like lowx gluon
$$x g ( x ) = A \cdot x ^ { - \lambda } \quad \text{ with } \quad \lambda = 0. 1 3 5 \pm 0. 0 0 6,$$
Figure 2: The two diagrams describing exclusive J/ψ production at the LHC. The vertical lines represent two-gluon exchange. The left diagram, the W + component, is the major contribution to the pp → p + J/ψ + p cross section for a J/ψ produced at large rapidity Y . Thus such data allow a probe of very low x values, x ∼ M J/ψ exp( -Y ) / √ s , where √ s is the centre-of-mass energy of the pp system; recall that for two-gluon exchange we have x ≫ x ′ . The q T of the photon is very small and so the photon can be considered as a real on-mass-shell particle.
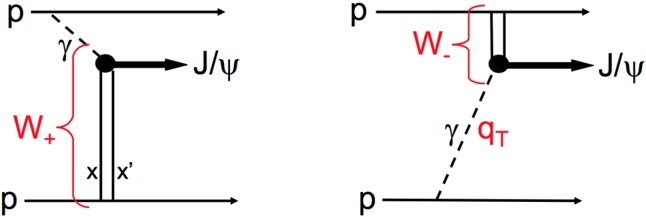
also shown in Fig. 3.
Moreover it was shown that after the optimal factorisation scale , 3 µ F = M J/ψ / 2, was chosen, where M J/ψ is the mass of the J/ψ , and the so-called Q 0 subtraction [21] 4 was performed, the quark contribution to σ + becomes negligible [23]. That is the value of
$$\sigma _ { + } \, \in \, \left ( \, 2 \xi \, g ( 2 \xi ) \, \right ) ^ { 2 }$$
is just proportional to the gluon density squared. 5
Now for each data point, i , we calculate the predicted J/ψ cross section σ + (fit) i based on the gluons from our fit and compare it with the experimental value σ + (data) . i The ratio σ + (data) i /σ + (fit) i is equal to the square of the ratio of the gluon densities
$$\frac { \sigma _ { + } ( \text{data} ) _ { i } } { \sigma _ { + } ( \text{fit} ) _ { i } } \ = \ \left ( \frac { g _ { \text{eff} } ( 2 \xi _ { i } ) } { g _ { \text{fit} } ( 2 \xi _ { i } ) } \right ) ^ { 2 }.$$
In other words, in this way we can calculate the effective gluon density (PDF) corresponding to x i = 2 ξ i as
$$g _ { \text{eff} } ( x _ { i }, \mu _ { \text{opt} } ) \ = \ g _ { \text{fit} } ( x _ { i }, \mu _ { \text{opt} } ) \ \sqrt { \frac { \sigma _ { + } ( \text{data} ) _ { i } } { \sigma _ { + } ( \text{fit} ) _ { i } } }.$$
2 Actually, the subtraction of the W -contribution was done already in the LHCb analyses where the results are presented as the σ + ( γ + p → V + ) cross sections. p
3 At this optimal scale the large double-logarithmic contributions of the form c n ( α s ln(1 /ξ ) ln µ 2 F ) n are resummed into the incoming PDF/GPD [20].
4 The Q 0 subtraction is necessary to exclude the double counting between the low l T part of the coefficient function and the PDFinput . This, together with the resummation of the aforementioned double-logarithmic terms [20], helps mitigate the problem of the strong factorisation scale dependence [22] of the NLO amplitude.
5 Strictly speaking, the value of σ + is proportional to the square of the corresponding GPD.
Figure 3: The description of the J/ψ photoproduction HERA [14, 15, 16, 17] and LHCb [4, 5] data based on using the central value of the global gluon PDF from the MMHT14 global analysis for x > 10 -3 and a fitted power-like gluon PDF, see eqn. (3) , for x < 10 -3 . The blue solid line and shaded region show, respectively, the central prediction and propagation of the ± 1 σ errors on the fitted parameters to the cross-section level.
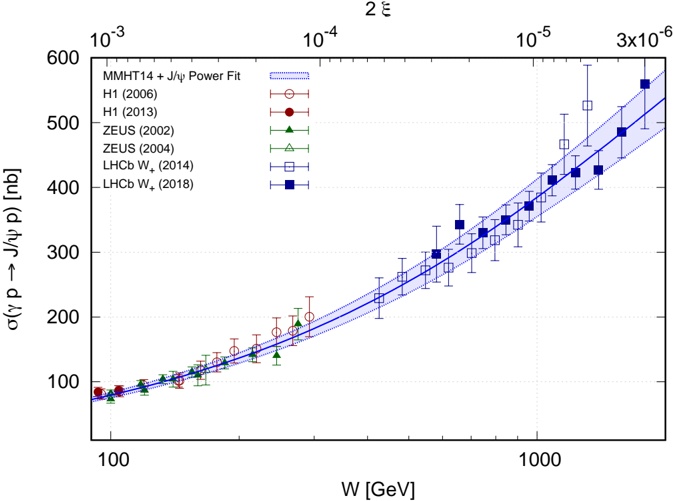
Correspondingly the error
$$\delta g _ { _ { \text{eff} } } ( x _ { i } ) = \frac { 1 } { 2 } \ g _ { \text{eff} } ( x _ { i } ) \ \frac { \delta \sigma _ { + } ( \text{data} ) _ { i } } { \sigma _ { + } ( \text{data} ) _ { i } }.$$
The error of the lower energy contribution, σ -( x i ), is accounted for in the experimental value of σ + (data) . i Recall that this lower energy contribution is small and its errors are negligible.
To summarize: we propose to include these 'effective' gluon PDF data points calculated according to eqns. (6), (7) in our parton analysis in order to reduce the present uncertainties in the behaviour of the lowx partons.
Since the final parton distribution may differ from eqn. (3) obtained from [18], to achieve greater accuracy several iterations may be needed such that the resulting output parameters in iteration i do not differ from those in iteration i -1 by ± 1 σ . The final determined iterated data points are given in Table 1. 6
6 Note that we do not fit to the individual σ γ ( + p → J/ψ + ) data points in our approach. p Instead, we use effective xg eff ( x ) points. Recall the values of xg fit ( x ) were obtained from a previous fit to the J/ψ cross section only, and thus may not be sufficiently accurate for a global analysis. Therefore we do not use the values
Table 1: The values of xg eff and δxg eff obtained from eqns. (6) and (7) at Q 2 = M 2 J/ψ / 4 = 2 4 GeV . 2 using the exclusive J/ψ production data at 7 TeV [4] and 13 TeV [5] obtained by the LHCb collaboration.
| 13 TeV | x | xg eff | δxg eff |
|----------|-----------------|----------|-----------|
| | 2 . 84 × 10 - 5 | 3.83 | 0.26 |
| | 2 . 21 × 10 - 5 | 4.08 | 0.17 |
| | 1 . 72 × 10 - 5 | 3.96 | 0.14 |
| | 1 . 34 × 10 - 5 | 4.05 | 0.13 |
| | 1 . 04 × 10 - 5 | 4.14 | 0.12 |
| | 8 . 14 × 10 - 6 | 4.32 | 0.13 |
| | 6 . 34 × 10 - 6 | 4.35 | 0.13 |
| | 4 . 93 × 10 - 6 | 4.34 | 0.14 |
| | 3 . 84 × 10 - 6 | 4.6 | 0.17 |
| | 2 . 99 × 10 - 6 | 4.91 | 0.27 |
| 7 TeV | 5 . 28 × 10 - 5 | 3.45 | 0.24 |
| | 4 . 11 × 10 - 5 | 3.65 | 0.2 |
| | 3 . 20 × 10 - 5 | 3.68 | 0.19 |
| | 2 . 49 × 10 - 5 | 3.67 | 0.19 |
| | 1 . 94 × 10 - 5 | 3.79 | 0.19 |
| | 1 . 51 × 10 - 5 | 3.88 | 0.19 |
| | 1 . 18 × 10 - 5 | 3.99 | 0.2 |
| | 9 . 18 × 10 - 6 | 4.19 | 0.2 |
| | 7 . 15 × 10 - 6 | 4.59 | 0.23 |
| | 5 . 57 × 10 - 6 | 4.84 | 0.28 |
Table 2: The values of xg eff and δxg eff obtained from eqns. (6) and (7) at Q 2 = M / 2 Υ 4 = 22 4 GeV . 2 using the exclusive Υ production data at 7, 8 TeV [6] obtained by the LHCb collaboration.
| 7, 8 TeV | x | xg eff | δxg eff |
|------------|-----------------|----------|-----------|
| | 1 . 01 × 10 - 4 | 19.9 | 3.1 |
| | 4 . 77 × 10 - 5 | 23.9 | 3.3 |
| | 2 . 26 × 10 - 5 | 31.1 | 4.1 |
In Table 2, we show the final effective iterated gluon points for exclusive Υ production [6] at the corresponding 'optimal' scale 22.4 GeV . 2 The accuracy of these points is worse than
of xg fit ( x ) from this former J/ψ fit, but instead fit to the corrected g eff ( x ) = g fit ( x ) √ σ (data)( x /σ ) (fit)( x ) data points. These effective values will provide a better overall description of the data and a better stability, so that the true values will not be changed too much in the fit iteration.
that obtained from J/ψ production, but they allow for a constraint on the Q 2 -evolution in the lowx region. 7
For the results presented in Tables 1 & 2, we actually use the Shuvaev transform for x ≤ 10 -4 ( x ≤ 10 -3 for the data presented in Fig. 3).
## 3 The impact of the lowx gluon effective data points on a global analysis
The gluon parton distribution resulting from a global xFitter [11] NLO analysis of pure DeepInelastic-Scattering (DIS) data (red) and DIS data supplemented with the effective gluon points extracted from the exclusive J/ψ and Υ production at the LHC (blue) are shown in Fig. 4. Here we have used the standard xFitter ensemble of DIS data and the standard xFitter ansatz for the input parton parametrizations with the kinematic cut Q > 2 2 4 GeV . NLO coefficient . 2 functions and NLO PDFs were used to obtain the g fit values. The datasets used and the partial and total minimum χ 2 figure of merit per degree of freedom, χ 2 min / d.o.f, for both fits are shown in Table 3.
It is clearly seen in Fig. 4 that the inclusion of the lowx effective gluon points extracted from the exclusive heavy vector-meson production at the LHC essentially improve the accuracy of the global parton analysis, and we obtain a good overall final χ 2 min / d.o.f ∼ O (1). The blue error band is much smaller than the red one. 8 Moreover, the inclusion of new information obtained from the heavy vector-meson ultraperipheral production affects (albeit expectedly not so strongly) even the quark distribution as demonstrated, for example, in Fig. 5. The new g eff lowx points affect the quark distribution even at a rather large x due to the energy-momentum sum rules and the particular choice of the fixed form of the input ansatz.
7 So far the exclusive Υ data for the γp → Υ p cross section from the LHCb collaboration have been obtained using gap survival factors S 2 ( W ± ) and photon fluxes dn/dk ± that need updating or correcting, see [24]. Nevertheless, the resulting Υ data shown in Table 2 already include the corresponding corrections, which however never exceed the experimental error bars. Note that the resulting Υ points already show evidence of a rising gluon PDF power behaviour in the region 10 -5 < x < 10 -4 and Q 2 = m 2 b ∼ 22 GeV 2 (see Fig. 2 of [24]). Recall that as was shown in [24], at the border of the LHCb acceptance, the choice of survival factor and photon flux only amounted to 5% for J/ψ production, while for Υ production it is of the order of 25%.
8 As usual, additional theoretical uncertainties such as the correction to the Non-Relativistic QCD (NRQCD) approach used for the qq ¯ → V transition in the computation of σ γp ( → V + ), or possible higher twist effects, p or effects of absorptive corrections, or other higher-order corrections, are not shown. Note that, apart from the absorptive effects, all other corrections (e.g. NRQCD) do not affect the energy behaviour of the amplitude, but just change its normalisation. Indeed, to 'know' the initial energy we need an additional gluon, which connects the upper (photon block in Fig. 1) with the lower/target parts of the diagram. This would correspond to a higher-twist contribution and should be suppressed by a large factorisation scale µ F . Typically, these corrections act 'locally' in rapidity space and therefore do not affect the energy behaviour of the amplitude, only its normalisation. On the other hand, our approach, in its present form, satisfactorily describes the available HERA data [18]. Recall that, as was shown in [19], normalising the vector-meson wave function to the experimentally measured J/ψ → l + l -decay width allows us to account for relativistic corrections in the NRQCD approach with good accuracy (within a few percent).
| Dataset | χ 2 min / d.o.f (DIS) | χ 2 min / d.o.f (DIS+eff. gluon pts.) |
|-------------------------|-------------------------|-----------------------------------------|
| HERA1+2 NCep 820 | 80/73 | 79/73 |
| HERA1+2 NCep 460 | 220/207 | 220/207 |
| HERA1+2 CCep | 43/39 | 44/39 |
| HERA1+2 NCem | 221/159 | 220/159 |
| HERA1+2 CCem | 54/42 | 56/42 |
| HERA1+2 NCep 575 | 223/257 | 227/257 |
| HERA1+2 NCep 920 | 465/391 | 470/391 |
| LHC excl. J/ψ pp 7 TeV | N/A | 8.95/10 |
| LHC excl. J/ψ pp 13 TeV | N/A | 3.51/10 |
| LHC excl. Υ pp 7,8 TeV | N/A | 3.23/3 |
| Total χ 2 min / d.o.f | 1412/1154 ≈ 1.22 | 1444/1177 ≈ 1.23 |
Table 3: The partial χ 2 min / d.o.f for each dataset included in the baseline fit (DIS) and with the effective gluon data points added (DIS + eff. gluon pts.). Here, we use the DIS data in the kinematic range Q > 2 2 4 . GeV . The total 2 χ 2 min / d.o.f is also given.
## 4 Working to NNLO via a K factor
In principle, the method of 'effective gluon points' described above can be extended to NNLO. Unfortunately at present the coefficient functions for J/ψ and Υ photo- and electroproduction are known only at NLO level [22, 25, 26].
However, it is possible to include these points in a NNLO global analysis in an approximate way by introducing a NNLO/NLO K factor, whose value can be extracted from the description of existing HERA γ + p → J/ψ + p (and/or γ + p → Υ+ ) data. In the following, we denote p this analysis NNLO* to distinguish it from an analysis in which the full NNLO coefficient functions would be used when they become available. In general the K factor may depend on the factorization scale and on the ratio z = ( X + ) 2 ξ / ξ of the parton momentum fractions x = ( X + ) to ξ ξ . That is the K factor should be included in the convolution for the γ + p → J/ψ + p amplitude
$$\mathcal { M } ( \gamma + p \to J / \psi + p ) \ = \ \sum _ { i = g, q } N _ { i } \int _ { - 1 } ^ { 1 } \frac { d X } { X } \ F _ { i } ( X, \xi ) \ K \ C _ { i } ^ { \text{NLO} } ( \xi / X )$$
where the constants N i provide the correct normalization, see e.g. [18], and F i and C i denote quark and gluon GPDs and coefficient functions respectively. In our case the factorization scale is fixed, µ F = M J/ψ / 2, and the four-momentum transfer t = t min = (2 ξm p ) 2 / (1 -2 ) ξ ∼ 0, so these parameters are not shown explicitly in eqn. (8). The integral in eqn. (8) converges 9 at
9 It is known that the γ + p → J/ψ + p amplitude increases as a power of the photon energy (i.e. as a power of 1 /ξ ). On the other hand the NNLO gluon coefficient function can contain only ln 2 z from the higher-order
1
-
10
1
-
10
x
x
1
1
0.1
0
10
10
10
10
10
1
5
-
4
-
3
-
2
-
1
-
x
0.1
0
10
10
10
10
10
1
5
-
4
-
3
-
2
-
1
-
x
x
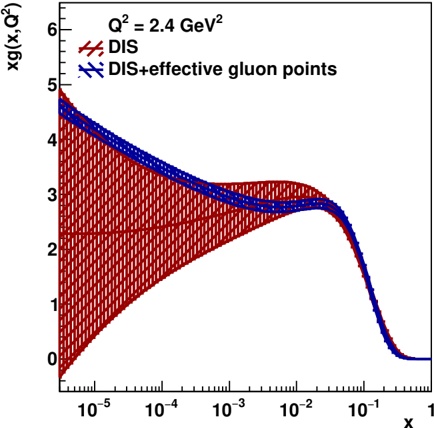
1
Figure 4: The gluon distributions xg at scales µ 2 F = Q 2 = 2.4 GeV 2 (left) and 22 GeV 2 (right) obtained in xFitter fitting DIS (red) and DIS+effective gluon data points (blue).
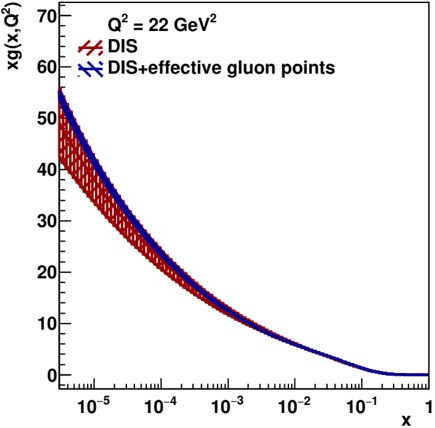
X ∼ ξ . This means that actually after the convolution of the coefficient function with the gluon distribution the effective NNLO/NLO K factor may be considered as a constant assuming that the power λ of eqn. (3) does not vary in the interval of interest .
Thus the value of this K factor can be estimated by describing the exclusive J/ψ photoproduction data from HERA with the NNLO partons and NLO coefficient functions in the region 0 01 . > x > 0 001 since here the uncertainties in the gluon distribution given by the present . global analysis are relatively small. In other words the square of the K factor can be obtained as the ratio of the measured γ + p → J/ψ + p cross section, σ (data), to σ NLO NNLO / calculated using the NLO coefficient function but NNLO input partons (PDF/GPD). That is,
$$K _ { i } = \sqrt { \left ( \frac { \sigma ( \text{data} ) } { \sigma ^ { \text{NLO} / \text{NNLO} } } \right ) _ { i } } \,,$$
and then make the trivial average of the K factors for each data point. From Fig. 3 we may hope that the power λ which describes the energy behaviour of the γ + p → J/ψ + p cross section is more or less constant. However, as it is seen from eqn. (8), this would require the pure power behaviour for the gluons and not for the J/ψ cross section. Unfortunately in the present analysis just in the region of interest 0 01 . > x > 0 001 we observe that the gluon PDF . is too flat (see Fig. 4 left). The power growth starts only at x < 0 001. . Most probably this gluon loop insertions. Thus at large energy (i.e. very small ξ ) the dominant contribution to (8) comes from z ∼ O (1) (i.e. X ∼ ξ ) while the power growth of the amplitude is provided by the GPD power behaviour. In this case we have to calculate the γ + p → J/ψ + p NNLO amplitude, M , by multiplying the NLO coefficient functions, C i NLO with i = g, q , by this K factor.
)
(x,Q
0.05
0
2
Σ
x
12
10
8
6
4
2
0
-
10
-
10
5
2
Q
DIS
DIS
5
)
xg(x,Q
2
x
0
-
5
-
4
-
3
-
2
-
1
-
5
-
4
-
3
-
2
-
1
-
5
4
-
3
-
2
-
1
-
5
0.1
0
0
0.05
0
10
10 10
10 10
10 10
10 10
10
1
-
4
-
3
-
2
-
1
-
x
x
10 10
10 10
10 10
10 10
10
1
x
1
10
1
x
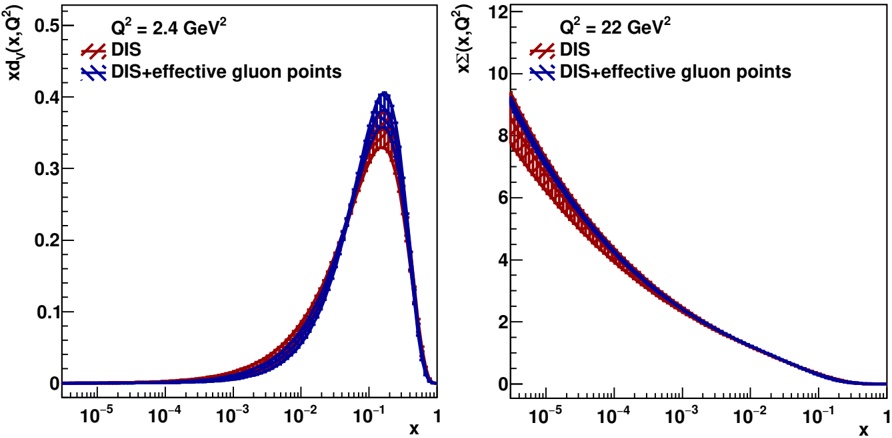
1
Figure 5: The valence xd v quark distribution at scale 2.4 GeV 2 (left) and the singlet x Σ quark distribution at 22 GeV 2 (right) obtained in xFitter fitting DIS data (red) and DIS+effective gluon data points (blue).
is explained by the fact that the DGLAP evolution does not account for the (higher twist) absorptive corrections which are not negligible in this lowx region. To mimic the role of these corrections in DIS data the fit chooses gluons which slightly decrease at x < 0 01. .
In a future analysis, we have two possibilities. Either to include these absorptive effects into the DGLAP evolution following the GLR-MQ scheme [27, 28] (with the possibility that this will generate power increasing gluons already in the HERA domain, x < 0 01), or to have . at hand the full NNLO coefficient function to reach complete NNLO accuracy and go beyond the NNLO* approach discussed here.
In any case in order to obtain realistic partons at such low x and scales, the absorptive effect should be accounted for.
## 5 Conclusion and outlook
We have described the method of 'effective gluon points' which readily allows for the inclusion of exclusive heavy vector-meson V photoproduction data, where V = J/ψ, Υ (as well as the exclusive production in ultraperipheral events at the LHC) in a conventional global parton analysis. Using xFitter , we fit DIS data together with these effective gluon points extracted from the J/ψ and Υ exclusive production data from LHCb and demonstrate that this crucially improves the accuracy of the obtained gluon distribution in the lowx domain. The values of
xg eff ( x ) extracted from the available exclusive J/ψ and Υ data from LHCb are presented in Tables 1 and 2.
Since at present the NNLO coefficient functions for the photon to vector meson ( γ → V ) transition are not available, our computations were performed at NLO level. However, there is the possibility to reach NNLO* accuracy, by extracting the NNLO/NLO K factor from the existing HERA γ + p → J/ψ + p data as discussed in Section 4. Moreover, exclusive vectormeson production data have already been collected by the LHC and more should follow. This merits further theoretical study of the NNLO* analysis, which we reserve for future work.
The analysis presented in this work has demonstrated the potential of existing exclusive data to significantly improve the NLO global parton distributions at small x .
## 6 Acknowledgements
This project has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No. 824093 in order to contribute to the EU Virtual Access 'NLOAccess'. This project has also received funding from the Agence Nationale de la Recherche (ANR) via the grant ANR-20-CE31-0015 ('PrecisOnium') and via the IDEX ParisSaclay 'Investissements d'Avenir' (ANR-11-IDEX-0003-01) through the GLUODYNAMICS project funded by the 'P2IO LabEx (ANR-10-LABX-0038)'. This work was also partly supported by the French CNRS via the IN2P3 Master Project 'QCDFactorisation@NLO'. The work of TT was supported by the STFC Consolidated Grant ST/T000988/1 and currently by ST/X000699/1.
## References
- [1] S. Bailey, T. Cridge, L. A. Harland-Lang, A. D. Martin and R. S. Thorne, Eur. Phys. J. C 81 (2021) no.4, 341 [arXiv:2012.04684 [hep-ph]].
- [2] R. D. Ball et al. [NNPDF], Eur. Phys. J. C 82 (2022) no.5, 428 [arXiv:2109.02653 [hep-ph]].
- [3] T. J. Hou, J. Gao, T. J. Hobbs, K. Xie, S. Dulat, M. Guzzi, J. Huston, P. Nadolsky, J. Pumplin and C. Schmidt, et al. Phys. Rev. D 103 (2021) no.1, 014013 [arXiv:1912.10053 [hep-ph]].
- [4] R. Aaij et al. [LHCb], J. Phys. G 41 (2014), 055002 [arXiv:1401.3288 [hep-ex]].
- [5] R. Aaij et al. [LHCb], JHEP 10 (2018), 167 [arXiv:1806.04079 [hep-ex]].
- [6] R. Aaij et al. [LHCb], JHEP 09 (2015), 084 [arXiv:1505.08139 [hep-ex]].
- [7] M. Diehl, Phys. Rept. 388 (2003), 41-277 [arXiv:hep-ph/0307382 [hep-ph]].
- [8] A. G. Shuvaev, K. J. Golec-Biernat, A. D. Martin and M. G. Ryskin, Phys. Rev. D 60 (1999), 014015 [arXiv:hep-ph/9902410 [hep-ph]]; A. Shuvaev, Phys. Rev. D 60 (1999), 116005 [arXiv:hep-ph/9902318 [hep-ph]].
- [9] T. Ohrndorf, Nucl. Phys. B 198 (1982), 26-44.
- [10] X. D. Ji, J. Phys. G 24 (1998), 1181-1205 [arXiv:hep-ph/9807358 [hep-ph]].
- [11] S. Alekhin, O. Behnke, P. Belov, S. Borroni, M. Botje, D. Britzger, S. Camarda, A. M. Cooper-Sarkar, K. Daum and C. Diaconu, et al. Eur. Phys. J. C 75 (2015) no.7, 304 [arXiv:1410.4412 [hep-ph]].
- [12] V. A. Khoze, A. D. Martin and M. G. Ryskin, Eur. Phys. J. C 74 (2014) no.2, 2756 [arXiv:1312.3851 [hep-ph]].
- [13] V. M. Budnev, I. F. Ginzburg, G. V. Meledin and V. G. Serbo, Phys. Rept. 15 (1975), 181-281
- [14] S. Chekanov et al. [ZEUS], Eur. Phys. J. C 24 (2002), 345-360 [arXiv:hep-ex/0201043 [hep-ex]].
- [15] S. Chekanov et al. [ZEUS], Nucl. Phys. B 695 (2004), 3-37 [arXiv:hep-ex/0404008 [hep-ex]].
- [16] A. Aktas et al. [H1], Eur. Phys. J. C 46 (2006), 585-603 [arXiv:hep-ex/0510016 [hep-ex]].
- [17] C. Alexa et al. [H1], Eur. Phys. J. C 73 (2013) no.6, 2466 [arXiv:1304.5162 [hep-ex]].
- [18] C. A. Flett, A. D. Martin, M. G. Ryskin and T. Teubner, Phys. Rev. D 102 (2020), 114021 [arXiv:2006.13857 [hep-ph]].
- [19] P. Hoodbhoy, Phys. Rev. D 56 (1997), 388-393 [arXiv:hep-ph/9611207 [hep-ph]].
- [20] S. P. Jones, A. D. Martin, M. G. Ryskin and T. Teubner, J. Phys. G 43 (2016) no.3, 035002 [arXiv:1507.06942 [hep-ph]]; E. G. de Oliveira, A. D. Martin and M. G. Ryskin, Eur. Phys. J. C 72 (2012), 2069 [arXiv:1205.6108 [hep-ph]].
- [21] S. P. Jones, A. D. Martin, M. G. Ryskin and T. Teubner, Eur. Phys. J. C 76 (2016) no.11, 633 [arXiv:1610.02272 [hep-ph]].
- [22] D. Y. Ivanov, A. Schafer, L. Szymanowski and G. Krasnikov, Eur. Phys. J. C 34 (2004) no.3, 297-316 [erratum: Eur. Phys. J. C 75 (2015) no.2, 75] [arXiv:hep-ph/0401131 [hep-ph]].
- [23] C. A. Flett, S. P. Jones, A. D. Martin, M. G. Ryskin and T. Teubner, Phys. Rev. D 101 (2020) no.9, 094011 [arXiv:1908.08398 [hep-ph]].
- [24] C. A. Flett, S. P. Jones, A. D. Martin, M. G. Ryskin and T. Teubner, Phys. Rev. D 105 (2022) no.3, 034008 [arXiv:2110.15575 [hep-ph]].
- [25] S. P. Jones, PhD thesis, University of Liverpool, 2014, Unpublished.
- [26] C. A. Flett, J. A. Gracey, S. P. Jones and T. Teubner, JHEP 08 (2021), 150 [arXiv:2105.07657 [hep-ph]].
- [27] L. V. Gribov, E. M. Levin and M. G. Ryskin, Phys. Rept. 100 (1983), 1-150.
- [28] A. H. Mueller and J. W. Qiu, Nucl. Phys. B 268 (1986), 427-452. | null | [
"C. A. Flett",
"A. D. Martin",
"M. G. Ryskin",
"T. Teubner"
] | 2024-08-02T09:12:42+00:00 | 2025-01-28T10:37:29+00:00 | [
"hep-ph"
] | A method to include exclusive heavy vector-meson production data at small $x$ in global parton analyses | We propose a method which allows the inclusion of exclusive heavy
vector-meson production data at low $x$ in future global parton analyses. As an
example we perform a study within xFitter to determine the gluon parton
distribution function (PDF) at next-to-leading order (NLO) at moderate-to-low
$x$ using the measurements of exclusive $J/\psi$ production in ep and pp
collisions from HERA and LHC. We further study the constraints from the
corresponding $\Upsilon$ production process. We finish by discussing the
possible effects at next-to-next-to-leading order (NNLO) through incorporation
of a K factor for the exclusive heavy vector-meson coefficient function at NLO. |
2408.01129v5 | ## A Survey of Mamba
HAOHAO QU,
The Hong Kong Polytechnic Univeristy, China
YIFENG ZHANG,
The Hong Kong Polytechnic Univeristy, China
LIANGBO NING,
The Hong Kong Polytechnic Univeristy, China
WENQI FAN ∗ ,
The Hong Kong Polytechnic Univeristy, China
TYLER DERR,
Vanderbilt University, USA
HUI LIU,
Michigan State University, USA
XIN XU,
The Hong Kong Polytechnic Univeristy, China
QING LI, The Hong Kong Polytechnic Univeristy, China
Deep learning (DL), as a vital technique, has sparked a notable revolution in artificial intelligence (AI), resulting in a great change in human lifestyles. As one of the most representative DL techniques, Transformer architecture has empowered numerous advanced models, especially the large language models (LLMs) that comprise billions of parameters, becoming a cornerstone in deep learning. Despite the impressive achievements, Transformers still face inherent limitations, particularly the time-consuming inference resulting from the quadratic computation complexity of attention calculation. Recently, a novel architecture named Mamba , drawing inspiration from classical state space models (SSMs), has emerged as a promising alternative for building foundation models, delivering comparable modeling abilities to Transformers while preserving near-linear scalability concerning sequence length. This has sparked an increasing number of studies actively exploring Mamba's potential to achieve impressive performance across diverse domains. Given such rapid evolution, there is a critical need for a systematic review that consolidates existing Mamba-empowered models, offering a comprehensive understanding of this emerging model architecture. In this survey, we therefore conduct an in-depth investigation of recent Mamba-associated studies, covering three main aspects: the advancements of Mamba-based models , the techniques of adapting Mamba to diverse data , and the applications where Mamba can excel . Specifically, we first review the foundational knowledge of various representative deep learning models and the details of Mamba-1&2 as preliminaries. Then, to showcase the significance of Mamba for AI, we comprehensively review the related studies focusing on Mamba models' architecture design, data adaptability, and applications. Finally, we present a discussion of current limitations and explore various promising research directions to provide deeper insights for future investigations.
## CCS Concepts: · Computing methodologies → Neural Networks .
Additional Key Words and Phrases: State Space Models, Mamba, Sequence Modeling, Foundation Models, Language Models
∗ Corresponding author: Wenqi Fan, Department of Computing (COMP) & Department of Management and Marketing (MM).
Authors' Contact Information: Haohao Qu, [email protected], The Hong Kong Polytechnic Univeristy, Hong Kong, China; Yifeng Zhang, [email protected], The Hong Kong Polytechnic Univeristy, Hong Kong, China; Liangbo Ning, [email protected], The Hong Kong Polytechnic Univeristy, Hong Kong, China; Wenqi Fan, [email protected], The Hong Kong Polytechnic Univeristy, Hong Kong, China; Tyler Derr, [email protected], Vanderbilt University, Nashville, USA; Hui Liu, Michigan State University, USA, [email protected]; Xin Xu, [email protected], The Hong Kong Polytechnic Univeristy, Hong Kong, China; Qing Li, [email protected], The Hong Kong Polytechnic Univeristy, Hong Kong, China.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected]. © 2024 Copyright held by the owner/author(s). Publication rights licensed to ACM.
Manuscript submitted to ACM
## ACMReference Format:
Haohao Qu, Yifeng Zhang, Liangbo Ning, Wenqi Fan, Tyler Derr, Hui Liu, Xin Xu, and Qing Li. 2024. A Survey of Mamba. In Proceedings of Make sure to enter the correct conference title from your rights confirmation emai (Conference acronym 'XX). ACM, New York, NY, USA, 39 pages. https://doi.org/XXXXXXX.XXXXXXX
## 1 Introduction
Over the past two decades, deep learning (DL), as the most prominent artificial intelligence (AI) technique, has brought about a revolution in various domains such as healthcare [89], autonomous systems [36, 61], recommender systems [105, 237], and financial services [147, 225]. This period has witnessed the emergence of numerous deep neural networks (DNNs) that have significantly altered human lifestyles, offering immense convenience to individuals. One notable example is U-Net [155, 168], a robust deep learning model within the field of vision, which is extensively employed in medical imaging for the examination of radiology scans like MRI and CT scans. Its application assists in the identification and diagnosis of diseases, showcasing its effectiveness in this critical healthcare domain [113, 198]. Moreover, Graph Neural Networks (GNNs) are employed in handling graph-structured data to support smart services, such as recommender systems that suggest personalized content, products, or services to users [40, 41, 201]. Furthermore, Recurrent Neural Networks (RNNs) are extensively adopted in machine translation due to their ability to capture the sequential and contextual information essential for accurate translations [120, 171], empowering individuals from diverse linguistic backgrounds to effectively communicate and comprehend each other's ideas, opinions, and information.
Among the various DL architectures, Transformers have recently stood out and established their dominance across a broad spectrum of applications [33, 180]. For instance, as the most representative large foundation models, large language models (LLMs) like ChatGPT and GPT4 are fundamentally built on the Transformer architecture [2, 149, 237]. By scaling their model sizes to billions and training on a mix of diverse data sources, these Transformer-based models have demonstrated human-level intelligence with their impressive capabilities in language understanding, common sense reasoning, and in-content-learning [43, 226]. This remarkable success is bolstered by the attention mechanism [179], which enables the Transformer-based models to concentrate on relevant parts of the input sequence and facilitate better contextual understanding. However, the attention mechanism also introduces a significant computational overhead that increases quadratically with the input size [125, 242], which presents challenges in processing lengthy inputs. For example, the rapid growth in computational cost makes Transformers impractical or infeasible to process substantial sequences, thereby limiting their applicability in tasks like document-level machine translation [132] or long document summarization [95].
Recently, a promising architecture, structured state space sequence models (SSMs) [59], have emerged to efficiently capture complex dependencies in sequential data, becoming a formidable competitor to Transformer. These models, inspired by classical state space models [90], can be considered a fusion of recurrent neural networks and convolutional neural networks. They can be computed efficiently using either recurrence or convolution operations, achieving linear or near-linear scaling with sequence length, thus significantly reducing the computational costs. More specifically, as one of the most successful SSM variants, Mamba achieves comparable modeling capabilities to Transformers while maintaining linear scalability with sequence length [56], propelling it into the realm of focal topics. Mamba first introduces a simple yet effective selection mechanism that enables the model to filter out irrelevant information while retaining necessary and relevant data indefinitely by parameterizing the SSM parameters based on the input. Then, Mamba proposes a hardware-aware algorithm to compute the model recurrently with a scan instead of convolution, achieving up to 3 × faster computation on A100 GPUs. As shown in Figure 1, the powerful modeling capabilities for Manuscript submitted to ACM
complex and lengthy sequential data, along with near-linear scalability, position Mamba as an emerging foundation model, poised to revolutionize various domains of research and applications, such as computer vision [207, 243], natural language processing [112, 235], healthcare [156, 184, 205], etc. For example, Zhu et al. [243] propose Vim, which is 2.8 × faster than DeiT [178] and saves 86.8% GPU memory when extracting features for high-resolution images. Dao and Gu [28] show the connections between SSMs and variants of attention and propose a new architecture that refines selective SSM, achieving 2-8 × faster on language modeling.
Fig. 1. Examples of the applications of Mamba-based models for different downstream tasks.
Motivated by the powerful long-sequence modeling capabilities of Mamba and its great efficiency, a substantial body of literature has emerged, focusing on employing and improving Mamba on various downstream tasks. Given this significant surge in studies related to Mamba, it is crucial to conduct a comprehensive review of existing literature and deliberate on potential directions for future research. In this survey, we thus conduct a comprehensive review of Mamba from several perspectives to provide newcomers with a fundamental understanding of Mamba's inner workings while helping experienced practitioners stay abreast of its latest developments. Specifically, the remaining survey is organized as follows: In Section 2, we recall the background knowledge of various representative deep neural networks, including RNNs, Transformers, and State Space Models, while the details of Mamba are introduced in Section 3. Subsequently, we summarize the recent advancements in Mamba-based studies from the perspectives of block design, scanning mode, and memory management in Section 4. Then, Section 5 presents the techniques of adapting Mamba to diverse data, including sequential and non-sequential data. Besides, representative applications of Mamba models are introduced in Section 6, while the challenges and future directions are presented in Section 7. Finally, we summarize the whole survey in Section 8.
Concurrent with our survey, several related surveys have been released, purely focusing on state space models [140, 190] and Vision Mamba [121, 207, 227]. Diverging from these surveys, this paper is centered on the associated research
Manuscript submitted to ACM
concerning Mamba. It systematically analyzes existing literature from a novel standpoint to explore the evolution of Mamba architecture and the data adaptation methods utilized in Mamba-based models .
## 2 Preliminary
Mamba is deeply intertwined with the recurrent framework of Recurrent Neural Networks (RNNs), the parallel computation and attention mechanism of Transformers, and the linear property of State Space Models (SSMs). Therefore, this section aims to present an overview of these three prominent architectures.
## 2.1 Recurrent Neural Networks (RNNs)
RNNs excel in processing sequential data due to their capability to retain internal memory [55]. Such networks have demonstrated remarkable effectiveness in a multitude of tasks that involve analyzing and predicting sequences, e.g., speech recognition, machine translation, natural language processing, and time-series analysis [70, 174]. In order to grasp the foundations of recurrent models, this section will offer a brief overview of the standard RNN formulation.
Specifically, at each discrete time step 𝑘 , the standard RNN specifically processes a vector 𝑥 𝑘 ∈ R 𝐷 along with the previous step's hidden state ℎ 𝑘 -1 ∈ R 𝑁 to produce an output vector 𝑜 𝑘 ∈ R 𝑂 and update the hidden state to ℎ 𝑘 ∈ R 𝑁 . The hidden state serves as the network's memory and retains information about the past inputs it has seen. This dynamic memory allows RNNs to process sequences of varying lengths. Formally, it can be written as
$$h _ { k } & = \tanh ( W _ { h x } x _ { k } + W _ { h h } h _ { k - 1 } + b _ { h } ), & ( 1 )$$
$$o _ { k } & = \mathbf W _ { o h } h _ { k } + b _ { o },$$
where W ℎ𝑥 ∈ R 𝑁 × 𝐷 is the weight matrix responsible for processing model inputs into hidden states, W ℎℎ ∈ R 𝑁 × 𝑁 is the recurrent connections between hidden states, W 𝑜ℎ ∈ R 𝑂 × 𝑁 represents the weight used to generate outputs derived from hidden states, 𝑏 ℎ ∈ R 𝑁 and 𝑏 𝑜 ∈ R 𝑂 correspond the biases, and tanh denotes the hyperbolic tangent activation function introducing non-linearity to the RNN model. In other words, RNNs are nonlinear recurrent models that effectively capture temporal patterns by harnessing the historical knowledge stored in hidden states.
However, there are several limitations associated with RNNs. First, RNNs have a restricted capability to effectively extract long-range dynamics within input sequences. As information traverses through successive time steps, the repeated multiplication of weights in the network can lead to dilution or loss of information. Consequently, it becomes challenging for RNNs to retain and recall information from earlier time steps while making predictions. Second, RNNs process sequential data incrementally, restricting their computational efficiency since each time step relies on the preceding one. This makes parallel computations challenging for them. Furthermore, conventional RNNs lack built-in attention mechanisms, which allow the network to capture global information within input sequences. This absence of attention mechanisms hinders the network's ability to selectively model the crucial segments of the data. To overcome these constraints, Transformers and State Space Models have emerged, each tackling these challenges from different perspectives. These two approaches will be further elaborated upon in the subsequent subsections.
## 2.2 Transformers
The Transformer [179] is a groundbreaking model in the realm of deep learning, revolutionizing various AI applications. Its introduction marked a significant departure from traditional sequence-to-sequence models by employing a selfattention mechanism, facilitating the capture of global dependencies within model inputs. For instance, in natural Manuscript submitted to ACM
language processing, this self-attention capability allows the model to comprehend relationships between various positions in a sequence. It achieves this by assigning weights to each position based on its significance relative to other positions. More specifically, a sequence of input vectors x is first transformed into three types of vectors: Query 𝑄 , Key 𝐾 , and Value 𝑉 by utilizing linear transformations of the original input, defined by:
$$Q = \mathbf x \cdot W ^ { Q }, K = \mathbf x \cdot W ^ { K }, V = \mathbf x \cdot \mathbf W ^ { V },$$
where W 𝑄 , W 𝐾 , and W 𝑉 are the trainable parameters. The attention scores are computed by calculating the dot product of 𝑄 and 𝐾 , then scaling the result by √︁ 𝑑 𝐾 , where 𝑑 𝐾 is the dimension of the key vectors. Such procedures are then passed through a Softmax function to normalize the scores 𝑆 and produce attention weights, defined by:
$$S = \text{Softmax} ( \frac { Q K ^ { T } } { \sqrt { d _ { K } } } ) V,$$
Apart from performing a single attention function, multi-head attention is introduced to enhance the model's ability to capture different types of relationships and provide multiple perspectives on the input sequence. In multi-head attention, an input sequence is processed in parallel by multiple sets of self-attention modules. Each head operates independently, performing the exact computations as in the standard self-attention mechanism. The attention weights from each head are then combined to create a weighted sum of the value vectors. This aggregation step allows the model to leverage information from multiple heads and capture diverse patterns and relationships in the input sequence. Mathematically, the multi-head attention is computed as follows:
MultiHead
(
𝑄, 𝐾,𝑉
)
=
(
𝑆
𝑂
1
⊕
𝑆
2
⊕
...
⊕
𝑆
𝑚
) ·
W
,
$$\text{where } S _ { i } = \text{Softmax} ( \frac { Q _ { i } K _ { i } ^ { T } } { \sqrt { d _ { K } } } ) V _ { i }, \ i \in [ 1, m ],$$
where 𝑚 is the number of attention heads, ⊕ is the concatenation operation, and W 𝑂 is the linear transformation to project the multi-head attention scores to the final values.
## 2.3 State Space Models
State Space Models (SSMs) are a traditional mathematical framework utilized to depict the dynamic behavior of a system over time [90]. Recent years have found the widespread applications of SSMs in diverse fields like control theory, robotics, and economics [59, 60]. At its core, SSMs embody the system's behavior through a collection of hidden variables referred to as "states", enabling it to capture temporal data dependencies effectively. Different from RNNs, SSMs are linear models characterized by their associative properties. To be specific, in a classical state space model, two fundamental equations are formulated, i.e., state equation and observation equation, to model the relationships between input 𝑥 ( 𝑡 ) ∈ R and output 𝑦 𝑡 ( ) ∈ R at current time 𝑡 , through a N-dimensional hidden state ℎ 𝑡 ( ) ∈ R 𝑁 . The process can be written by
$$h ^ { \prime } ( t ) & = A h ( t ) + B x ( t ),$$
$$y ( t ) = C h ( t ) + D x ( t ),$$
where ℎ ′ ( 𝑡 ) is the derivative of current state ℎ 𝑡 ( ) , A ∈ R 𝑁 × 𝑁 is the state transition matrix that describes how states change over time, B ∈ R 𝑁 × 1 is the input matrix that controls how inputs affect state changes, C ∈ R 1 × 𝑁 denotes the output matrix that indicates how outputs are generated based on current states, and D ∈ R represents the command
coefficient that determines how inputs affect outputs directly. In general, most SSMs exclude the second term in the observation equation, i.e., set D 𝑥 ( 𝑡 ) = 0, which can be recognized as a skip connection in deep learning models.
2.3.1 Discretization . To adhere to the requirements of machine learning settings for various real-world scenarios, SSMs must undergo a process of discretization that transforms continuous parameters into discrete parameters. Discretization methods generally aim to partition continuous time into 𝐾 discrete intervals with equal integration area as possible. To achieve the goal, as one of the most representative solutions, Zero-Order Hold (ZOH) [141, 232] is successfully employed in SSMs, which assumes that the function value remains constant over the interval Δ = [ 𝑡 𝑘 -1 , 𝑡 𝑘 ] . After ZOH discretization, the SSM equations can be rewritten by
$$h _ { k } = \overline { A } h _ { k - 1 } + \overline { B } x _ { k },$$
$$y _ { k } = C h _ { k },$$
where A = exp ( Δ A ) , and B = ( Δ A ) -1 ( exp ( Δ A ) -I ) · Δ B , 𝑘 is the discrete time step. From these formulas, it is clear that the discrete SSM has a similar structure to recurrent neural networks and, therefore, discrete SSMs can accomplish inference processes with higher efficiency compared to Transformer-based models that compute attention on all inputs in each auto-regressive decoding iteration.
2.3.2 Convolutional Computation . The discrete SSM, being a linear system, possesses the associated property and, therefore, integrates seamlessly with convolutional computation. More specifically, it can calculate the output at each time step independently as follows:
$$y _ { 0 } & = C \overline { A } ^ { 0 } \overline { B } x _ { 0 },$$
$$y _ { 1 } & = C \overline { A } ^ { 1 } \overline { B } x _ { 0 } + C \overline { A } ^ { 0 } \overline { B } x _ { 1 },$$
$$y _ { 2 } = C ^ { - 2 } \bar { B } x _ { 0 } + C ^ { - 1 } \bar { B } x _ { 1 } + C ^ { - 0 } \bar { B } x _ { 2 },$$
......
(13)
$$y _ { k } & = C \overline { A } ^ { k } \overline { B } x _ { 0 } + C \overline { A } ^ { k - 1 } \overline { B } x _ { 1 } + \dots + C \overline { A } ^ { 1 } \overline { B } x _ { k - 1 } + C \overline { A } ^ { 0 } \overline { B } x _ { k }.$$
By creating a set of convolutional kernels K = ( CB , ..., CA B 𝑘 , ... ) , the recurrent computation can be converted to a convolutional form as:
$$y = x * \overline { K },$$
where x = [ 𝑥 , 𝑥 0 1 , ... ] and y = [ 𝑦 ,𝑦 , ... 0 1 ] ∈ R 𝐿 denote the input and output sequences, respectively, while 𝐿 is the sequence length. This convolutional computation allows SSMs to take full advantage of modern matrix computation hardware (e.g., GPUs) to enable parallel computing during the training process, which is impossible with RNNs utilizing nonlinear activation functions. Notably, given an input 𝑥 𝑘 ( ) with 𝐷 dimensions, the SSM computation will be calculated separately for each dimension to produce a 𝐷 -dimensional output 𝑦 𝑡 ( ) . In this case, the input matrix B ∈ R 𝑁 × 𝐷 , the output matrix C ∈ R 𝐷 × 𝑁 , and the command matrix D ∈ R 𝐷 × 𝐷 , while the state transition matrix remains unchanged, i.e., A ∈ R 𝑁 × 𝑁 .
2.3.3 Relationship among RNN, Transformer, and SSM . The computation algorithms of RNN, Transformer, and SSM are depicted in Figure 2. On the one hand, the conventional RNN operates within a non-linear recurrent Manuscript submitted to ACM
Fig. 2. An illustration of representative model architectures, namely Recurrent Neural Network (RNN), Transformer, and State Space Model (SSM). (a) RNNs function within a nonlinear recurrent framework, facilitating rapid outputs during auto-regressive inference. (b) Transformers execute matrix multiplications concurrently across numerous query-key pairs, facilitating parallel training. (c) SSMs exhibit versatility by accommodating both recurrent and convolutional computations due to their linear nature. This fusion harnesses the strengths of RNNs and Transformers, allowing SSMs for recurrent inference and parallel training. Despite this, traditional time-invariant SSMs fall short in context-aware modeling, resulting in diminished performance in specific tasks.
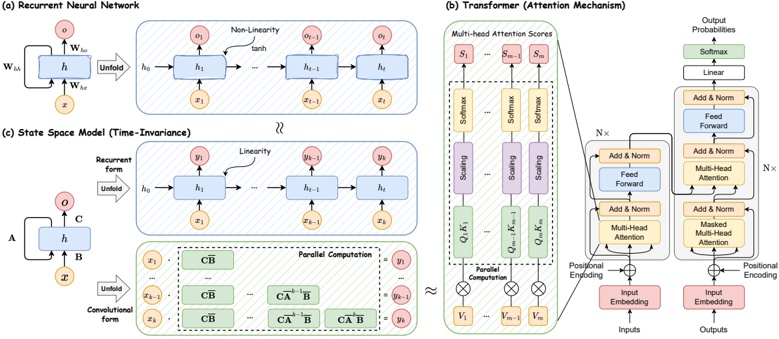
framework where each computation depends solely on the previous hidden state and the current input. While this format allows RNNs to quickly generate outputs during auto-regressive inference, it hampers their ability to fully exploit GPU parallel computing, leading to slower model training. On the other hand, the Transformer architecture performs matrix multiplications in parallel across multiple query-key pairs, which can be efficiently distributed across hardware resources, which enables faster training of attention-based models. However, when it comes to generating responses or predictions from Transformer-based models, the inference process can be time-consuming. For instance, the auto-regressive design of language models entails generating each token in the output sequence sequentially, which requires repetitive calculations of attention scores at each step, leading to slower inference times. As shown in Table 1, unlike RNNs and Transformers, which are limited to supporting only one type of computation, discrete SSMs have the flexibility to support both recurrent and convolutional computations, given their linear properties. This unique capability allows SSMs to achieve not only efficient inference but also parallel training. However, it should be noted that the most conventional SSMs are time-invariant, meaning that their A B C , , , and Δ are unrelated to the model input 𝑥 . This would limit context-aware modeling, which leads to inferior performance of SSMs in certain tasks such as selective copying [56].
Table 1. Pros and cons of three primary architectures-RNNs, Transformers, and SSMs-in auto-regressive sequential modeling tasks.
| Comparison | RNNs | Transformers | SSMs |
|-----------------------------------------------------------------|-------------------------------------------------------------|---------------------------------------------------------------|--------------------------------------------------------------------|
| Training Speed Inference Speed Complexity Modeling Capabilities | Slow (Recurrent) Fast (Recurrent) 𝑂 ( 𝐿𝐷 2 ) (Hidden State) | Fast (Parallel) Slow (Quadratic-Time) 𝑂 ( 𝐿 2 𝐷 ) (Attention) | Fast (Convolutional) Fast (Recurrent) 𝑂 ( 𝐿𝐷 2 ) (Time-Invariance) |
Manuscript submitted to ACM
## 3 Mamba
To address the aforementioned drawback of traditional SSMs in terms of their inferior context-aware capabilities, Mamba is proposed by [56] as a potential alternative that promises to be a general sequence foundation model backbone. More recently, Mamba-2 [28] proposes Structured Space-State Duality (SSD) that establishes a robust theoretical framework connecting structured SSMs and various forms of attention, allowing us to transfer algorithmic and systems optimizations originally developed for Transformers to SSMs. In this section, we will give a concise and clear introduction to Mamba and Mamba-2.
## 3.1 Mamba-1: Selective State Space Model with Hardware-aware Algorithms
Conventional SSMs have shown limited effectiveness in modeling text and other information-dense data [56], impeding their progress in deep learning. In the pursuit of empowering SSMs with Transformers' modeling capabilities, Gu and Dao [56] introduce three innovative techniques based on Structured State Space Models, i.e., High-order Polynomial Projection Operator (HiPPO)-based Memory Initialization, Selection Mechanism, and Hardware-aware Computation, as illustrated in Figure 3. These techniques aim to enhance the capabilities of SSMs in long-range linear-time sequence modeling. In particular, the initialization strategy establishes a coherent hidden state matrix, effectively facilitating long-range memory. Then, the Selection Mechanism empowers SSMs to acquire content-aware representations. Lastly, Mamba crafts two hardware-aware computation algorithms, Parallel Associative Scan and Memory Recomputation, to enhance training efficiency.
3.1.1 HiPPO-based Memory Initialization . Modeling and learning from sequential data represent foundational challenges in contemporary machine learning, forming the bedrock for various tasks, including language modeling, speech recognition, and video processing. A fundamental component for modeling intricate and long-term temporal dependencies lies in memory, encompassing the ability to store and integrate information from preceding time steps [74]. Similar to RNNs, preserving and forgetting the historical hidden states (i.e., the matrix A ) play a critical role in SSMs to
Fig. 3. Overview of the Selective State Space Model with hardware-aware state expansions. The selective mechanism introduces input-dependent dynamics, while the hardware computation algorithm optimizes memory usage within the more efficient levels of GPU memory hierarchy.
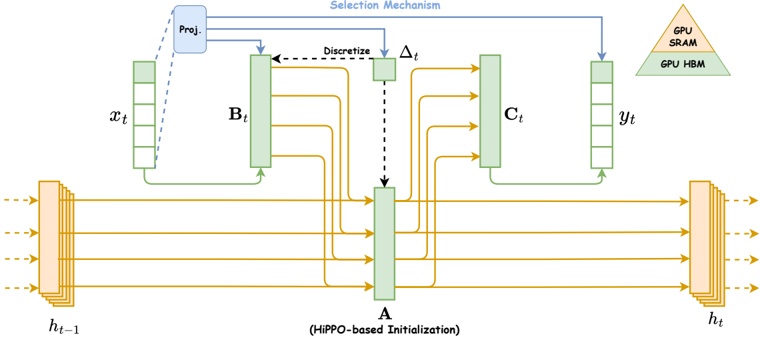
Manuscript submitted to ACM
achieve satisfying performances. In previous structured state space sequence models (SSMs), there have been suggestions for special initializations, especially in the case of complex-valued models. These special initializations have proven beneficial in various scenarios, including situations with limited data availability. Similarly, Mamba focuses primarily on the initialization of the hidden state matrix A to capture complex temporal dependencies. This is accomplished through the utilization of the HiPPO theory [57] with an innovative scaled Legendre measure (LegS), ensuring careful consideration of the complete historical context rather than a limited sliding window. To be specific, the HiPPO-LegS assigns uniform weight to all historical data points, which can be expressed as:
$$A _ { n k } ^ { \text{HPPO} } = - \begin{cases} ( 2 n + 1 ) ^ { \frac { 1 } { 2 } } ( 2 k + 1 ) ^ { \frac { 1 } { 2 } } & \text{if $n > k$} \\ n + 1 & \text{if $n = k$} \, & ( 1 6 ) \\ 0 & \text{if $n < k$} \end{cases} \\. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \.$$
where 𝑛 is the number of polynomials, and 𝑘 denotes the particular discrete time steps. Building upon the HiPPO theory, Mamba introduces two simple initialization methods for the complex and real cases, i.e., S4D-Lin and S4D-Real [58], as presented in
$$A _ { d n } = - \begin{cases} \frac { 1 } { 2 } - n i & S 4 D \text{-Lin} \\ n + 1 & S 4 D \text{-Real} \end{cases},$$
where 𝑛 is the 𝑛 -th element of A for all input dimensions 𝑑 = 1 2 , , ..., 𝐷 . Given such an initialization, the model can learn long-dependent memory that experiences smaller degradation of newer steps and larger degradation of older steps by compressing and reconstructing the input information signal. According to the formulas, HiPPO-LegS possesses advantageous theoretical properties: it remains consistent across input timescales and offers rapid computation [57]. Additionally, it has bounded gradients and approximation errors, facilitating the parameter learning process.
3.1.2 Selection Mechanism . Conventional state space models are unable to produce personalized outputs based on specific model inputs (i.e., the content-aware modeling ability) due to the property of Time Invariance. To provide SSMs with such a capability similar to the attention mechanisms, Mamba designs a time-varying selection mechanism that parameterizes the weight matrices according to model input. Such innovation empowers SSMs to filter out extraneous information while retaining pertinent details indefinitely. Formally, the selection mechanism involves setting the interval Δ , and matrices B C , as functions of the input x ∈ R 𝐵 × 𝐿 × 𝐷 , which can be formulated as:
$$B \rightarrow S ^ { B } = W ^ { B } x,$$
$$C \rightarrow S ^ { C } = w ^ { C } x,$$
$$\Delta \to S ^ { \Delta } = \tau _ { \Delta } \cdot \text{BroadCast} _ { D } ( W ^ { \Delta } x ),$$
where S B ∈ R 𝐵 × 𝐿 × 𝑁 , S C ∈ R 𝐵 × 𝐿 × 𝑁 , and S Δ ∈ R 𝐵 × 𝐿 × 𝐷 are the selective space matrices that function of the input to achieve content-aware modeling. 𝐵 , 𝐿 , 𝐷 , and 𝑁 represent the batch size, input length, input feature size, and hidden channel number, respectively. The activation function ( 𝜏 Δ = softplus ) is utilized for Δ . Notably, W B ∈ R 𝑁 × 𝐷 , W C ∈ R 𝑁 × 𝐷 , and W Δ ∈ R 𝐷 × 1 are the selection weights (i.e., linear parameterized projections) for corresponding components, and BroadCast 𝐷 means to broadcast the result to all the dimensions 𝑑 = 1 2 , , .., 𝐷 . Subsequently, the selective SSMs undergo discretization using a common statistical technique, Zero-Order Hold (ZOH) [141], as presented
$$\overline { A } \rightarrow S ^ { \overline { A } } = \exp ( S ^ { \Delta } A ),$$
$$\bar { B } \rightarrow S ^ { \bar { B } } = ( S ^ { \Delta } A ) ^ { - 1 } ( \exp ( S ^ { \Delta } A ) - I ) \cdot S ^ { \Delta } S ^ { B },$$
where S A ∈ R 𝐵 × 𝐿 × 𝐷 × 𝑁 and S B ∈ R 𝐵 × 𝐿 × 𝐷 × 𝑁 are the selective state transition matrix and the input matrix, respectively, which become the functions of input x . By doing so, the discrete SSM has changed from time-invariant to time-varying (i.e., content-aware) as
$$y = S S M ( A, B, C ) ( x ),$$
which generates output y ∈ R 𝐵 × 𝐿 × 𝐷 depending on the input x . Note that the time-varying selection mechanism in Mamba has a similar structure to the attention mechanism in Transformer, i.e., both perform operations based on inputs and their projections, which allows Mamba's SSM to achieve a flexible content-aware modeling. Nevertheless, it loses the equivalence to convolutions, which negatively impacts its efficiency.
3.1.3 Hardware-aware Computation . The selection mechanism is crafted to surpass the limitations of linear timeinvariant models. Still, it challenges efficient training: SSMs' convolutional kernels become input-dependent, resulting in the inability to perform parallel computations. To tackle the problem, Mamba utilizes two computation techniques, i.e., Parallel Associative Scan (also called Parallel Prefix-Sum) [65] and Memory Recomputation . First, the Parallel Associative Scan leverages the property of linear associative computation and the parallelism of modern accelerators (GPU and TPU) to perform the calculation of selective SSMs in a memory-efficient manner. More specifically, the parallel associative scan reduces the computation complexity of model training from O ( 𝑁 𝑑 2 ) to O ( 𝑁 𝑡 / ) . At its core, the scan revolves around constructing a balanced binary tree on the given input and sweeps it to and from the root. In other words, the parallel associative scan begins by traversing from the leaves to the root (i.e., Sweep-Up), creating partial sums at the internal nodes of the tree. Then, it reverses the traversal, moving from the root back up the tree to construct the whole scan using the partial sums (i.e., Sweep-Down).
On the other hand, Mamba leverages the traditional approach of recomputation to diminish the overall memory demand for training selective SSM layers. In particular, Mamba abstains from storing intermediate states of size ( 𝐵 𝐿 , , 𝐷 𝑁 , ) during the forward pass of the Parallel Associative Scan to prevent memory expansion. Instead, it recomputes those intermediate states in the backward pass for gradient computation. By doing so, recomputation sidesteps the necessity of reading 𝑂 𝐵𝐿𝑁𝐷 ( ) elements between GPU memory cells. In addition to optimizing the memory needs of the scan operation, Mamba-1 extends its use of recomputation to enhance the efficiency of the entire SSM layer. This optimization encompasses projections, convolutions, and activations, which typically demand significant memory resources but can be rapidly recomputed.
## 3.2 Mamba-2: State Space Duality
Transformers, which have played a crucial role in the success of deep learning for various areas, have inspired the development of various techniques, such as Parameter-efficient Fine-tuning [96], Catastrophic Forgetting Mitigation [97], and Model Quantization [202], aimed at improving model performance from diverse perspectives. To enable state space models to access and benefit from the valuable techniques initially developed for Transformers, Mamba-2 [28] have introduced a comprehensive framework called Structured State-Space Duality (SSD), which establishes theoretical
Manuscript submitted to ACM
Fig. 4. The block architectures of Mamba-1 and Mamba-2.
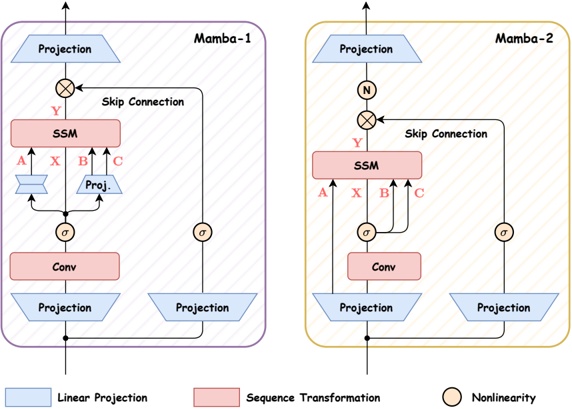
connections between SSMs and different forms of attention. Formally,
$$y = S S D ( A, B, C ) ( x ) = M x,$$
where M denotes the matrix form of SSMs that uses the sequentially semi-separable representation, and M 𝑗𝑖 = C A T 𝑗 𝑗 : 𝑖 B 𝑖 . Notably, C 𝑗 and B 𝑖 represent the selective space state matrices associated with input tokens x 𝑗 and x 𝑖 , respectively. A 𝑗 : 𝑖 denotes the selective matrix of hidden states corresponding to the input tokens ranging from 𝑗 to 𝑖 . In essence, SSD demonstrates that both the attention mechanism used by Transformers and the linear time-variant system employed in SSM can be seen as semi-separable matrix transformations. Furthermore, Dao and Gu [28] also prove that the selective SSM is equivalent to a structured linear attention mechanism implemented with a semi-separable masking matrix.
Based on SSD, Mamba-2 has devised a more hardware-efficient computation through a block decomposition matrix multiplication algorithm. Specifically, by viewing state space models as semi-separable matrices through the matrix transformation, Mamba-2 decomposes the computation into matrix blocks, in which diagonal blocks represent intrachunk computations. In contrast, the off-diagonal blocks represent inter-chunk computations factored through the SSM's hidden state. This approach enables Mamba-2 to achieve a 2-8 × faster training process than Mamba-1's parallel associative scan while remaining competitive with Transformers.
## 3.3 Mamba Block
In this subsection, we provide a summary of the block design for Mamba-1 and Mamba-2. Figure 4 illustrates the comparison of these two architectures. Mamba-1 is motivated by an SSM-centric point of view where the selective SSM layer is tasked with conducting a map from input sequences X to Y . In this design, the linear projections of ( A B , , C ) are applied after the initial linear projection that creates X . The input tokens and state matrices are then passed through the selective SSM cell, utilizing the parallel associative scan, to produce the output Y . After that, Mamba-1 employs a skip connection to encourage feature reuse and alleviate the degradation problem often occurring during
the model training process. Finally, the Mamba model is constructed by stacking this block interleaved with standard normalization and residual connections.
As for Mamba-2, it introduces the SSD layer aiming to create a map from [ X A B C , , , ] to Y . This is achieved by simultaneously processing [ X A B C , , , ] with a single projection at the beginning of the block, similar to how standard attention architectures generate the Q K V , , projections in parallel. In other words, the Mamba-2 block simplifies the Mamba-1 block by removing sequential linear projections. This enables faster computation of the SSD structure compared to the parallel selective scanning in Mamba-1. Additionally, a normalization layer is added after the skip connection, aiming to improve training stability.
Table 2. Representative Open-Access Foundation Models Utilizing Mamba Architecture.
| Name | Modality | Affiliations | Sizes | Access Link |
|-----------------|------------|---------------------------------------------------|-----------|---------------|
| Mamba 1&2 | Language | Carnegie Mellon University & Princeton University | 130M-2.8B | 1 |
| Falcon Mamba 7B | Language | Technology Innovation Institute | 7B | 2 |
| Mistral 7B | Language | Mistral AI & NVIDIA | 7B | 3 |
| Jamba | Language | AI21 Lab | 12B/52B | 4 |
| Vision Mamba | Vision | Huazhong University of Science and Technology | 7M-98M | 5 |
| VideoMamba | Video | OpenGVLab, Shanghai AI Laboratory | 28M-392M | 6 |
| Codestral Mamba | Code | Mistral AI | 7B, 22B | 7 |
- 1. https://github.com/state-spaces/mamba
- 2. https://huggingface.co/tiiuae/falcon-mamba-7b
- 3. https://huggingface.co/mistralai/Mistral-7B-v0.1
- 4. https://huggingface.co/ai21labs/Jamba-v0.1
- 5. https://huggingface.co/hustvl/Vim-base-midclstok
- 6. https://huggingface.co/OpenGVLab/VideoMamba
- 7. https://mistral.ai/news/codestral-mamba/
## 4 Advancements in Mamba Models
State Space Models and Mamba have been recently explored and have become one promising alternative as the foundational model backbone. As shown in Table 2, large-scale Mamba-based models have not only thrived within academic research but have also made significant strides in industry, such as Falcon Mamba 7B and Mistral 7B , demonstrating their efficacy through successful training on GPUs. Despite that, the Mamba architecture still encounters challenges, such as memory loss, generalization to diverse tasks, and inferior capability to capture complex patterns to Transformer-based language models. To overcome these challenges, plenty of efforts have been made to improve the Mamba architecture. Existing research studies primarily concentrate on modifying the block design , scanning mode , and memory management aspects. This section will introduce several vital techniques from these three aspects, and a summary of related studies is presented in Table 3.
## 4.1 Block Design
The design and structure of the Mamba block have a significant impact on the overall performance of Mamba models, making it an emerging research focus. As illustrated in Figure 5, based on different approaches to constructing new Mamba blocks, existing research can be categorized into three categories: a) Integration methods aim to integrate the Mamba block with other well-known models, so as to strike a balance between effectiveness and efficiency; b) Manuscript submitted to ACM
Table 3. Summary of Existing Studies on Improving the Mamba Model.
| Modules | Methods | Classes | Representative References |
|-----------|-----------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------|
| Block | Integration | Transformer Convolutional Neural Network (CNN) Graph Neural Network (GNN) Recurrent Neural Network (RNN) Spiking Neural Network (SNN) | [52, 66, 112, 139, 144, 145, 208] [54, 108, 108, 165, 194, 213, 222, 223] [9, 104, 116, 183, 212] [31, 77, 175] [8, 107] |
| Block | Substitution | U-Net Diffusion Models Others | [29, 72, 85, 111, 119, 126, 156, 157, 161, 167, 184, 185] [46, 49, 138, 194, 218] [19, 102] |
| Block | Modification | Mix-of-Expert K-way/Parallel Structure Register | [5, 112] [80, 114, 182, 200, 244] [184, 211] |
| Scan | Flatten | Bidirectional Scan Sweeping Scan Continuous Scan Efficient Scan | [88, 102, 106, 151, 243] [122, 195, 223] [67, 76, 210] [142, 204] |
| Scan | Stereo | Hierarchical Scan Spatiotemporal Scan Hybrid Scan | [12, 24, 26, 64, 166, 185] [21, 103, 214, 216] [10, 29, 32, 54, 69, 167] |
| Memory | Initialization [35], Compression [124, 136], Connection [68, 153], State-Tracking [134] | Initialization [35], Compression [124, 136], Connection [68, 153], State-Tracking [134] | Initialization [35], Compression [124, 136], Connection [68, 153], State-Tracking [134] |
| Others | Autoregressive Pretraining [154], Explainability [84] | Autoregressive Pretraining [154], Explainability [84] | Autoregressive Pretraining [154], Explainability [84] |
Fig. 5. Representative examples of improved Mamba models based on the perspective of block design: (a) Integration methods combine orthogonal architectural designs (e.g., Transformer) with Mamba, leading to enhanced model performance and increased throughput, all while upholding a manageable memory footprint [144, 208]; (b) Substitution methods enhance the learning capabilities of standard learning frameworks (e.g., UNet) by integrating the Mamba block as a substitute for their primary layers [111, 223]; (c) Modification methods employ cutting-edge techniques, such as Mix-of-Expert (MoE), to refine the Mamba block [112].
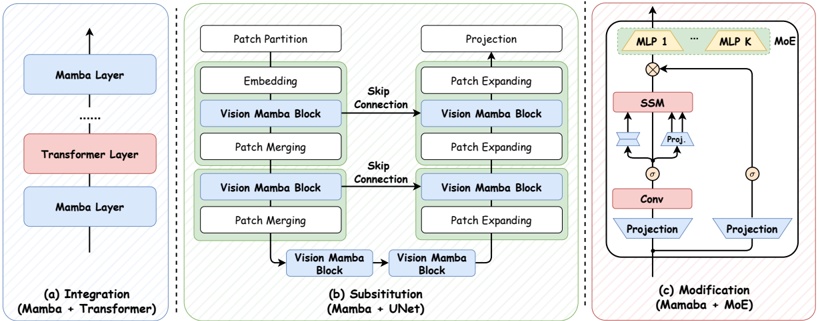
Substitution methods attempt to utilize Mamba block as a substitution for main layers in advanced model frameworks; and c) Modification methods focus on modifying the components within the classical Mamba block. Accordingly, we will present a detailed review of these methods in the following subsections.
- 4.1.1 Integration . Given Mamba's exceptional ability to capture long-term dynamics, it has been extensively integrated with other models, leveraging its strengths to deliver a robust framework tailored to specific scenarios. The integration specifically encompasses advanced models like Transformers, Graph Neural Networks (GNNs), Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and Spiking Neural Networks (SNNs). Specific examples are described below.
- · Transformer -based models have exhibited remarkable performance in numerous tasks, but their quadratic computational complexity still hampers them during inference process [59]. In the pursuit of efficient generation, some researchers have proposed incorporating Mamba blocks with Transformer-based models [52, 66, 139, 144, 145]. For example, Jamba [112] combines blocks of Transformer and Mamba layers to tackle long-content Natural Language Processing tasks, capitalizing on the advantages of both model families. The Attention-Mamba hybrid model demonstrated superior performance compared to the standalone Transformer and Mamba models, achieving better throughput than the vanilla Transformer model. Mambaformer [208] utilizes the hybrid framework to forecast multiple time series, which internally combines Mamba blocks and Transformer layers for long- and short-range dependencies, respectively. Due to the integration of Mamba and Transformer, Mambaformer outperforms Transformer-based predictors in long-short range time series forecasting.
- · GNN has demonstrated promising potential in capturing neighboring relationships through message-passing mechanisms, where information is propagated over a connection graph through stacked layers. Nonetheless, these models face a significant limitation known as over-smoothing [20], particularly when attempting to capture highorder adjacency signals. To tackle such a challenge, Mamba has been employed for graph representation learning [104, 116, 183, 212]. For example, Graph Mamba [9] reformulates graph-structured data into sequential tokens in a particular order and leverages a selective SSM layer within the Mamba block to construct a novel Graph Mamba Network (GMN) architecture, which achieves superior graph representation learning capabilities, particularly in the datasets that require high-order dependencies between nodes.
- · RNN -based models have yielded outstanding results in capturing temporal dynamics. Nevertheless, RNNs still face significant challenges, including time-consuming recurrent training and limitations in memory capacity for hidden states. Inspired by the emergence of recent Mamba-based architectures, some researchers have developed a fusion of Mamba blocks and RNNs. For instance, VMRNN [175] achieves state-of-the-art performance in spatio-temporal forecasting while minimizing floating-point operations (FLOPs) compared to recurrent-based and recurrent-free methods. It accomplishes this by introducing a novel recurrent unit that combines Mamba blocks with Long Short-Term Memory (LSTM).
- · CNN -based methods are constrained by local receptive fields, resulting in suboptimal performance capturing global and long-range semantics [56]. Known for the superior capability of state space models to learn long-range patterns, some studies [108, 194, 213] have explored the potential of utilizing Mamba blocks to enhance CNN-based models, especially in the field of computer vision. For instance, MedMamba [223] and nnMamba [54] showcase how the integration of visual Mamba blocks improves the performance of CNNs in image analysis tasks.
- · SNN has been recently proposed as a promising network architecture inspired by the behavior of biological neurons in the brain: transmitting knowledge between neurons through discrete spikes. One of the key advantages of SNNs lies in their potential for low-power implementation, as they can exploit the sparse and event-driven nature of neural activity. Motivated by the energy-efficient implementation of SNNs and SSMs' superior long-range learning capabilities, pioneering studies have delved into integrating these two methods. For example, SpikeMba [107] combines them to
handle confidence bias towards prominent objects and to capture enduring dependencies within video sequences. Through extensive evaluations, the authors claim that integrating these two models improves the effectiveness of temporal video grounding tasks, precisely moment retrieval and highlight detection.
- 4.1.2 Substitution . Inspired by the outstanding capabilities of the selective SSM in efficient computation and long sequence learning, the adoption of Mamba modules to replace critical components in classical modeling frameworks such as U-Net [155] and Diffusion Model [71] has attracted a lot of attention. By introducing the selective SSM layer, these methods achieve long-range learning and efficient computation for their specific tasks. Below, we demonstrate instances of substitution using the Mamba module, specifically for advanced frameworks such as U-Net and Diffusion models.
- · U-Net . Many efforts [111, 167, 184, 185] have been made to synergize U-Net with Mamba's capability in capturing intricate and broad semantics so as to advance model performance in computer vision tasks. For example, MambaUNet [184] utilizes Visual Mamba blocks exclusively to construct a U-Net-like model (i.e., an encoder-decoder model infused with skip connections) for medical image segmentation. Their evaluation demonstrates that Mamba-UNet surpasses several U-Net variations, which can be attributed to the efficacy and efficiency of Mamba blocks in handling long-range patch sequences.
- · Diffusion Model . Some endeavors [46, 49, 138] have been undertaken to build a novel type of diffusion model, Diffusion State Space Model (DiS), which replace the typical backbone (e.g., CNNs, Attentions, U-Nets) with a state space backbone. Given the remarkable efficiency and efficacy of Mamba blocks in accommodating long-range dependencies, DiS is distinguished by generating longer sequences using diffusion models [46]. For example, Oshima et al. [138] propose a Mamba-based diffusion model that substantially decreases memory consumption for long video sequences, while still maintaining competitive performance metrics when compared to Transformer-based models. Moreover, MD-Dose [49] and P-Mamba [218] construct noise predictors using Mamba blocks in the backward process of diffusion models, ultimately generating specific targets for medical image processing.
- · Others . Besides the U-Net and Diffusion Models, there are a few substitutions. For example, Res-VMamba [19] adopts Visual Mamba blocks in a residual learning framework for food category classification. Furthermore, SPMamba [102] adopts the TF-GridNet [196], a recently developed time-frequency model, as its base architecture followed by succeeding the Transformer components with bidirectional Mamba blocks. This adaptation enables the model to encompass a wider scope of contextual information efficiently for the task of speech separation.
- 4.1.3 Modification . Apart from integration and substitution methods that directly employ the Mamba block, some other efforts have been made to modify the Mamba block with the aim of enhancing its performance in different scenarios. For example, Jamba [112] borrows the conception of Mix-of-Experts (MoE) [45, 83] to enable their hybrid (Transformer-Mamba) decoder-only model to be pretrained with far less compute and allow flexible objective-specific configurations. Notably, the Jamba model (56B available parameters, 12B active parameters, 4GB KV cache) requires a 32x smaller KV cache compared to a representative Transformer-based language model, LLaMA-2-7B (6.7B available parameters, 12B active parameters, 128GB KV cache), while providing more extensive available and active parameters. This allows Jamba to swallow a context length of 140K on a single A100 GPU (80GB), seven times the length supported by LLaMA-2-70B. In addition to MoE, some studies propose modifying the SSM layer into a K-way structure, which involves processing model inputs using parallel SSM cells, allowing for capturing information and knowledge from multiple perspectives. For example, Sigma [182] develops a novel Mamba-based visual encoder that handles multimodal
inputs by utilizing parallel SSM layers. UltraLight VM-UNet [200] proposes a vision Mamba layer with parallel SSM cells that process deep features in different channels. To recap, by implementing such modifications (i.e., K-way, MoE), these Mamba-based models gain enhanced learning capabilities, particularly in processing multimodal inputs and fast adapting to multiscale tasks. In addition, a pioneering study, Mamba ® , has introduced a novel approach that suggests incorporating registers evenly within the visual input tokens before passing the inputs through the SSM layers. This modification aims to enhance the representation of the sequence direction of image patches, thereby enabling the unidirectional inference paradigm of the Mamba block to be applicable to visual tasks. Despite these successes, the exploration of modifying Mamba blocks remains a promising yet under-explored area.
## 4.2 Scanning Mode
The parallel associative scan operation serves as a crucial component within the Mamba model, which aims to address the computation problem caused by the selection mechanism, accelerate the training process, and reduce memory requirements. It achieves this by leveraging the linear property of time-varying SSMs to design kernel fusion and re-computation at the hardware level. However, Mamba's uni-directional sequence modeling paradigm hinders a comprehensive learning process for various data, such as images and videos. To mitigate this issue, several studies have focused on designing efficient scanning methods to enhance model performance and facilitate the training process of Mamba models. As shown in Figure 6, existing studies that concentrate on developing the scanning mode techniques can be categorized into two classes: 1) Flatten Scan approaches process model inputs from a flat perspective of token sequence; and 2) Stereo Scan methods scan model inputs across dimensions, channels, or scales.
- 4.2.1 Flattening Scan . Flattening scan refers to the process of flattening the model input into token sequences and scanning them accordingly from different directions. This type of scanning is commonly employed for both one-dimensional (e.g., time series) and two-dimensional (e.g., image) data. In this section, we further categorize it into four classes, namely Bidirectional Scan , Sweeping Scan Continuous Scan , , and Efficient Scan .
- · Bidirectional Scan . Borrowing the conception of bidirectional recurrent neural networks (Bi-RNNs) [159], Visual Mamba [243] introduces a scanning method for visual data, called Bidirectional Scan (Bi-Scan), which involves processing input tokens using simultaneous forward and backward SSMs, thus enhancing the model capacity for spatially-aware processing. Recently, a number of studies have leveraged the Bi-Scan method to facilitate the learning abilities of their Mamba-based models [106]. For example, DPMamba [88] and SPMamba [102] have both leveraged a pair of dual-path (forward and backward) selective SSMs to model the dependency of speech signals, enabling a bidirectional knowledge processing for speech separation. Such notable successes can be attributed to the effectiveness of Bi-Scan and its ease of deployment.
- · Sweeping Scan. As illustrated in Figure 6, the Sweeping Scan technique processes the model inputs in a specific direction, analogous to a cleaner meticulously sweeping a floor [195, 223]. For instance, Cross-Scan [122] entails dividing the input image into patches and subsequently flattening it along four distinct paths, which is regarded as a fusion of two bidirectional scans. By adopting these complementary traversal paths, Cross Scan enables each patch in the image to efficiently integrate information from its neighbors in different directions, thereby facilitating the establishment of informative, receptive fields. Omni-Scan [167, 236] incorporates the modeling of image information flows from multiple directions, e.g., 2 (forward and backward) × 4 (left-right, top-bottom, top right-bottom left, top left-bottom right). Such a strategy augments the global modeling capability of contextual information in various directions, enabling the extraction of comprehensive global spatial features.
Fig. 6. Recently developed scanning methods in Mamba-based models: Flatten Scans (a-c) involve flattening the model input into token sequences and scanning them accordingly from different directions, and Stereo Scans (d-e) process inputs from additional perspectives, capturing a broader spectrum of knowledge compared to flatten scan methods.
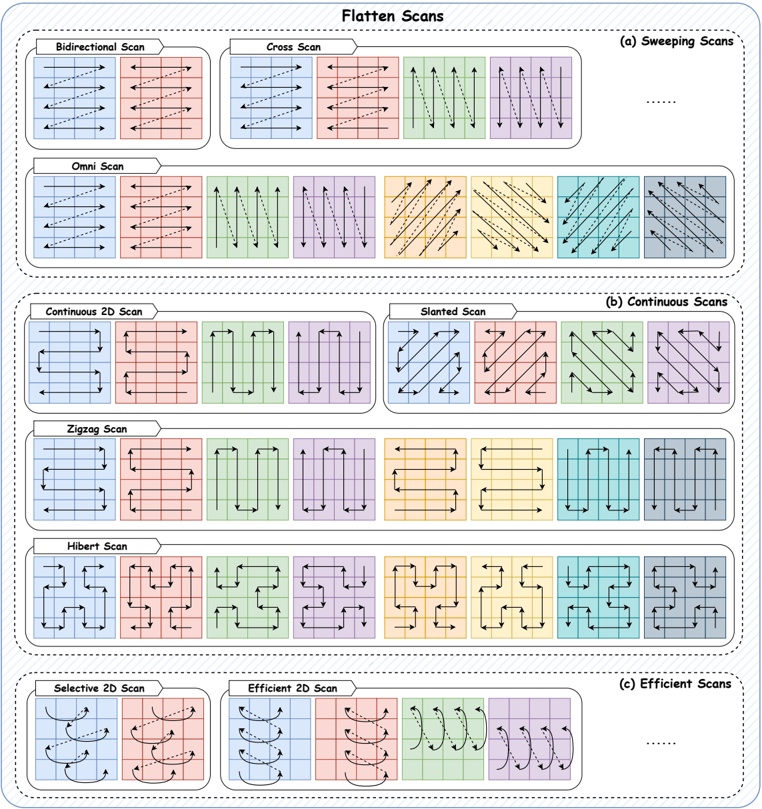
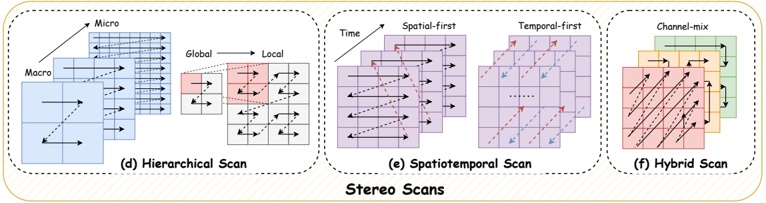
Manuscript submitted to ACM
- · Continuous Scan. To ensure the continuity of input sequences, Continuous Scan techniques scan the adjacent tokens between columns or rows [67], as shown in Figure 6. For example, in order to better cope with 2D spatial inputs, PlainMamba [210] introduced a continuous scanning approach, known as Continuous Scan, which scans the adjacent tokens between columns (or rows), instead of traveling to the opposite tokens in Cross Scan. Moreover, Hilbert Scan [67] travels a sinuous path based on the Hilbert matrix. Based on their evaluation results, it can be inferred that enhancing the semantic continuity of input tokens leads to superior performance in various visual recognition tasks for Mamba-based models.
- · Efficient Scan . In contrast to the aforementioned scanning methods, which focus on achieving a more comprehensive input modeling, efficient scanning methods aim to accelerate the training and inference process. Generally, the efficient scan separates the given input into several parts and processes them in parallel, thus reducing computational time. For example, Efficient-2D Scan [142] proceeds images by skipping patches, thus reducing four times of computational demands while preserving global feature maps. Moreover, Gao et al. [51] introduce an effective bi-directional subspace scanning scheme within their Mamba framework. This scheme is designed to capture long-term spatial-angular correspondences efficiently for 4D light field super-resolution tasks. Specifically, it decomposes the patch sequences into two parts and processes them through two bi-directional scanning schemes. By doing so, the scanning method lowers the input length and addresses the long-term memory issues without sacrificing the complete 4D global information.
- 4.2.2 Stereo Scan . By modeling inputs from additional perspectives, stereo-scan methods excel in capturing a broader spectrum of knowledge during the scanning process when compared to flattened scan methods. This enhanced capability allows for a more thorough comprehension of model inputs. To be specific, these methods can be classified into three primary categories: Hierarchical Scan Spatiotemporal Scan , , and Hybrid Scan . The Hierarchical Scan processes the input from different levels, while the Spatiotemporal Scan considers input patterns from both temporal and spatial perspectives. Additionally, Hybrid Scan combines multiple scanning methods to leverage the benefits of different scan techniques.
- · Hierarchical Scan methods involve employing different kernel sizes of scanning to capture the semantic knowledge from global to local or from macro to micro perspectives [26, 64, 166, 185]. For example, a Mamba-in-Mamba hierarchical encoder is proposed by [24] for infrared small target detection, combining inner and outer selective SSM blocks. The inner one is specifically tailored to capture the interplay among visual patches for local pattern extraction. Conversely, the outer block is designed to characterize the relationship between visual sentences to capture global features. HiSS [12] divides an input sequence into chunks and models the chunk features hierarchically for continuous sequential prediction. The chunks are first processed by a low-level SSM cell, and the processed features are mapped into an output sequence by a high-level SSM block.
- · Spatiotemporal Scan . Driven by the prevalence of dynamic systems in the real world, there has been a growing interest in spatiotemporal scanning methods to enhance the performance of Mamba block [214, 216]. For instance, VideoMamba [103] expands the original 2D scan for images into two 3D scans: spatial-first scanning and temporal-first scanning. Combining these two scanning approaches, VideoMamba demonstrates exceptional efficiency in handling long, high-resolution videos. Additionally, ChangeMamba [21] integrates three spatiotemporal scanning mechanisms (sequential modeling, cross modeling, and parallel modeling) to enable contextual information interaction among multi-temporal features for remote sensing change detection.
- · Hybrid Scan . In the pursuit of comprehensive feature modeling, many efforts have focused on combining the advantages of different scanning methods [29, 32, 54, 167, 238], so-called Hybrid Scan. For example, Mambamixer [10] presents Switch of Scan that dynamically employs a set of image scanning methods, namely Cross-Scan, Zigzag Scan, and Local Scan, to traverse image patches. Mambamixer also introduces a dual selection mechanism to mix information across tokens and channels. By doing so, they show competitive performance with other vision models. Pan-Mamba [69] introduces two scanning methods built upon the Mamba architecture: channel swapping scan and cross-modal scan. By incorporating these two scanning approaches, Pan-Mamba enhances its capabilities in efficient cross-modal information exchange and fusion for image pan-sharpening.
## 4.3 Memory Management
Like RNNs, the memory of hidden states within state space models effectively stores information from previous steps, thereby playing a crucial role in SSM's overall functionality. While Mamba has introduced the HiPPO-based method for memory initialization [56], challenges still exist in the memory management of the SSM cell, including transferring hidden information between layers and achieving lossless memory compression. To this end, a handful of pioneering studies have proposed different solutions [188]. For example, Ezoe and Sato [35] have attempted to refine the initialization process of selective SSMs by using a balanced truncation method during model retraining. Moreover, DGMamba [124] introduces a Hidden State Suppressing method to bolster the domain generalization capabilities of the hidden states within State Space Models. This method works to alleviate the negative effects stemming from these hidden states, thereby narrowing the gap between hidden states across different domains. On a similar note, DenseMamba [68] has put forth a dense connection method to enhance the propagation of hidden information between layers in SSMs. This strategy aims to mitigate memory degradation and preserve detailed information for output generation by selectively integrating hidden states from shallower layers into deeper ones. Moreover, Merrill et al. [134] delve into the concept of the illusion of "State" in SSMs through extensive experiments, revealing their constraints in addressing practical state-tracking challenges like monitoring chess moves. Expanding on this, the researchers enhance SSMs with a subtle modification: by introducing input-dependent transition matrices, enabling effective state tracking and permutation composition.
## 5 Adapting Mamba to Diverse Data
The Mamba architecture represents an extension of selective state space models, which possesses fundamental properties of recurrent models that make it well-suited as general foundation models operating on sequences like text, time series, speech, and more. Meanwhile, recent pioneering studies have extended the utilization of the Mamba architecture beyond sequential data, encompassing domains such as images and graphs, as depicted in Figure 7. These studies aim to harness Mamba's remarkable capabilities in capturing long-range dependencies while leveraging its efficiency in learning and inference processes. In this section, we therefore aim to investigate the emerging techniques that adapt Mamba to various types of data. A summary of related studies is illustrated in Table 4.
## 5.1 Sequential Data
Sequential data refers to data gathered or organized in a particular order, where the order of the data points holds significance. To explore the potential of utilizing Mamba as a foundation model for tasks concerning sequential data, we provide a comprehensive review presented in the subsequent sections, which cover various sequential data, including natural language, video, time series, speech, and human motion.
Fig. 7. Representative strategies exist for adapting Mamba to diverse types of data. (a-e) The Mamba architecture, imbued with essential characteristics of recurrent models, serves as an ideal foundational model for handling sequences like language, time series, and speech. (f-h) To address non-sequential data, a common approach involves segmenting or sampling the data into discrete tokens and organizing them into sequences following a defined rule. Additionally, Mamba exhibits the capability to process multimodal data by either concatenating their respective sequences or projections.
Table 4. Summary of Mamba-associated research in different types of data.
| Category | Data | Typical Tasks | Representative References |
|---------------------|------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------|
| Sequential Data | Language Video Time Series Speech Motion | Long-Context Language Modelling Long Video Generation Long-Term Forecasting Speech Separation Continuous Human Motion Understanding | [5, 10, 12, 59, 68, 112, 136, 146, 164] [6, 103, 107, 123, 138, 214, 244] [3, 3, 4, 109, 157, 208, 222, 239] [1, 27, 88, 102] [189, 224, 234] |
| Non-Sequential Data | Image Graph Point Cloud | High-Resolution Medical Vision Large Graph Learning Efficient 3D Point Cloud Restoration | [21, 23, 115, 156, 178, 184, 184, 223, 243] [9, 40, 78, 82, 116, 183, 217] [63, 64, 110, 219, 220, 229, 241] |
| Multimodal Data | Vision-Languge Multimodality | Visual and Linguistic Awareness Semantic Recognition | [118, 148, 189, 199, 215] [32, 182] |
5.1.1 Natural Language . As one of the most representative architectures, Mamba performs content-based reasoning while ensuring efficiency, which is considered a promising alternative for the backbone of large language models to address Transformers' computational inefficiency on long sequences. Building upon this insight, many studies have explored the potential of Mamba for various downstream tasks in natural language processing (NLP) [10, 12, 68, 136]. For example, MambaByte [187] is proposed to utilize Mamba on byte sequences, aiming to leverage the advantages of Mamba in capturing long-range dependencies for token-free language models. Their evaluations show that MambaByte avoids the inductive bias of subword tokenization and outperforms state-of-the-art subword Transformers on long-term language modeling tasks. Besides, Jamba [112] and BlackMamba [5] incorporate the concept of Mix-of-Experts (MoE) to enhance Mamba's performance on language processing by integrating the linear-complexity generation from SSMs with the rapid and economical inference capabilities offered by MoE.
Manuscript submitted to ACM
- 5.1.2 Video . The core objective for video understanding and generation lies in learning spatiotemporal representations, which inherently presents two formidable challenges: the large spatiotemporal redundancy within short video clips and the complex spatiotemporal dependencies among long contexts [6, 123]. In the pursuit of addressing both challenges simultaneously, Mamba stands out with its capabilities in distinguishing short-term actions and interpreting long videos [52, 107, 138, 244]. For instance, VideoMamba [103] first projects the input videos into a set of non-overlapping spatiotemporal patches through 3D convolution, and then utilizes stacked bidirectional Mamba blocks to encode these patches into vectorized representations for downstream tasks like video understanding and generation. Moreover, Vivim [214] presents a novel temporal Mamba block to effectively compress extensive spatiotemporal representations into multi-scale sequences for medical video segmentation.
- 5.1.3 Time-Series . As typical sequential data, time-series data is ubiquitous in various facets of our lives, including stock market analysis, traffic modeling, and weather forecasting [150, 239]. Motivated by the recent progress on Mamba in modeling long-range sequences, many efforts have been made to investigate its potential for time-series data [3, 4, 109, 208]. For example, TimeMachine [3] harnesses Mamba to capture enduring patterns in multivariate time-series data, ensuring linear-complexity computation and minimal memory footprints for streamlined time-series processing. Moreover, Mambaformer [208] combines selective SSM and Attention layers for the long- and short-term forecasting of weather, traffic flow, and more.
- 5.1.4 Speech . Speech specifically refers to the vocalized form of human communication that involves vocalized expressions using specific phonetic sounds, words, grammar, and intonation patterns [1]. Recently, in the realm of speech-related tasks, researchers [27] have made significant progress in developing Mamba-based models to tackle the emerging challenges encountered by existing model architectures, such as RNNs and Transformers. For example, SPMamba [102] and DPMamba [88] utilize bidirectional Mamba modules to capture a broader range of contextual information for speech separation, demonstrating a substantial improvement of 13% in model performance and a 566% reduction in computational complexity compared to a Transformer-based baseline when addressing speech separation tasks.
- 5.1.5 Motion . Human motion understanding and generation stand as a significant pursuit in a broad range of practical applications, including computer animation, game development, and robot manipulation. However, semantic actions that occur infrequently within lengthy motion sequences make long-range motion modeling difficult. To address this issue, several studies have proposed the use of Mamba to capture spatiotemporal patterns in motion sequences [189]. For instance, Motion Mamba [234] proposes a hybrid Mamba model, which leverages a hierarchical SSM layer to capture temporal patterns and introduces a bidirectional SSM layer to learn spatial knowledge, preserving motion consistency between frames. Based on the comprehensive experiments, the Mamba-based model outperforms representative diffusion-based methods in human motion generation tasks, achieving a 50% FID improvement and four times faster performance. Additionally, MambaMOS [224] designs a motion-aware state space model that focuses explicitly on capturing variations in motion between consecutive time steps, which further emphasizes the exceptional capabilities of Mamba in achieving high-quality, lengthy sequence motion modeling.
## 5.2 Non-Sequential Data
Non-sequential data differs from sequential data by not adhering to a specific order. Its data points can be organized or accessed in any sequence without significantly impacting the data's meaning or interpretation [81]. This absence
of inherent order presents difficulties for recurrent models such as RNNs and SSMs specifically designed to capture temporal dependencies in data. Surprisingly, Mamba, representing SSMs, has shown outstanding success in efficiently dealing with non-sequential data in recent developments. In this section, we will review relevant studies about how Mamba effectively handles non-sequential data, including images, graphs, and point clouds.
5.2.1 Image . As one of the most prevalent modalities, image data forms the foundation of various computer vision applications, e.g., face recognition, medical vision [223], and remote sensing [21, 23]. Drawing inspiration from the success of Mamba in sequence modeling, there exists an intriguing opportunity to transfer this accomplishment from text processing to image analysis. It involves treating an image as a series of patches, potentially paving the way for new avenues of exploration within the realm of computer vision. Thus, plenty of Mamba-based vision models have recently been developed to alleviate heavy computational resources and memory pressures while exhibiting competitive modeling capabilities [48, 115, 156, 184, 184, 186]. For example, Vision Mamba [243] incorporates bidirectional SSM to facilitate global visual semantic modeling and incorporates positional embeddings for location-aware visual comprehension. Not requiring attention mechanisms, Vision Mamba matches the modeling capacity of Vision Transformers while substantially decreasing computation time to subquadratic levels and upholding linear memory complexity. Specifically, it outperforms the state-of-the-art baseline DeiT [178] in terms of speed, being 2.8× faster, and also presents a remarkable reduction of 86.8% in GPU memory usage during batch inference for feature extraction on high-resolution images (1248×1248). Moreover, VMamba [122] introduces 2D Selective Scan (SS2D) that serves as a bridge between 1D array scanning and 2D plane traversal, enabling Mamba to process visual data effectively. Additionally, LKM-UNet [186] presents a Mamba-based model designed for medical image segmentation. This model leverages large Mamba kernels within a UNet architecture, showcasing superior performance in both local and global spatial modeling for visual inputs in medical imaging tasks.
5.2.2 Graph-structured Data . Graph modeling has found extensive utility in managing complex structures and relationships, including applications in domains like social networks [40, 41], recommender systems [39], and molecular interactions [78]. Due to the powerful capabilities of Mamba in long-range modeling and high efficiency, several pioneering investigations have embraced the selective State Space Model (SSM) for non-sequential graph data [116]. These studies utilize state space models to encode context through hidden states during recurrent scans, allowing for input flow control, which resembles attention sparsification on graphs, presenting a data-dependent node selection process within graph modeling contexts [217]. Moreover, Mamba is anticipated to enhance model efficiency during large-graph training tasks. For example, Graph-Mamba [183] introduces a novel Mamba-based block as a foundational component for graph modeling. This block combines a graph flattening mechanism with the selection mechanism offered by Mamba, transforming sub-graphs into node sequences and facilitating input-dependent context filtering, respectively. In a recent work, Behrouz and Hashemi [9] propose a Graph Mamba Network (GMN), a new graph neural network format based on selective SSMs. The authors reformulate the selective SSM into a graph learning format and provide theoretical justification for the power of the proposed network. By addressing the emerging challenges in crucial steps of graph message passing, GMNs achieve remarkable performance in various aspects, surpassing GNNs and Transformer-based models in multiple benchmark datasets with diverse graph scales. Furthermore, Huang et al. [82] introduce the Graph State Space Convolution (GSSC) as a systematic extension of SSMs tailored for graph-structured data. Specifically, GSSC incorporates distance-based graph convolution kernels into the SSM cell, aiming at enhancing expressive power and capturing long-range dependencies. Through assessments conducted on ten benchmark datasets, the study [82] underscores the potential of GSSC as a potent and scalable model for graph machine learning. Manuscript submitted to ACM
5.2.3 Point Cloud . Point cloud is a crucial modality in computer vision, with a multitude of practical applications across domains like robotics, autonomous driving, and augmented reality [63]. Unlike image processing and graph learning, the analysis of point clouds presents unique challenges stemming from point clouds' inherent irregularity and sparsity, a 3D non-structured data. To tackle these challenges, notable advancements have been made in deep learning-based approaches, with particular emphasis on Transformer-based models [220]. However, the complexity of attention mechanisms is quadratic, bringing significant computational cost, which is not friendly to low-resource devices. Noted by the recent advance of State Space Models (SSMs) in handling 1D sequences (e.g., language and speech) and 2D data (e.g., image and graph), there have been efforts to extend the application of Mamba to 3D point clouds [219]. In general, these Mamba-based methods for point cloud analysis employ a two-step process [64, 241]. First, the point cloud data is tokenized into discrete tokens using specific scanning methods. Then, Mamba is utilized to capture the underlying patterns within these tokens. For instance, PointMamba [110] proposes a hierarchical scanning strategy to encode local and global information of 3D point cloud and then utilizes plain Mamba as the backbone to extract features from serialized point tokens without incorporating additional complex techniques. Point Cloud Mamba [229] incorporates Mamba as the foundational model backbone to significantly reduce memory usage, demonstrating comparable (or superior) performance compared to Transformer-based counterparts.
## 5.3 Multimodal Data
Integrating multiple modalities, such as language (sequential data) and images (non-sequential data), offers valuable and complementary information for artificial intelligence perception and scene understanding. Recently, there has been significant research attention on Multimodal Large Language Models (MLLMs) that inherit the advanced capabilities of Large Language Models [199], including powerful language expression and logical reasoning. While Transformers have been the dominant approach in this field, Mamba has emerged as a strong competitor by demonstrating impressive performance in aligning mixed-source data and achieving linear complexity scaling in sequence length, which makes Mambaapromising alternative to Transformers for multimodal learning [118, 215]. For example, Qiao et al. [148] propose VL-Mamba to explore the utilization of Mamba's efficient architecture for solving vision-language tasks, utilizing the pre-trained Mamba model for language understanding and incorporating a connector module to align visual patches with language tokens. Wang et al. [189] propose Text-controlled Motion Mamba [189], which leverages Mamba to dynamically capture global temporal information based on text queries to enhance human motion understanding. Additionally, Fusion-Mamba [32] and Sigma [182] have tried to fuse complementary information from different modalities such as thermal, depth, and RGB. Fusion-Mamba focuses on improving object detection, while Sigma aims to enhance semantic segmentation.
## 6 Applications
In this section, we introduce several notable applications of Mamba-based models. To provide a comprehensive overview, we categorize these applications into: Natural Language Processing , Computer Vision , Speech Analysis , Drug Discovery , Recommender Systems , and Robotics and Autonomous Systems .
## 6.1 Natural Language Processing
In the natural language processing domain, recently, some Mamba-based models have emerged as alternatives to Transformer-based models for language modeling [5, 14, 68, 112, 181, 209, 235], especially in applications involving extensive contexts such as Question Answering Systems and Text Summarization .
6.1.1 Question Answering Systems . Question Answering (QA) involves AI models comprehending, reasoning, and responding using extensive knowledge bases, enabling coherent and contextually rich conversations, widely applied in chatbots and virtual assistants. Incorporating context from previous interactions is crucial for accurately addressing follow-up questions in multi-turn conversations. However, existing models face challenges in inference speed and computational efficiency, particularly in complex reasoning tasks. This leads to significant memory use and computational overhead, which limits scalability and real-time application efficiency. To address these limitations, recent studies have explored Mamba-based models to improve long-term dialogue management in QA Systems [112, 112, 133]. For instance, Mamba-Chat [133] is the first chat language model utilizing a state-space framework. The model maintains and updates its understanding of dialogues by employing state space representations, ensuring context awareness. Jamba [112] strategically alternates between Transformer and Mamba layers, incorporating MoE to enhance model capacity while optimizing parameter utilization. In common sense reasoning and reading comprehension tasks, Jamba achieves performance comparable to larger Llama-2 models but with fewer parameters, demonstrating efficiency and effectiveness. Similarly, DenseMamba [68] introduces a novel method to enrich the propagation of hidden information across layers in SSMs by selectively incorporating hidden states from shallow layers into deeper layers. Compared to traditional Transformer-based models, this preserves crucial fine-grained information for superior performance in question-answering tasks. Overall, integrating Mamba-based models shows promising potential to advance QA systems by improving dialogue management and enhancing performance in complex reasoning tasks.
6.1.2 Text Summarization. Text summarization aims to condense long texts by preserving essential information. Maintaining coherence and relevance is crucial in this task. Transformer-based models often struggle with long-sequence dependencies, potentially compromising coherence and relevance. In contrast, Mamba-based models leverage robust long-sequence processing capabilities, making them well-suited for processing coherent and context-rich text. Their robust architecture allows them to excel in summarization tasks by accurately capturing and condensing the essence of extensive documents. For instance, LOCOST [14], based on state space models, processes significantly longer sequences than sparse attention models. In long document abstractive summarization, LOCOST achieves performance comparable to the highest-performing sparse transformers of equivalent dimensions while reducing memory usage by up to 50% during training and 87% during inference. Additionally, SAMBA [153] integrates Mamba with sliding window attention, enabling selective sequence compression into recurrent hidden states while retaining precise memory recall through attention mechanisms. SAMBA achieves a throughput of 3.73 times higher than Transformers when handling input lengths of 128K, showcasing superior performance in tasks requiring long-context summarization.
## 6.2 Computer Vision
In addition to NLP applications, Mamba-based models have shown potential in the computer vision domain, representative applications like Disease Diagnosis and Motion Recognition and Generation .
6.2.1 Disease Diagnosis. In clinical practice, medical images and videos provide critical insights into the morphology of organs or tissues. Efficient analysis of biomedical objects, such as lesions in large-scale 2D/3D images or videos, significantly enhances disease diagnosis and clinical treatment. However, CNN-based models like UNet face challenges in handling long-range dependencies because of their restricted receptive fields. This challenge is intensified by the typically larger sizes and higher resolution of medical images than natural images. Meanwhile, Transformerbased algorithms are computationally intensive, limiting their practicality in resource-constrained clinical settings. To overcome these limitations, numerous studies have adopted Mamba-based models in real medical environments [111, Manuscript submitted to ACM
128, 156, 194]. For instance, U-Mamba [128] and SegMamba [205] both integrate a hybrid CNN-SSM block, merging the local feature extraction capabilities of convolutional layers with the long-range dependency modeling offered by SSMs. This hybrid approach outperforms the existing models in tasks such as 3D segmentation of abdominal organs in CT and MR images, segmentation of instruments in endoscopy images, and segmentation of cells in microscopy images. Similarly, CMViM [211] addresses challenges in Alzheimer's disease (AD) diagnostic imaging by leveraging masked Vim autoencoders and contrastive learning across modalities, achieving the best performance in AD diagnostic imaging classification. Additionally, ProMamba [203] specializes in polyp segmentation. By incorporating VisionMamba architecture and prompt technology, this model achieves higher accuracy and better generalization than previous methods. For dynamic medical object segmentation in videos, Vivim [214] effectively compresses long-term spatiotemporal representations across different scales into sequences using the Temporal Mamba Block. This approach demonstrates enhanced performance and computational efficiency in disease diagnosis, such as ultrasound breast lesions segmentation and polyp segmentation in colonoscopy videos.
6.2.2 Motion Recognition and Generation. Motion recognition and generation are critical in motion monitoring [53], computer animation [169], game development [135], and film production [191]. However, transformer-based models encounter challenges related to computational and memory demands, limiting their applicability in resourceconstrained environments. Additionally, Transformers and GCNs-based models struggle with effectively capturing long motion sequences and complex spatial-temporal patterns in videos and 4D point clouds. Recent studies have explored the use of Mamba to address these challenges, leveraging its robust performance and lower computational demands [18, 106, 233, 234]. For instance, HARMamba [106] utilizes a bidirectional SSM architecture to process data from wearable sensors, significantly reducing computational load and memory usage while maintaining high accuracy in real-time human motion recognition. Similarly, Simba [18] integrates Mamba within a U-ShiftGCN framework, effectively handling longer sequences and complex spatial-temporal interactions, achieving the best results in skeletal action recognition from videos. Furthermore, Motion Mamba [234] and InfiniMotion [233] are both for motion generation. Specifically, Motion Mamba [234] utilizes hierarchical temporal Mamba blocks for processing temporal data and bidirectional spatial Mamba blocks for handling latent poses, ensuring motion consistency across frames and enhancing motion generation accuracy within temporal frames. InfiniMotion [233] introduces the Motion Memory Transformer with Bidirectional Mamba Memory, improving the transformer's memory capabilities to efficiently generate continuous, long-duration human motions (up to one hour and 80,000 frames) without overwhelming computational resources.
## 6.3 Speech Analysis
Speech signals inherently consist of thousands of samples. While this broad temporal context provides rich acoustic features, it also poses significant computational demands. To process speech signals effectively, several Mamba-based models have been successfully employed in diverse speech applications, notably in Speech Separation and Tagging and Speech Enhancement .
- 6.3.1 Speech Separation and Tagging. Speech separation involves isolating individual speech signals from a multispeaker environment. It is critical for enhancing the intelligibility and quality of audio communications. Meanwhile, audio tagging or classification involves mapping audio samples to their corresponding categories. Both tasks depend on capturing short-range and long-range audio sequential patterns. Although transformer-based models have been the leading architecture of these applications, they face significant challenges in quadratic computational and memory costs due to their self-attention mechanisms. Recently, there has been a shift toward employing state space models Manuscript submitted to ACM
for speech separation [88, 102] and audio tagging [11, 231]. Specifically, DPMamba [88] utilizes selective state spaces to capture dynamic temporal dependencies in speech signals, encompassing both short-term and long-term forward and backward dependencies. SPMamba [102] integrates the TF-GridNet model, replacing its transformer components with bidirectional Mamba modules. DASS [11] integrates knowledge distillation with state-space models, allowing for tagging sound events in audio files lasting up to 2.5 hours. Meanwhile, MAMCA [231] focuses on Automatic Modulation Classification (AMC) by introducing the selective state-space model as its backbone, effectively addressing both accuracy and efficiency challenges associated with long-sequence AMC. By adopting state-space models, these models demonstrate a qualitative improvement, capturing a broader range of contextual information and enhancing overall effectiveness, thereby proving the superior scalability of SSMs in handling long duration.
6.3.2 Speech Enhancement. Speech enhancement (SE) aims to extract clear speech components from distorted signals, producing enhanced signals with improved acoustic characteristics. As a front-end processor, SE is pivotal in numerous speech applications, including assistive hearing technologies [99], speaker recognition [7], and automatic speech recognition [130]. Mobile audio devices face challenges due to limited resources. Recent studies have explored the application of Mamba, leveraging its powerful performance and reduced computational demands in SE tasks [17, 152, 163, 172, 230]. For instance, TRAMBA [172] leverages a hybrid architecture combining Transformers and Mamba to improve speech quality for mobile and wearable platforms, specifically targeting acoustic and bone conduction. It achieves a remarkable tenfold reduction in memory consumption compared to current leading models. Additionally, oSpatialNet-Mamba [152] leverages Mamba for long-term multichannel speech enhancement, achieving outstanding results for static and moving speakers.
## 6.4 Drug Discovery
Protein design, molecular design, and genomic analysis are pivotal in advancing drug discovery and biotechnology [101, 160]. Leveraging the Mamba-based model significantly reduces the complexities of modeling long sequences in these domains [62, 143, 143, 158, 158]. Specifically, PTM-Mamba [143] and ProtMamba [162] are protein language models based on the Mamba architecture. PTM-Mamba utilizes bidirectional gated Mamba blocks and structured state space models, efficiently processing long sequences while reducing computational demands. ProtMamba is designed to be homology-aware yet alignment-free, adept at handling extensive contexts across hundreds of protein sequences. Both models maintain high efficiency and accuracy even with large data sets, providing critical tools for protein design. Meanwhile, generative molecular design aims to simulate molecules with tailored property profiles from a specific distribution. However, current models lack the efficiency required to optimize high-fidelity oracles, directly resulting in low success rates. Saturn [62], applying the Mamba architecture, utilizes its linear complexity and computational efficiency to surpass 22 competing models in drug discovery. Furthermore, understanding genomes is crucial for gaining insights into cellular biology. Challenges in genomic modeling include capturing interactions between distant tokens, considering the impacts of both upstream and downstream regions, and ensuring the complementarity of DNA sequences. Caduceus [158] and MSAMamba [177], both leveraging the Mamba model, excel in addressing these challenges. Caduceus, a DNA foundation model, enhances the Mamba architecture with BiMamba and MambaDNA components for bi-directional modeling and ensuring reverse complement equivariance, significantly outperforming existing models in long-range genomic tasks. Similarly, MSAMamba [177] addresses the limitations of transformer-based models for DNA multiple sequence alignments by implementing a selective scan operation along the sequence dimension. This design extends the training context length of previous methods by eightfold, allowing a more comprehensive Manuscript submitted to ACM
analysis of extensive DNA sequences. Another illustration is SMILES-Mamba [206], a system that pre-trains and fine-tunes Mamba models to forecast the absorption, distribution, metabolism, excretion, and toxicity characteristics of small-molecule drugs.
## 6.5 Recommender Systems
Recommender Systems are widely utilized in e-commerce [25, 228, 240] and social networks [37, 38, 42], aiming to capture users' evolving preferences and the interdependencies among their past behaviors [39, 237]. Although transformer-based models have demonstrated effectiveness in recommender systems [173], they face computational efficiency challenges because of the quadratic complexity of attention mechanisms, especially when dealing with longer sequences of behaviors. Recently, several Mamba-based models have been applied to analyze long-term user behavior for personalized recommendations [16, 116, 170, 192, 212]. For example, Mamba4Rec [116] pioneers the use of selective state space models for efficient sequential recommendation, enhancing model performance while maintaining inference efficiency. Similarly, RecMamba [212] explores Mamba's effectiveness in lifelong sequential recommendation scenarios (i.e., sequence length ≥ 2k), achieving comparable performance to benchmark models while cutting down training time by 70% and reducing memory costs by 80%. Furthermore, EchoMamba4Rec [192] integrates a bidirectional Mamba module with frequency-domain filtering to accurately capture intricate patterns and interdependencies within user interaction data. It demonstrates superior performance over existing models, delivering more precise and personalized recommendations. Additionally, Mamba4KT [16] is designed explicitly for knowledge tracing in intelligent education, leveraging the Mamba model to capture enduring correlations between exercises and student knowledge levels. As educational datasets expand, this method suggests a promising avenue for enhancing prediction accuracy, model efficiency, and resource utilization in knowledge tracing research. More recently, SSD4Rec [151] proposes a novel pure-SSM structure for efficient sequential recommendation, which harnesses the advanced nature of Structured State-Space Duality to enable attention-like parallel computation on item sequences while scaling linearly with the input lengths. SSD4Rec allows variable-length input without any padding/truncation and achieves comprehensive long-range user behavior modeling from bi-directional perspectives.
## 6.6 Robotics and Autonomous Systems
The main goal of robotics and autonomous systems is to develop models capable of comprehending visual environments and performing intricate actions. Multimodal Large Language Models (MLLMs) currently used in robotics face significant challenges in two primary aspects: 1) limited capacity for handling intricate tasks requiring advanced reasoning, and 2) substantial computational expenses with fine-tuning and inference tasks. Due to their advantages in inference speed, memory utilization, and overall efficiency, Mamba models are emerging as a promising foundation for autonomous and intelligent systems [15, 86, 118], promising superior performance and substantial scalability potential. For example, RoboMamba [118] integrates a vision encoder with Mamba to create an end-to-end robotic MLLM. This method aligns visual data with language embeddings by co-training, enhancing the model with visual common sense and robot-specific reasoning while ensuring efficient fine-tuning and inference capabilities. Similarly, Jia et al. [86] introduce MaIL, an imitation learning (IL) policy architecture that uses Mamba as a backbone. MaIL bridges the gap between efficiency and performance in handling sequences of observations. Extensive evaluations of real robot experiments demonstrate that MaIL provides a competitive alternative to traditional, large, and complex Transformer-based IL policies.
## 7 Challenges and Opportunities
The preceding sections have thoroughly surveyed the latest advanced techniques and varied applications associated with Mamba. However, the studies of Mamba are still in its nascent stages, and there exist considerable challenges and opportunities ahead.
## 7.1 Mamba-based Foundation Models
By scaling up the model sizes to the billion level over large-scale mixture-of-source corpora, foundation models (FMs) exhibit impressive zero-shot learning capabilities, which has enabled FMs to excel in a wide range of general tasks [13]. As a representative example, recent years have witnessed the booming success of Transformer-based large language models, especially ChatGPT, motivating a growing enthusiasm for exploring foundation models in various domains. Even though Transformers are the main drivers of the success, they suffer from pressing computation and memory efficiency issues [176], which come with the exponentially growing training memory proportional to the attention-based model size and the laboriously auto-regressive decoding during inference. In response to these issues, a promising alternative backbone, i.e., Mamba [28, 56], for foundation models has recently emerged. Mamba offers the content-aware learning capabilities of Transformers while scaling the computation linearly with input length, making it effective in capturing long-range dependencies and enhancing efficiency in both training and inference. Given these advantages, developing Mamba-based foundation models for specific domains holds great potential, which offers an opportunity to address the issues faced by Transformer-based models.
## 7.2 Hardware-Awareness Computation
Foundation models, characterized by their large sizes and intensive matrix operations like matrix multiplications and convolutions, require cutting-edge hardware such as GPUs and TPUs for high-throughput training and inference. These advanced hardware enable researchers to work with larger datasets and achieve state-of-the-art performance across various domains. Nonetheless, the existing foundation models still fall short of fully exploiting the computational capabilities of the hardware, resulting in limited model efficiency [176]. As a promising alternative for enhancing computation efficiency, Mamba-1 [56] and Mamba-2 [28] put forth hardware-aware computation algorithms, namely the Parallel Associative Scan and the Block-decomposition Matrix Multiplication. These algorithms take into account the inherent characteristics of GPUs and TPUs, including factors such as message transmission between devices, offering a fresh perspective on addressing the computation efficiency problem. Inspired by this, exploring novel hardware-efficient algorithms, such as FlashButterfly [47], to optimize hardware utilization offers a promising avenue for conserving resources and accelerating computation, benefiting not only SSMs but also other architectures like Transformers and RNNs.
## 7.3 Trustworthy Mamba Models
The development of SSMs is expected to bring significant benefits to various industries, including e-commerce, healthcare, and education. At the same time, being a data-dependent model like many existing architectures, Mamba models could pose severe threats to users and society [131]. These threats arise from several factors like erratic decision-making, privacy concerns, and more. Therefore, ensuring trustworthiness in Mamba models is essential across four critical dimensions [117]: Safety&Robustness , Fairness , Explainability , and Privacy .
7.3.1 Safety&Robustness . Large foundation models have been proven to be highly vulnerable to adversarial perturbations, which can jeopardize the safety and robustness of these models when deployed in safety-critical applications [44, 137, 197]. Meanwhile, Mamba-based models are not exempt from these vulnerabilities [129]. In the pursuit of being a reliable alternative to Transformer, it is essential to investigate and enhance the safety and robustness of Mamba-based models. To be specific, the model outputs should be robust to small perturbations in their inputs. One potential solution could involve automatically pre-processing prompts before feeding them into Mamba-based models. Additionally, as a representative technique, adversarial machine training [79] can be employed to enhance the safety and robustness of Mamba models.
7.3.2 Fairness . Large foundation models, trained on extensive datasets, tend to be unintentionally exposed to the biases and stereotypes present in the extensive training corpus [127], which can manifest in the generated outputs. For instance, within the domain of LLMs, the biases can lead to discriminatory responses influenced by user profile attributes like gender and age, reinforcing stereotypes and unfairly treating specific user groups [87]. While recent efforts have been made to address the issue of fairness in LLMs, there is still a gap in research regarding the non-discrimination and fairness of Mamba models. Thus, further exploration and study are necessary to bridge this gap.
7.3.3 Explainability . Deep learning models have often been criticized for their "black-box" nature, and the explainability of deep learning models has emerged as a popular topic in the research community, which indicates the capacity to comprehend and interpret the decisions or predictions generated by a model [34]. By explaining model predictions, users can make more informed decisions based on the model's outputs. To this end, several techniques have been proposed to provide plausible innate explanations for neural architectures based on attention mechanism [75]. Moreover, researchers have investigated the capabilities of Transformer-based language models to generate natural language descriptions to explain their answers [221]. Although an increasing number of studies have attempted to take full advantage of Mamba, studies on comprehending the functioning of Mamba models are still at an early stage, and further investigation is still needed.
7.3.4 Privacy . The protection of privacy builds trust between users and Mamba-based models. When users have confidence that their privacy is respected, they are more likely to engage with the AI systems, share relevant information, and seek assistance without fear of misusing their data. Thus, this trust is vital for the widespread adoption and acceptance of Mamba models. One effective strategy for mitigating privacy risks involves cross-verifying the output of Mamba models and screening sensitive content [94]. Moreover, Federated Learning is poised to bolster privacy during the training of Mamba models, wherein the model is trained on numerous decentralized edge devices or servers housing local data samples, without data exchange. This methodology aids in preserving the localization and privacy of the data. Furthermore, integrating privacy-conscious regularization techniques such as differential privacy constraints during training shows promise in preventing overfitting on sensitive data.
## 7.4 Applying Emerging Techniques from Transformer to Mamba
The Transformer, being the dominant backbone, has led the AI community to develop numerous unique tools aimed at enhancing the performance of attention-based models. Fortunately, by connecting SSMs and attention, the SSD framework introduced by Mamba-2 [28] allows us to develop a shared vocabulary and library of techniques for Transformer and Mamba. In light of this, an important future direction arises, i.e., to explore how the emerging techniques designed for Transformer-based models can be effectively applied to Mamba-based models.
- 7.4.1 Parameter-efficient Finetuning . Large foundation models, scaling up their parameters to billions, have witnessed groundbreaking advancement in multiple fields. Nevertheless, their extensive scale and computational requirements present significant challenges when tailoring them for specific downstream tasks. To this end, several parameter-efficient finetuning (PEFT) techniques, including the LoRA [73] and Adapter families [50, 92], have been proposed, which involves minimizing the adjustment of parameters or the need for extensive computational resources during finetuning. Drawing inspiration from the recent achievements in employing PEFT for large language models constructed using Transformer layers, the adoption of PEFT for Mamba models has emerged as an intriguing topic, with the goal of broadening their range of applications in downstream tasks. For instance, the deployment of LoRA (Low-Rank Adaptation) is anticipated to facilitate rapid finetuning for the SSD models, thus enabling the widespread application of Mamba across various domains. However, the specifics of implementing these PEFT techniques for Mamba-based models are yet to be determined and require further investigation.
7.4.2 Catastrophic Forgetting Mitigation . Catastrophic forgetting, also known as catastrophic interference, refers to the phenomenon observed in machine learning models where they experience a significant loss in performance on previously learned tasks when trained on new tasks [93]. This issue poses a challenge for foundation models because they need to retain knowledge from pre-training tasks and demonstrate consistent performance across different downstream domains. As a promising architecture of the foundation model, Mamba necessitates a thorough investigation to address catastrophic forgetting issues. Recent research has suggested resolving this challenge by encapsulating task-specific needs through Reward Maximization and Distribution Matching strategies [97, 98]. Moreover, continual learning methods have also been developed to mitigate catastrophic forgetting in Transformer-based language models [91, 193]. These techniques can also be applied to Mamba models by connecting SSMs and attention but remain under-explored.
7.4.3 Retrieval-augmented Generation (RAG) . Being among the most sophisticated techniques in AI, RAG can provide dependable and current external knowledge, offering significant utility for a multitude of tasks [30, 100]. Large Language Models have recently showcased groundbreaking language comprehension and generation capabilities, despite encountering inherent limitations like hallucinations and outdated internal knowledge. In light of RAG's potent capacity to offer current and valuable supplementary information, Retrieval-Augmented LLMs have emerged to leverage extraneous knowledge databases for enhancing the generative quality of LLMs [22]. Similarly, RAG can be incorporated with Mamba language models to assist them in producing high-quality outputs, which is a promising future research direction.
## 8 Conclusion
Mamba, an emerging deep learning architecture, has demonstrated remarkable success across diverse domains, such as language generation, image classification, recommendation, and drug discovery, owing to its powerful modeling capabilities and computational efficiency. Recently, increasing efforts have been made to develop Mamba-based deep learning models with more powerful representation learning capabilities and lower computation complexity. Given the rapid advancement of Mamba, there arises an urgent demand for a systematic overview. To bridge this gap, in this paper, we provide a comprehensive review of Mamba, focusing on its architecture advancements, data adaptability, and application areas, offering researchers both an in-depth understanding and an overview of the latest developments in Mamba. Additionally, given that Mamba research is still in its nascent stages, we also discuss current limitations and present promising directions for future investigation.
Manuscript submitted to ACM
## References
- [1] Ossama Abdel-Hamid, Abdel-rahman Mohamed, Hui Jiang, Li Deng, Gerald Penn, and Dong Yu. 2014. Convolutional neural networks for speech recognition. IEEE/ACM Transactions on audio, speech, and language processing 22, 10 (2014), 1533-1545.
- [2] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
- [3] Md Atik Ahamed and Qiang Cheng. 2024. Timemachine: A time series is worth 4 mambas for long-term forecasting. arXiv preprint arXiv:2403.09898 (2024).
- [4] Md Atik Ahamed and Qiang Cheng. 2024. TSCMamba: Mamba Meets Multi-View Learning for Time Series Classification. arXiv preprint arXiv:2406.04419 (2024).
[5]
Quentin Anthony, Yury Tokpanov, Paolo Glorioso, and Beren Millidge. 2024. BlackMamba: Mixture of Experts for State-Space Models.
arXiv preprint arXiv:2402.01771
(2024).
- [6] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. 2021. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF international conference on computer vision . 6836-6846.
- [7] Zhongxin Bai and Xiao-Lei Zhang. 2021. Speaker recognition based on deep learning: An overview. Neural Networks 140 (2021), 65-99.
- [8] Malyaban Bal and Abhronil Sengupta. 2024. Rethinking Spiking Neural Networks as State Space Models. arXiv preprint arXiv:2406.02923 (2024).
- [9] Ali Behrouz and Farnoosh Hashemi. 2024. Graph Mamba: Towards Learning on Graphs with State Space Models. arXiv preprint arXiv:2402.08678 (2024).
- [10] Ali Behrouz, Michele Santacatterina, and Ramin Zabih. 2024. Mambamixer: Efficient selective state space models with dual token and channel selection. arXiv preprint arXiv:2403.19888 (2024).
- [11] Saurabhchand Bhati, Yuan Gong, Leonid Karlinsky, Hilde Kuehne, Rogerio Feris, and James Glass. 2024. DASS: Distilled Audio State Space Models Are Stronger and More Duration-Scalable Learners. arXiv preprint arXiv:2407.04082 (2024).
[12]
Raunaq Bhirangi, Chenyu Wang, Venkatesh Pattabiraman, Carmel Majidi, Abhinav Gupta, Tess Hellebrekers, and Lerrel Pinto. 2024. Hierarchical
State Space Models for Continuous Sequence-to-Sequence Modeling.
arXiv preprint arXiv:2402.10211
(2024).
- [13] Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. 2021. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258 (2021).
- [14] Florian Le Bronnec, Song Duong, Mathieu Ravaut, Alexandre Allauzen, Nancy F Chen, Vincent Guigue, Alberto Lumbreras, Laure Soulier, and Patrick Gallinari. 2024. LOCOST: State-Space Models for Long Document Abstractive Summarization. arXiv preprint arXiv:2401.17919 (2024).
[15]
Jiahang Cao, Qiang Zhang, Ziqing Wang, Jiaxu Wang, Hao Cheng, Yecheng Shao, Wen Zhao, Gang Han, Yijie Guo, and Renjing Xu. 2024. Mamba as Decision Maker: Exploring Multi-scale Sequence Modeling in Offline Reinforcement Learning.
arXiv preprint arXiv:2406.02013
(2024).
- [16] Yang Cao and Wei Zhang. 2024. Mamba4KT: An Efficient and Effective Mamba-based Knowledge Tracing Model. arXiv preprint arXiv:2405.16542 (2024).
- [17] Rong Chao, Wen-Huang Cheng, Moreno La Quatra, Sabato Marco Siniscalchi, Chao-Han Huck Yang, Szu-Wei Fu, and Yu Tsao. 2024. An Investigation of Incorporating Mamba for Speech Enhancement. arXiv preprint arXiv:2405.06573 (2024).
- [18] Soumyabrata Chaudhuri and Saumik Bhattacharya. 2024. Simba: Mamba augmented U-ShiftGCN for Skeletal Action Recognition in Videos. arXiv preprint arXiv:2404.07645 (2024).
- [19] Chi-Sheng Chen, Guan-Ying Chen, Dong Zhou, Di Jiang, and Dai-Shi Chen. 2024. Res-VMamba: Fine-Grained Food Category Visual Classification Using Selective State Space Models with Deep Residual Learning. arXiv preprint arXiv:2402.15761 (2024).
[20]
Deli Chen, Yankai Lin, Wei Li, Peng Li, Jie Zhou, and Xu Sun. 2020. Measuring and relieving the over-smoothing problem for graph neural networks from the topological view. In
Proceedings of the AAAI conference on artificial intelligence
,
Vol. 34. 3438-3445.
- [21] Hongruixuan Chen, Jian Song, Chengxi Han, Junshi Xia, and Naoto Yokoya. 2024. Changemamba: Remote sensing change detection with spatio-temporal state space model. arXiv preprint arXiv:2404.03425 (2024).
[22]
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. 2024. Benchmarking large language models in retrieval-augmented generation. In
Proceedings of the AAAI Conference on Artificial Intelligence
,
Vol. 38. 17754-17762.
- [23] Keyan Chen, Bowen Chen, Chenyang Liu, Wenyuan Li, Zhengxia Zou, and Zhenwei Shi. 2024. Rsmamba: Remote sensing image classification with state space model. arXiv preprint arXiv:2403.19654 (2024).
[24]
Tianxiang Chen, Zhentao Tan, Tao Gong, Qi Chu, Yue Wu, Bin Liu, Jieping Ye, and Nenghai Yu. 2024. Mim-istd: Mamba-in-mamba for efficient infrared small target detection.
arXiv preprint arXiv:2403.02148
(2024).
- [25] Xiao Chen, Wenqi Fan, Jingfan Chen, Haochen Liu, Zitao Liu, Zhaoxiang Zhang, and Qing Li. 2023. Fairly adaptive negative sampling for recommendations. In Proceedings of the ACM Web Conference 2023 . 3723-3733.
- [26] Ying Chen, Jiajing Xie, Yuxiang Lin, Yuhang Song, Wenxian Yang, and Rongshan Yu. 2024. Survmamba: State space model with multi-grained multi-modal interaction for survival prediction. arXiv preprint arXiv:2404.08027 (2024).
- [27] Yujie Chen, Jiangyan Yi, Jun Xue, Chenglong Wang, Xiaohui Zhang, Shunbo Dong, Siding Zeng, Jianhua Tao, Lv Zhao, and Cunhang Fan. 2024. RawBMamba: End-to-End Bidirectional State Space Model for Audio Deepfake Detection. arXiv preprint arXiv:2406.06086 (2024).
- [28] Tri Dao and Albert Gu. 2024. Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality. In International Conference on Machine Learning (ICML) .
- [29] Rui Deng and Tianpei Gu. 2024. CU-Mamba: Selective State Space Models with Channel Learning for Image Restoration. arXiv preprint arXiv:2404.11778 (2024).
- [30] Yujuan Ding, Wenqi Fan, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A survey on rag meets llms: Towards retrieval-augmented large language models. arXiv preprint arXiv:2405.06211 (2024).
- [31] Rares Dolga, Kai Biegun, Jake Cunningham, and David Barber. 2024. RotRNN: Modelling Long Sequences with Rotations. arXiv preprint arXiv:2407.07239 (2024).
- [32] Wenhao Dong, Haodong Zhu, Shaohui Lin, Xiaoyan Luo, Yunhang Shen, Xuhui Liu, Juan Zhang, Guodong Guo, and Baochang Zhang. 2024. Fusion-mamba for cross-modality object detection. arXiv preprint arXiv:2404.09146 (2024).
- [33] Xin Luna Dong, Seungwhan Moon, Yifan Ethan Xu, Kshitiz Malik, and Zhou Yu. 2023. Towards next-generation intelligent assistants leveraging llm techniques. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . 5792-5793.
- [34] Filip Karlo Došilović, Mario Brčić, and Nikica Hlupić. 2018. Explainable artificial intelligence: A survey. In 2018 41st International convention on information and communication technology, electronics and microelectronics (MIPRO) . IEEE, 0210-0215.
- [35] Haruka Ezoe and Kazuhiro Sato. 2024. Learning method for S4 with Diagonal State Space Layers using Balanced Truncation. arXiv preprint arXiv:2402.15993 (2024).
- [36] Lili Fan, Junhao Wang, Yuanmeng Chang, Yuke Li, Yutong Wang, and Dongpu Cao. 2024. 4D mmWave radar for autonomous driving perception: a comprehensive survey. IEEE Transactions on Intelligent Vehicles (2024).
- [37] Wenqi Fan, Tyler Derr, Yao Ma, Jianping Wang, Jiliang Tang, and Qing Li. 2019. Deep Adversarial Social Recommendation. In 28th International Joint Conference on Artificial Intelligence (IJCAI-19) . International Joint Conferences on Artificial Intelligence, 1351-1357.
- [38] Wenqi Fan, Qing Li, and Min Cheng. 2018. Deep modeling of social relations for recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 32.
- [39] Wenqi Fan, Xiaorui Liu, Wei Jin, Xiangyu Zhao, Jiliang Tang, and Qing Li. 2022. Graph Trend Filtering Networks for Recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval . 112-121.
- [40] Wenqi Fan, Yao Ma, Qing Li, Yuan He, Eric Zhao, Jiliang Tang, and Dawei Yin. 2019. Graph neural networks for social recommendation. In The world wide web conference . 417-426.
[41]
Wenqi Fan, Yao Ma, Qing Li, Jianping Wang, Guoyong Cai, Jiliang Tang, and Dawei Yin. 2020. A graph neural network framework for social recommendations.
IEEE Transactions on Knowledge and Data Engineering
34, 5 (2020), 2033-2047.
Wenqi Fan, Yao Ma, Dawei Yin, Jianping Wang, Jiliang Tang, and Qing Li. 2019. Deep social collaborative filtering. In
[42]
Proceedings of the 13th ACM
Conference on Recommender Systems
.
305-313.
- [43] Wenqi Fan, Shijie Wang, Jiani Huang, Zhikai Chen, Yu Song, Wenzhuo Tang, Haitao Mao, Hui Liu, Xiaorui Liu, Dawei Yin, et al. 2024. Graph machine learning in the era of large language models (llms). arXiv preprint arXiv:2404.14928 (2024).
- [44] Wenqi Fan, Xiangyu Zhao, Qing Li, Tyler Derr, Yao Ma, Hui Liu, Jianping Wang, and Jiliang Tang. 2023. Adversarial Attacks for Black-Box Recommender Systems Via Copying Transferable Cross-Domain User Profiles. IEEE Transactions on Knowledge and Data Engineering (2023).
- [45] William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research 23, 120 (2022), 1-39.
- [46] Zhengcong Fei, Mingyuan Fan, Changqian Yu, and Junshi Huang. 2024. Scalable Diffusion Models with State Space Backbone. arXiv preprint arXiv:2402.05608 (2024).
- [47] Daniel Y Fu, Elliot L Epstein, Eric Nguyen, Armin W Thomas, Michael Zhang, Tri Dao, Atri Rudra, and Christopher Ré. 2023. Simple hardwareefficient long convolutions for sequence modeling. In International Conference on Machine Learning . PMLR, 10373-10391.
[48]
Guanyiman Fu, Fengchao Xiong, Jianfeng Lu, and Jun Zhou. 2024. Ssumamba: Spatial-spectral selective state space model for hyperspectral image denoising.
IEEE Transactions on Geoscience and Remote Sensing
(2024).
- [49] Linjie Fu, Xia Li, Xiuding Cai, Yingkai Wang, Xueyao Wang, Yali Shen, and Yu Yao. 2024. MD-Dose: A Diffusion Model based on the Mamba for Radiotherapy Dose Prediction. arXiv preprint arXiv:2403.08479 (2024).
[50]
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. 2024. Clip-adapter: Better vision- language models with feature adapters.
International Journal of Computer Vision
132, 2 (2024), 581-595.
- [51] Ruisheng Gao, Zeyu Xiao, and Zhiwei Xiong. 2024. Mamba-based Light Field Super-Resolution with Efficient Subspace Scanning. arXiv preprint arXiv:2406.16083 (2024).
- [52] Yu Gao, Jiancheng Huang, Xiaopeng Sun, Zequn Jie, Yujie Zhong, and Lin Ma. 2024. Matten: Video Generation with Mamba-Attention. arXiv preprint arXiv:2405.03025 (2024).
- [53] Negar Golestani and Mahta Moghaddam. 2020. Human activity recognition using magnetic induction-based motion signals and deep recurrent neural networks. Nature communications 11, 1 (2020), 1551.
- [54] Haifan Gong, Luoyao Kang, Yitao Wang, Xiang Wan, and Haofeng Li. 2024. nnmamba: 3d biomedical image segmentation, classification and landmark detection with state space model. arXiv preprint arXiv:2402.03526 (2024).
- [55] Alex Graves and Alex Graves. 2012. Long short-term memory. Supervised sequence labelling with recurrent neural networks (2012), 37-45.
- [56] Albert Gu and Tri Dao. 2023. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752 (2023).
- [57] Albert Gu, Tri Dao, Stefano Ermon, Atri Rudra, and Christopher Ré. 2020. Hippo: Recurrent memory with optimal polynomial projections. Advances in neural information processing systems 33 (2020), 1474-1487.
Manuscript submitted to ACM
## A Survey of Mamba
- [58] Albert Gu, Karan Goel, Ankit Gupta, and Christopher Ré. 2022. On the parameterization and initialization of diagonal state space models. Advances in Neural Information Processing Systems 35 (2022), 35971-35983.
- [59] Albert Gu, Karan Goel, and Christopher Ré. 2021. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396 (2021).
- [60] Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, and Christopher Ré. 2021. Combining recurrent, convolutional, and continuous-time models with linear state space layers. Advances in neural information processing systems 34 (2021), 572-585.
- [61] Yanchen Guan, Haicheng Liao, Zhenning Li, Jia Hu, Runze Yuan, Yunjian Li, Guohui Zhang, and Chengzhong Xu. 2024. World models for autonomous driving: An initial survey. IEEE Transactions on Intelligent Vehicles (2024).
- [62] Jeff Guo and Philippe Schwaller. 2024. Saturn: Sample-efficient Generative Molecular Design using Memory Manipulation. arXiv preprint arXiv:2405.17066 (2024).
- [63] Yulan Guo, Hanyun Wang, Qingyong Hu, Hao Liu, Li Liu, and Mohammed Bennamoun. 2020. Deep learning for 3d point clouds: A survey. IEEE transactions on pattern analysis and machine intelligence 43, 12 (2020), 4338-4364.
- [64] Xu Han, Yuan Tang, Zhaoxuan Wang, and Xianzhi Li. 2024. Mamba3d: Enhancing local features for 3d point cloud analysis via state space model. arXiv preprint arXiv:2404.14966 (2024).
- [65] Mark Harris, Shubhabrata Sengupta, and John D Owens. 2007. Parallel prefix sum (scan) with CUDA. GPU gems 3, 39 (2007), 851-876.
- [66] Ali Hatamizadeh and Jan Kautz. 2024. MambaVision: A Hybrid Mamba-Transformer Vision Backbone. arXiv preprint arXiv:2407.08083 (2024).
- [67] Haoyang He, Yuhu Bai, Jiangning Zhang, Qingdong He, Hongxu Chen, Zhenye Gan, Chengjie Wang, Xiangtai Li, Guanzhong Tian, and Lei Xie. 2024. Mambaad: Exploring state space models for multi-class unsupervised anomaly detection. arXiv preprint arXiv:2404.06564 (2024).
- [68] Wei He, Kai Han, Yehui Tang, Chengcheng Wang, Yujie Yang, Tianyu Guo, and Yunhe Wang. 2024. Densemamba: State space models with dense hidden connection for efficient large language models. arXiv preprint arXiv:2403.00818 (2024).
- [69] Xuanhua He, Ke Cao, Keyu Yan, Rui Li, Chengjun Xie, Jie Zhang, and Man Zhou. 2024. Pan-Mamba: Effective pan-sharpening with State Space Model. arXiv preprint arXiv:2402.12192 (2024).
[70]
Michiel Hermans and Benjamin Schrauwen. 2013.
Training and analysing deep recurrent neural networks.
Advances in neural information processing systems
26 (2013).
- [71] Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems 33 (2020), 6840-6851.
[72]
Alireza Hosseini, Amirhossein Kazerouni, Saeed Akhavan, Michael Brudno, and Babak Taati. 2024. SUM: Saliency Unification through Mamba for
Visual Attention Modeling.
arXiv preprint arXiv:2406.17815
(2024).
- [73] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021).
- [74] Hao Hu and Guo-Jun Qi. 2017. State-frequency memory recurrent neural networks. In International Conference on Machine Learning . PMLR, 1568-1577.
- [75] Lijie Hu, Yixin Liu, Ninghao Liu, Mengdi Huai, Lichao Sun, and Di Wang. 2023. Seat: stable and explainable attention. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 37. 12907-12915.
- [76] Vincent Tao Hu, Stefan Andreas Baumann, Ming Gui, Olga Grebenkova, Pingchuan Ma, Johannes Fischer, and Bjorn Ommer. 2024. Zigma: Zigzag mamba diffusion model. arXiv preprint arXiv:2403.13802 (2024).
[77]
Chensen Huang, Guibo Zhu, Xuepeng Wang, Yifei Luo, Guojing Ge, Haoran Chen, Dong Yi, and Jinqiao Wang. 2024. Recurrent Context Compression:
Efficiently Expanding the Context Window of LLM.
arXiv preprint arXiv:2406.06110
(2024).
- [78] Kexin Huang, Cao Xiao, Lucas M Glass, Marinka Zitnik, and Jimeng Sun. 2020. SkipGNN: predicting molecular interactions with skip-graph networks. Scientific reports 10, 1 (2020), 21092.
- [79] Ling Huang, Anthony D Joseph, Blaine Nelson, Benjamin IP Rubinstein, and J Doug Tygar. 2011. Adversarial machine learning. In Proceedings of the 4th ACM workshop on Security and artificial intelligence . 43-58.
[80]
Tao Huang, Xiaohuan Pei, Shan You, Fei Wang, Chen Qian, and Chang Xu. 2024. Localmamba: Visual state space model with windowed selective scan.
arXiv preprint arXiv:2403.09338
(2024).
- [81] Tzu-Kuo Huang and Jeff Schneider. 2011. Learning auto-regressive models from sequence and non-sequence data. Advances in Neural Information Processing Systems 24 (2011).
- [82] Yinan Huang, Siqi Miao, and Pan Li. 2024. What Can We Learn from State Space Models for Machine Learning on Graphs? arXiv preprint arXiv:2406.05815 (2024).
- [83] Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. 1991. Adaptive mixtures of local experts. Neural computation 3, 1 (1991), 79-87.
- [84] Farnoush Rezaei Jafari, Grégoire Montavon, Klaus-Robert Müller, and Oliver Eberle. 2024. MambaLRP: Explaining Selective State Space Sequence Models. arXiv preprint arXiv:2406.07592 (2024).
- [85] Zexin Ji, Beiji Zou, Xiaoyan Kui, Pierre Vera, and Su Ruan. 2024. Self-Prior Guided Mamba-UNet Networks for Medical Image Super-Resolution. arXiv preprint arXiv:2407.05993 (2024).
- [86] Xiaogang Jia, Qian Wang, Atalay Donat, Bowen Xing, Ge Li, Hongyi Zhou, Onur Celik, Denis Blessing, Rudolf Lioutikov, and Gerhard Neumann. 2024. MaIL: Improving Imitation Learning with Mamba. arXiv preprint arXiv:2406.08234 (2024).
Manuscript submitted to ACM
- [87] Meng Jiang, Keqin Bao, Jizhi Zhang, Wenjie Wang, Zhengyi Yang, Fuli Feng, and Xiangnan He. 2024. Item-side Fairness of Large Language Model-based Recommendation System. In Proceedings of the ACM on Web Conference 2024 . 4717-4726.
- [88] Xilin Jiang, Cong Han, and Nima Mesgarani. 2024. Dual-path mamba: Short and long-term bidirectional selective structured state space models for speech separation. arXiv preprint arXiv:2403.18257 (2024).
- [89] Charles Jones, Daniel C Castro, Fabio De Sousa Ribeiro, Ozan Oktay, Melissa McCradden, and Ben Glocker. 2024. A causal perspective on dataset bias in machine learning for medical imaging. Nature Machine Intelligence (2024), 1-9.
- [90] RE Kalman. 1960. A new approach to linear filtering and prediction problems. Trans. ASME, D 82 (1960), 35-44.
- [91] Sudipta Kar, Giuseppe Castellucci, Simone Filice, Shervin Malmasi, and Oleg Rokhlenko. 2022. Preventing catastrophic forgetting in continual learning of new natural language tasks. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . 3137-3145.
- [92] Rabeeh Karimi Mahabadi, James Henderson, and Sebastian Ruder. 2021. Compacter: Efficient low-rank hypercomplex adapter layers. Advances in Neural Information Processing Systems 34 (2021), 1022-1035.
- [93] Ronald Kemker, Marc McClure, Angelina Abitino, Tyler Hayes, and Christopher Kanan. 2018. Measuring catastrophic forgetting in neural networks. In Proceedings of the AAAI conference on artificial intelligence , Vol. 32.
- [94] Siwon Kim, Sangdoo Yun, Hwaran Lee, Martin Gubri, Sungroh Yoon, and Seong Joon Oh. 2024. Propile: Probing privacy leakage in large language models. Advances in Neural Information Processing Systems 36 (2024).
- [95] Huan Yee Koh, Jiaxin Ju, Ming Liu, and Shirui Pan. 2022. An empirical survey on long document summarization: Datasets, models, and metrics. ACM computing surveys 55, 8 (2022), 1-35.
- [96] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems 35 (2022), 22199-22213.
- [97] Tomasz Korbak, Hady Elsahar, German Kruszewski, and Marc Dymetman. 2022. Controlling conditional language models without catastrophic forgetting. In International Conference on Machine Learning . PMLR, 11499-11528.
[98]
Tomasz Korbak, Hady Elsahar, Germán Kruszewski, and Marc Dymetman. 2022.
On reinforcement learning and distribution matching for fine-tuning language models with no catastrophic forgetting.
Advances in Neural Information Processing Systems
35 (2022), 16203-16220.
- [99] L Ashok Kumar, D Karthika Renuka, S Lovelyn Rose, I Made Wartana, et al. 2022. Deep learning based assistive technology on audio visual speech recognition for hearing impaired. International Journal of Cognitive Computing in Engineering 3 (2022), 24-30.
- [100] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems 33 (2020), 9459-9474.
- [101] Jiatong Li, Yunqing Liu, Wenqi Fan, Xiao-Yong Wei, Hui Liu, Jiliang Tang, and Qing Li. 2024. Empowering molecule discovery for molecule-caption translation with large language models: A chatgpt perspective. IEEE Transactions on Knowledge and Data Engineering (2024).
- [102] Kai Li and Guo Chen. 2024. SPMamba: State-space model is all you need in speech separation. arXiv preprint arXiv:2404.02063 (2024).
- [103] Kunchang Li, Xinhao Li, Yi Wang, Yinan He, Yali Wang, Limin Wang, and Yu Qiao. 2024. Videomamba: State space model for efficient video understanding. arXiv preprint arXiv:2403.06977 (2024).
- [104] Lincan Li, Hanchen Wang, Wenjie Zhang, and Adelle Coster. 2024. Stg-mamba: Spatial-temporal graph learning via selective state space model. arXiv preprint arXiv:2403.12418 (2024).
- [105] Shiwei Li, Huifeng Guo, Xing Tang, Ruiming Tang, Lu Hou, Ruixuan Li, and Rui Zhang. 2024. Embedding Compression in Recommender Systems: A Survey. Comput. Surveys 56, 5 (2024), 1-21.
[106]
Shuangjian Li, Tao Zhu, Furong Duan, Liming Chen, Huansheng Ning, and Yaping Wan. 2024.
Harmamba: Efficient wearable sensor human activity recognition based on bidirectional selective ssm.
arXiv preprint arXiv:2403.20183
(2024).
- [107] Wenrui Li, Xiaopeng Hong, and Xiaopeng Fan. 2024. Spikemba: Multi-modal spiking saliency mamba for temporal video grounding. arXiv preprint arXiv:2404.01174 (2024).
- [108] Zhe Li, Haiwei Pan, Kejia Zhang, Yuhua Wang, and Fengming Yu. 2024. Mambadfuse: A mamba-based dual-phase model for multi-modality image fusion. arXiv preprint arXiv:2404.08406 (2024).
- [109] Aobo Liang, Xingguo Jiang, Yan Sun, and Chang Lu. 2024. Bi-Mamba4TS: Bidirectional Mamba for Time Series Forecasting. arXiv preprint arXiv:2404.15772 (2024).
- [110] Dingkang Liang, Xin Zhou, Xinyu Wang, Xingkui Zhu, Wei Xu, Zhikang Zou, Xiaoqing Ye, and Xiang Bai. 2024. PointMamba: A Simple State Space Model for Point Cloud Analysis. arXiv preprint arXiv:2402.10739 (2024).
- [111] Weibin Liao, Yinghao Zhu, Xinyuan Wang, Cehngwei Pan, Yasha Wang, and Liantao Ma. 2024. Lightm-unet: Mamba assists in lightweight unet for medical image segmentation. arXiv preprint arXiv:2403.05246 (2024).
[112]
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-
Shwartz, et al. 2024. Jamba: A hybrid transformer-mamba language model.
arXiv preprint arXiv:2403.19887
(2024).
- [113] Ailiang Lin, Bingzhi Chen, Jiayu Xu, Zheng Zhang, Guangming Lu, and David Zhang. 2022. Ds-transunet: Dual swin transformer u-net for medical image segmentation. IEEE Transactions on Instrumentation and Measurement 71 (2022), 1-15.
- [114] Baijiong Lin, Weisen Jiang, Pengguang Chen, Yu Zhang, Shu Liu, and Ying-Cong Chen. 2024. MTMamba: Enhancing Multi-Task Dense Scene Understanding by Mamba-Based Decoders. arXiv preprint arXiv:2407.02228 (2024).
## A Survey of Mamba
- [115] Wei-Tung Lin, Yong-Xiang Lin, Jyun-Wei Chen, and Kai-Lung Hua. 2024. PixMamba: Leveraging State Space Models in a Dual-Level Architecture for Underwater Image Enhancement. arXiv preprint arXiv:2406.08444 (2024).
[116]
Chengkai Liu, Jianghao Lin, Jianling Wang, Hanzhou Liu, and James Caverlee. 2024. Mamba4Rec: Towards Efficient Sequential Recommendation with Selective State Space Models.
arXiv preprint arXiv:2403.03900
(2024).
- [117] Haochen Liu, Yiqi Wang, Wenqi Fan, Xiaorui Liu, Yaxin Li, Shaili Jain, Yunhao Liu, Anil Jain, and Jiliang Tang. 2022. Trustworthy ai: A computational perspective. ACM Transactions on Intelligent Systems and Technology 14, 1 (2022), 1-59.
- [118] Jiaming Liu, Mengzhen Liu, Zhenyu Wang, Lily Lee, Kaichen Zhou, Pengju An, Senqiao Yang, Renrui Zhang, Yandong Guo, and Shanghang Zhang. 2024. RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation. arXiv preprint arXiv:2406.04339 (2024).
- [119] Jiarun Liu, Hao Yang, Hong-Yu Zhou, Yan Xi, Lequan Yu, Yizhou Yu, Yong Liang, Guangming Shi, Shaoting Zhang, Hairong Zheng, et al. 2024. Swin-umamba: Mamba-based unet with imagenet-based pretraining. arXiv preprint arXiv:2402.03302 (2024).
- [120] Shujie Liu, Nan Yang, Mu Li, and Ming Zhou. 2014. A recursive recurrent neural network for statistical machine translation. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) . 1491-1500.
- [121] Xiao Liu, Chenxu Zhang, and Lei Zhang. 2024. Vision Mamba: A Comprehensive Survey and Taxonomy. arXiv preprint arXiv:2405.04404 (2024).
- [122] Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, and Yunfan Liu. 2024. Vmamba: Visual state space model. arXiv preprint arXiv:2401.10166 (2024).
[123]
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. 2022. Video swin transformer. In
Proceedings of the IEEE/CVF
conference on computer vision and pattern recognition
.
3202-3211.
- [124] Shaocong Long, Qianyu Zhou, Xiangtai Li, Xuequan Lu, Chenhao Ying, Yuan Luo, Lizhuang Ma, and Shuicheng Yan. 2024. Dgmamba: Domain generalization via generalized state space model. arXiv preprint arXiv:2404.07794 (2024).
[125]
Jiachen Lu, Jinghan Yao, Junge Zhang, Xiatian Zhu, Hang Xu, Weiguo Gao, Chunjing Xu, Tao Xiang, and Li Zhang. 2021.
Soft: Softmax-free transformer with linear complexity.
Advances in Neural Information Processing Systems
34 (2021), 21297-21309.
- [126] Chao Ma and Ziyang Wang. 2024. Semi-Mamba-UNet: Pixel-Level Contrastive and Pixel-Level Cross-Supervised Visual Mamba-based UNet for Semi-Supervised Medical Image Segmentation. arXiv e-prints (2024), arXiv-2402.
[127]
Huan Ma, Changqing Zhang, Yatao Bian, Lemao Liu, Zhirui Zhang, Peilin Zhao, Shu Zhang, Huazhu Fu, Qinghua Hu, and Bingzhe Wu. 2024.
Fairness-guided few-shot prompting for large language models.
Advances in Neural Information Processing Systems
36 (2024).
- [128] Jun Ma, Feifei Li, and Bo Wang. 2024. U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv preprint arXiv:2401.04722 (2024).
- [129] Hashmat Shadab Malik, Fahad Shamshad, Muzammal Naseer, Karthik Nandakumar, Fahad Shahbaz Khan, and Salman Khan. 2024. Towards Evaluating the Robustness of Visual State Space Models. arXiv preprint arXiv:2406.09407 (2024).
[130]
Mishaim Malik, Muhammad Kamran Malik, Khawar Mehmood, and Imran Makhdoom. 2021. Automatic speech recognition: a survey.
Multimedia
Tools and Applications
80 (2021), 9411-9457.
- [131] Joao Marques-Silva and Alexey Ignatiev. 2022. Delivering trustworthy AI through formal XAI. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 36. 12342-12350.
[132]
Sameen Maruf, Fahimeh Saleh, and Gholamreza Haffari. 2021. A survey on document-level neural machine translation: Methods and evaluation.
ACM Computing Surveys (CSUR)
54, 2 (2021), 1-36.
- [133] Justus Mattern and Konstantin Hohr. 2023. Mamba-Chat. GitHub. https://github.com/havenhq/mamba-chat
- [134] William Merrill, Jackson Petty, and Ashish Sabharwal. 2024. The illusion of state in state-space models. arXiv preprint arXiv:2404.08819 (2024).
- [135] Nadia Nasri, Sergio Orts-Escolano, and Miguel Cazorla. 2020. An semg-controlled 3d game for rehabilitation therapies: Real-time time hand gesture recognition using deep learning techniques. Sensors 20, 22 (2020), 6451.
- [136] Piotr Nawrot, Adrian Łańcucki, Marcin Chochowski, David Tarjan, and Edoardo M Ponti. 2024. Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference. arXiv preprint arXiv:2403.09636 (2024).
[137]
Liang-bo Ning, Zeyu Dai, Jingran Su, Chao Pan, Luning Wang, Wenqi Fan, and Qing Li. 2024.
Interpretation-Empowered Neural Cleanse for
Backdoor Attacks. In
Companion Proceedings of the ACM on Web Conference 2024
.
951-954.
- [138] Yuta Oshima, Shohei Taniguchi, Masahiro Suzuki, and Yutaka Matsuo. 2024. Ssm meets video diffusion models: Efficient video generation with structured state spaces. arXiv preprint arXiv:2403.07711 (2024).
- [139] Jongho Park, Jaeseung Park, Zheyang Xiong, Nayoung Lee, Jaewoong Cho, Samet Oymak, Kangwook Lee, and Dimitris Papailiopoulos. 2024. Can mamba learn how to learn? a comparative study on in-context learning tasks. arXiv preprint arXiv:2402.04248 (2024).
- [140] Badri Narayana Patro and Vijay Srinivas Agneeswaran. 2024. Mamba-360: Survey of state space models as transformer alternative for long sequence modelling: Methods, applications, and challenges. arXiv preprint arXiv:2404.16112 (2024).
- [141] Georgia Pechlivanidou and Nicholas Karampetakis. 2022. Zero-order hold discretization of general state space systems with input delay. IMA Journal of Mathematical Control and Information 39, 2 (2022), 708-730.
- [142] Xiaohuan Pei, Tao Huang, and Chang Xu. 2024. Efficientvmamba: Atrous selective scan for light weight visual mamba. arXiv preprint arXiv:2403.09977 (2024).
- [143] Zhangzhi Peng, Benjamin Schussheim, and Pranam Chatterjee. 2024. PTM-Mamba: A PTM-Aware Protein Language Model with Bidirectional Gated Mamba Blocks. bioRxiv (2024), 2024-02.
Manuscript submitted to ACM
- [144] Jonathan Pilault, Mahan Fathi, Orhan Firat, Chris Pal, Pierre-Luc Bacon, and Ross Goroshin. 2024. Block-state transformers. Advances in Neural Information Processing Systems 36 (2024).
- [145] Hugo Pitorro, Pavlo Vasylenko, Marcos Treviso, and André FT Martins. 2024. How Effective are State Space Models for Machine Translation? arXiv preprint arXiv:2407.05489 (2024).
- [146] Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher Ré. 2023. Hyena hierarchy: Towards larger convolutional language models. In International Conference on Machine Learning . PMLR, 28043-28078.
- [147] Matteo Prata, Giuseppe Masi, Leonardo Berti, Viviana Arrigoni, Andrea Coletta, Irene Cannistraci, Svitlana Vyetrenko, Paola Velardi, and Novella Bartolini. 2024. Lob-based deep learning models for stock price trend prediction: a benchmark study. Artificial Intelligence Review 57, 5 (2024), 1-45.
- [148] Yanyuan Qiao, Zheng Yu, Longteng Guo, Sihan Chen, Zijia Zhao, Mingzhen Sun, Qi Wu, and Jing Liu. 2024. VL-Mamba: Exploring State Space Models for Multimodal Learning. arXiv preprint arXiv:2403.13600 (2024).
- [149] Haohao Qu, Wenqi Fan, Zihuai Zhao, and Qing Li. 2024. TokenRec: Learning to Tokenize ID for LLM-based Generative Recommendation. arXiv preprint arXiv:2406.10450 (2024).
- [150] Haohao Qu, Haoxuan Kuang, Qiuxuan Wang, Jun Li, and Linlin You. 2024. A physics-informed and attention-based graph learning approach for regional electric vehicle charging demand prediction. IEEE Transactions on Intelligent Transportation Systems (2024).
- [151] Haohao Qu, Yifeng Zhang, Liangbo Ning, Wenqi Fan, and Qing Li. 2024. SSD4Rec: A Structured State Space Duality Model for Efficient Sequential Recommendation. arXiv preprint arXiv:2409.01192 (2024).
- [152] Changsheng Quan and Xiaofei Li. 2024. Multichannel long-term streaming neural speech enhancement for static and moving speakers. arXiv preprint arXiv:2403.07675 (2024).
- [153] Liliang Ren, Yang Liu, Yadong Lu, Yelong Shen, Chen Liang, and Weizhu Chen. 2024. Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling. arXiv preprint arXiv:2406.07522 (2024).
- [154] Sucheng Ren, Xianhang Li, Haoqin Tu, Feng Wang, Fangxun Shu, Lei Zhang, Jieru Mei, Linjie Yang, Peng Wang, Heng Wang, et al. 2024. Autoregressive Pretraining with Mamba in Vision. arXiv preprint arXiv:2406.07537 (2024).
- [155] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolutional networks for biomedical image segmentation. In Medical image computing and computer-assisted intervention-MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18 . Springer, 234-241.
- [156] Jiacheng Ruan and Suncheng Xiang. 2024. Vm-unet: Vision mamba unet for medical image segmentation. arXiv preprint arXiv:2402.02491 (2024).
- [157] Kazi Shahriar Sanjid, Md Tanzim Hossain, Md Shakib Shahariar Junayed, and Dr Mohammad Monir Uddin. 2024. Integrating mamba sequence model and hierarchical upsampling network for accurate semantic segmentation of multiple sclerosis legion. arXiv preprint arXiv:2403.17432 (2024).
- [158] Yair Schiff, Chia-Hsiang Kao, Aaron Gokaslan, Tri Dao, Albert Gu, and Volodymyr Kuleshov. 2024. Caduceus: Bi-directional equivariant long-range dna sequence modeling. arXiv preprint arXiv:2403.03234 (2024).
- [159] Mike Schuster and Kuldip K Paliwal. 1997. Bidirectional recurrent neural networks. IEEE transactions on Signal Processing 45, 11 (1997), 2673-2681.
- [160] Duncan E Scott, Andrew R Bayly, Chris Abell, and John Skidmore. 2016. Small molecules, big targets: drug discovery faces the protein-protein interaction challenge. Nature Reviews Drug Discovery 15, 8 (2016), 533-550.
[161]
Mohammad Shahab Sepehri, Zalan Fabian, and Mahdi Soltanolkotabi. 2024. Serpent: Scalable and Efficient Image Restoration via Multi-scale
Structured State Space Models.
arXiv preprint arXiv:2403.17902
(2024).
- [162] Damiano Sgarbossa, Cyril Malbranke, and Anne-Florence Bitbol. 2024. ProtMamba: a homology-aware but alignment-free protein state space model. bioRxiv (2024), 2024-05.
- [163] Siavash Shams, Sukru Samet Dindar, Xilin Jiang, and Nima Mesgarani. 2024. Ssamba: Self-supervised audio representation learning with mamba state space model. arXiv preprint arXiv:2405.11831 (2024).
[164]
Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi, and Hongsheng Li. 2021.
Efficient attention: Attention with linear complexities. In
Proceedings of the IEEE/CVF winter conference on applications of computer vision
.
3531-3539.
- [165] Jiamu Sheng, Jingyi Zhou, Jiong Wang, Peng Ye, and Jiayuan Fan. 2024. DualMamba: A Lightweight Spectral-Spatial Mamba-Convolution Network for Hyperspectral Image Classification. arXiv preprint arXiv:2406.07050 (2024).
- [166] Yuheng Shi, Minjing Dong, and Chang Xu. 2024. Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model. arXiv preprint arXiv:2405.14174 (2024).
[167]
Yuan Shi, Bin Xia, Xiaoyu Jin, Xing Wang, Tianyu Zhao, Xin Xia, Xuefeng Xiao, and Wenming Yang. 2024. Vmambair: Visual state space model for image restoration.
arXiv preprint arXiv:2403.11423
(2024).
- [168] Chenyang Si, Ziqi Huang, Yuming Jiang, and Ziwei Liu. 2024. Freeu: Free lunch in diffusion u-net. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 4733-4743.
- [169] Aliaksandr Siarohin, Oliver J Woodford, Jian Ren, Menglei Chai, and Sergey Tulyakov. 2021. Motion representations for articulated animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 13653-13662.
- [170] Jinzhao Su and Zhenhua Huang. 2024. MLSA4Rec: Mamba Combined with Low-Rank Decomposed Self-Attention for Sequential Recommendation. arXiv preprint arXiv:2407.13135 (2024).
- [171] Jinsong Su, Zhixing Tan, Deyi Xiong, Rongrong Ji, Xiaodong Shi, and Yang Liu. 2017. Lattice-based recurrent neural network encoders for neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 31.
Manuscript submitted to ACM
## A Survey of Mamba
- [172] Yueyuan Sui, Minghui Zhao, Junxi Xia, Xiaofan Jiang, and Stephen Xia. 2024. TRAMBA: A Hybrid Transformer and Mamba Architecture for Practical Audio and Bone Conduction Speech Super Resolution and Enhancement on Mobile and Wearable Platforms. arXiv preprint arXiv:2405.01242 (2024).
- [173] Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management . 1441-1450.
- [174] Ilya Sutskever, James Martens, and Geoffrey E Hinton. 2011. Generating text with recurrent neural networks. In Proceedings of the 28th international conference on machine learning (ICML-11) . 1017-1024.
- [175] Yujin Tang, Peijie Dong, Zhenheng Tang, Xiaowen Chu, and Junwei Liang. 2024. Vmrnn: Integrating vision mamba and lstm for efficient and accurate spatiotemporal forecasting. arXiv preprint arXiv:2403.16536 (2024).
- [176] Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. 2022. Efficient transformers: A survey. Comput. Surveys 55, 6 (2022), 1-28.
- [177] Vishrut Thoutam and Dina Ellsworth. [n. d.]. MSAMamba: Adapting Subquadratic Models To Long-Context DNA MSA Analysis. In ICML 2024 Workshop on Theoretical Foundations of Foundation Models .
- [178] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. 2021. Training data-efficient image transformers & distillation through attention. In International conference on machine learning . PMLR, 10347-10357.
- [179] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- [180] Jean-Philippe Vert. 2023. How will generative AI disrupt data science in drug discovery? Nature Biotechnology 41, 6 (2023), 750-751.
- [181] Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, et al. 2024. An Empirical Study of Mamba-based Language Models. arXiv preprint arXiv:2406.07887 (2024).
- [182] Zifu Wan, Yuhao Wang, Silong Yong, Pingping Zhang, Simon Stepputtis, Katia Sycara, and Yaqi Xie. 2024. Sigma: Siamese mamba network for multi-modal semantic segmentation. arXiv preprint arXiv:2404.04256 (2024).
[183]
Chloe Wang, Oleksii Tsepa, Jun Ma, and Bo Wang. 2024. Graph-mamba: Towards long-range graph sequence modeling with selective state spaces.
arXiv preprint arXiv:2402.00789
(2024).
- [184] Feng Wang, Jiahao Wang, Sucheng Ren, Guoyizhe Wei, Jieru Mei, Wei Shao, Yuyin Zhou, Alan Yuille, and Cihang Xie. 2024. Mamba-R: Vision Mamba ALSO Needs Registers. arXiv preprint arXiv:2405.14858 (2024).
- [185] Jinhong Wang, Jintai Chen, Danny Chen, and Jian Wu. 2024. Large window-based mamba unet for medical image segmentation: Beyond convolution and self-attention. arXiv preprint arXiv:2403.07332 (2024).
[186]
Jinhong Wang, Jintai Chen, Danny Chen, and Jian Wu. 2024. LKM-UNet: Large Kernel Vision Mamba UNet for Medical Image Segmentation. In
International Conference on Medical Image Computing and Computer-Assisted Intervention
.
Springer, 360-370.
- [187] Junxiong Wang, Tushaar Gangavarapu, Jing Nathan Yan, and Alexander M Rush. 2024. Mambabyte: Token-free selective state space model. arXiv preprint arXiv:2401.13660 (2024).
[188]
Qianning Wang, He Hu, and Yucheng Zhou. 2024. Memorymamba: Memory-augmented state space model for defect recognition.
arXiv preprint arXiv:2405.03673
(2024).
- [189] Xinghan Wang, Zixi Kang, and Yadong Mu. 2024. Text-controlled Motion Mamba: Text-Instructed Temporal Grounding of Human Motion. arXiv preprint arXiv:2404.11375 (2024).
- [190] Xiao Wang, Shiao Wang, Yuhe Ding, Yuehang Li, Wentao Wu, Yao Rong, Weizhe Kong, Ju Huang, Shihao Li, Haoxiang Yang, et al. 2024. State space model for new-generation network alternative to transformers: A survey. arXiv preprint arXiv:2404.09516 (2024).
- [191] Yuwei Wang et al. 2023. 3D dynamic image modeling based on machine learning in film and television animation. Journal of Multimedia Information System 10, 1 (2023), 69-78.
- [192] Yuda Wang, Xuxin He, and Shengxin Zhu. 2024. EchoMamba4Rec: Harmonizing Bidirectional State Space Models with Spectral Filtering for Advanced Sequential Recommendation. arXiv preprint arXiv:2406.02638 (2024).
[193]
Zhen Wang, Liu Liu, Yiqun Duan, Yajing Kong, and Dacheng Tao. 2022. Continual learning with lifelong vision transformer. In
Proceedings of the
IEEE/CVF Conference on Computer Vision and Pattern Recognition
.
171-181.
- [194] Ziyang Wang and Chao Ma. 2024. Weak-Mamba-UNet: Visual Mamba Makes CNN and ViT Work Better for Scribble-based Medical Image Segmentation. arXiv preprint arXiv:2402.10887 (2024).
- [195] Ziyang Wang, Jian-Qing Zheng, Chao Ma, and Tao Guo. 2024. Vmambamorph: a visual mamba-based framework with cross-scan module for deformable 3d image registration. arXiv preprint arXiv:2404.05105 (2024).
- [196] Zhong-Qiu Wang, Samuele Cornell, Shukjae Choi, Younglo Lee, Byeong-Yeol Kim, and Shinji Watanabe. 2023. TF-GridNet: Making time-frequency domain models great again for monaural speaker separation. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 1-5.
- [197] Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2024. Jailbroken: How does llm safety training fail? Advances in Neural Information Processing Systems 36 (2024).
- [198] Christopher Williams, Fabian Falck, George Deligiannidis, Chris C Holmes, Arnaud Doucet, and Saifuddin Syed. 2024. A Unified Framework for U-Net Design and Analysis. Advances in Neural Information Processing Systems 36 (2024).
Manuscript submitted to ACM
- [199] Jiayang Wu, Wensheng Gan, Zefeng Chen, Shicheng Wan, and S Yu Philip. 2023. Multimodal large language models: A survey. In 2023 IEEE International Conference on Big Data (BigData) . IEEE, 2247-2256.
[200]
Renkai Wu, Yinghao Liu, Pengchen Liang, and Qing Chang. 2024. Ultralight vm-unet: Parallel vision mamba significantly reduces parameters for skin lesion segmentation.
arXiv preprint arXiv:2403.20035
(2024).
- [201] Shu Wu, Yuyuan Tang, Yanqiao Zhu, Liang Wang, Xing Xie, and Tieniu Tan. 2019. Session-based recommendation with graph neural networks. In Proceedings of the AAAI conference on artificial intelligence , Vol. 33. 346-353.
- [202] Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. Smoothquant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning . PMLR, 38087-38099.
- [203] Jianhao Xie, Ruofan Liao, Ziang Zhang, Sida Yi, Yuesheng Zhu, and Guibo Luo. 2024. ProMamba: Prompt-Mamba for polyp segmentation. arXiv preprint arXiv:2403.13660 (2024).
- [204] Xinyu Xie, Yawen Cui, Chio-In Ieong, Tao Tan, Xiaozhi Zhang, Xubin Zheng, and Zitong Yu. 2024. Fusionmamba: Dynamic feature enhancement for multimodal image fusion with mamba. arXiv preprint arXiv:2404.09498 (2024).
- [205] Zhaohu Xing, Tian Ye, Yijun Yang, Guang Liu, and Lei Zhu. 2024. Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation. arXiv preprint arXiv:2401.13560 (2024).
- [206] Bohao Xu, Yingzhou Lu, Chenhao Li, Ling Yue, Xiao Wang, Nan Hao, Tianfan Fu, and Jim Chen. 2024. Smiles-mamba: Chemical mamba foundation models for drug admet prediction. arXiv preprint arXiv:2408.05696 (2024).
- [207] Rui Xu, Shu Yang, Yihui Wang, Bo Du, and Hao Chen. 2024. A survey on vision mamba: Models, applications and challenges. arXiv preprint arXiv:2404.18861 (2024).
[208]
Xiongxiao Xu, Yueqing Liang, Baixiang Huang, Zhiling Lan, and Kai Shu. 2024. Integrating Mamba and Transformer for Long-Short Range Time
Series Forecasting.
arXiv preprint arXiv:2404.14757
(2024).
- [209] Zhichao Xu. 2024. RankMamba, Benchmarking Mamba's Document Ranking Performance in the Era of Transformers. arXiv preprint arXiv:2403.18276 (2024).
- [210] Chenhongyi Yang, Zehui Chen, Miguel Espinosa, Linus Ericsson, Zhenyu Wang, Jiaming Liu, and Elliot J Crowley. 2024. Plainmamba: Improving non-hierarchical mamba in visual recognition. arXiv preprint arXiv:2403.17695 (2024).
- [211] Guangqian Yang, Kangrui Du, Zhihan Yang, Ye Du, Yongping Zheng, and Shujun Wang. 2024. CMViM: Contrastive Masked Vim Autoencoder for 3D Multi-modal Representation Learning for AD classification. arXiv preprint arXiv:2403.16520 (2024).
[212]
Jiyuan Yang, Yuanzi Li, Jingyu Zhao, Hanbing Wang, Muyang Ma, Jun Ma, Zhaochun Ren, Mengqi Zhang, Xin Xin, Zhumin Chen, et al. 2024.
Uncovering Selective State Space Model's Capabilities in Lifelong Sequential Recommendation.
arXiv preprint arXiv:2403.16371
(2024).
- [213] Judy X Yang, Jun Zhou, Jing Wang, Hui Tian, and Alan Wee Chung Liew. 2024. Hsimamba: Hyperpsectral imaging efficient feature learning with bidirectional state space for classification. arXiv preprint arXiv:2404.00272 (2024).
- [214] Yijun Yang, Zhaohu Xing, and Lei Zhu. 2024. Vivim: a video vision mamba for medical video object segmentation. arXiv preprint arXiv:2401.14168 (2024).
- [215] Zhe Yang, Wenrui Li, and Guanghui Cheng. 2024. SHMamba: Structured Hyperbolic State Space Model for Audio-Visual Question Answering. arXiv preprint arXiv:2406.09833 (2024).
- [216] Jing Yao, Danfeng Hong, Chenyu Li, and Jocelyn Chanussot. 2024. Spectralmamba: Efficient mamba for hyperspectral image classification. arXiv preprint arXiv:2404.08489 (2024).
- [217] Yang Ye and Shihao Ji. 2021. Sparse graph attention networks. IEEE Transactions on Knowledge and Data Engineering 35, 1 (2021), 905-916.
- [218] Zi Ye and Tianxiang Chen. 2024. P-Mamba: Marrying Perona Malik Diffusion with Mamba for Efficient Pediatric Echocardiographic Left Ventricular Segmentation. arXiv preprint arXiv:2402.08506 (2024).
- [219] Xuanyu Yi, Zike Wu, Qiuhong Shen, Qingshan Xu, Pan Zhou, Joo-Hwee Lim, Shuicheng Yan, Xinchao Wang, and Hanwang Zhang. 2024. MVGamba: Unify 3D Content Generation as State Space Sequence Modeling. arXiv preprint arXiv:2406.06367 (2024).
[220]
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. 2022. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
.
19313-19322.
- [221] Chenhan Yuan, Qianqian Xie, Jimin Huang, and Sophia Ananiadou. 2024. Back to the future: Towards explainable temporal reasoning with large language models. In Proceedings of the ACM on Web Conference 2024 . 1963-1974.
- [222] Doncheng Yuan, Jianzhe Xue, Jinshan Su, Wenchao Xu, and Haibo Zhou. 2024. ST-Mamba: Spatial-Temporal Mamba for Traffic Flow Estimation Recovery using Limited Data. arXiv preprint arXiv:2407.08558 (2024).
- [223] Yubiao Yue and Zhenzhang Li. 2024. Medmamba: Vision mamba for medical image classification. arXiv preprint arXiv:2403.03849 (2024).
- [224] Kang Zeng, Hao Shi, Jiacheng Lin, Siyu Li, Jintao Cheng, Kaiwei Wang, Zhiyong Li, and Kailun Yang. 2024. MambaMOS: LiDAR-based 3D Moving Object Segmentation with Motion-aware State Space Model. arXiv preprint arXiv:2404.12794 (2024).
- [225] Cheng Zhang, Nilam Nur Amir Sjarif, and Roslina Ibrahim. 2024. Deep learning models for price forecasting of financial time series: A review of recent advancements: 2020-2022. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 14, 1 (2024), e1519.
- [226] Hanqing Zhang, Haolin Song, Shaoyu Li, Ming Zhou, and Dawei Song. 2023. A survey of controllable text generation using transformer-based pre-trained language models. Comput. Surveys 56, 3 (2023), 1-37.
- [227] Hanwei Zhang, Ying Zhu, Dan Wang, Lijun Zhang, Tianxiang Chen, and Zi Ye. 2024. A survey on visual mamba. arXiv preprint arXiv:2404.15956 (2024).
Manuscript submitted to ACM
## A Survey of Mamba
- [228] Jiahao Zhang, Rui Xue, Wenqi Fan, Xin Xu, Qing Li, Jian Pei, and Xiaorui Liu. 2024. Linear-Time Graph Neural Networks for Scalable Recommendations. In Proceedings of the ACM on Web Conference 2024 . 3533-3544.
- [229] Tao Zhang, Xiangtai Li, Haobo Yuan, Shunping Ji, and Shuicheng Yan. 2024. Point Could Mamba: Point Cloud Learning via State Space Model. arXiv preprint arXiv:2403.00762 (2024).
- [230] Xiangyu Zhang, Qiquan Zhang, Hexin Liu, Tianyi Xiao, Xinyuan Qian, Beena Ahmed, Eliathamby Ambikairajah, Haizhou Li, and Julien Epps. 2024. Mamba in Speech: Towards an Alternative to Self-Attention. arXiv preprint arXiv:2405.12609 (2024).
- [231] Yezhuo Zhang, Zinan Zhou, Yichao Cao, Guangyu Li, and Xuanpeng Li. 2024. MAMCA-Optimal on Accuracy and Efficiency for Automatic Modulation Classification with Extended Signal Length. arXiv preprint arXiv:2405.11263 (2024).
- [232] Zheng Zhang and Kil To Chong. 2007. Comparison between first-order hold with zero-order hold in discretization of input-delay nonlinear systems. In 2007 International Conference on Control, Automation and Systems . IEEE, 2892-2896.
- [233] Zeyu Zhang, Akide Liu, Qi Chen, Feng Chen, Ian Reid, Richard Hartley, Bohan Zhuang, and Hao Tang. 2024. InfiniMotion: Mamba Boosts Memory in Transformer for Arbitrary Long Motion Generation. arXiv preprint arXiv:2407.10061 (2024).
- [234] Zeyu Zhang, Akide Liu, Ian Reid, Richard Hartley, Bohan Zhuang, and Hao Tang. 2024. Motion mamba: Efficient and long sequence motion generation with hierarchical and bidirectional selective ssm. arXiv preprint arXiv:2403.07487 (2024).
- [235] Han Zhao, Min Zhang, Wei Zhao, Pengxiang Ding, Siteng Huang, and Donglin Wang. 2024. Cobra: Extending mamba to multi-modal large language model for efficient inference. arXiv preprint arXiv:2403.14520 (2024).
- [236] Sijie Zhao, Hao Chen, Xueliang Zhang, Pengfeng Xiao, Lei Bai, and Wanli Ouyang. 2024. Rs-mamba for large remote sensing image dense prediction. arXiv preprint arXiv:2404.02668 (2024).
- [237] Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, et al. 2024. Recommender systems in the era of large language models (llms). IEEE Transactions on Knowledge and Data Engineering (2024).
- [238] Zou Zhen, Yu Hu, and Zhao Feng. 2024. Freqmamba: Viewing mamba from a frequency perspective for image deraining. arXiv preprint arXiv:2404.09476 (2024).
- [239] Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. 2021. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence , Vol. 35. 11106-11115.
- [240] Meizi Zhou, Zhuoye Ding, Jiliang Tang, and Dawei Yin. 2018. Micro behaviors: A new perspective in e-commerce recommender systems. In Proceedings of the eleventh ACM international conference on web search and data mining . 727-735.
- [241] Qingyuan Zhou, Weidong Yang, Ben Fei, Jingyi Xu, Rui Zhang, Keyi Liu, Yeqi Luo, and Ying He. 2024. 3dmambaipf: A state space model for iterative point cloud filtering via differentiable rendering. arXiv preprint arXiv:2404.05522 (2024).
- [242] Chen Zhu, Wei Ping, Chaowei Xiao, Mohammad Shoeybi, Tom Goldstein, Anima Anandkumar, and Bryan Catanzaro. 2021. Long-short transformer: Efficient transformers for language and vision. Advances in neural information processing systems 34 (2021), 17723-17736.
- [243] Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. 2024. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv preprint arXiv:2401.09417 (2024).
- [244] Bochao Zou, Zizheng Guo, Xiaocheng Hu, and Huimin Ma. 2024. Rhythmmamba: Fast remote physiological measurement with arbitrary length videos. arXiv preprint arXiv:2404.06483 (2024). | null | [
"Haohao Qu",
"Liangbo Ning",
"Rui An",
"Wenqi Fan",
"Tyler Derr",
"Hui Liu",
"Xin Xu",
"Qing Li"
] | 2024-08-02T09:18:41+00:00 | 2024-12-13T06:16:06+00:00 | [
"cs.LG",
"cs.AI"
] | A Survey of Mamba | As one of the most representative DL techniques, Transformer architecture has
empowered numerous advanced models, especially the large language models (LLMs)
that comprise billions of parameters, becoming a cornerstone in deep learning.
Despite the impressive achievements, Transformers still face inherent
limitations, particularly the time-consuming inference resulting from the
quadratic computation complexity of attention calculation. Recently, a novel
architecture named Mamba, drawing inspiration from classical state space models
(SSMs), has emerged as a promising alternative for building foundation models,
delivering comparable modeling abilities to Transformers while preserving
near-linear scalability concerning sequence length. This has sparked an
increasing number of studies actively exploring Mamba's potential to achieve
impressive performance across diverse domains. Given such rapid evolution,
there is a critical need for a systematic review that consolidates existing
Mamba-empowered models, offering a comprehensive understanding of this emerging
model architecture. In this survey, we therefore conduct an in-depth
investigation of recent Mamba-associated studies, covering three main aspects:
the advancements of Mamba-based models, the techniques of adapting Mamba to
diverse data, and the applications where Mamba can excel. Specifically, we
first review the foundational knowledge of various representative deep learning
models and the details of Mamba-1&2 as preliminaries. Then, to showcase the
significance of Mamba for AI, we comprehensively review the related studies
focusing on Mamba models' architecture design, data adaptability, and
applications. Finally, we present a discussion of current limitations and
explore various promising research directions to provide deeper insights for
future investigations. |
2408.01130v1 | ## Closed-loop underwater soft robotic foil shape control using flexible e-skin
L.Micklem 1 4 , ∗ , H.Dong 4 ∗ , F.Giorgio-Serchi 4 , Y.Yang 4 , G.D.Weymouth 1 2 , B.Thornton 1 3 , ,
Abstract -The use of soft robotics for real-world underwater applications is limited, even more than in terrestrial applications, by the ability to accurately measure and control the deformation of the soft materials in real time without the need for feedback from an external sensor. Real-time underwater shape estimation would allow for accurate closedloop control of soft propulsors, enabling high-performance swimming and manoeuvring. We propose and demonstrate a method for closed-loop underwater soft robotic foil control based on a flexible capacitive e-skin and machine learning which does not necessitate feedback from an external sensor. The underwater e-skin is applied to a highly flexible foil undergoing deformations from 2% to 9% of its camber by means of soft hydraulic actuators. Accurate set point regulation of the camber is successfully tracked during sinusoidal and triangle actuation routines with an amplitude of 5% peak-to-peak and 10-second period with a normalised RMS error of 0.11, and 2% peak-topeak amplitude with a period of 5 seconds with a normalised RMS error of 0.03. The tail tip deflection can be measured across a 30 mm (0.15 chords) range. These results pave the way for using e-skin technology for underwater soft robotic closed-loop control applications.
effect is optimised in swimming animals by adjusting their flapping amplitude and frequency according to their travelling speed. This complex control task is executed in fish via a combination of stiffness tuning through muscle contraction, fin and tail shape alteration, and skin surface changes [9]. In some fish, the control feedback required to exert authority on the foil morphology comes from fin rays acting as proprioceptive sensors [11]. There is strong evidence that biological systems make use of shape feedback for efficient swimming and unsteady fluid load control.
## I. INTRODUCTION
Soft robots are becoming prominent in a variety of fields [1], [2], [3], [4], [5]. One area with potential for soft robots is bioinspired control surfaces and efficient actuation in subsea environments [6], [7], [8]. Flexibility is important for efficient animal swimming and, by extension, swimming robots [9]. Flexible swimmers are known to exert finetuned control over their propulsor to excite different resonant modes and in this way maximize propulsive efficiency. Such a degree of control obviously necessitates a refined degree of authority over the morphology of the propulsors. This is currently inaccessible by soft robotics devices due to the lack of integrated underwater sensors with sufficient resolution for feedback control.
Structural flexibility also allows for fine-tuning of the unsteady fluid loading on the propulsor with benefits on sustained swimming efficiency as well as agile manoeuvring. For example, deformations which optimise the lift-to-drag ratio have been found to offset structural failure and hence facilitate survival in leaves subject to increasing wind speeds by maintaining low drag [10]. This same hydrodynamic
Corresponding author [email protected] . Manuscript received: June, 19, 2024. 1 Southampton Marine and Maritime Institute, University of Southampton, UK, 2 Delft University of Technology, Netherlands, 3 Institute of Industrial Science, The University of Tokyo, Japan, 4 School of Engineering, The University of Edinburgh, UK. ∗ Leo Micklem and Huazhi Dong contributed equally to this work.
In their review of bioinspiration in underwater soft robotics, Youssef et al. [8] highlight the need for all actuators and sensors to be implemented using completely soft materials. This is to not adversely impact the inherent flexibility of the system itself by incorporating stiffer components. Hegde et al. [12] divide the current soft robotic shape estimation sensors into three categories; resistive/piezoresistive, optical, and capacitive sensors. Resistive sensors work on the principle of varying resistance with pressure or strain. They are typically used to detect external pressures such as on a gripper but they struggle to perform shape estimation of highly non-linear soft robotic systems. Optical sensors use optical fibres to estimate shape and strain but are limited in the magnitude of deformation due to occlusion [12]. Recently, Peng et al. [13] have used multiple inertial measurement units (IMUs) for shape estimation of soft manipulators. Reliance on IMUs and an Extended Kalman Filter offers a good degree of accuracy for the purpose of control but requires a reliable kinematic model of the body under investigation. Hu et al. [14] demonstrated a novel approach of utilising a specifically designed capacitive e-skin and deep learning which does not necessitate any pre-existing knowledge of the body and successfully demonstrated real-time, full 3D shape reconstruction of a flexible model robotic arm. For shape feedback and reconstruction of underwater objects there are many methods using visual feedback [15], [16], [17], [18], thus suffering from the constraint of relying on cameras. However, there are currently no ready-made solutions for estimating the state of flexible underwater objects without the use of an external sensing system that does not disrupt the body's flexibility and that allows for use outside of a lab setting. This severely limits the ability of these methods to be used in real-world applications as in the case of an untethered soft underwater vehicles.
Flexible foils have been studied extensively [19] and have been shown to be good biomimetic models for understanding fish propulsion [20]. Rigid foils have also been widely used
Fig. 1. (a) Schematic of the tunable-stiffness soft foil. The rigid nose houses the internal pressure tubing, and clamps the silicone tail. The soft silicone tail has holes to house the inflatable rubber tubes which can expand and contract with pressure. The e-skin is bonded to the silicone tail using a thin layer of EcoFlex-30. (b) (Left) Soft robotic foil with e-skin attached for deformation measurement. The red tracking markers allow for the position of the foil to be tracked underwater for training and ground truth comparison. (Right) e-skin module for the soft robotic foil before attachment to the robot. 6 wires allow for the reading of 9 signals for training and measurement.
as control surfaces for Autonomous Underwater Vehicles (AUVs) [21]. These control surfaces are used for vehicle trajectory control and stability, and in some cases thrust generation [22]. Flexible foils offer versatile options for soft underwater vehicle manoeuvring and propulsion, but suffer of the lack of a suitable sensing technology for full state estimation. Therefore, shape control of a flexible foil is an essential stepping stone in the advancement of underwater soft robotics and aquatic bioinspired locomotion.
In this work, we propose a 1 Degree of Freedom (DoF) test case of a flexible underwater foil with internal soft hydraulic actuators (Fig. 1a) [23]. The actuators provide authority over the stiffness and camber with increasing pressure which results in the deformation of the foil in the form of increasing camber (Fig. 2). We develop the first working method of underwater shape control using a flexible capacitive e-skin sensor following [14]. We employ the flexible capacitive e-skin with machine learning to track the centre line of the flexible foil which allows the camber to be monitored as a control variable (Fig. 1b). The camber is calculated in real time and fed to a PID controller to carry out a
Fig. 2. Outline of the key physical parameters for the control problem. The angle between any oncoming flow and the leading edge α is the angle of attack. The straight line from the leading edge to the trailing edge is the chord line. The line from leading edge to the trailing edge through the centre of the foil is the camber line. The perpendicular distance between the chord and the camber lines defines the camber.
variety of time-varying set point regulation tasks. While the method is validated here on a foil undergoing planar camber control, the solution proposed is readily extendable to spatial deformations of complex multi-DoF aquatic propulsors.
## II. MATERIALS AND METHODS
## A. Morphing Soft Foil
We designed, built and tested a tunable-stiffness foil using our previously developed second-moment-of-area actuation [23] (Fig. 1a and Table I). The foil is comprised of a rigid nose connected to a soft tail. Embedded within the tail are two inflatable elastic tubes. The tail has a base stiffness provided by the silicone, and the tubes can be pressurised to increase the second-moment-of-area and stiffness. When the tubes are inflated it causes the soft robotic foil to deform due to a natural curvature of the inflatable tubes [23]. The system is actuated hydraulically to avoid compressibility effects and negate buoyancy forces.
Hydraulic actuation affects the planar curvature of the foil, which is expressed here by the camber. The camber of a foil is described by its maximum value along the foil length as depicted in Fig. 2 and expressed according to
$$c a m b e r \, \% = 1 0 0 \times \frac { ( C h _ { n }, C _ { n } ) _ { m a x } } { C h } \quad \quad ( 1 )$$
where Ch is the chord length, and ( Chn Cn max , ) is the maximum perpendicular distance between the chord line and the camber line, hence camber is given as a percentage. For a prescribed angle-of-attack α (Fig. 2), a change in camber of a foil results in changes in lift and drag forces. Typically, cambers are in the range of 0-10%.
## B. Design and Fabrication of the e-skin
We developed a liquid metal-based e-skin for proprioceptive sensing of the flexible foil. Fig. 3 shows the fabrication process and design of the capacitive e-skin. This consists of a silicone layer, 6 copper and liquid metal electrodes and a sealing layer. The overall dimensions are 120 × 112 × 2 mm 3 . The contact area of each electrode with the conductive layer is 5 × 5 mm 2 . A silicone elastomer, made
Fig. 3. Fabrication process of the capacitive e-skin. (a) Deployment of copper electrodes on the 3D-printed mould, (b) Eco-flex 00-30 is poured into the 3D printed mould, (c) curing of the top layer at room temperature for 4 hours and release the mould, (d) fabrication of an additional silicone backing layer and bonding with the top layer by means of the uncured silicone mixture as the adhesive, (e) injection of Liquid metal into the hollow channels with a second needle used as an exhaust for the air and finally sealing of the holes created by the needles with additional silicone. (f) The fabricated Liquid metal e-skin.
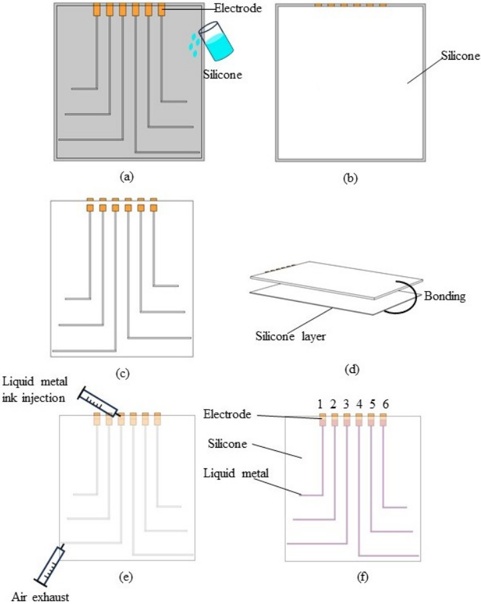
of Ecoflex 00-30 (Smooth-On Inc.) is cast in a 3D printed mould to create vacant channels in for the liquid metal. The cured silicone is removed from the mould and bonded with a new silicone layer using uncured silicone mixture as the adhesive. Liquid metal is injected using a syringe into the hollow channels with a second needle used as an exhaust for the air. The holes created by the needles are then sealed with additional silicone.
The sensor operates by measuring the relative capacitance of select pairs of close proximity liquid metal electrodes with the strongest signals coming from adjacent pairs. As a result, we selected nine specific pairs of electrodes: (1, 2), (1, 3), (2, 3), (2, 4), (3, 4), (3, 5), (4, 5), (4, 6), and (5, 6), Fig. 3(f). When the shape of the e-skin changes due to deformation of the underlying foil, the relative capacitance between electrode pairs varies accordingly. By normalising the sensor readings against the undeformed shape readings, it is possible to use the capacitance signal to sense the foil's change in shape. Each readout is normalised as follows
$$c = \frac { ( c ^ { \prime } - c _ { e m p } ) } { c _ { e m p } }$$
where c is the normalised capacitance readout, c ′ is the absolute readout, and cemp is the reference untrained readout. To quantify this change in shape, a model must be trained based on images of the robot taken at matching timestamps to the sensor readings, Fig. 5. Upon successful training, reliance on the external visual feedback is no longer required.
## C. Underwater E-skin Training
Fig. 4 shows the experimental setup for training and testing of the e-skin on the soft robotic foil. For the collection of training data, the foil is actuated for 10 cycles with 30 seconds of baseline data taken before and after actuation. The pressurisation of the foil is controlled using a linear actuator connected to a syringe which supplies the pressure. An underwater camera records the motion of the foil for training and ground truth comparison. The e-skin samples at 714 Hz and the camera at 30 Hz. The video is post-processed to track the five red markers and convert these to sets of five twodimensional coordinates for each image. The coordinate sets and time-corresponding training data are then employed to train a Multilayer Perceptron (MLP) model which ultimately allows association of instantaneous capacitance readouts to foil shape, thus removing the need for visual feedback.
We employ the MLP model because it is well-suited for handling structured data like the sensor readings from the e-skin, and it is able to capture complex non-linear relationships between the input sensor data and the output coordinates which would be expected from a more complex three-dimensional problem. Compared to recurrent or convolutional neural networks, the MLP is an effective, and more simplistic, choice for accurately estimating the foil shape from the sensor data as well as future 3D applications. The MLP model (Table II) has 1 input layer, 3 hidden layers, and 1 output layer. The input of this model is the 9 calibrated capacitance readouts in one frame from the e-skin. The output is a vector with a size of 10, indicating the coordinates of the five markers which can be used to calculate the camber.
During training the foil leading edge is kept stationary, allowing for the camber line of the foil to be accurately described by 6 geometrical points. A spline is fitted to populate the points from the trailing edge to the start of the silicone
TABLE I EXPERIMENTAL MATERIALS
| Stiffness foil | Stiffness foil | Stiffness foil |
|------------------|-----------------------------|------------------|
| Part | Material | Dimensions (mm) |
| Soft Tail | EcoFlex-30 | 120 x 140 x 30 |
| Rigid Nose | Polylactic Acid Plastic | 120 x 80 x 30 |
| Inflatable Tubes | Isobutylene Isoprene Rubber | 110 x 15 x 15 |
| Square Bar | Aluminium | 700 x 10 x 10 |
| Training Set Up | Training Set Up | Training Set Up |
| DAQ | Bespoke Measurement Board | |
| Motor Driver | Cytron MD10C | |
| Controller | Arduino Uno | |
| Camera | GoPro HERO 10 | |
| Resolution | 1920 x 1080 | |
| Frame Rate | 30 fps | |
Fig. 4. Schematic of the static testing set up. The pressurisation of the foil is controlled using a linear actuator connected to a syringe which supplies the pressure. An underwater camera records the motion of the foil for training and ground truth comparison.
Fig. 5. Signals of calibrated capacitance readouts, eq. 2, during foil deformation (top) and corresponding foil deformation (bottom) throughout five repetitive cycles of camber actuation.
and the chord line is calculated from the leading edge to the trailing edge, Fig. 2; eqn. 1 provides instantaneous estimate of the foil camber based on these two lines.
TABLE II TRAINING SPECIFICATIONS
| MLP | MLP |
|------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------|
| Neurons per hidden layer Training Method Learning Rate Epochs Batch size Training Data Validating, Testing | 32, 128, 32 Squared Error (MSE) loss function 0.0001 300,000 |
| Mean 256 24,000 frames Ratio 70/20/10 Minimum validation loss 0.397 | Mean 256 24,000 frames Ratio 70/20/10 Minimum validation loss 0.397 |
| K p , K i , K d | 50, 1, 1 |
| Training, | |
| PID Controller Gains | PID Controller Gains |
Fig. 6. Block diagram outlining the closed loop control structure of the system. The system is comprised of an Arduino controller, a linear actuator driven syringe, and the soft robotic foil. The e-skin sensor provides feedback for the system.
## D. Underwater Soft Robotic Shape Control
For a potential real world application the system needs to be able to reach a desired set point with different time scales and paths. For this work we tested a step function with 2% camber increases every 5 seconds, and triangle and sinusoidal motion profiles. The motion profiles were tested at 20 s, 10 s, 5 s periods around a mean value of 4.25% and amplitudes of 5% and 2%. Faster response times were not achievable due to the speed limitations of the linear actuator used to control the pressure.
The control loop is depicted in Fig. 6: relative capacitance measurements are read and the MLP model converts the signals into coordinates from which the camber is calculated. A PID controller compares the measured position to the set point and drives an input to the hydraulic actuator. Parameters for the MLP and PID were determined through preliminary experiments, and are given in Table II.
## III. RESULTS AND DISCUSSION
Fig. 7 shows camber time history for a 2% camber step increase every 5 seconds from 2.5% to 8.5%. This is equivalent of a tail tip position change of 10 mm per step.
Fig. 7. Plot of camber against time for a 2% camber step increase every 5 seconds from 2.5% to 8.5% (equivalent to a tip amplitude change of 10 mm per step) with a rise time of 1.7 s. Plotted is the instantaneous foil camber based on the e-skin and the ground truth measurement from the camera point-tracking, averaged across 10 trials.
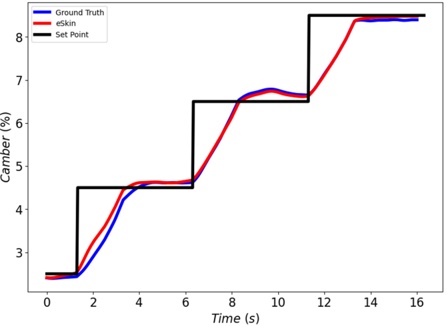
Fig. 8. (a) Mean phase averaged camber plotted for six set point motion profiles. The top row correspond to Sinwave inputs. The bottom row corresponds to Triangle wave inputs. Each profile has a peak-to-peak amplitude of 2% and a mean of 4.25%. Each column corresponds to a period of 20 s, 10 s, 5 s from left to right respectively. Plotted is the estimated position of the robot based on the e-skin measurement and the ground truth position of the robot based on the camera point-tracking, averaged across 20 cycles. (b) The same motion profiles are plotted, changing the peak-to-peak amplitude to 5%.
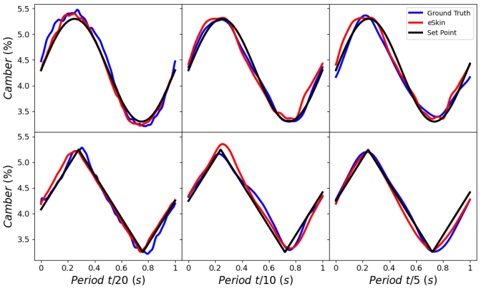
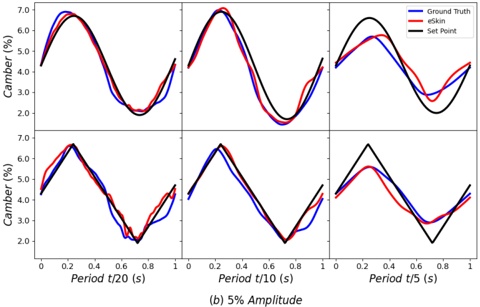
Plotted is the estimated position of the robot based on the eskin measurement and the ground truth position of the robot based on the camera point-tracking, averaged across 10 trials. The rise time is 1.7 s.
Fig. 8a shows the mean phase averaged camber plotted for six set point motion profiles. The top row corresponds to Sinwave inputs. The bottom row corresponds to Triangle wave inputs. Each profile has a peak-to-peak amplitude of 2% and a mean of 4.25% and each column corresponds to a period of 20 s, 10 s, 5 s from left to right respectively. Plotted is the estimated position of the robot based on the e-skin measurement and the ground truth position of the robot based on the camera point-tracking, averaged across 20 cycles. These results show excellent set point regulation for the 10 s period and even for the faster 5 s actuation routine.
Fig. 8b shows mean phase averaged camber plotted for the same six set point motion profiles, with a new peak-topeak amplitude of 5%, averaged across 20 cycles. Positional error observed for the 5 s period are mainly due to the slow
Fig. 9. Comparison of the measurement error between the e-skin and the ground truth as a percentage of the foil length at different camber magnitudes. Plotted is the mean error, the first standard deviation, σ , of the error and the maximum and minimum error values measured.
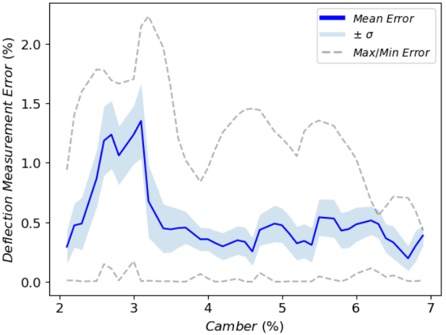
Fig. 10. Comparing the error between set point and ground truth measurement for triangle and sinusoidal wave inputs at 2% and 5% camber variation. Plotted is the Root Mean Square Error normalised by the average signal magnitude: RMSE y / ¯ (NRMSE).
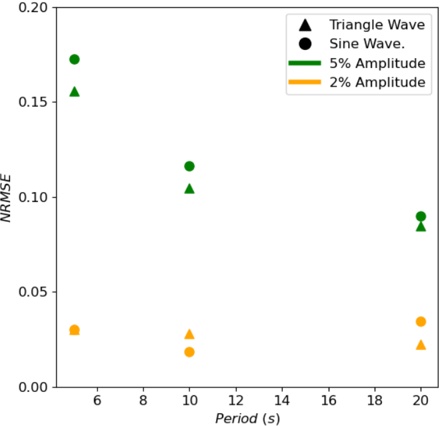
response of the hydraulic actuator, as expected given the rise time measured in Fig. 7. Discrepancies for the 20 s and 10 s cases for both the 2% and 5% test are attributed to high frequency signal noise.
Fig. 9 reports on the e-skin state estimation performance by comparing the measurement error between the e-skin and the ground truth as a percentage of the foil length at different camber magnitudes. The foil is calibrated based on the zero position so there is higher accuracy at this point. Plotted is the mean error, the first standard deviation, σ , of the error and the maximum and minimum error values measured. We demonstrate a maximum sensor error of less than 2.2% and an average sensor error of 0.52%. These errors are extremely small and sufficient given hydrodynamic considerations in unsteady natural flow. At relatively low camber values there is smaller overall deformation of the foil which leads to a worse signal-to-noise ratio and induces higher average error.
Fig. 10 assesses the closed-loop control performance by comparing the error between set point and ground truth measurement for triangle and sinusoidal wave inputs at 2% and 5% camber variation. Plotted is the Root Mean Square Error normalised by the average signal magnitude: RMSE y / ¯ (NRMSE). NRMSE decreases with a longer period due to the speed of actuation capabilities. NRMSE also decreases with a smaller desired amplitude due to the slower operation required and more linear response of the system. There is little difference in error between the triangle and sinusoidal wave setpoints.
The results presented give confidence in the robustness and accuracy of the underwater e-skin for the purpose of control of the flexible wing. Further extension of the operating envelope of the system would be feasible through revision of the actuator and optimization of the control strategy.
## IV. CONCLUSION AND ROBOTIC IMPLICATIONS
We have demonstrated the ability to perform real time shape estimation and control of a soft aquatic propulsor using an integrated e-skin, without the need for external sensing capabilities. We demonstrate measurements of foil camber with a maximum sensor error of less than 2.2% and an average sensor error of 0.52% which is comparable to that produced by an external optical system. The e-skin captures the high non-linearity of the soft robotic foil with a NRMSE of 0.11 and is not limited to small deformations. This method of underwater shape estimation is well suited for progression to more complex systems as it is agnostic to the shape of the system, making it suitable for more complex shapes and spatial deformations. Expansion to three-dimensional stateestimation is exclusively limited by the need to undertake training underwater, thus requiring adequate underwater motion tracking technology. Since this novel approach does not rely on external sensors, it paves the way for future real time state estimation and closed-loop control of aquatic soft robots for propulsive efficiency optimisation and disturbance rejection.
## REFERENCES
- [1] T. T. Hoang, J. J. S. Quek, M. T. Thai, P. T. Phan, N. H. Lovell, and T. N. Do. Soft robotic fabric gripper with gecko adhesion and variable stiffness. Sensors and Actuators, A: Physical , 323:112673, 2021.
- [2] D. Drotman, S. Jadhav, D. Sharp, C. Chan, and M. T. Tolley. Electronics-free pneumatic circuits for controlling soft-legged robots. Science Robotics , 6(51), 2021.
- [3] T. Umedachi, V. Vikas, and B. A. Trimmer. Softworms: The design and control of non-pneumatic, 3D-printed, deformable robots. Bioinspiration and Biomimetics , 11(2), 2016.
- [4] M. Porez, F. Boyer, and A. Belkhiri. A hybrid dynamic model for bio-inspired soft robots -Application to a flapping-wing micro air vehicle. Proceedings -IEEE International Conference on Robotics and Automation , pages 3556-3563, 2014.
- [5] N. D. Naclerio, A. Karsai, M. Murray-Cooper, Y. Ozkan-Aydin, E. Aydin, D. I. Goldman, and E. W. Hawkes. Controlling subterranean forces enables a fast, steerable, burrowing soft robot. Science Robotics , 6(55):1-12, 2021.
- [6] Federico Renda, Francesco Giorgio-Serchi, Frederic Boyer, and Cecilia Laschi. Locomotion and elastodynamics model of an underwater shell-like soft robot. In 2015 IEEE International Conference on Robotics and Automation (ICRA) , pages 1158-1165, 2015.
- [7] S. Aracri, F. Giorgio-Serchi, G. Suaria, M. E. Sayed, M. P. Nemitz, S. Mahon, and A. A. Stokes. Soft Robots for Ocean Exploration and Offshore Operations: A Perspective. Soft Robotics , 8(6):625-639, 2021.
- [8] S. M. Youssef, M. Soliman, M. A. Saleh, M. A. Mousa, M. Elsamanty, and A. G. Radwan. Underwater Soft Robotics: A Review of Bioinspiration in Design, Actuation, Modeling, and Control. Micromachines , 13(1):1-16, 2022.
- [9] D. Quinn and G. Lauder. Tunable stiffness in fish robotics: Mechanisms and advantages. Bioinspiration and Biomimetics , 17(1), 2022.
- [10] E. de Langre. Effects of wind on plants. Annual Review of Fluid Mechanics , 40:141-168, 2008.
- [11] Richard Williams Iv, Nicole Neubarth, and Melina E. Hale. The function of fin rays as proprioceptive sensors in fish. Nature Communications , 4, 2013.
- [12] Chidanand Hegde, Jiangtao Su, Joel Ming Rui Tan, Ke He, Xiaodong Chen, and Shlomo Magdassi. Sensing in soft robotics. ACS Nano , 17(16):15277-15307, 2023. PMID: 37530475.
- [13] Rui Peng, Yu Wang, and Peng Lu. A tendon-driven continuum manipulator with robust shape estimation by multiple imus. IEEE Robotics and Automation Letters , 9(4):3084-3091, 2024.
- [14] Delin Hu, Francesco Giorgio-Serchi, Shiming Zhang, and Yunjie Yang. Stretchable e-skin and transformer enable high-resolution morphological reconstruction for soft robots. Nature Machine Intelligence , 5:261272, 3 2023.
- [15] Haihang Wang, He Xu, Yihan Meng, Xinlei Ge, Aijing Lin, and Xiao Zhi Gao. Deep learning-based 3d pose reconstruction of an underwater soft robotic hand and its biomimetic evaluation. IEEE Robotics and Automation Letters , 2022.
- [16] Franc ¸ois Chadebecq, Francisco Vasconcelos, Ren´ e Lacher, Efthymios Maneas, Adrien Desjardins, S´ ebastien Ourselin, Tom Vercauteren, and Danail Stoyanov. Refractive two-view reconstruction for underwater 3d vision. International Journal of Computer Vision , 128:1101-1117, 5 2020.
- [17] Prabhakar C J and Praveen P Kumar U. 3d surface reconstruction of underwater objects, 2012.
- [18] Bradley Alfred Moran. Underwater shape reconstruction in two dimensions, 1994.
- [19] Silas Alben, Charles Witt, T. Vernon Baker, Erik Anderson, and George V. Lauder. Dynamics of freely swimming flexible foils. Physics of Fluids , 24(5):051901, 05 2012.
- [20] Ryan M. Shelton, Patrick J. M. Thornycroft, and George V. Lauder. Undulatory locomotion of flexible foils as biomimetic models for understanding fish propulsion. Journal of Experimental Biology , 217(12):2110-2120, 06 2014.
- [21] J.L.D. Dantas and E.A. de Barros. Numerical analysis of control surface effects on auv manoeuvrability. Applied Ocean Research , 42:168-181, 2013.
- [22] J.A. Bowker and N.C. Townsend. Evaluation of bow foils on ship delivered power in waves using model tests. Applied Ocean Research , 123:103148, 2022.
- [23] L. Micklem, G.D. Weymouth, and B. Thornton. Energy-efficient tunable-stiffness soft robots using second moment of area actuation. In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages 5464-5469, 2022. | null | [
"Leo Micklem",
"Huazhi Dong",
"Francesco Giorgio-Serchi",
"Yunjie Yang",
"Gabriel D. Weymouth",
"Blair Thornton"
] | 2024-08-02T09:19:24+00:00 | 2024-08-02T09:19:24+00:00 | [
"cs.RO"
] | Closed-loop underwater soft robotic foil shape control using flexible e-skin | The use of soft robotics for real-world underwater applications is limited,
even more than in terrestrial applications, by the ability to accurately
measure and control the deformation of the soft materials in real time without
the need for feedback from an external sensor. Real-time underwater shape
estimation would allow for accurate closed-loop control of soft propulsors,
enabling high-performance swimming and manoeuvring. We propose and demonstrate
a method for closed-loop underwater soft robotic foil control based on a
flexible capacitive e-skin and machine learning which does not necessitate
feedback from an external sensor. The underwater e-skin is applied to a highly
flexible foil undergoing deformations from 2% to 9% of its camber by means of
soft hydraulic actuators. Accurate set point regulation of the camber is
successfully tracked during sinusoidal and triangle actuation routines with an
amplitude of 5% peak-to-peak and 10-second period with a normalised RMS error
of 0.11, and 2% peak-to-peak amplitude with a period of 5 seconds with a
normalised RMS error of 0.03. The tail tip deflection can be measured across a
30 mm (0.15 chords) range. These results pave the way for using e-skin
technology for underwater soft robotic closed-loop control applications. |
2408.01131v1 | ## Strange Nonchaotic Attractor in an Unforced Turbulent Reactive Flow System
Thonti Beeraiah, 1, 2 Shruti Tandon, 1, 2 Premraj Durairaj, 3 and R. I. Sujith 1, 2
2
1 Department of Aerospace Engineering, Indian Institute of Technology Madras, Chennai 600 036, India Centre of Excellence for Studying Critical Transition in Complex Systems,
Indian Institute of Technology Madras, Chennai 600 036, India
3 Institute of Systems Science, Huaqiao University, Xiamen, 361021, China
(Dated: August 5, 2024)
We discover strange nonchaotic attractor (SNA) through experiments in an unforced system comprising turbulent reactive flow. While models suggest SNAs are common in dynamical systems, experimental observations are primarily limited to systems with external forcing. We observe SNA prior to the emergence of periodic oscillations from chaotic fluctuations. In complex systems, self-organization can lead to order, and inherent nonlinearity can induce chaos. The occurrence of SNA, which is nonchaotic yet nonperiodic in one such complex system, is intriguing.
Introduction -Strange nonchaotic attractor (SNA) is a non-trivial dynamical state that has attracted sustained interest in the nonlinear dynamics community [1-6]. SNAs exhibit intricate fractal geometries akin to those observed in chaotic systems. However, unlike chaotic systems, SNAs do not exhibit exponential sensitivity to initial conditions and are hence characterized as nonchaotic. Typically, a positive largest Lyapunov exponent indicates sensitivity to initial conditions; for SNAs, this exponent is nonpositive [1].
We discover the state of SNA in a system comprising turbulent reactive flow. Our finding is particularly intriguing given that our system is not externally forced and is rather a selforganized complex system owing to a web of inter-subsystem interactions [7, 8]. Turbulent flows are ubiquitous in nature and consist of eddies ranging from very small scale to very large scale [9]. These eddies interact nonlinearly, making turbulent flow a quintessential complex system [10]. Introducing an exothermic reaction into a turbulent flow adds to the intricacy and multifaceted nature of the system.
Turbulent reactive flows occur in natural systems, including stars, which are thermonuclear reactors composed of plasma, bounded by gravity. These stars undergo turbulent mixing [11], and in rotating stars, this turbulent mixing generates a magnetic field which, in turn, establishes a nonlinear interaction between turbulent mixing, rotation, and magnetic field. Such stars may exhibit chaotic fluctuations [12] or unstable pulsation modes [11]. Turbulent reactive flows also exist in human-made systems, such as combustors in gas turbine and rocket engines. Turbulent reactive flows in combustors comprise subsystems, namely the hydrodynamic field, heat release (flame) field, and acoustic field that interact in a nonlinear manner, increasing the overall complexity [13]. During the stable operation in such systems, the acoustic pressure fluctuations ( p ′ ) are low-amplitude and aperiodic in nature and are characterized as high-dimensional chaos [14, 15]. During this state, the subsystems are desynchronized [16, 17]. In contrast, during unstable operation, high-amplitude periodic acoustic pressure oscillations occur, characterized as limit cycle oscillations (order). Order emerges from the chaotic fluctuations when positive feedback is established between the heat release rate and the acoustic field, leading to their synchronization [7]. In these systems, the presence of chaotic and ordered states, and the transition from chaotic to ordered states via a state of intermittency-where high amplitude periodic epochs are interspersed with low amplitude aperiodic fluctuations-is well established [18, 19]. However, the discovery of the state of SNA, which is nonchaotic yet nonperiodic, in such a complex system is surprising.
FIG. 1. (a) Schematic of the experimental setup, (b) bluff body mounted on a shaft fixed at 30 mm from the backward-facing step, and (c) variation of root-mean-square of acoustic pressure fluctuations ( p ′ ) as a function of Re during the transition, with the highlighted points indicating various dynamical states present.
Typically, SNAs are found in dynamical systems driven by external quasiperiodic [16, 20-25] or periodic forcing [26, 27]. SNAs have also been observed in experimental systems with periodic forcing [28, 29]. Furthermore, a few studies using mathematical models have demonstrated that neither quasiperiodic force nor periodic force is essential for the occurrence of SNA [30, 31]. However, to date, only two physical systems have been reported to exhibit SNAs without being subjected to external force: a pulsating star KIC 5520878 network [32] and a laminar thermoacoustic system [33].
In this letter, we present the experimental discovery of state of SNA in a highly complex turbulent reactive flow system. In the experiments, we increase the Reynolds number ( Re ) as a bifurcation parameter in a quasi-static manner and observe a transition from lowamplitude aperiodic fluctuations to high-amplitude periodic oscillations. We show that the state of SNA occurs prior to the onset of high-amplitude periodic oscillations. While the computation of Lyapunov exponents is generally useful for determining the nature of dynamical states, ranging from regular to chaotic, it is often unreliable for noise-contaminated experimental data [34]. Therefore, we employ Fast Fourier Transform (FFT) and phase space reconstruction to distinguish different dynamical states. We then apply the 0 -1 test [35] and correlation dimension test [36] to characterize these states. Finally, to confirm the presence of SNA, we use singular continuous spectrum analysis [37].
Experimental setup -Weperform experiments in a lab-scale backward-facing step turbulent combustor, using a bluff body as a flame stabilizer, as depicted in figure 1a. The bluff body is fixed at a location of 30 mm from the backward-facing step throughout the
FIG. 2. Time series (a-e), Amplitude spectrum (f-j), and reconstructed phase space (k-o) of the five dynamical states. During the transition, periodicity emerges, as reflected in the amplitude spectrum and reconstructed phase space.
transition. The setup comprises three main components: a plenum chamber, a burner, and a combustion chamber. The combustion chamber has a square cross-section measuring 90 mm × 90 mm and a length of 1100 mm. The plenum chamber connects to the burner, which further leads to the combustion chamber. Gaseous fuel is injected into the air in the burner section, creating a partially premixed fuel-air mixture by the time it reaches the combustion chamber, where all reactions occur. To vary the Reynolds number ( Re ), we fix the fuel flow rate and increase the air flow rate using mass flow controllers (Alicat Scientific, MCR). The uncertainty in the measurement of the flow rate is ± (0.8% of reading + 0.2% of full scale), resulting in a maximum uncertainty of ± 2 5% in . Re . We flush-mount a piezoelectric pressure transducer (PCB103B02) on the combustion chamber at 40 mm from the backward-facing step to measure acoustic pressure fluctuations ( p ′ ). The sensor has an uncertainty of ± 0 15 . Pa. During the transition, we measure the acoustic pressure oscillations ( p ′ ) at a sampling rate of 20 kHz.
Results - In our experiments, we vary Re from 28 000 to 44 000 and observe a transition , , from low-amplitude aperiodic fluctuations to high-amplitude periodic oscillations (Fig. 1c). We primarily use Fast Fourier Transform and phase space reconstruction of p ′ to distinguish the dynamical states present, labeled as states I to V (Fig. 2). As the transition occurs from state I to V, we observe an increase in the amplitude of fluctuations in p ′ (Fig. 2a-
e). Concurrently, the periodicity of the signal increases, culminating in the emergence of a single prominent peak in the amplitude spectrum during state V (Fig. 2j) compared to the broad peak during state I (Fig. 2f). To further characterize these states, we apply 0 -1 test and correlation dimension test. Finally, we employ the singular continuous spectrum test to confirm the SNA, which we identify through the preceding analyses.
a. 0 -1 test Originally, Gottwald and Melbourne [35] proposed this method to discriminate between regular and chaotic time series. The initial step of the 0 -1 test is to transform the original signal into a new space where the underlying dynamics becomes more apparent. For the same purpose we calculate the translation variables ( p n ( n ) and q n ( n )), as defined by,
$$p _ { n } ( n ) = \sum _ { i = 1 } ^ { n } p ^ { \prime } ( i ) \cos ( i c ),$$
$$q _ { n } ( n ) = \sum _ { i = 1 } ^ { n } p ^ { \prime } ( i ) \sin ( i c ), n = 1, 2, 3, \dots, & & ( 1 b )$$
where, p ′ ( ) i denotes the acoustic pressure fluctuations at instant i and c is a parameter selected arbitrarily within π/ 5 to 4 π/ 5. The dynamics of variables p n ( n ) and q n ( n ) are closely related to the discrete variable n , which is significantly smaller than the length of the signal ( N ) (typically n = N/ 10). To quantify the evolution of the trajectory in the [ p n ( n , q ) n ( n )] plane as n increases, the mean square displacement D n ( ) is utilized, defined as:
$$D ( n ) = \frac { 1 } { N } ( \sum _ { i = 1 } ^ { N } [ p _ { n } ( i + n ) - p _ { n } ( i ) ] ^ { 2 } + [ q _ { n } ( i + n ) - q _ { n } ( i ) ] ^ { 2 } ).$$
To address convergence issues with D n ( ), a modified mean square displacement M n ( ) [38, 39] is proposed, which is calculated as:
$$M ( n ) = D ( n ) - V _ { o s c } ( c, n ),$$
where, V osc ( c, n ) = ∑ n i =1 p ′ ( ) i 1 -cos( ic ) 1 -cos( c ) , is an oscillatory term. The asymptotic growth rate K c is determined through linear regression fit of M n ( ) as:
$$K _ { c } = \lim _ { n \to \infty } \frac { \log M ( n ) } { \log n }.$$
n
FIG. 3. Modified mean square displacement ( M n ( )) (top row) and asymptotic growth rate ( K c ) (bottom row) during the dynamical states of (a, f) I, (b, g) II, (c, h) III, (d, i) IV, and (e, j) V. The value of K c decreases gradually from 1 to 0 during the transition from state I to V, indicating the emergence of periodicity.
The dynamical states are distinguished using the variation of M n ( ) and magnitude of K c . The value of M n ( ) grows linearly for chaotic dynamics owing to sensitivity to initial conditions while it remains bounded for periodic dynamics [38, 39]. This behavior causes the value of K c to fall within the range of 1 to 0, where a value of K c = 1 suggests chaotic dynamics and K c = 0 implies periodic behavior. For the dynamical state of SNA, the value of K c is distributed between 0 and 1, reflecting its nature as a state that is neither chaotic nor periodic.
In figure 3, we plot M n ( ) and K c for the dynamical states I-V. For state I, the value of M n ( ) increases linearly on average(Fig. 3a), and the value of K c is fairly lying close to 1 (Fig. 3f) depicting a chaotic nature of the state. During state II also, the value of M n ( ) increases linearly on average with slight fluctuations (Fig. 3b) and the values of K c distributed just below 1 (Fig. 3g), showing a chaotic nature.
For state III, the value of M n ( ) either increases or decreases in a bounded range on average as evident in figure 3c and the value of K c is distributed between 1 and 0 (Fig. 3h), depicting that the state III as neither chaotic nor periodic. During state IV, the value of M n ( ) becomes bounded and the average value remains constant with fluctuations present (Fig. 3d). The value of K c distributed just above 0 (Fig. 3i), showing a periodic behavior. During state V also, the value of M n ( ) bounded and the average value remains constant with fluctuations present (Fig. 3e), the values of K c are fairly lying close to 0 (Fig. 3j), delineating a clear periodic behavior, compared to the previous state.
FIG. 4. (a-e) Log-log plots showing the variation of correlation sum (C( )) with ϵ ϵ for the states I to V. The plots are shown for the embedding dimensions ranging from 5( · ), 6 ( ⋆ ) and 7 ( □ ). The solid line represents the power law fit for the straight-line portion of this plot, indicating the value of the correlation dimension ( D ). The value of D decreases as the system transitions from state I to state V, indicating the decrease of complexity.
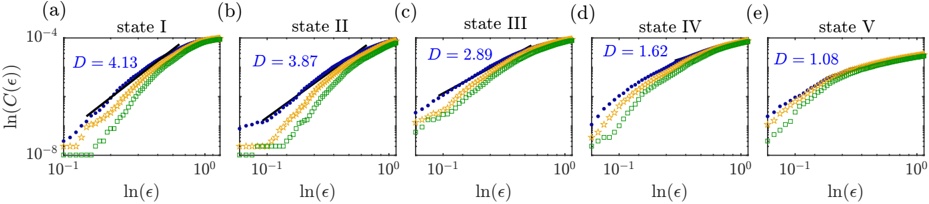
b. Correlation Dimension The correlation dimension is a topological measure of the fractal dimension of an attractor [40]. We compute the correlation dimension using the algorithm proposed by Grassberger and Procaccia [36]. The initial step is to calculate the delayed vectors s n = { p ′ i ( m ) } N -( m -1) τ i =1 from the time series of acoustic pressure fluctuations ( p ′ ). Here, N is the length of the time series, m is the embedding dimension, and τ is the time delay for which the average mutual information of the signal is minimum [41]. Then, we calculate the correlation sum as follows:
$$C ( \epsilon ) = \frac { 2 } { N ( N - 1 ) } \sum _ { j = 1 } ^ { N } \sum _ { k = j + 1 } ^ { N } \Theta ( \epsilon - | | s _ { j } - s _ { k } | | )$$
where Θ is the Heaviside function defined as:
$$\text{where $\Theta$ is the Heaviside} \\ \Theta ( x ) = \begin{cases} 1, & x > 0, \\ 0, & x \leq 0, \end{cases}$$
and ϵ is the threshold distance. The sum counts the number of pairs ( s , s j k ), whose distance is smaller than ϵ . In the limit of infinite data ( N →∞ ) and ϵ → 0, C ϵ ( ) scales as a power law i.e., C ϵ ( ) ∝ ϵ D . We can define the correlation dimension ( D ) from the correlation sum as follows:
$$d ( N, \epsilon ) = \frac { \partial ( \ln C ( \epsilon, N ) ) } { \partial ( \ln ( \epsilon ) ) },$$
$$D = \lim _ { N \to \infty } d ( N, \epsilon ).$$
The value of D can be used to estimate the dynamical state of a system. In general, the value of D is noninteger for the strange attractor, and it is an integer and approximately one for periodic attractors [42].
It is sufficient to choose a value of m greater than the box dimension to estimate the value of D [43]. To ensure the convergence of c ϵ ( ), we compute it for embedding dimensions ranging from 5 -7. In figure 4, we plot the variation of C ϵ ( ) with increasing ϵ at three embedding dimensions in a logarithmic plot for the states I to V. We apply a power law fit to the straight-line portion to obtain the correlation dimension ( D ).
For state I, the value of D is 4 13 (Fig. 4a). . This high fractional value of D indicates the necessity of a high-dimensional structure to describe the underlying chaotic dynamics. For the state II, the value of D is 3 87 (Fig. 4b), reflecting the need for a high-dimensional . structure to capture the dynamics of epochs of high-amplitude periodic oscillations amidst epochs of low-amplitude aperiodic fluctuations (Fig. 2b). The dynamics in the phase space indicate that the system switches between low-amplitude aperiodic fluctuations and highamplitude periodic oscillations (Fig. 2l), characteristics of the state of intermittency.
For state III, the reconstructed phase space exhibits complex folding and stretching (Fig. 2m), requiring a high value of dimension to fully describe the dynamics. The observed value of D of 2 89 (Fig. 4c) suggests a complex structure, although less intricate than chaos . and intermittency.
For state IV, the reconstructed phase space is found to be a thick ring (Fig. 2n). The trajectory during a few acoustic cycles deviates from the mean, resulting in a large thickness. This is reflected by a value of D of 1 62 (Fig. 4d), indicating the need for an additional . effective dimension to capture the noisy behavior. These noisy periodic oscillations with amplitude modulations are also called noisy limit cycle oscillations.
For state V, the reconstructed phase space exhibits a thin ring structure (Fig. 2o), indicating periodic oscillations with fewer amplitude modulations. The value of D is observed to be 1 08 (Fig. 4e), which is very close to the integer value 1. . These clean periodic oscillations essentially clean limit cycle oscillations.
The results of 0 -1 test show that state III is nonchaotic and nonperiodic. Additionally, the value of D falls between those of the chaotic and periodic states suggesting fractal characteristics. These findings imply that state III may be a strange nonchaotic attractor (SNA), which is a nonchaotic fractal. To confirm this, we perform a singular continuous
FIG. 5. Singular continuous spectrum analysis of acoustic pressure oscillations ( p ′ ) for state III. (a) log 10 | X α,N ( ) | 2 vs log 10 N . We have | X α,N ( ) | 2 ∼ N 1 49 . . The subplot shows the corresponding trajectory (Re X , Im X ), which is a fractal. (b) fractal dimension of 1 9 calculated . using boxcounting method following a power law with increasing box size.
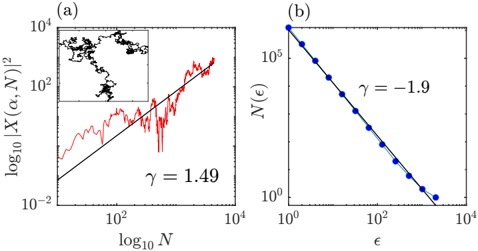
spectrum analysis.
- c. Singular continuous spectrum In dynamical systems, the power spectrum is continuous during chaotic dynamics and discrete during regular dynamics. A continuous spectrum displays a broadband distribution, while sharp peaks characterize a discrete spectrum. The singular continuous spectrum is a mixture of both continuous and discrete spectrums. For the time series of acoustic pressure fluctuations p ′ , the singular continuous spectrum is defined as [37, 44],
$$X ( \alpha, N ) = \sum _ { k = 1 } ^ { N } p ^ { \prime } ( k ) e ^ { 2 \pi i k \alpha }.$$
Here, α = √ 5 -1 2 , the golden mean ratio, and N is the length of the time series of p ′ . X α,N ( ) is a complex value. For chaotic signals, the power of the signal | X α,N ( ) | 2 is proportional to N , indicating a continuous (broadband) spectrum. For periodic signals, the power of signal | X α,N ( ) | 2 is proportional to N 2 , illustrating a discrete (sharp) spectrum. For the state of SNA, the spectrum exhibits a singular continuous spectrum. For SNA the power of signal | X α,N ( ) | 2 is proportional to N γ and the value of γ ranges between 1 and 2.
We apply singular continuous spectrum analysis for the state III. We observe that the value of γ is 1 49 (Fig. 5a) and the trajectory of . X α,N ( ) on the complex plane is a fractal as shown in the subplot of figure 5a. To confirm the fractal structure of the complex plane, we apply the box-counting dimension and calculate the fractal dimension of the structure.
- d. Box-counting dimension The concept of dimension is fundamental to fractal geometry, with self-similarity being a key characteristic of fractals [45]. There are various
definitions of fractal dimension (FD) [46], each suitable for specific contexts. Among the methods available to estimate FD, the box-counting method is frequently used due to its simplicity [47]. The FD can be calculated using the method as follows:
$$F D = - \lim _ { \epsilon \rightarrow 0 } \frac { \log ( N ( \epsilon ) ) } { \log ( \epsilon ) },$$
where N ϵ ( ) is the number of boxes of size ϵ required to completely cover the structure. The FD is estimated from the least square linear fit of log-log plot of N ϵ ( ) against ϵ .
We apply the box-counting method on the image of the structure in the complex plane shown in the subplot of figure 5b and observe that the FD of the image is 1 9 (Fig. 5c). . This fractional value of FD indicates that the trajectory (Re X , Im X ) in the complex plane is fractal in nature, confirming the presence of SNA.
In summary, we report the state of SNA in a self-organized system comprising turbulent reactive flow. We observe the state of SNA prior to the emergence of periodic oscillations from chaos. We distinguish the dynamical states present during the transition using tools from nonlinear dynamics, such as phase space reconstruction, 0 -1 test, and correlation dimension test. We substantiate the existence of the state of SNA with singular continuous spectrum analysis. The presence of SNAs offers the advantage of robustness to noise over chaos in synchronization phenomena owing to their insensitivity to initial conditions. This advantage of SNA and the possibility of SNAs in self-organized complex systems opens a new avenue for research. Further, exploration of spatiotemporal dynamics during the state of SNA could provide deeper insights into synchronization and other nonlinear phenomena.
We thank S. Anand, S. Thilagaraj, G. Sudha, M. Raghunathan, S. Sudarsanan, Ramesh S Bhavi, and Anaswara Bhaskaran for their help during the experiments. T.B. acknowledges the research assistantship from the Ministry of Human Resource Development, India, and the Indian Institute of Technology Madras. S.T. acknowledges the support from Prime Minister's Research Fellowship, Govt. of India. R.I.S. acknowledges the funding from the Science and Engineering Research Board (SERB) of the Department of Science and Technology (DST) through a J. C. Bose Fellowship (No. JCB 2018 000034 SSC) and from the IOE initiative / / /
(No. SP22231222CPETWOCTSHOC).
- [1] C. Grebogi, E. Ott, S. Pelikan, and J. A. Yorke, Physica D: Nonlinear Phenomena 13 , 261 (1984).
- [2] M. Ding, C. Grebogi, and E. Ott, Physical Review A 39 , 2593 (1989).
- [3] U. Feudel, J. Kurths, and A. S. Pikovsky, Physica D: Nonlinear Phenomena 88 , 176 (1995).
- [4] F. J. Romeiras and E. Ott, Physical Review A 35 , 4404 (1987).
- [5] J. Heagy and W. Ditto, Journal of Nonlinear Science 1 , 423 (1991).
- [6] T. Zhou, F. Moss, and A. Bulsara, Physical Review A 45 , 5394 (1992).
- [7] R. I. Sujith and S. A. Pawar, Thermoacoustic Instability (Springer, 2021).
- [8] S. Tandon and R. I. Sujith, Journal of Fluid Mechanics 966 , A9 (2023).
- [9] H. Tennekes and J. L. Lumley, A First Course in Turbulence , MIT Press (M.I.T.Pr., 1972).
- [10] R. T. Pierrehumbert, Journal of Fluid Mechanics 938 , F1 (2022).
- [11] W. D. Arnett and C. Meakin, Reports on Progress in Physics 79 , 102901 (2016).
- [12] J. R. Buchler, T. Serre, Z. Koll´th, a and J. Mattei, Phys. Rev. Lett. 74 , 842 (1995).
- [13] B.-T. Chu and L. S. G. Kovasznay, Journal of Fluid Mechanics 3 , 494-514 (1958).
- [14] V. Nair, G. Thampi, S. Karuppusamy, S. Gopalan, and R. I. Sujith, International Journal of Spray and Combustion Dynamics 5 , 273 (2013).
- [15] J. Tony, E. Gopalakrishnan, E. Sreelekha, and R. I. Sujith, Physical Review E 92 , 062902 (2015).
- [16] S. A. Pawar, A. Seshadri, V. R. Unni, and R. I. Sujith, Journal of Fluid Mechanics 827 , 664 (2017).
- [17] S. Mondal, V. R. Unni, and R. I. Sujith, Journal of Fluid Mechanics 811 , 659 (2017).
- [18] V. Nair, G. Thampi, and R. I. Sujith, Journal of Fluid Mechanics 756 , 470 (2014).
- [19] C. Aoki, H. Gotoda, S. Yoshida, and S. Tachibana, Journal of Applied Physics 127 , 224903 (2020).
- [20] M. Ding and J. S. Kelso, International Journal of Bifurcation and Chaos 4 , 553 (1994).
- [21] A. Bondeson, E. Ott, and T. M. Antonsen Jr, Physical Review Letters 55 , 2103 (1985).
- [22] J. Heagy and S. Hammel, Physica D: Nonlinear Phenomena 70 , 140 (1994).
- [23] A. Prasad, V. Mehra, and R. Ramaswamy, Physical Review Letters 79 , 4127 (1997).
- [24] X. Wang, M. Zhan, C.-H. Lai, and Y.-C. Lai, Physical Review Letters 92 , 074102 (2004).
- [25] A. Y. Jalnine and S. Kuznetsov, Technical Physics 52 , 401 (2007).
- [26] V. Anishchenko, T. Vadivasova, and O. Sosnovtseva, Physical Review E 54 , 3231 (1996).
- [27] Z. LIU, International Journal of Bifurcation and Chaos 11 , 225 (2001).
- [28] Y. Guan, M. Murugesan, and L. K. Li, Chaos: An Interdisciplinary Journal of Nonlinear Science 28 (2018), 10.1063/1.5026252.
- [29] A. Chithra and I. Raja Mohamed, Nonlinear Dynamics 105 , 3615 (2021).
- [30] S. S. Negi and R. Ramaswamy, Pramana 56 , 47 (2001).
- [31] S. Kumarasamy, A. Srinivasan, M. Ramasamy, and K. Rajagopal, Chaos: An Interdisciplinary Journal of Nonlinear Science 32 (2022), 10.1063/5.0089373.
- [32] J. F. Lindner, V. Kohar, B. Kia, M. Hippke, J. G. Learned, and W. L. Ditto, Physical Review Letters 114 , 054101 (2015).
- [33] D. Premraj, S. A. Pawar, L. Kabiraj, and R. I. Sujith, Europhysics Letters 128 , 54005 (2020).
- [34] P. Bryant, R. Brown, and H. D. I. Abarbanel, Phys. Rev. Lett. 65 , 1523 (1990).
- [35] G. A. Gottwald and I. Melbourne, Proceedings of the Royal Society of London. Series A: Mathematical, Physical and Engineering Sciences 460 , 603 (2004).
- [36] P. Grassberger and I. Procaccia, Physical Review Letters 50 , 346 (1983).
- [37] A. S. Pikovsky and U. Feudel, Journal of Physics A: Mathematical and General 27 , 5209 (1994).
- [38] G. A. Gottwald and I. Melbourne, SIAM Journal on Applied Dynamical Systems 8 , 129 (2009).
- [39] G. A. Gottwald and I. Melbourne, Nonlinearity 22 , 1367 (2009).
- [40] H. Kantz and T. Schreiber, Nonlinear Time Series Analysis , 2nd ed. (Cambridge University Press, 2003).
- [41] A. M. Fraser and H. L. Swinney, Physical Review A 33 , 1134 (1986).
- [42] C. J. McMahon, J. P. Toomey, and D. M. Kane, PLoS One 12 , e0181559 (2017).
- [43] T. Sauer and J. A. Yorke, International Journal of Bifurcation and Chaos 03 , 737 (1993).
- [44] T. Yal¸ cınkaya and Y.-C. Lai, Phys. Rev. E 56 , 1623 (1997).
- [45] B. B. Mandelbrot, The Fractal Geometry of Nature , Vol. 1 (WH Freeman New York, 1982).
- [46] K. Falconer, 'Alternative definitions of dimension,' in Fractal Geometry (John Wiley and Sons, Ltd, 2003) Chap. 3.
- [47] H.-O. Peitgen, H. J¨rgens, u D. Saupe, and M. J. Feigenbaum, Chaos and Fractals: New
Frontiers of Science , Vol. 106 (Springer, 2004). | null | [
"Beeraiah Thonti",
"Shruti Tandon",
"Premraj Durairaj",
"R. I. Sujith"
] | 2024-08-02T09:19:38+00:00 | 2024-08-02T09:19:38+00:00 | [
"nlin.CD",
"nlin.AO"
] | Strange Nonchaotic Attractor in an Unforced Turbulent Reactive Flow System | We discover strange nonchaotic attractor (SNA) through experiments in an
unforced system comprising turbulent reactive flow. While models suggest SNAs
are common in dynamical systems, experimental observations are primarily
limited to systems with external forcing. We observe SNA prior to the emergence
of periodic oscillations from chaotic fluctuations. In complex systems,
self-organization can lead to order, and inherent nonlinearity can induce
chaos. The occurrence of SNA, which is nonchaotic yet nonperiodic in one such
complex system, is intriguing. |
2408.01133v2 | ## A Mechanism of Stochastic Synchronization in the Climate System: an Interpretation of the Boundary Current Synchronization as a Maxwell's Demon
Yuki Yasuda a and Tsubasa Kohyama b a Supercomputing Research Center, Institute of Integrated Research, Institute of Science Tokyo b Department of Information Sciences, Ochanomizu University
ABSTRACT: This study has applied information thermodynamics to a bivariate linear stochastic differential equation (SDE) that describes a synchronization phenomenon of sea surface temperatures (SSTs) between the Gulf Stream and the Kuroshio Current, which is referred to as the boundary current synchronization (BCS). Information thermodynamics divides the entire system fluctuating with stochastic noise into subsystems and describes the interactions between these subsystems from the perspective of information transfer. The SDE coefficients have been estimated through regression analysis using observational and numerical simulation data. In the absence of stochastic noise, the solution of the estimated SDE shows that the SSTs relax toward zero without oscillation. The estimated SDE can be interpreted as a Maxwell's demon system, with the Gulf Stream playing the role of the 'Particle' and the Kuroshio Current playing the role of the 'Demon.' The Gulf Stream forces the SST of the Kuroshio Current to be in phase. By contrast, the Kuroshio Current maintains the phase by interfering with the relaxation of the Gulf Stream SST. In the framework of Maxwell's demon, the Gulf Stream is measured by the Kuroshio Current, whereas the Kuroshio Current performs feedback control on the Gulf Stream. When the Gulf Stream and the Kuroshio Current are coupled in an appropriate parameter regime, synchronization is realized with atmospheric and oceanic fluctuations as the driving source. This new mechanism, 'stochastic synchronization,' suggests that such fluctuations can be converted into directional variations in a subsystem of the climate system through synchronization by utilizing information (i.e., information-to-energy conversion).
## 1. Introduction
Stochastic modeling is an effective approach for various climate phenomena (e.g., Dijkstra 2013; Franzke et al. 2015). This approach is based on the time scale separation between slow and fast variations (Hasselmann 1976). Typically, slow processes include decadal climate variations, while fast processes include weather disturbances. The scale separation suggests that the correlation between slow and fast processes is weak; thus, the fast processes can effectively be represented by stochastic noise. Stochastic modeling describes the integral (or aggregated) responses of slow climate variables driven by stochastic noise. A major approach in stochastic modeling is the use of idealized dynamical systems with few variables (e.g., Dijkstra 2013). Although these models cannot describe phenomena in detail, they are expected to capture the essence of phenomena (e.g., Benzi 2010). In this study, we investigate the coupling of two western boundary currents using a stochastic dynamical system and propose a new mechanism for synchronization, which may be applicable to other climate phenomena.
Western boundary currents (WBCs) are strong upper flows located on the western side of ocean basins, playing an important role in the transport of heat in the climate system (Kwon et al. 2010). Two major examples of WBCs are the Gulf Stream in the North Atlantic and the Kuroshio Current in the North Pacific. These WBCs are primarily driven by atmospheric wind stress (Stommel 1948) and modulated through interactions with the atmosphere (Qiu et al. 2014; Ma et al. 2016). The heat transport by the WBCs influences the entire atmosphere, including storm tracks and annular modes (Hoskins and Valdes 1990; Minobe et al. 2008; Ogawa et al. 2012; Omrani et al. 2019). Furthermore, the WBCs sometimes contribute to explosive cyclogenesis, making them also important for daily weather (Sanders 1986; Kuwano-Yoshida and Minobe 2017).
The WBCs, namely the Gulf Stream and the Kuroshio Current, exhibit interannual to decadal variability (Qiu and Chen 2005; Kelly et al. 2010). Decadal variability due to the interaction of either the Gulf Stream or the Kuroshio Current with the atmosphere has been studied (Latif and Barnett 1994; Gallego and Cessi 2000; Hogg et al. 2006; Kwon et al. 2010; Qiu et al. 2014). Recently, the importance of the coexistence of both the Gulf Stream and the Kuroshio Current has been pointed out for ocean heat content (Kelly and Dong 2004) and atmospheric annular modes (Omrani et al. 2019). However, the roles of both ocean currents in the climate system are not yet fully understood.
Kohyama et al. (2021) discovered the boundary current synchronization (BCS) by using observational data and numerical experiments with coupled atmosphere-ocean models. The sea surface temperatures (SSTs) of the Gulf Stream and the Kuroshio Current show positive correlations on interannual to decadal time scales. An increase (decrease) in the SSTs is accompanied by a northward (southward) shift of the WBCs as well as a northward (southward) shift of the atmospheric baroclinic jet. The BCS is considered to arise from the interaction between the Gulf Stream and the Kuroshio Current via the atmosphere (i.e., the inter-basin coupling) rather than a passive response to atmospheric forcings. In fact, the BCS was not reproduced in low-resolution numerical experiments that could not resolve oceanic mesoscale eddies. These results suggest that the BCS occurs through the transfer of information on WBC variability through the atmosphere. However, the roles of the Gulf Stream and the Kuroshio Current in the BCS have not been well investigated, and further research is required.
Over the past decade, the fusion of information theory and non-equilibrium physics has led to the development of a new theoretical framework called 'information thermodynamics' (Parrondo et al. 2015; Peliti and Pigolotti 2021; Shiraishi 2023). Information thermodynamics divides nonlinear systems fluctuating with stochastic noise into subsystems and describes the interactions between these subsystems from the perspective of information transfer. Information transfer can be expressed as information flow (Allahverdyan et al. 2009) and is incorporated into the second law of thermodynamics (Horowitz and Esposito 2014). Applying this extended second law of thermodynamics (i.e., the second law of information thermodynamics), we can elucidate the dynamics of subsystems and the asymmetry between them. This new theoretical framework is applicable to stochastic systems that include deterministic forcing and dissipation. These points suggest that information thermodynamics is suitable for studying the climate system, which is a nonlinear system with multiple degrees of freedom driven by stochastic noise and deterministic forcings. However, since information thermodynamics is an emerging field, it has scarcely been used in atmospheric and oceanic sciences.
This study applies information thermodynamics to a dynamical system for the BCS and proposes that the coupled system of the Gulf Stream and the Kuroshio Current can be interpreted as a Maxwell's demon. Section 2 provides a review of Maxwell's demon. Section 3 introduces the bivariate linear dynamical system that describes the time evolution of the regional-mean SSTs of
the Gulf Stream and the Kuroshio Current. Section 4 applies information thermodynamics to this system and discusses the roles of the Gulf Stream and the Kuroshio Current. Section 5 presents the conclusions.
## 2. Review of Maxwell's demon
The resolution of Maxwell's demon is a landmark in information thermodynamics (Parrondo et al. 2015). Originally, Maxwell argued that if an intelligent being (a demon) had information about the velocities of particles, it could separate fast, hot particles from slow, cold particles without exerting any work on the system, thus appearing to violate the second law of thermodynamics. Szilard then developed a simple model, the Szilard engine, which captures the essential point of Maxwell's demon: information can be converted to work. Nowadays, this information-to-energy conversion has been realized experimentally (Toyabe et al. 2010; Koski et al. 2014). This type of system is called an information engine or loosely Maxwell's demon (e.g., Horowitz and Esposito 2014; Ito and Sagawa 2015). Here, we refer to the entire system of information conversion as the Maxwell's demon system and review the Szilard engine as such a system, which consists of a demon (i.e., a controller) and a subsystem operated by the demon. See further details in reviews and textbooks (Sagawa and Ueda 2013a; Parrondo et al. 2015; Peliti and Pigolotti 2021; Shiraishi 2023).
## a. Setup of the Szilard engine
Let us consider an isothermal cycle with a single particle. Figure 1 is a schematic of this experiment, where the memory (i.e., the demon) in the upper half is not considered for the moment. First, a partition is inserted in the middle of the box, separating the box into halves (Fig. 1a). The particle moves at random, so the probability of the particle being on the left (or right) side equals 1 2. Second, the position of the particle is measured (Fig. 1b). Third, based on the measurement / outcome, when the particle is on the left (resp. right), the partition is moved quasi-statically to the right (resp. left). (Fig. 1c). Such a measurement-based operation is called feedback control or simply, control. The energy source for this expansion is the surrounding thermal fluctuations, or equivalently, heat transferred through the box. Therefore, the Szilard engine appears to contradict
Fig. 1. Schematic of the Szilard engine (e.g., Parrondo et al. 2015). A box contains a single particle and is surrounded by an isothermal environment, where heat is transferred through the walls of the box. (a) A partition is inserted in the middle of the box. (b) The demon measures the position of the particle and records the result in its memory. (c) Based on the measurement outcome, the demon performs feedback control. Specifically, when the particle is on the left (resp. right), the demon moves the partition to the right (resp. left). The particle system is isothermally expanded and returns to the initial state. This process extracts a positive work from the isothermal environment. (d) The demon's memory is initialized, requiring external work (i.e., a negative work).
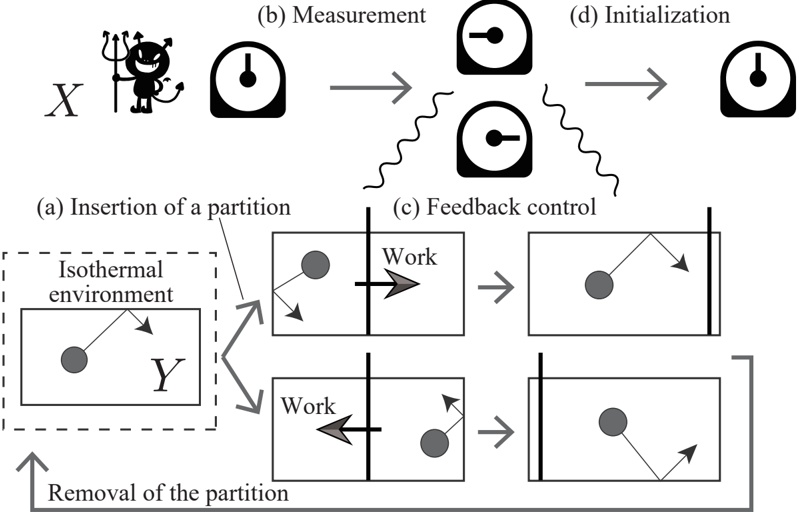
the second law of thermodynamics and to be a perpetual motion machine of the second kind that extracts work via isothermal cycles.
To resolve the paradox, it is necessary to consider the exchange of information quantities and the existence of memory (Sagawa and Ueda 2013a). The memory, also called the demon, is a subsystem that performs measurement and feedback control. The other subsystem is the particle within the box and is referred to as the particle. We denote the states of the demon and the particle by 𝑋 and 𝑌 and their realizations by lowercase letters 𝑥 and 𝑦 , respectively. The variables 𝑋 and 𝑌 are discrete, reflecting the particle position being either on the left or right. We first derive the second law of information thermodynamics and then consider the Szilard engine again.
## b. The second law of information thermodynamics
We define Shannon entropy and mutual information (e.g., Cover and Thomas 2005) to derive the second law of information thermodynamics.
$$S ( X ) \coloneqq \sum _ { x } p ( x ) [ - \ln p ( x ) ],$$
$$S ( Y ) \coloneqq \sum _ { y } p ( y ) [ - \ln p ( y ) ],$$
$$M ( X, Y ) \coloneqq \sum _ { x, y } ^ { \cdot } p ( x, y ) \ln \left [ \frac { p ( x, y ) } { p ( x ) p ( y ) } \right ].$$
Shannon entropies 𝑆 ( 𝑋 ) and 𝑆 𝑌 ( ) are indicators of uncertainty about the subsystems 𝑋 and 𝑌 , respectively. Mutual information 𝑀 𝑋,𝑌 ( ) is a non-negative indicator of the correlation between 𝑋 and 𝑌 , where 𝑀 𝑋,𝑌 ( ) is zero only when 𝑋 and 𝑌 are statistically independent.
Mutual information characterizes the non-additivity of Shannon entropy (e.g., Cover and Thomas 2005). For the joint Shannon entropy 𝑆 ( 𝑋,𝑌 ) , the following holds:
$$S ( X, Y ) \coloneqq \sum _ { x, y } p ( x, y ) [ - \ln p ( x, y ) ],$$
$$= S ( X ) + S ( Y ) - M ( X, Y ).$$
Addingtheuncertainties for the subsystems, 𝑆 ( 𝑋 ) + 𝑆 𝑌 ( ) , leads to an overestimation and is generally not equal to the uncertainty for the entire system 𝑆 ( 𝑋,𝑌 ) . It is necessary to subtract 𝑀 𝑋,𝑌 ( ) , which is non-negative and represents the magnitude of correlation between 𝑋 and 𝑌 .
The second law of information thermodynamics is derived using the non-additivity of Shannon entropy (Sagawa and Ueda 2013b). We consider the evolution from time 𝑡 to 𝑡 + Δ 𝑡 and assume the second law of thermodynamics for the entire system (Seifert 2005, 2012):
$$\Delta S ( X _ { t }, Y _ { t } ) + \frac { \Delta Q _ { t } } { T } \geq 0,$$
where changes are denoted by Δ , and time dependence is denoted by a subscript 𝑡 . For example, Δ 𝑆 ( 𝑋𝑡 ,𝑌 𝑡 ) : = 𝑆 ( 𝑋𝑡 + Δ 𝑡 ,𝑌 𝑡 + Δ 𝑡 ) -𝑆 ( 𝑋𝑡 ,𝑌 𝑡 ) . The symbol Δ 𝑄𝑡 represents the amount of heat dissipated from the joint system ( 𝑋,𝑌 ) to the surrounding environment, which corresponds to the entropy
change of the environment. Equation (6) expresses that the total entropy change, including the environment, is non-negative.
The second law of information thermodynamics for the subsystem 𝑋 is derived from Eq. (6) by assuming that only 𝑋 changes in time. Using the entropy decomposition [Eq. (5)], the following is derived:
$$\Delta S ( X _ { t }, Y _ { t } ) + \frac { \Delta Q _ { t } } { T } = \Delta S ( X _ { t } ) + \underbrace { \Delta S ( Y _ { t } ) } _ { = 0 } - \Delta M ( X _ { t }, Y _ { t } ) + \frac { \Delta Q _ { t } } { T } \geq 0,$$
where Δ 𝑆 𝑌 ( ) = 0 because 𝑌𝑡 does not change in time. This assumption also indicates that the entropy change of the environment Δ 𝑄𝑡 / 𝑇 is due to the change in 𝑋𝑡 . We finally obtain the following inequality:
$$\Delta \sigma \left ( X _ { t } \right ) \geq \Delta M \left ( X _ { t }, Y _ { t } \right ),$$
where
$$\Delta \sigma \left ( X _ { t } \right ) \coloneqq \Delta S \left ( X _ { t } \right ) + \frac { \Delta Q _ { t } \left ( X _ { t } \right ) } { T },$$
$$\Delta M \left ( X _ { t }, Y _ { t } \right ) = M ( X _ { t + \Delta t }, Y _ { t } ) - M ( X _ { t }, Y _ { t } ).$$
The total entropy change by 𝑋𝑡 is denoted as Δ 𝜎 𝑋𝑡 ( ) and is lower bounded by the change in mutual information Δ 𝑀 𝑋𝑡,𝑌𝑡 ( ) . Since 𝑌𝑡 does not change, Δ 𝑀 𝑋𝑡,𝑌𝑡 ( ) is attributed only to the change in 𝑋𝑡 . The second law of information thermodynamics [Eq. (8)] indicates that Δ 𝜎 𝑋𝑡 ( ) can be negative when Δ 𝑀 𝑋𝑡,𝑌𝑡 ( ) < 0. Thus, the entropy of the subsystem 𝑋 can be decreased by utilizing the change in mutual information without heat transfer. This conclusion is consistent with thermodynamics because this discussion started from the second law of thermodynamics for the entire system [Eq. (6)]. Note that Δ 𝜎 𝑌𝑡 ( ) ≥ 𝑀 𝑋𝑡,𝑌𝑡 ( + Δ 𝑡 ) -𝑀 𝑋𝑡,𝑌𝑡 ( ) is derived when only 𝑌 changes in time.
## c. Explanation of the Szilard engine
The second law of information thermodynamics is used to explain the Szilard engine. Time 𝑡 is not explicitly stated if there is no confusion. In the initial state, the states of the demon 𝑋 and the particle 𝑌 are uncorrelated, that is, 𝑀 𝑋,𝑌 ( ) is zero. First, the demon inserts a partition (Fig. 1a).
This causes the particle 𝑌 to be either on the right or the left. The mutual information 𝑀 𝑋,𝑌 ( ) remains zero because the demon's internal state (i.e., the memory 𝑋 ) has not changed.
Next, the demon measures the position of the particle and changes its memory 𝑋 to record the measurement outcome, which makes 𝑋 either right or left (Fig. 1b). The states of the demon and the particle become correlated, and the mutual information increases, Δ 𝑀 𝑋,𝑌 ( ) > 0. This increase in correlation is due to the change in the demon 𝑋 . According to the second law of information thermodynamics, the increase in correlation is accompanied by a positive entropy change, Δ 𝜎 𝑋 ( ) ≥ Δ 𝑀 𝑋,𝑌 ( ) ( > 0) [Eq. (8)].
Based on the memory value 𝑋 , the demon quasi-statically moves the partition to extract work (Fig. 1c). Regardless of the memory value, the particle 𝑌 returns to the initial state after this feedback control, and the correlation 𝑀 𝑋,𝑌 ( ) becomes zero again. This decrease in correlation is due to the change in the particle 𝑌 . According to the second law of information thermodynamics, the decrease in correlation can be accompanied by a negative entropy change, Δ 𝜎 𝑌 ( ) ≥ Δ 𝑀 𝑋,𝑌 ( ) ( < 0). This negative Δ 𝜎 𝑌 ( ) corresponds to the positive work extracted by the isothermal expansion.
Finally, work is performed from the outside to initialize the demon's memory 𝑋 (Fig. 1d). There is a trade-off for the memory between initialization and measurement, and it is more appropriate to consider both together (Sagawa and Ueda 2009, 2013b; Sagawa 2019). The positive work extracted by the isothermal expansion and the negative work required for the initialization (and measurement) cancel each other out. No net positive work can be extracted using the Szilard engine. Therefore, the Szilard engine is not a perpetual motion machine of the second kind.
Information thermodynamics clarifies that the positive work extracted during the control process is due to the change in mutual information; that is, the total entropy of a subsystem can decrease by consuming mutual information. In this way, information thermodynamics allows for the analysis of subsystems from the perspective of information.
## d. Autonomous Maxwell's demon systems
Maxwell's demon systems are also realized in an autonomous manner (Horowitz and Esposito 2014; Loos and Klapp 2020). The time evolution of an autonomous system can be expressed by stochastic differential equations without external interference, such as human manipulation. In such a system, one cannot isolate individual steps, such as measurement and control, since all
steps can occur simultaneously and continuously over time. This is a major difference between the Szilard engine and autonomous processes. Thus, the distinction between the 'Demon' and the 'Particle' appears unclear.
The determination of which subsystem is the 'Demon' or the 'Particle' is based on the direction of information flow (Allahverdyan et al. 2009; Horowitz and Esposito 2014; Loos and Klapp 2020).
$$i _ { X \leftarrow Y } \coloneqq \frac { M \left ( X _ { t + d t }, Y _ { t } \right ) - M \left ( X _ { t }, Y _ { t } \right ) } { d t },$$
$$i _ { Y \leftarrow X } \coloneqq \frac { M \left ( X _ { t }, Y _ { t + d t } \overset { \ddots } { \right ) } - M \left ( X _ { t }, Y _ { t } \right ) } { d t },$$
$$\frac { d } { d t } M \left ( X _ { t }, Y _ { t } \right ) = \dot { I } _ { X \leftarrow Y } + \dot { I } _ { Y \leftarrow X }.$$
The information flow / 𝐼 𝑋 ← 𝑌 from 𝑌 to 𝑋 is the change in mutual information 𝑀 𝑋𝑡,𝑌𝑡 ( ) due to the change in 𝑋 , whereas / 𝐼 𝑌 ← 𝑋 is due to the change in 𝑌 . The sum of both information flows is equal to the total rate of change of mutual information [Eq. (13)]. Information flow is regarded as a quantity that represents the flow of information between subsystems.
For autonomous systems, the second law of information thermodynamics becomes as follows (Horowitz and Esposito 2014; Loos and Klapp 2020):
$$\dot { \sigma } ( X ) \geq \dot { I } _ { X \leftarrow Y },$$
$$\dot { \sigma } ( Y ) \geq \dot { I } _ { Y \leftarrow X }.$$
The rate of change of total entropy is lower bounded by the information flow. Hereafter, the rate of change of total entropy is referred to as the production rate of total entropy or simply the entropy production rate. Equations (14) and (15) are derived for general autonomous systems (Appendix A).
We finally summarize the distinction between a 'Demon' and a 'Particle.' As in Section 2c, measurement is a change that increases correlation due to an evolution of the 'Demon', which is accompanied by a positive entropy production. On the other hand, control is a change that decreases correlation due to an evolution of the 'Particle', which is accompanied by a negative entropy production. Therefore, in an autonomous system, the 'Demon' (resp. 'Particle') is the subsystem showing a positive (resp. negative) information flow and entropy production rate
(Horowitz and Esposito 2014; Loos and Klapp 2020). In our study, a system consisting of a 'Demon' and a 'Particle' has been referred to as the Maxwell's demon system. Maxwell's demon systems are no longer thought experiments but have been experimentally realized in both nonautonomous and autonomous settings (Toyabe et al. 2010; Koski et al. 2015). We propose that such systems can also be realized in the atmosphere and ocean, that is, the coupled system of the Gulf Stream and the Kuroshio Current can be interpreted as a Maxwell's demon system.
## 3. Bivariate linear dynamical system for BCS
## a. Governing equations
This section introduces a bivariate dynamical system describing BCS, which is hereafter referred to as the dynamical system. This system consists of the regional-mean SST anomalies of the Gulf Stream and the Kuroshio Current, 𝑇𝐺 and 𝑇𝐾 , respectively. The subscripts 𝐺 and 𝐾 denote the Gulf Stream and the Kuroshio Current, respectively. Following Kohyama et al. (2021), 𝑇𝐺 is the spatially averaged SST in the Gulf Stream region (35 N-45 N, 80 W-50 W), and ◦ ◦ ◦ ◦ 𝑇𝐾 is the spatially averaged SST in the Kuroshio Current region (35 N-45 N, 140 E-170 E). Both ◦ ◦ ◦ ◦ 𝑇𝐺 and 𝑇𝐾 are standardized (i.e., non-dimensionalized) after removing the climatology and the linear trend.
The variables 𝑇𝐺 and 𝑇𝐾 are assumed to obey the following equations:
$$\frac { d T _ { G } } { d t } = - r _ { G } T _ { G } + c _ { G \leftarrow K } T _ { K } + \xi _ { G },$$
$$\frac { d T _ { K } } { d t } = - r _ { K } T _ { K } + c _ { K \leftarrow G } T _ { G } + \xi _ { K },$$
where 𝑟 𝐺 , 𝑐 𝐺 ← 𝐾 , 𝑟 𝐾 , and 𝑐 𝐾 ← 𝐺 are real constants. The unit of time is set to 1 month. The mutually independent white Gaussian noises 𝜉 𝐺 and 𝜉 𝐾 satisfy
$$\langle \xi _ { G } ( t ) \xi _ { G } ( s ) \rangle = 2 D _ { G } \delta ( t - s ),$$
$$\langle \xi _ { K } ( t ) \xi _ { K } ( s ) \rangle = 2 D _ { K } \delta ( t - s ),$$
$$\langle \xi _ { K } ( t ) \xi _ { G } ( s ) \rangle = 0,$$
where 𝐷𝐺 and 𝐷𝐾 are positive constants, 𝛿 𝑡 ( - ) 𝑠 is the Dirac delta function, 𝑡 -𝑠 is the time difference, and ⟨·⟩ represents the ensemble average over the noise realizations.
This type of a system that consists only of oceanic variables (e.g., SSTs) can be derived from a more complicated setting that include both oceanic and atmospheric variables. Indeed, Gallego and Cessi (2001) started with an atmosphere-ocean coupling model and then derived idealized equations that consist only of Atlantic and Pacific variables by representing the atmospheric effects in terms of the oceanic variables. Our dynamical system is interpreted as a simplified model derived through these procedures. The cross terms, 𝑐 𝐺 ← 𝐾𝑇𝐾 and 𝑐 𝐾 ← 𝐺𝑇𝐺 , may include interbasin couplings via the atmosphere.
## b. Regression analysis
The coefficients of the dynamical system were estimated by the regression analysis using two sets of SST time series, both of which are used in Kohyama et al. (2021). One is the observational data, Optimum Interpolation SST (OISST, Reynolds et al. 2007). The other is the numerical output from a coupled atmosphere-ocean model, GFDL-CM4C192 (Held et al. 2019; Eyring et al. 2016). Monthly mean values were used for both datasets. The OISST data range from December 1981 to September 2018, whereas the GFDL-CM4C192 data range from January 1950 to December 2014. Using the longer-period GFDL-CM4C192 data, we expect to enhance the reliability of the analysis results. All of the following analyses were performed independently for the OISST and GFDL-CM4C192 data.
Figure 2 shows the OISST data, GFDL-CM4C192 data, and their regression results, where a firstorder bivariate autoregressive (AR1) model was employed (Brockwell and Davis 1991; Mudelsee 2014). In estimating the AR1 model, the SST at the current time step was regressed onto the SST at the previous time step, and the regression coefficients were obtained. This regression method is known as the ordinary least squares (OLS) and is standard in time series analysis (Hamilton 1994; Mudelsee 2014). The AR1 model reproduces the SST variations well (Fig. 2), suggesting the validity of the AR1 model. The estimated AR1 model can be uniquely converted to the continuous-time dynamical system [Eqs. (16) and (17)]. Specifically, under the assumption of statistical stationarity, we require that the means and variances of the variations in 𝑇𝐺 and 𝑇𝐾 are the same between the AR1 model and the dynamical system (see Subsection a in Appendix B for
Fig. 2. Time series of the standardized SST anomalies for the Gulf Stream (blue) and the Kuroshio Current (orange) from the OISST and GFDL-CM4C192 data. The dashed gray lines represent the regression results for the corresponding time series with the first-order autoregressive (AR1) model.
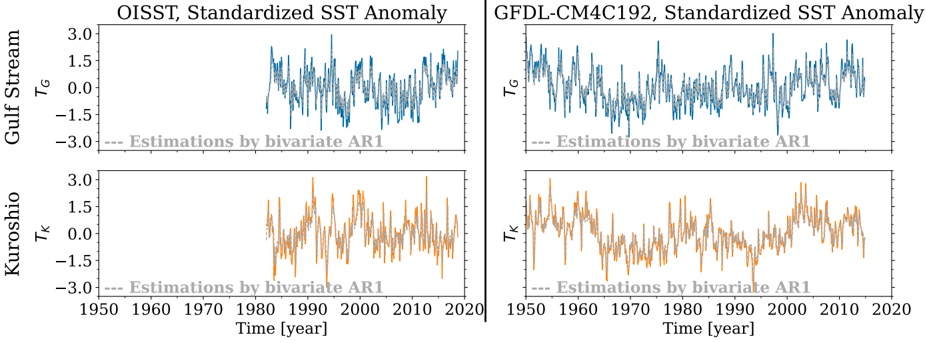
details). In other words, this conversion requires that the statistical properties of the AR1 model match those of the time-integrated values over each discrete time step (i.e., one month) using the dynamical system.
We used the moving block bootstrap method (Mudelsee 2014) to quantify the uncertainty in the estimated coefficients of the dynamical system. This bootstrap method is a non-parametric method that does not assume normality. This method first splits the original time series into blocks. These blocks are resampled with replacement, and the resampled blocks are connected to generate a new time series of the same length as the original time series, which is called the resampled time series. The coefficients of the dynamical system are estimated for each resampled time series. We can compute confidence intervals of the coefficients for the dynamical system by repeating this procedure and creating histograms of the coefficients. The block length was quantitatively determined from the auto-correlation coefficients (Michael Sherman and Speed 1998; Mudelsee 2014): the block lengths were 18 months for the OISST data and 30 months for the GFDLCM4C192 data. The shorter block length for the OISST data may be attributed to its shorter time series length. The number of resamples was set to 2000 following Mudelsee (2014).
Table 1 shows the estimation results of the coefficients of the dynamical system, where the brackets show the 95% confidence intervals by the bootstrap method. The relaxation coefficients
Table 1. Estimated coefficients of the dynamical system [Eqs. (16) and (17)] from the OISST and GFDLCM4C192 data. The values represent the estimates obtained from the regression analysis, and the brackets show the 95% confidence intervals obtained from the moving block bootstrap method.
| | OISST | GFDL-CM4C192 |
|---------|-------------------------|------------------------|
| 𝑟 𝐺 | 0.343 [0.327, 0.555] | 0.299 [0.289, 0.429] |
| 𝑟 𝐾 | 0.325 [0.301, 0.538] | 0.206 [0.196, 0.321] |
| 𝑐 𝐺 ← 𝐾 | 0.0280 [-0.0634, 0.117] | 0.105 [0.0433, 0.171] |
| 𝑐 𝐾 ← 𝐺 | 0.110 [0.00387, 0.240] | 0.0756 [0.0249, 0.144] |
| 𝐷 𝐺 | 0.343 [0.324, 0.545] | 0.253 [0.252, 0.382] |
| 𝐷 𝐾 | 0.308 [0.278, 0.519] | 0.176 [0.173, 0.283] |
𝑟 𝐺 and 𝑟 𝐾 are positive, and their inverses give the relaxation time scales. The time scale is about 3 months for the Gulf Stream and the Kuroshio Current. The estimates of the interaction coefficients 𝑐 𝐺 ← 𝐾 and 𝑐 𝐾 ← 𝐺 are positive. The confidence intervals suggest that 𝑐 𝐺 ← 𝐾 based on the OISST data may be negative. The impact of this negative value is discussed in Appendix C. The variances of the noise 𝐷𝐺 and 𝐷𝐾 are of similar magnitude. We confirmed that the uncertainty quantification is not strongly dependent on the choice of method, as similar results were obtained using a parametric approach based on normality (not shown).
In the absence of noise, the solution of the dynamical system decays to zero without oscillation. According to linear dynamical system theory (e.g., Strogatz 2018), solutions of a deterministic linear system are categorized using the trace and determinant of its coefficient matrix. In our case, the coefficient matrices from all 2000 resampled time series exhibit decaying solutions, indicating that the dynamical system is stable. Moreover, most of these estimated coefficients are categorized into the decaying solution without oscillation when 𝑐 𝐺 ← 𝐾 > 0 and 𝑐 𝐾 ← 𝐺 > 0: all estimates from the GFDL-CM4C192 data belong to this category, whereas 1624 out of 2000 estimates from the OISST data belong to this category. For the OISST, the remaining 376 estimates show decaying oscillators due to the negative 𝑐 𝐺 ← 𝐾 (Table 1), the case of which is discussed in Appendix C. The influences of noise are analyzed using information thermodynamics in Section 4.
## c. Validation of the assumptions for the dynamical system
We evaluate the validity of the estimated dynamical system. The following assumptions have been made regarding the dynamical system: (i) statistical stationarity and (ii) zero auto- and cross-correlations for the noises 𝜉 𝐺 and 𝜉 𝐾 . We verify these two assumptions.
First, regarding statistical stationarity, we used the Dickey-Fuller test (Hamilton 1994), which tests the null hypothesis of non-stationarity against the alternative hypothesis of a stationary AR1 process. For the OISST and GFDL-CM4C192 data, the 𝑝 -value was at most around 10 -13 . This result supports the validity of regarding each time series as stationary.
Second, we confirm the validity of no correlations, namely Eqs. (18)-(20). The first two equations indicate that the noises do not depend on the past, resulting in zero auto-correlations. Equation (20) indicates that the noises 𝜉 𝐺 and 𝜉 𝐾 are independent of each other, resulting in zero cross-correlations. In regression analysis, the residuals between the estimates and the target variables are considered as noise. Thus, we can verify the assumptions by examining the auto- and cross-correlation coefficients of these residuals.
Figure 3 shows the results of the correlation analysis for these residuals. The gray areas represent the 95% confidence intervals (Brockwell and Davis 1991). For most lags, the auto-correlation coefficients fall within the confidence intervals, suggesting that the auto-correlations can be considered zero. These results support the assumption that the noises do not strongly depend on the past. The cross-correlation coefficients also take values close to zero and fall within the confidence intervals for most time lags. This result supports the assumption that the noises of the Gulf Stream and the Kuroshio Current are statistically independent. Kohyama et al. (2021) showed that the BCS is not a passive phenomenon driven by the atmospheric baroclinic jet. Our results suggest that the SSTs of both currents are not driven by common noise, which is consistent with the result of Kohyama et al. (2021). These noises are attributed to atmospheric and oceanic fluctuations on time scales of a few months or less, likely encompassing the spatially localized effects of the atmospheric baroclinic jet and oceanic mesoscale eddies in the Gulf Stream and Kuroshio Current regions.
We finally clarify the relationship between noise and temperature. In non-equilibrium physics, the variance of stochastic noise is generally proportional to the temperature of an isothermal environment; this noise arises from collisions of small molecules with the larger target particle (e.g.,
Fig. 3. Auto- and cross-correlation coefficients of the residuals between the AR1-model estimates and the target time series for the OISST and GFDL-CM4C192 data. The gray shading indicates the 95% confidence intervals.
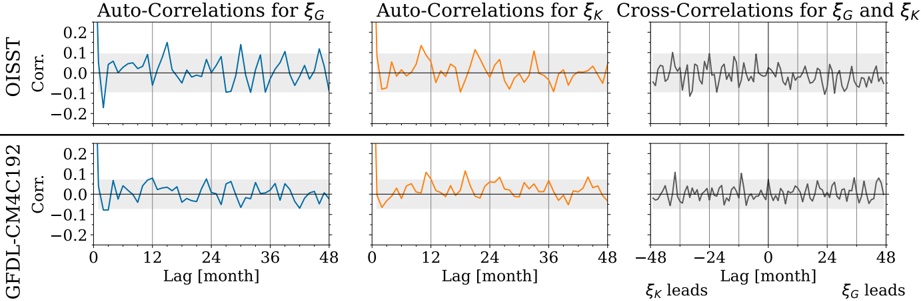
Sekimoto 2010). In our case, since the noises 𝜉 𝐺 and 𝜉 𝐾 represent atmospheric and oceanic fluctuations, their variances 𝐷𝐺 and 𝐷𝐾 are interpreted as the strengths of these small-scale disturbances. Thus, isothermal environments correspond to the disturbance fields, and 'temperature' in non-equilibrium physics corresponds to 𝐷𝐺 and 𝐷𝐾 . These effective temperatures should be distinguished from the SST anomalies 𝑇𝐺 and 𝑇𝐾 at longer time scales.
## d. Reproduction of the BCS by the dynamical system
Finally, we confirm that the estimated dynamical system reproduces the BCS between 𝑇𝐺 and 𝑇𝐾 . To show the BCS, we examine the lag correlation between 𝑇𝐺 and 𝑇𝐾 following Kohyama et al. (2021), who directly obtained the lag correlation coefficients from the time series. In the present study, we first estimated the coefficients of the dynamical system from the same time series. Then, using these coefficients, we calculated the analytical solutions of the lag correlation coefficients using the theoretical formulas (Subsection b in Appendix B).
Figure 4 shows the resultant lag correlations. Here, the 95% confidence interval for each lag correlation coefficient was estimated using the 2000 sets of resampled time series obtained by the moving block bootstrap method. The solid lines indicate that the correlation coefficient takes significant values larger than zero, which supports the existence of the synchronicity. The longer interval of significant correlations for the GFDL-CM4C192 data is likely due to its longer data range compared to that of the OISST data. The Gulf Stream slightly leads the Kuroshio Current
Fig. 4. Lag correlation coefficients between the Gulf Stream and Kuroshio Current SSTs for the OISST and GFDL-CM4C192 data. The solid lines indicate significant correlations at the 95% confidence level, while the dashed lines represent insignificant correlations.
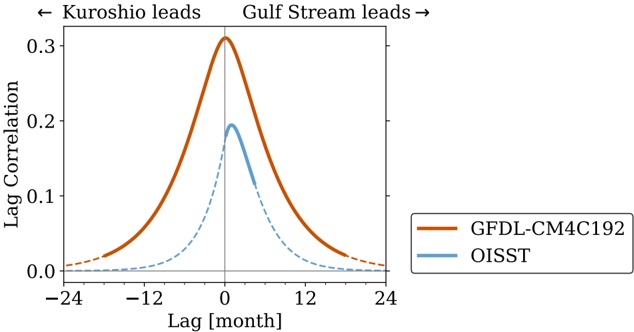
by 1 and 0.2 months for the OISST and GFDL-CM4C192 data, respectively. The significance of these small leads is difficult to assess given the short data periods. The obtained lag correlation coefficients are very close to the results of Kohyama et al. (2021) (see their Fig. 1D). Therefore, we can conclude that the dynamical system serves as an appropriate model for describing BCS.
## 4. Analysis of the dynamical system based on information thermodynamics
## a. Application of the second law of information thermodynamics
We apply the second law of information thermodynamics (Horowitz and Esposito 2014; Loos and Klapp 2020) to the Gulf Stream 𝑇𝐺 and the Kuroshio Current 𝑇𝐾 to clarify their asymmetric roles in the BCS. We assume a statistical steady state in which the probability distribution of 𝑇𝐺 and 𝑇𝐾 does not vary over time. The time-series analysis supports the validity of the steady-state assumption (Section 3c).
The second law of information thermodynamics gives the following inequalities and equality regarding the information flows and entropy production rates for the Gulf Stream and the Kuroshio
Current (Horowitz and Esposito 2014; Loos and Klapp 2020):
$$\dot { \sigma } _ { G } \geq i _ { G \leftarrow K },$$
$$\dot { \sigma } _ { K } \geq i _ { K \leftarrow G },$$
$$0 = \dot { I } _ { G \leftarrow K } + \dot { I } _ { K \leftarrow G },$$
where / 𝜎𝐺 and / 𝜎𝐾 represent the production rates of total entropy for the Gulf Stream 𝑇𝐺 and the Kuroshio Current 𝑇𝐾 , respectively, and / 𝐼 𝐺 ← 𝐾 and / 𝐼 𝐾 ← 𝐺 represent the information flow to the Gulf Stream and to the Kuroshio Current, respectively. Equations (21), (22), and (23) correspond to Eqs. (14), (15), and (13), respectively. The sum of the two information flows is zero in Eq. (23) because the time derivative of mutual information is zero due to the steady-state assumption (Appendix A). Moreover, under this assumption, the production rates of total entropy correspond to Δ 𝑄 in Eq. (9) because the change of Shannon entropies is zero. The interpretation of Δ 𝑄 for the dynamical system is discussed in Subsection e in Appendix A. Adding Eqs. (21) and (22) yields / 𝜎𝐺 + / 𝜎𝐾 ≥ 0, i.e., the total entropy production for the entire system is non-negative, indicating the consistency with the second law of thermodynamics. Considering each subsystem, / 𝜎𝐺 and / 𝜎𝐾 are lower bounded by / 𝐼 𝐺 ← 𝐾 and / 𝐼 𝐾 ← 𝐺 , respectively, one of which can be negative. By using information thermodynamics, we investigate the asymmetry between the dynamics of 𝑇𝐺 and 𝑇𝐾 from the perspective of entropy production and information transfer.
For the dynamical system [Eqs. (16) and (17)], the analytical solutions for the entropy production rates and information flows are obtained (Loos and Klapp 2020):
$$\dot { \sigma } _ { G } = \frac { c _ { G \leftarrow K } } { D _ { G } } \left \langle T _ { K } \frac { \text{d} T _ { G } } { \text{d} t } \right \rangle,$$
$$\dot { \sigma } _ { K } = \frac { c _ { K \leftarrow G } } { D _ { K } } \, \dot { \left < T _ { G } } \frac { \mathrm d T _ { K } } { \mathrm d t } \right >,$$
$$\dot { I } _ { G \leftarrow K } = \frac { \Sigma _ { G K } } { | \mathbf S | } \left \langle T _ { K } \frac { d T _ { G } } { d t } \right \rangle,$$
$$i _ { K \leftarrow G } = \frac { \overset { \cdot } { \Sigma _ { G K } } } { | \mathbf S | } \left \langle T _ { G } \frac { d T _ { K } } { d t } \right \rangle,$$
where we introduce the covariance matrix Σ between 𝑇𝐺 and 𝑇𝐾 . The off-diagonal component of Σ is represented by Σ 𝐺𝐾 , and the determinant of Σ is represented by | Σ | . Equations (24)-(27) indicate
that the entropy production rates and information flows are linked to the correlations between the SSTs and their rates of change. Thus, the temporal characteristics of the dynamical system can be examined using information thermodynamics. Details on the derivation of Eqs. (24)-(27) are given in Subsection c in Appendix B.
In the steady state, the entropy production rate and information flow of the Kuroshio Current are related to those of the Gulf Stream because of the following relationship (Subsection c in Appendix B):
$$\left \langle T _ { K } \frac { d T _ { G } } { d t } \right \rangle + \left \langle T _ { G } \frac { d T _ { K } } { d t } \right \rangle = 0.$$
Applying Eq. (28) into Eqs. (24)-(27), we obtain the following relationships:
$$\dot { \sigma } _ { K } = - \frac { c _ { K \leftarrow G } D _ { G } } { c _ { G \leftarrow K } D _ { K } } \dot { \sigma } _ { G },$$
$$\dot { I } _ { K \leftarrow G } = - \dot { I } _ { G \leftarrow K }.$$
Equation (30) can also be derived from the conservation of the information flows [Eq. (23)]. We analyze the dynamical system using the theoretical formulas (24)-(30).
## b. Analysis of regime diagrams for the BCS
Weshow that the dynamical system can be regarded as a Maxwell's demon system by examining the dependence of information thermodynamics quantities on the interaction coefficients 𝑐 𝐾 ← 𝐺 and 𝑐 𝐺 ← 𝐾 shown in Figs. 5 and 6. The parameters 𝑐 𝐾 ← 𝐺 and 𝑐 𝐺 ← 𝐾 are the most important because they characterize the interactions between the Gulf Stream and the Kuroshio Current. In Figs. 5 and 6, the white dots represent the estimated values of ( 𝑐 𝐾 ← 𝐺,𝑐𝐺 ← ) 𝐾 listed in Table 1. The error bars indicate the standard deviations obtained by the bootstrap method.
The error bars for the estimated values suggest that the true value is likely to lie in the region where 𝑐 𝐾 ← 𝐺 > 0 and 𝑐 𝐺 ← 𝐾 > 0 (Figs. 5 and 6), though the results based on the OISST data suggest that the true value may possibly lie in the region where 𝑐 𝐺 ← 𝐾 < 0. Since the period of the OISST data is shorter, the uncertainty in the estimation is larger compared to the results of the GFDL-CM4C192 data. Appendix C briefly discusses the case where 𝑐 𝐺 ← 𝐾 < 0. Hereafter, we focus on the region where 𝑐 𝐺 ← 𝐾 > 0.
## OISST
Fig. 5. Dependence of information thermodynamic quantities on the interaction coefficients 𝑐 𝐾 ← 𝐺 and 𝑐 𝐺 ← 𝐾 for the OISST data: (a) / 𝜎 𝐺 , (b) / 𝐼 𝐺 ← 𝐾 , (c) √︃ ⟨ 𝑇 2 𝐺 ⟩ -√︃ ⟨ 𝑇 2 𝐺 ⟩| 𝑐 𝐺 ← 𝐾 = 0 , (d) / 𝜎 𝐾 , (e) / 𝐼 𝐾 ← 𝐺 , and (f) √︃ ⟨ 𝑇 2 𝐾 ⟩ -√︃ ⟨ 𝑇 2 𝐾 ⟩| 𝑐 𝐾 ← 𝐺 = 0 . Sub-figures (c) and (f) show the differences in the standard deviations of the SSTs from those without the interactions, namely, when 𝑐 𝐺 ← 𝐾 = 0 and 𝑐 𝐾 ← 𝐺 = 0, respectively. The white dots represent the estimated values of ( 𝑐 𝐾 ← 𝐺 , 𝑐 𝐺 ← 𝐾 ) , whose values are listed in Table 1. The error bars indicate the standard deviations obtained from the bootstrap method. The gray dashed diagonal lines show the symmetric condition 𝑐 𝐺 ← 𝐾 𝐷 𝐾 = 𝑐 𝐾 ← 𝐺 𝐷 𝐺 .
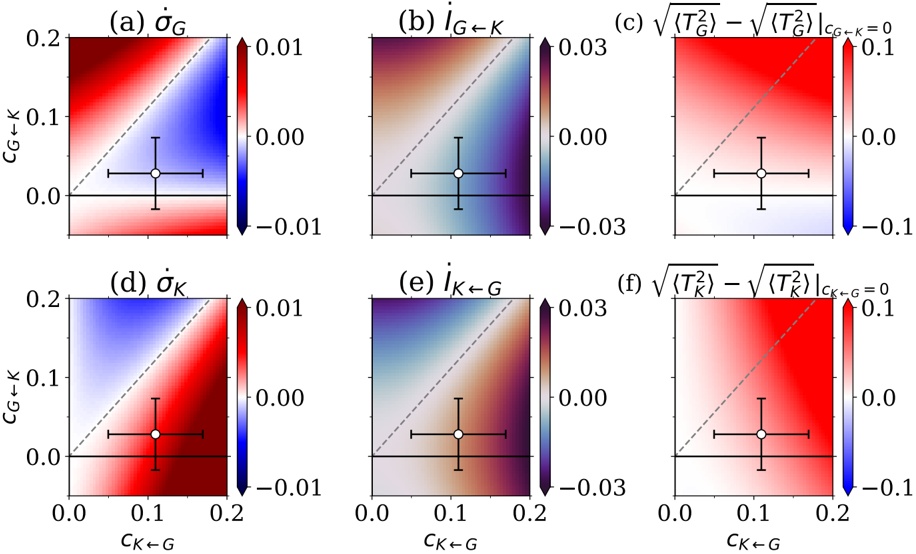
The Gulf Stream and the Kuroshio Current are symmetric on the gray dashed diagonal lines in Figs. 5 and 6, where 𝑐 𝐺 ← 𝐾 𝐷 𝐾 = 𝑐 𝐾 ← 𝐺 𝐷 𝐺 (Appendix D). On these lines, the interchange of 𝑇𝐺 and 𝑇𝐾 does not affect the entropy production rates and information flows because these quantities are zero (Loos and Klapp 2020). Below these lines, / 𝜎𝐺 and / 𝐼 𝐺 ← 𝐾 are negative for the Gulf Stream, whereas / 𝜎𝐾 and / 𝐼 𝐾 ← 𝐺 are positive for the Kuroshio Current. Above these lines, all the signs of these quantities are reversed. Thus, the roles of the Gulf Stream and the Kuroshio Current are reversed across the diagonal lines in Figs. 5 and 6.
## GFDL-CM4C192
cG
cG
Fig. 6. Same as Fig. 5 but for the GFDL-CM4C192 data.
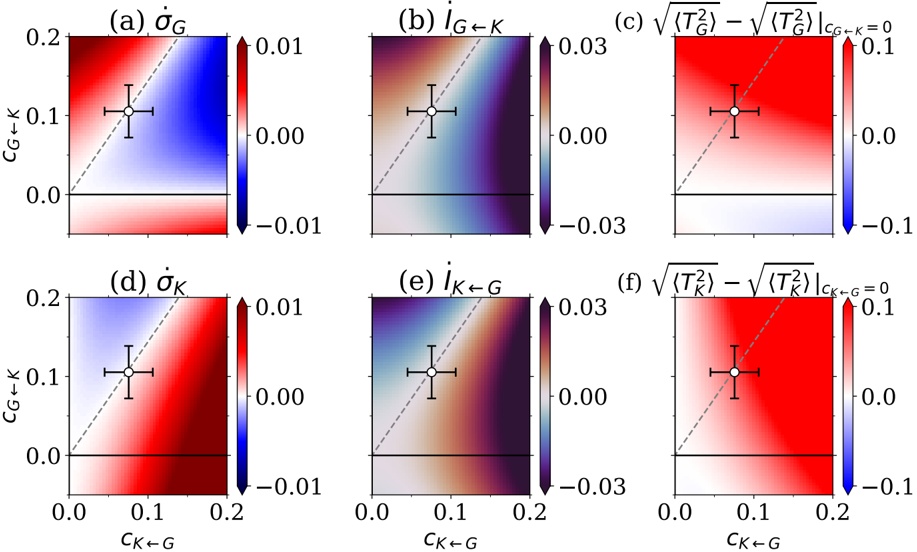
The Gulf Stream and the Kuroshio Current are likely to be asymmetric due to various factors, such as the land-sea distribution. This consideration suggests that the true value is not strictly on the gray dashed diagonal lines in Figs. 5 and 6, although the estimated values from the GFDL-CM4C192 data are quite close to these diagonal lines (Fig. 6). This result is probably due to the fact that small-scale disturbances regarded as noise are not sufficiently reproduced in the GFDL-CM4C192 model. Indeed, the noise variances 𝐷𝐺 and 𝐷𝐾 are smaller than those estimated from the OISST data (Table 1), and these parameters affect the symmetric condition 𝑐 𝐺 ← 𝐾 𝐷 𝐾 = 𝑐 𝐾 ← 𝐺 𝐷 𝐺 . Hereafter, we consider that the true value exists on the lower side of the diagonal lines, where both estimated values from the OISST and GFDL-CM4C192 data belong.
Figures 5 and 6 indicate that the dynamical system is a Maxwell's demon system, where the Gulf Stream is a 'Particle' and the Kuroshio Current is a 'Demon.' The entropy production rate and information flow of the Gulf Stream, / 𝜎𝐺 and / 𝐼 𝐺 ← 𝐾 , are negative (Figs. 5a, 5b, 6a, and 6b), whereas those of the Kuroshio Current, / 𝜎𝐾 and / 𝐼 𝐾 ← 𝐺 , are positive (Figs. 5d, 5e, 6d, and 6e). According
to the discussions on Maxwell's demon systems (Sections 2c and 2d), the Kuroshio Current as the 'Demon' tends to establish the correlation with the Gulf Stream SST by measuring it, which is reflected in the positive information flow ( / 𝐼 𝐾 ← 𝐺 > 0). Furthermore, the Kuroshio Current utilizes its own SST as a memory and exhibits a positive entropy production rate ( / 𝜎𝐾 > 0), which is attributed to the memory update process associated with the measurement. On the other hand, the Gulf Stream as the 'Particle' tends to decrease the correlation due to the feedback control by the Kuroshio Current, which is reflected in the negative information flow ( / 𝐼 𝐺 ← 𝐾 < 0). In addition, the Gulf Stream SST varies by rectifying noise and shows a negative entropy production rate ( / 𝜎𝐺 < 0). The term 'rectify' means to extract coherent directional output from random noise fluctuations.
We further discuss the rectification of noise. Figures 5c, 5f, 6c, and 6f show that the SST magnitudes √︃ ⟨ 𝑇 𝐺 2 ⟩ and √︃ ⟨ 𝑇 𝐾 2 ⟩ are increased compared to the case without interactions. As discussed in Section 3b, without noise, the dynamical system would decay to zero without oscillation. This result suggests that the driving source is noise. Moreover, in the absence of interactions, namely 𝑐 𝐺 ← 𝐾 = 𝑐 𝐾 ← 𝐺 = 0, the SSTs of the Gulf Stream and the Kuroshio Current would evolve independently, and BCS would not occur. Compared to the SST magnitudes in this case, they are increased due to the interactions. Within the framework of the dynamical system, the presence of both interactions and noises is essential for BCS.
We first investigate the reason for the increase in 𝑇𝐺 . The entropy production rate / 𝜎𝐺 is given as follows, which is negative (Figs. 5a and 6a):
$$0 > \dot { \sigma } _ { G } = \frac { c _ { G \leftarrow K } } { D _ { G } } \left \langle T _ { K } \frac { \mathrm d T _ { G } } { \mathrm d t } \right \rangle = \frac { ( c _ { G \leftarrow K } ) ^ { 2 } } { D _ { G } } \langle T _ { K } T _ { K } \rangle - \frac { r _ { G } c _ { G \leftarrow K } } { D _ { G } } \langle T _ { K } T _ { G } \rangle,$$
where all coefficients are positive. The rightmost side is obtained by substituting Eq. (16) into (24). The relative magnitudes of the two terms on the rightmost side characterize the behavior of the Gulf Stream. When the first term dominates, indicating a stronger influence from the Kuroshio Current, the Gulf Stream shows increased fluctuations and a larger entropy production rate / 𝜎𝐺 . Conversely, when the second term dominates, the relaxation is more effective, reducing the stochasticity of the Gulf Stream (i.e., decreasing / 𝜎𝐺 ). Clearly, the negative / 𝜎𝐺 indicates that the second term is dominant.
The negative / 𝜎𝐺 suggests that the action from the Kuroshio Current on the Gulf Stream, 𝑐 𝐺 ← 𝐾𝑇𝐾 , does not directly contribute to the increase in 𝑇𝐺 . Indeed, this action 𝑐 𝐺 ← 𝐾𝑇𝐾 is negatively
Fig. 7. Schematic of the increase in the Gulf Stream SST due to noise and feedback. Without the action from the Kuroshio Current, namely no feedback (top), the SST increases due to noise and quickly returns to zero through relaxation. With feedback from the Kuroshio Current (bottom), relaxation is interfered with, allowing the possibility of further increase by noise before returning to zero. The Kuroshio Current measures the Gulf Stream SST and inserts a 'partition' at an appropriate location.
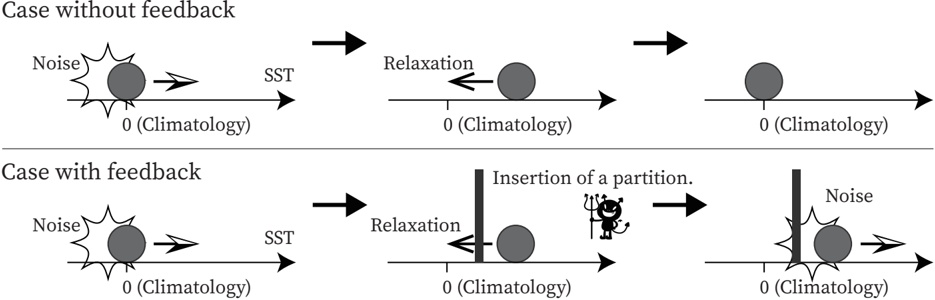
correlated with the tendency of the Gulf Stream SST, 𝑐 𝐺 ← ⟨ 𝐾 𝑇𝐾 d 𝑇𝐺 / d 𝑡 ⟩ = 𝐷𝐺𝜎𝐺 < / 0. This result is due to the relaxation. Without relaxation, the governing equation (16) would be d 𝑇𝐺 / d 𝑡 = 𝑐 𝐺 ← 𝐾𝑇𝐾 , and only the first term in Eq. (31) would remain, leading to a positive / 𝜎𝐺 . The mechanism for the increase in 𝑇𝐺 is then described as follows. For example, when 𝑇𝐺 is positive, it tends to decrease to zero due to relaxation, but this decrease is mitigated by 𝑐 𝐺 ← 𝐾𝑇𝐾 . In other words, the action from the Kuroshio Current suppresses the relaxation of the Gulf Stream. Consequently, the remaining term 𝜉 𝐺 in Eq. (16), namely the noise, becomes more effective and increase 𝑇𝐺 . This suppression of relaxation to zero corresponds to the feedback control that inserts a partition (Fig. 7).
We next investigate the reason for the increase in 𝑇𝐾 . The expression for the entropy production rate / 𝜎𝐾 is given as follows, which is positive (Figs. 5d and 6d):
$$0 < \dot { \sigma } _ { K } = \frac { c _ { K \leftarrow G } } { D _ { K } } \left \langle T _ { G } \frac { \mathrm d T _ { K } } { \mathrm d t } \right \rangle = \frac { \left ( c _ { K \leftarrow G } \right ) ^ { 2 } } { D _ { K } } \langle T _ { G } T _ { G } \rangle - \frac { r _ { K } c _ { K \leftarrow G } } { D _ { K } } \langle T _ { G } T _ { K } \rangle,$$
where all coefficients are positive. The rightmost side is obtained by substituting Eq. (17) into (25). Equation (32) is interpreted in the same manner as Eq. (31). When the first term dominates, the Kuroshio Current shows strong fluctuations and a larger entropy production rate / 𝜎𝐾 . Conversely,
when the second term dominates, the stochasticity of the Kuroshio Current is reduced and / 𝜎𝐾 decreases. The result of / 𝜎𝐾 > 0 indicates the dominance of the first term.
The positive / 𝜎𝐾 suggests that the action from the Gulf Stream on the Kuroshio Current, 𝑐 𝐾 ← 𝐺𝑇𝐺 , directly contributes to the increase in 𝑇𝐾 . Similar to the Gulf Stream, there is an effect of suppressing relaxation; however, its contribution is relatively small and / 𝜎𝐾 is positive. The amplification of 𝑇𝐾 occurs by following the changes in 𝑇𝐺 due to the action 𝑐 𝐾 ← 𝐺𝑇𝐺 from the Gulf Stream. According to the framework of Maxwell's demon systems, the Kuroshio Current (i.e., the 'Demon') uses its SST as memory and the SST fluctuations are increased by updating the memory value 𝑇𝐾 based on the measurement outcome of the Gulf Stream SST.
These analyses of 𝑇𝐺 and 𝑇𝐾 suggest that information-to-energy conversion (Toyabe et al. 2010) occurs in a subsystem (i.e., the Gulf Stream), even though the entire system is dissipative, as in other Maxwell demon systems. Generally, stochastic noise fluctuates a system back and forth, so the net energy or work is difficult to extract. However, using the information from measurements, fluctuations can be converted into directional movements in a subsystem (Toyabe et al. 2010), corresponding to the negative / 𝜎𝐺 or increased 𝑇𝐺 amplitude in our system. Such conversion cannot occur for the entire dissipative system (i.e., no net positive conversion), as reflected in the positive value of / 𝜎𝐺 + / 𝜎𝐾 .
Synchronicity is essential for this conversion. For instance, in Fig. 7, the partition needs to be inserted just behind the 'Particle.' This insertion is based on the memory value of the 'Demon,' as in the Szilard engine (Fig. 1), where the memory value becomes equal to the particle position after the measurement. Although it is difficult to directly compare our dynamical system to the Szilard engine because our system is autonomous (Section 2d), the memory value 𝑋 and particle position 𝑌 correspond to 𝑇𝐾 and 𝑇𝐺 , respectively. Both subsystems 𝑇𝐾 and 𝑇𝐺 are influenced by the small-scale disturbance fields (Section 3c), corresponding to isothermal environments in the Szilard engine. The 'Demon' ( 𝑇𝐾 ) follows a change in the 'Particle' ( 𝑇𝐺 ), thereby enabling feedback control to convert fluctuations. The 𝑇𝐾 amplitude increases due to this following (i.e., its continual updates based on 𝑇𝐺 ), although 𝑇𝐾 is dissipative (i.e., / 𝜎𝐾 > 0). In the Szilard engine, this dissipation corresponds to the work required to initialize the memory.
The dependence of the lag correlation is consistent with the description of the Kuroshio Current following the Gulf Stream. Figure 8 shows the dependence of the maximum lag correlation
Fig. 8. Maximum lag correlation coefficients and the corresponding lags between the Gulf Stream and Kuroshio Current SSTs as functions of the interaction coefficients 𝑐 𝐾 ← 𝐺 and 𝑐 𝐺 ← 𝐾 . The results are shown for the OISST and GFDL-CM4C192 data. The gray dashed diagonal lines show the symmetric condition 𝑐 𝐺 ← 𝐾 𝐷 𝐾 = 𝑐 𝐾 ← 𝐺 𝐷 𝐺 . The label 'GS leads' means that the Gulf Stream leads, whereas the label 'KC leads' means that the Kuroshio Current leads.
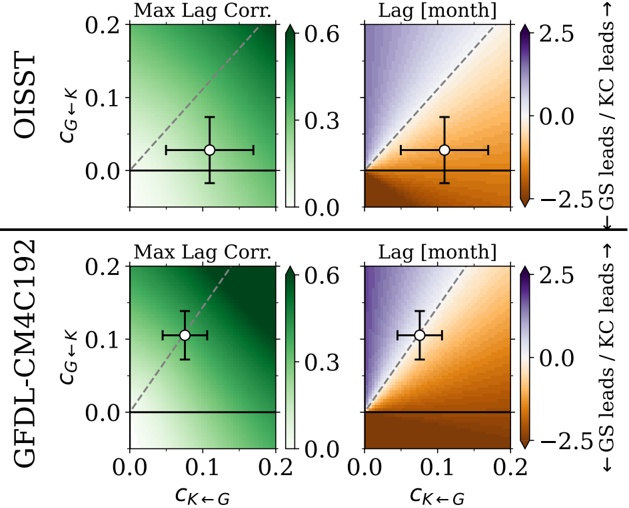
coefficient and the lag at that time over the same parameter space as in Figs. 5 and 6. Note that these lag correlation coefficients are theoretically computed as in Fig. 4. As confirmed in Section 3d, the lag correlation is positive in Fig. 8, suggesting that the BCS occurs. Above the gray dashed diagonal lines in Fig. 8, the SST of the Kuroshio Current leads by 1-2 months, while below the lines, the SST of the Gulf Stream leads. Across the diagonal lines, the roles of the 'Particle' and the 'Demon' are reversed because of the reversal of all signs of the entropy production rates and information flows. In the region below the diagonal lines, which we have been considering so far, the Gulf Stream (i.e., the 'Particle') leads. The Kuroshio Current (i.e., the 'Demon') measures the Gulf Stream SST and follows the changes in 𝑇𝐺 .
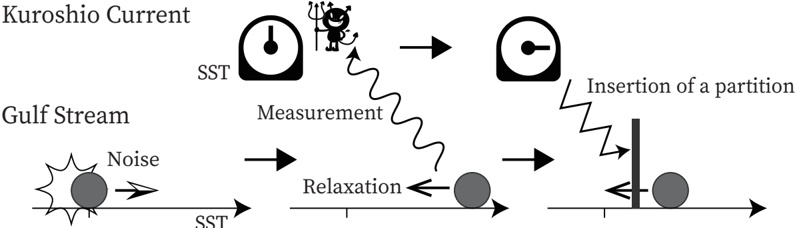
/gid00020/gid00020/gid00021
Fig. 9. Schematic of the interpretation of the BCS as a Maxwell's demon system (i.e., the stochastic synchronization). The Kuroshio Current plays the role of the 'Demon' and the Gulf Stream plays the role of the 'Particle.' See Section 4c for details.
## c. Interpretation of BCS as a Maxwell's demon system: stochastic synchronization
From the above results, we obtain an interpretation of the BCS as a Maxwell's demon system (Fig. 9), which implies the asymmetric roles of the Gulf Stream and the Kuroshio Current. First, the Gulf Stream forces the SST of the Kuroshio Current to be in phase. This effect of making the Kuroshio Current follow is represented by the term 𝑐 𝐾 ← 𝐺𝑇𝐺 in the dynamical system, Eq. (17). In the framework of Maxwell's demon, the Gulf Stream is interpreted as being measured by the Kuroshio Current. By contrast, the Kuroshio Current locks the phase of the Gulf Stream SST by interfering with its relaxation toward the climatology. This effect of interference with the relaxation is represented by the term 𝑐 𝐺 ← 𝐾𝑇𝐾 in the dynamical system, Eq. (16). In the framework of Maxwell's demon, the Kuroshio Current is interpreted as performing feedback control on the Gulf Stream. On one hand, for the dynamical system without noise, the SSTs would relax to zero without oscillating. On the other hand, without interactions between the Gulf Stream and the Kuroshio Current, their SSTs would fluctuate independently. When both currents are coupled in an appropriate parameter regime, synchronization is realized with atmospheric and oceanic noise as the driving source. The physical origins of this driving source can be attributed to the effects of atmospheric jet streams and oceanic mesoscale eddies on time scales of a few months or less.
In this regard, Yamagami et al. (2024) recently examined the asymmetric roles between the Gulf Stream and Kuroshio Current using a coupled atmosphere-ocean general circulation model through 'pacemaker' experiments. In these experiments, SST variations only in a western boundary current region are strongly relaxed toward (i.e., keep 'pace' with) a control run, so that the responses of the
other climate systems to the western boundary current variability are isolated. They showed that, when the Gulf Stream acts as a pacemaker, BCS is reproduced. The heat release from the Gulf Stream modulates the atmospheric annular mode, exciting oceanic Rossby waves in the Pacific and influencing the SST in the Kuroshio Current region. This mechanism serves as a plausible physical process that realizes the role of the 'Particle' in the context of the Maxwell's demon system, i.e., the Gulf Stream forces the SST of the Kuroshio Current to be in phase. Conversely, they also showed that, when the Kuroshio Current acts as a pacemaker, the BCS is not reproduced. This result is also consistent with our interpretation that, unlike the Gulf Stream, the Kuroshio Current does not force the SST of the Gulf Stream by itself. Rather, by responding to the Gulf Stream's forcing, the Kuroshio Current returns a feedback to interfere with the Gulf Stream SST relaxation toward its climatology. The absence of BCS in the Kuroshio pacemaker experiment can be understood that, because its SST varies independently from the state of the Gulf Stream, the Kuroshio Current cannot reproduce an optimal feedback in an appropriate timing. Our future work is to reveal what kind of physical processes regarding the Kuroshio Current realizes the role of the 'Demon' in the real world.
Our proposed mechanism can be realized in other stochastic dissipative systems with positive feedback. The dynamical system investigated here, Eqs. (16) and (17), is known as the Langevin system, one of the simplest and most common models with dissipation and stochastic forcing (e.g., Sekimoto 2010). Indeed, Langevin systems have been employed as simple models for climate phenomena (e.g., Dijkstra 2013). The key ingredient in our study is the positive feedback; that is, both interaction coefficients 𝑐 𝐾 ← 𝐺 and 𝑐 𝐺 ← 𝐾 are positive. Due to this positive feedback, atmospheric or oceanic fluctuations are converted into directional variations in a subsystem via synchronization (i.e., information-to-energy conversion; Toyabe et al. (2010)), although such conversion cannot be realized for the entire dissipative system. The wide applicability of Langevin systems suggests that the proposed mechanism of synchronization (Fig. 9), 'stochastic synchronization,' may describe other climate phenomena. Such applications remain an important topic for future work.
## 5. Conclusions
This study has introduced a bivariate linear dynamical system that describes the BCS and analyzed it using a theory of information thermodynamics (Horowitz and Esposito 2014; Loos and Klapp
2020). This system can be interpreted as a Maxwell's demon system, with the Gulf Stream playing the role of the 'Particle' and the Kuroshio Current playing the role of the 'Demon.' Information thermodynamics clarifies the asymmetric roles of the Gulf Stream and the Kuroshio Current from the perspective of entropy production and information transfer (Section 4c). Our results suggest that random noise fluctuations can be autonomously converted into coherent, directional variations (i.e., information-to-energy conversion), through synchronization between the Gulf Stream and the Kuroshio Current. The proposed mechanism, named 'stochastic synchronization,' may describe other climate phenomena because our analysis was based on a widely applicable Langevin system. For future research, we propose applying information thermodynamics to more realistic models that describe the BCS (e.g., Gallego and Cessi 2001; Kohyama et al. 2021). While the current study demonstrates that the Gulf Stream can be interpreted as the 'Particle' and the Kuroshio Current as the 'Demon,' what determines these roles remains unclear, and these roles might be reversed under certain conditions, such as due to temporal changes in interaction coefficients. Moreover, it is unclear how the interactions, such as the interference of the relaxation, are realized in the real climate system. These points will be revealed by applying the theory to realistic models.
Information thermodynamics is applicable to other climate phenomena, such as the El Ni˜ noSouthern Oscillation, and may provide new physical insights. However, the direct application may not be straightforward because information thermodynamics requires the estimation of probability, and such estimation is generally difficult for systems with large degrees of freedom. Recently developed data-driven methods, such as dimensionality reduction (Reddy et al. 2020; Hou and Behdinan 2022), may be effective for the probability estimation and expand the applicability of information thermodynamics.
Acknowledgments. During the preparation of this work, the authors used Claude 3 only for English editing. After using this service, the authors reviewed and edited the content as needed. The authors take full responsibility for the content of the publication. The second author is supported by Japan Society for the Promotion of Science (JSPS) Kakenhi (22H04487, 23H01241, and 23K13169), and the MEXT program for the advanced studies of climate change projection (SENTAN) Grant Number JPMXD0722680395. The authors thank Masaru Inatsu for initiating our connection, leading to this collaboration.
Data availability statement. The data and source code that support the findings of this study are preserved at the Zenodo repository ( https://doi.org/10.5281/zenodo.13085327 ) and developed openly at the GitHub repository ( https://github.com/YukiYasuda2718/bcs\_ maxwell\_demon ).
## APPENDIX A
## Review of information thermodynamics
We re-derive the second law of information thermodynamics and the conservation law of information flows, both of which are used in this study. The derivation is mainly based on Seifert (2012), Horowitz and Esposito (2014), and Loos and Klapp (2020). We show the derivation in detail because information thermodynamics is rarely applied to atmospheric and oceanic sciences, and comprehensive reviews for continuous-state systems are not readily available. Indeed, recent textbooks primarily focus on discrete-state Markov jump processes (Peliti and Pigolotti 2021; Shiraishi 2023), which are not directly applicable to the continuous-state climate system. Moreover, Ito (2016b) explains the concept of information thermodynamics clearly despite its concise description. Although not straightforward, according to Ito (2016a), the theory in Ito (2016b) is equivalent to the theory used in our study (Horowitz and Esposito 2014; Loos and Klapp 2020).
## a. Multivariate nonlinear SDEs
We derive the second law of information thermodynamics for 𝑁 -variable nonlinear stochastic differential equations (SDEs, e.g., Gardiner 2009).
$$d x _ { i } = - a _ { i } ( { \mathbf x } ) d t + \sqrt { 2 D _ { i } } \mathrm d W _ { i }, \quad ( i = 1, \dots, N ),$$
where x : = ( 𝑥 , . . . , 𝑥 1 𝑁 ) T , 𝑎𝑖 ( x ) is a nonlinear function of x , 𝐷𝑖 is a positive constant, d 𝑊𝑖 is the differential of mutually independent Wiener processes for each 𝑖 . Equation (A1) assumes that the coefficient matrix D for the Wiener processes is diagonal: D = diag ( √ 2 𝐷 ,..., 1 √ 2 𝐷𝑁 ) . This assumption corresponds to the bipartite condition (Horowitz and Esposito 2014) and is essential for the following derivation. For example, this condition is necessary for the transformation from Eq. (A3) to (A4), and Eq. (A4) is indispensable for the final inequality (A32). If D is non-diagonal, a noise d 𝑊𝑖 may change not only 𝑥 𝑖 but also other state variables. By taking the matrix D to be diagonal, it is guaranteed that d 𝑊𝑖 contributes only to the fluctuation of 𝑥 𝑖 . Moreover, if D is diagonal, each component can be taken positive without loss of generality. We expressed it as √ 2 𝐷𝑖 to simplify later equations.
The probability distribution 𝑝 tot ( x , 𝑡 ) of the ensemble of solutions to these SDEs follows the Fokker-Planck equation (FPE, e.g., Gardiner 2009). The subscript 'tot' emphasizes that 𝑝 tot is the joint probability of all variables:
$$\frac { \partial p _ { \text{tot} } ( \mathbf x, t ) } { \partial t } = \sum _ { i = 1 } ^ { N } \frac { \partial } { \partial x _ { i } } \left [ a _ { i } ( \mathbf x ) p _ { \text{tot} } ( \mathbf x, t ) \right ] + \sum _ { i = 1 } ^ { N } D _ { i } \frac { \partial ^ { 2 } } { \partial x _ { i } ^ { 2 } } p _ { \text{tot} } ( \mathbf x, t ) = - \sum _ { i = 1 } ^ { N } \frac { \partial } { \partial x _ { i } } J _ { i } ( \mathbf x, t ). \quad ( A 2 )$$
In the rightmost side, the probability flux J is introduced, explicitly expressing the conservation of probability. The 𝑖 -th component of J is defined as follows:
$$J _ { i } ( { \mathbf x }, t ) \coloneqq - a _ { i } ( { \mathbf x } ) p _ { \text{tot} } ( { \mathbf x }, t ) - D _ { i } \frac { \partial } { \partial x _ { i } } p _ { \text{tot} } ( { \mathbf x }, t ).$$
Using 𝐽 𝑖 , the derivative 𝜕𝑝 tot / 𝜕𝑥𝑖 is expressed as:
$$\frac { \partial p _ { \text{tot} } } { \partial x _ { i } } = - \frac { J _ { i } } { D _ { i } } - \frac { p _ { \text{tot} } a _ { i } } { D _ { i } }.$$
For boundary conditions for the FPE, we assume 𝑝 tot ( x , 𝑡 ) = 0 and J x ( , 𝑡 ) = 0 at sufficiently far away from the origin.
## b. Second law of information thermodynamics for subsystems
Wederive the second law of information thermodynamics by transforming the time derivative of the Shannon entropy 𝑆𝜁 for a subsystem 𝑧 (: = 𝑥 𝜁 ) (Horowitz and Esposito 2014; Loos and Klapp
2020):
$$S _ { \zeta } \coloneqq - \int d z \, p _ { \zeta } ( z, t ) \ln p _ { \zeta } ( z, t ),$$
where 𝜁 represents any index from 1 to 𝑁 . We introduced 𝜁 to distinguish it from other subscripts, such as 𝑖 and 𝑗 , and to emphasize that 𝜁 corresponds to 𝑧 ( = 𝑥 𝜁 ) . The marginal probability 𝑝𝜁 is defined by the integral of the joint probability 𝑝 tot :
$$p _ { \zeta } ( z, t ) \coloneqq & \int \left ( \prod _ { i = 1, i \neq \zeta } ^ { N } d x _ { i } \right ) \, p _ { \text{tot} } ( \mathbf x, t ),$$
«
‹
The time evolution of this marginal probability 𝑝𝜁 is given by the integral of the convergence of the probability flux:
$$\frac { \partial } { \partial t } p _ { \zeta } ( z, t ) = \frac { \partial } { \partial t } \int \left ( \prod _ { i = 1, i \neq \zeta } ^ { N } \mathrm d x _ { i } \right ) \, p _ { \text{tot} } ( \mathbf x, t ),$$
$$\overset { \cdot } { \cdot } \quad & \overset { \cdot } { \cdot } \quad \overset { \cdot } { \cdot } \quad \underset { \ell } { \vdots } = - \int \left ( \prod _ { i = 1, i \neq \zeta } ^ { N } \mathrm d x _ { i } \right ) \sum _ { j = 1 } ^ { N } \frac { \partial } { \partial x _ { j } } J _ { j } ( \mathbf x, t ), \\ & \overset { \cdot } { \cdot } \int \overset { N } { \underline { N } } \quad \underset { \ell } { \lambda }$$
$$= - \int \left ( \prod _ { i = 1, i \neq \zeta } ^ { N } d x _ { i } \right ) \, \frac { \partial } { \partial z } J _ { \zeta } ( { \mathbf x }, t ).$$
«
‹
In the last equation, we integrate the derivative 𝜕𝐽𝑖 / 𝜕𝑥𝑖 ( 𝑖 ≠ 𝜁 ) and use the boundary conditions, leading it to be zero. The point of the following derivation is to use the FPE via the joint probability 𝑝 tot ( x , 𝑡 ) to deal with the marginal probability 𝑝𝜁 ( 𝑧, 𝑡 ) .
We transform the time derivative of the Shannon entropy:
$$\frac { d } { d t } S _ { \zeta } = - \int \frac { \partial p _ { \zeta } } { \partial t } \ln p _ { \zeta } \, \mathrm d z - \underbrace { \int \frac { \partial p _ { \zeta } } { \partial t } \mathrm d z } _ { = 0 }, \\ \int _ { 0 } \,. \quad.$$
$$= \int d z \int \left ( \prod _ { i = 1, i \neq \zeta } ^ { N } d x _ { i } \right ) \left [ \frac { \partial } { \partial z } J _ { \zeta } ( { \mathbf x }, t ) \right ] \ln p _ { \zeta } ( z, t ),$$
$$& \vec { \nu } \quad \sum _ { i = 1 } ^ { \nu } \lambda \lambda ^ { \lambda } \lambda ^ { \lambda } \lambda ^ { \lambda } \\ = & \int \underbrace { \left ( \prod _ { i = 1 } ^ { N } d x _ { i } \right ) } _ { = d x } \left [ \frac { \partial J _ { \zeta } ( \mathbf x, t ) } { \partial z } \right ] \left [ \ln \frac { p _ { \zeta } ( z, t ) } { p _ { \text{tot} } ( \mathbf x, t ) } + \ln p _ { \text{tot} } ( \mathbf x, t ) \right ],$$
=
d
x
$$= i _ { \zeta \leftarrow } + \int \mathrm d { \mathbf x } \, \frac { \partial J _ { \zeta } ( { \mathbf x }, t ) } { \partial z } \ln p _ { \text{tot} } ( { \mathbf x }, t ).$$
In Eq. (A10), the conservation of probability was used. In Eq. (A12), the definition of 𝑧 is used: 𝑧 : = 𝑥 𝜁 . We define the information flow / 𝐼 𝑖 ← as follows (Allahverdyan et al. 2009; Loos and Klapp 2020):
$$\dot { I } _ { i \leftarrow } \coloneqq \int \mathrm d { \mathbf x } \, \frac { \partial J _ { i } ( { \mathbf x }, t ) } { \partial x _ { i } } \ln \frac { p _ { i } ( x _ { i }, t ) } { p _ { \text{tot} } ( { \mathbf x }, t ) },$$
where the marginal distribution for 𝑥 𝑖 is
$$p _ { i } ( x _ { i }, t ) \coloneqq \int \left ( \prod _ { j = 1, j \neq i } ^ { N } \mathrm d x _ { j } \right ) p _ { \text{tot} } ( \mathbf x, t ).$$
«
‹
The information flow / 𝐼 𝑖 ← represents changes in the mutual information by the subsystem 𝑥 𝑖 . We further discuss information flow in Subsection c in Appendix A. In Eq. (A13), the information flow / 𝐼 𝜁 ← (i.e., 𝑖 = 𝜁 ) was substituted.
We further transform the second term in Eq. (A13):
$$\int \mathrm d { \mathbf x } \, \frac { \partial J _ { \zeta } } { \partial z } \ln p _ { \text{tot} } = - \int \mathrm d { \mathbf x } \, J _ { \zeta } \frac { \partial \left ( \ln p _ { \text{tot} } \right ) } { \partial z } + \int \left ( \prod _ { i = 1, i \neq \zeta } ^ { N } \mathrm d { x } _ { i } \right ) \, \underbrace { \left [ J _ { \zeta } \ln p _ { \text{tot} } \right ] _ { z = - \infty } ^ { z = + \infty } } _ { = 0 },$$
$$= - \int \mathrm d { \mathrm x } \, \frac { J _ { \zeta } } { p _ { \text{tot} } } \frac { \partial p _ { \text{tot} } } { \partial z },$$
$$= \left \langle - \frac { 1 } { p _ { \text{tot} } } \frac { \dot { \partial } p _ { \text{tot} } } { \partial z } \circ \frac { d z } { \text{d} t } \right \rangle,$$
$$= \dot { \left \langle \frac { 1 } { p _ { \text{tot} } } } \left ( \frac { J _ { \zeta } } { D _ { \zeta } } + \frac { p _ { \text{tot} } \overset { \cdot } { a _ { \zeta } } } { D _ { \zeta } } \right ) \circ \frac { d z } { d t } \right \rangle,$$
$$= \stackrel {. } { \left \langle \frac { J _ { \zeta } } { p _ { \text{tot} } D _ { \zeta } } } \circ \frac {. } { d t } \right \rangle + \left \langle \frac { a _ { \zeta } } { D _ { \zeta } } \circ \frac { d z } { d t } \right \rangle,$$
where ◦ represents the Stratonovich product (e.g., Gardiner 2009) and Eq. (A4) with 𝑖 = 𝜁 is substituted in Eq. (A18) to replace 𝜕𝑝 tot / 𝜕𝑧 . We further explain the Stratonovich product and the conversion formula between 𝐽 𝜁 and d 𝑧 / d 𝑡 used in transforming Eq. (A17) to (A18).
First, the Stratonovich product is defined as follows (e.g., Gardiner 2009):
$$f ( { \mathbf x } ( t ) ) \circ d W \coloneqq \lim _ { \Delta t \to 0 } \frac { f ( { \mathbf x } ( t + \Delta t ) ) + f ( { \mathbf x } ( t ) ) } { 2 } \left ( W _ { t + \Delta t } - W _ { t } \right ),$$
where 𝑓 represents any smooth function. Using the Stratonovich product, the chain rules hold mathematically (Gardiner 2009), and the energy conservation law (i.e., the first law of thermodynamics) holds physically (Sekimoto 2010). The introduction of the Stratonovich product is also discussed in Shiraishi (2023). Because of these properties, the Stratonovich product is commonly used in information thermodynamics. The Stratonovich product is necessary only for terms where the differential d 𝑊 appears. For example, using Eq. (A21), the product of 𝑓 ( x ( 𝑡 )) and d 𝑧 / d 𝑡 becomes:
$$f ( \mathbf x ( t ) ) \circ \frac { \mathrm d z } { \mathrm d t } = f ( \mathbf x ( t ) ) \circ \left ( - a _ { \zeta } + \sqrt { 2 D _ { \zeta } } \frac { \mathrm d W _ { \zeta } } { \mathrm d t } \right ),$$
$$= - f ( \mathbf x ( t ) ) a _ { \zeta } + \sqrt { 2 D _ { \zeta } } f ( x ( t ) ) \circ \frac { \mathrm d W _ { \zeta } } { \mathrm d t },$$
where d 𝑊𝜁 / d cannot be defined mathematically because of the non-smoothness of 𝑡 𝑊𝜁 ( 𝑡 ) (Gardiner 2009), but in physics, d 𝑊𝜁 / d 𝑡 is often used for computational convenience as white Gaussian noise.
In the transformation from Eq. (A17) to (A18), the following formula was used (Seifert 2012):
$$\left \langle f ( { \mathbf x } ( t ) ) \circ \frac { d x _ { i } } { d t } \right \rangle = \int d { \mathbf x } \, f ( { \mathbf x } ) J _ { i } ( { \mathbf x }, t ).$$
The statistical average of the rate of change of the state variable d 𝑥 𝑖 / d 𝑡 becomes the integral of the 𝑖 -th component of the probability flux 𝐽 𝑖 ( x , 𝑡 ) in the phase space. To show this formula, we use the definition of the Stratonovich product [Eq. (A21)] and perform a Taylor expansion. To simplify the derivation, we ignore terms of order smaller than d . 𝑡
$$d t \left \langle f ( \mathbf x ( t ) ) \circ \frac { d x _ { i } } { d t } \right \rangle = \left \langle f ( \mathbf x ( t ) ) \circ d x _ { i } \right \rangle,$$
$$\L ^ { \prime } = \left \langle \left ( f + \sum _ { k = 1 } ^ { N } \frac { 1 } { 2 } \frac { \partial f } { \partial x _ { k } } \mathrm d x _ { k } \right ) \mathrm d x _ { i } \right \rangle,$$
$$= \left \langle f ( x ) \mathrm d x _ { i } + \frac { 1 } { 2 } \frac { \partial f } { \partial x _ { i } } \left ( \mathrm d x _ { i } \right ) ^ { 2 } \right \rangle,$$
$$= \overset { \cdot } { d t } \left \langle - a _ { i } f + D _ { i } \frac { \partial f } { \partial x _ { i } } \right \rangle,$$
$$= d t \, \int \mathrm d { \mathbf x } \, J _ { i } ( { \mathbf x }, t ) f ( { \mathbf x } ).$$
From Eq. (A25) to (A26), the definition of the Stratonovich product was used, and a Taylor expansion was performed. From Eq. (A26) to (A28), the Ito rule was used, where ⟨ d 𝑥 𝑘 d 𝑥 𝑖 ⟩ = 0 for 𝑘 ≠ 𝑖 due to the diagonal matrix D in the SDEs [Eq. (A1)]. In Eq. (A29), after integration by parts, the definition of the probability flux [Eq. (A3)] was substituted. Finally, Eq. (A24) is derived by comparing Eqs. (A25) and (A29).
To rewrite the numerator of the second term in Eq. (A20), we define the following quantity:
$$\dot { Q } _ { i } \coloneqq - \left \langle a _ { i } ( { \mathbf x } ) \circ \frac { d x _ { i } } { d t } \right \rangle,$$
$$= \left \langle \left ( \frac { \overset { \cdot } { d x _ { i } } } { d t } - \xi _ { i } \right ) \circ \frac { \overset { \cdot } { d x _ { i } } } { d t } \right \rangle,$$
where 𝜉 𝑖 : = √ 2 𝐷𝑖 d 𝑊𝑖 / d 𝑡 and the SDE for 𝑖 [Eq. (A1)] is used to obtain the second line. The quantity / 𝑄𝑖 can be regarded as the amount of heat dissipated by the subsystem 𝑥 𝑖 to the surrounding environment per unit time (Sekimoto 2010; Loos and Klapp 2020).
Combining Eqs. (A13), (A20), (A24), and (A30), we obtain
$$\underbrace { \frac { d S _ { \zeta } } { d t } + \frac { \dot { Q } _ { \zeta } } { D _ { \zeta } } } _ { = ; \dot { \sigma } _ { \zeta } } - \dot { I } _ { \zeta \leftarrow } = \left \langle \frac { J _ { \zeta } } { p _ { \text{tot} } D _ { \zeta } } \circ \frac { d z } { d t } \right \rangle = \int \mathrm d { \mathbf x } \, \frac { J _ { \zeta } ^ { 2 } } { p _ { \text{tot} } D _ { \zeta } } \geq 0,$$
where the equality holds when 𝐽 𝜁 = 0, that is, in the case of the detailed balance being satisfied for 𝑧 (Loos and Klapp 2020; Gardiner 2009). Since the subscript 𝜁 is arbitrary, the following inequality is derived:
$$\dot { \sigma } _ { i } = \frac { d S _ { i } } { d t } + \frac { \dot { Q } _ { i } } { D _ { i } } \geq \dot { I } _ { i \leftarrow }.$$
We defined the production rate of total entropy / 𝜎𝑖 as the sum of the rate of change of the Shannon entropy d 𝑆𝑖 / d 𝑡 of the subsystem 𝑥 𝑖 and the rate of change of the heat / 𝑄𝑖 / 𝐷𝑖 dissipated by the subsystem 𝑥 𝑖 to the surroundings. The production rate of total entropy / 𝜎𝑖 is lower bounded by the information flow / 𝐼 𝑖 ← . If / 𝐼 𝑖 ← is negative, / 𝜎𝑖 can be negative, that is, the total entropy can decrease. In the usual thermodynamic setup, 𝐷𝑖 is equal to the temperature of the environment (Sekimoto 2010; Loos and Klapp 2020). Thus, Eq. (A33) is considered a generalization of the Clausius inequality. The equality holds when 𝐽 𝑖 = 0. In this case, the detailed balance is satisfied mathematically (Gardiner 2009), and the subsystem 𝑥 𝑖 becomes an equilibrium state physically (Loos and Klapp 2020).
In the steady state, the time derivative of the Shannon entropy becomes zero, and the following holds:
$$\dot { \sigma } _ { i } = \frac { \dot { Q } _ { i } } { D _ { i } } \geq \dot { I } _ { i \leftarrow }.$$
The steady state is defined as a state in which joint probabilities of state variables between any time points depend only on the time differences (i.e., lags) and not on the absolute time itself. As a result, in the steady state, the marginal probability 𝑝𝑖 ( 𝑥 𝑖 , 𝑡 ) does not change over time; thus, the time derivative of the Shannon entropy 𝑆𝑖 becomes zero.
## c. Conservation law of information flows
We derive the conservation law of information flows (Allahverdyan et al. 2009; Loos and Klapp 2020). We first define the mutual information 𝑀 (e.g., Cover and Thomas 2005):
$$M \coloneqq \int \mathrm d { \mathbf x } \, p _ { \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \boldsymbol \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \cdot } } \ln \left [ \frac { p _ { \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \mathrm \boldsymbol } } } { \prod _ { i = 1 } ^ { N } p _ { i } ( x _ { i }, t ) } \right ]$$
Mutual information represents the magnitude of nonlinear correlations between subsystems. The value of mutual information is non-negative, and it becomes zero only when the subsystems are independent of each other.
We transform the time derivative of mutual information.
$$\frac { d M } { d t } = \int \mathrm d { \mathbf x } \, \frac { \partial p _ { \text{tot} } } { \partial t } \ln \left ( \frac { p _ { \text{tot} } } { \prod _ { i = 1 } ^ { N } p _ { i } } \right ) + \int \mathrm d { \mathbf x } \, p _ { \text{tot} } \left ( \frac { \partial } { \partial t } \ln p _ { \text{tot} } - \sum _ { i = 1 } ^ { N } \frac { \partial } { \partial t } \ln p _ { i } \right ),$$
$$= \sum _ { j = 1 } ^ { N } \left [ \int \mathrm d { \mathbf x } \, \frac { \partial J _ { j } } { \partial x _ { j } } \ln p _ { j } - \int \mathrm d { \mathbf x } \, \frac { \partial J _ { j } } { \partial x _ { j } } \ln p _ { \mathrm t o t } \right ],$$
$$\frac { d M } { d t } & = \int \mathrm d x \, \frac { \partial p _ { \text{totd} } } { \partial t } \ln \left ( \frac { p _ { \text{totd} } } { \prod _ { i = 1 } ^ { N } p _ { i } } \right ) + \int \mathrm d x \, p _ { \text{totd} } \left ( \frac { \partial } { \partial t } \ln p _ { \text{totd} } - \sum _ { i = 1 } ^ { N } \frac { \partial } { \partial t } \ln p _ { i } \right ), \\ & = \int \mathrm d x \, \frac { \partial p _ { \text{totd} } } { \partial t } \ln \left ( \frac { p _ { \text{totd} } } { \prod _ { i = 1 } ^ { N } p _ { i } } \right ) + \underbrace { \int \mathrm d x \, \frac { \partial p _ { \text{totd} } } { \partial t } } _ { = 0 } - \sum _ { i = 1 } ^ { N } \underbrace { \int \mathrm d x _ { i } } \frac { \partial p _ { i } } { \partial t }, \\ & = - \int \mathrm d x \left ( \sum _ { j = 1 } ^ { N } \frac { \partial J _ { j } ( \mathbf x, t ) } { \partial x _ { j } } \right ) \ln \left [ \frac { p _ { \text{totd} } ( \mathbf x, t ) } { \prod _ { i = 1 } ^ { N } p _ { i } ( x _ { i }, t ) } \right ], \\ & = \sum _ { j = 1 } ^ { N } \left [ \int \mathrm d x \, \frac { \partial J _ { j } } { \partial x _ { j } } \left ( \sum _ { i = 1 } ^ { N } \ln p _ { i } \right ) - \int \mathrm d x \, \frac { \partial J _ { j } } { \partial x _ { j } } \ln p _ { \text{totd} } \right ], \\ & = \sum _ { j = 1 } ^ { N } \left [ \int \mathrm d x \, \frac { \partial J _ { j } } { \partial x _ { j } } \ln p _ { j } - \int \mathrm d x \, \frac { \partial J _ { j } } { \partial x _ { j } } \ln p _ { \text{totd} } \right ],$$
In Eq. (A37), the conservation of probability and the definition of marginal probability were used. From Eq. (A39) to (A40), for all 𝑖 such that 𝑖 ≠ 𝑗 , the integral of 𝐽 𝑗 is executable and the result becomes zero due to the boundary conditions. Consequently, only the terms with 𝑖 = 𝑗 remain in Eq. (A40).
The conservation law of information flows is obtained by substituting Eq. (A14) into (A40):
$$\frac { \mathrm d M } { \mathrm d t } = \sum _ { i = 1 } ^ { N } \dot { I } _ { i \leftarrow }.$$
The sum of changes in the mutual information by the subsystem 𝑥 𝑖 (i.e., the information flow / 𝐼 𝑖 ← ) over all 𝑖 becomes the temporal change of the mutual information of the entire system. The information flow / 𝐼 𝑖 ← is interpreted as the sum of the inflow and outflow of information from all the other subsystems to 𝑥 𝑖 .
In the steady state, since the joint probability 𝑝 tot does not change over time, the time derivative of mutual information becomes zero. As a result, the following holds:
$$0 = \sum _ { i = 1 } ^ { N } \dot { I } _ { i \leftarrow \cdot \cdot }.$$
The source of information flow is uniquely determined when the entire system consists of only two variables (Allahverdyan et al. 2009). Here, the two random variables are denoted by uppercase letters 𝑋𝑡 and 𝑌𝑡 , and their realizations are denoted by lowercase letters 𝑥 𝑡 and 𝑦 𝑡 , respectively, where the time dependence is explicitly denoted by the subscript 𝑡 . In this case, the mutual information [Eq. (A35)] is expressed as follows:
$$M ( X _ { t }, Y _ { t } ) \coloneqq \int \mathrm d x _ { t } \mathrm d y _ { t } \ p ( x _ { t }, y _ { t } ) \ln \left [ \frac { p ( x _ { t }, y _ { t } ) } { p ( x _ { t } ) p ( y _ { t } ) } \right ].$$
The dependence on the variables 𝑋𝑡 and 𝑌𝑡 is explicitly written inside the parentheses as 𝑀 𝑋𝑡,𝑌𝑡 ( ) , where 𝑀 𝑋𝑡,𝑌𝑡 ( ) is symmetric with respect to 𝑋𝑡 and 𝑌𝑡 . In the bivariate case, the information flows are expressed as follows (Allahverdyan et al. 2009):
$$\dot { I } _ { X \leftarrow Y } = \lim _ { \Delta t \rightarrow 0 } \frac { M ( X _ { t + \Delta t }, Y _ { t } ) - M ( X _ { t }, Y _ { t } ) } { \dots \dots \dots \dots \dots },$$
$$i _ { Y \leftarrow X } = \lim _ { \Delta t \rightarrow 0 } \frac { M ( X _ { t }, Y _ { t + \Delta t } ) - M ( X _ { t }, Y _ { t } ) } { \Delta t }.$$
Based on the Leibniz rule for differentiation, the sum of these information flows satisfies the conservation law (A41). The variation of mutual information due to the time change of the random variable 𝑋 (or 𝑌 ) is defined as the information flow to 𝑋 (or 𝑌 ). Equation (A44) can be transformed into / 𝐼 𝑋 ← defined by Eq. (A14), and Eq. (A45) is also transformed into / 𝐼 𝑌 ← in the same manner (Allahverdyan et al. 2009). From the conservation law of information flows in the steady state, namely / 𝐼 𝑋 ← + / 𝑌 𝐼 𝑌 ← 𝑋 = 0, we see that information flows can be negative or positive.
## d. Second law of thermodynamics for the entire system
We derive the second law of thermodynamics for the entire system and confirm that focusing on subsystems is essential in information thermodynamics (Sagawa and Ueda 2013b). As a preparation, we define the Shannon entropy of the entire system:
$$S _ { \text{tot} } \coloneqq - \int \text{d} \mathbf x \, p _ { \text{tot} } ( \mathbf x, t ) \ln p _ { \text{tot} } ( \mathbf x, t ).$$
In general, additivity does not hold for Shannon entropy. The degree to which additivity does not hold is evaluated by mutual information.
$$\left ( \sum _ { i = 1 } ^ { N } S _ { i } \right ) - M & = - \left [ \sum _ { i = 1 } ^ { N } \int d x _ { i } \ p _ { i } ( x _ { i }, t ) \ln p _ { i } ( x _ { i }, t ) \right ] - \int d x \ p _ { t o t } ( \mathbf x, t ) \ln \left [ \frac { p _ { t o t } ( \mathbf x, t ) } { \prod _ { i = 1 } ^ { N } p _ { i } ( x _ { i }, t ) } \right ], \quad ( A 4 7 ) \\ & = - \left ( \sum _ { i = 1 } ^ { N } \int d \mathbf x \ p _ { t o t } \ln p _ { i } \right ) - \int d \mathbf x p _ { t o t } \ln \left ( \frac { p _ { t o t } } { \prod _ { i = 1 } ^ { N } p _ { i } } \right ), \\ & = - \int d \mathbf x \ p _ { t o t } \ln p _ { t o t }, \\ & = S _ { t o t },$$
where we use the definitions of 𝑆𝑖 , 𝑀 , and 𝑆 tot in Eqs. (A5), (A35), and (A46), respectively. From Eq. (A47) to (A48), the definition of marginal probability [Eq. (A15)] was applied to the first term. The Shannon entropies of the subsystems are additive only when the mutual information 𝑀 is zero.
We derive the second law for the entire system. Since Eq. (A33) holds for any 𝑖 , it can be summed over all 𝑖 . Applying Eqs. (A41) and (A50), we obtain the following:
$$\dot { \sigma } _ { \text{tot} } \coloneqq \frac { \text{d} S _ { \text{tot} } } { \text{d} t } + \sum _ { i = 1 } ^ { N } \frac { \dot { Q } _ { i } } { D _ { i } } \geq 0.$$
The first term in the middle represents the rate of change of the Shannon entropy of the entire system, and the second term represents the sum of the rates of change of the heat dissipated to the environment. In Eq. (A51), the production rate of total entropy for the entire system is lower bounded by zero, whereas in Eq. (A33), the production rate of total entropy for a subsystem is
lower bounded by the information flow, which can be negative. This information flow appears due to the non-additivity of Shannon entropy (Sagawa and Ueda 2013b). Historically, the second law of thermodynamics [Eq. (A51)] was derived first (Seifert 2005), and the second law of information thermodynamics [Eq. (A33)] was derived later (Horowitz and Esposito 2014; Loos and Klapp 2020).
## e. Interpretation of heat
The quantity / 𝑄𝑖 in Eq. (A30) is regarded as the heat dissipated by a subsystem 𝑥 𝑖 to the environment per unit time (Sekimoto 2010). When the environment is always in a thermal equilibrium state, this heat is equal to the entropy production rate of the environment (Peliti and Pigolotti 2021; Shiraishi 2023). However, this interpretation is not always possible.
Generally, in systems described by stochastic differential equations, noise is not always due to thermal fluctuations. For example, in the dynamical system considered in the current research [Eqs. (16) and (17)], noise represents the influence of small-scale disturbances in the atmosphere and ocean (Section 3c). Moreover, it is unclear whether such small-scale disturbance fields are always in an equilibrium state, although this point may be investigated using equilibrium statistical mechanics for geophysical fluids (Majda and Wang 2006; Bouchet and Venaille 2012; Campa et al. 2014). Indeed, the meanders of the Gulf Stream and the Kuroshio Current are consistent with analysis using equilibrium statistical mechanics (Venaille and Bouchet 2011), which implies that small-scale disturbance fields in both current regions can also be analyzed using equilibrium theory. Currently, however, such an analysis is not sufficient, and the interpretation of / 𝑄𝑖 needs to be considered for each application. In particular, / 𝜎𝑖 = / 𝑄𝑖 / 𝐷𝑖 holds in the steady state [Eq. (A34)], making this interpretation essential.
The present study has analyzed the dynamical system [Eqs. (16) and (17)] using the second law of information thermodynamics as a mathematical tool (Section 4). Although the second law is always derived for SDEs as shown above, mathematically deriving the second law is different from obtaining a meaningful physical insight from it. We have regarded / 𝜎𝐺 ( = / 𝑄𝐺 𝐷𝐺 / ) and / 𝜎𝐾 ( = / 𝑄𝐾 / 𝐷𝐾 ) as indicators of the contribution of interactions to the temporal tendencies of the SSTs. This interpretation does not rely on the interpretation of / 𝑄𝑖 as heat. As a similar example, Ito and Sagawa (2015) considered / 𝑄𝑖 as the robustness of signal transmission in a cell (i.e., not as
heat) and analyzed the processing efficiency of cell signaling using information thermodynamics. The application of information thermodynamics in this manner might yield interesting results for other atmospheric and oceanic systems. Investigating further applications is an important topic for future research in atmospheric and oceanic sciences.
## APPENDIX B
## Theoretical formulas used in Sections 3 and 4
## a. Correspondence between linear dynamical system and AR1 model
We convert the AR1 model to the linear dynamical system by comparing the means and covariances. The obtained theoretical formulas were used in Section 3b.
The linear dynamical system is described in the vector form as follows (Gardiner 2009):
$$d x & = - \mathbf A \, x d t + \mathbf B d W,$$
where x is an 𝑁 -dimensional real vector variable, time 𝑡 is continuous, and W represents 𝑁 Wiener processes that are independent of each other. We consider here a general case of 𝑁 ≥ 1, although the case of 𝑁 = 2 was used in Section 3. The constant real matrix A is assumed to have only eigenvalues with positive real parts, and B is a constant real matrix. Under these conditions, x has a stationary solution (Gardiner 2009). Integrating Eq. (B1) over a time step Δ 𝑡 , the following solution is obtained (Gardiner 2009):
$$\mathbf x ( t + \Delta t ) = e ^ { - \mathbf A \Delta t } \mathbf x ( t ) + \int _ { 0 } ^ { \Delta t } e ^ { - \mathbf A ( \Delta t - s ) } \mathbf B \, d \mathbf W ( s ).$$
The multivariate AR1 model is given as follow (Hamilton 1994):
$$y _ { t + \Delta t } = \mathbf C y _ { t } + \varepsilon _ { t },$$
where y is an 𝑁 -dimensional real vector variable and 𝜀 represents vector white noise. The absolute values of all eigenvalues of the real matrix C are assumed to be smaller than 1, which is the condition for stationarity (Hamilton 1994). Time 𝑡 is discrete and takes steps at a constant interval
## Δ 𝑡 . The covariance matrix V of the vector white noise is generally non-diagonal and is expressed as
$$\langle \varepsilon _ { t } \varepsilon _ { s } ^ { T } \rangle = \begin{cases} \mathbf v & ( t = s ), \\ 0 & ( \text{otherwise} ), \end{cases}$$
where ⟨·⟩ represents the statistical average over noise.
We obtain the condition for the mean values of x ( 𝑡 + Δ 𝑡 ) and y 𝑡 + Δ 𝑡 being equal:
$$\mathbf C = e ^ { - \mathbf A \Delta t },$$
where x ( 𝑡 ) = y 𝑡 is assumed. We also obtain the condition for the covariances of x ( 𝑡 + Δ 𝑡 ) and y 𝑡 + Δ 𝑡 being equal:
$$\mathbf V = \int _ { 0 } ^ { \Delta t } d s \, e ^ { - \mathbf A ( \Delta t - s ) } \mathbf B \mathbf B ^ { T } e ^ { - \mathbf A ^ { T } ( \Delta t - s ) }.$$
Under stationarity, Eqs. (B5) and (B6) become independent of 𝑡 .
The regression analysis with the AR1 model determines the matrices C and V , where the matrix V is estimated from the residuals of regression. Using Eqs. (B5) and (B6), A and B are then obtained. This method requires that the AR1 model and the dynamical system share the same statistical properties over the time interval Δ 𝑡 . Since the linear SDE [Eq. (B1)] describes a Gaussian process, its parameters are uniquely determined from the mean and covariance. Table 1 shows the coefficients of the dynamical system [Eqs. (16) and (17)], which were obtained by applying Eqs. (B5) and (B6) to the regression result with AR1.
## b. Theoretical expressions of lag correlation coefficients
We show here the theoretical expressions of lag correlation coefficients used in Sections 3d and 4b. The dynamical system [Eqs. (16) and (17)] describes a Gaussian process, so the statistical properties of the steady state are completely determined by the lag covariance matrix (Gardiner 2009). By normalizing the lag covariance, we obtain the lag correlation coefficient, which is an important indicator for the synchronization between the Gulf Stream and the Kuroshio Current (Kohyama et al. 2021).
We first show the instantaneous covariance matrix:
$$\mathfrak { z } = \begin{pmatrix} \Sigma _ { G G } & \Sigma _ { G K } \\ \Sigma _ { K G } & \Sigma _ { K K } \end{pmatrix} = \begin{pmatrix} \langle T _ { G } T _ { G } \rangle & \langle T _ { G } T _ { K } \rangle \\ \langle T _ { K } T _ { G } \rangle & \langle T _ { K } T _ { K } \rangle \end{pmatrix},$$
«
‹
«
‹
where the off-diagonal components are equal, Σ 𝐺𝐾 = Σ 𝐾𝐺 . Each component is given as follows:
$$\Sigma _ { G G } = \frac { ( r _ { K } ^ { 2 } + r _ { G } r _ { K } - c _ { G \leftarrow K } c _ { K \leftarrow G } ) D _ { G } + c _ { G \leftarrow K } ^ { 2 } D _ { K } } { ( r _ { G } + r _ { K } ) ( r _ { G } r _ { K } - c _ { G \leftarrow K } c _ { K \leftarrow G } ) },$$
$$\Sigma _ { K K } = \frac { ( r _ { G } ^ { 2 } + r _ { G } r _ { K } - c _ { G \leftarrow K } c _ { K \leftarrow G } ) D _ { K } + c _ { K \leftarrow G } ^ { 2 } D _ { G } } { ( r _ { G } + r _ { K } ) ( r _ { G } r _ { K } - c _ { G \leftarrow K } c _ { K \leftarrow G } ) },$$
$$\Sigma _ { G K } = \Sigma _ { K G } = \frac { \lambda \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \\ ( r _ { G } + r _ { K } ) ( r _ { G } r _ { K } - c _ { G \leftarrow K } c _ { K \leftarrow G } ) } { ( r _ { G } r _ { K } - c _ { G \leftarrow K } c _ { K \leftarrow G } ) }.$$
Details of the derivation for the instantaneous covariance can be found in Gardiner (2009), directly leading to Eqs. (B8)-(B10).
Using the instantaneous covariance Σ , the lag covariance matrix is given as follows (Gardiner 2009):
$$\langle T _ { i } ( t _ { 1 } ) T _ { j } ( t _ { 2 } ) \rangle = \begin{cases} \left ( e ^ { - \mathbf A ( t _ { 1 } - t _ { 2 } ) } \mathbf S \right ) _ { i j } & ( t _ { 1 } \geq t _ { 2 } ), \\ \left ( \mathbf S e ^ { - \mathbf A ^ { T } ( t _ { 2 } - t _ { 1 } ) } \right ) _ { i j } & ( t _ { 1 } < t _ { 2 } ), \end{cases}$$
where where Δ 𝑡 represents the lag.
$$\mathbf A = \begin{pmatrix} r _ { G } & - c _ { G \leftarrow K } \\ - c _ { K \leftarrow G } & r _ { K } \end{pmatrix}.$$
«
‹
The indices 𝐺 and 𝐾 are subscripts for the Gulf Stream and the Kuroshio Current, respectively. In Section 3d, Fig. 4 shows the lag correlation coefficients computed by normalizing the lag covariances with the instantaneous variances:
$$\rho ( \Delta t ) = \frac { ( e ^ { - \mathbf A \Delta t } \mathbf \Sigma ) _ { G K } } { \sqrt { \Sigma _ { G G } \Sigma _ { K K } } } \quad ( \Delta t \geq 0 ),$$
$$\rho ( \Delta t ) = \frac { \stackrel { \dots, - \infty \infty - \infty } { \left ( \Sigma e ^ { - \mathbf A ^ { T } | \Delta t | } \right ) } _ { G K } } { \sqrt { \Sigma _ { G G } \Sigma _ { K K } } } \quad ( \Delta t < 0 ),$$
## c. Theoretical expressions of information thermodynamic quantities
This section derives the expressions for information thermodynamic quantities, such as / 𝜎𝐺 , used in Section 4. In other words, the equations shown below are the specific forms of the theoretical equations in Appendix A applied to the dynamical system, Eqs. (16) and (17). Details of the derivation are discussed in Loos and Klapp (2020).
As a preparation, we first examine the expressions for the variances and covariances. In the steady state, the probability distribution does not change in time, so the following formulas hold:
$$\frac { 1 } { 2 } \frac { d } { d t } \langle T _ { G } T _ { G } \rangle = \left \langle T _ { G } \circ \frac { d T _ { G } } { d t } \right \rangle = 0,$$
$$\frac { 1 } { 2 } \frac { \mathrm d } { \mathrm d t } \langle T _ { K } T _ { K } \rangle = \left \langle T _ { K } \circ \frac { \mathrm d T _ { K } } { \mathrm d t } \right \rangle = 0,$$
$$\frac { \mathrm d } { \mathrm d t } \langle T _ { G } T _ { K } \rangle = \overset { \cdot } { \left \langle } T _ { G } \circ \frac { \mathrm d T _ { K } } { \mathrm d t } \right \rangle + \left \langle T _ { K } \circ \frac { \mathrm d T _ { G } } { \mathrm d t } \right \rangle = 0.$$
The temporal derivatives d 𝑇𝐺 / d 𝑡 or d 𝑇𝐾 / d 𝑡 include white Gaussian noise 𝜉 𝐺 or 𝜉 𝐾 , respectively. Thus, the Stratonovich product ◦ needs to be used (Appendix A). The symbol ◦ is omitted in Eqs. (24)-(28), (31), and (32) because the Stratonovich product is not explained in Section 4. By substituting the governing equations (16) and (17), each term in Eq. (B17) is given by
$$\left \langle T _ { G } \circ \frac { d T _ { K } } { \mathrm d t } \right \rangle = - r _ { K } \langle T _ { K } T _ { G } \rangle + c _ { K \leftarrow G } \langle T _ { G } T _ { G } \rangle,$$
$$\left \langle T _ { K } \circ \frac { d T _ { G } } { \mathrm d t } \right \rangle = - r _ { G } \langle T _ { G } T _ { K } \rangle + c _ { G \leftarrow K } \langle T _ { K } T _ { K } \rangle,$$
where the variances and covariances on the right-hand sides are given by Eqs. (B8)-(B10).
We next provide the expressions for the entropy production rates. From Eqs. (16), (17), (A30), and (A34), the following equations are derived for the steady state:
$$\dot { \sigma } _ { G } = \frac { \dot { Q } _ { G } } { D _ { G } } = - \frac { r _ { G } } { D _ { G } } \left \langle T _ { G } \circ \frac { d T _ { G } } { d t } \right \rangle + \frac { c _ { G } \leftarrow K } { D _ { G } } \left \langle T _ { K } \circ \frac { d T _ { G } } { d t } \right \rangle,$$
$$= \frac { c _ { G \leftarrow K } } { D _ { G } } \left \langle T _ { K } \circ \frac { d T _ { G } } { d t } \right \rangle,$$
$$\dot { \sigma } _ { K } = \frac { \dot { Q } _ { K } } { D _ { K } } = - \frac { \lambda } { D _ { K } } \Big < \binom { \cdot } { T _ { K } } \circ \frac { d T _ { K } } { d t } \Big > + \frac { c _ { K \leftarrow G } } { D _ { K } } \Big < T _ { G } \circ \frac { d T _ { K } } { d t } \Big >,$$
$$= \frac { c _ { K \leftarrow G } } { D _ { K } } \left \langle T _ { G } \circ \frac { \mathrm d T _ { K } } { \mathrm d t } \right \rangle,$$
where Eqs. (B15) and (B16) are substituted. Equations (B21) and (B23) are the same as Eqs. (24) and (25), respectively. Equation (29) is obtained using Eqs. (B17), (B21), and (B23).
Theexpressions for the information flows are easily derived in the steady state. Using the property that the probability distribution does not change in time, the time derivative of the Shannon entropy is zero. Thus, from Eq. (A13), the following holds in general:
$$i _ { i \leftarrow } = - \int \mathfrak { d } \mathbf x \, \frac { \partial J _ { i } } { \partial x _ { i } } \ln p _ { \text{tot} },$$
$$& = \int d { \mathbf x } \, J _ { i } \frac { \partial \ln p _ { \text{tot} } } { \partial x _ { i } } + \int \left ( \prod _ { j = 1, j \neq i } ^ { N } d { \mathbf x } _ { j } \right ) \underbrace { [ J _ { i } p _ { \text{tot} } ] _ { x _ { i } = - \infty } ^ { x _ { i } = \infty } } _ { = 0 },$$
$$= \left \langle \frac { \partial \ln p _ { \text{tot} } } { \partial x _ { i } } \circ \frac { d x _ { i } } { d t } \right \rangle,$$
where the boundary conditions and Eq. (A24) are used here. We only need to evaluate the derivatives of ln 𝑝 tot in Eq. (B26). For a linear SDE, the stationary distribution is a Gaussian (Gardiner 2009), and the derivative of its logarithm can be expressed using the variances and covariances. The information flows are then derived as
$$i _ { G \leftarrow K } = - ( \mathbf S ^ { - 1 } ) _ { K G } \left \langle T _ { K } \circ \frac { d T _ { G } } { d t } \right \rangle,$$
$$i _ { K \leftarrow G } = - ( \mathbf S ^ { - 1 } ) _ { G K } \overset {. } { \left < T _ { G } \circ \frac { d T _ { K } } { d t } \right > },$$
where Eqs. (B15) and (B16) are substituted, and the inverse of the covariance matrix Σ is denoted as Σ -1 . The off-diagonal components of Σ -1 are ( Σ -1 ) 𝐾𝐺 and ( Σ -1 ) 𝐺𝐾 , which are equal because Σ is symmetric. Using the specific expression of this off-diagonal component, we obtain Eqs. (26) and (27).
The information flows and entropy production rates become zero when 𝑐 𝐺 ← 𝐾 𝐷 𝐾 = 𝑐 𝐾 ← 𝐺 𝐷 𝐺 (Loos and Klapp 2020). This fact can be directly verified by substituting Eqs. (B8)-(B10), (B18), and (B19) into Eqs. (24)-(27). A simpler method to show this is through the application of the second law of information thermodynamics (see Appendix D). In the case of 𝑐 𝐺 ← 𝐾 𝐷 𝐾 = 𝑐 𝐾 ← 𝐺 𝐷 𝐺 , the two subsystems, namely the Gulf Stream and the Kuroshio Current, become symmetric. Mathematically, the detailed balance is satisfied and the probability flux J is zero (Loos and Klapp 2020).
## APPENDIX C
## Histograms of estimated quantities by the moving block bootstrap method
We quantified the uncertainty of the estimated coefficients using the moving block bootstrap method (Mudelsee 2014) in Section 3b, where the number of resampled time series was set to 2000. We discuss here the histograms of the entropy production rates and information flows obtained from the coefficients estimated by the bootstrap method.
Figure C1 shows the histograms of all estimated quantities, including the coefficients of the dynamical system, where the number of samples in each histogram is 2000. The 95% confidence intervals in Table 1 were obtained from these histograms. We focus on the entropy production rates and information flows, which are not listed in Table 1. The conservation of information flows, / 𝐼 𝐺 ← 𝐾 + / 𝐼 𝐾 ← 𝐺 = 0 [Eq. (23)], always holds. That is, for each resampled time series, / 𝐼 𝐾 ← 𝐺 = - / 𝐼 𝐺 ← 𝐾 . The histograms suggest that / 𝐼 𝐺 ← 𝐾 < 0 and / 𝐼 𝐾 ← 𝐺 > 0 for the OISST data, whereas these information flows take both signs for the GFDL-CM4C192 data. These results are also found in Figs. 5b, 5e, 6b, and 6e.
Wenext discuss the entropy production rates. Equation (29) always holds. Thus, when 𝑐 𝐺 ← 𝐾 > 0 and 𝑐 𝐾 ← 𝐺 > 0, / 𝜎𝐾 and / 𝜎𝐺 have opposite signs to each other. For the GFDL-CM4C192 data, this opposite-sign relationship was confirmed in 1996 out of 2000 samples. On the other hand, for the OISST data, this relationship was confirmed in 1413 samples. The other 587 samples are in the
Fig. C1. Histograms of all estimated quantities obtained from the moving block bootstrap method with 2000 resampled time series for the OISST and GFDL-CM4C192 data. The quantities include all coefficients of the dynamical system, the entropy production rates, and the information flows. The vertical lines are at zero.
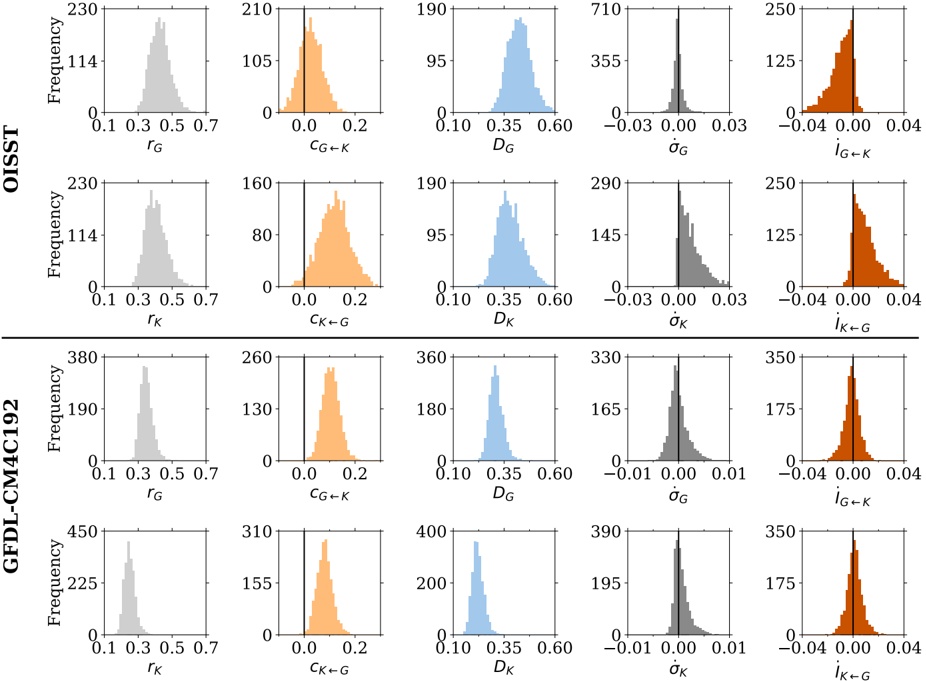
region where 𝑐 𝐺 ← 𝐾 < 0 and 𝑐 𝐾 ← 𝐺 > 0. In this region, both / 𝜎𝐺 and / 𝜎𝐾 are positive and have the same signs. This result is also found in Fig. 5, where the error bars cross the lines of 𝑐 𝐺 ← 𝐾 = 0.
In the region 𝑐 𝐺 ← 𝐾 < 0, the interpretation of Maxwell's demon systems is not possible because of the same signs of / 𝜎𝐺 and / 𝜎𝐾 , but an interesting phenomenon still occurs in terms of information thermodynamics, which is called feedback cooling (Horowitz and Sandberg 2014; Loos and Klapp 2020). For the interpretation of Maxwell's demon systems, the signs of the entropy production rates need to be opposite to each other (Sections 2c and 2d). As for the Kuroshio Current, the entropy production rate and information flow are positive, as in the case of Maxwell's demon. Thus, even in the scenario of feedback cooling, there is no change in the interpretation for the Kuroshio Current.
The difference arises in the Gulf Stream, which has a positive entropy production rate ( / 𝜎𝐺 > 0). The Gulf Stream still exhibits a negative information flow, which indicates that the Gulf Stream is interpreted as being controlled by the Kuroshio Current, like in Maxwell's demon. However, this control is done by negative feedback and reduces the effect of noise (Horowitz and Sandberg 2014; Loos and Klapp 2020). As a result, the SST magnitude of the Gulf Stream is reduced (Fig. 5c). This reduction is considered as being achieved by discarding heat to the environment, leading to the positive entropy production rate ( / 𝜎𝐺 > 0). Even in this parameter region, the correlation between 𝑇𝐺 and 𝑇𝐾 is positive (Fig. 8), suggesting that the BCS occurs. However, the interpretation is slightly different. The synchronization is achieved by the Kuroshio Current, which reduces the SST fluctuations of the Gulf Stream caused by atmospheric and oceanic noise.
## APPENDIX D
## Constraint based on the second law of information thermodynamics
The analysis in Section 4 is based only on the signs of entropy production rates and information flows, without explicitly using the inequalities between them (i.e., the second law of information thermodynamics). Here, we derive an inequality for the instantaneous correlation coefficient using the second law of information thermodynamics, Eqs. (21) and (22). The derived inequality is a constraint that the dynamical system [Eqs. (16) and (17)] must satisfy.
The second law of information thermodynamics is expressed as the following two inequalities:
$$\frac { c _ { G \leftarrow K } } { D _ { G } } \left \langle T _ { K } \circ \frac { d T _ { G } } { d t } \right \rangle \geq \frac { \Sigma _ { G K } } { | \mathbf z | } \left \langle T _ { K } \circ \frac { d T _ { G } } { d t } \right \rangle,$$
$$\frac { c _ { K \leftarrow G } } { D _ { K } } \left \langle T _ { G } \circ \frac { d T _ { K } } { d t } \right \rangle \geq \frac { \overset {. } { \Sigma } _ { G K } } { | \mathbf z | } \left \langle T _ { G } \circ \frac { d T _ { K } } { d t } \right \rangle.$$
Equation (D1) is obtained by substituting Eqs. (24) and (26) into (21); likewise, Eq. (D2) is obtained by substituting Eqs. (25) and (27) into (22). From the steady-state condition [Eq. (B17)], either ⟨ 𝑇𝐾 ◦ d 𝑇𝐺 / d 𝑡 ⟩ or ⟨ 𝑇𝐺 ◦ d 𝑇𝐾 / d 𝑡 ⟩ is positive, while the other is negative. Here, we assume ⟨ 𝑇𝐾 ◦ d 𝑇𝐺 / d 𝑡 ⟩ < 0. The above two inequalities are then combined into one:
$$\frac { c _ { G \leftarrow K } } { D _ { G } } \leq \frac { \Sigma _ { G K } } { \Sigma _ { K K } \Sigma _ { G G } - ( \Sigma _ { G K } ) ^ { 2 } } \leq \frac { c _ { K \leftarrow G } } { D _ { K } },$$
where we use | Σ | = Σ 𝐾𝐾 Σ 𝐺𝐺 -( Σ 𝐺𝐾 ) 2 . Including the other case where ⟨ 𝑇𝐾 ◦ d 𝑇𝐺 / d 𝑡 ⟩ > 0, the final inequality becomes
$$\min \left \{ \frac { c _ { K \leftarrow G } } { D _ { K } }, \frac { c _ { G \leftarrow K } } { D _ { G } } \right \} \leq \frac { \Sigma _ { G K } } { \Sigma _ { K K } \Sigma _ { G G } - ( \Sigma _ { G K } ) ^ { 2 } } \leq \max \left \{ \frac { c _ { K \leftarrow G } } { D _ { K } }, \frac { c _ { G \leftarrow K } } { D _ { G } } \right \}.$$
When 𝑐 𝐾 ← / 𝐺 𝐷𝐾 and 𝑐 𝐺 ← / 𝐾 𝐷𝐺 are equal, it corresponds to the diagonal lines in Figs 5, 6, and 8. Crossing these lines reverses the magnitude relation between 𝑐 𝐾 ← / 𝐺 𝐷𝐾 and 𝑐 𝐺 ← / 𝐾 𝐷𝐺 . The signs of ⟨ 𝑇𝐾 ◦ d 𝑇𝐺 / d 𝑡 ⟩ and ⟨ 𝑇𝐺 ◦ d 𝑇𝐾 / d 𝑡 ⟩ are also reversed across these lines.
The obtained inequality is transformed into an inequality for the instantaneous correlation coefficient. We define the instantaneous correlation coefficient as follows:
$$\rho _ { 0 } \coloneqq \frac { \Sigma _ { G K } } { \sqrt { \Sigma _ { G G } \Sigma _ { K K } } }.$$
Assuming the time series are standardized, the variances Σ 𝐺𝐺 and Σ 𝐾𝐾 are equal to 1. The following inequality is then obtained:
$$\min \left \{ \frac { c _ { K \leftarrow G } } { D _ { K } }, \frac { c _ { G \leftarrow K } } { D _ { G } } \right \} \leq \frac { \rho _ { 0 } } { 1 - ( \rho _ { 0 } ) ^ { 2 } } \leq \max \left \{ \frac { c _ { K \leftarrow G } } { D _ { K } }, \frac { c _ { G \leftarrow K } } { D _ { G } } \right \},$$
where the function 𝑓 ( 𝑥 ) = 𝑥 /( 1 -𝑥 2 ) is monotonically increasing in the interval (-1 1 , that is, , ) 𝑓 ( 𝑥 ) is invertible. The inequality (D6) means that 𝑓 ( 𝜌 0 ) is bounded by 𝑐 𝐾 ← / 𝐺 𝐷𝐾 and 𝑐 𝐺 ← / 𝐾 𝐷𝐺 , suggesting that 𝜌 0 increases as the interaction coefficients become larger or the noise amplitudes become smaller.
The inequality (D6) is a condition that the correlation coefficient 𝜌 0 must satisfy; thus, this inequality can be regarded as a constraint on the dynamical system. It is possible to obtain the explicit form of 𝜌 0 . However, this explicit form requires the use of the complex formulas (B8), (B9), and (B10). The second law of information thermodynamics provides the inequality (D6) without relying on these complex formulas. In other words, the inequality implies the dependence of 𝜌 0 on the parameters, such as 𝑐 𝐺 ← 𝐾 and 𝐷𝐺 , without knowing the explicit form of 𝜌 0 .
## References
Allahverdyan, A. E., D. Janzing, and G. Mahler, 2009: Thermodynamic efficiency of information and heat flow. Journal of Statistical Mechanics: Theory and Experiment , 2009 (09) , P09011, https://doi.org/10.1088/1742-5468/2009/09/P09011, URL https://dx.doi.org/10.1088/ 1742-5468/2009/09/P09011.
Benzi, R., 2010: Stochastic resonance: from climate to biology. Nonlinear Processes in Geophysics , 17 (5) , 431-441, https://doi.org/10.5194/npg-17-431-2010, URL https://npg. copernicus.org/articles/17/431/2010/.
Bouchet, F., and A. Venaille, 2012: Statistical mechanics of two-dimensional and geophysical flows. Physics Reports , 515 (5) , 227-295, https://doi.org/https://doi.org/10.1016/j.physrep. 2012.02.001, URL https://www.sciencedirect.com/science/article/pii/S0370157312000518, statistical mechanics of two-dimensional and geophysical flows.
Brockwell, P. J., and R. A. Davis, 1991: Time series: theory and methods . Springer science & business media.
Campa, A., T. Dauxois, D. Fanelli, and S. Ruffo, 2014: Physics of Long-Range Interacting Systems . Oxford University Press.
Cover, T. M., and J. A. Thomas, 2005: Elements of Information Theory . Second edition ed., John Wiley & Sons, Ltd.
Dijkstra, H. A., 2013: Nonlinear climate dynamics . Cambridge University Press.
Eyring, V., S. Bony, G. A. Meehl, C. A. Senior, B. Stevens, R. J. Stouffer, and K. E. Taylor, 2016: Overview of the coupled model intercomparison project phase 6 (cmip6) experimental design and organization. Geoscientific Model Development , 9 (5) , 1937-1958, https://doi.org/ 10.5194/gmd-9-1937-2016, URL https://gmd.copernicus.org/articles/9/1937/2016/.
Franzke, C. L. E., T. J. O'Kane, J. Berner, P. D. Williams, and V. Lucarini, 2015: Stochastic climate theory and modeling. WIREs Climate Change , 6 (1) , 63-78, https://doi.org/https:// doi.org/10.1002/wcc.318, URL https://wires.onlinelibrary.wiley.com/doi/abs/10.1002/wcc.318, https://wires.onlinelibrary.wiley.com/doi/pdf/10.1002/wcc.318.
Gallego, B., and P. Cessi, 2000: Exchange of heat and momentum between the atmosphere and the ocean: A minimal model of decadal oscillations. Climate Dynamics , 16 , 479-489.
Gallego, B., and P. Cessi, 2001: Decadal variability of two oceans and an atmosphere. Journal of Climate , 14 (13) , 2815 -2832, https://doi.org/10.1175/1520-0442(2001)014 2815: ⟨ DVOTOA 2.0.CO;2, ⟩ URL https://journals.ametsoc.org/view/journals/clim/14/13/1520-0442 2001 014 2815 dvotoa 2.0.co 2.xml.
Gardiner, C., 2009: Stochastic Methods . Springer Series in Synergetics, Springer Berlin, Heidelberg.
Hamilton, J. D., 1994: Time series analysis . Princeton university press.
Hasselmann, K., 1976: Stochastic climate models part i. theory. Tellus , 28 (6) , 473-485, https://doi.org/https://doi.org/10.1111/j.2153-3490.1976.tb00696.x, URL https://onlinelibrary. wiley.com/doi/abs/10.1111/j.2153-3490.1976.tb00696.x, https://onlinelibrary.wiley.com/doi/ pdf/10.1111/j.2153-3490.1976.tb00696.x.
Held, I. M., and Coauthors, 2019: Structure and performance of gfdl's cm4.0 climate model. Journal of Advances in Modeling Earth Systems , 11 (11) , 3691-3727, https://doi.org/https://doi. org/10.1029/2019MS001829, URL https://agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/ 2019MS001829, https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/2019MS001829.
Hogg, A. M. C., W. K. Dewar, P. D. Killworth, and J. R. Blundell, 2006: Decadal variability of the midlatitude climate system driven by the ocean circulation. Journal of Climate , 19 (7) , 1149 - 1166, https://doi.org/10.1175/JCLI3651.1, URL https://journals.ametsoc.org/view/journals/ clim/19/7/jcli3651.1.xml.
Horowitz, J. M., and M. Esposito, 2014: Thermodynamics with continuous information flow. Phys. Rev. X , 4 , 031 015, https://doi.org/10.1103/PhysRevX.4.031015, URL https://link.aps.org/doi/ 10.1103/PhysRevX.4.031015.
Horowitz, J. M., and H. Sandberg, 2014: Second-law-like inequalities with information and their interpretations. New Journal of Physics , 16 (12) , 125 007, https://doi.org/10.1088/1367-2630/ 16/12/125007, URL https://dx.doi.org/10.1088/1367-2630/16/12/125007.
Hoskins, B. J., and P. J. Valdes, 1990: On the existence of storm-tracks. Journal of Atmospheric Sciences , 47 (15) , 1854 - 1864, https://doi.org/10.1175/1520-0469(1990)047 1854:OTEOST 2.0. ⟨ ⟩ CO;2, URL https://journals.ametsoc.org/view/journals/atsc/47/15/1520-0469 1990 047 1854 oteost 2 0 co 2.xml.
Hou, C. K. J., and K. Behdinan, 2022: Dimensionality reduction in surrogate modeling: A review of combined methods. Data Science and Engineering , 7 (4) , 402-427.
Ito, S., 2016a: Backward transfer entropy: Informational measure for detecting hidden markov models and its interpretations in thermodynamics, gambling and causality. Scientific reports , 6 (1) , 36 831.
Ito, S., 2016b: Information thermodynamics on causal networks and its application to biochemical signal transduction . Springer.
Ito, S., and T. Sagawa, 2015: Maxwell's demon in biochemical signal transduction with feedback loop. Nature communications , 6 (1) , 1-6.
Kelly, K. A., and S. Dong, 2004: The relationship of western boundary current heat transport and storage to midlatitude ocean-atmosphere interaction. Earth's Climate , American Geophysical Union (AGU), 347-363, https://doi.org/https://doi.org/10.1029/ 147GM19, URL https://agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/147GM19, https:// agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/147GM19.
Kelly, K. A., R. J. Small, R. M. Samelson, B. Qiu, T. M. Joyce, Y.-O. Kwon, and M. F. Cronin, 2010: Western boundary currents and frontal air-sea interaction: Gulf stream and kuroshio extension. Journal of Climate , 23 (21) , 5644 - 5667, https://doi.org/10.1175/2010JCLI3346.1, URL https://journals.ametsoc.org/view/journals/clim/23/21/2010jcli3346.1.xml.
Kohyama, T., Y. Yamagami, H. Miura, S. Kido, H. Tatebe, and M. Watanabe, 2021: The gulf stream and kuroshio current are synchronized. Science , 374 (6565) , 341-346, https://doi.org/10. 1126/science.abh3295, URL https://www.science.org/doi/abs/10.1126/science.abh3295, https: //www.science.org/doi/pdf/10.1126/science.abh3295.
Koski, J. V., A. Kutvonen, I. M. Khaymovich, T. Ala-Nissila, and J. P. Pekola, 2015: On-chip maxwell's demon as an information-powered refrigerator. Phys. Rev. Lett. , 115 ,
260 602, https://doi.org/10.1103/PhysRevLett.115.260602, URL https://link.aps.org/doi/10. 1103/PhysRevLett.115.260602.
Koski, J. V., V. F. Maisi, J. P. Pekola, and D. V. Averin, 2014: Experimental realization of a szilard engine with a single electron. Proceedings of the National Academy of Sciences , 111 (38) , 13 786-13 789, https://doi.org/10.1073/pnas.1406966111, URL https://www.pnas.org/doi/abs/ 10.1073/pnas.1406966111, https://www.pnas.org/doi/pdf/10.1073/pnas.1406966111.
Kuwano-Yoshida, A., and S. Minobe, 2017: Storm-track response to sst fronts in the northwestern pacific region in an agcm. Journal of Climate , 30 (3) , 1081 - 1102, https://doi.org/10.1175/ JCLI-D-16-0331.1, URL https://journals.ametsoc.org/view/journals/clim/30/3/jcli-d-16-0331. 1.xml.
Kwon, Y.-O., M. A. Alexander, N. A. Bond, C. Frankignoul, H. Nakamura, B. Qiu, and L. A. Thompson, 2010: Role of the gulf stream and kuroshio-oyashio systems in largescale atmosphere-ocean interaction: A review. Journal of Climate , 23 (12) , 3249 - 3281, https://doi.org/10.1175/2010JCLI3343.1, URL https://journals.ametsoc.org/view/journals/clim/ 23/12/2010jcli3343.1.xml.
Latif, M., and T. P. Barnett, 1994: Causes of decadal climate variability over the north pacific and north america. Science , 266 (5185) , 634-637, https://doi.org/10.1126/science.266.5185.634, URL https://www.science.org/doi/abs/10.1126/science.266.5185.634, https://www.science.org/ doi/pdf/10.1126/science.266.5185.634.
Loos, S. A. M., and S. H. L. Klapp, 2020: Irreversibility, heat and information flows induced by non-reciprocal interactions. New Journal of Physics , 22 (12) , 123 051, https://doi.org/10.1088/ 1367-2630/abcc1e, URL https://dx.doi.org/10.1088/1367-2630/abcc1e.
Ma, X., and Coauthors, 2016: Western boundary currents regulated by interaction between ocean eddies and the atmosphere. Nature , 535 (7613) , 533-537.
Majda, A., and X. Wang, 2006: Nonlinear Dynamics and Statistical Theories for Basic Geophysical Flows . Cambridge University Press.
Michael Sherman, F. M. S. J., and F. M. Speed, 1998: Analysis of tidal data via the blockwise bootstrap. Journal of Applied Statistics , 25 (3) , 333-340, https://doi.org/10.1080/02664769823061, URL https://doi.org/10.1080/02664769823061, https://doi.org/10.1080/02664769823061.
Minobe, S., A. Kuwano-Yoshida, N. Komori, S.-P. Xie, and R. J. Small, 2008: Influence of the gulf stream on the troposphere. Nature , 452 (7184) , 206-209.
Mudelsee, M., 2014: Climate Time Series Analysis . Springer Cham.
Ogawa, F., H. Nakamura, K. Nishii, T. Miyasaka, and A. Kuwano-Yoshida, 2012: Dependence of the climatological axial latitudes of the tropospheric westerlies and storm tracks on the latitude of an extratropical oceanic front. Geophysical Research Letters , 39 (5) , https://doi.org/https://doi. org/10.1029/2011GL049922, URL https://agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/ 2011GL049922, https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/2011GL049922.
Omrani, N.-E., F. Ogawa, H. Nakamura, N. Keenlyside, S. W. Lubis, and K. Matthes, 2019: Key role of the ocean western boundary currents in shaping the northern hemisphere climate. Scientific reports , 9 (1) , 3014.
Parrondo, J. M., J. M. Horowitz, and T. Sagawa, 2015: Thermodynamics of information. Nature physics , 11 (2) , 131-139.
Peliti, L., and S. Pigolotti, 2021: Stochastic Thermodynamics: An Introduction . Princeton University Press.
Qiu, B., and S. Chen, 2005: Variability of the kuroshio extension jet, recirculation gyre, and mesoscale eddies on decadal time scales. Journal of Physical Oceanography , 35 (11) , 2090 - 2103, https://doi.org/10.1175/JPO2807.1, URL https://journals.ametsoc.org/view/journals/ phoc/35/11/jpo2807.1.xml.
Qiu, B., S. Chen, N. Schneider, and B. Taguchi, 2014: A coupled decadal prediction of the dynamic state of the kuroshio extension system. Journal of Climate , 27 (4) , 1751 - 1764, https://doi.org/10.1175/JCLI-D-13-00318.1, URL https://journals.ametsoc.org/view/journals/ clim/27/4/jcli-d-13-00318.1.xml.
Reddy, G. T., M. P. K. Reddy, K. Lakshmanna, R. Kaluri, D. S. Rajput, G. Srivastava, and T. Baker, 2020: Analysis of dimensionality reduction techniques on big data. IEEE Access , 8 , 54 776-54 788, https://doi.org/10.1109/ACCESS.2020.2980942.
Reynolds, R. W., T. M. Smith, C. Liu, D. B. Chelton, K. S. Casey, and M. G. Schlax, 2007: Daily high-resolution-blended analyses for sea surface temperature. Journal of Climate , 20 (22) , 5473 - 5496, https://doi.org/10.1175/2007JCLI1824.1, URL https://journals.ametsoc.org/view/ journals/clim/20/22/2007jcli1824.1.xml.
Sagawa, T., 2019: Second law, entropy production, and reversibility in thermodynamics of information. Energy Limits in Computation: A Review of Landauer's Principle, Theory and Experiments , Springer International Publishing, Cham, 101-139, https://doi.org/ 10.1007/978-3-319-93458-7 3, URL https://doi.org/10.1007/978-3-319-93458-7 3.
Sagawa, T., and M. Ueda, 2009: Minimal energy cost for thermodynamic information processing: Measurement and information erasure. Phys. Rev. Lett. , 102 , 250 602, https://doi.org/10.1103/ PhysRevLett.102.250602, URL https://link.aps.org/doi/10.1103/PhysRevLett.102.250602, erratum: Phys. Rev. Lett. 106, 189901.
Sagawa, T., and M. Ueda, 2013a: Information thermodynamics: Maxwell's demon in nonequilibrium dynamics. Nonequilibrium Statistical Physics of Small Systems , John Wiley & Sons, Ltd, chap. 6, 181-211, https://doi.org/https://doi.org/10.1002/9783527658701.ch6, URL https:// onlinelibrary.wiley.com/doi/abs/10.1002/9783527658701.ch6, https://onlinelibrary.wiley.com/ doi/pdf/10.1002/9783527658701.ch6.
Sagawa, T., and M. Ueda, 2013b: Role of mutual information in entropy production under information exchanges. New Journal of Physics , 15 (12) , 125 012, https://doi.org/10.1088/1367-2630/ 15/12/125012, URL https://dx.doi.org/10.1088/1367-2630/15/12/125012.
Sanders, F., 1986: Explosive cyclogenesis in the west-central north atlantic ocean, 1981-84. part i: Composite structure and mean behavior. Monthly Weather Review , 114 (10) , 1781 - 1794, https://doi.org/10.1175/1520-0493(1986)114 1781:ECITWC 2.0.CO;2, ⟨ ⟩ URL https://journals. ametsoc.org/view/journals/mwre/114/10/1520-0493 1986 114 1781 ecitwc 2 0 co 2.xml.
Seifert, U., 2005: Entropy production along a stochastic trajectory and an integral fluctuation theorem. Phys. Rev. Lett. , 95 , 040 602, https://doi.org/10.1103/PhysRevLett.95.040602, URL https://link.aps.org/doi/10.1103/PhysRevLett.95.040602.
Seifert, U., 2012: Stochastic thermodynamics, fluctuation theorems and molecular machines. Reports on Progress in Physics , 75 (12) , 126 001, https://doi.org/10.1088/0034-4885/75/12/ 126001, URL https://dx.doi.org/10.1088/0034-4885/75/12/126001.
Sekimoto, K., 2010: Stochastic Energetics . Lecture Notes in Physics, Springer Berlin, Heidelberg.
Shiraishi, N., 2023: An Introduction to Stochastic Thermodynamics: From Basic to Advanced , Vol. 212. Springer Nature.
Stommel, H., 1948: The westward intensification of wind-driven ocean currents. Eos, Transactions American Geophysical Union , 29 (2) , 202-206, https://doi.org/ https://doi.org/10.1029/TR029i002p00202, URL https://agupubs.onlinelibrary.wiley.com/ doi/abs/10.1029/TR029i002p00202, https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/ TR029i002p00202.
Strogatz, S. H., 2018: Nonlinear dynamics and chaos: with applications to physics, biology, chemistry, and engineering . Second edition ed., CRC press.
Toyabe, S., T. Sagawa, M. Ueda, E. Muneyuki, and M. Sano, 2010: Experimental demonstration of information-to-energy conversion and validation of the generalized jarzynski equality. Nature physics , 6 (12) , 988-992.
Venaille, A., and F. Bouchet, 2011: Oceanic rings and jets as statistical equilibrium states. Journal of Physical Oceanography , 41 (10) , 1860 - 1873, https://doi.org/10.1175/2011JPO4583.1, URL https://journals.ametsoc.org/view/journals/phoc/41/10/2011jpo4583.1.xml.
Yamagami, Y., H. Tatebe, T. Kohyama, S. Kido, and S. Okajima, 2024: Causality Between the Kuroshio and Gulf Stream SST Variability. Asia Oceania Geosciences Society (AOGS) 21st Annual Meeting , PyeongChang, Korea, Asia Oceania Geosci. Soc., AS35-A013. | null | [
"Yuki Yasuda",
"Tsubasa Kohyama"
] | 2024-08-02T09:21:35+00:00 | 2025-01-07T21:57:07+00:00 | [
"physics.ao-ph"
] | A Mechanism of Stochastic Synchronization in the Climate System: an Interpretation of the Boundary Current Synchronization as a Maxwell's Demon | This study has applied information thermodynamics to a bivariate linear
stochastic differential equation (SDE) that describes a synchronization
phenomenon of sea surface temperatures (SSTs) between the Gulf Stream and the
Kuroshio Current, which is referred to as the boundary current synchronization
(BCS). Information thermodynamics divides the entire system fluctuating with
stochastic noise into subsystems and describes the interactions between these
subsystems from the perspective of information transfer. The SDE coefficients
have been estimated through regression analysis using observational and
numerical simulation data. In the absence of stochastic noise, the solution of
the estimated SDE shows that the SSTs relax toward zero without oscillation.
The estimated SDE can be interpreted as a Maxwell's demon system, with the Gulf
Stream playing the role of the "Particle" and the Kuroshio Current playing the
role of the "Demon." The Gulf Stream forces the SST of the Kuroshio Current to
be in phase. By contrast, the Kuroshio Current maintains the phase by
interfering with the relaxation of the Gulf Stream SST. In the framework of
Maxwell's demon, the Gulf Stream is measured by the Kuroshio Current, whereas
the Kuroshio Current performs feedback control on the Gulf Stream. When the
Gulf Stream and the Kuroshio Current are coupled in an appropriate parameter
regime, synchronization is realized with atmospheric and oceanic fluctuations
as the driving source. This new mechanism, "stochastic synchronization,"
suggests that such fluctuations can be converted into directional variations in
a subsystem of the climate system through synchronization by utilizing
information (i.e., information-to-energy conversion). |
2408.01134v1 | ## The Impact of Program Reduction on Automated Program Repair
Linas Vidziunas Simula Research Laboratory Oslo, Norway [email protected]
David Binkley Loyola University Maryland Baltimore, MD, USA [email protected]
Leon Moonen Simula Research Laboratory & BI Norwegian Business School Oslo, Norway [email protected]
Abstract -Correcting bugs using modern Automated Program Repair (APR) can be both time-consuming and resourceexpensive. We describe a program repair approach that aims to improve the scalability of modern APR tools. The approach leverages program reduction in the form of program slicing to eliminate code irrelevant to fixing the bug, which improves the APR tool's overall performance. We investigate slicing's impact on all three phases of the repair process: fault localization, patch generation, and patch validation. Our empirical exploration finds that the proposed approach on average enhances the repair ability of the TBar APR tool, but we also discovered a few cases where it was less successful. Specifically, on examples from the widely used Defects4J dataset, we obtain a substantial reduction in median repair time, which falls from 80 minutes to just under 18 minutes. We conclude that program reduction can improve the performance of APR without degrading repair quality, but this improvement is not universal.
Index Terms -automated program repair, dynamic program slicing, fault localization, test-suite reduction, hybrid techniques.
## I. INTRODUCTION
Automated program repair (APR) is an active research area with growing tool support [1, 2]. However, APR struggles with scalability as it grows resource-intensive and time-consuming for larger programs. Of its three phases, fault localization, patch generation, and patch validation, this struggle is more pronounced in the first and third phases. For example, poor performance in the first phase can lead to poor overall performance because the actual faulty statement is found far down the list of suspicious statements [3, 4], leading to what has been termed the 'patch explosion' problem.
This paper aims to study the improvement possible using program reduction, specifically, that made possible through program slicing. Fixing a reduced program instead of the original program is expected to provide benefits to all three phases. For example, fault localization should be more focused when working with the reduced program. The impact on patch generation is less direct. The reduced program is, de facto, more cohesive, than the original program; thus, sampling potential patches from the reduced program should provide a higher probability of success. Finally, running the simpler reduced program should lower patch validation time. This is especially true because we introduce a test-suite reduction technique based on the reduced program. As others have noted, for test-based APR, the cost of patch validation depends

heavily on the size of the test suite, while at the same time, much of a test suite is irrelevant to fixing a given bug [2, 5].
To demonstrate the effectiveness of combining program reduction and APR we use TBar [6], a state-of-the-art templatebased APR tool, and select bugs from the widely studied Defects4J dataset [7]. We choose template-based APR because it is one of the most effective approaches for generating patches [3]. We use Defects4J to illustrate the effectiveness of our approach on several real applications and to facilitate comparison with previous work [7].
Significance and Impact: Empirical evidence [8-10] has shown that finding a valid patch often requires exploring a significant proportion of the patch space, which can grow quite expensive. We aim to show how a reduced program, such as that produced by program slicing, can effectively identify and eliminate code and tests that are irrelevant to the patching of a bug without adversely affecting the quality of the repair. Thus, in essence, we aim to improve program repair by reducing the size of the program being repaired. Two things are essential to this process. First, the reduced program must replicate the erroneous behavior of the bug being repaired, and, second, a patch for the reduced program must also be a patch for the original program. Satisfying these two requirements expands the set of programs to which modern APR tools can be applied. Contributions: This paper makes the following contributions:
- ⋆ We empirically investigate the impact of program reduction on the three phases of automated program repair: fault localization, patch generation, and patch validation.
- ⋆ We discuss a dynamic procedure for test-suite reduction that is based on program reduction and introduce a new metric NTE (Number of Tests Executed) to study the impact that program reduction has on patch validation.
- ⋆ We consider eight configurations that involve combinations of a reduced program, a reduced test suite, and a reduced suspicious-locations list.
- ⋆ Our results show a reduction in TBar's runtime without degrading its repair quality. On examples from the widely studied Defects4J dataset, we obtain substantial reductions that approach an order of magnitude.
- ⋆ To support open science, we make a replication package available via Zenodo. 1
1 https://doi.org/10.5281/zenodo.13074333
## II. MOTIVATING EXAMPLE
Consider the repair of Defects4J [7] bug Lang-10 using the TBar APR tool [6]. It takes TBar eight hours to find a plausible patch for this bug. During this time, it examines 1938 incorrect patches. The long processing time can be explained by the following observations. First, TBar spends significant time mutating suspicious statements that are not the actual faulty statement: fault location returns a ranked list of 261 suspicious statements, on which the faulty location has Rank 82. Second, the test suite for this bug includes two failing tests and 2196 passing tests, most of which are irrelevant to fixing the bug; thus, they can be omitted without adversely affecting the quality of the repair while saving considerable time. Applying our technique the faulty location improves to Rank 64. Furthermore, test-suite reduction reduces the test suite to 73 passing tests, greatly reducing the patch validation expense. As a result, the same patch is produced in approximately forty minutes, a 91% reduction in patch time!
## III. BACKGROUND
This section provides background on automated program repair (APR), the APR tool used (TBar), program slicing, and ORBS, the observation-based slicer used in the experiments.
APR needs a specification of correct program behavior to determine if a generated patch fixes the target bug. In the absence of a complete or formal specification, existing APR tools use the test suite as an oracle for determining the desired behavior. Thus, testing is the primary method used to ensure the correctness of a generated patch, causing the cost of patch validation to depend heavily on the size of the test suite. As a program evolves its test suite tends to grow in size, which increases the time and resources required.
APR commonly involves three-phases: (1) fault localization produces a ranked list of suspicious locations; (2) patch generation involves a range of program mutations; and (3) patch validation checks whether the mutated program passes the test suite of the program. In greater detail, APR's first phase employs automated fault localization to produce a ranked list of suspicious statements based on the bug being repaired. The significant expense in this first phase is the quality of the fault location. Because APR tools attempt to fix a bug by repeatedly applying a set of potential patches to each potentially buggy location in the ranked list, the sooner the actual location of the bug is considered, the better.
The second phase, patch generation, explores the latent patch space that is typically defined by the set of program mutation operators employed and the list of suspicious statements. This phase requires the most innovation from an APR tool. Typically, this phase makes use of the code itself to derive potential patches. This means that the more cohesive the code, the more likely a patch will be found in the code itself. As an example, consider an application that maintains inventory, orders, and taxes. Code taken from a reduced program that just computes the taxes is more likely to be relevant to fixing a tax-related bug.
The final step, patch validation, ensures the correct behavior of the repaired program. As mentioned previously, the test suite is typically used to ensure that the bug is fixed and that the patch does not introduce any unwanted behavior. In practice, most tests are irrelevant to the bug being repaired and thus a huge saving can be obtained by avoiding their repetitive execution. At the bare minimum, the test suite must include at least one failing test that exposes the bug. Passing this test implies the bug has been fixed. The existence of additional passing tests can constrain the repair when used as regression tests. 2 However, such tests provide diminishing returns, and as their number grows performance decreases without any improvement in patch quality. Our test-suite reduction process aims to omit tests that have no impact on patch quality and thus only affect efficiency.
Template-based APR, which utilizes predefined fix templates to fix specific bugs, is widely used in the APR literature, and known to be effective at generating correct patches [6, 10-20]. The TBar tool [6] used in this work combines fifteen commonly used fix templates from the APR literature, making it one of the most effective APR tools available and achieving a good repair rate on Defects4J. However, like most APR tools, TBar is highly sensitive to fault localization accuracy and to the size of the test suite [3].
The following description of Observation-Based Slicing (ORBS) is taken from existing work [21-23]. Readers familiar with ORBS need only skim this section as a reminder. The key requirement for constructing the reduced program is a sound program reduction technique. This enables the repair process to be conducted using the reduced program while being able to conclude that the repair is valid for the original program. The program reduction technique we study in this paper is a form of dynamic program slicing [24]. Informally, a slice is a subset of a program that preserves the behavior of the program for a specific slicing criterion [25]. While static slices [25] preserve this behavior for all possible inputs , dynamic slicing [24] does so only for a selected set of inputs.
The slicing technique used to produce the reduced program studied in our experiments is observation-based slicing (ORBS), which works by deleting statements and then observing the behavior at the slicing criterion. ORBS takes as input a program P , a slicing criterion identified by a program variable ν , a program location l , and a set of inputs I . The resulting slice preserves the values of ν at l for the inputs of I .
Operationally, ORBS observes behavior by instrumenting the program with a side-effect free line that tracks the value of variable ν immediately before line l . Then, starting with P , ORBS repeatedly forms candidate slices by deleting a sequence of one to δ lines from the current slice. The candidate is rejected if it fails to compile or produces different values for ν . Otherwise, the candidate becomes the current slice. ORBS systematically forms candidates until no more lines can be deleted.
2 Observe that passing tests are also needed to pinpoint suspicious statements in the initial fault localization step.
While there are more time-efficient dynamic slicers, ORBS is sound and very accurate. Its slices are nearly minimal [21]. Thus, our use of ORBS can be seen as paralleling APR studies that assume perfect fault localization [6, 26-30]. Faster dynamic slicers, such as JavaSlicer [31] and Slicer4J [32], and dynamic/static hybrid slicers such as QSES [33] compute less accurate slices, but can drop slicing time from days to a matter of minutes.
## IV. EXPERIMENTAL DESIGN
This section lays out the experimental design. It first introduces the bugs we consider and then the metrics we used in the analysis. We then describe the steps of the algorithm that we study and the execution environment used. Finally, we present the research questions used to evaluate our approach.
## A. Subject Bugs Studied
Defects4j is a collection of reproducible bugs widely used in software engineering research [7]. Our experiments employ Defects4J v2.0.1 [7], which has been used in prior APR experiments [6, 13]. We consider two of the Defects4j systems, Lang and Math , because each includes a large number of bugs. Lang provides a collection of utility methods that work with java.lang including basic numerical methods, concurrency support, as well as utility methods to help construct methods such as hashCode , equals , etc. Math provides common mathematical and statistical methods. The authors work to limit 'external' dependencies, which, among other things, makes it easier for us to experiment with their code.
Table I shows demographics for the 47 subject bugs studied. Each bug includes a Bug ID , BID, its size in non-comment, non-blank lines of code, SLoC , and the number of passing and failing tests. Program size is given for both the original production code (i.e., excluding the test code) and the slice along with the slice's size as a percent of the original code. Finally, in addition to the number of passing tests, the number that apply to the slice is also included.
The initial collection of subjects included the 40 bugs from Defects4J's Lang and Math projects that TBar is able to patch [6] when given an idealized suspicious locations list that consists of only the location of the human-written patch . To this set, we add a few additional bugs that TBar was able to patch in our environment. From this set, our modified process fails to patch the eight bugs at the bottom of the table. For two, the fault locater exhausts its five-hour time allotment. For the other six, the slicer is essentially too aggressive and removes code needed by TBar to recompile the file containing the failing test. This code is unrelated to the failing test. Because it does not recompile the tests, the removal does not inhibit the slicer. We solved this problem by hand for Lang-33, where the failing test had the Assertion Roulette smell [34], by refactoring the single failing test into four smell-free tests. In future work, we hope to automate a fix for the other six similar bugs.
TABLE I
| | | SLoC | SLoC | Slice | Passing | Tests | Failing |
|-----------|--------|-------------|-----------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|
| | BID | Orig | Slice | as % | Orig | Slice | Tests |
| Lang Lang | 10 22* | 20442 18870 | 836 571 | 4.1 3.0 | 2196 1823 | 73 35 | 2 2 |
| Lang | 33 | 17302 | 907 | 5.2 | 1669 | 67 | 1 |
| Lang | 39 | 16983 | 1437 | 8.5 | 1617 | 93 | 1 |
| Lang | 43 | 18817 | 409 | 2.2 | 1807 | 30 | 1 |
| Lang | 44 | 18814 | 661 | 3.5 | 1784 | 46 | 1 |
| Lang | 45 | 18777 | 549 | 2.9 | 1782 | 38 | 1 |
| Lang | 47 | 18490 | 998 | 5.4 | 1733 | 98 | 2 |
| Lang | 51 | 17028 | 601 | 3.5 | 1630 | 70 | 1 |
| Lang | | 16961 | 1098 | | | 81 | 1 |
| | 58 | | | 6.5 | 1594 | | 1 |
| Lang Lang | 59 63 | 16943 16791 | 571 1146 | 3.4 6.8 | 1592 1576 | 52 36 | 1 |
| Lang | 7 | 21495 | 836 | 3.9 | 2260 | 93 | 1 |
| Math | | | | | | | |
| Math | 3* 4 | 83115 82856 | 6048 5971 | 7.3 7.2 | 4281 4235 | 81 62 | 1 2 |
| Math | 5 | 81560 | 10386 | 12.7 | 4180 | 155 | 1 |
| Math | 6 | 81309 | 14883 | 18.3 | 4146 | 146 | 28 |
| Math | 22 | 68184 | 10616 | 15.6 | 3401 | 87 | 2 |
| Math | 28 | 65079 | 3559 | 5.5 | 3265 | 44 | 1 |
| Math | 32 | 63767 | 5403 | 8.5 | 2881 | 53 | 1 |
| Math | 33 | 63136 | 3384 | 5.4 | 2863 | 41 | 1 |
| Math | 35 | 63064 | 2632 | 4.2 | 2838 | 16 | 4 |
| Math | | | | | | | 1 |
| | 50 | 54718 | 3335 | 6.1 | 2486 | 29 | |
| Math | 58* | 45271 | 3367 | 7.4 | 2185 | 28 | 1 |
| | 60* | | | | | | |
| Math | | 44036 | 3234 | 7.3 | 2069 | 44 | 1 |
| Math | 62 | 47371 | 3902 | 8.2 9.5 | 2216 | 19 | 1 1 |
| Math Math | 63 65 | 44354 42470 | 4201 3573 | 8.4 | 2148 2139 | 84 55 | 1 |
| Math | 70 | 41186 | 3008 | 7.3 | 2088 | 45 | 1 |
| Math | 73* | 39234 | 3113 | 7.9 | 2047 | 40 | 1 |
| Math | 75 | 39884 | 2936 | 7.4 | 2039 | 39 | 1 |
| | | | | | 2012 | | 1 |
| Math Math | 79 82 | 39306 38672 | 2312 2754 | 5.9 7.1 | 1966 | 22 33 | 1 |
| Math | | | | | | | 1 |
| | 85 | 38458 | 2760 | 7.2 | 1903 | 40 | |
| Math | 89 | 30903 | 1002 | 3.2 | 1611 | 8 | 1 |
| Math | 95 | 19934 | 936 | 4.7 | 1223 | 22 | 1 |
| Math | 96 | 19511 | 653 | 3.3 | 1195 | 97 | 1 |
| Math | 98* | 16725 | 1389 | 8.3 | 1017 | 62 | 2 |
| Lang | 57 | | Test Source fails to compile | Test Source fails to compile | Test Source fails to compile | Test Source fails to compile | Test Source fails to compile |
| Math | 8 | | Fault Localization times out | Fault Localization times out | Fault Localization times out | Fault Localization times out | Fault Localization times out |
| Math | 30 | | Fault Localization times out | Fault Localization times out | Fault Localization times out | Fault Localization times out | Fault Localization times out |
| Math | 34 | | Test Source fails to compile | Test Source fails to compile | Test Source fails to compile | Test Source fails to compile | Test Source fails to compile |
| Math | 49 | | Test Source fails to compile | Test Source fails to compile | Test Source fails to compile | Test Source fails to compile | Test Source fails to compile |
| Math | 59 | | Test Source fails to compile | Test Source fails to compile | Test Source fails to compile | Test Source fails to compile | Test Source fails to compile |
| Math | 77 | | Test Source fails to compile Test Source fails to compile | Test Source fails to compile Test Source fails to compile | Test Source fails to compile Test Source fails to compile | Test Source fails to compile Test Source fails to compile | Test Source fails to compile Test Source fails to compile |
THE SUBJECT BUGS STUDIED.
## B. Metrics
The experiments employ six metrics, Source Lines of Code, SLoC , Test-Suite Size, TSS , Bug Rank, BR , Repair Time, RT , Number of Patch Candidates, NPC [35], and Number of Test Executions, NTE . SLoC measures the non-comment, non-blank lines of code. In contrast to simple line counts, SLoC better indicates the amount of effort involved when working with source code. The removal of code through slicing obviates the need for some of the tests. We capture this reduction in the size of the test suite, TSS . Ideally, having less unrelated code to consider should focus fault localization and improve, BR , the rank of the buggy statement in the list of suspicious locations. We report repair time, RT , as the wallclock time used by TBar to patch a bug. All of the experiments were run on the same hardware making the wall-clock time
Fig. 1. The lattice of all possible configurations of program ( P or P S ), test suite ( T , or T S ), and suspicious locations list ( L L , S , or L P ).
proportional to the CPU time thus we do not report both. NPC counts the number of patch attempts before a valid patch is found and has become a common metric for evaluating APR tools [3, 36, 37]. In our work, it is used to quantify the efficiency gain brought about by using the more cohesive reduced program.
Finally, we augment the use of NPC by introducing a new metric NTE , the number of test executions performed before a patch is found. We introduce this metric because a reduction in the size of the test suite is expected to improve RT but not NPC , so NPC cannot be used to study this RT improvement. The use of NTE parallels the use of NPC to study the RT improvement that comes from the improved ranking of the faulty statement. Our goal is that NTE and NPC together will accurately characterize the reduction in RT .
## C. Repair Process
Our repair process is applied to buggy program P and its test suite T , and consists of the four steps discussed below.
- 1) For the program reduction step we use program slicing to produce P S from P by eliminating code irrelevant to the bug being repaired.
- 2) The test-suite reduction step reduces the test suite T by removing tests for code not found in P S . The result is a reduced test suite T S that preserves T 's test coverage relative to the bug being repaired.
- 3) The reduced suspicious list is determined in one of two ways. The first method regenerates the list by applying fault localization to P S and T S producing L S , while the second method prunes from the original list all locations that are not present in the slice, producing L P .
The goal of the first approach is to focus fault localization on the relevant portions of the code (i.e., those found in the slice). The advantage of the second approach is that the rank of the buggy statement is guaranteed to be no worse.
- 4) The program repair step applies TBar to various combinations of P , T , L P , S , T S , L P , and L S , that conform the lattice shown in Figure 1, which is discussed below.
To isolate the impact of the various reductions on TBar's performance, we consider the lattice of possible configurations shown in Figure 1. With two programs ( P or P S ), two test suites ( T , or T S ), and three suspicious locations lists ( L L , S , or L P ) there are twelve possible configurations. However, those shown in red are not viable because T and L include program locations not found in the P S . In the lattice, each subscript indicates, in order, the program, the test suite, and the ranked list of suspicious locations used. Thus, C PT L is the original configuration while C P T L S S P uses P S , T S , and L P .
## D. Tools
Our experiments use the following tools: first, as previously mentioned, we use the APR tool TBar, available as part of the replication package for the paper introducing TBar [6], as a representative state-of-the-art template-based APR tool. The only modification required is to register the use of the sliced code or reduced test suite with the version control system via git add -u before applying TBar.
For Step 1, the reduction step, we use parallel ORBS version 5.0 [22]. The test-suite reduction uses tree-sitter to build the AST for each test file and then repeatedly removes test methods that fail when applied to P S or to P . Step 3 uses the spectrum-based fault locater GZoltar V.1.7.3 [38] with the Ochiai ranking strategy, which has empirically been shown to be one of the most effective metrics for fault localization [39]. Finally, the experiments were run in a Docker container on a cluster of AMD EPYC 7763's. Each run allotted TBar four processors and a time limit of 24 hours.
## E. Research Questions
Using these tools we consider the following Research Questions. We expect the overall improvement to come from two primary causes: improved fault localization rank of the buggy statement and the reduced test suite. RQ1 considers the impact of the reduction on the size of the buggy program. RQ2 and RQ3 break out the two causes of improvement and attempt to quantify the two reductions, while RQ4 and RQ5 consider their impact on TBar. RQ6 considers the impact of our reduction techniques on TBar's repair time.
- RQ1: How effective is slicing at reducing the size of the buggy program?
Slicing has never been applied to preserving JUnit error messages and thus might prove ineffective at the task. For this RQ we compare the SLoC found in P and P S .
RQ2: Howeffective is the reduced program when used for testsuite reduction?
This RQ isolates the impact of using the reduced program to cull the test suite, which we measure using TSS .
RQ3: How does program reduction impact fault localization? This RQ isolates the impact of using the reduced program to improve the rank of the buggy statement, which is measured using BR in both L S and L P .
RQ4: How does using a reduced test suite affect TBar?
RQ4 builds on RQ2 to investigate the test-suite reduction's impact on TBar's testing effort, as measured using NTE .
- RQ5: What is the impact of using the updated list of suspicious statements on TBar?
RQ5 builds on RQ3 to investigate the improvement better bug rank (lower BR ) has on TBar's performance as measured using NPC .
RQ6: What is the overall improvement obtained using TBar with the reduced program?
Finally, we use RT to study the end-to-end performance improvement that the reduced program has on TBar at various points in the lattice shown in Figure 1.
## V. RESULTS AND DISCUSSION
This section considers each of our research questions in turn and concludes with a discussion of the implications of the patterns seen in the data.
## A. RQ1
RQ1 considers the size reduction achieved using program slicing. Figure 2 shows the size of the production code, which excludes test code and alike, compared to the size of the reduced production code. As noted previously, slicing has never been applied to preserving JUnit error messages. While there are interesting issues such as Math-5's reciprocal test issue discussed with RQ3, overall the approach is quite effective. Compared to the average dynamic slice size of approximately 60% of the code [40], for the programs shown in Table I the slices range from 2.2% to 18.3% of the original code with an average size of only 6.6%. Some of this is likely related to the nature of the particular subjects, but using JUnit tests as a slicing criterion may prove worthy of future study. It would be interesting to do a more apples-to-apples comparison using subjects studied in prior dynamic slicing research.
In answer to RQ1, slicing is quite effective at reducing the size of the program necessary to reproduce the bug. Furthermore, this reduction is fairly uniform.
## B. RQ2
RQ2 considers the test-suite size reduction obtained by removing tests that apply to parts of the code not in the slice. Here again, as seen in Figure 3 as well as Table I, using the reduced program leads to a dramatic reduction in TSS . The original test suite includes an average 2249 tests per project, which is
Fig. 2. Reduction's impact on each program's SLoC .
reduced to an average of only 56! The greatest reduction, for Math-89 , leaves only eight passing and one failing test. The magnitude of the reduction is, de-facto related to the size of the original test suite. It would be interesting to study the reduction after applying traditional test-suite minimization [41].
One interesting question the dramatic reduction raises is, is the reduction too extreme. That is does it not leave sufficient tests for the downstream tools to work effectively? In theory TBar needs only a single failing test case. Of course, in the absence of good regression tests, overfitting is a potential problem. At the same time many of the tests in the original test suite have zero impact on the repair process and thus their repeated execution is a significant waste of time.
In answer to RQ2, slicing is quite effective reducing testsuite size.
## C. RQ3
Starting with RQ3 we remove from the dataset those projects that TBar fails to patch. The initial set of projects we started with includes all projects that TBar can patch given an ideal suspicious statements list of length one [6]. In less ideal situations (e.g., using GZoltar's list of suspicious statements in lieu of the ideal list) there are cases where TBar is unable to find a patch. These bugs are marked with a '*' in Table I.
RQ3 investigates BR , the rank in the list of suspicious statements of the statement to which TBar applies a successful patch. It is important to note that we are not reporting the location of a predetermined static statement but rather the statement dynamically chosen by TBar.
The predetermined static statement approach is clearly more straightforward: ahead of time, one selects a statement to be the correct patch location and then determines its rank on each suspicious statements list. In cases where there is only one correct patch location, this approach has some appeal. It also simplifies correctness arguments when, for example, the predetermined location is taken from a subsequently patched
Fig. 3. Reduction's impact on each program's TSS .
version of the code. However, this approach denies the possibility of alternate fixes at alternate fix locations and thus is rather limiting.
The dynamic approach is more flexible as it gives TBar credit for finding patches at alternative locations. Of course, alternative locations complicate the correctness argument. Because of this, we consider two sets of bugs. The first, all the data includes those bugs for which TBar finds a patch in the base C PT L configuration. These are listed in Table I without a '*'. We use these bugs to establish overall trends. The second set considers only those projects where the patch location is the same as that found using C PT L . As with the straightforward approach, this enables us to make direct correctness arguments. One interesting question here is whether this subset shows the same general trends.
For both all the data and the subset using the same patch location, our analysis considers two different reduced suspicious statements lists, L P and L S . By removing statements from L that are not in the slice, L P has the advantage that it is never larger than L . Assuming that location patch-ability does not change, using L P should enable TBar to choose a statement of lower or equal rank. As discussed below, this assumption is violated in one case.
The second list, L S , hopes that GZoltar does better when applied to the more focused P S and T S . It mostly does. In the data, there are only two cases, Math-5 and Math-75, where the list of suspicious statements produced by GZoltar is larger for L S than for L . We leave it to future work to better understand if these longer lists provide evidence of GZoltar finding a greater number of viable locations or if the longer lists simply include more false positives.
Turning to the BR data, we first consider all of the data. Showing the baseline L in the middle, the upper chart of Figure 4 compares BR separately for Lang and Math. TBar is unable to patch one bug, Math-6, under C PT L P and three, Math-6, Math-35, and Math-64 under C PT L S . Thus from an applicability perspective C PT L P is preferred.
The expected pattern, where the reduced list produces lower BR s, is mostly evident in the figure. For example, the max and median BR s using L P (shown to the right of L , in green) are lower than in L (the median is shown as the central dashed line). (Numerically, these are 69.0 and 7.0 verses 82.0 and 9.5.) For L S , Lang shows this same pattern, but Math does not, largely because of one bug discussed below.
Considering the individual bugs, both Lang and Math include a handful of bugs for which BR in L S is larger than BR in L . Most of the time the difference is small, but not always. For example, Math-82's BR is 89 in L S while only 49 in L . This one project accounts for the long thin spire of the L S Math violin plot and dominates the reason that Math does not follow the expected pattern.
For L P , pruning L can never make the list longer. It is therefore easy to likewise conclude that the BR of the patched statement can never be greater using L P . However, checking the data, we find one exception, Math-5 where the BR in L is one while the BR in L P is two. For this to happen, the rank-
Fig. 4. Reduction's impact on each program's L .
one statement from L cannot be in the slice and thus gets removed during pruning. That another viable patch location was found is interesting. Fortuitously, it was not at rank one, otherwise this anomaly might have gone unnoticed. The details are explored in the discussion at the end of this section.
The lower chart in Figure 4 shows only those bugs where TBar patches the same location using the three lists. For Lang all the bugs use the same location, thus the charts are identical. For Math fifteen of the bugs use the same location, while six are patched at different locations. The dominance of same-location patches means that most patches inherit patch correctness from the correctness of the C PT L patch. However, a different patch location does not mean the patch is incorrect, it simply means that it is harder to argue its correctness. Finally, as expected for this subset, L P always results in a patch location with an equal or lower BR .
To answer RQ3, while for the most part the rank of the statement that TBar patches is lower in C PT L P and C PT L S than in C PT L , this is not ubiquitous, nor is the reduction as dramatic as that seen for SLoC and TSS . It is encouraging that most patches are at the same location, which implies
that the reduction in rank does not negatively impact the patch. Finally, overall C PT L P performs better than C PT L S .
## D. RQ4
RQ4 investigates the effort TBar expends testing potential patches, measured using the number of test executions, NTE . Similar to our analysis of RQ3 we first consider all the data and then the subset where C PT L and C PT L S choose the same patch location. Figure 5 compares the testing effort using all of the data. Note that the y -axis uses a logarithmic scale.
The reduction is dramatic. For Lang, NTE drops from an average of 687,946 to an average of only 48,492, a 93% reduction. For Math, NTE drops from 227,604 to 6,649, a 97% reduction. Clearly, the reduction in TSS seen in RQ2 leads to a dramatic reduction in NTE .
Even better, unlike in RQ3, where using the reduced suspicious statements lists, caused TBar to fail to patch three of the bugs, when using the reduced test suite, TBar is able to patch all of the bugs. On top of this, it does so at the same location; thus Figure 5 is also the figure when using the same-location subset.
To answer RQ4, slicing is successful at reducing TBar's testing effort, NTE , without reducing its applicability.
## E. RQ5
RQ5 mirrors RQ4 replacing NTE with NPC , the number of patch candidates. The impact on NPC of using the updated list of suspicious statements is shown in Figure 6 where it is visually obvious that the improvement is less dramatic than for NTE . Comparing the center violin plot with its right and left neighbors, using L P always brings a benefit. The same is not true for L S where the inferior ranks for L S seen in RQ3 are again evident for Math.
For the pruned list L P , average NPC drops from 573 to 502 for Lang, a 12% reduction, and from 220 to 189 for Math, a 14% reduction. Using L S the results are mixed. For Lang NPC drops from 573 to 523, a 9% reduction, but for Math it rises from 220 to 389, a 77% increase . The inferior and
Fig. 5. Reduction in test-suite size's impact on each project's NTE .
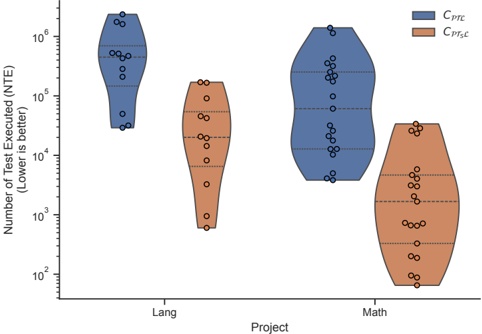
varied performance attained using L S stands in contrast to the expectation that performing fault localization on the reduced program would focus the fault locator and thus improve its performance. The data suggests that this is not the case. It would be interesting to investigate the interplay between the amount of code reduction and the performance of fault localization.
Turning to the subset where the same patch location is used, because all of the Lang patches are at the same location, the results for the same-location subset are identical. For Math the performance is mixed. Using L P NPC drops from 246 to 227, which is only an 8% reduction compared to the 14% for all the data. On the other hand, while still negative, for L S the increase from 246 to 352 is only a 43% increase, down from the 77% when using all the data.
In answer to RQ5, as expected the data mirror the L -data from RQ3. Compared with the NTE results for RQ4, slicing is notably less effective at reducing NPC .
## F. RQ6
RQ6 investigates the impact of combining the reductions of NTE and NPC on TBar's repair time, RT . The greatest
Fig. 6. Reduction's impact on each program repair's NPC .
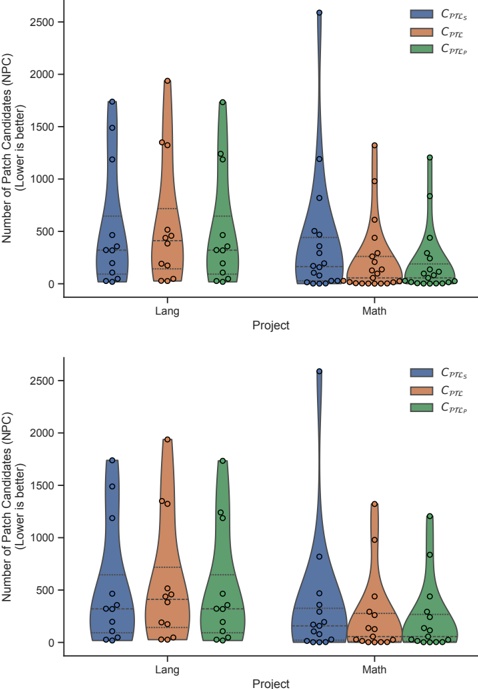
| Configuration | All | Lang | Math | Failures |
|-----------------|-------|--------|--------|------------|
| Three changes | | | | |
| C P S T S L P | 82% | 91% | 74% | 11 |
| C P S T S L S | 78% | 88% | 67% | 12 |
| Two changes | | | | |
| C PT S L P | 88% | 89% | 87% | 2 |
| C PT S L S | 83% | 89% | 76% | 3 |
| One change | | | | |
| C PT S L | 86% | 86% | 85% | 0 |
| C PTL P | 14% | 15% | 12% | 2 |
| C PTL S | -75% | 7% | -174% | 3 |
## TABLE II
REPAIR TIME REDUCTION RELATIVE TO C PTL . THE FINAL COLUMN REPORTS THE NUMBER OF BUGS WHERE TBAR SUCCEEDS USING C PTL BUT NOT THE LISTED CONFIGURATION.
reduction is expected with either C P T L S S P or C P T L S S S , which make use of the reduced program, the reduced test suite, and one of the reduced suspicious statements lists. Overall, these configuration yield almost an order of magnitude reduction, as can be seen in the top two rows of Table II, which breaks the repair time reduction down by project and also reports the number of bugs that TBar fails to patch despite C PT L succeeding. Breaking this down by project, for Lang using L P the mean repair time drops from 10946s to 990s, a 91% reduction, while for L S it drops to 1290, an 88% reduction. The reduction for Math is less dramatic. For Lang the L P reduction, from 8324s to 2251s, is 74%, while for L S the reduction to 2701s, is 67%, which is still notable. The drawback in these impressive reductions is the number of TBar failures. Using P S , TBar is unable to patch roughly a third of the bugs that it can patch using P . That TBar struggles to patch the smaller sliced program comes as a bit of a surprise and warrants future investigation.
To better understand the reduction and the failures, we consider the intermediate points of the configuration lattice shown in Figure 1. Starting with the second level of Figure 1, as shown in the last three lines of Table II, test-suite reduction clearly brings the larger benefit. In contrast the individual reduced suspicious statements lists bring mixed benefit. In the worst case, using L S actually hurts the performance of the Math bugs. The negative performance is dominated by Math5 whose repair time goes from 492s to 31671s. In contrast, the L S lists improve Lang's repair time by a modest 6%.
With Lang, L P fairs better, seeing a respectable 14% reduction. However, the 'reduction' for Math is again negative. It is notable that L P leads to an average reduction of 12.6% when Math-5 is excluded. We return to Math-5 in the discussion section, since this anomaly warrants deeper investigation.
The center of Table II considers the level in the lattice where two of the three possible reductions are applied. Here the test-case reduction's impact again clearly dominates. It is interesting that compared to C PT L S , C PT L S P provides a strict improvement for Lang and Math. This gives us optimism that
Fig. 7. Reduction's impact on overall repair time, RT , for C P T S S L S and C P T S S L P restricted to the bugs where TBar chooses the same patch location.
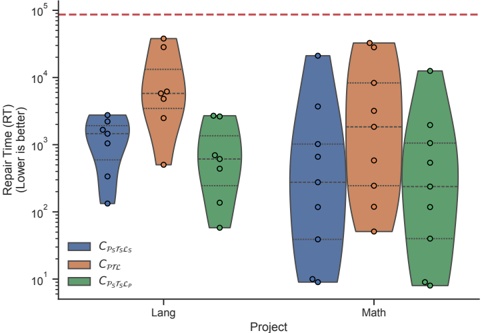
Fig. 8. Reduction's impact on overall repair time, RT , for C PT S L S and C PT S L P restricted to the bugs where TBar chooses the same patch location.
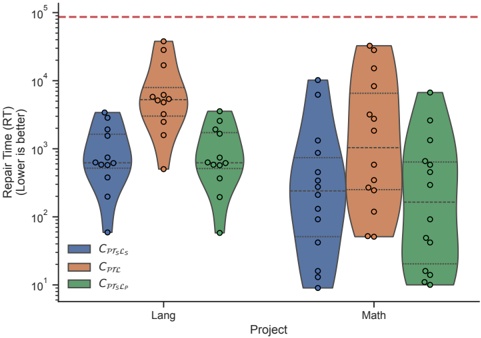
with additional effort we can devise suspicious statements list reduction techniques that are effective across all projects.
Comparing the two middle and the top two rows, using P S benefits only one case, with Lang using C P T L S S P , which is a bit discouraging. Much of the difference is caused by bugs where TBar uses different patch locations. To dig deeper, Figures 7 and 8 compare the performance on the subset where TBar uses the same patch location. Figure 7 compares C P T L S S S and C P T L S S P , while Figure 8 compares C PT L S S and C PT L S P . The two figures show very much the same reduction pattern, except that Figure 8 summarizes 50% more data, which underscores the challenge TBar faces trying to patch P S .
Finally, it is interesting that despite P S and T S showing similar large reductions, the T S reduction has a dramatic impact on RT while the P S reduction does not. The obvious challenge here is to find a way for P S to have a similar impact.
In answer to RQ6 the results are somewhat mixed. Clearly the T S reduction brings RT benefit. However, the P S reduction does not. The overall impact is still impressive, but would be even more impressive if future APR tools could better leverage the P S reduction.
## G. Discussion
This section reflects on some of the questions raised in the experiments. To begin with, the bottom of Table I includes eight bugs that failed before getting to the TBar stage of our tool pipeline. For two of these GZoltar times out. So, despite the fact the TBar can patch these two given the location of the bug, finding that location proves a challenge. One interesting question here is why GZoltar was not able to leverage the more focused P S and T S .
For the other six bugs, the slicer is essentially too aggressive and removes code needed by Defects4J to compile the test suite. (TBar works through the Defect4J interface.) For efficiency the slicer does not recompile the Java test files. This means that if there is test code in the same file as the failing test, the slicer may remove production code needed to compile that test even though it is never executed. An ad-hoc preliminary experiment that modified ORBS to verify that the test file compiled solved this problem in one case. We plan to work on better engineering solutions that more generally address this issue.
Second, compared with the NTE results for RQ4, slicing is notably less effective at reducing NPC and RT . In theory the search for locations in P S should be more efficient, so here again slice-aware fault location might be interesting to explore. Since most of the slices include the patch location, it seems reasonable to devise fault locators that can leverage being applied to the slice. Another consideration is that Lang and Math are both utility collections. It is possible that for a more monolithic program, P S would have greater impact. In terms of RT , one experiment worth running is to consider a project that involves computationally complex aspects. If such code is not in the slice then P S should lead to RT improvements akin to those T S provides.
While the test-suite reduction is impressive it is possible that insufficient tests remain. Math-6 had by far the most failing test cases (and the second highest number of passing tests in T S ), so it is worthwhile to consider if it was particularly easy or challenging to patch. For starters, the rank of the patch location in L is one. An optimistic reading of this is that all the failing tests helped locate the fault. Unfortunately plenty of other patches involve the Rank 1 location. Math-6 is one of two bugs that C PT L S is unable to patch, which suggests that insufficient tests is not limiting GZoltar. Comparing our other metrics, none stand out. Perhaps the silver lining here is that patch success does not depend on having a large number of failing or passing tests.
Finally, we consider two cases studies, Lang-33, which exhibits the Assertion Roulette test smell [34], and Math5, which was successfully patched at an alternate location.
```
learly = {
```
Fig. 9. Example from Lang-33.
To begin with, Figure 9 shows a code excerpt in which the test method testToClass\_object includes multiple asserts and thus exhibits the Assertion Roulette test smell [34]. Two of the test's four asserts are shown (on Lines 2 and 4). Following the test method, Lines 8-19 show the method under test. This code generates a null dereference exception on Line 16 when i=1 because array[i] is null for the test on Line 5.
The slicer unwantedly removes Lines 9-13 from the method toCLass without affecting the program behavior because it still generates a null dereference exception . However, the exception is now coming from the use of array.length on Line 14 and is now generated by the assert on Line 2. Lines 9-13 get removed because their absence does not change the program behavior. Refactoring the test method into four test methods, and thus removing the Assertion Roulette test smell, fixes the issue because the initial deletion of Lines 9-13 now causes the first test to fail in addition to the fourth. This example highlights one of the challenges caused by using bug error messages as a slicing criterion. The results for Lang-33 reported in this paper make use of the refactored test.
The second case study looks at the Math-5 anomaly. Although pruning L to produce L P should not result in the use of a lower-ranked location as it cannot make the list longer, our investigation of RQ3 found that this happened for Math-5, as the Rank 1 location was pruned away from L . The cause is complex but illustrative. Figure 10 shows excepts from the relevant code. To begin the assertion method used (Line 1 of Figure 10) takes as its first argument the expected value. The call, shown on Line 14, inverts expected and actual . It should use Complex.INF as the first argument. While this does not impact the slicer nor TBar, which both only look for differences in the output, it does impact human understanding. Specifically, the test output shown on Lines 5 and 6 is backwards. The correct output is shown on Lines 9 and 10. Again the slicer and TBar only monitor change, so the slice and the patch are correct but the order is relevant to understanding the interplay between L S and L . Using C PT L , the original TBar patch replaces Line 19 with Line 23. This patch correctly returns the reciprocal of 0 as the library's constant INF .
```
// assertion method used: assertEquals(expected, actual) that anol
//
// Original error output //
// Test failed!
```
Fig. 10. Example from Math-5.
Using C PT L P , the slice omits the original patch location (Lines 18-20), which means the location is pruned from L when producing L P and thus is not available to TBar. The slicer can remove Lines 18-20 because subsequent code (shown on Lines 27-30) results in a division by zero when real is 0 , which the Java runtime maps to the value infinity. The value returned by createComplex on Line 30 is Complex(Infinity, Infinity). It is important to note that this value is not the same value as the constant returned on Line 23, whose declaration is shown on Line 34. However, the two print the same; thus, the deletion leaves the error message unchanged. Detecting no change in the output, ORBS concludes that the relevant program behavior has not changed. While it may not appear serious, this is an informative limitation of using value-based slicers such as ORBS. Interestingly, if the program had printed INF differently from Java's default printing of infinity, the deletion would not have occurred.
Unfortunately, the patch TBar produced under C PT L P is inferior, or this would have made a great example of the value of considering alternate patch locations. The patch, shown on Line 43, modifies the equals method so that all complex numbers equal NaN, which is clearly undesired. Still, the fact that another viable patch location was found is interesting and suggests that APR's use of a 'perfect patch' may be undesirable.
ORBS is expensive. It is possible that other, unsound, lighter-weight reduction techniques might be sufficient, but to understand the tradeoffs, we first need to understand how effective ORBS is when applied to the buggy code.
Finally, our experiments make use of one-minimal ORBS slices. Because these are minimal and, by construction, capture the execution of the slicing criterion, their use allows us to focus on slicing's impact. This is akin to the experiments with TBar that use an optimal list of suspicious statements [6]. In practice, ORBS is too slow to be used in production (while some engineering work would reduce its runtime, the median slice time for Lang was just over seven hours and that for Math was just under 34 hours). Fortunately, there exist faster slicers. For example, the slicer studied by Wang et al. [31] when slicing JFreeChart (an application similar is size to Lang) slices at about 400 SLoC per second (including SDG construction time). Thus, we expect it to slice the largest of the systems we consider in under five minutes.
## VI. RELATED WORK
We distinguish several areas of related work, ranging from techniques to improve APR and fault localization, to related applications of program reduction.
Improving APR: Early research in APR focused on developing new patch-generation algorithms such as heuristicbased [5, 42], constraint-based [43, 44], and learningbased [45, 46], all aimed at improving the efficacy of APR by producing more correct patches and addressing the wellknown patch overfitting problem [47, 48].
More recently, researchers have started focusing on techniques to improve the efficiency of APR. Several techniques have been developed, including regression test selection [49, 50], patch filtering [51, 52], and on-the-fly patch generation [12] and validation [45, 53]. The goal of these techniques is to reduce the cost of patch compilation and test case execution, which are the dominant factors in APR efficiency. While each of these techniques has the potential to reduce program repair costs, they typically only affect a particular phase of the APR process. The combination of slicing with APR has the potential to improve all phases of APR, including fault localization, patch generation, and patch validation.
While this paper studies the impact of program reduction on a template-based APR, the impact on recent neural APR approaches that build on large language models (LLMs) could even be larger. For example, recent work that combines various LLM-based APR approaches reported generating plausible patches for the bugs in Defects4J in 2.5 hours using 'perfect fault localization' , i.e., using known bug locations and omitting the fault localization step [30]. Another study that does not assume perfect fault localization reported that most plausible patches are produced in 1 to 10 hours, and half of them are generated in 4.5 hours [54]. Reducing the size of the program to consider should greatly reduce these times, and
the corresponding test-suite reduction will further reduce the time needed for patch validation.
Fault localization in APR: Fault localization is one of the key phases of the APR process because it affects not only the performance but also the correctness of generated patches [4, 55-57]. Unfortunately, fault localization still suffers from accuracy issues [3, 4]. Moreover, some classes of APR tools are more sensitive to its accuracy than others and a recent study by Liu et al. showed that template-based APR is highly sensitive to fault localization noise [3].
Several papers aim to improve fault localization by reducing the program spectra (i.e., the code coverage data) that need to be analyzed. The reduction approaches range from delta debugging [58], program slicing [59-63], test generation [64], to test prioritization [65]. In particular, Zhang et al. [59] evaluate the effectiveness of three variants of dynamic slicing algorithms. Li and Orso [61] proposed the concept of potential memory-address dependence to improve the accuracy of dynamic slicing. Recently, Soha [63] conducted a thorough analysis of combining various slicing and spectrum-based fault localization algorithms. In contrast to our work, these papers do not empirically examine the effects of test-suite and code reduction, nor how the fault localization improvement obtained through slicing affects the efficiency of APR. Closer to our work, Guo et al. [66] analyze how Java slices impact the constraint-based APR tool Nopol [67] through its impact on the spectrum-based fault localization used by Nopol. They show how dynamic slicing impact on fault localization lowers NPC and RT .
Other applications of program reduction: Program slicing was originally developed as a debugging technique to help developers focus by reducing a program to exactly those statements relevant for the behavior at a point of interest [25, 68]. Since those early days, the abstraction capabilities of slicing have been used for various software engineering challenges, ranging from software testing, software maintenance and evolution, to finding elements for reuse [69, 70].
- A related idea applies dynamic Slicing to improve (spectrum-based) fault Localization [71]. The key intuition in this work is that highly ranked statements not covered by failing executions are likely unrelated to the fault. The paper shows that dynamic slicing substantially improves the rank of faulty statements. Our fault location results mirror these thus improving the validity of both studies.
Of particular interest in the context of this paper is the application of program slicing to reduce the scope of what needs to be analyzed in program verification and model checking [72, 73], which has been shown to be an effective way to reduce verification time [74, 75].
## VII. CONCLUDING REMARKS AND FUTURE WORK
Automatic program repair of large-scale programs is a difficult and time-consuming task. It can take hours, and in many situations APR tools are unable to exhaustively search the patch space. Prior work showed that the most challenging parts of the repair process are finding faulty statements and verifying the generated patch's correctness. Instead of examining an entire program, this work aims to focus the repair process on a relatively small portion of the program in the form of a program slice.
The experiments show that slicing can significantly improve the performance of template-based APR, but not in all cases. The benefit is primarily through test-suite size reduction. Like most research problems, this investigation raises as many question as it answers. Future work will consider addressing the limitations we encountered, such as how to better exploit the reduced program in fault localization. We also intend to consider other classes of APR tools, mainly neural and semantic-based APR tools.
Finally, we hope to develop a better understanding of TBar's inability to patch P S and the poor performance of GZoltar when applies to P S and T S . One possibility here is that as libraries, Math and Lang might prove harder to fix because they include less cohesive code, which makes it more likely that the code violates the plastic surgery hypothesis [76]. Nonlibrary slices are expected to be larger and more cohesive making them more likely to include reusable code. Thus we plan experiments that considers projects with a range of cohesiveness to see if there is any correlation with TBar's and GZoltar's performance.
## ACKNOWLEDGEMENTS
The research presented in this paper was financially supported by the Research Council of Norway through the secureIT project (grant #288787).
The authors wish to thank Lulu Wang for providing JavaSlicer and assisting in getting it to run for our experiments.
## REFERENCES
- [1] M. Monperrus. 'Automatic Software Repair: A Bibliography.' In: ACM Computing Surveys 51.1 (2018), pp. 1-24. DOI: 10.1145/3105906.
- [2] C. Le Goues, M. Pradel, and A. Roychoudhury. 'Automated Program Repair.' In: Communications of the ACM 62.12 (2019), pp. 56-65. DOI: 10.1145/3318162.
- [3] K. Liu et al. 'On the Efficiency of Test Suite Based Program Repair: A Systematic Assessment of 16 Automated Repair Systems for Java Programs.' In: International Conference on Software Engineering (ICSE) . ACM, 2020, pp. 615-627. DOI: 10.1145/3377811.3380338.
- [4] K. Liu, A. Koyuncu, T. F. Bissyande, D. Kim, J. Klein, and Y. Le Traon. 'You Cannot Fix What You Cannot Find! An Investigation of Fault Localization Bias in Benchmarking Automated Program Repair Systems.' In: Conference on Software Testing, Validation and Verification (ICST) . IEEE, 2019, pp. 102-113. DOI: 10.1109/icst.2019. 00020.
- [5] C. Le Goues, T. Nguyen, S. Forrest, and W. Weimer. 'GenProg: A Generic Method for Automatic Software Repair.' In: IEEE Transactions on Software Engineering 38.1 (2012), pp. 54-72. DOI: 10.1109/ tse.2011.104.
- [6] K. Liu, A. Koyuncu, D. Kim, and T. F. Bissyand´ e. 'TBar: Revisiting Template-Based Automated Program Repair.' In: International Symposium on Software Testing and Analysis (ISSTA) . ACM, 2019, pp. 31-42. DOI: 10.1145/3293882.3330577.
- [7] R. Just, D. Jalali, and M. D. Ernst. 'Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs.' In: International Symposium on Software Testing and Analysis (ISSTA) . ACM, 2014, pp. 437-440. DOI: 10.1145/2610384.2628055.
- [8] W. Weimer, Z. P. Fry, and S. Forrest. 'Leveraging Program Equivalence for Adaptive Program Repair: Models and First Results.' In: IEEE/ACM International Conference on Automated Software Engineering (ASE) . 2013, pp. 356-366. DOI: 10.1109/ASE.2013.6693094.
| [9] | C. Le Goues, S. Forrest, and W. Weimer. 'Current Challenges in Automatic Software Repair.' In: Software Quality Journal 21.3 (2013), |
|-------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [10] | pp. 421-443. DOI: 10.1007/s11219-013-9208-0. X. B. D. Le, D. Lo, and C. Le Goues. 'History Driven Program Repair.' In: IEEE 23rd International Conference on Software Analysis, Evolution, and Reengineering (SANER) . Vol. 1. 2016, pp. 213-224. DOI: 10.1109/SANER.2016.76. |
| [11] | T. Durieux, B. Cornu, L. Seinturier, and M. Monperrus. 'Dynamic Patch Generation for Null Pointer Exceptions Using Metaprogram- ming.' In: IEEE 24th International Conference on Software Analysis, Evolution and Reengineering (SANER) . 2017, pp. 349-358. DOI: 10. 1109/SANER.2017.7884635. |
| [12] | J. Hua, M. Zhang, K. Wang, and S. Khurshid. 'Towards Practical Pro- gram Repair with On-Demand Candidate Generation.' In: International Conference on Software Engineering . ACM, 2018, pp. 12-23. DOI: 10.1145/3180155.3180245. |
| [13] | J. Jiang, Y. Xiong, H. Zhang, Q. Gao, and X. Chen. 'Shaping Program Repair Space with Existing Patches and Similar Code.' In: ACM SIGSOFT International Symposium on Software Testing and Analysis . |
| [14] | ACM, 2018, pp. 298-309. DOI: 10.1145/3213846.3213871. A. Koyuncu, K. Liu, T. F. Bissyand´, e D. Kim, J. Klein, M. Monperrus, and Y. Le Traon. 'FixMiner: Mining Relevant Fix Patterns for Auto- mated Program Repair.' In: Empirical Software Engineering (2020). DOI: 10.1007/s10664-019-09780-z. arXiv: 1810.01791 [cs] . |
| [15] | K. Liu, A. Koyuncu, D. Kim, and T. F. Bissyand`. e 'AVATAR: Fixing Semantic Bugs with Fix Patterns of Static Analysis Violations.' In: IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER) . 2019, pp. 1-12. DOI: 10.1109/saner. |
| [16] | 2019.8667970. X. Liu and H. Zhong. 'Mining Stackoverflow for Program Repair.' In: International Conference on Software Analysis, Evolution and Reengineering (SANER) . IEEE, 2018, pp. 118-129. DOI: 10.1109/ saner.2018.8330202. |
| [17] | F. Long, P. Amidon, and M. Rinard. 'Automatic Inference of Code Transforms for Patch Generation.' In: Joint European Software Engi- neering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE) . ACM, 2017, pp. 727-739. DOI: 10.1145/ 3106237.3106253. |
| [18] | R. K. Saha, Y. Lyu, H. Yoshida, and M. R. Prasad. 'Elixir: Effective Object-Oriented Program Repair.' In: IEEE/ACM International Con- ference on Automated Software Engineering (ASE) . 2017, pp. 648-659. |
| [19] | DOI: 10.1109/ASE.2017.8115675. M. Wen, J. Chen, R. Wu, D. Hao, and S.-C. Cheung. 'Context-Aware Patch Generation for Better Automated Program Repair.' In: Interna- tional Conference on Software Engineering . ACM, 2018, pp. 1-11. DOI: 10.1145/3180155.3180233. |
| [20] | Q. Xin and S. P. Reiss. 'Leveraging Syntax-Related Code for Auto- mated Program Repair.' In: IEEE/ACM International Conference on Automated Software Engineering (ASE) . 2017, pp. 660-670. DOI: 10. 1109/ASE.2017.8115676. |
| [21] | D. Binkley, N. Gold, M. Harman, S. Islam, J. Krinke, and S. Yoo. 'ORBS: Language-Independent Program Slicing.' In: International Symposium on Foundations of Software Engineering (FSE) . ACM, |
| [22] | 2014, pp. 109-120. DOI: 10.1145/2635868.2635893. S. Islam and D. Binkley. 'PORBS: A Parallel Observation-Based Slicer.' In: International Conference on Program Comprehension (ICPC) . 2016, pp. 1-3. DOI: 10.1109/icpc.2016.7503745. |
| [23] | Q. Sti´venart, e D. Binkley, and C. De Roover. 'An Empirical Evaluation of Quasi-Static Executable Slices.' In: Journal of Systems and Software |
| [24] | 200 (2023), p. 111666. DOI: 10.1016/j.jss.2023.111666. B. Korel and J. Laski. 'Dynamic Program Slicing.' In: Information Processing Letters 29.3 (1988), pp. 155-163. DOI: 10.1016/0020- |
| [25] | 0190(88)90054-3. M. Weiser. 'Programmers Use Slices When Debugging.' In: Commu- nications of the ACM 25.7 (1982), pp. 446-452. DOI: 10.1145/358557. 358577. |
| [26] | N. Jiang, T. Lutellier, and L. Tan. 'CURE: Code-Aware Neural Machine Translation for Automatic Program Repair.' In: IEEE/ACM 43rd International Conference on Software Engineering (ICSE) . 2021, |
| [27] | pp. 1161-1173. DOI: 10.1109/icse43902.2021.00107. H. Ye, M. Martinez, and M. Monperrus. 'Neural Program Repair with Execution-Based Backpropagation.' In: International Conference on |
- [27] H. Ye, M. Martinez, and M. Monperrus. 'Neural Program Repair with Execution-Based Backpropagation.' In: International Conference on Software Engineering . ACM, 2022, pp. 1506-1518. DOI: 10.1145/ 3510003.3510222.
| [28] | X. Meng, X. Wang, H. Zhang, H. Sun, X. Liu, and C. Hu. 'Template- Based Neural Program Repair.' In: IEEE/ACM 45th International Conference on Software Engineering (ICSE) . 2023, pp. 1456-1468. DOI: 10.1109/icse48619.2023.00127. |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [29] | N. Jiang, T. Lutellier, Y. Lou, L. Tan, D. Goldwasser, and X. Zhang. 'KNOD: Domain Knowledge Distilled Tree Decoder for Automated Program Repair.' In: IEEE/ACM 45th International Conference on Software Engineering (ICSE) . 2023, pp. 1251-1263. DOI: 10.1109/ ICSE48619.2023.00111. |
| [30] | C. S. Xia, Y. Wei, and L. Zhang. 'Automated Program Repair in the Era of Large Pre-Trained Language Models.' In: International Conference on Software Engineering . regexpIEEE, 2023, pp. 1482-1494. DOI: 10. 1109/icse48619.2023.00129. |
| [31] | L. Wang, B. Li, and X. Kong. 'Type Slicing: An Accurate Object Oriented Slicing Based on Sub-Statement Level Dependence Graph.' In: Information and Software Technology 127 (2020), p. 106369. DOI: 10.1016/j.infsof.2020.106369. |
| [32] | K. Ahmed, M. Lis, and J. Rubin. 'Slicer4J: ADynamic Slicer for Java.' In: ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering . ACM, 2021, pp. 1570-1574. DOI: 10.1145/3468264.3473123. |
| [33] | Q. Sti´venart, e D. Binkley, and C. De Roover. 'QSES: Quasi-Static Executable Slices.' In: IEEE 21st International Working Conference on Source Code Analysis and Manipulation (SCAM) . 2021, pp. 209-213. DOI: 10.1109/SCAM52516.2021.00033. |
| [34] | A. van Deursen, L. Moonen, A. van den Bergh, and G. Kok. 'Refac- toring Test Code.' In: Proceedings 2nd International Conference on Extreme Programming and Flexible Processes in Software Engineering (XP) . Ed. by M. Marchesi and G. Succi. 2001. |
| [35] | Y. Qi, X. Mao, Y. Lei, and C. Wang. 'Using Automated Program Re- pair for Evaluating the Effectiveness of Fault Localization Techniques.' In: International Symposium on Software Testing and Analysis . ACM, 2013, pp. 191-201. DOI: 10.1145/2483760.2483785. |
| [36] | L. Chen, Y. Pei, and C. A. Furia. 'Contract-Based Program Repair without the Contracts.' In: IEEE/ACM International Conference on Automated Software Engineering (ASE) . 2017, pp. 637-647. DOI: 10. |
| [37] | 1109/ASE.2017.8115674. A. Ghanbari and L. Zhang. 'PraPR: Practical Program Repair via Bytecode Mutation.' In: IEEE/ACM International Conference on Au- tomated Software Engineering (ASE) . 2019, pp. 1118-1121. DOI: 10. |
| [38] | J. Campos, A. Riboira, A. Perez, and R. Abreu. 'GZoltar: An Eclipse Plug-in for Testing and Debugging.' In: IEEE/ACM International Conference on Automated Software Engineering . 2012, pp. 378-381. DOI: 10.1145/2351676.2351752. |
| [39] | D. Zou, J. Liang, Y. Xiong, M. D. Ernst, and L. Zhang. 'An Empirical Study of Fault Localization Families and Their Combinations.' In: IEEE Transactions on Software Engineering 47.2 (2021), pp. 332-347. DOI: 10.1109/tse.2019.2892102. |
| [40] | D. Binkley, N. Gold, S. Islam, J. Krinke, and S. Yoo. 'A Comparison of Tree- and Line-Oriented Observational Slicing.' In: Empirical Software Engineering 24.5 (2019), pp. 3077-3113. DOI: 10.1007/s10664-018- 9675-9. |
| [41] | E. Cruciani, B. Miranda, R. Verdecchia, and A. Bertolino. 'Scalable Approaches for Test Suite Reduction.' In: IEEE/ACM 41st Inter- national Conference on Software Engineering (ICSE) . IEEE, 2019, pp. 419-429. DOI: 10.1109/icse.2019.00055. |
| [42] | Y. Tian and B. Ray. 'Automatically Diagnosing and Repairing Error Handling Bugs in C.' In: Joint Meeting on Foundations of Software Engineering . ACM, 2017, pp. 752-762. DOI: 10 . 1145 / 3106237 . 3106300. |
| [43] | A. Afzal, M. Motwani, K. T. Stolee, Y. Brun, and C. Le Goues. 'SOSRepair: Expressive Semantic Search for Real-World Program Repair.' In: IEEE Transactions on Software Engineering 47.10 (2021), |
| [44] | pp. 2162-2181. DOI: 10.1109/TSE.2019.2944914. S. Mechtaev, M.-D. Nguyen, Y. Noller, L. Grunske, and A. Roychoud- hury. 'Semantic Program Repair Using a Reference Implementation.' In: International Conference on Software Engineering . ACM, 2018, pp. 129-139. DOI: 10.1145/3180155.3180247. |
| [45] | L. Chen, Y. Ouyang, and L. Zhang. 'Fast and Precise On-the-Fly Patch Validation for All.' In: IEEE/ACM 43rd International Conference on Software Engineering (ICSE) . 2021, pp. 1123-1134. DOI: 10.1109/ |
| [46] | R. Gupta, S. Pal, A. Kanade, and S. Shevade. 'DeepFix: Fixing Common C Language Errors by Deep Learning.' In: AAAI Conference on Artificial Intelligence . AAAI, 2017, pp. 1345-1351. |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [47] | Z. Qi, F. Long, S. Achour, and M. Rinard. 'An Analysis of Patch Plausibility and Correctness for Generate-and-Validate Patch Genera- tion Systems.' In: International Symposium on Software Testing and Analysis (ISSTA) . ACM, 2015, pp. 24-36. DOI: 10.1145/2771783. 2771791. |
| [48] | Y. Xiong, X. Liu, M. Zeng, L. Zhang, and G. Huang. 'Identifying Patch Correctness in Test-Based Program Repair.' In: International Conference on Software Engineering . 2018, pp. 789-799. DOI: 10. 1145/3180155.3180182. arXiv: 1706.09120 [cs] . |
| [49] | S. Yoo and M. Harman. 'Regression Testing Minimization, Selection and Prioritization: A Survey.' In: Software Testing, Verification and Reliability 22.2 (2012), pp. 67-120. DOI: 10.1002/stvr.430. |
| [50] | B. Mehne, H. Yoshida, M. R. Prasad, K. Sen, D. Gopinath, and S. Khurshid. 'Accelerating Search-Based Program Repair.' In: IEEE 11th International Conference on Software Testing, Verification and Validation (ICST) . 2018, pp. 227-238. DOI: 10.1109/ICST.2018.00031. |
| [51] | J. Liang, R. Ji, J. Jiang, S. Zhou, Y. Lou, Y. Xiong, and G. Huang. 'Interactive Patch Filtering as Debugging Aid.' In: IEEE International Conference on Software Maintenance and Evolution (ICSME) . 2021, pp. 239-250. DOI: 10.1109/ICSME52107.2021.00028. |
| [52] | C. Yang. 'Accelerating Redundancy-Based Program Repair via Code Representation Learning and Adaptive Patch Filtering.' In: ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering . ACM, 2021, pp. 1672-1674. DOI: 10.1145/3468264.3473496. |
| [53] | S. Benton, Y. Xie, L. Lu, M. Zhang, X. Li, and L. Zhang. 'Towards Boosting Patch Execution On-the-Fly.' In: International Conference on Software Engineering (ICSE) . 2022, pp. 2165-2176. DOI: 10.1145/ 3510003.3510117. |
| [54] | H. Ye and M. Monperrus. 'ITER: Iterative Neural Repair for Multi- Location Patches.' In: IEEE/ACM International Conference on Soft- ware Engineering . ACM, 2024, pp. 1-13. DOI: 10.1145/3597503. 3623337. |
| [55] | F. Y. Assiri and J. M. Bieman. 'Fault Localization for Automated Program Repair: Effectiveness, Performance, Repair Correctness.' In: Software Quality Journal 25.1 (2017), pp. 171-199. DOI: 10.1007/ s11219-016-9312-z. |
| [56] | S. Pearson, J. Campos, R. Just, G. Fraser, R. Abreu, M. D. Ernst, D. Pang, and B. Keller. 'Evaluating and Improving Fault Localization.' In: IEEE/ACM 39th International Conference on Software Engineering (ICSE) . 2017, pp. 609-620. DOI: 10.1109/ICSE.2017.62. |
| [57] | D. Yang, Y. Qi, X. Mao, and Y. Lei. 'Evaluating the Usage of Fault Localization in Automated Program Repair: An Empirical Study.' In: Frontiers of Computer Science 15.1 (2020), p. 151202. DOI: 10.1007/ s11704-020-9263-1. |
| [58] | A. Christi, M. L. Olson, M. A. Alipour, and A. Groce. 'Reduce Before You Localize: Delta-Debugging and Spectrum-Based Fault Lo- calization.' In: IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW) . 2018, pp. 184-191. DOI: 10.1109/ ISSREW.2018.00005. |
| [59] | X. Zhang, N. Gupta, and R. Gupta. 'A Study of Effectiveness of Dynamic Slicing in Locating Real Faults.' In: Empirical Software Engineering 12.2 (2007), pp. 143-160. DOI: 10.1007/s10664- 006- 9007-3. |
| [60] | E. Alves, M. Gligoric, V. Jagannath, and M. d'Amorim. 'Fault- Localization Using Dynamic Slicing and Change Impact Analysis.' In: IEEE/ACM International Conference on Automated Software Engineer- ing (ASE 2011) . 2011, pp. 520-523. DOI: 10.1109/ASE.2011.6100114. |
| [61] | X. Li and A. Orso. 'More Accurate Dynamic Slicing for Better Supporting Software Debugging.' In: IEEE 13th International Con- |
- ference on Software Testing, Validation and Verification (ICST) . 2020, pp. 28-38. DOI: 10.1109/ICST46399.2020.00014.
| | pp. 28-38. DOI: 10.1109/ICST46399.2020.00014. |
|------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [62] | E. Soremekun, L. Kirschner, M. B¨hme, o and A. Zeller. 'Locating Faults with Program Slicing: An Empirical Analysis.' In: Empirical Software Engineering 26.3 (2021), p. 51. DOI: 10.1007/s10664-020- 09931-7. |
| [63] | P. A. Soha. 'On The Efficiency Of Combination Of Program Slicing and Spectrum-Based Fault Localization.' In: IEEE Conference on Soft- ware Testing, Verification and Validation (ICST) . 2023, pp. 499-501. DOI: 10.1109/ICST57152.2023.00061. |
| [64] | B. Liu, Lucia, S. Nejati, and L. C. Briand. 'Improving Fault Localiza- tion for Simulink Models Using Search-Based Testing and Prediction Models.' In: IEEE 24th International Conference on Software Analysis, Evolution and Reengineering (SANER) . 2017, pp. 359-370. DOI: 10. 1109/SANER.2017.7884636. |
| [65] | M. Zhang, X. Li, L. Zhang, and S. Khurshid. 'Boosting Spectrum- Based Fault Localization Using PageRank.' In: ACM SIGSOFT Inter- national Symposium on Software Testing and Analysis . ACM, 2017, pp. 261-272. DOI: 10.1145/3092703.3092731. |
| [66] | A. Guo, X. Mao, D. Yang, and S. Wang. 'An Empirical Study on the Effect of Dynamic Slicing on Automated Program Repair Efficiency.' In: IEEE International Conference on Software Maintenance and Evolution (ICSME) . 2018, pp. 554-558. DOI: 10.1109/icsme.2018. 00066. |
| [67] | J. Xuan, M. Martinez, F. DeMarco, M. Cl´ment, e S. L. Marcote, T. Durieux, D. Le Berre, and M. Monperrus. 'Nopol: Automatic Repair of Conditional Statement Bugs in Java Programs.' In: IEEE Transactions on Software Engineering 43.1 (2017), pp. 34-55. DOI: 10.1109/tse. 2016.2560811. |
| [68] | M. Weiser. 'Program Slicing.' In: International Conference on Soft- ware Engineering (ICSE) . IEEE, 1981, pp. 439-449. |
| [69] | M. Harman and R. Hierons. 'An Overview of Program Slicing.' In: Software Focus 2.3 (2001), pp. 85-92. DOI: 10.1002/swf.41. |
| [70] | J. Silva. 'A Vocabulary of Program Slicing-Based Techniques.' In: ACM Computing Surveys 44.3 (2012), 12:1-12:41. DOI: 10 . 1145 / 2187671.2187674. |
| [71] | S. Reis, R. Abreu, and M. D'Amorim. 'Demystifying the Combination of Dynamic Slicing and Spectrum-Based Fault Localization.' In: International Joint Conference on Artificial Intelligence . AAAI Press, 2019, pp. 4760-4766. |
| [72] | J. Hatcliff and M. Dwyer. 'Using the Bandera Tool Set to Model- Check Properties of Concurrent Java Software.' In: CONCUR 2001 - Concurrency Theory . Ed. by K. G. Larsen and M. Nielsen. Springer, 2001, pp. 39-58. DOI: 10.1007/3-540-44685-0 5. |
| [73] | M. Chalupa, M. Vitovsk´, a T. Jaˇek, s M. ˇ Sim´ˇek, ac and J. Strejˇek. c 'Symbiotic 6: Generating Test Cases by Slicing and Symbolic Execution.' In: International Journal on Software Tools for Technology Transfer 23.6 (2021), pp. 875-877. DOI: 10.1007/s10009-020-00573- 0. |
| [74] | M. B. Dwyer, J. Hatcliff, M. Hoosier, V. Ranganath, Robby, and T. Wallentine. 'Evaluating the Effectiveness of Slicing for Model Reduction of Concurrent Object-Oriented Programs.' In: Tools and Algorithms for the Construction and Analysis of Systems . Ed. by H. Hermanns and J. Palsberg. Springer, 2006, pp. 73-89. DOI: 10. 1007/11691372 5. |
| [75] | M. Chalupa and J. Strejˇek. c 'Evaluation of Program Slicing in Soft- ware Verification.' In: Integrated Formal Methods . Ed. by W. Ahrendt and S. L. Tapia Tarifa. Springer, 2019, pp. 101-119. DOI: 10.1007/978- 3-030-34968-4 6. |
| [76] | E. T. Barr, Y. Brun, P. Devanbu, M. Harman, and F. Sarro. 'The Plastic Surgery Hypothesis.' In: ACM SIGSOFT International Symposium on Foundations of Software Engineering . ACM, 2014, pp. 306-317. DOI: 10.1145/2635868.2635898. | | null | [
"Linas Vidziunas",
"David Binkley",
"Leon Moonen"
] | 2024-08-02T09:23:45+00:00 | 2024-08-02T09:23:45+00:00 | [
"cs.SE"
] | The Impact of Program Reduction on Automated Program Repair | Correcting bugs using modern Automated Program Repair (APR) can be both
time-consuming and resource-expensive. We describe a program repair approach
that aims to improve the scalability of modern APR tools. The approach
leverages program reduction in the form of program slicing to eliminate code
irrelevant to fixing the bug, which improves the APR tool's overall
performance. We investigate slicing's impact on all three phases of the repair
process: fault localization, patch generation, and patch validation. Our
empirical exploration finds that the proposed approach, on average, enhances
the repair ability of the TBar APR tool, but we also discovered a few cases
where it was less successful. Specifically, on examples from the widely used
Defects4J dataset, we obtain a substantial reduction in median repair time,
which falls from 80 minutes to just under 18 minutes. We conclude that program
reduction can improve the performance of APR without degrading repair quality,
but this improvement is not universal.
A replication package is available via Zenodo at
https://doi.org/10.5281/zenodo.13074333.
Keywords: automated program repair, dynamic program slicing, fault
localization, test-suite reduction, hybrid techniques. |
2408.01135v1 | ## WEAK COMPACTNESS IN LIPSCHITZ-FREE SPACES OVER SUPERREFLEXIVE SPACES
## ZDEN ˇ K SILBER E
Abstract. We show that the Lipschitz-free space F ( X ) over a superreflexive Banach space X has the property that every weakly precompact subset of F ( X ) is relatively super weakly compact, showing that this space 'behaves like L 1 ' in this context. As consequences we show that F ( X ) enjoys the weak Banach-Saks property and that every subspace of F ( X ) with nontrivial type is superreflexive. Further, weakly compact subsets of F ( X ) are super weakly compact and hence have many strong properties. To prove the result, we use a modification of the proof of weak sequential completeness of F ( X ) by Kochanek and Perneck´ a and an appropriate version of compact reduction in the spirit of Aliaga, Noˆs, Petitjean and Proch´zka. u a
## 1. Introduction
This paper is dedicated to strengthening some results concerning weak compactness in Lipschitz-free spaces over superreflexive spaces. Note that the Lipschitz-free space over the real line, F ( R ), is isomorphic to L 1 (see Example 2.1. of [11]). Structure of Lipschitz-free spaces over Banach spaces of higher dimension seems to be more complicated, even when the dimension is finite. However, some properties of L 1 are shared by Lipschitz-free spaces over Banach spaces of higher dimension. In [7], the authors showed that for any M ⊆ R n , the Lipchitz-free space F ( M ) is weakly sequentially complete. Later, this result was extended in [13] for M compact subset of a superreflexive space. Both of these results used a modification of a method by Bourgain [3, 4] (see Theorem III.D.31 of [21]). Finally, in [2], the authors proved a compact reduction theorem for weak sequential completeness, showing that F ( X ) is weakly sequentially complete if X is a superreflexive Banach space.
The results above shed some light on the structure of Lipschitz-free spaces over superreflexive spaces. Weak sequential completeness gives us that a bounded subset A of F ( X ) is relatively weakly compact if and only if it is weakly precompact (i.e. if and only if there is no sequence in A equivalent to the canonical basis of ℓ 1 ), and also implies that no non weakly sequentially complete Banach space (in particular c 0 ) can be isomorphic to a subspace of F ( X ).
A different area of study is the theory of super weakly compact sets. Super weakly compact sets are a localization of superreflexivity in the same sense as weakly compact sets are a localization of reflexivity. Many papers were devoted to this study [5, 6, 12, 14, 15, 19], and many
2020 Mathematics Subject Classification. 46B03, 46B20, 46B50.
Key words and phrases. Lipschitz-free spaces, Schur property, superreflexivity, super weakly compact sets, weak sequential completeness.
interesting properties of super weakly compact sets are known (see Subsection 1.2. and references therein). There are spaces in which every weakly compact set is super weakly compact superreflexive spaces, Schur spaces, L 1 ( µ ), C K ( ) ∗ or preduals of JBW ∗ triples (see Section 6 of [14]). The main result of this paper is that the Lipschitz-free space F ( X ) for X superreflexive enjoys this property as well. Hence, in such F ( X ), it holds that a bounded set A is weakly precompact if and only if it is relatively weakly compact if and only if it is relatively super weakly compact (we call this property of Banach spaces property (R), see Section 2). This gives us that any weakly compact subset of F ( X ) for X superreflexive enjoys all of the strong properties of super weakly compact sets (see e.g. Propositions 1.7 and 1.8).
As mentioned in the above paragraph, we say that a Banach space X has property (R) if every weakly precompact subset of X is relatively super weakly compact. In [16], Rosenthal showed that every subspace of L 1 ( µ ), for finite µ , which does not contain ℓ 1 embeds in L p ( µ ) for some p > 1 (and such L p ( µ ) is superreflexive as it is uniformly convex). Property (R) can be thus understood as a localization of the above result of Rosenthal, where we consider weakly precompact sets instead of subspaces not containing ℓ 1 and relatively super weakly compact sets instead of superreflexive spaces. It is clear (see Propositon 2.2) that a Banach space has property (R) if and only if it is weakly sequentially complete and every weakly compact subset of X is super weakly compact. Property (R) is an intermediate property, stronger than weak sequential completeness but weaker than the Schur property (as being relatively compact implies being relatively super weakly compact, which in turn implies being relatively weakly compact). We devote Section 2 to the study of property (R).
Finally, once we show that F ( X ) has property (R) for superreflexive X , we can improve some non-embeddability results. In particular, we show that any subspace of such F ( X ) with nontrivial type is superreflexive (Proposition 2.4). This implies that the Banach spaces ( ⨁︁ ∞ N =1 ℓ N 1 ) ℓ p , ( ⨁︁ ∞ N =1 ℓ N ∞ ) ℓ p , for p > 1, cannot embed in F ( X ) (Corollary 2.6). Finally, we show that any Banach space with property (R), and thus F ( X ) for superreflexive X , has the weak Banach-Saks property (Proposition 2.5).
The paper is organised as follows. In the rest of the introductory section we recall all the key notions necessary for the paper, namely weak sequential completeness, Schur property, Lipschitz-free spaces and some propeties of relatively super weakly compact sets. In the second section we introduce the property (R), prove some of its properties and give examples. Third section is devoted to the proof that Lipschitz-free spaces over superreflexive spaces have property (R). In the last section we give a proof of compact reduction for the weak Banach-Saks property due to R. Aliaga, G. Grelier and A. Proch´zka and mention some open problems a
## 1.1. Weak sequential completeness and Schur property. Let us begin with the definition.
Definition 1.1. A sequence ( x n n ) ∈ N in a Banach space X is weakly Cauchy if for every x ∗ ∈ X ∗ the sequence of scalars ( x ∗ ( x n )) n ∈ N is convergent. A Banach space X is weakly sequentially complete if every weakly Cauchy sequence in X is weakly convergent.
Application of the uniform boundedness principle yields that a sequence ( x n n ) ∈ N in X is weakly Cauchy if and only if there is some x ∗∗ ∈ X ∗∗ such that ( x n n ) ∈ N converges to x ∗∗ in the weak ∗ topology of X ∗∗ . Clearly, every reflexive space is weakly sequentially complete. An example of a nonreflexive Banach space which is weakly sequentially complete is L 1 ( µ ).
Definition 1.2. A Banach space X has the Schur property (or X is a Schur space ) if every weakly convergent sequence in X is norm convergent.
It is easy to see that in a Schur space every weakly Cauchy sequence is norm Cauchy, and thus Schur spaces are weakly sequentially complete. The typical example of a Banach space with the Schur property is ℓ 1 . Schur property is, in a sense, very far away from reflexivity - if a Banach space is simultaneously reflexive and has the Schur property, then it must be finite dimensional (this follows from Eberlein- ˇ mulyan theorem). S
Weak sequential completeness is a property which is common to both reflexive and Schur spaces. Recall the statement of Rosenthal's ℓ 1 theorem [17]: Every bounded sequence in a Banach space X has a subsequence which is either weakly Cauchy or equivalent to the canonical basis of ℓ 1 . This theorem gives us a characterization of both weak sequential completness and Schur property. We first recall the definition of weakly precompact sets.
Definition 1.3. A bounded subset A of a Banach space X is weakly precompact if it does not contain a sequence equivalent to the canonical basis of ℓ 1 .
By Rosenthal's ℓ 1 theorem, a bounded set A is weakly precompact if and only if every sequence in A has a weakly Cauchy subsequence. Weakly precompact sets are preserved under convex hulls (see e.g. Addendum of [18]) and images under bounded linear operators (this follows from the fact that if a seminormalised sequence ( x n n ) ∈ N maps onto the canonical basis of ℓ 1 by a bounded linear map, then ( x n n ) ∈ N must itself be equivalent to the canonical basis ℓ 1 ). The following propositions follow immediately from the definitions, Rosenthal's ℓ 1 theorem and Eberlein- ˇ mulyan theorem. S
Proposition 1.4. Let X be a Banach space. The following are equivalent:
- (1) X is weakly sequentially complete;
- (2) every bounded sequence in X has a subsequence which is either weakly convergent or equivalent to the ℓ 1 basis;
- (3) every weakly precompact subset of X is relatively weakly compact.
Proposition 1.5. Let X be a Banach space. The following are equivalent:
- (1) X has the Schur property;
- (2) every bounded sequence in X has a subsequence which is either norm convergent or equivalent to the ℓ 1 basis;
- (3) every weakly precompact subset of X is relatively compact.
- 1.2. Lipchitz-free spaces. Let ( M,d ) be a pointed metric space (that is, a metric space with a distinguished point 0 ∈ M ). We denote by Lip ( 0 M ) the Banach space of Lipschitz functions on M which map 0 ∈ M to 0 ∈ R , equipped with the Lipschitz-constant norm defined by formula
̸
$$\| f \| _ { \text{Lip} } = \sup \left \{ \frac { | f ( p ) - f ( q ) | } { d ( p, q ) } \, \colon p, q \in M, p \neq q \right \}.$$
Then M embeds isometrically in the dual space Lip ( 0 M ) ∗ via the evaluation map δ : M → Lip ( 0 M ) ∗ , ⟨ δ p , f ( ) ⟩ = f ( p ), p ∈ M f , ∈ Lip ( 0 M ). The Lipschitz-free space F ( M ) is then the closed linear span of δ M ( ) with the norm ∥·∥ F induced by the dual norm of Lip ( 0 M ) ∗ .
The Lipschitz-free space F ( M ) is an isometric predual of Lip ( 0 M ) and is characterized by the following universality property: For any Banach space X and Lipschitz map L : M → X with L (0) = 0 there is a unique linear map L ˜ : F ( M ) → X such that L ˜ ◦ δ = L and ∥ L ˜ ∥ = ∥ L ∥ Lip . For more information about Lipchitz-free spaces see the book [20] or the survey paper [11].
- 1.3. Super weakly compact sets. In the same sense as weak compactness can be understood as a localization of reflexivity (that is X is reflexive if and only if B X is weakly compact), the notion of super weak compactness was introduced as a localization of superreflexivity.
Definition 1.6. Let A be a subset of a Banach space X . We say that A is relatively super weakly compact if K U is weakly compact in X U for every free ultrafilter U on N . We say that A is super weakly compact if it is relatively super weakly compact and weakly closed.
Let us recall that X U is the quotient of ℓ ∞ ( X ) by the null space N U = { ( x n n ) ∈ N ∈ ℓ ∞ ( X ) : lim U x n = 0 } and A U is the subset of X U , whose elements have representants ( x n n ) ∈ N where x n ∈ A for each n ∈ N . For more details see e.g. [14]. Every relatively norm compact set is relatively super weakly compact (this was shown in Corollary 2.15. of [6] for convex sets, but both relative compactness and relative super weak compactness are preserved by convex hulls, see [19]) and every relatively super weakly compact set is clearly relatively weakly compact.
It follows that a Banach space X is superreflexive if and only if B X is super weakly compact. However, there are super weakly compact sets which do not embed in superreflexive spaces [15, Example 3.11].
Super weakly compact sets admit many characterizations and have some very nice properties. We name a few, first for the case of convex sets. The following proposition is Proposition 2.1., Theorem 3.5. and Theorem 3.8. of [14], for unexplained notions see [14].
Proposition 1.7. Let A be a bounded closed convex subset of a Banach space X . The following are equivalent:
- (1) A is super weakly compact;
- (2) A is finitely dentable;
- (3) A does not have the finite tree property;
- (4) A supports a bounded uniformly convex function;
- (5) X has an equivalent norm whose square is uniformly convex on A ;
- (6) Every real Lipschitz (or uniformly continuous) function on A can be uniformly approximated by differences of convex Lipschitz functions;
- (7) There is no θ > 0 such that for every n ∈ N there are sequences ( x n k ) k ≤ n ⊆ A , ( f n k ) k ≤ n ⊆ B X ∗ such that f n k ( x n j ) = 0 if k > j and f n k ( x n j ) = θ if k ≤ j .
We will later use the equivalence (1) ⇔ (7) . The other points were mentioned to illustrate some strong properties of convex super weakly compact sets.
In the absence of convexity, super weakly compact sets do not behave as nicely. However, K. Tu showed in [19] that the closed convex hull of a relatively super weakly compact set is super weakly compact, so some of the results can be transferred to the non-convex case as well (the paper [14] is dedicated to this). In particular, in Corollary 2.4. of [14] the following is shown.
Proposition 1.8. Let A be a super weakly compact subset of a Banach space X . Then
- (1) A is uniformly Eberlein;
- (2) A has the Banach-Saks property;
- (3) A is finitely dentable.
None of the above can be reversed.
For some further characterization using equi bi-Lipschitz embeddability of some families of metric spaces see Section 5 of [14].
For a quantitative approach and further results, see [19] and references therein. We will need one of these results, namely a measure of relative super weak compactness introduced in [19] which is a quantitative analogue to the classical Grothendieck characterization of relative weak compactness.
Definition 1.9. Let A be a bounded subset of a Banach space X . We define
$$\sigma ( A ) = \inf \{ t > 0 \, \colon A \subseteq K + t B _ { X }, K \text{ is super weakly compact} \}.$$
In the next proposition we list some properties of the quantity σ we will need in further proofs, namely to show compact reduction for property (R) in Lipschitz-free spaces (Proposition 3.5).
Proposition 1.10. Let A, B be bounded subsets of a Banach space X . Then:
- (1) σ A ( ) = 0 if and only if A is relatively super weakly compact;
- (2) σ A ( + B ) ≤ σ A ( ) + σ B ( ) ;
- (3) σ A ( ) ≤ diam A .
Proof. The first two properties are shown in Theorem 4.3. of [19]. For the third property note that A ⊆ { } a +(diam A ) · B X for any a ∈ A , and that every singleton is clearly super weakly compact. □
## Z. SILBER
## 2. Property (R)
The following property is inspired by a well known result of Rosenthal [16]: Any subspace of L 1 ( µ ) either contains ℓ 1 or embeds in a superreflexive space . We consider a localised version of this property for sets instead of subspaces.
Definition 2.1. We say that a Banach space X has property (R) if every weakly precompact set in X is relatively super weakly compact.
Hence, in Banach spaces satisfying property (R), the only obstacle for relative super weak compactness comes from the presence of the canonical basis of ℓ 1 . In view of Propositions 1.4 and 1.5, property (R) can be considered as an intermediate property stronger than weak sequential completeness but weaker than the Schur property.
Proposition 2.2. Let X be a Banach space. Then X has property (R) if and only if X is weakly sequentially complete and every weakly compact subset of X is super weakly compact.
Proof.
This follows immediately from the definition and Proposition 1.4. □
Example 2.3. The following Banach spaces have property (R): superreflexive spaces; Schur spaces; L 1 ( µ ); C K ( ) ∗ ; preduals of JBW ∗ triples.
Proof. In superreflexive spaces every bounded set is relatively super weakly compact, so they clearly have property (R). On the other hand, in a Schur space every weakly precompact set is relatively norm compact, and thus relatively super weakly compact, so Schur spaces have property (R). The other cases follow from Proposition 6.1. of [14] and weak sequential completeness of the given space. □
Note that superreflexive spaces are, in a sense, as far from Schur spaces as possible. It could be reasoned that superreflexive spaces enjoy property (R) because it is easy for a subset to be relatively super weakly compact. On the other hand, Schur spaces enjoy property (R) because it is hard for a subset to not contain a sequence equivalent to the canonical ℓ 1 basis.
In the next proposition we point out some properties of spaces with property (R). We say that a subset A of a Banach space X contains ℓ N 1 bases uniformly if there is C > 0 such that A contains C -equivalent copy of the canonical basis of ℓ N 1 for every N ∈ N . It is a well known result by Pisier that X contains ℓ N 1 bases uniformly if and only if X has trivial type (see e.g. Theorem 13.3. of [8]).
Proposition 2.4. Let X be a Banach space with property (R). Then each of the following holds true:
- (1) A bounded subset of X contains ℓ N 1 bases uniformly if and only if it contains the canonical basis of ℓ 1 .
- (2) Any subspace of X with nontrivial type is superreflexive.
Proof. The point (1) follows as any set that contains ℓ N 1 bases uniformly is not relatively super weakly compact. The point (2) follows from (1) and the above-mentioned result of Pisier. □
Recall that a bounded subset A of a Banach space X is a (weak) Banach-Saks set if every (resp. every weakly convergent) sequence in A has Cesaro summable 1 subsequence. We say that a Banach space X has the (weak) Banach-Saks property if B X is a (weak) Banach-Saks set.
Proposition 2.5. Let X be a Banach space in which every relatively weakly compact set is relatively super weakly compact (e.g. a Banach space with property (R)). Then X has the weak Banach-Saks property.
Proof. Let ( x n n ) ∈ N be a weakly convergent sequence in X . Then the set { x n : n ∈ N } is relatively weakly compact and, by the assumption, relatively super weakly compact. We now appeal to Proposition 1.8 (2) and see that { x n : n ∈ N } is a Banach-Saks set, which implies that ( x n n ) ∈ N has a Cesaro summable subsequence. □
Immediately we get the following corollary.
Corollary 2.6. Let X be a Banach space with property (R). Then none of the following spaces can embed in X .
- (1) c 0 , non-reflexive quasi-reflexive Banach spaces;
- (2) the Schreier space and the Baernstein space;
- (3) ( ⨁︁ ∞ N =1 ℓ N 1 ) ℓ p , ( ⨁︁ ∞ N =1 ℓ N ∞ ) ℓ p , p > 1 .
Proof. All these items follow from Propositions 2.4 and 2.5. The first case follows as these spaces are not weakly sequentially complete. The second case follows as these spaces fail the weak Banach-Saks property. The case of the ℓ p sums follows from Proposition 2.4 as these spaces contain ℓ N 1 bases uniformly but do not contain ℓ 1 as they are reflexive. □
Remark 2.7. Note that X = ( ⨁︁ ∞ N =1 ℓ N ∞ ) ℓ 1 is a Schur space (as is any ℓ 1 sum of finite dimensional spaces), and thus has property (R). Further, X contains ℓ N ∞ 's isometrically, and so every Banach space is finitely representable in X (as every Banach space is finitely representable in c 0 [1, Example 11.1.2] and c 0 is clearly finitely representable in every Banach space which contains isometric copies of ℓ N ∞ 's). It follows that property (R) does not imply any nontrivial super-property.
## 3. Property (R) in Lipschitz-free spaces over superreflexive spaces
In this section we will prove that Lipschitz-free spaces over superreflexive spaces enjoy property (R). For this we will adapt a method by Bourgain [3, 4], which was modified and used in [7] to prove weak sequential completeness of Lipschitz-free spaces over R n , and further modified
1 Recall that a sequence ( x n n ) ∈ N is Cesaro summable if and only if the sequence ( n -1 ∑︁ n k =1 x k ) n ∈ N of its arithmetic means is norm convergent
in [13] to extend the result to Lipschitz-free spaces over compact subsets of superreflexive spaces. The main ingredient of our proof is the observation that a certain property, which was used in an essential way in proofs of both [7, 13], is satisfied not only for subsets that are not relatively weakly compact, but also by subsets which are not relatively super weakly compact. Hence, we will be able to strengthen the results and get relative super weak compactness instead of just relative weak compactness in the end. Later in this section, we will prove an analogue of compact reduction from [2] for property (R), which will allow us to get the result for superreflexive spaces instead of compact subsets of superreflexive spaces.
Before proceeding, let us recall the definition of WUC series.
Definition 3.1. Let ( x n n ) ∈ N be a sequence in a Banach space X . We say that the formal series ∑︁ ∞ n =1 x n is WUC (weakly unconditionally Cauchy) , if for every x ∗ ∈ X ∗ the series of scalars ∑︁ ∞ n =1 | x ∗ ( x n ) | is convergent.
The following proposition is a modification of Theorem 9 of [13]. Since, except for the very first step, the proof of our proposition is identical to the proof of Theorem 9 of [13], we will present only the first part and refer the reader to [13] for the rest of the proof.
Proposition 3.2. Let M be a compact subset of a superreflexive space X . Suppose that Γ ⊆ F ( M ) is closed convex bounded and not super weakly compact. Then there is a WUC series ∑︁ ∞ k =1 ρ k in Lip ( 0 M ) such that
$$\lim _ { k \to \infty } \sup \sup \{ | \langle \mu, \rho _ { k } \rangle | \, \colon \mu \in \Gamma \} > 0.$$
Proof. Following the proof of Theorem 9 of [13] we can assume, possibly by renorming X and passing to a subspace, that X is p -smooth for some p ∈ (1 , 2] and that X is separable. Further, by translating the set M , we can suppose that 0 ∈ M .
It was shown in the proof of Theorem 9 of [13] that if we can find C ≥ 1, ξ > 0 and for n ∈ N sequences
$$n$$
$$( f _ { j } ^ { n } ) _ { j \leq n } & \subseteq \text{Lip} _ { 0 } ( M ) \\ ( \mu _ { j } ^ { n } ) _ { j \leq n } & \subseteq \text{span} \{ \delta ( p ) \colon p \in M \}$$
such that the following conditions are satisfied:
- (1) ⃦ ⃦ µ n j ⃦ ⃦ F ≤ C for n ∈ N and j ≤ n ;
- (2) ⃦ ⃦ f n j ⃦ ⃦ Lip ≤ 1 for n ∈ N and j ≤ n ;
- (3) |⟨ µ , f n j n k ⟩| ≤ ξ 3 for n ∈ N and j < k ≤ n ;
- (4) ⟨ µ , f n j n k ⟩ ≥ ξ for n ∈ N and k ≤ j ≤ n ;
- (5) dist( µ , n j Γ) ≤ 6 Cξ ξ +48 C for n ∈ N and j ≤ n ,
then there is a WUC series ∑︁ ∞ k =1 ρ k in Lip ( 0 M ) with the required property. We are going to show how to find such ( f n j ) j ≤ n and ( µ n j ) j ≤ n and refer the reader to Theorem 9 of [13] for the
rest of the proof. Let us stress that the rest of the proof of Theorem 9 of [13] does not use that Γ is not relatively weakly compact.
So, suppose that Γ is as above. We can use Theorem 3.8. of [14] (that is the equivalence (1) ⇔ (7) of our Proposition 1.7) to find θ > 0 and for every n ∈ N finite sequences ( x n k ) k ≤ n ⊆ Γ and ( f n k ) k ≤ n ⊆ B Lip 0 ( M ) such that f n j ( x n k ) = 0 for j > k and f n j ( x n k ) = θ for j ≤ k .
Let C = 1 + sup {∥ γ ∥ F : γ ∈ Γ } and 0 < ξ < θ . Fix ϵ > 0 small enough such that
$$\epsilon < \min \left \{ \frac { 6 C \xi } { \xi + 4 8 C }, \frac { \xi } { 3 }, \theta - \xi, 1 \right \}.$$
We can use density of span { δ p ( ) : p ∈ M } in F ( M ) to find, for each n ∈ N and k ≤ n , an element µ n k ∈ span { δ p ( ) : p ∈ M } such that ∥ µ n k -x n k ∥ F ≤ ϵ . The required properties (1)-(5) then clearly follow from the properties of x n k 's and the choice of ϵ . □
Theorem 3.3. Let M be a compact subset of a superreflexive space X . Then the Lipschitz-free space F ( M ) has property (R).
Proof. Let Γ ′ ⊆ F ( M ) be a bounded subset which is not relatively super weakly compact. Set Γ = convΓ . As Γ is not super weakly compact, by Proposition 3.2 there is a WUC series ′ ∑︁ ∞ k =1 ρ k in Lip ( 0 M ) such that
$$\lambda = \lim _ { k \to \infty } \sup _ { k \to \infty } \{ | \langle \mu, \rho _ { k } \rangle | \, \colon \mu \in \Gamma \} > 0.$$
As ∑︁ ∞ k =1 ρ k is WUC, the operator T : F ( M ) → ℓ 1 , T µ ( ) = ( ⟨ µ, ρ k ⟩ ) k ∈ N , is well defined and bounded. It follows from the fact that λ > 0 that T (Γ) ⊆ ℓ 1 is a bounded set which is not relatively norm compact. By Proposition 1.5 and Schur property of ℓ 1 , T (Γ) is not weakly precompact. As weak precompactness is preserved under bounded linear images, Γ is not weakly precompact either.
Hence, Γ is not weakly precompact, and so neither is Γ ′ (as being weakly precompact is preserved under convex hulls and closures, see Addendum of [18]). □
Remark 3.4. In Theorem III.D.31 of [21] it is shown that the dual of a rich subspace X of C K, ( R n ) is weakly sequentially complete. In the same way as above, the proof can be modified to show that X ∗ has property (R). Indeed, the condition ( ∗ ) on the bottom of page 169 of [21] follows not only if the set not relatively weakly compact, but also when the given set is not relatively super weakly compact.
Now we prove the promised compact reduction for property (R).
Proposition 3.5. Let M be a complete metric space. Then F ( M ) has property (R) if and only if F ( K ) has property (R) for every compact K ⊆ M .
Proof. As property (R) is clearly passed to subspaces and F ( K ) is a subspace of F ( M ) for K ⊆ M , we need to show only the backwards implication. Let W ⊆ F ( M ) be weakly precompact. We will show that σ W ( ) = 0 and apply Proposition 1.10 to show that W is relatively super
weakly compact. Fix ϵ > 0 and use compact reduction for weakly precompact sets (Theorem 2.3. of [2]) to find compact K ⊆ M and linear (not necessarily bounded) T : span W →F ( K ) such that
- (1) ∥ µ -Tµ ∥ F ≤ ϵ for all µ ∈ W ,
- (2) There are bounded linear maps T k : F ( M ) → F ( M ), k ∈ N , such that ( T k | W ) k ∈ N converges to T W | uniformly on W .
First we show that T W ( ) is weakly precompact in F ( K ). As weak precompactness is preserved by bounded linear maps, for every k ∈ N the set T k ( W ) is weakly precompact. Suppose, for a contradiction, that T W ( ) contains a sequence C -equivalent to the canonical basis of ℓ 1 for some C > 0. Using (2) we find k ∈ N such that T k ( W ) contains a sequence C/ 2-equivalent to the canonical basis of ℓ 1 , contradicting that T k ( W ) is weakly precompact. Hence, T W ( ) is weakly precompact as required.
But T W ( ) ⊆ F ( K ), so by the assumption T W ( ) is relatively super weakly compact. It follows from Proposition 1.10 (1) that σ T ( ( W )) = 0. Further, by (1) we get that W ⊆ T W ( ) + ϵB F ( M ) , and thus by Proposition 1.10 (2) and (3)
$$\sigma ( W ) \leq \sigma ( T ( W ) ) + \sigma ( \epsilon B _ { \mathcal { F } ( M ) } ) \leq 0 + \text{diam} ( \epsilon B _ { \mathcal { F } ( M ) } ) = 2 \epsilon.$$
As ϵ > 0 was arbirary, σ W ( ) = 0 and W is relatively super weakly compact by Proposition 1.10 (1) as required to show that F ( M ) has property (R). □
Combining the results above, we get the main theorem of this section.
Theorem 3.6. Let X be a superreflexive space. Then F ( X ) has property (R).
Proof. By Proposition 3.5 it is enough to show that F ( K ) has property (R) for every K ⊆ X compact. But this follows from Theorem 3.3. □
Remark 3.7. It follows from Theorem 3.6 and Corollary 2.6 that F (( ⨁︁ ∞ N =1 ℓ N 1 ) ℓ 2 ) is not isomorphic to a subspace of F ( ℓ 2 ), and also not isomorphic to a subspace of F ( Y ) for finitedimensional Y . This was apparently unknown before the results of this paper.
## 4. Additional remarks and open problems
- 4.1. Compact reduction of weak Banach-Saks property. In what follows we show that compact reduction for the weak Banach-Saks property is also true. This observation and its proof is due to R. Aliaga, G. Grelier and A. Proch´zka. We thank them for kindly letting us a to include it in this paper.
Proposition 4.1. Let M be a complete metric space. Then F ( M ) has the weak Banach-Saks property if and only if F ( K ) has the weak Banach-Saks property for every compact K ⊆ M .
Proof. Let ( µ n n ) ∈ N ⊆ B F ( M ) be weakly null and let ( ϵ n n ) ∈ N ⊆ (0 , 1) be a sequence decreasing to 0. Then the set W = { µ n : n ∈ N } is weakly precompact, and thus by Theorem 2.3 of [2] there is a compact set K 1 ⊆ M and linear (not necessarily bounded) T : span W →F ( K 1 ) such that
- (1) ∥ µ n -Tµ n ∥ F ≤ ϵ for all n ∈ N ,
- (2) There are bounded linear maps T k : F ( M ) → F ( M ), k ∈ N , such that ( T k | W ) k ∈ N converges to T W | uniformly on W .
Set ξ 1 n = Tµ n for n ∈ N , then the sequence ( ξ 1 n ) n ∈ N is weakly null (see the proof of Corollary 2.4 of [2]). Since F ( K ) has the weak Banach-Saks property, we find an infinite subset N 1 ⊆ N such that all further subsequences of ( ξ 1 n ) n ∈ N 1 are Cesaro summable (the fact that we can choose a subsequence such that all its further subsequences are Cesaro summable follows from [9]). We now apply the same procedure for ( µ n n ) ∈ N 1 and ϵ 2 and obtain infinite N 2 ⊆ N 1 and ( ξ 2 n ) n ∈ N 1 ⊆ F ( K 2 ) such that ∥ µ n -ξ 2 n ∥ F ≤ ϵ 2 for all n ∈ N 1 , and such that every subsequence of ( ξ 2 n ) n ∈ N 2 is Cesaro summable. We can also suppose that min N 1 / N ∈ 2 . Following the same scheme we get
- · a decreasing sequence ( N j ) j ∈ N of infinite subsets of N with min N / N j ∈ j +1 for j ∈ N ,
- · for j ∈ N sequences ( ξ j n ) n ∈ N j such that
- i) Every subsequence of ( ξ j n ) n ∈ N j is Cesaro summable.
- ii) ∥ µ n -ξ j n ∥ F ≤ ϵ j for all n ∈ N j .
Take M = { min N i : i ∈ N } . We claim that ( µ n n ) ∈ M is Cesaro summable. Indeed, fix ϵ > 0 and let n ∈ N be such that ϵ n ≤ ϵ/ 3. Let us enumerate M = { m < m 1 2 < . . . } . Notice that ( m k ) ∞ k = n ⊆ N n for every n ∈ N . Hence, for k ≥ n we have
$$\left \| \frac { \mu _ { m _ { 1 } } + \dots + \mu _ { m _ { n - 1 } } + \mu _ { m _ { n } } + \dots + \mu _ { m _ { k } } } { k } \right \| & \leq \frac { n - 1 } { k } + \left \| \frac { \mu _ { m _ { n } } + \dots + \mu _ { m _ { k } } } { k - n + 1 } \right \| \\ & \leq \frac { n - 1 } { k } + \left \| \frac { \xi _ { m _ { n } } ^ { n } + \dots + \xi _ { m _ { k } } ^ { n } } { k - n + 1 } \right \| + \epsilon _ { n }, \\. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
where the second inequality follows from ii). Now we can use i) to see that for k large enough so that n -1 k < ϵ/ 3 and ⃦ ⃦ ⃦ ξ n mn + ··· + ξ n mk k -n +1 ⃦ ⃦ ⃦ < ϵ/ 3 we have that ⃦ ⃦ ⃦ µ m 1 + ··· + µ mk k ⃦ ⃦ ⃦ < ϵ , proving that ( µ n n ) ∈ M is Cesaro summable. □
- 4.2. Open problems. Note that all the examples of Banach spaces in which every relatively weakly compact set is relatively super weakly compact mentioned above are weakly sequentially complete. This inspires the following question:
Question 1. Is there a Banach space in which every relatively weakly compact set is relatively super weakly compact but which is not weakly sequentially complete?
A natural candidate to test for Question 1 is the James's space or some of its variants.
The next problem is concerned about super-variants of some properties studied in this paper.
Question 2. Is the space F ( X ) super weakly sequentially complete (does it have super weak Banach-Saks property), for X superreflexive? What about F ( R 2 ) ?
Positive answer to Question 2 would give us that F ( ℓ 2 ) has nontrivial cotype, solving the dichotomy of [10] (see the beginning of Section 5 of [10]).
## References
- [1] F. Albiac and N. Kalton , Topics in Banach Space Theory , no. sv. 10 in Graduate Texts in Mathematics, Springer, 2006.
- [2] R. J. Aliaga, C. Noˆs, C. Petitjean, and A. Proch´zka u a , Compact reduction in Lipschitz-free spaces , Stud. Math., 260 (2021), pp. 341-359.
- [3] J. Bourgain , On weak completeness of the dual of spaces of analytic and smooth functions , Bull. Soc. Math. Belg., S´r. B, 35 (1983), pp. 111-118. e
- [4] , The Dunford-Pettis property for the ball-algebras, the polydisc-algebras and the Sobolev spaces , Stud. Math., 77 (1984), pp. 245-253.
- [5] L. Cheng, Q. Cheng, S. Luo, K. Tu, and J. Zhang , On super weak compactness of subsets and its equivalences in Banach spaces , J. Convex Anal., 25 (2018), pp. 899-926.
- [6] L. Cheng, Q. Cheng, B. Wang, and W. Zhang , On super-weakly compact sets and uniformly convexifiable sets , Stud. Math., 199 (2010), pp. 145-169.
- [7] M. C´ uth, M. Doucha, and P. Wojtaszczyk , On the structure of Lipschitz-free spaces , Proc. Am. Math. Soc., 144 (2016), pp. 3833-3846.
- [8] J. Diestel, H. Jarchow, and A. Tonge , Absolutely summing operators , vol. 43 of Camb. Stud. Adv. Math., Cambridge: Cambridge Univ. Press, 1995.
- [9] P. Erd˝s and M. Magidor o , A note on regular methods of summability and the Banach-Saks property , Proc. Am. Math. Soc., 59 (1976), pp. 232-234.
- [10] L. C. Garc´ ıa-Lirola and G. Grelier , Lipschitz-free spaces, ultraproducts, and finite representability of metric spaces , J. Math. Anal. Appl., 526 (2023), p. 14. Id/No 127253.
- [11] G. Godefroy , A survey on Lipschitz-free Banach spaces , Commentat. Math., 55 (2015), pp. 89-118.
- [12] G. Grelier and M. Raja , On uniformly convex functions , J. Math. Anal. Appl., 505 (2022), p. 25. Id/No 125442.
- [13] T. Kochanek and E. Perneck´ a , Lipschitz-free spaces over compact subsets of superreflexive spaces are weakly sequentially complete , Bull. Lond. Math. Soc., 50 (2018), pp. 680-696.
- [14] G. Lancien and M. Raja , Nonlinear aspects of super weakly compact sets , Ann. Inst. Fourier, 72 (2022), pp. 1305-1328.
- [15] M. Raja , Super WCG Banach spaces , J. Math. Anal. Appl., 439 (2016), pp. 183-196.
- [16] H. P. Rosenthal , On subspaces of L p , Ann. Math. (2), 97 (1973), pp. 344-373.
- [17] , A characterization of Banach spaces containing l 1 , Proceedings of the National Academy of Sciences, 71 (1974), pp. 2411-2413.
- [18] , Point-wise compact subsets of the first Baire class , Am. J. Math., 99 (1977), pp. 362-378.
- [19] K. Tu , Convexification of super weakly compact sets and measure of super weak noncompactness , Proc. Am. Math. Soc., 149 (2021), pp. 2531-2538.
- [20] N. Weaver , Lipschitz algebras , Singapore: World Scientific, 1999.
- [21] Cambridge: Cambridge Univ. Press, 1996.
- P. Wojtaszczyk , Banach spaces for analysts , Email address : [email protected]
Institute of Mathematics of the Polish Academy of Sciences, ul. Sniadeckich 8, 00-656 ´ Warszawa, Poland | null | [
"Zdeněk Silber"
] | 2024-08-02T09:28:24+00:00 | 2024-08-02T09:28:24+00:00 | [
"math.FA",
"46B03, 46B20, 46B50"
] | Weak compactness in Lipschitz-free spaces over superreflexive spaces | We show that the Lipschitz-free space $\mathcal{F}(X)$ over a superreflexive
Banach space $X$ has the property that every weakly precompact subset of
$\mathcal{F}(X)$ is relatively super weakly compact, showing that this space
"behaves like $L_1$" in this context. As consequences we show that
$\mathcal{F}(X)$ enjoys the weak Banach-Saks property and that every subspace
of $\mathcal{F}(X)$ with nontrivial type is superreflexive. Further, weakly
compact subsets of $\mathcal{F}(X)$ are super weakly compact and hence have
many strong properties. To prove the result, we use a modification of the proof
of weak sequential completeness of $\mathcal{F}(X)$ by Kochanek and Perneck\'a
and an appropriate version of compact reduction in the spirit of Aliaga,
No\^us, Petitjean and Proch\'azka. |
2408.01137v1 | ## PGNeXt: High-Resolution Salient Object Detection via Pyramid Grafting Network
Changqun Xia, Chenxi Xie, Zhentao He, Tianshu Yu, and Jia Li, Senior Member, IEEE
Abstract -We present an advanced study on more challenging high-resolution salient object detection (HRSOD) from both dataset and network framework perspectives. To compensate for the lack of HRSOD dataset, we thoughtfully collect a large-scale high resolution salient object detection dataset, called UHRSD, containing 5,920 images from real-world complex scenarios at 4K-8K resolutions. All the images are finely annotated in pixellevel, far exceeding previous low-resolution SOD datasets. Aiming at overcoming the contradiction between the sampling depth and the receptive field size in the past methods, we propose a novel one-stage framework for HR-SOD task using pyramid grafting mechanism. In general, transformer-based and CNNbased backbones are adopted to extract features from different resolution images independently and then these features are grafted from transformer branch to CNN branch. An attentionbased Cross-Model Grafting Module (CMGM) is proposed to enable CNN branch to combine broken detailed information more holistically, guided by different source feature during decoding process. Moreover, we design an Attention Guided Loss (AGL) to explicitly supervise the attention matrix generated by CMGM to help the network better interact with the attention from different branches. Comprehensive experiments on UHRSD and widely-used SOD datasets demonstrate that our method can simultaneously locate salient object and preserve rich details, outperforming state-of-the-art methods. To verify the generalization ability of the proposed framework, we apply it to the camouflaged object detection (COD) task. Notably, our method performs superior to most state-of-the-art COD methods without bells and whistles.
Index Terms -Salient object detection, high-resolution segmentation, pyramid feature grafting
## I. INTRODUCTION
S ALIENT object detection (SOD) aims to locate the most attractive objects in the scene and accurately segment their structures. It has been used as a pre-processing step that can be widely applied to a variety of computer vision tasks, such as light field segmentation [2], [3], instance segmentation [4], video object segmentation [5], [6] and etc . [7][10]. Benefiting from the advances in deep learning [11][14], SOD methods are no longer limited to the hand-crafted features, leading to robustness in various complex scenarios. Most of SOD methods employ the feature-pyramid-network
This work was supported by the National Natural Science Foundation of China under the Grant 62132002 and Grant 62102206.
Changqun Xia and Chenxi Xie contribute equally to this work.
Changqun Xia is with the Peng Cheng Laboratory, Shenzhen 518055, China.
Chenxi Xie, Zhentao He, Tianshu Yu and Jia Li are with the State Key
Laboratory of Virtual Reality Technology and Systems, School of Computer
Science and Engineering, Beihang University, Beijing 100191, China.
Jia Li is the corresponding author (E-mail: [email protected]).
A preliminary version of this work has appeared in CVPR 2022 [1].


(a)Image
(c) PFSNet
(b) Ground Truth
(d) CNN
(e) Transformer
(f) Ours
Fig. 1. Comparison of the results of the different methods. (a) Input image. (b) Ground truth maks. (c) Down-sample then input to CNN-based PFSNet.(d) Directly input to ResNet-18 based FPN. (e) Down-sample then input to Swin-based FPN. (f) Ours.
(FPN)-style framework utilizing multi-level features that form a bottom-up decoding structure gradually recovering details of the saliency maps, and they have achieved remarkable achievements [15]-[20]. Although the existing methods have achieved impressive performance on several low-resolution (LR) benchmark datasets, there are limited attention given to high-resolution (HR) SOD task.
As daily accessible images are stepping towards highresolution ( e.g . 1080p, 2K and 4K), the ability to process high-resolution inputs is becoming increasingly important for SOD methods. Therefore, the advanced SOD models should be able to deal with the HR inputs to better cope with the requirements of real-world applications. However, existing SOD methods are mostly designed on the datasets at lowresolution (lower than 512 × 512 pixels), and applying them directly to high-resolution inputs leads to a series of issues. In Fig. 1, we illustrate several typical failures of several existing SOD methods in processing HR images. Fig. 1 (c) and Fig. 1 (e) show a straightforward scheme where the image is downsampled to a regular resolution and fed into the networks to obtain the saliency maps, and it is evident that although the overall region of the salient object is identified the fine details are severely corrupted. Besides, if we adopt high-resolution inputs without downsampling, it may lead to an incomplete structure of the salient object, as shown in Fig. 1 (d). Most of the existing LR SOD methods cannot simultaneously meet the requirements of ensuring that the salient object is accurate and complete while retaining sufficient details and sharp edges with high-resolution input. Thus we can observe the challenge of HR-SOD task, which is to simultaneously balance the
Fig. 2. Comparison of different methods for HR inputs. (a) Down-sampling strategy. (b) Two-stage coarse to fine framework. (c) Recurrent framework (d) Pyramid grafting framework.
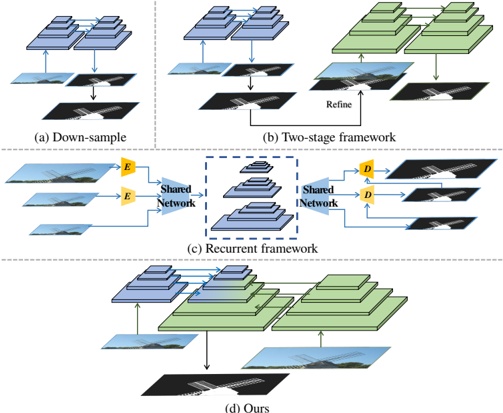
global integrity of the images as well as local details for high-resolution images. Besides, the inference speed is also an important requirement while ensuring accuracy.
To address the above challenges, researchers have begun to customize the strategies for the high-resolution input. The most straightforward scheme is shown in Fig. 2 (a), which is to first down-sample the images to obtain the saliency maps in low-resolution and then up-sample the coarse maps as the final results. In this way, many fine details of the image are inevitably lost during the downsampling process, and the size of extracted feature maps is small, which makes it difficult to recover the original fine structure and edge details in the bottom-up decoding process. Subsequently, to improve the process of simple up-sampling of the coarse maps, two-stage coarse-to-fine framework has been proposed [21], [22]. As shown in Fig. 2 (b), the first network captures global semantics at low-resolution to locate salient objects and generate a rough saliency map. The rough prediction map is then fed at highresolution to another local network for refinement, recovering the detailed structure and share edges. However, since some small objects are ignored on the low-resolution intermediate map and the high-resolution refining process is based on this map, these objects cannot be recovered at the highresolution stage. Therefore, such a multi-stage design leads to inconsistent contextual semantic transfer between stages. Lately, a new recurrent framework is proposed [23] that avoids the drawbacks associated with multi-stage framework, which is shown in Fig. 2 (c). The key of this framework is to use the same network to process inputs from low-resolution to high-resolution in a recurrent way and refine the multiscale intermediate results. Although this strategy shows better performance over previous ones, the multiple inferences lead to a drastic increase in computation burden.
By analyzing the shortcomings of the strategies, we can find that the key issue is that the specific features in a solitary network cannot settle the paradox of receptive field and detail retention simultaneously. In other words, traditional FPNbased networks can only extract a set of features with a limited range of resolution variations, which is impossible to cover both the required global semantics and rich details. Taking into above analysis, there are two main principles should be considered for the framework design.
1) Considering that limited range of feature resolution fails to settle the paradox between context and details, features with a larger range of resolution should be preserved so that a higher feature pyramid can be constructed to recover rich details.
2) Considering the fact that computation grows with the square of feature resolution, high and low resolution features should be treated unequally, balancing the problem of computational burden caused by high-resolution input, thus improving the overall efficiency of the network.
Regarding the above design criteria, we can asymmetrically extract two or more sets of features of different spatial sizes and then transfer the information from one branch to the other in the same network. As illustrated in Fig. 2 (d), we construct a higher feature pyramid fully preserving high-resolution details and global semantics, and it can be trained end-to-end to avoid inconsistent semantics. Based on this architecture, we propose a novel one-stage deep neural network for high-resolution saliency detection named Pyramid Grafting Network (PGNet). Specifically, we use both ResNet and Transformer as our encoders, extracting features with dual spatial sizes in parallel. The transformer branch first decode the features in the FPN style, then pass the global semantic information to the ResNet branch in the stage where the feature maps of two branches have similar spatial sizes. Eventually, the ResNet branch completes the decoding process with the grafted features. Compared to classic FPNs, we have constructed a higher feature pyramid at a lower cost. We call this process feature grafting. To better graft heterologous features cross two different types of models, we design the Cross-Model Grafting Module (CMGM) based on the attention mechanism and propose the Attention Guided Loss (AGL) to further guide the grafting. With CMGM and AGL, the heterologous features between multiple branches in parallel interact with each other to form complementary effects, eventually forming the grafting network. Considering that supervised deep learning method requires a large amount of high quality data, we have provided a 4K resolution SOD dataset (UHRSD) with the largest number to date in an effort to promote future high-resolution salient object detection research.
This paper is an extended version of our previous work [1]. In particular, (a) we provide more statistics and analysis on the proposed UHRSD dataset. (b) Based on the pyramid grafting mechanism, we further explored and found that progressively staggered stacking of branches can be applied to higher resolution input and achieve better performance. As an upgrade to the conference version, we distinguish the improved version based on hierarchical pyramid grafting framework as PGNeXt. (c) We take the window-based cross attention to replace the original global cross attention in CMGM, achieving improved grafting performance while significantly
reducing computational overhead, and this modified version is referred to as wCMGM. (d) We conduct more thorough experiments and ablation studies to validate the effectiveness of the network and each module within it. (e) We partition subsets for UHRSD based on the complexity of salient objects and provide benchmark on them for HR-SOD task. (f) We apply our method to the highly associated camouflaged object detection (COD) task to demonstrate the generalization ability of our proposed pyramid grafting strategy.
The following sections of the article are organized as follows. Sec II. briefly reviews previous work related to this work. Sec III. provides more details and analysis on proposed UHRSD dataset. Sec IV. thoroughly describes our new framework of PGNeXt and improvements of windowbased Cross-Model Grafting Module.
Sec V. provides SOD methods for benchmarking on the existing HR-SOD dataset and our UHRSD dataset to facilitate a better understanding of the differences between LR-SOD and HR-SOD tasks. Besides, it also gives and more ablation study of each module. Sec VI. presents the experimental results on COD tasks to demonstrate the generalizability of our method. Sec VII. concludes the whole paper.
## II. RELATED WORK
## A. Salient Object Detection
Salient Object Detection (SOD) has been studied as an important computer vision task for a long period of time. Traditional SOD methods [24]-[27] were mostly based on hand-crafted features. These low-level feature-based methods tend to work ineffectively when facing cluttered scenes. With the rise of deep learning, fully convolutional networks (FCNs)based methods can not only utilize the low-level features of images, but also learn the ability to parse complex context of scenes from large scale datasets, greatly enhancing the robustness of SOD methods. Most of them are based on a backbone ( e.g . ResNet [28], VGG [29], et al .) pre-trained on ImageNet [11] as feature encoders, varying the unique structures or modules under the paradigm of feature pyramid networks (FPNs [30]) to utilize multi-level features. A typical category of methods modifies the stream of high-level features based on the FPN architecture to improve performance. For example, Hou et al . [31] introduce short connections to skiplayer structure in FPN architecture to better locate salient region and refine irregular prediction maps. Liu et al . [32] and Chen et al . [33] design contextual modules to further capture global information of deep features and then use them to guide low-level features. Besides, several others add branches to introduce additional cues to help locate salient object and improve their boundary quality. Wei et al . [34] decouple the ground-truth maps into interior and edge regions to separately supervise two branches and then aggregate them. Zhao et al . [35] design trilateral decoder including semantic path, spatial path and boundary path to solve the dilution of semantics, loss of spatial information and absence of boundary information. Furthermore, with the success of Transformer in vision tasks, Liu et al . [36] propose VST, which is the first unified model based on pure transformer for both RGB and RGB-D SOD
task. Ma et al . [37] explore the combination of Transformer and CNN architecture, achieving state-of-the-art performance. Despite their impressive achievements on low-resolution SOD tasks, applying them directly to high-resolution inputs would be ineffective. On the one hand, the network is unable to capture global information due to the small receptive field relative to large resolution inputs, and on the other hand, it is hard to recover lost details if the inputs are down-sampled. Therefore, most of low-resolution methods cannot be directly applied to high-resolution scenes.
## B. High-resolution Salient Object Detection
Nowadays, with the common access to high-resolution images, focusing on high-resolution SOD is already trending. In response to the challenges posed by high-resolution SOD researchers have made many contributions in terms of methods and datasets.
High-resolution SOD datasets. DAVIS-S [21] contains 92 images suitable for saliency detection from video object detection dataset DAVIS [38], which is precisely annotated and have a high resolution of 1920 × 1080 . And all of the images are used for evaluation. Zeng et al . [21] collect and annotate the first high-resolution saliency detection dataset, named HRSOD. It contains 1,610 and 400 images for training and testing, respectively. All images are collected from the website of Flickr. 40 participants are involved in pixel-level annotating. However, prior to our work this was the only dataset specific to high-resolution SOD training, which is insufficient compared to the low-resolution SOD dataset ( e.g . DUT-TR [39], containing 10,553 images) for data-driven deep learningbased methods. Thus the goal of our UHRSD dataset is to support deep model learning to the more challenging details of high-resolution input and to provide comprehensive evaluation of methods performed on high-resolution conditions. More details and comparisons can be referred to Sec. III.
High-resolution SOD methods. Zeng et al . [21] propose a paradigm for high-resolution salient object detection using GSN for extracting semantic information, and APS guided LRN for optimizing local details and finally GLFN for prediction fusion. Similarly, Tang et al . [22] disentangle the SOD task into two tasks. They first design LRSCN to capture sufficient semantics at low resolution and generate the trimaps. By introducing the uncertainty loss, the designed HRRN can refine the tri-maps generated in first stage using lowresolution datasets. Both of them use multi-stage architecture, which lead to semantic incoherence between networks and slow inference. Besides, Zhang et al . [40] propose DRFNet which consists of shared feature extractor and two effective refinement heads, adopting a global-aware feature pyramid and hybrid dilated blocks respectively. Recently, Deng et al . [23] recurrently utilizes shared Transformers and multi-scale refinement architectures. In this way, high-resolution saliency maps can be generated with guidance of lower-resolution predictions. Although they are one-stage framework, treating large and small size of features equally leads to much slower inference.
Unlike existing methods, we consider the advantages of CNNs and Transformers to design an asymmetric architecture.
TABLE I
COMPARISON OF STATISTICS WITH EXISTING SOD DATASETS. THE TABLE OUTLINES AND COMPARES DATASET ATTRIBUTES INCLUDING TYPE, NUMBER, IMAGE DIMENSIONS, AND COMPLEXITY LEVELS. TE AND TR FOR TESTING AND TRAINING RESPECTIVELY, OPTIMAL METRICS SHOWS IN BOLD .
| Dataset | Type | Number | Dimension | Dimension | Complexity | Complexity | Complexity |
|-----------|--------|----------|-----------------------|-----------------------|-----------------|------------------|----------------------|
| Dataset | Type | I num | H ± σ H | W ± σ W | IPQ ± σ IPQ | C num ± σ C | E num ± σ E |
| SOD | Te | 300 | 366 . 87 ± 72 . 35 | 435 . 13 ± 72 . 35 | 5 . 98 ± 5 . 22 | 1 . 58 ± 1 . 11 | 0 . 92 ± 1 . 67 |
| PASCAL-S | Te | 850 | 387 . 63 ± 64 . 65 | 467 . 82 ± 61 . 46 | 4 . 04 ± 3 . 00 | 1 . 17 ± 0 . 69 | - 2 . 79 ± 11 . 75 |
| ECSSD | Te | 1000 | 311 . 11 ± 56 . 27 | 375 . 45 ± 47 . 70 | 4 . 05 ± 3 . 21 | 1 . 12 ± 0 . 46 | 0 . 55 ± 1 . 36 |
| HKU-IS | Tr+Te | 4447 | 292 . 42 ± 51 . 13 | 386 . 64 ± 37 . 42 | 5 . 45 ± 4 . 88 | 1 . 68 ± 1 . 17 | 1 . 14 ± 1 . 91 |
| DUT-OMRON | Te | 5168 | 320 . 93 ± 54 . 35 | 376 . 78 ± 46 . 02 | 4 . 44 ± 5 . 12 | 1 . 30 ± 1 . 01 | 0 . 34 ± 3 . 27 |
| DUTS | Tr+Te | 15572 | 322 . 10 ± 53 . 69 | 375 . 48 ± 47 . 03 | 3 . 76 ± 3 . 89 | 1 . 49 ± 12 . 19 | 0 . 12 ± 4 . 03 |
| SOC | Te | 3000 | 480 . 00 ± 0 . 00 | 640 . 00 ± 0 . 00 | 4 . 61 ± 3 . 79 | 1 . 77 ± 1 . 72 | - 10 . 09 ± 29 . 81 |
| XPIE | Te | 10000 | 399 . 44 ± 69 . 01 | 464 . 72 ± 63 . 46 | 4 . 19 ± 3 . 53 | 1 . 17 ± 0 . 50 | 0 . 56 ± 1 . 63 |
| MSRA10K | Te | 10000 | 324 . 51 ± 56 . 26 | 370 . 27 ± 50 . 25 | 3 . 12 ± 2 . 94 | 1 . 07 ± 0 . 53 | - 1 . 89 ± 17 . 60 |
| DAVIS-S | Te | 92 | 1299 . 13 ± 440 . 77 | 2309 . 57 ± 783 . 59 | 7 . 38 ± 5 . 17 | 2 . 84 ± 6 . 05 | - 9 . 92 ± 20 . 37 |
| HRSOD | Tr+Te | 2010 | 2713 . 12 ± 1041 . 70 | 3411 . 81 ± 1407 . 56 | 5 . 21 ± 4 . 79 | 1 . 74 ± 2 . 33 | - 2 . 70 ± 14 . 74 |
| UHRSD | Tr+Te | 5920 | 3718 . 60 ± 850 . 28 | 4943 . 79 ± 1026 . 38 | 6 . 77 ± 8 . 92 | 3 . 19 ± 9 . 16 | - 15 . 05 ± 121 . 21 |
Fig. 3. Categories of our UHRSD dataset. We illustrate 7 primary categories. For items within primary categories that are hard to classify, we categorize them as 'non-specific'. The columns' heights in this chart approximate the distribution of quantities across categories.
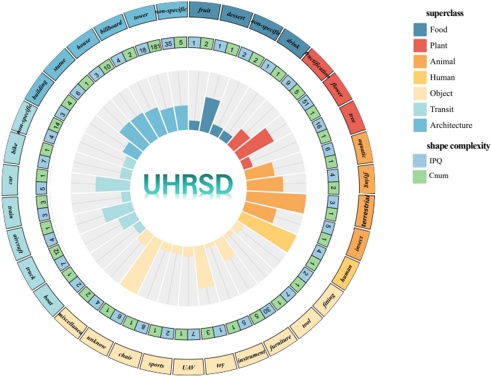
We use light-weight CNN to capture spatial features from large inputs and Transformer to capture contextual features from regular inputs, which not only can optimize the computational burden, but also the features extracted from heterogeneous encoders will form complementary effects. The novel grafting framework can fully leverage the advantages of heterogeneous encoders to better meet the demand of fast and accurate segmentation for real-life applications.
## III. ULTRA HIGH-RESOLUTION SALIENCY DETECTION DATASET
The existing common SOD datasets usually are in lowresolution (below 500 × 500 ), which present following drawbacks for training high-resolution networks and evaluating high-quality segmentation results. Firstly the low resolution of the images results in insufficient detail information. Secondly, the edge quality of annotations is poor. Lastly, the finer level
Fig. 4. Examples and corresponding annotations in UHRSD. UHRSD contains rich salinent objects in terms of classes and attributes.

of annotations is frequently inadequate, especially for hardcase annotations which are handled perfunctorily as shown in Fig. 5. Before this, the only available high-resolution dataset known is HRSOD [21]. However, the number of highresolution images in HRSOD is limited, training exclusively on it tend to cause over-fitting its specific data distribution, which significantly impacted the model's generalization ability. With this in mind, our goal is to contribute a larger and more challenging high-resolution dataset UHRSD for tackling the lack of training and evaluating dataset in highresolution SOD domain . We will provide more details in Dataset Collection and Annotation, and Dataset Analysis.
## A. Dataset Collection and Annotation
Considering that a single dataset is unlikely to perfectly encompass all aspects, having a clear objective and defined criteria during the collection process is crucial for dataset construction. In alignment with our goal, our construction criteria for UHRSD are threefold:
(1) adhering to the SOD dataset standards, which encompass basic characteristics such as contrast, center bias and etc .; (2) ensuring diversity in categories to cover common salient objects, thereby enhancing the model's generalization capability; (3) taking into account high-resolution image attributes, which guarantees higher resolution and more complex shape challenges compared to existing datasets. Adhering to our criteria, we have gathered 5,920 images, all surpassing 4K
Fig. 5. Comparison of annotation quality among UHRSD and other SOD datasets. From left to right: 2 sample images from UHRSD; comparison of annotation quality between UHRSD and HRSOD; comparison of annotation quality between UHRSD and DUTS. Best viewed by zoom-in.
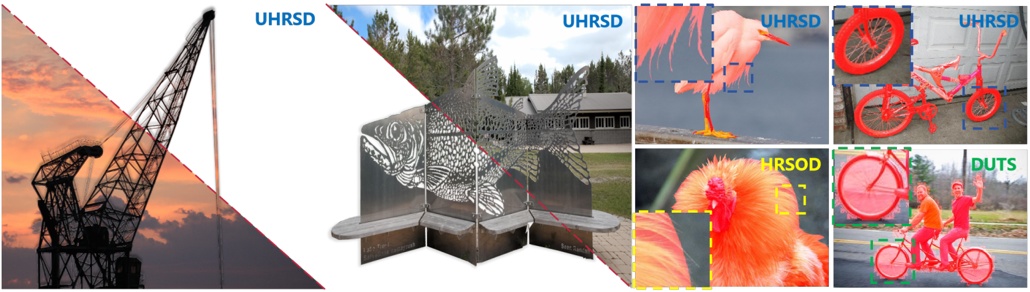
resolution and featuring a variety of salient objects. Most images were sourced from websites like Flickr and Pixabay and applied for academic use.
During the collection process, to ensure the diversity of salient objects, we initially analyzed the categories present in the widely used DUTS and then we devised keywords including food, animals, architecture, humans, etc . for the preliminary image gathering. Subsequently, multiple participants were involved in meticulously selecting images with noticeable salient objects, with an emphasis on selecting those with complex shapes. The categories and proportions of the final image set are illustrated in Fig. 3.
During the data labeling stage, we employed labeling standards of precision far exceeding those of previous datasets. Participants initially identified salient objects through eyetracking experiments, followed by pixel-level annotation. Examples from UHRSD are shown in Fig. 4. Notably, for transparent or hollow areas, which were not distinguished in prior datasets, we have accurately labeled them as shown in Fig. 5.
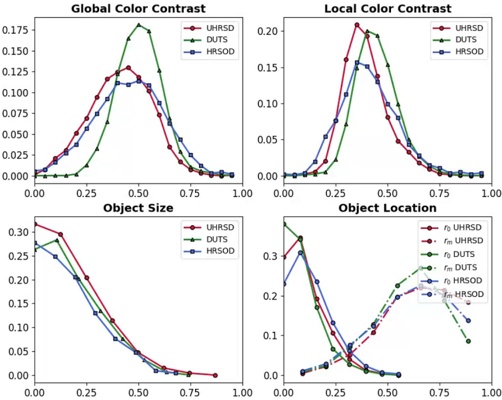
## B. Dataset Analysis
Our comprehensive comparison of UHRSD encompasses an in-depth analysis of its multiple aspects, as outlined in Tab. I. And details are as follows:
- · Resolution The fourth and fifth columns in Tab. I display the average resolution and variance of commonly used SOD datasets, indicating that most SOD datasets have a small resolution, making it challenging to include sufficient details. The UHRSD dataset, with its average dimensions meeting the 4K standard, significantly surpasses previous datasets like HRSOD and low-resolution SOD datasets. Its ultra-high resolution not only meets current demands but also expand opportunities for future high-resolution segmentation research.
- · Color contrast In accordance with [41], we present the global/local contrast to affirm that our collected images are salient in terms of low-level vision. Top-left/right in Fig. 6 reveals that the contrast intensity of the UHRSD dataset cluster around the median, aligning with the normative range for SOD datasets. The contrast intensity of
Fig. 6. Comparison of basic attributes among UHRSD, HRSOD and DUTS datasets. Top-left/right show the global/local color contrast distribution, aligning with the standards of SOD datasets. Bottom-left shows comparison of object size distribution in UHRSD. And the bottom-right displays the distribution of object locations, reflecting the center-bias of these datasets.
UHRSD is slightly lower than that of DUTS, suggesting that UHRSD poses a greater challenge to some extent.
- · Object size We utilize the foreground-to-backgroud area ratio to demonstrate the object size. Bottom-left in Fig. 6 shows that UHRSD offers a more varied distribution of object sizes, including a wide range of salient object sizes.
- · Center bias As shown in Fig. 6 bottom-right , we adopt distances between object center, object margin and the image center to explain the center bias of the datasets. Upon comparison, it is evident that the center bias distribution of UHRSD is similar to that of commonly used SOD datasets, aligning with the characteristic center bias of SOD datasets.
- · Shape complexity Inspired by [42], in the last 3 columns of Tab. I, we measure the complexity of salient objects using three metrics: isoperimetric inequality quotient ( IPQ ), number of object contours ( C num ) [42] and
Fig. 7. Pipeline of our PGNeXt framework. Three parallel encoders are set up, the two indicated in green are ResNet-18-based and the one indicated in blue at the bottom is Swin Transformer-based. The three feature groups extracted by corresponding encoders are connected in a staggered manner and grafted through the grafting union to construct a higher feature pyramid. The grafted features are decoded from the bottom up by the decoder. The decoder blocks that compose the decoder are all dual-input except the bottom one which is single-input.
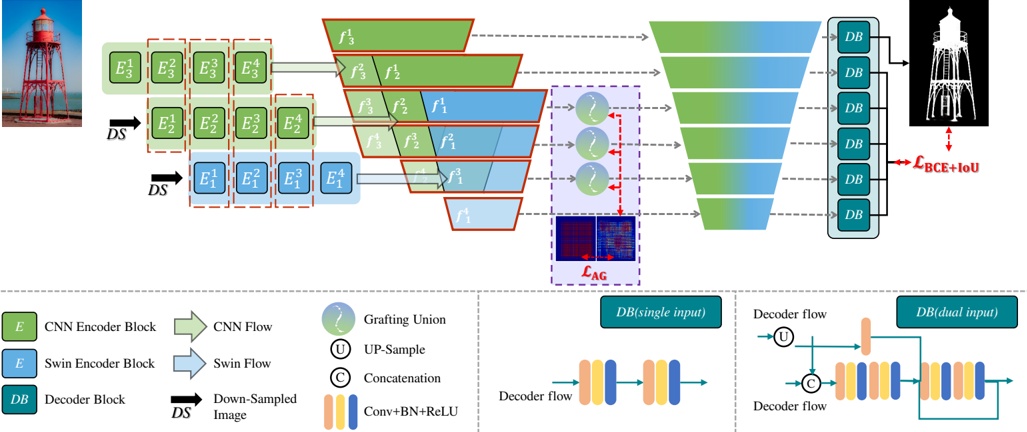
Euler number ( E num ) [43]. The IPQ is calculated based on the isoperimetric inequality IPQ = C 2 4 πA , where C and A denotes total perimeter and area respectively, measuring the overall compactness of the shape. C num reflects the complexity of the contour, with higher values indicating more intricate edges. E num represents the difference between the number of objects and holes, with smaller values indicating a greater number of holes than objects. From the Complexity columns in the table, it's evident that the complexity metrics of the UHRSD datasets considerably surpass those of existing datasets. Compared to the HRSOD dataset, the metrics of IPQ , C num , E num in UHRSD are higher by 29 9% . , 83 3% . and 457 4% . , respectively. This indicates that UHRSD better utilizes the advantages of high-resolution images and encompasses more complex details, thereby making it more challenging and valuable for research in HR-SOD field.
- · Dataset splitting For ease of use, we randomly divided 5,920 images into a training set of 4,932 images ( i.e . UHRSD-TR) and a test set of 988 images ( i.e . UHRSDTE), maintaining a roughly 5:1 ratio. This division ensures consistency in the categories between the training a test set. Given that SOD is a category-agnostic segmentation task and HR-SOD places a higher emphasis on the challenge of segmenting high-resolution details, we opted to split the test set based on the shape complexity. Therefore, inspired by [42] we sorted the 988 test images into four equally sized subsets ( i.e . UHRSD-TE 1-4) in ascending order according to their IPQ × C num scores. Testing on these four subsets, each representing a different level of shape complexity, allows for a more comprehensive assessment of the SOD model's ability to segment complex objects. The detailed quantitative evaluation for the subsets can be found in Sec. V-C.
- · Mask quality Fig. 5 shows some samples from our UHRSD dataset and other HR/LR-SOD datasets. The first two images in Fig. 5 demonstrate the complexity of images in UHRSD, all of which are carefully annotated with great manual effort. The four sub-images on the right illustrate UHRSD's superior annotation quality by comparing it with similar mask types from existing HR/LR-SOD datasets. For instance, in the comparison with HRSOD, the mask in HRSOD represents complex hair edges with approximate contours, whereas ours precisely follows the actual boundaries. In addition, our high quality is not only reflected in the precision. When contrasted with LR-SOD dataset DUTS, it is apparent that our annotations are of a higher standard, accurately dealing with challenges like hollow and obscured areas, which are always treated simply.
## IV. PGNEXT
## A. Network Overview
Feature pyramid networks (FPNs) have been widely used as a classic architecture and have proven to be effective for SOD tasks [31], [35], [44]. This U-shaped architecture first extracts a series of features from the bottom up and then fuses the multi-scale features in the top-down path. It is widely acknowledged that the low-level features preserve rich spatial features helpful for recovering the local details in saliency maps, and the high-level features contain contextual semantics conducive to the accurate identification of salient object. However, the fact that this architecture cannot be directly applied on high-resolution SOD tasks can be attributed to the contradiction of two factors. On the one hand, during bottom-up feature encoding, the relative receptive field to the
high-resolution feature maps is limited to extracting accurate high-level semantics. On the other hand, if we down-sample the input images to ensure the relative receptive field is enough, we cannot retain rich spatial features to recover the details during the top-down decoding process. Therefore, the main motivation of our method is to resolve the paradox in traditional FPNs architecture for HR-SOD task.
The pipeline of our method shows in Fig. 7. The pipeline can be regarded as three phases, pyramid feature extraction stage, pyramid feature grafting stage and pyramid feature decoding stage. Firstly, in the pyramid feature extraction stage, for the contradiction we adopt two strategies, i.) set up three parallel encoders to extract features from inputs with multiple resolutions, so that diverse features contain both low-level details and high-level semantics can be retained. ii.) to further obtain global contexts and rich details, we simultaneously use Transformer-based and CNN-based encoders to extract diverse features for following grafting stage. In grafting stage, for the extracted group of features we adopt hierarchical staggered grafting framework and introduce the window-based CrossModel-Grafting module (wCMGM) to progressively make semantic information transfer between parallel branches, so as to build a higher feature pyramid. Besides, the wCMGM generates a matrix named cross-attention matrix (CAM) to be supervised by Attention Guided Loss (AGL) for enhancing the cross attention in wCMGM. Finally, the constructed higher feature pyramid is decoded from coarse to fine to recover high-resolution details and we can get the final high-resolution saliency map. The final prediction and side outputs from each decoder block are supervised by the ground-truth maps. In what follows, we elaborate the details of the hierarchical staggered grafting framework, window-based Cross-Model Grafting modules and objective functions.
## B. Hierarchical Staggered Grafting Framework
Feature Extractor. For input image I ∈ R 3 × H × W , we can obtain a set of images of a specific resolution { I i ∈ R 3 × H/ 2 3 -i × W/ 2 3 -i } 3 i =1 by bilinear sampling. Correspondingly, we set up three parallel branches to extract three sets of features with different resolutions, which can be denoted as { E i } 3 i =1 . Based on the motivation mentioned above, we want to extract the global information while preserving it as much detail as possible during the feature extraction. Further, inspired by the existing research, transformer has strong global modeling capability due to its attention mechanism, while CNN can better preserve spatial details. Therefore, in order to balance the effectiveness and efficiency, for the smallest resolution branch E 1 we adopt transformer-based encoder to obtain the global context of the image, whereas for the larger resolution branch E 2 and E 3 we adopt light-weight CNN-based encoder to reduce the computational burden while extracting large-size spatial features. More specifically, we choose the representative Swin Transformer and ResNet-18 as transformer-based encoder and CNN-based encoder respectively. For ResNet-18, the feature map extracted by top 7 × 7 layer offers limited performance gains but consume huge computational effort, especially for high-resolution input.
Fig. 8. Architecture of window-based Cross-Model Grafting Module.
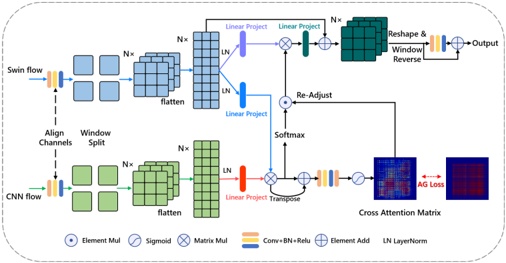
Thus we only adopt the features extracted in last four stages in ResNet-18, which can be denoted as { f j i } j =1 2 3 4 , , , i =2 3 , , where i denotes the i -th encoder and j denotes the j -th encoder stage. For Swin Transformer, since the resolution is same in last two stages, we simply fuse the output features of them as the last output feature, while adopting the patch embedding feature, which generates 4 features denoted as { f j i } j =1 2 3 4 , , , i =1 .
Hierarchical Staggered Connection. Although three groups of features from three parallel branches were obtained, covering the low-level details and high-level semantics of the high-resolution images, there are gaps between branches and layers, resulting in the failure to directly aggregate for prediction. To this end, we designed the hierarchical staggered connection to keep high resolution of feature maps and to allow global semantics to transfer gradually from low-resolution branch to higher-resolution branch, so that the high-resolution features which lack semantic due to insufficient receptive fields, are organized by the global contextual information. In particular, for feature f j i , its dimensions satisfy
$$f _ { i } ^ { j } \in \mathbb { R } ^ { C _ { i } ^ { j } \times H / 2 ^ { 4 - i + j } \times W / 2 ^ { 4 - i + j } }. \quad \quad ( 1 )$$
It can be inferred from Eq. (1) that for feature f j i and f j -1 i +1 , they are same in spatial resolution, which implies that they may be similar for spatial representations. Besides, these two features pass through network layers of approximate depth, which leads to a minor semantic discrepancy. Thus the way we use the spatial dimension as clues constitutes a kind of staggered connection, and further through the wCMGM the global semantic information is grafted from low-resolution branch to higher-resolution branch. Up to this point, we construct a higher feature pyramid through three lower pyramid using hierarchical staggered connection structure as shown in Fig. 7. In other word, the network achieves deeper sampling depth at low computational cost to adapt to the challenge caused by high-resolution input.
## C. window-based Cross-Model Grafting Module
We propose wCMGM to graft the features extracted by different types of encoders. For feature extracted by Swin backbone, due to the transformer's ability to capture information over long distance, it has global semantic information that is important for saliency detection. In contrast, CNNs perform well at extracting local information thus features { f j i } j =1 2 3 4 , , , i =2 3 ,
have relatively rich details. However, due to the contradiction between feature size and receptive field, there will be many noises in the background area of the saliency maps. For a salient prediction of a certain region, the predictions generated from different features can be roughly summarized as three cases : (a) Both right, (b) Some of them right and (c) Both wrong.
Existing fusion techniques, such as addition and multiplication, utilize element-wise convolutional operations that only can focus on limited local information, fail to address common errors in fusion methods. Therefore, they are effective only in the first two cases. Compared with the existing feature fusion, wCMGM recalculates the point-wise relationship between CNN feature and Transformer feature, transferring the global semantic information from Transformer branch to CNN branch so as to remedy the common errors. Since we aim to transfer global information to local branches rather than remodeling global relations on the feature map, we can compute within non-overlap window, and we found that this not only reduces the computation significantly but also improves the performance further.
Specifically, we first use two successive convolutional layers followed by batch normalization layer and ReLU layer for compressing the channel number of features from different branches. After that, we use element-wise addition merge inputs from ResNet-18 branch. As shown in Fig. 8, we denote the aggregated feature from ResNet and feature from Swin as f R ∈ R H × W C × and f S ∈ R H × W C × respectively. Then we partition the features in a non-overlapping manner into N windows of size S × S , where N equals to HW S 2 . For f i R ∈ R S × × S C , we flatten it to f i ′ R ∈ R 1 × × C S 2 and do the same to f i S to get f i ′ S . Inspired by the multi-head self-attention mechanism, we apply layer normalization and linear projection on them respectively to get f i R q , f i R v and f i S k . We can get the attention matrix Y by matrix multiplication, which can be denoted as
$$Y ^ { i } = ( f _ { R } ^ { i \, q } \times f _ { S } ^ { i \, k } ^ { T } ). \quad \ \ \ ( 2 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad Y ^ { i } = ( f _ { R } ^ { i \, q } \times f _ { S } ^ { T } ).$$
Next, we generate the cross attention matrix CAM based on Y , which can be expressed as
$$C A M ^ { i } = \sigma ( B N ( C o n v ( Y ^ { i } + Y ^ { i ^ { T } } ) ) ), \quad \ \ ( 3 ) \ \ a \text{ said}.$$
where Conv and BN denote convolutional layer and batch normalization respectively, and σ ( ) · is the sigmoid function. The generated CAM is supervised with proposed Attention Guided Loss (AGL) in order to readjusting the cross attention in wCMGM. Inspired by [45], the readjusting coefficient Y i re and enhanced attention map Y i final can be obtained from
$$Y ^ { i \text{re} } = ( \text{CAM} ^ { i } + 1 ) ^ { \alpha }, \text{ \quad \ \ } ( 4 ) \text{ \ } G ^ { a },$$
$$Y ^ { i } \stackrel { \text{final} } { ^ { \text{final} } } = \text{softmax} ( Y ^ { i } ) \odot Y ^ { i ^ { \text{re} } }, \text{ \quad \ \ } ( 5 ) \text{ \ } \frac { \mathcal { F } ( \cdot ) } { \text{mom} }.$$
where α is hyper-parameter used for adjusting the amplification rate and ⊙ is t he element-wise multiplication. The salient features should have a higher similarity, thus the dot production in CAM i should have a larger activation value. Therefore, Y i re will amplify the the positive value at these points in final attention map to further strengthen the ability of
Flatten
Fig. 9. The construction of attention matrix. The operation is used to create target and weights for proposed AGL.
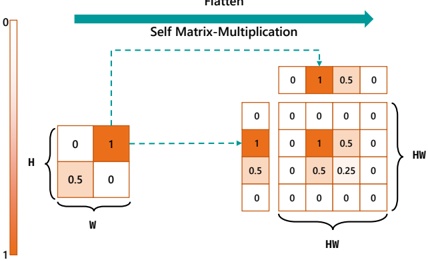
selecting discriminating features in cross attention. We obtain Z i by matrix multiplication as follow:
$$Z ^ { i } = Y ^ { i \text{final} } \times f _ { R$$
then we input Z i to the linear projection layer and reshape it to the size of R S × × S C . After processing all windows we merge the obtained { Z i } N i =1 . Two shortcut connections were performed in the process as shown in Fig. 8 and we can get the grafted feature.
## D. Attention Guided Loss
In order for wCMGM to better serve the purpose of transferring information from the Transformer branch to the CNN branch, we design the Attention Guided Loss (AGL) to explicitly supervise the CAM to enhance the attention in wCMGM. We argue that the CAM should be similar to the attention matrix generated from ground truth, because the salient features should have a higher similarity resulting in higher dot product value in CAM. Through supervising the CAM and using it as an enhancement coefficient, the value of specific locations in the attention matrix so that the features of salient regions are emphasized. As shown in Fig. 9 given a salient map M with size H × W , we first flatten it to M ′ to obtain corresponding attention matrix M a . The process can be denoted as M a = F ( M ) and the value of M a xy can be expressed as
$$M _ { x y } ^ { a } = M _ { \ x } ^ { i$$
Then we use the transformation M a = F · ( ) to construct G a , where G is the ground truth map. Before applying the F · ( ) , we split it into N non-overlapping windows just like the manner in wCMGM. We propose the AGL based on binary cross entropy (BCE) to supervise the Cross Attention Matrix generated in wCMGM shown in Fig. 8. The BCE [46] can be written as
$$\ell _ { \text{BCE} } ( G _ { x y }, P _ {$$
where G xy is the ground truth label of the pixel ( x, y ) , and P xy is the predicted probability in predicted map and both of them are in range [0 , 1] . Then our ℓ AG can be expressed as
$$\ell _ { A G } ( G, C A M ) = \frac { \sum _ {$$
where N equals to the number of windows and S is the window size. What's more, we also apply the widely-used intersection-over-union (IoU) loss [47] to pay more attention to the global structure of the images as suggested by [48]. The IoU loss L IoU can be expressed as
$$\begin{array} {$$
In the end, our total loss can be expressed as follow:
$$\mathcal { L } _ { \text{total} } = \sum _ { i = 1 } ^ { 6 } \mathcal { L } _ { \text{BCE+IoU} } ^ { i } + \sum _ { j = 1 } ^ { 3 } \mathcal { L } _ { \text{AG} } ^ { j }, \quad \quad ( 1 1 )$$
where L i BCE+IoU hybrid loss applied on the final prediction and other 5 side-outputs from decoder, and L j AG is used for supervising CAMs from 3 wCMGMs.
## V. HR-SOD BENCHMARK
## A. Experimental Settings
a) Implementation Details: We use PyTorch [49] to implement our model and one NVIDIA RTX 3090 GPU is used for both training and testing. For simplification, we utilize the ResNet-18 architecture for our CNN branches. It should be noted that we did not use pre-trained parameters for ResNet18 encoders, allowing for the flexibility to replace the CNN branch with more efficient or more effective CNN encoders for better performance or speed. Swin-B [50] is adopted as the transformer encoder to stay in line with the advanced HRSOD methods [23], [51]. The whole network is trained endto-end by using stochastic gradient descent (SGD). We set the maximum learning rate to 0.018, with the learning rate for Swin-B encoder frozen at 0.05 of the maximum learning rate. The learning rate first increases then decays during the training process, what's more momentum and weight decay are set to 0.9 and 0.0005 respectively. Batchsize is set to 8 and maximum epoch is set to 32.
- b) Datasets: We use DUTS-TR [39], HRSOD-TR [21] and UHRSD-TR datasets for training process. For fair comparison with existing methods [23] and alignment with our prior work [1], we adopt two training setups: DUTS+HRSOD ( DH ) and HRSOD+UHRSD ( UH ). To demonstrate the performance on high-resolution images, we evaluate the models on DAVISS [21], HRSOD-TE [21] and our UHRSD-TE datasets.
- c) Evaluation Metrics: We use following 5 metrics widely used in SOD tasks to evaluate the performance of all methods: mean absolute error ( M ), S -measure ( S α ) [52], E -measure ( E m ) [53], weighted F -measure ( F w β ) [54] and Max F -measure ( F M β ).
- · M : The mean absolute error M refers to the pixel-level average difference between prediction map P and ground truth G , which is defined as
$$\mathcal { M } = \frac { 1 } { H \times W } \sum _ { i = 1 } ^ { H } \sum _ { j = 1 } ^ { W } | P _ { i j } - G _ { i j } |. \quad ( 1 2 )$$
- · S-measure The S-measure evaluates region-aware and object-aware structural similarity between prediction maps and ground-truth by
$$S _ { \alpha } = \alpha \cdot S _ { o } + ( 1 - \alpha ) \cdot S _ { r }, \text{ \quad \ \ } ( 1 3 )$$
where α = 0 5 . . S o and S r refer to region-aware and object-aware similarity measure respectively.
- · E-measure The enhanced-alignment measure aligns with human visual perception by concurrently capturing pixellevel and image-level matching.
- · Max F-measure The Max F-measure can be calculated by
$$F _ { \beta } = \frac { ( 1 + \beta ^ { 2 } ) \cdot \text{precision} \cdot \text{recall} } { \beta ^ { 2 } \cdot \text{precision} + \text{recall} }, \quad ( 1 4 )$$
where β 2 is set to 0.3 as suggested in [55]. The Max F-measure refers to the maximum F β value from all precision-recall pairs generated after applying thresholds ranging from 0 to 255.
- · weighted F-measure The weighted F-measure follow the Eq. (14), replacing precision and recall with precision w and recall w , which intuitively generalize the primitive Fmeasure.
In addition, we also report the metric of mean boundary accuracy (mBA) [56] to further evaluate the boundary quality which is important in HR-SOD.
## B. Results and Analysis
1) Quantitative Comparison on 3 HR Datasets: We compare our proposed PGNeXt with 11 state-of-the-art existing SOD methods, of which 8 are designed for LR-SOD task, and 3 ( i.e . HRSOD [21], HQNet [22],RMFormer [23])are specifically tailored for HR-SOD scenarios. Besides, we present the comprehensive results from these HR-SOD methods and ours under different training settings, as shown in Tab. II.
Comparison between LR and HR methods. From Tab. II, we can observe that HR-SOD methods generally perform significantly better on these high-resolution datasets than LR-SOD methods. We attribute this significant improvement to two main factors, Firstly, HR-SOD methods can extract more complete structural information from high-resolution input while LR-SOD methods lose during the down-sampling process. This enables a considerable improvement in metrics reflecting overall quality e.g . E ξ and S α . Secondly, the improvement is due to the HR-SOD methods' particular focus on the boundary details in images. It can be observed that while HQNet-DH and the top LR-SOD method ICON are close, with some even being lower in these 5 overall metrics, HQNet-DH notably excels over ICON in the mBA metric by a large margin ( i.e . on UHRSD-TE, 0.715 vs . 0.660 ). Thus, it is evident that the
TABLE II
QUANTITATIVE COMPARISONS WITH STATE-OF-THE-ART SOD MODELS ON THREE HIGH-RESOLUTION BENCHMARK DATASETS IN TERMS OF MAX F-MEASURE, WEIGHTED F-MEASURE, MAE , E-MEASURE, S-MEASURE AND MBA. LR METHODS: TRAINED ON DUTS-TR, -DH: TRAINED ON DUTS-TR AND HRSOD-TR, -UH: TRAINED ON UHRSD-TR AND HRSOD-TR . THE BEST TWO RESULTS ARE HIGHLIGHTED IN BOLD AND UNDERLINED.
| Method | HRSOD-TE | HRSOD-TE | HRSOD-TE | HRSOD-TE | HRSOD-TE | HRSOD-TE | DAVIS-S | DAVIS-S | DAVIS-S | DAVIS-S | DAVIS-S | DAVIS-S | UHRSD-TE | UHRSD-TE | UHRSD-TE | UHRSD-TE | UHRSD-TE | UHRSD-TE |
|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|
| Method | F M β | F w β | M | E ξ | S α | mBA | F M β | F w β | M | E ξ | S α | mBA | F M β | F w β | M | E ξ | S α | mBA |
| LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods | LR-SOD methods |
| DASNet [57] | .894 | .847 | .032 | .925 | .898 | .657 | .902 | .861 | .020 | .949 | .911 | .665 | .916 | .868 | .044 | .894 | .890 | .676 |
| F3Net [44] | .901 | .835 | .035 | .913 | .897 | .661 | .915 | .848 | .020 | .940 | .914 | .667 | .911 | .856 | .046 | .889 | .892 | .684 |
| GCPA [33] | .889 | .816 | .036 | .898 | .898 | .656 | .922 | .846 | .020 | .934 | .929 | .663 | .912 | .851 | .047 | .886 | .896 | .680 |
| ITSD [58] | .896 | .828 | .036 | .912 | .898 | .676 | .899 | .825 | .022 | .922 | .909 | .684 | .911 | .863 | .045 | .897 | .899 | .706 |
| LDF [34] | .904 | .849 | .032 | .919 | .904 | .663 | .911 | .864 | .019 | .947 | .922 | .667 | .915 | .856 | .047 | .892 | .890 | .682 |
| CTD [35] | .906 | .848 | .031 | .921 | .905 | .646 | .904 | .844 | .019 | .938 | .911 | .649 | .919 | .869 | .042 | .899 | .898 | .669 |
| PFS [59] | .911 | .849 | .033 | .922 | .906 | .674 | .916 | .867 | .019 | .946 | .923 | .688 | .918 | .868 | .043 | .898 | .899 | .701 |
| ICON [60] | .920 | .878 | .025 | .939 | .922 | .636 | .928 | .886 | .015 | .966 | .933 | .635 | .933 | .896 | .032 | .907 | .919 | .660 |
| HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods | HR-SOD methods |
| HRSOD-DH [21] | .905 | .845 | .030 | .934 | .896 | .623 | .899 | .817 | .026 | .955 | .876 | .618 | - | - | - | - | - | - |
| HQNet-DH [22] | .922 | .891 | .022 | .947 | .920 | .690 | .938 | .912 | .012 | .974 | .939 | .717 | .927 | .880 | .039 | .899 | .900 | .715 |
| RMFormer-DH [23] | .941 | .911 | .020 | .949 | .940 | .716 | .955 | .928 | .010 | .978 | .952 | .717 | .949 | .916 | .027 | .914 | .931 | .744 |
| RMFormer-UH [23] | .945 | .914 | .019 | .949 | .941 | .736 | .963 | .941 | .008 | .982 | .958 | .736 | .961 | .938 | .019 | .921 | .947 | .784 |
| Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt | Our PGNet and PGNeXt |
| PGNet-DH | .937 | .898 | .020 | .946 | .935 | .714 | .950 | .916 | .012 | .975 | .948 | .715 | .935 | .888 | .036 | .905 | .912 | .736 |
| PGNet-UH | .945 | .901 | .020 | .946 | .938 | .727 | .957 | .929 | .010 | .979 | .954 | .730 | .949 | .917 | .026 | .916 | .935 | .765 |
| PGNeXt-DH | .952 | .929 | .016 | .960 | .949 | .740 | .966 | .945 | .008 | .982 | .960 | .741 | .950 | .920 | .026 | .913 | .934 | .765 |
| PGNeXt-UH | .945 | .920 | .019 | .953 | .944 | .745 | .964 | .943 | .008 | .982 | .960 | .748 | .960 | .938 | .020 | .919 | .947 | .789 |
edges in saliency maps produced by HR-SOD methods are far superior to those obtained by LR-SOD methods.
Comparison among HR-SOD methods. In Tab. II, we can observe that our PGNeXt outperforms all other HR-SOD methods in terms of metrics on 3 HR benchmarks. Firstly, compared to the previous state-of-the-art method, especially RMFormer [23], on the basis of other metrics to maintain advantages or comparable performance, our PGNeXt shows a marked superiority in the mBA metric, indicating a superior ability of PGNeXt to generate clearer and sharper edges in saliency maps, thereby better satisfying the specific requirements of HR-SOD task. Additionally, Tab. II shows that our PGNeXt has substantially improved our previous conference version PGNet, proving the effectiveness of our new proposed technical contributions in this latest version. Last but not least, through the comparison between the performance of same model under different training settings DH and UH,
TE and DAVIS-S, the performance on these two datasets is relatively improved. However, under the UH setting after adding the new dataset UHRSD-TR with more high-resolution details, our model not only has considerable performance on the conventional HR-SOD dataset, but also has obvious advantages on the more complex UHRSD-TE. This further verifies the challenges of our new constructed dataset, and highlights the advantages of our model in the face of highresolution tasks.
we observe an interesting point, that is, models trained under UH settings show minor fluctuations in overall metrics on HRSOD-TE and DAVIS-S, but with a more noticeable increase on UHRSD-TE. We attribute it to the unique highresolution challenge of the proposed UHRSD dataset. Under the training setting of DH, since the distribution and characteristics of training datasets are consistent with HRSOD-
2) Qualitative Comparison: In line with our previous discussion, visual results better highlight the characteristics of HR-SOD task, thus we present some saliency maps generated by different methods in Fig. 10. Firstly, it's evident that HRSOD methods possess a definitive advantage over LR-SOD methods. As shown in the last two columns in Fig. 10, LR-SOD methods can even not accurately locate all salient region. Secondly, it's noticeable that our PGNeXt outperforms other HR SOD methods in some hard regions. Specifically, as illustrated in first 2 rows in Fig. 10, our PGNeXt can capture accurate global semantics, enabling it to precisely determine whether a part belongs to potential targets such as antlers. Beyond this, PGNeXt can precisely segment extremely small structures, such as spokes in bicycle tires as shown in the last 3 rows. In contrast, other methods exhibit significantly lower segmentation quality, facing issues like inability to distinguish
Fig. 10. Qualitative comparisons with previous state-of-the-art methods. We show the saliency maps from both the best 2 LR-SOD methods and HR-SOD methods under different training settings for better observe the visual characteristics of different methods. We have zoomed some details and you can further zoom-in for better viewing.

## TABLE III
COMPARISON OF HR-SOD METHODS' EFFICIENCY. WE CONDUCTED THIS ASSESSMENTS ON A CONSISTENT PLATFORM FOLLOWING THE ORIGINAL SETTINGS. FLOPS REFERS TO THE FLOATING POINT OPERATIONS AND PARAMS REFERS TO THE SUM OF TRAINABLE PARAMETERS IN THE MODELS.
| Model | Resolution | FLOPs(G) | Params(M) | Speed(FPS) |
|---------------|--------------|------------|-------------|--------------|
| PGNeXt | 1536 × 1536 | 202.76 | 111.62 | 27.61 |
| HQNet [22] | 1024 × 1024 | 15.22 | 59.69 | 4.07 |
| RMFormer [23] | 1536 × 1536 | 1252.96 | 262.36 | 7.6 |
| PGNet [1] | 1024 × 1024 | 71.02 | 72.67 | 34.23 |
methods are insufficient in dealing with complex boundaries on high-resolution images. On the other hand, compared with LR-SOD method, the HR-SOD method such HQNet [22] and RMF [23] has a great improvement in dealing with complex boundaries, especially our method has the highest mBA performance on all subsets, which also shows that the proposed grafting mechanism has excellent processing ability in high-resolution details. This benchmark further shows that the segmentation ability at the complex boundary of HR images can be used as an important metric to measure the performance of HR models. These subsets divided according to complexity will also be released publicly.
closely adjacent fine regions and background noise. Lastly, compared with DH setting, we can observe that our model trained under UH setting has more surprising performance on the fine edges and contours of objects, such as ladders, chairs and bicycles shown in the last three rows. This further proves the quantitative advantage in mBA metric as shown in Tab. II. Besides, this also emphasizes the benefits of high quality HRSOD dataset and validates the importance of our purpose to provide a large-scale HR-SOD datasets.
## C. Benchmark on UHRSD-TE subsets
As we described in Sec. III-B, we split the UHRSD-TE datasets to 4 subsets according to their shape complexity, aiming to evaluate the performance of different methods on high-resolution images of various levels of shape complexity. The assessment could serve as a benchmark for HR-SOD methods and inform future researches. We evaluate 13 methods using 5 metrics and the evaluation results are shown in Tab. IV. On the one hand, we can see that as the structural complexity increases, the overall trend of mBA metrics of these LR-SOD methods drop significantly. This trend implies that the previous
## D. Efficiency Comparison
We report the efficiency comparison of several HR-SOD methods in Tab. III. All assessments are conducted in the same environment and the input resolution is following the original settings. Compared with the HQNet [22], PGNeXt has higher computation burden and parameters, but the average speed (FPS) is significantly higher. This is attributed to the fact that HQNet is a multi-stage methods, which has efficiency bottlenecks between stages, and the I/O between stages can further reduce its efficiency. And compared with the recent state-of-the-art method RMFormer [23], their floating point operations (FLOPs) and parameters are much higher, which results in a very slow inference speed of only 28.14% of ours. In general, the high efficiency of our method is due to the fact that we asymmetrically take into account the respective characteristics of high- and low-resolution features, using lightweight structures to extract spatial information from large-size input, which keeps the inference speed fast.
TABLE IV QUANTITATIVE EVALUATION ON UHRSD-TE SUBSETS. THE BEST TWO RESULTS ARE HIGHLIGHTED IN BOLD AND UNDERLINED.
| Dataset | Metric | F3Net [44] | ITSD [58] | LDF [34] | CTDNet [35] | PFSNet [59] | ICON- S [60] | HQNet [22] | RMF- DH [23] | RMF- UH [23] | PGNet- DH [1] | PGNet- UH [1] | PGNeXt- DH | PGNeXt- UH |
|------------|-----------------|-------------------------------|-------------------------------------|-------------------------|-------------------------------|-------------------------------|-------------------------------|-------------------------------|-------------------------------|-------------------------------|-------------------------------|-------------------------------|-------------------------------|-------------------------------|
| UHRSD- TE1 | M F w β S α E ξ | 0.056 0.879 0.895 0.868 0.696 | 0.052 0.061 0.889 0.869 0.888 0.873 | | 0.050 0.891 0.903 0.870 0.678 | 0.050 0.893 0.906 0.878 0.708 | 0.033 0.926 0.930 0.881 0.671 | 0.049 0.897 0.903 0.872 0.719 | 0.031 0.933 0.934 0.889 0.747 | 0.020 0.951 0.951 0.880 0.780 | 0.043 0.903 0.914 0.878 0.739 | 0.027 0.932 0.939 0.883 0.767 | 0.030 0.936 0.938 0.883 0.765 | 0.023 0.951 0.950 0.880 0.786 |
| UHRSD- TE1 | M w | 0.042 0.858 0.896 | 0.042 0.866 0.902 | 0.691 0.043 0.855 0.893 | 0.041 0.871 0.899 | 0.039 0.873 0.903 | 0.031 0.901 0.923 | 0.038 0.886 | 0.026 0.917 | 0.022 0.933 0.944 | 0.032 0.901 0.921 | 0.027 0.913 0.933 | 0.024 0.922 0.937 | |
| UHRSD- TE1 | | | 0.903 0.881 | | | | | | | | | | | |
| UHRSD- TE1 | mBA | | | | | | | | | | | | | |
| UHRSD- TE1 | | | 0.716 | | | | | | | | | | | |
| UHRSD- TE2 | | | | | | | | | | | | | | 0.021 |
| UHRSD- TE2 | F β | | | | | | | | | | | | | 0.938 |
| UHRSD- TE2 | S α | | | | | | | 0.905 | 0.933 | | | | | 0.947 |
| UHRSD- TE2 | E ξ | 0.888 | 0.904 | 0.891 | 0.901 | 0.905 | 0.915 | 0.907 | 0.918 | 0.924 | 0.913 | 0.926 | 0.919 | 0.930 |
| UHRSD- TE2 | mBA | 0.687 | 0.709 | 0.685 | 0.669 | 0.703 | 0.661 | 0.719 | 0.746 | 0.784 | 0.742 | 0.767 | 0.765 | 0.792 |
| UHRSD- TE3 | M | 0.038 | 0.037 | 0.040 | 0.034 | 0.035 | 0.030 | 0.035 | 0.023 | 0.016 | 0.033 | 0.021 | 0.020 | 0.015 |
| UHRSD- TE3 | F w β | 0.871 | 0.875 | 0.870 | 0.885 | 0.880 | 0.895 | 0.884 | 0.925 | 0.947 | 0.888 | 0.932 | 0.936 | 0.949 |
| UHRSD- TE3 | S α | 0.904 | 0.911 | 0.900 | 0.911 | 0.911 | 0.921 | 0.905 | 0.938 | 0.954 | 0.913 | 0.947 | 0.945 | 0.955 |
| UHRSD- TE3 | E ξ | 0.918 | 0.922 | 0.914 | 0.932 | 0.922 | 0.931 | 0.922 | 0.938 | 0.949 | 0.924 | 0.943 | 0.941 | 0.947 |
| UHRSD- TE3 | mBA | 0.687 | 0.710 | 0.685 | 0.671 | 0.707 | 0.657 | 0.719 | 0.749 | 0.793 | 0.740 | 0.775 | 0.774 | 0.798 |
| UHRSD- TE4 | M | 0.047 | 0.047 | 0.044 | 0.043 | 0.046 | 0.034 | 0.035 | 0.029 | 0.020 | 0.036 | 0.029 | 0.029 | 0.020 |
| UHRSD- TE4 | F w β | 0.816 | 0.823 | 0.833 | 0.831 | 0.826 | 0.860 | 0.861 | 0.891 | 0.922 | 0.860 | 0.891 | 0.891 | 0.919 |
| UHRSD- TE4 | S α | 0.872 | 0.880 | 0.881 | 0.881 | 0.876 | 0.902 | 0.894 | 0.918 | 0.938 | 0.898 | 0.921 | 0.918 | 0.939 |
| UHRSD- TE4 | E ξ | 0.881 | 0.883 | 0.893 | 0.893 | 0.887 | 0.902 | 0.904 | 0.912 | 0.929 | 0.904 | 0.912 | 0.912 | 0.921 |
| UHRSD- TE4 | mBA | 0.668 | 0.689 | 0.671 | 0.657 | 0.686 | 0.652 | 0.710 | 0.736 | 0.779 | 0.724 | 0.752 | 0.756 | 0.782 |
## E. Ablation Studies
We first provide detailed analysis of each component in PGNeXt. Furthermore, we experiment with different configuration within these components to better illustrate their effectiveness. All experiments in this section are based on the setting of PGNeXt-UH . And we evaluate them on HR-SOD datasets to directly demonstrate impact of each component on HR-SOD task.
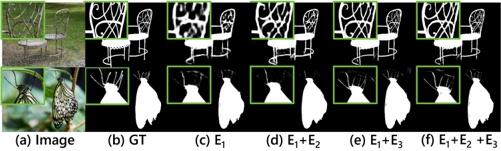
1) Ablation on components of PGNeXt: In Tab. V, we investigate the contribution of each main components in PGNeXt including hierarchical staggered connection (HSC), windowbased Cross-Model Grafting Module (wCMGM) and attention guided loss (AGL). The experiments are conducted based on the baseline composed of Swin encoder and plain decoder in traditional FPN style. Due to the component dependencies, we sequentially add HSC, wCMGM and AGL to the baseline:
Effectiveness of HSC We introduce extra two CNN branch to the baseline model (No. #1 in Tab. V) and connect them in the staggered style shown in Fig. 7, which is denoted as No. #2. Comparing with No. #1, we find that there is a significant improvement on all of the 3 datasets. In particular, the mBA on UHRSD-TE improved from 0.672 to 0.742 (10.4% increase), which is far more significant than the rest overall structural metrics. This improvement indicates that the additional large resolution CNN branches provide rich details on top of the Swin branch's semantics, resulting in greatly clear edges in saliency maps.
Effectiveness of wCMGM. Compared with No. #2, we replace the plain fusion strategy with our proposed wCMGM module at grafting points between branches, which is shown as No. #3. We can observe that the metrics on 3 datasets are further improved substantially. Compared to the performance gain from No. #1 to No. #2, this improvement is mainly in the
Fig. 11. Visualization comparisons for saliency maps among different combinations of branches in hierarchical staggered connection architecture. Best viewed by zoom-in.
overall metrics, e.g . increase from 0.912 to 0.914 vs. 0.914 to 0.920 in terms of E ξ on UHRSD-TE. Besides, the mBA metric exhibits a slight increase, which could partially be attributed to enhanced accuracy in locating salient regions. We believe the boost is due to the fact that wCMGM makes the auxiliary CNN branches not only provide details in large resolution, but also graft the context from global branch to local branches and make the heterogeneous feature complementary from each other, which ultimately leads to a more accurate saliency identification.
Effectiveness of AGL. As shown in last row in Tab. V, the adoption of AGL brings performance growth in terms of all metrics. In specific, the increase is minor in terms of S α and E ξ , which mainly reflects the accuracy of global structure of salient objects. And the main growth is in M and mBA , indicating AGL allows the model to concentrate on edge regions of salient objects, making the overall pixel-level error rate lower.
2) Ablation on hierarchical staggered connection: We delve into further exploration on the effect of hierarchical staggered connection. Tab. VI shows different combinations of
TABLE V
ABLATION ANALYSIS ON THE EFFECTIVENESS OF EACH COMPONENT IN PGNEXT. FPN DENOTES THE BASELINE MODEL OF PGNEXT WHICH ADOPTS THE PRELIMINARY FPN CONSISTING OF SWIN ENCODER AND SIMPLE DECODER. HSC DENOTES THE HIERARCHICAL STAGGERED CONNECTION. THE BEST RESULTS ARE HIGHLIGHTED IN BOLD .
| No. | Component | Component | Component | Component | UHRSD-TE | UHRSD-TE | UHRSD-TE | UHRSD-TE | UHRSD-TE | HRSOD-TE | HRSOD-TE | HRSOD-TE | HRSOD-TE | DAVIS-S | DAVIS-S | DAVIS-S | DAVIS-S | DAVIS-S |
|-------|-------------|-------------|-------------|-------------|------------|-------------|-------------|------------|------------|-------------|------------|------------|------------|-----------|-----------|-----------|-----------|-----------|
| No. | FPN | HSC | wCMGM | AGL | M | S α E | ξ F M β | | mBA | M | S α E ξ | F M β | mBA | M | S α | E ξ | F M β | mBA |
| #1 | ✓ | | | | 0.026 | 0.933 0.912 | 0.945 | | 0.672 | 0.025 0.927 | 0.937 | 0.926 | 0.644 | 0.013 | 0.944 | 0.973 | 0.940 | 0.645 |
| #2 | ✓ | ✓ | | | 0.023 | 0.939 0.914 | 0.954 | | 0.742 | 0.022 0.935 | 0.946 | 0.934 | 0.702 | 0.011 | 0.947 | 0.976 | 0.951 | 0.699 |
| #3 | ✓ | ✓ | ✓ | | 0.022 | 0.944 | 0.914 0.956 | | 0.776 | 0.021 0.940 | 0.949 | 0.941 | 0.731 | 0.009 | 0.957 | 0.980 | 0.962 | 0.726 |
| #4 | ✓ | ✓ | ✓ | ✓ | 0.019 | 0.947 0.921 | 0.961 | 0.784 | 0.019 | 0.941 | 0.949 | 0.945 | 0.736 | 0.008 | 0.958 | 0.982 | 0.963 | 0.736 |
feature pyramids, and the labels E i of encoders can correspond to Fig. 7. No. ★ 1 denotes the baseline model which only adopt the Swin encoder to construct the feature pyramid. In variants No. ★ 2 and No. ★ 3, we add the corresponding encoder branch to No. ★ 1, respectively, to aggregate features from branches of different resolution with our proposed staggered connection strategy to form a higher feature pyramid. We find that adding the E 2 branch gives a performance boost, but it is relatively limited. However, adding E 3 encoder the mBA metrics are significantly improved as shown in 3-th row in Tab. VI. Analyzing this result, we conclude that E 2 branch has a small resolution increase compared to E 1 , providing limited detail and not enough to improve the edge quality. On the other hand, E 3 branch is 4 times larger than E 1 branch in terms of the feature map size, and the network can learn more details from the large size feature maps to generate saliency maps with high edge quality. This is evidenced by the visual comparison in Fig. 11. Besides, we note that while the edge quality is greatly improved, the E ξ metric decrease relative to No. ★ 2. We believe this is due to the fact that while E 3 branch brings rich details, it also brings some error as well as background noise, because the relative receptive field is limited. Lastly, the variant No. ★ 4 is the hierarchical staggered connection we used in PGNeXt. In Tab. VI, the M and E ξ in the last row are increased a lot compared to the other rows. This is due to the hierarchical staggered connection that gradually aggregates features from low-resolution branch to higher-resolution branch. This process narrows the semantic gap among the three branches and provides a progressive fusion effect, enabling more accurate identification of salient regions. Besides, we find that compared to ★ 3, the mBA decreases, and we speculate that this may result from the incorporation of the relative coarse E 2 causing the fusion of the edge region to be confused, which also implies that we need further grafting strategy instead of the plain feature fusion.
3) Ablation on wCMGM: We provide the effect of different readjustment configuration in wCMGM on the performance in Tab. VII. In specific, we vary the α in Eq. (4) to adjust the amplification effect for the cross attention maps. The first row in Tab. VII is the result without readjusting strategy in wCMGM, and metrics are lower than results in the rest rows. It indicate that the readjustment in wCMGM is necessary for improving the performance. And in the comparison among ✳ 2, ✳ 3 and ✳ 4, we can observe that the performance is relatively
TABLE VI
ABLATION ANALYSIS ON THE NUMBER OF BRANCHES. E i DENOTES THE INVOLVEMENT OF THE i -TH ENCODER IN THE PYRAMID FEATURE GRAFTING PROCESS. THE BEST RESULTS ARE HIGHLIGHTED IN BOLD .
TABLE VII
| No. | Branch | UHRSD-TE | UHRSD-TE | UHRSD-TE | HRSOD-TE | HRSOD-TE | HRSOD-TE |
|-------|-------------|------------|------------|------------|------------|------------|------------|
| No. | E 1 E 2 E 3 | M | E ξ | mBA | M | E ξ | mBA |
| ★ 1 | ✓ | 0.026 | 0.912 | 0.672 | 0.025 | 0.937 | 0.644 |
| ★ 2 | ✓ ✓ | 0.026 | 0.913 | 0.673 | 0.025 | 0.944 | 0.653 |
| ★ 3 | ✓ ✓ | 0.024 | 0.911 | 0.751 | 0.024 | 0.941 | 0.707 |
| ★ 4 | ✓ ✓ ✓ | 0.023 | 0.914 | 0.742 | 0.022 | 0.946 | 0.702 |
ABLATION ANALYSIS ON READJUSTMENT STRATEGY IN WCMGM. THE BEST RESULTS ARE HIGHLIGHTED IN BOLD .
| No. | Readjust | UHRSD-TE | UHRSD-TE | UHRSD-TE | UHRSD-TE | HRSOD-TE | HRSOD-TE | HRSOD-TE | HRSOD-TE |
|-------|------------|------------|------------|------------|------------|------------|------------|------------|------------|
| No. | Readjust | M | S α | E ξ | mBA | M | S α | E ξ | mBA |
| ✳ 1 | w/o | 0.022 | 0.944 | 0.914 | 0.776 | 0.021 | 0.940 | 0.949 | 0.731 |
| ✳ 2 | α = 1 | 0.021 | 0.945 | 0.915 | 0.776 | 0.020 | 0.941 | 0.949 | 0.729 |
| ✳ 3 | α = 2 | 0.019 | 0.947 | 0.921 | 0.784 | 0.019 | 0.941 | 0.949 | 0.736 |
| ✳ 4 | α = 3 | 0.021 | 0.946 | 0.918 | 0.778 | 0.021 | 0.942 | 0.949 | 0.732 |
close, and overal the best performance is achieved when α = 2 .
## VI. GENERALIZATION TO CAMOUFLAGED OBJECT DETECTION
In this section, to demonstrate the generalization ability, we apply our PGNeXt to the closely related challenging task of camouflaged object detection (COD) [61], which aims to locate and segment objects blended into the background. We chose the COD task not only because it is a binary segmentation task like SOD, but also for two main reasons: 1) COD datasets typically have higher resolution to distinguish small camouflaged objects and show inconspicuous edge clues; 2) Existing researches [61], [62] indicate that the performance of COD methods is greatly influenced by input resolution. Hence, we argue that the application to COD task can reflect the PGNeXt's comprehensive capability in handling highresolution images.
Fig. 12. Visual comparison with state-of-the-art COD methods. Best viewed by zoom-in.
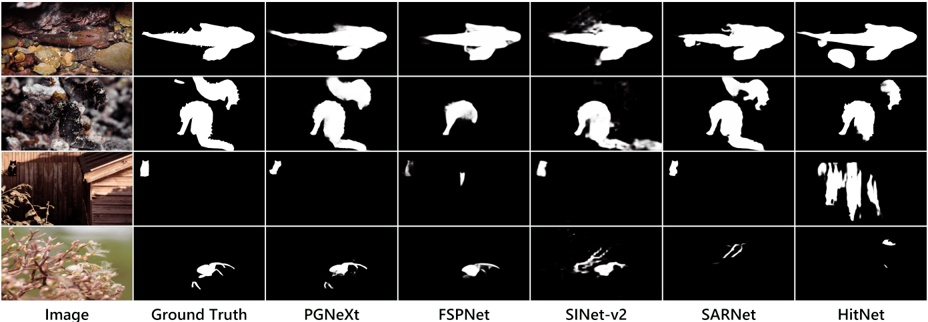
## A. Implementation Details
To verify the generalization ability of PGNeXt, we do not modify any modules when applying on COD task. For a fair comparison, we follow the training setting of recent COD methods [61]-[63] using the combination of COD10K and CAMO datasets for training process. And we evaluate our models on 3 widely-used COD benchmarks, i.e . COD10K [61], CAMO [64] and NC4K [65].
We set the maximum learning rate to 0.06, with the learning rate for Swin-B at 0.02 of the maximum learning rate. The size of mini-batch is set to 32 and the whole training process takes 56 epochs. The remaining training settings are similar to those used in HR-SOD task.
## B. Quantitative Comparison
In Tab. VIII we show the quantity results of several stateof-the-art COD methods and our PGNeXt on 3 widelyused benchmarks. It is noteworthy that HitNet [66] ,which has impressive performance in Tab. VIII, is also designed with the objective of detecting camouflaged objects in highresolution. As can be seen, without bells and whistles our PGNeXt surpasses most of existing COD methods by a large margin. We argue that the high-resolution design of PGNeXt effectively aids in detecting and segmenting small targets of structures that are challenging to discern at lower resolution, thereby contributing to its strong performance in COD task. The success of PGNeXt applying on COD task amply validates its generalization ability in similar binary segmentation tasks.
## C. Qualitative Comparison
We show visual comparison between PGNeXt and existing state-of-the-art COD methods including FSPNet [67], SINetV2 [61], SARNet [68] and HitNet [66]. As can be seen in Fig. 12, our PGNeXt is not only capable of accurately detecting multi-scale concealed objects, but it can also precisely segment the blurred boundaries of them. As shown in first two rows in Fig. 12, the global information captured by the transformer branch enables PGNeXt to precisely identify camouflaged objects, ensuring neither omissions nor redundancy.
## TABLE VIII
QUANTITATIVE COMPARISON OF OUR PGNEXT WITH STATE-OF-THE-ART COD METHODS ON THREE BENCHMARK DATASETS INCLUDING CAMO, COD10K AND NC4K. THE BEST RESULTS OF EACH METRIC ARE IN BOLD
| Method | CAMO COD10K | CAMO COD10K | NC4K |
|---------------|----------------|----------------|----------------|
| | M S α F M β | M S α F M β | M S α F M β |
| SINet [69] | .100 .751 .675 | .051 .771 .634 | .058 .808 .769 |
| Rank-Net [65] | .080 .787 .744 | .037 .804 .715 | .048 .840 .804 |
| UGTR [70] | .086 .784 .735 | .036 .817 .712 | .052 .839 .787 |
| BSA-Net [71] | .079 .794 .763 | .034 .818 .738 | .048 .841 .808 |
| SegMaR [72] | .071 .815 .795 | .034 .833 .757 | .046 .841 .821 |
| ZoomNet [73] | .066 .820 .794 | .029 .838 .766 | .043 .853 .818 |
| SINet-v2 [61] | .070 .820 .782 | .037 .815 .718 | .048 .847 .805 |
| FAPNet [74] | .076 .815 .776 | .036 .822 .731 | .047 .851 .810 |
| FEDER [75] | .071 .802 .781 | .032 .822 .751 | .044 .847 .824 |
| FSPNet [67] | .050 .856 .831 | .026 .851 .769 | .035 .879 .843 |
| SARNet [68] | .047 .868 .850 | .024 .864 .800 | .032 .886 .863 |
| HitNet [66] | .055 .849 .831 | .023 .871 .823 | .037 .875 .854 |
| PGNeXt | .047 .866 .872 | .023 .861 .833 | .031 .886 .885 |
From rows 3 and 4 we can clearly see that PGNeXt is capable of segmenting extremely small targets. While HitNet, another high-resolution method tailed for COD task, preserves sharp edges like PGNeXt, but it suffers from serious misidentification of camouflaged targets. Both quantitative and qualitative results demonstrate the potential of PGNeXt generalizing on other low-level segmentation tasks.
## VII. CONCLUSION
This paper presented an advanced study on the highresolution salient object detection (HR-SOD) from both dataset and network framework perspectives. Specifically, we comprehensively analyzed the challenges of HR-SOD and the disadvantages of existing HR-SOD methods, and proposed the pyramid grafting mechanism. Furthermore, we designed the window-based Cross-Model Grafting Module (wCMGM) and attention guided loss (AGL), based on which we con-
structed the PGNeXt. Considering the lack of available HRSOD datasets, we elaborately organize and annotate ultrahigh-resolution saliency detection (UHRSD) dataset. The high quantity and quality of UHRSD will provide more opportunity for future research in HR-SOD field. We have conducted a HR-SOD benchmark for cutting-edge SOD methods on both existing HR-SOD datasets and our newly proposed UHRSD. Extensive experiments demonstrate that our PGNeXt outperforms state-of-the-art methods. Besides, the generalization capabilities shown by PGNeXt represent a great potential for many real-world applications.
## REFERENCES
- [1] C. Xie, C. Xia, M. Ma, Z. Zhao, X. Chen, and J. Li, 'Pyramid grafting network for one-stage high resolution saliency detection,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2022, pp. 11 717-11 726.
- [2] N. Liu, W. Zhao, D. Zhang, J. Han, and L. Shao, 'Light field saliency detection with dual local graph learning and reciprocative guidance,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2021, pp. 4712-4721.
- [3] M. Zhang, J. Li, J. Wei, Y. Piao, and H. Lu, 'Memory-oriented decoder for light field salient object detection,' Advances in neural information processing systems , vol. 32, 2019.
- [4] Z. Zhou, Z. Wang, H. Lu, S. Wang, and M. Sun, 'Multi-type selfattention guided degraded saliency detection,' in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 34, no. 07, 2020, pp. 13 082-13 089.
- [5] G.-P. Ji, K. Fu, Z. Wu, D.-P. Fan, J. Shen, and L. Shao, 'Full-duplex strategy for video object segmentation,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2021, pp. 4922-4933.
- [6] M. Zhang, J. Liu, Y. Wang, Y. Piao, S. Yao, W. Ji, J. Li, H. Lu, and Z. Luo, 'Dynamic context-sensitive filtering network for video salient object detection,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2021, pp. 1553-1563.
- [7] S. Ge, J. Li, Q. Ye, and Z. Luo, 'Detecting masked faces in the wild with lle-cnns,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2017, pp. 2682-2690.
- [8] S. Ge, S. Zhao, C. Li, and J. Li, 'Low-resolution face recognition in the wild via selective knowledge distillation,' IEEE Transactions on Image Processing , vol. 28, no. 4, pp. 2051-2062, 2018.
- [9] Y. Zhao, K. Yan, F. Huang, and J. Li, 'Graph-based high-order relation discovery for fine-grained recognition,' in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , 2021, pp. 15 079-15 088.
- [10] B. He, J. Li, Y. Zhao, and Y. Tian, 'Part-regularized near-duplicate vehicle re-identification,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2019, pp. 3997-4005.
- [11] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, 'Imagenet: A large-scale hierarchical image database,' in 2009 IEEE conference on computer vision and pattern recognition . Ieee, 2009, pp. 248-255.
- [12] S. Li, X. Xia, S. Ge, and T. Liu, 'Selective-supervised contrastive learning with noisy labels,' in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , 2022, pp. 316-325.
- [13] L. Qiao, Y. Shi, J. Li, Y. Wang, T. Huang, and Y. Tian, 'Transductive episodic-wise adaptive metric for few-shot learning,' in Proceedings of the IEEE/CVF international conference on computer vision , 2019, pp. 3603-3612.
- [14] G. Chen, L. Qiao, Y. Shi, P. Peng, J. Li, T. Huang, S. Pu, and Y. Tian, 'Learning open set network with discriminative reciprocal points,' in Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part III 16 . Springer, 2020, pp. 507-522.
- [15] S. Chen, X. Tan, B. Wang, and X. Hu, 'Reverse attention for salient object detection,' in Proceedings of the European Conference on Computer Vision (ECCV) , 2018, pp. 234-250.
- [16] J. Su, J. Li, Y. Zhang, C. Xia, and Y. Tian, 'Selectivity or invariance: Boundary-aware salient object detection,' in ICCV , 2019.
- [17] J.-J. Liu, Q. Hou, and M.-M. Cheng, 'Dynamic feature integration for simultaneous detection of salient object, edge and skeleton,' arXiv preprint arXiv:2004.08595 , 2020.
- [18] X. Qin, Z. Zhang, C. Huang, M. Dehghan, O. R. Zaiane, and M. Jagersand, 'U2-net: Going deeper with nested u-structure for salient object detection,' Pattern Recognition , vol. 106, p. 107404, 2020.
- [19] W. Ji, J. Li, S. Yu, M. Zhang, Y. Piao, S. Yao, Q. Bi, K. Ma, Y. Zheng, H. Lu et al. , 'Calibrated rgb-d salient object detection,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2021, pp. 9471-9481.
- [20] D.-P. Fan, Y. Zhai, A. Borji, J. Yang, and L. Shao, 'Bbs-net: Rgb-d salient object detection with a bifurcated backbone strategy network,' in European Conference on Computer Vision . Springer, 2020, pp. 275292.
- [21] Y. Zeng, P. Zhang, J. Zhang, Z. Lin, and H. Lu, 'Towards high-resolution salient object detection,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2019, pp. 7234-7243.
- [22] L. Tang, B. Li, Y. Zhong, S. Ding, and M. Song, 'Disentangled high quality salient object detection,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2021, pp. 3580-3590.
- [23] X. Deng, P. Zhang, W. Liu, and H. Lu, 'Recurrent multi-scale transformer for high-resolution salient object detection,' in Proceedings of the 31st ACM International Conference on Multimedia , 2023, pp. 74137423.
- [24] C. Xia, J. Li, X. Chen, A. Zheng, and Y. Zhang, 'What is and what is not a salient object? learning salient object detector by ensembling linear exemplar regressors,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2017, pp. 4142-4150.
- [25] L. Itti, C. Koch, and E. Niebur, 'A model of saliency-based visual attention for rapid scene analysis,' IEEE Transactions on pattern analysis and machine intelligence , vol. 20, no. 11, pp. 1254-1259, 1998.
- [26] H. Jiang, J. Wang, Z. Yuan, Y. Wu, N. Zheng, and S. Li, 'Salient object detection: A discriminative regional feature integration approach,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2013, pp. 2083-2090.
- [27] Q. Yan, L. Xu, J. Shi, and J. Jia, 'Hierarchical saliency detection,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2013, pp. 1155-1162.
- [28] K. He, X. Zhang, S. Ren, and J. Sun, 'Deep residual learning for image recognition. 2016 ieee conf comput vispattern recognit. 2016: 770-778 https://doi. org/10.1109.' CVPR, 2016.
- [29] K. Simonyan and A. Zisserman, 'Very deep convolutional networks for large-scale image recognition,' arXiv preprint arXiv:1409.1556 , 2014.
- [30] T.-Y. Lin, P. Doll´ ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, 'Feature pyramid networks for object detection,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2017, pp. 2117-2125.
- [31] Q. Hou, M.-M. Cheng, X. Hu, A. Borji, Z. Tu, and P. H. Torr, 'Deeply supervised salient object detection with short connections,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2017, pp. 3203-3212.
- [32] J.-J. Liu, Q. Hou, M.-M. Cheng, J. Feng, and J. Jiang, 'A simple poolingbased design for real-time salient object detection,' in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2019, pp. 3917-3926.
- [33] Z. Chen, Q. Xu, R. Cong, and Q. Huang, 'Global context-aware progressive aggregation network for salient object detection,' arXiv preprint arXiv:2003.00651 , 2020.
- [34] J. Wei, S. Wang, Z. Wu, C. Su, Q. Huang, and Q. Tian, 'Label decoupling framework for salient object detection,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2020, pp. 13 025-13 034.
- [35] Z. Zhao, C. Xia, C. Xie, and J. Li, 'Complementary trilateral decoder for fast and accurate salient object detection,' in Proceedings of the 29th ACM International Conference on Multimedia , 2021, pp. 4967-4975.
- [36] N. Liu, N. Zhang, K. Wan, L. Shao, and J. Han, 'Visual saliency transformer,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2021, pp. 4722-4732.
- [37] M. Ma, C. Xia, C. Xie, X. Chen, and J. Li, 'Boosting broader receptive fields for salient object detection,' IEEE Transactions on Image Processing , vol. 32, pp. 1026-1038, 2023.
- [38] F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross, and A. Sorkine-Hornung, 'A benchmark dataset and evaluation methodology for video object segmentation,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2016, pp. 724-732.
- [39] L. Wang, H. Lu, Y. Wang, M. Feng, D. Wang, B. Yin, and X. Ruan, 'Learning to detect salient objects with image-level supervision,' in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2017, pp. 136-145.
- [40] P. Zhang, W. Liu, Y. Zeng, Y. Lei, and H. Lu, 'Looking for the detail and context devils: High-resolution salient object detection,' IEEE Transactions on Image Processing , vol. 30, pp. 3204-3216, 2021.
- [41] Y. Li, X. Hou, C. Koch, J. M. Rehg, and A. L. Yuille, 'The secrets of salient object segmentation,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2014, pp. 280-287.
- [42] X. Qin, H. Dai, X. Hu, D.-P. Fan, L. Shao, and L. V. Gool, 'Highly accurate dichotomous image segmentation,' in ECCV , 2022.
- [43] X. Lin, J. Ji, and Y. Gu, 'The euler number study of image and its application,' in 2007 2nd IEEE Conference on Industrial Electronics and Applications . IEEE, 2007, pp. 910-912.
- [44] J. Wei, S. Wang, and Q. Huang, 'F 3 net: Fusion, feedback and focus for salient object detection,' in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 34, no. 07, 2020, pp. 12 321-12 328.
- [45] S. Yu, J. Xiao, B. Zhang, and E. G. Lim, 'Democracy does matter: Comprehensive feature mining for co-salient object detection,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2022, pp. 979-988.
- [46] P.-T. De Boer, D. P. Kroese, S. Mannor, and R. Y. Rubinstein, 'A tutorial on the cross-entropy method,' Annals of operations research , vol. 134, no. 1, pp. 19-67, 2005.
- [47] G. M´ attyus, W. Luo, and R. Urtasun, 'Deeproadmapper: Extracting road topology from aerial images,' in Proceedings of the IEEE International Conference on Computer Vision , 2017, pp. 3438-3446.
- [48] X. Qin, Z. Zhang, C. Huang, C. Gao, M. Dehghan, and M. Jagersand, 'Basnet: Boundary-aware salient object detection,' in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2019, pp. 7479-7489.
- [49] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, 'Pytorch: An imperative style, highperformance deep learning library,' in NeurIPS , vol. 32, 2019.
- [50] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, 'Swin transformer: Hierarchical vision transformer using shifted windows,' arXiv preprint arXiv:2103.14030 , 2021.
- [51] T. Kim, K. Kim, J. Lee, D. Cha, J. Lee, and D. Kim, 'Revisiting image pyramid structure for high resolution salient object detection,' in Proceedings of the Asian Conference on Computer Vision (ACCV) , December 2022, pp. 108-124.
- [52] D.-P. Fan, M.-M. Cheng, Y. Liu, T. Li, and A. Borji, 'Structure-measure: A new way to evaluate foreground maps,' in Proceedings of the IEEE international conference on computer vision , 2017, pp. 4548-4557.
- [53] D.-P. Fan, C. Gong, Y. Cao, B. Ren, M.-M. Cheng, and A. Borji, 'Enhanced-alignment measure for binary foreground map evaluation,' arXiv preprint arXiv:1805.10421 , 2018.
- [54] R. Margolin, L. Zelnik-Manor, and A. Tal, 'How to evaluate foreground maps?' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2014, pp. 248-255.
- [55] A. Borji, M.-M. Cheng, H. Jiang, and J. Li, 'Salient object detection: A benchmark,' IEEE transactions on image processing , vol. 24, no. 12, pp. 5706-5722, 2015.
- [56] H. K. Cheng, J. Chung, Y.-W. Tai, and C.-K. Tang, 'Cascadepsp: Toward class-agnostic and very high-resolution segmentation via global and local refinement,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2020, pp. 8890-8899.
- [57] J. Zhao, Y. Zhao, J. Li, and X. Chen, 'Is depth really necessary for salient object detection?' in Proceedings of the 28th ACM International Conference on Multimedia , 2020, pp. 1745-1754.
- [58] H. Zhou, X. Xie, J.-H. Lai, Z. Chen, and L. Yang, 'Interactive twostream decoder for accurate and fast saliency detection,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2020, pp. 9141-9150.
- [59] M. Ma, C. Xia, and J. Li, 'Pyramidal feature shrinking for salient object detection,' in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 35, no. 3, 2021, pp. 2311-2318.
- [60] M. Zhuge, D.-P. Fan, N. Liu, D. Zhang, D. Xu, and L. Shao, 'Salient object detection via integrity learning,' IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 45, no. 3, pp. 3738-3752, 2022.
- [61] D.-P. Fan, G.-P. Ji, M.-M. Cheng, and L. Shao, 'Concealed object detection,' IEEE transactions on pattern analysis and machine intelligence , vol. 44, no. 10, pp. 6024-6042, 2021.
- [62] X. Hu, S. Wang, X. Qin, H. Dai, W. Ren, D. Luo, Y. Tai, and L. Shao, 'High-resolution iterative feedback network for camouflaged object detection,' in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 37, no. 1, 2023, pp. 881-889.
- [63] C. Xie, C. Xia, T. Yu, and J. Li, 'Frequency representation integration for camouflaged object detection,' in Proceedings of the 31st ACM International Conference on Multimedia , 2023, pp. 1789-1797.
- [64] T.-N. Le, T. V. Nguyen, Z. Nie, M.-T. Tran, and A. Sugimoto, 'Anabranch network for camouflaged object segmentation,' Comput. Vis. Image Und. , vol. 184, pp. 45-56, 2019.
- [65] Y. Lv, J. Zhang, Y. Dai, A. Li, B. Liu, N. Barnes, and D.-P. Fan, 'Simultaneously localize, segment and rank the camouflaged objects,' in CVPR , 2021, pp. 11 586-11 596.
- [66] X. Hu, S. Wang, X. Qin, H. Dai, W. Ren, D. Luo, Y. Tai, and L. Shao, 'High-resolution iterative feedback network for camouflaged object detection,' in AAAI , vol. 37, no. 1, 2023, pp. 881-889.
- [67] Z. Huang, H. Dai, T.-Z. Xiang, S. Wang, H.-X. Chen, J. Qin, and H. Xiong, 'Feature shrinkage pyramid for camouflaged object detection with transformers,' in CVPR , 2023, pp. 5557-5566.
- [68] H. Xing, Y. Wang, X. Wei, H. Tang, S. Gao, and W. Zhang, 'Go closer to see better: Camouflaged object detection via object area amplification and figure-ground conversion,' IEEE TCSVT , 2023.
- [69] D.-P. Fan, G.-P. Ji, G. Sun, M.-M. Cheng, J. Shen, and L. Shao, 'Camouflaged object detection,' in CVPR , 2020, pp. 2774-2784.
- [70] F. Yang, Q. Zhai, X. Li, R. Huang, A. Luo, H. Cheng, and D.-P. Fan, 'Uncertainty-guided transformer reasoning for camouflaged object detection,' in ICCV , 2021, pp. 4126-4135.
- [71] H. Zhu, P. Li, H. Xie, X. Yan, D. Liang, D. Chen, M. Wei, and J. Qin, 'I can find you! boundary-guided separated attention network for camouflaged object detection,' in AAAI , vol. 36, no. 3, 2022, pp. 3608-3616.
- [72] Q. Jia, S. Yao, Y. Liu, X. Fan, R. Liu, and Z. Luo, 'Segment, magnify and reiterate: Detecting camouflaged objects the hard way,' in CVPR , 2022, pp. 4703-4712.
- [73] Y. Pang, X. Zhao, T.-Z. Xiang, L. Zhang, and H. Lu, 'Zoom in and out: A mixed-scale triplet network for camouflaged object detection,' in CVPR , 2022, pp. 2150-2160.
- [74] T. Zhou, Y. Zhou, C. Gong, J. Yang, and Y. Zhang, 'Feature aggregation and propagation network for camouflaged object detection,' IEEE TIP , vol. 31, pp. 7036-7047, 2022.
- [75] C. He, K. Li, Y. Zhang, L. Tang, Y. Zhang, Z. Guo, and X. Li, 'Camouflaged object detection with feature decomposition and edge reconstruction,' in CVPR , 2023, pp. 22 046-22 055. | null | [
"Changqun Xia",
"Chenxi Xie",
"Zhentao He",
"Tianshu Yu",
"Jia Li"
] | 2024-08-02T09:31:21+00:00 | 2024-08-02T09:31:21+00:00 | [
"cs.CV"
] | PGNeXt: High-Resolution Salient Object Detection via Pyramid Grafting Network | We present an advanced study on more challenging high-resolution salient
object detection (HRSOD) from both dataset and network framework perspectives.
To compensate for the lack of HRSOD dataset, we thoughtfully collect a
large-scale high resolution salient object detection dataset, called UHRSD,
containing 5,920 images from real-world complex scenarios at 4K-8K resolutions.
All the images are finely annotated in pixel-level, far exceeding previous
low-resolution SOD datasets. Aiming at overcoming the contradiction between the
sampling depth and the receptive field size in the past methods, we propose a
novel one-stage framework for HR-SOD task using pyramid grafting mechanism. In
general, transformer-based and CNN-based backbones are adopted to extract
features from different resolution images independently and then these features
are grafted from transformer branch to CNN branch. An attention-based
Cross-Model Grafting Module (CMGM) is proposed to enable CNN branch to combine
broken detailed information more holistically, guided by different source
feature during decoding process. Moreover, we design an Attention Guided Loss
(AGL) to explicitly supervise the attention matrix generated by CMGM to help
the network better interact with the attention from different branches.
Comprehensive experiments on UHRSD and widely-used SOD datasets demonstrate
that our method can simultaneously locate salient object and preserve rich
details, outperforming state-of-the-art methods. To verify the generalization
ability of the proposed framework, we apply it to the camouflaged object
detection (COD) task. Notably, our method performs superior to most
state-of-the-art COD methods without bells and whistles. |
2408.01138v1 | 4
## Interplay of Traditional Methods and Machine Learning Algorithms for Tagging Boosted Objects
Camellia Bose , 1 Amit Chakraborty 2* , Shreecheta Chowdhury , 3 Saunak Dutta 4
1
Center for High Energy Physics, Indian Institute of Science, Bangalore, 560012, India. 2,3* Department of Physics, SRM University AP, Amaravati, 522240, India. School of Science & Technology, Vijaybhoomi University, Greater Mumbai, 410201, India.
*Corresponding author(s). E-mail(s): [email protected];
## Abstract
Interest in deep learning in collider physics has been growing in recent years, specifically in applying these methods in jet classification, anomaly detection, particle identification etc. Among those, jet classification using neural networks is one of the well-established areas. In this review, we discuss different tagging frameworks available to tag boosted objects, especially boosted Higgs boson and top quark, at the Large Hadron Collider (LHC). Our aim is to study the interplay of traditional jet substructure based methods with the state-of-the-art machine learning ones. In this methodology, we would gain some interpretability of those machine learning methods, and which in turn helps to propose hybrid taggers relevant for tagging of those boosted objects belonging to both Standard Model (SM) and physics beyond the SM.
## 1 Introduction
Despite the commendable triumph of the Standard Model (SM) in unifying the fundamental interactions [14] leading to the discovery of the Higgs boson at the Large Hadron Collider (LHC) experiment [5, 6], several observational discrepancies cumulated from different experiments and theoretical inconsistencies encountered within the SM framework indicate itself as a low-energy effective theory of a formalism with higher symmetries [2]. With many theories Beyond the Standard Model (BSM) proposed, and many more to be formulated, it is a challenging task to figure out which of these theories explains the nature. Observations made at particle colliders which recreate the early universe with high energy density are presently the only trails to trace back the framework, most favored by the nature.
The BSM probes are, fundamentally, the classification problems: identification of the events that are governed by a BSM framework, among the ones accommodated in SM. Traditionally, the cut-based techniques have been the principal tool for the BSM probes. It identifies regions in the phase space with abundant (model dependent) BSM signatures over the SM backgrounds, and redirects the BSM search in those regions. With robust influx of collision data, constraining the phase space and pushing New Physics to higher energy frontier, implementation of advanced search strategies are inevitable.
The focal point of attention in particle physics is presently the LHC [7]. It offers a distinctive chance to investigate the dynamics of the SM at the TeV scale and to explore potential new physics signatures. A collision event at the LHC encompassing various objects, namely hadrons, leptons (electrons/muons), photons, neutrinos, and also other stable exotic particles associated to BSM physics if any. After reconstructing the leptons and photons using tracker and calorimeter information, the hadrons are clustered into jets which are the collimated sprays of particles resulting from the hadronization of quarks and gluons, along with their
radiative effects. These are abundant in high-energy collisions, especially at the hadron colliders like LHC. Boosted objects, on the other hand, which are particles with high momentum relative to their mass, become more prevalent at higher energies. Therefore, analysis of jets and boosted objects at hadronic colliders provide great insights into the laws of nature. Over the recent past, an enormous amount of studies have been performed using the jet substructure method focusing on analyzing the physics with Higgs bosons and Top quarks at the highly boosted regime. Several ground-breaking advancements have been achieved in probing and tagging these objects, we refer [8] for a comprehensive review on this. Furthermore, proper identification and analysis of these boosted jets lead to an indirect probe of the properties of hypothetical new particles and potentially confirm or constrain the predictions of BSM theories. In other words, detecting such resonances in collider experiments can provide direct evidence for new physics beyond the SM. In view of anomaly detection, precise measurements of jet properties, such as their energy, angular distributions, and substructure, enables the comparison between experimental data with theoretical predictions based on the SM. Any deviations from these predictions could indicate the presence of new physics.
In parallel with technological advancement, the advent of Artificial Intelligence (AI) and Machine Learning (ML) algorithms have catered for the effective search strategies. ML algorithms are efficacious in carving out features pertinent for discerning BSM signatures, as deviations over the SM expectations. Contemporary machine learning techniques, encompassing deep learning, are finding application, adaptation, and advancement in the field of high-energy physics. The rapid progress in the field of Machine/Deep Learning and potential areas of application in High Energy Physics, especially in the context of tagging boosted objects using the complex and rich structure inside jets, has resulted in a renaissance.
In this review, we aim to provide an overview of the Machine Learning tools and their implementations in BSM searches focusing on the tagging of Higgs bosons and Top quarks at the LHC. We will also provide an outline of the challenges ahead, and some of the issues/strategies need to be addresses in the near future. As a wide range of studies have been already performed, we will be somewhat selective in our presentation, and will choose a few representative studies. However, for interested readers we refer the following articles [9-13] for modern dedicated reviews on this area, and also the Living Review of Machine Learning for Particle Physics [14] for a nearly comprehensive list of references which includes all the state-of-art techniques developed and applied in wide range of studies including the recent-most developments.
This work has been organized as follows: in Section 2 we provide a briefly outline of traditional machine learning algorithm, while relatively advanced variants of these techniques are discussed in Section 3. The main objective of this review is to discuss different studies on Jet tagging focussing on the Higgs boson and Top quark, which we discuss in Section 5. One of the major drawbacks of these machine learning models is the lack of interpretability. In Section 6, we highlight a few studies which focus on this domain and aim to capture relevant knowledge from a trained model in terms of the input features or high-level objects. In Section 7, we provide a summary along with the potential areas of improvement and directions to explore in future.
## 2 Artificial Neural Network and Deep Learning: An Overview
Traditional Machine Learning tools provide a plethora of classification algorithms [15, 16] for efficient identification of BSM signatures from the background events. One such algorithm, the Decision Tree [17], functions in a way that resembles the traditional cut-based technique. This algorithm progresses by recursive imposition of cuts, on a given feature at a time, thereby splitting the phase space into subspaces based on the most significant attribute or feature [18], and finally providing a tree structure, constructed over the set of events, where each leaf node, attributed to a given subspace, represents a class label (signal or background). Decision trees are interpretable, easy to visualize and capture complex patterns leading to attribution of the class. Nevertheless they are prone to over-fitting [19]. Ensemble learning techniques like Random Forest [20] and Gradient Boosting [21, 22] are implemented in improving the performance and robustness of decision trees. A Boosted Decision Tree (BDT) [23-25], is a boosting technique that combines multiple decision tree stumps, to create a more robust and accurate predictive model. BDT trains the decision tree stumps sequentially over the set of events, such that the events misclassified in the preceding training are given more emphasis by the succeeding tree stumps. This process continues iteratively, with each tree stump focusing on the mistakes of the previous ones. The boosting technique is used to improve the performance of weak learners (the decision tree stumps) by combining their predictions.
In parallel, there has been advancement in development of ML algorithms by imitating the action of human brains, since 1940's [26, 27], eventually leading to another paradigm of Machine Learning, the Neural Network (NN). A perceptron, that mimics the action of a neuron, the building block of nervous systems in intelligent species, was proposed in 1958 [28], paving the way for the development of an architecture containing a single hidden layer of perceptrons [29] in 60's, termed Artificial Neural Network (ANN). It turns out that, a feed-forward artificial neural network [30] with a single hidden layer containing a finite number of neurons can approximate any continuous function to any desired degree of accuracy, given a sufficiently large number of neurons [31-33]. In simpler terms, a neural network with just one hidden layer can approximate any function, as long as it has enough neurons in that hidden layer. This enables ANNs as universal function approximators, capable of representing a wide range of complex relations [34]. An ANN is trained upon finetuning the weights assigned between the neurons in adjacent layers, minimizing the error [35], calculated during forward propagation, which is then used to adjust the weights iteratively [36] in the network, using the process termed back propagation [37, 38]. This involves computing the gradient of the error function with respect to the weights and updating the weights in a direction that minimizes the error [39].
The performance of an ANN architecture can be further enhanced by insertion of multiple hidden layers, leading to what is known as deep neural network (DNN) architectures [40, 41]. DNNs have accomplished even greater capacity for learning complex functions and patterns in the phase space that distinguish BSM signatures from SM backgrounds.
We will encounter the implication of these architectures and their variants in appropriate identification of simulated entities bearing BSM signatures in subsequent sections. The following section sketches an overview of advanced variants of DNN architectures.
## 3 Advanced Variants of DNN: Autoencoders, Convolutional Nets, Transformers and Graph Network
The BSM signatures manifest themselves as anomalies in the background of the SM events. A model independent search of New Physics is therefore, fundamentally focused on the effective identification of anomalies. Autoencoders are the simplest DNN architectures that can serve the purpose [42, 43]. An autoencoder possesses a bottleneck architecture [44] of hidden layers of neurons, the bottleneck layer representing the compressed representation of the event features, while the preceding layers perform convolution and the following layers deconvolution of these features[45]. It learns the efficient representations of events by training the network to encode input data into a lower-dimensional latent space and then decode it back to its original form. Thus, when trained with a large number of SM events, the autoencoder shall learn to reconstruct the background efficiently, by minimizing the reconstruction loss. BSM signatures, significantly different from SM counterparts, can be detected as events with high reconstruction loss by an autoencoder, trained over events governed by the principles of SM. Identified anomalies can be put for further validation and analysis using either traditional analysis methods or more sophisticated ML algorithms, to confirm whether they represent genuine BSM signatures or are experimental artifacts. Masked autoencoders, designed and adapted to efficiently learn from visual data, have been equally effective in jet-tagging from large-scale datasets of jet-images [46].
Jet-tagging from jet images has been revolutionized with the implementation of Convolutional Neural Network [47]. This architecture learns hierarchical representations of features directly from the raw data, adapting to various jet signatures and complexities without the need for explicit feature engineering. With high scalability and inherent robustness to noises, CNNs exploit the property of spatial invariance for jets ( i.e. , the same convolutional filters are applicable across different regions of the jet image), to effectively capture local patterns and structures within jets, regardless of their position or orientation within the detector. The convolutional layer, the core building block of a CNN contains a set of learnable filters (termed kernels) that slide across the input image, computing the dot product between the filter and local regions of the input, leading to feature maps that highlight different aspects of the input image, such as edges, textures, or patterns [48]. We will explore the implementation of CNN in jet-tagging in the following sections.
The limitations of CNN in jet-image classification can be further overcome with the introduction of Transformers [49]. A transformer is a deep learning model adapted for processing of sequential data. Unlike CNNs, which typically rely on local receptive fields to capture spatial information, transformer models can
capture long-range dependencies in the data more effectively, achieved through the self-attention mechanism, which allows the model to weigh the importance of different entries in a sequence during processing, thus allowing the model to capture long-range dependencies in the input sequence without being limited by the fixed-length context windows of CNNs. While CNNs rely on spatial convolutional operations to implicitly capture positional relationships, transformers explicitly model these relationships through the addition of positional encodings, which is important for tasks where the spatial arrangement of objects matters. On top, Transformers typically require fewer parameters compared to the CNN counterparts. This is because transformers process the input sequence as a whole, whereas CNNs apply convolutional operations locally, resulting in a larger number of parameters, especially in deeper architectures. As a result, transformers can achieve comparable or better performance with fewer parameters, leading to more efficient models. Transformer models also offer greater interpretability compared to CNN architectures, particularly in terms of understanding the relationships between different parts of the input sequence. The attention mechanism in transformers allows for visualization of attention weights, which indicate the importance of each input token or position for the final prediction, providing valuable insights into how the model makes decisions and which parts of the input contribute most to object identification.
We will conclude the section with an algorithm which has found extensive uses in event reconstructions [50-54] and particle identifications [55-57]. The Graph Neural Network (GNN) is a variant of DNN, designed for analyzing graph-structured data. A Graph comprises of nodes (representing particles in a specific event) and edges (depicting relationships or connections between the nodes), with each node associated with a feature vector describing its properties ( eg . p T , η, ϕ ) and its associated edges representing the respective parents and daughters. GNNs are used in reconstruction of the underlying objects ( eg . jets, leptons, photons) from the raw detector data obtained in colliders. Taking the detector outputs as input, GNNs cluster particles into jets [58, 59]. GNNs identify individual particles with high efficiency and accuracy ( eg . electrons, muons, photons) based on their energy deposits and trajectories in the detector [60]. GNNs can learn to exploit subtle features and correlations in the detector data to improve the particle identification performance compared to traditional methods [61]. In addition, GNNs have been equally implemented in simulation of realistic collision events, essential for studying the performance of detectors, developing analysis techniques, and interpreting experimental results. GNN-based event generators can efficiently model the complex interactions of particles in the detector and provide samples that closely resemble real collision data. A generalization over traditional graph structures, the hyper-graphs [62], containing hyper-edges connecting more than two nodes provide additional flexibility of representing relationships among entities compared to traditional graphs. Hypergraphs provide lucid representations of the complex interactions between particles in high energy collisions [63, 64]. Each node in the hyper-graph represents a particle, and hyper-edges represent interactions between multiple particles, enabling the analysis of particle decays, especially in situations where multiple particles are involved in the decay chain, along with the possible decay paths and their probabilities [65]. From the robust data generated from the particle collider, hyper-graphs are used to analyze the topology of this data, identifying patterns and structures that may correspond to specific particle interactions or decay processes [66].
## 4 Identification of the Boosted Objects:
With technological advancement, as the collision energy progressively approaches the higher frontier, production of boosted objects [67] becomes more abundant. A boosted object refers to a particle or a group of particles that carry a significant amount of momentum in a particular direction due to the high-energy collisions involved. Boosted objects typically arise in scenarios where the decay products of heavy particles, viz. , top quarks, W or Z bosons, or Higgs bosons, are emitted with large momenta. Since these particles are produced with high momentum, their decay products tend to be collimated, forming a single, highly energetic jet of particles, encapsulating particles originating from the decay of the primary particle, with these decay products lying spatially close to each other within the detector. In Figure 1, we provide a schematic diagram showing the way in which the decay products of a top quark merge with increasing p T of the mother particle.
The analysis of boosted objects has an advantage: the depletion of QCD Background at a high energy boosted regime, that enables enhanced signal density over the background. In parallel, several BSM theories lead to propositions of particles with higher resonances, eventually decaying to different stable states. Retracing such excited states requires effective reconstruction of these heavy resonances, necessitating the
inclusion of their respective stable decay products in a single cluster. In a boosted regime, the stable states that originated from the decay of such a heavy particle can be enveloped in a single jet of large radius, known as large-R jets, enabling an opportunity to retrace the property of the intermediate resonance state.
Fig. 1 : A schematic diagram of the merger of top decay products with the increase of top quark p T . The angular separation ∆ R ∼ 1 has been used here. The figure has been adopted from [68].

There are several techniques to analyse boosted objects: traditionally, jet substructure algorithms are used to identify these patterns within a single large-radius jet. Substructure observables, namely, jet mass, N-subjettiness, energy correlation functions etc., are employed to distinguish between boosted objects from ordinary QCD background [8]. Boosted bosons like, W, Z, H , are identified from clustering their respective decay products and calculating their combined invariant masses after applying certain grooming techniques. Specific jet clustering algorithms, for example, Cambridge/Aachen or anti-kT clustering [69] with a large radius parameter are often used to capture the entirety of the boosted object within a single jet and identify it. We refer Ref.[8] for a detailed discussion covering the basic principles underlying the calculation of jet substructure observables, the development of new observables leading to state-of-the-art machine learning techniques for jet substructure.
The accuracy of boosted object identification has been enhanced with the implementation of ML techniques, stand-alone, or in association with the traditional approaches. Deep Learning models, trained on simulated data to recognize the characteristic features of boosted objects at colliders, are increasingly used in particle phenomenology for boosted object identification. Several tagging algorithms specifically designed to identify boosted objects, such as top quarks or Higgs bosons, have been formulated. These algorithms often exploit the unique properties of the boosted objects, such as their large transverse momentum or distinctive substructure. Particle flow algorithms enable effective reconstruction of individual particles from the collision debris, aiding in the identification of the boosted objects by accurately associating particles belonging to the same object. Overall event characteristics, such as missing transverse energy (MET), total transverse momentum, or other global event variables, can be analyzed to identify events containing boosted objects.
These techniques are often used in combination to enhance the efficiency and reliability of boosted object identification in particle phenomenology experiments. Additionally, they are continuously evolving with advances in both experimental techniques and theoretical understanding. Below we discuss some of the recent-most developments for tagging the boosted Higgs boson and top quarks at the hadron collider environments such as the LHC.
## 5 The Higgs and Top Tagging Algorithms
## 5.1 Higgs tagging
Higgs boson, proposed by Brout, Englert and Higgs, is a neutral, spin-0 scalar accommodated in the SM to address the mass generation of the fermions and spin-1 gauge bosons after the breaking of electroweak symmetry. Probes carried out by LEP-2 collaboration in 2003 on Higgstrahlung ( e + e -→ HZ ) set the lower bound of the mass of Higgs boson to be, M H ⩾ 114.4 GeV [70]. However, the result was debatable for its assumption on high HZZ coupling strength, and therefore could be nullified with BSM theories accommodating smaller HZZ coupling strengths. Observation of a CP-even, spin-0, neutral scalar was finally made at LHC, separately by ATLAS and CMS collaborations in from the di-photon excess around the invariant mass of, m γγ ∼ 125 5 GeV [5, 6]. The newly discovered particle was attributed to be the Higgs . Boson, and today, Higgs has been observed through its (almost) all possible dominant decay modes.
The pre-LHC colliders, viz. , LEP, Tevatron, HERA provided the collision energies principally within the range between few 10's to 100's of GeV. The high energy collisions presently on the roll, at LHC, lead to abundant productions of heavy species ( viz. , W Z H , , and t ) with high transverse momentum. They are boosted, therefore their decay products are highly collimated along its axis of production and are observed in the calorimeters as a cluster of particles (abundantly, hadrons) within closer spatial vicinity between each other, as already discussed in previous section. After the discovery of the Higgs Boson at LHC in 2012 from its di-photon decay, it was difficult to probe the most abundant decay mode of Higgs to a pair of b quarks due to an insurmountable QCD background. Efforts were made to identify this decay mode, with initial advancements presented in the 2013 Moriond conference [71], made over an integrated luminosity of 5 fb -1 and 21 fb -1 respectively for the collision energies, √ s = 7TeV and √ s = 8TeV. The measurement reached higher precision almost five years after the Higgs boson discovery, with the advancement of boosted b-tagging techniques [72-74]. Analysis of jet substructures for a boosted large-radius Higgs-jet turned out to be obvious in identifying the Higgs boson through collimated b-quark pairs. Below we start our discussion with the widely used BDRS Higgs tagger followed by recent-most developments employing Machine Learning methods to tag a boosted Higgs boson jet.
## 5.1.1 The BDRS Tagger and its applications
The first successful attempt to probe a Higgs boson with mass around 120 GeV at high transverse momenta employing state-of-the-art jet substructure technique was made at 2008 by Butterworth, Davison, Rubin and Salam [75][75]. The approach proposed and followed in this work, popularly known as BDRS algorithm, termed after the authors, accomplished a remarkable improvement in Higgs boson tagging by accounting the jet substructures within a large-radius boosted Higgs-jet. The decay of the Higgs boson to a pair of b-quarks ( H → bb ¯ ) is considered, and the following steps are followed to identify a Higgs jet,
- 1. The large-radius jet j is dissected to obtain two subjets by reversing the final step of the clustering used to reconstruct the jet j . The two subjets, j 1 and j 2 are labelled such that m j 1 > m j 2 .
- 2. In the context where a substantial mass drop is observed, i.e. , m j 1 < µm j and the mass splitting between the two subjets is not large, ( i.e min p ( 2 tj 1 ,p 2 tj 2 ) m 2 j ∆ R 2 j 1 ,j 2 > y cut ), assume j to be the desired clustered object capturing the heavy particle and exit the loop.
- 3. Else, redefine j to be j 1 and restart the steps from 1.
- 4. Consider the final jet j as the candidate Higgs boson only if both j 1 and j 2 are b-tagged.
The two parameters y cut and µ are chosen such that the in addition to the dominant symmetric decay of Higgs boson to a pair of b-quarks, radiative decays of the final state quarks are also successfully captured within the large-R jet; the proposed analysis consider µ = 0 67, and . y cut = 0 09. In reality, . the above prescription is not yet optimal for LHC, especially at the High p T regime. The primary reason for this is the significantly large contamination coming from underlying events (UE) due to the choice of a large jet radius. Therefore, a grooming technique, called Filtering, was proposed in addition to the above-mentioned procedure. The constituents of the large-R jet are re-clustered with a finer angular scale, R filt < R bb ¯ , and the three leading (in p T ) subjets are considered, among with the leading two subjets must be b-tagged. This last procedure helps in reducing the impact of UE events as well as improving the reconstruction efficiency. We summarize this procedure in Figure 2.
Fig. 2 : Different stages of the BDRS Higgs tagging algorithm [75].

The success of the BDRS algorithm in reconstructing the Higgs boson jet (in fact the algorithm is very generic, it's applicable to any particle decaying to a pair of quarks) has found a plethora of applications in different studies involving SM as well as new physics particles.
Even though jet substructure technique seems to be quite efficient in identifying and reconstructing the Higgs boson jets, the advent of machine learning algorithms has changed the whole landscape completely. The Higgs jet tagging methods driven by machine learning algorithms have achieved unprecedented success, showcasing promising performances, for example using Neural Network architecture in conjunction with NSubjettiness variables [76, 77], Convolutional Neural Networks and Graph Neural Networks [78-82] and its variants, Interaction Network [83].
There has been progresses in other aspects of the study of Higgs boson using Machine Learning, which encompasses the effective identification of the production channel of boosted Higgs-boson from its substructure and event information [84], probing the magnitude and the phase of bottom Yukawa coupling ( y b ) from the production of Higgs boson associated with bb ¯ [85] with Decision Trees, probing BSM theories with extended Higgs sector through cascade Higgs decays to SM states using Long-Short Term Memory model [86], constraining the total decay width of Higgs boson from its inclusive production cross-section determined from modified Higgs jet reconstruction [87], and identifying the invisible decay modes of Higgs boson using DNN over low-level calorimeter observations [88].
Below we discuss a few studies on Higgs jet tagging using machine learning methods which found significant improvement over the existing Higgs tagging efficiencies.
## 5.1.2 Identification of Boosted Higgs using Two Stream CNN:
An attempt to probe the Higgs bosons at the large p T regime through the dominant production and decay modes, namely production through the Gluon-fusion process and decay via bb ¯ final states, found to be very successful even though it receives a large contamination from the QCD backgrounds [79]. it's been achieved upon incorporating both the internal structure of the boosted Higgs jet and the global event features. The primary motivation to incorporate the global information comes from a couple of studies performed earlier which observed that there is additional information beyond traditional n -prong tagging methods for a boson which an image based analysis using CNN can capture [89] or can be estimated using a few simple observables [76, 90]. In Ref.[79], the authors therefore study the full potential of the Higgs tagging algorithm using all the available information in boosted Higgs events.
Fig. 3 : A schematic diagram of the two-stream CNN used in [79]. The upper stream uses the full event information, while the bottom one relies on the jet substructure inputs.
jets with a two-prong substructure using the double
The model deployed in [79] comprises of two CNN architectures functioning in parallel, as shown in Figure 3. While One layer analyses the information involving the double b-tagged substructures within the large-radius jet, the other layer processes the global event information. The network shown in Figure 3 contain the following details: size of each convolution filter is 5 × 5, the size of the pooling layers are 2 × 2, ReLu activation functions are used, along with a stride of 1. The first convolutional layer in each stream contains 32 filters, while the second convolutional layer possesses 64 of them. Each stream of the convolution networks flatten the respective output and passes the information through a dense layer of 300 neurons. Their respective outputs, carrying processed information on both the local and global traits, are finally transferred to the single neuron at the output layer of the combined two-stream architectures, equipped with sigmoid activation function, enabling the segregation of signal from the background. jets with a two-prong substructure using the double b -tag, standard tagging observables provide minimal gains, and the primary difference between the two decays are their color flows, shown in Fig. 6, with the Higgs being a color singlet, and the gluon a color octet. The gluon radiates much more widely away from the dipole, as is clearly seen in the jet images in Fig. 5. ijm (Are there any experimental benefits of Rb2? It might be cleaner to just use beta. Rb2 is also IRC unsafe -ijm) Having identified from the neural network that significant discrimination power can be extracted from the jet, and building on the intuition from the jet images and our physical minimal gains, and the primary difference between the two decays are their color flows, shown in Fig. 6, with the Higgs being a color singlet, and the gluon a color octet. The gluon radiates much more widely away from the dipole, as is clearly seen in the jet images in Fig. 5. ijm (Are there any experimental benefits of Rb2? It might be cleaner to just use beta. Rb2 is also IRC unsafe -ijm) Having identified from the neural network that significant discrimination power can be extracted from the jet, and building on the intuition from the jet images and our physical understanding of the decay channels, that this information should be contained in the color flow, we now show that this additional discrimination power can largely be extracted using a simple observable to identify the color flow. A number of observables exist to probe the color flow within a jet. Here we consider the recently introduced observable β 3 [47] β 3 = ( τ (0 5) . 1 ) ( 2 τ (1) 2 ) 0 5 . τ (2) 2 , (3.1) where τ j n is the n -jettiness observable [37, 38] with angular exponent j defined with the winner takes all axes [68]. In Fig. 7 we show an SIC curve comparing the performance of the β 3 observable with the
b
-tag, standard tagging observables provide full neural network architecture.
understanding of the decay channels, that this information should be contained in the color flow, we now show that this additional discrimination power can largely be extracted using a
The full neural network sets an upper bound on the achievable discrimination power, and we find that the majority of the improved discrimination power
identified by the neural network is reproduced by the simple simple observable to identify the color flow.
A number of observables exist to probe the color flow within a jet.
β
observable.
This is promising for immediate application to LHC searches. It also supports our intuition that the dominant
remaining information lies in the color flow.
tagging, and relatively limited attention has been payed to the study of color flow, we believe that variable such as
β
3
may be more widely applicable to improving jet substructure searches.
where
τ
j
n
is the
b
¯
b
Figure 7
takes all axes [68].
full neural network architecture.
remaining information lies in the color flow.
.
Color flow for
H
bb
¯
and
g
bb
¯
,
The numbers 1 and 2 label different color lines.
that variable such as
3.3.2
Global Event
(can we identify what is actually going on here -ijm)
cite Lisa's paper, Matt's paper.
[71][72][73]
jet pull:
[49]
→
Figure 7
.
Color flow for
H
bb
¯
and
g
bb
¯
,
the main irreducible QCD background to our signal.
- 8 -
The numbers 1 and 2 label different color lines.
→
3.3.2 Global Event ijm (can we identify what is actually going on here -ijm) cite Lisa's paper, Matt's paper. [71][72][73] Fig. 4 : This figure, borrowed from [79], represents effective differences in the three channels of a Higgs-jet from a QCD-jet. The large-radius jet of the color-neutral Higgs boson possesses a more contained color flow pattern than its QCD counterpart.
jet pull:
[49]
- 8 Both the jet (local) and event (global) images include three types of information i.e., the pixel intensity of the images are defined in terms of the number of charged particles, p T of the charged particles, and p T of the neutral particles present in the jet/event. In Figure 4, we show the average jet image for 100 background (top panel) and signal (bottom panel) events for the three above-mentioned channels. From the images of the three channels, the two-prong structure of both signal and background jets is evident. The crucial difference lies in the radiation pattern and color connection between the two prongs constituted by the quarks and gluons. The Gluon being a colored object, the radiation is more spread out between the two prongs compared to the Higgs boson which is a color neutral object. The pixels between the two dominant prongs are therefore populated for the background jet unlike the signal jet. In order to encapsulate the color flow information, the authors of [79] used the variable β 3 calculated using the ratios of the N-subjettiness variable. The novel method has achieved a maximum significance gain of 2.2 σ against the signal efficiency of 25%. Individually, the stream concerned with the local information on jet substructures contributes to a significance of 2 σ , and the one incorporating the global properties of the event touched a significance of 1.4 σ . As the numbers suggest, the local jet substructure based technique is indeed the most efficient approach, underscoring the notable contribution of global event information that can neither be overlooked.
## 5.1.3 Machine Learning algorithms over Lund-Plane:
Lund diagrams [91] are theoretical representations of the phase space within the jets. They are constructed for individual jets from recursive declustering of the large-radius jet using Cambridge-Achen algorithm. The available phase-space, for a constituent at a given stage of declustering, in a Lund diagram, is mapped to a bi-dimensional logarithmic plane that portrays the transverse momentum and the angle of a given emission with respect to the emitter. Each subsequent emission leads to new phase space, represented as triangular
→
H
1
→
leaf, for further emissions. They are particularly effective in analyzing parton showers and resummations and provide a powerful tool for visualization of the radiation taking within an individual jet [92]. This representation has found its robust usage in context of W -tagging [92], later in top tagging [93], and even for the identification of a charged species at LHC from embedding the tracker information on the phase space [94]. Most importantly, Lund jet plane provides us the opportunity to gain insight on different underlying theoretical concepts which in turn improves classification performance.
The success of Jet image technique in identifying and tagging boosted objects lead several studies improvising on the simple proposal, as already mentioned. One such attempt was made in [95], where unprocessed jet images in (Primary) Lund plane were utilized to identify Higgs jets through a CNN architecture. Note that, Lund plane has the advantage in capturing the jet information in terms of the kinematic variables over the ordinary jet image method built using the calorimetric information in η -ϕ plane. The study analyzes the prospect of Higgs tagging through the pp → ZH process with Higgs decaying to a pair of b-quarks and Z boson decay to muons. The background jets are constructed using the same process except the Higgs decaying to a pair of gluons. The authors studied both moderate and high p T regimes of the Higgs boson.
In Ref.[95], the authors compare the performance of jet Lund Plane images with another well-established observable for tagging the color singlet particles, namely the jet color ring [96]. This observable is formulated through the comparison of signal and background matrix elements in the soft limit. Its construction ensures monotonicity concerning the likelihood ratio, establishing it as an optimal tagger under the provided approximations. Nevertheless, as indicated in [96], the efficiency of the observable is found to be commendable for the H → bb ¯ , yet it proves insufficient when assessing the H → gg mode. Using Lund jet images and color ring observable separately as input, a CNN architecture is designed, consisting of 4 convolutional layers followed by a dense layer of 800 nodes. The Max pooling layers after the second and fourth convolutional layers help in down-sampling the features. Additionally, to prevent overfitting of data, dropout of different strengths is applied after the second, third, and fourth convolutional layers. In each convolutional layer, a filter size of 3 is employed, but the number of filters differs for different datasets. Throughout the network, the ReLU activation function is used for introducing non-linearity.
The study found that for H → bb ¯ process with moderate boost, for 80% signal efficiency, the background efficiency is around 20%. Whereas at the high boosted regime, background efficiency is less than 10% for the same signal efficiency. On the other hand, for the H → gg process with moderate boost, at 80% signal efficiency, the background efficiency is around 40%, which reduces to 15% at the high boost regime. The ROC yields, as anticipated from [96], the color ring variable has better efficiency in tagging the H → bb ¯ mode than H → gg . Comparison of the color ring observable to the Lund plane image concludes that it has a similar performance to the Lund plane image for moderate boost regime of H → bb ¯ mode, while for the other three modes i.e., H → bb ¯ in highly boosted regime and H → gg in both moderate and high boost regime, lund plane images outperforms color ring variables in the larger margin. Similar analyses combining the high-level observables with the Lund jet plane were performed in Ref.[97]; the observations are similar to the one discussed above.
## 5.1.4 Graph Neural Network driven Higgs Tagging
Graph Neural Networks (GNNs) constitute a class of deep learning techniques designed for obtaining inference on data characterized by graphs. These networks offer a simple and straightforward way to perform tasks involving node-level, edge-level, and graph-level predictions. They have found applications in mitigating pileup effects at hadron colliders, reconstructing trackers, identifying jets, classifying events, and study
the interplay with traditional jet substructure methods; see for example [55, 58, 98-104]. Reconstruction of a large-radius Higgs-jet in boosted regime using a dynamic Graph Convolutional Network (GCN) architecture [105] has been studied in [78]. Each collision event, which is an agglomeration of detected particles characterized individually by η, ϕ, p T , E and a particle identity, is represented by a point cloud. The point cloud representation provides additional flexibility for the accommodation of all the particles, from a given event, in higher dimension feature space. Treating the point cloud as a graph, the network analyzes each event using K-Nearest-Neighbour algorithm to cluster individual node (representing a detected particle) with another node recursively, using the Euclidean metric between η and ϕ of the pair of nodes under consideration. The architecture proposed in [78] contains three EdgeConv blocks, with each block consisting of three multilayer perceptrons with 32, 64, 32 filters respectively. This is followed by two convolutional layers containing 32 and 2 kernels respectively, with a kernel dimension of 1 × 1. Over-fitting of the model is restricted by the introduction of a dropout layer with 25% dropping rate. The final classification layer consists of neurons dotted with softmax activation function. The input feature consumed by the model is just the pseudo-rapidity and the azimuthal angle of the stable particles. The model is trained for a sample containing Higgs boson with p T > 200 GeV produced in association with jets, considering the Higgs decay to a pair of b-quarks. The training samples were overlaid with ⟨ µ ⟩ = 50 pileup events to account for the presence of multiple jets in each event. Special measures were taken to regularize the spatial coordinates of the boosted Higgs boson (in the particle-level) and its stable constituents. Additionally, the training sample was also purified from spurious backgrounds, by removing events with large-radius jet mass below 115 GeV.
One of the key observations of this work is that the GCN driven analysis outperforms (by a factor of ∼ 1.5) the traditional jet substructure based analysis in the context of Higgs tagging efficiency as well as precision in momentum reconstruction. In fact, the sensitivity of pile up events to the overall performance of GCN is found to be negligible. It is noteworthy that the trained model is also capable to identify and tag the boosted Higgs jet in events of other production processes, however the performance of the tagger is degraded if additional boosted objects are present in the collision event in addition to the Higgs boson.
For interested reader, we refer some of the recent-most studies where several state-of-the-art architectures based on GNN algorithms are proposed, for example [51, 106, 107]. The tagging efficiencies have improved significantly in some of these cases.
Before we conclude this section, we would like to compare the performance of different Higgs taggers. In Table 1, we show the comparison of different architectures used for the Higgs tagging (first column), area under the curve (AUC) which is a measure of the ability of the classifier in distinguishing the signal over the backgrounds (second column), and the background rejection rate at 30% signal efficiency (Rej 30% ). In the table, along with the previously discussed Higgs taggers, we also display the performance of the Double-b tagger widely used by the CMS collaboration at the LHC [108]. The performance of the Double-b tagger is comparable to some of the ML-based Higgs taggers discussed above. Note, we have estimated the background rejection rates from the available ROC curves.
Table 1 : Performance comparison between different
| Architecture | AUC | Rej 30% |
|---------------------------------------|-------|-----------|
| BDT[81] | 0.73 | 1.05 |
| Resnet-50[81] | 0.83 | 1.11 |
| Two Stream CNN (ggF)[84] | 0.89 | 80 |
| Two Stream CNN (VBF)[84] | 0.96 | 900 |
| Graph Convolutional Network (GCN)[78] | - | 800 |
| CS + LPCNN[97] | 0.89 | 25 |
| CMS Double-b tagger [108] | - | 500 |
Higgs tagging algorithms.
## 5.2 Top Jet tagging
Top quark is the heaviest candidate in the SM with a mass of 172.2 GeV [109]. It has a very short lifetime ( 10 -25 s) [110], much shorter than the time required for hadronisation [111-114], and therefore decays
to bW with 100% branching ratio [115], instead of undergoing hadonisation like other quarks. The W -boson thus produced may either undergo leptonic decay( W → ℓν ℓ ), characterised by the registration of a charged lepton in the calorimeter and missing transverse energy, or hadronic decay ( W → qq ¯), manifested as localised deposition of, predominantly, hadronic energies at the calorimeters. The hadronic decay of W is more abundant ( BR ( W → qq ¯) 67%) [116]. When the top quark is produced with sufficient boost, the hadronic decay of W leads to a large-radius top jet, comprising ideally of a 3-prong subjet-structures with an invariant mass close to the top-mass, and the invariant mass of two subjets, out of the three, around the W -mass. Such boosted large-R jets are crucial in different tests within the SM framework [117] and beyond [118]. This section provides an overview of different techniques proposed for effective tagging of such boosted large-R top-jets. The first top-tagger was proposed in 1994 [119], way before the discovery of top at Tevatron in 1995 [120, 121]. This top-tagger, based on a recombination algorithm, achieved better toptagging efficiency over the pre-existing cone algorithms [122, 123]. The topjet was identified from the leptonic decay mode of W , assuming the top-mass ≲ 200 GeV. Events with top-pair production from pp ¯-collision ( pp ¯ → tt ¯ ) were considered, followed by semi-leptonic decay of the top ( t → bW, W → ℓν ℓ ). This resulted in the observation of events with four jets, two originated from the b-quarks and two from the charged leptons, and missing transverse energy, along with few possible QCD jets due to radiative effects of b-hadrons. This tagger did not employ any b-tagging algorithm to identify the b-jets originated from the top-decay. There have been several improvisations, [124-127] proposed over the first top tagging algorithm, addressing both the hadronic and semi-leptonic[128, 129] decay channels of top.
## 5.2.1 Traditional Top taggers
The first public top tagger with BDRS setup was the Johns Hopkins top tagger[130], which considers the top decaying hadronically in a highly boosted regime, with a minimum transverse energy ( E T ) of 1 TeV and the p T accounting for 35% of its E T , constructed with Cambridge-Achen jet clustering algorithm. The radius of the large-R top-jet for this tagger is set to be 0.8, and jet substructures carrying at least 10% of the large-R jet p T inside the large-R jet with a minimum angular separation of 0.19 are determined following sequential de-clustering of the parent jet. The process terminates once the clusters corresponding to the W and the top from two successive clustering are identified, imposing the following criteria:
- 1. The invariant mass of the three subjets must lie within a window of 30 GeV of the top-mass,
$$m _ { j j j } \, = \, m _ { t } \, \pm 3 0 \, \text{GeV}.$$
- 2. The invariant mass of one of the pairwise combinations of the subjets must lie within a window of 15 GeV of the W -mass,
$$m _ { j j } \, = \, m _ { W } \, \pm 1 5 \, \text{GeV}. \\ \i r e d \, \text{in the rest frame of the rec}$$
- 3. The helicity angle of the top, measured in the rest frame of the reconstructed W -boson is small,
$$\cos \theta _ { h } \, < \, 0. 7.$$
The reconstruction of the W -boson from its hadronic decay, in general, is overshadowed by the predominant existence of the QCD background, which peaks around 50 GeV and depletes slowly with a flatter tail. This tagger, therefore, in order to minimise the QCD background from the W -resonance window, focuses on high energy boosted regime of the top-production, thereby further narrowing the available phase space and consequently the cross-section for the top production for the energy reach of the contemporary colliders. Hence there were propositions with certain modifications that could relax the constricted phase space the JHTopTagger demands with minimal compromise over the QCD background.
The CMS toptagger [131], which focuses on large-R jets with identical jet radius but with minimum transverse momentum, p min T = 250 GeV, follows similar declustering process and imposes:
- · Pair of jet substructures emerged within the large-R jet, after reversing the final clustering step, must carry at least 5% of the large-R jet p T , p sub -cluster T > 0 05 . × p fatjet T individually. The pair is retained and the rest of the cluster is removed, to eliminate the low-energy subclusters, which originated mainly from the radiative effects within the large-R jet.
- · If only one such substructure is obtained satisfying the above condition, then the above approach is repeated on the said sub-structure until one obtains a pair of them, satisfying the lower bound on the transverse momentum mentioned above. Else the large-R jet is no longer taken into consideration.
- · The invariant mass of these maximum of four subjet structures must satisfy, 100 Gev ≤ m jet ≤ 250 Gev and the minimum of the pair-wise invariant mass of all possible combinations of these subjets must be greater than 50 GeV.
- · Once the substructure pair is determined, an identical approach is made to de-cluster them individually, satisfying the same p T constraint. After the completion of this step one either obtains four jet substructures carrying at least 5% of the large-R jet p T , or three subjet structures followed from absence of a hard cluster within one of the two parent sub-structures.
HEPTopTagger [132], on the other hand, further relaxes the minimum p T -cut over the boosted large-R jet. It considers a large-R jet with p min T = 200 GeV and radius R = 1 5, optimised to incorporate the . stable hadronised states formed from the three principal decay products of the top quark ( b, q, q ′ ), keeping an option to implement b-tagging to further reduce the QCD background. The tagging algorithm advances similar to the BDRS algorithm, in the following fashion:
- · The first de-clustering step leads to two subclusters, labelled j 1 and j 2 , such that m j 1 > m j 1 . If m j 1 < . m 0 8 j ( j refers to the jet), then both the substructures are retained, else j 2 is rejected from further consideration.
- · Once all the subclusters are obtained, jet filtering is performed to obtain subjets with size, R = 0 3, . retaining at most five hardest subjets. Next, all possible combinations of three out of five subjets are considered and their invariant masses are determined. The combination with invariant mass closest to the top-mass is retained for further considerations.
- · For each jet substructure j i , the sequential de-clustering is iteratively implemented till further de-clustering leads to subclusters of mass < 30 GeV. This terminates the de-clustering process.
- · Of the three subjets finally retained, labelled j 1 , j 2 and j 3 , pairwise invariant masses are calculated m 12 , m 23 and m 31 . The candidate large-R jet is top-tagged if one of the following conditions are satisfied:
Figure 5 shows the effective discriminators, m 13 m 12 and m 23 m 123 which efficiently dissect portions on the phase space with abundant top-jet events from W and QCD jets.
$$\begin{array} { l l } \times \ v a v c o n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w e i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g ew i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e W i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e s t o w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g o w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n w e i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n w e j u n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w j u n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g o w e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i ng e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n u n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g ew e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n t o w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g ews t o w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i n g e w i$$
Fig. 5 : The distribution of events in the arctan ( m 13 m 12 ) vs m 23 m 123 plane for tt ¯ , W -jet and QCD events [132]. The region in red shows comparatively higher density of events.
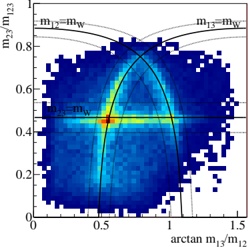
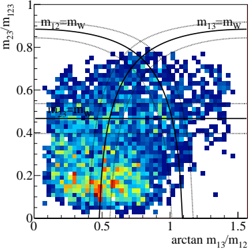
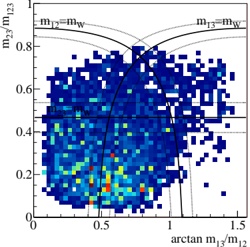
There have been several other traditional top-tagging algorithms, interested readers may look into [133] for ready references.
Despite the commendable success these traditional approaches accomplish, advent and implementation of Machine Learning techniques have enhanced the top tagging efficiency remarkably. Propositions of effective tagging algorithms involving different variants of Neural Network architectures, namely, CNN [58, 134, 135], GNN [93, 136], Autoencoders [137] and Transformers [138] have revolutionized the top-tagging strategies. Below we introduce some of these state-of-the-art taggers.
## 5.2.2 Multi Layered Perceptron and top-tagging
Multi Layered Perceptron (MLP) or Deep Neural Network composed of multiple hidden layers of perceptrons has been discussed in Section 2. With densely connected architecture,they are effective in determining the complex relation between the features that tells apart a given jet flavour from the rest. DNN has been successfully implemented in [139] for the identification of a boosted top-jet. The architecture incorporates 4 densely connected hidden layers, containing respectively 200, 102, 12 and 6 perceptrons, with each layer using ReLU activation function to counter vanishing gradient problems during the model training. The output layer consists of a single perceptron with sigmoid function to distinguish top-jets from the rest. Inputs, which are the observables related to the candidate large-R jet, are given into the network as vectors for training and validation. The model achieved a signal efficiency of 50% against a background rejection rate of 45%, for the top samples with p T ∈ [600, 2500] GeV. The performance of such architecture enhances twofold compared to the cut-based taggers, with a DNN dotted with densely connected 5 hidden layers using ReLU activation function and containing 18, 16, 14, 10 and 5 perceptrons respectively [140], for the topcandidates with p T ∈ [400 , 2000] GeV. We will conclude the discussion with DeepTopLoLa tagger [141], which consumes the Lorentz vectors of jet constituents as inputs. This tagger comprises of a combination layer that emulates QCD-inspired jet recombination, a Lorentz layer translating the 4-vectors into relevant kinematic observables, and two fully connected hidden layers. Using the calorimeter and tracker information at full experimental resolution, the tagger turns out to be effective in the highly boosted regime, matching with the performance of image based CNN tagging algorithms.
## 5.2.3 RNN based top-tagger
Recurrent Neural Network (RNN) is designed to process sequential data, with recurrence of the input sequence used by the successive layers of the architecture [142-145]. This leads to recursive imposition of a single weight, fine tuned by the gradient descent, which in turn ends up at vanishing/exploding gradient problem [146]. Long Short-Term Memory(LSTM) models bypass this problem by truncating the gradient [147], and assign non-trivial weights at individual inputs in the sequence. This algorithm has been implemented in tagging boosted top-jets from their respective constituents [148]. The architecture comprises of an LSTM layer with a state width of 128, followed by a fully connected dense layer containing 64 perceptrons. Adam optimizer, used in the model provided the most stable training with best performance over the unseen dataset. Large-R jets with p T ∈ [600, 2500] GeV and | η | ≤ 2.0 were considered. The jet substructure information, i.e. , p T , η , ϕ , along with the subjet constituents were taken as model input. The tagger achieved better performance than a DNN-based tagger [139] across all signal efficiencies, accomplishing 100% background rejection rate for the signal efficiency of 50%, as presented in Figure 6.
## 5.2.4 CNN based top-tagger:
Convolutional neural network(CNN) is a deep learning architecture, predominantly used for object identification from respective images. CNN has a noteworthy contribution in particle physics phenomenology, particularly in recognition of particle tracks [60], characterization of rare decay events [149], identification of of jet flavours through jet images [108].
CNN has been a rapidly developing paradigm of Deep Learning and has witnessed remarkable breakthroughs in layer design, regularizations, optimizations and swift computations [150]. It has proved to be very effective for tagging top jets in both the high and low p T regimes. The pioneering work on incorporation of Computer Vision techniques in jet images analysis was done in [151]. Constructing the image of a given jet from the calorimeter tower information, Fisher discriminant analysis was implemented to obtain
Fig. 6 : The ROC curve depicting the top tagging efficiency for the RNN based top tagger used in [148].
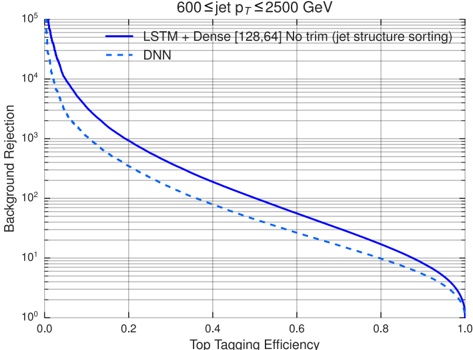
a discriminant that could tell apart jet images obtained from hadronic decay of boosted W -boson from the QCD background. The prescription followed in [151] accomplished better discrimination power over the contemporary substructure approaches, additionally providing significant insight into the internal structure of jets.
An extended version of this work has been carried forward in [134], identifying boosted W -jets with p T ∈ [250 , 300] GeV, reconstructed using antik T algorithm from respective hadronic decays. The large-R W -jet was first trimmed by reclustering its constituents into R = 0.3 with k T algorithm, and dropping those subjets with p subjet T < 0 5 . × p jet T . The jet image is constructed pixel-by-pixel from the energy deposition of its constituents on the ( η, ϕ )-plane, by matching the pixel-size with the granularity of the calorimeter tower, and the intensity of each pixel determined by, either of, the total energy deposition of all jet constituents inside the concerned ( η, ϕ )-pixel, or the transverse projection of the jet energy in the tower corresponding to the spatial coordinates, ( η, ϕ ). The pre-processing of the image thus obtained was performed in four steps:
- 1. Translation of jet images such that the leading subjet lies at ( η = 0 , ϕ = 0). In order to preserve the pixel intensity under translation, transverse momentum replaces the transverse energy for reconstituting jet images.
- 2. Rotation of the jet image around its center, such that the second leading subjet, if exists, is at -π/ 2. Else, the image is so rotated that the first principle component axis of the pixel intensity distribution is aligned vertically.
- 3. Re-pixelation of the rotated image, followed by the redistribution of the energy deposits in the rotated grid using a cubic spline interpolation, such that the rotated grid is aligned with the original grid.
- 4. Inversion of the jet image, resulting from a parity flip, such that the right side of the jet image possesses the highest sum pixel intensity.
The CNN architecture consists of total 14 hidden layers: 3 sequential units, each consisting of a convolution layer, a Max-Pool layer and a DropOut layer, followed by a Local Response Normalization layer and two fully connected dense layers. The processed information finally reaches the output layer containing a perceptron with sigmoid activation to identify the W -jets from QCD counterparts, through another DropOut layer. All three convolution layers use 32 filters, with dimensions, 11 × 11, 3 × 3 and 3 × 3 respectively, regularised with the L 2 norm. Three MaxPool layers perform down-sampling of (2, 2), (3, 3), and (3, 3) respectively and all three dropout layers encountered in the sequential units uses a dropout of 20%, while the one preceding the output layer applies the same amounting to 10%. The dense layers individually carry 64 perceptrons.
The application of CNN for tagging top-jets was introduced in [152]. Jet images were preprocessed following the steps prescribed in [134] and were cropped into dimensions of 40 × 40. Figure 7 presents the jet images of a top-candidate and a QCD jet after the image preprocessing. The model architecture proposed and trained in [152] is shown in Figure 8. Each 40 × 40 jet-images were passed through two successive CNN Blocks, each implementing filters with dimensions 4 × 4 and stride 1, to construct 8 Feature Maps, of dimensions shorter by 1 compared to that of the preceding input. The output of 8 Feature Maps of dimensions 38 × 38,
Fig. 7 : Figure borrowed from [152] portraying the top and QCD jet-images used as input. Left panel: Image of the top candidate jet with three prong structure, with the leading E T -ordered subjet lying at the center, the sub-leading one at 12 o'clock position, and the third one to the right of the leading subjet. Right panel: Image of the background QCD jet with the leading subjet at the center.
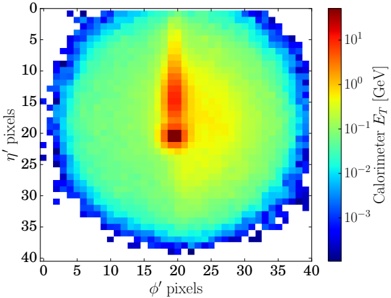
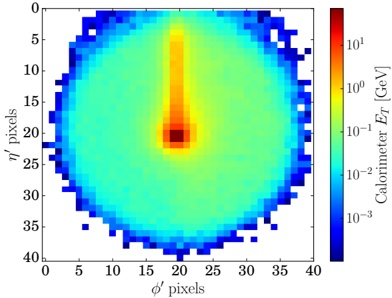
thus obtained, were next passed through a Max-Pool layer followed by a CNN layer to create 8 Feature Maps of size 18 × 18, and through another CNN layer to reduce them to 17 × 17. The resultant output is then flattened, and propagated through three dense, fully connected hidden layers, each containing 64 perceptrons, and finally to the output layer containing a single perceptron dotted with sigmoid function to classify topjets from the QCD background. The performance of the model thus proposed, when compared to that of
Fig. 8 : Detailed outline of the CNN architecture of DeepTopTagger, proposed in [152].
a conventional, multivariate QCD-based top-tagging using standard large-R jets, infers the convolutional networks a prospective novel approach for multivariate hypothesis-based top tagging. The work has been further extended in [153] where the same architectural set up, as in [152], was followed. Increasing the number of feature maps to 128, and perceptrons in the dense layers to 256, an overall improvement of a factor of ∼ 10 is achieved over the preceding model [152].
There have been further studies on CNN based tagging, on 30 × 30 pixelated images constructed from HCAL [154], with each pixel representing energy deposits of the jet constituents. The architecture incorporates a single convolution layer comprising of 30 filters followed by a dense layer leading to the output layer with a single perceptron dotted with sigmoid activation segregating the signal from the QCD background. The CNN defined observables for the tagger are IRC safe as long as the gluons are non-collinear with all the quarks inside the jet, along with the performance of this tagger being resilient to the kind of signal used, as established using two different signal samples, one as boosted top quark and the other with a gluon in the final state.
The tagger proposed in [155] works for both hadronically and leptonically decaying tops in high p T regime. The architecture proposed in [155] consists of 3 convolution layers with 10 × 10, 5 × 5 and 2 × 2 kernels respectively, with each convolution layer containing ReLU activation function followed by a MaxPool layer of stride 2 × 2 with 2 × 2 kernels, and finally flattening the output before propagating through 2 dense layers
with respectively 90 and 50 perceptrons along with ReLU and Sigmoid activation functions. The tagger is advantageous in the sense that it does not require lepton identification to tag leptonically decaying top events. It turns out to perform slightly better with the leptonically decaying sample than the hadronic ones.
## 5.2.5 GNN based top-tagger:
The Graph Neural Network has been an emerging tool for tagging jet flavours. The ParticleNet algorithm, using GNN architecture, is a recent advancement in top tagging, with the jets treated as an unordered collection of particles, termed particle cloud [58]. The architecture of ParticleNet algorithm is presented in Figure 9.
Fig. 9 : Figure portraying the ParticleNet architecture employed in [58].
The algorithm of ParticleNet rests on the notion of Dynamic Graph Convolutional Neural Network (DGCNN): 3 EdgeConv block with (64, 64, 64), (128, 128, 128), and (256, 256, 256) channels respectively is employed seeking 16 nearest neighbors, followed by a global average pooling layer aggregating all the learned features of the constituents of particle clouds. Thereafter 2 fully connected dense layers along with a single perceptron containing the output layer completes the architecture and generates binary classification output.
An alternative architecture, the LorentzNet, comprising of 6 Lorentz Group Equivalent Blocks, followed by a single fully connected scalar embedding layer, responsible for mapping scalars to a latent space of width 72 is proposed in [156]. The transformations ϕ , ϕ x e , ϕ h follow the schema: Linear(72 72) , → ReLU → BatchNorm1d(72) → Linear(72 72), , while ϕ m follows: Linear(72 1) , → Sigmoid. The decoding occurs through: Linear(72 72) , → ReLU → Linear(72 2), with a dropout rate of 0.2. The network architecture is , articulated in Figure 10. LorentzNet achieves an accuracy of 94.2% with an AUC of 0.9868. A comparative study of LorentzNet with other representative algorithms shows, only ParticleNet with AUC 0.9858 achieves a similar performance compared to the LorentzNet.
A more recent study to generalize the extraction of infrared and collinear safe observables for LHC phenomenology was performed in [157] using Hypergraphs. The underlying concept of these hypergraphs are the same as the traditional graphs, but it generalizes the connection between the edges and vertices offering more flexibility in the extraction of event information.
A variant of geometric data structure, dealing with points represented in some relevant vector space, referred to as point clouds [158], has found pertinence in Computer Vision problems, with the advent of algorithms that consume point clouds as inputs and train a DNN architecture over them [159]. This approach
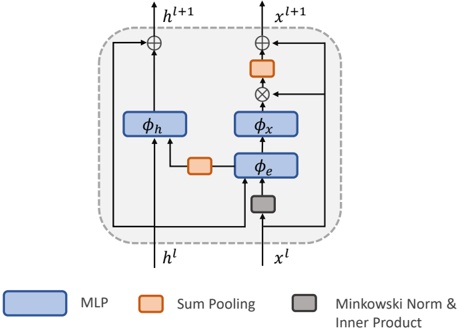
Lorentz Group Equivariant Block (LGEB)
Fig. 10 : The architectures of the Lorentz Group Equivariant Block (left) and LorentzNet (right), as proposed in [156].
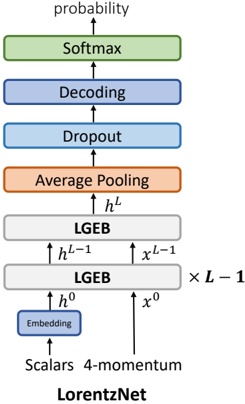
has found its way into object identification in particle collision data using the DeepSet framework, constructing an algorithm accounting for the infrared and collinear safe observables, termed Energy Flow Network (EFN) [60], which forms a part of the EnergyFlow Python package [160]. A similar architectural framework, Particle Flow Network (PFN), from the same group [60], has been proposed for the same purpose. There, nevertheless, exists a difference between the execution of EFN and PFN, related to the way these formalisms represent and analyze the collision events and the resulting particle interactions within the collider experiments: the EFN architecture primarily focuses on tracking the distribution and transfer of energy resulting from particle collisions with nodes representing specific energy deposits in the calorimeters and the edges depicting the flow of energy between these nodes, indicating the paths taken by particles as they deposit energy in the detector, while the PFN focuses on tracking individual particles produced in the collision from their subsequent interactions with the detector material with the nodes presenting individual particles detected in the collision, ( e.g. ,leptons, photons and hadrons) and edges portraying the trajectory taken by these particles through the detector, including interactions with detector material and particle identification.
EFN has been implemented for the segregation of quark-jets from gluon-jets in [60], using the dataset from [161] for collisions at a center of mass energy of 14 TeV. Pythia was used for the large-R jet reconstructions ( R = 0 8) with anti-. k T clustering algorithm, and a jet selection criteria were imposed: p T,jet ∈ [550, 650] GeV, | η | < 2 and ∆ R i,jet < 0.8, where i runs over all the jet constituents ensuring the existence of all the decay products of top quark inside the jet radius. The jets are then preprocessed following the approach taken in [134], and in addition, the net transverse momentum registered in each pixel of the jetimage was normalized. Different approaches associated with graphs, point clouds and computer vision were implemented for the jet image analysis and a comparative study on the performances of different algorithms were presented in Figure 11.
## 5.2.6 Hybrid Top Tagger:
The work done in [135] uses a convolution neural network (CNN) for the classification of top against QCD jets( pp → jj ) using both infra-red and collinear (IRC) safe as well as unsafe observables. IRC safe observables include the two-point energy correlation, jet spectrum as a function of distance between the jet constituents, while IRC unsafe includes Minkowski sequence with the first element of it to be the number of active pixels in a jet image and the second one as the sum of active pixels and adjacent pixels. The top tagger proposed in [135] considers pair production of top quark from pp collision ( pp → tt ¯ ) in 13 TeV center of mass energy, where the top further decays to bW . Madgraph 5 2.6.6 is used for the simulation of parton level events, which were further passed through Pythia 8.226 and Herwig 7.1.3 for parton shower and hadronisation. Delphes
Fig. 11 : The ROC curves comparing the performances of different EFP formalisms introduced in [60], we refer to the original work for the details on this.
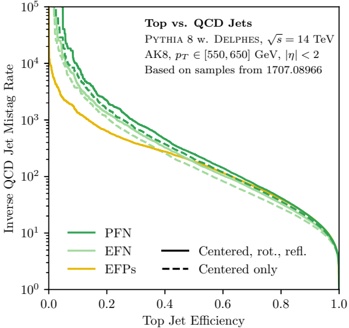
3.4.1, with the default ATLAS card was employed to consider detector limitations. Reconstructions of the jets were made by fastjet 3.3.0 with antik T clustering algorithm for the radius parameter R = 1 0. The tagger . was optimised for tagging top-jets satisfying the p T,J ∈ [500 600]GeV and the mass, m , J ∈ [150 200]GeV. , This work equally explores the prospect of implementation of graph network architecture, namely, relation network (RN), useful for making two-point correlations, for 1 → 2 splitting of partons in the kernel of the parton shower model. A comparative study of the performances between CNN and RN models are performed, and the analysis indicates that the classification ability of RN agrees with that of CNN, upon including IRC unsafe observables, which leads to the inference that the CNN utilises geometric information of soft radiation for the classification task. The RN model is found to outperform its CNN counterpart in terms of stability, and is a more acceptable one for having less complexity in the loss function. The approach taken in [135] is intended to implement physics-motivated high-level features in a simple network instead of using low-level features in complex networks. Figure 12 shows the graph representation of the top and QCD jet images in terms of their respective constituents. A line joining two points, individually articulating the energy deposition of a given jet constituent, represent the graphs on the jet images. The red solid lines represent edges between the constituents of the trimmed jet, while the green dashed lines portray the edges between the constituents of the trimmed jet and the constituents of the cluster not encapsulated in the trimmed jet. The blue dot-dashed lines, in turn, present edges between the pair of constituents of the large-R jet not encapsulated in the trimmed jet.
A recent study based on the two-point energy correlations, Minkowski functionals using jet constituents, and a recursive neural network analyzing subjet constituents was performed in the context of top tagging [162]. The study observes performance comparable to the Particle Transformer, and, most importantly, the training of the model is reasonably much faster than the transformer network. In addition, the proposed framework also provides some interpretability of the trained model. Another study worth mentioning is [163], where the authors have analyzed the importance of leveraging the combined information from the calorimeter towers and tracker at the LHC for ML-based Top Taggers. An extensive examination was conducted on the performance of three machine learning algorithms: the high-level feature (HLF)-based Boosted Decision Tree (BDT), low-level feature (LLF)-based Convolutional Neural Network (CNN), and Graph Neural Network (GNN). The study finds that the information of the distribution and composition of charged and neutral constituents of the jets enhance the performance of the classifiers significantly over a wider p T range. This enhancement comes due to the different radiation profile of quarks and gluons following QCD principles. However note that this improvement introduces large systematic uncertainties, primarily originating from the different modeling of the parton shower and hadronization, which can be as large as 30-40%. Interestingly, composite classifiers combining the information of low-level and high-level objects together help in both improving the performance of the classifier and reduce the systematic uncertainty to below 20%. Additionally,
∈
∑
∈
∑
∈
∑
-
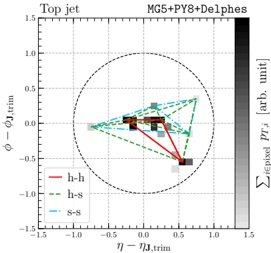
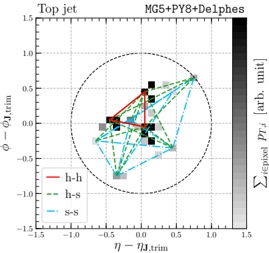
-
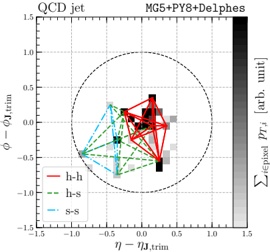
-
Fig. 12 : The graph representations of different jets - the left and middle figures represent the top jets, while the right-most figure for a QCD jet [135]. The Lines represent the graphs on the jet images. Different colored lines show the edges between the constituents of the ungroomed and groomed (trimmed) jet.
the sensitivity of transverse momentum and mass of the reconstructed jet on the trained models are also examined.
Before we conclude this section, we would like to highlight the results of a comparative study involving different top-taggers using the same test sample as inputs [164]. The ROC curve for different top-taggers are shown in Figure 13, estimating the background rejection over signal efficiencies for each of them. As is evident from the figure, the performance of ParticleNet, the 4-vector based tagger, is the best among the rest, with an AUC value of 0.98. In addition, RestNeXt (image-based), TreeNiN (4-vector-based), and PFN (theory-inspired) taggers also exhibit comparable performance. However, we should keep in mind many of the recent-most studies which we discussed previously obtained performances that are comparable (or sometimes better) in background rejection rate.
Fig. 13 : The figure showing the performance of different top taggers using overlaid ROC lines [164].
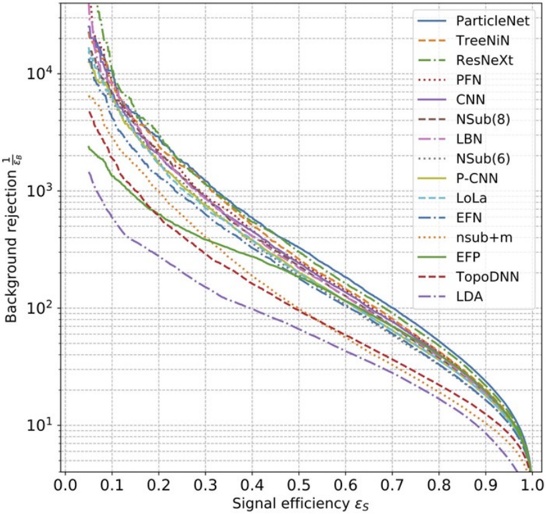
## 5.3 Application of Higgs/Top Taggers in BSM Physics searches
Having discussed different implementations of Higgs and Top taggers, it is interesting to discuss their application to BSM physics searches. For example, in the context of Type-II Higgs doublet model and Supersymmetric models, the charged Higgs bosons after being produced at the LHC, can decay into tb ¯ final state. Applying the boosted top jet tagging using jet substructure/ML algorithms, we can first reconstruct the top jet and then reconstruct the charged Higgs mass [165-167]. In theories with extended Higgs sector, boosted SM Higgs bosons can stem from the chain decay of a heavy Higgs state that further decays into bottomantibottom quark pairs. The proposed BDRS tagger can successfully reconstruct the mass of the SM Higgs boson and thereby the mass of the heavy Higgs boson [168]. Even boosted boson tagging can help in probing the compressed SUSY scenario with heavier top/bottom squarks [169]. On the other hand, Top tagging can be useful for the searches of third generation squarks, namely stop and sbottom, at the LHC; a partial list of studies include [170-176]. In [177], the authors use boosted Higgs tagging algorithm to probe Electroweak Precision Physics via boosted Higgs-strahlung at the LHC. Several studies have been performed by the ATLAS and CMS collaborations at the LHC using the boosted Higgs/Top tagging method to probe the new exotic light/heavy particles associated to different BSM physics scenarios; we refer some of the interesting recent-most studies performed using LHC data [178-188]. Note that, while jet substructure was not initially planned for the LHC experiments, it has become indispensable for the current physics program. The interplay of jet substructure and Machine Learning algorithms is poised to play a crucial role in the dynamic interplay between theoretical advancements and experimental research and development programs in the upcoming colliders [8, 189].
## 6 Interpretability of the Trained Models
Machine learning models although highly effective for tasks like classification, regression, clustering, anomaly detection, etc., often pose challenges in terms of complexity. In the context of HEP, where complex physical processes and particle interactions are studied, interpretability is crucial for gaining insights into the underlying physics and ensuring the reliability of machine learning models. It helps understand the importance of each feature of interest on the outcome, globally, i.e., analyzing the features concerning the whole dataset, as well as locally, i.e., understanding the reason for each decision event-by-event. Additionally, there are some physics-informed models, which help in understanding how the model incorporates the physical laws into making decisions, while some also include the ability to estimate the uncertainty in the model prediction.
The performance of deep neural networks, which are one of the most popular choices for object classification purposes, are often achieved at the cost of interpretability. In [190], the authors propose an interpretable network trained on the 'jet spectrum', denoted by S 2( R ), which is a essentially an Infra-red and collinear safe two-point correlation function of the jet constituents. An interpretable framework can be obtained by truncating the functional Taylor series constructed using the energy flows. The spectrum as a function of a variable angular scale R reveals the important values (or ranges) of R responsible for classifying Higgs jets from quark/gluon originated jets. The performance of the proposed architecture is not comparable with that of a CNN architecture, but the training time is also significantly less compared to more complex networks like a CNN.
Lloyd Shapley introduced a method in the 1950s within Cooperative Game Theory, which has been widely applied in enhancing the interpretability of Machine Learning models [191, 192]. This technique, named after him, assigns a value to each player in the coalition, representing their marginal contribution to the coalition's overall worth. The Shapley value is based on the idea of considering all possible permutations of player orderings and calculating the average marginal contribution of each player over all possible coalitions. It takes into account the various ways in which players can join or leave the coalition and how their inclusion affects the coalition's worth. It provides a way to fairly distribute the surplus generated by cooperation among players who might have different levels of contribution or bargaining power.
In the context of particle phenomenology and Machine Learning (ML), the Shapley value contributes to the interpretability of ML models by providing insights into how features (or variables) contribute to the model's predictions [193-195]. Shapley values provide an estimate of the importance of different features in the predictions of the ML model. Upon calculating the Shapley value for each feature, one identifies the features with the most significant impact on the model's output. Besides, Shapley values provide a clear
comprehension of how individual features interact with each other in influencing the model's predictions. This understanding provides the identification of complex relationships and interactions between different variables in segregation of particular signatures. For event datasets containing numerous features, Shapley values help to identify the most relevant features for making predictions, aiding in feature selection and dimensionality reduction, improving model efficiency and interpretability. Understanding the contribution of each feature to the model's predictions assists in validating the model's decisions, ensuring its reliability and enhancing the interpretability, transparency, and trust in the models' predictions, ultimately advancing our understanding of fundamental particles and their interactions. In Ref.[193], the authors study the top taggers using N-Subjettiness ratios and several observables of the Energy Correlation functions as input features to train the eXtreme Gradient BOOSTed decision tree (XGBOOST). The effect of matching the parton level top and its decay products to the reconstructed boosted top jet are found to be significant. Using Shapley values, it is found that along with individual contributions, the interaction effects (i.e., cross correlations) also control the performance of the tagger. This in turn motivates the author to propose a hybrid top tagger combining the important input features.
Even though for top tagging, majority of the analysis focus on the case when the boosted top quark either decays hadronically or leptonically, in certain BSM theories, a top quark can decay to a charm quark and a Higgs boson which eventually decays to a pair of b-quarks. This decay is extremely rare in SM, as flavor changing neutral currents are highly suppressed at the tree level. However, even though branching ratios are low, no existing top tagger would be sensitive to probe such decay modes of top quark at the boosted regime. The authors in Ref.[194] made an attempt to build a top tagger which specifically focuses on this particular decay mode. A MultiVariate Analysis using two different boosting algorithms, viz., XGBoost and AdaBoost, the authors perform a comparative analysis on the performance of the proposed top tagger for the two boosting algorithms along with conventional cut-based top tagging algorithms. The Shapley values are also calculated to articulate the contribution of observables towards appropriate identification of the signal and background events, and consequently providing an insight of the trained model.
Layerwise relevance propagation (LRP) method is one of most popular methods of interpreting the decision of machine learning models based on neural networks. A framework was introduced to extract and understand the decision-making information of top tagger build from a deep neural network (DNN) architecture using substructure based observables [196]. The authors aimed to identify the expert variables that augment inputs ('eXpert AUGmented' variables, or XAUG variables), and then apply LRP method to networks both with and without XAUG variables. The LRP technique finds the relevant information the network is using, and helps in improving the network performance significantly when XAUG variables are introduced to the network. A similar analysis using LRP method in the context of a GNN based particle-flow (PF) algorithm has been performed to identify the relevant nodes and features for its predictions [197].
One of the most comprehensive studies in the context of top tagging models was performed in [195]. There exists several methods of explainable AI (XAI) which helps in exploring the working principles of different deep neural networks, especially it provides the all important input-output relationship present in the data. Considering a few important mathematical frameworks of XAI, namely the ∆AUC method, Shapely Additive Explanations (SHAP), Layerwise Relevance Propagation (LRP), and Neural Activation Pattern (NAP) Diagrams, the authors have showed a number of important aspects connecting the data with the trained models. In fact, the authors have cautioned on making an interpretation from the feature importances/ranking without making a thorough study especially for the cases when the input features are highly correlated. Each of those frameworks has some advantages over the other choices. For example, while the RNA scores provide better understanding of how information is transferred through different layers of the network, the NAP diagrams help in estimating the uncertainties in event classification. The study of these interpretable networks also leads to propose a hybrid interpretable network, called the Particle Flow Interaction Network (FPIN) which not only outperforms (or, at least comparable to) the existing top tagging models, but the network also consists of a smaller number of parameters leading to quicker training and better convergence rate. It is noteworthy that a similar strategy for better and faster training with less number of trainable parameters has been proposed based on Distance Correlation (DisCo) [198].
A versatile network, called permutation equivariant and Lorentz invariant or covariant aggregator network, in short PELICAN, that takes into account symmetry principles (specifically full Lotentz symmetry)
was proposed to reduce the complexity of the architecture and increase the interpretability without compromising the performance [199]. The PELICAN network outperforms many traditional taggers especially designed for tagging boosted top quarks and quarks/gluons with fewer number of trainable parameters. In fact, the network achieves similar classification performance is 5 different categories of jets (gluon jets, light quark jets, W -boson, Z -boson, and top quark jets) showing efficient utilization of training parameters. Furthermore, the network is capable of reconstructing charge particle track, W-boson mass from top quark decay and even reconstructing the full collision event. The combination of the full Lorentz symmetry and permutation symmetry helps in explaining the PELICAN weights as the clustering coefficients which in turn makes the network explainable.
The Shower Deconstruction methodology plays the central role in distinguishing between signal and background jets by leveraging the details of parton shower. This method, however, suffers from combinatorics issues as the number of jet constituents increases. In Ref.[200], the authors propose a novel method (likelihood analysis) of identifying the most probable shower history as a Markov Decision Process (MDP). Employing a sophisticated modular point-transformer architecture, the proposed algorithm efficiently learns the optimal policy and the resulting neural agent excels in constructing likely shower histories with robust generalization capabilities on unseen test data. More importantly, this method reduces the inherent complexity of the inference process, and thereby establishes a linear scaling relationship with the number of constituents of a given jet.
As we have already discussed in previous sections, the majority of the studies providing remarkable improvements using machine learning algorithms over the traditional methods analyse low-level features. However, this methodology often lacks interpretability, therefore interpretable architectures with transparent decision making processes are desperately needed. One such attempt was made very recently in Ref.[162], where authors have proposed an Analysis Model (AM) that processes a few selected high level features designed to capture important features of the top jets. The model is set up in a modular structure which includes a relation network that examines two-point energy correlations, mathematical morphology, and Minkowski functionals, and a recursive neural network involving subjet multiplicity and their color charges. The proposed framework obtains performance comparable to the Particle Transformer (ParT) in top jet tagging with smaller training uncertainties.
## 7 Summary and Outlook
Through the years of experimental and theoretical studies, the SM of particle physics, a theory which unifies the fundamental constituents of Nature and their interactions, found to be mostly successful in explaining the Nature except in a few cases. In this quest, several BSM studies have been performed, where the BSM events are searched over the SM-driven events. Jets and their substructure analysis in the boosted regime are proven to be providing remarkable success in this thrive. With the increase of luminosity in the LHC, the study of SM has also found new directions, especially in the boosted regime. Though the cut-based techniques left a prominent footprint in the SM and BSM searches, the vigorous development of ML and AI, added new heights to it. This work summarizes the development of different tagging algorithms in the ML era, especially in the light of top and Higgs tagging.
One of the most initial and effective ML algorithms in the area of High energy physics was the Decision tree algorithm. Similar to the cut-based techniques, it splits the phase space based on the features in an event iteratively thereby constructing a tree-like structure containing a set of events in each final leaf node. The sets are representations of different classes, differentiating BSM events of interest from similar irreducible backgrounds of SM processes. A further development to the decision tree algorithm is the Boosted Decision Tree, where the misclassified events in the previous iteration of training get more focus in the next training, improving the overall training performance.
The more advanced development towards ML was seen around 1940's, when by mimicking the human brain a new algorithm entered the ML paradigm. In this new algorithm, except for the input and output layer, a hidden layer with a finite number of perceptrons is employed. Similar to brain neurons, these perceptrons are designed such that the network can decode any complex functions hidden within the patterns of the values of the features. These feed-forward networks with one hidden layer are termed as Artificial Neural Networks or ANN. The training process of these networks aim to minimize the error in assigning the weights of each neuron in forward propagation by updating them during backward propagation.
A further improvement in the result of NN is seen, when implemented with multiple hidden layers, leading to a new network architecture termed as Deep Neural Network or DNN. In the view of jet tagging, especially Higgs and Top tagging, we find that the DNN with more hidden layers with less number of nodes sometimes performs better than the DNNs with a large number of nodes comprised in a smaller number of hidden layers. One step ahead the DNN is further improvised by taking a combination of convolutional layers. These networks termed as CNN are established to be good at understanding complex structures of the boosted jets without any feature engineering. Sliding a kernel or learnable filter throughout the jet image, the CNN architecture captures the pattern in an image. This understanding helps to segregate between the jet image of the process of interest from backgrounds of similar kind. It is found through several studies that increasing the feature map and the number of nodes of dense layers improve the top tagging efficiency over mistagging rate significantly. Additionally it is also found that this network trained with low level features performs almost 3 times better than the BDT trained with high level features. However, the taggers like DeepTopLoLa which uses Lorentz Vectors as input and adds a Lorentz layer to the DNN for converting the vectors to relevant kinematic variables, can produce similar results.
In this review, we first discuss the traditional tagging method of boosted Higgs jet, namely the BDRS algorithm, and then highlighted the observation of different studies using state-of-the-art machine learning algorithms, starting with constituent based methods, image based algorithms using CNNs, combination of high level objects and image based analysis, Lund Plane, and more recent-most ones using GNN architectures. In the majority of these studies, a significant amount of improvement in the tagging performance has been observed while using these advanced methods. Similar observations were also found while analyzing the top quarks in the boosted regime through top tagging methods. We discussed that even though traditional substructure based algorithms as implemented in HEPTopTagger performed reasonably well in moderate to large p T regime of the top quark, advanced machine learning involved algorithms based on jet images, constituent based RNN architecture, or graph based ones provide amazing performance in classifying top jets from quark/gluon jets.
These sophisticated algorithms, even though extremely powerful in classification, regression or clustering events, come with a lot of complexity, a large number of trainable free parameters, and most importantly, lack in interpretability. Several attempts have been made in the recent past to propose trainable models that are explainable, so that, along with improved performance at a given task, we also understand the decision making process in achieving the result. Some of these methods that help in explaining a neural network are SHAP analysis, Layerwise Relevance Propagation method, Neural activation pattern etc. We have highlighted several studies involving these explainable algorithms, along with their merits and demerits. Tremendous amounts of efforts are ongoing to extend the applicability of these novel methods, diving deeper into their adaptability and usefulness across different data structures, especially in complex structures like graph nets and transformers. These will certainly revolutionize the current landscape of Higgs and Top taggers, and also broaden generic jet classification scenarios.
## 8 Acknowledgements
The work of AC is funded by the Department of Science and Technology, Government of India, under Grant No. IFA18-PH 224 (INSPIRE Faculty Award).
Data Availability Statement : No Data associated in the manuscript.
## References
- [1] Glashow, S.L.: Partial Symmetries of Weak Interactions. Nucl. Phys. 22 , 579-588 (1961) https://doi. org/10.1016/0029-5582(61)90469-2
- [2] Weinberg, S.: A Model of Leptons. Phys. Rev. Lett. 19 , 1264-1266 (1967) https://doi.org/10.1103/ PhysRevLett.19.1264
- [3] Salam, A.: Weak and Electromagnetic Interactions. Conf. Proc. C 680519 , 367-377 (1968) https: //doi.org/10.1142/9789812795915 0034
- [4] Weinberg, S.: The Making of the standard model. Eur. Phys. J. C 34 , 5-13 (2004) https://doi.org/10. 1140/epjc/s2004-01761-1 arXiv:hep-ph/0401010
- [5] Chatrchyan, S., et al. : Observation of a New Boson with Mass Near 125 GeV in pp Collisions at √ s = 7 and 8 TeV. JHEP 06 , 081 (2013) https://doi.org/10.1007/JHEP06(2013)081 arXiv:1303.4571 [hep-ex]
- [6] Aad, G., et al. : Observation of a new particle in the search for the Standard Model Higgs boson with the ATLAS detector at the LHC. Phys. Lett. B 716 , 1-29 (2012) https://doi.org/10.1016/j.physletb. 2012.08.020 arXiv:1207.7214 [hep-ex]
- [7] Evans, L., Bryant, P. (eds.): LHC Machine. JINST 3 , 08001 (2008) https://doi.org/10.1088/1748-0221/ 3/08/S08001
- [8] Larkoski, A.J., Moult, I., Nachman, B.: Jet Substructure at the Large Hadron Collider: A Review of Recent Advances in Theory and Machine Learning. Phys. Rept. 841 , 1-63 (2020) https://doi.org/10. 1016/j.physrep.2019.11.001 arXiv:1709.04464 [hep-ph]
- [9] Guest, D., Cranmer, K., Whiteson, D.: Deep Learning and its Application to LHC Physics. Ann. Rev. Nucl. Part. Sci. 68 , 161-181 (2018) https://doi.org/10.1146/annurev-nucl-101917-021019 arXiv:1806.11484 [hep-ex]
- [10] Albertsson, K., et al. : Machine Learning in High Energy Physics Community White Paper. J. Phys. Conf. Ser. 1085 (2), 022008 (2018) https://doi.org/10.1088/1742-6596/1085/2/022008 arXiv:1807.02876 [physics.comp-ph]
- [11] Radovic, A., Williams, M., Rousseau, D., Kagan, M., Bonacorsi, D., Himmel, A., Aurisano, A., Terao, K., Wongjirad, T.: Machine learning at the energy and intensity frontiers of particle physics. Nature 560 (7716), 41-48 (2018) https://doi.org/10.1038/s41586-018-0361-2
- [12] Bourilkov, D.: Machine and Deep Learning Applications in Particle Physics. Int. J. Mod. Phys. A 34 (35), 1930019 (2020) https://doi.org/10.1142/S0217751X19300199 arXiv:1912.08245 [physics.dataan]
- [13] Araz, J.Y., et al.: Les Houches guide to reusable ML models in LHC analyses (2023) arXiv:2312.14575 [hep-ph]
- [14] Feickert, M., Nachman, B.: A Living Review of Machine Learning for Particle Physics (2021) arXiv:2102.02770 [hep-ph]
- [15] Kotsiantis, S.B.: Supervised machine learning: A review of classification techniques. In: Informatica (2007). https://api.semanticscholar.org/CorpusID:47128183
- [16] Kotsiantis S.B., Z.I.D., Pintelas, P.E.: Machine learning: a review of classification and combining techniques. Artif Intell Rev 26 , 159-190 (2006) https://doi.org/10.1007/s10462-007-9052-3
- [17] Quinlan, J.R.: Induction of decision trees. Mach Learn 1 , 81-106 (1986) https://doi.org/10.1007/ BF00116251.
- [18] Song YY, L.Y.: Decision tree methods: applications for classification and prediction. Shanghai Arch Psychiatry 27 , 130-135 (2015) https://doi.org/10.11919/j.issn.1002-0829.215044
- [19] Ying, X.: An Overview of Overfitting and its Solutions. Journal of Physics 1168 (2019) https://doi. org/10.1088/1742-6596/1168/2/022022
- [20] Breiman, L.: Random Forests. Machine Learning 45 , 5-32 (2001) https://doi.org/10.1023/A: 1010933404324.
- [21] Friedman, J.H.: Greedy Function Approximation: A Gradient Boosting Machine. The Annals of Statistics 29 , 1189-1232 (2001) https://doi.org/http://www.jstor.org/stable/2699986.
- [22] Z. He, T.L.e.a. D. Lin: Gradient Boosting Machine: A Survey (2019) arXiv:1908.06951
- [23] T. Chen, C.G.: XGBoost: A Scalable Tree Boosting System (2016) arXiv:1603.02754
- [24] Coadou, Y.: Boosted decision trees (2022) https://doi.org/10.1142/9789811234033 0002 arXiv:2206.09645 [physics.data-an]
- [25] Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., Liu, T.-Y.: Lightgbm: A highly efficient gradient boosting decision tree. In: Advances in Neural Information Processing Systems (2017)
- [26] McCulloch, W.S., Pitts, W.: A logical calculus of the ideas immanent in nervous activity. The bulletin of mathematical biophysics 5 (4), 115-133 (1943)
- [27] Hebb, D.O.: The Organization of Behavior: A Neuropsychological Theory. Taylor & Francis, London (2005)
- [28] Rosenblatt, F.: The perceptron: a probabilistic model for information storage and organization in the brain. Psychol. Rev. 65 (6), 386-408 (1958)
- [29] Widrow, B., Hoff, M.E., et al. : Adaptive switching circuits. In: IRE WESCON Convention Record, vol. 4, pp. 96-104 (1960). New York
- [30] Ivakhnenko, A.G., Lapa, V.G.: Cybernetics and Forecasting Techniques. American Elsevier Publishing Company, Madison (1967)
- [31] Barron, A.R.: Universal approximation bounds for superpositions of a sigmoidal function. IEEE Transactions on Information Theory 39 (3), 930-945 (1993) https://doi.org/10.1109/18.256500
- [32] Cybenko, G.: Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals and Systems 2 (4), 303-314 (1989)
- [33] Hornik, K., Stinchcombe, M., White, H.: Multilayer feedforward networks are universal approximators. Neural Netw. 2 (5), 359-366 (1989)
- [34] Hopfield, J.J.: Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. U. S. A. 79 (8), 2554-2558 (1982)
- [35] Hopfield, J.J., Tank, D.W.: 'neural' computation of decisions in optimization problems. Biol. Cybern. 52 (3), 141-152 (1985)
- [36] Han, S.-H., Kim, K.W., Kim, S., Youn, Y.C.: Artificial neural network: Understanding the basic concepts without mathematics. Dement. Neurocognitive Disord. 17 (3), 83-89 (2018)
| [37] | Werbos, P.J.: Backpropagation through time: what it does and how to do it. Proc. IEEE Inst. Electr. Electron. Eng. 78 (10), 1550-1560 (1990) |
|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [38] | Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning representations by back-propagating errors. Nature 323 (6088), 533-536 (1986) |
| [39] | Ruder, S.: An overview of gradient descent optimization algorithms. CoRR abs/1609.04747 (2016) 1609.04747 |
| [40] | LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature 521 (7553), 436-444 (2015) |
| [41] | Schmidhuber, J.: Deep learning in neural networks: An overview. CoRR abs/1404.7828 (2014) 1404.7828 |
| [42] | Dillon, B.M., Favaro, L., Plehn, T., Sorrenson, P., Kr¨mer, a M.: A normalized autoencoder for LHC triggers. SciPost Phys. Core 6 (4) (2023) |
| [43] | Cerri, O., Nguyen, T.Q., Pierini, M., Spiropulu, M., Vlimant, J.-R.: Variational Autoencoders for New Physics Mining at the Large Hadron Collider. JHEP 05 , 036 (2019) https://doi.org/10.1007/ JHEP05(2019)036 arXiv:1811.10276 [hep-ex] |
| [44] | Baldi, P.: Autoencoders, unsupervised learning, and deep architectures. In: Guyon, I., Dror, G., Lemaire, V., Taylor, G., Silver, D. (eds.) Proceedings of ICML Workshop on Unsupervised and Transfer Learning. Proceedings of Machine Learning Research, vol. 27, pp. 37-49. PMLR, Bellevue, Washington, USA (2012). https://proceedings.mlr.press/v27/baldi12a.html |
| [45] | Honkela, T., Duch, W., Girolami, M., Kaski, S. (eds.): Artificial Neural Networks and Machine Learning - ICANN 2011. Lecture notes in computer science. Springer, Berlin, Germany (2011) |
| [46] | He, K., Chen, X., Xie, S., Li, Y., Doll´r, a P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16000-16009 (2022) |
| [47] | O'Shea, K., Nash, R.: An introduction to convolutional neural networks. arXiv preprint arXiv:1511.08458 (2015) |
| [48] | Yamashita, R., Nishio, M., Do, R.K.G., Togashi, K.: Convolutional neural networks: an overview and application in radiology. Insights into Imaging 9 (4), 611-629 (2018) |
| [49] | Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, glyph[suppress] L., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30 (2017) |
| [50] | Thais, S., Calafiura, P., Chachamis, G., DeZoort, G., Duarte, J., Ganguly, S., Kagan, M., Murnane, D., Neubauer, M.S., Terao, K.: Graph Neural Networks in Particle Physics: Implementations, Innovations, and Challenges. In: Snowmass 2021 (2022) |
| [51] | Ehrke, L., Raine, J.A., Zoch, K., Guth, M., Golling, T.: Topological reconstruction of particle physics processes using graph neural networks. Phys. Rev. D 107 (11), 116019 (2023) https://doi.org/10.1103/ PhysRevD.107.116019 arXiv:2303.13937 [hep-ph] |
| [52] | Biscarat, C., Caillou, S., Rougier, C., Stark, J., Zahreddine, J.: Towards a realistic track reconstruction algorithm based on graph neural networks for the hl-lhc. EPJ Web of Conferences (2021) |
| [53] | Andrews, M., Paulini, M., Gleyzer, S., Poczos, B.: End-to-End Physics Event Classification with CMS Open Data: Applying Image-Based Deep Learning to Detector Data for the Direct Classifica- tion of Collision Events at the LHC. Comput. Softw. Big Sci. 4 (1), 6 (2020) https://doi.org/10.1007/ |
s41781-020-00038-8 arXiv:1807.11916 [physics.data-an]
| [54] | Andrews, M., Alison, J., An, S., Bryant, P., Burkle, B., Gleyzer, S., Narain, M., Paulini, M., Poczos, B., Usai, E.: End-to-end jet classification of quarks and gluons with the CMS Open Data. Nucl. Instrum. Meth. A 977 , 164304 (2020) https://doi.org/10.1016/j.nima.2020.164304 arXiv:1902.08276 [hep-ex] |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [55] | Ju, X., et al. : Graph Neural Networks for Particle Reconstruction in High Energy Physics detectors. In: 33rd Annual Conference on Neural Information Processing Systems (2020) |
| [56] | Duarte, J., Vlimant, J.-R.: Graph Neural Networks for Particle Tracking and Reconstruction (2020) https://doi.org/10.1142/9789811234033 0012 arXiv:2012.01249 [hep-ph] |
| [57] | Qasim, S.R.: Multi-particle reconstruction with dynamic graph neural networks. PhD thesis, Manch- ester Metropolitan University, 2023, U. Manchester (main) (2023) |
| [58] | Qu, H., Gouskos, L.: ParticleNet: Jet Tagging via Particle Clouds. Phys. Rev. D 101 (5), 056019 (2020) https://doi.org/10.1103/PhysRevD.101.056019 arXiv:1902.08570 [hep-ph] |
| [59] | Dreyer, F.A., Grabarczyk, R., Monni, P.F.: Leveraging universality of jet taggers through trans- fer learning. Eur. Phys. J. C 82 (6), 564 (2022) https://doi.org/10.1140/epjc/s10052-022-10469-9 arXiv:2203.06210 [hep-ph] |
| [60] | Komiske, P.T., Metodiev, E.M., Thaler, J.: Energy Flow Networks: Deep Sets for Particle Jets. JHEP 01 , 121 (2019) https://doi.org/10.1007/JHEP01(2019)121 arXiv:1810.05165 [hep-ph] |
| [61] | Li, C.-T., Tsai, Y.-C., Chen, C.-Y., Chiehen Liao, J.: Graph Neural Networks for Tabular Data Learn- ing: A Survey with Taxonomy and Directions. arXiv e-prints, 2401-02143 (2024) https://doi.org/10. 48550/arXiv.2401.02143 arXiv:2401.02143 [cs.LG] |
| [62] | Ouvrard, X.: Hypergraphs: an introduction and review. arXiv e-prints, 2002-05014 (2020) https://doi. org/10.48550/arXiv.2002.05014 arXiv:2002.05014 [cs.DM] |
| [63] | Chuong Nguyen, Q., Kien Le, T.: Toward a comprehensive simulation framework for hypergraphs: a Python-base approach. arXiv e-prints, 2401-03917 (2024) https://doi.org/10.48550/arXiv.2401.03917 arXiv:2401.03917 [cs.MS] |
| [64] | Xu, C., Li, M., Ni, Z., Zhang, Y., Chen, S.: GroupNet: Multiscale Hypergraph Neural Networks for Trajectory Prediction with Relational Reasoning. arXiv e-prints, 2204-08770 (2022) https://doi.org/ 10.48550/arXiv.2204.08770 arXiv:2204.08770 [cs.CV] |
| [65] | Shlomi, J., Battaglia, P., Vlimant, J.-R.: Graph Neural Networks in Particle Physics (2020) https: //doi.org/10.1088/2632-2153/abbf9a arXiv:2007.13681 [hep-ex] |
| [66] | Di Bello, F.A., et al. : Reconstructing particles in jets using set transformer and hypergraph predic- tion networks. Eur. Phys. J. C 83 (7), 596 (2023) https://doi.org/10.1140/epjc/s10052-023-11677-7 arXiv:2212.01328 [hep-ex] |
| [67] | Haller, J., Kogler, R., Tackmann, F.: In: Haller, J., Grefe, M. (eds.) Studies of Boosted Topologies and Jet Substructure at the LHC, pp. 155-168 (2018). https://doi.org/10.3204/PUBDB-2018-00782/B2a |
| [68] | Hinkle, E.: Tagging Hadronically Decaying Top Quarks with Deep Neural Networks. PhD thesis, Brown University, 2019 (2019) |
| [69] | Salam, G.P.: Towards Jetography. Eur. Phys. J. C 67 , 637-686 (2010) https://doi.org/10.1140/epjc/ s10052-010-1314-6 arXiv:0906.1833 [hep-ph] |
| [70] | Barate, R., et al. : Search for the standard model Higgs boson at LEP. Phys. Lett. B 565 , 61-75 (2003) https://doi.org/10.1016/S0370-2693(03)00614-2 arXiv:hep-ex/0306033 |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [71] | Andersen, J.R., et al.: Handbook of LHC Higgs Cross Sections: 3. Higgs Properties (2013) https: //doi.org/10.5170/CERN-2013-004 arXiv:1307.1347 [hep-ph] |
| [72] | Expected Performance of Boosted Higgs ( → bb ¯ ) Boson Identification with the ATLAS Detec- tor at √ s = 13 TeV. Technical report, CERN, Geneva (2015). All figures including auxil- iary figures are available at https://atlas.web.cern.ch/Atlas/GROUPS/PHYSICS/PUBNOTES/ATL- PHYS-PUB-2015-035. https://cds.cern.ch/record/2042155 |
| [73] | Sirunyan, A.M., et al. : Identification of heavy-flavour jets with the CMS detector in pp collisions at 13 TeV. JINST 13 (05), 05011 (2018) https://doi.org/10.1088/1748-0221/13/05/P05011 arXiv:1712.07158 [physics.ins-det] |
| [74] | Dhingra, N.: Performance of b-tagging algorithms at the CMS experiment with pp collision data at √ s =8 TeV. In: 2nd Large Hadron Collider Physics Conference (2014) |
| [75] | Butterworth, J.M., Davison, A.R., Rubin, M., Salam, G.P.: Jet substructure as a new Higgs search channel at the LHC. Phys. Rev. Lett. 100 , 242001 (2008) https://doi.org/10.1103/PhysRevLett.100. 242001 arXiv:0802.2470 [hep-ph] |
| [76] | Datta, K., Larkoski, A.J.: Novel Jet Observables from Machine Learning. JHEP 03 , 086 (2018) https: //doi.org/10.1007/JHEP03(2018)086 arXiv:1710.01305 [hep-ph] |
| [77] | Datta, K., Larkoski, A., Nachman, B.: Automating the Construction of Jet Observables with Machine Learning. Phys. Rev. D 100 (9), 095016 (2019) https://doi.org/10.1103/PhysRevD.100.095016 arXiv:1902.07180 [hep-ph] |
| [78] | Guo, J., Li, J., Li, T., Zhang, R.: Boosted Higgs boson jet reconstruction via a graph neural network. Phys. Rev. D 103 (11), 116025 (2021) https://doi.org/10.1103/PhysRevD.103.116025 arXiv:2010.05464 [hep-ph] |
| [79] | Lin, J., Freytsis, M., Moult, I., Nachman, B.: Boosting H → bb ¯ with Machine Learning. JHEP 10 , 101 (2018) https://doi.org/10.1007/JHEP10(2018)101 arXiv:1807.10768 [hep-ph] |
| [80] | Li, J., Li, T., Xu, F.-Z.: Reconstructing boosted Higgs jets from event image segmentation. JHEP 04 , 156 (2021) https://doi.org/10.1007/JHEP04(2021)156 arXiv:2008.13529 [hep-ph] |
| [81] | Alves, A., Freitas, F.F.: Towards recognizing the light facet of the Higgs Boson. Mach. Learn. Sci. Tech. 1 (4), 045025 (2020) https://doi.org/10.1088/2632-2153/aba8e6 arXiv:1912.12532 [hep-ph] |
| [82] | Choi, S.K., Li, J., Zhang, C., Zhang, R.: Automatic detection of boosted Higgs boson and top quark jets in an event image. Phys. Rev. D 108 (11), 116002 (2023) https://doi.org/10.1103/PhysRevD.108. 116002 arXiv:2302.13460 [hep-ph] |
| [83] | Moreno, E.A., Nguyen, T.Q., Vlimant, J.-R., Cerri, O., Newman, H.B., Periwal, A., Spiropulu, M., Duarte, J.M., Pierini, M.: Interaction networks for the identification of boosted H → bb decays. Phys. Rev. D 102 (1), 012010 (2020) https://doi.org/10.1103/PhysRevD.102.012010 arXiv:1909.12285 [hep- ex] |
| [84] | Chung, Y.-L., Hsu, S.-C., Nachman, B.: Disentangling Boosted Higgs Boson Production Modes with Machine Learning. JINST 16 , 07002 (2021) https://doi.org/10.1088/1748-0221/16/07/P07002 arXiv:2009.05930 [hep-ph] |
| [85] | Grojean, C., Paul, A., Qian, Z.: Resurrecting bbh with kinematic shapes. JHEP 04 , 139 (2021) https: |
- //doi.org/10.1007/JHEP04(2021)139 arXiv:2011.13945 [hep-ph]
| [86] | Englert, C., Fairbairn, M., Spannowsky, M., Stylianou, P., Varma, S.: Sensing Higgs boson cascade decays through memory. Phys. Rev. D 102 (9), 095027 (2020) https://doi.org/10.1103/PhysRevD.102. 095027 arXiv:2008.08611 [hep-ph] |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [87] | Harris, P.C., Rankin, D.S., Mantilla Suarez, C.: An approach to constraining the Higgs width at the LHC and HL-LHC (2019) arXiv:1910.02082 [hep-ph] |
| [88] | Ngairangbam, V.S., Bhardwaj, A., Konar, P., Nayak, A.K.: Invisible Higgs search through Vector Boson Fusion: A deep learning approach. Eur. Phys. J. C 80 (11), 1055 (2020) https://doi.org/10.1140/ epjc/s10052-020-08629-w arXiv:2008.05434 [hep-ph] |
| [89] | Oliveira, L., Kagan, M., Mackey, L., Nachman, B., Schwartzman, A.: Jet-images - deep learning edition. JHEP 07 , 069 (2016) https://doi.org/10.1007/JHEP07(2016)069 arXiv:1511.05190 [hep-ph] |
| [90] | Lim, S.H., Nojiri, M.M.: Spectral Analysis of Jet Substructure with Neural Networks: Boosted Higgs Case. JHEP 10 , 181 (2018) https://doi.org/10.1007/JHEP10(2018)181 arXiv:1807.03312 [hep-ph] |
| [91] | Andersson, B., Gustafson, G., Lonnblad, L., Pettersson, U.: Coherence Effects in Deep Inelastic Scattering. Z. Phys. C 43 , 625 (1989) https://doi.org/10.1007/BF01550942 |
| [92] | Dreyer, F.A., Salam, G.P., Soyez, G.: The Lund Jet Plane. JHEP 12 , 064 (2018) https://doi.org/10. 1007/JHEP12(2018)064 arXiv:1807.04758 [hep-ph] |
| [93] | Dreyer, F.A., Qu, H.: Jet tagging in the Lund plane with graph networks. JHEP 03 , 052 (2021) https://doi.org/10.1007/JHEP03(2021)052 arXiv:2012.08526 [hep-ph] |
| [94] | Aad, G., et al. : Measurement of the Lund Jet Plane Using Charged Particles in 13 TeV Proton-Proton Collisions with the ATLAS Detector. Phys. Rev. Lett. 124 (22), 222002 (2020) https://doi.org/10. 1103/PhysRevLett.124.222002 arXiv:2004.03540 [hep-ex] |
| [95] | Khosa, C.K., Marzani, S.: Higgs boson tagging with the Lund jet plane. Phys. Rev. D 104 (5), 055043 (2021) https://doi.org/10.1103/PhysRevD.104.055043 arXiv:2105.03989 [hep-ph] |
| [96] | Buckley, A., Callea, G., Larkoski, A.J., Marzani, S.: An Optimal Observable for Color Singlet Identi- fication. SciPost Phys. 9 , 026 (2020) https://doi.org/10.21468/SciPostPhys.9.2.026 arXiv:2006.10480 [hep-ph] |
| [97] | Cavallini, L., Coccaro, A., Khosa, C.K., Manco, G., Marzani, S., Parodi, F., Rebuzzi, D., Rescia, A., Stagnitto, G.: Tagging the Higgs boson decay to bottom quarks with colour-sensitive observables and the Lund jet plane. Eur. Phys. J. C 82 (5), 493 (2022) https://doi.org/10.1140/epjc/s10052-022-10447-1 arXiv:2112.09650 [hep-ph] |
| [98] | Arjona Mart´nez, ı J., Cerri, O., Pierini, M., Spiropulu, M., Vlimant, J.-R.: Pileup mitigation at the Large Hadron Collider with graph neural networks. Eur. Phys. J. Plus 134 (7), 333 (2019) https: //doi.org/10.1140/epjp/i2019-12710-3 arXiv:1810.07988 [hep-ph] |
| [99] | Mikuni, V., Canelli, F.: ABCNet: An attention-based method for particle tagging. Eur. Phys. J. Plus 135 (6), 463 (2020) https://doi.org/10.1140/epjp/s13360-020-00497-3 arXiv:2001.05311 [physics.data- an] |
| [100] | Ju, X., Nachman, B.: Supervised Jet Clustering with Graph Neural Networks for Lorentz Boosted Bosons. Phys. Rev. D 102 (7), 075014 (2020) https://doi.org/10.1103/PhysRevD.102.075014 arXiv:2008.06064 [hep-ph] |
| [101] | DeZoort, G., Battaglia, P.W., Biscarat, C., Vlimant, J.-R.: Graph neural networks at the Large Hadron Collider. Nature Rev. Phys. 5 (5), 281-303 (2023) https://doi.org/10.1038/s42254-023-00569-0 |
|---------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [102] | Mokhtar, F., Kansal, R., Duarte, J.: Do graph neural networks learn traditional jet substructure? In: 36th Conference on Neural Information Processing Systems: Workshop on Machine Learning and the Physical Sciences (2022) |
| [103] | Apresyan, A., et al. : Improving Di-Higgs Sensitivity at Future Colliders in Hadronic Final States with Machine Learning. In: Snowmass 2021 (2022) |
| [104] | Hammad, A., Moretti, S., Nojiri, M.: Multi-scale cross-attention transformer encoder for event classification (2023) arXiv:2401.00452 [hep-ph] |
| [105] | Wang, Y., Sun, Y., Liu, Z., Sarma, S.E., Bronstein, M.M., Solomon, J.M.: Dynamic Graph CNN for Learning on Point Clouds (2018) arXiv:1801.07829 [cs.CV] |
| [106] | Semlani, Y., Relan, M., Ramesh, K.: PCN: A Deep Learning Approach to Jet Tagging Utilizing Novel Graph Construction Methods and Chebyshev Graph Convolutions (2023) arXiv:2309.08630 [hep-ph] |
| [107] | Aguilar-Saavedra, J.A., Arganda, E., Joaquim, F.R., Sand´ a Seoane, R.M., Seabra, J.F.: Gradient Boosting MUST taggers for highly-boosted jets (2023) arXiv:2305.04957 [hep-ph] |
| [108] | Sirunyan, A.M., et al. : Identification of heavy, energetic, hadronically decaying particles using machine- learning techniques. JINST 15 (06), 06005 (2020) https://doi.org/10.1088/1748-0221/15/06/P06005 arXiv:2004.08262 [hep-ex] |
| [109] | Tumasyan, A., Adam, W., Andrejkovic, J., Bergauer, T., Chatterjee, S., Dragicevic, M., Valle, A., Fr¨hwirth, u R., Jeitler, M., Krammer, N., Lechner, L., Liko, D., Mikulec, I., Paulitsch, P., Pitters, F., Schieck, J., Xie, S., Spanring, M., Templ, S., Vetens, W.: Measurement of the top quark mass using events with a single reconstructed top quark in pp collisions at √ s = 13 TeV. Journal of High Energy Physics 2021 (2021) https://doi.org/10.1007/JHEP12(2021)161 |
| [110] | Quadt, A.: Top quark physics at hadron colliders. Eur. Phys. J. C 48 , 835-1000 (2006) https://doi. org/10.1140/epjc/s2006-02631-6 |
| [111] | Webber, B.R.: Fragmentation and hadronization. Int. J. Mod. Phys. A 15S1 , 577-606 (2000) https: //doi.org/10.1142/S0217751X00005334 arXiv:hep-ph/9912292 |
| [112] | Albino, S.: Hadronization of partons. Rev. Mod. Phys. 82 , 2489-2556 (2010) https://doi.org/10.1103/ RevModPhys.82.2489 |
| [113] | Grossman, Y., Nachshon, I.: Hadronization, spin, and lifetimes. JHEP 07 , 016 (2008) https://doi.org/ 10.1088/1126-6708/2008/07/016 arXiv:0803.1787 [hep-ph] |
| [114] | Humanic, T.J.: Extracting the hadronization timescale in √ s = 7 TeV proton-proton collisions from pion and kaon femtoscopy. J. Phys. G 41 , 075105 (2014) https://doi.org/10.1088/0954-3899/41/7/ 075105 arXiv:1312.2303 [hep-ph] |
| [115] | D´liot, e F., Mulders, P.V.: Top quark physics at the LHC. Comptes Rendus Physique 21 (1), 45-60 (2020) https://doi.org/10.5802/crphys.9 |
| [116] | Tumasyan, A., et al. : Precision measurement of the Wboson decay branching fractions in proton-proton collisions at √ s = 13 TeV. Phys. Rev. D 105 (7), 072008 (2022) https://doi.org/10.1103/PhysRevD. 105.072008 arXiv:2201.07861 [hep-ex] |
| [117] | ALTARELLI, G.: The Standard model of particle physics (2005) arXiv:hep-ph/0510281 |
| [118] | Abdesselam, A., et al. : Boosted Objects: A Probe of Beyond the Standard Model Physics. Eur. Phys. J. C 71 , 1661 (2011) https://doi.org/10.1140/epjc/s10052-011-1661-y arXiv:1012.5412 [hep-ph] |
|---------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [119] | Seymour, M.H.: Searches for new particles using cone and cluster jet algorithms: A Comparative study. Z. Phys. C 62 , 127-138 (1994) https://doi.org/10.1007/BF01559532 |
| [120] | Yagil, A.: Observation of top quark production in ¯ pp collisions with the Collider Detector at Fermilab, 13-22 (1995) |
| [121] | Abachi, S., et al. : Observation of the top quark. Phys. Rev. Lett. 74 , 2632-2637 (1995) https://doi. org/10.1103/PhysRevLett.74.2632 arXiv:hep-ex/9503003 |
| [122] | Andrieu, B.: Jet finding algorithms at Tevatron. Acta Phys. Polon. B 36 , 409-415 (2005) |
| [123] | Seymour, M.H.: Jets in hadron collisions. In: 8th International Workshop on Deep Inelastic Scattering and QCD (DIS 2000), pp. 27-41 (2000) |
| [124] | Ellis, S.D., Vermilion, C.K., Walsh, J.R.: Recombination Algorithms and Jet Substructure: Pruning as a Tool for Heavy Particle Searches. Phys. Rev. D 81 , 094023 (2010) https://doi.org/10.1103/PhysRevD. 81.094023 arXiv:0912.0033 [hep-ph] |
| [125] | Butterworth, J.M., Cox, B.E., Forshaw, J.R.: WW scattering at the CERN LHC. Phys. Rev. D 65 096014 (2002) https://doi.org/10.1103/PhysRevD.65.096014 arXiv:hep-ph/0201098 |
| [126] | Ellis, S.D., Vermilion, C.K., Walsh, J.R.: Techniques for improved heavy particle searches with jet substructure. Phys. Rev. D 80 , 051501 (2009) https://doi.org/10.1103/PhysRevD.80.051501 arXiv:0903.5081 [hep-ph] |
| [127] | Plehn, T., Spannowsky, M., Takeuchi, M.: How to Improve Top Tagging. Phys. Rev. D 85 , 034029 (2012) https://doi.org/10.1103/PhysRevD.85.034029 arXiv:1111.5034 [hep-ph] |
| [128] | Chakraborty, A., De, A., Godbole, R.M., Guchait, M.: Tagging a boosted top quark with a τ final state. Phys. Rev. D 108 (3), 035011 (2023) https://doi.org/10.1103/PhysRevD.108.035011 arXiv:2304.12846 [hep-ph] |
| [129] | Chatterjee, S., Godbole, R., Roy, T.S.: Tagging top in leptonic decay. PoS EPS-HEP2019 , 672 (2020) https://doi.org/10.22323/1.364.0672 |
| [130] | Kaplan, D.E., Rehermann, K., Schwartz, M.D., Tweedie, B.: Top Tagging: A Method for Identifying Boosted Hadronically Decaying Top Quarks. Phys. Rev. Lett. 101 , 142001 (2008) https://doi.org/10. 1103/PhysRevLett.101.142001 arXiv:0806.0848 [hep-ph] |
| [131] | A Cambridge-Aachen (C-A) based Jet Algorithm for boosted top-jet tagging (2009) |
| [132] | Plehn, T., Spannowsky, M., Takeuchi, M., Zerwas, D.: Stop Reconstruction with Tagged Tops. JHEP 10 , 078 (2010) https://doi.org/10.1007/JHEP10(2010)078 arXiv:1006.2833 [hep-ph] |
| [133] | Plehn, T., Spannowsky, M.: Top Tagging. J. Phys. G 39 , 083001 (2012) https://doi.org/10.1088/ 0954-3899/39/8/083001 arXiv:1112.4441 [hep-ph] |
| [134] | Oliveira, L., Kagan, M., Mackey, L., Nachman, B., Schwartzman, A.: Jet-images - deep learning edition. JHEP 07 , 069 (2016) https://doi.org/10.1007/JHEP07(2016)069 arXiv:1511.05190 [hep-ph] |
| [135] | Chakraborty, A., Lim, S.H., Nojiri, M.M., Takeuchi, M.: Neural Network-based Top Tagger with Two- Point Energy Correlations and Geometry of Soft Emissions. JHEP 07 , 111 (2020) https://doi.org/10. 1007/JHEP07(2020)111 arXiv:2003.11787 [hep-ph] |
| [136] | Shlomi, J., Battaglia, P., Vlimant, J.-R.: Graph Neural Networks in Particle Physics (2020) https: //doi.org/10.1088/2632-2153/abbf9a arXiv:2007.13681 [hep-ex] |
|---------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [137] | Finke, T., Kr¨mer, a M., Morandini, A., M¨ck, u A., Oleksiyuk, I.: Autoencoders for unsupervised anomaly detection in high energy physics. JHEP 06 , 161 (2021) https://doi.org/10.1007/JHEP06(2021)161 arXiv:2104.09051 [hep-ph] |
| [138] | Qu, H., Li, C., Qian, S.: Particle transformer for jet tagging. ArXiv abs/2202.03772 (2022) |
| [139] | Pearkes, J., Fedorko, W., Lister, A., Gay, C.: Jet Constituents for Deep Neural Network Based Top Quark Tagging (2017) arXiv:1704.02124 [hep-ex] |
| [140] | Performance of Top Quark and W Boson Tagging in Run 2 with ATLAS (2017) |
| [141] | Butter, A., Kasieczka, G., Plehn, T., Russell, M.: Deep-learned Top Tagging with a Lorentz Layer. SciPost Phys. 5 (3), 028 (2018) https://doi.org/10.21468/SciPostPhys.5.3.028 arXiv:1707.08966 [hep- ph] |
| [142] | McCulloch, W.S., Pitts, W.: A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics 5 , 115-133 (1943) https://doi.org/10.1007/BF02478259 |
| [143] | Elman, J.L.: Finding Structure in Time. Cognitive Science 14 (2), 179-211 (1990) https://doi.org/10. 1207/s15516709cog1402 1 |
| [144] | Rumelhart, D.E., McClelland, J.L.: Learning Internal Representations by Error Propagation, pp. 318- 362. MIT Press, ??? (1987). https://ieeexplore.ieee.org/document/6302929 |
| [145] | Jordan, M.I.: Serial order: a parallel distributed processing approach. technical report, june 1985-march 1986 (1986) |
| [146] | Pascanu, R., Mikolov, T., Bengio, Y.: On the difficulty of training Recurrent Neural Networks. arXiv e-prints, 1211-5063 (2012) https://doi.org/10.48550/arXiv.1211.5063 arXiv:1211.5063 [cs.LG] |
| [147] | Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9 (8), 1735-1780 (1997) https://doi.org/10.1162/neco.1997.9.8.1735 |
| [148] | Egan, S., Fedorko, W., Lister, A., Pearkes, J., Gay, C.: Long Short-Term Memory (LSTM) networks with jet constituents for boosted top tagging at the LHC (2017) arXiv:1711.09059 [hep-ex] |
| [149] | Baldi, P., Sadowski, P., Whiteson, D.: Searching for Exotic Particles in High-Energy Physics with Deep Learning. Nature Commun. 5 , 4308 (2014) https://doi.org/10.1038/ncomms5308 arXiv:1402.4735 [hep-ph] |
| [150] | Gu, J., Wang, Z., Kuen, J., Ma, L., Shahroudy, A., Shuai, B., Liu, T., Wang, X., Wang, L., Wang, G., Cai, J., Chen, T.: Recent Advances in Convolutional Neural Networks. arXiv e-prints, 1512-07108 (2015) https://doi.org/10.48550/arXiv.1512.07108 arXiv:1512.07108 [cs.CV] |
| [151] | Cogan, J., Kagan, M., Strauss, E., Schwarztman, A.: Jet-Images: Computer Vision Inspired Techniques for Jet Tagging. JHEP 02 , 118 (2015) https://doi.org/10.1007/JHEP02(2015)118 arXiv:1407.5675 [hep-ph] |
| [152] | Kasieczka, G., Plehn, T., Russell, M., Schell, T.: Deep-learning Top Taggers or The End of QCD? JHEP 05 , 006 (2017) https://doi.org/10.1007/JHEP05(2017)006 arXiv:1701.08784 [hep-ph] |
| [153] | Macaluso, S., Shih, D.: Pulling Out All the Tops with Computer Vision and Deep Learning. JHEP 10 , 121 (2018) https://doi.org/10.1007/JHEP10(2018)121 arXiv:1803.00107 [hep-ph] |
| [154] | Choi, S., Lee, S.J., Perelstein, M.: Infrared Safety of a Neural-Net Top Tagging Algorithm. JHEP 02 , 132 (2019) https://doi.org/10.1007/JHEP02(2019)132 arXiv:1806.01263 [hep-ph] |
|---------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [155] | Bhattacharya, S., Guchait, M., H. Vijay, A.: Boosted Top Quark Tagging and Polarization 2 Mea- surement using Machine Learning. PoS ICHEP2020 , 318 (2021) https://doi.org/10.22323/1.390. 0318 |
| [156] | Gong, S., Meng, Q., Zhang, J., Qu, H., Li, C., Qian, S., Du, W., Ma, Z.-M., Liu, T.-Y.: An efficient Lorentz equivariant graph neural network for jet tagging. JHEP 07 , 030 (2022) https://doi.org/10. 1007/JHEP07(2022)030 arXiv:2201.08187 [hep-ph] |
| [157] | Konar, P., Ngairangbam, V.S., Spannowsky, M.: Hypergraphs in LHC phenomenology - the next frontier of IRC-safe feature extraction. JHEP 01 , 113 (2024) https://doi.org/10.1007/JHEP01(2024) 113 arXiv:2309.17351 [hep-ph] |
| [158] | Grilli, E., Menna, F., Remondino, F.: a Review of Point Clouds Segmentation and Classification Algorithms. ISPRS - International Archives of the Photogrammetry, Remote Sensing and Spatial Infor- mation Sciences 42W3 , 339-344 (2017) https://doi.org/10.5194/isprs-archives-XLII-2-W3-339-2017 |
| [159] | Qi, C.R., Su, H., Mo, K., Guibas, L.J.: PointNet: Deep Learning on Point Sets for 3D Classifica- tion and Segmentation. arXiv e-prints, 1612-00593 (2016) https://doi.org/10.48550/arXiv.1612.00593 arXiv:1612.00593 [cs.CV] |
| [160] | Komiske, P.T., Metodiev, E.M., Thaler, J.: Energy flow polynomials: A complete linear basis for jet substructure. JHEP 04 , 013 (2018) https://doi.org/10.1007/JHEP04(2018)013 arXiv:1712.07124 [hep-ph] |
| [161] | Butter, A., Kasieczka, G., Plehn, T., Russell, M.: Deep-learned Top Tagging with a Lorentz Layer. SciPost Phys. 5 , 028 (2018) https://doi.org/10.21468/SciPostPhys.5.3.028 |
| [162] | Furuichi, A., Lim, S.H., Nojiri, M.M.: Jet Classification Using High-Level Features from Anatomy of Top Jets (2023) arXiv:2312.11760 [hep-ph] |
| [163] | Sahu, R., Ghosh, K.: ML-Based Top Taggers: Performance, Uncertainty and Impact of Tower &Tracker Data Integration (2023) arXiv:2309.01568 [hep-ph] |
| [164] | Butter, A., et al. : The Machine Learning landscape of top taggers. SciPost Phys. 7 , 014 (2019) https: //doi.org/10.21468/SciPostPhys.7.1.014 arXiv:1902.09914 [hep-ph] |
| [165] | Yang, S., Yan, Q.-S.: Searching for Heavy Charged Higgs Boson with Jet Substructure at the LHC. JHEP 02 , 074 (2012) https://doi.org/10.1007/JHEP02(2012)074 arXiv:1111.4530 [hep-ph] |
| [166] | Pedersen, K., Sullivan, Z.: Probing the two Higgs doublet wedge region with charged Higgs boson decays to boosted jets. Phys. Rev. D 95 (3), 035037 (2017) https://doi.org/10.1103/PhysRevD.95. 035037 arXiv:1612.03978 [hep-ph] |
| [167] | Guchait, M., Vijay, A.H.: Probing Heavy Charged Higgs Boson at the LHC. Phys. Rev. D 98 (11), 115028 (2018) https://doi.org/10.1103/PhysRevD.98.115028 arXiv:1806.01317 [hep-ph] |
| [168] | Chakraborty, A., Dasmahapatra, S., Day-Hall, H., Ford, B., Jain, S., Moretti, S.: Fat b-jet analyses using old and new clustering algorithms in new Higgs boson searches at the LHC. Eur. Phys. J. C 83 (4), 347 (2023) https://doi.org/10.1140/epjc/s10052-023-11537-4 arXiv:2303.05189 [hep-ph] |
| [169] | Kang, Z., Li, J., Zhang, M.: Uncover Compressed Supersymmetry via Boosted Bosons from the Heavier Stop/Sbottom. Eur. Phys. J. C 77 (6), 371 (2017) https://doi.org/10.1140/epjc/s10052-017-4951-1 arXiv:1703.08911 [hep-ph] |
| [170] | Goncalves, D., Sakurai, K., Takeuchi, M.: Tagging a monotop signature in natural SUSY. Phys. Rev. D 95 (1), 015030 (2017) https://doi.org/10.1103/PhysRevD.95.015030 arXiv:1610.06179 [hep-ph] |
|---------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [171] | Plehn, T., Spannowsky, M., Takeuchi, M., Zerwas, D.: Stop Reconstruction with Tagged Tops. JHEP 10 , 078 (2010) https://doi.org/10.1007/JHEP10(2010)078 arXiv:1006.2833 [hep-ph] |
| [172] | Chakraborty, A., Ghosh, D.K., Ghosh, D., Sengupta, D.: Stop and sbottom search using dileptonic M T 2 variable and boosted top technique at the LHC. JHEP 10 , 122 (2013) https://doi.org/10.1007/ JHEP10(2013)122 arXiv:1303.5776 [hep-ph] |
| [173] | Bhattacherjee, B., Chakraborty, A.: Study of the baryonic R-parity violating MSSM using the jet substructure technique at the 14 TeV LHC. Phys. Rev. D 89 (11), 115016 (2014) https://doi.org/10. 1103/PhysRevD.89.115016 arXiv:1311.5785 [hep-ph] |
| [174] | Bardhan, D., Chakraborty, A., Choudhury, D., Ghosh, D.K., Maity, M.: Search for bottom squarks in the baryon-number violating MSSM. Phys. Rev. D 96 (3), 035024 (2017) https://doi.org/10.1103/ PhysRevD.96.035024 arXiv:1611.03846 [hep-ph] |
| [175] | Bhaskar, A., Mandal, T., Mitra, S.: Boosting vector leptoquark searches with boosted tops. Phys. Rev. D 101 (11), 115015 (2020) https://doi.org/10.1103/PhysRevD.101.115015 arXiv:2004.01096 [hep-ph] |
| [176] | Bai, Y., Berger, J., Osborne, J., Stefanek, B.A.: Search for Heavy Stops with Merged Top-Jets. Phys. Rev. D 96 (9), 095035 (2017) https://doi.org/10.1103/PhysRevD.96.095035 arXiv:1611.05046 [hep-ph] |
| [177] | Banerjee, S., Englert, C., Gupta, R.S., Spannowsky, M.: Probing Electroweak Precision Physics via boosted Higgs-strahlung at the LHC. Phys. Rev. D 98 (9), 095012 (2018) https://doi.org/10.1103/ PhysRevD.98.095012 arXiv:1807.01796 [hep-ph] |
| [178] | Khachatryan, V., et al. : Search for supersymmetry in the all-hadronic final state using top quark tagging in pp collisions at √ s = 13 TeV. Phys. Rev. D 96 (1), 012004 (2017) https://doi.org/10.1103/ PhysRevD.96.012004 arXiv:1701.01954 [hep-ex] |
| [179] | Tumasyan, A., et al. : Search for new heavy resonances decaying to WW, WZ, ZZ, WH, or ZH boson pairs in the all-jets final state in proton-proton collisions at s=13TeV. Phys. Lett. B 844 , 137813 (2023) https://doi.org/10.1016/j.physletb.2023.137813 arXiv:2210.00043 [hep-ex] |
| [180] | Tumasyan, A., et al. : Search for electroweak production of charginos and neutralinos at s=13TeV in final states containing hadronic decays of WW, WZ, or WH and missing transverse momentum. Phys. Lett. B 842 , 137460 (2023) https://doi.org/10.1016/j.physletb.2022.137460 arXiv:2205.09597 [hep-ex] |
| [181] | Tumasyan, A., et al. : Search for light Higgs bosons from supersymmetric cascade decays in pp collisions at √ s = 13 TeV. Eur. Phys. J. C 83 (7), 571 (2023) https://doi.org/10.1140/epjc/s10052-023-11581-0 arXiv:2204.13532 [hep-ex] |
| [182] | Tumasyan, A., et al. : Search for a massive scalar resonance decaying to a light scalar and a Higgs boson in the four b quarks final state with boosted topology. Phys. Lett. B 842 , 137392 (2023) https: //doi.org/10.1016/j.physletb.2022.137392 arXiv:2204.12413 [hep-ex] |
| [183] | Tumasyan, A., et al. : Search for new particles in an extended Higgs sector with four b quarks in the final state at s=13TeV. Phys. Lett. B 835 , 137566 (2022) https://doi.org/10.1016/j.physletb.2022.137566 arXiv:2203.00480 [hep-ex] |
| [184] | Tumasyan, A., et al. : Search for a W' boson decaying to a vector-like quark and a top or bottom quark in the all-jets final state at √ s =13 TeV. JHEP 09 , 088 (2022) https://doi.org/10.1007/JHEP09(2022)088 arXiv:2202.12988 [hep-ex] |
| [185] | Aad, G., et al. : Search for tt resonances in fully hadronic final states in pp collisions at s = 13 TeV with the ATLAS detector. JHEP 10 , 061 (2020) https://doi.org/10.1007/JHEP10(2020)061 arXiv:2005.05138 [hep-ex] |
|---------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [186] | Aad, G., et al. : Search for top-philic heavy resonances in pp collisions at √ s = 13 TeV with the ATLAS detector. Eur. Phys. J. C 84 (2), 157 (2024) https://doi.org/10.1140/epjc/s10052-023-12318-9 arXiv:2304.01678 [hep-ex] |
| [187] | Aad, G., et al. : Anomaly detection search for new resonances decaying into a Higgs boson and a generic new particle X in hadronic final states using √ s = 13 TeV pp collisions with the ATLAS detector. Phys. Rev. D 108 , 052009 (2023) https://doi.org/10.1103/PhysRevD.108.052009 arXiv:2306.03637 [hep-ex] |
| [188] | Aad, G., et al. : Search for single vector-like B quark production and decay via B → bH( bb ) in pp collisions at √ s = 13 TeV with the ATLAS detector. JHEP 11 , 168 (2023) https://doi.org/10.1007/ JHEP11(2023)168 arXiv:2308.02595 [hep-ex] |
| [189] | Nachman, B., et al. : Jets and Jet Substructure at Future Colliders. Front. in Phys. 10 , 897719 (2022) https://doi.org/10.3389/fphy.2022.897719 arXiv:2203.07462 [hep-ph] |
| [190] | Chakraborty, A., Lim, S.H., Nojiri, M.M.: Interpretable deep learning for two-prong jet classification with jet spectra. JHEP 07 , 135 (2019) https://doi.org/10.1007/JHEP07(2019)135 arXiv:1904.02092 [hep-ph] |
| [191] | Rozemberczki, B., Watson, L., Bayer, P., Yang, H.-T., Kiss, O., Nilsson, S., Sarkar, R.: The Shapley Value in Machine Learning. arXiv e-prints, 2202-05594 (2022) https://doi.org/10.48550/arXiv.2202. 05594 arXiv:2202.05594 [cs.LG] |
| [192] | Roth, A.E.: The Shapley Value: Essays in Honor of Lloyd S. Shapley. Cambridge University Press, ??? (1988). https://books.google.co.in/books?id=JK7MKu2A9cIC |
| [193] | Bhattacherjee, B., Bose, C., Chakraborty, A., Sengupta, R.: Boosted top tagging and its interpretation using Shapley values (2022) arXiv:2212.11606 [hep-ph] |
| [194] | Chowdhury, S., Chakraborty, A., Dutta, S.: Boosted Top Tagging through Flavour-violating interac- tions at the LHC (2023) arXiv:2310.10763 [hep-ph] |
| [195] | Khot, A., Neubauer, M.S., Roy, A.: A detailed study of interpretability of deep neural network based top taggers. Mach. Learn. Sci. Tech. 4 (3), 035003 (2023) https://doi.org/10.1088/2632-2153/ace0a1 arXiv:2210.04371 [hep-ex] |
| [196] | Agarwal, G., Hay, L., Iashvili, I., Mannix, B., McLean, C., Morris, M., Rappoccio, S., Schubert, U.: Explainable AI for ML jet taggers using expert variables and layerwise relevance propagation. JHEP 05 , 208 (2021) https://doi.org/10.1007/JHEP05(2021)208 arXiv:2011.13466 [physics.data-an] |
| [197] | Mokhtar, F., Kansal, R., Diaz, D., Duarte, J., Pata, J., Pierini, M., Vlimant, J.-R.: Explaining machine- learned particle-flow reconstruction. In: 35th Conference on Neural Information Processing Systems (2021) |
| [198] | Das, R., Kasieczka, G., Shih, D.: Feature selection with distance correlation. Phys. Rev. D 109 (5), 054009 (2024) https://doi.org/10.1103/PhysRevD.109.054009 arXiv:2212.00046 [hep-ph] |
| [199] | Bogatskiy, A., Hoffman, T., Miller, D.W., Offermann, J.T., Liu, X.: Explainable Equivariant Neural Networks for Particle Physics: PELICAN (2023) arXiv:2307.16506 [hep-ph] |
| [200] | Ngairangbam, V.S., Spannowsky, M.: Interpretable deep learning models for the inference and classification of LHC data (2023) arXiv:2312.12330 [hep-ph] | | 10.1140/epjs/s11734-024-01256-6 | [
"Camellia Bose",
"Amit Chakraborty",
"Shreecheta Chowdhury",
"Saunak Dutta"
] | 2024-08-02T09:31:28+00:00 | 2024-08-02T09:31:28+00:00 | [
"hep-ph",
"hep-ex"
] | Interplay of Traditional Methods and Machine Learning Algorithms for Tagging Boosted Objects | Interest in deep learning in collider physics has been growing in recent
years, specifically in applying these methods in jet classification, anomaly
detection, particle identification etc. Among those, jet classification using
neural networks is one of the well-established areas. In this review, we
discuss different tagging frameworks available to tag boosted objects,
especially boosted Higgs boson and top quark, at the Large Hadron Collider
(LHC). Our aim is to study the interplay of traditional jet substructure based
methods with the state-of-the-art machine learning ones. In this methodology,
we would gain some interpretability of those machine learning methods, and
which in turn helps to propose hybrid taggers relevant for tagging of those
boosted objects belonging to both Standard Model (SM) and physics beyond the
SM. |
2408.01139v2 | ## Interpreting Global Perturbation Robustness of Image Models using Axiomatic Spectral Importance Decomposition
Róisín Luo (Jiaolin Luo)
[email protected]
James McDermott
[email protected]
Colm O'Riordan
[email protected]
SFI Centre for Research Training in Artificial Intelligence School of Computer Science, University of Galway Galway, H91 TK33, Ireland
Reviewed on OpenReview: https: // openreview. net/ forum? id= uQYomAuo7M
## Abstract
Perturbation robustness evaluates the vulnerabilities of models, arising from a variety of perturbations, such as data corruptions and adversarial attacks. Understanding the mechanisms of perturbation robustness is critical for global interpretability. We present a model-agnostic, global mechanistic interpretability method to interpret the perturbation robustness of image models. This research is motivated by two key aspects. First, previous global interpretability works, in tandem with robustness benchmarks, e.g. mean corruption error (mCE), are not designed to directly interpret the mechanisms of perturbation robustness within image models. Second, we notice that the spectral signal-to-noise ratios (SNR) of perturbed natural images exponentially decay over the frequency. This power-law-like decay implies that: Low-frequency signals are generally more robust than high-frequency signals - yet high classification accuracy can not be achieved by low-frequency signals alone. By applying Shapley value theory, our method axiomatically quantifies the predictive powers of robust features and non-robust features within an information theory framework. Our method, dubbed as I-ASIDE ( I mage A xiomatic S pectral I mportance D ecomposition E xplanation), provides a unique insight into model robustness mechanisms. We conduct extensive experiments over a variety of vision models pre-trained on ImageNet, including both convolutional neural networks ( e.g. AlexNet , VGG GoogLeNet/Inception-v1 , , Inception-v3 , ResNet , SqueezeNet , RegNet , MnasNet , MobileNet , EfficientNet , etc.) and vision transformers ( e.g. ViT , Swin Transformer , and MaxViT ), to show that I-ASIDE can not only measure the perturbation robustness but also provide interpretations of its mechanisms.
## 1 Introduction
Image modeling with deep neural networks has achieved great success (Li et al., 2021; Khan et al., 2022; Han et al., 2022). Yet, deep neural networks are known to be vulnerable to perturbations. For example, the perturbations may arise from corruptions and adversarial attacks (Goodfellow et al., 2014; Hendrycks & Dietterich, 2019; Szegedy et al., 2013), etc. Perturbation robustness, henceforth referred to as robustness, characterizes a crucial intrinsic property of models (Hendrycks & Dietterich, 2019; Bai et al., 2021; Goodfellow et al., 2014; Silva & Najafirad, 2020).
Robustness mechanisms refer to the mechanisms which lead to robustness in models. The study of robustness mechanisms aims to answer the question ' why some models are more robust than others ' (Lipton, 2018; Zhang et al., 2021; Bereska & Gavves, 2024). The causes within this question can arise from multifarious
The 2D spectrum is mapped into 1D radial spectrum and further divided into M bands which are denoted from I 0 to I M ´ 1 .
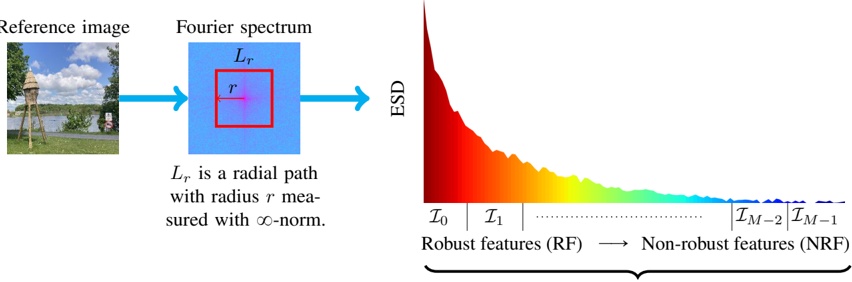
Figure 1: Power-law-like energy spectral density (ESD) distribution of natural images over the frequency. The signal spectrum is divided into M bands (from I 0 to I M ´ 1 ). Each spectral band is a robustness band.
aspects, including architecture designs (Zhou et al., 2022), data annotations, training methods (Pang et al., 2020), inferences, etc. For example, noisy labels can arise from data annotations (Frénay & Verleysen, 2013; Wei et al., 2021); adversarial attacks often take place in inferences. This research provides a unified view regarding the mechanisms of image model robustness on spectra. We only focus on global interpretation of robustness mechanisms of image models. Our method is primarily motivated by two key aspects, as detailed below.
Despite the substantial advances in previous global interpretability works (Covert et al., 2020; Kolek et al., 2022), in tandem with the wide adoption of empirical robustness benchmarks (Hendrycks & Dietterich, 2019; Zheng et al., 2016; Zhang et al., 2021), these methods are not designed to provide global interpretations regarding model robustness. For example, SAGE (Covert et al., 2020), a global interpretability work, can attribute the decisive pixel features in decision-makings. Yet, the importance of decisive pixel features fails to interpret the global robustness. Although the robustness of image models can be quantified by mean corruption errors (mCE) (Hendrycks & Dietterich, 2019) or the distances in feature spaces between clean and perturbed image pairs (Zheng et al., 2016; Zhang et al., 2021), these scalar metrics often fall short in interpreting the underlying 'why' question. This gap prompts us to provide global mechanistic interpretations of perturbation robustness.
Motivation also arises from the robustness characterization of the spectral signals within natural images. Images can be represented as spectral signals (Körner, 2022; Sherman & Butler, 2007). The signal-to-noise ratios (SNR) (Sherman & Butler, 2007) of spectral signals can be used to characterize the signal robustness with respect to perturbations. Our later empirical study, as illustrated in Figure 2, suggests that the spectral SNRs of perturbed natural images decay over the frequency with a power-law-like distribution. We refer to the spectral SNR as the ratio of the point-wise energy spectral density (ESD) (Stoica et al., 2005) of spectral signal to noise ( i.e. perturbation):
$$S N R ( r ) \coloneqq \frac { E S D _ { r } ( x ) } { E S D _ { r } ( \Delta x ) } \quad \quad \quad$$
where r is a radial frequency point, x is an image, ∆ x is the perturbation, ESD r p¨q gives the point-wise energy density at r . The ESD r p¨q is defined as:
$$E S D _ { r } ( x ) \coloneqq \frac { 1 } { | L _ { r } | } \cdot \sum _ { ( u, v ) \in L _ { r$$
where L r denotes a circle as illustrated in Figure 1, | L r | denotes the circumference of L r , and F p x q denotes the 2D Discrete Fourier Transform (DFT) of x . Readers can further refer to more details in Appendix B.1.
Why do the spectral SNRs of some corruptions and adversarial attacks exhibit a power-law-like decay over the frequency? We surmise that the ESDs of many perturbations are often not power-law-like, while the ESDs of natural images are power-law-like empirically, as shown in Figure 1. For example, the spatial perturbation drawn from N p 0 , σ 2 q ( i.e. white noise) has a constant ESD: ESD r p ∆ x q ' σ 2 . In Figure 2, we characterize the spectral SNR distributions of perturbed images. We set the energy of perturbations to 10% of the energy of the clean image for a fair comparison. The perturbation sources include corruptions (Hendrycks & Dietterich, 2019) and adversarial attacks (Szegedy et al., 2013; Tsipras et al., 2018). We notice that the SNR distributions are also power-law-like over the frequency. We refer to spectral signals as spectral features or simply as features if without ambiguity. This power-law-like SNR decay suggests an empirical feature robustness prior: Low-frequency features are robust features (RFs) while high-frequency features are non-robust features (NRFs) . The experiments in Figure 3 demonstrate that models trained with low-frequency signals exhibit higher robustness compared to the models trained with high-frequency signals. This also echoes with our earlier claim 'low-frequency signals are generally more robust than high-frequency signals - yet high classification accuracy can not be achieved by low-frequency signals alone'.
Contributions . By applying the Shapley value theory framework (Shapley, 1997; Roth, 1988; Hart, 1989), we are able to assess the predictive powers (Zheng & Agresti, 2000) of RFs and NRFs. Further leveraging a specifically designed characteristic function of the Shapley value theory framework, the predictive powers are assessed on the basis of their information gains. I-ASIDE uses information theory within the Shapley value theory framework, for interpreting robustness mechanisms, as detailed in Section 3. We claim our major contributions as:
- · We propose a model-agnostic, global interpretability method, for interpreting robustness mechanisms of image models, through the lens of the predictive powers of robust features and non-robust features;
- • We analyze the robustness mechanisms of image models within information theory on spectra;
- · We showcase a case study that I-ASIDE has the potential to interpret how supervision noise levels affect model robustness.
## 2 Notations
Þ
Dataset and annotation . We use a tuple x X Y , y to denote an image classification dataset, where X is the image set and Y is the label set. We use | Y | to denote the number of classes ( i.e. the cardinality of set Y ). The annotation task of image classification datasets is to assign each image with a discrete class probability distribution. We use P y x p | q to denote the ground-truth probability that an image x is assigned as a class y . We use P x p q to denote the probability of x in set X . We use P y p q to denote the probability of y in set Y . In class-balanced datasets, P y p q ' 1 | Y | .
Image classifier . The primary task of an image classifier is to predict the probability distributions over discrete classes for given images. We use Q y x θ p | ; q : p x, y q Ñ r 0 1 , s to denote a classifier in the form of conditional probability. The Q predicts the probability that an image x is of class y . The θ are the parameters. For brevity, we ignore the parameter θ . For example, we denote Q y x θ p | ; q as Q y x p | q .
## 3 Method
High-level overview . We apply Shapley value theory for axiomatically assigning credits to spectral bands. Within this framework, the specially devised characteristic function measures the information gains of spectral bands. I-ASIDE interprets robustness mechanisms using this axiomatic framework with the information theory.
Problem formulation . Quantifying the predictive powers of features can be viewed as a value decomposition problem. In this research, the value is the information quantities that the features contribute to decisions.
Figure 2: Spectral SNR characterization with multiple corruptions and adversarial attacks. The corruptions include: white noise, Poisson noise, Salt-and-pepper noise, and Gaussian blur. The adversarial attacks include: FGSM (Goodfellow et al., 2014), PGD (Madry et al., 2017), SparseFool (Modas et al., 2019) and Pixel (Pomponi et al., 2022). We set the perturbation energy to 10% of the energy of the reference image. The results are shown in decibels (dB) for better visualization. The dB below zero indicates that the perturbations overwhelm the spectral features.
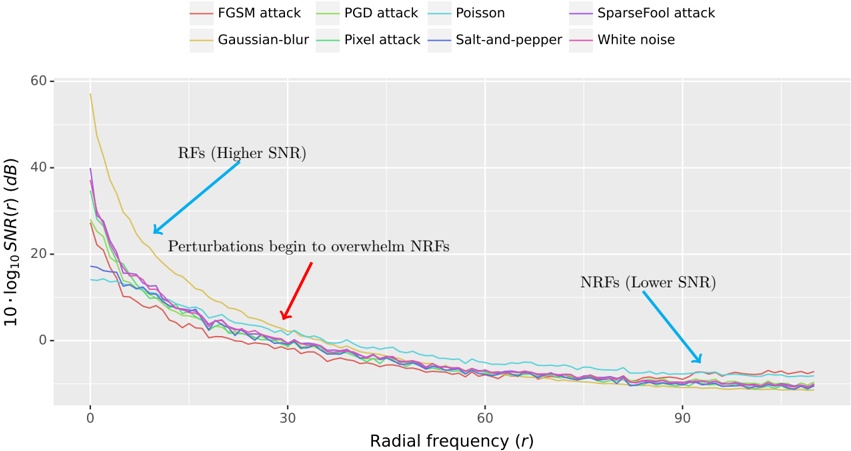
Specifically, the value is in the form of the log-likelihood expectation of predictions ( i.e. the negative crossentropy loss). The value decomposition aims to assign each robustness band a predictive power such that: (1) The sums of the predictive powers are equal to the value , and (2) the assigned predictive powers should reflect their importance in the decisions. In the coalitional game theory, this decomposition scheme is known as an axiomatic fairness division problem (Roth, 1988; Hart, 1989; Winter, 2002; Klamler, 2010; Han & Poor, 2009). The fairness division must satisfy four axioms: efficiency , symmetry , linearity and dummy player (Roth, 1988). We refer to the axiomatic fairness division as axiomatic decomposition . Of the scheme, the axioms guarantee uniqueness and fairness (Aumann & Maschler, 1985; Yaari & Bar-Hillel, 1984; Aumann & Dombb, 2015; Hart, 1989; Roth, 1988). The property fairness refers to the principle ' equal treatment of equals ' (Yokote et al., 2019; Navarro, 2019). Shapley value theory is the unique solution satisfying the above axioms. However, the theory merely provides an abstract framework. To employ, we have to instantiate two abstracts: (1) players and coalitions, and (2) characteristic function.
Abstract (1): players and coalitions . The spectral bands are dubbed as spectral players . A subset of the spectral player set is dubbed as a spectral coalition . The details are as shown in Section 3.1. The M spectral players can forge 2 M spectral coalitions. We represent the presences and absences of the spectral players as the pass-bands and stop-bands in a multi-band-pass digital signal filter (Oppenheim, 1978; Roberts & Mullis, 1987; Pei & Tseng, 1998), as shown in Section 3.2.
Abstract (2): characteristic function . The characteristic function is designed to measure the contributions that the coalitions contribute in decisions. The contributions of the 2 M coalitions are then combined to compute their marginal contributions in decisions. We specially design the characteristic function, as shown in Section 3.3 and Appendix B.3, to measure the information gains. Figure 4 shows the framework of applying the Shapley value theory. Figure 5 shows the block diagram of the spectral coalition filtering. Figure 6 shows an example of 2 M spectral coalitions.
| | training frequency range | training frequency range | training frequency range |
|---------------------------------------|----------------------------|----------------------------|----------------------------|
| | full-freq r 0 , 1 s | low-freq r 0 , 0 . 3 s | high-freq r 0 . 3 , 1 s |
| train acc. | 98 . 05% | 97.13 % | 96 . 18% |
| val. acc. w/ clean generalization gap | 96 . 10% | 98.80 % | 56 . 70% |
| | ´ 1 . 95 | ` 1 . 67 | ´ 39 . 48 Ó |
| val. acc. w/ Gaussian | Ó 92 . 60% | Ò 98.00 % | 26 . 70% |
| generalization gap | 5 . 45 | 0 . 87 | 69 . 48 |
Figure 3: Understanding the role of spectral signals. We train a resnet18 on three datasets derived from STL10 (Coates et al., 2011): r 0 1 , s contains full-frequency signals; r 0 0 3 , . s only contains low-frequency signals with a cut-off frequency by 0 3; and . r 0 3 . , 1 s only contains the high-frequency signal with a cut-off frequency by 0 3. . In the derived datasets, the filtered high or low frequency signals are randomly replaced by the high or low frequency signals sampled from the full-frequency train set. We visualize the embeddings in the left figure with respect to clean samples and perturbed samples with Gaussian noise ( σ ' 0 1). . The samples are from the validation set. The accuracy on both the train and validation sets is provided in the right table. We also provide generalization gaps, measured by the differences between validation accuracy and train accuracy ( i.e. acc val ´ acc train ). We have noted in that: (1) both high-frequency and low-frequency signals contain sufficient discriminative information to achieve high training accuracy; (2) high-frequency signals alone are not robust signals because they fail to generalize well from train to validation; (3) overall, low-frequency signals are more robust signals because models trained alone with them generalize better and exhibit higher robustness. We summarize these empirical observations into Assumption 3.8.
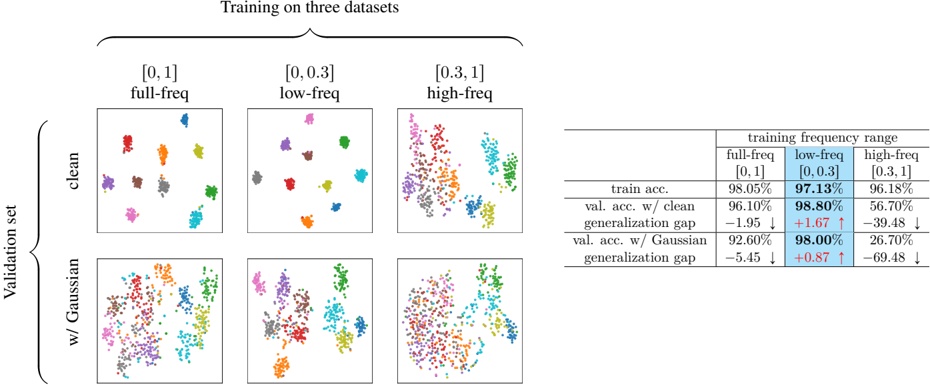
We organize the implementation details of instantiating the aforementioned two abstracts from three aspects: (1) formulating a spectral coalitional game, (2) the implementation of spectral coalitions and (3) the design of the characteristic function.
## 3.1 Spectral coalitional game
Spectral player . We use I i (where i P r M s : ' t 0 1 , , ¨ ¨ ¨ , M ´ u 1 ) to denote the i -th spectral player. The I 0 contains the most robust features and the I M ´ 1 contains the most non-robust features. The M spectral players constitute a player set I : ' t I i u M ´ 1 i ' 0 . Figure 15 in Appendix C.1 shows two partition schemes to partition spectral bands ( /lscript 8 and /lscript 2 ). We empirically choose /lscript 8 .
Þ
Spectral coalition . A subset r I Ď I is referred to as the spectral coalition . The player set I is often referred to as the grand coalition .
r Shapley value . A spectral coalitional game p I , v q is defined on a spectral player set I equipped with a characteristic function v . The weighted marginal contribution of a spectral player I i over all possible coalitions is referred to as the Shapley value of the spectral player I i . We use ψ i p I , v q to represent the Shapley value of
Characteristic function . A characteristic function v p r I q : r I Ñ R measures the contribution for a given coalition and satisfies v pHq ' 0. In this research, the contribution of r I is measured in the form of the log-likelihood expectation of the predictions by the Q , in which the input images only contain the signals present in the r I . We show that this design of v theoretically measures how much information the Q uses from the features in the I for decisions.
Þ
P
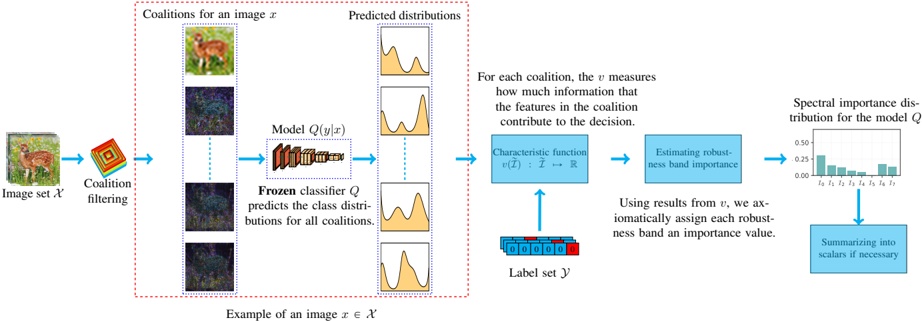
X
Figure 4: Framework of applying Shapley value theory. Spectral coalition filtering creates spectral coalitions over X . Each coalition contains a unique combination of spectral signals, in which some spectral bands are present and others are absent. The coalitions are fed into a classifier Q . For each coalition, Q outputs the predictions. The characteristic function v then uses the predictions to estimate the contributions of the features present in the coalitions. The results from v are combined to compute the marginal contributions of spectral bands i.e. the spectral importance distribution of Q .
the player I i . The Shapley value ψ i p I , v q is uniquely given by:
$$\psi _ { i } ( \mathcal { I }, v ) = \sum _ { \tilde { I } \subseteq \mathcal { I } \overline { \mathcal {$$
where 1 M ` M ´ 1 | ˜ I | ˘ ´ 1 gives the weight of the player I i presenting in the coalition ˜ . I
Spectral importance distribution (SID) . We use Ψ p v q : ' p ψ i q i Pr M s P R M to denote the collection of ψ i p I , v q over all players. We min-max normalize Ψ p v q by taking Ψ ¯ p v q ' Ψ p v q´ minΨ p v q || Ψ p v q´ minΨ p v q|| 1 . The reason for normalizing the SIDs is that we want to scalarize the SIDs for numerical comparisons. The ¯ Ψ p v q is referred to as spectral importance distribution . Figure 7 shows examples of the spectral importance distributions of trained and un-trained models.
Þ
Spectral robustness score (SRS) . We can also summarize spectral importance distributions into scalar values. We refer to the summarized scalar values as spectral robustness scores . We use S v p q : v Ñr 0 1 , s to denote the summarizing function.
## 3.2 Spectral coalition filtering
We represent the presences and absences of the spectral players through the signal pass-bands and stop-bands using a multi-band-pass digital signal filtering (Oppenheim, 1978; Pei & Tseng, 1998; Steiglitz, 2020), as shown in Figure 5. For example, the example spectral coalition t I 0 , I 2 u signifies the signals present only in I 0 and I 2 . With the spectral coalition filtering, we are able to evaluate the contributions of the combinations of various spectral features. Figure 6 shows an example of 2 M spectral coalitions.
Þ
$$\text{mm-wise} \ e n n e u a s. \\ \mathbb { T } ( \widetilde { \mathcal { I } } ) ( m, n ) = \begin{$$
To implement the presences and absences of spectral signals, we define a mask map ❚ p r I q : r I Ñt 0 1 , u M N ˆ on 2D spectrum, where r I is a spectral coalition and M ˆ N denotes 2D image dimensions. The mask map is point-wisely defined as:
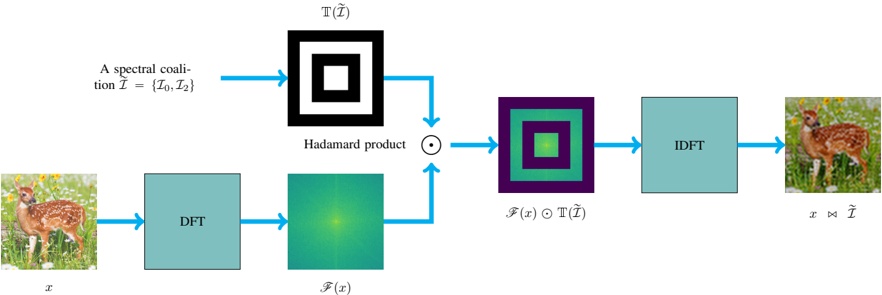
p
q
Figure 5: Spectral coalition filtering. In this example, the mask map ❚ p r I q ( i.e. transfer function) only allows to pass the signals present in the spectral coalition t I 0 , I 2 u . The M is 4 and the absences are assigned to zeros. The images after spectral coalition filtering ( x ' r I ) are then fed into frozen classifiers to assess the contributions of spectral coalitions. The binary operation notation ' denotes coalition filtering given by Definition 3.1. The notation d denotes Hadamard product.
where p m,n q P r M s ˆ r N s . In the digital signal processing literature, this mask map is known as a transfer function (Steiglitz, 2020). In the 2D mask map, the frequency points are '1' in pass-bands (presences) and '0' in stop-bands (absences). The process of spectral coalition filtering with the mask map for a given spectral coalition I is shown as in Figure 5.
r We apply the transfer function ❚ p r I q on the spectra of images with element-wise product ( i.e. Hadamard product (Horn, 1990; Horadam, 2012)). Let F be the Discrete Fourier transform (DFT) operator and F ´ 1 be the inverse DFT (IDFT) operator (Tan & Jiang, 2018). Readers can further refer to Appendix B.1.
Definition 3.1 (Spectral coalition filtering) . We define a binary operator ' ' ' to represent the signal filtering by:
$$x \rtimes \widetilde { \mathcal { I } } \coloneqq \mathcal { F } ^ { - 1 } \left [ \underbrace { \mathcal { F } ( x$$
Remark 3.2 (Absence baseline) . Formally, in the context of attribution analysis, the term 'baseline' defines the absence assignments of players (Sundararajan et al., 2017; Shrikumar et al., 2017; Binder et al., 2016). For example, if we use 'zeros' to represent the absence of players, the 'zeros' are dubbed as the 'baseline' in the attribution analysis. We have discussed multiple baselines in Appendix B.2.
where ' d ' denotes Hadamard product ( i.e. element-wise product), ✶ P R M N ˆ denotes an all-ones matrix and b P C M N ˆ represents the assignments of the absences of spectral players. In the context of attribution analysis, b is often referred as the baseline. In our implementation, we empirically set b ' 0 .
Definition 3.3 (Spectral coalition filtering over set) . Accordingly, we define the filtering over a set X as:
$$\mathcal { X } \rtimes \widetilde { \mathcal { I } } \coloneqq \{ x \rtimes \widetilde { \mathcal { I } } | x \in \mathcal { X } \}.$$
## 3.3 Characteristic function design
The characteristic function is needed in order to measure the contributions of the features in r I . We define the characteristic function as the gains of the negative cross-entropy loss values between feature presences and absences.
Figure 6: An example of a complete 2 M spectral coalitions. This example shows 16 spectral coalitions with M ' 4. Each coalition provides various information relevant to decisions. Each image is a coalition. Each coalition contains a unique spectral signal combination. We use binary code to index these coalitions. The '1' in the i -th position indicates the presence of the i -th player. For example, 1001 indicates the presences of two spectral players ( I 0 and I 3 ) in the coalition.

Definition 3.4 (Characteristic function) . The characteristic function v p I q : I Ñ R is defined as:
Þ
where the constant term C : ' E x ∼ X ř y P Y P y x p | q ¨ log Q y x p | ' Hq is used to fulfil v pHq ' 0 . We refer to the C as the Dummy player constant.
$$\text{fint} \ 3. 4 \ ( \text{Characteristic function} ). \ The characteristic function v ( \widetilde { \mathcal { I } } ) \, \cdot \, \widetilde { \mathcal { I } } \mapsto \mathbb { R } \, \text{is defined as} \colon \\ v ( \widetilde { \mathcal { I } } ) \colon = \underset { x \sim \mathcal { X } } { \mathbb { E } } \sum _ { y \in \mathcal { Y } } \left \{ \underbrace { P ( y | x ) \cdot \log Q ( y | x \rtimes \widetilde { \mathcal { I } } ) } { \text{Feature presence} } - \underbrace { P ( y | x ) \cdot \log Q ( y | x \rtimes \widetilde { \mathcal { I } } ) } { \text{Absence baseline} } \right \} \\ = \underset { x \sim \mathcal { X } } { \mathbb { E } } \sum _ { y \in \mathcal { Y } } P ( y | x ) \cdot \log Q ( y | x \rtimes \widetilde { \mathcal { I } } ) - C \\ \ast e \text{ the constant term} \ C \, \colon = \underset { x \sim \mathcal { X } } { \mathbb { E } } \sum _ { y \in \mathcal { Y } } P ( y | x ) \cdot \log Q ( y | x \rtimes \widetilde { \mathcal { I } } ) \, \text{is used to fulfill } v ( \mathcal { \mathcal { I } } ) = 0. \ W e r \, \text{fer to the } C \\. \ \sim \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim}\ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim} \ \text{$\sim}$$
Remark 3.5. If the labels are one-hot, then Equation 7 is simplified into:
and C : ' E x,y ∼ x X Y , y log Q y x p | ' Hq .
$$v ( \widetilde { \mathcal { I } } ) \coloneqq \underset { x, y \sim \langle \mathcal { X }, \mathcal { Y } \rangle } { \mathbb { E } } \log Q ( y | x \rtimes \widetilde { \mathcal { I } } ) - C \\ Q ( y | x \rtimes \emptyset ).$$
Linking to information theory . The relationship between information theory and the characteristic function in the form of negative log-likelihood of Bayes classifiers has been discussed in the literature (Covert et al., 2020; Aas et al., 2021; Lundberg & Lee, 2017). Following on from their discussions, we show that the v in Equation 7 profoundly links to information theory in terms of spectral signals. The maximal information of features relevant to labels in r I is the mutual information I p X ' r I Y , q . A classifier Q can merely utilize a proportion of the information. Theorem 3.6 states an information quantity identity regarding the I p X ' r I Y , q and the v . The term D KL r P || Q s measures the point-wise ( i.e. for an image x ) KL-divergence between the predictions and ground-truth labels. On the basis of the information quantity identity, the v can be interpreted as the information gains between the presences and absences of the features, which the Q utilizes in decisions from the r I . By enumerating all coalitions, the information gains are then combined to compute the marginal information gains of features in decisions via Equation 3.
Theorem 3.6 (Spectral coalition information identity) . The information quantity relationship is given as:
$$\mathbb { I } ( \mathcal { X } \rtimes \widetilde { \mathcal { I } }, \mathcal { Y } ) \equiv \mathbb { E } _ { x \in \mathcal { X } \rtimes \widetilde { \mathcal { I } } } D _ { K L } [ P ( y | x ) | | Q ( y | | x ) ] + H ( \mathcal { Y } ) + v ( \widetilde { \mathcal { I } } ) + C \quad \quad ( 9 ) \\ \intertext { v is defined in Equation } \gamma \text{ and } H ( \mathcal { Y } ) \text{ is the Shannon entropy of the label set } \mathcal { Y }. \text{ The proof is provided}$$
where v is defined in Equation 7 and H p Y q is the Shannon entropy of the label set Y . The proof is provided in Appendix B.3.
Figure 7: Spectral importance distributions (SIDs) of trained models and un-trained models. The experimental models are pre-trained on ImageNet . We also include the models with random weights as a control marked by the blue box. We have noticed that: (1) The spectral importance distributions of trained models exhibit non-uniformity, and (2) the spectral importance distributions of un-trained models exhibit uniformity. We summarize these empirical observations as Assumption 3.7.
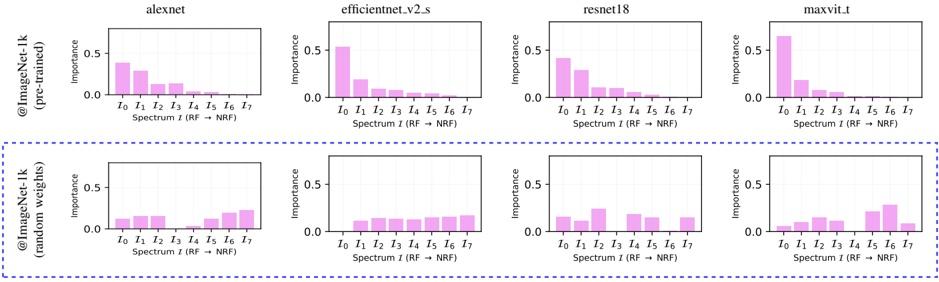
## 3.4 Spectral robustness score (SRS)
Although we are firstly interested in using the spectral importance distributions (SID) for robustness interpretations, they can also be summarized into scalar scores for purposes such as numerical comparisons, and later correlation studies.
Assumption 3.7 (Spectral uniformity assumption of random decisions) . The second row in Figure 7 shows the SIDs from various models with randomized weights. We randomize the model weights with Kaiming initialization (He et al., 2015). The measured SIDs exhibit spectral uniformity. This suggests: Un-trained models do not have spectral preferences . We refer to 'the models with randomized parameters' as random decisions. Therefore, we assume that the SIDs of random decisions are uniform: M .
✶ Assumption 3.8 (Robustness prior) . We assume: Higher utilization of robust features in decisions implies robust models . This is further substantiated by the experiments in Figure 3. To reflect this robustness prior, we empirically design a series β : ' p β , β 0 1 , ¨ ¨ ¨ , β M ´ 1 q T where β P p 0 1 , q as the summing weights of SIDs. Empirically, we choose β ' 0 75 . because this choice achieves the best correlation with model robustness.
Summarizing with weighted sum . Let Ψ p v q be the measured spectral importance distribution (SID). Set ¯ Ψ p v q ' Ψ p v q´ minΨ p v q || Ψ p v q´ minΨ p v q|| 1 with min-max normalization. The weighted sum of the Ψ p v q with the weights β is given by:
$$\left | \beta ^ { T } \bar { \Psi } ( v ) - \beta ^ { T } \frac { 1 } { M } \right | & ( 1 0 ) \\ \text{m decision baseline. } \text{ Let } S ( v ) \, \colon v \mapsto [ 0, 1 ] \, & \text{be the normalized result in}$$
Þ
$$\i e \, S ( v ) & \text{ is given by} \colon \\ S ( v ) & \colon = \frac { \left | \beta ^ { T } \bar { \Psi } ( v ) - \beta ^ { T } \frac { 1 } { M } \right | } { \sup _ { \bar { \Psi } } \left | \beta ^ { T } \bar { \Psi } ( v ) - \beta ^ { T } \frac { 1 } { M } \right | } = \left | \frac { \bar { \beta } ^ { T } \bar { \Psi } ( v ) - \eta } { 1 - \eta } \right | \\ \omega, \bar { \beta } & = \frac { \beta } { \| \beta \| _ { 2 } } \text{ and } \eta = \frac { 1 } { M } \| \frac { \| \beta \| _ { 1 } } { \beta \| _ { 2 } }. \ \text{ Readers can refer to Appendix C.2 for the simplification}$$
where β T ✶ M is served as a random decision baseline. Let S v p q : v Ñ r 0 1 , s be the normalized result in Equation 10. The S v p q is given by:
where β P p 0 1 , , q ¯ β ' β || β || 2 and η ' 1 M || β || 1 || β || 2 . Readers can refer to Appendix C.2 for the simplification deduction.
## 4 Experiments
We design experiments to show the dual functionality of I-ASIDE , which can not only measure robustness and but also interpret robustness. We organize the experiments in three categories:
Figure 8: The spectral robustness scores (SRS), measured with I-ASIDE, correlate to the mean corruption errors (mCE) in the literature (Hendrycks & Dietterich, 2019).
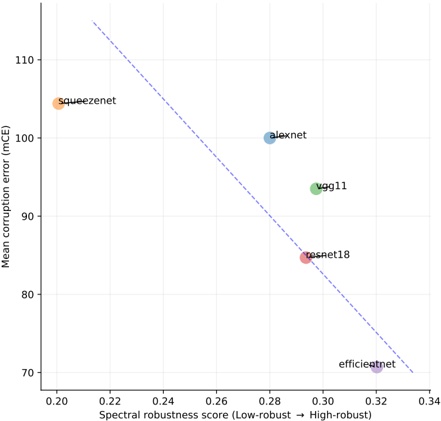
- • Section 4.1: Correlation to a variety of robustness metrics;
- • Section 4.2: Studying architectural robustness;
- • Section 4.3: A case study interpreting how supervision noise levels affect model robustness.
Section 4.1 shows that the scores obtained with I-ASIDE correlate with the model robustness scores measured with other methods. Section 4.2 and Section 4.3 show that I-ASIDE is able to interpret robustness by examining SIDs.
Reproducibility . We choose M ' 8 and 200 samples to conduct experiments. We choose 200 samples because the experiments in Appendix C.3. The experiment shows that: A small amount of examples are sufficiently representative for spectral signals .
## 4.1 Correlation to robustness metrics
Definition 4.1 ( Mean prediction error . ) In our experiments, we measure model perturbation robustness with mean prediction errors (mPE) besides the mean corruption errors (mCE). Let x be some clean image and x ˚ be the perturbed image. For a classifier Q , we define the mean prediction error (mPE) as:
$$\Delta \mathcal { P } \coloneqq \mathbb { E } _ { x, y \sim \langle \mathcal { X }, \mathcal { Y } \rangle } | Q ( y | x ) - Q ( y | x ^ { * } ) |.$$
We demonstrate that I-ASIDE is able to measure model robustness. The experiments are broken down into three aspects: (1) correlation to mCE scores, (2) correlation to adversarial robustness, and (3) correlation to corruption robustness.
Correlation to mCE scores . Figure 8 shows the correlation between spectral robustness scores (SRS) and the mean corruption errors (mCE). The mCE scores are taken from the literature (Hendrycks & Dietterich, 2018). The mCE scores are measured on a corrupted ImageNet which is known as ImageNet-C in the literature (Hendrycks & Dietterich, 2019). The ImageNet-C includes 75 common visual corruptions with five levels of severity in each corruption. This correlation suggests that the results measured with I-ASIDE correlate with the results measured with robustness metric mCE.
)
Mean prediction error (
10
10
10
10
10
10
1.0
1.7
2.3
3.0
3.6
4.3
regnet\_y\_400mfresnet50
vgg16
mobilenet\_v2
resnet18
googlenet efficientnet\_v2\_s
vit\_b\_16
0.28
0.26
0.30
0.32
Spectral robustness score (Low-robust
0.34
0.36
High-robust)
(a) FGSM (
eps
'
0 1)
.
0.26
regnet\_y\_400mf resnet50
vgg16
mobilenet\_v2
resnet18
googlenet efficientnet\_v2\_s
vit\_b\_16
0.28
0.30
0.32
Spectral robustness score (Low-robust
(b) FGSM (
eps
'
0 2)
.
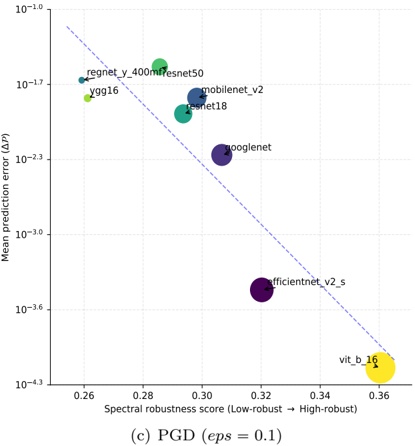
0.26
regnet\_y\_400mf resnet50
vgg16
mobilenet\_v2
resnet18
googlenet efficientnet\_v2\_s
vit\_b\_16
0.28
0.30
0.32
Spectral robustness score (Low-robust
0.34
0.36
High-robust)
eps
(d) PGD (
'
0 2)
.
Figure 9: The spectral robustness scores (SRS), measured with I-ASIDE, correlate with the mean prediction errors (mPE) in adversarial attacks. The circle sizes in (b) are proportional to the SRS.
Correlation to adversarial robustness . Figure 9 shows the correlation between the correlation between spectral robustness scores (SRS) and the mean prediction errors (mPE) of the adversarial attacks with FGSM and PGD. We vary the eps from 0 1 to 0 2. . . The results show that our scores correlate with the mean prediction errors in various eps settings. This suggests that the results measured by our method correlate with adversarial robustness.
Correlation to corruption robustness . Figure 10 shows the correlation between the correlation between spectral robustness scores (SRS) and the mean prediction errors (mPE) of the corruptions with white noise and Gaussian blurring. We vary the σ of white noise from 0 1 to 0 2. . . We vary the Gaussian blurring kernel sizes from 3 ˆ 3 to 7 ˆ 7. The results show that our scores correlate with the mean prediction errors in all cases. This suggests that the results measured by our method can reflect the corruption robustness.
0.34
0.36
High-robust)
)
Mean prediction error (
)
Mean prediction error (
10
10
10
10
10
10
10
10
10
10
10
10
1.1
1.7
2.2
2.8
3.3
3.8
1.1
1.7
2.2
2.8
3.3
3.8
Figure 10: The spectral robustness scores (SRS), measured with I-ASIDE, correlate to the mean prediction errors (mPE) in corruptions. The circle sizes in (b) are proportional to the SRS.
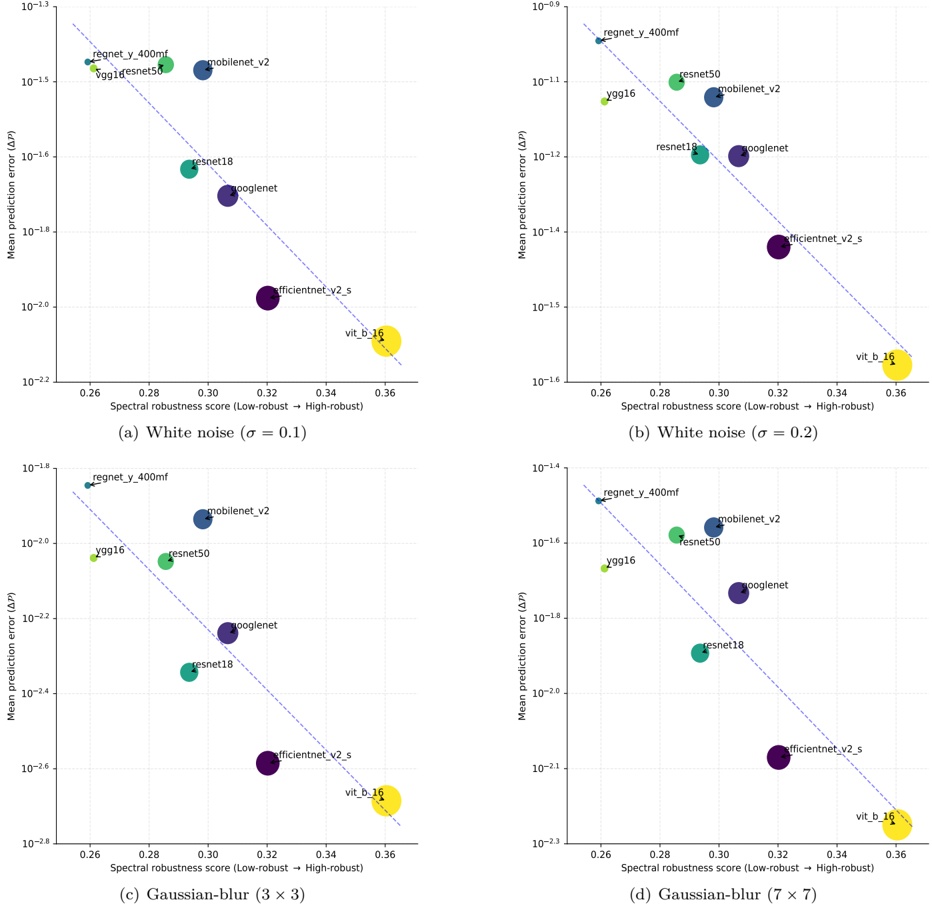
## 4.2 Studying architectural robustness
I-ASIDE is able to answer questions such as:
- • Does model parameter size play a role in robustness?
- • Are vision transformers more robust than convolutional neural networks (ConvNets)?
Does model parameter size play a role in robustness ? Figure 11 (a) shows parameter counts do not correlate with model robustness. Thus, the tendency of a model to use robust features is not determined by parameter counts alone . We would like to carry out further investigation in future work.
(a) Spectral robustness score (SRS) comparison
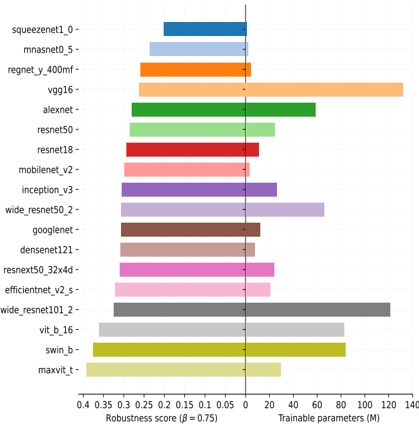
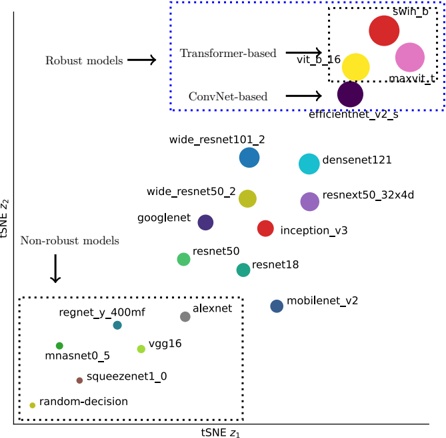
- (b) Spectral importance distribution (SID) t-SNE projection
Figure 11: How do architectural elements affect robustness? The left figure is to answer: 'Does model parameter size play a role on robustness?'. The right figure, a t-SNE projection of SIDs, is to answer: 'Are vision transformers more robust than convolutional neural networks?'. For the two questions, the answers suggested by using I-ASIDE are yes. But the story is more complicated, we have provided a brief discussion regarding this case study within Section 4.2. We also have noted that efficientnet surprisingly exhibits comparable perturbation robustness as the architectures in Transformer family. All experimental models are pre-trained on ImageNet . The circle sizes in (b) are proportional to SRS.
Are vision transformers more robust than ConvNets ? Figure 11 (b) shows a t-SNE projection of the spectral importance distributions of a variety of models. The results show that vision transformers form a cluster ( swin\_b , maxvit\_t and vit\_b\_16 ) and outperform ConvNets in terms of robustness. This results correlate with the recent robustness research in the literature (Paul & Chen, 2022; Zhou et al., 2022; Shao et al., 2021). The interpretation is that: Vision transformers tend to use more robust features than ConvNets .
Discussion . Vision transformers generally outperform ConvNets; nevertheless, state-of-the-art ConvNets, e.g. efficientnet (Tan & Le, 2019), can achieve comparable robustness performance ( e.g. by error rates on benchmark datasets) (Li & Xu, 2023). The literature (Devaguptapu et al., 2021) affirms that efficientnet is more robust than most ConvNets. But, why efficientnet is unique? The efficientnet introduces an innovative concept in that the network sizes can be controlled by scaling the width, depth, and resolution with a compound coefficient (Tan & Le, 2019). The base architecture is then searched with neural architecture searching (NAS) (Ren et al., 2021) instead of hand-crafted design. The NAS optimization objective is to maximize the network accuracy subject to arbitrary image resolutions. The searching implicitly encourages that the network structure of efficientnet uses more robust features. This is because: The low-frequency signals in various resolutions are robust signals while high-frequency signals are not. The second column in Figure 7 shows the SID of efficientnet pre-trained on ImageNet . The SID shows that efficientnet\_v2\_s uses more robust features than alexnet and resnet18 .
Figure 12: How do models respond to label noise? Our results show that models trained with higher label noise levels tend to use spectral signals uniformly, i.e. without a preference for robust (low-frequency) features.
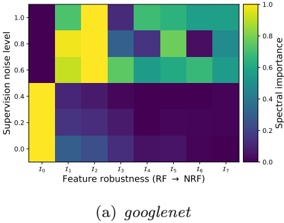
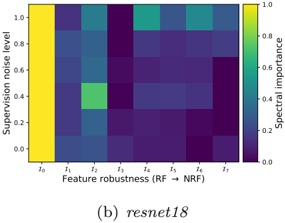
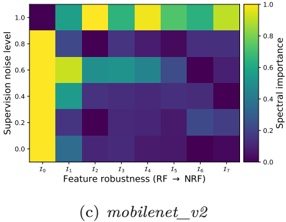
## 4.3 Interpreting how supervision noise levels affect model robustness
The previous robustness benchmarks with mean corruption errors (mCE) are not able to answer the longstanding question: ' How and why label noise levels affect robustness? '. We demonstrate that I-ASIDE is able to answer this question.
Learning with noisy labels . Supervision signals refer to the prior knowledge provided by labels (Sucholutsky et al., 2023; Zhang et al., 2020; Shorten & Khoshgoftaar, 2019; Xiao et al., 2020). There is a substantial line of previous research on the question of 'how supervision noise affects robustness' (Gou et al., 2021; Frénay & Verleysen, 2013; Lukasik et al., 2020; Rolnick et al., 2017). This question is not completely answered yet. For example, Flatow & Penner add uniform label noise into CIFAR-10 and study its impact on model robustness (Flatow & Penner, 2017). Their results show that classification test accuracy decreases as the training label noise level increases. However, empirical studies like this are not able to answer the underlying 'why' question.
Noisy-label dataset . We derive noisy-label datasets from a clean Caltech101 . We randomly assign a proportion of labels with a uniform distribution over label classes to create a noisy-label dataset. We refer to the randomly assigned proportion as supervision noise level. We vary the noise level from 0 2 to 1 0 to derive . . five training datasets.
Experiment . We train three models ( googlenet , resnet18 and mobilenet\_v2 ) over the clean and the five noisy-label datasets for 120 epochs respectively. We then measure their SIDs. The results are visualized in Figure 12 with heat maps. The results show that there is a pattern across the above three models in that: The SIDs are more uniform with higher supervision noise levels . The interpretation regarding the learning dynamics with the presence of label noise is that: Models tend to use more non-robust features in the presence of higher label noise within training set .
## 5 Related work
We further conduct a literature investigation from three research lines: (1) global interpretability, (2) model robustness, and (3) frequency-domain research. This literature study shows that I-ASIDE provides unique insights in these research lines.
Global interpretability . Global interpretability summarizes the decision behaviours of models from a holistic view. In contrast, local interpretability merely provides explanations on the basis of instances (Sundararajan et al., 2017; Smilkov et al., 2017; Linardatos et al., 2020; Selvaraju et al., 2017; Arrieta et al., 2020; Zhou et al., 2016; Ribeiro et al., 2016; Lundberg & Lee, 2017; Lakkaraju et al., 2019; Guidotti et al., 2018; Bach et al., 2015; Montavon et al., 2019; Shrikumar et al., 2017). There are four major research lines in image models: (1) feature visualization, (2) network dissection, (3) concept-based method, and (4) feature importance.
Feature visualization seeks the ideal inputs for specific neurons or classes by maximizing activations (Olah et al., 2017; Nguyen et al., 2019; Zeiler et al., 2010; Simonyan et al., 2013; Nguyen et al., 2016a;b). This method provides intuitions regarding the question: 'What inputs maximize the activations of specific neurons or classes?' . Network dissection aims to connect the functions of network units ( e.g. channels or layers ) with specific concepts ( e.g. eyes or ears ) (Bau et al., 2017). Concept-based methods understand the decisions by answering the question 'how do models use a set of given concepts in decisions?' (Kim et al., 2018; Ghorbani et al., 2019; Koh et al., 2020; Chen et al., 2020). For example, TCAV explains model decisions by evaluating the importance of a given set of concepts ( e.g. the textures dotted , striped and zigzagged ) for a given class ( e.g. the class zebra ) (Kim et al., 2018).
Global input feature importance analysis, often by using Shapley value theory framework, attempts to answer the question: 'How do input features contribute to predictions?' (Altmann et al., 2010; Greenwell et al., 2018; Lundberg & Lee, 2017; Ribeiro et al., 2016; Simonyan et al., 2013; Sundararajan et al., 2017; Covert et al., 2020). However, there are few works falling in the scope of global interpretability with feature importance analysis. A related work, SAGE, applying the Shapley value theory framework, globally assigns spatial input features with importance values for interpreting spatial feature contributions (Covert et al., 2020).
Although the aforementioned global interpretability methods provide insights into understanding decisions inside black-box models, they do not provide interpretations regarding robustness mechanisms. Our work fundamentally differs from them in that: We provide interpretations regarding robustness mechanisms. We attempt to answer the fundamental question: 'Why some models are more robust than others?'.
Model robustness . Model robustness refers to the prediction sensitivity of models to perturbations. The perturbations can perturb in spaces such as the input space and the parameter space (Hendrycks & Dietterich, 2019; Drenkow et al., 2021). In this research, we focus on the perturbations within the input space. The perturbations can stem from sources such as adversarial attacks (Szegedy et al., 2013; Goodfellow et al., 2014), corruptions (Hendrycks & Dietterich, 2019), outliers (Hendrycks et al., 2018a; Pang et al., 2021) and supervision signal noise (Hendrycks et al., 2018b).
Model robustness is often assessed using scalar metrics (Hendrycks & Dietterich, 2019; Krizhevsky et al., 2012; Laugros et al., 2019; Taori et al., 2020). For example, robustness can be measured by the distances between clean and perturbed pairs in feature spaces (Zheng et al., 2016). Hendrycks & Dietterich benchmark the corruption robustness with mean corruption errors (mCE) over a set of corrupted datasets like ImageNet-C (Hendrycks & Dietterich, 2019), using AlexNet (Hendrycks & Dietterich, 2019) as a normalization baseline.
Despite their widespread adoption in previous literature, these scalar metrics lack the ability to provide detailed insights into the robustness mechanisms. Our work not only serves as a robustness metric but also offers mechanistic interpretations, answering the 'why' question behind model robustness. This dual functionality distinguishes our approach, providing a deeper understanding of the mechanisms.
Frequency-domain research . Neural networks are non-linear parameterized signal processing filters. Investigating how neural networks respond to input signals in the frequency-domain can provide a unique insight into understanding its functions. Xu et al. delve into the learning dynamics of neural networks in the frequency-domain (Xu et al., 2019a;b). They present their findings as 'F-Principle'. Their work suggests that the learning behaviors of neural networks exhibit spectral non-uniformity: Neural networks fit low-frequency components first, then high-frequency components.
In a related study, Tsuzuku & Sato show that convolutional neural networks have spectral non-uniformity with respect to Fourier bases (Tsuzuku & Sato, 2019). Later, Wang et al. connect model generalization behaviors and image spectrum (Wang et al., 2020). They argue that: (1) The supervision signals provided by humans use more low-frequency signals in images and (2) models trained on it tend to use more low-frequency signals. Our showcase experiment in Figure 12 provides the interpretations regarding their empirical findings.
In the interpretability research line within the frequency-domain, Kolek et al. propose 'CartoonX' based on the rate-distortion explanation (RDE) framework (Macdonald et al., 2019; Heiß et al., 2020). The RDE framework identifies decision-critical features by partially obfuscating the features. They refer to 'the prediction errors between clean inputs and the partially obfuscated inputs' as distortions. CartoonX pinpoints the decision-critical features within wavelet domain to answer the query: 'What features are crucial for
decisions?' (Kolek et al., 2022). Our work differs from CartoonX in that: (1) Our method aims to interpret model robustness mechanisms while CartoonX does not, (2) our method is a global interpretability method while CartoonX is a local interpretability method, (3) our method analyzes within an information theory framework while CartoonX uses RDE framework, and (4) our method uses Fourier bases while CartoonX uses wavelet bases.
## 6 Limitations
I-ASIDE provides a unique insight into the perturbation robustness mechanisms. Yet, our method has two major limitations: (1) The spectral perspective can merely reflect one aspect of the holistic view of model robustness, and (2) the SID resolutions are low.
Limitation (1) . For example, carefully crafted malicious adversarial perturbations on low-frequency components can fool neural networks (Luo et al., 2022; Liu et al., 2023; Maiya et al., 2021). Luo et al. demonstrate that attacking low-frequency signals can fool neural networks, resulting in attacks which are imperceptible to humans. This further implies the complexity of this research topic.
Limitation (2) . The computation cost is imposed by O p 2 M q . Fortunately, we do not need high SID resolution to analyze the model robustness problem. For example, a choice with M ' 8 is sufficient to interpret robustness mechanisms (as we have shown) while the computational cost remains reasonable.
## 7 Conclusions
On the solid ground provided by information theory and coalitional game theory, we present an axiomatic method to interpret model robustness mechanisms, by leveraging the power-law-like decay of SNRs over the frequency. Our method addresses the limitation that scalar metrics fail to interpret robustness mechanisms. We carry out extensive experiments over a variety of architectures. The SIDs, when scalarized, can largely reproduce the results found with previous methods, but addresses their failures to answer the underlying 'why' questions. Our method goes beyond them with the dual functionality in that: I-ASIDE can not only measure the robustness but also interpret its mechanisms. Our work provides a unique insight into the robustness mechanisms of image classifiers.
## Acknowledgments
This publication has emanated from research conducted with the financial support of Science Foundation Ireland under grant number 18/CRT/6223. For the purpose of Open Access, the author has applied a CC BY public copyright licence to any Author Accepted Manuscript version arising from this submission. We also thank reviewers for their constructive comments which can significantly improve our research quality. We thank the support from the ICHEC (Irish Centre for High-End Computing). We also thank the help from Prof. Dr. Michael Madden from University of Galway, Ireland.
## References
Kjersti Aas, Martin Jullum, and Anders Løland. Explaining individual predictions when features are dependent: More accurate approximations to shapley values. Artificial Intelligence , 298:103502, 2021.
André Altmann, Laura Toloşi, Oliver Sander, and Thomas Lengauer. Permutation importance: a corrected feature importance measure. Bioinformatics , 26(10):1340-1347, 2010.
Alejandro Barredo Arrieta, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador García, Sergio Gil-López, Daniel Molina, Richard Benjamins, et al. Explainable artificial intelligence (xai): Concepts, taxonomies, opportunities and challenges toward responsible ai. Information fusion , 58:82-115, 2020.
Robert J Aumann and Michael Maschler. Game theoretic analysis of a bankruptcy problem from the talmud. Journal of economic theory , 36(2):195-213, 1985.
| Yonatan Aumann and Yair Dombb. The efficiency of fair division with connected pieces. ACM Transactions on Economics and Computation (TEAC) , 3(4):1-16, 2015. |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PloS one , 10(7):e0130140, 2015. |
| Tao Bai, Jinqi Luo, Jun Zhao, Bihan Wen, and Qian Wang. Recent advances in adversarial training for adversarial robustness. arXiv preprint arXiv:2102.01356 , 2021. |
| David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the IEEE conference on computer vision and pattern recognition , pp. 6541-6549, 2017. |
| Leonard Bereska and Efstratios Gavves. Mechanistic interpretability for ai safety-a review. arXiv preprint arXiv:2404.14082 , 2024. |
| Alexander Binder, Grégoire Montavon, Sebastian Lapuschkin, Klaus-Robert Müller, and Wojciech Samek. Layer-wise relevance propagation for neural networks with local renormalization layers. In Artificial Neural Networks and Machine Learning-ICANN 2016: 25th International Conference on Artificial Neural Networks, Barcelona, Spain, September 6-9, 2016, Proceedings, Part II 25 , pp. 63-71. Springer, 2016. |
| Zhi Chen, Yijie Bei, and Cynthia Rudin. Concept whitening for interpretable image recognition. Nature Machine Intelligence , 2(12):772-782, 2020. |
| Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics pp. 215-223. JMLR Workshop and Conference Proceedings, 2011. |
| Ian Covert, Scott M Lundberg, and Su-In Lee. Understanding global feature contributions with additive importance measures. Advances in Neural Information Processing Systems , 33:17212-17223, 2020. |
| Chaitanya Devaguptapu, Devansh Agarwal, Gaurav Mittal, Pulkit Gopalani, and Vineeth N Balasubramanian. On adversarial robustness: A neural architecture search perspective. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pp. 152-161, 2021. |
| Nathan Drenkow, Numair Sani, Ilya Shpitser, and Mathias Unberath. A systematic review of robustness in deep learning for computer vision: Mind the gap? arXiv preprint arXiv:2112.00639 , 2021. |
| David Flatow and Daniel Penner. On the robustness of convnets to training on noisy labels. Technical report, Stanford University , 2017. |
| Benoît Frénay and Michel Verleysen. Classification in the presence of label noise: a survey. IEEE transactions on neural networks and learning systems , 25(5):845-869, 2013. |
| Amirata Ghorbani, James Wexler, James Y Zou, and Been Kim. Towards automatic concept-based explanations. Advances in Neural Information Processing Systems , 32, 2019. |
| Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 , 2014. |
| Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey. International Journal of Computer Vision , 129(6):1789-1819, 2021. |
| Brandon M Greenwell, Bradley C Boehmke, and Andrew J McCarthy. A simple and effective model-based variable importance measure. arXiv preprint arXiv:1805.04755 , 2018. |
| Riccardo Guidotti, Anna Monreale, Salvatore Ruggieri, Dino Pedreschi, Franco Turini, and Fosca Giannotti. Local rule-based explanations of black box decision systems. arXiv preprint arXiv:1805.10820 , 2018. |
| Chunjing Xu, Yixing Xu, et al. A survey on vision transformer. IEEE transactions on pattern analysis and machine intelligence , 45(1):87-110, 2022. |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Zhu Han and H Vincent Poor. Coalition games with cooperative transmission: a cure for the curse of boundary nodes in selfish packet-forwarding wireless networks. IEEE transactions on communications , 57 (1):203-213, 2009. |
| Sergiu Hart. Shapley value. In Game theory , pp. 210-216. Springer, 1989. |
| Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human- level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision , pp. 1026-1034, 2015. |
| Cosmas Heiß, Ron Levie, Cinjon Resnick, Gitta Kutyniok, and Joan Bruna. In-distribution interpretability for challenging modalities. arXiv preprint arXiv:2007.00758 , 2020. |
| Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. arXiv preprint arXiv:1903.12261 , 2019. |
| Dan Hendrycks and Thomas G Dietterich. Benchmarking neural network robustness to common corruptions and surface variations. arXiv preprint arXiv:1807.01697 , 2018. |
| Dan Hendrycks, Mantas Mazeika, and Thomas Dietterich. Deep anomaly detection with outlier exposure. arXiv preprint arXiv:1812.04606 , 2018a. |
| Dan Hendrycks, Mantas Mazeika, Duncan Wilson, and Kevin Gimpel. Using trusted data to train deep networks on labels corrupted by severe noise. Advances in neural information processing systems , 31, 2018b. |
| Kathy J Horadam. Hadamard matrices and their applications . Princeton university press, 2012. |
| Roger A Horn. The hadamard product. In Proc. Symp. Appl. Math , volume 40, pp. 87-169, 1990. |
| Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak Shah. Transformers in vision: A survey. ACM computing surveys (CSUR) , 54(10s):1-41, 2022. |
| Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). In International conference on machine learning , pp. 2668-2677. PMLR, 2018. |
| Christian Klamler. Fair division. Handbook of group decision and negotiation , pp. 183-202, 2010. |
| Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. In International Conference on Machine Learning , pp. 5338-5348. PMLR, 2020. |
| Stefan Kolek, Duc Anh Nguyen, Ron Levie, Joan Bruna, and Gitta Kutyniok. Cartoon explanations of image classifiers. In European Conference on Computer Vision , pp. 443-458. Springer, 2022. |
| Thomas William Körner. Fourier analysis . Cambridge university press, 2022. |
| Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems , 25, 2012. |
| Himabindu Lakkaraju, Ece Kamar, Rich Caruana, and Jure Leskovec. Faithful and customizable explanations of black box models. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society , pp. 131-138, 2019. |
| Alfred Laugros, Alice Caplier, and Matthieu Ospici. Are adversarial robustness and common perturbation robustness independant attributes? In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops , pp. 0-0, 2019. |
| Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 7558-7568, 2023. |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Zewen Li, Fan Liu, Wenjie Yang, Shouheng Peng, and Jun Zhou. A survey of convolutional neural networks: analysis, applications, and prospects. IEEE transactions on neural networks and learning systems , 33(12): 6999-7019, 2021. |
| Pantelis Linardatos, Vasilis Papastefanopoulos, and Sotiris Kotsiantis. Explainable AI: A review of machine learning interpretability methods. Entropy , 23(1):18, 2020. |
| Zachary C Lipton. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue , 16(3):31-57, 2018. |
| Jiyuan Liu, Bingyi Lu, Mingkang Xiong, Tao Zhang, and Huilin Xiong. Low frequency sparse adversarial attack. Computers & Security , 132:103379, 2023. |
| Michal Lukasik, Srinadh Bhojanapalli, Aditya Menon, and Sanjiv Kumar. Does label smoothing mitigate label noise? In International Conference on Machine Learning , pp. 6448-6458. PMLR, 2020. |
| Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in neural information processing systems , 30, 2017. |
| Cheng Luo, Qinliang Lin, Weicheng Xie, Bizhu Wu, Jinheng Xie, and Linlin Shen. Frequency-driven imperceptible adversarial attack on semantic similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 15315-15324, 2022. |
| Jan Macdonald, Stephan Wäldchen, Sascha Hauch, and Gitta Kutyniok. A rate-distortion framework for explaining neural network decisions. arXiv preprint arXiv:1905.11092 , 2019. |
| Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083 , 2017. |
| Shishira R Maiya, Max Ehrlich, Vatsal Agarwal, Ser-Nam Lim, Tom Goldstein, and Abhinav Shrivastava. A frequency perspective of adversarial robustness. arXiv preprint arXiv:2111.00861 , 2021. |
| Apostolos Modas, Seyed-Mohsen Moosavi-Dezfooli, and Pascal Frossard. Sparsefool: a few pixels make a big difference. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. 9087-9096, 2019. |
| Grégoire Montavon, Alexander Binder, Sebastian Lapuschkin, Wojciech Samek, and Klaus-Robert Müller. Layer-wise relevance propagation: an overview. Explainable AI: interpreting, explaining and visualizing deep learning , pp. 193-209, 2019. |
| Florian Navarro. Necessary players, myerson fairness and the equal treatment of equals. Annals of Operations Research , 280:111-119, 2019. |
| Anh Nguyen, Alexey Dosovitskiy, Jason Yosinski, Thomas Brox, and Jeff Clune. Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. Advances in neural information processing systems , 29, 2016a. |
| Anh Nguyen, Jason Yosinski, and Jeff Clune. Multifaceted feature visualization: Uncovering the different types of features learned by each neuron in deep neural networks. arXiv preprint arXiv:1602.03616 , 2016b. |
| Anh Nguyen, Jason Yosinski, and Jeff Clune. Understanding neural networks via feature visualization: A survey. Explainable AI: interpreting, explaining and visualizing deep learning , pp. 55-76, 2019. |
| Chris Olah, Alexander Mordvintsev, and Ludwig Schubert. Feature visualization. Distill , 2(11):e7, 2017. |
| Alan V Oppenheim. Applications of digital signal processing. Englewood Cliffs , 1978. |
| Guansong Pang, Chunhua Shen, Longbing Cao, and Anton Van Den Hengel. Deep learning for anomaly detection: A review. ACM computing surveys (CSUR) , 54(2):1-38, 2021. |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Tianyu Pang, Xiao Yang, Yinpeng Dong, Hang Su, and Jun Zhu. Bag of tricks for adversarial training. arXiv preprint arXiv:2010.00467 , 2020. |
| Sayak Paul and Pin-Yu Chen. Vision transformers are robust learners. In Proceedings of the AAAI conference on Artificial Intelligence , volume 36, pp. 2071-2081, 2022. |
| Soo-Chang Pei and Chien-Cheng Tseng. A comb filter design using fractional-sample delay. IEEE Transactions on Circuits and Systems II: Analog and Digital Signal Processing , 45(5):649-653, 1998. |
| Jary Pomponi, Simone Scardapane, and Aurelio Uncini. Pixle: a fast and effective black-box attack based on rearranging pixels. In 2022 International Joint Conference on Neural Networks (IJCNN) , pp. 1-7. IEEE, 2022. |
| Pengzhen Ren, Yun Xiao, Xiaojun Chang, Po-Yao Huang, Zhihui Li, Xiaojiang Chen, and Xin Wang. A comprehensive survey of neural architecture search: Challenges and solutions. ACM Computing Surveys (CSUR) , 54(4):1-34, 2021. |
| Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. " why should i trust you?" explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining , pp. 1135-1144, 2016. |
| Richard A Roberts and Clifford T Mullis. Digital signal processing . Addison-Wesley Longman Publishing Co., Inc., 1987. |
| David Rolnick, Andreas Veit, Serge Belongie, and Nir Shavit. Deep learning is robust to massive label noise. arXiv preprint arXiv:1705.10694 , 2017. |
| Alvin E Roth. The Shapley value: essays in honor of Lloyd S. Shapley . Cambridge University Press, 1988. |
| Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision , pp. 618-626, 2017. |
| Rulin Shao, Zhouxing Shi, Jinfeng Yi, Pin-Yu Chen, and Cho-Jui Hsieh. On the adversarial robustness of vision transformers. arXiv preprint arXiv:2103.15670 , 2021. |
| Lloyd S Shapley. A value for n-person games. Classics in game theory , 69, 1997. |
| Charles H Sherman and John L Butler. Transducers and arrays for underwater sound , volume 4. Springer, 2007. |
| Connor Shorten and Taghi M Khoshgoftaar. A survey on image data augmentation for deep learning. Journal of big data , 6(1):1-48, 2019. |
| Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through propagating activation differences. In International conference on machine learning , pp. 3145-3153. PMLR, 2017. |
| Samuel Henrique Silva and Peyman Najafirad. Opportunities and challenges in deep learning adversarial robustness: A survey. arXiv preprint arXiv:2007.00753 , 2020. |
| Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034 , 2013. |
| Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda Viégas, and Martin Wattenberg. Smoothgrad: removing noise by adding noise. arXiv preprint arXiv:1706.03825 , 2017. |
| Kenneth Steiglitz. Digital Signal Processing Primer . Courier Dover Publications, 2020. |
| Spectral analysis of signals Saddle River, NJ, 2005. |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Ilia Sucholutsky, Ruairidh M Battleday, Katherine M Collins, Raja Marjieh, Joshua Peterson, Pulkit Singh, Umang Bhatt, Nori Jacoby, Adrian Weller, and Thomas L Griffiths. On the informativeness of supervision signals. In Uncertainty in Artificial Intelligence , pp. 2036-2046. PMLR, 2023. |
| Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International conference on machine learning , pp. 3319-3328. PMLR, 2017. |
| Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199 , 2013. |
| Lizhe Tan and Jean Jiang. Digital signal processing: fundamentals and applications . Academic Press, 2018. |
| Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning , pp. 6105-6114. PMLR, 2019. |
| Rohan Taori, Achal Dave, Vaishaal Shankar, Nicholas Carlini, Benjamin Recht, and Ludwig Schmidt. Measuring robustness to natural distribution shifts in image classification. Advances in Neural Information Processing Systems , 33:18583-18599, 2020. |
| Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, and Aleksander Madry. Robustness may be at odds with accuracy. arXiv preprint arXiv:1805.12152 , 2018. |
| Yusuke Tsuzuku and Issei Sato. On the structural sensitivity of deep convolutional networks to the directions of fourier basis functions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 51-60, 2019. |
| Haohan Wang, Xindi Wu, Zeyi Huang, and Eric P Xing. High-frequency component helps explain the generalization of convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 8684-8694, 2020. |
| Jiaheng Wei, Zhaowei Zhu, Hao Cheng, Tongliang Liu, Gang Niu, and Yang Liu. Learning with noisy labels revisited: A study using real-world human annotations. arXiv preprint arXiv:2110.12088 , 2021. |
| Eyal Winter. The shapley value. Handbook of game theory with economic applications , 3:2025-2054, 2002. |
| Tete Xiao, Xiaolong Wang, Alexei A Efros, and Trevor Darrell. What should not be contrastive in contrastive learning. arXiv preprint arXiv:2008.05659 , 2020. |
| Zhi-Qin John Xu, Yaoyu Zhang, Tao Luo, Yanyang Xiao, and Zheng Ma. Frequency principle: Fourier analysis sheds light on deep neural networks. arXiv preprint arXiv:1901.06523 , 2019a. |
| Zhi-Qin John Xu, Yaoyu Zhang, and Yanyang Xiao. Training behavior of deep neural network in frequency domain. In International Conference on Neural Information Processing , pp. 264-274. Springer, 2019b. |
| Menahem E Yaari and Maya Bar-Hillel. On dividing justly. Social choice and welfare , 1:1-24, 1984. |
| Koji Yokote, Takumi Kongo, and Yukihiko Funaki. Relationally equal treatment of equals and affine combinations of values for tu games. Social Choice and Welfare , 53:197-212, 2019. |
| Matthew D Zeiler, Dilip Krishnan, Graham WTaylor, and Rob Fergus. Deconvolutional networks. In 2010 IEEE Computer Society Conference on computer vision and pattern recognition , pp. 2528-2535. IEEE, 2010. |
| Yu Zhang, Peter Tiňo, Aleš Leonardis, and Ke Tang. A survey on neural network interpretability. IEEE Transactions on Emerging Topics in Computational Intelligence , 2021. |
Zhenyu Zhang, Xiaobo Shu, Bowen Yu, Tingwen Liu, Jiapeng Zhao, Quangang Li, and Li Guo. Distilling knowledge from well-informed soft labels for neural relation extraction. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 34, pp. 9620-9627, 2020.
Beiyao Zheng and Alan Agresti. Summarizing the predictive power of a generalized linear model. Statistics in medicine , 19(13):1771-1781, 2000.
Stephan Zheng, Yang Song, Thomas Leung, and Ian Goodfellow. Improving the robustness of deep neural networks via stability training. In Proceedings of the ieee conference on computer vision and pattern recognition , pp. 4480-4488, 2016.
Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In Proceedings of the IEEE conference on computer vision and pattern recognition , pp. 2921-2929, 2016.
Daquan Zhou, Zhiding Yu, Enze Xie, Chaowei Xiao, Animashree Anandkumar, Jiashi Feng, and Jose M Alvarez. Understanding the robustness in vision transformers. In International Conference on Machine Learning , pp. 27378-27394. PMLR, 2022.
## A Appendix
## B Fairness division axioms
Symmetry axiom : Let r I P 2 I be some spectral player coalition. For @ I i , I j P I ^ I i , I j R r I , the statement v p r I Yt I i uq ' v p r I Yt I j uq implies ψ i p I , v q ' ψ j p I , v q . This axiom restates the statement ' equal treatment of equals ' principle mathematically. This axiom states that the 'names' of players should have no effect on the 'treatments' by the characteristic function in coalition games (Roth, 1988).
Linearity axiom : Let u and v be two characteristic functions. Let p I , u q and p I , v q be two coalition games. Let p u ` v qp r I q : ' u p r I q ` v p r I q where r I P 2 I . The divisions of the new coalition game p I , u ` v q should satisfy: ψ i p I , u ` q ' v ψ i p I , u q ` ψ i p I , v q . This axiom is also known as ' additivity axiom' and guarantees the uniqueness of the solution of dividing payoffs among players (Roth, 1988).
Efficiency axiom : This axiom states that the sum of the divisions of all players must be summed to the worth of the player set (the grand coalition): M ´ 1 ψ i p I , v q ' v p I q .
Dummy player axiom : A dummy player (null player) I ˚ is the player who has no contribution such that: ψ ˚ p I , v q ' 0 and v p I Yt I ˚ uq ' v p I q for @ I ˚ R I ^ I ˚ Ď I .
$$\ u e s _ { M - 1 } \\ \sum _ { i = 0 } ^ { \ } \\ \ u l l _ { \L }$$
r r r Remark B.1. In the literature (Roth, 1988), the efficiency axiom and the dummy player axiom are also combined and relabeled as carrier axiom.
## B.1 Spectral signal-to-noise ratio (SNR)
Discrete Fourier Transform . The notion 'frequency' measures how 'fast' the outputs can change with respect to inputs. High frequency implies that small variations in inputs can cause large changes in outputs. In terms of images, the 'inputs' are the pixel spatial locations while the 'outputs' are the pixel values.
Þ
Let x : p i, j q ÞÑ R be some 2D image with dimension M ˆ N which sends every location p i, j q to some real pixel value where p i, j q P r M s ˆ r N s . Let F : R 2 Ñ C 2 be some DFT functional operator. The DFT of x is given by:
$$\mathcal { F } ( x ) ( u, v ) = \sum _ { j = 0 } ^ { N - 1 } \sum _ { i = 0 } ^ { M - 1 } x ( i, j ) e ^ { - i 2 \pi ( \frac { 1 } { M } i + \frac { 1 } { N } j ) }. \\ \int _ { \cdots \cdots \cdots } ^ { N } \int _ { \mathcal { C } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } \mathcal { D } }.$$
Point-wise energy spectral density (ESD) . The ESD measures the energy quantity at a frequency. To simplify discussions, we use radial frequency , which is defined as the radius r with respect to zero frequency point ( i.e. the frequency center). The energy is defined as the square of the frequency magnitude according to Parseval's Power Theorem.
Let L r be a circle with radius r on the spectrum of image x , as illustrated in Figure 1. The r is referred to as radial frequency. The point-wise ESD function is given by:
$$\cdot \quad & \quad E S D _ { r } ( x ) \colon = \frac { 1 } { | L _ { r } | } \cdot \sum _ { ( u, v ) \in L _ { r } } | \mathcal { F } ( x ) ( u, v ) | ^ { 2 } \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{array}$$
where p u, v q is the spatial frequency point and | L r | is the circumference of L r .
Spectral signal-to-noise ratio (SNR) . The SNR can quantify signal robustness. We define the spectral SNR at radius frequency r as:
$$S N R ( r ) \coloneqq \frac { E S D _ { r } ( x$$
where ∆ x is some perturbation. We have characterized the SNRs of some corroptions and adversarial attacks in Figure 2.
## B.2 Absence assignment scheme
There exist multiple choices for the assignments of the absences of spectral layers in coalition filtering design: (1) Assigning to constant zeros (Zeroing), (2) assigning to complex Gaussian noise (Complex Gaussian) and (3) assigning to the corresponding frequency components randomly sampled from other images at the same dataset (Replacement).
Zeroing . The b in Equation 5 is set to zeros.
Complex Gaussian . The b in Equation 5 is sampled from a i.i.d. complex Gaussian distribution: N p µ, σ 2 2 q ` i N p µ, σ 2 2 q .
Replacement . The b in Equation 5 is set to: b ' F p x ˚ q (where x ˚ ∼ X is a randomly sampled image from some set X ).
In our implementation, we simply choose 'zeroing': b ' 0 . Figure 13 shows the filtered image examples by using the above three strategies and also show the examples of measured spectral importance distributions. Empirically, the three strategies have rather similar performance. In this research, we do not unfold the discussions regarding the masking strategy choices.
(a) Zeroing






(b) Gaussian
Complex
(g) resnet18 w/ Zeroing
(c) Replacement
(d) Zeroing
(e) Gaussian
Complex
(f) Replacement
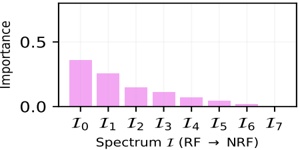
(h) resnet18 w/ Complex Gaussian
(i) resnet18 w/ Replacement
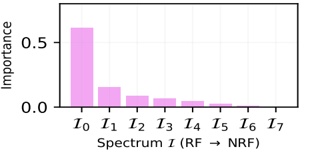
(j) efficientnet\_v2\_s w/ Zeroing
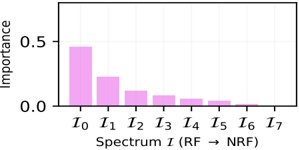
(k) efficientnet\_v2\_s w/ Complex Gaussian
(l) efficientnet\_v2\_s w/ Replacement
Figure 13: Three absence assignment strategies: (1) Assigning the spectral absences with constant zeros (Zeroing), (2) assigning the spevtral absences with Gaussian noise (Complex Gaussian) and (3) randomly sampling spectral components from the same image datasets (Replacement). The standard complex Gaussian distribution is given by: N p 0 , 1 2 q ` i N p 0 , 1 2 q . The figures (a), (b) and (c) show the coalition filtering results with the spectral coalition: t I 0 u . The figures (d), (e) and (f) show the coalition filtering results with the spectral coalition: t I 1 , I 2 , I 3 , I 4 , I 5 , I 6 , I 7 u . The figures (g) to (l) show the examples of the measured spectral importance distributions of a resnet18 and a efficientnet\_v2\_s (both are pre-trained on ImageNet ) with the three assignment strategies.
## B.3 Proof for Spectral Coalition Information Identity Theorem
Proof for Spectral Coalition Information Identity. Suppose the probability measures P x p q , P x, y p q , P y x p | q , and Q y x p | q are absolutely continuous with respect to x on domain X ' r I .
$$\begin{array} {$$
$$\mathbb { I } ( \mathcal { X } \rtimes \tilde { \math$$
$$& \underset { x \ltimes \tilde { \mathcal { I } } } {$$
$$\prod _ { \chi \in \tilde { \mathcal { X } } } ^$$
$$& \underset { x \ltimes \tilde { \mathcal { I } } } { J } \underset { y \in \mathcal { Y } } { \overleftarrow { y \in \mathcal { Y } } } \theta \overset { \bullet \, \cdots } { \bullet \, \cdots } \theta \ \mathcal { M } ( y | x ) \ P ( y ) \ \mathcal { M } \overset { \bullet \, \cdots } { \bullet \, \cdots } \theta \ \mathcal { M } ^ { \prime } \\ = & \int _ { x \ltimes \tilde { \mathcal { I } } } P ( x$$
$$& \overleftarrow { y \in \mathcal { Y } } \bigwedge _ { \chi \rtimes \tilde { \mathcal { I } } } ^ { J } \stackrel { \cdot \cdot \cdot \cdot } { \cdot \cdot \cdot } \int _ { \real } ^ { \cdot \cdot \cdot \cdot } P ( x, y ) \cdot \log Q ( y | x ) d x \\ & + \int _ { \real } \sum _ { \chi \rtimes \tilde { \mathcal { I } } } P ( x, y ) \cdot \log Q ( y | x ) d x \\ & \quad \quad \quad$$
$$& \underset { x \in \mathcal { X } \lll \widetilde { \mathcal { I } } } { \underset { \overbrace { x \in \widetilde { \mathcal { X } } \lll \widetilde { \mathcal { I } } } } { \underset { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace { \overbrace {$$
$$& \cdot \bigotimes _ { \mathcal { X } \ll \widetilde { \mathcal { I } } } \bigoplus _ { y \in \mathcal { Y } } ^ { \bigoplus \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cdot \nu \cd$$
$$= \underset { x \in \mathcal { X } \times \widetilde { \mathcal { I } } } { E } \underset { \widetilde { \mathcal { I } } } { \underset { \widetilde { \mathcal { I } } } { \underbrace { K L } ( P ( y | x ) | | Q ( y | | x ) ) } } \underset { \widetilde { \mathcal { I } } } { \text{point-wise} } } + H ( \mathcal { Y } ) + v ( \widetilde { \mathcal { I } } ) + C \\ H ( \mathcal { Y } ) \text{ is the Shannon entropy of the label set } \$$
where H p Y q is the Shannon entropy of the label set Y .
## C Information quantity relationship in spectral coalitions
Figure 14: Information quantity relationship. This shows the theoretical information quantity relationship between what the characteristic function v measures and the mutual information ■ p X ' r I Y , q . For a given coalition r I , a dataset x X Y , y and a classifier Q , the v measures how much information the classifier Q utilizes in decisions. The measured results are then used to compute the marginal contributions of features.
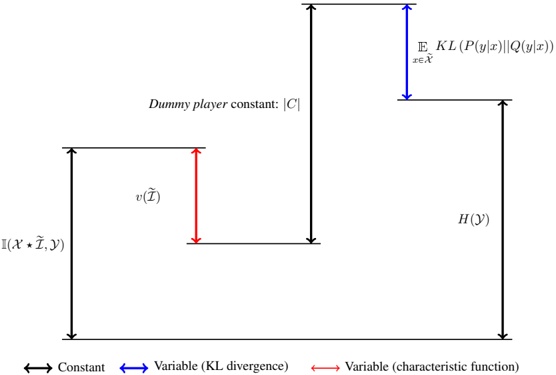
## C.1 Partitioning spectrum with /lscript 8 ball over /lscript 2 ball
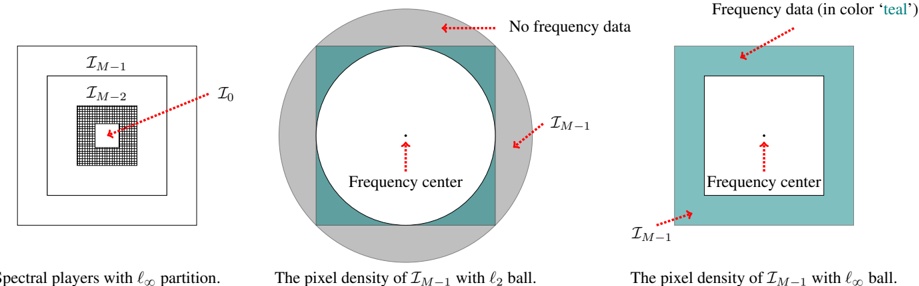
Spectral players with /lscript 8 partition.
The pixel density of I M ´ 1 with /lscript 2 ball.
The pixel density of I M ´ 1 with /lscript 8 ball.
Figure 15: Two spectral band partitioning schemes. This shows the motivation we choose /lscript 8 ball over /lscript 2 ball in partitioning the frequency domain into the M bands (i.e., M 'spectral players') over 2D Fourier spectrum. The frequency data density of the spectral players with /lscript 8 remains a constant. However, the frequency data density of the spectral players with /lscript 2 is not a constant since some frequency components do not present. This motives us to empirically choose /lscript 8 metric to form spectral players in implementation.
## C.2 Normalizing summarized SIDs
We normalize the above result and set:
$$S ( v ) \coloneqq \frac { \left | \beta ^ { T } \bar { \Psi } ( v ) - \frac { \| \beta \| _ { 1 } } { M } \right | } { \sup \left | \beta ^ { T } \bar { \Psi } ( v ) - \frac { \| \beta \| _ { 1 } } { M } \right | } \\ | \alpha T \bar { \tau } _ { \tilde { \tau } } / \dots \quad \| \beta \| _ { 1 } |$$
$$= \frac { \Phi ^ { T } \bar { \Psi } ( v ) - \frac { | | \beta | | _ { 1 } } { M } \Big | } { \left | | | \beta | | _ { 2 } - \frac { | | \beta | | _ { 1 } } { M } \Big | } \\ | \bar { \partial } T \bar { \partial } \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \ Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi$$
$$= \frac { \ell ^ { \prime } \lambda ^ { \prime } \lambda ^ { \prime } \lambda ^ { \prime } } { \left | \beta ^ { T } \bar { \Psi } ( v ) - \frac { \| \beta \| _ { 1 } } { M } \right | } \\ \sup \left | | | \beta | | _ { 2 } \cdot | | \bar { \Psi } ( v ) | | _ { 2 } - \frac { \| \beta \| _ { 1 } } { M } \right | } \\ | \alpha T \bar { \Psi } \lambda \lambda _ { \dots } \quad \| \beta \| _ { 1 } |$$
$$= \left | \frac { \bar { \beta } ^ { T } \bar { \Psi } ( v ) - \frac { 1 } { M } \frac { \| \beta \| _ { 1 } } { \| \beta \| _ { 2 } } } { 1 - \frac { 1 } { M } \frac { \| \beta \| _ { 1 } } { \| \beta \| _ { 2 } } } \right |.$$
where ¯ β ' β || β || 2 and sup ∣ ∣ ∣ β T ¯ Ψ p v q ´ || β || 1 M ∣ ∣ ∣ is derived by:
$$\sup \left | \beta ^ { T } \bar { \Psi } ( v ) - \frac { | | \beta | | _ { 1 } } { M } \right | = \left | \sup \beta ^ { T } \bar { \Psi } ( v ) - \frac { | | \beta | | _ { 1 } } { M } \right | \, \quad \, \\ \dots \dots \.$$
$$\ell = \ell \left | \sup | | \beta | | _ { 2 } \cdot | | \bar { \Psi } ( v ) | | _ { 2 } - \frac { \ell } { M } \right | \ s. t. \, | | \bar { \Psi } ( v ) | | _ { 1 } = 1 \quad \quad ( 3 0 )$$
$$= \stackrel { \cdot } { \left | } | | \beta | | _ { 2 } - \frac { | | \beta | | _ { 1 } } { M } \right | \quad \text{since} \ | | \bar { \Psi } ( v ) | | _ { 2 } ^ { 2 } \leqslant | | \bar { \Psi } ( v ) | | _ { 1 } ^ { 2 }.$$
$$S ( v ) & = \left | \frac { \bar { \beta } ^ { T } \bar { \Psi } ( v ) - \eta } { 1 - \eta } \right |. & ( 3 2 ) \\ & \quad \ \, \cap \, \varepsilon$$
Q.E.D.
Set η ' 1 M || β || 1 || β || 2 :
## C.3 How much samples are sufficient?
(a)
resnet18 @CIFAR10
Figure 16: Convergence of relative estimation errors converge with respect to the numbers of samples K . The errors are measured by: 1 M || Ψ p ` q i 1 p v q ´ Ψ p q i p v q|| 1 where Ψ p q i p v q denotes the i -th measured spectral importance distribution with respect to characteristic function v . The experiments are conducted on CIFAR10 , CIFAR100 and ImageNet with resnet18 .
Error bound analysis . Let K be the number of the samples of some baseline dataset. Let:
$$\Delta v ( \tilde { \mathcal { I } }, \mathcal { I } _ { i } ) \coloneqq v ( \tilde { \mathcal { I } } \cup \{ \mathcal { I } _ { i } \} ) - v ( \tilde { \mathcal { I } } )$$
and and
$$\Delta v ( \mathcal { I } _ { i } ) \coloneqq ( \Delta v ( \tilde { \mathcal { I } }, \mathcal { I } _ { i } ) ) _ { \tilde { \mathcal { I } } \subseteq \mathcal { I } }$$
$$W \coloneqq \left ( \frac { 1 } { M } \binom { M - 1 } { | \tilde { \mathcal { I } } | } ^ { - 1 } \right ) _ { \tilde { \mathcal { I } } \subset \mathcal { I } }.$$
Hence:
$$\psi _ { i } ( \mathcal { I }, v ) = W ^ { T } \Delta v ( \mathcal { I } _ { i } )$$
where || W || 1 ' 1 since W is a probability distribution. Let ¯ , ∆¯ ψ i v p I i q and ∆¯ ˜ v p I I , i q be estimations with K samples using Monte Carlo sampling. The error bound with /lscript 1 norm is given by:
$$\epsilon \stackrel { \text{def} } { = } \sup _ { i } | | \bar { \psi } _ { i } ( \mathcal { I }, v ) - \psi _ { i } ( \mathcal { I }, v ) | | _ { 1 } = \sup _ { i } | | W ^ { T } \Delta \bar { v } ( \mathcal { I } _ { i } ) - W ^ { T } \Delta v ( \mathcal { I } _ { i } ) | | _ { 1 } \\.$$
$$& \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \stackrel { \sim } { \stackrel { \stackrel { \sim } { \stackrel { \sim } { \stackrel { \stackrel { \sim } { \stackrel { \stackrel { \stackrel { \sim } { \stackrel { \stackrel { \sim } { \stackrel { \stackrel { \stackrel { \stackrel { \stack { \stackrel { \stack { \stackrel { \stack { \stackrel { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack { \stack \stack { \stack \stack { \stack \stack { \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack { \stack { \stack \stack { \stack { \stack \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack \stack \stack { \stack \stack { \stack \stack { \stack \stack { \stack \stack \stack \stack { \stack \stack \stack { \stack \stack \stack \stack { \stack \stack \stack { \stack \stack { \stack \stack \stack \stack { \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \ \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \text \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \Stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \text \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \text \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \stack \text \stack \stack \stack \text \stack \stack \stack \text \stack \stack \stack \text \stack \text \stack \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \text \endlisp} } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } ) } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } _ } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } { } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } \ } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } ; } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } }, } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } }$$
$$\lambda & \stackrel { \psi \psi } { i } r _ { i } \psi _ { i } \psi _ { i }, \psi _ { i } \psi _ { i }, \psi _ { i } \psi _ { i } \psi _ { i } \cdots \stackrel { \psi \psi } { i } } \cdots \stackrel { \psi \psi _ { i } } \cdots \stackrel { \psi \psi _ { i } } \cdots \stackrel { \psi \psi _ { i } } \cdots \stackrel { \psi \psi _ { i } } \cdots \\ & \leqslant \sup _ { i } \| W \| _ { 1 } \cdot \| \Delta \bar { v } ( \mathcal { I } _ { i } ) - \Delta v ( \mathcal { I } _ { i } ) \| _ { \infty } \quad \text{(Hölder$'s inequality)} \\ & = \sup _ { j } \| \sum \quad \left ( \Delta \bar { v } ( \tilde { \mathcal { I } }, \mathcal { I } _ { i } ) - \Delta v ( \tilde { \mathcal { I } }, \mathcal { I } _ { i } ) \right ) \| _ { \infty }$$
$$\begin{array} { c } \underset { i } { \sup } 2 ^ { M - 1 } \cdot \sup _ { \tilde { I } } \| \Delta \bar { v } ( \tilde { \mathcal { I } }, \mathcal { I } _ { i } ) - \Delta v ( \tilde { \mathcal { I } }, \mathcal { I } _ { i } ) \| _ { \infty } \\ \dots \cdot \end{array}$$
$$\begin{matrix} & & i & & \mathcal { I } \\ & & \leqslant 2 ^ { M - 1 } \cdot \left \{ \frac { V a r ( \Delta \bar { v } ) } { K } \right \} ^ { \frac { 1 } { 2 } } & & & \\ & & & & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \ \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \ & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad &\quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad \\ \quad & \leqslant & 2 ^ { M - 1 } \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \dot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot
\end{matrix}$$
$$= \sup _ { i } 2 ^ { M - 1 } \cdot \sup _ { \tilde { \mathcal { I } } } \| \Delta \tilde { v } ( \tilde { \mathcal { I } }, \mathcal { I } _ { i } ) - \Delta v ( \tilde { \mathcal { I } }, \mathcal { I } _ { i } ) \| _ { 1 } \\.$$
where V ar p ∆¯ v q gives the upper bound of the variance of ∆¯ v p ˜ I I , i q . | null | [
"Róisín Luo",
"James McDermott",
"Colm O'Riordan"
] | 2024-08-02T09:35:06+00:00 | 2024-08-18T17:13:31+00:00 | [
"cs.AI",
"cs.CV"
] | Interpreting Global Perturbation Robustness of Image Models using Axiomatic Spectral Importance Decomposition | Perturbation robustness evaluates the vulnerabilities of models, arising from
a variety of perturbations, such as data corruptions and adversarial attacks.
Understanding the mechanisms of perturbation robustness is critical for global
interpretability. We present a model-agnostic, global mechanistic
interpretability method to interpret the perturbation robustness of image
models. This research is motivated by two key aspects. First, previous global
interpretability works, in tandem with robustness benchmarks, e.g. mean
corruption error (mCE), are not designed to directly interpret the mechanisms
of perturbation robustness within image models. Second, we notice that the
spectral signal-to-noise ratios (SNR) of perturbed natural images exponentially
decay over the frequency. This power-law-like decay implies that: Low-frequency
signals are generally more robust than high-frequency signals -- yet high
classification accuracy can not be achieved by low-frequency signals alone. By
applying Shapley value theory, our method axiomatically quantifies the
predictive powers of robust features and non-robust features within an
information theory framework. Our method, dubbed as \textbf{I-ASIDE}
(\textbf{I}mage \textbf{A}xiomatic \textbf{S}pectral \textbf{I}mportance
\textbf{D}ecomposition \textbf{E}xplanation), provides a unique insight into
model robustness mechanisms. We conduct extensive experiments over a variety of
vision models pre-trained on ImageNet to show that \textbf{I-ASIDE} can not
only \textbf{measure} the perturbation robustness but also \textbf{provide
interpretations} of its mechanisms. |
2408.01140v1 | ## Self-Excited Gravitational Instantons
Martin Krˇ sˇ´k sa 1,2, ∗
1
Department of Theoretical Physics, Faculty of Mathematics, Physics and Informatics, Comenius University in Bratislava, 84248, Slovak Republic 2 Department of Astronomy, School of Astronomy and Space Science, University of Science and Technology of China, Hefei, Anhui 230026, China (Dated: August 5, 2024)
We present a novel approach to constructing gravitational instantons based on the observation that the gravitational action of general relativity in its teleparallel formulation can be expressed as a product of the torsion and excitation forms. We introduce a new class of solutions where these two forms are equal, which we term the self-excited instantons, and advocate for their use over the self-dual instantons of Eguchi and Hanson. These new self-excited instantons exhibit striking similarities to BPST instantons in Yang-Mills theory, as their action reduces to a topological NiehYan term, which allows us to identify the axial torsion as a topological current and to define a topological charge.
## INTRODUCTION
Finite Euclidean action solutions, known as instantons, are essential for understanding the non-perturbative aspects of quantum field theories [1-4]. In the Yang-Mills case, we consider a gauge connection A with a field strength F = DA = dA + A ∧ A , which satisfies the field equations
The BPST instanton solution was instrumental in understanding the non-trivial structure of the vacuum [6], tunneling between different vacuum states [7], and establishing the use of differential geometry and topology in the study of gauge theories [3, 4, 8].
$$D F = 0, \quad D * F = 0, \quad \quad ( 1 ) \quad \stackrel { \cdots \circ } { \text{the} }$$
where ⋆ is the Hodge dual operator. The first equation is the Bianchi identity, which the field strength F automatically satisfies, and the second one is derived from the action
$$\mathcal { S } _ { \text{YM} } = \int _ { \mathcal { M } } \text{Tr} \, F \wedge * F. \quad \quad ( 2 ) \quad ( \begin{matrix} \lim \\ \end{matrix} )$$
Following the BPST construction [5], we consider solutions with an (anti) self-dual field strength F = ± ⋆ F , which obeys the Bianchi identity and consequently satisfies the second field equation as well. Thus, by solving the relatively simpler (anti) self-duality condition, we can solve more complicated field equations (1).
While this simplification is useful, the truly intriguing aspect of the BPST solution is that the action (2) reduces to a topological term
$$\tilde { \mathcal { S } } _ { \text{YM} } = \pm \int _ { \mathcal { M } } \text{Tr} \, F \wedge F = \pm \int _ { \mathcal { M } } d \mathcal { K } = \pm 8 \pi ^ { 2 } k, \quad ( 3 ) \quad \text{Te}$$
where K is the Chern-Simons form. Applying Stokes' theorem, we find that the integral of K over well-behaved connections at infinity is not only finite but equal to the integer k , known as the winding or instanton number.
Moreover, it is possible to show that the lower bound for the Yang-Mills action, known as the BPS bound, is
$$S _ { Y M } \geq 8 \pi ^ { 2 } | k |, \quad \ \ \ ( 4 ) \quad -$$
and hence the BPST instantons are the absolute minima of the action and represent the dominant contribution. to the path integral.
With a motivation to gain a deeper understanding of the non-perturbative structure of gravity, the idea of selfdual gravitational instantons was introduced by Hawking [9], and followed by Eguchi and Hanson who found the first self-dual solution of the Einstein field equations [10-12]. While the Eguchi-Hanson construction simplifies solving the field equations along the lines of the BPST approach, its action is not associated with any topological term in the Riemannian geometry, what considerably limits the analogy with the Yang-Mills case.
Our goal here is to demonstrate that by considering a new kind of self-excited solutions, which appear naturally in the teleparallel formulation of general relativity [1315], we can reduce the gravitational action to the NiehYan topological term. We argue that this provides a better gravitational analogy to the BPST construction.
## SELF-DUAL INSTANTONS IN GENERAL RELATIVITY
Let us first introduce general relativity in Cartan's formalims of differential forms [16]. The basic variables are the (co-)tetrad 1-forms h a = h a µ dx µ , related to the metric tensor through g µν = δ ab h a µ h b ν , where δ ab = diag 1 1 1 1 ( , , , ) in the Euclidean case . 1
The connection form is an a priori independent variable, but in the case of the Riemannian connection (denoted by ○ ), ○ ω a b is fully determined from the tetrad by
1 Since the Latin indices are raised/lowered by the Euclidean metric δ ab , we do not have to care about their position, and summation convention applies whenever some index is repeated twice.
conditions of metric compatibility, implying ○ ω ab = -○ ω ba , and vanishing torsion
$$0 = d h ^ { a } + \stackrel { \circ } { \omega } ^ { a } _ { b } \wedge h ^ { b }. \quad \quad \ \ ( 5 ) \quad \text{is}$$
The curvature 2-form ○ R a b = 1 2 ○ R a bµν dx µ ∧ dx ν , where ○ R α βµν = h a α h b β ○ R a bµν are the components of the Riemannian curvature tensor, is fully determined by
$$\stackrel { \circ } { \mathcal { R } } ^ { a } _ { b } \ = \ d \stackrel { \circ } { \omega } ^ { a } _ { b } + \stackrel { \circ } { \omega } ^ { a } _ { c } \wedge \stackrel { \circ } { \omega } ^ { c } _ { b }. \quad \quad ( 6 ) \quad \text{ins} ^ { 1 }$$
In general relativity, gravity is described using the Riemannian geometry of spacetime, the dynamics of which is derived from the Hilbert action
$$\mathcal { S } _ { \text{EH} } = - \int _ { \mathcal { M } } h \stackrel { \circ } { R } d ^ { 4 } x = - \int _ { \mathcal { M } } \stackrel { \circ } { \mathcal { R } } _ { a b } \wedge \ast ( h ^ { a } \wedge h ^ { b } ), \ \ ( 7 ) \quad \text{TEL}$$
where h = det h a µ , ○ R = ○ R αβ αβ is the Ricci scalar, in units 16 πG c / 4 = 1.
Following the Eguchi-Hanson construction [10-12], we first introduce the dual curvature ☆R ○ ab = 1 2 /epsilon1 abcd ○ R cd , which allows us to write the Einstein field equations as
$$\ast \overset { \circ } { \mathcal { R } } ^ { a } _ { b } \wedge h ^ { b } = 0. \quad \quad \quad ( 8 )$$
The (anti) self-dual curvature ○ R ab = ± ☆ R ○ ab then automatically satisfies the Einstein field equations (8) on the account of the Bianchi identity ○ R a b ∧ h b = 0, and implies (anti) self-duality of the connection
$$\overset { \circ } { \omega } _ { a b } = \pm \overset { \circ } { \tilde { \omega } } _ { a b }.$$
Eguchi and Hanson then considered an ansatz
$$h ^ { a } = ( f d r, r \sigma _ { x }, r \sigma _ { y }, r g \sigma _ { z } ), \quad \quad ( 1 0 )$$
where σ i are the SU ( 2 ) Cartan-Maurer forms on S 3
$$\sigma _ { x } = \frac { 1 } { 2 } ( \sin \psi d \theta - \sin \theta \cos \psi d \phi ), \quad \ \ ( 1 1 ) \quad \ \ t e l e _ { 1 } ^ { \ w m }$$
$$\sigma _ { x } = \frac { \overline { 1 } } { 2 } ( \sin \psi d \theta - \sin \theta \cos \psi d \phi ), \quad \ \ ( 1 2 ) \quad \ n i a l$$
$$\sigma _ { z } = \frac { \tilde { 1 } } { 2 } ( d \psi - \cos \theta d \phi ), \quad \quad ( 1 3 ) \quad \quad \text{when}$$
and found a solution
$$f ^ { 2 } = g ^ { - 2 } = 1 - \frac { a ^ { 4 } } { r ^ { 4 } }. \quad \quad \ \ ( 1 4 )$$
The process of finding this solution is indeed analogous to the BPST method: instead of solving the field equations (8) directly, we solve the self-duality condition (9), and our solution is then guaranteed to automatically solve the field equations as well.
However, there are some significant differences including the fact that ☆ is not the usual Hodge dual but rather the 'tangent space Hodge dual' [17], which acts on the algebraic indices of differential forms.
The key difference is that, while the BPST action is a topological term (3), the full gravitational actionincluding the Gibbons-Hawking boundary terms and appropriate counterterms [18]-is not associated with any topological term in Riemannian geometry. There are two other topological terms, the Euler class χ and Pontryagin class P 1 (see Table I), which can be used to classify instantons [8, 10]. However, these are quadratic in curvature and thus cannot be related to the action. As a consequence, we cannot discuss any topological aspects of the gravitational action, which, in our view, limits the analogy with the BPST construction.
## TELEPARALLEL FORMULATION OF GENERAL RELATIVITY
Teleparallel gravity is a reformulation of general relativity [14, 15], where instead of the Riemannian connection ○ ω a b , we use the teleparallel connection ω a b , defined in a complimentary way as a metric connection with vanishing curvature
$$d \omega ^ { a } _ { \, b } + \omega ^ { a } _ { \, c } \wedge \omega ^ { c } _ { \, b } = 0, \text{ \quad \quad } ( 1 5 )$$
which has generally non-vanishing teleparallel torsion
$$T ^ { a } = d h ^ { a } + \omega ^ { a } _ { \, b } \wedge h ^ { b },$$
and satisfies the Bianchi identity
$$D T ^ { a } \equiv d T ^ { a } + \omega ^ { a } _ { \, b } \wedge T ^ { b } = 0. \quad \quad ( 1 7 )$$
We can then consider d h ( a ∧ T a ) and by straightforwardly applying (16) and (17) we find
$$d ( h ^ { a } \wedge T _ { a } ) = T ^ { a } \wedge T _ { a }, \text{ \quad \ \ } ( 1 8 )$$
which is just the Nieh-Yan identity [19] for the flat teleparallel connection.
The teleparallel connection is related to the Riemannian connection by the Ricci theorem
$$\omega ^ { a } _ { \, b } = \stackrel { \circ } { \omega } ^ { a } _ { \, b } + K ^ { a } _ { \, b },$$
where K a b is the contortion 1-form related to the torsion as T a = K a b ∧ h b . Using (19) we can rewrite the Ricci scalar in terms of teleparallel geometric quantities as [13]
$$- \overset { \circ } { R } = T + \frac { 2 } { h } \partial _ { \mu } ( T ^ { \nu \mu } _ { \nu } ), \text{ \quad \ \ } ( 2 0 )$$
where T is the teleparallel torsion scalar
$$T = \frac { 1 } { 4 } T _ { \rho \mu \nu } T ^ { \rho \mu \nu } + \frac { 1 } { 2 } T _ { \rho \mu \nu } T ^ { \nu \mu \rho } - T ^ { \nu } _ { \ \mu \nu } T ^ { \rho \mu } _ { \ \rho }. \quad ( 2 1 )$$
The idea of teleparallel gravity is to consider an action given by the torsion scalar (21), which is guaranteed to
be dynamically equivalent to general relativity since it differs from the Ricci scalar only by a total derivative (20). This can be understood as removing the problematic total derivative term hidden in the Hilbert action and geometrically covariantizing the remaining bulk Einstein action [15, 20, 21].
The key observation is that since the torsion scalar is quadratic in torsion, the teleparallel action can be naturally written as a product of two forms [22, 23]
$$\mathcal { S } _ { \text{TG} } = \int _ { \mathcal { M } } h T d ^ { 4 } x = \int _ { \mathcal { M } } T ^ { a } \wedge H _ { a }, \quad \ \ ( 2 2 ) \quad \ \ \ \ \ \ w h e$$
where H a = 1 2 H a ρσ dx ρ ∧ dx σ is the so-called excitation form, the components of which are given by
$$H ^ { a } _ { \ \rho \sigma } = h \epsilon _ { \rho \sigma \alpha \beta } \left ( \frac { 1 } { 4 } T ^ { a \alpha \beta } + \frac { 1 } { 2 } T ^ { \alpha a \beta } - h ^ { a \beta } T ^ { \alpha } \right ), \quad ( 2 3 ) \quad \text{(3)} \quad \text{(the $\varepsilon$)}$$
where /epsilon1 ρσαβ is the Levi-Civita symbol with /epsilon1 0123 = 1.
Varying (22) with respect to h a , we obtain the vacuum field equations
$$\ D H ^ { a } + E ^ { a } \ = \ 0. \quad \quad \quad ( 2 4 )$$
where E a is the gravitational energy-momentum current form, and variation with respect to ω a b is trivial [24, 25] These equations are fully equivalent to the Einstein field equations, but have a form strikingly similar to the YangMills theory.
## SELFEXCITED INSTANTONS IN TELEPARALLEL GRAVITY
Let us start with an observation that self-duality is not required to show that the BPST action is topological (3). The whole construction would work more generally if we would replace ⋆ F by H in (2), considered F = ± H , and (3) would still follow from Bianchi identities. This goes in the spirit of the premetric or axiomatic electromagnetism, which suggests to treat electromagnetism more generally in terms of F and H , and then view the Maxwell electromagnetism only as a special case of the constitutive relation H = ⋆ F [26, 27].
Motivated by this observation and the recent works suggesting that teleparallel gravity can be treated in a similar way [28-30], we consider a new class of solutions where the torsion form is (up to a sign) equal to the excitation form. Instead of (anti) self-dual solutions, we have then (anti) self-excited solutions
$$T ^ { a } = \pm H ^ { a }. \text{ \quad \ \ } ( 2 5 )$$
It is obvious that we again obtain automatic solutions of the field equations since torsion automatically obeys the Bianchi identity and we have then DT a = ± DH a = 0. This also implies vanishing gravitational energymomentum current E a = 0 for our (anti) self-excited solutions.
The novelty compared to Eguchi-Hanson is that for (anti) self-excited solutions (25) the action (22) reduces to the Nieh-Yan term (18), and we can write it as
$$\inf _ { \substack { \i d \\ \mathcal { B } } _ { \text{TG} } } = \pm \int _ { \mathcal { M } } T ^ { a } \wedge T _ { a } = \pm \int _ { \mathcal { M } } d ( h ^ { a } \wedge T _ { a } ) = \pm \mathcal { N }. \quad ( 2 6 )$$
The total derivative term is the so-called axial torsion, which can be written in components as
$$d ( h ^ { a } \wedge T _ { a } ) = \frac { 1 } { 2 } \partial _ { \mu } ( \epsilon ^ { \mu \nu \rho \sigma } T _ { \nu \rho \sigma } ) d ^ { 4 } x = 3 \left ( \partial _ { \mu } a ^ { \mu } \right ) d ^ { 4 } x, \ \ ( 2 7 )$$
where a µ = 1 6 /epsilon1 µνρσ T νρσ [13].
Applying the Stokes' theorem, we find that the action is given only by the asymptotic value of the axial torsion, and we denote its value as the Nieh-Yan charge N . The axial torsion then plays the role of the Chern-Simons current and the Nieh-Yan charge is analogous to the instanton number.
## EXAMPLES
We can verify that the Eguchi-Hanson instanton (10)(14) is a self-excited solution. Here, it is essential to address the role of the teleparallel connection ω a b in teleparallel gravity. While this connection is not dynamical, it is relevant for determining the value of the action [20, 31]. To illustrate this, we consider the ansatz (10) in the socalled the Weitzenb¨ck gauge o ω a b = 0 [22], and confirm that it is indeed a self-excited solution (25). However, the axial torsion behaves as ∝O ( r 2 ) , causing the action to diverge.
The well-known solution is to consider a reference tetrad 0 h a = ( dr, rσ x , rσ y , rσ z ) and calculate the teleparallel connection as the Riemannian connection of the reference tetrad ω a b = ○ ω a b ( 0 h a ) [14, 20, 31]. We can then check that the resulting torsion remains self-excited, but the asymptotic behavior of the axial torsion is changed to ∝ O ( r -6 ) , which vanishes at infinity. We then find that the Nieh-Yan charge vanishes and hence recover the Eguchi-Hanson result that the full gravitational action for their instanton is zero [10]. This is consistent with our recent argument that the teleparallel action (22) with a suitably chosen teleparallel connection is fully equivalent to the full general relativity action including all boundary and counterterms [20]. See [15, 21] as well.
An example with a non-trivial topological charge can be obtained using ω a b = 0 and an ansatz
$$h ^ { a } = ( f d r, g \, \sigma _ { x }, g \, \sigma _ { y }, g \, \sigma _ { z } ), \quad \quad ( 2 8 )$$
which was considered in [32] with f = r -1 , g = 1, while in [33] authors have used 2 f = ± g ′ , obtained from the (anti) self-duality condition T a = ± ⋆ T a . While both these choices of f and g can be used to calculate the non-trivial Nieh-Yan charge (26), the problem is that they are not actually solutions of the field equations.
TABLE I. A comparison of self-dual and self-excited solutions in Yang-Mills theory, general relativity, and teleparallel gravity.
| | Yang-Mills Theory | General Relativity | Teleparallel Gravity |
|--------------------------|---------------------|------------------------------------------------------|---------------------------------|
| Basic variables | A | h a | h a , ω a b |
| Field strength | F = DA = dA + A ∧ A | ○ R a b = dω ○ a b + ○ ω a c ∧ ○ ω c b | T a = Dh a = dh a + ω a b ∧ h b |
| Action | ∫ Tr F ∧⋆ F | - ∫ ○ R ab ∧⋆ ( h a ∧ h b ) | ∫ T a ∧ H a |
| Bianchi identity | DF = 0 | ○ R a b ∧ h b = 0 | DT a = 0 |
| Field equations | D ⋆ F = 0 | ☆R ○ a b ∧ h b = 0 | DH a + E a = 0 |
| Self-dual field strength | F = ±⋆ F | ○ R ab = ±☆R ○ ab | T a = ± H a |
| Self-dual solution | F = ±⋆ F | ○ ω a b = ±☆ ○ ω a b | T a = ± H a |
| Topological term(s) | ∫ Tr F ∧ F | ∫ /epsilon1 abcd ○ R ab ∧ ○ R cd ∫ ○ R a b ∧ ○ R b a | ∫ T a ∧ T a |
| Topological charge(s) | k | χ,P 1 | N |
In contrast, our (anti) self-excitement condition (25) coincidentally implies a similar result f = ± g ′ , which, crucially, does solve the field equations (24). We find that the axial torsion can be written as
$$h ^ { a } \wedge T _ { a } = 6 g ^ { 2 } \, \sigma _ { x } \wedge \sigma _ { y } \wedge \sigma _ { z }. \quad \ \ ( 2 9 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
For all functions that goes as g → 1 at r → ∞ , and using
## DISCUSSION AND CONCLUSIONS
Let us explain the relation between our results and previous works. The Nieh-Yan term was originally discovered in Riemann-Cartan geometry [19], which is the underlying geometry of various metric-affine theories of gravity [34-36]. In these theories, torsion appears in addition to curvature, representing additional degrees of freedom compared to general relativity. The NiehYan term then emerges as an additional topological term alongside the Euler and Pontryagin terms, and it is relevant for the axial anomaly because the axial torsion couples directly to fermionic fields in metric-affine gravity [37]. Most of the previous works discussing torsional instantons or the Nieh-Yan term were conducted either in this context [32, 33, 38], or various axion-like modified gravity theories [39-45].
This differs significantly from our approach and overall philosophy, as we consider the teleparallel formulation of general relativity, where torsion represents the same degrees of freedom as in general relativity [15]. Nevertheless, these previous works are relevant to us, particularly [32, 33, 38], where the authors have simplified their analysis of torsional instantons by setting curvature to zero, thereby reducing their Riemann-Cartan geometry to teleparallel geometry. However, with a primary motivation being the metric-affine gravity, their intention was to present just illustrative examples of the non- that the volume of S 3 is ∫ S 3 σ x ∧ σ y ∧ σ z = 2 π 2 , we obtain the Nieh-Yan charge as
$$\mathcal { N } = 1 2 \, \pi ^ { 2 },$$
which is the same result as obtained in [32] since the axial torsion (29) is independent of f . Note that the Nieh-Yan charge does not depend on the functions f and g , as expected from a topological charge.
trivial Nieh-Yan term (18) without specifying the action of the theory. This explains why they calculated the Nieh-Yan term for some teleparallel torsion without addressing whether this torsion actually satisfies any field equations.
In contrast, we discuss teleparallel gravity given by the action (22), where torsion must satisfy the Einstein field equations in their teleparallel form (24). For the example (28), this results in the relation f = ± g ′ . However, since the Nieh-Yan charge is independent of f and g , we still obtain the same result [32].
Our work was originally motivated by the premetric approach to gravity [28-30] and the new kind of selfduality introduced in discussion of linearized gravity [46]. This new self-duality was meant in terms of a novel 'soldered' duality operator ⊛ , which would allow us to write the excitation form as H a = ⊛ T a [13, 47]. However, the recent analysis has shown that this operator is not welldefined [48], and our results here demonstrate that such an operator is actually not needed.
Indeed, our work suggests that the concept of selfexcitement is more useful than self-duality in gravity theories. It naturally provides a gravitational analogue of the BPST solution, which not only automatically satisfies the field equations but also has an action that reduces to a topological term, allowing us to define a topological charge. We anticipate that this approach will open up new perspective for studying the topological aspects
of the gravitational action and, hopefully, provide important insights similar to those obtained in Yang-Mills theory.
This leads us to the final question of the relevance of self-duality in instanton construction and whether it can be completely replaced by the concept of self-excited solutions. Returning to the BPST case, we can recognize that self-duality plays an important role in the proof of the BPS bound (4), where ⋆ F cannot be replaced by H .
Therefore, we do not expect an analogue of the BPS bound for our (anti) self-excited solutions. While this certainly limits their importance for the Euclidean quantization [49], as we cannot prove that they are the dominant contribution to the path integral, it is consistent with the well-known result that the gravitational action is not bounded from below [50]. We hope that our approach will provide a better understanding of this problem using the topological insights offered by our construction.
## ACKNOWLEDGEMENTS
This work was funded through SASPRO2 project AGE of Gravity: Alternative Geometries of Gravity , which has received funding from the European Union's Horizon 2020 research and innovation programme under the Marie Sk/suppressodowska-Curie grant agreement No. l 945478.
- ∗ [email protected], [email protected]
- [1] A. I. Vainshtein, V. I. Zakharov, V. A. Novikov, and M. A. Shifman, ABC's of Instantons , Sov. Phys. Usp. 25 (1982) 195.
- [2] S. R. Coleman, The Uses of Instantons , Subnucl. Ser. 15 (1979) 805.
- [3] N. S. Manton and P. Sutcliffe, Topological solitons . Cambridge University Press, 2004.
- [4] C. Nash and S. Sen, Topology and Geometry for Physicists . Academic Press, 1983.
- [5] A. A. Belavin, A. M. Polyakov, A. S. Schwartz, and Y. S. Tyupkin, Pseudoparticle Solutions of the Yang-Mills Equations , Phys. Lett. B 59 (1975) 85-87.
- [6] C. G. Callan, Jr., R. F. Dashen, and D. J. Gross, The Structure of the Gauge Theory Vacuum , Phys. Lett. B 63 (1976) 334-340.
- [7] G. 't Hooft, Computation of the Quantum Effects Due to a Four-Dimensional Pseudoparticle , Phys. Rev. D 14 (1976) 3432-3450. [Erratum: Phys.Rev.D 18, 2199 (1978)].
- [8] T. Eguchi, P. B. Gilkey, and A. J. Hanson, Gravitation, Gauge Theories and Differential Geometry , Phys. Rept. 66 (1980) 213.
- [9] S. W. Hawking, Gravitational Instantons , Phys. Lett. A 60 (1977) 81.
- [10] T. Eguchi and A. J. Hanson, Selfdual Solutions to Euclidean Gravity , Annals Phys. 120 (1979) 82.
- [11] T. Eguchi and A. J. Hanson, Asymptotically Flat Selfdual Solutions to Euclidean Gravity , Phys. Lett. B 74 (1978) 249-251.
- [12] T. Eguchi and A. J. Hanson, Gravitational Instantons , Gen. Rel. Grav. 11 (1979) 315-320.
- [13] R. Aldrovandi and J. G. Pereira, Teleparallel Gravity: An Introduction . Springer, Dordrechts, 2012.
- [14] M. Krˇ sˇ´k, R. J. van den Hoogen, J. G. Pereira, C. G. sa B¨ ohmer, and A. A. Coley, Teleparallel theories of gravity: illuminating a fully invariant approach , Class. Quant. Grav. 36 (2019), no. 18 183001, [ arXiv:1810.12932 ].
- [15] M. Krˇ sˇ´k, sa Teleparallel Gravity, Covariance and Their Geometrical Meaning , in Tribute to Ruben Aldrovandi (F. Caruso, J.G. Pereira and A. Santoro, ed.). Editora Livraria da F´ ısica, S˜o Paulo, 2024. a arXiv:2401.08106 .
- [16] M. Fecko, Differential geometry and Lie groups for physicists . Cambridge University Press, 2011.
- [17] U. Kol and S.-T. Yau, Duality in Gauge Theory, Gravity and String Theory , arXiv:2311.07934 .
- [18] G. W. Gibbons and S. W. Hawking, Action Integrals and Partition Functions in Quantum Gravity , Phys. Rev. D15 (1977) 2752-2756.
- [19] H. T. Nieh and M. L. Yan, An Identity in Riemann-cartan Geometry , J. Math. Phys. 23 (1982) 373.
- [20] M. Krˇ sˇ´k, sa Einstein Gravity from Einstein Action: Counterterms and Covariance , arXiv:2406.08452 .
- [21] M. Krˇ sˇ´k, sa Bulk action growth for holographic complexity , Phys. Rev. D 109 (2024), no. 8 086002, [ arXiv:2308.04354 ].
- [22] Yu. N. Obukhov and J. G. Pereira, Metric affine approach to teleparallel gravity , Phys. Rev. D67 (2003) 044016, [ gr-qc/0212080 ].
- [23] T. G. Lucas, Y. N. Obukhov, and J. G. Pereira, Regularizing role of teleparallelism , Phys. Rev. D80 (2009) 064043, [ arXiv:0909.2418 ].
- [24] M. Krˇ sˇ´k, sa Holographic Renormalization in Teleparallel Gravity , Eur. Phys. J. C77 (2017), no. 1 44, [ arXiv:1510.06676 ].
- [25] A. Golovnev, T. Koivisto, and M. Sandstad, On the covariance of teleparallel gravity theories , Class. Quant. Grav. 34 (2017), no. 14 145013, [ arXiv:1701.06271 ].
- [26] F. W. Hehl and Y. N. Obukhov, Foundations of classical electrodynamics . Birkh¨user Boston, 2003. a
- [27] F. W. Hehl, Y. Itin, and Y. N. Obukhov, On Kottler's path: origin and evolution of the premetric program in gravity and in electrodynamics , Int. J. Mod. Phys. D 25 (2016), no. 11 1640016, [ arXiv:1607.06159 ].
- [28] Y. Itin, F. W. Hehl, and Y. N. Obukhov, Premetric equivalent of general relativity: Teleparallelism , Phys. Rev. D 95 (2017), no. 8 084020, [ arXiv:1611.05759 ].
- [29] M. Hohmann, L. J¨ arv, M. Krˇ sˇ´k, and C. Pfeifer, sa Teleparallel theories of gravity as analogue of nonlinear electrodynamics , Phys. Rev. D 97 (2018), no. 10 104042, [ arXiv:1711.09930 ].
- [30] Y. Itin, Y. N. Obukhov, J. Boos, and F. W. Hehl, Premetric teleparallel theory of gravity and its local and linear constitutive law , Eur. Phys. J. C 78 (2018), no. 11 907, [ arXiv:1808.08048 ].
- [31] M. Krˇ sˇ´k and J. G. Pereira, sa Spin Connection and Renormalization of Teleparallel Action , Eur. Phys. J. C75 (2015), no. 11 519, [ arXiv:1504.07683 ].
- [32] O. Chandia and J. Zanelli, Topological invariants, instantons and chiral anomaly on spaces with torsion , Phys. Rev. D 55 (1997) 7580, [ hep-th/9702025 ].
- [33] Y. N. Obukhov, E. W. Mielke, J. Budczies, and F. W. Hehl, On the chiral anomaly in non-Riemannian spacetimes , Found. Phys. 27 (1997) 1221-1236, [ gr-qc/9702011 ].
- [34] F. W. Hehl, P. Von Der Heyde, G. D. Kerlick, and J. M. Nester, General Relativity with Spin and Torsion: Foundations and Prospects , Rev. Mod. Phys. 48 (1976) 393-416.
- [35] F. W. Hehl, J. D. McCrea, E. W. Mielke, and Y. Ne'eman, Metric affine gauge theory of gravity: Field equations, Noether identities, world spinors, and breaking of dilation invariance , Phys. Rept. 258 (1995) 1-171, [ gr-qc/9402012 ].
- [36] M. Blagojevic and M. Vasilic, Gauge symmetries of the teleparallel theory of gravity , Class. Quant. Grav. 17 (2000) 3785-3798, [ hep-th/0006080 ].
- [37] Y. N. Obukhov, Spectral Geometry of the Riemann-Cartan Spacet-Time and the Axial Anomaly , Phys. Lett. B 108 (1982) 308-310.
- [38] S. Li, The Topological structure of Nieh-Yan form and chiral anomaly in spaces with torsion , J. Phys. A 32 (1999) 7153-7162, [ hep-th/9905058 ].
- [39] E. W. Mielke and E. S. Romero, Cosmological evolution of a torsion-induced quintaxion , Phys. Rev. D 73 (2006) 043521.
- [40] E. W. Mielke, Topologically modified teleparallelism, passing through the Nieh-Yan functional , Phys. Rev. D 80 (2009) 067502.
- [41] M. Li, H. Rao, and D. Zhao, A simple parity violating gravity model without ghost instability , JCAP 11 (2020)
- 023, [ arXiv:2007.08038 ].
- [42] M. Hohmann and C. Pfeifer, Teleparallel axions and cosmology , Eur. Phys. J. C 81 (2021), no. 4 376, [ arXiv:2012.14423 ].
- [43] A. Chatzistavrakidis, G. Karagiannis, G. Manolakos, and P. Schupp, Axion gravitodynamics, Lense-Thirring effect, and gravitational waves , Phys. Rev. D 105 (2022), no. 10 104029, [ arXiv:2111.04388 ].
- [44] M. Li, H. Rao, and Y. Tong, Revisiting a parity violating gravity model without ghost instability: Local Lorentz covariance , Phys. Rev. D 104 (2021), no. 8 084077, [ arXiv:2104.05917 ].
- [45] M. Li and H. Rao, Irregular universe in the Nieh-Yan modified teleparallel gravity , Phys. Lett. B 841 (2023) 137929, [ arXiv:2301.02847 ].
- [46] V. C. de Andrade, A. L. Barbosa, and J. G. Pereira, Gravitation and duality symmetry , Int. J. Mod. Phys. D 14 (2005) 1635-1648, [ gr-qc/0501037 ].
- [47] T. G. Lucas and J. G. Pereira, Hodge dual for soldered bundles , J. Phys. A 42 (2009) 035402, [ arXiv:0811.2066 ].
- [48] M. Horˇ´ ak, n Duality operator in teleparallel gravity , Master's thesis, Department of Theoretical Physics, Comenius University in Bratislava (2024) [ arXiv:2407.00691 ].
- [49] S. W. Hawking, Euclidean Quantum Gravity , NATO Sci. Ser. B 44 (1979) 145.
- [50] G. W. Gibbons, S. W. Hawking, and M. J. Perry, Path Integrals and the Indefiniteness of the Gravitational Action , Nucl. Phys. B 138 (1978) 141-150. | null | [
"Martin Krššák"
] | 2024-08-02T09:36:05+00:00 | 2024-08-02T09:36:05+00:00 | [
"gr-qc",
"hep-th",
"math-ph",
"math.MP"
] | Self-Excited Gravitational Instantons | We present a novel approach to constructing gravitational instantons based on
the observation that the gravitational action of general relativity in its
teleparallel formulation can be expressed as a product of torsion and
excitation forms. We introduce a new class of solutions where these two forms
are equal, which we term the self-excited instantons, and advocate for their
use over the self-dual instantons of Eguchi and Hanson. These new self-excited
instantons exhibit striking similarities to BPST instantons in Yang-Mills
theory, as their action reduces to a topological Nieh-Yan term, which allows us
to identify the axial torsion as a topological current and to define a
topological charge. |
2408.01141v1 | ## Machine learning topological energy braiding of non-Bloch bands
Shuwei Shi, 1,2 Shibing Chu, 1,2, ∗ Yuee Xie, 1,2 and Yuanping Chen 1,2, † 1 School of Physics and Electronic Engineering, Jiangsu University, Zhenjiang, Jiangsu 212013, People's Republic of China 2 Jiangsu Engineering Research Center on Quantum Perception and Intelligent Detection of Agricultural Information, Zhenjiang 212013, People's Republic of China
(Dated: August 5, 2024)
Machine learning has been used to identify phase transitions in a variety of physical systems. However, there is still a lack of relevant research on non-Bloch energy braiding in non-Hermitian systems. In this work, we study non-Bloch energy braiding in one-dimensional non-Hermitian systems using unsupervised and supervised methods. In unsupervised learning, we use diffusion maps to successfully identify non-Bloch energy braiding without any prior knowledge and combine it with k-means to cluster different topological elements into clusters, such as Unlink and Hopf link. In supervised learning, we train a Convolutional Neural Network (CNN) based on Bloch energy data to predict not only Bloch energy braiding but also non-Bloch energy braiding with an accuracy approaching 100% . By analysing the CNN, we can ascertain that the network has successfully acquired the ability to recognise the braiding topology of the energy bands. The present study demonstrates the considerable potential of machine learning in the identification of non-Hermitian topological phases and energy braiding.
## I. INTRODUCTION
In nature, braids and knots are prevalent structural forms across various fields[1]. These concepts are often employed to describe topological phase transitions, where systems with braiding structures exhibit rich and stable topological properties. Unlike Hermitian systems, non-Hermitian systems feature complex eigenenergies, leading to unique phenomena such as exceptional points[2-7] and non-Hermitian skin effect[8-14]. Studies have shown that the complex energy bands in one-dimensional non-Hermitian systems can form intricate and diverse braiding topologies, which are classified through the conjugacy classes of braid groups[11, 1522]. These complex braiding structures have been experimentally verified on platforms including photonic systems[19, 23], acoustic systems[22, 24, 25] and quantum circuits[26]. However, identifying complex energy braiding[27], especially non-Bloch braiding[28], remains challenging. An efficient identification method is urgently needed.
Machine learning methods have rapidly developed and found applications in fields such as image recognition[29, 30], natural language processing[23], recommender systems[31], and motion data analysis[32]. Their powerful ability to analyze large-scale data and uncover hidden patterns has led to advances in condensed matter physics, quantum physics, and astrophysics[33]. In physics, supervised learning has been used to identify phase transitions and topological invariants[34, 35]. Unsupervised methods, such as diffusion maps combined with k-means, can identify phase transition points and Bloch braiding quickly and in a purely data-driven manner without prior physical knowledge[27, 36-40]. However, most current research has focused on Bloch bands under periodic boundary conditions, yielding idealized results.
∗ [email protected]
† [email protected]
Non-Hermitian systems under open boundary conditions are more representative of realistic systems, exhibiting phenomena such as the non-Hermitian skin effect, where eigenenergies collapse. This disrupts the topological braids of the Bloch bands and invalidates the topological invariants defined in the Brillouin zone, making non-Bloch braiding identification more challenging[28].
In this work, we utilize diffusion maps and Convolutional Neural Networks (CNN) to predict energy braiding in nonHermitian systems. We employ diffusion maps to identify non-Bloch braiding without prior knowledge and train a CNN to predict Bloch energy braiding, achieving high accuracy even for topological elements not included in the training set. Our study demonstrates the potential of machine learning for studying phase transitions and energy braiding in nonHermitian systems.
## II. ALGORITHMS
## A. unsupervised algorithm
When trying to identify topological phase transitions in non-Hermitian systems, linear downscaling methods (e.g., PCA) may not be effective in capturing the topology structure because they assume that the main direction of change in the data is linear. In contrast, nonlinear dimensionality reduction methods (e.g., diffusion maps) can capture the topology structure by constructing a neighbourhood map that preserves this nonlinear structure in the low-dimensional space[36].
For example, consider a two-band non-Hermitian system with the Hamiltonian expressed as:
$$H ( k ) = d ( k ) \hat { \sigma } = d _ { x } ( k ) \hat { \sigma } _ { x } + d _ { y } ( k ) \hat { \sigma } _ { y } + d _ { z } ( k ) \hat { \sigma } _ { z }, \quad ( 1 )$$
where ˆ σ x,y,z are the Pauli matrices and k is the Bloch wave vector. We can construct such a dataset X = { x 1 , x 2 , · · · x l } , where x i = d i ( k / E ) ( i + ( k ) -E i -( k )) rep-
resenting the i -th normalized Hamiltonian sample with E ± ( k ) = ± √ d 2 x ( k ) + d 2 y ( k ) + d 2 z ( k ) .
The distance between x i and x j is defined as: M i,j = ∥ x i -x j ∥ 2 p . In recent research, there has been discussion regarding the utilization of p = 1 , 2 , ∞ cases in unsupervised clustering topological phases[37] . In this paper, we set p = 1 , unless otherwise specified. The similarity matrix is derived from the Gaussian kernel
$$A _ { i, j } = \exp \left ( - \frac { M _ { i, j } } { 2 \epsilon N ^ { 2 } } \right ),$$
where ϵ is the Gaussian kernel coefficient( 0 < ϵ ≪ 1 ). N is an adjustable parameter related to the specific model. A i,j ∈ [0 , 1] represents the similarity between x i and x j . The probability transition matrix is defined as P i,j = A i,j / ∑ N j =1 A i,j . After 2 t steps of random walk, we can use diffusion distance to describe the connectivity between x i and x j
$$D _ { t } ( i, j ) = \sum _ { k = 1 } ^ { l } \frac { \left ( P _ { i, k } ^ { t } - P _ { j, k } ^ { t } \right ) ^ { 2 } } { \sum _ { q } A _ { k, q } } = \sum _ { k = 1 } ^ { l - 1 } \lambda _ { k } ^ { 2 t } [ ( \psi _ { k } ) _ { i } - ( \psi _ { k } ) _ { j } ] ^ { 2 }, \quad \text{$\stackrel{i,\searrow$ breaks} \\ ( 3 ) } \quad \text{$\text{terizes} \\ \text{where $\lambda$, and $\sqrt{i,i}$, are the $i$th eisonvalue and right to onevector}$} \quad \text{$\text{the}$}$$
where λ k and ψ k are the k -th eigenvalue and right eigenvector of P , respectively.
After prolonged diffusion, only the few components ψ k with λ k ≈ 1 dominate the diffusion process. Therefore, the manifold diffusion distance information of the samples is encoded in these components, thus enabling the downscaling of high dimensional data[36]. By further applying clustering algorithms (e.g., k-means) to low-dimensional data, it is possible to cluster different topological phases without prior knowledge. Previous research has demonstrated that the number of λ k ≈ 1 corresponds to the the number of topological clusters[37].
## B. supervised algorithm
For supervised learning, we use a CNN as shown in Fig. 1.
FIG. 1. Schematic of the CNN. Here d r and d i represent the real and imaginary parts of the input data, respectively.
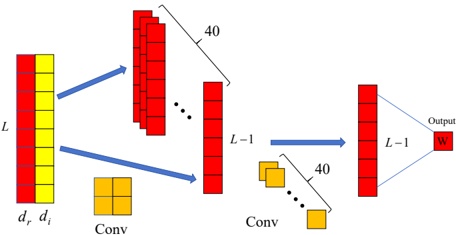
## III. MODEL AND RESULTS
## A. unsupervised learning results
Let us begin with a two-band non-Hermitian lattice as shown in Fig. 2(a). The Hamiltonian of this lattice model takes the form
$$H & = \sum _ { n } \sum _ { \sigma \in \{ A, B \} } \left ( \Delta ^ { - } c _ { n, \sigma } ^ { \dagger } c _ { n + 1, \sigma } + \Delta ^ { + } c _ { n + 1, \sigma } ^ { \dagger } c _ { n, \sigma } \right ) \\ & \quad + \frac { m } { 2 } \left ( c _ { n + 1, A } ^ { \dagger } c _ { n, B } - c _ { n + 1, B } ^ { \dagger } c _ { n, A } + H. c. \right ) \\ \vdots \\.$$
here c † n,σ ( c n,σ ) denotes the creation (annihilation) operator of the sublattice σ ∈ { A,B } on the n th site. The terms ∆ ± = (∆ ± δ / ) 2 represent the non-reciprocal nearest-neighbour hopping within the same sublattice. The nonzero parameter δ breaks the Hermicity of the model. The parameter m characterizes the reciprocal nearest-neighbor hopping between distinct sublattices, while γ denotes the intracell coupling. All parameters are real[28].
The form of the real-space Hamiltonian expressed by Eq.(4) can be written in the form of the Bloch Hamiltonian in momentum space as H k ( ) = ∆cos k -iδ sin k + ( γ + m sin k σ )ˆ y . We can obtain the non-Bloch Hamiltonian H β ( ) by extending the BZ into GBZ with β = re ik , r = √ | (∆ + δ + im / ) (∆ -δ -im ) | , k ∈ R . The energies of the non-Bloch bands take the form E ± ( β ) = ± γ +0 5(∆ . -δ ∓ im β ) +0 5(∆+ . δ ± im β ) -1 . The non-Bloch winding number is defined as
$$W = \frac { 1 } { 2 \pi i } \oint _ { C _ { \beta } } d \ln \det \left [ H ( \beta ) - \frac { 1 } { 2 } \text{Tr} [ H ( \beta ) ] \right ], \quad ( 5 )$$
which describes the braid degree of two non-Bloch bands[28].
In order to explore the non-Bloch braiding in this model as shown in Fig. 2(b), we consider a dataset X = { x 1 , x 2 , · · · x l } with m = 0 5 . , ∆ = 1 , δ = 0 7 . and variable γ ∈ [0 , 1 2] . , where x i = d i ( β / E ) ( i + ( β ) -E i -( β )) . The results of unsupervised learning are shown in Fig. 2(c-d). From Fig. 2(c), the similarity matrix is separated into two blocks, which corresponding to the two largest eigenvalues λ ≈ 1 of the diffusion matrix shown in Fig. 2(d). As a result, the diffusion maps identifies two distinct topological phases. In addition, we can get the phase transition point γ ≈ 0 58 . form Fig. 2(c), which is consistent with the theoretical value γ c = m r ( 2 +1) 2 / r ≈ 0 579 . .
We compare the results of unsupervised learning with those calculated in Eq. 5. For γ < γ c , W = 2 , corresponding to Hopf link, and for γ > γ c , W = 0 , corresponding to Unlink, as shown in Fig. 2(b). In Fig. 2(e-f), we display the braiding of non-Bloch bands in (Re [ E ] ,Im [ E k ] , ) space with γ = 0 3 . and γ = 0 8 . , corresponding to the blue and red topological clusters in the inset of Fig. 2(d), respectively.
FIG. 2. (a) Sketch of the two bands non-Hermitian lattice model. (b) Phase diagram of the non-Hermitian system under open boundary condition with ∆ = 1 0 . and δ = 0 7 . . (c) The visualisation of the Gaussian kernel. The breakpoint indicates the predicted phase transition point γ ≈ 0 58 . . (d) The first eight eigenvalues of the diffusion matrix P . The inset shows the result of k-means. The first two largest eigenvalues correspond to the two topological clusters in the inset. The samples are generated uniformly of γ ∈ [0 , 1 2] . with ∆ = 1 , δ = 0 7 . and m = 0 5 . . The Gaussian kernel coefficient ϵ = 0 01 . . (e-f) Complex energy braiding of non-Bloch bands in (Re[ E , ] Im[ E , k ] ) space. (e) and (f) are topologically distinct and correspond to Hopf link and Unlink, respectively.
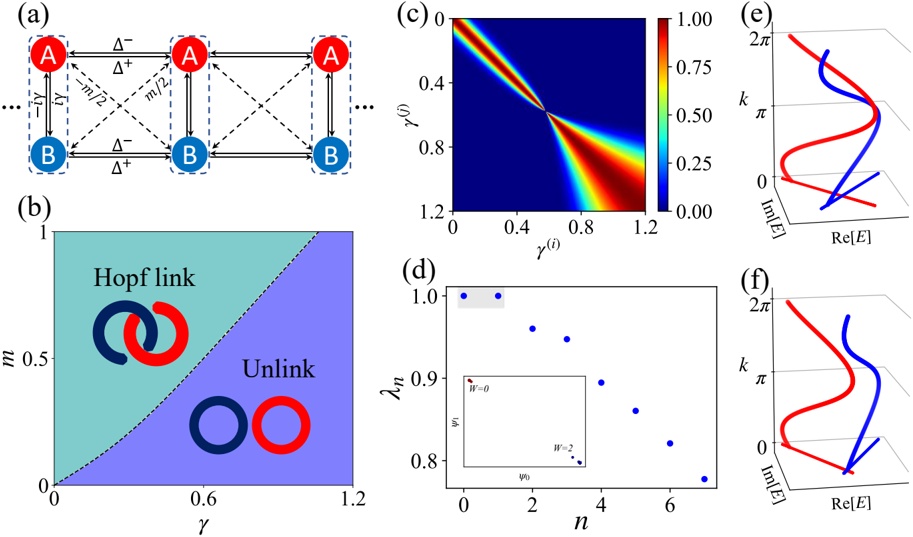
## B. supervised and transfer learning results
## 1. learning Bloch braiding
In this section, we consider a two-band non-Hermitian lattice as shown in Fig. 3(a). The Hamiltonian of this lattice model takes the form
$$H _ { ( m, n ) } = \begin{pmatrix} 0 & t _ { 0 } \\ t _ { 0 } + t _ { m } e ^ { i m k } + t _ { n } e ^ { i n k } & 0 \end{pmatrix}, \quad ( 6 ) \quad \breve { \text{the C} }$$
1 kernel of size ( 40 1 1 , , ), followed by a fully connected layer before the output layer. Similar to but different from previous studies[41, 42], only the first convolutional layer is followed by the nonlinear activation function ReLU. We find that the prediction accuracy of the CNN depends on the first convolutional layer and its activation function. Shallow networks are more effective than deep networks in learning braid degree. Specifically, simply increasing the number of layers of the CNN can instead cause it to lose its generalisation ability.
where t 0 is reciprocal intracell coupling. t m and t n are nonreciprocal intercell hoppings that spans m and n lattices, respectively[22].
̸
The complex energy spectra reads E ± ( k ) = ± √ t 0 ( t 0 + t m imk e + t n e ik ) . For any two energy bands satisfy the separable band condition( E + ( k ) = E -( k ) for all k ∈ [0 , 2 π ] ), a topological invariant W can be defined to classify their braiding topology[22],
$$W = \frac { 1 } { 2 \pi i } \oint _ { 0 } ^ { 2 \pi } \left ( \frac { d \ln E _ { + } } { d k } + \frac { d \ln E _ { - } } { d k } \right ) d k. \quad ( 7 ) \quad \text{where}$$
We trained a generic CNN as shown in Fig. 1 to predict the Bloch energy braiding in this model. The CNN in our research has two convolution layers with 40 kernels of size ( 1 2 2 , , ) and
The input data are normalised spectral correlation configurations d ( n ) = { Re[ E 2 (2 πn/L )] , Im[ E 2 (2 πn/L )] } , E = E + ( k ) -E -( k ) . In the following, we set L = 201 , which is large enough for the CNN to capture the topology of the complex energy bands.
The labels corresponding to each configuration are calculated by the Eq. 7. The output of the CNN is a real number w representing the braid degree. The objective function to be optimized is defined by
$$J = \frac { 1 } { N } \sum _ { i = 1 } ^ { N } ( w _ { i } - W _ { i } ) ^ { 2 },$$
where w i and W i are, respectively, the predicted and true braid degree of i th sample, and N represents the size of the training data set. We uniformly sample 9 × 10 4 configurations from H (1 2) , and H (1 3) , , containing Unlink ( W = 0) ,
FIG. 3. (a) Sketch of the two-band non-Hermitian lattice model H ( m,n ) . (b) The loss with each training and validation. (c-g) The predicted phase diagrams, along with the corresponding braid degrees across different parameter spaces.
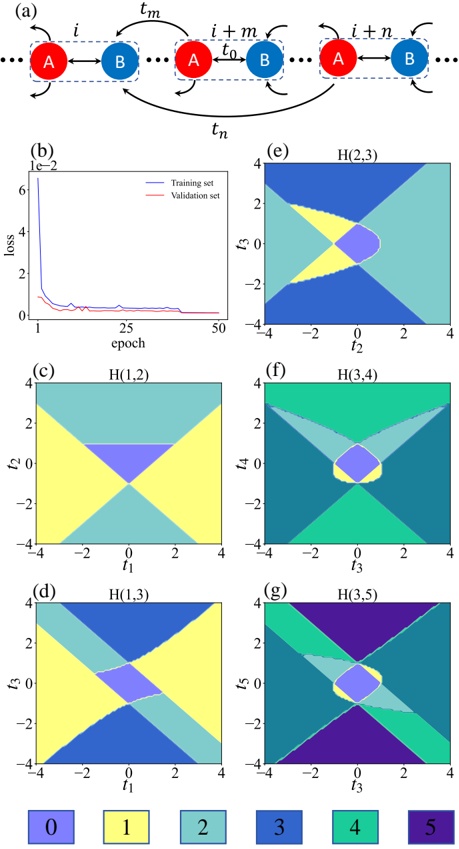
Unknot ( W = 1) , Hopf link ( W = 2) and Trefoil ( W = 3) , respectively. There are five different types of test data, (i,ii) two test sets with 1 × 10 4 configurations generated from H (1 2) , and H (1 3) , , respectively, (iii,iv,v) 1 × 10 4 configurations sampled from H (2 3) , , H (3 4) , and H (3 5) , , respectively. The batch size for training is set to 50 and the epoch is set to 50.
After training, the losses on the training and validation sets are shown in Fig. 3(b). It can be observed that the neural network converges very quickly and the losses stay at a low level and no overfitting occurs. We test with the test data and round the output to plot the phase diagram of the predictions on the different test sets as shown in Fig. 3(c-g). In Fig. 3(c) and (d), the CNN successfully predicts the phase diagram using the test sets (i) and (ii), which seems natural since our train-
FIG. 4. The phase diagram predicted by the pre-trained CNN in the γ -m plane with ∆ = 1 0 . and δ = 0 9 . .
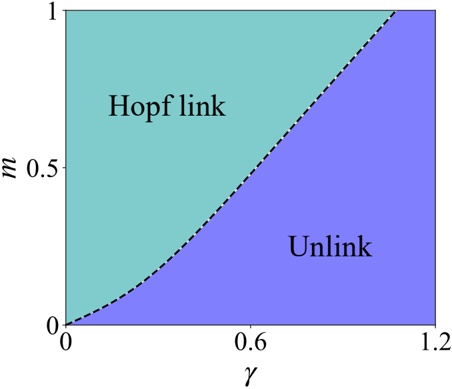
ing data are also sampled with the same parameters. However, we can verify the effectiveness of the CNN in Fig. 3(e-g). In Fig. 3(e), the CNN successfully predicts the braid degrees under the H (2 3) , case, which are contained in the training set. In Fig. 3(f) and (g), the CNN also predicts the braid phases with high accuracy, even predicting two braid degrees, W = 4 and W = 5 , that are not included in the training set. At this point, we have demonstrated the ability of the CNN to predict the braid degree under different parameter spaces of the same model.
## 2. transfer learning non-Bloch braiding
Further, we use the above pre-trained CNN to recognise non-Bloch braiding in the non-Hermitian system as shown in Fig. 2(a). The input data can be chosen as d ( n ) = { Re[ E 2 (2 πn/L )] , Im[ E 2 (2 πn/L )] } , E = E + ( β ) -E -( β ) with ∆ = 1 0 . and δ = 0 9 . , varying γ ∈ [0 , 1 2] . and m ∈ [0 , 1] . The predicted phase diagram with respect to the parameters γ and m is shown in Fig. 4. The dashed line is the theoretical value of the phase boundary. Without retraining, the CNN almost perfectly predicts the presence of Unlink and Hopf link elements accompanied by the exact phase boundary in the phase diagram.
To further understand the workflow of the CNN, we analyse the training details. The first layer of the CNN is a convolutional layer with 40 convolutional kernels to perform convolutional operations on the input data,
$$\text{al net-} _ { \boldsymbol x \text{ level} } \quad B ^ { i } ( n ) = f [ A _ { 1 1 } ^ { i } d _ { r } ( 2 \pi ( n - 1 ) / L ) + A _ { 1 2 } ^ { i } d _ { i } ( 2 \pi ( n - 1 ) / L ) \\ \text{round} _ { \text{on the} } \quad \quad + A _ { 2 1 } ^ { i } d _ { r } ( 2 \pi n / L ) + A _ { 2 2 } ^ { i } d _ { i } ( 2 \pi n / L ) + A _ { 0 } ^ { i } ],$$
where A is a kernel of size 2 × 2 , i = 1 , ..., 40 , n = 1 , ..., L and f ( x ) is the activation function. The second layer is a convolutional layer without an activation function that takes
the form,
$$D ^ { i } ( n ) = \sum _ { i = 1 } ^ { 4 0 } C ^ { i } B ^ { i } ( n ) + C _ { 0 } ^ { i }, \quad \ \ ( 1 0 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where C i is the 1 × 1 kernel. D n i ( ) depend on the winding angle of the two bands. Finally, all 40 neurons are mapped to a single output neuron to obtain the braid degree,
$$W = \sum _ { n = 1 } ^ { L } M _ { n } D ( n ) + M _ { 0 }. \quad \quad ( 1 1 ) \quad \text{ple}$$
During the training process, the neural network successfully fit all the parameters above. Through the above analysis, we find that the Eq. 9 used to extract the braid information is universal, and then the output of the Eq. 9 can be linearly summed to obtain the braid degree.
## IV. CONCLUSION
In summary, we applied unsupervised and supervised methods to identify the energy braiding in non-Hermitian sys-
- [1] C. C. Adams, The knot book (American Mathematical Soc., 1994).
- [2] K. Kawabata, T. Bessho, and M. Sato, Phys. Rev. Lett. 123 , 066405 (2019).
- [3] W. B. Rui, Y. X. Zhao, and A. P. Schnyder, Phys. Rev. B 99 , 241110 (2019).
- [4] X. Zhang and J. Gong, Phys. Rev. B 101 , 045415 (2020).
- [5] L. Xiao, T. Deng, K. Wang, Z. Wang, W. Yi, and P. Xue, Phys. Rev. Lett. 126 , 230402 (2021).
- [6] S. Sayyad, M. St˚ alhammar, L. Rødland, and F. Kunst, SciPost Physics 15 (2023), 10.21468/SciPostPhys.15.5.200.
- [7] B.-B. Wang, Y. Ge, S.-Q. Yuan, D. Jia, and H.-X. Sun, Progress In Electromagnetics Research 176 , 1 (2023).
- [8] S. Yao and Z. Wang, Physical Review Letters 121 , 086803 (2018).
- [9] F. Song, S. Yao, and Z. Wang, Phys. Rev. Lett. 123 , 170401 (2019).
- [10] L. Li, C. H. Lee, S. Mu, and J. Gong, Nature Communications 11 , 5491 (2020).
- [11] L. Zhang, Y. Yang, Y. Ge, Y.-J. Guan, Q. Chen, Q. Yan, F. Chen, R. Xi, Y. Li, D. Jia, S.-Q. Yuan, H.-X. Sun, H. Chen, and B. Zhang, Nature Communications 12 , 6297 (2021).
- [12] Q. Liang, D. Xie, Z. Dong, H. Li, H. Li, B. Gadway, W. Yi, and B. Yan, Phys. Rev. Lett. 129 , 070401 (2022).
- [13] K. Kawabata, T. Numasawa, and S. Ryu, Phys. Rev. X 13 , 021007 (2023).
- [14] Q. Zhou, J. Wu, Z. Pu, J. Lu, X. Huang, W. Deng, M. Ke, and Z. Liu, Nature Communications 14 , 4569 (2023).
- [15] H. Shen, B. Zhen, and L. Fu, Phys. Rev. Lett. 120 , 146402 (2018).
- [16] K. Kawabata, K. Shiozaki, M. Ueda, and M. Sato, Phys. Rev. X 9 , 041015 (2019).
tems. The unsupervised learning algorithm, diffusion maps, can identify the phase transition points and separate different braiding elements into clusters. In supervised learning, we trained a CNN to capture the braiding topology of complex energy in non-Hermitian systems. It is worth noting that the CNN trained under Bloch conditions can predict not only Bloch braiding but also non-Bloch braiding. Our methods can be extended to identify other knots and links in non-Bloch bands. Our study demonstrates the potential of machine learning in identifying non-Hermitian topological phases and complex energy braiding.
## V. DATA AVAILABILITY STATEMENT
The data that support the findings of this study are available upon reasonable request from the authors.
## VI. ACKNOWLEDGMENTS
This work was supported by the National Natural Science Foundation of China (No. 12074150, 12174157 and 11904137).
- [17] C. C. Wojcik, X.-Q. Sun, T. c. v. Bzduˇ sek, and S. Fan, Phys. Rev. B 101 , 205417 (2020).
- [18] Z. Li and R. S. K. Mong, Phys. Rev. B 103 , 155129 (2021).
- [19] K. Wang, A. Dutt, C. C. Wojcik, and S. Fan, Nature 598 , 59 (2021).
- [20] K. Wang, A. Dutt, K. Y. Yang, C. C. Wojcik, J. Vuˇ ckovi´ c, and S. Fan, Science 371 , 1240 (2021).
- [21] Y. S. S. Patil, J. H¨ oller, P. A. Henry, C. Guria, Y. Zhang, L. Jiang, N. Kralj, N. Read, and J. G. E. Harris, Nature 607 , 271 (2022).
- [22] Q. Zhang, Y. Li, H. Sun, X. Liu, L. Zhao, X. Feng, X. Fan, and C. Qiu, Phys. Rev. Lett. 130 , 017201 (2023).
- [23] J. Hirschberg and C. Manning, Science (New York, N.Y.) 349 , 261 (2015).
- [24] H. Qiu, Q. Zhang, T. Liu, X. Fan, F. Zhang, and C. Qiu, Nature Communications 14 , 1261 (2023).
- [25] Q. Zhang, L. Zhao, X. Liu, X. Feng, L. Xiong, W. Wu, and C. Qiu, Phys. Rev. Res. 5 , L022050 (2023).
- [26] Y. Yu, L.-W. Yu, W. Zhang, H. Zhang, X. Ouyang, Y. Liu, D.L. Deng, and L.-M. Duan, npj Quantum Information 8 , 116 (2022).
- [27] J. Chen, Z. Wang, Y.-T. Tan, C. Wang, and J. Ren, Communications Physics 7 , 209 (2024).
- [28] Y. Li, X. Ji, Y . Chen, X. Yan, and X. Yang, Phys. Rev. B 106 , 195425 (2022).
- [29] K. He, X. Zhang, S. Ren, and J. Sun, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016) pp. 770-778.
- [30] D. Zhang, Y. Liu, Y. Zhao, J. Liang, B. Sun, and S. Chu, Applied Sciences 13 (2023), 10.3390/app132312649.
- [31] G. Adomavicius and A. Tuzhilin, IEEE Transactions on Knowledge and Data Engineering 17 , 734 (2005).
- [32] J. Yin, M. Chen, Y. Ge, Q. Song, and H. Zheng, Journal of Sensors 2022 , 3907002 (2022).
- [33] G. Carleo, I. Cirac, K. Cranmer, L. Daudet, M. Schuld, N. Tishby, L. Vogt-Maranto, and L. Zdeborov´ a, Rev. Mod. Phys. 91 , 045002 (2019).
- [34] B. Narayan and A. Narayan, Phys. Rev. B 103 , 035413 (2021).
- [35] L.-F. Zhang, L.-Z. Tang, Z.-H. Huang, G.-Q. Zhang, W. Huang, and D.-W. Zhang, Phys. Rev. A 103 , 012419 (2021).
- [36] R. R. Coifman and S. Lafon, Applied and Computational Harmonic Analysis 21 , 5 (2006), special Issue: Diffusion Maps and Wavelets.
- [37] Y. Che, C. Gneiting, T. Liu, and F. Nori, Phys. Rev. B 102 , 134213 (2020).
- [38] L.-W. Yu and D.-L. Deng, Phys. Rev. Lett. 126 , 240402 (2021).
- [39] Q. Zhou, J. Wu, Z. Pu, J. Lu, X. . J. Huang, Y. Yu, L.-W. Yu, W. Zhang, H. Zhang, X. Ouyang, Y. Liu, D.-L. Deng, and L.M. Duan, npj Quantum Information 8 , 116 (2022).
- [40] Y. Long, H. Xue, and B. Zhang, Nature Machine Intelligence (2024).
- [41] P. Zhang, H. Shen, and H. Zhai, Phys. Rev. Lett. 120 , 066401 (2018).
- [42] L.-F. Zhang, L.-Z. Tang, Z.-H. Huang, G.-Q. Zhang, W. Huang, and D.-W. Zhang, Phys. Rev. A 103 , 012419 (2021). | 10.1088/1402-4896/ad9a1e | [
"Shuwei Shi",
"Shibing Chu",
"Yuee Xie",
"Yuanping Chen"
] | 2024-08-02T09:37:55+00:00 | 2024-08-02T09:37:55+00:00 | [
"cond-mat.mes-hall",
"cond-mat.dis-nn",
"cs.LG"
] | Machine learning topological energy braiding of non-Bloch bands | Machine learning has been used to identify phase transitions in a variety of
physical systems. However, there is still a lack of relevant research on
non-Bloch energy braiding in non-Hermitian systems. In this work, we study
non-Bloch energy braiding in one-dimensional non-Hermitian systems using
unsupervised and supervised methods. In unsupervised learning, we use diffusion
maps to successfully identify non-Bloch energy braiding without any prior
knowledge and combine it with k-means to cluster different topological elements
into clusters, such as Unlink and Hopf link. In supervised learning, we train a
Convolutional Neural Network (CNN) based on Bloch energy data to predict not
only Bloch energy braiding but also non-Bloch energy braiding with an accuracy
approaching 100%. By analysing the CNN, we can ascertain that the network has
successfully acquired the ability to recognise the braiding topology of the
energy bands. The present study demonstrates the considerable potential of
machine learning in the identification of non-Hermitian topological phases and
energy braiding. |
2408.01142v1 | ## Assessment of the near-Sun magnetic field of the 10 March 2022 coronal mass ejection observed by Solar Orbiter
S.Koya 1 3 , , S.Patsourakos 1 , M.K Georgoulis 2 4 , , and A. Nindos 1
- 1 Section of Astrogeophysics, Department of Physics, University of Ioannina, 45110, Greece e-mail: [email protected]
- 2 Space Exploration Sector, Johns Hopkins Applied Physics Laboratory, Laurel, MD 20723, USA
- 3 Institute of Physics, University of M. Curie-Skłodowska, Pl. M. Curie-Skłodowskiej 1, 20-031 Lublin, Poland
- 4 Research Center for Astronomy and Applied Mathematics, Academy of Athens, 11527 Athens, Greece
Received date / Accepted date
## ABSTRACT
Aims. We estimate the near-Sun axial magnetic field of a coronal mass ejection (CME) on 10 March 2022. Solar Orbiter's in situ measurements, 7.8 degrees east of the Sun-Earth line at 0.43 AU, provided a unique vantage point, along with the WIND measurements at 0.99 AU. We determine a single power-law index from near-Sun to L1, including in situ measurements from both vantage points. Methods. We tracked the temporal evolution of the instantaneous relative magnetic helicity of the source active region (AR), NOAA AR 12962. By estimating the helicity budget of the pre-and post-eruption AR, we estimated the helicity transported to the CME. Assuming a Lundquist flux-rope model and geometrical parameters obtained through the graduated cylindrical shell (GCS) CME forward modelling, we determined the CME axial magnetic field at a GCS-fitted height. Assuming a power-law variation of the axial magnetic field with heliocentric distance, we extrapolated the estimated near-Sun axial magnetic field to in situ measurements at 0.43 AU and 0.99 AU.
Results. The net helicity di ff erence between the post-and pre-eruption AR is ( -7 1 . ± 1 2) . × 10 41 Mx 2 , which is assumed to be bodily transported to the CME. The estimated CME axial magnetic field at a near-Sun heliocentric distance of 0.03 AU is 2067 ± 405 nT. From 0.03 AU to L1, a single power-law fallo ff , including both vantage points at 0.43 AU and 0.99 AU, gives an index -1 23 . ± 0 18. . Conclusions. We observed a significant decrease in the pre-eruptive AR helicity budget. Extending previous studies on innerheliospheric intervals from 0.3 AU to ∼ 1 AU, referring to estimates from 0.03 AU to measurements at ∼ 1 AU. Our findings indicate a less steep decline in the magnetic field strength with distance compared to previous studies, but they align with studies that include near-Sun in situ magnetic field measurements, such as from Parker Solar Probe.
Key words. Sun: magnetic fields - Sun: coronal mass ejections (CMEs) - Sun: corona
## 1. Introduction
Coronal mass ejections (CMEs) are energetic eruptions of plasma and magnetic fields from the solar atmosphere (Forbes 2000; Chen 2011; Webb & Howard 2012). When detected in situ in interplanetary space, they are called interplanetary CMEs (ICMEs). Despite substantial aerodynamic drag and subsequent magnetic erosion during interplanetary (IP) propagation (Gopalswamy et al. 2001; Tappin 2006; Sachdeva et al. 2015; Stamkos et al. 2023), understanding the near-Sun magnetic field strength of CMEs is crucial as it plays a key role in shaping the early evolution of CME dynamics and the potential Earth impact at L1. This knowledge could be vital in space weather research, especially for Earth-directed CMEs. The intensity of the southward IP magnetic field associated with Earth-directed CMEs is crucial in determining the magnitude of the ensuing geomagnetic storms (Wu & Lepping 2005). In order to evaluate the geoe ff ectiveness of CMEs, only a few estimates of the near-Sun magnetic field are available, such as a few indirect methods (Kunkel &Chen 2010; Savani et al. 2015) and some based on rare radioemission configurations such as gyrosynchrotron emission from CME cores and Faraday rotation (Bastian et al. 2001; Jensen & Russell 2008; Tun & Vourlidas 2013). These diagnostic tools are unsuitable for routine use due to the lack of solar radio arrays with the necessary sensitivity and capabilities for continuous observations.
The significance of free (above the lower-level vacuum [potential] solution) and total magnetic energy in initiating CMEs is widely recognised (Priest 2014). However, the precise role of magnetic helicity in the initiation of solar eruptions is still being investigated. In active regions (ARs), the total magnetic energy encompasses both the stable potential energy and the dynamic non-potential (free) terms. The free magnetic energy in ARs results from the combination of magnetic flux emergence and the intricate movements of plasma, corroborated by emerging, electric current-carrying magnetic flux tubes (e.g. Leka et al. 1996). The release of free magnetic energy, believed to occur through intermittent episodes of magnetic reconnection, is the key reason for solar magnetic activity. Meanwhile, magnetic helicity, which represents a measure of the twist, writhe and linkage of magnetic field lines, is also found essential in understanding solar eruptions (Berger 1984). Observational support for the importance of magnetic helicity in the initiation of solar eruptions includes works by Rust & Kumar (1996), Nindos & Andrews (2004), Park et al. (2008, 2010), Goto et al. (2012), Liu et al. (2023), Liokati et al. (2022), and Liokati et al. (2023). Earlier analysis and modelling works have presented solar eruptions as a necessary outcome of the presence of magnetic helicity (Low 1994; Kumar & Rust 1996). There are multiple methods for computing the relative magnetic helicity (that is, the helicity due to nonpotential magnetic fields) using observational data - a compari-
son of di ff erent methods can be found in Thalmann et al. (2021). The combined knowledge of free magnetic energy and relative magnetic helicity may present a path for a more substantive understanding of magnetic configurations in the solar atmosphere.
The magnetic helicity of an AR source can be indirectly used to understand the near-Sun magnetic field of the associated CME by linking it to an idealised magnetic flux rope structure. Patsourakos et al. (2016) introduced a method based on the conservation of magnetic helicity during CMEs. The approach involves calculating eruption-related magnetic helicity from photospheric magnetic fields and employing the graduated cylindrical shell (GCS) model of Thernisien et al. (2006) and Thernisien et al. (2009) on multi-viewpoint coronagraph observations such as from Solar Terrestrial Relationship Observatory (STEREO; Kaiser et al. 2008) and Large Angle and Spectrometric Coronagraph (Brueckner et al. 1992, LASCO;) on board the Solar and Heliospheric Observatory (SOHO; Domingo et al. 1995). The method utilises analytical relationships developed for various models, such as those by Dasso et al. (2006), to determine the ICME's magnetic field magnitude. This magnitude is then extrapolated to various heliocentric distances up to 0.99 AU by assuming a self-similar, power-law decrease with radial distance.
Patsourakos et al. (2016) applied this methodology to the major geoe ff ective CME on 7 March 2012. The study utilised three relative helicity estimation methods: the helicity injection method from Pariat et al. (2006), the nonlinear force-free connectivity-based (CB) method by Georgoulis et al. (2012), and a nonlinear force-free volume calculation of helicity as described in Moraitis et al. (2014). Using analytical expressions relating magnetic helicity to cylindrical flux rope configurations, the study estimated the near-Sun magnetic field at 13 R ⊙ in the range [0.01, 0.16] G. This magnetic field exhibited a steep radial fallo ff with a power-law index of -2.0 when compared to the magnetic fields of corresponding ICMEs at a distance of 0.99 AU from the Sun. In a subsequent study by Patsourakos & Georgoulis (2016), a parametric analysis of the CB method was conducted to evaluate its robustness. The study used the input parameter distributions derived from observations to determine near-Sun and L1 magnetic fields for synthetic CMEs. It was found that the near-Sun CME magnetic fields at 10 R ⊙ ranged between 0.004 G and 0.02 G, which is comparable to, or higher than, the nominal magnetic field in the quiescent corona at the same distance. A power-law exponent α B = -1 6 . ± 0 2 was found to be most . consistent with magnetic cloud (MC) field magnitudes at L1. In Patsourakos & Georgoulis (2017), this parametric study was extended to encompass a variety of proposed theoretical CME models, thereby further refining the understanding of radial field evolution in these events. The study also expanded to non-solar CME cases, particularly stars that host superflares. It aimed to determine magnetic fields of extreme stellar CMEs, knowledge that was later used even to define preliminary conditions for the habitability of exoplanets subjected to such CMEs (Samara et al. 2021). Nevertheless, it is crucial to validate this approach more extensively by including a broader range of events and conducting comprehensive comparisons with other methods. The current landscape, enriched by data acquired from missions such as Solar Orbiter(SolO) and Parker Solar Probe (PSP), provides more observational possibilities that could further facilitate this validation process.
We present the estimation of the near-Sun axial magnetic field, coupled with a Sun-to-Earth analysis of the CME observed at L1 and by the SolO mission (Müller et al. 2020) on 10 March 2022, employing the methodology proposed in Patsourakos et al. (2016). The novelty of this study is the advantageous SolO po- sition, just 7.8 degrees east of the Sun-Earth line (see Fig.1), at a heliocentric distance of 0.43 AU along with the L1 measurements by the WIND spacecraft (Lepping et al. 1995). The two spacecraft measurements provided a rare opportunity for robust cross-validation of the ICME magnetic field at di ff erent heliocentric distances. The specialised spacecraft configuration draws particular attention to this event, such as in Jackson et al. (2023), who utilised 3D reconstruction modelling from interplanetary scintillation forecast techniques to analyse this CME and its potential impact. Laker et al. (2024) used real-time measurements from SolO to predict the CME's arrival time and magnetic structure more than a day before it arrived at Earth. Furthermore, Zhuang et al. (2024) investigated the correspondence between remote observations and in situ measurements of this CME using data from SolO and STEREO heliospheric imagers. This was / achieved by comparing CME properties derived from both techniques, such as size and radial expansion, within 0.5 AU. Our work contributes to a better understanding of the event by focusing on the magnetic field evolution of this CME from the nearSun to Earth, using the source active region's helicity budget and SolO measurements taken halfway between the Sun and Earth. This work also paves the way for further works, particularly in cases in which SolO is similarly positioned or aligned with other spacecrafts, such as PSP.
Fig. 1: Spacecraft configuration of STEREO B (blue circle), STEREO-A (red circle), SolO ( magenta circle), Bepi Colombo (orange circle), Earth (green circle) and Sun (yellow) on 10 March 2022 at 00:00 UT in heliocentric Earth ecliptic (HEE) system. The dotted lines show the angular di ff erence of STEREO A and B from the Sun-Earth line. Units are in AU.
The article is organised as follows: Section 2 summarises remote-sensing and in situ measurements of the 10 March 2022 CME. Section 3 describes the methodology used to estimate the near-Sun axial magnetic field of the CME. The extrapolation of the estimated magnetic field from near-Sun to 0.43 AU and 0.99 AUis then presented in Section 4. Then, Section 5 compares our results with previous studies and discusses advances in understanding and potential future research in this direction. The article includes two appendices: Appendix A explains the methodology used to address the data gap seen in SolO magnetic field measurements during the ICME, while Appendix B describes
the Monte Carlo approach used to estimate uncertainties in our near-Sun axial magnetic field estimation.
## 2. Observations
## 2.1. Solar source active region
On 10 March 2022, the Atmospheric Imaging Assembly (AIA; Lemen et al. 2012) telescope on board the Solar Dynamics Observatory(SDO) (Pesnell et al. 2012), SWAP PROBA-II (Seaton / et al. 2013; Halain et al. 2013) and Extreme Ultraviolet Imager (EUI) / Full Sun Imager (FSI) (Rochus et al. 2020) 174 Å channel on board SolO observed signs of the eruption from NOAA AR 12962 using full-disk Extreme Ultraviolet (EUV) images (see Fig.2a). Key observations included loop expansion starting at 17:10 UT on March 10 in the EUI FSI 174 Å channel, / and coronal dimmings start time at 16:22 UT in AIA 211 Å channel, followed with a dimming peak time at 18:58 UT in the AIA 211 Å channel (see Fig.2b). This is followed by the appearance of a post-eruption arcade, visible in the AIA 304 Å channel and, 30 minutes later, in the 174Å AIA channel. An accompanying Geostationary Operational Environmental Satellites (GOES) C2.8 class flare was observed with the start time around 19:00 UT and peak at 20:33 UT. The LASCO SOHO later observed / this event as a partial halo CME at around 19:00 UT (see Fig.2c) along with the detection by the Sun-Earth Connection Coronal and Heliospheric Investigation (SECCHI) aboard the STEREO spacecraft (Howard et al. 2008a; Kaiser et al. 2008) as a limb CME.
## 2.2. CME- ICME connection
Here, we show evidence of the CME-ICME connection for this event. Based on the positioning of the spacecraft (see Fig.1) and AR location along with the CME's tilt, orientation and angular width derived from GCS modelling ( see Sect.4.1.2), we infer that the CME observed in full-disk and coronagraphic images on 10 March 2022 likely impacted both SolO and WIND. To further confirm this, we followed the procedure described in Zhang et al. (2007): by assuming a constant propagation speed, we find the di ff erence between the estimated time of arrival and the actual arrival time both at SolO at 0.43 AU and at WIND at 0.99 AU. Table 1 lists the results using various detection tools and databases. We used speed estimations from various CME catalogues such as CACTUS 1 , Solar Eruptive Event Detecting System (SEEDS) / LASCO and SEEDS STEREO / 2 , LASCO CME catalogue 3 , The Space Weather Database Of Notifications, Knowledge, Information (DONKI) catalogue 4 and ARRival CATalog (ARRCAT) 5 . The ARRCAT catalogue estimates CMEspeed by modelling the HELiospheric Cataloguing, Analysis and Techniques Service (HELCATS) 6 CMEstime-elongation tracks with the SSEF30 model (Davies et al. 2012; Mostl et al. 2014) single-spacecraft fitting technique. In Table 1, the time of arrival (ToA) estimate, which is later than the actual arrival time (this is discussed in detail in Sect.2.3), is indicated as positive, and an earlier ToA than the actual is indicated as negative. We
1 https://www.sidc.be/cactus/catalog.php
2 http://spaceweather.gmu.edu/seeds/
3 https://cdaw.gsfc.nasa.gov/CME\_list/
4 https://kauai.ccmc.gsfc.nasa.gov/DONKI/
5 https://helioforecast.space/arrcat
6 https://www.helcats-fp7.eu/catalogues/wp3\_cat.html
also included the estimated ToA from the GCS speed estimation from our GCS fitting using a linear fit of height-time data in consecutive GCS images ( see Fig.8 ). Further evidence for our CME-ICME connection results from the GCS model application is also discussed in Sect.4.1.2.
Table 1 shows that the maximum obtained di ff erence between the estimated and the actual ToA at SolO is 1 day 4 hours 37 minutes when using the SEEDS LASCO speed of 335 km s, / / and a minimum is 49 min when using the ARRCAT speed estimation. The corresponding di ff erence in time estimations at 0.99 AU also shows a similar trend, with a maximum di ff erence of 1 day 18 hours 44 minutes with the SEEDS LASCO / speed estimate and 03 hours 01 minutes early estimation from the ARRCAT catalogue. The large di ff erence between actual and estimated time of arrival, calculated using LASCO speed estimation, is largely caused by the projection e ff ects of the CME onto a two-dimensional plane. It is important to note that the two-dimensional projection of CMEs does not accurately represent their true three-dimensional propagation shape and structure. Studies by Temmer et al. (2009), Howard et al. (2008b) and Vrvsnak et al. (2007) have shown that the velocity and angular width of CMEs are particularly a ff ected by the projection e ff ect and the angle of observation. However, these e ff ects are minimised for limb CMEs (Burkepile et al. 2004; Cid et al. 2012). This CME appears as a partial halo CME in the SOHO LASCO / field of view, while it is a limb CME in the STEREO field of view. As viewed from the Earth the source of the CME was not far from the central meridian. Hence, the speeds inferred by LASCO images may not be close to the actual speed.
To summarise, the di ff erences between the predicted and observed ToAs, as presented in Table 1, range from a maximum of 1 day, 18 hours, 44 minutes (according to the CACTUS catalogue) to a minimum of 49 minutes (according to the ARRCAT catalogue). Considering the aforementioned caveats, as well as the uncertainties introduced by assuming constant speed propagation, which could account for these di ff erences, we conclude that the CME observed in the full disk EUV and coronagraphic images on 10 March 2022 has indeed reached both the SolO at a distance of 0.43 AU and then the WIND spacecraft at 0.99 AU. This CME-ICME identification is in agreement with recent studies of this event, such as Laker et al. (2024),Berghmans et al. (2023),Jackson et al. (2023) and Zhuang et al. (2024).
## 2.3. In situ ICME observations at 0.43 AU and 0.99 AU
We now discuss the in situ ICME measurements associated with the CME by SolO at 0.43 AU and WIND at 0.99 AU. Fig.3 presents solar wind plasma and magnetic field measuremnts obtained from the Proton and Alpha Sensor (PAS) (Owen et al. 2020) and magnetometer (MAG) (Horbury et al. 2020) instruments on board SolO. We analysed SolO Level 2 Magnetometer Data in Radial Tangential Normal (RTN) Coordinates in Normal Mode with a 1-minute cadence collected from 11 March 2022, 00:00 UT, to 14 March 2022, 06:00 UT. The top panel (Fig.3a) illustrates the magnetic field vector components Br , Bt , Bn in the RTN system along with the magnitude of the magnetic field ( BSolO ). The figure also includes plasma data on proton temperature (Fig.3b), density (Fig.3c), and solar wind bulk velocity (Fig.3d) Level 2 data with a 1-minute cadence. These temporal variations of ICME plasma parameters and magnetic field components are used for identifying the shock, sheath, and ICME boundaries. The dashed vertical lines in each panel mark the identified shock arrival (yellow), ICME start and end times (black).

Fig. 2: (a) Full-disk image by the EUI FSI 174 Å imager. The source AR 12962 is enclosed by the white box. The image shows / a post-eruption arcade. (b) Full-disk base di ff erence image at near dimming peak at 19:03 UT by SDO AIA 211 Å channel with / respect to the image at 17:00UT (c) Partial halo CME observed by SOHO LASCO C2 on 10 March at 20:17 UT with the overlaid / full-disk image by SDO AIA 211 Å channel. /

Table 1: CME -ICME connection table;a comparison of the estimated and actual arrival time of ICME at SolO and WIND.
| Detection tool | Time stamp used in the calculations of the ToAs, 2022-03-10 | Speed (km / s) | Estimated time of arrival at 0.43 AU | Estimated time of arrival at 0.99 AU | T est.SolO - T actual | T est.WIND - T actual |
|------------------|---------------------------------------------------------------|------------------|----------------------------------------|----------------------------------------|-------------------------|-------------------------|
| CACTUS | 18:48 | 385 | 2022-03-12 17:21 | 2022-03-15 04:51 | 0D 21H 29M | 1D 18H 44M |
| SEEDS / LASCO | 19:00 | 335 | 2022-03-13 00:29 | 2022-03-15 20:53 | 1D 04H 37M | 1D 18H 44M |
| SEEDS / STEREO | 20:53 | 657 | 2022-03-12 00:09 | 2022-03-13 11:02 | 0D 04H 16M | 0D 00H 55M |
| LASCO | 18:48 | 742 | 2022-03-11 18:57 | 2022-03-13 01:49 | 0D 0H 56M | 0D -09H 58M |
| DONKI | 19:47 | 677 | 2022-03-11 22:15 | 2022-03-13 08:05 | 0D 02H 22M | 0D -02H 42M |
| ARRCAT | 18:14 | 677 | 2022-03-11 20:56 | 2022-03-13 06:32 | 0D 00H 49M | 0D -03H 01M |
On approximately 11 March 2022, around 19:53 UT, a marked jump in magnetic field magnitude, proton temperature, proton density, and solar wind velocity indicated the arrival of the shock at SolO. The shock is followed by a sheath region characterised by significant fluctuations in all related physical parameters. Around March 11, 22:47 UT marks the ICME start time, which is characterised by more gradual changes in these parameters. An intriguing observation occurred on 11 March around 22:48 UT, when magnetic field components started to exhibit significant rotations. A smooth rotation of both the Bt and Bn components was observed. The Bt component transitioned from a positive to a negative value, while the Bn component transitioned from a negative to a positive value. This rotation indicated a progression towards the maximum field of an ICME. However, there is a discontinuity due to a data gap. Subsequently, it was observed that the Bt component reached a negative peak, and the Bn component reached a positive peak. This rotation suggests the possible existence of an MC structure within the ICME (Burlaga 1988).
There is a significant data gap in both magnetic field and PAS measurements during the sheath region pass (from 23:49 UT to 04:36 UT) and the ICME region (from 07:21 UT to 06:10 UT) that obscured further changes, making it challenging to establish definitive boundaries for the ICME. Nonetheless, by analysing magnetic field components and solar wind parameters until March 14 around 06:00 UT (when the variation exhibits a more gradual trend in magnetic field components) and comparing them to the ambient solar wind, we determined ICME end time to be around March 12 12:00 UT. To determine the maximum magnetic field strength of the ICME ( B 0 SolO ) at SolO and its potential uncertainty, a technique for resolving data gaps (as described in Appendix A) was utilised. This led to an estimation of B 0 SolO = 109.72 ± 20.27 nT.
Similarly, Fig.4 shows solar wind plasma measurements by SWE (Ogilvie et al. 1995) and magnetic field measurements by MFI (Lepping et al. 1995) from the WIND spacecraft at 0.99 AU. These are Level 2 data with a 1-minute cadence between 11 March 2022 at 02:00 UT and 16 March 2022 at 07:00 UT. Fig.4a displays the magnetic field vector components Bx , B y and Bz all in the GSE (Geocentric Solar Ecliptic)) coordinates along with the magnitude of the magnetic field ( BWIND ). Subsequently, proton temperature (Fig.4b), proton density (Fig.4c), solar wind bulk speed (Fig.4d), and plasma beta (Fig.4e), all with a 1-minute cadence, are shown. Similar to SolO in situ data, these plasma parameters and the magnetic field variation are used to define the shock, sheath and ICME boundary, represented by vertical lines.
At around 09:53 UT on 13 March 2022, the shock arrived at L1 with a speed of 586 km s, indicated by the sudden jump in / magnetic field magnitude and other solar wind parameters. The shock is followed by a period of magnetic field magnitude fluctuations, and all monitored solar wind parameters, such as proton plasma β parameter below 1, signifying the sheath region. Subsequently, starting from 13 March 22:35 UT, the sheath transitioned into the ICME region with speeds reaching up to 450 km s / by 13 March 23:00 UT. Immediately after the ICME arrival, that is at around 13 March 22:35 UT; there was a significant rotation in the magnetic field components Bz and B y ( Bz shifted from northward to southward and B y southward to northward). This rotation of the magnetic field components suggested the possible
Fig. 3: Solar Orbiter in situ observations at 0.43 AU: a) magnetic field components in the RTN system and the magnitude of the magnetic field, b) proton temperature, c) proton density, and d) solar wind bulk velocity. The vertical dashed line marks the shock's arrival (orange), and the two black vertical dashed lines represent ICME start and end times, respectively.
presence of an MC within the ICME structure. During this rotation, proton density, temperature, and protonβ plasma parameter exhibited abrupt increases, while the latter remained below 1. On 14 March at about 06:47 UT, the magnetic field magnitude attained a maximum B 0 WIND = 24.41 ± 0.05 nT.
The uncertainty shown is the standard uncertainty associated with MFI WIND (Lepping et al. 1995) measurements. Follow-/ ing the rotation phase, the magnetic field evolved more smoothly. The ICME event concluded at 23:46 UT on March 15 when the WIND-measured magnetic field transitioned into an area with consistently stable lower magnetic field values, and the plasma β value exceeded 1.
As previously mentioned, a recent study by Laker et al. (2024) examined the same event. They employed a magnetic cloud fitting using the Lundquist model to analyse in situ magnetic field data from both SolO (0.43 AU) and WIND (0.99 AU). They found impact parameter values, which indicate how close the spacecraft came to the central axis of the flux rope, of -0.18 ± 0.02 R E (where R E represents Earth's radius) for SolO and -6.3 ± 0.24 R E for WIND. Zhuang et al. (2024) estimated the average radial size of this ICME as 0.125 AU ( 3 05 . × 10 3 RE ) and 0.35 AU ( 8 2 . × 10 3 RE ) at SolO and WIND, respectively. Considering the radial size of the ICME at both SolO and WIND, the impact parameter is significantly smaller, indicating a nearaxis crossing. Interestingly, the orientation of the flux ropes was consistent between the spacecraft, indicating a stable magnetic structure. These findings underscore that despite a separation of 0.5 AU, the magnetic structure of the flux rope remained relatively stable across the spacecraft, with the observed maximum magnetic field strength essentially corresponding to the axis of this structure. Therefore, our approach of considering the maximum magnetic field from in situ measurements as axial fields, which is later compared with the axial field from the theoretical flux rope model (Lundquist) ( see Sect.4.1.3), is justified.
Lastly, we mention that at the time of this CME, BepiColombo was about 5 o east of the Sun-STEREO A, which was 34 o east of Earth, and 6.8 o north of the STEREO A ecliptic latitude. (see Fig 1). The recent study of Jackson et al. (2023) has explored the in situ magnetic field and electron density measurements of the event from BepiColombo data. However, from the orientation of the CME (latitude, longitude, tilt), the angular width ( detailed in Sect.4.1.2) and the position of the spacecraft, we infer that the possible arrival of our analysed ICME at BepiColombo could have resulted in a flank impact from its western side. Therefore, BepiColombo measurements may not be suitable for estimating the axial magnetic field. For this reason, we have not used BepiColombo data in our analysis.
We would now like to mention in situ measurement indications of the possibility of a complex ICME structure. Distinctive features in the ICME sheath structure are observed in WIND data (see Fig.4), which includes prolonged sheath and magnetic ejecta that exceed typical lengths beyond the end of the rotation period, suggesting a more complex structure. Analysing temperature trends during the ICME reveals a monotonous increase in the start, followed by steep changes. Simultaneously, the velocity profile during the expansion phase exhibits significant complexity, hinting at a possible composite ICME structure. These intricate temperature and velocity patterns further support the notion of a dynamically evolving CME during propagation. These interpretations are not further tested analysed extensively / as they are beyond the scope of this study.
## 3. Methodology
Throughout this work, we follow the methodology introduced by Patsourakos et al. (2016) to estimate the near-Sun axial magnetic field of the CME based on the helicity conservation principle. This session is divided into two subsections. In Sect.3.1,
Fig. 4: Wind L1 in situ observations (from top to bottom): a) magnetic-field components in the GSE system with the magnitude of the magnetic field, b) proton temperature, c) proton density, d) solar wind bulk velocity, and e) proton plasma β . The vertical orange dashed line marks the shock's arrival, and the two black vertical dashed lines represent ICME start and end times.
Sect. 3.1.1 outlines the calculation of the magnetic helicity ( Hm ) in the CME source region, followed by an assessment of the helicity budget di ff erence between the pre-and post-eruption phases in the source AR. Sect.3.1.2 describes the determination of the CME's geometrical characteristics by applying the GCS model fitting to multi-viewpoint coronagraph observations to derive parameters such as flux-rope radius and length. Sect.3.1.3, which explains the methodology for estimating the near-Sun axial magnetic field at the maximum height obtained from forward modelling of the CME using the Lundquist flux rope model (Lundquist 1950). In Sect.3.2, the magnetic field extrapolation method is described. This method is used to understand the magnetic field evolution during CME propagation to two vantage points, namely, 0.43 AU and 0.99 AU. It assumes a powerlaw variation of the magnetic field with the heliocentric distance, utilising in situ magnetic field measurements obtained from MAG SolO and MFI WIND. / /
an ensemble of N (assumed slender) force-free flux tubes, each characterised by known footpoint locations, magnetic flux, and force-free parameters. The relative magnetic helicity, Hm is the sum of self and mutual terms, corresponding to the twist of the flux tube and linkage between di ff erent tubes, respectively. Since helicity is a signed quantity, the negative sign in Hm corresponds to a left-handed helicity, and the positive sign corresponds to a right-handed helicity. Hereafter, we use the term 'helicity' to refer to the relative magnetic helicity.
## 3.1. Near -Sun analysis
## 3.1.1. Magnetic helicity budget of the CME
To understand the temporal evolution of relative magnetic helicity and free magnetic energy budgets of AR 12962, we use the CB discrete flux tube method developed by Georgoulis et al. (2012). This CB method computes the instantaneous relative magnetic helicity and free magnetic energy budgets above a potential field reference by using a single vector magnetogram, in which the magnetic flux distribution is partitioned. This method generates a connectivity matrix, accounting for magnetic flux connections between positive and negative polarity partitions. This computation employs a simulated annealing method to prioritise connections between opposite polarity partitions while minimising connection lengths. The resulting connections form
To calculate the energy and helicity budgets, we used SDO HMI vector magnetograms (Hoeksema et al. 2014), specif-/ ically the HMI.SHARP\_CEA\_720s data series (Bobra et al. 2014). This dataset includes Lambert cylindrical equal-area (CEA) projections of the photospheric magnetic field vector. This HMI data product has been transformed into three spherical heliographic components, Br , B θ , and B ϕ . These components are related to the heliographic field components as [ Bx , B y , Bz ] = [ B ϕ , B θ , Br ], where x , y , and z indicate the solar westward, northward, and vertical directions, respectively (see Sun 2013). The spatial resolution of the CEA vector field images is 0.03 degrees, equivalent to about 360 km per pixel at the disk centre, and the cadence of the magnetogram time series is 12 min. Fig. 5 represents the Bz component of the AR 12962 on 09 March 2022 at 09:36:34 UT. The AR is seen to be bipolar, with a dispersed magnetic field distribution, and the maximum vertical magnetic field in the shown magnetogram is 1242.01 Gauss.
For this study, we used 134 magnetograms from 10 March 2022, 08:00UT to 11 March 2022, 10:46UT. This includes 41 magnetograms before the dimming start time, 13 magnetograms between the dimming start and peak time, and 82 magnetograms after the dimming peak time. To implement the CB method, we used specific thresholds for magnetogram partitioning to streamline the analysis and reduce computation time: (1) a threshold of 50 G for the minimum Bz participating in the partition map, (2)
## HMI 2022-03-09 09:46:34
Fig. 5: Bz component of photospheric vector magnetogram of AR 12962 on 2022-03-09 09:46 UT.

a minimum magnetic flux of 2 × 10 19 Mx per partition, and (3) a minimum area of 30 pixels per partition, that is ∼ 3 9 . × 10 6 km 2 in solar surface, and (4) typical uncertainties for vertical and horizontal fields set at 5 G and 50 G, respectively Georgoulis et al. (2012). These thresholds aim to exclude quiet-Sun, weakfield regions, and very small-scale structures from the calculation. The thresholds are optimised to include the majority of the total unsigned flux of the vector magnetogram while maintaining computational e ffi ciency. Through a trial and error method, thresholds were identified beyond which additional regions do not significantly a ff ect helicity and energy values, which remain relatively stable. For example, changing the minimum flux per partition threshold from 2 × 10 19 Mx to 1 × 10 19 Mx increases the helicity value by an average of 15-20%, while the ratio of partitioned flux to total unsigned flux rises from ∼ 70% to ∼ 85%. This increase in helicity is rather insignificant compared to the increase in computational time due to the inclusion of the quietSun regions. Hence, we fixed our minimum flux per partition as 2 × 10 19 Mx. We calculated the standard deviations of the moving five-point averages (48 min) to determine uncertainties for all quantities. This approach is preferred over the default uncertainty mentioned in Georgoulis et al. (2012), which tends to give rise to smaller uncertainty amplitudes.
## 3.1.2. Forward modelling of the CME
In order to determine the geometrical parameters of the CME, we used the GCS model of Thernisien et al. (2006) and Thernisien et al. (2009). This geometrical representation of flux rope CME fits the CME envelope with simultaneous observations from two or three vantage points. The model relies on various free geometrical and positional parameters. The positional parameters determine the location and orientation of the flux rope, which is achieved by supplying the model flux rope's apex's heliographic (Stonyhurst) longitude ϕ and latitude θ and the orientation of its axis of symmetry (tilt) γ . The geometrical parameters such as the height of the flux rope ( h ), the angular width between its two legs (2 w ), and its aspect ratio ( κ ), control how fast the structure expands relative to its height, assuming a self-similar expansion. The user varies these six parameters on a trial-and-error basis until a good agreement is reached between the multi-viewpoint observations and the corresponding model projections. From model-fitted results, we calculate the radius R and length LCME of the CME flux rope. The radius R is calculated using the relation,
$$\begin{smallmatrix} \text{mendo}, \\ \text{gions do} & R = \frac { h } { 1 + \frac { 1 } { \kappa } } \\ \text{flux ner} \end{smallmatrix}$$
which is derived using Equation (1) of Thernisien et al. (2006).
We calculated the length of the CME flux rope using two approaches: 1) as in Patsourakos et al. (2016) and 2) as in Pal et al. (2017). The Patsourakos et al. (2016) approach assumes that the CME front is a cylindrical section with an angular width given by the GCS fitting. The length of the CME flux rope according to Patsourakos et al. (2016) is given by:
$$\i i u n c e r { - } { \i i u n c e r { - } { L _ { C M E } } } = 2 t a n ( w ) r _ { m i d }$$
where rmid = h -R is the heliocentric distance halfway through the model's cross-section along its axis of symmetry, and w is the half angular width in radians. On the other hand, using the approach in Pal et al. (2017) we have,
$$\text{$\mathfrak{rc} \text{svd}$,} \\ \text{and } \text{Th} \text{-} \text{ } L _ { \text{CME} } = 2 h _ { \text{leg} } + y \left ( h - h _ { \text{leg} } / \cos \gamma \right ) / 2 - 2 R _ { \odot }$$
where hle g is the height of the legs of the CME flux rope computed using Equation (3) of Thernisien et al. (2006), GLYPH<16> h -h leg / cos γ GLYPH<17> / 2 is the radius of the arc of the flux rope, y = 2( π/ 2 + γ ) is the arc angle in radians, and R ⊙ represents the solar radius.
To introduce the magnetic field of the flux rope, we consider the Lundquist cylindrical model (Lundquist 1950). This is an axisymmetric linear force-free solution with the following form in
cylindrical coordinates (r, ϕ , z):
$$B _ { r } & = 0, B _ { \phi } = \sigma _ { H } B _ { 0 } J _ { 1 } ( \alpha r ), B _ { z } = B _ { 0 } J _ { 0 } ( \alpha r ) & ( 4 ) \quad \text{power-la}$$
where B 0 is the maximum axial field, J 0 and J 1 are the Bessel functions of the zeroth and first kinds, respectively, σ H = ± 1 is the helicity sign, and α is the constant force-free parameter. Assuming that the first zero of J 0 is reached at the edge of the flux rope, namely
$$\alpha R = 2. 4 0 5 & & ( 5 ) \quad \text{both} \, \sin \,.$$
then R corresponds to the flux-rope radius. This essentially leads to a purely axial (azimuthal) magnetic field at the flux-rope axis (edge).
The Lundquist flux rope model is widely used to describe flux ropes in ICMEs. Patsourakos & Georgoulis (2016) analysed di ff erent analytical flux rope models for the same input parameters to estimate the axial magnetic field of modelled CMEs. They found that the Lundquist flux rope model gave the highest axial magnetic field values among the other models. Recently, Lynch et al. (2022) supported its application in the near-Sun environment: their study evaluates the performance of the Lundquist flux rope model by fitting it to synthetic spacecraft trajectories derived from the spatial coordinates of PSP's encounters. The results of the study indicate that the in situ flux rope models, including the Lundquist model, are generally a decent approximation to the magnetic field structure within 30 R ⊙ compared to MHDmodels.
## 3.1.3. Estimation of Near-Sun magnetic field
Assuming the Lundquist flux rope model with LCME , R derived from GCS fitting, to obtain the magnetic helicity of the cylindrical flux rope, we follow DeVore (2000), Démoulin et al. (2002) and Dasso et al. (2003) as
$$B _ { 0 } & = \sqrt { \frac { H _ { m } } { 0. 7 \cdot R ^ { 3 } \cdot L _ { C M E } } }. & & ( 6 ) & \text{the exp} \\ & \text{used to } d$$
A Monte Carlo simulation determines the associated uncertainty in the estimated CME axial magnetic field B 0 . This approach generates multiple samples by randomly selecting input parameter values from assumed uniform probability distributions of input GCS parameters. The procedure is described in detail in Appendix B.
## 3.2. Extrapolating the CME axial field to 0.43 and 0.99 AU
As CMEs propagate in the heliosphere, their magnetic field decreases with increasing distance from the Sun and subsequent expansion. A number of previous studies such as Bothmer & Schwenn (1998), Wang et al. (2005), Farrugia et al. (2005), Demoulin & Dasso (2009), Winslow et al. (2015) and Patsourakos & Georgoulis (2016) find that this decrease resembles a selfsimilar behaviour, that is, it can be approximated by a power law. Therefore, we extrapolate the estimated axial magnetic field of the CME at GCS fitted height 0.03AU to 0.43 AU and 0.99 AU by assuming a power-law variation of the axial magnetic field with the heliocentric distance r given by
$$B _ { 0 } ( r ) & = B _ { * } \left ( r / r _ { * } \right ) ^ { \alpha _ { B } }. & ( 7 ) \quad \text{licity $\cos$}$$
Here, B ∗ corresponds to the estimated axial magnetic field at GCS fitted height r ( from Eq.7), and B0( ) corresponds to ∗ r the maximum ICME magnetic field from in situ measurements at distances (r) of 0.43 AU and 0.99 AU, respectively. α B is the power-law index.
In this extrapolation, we utilised the approach described in Patsourakos et al. (2016) to find optimal values for α B . We examined α B within the range of [-2.7, -1.0], with a step size of 0.1. This specific range was derived primarily from diverse theoretical and observational studies, encompassing both the outer corona and the inner heliosphere and, in some cases, addressing both simultaneously (Patzold et al. 1987; Kumar & Rust 1996; Bothmer & Schwenn 1997; Vršnak et al. 2004; Liu et al. 2006; Forsyth et al. 2006; Leitner et al. 2007; Poomvises et al. 2012; Mancuso & Garzelli 2013). In addition, we employed linear regression to the log-log pairs to three points in the inner heliosphere, namely, the estimated B 0 at GCS fitted height, ICME B 0 SolO at 0.43 AU from MAG SolO, and ICME / B WIND 0 at 0.99 AU from WIND.
## 4. Results
## 4.1. Near-Sun analysis
## 4.1.1. Magnetic helicIty budget of the CME
To comprehend the preand post-eruption behaviour of the source AR, we pinpointed temporal milestones of the eruption, such as the CME onset. The time stamps of coronal dimmings can serve as a proxy indicator for CME onset. Coronal dimmings are a widely recognised indicator of the initiation of CMEs (Howard & Harrison 2004), which refers to areas with significantly decreased emission in EUV wavelengths (Thompson et al. 1998) and soft X-rays (Hudson et al. 1996; Sterling & Hudson 1997). These dimmings, observed in the corona, occur in conjunction with CMEs and serve as indicators of the extraction and depletion of coronal plasma due to the CME expansion and ascent in the corona (Thompson et al. 1998; Harrison & Lyons 2000). Hence, we consider the dimming start and peak time as the eruption onset and maximum, respectively, which is then used to define the pre- and post-eruption phase of the source AR. Weused the Solar Demon Dimming Detection tool 7 (Kraaikamp & Verbeeck 2015) which runs in real-time on SDO AIA 211 / Ådata with 3-minute cadence to obtain the intensity of the darkest region within the dimming regions in AR 12962 (see Fig.2b). The GOES 1 - 8 Å X-ray flux X-ray sensor (XRS) 1-minute data shows the associated flare timing. 8
Fig.6a represents the temporal evolution of instantaneous values of relative magnetic helicity of AR 12962 from 11 March 2022 08:00 UT to 11 March 2022 11:00 UT, along with a 48minute moving average and respective uncertainty. Following this, Fig.6b and Fig.6c illustrate the temporal progression of the base di ff erence intensity of the darkest region within the dimming and the GOES X-ray flux, respectively. The dimming start and peak times are marked as vertical black dashed lines in all panels.
An inspection of Fig.6a shows that the net helicity sign is negative throughout the time period under investigation. Since the AR is in the northern hemisphere, this is consistent with the hemispheric helicity rule (Pevtsov et al. (2014) and references therein). The helicity shows that it is decreasing in magnitude starting on 10 March 2022, at 15:10 UT until 18:58 UT the same day. During this period, the absolute value of net helicity continuously decreased from ( -0 99 . ± 0 12) . × 10 42 Mx 2
7 https://www.sidc.be/solardemon/dimmings.php
8 https://www.swpc.noaa.gov/products/goes-x-ray-flux
Fig. 6: Temporal evolution of magnetic properties of NOAA AR 12962. Top to bottom: a) Blue lines represent the instantaneous values of the relative magnetic helicity estimated from the CB method. The over-plotted orange curve and green error bars are the running averages of the estimated values over a 48-minute window, with the standard deviation of each 48-minute moving average, respectively. b) Red dots represent the base di ff erence intensity of the darkest region within the dimming. c) The blue curve represents GOES 1 - 8 Å X-ray flux 1-minute data. In all panels, vertically dashed black lines indicate the dimming start and peak time, and the orange line represents the GOES flare peak time.
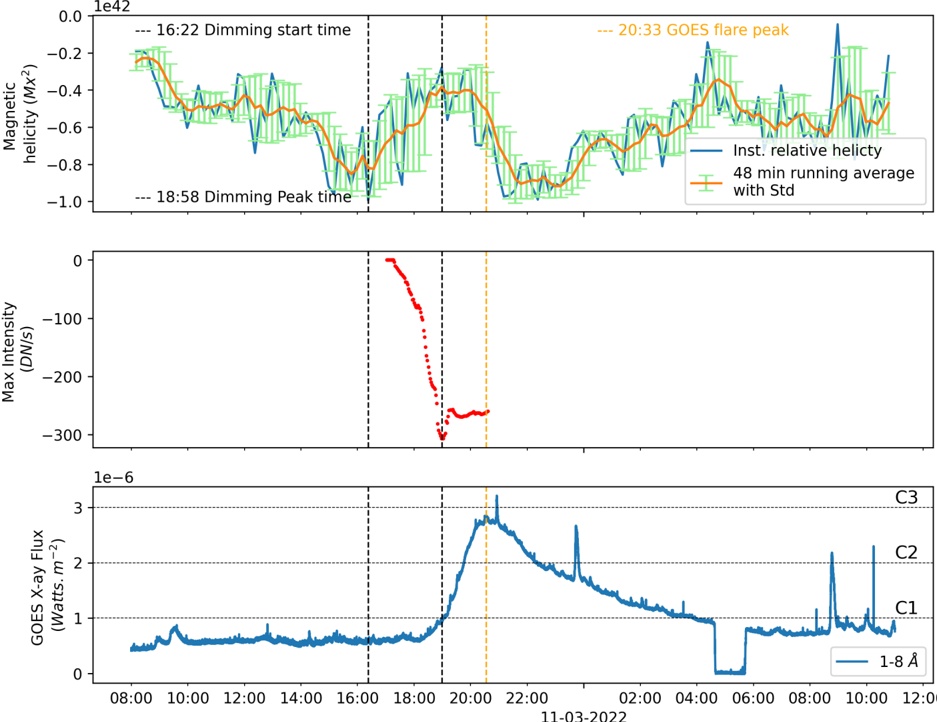
to ( -0 28 . ± 0 12) . × 10 42 Mx 2 , so the net helicity decrease is ( -0 71 . ± 0 12) . × 10 42 Mx 2 . The uncertainty in this value is calculated by employing error propagation in the pre-and posteruption helicity values. The interval of Hm decrease is roughly bracketed between the timestamps of start and peak dimming intensities (check out Fig. 6b), which implies a potentially close connection between the CME onset and early evolution of Hm . We note that the di ff erence between the pre-and post-eruption helicity is well above the applicable uncertainty. As evidenced from full-disk images in the EUV, transfer of this helicity to global solar structures via magnetic reconnection is rather limited as the unstable structure seems fairly isolated. Hence, we assume that the di ff erence in helicity is entirely transferred to the CME. It is noted that after the dimming's peak time, at around 18:58 UT, total helicity enters a recovery phase of 2 h 48 min and reaches a maximum close to that of the pre-eruption stage, at ( -0 99 . ± 0 12) . × 10 42 Mx 2 around 21:46 UT. From Fig.6c, which shows the GOES X-ray flux, we infer that the XRS values took several hours past the flare peak to return to pre-flare values, inferring this was a long-duration event typical of eruptive flares.
Fig.7 illustrates the temporal variation of other magnetic properties of the AR. Fig.7a displays the normalised helicity variation, calculated as the ratio of the instantaneous relative magnetic helicity to the square of the total connected flux. The normalised helicity provides a generalised helicity measure independent of AR flux distribution. As seen in Fig.7a, this time series is more featureless (that is, less responsive to eruptions) than the actual helicity budget of Fig.6a, as also suggested by LaBonte et al. (2007) and Thalmann et al. (2019).
In Fig.7b, the components contributing to the total helicity are presented separately, namely, the total negative helicity and total positive helicity. Throughout the observed period, the dominant helicity is negative (left-handed); there is a declining trend in left- and right-handed helicity before the eruption, resulting in a decreasing net helicity, with left-handed helicity (negative sign) domination. Fig.7c represents the temporal evolution of free magnetic energy, starting from 10 March 2022, at 16:58 UT, which has decreased from 8 33 . × 10 31 erg to 4 15 . × 10 31 erg at 19:03 UT, marking a di ff erence between pre-and post-eruption free energy budget as 4 18 . × 10 31 erg which is within the range of CME mechanical energies discussed in Vourlidas et al. (2010).
Fig. 7: Temporal evolution of other magnetic attributes of NOAA AR 12962. Top to bottom: a) The red curve is the normalized helicity value. The blue overplotted curve and the green error bar correspond to the 48-minute moving average and the standard deviation, respectively. b) The blue line represents instantaneous normalised negative helicity, and the orange line represents the normalized positive helicity. c) The black line represents the normalized instantaneous magnetic free energy. d) The black line represents the instantaneous total unsigned flux. In all panels, the vertically dashed black lines indicate the dimming start time (16:22) and dimming peak time (18:58), and the dashed orange line represents the GOES flare peak time.
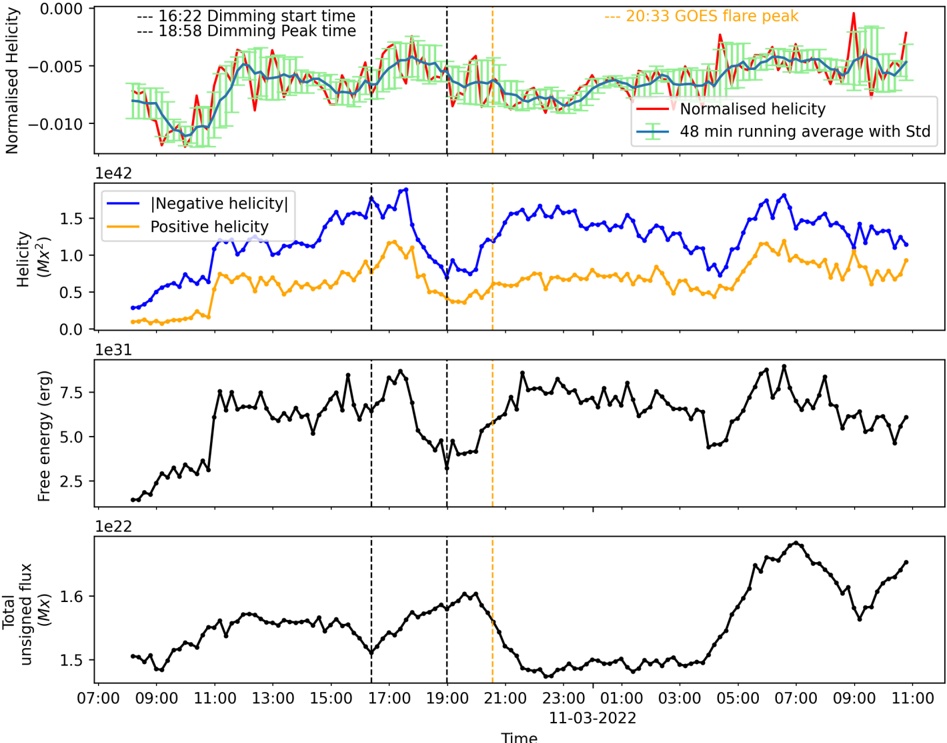
Similarly to the Hm , the period of free magnetic energy decrease is co-temporal with the period of dimming start-peak. It then enters a stage of recovery to a maximum of 8 6 . × 10 31 erg at 21:34 UT.
Fig.7d shows the total unsigned flux variation. It initially goes through an increasing phase just before the eruption. It has a minimum value of 1 51 . × 10 22 Mx on 10 March 16:22 UT and reaches a maximum of 1 6 . × 10 22 Mx on 10 March 19:58 UT. After the eruption, flux decreases to approximately its initial value and persists in that value for nearly six hours. This is likely attributed to the enhanced horizontal magnetic field in the post-eruption AR caused by magnetic implosion (Hudson 2000). As flux entirely depends on the vertical component of the magnetic field ( Bz ), a smaller flux may indicate a reduced Bz after the eruption. This can also explain the absolute helicity value increase around the flare peak, which continued after the CME, potentially due to an enhanced horizontal field and increased force-free parameters right after the eruption, as seen by Liu et al. (2023). This can be attributed to the delayed in- teraction between the photosphere's ongoing processes and the coronal events.
## 4.1.2. Forward modelling of the CME
To estimate the geometrical parameters of the CME, we used white light observations from SECCHI COR2 and LASCO C2 / / coronographs, which have a FOV of 2.5-15 R ⊙ and 2-6 R ⊙ , respectively. STEREO-A was 33 0 . ◦ ahead of Earth at the time of the CME. The CME was observed nearly simultaneously as a west limb event in STEREO-A and as a partial halo CME in the SOHO C2 and C3 coronagraphs. However, in the LASCO C3 observations, the CME appeared more di ff use, making its boundaries harder to identify reliably and, therefore, unsuitable for a GCS fit.
In Fig.8, the top row represents two nearly simultaneous observations of the CME, one with LASCO C2 at 20:36 (left) and another with STEREO-A at 20:38 UT (right). The bottom row includes the overplotted GCS wire frame. The best-fit parameter values and applicable uncertainties are listed in Table 2.
Fig. 8: GCS model fits on the 10 March 2022 CME. Top row: Images of the CME by LASCO C2 (left) and / SECCHI COR2 STEREO-A (right). Bottom row: The same images, with the GCS wireframe, overlaid. /




The uncertainties are estimated manually, similar to the sensitivity analysis outlined in Thernisien et al. (2009). Specifically, our approach involves perturbing the optimal fit of one parameter at a time, up to an extent the deviations are within visually acceptable range while keeping the other parameters constant at their optimal fit. The uncertainties in the parameters are hence measured in terms of deviations from their optimal values, considering both positive and negative extremes. The fitted results of the position, tilt, and angular width of the CME are consistent with the conclusion that this CME is propagating towards SolO.
Our obtained GCS fitting results are also consistent with those of Zhuang et al. (2024).
From GCS fitting results, we obtain the height of the CME as 7.6 R ⊙ , that is, at a distance of 6.6 R ⊙ from the solar surface. We calculate the radius R using Eq.1. The length LCME is calculated using two approaches mentioned in Eq.2 and Eq.3. We employed a Monte Carlo simulation to estimate uncertainties in these derived parameters. The variations in these parameters are simulated by assuming a uniform distribution within specified ranges. We obtained the length of the CME following Patsourakos et al.
Table 2: CME GCS fitted parameters along with the positive and negative limits of uncertainty.
| CMEparameter | Value |
|----------------------|----------------------------|
| latitude (degrees) | 20.7 ± 4.3 |
| longitude (degrees) | 7.8 ± 1.8 |
| tilt angle (degrees) | -50.9 ± 22 |
| height (solar radii) | 7.6 ± 0.4 |
| aspect ratio | 0.3, - 0 . 05, + 0 . 03 |
| half-angle (degrees) | 55.6 , - 10 . 62, + 9 . 22 |
| R (solar radii) | 1.8 ± 0.4 |
| L CME (Solar radii) | 17.0 ± 3.7 |
(2016) as 17.02 ± 3.85 R ⊙ and by following Pal et al. (2017) we obtained 13.65 ± 0.68 R ⊙ .
## 4.1.3. Estimation of the near-Sun magnetic field of the CME
We now have three approaches for estimating the near-Sun axial magnetic field of the CME from Eq. 6. First, we estimate the helicity budget of the CME by assuming the net helicity di ff erence between the pre- and post-eruption phase of AR, yielding ( -7 1 . ± 1 2) . × 10 41 Mx 2 . Under this assumption, the axial magnetic field at 6.6 R ⊙ is determined as B 0 = 2067 ± 405 nT, with the CME length calculated following Eq. 2. Secondly, adopting the same helicity budget assumption but employing the length of the CME derived from Eq. 3, we obtain B 0 = 2600 ± 440 nT. Thirdly, we estimate the magnetic field value by attributing the total pre-eruption helicity budget to the CME, as proposed by Patsourakos et al. (2016), resulting in B 0 = 2437 ± 381 nT, while still following the length calculation method from Eq. 2. Both methods for calculating the length (first and second) and the third method of assigning pre-eruption helicity to the AR yield similar B 0 values within the uncertainty range. Therefore, we choose the second method, that is B 0 = 2067 ± 405 nT.
## 4.2. Extrapolating near-Sun CME magnetic field to 0.43 AU and 0.99 AU
Fig. 9: Extrapolated CME magnetic field at 0.43 AU (orange points) and 0.99 AU (blue points) as a function of the radial power-law index ( α B ) of Eq.7. The orange and blue horizontal dashed lines correspond to the ICME maximum magnetic field measurement from SolO and WIND, respectively.
As explained in Sect.3.2, using Eq.7, we plotted the extrapolated CME magnetic field as a function of the power-law index α B in Fig.9. The figure marks these maximum magnetic fields as dashed lines. From Fig.9, the α B value that intersects with the maximum magnetic-field measurement of SolO is -1.1, and that of WIND is -1.2.
In addition, we employed linear regression to the log-log pairs of the maximum magnetic field measurements from three points in the inner heliosphere, namely, the estimated near-Sun axial magnetic field at GCS fitted distance of 6.6 R ⊙ or 0.03 AU ( B 0 ), B SolO 0 at 0.43 AU, and B WIND 0 at 0.99 AU. This is illustrated in Fig.10. From the linear least-squares best fit, we found a single power-law fallo ff index, α B = -1 23 . ± 0 18, which can . represent the variation of B0 from near-Sun to 0.99 AU.
Fig. 10: CME magnetic field variation with distance. Blue points with error bars depict the maximum magnetic field B 0 . The nearSun field is estimated, while the fields at 0.43 AU (Solar Orbiter) and 0.99 AU (WIND) rely on in situ measurements. The 0.99 AU measurements have minimal error (on the order pT), and the red line represents the least-squares best fit.
## 5. Discussion and conclusions
This work estimates the near-Sun axial magnetic field of a CME that occurred on 10 March 2022 from source NOAA AR 12962. We followed the methodology of Patsourakos et al. (2016), which relies on the magnetic helicity conservation principle. At the time of the eruption, the SolO spacecraft was located 7.8 degrees east of the Sun-Earth line, allowing for both in situ and remote sensing SolO observations at 0.43 AU. The WIND mission at L1 (0.99 AU) complements the in situ measurements, while STEREO and SOHO LASCO contribute multi-viewpoint / coronographic remote-sensing observations. We analysed the temporal evolution of the magnetic helicity of AR 12962 using the CB discrete flux tube method proposed by Georgoulis et al. (2012). Our estimations revealed a decrease in helicity within the AR region near CME onset, which is assumed to correspond to the helicity bodily transported to the CME. To estimate the near-Sun axial magnetic field of the CME, we employed the Lundquist flux rope model, utilising Eq.6 at a distance of 0.03 AU. We then extrapolated the near-Sun magnetic field using a power-law radial decrease assumption at di ff erent distances (near-Sun, 0.43 AU, 0.99 AU) and estimated a single power-law index α B .
Our main findings are as follows:
- 1. The maximum helicity budget of the source AR in the preeruption phase, recorded on 10 March 2022, at 16:22 UT, is ( -9 94 . ± 1 2) . × 10 41 Mx 2 .
- 2. The net helicity di ff erence in AR 12962 between the preand post-eruption phases is ( -7 1 . ± 1 2) . × 10 41 Mx 2 . This represents approximately 71% of the total helicity budget, which is assumed to be fully transferred to the CME.
- 3. Utilising the Lundquist flux rope model, the axial magnetic field of the analysed CME at a distance of 0.03 AU is estimated at 2067 ± 405 nT.
- 4. Based on the power-law variation of B 0 with heliocentric distance, a single power-law index value, α B from near-SunSolO-Earth is estimated to be 1 23 . ± 0 18. .
- 5. The estimated α B from the near-Sun to SolO is -1 17 . ± 0 14, . and from in situ measurements between SolO and WIND, it is 1 95 . ± 0 13. .
We would like to compare the magnitude of our estimated CME helicity budget of ( -7 1 . ± 1 2) . × 10 41 Mx 2 with previous studies on other CMEs ARs. Using the helicity injection / method, Georgoulis et al. (2009) studied solar magnetic helicity injected into the heliosphere over solar cycle 23 and found that the average helicity content per active-region CME varies between 1 8 . × 10 42 Mx 2 and 7 × 10 42 Mx 2 , with the upper extreme being an order of magnitude higher than ours. DeVore (2000), who studied magnetic helicity generation by solar di ff erential rotation, employs the surface rate integral as a diagnostic tool to analyse the generation of helicity by horizontal motions of the footpoints of magnetic structures and finds that a typical interplanetary magnetic cloud contains a helicity of approximately -2 × 10 42 Mx 2 and a magnetic flux of ∼ 10 21 Mx, marking an order of magnitude higher than ours for helicity content. In Patsourakos et al. (2016), three methods were used to calculate the helicity of the CME, all indicating a net negative helicity, with smaller changes in positive helicity also observed. The helicity injection method (Pariat et al. 2006) yielded -3 26 . × 10 43 Mx 2 , marking two orders of magnitude higher. The CB method of Georgoulis et al. (2012) had an estimate of - × 4 10 42 Mx 2 and the volume calculation (Moraitis et al. 2014) yielded -8 × 10 42 Mx 2 , both marking a order magnitude higher. However, the helicity injection method is expected to yield higher helicity values, as these values represent the total helicity injected into the system from the photospheric boundary and from the beginning of the observing sequence to the eruption onset. On the other hand, the CB method provides a lower-limit estimate of the CME's helicity because it assumes simple arch-like tubes and does not account for the braiding of flux tubes in the corona (Georgoulis et al. 2012). A comparison of the CB method with several other helicity estimation methods, demonstrating its lower-limit estimations, has been discussed by Thalmann et al. (2021). Furthermore, Tziotziou et al. (2012), using the connectivity matrix of the CB method, distinguished eruptive ARs from non-eruptive ones using both relative helicity and free magnetic energy, with helicity and free energy thresholds for the occurrence of major flares of 2 × 10 42 Mx 2 and 4 × 10 31 erg, respectively marking an order of magnitude higher than ours for helicity budget. Additionally, a recent study by Liokati et al. (2022), using helicity injection method, found thresholds for both the magnetic helicity and energy thresholds of 9 × 10 41 Mx 2 and 2 × 10 32 erg, respectively, which, if exceeded, suggest the host AR is likely to erupt. Estimates in this latter study are closer to our results.
In the era of PSP and SolO missions, co-aligned observations of eruptions such as the one studied here will provide stronger observational tests for estimating the axial magnetic field of Earth-directed CMEs. An example of such a coordinated observation occurred on 5 September 2022, when PSP observed from a heliocentric distance of 13.3 R ⊙ an event originating from AR
13088. This particular event has been extensively analysed by Romeo et al. (2023), Long et al. (2023) and Paouris et al. (2023). PSP's recordings at 13.3 R ⊙ indicated a maximum ICME magnetic field strength of 1104 nT. A rough comparison between the estimated near-Sun magnetic field strength of 2067 ± 405 nT a distance of 6.6 R ⊙ of our event and the first-ever near-Sun in situ magnetic field measurement at 13.3 R ⊙ falls nearly at the same range.
In short, while variations exist, as the choice of methodology significantly influences the reported helicity values, our estimation of the helicity content agrees with previous studies within an order of magnitude. We tend to give a relatively low helicity content for the CME. This can also be attributed to our relatively weak AR source. It could also well be because of two reasons besides the weak source: first, the CB method provides a lower limit of helicity. Second, we assign the di ff erence between the pre-and post-eruption phases to the CME rather than the entire helicity content of the source.
We now compare our estimated single power-law index from near-Sun to 0.99 AU ( α B = -1 23 . ± 0 18) with previous stud-. ies that considered either near-Sun magnetic field estimations or measurements. Patsourakos et al. (2016) found a value of ∼ -2 for their study of the 2012 March 7 event using the same methodology, which is beyond the uncertainty limits of our result. However, this CME originated from a flux-laden AR with significantly higher helicity values and corresponded to an ultra-fast CME from NOAA AR 11429. On a follow-up statistical study of this methodology, in Patsourakos & Georgoulis (2016) used the input parameter distributions derived from observations to determine near-Sun and L1 magnetic fields for synthetic CMEs obtained α B = -1 6 . ± 0 2 , which marginally falls within our . estimated range within the uncertainty range. This study has considered more flux rope models along with the Lundquist model. Furthermore, a recent study of Salman et al. (2024), which presents a statistical investigation of the radial evolution of 28 ICMEs, measured in situ by PSP, at various heliocentric distances ranging from 0.23 to 0.83 AU, from October 2018 to August 2022. They considered ICME average magnetic field in contrast to the maximum value in our study and found an average value of -1.21 ± 0.44 for α B , suggesting a less steep fall-o ff of the magnetic field with distance, which is in significant alignment with our results.
Additionally, we compare the obtained power-law index of -1.95 ± 0.13 from SolO-L1 obtained from in situ measurements in the inner heliosphere (r < 1 AU) to other previous studies within the inner heliospheric region spanning 0.3 to 0.99 AU. Comparison with a study by Salman et al. (2020), which examined 47 ICMEs measured in situ by multiple spacecraft, studied the variation of magnetic sheath and ejecta separately; for the ejecta, the median was -1.75, with 50% of the values falling within the range of -2.29 to -1.35. Additionally, in Good et al. (2019), a fitting analysis of 26 ensemble values of B 0 yielded a α B = -1.76 ± 0.04. Both of these studies fall within the uncertainty limits of our estimated value, indicating consistency in magnetic field variation trends. Conversely, a study by Leitner et al. (2007) for 130 events resulted in α B = -1.64 ± 0.40. This finding suggests a similar decreasing trend in B 0 with distance, though with a slightly di ff erent rate compared to Good et al. (2019). It also explores the individual radial decrease B 0 in each ICME by performing separate power-law fits to the two B0 values obtained from each of the 13 events and obtained a mean fit α B = -1.34 ± 0.71. These α B values have a slightly broader range of uncertainty, suggesting a potential variation in magnetic field behaviour within the inner heliosphere, though
still overlapping with our results. Similar work is found in Farrugia et al. (2005), where a study on the statistical variation of quantities associated with magnetic cloud propagation in inner heliospheric distances, utilising data from 31 events from Helios 1, 2 and Wind spacecraft data, concluded a α B of -1.38 for the axial magnetic field. This estimation lies outside the uncertainty limits of our results. However, the absence of uncertainty reporting in Salman et al. (2020) and Farrugia et al. (2005) studies poses challenges in definitive comparison.
In conclusion, the studies in the region 0.3-0.99 AU give rise to significant variability in α B values. Our study contributes an important perspective with an estimated single α B of -1.23 ± 0.18, encompassing observations from near- Sun to 0.43 AU up to 0.99 AU. The inclusion of the 0.43 AU data point o ff ers a valuable validation opportunity for our methodology. Notably, our findings exhibit qualitative alignment with prior studies of Patsourakos & Georgoulis (2016), which employed the same methodology for estimating near-Sun magnetic field characteristics for CME events. Successively, the alignment of our results with the statistical results of PSP measurements in Salman et al. (2024) is encouraging. These findings also support the need for a more nuanced approach to modelling and predicting the dynamics of CMEs and ICMEs, considering their individual characteristics and the specific conditions of each event.
In summary, in addition to the estimation of the near-Sun magnetic field of this CME and an enhancement of understanding of the power-law variation of the CME magnetic field with heliocentric distance, our study confirms that the pre-and posteruptive helicity di ff erence in source ARs can be used for further study of the resulting CME. The current availability of multiple viewpoints and co-aligned observations of CME events allows the construction of a database intended to establish a maximum likelihood near-Sun CME B 0 that stems from observations rather than models. Our methodology has the potential to provide a foundation for routine calculations of magnetic helicity in the lower solar atmosphere combined with existing geometric modelling of CMEs in the outer corona. The creation of a nearSun CME B 0 database and our methodology will hopefully contribute to a more systematic understanding of the near-Sun CME evolution. The maximum likelihood values of near-Sun CME B 0 and the understanding of its variation with heliocentric distance could also be used as initial conditions for MHD models simulating CME propagation in the inner heliosphere, such as the European Heliospheric FORecasting Information Asset (EUHFORIA) modelling facility (Pomoell & Poedts 2018).
Acknowledgements. This work is part of the SWATNet project funded by the European Union's Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 955620. AN and SP acknowledge support from the ERC Synergy Grant 'Whole Sun' (GAN: 810218). The authors thank the referee for constructive comments suggestions. /
## References
Bastian, T. S., Pick, M., Kerdraon, A., Maia, D., & Vourlidas, A. 2001, ApJ, 558, L65
- Berger, M. A. 1984, Geophysical & Astrophysical Fluid Dynamics, 30, 79
- Berghmans, D., Antolin, P., Auchère, F., et al. 2023, A&A, 675, A110
- Bobra, M. G., Sun, X., Hoeksema, J. T., et al. 2014, Sol. Phys., 289, 3549
- Bothmer, V. & Schwenn, R. 1997, Annales Geophysicae, 16, 1
- Bothmer, V. & Schwenn, R. 1998, Annales Geophysicae, 16, 1
- Brueckner, G. E., Howard, R. A., Koomen, M. J., et al. 1992, in ESA Special Publication, Vol. 348, Coronal Streamers, Coronal Loops, and Coronal and Solar Wind Composition, ed. C. Mattok, 27-34
- Burkepile, J. T., Hundhausen, A. J., Stanger, A. L., St.Cyr, O. C., & Seiden, J. A. 2004, Journal of Geophysical Research: Space Physics, 109
Burlaga, L. F. 1988, J. Geophys. Res., 93, 7217
- Chen, P. F. 2011, Living Reviews in Solar Physics, 8, 1
- Cid, C., Cremades, H., Aran, A., et al. 2012, Journal of Geophysical Research: Space Physics, 117
- Dasso, S., Mandrini, C. H., Démoulin, P., & Luoni, M. L. 2006, Astronomy and Astrophysics, 455, 349
- Dasso, S., Mandrini, C. H., Démoulin, P., & Farrugia, C. J. 2003, Journal of Geophysical Research: Space Physics, 108
- Davies, J. A., Harrison, R. A., Perry, C. H., et al. 2012, ApJ, 750, 23
- Démoulin, Mandrini, C. H., van Driel-Gesztelyi, L., et al. 2002, A&A, 382, 650 Demoulin, P. & Dasso, S. 2009, http: // dx.doi.org 10.1051 0004-/ / 6361 200810971, 498 /
- DeVore, C. R. 2000, The Astrophysical Journal, 539, 944
- DeVore, C. R. 2000, ApJ, 539, 944
- Domingo, V., Fleck, B., & Poland, A. I. 1995, Sol. Phys., 162, 1
- Farrugia, C. J., Leiter, M., Biernat, H. K., et al. 2005, in ESA Special Publication, Vol. 592, Solar Wind 11 SOHO 16, Connecting Sun and Heliosphere, ed. / B. Fleck, T. H. Zurbuchen, & H. Lacoste, 723
- Forbes, T. G. 2000, Journal of Geophysical Research: Space Physics, 105, 23153 Forsyth, R. J., Bothmer, V., Cid, C., et al. 2006, Space Science Reviews, 123, 383
- Georgoulis, M. K., Rust, D. M., Pevtsov, A. A., Bernasconi, P. N., & Kuzanyan, K. M. 2009, ApJ, 705, L48
- Georgoulis, M. K., Tziotziou, K., & Raouafi, N.-E. 2012, The Astrophysical Journal, 759, 1
- Georgoulis, M. K., Tziotziou, K., & Raouafi, N.-E. 2012, ApJ, 759, 1
- Good, S. W., Kilpua, E. K. J., LaMoury, A. T., et al. 2019, Journal of Geophysical Research (Space Physics), 124, 4960
- Gopalswamy, N., Lara, A., Yashiro, S., Kaiser, M. L., & Howard, R. A. 2001, J. Geophys. Res., 106, 29207
- Goto, M., Carmona, A., Linz, H., et al. 2012, The Astrophysical Journal, 748, 6 Halain, J. P., Berghmans, D., Seaton, D. B., et al. 2013, Sol. Phys., 286, 67 Harrison, R. A. & Lyons, M. 2000, A&A, 358, 1097
- Hoeksema, J. T., Liu, Y., Hayashi, K., et al. 2014, Sol. Phys., 289, 3483
- Horbury, T. S., O'Brien, H., Carrasco Blazquez, I., et al. 2020, A&A, 642, A9
- Howard, R. A., Moses, J. D., Vourlidas, A., et al. 2008a, Space Sci. Rev., 136, 67
- Howard, T. A. & Harrison, R. A. 2004, Solar Physics, 219, 315
- Howard, T. A., Nandy, D., & Koepke, A. C. 2008b, Journal of Geophysical Research (Space Physics), 113, A01104
- Hudson, H. S. 2000, The Astrophysical Journal, 531, L75
- Hudson, H. S., Acton, L. W., & Freeland, S. L. 1996, ApJ, 470, 629
- Jackson, B. V., Tokumaru, M., Iwai, K., et al. 2023, Solar Physics, 298, 1
- Jensen, E. A. & Russell, C. T. 2008, Geophysical Research Letters, 35
- Kaiser, M. L., Kucera, T. A., Davila, J. M., et al. 2008, Space Sci. Rev., 136, 5 Kraaikamp, E. & Verbeeck, C. 2015, Journal of Space Weather and Space Climate, 5, A18
- Kumar, A. & Rust, D. M. 1996, J. Geophys. Res., 101, 15667
- Kunkel, V. & Chen, J. 2010, The Astrophysical Journal Letters, 715, L80
- LaBonte, B. J., Georgoulis, M. K., & Rust, D. M. 2007, ApJ, 671, 955 Laker, R., Horbury, T. S., O'Brien, H., et al. 2024, Space Weather, 22, e2023SW003628
- Leitner, M., Farrugia, C. J., Möstl, C., et al. 2007, Journal of Geophysical Research (Space Physics), 112, A06113
- Leka, K. D., Canfield, R. C., McClymont, A. N., & van Driel-Gesztelyi, L. 1996, ApJ, 462, 547
- Lemen, J. R., Title, A. M., Akin, D. J., et al. 2012, Sol. Phys., 275, 17
- Lepping, R. P., Ac˜ una, M. H., Burlaga, L. F., et al. 1995, Space Sci. Rev., 71, 207
- Liokati, E., Nindos, A., & Georgoulis, M. K. 2023, A&A, 672, A38
- Liokati, E., Nindos, A., & Liu, Y. 2022, A&A, 662, A6
- Liu, Y., Richardson, J. D., Belcher, J. W., Kasper, J. C., & Skoug, R. M. 2006,
Journal of Geophysical Research (Space Physics), 111, A09108
Liu, Y., Welsch, B. T., Valori, G., et al. 2023, ApJ, 942, 27
Long, D. M., Green, L. M., Pecora, F., et al. 2023, ApJ, 955, 152
- Low, B. C. 1994, Physics of Plasmas, 1, 1684
Lundquist, S. 1950, Ark. Fys., 2, 361
Lynch, B. J., Al-Haddad, N., Yu, W., Palmerio, E., & Lugaz, N. 2022, Advances in Space Research, 70, 1614, magnetic Flux Ropes in Solar Environments Mancuso, S. & Garzelli, M. V. 2013, Astronomy and Astrophysics, 560 Moraitis, K., Tziotziou, K., Georgoulis, M. K., & Archontis, V. 2014, Sol. Phys., 289, 4453
- Mostl, C., Amla, K., Hall, J. R., et al. 2014, The Astrophysical Journal, 787 Müller, D., St. Cyr, O. C., Zouganelis, I., et al. 2020, A&A, 642, A1
- Nindos, A. & Andrews, M. D. 2004, The Astrophysical Journal Letters, 616, L175
- Ogilvie, K. W., Chornay, D. J., Fritzenreiter, R. J., et al. 1995, Space Sci. Rev., 71, 55
- Owen, C. J., Bruno, R., Livi, S., et al. 2020, A&A, 642, A16
- Pal, S., Gopalswamy, N., Nandy, D., et al. 2017, The Astrophysical Journal, 851, 123
- Paouris, E., Vourlidas, A., Kouloumvakos, A., et al. 2023, The Astrophysical Journal, 956, 58
Pariat, E., Nindos, A., Démoulin, P., & Berger, M. A. 2006, A&A, 452, 623 Park, S.-h., Chae, J., & Wang, H. 2010, ApJ, 718, 43
Park, S.-H., Lee, J., Choe, G. S., et al. 2008, ApJ, 686, 1397
- Patsourakos, S. & Georgoulis, M. 2017, Solar Physics, 292
- Patsourakos, S., Georgoulis, M., Vourlidas, A., et al. 2016, The Astrophysical Journal, 817, 14
Patsourakos, S. & Georgoulis, M. K. 2016, A&A, 595, A121
- Patzold, M., Bird, M. K., Volland, H., et al. 1987, Sol. Phys., 109, 91
Pesnell, W. D., Thompson, B. J., & Chamberlin, P. C. 2012, Sol. Phys., 275, 3
- Pevtsov, A. A., Berger, M. A., Nindos, A., Norton, A. A., & van Driel-Gesztelyi, L. 2014, Space Science Reviews, 186, 285
- Pomoell, J. & Poedts, S. 2018, Journal of Space Weather and Space Climate, 8, A35
- Poomvises, W., Poomvises, W., Gopalswamy, N., et al. 2012, The Astrophysical Journal, 758
- Priest, E. 2014, Magnetohydrodynamics of the Sun (Cambridge University Press)
- Rochus, P., Auchère, F., Berghmans, D., et al. 2020, A&A, 642, A8
- Romeo, O. M., Braga, C. R., Badman, S. T., et al. 2023, The Astrophysical Journal, 954, 168
- Rust, D. M. & Kumar, A. 1996, ApJ, 464, L199
- Sachdeva, N., Subramanian, P., Colaninno, R., & Vourlidas, A. 2015, ApJ, 809, 158
- Salman, T. M., Nieves-Chinchilla, T., Jian, L. K., et al. 2024, The Astrophysical Journal, 966, 118
- Salman, T. M., Winslow, R. M., & Lugaz, N. 2020, Journal of Geophysical Research (Space Physics), 125, e27084
- Samara, E., Patsourakos, S., & Georgoulis, M. K. 2021, The Astrophysical Journal Letters, 909, L12
- Savani, N. P., Vourlidas, A., Szabo, A., et al. 2015, Space Weather, 13, 374 Seaton, D. B., Berghmans, D., Nicula, B., et al. 2013, Sol. Phys., 286, 43 Stamkos, S., Patsourakos, S., Vourlidas, A., & Daglis, I. A. 2023, Solar Physics, 298
Sterling, A. C. & Hudson, H. S. 1997, The Astrophysical Journal, 491, L55 Sun, X. 2013, arXiv e-prints, arXiv:1309.2392
Tappin, S. J. 2006, Sol. Phys., 233, 233
- Temmer, M., Preiss, S., & Veronig, A. M. 2009, Sol. Phys., 256, 183
- Thalmann, J. K., Georgoulis, M. K., Liu, Y. D., et al. 2021, The Astrophysical Journal, 922
- Thalmann, J. K., Moraitis, K., Linan, L., et al. 2019, ApJ, 887, 64
- Thernisien, A., Vourlidas, A., & Howard, R. A. 2009, Sol. Phys., 256, 111
Thernisien, A. F. R., Howard, R. A., & Vourlidas, A. 2006, The Astrophysical
Journal, 652, 763
- Thompson, B. J., Plunkett, S. P., Gurman, J. B., et al. 1998, Geophys. Res. Lett., 25, 2465
- Tun, S. D. & Vourlidas, A. 2013, ApJ, 766, 130
- Tziotziou, K., Georgoulis, M. K., & Raouafi, N.-E. 2012, The Astrophysical Journal Letters, 759, L4
- Vourlidas, A., Howard, R. A., Esfandiari, E., et al. 2010, The Astrophysical Journal, 722, 1522
- Vršnak, B., Magdaleni´ c, J., & Zlobec, P. 2004, A&A, 413, 753
- Vrvsnak, B., Sudar, D., Ruvzdjak, D., & zic, T. 2007, Astronomy and Astrophysics, 469, 339
- Wang, C., Du, D., & Richardson, J. D. 2005, Journal of Geophysical Research: Space Physics, 110
- Webb, D. F. & Howard, T. A. 2012, Living Reviews in Solar Physics, 9, 3 Winslow, R. M., Lugaz, N., Philpott, L. C., et al. 2015, Journal of Geophysical Research: Space Physics, 120, 6101
- Wu, C.-C. & Lepping, R. 2005, Journal of Atmospheric and Solar-Terrestrial Physics, 67, 283
- Zhang, J., Richardson, I., Webb, D., et al. 2007, Journal of Geophysical Research (Space Physics), 112, 10102
- Zhuang, B., Lugaz, N., Al-Haddad, N., et al. 2024, A&A, 682, A107
Appendix A: Data gap resolution of MAG/SolO in situ observations
Fig. A.1: Scattered blue data points show in situ measurements of BSolO over time. The red curve represents the quadratic fit approximating the data trends. Extrapolated linear fits of BSolO nT and their intersection point (magenta dot) suggest potential B SolO 0 at 0.43 AU.
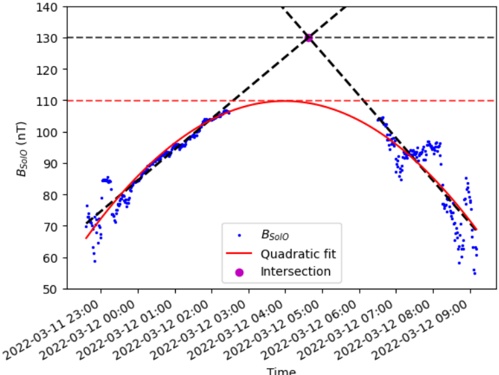
We identified a significant data gap in SolO MAG and PAS measurements from 12-03-2022 02:30 UT to 12-03-2022 06:30UT due to instrumental problems. The low latency data published from these instruments didn't have the data gap which is used in some recent studies such as in Laker et al. (2024). However, even after meticulous calibration procedures, it is noted that the L2 level normal 1-minute MAG data with the latest access on 14 March 2024 (the data used in this study) still exhibits a gap during the aforementioned period. This period encompasses the expected maximum magnetic field of our ICME.
To interpolate data in the gap, we used linear and quadratic fitting routines, as shown in Fig.A.1: we selected the maximum magnetic field measurements ranging from 2022-03-11 22:36:00 UT to 2022-03-12 09:11:00. These time points correspond to the beginning and end of the period in which the magnetic field strength is anticipated to the peak. Firstly, we performed two separate linear fits to the data and then found the intersection between these lines. This value, found to be 130 nT, estimates the maximum anticipated magnetic field peak by at 0.43 AU. Secondly, a single quadratic fit was applied to all data points, yielding a peak of 109.72 nT. The discrepancy between the maximum anticipated peak (linear fits) and the quadratically inferred peak is considered as the uncertainty in the maximum magnetic field at SolO; hence, the ICME maximum magnetic field measurement at 0.43 AU ( B SolO 0 ) by MAG SolO is calculated as 109.72 / ± 20.27 nT.
## Appendix B: Monte-carlo simulation for estimation of the near-Sun B 0 uncertainty
We employed a Monte Carlo simulation approach to calculate the axial magnetic field and its associated uncertainty. We compared the e ff ects of uniform and normal distributions of input parameters on the results, focusing on the convergence and statistical reliability of the estimated axial magnetic field. However,
Table B.1: Results of Normal distribution trials
| N.samples | N. Eliminated combinations | B 0 mean (Gauss) | B 0 std (Gauss) |
|-------------|------------------------------|--------------------|-------------------|
| 100 | 5 | 0.025 | 0.013 |
| 500 | 23 | 0.023 | 0.017 |
| 1000 | 175 | 0.024 | 0.022 |
| 10000 | 4074 | 0.017 | 0.024 |
Table B.2: Results of uniform distribution trials
| N.samples | N. Eliminated combinations | B 0 mean (Gauss) | B 0 std (Gauss) |
|-------------|------------------------------|--------------------|-------------------|
| 100 | 0 | 0.021 | 0.004 |
| 500 | 0 | 0.021 | 0.005 |
| 1000 | 0 | 0.021 | 0.004 |
| 10000 | 0 | 0.021 | 0.004 |
our normal distribution simulations revealed a critical issue: a significant portion of the samples resulted in negative values for parameters such as Hm , R or LCME . These negative values are unphysical in the case of R or LCME , leading to impossible estimates of B 0 , that is, negative values inside the square root in Eq.6. This caused us to discard samples with at least one negative input value, as indicated in Table B.1 and Table B.2. This process eliminated half of the samples in the normal distribution, undermining its statistical reliability and preventing the convergence of the estimated value of B 0 . In contrast, assigning a uniform distribution that assigns equal probability to all values within an uncertainty range, which is useful when prior knowledge is limited, yielded no combinations with negative or unphysical inputs, as seen in Table B.2. This made the sampling statistically significant and showed improved convergence regardless of sample size.
Our analysis has revealed that selecting a probability distribution in Monte Carlo simulations can substantially a ff ect the outcomes, particularly in systems sensitive to input variability. The normal distribution, which is often used, was found to be inadequate in our study due to its tendency to generate unrealistic scenarios. Therefore, it is important to be careful when selecting distributions, particularly when the physical meaning of inputs is essential. The uniform distribution within the Monte Carlo simulation framework was found to be more suitable for this context. It provided more precise estimations of B 0 and applicable uncertainty, avoiding convergence issues and producing realistic results. Additionally, the estimated uncertainty remained relatively consistent regardless of the sample size. We suggest that future research explore other distributions or hybrid approaches, particularly in situations with limited prior knowledge about the true distribution of input parameters. | 10.1051/0004-6361/202450204 | [
"Shifana Koya",
"Spiros Patsourakos",
"Manolis K. Georgoulis",
"Alexander Nindos"
] | 2024-08-02T09:40:41+00:00 | 2024-08-02T09:40:41+00:00 | [
"astro-ph.SR"
] | Assessment of the near-Sun magnetic field of the 10 March 2022 coronal mass ejection observed by Solar Orbiter | We estimate the near-Sun axial magnetic field of a coronal mass ejection
(CME) on 10 March 2022. Solar Orbiter's in situ measurements, 7.8 degrees east
of the Sun-Earth line at 0.43 AU, provided a unique vantage point, along with
the WIND measurements at 0.99 AU. We determine a single power-law index from
near-Sun to L1, including in situ measurements from both vantage points. We
tracked the temporal evolution of the instantaneous relative magnetic helicity
of the source active region (AR), NOAA AR 12962. By estimating the helicity
budget of the pre-and post-eruption AR, we estimated the helicity transported
to the CME. Assuming a Lundquist flux-rope model and geometrical parameters
obtained through the graduated cylindrical shell (GCS) CME forward modelling,
we determined the CME axial magnetic field at a GCS-fitted height. Assuming a
power-law variation of the axial magnetic field with heliocentric distance, we
extrapolated the estimated near-Sun axial magnetic field to in situ
measurements at 0.43 AU and 0.99 AU. The net helicity difference between the
post-and pre-eruption AR is $(-7.1 \pm 1.2) \times 10^{41} \mathrm{Mx^{2}}$,
which is assumed to be bodily transported to the CME. The estimated CME axial
magnetic field at a near-Sun heliocentric distance of 0.03 AU is 2067 $\pm$ 405
nT. From 0.03 AU to L1, a single power-law falloff, including both vantage
points at 0.43 AU and 0.99 AU, gives an index $-1.23 \pm 0.18$. We observed a
significant decrease in the pre-eruptive AR helicity budget. Extending previous
studies on inner-heliospheric intervals from 0.3 AU to $\sim$1 AU, referring to
estimates from 0.03 AU to measurements at $\sim$1 AU. Our findings indicate a
less steep decline in the magnetic field strength with distance compared to
previous studies, but they align with studies that include near-Sun in situ
magnetic field measurements, such as from Parker Solar Probe. |
2408.01143v2 | ## Type-II seesaw of a non-holomorphic modular A 4 symmetry
Takaaki Nomura 1, ∗ and Hiroshi Okada 2, †
1 College of Physics, Sichuan University, Chengdu 610065, China 2 Department of Physics, Henan Normal University, Xinxiang 453007, China (Dated: March 13, 2025)
We search for predictability of lepton masses and mixing patterns of type-II seesaw scenario in a non-holomorphic modular A 4 symmetry recently proposed by Qu and Ding. We propose three types of minimum predictive models with different assignments of modular weight, satisfying the neutrino oscillation data in Nufit 5.2. The cosmological bound on the sum of neutrino mass is stringent to our models and CMB bound ∑ D ν ≤ 0 12 eV can be satisfied . by one of three models playing an important role in discriminating them.
PACS numbers:
∗ Electronic address: [email protected]
† Electronic address: [email protected]
## I. INTRODUCTION
Clarifying the neutrino physics is one of the important tasks to understand our world which would be described beyond the standard model(SM). Especially, neutrino masses and mixing patterns in the lepton sector are totally different from the quark one; tiny neutrino masses and large mixing angles. Therefore, these differences would underlie some unique mechanisms. In fact, there exist some promising mechanisms; canonical seesaw [1-3], type-II seesaw [4, 5] inverse seesaw [6, 7], linear seesaw [7-9], radiative seesaw [10-17], and so on. In addition to these mechanisms, flavor symmetries are often applied in order to predict neutrino mass and their mixing patterns. In particular, a breakthrough idea has been proposed by Qu and Ding [18], in which they have shown that modular flavor symmetries can be applied in a non-supersymmetric framework. It suggests that we would describe predictive and(or) reconstructive mass matrices and their mixing patterns of flavor physics in a more realistic and reliable theory , even though original modular symmetries still be verifiable and strong predictions in models [19-55]. Moreover we can reduce field contents considering non-supersymmetric framework. For example, we need to introduce two isospin triplet superfields in type-II seesaw model in order to cancel gauge anomaly. It is worth analyzing neutrino models under non-holomorphic modular symmetry as we expect different prediction since some modular forms are different from holomorphic one.
In our paper, we apply a type-II seesaw mechanism in addition to a non-holomorphic modular A 4 symmetry. We show three types of minimum models which are distinguished from a neutrino mass model via Weinberg operator analyzed by Qu and Ding [18], satisfying the neutrino oscillation data in Nufit 5.2 [56]. Then, we demonstrate each the predictions through chi-square numerical analysis. Interestingly, when we impose cosmological bound on the sum of neutrino mass, an only one of three models with normal hierarchy can be survived from CMB bound.
This paper is organized as follows. In Sec. II, we show our setup of the modular A 4 assignments in the framework of type-II seesaw. In Sec. III, we provide chi-square numerical analyses for three types of minimum models and show each of prediction. Finally, we summarize and conclude in Sec. IV.
## II. MODEL SETUP
Here, we review our model setup. We assign the left-handed leptons L L to be triplet under A 4 with +1 modular weight. We assign the right-handed leptons ℓ R to be three different types of
TABLE I: Charge assignments of the SM leptons L L and ℓ R and ∆ under SU (2) L ⊗ U (1) Y ⊗ A 4 where -k I is the number of modular weight. Here { 1 } = { 1 1 , ′ , 1 ′′ } indicates assignment of A 4 singlets. We consider three cases of r = ( -1 +1 +3). , ,
| | L L | ℓ R | H | ∆ † |
|----------|-------|-------|-----|-------|
| SU (2) L | 2 | 1 | 2 | 3 |
| U (1) Y | 1 2 | - 1 | 1 2 | - 1 |
| A 4 | 3 | { 1 } | 1 | 1 |
| - k I | +1 | r | 0 | +2 |
singlets (1 , 1 ′ , 1 ) ′′ 1 under A 4 with + r modular weight where r is a positive integer. In addition, we introduce an isospin triplet scalar field ∆ to generate neutrino mass matrix that is assigned by A 4 singlet with +2 modular weight . This field is requested to realize type-II seesaw mechanism. H is denoted by the SM Higgs that is totally neutral under the modular symmetry. Their fields and assignments are summarized in Table I. Here, we search for some predictions in three models characterized by r = ( -1 +1 +3) that are minimum assignments to satisfy the neutrino oscillation , , data in Nufit 5.2 [56]. The renormalizable Lagrangian under the modular A 4 is found as
$$\mathcal { L } _ { \ell } = [ Y _ { 3 } ^ { ( - 1 - r ) } \overline { L _ { L } } H \ell _ { R } ] + [ Y _ { 1, 3 } ^ { ( - 4 ) } \overline { L _ { L } } \Delta ^ { \dagger } ( i \tau _ { 2 } ) L _ { L } ^ { c } ] + \text{h.c.},$$
where τ 2 is the second Pauli matrix, Y ( k Y ) A shows a non-holomorphic modular form with A 4 representation A and modular weight k Y , and [ · · · ] represents a trivial A 4 singlet 1 constructed by fields and a modular form inside. We denote three models as Model04, Model24 and Model44 corresponding to choice of r = -1, +1 and +3 (two numbers associated with models are that of weights for modular forms in Yukawa Lagrangian).
## A. Charged-lepton mass matrix
The mass matrix of charged-lepton originates from the first term in Eq.(1). After spontaneous electroweak symmetry breaking, the mass matrix is given by
$$m _ { \ell } = \frac { v _ { H } } { \sqrt { 2 } } \begin{pmatrix} y _ { 1 } ^ { ( - 1 - r ) } & y _ { 3 } ^ { ( - 1 - r ) } & y _ { 2 } ^ { ( - 1 - r ) } \\ y _ { 3 } ^ { ( - 1 - r ) } & y _ { 2 } ^ { ( - 1 - r ) } & y _ { 1 } ^ { ( - 1 - r ) } \\ y _ { 2 } ^ { ( - 1 - r ) } & y _ { 1 } ^ { ( - 1 - r ) } & y _ { 3 } ^ { ( - 1 - r ) } \end{pmatrix} \begin{pmatrix} a _ { e } & 0 & 0 \\ 0 & b _ { e } & 0 \\ 0 & 0 & c _ { e } \end{pmatrix},$$
1 If we assign triplet instead of three types of triplets, we would not find any solutions to satisfy the current neutrino oscillations in Nufit 5.2 [56].
where v H is vacuum expectation value (VEV) of H , and { a , b e e , c e } are real parameters without loss of generality and used to fix the charged-lepton mass observables as can be seen below. Y ( - -1 r ) 3 ≡ [ y ( - -1 r ) 1 , y ( - -1 r ) 2 , y ( - -1 r ) 3 ] T 2 . The mass eigenvalues for the charged-leptons are simply obtained via diag.( m ,m ,m e µ τ ) ≡ V † L m V ℓ R . Therefore, V † L m m V ℓ † ℓ L = diag ( . | m e | 2 , | m µ | 2 , | m τ | 2 ). { a , b e e , c e } are determined in order to fit the three observed charged-lepton masses by the following relations:
$$& \text{Tr} [ m _ { \ell } m _ { \ell } ^ { \dagger } ] = | m _ { e } | ^ { 2 } + | m _ { \mu } | ^ { 2 } + | m _ { \tau } | ^ { 2 }, \quad \text{Det} [ m _ { \ell } m _ { \ell } ^ { \dagger } ] = | m _ { e } | ^ { 2 } | m _ { \mu } | ^ { 2 } | m _ { \tau } | ^ { 2 }, \\ & ( \text{Tr} [ m _ { \ell } m _ { \ell } ^ { \dagger } ) ^ { 2 } - \text{Tr} [ ( m _ { e } m _ { e } ^ { \dagger } ) ^ { 2 } ] = 2 ( | m _ { e } | ^ { 2 } | m _ { \mu } | ^ { 2 } + | m _ { \mu } | ^ { 2 } | m _ { \tau } | ^ { 2 } + | m _ { e } | ^ { 2 } | m _ { \tau } | ^ { 2 } ).$$
## B. Neutrino mass matrix
The mass matrix of neutrino comes from the second term in Eq.(1). After spontaneous electroweak symmetry breaking, ∆ develops a VEV ( v ∆ ), and the mass matrix is given by
$$m _ { \nu } = \frac { a _ { \nu } v _ { \Delta } } { \sqrt { 2 } } \left ( \begin{array} { c c c } b _ { \nu } + 2 y _ { 1 } ^ { ( - 4 ) } & - y _ { 3 } ^ { ( - 4 ) } & - y _ { 2 } ^ { ( - 4 ) } \\ - y _ { 3 } ^ { ( - 4 ) } & 2 y _ { 2 } ^ { ( - 4 ) } & b _ { \nu } - y _ { 1 } ^ { ( - 4 ) } \\ - y _ { 2 } ^ { ( - 4 ) } & b _ { \nu } - y _ { 1 } ^ { ( - 4 ) } & 2 y _ { 3 } ^ { ( - 4 ) } \end{array} \right ),$$
where { a , b ν ν , are complex free parameters and Y ( -4) 1 is included by a ν . Note here that v ∆ is required to be v ∆ ≲ O (1) GeV to satisfy the constraint on the ρ parameter [57]. The mass eigenvalues for the active neutrinos D ν = { D ,D ν 1 ν 2 , D ν 3 } are obtained by D ν ≡ V † ν m V ν ∗ ν . Therefore, V † ν m m V ν † ν ν = diag ( . | D ν 1 | 2 , | D ν 2 | 2 , | D ν 3 | 2 ) where D ν 1 2 3 , , are the neutrino mass eigenvalues. Pontecorvo-Maki-Nakagawa-Sakata (PMNS) mixing matrix U ( ≡ U PMNS ) is defined by U = V † L V ν . Here, we define dimensionless neutrino mass matrix; m ν ≡ κm ˜ ν , κ ≡ a ν v ∆ √ 2 being a flavor independent mass dimensional parameter. Therefore, we can rewrite κ in terms of rescaled neutrino mass eigenvalues ˜ D ν ( ≡ D /κ ν ) and atmospheric neutrino mass-squared difference ∆ m 2 atm as follows:
$$( \text{NH} ) \, \colon \, \kappa ^ { 2 } = \frac { | \Delta m _ { \text{atm} } ^ { 2 } | } { \tilde { D } _ { \nu _ { 3 } } ^ { 2 } - \tilde { D } _ { \nu _ { 1 } } ^ { 2 } }, \quad ( \text{IH} ) \, \colon \, \kappa ^ { 2 } = \frac { | \Delta m _ { \text{atm} } ^ { 2 } | } { \tilde { D } _ { \nu _ { 2 } } ^ { 2 } - \tilde { D } _ { \nu _ { 3 } } ^ { 2 } },$$
where NH and IH stand for the normal and inverted hierarchies, respectively. Subsequently, the solar neutrino mass-squared difference is described by
$$\Delta m _ { \text{sol} } ^ { 2 } = \kappa ^ { 2 } ( \tilde { D } _ { \nu _ { 2 } } ^ { 2 } - \tilde { D } _ { \nu _ { 1 } } ^ { 2 } ).$$
2 In details, see ref. [18].
FIG. 1: Numerical ∆ χ 2 analyses in case of r = -1, where the blue color represents the range of 0 -1, the green 1 -2, the yellow 2 -3, and the red 3 -5 σ standard deviation estimated by √ ∆ χ 2 . The black solid line is the boundary of the fundamental domain at | τ | = 1. The left figure represents the case of NH and the right one IH. Circle points satisfy ∑ D ν ≤ 120 meV, otherwise triangle plots are depicted.
This should be within the range of the experimental value. Later, we will adopt NuFit 5.2 [56] to our numerical analysis. The effective mass for neutrinoless double beta decay is given by
$$\langle m _ { e e } \rangle = \kappa | \tilde { D } _ { \nu _ { 1 } } \cos ^ { 2 } \theta _ { 1 2 } \cos ^ { 2 } \theta _ { 1 3 } + \tilde { D } _ { \nu _ { 2 } } \sin ^ { 2 } \theta _ { 1 2 } \cos ^ { 2 } \theta _ { 1 3 } e ^ { i \alpha _ { 2 } } + \tilde { D } _ { \nu _ { 3 } } \sin ^ { 2 } \theta _ { 1 3 } e ^ { i ( \alpha _ { 3 } - 2 \delta _ { C P } ) } |. \quad ( 7 )$$
Its predicted value is constrained by the current KamLAND-Zen data and could be measured in future [58]. The upper bound is found as ⟨ m ee ⟩ < (36 -156) meV at 90 % confidence level where the range of the bound comes from the use of different method estimating nuclear matrix elements. Sum of neutrino masses is constrained by the minimal cosmological model ΛCDM + ∑ D ν i that provides the upper bound on ∑ D ν ≤ 120 meV [59, 60], although it becomes weaker if the data are analyzed in the context of extended cosmological models [61]. Recently, DESI and CMB data combination provides more stringent upper bound on the sum of neutrino masses ∑ D ν ≤ 72 meV [62]. The two observable ⟨ m ee ⟩ and ∑ D ν i are also taken into account in the numerical analysis.
## III. NUMERICAL ANALYSIS AND PHENOMENOLOGY
In this section, we carry out numerical analysis to fit the neutrino data and find some predictions of the models. Then some implications for phenomenology are discussed. We randomly select our input parameters within the following ranges
$$\tau _ { \text{Re} } \in [ - 0. 5, 0. 5 ], \quad \tau _ { \text{Im} } \in \left [ \frac { \sqrt { 3 } } { 2 }, 5 \right ], \ \ | b _ { \nu } | \in [ 1 0 ^ { - 3 }, 1 0 ^ { 3 } ], \ \ \arg [ b _ { \nu } ] \in [ - \pi, \pi ].$$
FIG. 2: Numerical analyses in case of r = -1. The up and down figures represent the NH and the IH cases, respectively. The left one demonstrates neutrinoless double beta decay ⟨ m ee ⟩ in terms of the lightest neutrino mass where red dashed horizontal lines indicate the current upper bound from KamLAND-Zen with different estimation for nuclear matrix elements.. The center one shows Majorana phases α 21 and α 31 . The right one depicts the Dirac CP phase in terms of the sum of neutrino masses where the red(magenta) dashed vertical lines indicate the upper bound on ∑ D ν from Planck CMB (+ DESI BAO) data. The colors of plots and shapes are the same as the ones of Fig. 1.
$$\mathbf A. \ r = - 1$$
In Fig. 1, we figure out the allowed range of τ in case of r = -1 where the left figure represents the case of NH and the right one IH. The blue color represents the range of 0 -1, the green 1 -2, the yellow 2 -3, and the red 3 -5 σ standard deviation estimated by √ ∆ χ 2 . The black solid line is the boundary of the fundamental domain at | τ | = 1. Circle points satisfy ∑ D ν ≤ 120 meV, otherwise triangle plots are depicted. NH solutions are localized at nearby two regions τ = 1 5 . i and τ = ± 0 35 + 0 96 , while IH solutions are localized at nearby . . i τ = ± 0 07 + . i .
In Fig. 2, we show predictions in the case of r = -1. The up and down figures represent the NH and the IH cases, respectively. The plot-legends of color and shape are the same as the ones of Fig. 1. The left one demonstrates neutrinoless double beta decay ⟨ m ee ⟩ in terms of the lightest neutrino mass. The dotted horizontal lines are bounds from the current KamLAND-Zen ⟨ m ee ⟩ < (36 -156) meV as discussed in the neutrino sector. In case of NH, there exist two localized regions; D ν 1 ≈ (0 02 . , 0 09 . -0 13) eV and . ⟨ m ee ⟩ ≈ (0 02 . , 0 08 . -0 12) eV. In case of IH, we have .
FIG. 3: Numerical ∆ χ 2 analyses in case of r = +1, where all the legends are the same as Fig. 1. We would not find any solutions in case of IH
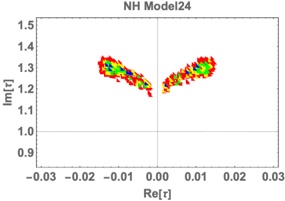
allowed region at D ν 3 ≈ (0 15 . -0 21) eV and . ⟨ m ee ⟩ ≈ (0 15 . -0 21) eV. Note here that the only NH . satisfies the CMB bound on the sum of neutrino mass. The center one shows Majorana phases α 31 and α 21 . There exist four main localized regions in case of NH; α 31 ≈ (0 -60 , 160 -200 , 310 -360) deg and α 21 ≈ (10 -30 , 50 -80 , 270 -310 , 330 -350) deg. There exist two localized regions in case of IH; α 31 ≈ (35 -50 , 320 -330) deg and α 21 ≈ (0 -10 , 330 -340) deg. The right one depicts the Dirac CP phase in terms of the sum of neutrino masses . The vertical red dashed line shows the upper bound of cosmological limit ∑ D ν ≤ 0 12 eV while the vertical magenta dashed . line shows the upper bound of ∑ D ν ≤ 0 072 eV. In case of NH, there exist four localized regions; . sum D ν ≈ (0 1 . , 0 28 . -0 4) eV and . δ CP ≈ (80 -100 , 120 -140 , 220 -240 , 260 -280) deg. In case of IH, there exist two localized regions; sum D ν ≈ (0 5 . -0 65) eV and . δ CP ≈ (0 -20 , 340 -360) deg.
## B. r = +1
In Fig. 3, we figure out the allowed range of τ in case of r = +1 where we would not find any solutions in case of IH. All the legends are the same as Fig. 1. We have a specific region of τ ; | Re[ τ ] |≈ [0 -0 016] and Im[ . τ ] ≈ [1 18 . -1 35]. .
In Fig. 4, we show predictions in the case of r = +1, where All the legends are the same as Figs. 2. We would not find any solutions in case of IH The left figure suggests D ν 1 ≈ (0 04 . -0 08) . eV and ⟨ m ee ⟩ ≈ (0 04 . -0 08) eV. The center one shows there exist four regions; . α 31 ≈ (80 -280) deg and α 21 ≈ (0 -80 , 280 -360) deg. The right one shows that there exist two localized regions; sum D ν ≈ (0 14 . -0 28) eV and . δ CP ⟩ ≈ (40 -160 , 200 -300) deg.
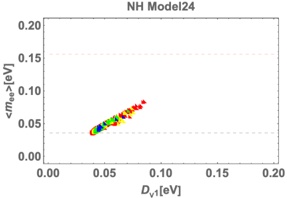
FIG. 4: Numerical ∆ χ 2 analyses in case of r = +1, where All the legends are the same as Fig. 2. We would not find any solutions in case of IH
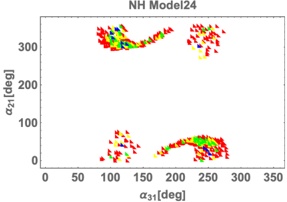
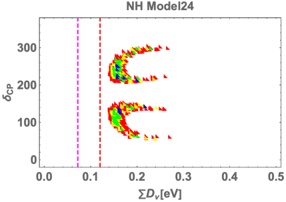
FIG. 5: Numerical ∆ χ 2 analyses in case of r = +3, where all the legends are the same as Fig. 1.
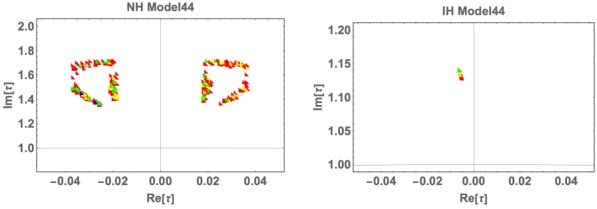
$$C. \ r = + 3$$
In Fig. 5, we figure out the allowed range of τ in case of r = +3. All the legends are the same as Fig. 1. In case of NH, we have a unique allowed shape of τ ; | Re[ τ ] |≈ [0 018 . -0 04] and . Im[ τ ] ≈ [1 3 . -1 7]. . In case of IH, we have a localized region of τ ; Re[ τ ] ≈ 0 002 and Im[ . τ ] ≈ 1 13. .
In Fig. 6, we show predictions in the case of r = +3, where all the legends are the same as Fig. 2. In case of NH, we have the allowed regions at D ν 1 ≈ (0 11 . -0 19) eV and . ⟨ m ee ⟩ ≈ (0 1 . -0 18) eV. . In case of IH, we have allowed region at D ν 3 ≈ (1 8 . -2 2) eV and . ⟨ m ee ⟩ ≈ (1 8 . -2 2) eV. There . exist two localized regions in case of NH; α 31 ≈ (150 -200) deg and α 21 ≈ (0 -10 , 350 -360) deg. There exist a localized region in case of IH; α 31 ≈ 100 deg and α 21 ≈ 0 deg. In case of NH, there exist two localized regions; sum D ν ≈ (0 35 . -0 58) eV and . δ CP ⟩ ≈ (80 -100 , 260 -280) deg. In case of IH, there exist a localized region; sum D ν ≈ (5 5 . -6 5) eV and . δ CP ⟩ ≈ 270 deg.
FIG. 6: Numerical ∆ χ 2 analyses in case of r = +1, where All the legends are the same as Fig. 2.
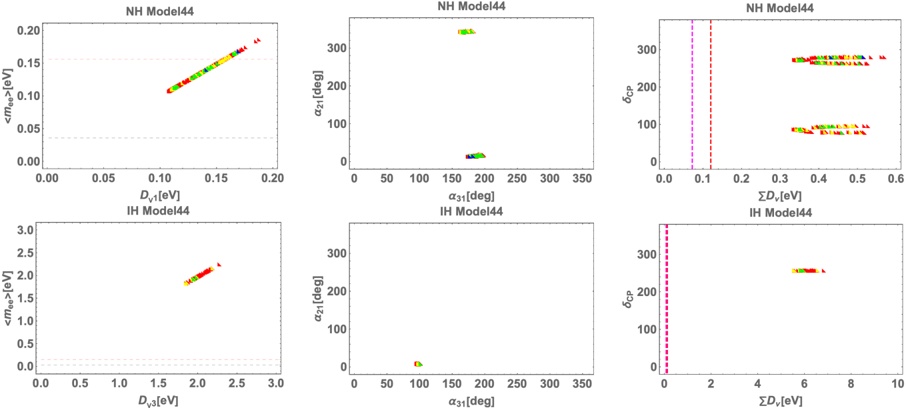
## IV. SUMMARY AND DISCUSSION
We have searched for predictability of lepton masses and mixing of type-II scenario in a nonholomorphic modular A 4 symmetry. We have found three types of minimum models in addition to the Qu and Ding model, satisfying the neutrino oscillation data in Nufit 5.2. However, if we impose the cosmological bound ∑ D ν ≤ 0 12 eV, the only normal hierarchical model with . r = -1 is survived. Furthermore, we have sharp predictions in this case as follows: There are two localized regions; D ν 1 ≈ (0 02 . , 0 09 . -0 13) eV and . ⟨ m ee ⟩ ≈ (0 02 . , 0 08 . -0 12) eV. We also found four main . localized regions α 31 ≈ (0 -60 , 160 -200 , 310 -360) deg and α 21 ≈ (10 -30 , 50 -80 , 270 -310 , 330 -350) deg. There exist four localized regions; sum D ν ≈ (0 1 . , 0 28 . -0 4) . eV and δ CP ⟩ ≈ (80 -100 , 120 -140 , 220 -240 , 260 -280) deg. This model is well-tested by upcoming experiments in near future.
## Acknowledgments
The work was supported by the Fundamental Research Funds for the Central Universities (T. N.).
[1] T. Yanagida, Phys. Rev. D 20 , 2986 (1979).
- [2] P. Minkowski, Phys. Lett. B 67 , 421 (1977).
- [3] R. N. Mohapatra and G. Senjanovic, Phys. Rev. Lett. 44 , 912 (1980).
- [4] M. Magg and C. Wetterich, Phys. Lett. B 94 , 61 (1980).
- [5] T. P. Cheng and L.-F. Li, Phys. Rev. D 22 , 2860 (1980).
- [6] R. N. Mohapatra and J. W. F. Valle, Phys. Rev. D 34 , 1642 (1986).
- [7] D. Wyler and L. Wolfenstein, Nucl. Phys. B 218 , 205 (1983).
- [8] E. K. Akhmedov, M. Lindner, E. Schnapka, and J. W. F. Valle, Phys. Lett. B 368 , 270 (1996), hepph/9507275.
- [9] E. K. Akhmedov, M. Lindner, E. Schnapka, and J. W. F. Valle, Phys. Rev. D 53 , 2752 (1996), hepph/9509255.
- [10] A. Zee, Phys. Lett. B 93 , 389 (1980), [Erratum: Phys.Lett.B 95, 461 (1980)].
- [11] E. Ma, Phys. Rev. D 73 , 077301 (2006), hep-ph/0601225.
- [12] Y. Kajiyama, H. Okada, and K. Yagyu, Nucl. Phys. B 874 , 198 (2013), 1303.3463.
- [13] A. Zee, Nucl. Phys. B 264 , 99 (1986).
- [14] K. S. Babu, Phys. Lett. B 203 , 132 (1988).
- [15] L. M. Krauss, S. Nasri, and M. Trodden, Phys. Rev. D 67 , 085002 (2003), hep-ph/0210389.
- [16] M. Aoki, S. Kanemura, and O. Seto, Phys. Rev. Lett. 102 , 051805 (2009), 0807.0361.
- [17] M. Gustafsson, J. M. No, and M. A. Rivera, Phys. Rev. Lett. 110 , 211802 (2013), [Erratum: Phys.Rev.Lett. 112, 259902 (2014)], 1212.4806.
- [18] B.-Y. Qu and G.-J. Ding (2024), 2406.02527.
- [19] F. Feruglio, Are neutrino masses modular forms? (2019), pp. 227-266, 1706.08749.
- [20] J. C. Criado and F. Feruglio, SciPost Phys. 5 , 042 (2018), 1807.01125.
- [21] T. Kobayashi, N. Omoto, Y. Shimizu, K. Takagi, M. Tanimoto, and T. H. Tatsuishi, JHEP 11 , 196 (2018), 1808.03012.
- [22] H. Okada and M. Tanimoto, Phys. Lett. B 791 , 54 (2019), 1812.09677.
- [23] T. Nomura and H. Okada, Phys. Lett. B 797 , 134799 (2019), 1904.03937.
- [24] H. Okada and M. Tanimoto, Eur. Phys. J. C 81 , 52 (2021), 1905.13421.
- [25] F. J. de Anda, S. F. King, and E. Perdomo, Phys. Rev. D 101 , 015028 (2020), 1812.05620.
- [26] P. Novichkov, S. Petcov, and M. Tanimoto, Phys. Lett. B 793 , 247 (2019), 1812.11289.
- [27] T. Nomura and H. Okada, Nucl. Phys. B 966 , 115372 (2021), 1906.03927.
- [28] H. Okada and Y. Orikasa (2019), 1907.13520.
- [29] G.-J. Ding, S. F. King, and X.-G. Liu, JHEP 09 , 074 (2019), 1907.11714.
- [30] T. Nomura, H. Okada, and O. Popov, Phys. Lett. B 803 , 135294 (2020), 1908.07457.
- [31] T. Kobayashi, Y. Shimizu, K. Takagi, M. Tanimoto, and T. H. Tatsuishi, Phys. Rev. D 100 , 115045 (2019), [Erratum: Phys.Rev.D 101, 039904 (2020)], 1909.05139.
- [32] T. Asaka, Y. Heo, T. H. Tatsuishi, and T. Yoshida, JHEP 01 , 144 (2020), 1909.06520.
- [33] D. Zhang, Nucl. Phys. B 952 , 114935 (2020), 1910.07869.
- [34] G.-J. Ding, S. F. King, X.-G. Liu, and J.-N. Lu, JHEP 12 , 030 (2019), 1910.03460.
- [35] T. Kobayashi, T. Nomura, and T. Shimomura, Phys. Rev. D 102 , 035019 (2020), 1912.00637.
- [36] T. Nomura, H. Okada, and S. Patra, Nucl. Phys. B 967 , 115395 (2021), 1912.00379.
- [37] X. Wang, Nucl. Phys. B 957 , 115105 (2020), 1912.13284.
- [38] H. Okada and Y. Shoji, Nucl. Phys. B 961 , 115216 (2020), 2003.13219.
- [39] H. Okada and M. Tanimoto, Phys. Dark Univ. 40 , 101204 (2023), 2005.00775.
- [40] M. K. Behera, S. Singirala, S. Mishra, and R. Mohanta, J. Phys. G 49 , 035002 (2022), 2009.01806.
- [41] M. K. Behera, S. Mishra, S. Singirala, and R. Mohanta, Phys. Dark Univ. 36 , 101027 (2022), 2007.00545.
- [42] T. Nomura and H. Okada, JCAP 09 , 049 (2022), 2007.04801.
- [43] T. Nomura and H. Okada (2020), 2007.15459.
- [44] T. Asaka, Y. Heo, and T. Yoshida, Phys. Lett. B 811 , 135956 (2020), 2009.12120.
- [45] H. Okada and M. Tanimoto, Phys. Rev. D 103 , 015005 (2021), 2009.14242.
- [46] K. I. Nagao and H. Okada, Nucl. Phys. B 980 , 115841 (2022), 2010.03348.
- [47] H. Okada and M. Tanimoto, JHEP 03 , 010 (2021), 2012.01688.
- [48] D. W. Kang, J. Kim, T. Nomura, and H. Okada, JHEP 07 , 050 (2022), 2205.08269.
- [49] G.-J. Ding, S.-Y. Jiang, S. F. King, J.-N. Lu, and B.-Y. Qu (2024), 2404.06520.
- [50] G.-J. Ding and S. F. King (2023), 2311.09282.
- [51] T. Nomura, H. Okada, and H. Otsuka, Nucl. Phys. B 1004 , 116579 (2024), 2309.13921.
- [52] T. Kobayashi, T. Nomura, H. Okada, and H. Otsuka, JHEP 01 , 121 (2024), 2310.10091.
- [53] S. T. Petcov and M. Tanimoto (2024), 2404.00858.
- [54] T. Kobayashi and M. Tanimoto (2023), 2307.03384.
- [55] T. Nomura and H. Okada (2024), 2407.13167.
- [56] I. Esteban, M. C. Gonzalez-Garcia, M. Maltoni, T. Schwetz, and A. Zhou, JHEP 09 , 178 (2020), 2007.14792.
- [57] P. A. Zyla et al. (Particle Data Group), PTEP 2020 , 083C01 (2020).
- [58] S. Abe et al. (KamLAND-Zen) (2024), 2406.11438.
- [59] S. Vagnozzi, E. Giusarma, O. Mena, K. Freese, M. Gerbino, S. Ho, and M. Lattanzi, Phys. Rev. D 96 , 123503 (2017), 1701.08172.
- [60] N. Aghanim et al. (Planck), Astron. Astrophys. 641 , A6 (2020), [Erratum: Astron.Astrophys. 652, C4 (2021)], 1807.06209.
- [61] K. A. Olive et al. (Particle Data Group), Chin. Phys. C 38 , 090001 (2014).
- [62] A. G. Adame et al. (DESI) (2024), 2404.03002.
- [63] H. Fritzsch, Z.-z. Xing, and S. Zhou, JHEP 09 , 083 (2011), 1108.4534. | null | [
"Takaaki Nomura",
"Hiroshi Okada"
] | 2024-08-02T09:41:49+00:00 | 2025-03-12T09:17:58+00:00 | [
"hep-ph"
] | Type-II seesaw of a non-holomorphic modular $A_4$ symmetry | We search for predictability of lepton masses and mixing patterns of type-II
seesaw scenario in a non-holomorphic modular $A_4$ symmetry recently proposed
by Qu and Ding. We propose three types of minimum predictive models with
different assignments of modular weight, satisfying the neutrino oscillation
data in Nufit 5.2. The cosmological bound on the sum of neutrino mass is
stringent to our models and CMB bound $\sum D_\nu\le0.12$ eV can be satisfied
by one of three models playing an important role in discriminating them. |
2408.01144v1 | ## ENHANCED PREDICTION OF VENTILATOR-ASSOCIATED PNEUMONIA IN PATIENTS WITH TRAUMATIC BRAIN INJURY USING ADVANCED MACHINE LEARNING TECHNIQUES
## A PREPRINT
## Negin Ashrafi
## Armin Abdollahi
Department of Industrial and Systems Engineering University of Southern California Los Angeles, CA 90089 [email protected]
Department of Electrical and Computer Engineering University of Southern California Los Angeles, CA 90089 [email protected]
## Maryam Pishgar
Department of Industrial and Systems Engineering University of Southern California Los Angeles, CA 90089 [email protected]
## ABSTRACT
Background: Ventilator-associated pneumonia (VAP) in traumatic brain injury (TBI) patients poses a significant mortality risk and imposes a considerable financial burden on patients and healthcare systems. Timely detection and prognostication of VAP in TBI patients are crucial to improve patient outcomes and alleviate the strain on healthcare resources.
Methods: We implemented six machine learning models using the MIMIC-III database. Our methodology included preprocessing steps including feature selection with CatBoost and expert opinion, addressing class imbalance with Synthetic Minority Oversampling Technique (SMOTE), and rigorous model tuning through 5-fold cross-validation to optimize hyperparameters. Key models evaluated included SVM, Logistic Regression, Random Forest, XGBoost, ANN, and AdaBoost. Additionally, we conducted SHAP analysis to determine feature importance and performed an ablation study to assess feature impacts on model performance.
Results: XGBoost outperformed the baseline models and the best existing literature. We used metrics, including AUC, Accuracy, Specificity, Sensitivity, F1 Score, PPV, and NPV. XGBoost demonstrated the highest performance with an AUC of 0.940 and an Accuracy of 0.875, which are 23.4% and 23.5% higher than the best results in the existing literature with an AUC of 0.706 and an Accuracy of 0.640, respectively. This enhanced performance underscores the models' effectiveness in clinical settings.
Conclusions: This study enhances the predictive modeling of VAP in TBI patients, improving early detection and intervention potential. Refined feature selection and advanced ensemble techniques significantly boosted model accuracy and reliability, offering promising directions for future clinical applications and medical diagnostics research.
Keywords Machine Learning · MIMIC-III · Ventilator-associated pneumonia · Traumatic brain injury · XGBoost
## 1 Background
Traumatic brain injury (TBI) affects approximately 250 per 100,000 individuals globally, contributing to 30-50% of trauma-related mortalities, with adolescents, young adults, and older adults being the most affected groups [1, 2]. TBI
occurs from forceful impacts to the head or body, resulting in varying degrees of cognitive and physical impairment [3]. Complicating the management of TBI is the frequent occurrence of ventilator-associated pneumonia (VAP), a lung infection that develops in patients requiring mechanical ventilation. V AP not only exacerbates the morbidity and mortality associated with TBI but also prolongs hospital stays and increases healthcare costs [4]. Therefore, early identification and prediction of V AP in TBI patients are crucial for improving patient outcomes and reducing the burden on healthcare systems.
Several studies have investigated the prediction and management of V AP in TBI patients, leveraging diverse methodologies and datasets to enhance our understanding of this complex clinical scenario. Wang et al. utilized machine learning techniques to predict V AP in patients with TBI, leveraging data from the Medical Information Mart for Intensive Care III (MIMIC-III) database. Their study explored various models, including XGBoost, SVM, Logistic Regression, and Random forest, emphasizing the importance of identifying pertinent features for accurate prediction [5]. Robba et al., on the other hand, conducted a large-scale prospective observational study to analyze the incidence, risk factors, and outcomes of VAP in TBI patients. Their findings underscored the multifactorial nature of VAP development, highlighting age and smoking as potential risk factors influencing patient susceptibility [6].
Luo et al. investigated the impact of VAP on the prognosis of ICU patients within 90 and 180 days, identifying critical factors such as diabetes, length of ICU stay, and COPD that influence patient outcomes. Their study also proposed methodologies for enhancing diagnostic approaches in identifying VAP patients [7]. Recent studies have shown significant improvements in the power of predicting mortality in mechanically ventilated ICU patients using advanced techniques and enhanced feature selection, demonstrating the effectiveness of deep learning and machine learning models in clinical predictions [8].
Collectively, these studies underscore the importance of predictive modeling, risk factor analysis, and feature selection in improving the identification and management of VAP in TBI patients. Machine learning algorithms offer promising avenues for predicting VAP development while understanding risk factors and prognosis aids in personalized patient care. Further research integrating diverse methodologies and datasets is warranted to enhance the accuracy and generalizability of predictive models in this critical domain.
## 2 Methodologies
## 2.1 Data Source and Inclusion Criteria
In this study, we employed the MIMIC-III database, a publicly available clinical dataset that includes detailed medical information from over 40,000 patients [9]. These patients were treated at two prominent hospitals in the United States between 2001 and 2012. The dataset encompasses over 60,000 hospital admissions and more than 20,000 intensive care unit (ICU) stays, amounting to more than 40 million individual clinical record entries. These entries cover a wide range of data points, including physiological signals, medication administrations, laboratory test results, and clinical notes. The extensive scope and detailed nature of MIMIC-III make it an invaluable resource for conducting rigorous biomedical research, enabling us to thoroughly analyze and validate our methodologies within a clinical setting.
## 2.2 Patient Extraction
To identify Traumatic Brain Injury (TBI) patients for our study, specific International Classification of Diseases and Ninth Revision (ICD-9) codes were utilized. Patients were initially selected based on the following codes: 80,000-80,199; 80,300-80,499; 8500-85419, which identified an initial cohort of 2,545 patients [10]. Exclusions were applied for patients lacking Glasgow Coma Scale (GCS) records at admission (19 patients) or those without recorded vital signs at admission (25 patients). Further exclusions were made for patients who underwent mechanical ventilation for less than 48 hours, impacting 1,665 patients. After all exclusions, the final cohort consisted of 836 patients. Within this group, 328 were identified as positive for Ventilator-Associated Pneumonia (VAP), while 508 were negative. This methodology ensures a focused examination of the impact of TBI on the risk of VAP, guided by our predefined clinical criteria. Figure1 shows the patient extraction process
## 2.3 Feature Selection
In our study, the target variable, Ventilator-Associated Pneumonia (V AP), is identified through a structured diagnostic approach that encompasses three key criteria: radiologic, systemic, and pulmonary signs. (1) For radiologic confirmation, a patient must show at least one of the following: new or progressive and persistent infiltrate, consolidation, or cavitation on lung imaging, indicative of the physical manifestations of pneumonia. (2) Systemically, the criteria require either a fever exceeding 38°C or an abnormal white blood cell count, with thresholds set below 4,000/mL or above 12,000/mL,
Figure 1: Flow diagram of the patient selection process
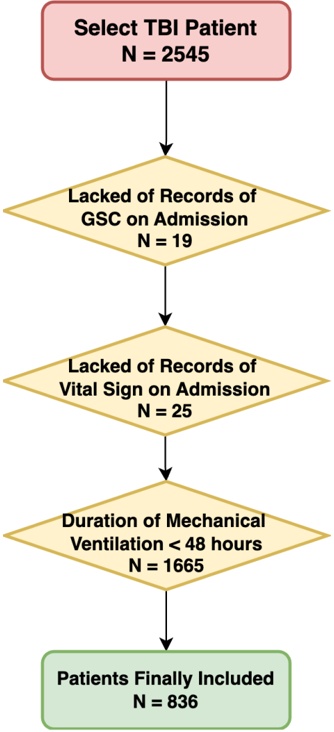
signaling an immune response to infection. (3) On the pulmonary front, a diagnosis is supported by the presence of at least two symptoms: purulent sputum, deteriorating gas exchange, and worsening of respiratory symptoms such as cough, dyspnea, tachypnea, or new breath sounds [11]. This multidimensional diagnostic framework ensures a thorough and precise identification of V AP in critically ill patients, capturing the complex clinical profile necessary for accurate diagnosis and subsequent treatment planning. This is summarized in Algorithm1.
37 candidate features were meticulously chosen to capture a broad spectrum of clinical information crucial for assessing the patients' health outcomes, which is shown in Table1. These features are categorized into demographic details, disease-related attributes, vital signs at admission, intracranial injury classifications, laboratory tests, medical interventions, and other relevant clinical data. The demographic features include age, gender, and ethnicity, which are foundational for adjusting clinical analyses. Disease-related features such as smoking history, diabetes, hypertension, and other significant conditions are included due to their potential impact on patient prognosis. Vital signs such as heart rate and blood pressure, recorded at admission, provide immediate clinical context. Intracranial injury features, including conditions like subarachnoid hemorrhage and subdural hematoma, are particularly critical for patients with traumatic brain injuries. Laboratory tests, including measurements of platelet count, hemoglobin levels, and blood urea nitrogen, among others, offer detailed biochemical insights that are indispensable for monitoring patient health and response to treatment. Medical interventions like tracheostomy and neurosurgery, recorded to capture the intensity and nature of the medical care provided, also contribute to understanding patient outcomes. The selection process was meticulously guided by consultations with a clinical expert and a comprehensive review of the existing literature. This rigorous approach ensured that each feature included in the study was highly relevant to the clinical questions posed, as a result significantly enhancing the robustness and practical applicability of our predictive models. This thoughtful compilation of features enables a holistic view of patient health, supporting the identification of patterns and predictors of recovery in a clinically diverse population.
## Algorithm 1 Diagnostic Algorithm for Identifying VAP
```
<_C++_>
```
To refine the feature set, we first applied a correlation matrix to identify and remove highly correlated features, thereby reducing redundancy within our dataset. This process led to the exclusion of features such as PEG (percutaneous endoscopic gastrostomy), serum chloride, and red blood cell count, which were found to provide overlapping information. Subsequently, we employed the CatBoost algorithm to determine the relative importance of the remaining features, guiding us to focus on those most influential for our predictive model. The top 15 features, as identified by CatBoost, include critical indicators such as ICU stay length, serum potassium, and hospital stay length, among others, as shown in the accompanying feature importance chart, which is shown in Figure2. These features were selected for their strong predictive power and clinical relevance, based on expert opinion, ensuring that our model is both accurate and interpretable in assessing patient outcomes.
## 2.4 Data Preprocessing
In the preprocessing stage of our data analysis, we implemented systematic approaches to manage missing values, encode categorical data, and scale features appropriately. For numerical data, missing values were imputed with the median of each respective feature, given its robustness to outliers, thereby maintaining the integrity of the data distribution. For categorical data, missing entries were filled using the mode, ensuring the most frequent category was used for a consistent and representative fill. Further enhancing our model's ability to process categorical variables, one-hot encoding was applied.
In terms of feature scaling, different strategies were employed based on the specific requirements of the algorithms used in subsequent analyses. For models sensitive to the scale of input features, a min-max scaler was utilized to normalize the data within a range of 0 to 1 [12]. This scaling preserves the relationships among the original data points. For other algorithms, we applied a standard scaler, which standardized features by removing the mean and scaling to unit variance. This approach is particularly beneficial for models that assume data is normally distributed, such as many linear models, and helps in reducing the influence of outliers.
Table 1: List of candidate features categorized by type, including vital signs, laboratory tests, demographics, Intracranial injury, disease-related features, and medical interventions.
| Feature Type | Feature Name | Feature Type | Feature Name |
|------------------------------|-----------------------------------------------------------------------------------------|--------------------------------|---------------------------------------------------------------------------------|
| Vital signs | Diastolic blood pres- sure Respiratory rate Systolic blood pres- sure Heart rate | Laboratory tests | Blood urea nitrogen Red blood cell Hemoglobin Glucose Platelet Serum sodium |
| Demographics | Age Gender Ethnicity | Laboratory tests | INR |
| Disease related features | Chronic renal disease Chronic liver disease Hypertension Previous myocardial infarction | Medical interventions features | Serum chloride Anion gap Serum potassium Anticoagulant within 24h |
| Intracranial injury features | Diabetes Subarachnoid hemor- rhage Subdural hematoma | Medical interventions features | Parenteral nutrition Platelet transfusion within 24h RBC transfusion within 24h |
| Other clinical features | 30 day mortality Hospital stay length ICU stay length | Medical interventions features | |
To handle the class imbalance, we integrated the Synthetic Minority Over-sampling Technique (SMOTE) within a 5-fold cross-validation framework, enhancing the representation of the minority class during the training phase [13]. SMOTE was applied to the training folds only, synthesizing new samples to augment the minority (positive) class. This ensured that each training set used in the cross-validation was balanced while the original distribution of the classes was preserved in the validation folds to maintain the integrity of the validation process. By doing so, we aimed to improve the model's generalizability and prevent data leakage, allowing us to evaluate the model's performance against unmodified data, thus ensuring more accurate and robust outcomes. Figure3 illustrates the workflow for data preprocessing.
## 2.5 Ablation process
We implemented a stepwise elimination process to determine if the 15 selected features had an adverse effect on the model's performance. This involved systematically removing variables that had an adverse effect on the model's performance, which we measured by calculating the 95% confidence interval (CI) of the Area Under the Receiver Operating Characteristic Curve (AUROC). We started by calculating the baseline AUROC using all 15 features.
Figure 2: Top 15 features based on CatBoost feature importance scores, highlighting the most impactful ones.
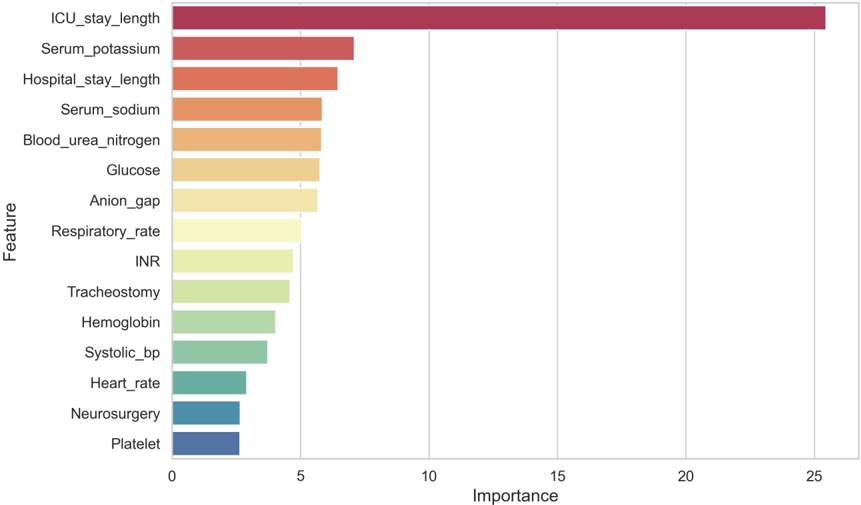
Figure 3: Data preprocessing workflow, illustrating the steps from patient selection to the creation of the final dataset.
In each iteration, we temporarily removed one feature from the current set and recalculated the AUROC. If the AUROC for the new set of features showed improvement, we updated the current feature set by permanently excluding the
feature and recorded the improved AUROC. This iterative process continued, with the model being re-evaluated after each removal, until no further improvements were observed[14].
Ultimately, all 15 features were found to positively influence the model's performance, leading us to retain the entire set. This process ensured the final model included only features that contributed to its predictive power. The details are provided in the results section.
## 2.6 Modeling
After data preprocessing, we used the top 15 important features for the modeling part. Then, we divided the dataset into training and testing sections [15]. 70% of the data was used for model training and 30% of the data for testing. Six models have been implemented in this project, including Support Vector Machine (SVM), Logistic Regression (LR), Random Forest (RF), XGBoost, Artificial Neural Network (ANN), and AdaBoost. A 5-fold cross-validation method has been utilized for model tuning to choose the best pair of Hyper-parameters of each model by using the training data, to ensure the performance of the models.
For the SVM, we adjusted the regularization parameter, kernel type, and kernel parameters to manage model complexity and fit [16]. In LR, we tuned the regularization strength and L1 and L2 penalty types to balance bias and variance, enhancing generalizability [17, 18]. The RF model was optimized by setting the number of trees, the maximum depth of the trees, and the quality criterion for splits to improve performance across different data subsets [19, 20]. In the XGBoost model, adjustments included the colsample\_bytree, learning rate, max\_depth, min\_child\_weight, n\_estimators, reg\_alpha, reg\_lambda, scale\_pos\_weight, and subsample to increase accuracy and prevent overfitting. The colsample\_bytree parameter specifies the fraction of features to be randomly sampled for each tree, helping to prevent overfitting. The learning rate controls the step size for each boosting iteration, balancing between learning quickly and preventing overfitting. Max\_depth sets the maximum depth of a tree, impacting model complexity and overfitting potential. Min\_child\_weight determines the minimum sum of instance weight (hessian) needed in a child, providing regularization by preventing overly specific trees. N\_estimators is the number of boosting rounds. The reg\_alpha and reg\_lambda are L1 and L2 regularization terms, respectively, which add penalties to the model to prevent overfitting. Scale\_pos\_weight balances the positive and negative weights, useful for handling class imbalance. Subsample is the fraction of samples to be used for fitting the individual base learners, which helps prevent overfitting by introducing randomness. These adjustments optimize model performance and robustness against overfitting [21, 22, 23].
The artificial neural network (ANN) consisted of an input layer, one hidden layer, and an output layer, utilizing ReLU (Rectified Linear Unit) activation functions for the input and hidden layers to facilitate non-linear learning and a sigmoid activation function in the output layer for binary classification probabilities [24, 25, 26]. Lastly, the AdaBoost model was fine-tuned by adjusting the depth of the base estimators, the learning rate, and the number of weak learners to enhance the fit and robustness of training data [27].
From a data perspective, using metrics such as AUC and sensitivity, it is evident that the proposed model not only performs better overall but also exhibits a superior ability to predict the minority class. The model demonstrating the highest performance on the test set was selected as the best. We also assessed our models' performance by calculating accuracy, precision, F1-score, and specificity. Details will be discussed in the results section.
## 3 RESULTS
## 3.1 Statistical Analysis between Cohorts
The dataset under examination divided patients into two cohorts: the training cohort (comprising 585 patients) and the test cohort (comprising 251 patients). These cohorts were selected to validate the accuracy and reliability of clinical predictions or treatment outcomes using statistical models.
For continuous variables, such as ICU stay length, serum sodium, and glucose levels, the differences between cohorts were assessed using two-sided t-tests. This test choice is appropriate under the assumption that the data approximately follow a normal distribution, though it is robust to mild deviations from this assumption. For binary or categorical variables like Tracheostomy and Neurosurgery, a Chi-Square test was employed to determine if the distribution of categories differs significantly between the cohorts [28]. This test is chosen assuming that the observed frequencies are large enough to meet the test's conditions.
The primary aim of this analysis is to evaluate whether there are statistically significant differences between the training and test cohorts across various clinical metrics. By understanding these differences, the study aims to ensure that the training data are representative of the test data, thereby validating the model's applicability to future, unseen patients. Table2 illustrates a comparison of the feature values between train and testing cohorts by capturing the mean and
standard deviation of features in each cohort along with the p-value associated with these two cohorts. the p-value of 0.05 is chosen as the threshold for observing significant differences between the cohorts.
Table 2: Cohort Comparison of Training and Test Sets for all 15 features with their associated p-value.
| Feature | Train Mean (Std) | Test Mean (Std) | P-Value |
|----------------------|--------------------|-------------------|-----------|
| ICU Stay Length | 6.736 (7.152) | 6.175 (6.487) | 0.286 |
| Serum Potassium | 3.989 (0.684) | 4.008 (0.717) | 0.723 |
| Hospital Stay Length | 12.434 (14.028) | 11.182 (10.698) | 0.206 |
| Serum Sodium | 139.767 (4.119) | 139.234 (4.381) | 0.093 |
| Blood Urea Nitrogen | 17.800 (10.823) | 17.390 (8.753) | 0.596 |
| Glucose | 156.784 (50.918) | 152.494 (47.112) | 0.254 |
| Anion Gap | 15.266 (3.589) | 15.013 (3.423) | 0.344 |
| Respiratory Rate | 17.629 (5.075) | 17.806 (3.485) | 0.615 |
| INR | 1.308 (0.466) | 1.402 (1.320) | 0.128 |
| Tracheostomy | 0.214 (0.410) | 0.199 (0.400) | 0.638 |
| Hemoglobin | 12.592 (2.169) | 12.501 (2.176) | 0.577 |
| Systolic BP | 132.213 (14.891) | 131.891 (16.211) | 0.78 |
| Heart Rate | 87.283 (15.525) | 86.852 (15.534) | 0.713 |
| Neurosurgery | 0.318 (0.466) | 0.283 (0.451) | 0.314 |
| Platelet | 232.297 (91.167) | 238.709 (89.538) | 0.349 |
The training and test cohorts consist of patients characterized by several clinical metrics. Notable measurements include the length of stay in the ICU and hospital, various blood chemistry markers like serum sodium, potassium, and urea nitrogen, as well as vital signs such as heart rate, and systolic blood pressure. Additional specific interventions or conditions, such as tracheostomies and neurosurgery, are also tracked.
The training cohort, larger in number, likely provides a base for developing and training predictive models, with values such as an average ICU stay of approximately 6.74 days and a mean serum sodium level of about 139.77 mmol/L. On the other hand, the smaller test cohort is utilized to evaluate the performance and generalizability of the models developed from the training cohort data. It shows slightly different averages, such as a shorter ICU stay at around 6.17 days and a serum sodium level averaging 139.24 mmol/L.
In both cohorts, metrics such as glucose level and heart rate are monitored to gauge the patient's overall health and immediate medical needs. These measurements, along with others, contribute to a comprehensive profile of each patient, which is crucial for accurate modeling and subsequent decision-making in a clinical setting.
## 3.2 Ablation Study
The results of our ablation study, comprehensively summarized in Figure4, provide a clear and detailed analysis of the model's performance with varying feature sets. This figure suggests that the inclusion of all features is crucial, as any attempt to remove even a single feature results in a noticeable drop in the AUROC. Specifically, the figure demonstrates that the removal of any feature does not lead to an increase in AUROC; rather, it leads to a reduction, indicating that each feature contributes uniquely to the model's predictive accuracy. The baseline model, which incorporates all 15 features, achieves a commendable AUROC of 0.94. The study further reveals that no feature removal leads to an AUROC value higher than this benchmark. This finding underscores the integral role of the current feature set in maintaining the model's optimal performance, thereby negating the necessity for any further deletions or adjustments of features. The robustness and reliability of the baseline model are thus validated, highlighting the synergistic effect of the included features in enhancing the model's predictive capability.
## 3.3 Evaluation results
To optimize the performance of our XGBoost model, a grid search was employed to identify the best hyperparameters. The grid search process involved systematically exploring a range of values for each parameter to find the combination that yield the highest model performance on train. Table3 presents the best parameters identified through this process.
Figure 4: Ablation study for proposed XGBoost model
Table 3: Parameters used in XGBoost Algorithm.
| Parameter | Best Value |
|------------------|--------------|
| colsample_bytree | 0.7 |
| learning_rate | 0.01 |
| max_depth | 5 |
| min_child_weight | 5 |
| n_estimators | 300 |
| reg_alpha | 0.1 |
| reg_lambda | 2 |
| scale_pos_weight | 2 |
| subsample | 0.7 |
The results of our study emphasize the predictive performance of various machine learning techniques for VAP in patients with TBI, focusing primarily on the test set. The evaluation metrics are Area Under the Curve (AUC), Accuracy, F1 Score, Specificity, Sensitivity, Positive Predictive Value (PPV), and Negative Predictive Value (NPV). The XGBoost algorithm emerged as the most effective model.
As shown in Table4, the performance of the models on the training set was initially assessed, with SVM achieving the highest AUC of 1.00. This was further illustrated by the Receiver Operating Characteristic (ROC) curves in Figure5, which highlight SVM's exceptional performance on the training data, followed closely by XGBoost with an AUC of 0.99.
However, the true test of a model's generalizability is its performance on unseen data. As shown in Table5, XGBoost achieved the highest AUC of 0.940 with a 95% Confidence Interval (CI) [0.935-0.954] on the test set, demonstrating
Table 4: Predictive performance of machine learning models for VAP among TBI patients in the training set.
| Models | AUC (95%CI) | Accuracy (95%CI) | F1 Score (95%CI) | Sensitivity (95%CI) | Specificity (95%CI) | PPV (95%CI) | NPV (95%CI) |
|----------|---------------------|---------------------|---------------------|-----------------------|-----------------------|---------------------|---------------------|
| SVM | 0.999 (0.998-1.000) | 0.997 (0.995-1.000) | 0.997 (0.993-1.000) | 0.998 (0.996-1.000) | 0.996 (0.993-1.000) | 0.995 (0.989-1.000) | 0.999 (0.997-1.000) |
| LR | 0.936 (0.914-0.949) | 0.872 (0.851-0.894) | 0.840 (0.810-0.869) | 0.855 (0.825-0.884) | 0.891 (0.867-0.915) | 0.829 (0.795-0.864) | 0.902 (0.888-0.915) |
| XGBoost | 0.988 (0.984-0.992) | 0.915 (0.896-0.935) | 0.904 (0.879-0.929) | 0.984 (0.973-0.996) | 0.866 (0.835-0.896) | 0.834 (0.796-0.872) | 0.989 (0.981-0.997) |
| ANN | 0.980 (0.921-0.976) | 0.875 (0.816-0.935) | 0.829 (0.735-0.923) | 0.811 (0.658-0.963) | 0.911 (0.892-0.929) | 0.866 (0.834-0.897) | 0.891 (0.808-0.974) |
| RF | 0.946 (0.920-0.963) | 0.870 (0.837-0.904) | 0.843 (0.799-0.886) | 0.895 (0.809-0.981) | 0.848 (0.772-0.924) | 0.802 (0.728-0.876) | 0.936 (0.887-0.985) |
| AdaBoost | 0.974 (0.963-0.991) | 0.918 (0.887-0.950) | 0.905 (0.871-0.939) | 0.967 (0.934-1.000) | 0.881 (0.820-0.942) | 0.845 (0.778-0.912) | 0.977 (0.955-1.000) |
## Train ROC Curve
Figure 5: ROC curves of the eight models for the training set. ROC curves of the six models for the test set. SVM, Logistic Regression, XGB, RF, ANN, AdaBoost.
superior overall performance compared to other models. This was further validated by the ROC curves depicted in Figure6, illustrating XGBoost's robust discriminative ability. Additionally, XGBoost maintained a high accuracy of 0.875, sensitivity of 0.896, and specificity of 0.857, indicating its balanced performance across different evaluation metrics.
Other model evaluations include Logistic Regression, Artificial Neural Networks (ANN), Random Forest (RF), and AdaBoost. The SVM, despite having the highest training set AUC, showed a lower AUC value of 0.882 in the test set, highlighting the importance of evaluating models on unseen data to ensure their generalizability. Random Forest, Logistic Regression, and AdaBoost also showed highly competitive results with AUCs 0.925, 0.914, and 0.918, respectively, but their performance did not surpass that of XGBoost. ANN demonstrated moderate performance with an AUC of 0.896.
The clear advantage of XGBoost in the test cohort highlights its efficacy in handling the complexities and nuances associated with predicting V AP in TBI patients. This model's ability to maintain high sensitivity and specificity makes it particularly suitable for clinical applications where accurate identification of at-risk patients is crucial. The findings
Table 5: Predictive performance of machine learning models for VAP among TBI patients in the test set.
| Models | AUC (95%CI) | Accuracy (95%CI) | F1 Score (95%CI) | Sensitivity (95%CI) | Specificity (95%CI) | PPV (95%CI) | NPV (95%CI) |
|----------|---------------------|---------------------|---------------------|-----------------------|-----------------------|---------------------|---------------------|
| SVM | 0.882 (0.862-0.903) | 0.807 (0.773-0.841) | 0.737 (0.691-0.783) | 0.723 (0.654-0.793) | 0.866 (0.822-0.911) | 0.762 (0.701-0.824) | 0.838 (0.804-0.873) |
| LR | 0.914 (0.893-0.924) | 0.847 (0.833-0.860) | 0.784 (0.762-0.806) | 0.745 (0.713-0.777) | 0.908 (0.904-0.911) | 0.828 (0.818-0.838) | 0.856 (0.840-0.872) |
| XGBoost | 0.940 (0.935-0.954) | 0.875 (0.861-0.888) | 0.842 (0.826-0.858) | 0.896 (0.877-0.915) | 0.857 (0.828-0.885) | 0.792 (0.761-0.823) | 0.933 (0.922-0.944) |
| ANN | 0.896 (0.895-0.921) | 0.845 (0.837-0.853) | 0.794 (0.781-0.806) | 0.793 (0.777-0.809) | 0.876 (0.866-0.885) | 0.793 (0.778-0.808) | 0.876 (0.867-0.885) |
| RF | 0.925 (0.896-0.935) | 0.845 (0.798-0.892) | 0.806 (0.751-0.862) | 0.837 (0.748-0.926) | 0.833 (0.755-0.911) | 0.761 (0.680-0.843) | 0.903 (0.856-0.949) |
| AdaBoost | 0.918 (0.861-0.936) | 0.857 (0.833-0.880) | 0.816 (0.784-0.848) | 0.835 (0.755-0.915) | 0.865 (0.822-0.908) | 0.793 (0.748-0.838) | 0.901 (0.861-0.942) |
## Test ROC Curve
Figure 6: ROC curves of the six models for the test set. ROC curves of the eight models for the test set. SVM, Logistic Regression, XGB, RF, ANN, AdaBoost.
suggest that implementing XGBoost in predictive analytics for healthcare could significantly enhance decision-making processes and patient outcomes.
## 3.4 SHAP analysis
The SHAP summary plot is demonstrated in Figure7. It provides a detailed understanding of the features impacting the prediction model for V AP in patients suffering from TBI. Notably, ICU length of stay and hospital length of stay are the most influential features as also shown in [29].
Longer ICU stays significantly decrease the model's predicted output, suggesting a higher risk or poorer outcome, while longer hospital stays also decrease the output but to a lesser extent. High serum potassium levels have a slight positive impact on the model's predictions, whereas high blood urea nitrogen levels show a varied but generally positive effect on the output.
Figure 7: SHAP values for the test set, derived from the XGBoost model.
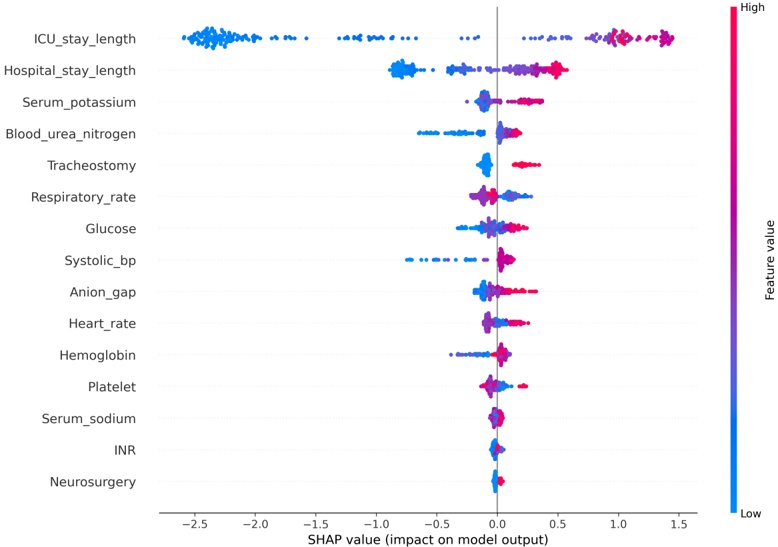
The analysis also reveals that features like respiratory rate and glucose levels, when elevated, positively influence the model's predictions, indicating better outcomes or lower risk. The presence of a tracheostomy shows mixed but generally positive impacts. The non-linear relationships captured by the model highlight the complexity of interactions between features and outcomes. This insight is crucial for improving early detection and interventions for V AP in TBI patients, enhancing model interpretability and clinical applicability. Compared to [5], our SHAP analysis provides a more detailed and nuanced understanding of feature importance. The SHAP summary plot in our study reveals a greater complexity and depth, highlighting the influence of features such as ICU stay length, hospital stay length, serum potassium, and blood urea nitrogen on the model's predictions. This level of detail offers a clearer insight into the factors contributing to V AP development, enhancing the interpretability and reliability of our predictive models.
## 4 DISCUSSION
## 4.1 Summary of Existing Model Compilation
In our study, XGBoost demonstrated better performance compared to other models. This advantage can be explained by the sophisticated mechanisms this model employs. Firstly, XGBoost employs ensemble learning techniques that combine multiple weak learners to form a strong learner, inherently reducing variance and bias for more robust and accurate models. Additionally, these models are particularly effective in handling imbalanced data, a common challenge in medical diagnostics, by optimizing the classification boundary better than simpler models that often struggle with minority class predictions. XGBoost also excels in managing different data types and missing values, and it incorporates built-in regularization to minimize overfitting. XGBoost also incorporates regularization techniques such as L1 (Lasso) and L2 (Ridge) regularization.
However, it is important to note that Logistic Regression showed better performance in terms of specificity and PPV. The specificity of Logistic Regression indicates its higher ability to correctly identify negative cases, reducing the number of false positives, which is crucial in medical diagnostics to avoid unnecessary treatments. Additionally, the higher PPV of Logistic Regression reflects its greater precision in predicting positive cases, which ensures that the identified cases are more likely to be true positives. Nonetheless, since XGBoost performed better in other metrics, we selected it for our proposed model.
## 4.2 Comparison with Literature Results
A related study by Wang et al. employed the MIMIC-III dataset, utilizing 52 features, significantly more than the 15 features in our analysis [5]. This larger number of features likely contributed to severe overfitting in their models on the training set. Their approach included seven different models: SVM, Logistic Regression, Random Forest, Light Gradient Boosting Machine (Light GBM), AdaBoost, Multilayer Perceptron (MLP), and XGBoost. In contrast, we included ANN in our study, which the literature did not utilize. We decided against using Light GBM and MLP after observing suboptimal performance with these models in the original research. The inclusion of ANN was to assess the efficacy of deep learning in our context, although it did not yield particularly satisfactory results.
The previous study provided a table of metrics for each model rather than presenting a single best model. Here, we confirm that our proposed model surpasses every model from the previous study in each metric by comparing our results with the best metrics reported for those models.
For the AUC (Area Under the Curve), our proposed XGBoost model achieved a remarkable 0.940 (95% CI: 0.935-0.954), significantly surpassing the best AUC of 0.706 (95% CI: 0.624-0.788) achieved by AdaBoost in the previous study. This substantial improvement of 0.234 in AUC indicates a markedly better discrimination capability of our model. When considering accuracy, our model recorded an impressive 0.875 (95% CI: 0.861-0.888), far exceeding the 0.640 (95% CI: 0.616-0.663) accuracy achieved by the previous study's XGBoost model. This demonstrates an improvement of 0.235, reflecting our model's superior ability to correctly predict both positive and negative cases. For sensitivity, our XGBoost model achieved 0.896 (95% CI: 0.877-0.915), a significant increase over the 0.692 (95% CI: 0.628-0.756) sensitivity of the previous study's XGBoost model. This improvement of 0.204 highlights our model's enhanced capability to correctly identify true positive cases. In terms of specificity, our model also excelled with a value of 0.857 (95% CI: 0.828-0.885), slightly improving on the 0.849 (95% CI: 0.815-0.883) specificity of the previous study's Light GBM model. Although the increase is marginal (0.008), it demonstrates our model's balanced performance in reducing false positives. The Positive Predictive Value (PPV) of our proposed model was 0.792 (95% CI: 0.761-0.823), which is higher than the 0.708 (95% CI: 0.615-0.801) PPV achieved by the previous study's Random Forest (RF) model. This improvement of 0.084 indicates better reliability in our model's positive predictions. For Negative Predictive Value (NPV), our model achieved a substantial 0.933 (95% CI: 0.922-0.944), significantly surpassing the 0.706 (95% CI: 0.686-0.726) NPV achieved by the previous study's AdaBoost model. This considerable improvement of 0.227 demonstrates our model's strong capability in correctly predicting negative cases. Lastly, for the F1 Score, our proposed XGBoost model achieved 0.842 (95% CI: 0.826-0.858), significantly higher than the F1 Score of 0.660 (95% CI: 0.571-0.748) achieved by the previous study's RF model. This improvement of 0.182 underscores our model's balanced precision and recall performance. Additionally, the ROC curves for our models in the test set shown in Figure6 further substantiate the robustness and generalizability of our approach.
The literature did not employ any method for feature selection and overlooked crucial aspects, such as addressing class imbalance. Our refined feature selection process, which involved eliminating features with high correlations to reduce multicollinearity, and selecting only the top 15 most relevant features based on CatBoost feature importance scores, ensured that our models were trained on the most impactful data. Additionally, we consulted with a clinical expert to verify the relevance of these selected features, further enhancing the robustness and applicability of our models. This approach significantly enhanced the predictive power of our models.
Furthermore, we utilized the SMOTE to address class imbalance, a critical step in medical datasets where the prevalence of conditions can vary significantly. This technique synthesized new examples in the minority class, providing a balanced dataset that improved the generalizability and fairness of our predictive models.
From these comparisons, it is evident that our results are significantly superior to those of the existing literature, particularly in terms of AUC, accuracy, and other related metrics. A higher AUC demonstrates our model's improved accuracy and consistency in distinguishing between patients who will develop VAP and those who will not. This indicates a more reliable predictive capability, crucial in clinical settings to ensure timely and appropriate interventions. Additionally, a higher sensitivity indicates our model's enhanced ability to correctly identify the majority of positive cases, essential in medical diagnostics to avoid missing patients who require urgent care and treatment.
Examining the feature importance derived from our models (shown in Figure7), ICU stay length and hospital stay length were the most influential features, followed by serum potassium, blood urea nitrogen, and tracheostomy. In contrast, the literature highlights tracheostomy, RBC transfusion, and percutaneous endoscopic gastrostomy (PEG) as the top features influencing their AdaBoost model. The differences in feature importance underline our model's ability to capture the critical factors impacting V AP development more accurately, enhancing its predictive performance.
The significant improvement in model performance can be primarily attributed to our refined feature selection process and the use of SMOTE. These methodological enhancements are crucial to achieving superior performance metrics
compared to the existing literature, highlighting the effectiveness and reliability of our predictive models in clinical applications.
## 4.3 Study Limitations
Despite the promising results, there are several limitations in our study that warrant discussion. Firstly, the scope of our data was confined to the MIMIC-III database. Although this dataset is comprehensive, it is over a decade old and may not fully capture the latest clinical practices and patient demographics. To enhance the generalizability of our model, future research should include validation using newer datasets such as MIMIC-IV or other similar repositories. Additionally, expanding the data sources to include text and image data could potentially augment our model's predictive capabilities, particularly in identifying nuanced clinical indicators of V AP.
Another limitation is the handling of class imbalance using the SMOTE. While this method helped in balancing the training dataset, future studies could investigate more advanced balancing techniques and their impact on model robustness.
Our current model does not account for temporal dependencies in the data, which are crucial for accurately predicting clinical outcomes in an ICU setting. Future work could benefit from incorporating time-series analysis and longitudinal data tracking to better capture patient trajectories and improve predictive accuracy.
Lastly, the practical implementation of our model in clinical settings remains to be tested. Developing user-friendly interfaces and integrating the model into existing electronic health record systems will be essential for real-world application. Collaborating with clinicians during this process can ensure that the tool is both practical and effective in everyday use.
In conclusion, while our study provides a strong foundation for predicting VAP incidence using machine learning, addressing these limitations through future research can significantly enhance the model's accuracy, generalizability, and clinical utility.
## 5 CONCLUSION
From data extraction and cleaning, through feature selection, and resampling, to model choice, hyperparameter selection, and model comparison and tuning, this study has conducted extensive research and effort across many aspects of a complete pipeline to achieve significant improvements in model performance.
These enhancements are notable; we increased the best AUC from 0.706 in the existing literature to 0.940, while also boosting the accuracy from 0.640 to 0.875. This indicates significant advancements in overall prediction, which is crucial for medical data research. Furthermore, most of our baseline models outperformed the previous best study across all metrics, and we successfully reduced the number of features from 52 to 15, streamlining the model without sacrificing performance.
These improvements were primarily achieved through broader feature exploration and selection, the application of data resampling techniques, and meticulous model tuning.
Given that our research area is currently underexplored and considering that TBI is widespread and imposes a substantial burden on families and society, while VAP frequently occurs in TBI patients, our findings hold substantial medical value. This enhanced performance can lead to better patient management and potentially reduce the mortality associated with complications from VAP, as well as help evaluate the risk of V AP early.
Looking to the future, this work lays a strong foundation for further research. It highlights the potential for using advanced machine learning techniques to tackle similar medical challenges, encourages the exploration of underutilized data within healthcare datasets, and suggests that future studies could focus on refining model accuracy and reliability further, especially in different or larger datasets. This could also inspire the development of real-time predictive tools that could be integrated into clinical workflows, providing timely and accurate support to medical professionals.
## Acknowledgment
The authors express their appreciation to the team behind MIMIC-III for their invaluable contribution in developing and maintaining such an extensive and detailed public electronic health record (EHR) dataset. This resource has been instrumental in enabling comprehensive research and facilitating significant advancements in the field.
## References
| [1] | T.A. Fatuki, V. Zvonarev, and A.W. Rodas. Prevention of traumatic brain injury in the united states: Significance, new findings, and practical applications. Cureus , (11225), 2020. |
|-------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [2] | Claudia Yaneth Rodríguez-Triviño, Isidro Torres Castro, and Zulma Dueñas. Hypochloremia in patients with severe traumatic brain injury: A possible risk factor for increased mortality. World Neurosurgery , 124:e783-e788, 2019. |
| [3] | David K Menon, Karen Schwab, David W Wright, Andrew I Maas, et al. Position statement: definition of traumatic brain injury. Archives of physical medicine and rehabilitation , 91(11):1637-1640, 2010. |
| [4] | Maryam Ahmadipour, Marzieh Lashkari, and Mehdi Ahmadinejad. Comparison of morbidity, mortality, and costs of vap patients with non-vap patients in the tertiary referral hospital of kerman, iran. Tanaffos , 22(1):61, 2023. |
| [5] | Ruoran Wang, Linrui Cai, Yan Liu, Jing Zhang, Xiaofeng Ou, and Jianguo Xu. Machine learning algorithms for prediction of ventilator associated pneumonia in traumatic brain injury patients from the mimic-iii database. Heart &Lung , 62:225-232, 2023. |
| [6] | Chiara Robba, Paola Rebora, Erika Banzato, Eveline JA Wiegers, Nino Stocchetti, David K Menon, Giuseppe Citerio, Cecilia Åkerlund, David Nelson, Krisztina Amrein, et al. Incidence, risk factors, and effects on outcome of ventilator-associated pneumonia in patients with traumatic brain injury: analysis of a large, multicenter, prospective, observational longitudinal study. Chest , 158(6):2292-2303, 2020. |
| [7] | Wenjuan Luo, Rui Xing, and Canmin Wang. The effect of ventilator-associated pneumonia on the prognosis of intensive care unit patients within 90 days and 180 days. BMC Infectious Diseases , 21(1):1-7, 2021. |
| [8] | Negin Ashrafi, Yiming Liu, Xin Xu, Yingqi Wang, Zhiyuan Zhao, and Maryam Pishgar. Deep learning model utilization for mortality prediction in mechanically ventilated icu patients. Informatics in Medicine Unlocked 2024. |
| [9] | A.E.W. Johnson, T.J. Pollard, and R.G. Mark. The mimic-iii clinical database. PhysioNet , 2016. version 1.4. |
| [10] | dhs.wisconsin. Wish injury-related traumatic brain injury icd-9-cm codes, 2024. |
| [11] | Steven M. Koenig and Jonathon D. Truwit. Ventilator-associated pneumonia: Diagnosis, treatment, and prevention. 2024. |
| [12] | B. Marapelli, S. Kadiyala, and C.S. Potluri. Performance analysis and classification of class imbalanced dataset using complement naive bayes approach. In 2023 Advanced Computing and Communication Technologies for High Performance Applications (ACCTHPA) , pages 1-7, 2023. |
| [13] | Nitesh V. Chawla et al. Smote: synthetic minority over-sampling technique. Journal of artificial intelligence research , 16:321-357, 2002. |
| [14] | Ping Xuan, Liyun Zhan, Hui Cui, Tiangang Zhang, Toshiya Nakaguchi, and Weixiong Zhang. Graph triple- attention network for disease-related lncrna prediction. IEEE journal of biomedical and health informatics 26(6):2839-2849, 2021. |
| [15] | Zongwen Fan, Jin Gou, and Shaoyuan Weng. A feature importance-based multi-layer catboost for student performance prediction. IEEE Transactions on Knowledge and Data Engineering , pages 1-13, 2024. |
| [16] | Yange Chen, Qinyu Mao, Baocang Wang, Pu Duan, Benyu Zhang, and Zhiyong Hong. Privacy-preserving multi- class support vector machine model on medical diagnosis. IEEE Journal of Biomedical and Health Informatics 26(7):3342-3353, 2022. |
| [17] | J. Qin and Y. Lou. L1-2 regularized logistic regression. In 2019 53rd Asilomar Conference on Signals, Systems, and Computers , pages 779-783, 2019. |
| [18] | Jiahong Zhang, Hexin Li, Negin Ashrafi, Zhijiang Yu, Greg Placencia, and Maryam Pishgar. Prediction of in-hospital mortality for icu patients with heart failure. medRxiv , pages 2024-06, 2024. |
| [19] | Philipp Probst, Marvin N. Wright, and Anne-Laure Boulesteix. Hyperparameters and tuning strategies for random forest. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , 9(3):e1301, 2019. |
| [20] | Jiayi Gao, Yuying Lu, Negin Ashrafi, Ian Domingo, Kamiar Alaei, and Maryam Pishgar. Prediction of sepsis mortality in icu patients using machine learning methods. medRxiv , pages 2024-03, 2024. |
| [21] | Ida Barkiah and Yuslena Sari. Overcoming overfitting challenges with hog feature extraction and xgboost-based classification for concrete crack monitoring. International Journal of Electronics and Telecommunications , pages |
| [22] | Shuhui Liu, Bo Fu, Wen Wang, Mei Liu, and Xin Sun. Dynamic sepsis prediction for intensive care unit patients using xgboost-based model with novel time-dependent features. IEEE Journal of Biomedical and Health Informatics , 26(8):4258-4269, 2022. |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [23] | H. Li, N. Ashrafi, C. Kang, G. Zhao, Y. Chen, and M. Pishgar. A machine learning-based prediction of hospital mortality in mechanically ventilated icu patients. MedRxiv , 2024. |
| [24] | Akhilesh A. Waoo and Brijesh K. Soni. Performance analysis of sigmoid and relu activation functions in deep neural network. In Intelligent Systems: Proceedings of SCIS 2021 , 2021. |
| [25] | Negin Ashrafi, Armin Abdollahi, Greg Placencia, and Maryam Pishgar. Effect of a process mining based pre-processing step in prediction of the critical health outcomes. arXiv preprint arXiv:2407.02821 , 2024. |
| [26] | Armin Abdollahi, Xinghong Ma, Jiahao Zhang, Daijia Wu, Tongshou Wu, Zizheng Ye, and Maryam Pishgar. Enhanced mortality prediction in icu stroke patients via deep learning. arXiv preprint arXiv:2407.14211 , 2024. |
| [27] | Cao Ying et al. Advance and prospects of adaboost algorithm. Acta Automatica Sinica , 39(6):745-758, 2013. |
| [28] | Rakesh Rana and Richa Singhal. Chi-square test and its application in hypothesis testing. Journal of Primary Care Specialties , 1(1):69-71, 2015. |
| [29] | Zhijiang Yu, Negin Ashrafi, Hexin Li, Kamiar Alaei, and Maryam Pishgar. Prediction of 30-day mortality for icu patients with sepsis-3. medRxiv , 2024. | | null | [
"Negin Ashrafi",
"Armin Abdollahi",
"Maryam Pishgar"
] | 2024-08-02T09:44:18+00:00 | 2024-08-02T09:44:18+00:00 | [
"cs.LG"
] | Enhanced Prediction of Ventilator-Associated Pneumonia in Patients with Traumatic Brain Injury Using Advanced Machine Learning Techniques | Background: Ventilator-associated pneumonia (VAP) in traumatic brain injury
(TBI) patients poses a significant mortality risk and imposes a considerable
financial burden on patients and healthcare systems. Timely detection and
prognostication of VAP in TBI patients are crucial to improve patient outcomes
and alleviate the strain on healthcare resources.
Methods: We implemented six machine learning models using the MIMIC-III
database. Our methodology included preprocessing steps, such as feature
selection with CatBoost and expert opinion, addressing class imbalance with the
Synthetic Minority Oversampling Technique (SMOTE), and rigorous model tuning
through 5-fold cross-validation to optimize hyperparameters. Key models
evaluated included SVM, Logistic Regression, Random Forest, XGBoost, ANN, and
AdaBoost. Additionally, we conducted SHAP analysis to determine feature
importance and performed an ablation study to assess feature impacts on model
performance.
Results: XGBoost outperformed the baseline models and the best existing
literature. We used metrics, including AUC, Accuracy, Specificity, Sensitivity,
F1 Score, PPV, and NPV. XGBoost demonstrated the highest performance with an
AUC of 0.940 and an Accuracy of 0.875, which are 23.4% and 23.5% higher than
the best results in the existing literature, with an AUC of 0.706 and an
Accuracy of 0.640, respectively. This enhanced performance underscores the
models' effectiveness in clinical settings.
Conclusions: This study enhances the predictive modeling of VAP in TBI
patients, improving early detection and intervention potential. Refined feature
selection and advanced ensemble techniques significantly boosted model accuracy
and reliability, offering promising directions for future clinical applications
and medical diagnostics research. |
2408.01145v1 | ## TransRx-6G-V2X : Transformer Encoder-Based Deep Neural Receiver For Next Generation of Cellular Vehicular Communications
Osama Saleem
Soheyb Ribouh
INSA Rouen Normandie, Univ Rouen Normandie Universit´ e Le Havre Normandie, Normandie Univ LITIS UR 4108, F-76000 Rouen, France [email protected]
Mohammed Alfaqawi VEDECOM Versailles, France [email protected]
Univ Rouen Normandie, INSA Rouen Normandie Universit´ e Le Havre Normandie, Normandie Univ LITIS UR 4108, F-76000 Rouen, France [email protected]
Abdelaziz Bensrhair LITIS, INSA Rouen, France [email protected]
Abstract -End-to-end wireless communication is new concept expected to be widely used in the physical layer of future wireless communication systems (6G). It involves the substitution of transmitter and receiver block components with a deep neural network (DNN), aiming to enhance the efficiency of data transmission. This will ensure the transition of autonomous vehicles (AVs) from self-autonomy to full collaborative autonomy, that requires vehicular connectivity with high data throughput and minimal latency. In this article, we propose a novel neural network receiver based on transformer architecture, named TransRx, designed for vehicle-to-network (V2N) communications. The TransRx system replaces conventional receiver block components in traditional communication setups. We evaluated our proposed system across various scenarios using different parameter sets and velocities ranging from 0 to 120 km/h over Urban Macrocell (UMa) channels as defined by 3GPP. The results demonstrate that TransRx outperforms the state-of-the-art systems, achieving a 3.5dB improvement in convergence to low Bit Error Rate (BER) compared to convolutional neural network (CNN)-based neural receivers, and an 8dB improvement compared to traditional baseline receiver configurations. Furthermore, our proposed system exhibits robust generalization capabilities, making it suitable for deployment in large-scale environments.
Index Terms -6G, End-to-end learning, Vehicular networks, Deep learning, Attention mechanism, Transformers encoder, Neural Receiver.
## I. INTRODUCTION
The sixth generation (6G) of cellular networks is expected to revolutionize wireless connectivity and bring significant advancements in communication system design. Technologies such as massive multiple-input multiple-output (MIMO), millimeter-wave (mmWave) communication, and intelligent reflecting surfaces (RIS) are set to boost the capacity and efficiency of wireless networks, enabling high data throughput with low latency, high reliability, and a high level of security against cyber-attacks [1]. To achieve this, Artificial Intelligence (AI) will be widely explored for various tasks
Pierre Merdrignac VEDECOM Versailles, France [email protected]
Fig. 1: Vehicular Communications in Urban Dense Environment
to improve the performance of the PHY layer. This has been widely motivated by the latest declaration from the 3GPP consortium, which has affirmed the integration of AI in wireless communication system design in the upcoming releases [2]. The benefits promised by 6G will potentially contribute to accelerating the launch of several technologies, where high wireless network connectivity is required such as Cooperative Connected and Autonomous Mobility (CCAM) which enables smart transportation system through the deployment of autonomous vehicles (AVs). AVs are equipped with multiple sensor, such as video cameras, radars and light detection and ranging (LiDAR) systems. These sensors and devices capture information and share it with surrounding vehicles and the environment to facilitate tasks with high precision. These cooperative systems are connected in a vehicular network to ensure information sharing through vehicle-to-everything (V2X) communications.
Moreover, applications like remote car control and safe intersection crossing require near real time processing with low error and latency, leading to Ultra-Reliable Low-latency Communication (URLLC) [3]. The integration of AI into AVs is set to play a pivotal role in maximizing the effectiveness of V2X communication. AI models can be deployed in vehicles to learn from large amounts of real-world data enabling them to make smart decisions. Similarly, the use of Deep Learning (DL) algorithms can further refine the responsiveness and adaptability of V2X communication. DL models can predict and react to changing network conditions, vehicle behaviors, and external environmental factors, thereby sustaining a high level of performance without human intervention. These capabilities are crucial for achieving inflexible quality of service (QoS) demands required by next-generation vehicular networks.
The concept of auto-encoder-based end-to-end (E2E) wireless communication system was initially proposed in [5]. The idea was to detect the non-linear imperfections of the real time channel using DL-based approaches. Although the research work in [5] considered a simple scenario, that has served as a breakthrough for physical layer design in the next generation of wireless communication. Since then, many methods have been proposed for the optimization of transmitter and receiver functionalities using DL. In [6], the authors leverages machine learning techniques to estimate conditionally Gaussian random vectors with random covariance matrices, reducing complexity in communication systems by using structured covariance matrices and neural networks to learn efficient estimators. Moreover, He et al., [7] use an approximation message passing network based on learned denoising to significantly enhance channel estimation in massive MIMO mmWave systems with minimal RF chains, outperforming conventional compressed sensing techniques. Furthermore, Chang et al., [8] examine how convolutional neural networks (CNNs) are applied to the equalization task. Their methodology yields a reduction in error vector magnitude, surpassing outcomes from established algorithms such as the multi-modulus algorithm and recursive least squares techniques. In the domain of demapping, Shental et al. [9] propose a deep neural network framework designed to efficiently compute bit Log-Likelihood Ratios (LLRs) for equalized symbols. The efficacy of this deep learning-based demapper closely aligns with that of the optimal log maximum a-posteriori algorithm, albeit with a considerable decrease in computational overhead. Moreover, several methods investigate the integration of deep learning mechanisms into the standard processing sequence of receivers [10] -[12]. These augmented systems demonstrate notable performance improvements over conventional receivers, through proper training. In the above approaches, although neural networks give close results to the baseline system in terms of performance, where they train their models to perform distinct operations of the receiver independently (e.g., either only estimation, equalization or demodulation).
The joint optimization of receiver functionalities using a neural network has also been addressed by many researchers. Ye et al., [13] delve into the integration of channel estimation and signal detection via deep learning methodologies. Their approach employs a fully connected neural network to analyze both pilot and data signals, demonstrating significant performance gains over traditional receivers based on minimum mean square error (MMSE) criteria, especially in scenarios with limited channel estimation pilots or in the absence of a cyclic prefix. In contrast, the research work presented in [14] utilizes convolutional neural networks (CNNs) to construct a receiver capable of deriving bit estimates directly from the time-domain received signal. This methodology exhibits superior performance in low to medium signal-to-noise ratio (SNR) conditions. Although the CNN-based approach continues to outperform receivers based on linear least squares at higher SNRs, it does not achieve the same level of accuracy as MMSE-based receivers with perfect channel knowledge. In [15], the authors propose a deep fully convolutional neural network designed for processing 5th Generation (5G) signals, achieving superior performance over traditional algorithms by leveraging data and pilot symbols for precise channel estimation and generating soft bits compatible with 5G channel coding. Although the research works presented in [13] -[15] propose joint optimization of neural receiver, their works lacked the domain generalization (DG) issue [16] i.e., when the model is tested on Out-Of-Distribution (OOD) data compared to the training data, its performance degrades drastically. This Domain Generalization (DG) [16] problem for neural receiver has been addressed in [17], where an Urban Microcell (UMi) channel model has been used in training task to avoid overfitting at the time of testing.
Transformers [18] have revolutionized the design of AI models, with the attention mechanism outperforming the convolution mechanism due to its ability to capture long range data dependencies in multiple domains [19] -[21]. However, their performance has not been evaluated for E2E wireless communication systems. Furthermore, almost all of the proposed neural receivers for wireless communication systems in the literature consider low mobility users in their experiments. In this paper, we propose a novel transformer encoder architecture for neural receiver. This receiver is designed to process 6G data symbols in the uplink scenario of Cellular Vehicle to Network (C-V2N) by handling frequency domain signals and predicting LLRs from the received resource grid. To the best of our knowledge, this is the first work aimed at using an attention-based neural receiver for 6G communication in C-V2N.
Our main contributions are as follows:
- 1) We propose a new deep neural receiver named TransRx designed for 6G-V2X communications. Built on an attention mechanism, TransRx utilizes multiple transformer encoder blocks as its core components to shape the neural network architecture. Our TransRx-6G-V2X receiver takes the received data as input and calculates the optimal LLRs at the output, leading to minimize bit error rate.
- 2) Our proposed TransRx was tested across various wireless channel characteristics and scenarios, different from
Fig. 2: End to end wireless communication
those used in the training task, to evaluate its performance on out-of-distribution data, demonstrating its strong generalization capabilities.
The rest of the paper is organized as follows: In Section II, we present our proposed neural receiver-based end-to-end communication system. Section III describes our experimental setup scenarios, followed by the results and discussion in Section IV. Finally, in Section V, we conclude the paper and outline future work.
## II. SYSTEM MODEL
We consider a set of vehicles V = { V 1 , V 2 , . . . , Vz } operating in an urban dense environment where each vehicle Va ∈ V , a = { 1 2 , , . . . , z } share its information with the base station. As the information bits reach the physical layer of the vehicle, they are first encoded by Low-Density Parity-Check (LDPC) code, as shown in Fig. 2. This encoded information then goes through the QAM modulator to generate the baseband symbol as output. In the next step, these baseband symbols go through resource grid mapper where known pilot symbols are added for estimating the wireless channel state information at the receiver side. Furthermore, in order to equalize the intersymbol interference (ISI) at the base station, a cyclic prefix is also added to these symbols. The resulted information is transmitted by the vehicle through the wireless channel. As illustrated in Fig. 2, once the signal reaches the base station, our proposed TransRx shifts it to log likelihood ratio (LLR) using a transformer encoder-based architecture. For comparison, we also consider the baseline receiver architecture that utilizes the combination of LS Estimator and LMMSE equalizer to recover the original message. Both of these receiver architectures are explained below:
## A. Baseline Receiver Architecture
The received signal at the base station can be expressed as follows:
$$y _ { i, j } = H _ { i, j } x _ { i, j } + n _ { i, j } \quad \quad \ \ ( 1 ) \ \text{ dem}$$
where i denotes the OFDM symbol and j denotes the subcarrier index. yi j , denotes the received symbols and xi j , denotes the transmitted symbols. Hi j , is the channel for i th OFDM symbol and j th subcarrier and ni j , is the channel noise.
As a first step, the base station estimates the channel state information through the known pilot symbols transmitted by the vehicle. The estimated channel ˆ H can be computed from eq. 1 as:
$$\hat { H } = y _ { i, j } x _ { i, j } ^ { * }$$
where ( ) denotes the complex conjugate. The signal plus ∗ interference noise ˆ σ 2 is also estimated at the time of channel estimation. Each of the data symbol received goes through LMMSE equalizer to provide equalized received symbols ˆ yi j , as follows:
$$\hat { y } _ { i, j } = ( \hat { H } _ { i, j } ^ { H } \hat { H } _ { i, j } + \hat { \sigma } ^ { 2 } I ) ^ { - 1 } \hat { H } _ { i, j } ^ { H } y _ { i, j }$$
where ( H ) denotes the hermition transpose operation, ' I ' denotes the identity matrix and ˆ σ 2 denotes the estimated noise power. The equalized symbols are then shifted to Log likelihood ratio (LLR) by the QAM demmaper as follows:
$$L L R _ { i, j, k } \equiv l o g \frac { P ( x _ { k } = 0 | \hat { y } _ { i, j } ) } { P ( x _ { k } = 1 | \hat { y } _ { i, j } ) }$$
where, P xk ( = 0 ˆ | yi j , ) is the probability that transmitted bit xk is '0' given the approximated received symbol ˆ yi j , and P xk ( = 1 ˆ | yi j , ) is the probability that transmitted bit xk is '1' given the approximated received symbol ˆ yi j , . However, k = 0 1 2 , , , . . . , N -1 where N denotes the number of bits per symbol. LLRs go through the LDPC decoder to recover the original message ( xi j , ) transmitted by the vehicle as shown in Fig. 2.
## B. Neural Receiver Architecture
Our proposed TransRx, based on transformer encoder shifts the received signal from the frequency domain to LLRs and replaces the LS estimator, LMMSE equalizer, and QAM demodulator blocks in the baseline receiver. The received
Fig. 3: TransRx Architecture
signal through the wireless channel, serves as input for TransRx, as shown in Fig. 2. The TransRx-based neural receiver architecture is illustrated in Fig. 3. It begins with a dense layer with an output feature dimension of 128. This is followed by 4 transformer encoder blocks, each including a multi-head self-attention layer with 4 attention heads and an embedding dimension of 128. The output of the multi-head self-attention block is added to the input and then fed into a normalization layer. The output of the normalization layer is subsequently fed into a feed forward network, including 2 dense layers. Both of these dense layers have an output feature dimension of 128, where the 'relu' activation function is applied to the first dense layer. As shown in Fig. 3, the output of the first normalization layer is added to the output of the feed forward network and fed into a second normalization layer. The final layer of our proposed TransRx architecture is a dense layer with an output feature dimension equal to the number of bits per symbol.
To train the proposed TransRx neural receiver model, we compute bit wise binary cross entropy (BCE) along with the sigmoid activation function to obtain difference between the actual bit value and predicted LLR as shown in Algorithm 1. The BCE can be formulated as:
$$\ B C E = - \frac { 1 } { N } \cdot \sum _ { i = 1 } ^ { n } y _ { i } \cdot \log ( P ( y _ { i } ) ) + ( 1 - y _ { i } ) \cdot \log ( 1 - P ( y _ { i } ) ) \ \ ( 5 ) \ \sinh ^ { \cdot } { \sinh ^ { \cdot } { \mathbf s } } |$$
where N is the batch size, n is the number of bits in one batch, yi is the transmitted information bit to be '1' and P yi ( ) is the probability of LLR to be '1'. Similarly, ( 1 -yi ) is the transmitted information bit to be '0', and ( 1 -P yi ( )) is the probability of LLR to be '0'. The loss function used to train and update the weights of TransRx is given as :
$$L o s s = 1 - \frac { B C E } { \ln { ( 2 ) } }$$
## III. IMPLEMENTATION AND EXPERIMENTAL SETUP
In our experiments, we consider an uplink scenario, where information is sent from the vehicle to the base station in an urban environment through an Urban Macro-cell (UMa) channel specified by 3GPP [22]. We assume that the vehicle speed ranges from 60 to 120km/h. As described in Algorithm 2, the message is encoded and modulated before transmission.
## Algorithm 1 TransRx Training
- 1: Input : Initial weights θ i , transmitted signal x , received signal y , noise power n
- 2: y ← stack real[y] imaginary[y] ( , )
- 3: y ← concatenate ( y n , )
- 4: y ← Dense ( y )
- 5: for in Transformer Layers do
- 6: y ← transformer layer ( y )
- 7: end for
- 8: y ← Dense ( y )
- 9: Error = BCE ( x y , )
- 10: Loss = 1 -Error
- 11: Compute: gradient
- 12: Compute: weights for next iteration
- 13: Update: θ
## Algorithm 2 TransRx Testing
1: Input : Binary data x , noise power n
2: z ← LDPC Encoder ( x )
3: z ← QAM Mapper ( ) z
4: z ← Resource Grid Mapper ( ) z
5: y ← Channel ( z n , )
6: llr ← Neural Receiver ( y n , )
7: llr ← Resource Grid Demapper llr ( )
8: ˆ x ← LDPC Decoder llr ( )
9: Compute: BER ( x x , ˆ)
Once the information is transmitted by the vehicle, it goes through an urban wireless channel. As the message is received by the base station (BS), it is transformed into the LLRs using our proposed TransRx neural receiver. These LLRs are shifted to the approximated original message (in the form of binary signal) sent by the vehicle through LDPC Decoder. Our proposed TransRx neural receiver has been implemented using the open source library for physical layer research called sionna [23]. TransRx is trained on Tesla P40 graphics card having 24GB of GPU with 12 million data. We created a 6G compatible wireless communication system using simulation parameters shown in Table I. The values of carrier frequency, QAM modulation scheme, subcarrier spacing and coderate are
TABLE I: Simulation Parameters
| Parameter | Value |
|-----------------------------|----------|
| Carrier Frequency | 28GHz |
| Physical Channel | UMa |
| Modulation | 64 QAM |
| Code rate | 0.5 |
| Subcarrier Spacing | 240KHz |
| Delay Spread | 266ns |
| No. of Transmitter Antenna | 1 |
| No. of Receiver Antenna | 2 |
| No. of OFDM symbol | 14 |
| Fast Fourier Transform Size | 128 |
| Minimum Vehicle Speed | 60 km/h |
| Maximum Vehicle Speed | 120 km/h |
set to 28GHz, 64, 240KHz and 0 5 respectively. The number of . the antenna transmission in the vehicle is 1, while the number of antenna receiver at the base station is 2.
## IV. RESULTS AND DISCUSSION
In this section, we present the experimental results achieved using our proposed TransRx. These results have been compared to the following state-of-the-art schemes:
- · Perfect CSI , this knows perfect channel state information (CSI) with zero error Variance.
- · LS Estimator , this estimates the channel conditions based on data symbols and subcarriers.
- · DeepRx , this CNN-based neural receiver architecture has been sourced from [15]. For a fair comparison with the proposed TransRx neural receiver, we re-trained the CNN model using the same data and UMa channel model.
The achieved performance of the proposed TransRx compared to state-of-the-art models are presented in Fig. 4. It shows the BER comparison of the different receiver architectures with respect to (w.r.t) Signal to noise ratio (SNR) over the UMa channel model. We observe that the proposed TransRx outperforms state-of-the-art methods, including LS estimator and Deep Rx. Our proposed TransRx converges to a BER close to 0 at an SNR value of 6 25 dB, which is close to . that achieved by the perfect CSI. In contrast, Deep Rx and the LS estimator reach a BER close to 0 at higher SNR values, around 7 5 dB and 15 dB respectively, showcasing a 1 25 dB . . and 11 dB disparity compared to our TransRx.
To validate the proposed TransRx on a large scale, we evaluated our neural receiver in different scenarios beyond the one it was trained on. Given that the vehicle operates in a dense urban environment, it is likely that the vehicle speed will reduce at certain instances. We tested the performance of TransRx at vehicle speeds ranging from 0 km/h to 60 km/h. The performance evaluation of the BER over different values of SNR is shown in Fig. 5. We can see that TransRx still performs well and outperforms state-of-the-art models, with minimal BER improvements of approximately 1 dB and 2 5 . dB compared to DeepRx and the LS estimator, respectively.
In addition, since the vehicular channel in a real-time environment frequently changes due to high mobility, we evaluated the performance of TransRx over a Clustered Delay Line (CDL) channel with vehicle speeds ranging from 60 to 120 km/h. As shown in Fig. 6, the performance of TransRx in terms of the achieved BER under various SNR values is
TABLE II: TransRx Parameters
| Parameter | Value |
|--------------------------------|---------|
| No. of Transformer Blocks | 4 |
| No. of Attention heads | 4 |
| Feed Forward Network Dimension | 128 |
| Embedding Dimension | 128 |
| Learning Rate | 1 e - 3 |
| Optimizer | AdamW |
| Activation Function | Relu |
| Training data | 12M |
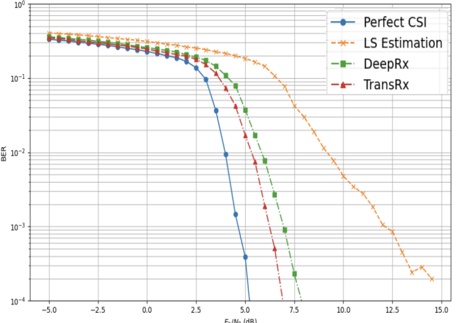
Fig. 4: Comparison of BER w.r.t SNR for UMa Channel Model with vehicle speed ranging from 60 to 120 km/h
Fig. 5: Comparison of BER w.r.t SNR for UMa Channel Model with vehicle speed ranging from 0 to 60 km/h
Fig. 6: Comparison of BER w.r.t SNR for CDL Channel Model with vehicle speed ranging from 60 to 120 km/h
superior to state-of-the-art methods, achieving a low BER with an SNR disparity of 3 5 dB compared to DeepRx and 8 dB .
Fig. 7: (a) Image transmitted by vehicle (b) Image reconstructed at the base station by TransRx (c) Image reconstructed at the base station by DeepRx (d) Image reconstructed at the base station by LS Estimator

TABLE III: PSNR Comparison
| Algorithm | PSNR (dB) |
|--------------|-------------|
| TransRx | 36.21 |
| DeepRx | 34.05 |
| LS Estimator | 29.66 |
compared to the LS estimator.
We assess the performance of our proposed TransRx for image transmission use cases. We used a real-world image taken by an AV as information shared from the vehicle to the base station at a speed of 90 km/h over an UMa channel model at an SNR of 5 dB. The reconstructed images at the receiver side using TransRx and the state-of-the-art methods are illustrated in Fig.7. Compared to the benchmark receiver algorithms, our proposed TransRx can reconstruct images with fewer missing pixels, resulting in an image closer to the one transmitted by the vehicle. To quantify the performance of TransRx, we compute the Peak Signal-to-Noise Ratio (PSNR) by measuring the reconstruction quality of the received image compared to the transmitted one. The obtained PSNR for TransRx and the state-of-the-art approaches is shown in Table.III. It is clear that TransRx achieves the highest PSNR ( 36.21dB ), outperforming DeepRx and the LS estimator, which achieve 34 05 dB and 29 66 dB, respectively. The success of the Tran-. . sRx receiver can be attributed to the attention mechanism's ability to capture long-range data dependencies compared to convolution.
## V. CONCLUSION AND FUTURE WORK
In this paper, we proposed an attention-based TransRx architecture as a neural receiver in the C-V2N uplink scenario. The proposed TransRx neural receiver extracts LLR from the frequency domain signal received at the base station. Simulation result shows that once trained on appropriate data, TransRx outperforms the state of the art (DeepRx) neural receiver model and LS estimator in all scenarios. Our proposed TransRx neural receiver shows 3 5dB improvement to achieve . minimal BER compared to the state of the art DeepRx and
11dB improvement to achieve the same compared to the LS estimator. As a future direction, we are planning to have a testbed implementation of the proposed TransRx-6G-V2X based neural receiver.
## REFERENCES
- [1] S. Ribouh and A. Hadid, 'Is Semantic Communication for Autonomous Driving Secured against Adversarial Attacks?,' 2024 IEEE 6th International Conference on AI Circuits and Systems (AICAS), Abu Dhabi, United Arab Emirates, 2024, pp. 139-143, doi: 10.1109/AICAS59952.2024.10595916.
- [2] X.Lin, 'Artificial Intelligence in 3GPP 5G-Advanced: A Survey,'arXiv preprint arXiv:2305.05092, 2023.
- [3] Yan, Jin, and J´ erˆme H¨ arri. o 'On the feasibility of URLLC for 5G-NR V2X sidelink communication at 5.9 GHz.' GLOBECOM 2022-2022 IEEE Global Communications Conference. IEEE, 2022.
- [4] S. Ribouh and A. Hadid, 'SEECAD: Semantic End-to-End Communication for Autonomous Driving,' 2024 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Korea, Republic of, 2024, pp. 1808-1813, doi: 10.1109/IV55156.2024.10588546.
- [5] T. O'Shea and J. Hoydis, 'An Introduction to Deep Learning for the Physical Layer,' in IEEE Transactions on Cognitive Communications and Networking, vol. 3, no. 4, pp. 563-575, Dec. 2017, doi: 10.1109/TCCN.2017.2758370.
- [6] D. Neumann, T. Wiese, and W. Utschick, 'Learning the MMSE channel estimator,' IEEE Transactions on Signal Processing, vol. 66, no. 11, pp. 2905-2917, June 2018.
- [7] H. He, C. Wen, S. Jin, and G. Li, 'Deep learning-based channel estimation for beamspace mmWave massive MIMO systems,' IEEE Wireless Communications Letters, vol. 7, no. 5, 2018
- [8] Z. Chang, Y. Wang, H. Li, and Z. Wang, 'Complex CNN-based equalization for communication signal,' in 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP), July 2019, pp. 513-517.
- [9] O. Shental and J. Hoydis, 'Machine LLRning: Learning to softly demodulate,' 2019.
- [10] X. Gao, S. Jin, C. Wen, and G. Y. Li, 'ComNet: Combination of deep learning and expert knowledge in OFDM receivers,' IEEE Communications Letters, vol. 22, no. 12, pp. 2627-2630, Dec 2018.
- [11] H. He, S. Jin, C. Wen, F. Gao, G. Y. Li, and Z. Xu, 'Modeldriven deep learning for physical layer communications,' IEEE Wireless Communications, vol. 26, no. 5, pp. 77-83, 2019.
- [12] N. Samuel, T. Diskin, and A. Wiesel, 'Learning to detect,' IEEE Transactions on Signal Processing, vol. 67, no. 10, pp. 2554-2564, May 2019.
- [13] H. Ye, G. Y. Li, and B.-H. Juang, 'Power of deep learning for channel estimation and signal detection in OFDM systems,' IEEE Communications Letters, vol. 7, no. 1, pp. 114-117, Feb. 2018.
- [14] Z. Zhao, M. C. Vuran, F. Guo and S. D. Scott, 'Deep-Waveform: A Learned OFDM Receiver Based on Deep Complex-Valued Convolutional Networks,' in IEEE Journal on Selected Areas in Communications, vol. 39, no. 8, pp. 2407-2420, Aug. 2021, doi: 10.1109/JSAC.2021.3087241.
- [15] M. Honkala, D. Korpi and J. M. J. Huttunen, 'DeepRx: Fully Convolutional Deep Learning Receiver,' in IEEE Transactions on Wireless Communications, vol. 20, no. 6, pp. 3925-3940, June 2021, doi: 10.1109/TWC.2021.3054520.
- [16] M. Akrout, A. Feriani, F. Bellili, A. Mezghani and E. Hossain, 'Domain Generalization in Machine Learning Models for Wireless Communications: Concepts, State of-the-Art, and Open Issues,' in IEEE Communications Surveys and Tutorials, vol. 25, no. 4, pp. 3014-3037, Fourthquarter 2023, doi: 10.1109/COMST.2023.3326399.
- [17] S. Cammerer et al., 'A Neural Receiver for 5G NR MultiUser MIMO,' 2023 IEEE Globecom Workshops (GC Wkshps), Kuala Lumpur, Malaysia, 2023, pp. 329-334, doi: 10.1109/GCWkshps58843.2023.10464486.
- [18] Vaswani, Ashish, et al. 'Attention is all you need.' Advances in neural information processing systems 30 (2017).
- [19] Dosovitskiy, Alexey, et al. 'An image is worth 16x16 words: Transformers for image recognition at scale.' arXiv preprint arXiv:2010.11929 (2020).
- [20] Liu, Xiaoyu, et al. 'Cat: causal audio transformer for audio classification.' ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023.
- [21] Bui, Nghi DQ, et al. 'Codetf: One-stop transformer library for state-ofthe-art code llm.' arXiv preprint arXiv:2306.00029 (2023).
- [22] https://www.atis.org/wp-content/uploads/3gppdocuments/Rel15/ATIS.3GPP.37.885.V1530.pdf
- [23] J. Hoydis, S. Cammerer, F. Ait Aoudia, A. Vem, N. Binder, G. Marcus, and A. Keller, 'Sionna: An Open-Source Library for Next-Generation Physical Layer Research,' preprint arXiv:2203.11854, 2022. | null | [
"Osama Saleem",
"Soheyb Ribouh",
"Mohammed Alfaqawi",
"Abdelaziz Bensrhair",
"Pierre Merdrignac"
] | 2024-08-02T09:47:51+00:00 | 2024-08-02T09:47:51+00:00 | [
"eess.SP"
] | TransRx-6G-V2X : Transformer Encoder-Based Deep Neural Receiver For Next Generation of Cellular Vehicular Communications | End-to-end wireless communication is new concept expected to be widely used
in the physical layer of future wireless communication systems (6G). It
involves the substitution of transmitter and receiver block components with a
deep neural network (DNN), aiming to enhance the efficiency of data
transmission. This will ensure the transition of autonomous vehicles (AVs) from
self-autonomy to full collaborative autonomy, that requires vehicular
connectivity with high data throughput and minimal latency. In this article, we
propose a novel neural network receiver based on transformer architecture,
named TransRx, designed for vehicle-to-network (V2N) communications. The
TransRx system replaces conventional receiver block components in traditional
communication setups. We evaluated our proposed system across various scenarios
using different parameter sets and velocities ranging from 0 to 120 km/h over
Urban Macro-cell (UMa) channels as defined by 3GPP. The results demonstrate
that TransRx outperforms the state-of-the-art systems, achieving a 3.5dB
improvement in convergence to low Bit Error Rate (BER) compared to
convolutional neural network (CNN)-based neural receivers, and an 8dB
improvement compared to traditional baseline receiver configurations.
Furthermore, our proposed system exhibits robust generalization capabilities,
making it suitable for deployment in large-scale environments. |
2408.01146v2 | ## Analytic Model for the Energy Spectrum of the Anharmonic Oscillator
Michel Caffarel 1, ∗
1 Laboratoire de Chimie et Physique Quantiques (UMR 5626), Universit´ de Toulouse, CNRS, UPS, France e
In a recent work we have proposed an original analytic expression for the partition function of the quartic oscillator. This partition function, which has a simple and compact form with no adjustable parameters , reproduces some key mathematical properties of the exact partition function and provides free energies accurate to a few percent over a wide range of temperatures and coupling constants. In this work, we present the derivation of the energy spectrum of this model. We also generalize our previous study limited to the quartic oscillator to the case of a general anharmonic oscillator. Numerical application for a potential of the form V ( x ) = ω 2 2 x 2 + gx 2 m show that the energy levels are obtained with a relative error of about a few percent, a precision which we consider to be quite satisfactory given the simplicity of the model, the absence of adjustable parameters, and the negligible computational cost.
The one-dimensional quantum anharmonic oscillator[1] plays an important role in quantum mechanics as a simple yet nontrivial model for describing nonlinear (anharmonic) effects. As such, it is commonly used in various scientific fields including molecular physics (rovibrational spectra), condensed matter physics (phonons), nuclear physics (collective vibrational motions of nuclei), and quantum field theory ( e.g. , ϕ 4 -theory, Higgs mechanism), to cite the main ones. No exact solution for a general anharmonic potential has been found so far, although some partial solutions have been developed for specific potentials, for example in the case of the so-called quasi-exactly-solvable problems; see Turbiner[2] and references therein. From a numerical point of view, the simplicity of the ordinary differential equation to solve allows very accurate solutions. To cite one numerical approach among many, let us mention the recently developed Lagrange Mesh method of Baye [3] as recently implemented by del Valle[4]. However, as for any physical model, having analytical solutions -even approximate ones- is important since it may lead a deeper insight into the nature of the problem, reveal underlying hidden structures that may not be evident from numerical solutions and, also, guide further analysis or generalizations. A great variety of approximate analytical approaches have been proposed, making it very difficult to provide an exhaustive account of the literature. In this work, we are more specifically interested in evaluating the energy levels of the anharmonic oscillator. Among the main approaches developed for this purpose, let us mention the semi-classical approaches, such as WKB[5, 6] or the phase-integral method based on the generalized Bohr-Sommerfeld quantization condition ([7] and references therein) and the methods based on the use of a variational approach either using parameterized excited wavefunctions[8] or path integrals[9, 10]. Other interesting approaches include the design of simple analytic expressions for the energy levels built from the weakand/or strong-coupling expansions[11, 12] and
∗ [email protected]
methods based on the tuning of boundary conditions[13] or eigenvector continuation [14].
The aim of this work is to present novel analytical expressions for the energy levels of the anharmonic oscillator. For that, we take advantage of a recently proposed partition function for the quartic oscillator,[15] which we extend here to an arbitrary potential. As shown in our previous study[15], this partition function provides an appealing simple and physically meaningful model for the exact solution. Indeed, it has a simple and compact form with no adjustable parameters , a desirable property for an analytical model. Furthermore, it reproduces some key mathematical properties of the exact partition function, thus supporting the idea that the important features of the non-trivial mathematical structure of the solution are, at least partially, accounted for.
These properties are the following: i) The harmonic and classical limits are exactly recovered, ii) the well-known divergence of the weak-coupling (RayleighSchr¨dinger) expansion of the energy is reproduced. o As for the exact solution, the energy corrections are found to be rational numbers and display a factorial-like growth in terms of the perturbational order, and iii) the functional form of the strong-coupling expansion is recovered.
From a quantitative point of view, the free energy is found to be accurate to a few percent over a wide range of temperatures and coupling constants. A similar precision is also obtained for the ground- and first-excited state energies.
To the best of our knowledge, no partition function in closed-form proposed so far is capable of simultaneously reproducing all these features (see, for example, references [9, 16-18] and a comparative study with other models in [15]).
Having at our disposal a simple and physically meaningful model for the partition function, it is of interest to derive the full energy spectrum of the model. This is the purpose of the present work. As we shall see, the energy levels obtained turn out to be accurate with a relative error of about a few percent, a precision which we consider to be quite satisfactory for such a simple model. Of course, a higher precision can be obtained without
difficulty by using some of the numerical/analytical approaches cited above. However, we emphasize that the aim of this work is not to achieve an ultimate precision in the spectrum but, instead, to propose a simple yet faithful analytical model for the spectrum of a general anharmonic oscillator that can be readily applied in various scientific contexts with essentially no computational cost.
The Hamiltonian considered here is as follows
$$H = - \frac { 1 } { 2 } \frac { d ^ { 2 } } { d x ^ { 2 } } + V ( x ) \quad \quad ( 1 ) \quad \text{i}$$
where V ( x ) is a rather general potential function bounded from below and verifying lim | x |→∞ V ( x ) = + ∞ (in other words, there are only discrete energies). In the numerical applications presented below, we will particularize the potential in the form
$$V ( x ) = \frac { \omega ^ { 2 } } { 2 } x ^ { 2 } + g x ^ { 2 m } \quad \quad ( 2 ) \quad \text{Fo} \\ \text{for} \\ \text{...} \colon$$
where ω 2 and g denote the harmonic force constant and coupling constant, respectively.
As a first step let us briefly recap the main steps leading to the model partition function.
i) The partition function is first expressed as a path integral in a standard way (see, e.g. , [19])
$$Z = \text{Tr} e ^ { - \beta H } = \lim _ { n \to \infty } Z _ { n } \quad \quad ( 3 ) \quad \text{iv} )$$
with
$$Z _ { n } & = \left ( \frac { 1 } { \sqrt { 2 \pi \tau } } \right ) ^ { n } \int _ { - \infty } ^ { \infty } d x _ { 1 } \dots \int _ { - \infty } ^ { \infty } d x _ { n } \\ & e ^ { - \frac { 1 } { 2 \tau } \sum _ { i = 1 } ^ { n } ( x _ { i + 1 } - x _ { i } ) ^ { 2 } } e ^ { - \tau \sum _ { i = 1 } ^ { n } V ( x _ { i } ) }. \quad \quad ( 4 ) \quad \text{with}$$
where τ = β n is the time-step and periodic conditions are used, x n +1 = x 1 .
ii) Second, the short-time anharmonic contribution, e -τV ( x ) , is approximated by a gaussian distribution centered on some position x ∗ (typically, the position of the lowest minimum of the potential; here, x ∗ = 0 in our applications) with an effective frequency ω g ( τ ), that is
$$\frac { e ^ { - \tau V ( x ) } } { \int _ { - \infty } ^ { \infty } d x e ^ { - \tau V ( x ) } } \sim \frac { e ^ { - \tau \frac { 1 } { 2 } \omega _ { g } ^ { 2 } ( \tau ) ( x - x ^ { * } ) ^ { 2 } } } { \int _ { - \infty } ^ { \infty } d x e ^ { - \tau \frac { 1 } { 2 } \omega _ { g } ^ { 2 } ( \tau ) ( x - x ^ { * } ) ^ { 2 } } }. \quad ( 5 ) \quad \text{ner}$$
To set the frequency ω g ( τ ) we have proposed to impose to the two distributions to have the same variance. In the case of the quartic oscillator treated previously,[15] it leads to ω g = ω √ [ B 4 g τω 4 ] where B is some function. In the more general case V ( x ) = ω 2 2 x 2 + gx 2 m , we get
$$\omega _ { g } ( \tau ) = \omega \sqrt { B ^ { ( m ) } \left [ \frac { 2 ^ { m } g } { \tau ^ { m - 1 } \omega ^ { 2 m } } \right ] } \quad \quad ( 6 ) \quad \text{ of } \colon$$
where the parameter-free function B ( m ) ( x ) is given by
$$B ^ { ( m ) } ( x ) = \frac { 1 } { 2 } \frac { \int _ { - \infty } ^ { \infty } d y \, e ^ { - y ^ { 2 } - x y ^ { 2 m } } } { \int _ { - \infty } ^ { \infty } d y \, y ^ { 2 } e ^ { - y ^ { 2 } - x y ^ { 2 m } } }. \quad \quad ( 7 )$$
For a general potential V the formula writes
$$\omega _ { g } ( \tau ) = \sqrt { \frac { 1 } { \tau } \frac { \int _ { - \infty } ^ { \infty } d x e ^ { - \tau V ( x ) } } { \int _ { - \infty } ^ { \infty } d x ( x - x ^ { * } ) ^ { 2 } e ^ { - \tau V ( x ) } } } \quad ( 8 )$$
iii) The gaussian approximation being made, the infiniten limit of Z n is no longer defined, lim n →∞ Z n = + ∞ . To circumvent this problem, we have proposed to introduce a Principle of Minimal Sensitivity (PMS) for the path integral. More precisely, we impose to the path integral to minimally depend on the effective frequency used in the gaussian approximation, that is, ∂Z n ∂ω g ( τ ) = 0. For a given temperature, the PMS condition holds only for a unique value of n denoted as n c ( β ) [and, thus, a unique time-step, τ c ( β ) = β n c ( β ) ]. We have then proposed to define the model partition function as the value of Z n at this 'optimal' value of n , Z ≡ Z n c ( β ) . In particular, the ill-defined n → ∞ -limit is avoided. The nonlinear implicit equation for n c ( β ) resulting from the PMS condition writes
$$n _ { c } ( \beta ) = \frac { \beta \omega _ { g } [ \tau _ { c } ( \beta ) ] } { 2 } \coth \frac { \beta \omega _ { g } [ \tau _ { c } ( \beta ) ] } { 2 }. \quad \ ( 9 )$$
iv) Finally, the analytical expression of the model partition function is given by
$$Z = \frac { C ( \beta ) ^ { n _ { c } ( \beta ) } } { e ^ { \frac { \beta \omega _ { g } [ \tau _ { c } ( \beta ) ] } { 2 } } - e ^ { - \frac { \beta \omega _ { g } [ \tau _ { c } ( \beta ) ] } { 2 } } } \quad \quad ( 1 0 )$$
with and
$$I _ { g } ( \beta ) = \int _ { - \infty } ^ { \infty } d x e ^ { - \tau _ { c } ( \beta ) V ( x ) }, \text{ \quad \ \ } ( 1 2 )$$
where the time-step τ c ( β ) = β n c ( β ) is obtained from Eq.(9).
At this point, an important remark is in order. Introducing a gaussian approximation of a nongaussian quantity is a standard practice in physics (harmonic phonons, Gaussian approximation for the Ginzburg-Landau action, etc.) In short, it is done by restricting to the second-order a Taylor expansion of some Hamiltonian or action. Here, our gaussian approximation is very different in nature. Instead of approximating the potential V ( x ) by a quadratic potential, we approximate the quantity e -τV ( x ) by a
$$C ( \beta ) = \sqrt { \frac { \omega _ { g } [ \tau _ { c } ( \beta ) ] } { \pi \coth \frac { \beta \omega _ { g } [ \tau _ { c } ( \beta ) ] } { 2 } } } I _ { g } ( \beta ) \quad \quad ( 1 1 )$$
gaussian distribution with an effective frequency which depends explicitly on the time-step . It is this dependence on the time-step that makes Z n to diverge in the largen limit, but which, after application of the PMS condition, allows to fix n at a finite value n c ( β ) and, then, leads to an accurate model for the exact partition function. Approximating V ( x ) using a quadratic potential independent on the time-step would merely lead to the partition function of a simple harmonic oscillator and, thus, to a very poor model for the exact partition function.
A. Ground-state energy. The ground-state energy is obtained from the largeβ behavior of Z
$$E _ { 0 } ( g ) = \lim _ { \beta \to \infty } - \frac { 1 } { \beta } \ln Z. \quad \quad ( 1 3 ) \quad \ t h e _ { \text{rat} }$$
At large β , the (unique) solution n c ( β ) of Eqs.(6) and (9) is proportional to β and given by
$$n _ { c } ( \beta ) = \frac { \beta \bar { \omega } _ { g } } { 2 }, \quad \quad \quad ( 1 4 ) \quad \quad \text{by}$$
where ¯ ω g = ω g [ τ c (+ ∞ )] is the solution of the implicit equation given by
$$\bar { \omega } _ { g } = \omega \sqrt { B ^ { ( m ) } \left ( \frac { 2 g \bar { \omega } _ { g } ^ { m - 1 } } { \omega ^ { 2 m } } \right ) }. \quad \quad ( 1 5 ) \quad \text{Let}$$
Using the zero-temperature limit of the free energy and the expression for the partition function we get
$$E _ { 0 } ( g ) = \frac { \bar { \omega } _ { g } } { 2 } \left [ 1 - \ln \left ( \sqrt { \frac { \bar { \omega } _ { g } } { \pi } } \bar { I } _ { g } \right ) \right ] \quad \text{(1)} \quad \text{ders} \\ \text{the}$$
where
$$\bar { I } _ { g } = \int _ { - \infty } ^ { \infty } d x e ^ { - \frac { 2 } { \omega _ { g } } V ( x ) }. \quad \quad ( 1 7 ) \quad \begin{smallmatrix} \Delta _ { \omega _ { g } } ^ { \cdot } \\ \omega _ { g } | \end{smallmatrix}$$
B. Excited-state energies. The exact partition function of the quartic oscillator decomposes as a discrete sum of exponentials
$$Z = \sum _ { n = 0 } ^ { \infty } e ^ { - \beta E _ { n } } \quad \quad \quad ( 1 8 ) \quad \text{th}.$$
where E n are the excited-state energies. As just seen, the ground-state energy E 0 is obtained by extracting the leading exponential component of the PF at large β . To get excited-state energies subleading components are to be evaluated.
In the following we will show that the model partition function actually does not write as a sum of simple exponentials, as it should be for the exact PF, but, instead, as a sum of exponentials multiplied by a polynomial term as follows
$$Z = \sum _ { n = 0 } ^ { \infty } P _ { n } ( \beta ) e ^ { - \beta ( E _ { 0 } + n \bar { \omega } _ { g } ) }$$
where P n ( β ) is a polynomial of degree n in β with P n (0) = 1. The partition function being no longer expressed as a sum of simple exponentials, the definition of what is meant by excited-state energies becomes problematic. Comparisons with the 'exact' numerical spectrum show that defining the excited energies as the exponents of the exponential contributions, that is,
$$E _ { n } = E _ { 0 } + n \bar { \omega } _ { g } \text{ \quad \ \ } ( 2 0 )$$
gives a very poor approximation of the exact spectrum. Note that this is not surprising since, in such a case, the energy differences between successive states would remain constant, a property which is clearly wrong for the exact spectrum. In sharp contrast, we have found that modifying the partition function by exponentiating the linear contribution of the polynomials and incorporating it into the exponential part leads to remarkably good energy levels. Precisely, we propose to replace the polynomial
$$P _ { n } ( \beta ) = 1 + P _ { n 1 } \beta + \dots + P _ { n n } \beta ^ { n } \quad \ \ ( 2 1 )$$
by e βP n 1 and to define the excited-state energies of our model as
$$E _ { n } = E _ { 0 } + n \bar { \omega } _ { g } - P _ { n 1 }. \text{ \quad \ \ } ( 2 2 )$$
Let us emphasize that this replacement should not be considered as a quantitative approximation, but rather, as a 'minimal' modification of the model to impose to the partition function to have the exact expansion, Eq.(18). Unfortunately, we have not been able to understand why this simple additional prescription to our model is so effective in giving accurate energy levels (see, the figures to follow). However, it should be considered as a salient result of this work.
To derive the functional form of the partition function, Eq.(19), we first need to expand the effective frequency ω g [ τ c ( β )] as a power series of exponential-like contributions.
̸
Let us first consider the case ω = 0. Using Eqs.(6) and (9), and introducing the variable y defined as
$$y = e ^ { - \beta \omega _ { g } }$$
the implicit equation obeyed by ω g is rewritten as
$$\frac { 1, } { g } \sum _ { \substack { g \\ \omega } } \omega _ { g } = \omega \sqrt { B \left [ \frac { 2 g } { \omega ^ { 2 m } } \omega _ { g } ^ { m - 1 } \left ( 1 + 2 \sum _ { n = 1 } ^ { \infty } y ^ { n } \right ) ^ { m - 1 } \right ] } \quad ( 2 4 )$$
where the coth function has been expanded in power series of y . Note that the superscript ( m ) has been removed from B ( m ) ( x ) to simplify the notation. This will also be the case in the following for most quantities depending on m when no confusion is possible. The function B being infinitely differentiable, ω g can be expanded in powers of y
$$\omega _ { g } = \bar { \omega } _ { g } + \sum _ { n = 1 } ^ { \infty } \omega _ { n } y ^ { n }. \text{ \quad \ \ } ( 2 5 )$$
Remark that the equation obeyed by ω g has no explicit dependence on β (the dependence on the temperature is only through the variable y ). Accordingly, the coefficients ω n are independent of β . Their evaluation is done i) by introducing the expansion of ω g in Eq.(24), ii) by Taylor-expanding the function B at x 0 = 2 g ω 2 m ¯ ω m -1 g , and, finally, by identifying the contributions corresponding to a given power of y . After some algebra, an explicit expression for the ω n 's can be derived. For example, the first coefficient, ω 1 's is given by
$$\omega _ { 1 } = \bar { \omega } _ { g } \frac { \frac { B _ { 1 } } { B _ { 0 } } x _ { 0 } ( m - 1 ) } { 1 - \frac { \frac { B _ { 1 } } { B _ { 0 } } x _ { 0 } } { 2 } ( m - 1 ) } \quad \quad ( 2 6 ) \quad \text{To}$$
where B 0 = B ( m ) ( x 0 ) and B 1 = dB ( m ) dx ( x 0 ). For n ≥ 2, ω n can be expressed as a function of the preceding coefficients, ω p with 1 ≤ p ≤ n -1. The explicit formula is given in Appendix A.
When ω = 0 the coefficients ω k are more easily derived. From the general expression of the effective frequency, Eq.(8), we get ω g ( τ ) = c 0 ( g τ ) 1 4 with c 0 = √ ∫ dxe -x 4 ∫ dxx e 2 -x 4 . Using the PMS condition, Eq.(9), we obtain
$$\omega _ { k } = \bar { \omega } _ { g } \sum _ { l = 1 } ^ { k } 2 ^ { l } \binom { \frac { 1 } { 3 } } { l } \binom { k - 1 } { l - 1 } \ k \geq 1 \quad \ ( 2 7 )$$
with
$$\bar { \omega } _ { g } = c _ { 0 } ^ { \frac { 4 } { 3 } } \left ( \frac { g } { 2 } \right ) ^ { \frac { 1 } { 3 } }. \quad \quad \quad ( 2 8 )$$
In this ω = 0-case, the ground-state energy can be explicitly written as
$$E _ { 0 } = \left [ \frac { \Gamma \left ( \frac { 5 } { 4 } \right ) } { \Gamma \left ( \frac { 3 } { 4 } \right ) } \right ] ^ { \frac { 2 } { 3 } } \left ( 1 - \log \sqrt { \frac { \left [ 2 \Gamma \left ( \frac { 5 } { 4 } \right ) \right ] ^ { 3 } } { \pi \Gamma \left ( \frac { 3 } { 4 } \right ) } } \right ) g ^ { \frac { 1 } { 3 } }. \quad ( 2 9 )$$
Now, to proceed, let us introduce the following new variable y 0
$$y _ { 0 } = e ^ { - \beta \bar { \omega } _ { 9 } }. \quad \quad \ \ ( 3 0 ) \quad \ \ a$$
The next step consists in expressing the partition function as a power series in y 0 , thus leading to Eq.(19). For that, we first need to derive the expansion of the effective frequency in terms of y 0 . We have
$$\omega _ { g } = \bar { \omega } _ { g } + \sum _ { n = 1 } ^ { \infty } \omega _ { n } y _ { 0 } ^ { n } e ^ { - \beta n [ \omega _ { g } - \bar { \omega } _ { g } ] }. \quad \quad ( 3 1 )$$
By expanding the exponential in power series and by simple inspection, the form of the solution is
$$\omega _ { g } = \bar { \omega } _ { g } + \sum _ { n = 1 } ^ { \infty } Q _ { n } ( \beta ) y _ { 0 } ^ { n } \text{ \quad \ \ } ( 3 2 ) \text{ \quad,}$$
where Q n ( β ) are polynomials of degree n -1 in β . The polynomials can be evaluated by differentiation
$$Q _ { n } ( \beta ) = \frac { 1 } { n! } \frac { \partial ^ { n } \omega _ { g } } { \partial y _ { 0 } ^ { n } } ( y _ { 0 } = 0 ). \text{ \quad \ \ } ( 3 3 )$$
Using Eq.(31) and the Leibniz formula for derivatives, the n -th derivative of ω g writes
$$\text{le, the} \\ \quad & \frac { 1 } { n! } \frac { \partial ^ { n } \omega _ { g } } { \partial y _ { 0 } ^ { n } } ( y _ { 0 } = 0 ) = \sum _ { k = 1 } ^ { n } \omega _ { k } \frac { 1 } { ( n - k )! } \frac { \partial ^ { n - k } } { \partial y _ { 0 } ^ { n - k } } \left [ e ^ { - \beta k ( \omega _ { g } - \bar { \omega } _ { g } ) } \right ] ( y _ { 0 } = 0 ). \\ \quad & \text{$T$} \text{ procedure two make one of the $E$} \, \text{$di$} \, \text{Runno formula}.$$
To proceed we make use of the Fa` di Bruno formula a
$$\underset { \substack { r \ n \geq \\ \coding } } { \underset { \substack { \longrightarrow \\ \text{remula} } } { \sum } } \frac { \partial ^ { n } } { \partial x ^ { n } } e ^ { f ( x ) } = e ^ { f ( x ) } \sum _ { m _ { 1 }, m _ { 2 } \dots, m _ { n } } ^ { \prime } \frac { n! } { m _ { 1 }! m _ { 2 }! \dots m _ { n }! } \prod _ { j = 1 } ^ { n } \left [ \frac { f ^ { ( j ) } ( x ) } { j! } \right ] ^ { m _ { j } } \\ \text{where the prime on the sum indicates the sum with the } \text{$\quad$}$$
where the prime on the sum indicates summing with the constraint
$$1 m _ { 1 } + 2 m _ { 2 } + \, \dots \, n m _ { n } = n. \quad \quad ( 3 6 )$$
We then have
$$\frac { 1 } { n! } \frac { \partial ^ { n } \omega _ { g } ( \beta ) } { \partial y _ { 0 } ^ { n } } ( y _ { 0 } = 0 ) = \sum _ { k = 1 } ^ { n } \omega _ { k } \frac { 1 } { ( n - k )! }$$
$$\times \sum _ { m _ { 1 }, m _ { 2 } \dots, m _ { n - k } } ^ { \prime } \frac { ( n - k )! } { m _ { 1 }! m _ { 2 }! \dots m _ { n - k }! } \prod _ { j = 1 } ^ { n - k } \left [ \frac { ( - k \beta ) ( \omega _ { g } ) ^ { ( j ) } ( x ) } { j! } \right ] ^ { m _ { j } } ( y _ { 0 } = 0 )$$
and, finally
$$Q _ { n } ( \beta ) = \omega _ { n } + \sum ^ { n - 1 } \omega _ { k }$$
$$k = 1$$
$$\text{new} \quad \times \sum _ { m _ { 1 }, m _ { 2 } \dots, m _ { n - k } } ^ { \prime } \frac { \left [ - k \beta Q _ { 1 } ( \beta ) \right ] ^ { m _ { 1 } } } { m _ { 1 }! } \dots \frac { \left [ - k \beta Q _ { n - k } ( \beta ) \right ] ^ { m _ { n - k } } } { m _ { n - k }! },$$
a relation which allows to evaluate iteratively the polynomials Q n ( β ). From this expression, we see that Q n ( β ) are indeed polynomials of degree n -1 as stated above. Let us give the first five polynomials
$$Q _ { 1 } ( \beta ) = \omega _ { 1 }$$
$$Q _ { 2 } ( \beta ) = \omega _ { 2 } - \beta \omega _ { 1 } ^ { 2 }$$
$$Q _ { 3 } ( \beta ) = \omega _ { 3 } - 3 \beta \omega _ { 1 } \omega _ { 2 } + \frac { 3 } { 2 } \beta ^ { 2 } \omega _ { 1 } ^ { 3 }$$
$$Q _ { 4 } ( \beta ) = \omega _ { 4 } - 2 \beta ( 2 \omega _ { 1 } \omega _ { 3 } + \omega _ { 2 } ^ { 2 } ) + 8 \beta ^ { 2 } \omega _ { 2 } \omega _ { 1 } ^ { 2 } - \frac { 8 } { 3 } \omega _ { 1 } ^ { 4 } \beta ^ { 3 }$$
$$Q _ { 5 } ( \beta ) = \omega _ { 5 } - 5 \beta ( \omega _ { 2 } \omega _ { 3 } + \omega _ { 1 } \omega _ { 4 } ) + \frac { 2 5 } { 2 } \beta ^ { 2 } ( \omega _ { 3 } \omega _ { 1 } ^ { 2 } + \omega _ { 1 } \omega _ { 2 } ^ { 2 } ) \quad \text{Let} \quad \text{$\alpha$} \quad \text{$\alpha$}$$
$$- \frac { 1 2 5 \beta ^ { 3 } } { 6 } \omega _ { 1 } ^ { 3 } \omega _ { 2 } + \frac { 1 2 5 } { 2 4 } \omega _ { 1 } ^ { 5 } \beta ^ { 4 }$$
We are now ready to derive the expansion of the partition function in the variable y 0 . It is convenient to introduce the following three quantities
$$\Delta \omega _ { g } \equiv \omega _ { g } - \bar { \omega } _ { g }, \quad \quad \ \ ( 3 7 ) \quad \stackrel { \cdots } { \text{th} }.$$
$$\Delta T \equiv \ln C ( \beta ) - \ln \sqrt { \frac { \bar { \omega } _ { g } } { \pi } } \bar { I } _ { g }, \quad \quad ( 3 8 ) \quad \text{ we }.$$
and
$$\Delta R \equiv \frac { 1 } { 2 } ( \coth \frac { \beta \omega _ { g } } { 2 } - 1 ). \quad \quad ( 3 9 ) \quad \text{$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$\,$$$
The partition function can be written as
$$Z = e ^ { - \beta E _ { 0 } } P.$$
Simple algebra shows that P can be expressed as
$$P = e ^ { \beta S } [ 1 + \Delta R ] \quad \quad \ \ ( 4 1 ) \quad \text{for}$$
where
$$S = c _ { 1 } \Delta \omega _ { g } + c _ { 2 } \Delta T + c _ { 3 } \Delta R$$
$$& + c _ { 4 } \Delta \omega _ { g } \Delta T + c _ { 5 } \Delta \omega _ { g } \Delta R + c _ { 6 } \Delta T \Delta R + c _ { 7 } \Delta \omega _ { g } \Delta T \Delta R \\ & \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots.$$
with the following coefficients
$$c _ { 1 } = \frac { 1 } { 2 } \left ( \ln \sqrt { \frac { \bar { \omega } _ { g } } { \pi } } \bar { I } _ { g } - 1 \right )$$
$$c _ { 2 } = \frac { \bar { \omega } _ { g } } { 2 }$$
$$c _ { 3 } = \bar { \omega } _ { g } \ln \sqrt { \frac { \bar { \omega } _ { g } } { \pi } } \bar { I } _ { g }$$
$$c _ { 4 } = \frac { 1 } { 2 }$$
$$c _ { 5 } = \ln \sqrt { \frac { \bar { \omega } _ { g } } { \pi } } \bar { I } _ { g }$$
$$c _ { 6 } = \bar { \omega } _ { g }$$
c 7
$$\dot { \iota } + c _ { 6 } \Delta T \Delta R + c \, \\ \text{ents} \, \\ \nolimits \sqrt { \frac { \varpi _ { g } } { \pi } } \dot { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \t \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \t \t } -1 +1 -2
. | \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde } { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \that { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \t -1
-0 " ) <1$$
Let us introduce the following form for the expansion of a quantity X
$$X = \sum _ { n = 1 } ^ { \infty } X _ { n } ( \beta ) y _ { 0 } ^ { n }$$
where X n is a polynomial of order n -1 in β . Note that this form is stable by multiplication by a scalar, addition, multiplication, and exponentiation. We have already seen that ∆ ω g admits such a representation. From the relation
$$y = y _ { 0 } e ^ { - \beta \Delta \omega _ { 9 } }$$
we see that it is also the case for y . The quantities ∆ T and ∆ R can be written as a function of the variable y only. By expanding these quantities in terms of y we thus find that they also both admit this representation. From (42) it is also true for S . Finally, the partition function, Eqs.(40,41), can be written as
$$Z = e ^ { - \beta E _ { 0 } } \left [ 1 + \sum _ { n = 1 } ^ { \infty } P _ { n } ( \beta ) y _ { 0 } ^ { n } \right ] \quad \quad ( 4 5 )$$
where P n ( β ) is a polynomial of order n in β . This is the form given in Eq.(19).
To get the excited-state energies the quantities P n 1 need to be evaluated, see Eq.(22). Using the formula
$$P _ { n 1 } = \frac { 1 } { n! } \frac { \partial ^ { n + 1 } P ( \beta ) } { \partial \beta \partial y _ { 0 } ^ { n } } ( \beta = 0, y _ { 0 } = 0 )$$
we get
$$P _ { n 1 } = S _ { n 0 } + \Delta R _ { n 1 } + \sum _ { k + l = n \ k \geq 1 } S _ { k 0 } \Delta R _ { l 0 }. \quad ( 4 6 )$$
where S nk and ∆ nk are the coefficients of the n -th order polynomial in the representation, Eq.(43), for S and ∆ R , respectively. Using Eq.(42) and Q n 0 = ω n we have
$$S _ { n 0 } = c _ { 1 } \omega _ { n } + c _ { 2 } \Delta T _ { n 0 } + c _ { 3 } \Delta R _ { n 0 }$$
$$+ c _ { 4 } \sum _ { k _ { 1 } + k _ { 2 } = n } \omega _ { k _ { 1 } } \Delta T _ { k _ { 2 } 0 } + c _ { 5 } \sum _ { k _ { 1 } + k _ { 2 } = n } \omega _ { k 1 } \Delta R _ { k _ { 2 } 0 }$$
$$+ c _ { 6 } \sum _ { k _ { 1 } + k _ { 2 } = n } \Delta T _ { k _ { 1 } 0 } \Delta R _ { k _ { 2 } 0 }$$
$$+ c _ { 7 } \sum _ { k _ { 1 } + k _ { 2 } = n } \left ( \sum _ { k _ { 3 } + k _ { 4 } = k _ { 1 } } \omega _ { k _ { 3 } } \Delta T _ { k _ { 4 } 0 } \right ) \Delta R _ { k _ { 2 } 0 } \quad ( 4 7 )$$
where ∆ T nk are the coefficients of the polynomial for ∆ . T In each sum above, k i ≥ 1. Let us evaluate the
quantities ∆ R n 0 , ∆ R n 1 , and ∆ T n 0 .
Starting from
$$\Delta R = \sum _ { n = 1 } ^ { \infty } y _ { 0 } ^ { n } e ^ { - \beta n \Delta \omega _ { g } }$$
$$\text{where} \, \bar { \tau } _ { c } = \tau _ { c } ( \infty ) = \frac { 2 } { \bar { \omega } _ { g } } \text{ and}$$
$$\bar { I } _ { n } \, \equiv \int _ { - \infty } ^ { \infty } d x x ^ { n } e ^ { - \bar { \tau } _ { c } V ( x ) }.$$
After some algebra we have
$$\Delta R = \sum _ { n = 1 } ^ { \infty } y _ { 0 } ^ { n } \sum _ { k = 1 } ^ { \infty } \frac { ( - \beta n ) ^ { k } } { k! } \left ( \sum _ { l = 1 } ^ { \infty } Q _ { l } ( \beta ) y _ { 0 } ^ { l } \right ) ^ { k } = \sum _ { n = 1 } ^ { \infty } y _ { 0 } ^ { n } \sum _ { k = 1 } \alpha _ { k } y _ { 0 } ^ { k } \text{ with } ^ { \lambda }$$
$$\Delta \tau _ { c } = \frac { 2 } { \bar { \omega } _ { g } } \sum _ { n = 1 } ^ { \infty } ( - 1 ) ^ { n } \left [ \sum _ { k = 1 } ^ { \infty } X _ { k } ( \beta ) y _ { 0 } ^ { k } \right ] ^ { n }$$
with
$$\alpha _ { k } = \sum _ { l = 1 } ^ { k } \frac { ( - \beta n ) ^ { l } } { l! } \sum _ { k _ { 1 } + \dots + k _ { l } = k } Q _ { k _ { 1 } } ( \beta ) \dots Q _ { k _ { l } } ( \beta )$$
$$X _ { k } ( \beta ) = 2 \Delta R _ { k } ( \beta ) + \frac { Q _ { k } ( \beta ) } { \bar { \omega } _ { g } } + \frac { 2 } { \bar { \omega } _ { g } } \sum _ { l + m = k \, l \geq 1 } Q _ { l } ( \beta ) Q _ { m } ( \beta ).$$
We then have which gives
$$\Delta R _ { n 0 } = 1, \ \Delta R _ { 1 1 } = 0, \ \text{and} \ \Delta R _ { n 1 } = - \sum _ { k = 1 } ^ { n - 1 } k \, \omega _ { n - k } \ \text{for} \ n \geq 2 \ \text{with} \\ \intertext { f o t n e n o w e c o l u l t a } \Delta T _ { n } \ \Delta T _ { n } \ \text{and} \ \text{and} \ \text{where} \ \text{$\mathcal{E}$} \ \text{$\mathcal{E}$} } Y _ { n } = \frac { \cdot } { \bar { u } }$$
Let us now calculate ∆ T n 0 . ∆ , as defined by Eq.(38), T is decomposed as
Then
Thus
Finally, with
$$\Delta B _ { n } = \sum _ { k = 1 } ^ { n } \frac { ( - 1 ) ^ { k } } { k \bar { I } _ { g } ^ { k } } \sum _ { l _ { 1 } + \dots + l _ { k } = n } Z _ { l _ { 1 } } \dots Z _ { l _ { k } }.$$
The quantities ∆ B n 0 are then evaluated by taking β = 0 in the preceding expressions.
$$\Delta \tau _ { c } = \sum _ { n = 1 } ^ { \infty } Y _ { n } ( \beta ) y _ { 0 } ^ { n }$$
$$Y _ { n } = \frac { 2 } { \bar { \omega } _ { g } } \sum _ { k = 1 } ^ { n } ( - 1 ) ^ { k } \sum _ { l _ { 1 } + \dots + l _ { k } = n } X _ { l _ { 1 } } \dots X _ { l _ { k } }$$
$$I _ { g } = \bar { I } _ { g } + \sum _ { n = 1 } ^ { \infty } \frac { ( - 1 ) ^ { n } \bar { I } _ { n } } { n! } \left ( \sum _ { k = 1 } ^ { \infty } Y _ { k } ( \beta ) y _ { 0 } ^ { k } \right ) ^ { n }$$
$$I _ { g } = \bar { I } _ { g } + \sum _ { n = 1 } ^ { \infty } Z _ { n } ( \beta ) y _ { 0 } ^ { n }$$
$$Z _ { n } = \sum _ { k = 1 } ^ { n } ( - 1 ) ^ { k } \frac { \bar { I } _ { k } } { k! } \sum _ { l _ { 1 } + \dots + l _ { k } = n } Y _ { l _ { 1 } } \dots Y _ { l _ { k } }$$
$$\ln I _ { g } = \ln \bar { I } _ { g } + \ln \left ( 1 + \sum _ { n = 1 } ^ { \infty } \frac { Z _ { n } } { \bar { I } _ { g } } y _ { 0 } ^ { n } \right ).$$
$$\ln I _ { g } = \ln \bar { I } _ { g } + \sum _ { n = 1 } ^ { \infty } \Delta B _ { n } ( \beta ) y _ { 0 } ^ { n }$$
$$\Delta T = \Delta A + \Delta B$$
with and
$$\Delta B = \ln I _ { g } ( \beta ) - \ln \bar { I } _ { g }$$
Let us begin with ∆ A which can be written as
$$\Delta A = \frac { 1 } { 2 } \ln \left [ \frac { 1 + \sum _ { n = 1 } ^ { \infty } \frac { Q _ { n } ( \beta ) } { \bar { \omega } _ { g } } y _ { 0 } ^ { n } } { 1 + \sum _ { n = 1 } ^ { \infty } 2 \Delta R _ { n } ( \beta ) y _ { 0 } ^ { n } } \right ].$$
Expanding the two logarithmic terms, we get after some algebra
$$\Delta A _ { n 0 } = \frac { 1 } { 2 } \sum _ { k = 1 } ^ { n } \frac { ( - 1 ) ^ { k - 1 } } { k } \sum _ { l _ { 1 } + \dots + l _ { k } = n } \left [ \left ( \frac { \omega _ { l _ { 1 } } } { \bar { \omega } _ { g } } \right ) \dots \left ( \frac { \omega _ { l _ { k } } } { \bar { \omega } _ { g } } \right ) - 2 ^ { k } \right ] ^ { \cdot \cdot }$$
We are now left wit the calculation of ∆ B n 0 . We have
$$I _ { g } ( \beta ) = \sum _ { n = 0 } ^ { \infty } \frac { ( - 1 ) ^ { n } \bar { I } _ { n } } { n! } \Delta \tau _ { c } ^ { n }$$
with
$$\Delta A = \ln \sqrt { \frac { \omega _ { g } ( \beta ) } { \pi \coth \frac { \beta \omega _ { g } [ \tau _ { c } ( \beta ) ] } { 2 } } } - \ln \sqrt { \frac { \bar { \omega } _ { g } } { \pi } }$$
$$\Delta \tau _ { c } \equiv \tau _ { c } - \bar { \tau } _ { c }$$
Figure 1 shows the ground-state energy and the first eight excited state energies of the quartic oscillator with ω = 1 versus the coupling constant g . The 'exact' numerical energies, obtained by diagonalization of the Hamiltonian in a sufficiently large Gaussian basis set, are shown as solid lines. At the scale of the figure, the energy levels and their overall behavior as functions of g and n are well reproduced and appear satisfactory. Quantitative results are presented in Table I, which reports the relative errors ϵ in the computed energies. We present results for three different potentials: the first two are the quartic ( m = 2, ω = 1) and sextic ( m = 3, ω = 1) anharmonic potentials, respectively. The third is the 'pure' quartic potential, defined by the absence of a quadratic term ( ω = 0). Results are given for five values of g ( g = 0 1 1 10 40, and 400), spanning the weak- to . , , , strong-coupling regimes. A first remark is that relative errors are all negative. In other words, the computed energies are always smaller than the exact ones. Unfortunately, we were not able to understand the origin of this interesting observed property. A second remark is that relative errors are all of the order of a few percent (up to 10% in the worst case of the sextic potential at large g ). We consider this level of accuracy as quite satisfactory in view of the simplicity of the model. Let us insist on the fact that the model partition function has a particularly simple and compact form, Eq.(10) with Eqs.(11) and (12); and, most importantly, no adjustable parameters. In addition, the computational cost for calculating the energies is negligible. Another remark is that for each potential the relative error is maximal for the two lowest energies. Quite remarkably, the errors on the higher energies ( n ≥ 2) are almost constant and, also, nearly independent on the value of g . This is a quite interesting feature of the model. The comparison between the three different potentials is instructive. As expected, the accuracy reached for the sextic oscillator is inferior to that obtained for the quartic oscillator, a consequence of the greater anharmonicity of the former potential. This is also the case at small values of g for the pure quartic oscillator in which the quadratic term has been removed. However, for large g 's the errors become nearly identical. A striking feature of the energies of the pure quartic potential is that the relative errors are independent on g (actually, all digits of the errors are identical for the different g 's, a result not shown here). This result is explained as follows. By a simple rescaling of the Schr¨dinger equation, the exact energies o E n ( g ) of the pure quartic oscillator can be shown to scale as g 1 3 . Quite satisfactorily, it is also the case for our model. This can be proved by noting that ¯ ω g , Eq.(28), and the ω k 's, Eq.(27) scale also as g 1 3 and, then, by invoking the series of equations, (22),(46),(47) and (48). The exact and model energies having the same scaling in g , the relative errors are thus independent on g .
Figure 1. Energy levels of the quartic oscillator as a function of g for n = 0 to n = 8. Exact results given by the solid lines. Harmonic frequency, ω = 1
## ACKNOWLEDGMENTS
I would like to thank the Centre National de la Recherche Scientifique (CNRS) for its continued support. I also acknowledge funding from the European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme (Grant agreement No. 863481).
Table I. Relative errors ϵ (in %) on the energy levels E n for different values of g and potentials V [ a,n ] ( x ) = ax 2 + gx n ; ϵ = ( E m odel -E ex ) /E e x .
$$\text{Table I. Relative errors} \, e (in %) on the energy levels E _ { n } \, \text{for} \\ \text{different values of} \, g \, \text{ and potentials} \, V _ { [ a, n ] } ( x ) = a x ^ { 2 } + g x ^ { \prime } ; \\ \epsilon = ( E _ { \text{model} } - E _ { e x } ) / E _ { e x }. \\ \text{$E_{0}$} \, = E _ { 1 } \, = E _ { 2 } \, = E _ { 3 } \, = E _ { 4 } \, = E _ { 5 } \, = E _ { 6 } \, = E _ { 7 } \, = E _ { 8 } \\ g = 0. 1 \\ V _ { [ \frac { 3 } { 2 }, 4 ] } - 0. 5 \, - 0. 4 \, - 0. 5 \, - 0. 6 \, - 0. 7 \, - 0. 8 \, - 0. 8 \, - 0. 9 \, - 0. 9 \\ V _ { [ \frac { 3 } { 2 }, 6 ] } - 2. 5 \, - 2. 6 \, - 2. 7 \, - 2. 9 \, - 3. 1 \, - 3. 2 \, - 3. 3 \, - 3. 4 \, - 3. 4 \\ V _ { [ 0, 4 ] } - 4. 2 \, - 2. 0 \, - 1. 6 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \quad \text{$\theta$} \\ V _ { [ \frac { 3 } { 2 }, 4 ] } - 3. 7 \, - 1. 9 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \, - 1. 6 \quad \text{$\theta$} \\ V _ { [ \frac { 3 } { 2 }, 4 ] } - 4. 0 \, - 2. 0 \, - 1. 6 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \, - 1. 7 \quad \text{where} \\ \text{Appendix A: Formula for evaluating} \, \omega ^ { \prime } s$$
## Appendix A: Formula for evaluating ω n 's
In this appendix, we give the explicit formulas for the coefficients of the expansion of ω g in powers of y written as
$$\omega _ { g } = \bar { \omega } _ { g } + \sum _ { n = 1 } ^ { \infty } \omega _ { n } y ^ { n }. \quad \quad ( A 1 )$$
Note that to simplify the notation the dependence on m of the various quantities considered here will be omitted.
Let us define now the following quantities
$$B _ { n } \equiv \frac { d ^ { n } B ^ { ( m ) } } { d x ^ { n } } ( x _ { 0 } ) \quad \text{(A2)}$$
$$x _ { 0 } = \frac { 2 g } { \omega ^ { 2 m } } \bar { \omega } _ { g } ^ { m - 1 } \quad \quad \text{(A3)}$$
$$\alpha _ { n } = \frac { 1 } { n! } \frac { B _ { n } } { B _ { 0 } } x _ { 0 } ^ { n } \quad \quad \text{(A4)} \quad m$$
and
$$\beta _ { n } = \frac { \frac { 1 } { 2 } \left ( \frac { 1 } { 2 } - 1 \right ) \dots \left ( \frac { 1 } { 2 } - ( n - 1 ) \right ) } { n! } \quad \quad ( A 5 )$$
¯ ω g is given by
$$\bar { \omega } _ { g } = \omega \sqrt { B _ { 0 } } \quad \text{(A6)}$$
The first coefficient ω 1 is given by
$$\omega _ { 1 } = A \alpha _ { 1 } ( m - 1 ) \text{ \quad \ \ } ( A 7 )$$
with
$$A = \frac { \bar { \omega } _ { g } } { 1 - \frac { \alpha _ { 1 } ( m - 1 ) } { 2 } } \, \quad \quad ( A 8 )$$
For n ≥ 2 the ω n 's are function of the previous coefficients ω p with 1 ≤ p ≤ n -1 as follows
$$\omega _ { n } = A \left [ \alpha _ { 1 } ( m - 1 ) S _ { n } + \frac { 1 } { 2 } \alpha _ { 1 } T _ { n } + U _ { n } + V _ { n } \right ] \quad ( \mathbf A 9 )$$
where
$$S _ { n } = 1 + \sum _ { k + l = n \, k \geq 1 } \frac { \omega _ { k } } { \bar { \omega } _ { g } } \quad \quad ( A 1 0 )$$
$$T _ { n } = \sum _ { k = 2 } ^ { m - 1 } \binom { m - 1 } { k } \sum _ { l _ { 1 } + \dots + l _ { k } = n } a _ { l _ { i } \geq 1 } \dots a _ { l _ { k } } \quad ( \mathbf A 1 1 )$$
with
$$a _ { n } = \frac { \omega _ { n } } { \bar { \omega } _ { g } } + 2 S _ { n } \ n \geq 1 \quad \quad ( \text{A12} )$$
$$U _ { n } = \frac { 1 } { 2 } \sum _ { k = 2 } ^ { n } \alpha _ { k } \sum _ { l _ { 1 } + \dots + l _ { k } = n } b _ { l _ { i } \geq 1 } \dots b _ { l _ { k } } \quad \ ( A 1 3 )$$
$$b _ { n } = ( m - 1 ) a _ { n } + T _ { n } \ n \geq 1 \quad \ \ ( \text{A14} )$$
$$V _ { n } = \sum _ { k = 2 } ^ { n } \beta _ { k } \sum _ { l _ { 1 } + \dots + l _ { k } = n } c _ { l _ { i } } \dots c _ { l _ { k } } \quad \text{(A15)}$$
with and
with
$$c _ { n } = \alpha _ { 1 } b _ { n } + 2 U _ { n } \ n \geq 1 \quad \quad ( A 1 6 )$$
When no index fulfills the constraint in the sum, the corresponding quantity is equal to zero. Here, it means that S 1 = 1, T 1 = 0, U 1 = 0, V 1 = 0, and T n = 0 for m = 2.
- [1] A. Turbiner and J.C. Del Valle Rosale. Quantum Anharmonic Oscillator . World Scientific, 2023.
- [2] Alexander V. Turbiner. One-dimensional quasi-exactly solvable schr¨dinger equations. o Physics Reports , 642:171, 2016.
- [3] Daniel Baye. The lagrange-mesh method. Physics Reports , 565:1-107, 2015. The Lagrange-mesh method.
- [4] J. C. del Valle. Solving the one-dimensional timeindependent schr¨dinger o equation with high accuracy: The lagrangemesh mathematica ® package. International Journal of Modern Physics C , 35(01):2450011, 2024.
- [5] Carl M. Bender, Kaare Olaussen, and Paul S. Wang. Numerological analysis of the wkb approximation in large order. Phys. Rev. D , 16:1740-1748, Sep 1977.
- [6] R. N. Kesarwani and Y. P. Varshni. Eigenvalues of an anharmonic oscillator. Journal of Mathematical Physics , 22(9):1983-1989, 09 1981.
- [7] M. Lakshmanan, F. Karlsson, and P. O. Fr¨man. Phaseo integral calculation of the energy levels of a quantal anharmonic oscillator. Phys. Rev. D , 24:2586-2598, Nov 1981.
- [8] C.C. Yao and K.S. Cheng. A simple variational method for excited states of coupled anharmonic oscillators. Nuov Cim B , 111:645-652, 1996.
- [9] R. P. Feynman and H. Kleinert. Effective classical partition functions. Phys. Rev. A , 34:5080-5084, Dec 1986.
- [10] H. Kleinert. Improving the variational approach to path integrals. Physics Letters B , 280(3):251-260, 1992.
- [11] Ranjan Bhattacharya, Dhiranjan Roy, and Siddhartha Bhowmick. Simple systematics in the ground state energies of quantum anharmonic oscillators. Physics Letters A , 244(1):9-12, 1998.
- [12] Ananda Dasgupta, Dhiranjan Roy, and Ranjan Bhattacharya. Simple systematics in the energy eigenvalues of quantum anharmonic oscillators. Journal of Physics A: Mathematical and Theoretical , 40(4):773, jan 2007.
- [13] David Leonard and Paul Mansfield. Solving the anharmonic oscillator: tuning the boundary condition. Journal of Physics A: Mathematical and Theoretical , 40(33):10291, aug 2007.
- [14] M. Companys Franzke, A. Tichai, K. Hebeler, and A. Schwenk. Excited states from eigenvector continuation: The anharmonic oscillator. Physics Letters B , 830:137101, 2022.
- [15] M. Caffarel. Path integral for the quartic oscillator: An accurate analytic expression for the partition function, arxiv quant-ph arXiv:2312.09859v3., 2023.
- [16] R.P. Feynman and A.R. Hibbs. Quantum Mechanics and Paths Integrals . McGraw-Hill, New York, 1965.
- [17] Riccardo Giachetti and Valerio Tognetti. Variational approach to quantum statistical mechanics of nonlinear systems with application to sine-gordon chains. Phys. Rev. Lett. , 55:912-915, Aug 1985.
- [18] H. B¨ uttner and N. Flytzanis. Effective free energies. Phys. Rev. A , 36:3443-3445, Oct 1987.
- [19] L.S. Schulman. Techniques And Applications of Path Integration . Dover Publications Inc., 2005. | null | [
"Michel Caffarel"
] | 2024-08-02T09:54:27+00:00 | 2024-09-20T07:27:19+00:00 | [
"quant-ph",
"cond-mat.stat-mech",
"physics.chem-ph"
] | Analytic Model for the Energy Spectrum of the Anharmonic Oscillator | In a recent work we have proposed an original analytic expression for the
partition function of the quartic oscillator. This partition function, which
has a simple and compact form with {\it no adjustable parameters}, reproduces
some key mathematical properties of the exact partition function and provides
free energies accurate to a few percent over a wide range of temperatures and
coupling constants. In this work, we present the derivation of the energy
spectrum of this model. We also generalize our previous study limited to the
quartic oscillator to the case of a general anharmonic oscillator. Numerical
application for a potential of the form $V(x)=\frac{\omega^2}{2} x^2 + g
x^{2m}$ show that the energy levels are obtained with a relative error of about
a few percent, a precision which we consider to be quite satisfactory given the
simplicity of the model, the absence of adjustable parameters, and the
negligible computational cost. |
2408.01147v1 | ## Actra: Optimized Transformer Architecture for Vision-Language-Action Models in Robot Learning
Yueen Ma , 1 Dafeng Chi , 2 Shiguang Wu , 2 Yuecheng Liu , 2 Yuzheng Zhuang , 2 Jianye Hao 2 , Irwin King 1 The Chinese University of Hong Kong 1 Huawei Noah's Ark Lab 2 {yema21, king}@cse.cuhk.edu.hk {chidafeng1, wushiguang, liuyuecheng1, zhuangyuzheng, haojianye}
@huawei.com
## Abstract
Vision-language-action models have gained significant attention for their ability to model trajectories in robot learning. However, most existing models rely on Transformer models with vanilla causal attention, which we find suboptimal for processing segmented multi-modal sequences. Additionally, the autoregressive generation approach falls short in generating multi-dimensional actions. In this paper, we introduce Actra, an optimized Transformer architecture featuring trajectory attention and learnable action queries, designed for effective encoding and decoding of segmented vision-language-action trajectories in robot imitation learning. Furthermore, we devise a multi-modal contrastive learning objective to explicitly align different modalities, complementing the primary behavior cloning objective. Through extensive experiments conducted across various environments, Actra exhibits substantial performance improvement when compared to state-of-the-art models in terms of generalizability, dexterity, and precision.
## 1 Introduction
Vision-language-action models (VLAs) have emerged as integral components of recent developments in robot learning. Previous multi-modality models, exemplified by vision-language models (VLMs), have demonstrated proficiency in handling both visual and textual inputs, successfully addressing a spectrum of tasks [8] such as visual question answering, image captioning, and image retrieval. Distinctively, VLAs extend beyond the capabilities of VLMs by incorporating the ability to execute actions based on multi-modal inputs. This unique capability empowers VLAs to interpret language prompts, visually perceive their environment, and subsequently execute actions to fulfill the specified tasks. The potential applications of VLAs in robotics are not confined to controlled environments in traditional domains like manufacturing. They also prove their suitability for everyday tasks such as room cleaning and cooking [5], thanks to their dexterity and generalizability.
To accommodate multi-modal inputs, previous Transformer-based VLMs [42] explored designing special self-attention schemes to better suit the unique properties of different modalities, such as UniLM [11], M6 [28], BLIP-2 [26] and Octo [33]. Consider the task of image captioning as an example, causal attention is not the best option to encode images because there is no clear causal relationship among the image patches. Thus, these VLMs allow bidirectional self-attention for the image tokens while maintaining causal attention for the text tokens.
VLAs predominantly build upon the pioneering foundations laid by Decision Transformer [9] and Trajectory Transformer [22]. These two works frame reinforcement learning (RL) policies as sequence modeling problems, leveraging the expressive power of Transformer models. This paradigm has
Preprint. Under review.
a₁
a₂
a₃
(a) Causal Attention.
(b) Trajectory Attention.
Figure 1: A comparison between causal attention and trajectory attention is illustrated for an action, comprising three action dimensions, referred to as a 'segment'. Each orange dot represents a token embedding, and a line corresponds to a valid attention connection from the input embedding (bottom) to the output embedding (top). In trajectory attention, tokens can attend to not only the preceding tokens but also the subsequent tokens within the same segment, as indicated by the green lines.
a₁ a₂ a₃ become a cornerstone across recent VLAs, but both models are Transformer decoders based on causal attention. Subsequent approaches, such as Gato [38] and RT-1 [5], also adopt Transformer decoders as their network backbone, passing in different modalities as a single sequence. VIMA [24] incorporates cross-attention mechanisms to condition the policy with multi-modal prompts, but the decoder stack still follows previous methods and uses causal attention.
On the contrary, we have identified that VLA trajectories in robotics exhibit unique properties better captured by a novel type of Transformer self-attention, as illustrated in Figure 1 & 2. Specifically, each language prompt, state, or action within a VLA trajectory can consist of multiple tokens, referred to as a 'segment' in this paper. For instance, robot systems usually make use of several cameras, and as a result, a state is represented with a segment of tokens, each corresponding to a camera. Similar to state tokens, tokens for action dimensions also lack causal relationships with each other. Traditional causal attention hinders full information flow within a segment, as tokens are restricted from attending to the subsequent tokens. To overcome this limitation, we introduce trajectory attention, optimized for VLA trajectories. Trajectory attention possesses two key characteristics: inter-segment attention is causal, and intra-segment attention is bidirectional. Since a VLA model only needs to encode the language prompt and follow the corresponding instruction, causal attention is also unnecessary for the prompt segment. Consequently, we advocate for processing trajectories at the segment level, rather than merely at the token level.
To complement trajectory attention, we devise a segment-level decoding scheme that generates a segment as a whole. Drawing inspiration from DETR's object query [6], we propose employing action queries to more effectively extract information for action generation. Concretely, we employ one learnable action query for each action dimension. Each action query aggregates the most relevant information in the trajectory for its corresponding action dimension and generates the most probable value for that dimension. Different action queries can execute this procedure in parallel, facilitating the simultaneous generation of all action dimensions. This represents a substantial acceleration in action generation speed compared to earlier approaches that generate one action dimension at a time, such as RT-2 [4]. By combining trajectory attention and action queries, we introduce an optimized Transformer architecture for VLA trajectories, which we name Act ion-query-based Tra jectory-attention Tra nsformer, or Actra for short.
Training the policy network with behavior cloning is a common practice for VLAs. However, it lacks explicit alignment between different modalities. Contrastive learning, which has been widely adopted to enhance inter-modality interaction, gained prominence in VLMs through the success of CLIP [34]. CLIP achieved state-of-the-art performance on image classification tasks by introducing a contrastive language-image pre-training approach on a large-scale dataset of image-text pairs. Despite its popularity in VLMs, contrastive learning remains relatively under-explored in VLAs. While R3M [32] proposed a time contrastive learning objective, and VIP [31] introduced value-implicit pretraining, both primarily focus on obtaining a robust visual encoder without emphasizing alignment among multiple modalities.
Therefore, we propose a VLA contrastive learning objective aimed at enhancing multi-modality encoding capability. Positive trajectories are obtained by introducing slight noise to the actions. The rationale is that a slightly noisy trajectory can still be valid, as a path in the close vicinity of an expert path can also lead to the target position. To construct negative trajectories for the three modalities of VLAs, we sample prompt, state, or action segments from other trajectories in the dataset and substitute the original segments with those mismatched ones. We then train Actra to encode positive
Figure 2: The architecture of Actra. Each square represents a token. A trajectory τ consists of a prompt segment p 1:4 , state segments s 1:2 ,t , action segments a 1:3 ,t . For clarity, the trajectory is a simplified example and does not reflect the actual specifications of Actra. In the Transformer, vertical dashed lines divide the segments. Learnable action queries q 1:3 ,t are inserted after each state segment to extract information for action generation. Each token embedding (orange dot) in the trajectory can attend to embeddings from all previous segments (horizontal arrows), as well as all the embeddings in its own segment (gray lines). Notably, action queries, which contain no trajectory information, are hidden from other tokens, but they can still attend to all preceding tokens. In addition to its primary function of decoding actions, Actra can also encode the entire trajectory by pooling the embeddings in the last segment (red box).
and negative trajectories and contrast them with the widely adopted InfoNCE loss [41]. This approach explicitly encourages multi-modality information exchange among the vision encoder, language encoder, and action decoder of Actra. With the enhanced multi-modality encoding capability, VLA's performance on primary robotics tasks is further improved.
The three main contributions of this paper are:
- · We introduce Actra, an optimized Transformer architecture featuring trajectory attention and action query, designed to model VLA trajectories on the segment level;
- · We propose a VLA contrastive learning objective to explicitly enhance Actra's multimodality encoding capability, complementing the primary behavior cloning objective of robot imitation learning;
- · Extensive experimental results across three environments demonstrate that Actra significantly outperforms state-of-the-art VLA models in terms of generalization, dexterity, and precision, showcasing the effectiveness of our method.
## 2 Related Work
Vision-language-action Model. Vision-language-action models (VLAs) constitute a class of multimodal models designed to generate actions based on specified language prompts and perceived environment. Coined by RT-2 [4], VLAs have garnered increasing attention due to their dexterity and generalizability in handling complex robotics tasks. Early attempts were based on existing visionlanguage models (VLMs), exemplified by CLIPort [39] and BC-Z [21]. Gato [38] explored the use of a single Transformer model [42] as the control policy for tasks spanning various domains, unifying multi-modal inputs into a single sequence. RT-1 [5] stands as a dedicated robotics transformer for robotics tasks. Our model is also a VLA but with an optimized Transformer architecture.
Multi-modal Transformer. Several VLMs, including UniLM [11], M6 [28], and Octo [33] have endeavored to optimize Transformer's self-attention for vision-language inputs. Despite these efforts, adapting self-attention to the multi-modal inputs of VLAs has been relatively unexplored. Gato [38] and RT-1 [5] maintain causal attention in Transformer decoders. VIMA [24] proposes passing the prompt into the policy through cross-attention, but their Transformer decoder stack still employs
causal attention. To the best of our knowledge, Actra is the first VLA designed to accommodate VLA trajectories with a unique self-attention mechanism.
First introduced in DETR [6], learnable object queries have shown promising results in extracting information for object detection. BLIP-2 [26] used a similar strategy to extract visual embeddings for vision-language tasks. In our approach, we employ learnable action queries at the action-dimension level to extract information most relevant to individual action dimensions.
Multi-modal Contrastive Learning. A series of VLMs, CLIP [34], ALIGN [23], Florence [46], FILIP [45], has demonstrated the significance of contrastive learning in enhancing multi-modal interaction. However, in VLAs like R3M [32] and VIP [31], where contrastive learning has been adopted, the primary emphasis remains on improving visual representations. In contrast, our proposed VLA contrastive learning task explicitly compels the model to align the three modalities, allowing for more effective encoding of multi-modal inputs. More related work is included in Appendix A.8.
## 3 Our Method
## 3.1 Preliminaries
Markov Decision Process (MDP) comprise states ( s ) and actions ( a ) and it can be conditioned by a language prompt ( p ). In the context of imitation learning, a VLA trajectory within the language-conditioned MDP is denoted as τ = ( p, s t =1 , a t =1 , . . . , s t = T , a t = T ) . Each element in the trajectoryp , s t , or a t -comprises a segment of tokens. For instance, a state s t corresponds to the segment s 1: M,t = ( s 1 ,t , s 2 ,t , . . . , s M,t ) , where each element is a token. Tokens in p are standard NLP tokens. State tokens in s t correspond to images or object poses. Action tokens in a t contain 6D poses or 2D coordinates. Therefore, a trajectory at the token level is written as τ = ( p 1: L , s 1: M,t =1 , a 1: N,t =1 , . . . , s 1: M,t = T , a 1: N,t = T ) . The goal is to train a policy that can generate an optimal action based on the past trajectory π θ ( a t | p, s ≤ t , a <t ) .
## 3.2 Actra
In natural language generation (NLG), language models such as GPT [35] employ Transformer decoders as the backbone. To prevent tokens from having visibility into subsequent tokens, a causal attention mask is applied in the Transformer decoder. Prior VLA models [9, 5] have followed this trend for action generation. While causal attention is well-suited for NLG, where language tokens are sequentially generated, it is not the optimal attention mechanism for modeling VLA trajectories.
Trajectory attention. Images of the state s t from multiple cameras arrive simultaneously, lacking causality among themselves. They are determined solely by the preceding action a t -1 and the environment. The same principle applies to actions: a t is only dependent on previous states and actions, and they are conditionally independent from each other. The action dimensions in an action do not exhibit a clear causal order. For instance, in a 3D coordinate, it is uncertain whether a 1 ,t depends on a 2 ,t or vice versa. Regarding the language prompt, as it is provided by the user, the model's job is to encode and understand it rather than generate the prompt, akin to BERT [10]. Vanilla causal attention might impede information flow within each segment of a VLA trajectory, prohibiting s 1 ,t from attending to s 2: M,t , and s 2 ,t from attending to s 3: M,t , and so forth. This similarly holds for prompts and actions.
To address the issue, we propose an optimized Transformer self-attention mechanism for languageconditioned VLA trajectories, termed trajectory attention . Trajectory attention exhibits two key properties: the inter-segment connections are causal, and the intra-segment connections are bidirectional. Its corresponding attention matrix is illustrated in Figure 5. Following the convention of the Transformer attention matrix, we designate the row index as the destination of self-attention and the column index as the source. Consequently, the causal attention matrix has all its lower triangle entries, ( i, j ) for i ≥ j , set to one, and the rest set to zero. Trajectory attention is achieved by unmasking the entries in the causal attention matrix corresponding to ( p , p i j ) , ( s i,t , s j,t ) or ( a i,t , a j,t ) for i < j . When compared with the original causal attention, there are L L ( -1) / 2+ T ( M M ( -1) / 2+ N N ( -1) / 2 ) additional entries joining the self-attention in every Transformer layer, which explains the effectiveness of trajectory attention. Consequently, Actra is designed to process VLA trajectories at the
Figure 3: VLA contrastive learning. Given the anchor in the first row, we construct a positive by adding slight noise to the actions. For each modality, we create negatives by injecting mismatched segments sampled from the dataset. Using Actra as a trajectory encoder, we contrast their trajectory embeddings as a complementary objective to robotic imitation learning.
segment level, which aligns well with the MDP setting as it involves states and actions rather than individual tokens.
Action query. Adapting to the segment-level trajectory attention mechanism, we introduce a segment-level decoding scheme based on learnable action queries. Most prior VLAs generate action dimensions autoregressively, where each action dimension depends on its preceding token embedding [4]. However, this approach is suboptimal because the embedding of the preceding token is highly dependent on its input and may lack the most relevant information for the action dimension. For instance, when generating a 1 ,t , its preceding token is s M,t . Although the embedding of s M,t can aggregate information from the past trajectory through self-attention, it is largely influenced by its corresponding input image and may not contain sufficient information about a 1 ,t . To overcome this limitation, we adopt learnable action queries q 1: N for individual action dimensions a 1: N , inspired by DETR [6]. Each action query q i is dedicated to one action dimension a i and is shared across all timesteps: q i,t =1 = q i,t =2 = · · · = q i,t = T for i ∈ { 1 . . . N } . We argue that this approach can find more relevant information for each action dimension because the action query q i can exclusively attend to information pertinent to a i,t . Since action queries have no associated input token, their embeddings fully retain action dimension information. Moreover, distinct from autoregressive generation, action queries can extract information and generate all dimensions of an action segment in parallel. Consequently, the decoding procedure operates at the segment level. This significantly speeds up action generation. As the action queries are solely used for information extraction and do not hold any trajectory information, they are masked out from the attention matrix, ensuring that other tokens cannot see them through the self-attention mechanism.
Actra Combining trajectory attention and action query, we introduce a novel Transformer variant named Actra. In Actra, all action tokens a i,t can fully attend to ( p, s t =1 , a t =1 , . . . , s t , a t ) , and all state tokens s i,t can fully attend to ( p, s t =1 , a t =1 , . . . , s t ) . Consequently, their embeddings are enhanced for VLA trajectories. Each action query q i,t aggregates this enriched information, collecting more pertinent information for its corresponding action dimension. This makes Actra a more suitable Transformer for action generation in VLA trajectories. The training process utilizes standard behavioral cloning in robotic imitation learning, optimizing the objective L BC = min θ ∑ T t =1 -log π θ ( a t | p, s ≤ t , a <t ) on offline expert trajectories.
## 3.3 VLA Contrastive Learning
The primary behavior cloning objective involves a generative decoding process, where Actra generates the next action based on the past trajectory. Although this implicitly requires the model to encode multi-modal inputs, we argue that the encoding capability can be further enhanced with an explicit objective. Several studies have demonstrated the efficacy of contrastive learning in aligning different modalities [34, 23, 46, 45]. Therefore, we propose a novel VLA contrastive learning objective to
| | | | Unseen tasks | Unseen tasks | Unseen tasks | Unseen tasks | Distractors | Distractors | Distractors | Distractors | Distractors | Distractors |
|--------------|--------|-------|----------------|----------------|----------------|----------------|---------------|---------------|---------------|---------------|---------------|---------------|
| Model | Params | Color | Size | Shape | Container | Both | Mean | 0 | 2-4 | 6-8 | Mean | Overall |
| RT-1 | 46M | 27.03 | 6.36 | 20.30 | 0.79 | 1.27 | 11.15 | 61.09 | 39.17 | 23.40 | 41.22 | 22.43 |
| VIMA- large | 695M | 26.00 | 26.00 | 17.20 | 30.75 | 19.33 | 23.86 | 47.93 | 41.47 | 36.33 | 41.91 | 30.63 |
| Gato- large | 309M | 46.00 | 74.00 | 42.00 | 44.40 | 40.00 | 49.28 | 76.4 | 73.33 | 62.67 | 70.80 | 57.35 |
| Actra- large | 198M | 72.00 | 91.00 | 52.40 | 63.43 | 70.67 | 69.90 | 90.93 | 90.53 | 79.07 | 86.84 | 76.25 |
Table 1: Performance comparison of success rate (%) on different generalization levels. The numbers under the 'Distractors' category specify the quantity of distractors present in the environment.
train Actra to encode and contrast different modalities, aiming to improve robotic imitation learning, as illustrated in Figure 3.
Concretely, we assume the anchor trajectory is τ = ( p, s t =1 , a t =1 , . . . , s t = T , a t = T ) . To construct a positive, τ + , we introduce small Gaussian noise to the actions, following the intuition that a slightly perturbed path can still lead to the destination. Subsequently, we design three types of negatives, each corresponding to one modality of VLAs. For language prompts, we create a negative by selecting an incorrect prompt p ′ from the dataset and substituting it for the correct prompt. The resulting negative trajectory for the language modality is τ -p = ( p , s ′ t =1 , a t =1 , . . . , s t = T , a t = T ) . Although prompts are not unique to trajectories, states and actions are unique, allowing us to find false state and action inputs within the batch. Given another trajectory τ ′ = ( p , s ′ ′ t =1 , a ′ t =1 , . . . , s ′ t = T , a ′ t = T ) in the same batch as τ , we can mismatch the states and actions to assemble negatives for the vision and action modalities: τ -s = ( p, s ′ t =1 , a t =1 , . . . , s ′ t = T , a t = T ) and τ -a = ( p, s t =1 , a ′ t =1 , . . . , s t = T , a ′ t = T ) . Finally, we contrast the positive τ + against three types of negatives: τ -= { τ -p , τ -s , τ -a } .
In VLA contrastive learning, our Transformer model encodes the entire trajectory into a sequence of embeddings. A max-pooling layer [27] then aggregates them into a single embedding, as shown in Figure 2. Finally, we utilize the standard InfoNCE [41] as the objective to train the model to distinguish between positive and negative embeddings:
$$\bar { \mathcal { L } } _ { \text{VLA-CL} } ( \tau, \tau ^ { + }, \tau ^ { - } ) = - \log \mathbb { E } \left [ \frac { \gamma } { \exp ( f ( \tau ) ^ { \intercal } f ( \tau ^ { + } ) ) } } { B } \sum _ { i = 1 } ^ { B } \sum _ { j \in \{ p, s, a \} } \exp ( f ( \tau ) ^ { \intercal } f ( \tau _ { i, j } ^ { - } ) ) } \right ], \quad ( 1 )$$
where f ( ) · is Actra coupled with the max-pooling layer; B is the batch size. During training, we mix the VLA contrastive learning the primary behavior cloning objective to establish the overall training loss: L = α L BC + β L VLA-CL.
## 4 Experimental Results
## 4.1 Experimental Setup
We compare various VLA models across seven skills in three different environments. For the 'pick and place' skill, we gather a large-scale dataset in the Maniskill2 environment [15] to evaluate generalization capabilities. In the Franka Kitchen environment [16], we assess the dexterity of the models across five skills: turn knob, toggle switch, slide door open, swing door open, lift by handle. Precision of actions is benchmarked using the Push-T environment [14]. We compare with the following state-of-the-art baselines in robot manipulation tasks: Gato [38]: The prompt, state, and action tokens are concatenated into a single sequence and a Transformer decoder serves as the policy network. RT-1 [5]: We upgrade the USE prompt encoder to a T5 encoder [37] and modify the token learner to accommodate images from multiple cameras. VIMA [24]: We adapt its original SE(2) poses to the action dimensions of the our environment. Since our prompt is textual, we also use the same T5 encoder. Diffusion : We also developed two types of diffusion-based VLA models for Franka kitchen and Push-T. One model is based on DDPM [19] for continuous actions, and the other is based on D3PM [2] for discrete actions.
## 4.2 Implementation Details
We define a family of Actra models and utilize the most suitable model configuration for different environments. Actrasmall (19.4M) consists of 6 layers, 8 attention heads, and an embedding size of 512. Actrabase (43.3M) comprises 6 layers, 12 attention heads, and an embedding size of 768. Actralarge (198M) is composed of 10 layers, 20 attention heads, and an embedding size of 1280.
Table 2: Performance comparison (%) in Franka Kitchen and Push-T.
| | Franka Kitchen | Franka Kitchen | Continuous Action | Continuous Action | Continuous Action | Continuous Action | Continuous Action | Discrete Action | Discrete Action | Discrete Action | Discrete Action | Discrete Action | Push-T Discrete Action | Push-T Discrete Action | Push-T Discrete Action |
|-----------|------------------|------------------|---------------------|---------------------|---------------------|---------------------|---------------------|-------------------|-------------------|-------------------|-------------------|-------------------|--------------------------|--------------------------|--------------------------|
| Model | Config | Params | p 1 | p 2 | p 3 | p 4 | Mean | p 1 | p 2 | p 3 | p 4 | Mean | Config | Params | Score |
| Diffusion | base | 43M | 100 | 94 | 72 | 34 | 76 | 54 | 18 | 10 | 2 | 21 | base | 43M | 83.89 |
| VIMA | base | 113M | 92 | 90 | 80 | 66 | 82 | 90 | 72 | 48 | 16 | 57 | small | 26M | 91.09 |
| Gato | base | 43M | 100 | 98 | 84 | 62 | 86 | 100 | 88 | 68 | 38 | 74 | small | 19M | 90.43 |
| Actra | base | 43M | 100 | 100 | 94 | 70 | 91 | 100 | 94 | 68 | 52 | 79 | small | 19M | 94.11 |
The baseline models adopt the same configurations unless specified otherwise. To encode the prompt, we utilize T5 encoder [37], whose pretrained weights are loaded and frozen during training. For the vision encoder, we experimented with both ResNet [18] and ViT [12], trained from scratch. However, as we did not observe a performance gain when using ViT, we opted for ResNet as the vision encoder to minimize memory footprint. We use the AdamW optimizer [29] with learning rate = 1 × 10 -4 and weight decay 1 × 10 -4 .
## 4.3 Performance Comparison in Maniskill
In the Maniskill environment [15], we evaluate one of the most commonly utilized skills: 'pick and place'. Its goal is to pick up a target object and place it into a container. A language prompt specifies which target object and container are intended, with one prompt corresponding to one task. To test generalizability, we limit the training set to 15 tasks and evaluate the models on 34 tasks. All items are randomly placed and therefore, by default, our evaluation includes placement generalization [24]. We conduct 50 trials for each task to minimize variance, and each trial is limited to 100 timesteps before a timeout. The models use the large configuration due to the large scale of our dataset.
We compare the success rates on various generalization levels, involving unseen target objects, containers, and distractors, as detailed in Table 1 & Figure 4. A seen task means that its language prompt is in the training set. For unseen tasks, we establish five main generalization levels. The first three levels ('Color', 'Size', 'Shape') involve target objects with unseen colors, sizes, and shapes. E.g., small marker vs large marker ('Size'), and apple vs bowl ('Shape'). The fourth level ('Container') introduces unseen containers. The fifth level ('Both') involves both unseen target objects and unseen containers. This is not the simple average of the first four levels, as they either have an unseen target object or an unseen container, not both. A distractor is an item that is neither the target object nor the container. They are randomly sampled from a pool of diverse items. The robot and environment are randomly initialized. For all five 'unseen tasks' levels, we sample 2-4 distractors and place them randomly. In seen tasks, we explore whether the number of distractors can impact the models' performance ('Distractors'). Detailed analysis can be found in Appendix A.4.
## 4.4 Performance Comparison in Franka Kitchen
Franka Kitchen [16] includes five skills that span seven specific tasks within the scene. The 'turn knob' skill involves turning the oven knob to activate either the top or bottom burner. 'Toggle switch' involves turning on the light switch. 'Slide door open' requires opening the slide cabinet, while 'swing door open' involves opening either the left hinge cabinet or the microwave door by the door handle. The 'lift by handle' skill entails moving the kettle by its handle. Performance is measured by the completion of multi-stage tasks, as summarized in Table 2. Results are averaged over 50 runs. In each run, the models are required to complete four random tasks within 280 steps. If p i = 1 , it means the model has completed i tasks and thus reached the i -th stage; otherwise, p i = 0 . Since the scale of Franka Kitchen is relatively small, we compare the models in their base configuration. We also compare the performance of models using continuous and discrete actions in this environment. Some examples by Actra in Franka Kitchen are shown in Appendix A.7.
## 4.5 Performance Comparison in Push-T
In Push-T [14], the models need to push a T-shaped object until it aligns perfectly with the target position. This task requires precise control, as performance is measured by the overlapping area, with perfect alignment equating to a score of 1.0. The performance of the models is compared in Table 2. Results are averaged over 30 trials. The maximum number of steps the models can take in each trial is 200, so they need to push the object precisely while maintaining adequate speed. Because this is a 2D task, we found that using small models is sufficient, except for the diffusion-based model, which uses the base configuration. Since the cross-attention layers in VIMA make its default
Figure 4: Comparison of success rate on different generalization levels. 'Unseen' for unseen tasks; 'Seen' for seen tasks. 'Distractors' involve at least two distractors, and 'Basic' involves no distractors.
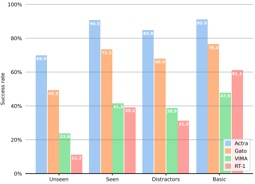
| Model | Overall | Hard | Medium | Easy |
|-----------------|--------------|--------------|--------------|--------------|
| Actra- large | 90.5 | 83.5 | 89.7 | 93.8 |
| w/o V-negatives | 89.2 (-1.3) | 79.0 (-4.5) | 88.3 (-1.4) | 93.7 (-0.1) |
| w/o L-negatives | 89.5 (-1.0) | 81.0 (-2.5) | 88.6 (-1.1) | 93.3 (-0.5) |
| w/o A-negatives | 88.0 (-2.5) | 78.0 (-5.5) | 86.3 (-3.4) | 93.3 (-0.5) |
| w/o VLA CL | 87.9 (-2.6) | 75.0 (-8.5) | 88.6 (-1.1) | 91.3 (-2.5) |
| w/o Traj Attn | 83.7 (-6.8) | 76.0 (-7.5) | 83.7 (-6.0) | 86.3 (-7.5) |
| w/o Act Query | 81.3 (-9.2) | 69.0 (-14.5) | 80.9 (-8.8) | 86.0 (-7.8) |
| w/o Both | 79.5 (-11.0) | 68.0 (-15.5) | 79.4 (-10.3) | 83.3 (-10.5) |
Table 3: Ablation study of the proposed components in Actra. We ablate each type of negative trajectory for VLA contrastive learning. Starting from the row 'w/o VLA CL', we remove VLA contrastive learning and only utilize the BC objective. We test them on seen tasks with 2-4 distractors. The values in the brackets represent the difference from the complete 'Actralarge '.
small model amount to 50.8M parameters, which is even larger than Actrabase , we use three Transformer blocks instead. We found that models fail to learn effective policies using continuous actions; therefore, we only report results of discrete actions. Several push-T examples by Actra are included in Appendix A.7.
## 4.6 Ablation Study
In our ablation study, we assess the novel components of Actra, as detailed in Table 3. We categorize the target objects of seen tasks into three difficulty levels: easy, medium, and hard. The details regarding the design of the difficulty levels are provided in Appendix A.5. VLA contrastive learning proves effective in enhancing primary robot imitation learning. We found that using VLA contrastive learning as a 'warmup' phase works best for Actra. That is, we set α = 0 , β = 1 for the first few epochs, and then α = 1 , β = 0 for the remainder of the training. This schedule allows the model to absorb necessary knowledge about multi-modality encoding initially without interfering with the primary objective later in the training. In our ablation study, we analyze each of the three negative types. We observe that the removal of action negatives has the most substantial impact on performance degradation. Notably, hard tasks exhibit a heightened dependence on VLA contrastive learning compared to easier tasks.
We further investigate the impact of ablating trajectory attention and action query in Actra. The removal of trajectory attention results in a noticeable decrease in success rates across all difficulty levels, underscoring its crucial role in processing segmented VLA trajectories. Similarly, the absence of action query leads to reduced success rates, highlighting its significance in enhancing information extraction for action generation. Interestingly, when trajectory attention and action query are used in combination, the performance benefit exceeds the sum of their individual contributions, indicating a synergistic effect that enhances Actra's precision in action generation.
## 4.7 Qualitative Analysis
We present a visualization of the attention matrices from the top layer of Actra, depicted in Figure 5. The explanation of the attention matrix can be found in the appendix. In the visualization, prompt tokens exhibit similar attention values. Notably, tokens from more recent timesteps receive a higher attention weight compared to those from earlier in the sequence. This aligns with our expectation that the latest timestep is the most informative one for generating the next action. Some of the attention weights above the main diagonal are strongly activated, indicating the additional attention connections facilitated by our trajectory attention are beneficial. In the right matrix, a clear distinction is observed between the attention weights produced by state tokens and query tokens. This distinction underscores that action queries extract information differently from state tokens, elucidating their role in improving action generation.
Upon further analysis of the evaluation trajectories, a crucial distinction between Actra and the baselines emerges: Actra masters 'instantaneous regrasp'. In most cases, baseline models struggle to recognize failed grasps and initiate another attempt promptly. Even if they identify a failed grasp,
P₁ P₂ P₃ P₄ S₁ S₂ A₁ A₂ A₃ S₁ S₂ Q₁ Q₂ Q₃ A₁ A₂ A₃ Figure 5: The attention matrix of trajectory attention (left, showing two timesteps) and the visualization of two trained matrices (middle and right, showing five timesteps). Brighter cells correspond to higher attention weights. The tick labels are shown for the last token of every segment.

Figure 6: An example of instantaneous regrasp. Four grasp attempts were completed within only 30 steps, a capability not observed in the baseline models. An elaborate description of the example is provided in Appendix A.6.
the time taken to start a new attempt is usually prolonged. In contrast, our Actra model promptly detects a failed grasp and continuously attempts to grasp the object until successful. This ability significantly reduces the failure rate with each regrasp, contributing to the substantially higher success rate observed in Actra. Figure 6 presents keyframes from an instantaneous regrasp corresponding to the most challenging task of 'pick blue tea box and place into clear box'.
## 5 Conclusion
This paper introduces Actra, an optimized Transformer architecture designed for VLA trajectories in robotic tasks. Actra distinguishes itself from vanilla Transformer decoders through two key components: trajectory attention and action query. Trajectory attention harnesses the unique characteristics of VLA trajectories, facilitating enhanced information flow among tokens within each segment. This allows Actra to encode the sequence at the segment level, and we introduce action queries to enable a segment-level decoding procedure. We incorporate an additional VLA contrastive learning task to explicitly train the model to encode multi-modal information, improving alignment between different modalities. This further elevates Actra's performance in robot imitation learning. Through comprehensive comparisons in various environments, our approach demonstrates significant performance gain over state-of-the-art models in terms of generalizability, dexterity, and precision. Detailed ablation study and qualitative analysis further validate the effectiveness of Actra.
## 6 Limitations
Due to the high computational cost of diffusion-based VLA models, we were unable to compare against them in our large-scale Maniskill environment. Although more powerful language and vision encoders could be explored for even better performance, we kept them identical across Actra and the baselines to ensure a fair comparison. Although we have evaluated Actra in various setups, our evaluations were primarily conducted using the Franka embodiment. Exploring multi-embodiment would be an interesting direction for future research.
## References
- [1] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob L. Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karén Simonyan. Flamingo: a visual language model for few-shot learning. In NeurIPS, 2022.
- [2] Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. In Marc'Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, editors, Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 17981-17993, 2021.
- [3] Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Yitzhak Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Wortsman, and Ludwig Schmidt. Openflamingo: An open-source framework for training large autoregressive vision-language models. CoRR, abs/2308.01390, 2023.
- [4] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil J. Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Lisa Lee, Tsang-Wei Edward Lee, Sergey Levine, Yao Lu, Henryk Michalewski, Igor Mordatch, Karl Pertsch, Kanishka Rao, Krista Reymann, Michael S. Ryoo, Grecia Salazar, Pannag Sanketi, Pierre Sermanet, Jaspiar Singh, Anikait Singh, Radu Soricut, Huong T. Tran, Vincent Vanhoucke, Quan Vuong, Ayzaan Wahid, Stefan Welker, Paul Wohlhart, Jialin Wu, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu, and Brianna Zitkovich. RT-2: vision-language-action models transfer web knowledge to robotic control. CoRR, abs/2307.15818, 2023.
- [5] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J. Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, Deeksha Manjunath, Igor Mordatch, Ofir Nachum, Carolina Parada, Jodilyn Peralta, Emily Perez, Karl Pertsch, Jornell Quiambao, Kanishka Rao, Michael S. Ryoo, Grecia Salazar, Pannag R. Sanketi, Kevin Sayed, Jaspiar Singh, Sumedh Sontakke, Austin Stone, Clayton Tan, Huong T. Tran, Vincent Vanhoucke, Steve Vega, Quan Vuong, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu, and Brianna Zitkovich. RT-1: robotics transformer for real-world control at scale. In Robotics: Science and Systems, 2023.
- [6] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV (1), volume 12346 of Lecture Notes in Computer Science, pages 213-229. Springer, 2020.
- [7] Yevgen Chebotar, Quan Vuong, Alex Irpan, Karol Hausman, Fei Xia, Yao Lu, Aviral Kumar, Tianhe Yu, Alexander Herzog, Karl Pertsch, Keerthana Gopalakrishnan, Julian Ibarz, Ofir Nachum, Sumedh Sontakke, Grecia Salazar, Huong T. Tran, Jodilyn Peralta, Clayton Tan, Deeksha Manjunath, Jaspiar Singh, Brianna Zitkovich, Tomas Jackson, Kanishka Rao, Chelsea Finn, and Sergey Levine. Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions. CoRR, abs/2309.10150, 2023.
- [8] Feilong Chen, Duzhen Zhang, Minglun Han, Xiuyi Chen, Jing Shi, Shuang Xu, and Bo Xu. VLP: A survey on vision-language pre-training. Int. J. Autom. Comput., 20(1):38-56, 2023.
- [9] Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. In NeurIPS, pages 15084-15097, 2021.
- [10] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT (1), pages 4171-4186. Association for Computational Linguistics, 2019.
| [11] | Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. Unified language model pre-training for natural language under- standing and generation. In NeurIPS, pages 13042-13054, 2019. |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [12] | Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR. OpenReview.net, 2021. |
| [13] | Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. Palm-e: An embodied multimodal language model. In ICML, volume 202 of Proceedings of Machine Learning Research, pages 8469-8488. PMLR, 2023. |
| [14] | Pete Florence, Corey Lynch, Andy Zeng, Oscar A. Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. Implicit behavioral cloning. In Aleksandra Faust, David Hsu, and Gerhard Neumann, editors, Conference on Robot Learning, 8-11 November 2021, London, UK, volume 164 of Proceedings of Machine Learning Research, pages 158-168. PMLR, 2021. |
| [15] | Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqiang Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei, Yunchao Yao, Xiaodi Yuan, Pengwei Xie, Zhiao Huang, Rui Chen, and Hao Su. Maniskill2: A unified benchmark for generalizable manipulation skills. In International Conference on Learning Representations, 2023. |
| [16] | Abhishek Gupta, Vikash Kumar, Corey Lynch, Sergey Levine, and Karol Hausman. Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning. In Leslie Pack Kaelbling, Danica Kragic, and Komei Sugiura, editors, 3rd Annual Conference on Robot Learning, CoRL 2019, Osaka, Japan, October 30 - November 1, 2019, Proceedings, volume 100 of Proceedings of Machine Learning Research, pages 1025-1037. PMLR, 2019. |
| [17] | Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross B. Girshick. Masked autoencoders are scalable vision learners. In CVPR, pages 15979-15988. IEEE, 2022. |
| [18] | Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770-778. IEEE Computer Society, 2016. |
| [19] | Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Hugo Larochelle, Marc'Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. |
| [20] | Brian Ichter, Anthony Brohan, Yevgen Chebotar, Chelsea Finn, Karol Hausman, Alexander Herzog, Daniel Ho, Julian Ibarz, Alex Irpan, Eric Jang, Ryan Julian, Dmitry Kalashnikov, Sergey Levine, Yao Lu, Carolina Parada, Kanishka Rao, Pierre Sermanet, Alexander Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Mengyuan Yan, Noah Brown, Michael Ahn, Omar Cortes, Nicolas Sievers, Clayton Tan, Sichun Xu, Diego Reyes, Jarek Rettinghouse, Jornell Quiambao, Peter Pastor, Linda Luu, Kuang-Huei Lee, Yuheng Kuang, Sally Jesmonth, Nikhil J. Joshi, Kyle Jeffrey, Rosario Jauregui Ruano, Jasmine Hsu, Keerthana Gopalakrishnan, Byron David, Andy Zeng, and Chuyuan Kelly Fu. Do as I can, not as I say: Grounding language in robotic affordances. In CoRL, volume 205 of Proceedings of Machine Learning Research, pages 287-318. PMLR, 2022. |
| [21] | Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, Sergey Levine, and Chelsea Finn. BC-Z: zero-shot task generalization with robotic imitation learning. In CoRL, volume 164 of Proceedings of Machine Learning Research, pages 991-1002. PMLR, 2021. |
| [22] | Michael Janner, Qiyang Li, and Sergey Levine. Offline reinforcement learning as one big sequence modeling problem. In NeurIPS, pages 1273-1286, 2021. |
| [23] | Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yun- Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In ICML, volume 139 of Proceedings of Machine Learning Research, pages 4904-4916. PMLR, 2021. |
| [24] | Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, and Linxi Fan. VIMA: general robot manipulation with multimodal prompts. CoRR, abs/2210.03094, 2022. |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [25] | Siddharth Karamcheti, Suraj Nair, Annie S. Chen, Thomas Kollar, Chelsea Finn, Dorsa Sadigh, and Percy Liang. Language-driven representation learning for robotics. In Robotics: Science and Systems, 2023. |
| [26] | Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. BLIP-2: bootstrapping language- image pre-training with frozen image encoders and large language models. In ICML, volume 202 of Proceedings of Machine Learning Research, pages 19730-19742. PMLR, 2023. |
| [27] | Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, Hang Li, and Tao Kong. Vision-language foundation models as effective robot imitators. CoRR, abs/2311.01378, 2023. |
| [28] | Junyang Lin, Rui Men, An Yang, Chang Zhou, Ming Ding, Yichang Zhang, Peng Wang, Ang Wang, Le Jiang, Xianyan Jia, Jie Zhang, Jianwei Zhang, Xu Zou, Zhikang Li, Xiaodong Deng, Jie Liu, Jinbao Xue, Huiling Zhou, Jianxin Ma, Jin Yu, Yong Li, Wei Lin, Jingren Zhou, Jie Tang, and Hongxia Yang. M6: A chinese multimodal pretrainer. CoRR, abs/2103.00823, 2021. |
| [29] | Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR (Poster). OpenReview.net, 2019. |
| [30] | Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In NeurIPS, pages 13-23, 2019. |
| [31] | Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, and Amy Zhang. VIP: towards universal visual reward and representation via value-implicit pre- training. In ICLR. OpenReview.net, 2023. |
| [32] | Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3M: A universal visual representation for robot manipulation. In CoRL, volume 205 of Proceedings of Machine Learning Research, pages 892-909. PMLR, 2022. |
| [33] | Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Charles Xu, Jianlan Luo, Tobias Kreiman, You Liang Tan, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. https: //octo-models.github.io , 2023. |
| [34] | Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML, volume 139 of Proceedings of Machine Learning Research, pages 8748-8763. PMLR, 2021. |
| [35] | Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019. |
| [36] | Ilija Radosavovic, Tete Xiao, Stephen James, Pieter Abbeel, Jitendra Malik, and Trevor Darrell. Real-world robot learning with masked visual pre-training. In CoRL, volume 205 of Proceedings of Machine Learning Research, pages 416-426. PMLR, 2022. |
| [37] | Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21:140:1-140:67, 2020. |
| [38] | Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gómez Colmenarejo, Alexander Novikov, Gabriel Barth-maron, Mai Giménez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, Tom Eccles, Jake Bruce, Ali Razavi, Ashley Edwards, Nicolas Heess, Yutian Chen, Raia Hadsell, Oriol Vinyals, Mahyar Bordbar, and Nando de Freitas. A generalist agent. Transactions on Machine Learning Research, 2022. Featured Certification. |
| [39] | Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Cliport: What and where pathways for robotic manipulation. In CoRL, volume 164 of Proceedings of Machine Learning Research, pages 894-906. PMLR, 2021. |
| [40] | Austin Stone, Ted Xiao, Yao Lu, Keerthana Gopalakrishnan, Kuang-Huei Lee, Quan Vuong, Paul Wohlhart, Brianna Zitkovich, Fei Xia, Chelsea Finn, and Karol Hausman. Open-world object manipulation using pre-trained vision-language models. CoRR, abs/2303.00905, 2023. |
| [41] | Aäron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. CoRR, abs/1807.03748, 2018. |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [42] | Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, pages 5998-6008, 2017. |
| [43] | Sai Vemprala, Rogerio Bonatti, Arthur Bucker, and Ashish Kapoor. Chatgpt for robotics: Design principles and model abilities. CoRR, abs/2306.17582, 2023. |
| [44] | Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation, 2023. |
| [45] | Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. FILIP: fine-grained interactive language-image pre-training. In ICLR. OpenReview.net, 2022. |
| [46] | Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, Ce Liu, Mengchen Liu, Zicheng Liu, Yumao Lu, Yu Shi, Lijuan Wang, Jianfeng Wang, Bin Xiao, Zhen Xiao, Jianwei Yang, Michael Zeng, Luowei Zhou, and Pengchuan Zhang. Florence: A new foundation model for computer vision. CoRR, abs/2111.11432, 2021. |
| [47] | Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. In Robotics: Science and Systems, 2023. |
## A Appendix
## A.1 Trajectory Attention Matrix
The trajectory attention is implemented with its corresponding attention mask, as illustrated in Figure 7. Output tokens on the left attend to input tokens at the top. For example, in the first row, the token p 1 can attend to tokens ( p , p 1 2 , p 3 , p 4 ) and no future tokens, hence other tokens starting from s 1 are masked out. For action generation, action queries can attend to all tokens up to the current state, while no other tokens can attend to action queries. Therefore, action query tokens are all masked from the input.
Although we can use the decoding attention matrix for both decoding and encoding, employing the right matrix can save compute for the action queries. Regardless of using the left or right matrix, the resulting embeddings are identical for the encoded trajectory in VLA contrastive learning, thanks to our modified positional embeddings.
(a) Trajectory attention matrix for decoding.

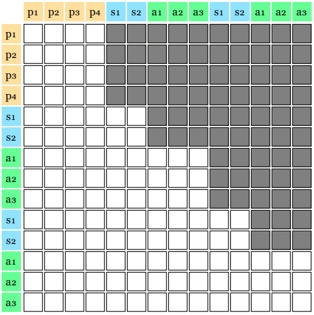
P₁ P₂ P₃ P₄ S₁ S₂ Q₁ Q₂ Q₃ A₁ A₂ A₃ S₁ S₂ Q₁ Q₂ (b) Trajectory attention matrix for encoding.
P₁ P₂ P₃ P₄ S₁ S₂ A₁ A₂ A₃ S₁ S₂ Q₁ Q₂ Q₃ A₁ A₂ A₃ Figure 7: The attention matrix of Trajectory Attention. Dark boxes represent masked entries in the attention matrix. The left attention matrix is used for decoding during action generation while the right attention matrix is used for encoding the trajectory in VLA contrastive learning.
## A.2 Positional Embeddings
We introduce two additional learnable embeddings, replacing the original GPT positional embedding [35]. The first is segment embedding, aiding the Transformer in distinguishing between prompt, state, query, and action segments, and is shared across different timesteps. The second is timestep embedding, enabling the Transformer to identify the timestep of each token and is identical for all tokens within the same timestep. Combining these two embeddings allows Actra to identify individual segments rather than individual tokens, as the order of tokens within a segment is irrelevant. Finally, the input embedding is the summation of all embeddings, following regular Transformers.
## A.3 Training Objectives of Diffusion-based VLA Models
The training objectives in diffusion-based VLA models [19, 2] can be written as:
$$\mathcal { L } _ { D D P M } & = \text{MSE} \left ( \varepsilon ^ { k }, \varepsilon _ { \theta } \left ( \mathbf x ^ { 0 } + \varepsilon ^ { k }, k \right ) \right ) \\ \mathcal { L } _ { D 3 P M } & = \text{CE} \left ( \varepsilon ^ { k }, \varepsilon _ { \theta } \left ( \mathbf x ^ { 0 } + \varepsilon ^ { k }, k \right ) \right )$$
Q₃
A₁
A₂
A₃
where x 0 is the original action and ε k is the noise of the k -th iteration; ε θ is the VLA model.
## A.4 Generalization Levels
For Actra, Gato, and VIMA, unseen shape proves to be the most challenging level, followed by unseen containers. VIMA also exhibits volatility when dealing with small objects from the 'Size' level. RT-1, in particular, struggles with identifying the container when an unseen container is introduced. It's important to note that not all seen target objects have a generalized version for every generalization level. For example, a strawberry is a seen target object, but there is no over-sized strawberry for the 'Shape' level. Consequently, models may achieve a higher success rate on some generalization levels than on seen tasks. Furthermore, since unseen color and size are part of the mixture, the success rate in 'Both' is not as low as in 'Shape' and 'Container'. The introduction of more distractors in the scene increases the likelihood of collisions and causes additional difficulty in grasping the objects. However, this negative effect is not severe enough to considerably degrade the performance.
## A.5 Difficulty Levels
In simple terms, easy tasks involve spherical, regular-sized target objects, such as a baseball. The medium difficulty level includes elongated or small target objects, such as a banana or strawberry. Hard tasks encompass oversized, non-spherical, or thin objects, such as a tea box or knife.
Easy tasks include spherical, regular-sized objects. The reason why round objects are easier to pick is that the robot arm can close the gripper in any direction. Size also has a big impact on the success rate because over-sized objects require more precise grasp poses. If a grasp is not precise, the two fingers of the gripper might have collision with the object and not be able to reach down on the object. Small objects can increase the difficulty because the gripper might miss them if the grasp is slightly off. An object like a remote controller or a banana should be picked up 'across' the object, not 'along' the object. Thus, we define the medium difficulty level as the objects that are too big, too small, or elongated. Hard tasks involve non-spherical, oversized, or thin objects, such as a tea box and a knife. A tea box is non-spherical and oversized and thus the robot arm can only grasp it precisely in parallel with the sides, not diagonally. A knife can be hard since it is very thin and close to the desk. The gripper might collide with the desk while grasping.
## A.6 Instantaneous Regrasp
More explanation for the example in Figure 6. The first grasp was unsuccessful as one finger of the gripper collided with the blue tea box and the grasp slipped. Subsequently, Actra swiftly initiated two additional grasps; however, the gripper closed too early, resulting in collisions with the tea box again. Shortly after the second and third failures, the gripper's fingers successfully reached down to opposite sides of the blue tea box, completing the fourth regrasp. Remarkably, all four grasp attempts were executed within a mere 30 timesteps, a feat not observed in the baselines.
## A.7 Franka Kitchen & Push-T Examples
We provide some execution examples by Actra in Franka Kitchen (Figure 8) and Push-T (Figure 9).
## A.8 Additional Related Work
MOO[40] introduced multi-modal prompt capability to RT-1, while Q-Transformer [7] adapted RT-1 to the Q-learning setting. RoboFlamingo [27] constructed a VLA based on the existing Flamingo VLM [1, 3]. ACT [47] adopts the DETR framework for robotics tasks but utilizes fixed position embeddings at the timestep level. Another category of VLAs focuses on building high-level planners for long-horizon robotics tasks and abstracting away the low-level control policies, such as SayCan [20], PaLM-E [13], and ChatGPT for Robotics [43].
In addition to the primary learning objective, auxiliary or pretraining objectives have proven useful in further enhancing model performance. The success of masked language modeling, as initially proposed in BERT [10], has prompted the adoption of similar objectives in various domains. In computer vision models and VLMs, representative works like MAE [17] and ViLBERT [30] have employed comparable strategies. VLAs have also utilized masked modeling objectives for their vision
Figure 8: Actra in Franka Kitchen. The model completes four random tasks. The top left image shows the initial state and the other three images are three different final states.
Figure 9: Actra in Push-T. The grey T is the object and the green T is its target position. The model controls the blue dot to push the T-shaped object towards the target position. The red cross is the cursor. The images on the left and right are two different initial states, and the middle image is the final state where the object perfectly overlaps with the target position.

encoders, such as MVP [36], Voltron [25], GR-1 [44]. While these approaches have proven beneficial for the vision encoder, they often overlook the crucial alignment between different modalities. | null | [
"Yueen Ma",
"Dafeng Chi",
"Shiguang Wu",
"Yuecheng Liu",
"Yuzheng Zhuang",
"Jianye Hao",
"Irwin King"
] | 2024-08-02T09:55:56+00:00 | 2024-08-02T09:55:56+00:00 | [
"cs.RO"
] | Actra: Optimized Transformer Architecture for Vision-Language-Action Models in Robot Learning | Vision-language-action models have gained significant attention for their
ability to model trajectories in robot learning. However, most existing models
rely on Transformer models with vanilla causal attention, which we find
suboptimal for processing segmented multi-modal sequences. Additionally, the
autoregressive generation approach falls short in generating multi-dimensional
actions. In this paper, we introduce Actra, an optimized Transformer
architecture featuring trajectory attention and learnable action queries,
designed for effective encoding and decoding of segmented
vision-language-action trajectories in robot imitation learning. Furthermore,
we devise a multi-modal contrastive learning objective to explicitly align
different modalities, complementing the primary behavior cloning objective.
Through extensive experiments conducted across various environments, Actra
exhibits substantial performance improvement when compared to state-of-the-art
models in terms of generalizability, dexterity, and precision. |
2408.01148v2 | A unified concept of the degree of ill-posedness for compact and non-compact linear operator equations in Hilbert spaces under the auspices of the spectral theorem
Frank Werner ∗
Bernd Hofmann †
November 27, 2024
## Abstract
Covering ill-posed problems with compact and non-compact operators regarding the degree of ill-posedness is a never ending story written by many authors in the inverse problems literature. This paper tries to add a new narrative and some new facets with respect to this story under the auspices of the spectral theorem. The latter states that any self-adjoint and bounded operator is unitarily equivalent to a multiplication operator on some (semifinite) measure space. We will exploit this fact and derive a distribution function from the corresponding multiplier, the growth behavior of which at zero allows us to characterize the degree of ill-posedness. We prove that this new concept coincides with the well-known one for equations with compact operators (by means of their singular values), and illustrate the implications along examples with non-compact operators, including the Hausdorff moment operator and convolutions.
## 1 Introduction
Let T : X → Y be a bounded and injective linear operator with range ran( T ), which is mapping between infinite dimensional separable real Hilbert spaces X and Y . In this study, we consider the operator equation
$$T u = g$$
that is ill-posed in correspondence with the fact that ran( T ) is assumed to be a non-closed subset of Y . In the seminal paper [29], the case of compact operators T well-studied in the literature was called ill-posedness of type II , and their strength of ill-posedness is clearly expressed by the decay rate of the singular values of T . The majority of occurring linear ill-posed problems (e.g., Fredhom and Volterra integral equations of first kind over some bounded domain in R d as well as history match problems for the heat equation with homogeneous boundary conditions) belong to that type. Such problems with compact forward operators are extensively analyzed in the inverse problems literature, see e.g. [23, 26, 30]. In the Hilbert space setting, the alternative ill-posedness of type I is characterized by non-compact operators T with non-closed range and arises for convolution operators on unbounded domains (see Subsection 4.2 below) as well as for Ces`ro operators (cf., a e.g., [4, 5, 24]) and in the context of the Hausdorff moment problem (see Subsection 4.1 below). The absence of singular values makes the things more difficult for non-compact T . Therefore, it is our goal to make a suggestion for classifying the strength of ill-posedness also for non-compact operators T with non-closed range by means of their spectral properties.
∗ Institute for Mathematics, University of W¨rzburg, Emil-Fischer-Str. 30, 97074 W¨rzburg, Germany. u u Email: [email protected]
† Chemnitz University of Technology, Faculty of Mathematics, 09107 Chemnitz, Germany. Email: [email protected]
Covering ill-posed problems with compact and non-compact operators regarding the nature and degree of ill-posedness is a never ending story written by many authors in the inverse problems literature. For example, we refer to the claim of Nashed in [29] that equations with non-degenerating compact operators mapping between infinite dimensional Hilbert spaces are always more ill-posed than those with non-compact ones. Arguments for that claim come from the comparison of illposed situations with two linear operators by partial orderings and associated range inclusions (see, e.g, [17, 27]). In this context, the range of a non-compact operator can never be a subset of the range of a compact operator. Also in [17], however, it was shown by observing the modulus of injectivity for various discretizations that the ill-posedness nature of non-compact operators is completely different from the nature of compact ones and that hence the simple claim of Nashed is rather problematic, because sequences of compact operators do never converge in norm to a non-compact operator. In the present paper, we try to discuss some new facets of the story of covering compact and non-compact cases under the auspices of the spectral theorem.
An illustration of those operators which are in our focus is given in Figure 1 at the end of this introduction. Let us briefly explain here this illustration of operator situations considered in the paper at hand. If T : X → Y is an injective, bounded linear operator, then T ∗ T : X → X is positive and self-adjoint and has as a consequence of Halmos' spectral theorem from [11] a spectral decomposition with a multiplier function λ on some measure space (Ω , µ ) (see Section 3 for details). Under the auspices of the spectral theorem, we will classify the operators T by means of properties of the multiplier function λ . Our focus is on the classification of ill-posed situations that are indicated by the occurrence of essential zeros of the function λ . Such ill-posed problem are characterized in Figure 1 by two areas marked hatched in red. The right crescent of this red area is devoted to the subcase of compact operators (type II ill-posedness), whereas the left part of the red area is reserved for non-compact operators (type I ill-posedness). However, we have to exclude the subsituations ( A ), ( B ) and ( C ), marked in black. First the exclave area (A) in black expresses the case of non-compact operators, where the measure µ (Ω) is finite (Assumption 1(a) below is violated). This case is widely discussed in the literature, in particular for multiplication operators on X = L 2 (0 , 1) with Lebesgue measure µ = µ Leb , and we give an overview of literature and specific approaches for that subcase in the appendix. The second black half-circle (B) in Figure 1 collects exceptional situations, where the corresponding distribution function Φ (see formula (7)) is not informative and Assumption 1(b) below is violated. Such situation is made explicit in Example 5 below. It also occurred in [17, Example 1] in form of a diagonal operator in /lscript 2 , where only a subsequence of the diagonal elements tends to zero. The last small black semi-circle (C) is reserved for possibly occurring situations, where µ cannot chosen to be the Lebesgue measure µ Leb on some subset of R d (Assumption 2 is violated). All three cases marked in black are beyond our focus of this paper.
The paper is organized as follows: In the following Section 2 we recall the well-known concept of the degree of ill-posedness for equations with compact operators and derive equivalent characterizations of the important interval of ill-posedness . Section 3 is dedicated to the inclusion of the non-compact case. We there state the Halmos version of the spectral theorem to be used in the following, define the corresponding distribution function, and illustrate along examples how it can be used to define the degree of ill-posedness. Afterwards, we give our definition and relate it to the compact subcase. Since the focus of our studies is on multiplication operators on infinite measure spaces , a glimpse of the finite measure case is given in an appendix. In Section 4 we discuss prominent examples of non-compact operators with non-closed range, such as the Hausdorff moment operator and convolutions, and derive their degree of ill-posedness. Section 5 is briefly devoted to the case of unbounded operators, which in principle could be handled similarly. We end our manuscript by a brief conclusion and outlook in Section 6.
## positive self-adjoint linear operators in X
Figure 1: Illustrative preview of occurring case distinctions
## 2 The degree of ill-posedness for equations with compact operators
To get a blueprint for an application to non-compact operators, we consider in this section compact and injective linear operators T : X → Y mapping between infinite dimensional Hilbert spaces X and Y that lead to ill-posed operator equations (1) of type II in the sense of Nashed. They are well-studied in the literature. These studies include reasonable definitions for moderately, severely and mildly ill-posed problems as well as for the degree of ill-posedness, which should be extendable to ill-posendness of type I.
For injective compact operators T leading to ill-posedness of type II, the degree of ill-posedness is typically defined by means of the singular value decomposition. Recall, that there exists a uniquely determined singular system { ( u , v n n , σ n ) } n ∈ N of T such that { u n } n ∈ N is a complete orthonormal system in X , { v n } n ∈ N is a complete orthonormal system on the range ran( T ), and σ 1 ≥ σ 2 ≥ ... ≥ σ n ≥ ... are the corresponding singular values obeying the conditions
$$T u _ { n } = \sigma _ { n } v _ { n }, \quad T ^ { * } v _ { n } = \sigma _ { n } u _ { n } \quad ( n \in \mathbb { N } ).$$
The ill-posedness of equations involving T is due to the fact that lim n →∞ σ n = 0, and the decay rate of { σ n } n ∈ N indicates the severeness of this ill-posedness. The first case of a polynomial decay of singular values for compact operators is well-known in the literature as moderate ill-posedness (cf., e.g., [13])), the second case of an exponential decay as severe ill-posedness (cf., e.g., [6]). The third case of a logarithmic decay can consequently be characterized as mild ill-posedness (cf., e.g, [1]).
For a refinement of ill-posedness measurements, in [20] (see also [17]) an interval of ill-posedness was introduced, which turns out to be helpful also when generalizing the degree of ill-posedness to non-compact operators. All the above nomenclature can be expressed by means of this interval as collected in the following definition:
Definition 1. Let T : X → Y be an injective and compact linear operator between infinitedimensional Hilbert spaces X and Y , and let σ n be the corresponding singular values. We define
the interval of ill-posedness of the operator equation (1) as
$$[ A _ { \sigma }, B _ { \sigma } ] \coloneqq \left [ \liminf _ { n \to \infty } \frac { - \log ( \sigma _ { n } ) } { \log ( n ) } \,, \, \limsup _ { n \to \infty } \frac { - \log ( \sigma _ { n } ) } { \log ( n ) } \right ] & \subset [ 0, \infty ]. & \quad \quad ( 2 ) \\. & \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \delta$$
Furthermore, we call the ill-posed operator equation (1) mildly ill-posed whenever A σ = B σ = 0 , severely ill-posed whenever A σ = B σ = ∞ , moderately ill-posed whenever 0 < A σ ≤ B σ < ∞ , and ill-posed of degree s > 0 if A σ = B σ = s ∈ (0 , ∞ ) .
Example 1 (Riemann-Liouville fractional integration of order α > 0 (cf. [35])) . For the family of the compact operators T := J α : X = L 2 (0 , 1) →Y = L 2 (0 , 1) defined as
$$[ J ^ { \alpha } x ] ( s ) \coloneqq \int _ { 0 } ^ { s } \frac { ( s - t ) ^ { \alpha - 1 } } { \Gamma ( \alpha ) } x ( t ) \, d t \ \ ( s \in [ 0, 1 ] ),$$
we have that σ n /equivasymptotic n -α as n →∞ , and (1) is ill-posed of degree s = α , since lim n →∞ -log( σ n ) log( n ) = α .
Example 2 (Multivariate integration in the d -dimensional case (cf. [15])) . For the compact integration operator T := J d : X = L 2 ((0 , 1) d ) →Y = L 2 ((0 , 1) d ) defined as
$$[ J _ { d } x ] ( s _ { 1 }, \dots, s _ { d } ) \coloneqq \int _ { 0 } ^ { s _ { 1 } } \dots \int _ { 0 } ^ { s _ { d } } x ( t _ { 1 }, \dots, t _ { d } ) \, d t _ { d } \dots d t _ { 1 } \ \ ( ( s _ { 1 }, \dots, s _ { d } ) \in ( 0, 1 ) ^ { d } ), \\ \intertext { n - w - 1 }$$
we derive that σ n /equivasymptotic [log( n )] d -1 n as n →∞ , and (1) is ill-posed of degree s = 1 ( independent of the dimension d ∈ N ), because lim n →∞ -log( [log( n )] d -1 n ) log( n ) = 1.
The aim of the paper at hand is to extend the above definition to the case of non-compact operators T leading to ill-posed operator equations (1) of type I. To do so, several issues have to be considered. First of all, a non-compact operator does not possess a singular value decomposition. This can be handled by considering the self-adjoint operator T ∗ T : X → X instead, which possesses a spectral decomposition to be discussed below. However, the lack of singular values for T (or of eigenvalues for T ∗ T ) still requires further amendments, since no decay rate can be defined directly. The idea we will elaborate therefore can be explained in case of compact linear operators as now described. Following [3], we define the counting function Φ : (0 , ∞ → ) R as
$$\Phi ( \epsilon ) = \# \{ n \in \mathbb { N } \, \colon \, \sigma _ { n } ^ { 2 } > \epsilon \} \quad ( \epsilon > 0 ) \,.$$
Then the degree of ill-posedness can also be measured by the rate of increase of Φ as /epsilon1 ↘ 0. Obviously, it holds Φ( ) = 0 for /epsilon1 /epsilon1 ≥ σ 2 1 = ‖ T ∗ T ‖ , 0 < Φ( ) /epsilon1 < ∞ for all 0 < /epsilon1 < σ 2 1 , and the limit condition lim n →∞ σ n = 0 indicating ill-posedness transforms into lim /epsilon1 ↘ 0 Φ( ) = /epsilon1 ∞ .
Theorem 1. The interval of ill-posedness of (1) is given by
$$[ A _ { \sigma }, B _ { \sigma } ] = \left [ \liminf _ { \epsilon \searrow 0 } \frac { \log ( \epsilon ) } { - 2 \log \left ( \Phi ( \epsilon ) \right ) }, \limsup _ { \epsilon \searrow 0 } \frac { \log ( \epsilon ) } { - 2 \log \left ( \Phi ( \epsilon ) \right ) } \right ].$$
Proof. For brevity, we denote
$$A _ { \Phi } \coloneqq & \liminf _ { \epsilon \searrow 0 } \frac { \log ( \epsilon ) } { - 2 \log \left ( \Phi ( \epsilon ) \right ) }, & B _ { \Phi } \coloneqq & \limsup _ { \epsilon \searrow 0 } \frac { \log ( \epsilon ) } { - 2 \log \left ( \Phi ( \epsilon ) \right ) }.$$
With this notation, we have to show that [ A ,B σ σ ] = [ A ,B Φ Φ ], which corresponds to A Φ = A σ and B Φ = B σ .
A Φ ≥ A σ By definition, for every δ > 0 there exists N 1 = N 1 ( δ ) such that -log( σ n ) log( n ) > A σ -δ for all n ≥ N 1 . This implies σ n < n δ -A σ for all n ≥ N 1 and hence
$$\left \{ n \in \mathbb { N } \, | \, n \geq N _ { 1 }, \sigma _ { n } ^ { 2 } > \epsilon \right \} & \subseteq \left \{ n \in \mathbb { N } \, | \, n \geq N _ { 1 }, n ^ { 2 \delta - 2 A _ { \sigma } } > \epsilon \right \}.$$
This implies
$$\Phi \left ( \epsilon \right ) \lesssim & \, \# \{ n \in \mathbb { N } \, | \, n ^ { 2 \delta - 2 A _ { \sigma } } > \epsilon \} \asymp \left ( \frac { 1 } { \epsilon } \right ) ^ { \frac { 1 } { 2 ( A _ { \sigma } - \delta ) } } \\ \text{s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.s.}$$
as /epsilon1 ↘ 0. Consequently -2 log(Φ( )) /epsilon1 ≥ -2 1 2( A σ -δ ) log ( 1 /epsilon1 ) = 1 A σ -δ log( ) as /epsilon1 /epsilon1 ↘ 0, and since log( ) /epsilon1 < 0 in this limiting process, we obtain
$$\liminf _ { \epsilon \searrow 0 } \frac { \log ( \epsilon ) } { - 2 \log \left ( \Phi ( \epsilon ) \right ) } \geq A _ { \sigma } - \delta.$$
Letting δ → 0 shows A Φ = lim inf /epsilon1 ↘ -0 log( /epsilon1 ) 2 log(Φ( )) /epsilon1 ≥ A σ .
A Φ ≤ A σ By definition, for every δ > 0 there exists /epsilon1 0 > 0 such that log( /epsilon1 ) -2 log(Φ( )) /epsilon1 > A Φ -δ for all 0 < /epsilon1 < /epsilon1 0 . This implies (for δ < A Φ , which we can assume w.l.o.g.) that Φ( ) /epsilon1 < ( 1 /epsilon1 ) 1 2( A Φ -δ ) for all 0 < /epsilon1 < /epsilon1 0 , and consequently σ n < n δ -A Φ as n → ∞ . This implies A σ > A Φ -δ , which by δ ↘ 0 yields A Φ ≤ A σ .
The proof of B Φ = B σ follows similarly.
Corollary 1. Let T : X → Y be an injective and compact linear operator between infinitedimensional Hilbert spaces X and Y , and let Φ its counting function as in (3) . Then the interval of ill-posedness of (1) is given as
$$[ A _ { \Phi }, B _ { \Phi } ] \coloneqq \left [ \liminf _ { \epsilon \searrow 0 } \frac { \log ( \epsilon ) } { - 2 \log \left ( \Phi ( \epsilon ) \right ) }, \limsup _ { \epsilon \searrow 0 } \frac { \log ( \epsilon ) } { - 2 \log \left ( \Phi ( \epsilon ) \right ) } \right ],$$
and the operator equation (1) is mildly ill-posed whenever A Φ = B Φ = 0 , severely ill-posed whenever A Φ = B Φ = ∞ , moderately ill-posed whenever 0 < A Φ ≤ B Φ < ∞ , and ill-posed of degree s > 0 if A Φ = B Φ = s .
As mentioned before, the counting function Φ as introduced by formula (3) received some attention when studying statistical inverse problems before, see [3]. The above corollary is advantageous whenever Φ can be computed directly without knowing the singular values σ n explicitly. An example for this is the following situation. Consider the negative Laplace operator -∆on some compact, smooth Riemannian manifold S of dimension d . Then it follows from Weyl's asymptotic law (see [34], Chap. 8, Thm. 3.1 and Cor. 3.5) that the counting function
$$N ( \lambda ) = \# \left \{ i \in \mathbb { N } \, | \, \lambda _ { i } \leq \lambda \right \}$$
of its eigenvalues λ i satisfies see also Sect. 5 in [3]. Consequently, if T ∗ T can be written as T ∗ T = Θ( -∆) with a monotonically decreasing function Θ satisfying lim t →∞ Θ( ) = 0, we obtain t
$$N ( \lambda ) & \sim \frac { \text{vol} ( S ) } { \Gamma \left ( \frac { d } { 2 } + 1 \right ) ( 4 \pi ) ^ { \frac { d } { 2 } } } \lambda ^ { \frac { d } { 2 } }, \\ \text{lently, if } T ^ { * } T \, \text{can be written as } T ^ { * } T = \\ \text{ng} \lim _ { \sim } \sim \Theta ( t ) = 0. \, \text{we obtain}$$
$$\Phi \left ( \epsilon \right ) & \sim c _ { S } \left ( \Theta ^ { - 1 } \left ( \epsilon \right ) \right ) ^ { \frac { d } { 2 } }. & & ( 4 ) \\ \text{gative Laplace operator in the $d$-dimensional case). For the special case} \\ \text{$m$} \, / \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \ \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \end{cases}$$
Example 3 (Inverse of negative Laplace operator in the d -dimensional case) . For the special case Θ( ) = t t -2 ( t > 0) of formula (4), we find for all d ∈ N that the self-adjoint compact operator T ∗ T := ( -∆) -2 on the manifold S corresponds to the counting function Φ( ) /epsilon1 ∼ c S /epsilon1 -d 4 . This yields the limit condition lim /epsilon1 ↘ -0 log( /epsilon1 ) 2 log(Φ( )) /epsilon1 = 2 d and indicates that the problem is ill-posed of degree s = 2 /d , which (in contrast to the multidimensonal Example 2) strongly depends on the space dimension d of the manifold S under consideration.
The above theorem and the derived corollary show that we can express the degree of illposedness in the compact case equivalently by means of the counting function Φ from (3). In the following, we will use this as a blueprint to consistently extend the corresponding definition to the non-compact case under certain restrictions.
Remark 1. For Example 3, solving the operator equation (1) requires to find u = ( -∆) , which g means that second partial derivatives of g have to be calculated. The factor 2 in the degree of ill-posedness s = 2 /d seems to express this. Namely, for the compact embedding operator T : H p ((0 , 1) d ) → L 2 ((0 , 1) d ) from the Sobolev space of degree p > 0 to L 2 in d dimensions we have singular values as σ n /equivasymptotic n -p d (cf.,e.g.,[25, § 3c]) implying a degree of ill-posedness as s = p/d , and just for p = 2 calculations up to second partial derivatives occur.
## 3 The spectral theorem as a tool for defining the degree of ill-posedness also in the non-compact case
At this point applying the adjoint operator T ∗ : Y → X for T to the operator equation (1), we restrict our considerations to the occurring normal equation T ∗ Tu = h for h = T ∗ g to (1) with the bounded, self-adjoint and positive semi-definite operator T ∗ T : X → X . Let us mention that the ill-posedness and the type of ill-posedness of equation (1) carry over to the normal equation.
## 3.1 The spectral theorem according to Halmos
Moreover, we recall the spectral theorem in multiplication operator form by Halmos [11] and take into account the additional notes in [10, p. 47] and [37, Chap. VII.1]. Then the following holds true for the normal operator T ∗ T : X → X : There exists a locally compact topological space Ω, a semi-finite (Radon) measure µ on Ω with finite or infinite measure value µ (Ω), a real-valued function λ ∈ L ∞ (Ω , µ ), and a unitary mapping W : L 2 (Ω , µ ) →X such that
$$W ^ { * } T ^ { * } T W = M _ { \lambda } \,,$$
with the multiplication operator M λ : L 2 (Ω , µ ) → L 2 (Ω , µ ) defined for all ξ ∈ L 2 (Ω , µ ) as
$$[ M _ { \lambda } \xi ] ( \omega ) \coloneqq \lambda ( \omega ) \cdot \xi ( \omega ) \quad ( \mu - \text{a.e. on } \Omega ).$$
We note that this existence assertion applies to compact and non-compact operators T : X → Y in the same way. Due to the positive semi-definiteness of the operator T ∗ T : X → X , the multiplier function λ is non-negative almost everywhere. Furthermore, its essential range
$$\text{essran} ( \lambda ) = \{ z \in [ 0, \infty ) \, \colon \, \mu ( \{ \omega \in \Omega \, \colon \, | z - \lambda ( \omega ) | \leq \eta \} ) > 0 \text{ for all } \eta > 0 \}$$
coincides with the spectrum spec( T ∗ T ) of the operator T ∗ T (cf., e.g., [10, Theorem 2.1(g)]) and is hence a subset of [0 , ‖ T ∗ T ‖ ] = [0 , ‖ T ‖ 2 ]. Let us mention that the injectivity requirement for T made throughout this paper implies that µ ( { ω ∈ Ω : λ ω ( ) = 0 } ) = 0.
The operator equation (1) is ill-posed if and only if 0 ∈ spec( T ∗ T ). Then as a consequence of the above mentioned coincidence between spectrum of T ∗ T and the essential range of the multiplier function λ , the criterion of ill-posedness for (1) is the occurrence of an essential zero of the function λ , which means that zero belongs to the essential range of λ . Our goal is to characterize the illposedness of the original operator equation (1) and its associated normal equation by properties of this multiplier function λ in (6) and their implications. However, this is not immediately possible without further restrictions, since the spectral decomposition (5) is not uniquely determined for the operator T as the following lemma indicates. Note that this observation was already employed in [3]:
Lemma 1. If κ : Ω → (0 , ∞ ) is a µ -measurable function, then also
$$\tilde { W } ^ { * } T ^ { * } T \tilde { W } = M _ { \lambda } \,,$$
with
$$\tilde { \mu } \coloneqq \kappa \mu, \quad \tilde { W } \colon L ^ { 2 } \left ( \Omega, \tilde { \mu } \right ) \rightarrow \mathcal { X }, \quad \tilde { W } = W \circ M _ { \kappa ^ { \frac { 1 } { 2 } } }$$
is a spectral decomposition of T ∗ T .
Proof. First we show that ˜ W is unitary. For f ∈ L 2 (Ω ˜) we have , µ
$$\left \langle \tilde { W } f, \tilde { W } g \right \rangle _ { \mathcal { X } } = \left \langle W ( \kappa ^ { \frac { 1 } { 2 } } f ), W ( \kappa ^ { \frac { 1 } { 2 } } g ) \right \rangle _ { \mathcal { X } } = \left \langle \kappa ^ { \frac { 1 } { 2 } } f, \kappa ^ { \frac { 1 } { 2 } } g \right \rangle _ { L ^ { 2 } ( \Omega, \mu ) } \\ = \int _ { \Omega } \kappa f \bar { g } \, d \mu = \int _ { \Omega } f \bar { g } \, d \bar { \mu } = \left \langle f, g \right \rangle _ { L ^ { 2 } ( \Omega, \bar { \mu } ) } \\ \text{since $\kappa$ is real-valued and $W$ unitarv. Furthermore the containment}$$
since κ is real-valued and W unitary. Furthermore, the computation
$$\left \langle \tilde { W } f, x \right \rangle _ { \chi } = \left \langle W \left ( \kappa ^ { \frac { 1 } { 2 } } f \right ), x \right \rangle _ { \chi } = \left \langle \kappa ^ { \frac { 1 } { 2 } } f, W ^ { * } x \right \rangle _ { L ^ { 2 } ( \Omega, \mu ) } \\ = \int _ { \Omega } \kappa ^ { \frac { 1 } { 2 } } f ( W ^ { * } x ) \, d \mu = \int _ { \Omega } \kappa ^ { - \frac { 1 } { 2 } } f ( W ^ { * } x ) \, d \tilde { \mu } = \left \langle f, \kappa ^ { - \frac { 1 } { 2 } } W ^ { * } x \right \rangle _ { L ^ { 2 } ( \Omega, \tilde { \mu } ) } \\ \text{shows that the adioint of } \tilde { W } \text{ is given } \text{by } \tilde { W } ^ { * } = M \quad \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ This yields finally}$$
shows that the adjoint of ˜ W is given by ˜ W ∗ = M κ -1 2 ◦ W ∗ . This yields finally
$$\tilde { W } ^ { * } T ^ { * } T \tilde { W } = M _ { \kappa ^ { - \frac { 1 } { 2 } } } W ^ { * } T ^ { * } T W M _ { \kappa ^ { \frac { 1 } { 2 } } } = M _ { \kappa ^ { - \frac { 1 } { 2 } } } M _ { \lambda } M _ { \kappa ^ { \frac { 1 } { 2 } } } = M _ { \lambda }.$$
Remark 2. The above non-uniqueness will lead to severe problems when defining the degree of ill-posedness for equations with non-compact T , but also in the compact case it brings in a subjective factor. To illustrate this, recall that our definition of the degree of ill-posedness for compact operators via the counting function Φ from (3) explicitly relies on the counting measure µ disc = # in (3). If we allow for other measures, we will obtain completely different asymptotical behaviors of Φ. As an example we next consider a history match problem.
## Example 4 (Periodic backwards heat equation) .
$$\frac { \partial u } { \partial t } u ( x, t ) & = \frac { \partial ^ { 2 } } { \partial t ^ { 2 } } \left ( x, t \right ) & \text{in $(-\pi,\pi)] \times (0,\bar{t}$),} \\ u ( x, 0 ) & = f ( x ) & \text{on $(-\pi,\pi]$,} \\ u ( - \pi, t ) & = u ( \pi, t ) & \text{on $(0,\bar{t}$),}$$
with a given terminal time ¯ t > 0, and denote by T BHE : L 2 ( -π, π ) → L 2 ( -π, π ). The corresponding operator equation (1) is widely understood to be exponentially ill-posed, and this is reflected by the series representation
$$( T _ { \text{BHE} } f ) ( x ) & = \sum _ { k \in \mathbb { Z } } \exp \left ( - k ^ { 2 } \vec { t } \right ) \exp \left ( i k x \right ) \hat { f } ( k ) \quad ( x \in [ - \pi, \pi ] ), \\.. \quad \hat { \ }. \. \.$$
with the Fourier coefficients ˆ ( f k ) of f . Note, that this representation corresponds to the spectral decomposition
$$\mathcal { F } ^ { * } T _ { \text{BHE} } \mathcal { F } = M _ { \lambda }$$
with λ ∈ /lscript 2 ( Z ) given by λ k ( ) = exp ( -k t 2 ¯ . ) The corresponding distribution function Φ from (3) is given by
$$\mathfrak { u } \, \upsilon y \\ \Phi ( \epsilon ) = \# \{ k \in \mathbb { Z } \ | \ \lambda ( k ) > \epsilon \} \asymp 2 \sqrt { \frac { 1 } { t } \log \left ( \frac { 1 } { \epsilon } \right ) } \quad \text{as} \quad \epsilon \searrow 0.$$
However, if we choose κ k ( ) := exp ( ¯ tk 2 ) in Lemma 1, then we obtain a different measure ˜ = µ κµ (actually a weighted counting measure) such that
$$\tilde { \Phi } ( \epsilon ) = \tilde { \mu } \left ( \left \{ k \in \mathbb { Z } \ | \ \lambda ( k ) > \epsilon \right \} \right ) = \sum _ { k \in \mathbb { Z }, k ^ { 2 } \leq \frac { 1 } { 1 } \log \left ( \frac { 1 } { \epsilon } \right ) } \kappa ( k ) \sim \frac { 1 } { \epsilon }.$$
This indicates a completely different degree of ill-posedness, and hence the counting measure has to be fixed as benchmark measure for compact operators to obtain a meaningful concept.
Remark 3. Note, that no further assumptions on the function κ in Lemma 1 are required, i.e. for any measurable κ , the corresponding ˜ = µ κµ is again a measure. Furthermore, even the additional properties of the measure space (Ω , µ ) gained from the spectral theorem, i.e. semi-finiteness, can be transferred to ˜ by requiring that µ κ is continuous. In contrast, by specific choices of κ we can obtain ˜(Ω) µ < ∞ even for µ (Ω) = ∞ and vice versa. In Figure 1 we have indicated that we will exclude the case µ (Ω) < ∞ , and hence the above consideration again indicates that we have to fix the measure µ later on in order to derive a meaningful concept of the degree of ill-posedness.
## 3.2 The distribution function measuring the strength of ill-posedness
Inspired by the counting function (3) we will consider, as an analog under the auspices of the spectral theorem and now applicable to both compact and non-compact operators T , the nonnegative, non-increasing and right-continuous distribution function
$$\Phi _ { \lambda, \mu } ( \epsilon ) \coloneqq \mu \left ( \{ \omega \in \Omega \, \colon \, \lambda ( \omega ) > \epsilon \} \right ) \quad ( \epsilon > 0 ).$$
This function Φ λ,µ is not in general informative, since it cannot be excluded that it might attain the value + ∞ on (0 , ∞ ):
Example 5 (Non-informative distribution function) . Consider Ω = [0 , ∞ ) and the associated Lebesgue measure µ = µ Leb on R with µ Leb (Ω) = ∞ . Then the function λ ω ( ) = sin ( 2 ω ) ( ω ∈ [0 , ∞ )) leads to
$$\Phi _ { \lambda, \mu _ { L e b } } ( \epsilon ) & = \begin{cases} \, \infty \quad \text{for} \quad 0 < \epsilon < 1, \\ 0 \quad \text{for} \quad \epsilon \geq 1 \end{cases} \\ \Pi _ { \infty \infty } \, \Phi. \quad \text{is not in} \, \Pi _ { \infty \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \outline } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty } \, \Phi _ { \infty }$$
as distribution function. Hence Φ λ,µ Leb is not informative at all. This is, however, an interesting example, because 0 ∈ essran( λ ) = spec( T ∗ T ) indicates ill-posedness.
As a consequence, we have to pose assumptions on the measure space (Ω , µ ) and the multiplier function λ such that the function Φ λ,µ is finite and hence informative. Furthermore, note that the function Φ λ,µ is determined by both λ and µ , and not solely by the operator T . The induced spectral decompositions in Lemma 1 might yield different functions Φ λ,µ for the same operator T . This corresponds to the problem outlined in Example 4 and indicates that we need to restrict to a certain benchmark measure space (Ω , µ ).
Assumption 1. Let, for the operator T ∗ T , for the measure space (Ω , µ ) and for the multiplier function λ in (6) defining the multiplication operator M λ from (5) obey the following two assumptions:
$$( a ) \ \mu ( \Omega ) = \infty.$$
- (b) For the distribution function Φ λ,µ it holds 0 ≤ Φ λ,µ ( /epsilon1 ) < ∞ for all /epsilon1 > 0 with the limit condition lim Φ /epsilon1 ↘ 0 λ,µ ( /epsilon1 ) = ∞ .
Proposition 1 (Ill-posedness) . If Assumption 1 is satisfied for the operator T and its corresponding measure space (Ω , µ ) and multiplier function λ , then the operator equation (1) is ill-posed.
Proof. We show that 0 ∈ essran( λ ), which is equivalent to 0 ∈ spec( T ∗ T ) and indicates the illposedness of (1). If µ ( { ω ∈ Ω : λ ω ( ) ≤ η } ) = 0 were valid for any η > 0 then, in view of µ (Ω) = ∞ and in contradiction to item (b) of Assumption 1, Φ λ,µ ( η ) = µ ( { ω ∈ Ω : λ ω ( ) > η } ) = ∞ would hold. Thus we have µ ( { ω ∈ Ω : λ ω ( ) ≤ η } ) > 0 for all η > 0, which means that 0 ∈ essran( λ ).
Let us briefly discuss sufficient conditions and counterexamples for item (b) in Assumption 1.
Lemma 2. Let µ (Ω) = ∞ . Then the following condition is sufficient for obtaining the assertion of item (b) in Assumption 1:
- (c) There exists a µ -measurable, non-negative and non-decreasing function f ( ζ ) (0 ≤ ζ < ∞ ) with f ( ζ ) > 0 for ζ > 0 such that it holds ∫ Ω f ( λ ω ( )) dµ < ∞ .
Proof. For /epsilon1 > 0 we can estimate due to the monotonicity of f and f ( /epsilon1 ) > 0 as follows:
$$0 \leq \Phi _ { \lambda, \mu } \left ( \epsilon \right ) = \int _ { \{ \omega \in \Omega \colon \epsilon < \lambda ( \omega ) \} } 1 \, d \mu & = \frac { 1 } { f ( \epsilon ) } \int _ { \{ \omega \in \Omega \colon \epsilon < \lambda ( \omega ) \} } f ( \epsilon ) \, d \mu \\ & \leq \frac { 1 } { f ( \epsilon ) } \int _ { \{ \omega \in \Omega \colon \epsilon < \lambda ( \omega ) \} } f ( \lambda ( \omega ) ) \, d \mu \leq \left ( \frac { 1 } { f ( \epsilon ) } \int f ( \lambda ( \omega ) ) \, d \mu < \infty. \right ) \\ \intertext { N e x t h t } \Phi _ { \lambda, \mu } \left ( \Phi _ { \lambda, \mu } \right ) \, \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \left ( \Phi _ { \lambda, \mu } \right ) \, \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \left ( \Phi _ { \lambda, \mu } \right ) \, \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi_ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leq \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \geq \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu } \leceil \, \Phi _ { \lambda, \mu }$$
Note that the last inequality is a consequence of the nonnegativity of the function λ and yields the finiteness of Φ λ,µ ( /epsilon1 ) for /epsilon1 > 0. The limit condition arises from lim /epsilon1 ↘ 0 Φ λ,µ ( /epsilon1 ) = µ (Ω) = ∞ if we let /epsilon1 tend to zero in (7).
An important example for condition (c) in Lemma 2 is the setting f ( ζ ) := ζ p for exponents 0 < p < ∞ , for which Lemma 2 under µ (Ω) = ∞ ensures the validity of Assumption 1. In particular, this is the case for λ ∈ L p (Ω , µ ) (1 ≤ p < ∞ ), and as a corollary to Lemma 2 we immediately find from this lemma:
Corollary 2 (Multiplier functions of L p -type) . If we have, under the condition µ (Ω) = ∞ , that λ ∈ L p (Ω , µ ) is true for some 1 ≤ p < ∞ , then item (b) of Assumption 1 is satisfied.
Note that for general operators T the assumption λ ∈ L p (Ω , µ ) for some p ∈ [1 , ∞ ) seems reasonable. In Lemma 2 in [3] it is shown that one can choose λ ∈ L 1 (Ω , µ ) as soon as T is injective and T ∗ transforms white noise into a Hilbert space valued random variable. Finally, allowing for p > 1, the assumption λ ∈ L p (Ω , µ ) generalizes this to more regular, colored noise.
Example 5 above and the following additional counterexample show that the assertion of item (b) in Assumption 1 may be violated for multiplier functions λ .
Example 6. Let µ (Ω) = ∞ and λ ω ( ) = c > 0 for all ω ∈ Ω. Then we have for the distribution function Φ λ,µ ( /epsilon1 ) = { ∞ for 0 < /epsilon1 < c 0 for /epsilon1 ≥ c , and hence item (b) in Assumption 1 is violated, but we have no ill-posedness, because 0 / ∈ essran( λ ).
In case that Assumption 1 holds true, it makes sense to formulate an analog to Definition 1 under the auspices of the spectral theorem as follows:
Definition 2. Let X and Y denote infinite-dimensional Hilbert spaces. Moreover, let T : X → Y be an injective and bounded linear operator with non-closed range, each mapping between X and Y such that the Assumption 1 is satisfied w.r.t. the distribution function Φ λ,µ from (7) . Then the interval of ill-posedness of the operator equation (1) is defined as
$$\left [ A _ { \Phi _ { \lambda, \mu } }, B _ { \Phi _ { \lambda, \mu } } \right ] \coloneqq \left [ \liminf _ { \epsilon \searrow 0 } \frac { \log ( \epsilon ) } { - 2 \log \left ( \Phi _ { \lambda, \mu } ( \epsilon ) \right ) }, \limsup _ { \epsilon \searrow 0 } \frac { \log ( \epsilon ) } { - 2 \log \left ( \Phi _ { \lambda, \mu } ( \epsilon ) \right ) } \right ], \\ \text{and the operator equation } ( 1 ) \text{ is called middle} \mu \text{ ill-posed whenever } A _ { \Phi }, \dots = B _ { \Phi }, \dots = 0. \text{ serve relay}$$
and the operator equation (1) is called mildly ill-posed whenever A Φ λ,µ = B Φ λ,µ = 0 , severely ill-posed whenever A Φ λ,µ = B Φ λ,µ = ∞ , moderately ill-posed whenever 0 < A Φ λ,µ ≤ B Φ λ,µ < ∞ , and ill-posed of degree s > 0 if A Φ λ,µ = B Φ λ,µ = s . Then the distribution functions
Theorem 2. For compact operators T , the intervals and degrees of ill-posedness from Definitions 1 and 2 agree.
Proof. For compact operators T with singular values { σ n } ∞ n =1 there is a unitary operator W : L 2 ( N , µ disc ) →X for Ω = N and the counting measure µ = µ disc such that the formulas (5) and (6) hold with the multiplier function λ n ( ) = σ 2 n ( n ∈ N ). Then the counting function Φ from (3) and the distribution function Φ λ,µ from (7) match. Taking into account the result of Corollary 1, this proves the theorem.
Indeed, by means of the spectral decomposition (5), all information of the equation T ∗ Tu = h with self-adjoint operator T ∗ T mapping in the Hilbert space X , which appears as normal equation to (1), is contained in the transformed multiplication operator equation
$$\lambda ( \omega ) \cdot \xi ( \omega ) = \zeta ( \omega ) \quad ( \mu - \text{a.e. on } \Omega )$$
in Ω, because the functions ξ, ζ ∈ L 2 (Ω , µ ) appear by unitary transformation from u and h . Formally, the inversion of equation (9) requires the division ξ ω ( ) = ζ ω ( ) λ ω ( ) ( ω ∈ Ω , µ -a.e.). Hence, instability grows if the decay rates to zero of the multiplier function λ become more and more pronounced. This motivates Definition 2 for a classification of ill-posedness strength within the class of compact operators under the measure space ( N , µ disc ) as well as for a classification within families of non-compact operators under the measure space ( R , µ Leb ), which will be discussed for example in the following subsection.
## 3.3 Ill-posedness of equations with multiplication operators on the real axis
To enter the world of ill-posed linear operator equations (1) for injective, bounded and non-compact operators T : X → Y with non-closed range, we first consider in this subsection pure multiplication operators T := M λ defined as [ M ξ λ ]( ω ) := λ ω ( ) · ξ ω ( ) ( µ -a.e. on Ω) for X = Y = L 2 (Ω) on the real axis with a measure space (Ω , µ Leb ), where Ω = R = ( -∞ , + ∞ ) is combined with the Lebesgue measure µ Leb over R . We assume that the multiplier functions λ is continuous everywhere on R and obeys the limit condition lim ω →±∞ λ ω ( ) = 0. Then we always have a non-compact operator T ∗ T with purely continuous spectrum spec( T ∗ T ) = [0 , ‖ T ∗ T ‖ ] = essran( λ ) = [0 , max ω ∈ R λ ω ( )] that implies ill-posedness of type I in the sense of Nashed of the associated operator equation (1). Definition 2 now applies here for this class of non-compact operators with non-closed range by considering the interval of ill-posedness (8) derived from the distribution function (7) with µ = µ Leb . As the variants in Example 7 below will show, also here moderately, severely and mildly ill-posed problems can be distinguished intuitively.
## Example 7.
## (a) Moderate ill-posedness:
(a1) λ ω ( ) = 1 (1+ ω 2 ) s ( ω ∈ R , s > 0) implies Φ λ,µ Leb ( /epsilon1 ) = 2 µ ( { ω ≥ 0 : 1+ ω 2 ≤ /epsilon1 -1 /s } ) , hence Φ λ,µ Leb ( /epsilon1 ) = 2 √ /epsilon1 -1 s -1 /equivasymptotic /epsilon1 -1 2 s as /epsilon1 → 0. The corresponding interval (8) hence reduces to a singleton [ A λ,µ Leb , B λ,µ Leb ] = { } s , indicating a moderate degree s > 0 of illposedness for the underlying operator equation here.
(a2) λ ω ( ) = ω 2 1+ ω 4 ( ω ∈ R , s = 1) implies Φ λ,µ Leb ( /epsilon1 ) = 2 µ ( { ω > 0 : ω 2 + ω -2 ≤ /epsilon1 -1 } ) , but for /epsilon1 /lessmuch 1 we have
Φ λ,µ Leb ( /epsilon1 ) ≈ 2 ( /epsilon1 -1 2 -/epsilon1 1 2 ) , where the zero of λ ω ( ) at ω = 0 causes the negative term .
The impact of this inner zero on the asymptotics of Φ λ,µ Leb ( /epsilon1 ) as /epsilon1 → 0 is negligible (cf. also [28, Prop. 1]), and due to the zeros of λ ω ( ) at infinity ω → ±∞ we have Φ λ,µ Leb ( /epsilon1 ) /equivasymptotic /epsilon1 -1 2 as well as [ A λ,µ Leb , B λ,µ Leb ] = 1 , expressing a degree one of ill-posedness. { }
## (b) Severe ill-posedness:
λ ω ( ) = exp ( -| ω | s ) ( ω ∈ R , s > 0) implies Φ λ,µ Leb ( /epsilon1 ) = 2 µ ( { ω ≥ 0 : ω s ≤ -log( ) /epsilon1 } ) and Φ λ,µ Leb ( /epsilon1 ) /equivasymptotic [log(1 //epsilon1 )] 1 s as /epsilon1 → 0 The zeros of λ ω ( ) at infinity ω → ±∞ imply [ A λ,µ Leb , B λ,µ Leb ] = {∞} , which is in agreement with the intuitive severe ill-posedness of the underlying operator equation.
## (c) Mild ill-posedness:
$$\lambda ( \omega ) = \begin{cases} \ [ \log ( | \omega | ) ] ^ { - 2 s } & \text{for} \quad | \omega | \geq e \\ 1 & \text{for} \quad | \omega | < e \end{cases} \quad ( s > 0 ) \quad \text{implies for} \ \ 0 < \epsilon \ll 1$$
$$\Phi _ { \lambda, \mu _ { L e b } } ( \epsilon ) = 2 \mu ( \{ \omega \geq 0 \, \colon \omega ^ { 2 s } \leq - \log ( \epsilon ) \} ) \, ( \epsilon \ll 1 ) \quad \text{and hence}$$
Φ λ,µ Leb ( /epsilon1 ) /equivasymptotic exp [ ( 1 /epsilon1 ) 1 2 s ] as /epsilon1 → 0, i.e. the interval in (8) is given by [ A λ,µ Leb , B λ,µ Leb ] = { 0 } . Again the zeros of λ ω ( ) at infinity ω →±∞ , which are of logarithmic type, determine the intuitive mild degree of ill-posedness.
For all s > 0, the variants (a1), (b) and (c) of Example 7 satisfy Assumption 1, and so does variant (a2). Furthermore, the multiplier function λ belongs to L p (Ω , µ ) in the sense of Corollary 2, for the moderately ill-posed case (a) whenever s > 1 2 p . It belongs for all s > 0 even to L 1 (Ω , µ ) in the severely ill-posed case (b). For the mildly ill-posed case (c), it makes sense to the recall Lemma 2 and in particular the condition (c) ibid. Then the increasing function f ( ζ ) = exp ( -2 /ζ 1 2 s ) is an appropriate choice for λ ω ( ) = [log( ω )] -2 s ( ω ≥ e ) from (c) such that Lemma 2 applies, because ∫ R f ( λ ω ( )) dω < ∞ . In general, such function f can be found if a setting f ( ζ ) := 1 /λ -1 ( ζ ) for sufficiently large ζ > 0 is useful, which requires a strict decay of λ ω ( ) as ω tends to infinity.
## 3.4 Chances and limitations of Lebesgue measure spaces
Lemma 1 has shown that the strength of ill-posedness expressed by interval and degree of illposedness in the sense of Definitions 1 and 2 strongly depends on the choice of the measure space (Ω , µ ). In order to overcome the difficulties arising from the ambiguity of possible measure spaces, we have great expectations of benchmark measure spaces . By using such benchmarks, the outcome of Definition 2 is uniquely determined for the operator T . The use of ( N , µ disc ) with the counting measure µ disc for the classification of compact operators is fairly uncontroversial. Likewise, the examples in Subsection 3.3 establish the Lebesgue measure µ Leb on R as a benchmark measure for the classification of families of non-compact operators, which motivates the following Assumption 2 as a supplement to Assumption 1.
Assumption 2. Let T : X → Y be a injective bounded non-compact linear operator with nonclosed range mapping between infinite-dimensional Hilbert spaces X and Y such that there exists a spectral decomposition (5) with a convex set Ω ⊆ R d , µ (Ω) = ∞ and µ = µ Leb .
This assumption might be restrictive at the moment, but we will discuss below in Section 4 several examples with non-compact operators satisfying this assumption, e.g. convolution operators and the Hausdorff moment problem. Let us emphasize that the Lebesgue measure employed in Assumption 2 is natural. Taking note of the transformations as in Lemma 1, the restriction to a situation with Lebesgue measure has the rationale background that its translation invariance ensures all frequencies to have the same influence.
It would be desirable to find a common measure space (Ω , µ ) which allows for a comparison of the ill-posedness strength between compact and non-compact operator. For example, an open question seems to be whether a severely ill-posed non-compact operator exists which in any sense proves to be more ill-posed than another moderately ill-posed compact operator. Trying to extend
Assumption 2 to compact cases, it had been an idea to use Ω = [0 , ∞ ) with the Lebesgue measure µ Leb over R as possible common measure space by exploiting the (generalized) inverse
$$\lambda ^ { * } ( \omega ) \coloneqq \inf \left \{ \tau > 0 \, \colon \, \Phi _ { \lambda, \mu } ( \tau ) \leq \omega \right \} \quad ( 0 \leq \omega < \infty )$$
of the distribution function Φ λ,µ . This decreasing rearrangement of the multiplier function λ is defined on this subset [0 , ∞ ) of the real axis, even if λ is originally defined on a subset of R d for d > 1. Moreover, λ and λ ∗ are closely related, because they have the same distribution function Φ λ,µ ( /epsilon1 ), and the growth rate of this distribution functions as /epsilon1 ↘ 0, which is relevant for Definition 2, can be rewritten under Assumption 1 as decay rate of λ ∗ ( ) t as t → ∞ , see in this context also [28].
Following this idea, compact operators T = T comp with singular values { σ n } ∞ n =1 and distribution (counting) function Φ from (3) possess the non-negative, non-increasing and piece-wise constant multiplier function λ comp defined by formula
$$\lambda _ { c o m p } ( \omega ) = \{ \sigma _ { n } ^ { 2 } \text{ if } n - 1 \leq \omega < n \ ( n = 1, 2, \dots ) \} \ \ ( 0 \leq \omega < \infty )$$
as inverse of Φ( ) /epsilon1 tending to zero as ω → ∞ . This function from (11) is the decreasing rearrangement of the original multiplier function λ comp ( n ) = σ 2 n ( n ∈ N ) assigned to T ∗ comp T comp . By bringing the Lebesgue measure over R into play, we find that
$$\Phi _ { \lambda _ { c o m p }, \mu _ { L e b } } ( \epsilon ) = \mu _ { L e b } ( \{ \omega \in [ 0, \infty ) \, \colon \, \lambda _ { c o m p } ( \omega ) > \epsilon \} ) \ \ ( \epsilon > 0 )$$
coincides with the corresponding counting function (3). If we consider the corresponding multiplication operator M λ mapping in L 2 ([0 , ∞ ) , µ Leb ) defined by formula (6) for the multiplier function λ = λ comp from (11), then this non-negative self-adjoint multiplication operator M λ comp has a pure point spectrum, and the eigenvalues of M λ comp are the same values as those of the compact operator T ∗ comp T comp . Namely, the essential range of the multiplier function and the spectrum values for a multiplication operator are identical. However, the following general assertion of Proposition 2 shows the limitation of the Lebesgue measure in this setting. Here, M λ comp is a non-compact operator with infinite dimensional eigenspaces for all eigenvalues, and the spectrum of M λ comp is not a discrete spectrum with only finite dimensional eigenspaces, which would be necessary for being a compact self-adjoint operator like T ∗ comp T comp . As a consequence we have that M λ comp as a non-compact operator cannot be derived from the compact operator T ∗ comp T comp by a unitary transformation, This implies that a desired comparison of compact and non-compact operators fails on this way.
Proposition 2. There is no compact injective non-negative multiplication operator
$$M _ { \lambda } \colon L ^ { 2 } ( [ 0, \infty ), \mu _ { L e b } ) \to L ^ { 2 } ( [ 0, \infty ), \mu _ { L e b } )$$
with real-valued multiplier function λ ∈ L ∞ ([0 , ∞ ) , µ Leb ) .
Proof. First note, that M λ is self-adjoint for any real-valued λ . Furthermore, it is bounded for λ ∈ L ∞ ([0 , ∞ ) , µ Leb ).
Since M λ is injective and non-negative, the function λ must be non-zero and non-negative itself. Hence, there exists a c > 0 such that the set S := { λ ≥ } c satisfies µ Leb ( S ) > 0. On the Hilbert space of all L 2 -functions supported in S , i.e.
$$\mathcal { V } \coloneqq \left \{ f \in L ^ { 2 } ( [ 0, \infty ), \mu _ { L e b } ) \ | \ f = f \cdot \chi _ { S } \right \}, \\ \text{urjective} \ ( \since { \mathbf e n c r } \ f \in \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r \ \mathbf e n c r } )$$
the operator M λ is surjective (since for h ∈ V it holds M λ ( hχ λ S -1 ) = hχ S = h ) and bounded (since χ λ S -1 ≤ c -1 < ∞ ). So if M λ : L 2 ([0 , ∞ ) , µ Leb ) → L 2 ([0 , ∞ ) , µ Leb ) was compact, so was
$$\text{id} _ { \mathcal { V } } = \left ( \left ( M _ { \lambda } \right ) _ { | \mathcal { V } } \right ) ^ { 1 } \left ( M _ { \lambda } \right ) _ { | \mathcal { V } } \colon \mathcal { V } \rightarrow \mathcal { V }. \\ \text{le, since } \mathcal { V } \text{ is infinite dimensional: There exist}$$
However, this is impossible, since V is infinite dimensional: There exists a partition S = ⋃ i ∈ N S i with pairwise disjoint sets S i , µ Leb ( S i ) > 0 for all i ∈ N , the indicator functions of which are linearly independent.
Remark 4. Note, that we exploited a specific property of the Lebesgue-measure here, namely that for each set S ⊆ R with µ Leb ( S ) > 0 there exists an infinite partition S = ⋃ i ∈ N S i of pairwise disjoint sets S i with µ Leb ( S i ) > 0 for all i ∈ N . However, this property is also true for any measure without atoms , including e.g. the Cantor measure on [0 1]. ,
## 4 Examples
## 4.1 The Hausdorff moment operator
Example 8 (The Hausdorff moment operator) . Apart from the simple multiplication operators on R outlined in Example 7, the operator A : L 2 (0 , 1) → /lscript 2 defined as
$$[ A x ] _ { j } \coloneqq \int _ { 0 } ^ { 1 } t ^ { j - 1 } x ( t ) \, d t \quad ( j = 1, 2, \dots ) & ( 1 2 ) \\ \text{the Handler for moment problem for } [ 1 0 ] \wr i c o n e of the most null-known non-$$
associated with the Hausdorff moment problem (cf. [12]) is one of the most well-known noncompact bounded linear operators with non-closed range. We consider as operator T : X → Y from (1) with X := /lscript 2 and Y := L 2 (0 , 1) the adjoint operator T := A ∗ : /lscript 2 → L 2 (0 , 1) to A from (12) of the form where the corresponding operator equation Tu = g is also ill-posed of type I. Then we have, for T from (13), a coincidence of T ∗ T with the infinite Hilbert matrix H such that T ∗ T = ( H i,j ) ∞ i,j =1 : /lscript 2 → /lscript 2 takes place with the entries
$$[ T u ] ( t ) \coloneqq & \sum _ { j = 1 } ^ { \infty } u _ { j } \, t ^ { j - 1 } \quad ( 0 \leq t \leq 1 ), & ( 1 3 ) \\ \text{onding operator equation } T u = q \text{ is also ill-posed of type I. Then we have, for } T$$
$$\mathcal { H } _ { i, j } = \left ( \frac { 1 } { i + j - 1 } \right ) \quad ( i, j = 1, 2, \dots ). \\ \intertext { v t \colon d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cdots d \cd.. }$$
It is well-known that T ∗ T is a non-compact linear bounded operator mapping in /lscript 2 with ‖ T ∗ T ‖ = π and pure continuous spectrum spec( T ∗ T ) = [0 , π ]. For further details concerning the Hausdorff moment problem we also refer, for example, to the studies in [9].
Concerning the spectral theorem applied to that non-negative self-adjoint operator T ∗ T : /lscript 2 → /lscript 2 we learn from [32] that the measure space (Ω , µ ) with Ω = [0 , ∞ ) and the corresponding Lebesgue measure µ = µ Leb on R is appropriate here and yields as multiplier function λ of the multiplication operator M λ from (5) the function
$$\lambda ( \omega ) = \frac { \pi } { \cosh ( \pi \omega ) } \quad ( \omega \in [ 0, \infty ) \text{ a.e.} ).$$
With respect to the function λ from (14) we simply derive as distribution function
$$\Phi _ { \lambda, \mu _ { L \epsilon b } } ( \epsilon ) & \approx \frac { 1 } { \pi } \log \left ( \frac { 2 \pi } { \epsilon } \right ) \quad \text{for sufficiently small} \, \epsilon > 0. \quad \text{(15)} \\. \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and}, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{\ } \, \text{and} \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and} \, \colon \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and} \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and} \\. \,. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \tilde {and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}.. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}". \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}\, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}.. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \text{and}. \, \text{and}. \, \text{and}. \, \text{and}.. \, \text{and}. \, \text{and}. \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \tilde {and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}. \, \text{and}.. \, \tilde {and}. \text{and}. \, \text{and}. \text{and}. \, \text{and}. \text{and}. \, \text{and}. \text{and}. \, \text{and}. \, \text{and$$
Evidently, Assumptions 1 and 2 agree in that example, and formula (15) gives as in case (b) of Example 7 that [ A Φ λ,µ Leb , B Φ λ,µ Leb ] = {∞} , which indicates severe ill-posedness of the Hausdorff moment problem.
Remark 5. If the measure µ were not fixed to be the Lebesque measure, then by choosing κ ω ( ) = 1 2 exp( πω ) in Lemma 1, we obtain a different spectral decomposition with ˜ = µ κµ Leb , which yields
$$\tilde { \Phi } _ { \lambda } & = \tilde { \mu } \left ( \{ \omega \in ( 0, \infty ) \, \colon \lambda ( \omega ) > \epsilon \} \right ) \\ & \asymp \int _ { 0 } ^ { \frac { 1 } { \pi } \log \left ( \frac { 2 \pi } { \epsilon } \right ) } \kappa ( \omega ) \, \mathrm d \omega \\ & = \frac { 1 } { 2 \pi } \exp \left ( \pi \omega \right ) \Big | _ { 0 } ^ { \frac { 1 } { \pi } \log \left ( \frac { 2 \pi } { \epsilon } \right ) } = \frac { 1 } { \epsilon } - \frac { 1 } { 2 \pi } \asymp \frac { 1 } { \epsilon } \quad \text{as} \quad \epsilon \to 0.$$
This way, a completely different asymptotic behavior indicating only moderate ill-posedness could be obtained. However, such measure ˜ would in an unnatural way up-weight the high frequencies µ exponentially.
## 4.2 Convolution operators
In this section, let us consider the injective linear convolution operator T : L 2 ( R d ) → L 2 ( R d ) , defined by with a convolution kernel h ∈ L 1 ( R d ) . The measure space (Ω , µ ) is here ( R d , µ Leb ) with the multi-dimensional Lebesgue measure over R d ( d ∈ N ) and µ Leb (Ω) = ∞ . Injectivity of T requires the condition
$$[ T u ] \left ( t \right ) = \int _ { \mathbb { R } ^ { d } } h ( t - \tau ) \, u ( \tau ) \, \mathrm d \tau \quad ( t \in \mathbb { R } ^ { d } ) \,, & ( 1 6 ) \\ \intertext { t i o n \, \text{normal} \, b \, \leq \, T ^ { 1 } \, ( \mathbb { R } ^ { d } ) \, \text{ } T h o m o s u r e n a c o f o } ( \mathcal { O } \, u \, \text{is hora } ( \mathbb { R } ^ { d } \, u \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \text{with to} }$$
$$\mu _ { \text{Leb} } ( \{ \tau \in \mathbb { R } ^ { d } \, \colon \, h ( \tau ) = 0 \} ) = 0.$$
In this case, it follows from the Fourier convolution theorem that
$$T = \mathcal { F } ^ { - 1 } M _ { \mathcal { F } h } \, \mathcal { F } \,,$$
with the Fourier transform [ F u ]( ξ ) := ∫ R d exp( -i πξx ) u x ( ) d x ( ξ ∈ R d ). Hence a spectral decomposition of T ∗ T is given as
$$\mathcal { F } T ^ { * } T \mathcal { F } ^ { - 1 } = M _ { | \mathcal { F } h | ^ { 2 } } \,.$$
/negationslash
Proposition 3. The linear convolution operator (16) mapping in L 2 ( R d ) is well-defined and bounded as soon as h ∈ L 1 ( R d ) . Moreover, the multiplier function λ assigned to T ∗ T for a measure space with Ω = R d and the Lebesgue measure µ Leb over R d satisfies Assumptions 1 and 2 whenever h ∈ L p ( R d ) for some 1 < p ≤ 2 . Proof. Let p ∈ (1 , ∞ ) with 1 /p +1 /q = 1. Then H¨ older's inequality implies
For h ∈ L 1 ( R d ) , we have that the complex function [ F h ]( ξ ) ( ξ ∈ R d ) is bounded, continuous and tends to zero as ‖ ‖ ξ tends to infinity. Thus, also the non-negative multiplier function λ ω ( ) = | [ F h ]( ω ) | 2 ( ω ∈ R d ) is bounded, continuous and tends to zero as ‖ ω ‖ → ∞ . This indicates for h = 0, which is excluded by the injectivity of T , pure continuous spectrum of T ∗ T , noncompactness of this operator and, as a consequence of 0 ∈ essran( λ ) = spec( T ∗ T ), ill-posedness of type I in the sense of Nashed of the underlying linear integral equation (1) of the first kind of convolution type in the Hilbert space L 2 ( R d ) .
| ( f ∗ h ) ( x ) | ≤ ∫ R d ( | f ( y ) || h x ( -y ) | 1 /q ) | h x ( -y ) | 1 /p d y ≤ ∥ ∥ ∥ f ( ) · | h x ( -· | ) 1 /q ∥ ∥ ∥ L q ∥ ∥ ∥ | h x ( -· | ) 1 /p ∥ ∥ ∥ L p = ∥ ∥ ∥ f ( ) · | h x ( -· | ) 1 /q ∥ ∥ ∥ L q ‖ h ‖ 1 /p L 1 almost everywhere. Therewith, it follows from Fubini's theorem that
$$\| f * h \| _ { L ^ { q } } ^ { q } & \leq \| h \| _ { L ^ { 1 } } ^ { q / p } \int _ { \mathbb { R } ^ { d } } \left \| f ( \cdot ) | h ( x - \cdot ) | ^ { 1 / q } \right \| _ { L ^ { q } } ^ { q } \, \mathrm d x = \| h \| _ { L ^ { 1 } } ^ { q / p } \int _ { \mathbb { R } ^ { d } } \int _ { \mathbb { R } ^ { d } } | f ( y ) | ^ { q } | h ( x - y ) | \, \mathrm d y \, \mathrm d x \\ & = \| h \| _ { L ^ { 1 } } ^ { q / p } \int _ { \mathbb { R } ^ { d } } | f ( y ) | ^ { q } \int _ { \mathbb { R } ^ { d } } | h ( x - y ) | \, \mathrm d x \, \mathrm d y = \| h \| _ { L ^ { 1 } } ^ { q / p + 1 } \int _ { \mathbb { R } ^ { d } } | f ( y ) | ^ { q } \, \mathrm d y = \| h \| _ { L ^ { 1 } } ^ { q } \, \| f \| _ { L ^ { q } } ^ { q } \,. \\ \text{This shows, that the convolution operator } T \, \text{in} \, ( 1 6 \, ) \, \text{is a bounded operator } T \, \colon L ^ { q } \, ( \mathbb { R } ^ { d } \, ) \rightarrow L ^ { q } \, ( \mathbb { R } ^ { d } \, )$$
This shows, that the convolution operator T in (16) is a bounded operator T : L q ( R d ) → L q ( R d ) whenever h ∈ L 1 R d .
( ) Evidently, we have µ Leb (Ω) = ∞ for Ω = R d yielding item (a) of Assumption 1. The assertion of item (b) of Assumption 1, however, is for 1 < p ≤ 2 an immediate consequence of the HausdorffYoung inequality
$$\| \mathcal { F } h \| _ { L ^ { q } ( \mathbb { R } ^ { d } ) } \leq C \, \| h \| _ { L ^ { p } ( \mathbb { R } ^ { d } ) } \quad \text{for} \ \ 1 < p \leq 2, \ \ \frac { 1 } { p } + \frac { 1 } { q } = 1 \quad \text{and} \ \ 0 < C < \infty$$
(see, e.g, [2, Theorem 1]). This implies for h ∈ L p ( R d ) (1 < p ≤ 2) that we have λ = |F h | 2 ∈ L r ( R d ) with r = p 2( p -1) ∈ [1 , ∞ ). Consequently, Corollary 2 is applicable. The proof is complete, because Assumption 2 is trivially satisfied.
Claim 1. If a convolution operator T is bounded as T : L 2 ( R d ) → H s ( R d ) with some s > 0 , then there exists a p ∈ [1 , ∞ ) such that the multiplier function λ = |F h | 2 in the spectral decomposition T ∗ T = F -1 M λ F satisfies λ ∈ L p (Ω , µ ) .
Proof. Since
$$\text{mce} \left \| g \right \| _ { H ^ { s } ( \mathbb { R } ^ { d } ) } ^ { 2 } = \int _ { \mathbb { R } ^ { d } } \left ( 1 + \left \| \xi \right \| ^ { 2 } \right ) ^ { s } | ( \mathcal { F } g ) ( \xi ) | ^ { 2 } \, \text{d} \xi = \left \| M _ { \mathcal { X } } \mathcal { F } g \right \| _ { L ^ { 2 } ( \mathbb { R } ^ { d } ) } ^ { 2 } \\ \right ) = \left ( 1 + \left \| \xi \right \| ^ { 2 } \right ) ^ { s }, \xi \in \mathbb { R } ^ { d }, \text{the composition}$$
$$M _ { \chi } \mathcal { F } T = M _ { \chi } M _ { \mathcal { F } h } \mathcal { F } = M _ { \chi \cdot \mathcal { F } h } \mathcal { F }$$
with χ ξ ( ) = ( 1 + ‖ ‖ ξ 2 ) s , ξ ∈ R d , the composition is bounded as an operator L 2 ( R d ) → L 2 ( R d ). Therefore, M χ ·F h : L 2 ( R d ) → L 2 ( R d ) needs to be bounded, which is the case if and only if χ · F h ∈ L ∞ ( R d ) . This proves the claim.
Example 9 (Simple Gaussian convolution kernel) . Consider the Gaussian convolution kernel h t ( ) = exp( -‖ ‖ t 2 ) ( t ∈ R d ) with the associated multiplier function
$$\lambda ( \omega ) = | [ \mathcal { F } h ] ( \omega ) | ^ { 2 } = \pi ^ { d } \, \exp \left ( - \| \omega \| ^ { 2 } / 2 \right ) \quad ( \omega \in \mathbb { R } ^ { d } ). \\ \mathrm e \, \lambda ( \omega ) > \epsilon \, \text{for} \, \| \omega \| < R \coloneqq \sqrt { 2 \log ( \pi ^ { d } / \epsilon ) }. \text{ However, the volume of a $d$-bal}$$
Then we have λ ω ( ) > /epsilon1 for ‖ ω ‖ < R := √ 2 log( π //epsilon1 d ). However, the volume of a d -ball with radius R is V d ( R ) = π d/ 2 Γ( d/ 2) d R d . This gives
$$\Phi _ { \lambda, \mu _ { L e b } } ( \epsilon ) & = \mu _ { L e b } \left ( \omega \in \mathbb { R } ^ { d } \, \colon \, \| \omega \| < \sqrt { 2 \log ( \pi ^ { d } / \epsilon ) } \right ) = \frac { \pi ^ { d / 2 } } { \Gamma ( d / 2 ) \, d } \, \left ( \sqrt { 2 \log ( \pi ^ { d } / \epsilon ) } \right ) ^ { d } \\ \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{-} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \, \text{--} \,$$
and leads to the asymptotics
$$\Phi _ { \lambda, \mu _ { L e b } } ( \epsilon ) \asymp \, [ \log ( 1 / \epsilon ) ] ^ { \frac { d } { 2 } } \ \text{ as } \ \epsilon \searrow 0,$$
which shows A Φ λ,µ Leb = B Φ λ,µ Leb = ∞ indicating severe ill-posedness.
Example 10 (Convolution kernel leading to mild ill-posedness) . Consider the convolution kernel h on R d defined by means of its Fourier transform
$$\mathcal { F } h ( \xi ) = \frac { 1 } { \left ( 1 + b \left \| \xi \right \| _ { 2 } ^ { 2 } \right ) ^ { a } } \\ \text{place-type kernels have been us}$$
for parameters a, b > 0. Such Laplace-type kernels have been used in super-resolution microscopy to approximate the point spread function of a STED microscope, see [31]. The associated multiplier function λ is given by
$$\lambda ( \omega ) = | [ \mathcal { F } h ] ( \omega ) | ^ { 2 } = \frac { 1 } { \left ( 1 + b \left \| \xi \right \| _ { 2 } ^ { 2 } \right ) ^ { 2 a } } \quad ( \omega \in \mathbb { R } ^ { d } ), \\ \text{similarly to Example 7 that}$$
which implies similarly to Example 7 that
$$\Phi _ { \lambda, \mu _ { L e b } } ( \epsilon ) \asymp \epsilon ^ { - \frac { 1 } { 4 a } } \text{ as } \epsilon \searrow 0,$$
indicating a degree 2 a of ill-posedness.
## 5 The case of unbounded operators
As in Section 3 we discuss the application of the spectral theorem, but with one substantial change: the injective linear operator T : D T ( ) ⊂ X → Y with domain D T ( ) dense in X and hence its self-adjoint non-negative companion T ∗ T : D T ( ) ⊂ X → X with 0 ∈ spec( T ∗ T ) are unbounded and consequently not compact. Then the spectral theorem in multiplication operator version is also available, and we refer for details to [37, Chapt. VII.3]. In particular, now in the factorization (5) there occurs an unbounded multiplication operator M λ (cf. (6)) with a µ -measurable multiplier function λ : Ω → R such that min essran( λ ) = 0 and sup essran( λ ) = + ∞ , since we have again the coincidence spec( T ∗ T ) = essran( λ ). Let Assumption 1 be valid, which implies that µ (Ω) = ∞ , the distribution function Φ λ,µ Leb ( /epsilon1 ) (cf. (7)) is finite for all /epsilon1 > 0 and its inverse λ ∗ , the decreasing rearrangement of λ , is well-defined and an index function at the infinity. It is not difficult to understand that poles of λ do not really influence the decay rate of λ ∗ ( ) as t t →∞ . Thus, Definition 2 seems to be applicable also here for verifying the degree of ill-posedness. Regularization approaches for ill-posed operator equations with unbounded forward operators are, for example, discussed in [19] and [36] by exploiting the role of corresponding multiplier functions.
Example 11 (Fractional integral operators on R ) . Following [33] we consider with X = Y = L 2 ( R ) the family of fractional integration operators T s : L 2 ( R ) → L 2 ( R ). This family depending on the parameter s > 0 is defined as
$$[ T _ { s } ( u ) ] ( t ) \coloneqq \frac { 1 } { \Gamma ( s ) } \int _ { - \infty } ^ { t } \frac { u ( \tau ) } { ( t - \tau ) ^ { 1 - s } } \, d \tau \quad ( t \in \mathbb { R } ). \quad \quad ( 1 7 ) \\. \quad \sim \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \cdots \quad.$$
All these operators T s are densely defined, injective and closed on their domains, which can be introduced by means of the Fourier transform F as
$$D ( T _ { s } ) = \{ u \in L ^ { 2 } ( \mathbb { R } ) \, \colon | \xi | ^ { - s } [ \mathcal { F } u ] ( \xi ) \in L ^ { 2 } ( \mathbb { R } ) \}.$$
The corresponding operator T ∗ s T s , however, is self-adjoint with domain
$$D ( T _ { s } ^ { * } T _ { s } ) = \{ u \in L ^ { 2 } ( \mathbb { R } ) \, \colon | \xi | ^ { - 2 s } [ \mathcal { F } u ] ( \xi ) \in L ^ { 2 } ( \mathbb { R } ) \}.$$
Moreover, we obtain with respect to the Lebesgue measure on R the multiplication operator F T ∗ T F -1 = M λ with the multiplier function
$$\lambda ( \omega ) = | \omega | ^ { - 2 s } \quad ( \omega \in \Omega = \mathbb { R } \text{ a.e.} ).$$
The inspection of formula (18) with some pole at ω = 0 shows that, for all s > 0, essran( λ ) = [0 , ∞ ) = spec( T ∗ s T s ). Hence the unbounded operator T ∗ s T s has continuous spectrum. In analogy to item (a1) of Example 7 on can show that the problem is moderately ill-posed with degree s > 0.
Example 12 (Source identification in parabolic PDEs) . We consider the final value problem for the non-homogeneous heat equation
$$\begin{cases} \ v _ { t } ( x, t ) - \kappa ^ { 2 } \Delta v ( x, t ) = u ( x ), & x \in \mathbb { R } ^ { d }, \quad t > 0, \\ \ v ( x, 0 ) = 0, & x \in \mathbb { R } ^ { d }, \\ \ v ( x, t _ { 0 } ) = g ( x ), & x \in \mathbb { R } ^ { d }, \quad t _ { 0 } > 0. \end{cases}$$
↦
For X = Y = L 2 ( R d ), given κ > 0 and t 0 > 0 let the equation (1) represent a source identification problem with the forward operator T : u → g , which is implicitly given by the above final value problem. Fourier transform F with respect to x yields the associated multiplication operator for T ∗ T of the form F T ∗ T F -1 = M λ with the multiplier function
$$\lambda ( \omega ) = \frac { \left [ 1 - \exp \left ( - t _ { 0 } \, \kappa ^ { 2 } \| \omega \| _ { 2 } ^ { 2 } \right ) \right ] ^ { 2 } } { \kappa ^ { 4 } \| \omega \| _ { 2 } ^ { 4 } } \quad ( \omega \in \mathbb { R } ^ { d } ).$$
One easily finds that here spec( T ∗ T ) = essran( λ ) = [0 , ∞ ), which means that T ∗ T is a noncompact, unbounded linear operator, because λ ω ( ) has a pole at ω = 0. Moreover, ill-posedness takes place with lim ‖ ω ‖ →∞ 2 λ ω ( ) = 0. Now we have λ ω ( ) /equivasymptotic ‖ ω ‖ -4 2 as ‖ ω ‖ 2 → ∞ , which should imply for the decreasing rearrangement λ ∗ of λ that λ ∗ ( ) t /equivasymptotic t -4 d as t → ∞ , which indicates moderate ill-posedness with degree s = 2 d . By applying for sufficiently small /epsilon1 > 0 the distribution function Φ λ,µ Leb ( /epsilon1 ) ≈ µ Leb ( { ω ∈ R d : ‖ ω ‖ 2 ≤ 1 κ/epsilon1 1 / 4 ) } ), the denominator d in the asymptotics of λ ∗ arises from the fact that the volume of a ball in R d with radius 1 κ/epsilon1 1 / 4 is proportional to /epsilon1 -d/ 4 .

We refer to [36] for more details and the discussion of the full parabolic source identification problem in the multidimensional case. Let us note here that such degree of ill-posedness s = 2 d with dimension d in the denominator also occurs for various compact multivariate forward operators, e.g. for the inverse of the negative Laplacian in L 2 (Σ) with homogeneous boundary conditions on a bounded domain Σ ⊂ R d and with such Σ for the embedding operator from H 1 (Σ) into L 2 (Σ) (see also Example 3).
## 6 Conclusion and outlook
In this paper, we have presented a unified framework for measuring the degree of ill-posedness for linear operator equations by means of its spectral decomposition. We have shown that the derived concept coincides with the well-known definition in the compact case and allows us to interpret several non-compact operator equations as moderately or severely ill-posed as well when the Lebesgue measure is chosen as benchmark case. Unfortunately, cross comparisons between compact and non-compact operators cannot be handled by our framework, because compact operators and the Lebesgue measure are not compatible with respect to multiplication operators, and we refer to Proposition 2 in this context.
Currently our concept is also limited concerning the special situations (A), (B) and (C) in Figure 1, which have to be excluded for different reasons. It will be an interesting topic for future research to investigate whether a situation of finite measure µ (Ω) can be handled similarly or not. Furthermore it is unclear if other concepts to measure ill-posedness by means of essential zeros of λ in the situation (B) can be related to our concept in some way. Finally, it would be an interesting question to find real-world examples for the situation (C). This mostly seems to be a measure-theoretic problem.
Compared to the compact subcase, it is also completely open what can be said about the degree of ill-posedness of the composition of two operators. The Courant-Fischer theorem yields an upper bound for the decay rate of the singular values of the composition of two compact operators, and hence a lower bound for its degree of ill-posedness. However, in the non-compact case no such result is known yet, and it is not clear if anything can be proven about a composition's degree of ill-posedness with our concept. Furthermore, if a compact and a non-compact operator are composed, strange things can happen as has been recently demonstrated in [5, 18, 22].
## Acknowledgment
The second named author has been supported by the German Science Foundation (DFG) under grant HO 1454/13-1 (Project No. 453804957).
## Appendix: A glimpse of the finite measure case
In this appendix, we return to the case of bounded linear operators T : X → Y , and we will briefly summarize references and specific approaches for the alternative case of finite measures µ (Ω) < ∞ . This case has been comprehensively studied in the literature for non-compact multiplication operators T mapping in L 2 (Ω) for some bounded subinterval Ω of R . The focus of most
papers is on the unit interval Ω = [0 , 1] and the Lebesgue measure µ = µ Leb over R . For that measure, non-negative multiplier functions λ ∈ L ∞ (0 , 1) are under consideration that possess essential zeros inside [0 , 1]. This leads to ill-posed situations of the corresponding operator equations (1), where the structure of the zeros seem to play a prominent role for the strength of the ill-posedness. We refer in this context to [8, 14, 16, 21, 22] and recently [28]. In the latter reference, in particular, the total influence of different essential zeros of the multiplier function λ on the increasing rearrangement of λ is discussed. This increasing rearrangement (see for details [7]) and its growth rate at a neighbourhood of zero are tools for characterizing the degree of ill-posedness for this class of non-compact operators modelled with finite measure spaces.
Unfortunately, the cross connections of this increasing rearrangement concept for Ω = [0 , 1] and the associated decreasing rearrangement concept for µ (Ω) = ∞ , see formula (10) above, are not completely clear. It is appropriate for the finite measure case to use instead of (7) the non-decreasing distribution function
$$d _ { \lambda } ( \epsilon ) \coloneqq \mu \left ( \{ \omega \in [ 0, 1 ] \, \colon \, \lambda ( \omega ) \leq \epsilon \} \right ) \ \ ( 0 \leq \epsilon \leq \| T \| )$$
of the non-negative multiplier function λ ω ( ) (0 ≤ ω ≤ 1), and instead of (10) the increasing rearrangement λ ∗ of λ defined as
$$\lambda ^ { * } ( t ) = \sup \left \{ \epsilon \in [ 0, \| T \| ] \colon \, d _ { \lambda } ( \epsilon ) \leq t \right \} \ \ ( 0 \leq t \leq 1 ),$$
which is the (generalized) inverse to the function d λ . Both d λ and λ ∗ are index functions at zero, which means that they are non-decreasing functions with positive values for positive arguments and zero limits as the arguments tend to zero. Then the most authors characterize the ill-posedness by the growth rate of the function λ ∗ ( ) t in a right neighborhood of t = 0. As shown in [28, Proposition 2] the strongest essential zero of the multiplier λ over the interval [0 , 1] is responsible for the degree of ill-posedness.
## References
- [1] S. Agapiou and P. Math´ e. Designing truncated priors for direct and inverse Bayesian problems. Electron. J. Stat. , 16(1):158-200, 2022.
- [2] W. Beckner. Inequalities in Fourier analysis. Annals of Mathematics , 102(1):159-182, 1975.
- [3] N. Bissantz, T. Hohage, A. Munk, and F. Ruymgaart. Convergence rates of general regularization methods for statistical inverse problems and applications. SIAM J. Numer. Anal. , 45(6):2610-2636 (electronic), 2007.
- [4] A. Brown, P. R. Halmos, and A. L. Shields. Ces` aro operators. Acta Sci. Math. (Szeged) , 26:125-137, 1965.
- [5] Y. Deng, H.-J. Fischer, and B. Hofmann. The degree of ill-posedness for some composition governed by the Ces`ro operator. a In B. Mejri, R. Ramlau, and O. Scherzer, editors, Inverse Problems on Large Scales - Mathematical Modelling and Computational Methods , Vol. 32 of Radon Serie on Computational and Applied Mathematics, pages 1-14. De Gruyter, Berlin/Boston, 2025. Preprint: https://arxiv.org/pdf/2401.11411.pdf.
- [6] H. W. Engl, M. Hanke, and A. Neubauer. Regularization of Inverse Problems . Kluwer, Dortrecht, 1996.
- [7] H. W. Engl, B. Hofmann, and H. Zeisel. A decreasing rearrangement approach for a class of ill-posed nonlinear integral equations. J. Integral Equations Appl. , 5(4):443-463, 1993.
- [8] M. Freitag and B. Hofmann. Analytical and numerical studies on the influence of multiplication operators for the ill-posedness of inverse problems. J. Inverse Ill-Posed Probl. , 13(2):123-148, 2005.
| [9] | D. Gerth, B. Hofmann, C. Hofmann, and S. Kindermann. The Hausdorff moment problem in the light of ill-posedness of type I. Eurasian Journal of Mathematical and Computer Applications , 9(2):57-87, 2021. https://drive.google.com/file/d/1HrfnEh2qYQms2xgCvpcCcFXBKBt8Pp0Y/view. |
|-------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [10] | M. Haase. Lectures on Functional Calculus . Virtual Lectures of 21st International Internet Seminar. University of Kiel, 2018. https://www.math.uni-kiel.de/isem21/en/course/phase1/isem21-lectures-on-functional- calculus. |
| [11] | P. R. Halmos. What does the spectral theorem say? American Mathematical Monthly , 70:241-247, 1963. |
| [12] | F. Hausdorff. Momentprobleme f¨r u ein endliches intervall (German). Math. Z. , 16(1):220-248, 1923. |
| [13] | B. Hofmann. Regularization for Applied Inverse and Ill-Posed Problems . B. G. Teubner, Leipzig, 1986. |
| [14] | B. Hofmann. Approximate source conditions in Tikhonov-Phillips regularization and con- sequences for inverse problems with multiplication operators. Math. Methods Appl. Sci. , 29(3):351-371, 2006. |
| [15] | B. Hofmann and H.-J. Fischer. A note on the degree of ill-posedness for mixed differentiation on the d-dimensional unit cube. J. Inv. Ill-Posed Problems , 31(6):949-957, 2023. |
| [16] | B. Hofmann and G. Fleischer. Stability rates for linear ill-posed problems with compact and non-compact operators. Z. Anal. Anwendungen , 18(2):267-286, 1999. |
| [17] | B. Hofmann and S. Kindermann. On the degree of ill-posedness for linear problems with non-compact operators. Methods Appl. Anal. , 17(4):445-461, 2010. |
| [18] | B. Hofmann and P. Math´. e The degree of ill-posedness of composite linear ill-posed problems with focus on the impact of the non-compact Hausdorff moment operator. Electron. Trans. Numer. Anal. , 57:1-16, 2022. |
| [19] | B. Hofmann, P. Math´, e and H. von Weizs¨cker. a Regularization in Hilbert space under un- bounded operators and general source conditions. Inverse Problems , 25(11):115013 (15pp), 2009. |
| [20] | B. Hofmann and U. Tautenhahn. On ill-posedness measures and space change in Sobolev scales. Z. Anal. Anwendungen , 16(4):979-1000, 1997. |
| [21] | B. Hofmann and L. von Wolfersdorf. Some results and a conjecture on the degree of ill- posedness for integration operators with weights. Inverse Problems , 21(2):427-433, 2005. |
| [22] | B. Hofmann and L. von Wolfersdorf. A new result on the singular value asymptotics of integration operators with weights. J. Integral Equations Appl. , 21(2):281-295, 2009. |
| [23] | T. Hohage. Regularization of exponentially ill-posed problems. Numerical Functional Analysis and Optimization , 21(3-4):439-464, 2000. |
| [24] | S. Kindermann and B. Hofmann. Curious ill-posedness phenomena in the composition of non-compact linear operators in Hilbert spaces. J. Inv. Ill-Posed Problems , 32(5):1001-1013, 2024. |
| [25] | H. K¨nig. o Eigenvalue Distribution of Compact Operators , volume 16 of Operator Theory: Advances and Applications . Birkh¨user, a 1986. |
| [26] | S. Lu and S. V. Pereverzev. Numerical differentiation from a viewpoint of regularization theory. Math. Comput. , 75:1853-1870, 2006. |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [27] | P. Math´ e and B. Hofmann. Comparing the ill-posedness for linear operators in Hilbert spaces, 2024. Paper submitted. Preprint: https://arxiv.org/pdf/2410.17729. |
| [28] | P. Math´, e M. T. Nair, and B. Hofmann. Regularization of linear ill-posed problems involving multiplication operators. Appl. Anal. , 101(2):714-732, 2022. |
| [29] | M. Z. Nashed. A new approach to classification and regularization of ill-posed operator equations. In Inverse and Ill-posed Problems (Sankt Wolfgang, 1986), volume 4 of Notes Rep. Math. Sci. Engrg. , pages 53-75. Academic Press, Boston, MA, 1987. |
| [30] | F. Natterer. The Mathematics of Computerized Tomography . B. G. Teubner, Stuttgart; John Wiley & Sons, Ltd., Chichester, 1986. |
| [31] | K. Proksch, F. Werner, and A. Munk. Multiscale scanning in inverse problems. Ann. Statist. , 46(6B):3569-3602, 2018. |
| [32] | M. Rosenblum. On the Hilbert matrix. II. Proc. Amer. Math. Soc. , 9:581-585, 1958. |
| [33] | U. Tautenhahn and R. Gorenflo. On optimal regularization methods for fractional differenti- ation. Z. Anal. Anwendungen , 18(2):449-467, 1999. |
| [34] | M. E. Taylor. Partial Differential Equations II: Qualitative Studies of Linear Equations. Springer-Verlag, New York, 1996. |
| [35] | Vu Kim Tuan and R. Gorenflo. Asymptotics of singular values of fractional integral operators. Inverse Problems , 10(4):949-955, 1994. |
| [36] | G. F. Umbricht. Identification of the source for full parabolic equations. Math. Model. Anal. , 26(3):339-357, 2021. |
- [37] D. Werner. Funktionalanalysis . Springer, 2005. | null | [
"Frank Werner",
"Bernd Hofmann"
] | 2024-08-02T09:56:08+00:00 | 2024-11-26T15:22:37+00:00 | [
"math.NA",
"cs.NA"
] | A unified concept of the degree of ill-posedness for compact and non-compact linear operator equations in Hilbert spaces under the auspices of the spectral theorem | Covering ill-posed problems with compact and non-compact operators regarding
the degree of ill-posedness is a never ending story written by many authors in
the inverse problems literature. This paper tries to add a new narrative and
some new facets with respect to this story under the auspices of the spectral
theorem. The latter states that any self-adjoint and bounded operator is
unitarily equivalent to a multiplication operator on some (semi-finite) measure
space. We will exploit this fact and derive a distribution function from the
corresponding multiplier, the growth behavior of which at zero allows us to
characterize the degree of ill-posedness. We prove that this new concept
coincides with the well-known one for compact operators (by means of their
singular values), and illustrate the implications along examples including the
Hausdorff moment operator and convolutions. |
2408.01149v4 | ## BTZ Black Hole In The Non-Extensive Generalizations of Gibbs Entropy
Amijit Bhattacharjee 1 ∗ and Prabwal Phukon 1 2 , † 1 . Department of Physics, Dibrugarh University, Dibrugarh, Assam,786004. 2 . Theoretical Physics Division, Centre for Atmospheric Studies, Dibrugarh University, Dibrugarh, Assam,786004.
## ABSTRACT
We study the thermodynamics and thermodynamic geometry of the (2+1) dimensional Banados-Teitelboim-Zanelli(BTZ) black hole within the framework of the non-extensive generalizations of Gibbs entropy. We investigate both the rotating (R-BTZ) and the charged (C-BTZ) BTZ black holes in these non-extensive entropy formalisms. We write down the Bekenstein-Hawking(BH) entropy of the black hole in terms of the non-extensive entropies namely: Kaniadakis entropy, Renyi entropy and Barrow entropy. We investigate their impact on the thermodynamic phase structure and geometry of the BTZ black holes in both the ensembles i.e. the fixed ( J ) and fixed (Ω) ensemble for the R-BTZ black hole and the fixed ( Q ) and the fixed (Φ) ensemble for the C-BTZ black hole where J , Ω, Q and Φ represent the angular momentum, angular velocity, charge and the electric potential of the respective black holes. We investigate the Ruppeiner and geometrothermodynamic(GTD) geometries of the black hole for all the non-extensive entropy cases. We find that there are Davies type along with Hawking-Page phase transitions in both the charged and rotating BTZ black hole for the Kaniadakis entropy case in all the above mentioned thermodynamic ensembles. These phase transitions were not seen in the BH entropy case. We also find that the Ruppeiner and the GTD scalar for the Kaniadakis entropy show curvature singularities corresponding to the Davies type phase transitions in both the rotating and charged BTZ black holes.
## I. INTRODUCTION:
It is by now well known that black holes are thermodynamic objects characterized by a temperature (Hawking temperature) proportional to surface gravity at its horizon and entropy (Bekenstein-Hawking entropy) proportional to the horizon area [1, 2].
$$T = \frac { \kappa } { 2 \pi }, \quad \ S _ { B H } = \frac { A } { 4 } \, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
These two quantities ( T and S BH ) constitute the basis of what is now known as black hole thermodynamics [3]. Over the years, black hole thermodynamics has evolved into an active area of research with a number of generalizations of its originial version [4-9] shedding light on the phase structures of black holes.
An important issue in the context of black hole thermodynamics that has recently come to focus is the modification of black hole entropy owing to different corrections. These corrections result in a number of non-extensive generalizations of Gibbs entropy. Some of these notable entropies are: Kaniadakis entropy, [10, 11], Renyi entropy [12] and Barrow entropy [13]. A brief introduction to these entropies will be provided in the next section. The impact of these entropies on the thermodynamic behaviour of a few black holes have been studied in a number of works [14-18]. Previously these entropy systems have been tested in cosmology [19-23] and quantum physics [24-28] with notable success.
Although we employ Kaniadakis, Renyi, and Barrow entropies individually for our convenience here, it is worth noting that generalized entropy constructs with different parameters have been introduced in [22, 23] that generalizes all the above mentioned entropies. These generalized entropy constructs are formulated such that they reduce to all the required entropy paradigms under appropriate limits. For example, the six-parameter entropy formulation proposed in [23] is given as:
$$S _ { G } ( \alpha _ { \pm }, \beta _ { \pm }, \gamma _ { \pm } ) = \frac { 1 } { \alpha _ { + } + \alpha _ { - } } \left [ \left ( 1 + \frac { \alpha _ { + } } { \beta _ { + } } S ^ { \gamma _ { + } } \right ) ^ { \beta _ { + } } - \left ( 1 + \frac { \alpha _ { - } } { \beta _ { - } } S ^ { \gamma _ { - } } \right ) ^ { - \beta _ { - } } \right ],$$
∗ rs amijitbhattacharjee @ dibru.ac.in
† [email protected]
where all parameters ( α ± , β ± , γ ± ) are positive. This expression reduces to the above mentioned entropy formulations under specific parameter limits, as has been outlined below:
- · Kaniadakis Entropy: By taking β ± → 0, γ ± = 1, and α ± = K , the generalized entropy simplifies to
$$S _ { G } \rightarrow \frac { 1 } { K } \sinh ( K S ),$$
which corresponds to the Kaniadakis entropy.
- · Renyi Entropy: From the Sharma-Mittal limit, if α + → 0, β + → 0, and α + /β + → α , with γ + = 1, we recover the Renyi entropy:
$$S _ { G } \to \frac { 1 } { \alpha } \ln ( 1 + \alpha S ).$$
- · Sharma-Mittal Entropy: Setting α -= 0 and γ + = 1, we obtain
$$S _ { G } = \frac { 1 } { \alpha _ { + } } \left [ \left ( 1 + \frac { \alpha _ { + } } { \beta _ { + } } S ^ { \gamma _ { + } } \right ) ^ { \beta _ { + } } - 1 \right ].$$
Choosing α + = R β , + = R/δ , and γ + = , the Sharma-Mittal entropy is reproduced. δ
- · Tsallis and Barrow Entropy: In the limit α + = α -→ 0 and γ + = γ -= γ , the generalized entropy reduces to S G → S γ . By further choosing γ = δ or γ = 1 + ∆ 2, we recover the Tsallis entropy and Barrow entropy, / respectively.
- · Loop Quantum Gravity Entropy: Setting α -= 0 and γ + = 1, the entropy becomes
$$S _ { G } = \frac { 1 } { \alpha _ { + } } \left [ e ^ { \beta _ { + } S } - 1 \right ].$$
In the limit β + →∞ and α + = 1 -q , this reduces to the Loop Quantum Gravity entropy
$$S _ { G } \approx \frac { 1 } { 1 - q } \left [ e ^ { ( 1 - q ) S } - 1 \right ],$$
which approaches the Bekenstein-Hawking entropy as q → 1.
The entropy S G defined above do satisfy the generalized third law of thermodynamics and is seen to vanish when S → 0. S G is found to be a monotonically increasing function of S , thus reducing to the Bekenstein-Hawking entropy under suitable limits.
Although black hole thermodynamics in its different forms have largely been successful in providing deep insights about the thermodynamic properties of black holes, there are a number of important issues which are far from being completely understood. One such issue is the microscopic origin of Bekenstein-Hawking(BH) entropy. In absence of a complete theory of quantum gravity, thermodynamic geometry studies of black holes have been used to extract qualitative ideas about microscopic interaction in black holes [29-31]. Thermodynamic geometry is a key concept in the study of black holes as they provide an understanding of the phase transitions in terms of the curvature singularities obtained through a particular thermodynamic metric. Three such metrics which have been used in black hole thermodynamics are Weinhold, Ruppeiner and geometrothermodynamic metric (GTD).
Weinhold [32] introduced a Riemannian metric in the equilibrium space which is defined as the second derivative of the internal energy with respect to other extensive variables. The Weinhold metric is defined as:
$$g _ { i j } ^ { W } = \partial _ { i } \partial _ { j } U ( S, X )$$
where the internal energy ' U S,X ( )' is a function of entropy S and other extensive variables X.
Ruppeiner [33] later introduced a Riemannian metric which is defined as the negative hessian of the entropy with respect to the other extensive variables. The Ruppeiner metric is a concept based on the thermodynamic fluctuation theory of equilibrium thermodynamics, where the thermodynamic length is related to the probability of fluctuation between two states of the thermodynamic system [34]. The two are inversely related as an increase in the probability
of fluctuation would mean a significant decrease in the thermodynamic length and vice-versa. The Ruppeiner metric is defined as:
$$g _ { i j } ^ { R } = - \partial _ { i } \partial _ { j } S ( U, X )$$
where the entropy ' S U,X ( )' is a function of internal energy U and other extensive variables X. The Riemannian scalar which is defined here as ' R rupp ' is a scalar invariant function in thermodynamic geometry. The sign of the scalar curvature has been linked to the nature of microscopic interactions in the thermodynamic system. For positive or negative scalar curvatures, the underlying interaction is either repulsive or attractive accordingly. Whereas the null curvature would mean an absence of interaction with a flat thermodynamic geometry. The Ruppeiner and the Weinhold metrics are conformally related to each other by the following relation [35, 36]:
$$g _ { i j } ^ { R } d U ^ { i } d U ^ { j } = \frac { 1 } { T } g _ { i j } ^ { W } d S ^ { i } d S ^ { j }$$
where T = ∂U ∂S is the Hawking temperature of the system with U i = ( U, X ) and S i = ( S, X ).
The Ruppeiner and Weinhold geometries have successfully predicted the occurrence of phase transitions in the case of ordinary thermodynamic systems. However there has been contradictory results for the case of black holes where for instance in Kerr-black hole [37] the Weinhold metric showed no phase transition whereas the Ruppeiner metric could show phase transitions only for a specific thermodynamic potential. However such problems were successfully addressed in the new geometric formalism of geometrothermodynamics(GTD)[38] where the properties of the phase space and the space of equilibrium states could be unified [39]. The GTD metric is a Legendre invariant metric and therefore would not depend on any specific choice of thermodynamic potential. The phase transitions obtained from the specific heat capacity of the black hole are properly contained in the scalar curvature of the GTD metric, such that a curvature singularity in the GTD scalar ' R GTD ' would imply the occurrence of a phase transition. The general form of the GTD metric is given by [40]:
$$g = \left ( E ^ { c } \frac { \partial \varphi } { \partial E ^ { c } } \right ) \left ( \eta _ { a b } \delta ^ { b c } \frac { \partial ^ { 2 } \varphi } { \partial E ^ { c } \partial E ^ { d } } d E ^ { a } d E ^ { d } \right )$$
where ' φ ' is the thermodynamic potential and ' E a ' is an extensive thermodynamic variable with a = 1 2 3 , , .... .
In this paper, we study the thermodynamics and thermodynamic geometry of the (2+1) dimensional BanadosTeitelboim-Zanelli(BTZ) black hole within the framework of the non-extensive generalizations of Gibbs entropy. We investigate both the rotating (R-BTZ) and the charged (C-BTZ) BTZ black holes in these non-extensive entropy formalisms. We write down the Bekenstein-Hawking(BH) entropy of the black hole in terms of the non-extensive entropies namely: Kaniadakis entropy, Renyi entropy and Barrow entropy. We investigate their impact on the thermodynamic phase structure and geometry of the BTZ black hole in both the ensembles i.e. the fixed ( J ) and fixed (Ω) ensemble for the R-BTZ black hole and the fixed ( Q ) and the fixed (Φ) ensemble for the C-BTZ black hole where J , Ω, Q and Φ represent the angular momentum, angular velocity, charge and the electric potential of the respective black holes. We investigate the Ruppeiner and geometrothermodynamic(GTD) geometries of the black hole for all the non-extensive entropy cases.
In this study, we adopt the energy definition of General Relativity, the first law of thermodynamics and the conventional definition of thermodynamic temperature as fundamental. However we accept the alternative viewpoint that has been adopted in [24, 25] based on the assumption that the Hawking temperature must be kept unaffected. Furthermore, it has been demonstrated that non-extensive entropy paradigms can lead to wrong expressions for the Hawking temperature or black hole energy that differ from the standard ones. While we acknowledge these critiques, we argue that any modification to these quantities such as the Hawking temperature under these non-extensive entropy formalisms, should be interpreted as a shift in the effective thermodynamic description rather than a fundamental change to the Hawking temperature itself. These effective temperatures reflect the corrections introduced by non-extensive statistical mechanics and are not meant to replace the fundamental Hawking temperature. The effective temperatures characterize the modified thermodynamic equilibrium within each of the non-extensive paradigms and provide insights into how such generalizations affect black hole systems. These differences highlight the speculative yet potentially valuable role of non-extensive frameworks in exploring new physical scenarios and enriching our understanding of black hole thermodynamics. We stress upon the fact that the exploration of different non-extensive entropies is motivated by their success in describing physical systems beyond black holes [41-46]. The study of their implications for black hole thermodynamics provides us with an opportunity to test the limits of our current understanding and to further explore potential extensions of the standard approach.
The paper is structured as follows: In section II we review some known facts about the non-extensive generalisations of Gibbs entropy. The section III is about the rotating BTZ black hole and its thermodynamic investigation within the framework of non-extensive entropies in two different ensembles. In section IV we examine the thermodynamic geometry of the black hole system both in Ruppeiner and in the GTD formalisms. The section V is about the thermodynamic investigation of charged BTZ black hole within the framework of non-extensive entropies in two different ensembles. In section VI we examine the thermodynamic geometry of the black hole in both the Ruppeiner and the GTD formalisms. The final section contains our conclusions.
## II. NON-EXTENSIVE GENERALIZATIONS OF GIBBS ENTROPY
The entropy of a black hole scales with its area rather than its volume and is therefore regarded as a non-extensive quantity. Due to its non-extensive nature, the black hole entropy is also non-additive and follows a non-additive composition rule. But in the case of Gibbs thermodynamics the entropy is defined to be both extensive and additive as it scales with the size of the system. However, the assumption of extensivity of Gibbs entropy is due to ignoring the long range forces that are prevalent between the thermodynamic sub-systems. Gibbs thermodynamics ignores these forces because the size of the system exceeds the interaction range between the thermodynamic sub-systems. The total entropy thus becomes equal to the sum of the entropies of its components. It therefore grows with the size of the thermodynamic system.
But these long range forces are important in various thermodynamic systems such as black holes. We can therefore infer that Gibbs thermodynamics may not be a suitable choice for studying black hole thermodynamics. Therefore in order to understand the non-extensive nature of black hole entropy, several non-extensive generalizations of Gibbs entropy have been prescribed. We give a brief outline of a few of those entropies below which we will use later in order to study the thermodynamics and thermodynamic geometry of both the rotating and charged BTZ black holes respectively:
## A. Kaniadakis entropy
Kaniadakis entropy[10, 11, 14, 47-50] is a relativistic non-extensive generalization of Boltzmann-Gibbs entropy. It was proposed by Kaniadakis so as to accomodate special relativity with non-extensive statistical mechanics. Kaniadakis entropy is premised upon the fact that physical observables such as momentum and energy when generalised under special relativity are viewed as a one-parameter deformation of the corresponding non-relativistic formula i.e P ′ = P √ 1 -x 2 where, P ′ is the relativistic momentum and x = v c is the deformation parameter. It is therefore quite obvious that the entropy of a relativistic system could also be seen as a one parameter deformation of the classical non-relativistic entropy. In order to achieve a relativistic formula for Boltzmann Gibbs entropy, Kaniadakis proposed a deformed logarithmic function in the entropy formula which in turn deforms the Maxwell-Boltzmann distribution function. These deformed functions are given as:
$$\ln _ { K } ( x ) = \frac { x ^ { K } - x ^ { - K } } { 2 K }$$
$$e x p _ { K } ( x ) = \left ( \sqrt { 1 + K ^ { 2 } x ^ { 2 } } + K x \right ) ^ { \frac { 1 } { K } }$$
where x is a variable and K is the deformation parameter called the Kaniadakis parameter and both the above mentioned deformed functions reduce to their original form as the deformed parameter, K approaches appropriate limit i.e. K → 0. The Kaniadakis entropy is then defined as:
$$S _ { K } = - \sum _ { i = 1 } ^ { n } P _ { i } \ln _ { K } ( P _ { i } )$$
where,
$$\ln _ { K } ( P _ { i } ) = \frac { P _ { i } ^ { K } - P _ { i } ^ { - K } } { 2 K }$$
In the limit K → 0, the Kaniadakis entropy reduces to the Boltzmann-Gibbs entropy. Considering the equiprobability of microstates inside the black hole we can reduce the Kaniadakis entropy to:
$$S _ { K } = - \sum _ { i = 1 } ^ { n } \frac { 1 } { n } \ln _ { K } \left ( \frac { 1 } { n } \right )$$
$$\zeta = - \sum _ { i = 1 } ^ { n } \frac { 1 } { n } \ln _ { K } \left ( \frac { 1 } { n } \right ) \\ S _ { K } = \ln _ { K } ( n ) \\ \cdot \quad \cdot \quad \cdot \quad.$$
where ' n ' is the number of microstates of the thermodynamic system and 'K' is the kaniadakis parameter. On further simplification we obtain:
$$S _ { K } = \frac { n ^ { K } - n ^ { - K } } { 2 K }$$
$$S _ { K } = \frac { S i n h [ K \ln ( n ) ] } { K }$$
Considering that the Bekenstein-Hawking entropy is obtained by counting the number of microstates inside the black hole as was showed by Strominger and Vafa in their seminal work [51], we write the Bekenstein -Hawking entropy, S BH = ln( n ) such that the above equation reduces to:
$$S _ { K } = \frac { S i n h [ K S _ { B H } ] } { K }$$
where, for the limit K → 0, S K → S BH
## B. Renyi entropy
The Renyi entropy[52-58] is a non-extensive generalization of Boltzmann-Gibbs entropy where unlike the case where all the probabilities are treated uniformly, Renyi entropy allows for a parameter adjustment to the sensitivities of different probabilities in the system. This becomes very useful in situation where either rare or high probable events demand separate emphasis. The Renyi entropy is a measure of the quantum entanglement of a system. A phenomena where the quantum states of two or more particles could become correlated. It is defined as:
$$S _ { R } = \frac { 1 } { 1 - q } \left ( \ln \sum _ { i = 1 } ^ { n } P ^ { q } ( i ) \right )$$
where 'P(i)' is the probability distribution and 'q' is the non-extensive Tsallis parameter. We here assume that the black hole entropy is just the Tsallis entropy [59-61] which is a one parameter generalization of Boltzmann-Gibbs entropy so as to include both extensive and non-extensive statistical systems. The Tsallis entropy is given by :
$$S _ { T } = S _ { B H } = \frac { 1 } { 1 - q } \left ( \sum _ { i = 1 } ^ { n } P ^ { q } ( i ) - 1 \right )$$
where for q → 1, S T reduces to the usual Boltzmann-Gibbs entropy. The parameter q is responsible for the degree of non-extensivity of the entropy:
- · For q = 1: Tsallis entropy reduces to the extensive Boltzmann-Gibbs entropy which is appropriate for the system that comprises of weak correlations and short-range interactions.
- · For q < 1: The entropy is sub-extensive and is useful in describing systems where the probability for the occurrence of rare states is higher than the occurence of frequent states.
- · For q > 1: The entropy shows super-extensive behaviour where frequent states do contribute more to the entropy.
By performing necessary subsitutions, the Renyi entropy could be defined as follows:
$$S _ { R } = \frac { \ln \left [ ( 1 - q ) S _ { B H } + 1 \right ] } { 1 - q }$$
and after putting 1 -q = λ we get the Renyi entropy in terms of Bekenstein-Hawking entropy as:
$$S _ { R } = \frac { \ln [ 1 + \lambda S _ { B H } ] } { \lambda }$$
where ' λ ' is the Renyi parameter and for the limit λ → 0, S R → S BH
$$( 1 1 )$$
## C. Barrow entropy
The Barrow entropy[13, 62, 63], as introduced by John Barrow is proposed to measure the entropy of a black hole system whose smooth horizon has been replaced by the rough fractal structures. Unlike the above two entropy formalisms, Barrow entropy does not have a statistical root. It is a modification introduced in the context of quantum gravity and the fractal structure of space-time. It is formulated by considering quantum-gravitational effects that modify the surface of the black hole's event horizon by considering the structure of the horizon to be fractal-like. John Barrow's approach to entropy suggests that the horizon area might have a fractal dimension which alters the traditional Bekenstein-Hawking entropy formula. This modification puts forth a parameter that can quantify the degree of deviation from the standard horizon geometry due to quantum corrections while capturing the complexity of space-time at smaller scales. The Barrow entropy is formulated as:
$$S _ { \Delta } = ( S _ { B H } ) ^ { 1 + \Delta / 2 }$$
where, '∆' is the Barrow parameter that is linked to the fractal structure of the system with range 0 < ∆ ≤ 2. where ∆ → 2 would yield maximal fractal structure. And for the limit ∆ → 0, S ∆ → S BH
## III. THERMODYNAMICS OF THE ROTATING BTZ BLACK HOLE
The action which facilitates the field equations[64-69] from which the (2 + 1) dimensional rotating BTZ black hole solutions are obtained is given as:
$$I = \frac { 1 } { 2 \pi } \int d ^ { 3 } x \sqrt { - g } \left ( R - 2 \Lambda \right )$$
where, the AdS length l is related to the cosmological constant Λ by the relation: Λ = -1 l 2 and the Einstein's field equations are given by:
$$G _ { \mu \nu } - \Lambda g _ { \mu \nu } = 0$$
The line element that corresponds to the given solution is:
$$d s ^ { 2 } = - f ( r ) d t ^ { 2 } + \frac { d r ^ { 2 } } { f ( r ) } + r ^ { 2 } \left ( d \phi - \frac { J } { 2 r ^ { 2 } } d t \right ) ^ { 2 }$$
where f ( r ) = -M + r 2 l 2 + J 2 4 r 2 and 'M' and 'J' are the mass and angular momentum carried by the black hole. Solving the function for f ( r ) = 0 would give us the roots which determine the horizon radius. For an exterior horizon radius, ' r + ' the black hole mass is given by:
$$M = \frac { r _ { + } ^ { 2 } } { l ^ { 2 } } + \frac { J ^ { 2 } } { 4 r _ { + } ^ { 2 } }$$
and the black hole entropy is given by:
$$S _ { B H } = 4 \pi r _ { + }$$
## III.1. The Kaniadakis entropy case
The Kaniadakis entropy, S K in terms of the black hole entropy, S BH is given by (10) as:
$$S _ { K } = \frac { S i n h ( K S _ { B H } ) } { K }$$
where 'K' is the Kaniadakis parameter and for K → 0, S K → S BH . Starting with the above equation we get the modified horizon radius for the CR-BTZ black hole as:
$$S _ { K } = \frac { S i n h ( 4 \pi K r _ { + } ) } { K }$$
$$r _ { + } = \frac { A r c S i n h ( K S _ { K } ) } { 4 \pi K }$$
## Fixed ( J ) ensemble :
We replace the horizon radius in (13) by the one obtained in (14) to get the modified mass M K for the R-BTZ black hole which is given by :
$$M _ { K } = \frac { 4 \pi ^ { 2 } K ^ { 2 } J ^ { 2 } } { A r c S i n h ^ { 2 } [ K S _ { K } ] } + \frac { A r c S i n h ^ { 2 } [ K S _ { K } ] } { 1 6 \pi ^ { 2 } l ^ { 2 } K ^ { 2 } }$$
The function, ArcSinh KS [ K ] can be replaced by its logarithmic form, ln [ KS K + √ 1 + K S 2 2 K ] and therefore the expression for mass becomes:
$$M _ { K } = \frac { 4 \pi ^ { 2 } K ^ { 2 } J ^ { 2 } } { \ln [ K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ] ^ { 2 } } + \frac { \ln [ K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ] ^ { 2 } } { 1 6 \pi ^ { 2 } l ^ { 2 } K ^ { 2 } }$$
The heat capacity for the Kaniadakis entropy case in the fixed ( J ) ensemble can be obtained as:
$$C _ { K } = \frac { \frac { \partial M _ { K } } { \partial S _ { K } } } { \frac { \partial ^ { 2 } M _ { K } } { \partial S _ { K } ^ { 2 } } } = - \frac { A } { B }$$
where,
$$A = \left ( \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) \left ( 6 4 J ^ { 2 } K ^ { 4 } \pi ^ { 4 } - \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) ^ { 4 } \left ( 1 + K ^ { 2 } S _ { K } ^ { 2 } \right ) \right ) \right ) \quad \ \ ( 1 7 )$$
and
$$B = K & \Big ( 6 4 S _ { K } J ^ { 2 } K ^ { 5 } \pi ^ { 4 } \ln \Big ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \Big ) - K S _ { K } \ln \Big ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \Big ) ^ { 5 } + 1 9 2 J ^ { 2 } K ^ { 4 } \pi ^ { 4 } \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \\ & \quad + \ln \Big ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \Big ) ^ { 4 } \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \Big )$$
In Fig.1 the heat capacity, C K is plotted against the Kaniadakis entropy, S K for l = 1 and J = 1 in the fixed ( J ) ensemble. Here the solid blue curve represents the heat capacity for the Kaniadakis parameter, K = 0 012 whereas the . black dashed line represents the heat capacity for the Bekenstein-Hawking(BH) entropy case ( K = 0). We find that for K = 0 012, the heat capacity has a divergence at . S K = 125 77 which indicates the presence of a Davies type phase . transition present in the Kaniadakis modified black hole whereas the heat capacity for the BH entropy case shows no such behaviour.
The Gibbs free energy for the Kaniadakis entropy case in the fixed ( J ) ensemble can be obtained as:
$$G _ { K } = M _ { K } - T _ { K } S _ { K }$$
$$G _ { K } = \frac { \mathcal { A } } { 1 6 K ^ { 2 } \pi ^ { 2 } \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) ^ { 3 } }$$
FIG. 1: The heat capacity versus Kaniadakis entropy plot in the fixed ( J ) ensemble for l = 1 and J = 1
where,
$$\mathcal { A } & = 1 2 8 J ^ { 2 } K ^ { 5 } \pi ^ { 4 } S _ { K } + 6 4 J ^ { 2 } K ^ { 4 } \pi ^ { 4 } \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) - 2 K S _ { K } \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) ^ { 5 } \\ & \quad + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) ^ { 5 }.$$
In Fig.2a and Fig.2b the Gibbs free energy, G K is plotted against the Kaniadakis entropy, S K for l = 1 and J = 1 in the fixed ( J ) ensemble. We draw two different plots so as to make the presence of the phase transitions more transparent. Here the solid blue curve represents the Gibbs free energy for the Kaniadakis parameter, K = 0 012 whereas the black . dashed line represents the free energy for the Bekenstein-Hawking(BH) entropy case ( K = 0). The free energy for the K = 0 case has been scaled down by multiplying it with 1 10 whereas the free energy for the K = 0 012 case is . kept the same, this difference in scaling is just so that the distinct behaviour of both the curves could be seen more clearly. We keep in mind that the scaling does not affect the position or occurrence of the phase transitions. We find that in Fig.2a the Gibbs free energy goes to zero for both the entropy cases, where for K = 0, the zero point is at S K = 11 69 and for . K = 0 012, the zero point is found to be at . S K = 11 75, these zero points refer to the presence of . a Hawking-Page phase transition present in the rotating BTZ black hole for both the Bekenstein-Hawking as well as the Kaniadakis entropy cases. We again find that for K = 0 012, the Gibbs free energy in Fig.2b has a zero point at . S K = 276 64 only for the Kaniadakis entropy case which indicates the presence of a Hawking-Page phase transition . present in the Kaniadakis modified black hole whereas the Gibbs free energy for the BH entropy case shows no such behaviour. In Fig.2c we plot the inverse of specific heat capacity (purple) and the Gibbs free energy (orange) against the Kaniadakis entropy. The inverse of specific heat capacity has been scaled up by multiplying it with 3000 whereas the free energy is kept the same, this difference in scaling is just so that the distinct behaviour of both the curves could be seen more clearly. We keep in mind that the scaling does not affect the position or occurrence of the phase transitions. The points where these curves intersect the horizontal axis would represent the Davies-type (Purple) and Hawking-Page (Orange) phase transition respectively which are seen to be quite distant from each other.
## Fixed (Ω) ensemble :
The modified mass for the Kaniadakis entropy case in the fixed (Ω) ensemble is given by:
$$M _ { K } ^ { \prime } = M _ { K } - J \frac { \partial M _ { K } } { \partial J }$$
where ∂M K ∂J = Ω is the angular velocity of the black hole with respect to the angular momentum J. By writing the term M ′ K as M K for convenience we get:
$$M _ { K } = \frac { ( 1 - \Omega ^ { 2 } ) \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) ^ { 2 } } { 1 6 K ^ { 2 } \pi ^ { 2 } }$$
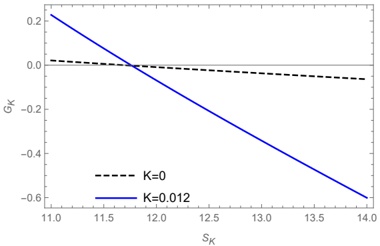
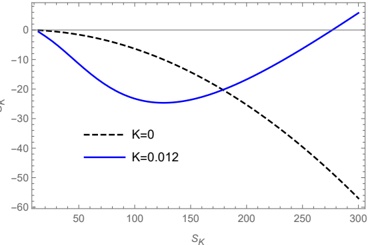
G K
(a) Gibbs free energy versus Kaniadakis entropy (11 < S K < 14).
(b) Gibbs free energy versus Kaniadakis entropy ( S K > 14).
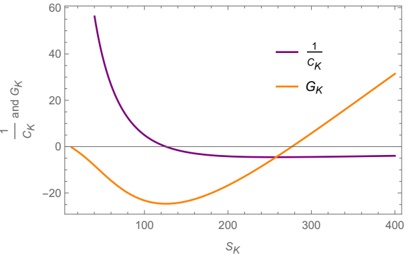
(c) Inverse specific heat and Gibbs free energy versus Kaniadakis entropy.
FIG. 2: The Gibbs free energy curves for Kaniadakis entropy in the fixed ( J ) ensemble for l = 1 and J = 1.
The heat capacity for the Kaniadakis entropy case in the fixed (Ω) ensemble can be obtained as:
$$C _ { K } = \frac { \frac { \partial M _ { K } } { \partial S _ { K } } } { \frac { \partial ^ { 2 } M _ { K } } { \partial S _ { K } ^ { 2 } } } = \frac { \left ( 1 + K ^ { 2 } S _ { K } ^ { 2 } \right ) \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) } { K \left ( \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } - K S _ { K } \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) \right ) }$$
The heat capacity of the rotating BTZ black hole is independent of Ω as can be seen from the above expression and therefore the presence or absence of Davies type phase transitions in fixed (Ω) ensemble is independent of Ω. In Fig.3 the heat capacity, C K is plotted against the Kaniadakis entropy, S K for l = 1 in the fixed (Ω) ensemble. Here the solid blue curve represents the heat capacity for the Kaniadakis parameter, K = 0 012 whereas the black dashed line . represents the heat capacity for the Bekenstein-Hawking(BH) entropy case ( K = 0). We find that for K = 0 012, the . heat capacity has a divergence at S K = 125 74 which indicates the presence of a Davies type phase transition present . in the Kaniadakis modified black hole whereas the heat capacity for the BH entropy case shows no such behaviour.
The Gibbs free energy for the Kaniadakis entropy case in the fixed (Ω) ensemble can be obtained as:
$$G _ { K } = M _ { K } - T _ { K } S _ { K }$$
$$G _ { K } = \frac { ( 1 - \Omega ^ { 2 } ) \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) \left ( - 2 K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) \right ) } { 1 6 K ^ { 2 } \pi ^ { 2 } \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } } \quad \ \ ( 2 2 )$$
In Fig.4a the Gibbs free energy, G K is plotted against the Kaniadakis entropy, S K for l = 1 and Ω = 0 2 in the fixed (Ω) . ensemble. Here the solid blue curve represents the Gibbs free energy for the Kaniadakis parameter, K = 0 012 whereas .
FIG. 3: The heat capacity versus Kaniadakis entropy plot in the fixed (Ω) ensemble for l = 1 and Ω = 0 2 .
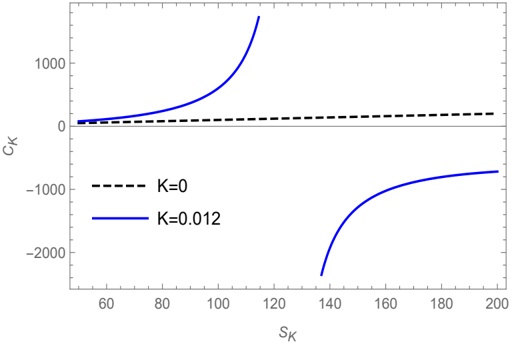
the black dashed line represents the free energy for the Bekenstein-Hawking(BH) entropy case ( K = 0). The free energy for the K = 0 case has been scaled down by multiplying it with 1 10 whereas the free energy for the K = 0 012 . case is kept the same, this difference in scaling is just so that the distinct behaviour of both the curves could be seen more clearly. We keep in mind that the scaling does not affect the position or occurrence of the phase transition. We find that for K = 0 012, the Gibbs free energy has a zero point at . S K = 276 65 which indicates the presence of a . Hawking-Page phase transition present in the Kaniadakis modified black hole whereas the Gibbs free energy for the BH entropy case shows no such behaviour. In Fig.4b we plot the inverse of specific heat capacity (purple) and the Gibbs free energy (orange) against the Kaniadakis entropy. The inverse of specific heat capacity has been scaled up by multiplying it with 3000 whereas the free energy is kept the same, this difference in scaling is just so that the distinct behaviour of both the curves could be seen more clearly. We keep in mind that the scaling does not affect the position or occurrence of the phase transitions. The points where these curves intersect the horizontal axis would represent the Davies-type (Purple) and Hawking-Page (Orange) phase transition respectively which are seen to be quite distant from each other.
FIG. 4: The Gibbs free energy curves for Kaniadakis entropy in the fixed (Ω) ensemble for l = 1 and Ω = 0 2. .
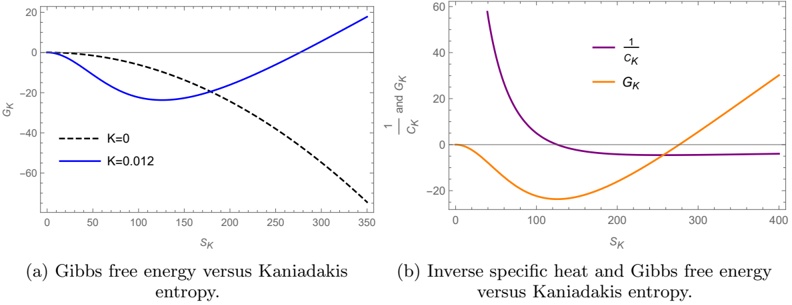
## III.2. The Renyi entropy case
The Renyi entropy, S R in terms of the black hole entropy, S BH is given by (11) as:
$$S _ { R } = \frac { \ln [ 1 + \lambda S _ { B H } ] } { \lambda }$$
where ' λ ' is the Renyi parameter and for the limit λ → 0, S R → S BH . Starting with the above equation we get the modified horizon radius for the R-BTZ black hole as:
$$S _ { R } = \frac { \ln ( 1 + 4 \pi \lambda r _ { + } ) } { \lambda }$$
$$r _ { + } = \frac { ( e ^ { \lambda S _ { R } } - 1 ) } { 4 \pi \lambda }$$
## Fixed ( J ) ensemble :
We replace the horizon radius in (13) by the one obtained in (23) to get the modified mass M R for the R-BTZ black hole which is given by :
$$M _ { R } = \frac { 4 \pi ^ { 2 } \lambda ^ { 2 } J ^ { 2 } } { \left ( e ^ { \lambda S _ { R } } - 1 \right ) ^ { 2 } } + \frac { \left ( e ^ { \lambda S _ { R } } - 1 \right ) ^ { 2 } } { 1 6 \pi ^ { 2 } \lambda ^ { 2 } l ^ { 2 } }$$
The heat capacity for the Renyi entropy case in the fixed ( J ) ensemble can be calculated as:
$$C _ { R } = \frac { \frac { \partial M _ { R } } { \partial S _ { R } } } { \frac { \partial ^ { 2 } M _ { R } } { \partial S _ { R } ^ { 2 } } } = \frac { A } { B }$$
where, and
$$B = \lambda \left ( \, - 1 + 6 e ^ { \lambda S _ { R } } - 1 4 e ^ { 2 \lambda S _ { R } } + 1 6 e ^ { 3 \lambda S _ { R } } - 9 e ^ { 4 \lambda S _ { R } } + 2 e ^ { 5 \lambda S _ { R } } + 6 4 J ^ { 2 } \pi ^ { 4 } \lambda ^ { 4 } + 1 2 8 J ^ { 2 } \pi ^ { 4 } \lambda ^ { 4 } e ^ { \lambda S _ { R } } \right ) \, \quad ( 2 6 )$$
We see from Fig.5a that the heat capacity, C R for the rotating BTZ black hole is plotted against the Renyi entropy, S R in the fixed ( J ) ensemble. Here the solid green curve represents the heat capacity for the Renyi parameter, λ = 0 012 . whereas the black dashed line represents the heat capacity for the Bekenstein-Hawking(BH) entropy case ( λ = 0). For the parameter l = 1 and J = 1 we find that there are no divergences in the heat capacity curve for both the Renyi and Bekenstein-Hawking (BH) entropy cases.
The Gibbs free energy for the Renyi entropy case in the fixed ( J ) ensemble can be obtained as:
$$G _ { R } = M _ { R } - T _ { R } S _ { R }$$
$$G _ { R } = \frac { \left ( - 1 + e ^ { \lambda S _ { R } } \right ) \left ( 6 4 J ^ { 2 } \pi ^ { 4 } \lambda ^ { 4 } + \left ( - 1 + e ^ { \lambda S _ { R } } \right ) ^ { 4 } \right ) - 2 \lambda S _ { R } e ^ { \lambda S _ { R } } \left ( 1 - 4 e ^ { \lambda S _ { R } } + 6 e ^ { 2 \lambda S _ { R } } - 4 e ^ { 3 \lambda S _ { R } } + e ^ { 4 \lambda S _ { R } } - 6 4 J ^ { 2 } \pi ^ { 4 } \lambda ^ { 4 } \right ) } { 1 6 \left ( - 1 + e ^ { \lambda S _ { R } } \right ) ^ { 3 } \pi ^ { 2 } \lambda ^ { 2 } } }$$
In Fig.6a the Gibbs free energy, G R is plotted against the Renyi entropy, S R for l = 1 and J = 1 in the fixed ( J ) ensemble. Here the solid green curve represents the Gibbs free energy for the Renyi parameter, λ = 0 012 whereas the . black dashed line represents the free energy for the Bekenstein-Hawking(BH) entropy case ( λ = 0). The free energy for the λ = 0 case has been scaled down by multiplying it with 1 10 whereas the free energy for the λ = 0 012 case is kept . the same, this difference in scaling is just so that the distinct behaviour of both the curves could be seen more clearly. We find that in Fig.6a the Gibbs free energy goes to zero for both the entropy cases, where for λ = 0, the zero point is at S R = 11 69 and for . λ = 0 012, the zero point is found to be at . S R = 10 74, these zero points refer to the presence of . a Hawking-Page phase transition present in the rotating BTZ black hole for both the Bekenstein-Hawking as well as
$$A = ( - 1 + e ^ { \lambda S _ { R } } ) \left ( 1 - 4 e ^ { \lambda S _ { R } } + 6 e ^ { 2 \lambda S _ { R } } - 4 e ^ { 3 \lambda S _ { R } } + e ^ { 4 \lambda S _ { R } } - 6 4 J ^ { 2 } \pi ^ { 4 } \lambda ^ { 4 } \right )$$
the Renyi entropy cases.
## Fixed (Ω) ensemble :
The modified mass for the Renyi entropy case in the fixed (Ω) ensemble is given by:
$$M _ { R } ^ { \prime } = M _ { R } - J \frac { \partial M _ { R } } { \partial J }$$
$$M _ { R } ^ { \prime } = M _ { R } - J \Omega$$
where ∂M R ∂J = Ω is the angular velocity of the black hole with respect to the angular momentum J. By making the necessary replacements and putting l = 1, we get the final equation as follows:
$$M _ { R } = \frac { \left ( 1 - \Omega ^ { 2 } \right ) \left ( e ^ { \lambda S _ { R } } - 1 \right ) ^ { 2 } } { 1 6 \pi ^ { 2 } \lambda ^ { 2 } }$$
$$\frac { \Omega ^ { 2 } ) \left ( e ^ { \lambda S _ { R } } - 1 \right ) ^ { 2 } } { 1 6 \pi ^ { 2 } \lambda ^ { 2 } }$$
We have here used the term M R instead of M ′ R for convenience. Here M R is the modified mass for the fixed (Ω) ensemble. The heat capacity for the Renyi entropy case in the fixed (Ω) ensemble can be calculated as:
$$C _ { R } = \frac { \frac { \partial M _ { R } } { \partial S _ { R } } } { \frac { \partial ^ { 2 } M _ { R } } { \partial S _ { R } ^ { 2 } } } = \frac { e ^ { \lambda S _ { R } } - 1 } { \lambda \left ( 2 e ^ { \lambda S _ { R } } - 1 \right ) }$$
The heat capacity of the rotating BTZ black hole is independent of Ω as can be seen from the above expression and therefore the presence or absence of Davies type phase transitions is independent of Ω. We see from Fig.5b that the heat capacity, C R for the rotating BTZ black hole is plotted against the Renyi entropy, S R in the fixed (Ω) ensemble. Here the solid green curve represents the heat capacity for the Renyi parameter, λ = 0 012 whereas the . black dashed line represents the heat capacity for the Bekenstein-Hawking(BH) entropy case ( λ = 0). We see that for l = 1 there are no divergences in the heat capacity curve for both the Renyi and Bekenstein-Hawking (BH) entropy cases.
The Gibbs free energy for the Renyi entropy case in the fixed (Ω) ensemble can be obtained as:
$$G _ { R } = M _ { R } - T _ { R } S _ { R }$$
$$G _ { R } = \frac { \left ( - 1 + e ^ { \lambda S _ { R } } \right ) \left ( 1 + e ^ { \lambda S _ { R } } \left ( - 1 + 2 \lambda S _ { R } \right ) \right ) \left ( - 1 + \Omega ^ { 2 } \right ) } { 1 6 \lambda ^ { 2 } \pi ^ { 2 } }$$
In Fig.6b the Gibbs free energy, G R is plotted against the Renyi entropy, S R for l = 1 and Ω = 0 2 in the fixed (Ω) . ensemble. Here the solid green curve represents the Gibbs free energy for the Renyi parameter, λ = 0 012 whereas the . black dashed line represents the free energy for the Bekenstein-Hawking(BH) entropy case ( λ = 0). The free energy for the λ = 0 case has been scaled down by multiplying it with 1 10 whereas the free energy for the λ = 0 012 case is kept . the same, this difference in scaling is just so that the distinct behaviour of both the curves could be seen more clearly. We find that unlike the Kaniadakis entropy there is no Hawking-Page phase transition present in the Renyi entropy case for the fixed (Ω) ensemble.
## III.3. The Barrow entropy case
The Barrow entropy, S ∆ in terms of the black hole entropy, S BH is given by (12) as:
$$S _ { \Delta } = ( S _ { B H } ) ^ { 1 + \Delta / 2 }$$
where, '∆' is the parameter that is linked to the fractal structure of the system and for the limit ∆ → 0, S ∆ → S BH . Starting with the above equation we get the modified horizon radius for the R-BTZ black hole as:
$$S _ { \Delta } = ( 4 \pi r _ { + } ) ^ { 1 + \Delta / 2 }$$
(a) Heat capacity in the fixed ( J ) ensemble for (b) Heat capacity in the fixed (Ω) ensemble for l = 1 and J = 1 l = 1 and Ω = 0 2 .
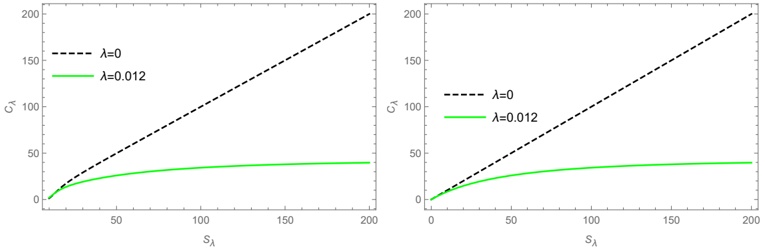
FIG. 5: The heat capacity versus Renyi entropy plots in the fixed ( J ) and fixed (Ω) ensembles.
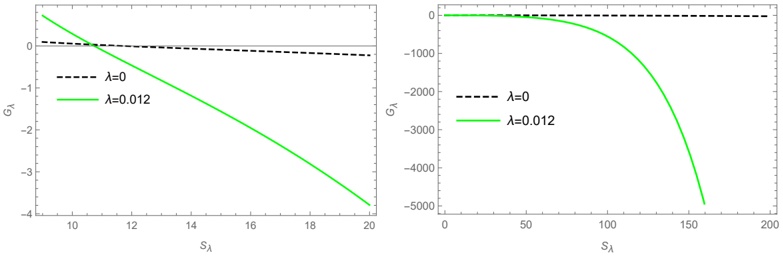
(a) Free energy in the fixed (
J
) ensemble for
(b) Free energy in the fixed (Ω) ensemble for
l
= 1
l
= 1 and
J
= 1
and Ω = 0 2.
.
FIG. 6: The Gibbs free energy versus Renyi entropy plots in the fixed ( J ) and fixed (Ω) ensembles.
$$r _ { + } = \frac { S _ { \Delta } ^ { \frac { 2 } { 2 + \Delta } } } { 4 \pi }$$
## Fixed ( J ) ensemble :
We replace the horizon radius in (13) by the one obtained in (30) to get the modified mass M ∆ for the R-BTZ black hole which is given by :
$$M _ { \Delta } = 4 J ^ { 2 } \pi ^ { 2 } S _ { \Delta } ^ { - \left ( \frac { 4 } { 2 + \Delta } \right ) } + \left ( \frac { S _ { \Delta } ^ { \left ( \frac { 4 } { 2 + \Delta } \right ) } } { 1 6 \pi ^ { 2 } } \right )$$
The heat capacity for the Barrow entropy case in the fixed ( J ) ensemble can be calculated as:
$$C _ { \Delta } = \frac { \frac { \partial M _ { \Delta } } { \partial S _ { \Delta } } } { \frac { \partial ^ { 2 } M _ { \Delta } } { \partial S _ { \Delta } ^ { 2 } } } = - \frac { S _ { \Delta } \left ( - 6 4 J ^ { 2 } \pi ^ { 4 } + S _ { \Delta } ^ { \frac { 8 } { 2 + \Delta } } \right ) ( 2 + \Delta ) } { - 3 8 4 J ^ { 2 } \pi ^ { 4 } - 2 S _ { \Delta } ^ { \frac { 8 } { 2 + \Delta } } - 6 4 J ^ { 2 } \pi ^ { 4 } \Delta + S _ { \Delta } ^ { \frac { 8 } { 2 + \Delta } } \Delta }$$
We see from Fig.7a that the heat capacity, C ∆ for the rotating BTZ black hole is plotted against the Barrow entropy, S ∆ in the fixed ( J ) ensemble. Here the solid red curve represents the heat capacity for the Barrow parameter, ∆ = 0 012 whereas the black dashed line represents the heat capacity for the Bekenstein-Hawking(BH) entropy case . (∆ = 0). For the parameter l = 1 and J = 1 we find that there are no divergences in the heat capacity curve for both the Barrow and Bekenstein-Hawking (BH) entropy cases.
The Gibbs free energy for the Renyi entropy case in the fixed ( J ) ensemble can be obtained as:
$$G _ { \Delta } = M _ { \Delta } - T _ { \Delta } S _ { \Delta }$$
$$G _ { \Delta } = \frac { S _ { \Delta } ^ { - \frac { 4 } { 2 + \Delta } } \left ( S _ { \Delta } ^ { \frac { 8 } { 2 + \Delta } } ( - 2 + \Delta ) + 6 4 J ^ { 2 } \pi ^ { 4 } ( 6 + \Delta ) \right ) } { 1 6 \pi ^ { 2 } ( 2 + \Delta ) }$$
In Fig.8a the Gibbs free energy, G ∆ is plotted against the Barrow entropy, S ∆ for l = 1 and J = 1 in the fixed ( J ) ensemble. Here the solid red curve represents the Gibbs free energy for the Barrow parameter, ∆ = 0 012 whereas the . black dashed line represents the free energy for the Bekenstein-Hawking(BH) entropy case (∆ = 0). The free energy for the ∆ = 0 case has been scaled down by multiplying it with 1 10 whereas the free energy for the ∆ = 0 012 case is . kept the same, this difference in scaling is just so that the distinct behaviour of both the curves could be seen more clearly.We find that in Fig.8a the Gibbs free energy goes to zero for both the entropy cases, where for ∆ = 0, the zero point is at S R = 11 69 and for ∆ = 0 012, the zero point is found to be at . . S R = 11 89, these zero points refer to the . presence of a Hawking-Page phase transition present in the rotating BTZ black hole for both the Bekenstein-Hawking as well as the Barrow entropy cases.
## Fixed (Ω) ensemble :
The modified mass for the Barrow entropy case in the fixed (Ω) ensemble is given by:
$$M _ { \Delta } ^ { \prime } = M _ { \Delta } - J \frac { \partial M _ { \Delta } } { \partial J }$$
$$M _ { \Delta } ^ { \prime } = M _ { \Delta } - J \frac { \mu } { \partial J } \\ M _ { \Delta } ^ { \prime } = M _ { \Delta } - J \Omega$$
where ∂M ∆ ∂j = Ω is the angular velocity of the black hole with respect to the angular momentum, J. By making the necessary replacements and putting l = 1, we get the final equation as follows:
$$M _ { \Delta } = \frac { S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } ( 1 - \Omega ^ { 2 } ) } { 1 6 \pi ^ { 2 } }$$
We have here used the term M ∆ instead of M ′ ∆ for convenience. Here M ∆ is the modified mass for the fixed (Ω) ensemble. The heat capacity for the Barrow entropy case in the fixed (Ω) ensemble can be calculated as:
$$C _ { \Delta } = \frac { \frac { \partial M _ { \Delta } } { \partial S _ { \Delta } } } { \frac { \partial ^ { 2 } M _ { \Delta } } { \partial S _ { \Delta } ^ { 2 } } } = \frac { ( 2 + \Delta ) S _ { \Delta } } { ( 2 - \Delta ) }$$
The heat capacity of the rotating BTZ black hole is independent of Ω as can be seen from the above expression and therefore the presence or absence of Davies type phase transitions is independent of Ω. We see from Fig.7b that the heat capacity, C ∆ for the rotating BTZ black hole is plotted against the Barrow entropy, S ∆ in the fixed (Ω) ensemble. Here the solid red curve represents the heat capacity for the Barrow parameter, ∆ = 0 012 whereas the black dashed . line represents the free energy for the Bekenstein-Hawking(BH) entropy case (∆ = 0). We see that for l = 1 there are no divergences in the heat capacity curve for both the Barrow and Bekenstein-Hawking (BH) entropy cases.
The Gibbs free energy for the Barrow entropy case in the fixed (Ω) ensemble can be obtained as:
$$G _ { \Delta } = M _ { \Delta } - T _ { \Delta } S _ { \Delta }$$
$$G _ { \Delta } = \frac { S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } ( 2 - \Delta ) ( - 1 + \Omega ^ { 2 } ) } { 1 6 \pi ^ { 2 } ( 2 + \Delta ) }$$
In Fig.8b the Gibbs free energy, G ∆ is plotted against the Barrow entropy, S ∆ for l = 1 and Ω = 0 2 in the fixed (Ω) . ensemble. Here the solid red curve represents the Gibbs free energy for the Renyi parameter, ∆ = 0 012 whereas the . black dashed line represents the free energy for the Bekenstein-Hawking(BH) entropy case (∆ = 0). Here the solid red curve represents the Gibbs free energy for the Barrow parameter, ∆ = 0 012 whereas the black dashed line represents . the free energy for the Bekenstein-Hawking(BH) entropy case (∆ = 0). The free energy for the ∆ = 0 case has been scaled down by multiplying it with 1 10 whereas the free energy for the ∆ = 0 012 case is kept the same, this difference in . scaling is just so that the distinct behaviour of both the curves could be seen more clearly. We find that unlike the Kaniadakis entropy there is no Hawking-Page phase transition present in the Barrow entropy case for the fixed (Ω) ensemble.
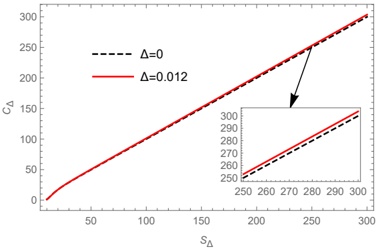
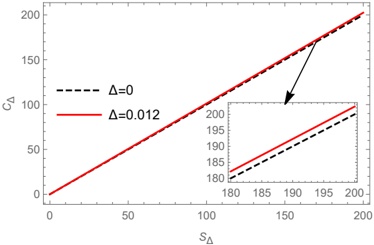
(a) Heat capacity in the fixed (
J
) ensemble for
l
= 1 and
J
= 1
(b) Heat capacity in the fixed (Ω) ensemble for l = 1 and Ω = 0 2 .
FIG. 7: The heat capacity versus Barrow entropy plots in the fixed ( J ) and fixed (Ω) ensembles.
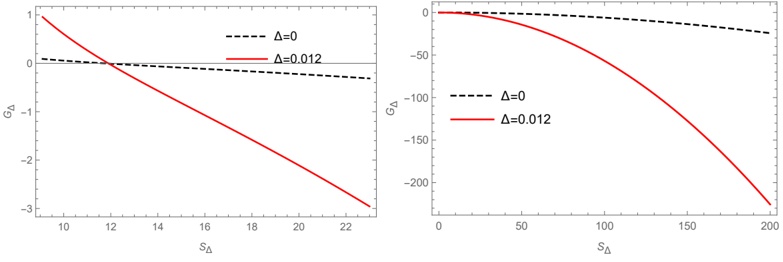
(a) Free energy in the fixed (
J
) ensemble for
(b) Free energy in the fixed (Ω) ensemble for
l
= 1
l
= 1 and
J
= 1
and Ω = 0 2.
.
FIG. 8: The Gibbs free energy versus Barrow entropy plots in the fixed ( J ) and fixed (Ω) ensembles.
## IV. THERMODYNAMIC GEOMETRY OF THE R-BTZ BLACK HOLE
We discuss the thermodynamic geometry of the rotating BTZ black hole for both the Ruppeiner and geometrothermodynamic (GTD) formalisms. The Ruppeiner metric is defined as the negative hessian of entropy with respect to other extensive variables. Therefore it is only the fixed ( J ) ensemble which holds good in the Ruppeiner formalism as J is an extensive thermodynamic quantity whereas Ω is not.
Therefore the fixed (Ω) ensemble do not hold good as per the definition of the Ruppeiner metric. We therefore discuss the thermodynamic geometry of the fixed (Ω) ensemble in the GTD formalism which is defined on a multidimensional phase space that comprises of both the extensive and intensive variables of the thermodynamic system.
The GTD formalism is therefore the appropriate geometric formalism for discussing both the thermodynamic ensembles.
We first discuss the Ruppeiner geometry of the rotating BTZ black hole in the fixed ( J ) ensemble where we observe a curvature singularity in the Ruppeiner scalar curve only for the Kaniadakis entropy case. We then discuss the GTD geometry of the black hole for both the thermodynamic ensembles, where we observe curvature singularities in the GTD scalar curves in Kaniadakis entropy case only. These curvature singularities are seen to occur exactly at the points where we saw divergences in the corresponding heat capacity curves in the previous section.
## IV.1. Ruppeiner formalism
The Ruppeiner metric for the R-BTZ black hole in the fixed ( J ) ensemble can be obtained from the relation (8) and is given as :-
$$d S _ { R } ^ { 2 } = \frac { 1 } { T } \left ( \frac { \partial ^ { 2 } M } { \partial S ^ { 2 } } d S ^ { 2 } + \frac { \partial ^ { 2 } M } { \partial J ^ { 2 } } d J ^ { 2 } + 2 \frac { \partial ^ { 2 } M } { \partial S \partial J } d S d J \right )$$
where M S T , , and J are the mass, entropy, Hawking Temperature and angular momentum for the rotating BTZ black hole respectively.
From the above metric we calculate the Ruppeiner scalar for all the non-extensive entropy cases in the fixed ( J ) ensemble. We find that there is a curvature singularity in the Ruppeiner scalar curve only for the Kaniadakis entropy case . For all the other entropy cases namely: the Renyi and Barrow entropy cases the Ruppeiner scalar curves remain regular with no singularities therein. We have not presented here either the derivation or the final expressions for the Ruppeiner scalar due to their considerable length. However obtaining these expressions is fairly straight forward and involves only routine mathematical computations. We present a detailed analysis of the Ruppeiner thermodynamic geometry for the Kaniadakis entropy case in the fixed ( J ) ensemble as follows:
We see from Fig.9 that the Ruppeiner scalar R rupp is plotted against the Kaniadakis entropy S K in the fixed ( J ) ensemble. We see that for l = 1 and J = 1, for the Kaniadakis parameter K = 0 012 the Ruppeiner scalar curve has a . curvature singularity specifically at S K = 125 74, which is depicted by the solid blue curve in the figure. . The point of singularity here is dissimilar to the point of divergence S K = 125 77 obtained in the corresponding heat capacity curve . for the Kaniadakis entropy case in the fixed ( J ) ensemble. For the K = 0 case however the Ruppeiner scalar curve is found to be regular everywhere with no curvature singularities as is depicted in the figure by the black dashed curve.
FIG. 9: The Ruppeiner scalar versus Kaniadakis entropy plot in the fixed ( J ) ensemble for l = 1 and J = 1.
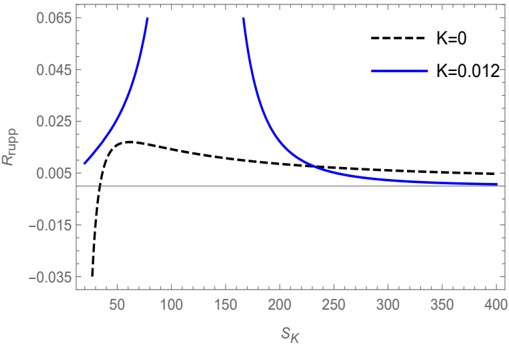
## IV.2. Geometrothermodynamic(GTD) formalism
To describe the rotating BTZ black hole in GTD formalism, we first assume a five-dimensional phase space T with co-ordinates M,S,J,T and Ω which are the mass, entropy, angular momentum, temperature and angular velocity for
the black hole. The contact 1-form for these set of co-ordinates can be written as:-
$$\Theta = d M - T d S - \Omega d J$$
̸
The 1-form satisfies the condition Θ ∧ ( d Θ) 3 = 0 and a legendre invariant metric that goes by :-
$$G = ( d M - T d S - \Omega d J ) ^ { 2 } + T S ( - d T d S + d \Omega d J )$$
We then assume a two-dimensional sub-space of T with co-ordinates E a where a = 1 2. We denote this subspace with , ϵ which is defined as a smooth mapping, ϕ : ϵ →T . The subspace ϵ becomes the space of equilibrium states if the pullback of ϕ is 0 i.e. ϕ ∗ (Θ) = 0. A metric structure g is then naturally induced on ϵ by applying the same pullback on the metric G of T . This induced metric determines all the geometric properties of the equilibrium space for the R-BTZ black hole.
## IV.2.1. The Kaniadakis entropy case
## Fixed ( J ) ensemble :
We write the GTD metric for the Kaniadakis entropy case in the fixed ( J ) ensemble from the general metric given in (9). We consider the thermodynamic potential φ to be the mass M K for the Kaniadakis entropy case in the fixed ( J ) ensemble as obtained in equation (15). The GTD metric is given by :-
$$g = S _ { K } \left ( \frac { \partial M _ { K } } { \partial S _ { K } } \right ) \left ( - \frac { \partial ^ { 2 } M _ { K } } { \partial S _ { K } ^ { 2 } } d S _ { K } ^ { 2 } + \frac { \partial ^ { 2 } M _ { K } } { \partial J ^ { 2 } } d J ^ { 2 } \right )$$
From the above metric we calculate the GTD scalar for the Kaniadakis entropy case in the fixed ( J ) ensemble. We have not presented here either the derivation or the final expressions for the GTD scalar due to their considerable length. However obtaining these expressions is fairly straight forward and involves only routine mathematical computations. We present a detailed analysis of the GTD thermodynamic geometry for the Kaniadakis entropy case in the fixed ( J ) ensemble as follows:
We see from Fig.10 that the GTD scalar R GTD is plotted against the Kaniadakis entropy S K for the Kaniadakis parameter K = 0 012 in the fixed ( . J ) ensemble. We find that for l = 1 and J = 1, the GTD scalar has a curvature singularity at S K = 125 77 for . K = 0 012 as depicted by the blue solid curve whereas for the BH entropy case ( . K = 0) the curve remains regular everywhere with no curvature singularities, as is depicted in the figure by the black dashed curve. Unlike Ruppeiner scalar, the singularity obtained from the GTD scalar curve matches exactly with the point of divergence obtained from the corresponding heat capacity curve for the Kaniadakis entropy case in the fixed ( J ) ensemble.
FIG. 10: The GTD scalar versus Kaniadakis entropy plot in the fixed ( J ) ensemble for l = 1 and J = 1.
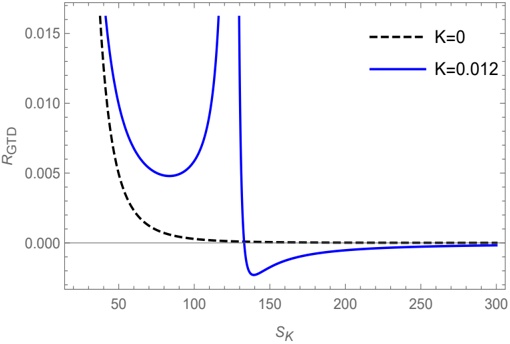
## Fixed (Ω) ensemble :
We write the GTD metric for the Kaniadakis entropy case in the fixed (Ω) ensemble from the general metric given in (9). We consider the thermodynamic potential φ to be the mass M K for the Kaniadakis entropy case in the fixed (Ω) ensemble as obtained in equation (21). The GTD metric is given by :-
$$g = S _ { K } \left ( \frac { \partial M _ { K } } { \partial S _ { K } } \right ) \left ( - \frac { \partial ^ { 2 } M _ { K } } { \partial S _ { K } ^ { 2 } } d S _ { K } ^ { 2 } + \frac { \partial ^ { 2 } M _ { K } } { \partial \Omega ^ { 2 } } d \Omega ^ { 2 } \right )$$
From the above metric we calculate the GTD scalar for the Kaniadakis entropy case in the fixed (Ω) ensemble. We have not shown here either the derivation or the final expressions for the GTD scalar due to their considerable length. However obtaining them is fairly straight forward and involves only routine mathematical computations. We present a detailed analysis of the GTD thermodynamic geometry for the Kaniadakis entropy case in the fixed (Ω) ensemble as follows:
We see from Fig.11 that the GTD scalar R GTD is plotted against the Kaniadakis entropy S K in the fixed (Ω) ensemble. We find that for l = 1 and Ω = 0 2, the GTD scalar has a curvature singularity at . S K = 125 74 for . K = 0 012 as . depicted by the blue solid curve whereas for the BH entropy case ( K = 0) the curve remains regular everywhere with no curvature singularities, as is depicted in the figure by the black dashed curve. Unlike Ruppeiner scalar, the singularity obtained from the GTD scalar curve matches exactly with the point of divergence obtained from the corresponding heat capacity curve for the Kaniadakis entropy case in the fixed (Ω) ensemble.
FIG. 11: The GTD scalar versus Kaniadakis entropy plot in the fixed (Ω) ensemble for l = 1 and Ω = 0 2 .
## V. THERMODYNAMICS OF THE CHARGED BTZ BLACK HOLE
The action which facilitates the field equations[64-66, 69, 70] from which the (2 + 1) dimensional charged BTZ black hole solutions are obtained is given as:
$$I = \frac { 1 } { 2 \pi } \int d ^ { 3 } x \sqrt { - g } \left ( R - 2 \Lambda - \frac { \pi } { 2 } F _ { \mu \nu } F ^ { \mu \nu } \right )$$
where, the AdS length l is related to the cosmological constant Λ by the relation: Λ = -1 l 2 and the Einstein's field equations are given by:
$$G _ { \mu \nu } - \Lambda g _ { \mu \nu } = \pi T _ { \mu \nu }$$
and the energy momentum tensor for the same is given as:
$$T _ { \mu \nu } = F _ { \mu \rho } F _ { \nu \sigma } g ^ { \rho \sigma } - \frac { 1 } { 4 } g _ { \mu \nu } F ^ { 2 }$$
The line element that corresponds to the given solution is:
$$d s ^ { 2 } = - f ( r ) d t ^ { 2 } + \frac { d r ^ { 2 } } { f ( r ) } + r ^ { 2 } d \phi ^ { 2 }$$
where f r ( ) = -M + r 2 l 2 -πQ 2 2 ln [ r ] and 'M' and 'Q' are the mass and electric charge carried by the black hole. Solving the function for f ( r ) = 0 would give us the roots which determine the horizon radius. For an exterior horizon radius, ' r + ' the black hole mass is given by:
$$M = \frac { r _ { + } ^ { 2 } } { l ^ { 2 } } + \frac { \pi Q ^ { 2 } } { 2 } \ln \left [ r _ { + } \right ]$$
and the black hole entropy is given by:
$$S _ { B H } = 4 \pi r _ { + }$$
## V.1. The Kaniadakis entropy case
## Fixed ( Q ) ensemble :
We replace the horizon radius in (34) by the one obtained in (14) to get the modified mass M K for the charged BTZ black hole which is given by :
$$M _ { K } = \frac { A r c S i n h ^ { 2 } [ K S _ { K } ] } { 1 6 \pi ^ { 2 } l ^ { 2 } K ^ { 2 } } - \frac { \pi Q ^ { 2 } } { 2 } \ln \left [ \frac { A r c S i n h [ K S _ { K } ] } { 4 \pi K } \right ]$$
The function, ArcSinh KS [ K ] can be replaced by its logarithmic form, ln [ KS K + √ 1 + K S 2 2 K ] and therefore the expression for mass becomes:
$$M _ { K } = \frac { \ln [ K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ] ^ { 2 } } { 1 6 \pi ^ { 2 } l ^ { 2 } K ^ { 2 } } - \frac { \pi Q ^ { 2 } } { 2 } \ln \left [ \frac { \ln [ K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ] } { 4 \pi K } \right ]$$
The heat capacity for the Kaniadakis entropy case in the fixed ( Q ) ensemble can be obtained as:
$$C _ { K } = \frac { \frac { \partial M _ { K } } { \partial S _ { K } } } { \frac { \partial ^ { 2 } M _ { K } } { \partial S _ { K } ^ { 2 } } } = \frac { A } { B }$$
where, and
$$B = K & \Big ( 4 K ^ { 3 } \pi ^ { 3 } Q ^ { 2 } \ln \Big ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \Big ) - K \ln \Big ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \Big ) ^ { 3 } S _ { K } + \Big ( 4 K ^ { 2 } \pi ^ { 3 } Q ^ { 2 } \\ & \quad + \ln \Big ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \Big ) ^ { 2 } \Big ) \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \Big ).$$
In Fig.25 the heat capacity, C K is plotted against the Kaniadakis entropy, S K for l = 1 and J = 1 in the fixed ( Q ) ensemble. Here the solid blue curve represents the heat capacity for the Kaniadakis parameter, K = 0 012 whereas the . black dashed line represents the heat capacity for the Bekenstein-Hawking(BH) entropy case ( K = 0). We find that for K = 0 012, the heat capacity has a divergence at . S K = 128 82 which indicates the presence of a Davies type phase . transition present in the Kaniadakis modified black hole whereas the heat capacity for the BH entropy case shows no such behaviour.
$$A = \left ( 1 + K ^ { 2 } S _ { K } ^ { 2 } \right ) \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) \left ( - 4 K ^ { 2 } \pi ^ { 3 } Q ^ { 2 } + \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) ^ { 2 } \right )$$
FIG. 12: The heat capacity versus Kaniadakis entropy plot in the fixed ( Q ) ensemble for l = 1 and Q = 1
The Gibbs free energy for the Kaniadakis entropy case in the fixed ( Q ) ensemble can be obtained as:
$$G _ { K } = M _ { K } - T _ { K } S _ { K }$$
$$G _ { K } & = \frac { 1 } { 2 } \pi Q ^ { 2 } \ln { ( 4 \pi ) } - \frac { 1 } { 2 } \pi Q ^ { 2 } \ln { \left ( \frac { \ln { ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } ) } } } { K } \right ) } + \frac { \ln { ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } ) } } } { 1 6 \pi ^ { 2 } K ^ { 2 } } \\ & \quad + \frac { \pi K Q ^ { 2 } S _ { K } } { 2 \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \ln { ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } ) } } } - \frac { S _ { K } \ln { ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } ) } } } { 8 \pi ^ { 2 } K \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } }.$$
In Fig.13a and Fig.13b the Gibbs free energy, G K is plotted against the Kaniadakis entropy, S K for l = 1 and Q = 1 in the fixed ( Q ) ensemble. We draw two different plots so as to make the presence of the phase transitions more transparent. Here the solid blue curve represents the Gibbs free energy for the Kaniadakis parameter, K = 0 012 . whereas the black dashed line represents the free energy for the Bekenstein-Hawking(BH) entropy case ( K = 0). The free energy for the K = 0 case has been scaled down by multiplying it with 1 10 whereas the free energy for the K = 0 012 case is kept the same, this difference in scaling is just so that the distinct behaviour of both the . curves could be seen more clearly. We keep in mind that the scaling does not affect the position or occurrence of the phase transitions. We find that in Fig.13a the Gibbs free energy goes to zero for both the entropy cases, where for K = 0, the zero point is at S K = 14 55 and for . K = 0 012, the zero point is found to be at . S K = 14 67, these zero . points refer to the presence of a Hawking-Page phase transition present in the rotating BTZ black hole for both the Bekenstein-Hawking as well as the Kaniadakis entropy cases. We again find that for K = 0 012, the Gibbs free energy . in Fig.13b has a zero point at S K = 289 97 only for the Kaniadakis entropy case which indicates the presence of a . Hawking-Page phase transition present in the Kaniadakis modified black hole whereas the Gibbs free energy for the BH entropy case shows no such behaviour. In Fig.13c we plot the inverse of specific heat capacity (purple) and the Gibbs free energy (orange) against the Kaniadakis entropy. The inverse of specific heat capacity has been scaled up by multiplying it with 3000 whereas the free energy is kept the same, this difference in scaling is just so that the distinct behaviour of both the curves could be seen more clearly. We keep in mind that the scaling does not affect the position or occurrence of the phase transitions. The points where these curves intersect the horizontal axis would represent the Davies-type (Purple) and Hawking-Page (Orange) phase transition respectively which are seen to be quite distant from each other.
## Fixed (Φ) ensemble :
The modified mass for the Kaniadakis entropy case in the fixed (Φ) ensemble is given by:
$$M _ { K } ^ { \prime } = M _ { K } - Q \frac { \partial M _ { K } } { \partial Q }$$
G K
(a) Gibbs free energy versus Kaniadakis entropy (11 < S K < 24).
(b) Gibbs free energy versus Kaniadakis entropy (
S
K
>
24).
(c) Inverse specific heat and Gibbs free energy versus Kaniadakis entropy.
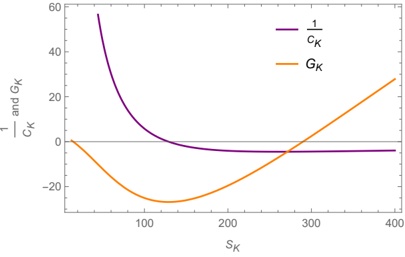
FIG. 13: The Gibbs free energy curves for Kaniadakis entropy in the fixed ( Q ) ensemble for l = 1 and Q = 1.
where ∂M K ∂Q = Φ is the electric potential of the black hole with respect to the electric charge Q . By writing the term M ′ K as M K for convenience we get:
$$M _ { K } = \frac { \Phi ^ { 2 } } { 2 \pi \left ( \ln \left ( \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) - \ln ( 4 \pi K ) \right ) \right ) } + \frac { \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) ^ { 2 } } { 1 6 \pi ^ { 2 } K ^ { 2 } } \, \quad \, \quad ( 4 0 )$$
The heat capacity for the Kaniadakis entropy case in the fixed (Φ) ensemble can be obtained as:
$$C _ { K } = \frac { \frac { \partial M _ { K } } { \partial S _ { K } } } { \frac { \partial ^ { 2 } M _ { K } } { \partial S _ { K } ^ { 2 } } } = \frac { A } { B }$$
where,
$$A & = \left ( \ln ( 4 \pi ) - \ln \left ( \frac { \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) } { K } \right ) \right ) \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) \left ( - 4 \pi K ^ { 2 } \Phi ^ { 2 } \\ & \quad + \ln \left ( \frac { \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) } { 4 K \pi } \right ) ^ { 2 } \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) ^ { 2 } \right ) \left ( 1 + K ^ { 2 } S _ { K } ^ { 2 } \right )$$
and
$$& \text{and} \\ & B = K \left ( \left ( \left ( \ln ( 4 \pi ) - \ln \left ( \frac { \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) } { K } \right ) \right ) \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) \right ) \left ( 4 K ^ { 2 } \pi \Phi ^ { 2 } \\ & \quad - \ln \left ( \frac { \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) } { 4 K \pi } \right ) ^ { 2 } \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) ^ { 2 } \right ) S _ { K } + \left ( 4 K ^ { 2 } \pi \Phi ^ { 2 } ( - 2 + \ln ( 4 \pi ) \right ) \\ & \quad + \ln ( 4 \pi ) ^ { 3 } \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) ^ { 2 } \quad + 3 \ln ( 4 \pi ) \ln \left ( \frac { \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) } { K } \right ) ^ { 2 } \\ & \quad \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) ^ { 2 } \quad - \ln \left ( \frac { \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) } { K } \right ) ^ { 3 } \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) ^ { 2 } \\ & \quad - \ln \left ( \frac { \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) } { K } \right ) \left ( 4 K ^ { 2 } \pi \Phi ^ { 2 } + 3 \ln ( 4 \pi ) ^ { 2 } \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) ^ { 2 } \right ) \right ) \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) \ \text{(42)} \\ & \quad \text{In Fig.14 the heat capacity, C$_{K} for the charged BTZ black hole is plotted against the Kaniadakis entropy, S$_{K}$ in the} \\ & \text{fixed} \, \text{$\mathbb{i}$ ensemble, We draw the same niot in two different entropy ranges so as to make all theanearing differences}$$
In Fig.14 the heat capacity, C K for the charged BTZ black hole is plotted against the Kaniadakis entropy, S K in the fixed (Φ) ensemble. We draw the same plot in two different entropy ranges so as to make all the appearing divergences in the heat capacity curve visible. We see from Fig.14a that for l = 1 and Φ = 0 2 there is a divergence at . S K = 10 26 . for K = 0 012 as shown by the solid blue curve. . The heat capacity in the Bekenstein-Hawking(BH) entropy case ( K = 0) here also produces a divergence at S K = 10 24 as shown by the black dashed curve. In Fig.14b we see that . there is a divergence in the heat capacity curve at S K = 125 74 for . K = 0 012 whereas here the heat capacity in the . BH entropy case ( K = 0) remains a monotonically increasing function of entropy with no divergences.
100
50
0
50
-
-
100
9.6
K 0
=
K 0.012
=
9.8
10.0
10.2
10.4
10.6
10.8
S K
(a) Heat capacity versus Kaniadakis entropy ( S < 11).
(b) Heat capacity versus Kaniadakis entropy (11 < S < 300).
FIG. 14: The heat capacity versus Kaniadakis entropy plot in the fixed (Φ) ensemble for l = 1 and Φ = 0 2 .
The Gibbs free energy for the Kaniadakis entropy case in the fixed (Φ) ensemble can be obtained as:
$$G _ { K } = M _ { K } - T _ { K } S _ { K } = \frac { \mathcal { C } } { \mathcal { D } }$$
where,
$$\mathcal { C } & = \frac { - \Phi ^ { 2 } } { 4 \pi ( \ln ( 4 \pi ) - \ln ( \frac { \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) } { K } ) ) } + \frac { \ln \left ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } \right ) ^ { 2 } } { 1 6 K ^ { 2 } \pi ^ { 2 } } \\ & \quad - S _ { K } \left ( - 4 \pi K ^ { 2 } \Phi ^ { 2 } \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) ^ { 2 } + \ln ( 4 \pi ) ^ { 2 } \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) ^ { 4 } \\ & \quad \left ( \ln ( \frac { \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) } { K } ) - 2 \ln ( 4 \pi ) \right ) \ln ( \frac { \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) } { K } ) \ln ( K S _ { K } + \sqrt { 1 + K ^ { 2 } S _ { K } ^ { 2 } } ) ^ { 4 } \right ) \quad ( 4 3 ) \\ \text{and}$$
and
$$\mathcal { D } = 8 K \pi ^ { 2 } \sqrt { 1 + K ^ { 2 } S ^ { 2 } } \ln \left ( K S + \sqrt { 1 + K ^ { 2 } S ^ { 2 } } \right ) ^ { 3 } \left ( \ln \left ( 4 \pi \right ) - \ln \left ( \frac { \ln \left ( K S + \sqrt { 1 + K ^ { 2 } S ^ { 2 } } \right ) } { K } \right ) \right ) ^ { 2 } \text{ \quad \ \ } \text{(44)}$$
C K
C K
In Fig.15a the Gibbs free energy, G K is plotted against the Kaniadakis entropy, S K for l = 1 and Φ = 0 2 in the fixed . (Φ) ensemble. Here the solid blue curve represents the Gibbs free energy for the Kaniadakis parameter, K = 0 012 . whereas the black dashed line represents the free energy for the Bekenstein-Hawking(BH) entropy case ( K = 0). The free energy for the K = 0 case has been scaled down by multiplying it with 1 10 whereas the free energy for the K = 0 012 case is kept the same, this difference in scaling is just so that the distinct behaviour of both the curves . could be seen more clearly. We keep in mind that the scaling does not affect the position or occurrence of the phase transition. We find that for K = 0 012, the Gibbs free energy has a zero point at . S K = 276 64 which indicates the . presence of a Hawking-Page phase transition present in the Kaniadakis modified black hole whereas the Gibbs free energy for the BH entropy case shows no such behaviour. In Fig.15b we plot the inverse of specific heat capacity (purple) and the Gibbs free energy (orange) against the Kaniadakis entropy. The inverse of specific heat capacity has been scaled up by multiplying it with 3000 whereas the free energy is kept the same, this difference in scaling is just so that the distinct behaviour of both the curves could be seen more clearly. We keep in mind that the scaling does not affect the position or occurrence of the phase transitions. The points where these curves intersect the horizontal axis would represent the Davies-type (Purple) and Hawking-Page (Orange) phase transition respectively which are seen to be quite distant from each other.
1
(a) Gibbs free energy versus Kaniadakis entropy.
(b) Inverse specific heat and Gibbs free energy versus Kaniadakis entropy.
FIG. 15: The Gibbs free energy curves for Kaniadakis entropy in the fixed (Φ) ensemble for l = 1 and Φ = 0 2. .
## V.2. The Renyi entropy case
## Fixed ( Q ) ensemble :
We replace the horizon radius in (34) by the one obtained in (23) to get the modified mass M R for the charged BTZ black hole which is given by :
$$M _ { R } = \frac { 1 - 2 e ^ { \lambda S _ { R } } + e ^ { 2 \lambda S _ { R } } + 8 \pi ^ { 3 } Q ^ { 2 } \lambda ^ { 2 } \ln ( 4 \pi ) - 8 \pi ^ { 3 } Q ^ { 2 } \lambda ^ { 2 } ( \ln ( - 1 + e ^ { \lambda S _ { R } } ) - \ln ( \lambda ) ) } { 1 6 \pi ^ { 2 } \lambda ^ { 2 } }$$
The heat capacity for the Renyi entropy case in the fixed ( Q ) ensemble can be calculated as:
$$C _ { R } = \frac { \frac { \partial M _ { R } } { \partial S _ { R } } } { \frac { \partial ^ { 2 } M _ { R } } { \partial S _ { R } ^ { 2 } } } = \frac { \left ( - 1 + e ^ { \lambda S _ { R } } \right ) \left ( 1 - 2 e ^ { \lambda S _ { R } } + e ^ { 2 \lambda S _ { R } } - 4 \pi ^ { 3 } Q ^ { 2 } \lambda ^ { 2 } \right ) } { \lambda \left ( - 1 + 4 e ^ { \lambda S _ { R } } - 5 e ^ { 2 \lambda S _ { R } } + 2 e ^ { 3 \lambda S _ { R } } + 4 \pi ^ { 3 } Q ^ { 2 } \lambda ^ { 2 } \right ) }$$
We see from Fig.16a that the heat capacity, C R for the charged BTZ black hole is plotted against the Renyi entropy, S R in the fixed ( Q ) ensemble. Here the solid green curve represents the heat capacity for the Renyi parameter, λ = 0 012 . whereas the black dashed line represents the heat capacity for the Bekenstein-Hawking(BH) entropy case ( λ = 0). For the parameter l = 1 and Q = 1 we find that there are no divergences in the heat capacity curve for both the Renyi and Bekenstein-Hawking (BH) entropy cases.
The Gibbs free energy for the Renyi entropy case in the fixed ( Q ) ensemble can be obtained as:
$$G _ { R } = M _ { R } - T _ { R } S _ { R }$$
$$G _ { R } & = \frac { 1 } { 1 6 \pi ^ { 2 } \lambda ^ { 2 } ( - 1 + e ^ { \lambda S _ { R } } ) } \left ( - 1 + e ^ { 3 \lambda S _ { R } } ( 1 - 2 \lambda S _ { R } ) + e ^ { 2 \lambda S _ { R } } ( - 3 + 4 \lambda S _ { R } ) - 8 \pi ^ { 3 } Q ^ { 2 } \lambda ^ { 2 } \ln ( 4 \pi ) + e ^ { \lambda S _ { R } } ( 3 \\ & \quad - 2 \lambda S _ { R } + 8 \pi ^ { 2 } Q ^ { 2 } S _ { R } \lambda ^ { 3 } + 8 \pi ^ { 2 } Q ^ { 2 } \lambda ^ { 2 } \ln ( 4 \pi ) ) - 8 ( - 1 + e ^ { \lambda S _ { R } } ) \pi ^ { 3 } Q ^ { 2 } \lambda ^ { 2 } ( \ln ( - 1 + e ^ { \lambda S _ { R } } ) - \ln ( \lambda ) ) \right ).$$
In Fig.17a the Gibbs free energy, G R is plotted against the Renyi entropy, S R for l = 1 and Q = 1 in the fixed ( Q ) ensemble. Here the solid green curve represents the Gibbs free energy for the Renyi parameter, λ = 0 012 whereas the . black dashed line represents the free energy for the Bekenstein-Hawking(BH) entropy case ( λ = 0). The free energy for the λ = 0 case has been scaled down by multiplying it with 1 10 whereas the free energy for the λ = 0 012 case is kept . the same, this difference in scaling is just so that the distinct behaviour of both the curves could be seen more clearly. We find that in Fig.19a the Gibbs free energy goes to zero for both the entropy cases, where for λ = 0, the zero point is at S R = 14 55 and for . λ = 0 012, the zero point is found to be at . S R = 13 17, these zero points refer to the presence . of a Hawking-Page phase transition present in the charged BTZ black hole for both the Bekenstein-Hawking as well as the Renyi entropy cases.
## Fixed (Φ) ensemble :
The modified mass for the Renyi entropy case in the fixed (Φ) ensemble is given by:
$$M _ { R } ^ { \prime } = M _ { R } - Q \frac { \partial M _ { R } } { \partial Q }$$
$$M _ { R } ^ { \prime } = M _ { R } - Q \Phi$$
where ∂M R ∂Q = Φ is the electric potential of the black hole with respect to the electric charge Q . By making the necessary replacements and putting l = 1, we get the final equation as follows:
$$M _ { R } = \frac { - 8 \pi \lambda ^ { 2 } \Phi ^ { 2 } + ( - 1 + e ^ { S _ { R } \lambda ) ^ { 2 } } \ln ( 4 \pi ) - ( - 1 + e ^ { S _ { R } \lambda } ) ^ { 2 } \left ( \ln ( - 1 + e ^ { \lambda S _ { R } } ) - \ln ( \lambda ) \right ) } { 1 6 \pi ^ { 2 } \lambda ^ { 2 } \left ( \ln ( 4 \pi \lambda ) - \left ( \ln ( - 1 + e ^ { \lambda S _ { R } } ) \right ) }$$
We have here used the term M R instead of M ′ R for convenience. Here M R is the modified mass for the fixed (Φ) ensemble. The heat capacity for the Renyi entropy case in the fixed (Φ) ensemble can be calculated as:
$$C _ { R } = \frac { \frac { \partial M _ { R } } { \partial S _ { R } } } { \frac { \partial ^ { 2 } M _ { R } } { \partial S _ { R } ^ { 2 } } } = \frac { A } { B }$$
where,
$$A = & \left ( - 1 + e ^ { S _ { R } \lambda } \right ) \left ( \ln ( 4 \pi ) - \ln \left ( \frac { - 1 + e ^ { S _ { R } \lambda } } { \lambda } \right ) \right ) \left ( - 4 \pi \lambda ^ { 2 } \Phi ^ { 2 } + \left ( - 1 + e ^ { S _ { R } \lambda } \right ) ^ { 2 } \ln ( 4 \pi ) ^ { 2 } \\ & - 2 ( - 1 + e ^ { S _ { R } \lambda } ) ^ { 2 } \ln ( 4 \pi ) \ln \left ( \frac { - 1 + e ^ { S _ { R } \lambda } } { \lambda } \right ) \quad + \left ( - 1 + e ^ { S _ { R } \lambda } \right ) ^ { 2 } \ln \left ( \frac { - 1 + e ^ { S _ { R } \lambda } } { \lambda } \right ) ^ { 2 } \right )$$
$$B & = \lambda \Big ( 4 \pi ^ { 2 } \Phi ^ { 2 } \ln ( 4 \pi ) - \ln ( 4 \pi ) ^ { 3 } - 5 e ^ { 2 S _ { R } \lambda } \ln ( 4 \pi ) ^ { 3 } \quad + 2 e ^ { 3 S _ { R } \lambda } \ln ( 4 \pi ) ^ { 3 } + e ^ { S _ { R } \lambda } \Big ( - 8 \pi \lambda ^ { 2 } \Phi ^ { 2 } + 4 \ln ( 4 \pi ) ^ { 3 } ) \\ & \quad + \Big ( - 4 \pi \lambda ^ { 2 } \Phi ^ { 2 } - 3 ( - 1 + e ^ { S _ { R } \lambda } ) ^ { 2 } ( - 1 + 2 e ^ { S _ { R } \lambda } ) \ln ( 4 \pi ) ^ { 2 } \Big ) \ln \Big ( \frac { - 1 + e ^ { S _ { R } \lambda } } { \lambda } \Big ) + 3 ( - 1 + e ^ { S _ { R } \lambda } ) ^ { 2 } \\ & \quad ( - 1 + 2 e ^ { S _ { R } \lambda } ) \ln ( 4 \pi ) \ln \Big ( \frac { - 1 + e ^ { S _ { R } \lambda } } { \lambda } \Big ) ^ { 2 } - ( - 1 + e ^ { S _ { R } \lambda } ) ^ { 2 } ( - 1 + 2 e ^ { S _ { R } \lambda } ) \ln \Big ( \frac { - 1 + e ^ { S _ { R } \lambda } } { \lambda } \Big ) ^ { 3 } \Big )$$
We see from Fig.16b that the heat capacity, C R for the charged BTZ black hole is plotted against the Renyi entropy, S R in the fixed (Φ) ensemble. Here the solid green curve represents the heat capacity for the Renyi parameter, λ = 0 012 whereas the black dashed line represents the heat capacity for the Bekenstein-Hawking(BH) entropy case . ( λ = 0). We see that for l = 1 and Φ = 0 2 there is a divergence in the heat capacity curve for both the Renyi and BH . entropy cases. The divergence for the Renyi entropy case ( K = 0 012) is seen to be at . S K = 9 71 whereas for the . Bekenstein-Hawking entropy case ( K = 0) the divergence is found to be at S K = 10 24. .
The Gibbs free energy for the Renyi entropy case in the fixed (Φ) ensemble can be obtained as:
$$G _ { R } = M _ { R } - T _ { R } S _ { R }$$
$$G _ { R } = \frac { C } { D }$$
where,
$$\cdots \cdots, \\ C & = ( 8 \pi \lambda ^ { 2 } \Phi ^ { 2 } - \ln ( 4 \pi ) ) \ln ( 4 \pi ) - e ^ { 3 S _ { R } \lambda } ( - 1 + 2 S _ { R } \lambda ) \ln ( 4 \pi ) ^ { 2 } + e ^ { 2 S _ { R } \lambda } ( - 3 + 4 S _ { R } \lambda ) \ln ( 4 \pi ) ^ { 2 } + e ^ { S _ { R } \lambda } \left ( 8 \pi \lambda ^ { 2 } \Phi ^ { 2 } \\ & \quad ( S _ { R } \lambda - \ln ( 4 \pi ) ) + ( 3 - 2 S _ { R } \lambda ) \ln ( 4 \pi ) ^ { 2 } \right ) + 2 ( - 1 + e ^ { S _ { R } \lambda } ) \left ( 4 \pi \lambda ^ { 2 } \Phi ^ { 2 } + ( - 1 + e ^ { S _ { R } \lambda } ) ( 1 + e ^ { S _ { R } \lambda } \\ & \quad ( - 1 + 2 S _ { R } \lambda ) ) \ln ( 4 \pi ) \right ) \ln \left ( \frac { - 1 + e ^ { S _ { R } \lambda } } { \lambda } \right ) - \left ( - 1 + e ^ { S _ { R } \lambda } \right ) ^ { 2 } ( 1 + e ^ { S _ { R } \lambda } ( - 1 + 2 S _ { R } \lambda ) ) \ln \left ( \frac { - 1 + e ^ { S _ { R } \lambda } } { \lambda } \right ) ^ { 2 } \quad ( 5 0 )$$
$$D = 1 6 ( - 1 + e ^ { S _ { R } \lambda } ) \pi ^ { 2 } \lambda ^ { 2 } \left ( \ln ( 4 \pi ) - \ln \left ( \frac { - 1 + e ^ { S _ { R } \lambda } } { \lambda } \right ) \right ) ^ { 2 }$$
In Fig.17b the Gibbs free energy, G R is plotted against the Renyi entropy, S R for l = 1 and Φ = 0 2 in the fixed (Φ) . ensemble. Here the solid green curve represents the Gibbs free energy for the Renyi parameter, λ = 0 012 whereas the . black dashed line represents the free energy for the Bekenstein-Hawking(BH) entropy case ( λ = 0). The free energy for the λ = 0 case has been scaled down by multiplying it with 1 10 whereas the free energy for the λ = 0 012 case is kept . the same, this difference in scaling is just so that the distinct behaviour of both the curves could be seen more clearly. We find that unlike the Kaniadakis entropy there is no Hawking-Page phase transition present in the Renyi entropy case for the fixed (Φ) ensemble.
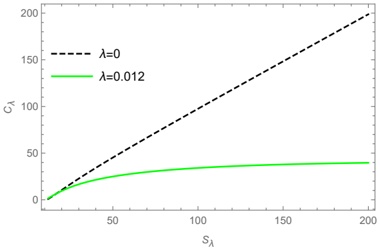
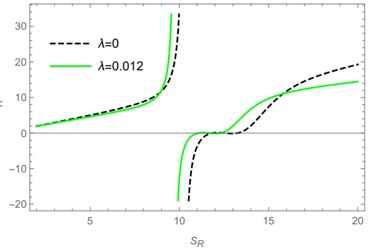
C R
(a) Heat capacity in the fixed ( Q ) ensemble for (b) Heat capacity in the fixed (Φ) ensemble for l = 1 and Q = 1 l = 1 and Φ = 0 2 .
FIG. 16: The heat capacity versus Renyi entropy plots in the fixed ( J ) and fixed (Φ) ensembles.
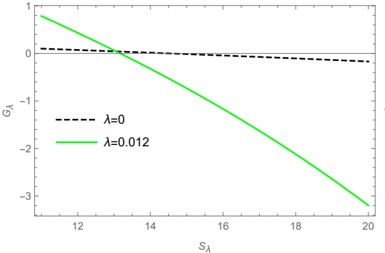
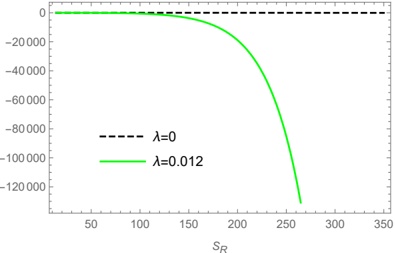
G R
- (a) Free energy in the fixed ( Q ) ensemble for l = 1 and Q = 1
(b) Free energy in the fixed (Φ) ensemble for l = 1 and Φ = 0 2. .
FIG. 17: The Gibbs free energy versus Renyi entropy plots in the fixed ( Q ) and fixed (Φ) ensembles.
## V.3. The Barrow entropy case
## Fixed ( Q ) ensemble :
We replace the horizon radius in (34) by the one obtained in (30) to get the modified mass M ∆ for the charged BTZ black hole which is given by :
$$M _ { \Delta } = \frac { S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } + 8 \pi ^ { 3 } Q ^ { 2 } \ln ( 4 \pi ) - 8 \pi ^ { 3 } Q ^ { 2 } \ln \left ( S _ { \Delta } ^ { \frac { 2 } { 2 + \Delta } } \right ) } { 1 6 \pi ^ { 2 } }$$
The heat capacity for the Barrow entropy case in the fixed ( Q ) ensemble can be calculated as:
$$C _ { \Delta } = \frac { \frac { \partial M _ { \Delta } } { \partial S _ { \Delta } } } { \frac { \partial ^ { 2 } M _ { \Delta } } { \partial S _ { \Delta } ^ { 2 } } } = \frac { \left ( S _ { \Delta } \left ( 4 \pi ^ { 3 } Q ^ { 2 } - S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } \right ) ( 2 + \Delta ) \right ) } { S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } ( - 2 + \Delta ) - 4 \pi ^ { 3 } Q ^ { 2 } ( 2 + \Delta ) }$$
We see from Fig.18a that the heat capacity, C ∆ for the charged BTZ black hole is plotted against the Barrow entropy, S ∆ in the fixed ( Q ) ensemble. Here the solid red curve represents the heat capacity for the Barrow parameter, ∆ = 0 012 whereas the black dashed line represents the heat capacity for the Bekenstein-Hawking(BH) entropy case . (∆ = 0). For the parameter l = 1 and Q = 1 we find that there are no divergences in the heat capacity curve for both the Barrow and Bekenstein-Hawking (BH) entropy cases.
The Gibbs free energy for the Renyi entropy case in the fixed ( Q ) ensemble can be obtained as:
$$G _ { \Delta } = M _ { \Delta } - T _ { \Delta } S _ { \Delta }$$
$$G _ { \Delta } = \frac { S _ { \Delta } ^ { \frac { 4 } { 2 } + \Delta } ( - 2 + \Delta ) + 8 \pi ^ { 3 } Q ^ { 2 } ( 2 + 2 \ln ( 4 \pi ) + \Delta \ln ( 4 \pi ) ) - 8 \pi ^ { 3 } Q ^ { 2 } ( 2 + \Delta ) \ln \left ( S _ { \Delta } ^ { \frac { 2 } { 2 } + \Delta } \right ) } { 1 6 \pi ^ { 2 } ( 2 + \Delta ) }$$
In Fig.19a the Gibbs free energy, G ∆ is plotted against the Barrow entropy, S ∆ for l = 1 and Q = 1 in the fixed ( Q ) ensemble. Here the solid red curve represents the Gibbs free energy for the Barrow parameter, ∆ = 0 012 whereas the . black dashed line represents the free energy for the Bekenstein-Hawking(BH) entropy case (∆ = 0). The free energy for the ∆ = 0 case has been scaled down by multiplying it with 1 10 whereas the free energy for the ∆ = 0 012 case is kept . the same, this difference in scaling is just so that the distinct behaviour of both the curves could be seen more clearly.
We find that in Fig.19a the Gibbs free energy goes to zero for both the entropy cases, where for ∆ = 0, the zero point is at S ∆ = 14 55 and for ∆ = 0 012, the zero point is found to be at . . S ∆ = 14 81, these zero points refer to the presence . of a Hawking-Page phase transition present in the charged BTZ black hole for both the Bekenstein-Hawking as well as the Barrow entropy cases.
## Fixed (Φ) ensemble :
The modified mass for the Barrow entropy case in the fixed (Φ) ensemble is given by:
$$M _ { \Delta } ^ { \prime } = M _ { \Delta } - Q \frac { \partial M _ { \Delta } } { \partial Q }$$
$$M _ { \Delta } ^ { \prime } = M _ { \Delta } - Q \Phi$$
where ∂M ∆ ∂Q = Φ is the electric potential of the black hole with respect to the electric charge Q . By making the necessary replacements and putting l = 1, we get the final equation as follows:
$$\begin{array} { c c c } \mu & \mu & \mu & \mu & \mu \\ \mu & \mu & \mu & \mu & \mu \\ M _ { \Delta } = - \frac { 8 \pi \Phi ^ { 2 } - S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } \ln ( 4 \pi ) + S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } \ln \left ( S _ { \Delta } ^ { \frac { 2 } { 2 + \Delta } } \right ) } { 1 6 \pi ^ { 2 } \left ( \ln ( 4 \pi ) - \ln \left ( S _ { \Delta } ^ { \frac { 2 } { 2 + \Delta } } \right ) \right ) } \end{array}$$
We have here used the term M ∆ instead of M ′ ∆ for convenience. Here M ∆ is the modified mass for the fixed (Φ) ensemble. The heat capacity for the Barrow entropy case in the fixed (Φ) ensemble can be calculated as:
$$C _ { \Delta } = \frac { \frac { \partial M _ { \Delta } } { \partial S _ { \Delta } } } { \frac { \partial ^ { 2 } M _ { \Delta } } { \partial S _ { \Delta } ^ { 2 } } } = \frac { A } { B }$$
where,
$$A = ( 2 S _ { \Delta } + \Delta S _ { \Delta } ) \ln \left ( \frac { \left ( S _ { \Delta } ^ { \frac { 2 } { 2 + \Delta } } \right ) } { 4 \pi } \right ) \left ( - 4 \pi \Phi ^ { 2 } + S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } \ln ( 4 \pi ) ^ { 2 } - 2 S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } \ln ( 4 \pi ) \ln \left ( S _ { \Delta } ^ { \frac { 2 } { 2 + \Delta } } \right ) + S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } \ln \left ( S _ { \Delta } ^ { \frac { 2 } { 2 + \Delta } } \right ) ^ { 2 } \right ) \ ( 5 4 )$$
and
$$& \dots \\ & B = S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } ( - 2 + \Delta ) \ln ( 4 \pi ) ^ { 3 } - 4 \pi \Phi ^ { 2 } ( - 4 + 2 \ln ( 4 \pi ) + \Delta \ln ( 4 \pi ) ) + \left ( 4 \pi ( 2 + \Delta ) \Phi ^ { 2 } - 3 S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } ( - 2 + \Delta ) \ln ( 4 \pi ) ^ { 2 } \right ) \\ & \quad \ln ( S _ { \Delta } ^ { \frac { 2 } { 2 + \Delta } } ) + 3 S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } ( - 2 + \Delta ) \ln ( 4 \pi ) \ln ( S _ { \Delta } ^ { \frac { 2 } { 2 + \Delta } } ) ^ { 2 } - S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } ( - 2 + \Delta ) \ln ( S _ { \Delta } ^ { \frac { 2 } { 2 + \Delta } } ) ^ { 3 } \\ & \dots \quad \cdot \quad \dots \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{$$
We see from Fig.18b that the heat capacity, C ∆ for the charged BTZ black hole is plotted against the Barrow entropy, S ∆ in the fixed (Φ) ensemble. Here the solid red curve represents the heat capacity for the Barrow parameter, ∆ = 0 012 whereas the black dashed line represents the free energy for the Bekenstein-Hawking(BH) . entropy case (∆ = 0). We see that for l = 1 and Φ = 0 2 there is a divergence in the heat capacity curve . for both the Barrow and BH entropy cases. The divergence for the Barrow entropy case (∆ = 0 012) is seen to . be at S ∆ = 10 37 whereas for the Bekenstein-Hawking entropy case (∆ = 0) the divergence is found to be at . S ∆ = 10 24. .
The Gibbs free energy for the Barrow entropy case in the fixed (Φ) ensemble can be obtained as:
$$G _ { \Delta } = M _ { \Delta } - T _ { \Delta } S _ { \Delta }$$
$$G _ { \Delta } & = \frac { 1 } { 1 6 \pi ^ { 2 } ( 2 + \Delta ) ( \ln ( \frac { S _ { \Delta } ^ { \frac { 4 } { 2 } + \Delta } } { 4 \pi } ) ) ^ { 2 } } \left ( S _ { \Delta } ^ { \frac { \pi ^ { 4 } + \Delta } { 2 + \Delta } } ( - 2 + \Delta ) \ln ( 4 \pi ) ^ { 2 } - 8 \pi \Phi ^ { 2 } ( - 2 + 2 \ln ( 4 \pi ) + \Delta \ln ( 4 \pi ) ) \\ & \quad + 2 \left ( 4 \pi ( 2 + \Delta ) \Phi ^ { 2 } - S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } ( - 2 + \Delta ) \ln ( 4 \pi ) \right ) \ln ( S _ { \Delta } ^ { \frac { 2 } { 2 + \Delta } } ) + S _ { \Delta } ^ { \frac { 4 } { 2 + \Delta } } ( - 2 + \Delta ) \ln ( S _ { \Delta } ^ { \frac { 2 } { 2 + \Delta } } ) ^ { 2 } \right ).$$
In Fig.19b the Gibbs free energy, G ∆ is plotted against the Barrow entropy, S ∆ for l = 1 and Φ = 0 2 in the fixed (Φ) . ensemble. Here the solid red curve represents the Gibbs free energy for the Renyi parameter, ∆ = 0 012 whereas the . black dashed line represents the free energy for the Bekenstein-Hawking(BH) entropy case (∆ = 0). Here the solid red curve represents the Gibbs free energy for the Barrow parameter, ∆ = 0 012 whereas the black dashed line represents . the free energy for the Bekenstein-Hawking(BH) entropy case (∆ = 0). The free energy for the ∆ = 0 case has been scaled down by multiplying it with 1 10 whereas the free energy for the ∆ = 0 012 case is kept the same, this difference in . scaling is just so that the distinct behaviour of both the curves could be seen more clearly. We find that unlike the Kaniadakis entropy there is no Hawking-Page phase transition present in the Barrow entropy case for the fixed (Φ) ensemble.
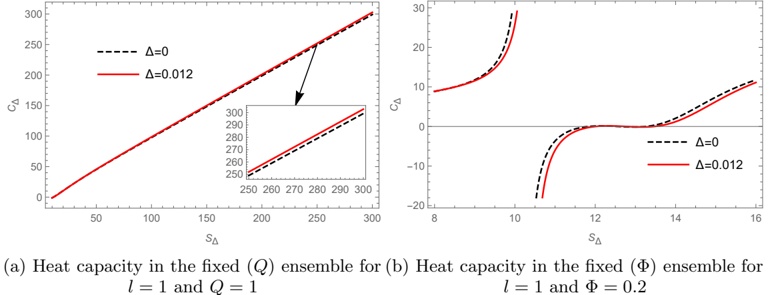
FIG. 18: The heat capacity versus Barrow entropy plots in the fixed ( J ) and fixed (Φ) ensembles.
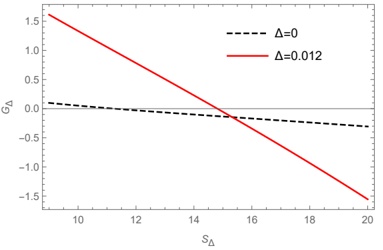
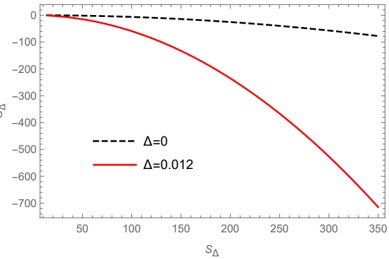
Δ
G
(a) Free energy in the fixed (
Q
) ensemble for
(b) Free energy in the fixed (Φ) ensemble for
l
= 1
l
= 1 and
Q
= 1
and Φ = 0 2.
.
FIG. 19: The Gibbs free energy versus Barrow entropy plots in the fixed ( Q ) and fixed (Φ) ensembles.
## VI. THERMODYNAMIC GEOMETRY OF THE CHARGED BTZ BLACK HOLE
We discuss the thermodynamic geometry of the charged BTZ black hole for both the Ruppeiner and geometrothermodynamic (GTD) formalisms. The Ruppeiner metric is defined as the negative hessian of entropy with respect to other extensive variables. Therefore it is only the fixed ( Q ) ensemble which holds good in the Ruppeiner formalism as Q is an extensive thermodynamic quantity whereas Φ is not.
Therefore the fixed (Φ) ensemble do not hold good as per the definition of the Ruppeiner metric. We therefore discuss the thermodynamic geometry of the fixed (Φ) ensemble in the GTD formalism which is defined on a multidimensional phase space that comprises of both the extensive and intensive variables of the thermodynamic system. The GTD formalism is therefore the appropriate geometric formalism for discussing both the thermodynamic ensembles.
We first discuss the Ruppeiner geometry of the charged BTZ black hole in the fixed ( Q ) ensemble where we observe a curvature singularity in the Ruppeiner scalar curve only for the Kaniadakis entropy case. We then discuss the GTD geometry of the black hole for both the thermodynamic ensembles, where we observe curvature singularities in the GTD scalar curves in Kaniadakis entropy case only. These curvature singularities are seen to occur exactly at the points where we saw divergences in the corresponding heat capacity curves in the previous section.
## VI.1. Ruppeiner formalism
The Ruppeiner metric for the C-BTZ black hole in the fixed ( Q ) ensemble can be obtained from the relation (8) and is given as :-
$$d S _ { R } ^ { 2 } = \frac { 1 } { T } \left ( \frac { \partial ^ { 2 } M } { \partial S ^ { 2 } } d S ^ { 2 } + \frac { \partial ^ { 2 } M } { \partial Q ^ { 2 } } d Q ^ { 2 } + 2 \frac { \partial ^ { 2 } M } { \partial S \partial Q } d S d Q \right )$$
where M S T , , and Q are the mass, entropy, Hawking Temperature and electric charge for the charged BTZ black hole respectively.
From the above metric we calculate the Ruppeiner scalar for all the non-extensive entropy cases in the fixed ( Q ) ensemble. We find that there is a curvature singularity in the Ruppeiner scalar curve only for the Kaniadakis entropy case . For all the other entropy cases namely: the Renyi and Barrow entropy cases the Ruppeiner scalar curves remain regular with no singularities therein. We have not presented here either the derivation or the final expressions for the Ruppeiner scalar due to their considerable length. However obtaining these expressions is fairly straight forward and involves only routine mathematical computations. We present a detailed analysis of the Ruppeiner thermodynamic geometry for the Kaniadakis entropy case in the fixed ( Q ) ensemble as follows:
We see from Fig.20 that the Ruppeiner scalar R rupp is plotted against the Kaniadakis entropy S K in the fixed ( Q ) ensemble. We see that for l = 1 and Q = 1, for the Kaniadakis parameter K = 0 012 the Ruppeiner scalar curve has a . curvature singularity specifically at S K = 128 82, which is depicted by the solid blue curve in the figure. . The point of singularity here unlike the rotating BTZ black hole is similar to the point of divergence obtained in the corresponding heat capacity curve for the Kaniadakis entropy case in the fixed ( Q ) ensemble. For the K = 0 case however the Ruppeiner scalar curve is found to be regular everywhere with no curvature singularities as is depicted in the figure by the black dashed curve.
FIG. 20: The Ruppeiner scalar versus Kaniadakis entropy plot in the fixed ( Q ) ensemble for l = 1 and Q = 1.
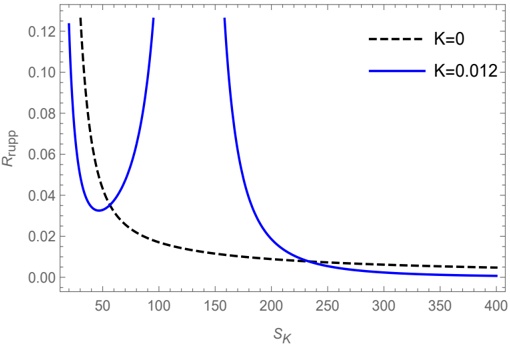
## VI.2. Geometrothermodynamic(GTD) formalism
To describe the charged BTZ black hole in GTD formalism, we first assume a five-dimensional phase space T with co-ordinates M,S,Q,T and Φ which are the mass, entropy, electric charge, temperature and electric potential for the
black hole. The contact 1-form for these set of co-ordinates can be written as:-
$$\Theta = d M - T d S - \Phi d Q$$
̸
The 1-form satisfies the condition Θ ∧ ( d Θ) 3 = 0 and a legendre invariant metric that goes by :-
$$G = ( d M - T d S - \Phi d Q ) ^ { 2 } + T S ( - d T d S + d \Phi d Q )$$
We then assume a two-dimensional sub-space of T with co-ordinates E a where a = 1 2. We denote this subspace with , ϵ which is defined as a smooth mapping, ϕ : ϵ →T . The subspace ϵ becomes the space of equilibrium states if the pullback of ϕ is 0 i.e. ϕ ∗ (Θ) = 0. A metric structure g is then naturally induced on ϵ by applying the same pullback on the metric G of T . This induced metric determines all the geometric properties of the equilibrium space for the charged BTZ black hole.
## VI.2.1. The Kaniadakis entropy case
## Fixed ( Q ) ensemble :
We write the GTD metric for the Kaniadakis entropy case in the fixed ( Q ) ensemble from the general metric given in (9). We consider the thermodynamic potential φ to be the mass M K for the Kaniadakis entropy case in the fixed ( Q ) ensemble as obtained in equation (15). The GTD metric is given by :-
$$g = S _ { K } \left ( \frac { \partial M _ { K } } { \partial S _ { K } } \right ) \left ( - \frac { \partial ^ { 2 } M _ { K } } { \partial S _ { K } ^ { 2 } } d S _ { K } ^ { 2 } + \frac { \partial ^ { 2 } M _ { K } } { \partial Q ^ { 2 } } d Q ^ { 2 } \right )$$
From the above metric we calculate the GTD scalar for the Kaniadakis entropy case in the fixed ( Q ) ensemble. We have not presented here either the derivation or the final expressions for the GTD scalar due to their considerable length. However obtaining these expressions is fairly straight forward and involves only routine mathematical computations. We present a detailed analysis of the GTD thermodynamic geometry for the Kaniadakis entropy case in the fixed ( Q ) ensemble as follows:
We see from Fig.21 that the GTD scalar R GTD is plotted against the Kaniadakis entropy S K for the Kaniadakis parameter K = 0 012 in the fixed ( . Q ) ensemble. We find that for l = 1 and Q = 1, the GTD scalar has a curvature singularity at S K = 128 82 for . K = 0 012 as depicted by the blue solid curve whereas for the BH entropy case . ( K = 0) the curve remains regular everywhere with no curvature singularities, as is depicted in the figure by the black dashed curve. The singularity obtained from the GTD scalar curve matches exactly with the point of divergence obtained from the corresponding heat capacity curve for the Kaniadakis entropy case in the fixed ( Q ) ensemble.
FIG. 21: The GTD scalar versus Kaniadakis entropy plot in the fixed ( Q ) ensemble for l = 1 and Q = 1.
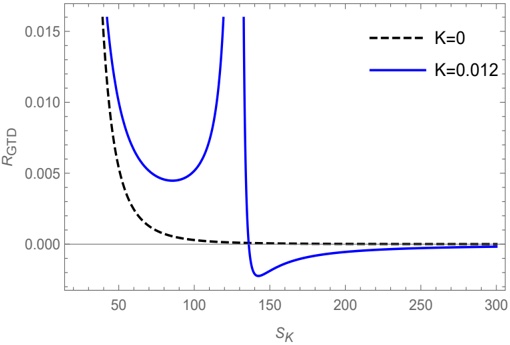
## Fixed (Φ) ensemble :
We write the GTD metric for the Kaniadakis entropy case in the fixed (Φ) ensemble from the general metric given in (9). We consider the thermodynamic potential φ to be the mass M K for the Kaniadakis entropy case in the fixed (Φ) ensemble as obtained in equation (21). The GTD metric is given by :-
$$g = S _ { K } \left ( \frac { \partial M _ { K } } { \partial S _ { K } } \right ) \left ( - \frac { \partial ^ { 2 } M _ { K } } { \partial S _ { K } ^ { 2 } } d S _ { K } ^ { 2 } + \frac { \partial ^ { 2 } M _ { K } } { \partial \Phi ^ { 2 } } d \Phi ^ { 2 } \right )$$
From the above metric we calculate the GTD scalar for the Kaniadakis entropy case in the fixed (Φ) ensemble. We have not shown here either the derivation or the final expressions for the GTD scalar due to their considerable length. However obtaining them is fairly straight forward and involves only routine mathematical computations. We present a detailed analysis of the GTD thermodynamic geometry for the Kaniadakis entropy case in the fixed (Φ) ensemble as follows:
In Fig.22 the GTD scalar, R GTD for the charged BTZ black hole is plotted against the Kaniadakis entropy, S K in the fixed (Φ) ensemble. We draw the same plot in two different entropy ranges so as to make all the appearing singularities in the GTD scalar curve visible. We see from Fig.22a that for l = 1 and Φ = 0 2 there is a singularity at . S K = 10 26 . for K = 0 012 as shown by the solid blue curve. . The heat capacity in the Bekenstein-Hawking(BH) entropy case ( K = 0) here also produces a singularity at S K = 10 24 as shown by the black dashed curve. Although we can see the . presence of two additional curvature singularities observed in the figure for both the Kaniadakis and BH entropy cases, however it was found that these additional curvature singularities correspond to the points where the heat capacity goes to zero for both the Kaniadakis and BH entropy cases in the fixed (Φ) ensemble. In Fig.22b we see that there is a singularity in the heat capacity curve at S K = 125 74 for . K = 0 012 whereas here for ( . K = 0) case no such behaviour is observed in the GTD scalar curve.
GTD
(a) GTD scalar versus Kaniadakis entropy ( S ≤ 15).
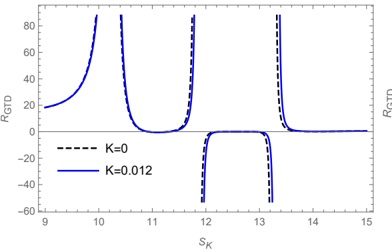
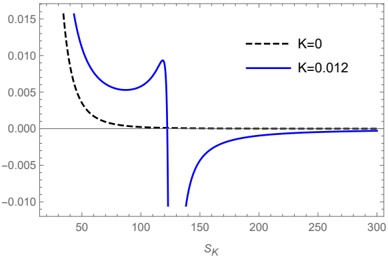
(b) GTD scalar versus Kaniadakis entropy (15 < S ≤ 300).
FIG. 22: The GTD scalar versus Kaniadakis entropy plot in the fixed (Ω) ensemble for l = 1 and Φ = 0 2 .
## VI.2.2. The Renyi entropy case
## Fixed (Φ) ensemble :
We write the GTD metric for the Renyi entropy case in the fixed (Φ) ensemble from the general metric given in (9). We consider the thermodynamic potential φ to be the mass M K for the Renyi entropy case in the fixed (Φ) ensemble. The GTD metric is given by :-
$$g = S _ { R } \left ( \frac { \partial M _ { R } } { \partial S _ { R } } \right ) \left ( - \frac { \partial ^ { 2 } M _ { R } } { \partial S _ { R } ^ { 2 } } d S _ { R } ^ { 2 } + \frac { \partial ^ { 2 } M _ { R } } { \partial \Phi ^ { 2 } } d \Phi ^ { 2 } \right )$$
From the above metric we calculate the GTD scalar for the Renyi entropy case in the fixed (Φ) ensemble. We have not shown here either the derivation or the final expressions for the GTD scalar due to their considerable length.
However obtaining them is fairly straight forward and involves only routine mathematical computations. We present a detailed analysis of the GTD thermodynamic geometry for the Renyi entropy case in the fixed (Φ) ensemble as follows:
We see from Fig.23 that the GTD scalar, R GTD for the charged BTZ black hole is plotted against the Renyi entropy, S R in the fixed (Φ) ensemble. We see that for l = 1 and Φ = 0 2 there are curvature singularities in the GTD scalar . curve for both the Renyi ( λ = 0 012) and Bekenstein-Hawking (BH) entropy ( . λ = 0) cases. We find that for λ = 0 012 . there is a curvature singularity observed in the GTD scalar curve at S R = 9 71 as depicted by the solid green curve in . the figure. For the BH entropy case ( λ = 0) we find that the GTD scalar has a curvature singularity at S R = 10 24 as . shown in the figure by the black dashed curve. These singularities match exactly with the points of Davies type phase transitions observed in the corresponding heat capacity curve in the fixed (Φ) ensemble. There are two additional curvature singularities observed in the figure for both the Renyi and BH entropy cases, however it was found that these additional curvature singularities correspond to the points where the heat capacity goes to zero for both the Renyi and BH entropy cases in the fixed (Φ) ensemble.
FIG. 23: The GTD scalar versus Renyi entropy plot in the fixed (Φ) ensemble for l = 1 and Φ = 0 2 .
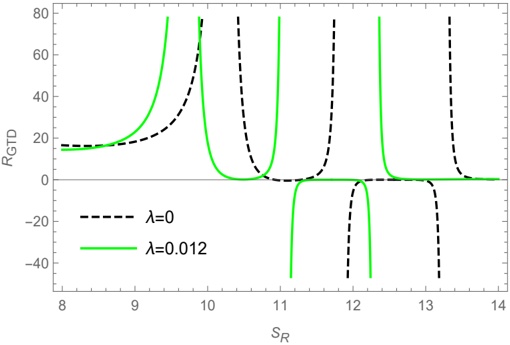
## VI.2.3. The Barrow entropy case
## Fixed (Φ) ensemble :
We write the GTD metric for the Barrow entropy case in the fixed (Φ) ensemble from the general metric given in (9). We consider the thermodynamic potential φ to be the mass M ∆ for the Barrow entropy case in the fixed (Φ) ensemble. The GTD metric is given by :-
$$g = S _ { \Delta } \left ( \frac { \partial M _ { \Delta } } { \partial S _ { \Delta } } \right ) \left ( - \frac { \partial ^ { 2 } M _ { \Delta } } { \partial S _ { \Delta } ^ { 2 } } d S _ { \Delta } ^ { 2 } + \frac { \partial ^ { 2 } M _ { \Delta } } { \partial \Phi ^ { 2 } } d \Phi ^ { 2 } \right )$$
From the above metric we calculate the GTD scalar for the Barrow entropy case in the fixed (Φ) ensemble. We have not shown here either the derivation or the final expressions for the GTD scalar due to their considerable length. However obtaining them is fairly straight forward and involves only routine mathematical computations. We present a detailed analysis of the GTD thermodynamic geometry for the Barrow entropy case in the fixed (Φ) ensemble as follows:
We see from Fig.24 that the GTD scalar, R GTD for the charged BTZ black hole is plotted against the Barrow entropy, S ∆ in the fixed (Φ) ensemble. We see that for l = 1 and Φ = 0 2 there are curvature singularities in the GTD scalar . curve for both the Barrow (∆ = 0 012) and Bekenstein-Hawking (BH) entropy (∆ = 0) cases. . We find that for ∆=0012 there is a curvature singularity observed in the GTD scalar curve at . S ∆ = 10 37 as depicted by the solid . red curve in the figure. For the BH entropy case (∆ = 0) we find that the GTD scalar has a curvature singularity at S ∆ = 10 24 as shown in the figure by the black dashed curve. . These singularities match exactly with the points of Davies type phase transitions observed in the corresponding heat capacity curve in the fixed (Φ) ensemble. There are two additional curvature singularities observed in the figure for both the Barrow and BH entropy cases, however it was
found that these additional curvature singularities correspond to the points where the heat capacity goes to zero for both the Barrow and BH entropy cases in the fixed (Φ) ensemble.
FIG. 24: The GTD scalar versus Barrow entropy plot in the fixed (Φ) ensemble for l = 1 and Φ = 0 2 .
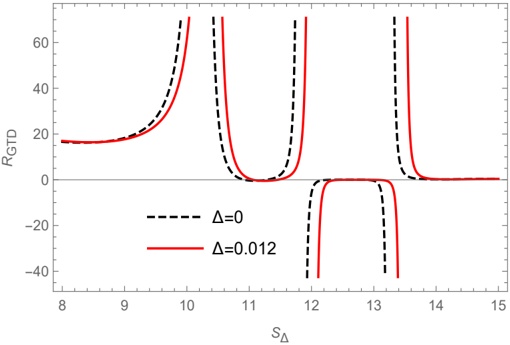
## VII. CONCLUSIONS:
We investigated the thermodynamics and thermodynamic geometry of the rotating(R-BTZ) and charged (C-BTZ) Banados-Teitelboim-Zanelli black hole in three different non extensive entropy formalisms namely: the Kaniadakis entropy, Renyi entropy and Barrow entropy respectively. We investigated all the thermodynamic ensembles of these black holes namely: the fixed ( J ) and fixed (Ω) ensemble for the rotating BTZ black hole and the fixed ( Q ) and fixed (Φ) ensemble for the charged BTZ black hole. We find that there are Davies type along with the Hawking-Page phase transitions in both the black holes observed in the Kaniadakis entropy case for all the thermodynamic ensembles. We found that both the Ruppeiner and the GTD scalar were observed to have curvature singularities corresponding to Davies type of phase transitions in the corresponding cases. The location of the curvature singularities in the GTD scalar exactly matched the Davies type phase transition points in both the ensembles. The Ruppeiner scalar, although showed curvature singularities, the location of those singularities were found to be not exactly the same as the corresponding Davies type transition points for the R-BTZ black hole. For all the other non-extensive entropy cases, the thermodynamic structure were found to resemble their counterparts in the Bekenstein-Hawking entropy. A table each for the two black holes are shown below summarising our results where we write the number of phase transition points (both Davies type and Hawking-Page) observed against each of the non extensive entropy cases along with the BH entropy for all the thermodynamic ensembles. The table representing the R-BTZ black hole is as follows:
| Entropy | Fixed (J) ensemble | Fixed (J) ensemble | Fixed ( Ω ) ensemble | Fixed ( Ω ) ensemble |
|--------------------|------------------------------|-------------------------------|------------------------------|-------------------------------|
| | Davies-type phase transition | Hawking-Page phase transition | Davies-type phase transition | Hawking-Page phase transition |
| Bekenstein-Hawking | 0 | 1 | 0 | 0 |
| Kaniadakis | 1 | 2 | 1 | 1 |
| Renyi | 0 | 1 | 0 | 0 |
| Barrow | 0 | 1 | 0 | 0 |
The table representing the C-BTZ black hole is as follows:
The key distinction of Kaniadakis entropy lies in its impact on the behaviour of black hole temperature. In contrast to the other considered entropic formalisms, where temperature is a monotonically increasing function of entropy, Kaniadakis entropy introduces a different thermal evolution. We have observed that in the Kaniadakis entropy framework, black hole temperature rises to a maximum value before gradually declining and asymptotically tending to zero for larger values of entropy. This non-monotonic behaviour in the temperature is what gives rise to the advent of the phase transitions (both Davies type and Hawking-Page) in the specific heat capacity and the Gibbs free energy
| Entropy | Fixed (Q) ensemble | Fixed (Q) ensemble | Fixed ( Φ ) ensemble | Fixed ( Φ ) ensemble |
|--------------------|------------------------------|-------------------------------|------------------------------|-------------------------------|
| | Davies-type phase transition | Hawking-Page phase transition | Davies-type phase transition | Hawking-Page phase transition |
| Bekenstein-Hawking | 0 | 1 | 1 | 0 |
| Kaniadakis | 1 | 2 | 2 | 1 |
| Renyi | 0 | 1 | 1 | 0 |
| Barrow | 0 | 1 | 1 | 0 |
respectively for the rotating and charged BTZ black holes. The behaviour of temperature in the R-BTZ black hole for both the Kaniadakis and Bekenstein Hawking entropy case is depicted in Fig.25.
We know that the specific heat capacity of a black hole is given by, C = T ( ∂T ∂S ) . Thus, when the temperature attains its maximum value, the slope of the graph i.e. ∂T ∂S equals zero and the specific heat capacity undergoes a divergence. When the temperature starts decreasing, the slope of the T-S graph becomes negative and so does the heat capacity. We also know that the black hole temperature is a first order derivative of mass with respect to entropy i.e. T = ( ∂M ∂S ) where the mass M for the rotating BTZ black hole is given by:
$$M = \frac { 4 \pi ^ { 2 } J ^ { 2 } } { S _ { B H } ^ { 2 } } + \frac { S _ { B H } ^ { 2 } } { 1 6 \pi ^ { 2 } l ^ { 2 } }$$
where after writing the Bekenstein-Hawking entropy, S BH in terms of the Kaniadakis entropy i.e. S BH = ArcSinh KS ( ) K gives the Kaniadakis corrected mass which is given by:
$$M = \frac { 4 \pi ^ { 2 } K ^ { 2 } J ^ { 2 } } { A r c S i n h ^ { 2 } [ K S ] } + \frac { A r c S i n h ^ { 2 } [ K S ] } { 1 6 \pi ^ { 2 } l ^ { 2 } K ^ { 2 } }$$
It is actually the second term in the above equation which is responsible for the unusual behaviour in the the temperature of the black hole. Here, the term ArcSinh 2 [ KS ] 16 π l 2 2 K 2 when differentiated with respect to the entropy in order to obtain the temperature becomes ArcSinh KS [ ] 8 πlK √ 1+ K S 2 2 . This term is directly responsible for the dipping behaviour in the temperature because here as ArcSinh KS [ ] K is an increasing function of entropy, the term 1 √ 1+ K S 2 2 decreases with an increase in entropy and thus they together produce this unusual behaviour in the temperature where it starts to fall after reaching a maximum value. The value of the maximum attainable temperature for a given set of ( J, l ) values is fixed by the kaniadakis parameter,K as is evident from the above analysis. The non trivial temperature profile in the Kaniadakis entropy formalism is also responsible for the Hawking-Page phase transition obtained from the Gibbs free energy of the black hole. The Gibbs free energy is given by G = M -TS where the Gibbs free energy is negative for small entropy values but as temperature starts falling after having attained its maximum value, G starts to increase and finally reaches a zero point. On further increase in entropy the free energy becomes positive and thus the black hole becomes thermodynamically unstable as can be seen from Fig.2 and Fig.4. The case is similar for the charged BTZ black hole where the Kaniadakis corrected mass for the C-BTZ black hole is given by:
$$M _ { K } = \frac { A r c S i n h ^ { 2 } [ K S _ { K } ] } { 1 6 \pi ^ { 2 } l ^ { 2 } K ^ { 2 } } - \frac { \pi Q ^ { 2 } } { 2 } \ln \left [ \frac { A r c S i n h [ K S _ { K } ] } { 4 \pi K } \right ]$$
It can be seen here as well that the term ArcSinh 2 [ KS ] 16 π l 2 2 K 2 when differentiated with respect to the entropy in order to obtain the temperature becomes ArcSinh KS [ ] 8 πlK √ 1+ K S 2 2 . We therefore observe the dip in the temperature here as well which in turn results in the occurrence of a Davies type phase transition accompanied by a Hawking-Page phase transition in the charged BTZ black hole.
This unusual behaviour of the temperature in the Kaniadakis entropy case seems to be inherent in the formulation of this entropy where it has been shown in [49] that its mathematical structure is compatible with Einstein's special theory of relativity along with the second law of thermodynamics. It was also seen in [71] where the author showed that the corrections in the black hole entropy obtained by Kaniadakis statistics in high temperature limit are indeed logarithmic in nature which prove that these corrections are indeed legitimate. We could not find any specific reasons as to why a relativistic statistical approach to black holes should cause the temperature to behave so non-trivially. It would perhaps need a more sophisticated analysis of black holes in Kaniadakis formalism and also Kaniadakis entropy
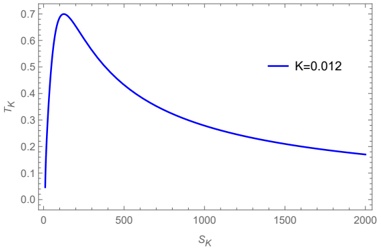
(a) Temperature versus Kaniadakis entropy in the fixed ( J ) ensemble .
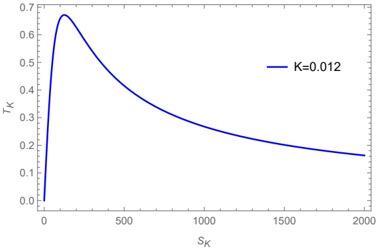
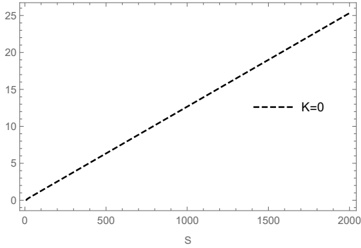
T
(b) Temperature versus Bekenstein-Hawking entropy in the fixed ( J ) ensemble.
T
- (c) Temperature versus Kaniadakis entropy in the fixed (Ω) ensemble.
(d) Temperature versus Bekenstein-Hawking entropy in the fixed (Ω) ensemble.
FIG. 25: The temperature curves for Kaniadakis entropy in the fixed ( J ) and (Ω) ensemble for l = 1 , J = 1 and Ω = 0 2. .
in general to find out why such non-triviality should occur.
To conclude, our analysis shows that the thermodynamic phase structure on (2 + 1) dimensional BTZ black hole with Kaniadakis entropy differs from the one with the conventional Bekenstein-Hawking entropy in all the ensembles. This result is in contrast to that found in [14], in the context of charged AdS black holes where both Kaniadakis entropy and Bekenstein-Hawking entropy yielded similar phase structures. It will be interesting to extend the study of black hole thermodynamics in the framework of non-extensive entropy to other black holes to get a clearer picture. We plan to address this issue in our future works.
## VIII. ACKNOWLEDGMENTS
The authors would like to thank Himanshu Bora for numerous enlightening discussions and certain exquisite suggestions he offered during the course of this work.
[1] S. W. Hawking, Particle creation by black holes, Communications in mathematical physics 43 , 199 (1975).
[2] J. D. Bekenstein, Black holes and entropy, Physical Review D 7 , 2333 (1973).
[3] S. W. Hawking, Black holes and thermodynamics, Physical Review D 13 , 191 (1976).
- [4] R.-G. Cai, L.-M. Cao, L. Li, and R.-Q. Yang, Pv criticality in the extended phase space of gauss-bonnet black holes in ads space, Journal of High Energy Physics 2013 , 1 (2013).
[5] D. Kubizˇ´ ak, R. B. Mann, and M. Teo, Black hole chemistry: n thermodynamics with lambda, Classical and Quantum Gravity 34 , 063001 (2017).
[6] M. R. Visser, Holographic thermodynamics requires a chemical potential for color, Physical Review D 105 , 106014 (2022).
[7] W. Cong, D. Kubizˇ´ ak, and R. B. Mann, Thermodynamics of ads black holes: n critical behavior of the central charge, Physical Review Letters 127 , 091301 (2021).
- [8] Z. Gao and L. Zhao, Restricted phase space thermodynamics for ads black holes via holography, Classical and Quantum Gravity 39 , 075019 (2022).
- [9] Z. Gao, X. Kong, and L. Zhao, Thermodynamics of kerr-ads black holes in the restricted phase space, The European Physical Journal C 82 , 112 (2022).
- [10] G. Kaniadakis, Statistical mechanics in the context of special relativity, Physical review E 66 , 056125 (2002).
- [11] N. Drepanou, A. Lymperis, E. N. Saridakis, and K. Yesmakhanova, Kaniadakis holographic dark energy and cosmology, The European Physical Journal C 82 , 449 (2022).
- [12] A. R´ enyi, On the dimension and entropy of probability distributions, Acta Mathematica Academiae Scientiarum Hungarica 10 , 193 (1959).
- [13] J. D. Barrow, The area of a rough black hole, Physics Letters B 808 , 135643 (2020).
- [14] G. G. Luciano and E. Saridakis, P- v criticalities, phase transitions and geometrothermodynamics of charged ads black holes from kaniadakis statistics, Journal of High Energy Physics 2023 , 1 (2023).
- [15] C. Promsiri, E. Hirunsirisawat, and R. Nakarachinda, Emergent phase, thermodynamic geometry, and criticality of charged black holes from r´nyi statistics, Physical Review D e 105 , 124049 (2022).
- [16] S. Ghaffari, A. Ziaie, H. Moradpour, F. Asghariyan, F. Feleppa, and M. Tavayef, Black hole thermodynamics in sharma-mittal generalized entropy formalism, General Relativity and Gravitation 51 , 1 (2019).
- [17] G. G. Luciano and A. Sheykhi, Black hole geometrothermodynamics and critical phenomena: A look from tsallis entropybased perspective, Physics of the Dark Universe 42 , 101319 (2023).
- [18] A. Jawad and S. R. Fatima, Thermodynamic geometries analysis of charged black holes with barrow entropy, Nuclear Physics B 976 , 115697 (2022).
- [19] E. N. Saridakis, Barrow holographic dark energy, Physical Review D 102 , 123525 (2020).
- [20] E. N. Saridakis, K. Bamba, R. Myrzakulov, and F. K. Anagnostopoulos, Holographic dark energy through tsallis entropy, Journal of Cosmology and Astroparticle Physics 2018 (12), 012.
- [21] M. Tavayef, A. Sheykhi, K. Bamba, and H. Moradpour, Tsallis holographic dark energy, Physics Letters B 781 , 195 (2018).
- [22] S. Nojiri, S. D. Odintsov, and V. Faraoni, From nonextensive statistics and black hole entropy to the holographic dark universe, Physical Review D 105 , 044042 (2022).
- [23] S. Nojiri, S. D. Odintsov, and T. Paul, Early and late universe holographic cosmology from a new generalized entropy, Physics Letters B 831 , 137189 (2022).
- [24] S. Nojiri, S. D. Odintsov, and V. Faraoni, Area-law versus r´nyi and tsallis black hole entropies, Physical Review D e 104 , 084030 (2021).
- [25] S. Nojiri, S. D. Odintsov, and V. Faraoni, Alternative entropies and consistent black hole thermodynamics, International Journal of Geometric Methods in Modern Physics 19 , 2250210 (2022).
- [26] H. Shababi and K. Ourabah, Non-gaussian statistics from the generalized uncertainty principle, The European Physical Journal Plus 135 , 697 (2020).
- [27] G. G. Luciano, Tsallis statistics and generalized uncertainty principle, The European Physical Journal C 81 , 672 (2021).
- [28] M. Moussa, Schwarzschild black hole thermodynamics and generalized uncertainty principle, International Journal of Theoretical Physics 60 , 994 (2021).
- [29] P. Wang, H. Wu, and H. Yang, Thermodynamic geometry of ads black holes and black holes in a cavity, The European Physical Journal C 80 , 1 (2020).
- [30] M. U. Shahzad, M. I. Asjad, and S. Nafees, Study of thermodynamical geometries of conformal gravity black hole, The European Physical Journal C 82 , 1044 (2022).
- [31] B. Wu, C. Wang, Z.-M. Xu, and W.-L. Yang, Ruppeiner geometry and thermodynamic phase transition of the black hole in massive gravity, The European Physical Journal C 81 , 1 (2021).
- [32] F. Weinhold, Metric geometry of equilibrium thermodynamics, The Journal of Chemical Physics 63 , 2479 (1975).
- [33] G. Ruppeiner, Thermodynamics: A riemannian geometric model, Physical Review A 20 , 1608 (1979).
- [34] P. Salamon, J. Nulton, and E. Ihrig, On the relation between entropy and energy versions of thermodynamic length, The Journal of chemical physics 80 , 436 (1984).
- [35] G. Ruppeiner, Riemannian geometry in thermodynamic fluctuation theory, Reviews of Modern Physics 67 , 605 (1995).
- [36] R. Mrugaglyph[suppress]a, l On equivalence of two metrics in classical thermodynamics, Physica A: Statistical Mechanics and its Applications 125 , 631 (1984).
- [37] J. E. ˚ man, I. Bengtsson, and N. Pidokrajt, Geometry of black hole thermodynamics, General Relativity and Gravitation A 35 , 1733 (2003).
- [38] H. Quevedo, Geometrothermodynamics, Journal of Mathematical Physics 48 (2007).
- [39] H. Quevedo, Geometrothermodynamics of black holes, General Relativity and Gravitation 40 , 971 (2008).
- [40] S. Soroushfar, R. Saffari, and N. Kamvar, Thermodynamic geometry of black holes in f (r) gravity, The European Physical Journal C 76 , 1 (2016).
- [41] R. Silva, The relativistic statistical theory and kaniadakis entropy: an approach through a molecular chaos hypothesis, The European Physical Journal B-Condensed Matter and Complex Systems 54 , 499 (2006).
- [42] M. Yarahmadi and A. Salehi, Using the kaniadakis horizon entropy in the presence of neutrinos to alleviate the hubble and s 8 tensions, The European Physical Journal C 84 , 1 (2024).
- [43] J. McMinis and N. M. Tubman, Renyi entropy of the interacting fermi liquid, Physical Review B-Condensed Matter and Materials Physics 87 , 081108 (2013).
- [44] Y.-T. Tu, Y.-C. Tzeng, and P.-Y. Chang, Renyi entropies and negative central charges in non-hermitian quantum systems, SciPost Physics 12 , 194 (2022).
- [45] G. Leon, J. Magana, A. Hernandez-Almada, M. A. Garcia-Aspeitia, T. Verdugo, and V. Motta, Barrow entropy cosmology: an observational approach with a hint of stability analysis, Journal of Cosmology and Astroparticle Physics 2021 (12), 032.
- [46] Q.-M. Feng, Z.-W. Feng, X. Zhou, and Q.-Q. Jiang, Barrow entropy and stochastic gravitational wave background generated from cosmological qcd phase transition, Physics Letters B 838 , 137739 (2023).
- [47] G. Kaniadakis, A. Lavagno, and P. Quarati, Generalized fractional statistics, Modern Physics Letters B 10 , 497 (1996).
- [48] G. Kaniadakis, M. Lissia, and A. Scarfone, Deformed logarithms and entropies, Physica A: Statistical Mechanics and its Applications 340 , 41 (2004).
- [49] G. Kaniadakis, Statistical mechanics in the context of special relativity. ii., Physical Review E-Statistical, Nonlinear, and Soft Matter Physics 72 , 036108 (2005).
- [50] J. Housset, J. F. Saavedra, and F. Tello-Ortiz, Cosmological flrw phase transitions and micro-structure under kaniadakis statistics, Physics Letters B 853 , 138686 (2024).
- [51] A. Strominger and C. Vafa, Microscopic origin of the bekenstein-hawking entropy, Physics Letters B 379 , 99 (1996).
- [52] R. Nakarachinda, C. Promsiri, L. Tannukij, and P. Wongjun, Thermodynamics of black holes with r \ 'enyi entropy from classical gravity, arXiv preprint arXiv:2211.05989 (2022).
- [53] E. Lenzi, R. Mendes, and L. Da Silva, Statistical mechanics based on renyi entropy, Physica A: Statistical Mechanics and its Applications 280 (2000).
- [54] P. Jizba and T. Arimitsu, The world according to r´nyi: thermodynamics of multifractal systems, Annals of Physics e 312 , 17 (2004).
- [55] P. Jizba and T. Arimitsu, Observability of r´nyi's entropy, Physical review E e 69 , 026128 (2004).
- [56] J. Dowker, Sphere r´nyi entropies, Journal of Physics A: Mathematical and Theoretical e 46 , 225401 (2013).
- [57] H. Liu and M. Mezei, A refinement of entanglement entropy and the number of degrees of freedom, Journal of High Energy Physics 2013 , 1 (2013).
- [58] D. V. Fursaev, Entanglement r´nyi entropies in conformal field theories and holography, Journal of High Energy Physics e 2012 , 1 (2012).
- [59] C. Tsallis and L. J. Cirto, Black hole thermodynamical entropy, The European Physical Journal C 73 , 1 (2013).
- [60] S. Furuichi, Information theoretical properties of tsallis entropies, Journal of Mathematical Physics 47 (2006).
- [61] R. J. dos Santos, Generalization of shannon's theorem for tsallis entropy, Journal of Mathematical Physics 38 , 4104 (1997).
- [62] S. Rani, A. Jawad, and M. Hussain, Impact of barrow entropy on geometrothermodynamics of specific black holes, The European Physical Journal C 83 , 710 (2023).
- [63] J. D. Barrow, Chaotic behaviour in general relativity, Physics Reports 85 , 1 (1982).
- [64] M. Banados, C. Teitelboim, and J. Zanelli, Black hole in three-dimensional spacetime, Physical review letters 69 , 1849 (1992).
- [65] G. Clement, Classical solutions in three-dimensional einstein-maxwell cosmological gravity, Classical and Quantum Gravity 10 , L49 (1993).
- [66] G. Clement, Spinning charged btz black holes and self-dual particle-like solutions, Physics Letters B 367 , 70 (1996).
- [67] H. Kim, Spinning btz black hole versus kerr black hole: a closer look, Physical Review D 59 , 064002 (1999).
- [68] R. A. Hennigar, D. Kubizˇ´k, and R. B. Mann, Rotating and charged gauss-bonnet btz black holes, Classical and Quantum na Gravity 38 , 03LT01 (2020).
- [69] H. Maeda and J. Podolsk`, Charged rotating btz solution revisited: y New coordinates and algebraic classifications, Classical and Quantum Gravity 41 , 115012 (2024).
- [70] S. Konewko and E. Winstanley, Charge superradiance on charged btz black holes, The European Physical Journal C 84 , 594 (2024).
- [71] N. Kumar, Relativistic correction to black hole entropy, General Relativity and Gravitation 56 , 1 (2024). | null | [
"Amijit Bhattacharjee",
"Prabwal Phukon"
] | 2024-08-02T10:03:59+00:00 | 2025-01-21T13:14:13+00:00 | [
"hep-th"
] | BTZ Black Hole In The Non-Extensive Generalizations of Gibbs Entropy | We study the thermodynamics and thermodynamic geometry of the (2+1)
dimensional Banados-Teitelboim-Zanelli(BTZ) black hole within the framework of
the non-extensive generalizations of Gibbs entropy. We investigate both the
rotating (R-BTZ) and the charged (C-BTZ) BTZ black holes in these non-extensive
entropy formalisms. We write down the Bekenstein-Hawking(BH) entropy of the
black hole in terms of the non-extensive entropies namely: Kaniadakis entropy,
Renyi entropy and Barrow entropy. We investigate their impact on the
thermodynamic phase structure and geometry of the BTZ black holes in both the
ensembles i.e. the fixed $(J)$ and fixed $(\Omega)$ ensemble for the R-BTZ
black hole and the fixed $(Q)$ and the fixed $(\Phi)$ ensemble for the C-BTZ
black hole where $ J$, $\Omega$, $Q$ and $\Phi$ represent the angular momentum,
angular velocity, charge and the electric potential of the respective black
holes . We investigate the Ruppeiner and geometrothermodynamic(GTD) geometries
of the black hole for all the non-extensive entropy cases. We find that there
are Davies type along with Hawking-Page phase transitions in both the charged
and rotating BTZ black hole for the Kaniadakis entropy case in all the above
mentioned thermodynamic ensembles. These phase transitions were not seen in the
BH entropy case. We also find that the Ruppeiner and the GTD scalar for the
Kaniadakis entropy show curvature singularities corresponding to the Davies
type phase transitions in both the rotating and charged BTZ black holes. |
2408.01151v2 | ## Calibration of the strain amplitude recorded with DAS using a strainmeter array
Thomas Forbriger ∗ 1 , Nasim Karamzadeh 1 2 , J´ erˆme Azzola , o 3 , Emmanuel Gaucher 3 , Rudolf Widmer-Schnidrig 4 , Andreas Rietbrock 1
- 1 Karlsruhe Institute of Technology (KIT), Geophysical Institute, Karlsruhe, Germany
- 2 now at University of M¨ unster Institut f¨r Geophysik, M¨nster, Germany u u
- 3 Karlsruhe Institute of Technology (KIT), Institute for Applied Geosciences, Karlsruhe, Germany
- 4 Institute of Geodesy, University of Stuttgart, Stuttgart, Germany
- ∗ Corresponding author: [email protected], Karlsruhe Institute of Technology (KIT), Geophysical Institute (GPI), Black Forest Observatory (BFO), Heubach 206, 77709 Wolfach, Germany
## Abstract
The power of distributed acoustic sensing (DAS) lies in its ability to sample deformation signals along an optical fiber at hundreds of locations with only one interrogation unit (IU). While the IU is calibrated to record 'fiber strain', the properties of the cable and its coupling to the rock control the 'strain transfer rate' and hence how much of 'rock strain' is represented in the recorded signal. We use DAS recordings in an underground installation near an array of strainmeters in order to calibrate the 'strain transfer rate' in situ, using earthquake signals between 0.05 Hz and 0.1 Hz. A tight-buffered cable and a standard loose-tube telecommunication cable (running in parallel) are used, where a section of both cables loaded down by loose sand and sand bags is compared to a section, where cables are just unreeled on the floor. The 'strain transfer rate' varies between 0.13 and 0.53 depending on cable and installation type. The sandbags show no obvious effect and the tight-buffered cable generally provides a larger 'strain transfer rate'. Calibration of the 'strain transfer rate' with respect to the strainmeter does not depend on wave propagation parameters. Hence it is applicable to the large amplitude surface wave signal in a strain component almost perpendicular to the great-circle direction for which a waveform comparison with seismometer data does not work. The noise background for 'rock strain' in the investigated band is found at about an rms-amplitude of 0.1 nstrain in 1/6 decade for the tight-buffered cable. This allows a detection of marine microseisms at times of high microseism amplitude.
## 1 Introduction
gressions and outlines applications of distributed optical fiber sensors across various domains.
Distributed Acoustic Sensing (DAS) measures dynamic strain in an optical fiber. The DAS interrogation unit (IU) sends laser-generated coherent light into an optical fiber possibly extending for tens of kilometers. The light gets partly back-scattered by Rayleigh scattering due to manufacturing imperfections along the optical fiber and is sensitive to rapid variations in strain, commonly referred to as dynamic strain. Pioneering work by Dakin (1990), followed by Taylor and Lee (1993), recognized the potential of coherent Rayleigh back-scatter in assessing spatial disturbances in optical fibers. Following this work a range of techniques has been developed and implemented in IUs to measure the phase of the backscattered signal. Hartog (2017) summarizes these pro-
In seismology, the power of DAS lies in its ability to sample deformation signals along an optical fiber at hundreds of locations over distances of many kilometers with a single IU. In some applications, unused telecommunication infrastructures (so-called dark-fibers) can be leveraged, which significantly reduces the necessary effort for field deployment. Lindsey and Martin (2021) and Li et al. (2021) present an overview of fields of application in geosciences. Most of these applications rely only on the phase information in the recorded data.
Use cases, which rely on amplitude are less frequent. Such a use case would be the measurement of volume strain for the reduction of Newtonian Noise (Harms, 2015; Harms et al., 2022), as being planned for the Ein-
stein Telescope (ET Steering Committee, 2020). With well calibrated DAS strain recordings on cables running in six different directions from a single location, the full strain tensor could be composed. This requires a proper calibration of the 'strain transfer rate' (the fraction of 'rock strain' picked up as 'fiber strain') and a sufficiently low detection level, such that the strain background signal is resolved. Rademacher (2024) recently pointed at the limitations which still exist for DAS in both respects. We investigate these in the current study.
Signals recorded by the DAS IU represent the deformation of the fiber (denoted here as 'fiber strain'). However, observations showing that the signal from two colocated cables might differ in amplitude (Azzola et al., 2022, and the current study) suggest that 'fiber strain' does not always represent the actual 'rock strain'. This discrepancy can arise from the coupling of the fiber to the ground through the various layers of the cable.
Reinsch et al. (2017), for example, focus on the internal structure of an optic fiber cable and discuss this discrepancy based on a physical model (Li et al., 2006) of a DAS cable, based on actual material properties. They derive the 'strain transfer rate' as the ratio between 'fiber strain' and 'rock strain'. In particular gel layers in loose-tube cables let the 'strain transfer rate' be less than 1 due to their small value of Young's modulus. These thixotropic fluids are used to protect the fibers from damage. Reinsch et al. (2017) estimate that during measurement their yield point is not exceeded, such that they behave in a linear elastic way. In practice the parameters of the different layers in the cable are not available from manufacturers and the coupling to the rock is controlled by the actual installation conditions. For this reason the 'strain transfer rate' can be determined empirically only.
The studies by Lindsey et al. (2020) and Paitz et al. (2020) are two examples for in-situ calibration experiments. Both use a Silixa iDAS IUs and both primarily use surface wave signals.
Lindsey et al. (2020) focus on the low-frequency band from about 0.08 Hz to 1 Hz. They not only describe the calibration experiment, but also provide a well-written introduction to DAS including the conversion from optical phase to strain, the coupling of rock to fiber, and typical optical sources of noise. The DAS signals in their study are recorded on a gel-filled loosetube dark fiber installed in a conduit. They convert the signals to particle velocity based on the assumption of plane waves and compare with the recordings of a broad-band seismometer at 66 m distance. The needed scaling factor, which is phase velocity along the fiber, is obtained by fk-analysis of 1 km of DAS data, which allows to capture wave dispersion and does not rely on the assumption of great-circle propagation. Though the superposition of Rayleigh- and Love-waves (both prop- agating at difference phase velocity) might still present a problem. The authors use surface waves from four teleseismic earthquakes to demonstrate that the amplitude response of the DAS is like nominally expected for frequencies below 0.1 Hz, although there is a significant amplitude fluctuation of a factor of 10 along the fiber (Lindsey et al., 2020, their figure 6b). For frequencies higher than 0.1 Hz, they find DAS amplitudes larger than nominal by up to about 10 dB (about a factor of 3). The analysis of earthquakes and marine microseisms in this band yields inconsistent results in that the amplification seen for marine microseisms is larger. As a potential cause, the authors mention possible problems with the fk-analysis at near-perpendicular incidence of marine microseisms. While they prefer fiber coupling issues as the explanation for the amplification, they do not clarify how a passive mechanism could account for the signal amplification.
Paitz et al. (2020) derive a frequency dependent transfer function of DAS signals with respect to reference recordings for seven frequency bands, spanning a total range from 0.34 mHz to 60 Hz. As test signals, they use hydraulic stimulation and surface waves from four earthquakes (one per analyzed frequency band) and one icequake. The installation types of DAS cables in the various experiments differ significantly, without the possibility to track down systematic variations to the type of installation. The hydraulic stimulation experiment carried out for the lowest frequency bands is exceptional in that the DAS fiber is cemented in a borehole and in that a fiber-Bragg-grating (FBG) strainmeter could be used as a reference, while for the others strain had to be estimated from particle velocity. Though the results for this hydraulic stimulation does not appear exceptional in terms of deviation from the expected nominal response. Overall the authors report a variation of the amplitude response by ± 10 dB (about a factor of 0.3 to 3) around the nominal value.
When comparing DAS recordings with seismometer recordings a translating of strain or strain rate into particle displacement or velocity (or vice versa) is necessary. This is only possible for non-dispersive plane waves with known ray-parameter. The limitations of this approach and the resulting waveform dissimilarity are shown by Lindsey et al. (2020, their figure 4a) for example. Paitz et al. (2020) mention incorrect phasevelocity estimates as a possible source of inaccuracy.
In the current study, we directly compare the recordings of a DAS IU with those from the long-running array of Invar-wire strainmeters at the Black Forest Observatory (BFO). Both, the DAS recorded strain and the signal from the strainmeter can be expected to represent the same rock deformation, independent of its cause and independent of wave parameters in particular. Hence, this comparison allows for direct calibration of the DAS
system's amplitude response, not limited to a specific wave type and without additional uncertainties due to limited accuracy of ray-parameters. Based on this calibration we estimate the detection threshold for strain recordings. The signal-to-noise ratio of both systems is appropriate for this purpose in the frequency band between 0.05 Hz and 0.1 Hz.
Our study further extends beyond the work of Lindsey et al. (2020) and Paitz et al. (2020) by interrogating two fibers in each cable, allowing us to distinguish coupling issues that effect all fibers in a cable, from photonic effects (like optical fading), which are specific to each fiber. We use a significantly larger dataset, comprising 19 earthquakes, covering almost all backazimuths and include body waves in the analysis. The simultaneous interrogation of fibers in two cables at two locations enables us to investigate the direct differences observed under four different coupling conditions.
## 2 DAS installation and instruments
Black Forest Observatory (BFO) is situated in a former silver mine in the central Black Forest, Germany (Emter et al., 1994). The gallery that hosts the instruments (Fig. 1) is mostly horizontal and is excavated in granite. The granite is covered with Triassic sedimentary rocks (Emter et al., 1994). The study focuses on two straight sections of the tunnel, 'Anton Gang' and 'Vorstollen'. Overburden increases with distance to the tunnel entrance, is about 100 m at the 'Anton Gang' and reaches 170 m at the 'Strainmeter array'.
## 2.1 Distributed acoustic sensing (DAS)
Two fiber optic cables are installed in the tunnel. They are unreeled on the floor of the gallery and are in direct contact with the formation. In the section called 'Anton Gang' the cables are loaded down by sand and tightly spaced sandbags in order to improve the mechanical coupling to the rock, provide thermal shielding and cover the cable against water dripping from the gallery ceiling. The blue cable in Fig. 1 is a standard flexible telecommunication cable with loose-tube fibers embedded in gel. The green cable in Fig. 1 has a stiff jacket containing tight-buffered fibers (see section S1.2 in the supplemental material for additional details). We use two single mode fibers in each of the cables and splice them in series, such that the 'Anton Gang' and the 'Vorstollen' are both sampled four times. The signals from the fibers are sampled by a Febus A1-R interrogation unit (IU) installed in the laboratory (Fig. 1). The DAS recording parameters are listed in Table 1. The Febus A1-R recording time is synchronized by GPS, like all other digitizers involved in the current study. When the IU was installed in the mine, the GPS timing signal was provided through an optical link (Meinberg GOAL: GPS Optical Antenna Link).
The Febus A1-R IU operates on the principle of differential phase-measuring distributed acoustic sensing. The light that is back-scattered in the optical fiber is mixed with a reference signal to measure the differential phase over a gauge length, subsequently leading to distributed strain-rate measurements, which is converted to strain by integration over time. The A1-R falls within the category of heterodyne Distributed Vibration Sensing (hDVS) systems, using a single-pulse heterodyne approach for phase detection, as described by Pan et al. (2011).
## 2.2 Reference instruments
BFO operates an array of three well calibrated, 10 m long, horizontal, Invar-wire strainmeters (Fig. 1). The SEED codes for the instruments are II.BFO.00.BSA, II.BFO.00.BSB, and II.BFO.00.BSC. Their design is based on the instruments by King and Bilham (1976) and are discussed in more detail by Z¨rn et al. (2015). u Agnew (1986) and Z¨ urn (2012) discuss instruments of this type and their properties. These instruments are primarily designed to record very-long period signals, such as tidal strain or Earth's free oscillations. For this reason they are equipped with an in-situ calibration device, which makes use of interferometrically calibrated 'Crapaudines' (Verbaandert, 1959). The accuracy of this calibration for the strainmeters is about 2 per cent. Comparison against theoretical tidal strain ensures a stability of the calibration of about 5 per cent in the long run. Section S2.4 in the supplemental material gives further details.
At short signal period the Invar-wire strainmeters show a linear parasitic sensitivity to vertical ground acceleration because of the inertia of the pick-up system. They provide useful strain signals at frequencies below 1 Hz. We use the instruments at frequencies below 0.1 Hz (which provides a safety-margin to the parasitic response) as a reference to present 'rock strain'.
We use signals recorded by the STS-2 broad-band seismometer (Fig. 1) to demonstrate the limitations of waveform comparisons with particle velocity derived strain. The SEED codes for its three components are GR.BFO..BHZ, GR.BFO..BHN, and GR.BFO..BHE.
## 3 Data and data processing
## 3.1 Available data
The installation of DAS cables as shown in Fig. 1 was used for recording from May 22, 2022 until March 13,
## BFO (Black Forest Observatory)
Figure 1: Floor map of the gallery of the former silver mine in which the instruments are installed. Two fiber optic cables are installed in the part in front of the air-locks. The cables are loaded down with tightly packed sandbags in the section called 'Anton Gang' (azimuth N330 ◦ E). We compare signals recorded in the 'Anton Gang' (69 m long) with signals recorded in the straight section called 'Vorstollen' (80 m long, azimuth N90 ◦ E), strain derived from the 'Strainmeter array', and strain simulated from the STS-2 broad-band seismometer in the 'Seismometer vault'. The overburden increases from the 'Tunnel entrance' (0 m) to the 'Anton Gang' (100 m) to the 'Strainmeter array' (170 m). 585 m of the tight-buffered cable are rolled up on a 'Drum' that is used to remove coherent laser noise.
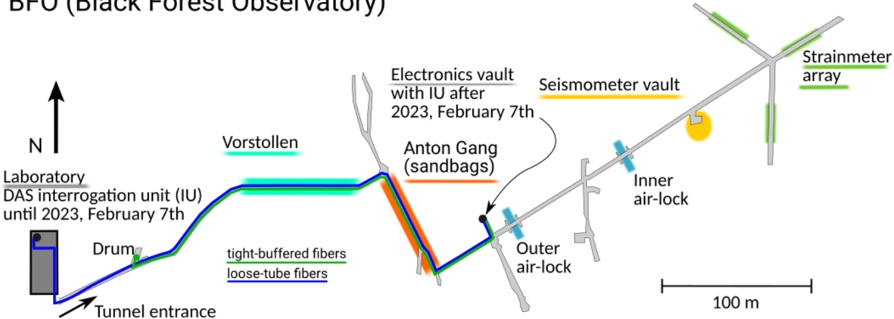
Table 1: Recording parameters for the Febus A1-R.
## Interrogation unit (IU) Febus A1-R
Software:
version 2.2.2
optical wavelength:
1550.12 nm
Fiber length:
2200 m
Pulse width:
5 m
Block rate:
1 Hz
Pulse rate frequency:
5 kHz
Ampli power:
28 dBm
Sampling resolution:
80 cm
Gauge length (GL):
50 m
Derivation time (DT):
20 ms
Channel spacing:
24.8 m
2023. The IU was moved on February 7, 2023 from the laboratory to the electronics vault in the mine (see Fig. 1 and Figs. S1 and S2 in the supplemental material for additional details). In both, 'Anton Gang' and 'Vorstollen', we focus on four almost colocated read-out locations that are separated by 5 m to 15 m. In all cases, the section of gauge length completely falls into the 'Anton Gang' or 'Vorstollen', such that the strain recordings are representative of the azimuth of these gallery sections.
From the GEOFON catalog (Quinteros et al., 2021) we find 84 earthquakes with moment magnitude larger than 6 in the recording time period. 21 of them show a maximum strain amplitude of larger than 1 nstrain in a visual inspection, which is considered large enough to provide a sufficient signal-to-noise ratio in the DAS data. For 19 of the events DAS data is available and allows an analysis. Their backazimuths (BAZ) cover all directions with an azimuthal gap of 107 ◦ (BAZ between N110 E and N217 E). ◦ ◦ Event characteristics are detailed in the supplementary material (see Table S2). The largest amplitudes are found in the surface wave train. For body-waves, the horizontal strain amplitude is the smaller the steeper the ray incidence.
The strongest signals are recorded from the main shocks (Mw 7.7 and Mw 7.6) of the Kahramanmaras ¸ earthquake sequence (Melgar et al., 2023) on February 6th 2023. Their body-wave signals have large enough amplitude of a few nstrain to be included in the analysis. This is due to the larger earthquake magnitude and the smaller epicentral distance (23 ◦ ), compared to the other analyzed events in this study, which both result in rather large amplitude in general. In the set of analyzed events their surface waves provide by far the largest strain amplitudes of about 130 nstrain and about 250 nstrain, respectively, as measured by the Invar-wire strainmeters in the investigated frequency band of 0.05 Hz to 0.1 Hz.
For the comparison of strain waveforms, we can use 46 recordings for each combination of cable (tightbuffered and loose-tube) and location ('Anton Gang' and 'Vorstollen'). For the loose-tube cable in 'Anton Gang' we use only 44 recordings, as the configuration was modified on 2023, February 7th.
## 3.2 Pre-processing of DAS data
Waveforms sampled simultaneously on a section of the tight-buffered cable rolled up on a 'Drum' (see Fig. 1 and Table S1 in the supplemental material) get averaged and subtracted from the recordings in order to reduce common mode laser noise (Lindsey et al., 2020, their section 2.6 Optical Noise). For a gauge-length of 50 m this coherent noise component clearly dominates the background level of the DAS signal at frequencies below 0.5 Hz and peaks at about 0.07 Hz with 'fiber strain'-amplitudes of a few nstrain. By subtracting this coherent signal component, the background level is lowered by up to 20 dB near 0.1 Hz. In the current application, it is essential that the drum is sufficiently decoupled from the rock and that the fiber coiled on the drum does not pick up the earthquake signal. Otherwise the correction procedure would affect the earthquake signal amplitude. In the supplemental material (section S2.3 and Figures S26 and S27) we demonstrate that no signature of the earthquake is apparent in the correction signal.
Data is converted from strain rate to strain for which the noise floor rapidly increases at low frequencies, such that we focus our analysis on frequencies higher than 0.05 Hz.
## 3.3 Linear strain from the strainmeter array
In order to compare the DAS recordings with recordings of the strainmeters, we derive linear strain in either the direction 'Anton Gang' or 'Vorstollen' by a linear combination of the signals recorded by the three strainmeters. Z¨ urn et al. (2015, their eq. 2) specify linear strain
$$\underset { \ v s i s. } { \overset { \text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text \text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\tt{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{ \text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{ \text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{ \text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\font{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{ \text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{ \text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text$\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\font$\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{
\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\test{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{
\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{\text{
}
}$$
in azimuth ψ as a function of the components εθθ , εφφ , and εθφ of the 2D strain tensor. Here, 'Anton Gang' and 'Vorstollen' are in azimuth N330 ◦ E and N90 E, re-◦ spectively. Based on this, we compute linear strain in azimuth ψ
$$\varepsilon ( \psi ) = \begin{pmatrix} \cos ^ { 2 } ( \psi ) \\ \sin ^ { 2 } ( \psi ) \\ - \sin ( 2 \psi ) \end{pmatrix} \, \mathbf M ^ { - 1 } \begin{pmatrix} \varepsilon _ { A } \\ \varepsilon _ { B } \\ \varepsilon _ { C } \end{pmatrix}, \quad ( 2 )$$
from the strain recorded by the three array-instruments, where ε A , ε B , and ε C are in azimuth N2 E, N60 E, and ◦ ◦ N300 E, respectively. ◦ They correspond to the SEED channel names BSA, BSB, and BSC. The rotation matrix
$$\mathbf M ^ { - 1 } = \begin{pmatrix} 1. 0 0 2 & - 0. 0 4 1 & 0. 0 4 0 \\ - 0. 3 3 4 & 0. 6 8 0 & 0. 6 5 3 \\ 0. 0 0 0 & - 0. 5 7 7 & 0. 5 7 7 \end{pmatrix} \quad ( 3 )$$
is the inverse of
$$\begin{pmatrix} 2 0 2 0, \\ \text{gth of} \\ \text{inates} \\ \text{$M=\begin{pmatrix} \cos^{2(\circ)} & \sin^{2(\circ)} & - \sin(2\times2^{\circ)} \\ \cos^{2(\circ)} & \sin^{2(\circ)} & - \sin(2\times60^{\circ)} \\ \cos^{2(\circ)} & \sin^{2(\circ)} & - \sin(2\times300^{\circ)} \\ \end{pmatrix}. \\ \text{fiber} \end{pmatrix}.$$
## 4 Comparison of strain measurements
## 4.1 Strain transfer rate
By fitting the strainmeter data to the DAS data with a linear regression, we compute the 'strain transfer rate'
$$r = \frac { \sum _ { k } x _ { k } y _ { k } } { \sum _ { k } y _ { k } ^ { 2 } }, \quad \quad ( 5 ) \begin{array} { c } \frac { \text{acr} } { \text{in $S$} } \\ \text{mal} \\ \text{con} \\ \dots \end{array}.$$
where xk is the DAS time series of 'fiber strain' and yk is the strainmeter time series of 'rock strain'. Data are filtered by a Butterworth high-pass (0.05 Hz, 4th order) and low-pass (0.1 Hz, 4th order). The average is thus removed from the signals prior to the computation. Fig. 2 (left) shows the 'strain transfer rate' r and Table 2 summarizes the ranges of values. They are between 0.13 and 0.53 in all cases and primarily depend on location and cable type. The variability in the values calculated for a single installation (i.e., one cable at one location) is depicted using a violin plot, where the edges illustrate the density of dots in Fig. 2.
The variability within individual violin plots is smaller than the differences between the median values for different cables and locations. This observation remains consistent across all considered installations, regardless of cable type or location. It underlines the significance of the differences observed between the installations. Differences between colocated fibers for the same cable, location, and event are smaller than 0.05 in almost all cases, which lets us rule out that fiber related causes (like optical fading) would dominate the observed differences. We find no discernible correlation of 'strain transfer rate' with signal amplitude, backazimuth or other earthquake specific parameters (see Figs. S28 and S29 in the supplemental material for example).
The largest values of 'strain transfer rate' are found for the tight-buffered cable, which was expected. Although the loose-tube cable in the 'Anton Gang' is loaded down by sandbags as well, its 'strain transfer rate' is the lowest among all fibers. Hence, we do not observe a significant benefit from sand and sandbags to improve overall coupling.
## 4.2 Waveform similarity
The linear regression used to derive the 'strain transfer rate' requires that the 'fiber strain' waveform as recorded by DAS is consistent with the 'rock strain' waveform obtained from the strainmeters. We use the normalized correlation coefficient
$$c = \frac { \sum _ { k } x _ { k } y _ { k } } { \sqrt { \sum _ { k } x _ { k } ^ { 2 } } \sqrt { \sum _ { k } y _ { k } ^ { 2 } } }$$
as a measure of waveform similarity. Fig. 3 compares the P-waves radiated by the Mw 7.7 Pazarcık earthquake across all measurement types and illustrates differences in SNR. Fig. 2 (right) shows the distribution of the normalized correlation coefficients obtained for all tested configurations. They primarily depend on signal amplitude and thus on signal-to-noise ratio for the DAS data (see Fig. S33 in the supplemental material). The values are largest and larger than 0.92 for all signals of the Mw7.7 and Mw 7.6 earthquakes of the Kahramanmaras ¸ earthquake sequence (see Fig. S31 in the supplemental material). For the surface waves recorded by the tightbuffered cable in the 'Anton Gang' they are even larger than 0.99. The distribution shown in Fig. 2 (right) indicates a generally better signal quality for data recorded with the tight-buffered cable. The loose-tube cable, if not protected by sand-bags ('Vorstollen'), appears to be prone to glitches caused by water drops (see Fig. S12 in the supplemental material for example).
The signal-to-noise ratio of the strainmeter generally is better than that of the DAS cables. This can be seen in Fig. 3, where the first P-wave arrival is clearly seen in the seismometer and strainmeter data at 50 s on the time scale. Only after 70 s the signal amplitude is large enough to allow the DAS recording to capture the P-waves. The high signal-to-noise ratio of the 'rock strain' allows the strainmeter signal to lock onto the 'rock strain'-waveform in the DAS data in the linear regression. The high signal-to-noise ratio time series is in the denominator of Eq. (6) and thus there is no correlation between 'strain transfer rate' and normalized correlation coefficient found in the results.
## 4.3 Intercomparison of fibers at higher frequency
The comparison with strainmeter data is limited to frequencies below 0.1 Hz. Due to their short-period signal energy we can use the body-waves of the Kahramanmaras ¸ earthquakes to extend the study to a larger frequency range by comparing the DAS signals of the main shocks (Mw 7.7 and Mw 7.6) with one another. Hence, the regression is computed with respect to recordings of read-out locations on the tight-buffered fibers. Fig. 4 shows the analysis results for a comparison between different fibers (all with respect to one of the tight-buffered fibers). The normalized correlation coefficients (waveform similarity) generally are higher than 0.970 and reach 1.000 for some of the combinations. At
frequencies above 1 Hz the signal-to-noise ratio for Swaves quickly drops because of the decrease of S-wave energy with increasing signal frequency. This results in reduced signal-to-noise ratio and thus waveform similarity and regression coefficients are reduced as well. A frequency dependence of regression factors beyond the scatter is not apparent up to 1 Hz.
In the frequency range up to 1 Hz, colocated fibers in the same cable practically pick up the same strain amplitude. Regression coefficients listed in Table 3 scatter about unity, where the scatter is smaller for the tightbuffered cable (smallest in the 'Vorstollen' with a range of 0.96 to 1.02) and largest for the loose-tube cable in the 'Anton Gang' (0.80 to 1.23). The ratios of 'strain transfer rate' given in Table 2 are consistent with the regression factors for colocated cables in the extended frequency range given in Table 3.
## 4.4 Comparison with seismometer data
Strainmeter installations recording at seismic frequencies are rare and available only in a few observatories. In the absence of strainmeters many studies use strain signals estimated from particle velocity recorded by seismometers, which appears possible for plane waves of known incidence and phase-velocity. The scaling relation is given by
$$\varepsilon _ { x x } ( { \mathbf r }, t ) = - s _ { h } \cos \left ( \psi _ { \text{BAZ} } - \psi _ { x } - 1 8 0 ^ { \circ } \right ) v _ { x } ( { \mathbf r }, t ), \ \ ( 7 ) \ \underset { \text{velocit} } { \partial }$$
where vx and ε xx are horizontal particle velocity and linear strain in azimuth of ψ x , respectively, ψ BAZ -180 ◦ is the azimuth of wave propagation, and sh is the horizontal component of slowness (see section S4.1 in the supplemental material for additional details). The accuracy of the scaled seismometer signal in representing strain depends on the validity of the plane-wave assumption underlying the conversion. While strainmeters and DAS can be expected to record the same quantity, namely linear strain in a given azimuth, independent of the nature of the signal, this is not the case for the seismometer derived strain signals. This is not only the case because the recorded waveform is a superposition of non-plane waves with different phase slowness, but also because of the local free surface affecting the particle velocity and the strain in different ways (see section S2.5 in the supplemental material for additional details).
The signal derived from the STS-2 recording in Fig. 3 matches the strain signals quite well near the first P-wave arrival (75 s). In later parts (220 s) the P-wave signal of particle velocity obviously provides only half the amplitude of the signals from the strainmeter and the scaled DAS signals.
The surface waves with good signal-to-noise ratio used in the current study not only propagate at varying slowness (dispersion and superposition of Love- and Rayleigh-waves), they also contain significant nonplane wavefield components due to scattering in particular on continental paths. Wielandt (1993) discusses the consequences of the non-plane nature of waves for the spatial derivatives of displacement. The scaling in Eq. (7) lets ε xx vanish for ψ BAZ being perpendicular to ψ x . In cases where ψ BAZ comes close to being perpendicular to ψ x the actual strain component is dominated by off-great-circle propagation and non-plane wave contributions, which results in a large scatter of regression coefficients (see Fig. S34 in the supplemental material). In these cases, seismometers cannot reasonably be used to calibrate DAS signals.
Here, we illustrate the limitations of the comparison with seismometer data using the surface waves recorded on February 23rd 2023 after the Mw 6.8 earthquake in the the Tajikistan-Xinjiang Border Region. The great-circle backazimuth for this earthquake is ψ BAZ = N77 2 E, which is only by 17 . ◦ ◦ off the direction perpendicular to the 'Anton Gang' azimuth of ψ x = N330 E. ◦ Fig. 5 (top panel) shows the signal comparison. Lovewaves (300 s) and Rayleigh-waves (400 s) are inseparably superimposed. Both are dispersive and arrive at different phase velocity with non-plane wavefronts due to scattering on the continental path. Slowness sh = 280mskm -1 is used for scaling the seismometer signal, which corresponds to the average phase velocity of about 3.6 km s -1 , the value of Rayleigh-wave phase velocity at 0.05 Hz in Southern Germany (Friederich and Huang, 1996, their Table 1). The bottom panel of Fig. 5 shows the waveform residuals with respect to the strainmeter signal. The residual amplitude for the tightbuffered cable is about three to five times the noise level. For the seismometer the largest residual amplitude is five times larger and the waveform mismatch renders the seismometer signal unusable for a calibration. The adjustment of a scaling factor would not solve the problem. The seismometer derived amplitude for the first wave group (300 s - 500 s) is larger than that of strainmeter and DAS, while it is too small after 500 s. Additionally, Fig. 5 shows a significant mismatch throughout the wavetrain, while DAS and strainmeter waveforms are rather consistent. In practically all cases examined the normalized correlation coefficient between seismometer signal and DAS is smaller than between strainmeter signal and DAS (see Fig. S35 in the supplemental material). In most cases it is significantly smaller and in some cases it is even negative (anti-correlation).
## 5 Detection threshold for 'rock strain'
The signal of largest amplitude in the natural seismic background are the marine microseisms. This can be a
complete data set
complete data set
Figure 2: Values of 'strain transfer rate' (left diagram, representing the ratio of 'fiber strain' to 'rock strain' as recorded by the strainmeter) derived by Eq. (5) and the normalized correlation coefficients (right diagram) calculated using Eq. (6). The results are shown separately for two locations: 'Anton Gang' (left, N330 E) and ◦ 'Vorstollen' (right, N90 ◦ E). They are presented for two different cables: a tight-buffered (green, left) and a loosetube cable (blue, right) at each location. These values are derived in two fibers per cable, for surface wave signals of 19 teleseismic earthquakes and the P- and S-wave signals of the two Turkey-events on 2023-02-06. All signals are consistently filtered with 4th order Butterworth high-pass (0.05 Hz) and low-pass (0.1 Hz) filters. For each set of cable and location, the black dots represent individual results from the 46 analyses and a summary of the values is provided in Table 2. The kernel density estimates that define the edges of the violin plot illustrate the spread in the distribution of numerical values.
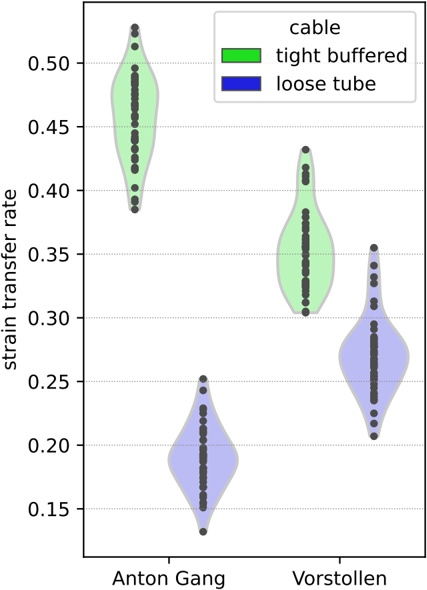
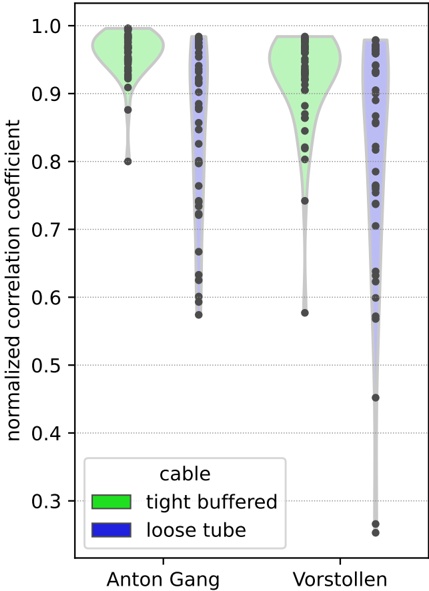
Table 2: Ranges of 'strain transfer rate'.
| cable | location | minimum | median | maximum |
|----------------|--------------|-----------|----------|-----------|
| tight-buffered | 'Anton Gang' | 0.39 | 0.46 | 0.53 |
| tight-buffered | 'Vorstollen' | 0.3 | 0.35 | 0.43 |
| loose-tube | 'Vorstollen' | 0.21 | 0.27 | 0.36 |
| loose-tube | 'Anton Gang' | 0.13 | 0.19 | 0.25 |
Values are as presented in Fig. 2 (left). Strainmeter signals are fitted to DAS (distributed acoustic sensing) recorded waveforms by linear regression in the frequency band from 0.05 Hz to 0.1 Hz.
Turkey Mw 7.7 2023-02-06 01:17:34.9 UTC, 37.05°E 37.23°N, 10 km filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
receiver location: Anton Gang (sandbags)
Figure 3: Waveforms of the P-waves radiated by the Mw 7.7 Pazarcık earthquake on February 6th, 2023. Traces are shifted vertically for better visibility. The legend (top to bottom, left to right) specifies the traces in order from top to bottom. All signals are consistently filtered with Butterworth high-pass (0.05 Hz, 4th order) and low-pass (0.1 Hz, 4th order) filters. The seismometer response is removed from the STS-2 data. The DAS signals of 'fiber strain' from the tight-buffered cable (green, signal amplified by a factor of 2) and the loose-tube cable (blue, signal amplified by 4) are taken with a gauge length of 50 m at a location in the center of the 'Anton Gang' (Fig. 1). Linear strain in azimuth N330 E of 'Anton Gang' is obtained from the BFO strainmeter array by Eq. (2). ◦ For comparison we show an estimate of linear strain simulated from ground velocity for a plane wave of slowness 100 ms km -1 and incoming from backazimuth N107 2 E. . ◦ The basis for this simulation is the recording of the STS-2 seismometer converted by Eq. (7). The slowness of 100 ms km -1 , which acts as a scaling factor in Eq. (7) is not appropriate throughout the entire time window. This makes calibration with respect to strain simulated from ground velocity disputable. While the first P-wave onset is apparent near 01:22:50 UT (50 s on timescale) in the strainmeter and STS-2 data, the noise level in the DAS data is too high to detect the small amplitude signals before 01:23:10 UT (70 s).
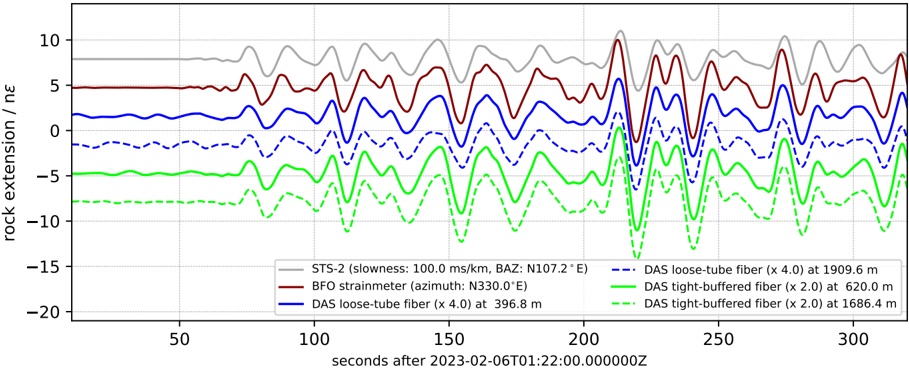
Table 3: Ranges of regression coefficients for an intercomparison of fibers.
| DAS with respect to colocated DAS fibers (in the same cable) | DAS with respect to colocated DAS fibers (in the same cable) |
|----------------------------------------------------------------|----------------------------------------------------------------|
| tight-buffered 'Vorstollen' | 0.96 - 1.02 |
| tight-buffered 'Anton Gang' | 0.92 - 1.08 |
| loose-tube 'Vorstollen' | 0.89 - 1.11 |
| loose-tube 'Anton Gang' | 0.80 - 1.23 |
| DAS with respect to colocated DAS fibers (in the other cable) | DAS with respect to colocated DAS fibers (in the other cable) |
| loose-tube vs. tight-buffered 'Vorstollen' | 0.72 - 0.83 |
| loose-tube vs. tight-buffered 'Anton Gang' | 0.32 - 0.47 |
The presented values cover the frequency band from 0.05 Hz to 1.0 Hz.
eqs: 7.7,7.6; win: eP,P,S; loc: Vorstollen,Anton Gang; sig: 3,4,5
reference signal: tight-buffered fiber
Figure 4: Regression factor derived by Eq. (5) and normalized correlation coefficient by Eq. (6) with respect to one colocated fiber in the tight-buffered cable (location 620.0 m in the 'Anton Gang' and 719.2 m in the 'V orstollen', respectively, see Fig. 1). We use body-wave signals of both main shocks (Mw 7.7 and Mw 7.6) of the Kahramanmaras ¸ earthquake sequence on February 6th 2023 for both locations, fibers and cables. The S-waves contain less shortperiod energy. The signal-to-noise ratio for them is reduced above 1 Hz, which results in a reduced waveform similarity (normalized correlation coefficient). This also affects the regression factors derived for S-waves. A summary of the values up to 1 Hz is given in Table 3.
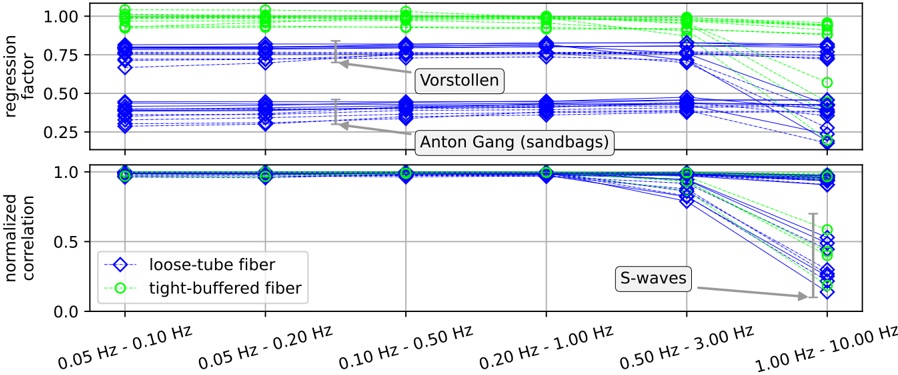
helpful test signal for the investigation of instrumental properties at frequencies of 0.1 Hz to 1 Hz. In applications for Newtonian Noise mitigation the strain background at even smaller amplitude must be resolved.
We analyze the signals at times of large marine microseism amplitude. The rms-amplitude levels are shown in Fig. 6 (top) together with the pair-wise magnitude-squared coherence (Carter et al., 1973, their eq. 2) of signals (bottom). The signal of the BFO strainmeters shows the signature of the primary microseism peak at about 0.07 Hz as well as the secondary peak at 0.14 Hz. The tight-buffered cable appears to detect the secondary microseism peak, while the scaled noise in the loose-tube fibers is above the background 'rock strain' level. The coherence between the BFO strainmeter signal and the tight-buffered fibers (at 620.0 m and 1686.4 m), as well as among the tight-buffered fibers themselves, peaks at 0.8 at the frequency of the secondary microseisms, i.e. 0.14 Hz. The coherence for all other signal combinations reaches a maximum of 0.6 or less. The lower envelope of the coherence curves peaks at 0.3 at 0.14 Hz, which may indicate that all signals contain at least a portion of the marine microseisms. Nevertheless the similarity of the waveforms shown in Fig. 7 is not as good as for the earthquake signals, even though a narrow bandpass is applied. This is consistent with the coherence not exceeding a value of 0.8.
The amplitude levels of the marine microseisms at BFO strongly vary with weather conditions over the North Atlantic and are typically lower during northern hemisphere summer 1 . A similar analysis for signals recorded on 2022-07-10 shows the background level of the BFO strainmeter recordings at below 0.02 nstrain with no indication of a microseism peak. At the same time, the amplitude levels of the DAS recordings range between 0.05 nstrain (0.3 Hz) and 0.4 nstrain (0.05 Hz), with the lowest levels observed for the tight-buffered fibers and rms values decreasing with increasing frequency for all fibers. Coherence between any pair of fibers, or between DAS recording and BFO strainmeter, is below 0.25 at these times. Thus, at times of low marine microseism amplitude, the DAS fibers are not able to pick up the background 'rock strain' in the discussed frequency band.
## 6 Conclusions
The waveform similarity between DASand strainmeter-recorded signals, as well as in the intercomparison of DAS signals, is high for signals with large amplitudes. For the bodyand surface waves recorded after the main shocks (Mw 7.7 and Mw 7.6) of the Kahramanmaras ¸ earthquake sequence on February
1 The seasonal variation of marine microseism energy is seen in the analyses presented by the Waveform Quality Center at Lamont-Doherty Earth Observatory: https://www.ldeo.columbia.edu/ ˜ ekstrom/Projects/WQC/MONTHLY\_HTML/BFO-II.LHZ-00\_time.html .
20.0 minutes starting at 2023-02-23T01:00:00.019538Z
STS-2 slowness: 280.0 ms/km, BAZ: N77.2
Tajikistan-Xinjiang Mw6.8 Anton (N330.°E)
E strainazimuth: N 330.0°E time-shift: 0.000s factors adjusted filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
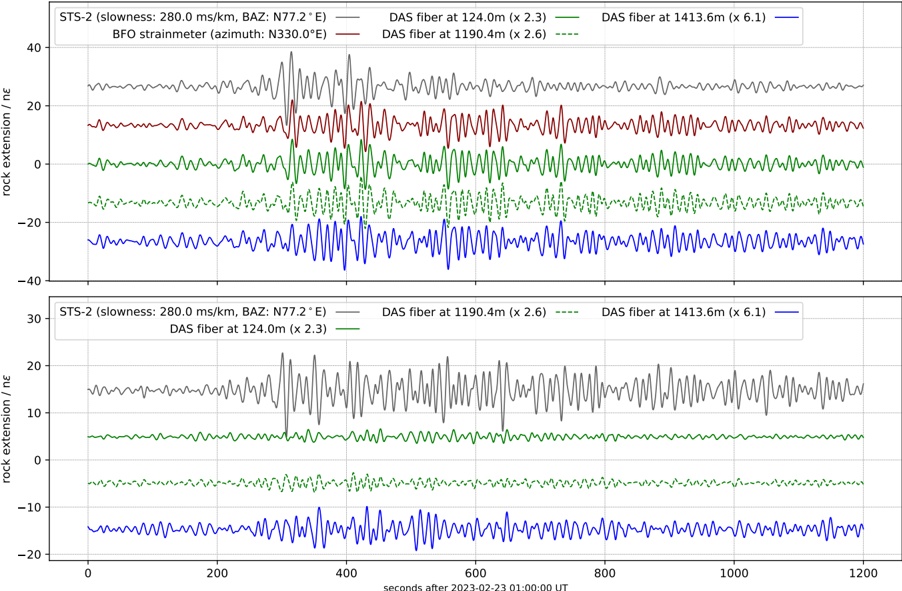
seconds after 2023-02-23 01:00:00 UT
Figure 5: Surface waves (top) and residuals with respect to the strainmeter data (bottom) for the Mw 6.79 Tajikistan-Xinjiang Border Region earthquake (origin: 2023-02-23 00:37:39.01 UTC, 38 06 N, 73 29 E, 10.0 km . ◦ . ◦ depth, BAZ=N77 24 E, . ◦ ∆ =47 06 ). Traces are shifted vertically for better visibility. . ◦ The legends (top to bottom, left to right) specify the traces in the order from top to bottom. Love-waves (300 s) and Rayleigh-waves (400 s) are inseparably superimposed. All direct body wave phases arrived prior to 1:00 UT (outside the displayed window). Displayed are strain signals for the azimuth N330 ◦ E ('Anton Gang'). Top panel traces from top to bottom: gray: particle velocity scaled to apparent strain by Eq. (7) with ψ BAZ = N77 2 E and slowness . ◦ sh = 280mskm -1 . The backazimuth is only by 17 ◦ off the direction perpendicular to the 'Anton Gang' azimuth of ψ x = N330 E. ◦ red: BFO strainmeters. green solid, green dashed: tight-buffered DAS cable (read-out locations 124.0 m and 1190.4 m). blue: loose-tube DAS cable (1413.6 m). The DAS signals are scaled to minimize the rms-residual with respect to the strainmeter (factors are given in the legend). Bottom panel: Waveform difference of the traces in the top panel with respect to the strainmeter signal.
56.7 minutes starting at 2023-01-08T00:40:00.000000Z
duration of segments: 120.0s rms amplitude in 1/6 decade
1.000
1.000
Figure 6: Analyses of the strain background signal in the 'Anton Gang' for 50 minutes after 2023-01-08 0:40 UT at times of large marine microseism amplitude. Top: rms-amplitude in 1/6 decade. The peaks of the primary (0.07 Hz) and secondary (0.14 Hz) microseisms are observed in the BFO strainmeter data. DAS recorded signals are multiplied by the average reciprocal 'strain transfer rate' as given in Table 3. The values from the loose-tube cable (1909.6 m and 396.8 m) are largest. The values for the BFO strainmeter are the smallest below 0.1 Hz and above 0.25 Hz. At 0.14 Hz the curves for the tight-buffered cable (1686.4 m and 620.0 m) coalesce with the curve for the BFO strainmeter. Bottom: magnitude-squared coherence of pairs of signals. The curves for the BFO strainmeter versus the tight-buffered cable (620.0 m and 1686.4 m) and the intercomparison of the tight-buffered fibers (620.0 m versus 1686.4 m) have a peak value of 0.8 at 0.14 Hz. Values for all other pairs are smaller at this frequency.
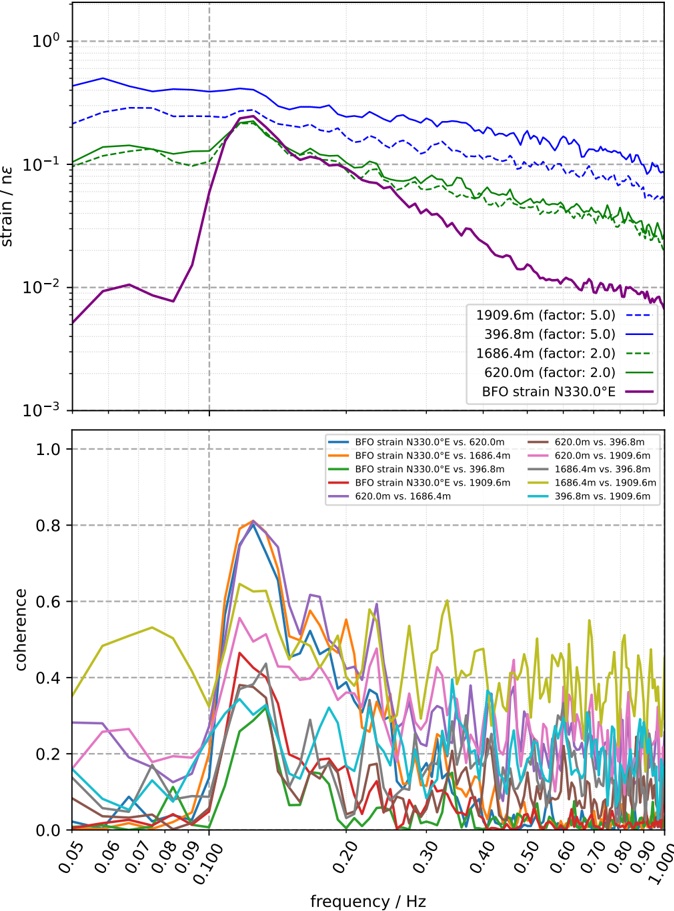
56.7 minutes starting at 2023-01-08T00:40:00.000000Z
duration of segments: 120.0s bandpass: 0.100 Hz - 0.160 Hz
Figure 7: Waveforms of the recorded background signal at large amplitudes of marine microseisms. Traces are shifted vertically for better visibility. The legend (top to bottom, left to right) specifies the traces in order from top to bottom. Read-out locations 1909.6 m and 396.8 m are from the loose-tube cable and locations 1686.4 m and 620.0 m are from the tight-buffered cable, both in the 'Anton Gang'. A narrow bandpass from 0.1 Hz to 0.16 Hz is applied in order to focus on the signal of the secondary microseisms. DAS recorded signals are multiplied by the average reciprocal 'strain transfer rate' as given in Table 2.
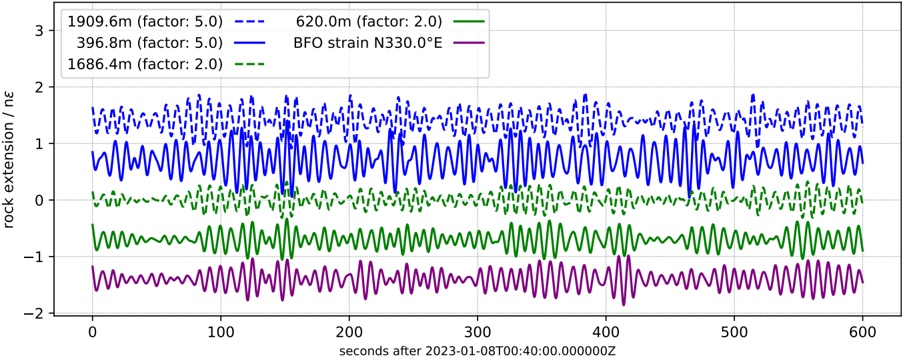
6th 2023 the normalized correlation coefficient (NCC) with respect to the strainmeter is larger than 0.92 for all DAS fibers in the frequency band from 0.05 Hz to 0.1 Hz. In an intercomparison of colocated DAS fibers for the body-wave signals up to 1 Hz, the NCC is larger than 0.97 and reaches 1.000 in some cases. For smaller signal amplitude the DAS signal-to-noise ratio worsens and the NCC becomes smaller. The signal quality in this respect is better for the tight-buffered cable and worst for the loose-tube cable in the 'Vorstollen', where it is not protected by a sand bed against water dripping from the ceiling.
high similarity of signals from two fibers in the same cable, we can rule out fiber related causes for the difference, like optical fading. We find no systematic dependency of 'strain transfer rate' on backazimuth of the event, nor do we find any other systematic correlation except with respect to cable type and location. The 'strain transfer rate' of the cables cannot be specified independently of local installation conditions.
The DAS recorded 'fiber strain' at large amplitude hence well represents the waveform and the signal phase of 'rock strain'. This is, however, not the case for the signal amplitude. The values of 'strain transfer rate' (amplitude ratio of 'fiber strain' versus 'rock strain'), which we calibrate by linear regression, cover a range from 0.13 to 0.53 (Table 2). None of the installed cables provides a 'strain transfer rate' equal 1, which would make 'fiber strain' equal 'rock strain'. The largest value is obtained for the tight-buffered cable in the 'Anton Gang', where cables are loaded down by loose sand and sand bags. While the tight-buffered cable generally provides a larger 'strain transfer rate', the smallest values are obtained for the loose-tube cable in the 'Anton Gang'. We hence find no consistent effect of the sand bags on coupling the fiber to the rock.
The scatter in 'strain transfer rate' values for a single cable at one location is smaller than the differences observed between different cables and locations. By the
An amplitude correction factor to be applied to DAS recorded strain not only adjusts the signal amplitude, but also amplifies the instrument generated background noise. Consequently the peak of the secondary marine microseisms is only detected by the installation with largest 'strain transfer rate' in Table 3. We estimated the detection threshold for the tight-buffered cable in the 'Anton Gang' at 0.1 nstrain rms-amplitude in 1/6 decade near 0.1 Hz.
Even if we attribute the 'strain transfer rate' to the cable type and installation here, we cannot rule out the possibility that some other effect reduces the recorded 'fiber strain'. In a next step, we plan to install a testbed of fibers (just core, cladding, coating, and tight-buffer) directly cemented into the floor of the mine. We expect that this would make the DAS recordings more sensitive and would make 'fiber strain' equal 'rock strain'.
## Data and Resources
All data were recorded locally at (Black Forest Observatory [BFO], 1971, https://dx.doi.org/10.5880/
BFO ). Strainmeter and seismometer data are available through data centers at the (Scripps Institution of Oceanography, 1986, https://dx.doi.org/10. 7914/SN/II ) and the (Federal Institute for Geosciences and Natural Resources, BGR, 1976, https://dx.doi. org/10.25928/MBX6-HR74 ), respectively. DAS data can be provided upon request. Event parameters were taken from the GEOFON catalog (Quinteros et al., 2021, https://geofon.gfz-potsdam.de/eqinfo/ ). Data analysis was carried out with ObsPy (The ObsPy Development Team, 2022, https://dx.doi.org/10.5281/ zenodo.6327346 ). We provide a supplemental text file with figures, tables, and math to further support the findings presented in this paper.
## Acknowledgments
We thank Peter Duffner for taking care of the BFO strainmeters and their calibration devices. We are grateful to Walter Z¨ urn for many fruitful discussions and his continuing support of the operation of the Invarwire strainmeters. Gaetan Calbris and Vincent Lanticq from Febus Optics provided helpful information on the measurement principle used in the Febus A1-R. Peter Duffner, Felix B¨gelspacher, and Leon Merkel supo ported the installation of the experiment. We are grateful for the well-considered comments provided by two anonymous reviewers. The cable with the tight-buffered fibers (green cable) has been made available for the experiments through the INSIDE project. INSIDE is supported by the German Federal Ministry for Economic Affairs and Climate Action and the Project Management J¨ ulich (PtJ) under the grant agreement number 03EE4008C.
## References
Agnew, D. C. (1986). Strainmeters and tiltmeters. Rev. Geophys. 24 (3), 579-624. doi: 10.1029/RG024i003p00579.
Azzola, J., N. K. Toularoud, E. Gaucher, T. Forbriger, R. Widmer-Schnidrig, F. B¨ ogelspacher, M. Frietsch, and A. Rietbrock (2022). Comparison between distributed acoustic sensing (DAS) and strain meter measurements at the Black Forest Observatory. In EGU General Assembly 2022 . doi: 10.5194/egusphere-egu22-6976.
Baker, T. and G. Lennon (1973). Tidal tilt anomalies. Nature 243 , 75-76. doi: 10.1038/243075a0.
Black Forest Observatory [BFO] (1971). Black Forest Observatory data. doi: 10.5880/BFO.
- Carter, G., C. Knapp, and A. Nuttall (1973). Estimation of the magnitude-squared coherence function via overlapped fast Fourier transform processing. IEEE Trans. Audio and Electroacoustics 21 (4), 337-344. doi: 10.1109/TAU.1973.1162496.
Dakin, J. P. (1990). Distributed optical fibre sensors. In OFS-7: Conference on Optical Fiber Sensors (02/12/90 - 06/12/90) . https://eprints.soton. ac.uk/77464/ (last accessed: 2023-12-07).
Emter, D., H.-G. Wenzel, and W. Z¨ urn (1994). The Black Forest Observatory, Schiltach. Soil Dynamics and Earthquake Engineering 13 (1), 73-75. doi: 10.1016/0267-7261(94)90043-4.
Emter, D. and W. Z¨ urn (1985). Observations of local elastic effects on earth tide tilts and strains. In J. C. Harrison (Ed.), Earth Tides , Chapter 14, pp. 309-327. New York: Van Nostrand Reinhold Company.
- ET Steering Committee (2020). Einstein Telescope design report update 2020. available from European Gravitational Observatory, document number ET-0007B-20.
Federal Institute for Geosciences and Natural Resources, BGR (1976). German Regional Seismic Network (GRSN). doi: 10.25928/MBX6-HR74.
Forbriger, T., R. Widmer-Schnidrig, L. Hillmann, H. Xiao, A. Rietbrock, V. R. Tribaldos, A. Strollo, and P. Jousset (2024). Cemented fibers as a test-bed for distributed acoustic sensing (das). In AG Seismologie, 50th annual conference , Hamburg.
Friederich, W. and Z.-X. Huang (1996). Evidence for upper mantle anisotropy beneath southern Germany from Love and Rayleigh wave dispersion. Geophys. Res. Lett. 23 (10), 1135-1138. doi: doi.org/10.1029/96GL01216.
Harms, J. (2015). Terrestrial gravity fluctuations. Living Rev. Relativ. 18 (3). doi: 10.1007/lrr-2015-3.
- Harms, J., L. Naticchioni, E. R. D. R. Calloni, F. Ricci, and D. D'Urso (2022). A lower limit for Newtoniannoise models of the Einstein Telescope. Eur. Phys. J. Plus 137 (687). doi: 10.1140/epjp/s13360-02202851-z.
Harrison, J. C. (1976). Cavity and topographic effects in tilt and strain measurement. J. Geophys. Res. 81 (2), 319-328. doi: 10.1029/JB081i002p00319.
Hartog, A. H. (2017). An Introduction to Distributed Optical Fibre Sensors (1 ed.). CRC Press. doi: 10.1201/9781315119014.
Kennett, B. L. N. (1991). The removal of free surface interactions from three-component seismograms. Geophys. J. Int. 104 (1), 153-163. doi: 10.1111/j.1365246X.1991.tb02501.x.
King, G. and R. Bilham (1973). Tidal tilt measurement in europe. Nature 243 , 74-75. doi: 10.1038/243074a0.
King, G. and R. Bilham (1976). A geophysical wire strainmeter. Bull. Seismol. Soc. Am. 66 (6), 20392047. doi: 10.1785/BSSA0660062039.
Li, D., H.-N. Li, L. Ren, and G. Song (2006, February). Strain transferring analysis of fiber bragg grating sensors. Optical Engineering 45 (2), 024402-. doi: 10.1117/1.2173659.
Li, Y., M. Karrenbach, and J. B. Ajo-Franklin (2021). A literature review. In Distributed Acoustic Sensing in Geophysics , pp. 229-291. American Geophysical Union (AGU). doi: 10.1002/9781119521808.ch17.
Lindsey, N. J. and E. R. Martin (2021). Fiber-optic seismology. Annu. Rev. Earth Planet. Sci. 49 (1), 309336. doi: 10.1146/annurev-earth-072420-065213.
Lindsey, N. J., H. Rademacher, and J. B. AjoFranklin (2020). On the broadband instrument response of fiber-optic DAS arrays. J. Geophys. Res. 125 (2), e2019JB018145. doi: doi.org:10.1029/2019JB018145.
Longman, I. M. (1959). Formulas for computing the tidal accelerations due to the moon and the sun. J. Geophys. Res. 64 (12), 2351-2355. doi: 10.1029/JZ064i012p02351.
Melchior, P. (1966). The earth tides (1. ed. ed.). Oxford: Pergamon Press.
Melchior, P. (1978). The tides of the planet Earth (1. ed. ed.). Oxford: Pergamon Press.
Melgar, D., T. Taymaz, A. Ganas, B. Crowell, T. Ocalan, ¨ M. Kahraman, V. Tsironi, S. Yolsal-Cevikbilen, ¸ S. Valkaniotis, T. S. Irmak, T. Eken, C. Erman, B. Ozkan, A. H. Dogan, and C. Altuntas ¸ (2023). Sub-¨ and super-shear ruptures during the 2023 Mw 7.8 and Mw 7.6 earthquake doublet in SE T¨ urkiye. Seismica 2 (3), 10. doi: 10.26443/seismica.v2i3.387.
Paitz, P., P. Edme, D. Gr¨ aff, F. Walter, J. Doetsch, A. Chalari, C. Schmelzbach, and A. Fichtner (2020). Empirical investigations of the instrument response for distributed acoustic sensing (DAS) across 17 octaves. Bull. Seismol. Soc. Am. 111 (1), 1-10. doi: 10.1785/0120200185.
Pan, Z., K. Liang, Q. Ye, H. Cai, R. Qu, and Z. Fang (2011). Phase-sensitive OTDR system based on digital coherent detection. In 2011 Asia Communications and Photonics Conference and Exhibition (ACP) , pp. 1-6. doi: 10.1117/12.905657, ISSN: 2162-1098.
Quinteros, J., A. Strollo, P. L. Evans, W. Hanka, A. Heinloo, S. Hemmleb, L. Hillmann, K.-H. J¨ ackel, R. Kind, J. Saul, T. Zieke, and F. Tilmann (2021). The GEOFON program in 2020. Seism. Res. Lett. 92 (3), 1610--1622. doi: 10.1785/0220200415.
Rademacher, H. (2024, 02). Is the era of broadband seismometry coming to an end? Seism. Res. Lett. 95 (3), 1467-1468. doi: 10.1785/0220240007.
Reinsch, T., T. Thurley, and P. Jousset (2017). On the mechanical coupling of a fiber optic cable used for distributed acoustic/vibration sensing applications-a theoretical consideration. Measurement Science and Technology 28 (12), 127003. doi: 10.1088/1361-6501/aa8ba4.
Scripps Institution of Oceanography (1986). Global Seismograph Network -IRIS/IDA. doi: 10.7914/SN/II.
Taylor, H. F. and C. E. Lee (1993). Apparatus and method for fiber optic intrusion sensing. https://patents.google.com/patent/ US5194847A/en (last accessed: 2023-12-07), US patent no. 5194847A.
The ObsPy Development Team (2022, March). ObsPy 1.3.0. doi: 10.5281/zenodo.6327346.
Verbaandert, J. (1959). Etalonnage des pendules horizontaux par crapaudine dilatable ´tudi´ ee e interf´rom´ etriquement. e In III`me Symp. Mar´ ees Terr. e , Trieste, pp. 81-90. Observatoire royal de Belgique.
Verbaandert, J. (1962). L'´ etalonnage des pendules horizontaux. Boll. Geofis. 4 (16), 419-446. Bolletino di Geofisica Teorica ed Applicata.
Verbaandert, J. (1963). L'´ etalonnage des pendules horizontaux. Comm. Obs. Roy. Belg., S. G´ eoph., No. 62 214 , 419-446.
Wielandt, E. (1993, 04). Propagation and Structural Interpretation of Non-Plane Waves. Geophys. J. Int. 113 (1), 45-53. doi: 10.1111/j.1365246X.1993.tb02527.x.
Z¨ urn, W. (2012). Strainmeters. In P. Bormann (Ed.), New Manual of Seismological Observatory Practice 2 (NMSOP2) (2 ed.)., Technical report Information Sheet 5.1, pp. 1-11. Potsdam, Germany: GeoForschungsZentrum. doi: 10.2312/GFZ.NMSOP2 IS 5.1.
Z¨ urn, W., A. M. G. Ferreira, R. Widmer-Schnidrig, K. Lentas, L. Rivera, and E. Cl´ ev´ ed´ (2015). e Highquality lowest-frequency normal mode strain observations at the Black Forest Observatory (SW-
Germany) and comparison with horizontal broadband seismometer data and synthetics. Geophys. J. Int. 203 (3), 1787-1803. doi: 10.1093/gji/ggv381.
## Electronic supplement to
## Calibration of the strain amplitude recorded with DAS
## using a strainmeter array
Thomas Forbriger, J´ erˆme Azzola, Nasim Karamzadeh, o Emmanuel Gaucher, Rudolf Widmer-Schnidrig, Andreas Rietbrock
## Introduction
This electronic supplement introduces additional information and diagrams that are not essential to an understanding of the manuscript, but provide further insight into the data analysis and support the results of the study.
STR and NCC and evaluate the symmetry of the regression matrix, analyzing differences in fitting strainmeter data against DAS data or the opposite. The correlation of NCC and STR to earthquake parameters, including backazimuth and observed maximum strain, is also evaluated.
The supplementary material focuses first on the recording environment. It details the position of the DAS read-out locations in the 'Anton Gang' and 'Vorstollen' and the extent of the associated gauges on the floor of the gallery (Sec. S1.1 'Location of sensing points and gauges in the mine'). It also details the characteristics of the fiber optic cables used in the study (Sec. S1.2 'Specifications of optical fibers').
The supplement gives then further details about the 19 earthquakes used to carry out a waveform comparison in the main study. In Section S2.1 'Earthquakes used in the analysis', earthquake parameters for all 19 events are detailed. We show the DAS and strainmeter surface wave signals corresponding to each event, for read-out locations in 'Anton Gang' and 'Vorstollen' (Sec. S2.2.1 'Surface wave signals'). For the two Kahramanmaras ¸ earthquakes, we also include the body wave data (Sec. S2.2.2 'Body wave signals'). We complement the discussion in Section S2 'Analyzed data' by details on the pre-processing of DAS data in section S2.3 'Reduction of coherent noise'. Section S2.4 'Calibration of the strainmeters' provides information on the calibration of the BFO strainmeters and section S2.5 'Distortion of the strain field due to local heterogeneity' adds considerations on strain-strain coupling.
Extended results are then introduced to support the main findings of the study (Sec. S3 'Additional diagrams to complement the main results'). They focus on the analysis of 'strain transfer rate' (shortened to STR), which quantifies how much of 'rock strain' is transferred to the signal recorded by the IU, and on normalized correlation coefficients (shortened to NCC), which quantify the waveform similarity between the two strain measurements. We assess the correlation between
Section S4 'Plane wave strain from seismometer recordings' gives further insight into the comparison of DAS recordings to strain signals computed from seismometer data. Section S4.1 'Scaling rule for plane waves' details the procedure used for the conversion from particle velocity to strain and Sec. S4.2 'Regression with respect to seismometer data' compares the regression coefficients computed when fitting strainmeter signals to DAS signals with those obtained by fitting scaled seismometer data to DAS. Seismometer and strainmeter data are finally compared in Sec. S4.3 'Comparison of seismometer and strainmeter data'.
## Pre-processing
Signal pre-processing is carried out following the procedure described in the main paper. All signals shown in the supplemental material are band-pass filtered between 0.05 Hz and 0.1 Hz, where the DAS signal-tonoise ratio is good enough and strainmeter signals are free from parasitic components.
## S1 Fiber Optic Cable setting
## S1.1 Location of sensing points and gauges in the mine
Table S1 details the position of the read-out locations identified near the centers of 'Anton Gang' and 'Vorstollen'. The read-out locations shown in the Figs. S1 and S2 are the ones used in the study.
DAS strain is computed over so-called gauges, defined by the gauge length (GL) parameter, which cor-
respond to the length of optical fiber over which optical dephasing is measured by the IU. The extent of the gauge on the cable plays therefore a significant role in the measured strain. The gauge-sections are displayed in detail in Figs. S1 and S2 for this reason. Fig. S2 applies to the modified cable setup, after February 7, 2023. For each read-out location considered in the analysis on 'Anton Gang' and 'Vorstollen', the physical location of the sensing point is represented as a symbol with the cable offset indicated in the legend, and the extent of the gauge is represented as a colored line.
The read-out locations were selected because of their position, near the center of 'Anton Gang' and 'Vorstollen'. The figures show the small distance between the read-out locations positioned in each section of interest. It shows also that the associated gauges cover these sections with a consistent azimuth.
## S1.2 Specifications of optical fibers
The analysis explores the capacities of two fiber optic cables with different characteristics. We use on one hand a standard flexible telecommunication cable with loose-tube fibers embedded in gel (blue cable on the diagrams). It is distributed by Prysmian Group. The print on the cable is:
DRAKA UC FIBRE I/O CT LSHF 3.0kN 4 SM2D G.652.D/SM7A1 BendBright 60011347 15 20506485 009201015 .
On the other hand, we use a second cable that has a stiff jacket containing tight-buffered fibers (green cable in the diagrams). It is distributed by Solifos AG and specified as a 'BRUsens DAS & DTS & Communication Hybrid' cable. For distributed acoustic sensing, we use two 2.4 mm simplex elements with tight-buffered single mode fiber with Aramid, glass strain relief and plastic outer sheath. The print on the cable is:
BRUSENS ACOUSTIC TEMPERATURE HYBRID BSAH 2SMF+2MMF+10SMF FIBRE OPTIC CABLE 00241904 .
BFO DAS installation 2022-05-20 to 2023-02-07
Figure S1: Floor map of the gallery of the mine with a zoom on the 'Anton Gang' (70 m long, azimuth N330 E) ◦ and on the 'Vorstollen' (80 m long, azimuth N90 E). ◦ It includes the extent of the gauge length, i.e. the optical fiber length over which optical dephasing is measured to produce a single sensing point located at the middle. The associated symbol shows the position of the measurement, as estimated by tap-tests. The figure includes the gauge lengths used for the study, considering the cable setup used in the mine from May 20, 2022 to February 7, 2023.
BFO DAS installation 2023-02-07 to 2023-03-13
Figure S2: Same as previous figure, for the cable setup used in the mine from February 7 to March 13, 2023.
Table S1: Read-out locations along the fiber near the centers of 'Anton Gang' and 'Vorstollen' (see Figs. S1 and S2). The locations are specified by the linear distance from the IU (interrogation unit) along the fiber route.
## 'Anton Gang' (azimuth N 330 ◦ E)
cables covered with sand and sandbags
## UTM32N
location / m cable
396.8
620.0
1686.4
loose-tube tight-buffered
tight-buffered
1909.6
loose-tube easting / m
northing / m
450102.6
450098.3
450101.6
450099.3
5353139.4
5353146.5
5353141.0
5353144.9
## 'Vorstollen' (azimuth N 90 ◦ E)
| | | UTM32N | UTM32N |
|--------------|----------------|-------------|--------------|
| location / m | cable | easting / m | northing / m |
| 297.6 | loose-tube | 450028.3 | 5353161.0 |
| 719.2 | tight-buffered | 450017.0 | 5353161.1 |
| 1587.2 | tight-buffered | 450023.4 | 5353161.1 |
| 2008.8 | loose-tube | 450022.0 | 5353161.1 |
## 'Anton Gang' (azimuth N 330 ◦ E) after 2023-02-07
UTM32N
location / m
124.0
1190.4
cable tight-buffered
tight-buffered easting / m
northing / m
450101.4
450098.5
5353141.4
5353146.2
1413.6
loose-tube
450102.4
5353139.7
## 'Vorstollen' (azimuth N 90 ◦ E) after 2023-02-07
UTM32N
location / m
223.2
1091.2
1512.8
2058.4
## 'Drum'
location / m
857.5
1150.0
cable tight-buffered
tight-buffered loose-tube
loose-tube easting / m
northing / m
450023.0
450017.4
450027.9
450019.3
cable tight-buffered, drum start
tight-buffered, drum center
1442.5
tight-buffered, drum end
## 'Drum' after 2023-02-07
location / m cable
367.5
660.0
952.5
tight-buffered, drum start tight-buffered, drum center
tight-buffered, drum end
5353161.1
5353161.1
5353161.0
5353161.1
## S2 Analyzed data
## S2.1 Earthquakes used in the analysis
Table S2 details the seismic events used in the analysis with the main source parameters, which are taken from the GEOFON catalog. From the GEOFON catalog (Quinteros et al., 2021) we find 84 earthquakes with moment magnitude larger than 6 in the recording time period. For 21 of them, we measure a maximum strain amplitude larger than 1 nstrain in a visual inspection of strainmeter data, which is considered large enough to provide a sufficient signal-to-noise ratio in the DAS data. For 19 of these events, DAS data is available and allows an analysis. The largest amplitudes are found in the surface wave train. For body waves, the horizontal strain amplitude decreases as the ray incidence becomes steeper.
The table details the backazimuth (BAZ) and epicentral distance ( ∆ ) that are given with respect to BFO (48 33 N, 8 33 E), as well as the maximum strain am-. ◦ . ◦ plitude associated with surface wave signals, A max. The latter is visually read from the strainmeter data and should be understood as a proxy of the actual maximum signal amplitude in the analysis.
## S2.2 Strain waveforms
In Figs. S3 to S25 we display waveforms of the analyzed data. All signals are consistently filtered with Butterworth high-pass (0.05 Hz, 4th order) and low-pass (0.1 Hz, 4th order) filters. Where STS-2 data is shown, the seismometer response is equalized to the response of the strain signals. Traces are shifted vertically for better visibility.
The DAS signals from the tight-buffered cable (green) and the loose-tube cable (blue) are taken with a gauge length of 50 m at a location in the center of the 'Anton Gang' and the 'Vorstollen', respectively (see Table S1 and Figs. S1 and S2). Linear strain in azimuth N330 E of 'Anton Gang' and azimuth N90 E of ◦ ◦ 'Vorstollen' is obtained from the BFO strainmeter array like explained in the main paper.
## S2.2.1 Surface wave signals
Figures S3 to S21 detail the surface wave signals of the 19 events used in the manuscript to compare the DAS recorded 'fiber strain' with the strainmeter recorded 'rock strain'. The figures focus on an ad-hoc waveform comparison of surface waves for linear strain in the direction of 'Anton Gang' (top) and 'Vorstollen' (bottom). Details about the analyzed frequency band, the event origin time and beam parameters are included in the caption.
## S2.2.2 Body wave signals
For the large amplitude signals of the two main shocks (Mw 7.7 and Mw 7.6) of the Kahramanmaras ¸ earthquake sequence, we also analyze the body wave signals. The body-wave signals of the Mw 7.7 Pazarcık earthquake are displayed for the 'Anton Gang' in Fig. S22 and in Fig. S23 for the 'Vorstollen'. The surface wave signals are shown in Fig. S6. The corresponding diagrams for the Mw 7.6 Ekin¨ oz¨ earthquake are shown in u Figs. S24, S25, and S5.
## S2.3 Reduction of coherent noise
The Febus A1-R recordings contain a significant component of coherent noise at frequencies below 0.5 Hz. Lindsey et al. (2020, their section 2.6 Optical Noise) attribute this type of noise to vibrations of the optoelectronic system.
Other studies use the average over all recorded channels to capture the coherent component of noise. This relies on the earthquake signal not being coherent (because of propagation delay and varying orientation of the fiber), such that it more or less cancels out in the average and the earthquake signal in a single channel is not deteriorated by subtracting the average over all channels.
We follow a different approach. The idea behind using the reference coil on the drum is, that this section of the fiber is sufficiently decoupled from the rock and hence does not pick up a signal of the teleseismic earthquakes. For this reason it can be subtracted without affecting the amplitude of the earthquake signal.
In Figs. S26 and S27 we demonstrate this with the recordings of the Mw 7.7 Pazarcık earthquake. This is the earthquake which produced the by far largest strain amplitudes in the set of analyzed earthquakes. Even for the large amplitude surface waves, no signature of the earthquake signal is present in the recording from the reference coil (center diagram in Fig. S27). If a fraction of the earthquake signal should be hidden in the coherent noise on the reference drum, its amplitude is reduced to below 1.5 per cent of the full signal.
The P-wave signal of the earthquake becomes only apparent after this type of correction is applied, as shown in Fig. S26.
## S2.4 Calibration of the strainmeters
The strainmeters operated at BFO are Invar-wire strainmeters of the design by King and Bilham (1976). Agnew (1986) and Z¨ urn (2012) discuss instruments of this type and their properties. These instruments are primarily designed to record very-long period signals, such as tidal strain or Earth's free oscillations. For the analysis of tidal strain amplitudes instrument calibration is of
utmost importance. The original calibration of the instruments was based on separate calibrations of several components, which then were put in series. In unfortunate cases the individual calibration inaccuracies added up constructively, which resulted in an unacceptable inaccuracy for the entire strainmeter.
For this reason an in-situ calibration mechanism for these instruments was developed at BFO, based on so-called 'Crapaudines', which provides an accuracy of about 2 per cent. They were originally used by Verbaandert (1959, 1962, 1963) in the calibration of tiltmeters. This application is described by Melchior (1966, pages 161 to 166), Melchior (1978, his section 8.8) and Agnew (1986, his section 4.1.5). Melchior (1966) calls them 'Expandable bearing plates of Verbaandert'. Agnew (1986) calls them 'distensible support of Verbaandert'. The 'Crapaudines' themselves are calibrated interferometrically (Verbaandert, 1959, 1962) and are used to impose a well defined motion on the fixed end of the wire in the strainmeter. The calibration factors of a few 'Crapaudines' used at BFO were confirmed by an independent interferometric measurement.
Because calibrations disturb the long-term tidal recordings, the stability of the calibration is occasionally tested by a comparison against theoretical tidal strain (Longman, 1959). This way we ensure a calibration accuracy and stability of about 5 per cent. Z¨ urn et al. (2015) documented an episode of unstable calibration during the 2011 T¯ ohoku earthquake and how this was resolved. They were able to obtain strain amplitudes for radial mode 0S0, which were consistent with Earth's radius and the observed radial surface motion within 15 per cent after the 2004 Sumatra-Andaman earthquake (their table 2).
The STR cannot be more accurate than the strainmeter calibration. The variation of STR between locations and cable type, however, cannot be due to limited calibration accuracy. This is because the differences exceed the level of 5 per cent and because the STR for the blue cable is larger in the 'Anton Gang' than in 'Vorstollen', while it is the opposite for the green cable, which cannot be caused by a calibration bias in principle.
## S2.5 Distortion of the strain field due to local heterogeneity
Strain measurements and tilt measurements both are affected by local heterogeneity, sometimes called 'cavity effects'. This was first reported by King and Bilham (1973) and Baker and Lennon (1973) for measurements of tidal tilt and limits the usefulness of tidal strain and tilt amplitudes in the investigation of Earth's elastic properties. These effects are strongest at free surfaces of the chambers (cavities) in which instruments are in- stalled and near the free surface of the Earth, which can have a significant topography. The free-surface condition lets components of the stress tensor vanish and this enforces specific linear combinations for the components of the deformation tensor through the stress-strain relation. Harrison (1976) investigated this by finiteelement modeling.
All strain measurements are affected by such strainstrain coupling. This applies to DAS recordings as well as to conventional strainmeters. In a more general sense the coupling issues between rock and fiber could also be summarized under these effects of local heterogeneity. Likewise particle motion is affected by free-surface conditions (Kennett, 1991). When comparing DAS recorded strain with signals from reference instruments, these effects generally could limit the usefulness of the observations, but are commonly ignored in the respective studies (except for cable coupling). The problem is even more critical, when comparing DAS recorded strain with particle motion recorded by seismometers, because the effect of the free surface on both is different and most likely the plane wave assumption (see section S4 'Plane wave strain from seismometer recordings') is violated in this way. If DAS recorded strain is compared to recordings of a strainmeter, as is done in the current study, a problem may arise from spatially varying strain-strain coupling, if instruments are installed at a distance from each other.
The 10 m long Invar-wire strainmeters show little cavity effects due to their installation in the center and along the symmetry axes of 60 m long tunnels. For the DAS cables the cavity effects in a more general sense are addressed as coupling issues controlled by installation and cable type.
Topography at BFO, however, alters the strain field as demonstrated by Emter and Z¨ urn (1985) with finite element simulations. In particular the strainmeter in azimuth N60 E experiences significant strain-strain cou-◦ pling through the local topography. Z¨ urn et al. (2015, their table S2 in the supporting material) list the strainstrain coupling coefficients derived from tidal analysis. Their analysis of the radial mode 0S0 (Z¨ urn et al., 2015, their table 2) suggests that not the same coupling might be at work for this type of straining. The factor 0.58 (for N60 E) given by Z¨ urn et al. (2015, their table S2 in the ◦ supporting material) for tidal analysis is consistent with the factor of 0.67 derived in a 2D finite element analysis by Emter and Z¨ urn (1985, their figure 5). For strain in the azimuth N90 E of the 'Vorstollen' we presumably ◦ observe part of this topography effect. The seismometer data systematically over-estimates the strain amplitude in this azimuth, as discussed in section S4.2 'Regression with respect to seismometer data'.
In the current experiment we use the Invar-wire strainmeter in a comparison with DAS data recorded at
a distance of about 350 m. If the strain-strain coupling would vary along this distance, it would contribute to the amplitude difference seen between DAS recordings and strainmeter recordings. The difference shown by Emter and Z¨ urn (1985, their Fig. 5), with strain amplitude increasing towards the tunnel entrance near the free surface, however, is opposite to the observed difference. Because the section of the 'Vorstollen', which is used in the current analysis, is at distance of about 200 m to the entrance the expected strain-strain coupling would be almost the same as for the strainmeters, according to Emter and Z¨ urn (1985, their Fig. 5).
For strain recordings with cemented fibers in the 'Vorstollen' Forbriger et al. (2024) recently found a STR of about 1 with respect to the strainmeters for four different IUs, independently. We take this as a confirmation that the DAS cable and the strainmeters experience the same topography-effect, indeed.
| gfz2022riez gfz2022oogo | | | | | | | | | | | | | | | | | | ID | ID |
|---------------------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|---------------------|-----------|-----------|
| | | | gfz2022sggk | | | | | gfz2022vpri | gfz2022wcnj | | | | | | gfz2023coos | | | | |
| | | | | | | | | | | | | | | | | | gfz2023dswx | | |
| | gfz2022rjqx | gfz2022rufw | | gfz2022shod | gfz2022skgc | gfz2022sovf | gfz2022uoko | | | gfz2022wpnl | gfz2022wvyo | gfz2022wxsg | gfz2023apzg | gfz2023cnwr | | gfz2023doqy | | | |
| | | | | | | | 6.78 | 6.08 | | | | | | | | | | | |
| 6.88 6.99 | 6.60 | 7.51 | 6.46 | 6.92 | 7.59 | 6.79 | | | 7.28 | 6.83 | 7.01 | 6.06 | 7.58 | 7.69 | 7.59 | 6.34 | 6.79 | Mw | Mw |
| | 2022-09-05 | 2022-09-10 | 2022-09-17 | 2022-09-18 | 2022-09-19 | 2022-09-22 | 2022-10-20 | 2022-11-04 | 2022-11-11 | 2022-11-18 | 2022-11-22 | 2022-11-23 | 2023-01-09 | 2023-02-06 | 2023-02-06 | 2023-02-20 | | origin | origin |
| | | | | | | | | | | | | | | | | | 2023-02-23 | | |
| 2022-09-04 2022-07-27 | | | | | | | | | | | | | | | | | | time | time |
| | | | | | | | | | | | | | | 01:17:34.97 | | | | | |
| | | | | | | | | | | 13:37:09.2 | | | | | | | | | |
| | | | | | | | | | | | 02:03:07.65 | | | | | | | | |
| 09:42:20.22 00:43:25.36 | 04:52:19.87 | 23:46:59.95 | 13:41:20.35 | 06:44:16.55 | 18:05:08.76 | 06:16:08.89 | 11:57:11.66 | | 10:48:48.57 | | | 01:08:16.89 | 17:47:35.03 | | 10:24:49.96 | | 00:37:39.01 | | |
| | | | | | | | | 10:02:51.02 | | | | | | | | 17:04:30.09 | | | |
| Central Luzon, | Sichuan, | Papua | Taiwan | Taiwan | Near | Michoacan, | South | Gulf | Tonga | | Solomon | Turkey | Banda | Turkey | | Turkey | | | |
| | | | | | | | | | | | | | | | | | | region | region |
| | | | | | | | | of | | | | | | | Turkey | | | | |
| | | New | | | Coast | | of | | | Southwest | | | Sea | | | | | | |
| | | | | | | | | | Islands | of | Islands | | | | | | | | |
| Mid-Atlantic Philippines | China | Guinea | | | of | | Panama | California | | | | | | | | | | | |
| | | Region | | | | Mexico | | | Region | | | | | | | | Tajikistan-Xinjiang | | |
| Ridge | | | | | Michoacan, | | | | | Sumatra, | | | | | | | | | |
| | 29 . - | | | | Mexico | | | | | Indonesia | | | | | | | Border | | |
| | | | 23 . | 23 . | 18 . | 18 | 7 . | 28 . | - 19 . | - 4 | | | | | | | Region | Region | Region |
| 17 | 0 | - . | 11 | 20 | 44 | | | | | | 40 - | | - 7 | 37 | 38 . | 36 | 38 | latitude | latitude |
| . 85 . 50 | 64 | 6 | | | | 33 ◦ | 66 . | 13 | 27 | . | 9 . | . | . 11 | . 23 | . 11 | | . | | |
| ◦ | ◦ | 25 | ◦ | ◦ | ◦ | | ◦ | ◦ | ◦ | 77 ◦ | 78 | 97 ◦ | ◦ | ◦ | ◦ | | 06 | | |
| N N | N ◦ | ◦ N | N | N | N | N | N | N | N | N | ◦ N | N | N | 11 ◦ N N | N | | ◦ N | | |
| - 21 . 120 . | 102 . | 146 . | 121 . | 121 | - 103 | - 102 | - 82 | - 112 | - 172 | 100 | 159 | 31 | 129 | 37 | 35 | | 73 | longitude | longitude |
| | | 48 | 29 | . | . | . 94 | . 32 | . 15 | . 38 | . 90 | . | . | . | . | 37 . | . 93 | . | | |
| 76 ◦ E 82 ◦ E | 16 ◦ E | ◦ E | ◦ E | 35 ◦ E | 01 ◦ E | ◦ E | ◦ E | ◦ E | E ◦ E | E ◦ | E 57 ◦ | E 05 ◦ | E 98 ◦ | 05 ◦ | 22 ◦ E | ◦ E | 29 ◦ E | | |
| 10.0 21.0 | | | | 10.0 | 20.0 | 15.0 | | | | | | | | | | | | / | / |
| | 10.0 | 100.0 | 10.0 | | | | 10.0 | 10.0 | 44.5 | 10.0 | 9.7 | 10.0 | 108.1 | 10.0 | 10.0 | 10.0 | km | depth | depth |
| | | | | | | | | | | | | | | | | 10.0 | | | |
| N217 . N61 . | N66 . | . | N57 . | N57 . | N298 . | N297 | N275 | N310 . | N1 | N91 | N41 | N106 . | N69 . | N107 | N105 | N110 | | | |
| 51 70 | 71 | | 93 | 83 | | . | . | | . | . | . | | | . | . | . | | BAZ | BAZ |
| | | N53 | | | | | | 50 | | | | | | | | N77 | | | |
| | ◦ | 88 | ◦ | | 02 | 89 | 73 | | 38 | 10 | 48 | 06 | 87 | 24 | . 26 | 83 | 24 | | |
| ◦ E ◦ E | E | E | E | ◦ E | ◦ E | ◦ E | ◦ E | ◦ E | ◦ E | ◦ E | ◦ E | ◦ | ◦ E | ◦ E | ◦ E | ◦ | ◦ E | | |
| | | ◦ | | | | | | | | | | E | | | | E | | | |
| 55 . 91 . | 70 . | 124 | 86 | 86 | | 89 | 84 | 86 | 150 | 95 | 134 | 17 | 115 | 23 | 23 . | 47 . | | ∆ | |
| 46 ◦ 06 ◦ | 75 | . 91 ◦ | . 92 ◦ | . 89 ◦ | 89 . 65 ◦ | . 69 ◦ | . 68 ◦ | . 94 ◦ | . 73 ◦ | ◦ | . 41 ◦ | . 92 | . 64 | 23 ◦ | 06 | | ◦ | ◦ | ◦ |
| | | | | | ◦ | | | | | . 16 | . 69 | | ◦ | . 24 | 63 ◦ | | | | A max |
| | ◦ | | | | | | | | | | | ◦ | | | | | 20.0 | | |
| | | | 2.0 | | 19.0 | 5.0 | 1.5 | 1.2 | 3.0 | | | | | 8.0 | | | | / nstrain | |
| | | 2.5 | | 10.0 | | | | | | | | 250.0 | 130.0 | | | | | | |
| 2.5 2.5 | 2.0 | | | | | 2.0 | | | | | 3.0 2.5 | 1.5 | | | | | | | |
33.3 minutes starting at 2023-02-23T00:54:19.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2023dswx Mw 6.79 Tajikistan-Xinjiang Border Region 2023-02-23T00:37:39.01 38.062°N 73.291°E 10.0 km dist: 47.059° BAZ: N 77.240°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz gfz2023dswx
seconds after 2023-02-23 00:54:19 UT
Figure S3: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 6.79 Tajikistan-Xinjiang Border Region 2023-02-23 00:37:39.01 UTC 38 06 N 73 29 E 10.0 km (BAZ=N77 24 E, . ◦ . ◦ . ◦ ∆ =47 06 ). Top: 'Anton Gang' . ◦ (N330 E), bottom: 'Vorstollen' (N90 E). ◦ ◦ DAS data are scaled (factors are given in the legend) to minimize the rms misfit with respect to the strainmeter waveform.
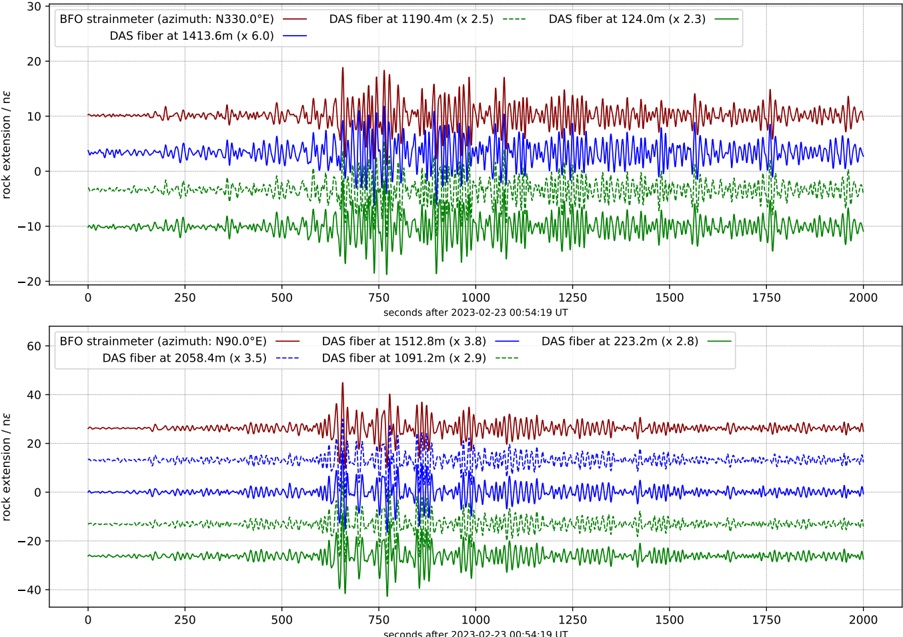
15.0 minutes starting at 2023-02-20T17:23:00.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2023doqy Mw 6.34 Turkey 2023-02-20T17:04:30.09 36.106°N 35.926°E 10.0 km dist: 23.633° BAZ: N110.829°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
Figure S4: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 6.34 Turkey 2023-02-20 17:04:30.09 UTC 36 11 N 35 93 E 10.0 km (BAZ=N110 83 E, . ◦ . ◦ . ◦ ∆ =23 63 ). . ◦ Top: 'Anton Gang' (N330 E), bot-◦ tom: 'Vorstollen' (N90 E). DAS data are scaled (factors are given in the legend) to minimize the rms misfit with ◦ respect to the strainmeter waveform.
25.0 minutes starting at 2023-02-06T10:33:09.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2023coos Mw 7.59 Turkey 2023-02-06T10:24:49.96 38.106°N 37.225°E 10.0 km dist: 23.241° BAZ: N105.263°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
seconds after 2023-02-06 10:33:09 UT
Figure S5: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 7.59 Turkey 2023-02-06 10:24:49.96 UTC 38 11 N 37 22 E 10.0 km (BAZ=N105 26 E, . ◦ . ◦ . ◦ ∆ =23 24 ). . ◦ Top: 'Anton Gang' (N330 E), bot-◦ tom: 'Vorstollen' (N90 E). DAS data are scaled (factors are given in the legend) to minimize the rms misfit with ◦ respect to the strainmeter waveform.
25.0 minutes starting at 2023-02-06T01:25:54.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2023cnwr Mw 7.69 Turkey 2023-02-06T01:17:34.97 37.233°N 37.046°E 10.0 km dist: 23.641° BAZ: N107.240°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
seconds after 2023-02-06 01:25:54 UT
Figure S6: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 7.69 Turkey 2023-02-06 01:17:34.97 UTC 37 23 N 37 05 E 10.0 km (BAZ=N107 24 E, . ◦ . ◦ . ◦ ∆ =23 64 ). . ◦ Top: 'Anton Gang' (N330 E), bot-◦ tom: 'Vorstollen' (N90 E). DAS data are scaled (factors are given in the legend) to minimize the rms misfit with ◦ respect to the strainmeter waveform.
41.7 minutes starting at 2023-01-09T18:45:55.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2023apzg Mw 7.58 Banda Sea 2023-01-09T17:47:35.03 -7.109°N 129.976°E 108.1 km dist: 115.917° BAZ: N 69.869°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
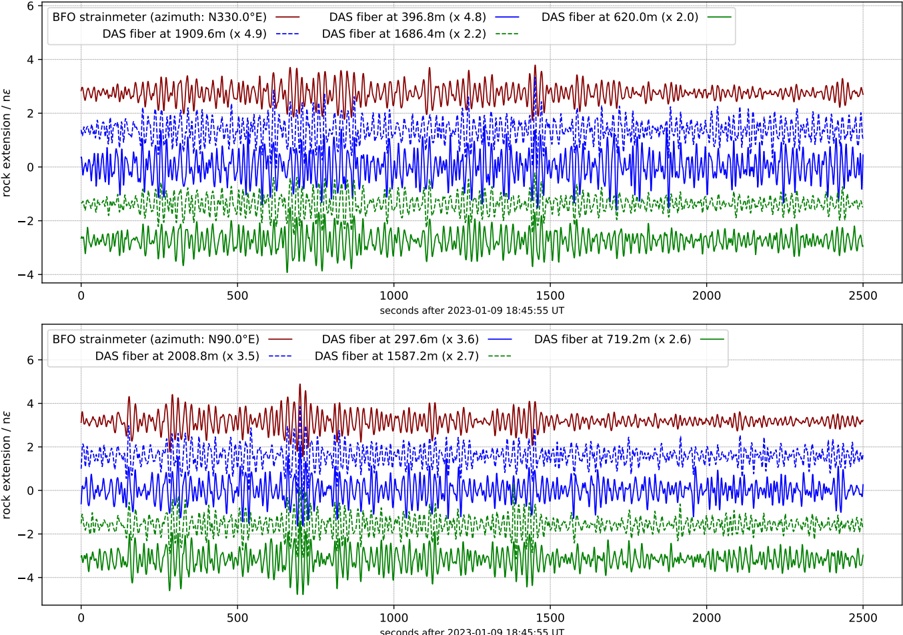
seconds after 2023-01-09 18:45:55 UT
Figure S7: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 7.58 Banda Sea 2023-01-09 17:47:35.03 UTC -7 11 N 129 98 E km km (BAZ=N69 87 E, . ◦ . ◦ . ◦ ∆ =115 92 ). Top: 'Anton Gang' (N330 E), bot-. ◦ ◦ tom: 'Vorstollen' (N90 E). DAS data are scaled (factors are given in the legend) to minimize the rms misfit with ◦ respect to the strainmeter waveform.
15.0 minutes starting at 2022-11-23T01:25:00.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022wxsg Mw 6.06 Turkey 2022-11-23T01:08:16.89 40.967°N 31.051°E 10.0 km dist: 17.693° BAZ: N106.064°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
Figure S8: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 6.06 Turkey 2022-11-23 01:08:16.89 UTC 40 97 N 31 05 E 10.0 km (BAZ=N106 06 E, . ◦ . ◦ . ◦ ∆ =17 69 ). . ◦ Top: 'Anton Gang' (N330 E), bot-◦ tom: 'Vorstollen' (N90 E). DAS data are scaled (factors are given in the legend) to minimize the rms misfit with ◦ respect to the strainmeter waveform.
13.7 minutes starting at 2022-11-22T03:09:47.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022wvyo Mw 7.01 Solomon Islands 2022-11-22T02:03:07.65 -9.783°N 159.572°E 9.7 km dist: 134.413° BAZ: N 41.484°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
Figure S9: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 7.01 Solomon Islands 2022-1122 02:03:07.65 UTC -9 78 N 159 57 E 9.7 km (BAZ=N41 48 E, . ◦ . ◦ . ◦ ∆ =134 41 ). . ◦ Top: 'Anton Gang' (N330 E), ◦ bottom: 'Vorstollen' (N90 E). ◦ DAS data are scaled (factors are given in the legend) to minimize the rms misfit with respect to the strainmeter waveform.
50.0 minutes starting at 2022-11-18T14:27:09.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022wpnl Mw 6.83 Southwest of Sumatra, Indonesia 2022-11-18T13:37:09.2 -4.772°N 100.899°E 10.0 km dist: 95.160° BAZ: N 91.102°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz gfz2022wpnl
seconds after 2022-11-18 14:27:09 UT
Figure S10: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 6.83 Southwest of Sumatra, Indonesia 2022-11-18 13:37:09.2 UTC -4 77 N 100 90 E 10.0 km (BAZ=N91 10 E, . ◦ . ◦ . ◦ ∆ =95 16 ). . ◦ Top: 'Anton Gang' (N330 E), bottom: 'Vorstollen' (N90 E). DAS data are scaled (factors are given in the legend) to minimize ◦ ◦ the rms misfit with respect to the strainmeter waveform.
38.3 minutes starting at 2022-11-11T11:58:48.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022wcnj Mw 7.28 Tonga Islands Region 2022-11-11T10:48:48.57 -19.269°N -172.385°E 44.5 km dist: 150.734° BAZ: N 1.376°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
Figure S11: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 7.28 Tonga Islands Region 2022-11-11 10:48:48.57 UTC -19 27 N . ◦ -172 38 E 44.5 km (BAZ=N1 38 E, . ◦ . ◦ ∆ =150 73 ). . ◦ Top: 'Anton Gang' (N330 E), bottom: 'Vorstollen' (N90 E). ◦ ◦ DAS data are scaled (factors are given in the legend) to minimize the rms misfit with respect to the strainmeter waveform.
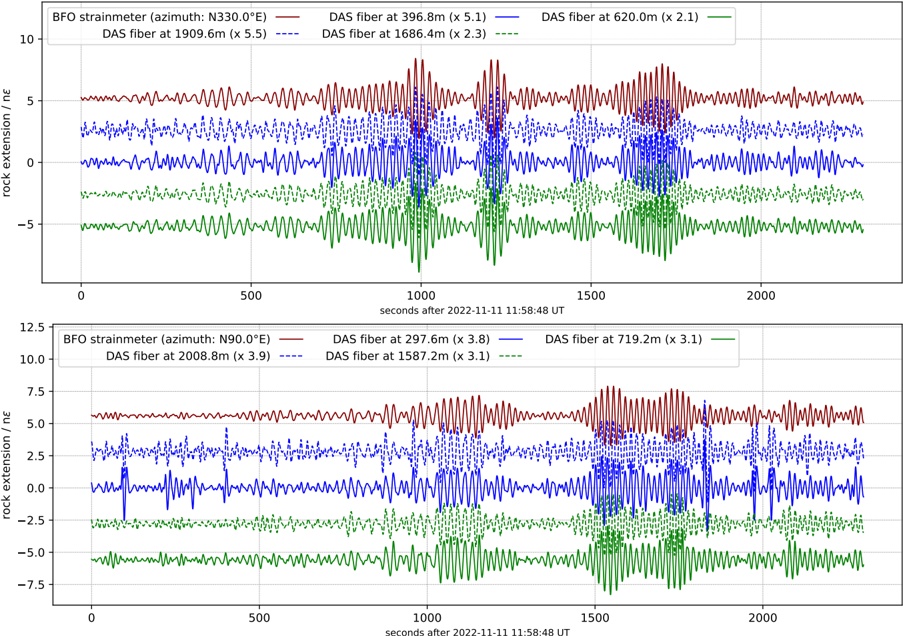
33.3 minutes starting at 2022-11-04T10:44:31.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022vpri Mw 6.08 Gulf of California 2022-11-04T10:02:51.02 28.129°N -112.155°E 10.0 km dist: 86.945° BAZ: N310.502°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
Figure S12: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 6.08 Gulf of California 2022-1104 10:02:51.02 UTC 28 13 N . ◦ -112 15 E 10.0 km (BAZ=N310 50 E, . ◦ . ◦ ∆ =86 94 ). Top: 'Anton Gang' (N330 E), . ◦ ◦ bottom: 'Vorstollen' (N90 E). ◦ DAS data are scaled (factors are given in the legend) to minimize the rms misfit with respect to the strainmeter waveform.
17.0 minutes starting at 2022-10-20T12:38:51.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022uoko Mw 6.78 South of Panama 2022-10-20T11:57:11.66 7.66°N -82.324°E 10.0 km dist: 84.681° BAZ: N275.725°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
seconds after 2022-10-20 12:38:51 UT
Figure S13: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 6.78 South of Panama 2022-1020 11:57:11.66 UTC 7 66 N . ◦ -82 32 E 10.0 km (BAZ=N275 73 E, . ◦ . ◦ ∆ =84 68 ). . ◦ Top: 'Anton Gang' (N330 E), ◦ bottom: 'Vorstollen' (N90 E). ◦ DAS data are scaled (factors are given in the legend) to minimize the rms misfit with respect to the strainmeter waveform.
26.0 minutes starting at 2022-09-22T07:05:00.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022sovf Mw 6.79 Michoacan, Mexico 2022-09-22T06:16:08.89 18.33°N -102.938°E 15.0 km dist: 89.692° BAZ: N297.891°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz gfz202
seconds after 2022-09-22 07:05:00 UT
Figure S14: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 6.79 Michoacan, Mexico 2022-0922 06:16:08.89 UTC 18 33 N . ◦ -102 94 E 15.0 km (BAZ=N297 89 E, . ◦ . ◦ ∆ =89 69 ). Top: 'Anton Gang' (N330 E), . ◦ ◦ bottom: 'Vorstollen' (N90 E). ◦ DAS data are scaled (factors are given in the legend) to minimize the rms misfit with respect to the strainmeter waveform.
45.0 minutes starting at 2022-09-19T18:46:48.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022skgc Mw 7.59 Near Coast of Michoacan, Mexico 2022-09-19T18:05:08.76 18.441°N -103.012°E 20.0 km dist: 89.649° BAZ: N298.015°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
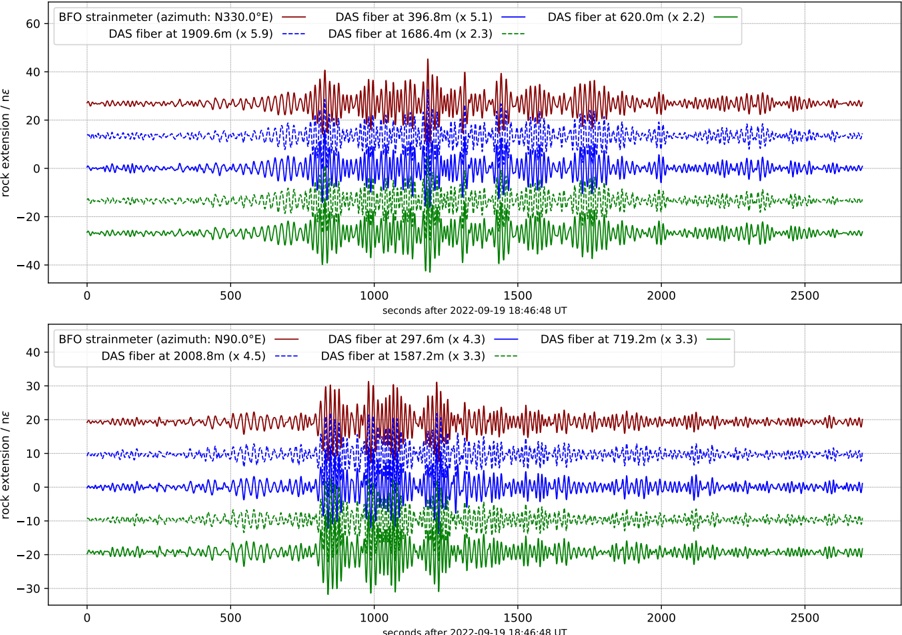
seconds after 2022-09-19 18:46:48 UT
Figure S15: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 7.59 Near Coast of Michoacan, Mexico 2022-09-19 18:05:08.76 UTC 18 44 N . ◦ -103 01 E 20.0 km (BAZ=N298 02 E, . ◦ . ◦ ∆ =89 65 ). Top: 'Anton . ◦ Gang' (N330 E), bottom: 'Vorstollen' (N90 E). DAS data are scaled (factors are given in the legend) to minimize ◦ ◦ the rms misfit with respect to the strainmeter waveform.
28.0 minutes starting at 2022-09-18T07:29:16.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022shod Mw 6.92 Taiwan 2022-09-18T06:44:16.55 23.201°N 121.349°E 10.0 km dist: 86.887° BAZ: N 57.832°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
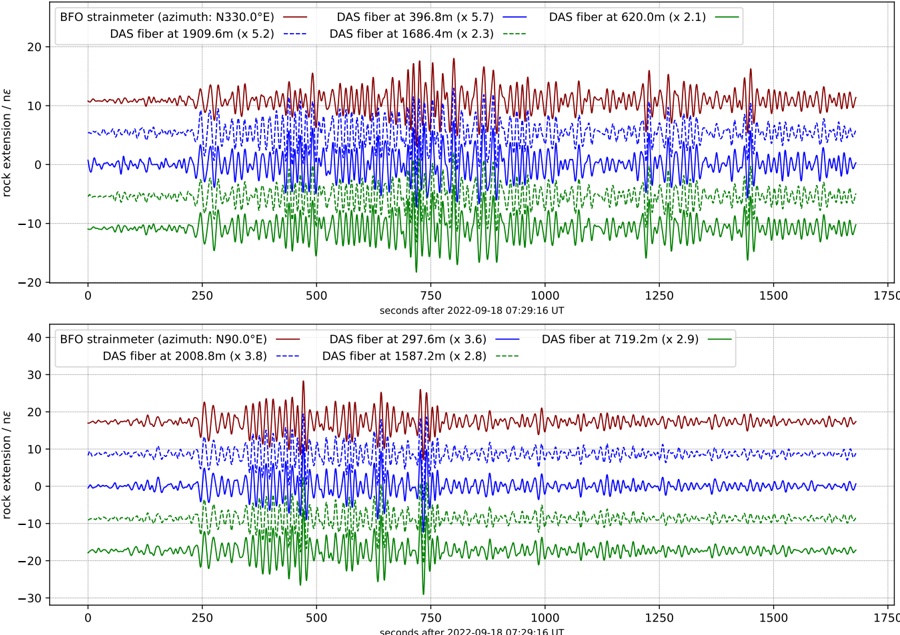
seconds after 2022-09-18 07:29:16 UT
Figure S16: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 6.92 Taiwan 2022-09-18 06:44:16.55 UTC 23 20 N 121 35 E 10.0 km (BAZ=N57 83 E, . ◦ . ◦ . ◦ ∆ =86 89 ). . ◦ Top: 'Anton Gang' (N330 E), bot-◦ tom: 'Vorstollen' (N90 E). DAS data are scaled (factors are given in the legend) to minimize the rms misfit with ◦ respect to the strainmeter waveform.
30.0 minutes starting at 2022-09-17T14:26:20.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022sggk Mw 6.46 Taiwan 2022-09-17T13:41:20.35 23.115°N 121.29°E 10.0 km dist: 86.922° BAZ: N 57.927°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
Figure S17: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 6.46 Taiwan 2022-09-17 13:41:20.35 UTC 23 11 N 121 29 E 10.0 km (BAZ=N57 93 E, . ◦ . ◦ . ◦ ∆ =86 92 ). . ◦ Top: 'Anton Gang' (N330 E), bot-◦ tom: 'Vorstollen' (N90 E). DAS data are scaled (factors are given in the legend) to minimize the rms misfit with ◦ respect to the strainmeter waveform.
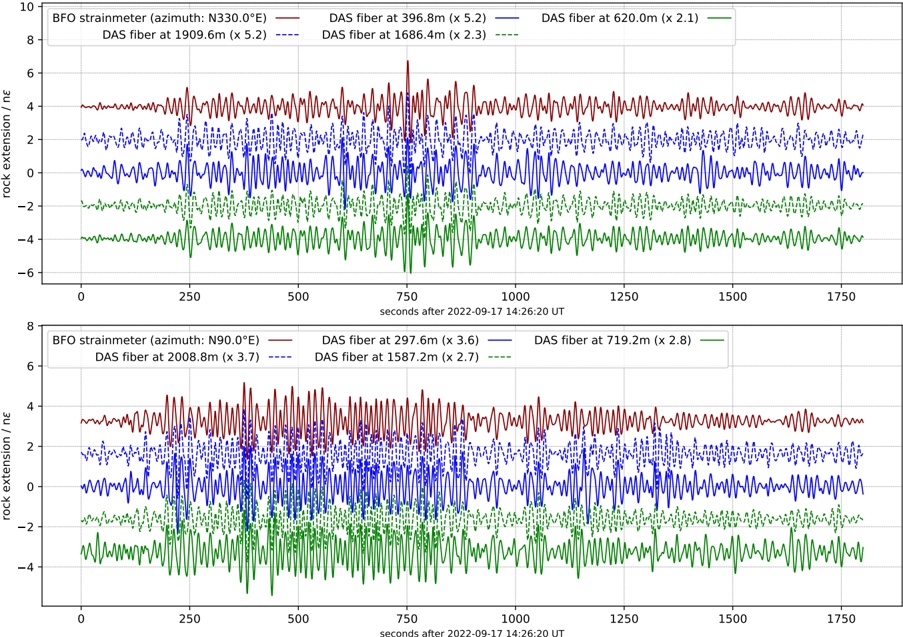
30.0 minutes starting at 2022-09-11T00:45:19.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022rufw Mw 7.51 Papua New Guinea Region 2022-09-10T23:46:59.95 -6.252°N 146.479°E 100.0 km dist: 124.913° BAZ: N 53.876°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz gfz2022ru
seconds after 2022-09-11 00:45:19 UT
Figure S18: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 7.51 Papua New Guinea Region 2022-09-10 23:46:59.95 UTC -6 25 N 146 48 E km km (BAZ=N53 88 E, . ◦ . ◦ . ◦ ∆ =124 91 ). . ◦ Top: 'Anton Gang' (N330 E), bottom: 'Vorstollen' (N90 E). ◦ ◦ DAS data are scaled (factors are given in the legend) to minimize the rms misfit with respect to the strainmeter waveform.
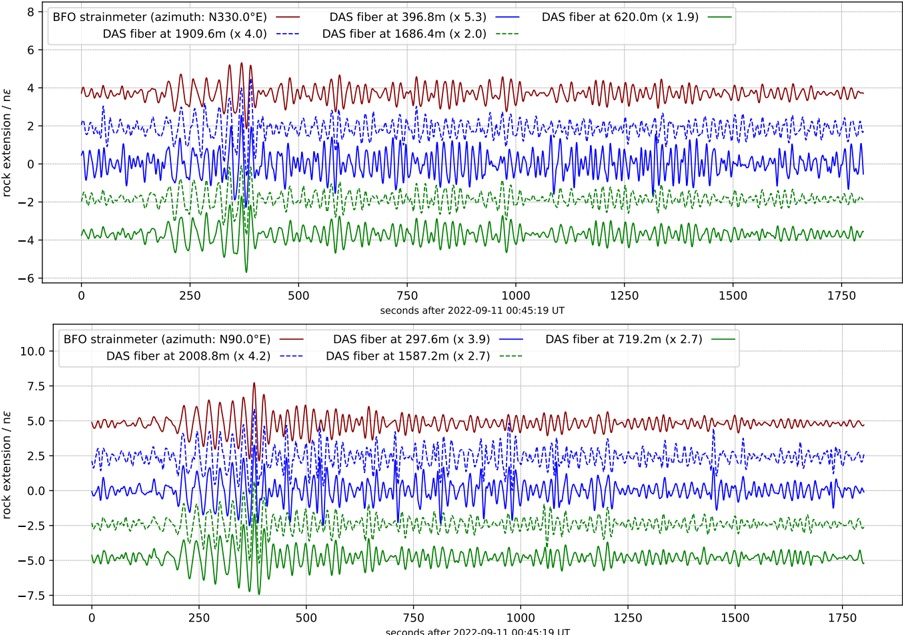
40.0 minutes starting at 2022-09-05T05:25:39.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022rjqx Mw 6.6 Sichuan, China 2022-09-05T04:52:19.87 29.641°N 102.164°E 10.0 km dist: 70.753° BAZ: N 66.706°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
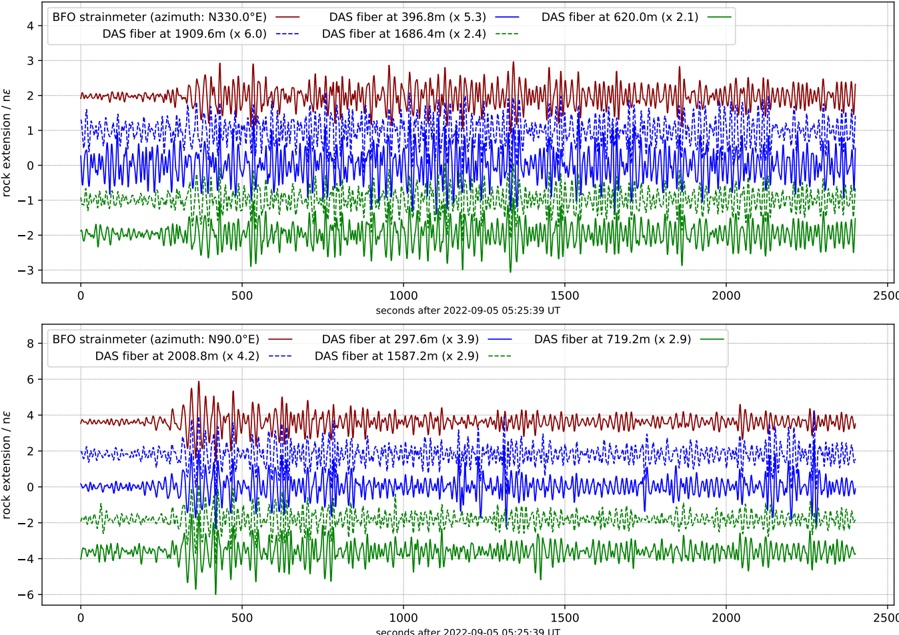
seconds after 2022-09-05 05:25:39 UT
Figure S19: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 6.60 Sichuan, China 2022-0905 04:52:19.87 UTC 29 64 N 102 16 E 10.0 km (BAZ=N66 71 E, . ◦ . ◦ . ◦ ∆ =70 75 ). . ◦ Top: 'Anton Gang' (N330 E), ◦ bottom: 'Vorstollen' (N90 E). ◦ DAS data are scaled (factors are given in the legend) to minimize the rms misfit with respect to the strainmeter waveform.
30.0 minutes starting at 2022-09-04T10:20:40.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022riez Mw 6.88 Central Mid-Atlantic Ridge 2022-09-04T09:42:20.22 -0.845°N -21.76°E 10.0 km dist: 55.460° BAZ: N217.509°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz gfz2022r
seconds after 2022-09-04 10:20:40 UT
Figure S20: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 6.88 Central Mid-Atlantic Ridge 2022-09-04 09:42:20.22 UTC -0 85 N . ◦ -21 76 E 10.0 km (BAZ=N217 51 E, . ◦ . ◦ ∆ =55 46 ). . ◦ Top: 'Anton Gang' (N330 E), bottom: 'Vorstollen' (N90 E). ◦ ◦ DAS data are scaled (factors are given in the legend) to minimize the rms misfit with respect to the strainmeter waveform.
30.0 minutes starting at 2022-07-27T01:33:25.000000Z
strainazimuth: N 330.0°E factors adjusted gfz2022oogo Mw 6.99 Luzon, Philippines 2022-07-27T00:43:25.36 17.505°N 120.82°E 21.0 km dist: 91.056° BAZ: N 61.700°E
filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
seconds after 2022-07-27 01:33:25 UT
Figure S21: Surface wave data in the frequency band 0.05 Hz to 0.1 Hz for Mw 6.99 Luzon, Philippines 202207-27 00:43:25.36 UTC 17 50 N 120 82 E 21.0 km (BAZ=N61 70 E, . ◦ . ◦ . ◦ ∆ =91 06 ). Top: 'Anton Gang' (N330 E), . ◦ ◦ bottom: 'Vorstollen' (N90 E). ◦ DAS data are scaled (factors are given in the legend) to minimize the rms misfit with respect to the strainmeter waveform.
Turkey Mw 7.7 2023-02-06 01:17:34.9 UTC, 37.05°E 37.23°N, 10 km filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
receiver location: Anton Gang (sandbags)
Figure S22: Strain waveforms as recorded for the azimuth (N330 E) of the 'Anton Gang' for the first of the main ◦ shocks of the Kahramanmaras ¸ earthquakes: Mw 7.69 Turkey 2023-02-06 01:17:34.97 UTC 37 23 N 37 05 E . ◦ . ◦ 10.0 km (BAZ=N107 24 E, . ◦ ∆ =23 64 ). . ◦ Top: P-waves, bottom: P- and S-waves. First arrival times according to raytracing (obspy.taup.TauPyModel) with IASP91 are: P: 2023-02-06 01:22:46.44 UT and S: 2023-0206 01:27:22.57 UT. P-waves arrive with a minimum slowness of 82 3mskm . -1 and a maximum slowness of 94 2mskm . -1 . The value range for the S-waves is 146 0mskm . -1 to 214 5mskm . -1 . The seismometer data are scaled by Eq. (S6). A band-pass from 0.05 Hz to 0.1 Hz is applied to all signals. The seismometer data was equalized to this filter response.
Turkey Mw 7.7 2023-02-06 01:17:34.9 UTC, 37.05°E 37.23°N, 10 km filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
receiver location: Vorstollen
Figure S23: Strain waveforms as recorded for the azimuth (N90 E) of the 'Vorstollen' for the first of the main ◦ shocks of the Kahramanmaras ¸ earthquakes: Mw 7.69 Turkey 2023-02-06 01:17:34.97 UTC 37 23 N 37 05 E . ◦ . ◦ 10.0 km (BAZ=N107 24 E, . ◦ ∆ =23 64 ). . ◦ Top: P-waves, bottom: P- and S-waves. First arrival times according to raytracing (obspy.taup.TauPyModel) with IASP91 are: P: 2023-02-06 01:22:46.44 UT and S: 2023-0206 01:27:22.57 UT. P-waves arrive with a minimum slowness of 82 3mskm . -1 and a maximum slowness of 94 2mskm . -1 . The value range for the S-waves is 146 0mskm . -1 to 214 5mskm . -1 . The seismometer data are scaled by Eq. (S6). A band-pass from 0.05 Hz to 0.1 Hz is applied to all signals. The seismometer data was equalized to this filter response.
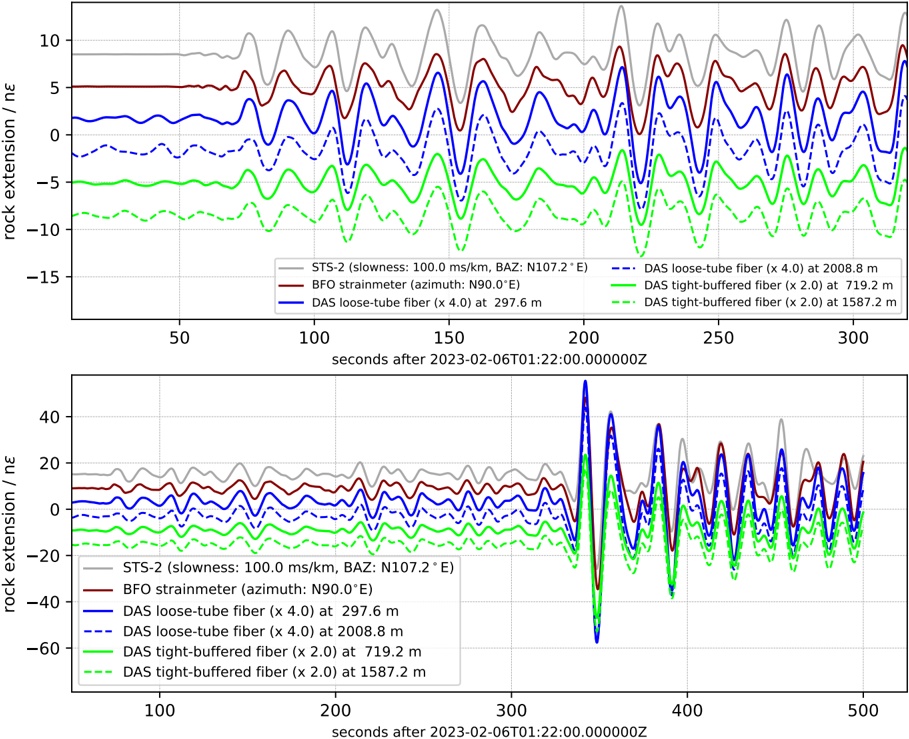
Turkey Mw 7.6 2023-02-06 10:24:49.9 UTC, 37.23°E 38.11°N, 10 km filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
receiver location: Anton Gang (sandbags)
Figure S24: Strain waveforms as recorded for the azimuth (N330 E) of the 'Anton Gang' for the first of the main ◦ shocks of the Kahramanmaras ¸ earthquakes: Mw 7.59 Turkey 2023-02-06 10:24:49.96 UTC 38 11 N 37 22 E . ◦ . ◦ 10.0 km (BAZ=N105 26 E, . ◦ ∆ =23 24 ). . ◦ Top: P-waves, bottom: P- and S-waves. First arrival times according to raytracing (obspy.taup.TauPyModel) with IASP91 are: P: 2023-02-06 10:29:57.35 UT and S: 2023-0206 10:34:27.98 UT. P-waves arrive with a minimum slowness of 82 4mskm . -1 and a maximum slowness of 94 7mskm . -1 . The value range for the S-waves is 146 7mskm . -1 to 214 7mskm . -1 . The seismometer data are scaled by Eq. (S6). A band-pass from 0.05 Hz to 0.1 Hz is applied to all signals. The seismometer data was equalized to this filter response.
Turkey Mw 7.6 2023-02-06 10:24:49.9 UTC, 37.23°E 38.11°N, 10 km filters: BW HP at 0.050 Hz BW LP at 0.100 Hz
receiver location: Vorstollen
Figure S25: Strain waveforms as recorded for the azimuth (N90 E) of the 'Vorstollen' for the first of the main ◦ shocks of the Kahramanmaras ¸ earthquakes: Mw 7.59 Turkey 2023-02-06 10:24:49.96 UTC 38 11 N 37 22 E . ◦ . ◦ 10.0 km (BAZ=N105 26 E, . ◦ ∆ =23 24 ). . ◦ Top: P-waves, bottom: P- and S-waves. First arrival times according to raytracing (obspy.taup.TauPyModel) with IASP91 are: P: 2023-02-06 10:29:57.35 UT and S: 2023-0206 10:34:27.98 UT. P-waves arrive with a minimum slowness of 82 4mskm . -1 and a maximum slowness of 94 7mskm . -1 . The value range for the S-waves is 146 7mskm . -1 to 214 7mskm . -1 . The seismometer data are scaled by Eq. (S6). A band-pass from 0.05 Hz to 0.1 Hz is applied to all signals. The seismometer data was equalized to this filter response.
Turkey Mw7.7 bandpass: 0.050 Hz - 0.100 Hz; scaled to 5.000 m/nstrain seconds after 2023-02-06T01:22:00.000000Z
Figure S26: Demonstration of the reduction of coherent (common-mode) noise. The P-waves from the Mw 7.7 Pazarcık earthquake arrive in the displayed time window. All signals are filtered to the frequency band of 0.05 Hz to 0.1 Hz and are scaled to the same 5 m/nstrain. Top: recorded waveforms for channels between 570 m and 670 m. Center: recorded waveforms for channels between 1000 m and 1100 m (on the reference drum). Bottom: recorded waveforms for channels between 570 m and 670 m after the average of the recorded waveforms between 1000 m and 1100 m has been removed. The channel at 620 m is one of the two channels from the tight-buffered cable in the 'Anton Gang'.
Only after subtracting the signal from the reference coil, the P-wave arrival (at 70 s on the time scale) becomes apparent.
Turkey Mw7.7 bandpass: 0.050 Hz - 0.100 Hz; scaled to 5.000 m/nstrain seconds after 2023-02-06T01:22:00.000000Z
Figure S27: Demonstration of the reduction of coherent (common-mode) noise. The wave-train (including P-, S-, and surface waves) of the Mw 7.7 Pazarcık earthquake arrives in the displayed time window. All signals are filtered to the frequency band of 0.05 Hz to 0.1 Hz and are scaled to the same 5 m/nstrain, while the total axes range differs for the three panels. Top: recorded waveforms for channels between 570 m and 670 m. Center: recorded waveforms for channels between 1000 m and 1100 m (on the reference drum). Bottom: recorded waveforms for channels between 570 m and 670 m after the average of the recorded waveforms between 1000 m and 1100 m has been removed. The channel at 620 m is one of the two channels from the tight-buffered cable in the 'Anton Gang'. The surface waves of the Mw 7.7 Pazarcık earthquake are the largest amplitude strain signals in the entire analyzed data. No signature of this earthquake signal, which has a signal-to-noise ratio of about 60 with respect to the coherent noise in the raw recording shown in the top panel, is apparent in the recording from the reference drum.
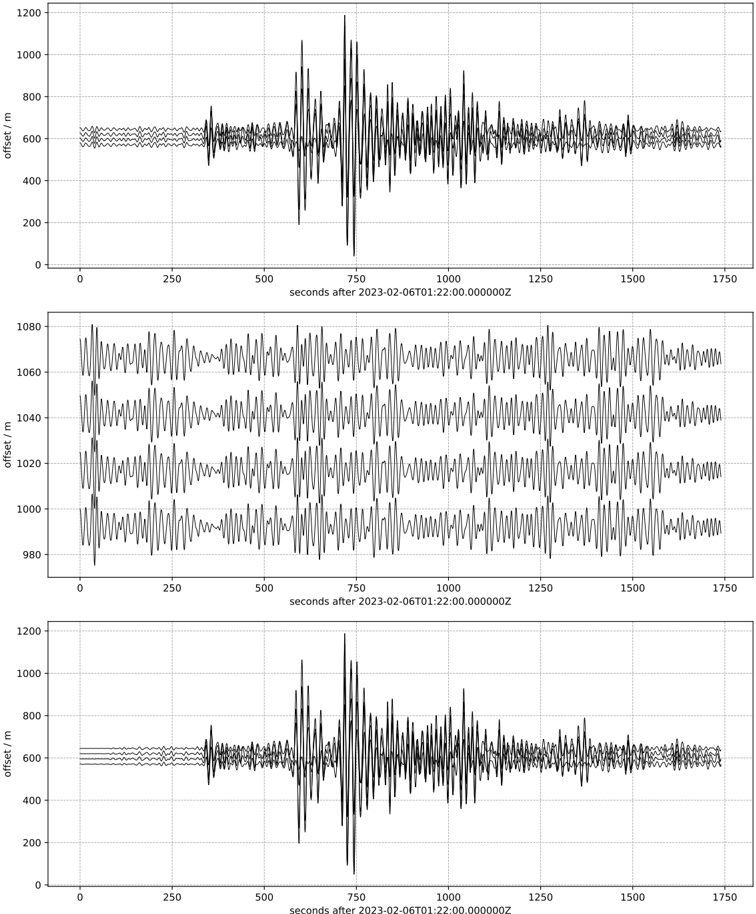
## S3 Additional diagrams to complement the main results
Here we present some additional diagrams to support the main findings of the study. In Fig. S28 'strain transfer rate' (STR) is plotted against the backazimuth (BAZ) of the respective event. We observe no significant correlation between both parameters. Fig. S29 shows STRs against NCCs. We find no correlation either. These results highlight that the STRs predominantly depends on cable type and installation conditions.
For the main shocks (Mw 7.7 and Mw 7.6) of the Kahramanmaras ¸ earthquake sequence on February 6th 2023, we analyze the body waves in addition to the surface waves. Fig. S30 shows STRs and Fig. S31 displays NCCs. For these large amplitude signals, we observe large signal-to-noise ratio, which implies a high waveform similarity. Hence, the NCCs generally are larger than 0.92 and are largest ( > . 0 99) for the surface wave signals recorded in the 'Anton Gang' with the tightbuffered cable.
The 'strain transfer rate' is not correlated to the normalized correlation coefficient, like shown in Fig. S29, because smaller values of NCC are due to noise in the
DAS data, not in the strainmeter data. In this study, we fit strainmeter against DAS data in order to determine the STR. This approach provides reasonable STR, even for heavily disturbed DAS data. This is particularly the case in the 'V orstollen', with the loose-tube cable, for which NCC are globally small. Among the 19 events, illustrative examples of the situation are shown in Figs. S12, S8, S9, and S13 (bottom panels),
In the linear regression the noise in the regressor causes a bias for the regression coefficients to smaller values. If we use the DAS data as regressors in fitting the DAS waveform to the strainmeter data, we find a correlation of the regression coefficients with the NCC, which is demonstrated in Fig. S32. The signal-to-noise ratio for the strainmeter data is much better in all cases, such that no bias is found in Fig. S29, where the strainmeter data is used as regressor.
Fig. S33 displays a plot of NCC against the maximum strain amplitude. We observe a clear trend where smaller strain amplitudes are associated with lower NCC values. For smaller strain amplitudes the noise in the DAS data takes a larger fraction of the signal energy. The effect is stronger for the loose-tube cable than for the tight-buffered cable and is strongest in the 'Vorstollen', where cables are not embedded in sand.
compare seismometer and strainmeter factors compare seismometer and strainmeter factors
Figure S28: 'strain transfer rate' (regression coefficients for fitting strainmeter data to the DAS data) plotted against the backazimuth. Results for both cables (left: tight-buffered, right: loose-tube) and both locations (top: 'Anton Gang', bottom: 'Vorstollen') are displayed.
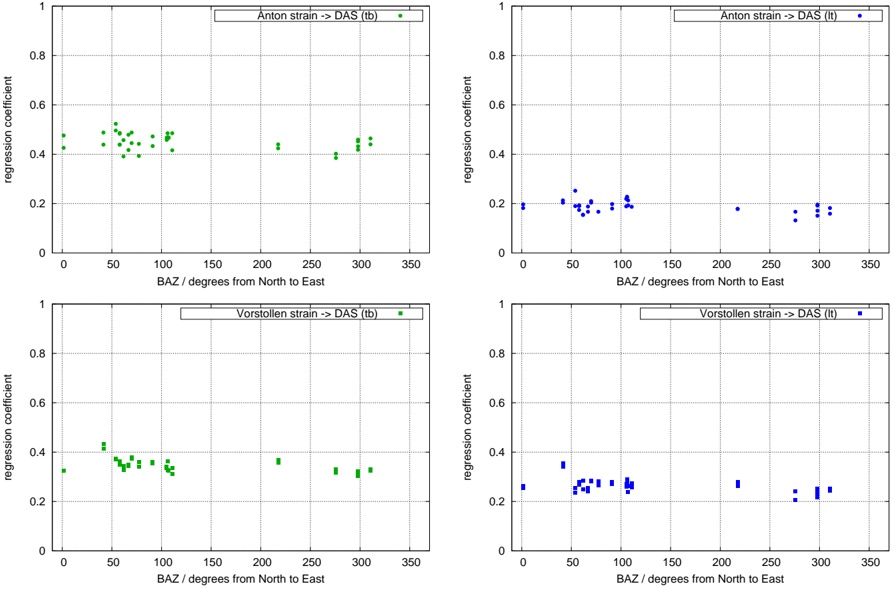
DAS calibration using surface waves wrt strainmeter
Figure S29: Measured 'strain transfer rate' plotted against the normalized correlation coefficient for each of the 19 events studied in the analysis. The analysis focuses on surface waves and on the comparison between linear strain recorded by the DAS and strainmeter in a given azimuth. The measurements are carried out on sensing points situated along the 'Anton Gang' (crosses) and 'Vorstollen' (circles) and in loose-tube (blue) and tight-buffered (green) cables.
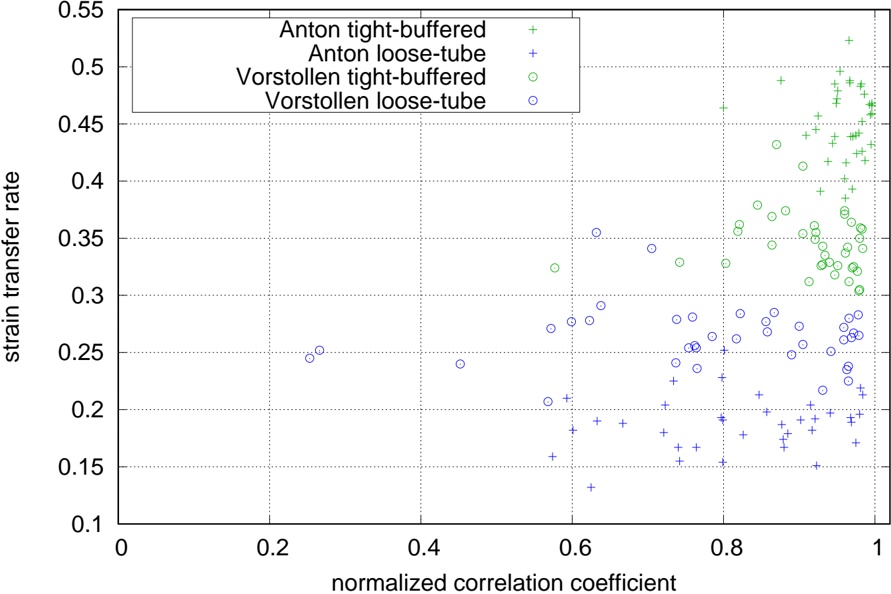
DAS calibration using P, S, and surface waves wrt strainmeter
Turkey 2023-02-06 events Mw 7.6 and Mw 7.7
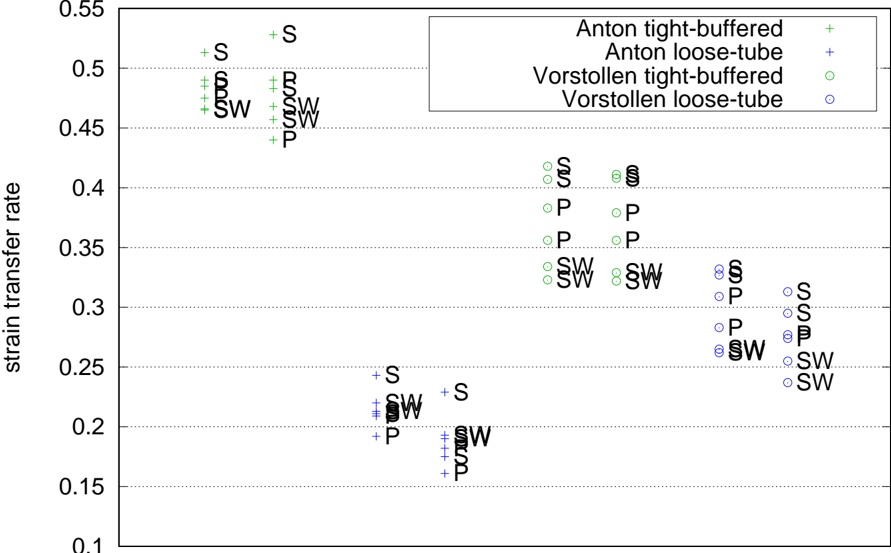
0.1
Figure S30: Measured 'strain transfer rate' for the main shocks (Mw 7.7 and Mw 7.6) of the Kahramanmaras ¸ earthquake sequence on February 6th 2023. The analysis focuses on P, S and surface waves (SW), on the comparison between linear strain recorded by the strainmeter versus the DAS, in a given azimuth. For each phase, the measurements are carried out on sensing points situated along the 'Anton Gang' (crosses) and 'Vorstollen' (circles) and in loose-tube (blue) and tight-buffered (green) cables. The corresponding phases are indicated near the data points.
DAS calibration using P, S, and surface waves wrt strainmeter
Turkey 2023-02-06 events Mw 7.6 and Mw 7.7
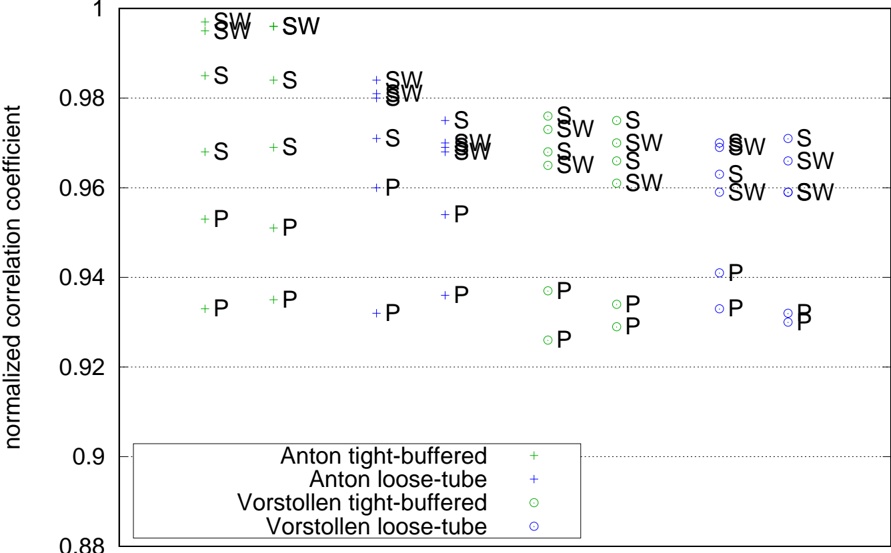
0.88
Figure S31: Normalized correlation coefficients for the main shocks (Mw 7.7 and Mw 7.6) of the Kahramanmaras ¸ earthquake sequence on February 6th 2023. The analysis focuses on P, S and surface waves (SW), on the comparison between linear strain recorded by the strainmeter versus the DAS, in a given azimuth. For each phase, the measurements are carried out on sensing points situated along the 'Anton Gang' (crosses) and 'Vorstollen' (circles) and in loose-tube (blue) and tight-buffered (green) cables. The corresponding phases are indicated near the data points.
DAS calibration using surface waves wrt strainmeter
Figure S32: Regression coefficient for fitting DAS data to strainmeter waveforms plotted against the normalized correlation coefficient for each of the 19 events studied in the analysis. The analysis focuses on surface waves and on the comparison between linear strain recorded by the DAS and strainmeter in a given azimuth. The measurements are carried out on sensing points situated along the 'Anton Gang' (crosses) and 'Vorstollen' (circles) and in loose-tube (blue) and tight-buffered (green) cables.
DAS calibration using surface waves wrt strainmeter
maximum amplitude / nstrain
Figure S33: Normalized correlation coefficient plotted against the maximum signal amplitude for each of the 19 events studied in the analysis. The values of maximum amplitude are those in listed in Table S2 and are given per event and not per actual time series and should be understood as a proxy for the actual signal amplitude. The analysis focuses on surface waves and on the comparison between linear strain recorded by the DAS and strainmeter in a given azimuth. The measurements are carried out on sensing points situated along the 'Anton Gang' (crosses) and 'Vorstollen' (circles) and in loose-tube (blue) and tight-buffered (green) cables.
## S4 Plane wave strain from seismometer recordings
In this study, we fit waveforms of 'rock strain' recorded by the array of Invar-wire strainmeters at BFO (Z¨ urn et al., 2015) to 'fiber strain' recorded by DAS. The regression coefficient is the 'strain transfer rate' (STR), a measure of how much of the strain amplitude is picked up by the DAS fibers. Strainmeters are rare installations and in the absence of these types of sensors studies of DAS recorded strain occasionally compare the signals with strain simulated from particle velocity recorded by seismometers, or convert DAS signals to equivalent particle velocity recordings. This conversion is possible in cases where the waveform represents a plane wave of known phase velocity and azimuth of propagation.
In section S4.1 'Scaling rule for plane waves' we summarize the theory behind this conversion. The final conversion rule is given by Eq. (S6) and is valid for a single, non-dispersive plane wave.
When using surface wave-data, which provide superior signal-to-noise ratio because of their large amplitudes (compared to body-wave signals) the limitations of the plane-wave approximation become significant. The surface waves are dispersive and do not propagate with a single phase-velocity and Love- and Rayleigh-waves are inseparably superimposed. Due to their propagation along the surface of the heterogeneous Earth's crust, they have non-plane character and contain significant components, which do not propagate along the backazimuth (BAZ) great circle. These limitation become most obvious for BAZ being perpendicular to the azimuth of measured linear strain. The plane wave does not strain the material perpendicular to the direction of propagation and the value of the cosine in Eq. (7) necessarily vanishes. The recorded signals then entirely are composed by the non-plane components of the wave, not propagating along the BAZ great circle. The problem becomes already apparent for BAZ being close to perpendicular to strain azimuth. The seismometer recorded particle velocity contains as well these nonplane components, which are at variance with the expected polarization of the plane wave. Thus the scaling in Eq. (S6) is not valid for them. We discuss the consequences of this on the regression coefficients in section S4.2 'Regression with respect to seismometer data'. In section S4.3 'Comparison of seismometer and strainmeter data' we discuss a direct comparison of strainmeter and seismometer data.
## S4.1 Scaling rule for plane waves
For signals of single non-dispersive plane waves, strain can be simulated from particle velocity recorded by a seismometer. Consider that ground deformation is due to a non-dispersive plane wave, then particle displacement at location ⃗ r and time t is
$$\vec { u } ( \vec { r }, t ) = \vec { U } \, f ( \vec { s } \vec { r } - t ), \text{ \quad \ \ } ( S 1 )$$
where ⃗ s is the slowness-vector of the plane wave, ⃗ U defines the polarization and f ( ) t is the shape of the wave (d'Alembert's solution to the wave equation), which propagates in direction of the slowness vector.
The linear strain in x -direction for this wave is
$$\mathfrak { f } _ { \mathfrak { z } } \quad \varepsilon _ { x x } ( \vec { r }, t ) = \frac { \mathrm d } { \mathrm d x } \, u _ { x } ( \vec { r }, t ) = U _ { x } s _ { x } f ^ { \prime } ( \vec { s } \vec { r } - t ), \quad ( \mathbf S 2 )$$
where f ′ ( ) t is the derivative of f ( ) t with respect to t and ux , sx , and Ux are the x -components of the slowness vector ⃗ s , of ⃗ u , and of ⃗ U , respectively. Likewise the x -component of particle velocity is
$$v _ { x } ( \vec { r }, t ) = \frac { \mathrm d } { \mathrm d t } \, u _ { x } ( \vec { r }, t ) = - U _ { x } f ^ { \prime } ( \vec { s } \vec { r } - t ). \quad ( \mathrm S 3 )$$
Hence
$$\frac { \epsilon _ { x x } ( \vec { r }, t ) } { v _ { x } ( \vec { r }, t ) } = - s _ { x }. \text{ \quad \quad \ \ } ( S 4 )$$
If the x -direction is the horizontal direction along the 'Anton Gang' or the 'Vorstollen', given by azimuth ψ x and sh is the horizontal component of the plane wave slowness for propagation in a 1D structure, as can be derived by ray-tracing, then
$$s _ { x } = s _ { h } \cos \left ( \psi _ { \text{BAZ} } - \psi _ { x } - 1 8 0 ^ { \circ } \right ), \quad \text{(S5)}$$
where ψ BAZ is the backazimuth of the source. In this way we estimate the linear strain in x -direction
$$\underset { \text{long} } { \text{dic} } \quad \varepsilon _ { x x } ( \vec { r }, t ) = - s _ { h } \cos \left ( \psi _ { \text{BAZ} } - \psi _ { x } - 1 8 0 ^ { \circ } \right ) v _ { x } ( \vec { r }, t ) \ \ ( S 6 )$$
from the particle velocity vx ( ⃗, r t ) as recorded by the broad-band seismometer.
## S4.2 Regression with respect to seismometer data
Fig. S34 compares the regression coefficients measured by fitting strainmeter signals to DAS signals (filled symbols), with those obtained by fitting scaled seismometer data to DAS signals (open symbols). The seismometer data is scaled according to Eq. (S6) to represent linear strain in the direction of the DAS fiber in cases where the waves propagate along the BAZ great circle with phase slowness sh = 280mskm -1 . This value corresponds to phase velocity of 3 57kms . -1 , which is the value for Rayleigh waves at 0.05 Hz (the lower end of the investigated frequency band) as shown for Southern Germany by Friederich and Huang (1996). Lovewaves propagate with a higher phase velocity. For both wave types phase velocity decreases with increasing frequency, such that the chosen value lies within the range to be expected in the observed wave trains.
The regression coefficients obtained by fitting the strainmeter waveform against the DAS waveform are the STRs, as displayed in Fig. S28. They are reproduced for reference. The regression coefficients for fitting the scaled seismometer waveform against the DAS waveform show a considerably stronger scatter, not only for cases where BAZ is close to perpendicular to the strain azimuth.
Cases where BAZ is close to N60 E or N240 E have ◦ ◦ a great-circle propagation direction almost perpendicular to the azimuth of the 'Anton Gang' (N330 E). ◦ For the Vorstollen (N90 ◦ E), the same applies when BAZ is close to N0 E or N180 E. ◦ ◦ Most of these cases are illustrated in Fig. S34. The coefficients are significantly outside reasonable limits, with some even being negative. The scatter is more substantial for the 'Anton Gang', where we find several cases with BAZ almost perpendicular to the strain azimuth. For the 'Vorstollen' the study includes one case with BAZ near N0 E, but ◦ none with BAZ near N180 E. In consequence the over-◦ all scatter is less strong.
For data from the 'Vorstollen' we also observe a systematic shift between coefficients obtained for regression with respect to strainmeter data compared to regression with respect to seismometer data. The seismometer data appears to over-estimate the strain amplitude, such that it has to be downscaled by a factor of about 0.5 with respect to the coefficients obtained with the strainmeter data. The P-wave signals in Figs. S23 and S25 show an amplitude mismatch of a similar size. This might be a consequence of strain-strain coupling due to the local topography as discussed in section S2.5 'Distortion of the strain field due to local heterogeneity'. The East-West strain measured by the strainmeters as well as by the DAS fibers in the 'Vorstollen' is reduced compared to what is estimated from particle velocity (seismometer data). From tidal analysis Z¨ urn et al. (2015, their table S2 in the supporting material) estimate a factor of 0.58 for N60 ◦ E and Emter and Z¨ urn (1985, their figure 5) derive a factor of 0.67 by a 2D finite element analysis. Both are in the order of magnitude of the bias seen in Fig. S34 for the 'Vorstollen'.
Apart from these amplitude related issues, the DAS waveforms also show greater similarity to the strainmeter waveforms than to the seismometer waveforms. This is shown in Fig. S35, where the values of NCCs are plotted against backazimuth. The NCC measured by comparing DAS data with respect to seismometer data are generally smaller than for DAS with respect to the strainmeter data. For BAZ nearly perpendicular to the fiber optic cable azimuth, some of the signals are even anti-correlated (Fig. S35). This results from the change in the sign of the cosine in Eq. (S6).
The dissimilarity is attributed to the non-plane components of the waves, rather than to instrumental noise or signal-to-noise ratio (SNR) issues. Both the strainmeter and seismometer data exhibit significantly better SNR than the DAS data, with the seismometer having the highest SNR among the instruments compared. This can be seen in Figs. S22, S24, S23, and S25, where the signal level prior to the P-wave onset is least for the seismometer data, when compared to the P-wave amplitude.
## S4.3 Comparison of seismometer and strainmeter data
To evaluate how well strain from particle velocity recorded by the seismometer can represent 'rock strain', we perform a direct comparison between the strain waveforms from the strainmeter array and those derived from the particle velocity recorded by the seismometer. Fig. S36 shows the results of the comparison. If the seismometer signal scaled by Eq. (S6) would be a good representation of 'rock strain', all these coefficients would equal 1. This takes place in only very few cases. If the mismatch would be due to an amplitude factor only, the coefficients for fitting the strainmeter data to the seismometer data would be the reciprocals of the coefficients computed when fitting seismometer data to strainmeter data. This is not the case, due to a considerable waveform mismatch caused by non-plane components of the surface waves.
compare seismometer and strainmeter factors compare seismometer and strainmeter factors
Figure S34: Regression coefficients obtained when fitting to the DAS data and using the strainmeter data (filled symbols) as regressor on the one hand and seismometer data (open symbols) on the other hand. The values are plotted against the BAZ of the respective earthquake. The diagrams on the left are limited to values from 0 to 1. The diagrams on the right show the full scatter. From top to bottom: tight-buffered in the 'Anton Gang', loose-tube in the 'Anton Gang', tight-buffered in the 'Vorstollen', loose-tube in the 'Vorstollen'. The seismometer data is scaled for a slowness of 280 ms km -1 , equivalent to a phase velocity of 3.57 km s -1 .
compare seismometer and strainmeter factors compare seismometer and strainmeter factors
Figure S35: Normalized correlation coefficients for DAS data and strainmeter data (filled symbols) on the one hand and seismometer data (open symbols) on the other hand. Results are plotted against the backazimuth. Results for both cables (left: tight-buffered, right: loose-tube) and both locations (top: 'Anton Gang', bottom: 'V orstollen') are displayed.
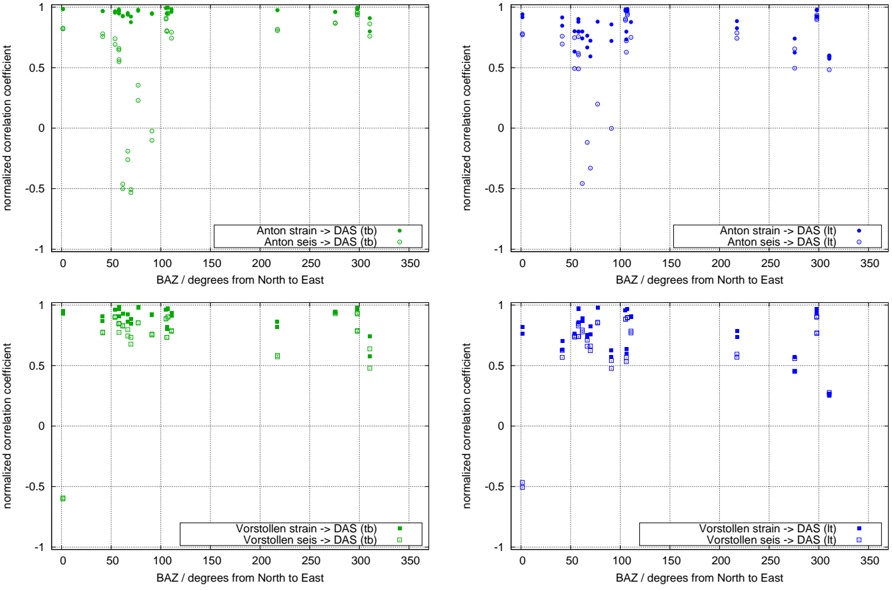
compare seismometer data against strainmeter compare seismometer data against strainmeter
Figure S36: Regression coefficients when fitting surface wave strainmeter data to seismometer data (green) and fitting seismometer data to strainmeter data (blue). Results are displayed for the azimuths of the 'Anton Gang' (circles and pluses) and the 'Vorstollen' (squares and crosses). The values are plotted against the backazimuth (BAZ) of the respective earthquake. Left: limited value range. Right: full range. In cases, where the seismometer derived strain signal represents rock strain, the values equal 1. These cases are rare.
 | null | [
"Thomas Forbriger",
"Nasim Karamzadeh",
"Jérôme Azzola",
"Emmanuel Gaucher",
"Rudolf Widmer-Schnidrig",
"Andreas Rietbrock"
] | 2024-08-02T10:08:35+00:00 | 2024-10-19T17:10:42+00:00 | [
"physics.geo-ph"
] | Calibration of the strain amplitude recorded with DAS using a strainmeter array | The power of distributed acoustic sensing (DAS) lies in its ability to sample
deformation signals along an optical fiber at hundreds of locations with only
one interrogation unit (IU). While the IU is calibrated to record 'fiber
strain', the properties of the cable and its coupling to the rock control the
'strain transfer rate' and hence how much of 'rock strain' is represented in
the recorded signal. We use DAS recordings in an underground installation near
an array of strainmeters in order to calibrate the 'strain transfer rate' in
situ, using earthquake signals between 0.05 Hz and 0.1 Hz. A tight-buffered
cable and a standard loose-tube telecommunication cable (running in parallel)
are used, where a section of both cables loaded down by loose sand and sand
bags is compared to a section, where cables are just unreeled on the floor. The
'strain transfer rate' varies between 0.13 and 0.53 depending on cable and
installation type. The sandbags show no obvious effect and the tight-buffered
cable generally provides a larger 'strain transfer rate'. Calibration of the
'strain transfer rate' with respect to the strainmeter does not depend on wave
propagation parameters. Hence it is applicable to the large amplitude surface
wave signal in a strain component almost perpendicular to the great-circle
direction for which a waveform comparison with seismometer data does not work.
The noise background for 'rock strain' in the investigated band is found at
about an rms-amplitude of 0.1 nstrain in 1/6 decade for the tight-buffered
cable. This allows a detection of marine microseisms at times of high
microseism amplitude. |
2408.01152v2 | ## Vertiport Terminal Scheduling and Throughput Analysis for Multiple Surface Directions
Ravi Raj Saxena, T.V. Prabhakar, Joy Kuri, Manogna Yadav
August 6, 2024
## Abstract
Vertical Take-Off and Landing (VTOL) vehicles have gained immense popularity in the delivery drone market and are now being developed for passenger transportation in urban areas to efficiently enable Urban Air Mobility (UAM). UAM aims to utilize the urban airspace to address the problem of heavy road congestion in dense urban cities. VTOL vehicles require vertiport terminals for landing, take-off, passengers boarding or deboarding, refuelling (or charging), and maintenance. An efficient scheduling algorithm is essential to maximize the throughput of the vertiport terminal (vertiminal) while maintaining safety protocols to handle the UAM traffic. While traditional departure and taxiing operations can be applied in the context of vertiminal, specific algorithms are required for take-off and landing schedules. Unlike fixed-wing aircraft that require a runway to take-off and climb in a single direction, VTOL vehicles can approach and climb in several directions. We propose a Mixed Integer Linear Program (MILP) formulation to schedule flights for taxiing, climbing (or approaching) using multiple directions after take-off (before landing) and turnaround on gates. We also derived equations to thoroughly analyze the throughput capacity of a vertiminal considering all its core elements. We have shown that our MILP can achieve the maximum throughput obtained through the equations. Given the input parameters, our analysis can be used to analyze the capacity of a vertiminal without running any simulation, while our MILP can be used to get the most efficient schedule.
## 1 Introduction
Future modes of transportation in domestic mobility are expected to integrate Urban Air Mobility (UAM) with surface transport. This acceleration is due to road congestion caused by an increase in the number of vehicles for personalized transport. Frequent traffic rerouting, either because of road accidents or construction work or due to ad-hoc events such as public and political demonstrations etc., cause unpredictable delays. UAM is expected to provide cost-effective air travel by deploying fuel-efficient small drones and electric aircraft. The system is expected to be fully automated and, thus, highly efficient in operational procedures [1].
UAMvehicles, owing to their small size and primarily rotary wing structure, are equipped with the ability to take off and land vertically, making them ideally suited for widespread usage in congested and spaceconstrained cities. The urban air traffic constituting such UAM vehicles, along with other Unmanned Aerial Systems (UAS) such as delivery drones, are governed by UAS Traffic management or UTM. UTM mandates that UAM vehicles land and take off only at specified vertiports (vertical spaces) constructed within cities. UAM is projected as above $ 40 billion industry [2]. Especially in Europe, companies such as Volocopter and Skyroads, in Italy and Germany, are already developing Vertical Take-Off and Landing (VTOL) technology, vertiports and air traffic automation technology [3, 4, 5]. Designing vertiports for a city is a nontrivial task as there is a requirement for efficient space usage along with maintaining regulations. Several international aviation bodies such as EASA [6], FAA [7], and UAE General Civil Aviation Authority[8] have recently published design guidelines for the construction of vertiports.
Some analogy can be drawn between UTM and conventional Air Traffic Management (ATM). The capacity and demand of the UTM system in a city can be analogous to the high traffic volume observed
between major airports of metropolitan areas. The vertiport terminal, will be the bottleneck for UTM under high demand conditions that might result in congestion and associated wastage of resources such as fuel (energy), manpower, time; leading to uneconomical operation. Hence, optimizing vertiport operations is vital in intelligent transportation research, and several approaches have already been investigated for airport ground operations which can be applied to vertiport terminals. Constraints such as wake vortex separation and minimum distance separation between VTOL vehicles on taxiways, climbing and approach must be considered. Unlike traditional aircraft where take-off and climb from a runway are a bottleneck, VTOL aircraft use TLOF (Touchdown and Lift-Off) pads to take-off and can climb in any direction. This simple operation, of climbing in any direction, can be exploited to design an appropriate schedule to increase a vertiport terminal's throughput. The details about VTOL vehicle operations are described in Section 3.
In this paper, we formulate an optimization problem for scheduling vertiport terminal operations incorporating the concept of multiple climb directions. The scheduling problem formulation leads to a Mixed Integer Linear Program (MILP), illustrated using a sample topology. We also formulate equations to calculate a vertiport terminal's maximum achievable throughput capacity and verify it with the MILP. The rest of the paper is organized as follows. Section 2 is on related work in literature along with the list of contributions of the paper. Formulation and explanation of the optimization problem are presented in Section 3. Section 4 derives the equations required to calculate the throughput of a vertiminal. The computational results of the optimization problem and the throughput calculations, along with their comparison, are explained in Section 5. Finally, in Section 6, we summarise our work and discuss the future scope of the study.
## 2 Related Work
Taxiing and runaway scheduling is a well-researched area for traditional aircraft and airports. Numerous works like ([9, 10, 11]) have developed genetic algorithms for solving taxiing problems. These works calculated a fit function based on taxiing length, delays, conflicts, etc. Genetic algorithms provide suboptimal solutions but are computationally faster than an optimization solver. The framework presented in [12] describes a single mixed-integer linear programming (MILP) method for the coupled problems of airport taxiway routing and runway scheduling. The receding-horizon formulation is applied for scalability. Work presented in [13] suggests two strategies for jointly optimizing taxiway and runway schedules. While the first one uses a MILP model and is an integrated approach, the second strategy sequentially integrates the runway and taxiway scheduling algorithms. The thesis work of Simaiakis [14] analyses the departure process at an airport using queuing models and proposes dynamic programming algorithms for controlling the departure process. For arriving aircraft, a novel approach described in [15] shows improvement in taxiing scheduling by considering uncertain runway exit times and usage patterns, and subsequently selecting the appropriate runway exit. The work in [16] has used Machine Learning (ML) techniques to determine runway exit, and its inference is utilised in [17] for calculating runway utilization and validation. Under the large context of airport scheduling, the works in [18, 19, 20] consider the gate assignment problem as an essential part of taxiing route from runway to gate and vice-versa. However, they are either passenger-centric or use a genetic algorithm.
Recent works on vertiport scheduling and design such as [21] present the methods to determine optimal 'Required time of arrival' by MILP considering energy and flight dynamics, while [22] proposes a multi-ring structure over a multi-vertiport. The multi-ring structure only handles air traffic and does not consider ground traffic. The thesis work in [23] discusses the software tools for vertiport design simulation and analysis. Since a vertiport can have multiple gates and TLOF pads, several works such as [24, 25, 26] have done extensive studies on the design of vertiport and its capacity and throughput analysis. The work presented in [24] reviewed various heliport topologies (linear, satellite, pier, and remote apron) for vertiport terminals and developed an integer program based on the Bertsimas-Stock multi-commodity flow model to analyze vertiport operations. Their extensive experiments investigated the impact of factors like gate-toTLOF pad ratio, operational policies, and staging stand availability on throughput and capacity envelope. However, they have not considered the inter-separation distance on taxiways and surface directions among different classes or types of flights. The study in [25] analyzed various topologies for maximizing throughput
at Gimpo airport vertiport. These topologies are based on EASA and FAA guidelines. While the authors have used obstacle-free volume, they do not explore the concept of multiple surface directions. The work of [26] proposed a heuristic for vertiport design focusing on efficient ground operations in UAM. Their work analyzed average passenger delay based on vertiport layout and demand profile throughout the day.
To the best of our knowledge, no work has considered multiple climb and approach directions for take-off and landing, along with ground operation processes such as taxiing and turn around on gates on a vertiport terminal, termed as vertiminal. Also, no work has studied and analyzed the impact on the throughput of vertiminal by arrival and departure operations, considering different sequences of operations such as arrivalarrival, arrival-departure etc., with different classes or types of VTOL vehicles. The optimization problem proposed in [27], which is used as our base, minimises the weighted sum of the gate, taxiing, and queuing delays at a conventional airport. The work models runway entrance as a queue to adhere to the schedule developed by the deterministic optimization process. Unlike their work, we are not using queues at the entrance of the TLOF pad. The impact of queuing, if any, is left for future study.
The paper presents the following contributions:
- 1. A novel operational procedure is proposed where a UAM flight can climb and approach using multiple surface directions.
- 2. The MILP model [28] is extended to incorporate arriving flights and turn around at gates. We pruned the model to reduce the number of variables & constraints, and have compared our formulation with First Come First Serve (FCFS) scheduling.
- 3. We developed equations to determine the theoretical bounds of throughput of a vertiminal that consider various sequences of aircraft movements and different flight classes. The accuracy of these equations is verified using the formulated MILP model.
## 3 Vertiminal Operations
The ground operations on a vertiport terminal are similar to those of an airport, however, the difference lies in their arrival or departure operations. Figure 1a shows a conventional airport system where an aircraft occupies the runway, accelerates to the required ground speed, take-off, and after attaining a certain altitude will deviate in the direction of the approved flight plan. The two line segments 'A to B' and 'B to C' depict the common distance occupied by only one flight at a time, thus being a bottleneck to back-to-back departing traffic.
We define vertiminal as a vertiport terminal, which may be regarded as similar to a bus terminal, and a vertiport is like a bus stop. A vertiminal handles traffic of UAM VTOL capable aircraft . Such aircraft are defined as heavier-than-air aircraft, other than an aeroplane or helicopter, capable of performing VTOL using more than two lift or thrust units to provide lift during the take-off and landing [6]. A UAM aircraft departs from the Gate and travels a defined path on vertiminal called a taxiway , either on the ground or by air, before reaching the TLOF pad . Figure 1b shows a VTOL vehicle take-off from a TLOF pad. The line segment 'A to B' shows the vertical take-off and unlike in Figure 1a, the line segments 'B to C' is of 0 length. Unlike conventional runways, these pads are compact, and thus, a VTOL vehicle can reach cruising altitude (point C) quickly and start its approved flight plan. Figure 2 shows an example of Obstacle Free Volume (OFV), which is a funnel-shaped area with several climb surface directions (2 in Fig 2) available to the TLOF pad. The OFV guarantees that VTOLs can accomplish take-offs and landings within a sizable vertical segment, allowing them to account for environmental and noise limits in urban settings. At the end of the OFV boundary, there can be multiple climb surface directions for VTOL vehicles to climb to the vertiexit ; an altitude where the UAM VTOL aircraft exits from the vertiminal airspace. A minimum separation time is required for successive take-offs and landing due to wake turbulence on the TLOF pad. Two UAM aircraft flying in the same surface direction must be separated by the minimum separation distance. However, this is not required to be maintained if the two aircraft fly in different surface directions. Hence, with more than one surface direction, the total delay can be reduced compared to a single surface
Figure 1: Comparison of flight paths
direction, provided the scheduling algorithm takes advantage of the multiple directions when deciding the take-off/landing sequence. The addition of multiple directions thus effectively reduces shared path length and increases throughput.
A departure-ready flight can experience delays along its path due to the following:
- 1. Separation requirements on the taxiways;
- 2. TLOF pad availability while the previous VTOL aircraft climbs the OFV boundary;
- 3. Wake turbulence time separation requirements on TLOF pad;
- 4. Separation requirements on the climb surface direction in case multiple consecutive UAM vehicles take the same direction.
Arriving flights will experience similar delays - however, in the reverse order. Our goal is to formulate a scheduling problem to minimize a weighted sum of all such delays that should help improve the throughput of a vertiminal.

Figure 2: Example of OFV with 2 approach and climb surface directions
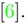
## 3.1 Problem Formulation
Given the number of UAM aircraft, their classes, their operation routes and their arrival & desired departure times, we need to design an efficient scheduling problem. We use a MILP technique to formulate the scheduling problem. The objective is to minimize the weighted sum of delays a UAM aircraft experiences during its complete operation. The time consumed on constrained resources like TLOF pads would be penalized more than the less constrained resources such as gates. The constraints for the objective problem are the physical constraint, separation requirements and other ATM regulations. We use the term VTOL or flight interchangeably instead of UAM aircraft throughout. We use the term 'surface direction' in the optimization problem to denote both the take-off climb surface direction and approach surface direction. In Section 5.1, we will discuss the effect of multiple surface directions on departure delay experienced by different flight loads and their classes using the formulation presented in this section. We will also compare our formulation with First Come First Serve (FCFS) scheduling.
## 3.1.1 Assumptions
As explained below, several simplifying assumptions are made in modelling vertiminal operations.
- · Vertiminals will provide a standard fixed-width surface direction to ensure VTOL remains within this specified limit.
- · The approach or climbing speed of a VTOL is assumed to be given and governed by equipment type, environment and regulations.
- · Given a TLOF pad and a gate, the taxi route of each VTOL is predefined.
- · Nominal taxi speed is assumed to be given. Thus, given the length of the taxiway, the minimum and maximum travel time can be estimated.
- · The passage times at critical points along taxi routes, OFV and surface direction given by the solution to the optimization problem can be met by a VTOL. We also assume hovering is not allowed for VTOLs.
- · For the flights that do not have to turn around, gates act as a source of flights and vertiexit act as a sink of flights for the departures. While for arrivals, vertiexit is a source of flights, and gates act as a sink.
- · The number of VTOLs that have to turn around on the gates will not exceed the holding capacity of the gate.
- · At the gates, the flight whose boarding completes first will be ready to leave first.
Table 1: Vertiminal Parameters
| N G | The set of gate nodes. Each physical gate node has an entrance node n en g ∈ N en g and an exit node n ex g ∈ N ex g ∀ g ∈ N G . Each gate node has a holding capacity of c g . |
|-------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| N R | The set of nodes representing all TLOF pads at the vertiminal. Each TLOF pad has an entrance node n en r ∈ N en r and an exit node n ex r ∈ N ex r ∀ r ∈ N R . |
| N n r O | The set of nodes representing OFV boundary on a TLOF pad n r ∈ N R |
| N n r F | The set of nodes representing the vertiexit reached from TLOF pad n r ∈ N R |
| N O = ⋃ n r ∈ N R N n r O ; N F = ⋃ n r ∈ N R N n r F | N O = ⋃ n r ∈ N R N n r O ; N F = ⋃ n r ∈ N R N n r F |
| N T | The set of all nodes n on the ground, where a node could be the intersection of two taxiways, an entrance or exit to a taxiway or a TLOF pad. |
| N | N G ∪ N T ∪ N R ∪ N O ∪ N F |
| L G | Set of links connecting gate nodes n g ∈ N G and taxiing nodes n t ∈ N T |
| L T | Set of links connecting taxing nodes nodes n t ∈ N T |
| L R | Set of links connecting taxing nodes n t ∈ N T and TLOF pads n r ∈ N R . |
| L O | Set of links connecting TLOF pads n r ∈ N R and OFV boundary n o ∈ N n r O |
| L F | Set of links connecting OFV boundary nodes n o ∈ N n r O and vertiexit nodes n f ∈ N n r F ∀ n r ∈ N R |
| L | L T ∪ L R ∪ L O ∪ L F ∪ L G |
| l a,b | ∈ L A link connecting nodes a and b also represented as (a,b). |
| G | ( N,L ), The vertiminal network |
## 3.1.2 VTOL Operations on a vertiminal
The Table 1 and Table 2 represent notation for a vertiminal and VTOL on a vertiminal, respectively. Figure 3 shows the nodes and links explained in Table 1. Let P i ∀ i ∈ A represent the physical taxi route for a VTOL i , from its first node to its last node. P i is represented by an ordered set of k i nodes { n , n i 1 i 2 , ..., n i k i } ∈ N T starting with the first node n i 1 of the route, which is the exit of assigned TLOF pad for i ∈ A Arr and gate exit for i ∈ A Dep , progressing through the intermediate nodes and ending at the last node of route n i k i which is the gate entrance for i ∈ A Arr or assigned TLOF pad entrance for i ∈ A Dep , where k i denotes the total number of nodes involved in P i . P a i represents taxiing route ∀ i ∈ A Arr while P d i represent taxiing route ∀ i ∈ A dep .
A VTOL i with a stop on the vertiminal will follow the following route:
- 1. Link Λ Arr ( ) represents approach direction to the assigned TLOF pad i τ Arr ( ). i
- 2. Link connecting OFV boundary node Λ Arr O ( ) and TLOF pad i τ Arr ( ). i
- 3. A sequentially ordered set P a i of nodes n ∈ N T , from the TLOF pad exit node τ ex ( ) to the entrance i of the gate γ en ( ). i
̸
| A | The set of all VTOL. |
|------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| A Dep | The set of all departing VTOL. |
| A Arr | The set of all arriving VTOL. |
| A TAT | A Dep ∩ A Arr , the set of VTOL that have to turn around. |
| A n | The set of all VTOL whose route passes through node n ∈ N . |
| ARAPPR i | ∀ i ∈ A Arr the time at which an arriving flight i enters the airspace of vertiminal i.e. enters vertiexit. |
| DRGATE i | ∀ i ∈ A the time at which a departing flight i is ready to leave the gate after passenger boarding. |
| γ ( i ) | ∀ i ∈ A Gate g ∈ N G assigned to VTOL i |
| γ en ( i ) | Entrance node n en g ∈ N en g of gate g ∈ N G assigned to VTOL i ∈ A Arr |
| γ ex ( i ) | Exit node n ex g ∈ N ex g of gate g ∈ N G assigned to VTOL i ∈ A Dep |
| τ ( i ) | ∀ i ∈ A TLOF pad n r ∈ N R assigned to VTOL i . τ Arr ( i ) is a TLOF pad assigned to i ∈ A Arr while τ Dep ( i ) is assigned to i ∈ A Dep . |
| τ en ( i ) | Entrance node n en r ∈ N en r of the TLOF pad n r ∈ N R assigned to VTOL i ∈ A Dep . |
| τ ex ( i ) | Exit node n ex r ∈ N ex r of the TLOF pad n r ∈ N R assigned to VTOL i ∈ A Arr . |
| Λ( i ) | ∀ i ∈ A Surface direction l i n f ,n o ∈ L F , n f ∈ N n r F , n o ∈ N n r O assigned to VTOL i from TLOF pad n r ∈ N R . Λ Arr ( i ) is the surface direction assigned to i ∈ A Arr while Λ Dep ( i ) is assigned to i ∈ A Dep . |
| Λ F ( i ) | ∀ i ∈ A Vertiexit node n f ∈ N F on surface direction Λ( i ). |
| Λ O ( i ) | ∀ i ∈ A OFV boundary node n o ∈ N O on surface direction Λ( i ). |
| TAT i | Turn Around Time of VTOL i ∈ A TAT . |
| TOT Arr i | TLOF pad Occupancy Time of arriving VTOL i . It is the time a VTOL takes to stop its motor and cool down before it can exit the TLOF pad. |
| TOT Dep i | TLOF pad Occupancy Time of departing VTOL i . It is the time a VTOL takes to reach the centre of the TLOF pad, start its motor, and prepare for take-off. |
| W tsep ij | Required safe separation time at landing or takeoff of VTOL i from its immediate trailing VTOL j , ∀ i, j ∈ A,i = j . |
Table 2: VTOL sets and parameters
- 4. For the turnaround flights i ∈ A TAT , VTOL would be in the holding space of the gate γ i ( ), where boarding and deboarding occur.
- 5. A sequentially ordered set P d i of nodes n ∈ N T , from the starting gate node γ ex ( ) to the entrance of i the assigned TLOF pad τ en ( ) i
- 6. Link connecting OFV boundary Λ Dep O ( ) and TLOF pad i τ Dep ( ). i
- 7. Link Λ Dep ( ) represents climb direction to the assigned TLOF pad i τ Dep ( ). i
- t n i ∀ i ∈ A, ∀ n ∈ N , Non-negative variable representing the time at which VTOL i reaches node n . Note that the VTOL does not slow down, let alone stop, before reaching a node and continues to achieve smooth travel unless the node is the exit or entrance of a TLOF pad or gate.
Figure 3: The nodes and link representation for the optimisation problem that are explained in Table 1. The orange line represents the path of a VTOL from gate to vertiexit.
̸
- y n ij ∀ n ∈ N, ∀ i, j ∈ A i n = j Binary variable, indicating if VTOL i reaches node n before VTOL j does. y n ij = 1 if and only if VTOL i reaches node n before VTOL j does; y n ij = 0 otherwise.
̸
- z ij ∀ i, j ∈ A TAT , i = j Binary variable used for selecting the minimum exit time for VTOLs in the TurnAround Time (TAT) set.
Table 3: Decision Variables
Table 4: Description of Weight Symbols
| W g | Weight assigned to a departing VTOL for the time it expends at the gate. 0 ≤ W g ≤ 1. |
|---------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| W Dep t | Weight assigned to a departing VTOLfor the taxiing time it expends. The requirement W g ≤ W Dep t ≤ 1 ensures that a VTOL should spend more time on the gate rather than on taxiways so as to avoid congestion and save energy. Also, it is beneficial for a multirotor to fly (in the case of air taxi) at the maximum optimal speed in order to reduce energy consumption[29]. |
| W Dep r | Weight assigned to a VTOL for the time it spends on the TLOF pad and inside the OFV during take-off. TLOF pad and OFV are highly constrained resources and a bottleneck; hence, this weight value should be kept high. 0 ≤ W Dep r ≤ 1. |
| W Arr r | Weight assigned to a VTOL for the time it spends inside the OFV and on the TLOF pad during landing. TLOF pad and OFV are highly constrained resources and a bottleneck; hence, this weight value should be kept high. 0 ≤ W Arr r ≤ 1. |
| W Arr t | Weight assigned to an arriving VTOL for the taxiing time it expends. The requirement 0 ≤ W Arr t ≤ W r ensures that the VTOL will leave the TLOF pad at the earliest. |
| W Dep c | Weight assigned to a departing VTOL to the time it expends to reach vertiexit from a TLOF pad. 0 ≤ W Dep c ≤ 1. |
| W Arr c | Weight assigned to an arriving VTOL to the time it expends to reach the TLOF pad from a vertiexit. 0 ≤ W Arr c ≤ 1. |
| W q | Weight assigned to a VTOL for spending time on holding space of a gate. 0 ≤ W q ≤ 1. |
## 3.1.3 Formulation
Objective function: minimizes the weighted sum of delays; equation(1)
- · For departures: (a) waiting at the departure gate, (b)while taxiing, (c) climbing inside OFV and (d) climbing time to vertiexit
- · For arrivals: (a) during approach, (b) leaving the TLOF pad and (c) reaching the gate
- · For turnaround VTOLs: turnaround time on the gates due to passenger boarding and deboarding.
The decision variables and weights are described in Table 3 and Table 4, respectively.
$$\text{csion variables and weights are described in Table 3 and Table 4, respectively.} \\ \sum _ { i \in A ^ { D e p } } [ W _ { g } ( t _ { i } ^ { e ^ { e ^ { * } } ( i ) } - DRGATE _ { i } ) + W _ { t } ^ { D e p } ( t _ { i } ^ { e ^ { e ^ { n } } ( i ) } - t _ { i } ^ { e ^ { * } } ( i ) ) \\ + W _ { r } ^ { D e p } ( t _ { i } ^ { \Lambda ^ { D e p } ( i ) } - t _ { i } ^ { r ^ { e ^ { n } } ( i ) } ) + W _ { c } ^ { D e p } ( t _ { i } ^ { \Lambda ^ { D e p } ( i ) } - t _ { i } ^ { \Lambda ^ { D e p } ( i ) } ) ] \\ + W _ { Q } \sum _ { i \in A ^ { T A T } } ( t _ { i } ^ { e ^ { e ^ { * } } ( i ) } - t _ { i } ^ { r ^ { e ^ { n } } ( i ) } ) \\ + \sum _ { i \in A ^ { A r r } } [ W _ { c } ^ { A r r } ( t _ { i } ^ { \Lambda ^ { A r r } ( i ) } - A R A P P R _ { i } ) \\ + W _ { r } ^ { A r r } ( t _ { i } ^ { r ^ { e ^ { * } } ( i ) } - t _ { i } ^ { \Lambda ^ { A r r } ( i ) } ) + W _ { t } ^ { A r r } ( t _ { i } ^ { \gamma ^ { e ^ { n } } ( i ) } - t _ { i } ^ { r ^ { e ^ { * } } ( i ) } ) ] \\ \text{mpose constraint equation (2) to ensure that an arriving VTOL starts on the approach surface}$$
C1: We impose constraint equation (2) to ensure that an arriving VTOL starts on the approach surface direction starting from vertiexit.
$$t _ { i } ^ { \Lambda _ { F } ^ { A r r } ( i ) } = A R A P P R _ { i } \quad \forall i \in A ^ { A r r }$$
C2: A VTOL i ∈ A Arr traverses physical nodes p ∈ { Λ Arr F ( ) i ∪ Λ Arr O ( ) i ∪ τ Arr ( ) i ∪ P a i ∪ γ i ( ) } while a VTOL i ∈ A Dep traverses physical nodes p ∈ { P d i ∪ τ Dep ( ) i ∪ Λ Dep O ( ) i ∪ Λ Dep F ( ) i } . For speed control and smooth travel over all the links,i.e. taxiing ways, OFV and surface direction, constraint equation (3) is required. The terms T min il i p and T max il i p are the respective minimum and maximum time taken by VTOL i on the link l i p,p +1 ∈ L .
$$t _ { i } ^ { p } + T _ { i l _ { p, p + 1 } ^ { i } } ^ { m i n } \leq t _ { i } ^ { p + 1 } \leq t _ { i } ^ { p } + T _ { i l _ { p, p + 1 } ^ { i } } ^ { m a x }$$
C3: A VTOL will spend time on the gate not less than its turn around time, which is ensured by the constraint equation (4)
$$t _ { i } ^ { \gamma ^ { e x } ( i ) } - t _ { i } ^ { \gamma ^ { e n } ( i ) } \geq T A T _ { i } \quad \forall i \in A ^ { T A T }$$
C4: The constraint equation (5) is the minimum time when the VTOL should leave the gate and start taxiing.
$$t _ { i } ^ { \gamma ^ { e x } ( i ) } \geq \text{DRGATE} _ { i } \quad \forall i \in A ^ { D e p }$$
C5: Definition of Predecessors y n ij :
̸
$$t _ { j } ^ { n } \geq t _ { i } ^ { n } - ( 1 - y _ { i j } ^ { n } ) M \quad \forall n \in N, \forall i, j \in A ^ { n }, i \neq j$$
̸
$$y _ { i j } ^ { n } + y _ { j i } ^ { n } = 1 \quad \forall n \in N, \forall i, j \in A ^ { n }, i \neq j$$
C6: The following constraint prevents overtaking in terms of y n ij :
̸
$$y _ { i j } ^ { n } - y _ { i j } ^ { m } = 0 \\ \forall i, j \in A, i \neq j, \forall l _ { n, m } \in ( P _ { i } \cup \Lambda ( i ) ) \cap ( P _ { j } \cup \Lambda ( j ) )$$
C7: For preventing head-on collision of two VTOLs on a link l n,m , following constraint is used:
̸
$$y _ { i j } ^ { n } - y _ { i j } ^ { m } = 0 \quad \forall i, j \in A, i \neq j, \\ \forall l _ { n, m } \in ( P _ { i } \cup \Lambda ( i ) \cup L _ { O } ) \ a n d \ l _ { m, n } \in ( P _ { j } \cup \Lambda ( j ) \cup L _ { O } )$$
C8: This constraint maintains the separation requirement on the Taxi and surface direction, where L sep ij is the separation requirement between VTOL in units of distance over the edge(or link) of length L n, m ( ).
̸
$$t _ { j } ^ { n } & \geq t _ { i } ^ { n } + \frac { L _ { i j } ^ { s e p } } { L ( n, m ) } ( t _ { i } ^ { m } - t _ { i } ^ { n } ) - ( 1 - y _ { i j } ^ { n } ) M \\ & \forall l _ { n, m } \in L _ { G } \cup L _ { T } \cup L _ { F } \ \forall i, j \in A ^ { n }, i \neq j$$
C9: The constraint (10) enforces the gate holding capacity of a gate g ∈ N G that should not be exceeded. We have shown for holding capacity of 3. The equations (11) linearize the constraint.
̸
̸
̸
$$\circ \dashrightarrow _ { r \, \dots \, \nu } \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightage \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \Dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \mathbb { m } ( 1 0 ) \\ \forall i, j, k, l \in A ^ { T A T }, i \neq j \neq k \neq l$$
$$t _ { i } ^ { g ^ { e n } } \geq t _ { j } ^ { g ^ { e z } } - ( 1 - y _ { j i } ^ { g } ) M - ( 1 - z _ { i j } ) M & & ( 1 1 \tt a )$$
$$t _ { i } ^ { g ^ { e n } } \geq t _ { k } ^ { g ^ { e x } } - ( 1 - y _ { k i } ^ { g } ) M - ( 1 - z _ { i k } ) M & & ( 1 1 b )$$
$$t _ { i } ^ { g ^ { e n } } \geq t _ { l } ^ { g ^ { e x } } - ( 1 - y _ { l i } ^ { g } ) M - ( 1 - z _ { i l } ) M & & ( 1 1 c )$$
$$z _ { i j } + z _ { i k } + z _ { i l } \geq 1 & & ( 1 1 d )$$
C10: Constraint equation (12) maintains the wake vortex requirement on the TLOF pad when a VTOL i lands (or does a take-off) where W tsep ij is the minimum time VTOL j should wait to either arrive or depart after the arrival(or departure) of VTOL i .
̸
$$t _ { j } ^ { r } & \geq t _ { i } ^ { r } + W _ { i j } ^ { t s e p } - ( 1 - y _ { i j } ^ { r } ) M \\ \forall i, j & \in A ^ { r }, i \neq j, \tau ( i ) = \tau ( j ) = r$$
C11: The time taken to reach the TLOF pad exit point upon landing is captured by constraint (13).
$$t _ { i } ^ { \tau ^ { e x } ( i ) } \geq t _ { i } ^ { \tau ^ { A r r } ( i ) } + T O T _ { i } ^ { A r r } \quad \forall i \in A ^ { A r r }$$
C12: The time taken to take-off after entering the TLOF pad from an entry point is captured by constraint (14). Constraint equations (14) and (13) along with (3) maintain the time continuity over the VTOL's route.
$$t _ { i } ^ { \tau ^ { D e p } ( i ) } \geq t _ { i } ^ { \tau ^ { e n } ( i ) } + T O T _ { i } ^ { D e p } \quad \forall i \in A ^ { D e p }$$
C13: Upon arrival of VTOL i , the following VTOL j should reach the OFV boundary only after VTOL i has left the TLOF pad through its exit point. Constraint equation (15) satisfies this requirement
̸
$$t _ { j } ^ { A _ { \delta ^ { \text{rr} } ( j ) } } \geq t _ { i } ^ { \tau ^ { e \pm } ( i ) } - ( 1 - y _ { i j } ^ { r } ) M \\ \forall i, j \in A ^ { A r r }, i \neq j, \tau ^ { A r r } ( i ) = \tau ^ { A r r } ( j ) = r$$
C14: When a VTOL i departs from the assigned TLOF pad, its immediate follower VTOL j cannot enter the TLOF pad till VTOL i has crossed its OFV boundary. Constraint equation (16) ensures this.
̸
$$t _ { j } ^ { \tau ^ { e n } ( j ) } & \geq t _ { i } ^ { \Lambda _ { O } ^ { D e p } ( i ) } - ( 1 - y _ { i j } ^ { r } ) M \\ \forall i, j & \in A ^ { D e p }, i \neq j, \tau ^ { D e p } ( i ) = \tau ^ { D e p } ( j ) = r$$
C15: A departing VTOL must enter a TLOF pad only after the arriving VTOL has left the TLOF pad.
$$t _ { j } ^ { \tau ^ { e n } ( j ) } \geq t _ { i } ^ { \tau ^ { e x } ( i ) } - ( 1 - y _ { i j } ^ { r } ) M \\ \forall i \in A ^ { A r r }, j \in A ^ { D e p }, \tau ^ { D e p } ( j ) = \tau ^ { A r r } ( i ) = r$$
C16: Binary and non-negativity constraints:
$$t _ { i } ^ { n } \in R ^ { + } \quad \forall i \in A, \forall n \in N$$
̸
$$y _ { i j } ^ { n } \in \{ 0, 1 \} \quad \forall n \in N, \forall i, j \in A _ { 0 } ^ { n }, i \neq j$$
## 3.2 Comparison to the previous formulation
In our earlier work [28], we formulated the optimisation problem ( opt A ) with two binary variables: immediate predecessor x and predecessor y . Our present optimisation formulation ( opt B ) has eliminated the immediate predecessor variable x because y implicitly incorporates the information conveyed by x . This change eliminated the need for a dummy VTOL and also resulted in a reduction of 10 constraints and thus, drastically reduces the time to reach the solution.
## 4 Throughput Capacity Equations
In the previous section, our objective was to minimize a weighted sum of delays, subject to constraints arising from vertiminal operations. While the weighted sum of delays is optimized, we do not know if the optimal strategy in Section 3.1 ends up affecting the throughput of the vertiminal. To answer this question, we study the maximum throughput that can be achieved - this is what we call 'throughput capacity.' The capacity of the system comprising of: (a) gates at the apron, (b) taxiways and (c) TLOF pads would determine the maximum throughput capacity of a vertiminal. We analyze each of these elements independently and base our analysis on [31]. Finally, the throughput obtained using the optimal strategy in Section 3.1 is compared with the throughput capacity.
## 4.1 TLOF pad system
The TLOF pad system consists of TLOF pad, OFV and surface directions as illustrated in Figure 4. We analyse the throughput capacity by considering the arrivals and departures of VTOLs to and from the system. While a few factors such as visibility, precipitation, wind direction, etc. have been ignored, the following factors are considered in the capacity calculations:
- · Number of TLOF pads
- · Number of surface directions
- · Separation requirements between VTOLs imposed by the ATM system
- · Mix of VTOL classes using the vertiminal
- · Mix of movements such as arrivals, departures, or mixed on each TLOF pad and their sequencing
We define the term maximum throughput capacity as the maximum number of movements that can be performed in unit time on a TLOF pad without violating ATM rules such as wake vortex and other separation timing between two VTOLs. We first calculate for a single TLOF pad and then extend our calculations to multiple TLOF pads. On a TLOF pad, there are 4 possible sequences of movement pairs: Arrival-Arrival ( AA ), Departure-Departure ( DD ), Arrival-Departure ( AD ) and Departure-Arrival ( DA ). Recall that ATM regulations require safe separation distance on surface directions and wake vortex time separation on the TLOF pad. These separation requirement values depend on the classes of the VTOLs involved. Additionally, during departure or arrival operations, only 1 VTOL can occupy the OFV. The throughput capacity is determined by the time separation enforced by ATM rules for various VTOL classes executing different movements.
Figure 4: TLOF pad system with two surface directions 'X-N' and 'X-E'
The different time parameters we are going to utilise for analysis are:
- 1. t sep ij : The safe separation distance required on the surface direction between VTOL i and j , i followed by j , is converted into time separation (constraint equation (9)).
- 2. t w ij : Wake vortex separation on TLOF pad between VTOL i and j
- 3. t TOT i : Occupancy time of a VTOL i entering a TLOF pad before take-off or after landing on a TLOF pad before exit.
- 4. t R -X i , t X -R i : OFV travel time by a VTOL during departure or arrival, respectively.
- 5. t X -N i , t N -X i : Surface direction travel time by a VTOL during departure or arrival, respectively.
The following equations calculate the maximum time T MM ij required in different sequences of movements ( MM ) , where M ∈ { D A , } , and VTOL i is followed by VTOL j .
- · Arrival-Arrival: Two VTOLs are arriving from vertiexit to the TLOF pad. If the VTOLs i and j are arriving from different surface directions, then set t sep ij to 0.
$$T _ { i j } ^ { \text{AA} } = m a x ( t _ { i j } ^ { s e p }, t _ { i j } ^ { w }, t _ { i } ^ { X - R } + t _ { i } ^ { T O T } )$$
- · Departure-Departure: Two VTOLs are departing from the TLOF pad to vertiexit. If the VTOLs i and j are departing in different surface directions, then set t sep ij to 0.
$$T _ { i j } ^ { \mathbb { D D } } = m a x ( t _ { i j } ^ { s e p }, t _ { i j } ^ { w }, t _ { i } ^ { T O T } + t _ { i } ^ { R - X } )$$
- · Arrival-Departure: When an arrival is followed by a departure on a TLOF pad. In case the VTOLs i and j are using different surface directions, set t N -X i to 0.
$$T _ { i j } ^ { \text{A} } = m a x ( t _ { i } ^ { N - X } + t _ { i } ^ { X - R } + t _ { i } ^ { T O T }, t _ { i j } ^ { w } )$$
- · Departure-Arrival: When a departure is followed by an arrival on a TLOF pad. In case the VTOLs i and j are using different surface directions, set t X -N i to 0.
$$T _ { i j } ^ { \mathbb { D A } } = m a x ( t _ { i } ^ { T O T } + t _ { i } ^ { R - X } + t _ { i } ^ { X - N }, t _ { i j } ^ { w } )$$
The maximum throughput of the movement pair MM per unit time is given as
̸
$$\mu ^ { \text{MM} } = \lfloor \frac { 1 } { m i n ( T _ { i j } ^ { \text{MM} } ) } \rfloor, \mathbb { M } \in \{ \mathbb { D }, A \}, i, j \in A, i \neq j$$
The work in [31] calculates the expected capacity of a runway by considering all the possible aircraft classes and all possible permissible pairs of movements that have occurred in the past and then using a probability of occurrence for each of these events. Due to lack of any real-world data on UTM, our calculation is limited to the maximum throughput of any system. The maximum throughput of any movement pair ( MM ) is calculated by evaluating the VTOL classes that have minimum time parameter values. In the random sequence of arrivals and departures, the occurrence of movement pair ( DA ) or ( AD ) has a low probability. Thus, we take the maximum time of the movement pairs ( AA ) and ( DD ) to find the bottleneck in the system and define the capacity.
$$T _ { i j } = m a x ( T _ { i j } ^ { \text{AA} }, T _ { i j } ^ { \text{DD} } )$$
The maximum throughput capacity of the TLOF pad system, per unit time, is then given as:
$$\mu ^ { T L O F } = \lfloor \frac { 1 } { T _ { i j } } \rfloor$$
A TLOF pad can facilitate both arrival and departure movements or can also cater to a single type of movement. In the case of a vertiminal equipped with multiple TLOF pads, its capacity is decided according to the configuration, i.e., there can be several combinations of assigning arrivals and departures movements to the TLOF pads. For instance, in a vertiminal with two TLOF pads, one configuration might utilize both pads for both arrival and departure. In contrast, another configuration might designate one TLOF pad exclusively for arrivals and the other for departures. In either case, the overall capacity of the vertiminal is determined by the combined throughput capacity of each individual TLOF pad.
$$\mu _ { c } ^ { T L O F } = \sum _ { r \in N _ { R } } \lfloor \frac { 1 } { T _ { i j } ^ { r } } \rfloor, c \in C$$
where T r ij is calculated for each TLOF pad r ∈ N R using equation (25) and C is set of configuration.
## 4.2 Taxiway system
Figure 5: Taxiway system connecting TLOF pad and gates
The traditional airport always has a taxiway running parallel to the runway. These long, well-designed taxiways are not a factor limiting the capacity of an airport. However, the taxiway system of vertiminal would be different as they are shorter, linking TLOF pads' entry and exit points to the gate exit and entry points, respectively, as shown in Figure 5. There might be a single taxiway link or multiple taxiways with intersections among them on the vertiminal, each being a half-duplex link. Considering the gates and TLOF pads as sources and sinks, respectively (or even vice versa), the taxiway system can be conceptualized as a flow network problem. By deriving each link's flow capacity, the flow network's maximum capacity can be calculated using the max-flow min-cut theorem [32].
Each taxiway link has a static and dynamic capacity. Static capacity can be defined as the maximum number of stationary vehicles on it, while the dynamic capacity is the maximum number of vehicles passing through it per unit time, which is independent of taxiway length. Assuming uniform taxi velocities for all VTOL classes, the minimum sum of vehicle length and safe separation distance between two vehicles determines the dynamic capacity on any taxiway link and, thus, its flow rate. Given the size of the VTOL vehicle as d len , the separation distance d sep and the maximum taxi-velocity of the VTOLs as v taxi , the maximum flow rate of a taxiway link can be calculated as:
$$\max F l o w R a t e = \lfloor \frac { 1 } { ( d _ { l e n } + d _ { s e p } ) / v _ { t a x i } } \rfloor$$
If the three parameters in Equation (27) remain constant for each taxiway link, the maximum flow rate remains uniform across the entire taxiway network. However, varying d sep and v taxi for each link necessitates the use of the max-flow min-cut theorem to calculate the overall maximum flow rate for the network( µ taxi ).
## 4.3 Gate system
Figure 6: Gate system with 4 gates, each having 3 slots
The gate system on a vertiminal can consist of multiple gates, each having multiple parking slots for VTOLs, as shown in Figure 6. The most basic and standard way to calculate the capacity of a gate system is the total number of VTOLs that can stand on a vertiminal simultaneously, referred to as static capacity ( C G = ∑ g ∈ N G c g ). However, a better measure of the capacity is the dynamic capacity, defined as the number of VTOLs per unit time that can be accommodated by the gate system and this is affected by the VTOLs' turnaround times. For calculating the maximum throughput of the gate system, the class of vehicle having the minimum turnaround time TAT should be considered. The maximum throughput is then calculated as:
$$\mu ^ { G } = \lfloor \frac { \mathbb { C } _ { G } } { T A T _ { s m a l l } } \rfloor$$
Till now, we showed individual throughput calculations for TLOF pad, taxiway and gate systems considering them independently. The overall vertiminal's throughput is limited by the minimum of the three systems as shown in equation (29).
$$\mu ^ { v e r t i m i n a l } = \min ( \mu ^ { T L O F }, \mu ^ { t a x i }, \mu ^ { G } )$$
## 5 Evaluation of the results
We used MATLAB version 2022a (9.12) with an optimization toolbox of version 9.3 on a Desktop PC equipped with an i7-11700F processor having 16 cores (8 physical) @ 2.5GHz and 64GB RAM to solve the optimization problem described in 3.1. Our implementation is available on GitHub for reproducibility [30].
Figure 7 shows the topology used in our computational setup. All taxi edges in the network are equal in length, and similarly, all surface direction edges are equal. However, the length of the surface direction edges is greater than that of the taxi edges. The Table 5 mentions the weights used in objective (1) of MILP and other parameters that encompass several edge lengths and speeds. We randomly assign gate, surface direction, DRGATE i and ARAPPR i to VTOLs. The large constant M is set as ( ⌈ | ( A / | 10) ⌉ +1) ∗ 2000.
## 5.1 Results from the MILP formulation for VTOL departures
The solution provides the exact schedule of a VTOL movement from gate to vertiexit - the times at which a VTOL: (i) departs from the gate, (ii) crosses each node on in its path, (iv) arrives at the TLOF pad, (v) crosses OFV boundary and (vi) exits from the vertiexit.
Figure 7: Sample topology with 4 gates, 3 parking slots each and 2 surface directions.
The MinTravelTime for a VTOL is calculated as t Λ Dep F ( ) i i -DRGATE i , i ∈ A Dep , where DRGATE i is the desired time to depart from the gate and t Λ Dep F ( ) i i is time to reach the vertiexit. It is achievable only when no other VTOLs are present in the vertiminal. By comparing the actual time (provided by the MILP solution) with MinTravelTime , we determine the ExcessDelay . Our goal is to observe the effect of multiple surface directions on ExcessDelay incurred by departing flights. We consider a total of 4 surface directions from the OFV boundary ('X' in Figure 7). The total number of runs is 24 (6 different sets of flights and 4 directions). We compare the ExcessDelay obtained from our formulation with that of FCFS scheduling. Our implementation of FCFS uses the same set of constraints described in Section 3.1 with an additional constraint that forces the VTOLs to take off according to the order of their DRGATE i . We recall that a route is defined by the following 4 elements: departing gate, a taxiing path from gate to TLOF pad, TLOF pad and surface direction. For comparison, in each run MILP and FCFS are provided with the same set of flights along with their route and DRGATE i .
When two successive VTOLs use different surface directions, since there is no separtion requirement it is sufficient for the follower to take off by adhering only to wake vortex separation, thus reducing its overall delay i.e. ExcessDelay . This delay reduction is observed in Figure 8 by comparing delay distribution among flights with an increase in the number of surface directions. From Figure 8, we see a delay reduction of about 50% as we increase the number of surface directions from 1 to 2. Furthermore, as we increase the number of flights, the delay is increased due to congestion on vertiminal. An analysis of delay distribution for a flight set between our MILP and FCFS scheduling reveals notable differences. The third quartile (75%) of MILP is lower than the third quartile of FCFS (with exception of single surface direction and 150 flights). The mean and median of MILP are always less than that of FCFS. Our MILP delays tend to skew away from the maximum delay, as evidenced by a higher mean value than the median. In contrast, the FCFS delays are uniformly distributed among flights, with coinciding mean and median values. In the presence of multiple surface directions, our formulation provides a significantly lower mean delay. More than 50% of the flights have a 50% reduction in delay. In summary, our MILP formulation prioritizes on minimizing overall flight delays.
The bar plots shown in Figure 9 represents the distribution of ExcessDelay components such as gate delay (waiting at the gate), taxiing delay, OFV delay, and climb delay for each flight. Taxing delays signify congestion on taxiways, while OFV delay indicates a lack of availability of resources such as TLOF pad and OFV. Due to congestion on taxiways, a VTOL may not be able to fly or move at the optimal speed that may result in energy wastage [29]. Thus, taxi delays are undesirable and it is more energy-efficient to wait at the gate. We used 40 flights with 4 surface directions and compared the results with FCFS scheduling. Figure 9a shows the MILP formulation where all the flights experience only gate delay. Additionally, we
Table 5: Parameters used in the MILP (* Used in Section 5.2)
| W g | 0.2 |
|-------------------------------------|-----------------|
| W Dep t | 0.8 |
| W Dep r | 1 |
| W Dep c | 0.7 |
| W Q * | 0.1 |
| W Arr c * | 0.7 |
| W Arr r * | 1 |
| W Arr t * | 0.8 |
| Gate taxiway length | 30 units |
| Taxiway edge length | 45 units |
| OFV length | 75 units |
| surface direction length | 300 |
| Average Taxi-speed | 6 units/sec |
| Maximum OFV climb speed | 17.14 units/sec |
| Maximum Surface direction speed | 23.73 units/sec |
| Separation distance on taxi (Small) | 5 units |
analyze the impact of equal weights used in the objective to study the VTOL delay. This effectively changes the objective to minimize the sum of delay i.e., ∑ i ∈ A Dep ( t Λ Dep F ( ) i i -DRGATE i ). Figure 9b shows the MILP with equal weights. The delay constitutes gate delay and taxiing delay. The taxiing delay (orange bars) occur as flights are slowly moving on taxiways instead of waiting at the gate even though the overall delay is at par with MILP (shown in Figure 9a). Figure 9c shows gate delay, taxiing delay and OFV delay (green bars) for FCFS scheduling. The OFV delay component is large compared to zero OFV delay in MILP. In summary, the delay breakup not only demonstrates the importance of weighted delays in the objective function, it also shows that FCFS scheduling leads to increased delay incurred by the VTOLs.
## 5.2 Results from Throughput Capacity
Recall that in Section 4, we discussed the capacity equations for: (a) TLOF pad system, (b) Taxiway system, and (c) Gate system. We determine the maximum achievable throughput of the vertiminal using the equations and the parameters shown in Table 5. We had considered the smallest class of VTOLs because they have the shortest turnaround time and minimum separation distance requirements. Using the time stamp of the VTOLs to reach the TLOF pad, we analyze the throughput achieved by the optimal strategy for solving the problem in Sec 3.1. We have varied the number of flights and the number of surface directions for all possible combinations of movements. For the TLOF pad system computation, we will use only A Arr (or A Dep ) where the vertiexit is a source (sink), and gates act as sinks (sources).
The following are the two sets of parameters used in comparison of throughput analysis using MILP and the equations from Section 4:
- · Set1: Separation requirement on surface direction is 75 units, Turn Around Time (TAT) on the gate is 90 seconds.
- · Set2: Separation requirement on surface direction is 280 units, Turn Around Time (TAT) on the gate is 120 seconds.
TLOF pad system: The time parameters described in the Section 4.1 equations (19)-(22), are presented in Table 6. We calculate the maximum time required for all the movement sequence pairs shown in Table 7. For Set1, the movement pair arrival-arrival or departure-departure gives the maximum achievable throughput ( µ AA or µ DD ) of ( 60 6 375 . ) 9 41 VTOLs per minute. . Whereas for Set2, the movement pair arrival-arrival or
Figure 8: Results from MILP overlapped with FCFS for multiple surface directions. The results are generated for 20, 40, 60, 80, 100, and 150 flights (indicated by different colours). It shows a reduction in delay by increasing the number of surface directions. The mean value of each box plot is marked in a small circle for MILP and a big circle for FCFS. Observe that the FCFS mean delay is aligned with its median and is always higher than the mean delay of MILP.
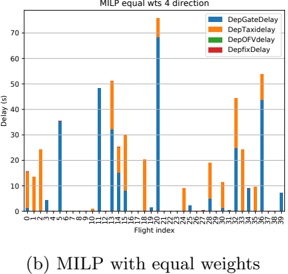
MILP equal wts 4 direction
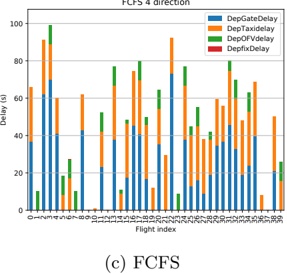
FCFS 4 direction
Figure 9: Distribution of delays of 40 flights among gate delay (blue bars), taxing delay (orange bars), OFV delay (green bars) and climb delay on 4 directions. For MILP the weights used are W g = 0 2 . , W Dep t = 0 8 . , W Dep r = 1 , W Dep c = 0 7. . It can be observed that the MILP with equal weights faces taxing delays while FCFS additionally faces OFV delays, causing delays on other flights.
departure-departure gives the maximum achievable throughput ( µ AA or µ DD ) of ( 60 11 67 . ) 5 14 VTOLs per . minute for single surface direction and ( 60 6 375 . ) 9 41 VTOLs per minute for multiple surface directions. .
If two consecutive VTOLs have different routes, then the separation requirement for the same surface direction, t sep ij , is set to 0. In Set1, since the TLOF pad occupancy time and OFV travel time ( T TOT + t R -X ) is greater than t sep ij , there is no advantage of multiple surface directions. In Set2, T TOT + t R -X < t sep ij and thus having multiple surface directions gives a higher throughput. The same can be observed in Figures 10
Table 6: TLOF pad system time parameters
Table 7: TLOF pad system maximum time calculation for each movement pair
| Set | Surface Directions | Movement Pair | TLOF Times (s) |
|-------|---------------------------------|------------------------------------------------------------------------------------------|-------------------------|
| 1 | Single Single Multiple Multiple | T AA ij or T DD ij T AD ij or T DA ij T AA ij or T DD ij T AD ij or T DA ij T AA or T DD | 6.375 19.02 6.375 6.375 |
| 2 | Single Single | ij ij T AD DA | 11.67 19.02 6.375 |
| | Multiple Multiple | ij or T ij T AA ij or T DD ij T AD ij or T DA ij | 6.375 |
-11, which show the throughput achieved by solving the MILP formulation (1) with different number of flights and surface directions for the TLOF pad system . To observe the maximum throughput, the input number of flights needs to be significantly high. The plots of 100 and 150 flights thus validate both our MILP formulation and the throughput calculations, including the advantage of multiple surface directions as mentioned in Set2.
Gate system: Recall the topology shown in Figure 7 which has 4 gates with 3 parking slots each, resulting in a static capacity ( C G ) of 12 VTOLs. For Set1, the gate system has a maximum dynamic capacity or throughput ( µ G ) of ( 60 ∗ 12 90 ) 8 VTOLs per minute. For Set2, the throughput is µ G = 60 ∗ 12 120 = 6 VTOLs per minute.
Taxiway system: Using the equation (27) from Section 4.2, the maximum flow rate of the taxiway link is calculated to be ( 60 (10 / 6) )36 VTOLs per minute, which represents the entire taxiway network. This is significantly higher than the maximum throughput of the TLOF pad system and Gate system, indicating that taxiway flow rate is not a limiting factor for vertiminal capacity.
Finally, We obtain the vertiminal's maximum throughput using equation (29). For Set1 it is 8 VTOLs per minute, while for Set2, it is 5.14 VTOLs per minute for single surface direction and 6 VTOLs per minute for multiple surface directions.
Our throughput results also align with other works mentioned in [24]. The authors consider only consolidated arrival and departure times without any consideration of separation requirements. In contrast, from Section 4.1, for a single VTOL, arrival time = t N -X i + t X -R i + t TOT i and departure time = t TOT i + t R -X i + t X -N i , shows in detail the occupancy time of TLOF pad, OFV, and travel time on a surface direction. Furthermore, from equations (19) - (22), the TLOF pad throughput is affected by the maximum of individual time parameters rather than the consolidated arrival or departure time. By increasing any time parameter, arrival and/or departure time may increase, which decreases the throughput, thus validating the results shown in [24]. Consequently, the estimation of C G required for a single TLOF pad is shown in equation (30).
$$\mu ^ { G } = \mu ^ { T L O F } = > \mathbb { C } _ { G } = \frac { T A T } { \max ( T ^ { A A } _ { i j }, T ^ { D D } _ { i j } ) }$$
Unlike [24], our equations allow a detailed analyses of throughput of the TLOF pad system ( µ TLOF ), taxiway system ( µ taxiway ) and the gate system ( µ G ), and thus enables deeper understanding and the significance of the TLOF pad to gate ratio.
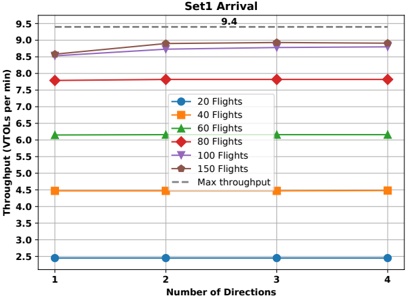
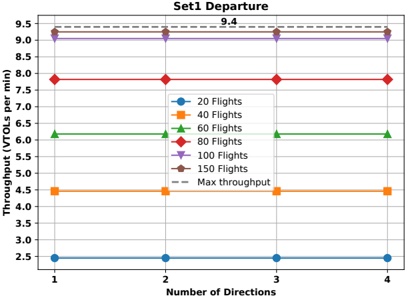
(a) Arrival
(b) Departure
Figure 10: Set1: Throughput vs Number of directions for a varying number of flights. There is no advantage of multiple surface directions since T TOT + t R -X > t sep ij
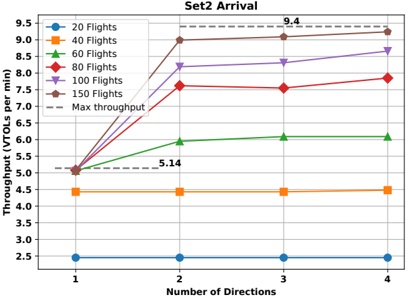
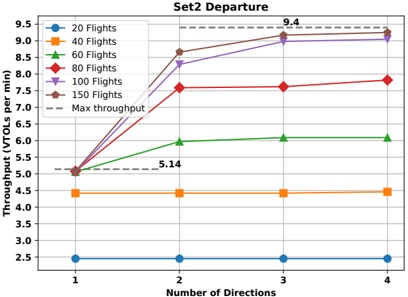
(a) Arrival
(b) Departure
Figure 11: Set2: Throughput vs Number of directions for a varying number of flights. As T TOT + t R -X < t sep ij , the advantage of multiple surface directions is visible as we increase the number of flights
## 6 Conclusion
This paper is an extension to our previous work [28]. We have extended the optimization formulation to include arrival flights and flights with turnarounds at the gate, thus enabling optimization for a broader range of operations. We have shown that our formulation gives a 50% delay reduction as compared to FCFS scheduling. Our work delves deeper into vertiminal's throughput by holistically analyzing its three core elements: the TLOF pad, taxiway network, and gates using the derived equations (19)-(28). We conducted computations to validate our optimization formulation and the accuracy of the throughput calculations. We further demonstrated that when the separation time requirement between flights is more than the occupancy time of OFV, multiple surface directions significantly affects the throughput. Thus, by providing precise throughput calculations using equations (without further simulations), our work empowers practitioners to optimize vertiminal design and operations for maximum efficiency.
For our further work, we will work on a case study using the design of Gimpo vertiminal [25] and find methods to decrease the computation time. One of the methods would be to use a rolling horizon which would also help in scalability. We can also make the optimization problem stochastic instead of deterministic operation. The formulation presented in this work does not consider Quality of Service (QoS), and hence, we will enhance this aspect. Future analysis would involve developing a capacity envelope for a vertiminal.
## References
- [1] NASA. Uam vision concept of operations (conops) uam maturity level (uml) 4.
- [2] Future air mobility: Major developments in 2022 and significant milestones ahead, 2023.
- [3] Hayley Everett. Italy's first vertiport deployed at fiumicino airport, 2022.
- [4] FutureFlight. Volocopter concludes european urban air mobility airspace integration flight trials, 2022.
- [5] FutureFlight. Advanced air mobility flight test site to open at german airport, 2023.
- [6] EASA. Prototype Technical Specifications for the Design of VFR Vertiports for Operation with Manned VTOL-Capable Aircraft Certified in the Enhanced Category .
- [7] FAA. ENGINEERING BRIEF #105 Vertiport Design .
- [8] UAE General Civil Aviation Authority, 2022.
- [9] J-B Gotteland and Nicolas Durand. Genetic algorithms applied to airport ground traffic optimization. In The 2003 Congress on Evolutionary Computation, 2003. CEC'03. , volume 1, pages 544-551. IEEE, 2003.
- [10] Yu Jiang, Xinxing Xu, Honghai Zhang, and Yuxiao Luo. Taxiing route scheduling between taxiway and runway in hub airport. Mathematical Problems in Engineering , 2015, 2015.
- [11] Changyou Liu and Kaifeng Guo. Airport taxi scheduling optimization based on genetic algorithm. In 2010 International Conference on Computational Intelligence and Security , pages 205-208. IEEE, 2010.
- [12] Gillian Clare and Arthur G Richards. Optimization of taxiway routing and runway scheduling. IEEE Transactions on Intelligent Transportation Systems , 12(4):1000-1013, 2011.
- [13] Hanbong Lee and Hamsa Balakrishnan. A comparison of two optimization approaches for airport taxiway and runway scheduling. In 2012 IEEE/AIAA 31st Digital Avionics Systems Conference (DASC) , pages 4E1-1. IEEE, 2012.
- [14] Ioannis Simaiakis. Analysis, modelling and control of the airport departure process . PhD thesis, Massachusetts Institute of Technology, 2013.
| [15] | Peng Cheng, Xiang Zou, and Wenda Liu. Airport surface trajectory optimization considering runway exit selection. In 17th International IEEE Conference on Intelligent Transportation Systems (ITSC) , pages 2656-2662. IEEE, 2014. |
|--------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [16] | Floris Herrema, Ricky Curran, Sander Hartjes, Mohamed Ellejmi, Steven Bancroft, and Michael Schultz. A machine learning model to predict runway exit at vienna airport. Transportation Research Part E: Logistics and Transportation Review , 131:329-342, 2019. |
| [17] | Catherine Chalon Morgan, Mohamed Ellejmi, Floris Herrema, and Ricky Curran. Validation of the runway utilisation concept. 9th SESAR Innovation Days , 2019. |
| [18] | John A Behrends and John M Usher. Aircraft gate assignment: using a deterministic approach for integrating freight movement and aircraft taxiing. Computers & Industrial Engineering , 102:44-57, 2016. |
| [19] | Wu Deng, Junjie Xu, Huimin Zhao, and Yingjie Song. A novel gate resource allocation method using improved pso-based qea. IEEE Transactions on Intelligent Transportation Systems , 2020. |
| [20] | Wu Deng, Meng Sun, Huimin Zhao, Bo Li, and Chunxiao Wang. Study on an airport gate assignment method based on improved aco algorithm. Kybernetes , 47(1):20-43, 2017. |
| [21] | Imke C Kleinbekman, Mihaela A Mitici, and Peng Wei. evtol arrival sequencing and scheduling for on- demand urban air mobility. In 2018 IEEE/AIAA 37th Digital Avionics Systems Conference (DASC) , pages 1-7. IEEE, 2018. |
| [22] | Quan Shao, Mengxue Shao, and Yang Lu. Terminal area control rules and evtol adaptive scheduling model for multi-vertiport system in urban air mobility. Transportation Research Part C: Emerging Technologies , 132:103385, 2021. |
| [23] | Hack V´zquez a et al. Vertiport sizing and layout planning through integer programming in the context of urban air mobility, 2021. |
| [24] | Parker D Vascik and R John Hansman. Development of vertiport capacity envelopes and analysis of their sensitivity to topological and operational factors. In AIAA Scitech 2019 Forum , page 0526, 2019. |
| [25] | Byeongseon Ahn and Ho-Yon Hwang. Design criteria and accommodating capacity analysis of vertiports for urban air mobility and its application at gimpo airport in korea. Applied Sciences , 12(12):6077, 2022. |
| [26] | Lukas Preis and Mirko Hornung. A vertiport design heuristic to ensure efficient ground operations for urban air mobility. Applied Sciences , 12(14):7260, 2022. |
| [27] | H-S Jacob Tsao, Wenbin Wei, Agus Pratama, and JR Tsao. Integrated taxiing and take-off scheduling for optimization of airport surface operations. In Proc. 2nd Annual Conference of Indian Subcontinent Decision Science Institute (ISDSI 2009) , pages 3-5, 2009. |
| [28] | Ravi Raj Saxena, Tejas Joshi, DK Yashashav, TV Prabhakar, and Joy Kuri. Integrated taxiing and tlof pad scheduling using different surface directions with fairness analysis. In 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC) , pages 1747-1752. IEEE, 2023. |
| [29] | Ravi Raj Saxena, Joydeep Pal, Srinivasan Iyengar, Bhawana Chhaglani, Anurag Ghosh, Venkata N. Padmanabhan, and Prabhakar T. Venkata. Holistic energy awareness and robustness for intelligent drones. ACM Trans. Sen. Netw. , jan 2024. Just Accepted. |
| [30] | https://github.com/rrsaxena92/Vertiport schedule/. |
[31] Richard De Neufville. Airport systems planning, design, and management. In Air Transport Management , pages 79-96. Routledge, 2020.
- [32] Tom Leighton and Satish Rao. Multicommodity max-flow min-cut theorems and their use in designing approximation algorithms. J. ACM , 46(6):787-832, nov 1999. | null | [
"Ravi Raj Saxena",
"T. V. Prabhakar",
"Joy Kuri",
"Manogna Yadav"
] | 2024-08-02T10:11:41+00:00 | 2024-08-05T08:00:01+00:00 | [
"cs.ET",
"cs.SY",
"eess.SY"
] | Vertiport Terminal Scheduling and Throughput Analysis for Multiple Surface Directions | Vertical Take-Off and Landing (VTOL) vehicles have gained immense popularity
in the delivery drone market and are now being developed for passenger
transportation in urban areas to efficiently enable Urban Air Mobility (UAM).
UAM aims to utilize the urban airspace \hidetxt{vertical dimension} to address
the problem of heavy road congestion in dense urban cities. VTOL vehicles
require vertiport terminals for landing, take-off, passengers boarding or
deboarding, refuelling (or charging), and maintenance. An efficient scheduling
algorithm is essential to maximize the throughput of the vertiport terminal
(vertiminal)\hidetxt{ as well as efficient use of airspace} while maintaining
safety protocols to handle the UAM traffic. While traditional departure and
taxiing operations can be applied in the context of vertiminal, specific
algorithms are required for take-off and landing schedules. Unlike fixed-wing
aircraft that require a runway to take-off and climb in a single direction,
VTOL vehicles can approach and climb in several directions. We propose a Mixed
Integer Linear Program (MILP) formulation to schedule flights for taxiing,
climbing (or approaching) using multiple directions after take-off (before
landing) and turnaround on gates. We also derived equations to thoroughly
analyze the throughput capacity of a vertiminal considering all its core
elements. We have shown that our MILP can achieve the maximum throughput
obtained through the equations. Given the input parameters, our analysis can be
used to analyze the capacity of a vertiminal without running any simulation,
while our MILP can be used to get the most efficient schedule. |
2408.01153v1 | ## Frame-filtered ghost imaging with a SPAD array used both as a multiple "bucket" detector and an imaging camera
V. S. Starovoitov, V. N. Chizhevsky, D. Mogilevtsev, A. Smaliakou, and S. Kilin B.I.Stepanov Institute of Physics, NAS of Belarus, Nezavisimosti ave. 68, 220072 Minsk, Belarus
## M. Perenzoni
Fondazione Bruno Kessler FBK, 38122 Trento, Italy and now at Sony Semiconductor Solutions Europe, Trento, Italy
## L. Gasparini
Fondazione Bruno Kessler FBK, 38122 Trento, Italy
## D. B. Horoshko
Univ. Lille, PhLAM - Physique des Lasers Atomes et Molecules, F-59000 Lille, France (Dated: April 2024)
An approach to ghost imaging with a single SPAD array used simultaneously as a several-pixel "bucket" detector and an imaging camera is described. The key points of the approach are filtering data frames used for ghost-image reconstruction by the number of per-frame counts and superposing correlation images obtained for different "bucket" pixels. The imaging is performed in an experiment with a pseudo-thermal light source where the light intensity is so low that the dark counts have a noticeable effect on imaging. We demonstrate that the approach is capable to significantly reduce the destructive effect of dark counts on the ghost image and improve image contrast, spatial resolution, and image similarity to a reference image.
## I. INTRODUCTION
Ghost imaging (GI) is already a mature research field dating back nearly a quarter of century. Since the first demonstration for GI with twin-photons [1] and subsequent GI realization with classically correlated light [24], a large corpus of experimental and theoretical works has appeared addressing particular aspects of GI and its applications for imaging/sensing (see, for example, review works [5-10]). The major practical appeal of GI is a possibility to use for image detection a maximally simple bucket detector unable to produce an image by itself. One has to use high-resolution detection only with the reference beam (a part of the correlated light not interacting with the object). Moreover, even correlations of the bucket-detector photo-current with the reference current are able to provide data sufficient for building a correlation image [11] (this possibility gave rise to a rapidly developing "single-pixel" imaging technique with such possible applications as detection of gas leaks and sensors for situational awareness for vehicles [12]).
ple, in near-infrared fluorescence lifetime imaging [16], super-resolving quantum imaging [17, 18], demonstrating of EPR inequality violation by measurement of photon correlations [19], correlation plenoptic imaging [20], Hong-Ou-Mandel interference microscopy [21], LIDAR applications [22]. In these applications, the image is reconstructed from data acquired in fixed temporal windows, hereafter referred to as frames.
One of the most perspective GI ways to enhance imaging sensitivity and account for non-classical light correlations is to apply recently developed single photon avalanche diode (SPAD) arrays for the reference-beam detection [7]. Currently, the SPAD arrays operated in various detection regimes (such as time-stamping, counting, and gating) have reached a high technological maturity [13], featuring observation rates up to 1 MHz, 200 ps time resolution [14], close to 100 % fill factor with megapixel spatial resolution [15]. SPAD cameras have already found a widespread use in imaging, for exam-
The dark counts (DC) are an inevitable effect that limits the sensitivity of SPAD-based imaging. The DC are caused by intrinsic generation of carriers within the detector in absence of illumination. The DC are not correlated with the photocounts, but they, however, cannot be separated from them. The higher the rate of DC in a pixel, the lower the correlation with the light for the events it detects. In large-size detector arrays, a significant percentage of detector-pixels (such pixels are called 'hot' pixels) could show a DC rate much higher than the median DC rate of the array, sometimes even exceeding the typical detected signal. In correlation-based imaging applications, the destructive action of DC cannot be reduced by data averaging over time. Eventually, the effect of dark counts on measurement may be minimized by disabling noisy pixels [23-25].
In this work we use the SPAD array for a ghost imaging modality that makes a step further toward full-size quantum correlation imaging with aim to improve image quality. Namely, instead of a single-pixel bucket detector we use several pixels of the imaging SPAD camera (as in [4, 26]) and perform averaging over a ghost images obtained for each "bucket" pixel. Also, we propose procedures allowing to deal with intrinsic shortcomings of SPADs in the low-light regime. The procedures are
FIG. 1: The scheme of the ghost imaging experiment: ( LD ) laser diode; ( LDM ) laser diode mount; C LD fiber collimator; ( F BB ) broadband filter; ( R B ) beam reducer; ( D ) rotating ground-glass disk; ( L C , L T ) lenses; ( D I ) iris diaphragm; ( S 1 , S 2 ) beam splitters; ( R Ref , R T ) reflectors; ( T ) target; ( F NB ) narrow-band filter; ( A SPAD ) SPAD array; ( Cam ) camera "SuperEllen"; ( PC ) computer. The inset shows how the SPAD array is illuminated by the object and reference beams. The dashed line in the inset shows boundaries of the 'Flare' area; the "bucket" pixels are there.
frame-filtering on the number of counts per frame and algorithms for dealing with dark counts in-homogeneously distributed over the SPAD pixels. We demonstrate that for a standard pseudo-thermal source of correlated photons (namely, a rotating ground-glass disk) such an approach can significantly rise the ghost-image quality.
It should be emphasized that key points of our approach, namely, filtering frames with respect to a specific number of counts and averaging over several simultaneously obtained intensity correlation images look to be rather general and applicable not only for different ghost imaging modalities, but also for generic correlation imaging with light on the few-photon level, first of all, for quantum microscopy/sensing applications.
The outline of the paper is as follows. In the second Section we describe the ghost imaging set-up, the object and the SPAD camera used for imaging. In the third Section we outline the data post-processing procedure, give the definition of the ghost image for the case of multiple bucket detectors and define two measures of image quality: the contrast-to-noise ratio and the correlation coefficient to the reference image. In the fourth Section the ghost image inference and quantification of the image contrast and quality are discussed. Here we demonstrate ghost imaging with filtered and unfiltered data, and also compare results averaged over multiple "bucket" pixels and just a single "bucket" pixel. In the Appendix, the influence of dark counts on the ghost image is discussed.
## II. SETUP
## A. Optical layout
In the work, the GI is performed by an experimental way using correlated light beams produced with help of a laser and a rotating ground-glass disk. The initial light beam is generated by a CW-operated laser source. The experimental setup is shown in Fig 1. The source is a fiber-pigtailed single-transverse-mode FabryPerot laser diode (LDS-670-FP-5-U-3-SMP04-FU-CW0.5, LaserCom LLC) operated near a wavelength λ ≈ 671 nm with an output power less than 8 mW. The diode is thermally stabilized inside a laser mount (Thorlabs LDM9T) and operates at constant current in nearthreshold mode (power supply Thorlabs LDC201CU). The laser beam is output from a PM-fiber and a fiber collimator ( C LD , efficient focus length of 7.5 mm) mounted in a Thorlabs PAF2-7B fiber-port. This beam is collimated. Its cross section has a Gaussian profile with a diameter of approximately 1.4 mm. The beam is directed through a broadband filter F BB and a free-space beam reducer ( R B , of about 3 times reduction factor) towards a rotating ground-glass disk (D). The distances | C LD D | and | R D B | are about 100 mm and 20 mm, respectively. The diameter of spot illuminated by this beam on the rotating disk is d d ≈ 0 47 . mm. Disc D has a matte surface with a random grained transparent pattern that scatters the input optical beam over a wide solid angle. The luminous laser spot on the surface of disk D is a pseudo-thermal source of correlated photons that form random structure of light spots (also called speckles) in space. The distance between the optical axis and the axis of disk rotation is 52 mm. The disk rotates at a frequency of 10 Hz. A lens ( L C , focal length F LC = 80 mm) positioned at a distance | DL C | ≈ F LC collects photons scattered by the disk, collimates and directs them through an iris diaphragm ( D I , | DD I | ≈ 20 mm) towards a beam splitter ( S 1 , | DS 1 | ≈ 55 mm).
Splitter S 1 divides the collimated speckle beam into two arms: object and reference. In the reference arm, the beam is directed through a reflector ( R Ref , | S R 1 Ref | ≈ 105 mm) and another beam splitter ( S 2 , | R S T 2 | ≈ 85 mm) towards a SPAD array ( A SPAD ) mounted in a camera (Cam). In the object arm, the beam is directed by a reflector ( R T , | S R 1 T | ≈ 85 mm) to a target (T). A lens ( L T , focus length F LT = 67 mm) collects the light transmitted by target T and focuses it (through beam splitter S 2 ) on array A SPAD ( | L A T SPAD | ≈ F LT ). Target T is positioned as close as possible to splitter S 2 . The distances | TL T | and | L S T 2 | are 13 and 15 mm, respectively. A 20 nm narrowband filter ( F NB ) is located in front of the camera for suppressing influence of stray light. The distance | S A 2 SPAD | ≈ 50 mm. The beam splitters S 1 and S 2 are 50:50 non-polarizing beamsplitter cubes BS011 (Thorlabs). The reflectors R Ref and R T are Thorlabs right-angle prism FS910L-B.
Splitter S 2 directs photons from both the reference and
FIG. 2: Resolution test target (left) and high-resolution contour plot of the object with sizes (right): a ≈ 1 3 . mm; b ≈ 0 94 . mm; c ≈ 0 20 . mm; d ≈ 0 16 . mm; e ≈ 0 116 . mm; f ≈ 0 12 . mm; g ≈ 0 19 . mm.
object arms to array A SPAD . The reference beam uniformly fills the entire surface of array A SPAD . The object arm is adjusted so that the light spot focused by lens L T on the surface of array A SPAD falls on the upper right part of A SPAD (see the inset in Fig. 1(a)). The diameter of this spot is d T = d F d LT /F C ≈ 0 39 . mm. The central part of this spot (referred to as 'bucket') is intended to be used as a bucket detector. A larger area (an area limited by dashed lines in the inset in Fig. 1(a)) around the object-beam spot is considered as a flare area, unsuitable for image reconstruction. The remaining part of array A SPAD (called 'Ghost') lighted only by the reference beam is reserved for ghost image reconstruction. A similar arrangement of having a "bucket" and "ghost" images in the region of just a single camera (albeit a CCD one) was used in an earlier work on ghost imaging with quasi-classical field [4]. Recently, a similar set-up was used in works on ghost polarimetry [26-28].
## B. Imaged object and SPAD array
The imaged object is a part of a 1951 USAF resolution test target (negative chrome-on-glass version, see Fig. 2) discussed in detail in [29]. We reproduce the images for the digit template '2' (Element 2 of Group 0) of the test target. In order to illuminate the template '2' selectively from other target patterns, the light beams are restricted by diaphragm D I . The height and width of the selected template are 1.3 and 0.94 mm. The font-line thickness for this object is a value varying from 0.11 to 0.20 mm. The image of the selected digit template is shown in Fig. 2.
The SPAD camera (Cam) is based on the "SuperEllen" sensor, specifically developed by Fondazione Bruno Kessler to target quantum imaging applications [14, 18] and implemented recently also for ghost imaging
[30, 31]. The array consists of 32 × 32 = 1024 pixels with a pitch of δ s = 44 54 . µm and a total sensitive area of 1 4 . × 1 4 . mm 2 manufactured in 150 nm CMOS standard technology. The pixels are addressed by their linear index k ∈ { 1 , . . . , 1024 } such that k = y k + 32( x k -1) where x , y k k ∈ { 1 , . . . , 32 } are the discrete Cartesian coordinates of pixels. For every pixel there is a time-to-digital converter (TDC) which timestamps the first count with up to 204 ps resolution within a frame of exposure time of up to 100 ns. Using on-chip features for reading empty rows or frames, a frequency of exposure repetition (i.e. an observation rate) of 800 kHz is achieved leading to a measurement duty-cycle of 3.6 % . The photon detection efficiency reaches 5% at 400 nm and 0 8% . at 810 nm. We did not specifically measure the efficiency at the used wavelength 671 nm. However, we estimate it as being between 1 5% . and 2% . The median dark count rate per pixel is approximately 0 7 . kHz over the whole pixel population. The timestamped counts are registered in a frame-by-frame way.
In our experiment, each frame is a result of light exposition during the time of 45 ns. As it is natural to expect with our pseudo-thermal light source, there are timecorrelation between frames. We have addressed these correlations in our recent work [32]. However, their presence does not affect current consideration. The data related to an individual frame is converted into a compressed sparse structure
$$\mathcal { D } _ { f } \coloneqq \{ f, n _ { f }, \{ x _ { k } ^ { ( i ) }, y _ { k } ^ { ( i ) }, \tau ^ { ( i ) } \} _ { i = 1, \dots, n _ { f } } \}, \quad ( 1 )$$
where f is the serial number of frame repetition; n f is the total number of events (counts) detected by all pixels in frame f ; x ( ) i k , y ( ) i k and τ ( ) i are the discrete Cartesian coordinates and the detection time for the i -th event registered in frame f . The registered data is collected and transferred to a computer (PC) as a stream of multiple frames F = {D f ∣ ∣ n f ≥ 1 } . The frames {D | f n f = 0 } (frames for which no events were detected) are not included in the stream for accelerating the data transfer process.
## III. POST-PROCESSING
## A. Datasets and correlation functions
For ghost imaging both unfiltered and filtered datasets will be used. The unfiltered dataset F 0 = { D f ∣ ∣ n f ≥ 0 } , contains all frames registered in the experiment (including the frames of original stream F and the frames {D | f n f = 0 } omitted at data transfer. The total number of frames in this dataset is N 0 .
The frame-filtered datasets
$$F ( n ^ { * } ) = F _ { 0 } | _ { n _ { f } = n ^ { * } } = \left \{ \mathcal { D } _ { f } | n _ { f } = n ^ { * } \right \} \quad \ \ ( 2 )$$
are non-overlapping sub-sets of F 0 with fixed number of
FIG. 3: Functions g (2) ( m ,k ∗ ) depending on the distance ∆ y m k ∗ for the pixel m ∗ = 496 ( x m ∗ = y m ∗ = 16 ). The functions are acquired from a frame-filtered dataset F (8) (blue squares) and unfiltered data F 0 (red stars). The blue solid ( F (8) ) and red dashed ( F 0 ) lines indicate approximation (6) to the acquired functions.
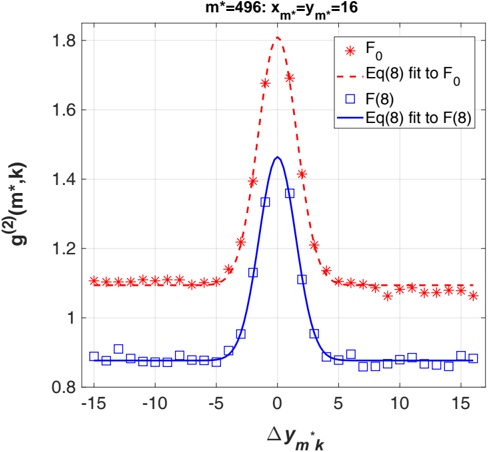
counts n ∗ in frame. The ratio
$$p ( n _ { f } = n ^ { * } ) = N ( n ^ { * } ) / N _ { 0 } \quad \quad ( 3 ) \quad \text{pro}$$
is normalised distribution of filtered sub-sets number N n ( ∗ ) .
The prepared dataset is used to calculate both a per-frame distribution of counts and their pairwise correlations[32]:
$$G ^ { ( 1 ) } ( k ) = \langle P _ { k } \rangle _ { \{ f \} }, \ \ G ^ { ( 2 ) } ( m, k ) = \langle P _ { m } P _ { k } \rangle _ { \{ f \} }, \ \ ( 4 ) \quad \text{the p}$$
where k and m are linear pixel indices, and ⟨ . . . ⟩ { f } denotes averaging over the dataset frames. The quantities P k in (4) are random binaries taking the value 1 for a count registration at the pixel k or zero in its absence. In the following consideration we use the normalized secondorder correlation function
$$g ^ { ( 2 ) } ( m, k ) = G ^ { ( 2 ) } ( m, k ) / G ^ { ( 1 ) } ( m ) G ^ { ( 1 ) } ( k ), \quad ( 5 ) \quad \text{where}$$
conditioned by the choice of dataset.
The ghost imaging implies knowledge of parameters (spatial resolution, correlation strength and background) that specify the correlation over SPAD pixels for the applied light beams. The correlation g (2) ( m ,k ∗ ) between a 'probing' low-noise pixel m = m ∗ , selected inside the "ghost" area (Fig. 1), and all other pixels of the SPAD array is well approximated by the Gaussian
$$g ^ { ( 2 ) } ( m ^ { * }, k ) \approx A _ { m ^ { * } } \exp \left \{ - \frac { | r _ { m ^ { * } k } | ^ { 2 } } { 2 B _ { m ^ { * } } ^ { 2 } } \right \} + C _ { m ^ { * } }, \quad ( 6 ) \quad \sin ^ { \infty c } \text{sim} \text{ }$$
with the distance | r m k ∗ | = √ ∆ x 2 m k ∗ +∆ y 2 m k ∗ between k -th and m ∗ -th pixels. Typical functions g (2) ( m ,k ∗ ) depending on the distance ∆ y m k ∗ acquired from different datasets for a '"probing" pixel m ∗ (the pixel is located in the middle of the SPAD array) are demonstrated in Fig. (3).
## B. Ghost image and its quality
In the work, we define the ghost image as a weighted sum of several correlation functions
$$\epsilon \Big | \quad \mathcal { I } _ { k } ^ { \prime } = \sum _ { m \in \{ B \} } G ^ { ( 1 ) } ( m ) g ^ { ( 2 ) } ( m, k ) / \sum _ { m \in \{ B \} } G ^ { ( 1 ) } ( m ). \quad ( 7 )$$
The pixels labeled by m are "bucket" pixels belonging to the set { B } . These pixels are chosen as located near the center of the object-beam spot on the SPAD area. The image pixels labeled by k are in the "ghost" area.
The scaling factor and background of the image I ′ k are dataset dependent. In order to minimize such an uncertainty and, hence, to facilitate analyzing the images produced from different datasets the array (7) is converted into a background-subtracted normalized image structurally identical to I ′ k :
$$\mathcal { I } ( x _ { k }, y _ { k } ) \equiv \mathcal { I } _ { k } = ( \mathcal { I } _ { k } ^ { \prime } - \bar { C } ) / \bar { A }. \text{ \quad \ \ } ( 8 )$$
In our experiment, quality assessment for the reconstructed ghost images is performed by analyzing the properties of I k . In accordance with (6), the spatial resolution of GI is limited by a quantity of ∼ 2 ¯ Bδ s .
We apply two measures specifying the image quality. The contrast-to-noise ratio ( CNR ) is a measure traditionally applied to characterize the quality of spatially restricted image parts. In imaging applications, these parts usually refer to transmitting ('In') or non-transmitting ('Out') areas of the imaged object. In our experiment, the pixels of these parts are addressed by the indices k belonging to the sets { In } or { Out } , respectively. The CNR defined as a ratio of the image contrast K to the total error σ is found in the form:
$$C N R = \frac { K } { \sigma } = \frac { \langle \mathcal { I } _ { k } \rangle _ { \{ I n \} } - \langle \mathcal { I } _ { k } \rangle _ { \{ O u t \} } } { \sqrt { \sigma _ { I n } ^ { 2 } + \sigma _ { O u t } ^ { 2 } } }, \quad \ ( 9 )$$
where the averaging ⟨ . . . ⟩ { In,Out } is carried out over the sets { In } or { Out } . The quantities σ 2 In,Out are corresponding variances of I k . At evaluating CNR , we cannot properly assess the influence of strong-noise pixels on the ghost image since they are sparsely dispersed over the SPAD array and the area 'In' is essentially small. Therefore, for definiteness, the sets { In } and { Out } includes only indices of low-noise pixels.
The quality of image can also be assessed with help of a correlation coefficient which pixel-by-pixel measures the strength of linear relationship (that is, a structural similarity [33]) between the analyzed image and a higherquality reference image of the same object. Unlike CNR ,
FIG. 4: A high-resolution conventional image (a) and a 32 × 32 -pixel reference image I ( r ) ( x , y k k ) (b) of the object.
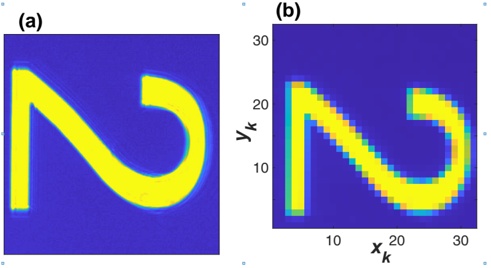
this measure is applicable to the entire image. We apply the correlation coefficient to evaluate the quality for the entire "ghost" area including highly noised pixels. To produce a reference image of suitable quality, we project a conventional image of the object (back-lighted by a laser beam) with help of a converging lens on the photosensitive matrix of a high-resolution digital camera (UI3240CP-NIR-GL Rev.2, DS Imaging Development Systems GmbH, pixel size of 5 3 . µm ) at a lens magnification of ∼ 1 5 . . A high-resolution image (spatial resolution of ∼ 3 5 . µm /pixel, this image is illustrated in Fig. 4(a)) stored by the digital camera is converted into a 32 × 32 -pixel image I ( r ) ( x , y k k ) ≡ I ( r ) k (resolution of ∼ 45 µm /pixel). The obtained high-contrast and lownoise image I ( r ) k (the image is shown in Fig. 4(b)) is then exploited as a reference in order to find the correlation coefficient:
$$R = \frac { \left | \sum _ { k \in \{ g h o s t \} } ( I _ { k } ^ { ( r ) } - \langle I _ { k } ^ { ( r ) } \rangle ) ( \mathcal { I } _ { k } - \langle \mathcal { I } _ { k } \rangle ) \right | } { \sqrt { \sum _ { l, k \in \{ g h o s t \} } ( I _ { l } ^ { ( r ) } - \langle I _ { l } ^ { ( r ) } \rangle ) ^ { 2 } ( \mathcal { I } _ { k } - \langle \mathcal { I } _ { k } \rangle ) ^ { 2 } } }, \quad ( 1 0 ) \quad \text{Th} _ { \substack { F _ { 0 }, \text{ is} } }.$$
where the summation is done over the "ghost" part of the SPAD area. In equation (10) brackets ⟨ . . . ⟩ denote averaging over the "ghost" area pixels. To achieve an accurate correspondence between the ghost and reference images, (i.e., to ensure the same position and the same scaling factor for the both images on the 32 × 32 pixel grid) the correlation coefficient R is maximized at image converting. The error of R evaluation is less than 0 01 . .
Overall the following procedure of ghost-image reconstruction is implemented. First of all, a dataset is prepared. The prepared dataset is applied to calculate G (1) ( m ) and G (2) ( m,k ) and find normalized correlation function g (2) ( m,k ) as described in equations (4) and (5). After that the averaged parameters ¯ A B C , ¯ , ¯ and A/C of correlation function (6) are evaluated. Then, a ghost image I k is computed in accordance with equations (7) and (8). Finally, quality of the obtained image is examined visually and estimated using CNR (9) and correlation
## IV. RESULTS AND DISCUSSION
In our GI experiment, the light beams are registered under conditions where ⟨ n f ⟩ ≈ 8 . The registered data stream F is collected over 186 minutes, stored on the computer and later post-processed. At post-processing, this dataset is used to prepare an unfiltered dataset F 0 and then to produce a number of frame-filtered sets F n ( ∗ ) .
The maximum count rate for the object-beam spot on the SPAD array is realized near the point (20 29) , (here and further we denote the pixels coordinates x and y just by a pair of indices ( x, y ) ). The "flare" area is taken as a rectangle with vertices at the pixels (12,32), (12,24), (26,24), (26,32). The rectangle contains 15 × 9 = 135 pixels. So, the remaining "ghost" area includes J max = 1024 -135 = 889 pixels. Twenty four low-noise pixels uniformly and randomly distributed across the "ghost" area are selected as the "probing" pixels m ∈ { m ∗ } required to determine the averaged parameters ¯ A B C , ¯ , ¯ and A/C .
In the study, we apply two sets { B } of "bucket" pixels. Eight low-noise pixels around the pixel (20 29) , and this pixel are used as a "bucket" set. On the other hand, to highlight advantages offered by our approach, we also demonstrate a traditional GI technique. For that we just choose as a "bucket" detector a single pixel in the "bucket" region. This pixel is the point (20 29) , . The "flare" area, the exploited "probing" and "bucket" pixels are indicated in Fig 5(a).
## A. GI with unfiltered data
The total number of frames in the unfiltered dataset F 0 is N 0 ∼ 1 9 . × 10 9 . The per-frame probabilities G (1) ( x , y k k ) ≡ G (1) ( k ) obtained for all pixels of the SPAD array from this dataset are shown in Fig. 5(a). The averaged values of shape parameters and the corresponding standard deviations are as follows: ¯ A ≈ 0 780 . , σ A ≈ 0 047 . ; ¯ B ≈ 1 72 . , σ B ≈ 0 085 . ; and ¯ C ≈ 1 085 . , σ C ≈ 0 0046 . . According to the obtained data, the spatial resolution of the image computed from the data F 0 is of ∼ 2 ¯ Bδ s ≈ 3 44 . δ s ≈ 0 15 . mm. The average perframe probability of counts detected by the "bucket" pixels ⟨ G (1) ( k ) ⟩ k ∈{ B } ≈ 0 057 . (this quantity is obtained by averaging of ⟨ G (1) ( k ) ⟩ over the nine 'bucket' pixels) is ∼ 300 times higher than the corresponding averaged probability of dark counts ⟨ G (1) DC ( k ) ⟩ k ∈{ B } ≈ 1 8 . × 10 -4 .
The computed ghost image I ( x , y k k ) is represented in Fig. 5(b). The visual examination of this figure shows that the imaged object is recognizable in the ghost image. However, the presented figure clearly demonstrates a serious drawback. The number of noisy pixels is so high
FIG. 5: GI based on the unfiltered dataset F 0 . The white x's show the pixels belonging to the "bucket' region. The white squares and black circles show, respectively, the pixels belonging to the sets { In } and { Out } . Panel (a) : distribution of log 2 [ G (1) ( x , y k k )] ; the white cross shows the point (20,29) corresponding to the maximal intensity of the object-beam spot; the white dashed line indicates a rectangle containing the 'flare' region; the white circles show the 'probing' pixels. Panel (b) : ghost image I ( x , y k k ) ; white crosses indicate positions of 9 pixels chosen as a "bucket". Panel (c) : ghost image reconstructed with the single-pixel "bucket" marked by x in the "flare" area.
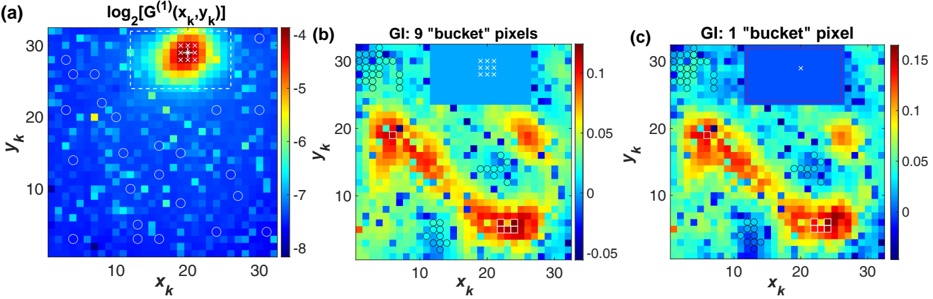
that they have a strong destructive effect on the quality of the entire image. According to Appendix, the efficient number of pixels distinguishable (due to the dark-count effect) in the ghost image reconstructed from the dataset F 0 is of ∼ 100 . In addition, the spatial resolution is clearly suffering. The resolution is not high enough to resolve all parts of the object. The "tail" of the imaged digit "2" (a ∼ 0 1 . mm wide strip) is not visible in the reconstructed image.
The quality of the obtained image I k is estimated numerically in terms of CNR (9) and structure similarity with the reference image (10). In the CNR evaluation we exploit 6 low-noise pixels for the set { In } and 43 low-noise pixels for the set { Out } (these pixels are indicated in Fig. 5(b)). The { In } pixels are located near the maxima of the observed ghost image. For these pixels sets we have ⟨I k ⟩ { In } ≈ 0 1170 . , σ In ≈ 0 0046 . and ⟨I k ⟩ { Out } ≈ 0 0163 . , σ Out ≈ 0 0073 . . According to (9), the image CNR ≈ 11 7 . is achieved at the contrast of K ≈ 0 101 . and the total error σ ≈ 0 0086 . . Along our estimation (10), the coefficient of correlation R between the image I k and the reference image I ( r ) k is of ∼ 0 62 . .
The unfiltered data F 0 is a composition of frames with different values of n f . Fig. 6 shows the probability distribution that expresses a per-frame probability (3). The shape of this distribution is rather close to the shape of the Poisson distribution with the same average number of counts per frame. The obtained p n ( f = n ′ ) distribution has a maximum near n ′ = 7 and a half-maximum width of ∼ 9 .
## B. GI with filtered data
In this subsection, we exploit frame-filtered datasets F n ( ∗ ) that are produced by filtering the data F 0 consid-
FIG. 6: Distribution of per-frame probabilities p n ( f = n ′ ) over realizations of n f (blue squares) for the unfiltered dataset F 0 . The Poisson probability distribution of the same ⟨ n f ⟩ are shown by the red solid line. The Poisson distribution that represents the dark counts typical for the applied SPAD array is depicted by the black dashed line
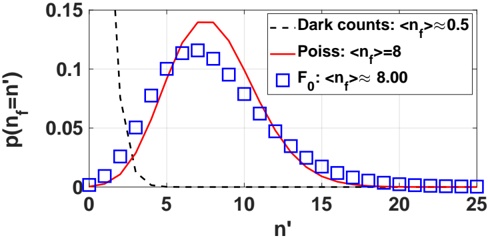
ered in the previous subsection. For the exploited data, the parameter n ∗ ranges from 2 to 24 (see Fig.6).
The datasets F n ( ∗ ) are used to clarify how the dataset composition may affect the correlation function (6). Fig.7 shows the dependence of the half-width ¯ B and the ratio A/C on n ∗ (the scatters show the corresponding rootmean-squared deviations). As can be seen from this figure, the parametric ratio A/C , within the error of its determination, does not depend on n ∗ . On the other hand, the half-width ¯ B monotonically increases with n ∗ from 1.4 to 2 pixels. As a result, the spatial resolution of GI will worsen from ∼ 0 12 . mm up to ∼ 0 18 . mm with the parameter n ∗ . The GI based on a frame-filtered dataset with n ∗ < 12 must exhibit better spatial resolution than the GI reconstructed from the unfiltered data F 0 . The observed dispersion-like phenomenon for the half-width
FIG. 7: Dependence on n ∗ for averaged ratio A/C ( left Y axis: blue circles) and half-width ¯ B ( right Y axis: red stars) obtained from frame-filtered datasets F n ( ∗ ) . The relevant parameters acquired from the unfiltered data F 0 are shown by a blue dash-dotted line with a blue square (left Y axis: A/C ) and a red dashed line with a red square (right Y axis: ¯ B ).
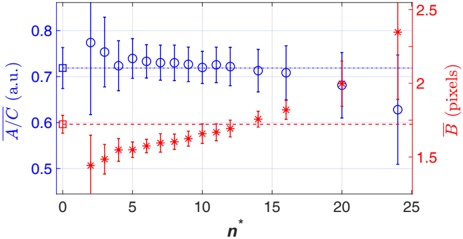
FIG. 8: Ghost images reconstructed from the frame-filtered datasets F (4) (a), F (8) (b) and F (16) (c). Ghost image computed from the frame-filtered dataset F (8) with the single-pixel "bucket" (d). The white squares, circles and x's show, respectively, the pixels belonging to the sets { In } , { Out } and { B } .
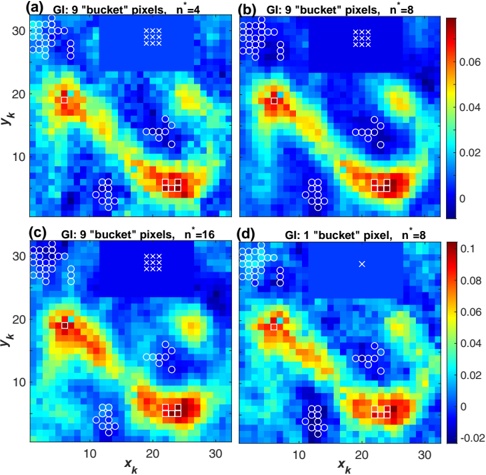
¯ B may be associated with specific optical properties of the rotating disk D. The datasets F n ( ∗ ) are used to reconstruct ghost images. Fig. 8 demonstrates images I k computed from frame-filtered datasets F n ( ∗ ) at n ∗ = 4 , 8 and 16 . In terms of contrast, spatial resolution, and number of distinguishable noised pixels, the presented images look significantly better compared to the ghost image obtained from unfiltered data. Image qualities (such as spa-
FIG. 9: CNR (left Y axis: blue stars) and correlation coefficient R (right Y axis: red squares) as functions of n ∗ for ghost images reconstructed from frame-filtered datasets F n ( ∗ ) . The blue dashed and red solid lines indicates CNR (left Y axis) and R (right Y axis) for the unfiltered data F 0 .
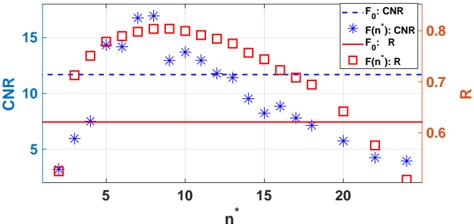
tial resolution and contrast) depend on the parameter n ∗ . Based on visual inspection of the presented images one can conclude that ghost images of the highest quality are realized for datasets F n ( ∗ ) with n ∗ ∼ 8 . As can be seen from Fig 8 (b), the spatial resolution of the image I k based on the dataset F(8) is high enough to resolve all parts of the imaged object. In accordance with Appendix, only a few pixels of the image reconstructed from F(8) can be identified as pixels affected by dark counts.
This conclusion is corroborated with the results of numeric evaluation of CNR (9) and the correlation coefficient (10) represented in Fig. 9. In the CNR evaluation, the pixels k ∈ { In } and k ∈ { Out } are the same pixels as in the previous subsection. Generally, for the ghost image based on the frame-filtered data, the maximum CNR and correlation coefficient R are achieved near those values of n ∗ that correspond to the maximum probability p n ( f = n ′ ) of the distribution analyzed in the previous subsection and represented in Fig.6. As shown in Fig. 9 (left Y axis), compared to the "unfiltered" image, the "frame-filtered" image I k has a higher CNR when the parameter n ∗ ranges from 5 to 10. At n ∗ = 8 , the filtered GI reaches its maximal CNR ≈ 17 0 . ( ⟨I k ⟩ { In } ≈ 0 0744 . , σ In ≈ 0 0033 . , ⟨I k ⟩ { Out } ≈ 0 0009 . , σ Out ≈ 0 0028 . , K ≈ 0 0735 . , σ ≈ 0 0043 . ) which is nearly 45% higher as compared to the CNR of unfiltered GI.
Unlike CNR , the measure of structural similarity (10) takes into account the effect of strong-noise pixels on the image. Therefore, the range 3 ≤ n ∗ ≤ 19 , where the "low-noise" filtered GI leads to a higher coefficient R (as compared to the "noisy" unfiltered GI), covers almost all of the considered values of n ∗ . Like CNR , the structural similarity between the reference and ghost images attains its maximum at n ∗ = 8 leading to R ≈ 0 8 . (right Y axis of Fig. 9).
## C. GI with a single-pixel "bucket"
The per-frame probability of counts detected by the single "bucket" pixel G (1) (20 29) , ≈ 0 069 . obtained from the unfiltered data F 0 is substantially high compared to the corresponding probability of dark counts G (1) DC (20 29) , ≈ 4 5 . × 10 -5 . The ghost images computed with the single-pixel "bucket" from the unfiltered data F 0 and the filtered dataset F (8) are shown in Fig 5(c) and Fig 8(d), respectively. The resulting ghost image obtained with the data F 0 is the image that one gets with traditional ghost imaging technique for the case. It seems close to the GI of Fig 5(b) obtained with our approach for the data F 0 . Indeed, the correlation coefficient is only slightly lower, R ≈ 0 6 . in comparison to the correlation for the multiple-pixel "bucket" image ( R ≈ 0 62 . ). However, CNR is nearly twice lower, CNR ≈ 6 73 . .
Using the filtered dataset F (8) improves the correlation giving R ≈ 0 724 . . However, simultaneously it leads to degradation of the contrast, CNR ≈ 5 46 . . Thus, a single-pixel "bucket" imaging modality for the case cannot ensure the quality of image given by averaging over several GI in our approach.
## V. CONCLUSIONS
We have presented an approach to ghost imaging and analyzed the approach capabilities in an experiment where the light intensity is so low that the dark counts have a noticeable effect on the imaging. We have demonstrated that filtering the acquired data with respect to the number of counts per frame and obtaining the image as a weighted average over the images for different "bucket" pixels, one can significantly reduce the destructive effect of dark counts on the ghost image, improve the image contrast, spatial resolution and image similarity to the reference image. The proposed approach allowed us inferring ghost images for dark counts reaching 20% of the the total "bucket" counts and with the photon fluxes of just few photons per time-frame. In our opinion, using multiple bucket detectors instead of just one is compatible with most applications of ghost imaging and will allow one to greatly enhance imaging quality in the extremely-low-light condition. These results can be extended to computational [5, 11-13] and temporal [34-36] ghost imaging. Our findings are important for developing correlation imaging schemes with light on a-few-photon level, first of all, for quantum sensing applications.
We feel that as a concluding remark it would be useful to emphasize our motivation. As it is shown in Appendix, the proposed frame-filtering approach improves considerably the reconstructed ghost images and, simultaneously, has no effect on the quality of G (1) . Thus, we do not expect any improvement compared to the conventional imaging with the same light source and detection system [37]. Our motivation was to improve the quality of the ghost imaging with very low photon fluxes using very realistic noisy SPADs with inhomogeneous quality of pixels. We see this task as quite actual and practical for improving ghost imaging in its application niche.
## FUNDING
V.S., S.K., V.C. and A. S. acknowledge financial support from the State Research Program "Convergence" subprogram 3.01.2. D.M. acknowledges financial support from the BRFFR project F23UZB-064. This work was supported by the European Commission through the SUPERTWIN Project under Grant 686731.
## DISCLOSURES
The authors declare no conflicts of interest.
## DATA AVAILABILITY
Data underlying the results presented in this paper are not publicly available at this time but may be obtained from the authors upon reasonable request.
## Appendix A: Dark counts of the SPAD array and their effect on reconstructed ghost images
To analyze the effect of dark-counts (DC) for the SPAD array we, first of all, measure the probability of counts for each SPAD pixel under conditions where the detection events are DC. To ensure this condition, the SPAD array is blocked by a light-tight screen from any light source (including ambient light). The registered data are stored in the computer as a frame-unfiltered dataset F DC including ∼ 2 8 . × 10 9 frames. The per-frame probabilities of DC G (1) DC ( k ) for all SPAD pixels are found from the dataset F DC , as described in Section III. The distribution of measured G (1) DC ( x , y k k ) over the pixels of the SPAD array is shown in Fig 10. The bright pixels of this distribution are strongly noised pixels of the SPAD array. The brightest pixel is the pixel k = 212 with coordinates x k = 7 , y k = 20 . One can see in Fig 10 that distribution of DC rates over the SPAD pixels is quite inhomogeneous and randomized. The measured probabilities G (1) DC ( k ) are in a wide range of values from ∼ 10 -5 to ∼ 10 -2 . The average DC probability per pixel and per frame reaches a value of ⟨ G (1) DC ⟩ ≈ 4 9 . × 10 -4 (or approximately 0.5 per frame). The dependence of per-frame probability p n ( f = n ′ ) on n ′ for this data is represented by the Poisson distribution with ⟨ n f ⟩ ≈ 0 5 . and shown in Fig.6.
In general, despite the substantial inhomogeneity and randomness, the influence of DC on the measurement can be evaluated if the evaluation operates with specially
FIG. 10: Per-frame dark counts distribution G (1) over the SPAD pixels. The colorbar shows the corresponding normalized values.
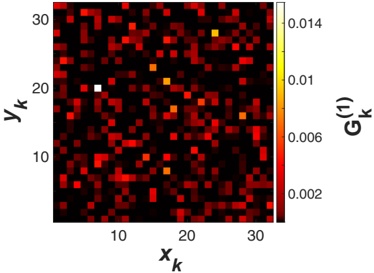
FIG. 11: 'DC-ordered' sequences G (1) DC ( S j ) (a, black dashed line), G (1) ( S j ) (a) and ∆ ( I S j ) (b) as functions of the serial number j . The red circles show the sequences calculated from the unfiltered data F 0 . The blue solid line and dots indicate the sequences found from the frame-filtered dataset F (8) . The inset of panel (a) demonstrates the same data (as in the main panel) at a larger Y-axis scale. The red dashed line in this inset indicates the average probability ⟨ G (1) DC ⟩ . The inset of panel (b) shows the same data (as in the main panel) in a log scale on the X-axis.
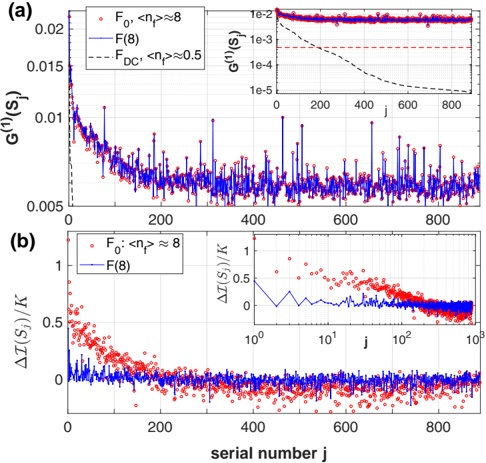
organized sequences of pixels. In these sequences, the pixels are arranged so that their dark count rates G (1) DC ( k ) are ordered in descending order ('DC-ordering'):
$$G _ { D C } ^ { ( 1 ) } ( k ) \xrightarrow { D C - o r d e r i n g } G _ { D C } ^ { ( 1 ) } ( S _ { j } ), \quad ( \text{A} 1 ) \quad \overset { \psi \nu } { \text{is} \nu_{\ell} }$$
where j is the serial number for each term of the se- quence G (1) DC ( S j ) . The sort index S j specifies how the data G (1) DC ( k ) should be rearranged to obtain the ordered sequence G (1) DC ( S j ) . The first terms of the DC-ordered sequence belong to strongly noisy pixels, the last to lownoise pixels.
The DC effect on a measured quantity Q k ( ) is evaluated by analyzing a 'DC-ordered' sequence Q S ( j ) . For the pixels with a weak influence of DC on Q (e.g., for low-noise pixels with j ≫ 1 ) the measured Q S ( j ) fluctuates around a certain value Q 0 , independent of j . On the other hand, for a pixel k ′ where the influence of DC on Q is significant, the quantity Q k ( ′ ) is a function of G (1) DC ( k ′ ) . For several pixels with strong DC effect, the DC-ordered sequence Q S ( j ) explicitly reproduces the sequence G (1) DC ( S j ) within a j index range ν Q . In a sense, the deviation χ Q = max ( | Q S ( j ) -Q 0 | ) realized near j = 1 and the width of the range ν Q can be accepted as measures of the DC effect. The width ν Q can be associated, for instance, with an efficient number of noised pixels that have a destructive effect on the measured quantity Q . The deviation χ Q characterizes the effect strength for the "hot" pixels.
To evaluate the DC effect on a reconstructed ghost image I ( x , y k k ) we compute a pixel-by-pixel image difference ∆ ( ) I k ≡ ∆ ( I x , y k k ) = ˜ ( I x , y k k ) - I ( x , y k k ) . Here, ˜ ( I x , y k k ) is an image obtained from I ( x , y k k ) by a 2D smoothing in which the convolution kernel is a 3 × 3 pixel square. The quantity ∆ ( ) I k is insensitive to pattern variation for the imaged object and approximately equal to fluctuation in I ( x , y k k ) between the neighboring pixels. Owing to these properties, the difference ∆ I is well adapted to register one-pixel-ranged correlation drops typical for strongly noised pixels sparsely dispersed across the SPAD array. We analyze the dependence of the 'DC-ordered' difference ∆ ( I S j ) on the index j . In a similar way, the DC influence on the measured probabilities G (1) can be evaluated by considering the sequence G (1) ( S j ) as a function of j . The 'DCordered' sequences G (1) ( S j ) and ∆ ( I S j ) calculated for the pixels k ∈ { ghost } ( j = 1 , . . . , J max ) from framefiltered and unfiltered datasets (they are datasets F (8) and F 0 applied for ghost image computation in Section IV) are represented in Fig. 11. For illustrative purposes (to demonstrate the effect manifestation in comparison with the image contrast K ), the difference ∆ ( I S j ) in the figure is normalized by K .
Regardless of the type of filtering (with or without frame filtering), the DC have an equal influence on the probabilities G (1) obtained from data with the same average numbers ⟨ n f ⟩ . As shown in Fig. 11 (a), the dependencies of G (1) ( S j ) on the j index for filtered and unfiltered data ( F (8) and F 0 with ⟨ n f ⟩ ≈ 8 ) are very similar. The efficient number of pixels distinguishable due to the DC effect in the imaged distribution G (1) ( x , y k k ) is ν G 1 ∼ 100 for the both datasets. Contrary to G (1) , the manifestation of DC effect in ghost images (see Fig. 11 (b)) depends significantly on what data (frame-filtered or
not) is used to compute the images. The efficient number of pixels distinguishable (due to the DC effect) in the ghost image computed from the unfiltered data F 0 is ν ∆ I ∼ ν G 1 ∼ 100 . For the frame-filtered dataset F (8) , the manifestation of the DC effect is essentially small. In fact, only a few pixels can be identified that are affected
- [1] T. B. Pittman, Y. H. Shih, D. V. Strekalov, and A. V. Sergienko, Optical imaging by means of two-photon quantum entanglement, Phys. Rev. A 52 , R3429 (1995).
- [2] R. S. Bennink, S. J. Bentley, and R. W. Boyd, Twophoton coincidence imaging with a classical source, Phys. Rev. Lett. 89 , 113601 (2002).
- [3] A. Valencia, G. Scarcelli, M. D'Angelo, and Y. Shih, Twophoton imaging with thermal light, Phys. Rev. Lett. 94 , 063601 (2005).
- [4] A. Gatti, M. Bache, D. Magatti, E. Brambilla, F. Ferri, and L. A. Lugiato, Coherent imaging with pseudothermal incoherent light, Journal of Modern Optics 53 , 739 (2006).
- [5] B. I. Erkmen and J. H. Shapiro, Ghost imaging: from quantum to classical to computational, Adv. Opt. Photon. 2 , 405 (2010).
- [6] J. H. Shapiro and R. W. Boyd, The physics of ghost imaging, Quantum Information Processing 11 , 949 (2012).
- [7] M. J. Padgett and R. W. Boyd, An introduction to ghost imaging: quantum and classical, Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 375 , 20160233 (2017).
- [8] D. S. Simon, G. Jaeger, and A. V. Sergienko, Ghost imaging and related topics, in Quantum Metrology, Imaging, and Communication (Springer International Publishing, Cham, 2017) pp. 131-158.
- [9] G. M. Gibson, S. D. Johnson, and M. J. Padgett, Singlepixel imaging 12 years on: a review, Opt. Express 28 , 28190 (2020).
- [10] M. Padgett, Quantum imaging overview, in Quantum Sensing, Imaging, and Precision Metrology , Vol. 12447, edited by J. Scheuer and S. M. Shahriar, International Society for Optics and Photonics (SPIE, 2023) p. 1244702.
- [11] J. H. Shapiro, Computational ghost imaging, Phys. Rev. A 78 , 061802 (2008).
- [12] M. P. Edgar, G. M. Gibson, and M. J. Padgett, Principles and prospects for single-pixel imaging, Nature Photonics 13 , 13 (2019).
- [13] C. Bruschini, H. Homulle, I. M. Antolovic, S. Burri, and E. Charbon, Single-photon avalanche diode imagers in biophotonics: review and outlook, Light: Science and Applications 8 , 1 (2019).
- [14] M. Zarghami, L. Gasparini, L. Parmesan, M. MorenoGarcia, A. Stefanov, B. Bessire, M. Unternährer, and M. Perenzoni, A 32 x 32-pixel CMOS imager for quantum optics with Per-SPAD TDC, 19.48 % fill-factor in a 44.64µ m pitch reaching 1-MHz observation rate, IEEE Journal of Solid-State Circuits 55 , 2819 (2020).
- [15] K. Morimoto, J. Iwata, M. Shinohara, H. Sekine, A. Abdelghafar, H. Tsuchiya, Y. Kuroda, K. Tojima, W. Endo, Y. Maehashi, Y. Ota, T. Sasago, S. Maekawa, S. Hikosaka, T. Kanou, A. Kato, T. Tezuka, S. Yoshizaki, T. Ogawa, K. Uehira, A. Ehara, F. Inui, Y. Matsuno,
by DC. The deviation χ ∆ I realized for the "hottest" pixel k = 212 is more than three times smaller than for unfiltered data. Such a dramatic reducing (compared to F 0 ) in the DC effect is observed for all frame-filtered datasets used in Section IV at GI reconstructing. All pixels with the index j > 300 are accepted to be low-noise.
- K. Sakurai, and T. Ichikawa, 3.2 megapixel 3D-stacked charge focusing SPAD for low-light imaging and depth sensing, 2021 IEEE International Electron Devices Meeting (IEDM) , 20.2.1 (2021).
- [16] J. T. Smith, A. Rudkouskaya, S. Gao, J. M. Gupta, A. Ulku, C. Bruschini, E. Charbon, S. Weiss, M. Barroso, X. Intes, and X. Michalet, In vitro and in vivo NIR fluorescence lifetime imaging with a time-gated SPAD camera, Optica 9 , 532 (2022).
- [17] H. Defienne, P. Cameron, B. Ndagano, A. Lyons, M. Reichert, J. Zhao, A. Harvey, E. Charbon, J. Fleischer, and D. Faccio, Pixel super-resolution with spatially entangled photons, Nature Communications 13 (2022).
- [18] M. Unternährer, B. Bessire, L. Gasparini, M. Perenzoni, and A. Stefanov, Super-resolution quantum imaging at the heisenberg limit, Optica 5 , 1150 (2018).
- [19] B. Eckmann, B. Bessire, M. Unternährer, L. Gasparini, M. Perenzoni, and A. Stefanov, Characterization of space-momentum entangled photons with a time resolving CMOS SPAD array, Opt. Express 28 , 31553 (2020).
- [20] C. Abbattista, L. Amoruso, S. Burri, E. Charbon, F. Di Lena, A. Garuccio, D. Giannella, Z. Hradil, M. Iacobellis, G. Massaro, P. Mos, L. Motka, M. Paúr, F. V. Pepe, M. Peterek, I. Petrelli, J. Řeháček, F. Santoro, F. Scattarella, A. Ulku, S. Vasiukov, M. Wayne, C. Bruschini, M. D'Angelo, M. Ieronymaki, and B. Stoklasa, Towards quantum 3D imaging devices, Applied Sciences 11 , 10.3390/app11146414 (2021).
- [21] B. Ndagano, H. Defienne, D. Branford, Y. Shah, A. Lyons, N. Westerberg, E. Gauger, and D. Faccio, Quantum microscopy based on Hong-Ou-Mandel interference, Nature Photonics 16 , 384 (2022).
- [22] J. Zhao, A. Lyons, A. C. Ulku, H. Defienne, D. Faccio, and E. Charbon, Light detection and ranging with entangled photons, Opt. Express 30 , 3675 (2022).
- [23] L. H. C. Braga, L. Gasparini, L. Grant, R. K. Henderson, N. Massari, M. Perenzoni, D. Stoppa, and R. Walker, A fully digital 8 × 16 SiPM array for PET applications with per-pixel TDCs and real-time energy output, IEEE Journal of Solid-State Circuits 49 , 301 (2014).
- [24] A. Carimatto, A. Ulku, S. Lindner, E. Gros-Daillon, B. Rae, S. Pellegrini, and E. Charbon, Multipurpose, fully integrated 128 × 128 event-driven MD-SiPM with 512 16-bit TDCs with 45-ps LSB and 20-ns gating in 40nm CMOS technology, IEEE Solid-State Circuits Letters 1 , 241 (2018).
- [25] H. Xu, L. Pancheri, G.-F. D. Betta, and D. Stoppa, Design and characterization of a p + /n-well SPAD array in 150nm CMOS process, Opt. Express 25 , 12765 (2017).
- [26] S. Magnitskiy, D. Agapov, and A. Chirkin, Quantum ghost polarimetry with entangled photons, Opt. Lett. 47 , 754 (2022).
- [27] S. Magnitskiy, D. Agapov, and A. Chirkin, Ghost po-
larimetry with unpolarized pseudo-thermal light, Opt. Lett. 45 , 3641 (2020).
- [28] S. A. Magnitskiy, D. P. Agapov, I. A. Belovolov, P. P. Gostev, D. N. Frolovtsev, and A. S. Chirkin, Ghost Polarimetry in Classical and Quantum Light, Moscow University Physics Bulletin 76 , 424 (2021).
- [29] https://www.savazzi.net/photography/1951usaf. html .
- [30] C. Pitsch, D. Walter, L. Gasparini, H. Bürsing, and M. Eichhorn, 3D quantum ghost imaging, Appl. Opt. 62 , 6275 (2023).
- [31] V. F. Gili, D. Dupish, A. Vega, M. Gandola, E. Manuzzato, M. Perenzoni, L. Gasparini, T. Pertsch, and F. Setzpfandt, Quantum ghost imaging based on a 'looking back' 2D SPAD array, Appl. Opt. 62 , 3093 (2023).
- [32] V. S. Starovoitov, V. N. Chizhevsky, D. B. Horoshko, and S. Y. Kilin, Spatio-Temporal Correlations of Pho-
- tons from a Pseudo-Thermal Source, Journal of Applied Spectroscopy 90 , 377 (2023).
- [33] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, Image quality assessment: from error visibility to structural similarity, IEEE transactions on image processing 13 , 600 (2004).
- [34] P. Ryczkowski, M. Barbier, A. T. Friberg, J. M. Dudley, and G. Genty, Ghost imaging in the time domain, Nature Photonics 10 , 167 (2016).
- [35] F. Devaux, P.-A. Moreau, S. Denis, and E. Lantz, Computational temporal ghost imaging, Optica 3 , 698 (2016).
- [36] D. B. Horoshko, Time-to-space ghost imaging, Opt. Lett. 48 , 3247 (2023).
- [37] P.-A. Moreau, E. Toninelli, P. A. Morris, R. S. Aspden, T. Gregory, G. Spalding, R. W. Boyd, and M. J. Padgett, Resolution limits of quantum ghost imaging, Opt. Express 26 , 7528 (2018). | null | [
"V. S. Starovoitov",
"V. N. Chizhevsky",
"D. Mogilevtsev",
"A. Smaliakou",
"M. Perenzoni",
"L. Gasparini",
"D. B. Horoshko",
"S. Kilin"
] | 2024-08-02T10:11:51+00:00 | 2024-08-02T10:11:51+00:00 | [
"physics.optics"
] | Frame-filtered ghost imaging with a SPAD array used both as a multiple "bucket" detector and an imaging camera | An approach to ghost imaging with a single SPAD array used simultaneously as
a several-pixel "bucket" detector and an imaging camera is described. The key
points of the approach are filtering data frames used for ghost-image
reconstruction by the number of per-frame counts and superposing correlation
images obtained for different "bucket" pixels. The imaging is performed in an
experiment with a pseudo-thermal light source where the light intensity is so
low that the dark counts have a noticeable effect on imaging. We demonstrate
that the approach is capable to significantly reduce the destructive effect of
dark counts on the ghost image and improve image contrast, spatial resolution,
and image similarity to a reference image. |
2408.01154v1 | ## DERA: Dense Entity Retrieval for Entity Alignment in Knowledge Graphs
Zhichun Wang and Xuan Chen Beijing Normal University, Beijing, China [email protected]
## Abstract
Entity Alignment (EA) aims to match equivalent entities in different Knowledge Graphs (KGs), which is essential for knowledge fusion and integration. Recently, embeddingbased EA has attracted significant attention and many approaches have been proposed. Early approaches primarily focus on learning entity embeddings from the structural features of KGs, defined by relation triples. Later methods incorporated entities' names and attributes as auxiliary information to enhance embeddings for EA. However, these approaches often used different techniques to encode structural and attribute information, limiting their interaction and mutual enhancement. In this work, we propose a dense entity retrieval framework for EA, leveraging language models to uniformly encode various features of entities and facilitate nearest entity search across KGs. Alignment candidates are first generated through entity retrieval, which are subsequently reranked to determine the final alignments. We conduct comprehensive experiments on both cross-lingual and monolingual EA datasets, demonstrating that our approach achieves state-of-the-art performance compared to existing EA methods.
The problem of EA has been studied for years and many approaches have been proposed. Early EA approaches rely on manually designed features to compute similarities of entities(Noy et al., 2017). Recently, embedding-based EA has attracted much attention, many approaches have been proposed and achieved promising performance. These approaches first embed entities in low-dimensional vector spaces, and then discover entity alignments based on distances of entity embeddings. There are mainly two paradigms of KG embedding, translation-baed methods and Graph Neural Network(GNN)-based methods. Translation-based methods learn entity embeddings using TransE or its extended models, including MTransE(Chen et al., 2017), JAPE(Sun et al., 2017), and BootEA(Sun et al., 2018), etc. GNN-based methods learn neighborhood-aware representations of entities by aggregating features of their neighbors, such approaches include GCNAlign(Wang et al., 2018), MuGNN(Cao et al., 2019), and AliNet(Sun et al., 2020a), etc.
## 1 Introduction
Knowledge Graphs (KGs) represent structured information of entities in various domains, which facilitates machines to handle domain knowledge. Most published KGs, such as YAGO(Rebele et al., 2016), DBpedia(Bizer et al., 2009), and WikiData(Vrandeˇ ci´ c and Krötzsch, 2014), are heterogeneous because they are either built from different data sources or by different organizations using varying terminologies. To integrate knowledge in separate KGs, it is essential to perform Entity Alignment (EA), which aims to discover equivalent entities in different KGs.
Early embedding-based methods focus on structure embedding of KGs, to further improve the EA results, some latter approaches explore entities' names and attributes as side information to enhance the entity embeddings. Names and attribute values are encoded by using character or word embedding techniques, for example in MultiKE(Zhang et al., 2019), AttrGNN(Liu et al., 2020) and CEA(Zeng et al., 2020), etc. Most recently, pre-trained language models (PLMs) have also been used to encode the names and attribute values, such as in BERT-INT(Tang et al., 2020), SDEA(Zhong et al., 2022).
Although continuous progress has been achieved in recently years, we find that there lacks a unified and effective way to encode all kinds of information of entities for EA. Most of the existing approaches encode structure information (relations) and attribute information (names, attributes, and descriptions, etc.) separately. Two kinds of information are encoded in different spaces, which are integrated before matching entities. Such EA paradigm faces both structure heterogeneity and attribute heterogeneity problems, which hinders their mutual enhancement.
Recently, the emergence of pre-trained language models has significantly enhanced the quality of text embeddings, proving highly effective in information retrieval, question answering and retrieval-augmented language modeling. Inspired by the recent development of embedding-based IR (dense retrieval), where relevant answers to a query are retrieved based on their embedding similarities, we formalize entity alignment in KGs as an entity retrieval problem. To find equivalent entities of two KGs, entities in one KG are used as queries to retrieval the most similar entities in the other KG. In this entity retrieval framework, different kinds of entities' information can be uniformly represented in textual forms, and we can leverage the advance of language models in embedding and searching similar entities.
More specifically, we make the following contributions in this work:
- · We formalize the EA problem as an entity retrieval task, and propose a language model based framework for this task. Within this framework, entities' information are uniformly transformed into textual descriptions, which are then encoded by language model based embedding model for nearest entity search between KGs.
- · We propose an entity verbalization model to generate homogenous textual descriptions of entities from their heterogeneous triples. We build a synthetic triple-to-text dataset by prompting GPT, which is used for effective training the verbalization model.
- · We design embedding models for entity retrieval and alignment reranking. The embedding model for entity retrieval encodes entities independently, which can efficiently find alignment candidates; the embedding model for alignment reranking encodes features of entity pairs, which captures the interactions of entities and guarantees the precision of alignments.
- · We conduct comprehensive experiments on five datasets, and compare our approach with
the existing EA approaches. The results show that our approach achieves state-of-the-art results.
The rest of this paper is organized as follows: Section 2 covers the preliminaries of our work, Section 3 details our proposed approach, Section 4 presents the experiments, Section 5 discusses related work, and Section 6 provides the conclusion.
## 2 Preliminaries
In this section, we introduce the problem of entity alignment in knowledge graphs, and formalize the task of dense entity retrieval for EA.
## 2.1 KGand Entity Alignment
Knowledge Graph (KG). KGs represent structural information about entities as triples having the form of ⟨ s, p, o ⟩ . A triple can be relational or attributional, a relational triple describes certain kind of relation between entities, and an attributional triple describes an attribute of an entity. In this work, we consider both relational and attributional triples in KGs. Formally, we represent a KG as G = ( E,R,A,L,T ) , where E R A , , and L are sets of entities, relations, attributes, and literals; T ⊆ ( E × R × E ) ∪ ( E × A × L ) is the sets of triples.
Entity Alignment (EA). Given two KGs G s and G t , and a set of pre-aligned entity pairs S = { ( u, v ) | u ∈ G , v s ∈ G , u t ≡ v } ( ≡ denotes equivalence), the task of entity alignment is to find new equivalent entity pairs between G s and G t .
## 2.2 Dense Entity Retrieval
In this work, we formalize EA as an entity retrieval task. Given a source KG G s and a target KG G t , entity retrieval aims to, for each entity s ∈ G s , return a ranked list of k most similar entities [ t 1 , t 2 , ..., t k ] in G t . The top-ranked entity t 1 is considered as be equivalent to the source entity s , i.e. s ≡ t 1 .
To achieve accurate entity retrieval, LM-based embedding models are leveraged in our approach to encode entities into dense vectors, and the similarities of entities are computed using their vectors:
$$f ( s, t ) = \sin ( \phi ( s ), \psi ( t ) ) \quad \quad ( 1 )$$
where ϕ ( ) · ∈ R d and ψ ( ) · ∈ R d are encoders mapping the source and target entities into ddimensional vector space, respectively. In this
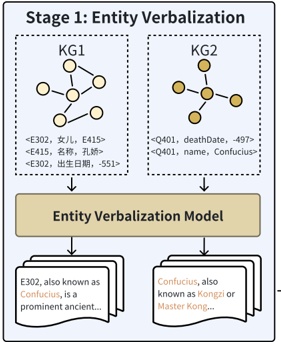
Figure 1: Framework of DERA.
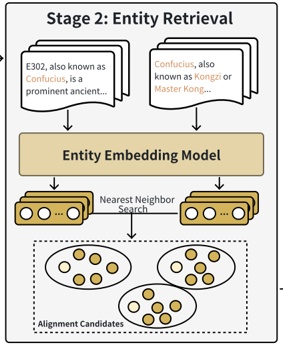
work, we will use the same encoder for source and target entities, and use dot-product for computing the similarity of entities.
balization can be formally defined as a mapping g ( N e , L e ) → s e , where s e is the textual sequence of e .
## 3 Method
In this section, we present the proposed EA framework DERA ( D ense E ntity R etrieval for entity A lignment), which is shown in Figure 1. Given two KGs to be aligned, DERA works in three main stages. (1) Entity Verbalization (EV) : this stage converts heterogeneous triples of entities into homogeneous natural language descriptions. Relations and attributes expressed in different languages will also be converted into one language. (2) Entity Retrieval (ER) : entities' textual descriptions are encoded in the same vector space. Entities are indexed using their embeddings, similar entities are retrieved based on embedding similarity to obtain alignment candidates. (3) Alignment Reranking (AR) : candidate alignments are further reranked by an reranking model to produce the final results.
## 3.1 Entity Verbalization
The purpose of entity verbalization is to convert relational and attribute triples of entities into textual descriptions in one language, which can be well encoded by a language model based embedding model. Given an entity e in a KG, let N e = { ( r , e i i ) } k i =1 be the set of neighbors and associated relations of entity e , L e = { ( a , v j j ) } m j =1 be the set of attributes and values of entity e ; here e i is an entity and r i is the relation connecting two entities, v j is the value of a j of e . Entity ver-
To get high-qualified verbalization results, we train a generative language model which takes triples as input context and generate textual descriptions as outputs. More specifically, we take open Large Language Models (LLMs) as base models, and build triple-to-text dataset to fine-tune base models.
Dataset Building. The triple-to-text dataset is built by instructing the GPT4 using a designed prompt template, which is shown in Figure 2. There are four parts in the prompt: (1) The first part is an instruction prefix to describe the task of generating triples of entities of specified type; we predefined 25 common entity types, including person, organization, movie, disease, etc. (2) The second part tells the model to generate a short and precise description of the generated triples; (3) The third part specifies the formates of generated triples and textual descriptions; (4) The fourth parts gives an example to the model.
Using the above prompt, we build a dataset contain triples and textual descriptions of 18,572 entities.
Model Training. Using the generated dataset, we fine-tune the LLMs with the next word prediction task, which is a universal approach to training LLMs. For an entity, given the sequence of triples x = ( e, r 1 , e 1 , ..., r k , e k , a 1 , v 1 , ..., a m , v m ) and its target textual description y = ( y , y 1 2 , . . . , y n ) , the training objective of EV model can be formu-
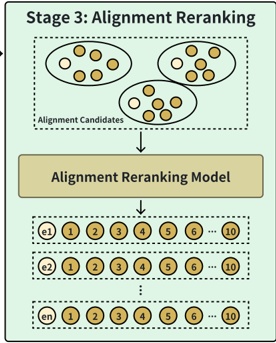
## Prompt for Dataset Building
You need to generate some imaginary triples about {Entity Type} Each of these triples has a central entity. These triples contain the oneneighbors of central entity and the properties of those neighbors Finally; the properties of central entity itself are included. The type of entity can be arbitrary; as long as it matches the distribution of the real-world knowledge graph. To ensure that the data conforms to a realistic distribution; entities contain names 75% of the time and 25% of the time; the entity's name is represented by a hop string:
Then you need to generate a short and precise description of that central entity for dense retrieval based on you generating these triples\_ The generated description is required to contain some more ontological information of central entity in order to better generalize to the information retrieval model.
You need to generate according to the following format: Triples: {{Generated content}} Description: {{Generated content}} Do not output superfluous information outside the given format. Finally; let me give you an example of triples for reference, but do not copy exactly the reference examples provided to you.
{An Example}
Figure 2: Prompt for Building Training Dataset for Entity Verbalization Model.
lated as:
$$\mathcal { L } _ { \text{EV} } = - \frac { 1 } { n } \sum _ { t = 1 } ^ { n } \log P ( y _ { t } | x, y _ { < t } ; \theta ) \quad ( 2 ) \quad \text{enc} \quad \text{$\text{date}$} \quad.$$
where n is the length of y , y t ( t = 1 2 , , ..., n ) denotes the textual tokens of the sequence y , θ represents the model parameters.
In this work, we choose LLMs of 7B size as the base models of EV. More specifically, Mistral7B-Instruct-v0.2(Jiang et al., 2023) and Qwen1.57B-Chat(Bai et al., 2023) are used because they have excellent performances in small-size LLMs. QWen is used for EA tasks involving Chinese language, because it has great ability of handling Chinese texts. In the other EA tasks, Mistral model is used in EV stage. EV models are trained independent of specific EA tasks, once two EV models have been trained, their parameters are frozen and will not be changed in the following two stages.
## 3.2 Entity Retrieval
In this stage, entity embedding model is trained to encode entity descriptions into vector space, where entities are close to their equivalent counterparts. Using the entity embedding results, alignment candidates are produced based on embedding similarities of entities. In this work, we use a text embedding model as the basis, and fine-tune it with pre-aligned entities to further improve the embedding quality. More specifically, BGE(Chen et al., 2024) embedding model is used here because it achieves state-of-the-art performances on multilingual and cross-lingual retrieval tasks.
Model Training. As defined in Section 2.2, the similarity of two entities s and t is computed as the doc product of their embeddings:
$$f ( u, v ) = \phi ( u ) \cdot \phi ( v ). \text{ \quad \ \ } ( 3 )$$
Here ϕ ( ) · ∈ R d denotes the entity embedding model which maps the entity into d -dimensional vector space. Given a set of seed alignments S = { ( u, v ) | u ∈ G , v s ∈ G , u t ≡ v } , the entity embedding model in our approach is trained by minimizing the following contrastive loss:
$$\mathcal { L } _ { \text{ER} } = - \sum _ { ( u, v ) \in S } \log \frac { e ^ { f ( u, v ) } } { e ^ { f ( u, v ) } + \sum _ { v ^ { \prime } \in N _ { u } } e ^ { f ( u, v ^ { \prime } ) } } \ ( 4 )$$
where N u is a set of negative (inequivalent) entities for u .
Candidate Selection. After the entity embedding model is trained, all the entities in two KGs can be encoded as vectors in the same space. Then candidate alignments are obtained by using each source entity to retrieval nearest target entities based on their embeddings. More specifically, for each source entity u ∈ G s , a set of top-k nearest target entities in G t are retrieved, which are candidate alignments u , denoted as V u .
## 3.3 Alignment Reranking
In the entity retrieval stage, entities' descriptions are encoded independently from each other. To further improve the EA results, we design an alignment reranking model which capture the interactions of entities' features. Here a reranker built upon BERT is trained, which takes features of two entities as inputs, and predict the finegrained similarities of entity pairs. Entity pairs are restricted to the candidates generated by the entity retrieval stage, which helps our approach to control the computation costs in alignment reranking.
Let C = { ( u , V j u j ) } l j =1 be the alignment candidates, where u j is a source entity and V u j is the set of its candidate equivalent entities. We construct a dataset for training our alignment reranking model, let it be R = { ( u , v j j , N j ) } l j =1 , where ( u , v j j ) ∈ S is the pre-aligned entity pair and N j = V u j / v { j } is the set of candidate entities that are not equivalent to u j . The reranking model is trained by minimizing the following loss:
$$\mathcal { L } _ { \text{AR} } = & - \sum _ { ( u _ { j }, v _ { j }, N _ { j } ) \in R } \log \frac { e ^ { \delta ( u _ { j }, v _ { j } ) } } { e ^ { \delta ( u _ { j }, v _ { j } ) } + \sum _ { v _ { k } ^ { \prime } \in N _ { j } } e ^ { \delta ( u _ { j }, v _ { k } ^ { \prime } ) } } } \begin{array} { c } \text{ base } 1 \\ \text{Chat} ( B \\ \text{MED-} ) \\ \text{Instruc} \end{array}$$
Here δ ( u, v ) is the similarity score computed by the reranking model based on the inputs of two entities:
$$\delta \left ( u, v \right ) = \text{MLP} \left ( \text{BERT} _ { [ \text{CLS} ] } \left ( d _ { u }, d _ { v } \right ) \right ) \quad \left ( 6 \right ) \quad \text{in} \mathfrak { G }$$
where d u and d v represent the textual descriptions of u and v , respectively.
## 4 Experiments
## 4.1 Datasets
Datasets. To evaluate the performance of our approach, we conduct experiments on both crosslingual and monolingual datasets, including:
- · DBP15K(Sun et al., 2017) contains three cross-lingual EA datasets build from DBpedia, including Chinese-English (ZH-EN), Japanese-English (JA-EN), and FrenchEnglish (FR-EN).
- · D-W-15K(Sun et al., 2020b) is a monolingual EA dataset built from DBpedia and Wikipedia by using an iterative degree-based sampling method. Compared with DBP15K, D-W-15K contains KGs that are more like real-world ones.
- · MED-BBK-9K(Zhang et al., 2020) is a dataset built from two medical knowledge graphs, containing triples on diseases, symptoms, drugs, and diagnosis methods. It poses a more complex and realistic scenario for EA compared to traditional datasets like DBpedia.
Table 1 shows the detailed statistics of these datasets.
## 4.2 Training Details
We train the Entity Verbalization (EV), Entity Retrieval (ER), and Alignment Reranking (AR) models sequentially.
EV Model. In the training of EV model, we employ Deepspeed 1 with a context window length of 2048, the learning rate is set to 9 65 . e -
1 https://github.com/microsoft/
6 , and the batch size is 24 per GPU. For the base language models, we use Qwen1.5-7BChat(Bai et al., 2023) for DBP15KZH-EN and MED-BBK-9K datasets, and use Mistral-7BInstruct-v0.2(Jiang et al., 2023) for DBP15KJA-EN, DBP15KFR-EN, and D-W-15K datasets. Gradient accumulation is set to 1. To optimize memory usage and computation speed, we utilize Zero-Stage3(Rajbhandari et al., 2020), gradient checkpointing(Chen et al., 2016), and flash attention 2(Dao, 2023). The model is trained on 8 NVIDIA A800 GPU for 3 epochs using the AdamW optimizer.
ER Model. In the training of ER model, for each positive entity, 64 negative entities are randomly sampled from the top-200 nearest ones. The learning rate is set to 1 e -5 , and the batch size to 16. We utilize distributed negative sample sharing and gradient checkpointing(Chen et al., 2016), evaluate the model every 20 steps and saving the best model based on the MRR metric on the validation set. Training is performed on 2 NVIDIA A800 GPUs for 5 epochs.
AR Model. In the training of AR model, for each positive entity, 110 negative entities are randomly sampled from the top-200 nearest ones. The maximum text length is set to 512; the learning rate to 1 e -5 , and the batch size to 12 per GPU. Gradient accumulation steps are set to 8. We enable gradient checkpointing, evaluate the model every 10 steps, and save the best model based on the Hits@1 metric on the validation set. Training is carried out on 2 NVIDIA A800 GPUs for 5 epochs.
## 4.3 Results on DBP15K
We compare our approach with four groups of baselines on DBP15K datasets, which are categorized by the used side information: (1) approaches using attributes as side information, including JAPE(Sun et al., 2017), GCN-Align(Wang et al., 2018), JarKA(Chen et al., 2020); (2) approaches using entity names as side information, including GMNN(Xu et al., 2019), SelfKG(Liu et al., 2022) and TEA-NSP, TEA-MLM(Zhao et al., 2023); (3) approaches using attributes and names as side information, including HMAN(Yang et al., 2019), AttrGNN(Liu et al., 2020), BERT-INT(Tang et al., 2020), ICLEA(Zeng et al., 2022) and TEA-NSP, TEA-MLM(Zhao et al., 2023); (4) approaches using translated entity names as side information, including HGCN-JE(Wu et al., 2019b),
Table 1: Statistics of Experimental Datasets
| Dataset | Language | Entities | Relations | Attributes | Rel. Triples | Attr. Triples |
|--------------|------------|------------|-------------|--------------|----------------|-----------------|
| DBP15K ZH-EN | ZH | 19,388 | 1,701 | 8,113 | 70,414 | 379,684 |
| | EN | 19,572 | 1,323 | 7,173 | 95,142 | 567,755 |
| DBP15K JA-EN | JA | 19,814 | 1,299 | 5,882 | 77,214 | 354,619 |
| DBP15K JA-EN | EN | 19,780 | 1,153 | 6,066 | 93,484 | 497,230 |
| DBP15K | FR | 19,661 | 903 | 4,547 | 105,998 | 354,619 |
| FR-EN | EN | 19,993 | 1,208 | 6,422 | 115,722 | 497,230 |
| D-W-15K-V2 | EN | 15,000 | 167 | 175 | 73,983 | 66,813 |
| | EN | 15,000 | 121 | 457 | 83,365 | 175,686 |
| MED-BBK-9K | ZH | 9,162 | 32 | 19 | 158,357 | 11,467 |
| | ZH | 9,162 | 20 | 21 | 50,307 | 44,987 |
RDGCN(Wu et al., 2019a), NMN(Wu et al., 2020), DATTI(Mao et al., 2022a), SEU(Mao et al., 2021), EASY(Ge et al., 2021), CPL(Ding et al., 2022), UED(Luo and Yu, 2022) and LigthEA(Mao et al., 2022b). Our approach is compared to baselines in each group using the same inputs as them. Table 2 outlines the results of all the approaches on DBP15K datasets. The best results in each group are highlighted in boldface, the second best results are highlighted with underlines.
in this group also employ optimal transport strategies to draw final alignments from entity similarities, which can effectively promote the results. To be fairly compared with these approach, we also report the results of our approach with the optimal transport strategy. According to the results, our approach gets the best results among all the approaches in this group. Among approaches without optimal transport strategies, our approach also gets the best results.
Attributes as Side Information. Approaches in this group align entities based on relations and attributes in KGs. Compared with approaches in this group, our approach obtains significantly better results, with average improvements of 25.3% of Hits@1 and 20.7% of MRR over the second best approach on three datasets.
Names as Side Information. Approaches in this group use entity names and relations to discover equivalent entities. Our approach gets the best results of Hits and MRR on ZH-EN and FR-EN datasets, it obtains 1.5% and 1.4% improvements of Hits@1 over the second best approach TEAMLM. While on the JA-EN dataset, TEA-NSP gets slightly better results than ours.
Names and Attributes as Side Information. When using both names and attributes, our approach still obtain top-ranked results. Except for the Hits@10 on JA-EN and Hits@1 on FR-EN datasets, our approach gets the best results among all the compared approaches in this group.
Translated Names as Side Information. Approaches in this group use machine translation tool to convert non-English names into English ones, and takes translated names as side information. Some of the approaches (annotated with † )
## 4.4 Results of Hard Setting on DBP15K
In the work of AttrGNN(Liu et al., 2020), a hard setting of evaluations on DBP15K was proposed. The purpose of this hard setting is to build more difficult testing set on DBP15K. Specifically, similarities of equivalent entities in the datasets are first measured using embeddings of their names, 60% entity pairs with the lowest similarities are selected as the testing set, and the remaining entity pairs are randomly split into training set (30%) and validation set (10%).
Table 3 shows that results of hard setting on DBP15K. Our approach is compared with eight baselines, including JAPE (Sun et al., 2017), BootEA(Sun et al., 2018), GCN-Align(Wang et al., 2018), MuGNN(Cao et al., 2019), MultiKE(Zhang et al., 2019), RDGCN(Wu et al., 2019a), AttrGNN(Liu et al., 2020), and FGWEA(Tang et al., 2023). According to the results, our approach DERA gets the best Hits and MRR on all of the three datasets. Figure 3 compares the Hits@10 of approaches in regular setting and hard setting on DBP15KZH\_EN. All the baselines have significant decreases of Hits@10, while DERA (using names and attributes as side
Table 2: Results on DBP15K Datasets
| Info. | Model | DBP15K-ZH-EN | DBP15K-ZH-EN | DBP15K-ZH-EN | DBP15K-JA-EN | DBP15K-JA-EN | DBP15K-JA-EN | DBP15K-FR-EN | DBP15K-FR-EN | DBP15K-FR-EN |
|-------------------|---------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| Info. | Model | Hits@1 | Hits@10 | MRR | Hits@1 | Hits@10 | MRR | Hits@1 | Hits@10 | MRR |
| Attributes | JAPE | 0.412 | 0.745 | 0.490 | 0.363 | 0.685 | 0.476 | 0.324 | 0.667 | 0.430 |
| Attributes | GCN-Align | 0.413 | 0.744 | 0.549 | 0.399 | 0.745 | 0.546 | 0.373 | 0.745 | 0.532 |
| Attributes | JarKA | 0.706 | 0.878 | 0.766 | 0.646 | 0.855 | 0.708 | 0.704 | 0.888 | 0.768 |
| Attributes | DERA(Ours) | 0.946 | 0.982 | 0.961 | 0.921 | 0.959 | 0.937 | 0.949 | 0.985 | 0.964 |
| Names | GMNN | 0.679 | 0.785 | - | 0.740 | 0.872 | - | 0.894 | 0.952 | - |
| Names | SelfKG | 0.745 | 0.866 | - | 0.816 | 0.913 | - | 0.957 | 0.992 | - |
| Names | TEA-NSP | 0.815 | 0.953 | 0.870 | 0.890 | 0.967 | 0.920 | 0.968 | 0.995 | 0.980 |
| Names | TEA-MLM | 0.831 | 0.957 | 0.880 | 0.883 | 0.966 | 0.910 | 0.968 | 0.994 | 0.980 |
| Names | DERA(Ours) | 0.846 | 0.962 | 0.900 | 0.866 | 0.951 | 0.889 | 0.980 | 0.996 | 0.987 |
| Names &Attributes | HMAN | 0.871 | 0.987 | - | 0.935 | 0.994 | - | 0.973 | 0.998 | - |
| Names &Attributes | AttrGNN | 0.796 | 0.929 | 0.845 | 0.783 | 0.921 | 0.834 | 0.919 | 0.978 | 0.910 |
| Names &Attributes | BERT-INT | 0.968 | 0.990 | 0.977 | 0.964 | 0.991 | 0.975 | 0.992 | 0.998 | 0.995 |
| Names &Attributes | ICLEA | 0.884 | 0.972 | - | 0.924 | 0.978 | - | 0.991 | 0.999 | - |
| Names &Attributes | TEA-NSP | 0.941 | 0.983 | 0.960 | 0.941 | 0.979 | 0.960 | 0.979 | 0.997 | 0.990 |
| Names &Attributes | TEA-MLM | 0.935 | 0.982 | 0.950 | 0.939 | 0.978 | 0.950 | 0.987 | 0.996 | 0.990 |
| Names &Attributes | DERA(Ours) | 0.968 | 0.994 | 0.979 | 0.967 | 0.992 | 0.978 | 0.989 | 0.999 | 0.995 |
| Translated Names | HGCN-JE | 0.720 | 0.857 | - | 0.766 | 0.897 | - | 0.892 | 0.961 | - |
| Translated Names | RDGCN | 0.708 | 0.846 | 0.746 | 0.767 | 0.895 | 0.812 | 0.886 | 0.957 | 0.911 |
| Translated Names | NMN | 0.733 | 0.869 | - | 0.785 | 0.912 | - | 0.902 | 0.967 | - |
| Translated Names | DERA(Ours) | 0.930 | 0.982 | 0.950 | 0.917 | 0.978 | 0.941 | 0.972 | 0.995 | 0.982 |
| Translated Names | DATTI † | 0.890 | 0.958 | - | 0.921 | 0.971 | - | 0.979 | 0.990 | - |
| Translated Names | SEU † | 0.900 | 0.965 | 0.924 | 0.956 | 0.991 | 0.969 | 0.988 | 0.999 | 0.992 |
| Translated Names | EASY † | 0.898 | 0.979 | 0.930 | 0.943 | 0.990 | 0.960 | 0.980 | 0.998 | 0.990 |
| Translated Names | CPL-OT † | 0.927 | 0.964 | 0.940 | 0.956 | 0.983 | 0.970 | 0.990 | 0.994 | 0.990 |
| Translated Names | UED † | 0.915 | - | - | 0.941 | - | - | 0.984 | - | - |
| Translated Names | LightEA † | 0.952 | 0.984 | 0.964 | 0.981 | 0.997 | 0.987 | 0.995 | 0.998 | 0.996 |
| Translated Names | DERA † (Ours) | 0.985 | 0.997 | 0.990 | 0.994 | 0.999 | 0.996 | 0.996 | 0.999 | 0.997 |
Approaches with † employ optimal transport strategy.
information) has only 0.1% decrease, showing its remarkable robustness.
## 4.5 Results on DW-15K and MED-BBK-9K
DW15K and MED-BBK-9K are two challenging datasets of entity alignment. DW-15K is built from Wikipedia, where entity names are replaced with ids; there are also significant missing and corrupted attribute values. The dataset of MEDBBK-9K is built from an authoritative medical KG and a KG built from a Chinese online encyclopedia (Baidu Baike); many entities in MEDBBK-9K lack names and attributes, which makes the EA task more difficult. We compared our approach with seven approaches, three of them are probabilistic ones including LogMap(JiménezRuiz and Cuenca Grau, 2011), PARIS(Suchanek et al., 2011), and PRASE(Qi et al., 2021); four of them are embedding-based ones including MultiKE(Zhang et al., 2019), BootEA(Sun et al., 2018), RSNs(Guo et al., 2019) and FGWEA(Tang et al., 2023). Following the same evaluation settings of SOTA approaches on these two datasets, we report the Precision, Recall and F1 of all the compared approaches.
Table 4 outlines the results. Our approach DERA obtains 98.2% and 84.1% F1 scores on D-W-15K-V2 and MED-BBK-9K, respectively. Compared to the former best approach FGWEA, DERA gets 5.5% and 1.8% improvements of F1 scores on two datasets, respectively. It demonstrates DERA's superior performances on difficult EA tasks.
## 4.6 Ablation Study
To analyze the effectiveness and contribution of each component in the proposed approach, we conduct ablation studies on DBP15K datasets. We ran two groups of experiments, one group uses attributes as side information, and the other group uses both names and attributes as side information. In each group, we ran three variations of DERA: 1)
Figure 3: Hits@10 (%) of approaches under the regular setting and the hard setting on DBP15k.
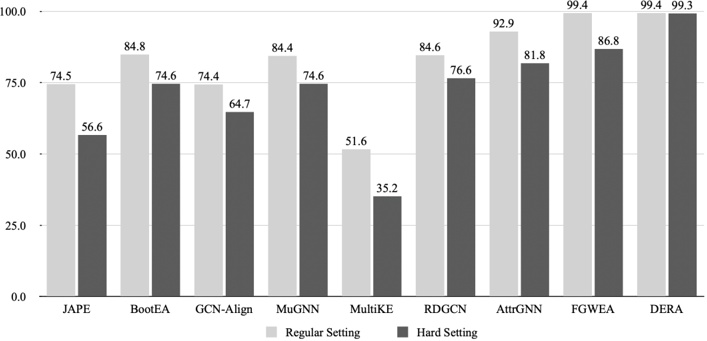
Table 3: Results of Hard Setting on DBP15K
| Model | DBP15K-ZH-EN | DBP15K-ZH-EN | DBP15K-ZH-EN | DBP15K-JA-EN | DBP15K-JA-EN | DBP15K-JA-EN | DBP15K-FR-EN | DBP15K-FR-EN | DBP15K-FR-EN |
|------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| Model | Hits1 | Hits10 | MRR | Hits1 | Hits10 | MRR | Hits1 | Hits10 | MRR |
| JAPE | 0.350 | 0.566 | 0.451 | 0.311 | 0.520 | 0.410 | 0.253 | 0.483 | 0.361 |
| BootEA | 0.513 | 0.746 | 0.593 | 0.493 | 0.746 | 0.578 | 0.513 | 0.769 | 0.603 |
| GCN-Align | 0.366 | 0.647 | 0.464 | 0.339 | 0.653 | 0.448 | 0.303 | 0.637 | 0.414 |
| MuGNN | 0.406 | 0.746 | 0.521 | 0.399 | 0.753 | 0.515 | 0.407 | 0.783 | 0.531 |
| MultiKE | 0.279 | 0.352 | 0.306 | 0.482 | 0.557 | 0.509 | 0.647 | 0.695 | 0.665 |
| RDGCN | 0.604 | 0.766 | 0.662 | 0.682 | 0.838 | 0.737 | 0.829 | 0.931 | 0.866 |
| AttrGNN | 0.662 | 0.818 | 0.719 | 0.774 | 0.903 | 0.821 | 0.886 | 0.956 | 0.912 |
| FGWEA | 0.756 | 0.868 | 0.796 | 0.788 | 0.897 | 0.828 | 0.983 | 0.997 | 0.988 |
| DERA(Ours) | 0.967 | 0.993 | 0.977 | 0.959 | 0.992 | 0.973 | 0.987 | 1.000 | 0.993 |
DEAR without EV module, triples of entities are directly serialized to generate inputs of ER module; 2) DERA without AR module, the final alignments are returned based on the similarities computed by ER module; 3) DERA without EV and AR module. The results of the above variations of DERA are compared to the original version of DERA,changes in results are shown in small numbers after the results.
that EV module is important in handling language heterogeneity in EA tasks.
Table 5 shows the results of ablation study. According to the results, we have the following observations:
(1) Removing the EV module in DERA leads to average 1.6% decrease of Hits@1 and 1.5% decrease of MRR when using attributes as side information. The average decreases become 3.6% of Hits@1 and 3.2% of MRR when using attributes and names as side information. It shows that EV module has positive effects on the EA results. The performance decreases more on ZH-EN and JAEN datasets, where the involving languages are more different than the FR-EN dataset. It indicates
(2) Removing the ER module in DERA leads to average 1.3% decrease of Hits@1 and 1.0% of MRR when using attributes on three datasets. If attributes and names are all used as side information, DERA without AR module gets 1.5% decrease of Hits@1 and 1.1% decrease of MRR on ZH-EN and JA-EN datasets, 0.2% and 0.1% improvements of Hits@1 and MRR on FR-EN dataset. It shows that AR module works more effectively on EA tasks with high heterogeneity and linguistic differences. When the alignment results are already good enough (e.g. >99% Hits@1 on FR-EN dataset), it is difficult for AR module to further improve the results.
(3) Removing both AR and RR modules in DERA leads to significant performance drops on all the datasets, there are average 4.7% decrease of Hits@1 and 3.9% decrease of MRR when attributes are used as side information. The decreases become 8.3% of Hits@1 and 6.8% of
Table 4: Results on DW-15K and MED-BBK-9K Datasets
| Model | DW-15K-V2 | DW-15K-V2 | DW-15K-V2 | MED-BBK-9K | MED-BBK-9K | MED-BBK-9K |
|---------------|-------------|-------------|-------------|--------------|--------------|--------------|
| | Precision | Recall | F1 | Precision | Recall | F1 |
| LogMap | - | - | - | 86.4 | 44.1 | 58.4 |
| PARIS | 95.0 | 85.0 | 89.7 | 77.9 | 36.7 | 49.9 |
| PRASE | 94.8 | 90.0 | 92.3 | 83.7 | 61.9 | 71.1 |
| MultiKE | 49.5 | 49.5 | 49.5 | 41.0 | 41.0 | 41.0 |
| BootEA | 82.1 | 82.1 | 82.1 | 30.7 | 30.7 | 30.7 |
| RSNs | 72.3 | 72.3 | 72.3 | 19.5 | 19.5 | 19.5 |
| FGWEA † | 95.2 | 90.3 | 92.7 | 93.9 | 73.2 | 82.3 |
| DERA † (Ours) | 98.2 | 98.2 | 98.2 | 84.1 | 84.1 | 84.1 |
Table 5: Results of Ablation Study
| | EV | ER | AR | DBP15K-ZH-EN | DBP15K-ZH-EN | DBP15K-JA-EN | DBP15K-JA-EN | DBP15K-FR-EN | DBP15K-FR-EN |
|------------|------|------|------|-----------------|-----------------|-----------------|-----------------|-----------------|-----------------|
| | EV | ER | AR | Hits@1 | MRR | Hits@1 | MRR | Hits@1 | MRR |
| | ✓ | ✓ | ✓ | 0.946 | 0.962 | 0.923 | 0.940 | 0.949 | 0.963 |
| | × | ✓ | ✓ | 0.926 0 . 020 ↓ | 0.943 0 . 019 ↓ | 0.914 0 . 009 ↓ | 0.928 0 . 012 ↓ | 0.931 0 . 018 ↓ | 0.948 0 . 015 ↓ |
| Attributes | ✓ | ✓ | × | 0.927 0 . 019 ↓ | 0.948 0 . 014 ↓ | 0.903 0 . 020 ↓ | 0.924 0 . 016 ↓ | 0.948 0 . 001 ↓ | 0.963 0 . 000 - |
| | × | ✓ | × | 0.892 0 . 054 ↓ | 0.918 0 . 044 ↓ | 0.859 0 . 064 ↓ | 0.885 0 . 055 ↓ | 0.927 0 . 022 ↓ | 0.946 0 . 017 ↓ |
| Names | ✓ | ✓ | ✓ | 0.968 | 0.979 | 0.967 | 0.978 | 0.989 | 0.994 |
| | × | ✓ | ✓ | 0.926 0 . 042 ↓ | 0.945 0 . 034 ↓ | 0.909 0 . 058 ↓ | 0.923 0 . 055 ↓ | 0.980 0 . 009 ↓ | 0.988 0 . 006 ↓ |
| Attrs.& | ✓ | ✓ | × | 0.955 0 . 013 ↓ | 0.970 0 . 009 ↓ | 0.950 0 . 017 ↓ | 0.965 0 . 013 ↓ | 0.991 0 . 002 ↑ | 0.995 0 . 001 ↑ |
| | × | ✓ | × | 0.883 0 . 085 ↓ | 0.911 0 . 068 ↓ | 0.812 0 . 155 ↓ | 0.848 0 . 130 ↓ | 0.980 0 . 009 ↓ | 0.988 0 . 006 ↓ |
MRR when attributes and names are used. Comparing with DERA variation with EV and ER module, DERA also have significant performance drops, which shows that EV module is necessary for obtaining good results.
## 5 Related Work
## 5.1 Embedding-based EA
of attributes in KGs. GCN-Align (Wang et al., 2018) encodes attribute information of entities into their embeddings by using GCNs. MultiKE (Zhang et al., 2019) uses a framework unifying the views of entity names, relations and attributes to learn embeddings for aligning entities. CEA (Zeng et al., 2020) combines structural, semantic and string features of entities, which are integrated with dynamically assigned weights.
Embedding-based KG alignment approaches employ TransE and GNN to learn entities' embeddings, and then find equivalent entities in the vector spaces. Early approaches mainly rely on the structure information in KGs to find alignments, including TransE-based approaches MTransE (Chen et al., 2017), IPTransE (Zhu et al., 2017), BootEA (Sun et al., 2018), etc, and GNNbased approaches MuGNN (Cao et al., 2019), NAEA (Zhu et al., 2019), RDGCN (Wu et al., 2019a) and AliNet (Sun et al., 2020a), etc. To get improved results, some approaches utilize entity attributes or names in KGs. JAPE (Sun et al., 2017) performs attribute embedding by Skip-Gram model which captures the correlations
## 5.2 Language Model-based EA
As Pre-trained Language Models(PLMs) being successfully used in various tasks, some approaches utilize PLMs to model the semantic information of entities in the task of KG alignment. AttrGNN(Liu et al., 2020) uses BERT to encode attribute features of entities. It encode each attribute and value separately, and then uses a graph attention network to compute the weighted average of attributes and values. BERTINT(Tang et al., 2020) embeds names, descriptions, attributes and values of entities using a LM; pair-wise neighbor-view and attribute-view interactions are performed to get the matching score of entities. The interactions are timeconsuming, thus BERT-INT cannot scale to large KGs. SDEA(Zhong et al., 2022) find-tunes BERT to encode attribute values of an entity into attribute embedding; attribute embeddings of neighbors are fed to BiGRU to get relation embedding of an entity. TEA(Zhao et al., 2023) sorts triples in alphabetical order by relations and attributes to form sequences, and uses a textual entailment framework for entity alignment. TEA takes entity-pair sequence as the input of PLM, and let the PLM to predict the probability of entailment. It takes pairwise input, cannot scale to large KGs. AutoAlign(Zhang et al., 2023) gets attribute character embeddings and predicate-proximity-graph embeddings by using large language models. AttrGNN, BERT-INT and SDEA use BERT to encode attribute information of entities, and then employ GNNs to incorporate relation information into entities' embeddings. Being different from these approaches, our approach directly use language model to encode both the attributes and relations of entities. TEA uses similar way to encode attribute and relation information, but it takes entity pair as input, which cannot scale to large-scale KG alignment tasks.
As the advent of Large Language Models (LLMs), there are several approaches exploring LLMs for EA. LLMEA(Yang et al., 2024) fuses the knowledge from KGs and LLMs to predict entity alignments. It first uses RAGAT to learn entity embeddings which are used to draws alignment candidates; it then uses candidate alignments as options to generates multi-choice questions, which are passed to LLMs to predict the answer. ChatEA(Jiang et al., 2024a) first uses SimpleHHEA(Jiang et al., 2024b) to obtain candidate alignments, and then leverages LLMs' reasoning abilities to predict the final results. LLMEA and ChatEA all explore the reasoning abilities of LLM to predict entity alignments. Because the number of potential alignments are usually huge, they use exiting EA methods to generate alignment candidates, from which LLMs are used to select the final results. According to the results, the improvements contributed by LLMs are restricted.
## 6 Conclusion
In this paper, we propose a dense entity retrieval approach, DERA, for entity alignment in knowledge graphs. DERA first converts entity triples into unified textual descriptions using an entity verbalization model, and then trains a language model-based embedding model to encode the entities. Candidate alignments are identified based on their similarities in the embedding space and are further reranked by an alignment reranking model. Experiments demonstrate that DERA achieves state-of-the-art results on entity alignment tasks of varying difficulty levels.
## Limitations
The primary limitation of DERA is its pipelined framework, where models in its three stages are trained sequentially. Consequently, the component models in DERA are not optimized jointly during training. Exploring efficient methods for the joint learning of these models would be a valuable direction for future work, potentially enhancing the results further. Additionally, DERA consumes more GPU power than traditional models, which is another limitation.
## References
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. 2023. Qwen technical report.
Christian Bizer, Jens Lehmann, Georgi Kobilarov, Sören Auer, Christian Becker, Richard Cyganiak, and Sebastian Hellmann. 2009. Dbpediaa crystallization point for the web of data. Web Semantics: science, services and agents on the world wide web, 7(3):154-165.
Yixin Cao, Zhiyuan Liu, Chengjiang Li, Zhiyuan Liu, Juanzi Li, and Tat-Seng Chua. 2019. Multi-channel graph neural network for entity alignment. In Proceedings of the 57th Annual Meeting of the Association for Computational
Linguistics, pages 1452-1461, Florence, Italy. Association for Computational Linguistics.
Bo Chen, Jing Zhang, Xiaobin Tang, Hong Chen, and Cuiping Li. 2020. Jarka: Modeling attribute interactions for cross-lingual knowledge alignment. In Advances in Knowledge Discovery and Data Mining, pages 845-856, Cham. Springer International Publishing.
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. Bge m3embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through selfknowledge distillation.
Muhao Chen, Yingtao Tian, Mohan Yang, and Carlo Zaniolo. 2017. Multilingual knowledge graph embeddings for cross-lingual knowledge alignment. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (AAAI2017), pages 1511-1517.
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. 2016. Training deep nets with sublinear memory cost.
Tri Dao. 2023. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691.
Qijie Ding, Daokun Zhang, and Jie Yin. 2022. Conflict-aware pseudo labeling via optimal transport for entity alignment. In 2022 IEEE International Conference on Data Mining (ICDM), pages 915-920.
Congcong Ge, Xiaoze Liu, Lu Chen, Baihua Zheng, and Yunjun Gao. 2021. Make it easy: An effective end-to-end entity alignment framework. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '21, pages 777-786, New York, NY, USA. Association for Computing Machinery.
Lingbing Guo, Zequn Sun, and Wei Hu. 2019. Learning to exploit long-term relational dependencies in knowledge graphs. In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2505-2514. PMLR.
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7b.
Xuhui Jiang, Yinghan Shen, Zhichao Shi, Chengjin Xu, Wei Li, Zixuan Li, Jian Guo, Huawei Shen, and Yuanzhuo Wang. 2024a. Unlocking the power of large language models for entity alignment.
Xuhui Jiang, Chengjin Xu, Yinghan Shen, Yuanzhuo Wang, Fenglong Su, Zhichao Shi, Fei Sun, Zixuan Li, Jian Guo, and Huawei Shen. 2024b. Toward practical entity alignment method design: Insights from new highly heterogeneous knowledge graph datasets. In Proceedings of the ACM on Web Conference 2024, WWW '24, pages 2325-2336, New York, NY, USA. Association for Computing Machinery.
Ernesto Jiménez-Ruiz and Bernardo Cuenca Grau. 2011. Logmap: Logic-based and scalable ontology matching. In Proceedings of the Tenth International Semantic Web Conference(ISWC2011), pages 273-288.
Xiao Liu, Haoyun Hong, Xinghao Wang, Zeyi Chen, Evgeny Kharlamov, Yuxiao Dong, and Jie Tang. 2022. Selfkg: Self-supervised entity alignment in knowledge graphs. In Proceedings of the ACM Web Conference 2022, WWW '22, pages 860-870, New York, NY, USA. Association for Computing Machinery.
Zhiyuan Liu, Yixin Cao, Liangming Pan, Juanzi Li, Zhiyuan Liu, and Tat-Seng Chua. 2020. Exploring and evaluating attributes, values, and structures for entity alignment. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6355-6364, Online. Association for Computational Linguistics.
Shengxuan Luo and Sheng Yu. 2022. An accurate unsupervised method for joint entity alignment and dangling entity detection. In Findings of the Association for Computational Linguistics:
ACL 2022, pages 2330-2339, Dublin, Ireland. Association for Computational Linguistics.
Xin Mao, Meirong Ma, Hao Yuan, Jianchao Zhu, ZongYu Wang, Rui Xie, Wei Wu, and Man Lan. 2022a. An effective and efficient entity alignment decoding algorithm via third-order tensor isomorphism. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5888-5898, Dublin, Ireland. Association for Computational Linguistics.
Xin Mao, Wenting Wang, Yuanbin Wu, and Man Lan. 2021. From alignment to assignment: Frustratingly simple unsupervised entity alignment. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 2843-2853, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Xin Mao, Wenting Wang, Yuanbin Wu, and Man Lan. 2022b. LightEA: A scalable, robust, and interpretable entity alignment framework via three-view label propagation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 825-838, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Natasha Noy, Markus Nentwig, Michael Hartung, Axel-Cyrille Ngonga Ngomo, and Erhard Rahm. 2017. A survey of current link discovery frameworks. Semantic Web, 8(3):419-436.
Zhiyuan Qi, Ziheng Zhang, Jiaoyan Chen, Xi Chen, Yuejia Xiang, Ningyu Zhang, and Yefeng Zheng. 2021. Unsupervised knowledge graph alignment by probabilistic reasoning and semantic embedding. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, pages 20192025. International Joint Conferences on Artificial Intelligence Organization. Main Track.
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1-16. IEEE.
Thomas Rebele, Fabian M. Suchanek, Johannes Hoffart, Joanna Asia Biega, Erdal Kuzey, and Gerhard Weikum. 2016. Yago: A multilingual knowledge base from wikipedia, wordnet, and geonames. In Proceedings of the Fifteenth International Semantic Web Conference (ISWC2016), pages 177-185.
Fabian M. Suchanek, Serge Abiteboul, and Pierre Senellart. 2011. Paris: probabilistic alignment of relations, instances, and schema. Proc. VLDB Endow., 5(3):157-168.
Zequn Sun, Wei Hu, and Chengkai Li. 2017. Cross-lingual entity alignment via joint attribute-preserving embedding. In The Semantic Web-ISWC 2017: 16th International Semantic Web Conference, Vienna, Austria, October 21-25, 2017, Proceedings, Part I 16, pages 628-644. Springer.
Zequn Sun, Wei Hu, Qingheng Zhang, and Yuzhong Qu. 2018. Bootstrapping entity alignment with knowledge graph embedding. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, pages 4396-4402. International Joint Conferences on Artificial Intelligence Organization.
Zequn Sun, Chengming Wang, Wei Hu, Muhao Chen, Jian Dai, Wei Zhang, and Yuzhong Qu. 2020a. Knowledge graph alignment network with gated multi-hop neighborhood aggregation. Proceedings of the AAAI Conference on Artificial Intelligence, 34(01):222-229.
Zequn Sun, Qingheng Zhang, Wei Hu, Chengming Wang, Muhao Chen, Farahnaz Akrami, and Chengkai Li. 2020b. A benchmarking study of embedding-based entity alignment for knowledge graphs. Proceedings of the VLDB Endowment, 13:2326 - 2340.
Jianheng Tang, Kangfei Zhao, and Jia Li. 2023. A fused Gromov-Wasserstein framework for unsupervised knowledge graph entity alignment. In Findings of the Association for Computational Linguistics: ACL 2023, pages 3320-3334, Toronto, Canada. Association for Computational Linguistics.
Xiaobin Tang, Jing Zhang, Bo Chen, Yang Yang, Hong Chen, and Cuiping Li. 2020. BERTINT:a bert-based interaction model for knowledge graph alignment. In Proceedings of the
Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI-20, pages 3174-3180. International Joint Conferences on Artificial Intelligence Organization. Main track.
Denny Vrandeˇ ci´ c and Markus Krötzsch. 2014. Wikidata: a free collaborative knowledgebase. Commun. ACM, 57(10):78-85.
Zhichun Wang, Qingsong Lv, Xiaohan Lan, and Yu Zhang. 2018. Cross-lingual knowledge graph alignment via graph convolutional networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 349-357, Brussels, Belgium. Association for Computational Linguistics.
Yuting Wu, Xiao Liu, Yansong Feng, Zheng Wang, Rui Yan, and Dongyan Zhao. 2019a. Relation-aware entity alignment for heterogeneous knowledge graphs. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, pages 5278-5284. International Joint Conferences on Artificial Intelligence Organization.
Yuting Wu, Xiao Liu, Yansong Feng, Zheng Wang, and Dongyan Zhao. 2019b. Jointly learning entity and relation representations for entity alignment. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 240-249, Hong Kong, China. Association for Computational Linguistics.
Yuting Wu, Xiao Liu, Yansong Feng, Zheng Wang, and Dongyan Zhao. 2020. Neighborhood matching network for entity alignment. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6477-6487, Online. Association for Computational Linguistics.
Kun Xu, Liwei Wang, Mo Yu, Yansong Feng, Yan Song, Zhiguo Wang, and Dong Yu. 2019. Cross-lingual knowledge graph alignment via graph matching neural network. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 31563161, Florence, Italy. Association for Computational Linguistics.
Hsiu-Wei Yang, Yanyan Zou, Peng Shi, Wei Lu, Jimmy Lin, and Xu Sun. 2019. Aligning cross-lingual entities with multi-aspect information. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4431-4441, Hong Kong, China. Association for Computational Linguistics.
Linyao Yang, Hongyang Chen, Xiao Wang, Jing Yang, Fei-Yue Wang, and Han Liu. 2024. Two heads are better than one: Integrating knowledge from knowledge graphs and large language models for entity alignment.
Kaisheng Zeng, Zhenhao Dong, Lei Hou, Yixin Cao, Minghao Hu, Jifan Yu, Xin Lv, Lei Cao, Xin Wang, Haozhuang Liu, Yi Huang, Junlan Feng, Jing Wan, Juanzi Li, and Ling Feng. 2022. Interactive contrastive learning for selfsupervised entity alignment. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, CIKM '22, pages 2465-2475, New York, NY, USA. Association for Computing Machinery.
Weixin Zeng, Xiang Zhao, Jiuyang Tang, and Xuemin Lin. 2020. Collective entity alignment via adaptive features. In 2020 IEEE 36th International Conference on Data Engineering (ICDE), pages 1870-1873.
Qingheng Zhang, Zequn Sun, Wei Hu, Muhao Chen, Lingbing Guo, and Yuzhong Qu. 2019. Multi-view knowledge graph embedding for entity alignment. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, pages 5429-5435. International Joint Conferences on Artificial Intelligence Organization.
Rui Zhang, Yixin Su, Bayu Distiawan Trisedya, Xiaoyan Zhao, Min Yang, Hong Cheng, and Jianzhong Qi. 2023. Autoalign: Fully automatic and effective knowledge graph alignment enabled by large language models. IEEE Transactions on Knowledge and Data Engineering, pages 1-14.
Ziheng Zhang, Hualuo Liu, Jiaoyan Chen, Xi Chen, Bo Liu, YueJia Xiang, and
Yefeng Zheng. 2020. An industry evaluation of embedding-based entity alignment. In Proceedings of the 28th International Conference on Computational Linguistics: Industry Track, pages 179-189, Online. International Committee on Computational Linguistics.
Yu Zhao, Yike Wu, Xiangrui Cai, Ying Zhang, Haiwei Zhang, and Xiaojie Yuan. 2023. From alignment to entailment: A unified textual entailment framework for entity alignment. In Findings of the Association for Computational Linguistics: ACL 2023, pages 8795-8806, Toronto, Canada. Association for Computational Linguistics.
Ziyue Zhong, Meihui Zhang, Ju Fan, and Chenxiao Dou. 2022. Semantics driven embedding learning for effective entity alignment. In 2022 IEEE 38th International Conference on Data Engineering (ICDE), pages 2127-2140.
Hao Zhu, Ruobing Xie, Zhiyuan Liu, and Maosong Sun. 2017. Iterative entity alignment via joint knowledge embeddings. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, pages 4258-4264.
Qiannan Zhu, Xiaofei Zhou, Jia Wu, Jianlong Tan, and Li Guo. 2019. Neighborhoodaware attentional representation for multilingual knowledge graphs. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, pages 1943-1949. International Joint Conferences on Artificial Intelligence Organization. | null | [
"Zhichun Wang",
"Xuan Chen"
] | 2024-08-02T10:12:42+00:00 | 2024-08-02T10:12:42+00:00 | [
"cs.CL",
"cs.AI"
] | DERA: Dense Entity Retrieval for Entity Alignment in Knowledge Graphs | Entity Alignment (EA) aims to match equivalent entities in different
Knowledge Graphs (KGs), which is essential for knowledge fusion and
integration. Recently, embedding-based EA has attracted significant attention
and many approaches have been proposed. Early approaches primarily focus on
learning entity embeddings from the structural features of KGs, defined by
relation triples. Later methods incorporated entities' names and attributes as
auxiliary information to enhance embeddings for EA. However, these approaches
often used different techniques to encode structural and attribute information,
limiting their interaction and mutual enhancement. In this work, we propose a
dense entity retrieval framework for EA, leveraging language models to
uniformly encode various features of entities and facilitate nearest entity
search across KGs. Alignment candidates are first generated through entity
retrieval, which are subsequently reranked to determine the final alignments.
We conduct comprehensive experiments on both cross-lingual and monolingual EA
datasets, demonstrating that our approach achieves state-of-the-art performance
compared to existing EA methods. |
2408.01155v1 | ## Efficient conversion from fermionic Gaussian states to matrix product states
Tong Liu, 1, 2 Ying-Hai Wu, 3 Hong-Hao Tu, 4, ∗ and Tao Xiang 1, 5, 2, †
1 Institute of Physics, Chinese Academy of Sciences, Beijing 100190, China
School of Physical Sciences, University of Chinese Academy of Sciences, Beijing 100049, China 3 School of Physics and Wuhan National High Magnetic Field Center, Huazhong University of Science and Technology, Wuhan 430074, China 4 Physics Department and Arnold Sommerfeld Center for Theoretical Physics,
Ludwig-Maximilians-Universit¨t a M¨ unchen, 80333 Munich, Germany
5 Beijing Academy of Quantum Information Sciences, Beijing 100190, China
Fermionic Gaussian states are eigenstates of quadratic Hamiltonians and widely used in quantum many-body problems. We propose a highly efficient algorithm that converts fermionic Gaussian states to matrix product states. It can be formulated for finite-size systems without translation invariance, but becomes particularly appealing when applied to infinite systems with translation invariance. If the ground states of a topologically ordered system on infinite cylinders are expressed as matrix product states, then the fixed points of the transfer matrix can be harnessed to filter out the anyon eigenbasis, also known as minimally entangled states. This allows for efficient computation of universal properties such as entanglement spectrum and modular matrices. The potential of our method is demonstrated by numerical calculations in two chiral spin liquids that have the same topological orders as the bosonic Laughlin and Moore-Read states, respectively. The anyon eigenbasis for the first one has been worked out before and serves as a useful benchmark. The anyon eigenbasis of the second one is, however, not transparent and its successful construction provides a nontrivial corroboration of our method.
## I. INTRODUCTION
At the fundamental level, particles in a quantum manybody system interact with each other. However, the essential physics in many cases are captured by a free particle description, notably in the framework of mean-field theory. A plethora of fascinating states can be generated when free fermions roam in diverse lattice potentials and repel each other solely according to Pauli's exclusion principle. In general, the Hamiltonians of free fermions are quadratic in terms of the creation and annihilation operators so they can be diagonalized easily using singleparticle basis transformations. The solutions can be expressed as fermionic Gaussian states (FGSs) whose correlations obey the Wick's theorem [1-4]. If strong correlations invalidate mean-field treatment, many-body problems become very difficult due to the exponential growth of the Hilbert space.
projected entangled pair states (PEPSs) [6-11]. The two methods have their respective strengths and weaknesses but both can provide successful variational Ans¨tze. Due a to the apparent differences, these approaches have been almost independent from each other when they were developed and applied in concrete problems.
In a variety of strongly correlated phases, mean-field theory can still provide useful insight when it is applied on fictitious partons that emerge from breaking each physical object into multiple pieces. FGSs are still useful when the partons are fermionic and described by quadratic Hamiltonians [5]. It is necessary to impose physical constraint using Gutzwiller projection such that partons are glued together to become physical objects. While FGSs of partons are simple, the final wave functions are generally not easy to analyze. Another fruitful approach for strongly correlated systems is tensor networks that include matrix product states (MPSs) and
∗ [email protected]
† [email protected]
It is natural to explore if FGSs and tensor networks can be combined to harness their advantages in collaboration. One attempt is to design hybrid ansatz that contains both of them as ingredients [12, 13]. Another route is converting (physically motivated or post-optimized) FGSs into tensor networks that may serve as initial states for numerical simulations to facilitate better convergence. Along this line of thought, several methods have been developed to convert FGSs into MPSs [14-19] and they are indeed useful in density matrix renormalization group (DMRG) calculations [19-24]. In particular, feeding a DMRG program with suitable initial states could simplify the search for the degenerate ground states in a two-dimensional (2D) system with intrinsic topological order [21, 22, 24]. The PEPS representations of FGSs have also been investigated [25-28] and their application in optimization algorithms is anticipated [29-36].
In this work, we develop an algorithm that efficiently converts FGS to MPS by making full usage of the FGS correlation matrix formalism. While this method is capable of dealing with cases without translation symmetry, its potential can be most clearly demonstrated using translationally invariant infinite matrix product states (iMPSs). It can be applied when each unit cell contains multiple sites cells such as 2D systems on infinite cylinders. We have achieved significant reduction of computational cost and constructed reliable iMPSs for very large systems. This method also leads to another im-
2
portant discovery about spontaneous symmetry breaking or topological order. It is well-known that the ground states of such systems are degenerate and their MPSs are 'non-injective' in the sense that local matrices generally have more than one blocks in the canonical form [37]. Nevertheless, injective MPSs can be obtained from noninjective ones by projecting onto each irreducible block in the virtual space. This progress enriches our toolbox for characterizing topological order in Guzwiller pojected FGSs. For a given iMPS representation, ground-state degeneracy manifests itself in the multiplicity of the leading eigenvectors ('fixed points') of the iMPS transfer matrix. If we perform the projection to constructed an injective MPS, its bipartite entanglement entropy would be minimized. For 2D topological order, injective MPSs with this property are called anyon eigenstates (or 'minimally entangled states' [38, 39]), which are particularly useful for extracting topological data [40-42]. As benchmark examples, this procedure is employed to find the anyon eigenbasis in two chiral spin liquid models and characterize their topological orders. The first system has Abelian SU(2) 1 topological order and its anyon eigenbasis has not been constructed before. The second system has nonAbelian SU(2) 2 topological order but its anyon eigenbasis is unknown and clearly illustrates the utility of our approach.
The rest of this paper is organized as follows. In Sec. II, we describe the algorithm in detail. It has three main steps: (i) Get the correlation matrix of the FGS to be converted; (ii) Decompose the correlation matrix of the whole system into local projectors and virtual bonds; (iii) Perform mode decimation and reconfigure local projectors and virtual bonds as local tensors. In Sec. III, the algorithm is applied on two chiral spin liquid models to construct their anyon eigenbases from which entanglement spectra are computed. This paper is summarized with an outlook in Sec. IV.
## II. METHOD
In this section, we present our algorithm in detail. This section is organized as follows. We first introduce FGSs and the correlation matrix formalism in Sec. II A. Next we derive and solve the recursion equation for the correlation matrix of the MPS local tensor in Sec. II B. Then, we discuss how to generate local tensors from the local correlation matrix and perform truncation in Sec. II C. Finally, we propose the mode decimation scheme to accelerate the computation of the MPS local tensor in Sec. II D and discuss how to implement the anyon eigenbasis filtration using iMPS in Sec. II E.
## A. Fermionic Gaussian states and correlation matrix formalism
Since we will extensively use FGSs in this work, we first give a brief review of the formulation and introduce necessary concepts. For notational simplicity, we restrict ourselves in Sec. II to particle-number-conserving FGSs [termed as U(1)-FGSs]. The extension to the more general case with pairing is straightforward but requires some adaptions of the formalism (see, e.g., Ref. [19]).
We start with a fermionic lattice system. The fermionic creation and annihilation operators are written as c † j and c j , respectively. When presenting the algorithm, we treat j as the site index, with j = 1 , . . . , N . For cases where fermions have internal degrees of freedom (e.g., spin or orbital), one may view j as the combination of site and internal state indices, e.g., j = ( i, σ ).
Let us consider a pure U(1)-FGS | ψ ⟩ , which is fully characterized by its correlation matrix [3, 43]
$$\mathcal { C } _ { j, j ^ { \prime } } = 2 \, \langle \psi | c _ { j } ^ { \dagger } c _ { j ^ { \prime } } | \psi \rangle - \delta _ { j, j ^ { \prime } } \,. \quad \quad ( 1 )$$
C is an N × N Hermitian matrix satisfying C 2 = ✶ N . Diagonalizing the correlation matrix C gives
✶ where M is a unitary matrix. Q is the number of occupied modes in | ψ ⟩ , and the corresponding eigenvectors (first Q rows of the unitary matrix M † ) can be used to write | ψ ⟩ explicitly as a Fermi sea state
$$M ^ { \dagger } \mathcal { C } M & = \begin{pmatrix} 1 _ { Q } & 0 \\ 0 & - 1 _ { N - Q } \end{pmatrix}, \quad & ( 2 ) \\ M \text{ is a unitary matrix. } Q \text{ is the number of oc-}$$
$$| \psi \rangle = \prod _ { q = 1 } ^ { Q } f _ { q } ^ { \dagger } | 0 \rangle \,,$$
where f † q = ∑ N j =1 M † q,j c † j with q = 1 , . . . , Q ( q = Q + 1 , . . . , N ) are occupied (unoccupied) modes in | ψ ⟩ , and | 0 ⟩ is the vacuum, c j | 0 ⟩ = 0 ∀ j .
For our algorithm, we need the Schmidt decomposition of U(1)-FGSs. Let us partition the first N L sites (index j = 1 , . . . , N L ) of the system into the left part (denoted as 'L') and remaining N R = N -N L sites into the right part (denoted as 'R'). Accordingly, the correlation matrix in Eq. (1) is decomposed into four blocks
$$\mathcal { C } = \begin{pmatrix} \mathcal { C } ^ { \text{LL} } & \mathcal { C } ^ { \text{LR} } \\ ( \mathcal { C } ^ { \text{LR} } ) ^ { \dagger } & \mathcal { C } ^ { \text{RR} } \end{pmatrix},$$
where C LL and C RR are N L × N L and N R × N R Hermitian matrices, respectively. Actually, C LL is the correlation matrix of the reduced density operator ρ L for the left subsystem
$$\mathcal { C } _ { j, j ^ { \prime } } ^ { L L } = 2 \, \text{tr} _ { L } ( \rho ^ { L } c _ { j } ^ { \dagger } c _ { j ^ { \prime } } ) - \delta _ { j, j ^ { \prime } } \, \text{ \quad \ \ } ( 5 )$$
with 1 ≤ j, j ′ ≤ N L and 'tr L ' being the trace over degrees of freedom in the left subsystem. Similar definition holds for C RR in the right subsystem.
Substituting Eq. (4) into C 2 = ✶ N gives ( C LL 2 ) + C LR ( C LR ) † = ✶ N L and ( C LR ) † C LR + ( C RR 2 ) = ✶ N -N L . It becomes clear that the two unitary matrices obtained from the singular value decomposition (SVD) of C LR can diagonalize C LL and C RR . For instance, we have
$$U ^ { \dagger } \mathcal { C } ^ { \text{LL} } U = \begin{pmatrix} \Lambda & 0 & 0 \\ 0 & \mathbb { 1 } & 0 \\ 0 & 0 & - \mathbb { 1 } \end{pmatrix} \,, \quad & ( 6 ) & \text{for} \\ \underset { - 1 } { \text{is a diagonal matrix with diagonal entries } } \Lambda _ { \mu } \in \begin{pmatrix} \Lambda & 0 & 0 \\ \Lambda & 0 \\ \Lambda & 0 \end{pmatrix} \,,$$
✶ where Λ is a diagonal matrix with diagonal entries Λ µ ∈ ( -1 1). , The size of the three diagonal blocks in Eq. (6) depends on the entanglement structure of | ψ ⟩ . We shall denote these blocks as 'occupied', 'entangled', and 'unoccupied' (abbreviated as O, E, and U, respectively), for the reason that will become clear soon. The unitary matrix U defines a single-particle basis rotation in the left subsystem
$$d _ { \text{L}, \mu } ^ { \dagger } = \sum _ { j = 1 } ^ { N _ { \text{L} } } U _ { \mu, j } ^ { \dagger } c _ { j } ^ { \dagger } & & ( 7 ) & & \text{(} \mu \\ & & \text{Sc} \\ & & \text{u} \colon & &$$
with µ = 1 , . . . , N L . In this new basis, the three blocks in the diagonalized subsystem correlation matrix [Eq. (6)] translates into
$$\langle \psi | d _ { \mathrm L, \mu } ^ { \dagger } d _ { \mathrm L, \mu } | \psi \rangle = \begin{cases} 1 & \text{if } \mu \in \mathrm O \\ ( 1 + \Lambda _ { \mu } ) / 2 & \text{if } \mu \in \mathrm E \\ 0 & \text{if } \mu \in \mathrm U \end{cases},$$
where µ ∈ O E U distinguish , , three type of modes: d † L ,µ ∈ O ( d † L ,µ ∈ U ) modes are completely occupied (unoccupied) in | ψ ⟩ and have no entanglement with the right subsystem, and d † L ,µ ∈ E are only partially occupied in | ψ ⟩ and hence entangle with certain modes in the right subsystem. In this context, O , E U should not be viewed as , particular sets; they are rather labels for modes (we will use them for the right subsystem, too).
Similarly, the diagonalization of C RR gives
$$V ^ { \dagger } \mathcal { C } ^ { \text{RR} } V = \begin{pmatrix} - \Lambda & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & - 1 \end{pmatrix} \,, \quad & ( 9 ) \\ \text{the unitary matrix } V \text{ defines an orthonormal } \text{ the } \text{ua}$$
✶ where the unitary matrix V defines an orthonormal single-particle basis for the right subsystem
$$d _ { \text{R}, \nu } ^ { \dagger } = \sum _ { j = N _ { \text{L} } + 1 } ^ { N } V _ { \nu, j } ^ { \dagger } c _ { j } ^ { \dagger } & & ( 1 0 ) \quad \text{wh} \\ & \text{for}$$
with ν = 1 , . . . , N R . The occupation of these modes in | ψ ⟩ is given by
$$\langle \psi | d _ { R, \nu } ^ { \dagger } d _ { R, \nu } | \psi \rangle = \begin{cases} 1 & \text{if $\nu\in O$} \\ ( 1 - \Lambda _ { \nu } ) / 2 & \text{if $\nu\in E$} \\ 0 & \text{if $\nu\in U$} \end{cases} \quad ( 1 1 ) \quad \text{not $\cosh$} \\ \text{or $p$} \end{cases}$$
Combining that the unitary matrices U † and V SVDdiagonalize C LR [i.e., ( U † C LR V ) µ,ν = ⟨ ψ d | † L ,µ d R ,ν | ψ ⟩ ∝ δ µ,ν ] and that C 2 = ✶ N (valid also in the new basis), we obtain
$$\langle \psi | d _ { \text{L}, \mu } ^ { \dagger } d _ { \text{R}, \nu } | \psi \rangle = \frac { \sqrt { 1 - \Lambda _ { \mu } ^ { 2 } } } { 2 } \delta _ { \mu, \nu } \text{ \quad \ \ } ( 1 2 )$$
for µ, ν ∈ E. Together with Eqs. (8) and (11), we can reconstruct | ψ ⟩ in terms of the orthonormal modes defined in two subsystems as follows:
$$| \psi \rangle & = \prod _ { \mu \in \mathbb { E } } \left [ \sqrt { \frac { 1 + \Lambda _ { \mu } } { 2 } } d _ { \mathbb { L }, \mu } ^ { \dagger } + \sqrt { \frac { 1 - \Lambda _ { \mu } } { 2 } } d _ { \mathbb { R }, \mu } ^ { \dagger } \right ] \\ & \quad \times \prod _ { \mu \in \mathcal { O } } d _ { \mathbb { L }, \mu } ^ { \dagger } \prod _ { \nu \in \mathcal { O } } d _ { \mathbb { R }, \nu } ^ { \dagger } | 0 \rangle \,. \\ \dots & \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots$$
When multiplying out the product for entangled modes ( µ ∈ E), this gives the Schmidt decomposition of | ψ ⟩ .
For later discussions, it will be useful to encode the Schmidt vectors in two U(1)-FGSs living in enlarged Hilbert spaces
$$\dots & \dots \dots \dots \dots \dots \\ & | \phi ^ { L } \rangle = \prod _ { \mu = 1 } ^ { N _ { L } } \left [ \frac { 1 } { \sqrt { 2 } } \left ( d _ { L, \mu } ^ { \dagger } + b _ { N _ { L }, \mu } ^ { \dagger } \right ) \right ] | 0 \rangle _ { p, \nu }, \\ & | \phi ^ { R } \rangle = \prod _ { \nu = 1 } ^ { N _ { R } } \left [ \frac { 1 } { \sqrt { 2 } } \left ( d _ { R, \nu } ^ { \dagger } + b _ { N _ { L + 1 }, \nu } ^ { \dagger } \right ) \right ] | 0 \rangle _ { p, \nu }, \\. & \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots.$$
where every subsystem orthonormal mode ( d † L ,µ and d † R ,ν ) entangles with one virtual mode ( b † N ,µ L and b † N L +1 ,ν ). | 0 ⟩ p v , is the shared vacuum of physical ('p') and virtual ('v') modes. The virtual modes, indicated by their site indices N L and N L+1 , locate at the 'entangling edge' of the Schmidt decomposition. Introducing a virtual bond state between virtual modes
$$| S \rangle = \prod _ { \mu \in \mathbb { E } } \left [ \sqrt { \frac { 1 - \Lambda _ { \mu } } { 2 } } b _ { N _ { L }, \mu } ^ { \dagger } - \sqrt { \frac { 1 + \Lambda _ { \mu } } { 2 } } b _ { N _ { L } + 1, \mu } ^ { \dagger } \right ] \\ & \times \prod _ { \mu \in \mathbb { U } } b _ { N _ { L }, \mu } ^ { \dagger } \prod _ { \nu \in \mathbb { U } } b _ { N _ { L } + 1, \nu } ^ { \dagger } | 0 \rangle _ { \nu } \,,$$
the original state | ψ ⟩ is restored by contracting the virtual modes (depicted in Fig. 1):
$$\left | \psi \right \rangle = \left \langle S \right | \left ( \left | \phi ^ { L } \right \rangle \otimes \left | \phi ^ { R } \right \rangle \right ) \,, \quad \quad \left ( 1 6 \right )$$
where an unimportant overall factor is ignored. This form of the Schmidt decomposition will be used in Sec. II B. As a minor remark, the tensor product notation in Eq. (16) is not entirely rigorous in mathematical sense, since fermionic systems need a Z 2 -graded tensor product for suitably bookkeeping the fermionic signs. Nevertheless, for our purpose, this notation is intuitive and does not cause sign inconsistency. Below we shall continue with such notations (and sometimes even drop the tensor product symbol).
FIG. 1. Schematic of the Schmidt decomposition of a fermionic Gaussian state | ψ ⟩ via introducing virtual fermionic modes and the associated virtual bond state ⟨ S | .
## B. Calculation of the MPS local correlation matrix
In this subsection, we illustrate how to obtain an MPS representation of | ψ ⟩ . The elementary building blocks of MPSs are single-site tensors. The key part of our algorithm is the calculation of a central-site tensor of the MPS. For finite-size systems without translation invariance, MPS tensors at other lattice sites can be obtained by iterating this algorithm. For one-site translation invariant systems, one can gradually increase system sizes such that the central-site tensor is converged; this gives an iMPS (by copying the single-site tensor to every site) in the thermodynamic limit. For systems with multi-site unit cells (e.g., cylinders), iMPSs can be obtained by calculating single-site tensors separately for all sites within one unit cell.
Let us choose a central site with index m m ( ∼ N/ 2). We first follow the procedure in Sec. II A and decompose | ψ ⟩ in the form of Eq. (16):
$$| \psi \rangle = \langle S _ { m, m + 1 } | \left ( | \phi ^ { [ \leq m ] } \rangle \otimes | \phi ^ { [ > m ] } \rangle \right ), \quad ( 1 7 ) \quad \text{and}$$
where ⟨ S m,m +1 | is the virtual bond state, and | ϕ [ ≤ m ] ⟩ and | ϕ [ >m ] ⟩ ) are U(1)-FGSs encoding the Schmidt vectors of the left (sites 1 to m ) and right (sites m + 1 to N ) subsystems, respectively. For the derivations below, we only need | ϕ [ ≤ m ] ⟩ :
$$| \phi ^ { [ \leq m ] } \rangle = \prod _ { \mu = 1 } ^ { m } \left [ \frac { 1 } { \sqrt { 2 } } \left ( d _ { [ \leq m ], \mu } ^ { \dagger } + b _ { m, r, \mu } ^ { \dagger } \right ) \right ] | 0 \rangle _ { p, \nu } \,, \quad ( 1 8 ) \quad \begin{array} { c } \dot { c } _ { m } ^ { \dagger } \, \text{a} \\ b _ { m, r, \mu } ^ { \dagger } \end{array}$$
where d † [ ≤ m,µ ] are orthonormal modes for the left subsystem [see Eq. (7)], and b † m,r,µ are virtual modes on site m (index ' r ' means right side), maximally entangling with d † [ ≤ m,µ ] [see Eq. (14)].
To get a local state at site m (playing the role of an
FIG. 2. Further decomposition of the fermionic Gaussian state | ψ ⟩ to obtain the local state | A [ m ] ⟩ at site m .
MPS tensor), we decompose | ψ ⟩ further as
$$| \psi \rangle = & \left ( \langle I _ { m - 1, m } | \otimes \langle S _ { m, m + 1 } | \right ) \\ & \times \left ( | \phi ^ { [ < m ] } \rangle \otimes | A ^ { [ m ] } \rangle \otimes | \phi ^ { [ > m ] } \rangle \right ) \quad ( 1 9 )$$
by requiring
$$| \phi ^ { [ \leq m ] } \rangle = \langle I _ { m - 1, m } | \left ( | \phi ^ { [ < m ] } \rangle \otimes | A ^ { [ m ] } \rangle \right ) \quad ( 2 0 )$$
in Eq. (17). Here | ϕ [ <m ] ⟩ is the state encoding the Schmidt vectors of the new left subsystem (including sites 1 to m -1)
$$\underset { \gamma = 1 } { s e } | \phi ^ { [ < m ] } \rangle = \prod _ { \gamma = 1 } ^ { m - 1 } \left [ \frac { 1 } { \sqrt { 2 } } \left ( d _ { [ < m ], \gamma } ^ { \dagger } + b _ { m - 1, r, \gamma } ^ { \dagger } \right ) \right ] | 0 \rangle _ { v } \,, \quad ( 2 1 )$$
and | I m -1 ,m ⟩ is a maximally entangled virtual bond state between sites m -1 and m :
$$\underset { \text{to} } { m } \Big | \Big > = \prod _ { \alpha = 1 } ^ { m - 1 } \left [ \frac { 1 } { \sqrt { 2 } } \left ( b _ { m - 1, r, \alpha } ^ { \dagger } + b _ { m, l, \alpha } ^ { \dagger } \right ) \right ] | 0 \Big > _ { \nu }, \quad ( 2 2 )$$
where b † m,l,α are virtual modes on site m (index ' ' means l left side). The state | A [ m ] ⟩ , appearing in Eq. (20), is a U(1)-FGS at site m , which consists of the physical mode c † m and virtual modes b † m,l,α [ α = 1 , . . . , ( m -1)] and b † m,r,µ ( µ = 1 , . . . , m ). The explicit form of | A [ m ] ⟩ needs to be determined. The graphical representation of the decompositions in Eqs. (17), (19) and (20) is depicted in Fig. 2. To determine | A [ m ] ⟩ , we observe that a result in Ref. [26] [Eq. (A14) thereof] can be used to translate Eq. (20) into a relation of correlation matrices of the U(1)-FGSs involved, from which the correlation matrix of | A [ m ] ⟩ can be calculated. Before using that result,
one should first decompose the correlation matrices into blocks corresponding to certain modes. For instance, the correlation matrix of | A [ m ] ⟩ , denoted by C [ m ] , takes a 3 × 3 block form
$$\mathcal { C } ^ { ( m, l, \alpha ^ { \prime } ) } = ( m ) \begin{pmatrix} \mathcal { C } ^ { [ m ] } _ { 1, 1 } & \mathcal { C } ^ { [ m ] } _ { 1, 2 } & \mathcal { C } ^ { [ m ] } _ { 1, 3 } \\ [ \mathcal { C } ^ { [ m ] } _ { 1, 2 } ] ^ { \dagger } & \mathcal { C } ^ { [ m ] } _ { 2, 2 } & \mathcal { C } ^ { [ m ] } _ { 2, 3 } \\ [ \mathcal { C } ^ { [ m ] } _ { 1, 3 } ] ^ { \dagger } & [ \mathcal { C } ^ { [ m ] } _ { 2, 3 } ] ^ { \dagger } & \mathcal { C } ^ { [ m ] } _ { 3, 3 } \end{pmatrix} \quad ( 2 3 ) \quad \searrow \searrow \mathcal { C }$$
with
$$\text{with} & & \text{$\quad \colon$} \quad \colon \\ \left | \phi ^ { [ \leq m ] } \right \rangle, \\ ( \mathcal { C } ^ { [ m ] } _ { 2, 2 } ) _ { ( m ), ( m ) } & = 2 \langle A ^ { [ m ] } | b ^ { \dagger } _ { m, l, \alpha } b _ { m, l, \alpha ^ { \prime } } | A ^ { [ m ] } \rangle - \delta _ { \alpha, \alpha ^ { \prime } }, \\ ( \mathcal { C } ^ { [ m ] } _ { 2, 2 } ) _ { ( m ), ( m ) } & = 2 \langle A ^ { [ m ] } | c ^ { \dagger } _ { m } c _ { m } | A ^ { [ m ] } \rangle - 1, \\ ( \mathcal { C } ^ { [ m ] } _ { 3, 3 } ) _ { ( m, r, m u ), ( m, r, \mu ^ { \prime } } & = 2 \langle A ^ { [ m ] } | b ^ { \dagger } _ { m, r, \mu } b _ { m, r, \mu ^ { \prime } } | A ^ { [ m ] } \rangle - \delta _ { \mu, \mu ^ { \prime } }, \\ ( \mathcal { C } ^ { [ m ] } _ { 1, 2 } ) _ { ( m, l, \alpha ), ( m ) } & = 2 \langle A ^ { [ m ] } | b ^ { \dagger } _ { m, l, \alpha } c _ { m } | A ^ { [ m ] } \rangle, \\ ( \mathcal { C } ^ { [ m ] } _ { 1, 3 } ) _ { ( m, l, \alpha ), ( m, r, \mu ^ { \prime } } & = 2 \langle A ^ { [ m ] } | b ^ { \dagger } _ { m, l, \alpha } b _ { m, r, \mu ^ { \prime } } | A ^ { [ m ] } \rangle, \\ ( \mathcal { C } ^ { [ m ] } _ { 2, 3 } ) _ { ( m ), ( m, r, \mu ^ { \prime } } & = 2 \langle A ^ { [ m ] } | c ^ { \dagger } _ { m } b _ { m, r, \mu ^ { \prime } } | A ^ { [ m ] } \rangle. \quad \text{(24)} & & \mathcal { C } ^ { [ \leq } \\ \text{For} \text{ ease of reading. } we have indicated the blocks in}$$
For ease of reading, we have indicated the blocks in Eq. (23) with the corresponding indices of the fermionic modes (this will also be used for other correlation matrices below). For rows and columns in Eq. (23) involving the physical mode, ( m ) is an index with dimension one (physical modes are 'spinless'); nevertheless, we keep it to have a uniform format (it will be convenient for extensions to cases where physical modes do have internal degrees of freedom).
The correlation matrix of | ϕ [ <m ] ⟩ [Eq. (21)], denoted by C [ <m ] , has a 2 × 2 block form
$$\mathcal { C } ^ { [ < m ] } = \underset { ( m - 1, r, \gamma ) } { ( j ^ { \prime } < m ) } & \quad ( m - 1, r, \gamma ^ { \prime } ) \\ ( m - 1, r, \gamma ) & \quad \mathcal { C } ^ { [ < m ] } _ { 1, 2 } \\ [ \mathcal { C } ^ { [ < m ] } _ { 1, 2 } ] ^ { \dagger } & 0 \ \end{array} \longrightarrow \, \longrightarrow _ { - }$$
where C [ <m ] 1 2 , has entries ( C [ <m ] 1 2 , ) ( j ) ( , m -1 ,r,γ ′ ) = 2 ⟨ ϕ [ <m ] | c b † j m -1 ,r,γ ′ | ϕ [ <m ] ⟩ . Here j and γ ′ range from 1 to ( m -1). Following Eq. (7), we write the subsystem orthonormal modes as d † [ <m ,γ ] = ∑ m -1 j =1 ( U [ <m ] ) † γ,j c † j , where the unitary matrix U [ <m ] diagonalizes the subsystem correlation matrix from site 1 to ( m -1) [c.f. Eq. (6)]. The definition of | ϕ [ <m ] ⟩ in Eq. (21) gives 2 ⟨ ϕ [ <m ] | d † [ <m ,γ ] b m -1 ,r,γ ′ | ϕ [ <m ] ⟩ = δ γ,γ ′ , which leads to
$$\mathcal { C } _ { 1, 2 } ^ { [ < m ] } = U ^ { [ < m ] }. \quad \text{(26)}$$
Moreover, we obtain 2 ⟨ ϕ [ <m ] | c c † j j ′ | ϕ [ <m ] ⟩ -δ j,j ′ = 2 ⟨ ϕ [ <m ] | b † m -1 ,r,γ b m -1 ,r,γ ′ | ϕ [ <m ] ⟩ -δ γ,γ ′ = 0, which correspond to the vanishing diagonal blocks in Eq. (25).
FIG. 3. Physical and virtual modes forming the vectors | ϕ [ ≤ m ] ⟩ , | ϕ [ <m ] ⟩ , | A [ m ] ⟩ , and | I m -1 ,m ⟩ in Eq. (20).
The correlation matrix of | ϕ [ ≤ m ] ⟩ [Eq. (18)] is given by
$$( j ^ { \prime } < m ) \quad ( m ) \quad ( m, r, \mu ^ { \prime } ) \\ ) _ { \mathcal { C } ^ { [ \leq m ] } } = \quad ( m ) \begin{pmatrix} 0 & 0 & \mathcal { C } _ { 1, 3 } ^ { [ \leq m ] } \\ 0 & 0 & \mathcal { C } _ { 2, 3 } ^ { [ \leq m ] } \\ [ \mathcal { C } _ { 1, 3 } ^ { [ \leq m ] } ] ^ { \dagger } & [ \mathcal { C } _ { 2, 3 } ^ { [ \leq m ] } ] ^ { \dagger } & 0 \end{pmatrix} \quad ( 2 7 ) \\ _ { \mathcal { C } }$$
with ( C [ ≤ m ] 1 3 , ) ( j ) ( , m,r,µ ′ ) = 2 ⟨ ϕ [ ≤ m ] | c b † j m,r,µ ′ | ϕ [ ≤ m ] ⟩ and ( C [ ≤ m ] 2 3 , ) ( m , m,r,µ ) ( ′ ) = 2 ⟨ ϕ [ ≤ m ] | c † m m,r,µ b ′ | ϕ [ ≤ m ] ⟩ , where j ranges from 1 to ( m -1) and µ ′ from 1 to m . The remaining derivation is very similar to that for | ϕ [ <m ] ⟩ above and will not be repeated. If we write the subsystem orthonormal modes as d † [ ≤ m,µ ] = ∑ m j =1 ( U [ ≤ m ] ) † µ,j c † j ≡ ∑ m -1 j =1 ( U [ ≤ m ] 1 ) † µ,j c † j +( U [ ≤ m ] 2 ) † c † m , we obtain
$$\begin{pmatrix} \mathcal { C } _ { 1, 3 } ^ { [ \leq m ] } \\ \mathcal { C } _ { 2, 3 } ^ { [ \leq m ] } \end{pmatrix} = U ^ { [ \leq m ] } = \begin{pmatrix} U _ { 1 } ^ { [ \leq m ] } \\ U _ { 2 } ^ { [ \leq m ] } \end{pmatrix}, \quad \quad ( 2 8 )$$
where U [ ≤ m ] 1 ( U [ ≤ m ] 2 ) is an ( m -1) × m matrix (a 1 × m row vector).
The correlation matrix of the virtual bond state | I m -1 ,m ⟩ [Eq. (22)] is most easily obtained
$$\mathcal { C } ^ { I } = \frac { ( m - 1, r, \gamma ) } { ( m, l, \alpha ) } \binom { 0 } { 1 } _ { m - 1 }, \quad ( 2 9 ) \\ \intertext { \i e r e the non-vanishing off-diagonal block comes from } r = \frac { 1 } { 1 } \vdash \frac { 1 } { 2 } + r \sum \tilde { c } = \tilde { r } _ { m - 2 } \dots \dots \dots }$$
where the non-vanishing off-diagonal block comes from 2 ⟨ I m -1 ,m | b † m -1 ,r,γ b m,l,α ′ | I m -1 ,m ⟩ = δ γ,α ′ . By using Eq. (A14) in Ref. [26], Eq. (20) translates into the fol-
lowing correlation matrix equation:
$$& \text{long correlation matrix equation:} \quad \text{basis} \, \cdot \\ & \quad \left ( \begin{matrix} 0 & 0 & \mathcal { C } _ { 1, 3 } ^ { [ \leq m ] } \\ 0 & 0 & \mathcal { C } _ { 2, 3 } ^ { [ \leq m ] } \\ [ \mathcal { C } _ { 1, 3 } ^ { [ \leq m ] } ] ^ { \dagger } & [ \mathcal { C } _ { 2, 3 } ^ { [ \leq m ] } ] ^ { \dagger } & 0 \end{matrix} \right ) = \left ( \begin{matrix} 0 & 0 & 0 \\ 0 & \mathcal { C } _ { 2, 2 } ^ { [ m ] } & \mathcal { C } _ { 2, 3 } ^ { [ m ] } \\ 0 & [ \mathcal { C } _ { 2, 3 } ^ { [ m ] } ] ^ { \dagger } & \mathcal { C } _ { 3, 3 } ^ { [ m ] } \end{matrix} \right ) \\ & - \left ( \begin{matrix} \mathcal { C } _ { 1, 2 } ^ { [ < m ] } & 0 \\ 0 & [ \mathcal { C } _ { 1, 2 } ^ { [ m ] } ] ^ { \dagger } \\ 0 & [ \mathcal { C } _ { 1, 3 } ^ { [ m ] } ] ^ { \dagger } \end{matrix} \right ) \left ( \begin{matrix} 0 & 1 \\ 1 & \mathcal { C } _ { 1, 1 } ^ { [ m ] } \end{matrix} \right ) ^ { - 1 } \left ( \begin{matrix} [ \mathcal { C } _ { 1, 2 } ^ { [ < m ] } ] ^ { \dagger } & 0 & 0 \\ 0 & \mathcal { C } _ { 1, 2 } ^ { [ m ] } & \mathcal { C } _ { 1, 3 } ^ { [ m ] } \end{matrix} \right ), \quad \text{where} \quad \text{$(30)$} \quad \text{$(n_{0}$} \}, \\ & \text{$(30)$} \quad \text{$instan} \\ & \text{from which the solution for the correlation matrix $\mathcal{C}_{\dots.d.e.}$} \quad \text{$end} \quad a _ { A ^ { [ n _ { 0 } } } }$$
from which the solution for the correlation matrix C [ m ] of the local state | A [ m ] ⟩ reads
$$\mathcal { C } _ { 1, 1 } ^ { [ m ] } & = 0, \quad \mathcal { C } _ { 1, 2 } ^ { [ m ] } = 0, \quad \mathcal { C } _ { 2, 2 } ^ { [ m ] } = 0, \quad \mathcal { C } _ { 3, 3 } ^ { [ m ] } = 0, \quad \text{taker} \\ \mathcal { C } _ { 1, 3 } ^ { [ m ] } & = - [ \mathcal { C } _ { 1, 2 } ^ { [ < m ] } ] ^ { \dagger } C _ { 1, 3 } ^ { [ \leq m ] }, \quad \mathcal { C } _ { 2, 3 } ^ { [ m ] } = C _ { 2, 3 } ^ { [ \leq m ] }. \quad \text{(3 1)} \quad \text{phys} _ { e } ^ { \dagger }.$$
Together with Eqs. (26) and (28), the solution for Eq. (23) is given by
$$\mathcal { C } ^ { [ m ] } = \begin{pmatrix} 0 & 0 & - ( U ^ { [ < m ] } ) ^ { \dagger } U _ { 1 } ^ { [ \leq m ] } \\ 0 & 0 & U _ { 2 } ^ { [ \leq m ] } \\ - ( U _ { 1 } ^ { [ \leq m ] } ) ^ { \dagger } U ^ { [ < m ] } & ( U _ { 2 } ^ { [ \leq m ] } ) ^ { \dagger } & 0 \\ 0 & & & ( 3 2 ) & D \ ( D \\ & & & & \text{total $fc$} \end{pmatrix}$$
Thus, once the unitary matrices diagonalizing subsystem correlation matrices are determined, C [ m ] as the local correlation matrix of the MPS is also obtained.
## C. Calculation of the MPS local tensor
With the local correlation matrix C [ m ] in Eq. (32), we now demonstrate how to obtain a concrete form of the its corresponding Gaussian state | A [ m ] ⟩ and write it explicitly as an MPS local tensor. As the correlation matrix of a U(1)-FGS, C [ m ] can be diagonalized as
$$S ^ { \dagger } \mathcal { C } ^ { [ m ] } S = \begin{pmatrix} 1 _ { Q _ { m } } & 0 \\ 0 & - 1 _ { 2 m - Q _ { m } } \end{pmatrix}, \quad & ( 3 3 ) \quad & \text{MP} \\ \text{e the total number of local modes (including both} \quad & \text{app} \end{pmatrix}$$
✶ where the total number of local modes (including both virtual and physical modes) in | A [ m ] ⟩ is 2 m and S is a unitary matrix. Then, we can write | A [ m ] ⟩ as
$$| A ^ { [ m ] } \rangle = \prod _ { p = 1 } ^ { Q _ { m } } d _ { p } ^ { \dagger } | 0 \rangle _ { p, \nu }, \quad \quad ( 3 4 ) \quad \begin{matrix} \text{on} \\ \text{tio} \\ \text{cor} \\ \text{cui} \end{matrix}$$
where the Q m occupied modes are given by
$$d _ { p } ^ { \dagger } = S _ { p, 0 } ^ { \dagger } c _ { m } ^ { \dagger } + \sum _ { \alpha = 1 } ^ { m - 1 } S _ { p, ( l, \alpha ) } ^ { \dagger } b _ { m, l, \alpha } ^ { \dagger } + \sum _ { \beta = 1 } ^ { m } S _ { p, ( r, \beta ) } ^ { \dagger } b _ { m, r, \beta } ^ { \dagger }. \quad \text{$\substack{$\text{move}$} \\ \text{ter $G$} \\ \text{comp} \\ \text{In $1$} \\ \text{e$} \dots$} \colon$$
The 'column index' 0 in S † p, 0 is used for denoting the local physical mode. If we rewrite Eq. (34) in the Fock basis of physical and virtual modes, it becomes
$$| A ^ { [ m ] } \rangle = & \sum _ { \{ n _ { 0 }, n _ { l, \alpha }, n _ { r, \beta } \} } A ^ { \{ n _ { 0 } \} } _ { \{ n _ { l, \alpha } \}, \{ n _ { r, \beta } \} } \\ & \times ( c ^ { \dagger } _ { m } ) ^ { n _ { 0 } } ( b ^ { \dagger } _ { m, l, \alpha } ) ^ { n _ { l, \alpha } } ( b ^ { \dagger } _ { m, r, \beta } ) ^ { n _ { r, \beta } } | 0 \rangle _ { p, v }, \quad ( 3 6 )$$
where n 0 , n l,α and n r,β are occupation numbers of the local physical, left virtual, and right virtual modes, respectively. Here, we have used a binary list { n 0 } { , n l,α } { , n r,β } to label the fermionic states. For instance, { 0101 } represents a state with only the second and the fourth modes occupied. The coefficient A { n 0 } { n l,α } { , n r,β } in Eq. (36) is the Slater determinant defined with S [ { n 0 } { , n l,α } { , n r,β } ], which is the sub-matrix taken form the unitary matrix S by choosing its first Q m rows and the columns chosen with respect to occupied physical and virtual fermionic modes. The coefficients for virtual states, such as | I m,m +1 ⟩ and | S m,m +1 ⟩ , can be calculated in the same way.
The main bottleneck for this step is that for large systems, converting the local correlation matrix into a local tensor (or calculating all the coefficients) is not manageable, as the bond dimension would grow exponentially. For obtaining an MPS with a feasible bond dimension D ( D = 10 3 ∼ 10 ), 4 we keep only D states of virtual fermions, corresponding to D elements in binary lists { n l,α } and { n r,β } . The selection criterion for the kept elements is that they have dominant contributions to the bipartite entanglement according to the Schmidt decompsition in Eq. (15) (this is equivalent to the SVD truncation [18]). For FGSs with relatively small entanglement (or with small system sizes), this method is already sufficient. However, for FGSs that require large system sizes to obtain a converged MPS local tensor, this method is not efficient enough. In Sec. II D below, we describe an improved method for calculating the MPS local tensor.
It is worth noting that the 'single SVD truncation' scheme described above (i.e., without further DMRG sweeps) is not guaranteed to provide the most accurate MPS approximation for a fixed bond dimension D , as we simultaneously truncate all the virtual bonds. Nevertheless, we observe that this scheme already provides a good approximation as long as the bond dimension D is not too small.
As a further note, we mainly focus in this manuscript on Gutzwiller projected U(1)-FGSs as trial wave functions for spin systems, where a local fermion-number constraint restores the spin Hilbert space (e.g., singly occupied two-component fermions at each site representing spin-1/2). With a fixed number of local physical modes implemented by the Gutzwiller projection, virtual states at each sites also have a fixed particle number after Gutzwiller projection. This can obviate the need to compute unnecessary MPS local tensor entries.
In the construction of a fermionic tensor network, the fermionic sign should be carefully managed. For practical calculations, one needs to contract the virtual modes in Eq. (36) with those in the virtual bond states to ob-
tain an ordinary MPS, where fermionic signs arise due to moving and contracting the virtual modes. However, these signs can be absorbed into the definition of the MPS local tensor (see Ref. [44]).
## D. Mode decimation
In Sec. II A, II B, and II C, we have described a complete conversion algorithm, as we start from a U(1)-FGS | ψ ⟩ and arrive at an explicit form of the MPS local tensor. There, the elements of the MPS local tensor are given by the Slater determinants of some sub-matrix of S [Eqs. (33) and (35)], so the computational complexity scales as O N ( 3 ), where N is the system size. This scaling is polynomial but may still prevent us from simulating large systems. As reaching large system sizes is crucial for obtaining iMPS, the present subsection provides an improved method to compute the MPS local tensor.
If we follow the SVD truncation scheme in Sec. II C and restrict the number of virtual states in Eq. (36) to D (by choosing elements in { n l,α } and { n r,β } with dominant entanglement support), some virtual modes ( b † m,l,α and b † m,r,β ) are occupied or unoccupied [see Eq. (15); for these modes Λ µ are close to ± 1]. We estimate that only around log ( 2 D ) modes are 'active' (with Λ µ not close to ± 1) in these D virtual states. With this observation in mind, we find that it is possible to define another local U(1)-FGS | ˜ A [ m ] ⟩ which has less virtual modes (and thus a smaller correlation matrix ˜ C [ m ] ) but gives exactly the same result when calculating the MPS local tensor with bond dimension D . As the size of ˜ C [ m ] is of order log 2 ( D ), the cost of generating a single MPS local tensor element can be reduced from O N ( 3 ) to O ((log 2 ( D )) 3 ). This is also more efficient than O N ( 2 log 2 ( D )), where the latter requires a fast update strategy for Slater determinants (see Ref. [18]).
In the following, we describe how to construct | ˜ A [ m ] ⟩ by mode decimation and generate the MPS local tensor from it. Hereafter, we use a tilde hat for quantities where the mode decimation has been performed.
Due to the SVD truncation, some entangled modes in the Schmidt decomposition become occupied (unoccupied) modes. To simplify the notation, we transfer this kind of entangled modes from set E to set O (U) and denote the resulting set as E, O and U. ˜ ˜ ˜ Then, the local Gaussian state under mode decimation can be expressed as
$$| \tilde { A } ^ { [ m ] } \rangle = ( \langle I ^ { ( m, l ) } | \otimes \langle I ^ { ( m, r ) } | ) ( | P ^ { ( m, l ) } \rangle \otimes | A ^ { [ m ] } \rangle \otimes | P ^ { ( m, r ) } \rangle ) \quad \text{the co}$$
FIG. 4. Schematic of the Gaussian states (a) | ˜ A [ m ] ⟩ and (b) ⟨ S m,m +1 | . The solid dots represent fermionic modes. The modes connected by a spiral line belong to the same Gaussian state. Different dots or modes in a single dashed rectangular are contracted.
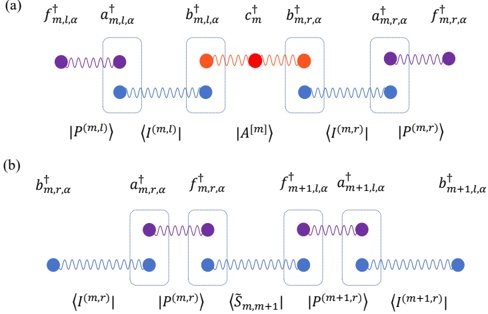
with
$$C _ { \alpha } & \text{ with } \\ | P ^ { ( m, l ) } \rangle = \prod _ { \beta \in \tilde { U } } a _ { m, l, \beta } ^ { \dagger } \prod _ { \alpha \in \tilde { E } } ( f _ { m, l, \alpha } ^ { \dagger } - a _ { m, l, \alpha } ^ { \dagger } ) | 0 \rangle, \\ \mathcal { r } _ { \alpha } & | I ^ { ( m, l ) } \rangle = \prod _ { \alpha = 1 } ^ { m - 1 } ( a _ { m, l, \alpha } ^ { \dagger } + b _ { m, l, \alpha } ^ { \dagger } ) | 0 \rangle, \\ \mathfrak { i } _ { \alpha } & | I ^ { ( m, r ) } \rangle = \prod _ { \alpha = 1 } ^ { m } ( b _ { m, r, \alpha } ^ { \dagger } + a _ { m, r, \alpha } ^ { \dagger } ) | 0 \rangle, \\ | P ^ { ( m, r ) } \rangle = \prod _ { \alpha \in \tilde { E } } ( a _ { m, r, \alpha } ^ { \dagger } - f _ { m, r, \alpha } ^ { \dagger } ) \prod _ { \beta \in \tilde { U } } a _ { m, r, \beta } ^ { \dagger } | 0 \rangle. \quad ( 3 8 ) \\ \mathfrak { h } ), & \text{ Here we have introduced two new types of virtual modes,}$$
Here we have introduced two new types of virtual modes, denoted by f † and a † , their positions are depicted in Fig. 4(a). The projectors P ( m,r ) and P ( m,l ) can help fix or freeze modes belonging to U or O. ˜ ˜ As f † µ ∈ ˜ , E the number of f modes can be smaller than that of b modes, so | ˜ A [ m ] ⟩ has less virtual modes.
To calculate tensor elements using | ˜ A [ m ] ⟩ , we should also perform mode decimation on the virtual states. For instance, if we start with the virtual state { 101100 } and find that the first and the last modes should be fixed, then the virtual state for | ˜ A [ m ] ⟩ should be { 0110 } . Then | P ( m,r ) ⟩ together with ⟨ I ( m,r ) | can be treated as a 'signal processor'. If the input on the right side is { 0110 } (configuration of f † m,r,α ), the output on the left side is { 101100 } (configuration of b † m,r,α ). Following this procedure, one can easily verify that calculating the local tensor using | ˜ A [ m ] ⟩ or | A [ m ] ⟩ gives the same result.
The block structure of ˜ C [ m ] is much more complicated than that of C [ m ] as some blocks no longer vanish due to mode decimation. To derive ˜ C [ m ] , we should first obtain the correlation matrices for those truncation projectors. The correlation matrix of | P ( m,r ) ⟩ can be easily calcu-
lated:
where
$$\mathcal { C } ^ { ( m, r ) } = \frac { a } { f } \begin{pmatrix} a & f \\ C _ { 1, 1 } ^ { ( m, r ) } & C _ { 1, 2 } ^ { ( m, r ) } \\ [ C _ { 1, 2 } ^ { ( m, r ) } ] ^ { \dagger } & C _ { 2, 2 } ^ { ( m, r ) } \end{pmatrix}, \quad \text{ (3 9)}$$
$$\mathcal { C } _ { 2, 2 } ^ { ( m, r ) } = 0,$$
$$[ C _ { 1, 2 } ^ { ( m, r ) } ] _ { \alpha, \beta } = - \delta _ { \alpha \beta },$$
$$[ C ^ { ( m, r ) } _ { 1, 1 } ] _ { \alpha, \beta } = \delta _ { \alpha \beta } \begin{cases} - 1, & \alpha \in \tilde { \mathbf U } \\ 1, & \alpha \in \tilde { \mathbf O } \, & \quad ( 4 2 ) & \text{Con} \\ 0, & \alpha \in \tilde { \mathbf E } & \quad \text{ each} \\ \text{a 3} \end{cases}$$
and the correlation matrix of | P ( m,l ) ⟩ reads
$$C ^ { ( m, l ) } = \frac { f } { a } \begin{pmatrix} f & a \\ C _ { 1, 1 } ^ { ( m, l ) } & C _ { 1, 2 } ^ { ( m, l ) } \\ [ C _ { 1, 2 } ^ { ( m, l ) } ] ^ { \dagger } & C _ { 2, 2 } ^ { ( m, l ) } \end{pmatrix},$$
where
$$\Re ^ { ( m, l ) } _ { 1, 1 } & = 0, \\ [ C ^ { ( m, l ) } _ { 1, 2 } ] _ { \alpha, \beta } & = - \delta _ { \alpha \beta }, \\ [ C ^ { ( m, l ) } _ { 2, 2 } ] _ { \alpha, \beta } & = \delta _ { \alpha \beta } \begin{cases} 1, & \alpha \in \tilde { \mathbb { U } } \\ - 1, & \alpha \in \tilde { O } \\ 0, & \alpha \in \tilde { E } \end{cases}. \quad \ \ ( 4 4 ) \\ \dots \quad - \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \alpha \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Lambda \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \Delta \quad \epsilon \quad \quad \quad$$
Combining Eq. (A14) in Ref. [26] and Eq. (37), we obtain each block of the correlation matrix ˜ C [ m ] [which also takes a 3 × 3 block structure as C [ m ] in Eq. (23)]:
$$\tilde { c } ^ { [ m ] } _ { 1, 1 } & = \tilde { c } ^ { ( m, t ) } _ { 1, 2 } \{ 1 - \tilde { c } ^ { [ m ] } _ { 1, 3 } \tilde { c } ^ { ( m, r ) } _ { 1, 1 } [ \tilde { c } ^ { ( m ] } _ { 1, 3 } ] \tilde { c } ^ { ( m, t ) } _ { 2, 2 } \} ^ { - 1 } \tilde { c } ^ { [ m ] } _ { 1, 3 } \tilde { c } ^ { ( m, r ) } _ { 1, 1 } [ \tilde { c } ^ { ( m ] } _ { 1, 3 } ] \tilde { t } } _ { 1, 2 } ^ { ( m, t ) } ] \tilde { t } } _ { 1, 2 } ^ { ( m, t ) } ] \tilde { t } } _ { 1, 2 } ^ { ( m, t ) } ] \tilde { t } } _ { 1, 2 } ^ { \dagger }, \\ \tilde { c } ^ { [ m ] } _ { 1, 2 } & = \tilde { c } ^ { ( m, t ) } _ { 1, 2 } \{ 1 - \tilde { c } ^ { [ m ] } _ { 1, 3 } \tilde { c } ^ { ( m, r ) } _ { 1, 1 } [ \tilde { c } ^ { ( m ] } _ { 1, 3 } ] \tilde { t } } _ { 1, 3 } ^ { \dagger } \tilde { c } ^ { ( m, t ) } _ { 2, 2 } \} ^ { - 1 } \tilde { c } ^ { [ m ] } _ { 1, 3 } \tilde { c } ^ { ( m, r ) } _ { 1, 1 } [ \tilde { c } ^ { ( m ] } _ { 1, 3 } ] \tilde { t } } _ { 1, 3 } ^ { - 1 } \tilde { c } ^ { ( m, t ) } _ { 2, 2 } \} ^ { - 1 } \tilde { c } ^ { [ m ] } _ { 1, 3 } \tilde { c } ^ { ( m, r ) } _ { 1, 1 } [ \tilde { c } ^ { ( m ] } _ { 1, 3 } ] \tilde { t } } _ { 1, 3 } ^ { - 1 } \tilde { c } ^ { ( m, t ) } _ { 2, 2 } \} ^ { - 1 } \tilde { c } ^ { [ m ] } _ { 1, 3 } \tilde { c } ^ { ( m, r ) } _ { 1, 1 } [ \tilde { c } ^ { ( m ] } _ { 1, 3 } ] \tilde { t } } _ { 1 } \} ^ { - 1 } \tilde { c } ^ { ( m, t ) } _ { 2, 2 } \} ^ { - 1 } \tilde { c } ^ { [ m ] } _ { 1, 3 } \tilde { c } ^ { ( m, r ) } _ { 1, 1 } [ \tilde { c } ^ { ( m ] } _ { 1, 3 } ] \tilde { t } } _ { 1, 3 } ^ { - 1 } \tilde { c } ^ { ( m, t ) } _ { 2, 2 } \} ^ { - 1 } \tilde { c } ^ { [ m ] } _ { 1, 3 } \tilde { c } ^ { ( m, r ) } _ { 1, 1 } \} ^ { - 1 } \tilde { c } ^ { ( m, t ) } _ { 2, 2 } \} ^ { - 1 } \tilde { c } ^ { ( m, t ) } _ { 1, 3 } \tilde { c } ^ { ( m, r ) } _ { 1, 2 } \} ^ { - 1 }, \\ \tilde { c } ^ { [ m ] } _ { 1, 2 } & = \tilde { c } ^ { ( m ( m,$$
The mode decimation in the virtual bond states can be performed in a similar way. Here we only discuss ⟨ ˜ S m,m +1 | , and the calculation for ⟨ ˜ I m,m +1 | is similar. To make sure that ⟨ ˜ S m,m +1 | gives the same result as ⟨ S m,m +1 | when generating the local matrix on the virtual bond, we require that ⟨ S m,m +1 | = ( ⟨ I ( m,r ) | ⊗ ⟨ ˜ S m,m +1 | ⊗ ⟨ I ( m +1 ) ,l | ) ( | P ( m,r ) ⟩ ⊗ | P ( m +1 ) ,l ⟩ ); see Fig. 4(b). It turns out that the virtual bond state after mode decimation is given by
In the language of MPS, the MPS representation of any superposition of anyon eigenstates is non-injective and the leading eigenvalues of its transfer matrix are degenerate. The same is true for systems with spontaneous symmetry breaking.
$$| \tilde { S } _ { m, m + 1 } \rangle = \prod _ { \alpha \in \tilde { E } } \left [ \sqrt { \frac { 1 - \Lambda _ { \alpha } } { 2 } } f _ { m, r, \alpha } ^ { \dagger } - \sqrt { \frac { 1 + \Lambda _ { \alpha } } { 2 } } f _ { m + 1, l, \alpha } ^ { \dagger } \right ] | 0 \rangle. \begin{array} { c } \text{the iMP} \mathfrak { s } \\ \text{trix for t} \\ \text{state} \end{array} } \text{$the an} \text{$me$} \text{$a$}$$
## E. Filtration of anyon eigenbasis
Many Gutzwiller projected FGSs in two dimensions have intrinsic topological order, and this is also so for the two examples which we will consider subsequently. Generally, the ground states for topologically ordered systems on a cylinder are the superposition of anyon eigenstates.
If the Gutzwiller projected FGSs have already been converted to iMPSs, we can filter out the degenerate ground states by using the fixed points of the iMPS transfer matrix. Let us denote the transfer matrix by T . If the iMPS has a multi-site unit cell, T is the transfer matrix for the whole unit cell. Starting with some 'product state' Ans¨ atze E trial , we apply the transfer matrix on them and iterate many times to search for distinct fixed points (as left eigenvectors of T ), lim n →∞ E trial T n → E ζ with ζ = 1 , . . . , d deg , where d deg is the number of distinct fixed points (equivalently, the number of degenerate ground states). These fixed points can be normalized such that E E ζ † ζ ′ = δ ζ,ζ ′ .
Once all distinct fixed points have been found, we use the following steps to obtain the iMPS local tensor for each ground state: (i) Diagonalize each fixed point E ζ , E ζ = U S U ζ ζ † ζ with S ζ ≥ 0. (ii) Truncate S ζ (remove its
FIG. 5. (a) Diagonalizing the fixed points E ζ and truncating its vanishing eigenvalues to obtain the isometries V ζ . (b) Use the isometries to obtain the iMPS local tensor for each degenerate ground state.
zero eigenvalues) to obtain E ζ = V S V ζ ˜ ζ † ζ , where ˜ S ζ > 0 encodes positive eigenvalues. V ζ are isometries satisfying V V ζ † ζ = ✶ and V † ζ V ζ = P ζ , where P ζ are orthogonal projectors satisfying a completeness relation ∑ d deg ζ =1 P ζ = ✶ . (iii) Use the isometries to project onto the virtual space. If we denote the iMPS local matrix as A (physical index omitted; it may correspond to a block of local tensors if one deals with a multi-site unit cell), the iMPS local tensor for each degenerate ground state is given by ˜ A ζ = V † ζ AV ζ . The full procedure is depicted in Fig. 5.
## III. RESULTS
This section presents our numerical results in two chiral spin liquid models. The first (second) one has the same topological order as the Laughlin (Moore-Read) state of bosons at filling factor 1 / 2 (1) [45, 46]. In both cases, the anyon eigenbasis is constructed and their entanglement spectra are computed [47].
## A. S = 1 2 / Abelian chiral spin liquid
The first model is defined on the square lattice with each site occupied by one spin-1/2 [15, 41, 48]. There are N x ( N y ) sites along the x ( y ) direction. The spin1/2 operators are expressed in terms of fermionic parton operators as
$$S _ { j } ^ { a } = \frac { 1 } { 2 } \sum _ { \alpha, \beta = \uparrow, \downarrow } c _ { j, \alpha } ^ { \dagger } \sigma _ { \alpha, \beta } ^ { a } c _ { j, \beta }, \quad \quad ( 4 7 ) \quad \text{$any$} \\ \text{$true$} \\ \text{$the$}$$
where j is the lattice site index, σ a ( a = x, y, z ) are the Pauli matrices, and c j,α ( c † j,α ) is the fermionic annihilation (creation) operator. A single-occupancy constraint ∑ α = ↑ ↓ , c † j,α c j,α = 1 ensures that the physical states at each site are spin-1/2 states, represented by | ↑ ⟩ j = c † j, ↑ | vac ⟩ and | ↓ ⟩ j = c † j, ↓ | vac , where ⟩ | vac ⟩ is the vacuum of fermionic partons.
The hopping Hamiltonian for the fermionic partons is defined as [48]
$$H = \sum _ { \langle j k \rangle, \alpha } t _ { j k } c _ { j, \alpha } ^ { \dagger } c _ { k, \alpha } + \sum _ { \langle \langle j k \rangle \rangle, \alpha } i \Delta _ { j k } c _ { j, \alpha } ^ { \dagger } c _ { k, \sigma } \,, \quad ( 4 8 )$$
where ⟨ jk ⟩ and ⟨⟨ jk ⟩⟩ denote nearest and next-nearest neighbors, respectively. The hopping parameters have absolute values | t jk | = 1 0 and . | ∆ jk | = 0 5 and their . signs are displayed in Fig. 7(a). The lower band with Chern number 1 for each spin component is fully occupied. This Fermi sea is acted on by Gutzwiller projector P G to generate the desired chiral spin liquid.
To characterize the SU(2) 1 topological order of this model, it is convenient to employ cylinders that is open along the x direction and periodic along the y direction with boundary twist angle θ y . As already demonstrated in previous works, the anyon eigenbasis can be constructed easily when the parton Hamiltonian has exact zero modes localized at the two ends of the cylinders [15, 41]. If N y ∈ 4 N + and θ y = 0 or N y ∈ 4 N + -2 and θ y = π , there are four zero modes on either side of the cylinder (two for each spin component of the partons). The anyon eigenstate in the identity sector is obtained when the spin-up and spin-down zero modes on one end of the cylinder are occupied. The anyon eigenstate in the semion sector is obtained when the spin-up zero mode on one end and spin-down zero mode on the other end are occupied.
̸
One significant advance enabled by our method is that there is no need to manually select the edge modes. Instead, with the iMPS in hand, it is possible to filter out the anyon eigenbasis by analyzing the fixed points of the transfer matrix. When θ y = 0 , π , there is no exact zero mode. Tuning θ y from 0 to π , we numerically observed that only the identity sector is obtained. To get the semion sector, one needs to slightly couple the edge modes on each side. Two sectors get mixed in this case and the filtration scheme works. This procedure has been carried out in various systems and we focus on the case with N x = 64 and N y = 10. The lattice is mapped to a chain with a snake shape to accommodate the MPS. When the system is sufficiently long along the x direction, the MPS tensors at the center can be taken out to serve as unit cells of iMPS. There are 20 sites in each unit cell because the hopping Hamiltonian has period 2 along the x direction. We have constructed the iMPS representation with bond dimension D = 800 for both anyon eigenstates. To compute the entanglement spectrum, the system is divided into left and right halves so the good quantum numbers are K L y (the total momentum along y ) and S L z (the azimuthal spin). The edge physics of the 1 / 2 Laughlin state is captured by the chiral SU(2) 1 Wess-Zumino-Witten (WZW) model. This is a chiral conformal field theory (CFT) with two primary fields corresponding to affine Dynkin labels [0 1] ,
## (a) identity sector
FIG. 6. Λ p level for spin-up and spin-down orbitals in (a) the identity sector and (b) the semion sector of the spin-1/2 Laughlin chiral spin liquid. Only eight single-particle levels are plotted for depiction and those with Λ p = 0 are marked in orange. The Schmidt vectors with the largest and second largest singular value, denoted by λ 0 and λ 1 , respectively, are given and the red crosses represent the occupied virtual mode. In (b), we use arrows to indicate the eight degenerate virtual states at λ 1 (only one of the two modes connected by an arrow is occupied in each virtual state, so we have 2 3 virtual states).

| Λ p | | | |
|-----------------------|-------|----------------|------|
| spin | | | |
| edge | left | | |
| | | left left left | left |
| | left | left λ | left |
| (b) semion sector Λ p | λ | | |
| | 0 | 1 | |
| spin | | | |
| | right | | |
| edge | left | | |
| | | left right | |
| | λ 0 | 1 | |
| | | left right λ | |
and [1 0] [49]. , The energy spectrum of this model is well known. As shown in Figs. 7(b) and (c), the counting of entanglement levels agrees with the CFT predictions.
It is helpful to inspect the spin symmetry of the anyon eigenstates. Both the parton Hamiltonian and Gutzwiller projection respect SU(2) spin rotation symmetry. In the Schmidt decomposition of an SU(2)-symmetric MPS, the Schmidt vectors associated with the same virtual block must have the same singular values. For the identity sector, this symmetry can be preserved by the anyon eigenstate as shown in Fig. 6(a). The largest singular value λ 0 is unique when a cut is made at the center, so it belongs to the spin-0 sector. The second-largest singular value λ 1 is four-fold degenerate, which means that the associated Schmidt vectors arise from tensor product of two spin-
1 / 2 and their virtual block is 1 2 ⊗ 1 2 = 0 ⊕ 1. The other virtual blocks can be understood similarly. On the contrary, the SU(2) symmetry is broken done to U(1) in the semion sector. This is already evident in Fig. 7(c) as the entanglement levels with S L z = ± 1 are not identical. If we construct a spin-singlet ansatz for the semion state, the SU(2) symmetry can be restored [15]. The largest singular value λ 0 is two-fold degenerate so its virtual block has spin-1 / 2. The second largest singular value λ 1 corresponds to the virtual block 1 2 ⊗ 1 2 ⊗ 1 2 = 1 2 ⊕ 1 2 ⊕ 3 2 .
(c) [0,1] sector
(b) [1,0] sector
ξ
(e) [1,1] sector
(f) [0,2] sector
FIG. 7. (a) Schematics of signs of t i,j and ∆ i,j in parton Hamiltonian H . The signs of t i,j are indicated by the ± along the associated link. The signs of ∆ i,j are negative (positive) along (against) the arrows on the colored lines. Entanglement spectrum of (b) the identity sector and (c) the semion sector of the SU (2) 1 chiral spin liquid. Entanglement spectrum of (d) the identity sector, (e) the Ising anyon sector, and (f) the fermion sector of the SU (2) 2 chiral spin liquid.
## B. S = 1 non-Abelian chiral spin liquid
terms of fermionic partons as follows:
The (bosonic) Moore-Read state is a canonical example of non-Abelian topological order associated with the chiral SU(2) 2 WZW model [46]. Its three anyon eigenstates are labeled as [2,0] (identity sector), [1,1] (Ising anyon sector), and [0,2] (fermion sector). In the quantum Hall contexts, the bosonic Moore-Read state can be constructed using two copies of the bosonic Laughlin state with proper symmetrization. It has been proposed that the same topological order can be realized in spin-1 models [50-57] as well as the Yao-Lee model [58].
We use the fermionic parton approach to construct a spin-1 chiral spin liquid state which has the same topological order as the bosonic Moore-Read state. To this end, we adopt a two-orbital construction [59] and write the spin-1 operators as
$$S _ { j } ^ { a } = \frac { 1 } { 2 } \sum _ { \tau = 1, 2 } \sum _ { \alpha, \beta = \uparrow, \downarrow } c _ { j, \tau, \alpha } ^ { \dagger } \sigma _ { \alpha, \beta } ^ { a } c _ { j, \tau, \beta }, \quad ( 4 9 ) \quad \text{eige}.$$
where τ = 1 2 stands for two different orbitals , at the same site. The local constraint for restoring the spin-1 Hilbert space is imposed by requiring ⃗ S 2 j = 2, so that each orbital must occupy exactly one fermionic parton (carrying spin-1/2) and the two fermionic partons must form a spin-1 triplet. The three spin-1 states are expressed in
$$\begin{array} { c } \cdot \\ | 1 _ { j } \rangle = c _ { j, 1, \uparrow } ^ { \dagger } c _ { j, 2, \uparrow } ^ { \dagger } | \text{vac} \rangle, \\ | - 1 _ { j } \rangle = c _ { j, 1, \downarrow } ^ { \dagger } c _ { j, 2, \downarrow } ^ { \dagger } | \text{vac} \rangle, \\ | \ 0 _ { j } \rangle = \frac { 1 } { \sqrt { 2 } } ( c _ { j, 1, \downarrow } ^ { \dagger } c _ { j, 2, \uparrow } ^ { \dagger } + c _ { j, 1, \uparrow } ^ { \dagger } c _ { j, 2, \downarrow } ^ { \dagger } ) | \text{vac} \rangle. \quad ( 50 ) \\ \cdot \quad \cdot \cdot \cdot \cdot \cdot \end{array} \quad \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{array}$$
Accordingly, the Gutzwiller projector P G is defined to remove states other than those in Eq. (50).
The parton Hamiltonian of this system is identical to Eq. (48), except that the fermionic partons have an additional orbital index. In the ground state, the lower band with Chern number 1 for each spin and orbital component is fully occupied. The Gutzwiller projector is applied on top of the parton Fermi seas to generate a spin1 wave function which is expected to exhibit the SU(2) 2 chiral topological order. However, unlike the SU(2) 1 case in Sec. II A, it is a prior unclear how to define the anyon eigenbasis in the current spin-1 model.
Using our filtration scheme, three anyon eigenstates are constructed using bond dimension D = 1600 and their entanglement spectra are displayed in Fig. 7(d)-(f). The counting of entanglement levels agrees with theoretical predictions based on the chiral SU(2) 2 WZW model. This success is a highly nontrivial corroboration of our method. If the parton hopping Hamiltonian indeed has exact zero modes, we can write down the anyon eigenbasis explicitly. To begin with, all parton modes with
negative energy are occupied to generate the state | Φ . ⟩ The zero modes are created by the operators d † s,τ,α , where s = L, R indicates the left or right edge of the cylinder, τ = 1 2 stands for the two orbitals, and , α = ↑ ↓ , represents spin-up or spin-down partons. The anyon eigenbasis is given by
$$| \psi _ { [ 2, 0 ] } \rangle & = P _ { \text{G} } \, d _ { L, 1, \uparrow } ^ { \dagger } d _ { L, 1, \downarrow } ^ { \dagger } d _ { L, 2, \uparrow } ^ { \dagger } d _ { L, 2, \downarrow } ^ { \dagger } | \Phi \rangle, \quad \text{and} \\ | \psi _ { [ 1, 1 ] } \rangle & = P _ { \text{G} } \, d _ { L, 1, \uparrow } ^ { \dagger } d _ { L, 1, \downarrow } ^ { \dagger } d _ { L, 2, \uparrow } ^ { \dagger } d _ { R, 2, \downarrow } ^ { \dagger } | \Phi \rangle, \quad \text{and} \\ | \psi _ { [ 0, 2 ] } \rangle & = P _ { \text{G} } \, d _ { L, 1, \uparrow } ^ { \dagger } d _ { R, 1, \downarrow } ^ { \dagger } d _ { L, 2, \uparrow } ^ { \dagger } d _ { R, 2, \downarrow } ^ { \dagger } | \Phi \rangle \,. \quad \text{(51)} \quad \text{trith} \\ \text{way}.$$
This construction is not unique. For instance, the state in the identity sector, ψ [2 0] , , can also be expressed as P G d † L, 1 , ↑ d † L, 1 , ↓ d † R, , 2 ↑ d † R, , 2 ↓ | Φ . ⟩
The results in Eq. (51) reveal how to relate the anyon eigenbasis of the bosonic Moore-Read states to that of the bosonic Laughlin states. If we interpret the two different orbitals as different 'copies', the first line of Eq. (51) shows that the identity sector of the Moore-Read state is obtained using two copies of the Laughlin state in the identity sector. If one (both) copy of the Laughlin state is replaced by its semion sector, we would obtain the Ising anyon (fermion) sector of the Moore-Read state. This idea may also be utilized to generate other SU(2) k nonAbelian chiral spin liquid ( k > 2). In particular, the k = 3 case possesses Fibonacci anyons but there are not many studies in the spin liquid context [60].
## IV. SUMMARY AND DISCUSSIONS
In summary, we have demonstrated that the (infinite) MPSrepresentation of a particle-number-conserving FGS can be constructed efficiently using our algorithm. Thanks to the extensive usage of correlation matrices in the present work, computational cost is significantly reduced compared to previous studies so much larger sys-
- [1] P. Ring and P. Schuck, The Nuclear Many-Body Problem (Springer-Verlag, Berlin, 1980).
- [2] V. Bach, E. H. Lieb, and J. P. Solovej, J. Stat. Phys. 76 , 3 (1994).
- [3] S. Bravyi, Quantum Inf. and Comp. 5 , 216 (2005).
- [4] C. V. Kraus and J. I. Cirac, New J. Phys. 12 , 113004 (2010).
- [5] C. Gros, Ann. Phys. 189 , 53 (1989).
- [6] T. Xiang, Density Matrix and Tensor Network Renormalization (Cambridge University Press, 2023).
- [7] J. I. Cirac, D. P´ erez-Garc´ ıa, N. Schuch, and F. Verstraete, Rev. Mod. Phys. 93 , 045003 (2021).
- [8] F. Verstraete, V. Murg, and J. I. Cirac, Adv. Phys. 57 , 143 (2008).
- [9] J. I. Cirac and F. Verstraete, J. Phys. A 42 , 504004 (2009).
tem sizes can be reached. For a given MPS that describes a topologically ordered system, the anyon eigenbasis can be filtered out in a straightforward manner by analyzing the fixed points of the transfer matrix. This helps to eliminate the laborious process of adjusting the boundary conditions to search for proper edge mode occupations. The algorithm is applied to study two chiral spin liquids and the entanglement spectra of their anyon eigenbasis agree with the CFT predictions.
It would be very interesting to further test our algorithm. If the iMPSs on the cylinder are twisted in certain ways, the modular matrix could be computed to provide a quite comprehensive characterization [40-42]. Quantum phase transitions of topological states are routinely investigated in the parton framework and numerical verification of many theoretical predictions could be facilitated by our method. When a microscopic model is studied using DMRG, a wisely chosen initial state may substantial speedup the calculation. For a 2D system with topological order, feeding the program with suitable parton wave functions rather than random states could help us to find the anyon eigenbasis more easily.
Note added . In finalizing this manuscript, we became aware of the work [61], which also discussed how to construct fermionic Gaussian MPSs from correlation matrices with mode truncation.
## ACKNOWLEDGMENTS
T.L. thanks Tong-Zhou Zhao for helpful discussions. H.H.T. is grateful to Jan von Delft, Hui-Ke Jin, JhengWei Li, Rong-Yang Sun, Lei Wang, Qi Yang, Yi Zhou for stimulating discussions and fruitful collaborations on related topics. T.L. and T.X. are supported by the National Natural Science Foundation of China under Grant No. 12488201. Y.H.W. is supported by the National Natural Science Foundation of China under Grant No. 12174130.
- [10] U. Schollw¨ck, Ann. Phys. o 326 , 96 (2011).
- [11] R. Or´s, Ann. Phys. u 349 , 117 (2014).
- [12] C.-P. Chou, F. Pollmann, and T.-K. Lee, Phys. Rev. B 86 , 041105 (2012).
- [13] H.-H. Zhao, K. Ido, S. Morita, and M. Imada, Phys. Rev. B 96 , 085103 (2017).
- [14] M. T. Fishman and S. R. White, Phys. Rev. B 92 , 075132 (2015).
- [15] Y.-H. Wu, L. Wang, and H.-H. Tu, Phys. Rev. Lett. 124 , 246401 (2020).
- [16] H.-K. Jin, H.-H. Tu, and Y. Zhou, Phys. Rev. B 101 , 165135 (2020).
- [17] A. M. Aghaei, B. Bauer, K. Shtengel, and R. V. Mishmash, arXiv:2009.12435.
- [18] G. Petrica, B.-X. Zheng, G. K.-L. Chan, and B. K. Clark, Phys. Rev. B 103 , 125161 (2021).
- [19] H.-K. Jin, R.-Y. Sun, Y. Zhou, and H.-H. Tu, Phys. Rev. B 105 , L081101 (2022).
- [20] S. R. White, Phys. Rev. Lett. 69 , 2863 (1992).
- [21] H.-K. Jin, H.-H. Tu, and Y. Zhou, Phys. Rev. B 104 , L020409 (2021).
- [22] J.-Y. Chen, J.-W. Li, P. Nataf, S. Capponi, M. Mambrini, K. Totsuka, H.-H. Tu, A. Weichselbaum, J. von Delft, and D. Poilblanc, Phys. Rev. B 104 , 235104 (2021).
- [23] H.-K. Jin, W. M. H. Natori, and J. Knolle, Phys. Rev. B 107 , L180401 (2023).
- [24] R.-Y. Sun, H.-K. Jin, H.-H. Tu, and Y. Zhou, npj Quantum Mater. 9 , 16 (2024).
- [25] Q. Mortier, N. Schuch, F. Verstraete, and J. Haegeman, Phys. Rev. Lett. 129 , 206401 (2022).
- [26] J.-W. Li, J. von Delft, and H.-H. Tu, Phys. Rev. B 107 , 085148 (2023).
- [27] Q. Yang, X.-Y. Zhang, H.-J. Liao, H.-H. Tu, and L. Wang, Phys. Rev. B 107 , 125128 (2023).
- [28] Y. He, K. Li, Y. Zhang, and H. C. Po, Phys. Rev. Res. 6 , L022016 (2024).
- [29] H. C. Jiang, Z. Y. Weng, and T. Xiang, Phys. Rev. Lett. 101 , 090603 (2008).
- [30] J. Jordan, R. Or´s, G. Vidal, F. Verstraete, u and J. I. Cirac, Phys. Rev. Lett. 101 , 250602 (2008).
- [31] V. Murg, F. Verstraete, and J. I. Cirac, Phys. Rev. B 79 , 195119 (2009).
- [32] M. Lubasch, J. I. Cirac, and M.-C. Ba˜uls, Phys. Rev. n B 90 , 064425 (2014).
- [33] P. Corboz, Phys. Rev. B 94 , 035133 (2016).
- [34] L. Vanderstraeten, J. Haegeman, P. Corboz, and F. Verstraete, Phys. Rev. B 94 , 155123 (2016).
- [35] H.-J. Liao, J.-G. Liu, L. Wang, and T. Xiang, Phys. Rev. X 9 , 031041 (2019).
- [36] M. Scheb and R. M. Noack, Phys. Rev. B 107 , 165112 (2023).
- [37] D. Perez-Garcia, F. Verstraete, M. M. Wolf, and J. I. Cirac, Quantum Inf. and Comp. 7 , 401 (2007).
- [38] E. Keski-Vakkuri and X.-G. Wen, Int. J. Mod. Phys. B 07 , 4227 (1993).
- [39] Y. Zhang, T. Grover, A. Turner, M. Oshikawa, and A. Vishwanath, Phys. Rev. B 85 , 235151 (2012).
- [40] L. Cincio and G. Vidal, Phys. Rev. Lett. 110 , 067208 (2013).
- [41] H.-H. Tu, Y. Zhang, and X.-L. Qi, Phys. Rev. B 88 , 195412 (2013).
- [42] M. P. Zaletel, R. S. K. Mong, and F. Pollmann, Phys. Rev. Lett. 110 , 236801 (2013).
- [43] I. Peschel, J. Phys. A 36 , L205 (2003).
- [44] C. V. Kraus, N. Schuch, F. Verstraete, and J. I. Cirac, Phys. Rev. A 81 , 052338 (2010).
- [45] R. B. Laughlin, Phys. Rev. Lett. 50 , 1395 (1983).
- [46] G. Moore and N. Read, Nucl. Phys. B 360 , 362 (1991).
- [47] H. Li and F. D. M. Haldane, Phys. Rev. Lett. 101 , 010504 (2008).
- [48] Y. Zhang, T. Grover, and A. Vishwanath, Phys. Rev. B 84 , 075128 (2011).
- [49] P. D. Francesco, P. Mathieu, and D. S´n´chal, e e Conformal Field Theory (Springer-Verlag, New York, 1997).
- [50] M. Greiter and R. Thomale, Phys. Rev. Lett. 102 , 207203 (2009).
- [51] M. Greiter, D. F. Schroeter, and R. Thomale, Phys. Rev. B 89 , 165125 (2014).
- [52] P. Lecheminant and A. M. Tsvelik, Phys. Rev. B 95 , 140406 (2017).
- [53] Z.-X. Liu, H.-H. Tu, Y.-H. Wu, R.-Q. He, X.-J. Liu, Y. Zhou, and T.-K. Ng, Phys. Rev. B 97 , 195158 (2018).
- [54] J.-Y. Chen, L. Vanderstraeten, S. Capponi, and D. Poilblanc, Phys. Rev. B 98 , 184409 (2018).
- [55] H.-C. Zhang, Y.-H. Wu, H.-H. Tu, and T. Xiang, Phys. Rev. B 103 , 075130 (2021).
- [56] B. d. z. Jaworowski and A. E. B. Nielsen, Phys. Rev. B 106 , 115131 (2022).
- [57] Y. Huang, W. Zhu, S.-S. Gong, H.-C. Jiang, and D. N. Sheng, Phys. Rev. B 105 , 155104 (2022).
- [58] H. Yao and D.-H. Lee, Phys. Rev. Lett. 107 , 087205 (2011).
- [59] B. S. Shastry, Phys. Rev. B 46 , 8263 (1992).
- [60] W.-W. Luo, Y. Huang, D. N. Sheng, and W. Zhu, Phys. Rev. B 108 , 035130 (2023).
- [61] K. Li, Y.-B. Zhang, and H. C. Po, arXiv:2408.XXXXX. | null | [
"Tong Liu",
"Ying-Hai Wu",
"Hong-Hao Tu",
"Tao Xiang"
] | 2024-08-02T10:15:26+00:00 | 2024-08-02T10:15:26+00:00 | [
"cond-mat.str-el",
"quant-ph"
] | Efficient conversion from fermionic Gaussian states to matrix product states | Fermionic Gaussian states are eigenstates of quadratic Hamiltonians and
widely used in quantum many-body problems. We propose a highly efficient
algorithm that converts fermionic Gaussian states to matrix product states. It
can be formulated for finite-size systems without translation invariance, but
becomes particularly appealing when applied to infinite systems with
translation invariance. If the ground states of a topologically ordered system
on infinite cylinders are expressed as matrix product states, then the fixed
points of the transfer matrix can be harnessed to filter out the anyon
eigenbasis, also known as minimally entangled states. This allows for efficient
computation of universal properties such as entanglement spectrum and modular
matrices. The potential of our method is demonstrated by numerical calculations
in two chiral spin liquids that have the same topological orders as the bosonic
Laughlin and Moore-Read states, respectively. The anyon eigenbasis for the
first one has been worked out before and serves as a useful benchmark. The
anyon eigenbasis of the second one is, however, not transparent and its
successful construction provides a nontrivial corroboration of our method. |
2408.01156v1 | ## TCR-GPT: Integrating Autoregressive Model and Reinforcement Learning for T-Cell Receptor Repertoires Generation
## Yicheng Lin, Dandan Zhang, Yun Liu
School Of Basic Medical Sciences, Fudan University [email protected], [email protected], [email protected]
## Abstract
T-cell receptors (TCRs) play a crucial role in the immune system by recognizing and binding to specific antigens presented by infected or cancerous cells. Understanding the sequence patterns of TCRs is essential for developing targeted immune therapies and designing effective vaccines. Language models, such as auto-regressive transformers, offer a powerful solution to this problem by learning the probability distributions of TCR repertoires, enabling the generation of new TCR sequences that inherit the underlying patterns of the repertoire. We introduce TCR-GPT, a probabilistic model built on a decoder-only transformer architecture, designed to uncover and replicate sequence patterns in TCR repertoires. TCR-GPT demonstrates an accuracy of 0.953 in inferring sequence probability distributions measured by Pearson correlation coefficient. Furthermore, by leveraging Reinforcement Learning(RL), we adapted the distribution of TCR sequences to generate TCRs capable of recognizing specific peptides, offering significant potential for advancing targeted immune therapies and vaccine development. With the efficacy of RL, fine-tuned pretrained TCR-GPT models demonstrated the ability to produce TCR repertoires likely to bind specific peptides, illustrating RL's efficiency in enhancing the model's adaptability to the probability distributions of biologically relevant TCR sequences.
## Introduction
T-cell receptors (TCRs) are integral components of the immune system, playing a crucial role in recognizing and responding to antigens. Each TCR is composed of unique sequences of amino acids, enabling T cells to identify specific pathogens and infected cells. The diversity and specificity of TCR sequences are vital for the adaptive immune response, allowing the immune system to target a vast array of antigens with precision (Singh, N. K., et al. 2017; van der Merwe, P. A., and O. Dushek 2011).Understanding the repertoire of TCR sequences is essential for advancing immunological research and developing targeted therapies.
Text-generation models, inspired by natural language processing techniques (Chung, Junyoung, et al. 2014; Hochreiter, Sepp, and J¨rgen Schmidhuber 1997; Vaswani, Ashish, u et al. 2017), can potentially offer a transformative approach to this task. By building a probability distribution over TCR sequences, and even more, tailoring this distribution to generate TCR sequences of specific desired functionality, text- generation models can not only enhance our understanding of TCR diversity but also has practical applications in designing vaccines and immunotherapies.
In the realm of auto-regressive text generation, decoderonly transformers have become a cornerstone technology. This architecture processes input sequences to generate text in an auto-regressive manner, predicting the next token in a sequence based on the tokens it has previously generated. At each step, the model takes the current sequence of tokens as input, processes it through multiple layers of self-attention and feed-forward networks, and produces a probability distribution over the next possible tokens. The model then samples from this distribution to select the next token, appends it to the input sequence, and repeats the process until the desired output length is achieved or a stopping condition is met. Decoder-only transformers like GPT (Generative Pretrained Transformer) (Brown, Tom B., et al. 2020; Radford, Alec, et al. 2018, 2019) have demonstrated remarkable performance in various natural language processing tasks, from completing sentences and paragraphs to generating entire articles or dialogues, thus setting new benchmarks for text generation capabilities.
Reinforcement Learning (RL) involves training agents to maximize long-term rewards by interacting with complex environments. This method has been applied across diverse fields such as game playing (Souchleris, Sidiropoulos, and Papakostas 2023), robotics (Zhang and Mo 2021), drug discovery (Bilodeau et al. 2022; Du et al. 2022; Fromer and Coley 2023; Luukkonen et al. 2023; Tang, Ewalt, and Ng 2021), and more. Reinforcement learning has also emerged as an effective alternative training approach to enhance the performance of generative models, offering adaptable goals via its reward function, unlike the fixed distribution modeling objectives found in both supervised and unsupervised learning (Cao et al. 2023).
In this study, we introduce TCR-GPT, a probabilistic model based on a decoder-only transformer architecture designed to capture underlying sequence patterns in TCR repertoires and hence generate TCR sequences based on the learned probability distribution. And through reinforcement learning, we tailored the distribution of TCR sequences to generate TCRs that can recognize specific peptides, which holds great promise for advancing targeted immune therapy and vaccine design. TCR-GPT demonstrates greater ac- curacy in inferring sequence probability distributions compared to existing models, with average performance 0.953 as measured by the correlation coefficient. We further verified that TCR-GPT can efficiently adapt to different TCR sub-repertoires and provide learnable features for TCR sequences. After that, we demonstrate the effectiveness of RL in fine-tuning pretrained TCR-GPT models to generate TCR repertoires likely to bind specific peptides. Using PanPep (Gao, Yicheng, et al. 2023), a robust peptide-TCR binder prediction tool, we iteratively refine TCR-GPT through RL to generate peptide-specific TCR repertoires, showcasing RL's efficiency in significantly enhancing the model's ability to adapt to the underlying probability distribution of biologically relevant TCR sequences.
## Related work
Traditional methods for modeling TCR sequence patterns calculate the probability of a TCR sequence as the product of the selection factor and the generation probability, which are inferred separately from the processes of TCR selection and generation. A notable example of this approach is soNNia (Isacchini, G., et al. 2021).
Trials have also been conducted using variational autoencoders (VAEs) parameterized by deep neural networks to model TCR repertoires (Davidsen, K., et al. 2019). However, it requires TCR sequences to be padded to a fixed length, which can introduce noise into the original data and obscure valuable information about the diversity of sequence lengths.
Inspired by natural language processing and autoregressive text generation models, TCRpeg (Jiang, Y., and S. C. Li 2023) employs an auto-regressive framework to infer the probability of TCR sequences in an end-to-end manner. TCRpeg utilizes a deep autoregressive architecture with gated recurrent unit (GRU) layers (Chung, Junyoung, et al. 2014)to effectively model the probability of TCR sequences, offering a streamlined alternative to the above trials.
Transformer models, introduced by Vaswani et al. in 2017, have revolutionized the field of natural language processing (NLP) (Vaswani, Ashish, et al. 2017). Unlike previous sequence-to-sequence models that relied heavily on recurrent neural networks (RNNs) (Chung, Junyoung, et al. 2014; Hochreiter, Sepp, and J¨rgen Schmidhuber 1997; u Schulman, John, et al. 2017)and convolutional neural networks (CNNs) (O'Shea and Nash 2015), transformers leverage self-attention mechanisms to process input data in parallel, allowing for greater efficiency and scalability. The core innovation of the transformer architecture is its ability to capture long-range dependencies within the data, which is crucial for understanding and generating coherent text. A notable example that combines transformer and autoregressive models is the GPT (Generative Pre-trained Transformer) series (Brown, Tom B., et al. 2020; Radford, Alec, et al. 2018, 2019). These models generate text by predicting each word or token based on the preceding sequence, utilizing the attention mechanism inherent in transformer decoders to create coherent and contextually relevant text.
Reinforcement learning has demonstrated its efficacy as a robust method for training generative models, especially in NLP tasks (Cao et al. 2023). Reinforcement Learning with Human Feedback (RLHF) (Bai et al. 2022; Shi et al. 2018; Gao, Meyer, and Gurevych 2020; Kreutzer, Riezler, and Lawrence 2020; Ouyang et al. 2022) is a representative technique where reinforcement learning is used to fine-tune language models based on human-provided feedback. In the context of large language models (LLMs) like GPT, RLHF helps improve the model's performance by aligning its outputs with human preferences, leading to more contextually appropriate responses.
## Methods
## Autoregressive generative transformer for TCR sequences
Given the critical role of the CDR3β chain in TCR antigen recognition (Singh, N. K., et al. 2017; van der Merwe, P. A., and O. Dushek 2011), we utilized the CDR3β sequence as a representation of the entire TCR. We developed an autoregressive model, TCR-GPT, to estimate the probability of a TCR sequence x as p ( x | θ ) , where θ represents the parameters of a decoder-only transformer model. This probability p ( x | θ ) is computed by the autoregressive likelihood, which involves calculating the product of conditional probabilities over sequential residues of length L :
$$p \left ( { \mathbf x } | \theta \right ) = p \left ( { x _ { 1 } } | \theta \right ) \prod _ { i = 2 } ^ { L } p \left ( { x _ { i } } | { x _ { 1 } }, { x _ { 2 } }, \dots, { x _ { i - 1 } } ; \theta } \right ) \quad ( 1 )$$
Our model employs a decoder-only transformer equipped with attention mechanisms to capture interactive relationships among residues, thereby formulating the autoregressive likelihood efficiently. After embedding layers transform the discrete representation of each amino acid in batches of TCR sequences into continuous vectors of dimensionality 32, a total of 8 attention heads, each with 6 selfattention layers, collectively capture the features. Specifically, let X ∈ [0 , 1 2 , , ..., 22] B × L denote a batch of B TCRs of maximum length L . Each element in X is an integer representing an amino acid (a total of 20 different amino acids), as well as special tokens such as < SOS > (Start of Sequence), < EOS > (End of Sequence), and padding token. After embedding, X is transformed to a continuous tensor E ∈ R B × × L d , where each vector of dimension d = 32 represents the embedding of a single token. The multi-head attention layers, along with the linear layers after multi-head feature concatenation then transform E to features Z ∈ R B × × L d . These features are then processed by a position-wise feedforward network to output the probability distribution over all 20 possible amino acids at each position. The overall architecture of TCR-GPT is depicted in Figure 1A. We set the negative log likelihood as the loss function as the following:
$$L = - \sum _ { n = 1 } ^ { N } \sum _ { i = 1 } ^ { L } l o g p _ { i } \\ \dots \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
N is the batch size and p i is the output probability of the model on the right amino acid in i -th amino acid position.
Figure 1: (A) The overall architecture of TCR-GPT. (B) Main workflow of peptide-specific RL for TCR-GPT.
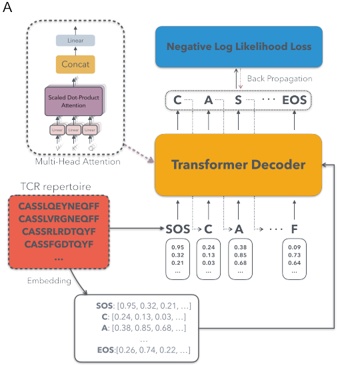
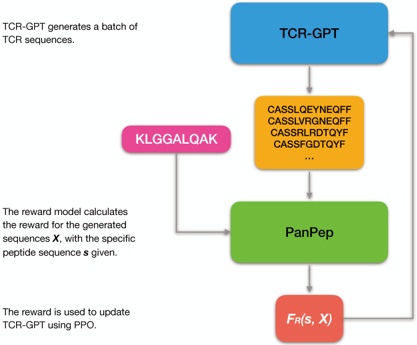
We trained the model on a dataset containing 50 million TCRs collected from a large cohort of 743 individuals, as described by Emerson et al (Emerson, R. O., et al. 2019).
acid. This approach can be summarized by the following formula:
## Jensen-Shannon Divergence
We use Jensen-Shannon divergence ( D js ( r , r i j ) ) to measure the ability of the trained model to distinguish two subrepertoires r i and r j , which is formulated as:
$$D _ { j s } ( r ^ { i }, r ^ { j } ) & = \frac { 1 } { 2 } K L ( P ^ { i } _ { i n f e r } | | M ) + \frac { 1 } { 2 } K L ( P ^ { j } _ { i n f e r } | | M ) \quad \stackrel { \text{aow} } { \text{seq} } \\ \cdot \quad \pi i \quad \cdot \pi i \quad \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
where P i infer and P j infer are probabilities computed from TCR-GPT trained on sub-repertoires r i and r j , M = 1 2 ( P i infer + P j infer ) , and KL P ( || Q ) denotes the KullbackLeibler divergence. A higher D js ( r , r i j ) indicates greater discrepancy between sub-repertoires.
For the scenario where we utilize Jensen-Shannon divergence to assess the difference of the inferred likelihood from the model P infer ( x ) and the observed frequencies P data ( x ) , we simply calculate D js ( P infer , P data ) as the following:
$$D _ { j s } ( P _ { i n f e r }, P _ { d a t a } ) = \frac { 1 } { 2 } K L ( P _ { i n f e r } ( { \mathbf x } ) | | M ) \quad ( 4 ) \quad \text{ see} \\ + \frac { 1 } { 2 } K L ( P _ { d a t a } ( { \mathbf x } ) | | M ) \quad ( 4 ) \quad \text{ see} \\ \quad \text{ is} \quad.$$
where M = 1 2 ( P infer ( x ) + P data ( x )) .
## Using TCR-GPT to generate TCR sequences
With the TCR-GPT model trained, we employed a straightforward sampling method to generate new TCR sequences. Initially, we input the start token ( < SOS > ) into the model and then sampled the amino acid for the next position from the resulting probability distribution. This sampled amino acid was appended to the previous tokens, and the process was repeated iteratively to generate each subsequent amino
$$A _ { t } = P ( A | A _ { 0 \colon t - 1 } ; \theta )$$
Here, A t represents the amino acid token at position t , and θ denotes the parameters of the TCR-GPT model. The generation process concludes when the < EOS > (End Of Sequence) token is generated. At this point, all the generated amino acids are collected to form the complete TCR sequence.
## Using the features from TCR-GPT for classification tasks
Upon training the TCR-GPT model, the features produced by the multi-head attention module can encode valuable information from the sequence input. We developed an additional classification network that utilizes these features for a downstream classification task. Specifically, let X ∈ [0 , 1 2 , , ..., 22] B × L represent a batch of B TCRs with a maximum length of L . The features extracted from the multihead attention module are denoted as Z ∈ R B × × L d , where the feature of the amino acid at each position in the L -length sequence is a d -dimensional tensor. We then flattened the feature Z to Z flatten ∈ R B × q , where each TCR sequence is represented as a q -dimensional tensor. We constructed a fully connected neural network for each classification task, which consists of three linear layers that can be formulated as follows:
$$Z _ { 0 } = Z _ { f l a t t e n }$$
$$Z _ { l } = \sigma ( W _ { l } Z _ { l - 1 } + b _ { l - 1 } ), l \in \{ 1, 2 \} \quad \ \ ( 7 )$$
$$P = s o f t m a x ( W _ { 3 } Z _ { 2 } + b _ { 3 } )$$
here, W l and b l represent the parameters of the l -th layer of the fully connected neural network, and σ denotes the activation function. The final layer, combined with the softmax operation, produces the predicted probability distribution of the classes.
## Fine-tuning TCR-GPT with RL to generate peptide-specific TCR repertoires
To generate TCR repertoires capable of binding to specific peptides, we employ peptide-specific RL to integrate knowledge from high-performance peptide-TCR binding predictors into our pretrained TCR-GPT model. PanPep (Gao, Yicheng, et al. 2023), a versatile and robust model for evaluating peptide-TCR binding affinity, leverages meta-learning and neural Turing machine concepts to achieve superior performance in both few-shot and zero-shot scenarios. We adopt PanPep as the reward model in our reinforcement learning framework. During the reinforcement learning iteration, PanPep rates the generated TCR sequences from TCR-GPT based on their binding affinity to the given peptide.
Specifically, with given peptide denoted as s , let the reward for the generated TCR sequences from the TCR-GPT model be denoted as F R ( s X , ) . Here, PanPep serves as the reward function F R for the generated TCR sequences. We constructed another transformer network parameterized by φ k at the k -th iteration as the critic V φ k , which shares the same architecture as the TCR-GPT model (the actor in this scenario). However, the critic's output is a single value representing the predicted return for each TCR sequence entry. Using PPO (Schulman, John, et al. 2017)as the reinforcement learning algorithm, we formulate the objective function as
$$& L \left ( s, X, \theta _ { k }, \theta \right ) \\ & = \min ( \frac { p _ { \theta } ( X | s ) } { p _ { \theta _ { k } } ( X | s ) } A ^ { p _ { \theta _ { k } } } \left ( s, \, X \right ), g ( \epsilon, A ^ { p _ { \theta _ { k } } } \left ( s, \, X \right ) ) ) \right ) \quad ( 9 ) \quad \text{$\text{$\text{$fetch}$} }$$
where
$$g ( \epsilon, A ) = \begin{cases} \begin{array} { c c } ( 1 + \epsilon ) A, & A \geq 0 \\ ( 1 - \epsilon ) A, & A < 0 \end{array} \end{cases} \quad ( 1 0 ) \quad \begin{array} { c } \mathbb { T } \\ \mathbb { a } \end{array}$$
$$A ^ { p _ { \theta _ { k } } } ( s, \, \mathbf X ) = F _ { R } ( s, \mathbf X ) - V ^ { \varphi _ { k } } ( \mathbf X ) \quad ( 1 1 )$$
The advantage A p θ ( s , X ) is the difference between reward F R ( s X , ) and the value V φ k ( X ) , the predicted reward of TCR sequence X by the critic network parameterized by φ in the k -th iteration. ϵ is a hyperparameter that we set at 0.2 as used in the previous paper (Schulman, John, et al. 2017). At k -th iteration, we update the parameters θ of TCRGPT, and the parameters φ of the crtic in the following formula:
$$\theta _ { k + 1 } = \arg \max _ { \theta } \frac { 1 } { | D _ { k } | } \sum _ { X \in D _ { k } } L \left ( s, X, \theta _ { k }, \theta \right ) \quad ( 1 2 ) \quad \text{rec} [ \text{Re} ]$$
$$\varphi _ { k + 1 } = \underset { \varphi } { \arg \min } \frac { 1 } { | D _ { k } | } \sum _ { X \in D _ { k } } \left [ V ^ { \varphi k } ( \mathbf X ) - F _ { R } ( s, \mathbf X ) \right ] ^ { 2 } \ ( 1 3 ) \quad \text{$\text{$\text{CD}$}$}.$$
Where D k is a batch of TCR sequences collected using TCR-GPT model during the k -th iteration. The peptidespecific RL workflow can be visualized in Figure 1B.
## Experiments
## TCR-GPT infers the probability distribution of TCR repertoires with high accuracy
To evaluate the performance of TCR-GPT, we first applied it to infer the probability distribution of TCRβ CDR3 sequences and compared its performance with two other algorithms, soNNia (Isacchini, G., et al. 2021)and TCRpeg (Jiang, Y., and S. C. Li 2023). We constructed a universal TCR repertoire by pooling the CDR3 sequences from a large cohort of 743 individuals (Emerson, R. O., et al. 2019). This comprehensive dataset provided a robust foundation for training and testing our model as well as the comparative algorithms. To assess the accuracy of these three methods, we randomly divided the universal repertoire into training and testing sets using a 50:50 ratio, the same strategy employed by TCRpeg. This approach ensured a fair and consistent comparison across the different models.
We measured the concordance between the inferred ( P infer ( x ) ) and the actual probability distributions ( P data ( x ) ) by Pearson correlation coefficients. TCR-GPT demonstrated greater concordance, achieving a Pearson correlation coefficient of r = 0 953 . , compared to soNNia ( r = 0 673 . ) and TCRpeg ( r = 0 932 . ) (Figure 2A-C). These results indicate that TCR-GPT has the highest accuracy among the three methods, as reflected by its closer alignment with the actual probability distributions.
In addition to Pearson correlation coefficients, we utilized the Jessen-Shannon divergency ( D js , Methods) to assess the difference between P infer ( x ) and P data ( x ) . The D js statistics provides a measure of divergence between two probability distributions, with a higher D js indicating a greater difference, and consequently lower model accuracy. The D js statistic further confirmed the higher accuracy of TCR-GPT, which had a D js value of 0.031. In contrast, soNNia and TCRpeg had D js values of 0.131 and 0.039, respectively. These results underscore the effectiveness of TCR-GPT in accurately inferring the probability distribution of TCRβ CDR3 sequences.
According to the comparisons above, we conclude that TCR-GPT outperformed soNNia and TCRpeg in both measures of accuracy, making it the most reliable method among the three for inferring the probability distribution of TCRβ CDR3 sequences. The superior performance of TCRGPT, as evidenced by both Pearson correlation coefficients and Jensen-Shannon divergence, highlights its potential as a powerful tool for TCR repertoire analysis.
## TCR-GPT captures specific features of TCR repertoires efficiently
We further investigated TCR-GPT's ability to learn the specific probability distributions of different TCR repertoires to compare their properties from a probabilistic perspective. CD4 and CD8 T cells have distinct roles in adaptive immunity across various tissues, which may be reflected by their
Figure 2: Performance comparison of TCR-GPT, soNNia and TCRpeg algorithms. A-C. The scatter plot of actual ( P data ) versus inferred probability ( P infer ) for soNNia (A), TCRpeg (B) and TCR-GPT (C) using test dataset from universal TCR repertoire. The corresponding Pearson correlation coefficients are displayed for each plot.
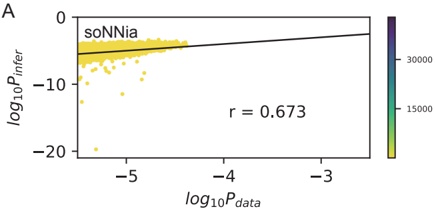
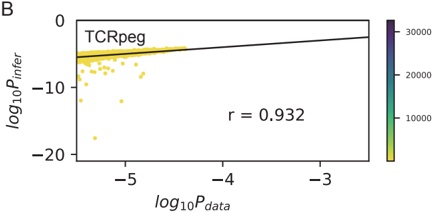
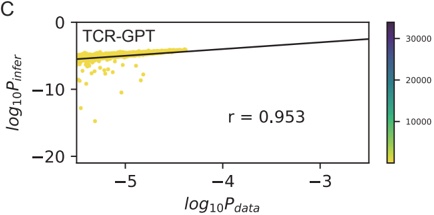
unique TCR repertoires. Utilizing a dataset (Jiang, Y., and S. C. Li 2023; Seay, H. R., et al. 2016)comprising three different cell types (CD8 cytotoxic T lymphocytes(CD8+), CD4 T help cells(Tconv) and CD4 Treg cells(Treg)) collected from three tissues (spleen, pancreatic draining lymph modes [pLN] or inguinal 'irrelevant' lymph nodes [iLN]), we compared the discrepancy among these nine sub-repertoires.
We used TCR-GPT to construct a probabilistic generative model for each of these nine TCR sub-repertoires. For each sub-repertoire, we inferred its probability using nine models: one trained from its own TCR repertoire (denoted as P ) and eight from the remaining TCR repertoires (denoted as Qs ). To estimate the distance between each pair of sub-repertoires, we calculated the Jessen-Shannon divergency ( D js ) for P and each Q . The D js matrix revealed an interesting pattern: sub-repertoires of the same cell type were more similar to each other than to those from different cell types, and CD4 T cell subtypes exhibited greater simi- larity to each other than to CD8 T cells (Figure 3).
Given the fundamental role of the CDR3 sequence in determining T-cell function through antigen recognition (PMID: 28923982), these results suggest that the same cell subtypes with similar CDR3 repertoire performed analogous functions across different tissues.
Moreover, the higher similarity observed among CD4 T cell subtypes compared to CD8 T cells aligns with the distinct functional roles that CD4 and CD8 T cells play in the immune system. CD4 T cells are primarily involved in helper or regulator functions, facilitating the activation or inhibition and coordination of other immune cells, while CD8 T cells are chiefly responsible for cytotoxic activities, directly targeting and eliminating infected or malignant cells.
This probabilistic comparison of TCR repertoires across different cell types and tissues enhances our understanding of the adaptive immune system's complexity. It provides insights into how specific TCR repertoires are tailored to meet the unique functional demands of different T cell subtypes in various tissue environments. Such knowledge is invaluable for advancing immunotherapy and vaccine development, where targeted manipulation of TCR repertoires could lead to more effective and precise treatments.
Figure 3: The heatmap of Jensen-Shannon divergence ( D js ) between pairwise sub-repertoire probability distribution inferred by TCR-GPT.
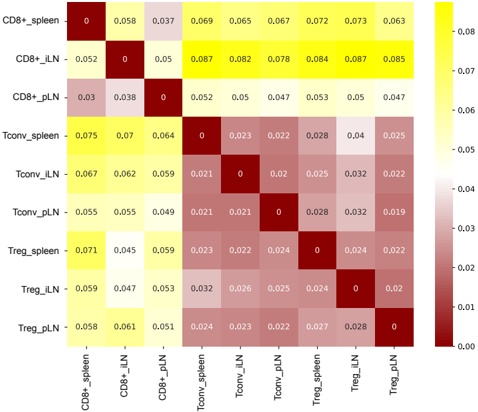
## Classification of cancer-associated TCRs and SARS-CoV-2 epitope-specific TCRs using features from TCR-GPT
During the process of TCR probability inference, TCR-GPT yields features for each TCR sequence. Unlike predefined embeddings, the features provided by TCR-GPT are generated in a learnable manner, allowing the model to adaptively capture the underlying patterns within the TCR sequences.
Figure 4: UMAP Visualization and Classification Performance of TCR-GPT. (A, B) UMAP plots of features learned by TCRGPT trained on caTCRs (A) and SARS-TCRs (B), along with motif logos of selected clustered TCR sequences. (C, D) Area under curve (AUC) for classifiers predicting caTCRs (C) and SARS-TCRs (D) trained with TCR-GPT.
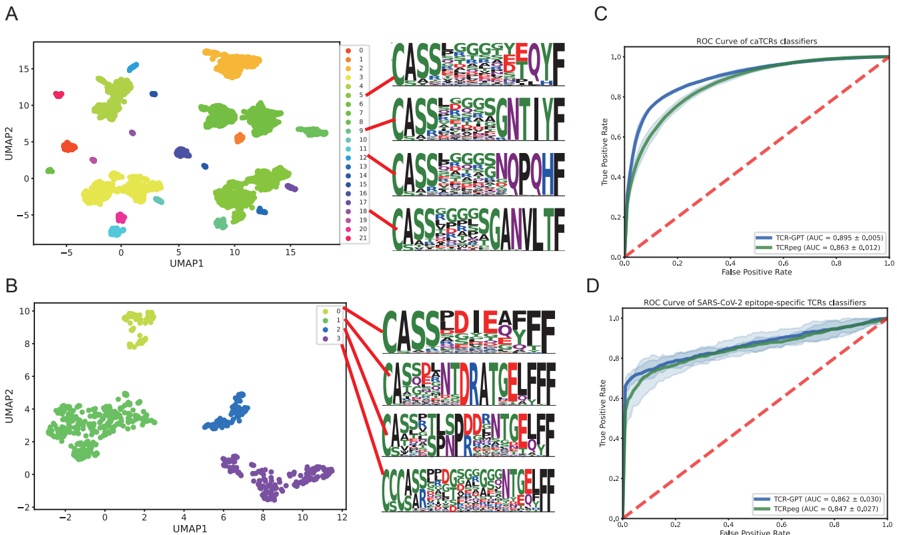
To depict the features of TCR sequences, we evaluated cancer-associated TCRs (caTCRs) from Beshnova et al (Beshnova, D., et al. 2020)( N ∼ 43 000 , ) and SARS-CoV-2 epitope (YLQPRTFLL) specific TCRs (SARS-TCRs) from VDJdb database (Shugay, M., et al. 2018)( N = 683 ). We trained TCR-GPT using these two TCR repertoires separately to obtain the representative feature vectors of each sequence.
The Uniform Manifold Approximation and Projection (UMAP) dimensionality reduction applied to the feature space revealed explicit clusters in the 2D map (Figure 4A, B). Sequences within the same cluster shared a similar motifs, suggesting that the features generated by TCR-GPT could accurately represent the TCR sequences.
Figure 5: Binding percentage of generated TCRs with specific peptide sequences increases with the number of PPO gradient steps.
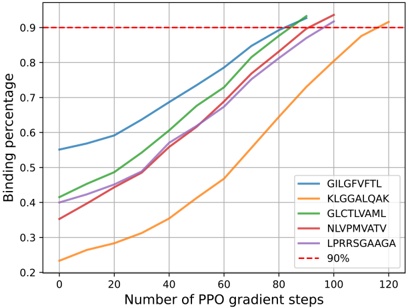
To further illustrate the effectiveness behind TCR-GPT's features of TCRs, we performed classification(Methods) of caTCRs and SARS-TCRs from control (negative) TCRs sampled from the universal TCR repertoire mentioned above. We extensively compared TCR-GPT with TCRpeg in both caTCR and SARS-TCR classification tasks. Using five-fold cross-validation, TCR-GPT exhibited more stable and accurate performance than TCRpeg in caTCRs classification task, achieving Aera Under the Curve (AUC) values of 0.895±0.005 for TCR-GPT and 0.863±0.012 for TCRpeg (Figure 4C).
The results from the SARS-TCR classification task also support the superior performance of TCR-GPT, with AUCs of 0.862±0.030 compared to 0.847±0.027 for TCRpeg (Figure 4D). The consistent performance of TCR-GPT across different classification tasks indicates its robustness and generalizability in modeling TCR sequences. The higher AUC values for TCR-GPT suggest that it can more effectively capture the relevant features that distinguish specific TCRs from the general repertoire, thereby enhancing its predictive accuracy.
Figure 6: Comparison of the percentage of TCRs generated from TCR-GPT overlapped with real TCRs binding to specific peptides, with and without RL fine-tuning.
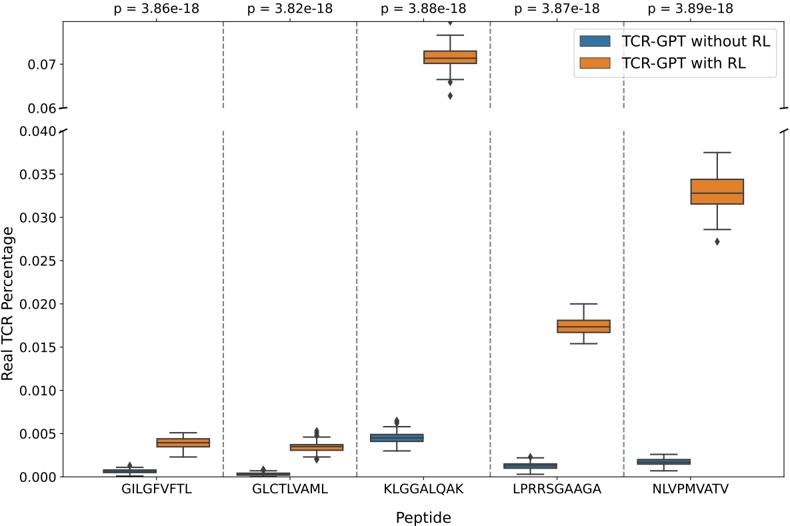
## Generating peptide-specific TCRs using TCR-GPT fine-tuned with RL
Using TCR-GPT trained with universal TCR sequences, we address a more practical scenario. For a specific peptide, we employ RL to fine-tune the learned distribution, adapting it from universal TCR sequences to those that can bind to the specific peptide(Methods). PanPep (Gao, Yicheng, et al. 2023)can output binding score ranges from 0 to 1 that indicate the binding probability of the given peptide and TCR. Based on this, we defined the binding percentage as the proportion of peptides generated by TCR-GPT with RL that have a binding score from PanPep exceeding threshold 0.5. RL demonstrated promising training efficiency, as evidenced by the significant increase in binding percentage of five tested peptides shown in Figure 5.
RLadjusts the distribution of learned TCR sequences, and it is crucial to ensure that the tuned model can generate TCR sequences similar to actual TCRs that bind to the target peptide. To verify this, we assess how many TCR sequences generated by the model-with and without RL-match real TCR sequences known to bind the target peptide. For each tested peptide, we compiled a set of known TCRs from IEDB (Vita et al. 2018) that can bind to it. We then used both models to generate 10,000 TCR sequences each and calculated the proportion of these sequences that matched the known TCRs. This process was repeated 100 times, with each proportion serving as a sample. we observed that the proportions of generated TCR sequences overlapped with real TCRs capable of binding to the given peptide were significantly higher for the TCR-GPT model fine-tuned with RL compared to the one without RL, as shown in Figure 6. This demonstrates that RL is capable of fine-tuning the TCR-GPT model to match the distribution of real TCRs specifically binding to the given peptide.
## Conclusion
Text-generation models, driven by advanced natural language processing (NLP) techniques, have the potential to transform our understanding and utilization of TCR diversity. In our research, we introduce TCR-GPT, a sophisticated probabilistic model based on a decoder-only transformer architecture. This model is designed to identify sequence patterns within TCR repertoires and generate TCR sequences from the learned probability distribution. By implementing RL, we tailored the TCR sequence distribution to produce repertoires capable of recognizing specific peptides. This advancement holds significant potential for revolutionizing targeted immune therapies and vaccine development, paving the way for practical and effective medical applications.
The limitations of this study primarily stem from the fact that TCR-GPT is a probabilistic model focused exclusively on the CDR3 region of the TCR beta chain, thereby excluding the full-length sequences of both the alpha and beta chains of TCR sequences. This narrowed focus restricts the comprehensiveness of the model in representing the complete TCR repertoire. Future research efforts will be directed towards collecting paired full-length TCR sequences and scaling up the model's parameters to accommodate the need for constructing a robust probability distribution of the fulllength TCRs. Despite these current limitations, we are confident in the potential of the TCR-GPT architecture to effectively address these challenges with an adequately sized dataset. Additionally, we believe that RL will continue to be a highly efficient method for fine-tuning the distribution to meet specific targets, thereby enhancing the applicability and precision of our model in practical scenarios.
## References
Bai, Y.; Jones, A.; Ndousse, K.; Askell, A.; Chen, A.; DasSarma, N.; Drain, D.; Fort, S.; Ganguli, D.; Henighan, T.; et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862 .
Beshnova, D., et al. 2020. De novo prediction of cancerassociated T cell receptors for noninvasive cancer detection. Science Translational Medicine , 12(557): eaaz3738.
Bilodeau, C.; Jin, W.; Jaakkola, T.; Barzilay, R.; and Jensen, K. F. 2022. Generative models for molecular discovery: Recent advances and challenges. Wiley Interdisciplinary Reviews: Computational Molecular Science , 12(5): e1608.
Brown, Tom B., et al. 2020. Language Models are Few-Shot Learners. arXiv e-prints , arXiv:2005.14165.
Cao, Y.; Yao, L.; McAuley, J.; and Sheng, Q. Z. 2023. Reinforcement learning for generative AI: A survey. arXiv preprint arXiv:2308.14328 .
Chung, Junyoung, et al. 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv e-prints , arXiv:1412.3555.
Davidsen, K., et al. 2019. Deep generative models for T cell receptor protein sequences. eLife , 8: e46935.
Du, Y.; Fu, T.; Sun, J.; and Liu, S. 2022. Molgensurvey: A systematic survey in machine learning models for molecule design. arXiv preprint arXiv:2203.14500 .
Emerson, R. O., et al. 2019. Immunosequencing identifies signatures of cytomegalovirus exposure history and HLAmediated effects on the T cell repertoire. Nat Genet , 5: 659665.
Fromer, J. C.; and Coley, C. W. 2023. Computer-aided multiobjective optimization in small molecule discovery. Patterns , 4(2).
Gao, Y.; Meyer, C. M.; and Gurevych, I. 2020. Preferencebased interactive multi-document summarisation. Information Retrieval Journal , 23(6): 555-585.
Gao, Yicheng, et al. 2023. Pan-Peptide Meta Learning for Tcell receptor-antigen binding recognition. Nature Machine Intelligence , 5: 337-339.
Hochreiter, Sepp, and J¨ urgen Schmidhuber. 1997. Long Short-Term Memory. Neural Computation , 9(8): 17351780.
Isacchini, G., et al. 2021. Deep generative selection models of T and B cell receptor repertoires with soNNia. Proceedings of the National Academy of Sciences , 118(14): e2023141118.
Jiang, Y., and S. C. Li. 2023. Deep autoregressive generative models capture the intrinsics embedded in T-cell receptor repertoires. Brief Bioinform , 2.
Kreutzer, J.; Riezler, S.; and Lawrence, C. 2020. Offline reinforcement learning from human feedback in real-world sequence-to-sequence tasks. arXiv preprint arXiv:2011.02511 .
Luukkonen, S.; van den Maagdenberg, H. W.; Emmerich, M. T.; and van Westen, G. J. 2023. Artificial intelligence in multi-objective drug design. Current Opinion in Structural Biology , 79: 102537.
O'Shea, K.; and Nash, R. 2015. An Introduction to Convolutional Neural Networks. arXiv:1511.08458.
Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems , 35: 27730-27744.
Radford, Alec, et al. 2018. Improving Language Understanding by Generative Pre-Training.
Radford, Alec, et al. 2019. Language Models are Unsupervised Multitask Learners.
Schulman, John, et al. 2017. Proximal Policy Optimization Algorithms. arXiv e-prints , arXiv:1707.06347.
Seay, H. R., et al. 2016. Tissue distribution and clonal diversity of the T and B cell repertoire in type 1 diabetes. JCI insight , 1(20): e88242.
Shi, Z.; Chen, X.; Qiu, X.; and Huang, X. 2018. Toward diverse text generation with inverse reinforcement learning. arXiv preprint arXiv:1804.11258 .
Shugay, M., et al. 2018. VDJdb: a curated database of T-cell receptor sequences with known antigen specificity. Nucleic acids research , 46(D1): D419-D427.
Singh, N. K., et al. 2017. Emerging Concepts in TCR Specificity: Rationalizing and (Maybe) Predicting Outcomes. The Journal of Immunology , 199(7): 2203-2213.
Souchleris, K.; Sidiropoulos, G. K.; and Papakostas, G. A. 2023. Reinforcement Learning in Game Industry-Review, Prospects and Challenges. Applied Sciences , 13(4).
Tang, B.; Ewalt, J.; and Ng, H.-L. 2021. Generative AI models for drug discovery. In Biophysical and Computational Tools in Drug Discovery , 221-243. Springer.
van der Merwe, P. A., and O. Dushek. 2011. Mechanisms for T cell receptor triggering. Nat Rev Immunol , 11: 47-55.
Vaswani, Ashish, et al. 2017. Attention Is All You Need. arXiv e-prints , arXiv:1706.03762.
Vita, R.; Mahajan, S.; Overton, J. A.; Dhanda, S. K.; Martini, S.; Cantrell, J. R.; Wheeler, D. K.; Sette, A.; and Peters, B. 2018. The Immune Epitope Database (IEDB): 2018 update. Nucleic Acids Research , 47(D1): D339-D343.
Zhang, T.; and Mo, H. 2021. Reinforcement learning for robot research: A comprehensive review and open issues. International Journal of Advanced Robotic Systems , 18(3): 17298814211007305. | null | [
"Yicheng Lin",
"Dandan Zhang",
"Yun Liu"
] | 2024-08-02T10:16:28+00:00 | 2024-08-02T10:16:28+00:00 | [
"cs.LG",
"cs.AI"
] | TCR-GPT: Integrating Autoregressive Model and Reinforcement Learning for T-Cell Receptor Repertoires Generation | T-cell receptors (TCRs) play a crucial role in the immune system by
recognizing and binding to specific antigens presented by infected or cancerous
cells. Understanding the sequence patterns of TCRs is essential for developing
targeted immune therapies and designing effective vaccines. Language models,
such as auto-regressive transformers, offer a powerful solution to this problem
by learning the probability distributions of TCR repertoires, enabling the
generation of new TCR sequences that inherit the underlying patterns of the
repertoire. We introduce TCR-GPT, a probabilistic model built on a decoder-only
transformer architecture, designed to uncover and replicate sequence patterns
in TCR repertoires. TCR-GPT demonstrates an accuracy of 0.953 in inferring
sequence probability distributions measured by Pearson correlation coefficient.
Furthermore, by leveraging Reinforcement Learning(RL), we adapted the
distribution of TCR sequences to generate TCRs capable of recognizing specific
peptides, offering significant potential for advancing targeted immune
therapies and vaccine development. With the efficacy of RL, fine-tuned
pretrained TCR-GPT models demonstrated the ability to produce TCR repertoires
likely to bind specific peptides, illustrating RL's efficiency in enhancing the
model's adaptability to the probability distributions of biologically relevant
TCR sequences. |
2408.01159v2 | ## Robust Curve Detection in Volumetric Medical Imaging via Attraction Field
Farukh Yaushev 1 2 , , Daria Nogina 1 3 , , Valentin Samokhin 1 2 , , Mariya Dugova , 1 Ekaterina Petrash , Dmitry Sevryukov , Mikhail Belyaev , and Maxim Pisov 1 1 4 4
1 IRA-Labs Ltd, Moscow, Russia
2 Kharkevich Institute for Information Transmission Problems, Moscow, Russia 3 Lomonosov Moscow State University, Moscow, Russia 4 AUMI AI Limited, London, United Kingdom [email protected]
Abstract. Understanding body part geometry is crucial for precise medical diagnostics. Curves effectively describe anatomical structures and are widely used in medical imaging applications related to cardiovascular, respiratory, and skeletal diseases. Traditional curve detection methods are often task-specific, relying heavily on domain-specific features, limiting their broader applicability. This paper introduces an novel approach for detecting non-branching curves, which does not require prior knowledge of the object's orientation, shape, or position. Our method uses neural networks to predict (1) an attraction field, which offers subpixel accuracy, and (2) a closeness map, which limits the region of interest and essentially eliminates outliers far from the desired curve. We tested our curve detector on several clinically relevant tasks with diverse morphologies and achieved impressive subpixel-level accuracy results that surpass existing methods, highlighting its versatility and robustness. Additionally, to support further advancements in this field, we provide our private annotations of aortic centerlines and masks, which can serve as a benchmark for future research. The dataset can be found at https://github.com/neuro-ml/curve-detection .
Keywords: Curve detection · Attraction fields · Deep learning · Subpixellevel accuracy.
## 1 Introduction
Semantic segmentation is inarguably one of the most prominent tasks in medical image analysis with a particular focus on volumetric images such as computed tomography (CT) and magnetic resonance imaging (MRI) [14]. Indeed, various applications such as brain tumor [2], ischemic stroke [29], or lung cancer [22] detection and localization stimulated the development of many 3D segmentation networks [13].
While many parts of the human body can be effectively represented as volumetric objects with corresponding segmentation masks, there are numerous
objects with an underlying low-dimensional structure that cannot be accurately described solely through segmentation masks. Important examples include the aortic centerline, vertebral column centerline, and ureters, which are essentially curves . A comprehensive understanding of the geometry associated with these curves is crucial for precise disease detection and severity assessment [34,33,28,7,24].
Curve detection in medical images presents several significant challenges . Firstly , the complex geometry of the structures being sought poses difficulties because curves within the human body can exhibit diverse orientations, localization, and, notably, significant curvature. Secondly , many curves in medical images are not bound to the edges of objects or organs. For example, the aortic centerline is defined by surrounding vessel semantics rather than explicit local signals solely bound to the centerline. This requires the detection method to infer the curve from surrounding anatomical and contextual information instead of relying solely on edge detection or segmentation. Finally , most medical imaging problems require detecting only anatomically relevant structures, omitting other potential proposals. Therefore, the method should be capable of differentiating similar local structures by carefully weighing the global context.
Numerous approaches have been proposed for curve detection. The most straightforward one is a direct segmentation at the pixel level [35,26]. However, the accuracy of this method is limited by the resolution of the raster, and it is not prone to the continuous nature of curves. Another class of approaches closely related to curve localization is edge and line segment detection methods, including classical algorithms like the Canny edge detector [4] or LCD [27], and modern deep learning-based methods [15,19,30,31,20]. A notable example is [15], where authors use a convolutional neural network (CNN) to predict an attraction field : for each pixel, the displacement to the closest edge is predicted, which is then used to generate a point cloud of potential edges. Attraction field proved to be a powerful concept, and several extensions have been proposed [19,32]. Despite these methods' broad applicability, they currently face the above-mentioned challenges in the medical domain, as we show for the relevant ones.
The curve detection also often appears in medical imaging domain. However, unlike edge or line detection methods, approaches in this field frequently rely heavily on task-specific features, limiting their generalizability. For instance, some methods depend on a heuristic starting point or the image's orientation [37,33,36]. Other methods rely on segmenting objects that form the curve, like the aorta or blood vessels [8,21,23,9,6], which limits their use in tasks without an explicit object for segmentation, such as in the vertebral column centerline detection. Additionally, accuracy of segmentation- or heatmap-based methods [8,9] is limited by the raster's resolution, making them overly sensitive to image spacing. These limitations highlight the need for more versatile and robust approaches in curve detection for medical applications.
In this article, we introduce a novel approach to detecting non-branching curves that surpasses current methods by combining their strengths while addressing their limitations. Our strategy offers a fresh perspective on solving the
challenge of curve detection in medical imaging, adapting the concept of an attraction field originally designed for line detection.
Our contribution is three-fold. First , we introduce a new method for localizing non-branching curves in volumetric medical images, easily adaptable to various target objects. It is robust to the object's geometry and does not require task-specific knowledge of orientation, shape, or position. Second , we demonstrate that the proposed method achieves subpixel-level accuracy and outperforms the existing approaches on two clinically significant and diverse tasks: aortic centerline and vertebral column centerline detection. Finally , to enhance reproducibility and comparability, we release all our available annotations of aortic centerlines and masks on several open datasets. They include complex cases on which, as we show, conventional methods perform poorly. The dataset can be found at https://github.com/neuro-ml/curve-detection .
## 2 Method
Our method Fig. 1 is based on a 3D two-headed CNN architecture with a VNetbased [13] backbone. The first head predicts the attraction field, pointing to the closest location on the curve in each voxel Fig. 1(b). The second head predicts the closeness map for each voxel. It represents a region of interest around the curve Fig. 1(c). At inference, predictions of two heads are combined. First, voxels are filtered according to the predicted closeness map and distances to the curve. Predicted attraction vectors of these voxels are then used to get the point cloud on the desired curve by shifting their coordinates. Finally, the point cloud is thinned using the non-maximum suppression algorithm, and then the points are parameterized using one-dimensional embedding.
## 2.1 Loss Function
The loss function consists of three pivotal components designed to refine specific aspects of the model's predictions.
Attraction Field The L field , component addresses the loss related to the attraction field F [15]. For any given voxel p within an image, its corresponding ground truth field vector, F p , is calculated as the projection vector from p to its nearest point r p on the ground truth curve: F p = r p -p . The norm of F p ( ∥ F p ∥ 2 ) is the distance to the curve. The network is trained to predict attraction field ˆ F p Fig. 1(c) for each voxel p by optimizing a MSE loss:
$$L _ { f i e l d } ( \hat { F }, F ) = \frac { 1 } { N } \sum _ { p } \| \hat { F } _ { p } - F _ { p } \| ^ { 1 }.$$
1 1 N ∑ p denotes averaging over all voxels of the image
Fig. 1. A schematic representation of the prediction pipeline for aortic centerline detection: a) a 3D input image, red circles denote the aorta; b) the predicted attraction field depicted for a given 2D slice, the red color indicates the field vectors that lead to inaccurate predictions; c) the closeness map predicted for a given 2D slice; d) the same 2D slice relative to the predicted point cloud, the black dots represent the unordered set of points; e) the result of ordering using Isomap - the final predicted 3D curve.
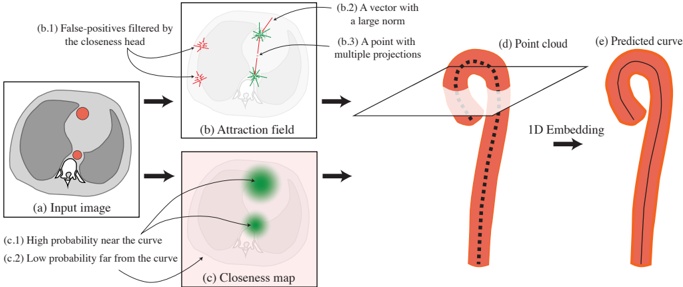
Closeness Map In practice, CNNs' limited receptive fields [11] hinder their ability to capture long relations, leading to inaccurate attraction field predictions far from the sought structure. For this reason, we predict for each voxel a closeness C p = I [ ∥ F p ∥ 2 ≤ R c ], where I is the indicator function and R c is a hyperparameter that regulates the maximal distance at which the network is allowed to make predictions. Predicted closeness, ˆ , C is utilized during inference to filter out voxels far from the desired curve. The closeness head Fig. 1(c) is trained by optimizing the binary cross entropy:
$$L _ { c l s } ( \hat { C }, C ) = \frac { 1 } { N } \sum _ { p } B C E ( \hat { C } _ { p }, C _ { p } ).$$
Handling multiple projections Some voxels can have several projections on the curve Fig. 1(b.3). This is a source of inconsistency that impedes the training of the regression head. Instead of picking a projection, the network averages all the possible directions, thus ending up with a near-zero prediction. Note that even though a point can have multiple projections, by definition, each projection will have the same norm, ∥ F p ∥ 2 . This observation motivates us to add a regularization term:
$$L _ { n o r m } ( \hat { F }, F ) = \frac { 1 } { N } \sum _ { p } \, | \, \| \hat { F } _ { p } \| _ { 2 } - \| F _ { p } \| _ { 2 } \, | \,.$$
Final Loss The resulting loss is the sum of all the above components:
$$L = L _ { f i e l d } + L _ { c l s } + L _ { n o r m },$$
where the L norm , L field are only computed inside the regions ∥ F p ∥ 2 ≤ R c and ∥ F p ∥ 2 ≤ R f respectively. R f should be chosen small enough to reduce the probability of encountering multiple projections problem.
## 2.2 Inference
The point cloud is obtained as follows:
$$\{ \hat { F } _ { p } + p \, | \, \hat { C } _ { p } \geq t, \| \hat { F } _ { p } \| _ { 2 } \leq R _ { f } \} _ { p },$$
where p iterates over all the voxels on the image, ˆ C , F p ˆ p , t, R f are the predicted closeness, attraction field, and their respective thresholds. Fig. 1(b,c) illustrates the motivation for both closeness- and norm-based filtration: the closeness head improves precision, and the regression head improves recall.
To refine the predicted point cloud, we employ a classic non-maximum suppression technique [16] where the closeness function is defined by the Euclidean distance, and the confidence is represented as -∥ ˆ F p ∥ 2 Fig. 1(d). After obtaining a point-reified cloud, we reorder the points to obtain a curve by reducing the dimensionality of the point cloud to 1D using Isomap [25]. This effectively gives us the internal parametrization of the curve, which is used to order the points Fig. 1(e).
## 3 Experimental Setup
Data Our method was evaluated on aortic centerline and vertebral column centerline detection tasks. Vertebral column annotations for 400 images were obtained from LungCancer500 [33] and VerSe2020 [12]. Aortic centerlines for 142 randomly selected images from LIDC-IDRI [1] and AMOS [10] were annotated in-house and shared on GitHub . Three experienced radiologists an2 notated each image, and their averaged annotations formed the ground truth curve.
Training Details We utilized a VNet-based backbone [13] with two output heads for all experiments. Each head comprises six Residual blocks with a kernel size of 3 and padding of 1. Training employed 75 , 000 iterations with Adam optimizer, batch size of 2, and a learning rate policy starting at 10 -4 and modified it to 5 · 10 -5 and 5 · 10 -6 at iterations 22 500 and 37 500 respectively. , , Preprocessing included resampling to 2 × 2 × 2 mm 3 resolution, intensity normalization, and simple data augmentation: rotations, flips, transpositions, and random patch sampling of size 150 × 150 × 150. In all our experiments, we use the following hyperparameters (see Section 2 for details): R c = 10 , R f = 5 , t = 0 5 . . The dependence of the metric on changes in hyperparameters is detailed in the Table 2.
2 https://github.com/neuro-ml/curve-detection
Metrics For all tasks, we use the 1D variants of metrics between sets of points: Hausdorff Distance ( HD ), the Average Symmetric Surface Distance ( ASSD ), and the Surface Dice ( SD ) introduced in [18], for the thresholds 1 mm and 3 mm . All results are computed via 5-fold cross-validation.
Baselines To validate our method, we compare it with various baselines, drawing inspiration from both general methods and task-specific strong 3 baselines for curve detection.
- 1. Skeleton : The skeletonization-based approach is widely used for extracting tubular organ centerlines [5,8]. It involves segmenting the aorta followed by applying a skeletonization algorithm to extract its centerline. However, it is unsuitable for vertebral column centerline detection due to the absence of a specific tubular object for segmentation.
- 2. Soft-argmax : A strong soft-argmax-based vertebral column centerline detection method, leveraging the vertical orientation of the backbone [33]. However, it is unsuitable for aortic centerline detection because it assumes each axial slice intersects the curve at most once, which does not hold for the complex geometry of the aorta, especially near its arch.
- 3. Seg : This method involves straightforward curve segmentation using binary masks with 1-voxel wide curves.
- 4. Htmp : Heatmap-based techniques, frequently used in key-point detection tasks, have demonstrated promising results [3,17]. Therefore, we compared our method with such an approach, which predicts distances ( heatmap ) to curve within the predicted closeness map. Points onto the curve are obtained by thresholding the heatmap . This approach is close to ours but does not use displacement vectors; it only considers their norms.
- 5. Att : We directly compare with the method proposed in [15], which shows state-of-the-art results in the task of line segment detection. We trained the network to predict the vectors of the attraction field solely for each voxel. Unlike our method, it does not include the closeness head.
The same VNet-based backbone architecture and postprocessing procedure 2.2 were used for all models.
## 4 Results
Our model demonstrates consistently robust and accurate prediction ability, significantly outperforming baselines Table 1, Fig. 2 and Fig. 3. Notably, our model surpasses baselines not only in terms of accuracy but in addressing specific challenges related to generability ( Skeleton , Soft-argmax ), prediction smoothness ( Seg , Htmp ), outliers far from the curve ( Att ).
3 Strong baseline is a baseline that significantly exploits the unique features of a particular task, like the spine's vertical orientation.
Table 1. Comparison of curve detection methods' metrics and their standard deviation (in brackets) for the aortic centerline and vertebral column centerline detection tasks. Bold numbers indicate the best performance. Omitted cells refer to methods not applicable to the task.
| Task Metrics | Skeleton | Soft-argmax | Seg | Htmp | Att | Ours |
|-------------------|-----------------|-----------------|-----------------|-----------------|-----------------------|-----------------|
| | AMOS, LIDC-IDRI | AMOS, LIDC-IDRI | AMOS, LIDC-IDRI | AMOS, LIDC-IDRI | AMOS, LIDC-IDRI | AMOS, LIDC-IDRI |
| SD-1 SD-3 HD | 0.30(0.11) | - | 0.43(0.12) | 0.49(0.16) | 0.43(0.17) 0.93(0.12) | 0.56(0.20) |
| | 0.88(0.16) | - | 0.91(0.11) | 0.95(0.05) | | 0.97(0.04) |
| Aortic centerline | 21(21) | - | 22(27) | 17(25) | 21(28) | 15(16) |
| ASSD | 2.5(2.2) | - | 2.5(3.0) | 2.1(4.5) | 2.9(5.4) | 1.4(1.1) |
| | Cancer500 | Cancer500 | Cancer500 | Cancer500 | Cancer500 | Cancer500 |
| SD-1 | - | 0.36(0.24) | 0.14(0.16) | 0.34(0.21) | 0.24(0.26) | 0.42(.30) |
| SD-3 | - | 0.94(0.11) | 0.61(0.30) | 0.94(0.08) | 0.87(0.19) | 0.96(.06) |
| HD | - | 8(3) | 31(33) | 6(2) | 11(10) | 4(2) |
| ASSD | - | 1.6(0.7) | 7.6(15.1) | 1.5(0.5) | 2.3(1.3) | 1.3(0.5) |
| | VerSe val | VerSe val | VerSe val | VerSe val | VerSe val | VerSe val |
| column SD-1 | - | 0.17(0.23) | 0.36(0.17) | 0.19(0.20) | 0.31(0.26) | 0.45(0.27) |
| centerline SD-3 | - | 0.80(0.23) | 0.90(0.09) | 0.80(0.23) | 0.89(0.12) | 0.93(0.01) |
| Vertebral HD | - | 28(12) | 35(32) | 28(11) | 43(97) | 24(14) |
| ASSD | - | 2.8(1.2) | 3.5(4.1) | 2.7(1.1) | 5.3(22.5) | 1.9(1.2) |
| VerSe test | VerSe test | VerSe test | VerSe test | VerSe test | VerSe test | VerSe test |
| SD-1 | - | 0.21(0.28) | 0.32(0.18) | 0.19(0.19) | 0.27(0.28) | 0.45(0.30) |
| SD-3 | - | 0.81(0.23) | 0.89(0.13) | 0.75(0.29) | 0.85(0.18) | 0.92(0.12) |
| HD | - | 29(12) | 31(26) | 27(13) | 45(102) | 22(12) |
| ASSD | - | 2.8(1.6) | 2.9(3.6) | 2.8(1.3) | 5.3(16.1) | 1.8(1.1) |
## 4.1 Models Performance
In this section, we analyze in detail and compare the performance of baselines and the proposed method separately for two tasks.
Aortic Centerline Metrics for task-specific Skeleton baseline are significantly inferior to Our Table 1. This is primarily due to the skeletonization algorithm's dependency on the quality of the predicted mask, making it highly sensitive to minor errors within the segmentation.
Fig. 2 demonstrates several typical predictions for Seg , Htmp , Att , and Our method. Note that the segmentation-based model yields sharp curves even in relatively simple cases because its accuracy is limited by the raster's resolution Fig. 2(b). The high HD value for Seg is explained by false-negative predictions due to the highly imbalanced segmentation problem. The Htmp model shows a similar behavior but with a lower occurrence of false-negative predictions, as evidenced by a lower HD value. On the other hand, the Att model tends to
Fig. 2. Aortic centerline predictions for various methods in sagittal or coronal projections, with the aorta highlighted in each case. Only relevant curves are displayed for clarity. a) Typical prediction without major defects; b) Magnified region showing the roughness of the Seg model's predicted curve; c) Example of a false-positive for the Att model caused by another tubular structure; d) Erroneous prediction by our method; e) Axial slice where our method did not make a prediction due to noisiness - the aorta is indistinguishable.
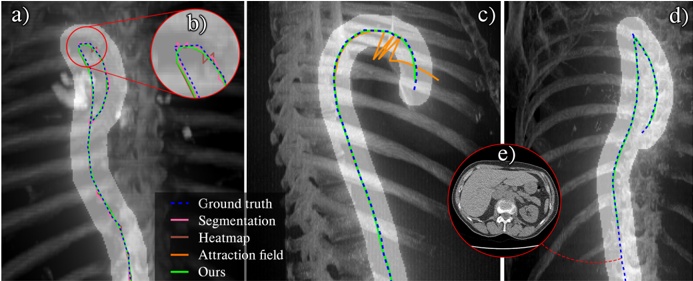
Fig. 3. Vertebral column centerline predictions for several methods in sagittal projections. For clarity, only curves of interest are shown. a) a typical prediction without major errors from our method; b) a magnified region highlighting the roughness of the predicted curve by the Seg model; c) a magnified region highlighting the roughness of the predicted curve by the Htmp model; d) an example of a typical false-positive for the Att model caused by another tubular structure; e) an example of an erroneous prediction by our method.
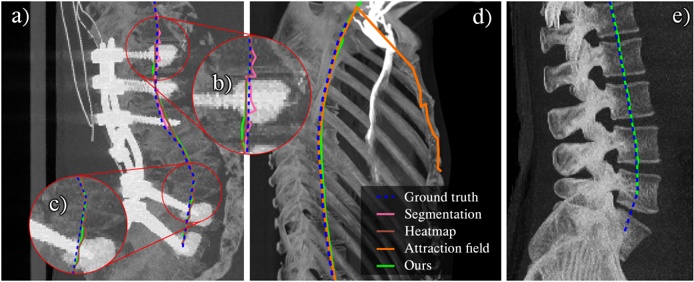
Fig. 4. A sagittal projection of an image with kyphosis. The red region indicates the range of axial slices intersecting the curve at two locations - the cause of the inapplicability of soft-argmax-based methods. The green curve represents the prediction generated by our model.
produce false-positives around tubular structures that resemble the aorta, such as the pulmonary trunk Fig. 2(c).
A rare issue observed with Our method is occasional under-prediction of the curve's limits Fig. 2(d). However, each failure has an explicable reason: noisy image region Fig. 2(e) or scanning artifacts.
Vertebral Column Centerline Our approach outperforms the strong Softargmax baseline on both the relatively simple Cancer500 and more diverse VerSe dataset. Moreover, unlike Soft-argmax , our method does not rely on additional structural knowledge of the vertebral column's shape, orientation, or position. This allows us to accurately localize the vertebral column centerline even in cases of extreme spinal curvature, such as severe kyphosis Fig. 4.
The predictions made by other models exhibit behaviors similar to those seen in aortic centerline predictions Fig. 3. The Att model, for instance, shows the same typical false-positive detections. Similarly, the Seg and Htmp baselines struggle to produce accurate and smooth curves due to their inherent limitations related to raster resolution constraints.
Summary Our model outperforms analyzed baselines in terms of accuracy and generality across both tasks. Overall, our method's observed Hausdorff Distance (HD) may appear high. This is because HD is generally very sensitive not only to false-positives (outliers) but also to false-negatives (e.g., near curve's limits), which our model is prone to Fig. 2(d). However, the more stable ASSD and Surface Dice metrics show that such errors are relatively rare. Furthermore, recall that our networks are trained with a 2 × 2 × 2 mm 3 spacing, which means that our method achieves subpixel-level accuracy: ASSD < 2 mm .
Table 2. The dependence of metric on the values of hyperparameters R c and R f . Note that overall, changing the parameters in a reasonable range gives a quality still superior to the quality of baselines. However, for the aortic centerline, excessively large values of R c and R f can diminish performance due to limited receptive field and challenges related to multiple projections. This highlights the significance of optimizing the training loss component F field specifically near the curve.
| Hyperparameter | SD-1 | mm | SD-3 | mm | HD | | ASSD |
|---------------------|----------------------------------------|----------------------------------------|----------------------------------------|----------------------------------------|----------------------------------------|----------------------------------------|----------------------------------------|
| | Aortic centerline, AMOS, LIDC-IDRI | Aortic centerline, AMOS, LIDC-IDRI | Aortic centerline, AMOS, LIDC-IDRI | Aortic centerline, AMOS, LIDC-IDRI | Aortic centerline, AMOS, LIDC-IDRI | Aortic centerline, AMOS, LIDC-IDRI | Aortic centerline, AMOS, LIDC-IDRI |
| R c = 5 , R f = 5 | 0.52 | (0.14) | 0.95 | (0.05) | 16 | (18) | 1.7 (1.2) |
| R c = 10 , R f = 5 | 0.56 | (0.20) | 0.97 | (0.04) | 15 | (16) | 1.4 (1.1) |
| R c = 15 , R f = 5 | 0.54 | (0.12) | 0.96 | (0.05) | 16 (17) | 1.6 | (1.3) |
| R c = 20 , R f = 5 | 0.52 | (0.21) | 0.97 | (0.06) | 15 (16) | 1.4 | (1.3) |
| R c = 10 , R f = 10 | 0.52 | (0.18) | 0.94 | (0.04) | 18 (15) | 1.8 | (1.1) |
| R c = 20 , R f = 20 | 0.50 | (0.23) | 0.93 | (0.06) | 18 (16) | 2.1 | (1.4) |
| | Vertebral column centerline, Cancer500 | Vertebral column centerline, Cancer500 | Vertebral column centerline, Cancer500 | Vertebral column centerline, Cancer500 | Vertebral column centerline, Cancer500 | Vertebral column centerline, Cancer500 | Vertebral column centerline, Cancer500 |
| R c = 5 , R f = 5 | 0.44 | (0.30) | 0.97 | (0.06) | 6 (12) | 1.3 | (1.1) |
| R c = 10 , R f = 5 | 0.42 | (0.30) | 0.96 | (0.06) | 4 (2) | 1.3 | (0.5) |
| R c = 15 , R f = 5 | 0.41 | (0.30) | 0.97 | (0.06) | 5 (2) | 1.3 | (0.5) |
| R c = 20 , R f = 5 | 0.42 | (0.30) | 0.97 | (0.06) | 7 (12) | 1.4 | (1.2) |
| R c = 10 , R f = 10 | 0.40 | (0.29) | 0.97 | (0.06) | 7 (11) | 1.4 | (1.0) |
| R c = 20 , R f = 20 | 0.40 | (0.30) | 0.97 | (0.05) | 5 (2) | 1.3 | (0.5) |
## 4.2 Ablation Study
For the ablation study, we demonstrate three aspects. (1) The importance of the closeness head to filter out the outliers. Att baseline produces many falsepositives far from the ground truth curve. In contrast, such problems are not observed in our model, which highlights this head's importance in filtering out false-positives. (2) The importance of the attraction field to achieve subpixel accuracy. Skeleton , Seg , and Htmp baselines share a problem of prediction sharpness because of limited spacing. The displacement vectors provide the subpixel accuracy for our model. (3) The validity of the training strategy. We tested a reasonable range of hyperparameter values Table 2. Within this range, our model's quality is still superior to the baselines'. However, for the aorta, overly large R c and R f values reduce the quality, probably due to a limited receptive field and multiple projection issues. This highlights the importance of optimizing the loss component F field near the ground truth curve.
## 5 Discussion and Conclusion
We have introduced and validated a novel method for detecting non-branching curves in medical imaging, surpassing existing approaches. To facilitate further
advancements in this field, we have released our private annotations, which can serve as a benchmark for future research.
Our method directly predicts coordinates of curve points, thereby preventing rounding errors that can occur in segmentation or heatmap-based methods. This allows our approach to fully utilize the information in the training data to construct smooth, subpixel-accurate curves.
To validate our method, we specifically focused on the tasks of detecting aortic and vertebral column centerlines. These tasks involve curves of different natures . The aortic centerline is cane-shaped and cannot be parameterized using one of the coordinates. In contrast, the vertebral column centerline has a more straightforward shape but is not associated with any tubular structure. Despite this, our model consistently outperforms baselines in accuracy and generality across both tasks.
It is important to note that our method is designed for non-branching curves and is not directly applicable to tasks involving anatomical configurations with branching structures, such as vascular networks or airway trees. However, our preliminary experiments suggest that our method can be extended to handle branching structures by incorporating the prediction of branching points.
## References
- 1. Armato, S.G., et al.: The lung image database consortium (lidc) and image database resource initiative (idri): a completed reference database of lung nodules on ct scans. Medical physics 38 (2), 915-931 (2011)
- 2. Bakas, S., et al.: Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the brats challenge. arXiv preprint arXiv:1811.02629 (2018)
- 3. Bulat, A., Tzimiropoulos, G.: Human pose estimation via convolutional part heatmap regression. In: Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part VII 14. pp. 717-732. Springer (2016)
- 4. Canny, J.: A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine Intelligence PAMI-8 (6), 679-698 (1986). https://doi.org/10.1109/TPAMI.1986.4767851
- 5. Gr´ elard, F., Baldacci, F., Vialard, A., Domenger, J.P.: New methods for the geometrical analysis of tubular organs. Medical image analysis 42 , 89-101 (2017)
- 6. Guo, Z., et al.: Deepcenterline: A multi-task fully convolutional network for centerline extraction. IPMI 2019 11492 , 441-453 (2019)
- 7. Hadjiiski, L., et al.: Ureter tracking and segmentation in ct urography (ctu) using compass. Medical Physics 41 (12), 121906 (2014)
- 8. Hahn, L.D., et al.: Ct-based true-and false-lumen segmentation in type b aortic dissection using machine learning. Radiology: Cardiothoracic Imaging 2 (3), e190179 (2020)
- 9. He, J., et al.: Learning hybrid representations for automatic 3d vessel centerline extraction. MICCAI 12266 , 24-34 (2020)
- 10. Ji, Y., et al.: Amos: A large-scale abdominal multi-organ benchmark for versatile medical image segmentation. arXiv preprint arXiv:2206.08023 (2022)
- 11. Le, H., Borji, A.: What are the receptive, effective receptive, and projective fields of neurons in convolutional neural networks? arXiv preprint arXiv:1705.07049 (2017)
- 12. L¨ offler, M., et al.: A vertebral segmentation dataset with fracture grading. Radiology: Artificial Intelligence 2 (4), e190138 (2020)
- 13. Milletari, F., Navab, N., Ahmadi, S.A.: V-net: Fully convolutional neural networks for volumetric medical image segmentation. 3DV pp. 565-571 (2016)
- 14. Minaee, S., Boykov, Y., Porikli, F., Plaza, A., Kehtarnavaz, N., Terzopoulos, D.: Image segmentation using deep learning: A survey. IEEE transactions on pattern analysis and machine intelligence 44 (7), 3523-3542 (2021)
- 15. Nan, X., Bai, S., Wang, F., Xia, G.S., Wu, T., Zhang, L.: Learning attraction field representation for robust line segment detection. CVPR (2019)
- 16. Neubeck, A., Gool, L.V.: Efficient non-maximum suppression. ICPR'06 3 , 850-855 (2006). https://doi.org/10.1109/ICPR.2006.479
- 17. Newell, A., Yang, K., Deng, J.: Stacked hourglass networks for human pose estimation. Computer Vision - ECCV 2016 pp. 483-499 (2016)
- 18. Nikolov, S., et al.: Clinically applicable segmentation of head and neck anatomy for radiotherapy: Deep learning algorithm development and validation study. Journal of Medical Internet Research 23 , e26151 (07 2021). https://doi.org/10.2196/26151
- 19. Pautrat, R., Barath, D., Larsson, V., Oswald, M.R., Pollefeys, M.: Deeplsd: Line segment detection and refinement with deep image gradients. arXiv preprint arXiv:2212.07766 (2022)
- 20. Poma, X.S., Riba, E., Sappa, A.: Dense extreme inception network: Towards a robust cnn model for edge detection. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 1923-1932 (2020)
- 21. Roug´ e, P., Passat, N., Merveille, O.: Cascaded multitask u-net using topological loss for vessel segmentation and centerline extraction. arXiv preprint arXiv:2307.11603 (2023)
- 22. Setio, A., et al.: Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the luna16 challenge. Medical image analysis 42 , 1-13 (2017)
- 23. Shit, S., et al.: cldice-a novel topology-preserving loss function for tubular structure segmentation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition pp. 16560-16569 (2021). https://doi.org/10.1109/CVPR46437.2021.01629
- 24. Spencer, T., Olson, J.A., McHardy, K.C., Sharp, P.F., Forrester, J.V.: An imageprocessing strategy for the segmentation and quantification of microaneurysms in fluorescein angiograms of the ocular fundus. Computers and biomedical research 29 (4), 284-302 (1996)
- 25. Tenenbaum, J.B., Silva, V., Langford, J.C.: A global geometric framework for nonlinear dimensionality reduction. Science 290 (5500), 2319-2323 (2000). https://doi.org/10.1126/science.290.5500.2319
- 26. Valente, M., Stanciulescu, B.: Real-time method for general road segmentation. 2017 IEEE Intelligent Vehicles Symposium (IV) pp. 443-447 (2017). https://doi.org/10.1109/IVS.2017.7995758
- 27. Von Gioi, R.G., Jakubowicz, J., Morel, J.M., Randall, G.: Lsd: A fast line segment detector with a false detection control. IEEE transactions on pattern analysis and machine intelligence 32 (4), 722-732 (2008)
- 28. Wang, F., Zheng, K., Lu, L., Xiao, J., Wu, M., Miao, S.: Automatic vertebra localization and identification in ct by spine rectification and anatomically-constrained optimization. IEEE/CVF Conference on Computer Vision and Pattern Recognition pp. 5280-5288 (2021)
- 29. Winzeck, S., et al.: Isles 2016 and 2017-benchmarking ischemic stroke lesion outcome prediction based on multispectral mri. Frontiers in neurology 9 , 679 (2018)
- 30. Xie, S., Tu, Z.: Holistically-nested edge detection. In: Proceedings of the IEEE international conference on computer vision. pp. 1395-1403 (2015)
- 31. Xu, Y., Xu, W., Cheung, D., Tu, Z.: Line segment detection using transformers without edges. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4257-4266 (2021)
- 32. Xue, N., Wu, T., Bai, S., Wang, F., Xia, G.S., Zhang, L., Torr, P.H.: Holisticallyattracted wireframe parsing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2788-2797 (2020)
- 33. Zakharov, A., et al.: Interpretable vertebral fracture quantification via anchor-free landmarks localization. Medical Image Analysis 83 , 102646 (2023)
- 34. Zhang, H., Kheyfets, V.O., Finol, E.A.: Robust infrarenal aortic aneurysm lumen centerline detection for rupture status classification. Medical engineering & physics 35 (9), 1358-1367 (2013)
- 35. Zhang, J., Xu, Y., Ni, B., Duan, Z.: Geometric constrained joint lane segmentation and lane boundary detection. Computer Vision - ECCV 2018 11205 , 486-502 (2018)
- 36. Zhang, P., Wang, F., Zheng, Y.: Deep reinforcement learning for vessel centerline tracing in multi-modality 3d volumes. Medical Image Computing and Computer Assisted Intervention - MICCAI 2018 11073 , 755-763 (2018)
- 37. Zhao, J., Feng, Q.: Automatic aortic dissection centerline extraction via morphology-guided crn tracker. IEEE Journal of Biomedical and Health Informatics 25 (9), 3473-3485 (2021) | null | [
"Farukh Yaushev",
"Daria Nogina",
"Valentin Samokhin",
"Mariya Dugova",
"Ekaterina Petrash",
"Dmitry Sevryukov",
"Mikhail Belyaev",
"Maxim Pisov"
] | 2024-08-02T10:21:10+00:00 | 2024-08-14T17:24:25+00:00 | [
"cs.CV"
] | Robust Curve Detection in Volumetric Medical Imaging via Attraction Field | Understanding body part geometry is crucial for precise medical diagnostics.
Curves effectively describe anatomical structures and are widely used in
medical imaging applications related to cardiovascular, respiratory, and
skeletal diseases. Traditional curve detection methods are often task-specific,
relying heavily on domain-specific features, limiting their broader
applicability. This paper introduces a novel approach for detecting
non-branching curves, which does not require prior knowledge of the object's
orientation, shape, or position. Our method uses neural networks to predict (1)
an attraction field, which offers subpixel accuracy, and (2) a closeness map,
which limits the region of interest and essentially eliminates outliers far
from the desired curve. We tested our curve detector on several clinically
relevant tasks with diverse morphologies and achieved impressive subpixel-level
accuracy results that surpass existing methods, highlighting its versatility
and robustness. Additionally, to support further advancements in this field, we
provide our private annotations of aortic centerlines and masks, which can
serve as a benchmark for future research. The dataset can be found at
https://github.com/neuro-ml/curve-detection. |
2408.01160v1 | ## Nanoscale spin rectifiers for harvesting ambient radiofrequency energy
Raghav Sharma 1,2 , Tung Ngo 1 , Eleonora Raimondo 3 , Anna Giordano , Junta Igarashi , Butsurin 4 5 Jinnai , Shishun Zhao , Jiayu Lei , Yong-Xin Guo , Giovanni Finocchio , Shunsuke Fukami 6 1 1 1 3 5-8 , Hideo Ohno 5-8 and Hyunsoo Yang 1*
- 1 Department of Electrical and Computer Engineering, National University of Singapore, 117576, Singapore
2 Department of Electrical Engineering, Indian Institute of Technology Ropar, Rupnagar 140001, India
3 Department of Mathematical and Computer Sciences, Physical Sciences and Earth Sciences, University of Messina, I-98166 Messina, Italy
4 Department of Engineering, University of Messina, I-98166 Messina, Italy
5 Laboratory for Nanoelectronics and Spintronics, Research Institute of Electrical Communication, Tohoku University, 2-1-1 Katahira, Aoba, Sendai 980-8577, Japan
- 6 Advanced Institute for Materials Research (WPI-AIMR), Tohoku University, Sendai 980-8577, Japan
7 Center for Science and Innovation in Spintronics, Tohoku University, 2-1-1 Katahira, Aoba, Sendai 980-8577, Japan
8 Center for Innovative Integrated Electronic Systems, Tohoku University, 468-1 Aramaki Aza Aoba, Sendai 980-0845, Japan
*e-mail: [email protected]
Radiofrequency harvesting using ambient wireless energy could be used to reduce the carbon footprint of electronic devices. However, ambient radiofrequency energy is weak (less than 20 dBm), and the performance of state-of-the-art radiofrequency rectifiers is restricted by thermodynamic limits and high-frequency parasitic impedance. Nanoscale spin rectifiers based on magnetic tunnel junctions have recently demonstrated high sensitivity, but suffer from a low a.c.-to-d.c. conversion efficiency (less than 1%). Here, we report a sensitive spin rectifier rectenna that can harvest ambient radiofrequency signals between 62 and 20 dBm. We also develop an on-chip co-planar waveguide-based spin rectifier
array with a large zero-bias sensitivity (around 34,500 mV mW 1 ) and high efficiency (7.81%). The self-parametric excitation driven by voltage-controlled magnetic anisotropy is a key mechanism that contributes to the performance of the spin-rectifier-array. We show that these spin rectifiers can be used to wirelessly power a sensor at a radiofrequency power of 27 dBm.
Wireless sensor networks (WSNs) play a critical role in applications such as health and environmental monitoring, and the Internet of Things (IoT). Sensors installed in difficult to access locations which are required, for example, in monitoring air quality, temperature, and moisture should ideally be battery-free. Large sensor and IoT device networks require numerous radiofrequency (rf) sources to exchange data. A considerable amount of the ambient rf energy from these sources remains unused and could thus be harvested and converted to dc power 1,2 to power electronic devices and sensors 3-8 (Fig. 1a). Compared to other energy harvesting sources (such as solar, vibration, thermal, and wind), rf energy harvesting offers all-day availability, easy accessibility, and can be integrated with small WSNs 9,10 .
A rf energy harvesting module (EHM) consists of a receiver antenna, a rectifier, a power management module, and a load that uses the harvested dc power (Fig. 1b). The EHM should work at an ambient available rf power level ( P rf ) of below 20 dBm (10 µW), as per the IEEE wireless LAN standards for the 2.4 GHz band (which is the most abundant waste rf source in the ambient) 11 . The rectifier is an important part of the EHM, and defines the overall efficiency ( P dc / P rf , where P dc is the harvested dc power). State-of-the-art rf rectifiers are based on Schottky diodes, transistors, and complementary metal-oxide-semiconductor (CMOS) technology 12-14 . The Schottky diodes (either on rigid substrates such as silicon and III-V compound semiconductors 15,16 or flexible substrate based on two-dimensional MoS2 14 ) and tunnel diodes 17 , are the most efficient 13,14,18,19
rectifiers for the electromagnetic energy harvesting. Efficiencies can reach 40-70% 5,6,14,20-25 , but in the low-power regime ( P rf less than 20 dBm), the thermodynamic limit creates a challenge 26,27 . Schottky diodes (with an antenna) have achieved an efficiency of 5-19% (2.45 GHz) at P rf between 30 and 20 dBm 5,24,28-33 , but practical implementation with an EHM operating at P rf less than 20 dBm remains a challenge 3,5,6,14,34 . A commercial 2.45 GHz EHM has been developed by Powercast, but only works at P rf larger than -10 dBm 34 .
Spin rectifiers (SRs) based on magnetic tunnel junctions (MTJs) could overcome the lowpower limitations of charge-based rectifiers and eliminate antenna and matching circuits SRs can convert a rf to a d.c. signal due to the spin diode effect 35,36 , where an applied rf current exerts a torque on the local spins of the free magnetic layer of the SRs, resulting in a precession motion and resistance oscillation at the same frequency as the rf signal. The resistance oscillation with a rf current produces a rectified voltage ( V r ) across the top and bottom contacts of the SR (Fig. 1c). SRs are nano-sized, sensitive 27 , CMOS compatible 37 , battery-free 38 and frequency-tunable 36 , making them a potential candidate for next-generation rectifiers. Sensitivities in the range of 1.2 10 4 10 6 mV mW 1 have been reported in dc-biased SRs 35 using a perpendicular free layer 27 , canted free-layer 38,39 , vortex-expulsion 40,41 and a spin bolometer 42 . Furthermore, SR-based EHMs can operate at P rf around 0 dBm at 2.45 GHz , but with an efficiency of less than 1%, which is 7 impractical for harvesting at ambient condition. Further advances in performance are thus needed before SRs can be used in applications such as detectors and sensors 4,7,37,43 . In particular, the narrow rectification band of less than 2 GHz 4,38,39,42 needs to be improved and the efficiency needs to be increased . 4
In this Article, we report on two SR prototypes: a 2.45 GHz SR rectenna for low-power energy harvesting at P rf between 62 dBm and 20 dBm, and a SR array integrated with an on-
chip co-planar waveguide for broadband rectification with a zero-bias sensitivity ( S ) of around 34,500 mV mW -1 and an efficiency of 7.81%. Micromagnetic simulations and microwave emissions data show that the approach relies on self-parametric excitations driven by voltagecontrolled magnetic anisotropy (VCMA), which reduces the threshold for excitation of a broadband rectification response and leads to enhanced sensitivity in the array arrangement of SRs. Our SRs can be integrated into EHMs, and their signal-to-noise ratio (SNR) and noise equivalent power (NEP) performances are suitable for low microwave power detector applications in noisy environments.
## Device engineering for low power operation
We use the uniformly magnetized SRs for GHz-range rectification. Our SRs consist of a CoFeB free layer (FL) and reference layer (RL) separated by an MgO spacer layer (Fig. 1c). The free and spacer layer thickness and SRs dimension are varied to control the interfacial anisotropy and tunneling magnetoresistance (TMR), in order to have the proper values of zero-bias resistance, resonance frequency, and equilibrium direction of the magnetization. We find that the SRs with the FL and spacer thickness of 1.9 nm and 1 nm, respectively, and dimensions of 40 × 100 nm to 2 80 × 200 nm 2 demonstrate the best rectification results (Supplementary Notes 1-3).
We study the detailed properties with the zero-bias and zero magnetic field conditions. Figure 1d shows the rectification response (rectified voltage vs. input microwave frequency) of 40 × 100 nm 2 and 80 × 200 nm devices at 2 P rf = 30 dBm. We select the SRs with the frequency close to WiFi (2.4 GHz), 4G (2.3-2.6 GHz) and 5G (3.5 GHz) bands. We observe that the rectified signal in the 40 × 100 nm to 80 × 200 nm SRs is a combination of symmetric and anti-symmetric 2 2 Lorentzian 44 .
We find the maximum sensitivity of ~3800 mV mW 1 and ~2200 mV mW 1 at P rf = 55 dBm and 40 dBm, respectively, for the 80 × 200 nm and 40 × 100 nm 2 2 SRs, which is higher than the zero-bias sensitivity of previous reports 7,27,38,44 and a state-of-the-art zero-bias Schottky diode 45 . The better sensitivity and rectification voltage in the 80 × 200 nm SRs are due to a high 2 zero-field TMR, R zb = ( R zb -R p )/ R p , 27,38 (Supplementary Fig. 2) and larger VCMA (Supplementary Note 4), where R zb is the zero-field resistance and R P is the parallel configuration resistance. The 80 × 200 nm SR shows VCMA > 50 fJ/Vm and 2 R zb > 30%. A high zero-field TMR ( R zb ) more than 30% is useful for acquiring a large zero-field and zero-bias rectified signal. Moreover, a significant VCMA > 50 fJ/Vm improves the sensitivity due to the nonlinear contribution 44 (Supplementary Note 4), where the observed VCMA is stronger than the reported value of 30-50 fJ/Vm in MTJ-based SRs 38,44,46 . Recent improvements of TMR to 631% 47 and the VCMA to 320 fJ Vm -1 48 may enhance the rectified voltage of SRs. A relatively low resistancearea (RA) product is another key requirement, as a large RA significantly reduces the rf current flow through the SRs. Furthermore, to produce a significant zero-field and zero-bias rectified signal, canted anisotropy with a R zb is required. Therefore, canted SRs with a high zero-field TMR, low RA, and high VCMA coefficient are useful for energy harvesting applications. The sensitivity decreases at P rf > 20 dBm (Fig. 1e) due to the decrease of R zb and saturation of the rectified voltage ( V r ) 7,27,38 (Supplementary Note 5).
## SR-rectenna for ultra-sensitive rf energy harvesting
While injecting an rf signal using a probe station, a rf power loss of 35 60% due to impedance mismatching is observed at 2.4 GHz (Supplementary Note 6). To improve sensitivity, a high-gain impedance matched antenna ( R x ) is designed and attached to the 80 × 200 nm SR 2 (Fig. 2a), to utilize them as a SR-rectenna. Figure 2b shows the antenna design, where the
transmission line dimensions are varied to match the SR impedance at 2.45 GHz (Supplementary Note 7). The rectified voltage and sensitivity in Fig. 2c,d shows significant enhancement due to an impedance-matched SR-rectenna, especially at ultra-low power P rf < 50 dBm. The sensitivity of probe station-based excitation in Fig. 1e and SR-rectenna-based wireless excitation in Fig. 2d shows similar results (shown in red), indicating that the SR-rectenna is well integrated. Using the matched SR-rectenna, the rectified voltage is V r = 6.27 µV at P rf = 62 dBm, corresponding to S ~10,000 mV mW 1 , which is larger than the S of 450-1850 mV mW 1 reported in other SRs 7,27,38 and the unmatched SR (3800 mV mW 1 ) in Fig. 1e. A high sensitivity more than 1000 mV mW 1 is observed for a wide range of P rf between 62 and 25 dBm.
## Role of magnetic anisotropy in designing SR-array
The matched SR-rectenna shows a significantly improved rf sensitivity. However, the voltage is insufficient for the EHM. Hence, it is necessary to connect SRs in an array for enhancing the output voltage. Compared to Schottky diode cascading (2 to 4 stages) for voltage multiplication, the SRs can be easily connected by the small wirebonds 7,37 , making them compact. Moreover, a potential on-chip integration of SRs with the CMOS technology is expected to have more benefits from our SR-array demonstration. Here, we discuss the influence of single SR behavior on the array design using 40 × 100 nm and 80 × 200 nm devices. 2 2
First, we consider the experimental rectification response of the individual SR. In contrast to the resonant behavior at P rf ≤ 30 dBm (Fig. 1d), the 40 × 100 nm SR shows a broadband 2 response (0.1 3.5 GHz) at P rf 25 dBm (Fig. 3a), whereas the 80 × 200 nm SR shows a resonant 2 behavior at both P rf 25 dBm (Fig. 3b) and P rf ≤ 30 dBm (Fig. 1d). In addition, due to tunability with the magnetic field, a large bandwidth of 0.1-6 GHz using a single SR is observed (Supplementary Fig. 8a). This bandwidth is twice of previous reports of SRs 4,49 .
To study the scalability of the SR technology, we connect 10 SRs (40 × 100 nm and 80 × 2 200 nm 2 ) in series without any external antenna to excite the SR-array directly by wireless rf energy, which is the key challenge for the development of ultra-compact EHMs. To save on-chip area for making ultra-compact EHMs, a small co-planar waveguide (240 × 500 µm ) is attached 2 to individual SRs to couple the rf power. The 40 × 100 nm SR-array shows a broadband response 2 compatible with the individual SRs response at P rf > 25 dBm (Fig. 3a). In contrast to the single SR broadband behaviour at a high magnetic field (Supplementary Fig. 8a), a SR-array due to the enhanced self-parametric effect achieves a wide range broadband behaviour without any magnetic field (Fig. 3a), making it more appropriate for on-chip applications. Compared to the 40 × 100 nm 2 SR-array, the 80 × 200 nm SR-array shows a transition from resonant to broadband with a 2 narrower detection bandwidth (Fig. 3b) but higher sensitivity. Hence, the 80 × 200 nm SR-array 2 can be used for a band-pass filter-rectifier. Overall, the peak rectified voltage is scaled by approximately N times upto 4-5 devices, where N is the number of the SRs connected in series. After that, the output starts to deviate from the N scaling and begins to saturate (Supplementary Fig. 9). In general, more number of SRs connected in series show a broadband rectification response, and hence increase the integrated rectification voltage.
We perform the micromagnetic simulations to reproduce the transition from resonant to broadband in a 40 × 100 nm 2 single SR. Fig. 3c summarizes a phase diagram of the rectification curves as a function of the frequency and amplitude of the current density ( J ac ) where the transition from resonant to broadband detection can be observed. Fig. 3d shows the amplitude of the x -component of the magnetization, Δ mx (parallel to the polarizer) as a function of the amplitude of J ac . Examples of simulated rectification curves are displayed in Fig. 3e. It can be noted that at a low input power (e.g. J ac = 0.1 MA/cm 2 ) in Fig. 3e, the detection curves are resonant with a small
precession angle. As the power increases (e.g. J ac = 10 MA/cm 2 ), a large amplitude magnetization precession Δ mx leads to the broadband response. This rectification mechanism is observed in small SRs (40 × 100 nm 2 ), where the canted equilibrium angle is 50-70 . On the other hand, for the 80 × 200 nm 2 SR, where the canted equilibrium angle is close to out-of-plane (79-95 ), the transition from resonant to broadband is not observed 7,38 .
In order to understand the potential origin of the transition from resonant to broadband response in the 40 × 100 nm SR-array, we have performed additional experimental studies. The 2 microwave emissions of a single and two series connected 40 × 100 nm SRs driven by a rf current 2 𝑖 ൌ 𝐼 𝑠𝑖𝑛ሺ 2 𝑓𝑡ሻ at a frequency of f are recorded in the spectrum analyzer (Fig. 3f,g). The microwave emissions of a single SR exhibit a weak second harmonics (2 component) at 6 GHz f (Fig. 3f), whereas the second harmonics peak power is enhanced by one order of magnitude in the two SRs connected in series (Fig. 3g). The decrease in the threshold power required for the onset of 2 f peak i.e., the self-parametric effect and the enhancement of 2 peak power in the seriesf connected SRs is shown in Fig. 3h. The presence of the second harmonics can be understood considering that the magnetoresistance oscillates at the same frequency of the input rf current 𝑅ሺ𝑡ሻ ൌ 𝛥𝑅ௌ 𝑠𝑖𝑛ሺ 2 𝑓𝑡 𝜑 ோ ሻ , where 𝜑ோ is a phase shift. The voltage across the SR is given by
$$V _ { r } = \frac { 1 } { 2 } \Delta R _ { S } I _ { a c } \, c o s ( \varphi _ { R } ) ( 1 - c o s ( 2 \pi f t + \varphi _ { R } ) ) + \frac { 1 } { 2 } \Delta R _ { S } I _ { a c } \, s i n ( \varphi _ { R } ) \, s i n ( 2 \pi f t + \varphi _ { R } ). \quad ( 1 )$$
As already demonstrated, these devices have large VCMA, when connected in series, the voltage at 2 f originated in one SR drives a parametric excitation in the other SR enhancing the magnetization precession angle. This mechanism recalls the self-parametric excitation 50,51 and it can explain the large voltage (large sensitivity) observed in Fig. 3b. To support this claim, we have performed a systematic micromagnetic study of the magnetization oscillation as a function of the VCMA amplitude considering an rf current at and a VCMA applied at 2 . Supplementary Fig. f f
10a shows an example of these calculation, comparing the response at VCMA field of 0 mT and 10 mT. The calculation results confirm that the amplitude of magnetization precession increases with increasing VCMA, supporting the idea of self-parametric excitation. The VCMA-based selfparametric effect opens a path for design of next generation of high-performance SRs. In addition, we expect that the microwave magnetic field of the incident electromagnetic wave can couple directly to the free layer magnetization enhancing the amplitude of the magnetization precession.
## SR-array based broadband low-powered EHM
Due to the high sensitivity and rectified voltage in the 80 × 200 nm SR-array (10 SRs in 2 series), we integrate them in an EHM as shown in Fig. 4a, in an ambient environment without an extra external antenna. The SR-array shows the rectification voltage ( V r ) of 20 mV and 11 mV using the 2.45 GHz and 3.5 GHz rf sources at P rf = 25 dBm, respectively (Fig. 4b). The voltage threshold of the boost converter is 20 mV, which SR-array achieves at 22 dBm at 2.45 GHz.
The SR-array voltage ( V r ) steps up from 20 50 mV to 1.6 4 V by the boost converter. The temperature sensor turns on at V step ~1.2 V, which is achieved at 27 dBm and 22 dBm using the dual sources (2.45 GHz and 3.5 GHz) and a single 2.45 GHz source, respectively, for the EHM demonstration. The EHM takes a total 15 30 seconds for powering the sensor initially. The response time of SR-array to accumulate ~20 mV takes only a few seconds due to the low capacitance (pF to fF), which is another major advantage of SRs. However, to avoid the fast charging-discharging effect of SRs due to a low capacitance, we use an external capacitor of 0.01 F (capacity 3.3 V) to hold a stable rectified voltage. The SR-array voltage is V r ~28 mV at P rf = 25 dBm using those two sources, which is converted to V step ~3.7 V by the boost converter. The estimated charging time of an external capacitor to reach 20 mV at P rf = 25 dBm is 23-24 seconds, which is close to the experimentally observed charging time of around 20-25 seconds for
the EHM to turn on the sensor. Here, the differential resistance of the SR-array is measured as 2 k . EHM can work steadily for one hour and the V step can be stored in the capacitor (Supplementary Note 11). The V step is then connected to a low-current driven handheld multimeter, showing a negligible discharging or leakage effect after turning off the wireless source (Fig. 4c). The 1.2 V temperature sensor and 1.6 V LED can remain ON for ~50 s and 30 s, respectively, after turning off the wireless source, useful for discontinuous rf environment. Hence, SR-array based EHM can be used for broadband operation to power various electronic devices.
## Comparison with existing rf energy harvesting technology
In 2014, Hemour et al . 13 predicted that an optimized SR could outperform state-of-the-art rectifiers in the rf power range of 70 to 10 dBm. We compare the SR-rectenna and SR-array with the two commercially available low-power Schottky diodes (HSMS-2860 and SMS-7630) under the same ambient condition in Fig. 5a,b. We measure the zero-bias differential resistance ( R zbr ) of SR, SR-array, HSMS 2860, and SMS 7630 when irradiated by 2.45 GHz at P rf = 25 dBm and find the values of 0.27, 2, 5, and 5.1 k , respectively. Here, P rf is the power emitted from the signal generator, without including any antenna gain and losses at the device interface due to impedance mismatching to determine the actual front-end efficiency (see method). Our results show that SR-rectenna works reliably (SNR > 20 dB) for 62 dBm < P rf < 20 dBm, enabling SRrectenna sensitive for the weak ambient condition (Supplementary Note 12). Furthermore, we measure the noise equivalent power (NEP) of a single SR, which is defined as the ratio of V noise /sensitivity, where V noise is the noise voltage. A low NEP of 2 × 10 -12 W Hz 0.5 is measured at P rf = 0.1 µW ( 40 dBm) without a dc bias ( I dc = 0 mA), which is slightly smaller than the NEP measured in previous reports of SRs with a dc bias 38 (Supplementary Note 12). The observed high SNR and low NEP imply that SRs are suitable for low-power microwave detector applications.
The SR-array shows a low SNR at P rf < 50 dBm in comparison to SR-rectenna due to an increased parasitic capacitance (Supplementary Fig. 12a). However, in the rf power range of 50 dBm to 20 dBm, an SR-array outperforms due to a high efficiency ( ~7.81% at 30 dBm) and sensitivity (~34,500 mV mW 1 at 50 dBm) as shown in Fig. 5a,b. The efficiency is 2-3 orders of magnitude higher than the previous SR (1.2 GHz) at 4 P rf < 20 dBm (Supplementary Fig. 13).
Although the performance of state-of-the-art rf rectifiers based on Si, GaAs or MoS2, can reach an efficiency of 40 80% at P rf > 10 dBm 6,14,20-25 , their performance at P rf < 20 dBm is limited (Supplementary Fig. 14) for the EHM demonstrations as summarized in Table 1. Only few works show a high-efficiency of 5 19% 5,24,28-33 at 30 dBm < P rf 20 dBm after including the antenna efficiency, whereas our work shows an SR-array efficiency without antenna in Fig. 5a.
Furthermore, the SR-array is connected in an equivalent electrical area of ~1 mm , 2 including the co-planar waveguide, which couples the rf power to the SR devices. Packaged Schottky diodes (> 10 mm ) with a high-efficiency antenna captures an overall area of at least few 2 cm 2 , impractical for on-chip scaling. Even with the miniaturized antenna, the size is reduced only to ~200 mm 2 for low-power applications . Our demonstration shows that the SR-array could be 5 the most-sensitive and compact solution for ambient energy harvesting technology (Table 1).
## Conclusions
We have reported a SR rectenna with a large rf sensitivity of around 10,000 mV mW 1 at 62 dBm, which can harvest rf energy in weak and noisy ambient environments. In the case of a single SR, intrinsic device properties such as the perpendicular anisotropy, device geometry, and dipolar field from the polarizer layer play a crucial role in defining the energy landscape of the nanomagnet, and the excitation of a large angle magnetization precession at low input power. The sensitivity is linked to the dynamical response of the MTJ and depends on the zero-field TMR and
the VCMA coefficient, which enhances the zero-bias rectified voltage driven by the spin-polarized current. Furthermore, an external matching setup can minimize input power losses and enhance the sensitivity of the SR-rectenna. In the case of the SR array, we observed a VCMA-driven selfparametric effect, which results in an enhancement of the sensitivity and detection bandwidth without incorporating any external antenna or matching setup. We showed that our SR-array-based EHM can power a commercial sensor at a low rf power of 27 dBm without the use of an extra antenna. Our SRs are compact, not prone to suffering from parasitic effects, easy to integrate, scalable, and efficient in ambient conditions.
## Methods
Device structure. The SR layered structure is sapphire substrate/Ta (5)/Ru (10)/Ta (5)/Pt38Mn62 (15)/Co (2.4)/Ru (0.88)/Co18.75Fe56.25B25 (2.4)/MgO ( t MgO)/Co18.75Fe56.25B25 ( t CoFeB)/Ta (5)/Ru (5) (thicknesses in nm). The MgO and other layers are deposited using the rf and dc magnetron sputtering, respectively, at room temperature and base pressure < 1 × 10 -6 Pa with the Ar gas flow. The thickness of topmost CoFeB free layer ( t CoFeB) and spacer MgO layer ( t MgO) are varied from 1.7 1.9 nm and 0.9 1.2 nm, respectively, to tune the canted equilibrium direction (along the z -direction from the x direction in Fig. 1c) as described in Supplementary Notes 1-3. The bottom CoFeB (2.4 nm) is the reference layer (RL), whose magnetization direction is pinned along the x direction due to Co/Ru/CoFeB synthetic antiferromagnetic (SAF) coupling, which is exchange biased by an antiferromagnet PtMn.
Device engineering. The SRs were first optimized by varying t CoFeB and t MgO. The SRs with t CoFeB = 1.9 nm and t MgO = 1 nm, show the best performance. For further tuning the SRs performance, the stack is processed into elliptical SRs with the dimensions of 40 × 100 nm to 160 × 400 nm 2 2
using e-beam lithography and Ar ion beam milling by keeping the aspect ratio of 2.5. The 40 × 100 nm 2 to 80 × 200 nm shows the best zero-bias rectification results due to canted equilibrium 2 magnetization. The bigger devices (100 × 250 nm to 160 × 400 nm 2 2 ) show low rectification performance. Here, we use the 40 × 100 nm and 80 × 200 nm for discussing the scalability and 2 2 diverse functionalities of SR. The best optimized 80 × 200 nm SR devices show the first-order 2 anisotropy ( µ H 0 k,eff ) of 0.25 0.3 T, TMR of 53 82%, RA of 4 6 Ω µm , frequency of 2.1 2 3.6 GHz, and resistance < 500 Ω .
Microwave measurement for the optimization. For the optimization of SRs, we use the probestation for the rf excitation and rectification measurements. The SRs rectification responses are measured using the spin torque ferromagnetic resonance (ST-FMR) technique. A rf signal modulated at a low frequency of 213 Hz is applied using a signal generator and the resulting rectified dc voltage is measured by a lock-in amplifier with a time constant of 100 milliseconds and a low pass filter slope of 24 dB/octave. The rf loss of 35-60% on the linear scale in the frequency range from 2.4 to 2.5 GHz is measured due to the impedance mismatch of 50 terminated probes and SRs using the reflection coefficient ( S 11 ) measured on the linear scale in the vector network analyser. We have included the rf loss in the sensitivity extraction for the probe station-based measurements in Fig. 1e and Supplementary Fig. 3d, where the sensitivity is calculated as S = V P r / . Here, P = P rf × (1-| S 11 | 2 ), is the power reaching the SR-devices after including the losses and P rf is the actual power fed from the signal generator (rf source) to the wires in the probe station-based measurements.
Rectenna Design. The rectenna is designed by attaching an antenna to the SR. For the antenna design shown in Fig. 2b, we first measure the S 11 of the SRs using VNA for the impedance calculation (Supplementary Fig. 7a). The patch antenna is fabricated on the RO4003C substrate.
The dimension of the transmission line is optimized to match the SR impedance at 2.45 GHz. The insertion loss of the matched antenna is 17.5 dB at 2.45 GHz and can cover the entire range of the WiFi band (2.4 2.5 GHz) with S 11 < 10 dB (Supplementary Fig. 7b). A high gain of 7.2 dBi is measured in the far-field region (Supplementary Fig. 7c). The SR-rectenna is tested successfully for a distance of 10 15 cm between the transmitter and receiver antenna. Another high-gain 50 Ω patch antenna is designed for the comparison. The coupling between the transmitting and receiving antenna used in the SR-rectenna is determined by the VNA measurement as shown in Supplementary Fig. 7d,e. The sensitivity for the rectenna measurement is S = V P r / rf , where P rf is determined by the S 21 parameter of the transmitting and receiving antennas (Supplementary Fig. 7d,e).
Spectrum analyzer measurement: In Fig. 3f,g, we have used the spectrum analyzer measurement. The details of the setup are given in ref. 7. In the spectrum analyser, the SRs oscillation signal and reflected signal due to the input rf signal ( P rf ) coexist. Even though the SRs oscillation signal is separated from the injected rf input signal through a directional coupler, the separation is imperfect. Since the linewidth of SRs (few MHz) and reflected signal (few Hz) from the injected rf input are very different, we can separate the injected input signal from the SR signal as a background subtraction. As the resolution of the spectrum analyzer is a few kHz (much larger than the reflection of the injected rf signal linewidth), the injected rf signal appears as a single data point, which could be easily subtracted by a proper Lorentzian fitting of the measured signal.
Multi-band rectification and EHM demonstration. The broadband rectification in Fig. 3a,b is performed using a high-gain (6 7 dBi) broadband (0.8 18 GHz) horn antenna. For the multi-band EHM demonstration, we used a resonant 2.4 2.5 GHz patch antenna (gain ~7.2 dBi) and 3.5 3.6 GHz whip antenna (gain ~3 dBi). The antennas are fed by the signal generator. The SR-array
voltage ( V r ) is stored in the capacitor before amplified by the boost converter to 1.5 4 V. For the stability analysis in Fig. 4c, the step-up voltage ( V step ~3.7 V) is first stored and then supplied to the multimeter, LED, and temperature sensor. The EHM demonstration is performed at varying distances of 2.5 5 cm. For the EHM demonstration at 27 dBm, the antenna is placed at ~2.5 cm from the SR-array chip. The co-planar waveguide design, on chip devices, and setup component images are shown in Supplementary Fig. 15.
Comparison with Schottky diode. For the comparison, the HSMS-2860 and SMS-7630 Schottky diodes are connected with the 50 antenna, whereas a single SR is attached with an impedance matched antenna. The efficiency is calculated by = P dc / P rf , where P dc = V r 2 / Rzbr . Here, Rzbr is the resistance of the SR-devices or Schottky diodes monitored during the measurement. The sensitivity is calculated as S = V P r / rf . Here, for a fair evaluation of all the systems together, the P rf is the actual power emitted from the rf source (signal generator), without correcting for the transmitting antenna gain and losses at the device interface or due to attenuation to estimate a front-end efficiency. Please note that the sensitivity calculation includes the losses only for probe station measurements used for optimization (Fig. 1e), while no losses are taken into account for the rectenna and energy harvesting measurements, underestimating the sensitivity. In the independent measurements using the VNA ( S 21 ), spectrum analyser connected with the receiving antenna, or rf power meter to measure the emitted wireless power from the transmitting antenna, we found that the power available at 2.5 cm differs from the power fed by the rf source ( P rf ) only by 0.5-3 dBm, which shows the high directivity of the transmitting antenna with minimal gain and attenuation in the near field region. Hence, in the near-field measurements, we find that the received power at 2.5 cm is very close to the actual power fed by the signal generator ( P rf ) and no correction due to any antenna gain or loss at the device interface is considered for the sensitivity estimation, independent
of using SR-rectenna, SR-array or Schottky diodes for the wireless energy harvesting. Since the losses at the device interface are ignored, the derived sensitivity denotes the lower bound of the device performance. The evaluated performances of the HSMS-2860 and SMS-7630 Schottky diodes are well matched with their data sheets. The SR-array is tested without an antenna, where the small ground-signal-ground co-planar waveguide (240 µm × 500 µm) of Cr (5 nm)/Au (100 nm) formed by photolithography and lift-off on the SR, couples the rf signals. The small wirebonds (< 1 mm), used to connect the MTJs, may couple a small amount of rf power to the MTJs. However, these wirebonds are mainly used as a dc or low frequency transmission path for the rectified signal.
Micromagnetic simulations. Micromagnetic simulations have been performed by solving numerically the Landau-Lifshitz-Gilbert-Slonczewski equation 52 :
$$\frac { d m } { d t } = \frac { \gamma M _ { S } } { ( 1 + \alpha _ { G } ^ { 2 } ) } \left [ - ( m \times h _ { e f f } ) - \alpha _ { G } ( m \times m \times h _ { e f f } ) + \sigma J ( m \times m \times p ) \right ]$$
where 𝛼ீ is the Gilbert damping, 𝒎ൌ𝑴 𝑀ௌ / is the normalized magnetization vector, 𝛾 is the gyromagnetic ratio and 𝑀ௌ is the saturation magnetization of the MTJ free layer (FL). The effective magnetic field, 𝒉 , includes the demagnetizing field, and the interfacial uniaxial perpendicular anisotropy. The spin-transfer torque (STT) term is proportional to the pre-factor 𝜎 ൌ ఓಳ | | | ఊ బ ெ | ೄ భ మ ௗ , where g is the gyromagnetic splitting factor, 𝜇 is the Bohr magneton, e is the electron charge, 𝑑௭ is the thickness of the FL, and P is the spin polarization. The ac current density flowing into the device is given by 𝐽 ൌ 𝐽 𝑠𝑖𝑛൫ 2 𝜋𝑓𝑡 𝜑 ൯ . The VCMA is included in the effective field as a changing anisotropy field. The amplitude of the VCMA field can be computed as ℎெ ൌ ଶక್ ఓబெೞ ௧ ௧ ೣ మ , where is the linear VCMA coefficient, ξ Ms is the saturation magnetization, 𝑡 ௭ is the free layer thickness, and 𝑡 ௫ is the oxide thickness. For a single device, the VCMA field ℎெ can be
larger than 2 mT ( Ms = 800 kA/m, 𝑡 ௭ = 1.9 nm, 𝑡 ௫ = 1 nm, microwave current density of 1 10 6 A/cm 2 , R AP = 1 k Ω , and ξ = 50 fJ/(mV)), where R AP is the resistance in anti-parallel configuration. However, in order to simulate the effect of self-parameter excitation at twice the input microwave frequency, which enhances the microwave emissions power as shown in Fig. 3h, the effect of the VCMA field is analyzed for a higher, more reasonable value of 10 mT in Supplementary Fig. 10a.
We have simulated an elliptical 40 nm × 100 nm × 1 nm hybrid device, where the perpendicular anisotropy is larger than the demagnetizing magnetic field and hence the equilibrium direction of the magnetization m is tilted from the out-of-plane direction as observed in the experiment. The polarizer magnetization p is in-plane along the x direction (Fig. 1c). The main micromagnetic parameters are 𝑀ௌ ൌ 800kA/m , perpendicular uniaxial anisotropy constant 𝐾௨ ൌ 0.39MJ/m ଷ , 𝛼ீ ൌ 0.02 , 𝑔 ൌ 2 , and 𝑃 ൌ 0.7 , and the dipolar field originated by the polarizer is added as a constant 𝐻 ൌ 5 mT. In simulations the rectification curves are computed for the amplitude of the ac current density raging from 𝐽 ൌ 0.1 to 10 MA/cm and a frequency scan 2 from 𝑓 ൌ 0.1 to 15 GHz. In the simulations presented in Supplementary Fig. 10a, the frequency of the VCMA is two times of that of the applied ac current density. For matching the frequency of the experimental data of rectification curves for the 40 × 100 nm single SR ( ~ 3.5 GHz) in Fig. 2 f 3e, the perpendicular uniaxial anisotropy constant is tuned to K u = 0.419 MJ/m 3 (Supplementary Fig. 10b).
Table 1 | Comparison of state-of-the-art 2.45 GHz rf rectifiers for the low-power operation and EHM demonstration.
| | Area (rectifier + antenna) | Low power Efficiency | Antenna | Power for EHM demo | Ref |
|-----------------------------|------------------------------|-------------------------------------------------|----------------------------------------------------|----------------------|-----------|
| MoS 2 flexible rectifier | ~few mm 2 | ~2% at 20 dBm | On-chip antenna | +3 dBm | 14 |
| HSMS-2852 | 214.1 mm 2 | ~20% at 20 dBm (including antenna efficiency) | Rectenna | +10 dBm | 5 |
| HSMS-2852 | Few cm 2 | ~7 8% at 25 dBm | Rectenna | +36 dBm | 6 |
| Powercast commercial module | Full board | 5 %at 10 dBm | Separate antenna | > 10 dBm | 34 |
| 65 nm CMOS technology | CMOS Chip | | 1.27 cm 2 antenna | +15.5 dBm | 53 |
| SR-array | 1.2 mm 2 | 7.8% at 27 dBm | On-chip co- planar waveguide (no external antenna) | 27 dBm | This work |
## References
| 1 | Shaikh, F. K. & Zeadally, S. Energy harvesting in wireless sensor networks: A comprehensive review. Renew. Sust. Energ. Rev. 55 , 1041-1054 (2016). |
|-----|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 2 | Shaikh, F. K., Zeadally, S. & Exposito, E. Enabling technologies for green internet of things. IEEE Syst. J. 11 , 983-994 (2015). |
| 3 | Bito, J., Kim, S., Tentzeris, M. & Nikolaou, S. Ambient energy harvesting from 2-way talk-radio signals for 'smart' meter and display applications. 2014 IEEE Antennas and Propagation Society International Symposium (APSURSI) , 1353-1354 (2014). |
| 4 | Fang, B. et al. Experimental demonstration of spintronic broadband microwave detectors and their capability for powering nanodevices. Phys. Rev. Appl. 11 , 014022 (2019). |
| 5 | Koohestani, M., Tissier, J. &Latrach, M. A miniaturized printed rectenna for wireless RF energy harvesting around 2.45 GHz. AEU - Int. J. Electron. 127 , 153478 (2020). |
| 6 | Olgun, U., Chen, C.-C. & Volakis, J. L. Wireless power harvesting with planar rectennas for 2.45 GHz RFIDs. 2010 URSI International symposium on electromagnetic theory , 329- 331 (2010). |
| 7 | Sharma, R. et al. Electrically connected spin-torque oscillators array for 2.4 GHz WiFi band transmission and energy harvesting. Nat. Commun. 12 , 2924 (2021). |
| 8 | Vallem, V., Sargolzaeiaval, Y., Ozturk, M., Lai, Y. C. &Dickey, M. D. Energy harvesting and storage with soft and stretchable materials. Adv. Mater. 33 , 2004832 (2021). |
| 9 | Iqbal, N., Masood, M., Nasir, A. A. & Qureshi, K. K. Review of contemporary energy harvesting techniques and their feasibility in wireless geophones. Int. J. Energy Res. 46 , 5703-5730 (2022). |
| 10 | Tran, L.-G., Cha, H.-K. & Park, W.-T. RF power harvesting: a review on designing methodologies and applications. Micro Nano Syst. Lett. 5 , 1-16 (2017). |
| 11 | Committee, I. C. S. L. M. S. IEEE Standard for Information technology- Telecommunications and information exchange between systems-Local and metropolitan area networks-Specific requirements Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications. IEEE Std 802.11 (2007). |
| 12 | Hemour, S. & Wu, K. Radio-frequency rectifier for electromagnetic energy harvesting: Development path and future outlook. Proc. IEEE 102 , 1667-1691 (2014). |
| 13 | Hemour, S. et al. Towards low-power high-efficiency RF and microwave energy harvesting. IEEE Trans. Microw. Theory Tech. 62 , 965-976 (2014). |
| 14 | Zhang, X. et al. Two-dimensional MoS2-enabled flexible rectenna for Wi-Fi-band wireless energy harvesting. Nature 566 , 368-372 (2019). |
| 15 | Strohm, K. M., Buechler, J. & Kasper, E. SIMMWIC rectennas on high-resistivity silicon and CMOS compatibility. IEEE Trans. Microw. Theory Tech. 46 , 669-676 (1998). |
| 16 | Suh, Y.-H. & Chang, K. A high-efficiency dual-frequency rectenna for 2.45-and 5.8-GHz wireless power transmission. IEEE Trans. Microw. Theory Tech. 50 , 1784-1789 (2002). |
| 17 | Lorenz, C. H. P. et al. Breaking the efficiency barrier for ambient microwave power harvesting with heterojunction backward tunnel diodes. IEEE Trans. Microw. Theory Techn. 63 , 4544-4555 (2015). |
| 18 | Cansiz, M., Altinel, D. & Kurt, G. K. Efficiency in RF energy harvesting systems: A comprehensive review. Energy 174 , 292-309 (2019). |
| 19 | Assogba, O., Mbodji, A. K. & Diallo, A. K. in 2020 IEEE International Conf on Natural and Engineering Sciences for Sahel's Sustainable Development-Impact of Big Data Application on Society and Environment (IBASE-BF). 1-10 (IEEE). |
|------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 20 | Chen, Y.-S. & Chiu, C.-W. Maximum achievable power conversion efficiency obtained through an optimized rectenna structure for RF energy harvesting. IEEE Trans. Antennas Propag. 65 , 2305-2317 (2017). |
| 21 | Kim, J. &Jeong, J. Design of high efficiency rectifier at 2.45 GHzusing parasitic canceling circuit. Microw. Opt. Technol. Lett. 55 , 608-611 (2013). |
| 22 | Mbombolo, S. E. F. & Park, C. W. in 2011 IEEE MTT-S International Microwave Workshop Series on Innovative Wireless Power Transmission: Technologies, Systems, and Applications. 23-26 (IEEE). |
| 23 | Olgun, U., Chen, C.-C. & Volakis, J. L. Investigation of rectenna array configurations for enhanced RF power harvesting. IEEE Antennas Wirel. Propag. Lett. 10 , 262-265 (2011). |
| 24 | Shi, Y. et al. An efficient fractal rectenna for RF energy harvest at 2.45 GHz ISM band. Int. J. RF Microw. 28 , e21424 (2018). |
| 25 | Wang, D. & Negra, R. Design of a rectifier for 2.45 GHz wireless power transmission. PRIME 2012; 8th Conference on Ph. D. Research in Microelectronics & Electronics , 1-4 (2012). |
| 26 | Valenta, C. R. Fundamental limitations for Schottky diode RF energy harvesting. 2015 IEEE International Conference on RFID Technology and Applications (RFID-TA) , 188- 193 (2015). |
| 27 | Miwa, S. et al. Highly sensitive nanoscale spin-torque diode. Nat. Mater. 13 , 50-56 (2014). |
| 28 | Valenta, C. R. & Durgin, G. D. Harvesting wireless power: Survey of energy-harvester conversion efficiency in far-field, wireless power transfer systems. IEEE Microw. Mag. 15 , 108-120 (2014). |
| 29 | Vera, G. A., Georgiadis, A., Collado, A. & Via, S. Design of a 2.45 GHz rectenna for electromagnetic (EM) energy scavenging. 2010 IEEE Radio and Wireless Symposium (RWS) , 61-64 (2010). |
| 30 | Assimonis, S. D., Fusco, V., Georgiadis, A. & Samaras, T. Efficient and sensitive electrically small rectenna for ultra-low power RF energy harvesting. Sci. Rep. 8 , 15038 (2018). |
| 31 | Adami, S.-E. et al. Aflexible 2.45-GHz power harvesting wristband with net system output from - 24.3 dBm of RF power. IEEE Trans. Microw. Theory Tech. 66 , 380-395 (2017). |
| 32 | Song, C. et al. A high-efficiency broadband rectenna for ambient wireless energy harvesting. IEEE Trans. Antennas Propag. 63 , 3486-3495 (2015). |
| 33 | Shen, S., Zhang, Y., Chiu, C.-Y. &Murch, R. A triple-band high-gain multibeam ambient RF energy harvesting system utilizing hybrid combining. IEEE Trans. Ind. Electron. 67 , 9215-9226 (2019). |
| 34 | P21XXPowerharvester Chipset Reference Design Evaluation Board , <www.powercastco.com/documentation/p21xxcsr-evb-datasheet/> (2018). |
| 35 | Finocchio, G. et al. Perspectives on spintronic diodes. Appl. Phys. Lett. 118 , 160502 (2021). |
| 36 | Tulapurkar, A. et al. Spin-torque diode effect in magnetic tunnel junctions. Nature 438 , 339-342 (2005). |
| 37 | Romera, M. et al. Vowel recognition with four coupled spin-torque nano-oscillators. Nature 563 , 230-234 (2018). |
| 38 | Fang, B. et al. Giant spin-torque diode sensitivity in the absence of bias magnetic field. Nat. Commun. 7 , 11259 (2016). |
|------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 39 | Zhang, L. et al. Ultrahigh detection sensitivity exceeding 10 5 V/W in spin-torque diode. Appl. Phys. Lett. 113 , 102401 (2018). |
| 40 | Jenkins, A. et al. Spin-torque resonant expulsion of the vortex core for an efficient radiofrequency detection scheme. Nat. Nanotechnol. 11 , 360-364 (2016). |
| 41 | Tsunegi, S. et al. Achievement of high diode sensitivity via spin torque-induced resonant expulsion in vortex magnetic tunnel junction. Appl. Phys. Express 11 , 053001 (2018). |
| 42 | Goto, M. et al. Uncooled sub-GHz spin bolometer driven by auto-oscillation. Nat. commun. 12 , 536 (2021). |
| 43 | Leroux, N. et al. Radio-frequency multiply-and-accumulate operations with spintronic synapses. Phys. Rev. Appl. 15 , 034067 (2021). |
| 44 | Zhu, J. et al. Voltage-induced ferromagnetic resonance in magnetic tunnel junctions. Phys. Rev. Lett. 108 , 197203 (2012). |
| 45 | Zero-Bias_Schottky_Diode_Detectors_100kHz-50Ghz.pdf , <http://www.herotek.com/datasheets> (2022). |
| 46 | Nozaki, T. et al. Electric-field-induced ferromagnetic resonance excitation in an ultrathin ferromagnetic metal layer. Nat. Phys. 8 , 491-496 (2012). |
| 47 | Scheike, T., Wen, Z., Sukegawa, H. & Mitani, S. 631% room temperature tunnel magnetoresistance with large oscillation effect in CoFe/MgO/CoFe(001) junctions. Appl. Physics. Lett. 122 , doi:10.1063/5.0145873 (2023). |
| 48 | Nozaki, T. et al. Highly efficient voltage control of spin and enhanced interfacial perpendicular magnetic anisotropy in iridium-doped Fe/MgO magnetic tunnel junctions. NPG Asia Mater. 9 , e451-e451, doi:10.1038/am.2017.204 (2017). |
| 49 | Zhang, L. et al. Enhanced broad-band radio frequency detection in nanoscale magnetic tunnel junction by interface engineering. ACS Appl. Mater. Interfaces 11 , 29382-29387 (2019). |
| 50 | Nitzan, S. H. et al. Self-induced parametric amplification arising from nonlinear elastic coupling in a micromechanical resonating disk gyroscope. Sci. Rep. 5 , 9036 (2015). |
| 51 | Rhodes Jr, J. Parametric self-excitation of a belt into transverse vibration. J. Appl. Mech. 37 , 1055-1060 (1970). |
| 52 | Tomasello, R. et al. Low-frequency nonresonant rectification in spin diodes. Phys. Rev. Appl. 14 , 024043 (2020). |
| 53 | Sadagopan, K. R., Kang, J., Ramadass, Y. & Natarajan, A. A 960 pW co-integrated- antenna wireless energy harvester for WiFi backchannel wireless powering. 2018 IEEE International Solid-State Circuits Conference-(ISSCC) , 136-138 (2018). |
Fig 1| The rf energy harvesting using spin-rectifiers. a , Illustration of the energy harvesting modules powering up small sensors and electronic components such as a light-emitting diode and temperature sensor by converting ambient rf energy (shown by dashed circles) to a useful dc voltage ( V dc ). The ambient rf energy is shared by various electronic gadgets and internet of things (IoT) devices, whereas WiFi routers and transmitters for the Bluetooth and Long-Term Evolution (LTE) represent the rf sources. b , Prototype model of the energy harvesting module, where an ambient rf power ( P rf ) is converted to a dc power ( P dc ) that can be used as a usable electric power by the load. c , Layered structure of spin-rectifier with top and bottom contacts. d , Zero-bias and zero magnetic field rectification ( V ) as a function of frequency ( ) of 40 × 100 nm and 80 × 200 f 2 nm 2 devices at P rf = 30 dBm. , Sensitivity ( e S ) at 3.5 GHz and 2.45 GHz from 40 × 100 nm and 2 80 × 200 nm 2 devices, respectively as a function of the rf power ( P rf ). The error bar in the S values shows the standard deviation of the peak rectified voltage from five measurements.
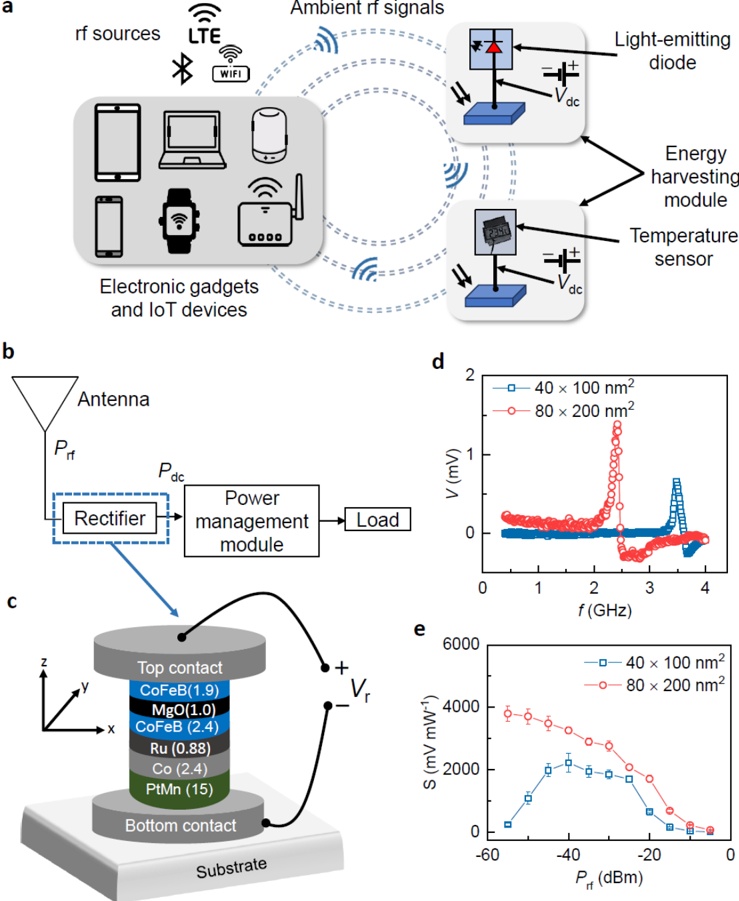
Fig. 2| Performance of SR-rectenna. a , Schematic of integration of the matched antenna with the SR. T x is the 50 Ω transmitting antenna and R x is the impedance matched receiving antenna. Another 50 Ω receiving antenna is also designed for comparison. b , Patch antenna designed to match the impedance of the matched part in a . c,d, Rectified voltage ( V r ) and sensitivity ( S ) comparison of 50 Ω and impedance matched receiving antenna attached to the 80 × 200 nm SR 2 with varying the rf power ( P rf ) at 2.45 GHz. To ensure the stable measurement of V r and corresponding S , the V r is measured after a waiting time of 5 seconds to reach the peak voltage and then averaged over 30 seconds. The standard deviation in V r and S values in rectenna measurement is less than 2% over time.
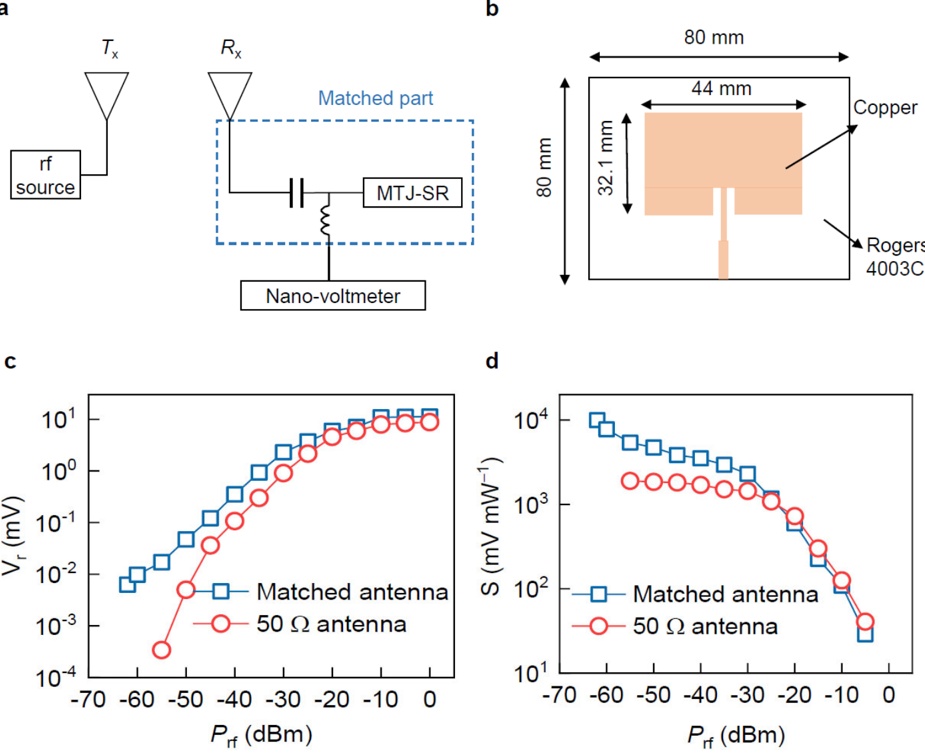
Fig. 3| Tuning of broadband and resonant recfication for designing SR-array. a , Experimental results of broadband rectification voltage ( V ) versus frequency ( ) response from a 40 f 100 nm 2 single SR and an array of ten SRs connected in series at rf power ( P rf ) of 20 dBm. The dashed rectangular boxes approximately show the region of broadband rectification, where the rectifition voltage is significant for the energy harvesting from 100 MHz to 3.5 GHz and 100 MHz to 6 GHz for the single SR and SR-array, respectively. b , Resonant and band-pass behavior of a 80 200 nm 2 single SR and an array of ten SRs connected in series, respectively, at P rf = 20 dBm. The rectangular boxes approximately shows the regions of resonant behaviour (a combination of symmetric and anti-symmetric Lorentzian) and band-pass behaviour for the single SR and SRarray, respectively. c , Simulated phase diagram of the precession amplitude of the x -component
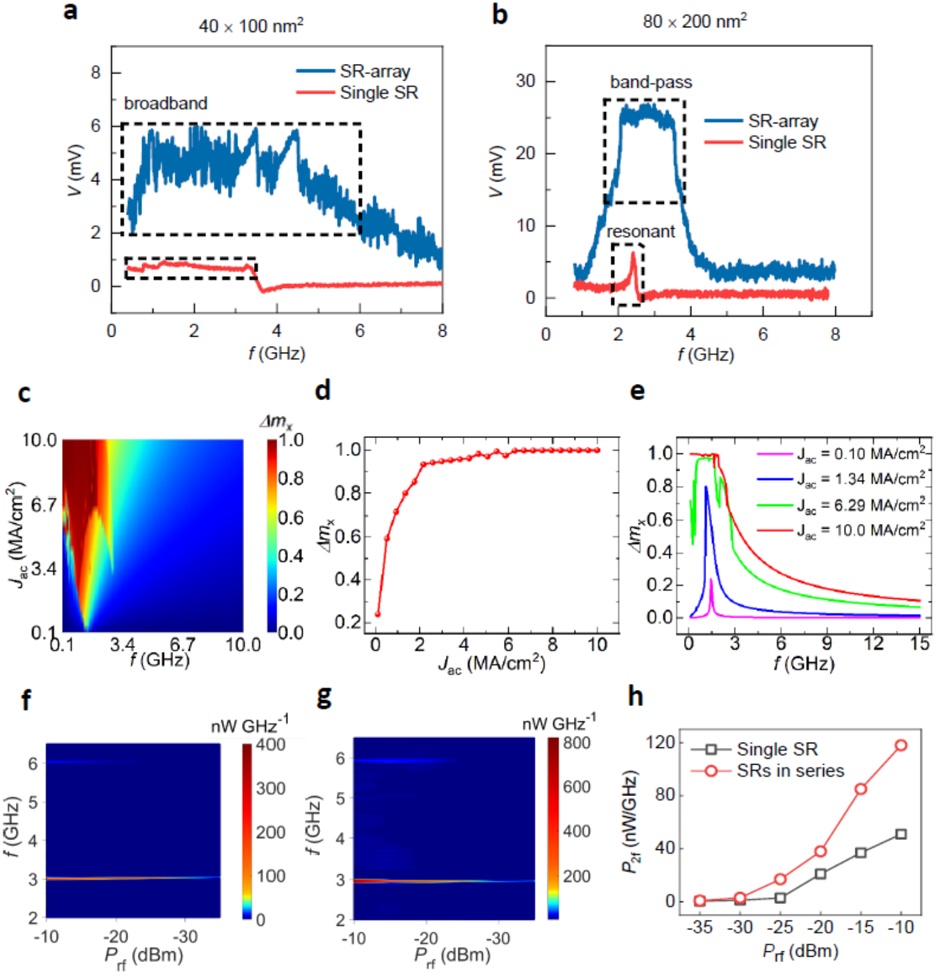
( mx ) of the magnetization (component originating the TMR) as a function of the microwave frequency ( ) and current density amplitude ( f J ac ). d , Simulated results of the maximum precession mx as a function of J ac for the 40 100 nm 2 single SR. e , Simulated ∆ m x as a function of at f various J ac with perpendicular uniaxial anisotropy constant, K u = 0.419 MJ/m , revealing the 3 transition from resonant to broadband behaviour. f g , , Comparison of experimentally observed spectrum emitted from the single ( ) and two series connected SRs ( f g ) excited by a rf signal ( I dc = 0 mA). h , Extracted 2 f peak power ( P 2f ) shows an enhancement in the case of SRs in series. The P 2f is calculated from the time-averaged data using the trace averaging function in the spectrum analyser over 5 sweeps.
Fig. 4 Demonstration of broadband low-power SR based energy harvesting module. a , A schematic of the energy harvesting module, where the harvested voltage ( V r ) from the SR-array is first stored in the capacitor, which is stepped up to a high-voltage ( V step ~1.6 4V) using the boost converter to power the temperature sensor. The ON state of temperature sensor corresponds to V step > 1.2 V. b , Rectified voltage ( V r ) from the SR-array at various rf powers ( P rf ) using 2.45 GHz and 3.5 GHz antenna. The rectified voltage at each P rf is recorded after 5 seconds waiting time to reach the peak voltage and then averaged over next 30 seconds to ensure the stable charging of the capacitor via the SR-array generated rectified voltage. The standard deviation in the measured V r is less than 4% over time, as shown in Supplementary Fig. 11a. The dashed line at V r ~ 20 mV is the threshold voltage for the ON state of boost converter. c , Discharging of stored V step when connected to different loads in the EHM after turning off the rf power source. Here, the SR-array is first irradiated by two rf sources, 2.45 GHz and 3.5 GHz antenna, simultaneously at P rf = 25 dBm for at least 30 seconds to reach the peak voltage, and then the rf sources are turned off for measuring the discharging V step . The V step represents a standard deviation of less than 1% over time, as shown in Supplementary Fig. 11b. c , Discharging of stored V step when connected to different loads in the EHM after turning off the rf power source. Here, the SR-array is first irradiated by two rf sources, 2.45 GHz and 3.5 GHz antenna, simultaneously at P rf = 25 dBm for at least 30 seconds to reach the peak voltage, and then the rf sources are turned off for measuring the discharging V step . The V step represents a standard deviation of less than 1% over time, as shown in Supplementary Fig. 11b.
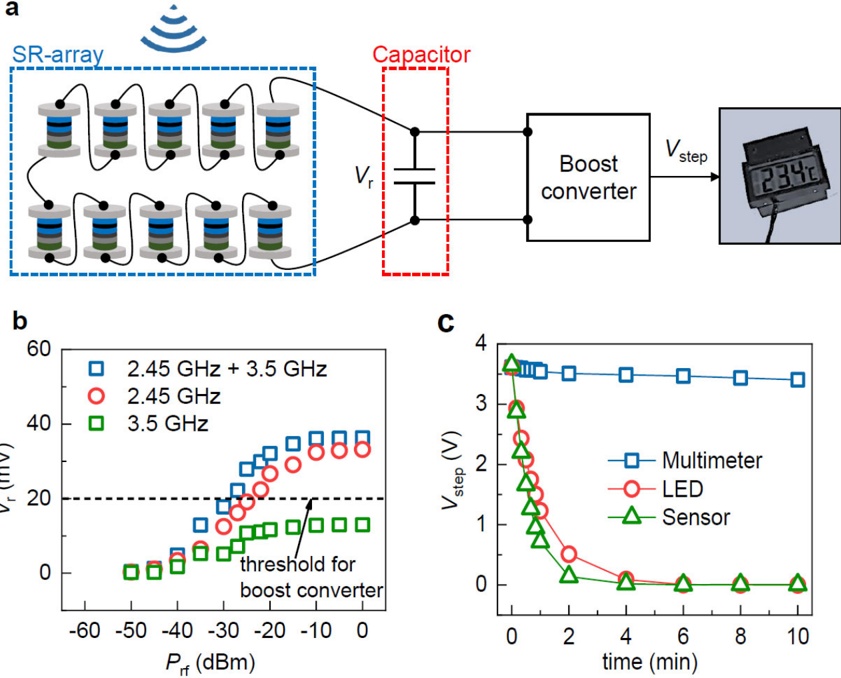
Fig. 5| Comparison of the rectification performance of Schottky diodes, SR-array and SRrectenna. a b , , The conversion efficiency, ( a ) and sensitivity, S ( b ) at 2.45 GHz with varying the rf power ( P rf ). The dashed rectangular boxs show the region of rf power, where the performance of SR-array and SR-rectenna surpass that of Schottky diodes. The Schottky diodes and a single SR are integrated with an antenna to form a rectenna, whereas the SR-array directly harvests the rf energy from the wireless source. The performance of both the Schottky diodes are well matched with literature (Supplementary Fig. 14). All rectifiers are under the same ambient condition.
## Supplementary Information
## Supplementary Note 1. Optimization of interfacial anisotropy
The optimization of MgO (tunnel barrier)/CoFeB (free layer) interface in magnetic tunnel junction (MTJ) based spin-rectifiers (SRs) are required to manipulate the interfacial perpendicular anisotropy (IPA) and to achieve a high rectification sensitivity without the magnetic field and dc bias. For this purpose, the CoFeB ( t CoFeB) and MgO ( t MgO) thicknesses are varied to tune the IPA. We have observed a canted equilibrium direction due to moderate IPA at t CoFeB = 1.9 nm and t MgO = 1 nm, a high tunneling magnetoresistance (Fig. S1a), a resonance frequency close to 2 GHz (Fig. S1b) and a high sensitivity (Fig. S1c) using an elliptical dimension of 80 × 200 nm . 2
Fig. S1| Optimization of 80 × 200 nm 2 SRs for the zero-bias and zero magnetic field operation with varying the thicknesses of the free layer ( t CoFeB) and spacer layer ( t MgO). a , Tunnelling tunneling magnetoresistance (TMR) versus t MgO. b , Resonance frequency ( ) corresponding to the f maximum rectification value at P rf = 30 dBm with varying t MgO. c , The rf senstivity ( S = V P r / rf ) at the resonance frequency at P rf = 30 dBm as a function of t MgO, where V r is the maximum rectification value corresponding to the resonant frequency. The thickness of the free layer ( t CoFeB) displayed inside the plots is varied from 1.7 to 1.9 nm.
## Supplementary Note 2. Optimization of the canted equilibrium direction of SRs
Beside the thickness optimization, we have optimized the junction dimensions of SRs for further controlling the equilibrium direction of the out-of-plane tilted magnetization at zero field. The canted equilibrium angle primarily arises from the competition of in-plane shape anisotropy and out-of-plane interfacial anisotropy. The canted equilibrium angle ( tilt ) between the magnetization of the in-plane reference layer and that of the tilted free layer can be estimated by 1,2
$$R ( \theta _ { u l t } ) = \frac { R _ { _ { P } } + R _ { _ { A P } } } { 2 } + \frac { R _ { _ { P } } - R _ { _ { A P } } } { 2 } \cos ( \theta _ { u l t } )$$
Here, R ( tilt ), R P, and R AP are the tilted, parallel, and anti-parallel configuration resistances, respectively. We have seen a significant canted equilibrium angle of 48 and 80 for the small- dimension devices: 40 × 100 nm to 80 × 200 nm (Fig. S2a,b), respectively. For bigger dimension 2 2 devices (>100 × 250 nm ), the out-of-plane anisotropy is significantly low, favoring in-plane easy2 axis anisotropy. Also, the zero-field TMR ( R zb = ( R zb -R p )/ R p ) reaches 30 40% in some of the 80 × 200 nm 2 SR devices as shown in Fig. S2b, resulting into a high rectified voltage. Here, R zb is the zero-field resistance.
Fig S2| Resistance ( R ) versus applied magnetic field ( µ H 0 app ). The canted equilibrium anisotropy of SRs due to competition between in-plane shape anisotropy and out-of-plane interfacial anisotropy is inferred from samples with a size of 40 × 100 nm ( 2 a ) and 80 × 200 nm 2 ( b ).
## Supplementary Note 3. Optimization of SR size for the best rf sensitivity
The SRs with dimensions 80 × 200 nm using 2 t CoFeB = 1.9 nm and t MgO = 1 nm showed the best TMR of ~75% and a resistance-area product of ~5 Ω µm 2 (Fig. S3a). Other characteristics are a canted equilibrium angle of 79 95 (Fig. S3b), a ferromagnetic resonance (FMR) frequency close to 2.4 GHz and a maximum sensitivity of 1000 mV mW -1 at zero bias and zero magnetic field (Fig. S3c,d).
a
100
b
80
)
(
tilt
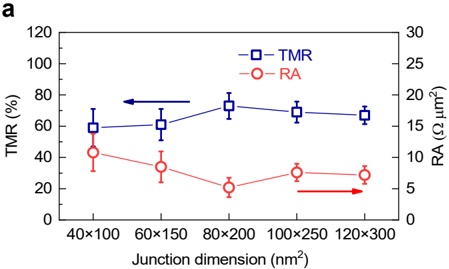
c
120
5
4
3
2
1
0
100
300 nm 2
250 nm 2
2
0
200 nm 2
150 nm 2
100 nm 2
1
10)
3
4
40×100
40×100
60×150
80×200
100×250 120×300
2
Junction dimension (nm )
f
S
60×150
80×200
100×250 120×300
f
(GHz)
Junction dimension (nm 2
)
Fig. S3| Optimization of SR dimentions varying from 40 × 100 nm 2 to 140 × 350 nm 2 . a , TMR and the resistance-area (RA) product versus the junction dimension. b , Canted equilibrium angle ( tilt ) calculated from Eq. (S1). The 120 × 300 nm SR shows a canted equilibrium angle close to 2 in-plane anisotropy. c , Zero-bias rectification signal voltage ( V ) at a rf power of P rf = 30 dBm. d, Frequency ( ) of peak rectification voltage ( f V r ) and corresponding zero bias rf senstivity ( S = V P r / ) at P rf = 30 dBm. Here, P = P rf × (1-| S 11 | 2 ), is the input power including the losses from the VNAbased S 11 measurement. The error bars in a, b, and d are the standard deviation after averaging for 5 SR devices.
d
(GHz)
f
60
40
20
0
4
2
0
2500
2000
1500
1000
500
0
(mV)
V
80
60
40
S (mV mW 1 )
## Supplementary Note 4. Contribution of the voltage controlled magnetic anisotropy
The voltage controlled magnetic anisotropy (VCMA) is known to enhance the rf senstivity in MTJs when the electric field is applied across the device, as it excites the voltage induced ferromagnetic resonance leading to an extra antisymmetric term in the rectification spectra 3,4 . The amplitude of VCMA can be calculated as the variation of the effective magnetic anisotropy energy ( E p ) per unit volume of the free layer from the area under the hysteresis loop M H ( ) 3,4
$$E _ { P } = \, \int _ { 0 } ^ { M _ { x } } H _ { x } \left ( M _ { x } \right ) d M _ { x } = \frac { 1 } { 2 } \, M _ { s } \, H _ { P }$$
where H P is the effective perpendicular anisotropy field. Figure S4a shows the change in H P with the dc bias, calculated by the shift in the conductance vs. magnetic field hysteresis loops with dc voltages. Figure S4b shows the extracted VCMA coefficient from the slope of Fig. S4a using Eq. (S2).The variation of the VCMA coefficient observed in SR-devices with the junction size is attributed to the trade-off between the effective magnetic anisotropy, the energy barrier between parallel and anti-parallel states, and the thermal stability of the MTJs 5,6 , which also influences TMR and perpendicular magnetic anisotropy (PMA). The MTJs with a size of 80 × 200 nm 2 demonstrated the best optimization of these parameters, resulting in the best combination of VCMA, PMA, and TMR. Our systematic analysis demonstrates that optimizing the junction size, as well as the thickness of the free and MgO layers, is required to achieve canted anisotropy with a high VCMA coefficient and TMR.
a
Fig. S4| Voltage controlled magnetic anisotropy. a , Shift of perpendicular anisotropic field ( H P) with applied dc bias voltages ( V dc ) determined from the conductance vs. magnetic field plots. b , Extracted voltage-controlled magnetic anisotropy (VCMA) coefficient from the slope of Fig. S4a using Eq. (S2). The error bar shows the standard deviation after averaging for 5 SR devices.
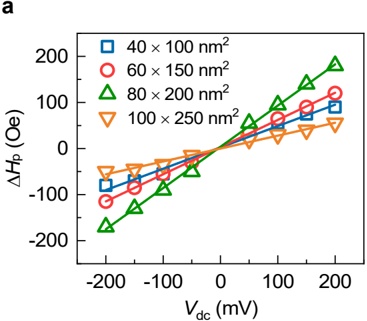
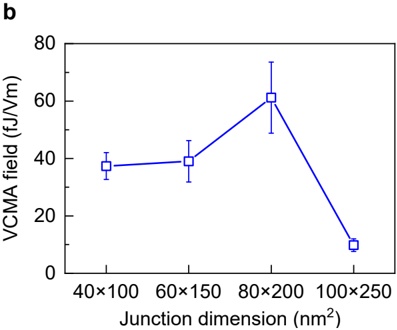
## Supplementary Note 5. Rectified voltage vs. rf power
Figure S5 shows the rectified voltage ( V r ) generated by the 40 × 100 nm and 80 × 200 nm 2 2 SRs. The corresponding senstivity is shown in Fig. 1e of the main text. The V r of 80 × 200 nm SR 2 saturates at a high P rf because of the achievement of large amplitude magnetization dynamics. In this regime, additional power is transferred to high order modes and then the sensitivity decrerases 7 as shown in Fig. 1e. The saturation voltage of the 40 × 100 nm SR is significantly less because of 2 the lower senstivity compared to 80 × 200 nm SR and transition of resonant to broadband 2 rectification response as explained in the main text.
Fig. S5| Rectified voltage with varying rf power. The maximum rectified voltage ( V r ) as a function of the input rf power ( P rf ). The voltage saturates at P rf > 15 dBm for the 80 × 200 nm 2 SR, whereas slightly decreases at P rf > 20 dBm for the 40 × 100 nm SR. 2
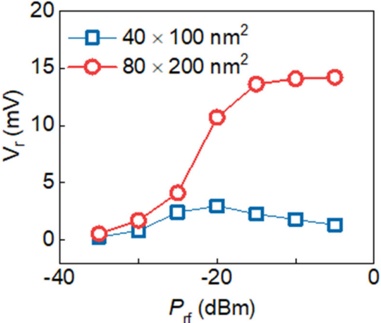
## Supplementary Note 6. Calibration of the rf power in the probe station measurement
In the probe station measurement of the rectification, the impedance of the magnetic tunnel junction-based spin rectifiers is mismatched with the 50 cables and connectors of the probe station, resulting in a considerable loss of rf power delivered into the SR devices. In order to calibrate the actual input power and the losses due to an impedance mismatch at the device interface, the rf power loss can be calculated using the S 11 measurement of the vector network analyser (VNA). Here, the S 11 parameter is measured in the VNA in logarithmic scale (dB) as a function of frequency with an applied power of 0 dBm, which is then converted to reflection coefficient (| S 11 |) on a linear scale using the formula ( S 11,dB = 20 × log10 (| S 11 |). Here, the reflection coefficient represents the ratio of the amplitude (or voltage) of the reflected wave to the amplitude of the incident wave. The rf loss can be calculated using | 8 S 11 | 2 × 100%. An example of S 11 measurement is shown in Fig. S6a, where the | S 11 | is measured as 0.616 ( S 11,dB = 4.10 dB on the log scale) at 2.45 GHz when a power of 0 dBm is applied from the signal generator, which is then converted to a rf power loss of | S 11 | 2 × 100% i.e., 38% at 2.45 GHz (Fig. S6b). In general, we measured many SR devices and found that the rf loss could vary from device to device in the range of 35-60%. Furthermore, the actual power received by the SRs can be calculated as P = P rf × (1|S11| 2 ), where P rf is the applied rf power.
Fig. S6| Power calibration for the probe station based measurement. a, The linear scale magnitude of the reflection coefficient ( S 11 ) measured in the VNA by scanning the frequency ( ). f b, The calculated rf power loss using the formula | S 11 | 2 × 100%.
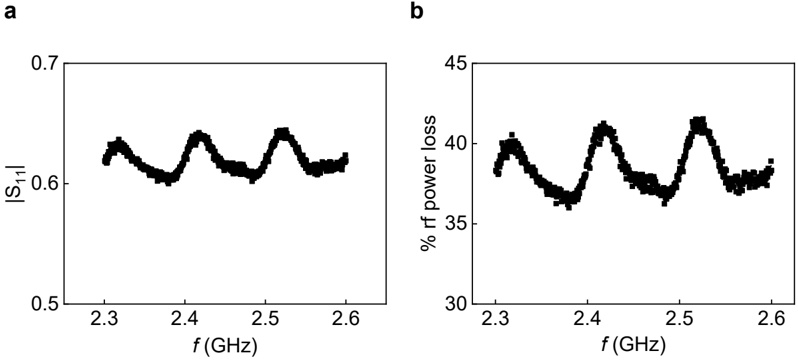
## Supplementary Note 7. Matched antenna design and coupling of R x and T x antenna
The impedance of the on-chip SRs (80 × 100 nm 2 ) is measured using a vector network analyzer (VNA) in Fig. S7a. The drastic change in the impedance around 2.45 GHz is attributed to the involvement of connectors attached to the chip. However, the impedance evaluated before and after designing the matched antenna shows a robust value. We believe that the impedance matching could be improved by designing an on-chip impedance matched antenna. The performance of the matched antenna is evaluated and illustrated in Fig. S7b. The antenna can cover the entire 2.4 2.5 GHz band with the reflection coefficient ( S 11 ) less than 10 dB as shown in Fig. S7b. The antenna is coupled with a high gain of 7.2 dBi in the far-field region, as shown by the radiation 3D pattern showing the gain in the vertical direction in Fig. S7c. For the near-field measurement (from 2.5 cm to 10 cm), the coupling between the receiving and transmitting antennas is directly estimated by the VNA measurement. Fig. S7d shows the received power measured in the VNA and corresponding peak power at 2.45 GHz is plotted in Fig. S7e. The received power at 2.45 GHz is very close to the power applied from the signal generator ( P rf ) in the near field region of 2.5 cm.
Fig. S7| Antenna design and properties. a , Real part of the measured impedance (Re Z) of the on-chip SR from the reflection coefficient ( S 11 ) measured by the VNA as a function of frequency ( ). f b , Reflection coefficient of designed antenna showing high return loss at 2.45 GHz. c , 3D radiation pattern of the designed antenna using a computer simulation technology (CST) software. The color bar shows the gain on the dBi scale. d , The received power, measured in the VNA as a function of input rf power at 2.5 cm, shows the coupling between transmitting ( T x ) and receiving ( R x ) antenna. e , The received power at 2.45 GHz as a function of input power ( P rf ).
## Supplementary Note 8. A single SR for the bandwidth up to 6 GHz
The SR rf bandwidth is tunable with the magnetic field. By applying a magnetic field of 98 mT, a large bandwidth of 0.1-6 GHz using a single 40 × 100 nm SR is observed as shown in 2 Fig. S8a. Figure S8b shows the peak resonant voltage with respect to the external magnetic field applied in-plane along the major axis of the elliptical SRs, which shows that the device works in a wide range of magnetic field. However, the rectification voltage response starts to degrade at > 120 mT, because of a low TMR as the free layer becomes magnetically harder at high magnetic field (Fig. S2).
Fig. S8| Rectification response of 40 × 100 nm 2 with respect to external magnetic field. a , Broadband rectification response (shown by the dashed rectangular box) of rectified voltage (V) versus frequency ( ) in single SR up to f 3 GHz at zero magnetic field and up to 6 GHz using a magnetic field of 98 mT and P rf = 20 dBm in a 40 × 100 nm 2 SR. Here, the magnetic field is applied in-plane along the major axis of the elliptical SR. b , Variation of the peak rectified voltage ( V r ) at P rf = 20 dBm with varying the in-plane magnetic field strength ( µ H 0 app ) along the major axis of the elliptical SR.
## Supplementary Note 9. Scaling of output voltage versus number of SRs connected in series
As the number of spin rectifiers increases, the peak response becomes saturated (Fig. S9a). However, the rectification bandwidth (BW) increases as the number of SRs increases (Fig. S9b). The rectification BW is defined when the peak rectification voltage drops to half.
Fig. S9 | Scaling of SRs in series. a , Peak rectified voltage ( V r ) versus the number of spin rectifiers connected in series P rf = 20 dBm. b , Rectification bandwidth (BW) at which the peak rectification voltage drops to half.
Supplementary Note 10. Effect of VCMA and perpendicular uniaxial anisotropy constant
Fig. S10| Simulation results for a 40 x100 nm 2 single SR. a, Micromagnetic simulations of the VCMA driven enhancement of magnetization precession amplitude of the x -component ( m x ) as a function of the rf current density ( J ac ) using the same parameter of Fig. 3c in the main text. b, Resonance frequency ( ) at Jac = 0.1 MA/cm as a function of the perpendicular uniaxial anisotropy f 2 constant Ku. The dashed blue lines highlight ~ 3.5 GHz, corresponding to f K u = 0.419 MJ/m , 3 which is used in Fig. 3e for matching the experimental data. The lines are the guide for the eye.
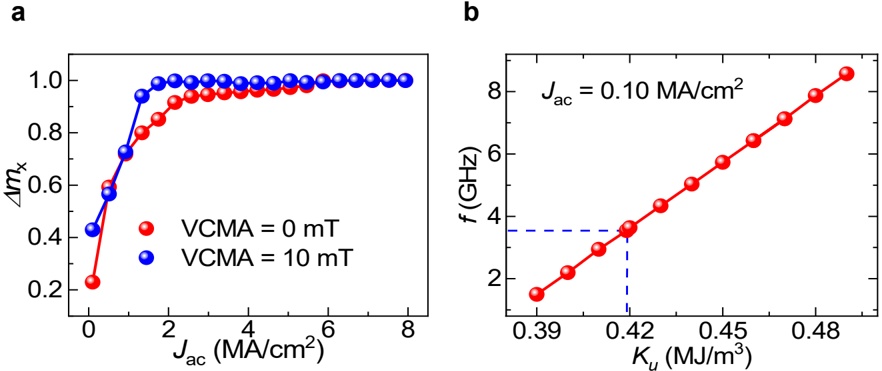
## Supplementary Note 11. Stability of spin-rectifier arrays for long-time operation
For testing the stability of SRs and energy harvesting module (EHM), we have stored the voltage from the SR and EHM module in the nanovoltmeter for one hour. When the source of wireless signal is available consistently in the ambient contion at P rf > 20 dBm, the SR as well as EHM show a very consistent voltage as shown in Fig. S11. This shows that there is no chargingdischarging, desynchronization of coupled SRs in series and microwave heating effect that affects the SRs performance over time.
Fig. S11| Stability test with turning the wireless signal on countinuouly for one hour. a , SR rectification voltage ( V r ) at P rf = 25 dBm. b , EHM voltage ( V step ) at P rf = 25 dBm. The dashed lines show the minimum V r and V step required to turn on the dc to dc booster and 1.6 V lightemitting diode, respectively.
## Supplementary Note 12. Signal-to-noise-ratio and noise equivalent power
The signal-to-noise ratio (SNR) determines the performance of the rf rectifiers in the noisy environment (Fig. S12a). The SNR is calculated using the formula, SNR = P signal / P noise , where the P signal = V dc,signal 2 / R dc and P noise = V dc,noise 2 / R dc . Here, The V dc,signal and V dc,noise are the dc voltage recorded in the nanovoltmeter when the 2.45 GHz wireless signal is ON and OFF, respectively. R dc is the dc resistance of the devices. Moreover, the noise equivalent power (NEP) of a single SR is estimated, which characterises the noise level in quadratic detectors. The NEP is defined as the ratio of noise voltage and sensitivity. For the measurement of noise voltage ( V noise ) in the spectrum analyser, we have followed the measurement setup of diode mixing noise in ref 3. We have chosen one of the SRs with a sensitivity > 1000 mV/mW. The NEP is plotted as a function of the rf power in Fig. S12b. The NEP of 2 × 10 -12 W Hz 0.5 (Fig. S12b) at P rf = 0.1 µW (-40 dBm) and I dc = 0 mA is very close to 8 × 10 -12 W Hz 0.5 or 3.6 × 10 -12 W Hz 0.5 as measured in the SRs with a dc bias . In general, a low NEP is observed in the SRs because of the high sensitivity, which leads to 3 a good SNR even in SR-array configurations.
Fig. S12| Noise perfomance of the SR-technology. a , Signal-to-noise ratio (SNR) with varying the rf power ( P rf ). The error bar defines the fluctuation of the dc voltages ( V dc,signal and V dc,noise ) over multiple cycles, when the 2.45 GHz wireless signal is ON and OFF, respectively. b , Noise equivalent power (NEP) versus varying rf power. The error bar defines the standard deviation in the value of noise voltage at low frequencies.
## Supplementary Note 13. Comparison SR with the other rectifiers
Fig. S13| Comparison of our SR (2.45 GHz) with other SR (1.2 GHz) for P rf < 20 dBm. The observed efficiency ( ) as a function of rf power ( P rf ) is 2 3 orders higher from the previous reported efficiencies for the other spin-rectifiers with a combination of resonant and broadband 3 7 behaviour. The lines are the guide for the eye.
Fig. S14| Efficiency comparison. Comparison of efficiency reported in various highly-efficient and low-powered 2.45 GHz state-of-the-art rectifiers 9-20 (without and with taking the antenna efficiency effect).
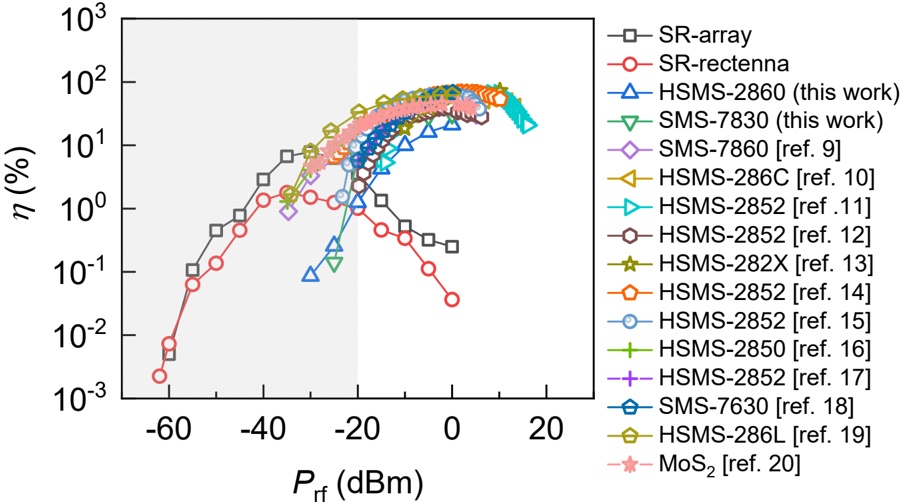
## Supplementary Note 14. SR device and EHM setup details
Fig. S15: Device and experimental setup details. a , Co-planar waveduide ground-signal-ground design over the SR devices (circled by a dashed red line) for the rf coupling. b , Chip, where the SR-array is connected to the rf connector, which provides a rf or dc output. The SR-devices are connected by the wirebonds. c , Output of the chip shown in b is connected across the capacitor (through black and red leads), which is connected to the input of dc to dc boost converter. A multimeter is connected to check the output of the SR-array (24.1 mV). The amplified voltage output (~3.9 V correponding to the input of 24.1 mV) from the boost converter charges the sensor, which shows a temperature of 23.4 C.
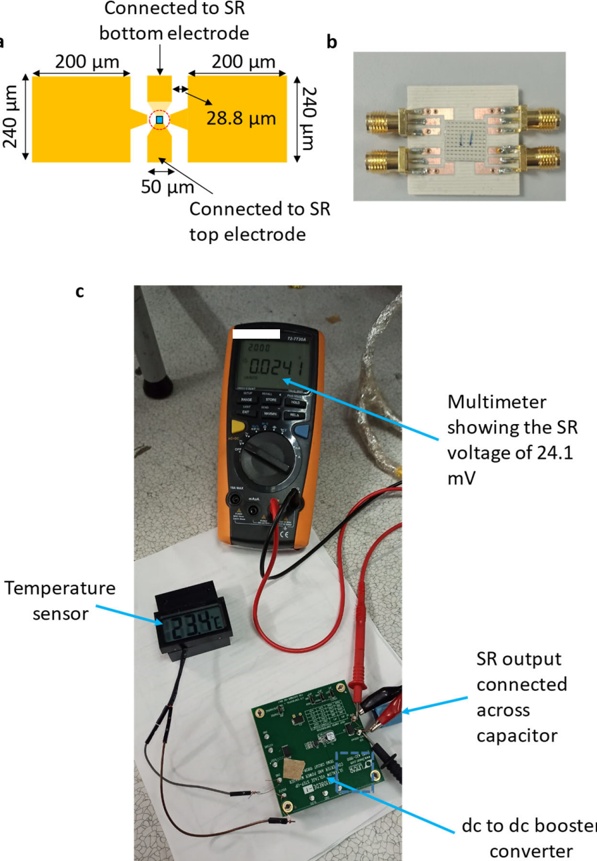
## References
| 1 | Slonczewski, J. C. Currents, torques, and polarization factors in magnetic tunnel junctions. Phys. Rev. B 71 , 024411 (2005). |
|-----|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 2 | Zeng, Z. et al. Ultralow-current-density and bias-field-free spin-transfer nano-oscillator. Sci. Rep. 3 , 1426 (2013). |
| 3 | Fang, B. et al. Giant spin-torque diode sensitivity in the absence of bias magnetic field. Nat. Commun. 7 , 11259 (2016). |
| 4 | Zhu, J. et al. Voltage-induced ferromagnetic resonance in magnetic tunnel junctions. Phys. Rev. Lett. 108 , 197203 (2012). |
| 5 | Miriyala, V. P. K., Fong, X. & Liang, G. Influence of size and shape on the performance of VCMA-based MTJs. IEEE Trans. Electron Devices 66 , 944-949 (2019). |
| 6 | Shao, Y. &Khalili Amiri, P. Progress and Application Perspectives of Voltage - Controlled Magnetic Tunnel Junctions. Adv. Mater. Technol. 8 , 2300676 (2023). |
| 7 | Fang, B. et al. Experimental demonstration of spintronic broadband microwave detectors and their capability for powering nanodevices. Phys. Rev. Appl. 11 , 014022 (2019). |
| 8 | Caspers, F. RF engineering basic concepts: S-parameters. arXiv preprint arXiv:1201.2346 (2012). |
| 9 | Adami, S.-E. et al. Aflexible 2.45-GHz power harvesting wristband with net system output from - 24.3 dBm of RF power. IEEE Trans. Microw. Theory Tech. 66 , 380-395 (2017). |
| 10 | Chen, Y.-S. & Chiu, C.-W. Maximum achievable power conversion efficiency obtained through an optimized rectenna structure for RF energy harvesting. IEEE Trans. Antennas Propag. 65 , 2305-2317 (2017). |
| 11 | Kim, J. &Jeong, J. Design of high efficiency rectifier at 2.45 GHzusing parasitic canceling circuit. Microw. Opt. Technol. Lett. 55 , 608-611 (2013). |
| 12 | Koohestani, M., Tissier, J. &Latrach, M. A miniaturized printed rectenna for wireless RF energy harvesting around 2.45 GHz. AEU - Int. J. Electron. 127 , 153478 (2020). |
| 13 | Mbombolo, S. E. F. & Park, C. W. in 2011 IEEE MTT-S International Microwave Workshop Series on Innovative Wireless Power Transmission: Technologies, Systems, and Applications. 23-26 (IEEE). |
| 14 | Olgun, U., Chen, C.-C. & Volakis, J. L. Wireless power harvesting with planar rectennas for 2.45 GHz RFIDs. 2010 URSI International symposium on electromagnetic theory , 329- 331 (2010). |
| 15 | Olgun, U., Chen, C.-C. & Volakis, J. L. Investigation of rectenna array configurations for enhanced RF power harvesting. IEEE Antennas Wirel. Propag. Lett. 10 , 262-265 (2011). |
| 16 | Shen, S., Zhang, Y., Chiu, C.-Y. &Murch, R. A triple-band high-gain multibeam ambient RF energy harvesting system utilizing hybrid combining. IEEE Trans. Ind. Electron. 67 , 9215-9226 (2019). |
| 17 | Shi, Y. et al. An efficient fractal rectenna for RF energy harvest at 2.45 GHz ISM band. Int. J. RF Microw. 28 , e21424 (2018). |
| 18 | Song, C. et al. A high-efficiency broadband rectenna for ambient wireless energy harvesting. IEEE Trans. Antennas Propag. 63 , 3486-3495 (2015). |
| 19 | Wang, D. & Negra, R. Design of a rectifier for 2.45 GHz wireless power transmission. PRIME 2012; 8th Conference on Ph. D. Research in Microelectronics & Electronics , 1-4 (2012). |
| 20 | Zhang, X. et al. Two-dimensional MoS 2 -enabled flexible rectenna for Wi-Fi-band wireless energy harvesting. Nature 566 , 368-372 (2019). | | 10.1038/s41928-024-01212-1 | [
"Raghav Sharma",
"Tung Ngo",
"Eleonora Raimondo",
"Anna Giordano",
"Junta Igarashi",
"Butsurin Jinnai",
"Shishun Zhao",
"Jiayu Lei",
"Yong-Xin Guo",
"Giovanni Finocchio",
"Shunsuke Fukami",
"Hideo Ohno",
"Hyunsoo Yang"
] | 2024-08-02T10:22:07+00:00 | 2024-08-02T10:22:07+00:00 | [
"cond-mat.mtrl-sci"
] | Nanoscale spin rectifiers for harvesting ambient radiofrequency energy | Radiofrequency harvesting using ambient wireless energy could be used to
reduce the carbon footprint of electronic devices. However, ambient
radiofrequency energy is weak (less than -20 dBm), and thermodynamic limits and
high-frequency parasitic impedance restrict the performance of state-of-the-art
radiofrequency rectifiers. Nanoscale spin rectifiers based on magnetic tunnel
junctions have recently demonstrated high sensitivity, but suffer from a low
a.c.-to-d.c. conversion efficiency (less than 1%). Here, we report a sensitive
spin rectifier rectenna that can harvest ambient radiofrequency signals between
-62 and -20 dBm. We also develop an on-chip co-planar waveguide-based spin
rectifier array with a large zero-bias sensitivity (around 34,500 mV/mW) and
high efficiency (7.81%). Self-parametric excitation driven by
voltage-controlled magnetic anisotropy is a key mechanism that contributes to
the performance of the spin-rectifier array. We show that these spin rectifiers
can wirelessly power a sensor at a radiofrequency power of -27 dBm. |
2408.01161v1 | Draft version August 5, 2024 Typeset using L T E X default style in AASTeX63 A
## Magnetization Factors of Gamma-Ray Burst Jets Revealed by a Systematic Analysis of the Fermi Sample
An Li, 1,2 He Gao, 1,2 Lin Lan, 3 and Bing Zhang 4,5
1 Institute for Frontier in Astronomy and Astrophysics, Beijing Normal University, Beijing 102206, China 2 Department of Astronomy, Beijing Normal University, Beijing 100875, China 3 CAS Key Laboratory of Space Astronomy and Technology, National Astronomical Observatories, Chinese Academy of Sciences, Beijing 100101, China 4 Nevada Center for Astrophysics, University of Nevada Las Vegas, Las Vegas, NV 89154, USA 5 Department of Physics and Astronomy, University of Nevada Las Vegas, Las Vegas, NV 89154, USA
## ABSTRACT
The composition of gamma-ray burst (GRB) jets remained a mystery until recently. In practice, we usually characterize the magnetization of the GRB jets ( σ 0 ) through the ratio between the Poynting flux and matter (baryonic) flux. With the increasing value of σ 0 , magnetic energy gradually takes on a dominant role in the acceleration and energy dissipation of the jet, causing the proportion of thermal component in the prompt-emission spectrum of GRBs to gradually decrease or even be completely suppressed. In this work, we conducted an extensive analysis of the time-resolved spectrum for all Fermi GRBs with known redshift, and we diagnose σ 0 for each time bin by contrasting the thermal and nonthermal radiation components. Our results suggest that most GRB jets should contain a significant magnetic energy component, likely with magnetization factors σ 0 ≥ 10. The value of σ 0 seems vary significantly within the same GRB. Future studies with more samples, especially those with lower-energy spectral information coverage, will further verify our results.
## 1. INTRODUCTION
After extensive research over the past 50 yr, substantial advancements have been achieved in comprehending gammaray bursts (GRBs; Zhang (2018)). Nonetheless, certain lingering questions persist, such as the exact proportion of magnetic energy within GRB jets.
In the very early picture, the magnetic field issue within GRB jets was not addressed, but rather it was assumed GRB outflows originate from an initially hot 'fireball' composed of photons, electron/positron pairs and a small amount of baryons (Paczynski 1986; Goodman 1986; Shemi & Piran 1990). After an initially rapid acceleration phase under fireball thermal pressure, a significant fraction of the initial fireball thermal energy is converted to the kinetic energy of the jet (Meszaros et al. 1993; Piran et al. 1993). As the jet expands to the radius of the photosphere, the hot photons escape while the baryonic matter continues to expand to even greater distances, reconverting the kinetic energy into energetic particles through internal collisional dissipation (internal shock model; Rees & Meszaros 1994). Synchrotron (and possibly also synchrotron self-Compton) radiation by these particles gives rise to the observed nonthermal gamma-ray emission (Meszaros et al. 1994; Tavani 1996). In this scenario, the GRB spectrum is expected to consist of a combination of thermal and nonthermal components.
Equipped with both the Gamma-ray Burst Monitor (GBM; Meegan et al. 2009) and the Large Area Telescope (Atwood et al. 2009), Fermi spacecraft broadened the observational range to cover 6-7 orders of magnitude in energy, thereby having a considerable advantage for a comprehensive study of spectral components within the prompt emission spectra of GRBs. Based on the Fermi sample, one speculation of the synthesized prompt emission spectrum for GRBs has been established, which may include three elemental spectral components (Zhang et al. 2011): (I) a nonthermal band component; (II) a quasithermal component; and (III) another nonthermal component extending to high energies,
and the significance of different spectral components may vary among different GRBs. These results have also been confirmed by other satellite data, such as Compton Gamma Ray Observatory/BATSE data (Guiriec et al. 2016a).
After more than a decade of observations, Fermi has detected a population of GRBs that exhibit pure nonthermal spectra across several orders of magnitude in energy (Abdo et al. 2009a; Zhang et al. 2011). The absence of photospheric emission poses a significant challenge to the 'fireball' model (Zhang & Yan 2011). One solution to solve this problem is that GRB outflows should contain certain proportion of magnetic energy so that the contribution of the thermal component can be significantly reduced (Daigne & Mochkovitch 2002; Zhang & Pe'er 2009; Zhang & Yan 2011; Lazarian et al. 2019). In this case, the total luminosity of GRB jets can be decomposed into the sum of the luminosity from hot components ( L h ) and the luminosity from cold (Poynting flux) components ( L c ), where the magnetization parameter at the central engine σ 0 can be defined as
$$\sigma _ { 0 } \equiv \frac { L _ { c, 0 } } { L _ { h, 0 } }.$$
In a hybrid jet scenario (Gao & Zhang 2015), if σ 0 ≪ 1, one gets back to a hot fireball. With the increasing value of σ 0 , magnetic energy gradually takes on a dominant role in the acceleration and energy dissipation of the jet, causing the nonthermal radiation component associated with magnetic dissipation to become stronger compared to the thermal radiation component. For moderate values of σ 0 , thermal radiation becomes subdominant. For extremely large values of σ 0 , the thermal component is completely suppressed, and only featureless nonthermal radiation can be observed.
From an observational perspective, we do have sources whose spectrum are dominated by thermal components (Abdo et al. 2009b), which should correspond to σ 0 ≪ 1; we also have cases where the thermal component is subdominant, (Guiriec et al. 2011, 2013, 2015b,a, 2016a,b, 2017; Axelsson et al. 2012; Burgess et al. 2014; Preece et al. 2014), which should correspond to moderate values of σ 0 . The most prevalent cases are sources with featureless nonthermal radiation, which are expected to have extremely large values of σ 0 (Abdo et al. 2009a; Zhang et al. 2011).
From a theoretical perspective, Gao & Zhang (2015) developed an analytical method to quantify the spectrum properties for a hybrid GRB jet with both a hot fireball component and a cold Poynting flux component. They developed (1) a 'bottom-up' approach to predict the temperature and luminosity of the photosphere emission for an arbitrary value of σ 0 ; (2) a 'top-down' approach to diagnose σ 0 using the observational quantities of the energy spectrum, especially by contrasting the thermal and nonthermal radiation components. Many studies have used this method to successfully explain specific GRBs that show a superposed thermal component in the spectra, 1 such as GRB 110721A (Iyyani et al. 2016), GRB 130310A (Qin et al. 2021), GRB 130518A (Siddique et al. 2022), GRB 211211A (Chang et al. 2023).
In this paper, we intend to systematically apply this method (the 'top-down' approach) to a large sample of GRBs observed by Fermi , estimating the exact value of σ 0 for bursts with a superposed thermal component or the lower limit of σ 0 for bursts with a featureless nonthermal component. Eventually, we plan to obtain the distribution of σ 0 for all the samples, enabling us to conduct a comprehensive investigation and gain insights into the various constituents comprising the GRB jet.
## 2. DATA REDUCTION AND SAMPLE SELECTION
In this work, we use the data observed by the Fermi GBM, which is downloaded from the Fermi Science Support Center's FTP site 2 and processed with GBM data tools v1.1.1. 3359 GRBs were detected by Fermi/GBM up to 2022 August 1. We use time-tagged event (TTE) data and response (RSP or RSP2) files for spectral analysis and simulation. The TTE data file records each photon's arrival time with 2 µ s temporal resolution and which of the 128 energy channels the photon registered. The RSP file records the response matrix of the detector at the trigger time. The RSP2 file records a time sequence of response matrices around the trigger point; it is used when the spectrum slice is significantly distant from the trigger time, making the response matrix in the RSP file inapplicable.
The GBM consists of two sets of detectors: 12 sodium iodide (NaI) scintillators sensitive to the lower end of the energy range and two cylindrical bismuth germanate (BGO) scintillators sensitive to the higher energy range. For the data sample, we selected two of the strongest triggered TTE data files from the NaI detectors, covering the energy range from 8 to 900 keV, and the strongest triggered TTE data file from the BGO detectors, covering the energy range from 500 keV to 30 MeV. Each TTE data file is accompanied by a corresponding calibration file.
1 There are also works applying similar methods to Gao & Zhang (2015), which theoretically explained individual sources with thermal and nonthermal superposed spectra and constrained their magnetization factors, e.g. GRB 100724B (Guiriec et al. 2011) and GRB 130323A (Guiriec et al. 2013).
2 https://heasarc.gsfc.nasa.gov/FTP/fermi/
For the purpose of this study, an initial screening of the data sample was conducted based on two criteria: (1) availability of redshift information, as the calculation method of σ 0 requires the redshift of the source; and (2) the signal-to-noise ratio (SNR) within the T 90 range higher than 30. This criterion ensures sufficient photon counts for credible results. The SNR calculation equation is as follows:
$$S N R & = \frac { N _ { \text{all} } - N _ { \text{bak} } } { \sqrt { N _ { \text{bak} } } },$$
where N all represents the photon counts within the source time range, including both source and background photon counts. The background photon counts, N bak , are estimated using background trends outside the T 90 time range via polynomial interpolation. Ultimately, 87 GRBs were selected for further analysis.
Given the evolving nature of central engine properties, the value of σ 0 might vary at different stages of GRB prompt emission. Therefore, utilizing time-resolved spectra with the smallest possible time bin is crucial for accurately constraining σ 0 . For the selected sample, each source was binned based on a criterion of an SNR higher than 30, consistent with the selection criteria above. Additionally, we recognized that relying solely on SNR for defining time intervals may lead to mixing peaks and valleys of the light curves at different energies. To address this, during the selection of time intervals for each source, a manual review was conducted, and if necessary, manual adjustments were made to avoid this issue. Consequently, a total of 87 GRBs were divided into 318 slices (see Table 1 for details).
We then fit each slice with three different spectral models: nonthermal, hybrid (nonthermal + thermal), and thermal. For the nonthermal spectrum, we adopt either cutoff power-law ('CPL' in the table) function or Band function ('Band' in the table; Band et al. 1993), which can be expressed as
$$F ( E ) = A e ^ { - ( 2 + \alpha ) E / E _ { \text{peak} } } ( \frac { E } { 1 0 0 \, \text{keV} } ) ^ { \alpha },$$
and
$$F ( E ) = \begin{cases} \ A ( \frac { E } { 1 0 0 \, \L } ) ^ { \alpha } e ^ { - ( 2 + \alpha ) E / E _ { \text{peak} } }, \text{ if } E < \frac { ( \alpha - \beta ) E _ { \text{peak} } } { 2 + \alpha }, \\ \ A ( \frac { ( \alpha - \beta ) E _ { \text{peak} } } { ( 2 + \alpha ) 1 0 0 \, \L } ) ^ { \alpha - \beta } e ^ { \beta - \alpha } ( \frac { E } { 1 0 0 \, \L } ) ^ { \beta }, \text{ otherwise} \end{cases}$$
respectively, where α and β are low-energy and high-energy photon spectral indices, respectively. E peak is the νFν peak in keV.
For the hybrid spectrum, we combined nonthermal spectral function with a blackbody function ('BB' in the talbe) described as follows:
$$F ( E ) = A \frac { E ^ { 2 } } { e ^ { E / k T } - 1 }$$
where kT is the temperature in unit of keV.
For the thermal spectrum, we adopt the multicolour blackbody model (Pe'er et al. 2012), which can be described as (Hou et al. 2018) :
$$N ( E ) = & \frac { 8. 0 5 2 5 ( m + 1 ) K } { ( \frac { T _ { \max } } { T _ { \min } } ) ^ { m + 1 } - 1 } ( \frac { k T _ { \min } } { \text{keV} } ) ^ { - 2 } I ( E ), \\ I ( E ) = & ( \frac { E } { k T _ { \min } } ) ^ { m - 1 } \int _ { \frac { k T _ { \max } ^ { E } } { k T _ { \min } } } ^ { \frac { E } { e ^ { x } - m } } \frac { x ^ { 2 - m } } { e ^ { x } - 1 } d x \\. \quad. \quad. \ \dots \ -. \quad. \quad. \quad.$$
$$( 6 )$$
where kT is the temperature in unit of keV. The spectrum consists of a superposition of Planck functions in the temperature range from T min to T max . m is the power-law index of the Planck functions' distribution.
Here we use the Bayesian information criterion (BIC) to determine the best-fitting model. The BIC is a criterion used to evaluate the best-fitting model from a finite set of models, where the model with the lowest BIC value is considered preferred. The BIC can be defined as follows: BIC = -2 ln L + k ln( n ), where k represents the number of model parameters, n is the number of data points, and L is the maximum value of the likelihood function for the estimated model.
Eventually, we have 225 slices (in 55 GRBs) that display a featureless nonthermal spectrum, 81 slices (in 30 GRBs) that display a hybrid spectrum and only 12 slices (in GRB 090902B and GRB 210610B) that display a multicolour blackbody spectrum. For all 318 slices, the best-fitting models are collected in Table 1 with their parameters.
## 3. σ 0 ESTIMATION
The fundamental properties of a GRB jet can be characterized by a series of parameters, including the initial radius ( r 0 ) at which the jet emanates from the central engine, the total luminosity ( L w, 0 ) of the jet, the dimensionless entropy ( η ) that defines average total energy (rest-mass energy plus thermal energy) per baryon in the hot component, and the magnetization parameter at the central engine ( σ 0 ). After leaving the central engine, the jet will continuously expand and accelerate under the combined effects of thermal pressure and magnetic pressure until it reaches its maximum velocity Γ c ≃ η (1 + σ 0 ) at the coasting radius r c . After the jet exceeds a radius of r ph , the photon optical depth for Thomson scattering drops below unity so that photons previously trapped in the jet can escape. The observed temperature and flux for the photosphere emission are essentially determined by the temperature at r 0 , which reads
$$T _ { 0 } \simeq \left ( \frac { L _ { w } } { 4 \pi r _ { 0 } ^ { 2 } a c ( 1 + \sigma _ { 0 } ) } \right ) ^ { 1 / 4 },$$
where a = 7 56 . × 10 -15 erg cm -3 K -4 is the radiation density constant and by the position of the photosphere, namely, whether the photospheric emission occurs during the acceleration phase or the coasting phase of the jet. Based on the relative magnitudes of η and σ 0 , as well as the different relationships between r ph and r c , Gao & Zhang (2015) divided the parameter space of the central engine into different regimes: 3 (I) η > (1 + σ 0 ) 1 / 2 and r ph < r c ; (II) η > (1 + σ 0 ) 1 / 2 and r ph > r c ; (III) η < (1 + σ 0 ) 1 / 2 and r ph < r c ; and (IV) η < (1 + σ 0 ) 1 / 2 and r ph > r c . For each regime, Gao & Zhang (2015) developed an analytical method to connect the observed quantities of GRB spectrum with the central engine parameters; for instance, they find that
$$\dots \dots \int _ { \Gamma } \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \\ 1 + \sigma _ { 0 } = \begin{cases} 2 5. 5 ( 1 + z ) ^ { 4 / 3 ( \frac { k T _ { b } } { 5 0 k e V } ) ^ { 4 / 3 } ( \frac { \ F _ { B B } } { 1 0 ^ { - 8 } e r g \ s ^ { - 1 } \text{cm} - 2 } ) ^ { - 1 / 3 } r _ { 0, 9 } ^ { 2 / 3 } f _ { t h, - 1 } ^ { - 1 } f _ { \gamma } ^ { - 1 } d _ { L, 2 8 } ^ { - 2 / 3 }, & \quad \text{Regime I} \text{ and I} \\ 5. 9 9 ( 1 + z ) ^ { 4 / 3 ( \frac { k T _ { b } } { 3 0 k e V } ) ^ { 4 / 3 } ( \frac { \ F _ { B B } } { 1 0 ^ { - 7 } e r g \ s ^ { - 1 } \text{cm} - 2 } ) ^ { - 1 / 3 } r _ { 0, 9 } ^ { 2 / 3 } f _ { t h, - 1 } ^ { - 1 } f _ { \gamma } ^ { - 1 } d _ { L, 2 8 } ^ { - 2 / 3 }, & \quad \text{Regime II and I} \\ 6. 4 3 ( 1 + z ) ^ { 4 / 3 ( \frac { k T _ { b } } { 1 0 k e V } ) ^ { 4 / 3 } ( \frac { \ F _ { B B } } { 1 0 ^ { - 9 } e r g \ s ^ { - 1 } \text{cm} - 2 } ) ^ { - 1 / 3 } r _ { 0, 9 } ^ { 2 / 3 } f _ { t h, - 1 } ^ { - 1 } f _ { \gamma } ^ { - 1 } d _ { L, 2 8 } ^ { - 2 / 3 }, & \quad \text{Regime IV} \\ \quad \Gamma \quad \Gamma \quad \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \cdots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \delta \quad \Gamma \quad \end{cases}$$
where T ob is the observed blackbody temperature and F BB is the observed blackbody flux. f th is defined as F BB /F ob , where F ob is the observed total flux (both thermal and nonthermal included). f γ = L /L γ w , which connects the total flux F ob to the wind luminosity L w . The L w is estimated by L w = 4 πd 2 L F ob /f γ , in which d L is the luminosity distance of the GRB.
Here we use the method proposed in Gao & Zhang (2015) to estimate the value of σ 0 for our selected sample. For slices that display a multicolour blackbody spectrum, we set their σ 0 equal to 0. For slices that display a hybrid spectrum, we first extract the observed quantities such as T ob , F BB and f th by fitting the spectrum. With these observed quantities, we can determine which regime these slices fall into by using the judgment criteria provided in Table 2 (see also Table 1 and 2 in Gao & Zhang (2015)). Then, we can use Equation 8 to calculate the corresponding σ 0 for these slices. The results are shown in Figure 1 and Table 1. It is worth noting that in our estimation, we fix f γ to be a typical value of 0.5, and we consider three r 0 values: 10 cm, 10 cm, and 10 8 9 10 cm.
For slices with a featureless nonthermal component, we adopted the following approach to estimate their lower limit of σ 0 :
- · For each slice, we first assume that its thermal component corresponds to a temperature of kT , with kT starting at 5 keV.
- · For a given kT , we assume a series of ratios of thermal component flux to nonthermal component flux ( f th ), with f th values starting at 0.005 and increasing with equal steps (0.1 dex) on a log scale.
- · For each pair of kT and f th , we use the same response file as the original data to simulate the corresponding thermal component photons with random noise through the GBM data tools (Goldstein et al. 2022).
- · We add these simulated photons to the original data, reperform spectral fitting, and compare the BIC results of the featureless nonthermal spectrum with the hybrid spectrum. If the nonthermal spectrum is the best fit,
3 The jet undergoes a rapid acceleration phase initially with Γ ∝ r until reaching the radius of r ra , which is defined by the larger one of the thermal coasting radius and the magnetosonic point. In Gao & Zhang (2015), two extreme regimes with r ph < r ra are also discussed. We do not consider these extreme scenarios here since they introduce an additional degeneracy so that central engine parameters cannot be inferred from observations.
Figure 1. Distribution plot of 1 + σ 0 and f th . The blue triangles represent the lower limit of 1 + σ 0 for slices with non-thermal spectrum, the orange points represent the value of 1 + σ 0 for slices with hybrid spectrum. The black dashed line in the sub figure represents the distribution result of 1 + σ 0 taken from Li (2019). The results shown in this figure are based on the same r 0 value as 10 9 cm.
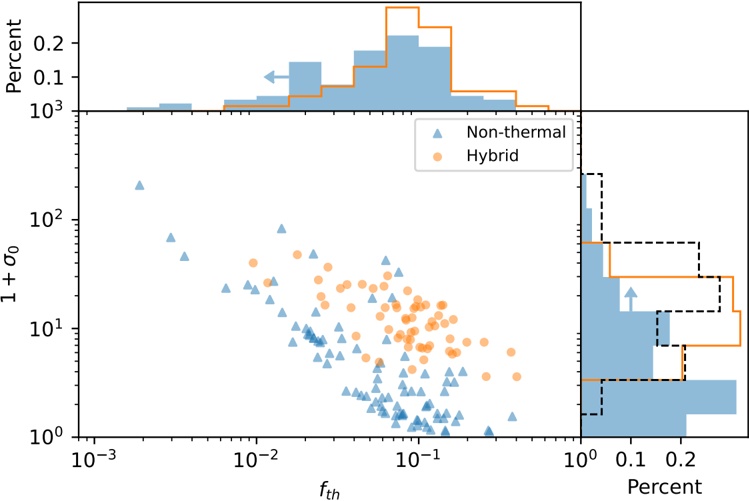
we continue to increase the f th value and resimulate more thermal photons until the hybrid spectrum becomes dominant. This way, we have found the upper limit of f th for a given kT .
- · Taking kT and the upper limit of f th as the observed quantities, we use the judgment criteria provided in Table 2 and equations 8 to calculate the corresponding σ 0 , which could be taken as the lower limit of σ 0 corresponding to kT .
- · We continuously increase the assumed value of kT (from 5 keV to 60 keV with a uniform step size of 5 keV), calculate the corresponding lower limit of σ 0 for each kT using the methods above, and take the minimum value of all the lower limits as the overall lower limit of σ 0 for this slice.
In Figure 1, we show the distribution plot of 1 + σ 0 vs. f th for all slices with both nonthermal and hybrid spectra. For the hybrid slice, we find that 1 + σ 0 values are distributed in the range of 3.6-47.7, and if fitted with a Gaussian function, its peak is at 11.9 with a variance of 0.3. On the other hand, f th is distributed in the range of 0.009-0.4, and if fitted with a Gaussian function on a log scale, its peak is at 0.08 with a variance of 0.3. Also, we show the distribution plot of 1 + σ 0 lower limit vs. f th upper limit for all slices with a featureless nonthermal spectrum. We find that the 1 + σ 0 lower limits are distributed in the range of 1.1-424.9, with ∼ 23% larger than 10. The f th upper limits are distributed in the range of 0.003-0.4.
As shown in Figure 2, we find that the values of kT ob for all slices with the hybrid spectrum are distributed in the range of 8.5-58.7 keV, with the average value located at 28.4 keV with a variance of 10.5 keV.
## 4. CONCLUSION AND DISCUSSION
In this study, we conducted an extensive analysis of the magnetic component within GRBs observed by the Fermi satellite. Our focus was on GRB data with known redshift, and we employed a time-resolved approach to determine the parameter σ 0 for each time bin. We categorized the GRBs into three distinct groups based on their dominant spectral components and applied different processing procedures for each:
Figure 2. The distribution of kT ob in the GRB with hybrid spectrum.
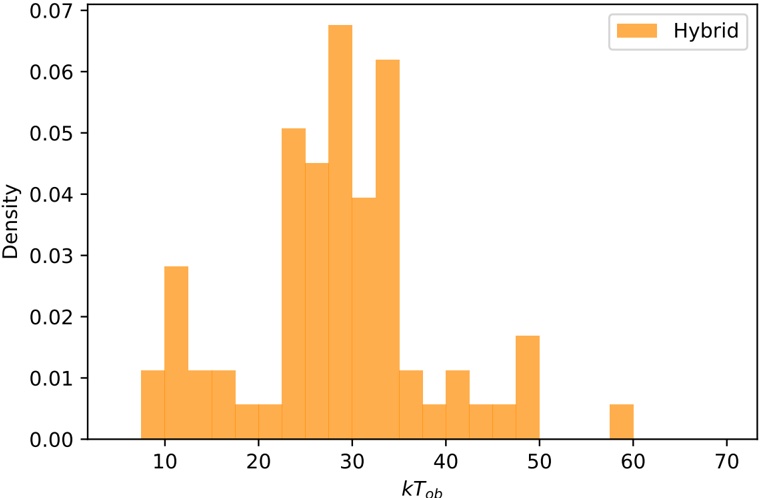
- · Thermal-dominant spectra: in the case of 12 slices with thermal-dominant spectra, we set their σ 0 equal to 0.
- · Hybrid spectra: we have 81 slices with hybrid spectra, for which we calculated their σ 0 values based on the extracted quantities such as T ob , F BB and f th by fitting the spectrum.
- · Nonthermal spectra: we have 225 slices with nonthermal spectra, for which we estimate the lower limit of their σ 0 value by simulating the upper limit of the thermal component.
We find that for all slices with the hybrid spectrum, the values of kT ob are distributed around 28 keV with a variance of 11 keV, and the values of f th are distributed around 0.08 with a variance of 0.3 on a log scale. In this case, their 1 + σ 0 values should be distributed around 11.9 with a variance of 0.3 on a log scale. These results are consistent with previous results obtained by using a limited number of specific GRBs (Zhang & Pe'er 2009; Guiriec et al. 2011; Iyyani et al. 2013; Li 2019; Chang et al. 2023). On the other hand, we find that for all slices with the featureless nonthermal spectrum, the 1 + σ 0 lower limits are distributed in the range of 1.1-424.9, with 22 7% larger than 10. .
Our results suggest that most GRB jets should contain a significant magnetic energy component, likely with magnetization factors σ 0 ≥ 10. In this case, the prompt emission mainly arises from magnetized dissipation in such highly magnetized environments as particle acceleration via internal shocks is suppressed. With detailed analysis of a small number of sources that show hybrid spectra in multiple slices, we find that the value of σ 0 varies significantly within the same GRB. In Figure 3, we present three examples (GRB 171010A, GRB 211211A, and GRB 130427A) that best reflect the evolution of σ 0 . These examples are selected because they have thermal components in three or more consecutive time bins. The evolution trend of σ 0 does not show an obvious relationship with those of lightcurve and E peak .
We would like to point out that we have only considered the case where kT varies from 5 to 60 keV when constraining the lower limit of the magnetization factor for the nonthermal spectra. The reasons are (1) the SNR of Fermi/GBM observations below 5 keV is too low to perform a good spectral fitting; and (2) according to the fitting results of the hybrid spectra slices, there are almost no cases where kT is greater than 60 keV. For these nonthermal spectra, if their true kT is greater than 60 keV, then the corresponding lower limit of the magnetization factor should be higher than our current results, which would further support our conclusion that GRB jets have high magnetization.
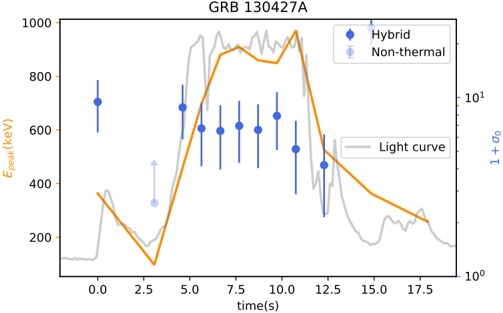
## GRB 211211A
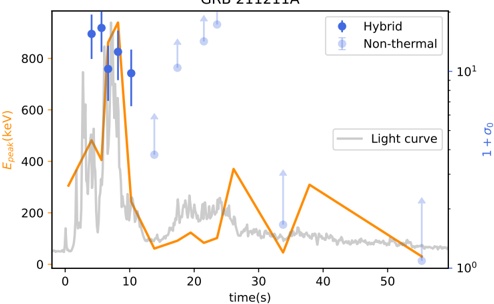
GRB 171010A
Figure 3. Evolution of photon counts, 1 + σ 0 and E peak , for sources that show hybrid spectra in multiple slices.
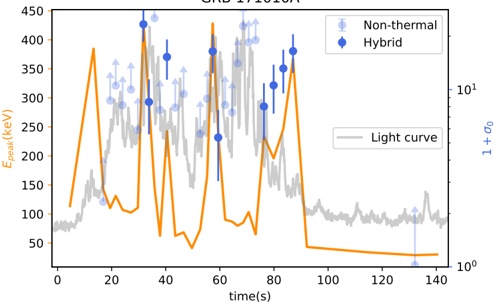
However, if the true kT is lower than 5 keV, then our current constraint on the lower limit of the magnetization factor may be overestimated to a certain extent. However, this uncertainty should be within a factor of 2. In the future, instruments like Fermi, Gravitational Wave High-energy Electromagnetic Counterpart All-sky Monitor, Einstein Probe (Yuan et al. 2018) and Space Variable Objects Monitor (Wei et al. 2016) are expected to form an observation network in a broadband and provide high-quality GRB data during the prompt emission and early-afterglow phases through joint analysis, which would significantly enhance the accuracy of our results.
Previous studies have indicated that if a more complex model is used to fit the energy spectrum, some slices that originally satisfy the pure nonthermal spectrum may show weaker evidence of the existence of a thermal spectrum (e.g., GRB 080916C and GRB 090926A; see Guiriec et al. (2016a) for details). The fitting of the energy spectrum performed here does not include such complexity. However, it is important to emphasize that the lower limit of σ 0 given by the pure nonthermal spectrum in this study is the most conservative constraint. If thermal components are indeed missed, the constraint on σ 0 brought by these thermal components will definitely be above the lower limit we have provided, which would further strengthen our conclusion that GRB jets generally possess high magnetization.
Finally, we note that the low-energy end of the BGO detector was excluded from the analysis due to its low SNR. To ensure proper calibration between the NaI and BGO detectors, we also conducted analysis by including the low-energy end of the BGO data (e.g. over the energy range from 300 keV to 30 MeV), and we found that our main results were barely affected.
## ACKNOWLEDGMENTS
We gratefully acknowledge the insightful comments provided by the anonymous referee and Asaf Pe'er. This work is supported by the National Natural Science Foundation of China (Projects 12373040,12021003), the National SKA Program of China (2022SKA0130100), the National Postdoctoral Program for Innovative Talents (grant No. GZB20230765) and the Fundamental Research Funds for the Central Universities.
Facilities: Fermi(GBM)
Software: astropy Astropy Collaboration et al. (2013), GBM data tools Goldstein et al. (2022)
## REFERENCES
Abdo, A. A., Ackermann, M., Arimoto, M., et al. 2009a, Science, 323, 1688, doi: 10.1126/science.1169101 Abdo, A. A., Ackermann, M., Ajello, M., et al. 2009b, ApJL, 706, L138, doi: 10.1088/0004-637X/706/1/L138 Astropy Collaboration, Robitaille, T. P., Tollerud, E. J., et al. 2013, A&A, 558, A33, doi: 10.1051/0004-6361/201322068 Atwood, W. B., Abdo, A. A., Ackermann, M., et al. 2009, ApJ, 697, 1071, doi: 10.1088/0004-637X/697/2/1071 Axelsson, M., Baldini, L., Barbiellini, G., et al. 2012, ApJL, 757, L31, doi: 10.1088/2041-8205/757/2/L31 Band, D., Matteson, J., Ford, L., et al. 1993, The Astrophysical Journal, 413, 281, doi: 10.1086/172995 Burgess, J. M., Preece, R. D., Connaughton, V., et al. 2014, ApJ, 784, 17, doi: 10.1088/0004-637X/784/1/17 Chang, X.-Z., L¨, H.-J., Yang, X., Chen, J.-M., & Liang, u E.-W. 2023, The Astrophysical Journal, 943, 146, doi: 10.3847/1538-4357/aca969 Daigne, F., & Mochkovitch, R. 2002, MNRAS, 336, 1271, doi: 10.1046/j.1365-8711.2002.05875.x Gao, H., & Zhang, B. 2015, ApJ, 801, 103, doi: 10.1088/0004-637X/801/2/103 Goldstein, A., Cleveland, W. H., & Kocevski, D. 2022, Fermi GBM Data Tools: v1.1.1. https://fermi.gsfc.nasa.gov/ssc/data/analysis/gbm
Goodman, J. 1986, ApJL, 308, L47, doi: 10.1086/184741 Guiriec, S., Gehrels, N., McEnery, J., Kouveliotou, C., & Hartmann, D. H. 2017, ApJ, 846, 138, doi: 10.3847/1538-4357/aa81c2
Guiriec, S., Gonzalez, M. M., Sacahui, J. R., et al. 2016a, ApJ, 819, 79, doi: 10.3847/0004-637X/819/1/79
Guiriec, S., Mochkovitch, R., Piran, T., et al. 2015a, ApJ, 814, 10, doi: 10.1088/0004-637X/814/1/10
Guiriec, S., Connaughton, V., Briggs, M. S., et al. 2011,
ApJL, 727, L33, doi: 10.1088/2041-8205/727/2/L33
Guiriec, S., Connaughton, V., Briggs, M., et al. 2011, 33, doi: 10.1063/1.3621732
Guiriec, S., Daigne, F., Hasco¨t, R., et al. 2013, ApJ, 770, e 32, doi: 10.1088/0004-637X/770/1/32
Guiriec, S., Kouveliotou, C., Daigne, F., et al. 2015b, ApJ, 807, 148, doi: 10.1088/0004-637X/807/2/148
Guiriec, S., Kouveliotou, C., Hartmann, D. H., et al. 2016b,
ApJL, 831, L8, doi: 10.3847/2041-8205/831/1/L8
Hou, S.-J., Zhang, B.-B., Meng, Y.-Z., et al. 2018, ApJ,
866, 13, doi: 10.3847/1538-4357/aadc07
Iyyani, S., Ryde, F., Burgess, J., Pe'er, A., & B´gu´, D. e e 2016, Monthly Notices of the Royal Astronomical Society, 456, 2157, doi: 10.1093/mnras/stv2751
| Iyyani, S., Ryde, F., Axelsson, M., et al. 2013, Monthly Notices of the Royal Astronomical Society, 433, 2739, doi: 10.1093/mnras/stt863 |
|----------------------------------------------------------------------------------------------------------------------------------------------------|
| A., Zhang, B., & Xu, S. 2019, ApJ, 882, |
| Lazarian, 184, doi: 10.3847/1538-4357/ab2b38 |
| Li, L. 2019, The Astrophysical Journal Supplement Series, 245, 7, doi: 10.3847/1538-4365/ab42de |
| Meegan, C., Lichti, G., Bhat, P. N., et al. 2009, ApJ, 702, 791, doi: 10.1088/0004-637X/702/1/791 |
| Meszaros, P., Laguna, P., & Rees, M. J. 1993, ApJ, 415, 181, doi: 10.1086/173154 |
| Meszaros, P., Rees, M. J., & Papathanassiou, H. 1994, ApJ, 432, 181, doi: 10.1086/174559 |
| Paczynski, B. 1986, The Astrophysical Journal, 308, L43, doi: 10.1086/184740 |
| Pe'er, A., Zhang, B.-B., Ryde, F., et al. 2012, Monthly Notices of the Royal Astronomical Society, 420, 468, doi: 10.1111/j.1365-2966.2011.20052.x |
| Piran, T., Shemi, A., & Narayan, R. 1993, MNRAS, 263, 861, doi: 10.1093/mnras/263.4.861 |
| Preece, R., Burgess, J. M., von Kienlin, A., et al. 2014, Science, 343, 51, doi: 10.1126/science.1242302 |
| Qin, S.-M., Jiang, L.-Y., & Wang, X.-G. 2021, Research in Astronomy and Astrophysics, 21, 072, doi: 10.1088/1674-4527/21/3/72 |
- Rees, M. J., & Meszaros, P. 1994, ApJL, 430, L93, doi: 10.1086/187446
- Shemi, A., & Piran, T. 1990, ApJL, 365, L55, doi: 10.1086/185887
Siddique, I., Sajjad, S., & Motiwala, K. 2022, The Astrophysical Journal, 938, 159, doi: 10.3847/1538-4357/ac8d05
Tavani, M. 1996, ApJ, 466, 768, doi: 10.1086/177551 Wei, J., Cordier, B., Antier, S., et al. 2016, arXiv e-prints, arXiv:1610.06892, doi: 10.48550/arXiv.1610.06892
Yuan, W., Zhang, C., Ling, Z., et al. 2018, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, Vol. 10699, Space Telescopes and Instrumentation 2018: Ultraviolet to Gamma Ray, ed. J.-W. A. den Herder, S. Nikzad, & K. Nakazawa, 1069925, doi: 10.1117/12.2313358
- Zhang, B. 2018, The Physics of Gamma-Ray Bursts (Cambridge University Press),
doi: 10.1017/9781139226530
Zhang, B., & Pe'er, A. 2009, ApJL, 700, L65, doi: 10.1088/0004-637X/700/2/L65
- Zhang, B., & Yan, H. 2011, The Astrophysical Journal, 726, 90, doi: 10.1088/0004-637X/726/2/90
Zhang, B.-B., Zhang, B., Liang, E.-W., et al. 2011, ApJ, 730, 141, doi: 10.1088/0004-637X/730/2/141
Li et al.
Table 1 . σ 0 constraint result
| Burst Name | Start Time( T 0 + s ) | End Time( T 0 + s ) | Fit Model | E peak (keV) | kT (keV) | f th | 1 + σ 0 | 1 + σ 0 | 1 + σ 0 |
|--------------|-------------------------|-----------------------|-------------|-------------------|---------------------|-------------------|-----------------|------------------|-------------------|
| | | | | | | | r 0 , 1 1 | r 0 , 2 1 | r 0 , 3 1 |
| GRB080804A | - 2 . 048 | 15 . 360 | CPL+BB | 209 . 948 | 26 . 682 | 0 . 1980 | 1 . 609 | 7 . 472 | - |
| GRB080810A | - 2 . 048 | 22 . 528 | CPL | 4265 . 090 | 5 . 000 | 0 . 3020 | - | - | 2 . 314 |
| GRB080916C | - 2 . 048 | 15 . 360 | Band | 149 . 793 | 5 . 000 | 0 . 3546 | - | - | 1 . 840 |
| GRB081121A | - 2 . 048 | 16 . 384 | Band | 129 . 227 | 5 . 000 | 0 . 1781 | - | - | 3 . 719 |
| GRB081221A | 20 . 480 | 24 . 576 | CPL | 123 . 083 | 20 . 000 | 0 . 4317 | - | - | 4 . 529 |
| GRB081222A | - 2 . 048 | 6 . 144 | Band | 147 . 967 | 5 . 000 | 0 . 1218 | - | 1 . 189 | 5 . 524 |
| | 6 . 144 | 14 . 336 | Band | 77 . 290 | 5 . 000 | 0 . 5013 | - | - | 1 . 004 |
| GRB090102A | 10 . 240 | 19 . 456 | Band | 1130 . 951 | 5 . 000 | 0 . 1575 | - | - | 3 . 349 |
| GRB090323A | - 2 . 048 | 26 . 624 | Band+BB | 261 . 177 | 33 . 910 | 0 . 1369 | 3 . 500 | 16 . 257 | - |
| | 26 . 624 | 53 . 248 | Band | 1060 . 073 | 5 . 000 | 0 . 1458 | - | 1 . 155 | 5 . 367 |
| | 53 . 248 | 64 . 512 | Band | 1021 . 761 | 5 . 000 | 0 . 1446 | - | - | 4 . 049 |
| GRB090328A | - 2 . 048 | 14 . 336 | Band | 581 . 272 | 5 . 000 | 0 . 1686 | - | - | 3 . 807 |
| | 14 . 336 | 23 . 552 | Band | 1287 . 037 | 5 . 000 | 0 . 1740 | - | - | 3 . 038 |
| | 23 . 552 | 38 . 912 | Band | 545 . 817 | 5 . 000 | 0 . 3475 | - | - | 1 . 521 |
| GRB090424A | - 2 . 048 | 2 . 048 | Band | 67 . 578 | 5 . 000 | 0 . 0595 | - | 2 . 303 | 10 . 698 |
| | 2 . 048 | 5 . 120 | Band+BB | 268 . 941 | 9 . 271 | 0 . 0563 | 1 . 057 | 4 . 906 | 22 . 788 |
| GRB090510A | 0 . 000 | 1 . 000 | CPL | 3864 | 50 . 000 | 0 . 0753 | 7 . 107 | 32 . 986 | - |
| GRB090516A | - 7 . 168 | 19 . 456 | Band | 4287 . 681 | 5 . 000 | 0 . 3353 | - | - | 2 . 420 |
| | 48 . 128 | 60 . 416 | Band | 130 . 992 | 10 . 000 | 0 . 4676 | - | - | 2 . 308 |
| | 60 . 416 | 64 . 512 | Band | 413 . 189 | 5 . 000 | 0 . 0611 | - | 1 . 853 | 8 . 607 |
| | 64 . 512 | 67 . 584 | Band | 156 . 887 | 5 . 000 | 0 . 0476 | - | 2 . 379 | 11 . 049 |
| | 67 . 584 | 70 . 656 | Band | 108 . 743 | 5 . 000 | 0 . 0587 | - | 1 . 930 | 8 . 964 |
| GRB090618A | 70 . 656 | 74 . 752 | Band | 70 . 328 | 20 . 000 | 0 . 1295 | 1 . 109 | 5 . 153 | - |
| | 74 . 752 | 79 . 872 | Band+BB | 286 . 238 | 23 . 984 | 0 . 1694 | 1 . 297 | 6 . 026 | - |
| | 79 . 872 | 83 . 968 | Band | 78 . 404 | 5 . 000 | 0 . 0640 | - | 2 . 146 | 9 . 970 |
| | 83 . 968 | 88 . 064 | Band | 98 . 230 | 10 . 000 | 0 . 1325 | - | 1 . 932 | 8 . 973 |
| | 88 . 064 | 93 . 184 | Band+BB | 48 . 621 | 28 . 964 | 0 . 1944 | 1 . 337 | 6 . 212 | - |
| | - 2 . 048 | 5 . 120 | mBB | 6 . 346 | - 0 . 064 | 0 . 0137 | . | 13 . 266 | 12 . 125 |
| GRB090902B | 5 . 120 | 8 . 192 | mBB | 5 . 000 | - 0 . 012 | 0 . 0481 | - 2 856 | 2 . 610 | 61 . 577 |
| | 8 . 192 | 10 . 240 | mBB | 4 . 951 | - 0 . 574 | 0 . 0380 | - | 2 . 101 | 9 . 757 |
| | 10 . 240 13 . 312 | 13 . 312 16 . 384 | mBB mBB | 20 . 000 10 . 000 | - 1 . 147 - 0 . 752 | 0 . 0482 0 . 0423 | 2 . 471 1 . 081 | 11 . 480 5 . 019 | 53 . 284 23 . 314 |
| | 16 . 384 | | | | | 0 . 0509 | | | 8 . 575 |
| | | 19 . 456 | mBB | 5 . 000 | - 0 . 775 | | - | 1 . 846 | - |
| | 19 . 456 | 22 . 528 | mBB | 28 . 219 | - 0 . 975 | 0 . 0891 | 1 . 992 | 9 . 253 | |
| | - 2 . 048 | 4 . 096 | Band | 759 . 906 | 5 . 000 | 0 . 0572 | - | 1 . 826 | 8 . 480 |
| GRB090926A | 4 . 096 | 7 . 168 | Band | 198 . 750 | 5 . 000 | 0 . 0357 | - | 2 . 657 | 12 . 340 |
| | 7 . 168 | 10 . 240 | Band | 230 . 006 | 10 . 000 | 0 . 0834 | - | 2 . 334 | 10 . 843 |
| | 10 . 240 | 13 . 312 | Band | 187 . 977 | 10 . 000 | 0 . 1064 | - | 1 . 829 | 8 . 496 |
| | - 2 . 048 | 10 . | Band | 680 . 186 | 5 . 000 | 0 . 1635 | - | - | 3 . 758 |
| GRB091003A | 10 . 240 | 240 20 . 480 | Band | 288 . 675 | 29 . 303 | 0 . 0852 | 3 . 819 | 17 . 740 | - |
| GRB091127A | - 2 . 048 | 2 . 048 | Band | 46 . 689 | 10 . 000 | 0 . 0250 | 4 . 944 | 22 . 963 | 106 . 585 |
| | 2 . 048 | 8 . 192 | Band | 19 . 917 | 5 . 000 | 0 . 0704 | - | 3 . 272 | 15 . 197 |
| GRB100414A | - 2 . 048 | 10 . 240 | CPL | 975 . 324 | 5 . 000 | 0 . 0821 | - | 1 . 530 | 7 . 106 |
| | 10 . 240 | 18 . 432 | CPL | 1730 . 237 | 5 . 000 | 0 . 0740 | - | 1 . 541 | 7 . 159 |
| | 18 . 432 | 25 . 600 | CPL | 2047 . 803 | 5 . 000 | 0 . 1245 | - | - | 3 . 506 |
| Burst Name | Start Time( T 0 + s ) | End Time( T 0 + s ) | Fit Model | E peak (keV) | kT (keV) | f th | 1 + σ 0 | 1 + σ 0 | 1 + σ 0 |
|--------------|-------------------------|-----------------------|-------------|----------------|------------|----------|-----------|-----------|-----------|
| | | | | | | | r 0 , 1 1 | r 0 , 2 1 | r 0 , 3 1 |
| GRB100728A | - 2 . 048 | 22 . 528 | CPL | 4287 . 280 | 5 . 000 | 0 . 2388 | - | - | 2 . 680 |
| GRB100728A | 22 . 528 | 48 . 128 | CPL | 4288 . 484 | 5 . 000 | 0 . 2873 | - | - | 2 . 228 |
| GRB100728A | 48 . 128 | 61 . 440 | CPL | 957 . 657 | 10 . 000 | 0 . 4029 | - | - | 2 . 441 |
| GRB100728A | 61 . 440 | 73 . 728 | CPL | 1005 . 259 | 10 . 000 | 0 . 4366 | - | - | 2 . 043 |
| GRB100728A | 73 . 728 | 82 . 944 | CPL | 230 . 883 | 5 . 000 | 0 . 1261 | - | - | 4 . 186 |
| GRB100728A | 82 . 944 | 91 . 136 | CPL | 932 . 038 | 5 . 000 | 0 . 1321 | - | - | 3 . 996 |
| GRB100728A | 91 . 136 | 102 . 400 | CPL | 411 . 993 | 20 . 000 | 0 . 4897 | - | 1 . 023 | 4 . 750 |
| GRB100728A | 102 . 400 | 117 . 760 | CPL | 173 . 773 | 10 . 000 | 0 . 4936 | - | - | 2 . 195 |
| GRB100728A | 117 . 760 | 132 . 096 | CPL | 280 . 561 | 10 . 000 | 0 . 5062 | - | - | 1 . 942 |
| GRB100728A | 132 . 096 | 146 . 432 | CPL | 185 . 942 | 5 . 000 | 0 . 2339 | - | - | 3 . 016 |
| GRB100728A | 146 . 432 | 171 . 008 | CPL | 4288 . 458 | 5 . 000 | 0 . 3292 | - | - | 1 . 944 |
| GRB100728A | 171 . 008 | 186 . 368 | CPL | 163 . 816 | 10 . 000 | 0 . 3202 | - | - | 4 . 524 |
| GRB100814A | - 2 . 048 | 17 . 408 | CPL+BB | 222 . 629 | 30 . 438 | 0 . 4026 | - | 3 . 598 | - |
| GRB100906A | - 2 . 048 | 12 . 288 | Band | 74 . 296 | 5 . 000 | 0 . 1849 | - | - | 2 . 855 |
| GRB101213A | - 2 . 048 | 18 . 432 | Band | 2485 . 779 | 5 . 000 | 0 . 2483 | - | - | 3 . 121 |
| GRB101219B | - 2 . 048 | 19 . 456 | CPL | 4286 . 129 | 5 . 000 | 0 . 2915 | - | - | 2 . 905 |
| GRB110721A | - 2 . 048 | 3 . 072 | Band+BB | 1334 . 871 | 34 . 419 | 0 . 0854 | 4 . 784 | 22 . 206 | - |
| GRB110721A | 3 . 072 | 10 . 240 | Band | 428 . 720 | 50 . 000 | 0 . 1595 | 4 . 376 | - | - |
| GRB110731A | - 2 . 048 | 5 . 120 | Band+BB | 192 . 040 | 47 . 753 | 0 . 2533 | 1 . 609 | 7 . 473 | - |
| GRB110731A | 5 . 120 | 9 . 216 | Band | 1094 . 638 | 5 . 000 | 0 . 1450 | - | - | 3 . 482 |
| GRB111228A | - 12 . 288 | 5 . 120 | Band | 13 . 423 | 5 . 000 | 0 . 2635 | - | - | 2 . 979 |
| GRB111228A | 12 . 288 | 54 . 272 | Band | 14 . 930 | 5 . 000 | 0 . 2000 | - | 1 . 370 | 6 . 365 |
| GRB120119A | - 2 . 048 | 14 . 336 | Band | 525 . 853 | 10 . 000 | 0 . 4796 | - | - | 2 . 051 |
| GRB120119A | 14 . 336 | 22 . 528 | Band | 95 . 258 | 5 . 000 | 0 . 1446 | - | - | 3 . 655 |
| GRB120119A | 22 . 528 | 36 . 864 | Band | 133 . 701 | 10 . 000 | 0 . 4273 | - | - | 2 . 796 |
| GRB120326A | - 7 . 168 | 9 . 216 | Band | 36 . 329 | 5 . 000 | 0 . 5097 | - | - | 1 . 037 |
| GRB120624B | - 2 . 048 | 13 . 312 | Band | 341 . 531 | 5 . 000 | 0 . 1411 | - | - | 4 . 141 |
| | - 2 . 048 | 12 . 288 | CPL+BB | 245 . 757 | 28 . 013 | 0 . 1208 | 2 . 492 | 11 . 574 | - |
| | 12 . 288 | 21 . 504 | Band+BB | 52 . 935 | 20 . 232 | 0 . 1653 | - | 4 . 368 | - |
| GRB120707A | 21 . 504 | 28 . 672 | Band | 116 . 720 | 5 . 000 | 0 . 1336 | - | - | 3 . 262 |
| GRB120707A | 28 . 672 | 34 . 816 | Band | 53 . 695 | 5 . 000 | 0 . 1193 | - | - | 3 . 654 |
| | 34 . 816 | 48 . 128 | Band | 32 . 675 | 5 . 000 | 0 . 3055 | - | - | 1 . 571 |
| | 48 . 128 | 72 . 704 | Band | 1801 . 327 | 5 . 000 | 0 . 0982 | - | 1 . 277 | 5 . 934 |
| | 72 . 704 | 80 . 896 | Band | 1351 . 595 | 5 . 000 | 0 . 1584 | - | - | 2 . 751 |
| GRB120711A | 80 . 896 | 90 . 112 | Band | 350 . 544 | 5 . 000 | 0 . 0019 | 44 . 793 | 207 . 915 | - |
| GRB120711A | 90 . 112 | 96 . 256 | Band | 2596 . 171 | 5 . 000 | 0 . 0597 | - | 1 . 733 | 8 . 050 |
| GRB120711A | 96 . 256 | 102 . 400 | Band | 2342 . 635 | 5 . 000 | 0 . 0623 | - | 1 . 659 | 7 . 708 |
| GRB120711A | 102 . 400 | 112 . 640 | Band | 1652 . 340 | 5 . 000 | 0 . 1987 | - | - | 2 . 416 |
| GRB120716A | 167 . 936 | 190 . 464 | Band | 115 . 188 | 5 . 000 | 0 . 3137 | - | - | 2 . 107 |
| GRB120909A | 22 . 528 | 59 . 392 | CPL | 4287 . 832 | 5 . 000 | 0 . 3488 | - | - | 2 . 298 |
| GRB121128A | - 2 . 048 | 15 . 360 | Band | 42 . 274 | 5 . 000 | 0 . 4014 | - | - | 1 . 213 |
| | - 2 . 048 | 2 . 048 | Band+BB | 363 . 389 | 24 . 066 | 0 . 0945 | 2 . 037 | 9 . 460 | - |
| | 2 . 048 | 4 . 096 | Band | 97 . 664 | 5 . 000 | 0 . 0527 | - | 2 . 572 | 11 . 948 |
| | | | Band+BB | | 33 . 025 | 0 . 0771 | 1 . 897 | | |
| | 4 . 096 | 5 . 120 | | 459 . 147 | | | | 8 . 814 | - |
| | 5 . 120 | 6 . 144 | Band+BB | 695 . 987 | 39 . 277 | 0 . 1016 | 1 . 447 | 6 . 722 | - |
| | 6 . 144 | 7 . 168 | Band+BB | 880 . 279 | 44 . 453 | 0 . 1132 | 1 . 401 | 6 . 510 | - |
GRB130427A
| Burst Name | Start Time( T 0 + s ) | End Time( T 0 + s ) | Fit Model | E peak | kT | f th | 1 + σ 0 | 1 + σ 0 | 1 + σ 0 |
|--------------|-------------------------|-----------------------|--------------|----------------------|-------------------|-------------------|------------|------------|-----------|
| | | | | (keV) | (keV) | | r 0 , 1 1 | r 0 , 2 1 | r 0 , 3 1 |
| | 7 . 168 | 8 . 192 | Band+BB | 909 . 531 | 48 . 543 | 0 . 1168 | 1 . 497 | 6 . 955 | - |
| | 8 . 192 | 9 . 216 | Band+BB | 859 . 654 | 41 . 976 | 0 . 1053 | 1 . 421 | 6 . 598 | - |
| | 9 . 216 | 10 . 240 | Band+BB | 849 . 200 | 40 . 612 | 0 . 0889 | 1 . 701 | 7 . 902 | - |
| | 10 . 240 | 11 . 264 | Band+BB | 969 . 636 | 33 . 876 | 0 . 1075 | 1 . 108 | 5 . 149 | 23 . 897 |
| | 11 . 264 | 13 . 312 | Band+BB | 525 . 769 | 17 . 370 | 0 . 0911 | - | 4 . 191 | 19 . 469 |
| | 13 . 312 | 16 . 384 | Band+BB | 362 . 916 | 29 . 569 | 0 . 0611 | 5 . 270 | 24 . 459 | - |
| | 16 . 384 | 19 . 456 | Band+BB | 257 . 621 | 58 . 742 | 0 . 1308 | 4 . 602 | - | - |
| GRB130518A | 8 . 192 | 22 . 528 | Band | 358 . 915 | 5 . 000 | 0 . 0634 | - | 3 . 005 | 13 . 957 |
| | 22 . 528 | 25 . 600 | Band | 882 . 595 | 5 . 000 | 0 . 0722 | - | 1 . 339 | 6 . 220 |
| | 25 . 600 | 28 . 672 | CPL+BB | 426 . 850 | 36 . 026 | 0 . 0794 | 3 . 231 | 15 . 007 | - |
| | 28 . 672 | 33 . 792 | CPL+BB | 172 . 195 | 31 . 294 | 0 . 0775 | 3 . 815 | 17 . 721 | - |
| | 33 . 792 | 47 . 104 | Band+BB | 298 . 825 | 22 . 358 | 0 . 0959 | 3 . 432 | 15 . 941 | - |
| GRB130610A | - 52 . 224 | - 19 . 456 | Band+BB | 255 . 818 | 30 . 196 | 0 . 2863 | 2 . 106 | - | - |
| | - 19 . 456 | 4 . 096 | CPL+BB | 232 . 275 | 30 . 121 | 0 . 3713 | 1 . 303 | 6 . 051 | - |
| GRB130702A | - 2 . 048 | 13 . 312 | CPL | 4219 . 994 | 5 . 000 | 0 . 2732 | - | 1 . 122 | 5 . 214 |
| GRB131011A | - 2 . 048 | 18 . 432 | CPL+BB | 277 . 374 | 33 . 383 | 0 . 1411 | 3 . 533 | 16 . 413 | - |
| GRB131105A | 16 . 384 | 40 . 960 | CPL | 3380 . 661 | 5 . 000 | 0 . 1977 | - | - | 3 . 934 |
| | 79 . 872 | 110 . 592 | CPL | 355 . 126 | 5 . 000 | 0 . 3202 | - | - | 2 . 203 |
| GRB131108A | - 7 . 168 | 7 . 168 | Band | 934 . 715 | 5 . 000 | 0 . 1726 | - | - | 2 . 851 |
| | 7 . 168 | 20 . 480 | Band | 122 . 518 | 10 . 000 | 0 . 4831 | - | - | 1 . 898 |
| | - 2 . 048 | 14 . 336 | Band | 904 . 124 | 10 . 000 | 0 . 4109 | - | - | 3 . 327 |
| | 14 . 336 | 19 . 456 | Band | 873 . 872 | 10 . 000 | 0 . 4104 | - | - | 1 . 863 |
| | 19 . 456 | 22 . 528 | Band | 357 . 972 | 10 . 000 | 0 . 1123 | - | 1 . 960 | 9 . 103 |
| GRB131231A | 22 . 528 | 24 . 576 | Band | 233 . 810 | 10 . 000 | 0 . 0601 | - | 4 . 032 | 18 . 730 |
| | 24 . 576 | 27 . 648 | Band | 131 . 167 | 5 . 000 | 0 . 0446 | - | 2 . 648 | 12 . 298 |
| | 27 . 648 | 30 . 720 | Band+BB | 46 . 439 | 10 . 519 | 0 . 0730 | 1 . 028 | 4 . 777 | 22 . 172 |
| | 30 . 720 | 33 . 792 | Band+BB | 313 . 132 | 26 . 616 | 0 . 2115 | - | 4 . 112 | - |
| | 33 . 792 | 38 . 912 | Band | 37 . 503 | 10 . 000 | 0 . 2922 | - | - | 3 . 500 |
| GRB140108A | 74 . 752 | 89 . 088 | Band | 1019 . 830 | 5 . 000 | 0 . 1748 | - | - | 4 . 283 |
| | - 2 . 048 | 4 . 096 | Band | 170 . 056 | 10 . 000 | 0 . 2303 | - | 1 . 026 | 4 . 765 |
| GRB140213A | 4 . 096 | 8 . 192 | Band | 43 . 292 | 20 . 000 | 0 . 4561 | - | - | 4 . 257 |
| | 8 . 192 - 38 . 912 | 18 . 432 - 21 . 504 | Band CPL+BB | 34 . 041 598 . 068 | 5 . 000 39 . 178 | 0 . 2557 0 . 0318 | - 14 . 142 | - 65 . 641 | 2 . 795 - |
| GRB140423A | - 21 . 504 | - 1 . 024 | | | | 0 . 0128 | | | 165 . 502 |
| | | | Band | 2 . 309 | 10 . 000 | | 7 . 676 | 35 . 656 | |
| GRB140508A | - 2 . 048 | 12 . 288 | Band+BB | 345 . 600 | 31 . 571 | 0 . 2286 | 1 . 132 | 5 . 257 | - |
| GRB140512A | 98 . 304 | 120 . 832 | CPL | 437 . 956 | 5 . 000 | 0 . 2413 | - | - | 2 . 941 |
| | 120 . 832 | 133 . 120 | CPL | 293 . 555 | 5 . 000 | 0 . 2356 | - | - | 2 . 481 |
| GRB140801A | - 2 . 048 | 7 . 168 | Band | 83 . 642 | 10 . 000 | 0 . 1393 | - | 2 . 251 | 10 . 457 |
| GRB141028A | - 7 . 168 13 . 312 | 13 . 312 19 . 456 | Band Band | 1040 . 886 319 . 573 | 5 . 000 5 . 000 | 0 . 1681 | - | - | 3 . 542 |
| | 19 . 456 | 31 . 744 | | 112 | | 0 . 1203 | - | - | 4 . 492 |
| | | | Band | . 096 | 5 . 000 | 0 . 2936 | - | - | 2 . 026 |
| GRB141220A | - 2 . 048 | 7 . 168 3 . 072 | Band Band+BB | 156 . 070 | 10 . 000 | 0 . 2873 | - 2 . 567 | - 11 . 925 | 4 . 604 - |
| GRB150314A | - 2 . 048 3 . 072 | 7 . 168 | Band | 305 . 738 162 . 641 | 31 . 625 20 . 000 | 0 . 0836 0 . 1280 | - | 3 . 922 | 18 . 205 |
| | | 14 . 336 | Band | 511 . 829 | 5 . 000 | 0 . 1753 | - | - | 2 . 484 |
| | 7 . 168 | 8 . 192 | Band | 275 . 877 | 30 . 911 | 0 . 0526 | 7 . | 35 . | - |
| | - 2 . 048 | | | | | | 640 | 462 | |
GRB150403A
| Burst Name | Start Time( T 0 + s ) | End Time( T 0 + s ) | Fit Model | E peak | kT (keV) | f th | 1 + σ 0 | 1 + σ 0 | 1 + σ 0 |
|--------------|-------------------------|-----------------------|-------------|------------|-----------------|----------|-----------|-----------|-----------------|
| | | | | (keV) | | | r 0 , 1 1 | r 0 , 2 1 | r 0 , 3 1 |
| | 8 . 192 | 12 . 288 | Band | 672 . 910 | 5 . 000 | 0 . 0714 | - | 1 . 461 | 6 . 788 |
| | 12 . 288 | 17 . 408 | Band | 248 . 756 | 20 . 000 | 0 . 3460 | - | 1 . 205 | 5 . 600 |
| | 17 . 408 | 29 . 696 | Band | 188 . 314 | 10 . 000 | 0 . 3647 | - | - | 3 . 644 |
| | 19 . 456 | 26 . 624 | Band | 117 . 491 | 5 . 000 | 0 . 2246 | - | - | 2 . 339 |
| GRB150821A | 26 . 624 | 35 . 840 | Band | 277 . 098 | 5 . 000 | 0 . 2255 | - | - | 2 . 566 |
| | 35 . 840 | 44 . 032 | Band | 482 . 127 | 60 . 000 | 0 . 2473 | 2 . 726 | - | - |
| | 53 . 248 | 66 . 560 | Band | 105 . 527 | 5 . 000 | 0 . 4988 | - | - | 1 . 053 |
| GRB151027A | - 2 . 048 | 9 . 216 | Band | 278 . 333 | 43 . 259 | 0 . 1597 | 4 . 859 | - | - |
| | 45 . 056 | 109 . 568 | CPL | 2945 . 402 | 5 . 000 | 0 . 2663 | - | - | 3 . 822 |
| | - 2 . 048 | 10 . 240 | CPL+BB | 321 . 717 | 32 . 865 | 0 . 1208 | 3 . 236 | 15 . 032 | - |
| | 10 . 240 | 12 . 288 | Band | 343 . 113 | 20 . 000 | 0 . 4122 | - | - | 2 . 913 |
| | 12 . 288 | 14 . 336 | Band | 396 . 505 | 10 . 000 | 0 . 0408 | 1 . 253 | 5 . 814 | 27 . 008 |
| GRB160509A | 14 . 336 | 16 . 384 | Band | 209 . 444 | 20 . 000 | 0 . 1444 | - | 2 . 637 | 12 . 248 |
| | 16 . 384 | 18 . 432 | Band | 285 . 852 | 20 . 000 | 0 . 1329 | - | 2 . 864 | 13 . 303 |
| | 18 . 432 | 22 . 528 | Band | 200 . 546 | 20 . 000 | 0 . 3022 | - | 1 . 260 | 5 . 852 |
| | 22 . 528 | 30 . 720 | Band | 200 . 724 | 5 . 000 | 0 . 2293 | - | - | 2 . 338 |
| | 178 . 176 | 188 . 416 | Band | 3123 . 807 | 60 . 000 | 0 . 0837 | 8 . 116 | - | - |
| | 188 . 416 | 189 . 440 | Band+BB | 438 . 593 | 47 . 696 | 0 . 0621 | 3 . 351 | 15 . 564 | - |
| | 189 . 440 | 191 . 488 | Band+BB | 372 . 393 | 33 . 625 | 0 . 0578 | 2 . 783 | 12 . 927 | - |
| | 191 . 488 | 193 . 536 | Band | 471 . 893 | 5 . 000 | 0 . 0049 | 7 . 446 | 34 . 586 | 160 . 532 |
| | 193 . 536 | 194 . 560 | Band+BB | 368 . 194 | 24 . 159 | 0 . 0241 | 6 . 018 | 27 . 956 | - |
| | 194 . 560 | 196 . 608 | Band+BB | 317 . 493 | 29 . 021 | 0 . 0329 | 5 . 035 | 23 . 387 | - |
| GRB160625B | 196 . 608 | 198 . 656 | Band+BB | 280 . 552 | 17 . 902 | 0 . 0250 | 4 . 235 | 19 . 670 | 91 . 301 |
| | 198 . 656 | 199 . 680 | Band+BB | 373 . 748 | 18 . 802 | 0 . 0231 | 4 . 862 | 22 . 582 | 104 . 817 |
| | 199 . 680 | 200 . 704 | Band | 969 . 729 | 5 . 000 | 0 . 0009 | 51 . 755 | 240 . 226 | 1115 . 029 |
| | 200 . 704 | 202 . 752 | Band+BB | 520 . 856 | 27 . 101 | 0 . 0178 | 10 . 277 | 47 . 701 | - |
| | 202 . 752 | 204 . 800 | Band | 345 . 542 | 40 . 000 | 0 . 0184 | 20 . 683 | 96 . 000 | - |
| | 204 . 800 | 206 . 848 | Band | 246 . 471 | 5 . 000 | 0 . 0094 | 3 . 481 | 16 . 167 | 75 . 042 |
| | 206 . 848 | 209 . 920 | Band | 116 . 407 | 10 . 000 | 0 . 1109 | - | 1 . 914 | 8 . 892 |
| | 214 . 016 | 222 . 208 | Band | 822 . 360 | 5 . 000 | 0 . 1938 | - | - | 2 . 728 |
| GRB160629A | 15 . 360 | 28 . 672 | Band | 856 . 776 | 50 . 000 | 0 . 3694 | 1 . 647 | - | - |
| GRB160804A | - 24 . 576 | 0 . 000 | Band | 42 . 214 | 5 . 000 | 0 . 4480 | - | - | 1 . 577 |
| GRB161117A | 36 . 864 | 47 . 104 | Band | 93 . 733 | 10 . 000 | 0 . 5017 | - | - | 2 . 160 |
| | - 2 . 048 | 12 . 288 | Band+BB | 2389 . 995 | 32 . 918 | 0 . 0457 | 13 . 218 | - | - |
| | 12 . 288 | 20 . 480 | Band | 272 . 135 | 5 . 000 | 0 . 1597 | - | - | 3 . 105 |
| | 20 . 480 | 28 . 672 | Band+BB | 320 . 507 | 33 . 556 | 0 . 1446 | 2 . 390 | 11 . 102 | - |
| | 28 . 672 | 36 . 864 | Band+BB | 2413 . 741 | 32 . 896 | 0 . 0332 | 15 . 696 | 72 . 855 | - |
| | 36 . 864 | 44 . 032 | Band+BB | 340 . 073 | 46 . 585 | 0 . 1635 | 2 . 604 | 12 . 095 | - |
| | 44 . 032 | 50 . 176 | Band+BB | 1449 . 851 | 41 . 194 | 0 . 0998 | 4 . 009 | 18 . 621 | - |
| GRB170214A | 50 . 176 | 57 . 344 | Band+BB | 347 . 149 | 37 . 892 | 0 . 1337 | 2 . 686 | 12 . 477 | - |
| | 57 . 344 | 63 . 488 | Band | 1087 . 015 | 5 . 000 | 0 . 1337 | - | - | 3 . 367 |
| | 63 . 488 | 69 . 632 | Band+BB | 2152 . 000 | 31 . 548 | 0 . 0262 | 17 . 838 | 82 . 794 | - |
| | 69 . 632 | 76 . 800 | Band | 1900 . 238 | 5 . 000 | 0 . 0227 | 1 . 996 | 9 . 271 | 43 . 032 |
| | 107 . 520 | 128 . 000 | Band | 3580 . 956 | 5 . 000 | 0 . 3316 | - | - | 1 . 998 |
| | 128 . 000 | 137 . 216 | CPL+BB | 230 . 044 | 32 . 561 | 0 . 0987 | 3 . 959 | 18 . 387 | - |
| | 137 . 216 | 148 . 480 | Band | 3576 . 749 | 5 . 000 5 . 000 | 0 . 2901 | - | - | 1 . 883 2 . 531 |
| | - 2 . 048 | 22 . 528 | Band | 1142 . 968 | | 0 . 2301 | - | - | |
GRB170405A
| Burst Name | Start Time( T 0 + s ) | End Time( T 0 + s ) | Fit Model | E peak (keV) | kT | f th | 1 + σ 0 | 1 + σ 0 | 1 + σ 0 |
|--------------|-------------------------|-----------------------|-------------|----------------|----------|----------|-----------|-----------|-----------|
| | | | | | (keV) | | r 0 , 1 1 | r 0 , 2 1 | r 0 , 3 1 |
| | 22 . 528 | 34 . 816 | Band | 770 . 655 | 5 . 000 | 0 . 1888 | - | - | 2 . 801 |
| | 34 . 816 | 53 . 248 | Band | 66 . 028 | 5 . 000 | 0 . 1734 | - | - | 3 . 704 |
| GRB171010A | - 2 . 048 | 11 . 264 | Band | 113 . 691 | 5 . 000 | 0 . 2126 | - | - | 3 . 642 |
| | 11 . 264 | 15 . 360 | Band | 647 . 195 | 5 . 000 | 0 . 0537 | - | 3 . 105 | 14 . 422 |
| | 15 . 360 | 18 . 432 | Band | 142 . 542 | 5 . 000 | 0 . 0650 | - | 2 . 329 | 10 . 818 |
| | 18 . 432 | 20 . 480 | Band | 110 . 204 | 5 . 000 | 0 . 0212 | 1 . 866 | 8 . 669 | 40 . 237 |
| | 20 . 480 | 22 . 528 | Band | 131 . 231 | 5 . 000 | 0 . 0175 | 2 . 265 | 10 . 522 | 48 . 837 |
| | 22 . 528 | 25 . 600 | Band | 107 . 062 | 5 . 000 | 0 . 0226 | 1 . 755 | 8 . 151 | 37 . 832 |
| | 25 . 600 | 28 . 672 | Band | 102 . 489 | 5 . 000 | 0 . 0203 | 2 . 152 | 9 . 997 | 46 . 403 |
| | 28 . 672 | 30 . 720 | Band | 110 . 762 | 5 . 000 | 0 . 0282 | 1 . 275 | 5 . 916 | 27 . 480 |
| | 30 . 720 | 32 . 768 | Band+BB | 431 . 974 | 29 . 396 | 0 . 0524 | 5 . 025 | 23 . 340 | - |
| | 32 . 768 | 34 . 816 | Band+BB | 293 . 178 | 11 . 267 | 0 . 0411 | 1 . 831 | 8 . 507 | 39 . 486 |
| | 34 . 816 | 36 . 864 | Band | 147 . 281 | 5 . 000 | 0 . 0088 | 5 . 434 | 25 . 242 | 117 . 164 |
| | 36 . 864 | 38 . 912 | Band | 62 . 595 | 5 . 000 | 0 . 0240 | 1 . 652 | 7 . 672 | 35 . 610 |
| | 38 . 912 | 41 . 984 | Band+BB | 242 . 835 | 29 . 220 | 0 . 0934 | 3 . 286 | 15 . 263 | - |
| | 41 . 984 | 45 . 056 | Band | 62 . 341 | 5 . 000 | 0 . 0256 | 1 . 703 | 7 . 910 | 36 . 714 |
| | 45 . 056 | 48 . 128 | Band | 68 . 396 | 5 . 000 | 0 . 0215 | 2 . 032 | 9 . 440 | 43 . 816 |
| | 48 . 128 | 51 . 200 | Band | 41 . 361 | 10 . 000 | 0 . 0659 | 1 . 496 | 6 . 947 | 32 . 245 |
| | 51 . 200 | 54 . 272 | Band | 73 . 462 | 5 . 000 | 0 . 0327 | 1 . 211 | 5 . 620 | 26 . 106 |
| | 54 . 272 | 56 . 320 | Band | 165 . 010 | 5 . 000 | 0 . 0207 | 1 . 912 | 8 . 880 | 41 . 217 |
| | 56 . 320 | 58 . 368 | Band+BB | 428 . 130 | 10 . 484 | 0 . 0264 | 3 . 535 | 16 . 418 | 76 . 205 |
| | 58 . 368 | 60 . 416 | Band+BB | 238 . 891 | 8 . 453 | 0 . 0473 | 1 . 155 | 5 . 362 | 24 . 905 |
| | 60 . 416 | 63 . 488 | Band | 90 . 191 | 5 . 000 | 0 . 0225 | 1 . 760 | 8 . 174 | 37 . 942 |
| | 63 . 488 | 65 . 536 | Band | 86 . 954 | 5 . 000 | 0 . 0247 | 1 . 601 | 7 . 432 | 34 . 520 |
| | 65 . 536 | 67 . 584 | Band | 79 . 856 | 5 . 000 | 0 . 0144 | 3 . 027 | 14 . 060 | 65 . 261 |
| | 67 . 584 | 69 . 632 | Band | 85 . 106 | 5 . 000 | 0 . 0098 | 4 . 901 | 22 . 766 | 105 . 670 |
| | 69 . 632 | 71 . 680 | Band | 103 . 378 | 5 . 000 | 0 . 0121 | 3 . 974 | 18 . 458 | 85 . 677 |
| | 71 . 680 | 74 . 752 | Band | 65 . 037 | 20 . 000 | 0 . 0518 | 4 . 089 | 18 . 994 | - |
| | 74 . 752 | 77 . 824 | Band+BB | 234 . 017 | 29 . 523 | 0 . 1561 | 1 . 729 | 8 . 032 | - |
| | 77 . 824 | 81 . 920 | Band+BB | 195 . 867 | 25 . 349 | 0 . 1258 | 2 . 274 | 10 . 563 | - |
| | 81 . 920 | 84 . 992 | Band+BB | 246 . 436 | 35 . 160 | 0 . 1327 | 2 . 830 | 13 . 144 | - |
| | 84 . 992 | 89 . 088 | Band+BB | 367 . 023 | 29 . 634 | 0 . 1105 | 3 . 545 | 16 . 466 | - |
| | 89 . 088 | 95 . 232 | Band | 43 . 240 | 5 . 000 | 0 . 1962 | - | - | 3 . 583 |
| | 110 . 592 | 118 . 784 | Band | 34 . 079 | 5 . 000 | 0 . 2292 | - | - | 3 . 380 |
| | 128 . 000 | 136 . 192 | Band | 29 . 093 | 5 . 000 | 0 . 1796 | - | 1 . 023 | 4 . 750 |
| | 136 . 192 | 144 . 384 | Band | 30 . 314 | 5 . 000 | 0 . 2910 | - | - | 2 . 415 |
| GRB180620B | - 7 . 168 | 14 . 336 | Band | 113 . 441 | 5 . 000 | 0 . 4164 | - | - | 1 . 294 |
| GRB180703A | - 7 . 168 | 10 . 240 | Band | 305 . 096 | 26 . 586 | 0 . 0643 | 6 . 569 | 30 . 491 | - |
| | - 7 . 168 | 6 . 144 | Band | 1631 . 934 | 5 . 000 | 0 . 0736 | - | 1 . 937 | 8 . 995 |
| | 6 . 144 | 9 . 216 | Band | 2376 . 161 | 5 . 000 | 0 . 0272 | 1 . 024 | 4 . 752 | 22 . 072 |
| | 9 . 216 | 11 . 264 | Band | 2401 . 166 | 5 . 000 | 0 . 0238 | 1 . 171 | 5 . 438 | 25 . 258 |
| | 11 . 264 | 14 . 336 | Band+BB | 271 . 121 | 29 . 747 | 0 . 0449 | 5 . 487 | 25 . 487 | - |
| GRB180720B | 14 . 336 | 16 . 384 | Band+BB | 277 . 642 | 26 . 802 | 0 . 0361 | 5 . 455 | 25 . 336 | - |
| | 16 . 384 | 18 . 432 | Band+BB | 474 . 485 | 28 . 498 | 0 . 0276 | 7 . 891 | 36 . 627 | - |
| | 18 . 432 | 22 . 528 | Band | 133 . 121 | 5 . 000 | 0 . 0372 | - | 3 . 831 | 17 . 793 |
| | 26 . 624 | 29 . 696 | Band | 125 . 858 | 60 . 000 | 0 . 0784 | 8 . 937 | - | - |
| | 29 . 696 | 35 . 840 | Band | 817 . 507 | 5 . 000 | 0 . 0793 | - | 1 . 632 | 7 . 581 |
| Burst Name | Start Time( T 0 + s ) | End Time( T 0 + s | Fit Model | E peak | kT | f th | 1 + σ 0 | 1 + σ 0 | 1 + σ 0 |
|--------------|-------------------------|---------------------|-------------|----------------------|------------------|-------------------|-----------|-----------|-----------------|
| | | | | (keV) | (keV) | | r 0 , 1 1 | r 0 , 2 1 | r 0 , 3 1 |
| | 47 . 104 | 52 . 224 | Band | 650 . 776 | 10 . 000 | 0 . 2550 | - | - | 3 . 989 |
| | - 7 . 168 | 11 . 264 | Band+BB | 32 . 534 | 4 . 725 | 0 . 0782 | 1 . 183 | 5 . 495 | 25 . 504 |
| GRB180728A | 11 . 264 | 13 . 312 | Band | 62 . 686 | 5 . 000 | 0 . 0225 | 2 . 729 | 12 . 676 | 58 . 839 |
| | 13 . 312 | 17 . 408 | Band | 39 . 554 | 5 . 000 | 0 . 0805 | - | 3 . 906 | 18 . 145 |
| GRB181020A | - 2 . 048 | 6 . 144 | Band | 1330 . 896 | 5 . 000 | 0 . 1082 | - | 1 . 229 | 5 . 711 |
| | 6 . 144 | 12 . 288 | Band | 635 . 015 | 5 . 000 | 0 . 0805 | - | 1 . 651 | 7 . 668 |
| | - 2 . 048 | 1 . 024 | CPL | 664 . 801 | 10 . 000 | 0 . 0582 | 1 . 038 | 4 . 819 | 22 . 386 |
| GRB190114C | 1 . 024 | 2 . 048 | CPL+BB | 404 . 340 | 12 . 120 | 0 . 0095 | 8 . 628 | 40 . 078 | 186 . 027 |
| | 2 . 048 | 3 . 072 | CPL | 1095 . 919 | 60 . 000 | 0 . 0263 | 19 . 111 | 88 . 706 | - |
| | 3 . 072 | 4 . 096 | Band+BB | 676 . 468 | 12 . 187 | 0 . 0117 | 5 . 656 | 26 . 273 | 121 . 950 |
| | 4 . 096 | 6 . 144 | CPL | 639 . 452 | 20 . 000 | 0 . 0090 | 19 . 249 | 89 . 346 | - |
| | 6 . 144 | 11 . 264 | CPL | 4290 . 623 | 60 . 000 | 0 . 2884 | 2 . 112 | - | - |
| | 11 . 264 | 17 . 408 | Band+BB | 241 . 065 | 13 . 750 | 0 . 0847 | 1 . 718 | 7 . 980 | - |
| | 17 . 408 | 22 . 528 | CPL | 32 . 926 | 5 . 000 | 0 . 1774 | - | - | 3 . 579 |
| GRB190324A | - 2 . 048 | 23 . 552 | Band | 140 . 940 | 10 . 000 | 0 . 5164 | - | - | 2 . 132 |
| | 23 . 552 | 33 . 792 | Band | 72 . 268 | 5 . 000 | 0 . 2236 | - | - | 2 . 911 |
| | 37 . 888 | 53 . 248 | Band | 8 . 944 | 5 . 000 | 0 . 2099 | - | 2 . 303 | 10 . 696 |
| GRB190829A | 53 . 248 | 59 . 392 | Band | 12 . 306 | 5 . 000 | 0 . 1160 | - | 4 . 594 | 21 . 322 |
| | - 2 . 048 | 8 . 192 | Band+BB | 4007 . 341 | 22 . 658 | 0 . 0917 | 2 . 642 | 12 . 272 | - |
| GRB200524A | 8 . 192 | 21 . 504 | Band+BB | 375 . 375 | 17 . 078 | 0 . 0830 | 2 . 664 | 12 . 374 | - |
| | - 2 . 048 | 7 . 168 | Band | 108 . 873 | 10 . 000 | 0 . 2856 | - | - | 4 . 228 |
| GRB200613A | 7 . 168 | 12 . 288 | Band | 71 . 854 | 10 . 000 | 0 . 3125 | - | - | 2 . 890 |
| | 12 . 288 | 16 . 384 | Band | 101 . 548 | 20 . 000 | 0 . 3052 | - | 1 . 507 | 6 . 998 |
| GRB200826A | 0 . 000 | 0 . 500 | CPL+BB | 151 | 23 . 666 | 0 . 0015 | 759 . 355 | - | - |
| | - 2 . 048 | 18 . 432 | Band | 302 . 776 | 5 . 000 | 0 . 1814 | - | - | 2 . 665 |
| | 18 . 432 | 20 . 480 | Band+BB | 359 . 650 | 32 . 662 | 0 . 0745 | 1 . 760 | 8 . 174 | - |
| GRB200829A | 20 . 480 | 23 . 552 | Band+BB | 378 . 778 | 27 . 293 | 0 . 0863 | 1 . 452 | 6 . 746 | 31 . 313 |
| | 23 . 552 | 38 . 912 | Band+BB | 120 . 767 | 29 . 659 | 0 . 1125 | 3 . 761 | 17 . 471 | - |
| GRB201020B | - 2 . 048 | 10 . 240 | CPL+BB | 591 . 720 | 22 . 627 | 0 . 1547 | 1 . 329 | 6 . 174 | - |
| | 10 . 240 | 17 . 408 | Band | 57 . 741 | 10 . 000 | 0 . 2761 | - | - | 3 . 496 |
| GRB201104C | - 2 . 048 | 27 . 648 | Band | 2 . 067 | 5 . 000 | 0 . 3917 | - | - | 2 . 234 |
| | - 7 . 168 | 8 . 192 12 . 288 | Band | 1226 . 549 170 . 307 | 5 . 000 10 . 000 | 0 . 0988 0 . 1504 | - - | 1 . 428 | 6 . 633 |
| | 8 . 192 | | Band | | | | | 1 . 440 | 6 . 691 |
| | 12 . 288 | 17 . 408 | Band | 110 . 066 | 5 . 000 | 0 . 0852 | - | 1 . 503 | 6 . 983 |
| GRB201216C | 17 . 408 | 21 . 504 | Band | 119 . 054 | 10 . 000 | 0 . 1512 | - | 1 . 433 | 6 . 655 |
| | 21 . 504 | 24 . 576 | Band | 127 . 093 | 10 . 000 | 0 . 1170 | - | 1 . 852 | 8 . 603 |
| | 24 . 576 | 26 . 624 | Band | 437 . 583 | 10 . 000 | 0 . 0555 | - | 4 . 304 | 19 . 994 |
| | 26 . 624 | 29 . 696 | Band | 353 . 328 | 5 . 000 | 0 . 0209 | 1 . 455 | 6 . 755 | 31 . 375 |
| | 29 . 696 | 34 . 816 | Band | 79 . 439 | 10 . 000 | 0 . 2306 | - | 1 . 035 | 4 . 808 |
| | 178 . 176 | 192 . 512 | Band | 157 . 621 | 5 . 000 | 0 . 2408 | - | - | 2 . 451 |
| GRB210204A | 192 . 512 200 . 704 | 200 . 704 204 . 800 | Band | 59 . 173 | 5 . 000 | 0 . 2732 0 . 3064 | - | - | 1 . 617 |
| | 210 . 944 | 217 . 088 | Band | 57 . 457 | 10 . 000 | | - | - | 2 . 688 |
| | 217 . 088 | 223 . 232 | Band | 45 . 935 | 5 . 000 | 0 . 2300 | - | - | 1 . 920 |
| | | | Band | 47 . 216 | 5 . 000 | 0 . 2626 | - | - - | 1 . 682 2 . 821 |
| | - 2 . 048 | 26 . 624 32 . 768 | mBB mBB | 190 . 347 951 . 700 | - 0 . 134 | 0 . 2101 0 . 1121 | - - | - | 3 . 591 |
| GRB210610B | 26 . 624 | 39 . 936 | mBB | 344 . 822 | - 0 . 276 | 0 . 2875 | - | - | |
| | 32 . 768 | | | | - 0 . 151 | | | | 2 . 876 |
Li et al.
| Burst Name | Start Time( T 0 + s ) | End Time( T 0 + s ) | Fit Model | E peak | kT | f th | 1 + σ 0 | 1 + σ 0 | 1 + σ 0 |
|--------------|-------------------------|-----------------------|--------------|----------------------|-------------------|-------------------|-----------------|------------------|-----------------|
| | | | | (keV) | (keV) | | r 0 , 1 1 | r 0 , 2 1 | r 0 , 3 1 |
| | 39 . 936 | 48 . 128 | mBB | 112 . 503 | - 1 . 882 | 0 . 1677 | - | - | 2 . 645 |
| | 48 . 128 | 60 . 416 | mBB | 68 . 578 | - 1 . 547 | 0 . 4964 | - | - | 2 . 020 |
| GRB210704A | - 7 . 168 | 4 . 096 | CPL | 659 . 428 | 5 . 000 | 0 . 1841 | - | - | 2 . 624 |
| | - 2 . 048 | 9 . 216 | Band | 397 . 962 | 10 . 000 | 0 . 4916 | - | - | 1 . 889 |
| | 9 . 216 | 19 . 456 | Band | 269 . 487 | 5 . 000 | 0 . 1661 | - | - | 3 . 642 |
| GRB211018A | 34 . 816 | 49 . 152 | Band | 1093 . 520 | 5 . 000 | 0 . 1905 | - | - | 3 . 177 |
| | 49 . 152 | 60 . 416 | Band | 1171 . 723 | 5 . 000 | 0 . 1814 | - | - | 3 . 025 |
| | 74 . 752 | 82 . 944 | Band | 1511 . 188 | 5 . 000 | 0 . 1275 | - | - | 4 . 307 |
| | 82 . 944 | 92 . 160 | Band | 689 . 554 | 5 . 000 | 0 . 1526 | - | - | 3 . 600 |
| | 61 . 440 | 66 . 560 | Band | 55 . 644 | 5 . 000 | 0 . 2053 | - | - | 2 . 382 |
| GRB211023A | 66 . 560 | | | | | | | | |
| | | 71 . 680 | Band | 55 . 427 | 20 . 000 | 0 . 1872 | - | 4 . 026 | - |
| | 83 . 968 | 89 . 088 | Band | 26 . 582 | 5 . 000 | 0 . 1106 | - | 1 . 546 | 7 . 180 |
| | - 2 . 048 | 3 . 072 | Band+BB | 305 . 909 | 32 . 429 | 0 . 0521 | 12 . 063 | - | - |
| | 3 . 072 | 5 . 120 | Band+BB | 481 . 812 | 23 . 429 | 0 . 0734 | 3 . 336 | 15 . 497 | - |
| | 5 . 120 | 6 . 144 | Band+BB | 404 . 987 | 25 . 219 | 0 . 0723 | 3 . 579 | 16 . 623 | - |
| | 6 . 144 | 7 . 168 | Band+BB | 862 . 219 | 33 . 844 | 0 . 1160 | 2 . 215 | 10 . 288 | - |
| | 7 . 168 | 9 . 216 | Band+BB | 939 . 338 | 28 . 202 | 0 . 0910 | 2 . 706 | 12 . 568 | - |
| | 9 . 216 | 11 . 264 | Band+BB | 243 . 001 | 11 . 269 | 0 . 0654 | 2 . 106 | 9 . 780 | - |
| GRB211211A | 11 . 264 | 16 . 384 | Band | 61 . 088 | 5 . 000 | 0 . 0793 | - | 3 . 769 | 17 . 508 |
| | 16 . 384 18 . 432 | 18 . 432 | Band | 91 . 632 123 . 170 | 20 . 000 17 . 379 | 0 . 1148 0 . 0978 | 2 . 244 2 . 151 | 10 . 424 9 . 991 | - - |
| | 20 . 480 | 20 . 480 22 . 528 | Band+BB Band | 83 . 240 | 5 . 000 | 0 . 0232 | 3 . 058 | 14 . 203 | 65 . 924 |
| | 22 . 528 | 24 . 576 | Band | 101 . 978 | 5 . 000 | 0 . 0191 | 3 . 724 | 17 . 300 | 80 . 298 |
| | | | | 370 . 581 | 31 . 578 | 0 . 0973 | 6 . 003 | - | |
| | 24 . 576 31 . 744 | 27 . 648 | Band+BB | 45 . 842 | 5 . 000 | 0 . 1482 | - | 1 . 662 | - 7 . 722 |
| | 35 . 840 | 35 . 840 | Band+BB | 309 . 212 | | 0 . 0874 | 10 . 366 | - | - |
| | 51 . 200 | 39 . 936 59 . 392 | Band Band | 30 . 446 | 35 . 714 5 . 000 | 0 . 2744 | - | 1 . 090 | 5 . 062 |
| | 93 . 184 | 102 . 400 | Band | 310 . 882 | 10 . 000 | 0 . 4839 | - | - | 1 . 995 |
| GRB220101A | 102 . 400 | 110 . 592 | Band | 463 . 488 | 5 . 000 | 0 . 1403 | - | - | 4 . 485 |
| | 110 . 592 | 119 . 808 | Band | 166 . 610 | 5 . 000 | 0 . 1579 | - | - | 4 . 387 |
| GRB220107A | - 2 . 048 | 10 . 240 | Band | 256 . 505 | 5 . 000 | 0 . 2435 | - | - | 2 . 189 |
| | - 2 . 048 | 4 . 096 | Band | 93 . 833 | 60 . 000 | 0 . 1453 | 4 . 512 | - | - |
| GRB220527A | 4 . 096 | 7 . 168 | Band | 97 . 901 | 5 . 000 | 0 . 0311 | - | 4 . 294 | 19 . 946 |
| | 7 . 168 | 11 . 264 | Band+BB | 221 . 878 | 34 . 365 | 0 . 2607 | - | 3 . 611 | - |
| | 11 . 264 | 23 . 552 | Band | 843 . 126 | 5 . 000 | 0 . 2946 | - | - | 2 . 103 |
| | 34 . 816 | 59 . 392 | Band | 369 . 824 | 5 . 000 | 0 . 2217 | - | - | 3 . 761 |
| | | 101 . 376 | Band | 196 . 188 | 5 . 000 | 0 . 3484 | - | - | 1 . 789 |
| | 82 . 944 | | | | | | | | |
| GRB220627A | 124 . 928 147 . 456 | 147 . 456 161 . 792 | Band Band | 1797 . 749 261 . 076 | 10 . 000 10 . 000 | 0 . 5087 0 . 4308 | - - | - - | 2 . 284 2 . 697 |
| | 161 . 792 | 178 . 176 | Band | 5000 . 000 | | 0 . 0005 | | - | |
| | | | | | 30 . 000 | | - | | - |
- 1 σ 0 is constrained in different r 0 , the unit of r 0 is cm. As we mentioned in 2, we choose 10 , 10 8 9 and 10 10 corresponding to the three different r 0 value in table: r 0 1 , , r 0 2 , and r 0 3 , .
Table 2. Non-dissipation regime criteria
| Regime | Criteria |
|--------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Regime II η > (1 + σ 0 ) 1 / 2 r c > r ph > r ra | 14 . 8(1 + z ) 1 / 4 ( kT ob 50 keV ) 1 / 4 ( F BB 10 - 8 erg s - 1 cm - 2 ) 3 / 16 r 1 / 8 0 , 9 f 1 / 2 th, - 1 f 1 / 2 γ d 3 / 8 L, 28 > 1 0 . 24(1 + z ) - 3 ( kT ob 50 keV ) - 3 ( F BB 10 - 8 erg s - 1 cm - 2 ) 3 / 4 r - 3 / 2 0 , 9 d 3 / 2 L, 28 > 1 1 . 43 × 10 - 5 (1 + z ) - 7 ( kT ob 50 keV ) - 7 ( F BB 10 - 8 erg s - 1 cm - 2 ) 7 / 4 r - 7 / 2 0 , 9 f 3 th, - 1 f 3 γ d 7 / 2 L, 28 < 1 |
| Regime III η > (1 + σ 0 ) 1 / 2 r ph > r c | 8 . 28(1 + z ) - 3 / 2 ( kT ob 30 keV ) - 3 / 2 ( F BB 10 - 7 erg s - 1 cm - 2 ) 5 / 8 r - 1 0 , 9 f 5 / 4 th, - 1 f 5 / 4 γ d 5 / 4 L, 28 > 1 9 . 42 × 10 - 2 (1 + z ) - 14 / 3 ( kT ob 30 keV ) - 14 / 3 ( F BB 10 - 7 erg s - 1 cm - 2 ) 7 / 6 r - 7 / 3 0 , 9 f 2 th, - 1 f 2 γ d 7 / 3 L, 28 > 1 |
| Regime V η < (1 + σ 0 ) 1 / 2 r c > r ph > r ra Regime VI η < (1 + σ 0 ) 1 / 2 r > r | 41 . 4(1 + z ) 1 / 2 ( kT ob 10 keV ) 1 / 2 ( F BB 10 - 9 erg s - 1 cm - 2 ) 3 / 8 r - 1 / 4 0 , 9 f th, - 1 f γ d 3 / 4 L, 28 < 1 5 . 28(1 + z ) - 3 ( kT ob 10 keV ) - 3 ( F BB 10 - 9 erg s - 1 cm - 2 ) 3 / 4 r - 3 / 2 0 , 9 d 3 / 2 L, 28 > 1 1 . 16 × 10 - 5 (1 + z ) - 8 ( kT ob 10 keV ) - 8 ( F BB 10 - 9 erg s - 1 cm - 2 ) r - 3 0 , 9 f th, - 1 f γ d 2 L, 28 < 1 8 . 28(1 + z ) - 3 / 2 ( kT ob 30 keV ) - 3 / 2 ( F BB 10 - 7 erg s - 1 cm - 2 ) 5 / 8 r - 1 0 , 9 f 5 / 4 th, - 1 f 5 / 4 γ d 5 / 4 L, 28 < 1 5 . 63 × 10 - 3 (1 + z ) - 8 / 3 ( kT ob 30 keV ) - 8 / 3 ( F BB 10 - 7 erg s - 1 cm - 2 ) 1 / 3 r - 1 0 , 9 f 1 / 3 th, - 1 f 1 / 3 γ d 2 / 3 L, 28 > 1 | | null | [
"An Li",
"He Gao",
"Lin Lan",
"Bing Zhang"
] | 2024-08-02T10:23:00+00:00 | 2024-08-02T10:23:00+00:00 | [
"astro-ph.HE"
] | Magnetization Factors of Gamma-Ray Burst Jets Revealed by a Systematic Analysis of the Fermi Sample | The composition of gamma-ray burst (GRB) jets remained a mystery until
recently. In practice, we usually characterize the magnetization of the GRB
jets ($\sigma_0$) through the ratio between the Poynting flux and matter
(baryonic) flux. With the increasing value of $\sigma_0$, magnetic energy
gradually takes on a dominant role in the acceleration and energy dissipation
of the jet, causing the proportion of thermal component in the prompt-emission
spectrum of GRBs to gradually decrease or even be completely suppressed. In
this work, we conducted an extensive analysis of the time-resolved spectrum for
all \textit{Fermi} GRBs with known redshift, and we diagnose $\sigma_0$ for
each time bin by contrasting the thermal and nonthermal radiation components.
Our results suggest that most GRB jets should contain a significant magnetic
energy component, likely with magnetization factors $\sigma_{0}\geq 10$. The
value of $\sigma_{0}$ seems vary significantly within the same GRB. Future
studies with more samples, especially those with lower-energy spectral
information coverage, will further verify our results. |
Subsets and Splits
No saved queries yet
Save your SQL queries to embed, download, and access them later. Queries will appear here once saved.